You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@druid.apache.org by GitBox <gi...@apache.org> on 2021/12/06 14:34:45 UTC
[GitHub] [druid] henriquekops opened a new issue #12028: Low intermediate persist disk space may caused segments view to be inconsistent
henriquekops opened a new issue #12028:
URL: https://github.com/apache/druid/issues/12028
Please provide a detailed title (e.g. "Broker crashes when using TopN query with Bound filter" instead of just "Broker crashes").
# Affected Version
The Druid version where the problem was encountered.
### 0.20.0
# Description
I'm currently running Druid with the following deployment:
- Druid on Kubernetes
- PSQL v13.3 as Metadata database (MDDB)
- S3 as deep storage (DS)
- NFS for segment cache
- GlusterFS for other volumes, such as `baseTaskDir`
This bug was found when ingesting batch data using `index_parallel` task with `"segmentGranularity": "DAY"`.
## The problem
**The problem occurs when running this kind of ingestion within more than 1 month of data (in my case). I have noticed that not all the expected days were showing up when querying at the UI / Broker API, even with the datasource labeled as fully available at the UI and all segments shown at the DS, segment cache and MDDB.**
## Possible root cause
The root cause may be the low amount of disk given to `baseTaskDir` volume, of which leads ingestion tasks to fail.
I also noticed that the same intervals highlighted at the failed tasks were retried afterwards, which caused them to be marked as succeeded.
The space exception can be seen at Middle Manager logs, which highlights intervals that are not shown by the broker process when querying:

## What I expect
I expect that if in fact the failed ingestion task causes segments to be corrupted because of intermediate persist disk space, the segment's intervals should not be loaded to S3, neither segment cache or MDDB, otherwise different services are showing different views of available (queryable) segments.
Otherwise, if the failed ingestion task doesn't causes segments to be corrupted, then all data points inside the consulted interval should be returned.
## Debug info
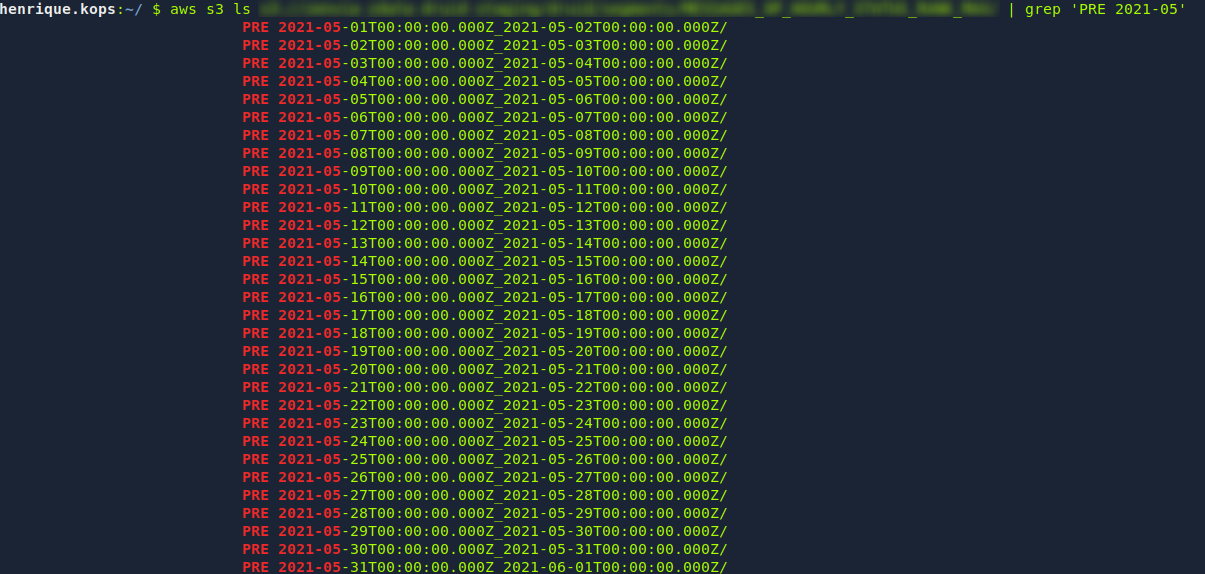
To illustrate this problem I'll provide some query results for the month of may:
### Querying at the broker process to return all days of specific interval (month of may):
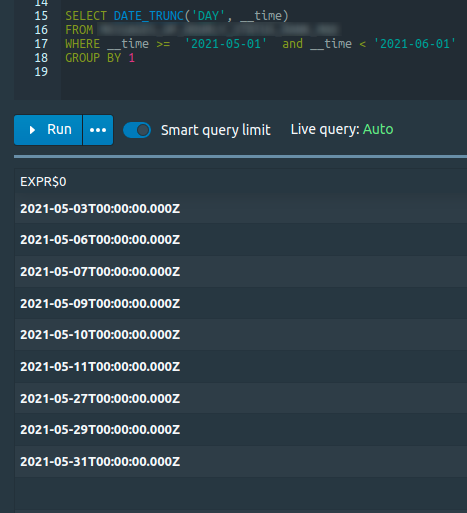
### Querying `sys.segments` table at the UI:
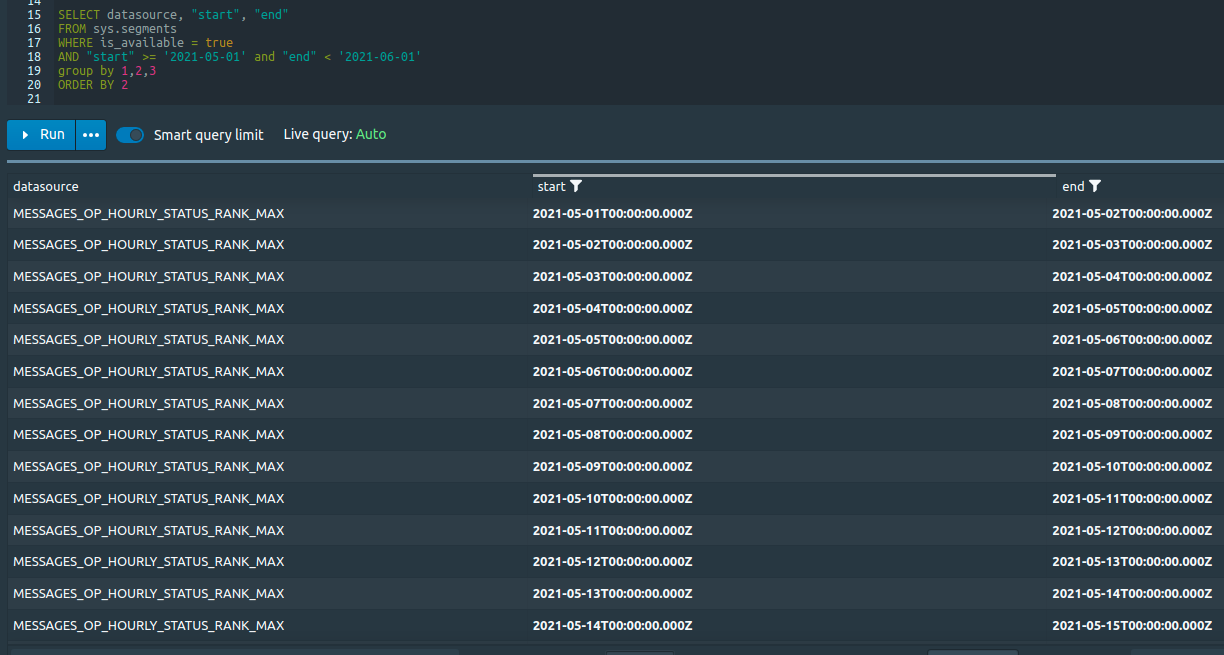
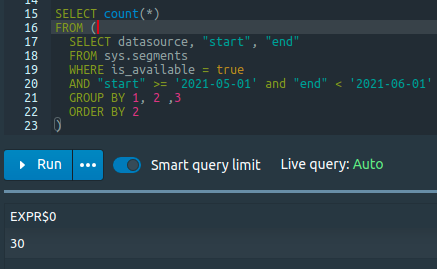
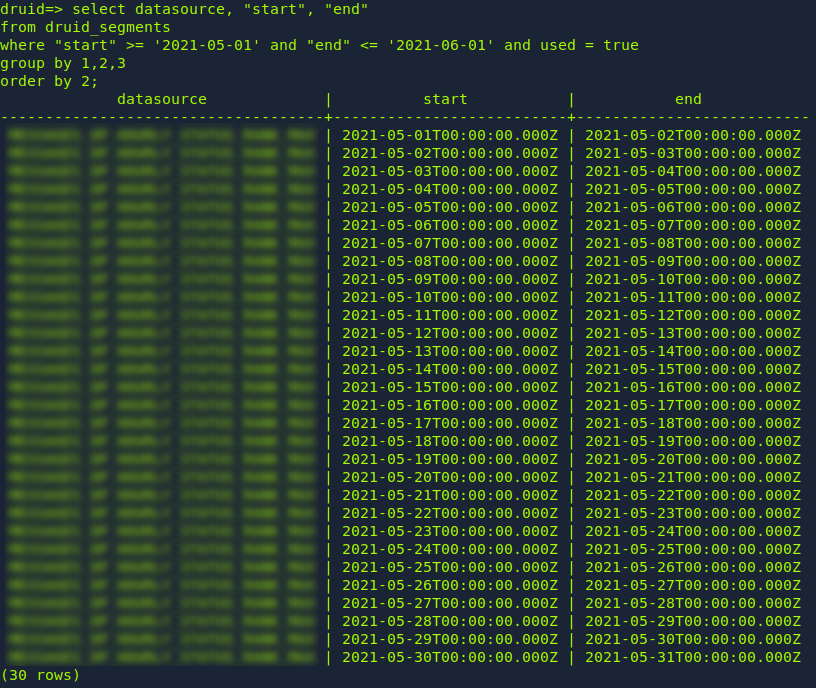
### Querying `druid_segments` at PSQL:
### Querying at S3:
### Ingestion Spec
I'll also provide the ingestion spec I used to load this datasource:
```json
{
"type": "index_parallel",
"spec": {
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "hdfs",
"paths": [
"hdfs://.../year=2021/month=1/*/*.gz",
"hdfs://.../year=2021/month=2/*/*.gz",
"hdfs://.../year=2021/month=3/*/*.gz"
]
},
"inputFormat": {
"type": "json",
"flattenSpec": {
"fields": [
{
"name": "timestamp",
"type": "path",
"expr": "$.message.timestamp"
},
...
]
}
}
},
"tuningConfig": {
"type": "index_parallel",
"maxNumConcurrentSubTasks": 27,
"partitionsSpec": {
"type": "dynamic"
}
},
"dataSchema": {
"dataSource": "<DATASOURCE_NAME>",
"granularitySpec": {
"type": "uniform",
"queryGranularity": "HOUR",
"segmentGranularity": "DAY",
"rollup": true
},
"timestampSpec": {
"column": "timestamp",
"format": "iso"
},
"dimensionsSpec": {
"dimensions": [
...
]
},
"metricsSpec": [
{
"name": "count_of_rows",
"type": "count"
},
...
]
}
}
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org