You are viewing a plain text version of this content. The canonical link for it is here.
Posted to dev@orc.apache.org by GitBox <gi...@apache.org> on 2021/11/01 03:24:59 UTC
[GitHub] [orc] guiyanakuang opened a new pull request #952: ORC-1004: Make orc writer support the selected vector
guiyanakuang opened a new pull request #952:
URL: https://github.com/apache/orc/pull/952
<!--
Thanks for sending a pull request! Here are some tips for you:
1. File a JIRA issue first and use it as a prefix of your PR title, e.g., `ORC-001: Fix ABC`.
2. Use your PR title to summarize what this PR proposes instead of describing the problem.
3. Make PR title and description complete because these will be the permanent commit log.
4. If possible, provide a concise and reproducible example to reproduce the issue for a faster review.
5. If the PR is unfinished, use GitHub PR Draft feature.
-->
### What changes were proposed in this pull request?
<!--
Please clarify what changes you are proposing. The purpose of this section is to outline the changes and how this PR fixes the issue.
If possible, please consider writing useful notes for better and faster reviews in your PR. See the examples below.
1. If you refactor some codes with changing classes, showing the class hierarchy will help reviewers.
2. If there is a discussion in the mailing list, please add the link.
-->
This pr is aimed at making ORC Writer support write thed selected vector.
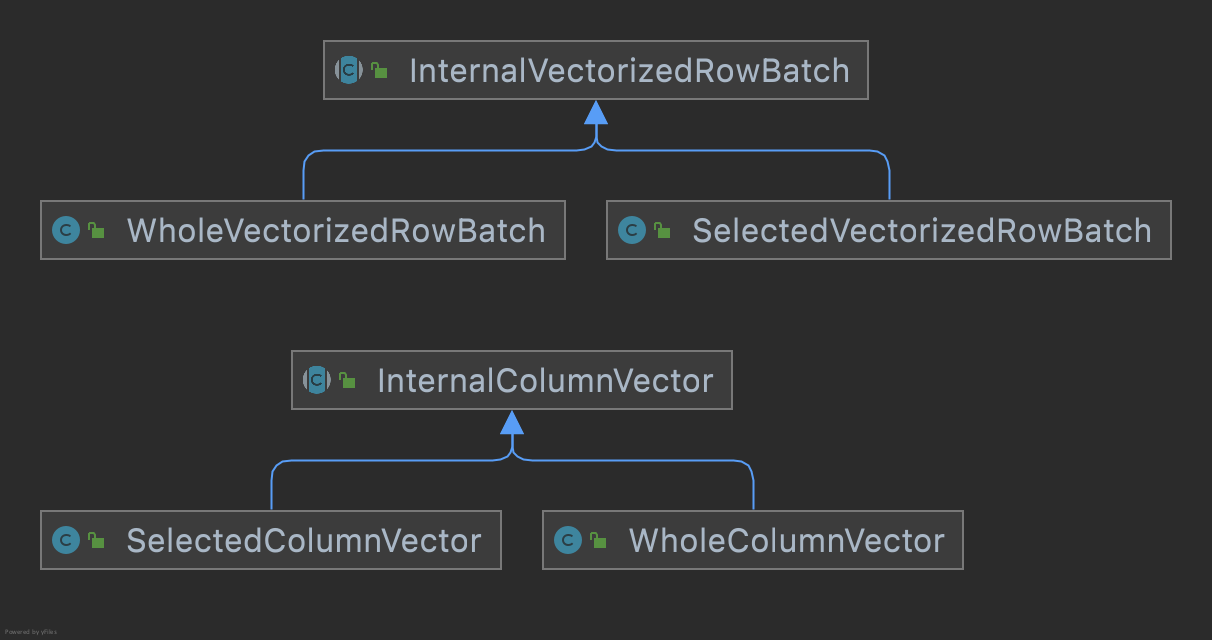
Added InternalVectorizedRowBatch and InternalColumnVector classes to encapsulate and replace VectorizedRowBatc and ColumnVector.
WholeVectorizedRowBatch/WholeColumnVector represents a batch/vector that does not use selected.
SelectedVectorizedRowBatch/SelectedColumnVector represents a batch/vector that does use selected.
During the write process we can use the same interface (`public int getValueOffset(int offset) `) to get the offsets, making the changes minimal and not doing anything redundant.
When writing to the encrypted column, a copy of the Selected Vector is made without modifying the maskData interface, resulting in an unused Selected Vector. Afterwards, the processing is the same as before.
### Why are the changes needed?
<!--
Please clarify why the changes are needed. For instance,
1. If you propose a new API, clarify the use case for a new API.
2. If you fix a bug, you can clarify why it is a bug.
-->
Currently the ORC writer doesn't support the selected vector. This could cause clients that expect it to be supported to get trash rows in the output.
### How was this patch tested?
<!--
If tests were added, say they were added here. Please make sure to add some test cases that check the changes thoroughly including negative and positive cases if possible.
If it was tested in a way different from regular unit tests, please clarify how you tested step by step, ideally copy and paste-able, so that other reviewers can test and check, and descendants can verify in the future.
If tests were not added, please describe why they were not added and/or why it was difficult to add.
-->
Add UT TestSelectedVector.java
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] guiyanakuang commented on pull request #952: ORC-1004: Make orc writer support the selected vector
Posted by GitBox <gi...@apache.org>.
guiyanakuang commented on pull request #952:
URL: https://github.com/apache/orc/pull/952#issuecomment-964903950
> > > @guiyanakuang I am wondering whether the selected vector only applies to the root struct-typed column vector. And I am curious if this patch is a part of some other big work items?
> >
> >
> > @wgtmac Yes, the selected marker is at the row level. It will only work on the root. The purpose of this pr is to resolve [issue](https://issues.apache.org/jira/projects/ORC/issues/ORC-1004?filter=allopenissues). This feature helps me to write the results to the ORC file by filtering, which is useful for creating materialized views. It just happens to be useful for my current work, so I implemented it
>
> As the selection vector only applies to the root struct type, is it possible to use null buffer of the root StructColumnVector (which is always not null for now)? We can ignore writing rows of null data there. This is much simpler but hacky.
Sorry I didn't answer accurately, but in fact the root may also be a single column primitive type. Also the final VectorizedRowBatch obtained by filter query, the unselected rows may not be null. StructColumnVector seems to be written in such a way that it only appears when the sub-column type is struct.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] guiyanakuang commented on a change in pull request #952: ORC-1004: Make orc writer support the selected vector
Posted by GitBox <gi...@apache.org>.
guiyanakuang commented on a change in pull request #952:
URL: https://github.com/apache/orc/pull/952#discussion_r779386491
##########
File path: java/core/src/java/org/apache/orc/impl/WriterImpl.java
##########
@@ -683,20 +683,22 @@ public void addUserMetadata(String name, ByteBuffer value) {
@Override
public void addRowBatch(VectorizedRowBatch batch) throws IOException {
+ InternalVectorizedRowBatch internalBatch = InternalVectorizedRowBatch.encapsulation(batch);
+ int batchSize = internalBatch.size();
try {
// If this is the first set of rows in this stripe, tell the tree writers
// to prepare the stripe.
- if (batch.size != 0 && rowsInStripe == 0) {
+ if (batchSize != 0 && rowsInStripe == 0) {
treeWriter.prepareStripe(stripes.size() + 1);
}
if (buildIndex) {
// Batch the writes up to the rowIndexStride so that we can get the
// right size indexes.
int posn = 0;
- while (posn < batch.size) {
- int chunkSize = Math.min(batch.size - posn,
+ while (posn < batchSize) {
+ int chunkSize = Math.min(batchSize - posn,
rowIndexStride - rowsInIndex);
- treeWriter.writeRootBatch(batch, posn, chunkSize);
+ treeWriter.writeRootBatch(internalBatch, posn, chunkSize);
Review comment:
The test passed perfectly. Very nice implementation. I'll close the pr. Wait for your pr and I can contribute test cases
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] guiyanakuang commented on a change in pull request #952: ORC-1004: Make orc writer support the selected vector
Posted by GitBox <gi...@apache.org>.
guiyanakuang commented on a change in pull request #952:
URL: https://github.com/apache/orc/pull/952#discussion_r778754272
##########
File path: java/core/src/java/org/apache/orc/impl/SelectedColumnVector.java
##########
@@ -0,0 +1,55 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.orc.impl;
+
+import org.apache.hadoop.hive.ql.exec.vector.ColumnVector;
+
+import java.util.function.Function;
+
+public class SelectedColumnVector extends InternalColumnVector {
+
+ private final int[] selected;
+
+ public SelectedColumnVector(ColumnVector columnVector, int[] selected) {
+ super(columnVector);
+ this.selected = selected;
+ }
+
+ @Override
+ public void ensureSize(int size, boolean preserveData) {
+ throw new UnsupportedOperationException(
+ "The ensureSize operation is not supported for SelectedColumnVector");
+ }
+
+ @Override
+ public boolean isNull(int offset) {
+ return columnVector.isNull[getValueOffset(offset)];
+ }
+
+ @Override
+ public int getValueOffset(int offset) {
+ return selected[offset];
Review comment:
@wgtmac I am very sorry, I missed the message so late to reply
The reason is that I can very easily construct the InternalColumnVector from vectorizedRowBatch, selected is actually an array passed in by vectorizedRowBatch, so there is no need to provide additional space to store selection information.
SelectedVectorizedRowBatch.java
```java
@Override
public InternalColumnVector cols(int col) {
return new SelectedColumnVector(vectorizedRowBatch.cols[col], vectorizedRowBatch.getSelected());
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] wgtmac commented on pull request #952: ORC-1004: Make orc writer support the selected vector
Posted by GitBox <gi...@apache.org>.
wgtmac commented on pull request #952:
URL: https://github.com/apache/orc/pull/952#issuecomment-962789109
@guiyanakuang I am wondering whether the selected vector only applies to the root struct-typed column vector. And I am curious if this patch is a part of some other big work items?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] guiyanakuang commented on pull request #952: ORC-1004: Make orc writer support the selected vector
Posted by GitBox <gi...@apache.org>.
guiyanakuang commented on pull request #952:
URL: https://github.com/apache/orc/pull/952#issuecomment-962796005
> @guiyanakuang I am wondering whether the selected vector only applies to the root struct-typed column vector. And I am curious if this patch is a part of some other big work items?
@wgtmac Yes, the selected marker is at the row level. It will only work on the root. The purpose of this pr is to resolve [issue](https://issues.apache.org/jira/projects/ORC/issues/ORC-1004?filter=allopenissues). This feature helps me to write the results to the ORC file by filtering, which is useful for creating materialized views. It just happens to be useful for my current work, so I implemented it
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] wgtmac commented on pull request #952: ORC-1004: Make orc writer support the selected vector
Posted by GitBox <gi...@apache.org>.
wgtmac commented on pull request #952:
URL: https://github.com/apache/orc/pull/952#issuecomment-964849664
> > @guiyanakuang I am wondering whether the selected vector only applies to the root struct-typed column vector. And I am curious if this patch is a part of some other big work items?
>
> @wgtmac Yes, the selected marker is at the row level. It will only work on the root. The purpose of this pr is to resolve [issue](https://issues.apache.org/jira/projects/ORC/issues/ORC-1004?filter=allopenissues). This feature helps me to write the results to the ORC file by filtering, which is useful for creating materialized views. It just happens to be useful for my current work, so I implemented it
As the selection vector only applies to the root struct type, is it possible to use null buffer of the root StructColumnVector (which is always not null for now)? We can ignore writing rows of null data there. This is much simpler but hacky.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] wgtmac commented on a change in pull request #952: ORC-1004: Make orc writer support the selected vector
Posted by GitBox <gi...@apache.org>.
wgtmac commented on a change in pull request #952:
URL: https://github.com/apache/orc/pull/952#discussion_r779370588
##########
File path: java/core/src/java/org/apache/orc/impl/WriterImpl.java
##########
@@ -683,20 +683,22 @@ public void addUserMetadata(String name, ByteBuffer value) {
@Override
public void addRowBatch(VectorizedRowBatch batch) throws IOException {
+ InternalVectorizedRowBatch internalBatch = InternalVectorizedRowBatch.encapsulation(batch);
+ int batchSize = internalBatch.size();
try {
// If this is the first set of rows in this stripe, tell the tree writers
// to prepare the stripe.
- if (batch.size != 0 && rowsInStripe == 0) {
+ if (batchSize != 0 && rowsInStripe == 0) {
treeWriter.prepareStripe(stripes.size() + 1);
}
if (buildIndex) {
// Batch the writes up to the rowIndexStride so that we can get the
// right size indexes.
int posn = 0;
- while (posn < batch.size) {
- int chunkSize = Math.min(batch.size - posn,
+ while (posn < batchSize) {
+ int chunkSize = Math.min(batchSize - posn,
rowIndexStride - rowsInIndex);
- treeWriter.writeRootBatch(batch, posn, chunkSize);
+ treeWriter.writeRootBatch(internalBatch, posn, chunkSize);
Review comment:
I think the root treeWriter can deal with selected nested columns very well. Let me demonstrate my idea in this patch: https://github.com/wgtmac/orc/commit/42ee957be4113af62ccb59319d861fb9462a7c1e
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] guiyanakuang commented on a change in pull request #952: ORC-1004: Make orc writer support the selected vector
Posted by GitBox <gi...@apache.org>.
guiyanakuang commented on a change in pull request #952:
URL: https://github.com/apache/orc/pull/952#discussion_r779375232
##########
File path: java/core/src/java/org/apache/orc/impl/WriterImpl.java
##########
@@ -683,20 +683,22 @@ public void addUserMetadata(String name, ByteBuffer value) {
@Override
public void addRowBatch(VectorizedRowBatch batch) throws IOException {
+ InternalVectorizedRowBatch internalBatch = InternalVectorizedRowBatch.encapsulation(batch);
+ int batchSize = internalBatch.size();
try {
// If this is the first set of rows in this stripe, tell the tree writers
// to prepare the stripe.
- if (batch.size != 0 && rowsInStripe == 0) {
+ if (batchSize != 0 && rowsInStripe == 0) {
treeWriter.prepareStripe(stripes.size() + 1);
}
if (buildIndex) {
// Batch the writes up to the rowIndexStride so that we can get the
// right size indexes.
int posn = 0;
- while (posn < batch.size) {
- int chunkSize = Math.min(batch.size - posn,
+ while (posn < batchSize) {
+ int chunkSize = Math.min(batchSize - posn,
rowIndexStride - rowsInIndex);
- treeWriter.writeRootBatch(batch, posn, chunkSize);
+ treeWriter.writeRootBatch(internalBatch, posn, chunkSize);
Review comment:
I feel a sense of clarity, @wgtmac thank you for the idea, I will use my test cases later to verify
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] guiyanakuang closed pull request #952: ORC-1004: Make orc writer support the selected vector
Posted by GitBox <gi...@apache.org>.
guiyanakuang closed pull request #952:
URL: https://github.com/apache/orc/pull/952
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] wgtmac commented on a change in pull request #952: ORC-1004: Make orc writer support the selected vector
Posted by GitBox <gi...@apache.org>.
wgtmac commented on a change in pull request #952:
URL: https://github.com/apache/orc/pull/952#discussion_r775949338
##########
File path: java/core/src/java/org/apache/orc/impl/SelectedColumnVector.java
##########
@@ -0,0 +1,55 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.orc.impl;
+
+import org.apache.hadoop.hive.ql.exec.vector.ColumnVector;
+
+import java.util.function.Function;
+
+public class SelectedColumnVector extends InternalColumnVector {
+
+ private final int[] selected;
+
+ public SelectedColumnVector(ColumnVector columnVector, int[] selected) {
+ super(columnVector);
+ this.selected = selected;
+ }
+
+ @Override
+ public void ensureSize(int size, boolean preserveData) {
+ throw new UnsupportedOperationException(
+ "The ensureSize operation is not supported for SelectedColumnVector");
+ }
+
+ @Override
+ public boolean isNull(int offset) {
+ return columnVector.isNull[getValueOffset(offset)];
+ }
+
+ @Override
+ public int getValueOffset(int offset) {
+ return selected[offset];
Review comment:
What the main reason for using an int array as the selected vector?
##########
File path: java/core/src/java/org/apache/orc/impl/WriterImpl.java
##########
@@ -683,20 +683,22 @@ public void addUserMetadata(String name, ByteBuffer value) {
@Override
public void addRowBatch(VectorizedRowBatch batch) throws IOException {
+ InternalVectorizedRowBatch internalBatch = InternalVectorizedRowBatch.encapsulation(batch);
+ int batchSize = internalBatch.size();
try {
// If this is the first set of rows in this stripe, tell the tree writers
// to prepare the stripe.
- if (batch.size != 0 && rowsInStripe == 0) {
+ if (batchSize != 0 && rowsInStripe == 0) {
treeWriter.prepareStripe(stripes.size() + 1);
}
if (buildIndex) {
// Batch the writes up to the rowIndexStride so that we can get the
// right size indexes.
int posn = 0;
- while (posn < batch.size) {
- int chunkSize = Math.min(batch.size - posn,
+ while (posn < batchSize) {
+ int chunkSize = Math.min(batchSize - posn,
rowIndexStride - rowsInIndex);
- treeWriter.writeRootBatch(batch, posn, chunkSize);
+ treeWriter.writeRootBatch(internalBatch, posn, chunkSize);
Review comment:
If I understand correctly, the selected vector only applies to each row in the root VectorizedRowBatch. We can simply use a bool array in the root VectorizedRowBatch to indicate whether each row is selected or not. Then we can split the input VectorizedRowBatch into smaller pieces of continuously selected VectorizedRowBatchs and thus change posn & chunkSize accordingly.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] guiyanakuang commented on pull request #952: ORC-1004: Make orc writer support the selected vector
Posted by GitBox <gi...@apache.org>.
guiyanakuang commented on pull request #952:
URL: https://github.com/apache/orc/pull/952#issuecomment-955904998
> Thank you for making a PR, @guiyanakuang . This looks like a big PR. :)
Yes, although the design prioritizes minimizing changes, it still requires changing the writer for each column. This results in a significant number of modified rows. : )
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] guiyanakuang commented on a change in pull request #952: ORC-1004: Make orc writer support the selected vector
Posted by GitBox <gi...@apache.org>.
guiyanakuang commented on a change in pull request #952:
URL: https://github.com/apache/orc/pull/952#discussion_r778773979
##########
File path: java/core/src/java/org/apache/orc/impl/WriterImpl.java
##########
@@ -683,20 +683,22 @@ public void addUserMetadata(String name, ByteBuffer value) {
@Override
public void addRowBatch(VectorizedRowBatch batch) throws IOException {
+ InternalVectorizedRowBatch internalBatch = InternalVectorizedRowBatch.encapsulation(batch);
+ int batchSize = internalBatch.size();
try {
// If this is the first set of rows in this stripe, tell the tree writers
// to prepare the stripe.
- if (batch.size != 0 && rowsInStripe == 0) {
+ if (batchSize != 0 && rowsInStripe == 0) {
treeWriter.prepareStripe(stripes.size() + 1);
}
if (buildIndex) {
// Batch the writes up to the rowIndexStride so that we can get the
// right size indexes.
int posn = 0;
- while (posn < batch.size) {
- int chunkSize = Math.min(batch.size - posn,
+ while (posn < batchSize) {
+ int chunkSize = Math.min(batchSize - posn,
rowIndexStride - rowsInIndex);
- treeWriter.writeRootBatch(batch, posn, chunkSize);
+ treeWriter.writeRootBatch(internalBatch, posn, chunkSize);
Review comment:
Reusing Selected within a VectorizedRowBatch actually ensures consistent processing across types.
Let's look at a complex case provided in the test case
```java
public void testWriteComplexTypeUseSelectedVector() throws IOException {
TypeDescription schema =
TypeDescription.fromString("struct<a:map<int,uniontype<int,string>>," +
"b:array<struct<c:int>>>");
....
}
```
For example, we have three rows of data, and the third row is selected after the filter. Before reading the third map, we need to determine the offsets of the key and value fields, since the first two maps may have multiple key-value pairs. Of course, if the key and value are also complex types, recursion may be required.
So processing only at the entry does not cover all cases and each type needs to be processed separately.
Imagine that the recursive processing eventually comes to the base type, which doesn't know what offset means. offset may be relative to the row, or it may be a value that has gone through multiple jumps.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] wgtmac commented on a change in pull request #952: ORC-1004: Make orc writer support the selected vector
Posted by GitBox <gi...@apache.org>.
wgtmac commented on a change in pull request #952:
URL: https://github.com/apache/orc/pull/952#discussion_r779399876
##########
File path: java/core/src/java/org/apache/orc/impl/WriterImpl.java
##########
@@ -683,20 +683,22 @@ public void addUserMetadata(String name, ByteBuffer value) {
@Override
public void addRowBatch(VectorizedRowBatch batch) throws IOException {
+ InternalVectorizedRowBatch internalBatch = InternalVectorizedRowBatch.encapsulation(batch);
+ int batchSize = internalBatch.size();
try {
// If this is the first set of rows in this stripe, tell the tree writers
// to prepare the stripe.
- if (batch.size != 0 && rowsInStripe == 0) {
+ if (batchSize != 0 && rowsInStripe == 0) {
treeWriter.prepareStripe(stripes.size() + 1);
}
if (buildIndex) {
// Batch the writes up to the rowIndexStride so that we can get the
// right size indexes.
int posn = 0;
- while (posn < batch.size) {
- int chunkSize = Math.min(batch.size - posn,
+ while (posn < batchSize) {
+ int chunkSize = Math.min(batchSize - posn,
rowIndexStride - rowsInIndex);
- treeWriter.writeRootBatch(batch, posn, chunkSize);
+ treeWriter.writeRootBatch(internalBatch, posn, chunkSize);
Review comment:
Thanks for the verification! I will do it later.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: dev-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org