You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2019/03/20 09:10:27 UTC
[GitHub] [spark] Nimfadora commented on a change in pull request #23791:
[SPARK-20597][SQL][SS][WIP] KafkaSourceProvider falls back on path as
synonym for topic
Nimfadora commented on a change in pull request #23791: [SPARK-20597][SQL][SS][WIP] KafkaSourceProvider falls back on path as synonym for topic
URL: https://github.com/apache/spark/pull/23791#discussion_r266027495
##########
File path: docs/structured-streaming-kafka-integration.md
##########
@@ -457,8 +463,17 @@ The following configurations are optional:
<td>string</td>
<td>none</td>
<td>streaming and batch</td>
+ <td>Sets the topic that all rows will be written to in Kafka. This option overrides
+ ```path``` option and any topic column that may exist in the data.</td>
+</tr>
+<tr>
+ <td>path</td>
+ <td>string</td>
+ <td>none</td>
+ <td>streaming and batch</td>
<td>Sets the topic that all rows will be written to in Kafka. This option overrides any
- topic column that may exist in the data.</td>
+ topic column that may exist in the data and is overridden by ```topic``` option.
Review comment:
@gaborgsomogyi I agree with you, that first solution seems to be right way to go. I hope that I will not miss any place where it is used, while writing unit tests. My concern is about checking the topic column value. We cannot move the projection out of KafkaRowWriter, but if we move all the validation inside, than it would no longer be fail-fast: in current implementation we are checking all that we can before RDD creation. Although, I do not really understand why checks are duplicated between [KafkaRowWriter#createProjection](https://github.com/apache/spark/blob/master/external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaWriteTask.scala#L101) and [KafkaWriter#validateQuery](https://github.com/apache/spark/blob/master/external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaWriter.scala#L45)? As I can see validateQuery is always called before createProjection. @gaborgsomogyi @jaceklaskowski do you know any reason for this duplication?
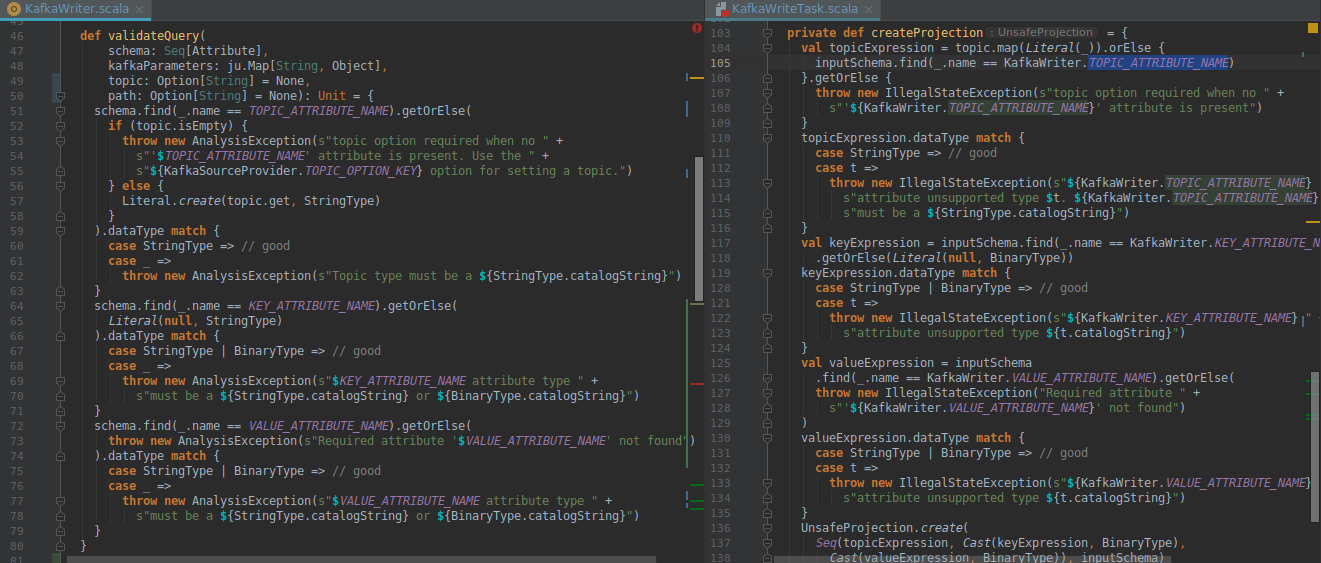
The solution I propose:
- remove duplicated checks from KafkaRowWriter#createProjection
- move check for topic and path option match to KafkaWriter#validateQuery
- add topic option and topic attribute match validation to KafkaRowWriter
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org