You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2021/09/03 08:05:48 UTC
[GitHub] [spark] zhengruifeng commented on a change in pull request #33893: [SPARK-36638][SQL] Generalize OptimizeSkewedJoin
zhengruifeng commented on a change in pull request #33893:
URL: https://github.com/apache/spark/pull/33893#discussion_r701688868
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/OptimizeSkewedJoin.scala
##########
@@ -101,166 +104,317 @@ object OptimizeSkewedJoin extends AQEShuffleReadRule {
sizes.sum / sizes.length
}
- /*
- * This method aim to optimize the skewed join with the following steps:
- * 1. Check whether the shuffle partition is skewed based on the median size
- * and the skewed partition threshold in origin shuffled join (smj and shj).
- * 2. Assuming partition0 is skewed in left side, and it has 5 mappers (Map0, Map1...Map4).
- * And we may split the 5 Mappers into 3 mapper ranges [(Map0, Map1), (Map2, Map3), (Map4)]
- * based on the map size and the max split number.
- * 3. Wrap the join left child with a special shuffle read that loads each mapper range with one
- * task, so total 3 tasks.
- * 4. Wrap the join right child with a special shuffle read that loads partition0 3 times by
- * 3 tasks separately.
- */
- private def tryOptimizeJoinChildren(
- left: ShuffleQueryStageExec,
- right: ShuffleQueryStageExec,
- joinType: JoinType): Option[(SparkPlan, SparkPlan)] = {
- val canSplitLeft = canSplitLeftSide(joinType)
- val canSplitRight = canSplitRightSide(joinType)
- if (!canSplitLeft && !canSplitRight) return None
-
- val leftSizes = left.mapStats.get.bytesByPartitionId
- val rightSizes = right.mapStats.get.bytesByPartitionId
- assert(leftSizes.length == rightSizes.length)
- val numPartitions = leftSizes.length
- // We use the median size of the original shuffle partitions to detect skewed partitions.
- val leftMedSize = medianSize(leftSizes)
- val rightMedSize = medianSize(rightSizes)
- logDebug(
- s"""
- |Optimizing skewed join.
- |Left side partitions size info:
- |${getSizeInfo(leftMedSize, leftSizes)}
- |Right side partitions size info:
- |${getSizeInfo(rightMedSize, rightSizes)}
- """.stripMargin)
-
- val leftSkewThreshold = getSkewThreshold(leftMedSize)
- val rightSkewThreshold = getSkewThreshold(rightMedSize)
- val leftTargetSize = targetSize(leftSizes, leftSkewThreshold)
- val rightTargetSize = targetSize(rightSizes, rightSkewThreshold)
-
- val leftSidePartitions = mutable.ArrayBuffer.empty[ShufflePartitionSpec]
- val rightSidePartitions = mutable.ArrayBuffer.empty[ShufflePartitionSpec]
- var numSkewedLeft = 0
- var numSkewedRight = 0
- for (partitionIndex <- 0 until numPartitions) {
- val leftSize = leftSizes(partitionIndex)
- val isLeftSkew = canSplitLeft && leftSize > leftSkewThreshold
- val rightSize = rightSizes(partitionIndex)
- val isRightSkew = canSplitRight && rightSize > rightSkewThreshold
- val leftNoSkewPartitionSpec =
- Seq(CoalescedPartitionSpec(partitionIndex, partitionIndex + 1, leftSize))
- val rightNoSkewPartitionSpec =
- Seq(CoalescedPartitionSpec(partitionIndex, partitionIndex + 1, rightSize))
-
- val leftParts = if (isLeftSkew) {
- val skewSpecs = ShufflePartitionsUtil.createSkewPartitionSpecs(
- left.mapStats.get.shuffleId, partitionIndex, leftTargetSize)
- if (skewSpecs.isDefined) {
- logDebug(s"Left side partition $partitionIndex " +
- s"(${FileUtils.byteCountToDisplaySize(leftSize)}) is skewed, " +
- s"split it into ${skewSpecs.get.length} parts.")
- numSkewedLeft += 1
+ private def optimize(plan: SparkPlan): SparkPlan = {
+ val logPrefix = s"Optimizing ${plan.nodeName} #${plan.id}"
+
+ // Step 0: Collect all ShuffledJoins (SMJ/SHJ)
+ def collectShuffledJoins(plan: SparkPlan): Seq[ShuffledJoin] = plan match {
+ case join: ShuffledJoin => Seq(join) ++ join.children.flatMap(collectShuffledJoins)
+ case _ => plan.children.flatMap(collectShuffledJoins)
+ }
+ val joins = collectShuffledJoins(plan)
+ logDebug(s"$logPrefix: ShuffledJoins: ${joins.map(_.nodeName).mkString("[", ", ", "]")}")
+ if (joins.isEmpty || joins.exists(_.isSkewJoin)) return plan
+ val topJoin = joins.head
+
+ // Step1: validate physical operators
+ // There are more and more physical operators, this list is used to avoid correctness issues
+ // TODO: support more operators like AggregateInPandasExec/FlatMapCoGroupsInPandasExec/etc
+ val invalidOperators = topJoin.collect {
+ case _: WholeStageCodegenExec => None
+ case _: AQEShuffleReadExec => None
+ case _: QueryStageExec => None
+ case _: SortExec => None
+ case _: BaseJoinExec => None
+ case _: ObjectHashAggregateExec => None
+ case _: HashAggregateExec => None
+ case _: SortAggregateExec => None
+ case _: WindowExec => None
+ case _: ProjectExec => None
+ case _: FilterExec => None
+ case _: SampleExec => None
+ case _: ColumnarToRowExec => None
+ case _: RowToColumnarExec => None
+ case _: DeserializeToObjectExec => None
+ case _: SerializeFromObjectExec => None
+ case _: MapElementsExec => None
+ case _: MapPartitionsExec => None
+ case _: MapPartitionsInRWithArrowExec => None
+ case _: MapInPandasExec => None
+ case _: EvalPythonExec => None
+ case _: CollectMetricsExec => None
+ case invalid => Some(invalid)
+ }.flatten
+ if (invalidOperators.nonEmpty) {
+ logDebug(s"$logPrefix: Do NOT support operators " +
+ s"${invalidOperators.map(_.nodeName).mkString("[", ", ", "]")}")
+ return plan
+ }
+
+ // Step 2: Collect all ShuffleQueryStages
+ val leaves = topJoin.collectLeaves()
+ // for a N-Join stage, there should be N+1 leaves.
+ if (leaves.size != joins.size + 1) return plan
+ // stageId -> MapOutputStatistics
+ val stageStats = leaves.flatMap {
+ case stage: ShuffleQueryStageExec if isSupported(stage.shuffle) =>
+ stage.mapStats.filter(_.bytesByPartitionId.nonEmpty).map(stats => stage.id -> stats)
+ case _ => None
+ }.toMap
+ // TODO: support Bucket Join with other types of leaves.
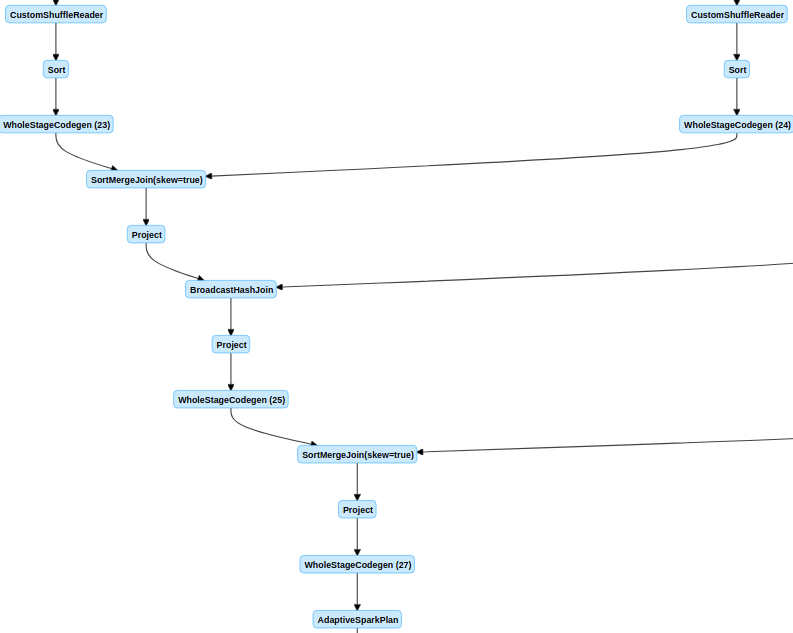
Review comment:
Great catch! BHJ is also considered in our internal system (based on 3.0). Some non-trivial changes were made to port it to master, and BHJ is ignored. I will update this PR.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org