You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2020/11/24 11:47:29 UTC
[GitHub] [spark] LuciferYang opened a new pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
LuciferYang opened a new pull request #30483:
URL: https://github.com/apache/spark/pull/30483
### What changes were proposed in this pull request?
Add File Metadata cache support for Parquet and Orc, this pr is WIP now
### Why are the changes needed?
Support Parquet and Orc datasource use File Metadata cache in long running scenario, such as use thrift servver.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Will add new Tests
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766854528
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39025/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-755318080
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/133731/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733897174
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766506362
No problem, @LuciferYang . :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733798922
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563212466
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -785,6 +785,13 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val PARQUET_META_CACHE_ENABLED = buildConf("spark.sql.parquet.metadataCache.enabled")
+ .doc("To indicate if enable parquet file meta cache, it is recommended to enabled " +
+ "this config in long-running process mode, such as Thrift Server, default is false")
Review comment:
Is this recommendation `true` when the files are updated frequently (maybe hourly) and Spark accesses the files only once (query daily)?
> it is recommended to enabled this config in long-running process mode, such as Thrift Server
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r689230185
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/orc/OrcFileMeta.scala
##########
@@ -0,0 +1,54 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources.orc
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+import org.apache.orc.OrcFile
+import org.apache.orc.impl.{OrcTail, ReaderImpl}
+
+import org.apache.spark.sql.execution.datasources.{FileMeta, FileMetaCacheManager, FileMetaKey}
+import org.apache.spark.util.Utils
+
+private[sql] case class OrcFileMetaKey(path: Path, configuration: Configuration)
+ extends FileMetaKey {
+ override def getFileMeta: OrcFileMeta = OrcFileMeta(path, configuration)
+}
+
+private[sql] case class OrcFileMeta(tail: OrcTail) extends FileMeta
+
+private[sql] object OrcFileMeta {
+ def apply(path: Path, conf: Configuration): OrcFileMeta = {
+ val fs = path.getFileSystem(conf)
+ val readerOptions = OrcFile.readerOptions(conf).filesystem(fs)
+ Utils.tryWithResource(new ForTailCacheReader(path, readerOptions)) { fileReader =>
+ new OrcFileMeta(fileReader.getOrcTail)
+ }
+ }
+
+ def readTailFromCache(path: Path, conf: Configuration): OrcTail =
+ readTailFromCache(OrcFileMetaKey(path, conf))
+
+ def readTailFromCache(key: OrcFileMetaKey): OrcTail =
+ FileMetaCacheManager.get(key).asInstanceOf[OrcFileMeta].tail
+}
+
+private[sql] class ForTailCacheReader(path: Path, options: OrcFile.ReaderOptions)
Review comment:
I found that `fileReader.getFileTail` and `fileReader.getSerializedFileFooter` can be used to rebuild a `OrcTail`,
So can we only cache 'new new OrcTail(fileReader.getFileTail, fileReader.getSerializedFileFooter)`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r529778176
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -765,6 +765,11 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val PARQUET_META_CACHE_ENABLED = buildConf("spark.sql.parquet.metadataCache.enabled")
Review comment:
Please add `.doc("...")`.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733726094
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899290378
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/142498/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899364996
**[Test build #142505 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142505/testReport)** for PR 30483 at commit [`104b125`](https://github.com/apache/spark/commit/104b1256a23300b7f7912c7bf37fc7b14ac5099c).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang edited a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang edited a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766505187
@dongjoon-hyun Thank you very much for your review @dongjoon-hyun ,there are some company things to do this week, so I'll update this PR later
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563213809
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileMetaCacheManager.scala
##########
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources
+
+import java.util.concurrent.TimeUnit
+
+import com.google.common.cache.{CacheBuilder, CacheLoader, CacheStats, RemovalListener, RemovalNotification}
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.internal.SQLConf
+
+private[sql] object FileMetaCacheManager extends Logging {
+
+ private lazy val removalListener = new RemovalListener[FileMetaKey, FileMeta]() {
+ override def onRemoval(n: RemovalNotification[FileMetaKey, FileMeta]): Unit = {
+ logDebug(s"Evicting Data File Meta ${n.getKey.path}")
+ }
+ }
+
+ private lazy val cacheLoader = new CacheLoader[FileMetaKey, FileMeta]() {
+ override def load(entry: FileMetaKey)
+ : FileMeta = {
+ logDebug(s"Loading Data File Meta ${entry.path}")
+ entry.getFileMeta
+ }
+ }
+
+ private lazy val ttlTime =
+ SparkEnv.get.conf.get(SQLConf.FILE_META_CACHE_TTL_SINCE_LAST_ACCESS)
+
+ private lazy val cache =
+ CacheBuilder
+ .newBuilder()
+ .expireAfterAccess(ttlTime, TimeUnit.SECONDS)
+ .recordStats()
+ .removalListener(removalListener)
+ .build[FileMetaKey, FileMeta](cacheLoader)
+
+ def get(dataFile: FileMetaKey): FileMeta = cache.get(dataFile)
+
+ def cacheStats: CacheStats = cache.stats()
Review comment:
This is visible for only `Testing`?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-749121447
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/37775/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766910911
**[Test build #134438 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134438/testReport)** for PR 30483 at commit [`b872010`](https://github.com/apache/spark/commit/b872010d3c4f2583ae229869d7de43261cad8bea).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899551975
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/142505/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733728143
**[Test build #131779 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131779/testReport)** for PR 30483 at commit [`7254d88`](https://github.com/apache/spark/commit/7254d884c1a387627b98b8761c867127a726e422).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-755318080
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/133731/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895953132
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/46781/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r684974038
##########
File path: sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
##########
@@ -77,28 +82,31 @@
protected ParquetFileReader reader;
+ protected ParquetMetadata cachedFooter;
+
@Override
public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext)
throws IOException, InterruptedException {
Configuration configuration = taskAttemptContext.getConfiguration();
FileSplit split = (FileSplit) inputSplit;
this.file = split.getPath();
- ParquetReadOptions options = HadoopReadOptions
- .builder(configuration)
- .withRange(split.getStart(), split.getStart() + split.getLength())
- .build();
- this.reader = new ParquetFileReader(HadoopInputFile.fromPath(file, configuration), options);
- this.fileSchema = reader.getFileMetaData().getSchema();
- Map<String, String> fileMetadata = reader.getFileMetaData().getKeyValueMetaData();
+ ParquetMetadata footer =
Review comment:
@dongjoon-hyun The key problem is here: after SPARK-32703, we use new API to create a `ParquetFileReader`, however, in order to reuse file footer, we have to use some deprecated APIs
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-894564492
I removed the `Stale` tag and reopen this for Apache Spark 3.3.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895068092
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/46727/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766505187
Thank you very much for your review @dongjoon-hyun , there are other things to do this week, I'll update this PR later
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-772441275
**[Test build #134816 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134816/testReport)** for PR 30483 at commit [`120678d`](https://github.com/apache/spark/commit/120678d8b4400cb67cd29787532f56d445acead4).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899354432
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/46999/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899319187
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/46992/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899209904
> In other words, can you spin off ORC-only PR?
OK, I will create a new Jira and give a ORC-only pr ~
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-786467222
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40074/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-755220687
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/38319/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766778951
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39023/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang edited a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang edited a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-768056895
> Could you file the corresponding JIRA to Apache Parquet and Apache ORC community and link them in the JIRA and the PR description?
[PARQUET-1965](https://issues.apache.org/jira/browse/PARQUET-1965) and [ORC-746](https://issues.apache.org/jira/browse/ORC-746)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563213655
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileMetaCacheManager.scala
##########
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources
+
+import java.util.concurrent.TimeUnit
+
+import com.google.common.cache.{CacheBuilder, CacheLoader, CacheStats, RemovalListener, RemovalNotification}
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.internal.SQLConf
+
+private[sql] object FileMetaCacheManager extends Logging {
Review comment:
Could you add more description? This PR seems to share this for both Parquet and ORC.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766752871
**[Test build #134438 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134438/testReport)** for PR 30483 at commit [`b872010`](https://github.com/apache/spark/commit/b872010d3c4f2583ae229869d7de43261cad8bea).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766864206
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39030/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] github-actions[bot] commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
github-actions[bot] commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-855488950
We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable.
If you'd like to revive this PR, please reopen it and ask a committer to remove the Stale tag!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733568636
**[Test build #131760 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131760/testReport)** for PR 30483 at commit [`3e2db1a`](https://github.com/apache/spark/commit/3e2db1a1cdec3df84e9ceb9cc64860b7f88c6720).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733840003
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733785521
**[Test build #131771 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131771/testReport)** for PR 30483 at commit [`92d2f37`](https://github.com/apache/spark/commit/92d2f371cc788154422139041b9554ad9df066f4).
* This patch **fails SparkR unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-749215846
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/133176/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899421972
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/47006/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899290378
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/142498/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-896060335
**[Test build #142273 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142273/testReport)** for PR 30483 at commit [`630f8db`](https://github.com/apache/spark/commit/630f8db424d5090d1c890e7dd414bc5b1960b8c6).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r684974038
##########
File path: sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
##########
@@ -77,28 +82,31 @@
protected ParquetFileReader reader;
+ protected ParquetMetadata cachedFooter;
+
@Override
public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext)
throws IOException, InterruptedException {
Configuration configuration = taskAttemptContext.getConfiguration();
FileSplit split = (FileSplit) inputSplit;
this.file = split.getPath();
- ParquetReadOptions options = HadoopReadOptions
- .builder(configuration)
- .withRange(split.getStart(), split.getStart() + split.getLength())
- .build();
- this.reader = new ParquetFileReader(HadoopInputFile.fromPath(file, configuration), options);
- this.fileSchema = reader.getFileMetaData().getSchema();
- Map<String, String> fileMetadata = reader.getFileMetaData().getKeyValueMetaData();
+ ParquetMetadata footer =
Review comment:
@dongjoon-hyun The key problem is here: after SPARK-32703, we use new API to create a `ParquetFileReader`.
However, in order to reuse file footer, we have to use some deprecated APIs
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-894582960
Hi, @LuciferYang . Are you still interested in this?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang edited a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang edited a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-772273452
Simple test:
```
val df = spark.read.parquet(or orc)("file:/home/work/xxx/data")
df.createOrReplaceTempView("test_table")
spark.sql("select sum(a), sum(b), sum(c) from test_table where id = 1381339").show
spark.sql("select sum(a), sum(b), sum(c) from test_table where id = 28643411").show
```
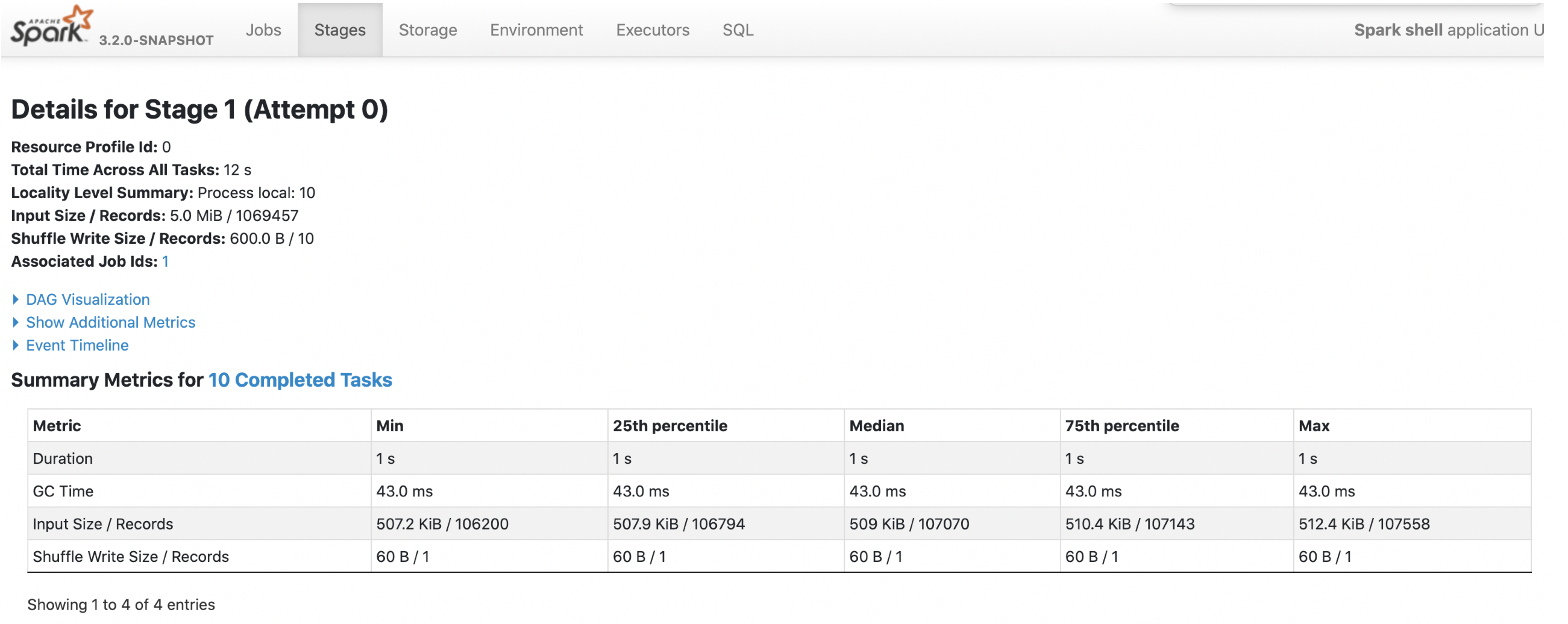
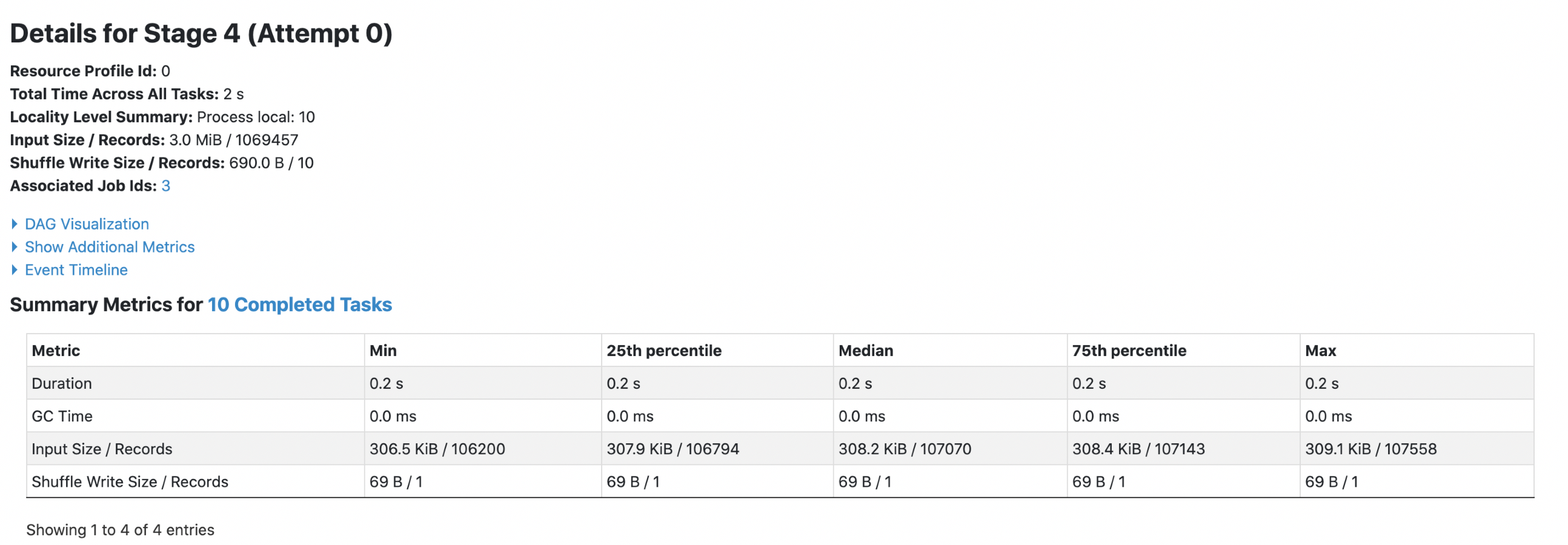
Data Source V1:
1. parquet with `spark.sql.fileMetaCache.parquet.enabled =false`
Each footer was read 4 times, both queries read 6.9m data.
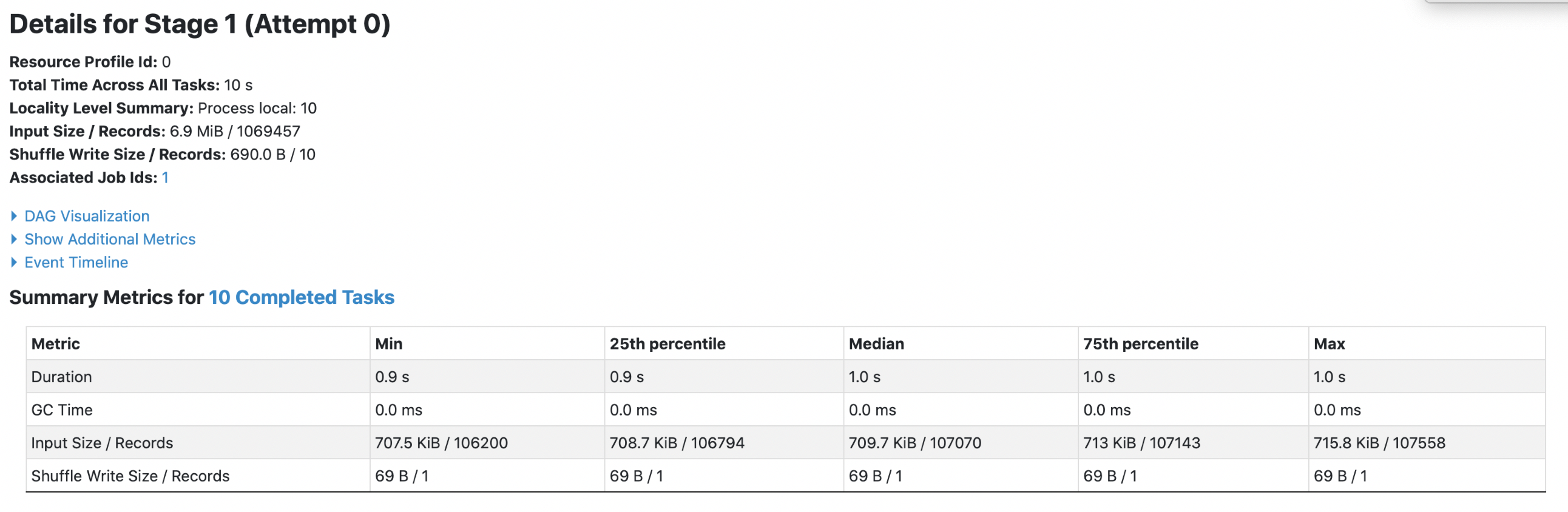
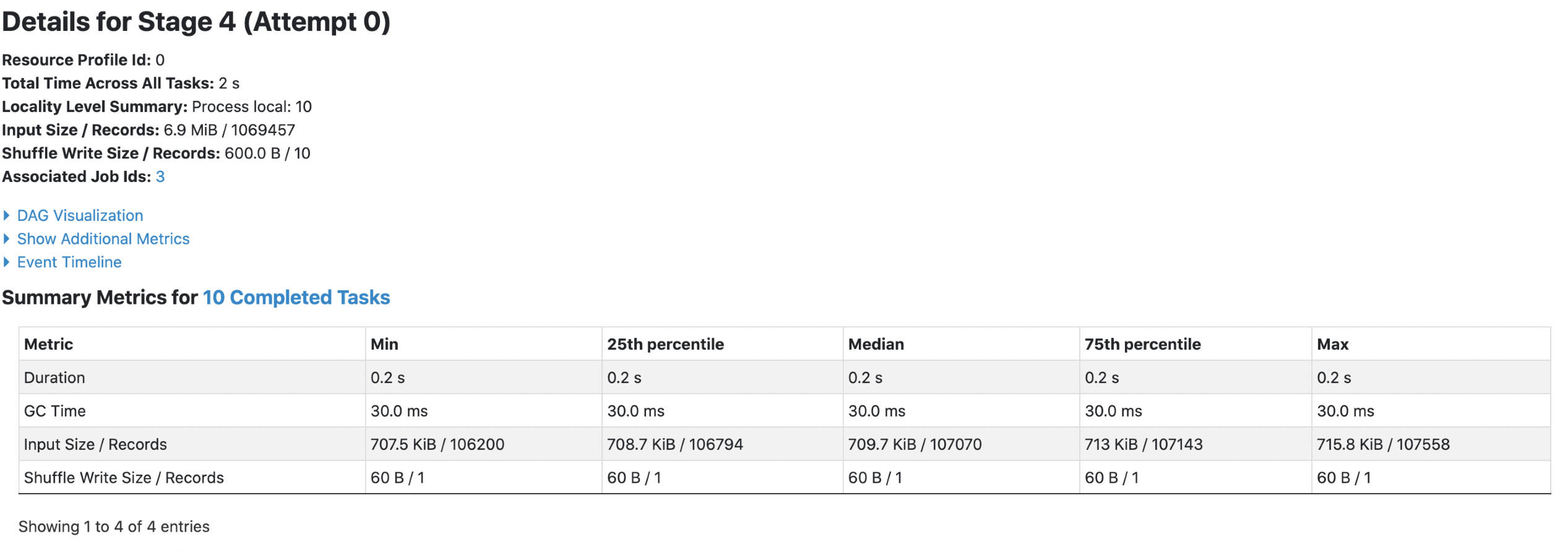
2. parquet with `spark.sql.fileMetaCache.parquet.enabled =true`
Each footer was read 1 times, 1st query read 5m data and 2nd query read 3m data.
3. orc with `spark.sql.fileMetaCache.orc.enabled =false`
Each footer was read 4 times, both queries read 52.3m data.
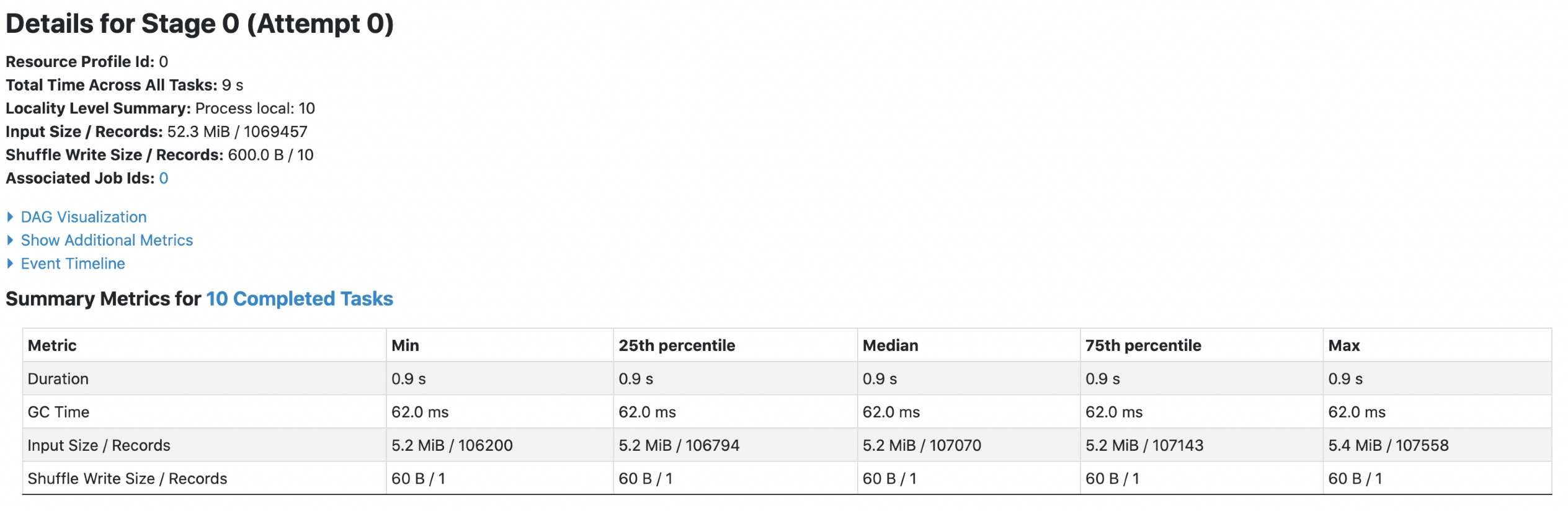
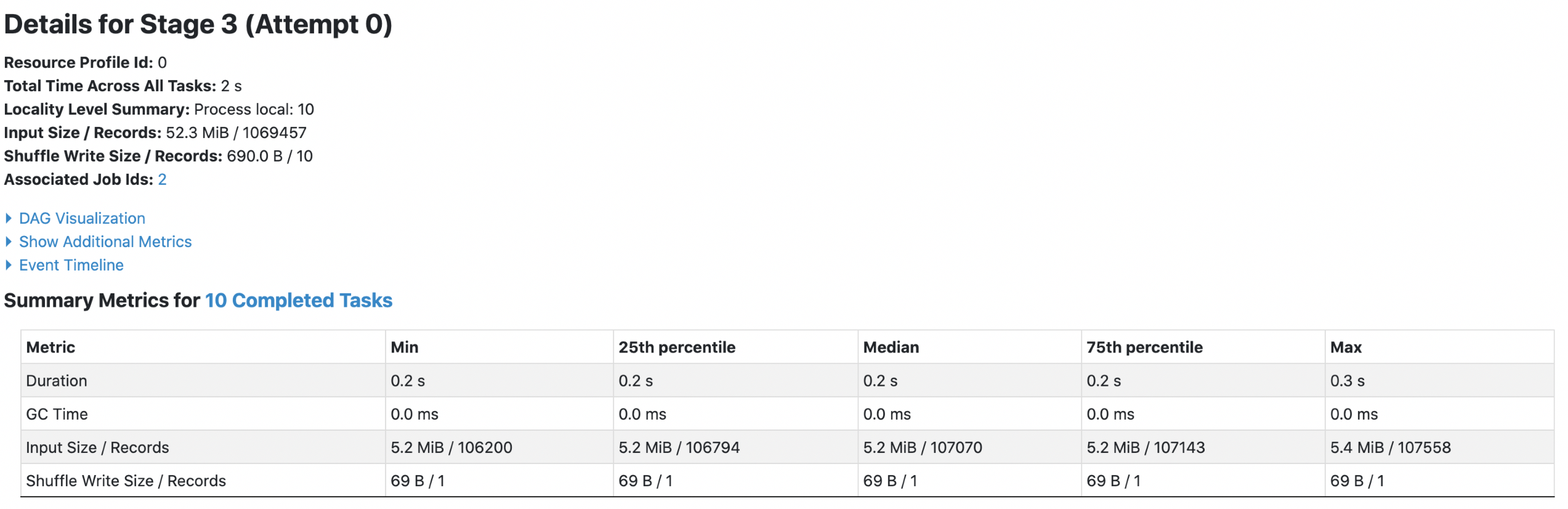
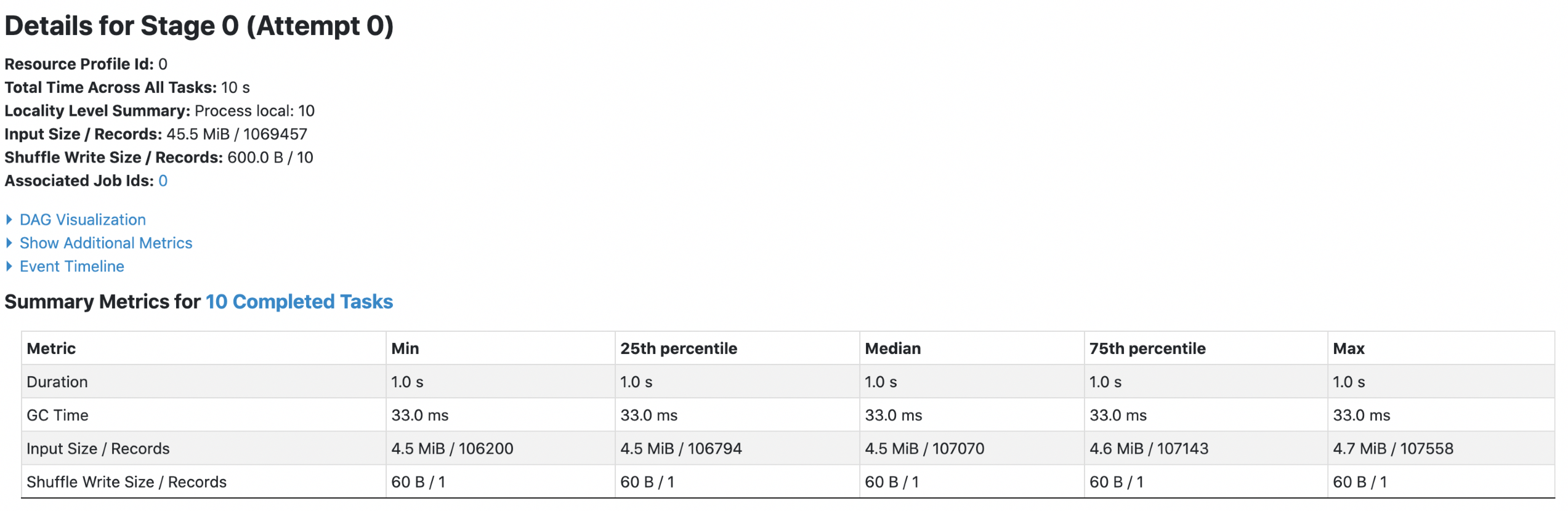
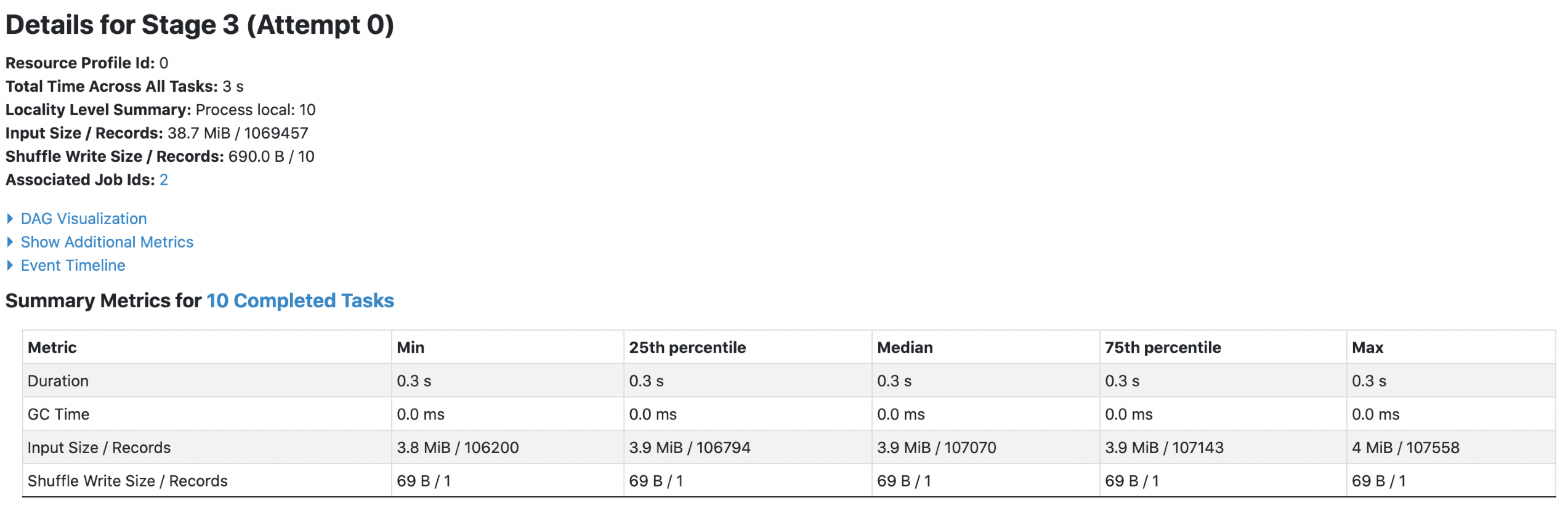
4. orc with `spark.sql.fileMetaCache.orc.enabled =true`
Each footer was read 1 times, 1st query read 45.5m data and 2nd query read 38.7m data.
DataSource V2 API has similar results.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766891690
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733798904
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-786442441
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40074/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733761478
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-749155894
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/37775/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-755202573
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/38319/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r546147756
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -765,6 +765,13 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val PARQUET_META_CACHE_ENABLED = buildConf("spark.sql.parquet.metadataCache.enabled")
+ .doc("To indicate if enable parquet file meta cache, it is recommended to enabled " +
+ "this config in long-running process mode, such as Thrift Server, default is false")
+ .version("3.1.0")
Review comment:
Let's use `3.2.0` because the master branch version is `3.2.0-SNAPSHOT`.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r689147442
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/orc/OrcFileMeta.scala
##########
@@ -0,0 +1,54 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources.orc
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+import org.apache.orc.OrcFile
+import org.apache.orc.impl.{OrcTail, ReaderImpl}
+
+import org.apache.spark.sql.execution.datasources.{FileMeta, FileMetaCacheManager, FileMetaKey}
+import org.apache.spark.util.Utils
+
+private[sql] case class OrcFileMetaKey(path: Path, configuration: Configuration)
+ extends FileMetaKey {
+ override def getFileMeta: OrcFileMeta = OrcFileMeta(path, configuration)
+}
+
+private[sql] case class OrcFileMeta(tail: OrcTail) extends FileMeta
+
+private[sql] object OrcFileMeta {
+ def apply(path: Path, conf: Configuration): OrcFileMeta = {
+ val fs = path.getFileSystem(conf)
+ val readerOptions = OrcFile.readerOptions(conf).filesystem(fs)
+ Utils.tryWithResource(new ForTailCacheReader(path, readerOptions)) { fileReader =>
+ new OrcFileMeta(fileReader.getOrcTail)
+ }
+ }
+
+ def readTailFromCache(path: Path, conf: Configuration): OrcTail =
+ readTailFromCache(OrcFileMetaKey(path, conf))
+
+ def readTailFromCache(key: OrcFileMetaKey): OrcTail =
+ FileMetaCacheManager.get(key).asInstanceOf[OrcFileMeta].tail
+}
+
+private[sql] class ForTailCacheReader(path: Path, options: OrcFile.ReaderOptions)
Review comment:
This looks a little hacky. Is this because `OrcTail` is `protected` variable inside `ReaderImpl`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899285161
**[Test build #142498 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142498/testReport)** for PR 30483 at commit [`fa75a95`](https://github.com/apache/spark/commit/fa75a95b061471081e1f5fadd7f42d1f7f492596).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-896063198
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/142273/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899345983
Kubernetes integration test unable to build dist.
exiting with code: 1
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/47001/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899359759
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/47001/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899285161
**[Test build #142498 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142498/testReport)** for PR 30483 at commit [`fa75a95`](https://github.com/apache/spark/commit/fa75a95b061471081e1f5fadd7f42d1f7f492596).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r530370659
##########
File path: sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
##########
@@ -102,13 +105,13 @@ public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptCont
// if task.side.metadata is set, rowGroupOffsets is null
if (rowGroupOffsets == null) {
// then we need to apply the predicate push down filter
- footer = readFooter(configuration, file, range(split.getStart(), split.getEnd()));
+ footer = getFooterByRange(configuration, split.getStart(), split.getEnd());
MessageType fileSchema = footer.getFileMetaData().getSchema();
FilterCompat.Filter filter = getFilter(configuration);
blocks = filterRowGroups(filter, footer.getBlocks(), fileSchema);
} else {
Review comment:
Actually, I think this `else` branch seems unreadable in Spark and https://github.com/apache/spark/pull/30484 try to remove this branch to make the code look simple
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733536900
**[Test build #131754 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131754/testReport)** for PR 30483 at commit [`8bba51a`](https://github.com/apache/spark/commit/8bba51a2c65393e92a494a9539064d94ad24ec50).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766505187
Thank you very much for your review @dongjoon-hyun , there are other things to do this week, I'll update this PR later
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-894595377
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/142183/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766778951
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39023/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733726094
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733206259
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766752871
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-755181596
**[Test build #133731 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133731/testReport)** for PR 30483 at commit [`c485cc5`](https://github.com/apache/spark/commit/c485cc547e47c9f66049e971e06f3b402266c354).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733430977
> Since your fix is merged here,
> could you fix Scala style and rebase to the master, @LuciferYang ?
OK~ will do it later ~
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895878424
**[Test build #142273 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142273/testReport)** for PR 30483 at commit [`630f8db`](https://github.com/apache/spark/commit/630f8db424d5090d1c890e7dd414bc5b1960b8c6).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895031080
**[Test build #142219 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142219/testReport)** for PR 30483 at commit [`36f502e`](https://github.com/apache/spark/commit/36f502e6e7982f5344eb7e493af8e193a01702ca).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-786453595
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40074/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733695990
**[Test build #131775 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131775/testReport)** for PR 30483 at commit [`44ca052`](https://github.com/apache/spark/commit/44ca052218dfac88f28f5b0e6cdc0eaf613d3bf7).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] sunchao commented on a change in pull request #30483: [SPARK-33449][SQL] Support File Metadata Cache for Parquet
Posted by GitBox <gi...@apache.org>.
sunchao commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r691697807
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -967,6 +967,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val FILE_META_CACHE_PARQUET_ENABLED = buildConf("spark.sql.fileMetaCache.parquet.enabled")
+ .doc("To indicate if enable parquet file meta cache, it is recommended to enabled " +
Review comment:
hmm curious whether this can help if your Spark queries is running as separate Spark jobs, where each of them may use different executors.
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -967,6 +967,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val FILE_META_CACHE_PARQUET_ENABLED = buildConf("spark.sql.fileMetaCache.parquet.enabled")
+ .doc("To indicate if enable parquet file meta cache, it is recommended to enabled " +
+ "this config when multiple queries are performed on the same dataset, default is false.")
+ .version("3.3.0")
+ .booleanConf
+ .createWithDefault(false)
+
+ val FILE_META_CACHE_TTL_SINCE_LAST_ACCESS =
Review comment:
nit: maybe `FILE_META_CACHE_TTL_SINCE_LAST_ACCESS_SEC` and `spark.sql.fileMetaCache.ttlSinceLastAccessSec` so it's easier to know that the unit is second?
##########
File path: sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
##########
@@ -77,28 +82,31 @@
protected ParquetFileReader reader;
+ protected ParquetMetadata cachedFooter;
+
@Override
public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext)
throws IOException, InterruptedException {
Configuration configuration = taskAttemptContext.getConfiguration();
FileSplit split = (FileSplit) inputSplit;
this.file = split.getPath();
- ParquetReadOptions options = HadoopReadOptions
- .builder(configuration)
- .withRange(split.getStart(), split.getStart() + split.getLength())
- .build();
- this.reader = new ParquetFileReader(HadoopInputFile.fromPath(file, configuration), options);
- this.fileSchema = reader.getFileMetaData().getSchema();
- Map<String, String> fileMetadata = reader.getFileMetaData().getKeyValueMetaData();
+ ParquetMetadata footer =
+ readFooterByRange(configuration, split.getStart(), split.getStart() + split.getLength());
+ this.fileSchema = footer.getFileMetaData().getSchema();
+ FilterCompat.Filter filter = ParquetInputFormat.getFilter(configuration);
+ List<BlockMetaData> blocks =
+ RowGroupFilter.filterRowGroups(filter, footer.getBlocks(), fileSchema);
Review comment:
does this apply all the filter levels? e.g., stats, dictionary, and bloom filter.
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileMetaCacheManager.scala
##########
@@ -0,0 +1,87 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources
+
+import java.util.concurrent.TimeUnit
+
+import com.github.benmanes.caffeine.cache.{CacheLoader, Caffeine}
+import com.github.benmanes.caffeine.cache.stats.CacheStats
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * A singleton Cache Manager to caching file meta. We cache these file metas in order to speed up
+ * iterated queries over the same dataset. Otherwise, each query would have to hit remote storage
+ * in order to fetch file meta before read files.
+ *
+ * We should implement the corresponding `FileMetaKey` for a specific file format, for example
+ * `ParquetFileMetaKey` or `OrcFileMetaKey`. By default, the file path is used as the identification
+ * of the `FileMetaKey` and the `getFileMeta` method of `FileMetaKey` is used to return the file
+ * meta of the corresponding file format.
+ */
+object FileMetaCacheManager extends Logging {
+
+ private lazy val cacheLoader = new CacheLoader[FileMetaKey, FileMeta]() {
+ override def load(entry: FileMetaKey): FileMeta = {
+ logDebug(s"Loading Data File Meta ${entry.path}")
+ entry.getFileMeta
+ }
+ }
+
+ private lazy val ttlTime =
+ SparkEnv.get.conf.get(SQLConf.FILE_META_CACHE_TTL_SINCE_LAST_ACCESS)
+
+ private lazy val cache = Caffeine
+ .newBuilder()
+ .expireAfterAccess(ttlTime, TimeUnit.SECONDS)
+ .recordStats()
+ .build[FileMetaKey, FileMeta](cacheLoader)
+
+ /**
+ * Returns the `FileMeta` associated with the `FileMetaKey` in the `FileMetaCacheManager`,
+ * obtaining that the `FileMeta` from `cacheLoader.load(FileMetaKey)` if necessary.
+ */
+ def get(dataFile: FileMetaKey): FileMeta = cache.get(dataFile)
+
+ /**
+ * This is visible for testing.
+ */
+ def cacheStats: CacheStats = cache.stats()
+
+ /**
+ * This is visible for testing.
+ */
+ def cleanUp(): Unit = cache.cleanUp()
+}
+
+abstract class FileMetaKey {
+ def path: Path
+ def configuration: Configuration
+ def getFileMeta: FileMeta
+ override def hashCode(): Int = path.hashCode
+ override def equals(other: Any): Boolean = other match {
+ case df: FileMetaKey => path.equals(df.path)
Review comment:
What if the same file gets replaced? how do we invalidate the cache? this is very common from my experience, e.g., Hive overwrite a partition.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733761478
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899297174
**[Test build #142500 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142500/testReport)** for PR 30483 at commit [`4c022d7`](https://github.com/apache/spark/commit/4c022d742771f866866fca4615b6126e86bdca2a).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang edited a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang edited a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766505187
@dongjoon-hyun Thank you very much for your review @dongjoon-hyun ,there are some company things to do this week, I'll update this PR later
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766774860
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39023/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766854490
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39025/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733641323
**[Test build #131771 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131771/testReport)** for PR 30483 at commit [`92d2f37`](https://github.com/apache/spark/commit/92d2f371cc788154422139041b9554ad9df066f4).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563696944
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileMetaCacheManager.scala
##########
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources
+
+import java.util.concurrent.TimeUnit
+
+import com.google.common.cache.{CacheBuilder, CacheLoader, CacheStats, RemovalListener, RemovalNotification}
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.internal.SQLConf
+
+private[sql] object FileMetaCacheManager extends Logging {
Review comment:
Already add some description of FileMetaCacheManager
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileMetaCacheManager.scala
##########
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources
+
+import java.util.concurrent.TimeUnit
+
+import com.google.common.cache.{CacheBuilder, CacheLoader, CacheStats, RemovalListener, RemovalNotification}
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.internal.SQLConf
+
+private[sql] object FileMetaCacheManager extends Logging {
+
+ private lazy val removalListener = new RemovalListener[FileMetaKey, FileMeta]() {
+ override def onRemoval(n: RemovalNotification[FileMetaKey, FileMeta]): Unit = {
+ logDebug(s"Evicting Data File Meta ${n.getKey.path}")
+ }
+ }
+
+ private lazy val cacheLoader = new CacheLoader[FileMetaKey, FileMeta]() {
+ override def load(entry: FileMetaKey)
+ : FileMeta = {
Review comment:
done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-755181596
**[Test build #133731 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133731/testReport)** for PR 30483 at commit [`c485cc5`](https://github.com/apache/spark/commit/c485cc547e47c9f66049e971e06f3b402266c354).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-749101097
**[Test build #133176 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133176/testReport)** for PR 30483 at commit [`190dc8a`](https://github.com/apache/spark/commit/190dc8a7e82ab5157e602b5b6e417724ebd3c63f).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r685857260
##########
File path: sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
##########
@@ -116,6 +124,28 @@ public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptCont
}
}
+ public void setCachedFooter(ParquetMetadata cachedFooter) {
Review comment:
If we don't want to add a similar API, we can also retrieve footer from cache in this file
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang edited a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang edited a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-772273452
Simple test:
```
val df = spark.read.parquet(or orc)("/xxx/data")
df.createOrReplaceTempView("test_table")
spark.sql("select sum(a), sum(b), sum(c) from test_table where id = 1381339").show
spark.sql("select sum(a), sum(b), sum(c) from test_table where id = 28643411").show
```
Data Source V1:
1. parquet with `spark.sql.fileMetaCache.parquet.enabled =false`
**Each footer was read 4 times, both queries read 6.9m data.**


2. parquet with `spark.sql.fileMetaCache.parquet.enabled =true`
**Each footer was read 1 times, 1st query read 5m data and 2nd query read 3m data.**


3. orc with `spark.sql.fileMetaCache.orc.enabled =false`
**Each footer was read 4 times, both queries read 52.3m data.**


4. orc with `spark.sql.fileMetaCache.orc.enabled =true`
**Each footer was read 1 times, 1st query read 45.5m data and 2nd query read 38.7m data.**


DataSource V2 API has similar results.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733841806
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet or ORC
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899258205
**[Test build #142494 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142494/testReport)** for PR 30483 at commit [`aace310`](https://github.com/apache/spark/commit/aace310b32b2d7500501939f73f3a16e004024f2).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895878424
**[Test build #142273 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142273/testReport)** for PR 30483 at commit [`630f8db`](https://github.com/apache/spark/commit/630f8db424d5090d1c890e7dd414bc5b1960b8c6).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733763576
**[Test build #131782 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131782/testReport)** for PR 30483 at commit [`bc25c4e`](https://github.com/apache/spark/commit/bc25c4e414c4da2058ef8ae6e24769fb66fcd784).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563678224
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -838,6 +845,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val ORC_META_CACHE_ENABLED = buildConf("spark.sql.orc.metadataCache.enabled")
+ .doc("To indicate if enable orc file meta cache, it is recommended to enabled " +
+ "this config in long-running process mode, such as Thrift Server, default is false")
+ .version("3.2.0")
Review comment:
@dongjoon-hyun
1. Now, change the 3 new config key start with `spark.sql.fileMetaCache.`, any better suggestions?
2. change the comments to `it is recommended to enabled this config when multiple queries are performed on the same dataset`, so default is `false`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733720524
**[Test build #131760 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131760/testReport)** for PR 30483 at commit [`3e2db1a`](https://github.com/apache/spark/commit/3e2db1a1cdec3df84e9ceb9cc64860b7f88c6720).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r530426279
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/orc/OrcFileMeta.scala
##########
@@ -0,0 +1,48 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources.orc
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+import org.apache.orc.OrcFile
+import org.apache.orc.impl.{OrcTail, ReaderImpl}
+
+import org.apache.spark.sql.execution.datasources.{FileMeta, FileMetaKey}
+import org.apache.spark.util.Utils
+
+private[sql] case class OrcFileMetaKey(path: Path, configuration: Configuration)
+ extends FileMetaKey {
+ override def getFileMeta: OrcFileMeta = OrcFileMeta(path, configuration)
+}
+
+case class OrcFileMeta(tail: OrcTail) extends FileMeta
Review comment:
@dongjoon-hyun Should Orc files cache OrcTail objects?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766506362
No problem, @LuciferYang . :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766809684
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39025/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733763576
**[Test build #131782 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131782/testReport)** for PR 30483 at commit [`bc25c4e`](https://github.com/apache/spark/commit/bc25c4e414c4da2058ef8ae6e24769fb66fcd784).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766891690
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-732918797
**[Test build #131655 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131655/testReport)** for PR 30483 at commit [`8357771`](https://github.com/apache/spark/commit/83577716a7ec03faf7d4ecdc86ca30afd942d947).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766786193
**[Test build #134439 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134439/testReport)** for PR 30483 at commit [`0a224ff`](https://github.com/apache/spark/commit/0a224ffd5c720165241a616cc06a2509b6fd8fea).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-765295934
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/134351/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-765269820
**[Test build #134351 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134351/testReport)** for PR 30483 at commit [`c485cc5`](https://github.com/apache/spark/commit/c485cc547e47c9f66049e971e06f3b402266c354).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563212548
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -838,6 +845,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val ORC_META_CACHE_ENABLED = buildConf("spark.sql.orc.metadataCache.enabled")
+ .doc("To indicate if enable orc file meta cache, it is recommended to enabled " +
+ "this config in long-running process mode, such as Thrift Server, default is false")
+ .version("3.2.0")
Review comment:
ditto. The same suggestion for the `config` namespace and the recommendation in the description.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733568636
**[Test build #131760 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131760/testReport)** for PR 30483 at commit [`3e2db1a`](https://github.com/apache/spark/commit/3e2db1a1cdec3df84e9ceb9cc64860b7f88c6720).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733536900
**[Test build #131754 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131754/testReport)** for PR 30483 at commit [`8bba51a`](https://github.com/apache/spark/commit/8bba51a2c65393e92a494a9539064d94ad24ec50).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] baibaichen commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
baibaichen commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-781817208
@LuciferYang, where footer is cached, driver or executor? As I understand, the footer will be used at executor side, are you caching the footer at executor side?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563678224
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -838,6 +845,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val ORC_META_CACHE_ENABLED = buildConf("spark.sql.orc.metadataCache.enabled")
+ .doc("To indicate if enable orc file meta cache, it is recommended to enabled " +
+ "this config in long-running process mode, such as Thrift Server, default is false")
+ .version("3.2.0")
Review comment:
@dongjoon-hyun
1. Now the change the 3 new config key start with `spark.sql.fileMetaCache.`, any better suggestions?
2. change the comments to `it is recommended to enabled this config when multiple queries are performed on the same dataset`, so default is `false`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563678846
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -838,6 +838,27 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val FILE_META_CACHE_PARQUET_ENABLED = buildConf("spark.sql.fileMetaCache.parquet.enabled")
+ .doc("To indicate if enable parquet file meta cache, it is recommended to enabled " +
+ "this config when multiple queries are performed on the same dataset, default is false.")
+ .version("3.2.0")
+ .booleanConf
+ .createWithDefault(false)
+
+ val FILE_META_CACHE_ORC_ENABLED = buildConf("spark.sql.fileMetaCache.orc.enabled")
+ .doc("To indicate if enable orc file meta cache, it is recommended to enabled " +
+ "this config when multiple queries are performed on the same dataset, default is false.")
+ .version("3.2.0")
+ .booleanConf
+ .createWithDefault(false)
+
+ val FILE_META_CACHE_TTL_SINCE_LAST_ACCESS =
+ buildConf("spark.sql.fileMetaCache.ttlSinceLastAccess")
+ .version("3.2.0")
+ .doc("Time-to-live for file metadata cache entry after last access, the unit is seconds.")
+ .timeConf(TimeUnit.SECONDS)
+ .createWithDefault(3600L)
Review comment:
change default value to 1hour (3600s)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r530370659
##########
File path: sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
##########
@@ -102,13 +105,13 @@ public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptCont
// if task.side.metadata is set, rowGroupOffsets is null
if (rowGroupOffsets == null) {
// then we need to apply the predicate push down filter
- footer = readFooter(configuration, file, range(split.getStart(), split.getEnd()));
+ footer = getFooterByRange(configuration, split.getStart(), split.getEnd());
MessageType fileSchema = footer.getFileMetaData().getSchema();
FilterCompat.Filter filter = getFilter(configuration);
blocks = filterRowGroups(filter, footer.getBlocks(), fileSchema);
} else {
Review comment:
Actually, I think this `else` branch is unreadable in Spark and https://github.com/apache/spark/pull/30484 try to remove this branch to make the code look simple
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899260894
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/142494/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895031080
**[Test build #142219 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142219/testReport)** for PR 30483 at commit [`36f502e`](https://github.com/apache/spark/commit/36f502e6e7982f5344eb7e493af8e193a01702ca).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-894581054
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/46695/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] baibaichen edited a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
baibaichen edited a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-781817208
@LuciferYang, where footer is cached, driver or executor? As I understand, the footer will be used at executor side, are you caching the footer at executor side?
If you cache footer at executor, how do you schedule tasks to the cached executor?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-894579866
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/46695/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895068056
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/46727/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895099676
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/46731/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899551975
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/142505/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766778951
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899364996
**[Test build #142505 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142505/testReport)** for PR 30483 at commit [`104b125`](https://github.com/apache/spark/commit/104b1256a23300b7f7912c7bf37fc7b14ac5099c).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895931578
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/46781/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895447363
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/142223/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895009182
**[Test build #142214 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142214/testReport)** for PR 30483 at commit [`61175ed`](https://github.com/apache/spark/commit/61175ed37aaface8b193d94fcc5f9bdae88324aa).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-894581353
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/46695/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899432041
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/47006/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895953105
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/46781/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733544301
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563678224
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -838,6 +845,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val ORC_META_CACHE_ENABLED = buildConf("spark.sql.orc.metadataCache.enabled")
+ .doc("To indicate if enable orc file meta cache, it is recommended to enabled " +
+ "this config in long-running process mode, such as Thrift Server, default is false")
+ .version("3.2.0")
Review comment:
@dongjoon-hyun
1. Now the change the 3 new config key start with `spark.sql.fileMetaCache.`, any better suggestions?
2. change the comments to `it is recommended to enabled this config when multiple queries are performed on the same dataset
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766752871
**[Test build #134438 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134438/testReport)** for PR 30483 at commit [`b872010`](https://github.com/apache/spark/commit/b872010d3c4f2583ae229869d7de43261cad8bea).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-765295934
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/134351/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-786565507
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135493/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733544301
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563212908
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -838,6 +845,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val ORC_META_CACHE_ENABLED = buildConf("spark.sql.orc.metadataCache.enabled")
+ .doc("To indicate if enable orc file meta cache, it is recommended to enabled " +
+ "this config in long-running process mode, such as Thrift Server, default is false")
+ .version("3.2.0")
+ .booleanConf
+ .createWithDefault(false)
+
+ val FILE_META_CACHE_TTL_SINCE_LAST_ACCESS =
+ buildConf("spark.sql.metadataCache.ttl.sinceLastAccess")
Review comment:
This also introduces `ttl` as a new namespace for only one configuration.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-732905089
@wangyum WIP now, missing some configuration entries, test suite and orc file support
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733206259
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563212195
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -785,6 +785,13 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val PARQUET_META_CACHE_ENABLED = buildConf("spark.sql.parquet.metadataCache.enabled")
Review comment:
Do we have another configuration in `spark.sql.parquet.metadataCache.` namespace? If not, we usually do not make a new namespace.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] wangyum commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
wangyum commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733556681
@LuciferYang It would be great if we had some benchmark numbers.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563213415
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileMetaCacheManager.scala
##########
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources
+
+import java.util.concurrent.TimeUnit
+
+import com.google.common.cache.{CacheBuilder, CacheLoader, CacheStats, RemovalListener, RemovalNotification}
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.internal.SQLConf
+
+private[sql] object FileMetaCacheManager extends Logging {
+
+ private lazy val removalListener = new RemovalListener[FileMetaKey, FileMeta]() {
Review comment:
Shall we remove this? If this is only for `log`, we can simply `FileMetaCacheManager` by simply removing this.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-755236741
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/38319/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-772332997
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39404/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563678224
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -838,6 +845,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val ORC_META_CACHE_ENABLED = buildConf("spark.sql.orc.metadataCache.enabled")
+ .doc("To indicate if enable orc file meta cache, it is recommended to enabled " +
+ "this config in long-running process mode, such as Thrift Server, default is false")
+ .version("3.2.0")
Review comment:
@dongjoon-hyun
1. Now the change the 3 new config key start with `spark.sql.fileMetaCache.`, any better suggestions?
2. change the comments to `it is recommended to enabled this config when multiple queries are performed on the same dataset
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -838,6 +845,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val ORC_META_CACHE_ENABLED = buildConf("spark.sql.orc.metadataCache.enabled")
+ .doc("To indicate if enable orc file meta cache, it is recommended to enabled " +
+ "this config in long-running process mode, such as Thrift Server, default is false")
+ .version("3.2.0")
Review comment:
@dongjoon-hyun
1. Now the change the 3 new config key start with `spark.sql.fileMetaCache.`, any better suggestions?
2. change the comments to `it is recommended to enabled this config when multiple queries are performed on the same dataset`, so default is `false`
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -838,6 +838,27 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val FILE_META_CACHE_PARQUET_ENABLED = buildConf("spark.sql.fileMetaCache.parquet.enabled")
+ .doc("To indicate if enable parquet file meta cache, it is recommended to enabled " +
+ "this config when multiple queries are performed on the same dataset, default is false.")
+ .version("3.2.0")
+ .booleanConf
+ .createWithDefault(false)
+
+ val FILE_META_CACHE_ORC_ENABLED = buildConf("spark.sql.fileMetaCache.orc.enabled")
+ .doc("To indicate if enable orc file meta cache, it is recommended to enabled " +
+ "this config when multiple queries are performed on the same dataset, default is false.")
+ .version("3.2.0")
+ .booleanConf
+ .createWithDefault(false)
+
+ val FILE_META_CACHE_TTL_SINCE_LAST_ACCESS =
+ buildConf("spark.sql.fileMetaCache.ttlSinceLastAccess")
+ .version("3.2.0")
+ .doc("Time-to-live for file metadata cache entry after last access, the unit is seconds.")
+ .timeConf(TimeUnit.SECONDS)
+ .createWithDefault(3600L)
Review comment:
change default value to 1hour (3600s)
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileMetaCacheManager.scala
##########
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources
+
+import java.util.concurrent.TimeUnit
+
+import com.google.common.cache.{CacheBuilder, CacheLoader, CacheStats, RemovalListener, RemovalNotification}
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.internal.SQLConf
+
+private[sql] object FileMetaCacheManager extends Logging {
+
+ private lazy val removalListener = new RemovalListener[FileMetaKey, FileMeta]() {
Review comment:
done
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileMetaCacheManager.scala
##########
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources
+
+import java.util.concurrent.TimeUnit
+
+import com.google.common.cache.{CacheBuilder, CacheLoader, CacheStats, RemovalListener, RemovalNotification}
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.internal.SQLConf
+
+private[sql] object FileMetaCacheManager extends Logging {
+
+ private lazy val removalListener = new RemovalListener[FileMetaKey, FileMeta]() {
+ override def onRemoval(n: RemovalNotification[FileMetaKey, FileMeta]): Unit = {
+ logDebug(s"Evicting Data File Meta ${n.getKey.path}")
+ }
+ }
+
+ private lazy val cacheLoader = new CacheLoader[FileMetaKey, FileMeta]() {
+ override def load(entry: FileMetaKey)
+ : FileMeta = {
+ logDebug(s"Loading Data File Meta ${entry.path}")
+ entry.getFileMeta
+ }
+ }
+
+ private lazy val ttlTime =
+ SparkEnv.get.conf.get(SQLConf.FILE_META_CACHE_TTL_SINCE_LAST_ACCESS)
+
+ private lazy val cache =
+ CacheBuilder
+ .newBuilder()
+ .expireAfterAccess(ttlTime, TimeUnit.SECONDS)
+ .recordStats()
+ .removalListener(removalListener)
+ .build[FileMetaKey, FileMeta](cacheLoader)
+
+ def get(dataFile: FileMetaKey): FileMeta = cache.get(dataFile)
+
+ def cacheStats: CacheStats = cache.stats()
Review comment:
Yes, add commnets
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileMetaCacheManager.scala
##########
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources
+
+import java.util.concurrent.TimeUnit
+
+import com.google.common.cache.{CacheBuilder, CacheLoader, CacheStats, RemovalListener, RemovalNotification}
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.internal.SQLConf
+
+private[sql] object FileMetaCacheManager extends Logging {
+
+ private lazy val removalListener = new RemovalListener[FileMetaKey, FileMeta]() {
+ override def onRemoval(n: RemovalNotification[FileMetaKey, FileMeta]): Unit = {
+ logDebug(s"Evicting Data File Meta ${n.getKey.path}")
+ }
+ }
+
+ private lazy val cacheLoader = new CacheLoader[FileMetaKey, FileMeta]() {
+ override def load(entry: FileMetaKey)
+ : FileMeta = {
+ logDebug(s"Loading Data File Meta ${entry.path}")
+ entry.getFileMeta
+ }
+ }
+
+ private lazy val ttlTime =
+ SparkEnv.get.conf.get(SQLConf.FILE_META_CACHE_TTL_SINCE_LAST_ACCESS)
+
+ private lazy val cache =
+ CacheBuilder
+ .newBuilder()
+ .expireAfterAccess(ttlTime, TimeUnit.SECONDS)
+ .recordStats()
+ .removalListener(removalListener)
+ .build[FileMetaKey, FileMeta](cacheLoader)
+
+ def get(dataFile: FileMetaKey): FileMeta = cache.get(dataFile)
+
+ def cacheStats: CacheStats = cache.stats()
Review comment:
Yes, add commets
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/parquet/ParquetPartitionReaderFactory.scala
##########
@@ -225,6 +230,7 @@ case class ParquetPartitionReaderFactory(
private def createVectorizedReader(file: PartitionedFile): VectorizedParquetRecordReader = {
val vectorizedReader = buildReaderBase(file, createParquetVectorizedReader)
.asInstanceOf[VectorizedParquetRecordReader]
+
Review comment:
done
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileMetaCacheManager.scala
##########
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources
+
+import java.util.concurrent.TimeUnit
+
+import com.google.common.cache.{CacheBuilder, CacheLoader, CacheStats, RemovalListener, RemovalNotification}
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.internal.SQLConf
+
+private[sql] object FileMetaCacheManager extends Logging {
Review comment:
Already add some description of FileMetaCacheManager
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileMetaCacheManager.scala
##########
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources
+
+import java.util.concurrent.TimeUnit
+
+import com.google.common.cache.{CacheBuilder, CacheLoader, CacheStats, RemovalListener, RemovalNotification}
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.internal.SQLConf
+
+private[sql] object FileMetaCacheManager extends Logging {
+
+ private lazy val removalListener = new RemovalListener[FileMetaKey, FileMeta]() {
+ override def onRemoval(n: RemovalNotification[FileMetaKey, FileMeta]): Unit = {
+ logDebug(s"Evicting Data File Meta ${n.getKey.path}")
+ }
+ }
+
+ private lazy val cacheLoader = new CacheLoader[FileMetaKey, FileMeta]() {
+ override def load(entry: FileMetaKey)
+ : FileMeta = {
Review comment:
done
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -838,6 +845,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val ORC_META_CACHE_ENABLED = buildConf("spark.sql.orc.metadataCache.enabled")
+ .doc("To indicate if enable orc file meta cache, it is recommended to enabled " +
+ "this config in long-running process mode, such as Thrift Server, default is false")
+ .version("3.2.0")
Review comment:
@dongjoon-hyun
1. Now, change the 3 new config key start with `spark.sql.fileMetaCache.`, any better suggestions?
2. change the comments to `it is recommended to enabled this config when multiple queries are performed on the same dataset`, so default is `false`
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -838,6 +845,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val ORC_META_CACHE_ENABLED = buildConf("spark.sql.orc.metadataCache.enabled")
+ .doc("To indicate if enable orc file meta cache, it is recommended to enabled " +
+ "this config in long-running process mode, such as Thrift Server, default is false")
+ .version("3.2.0")
+ .booleanConf
+ .createWithDefault(false)
+
+ val FILE_META_CACHE_TTL_SINCE_LAST_ACCESS =
+ buildConf("spark.sql.metadataCache.ttl.sinceLastAccess")
+ .version("3.2.0")
+ .doc("Time-to-live for file metadata cache entry after last access, the unit is seconds.")
+ .timeConf(TimeUnit.SECONDS)
+ .createWithDefault(1000L)
Review comment:
change to use 1 hour (3600s)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-784712958
@baibaichen footer will cached in Executor side, At present, the original scheduling strategy is reused, and the sensitive scheduling of footer cache is not considered
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-786564383
**[Test build #135493 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135493/testReport)** for PR 30483 at commit [`eb8fa71`](https://github.com/apache/spark/commit/eb8fa7119bebbb0943719299d9bf259237455003).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733641323
**[Test build #131771 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131771/testReport)** for PR 30483 at commit [`92d2f37`](https://github.com/apache/spark/commit/92d2f371cc788154422139041b9554ad9df066f4).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-772454879
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/134816/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766934127
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/134438/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563213189
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileMetaCacheManager.scala
##########
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources
+
+import java.util.concurrent.TimeUnit
+
+import com.google.common.cache.{CacheBuilder, CacheLoader, CacheStats, RemovalListener, RemovalNotification}
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.internal.SQLConf
+
+private[sql] object FileMetaCacheManager extends Logging {
+
+ private lazy val removalListener = new RemovalListener[FileMetaKey, FileMeta]() {
+ override def onRemoval(n: RemovalNotification[FileMetaKey, FileMeta]): Unit = {
+ logDebug(s"Evicting Data File Meta ${n.getKey.path}")
+ }
+ }
+
+ private lazy val cacheLoader = new CacheLoader[FileMetaKey, FileMeta]() {
+ override def load(entry: FileMetaKey)
+ : FileMeta = {
Review comment:
The following is better?
```scala
override def load(entry: FileMetaKey): FileMeta = {
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r546147807
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -818,6 +825,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val ORC_META_CACHE_ENABLED = buildConf("spark.sql.orc.metadataCache.enabled")
+ .doc("To indicate if enable orc file meta cache, it is recommended to enabled " +
+ "this config in long-running process mode, such as Thrift Server, default is false")
+ .version("3.1.0")
Review comment:
ditto.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733840003
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899478790
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/142500/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895204892
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/142214/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-786467222
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40074/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899290326
**[Test build #142498 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142498/testReport)** for PR 30483 at commit [`fa75a95`](https://github.com/apache/spark/commit/fa75a95b061471081e1f5fadd7f42d1f7f492596).
* This patch **fails to build**.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-894571802
**[Test build #142183 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142183/testReport)** for PR 30483 at commit [`eb8fa71`](https://github.com/apache/spark/commit/eb8fa7119bebbb0943719299d9bf259237455003).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899477637
**[Test build #142500 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142500/testReport)** for PR 30483 at commit [`4c022d7`](https://github.com/apache/spark/commit/4c022d742771f866866fca4615b6126e86bdca2a).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899377671
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/46999/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899319187
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/46992/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r686131240
##########
File path: sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
##########
@@ -77,28 +82,31 @@
protected ParquetFileReader reader;
+ protected ParquetMetadata cachedFooter;
+
@Override
public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext)
throws IOException, InterruptedException {
Configuration configuration = taskAttemptContext.getConfiguration();
FileSplit split = (FileSplit) inputSplit;
this.file = split.getPath();
- ParquetReadOptions options = HadoopReadOptions
- .builder(configuration)
- .withRange(split.getStart(), split.getStart() + split.getLength())
- .build();
- this.reader = new ParquetFileReader(HadoopInputFile.fromPath(file, configuration), options);
- this.fileSchema = reader.getFileMetaData().getSchema();
- Map<String, String> fileMetadata = reader.getFileMetaData().getKeyValueMetaData();
+ ParquetMetadata footer =
Review comment:
Oh, got it. Thank you for pointing out this issue, @LuciferYang .
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899260866
**[Test build #142494 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142494/testReport)** for PR 30483 at commit [`aace310`](https://github.com/apache/spark/commit/aace310b32b2d7500501939f73f3a16e004024f2).
* This patch **fails to build**.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899550395
**[Test build #142505 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142505/testReport)** for PR 30483 at commit [`104b125`](https://github.com/apache/spark/commit/104b1256a23300b7f7912c7bf37fc7b14ac5099c).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds the following public classes _(experimental)_:
* `abstract class FileMetaKey `
* `case class ParquetFileMetaKey(path: Path, configuration: Configuration)`
* `class ParquetFileMeta(val footer: ParquetMetadata) extends FileMeta`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895105127
**[Test build #142223 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142223/testReport)** for PR 30483 at commit [`850c52b`](https://github.com/apache/spark/commit/850c52b727bf36ac3019acd7cf9588d9f6ebfefc).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang closed pull request #30483: [SPARK-33449][SQL] Support File Metadata Cache for Parquet
Posted by GitBox <gi...@apache.org>.
LuciferYang closed pull request #30483:
URL: https://github.com/apache/spark/pull/30483
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563696439
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileMetaCacheManager.scala
##########
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources
+
+import java.util.concurrent.TimeUnit
+
+import com.google.common.cache.{CacheBuilder, CacheLoader, CacheStats, RemovalListener, RemovalNotification}
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.internal.SQLConf
+
+private[sql] object FileMetaCacheManager extends Logging {
+
+ private lazy val removalListener = new RemovalListener[FileMetaKey, FileMeta]() {
Review comment:
done
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileMetaCacheManager.scala
##########
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources
+
+import java.util.concurrent.TimeUnit
+
+import com.google.common.cache.{CacheBuilder, CacheLoader, CacheStats, RemovalListener, RemovalNotification}
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.internal.SQLConf
+
+private[sql] object FileMetaCacheManager extends Logging {
+
+ private lazy val removalListener = new RemovalListener[FileMetaKey, FileMeta]() {
+ override def onRemoval(n: RemovalNotification[FileMetaKey, FileMeta]): Unit = {
+ logDebug(s"Evicting Data File Meta ${n.getKey.path}")
+ }
+ }
+
+ private lazy val cacheLoader = new CacheLoader[FileMetaKey, FileMeta]() {
+ override def load(entry: FileMetaKey)
+ : FileMeta = {
+ logDebug(s"Loading Data File Meta ${entry.path}")
+ entry.getFileMeta
+ }
+ }
+
+ private lazy val ttlTime =
+ SparkEnv.get.conf.get(SQLConf.FILE_META_CACHE_TTL_SINCE_LAST_ACCESS)
+
+ private lazy val cache =
+ CacheBuilder
+ .newBuilder()
+ .expireAfterAccess(ttlTime, TimeUnit.SECONDS)
+ .recordStats()
+ .removalListener(removalListener)
+ .build[FileMetaKey, FileMeta](cacheLoader)
+
+ def get(dataFile: FileMetaKey): FileMeta = cache.get(dataFile)
+
+ def cacheStats: CacheStats = cache.stats()
Review comment:
Yes, add commnets
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileMetaCacheManager.scala
##########
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources
+
+import java.util.concurrent.TimeUnit
+
+import com.google.common.cache.{CacheBuilder, CacheLoader, CacheStats, RemovalListener, RemovalNotification}
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.internal.SQLConf
+
+private[sql] object FileMetaCacheManager extends Logging {
+
+ private lazy val removalListener = new RemovalListener[FileMetaKey, FileMeta]() {
+ override def onRemoval(n: RemovalNotification[FileMetaKey, FileMeta]): Unit = {
+ logDebug(s"Evicting Data File Meta ${n.getKey.path}")
+ }
+ }
+
+ private lazy val cacheLoader = new CacheLoader[FileMetaKey, FileMeta]() {
+ override def load(entry: FileMetaKey)
+ : FileMeta = {
+ logDebug(s"Loading Data File Meta ${entry.path}")
+ entry.getFileMeta
+ }
+ }
+
+ private lazy val ttlTime =
+ SparkEnv.get.conf.get(SQLConf.FILE_META_CACHE_TTL_SINCE_LAST_ACCESS)
+
+ private lazy val cache =
+ CacheBuilder
+ .newBuilder()
+ .expireAfterAccess(ttlTime, TimeUnit.SECONDS)
+ .recordStats()
+ .removalListener(removalListener)
+ .build[FileMetaKey, FileMeta](cacheLoader)
+
+ def get(dataFile: FileMetaKey): FileMeta = cache.get(dataFile)
+
+ def cacheStats: CacheStats = cache.stats()
Review comment:
Yes, add commets
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895040065
**[Test build #142219 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142219/testReport)** for PR 30483 at commit [`36f502e`](https://github.com/apache/spark/commit/36f502e6e7982f5344eb7e493af8e193a01702ca).
* This patch **fails Java style tests**.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r689990422
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/parquet/ParquetPartitionReaderFactory.scala
##########
@@ -131,8 +132,11 @@ case class ParquetPartitionReaderFactory(
val filePath = new Path(new URI(file.filePath))
val split = new FileSplit(filePath, file.start, file.length, Array.empty[String])
- lazy val footerFileMetaData =
+ lazy val footerFileMetaData = if (parquetMetaCacheEnabled) {
+ ParquetFileMeta.readFooterFromCache(filePath, conf).getFileMetaData
Review comment:
What happen if the file is removed and replaced?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766819247
**[Test build #134444 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134444/testReport)** for PR 30483 at commit [`98ef2de`](https://github.com/apache/spark/commit/98ef2de4ad1f16d9d9637643660f207a16bd2ca6).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r530072989
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -765,6 +765,11 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val PARQUET_META_CACHE_ENABLED = buildConf("spark.sql.parquet.metadataCache.enabled")
Review comment:
Thx, will add it later ~
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r530370659
##########
File path: sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
##########
@@ -102,13 +105,13 @@ public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptCont
// if task.side.metadata is set, rowGroupOffsets is null
if (rowGroupOffsets == null) {
// then we need to apply the predicate push down filter
- footer = readFooter(configuration, file, range(split.getStart(), split.getEnd()));
+ footer = getFooterByRange(configuration, split.getStart(), split.getEnd());
MessageType fileSchema = footer.getFileMetaData().getSchema();
FilterCompat.Filter filter = getFilter(configuration);
blocks = filterRowGroups(filter, footer.getBlocks(), fileSchema);
} else {
Review comment:
Actually, I think this branch is unreadable in Spark and https://github.com/apache/spark/pull/30484 try to remove this branch.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733897170
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-734040049
> @LuciferYang . In general, I have one concern. Is this robust on Parquet/ORC version changes? I'm wondering if this will block Apache Spark from upgrading them.
>
> Apache Parquet 1.12 has some incompatible changes and Apache Spark is still on Parquet 1.10.
> Apache ORC 1.6.0 has also incompatible API changes and Apache Spark is still using ORC 1.5.
More research work may be needed to determine if it is appropriate to continue this pr at this time, do you have any suggestions on this @wangyum ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-732922221
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-755307691
**[Test build #133731 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133731/testReport)** for PR 30483 at commit [`c485cc5`](https://github.com/apache/spark/commit/c485cc547e47c9f66049e971e06f3b402266c354).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang edited a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang edited a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766505187
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-786434812
**[Test build #135493 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135493/testReport)** for PR 30483 at commit [`eb8fa71`](https://github.com/apache/spark/commit/eb8fa7119bebbb0943719299d9bf259237455003).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang edited a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang edited a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-772273452
Simple test:
```
val df = spark.read.parquet(or orc)("file:/home/work/xxx/data")
df.createOrReplaceTempView("test_table")
spark.sql("select sum(a), sum(b), sum(c) from test_table where id = 1381339").show
spark.sql("select sum(a), sum(b), sum(c) from test_table where id = 28643411").show
```
Data Source V1:
1. parquet with `spark.sql.fileMetaCache.parquet.enabled =false`
**Each footer was read 4 times, both queries read 6.9m data.**


2. parquet with `spark.sql.fileMetaCache.parquet.enabled =true`
**Each footer was read 1 times, 1st query read 5m data and 2nd query read 3m data.**


3. orc with `spark.sql.fileMetaCache.orc.enabled =false`
**Each footer was read 4 times, both queries read 52.3m data.**


4. orc with `spark.sql.fileMetaCache.orc.enabled =true`
**Each footer was read 1 times, 1st query read 45.5m data and 2nd query read 38.7m data.**


DataSource V2 API has similar results.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-749214893
**[Test build #133176 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133176/testReport)** for PR 30483 at commit [`190dc8a`](https://github.com/apache/spark/commit/190dc8a7e82ab5157e602b5b6e417724ebd3c63f).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-772284582
**[Test build #134816 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134816/testReport)** for PR 30483 at commit [`120678d`](https://github.com/apache/spark/commit/120678d8b4400cb67cd29787532f56d445acead4).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733728143
**[Test build #131779 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131779/testReport)** for PR 30483 at commit [`7254d88`](https://github.com/apache/spark/commit/7254d884c1a387627b98b8761c867127a726e422).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-772454879
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/134816/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-786434812
**[Test build #135493 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135493/testReport)** for PR 30483 at commit [`eb8fa71`](https://github.com/apache/spark/commit/eb8fa7119bebbb0943719299d9bf259237455003).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r689310336
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/orc/OrcFileMeta.scala
##########
@@ -0,0 +1,54 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources.orc
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+import org.apache.orc.OrcFile
+import org.apache.orc.impl.{OrcTail, ReaderImpl}
+
+import org.apache.spark.sql.execution.datasources.{FileMeta, FileMetaCacheManager, FileMetaKey}
+import org.apache.spark.util.Utils
+
+private[sql] case class OrcFileMetaKey(path: Path, configuration: Configuration)
+ extends FileMetaKey {
+ override def getFileMeta: OrcFileMeta = OrcFileMeta(path, configuration)
+}
+
+private[sql] case class OrcFileMeta(tail: OrcTail) extends FileMeta
+
+private[sql] object OrcFileMeta {
+ def apply(path: Path, conf: Configuration): OrcFileMeta = {
+ val fs = path.getFileSystem(conf)
+ val readerOptions = OrcFile.readerOptions(conf).filesystem(fs)
+ Utils.tryWithResource(new ForTailCacheReader(path, readerOptions)) { fileReader =>
+ new OrcFileMeta(fileReader.getOrcTail)
+ }
+ }
+
+ def readTailFromCache(path: Path, conf: Configuration): OrcTail =
+ readTailFromCache(OrcFileMetaKey(path, conf))
+
+ def readTailFromCache(key: OrcFileMetaKey): OrcTail =
+ FileMetaCacheManager.get(key).asInstanceOf[OrcFileMeta].tail
+}
+
+private[sql] class ForTailCacheReader(path: Path, options: OrcFile.ReaderOptions)
Review comment:
Ya, it's also possible. Let me check ORC code if we can add some helper functions too.
I'm also taking a look at https://issues.apache.org/jira/browse/ORC-746 again too. Sorry for the delay.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899274344
There will be some duplicate codes in the two PR, and this part of the code will be synchronized after one of them is merged
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r689230185
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/orc/OrcFileMeta.scala
##########
@@ -0,0 +1,54 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources.orc
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+import org.apache.orc.OrcFile
+import org.apache.orc.impl.{OrcTail, ReaderImpl}
+
+import org.apache.spark.sql.execution.datasources.{FileMeta, FileMetaCacheManager, FileMetaKey}
+import org.apache.spark.util.Utils
+
+private[sql] case class OrcFileMetaKey(path: Path, configuration: Configuration)
+ extends FileMetaKey {
+ override def getFileMeta: OrcFileMeta = OrcFileMeta(path, configuration)
+}
+
+private[sql] case class OrcFileMeta(tail: OrcTail) extends FileMeta
+
+private[sql] object OrcFileMeta {
+ def apply(path: Path, conf: Configuration): OrcFileMeta = {
+ val fs = path.getFileSystem(conf)
+ val readerOptions = OrcFile.readerOptions(conf).filesystem(fs)
+ Utils.tryWithResource(new ForTailCacheReader(path, readerOptions)) { fileReader =>
+ new OrcFileMeta(fileReader.getOrcTail)
+ }
+ }
+
+ def readTailFromCache(path: Path, conf: Configuration): OrcTail =
+ readTailFromCache(OrcFileMetaKey(path, conf))
+
+ def readTailFromCache(key: OrcFileMetaKey): OrcTail =
+ FileMetaCacheManager.get(key).asInstanceOf[OrcFileMeta].tail
+}
+
+private[sql] class ForTailCacheReader(path: Path, options: OrcFile.ReaderOptions)
Review comment:
> This looks a little hacky. Is this because OrcTail is protected variable inside ReaderImpl?
Yes, but I found that `fileReader.getFileTail` and `fileReader.getSerializedFileFooter` can be used to rebuild a `OrcTail`,
So can we only cache `new new OrcTail(fileReader.getFileTail, fileReader.getSerializedFileFooter)`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563696651
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/parquet/ParquetPartitionReaderFactory.scala
##########
@@ -225,6 +230,7 @@ case class ParquetPartitionReaderFactory(
private def createVectorizedReader(file: PartitionedFile): VectorizedParquetRecordReader = {
val vectorizedReader = buildReaderBase(file, createParquetVectorizedReader)
.asInstanceOf[VectorizedParquetRecordReader]
+
Review comment:
done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-748374547
Could you file the corresponding JIRA to Apache Parquet and Apache ORC community and link them in the JIRA and the PR description?
> we certainly need to change the API of Apache Parquet and Apache ORC and upgrade the version.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-749136372
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/37775/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733853728
**[Test build #131775 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131775/testReport)** for PR 30483 at commit [`44ca052`](https://github.com/apache/spark/commit/44ca052218dfac88f28f5b0e6cdc0eaf613d3bf7).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733865432
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766845400
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39030/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899296529
Got it. Thank you for moving forward this efforts, @LuciferYang .
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-772273452
Simple test:
```
val df = spark.read.parquet(or orc)("file:/home/work/xxx/data")
df.createOrReplaceTempView("test_table")
spark.sql("select sum(a), sum(b), sum(c) from test_table where id = 1381339").show
spark.sql("select sum(a), sum(b), sum(c) from test_table where id = 28643411").show
```
Data Source V1:
1. parquet with `spark.sql.fileMetaCache.parquet.enabled =false`


2. parquet with `spark.sql.fileMetaCache.parquet.enabled =true`


3. orc with `spark.sql.fileMetaCache.orc.enabled =false`


4. orc with `spark.sql.fileMetaCache.orc.enabled =true`


----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733694247
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899271543
@dongjoon-hyun Because https://github.com/apache/spark/pull/33748 gives an ORC-only pr, I'll change this PR to Parquet-only
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r689995736
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/parquet/ParquetPartitionReaderFactory.scala
##########
@@ -131,8 +132,11 @@ case class ParquetPartitionReaderFactory(
val filePath = new Path(new URI(file.filePath))
val split = new FileSplit(filePath, file.start, file.length, Array.empty[String])
- lazy val footerFileMetaData =
+ lazy val footerFileMetaData = if (parquetMetaCacheEnabled) {
+ ParquetFileMeta.readFooterFromCache(filePath, conf).getFileMetaData
Review comment:
We can discuss it in https://github.com/apache/spark/pull/33748 first. I'll set this PR to draft first
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895035850
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/46727/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766854528
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39025/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563213572
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/orc/OrcFileMeta.scala
##########
@@ -0,0 +1,48 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources.orc
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+import org.apache.orc.OrcFile
+import org.apache.orc.impl.{OrcTail, ReaderImpl}
+
+import org.apache.spark.sql.execution.datasources.{FileMeta, FileMetaKey}
+import org.apache.spark.util.Utils
+
+private[sql] case class OrcFileMetaKey(path: Path, configuration: Configuration)
+ extends FileMetaKey {
+ override def getFileMeta: OrcFileMeta = OrcFileMeta(path, configuration)
+}
+
+case class OrcFileMeta(tail: OrcTail) extends FileMeta
Review comment:
Sorry, but I missed the context. Is the question for Apache ORC library or for this PR's implementation?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733891485
**[Test build #131779 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131779/testReport)** for PR 30483 at commit [`7254d88`](https://github.com/apache/spark/commit/7254d884c1a387627b98b8761c867127a726e422).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-749155894
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/37775/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-772284582
**[Test build #134816 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134816/testReport)** for PR 30483 at commit [`120678d`](https://github.com/apache/spark/commit/120678d8b4400cb67cd29787532f56d445acead4).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563213871
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/parquet/ParquetPartitionReaderFactory.scala
##########
@@ -225,6 +230,7 @@ case class ParquetPartitionReaderFactory(
private def createVectorizedReader(file: PartitionedFile): VectorizedParquetRecordReader = {
val vectorizedReader = buildReaderBase(file, createParquetVectorizedReader)
.asInstanceOf[VectorizedParquetRecordReader]
+
Review comment:
Let's avoid touching unnecessary part.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-765132302
**[Test build #134351 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134351/testReport)** for PR 30483 at commit [`c485cc5`](https://github.com/apache/spark/commit/c485cc547e47c9f66049e971e06f3b402266c354).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-894581353
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/46695/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563725302
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -838,6 +845,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val ORC_META_CACHE_ENABLED = buildConf("spark.sql.orc.metadataCache.enabled")
+ .doc("To indicate if enable orc file meta cache, it is recommended to enabled " +
+ "this config in long-running process mode, such as Thrift Server, default is false")
+ .version("3.2.0")
+ .booleanConf
+ .createWithDefault(false)
+
+ val FILE_META_CACHE_TTL_SINCE_LAST_ACCESS =
+ buildConf("spark.sql.metadataCache.ttl.sinceLastAccess")
+ .version("3.2.0")
+ .doc("Time-to-live for file metadata cache entry after last access, the unit is seconds.")
+ .timeConf(TimeUnit.SECONDS)
+ .createWithDefault(1000L)
Review comment:
change to use 1 hour (3600s)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899260894
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/142494/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [SPARK-33449][SQL] Support File Metadata Cache for Parquet
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r691796638
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -967,6 +967,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val FILE_META_CACHE_PARQUET_ENABLED = buildConf("spark.sql.fileMetaCache.parquet.enabled")
+ .doc("To indicate if enable parquet file meta cache, it is recommended to enabled " +
+ "this config when multiple queries are performed on the same dataset, default is false.")
+ .version("3.3.0")
+ .booleanConf
+ .createWithDefault(false)
+
+ val FILE_META_CACHE_TTL_SINCE_LAST_ACCESS =
Review comment:
good suggestion
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899283072
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/46992/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899258205
**[Test build #142494 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142494/testReport)** for PR 30483 at commit [`aace310`](https://github.com/apache/spark/commit/aace310b32b2d7500501939f73f3a16e004024f2).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899432041
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/47006/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899297174
**[Test build #142500 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142500/testReport)** for PR 30483 at commit [`4c022d7`](https://github.com/apache/spark/commit/4c022d742771f866866fca4615b6126e86bdca2a).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-894571802
**[Test build #142183 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142183/testReport)** for PR 30483 at commit [`eb8fa71`](https://github.com/apache/spark/commit/eb8fa7119bebbb0943719299d9bf259237455003).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766752871
**[Test build #134438 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134438/testReport)** for PR 30483 at commit [`b872010`](https://github.com/apache/spark/commit/b872010d3c4f2583ae229869d7de43261cad8bea).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-894595377
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/142183/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766934127
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/134438/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-734040800
In addition, in order for `RowBasedReader` to use file meta cache, we certainly need to change the API of `Apache Parquet` and `Apache ORC` and upgrade the version.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-772315668
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39404/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [SPARK-33449][SQL] Support File Metadata Cache for Parquet
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r691808961
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -967,6 +967,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val FILE_META_CACHE_PARQUET_ENABLED = buildConf("spark.sql.fileMetaCache.parquet.enabled")
+ .doc("To indicate if enable parquet file meta cache, it is recommended to enabled " +
Review comment:
Yes, this feature does have limitations, `NODE_LOCAL + thrift-server` with interactive analysis should be the best scene. If the architecture is storage and computing are separated, we need to consider the task scheduling.
In fact, [OAP](https://github.com/Intel-bigdata/OAP/tree/master/oap-cache) project, fileMetaCache is relies on dataCache(PROCESS_LOCAL)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-786565507
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135493/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899397150
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/46999/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [SPARK-33449][SQL] Support File Metadata Cache for Parquet
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r691808961
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -967,6 +967,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val FILE_META_CACHE_PARQUET_ENABLED = buildConf("spark.sql.fileMetaCache.parquet.enabled")
+ .doc("To indicate if enable parquet file meta cache, it is recommended to enabled " +
Review comment:
Yes, this feature does have limitations, `NODE_LOCAL + thrift-server` with interactive analysis should be the best scene. If the architecture is storage and computing are separated, we need to consider the task scheduling.
In fact, in the [OAP](https://github.com/Intel-bigdata/OAP/tree/master/oap-cache) project, fileMetaCache is relies on dataCache(PROCESS_LOCAL)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-772345399
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39404/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899089526
I've looking around the code. The most serious block is the following because both Apache Spark and Parquet community are reluctant to advertise the deprecated API. So, my suggestion here is to split this PR into two PRs. (Parquet PR and ORC PR). For Parquet PR, let's reuse this one because this has all your code. In other words, can you spin off ORC-only PR?
> Parquet no longer has non Deprecated API that can be used to pass footer to create new ParquetFileReader
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-765132302
**[Test build #134351 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134351/testReport)** for PR 30483 at commit [`c485cc5`](https://github.com/apache/spark/commit/c485cc547e47c9f66049e971e06f3b402266c354).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895040155
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/142219/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899397150
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/46999/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-896126902
GitHub seems to be out of order frequently. I'm hitting `You can't comment at this time` error messages.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895447363
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang edited a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang edited a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766505187
@dongjoon-hyun Thank you very much for your review @dongjoon-hyun , there are other things to do this week, I'll update this PR later
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733694232
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-896063198
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/142273/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [SPARK-33449][SQL] Support File Metadata Cache for Parquet
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r691809788
##########
File path: sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
##########
@@ -77,28 +82,31 @@
protected ParquetFileReader reader;
+ protected ParquetMetadata cachedFooter;
+
@Override
public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext)
throws IOException, InterruptedException {
Configuration configuration = taskAttemptContext.getConfiguration();
FileSplit split = (FileSplit) inputSplit;
this.file = split.getPath();
- ParquetReadOptions options = HadoopReadOptions
- .builder(configuration)
- .withRange(split.getStart(), split.getStart() + split.getLength())
- .build();
- this.reader = new ParquetFileReader(HadoopInputFile.fromPath(file, configuration), options);
- this.fileSchema = reader.getFileMetaData().getSchema();
- Map<String, String> fileMetadata = reader.getFileMetaData().getKeyValueMetaData();
+ ParquetMetadata footer =
+ readFooterByRange(configuration, split.getStart(), split.getStart() + split.getLength());
+ this.fileSchema = footer.getFileMetaData().getSchema();
+ FilterCompat.Filter filter = ParquetInputFormat.getFilter(configuration);
+ List<BlockMetaData> blocks =
+ RowGroupFilter.filterRowGroups(filter, footer.getBlocks(), fileSchema);
Review comment:
I need to investigate it again
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileMetaCacheManager.scala
##########
@@ -0,0 +1,87 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources
+
+import java.util.concurrent.TimeUnit
+
+import com.github.benmanes.caffeine.cache.{CacheLoader, Caffeine}
+import com.github.benmanes.caffeine.cache.stats.CacheStats
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * A singleton Cache Manager to caching file meta. We cache these file metas in order to speed up
+ * iterated queries over the same dataset. Otherwise, each query would have to hit remote storage
+ * in order to fetch file meta before read files.
+ *
+ * We should implement the corresponding `FileMetaKey` for a specific file format, for example
+ * `ParquetFileMetaKey` or `OrcFileMetaKey`. By default, the file path is used as the identification
+ * of the `FileMetaKey` and the `getFileMeta` method of `FileMetaKey` is used to return the file
+ * meta of the corresponding file format.
+ */
+object FileMetaCacheManager extends Logging {
+
+ private lazy val cacheLoader = new CacheLoader[FileMetaKey, FileMeta]() {
+ override def load(entry: FileMetaKey): FileMeta = {
+ logDebug(s"Loading Data File Meta ${entry.path}")
+ entry.getFileMeta
+ }
+ }
+
+ private lazy val ttlTime =
+ SparkEnv.get.conf.get(SQLConf.FILE_META_CACHE_TTL_SINCE_LAST_ACCESS)
+
+ private lazy val cache = Caffeine
+ .newBuilder()
+ .expireAfterAccess(ttlTime, TimeUnit.SECONDS)
+ .recordStats()
+ .build[FileMetaKey, FileMeta](cacheLoader)
+
+ /**
+ * Returns the `FileMeta` associated with the `FileMetaKey` in the `FileMetaCacheManager`,
+ * obtaining that the `FileMeta` from `cacheLoader.load(FileMetaKey)` if necessary.
+ */
+ def get(dataFile: FileMetaKey): FileMeta = cache.get(dataFile)
+
+ /**
+ * This is visible for testing.
+ */
+ def cacheStats: CacheStats = cache.stats()
+
+ /**
+ * This is visible for testing.
+ */
+ def cleanUp(): Unit = cache.cleanUp()
+}
+
+abstract class FileMetaKey {
+ def path: Path
+ def configuration: Configuration
+ def getFileMeta: FileMeta
+ override def hashCode(): Int = path.hashCode
+ override def equals(other: Any): Boolean = other match {
+ case df: FileMetaKey => path.equals(df.path)
Review comment:
This is a very good question, we discussed in https://github.com/apache/spark/pull/33748#discussion_r689993828,
```
If the file name has the timestamp, I think we don't have to worry too much. The names of the new file and the old file are different and they can ensure that they don't read the wrong data.
If it is manually file replaced and the file has the same name and the corresponding file meta exists in the cache, an incorrect file meta will be used to read the data. If the data reading fails, the job will fail. But if the data reading happens to be successful, the job will read the wrong data.
In fact, even if there is no `FileMetaCache`, there is a similar risk in manually replace files with same name, because the offset and length of PartitionedFile maybe don't match after manually replace for a running job
```
And At the same time, I added a warning for this feature in SQLConf.
Now Parquet is a draft because the Deprecated API, We are focusing on ORC (SPARK-36516) now
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-732918797
**[Test build #131655 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131655/testReport)** for PR 30483 at commit [`8357771`](https://github.com/apache/spark/commit/83577716a7ec03faf7d4ecdc86ca30afd942d947).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] github-actions[bot] closed pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
github-actions[bot] closed pull request #30483:
URL: https://github.com/apache/spark/pull/30483
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-749215846
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/133176/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-768056895
> Could you file the corresponding JIRA to Apache Parquet and Apache ORC community and link them in the JIRA and the PR description?
PARQUET-1965 and ORC-746
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r563212780
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -838,6 +845,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val ORC_META_CACHE_ENABLED = buildConf("spark.sql.orc.metadataCache.enabled")
+ .doc("To indicate if enable orc file meta cache, it is recommended to enabled " +
+ "this config in long-running process mode, such as Thrift Server, default is false")
+ .version("3.2.0")
+ .booleanConf
+ .createWithDefault(false)
+
+ val FILE_META_CACHE_TTL_SINCE_LAST_ACCESS =
+ buildConf("spark.sql.metadataCache.ttl.sinceLastAccess")
+ .version("3.2.0")
+ .doc("Time-to-live for file metadata cache entry after last access, the unit is seconds.")
+ .timeConf(TimeUnit.SECONDS)
+ .createWithDefault(1000L)
Review comment:
This looks like a magic number. Why do we need to choose `1000` second as a default? Usually, we choose 1 hour (3600s), 1 day, or 1 weeks, don't we?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733579848
@wangyum this is a very good suggestion ~
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-732922221
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-772345399
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39404/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-766777341
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39023/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899391092
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/47006/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-732922174
**[Test build #131655 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131655/testReport)** for PR 30483 at commit [`8357771`](https://github.com/apache/spark/commit/83577716a7ec03faf7d4ecdc86ca30afd942d947).
* This patch **fails Scala style tests**.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-765132302
**[Test build #134351 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134351/testReport)** for PR 30483 at commit [`c485cc5`](https://github.com/apache/spark/commit/c485cc547e47c9f66049e971e06f3b402266c354).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-749101097
**[Test build #133176 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133176/testReport)** for PR 30483 at commit [`190dc8a`](https://github.com/apache/spark/commit/190dc8a7e82ab5157e602b5b6e417724ebd3c63f).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733544254
**[Test build #131754 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131754/testReport)** for PR 30483 at commit [`8bba51a`](https://github.com/apache/spark/commit/8bba51a2c65393e92a494a9539064d94ad24ec50).
* This patch **fails Java style tests**.
* This patch merges cleanly.
* This patch adds the following public classes _(experimental)_:
* `case class TruncateTable(`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-733695990
**[Test build #131775 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131775/testReport)** for PR 30483 at commit [`44ca052`](https://github.com/apache/spark/commit/44ca052218dfac88f28f5b0e6cdc0eaf613d3bf7).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30483: [SPARK-33449][SQL] Support File Metadata Cache for Parquet
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on a change in pull request #30483:
URL: https://github.com/apache/spark/pull/30483#discussion_r691808961
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##########
@@ -967,6 +967,20 @@ object SQLConf {
.booleanConf
.createWithDefault(false)
+ val FILE_META_CACHE_PARQUET_ENABLED = buildConf("spark.sql.fileMetaCache.parquet.enabled")
+ .doc("To indicate if enable parquet file meta cache, it is recommended to enabled " +
Review comment:
Yes, this feature does have limitations, `NODE_LOCAL + thrift-server` with interactive analysis should be the best scene. If the architecture is storage and computing are separated, we need to consider the task scheduling.
In fact, in the [OAP](https://github.com/Intel-bigdata/OAP/tree/master/oap-cache) project, the fileMetaCache is relies on dataCache(PROCESS_LOCAL)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-765295934
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895009182
**[Test build #142214 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142214/testReport)** for PR 30483 at commit [`61175ed`](https://github.com/apache/spark/commit/61175ed37aaface8b193d94fcc5f9bdae88324aa).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895027558
**[Test build #142215 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/142215/testReport)** for PR 30483 at commit [`179e7b0`](https://github.com/apache/spark/commit/179e7b0a53266ec5b69b435057598581965a552e).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang edited a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang edited a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895898471
I have some problems now:
1. How should we pass the filemeta to the Reader? Now I add a new API named `setCachedXXX()`
2. Parquet no longer has non Deprecated API that can be used to pass footer to create new `ParquetFileReader`
3. Should we add more configs related to eviction policy, such as `maximumSize`
4. Should scheduling sensitivity be considered at present?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang edited a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
LuciferYang edited a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899271543
@dongjoon-hyun Because https://github.com/apache/spark/pull/33748 gives an ORC-only pr and use a new JIRA SPARK-36516, I'll change this PR to Parquet-only
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-899359759
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/47001/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-895040155
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org