You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@kyuubi.apache.org by ul...@apache.org on 2021/10/18 12:25:22 UTC
[incubator-kyuubi] branch master updated: [KYUUBI #1085]
Fix-Enforce maxOutputRows for Resolve View, Multi Insert and Distribute By
This is an automated email from the ASF dual-hosted git repository.
ulyssesyou pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/incubator-kyuubi.git
The following commit(s) were added to refs/heads/master by this push:
new f4094d6 [KYUUBI #1085] Fix-Enforce maxOutputRows for Resolve View, Multi Insert and Distribute By
f4094d6 is described below
commit f4094d652492cb20024a26465d6aaa17cc531098
Author: senmiaoliu <se...@trip.com>
AuthorDate: Mon Oct 18 20:25:10 2021 +0800
[KYUUBI #1085] Fix-Enforce maxOutputRows for Resolve View, Multi Insert and Distribute By
<!--
Thanks for sending a pull request!
Here are some tips for you:
1. If this is your first time, please read our contributor guidelines: https://kyuubi.readthedocs.io/en/latest/community/contributions.html
2. If the PR is related to an issue in https://github.com/apache/incubator-kyuubi/issues, add '[KYUUBI #XXXX]' in your PR title, e.g., '[KYUUBI #XXXX] Your PR title ...'.
3. If the PR is unfinished, add '[WIP]' in your PR title, e.g., '[WIP][KYUUBI #XXXX] Your PR title ...'.
-->
### _Why are the changes needed?_
1. Should not add limit when multi insert tables.
```sql
FROM tmp_table
insert into tmp_table1 select * limit 2
insert into tmp_table2 select *
```
We should not add any limit when insert table
2. Should add limit when distribute by
```sql
select * from tmp_table distribute by a
```
3. Should not add limit when resolve view
```sql
SELECT * FROM
(select * from tmp_view1 union select * from tmp_view2)
ORDER BY a DESC
```
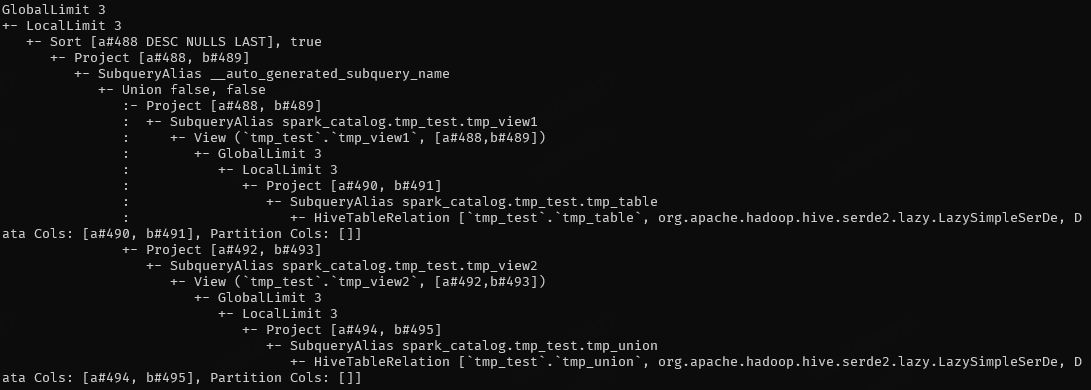
Like this, when the limit is added in resolve view, the complete data cannot be obtained, so the final result is incorrect
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [x] Add screenshots for manual tests if appropriate
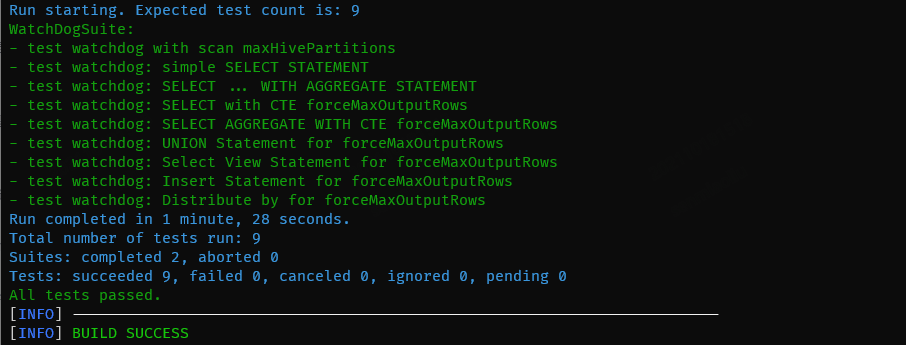
- [x] [Run test](https://kyuubi.readthedocs.io/en/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes #1247 from lsm1/fix/add_limit.
Closes #1085
a02a99c0 [senmiaoliu] Fix-Enforce maxOutputRows for Resolve View, Multi Insert and Distribute By
Authored-by: senmiaoliu <se...@trip.com>
Signed-off-by: ulysses-you <ul...@apache.org>
---
.../sql/watchdog/ForcedMaxOutputRowsRule.scala | 20 ++++-
.../scala/org/apache/spark/sql/WatchDogSuite.scala | 88 ++++++++++++++++++++++
2 files changed, 105 insertions(+), 3 deletions(-)
diff --git a/dev/kyuubi-extension-spark-3-1/src/main/scala/org/apache/kyuubi/sql/watchdog/ForcedMaxOutputRowsRule.scala b/dev/kyuubi-extension-spark-3-1/src/main/scala/org/apache/kyuubi/sql/watchdog/ForcedMaxOutputRowsRule.scala
index d82eead..e52a4c6 100644
--- a/dev/kyuubi-extension-spark-3-1/src/main/scala/org/apache/kyuubi/sql/watchdog/ForcedMaxOutputRowsRule.scala
+++ b/dev/kyuubi-extension-spark-3-1/src/main/scala/org/apache/kyuubi/sql/watchdog/ForcedMaxOutputRowsRule.scala
@@ -18,11 +18,13 @@
package org.apache.kyuubi.sql.watchdog
import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.catalyst.analysis.AnalysisContext
import org.apache.spark.sql.catalyst.dsl.expressions._
import org.apache.spark.sql.catalyst.expressions.Alias
-import org.apache.spark.sql.catalyst.plans.logical.{Aggregate, Distinct, Filter, Limit, LogicalPlan, Project, Sort, Union}
+import org.apache.spark.sql.catalyst.plans.logical.{Aggregate, Distinct, Filter, Limit, LogicalPlan, Project, RepartitionByExpression, Sort, Union}
import org.apache.spark.sql.catalyst.rules.Rule
import org.apache.spark.sql.catalyst.trees.TreeNodeTag
+import org.apache.spark.sql.execution.command.DataWritingCommand
import org.apache.kyuubi.sql.KyuubiSQLConf
@@ -56,16 +58,27 @@ case class ForcedMaxOutputRowsRule(session: SparkSession) extends Rule[LogicalPl
.aggregateExpressions.exists(p => p.getTagValue(ForcedMaxOutputRowsConstraint.CHILD_AGGREGATE)
.contains(ForcedMaxOutputRowsConstraint.CHILD_AGGREGATE_FLAG))
+ private def isView: Boolean = {
+ val nestedViewDepth = AnalysisContext.get.nestedViewDepth
+ nestedViewDepth > 0
+ }
+
private def canInsertLimitInner(p: LogicalPlan): Boolean = p match {
case Aggregate(_, Alias(_, "havingCondition")::Nil, _) => false
case agg: Aggregate => !isChildAggregate(agg)
+ case _: RepartitionByExpression => true
case _: Distinct => true
case _: Filter => true
case _: Project => true
case Limit(_, _) => true
case _: Sort => true
- case _: Union => true
+ case Union(children, _, _) =>
+ if (children.exists(_.isInstanceOf[DataWritingCommand])) {
+ false
+ } else {
+ true
+ }
case _ => false
}
@@ -74,7 +87,8 @@ case class ForcedMaxOutputRowsRule(session: SparkSession) extends Rule[LogicalPl
maxOutputRowsOpt match {
case Some(forcedMaxOutputRows) => canInsertLimitInner(p) &&
- !p.maxRows.exists(_ <= forcedMaxOutputRows)
+ !p.maxRows.exists(_ <= forcedMaxOutputRows) &&
+ !isView
case None => false
}
}
diff --git a/dev/kyuubi-extension-spark-3-1/src/test/scala/org/apache/spark/sql/WatchDogSuite.scala b/dev/kyuubi-extension-spark-3-1/src/test/scala/org/apache/spark/sql/WatchDogSuite.scala
index 29ddea6..51aae6c 100644
--- a/dev/kyuubi-extension-spark-3-1/src/test/scala/org/apache/spark/sql/WatchDogSuite.scala
+++ b/dev/kyuubi-extension-spark-3-1/src/test/scala/org/apache/spark/sql/WatchDogSuite.scala
@@ -291,4 +291,92 @@ class WatchDogSuite extends KyuubiSparkSQLExtensionTest {
}
}
}
+
+ test("test watchdog: Select View Statement for forceMaxOutputRows") {
+ withSQLConf(KyuubiSQLConf.WATCHDOG_FORCED_MAXOUTPUTROWS.key -> "3") {
+ withTable("tmp_table", "tmp_union") {
+ withView("tmp_view", "tmp_view2") {
+ sql(s"create table tmp_table (a int, b int)")
+ sql(s"insert into tmp_table values (1,10),(2,20),(3,30),(4,40),(5,50)")
+ sql(s"create table tmp_union (a int, b int)")
+ sql(s"insert into tmp_union values (6,60),(7,70),(8,80),(9,90),(10,100)")
+ sql(s"create view tmp_view2 as select * from tmp_union")
+ assert(!sql(
+ s"""
+ |CREATE VIEW tmp_view
+ |as
+ |SELECT * FROM
+ |tmp_table
+ |""".stripMargin)
+ .queryExecution.analyzed.isInstanceOf[GlobalLimit])
+
+ assert(sql(
+ s"""
+ |SELECT * FROM
+ |tmp_view
+ |""".stripMargin)
+ .queryExecution.analyzed.maxRows.contains(3))
+
+ assert(sql(
+ s"""
+ |SELECT * FROM
+ |tmp_view
+ |limit 11
+ |""".stripMargin)
+ .queryExecution.analyzed.maxRows.contains(3))
+
+ assert(sql(
+ s"""
+ |SELECT * FROM
+ |(select * from tmp_view
+ |UNION
+ |select * from tmp_view2)
+ |ORDER BY a
+ |DESC
+ |""".stripMargin)
+ .collect().head.get(0).equals(10))
+ }
+ }
+ }
+ }
+
+ test("test watchdog: Insert Statement for forceMaxOutputRows") {
+
+ withSQLConf(KyuubiSQLConf.WATCHDOG_FORCED_MAXOUTPUTROWS.key -> "10") {
+ withTable("tmp_table", "tmp_insert") {
+ spark.sql(s"create table tmp_table (a int, b int)")
+ spark.sql(s"insert into tmp_table values (1,10),(2,20),(3,30),(4,40),(5,50)")
+ val multiInsertTableName1: String = "tmp_tbl1"
+ val multiInsertTableName2: String = "tmp_tbl2"
+ sql(s"drop table if exists $multiInsertTableName1")
+ sql(s"drop table if exists $multiInsertTableName2")
+ sql(s"create table $multiInsertTableName1 like tmp_table")
+ sql(s"create table $multiInsertTableName2 like tmp_table")
+ assert(!sql(
+ s"""
+ |FROM tmp_table
+ |insert into $multiInsertTableName1 select * limit 2
+ |insert into $multiInsertTableName2 select *
+ |""".stripMargin)
+ .queryExecution.analyzed.isInstanceOf[GlobalLimit])
+ }
+ }
+ }
+
+ test("test watchdog: Distribute by for forceMaxOutputRows") {
+
+ withSQLConf(KyuubiSQLConf.WATCHDOG_FORCED_MAXOUTPUTROWS.key -> "10") {
+ withTable("tmp_table") {
+ spark.sql(s"create table tmp_table (a int, b int)")
+ spark.sql(s"insert into tmp_table values (1,10),(2,20),(3,30),(4,40),(5,50)")
+ assert(sql(
+ s"""
+ |SELECT *
+ |FROM tmp_table
+ |DISTRIBUTE BY a
+ |""".stripMargin)
+ .queryExecution.analyzed.isInstanceOf[GlobalLimit])
+ }
+ }
+ }
}