You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@druid.apache.org by GitBox <gi...@apache.org> on 2022/01/15 22:26:55 UTC
[GitHub] [druid] JulianJaffePinterest opened a new pull request #12159: Add Spark Writer support.
JulianJaffePinterest opened a new pull request #12159:
URL: https://github.com/apache/druid/pull/12159
Add code, utilities, tests, and documentation for writing data to Druid using Spark.
This is the final piecemeal PR recapitulating #10920 (see #11474 and #11823 for the previous two).
### Description
This connector writes Druid segment files to deep storage, one per input Spark partition. The connector also writes the segment descriptions to the Druid metadata SQL server, at which point the normal Druid coordination process handles loading, atomic updating, and overshadowing.
#### Writing Segments
Each Spark partition is assigned to an executor. For each partition, one or more `IncrementalIndex` is created and passed the rows in the source Spark partition for the index's interval. The indices are flushed to local storage while being built before being pushed to deep storage. Internally, this writer uses a two-phase commit model to push segments: if all Spark partitions are successfully written to Druid segment files on deep storage, the segment metadata is published and the Druid segment coordination process takes over. However, if one or more partitions fail, the write is aborted, the segments already written to deep storage are deleted, and control is passed back to Spark for error handling.
##### Key Classes
`DruidDataSourceWriter`
`DruidWriterFactory`
`DruidDataWriter`
#### Partitioning
Spark's architecture means that the source dataframe is already partitioned by the time this writer is called. By default, this writer will attempt to "rationalize" input segments such that all covered time intervals are contiguous and complete. This means that Druid can atomically load and overshadow the produced segments but doesn't prevent sub-optimal partitioning from passing through from Spark to Druid. To address this issue, callers can partition their dataframes themselves and pass the writer a partition map describing the partitioning scheme. The writer provides four partitioners out of the box that callers can use as well (see the [docs](docs/operations/spark.md#provided-partitioners) for more information).
##### Key Classes
`SegmentRationalizer`
`org.apache.druid.spark.partitioners.*`
#### User Interface
Users call this writer like any other Spark writer: they call `.write()` on a DataFrame, configure their writer if desired, and then call `.save()`. Like the reader introduced in #11823, there is also a more ergonomic and type-safe wrapper if desired. As always, the documentation contains a complete configuration reference with further examples.
Example configuration:
```scala
val metadataProperties = Map[String, String](
"metadata.dbType" -> "mysql",
"metadata.connectUri" -> "jdbc:mysql://druid.metadata.server:3306/druid",
"metadata.user" -> "druid",
"metadata.password" -> "diurd"
)
val writerConfigs = Map[String, String] (
"table" -> "dataSource",
"writer.version" -> 1,
"writer.deepStorageType" -> "local",
"writer.storageDirectory" -> "/mnt/druid/druid-segments/"
)
df
.write
.format("druid")
.mode(SaveMode.Overwrite)
.options(Map[String, String](writerConfigs ++ metadataProperties))
.save()
```
or using the convenience wrapper:
```scala
import org.apache.druid.spark.DruidDataFrameWriter
val deepStorageConfig = new LocalDeepStorageConfig().storageDirectory("/mnt/druid/druid-segments/")
df
.write
.metadataDbType("mysql")
.metadataUri("jdbc:mysql://druid.metadata.server:3306/druid")
.metadataUser("druid")
.metadataPassword("diurd")
.version(1)
.deepStorage(deepStorageConfig)
.mode(SaveMode.Overwrite)
.dataSource("dataSource")
.druid()
```
<hr>
This PR has:
- [x] been self-reviewed.
- [x] added documentation for new or modified features or behaviors.
- [x] added Javadocs for most classes and all non-trivial methods. Linked related entities via Javadoc links.
- [x] added or updated version, license, or notice information in [licenses.yaml](https://github.com/apache/druid/blob/master/dev/license.md)
- [x] added comments explaining the "why" and the intent of the code wherever would not be obvious for an unfamiliar reader.
- [x] added unit tests or modified existing tests to cover new code paths, ensuring the threshold for [code coverage](https://github.com/apache/druid/blob/master/dev/code-review/code-coverage.md) is met.
- [x] added integration tests.
- [x] been tested in a test Druid cluster.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1042657139
@JulianJaffePinterest I tested it this way
`Dataset<Row> dataset = sparkSession.createDataFrame(list, schema);`
` Dataset<Row> bucketedDataset = dataset.withColumn("quick_col",SparkUdfs.bucketRow().apply(functions.col("_timeBucketCol"),functions.lit("millis"),functions.lit("DAY")));`
` Dataset<Row> partitionedDataSet1 = bucketedDataset.repartition(functions.col("quick_col")).drop(functions.col("quick_col"));`
` Dataset<Row> partitionedDataSet2 = partitionedDataSet1.repartition(10);` // Increase parallelism
` partitionedDataSet2.write().format("druid").mode(SaveMode.Overwrite).options(map).save();`
but in log I find it :

I think it should be five segments, but only two segment
Corresponding code block:
Code url:
https://github.com/JulianJaffePinterest/druid/blob/2dd1cda37289b780328e26d08bedfb1f57bac0e3/spark/src/main/scala/org/apache/druid/spark/utils/SegmentRationalizer.scala
What configuration items do I need to modify ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1042657139
@JulianJaffePinterest I tested it this way
`Dataset<Row> dataset = sparkSession.createDataFrame(list, schema);`
` Dataset<Row> bucketedDataset = dataset.withColumn("quick_col",SparkUdfs.bucketRow().apply(functions.col("_timeBucketCol"),functions.lit("millis"),functions.lit("DAY")));`
` Dataset<Row> partitionedDataSet1 = bucketedDataset.repartition(functions.col("quick_col")).drop(functions.col("quick_col"));`
` Dataset<Row> partitionedDataSet2 = partitionedDataSet1.repartition(10);` // Increase parallelism
` partitionedDataSet2.write().format("druid").mode(SaveMode.Overwrite).options(map).save();`
but in log I find it :


I think it should be five segments, but only two segment
Corresponding code block:
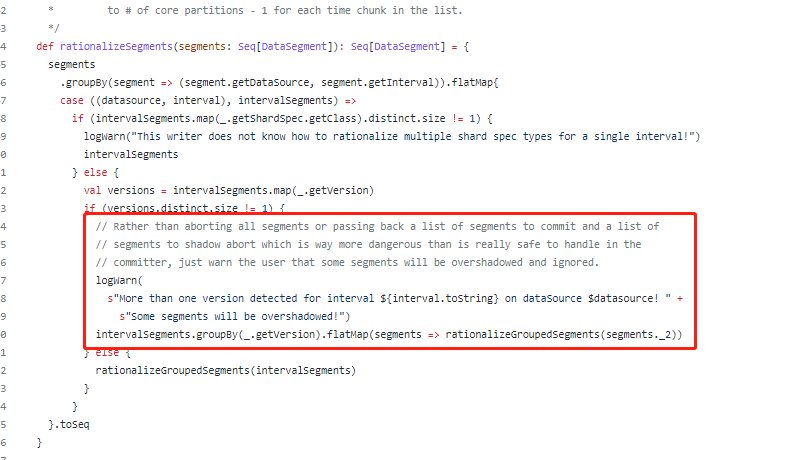
What configuration items do I need to modify ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] ilhanadiyaman commented on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
ilhanadiyaman commented on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1023724261
Hi @JulianJaffePinterest, thank you for your great work. We consider using this connector in the production, however, while testing this PR, we encountered an error while writing the segment that includes `thetaSketch`.
We first read a segment directly from the deep storage by providing the `reader.segments`.
| number | count | animal | __time | animalTheta |
|--------|-------|---------|---------------|---------------------------------------------------|
| 32 | 1 | bear | 1515459660000 | [01 03 03 00 00 3A CC 93 5E 90 53 47 FF 46 AD 47] |
| 3 | 1 | bird | 1515466860000 | [01 03 03 00 00 3A CC 93 AA 00 F4 1D D3 FF F8 14] |
| 4 | 1 | tiger | 1515466860000 | [01 03 03 00 00 3A CC 93 28 32 FA 04 88 6A BA 4B] |
Then we updated the `bear` to `giraffe` and try to write back the segment with `writer.metrics` and `writer.dimensions` provided.
| number | count | animal | __time | animalTheta |
|--------|-------|---------|---------------|---------------------------------------------------|
| 32 | 1 | giraffe | 1515459660000 | [01 03 03 00 00 3A CC 93 91 0C 5B F9 33 1B E6 17] |
| 3 | 1 | bird | 1515466860000 | [01 03 03 00 00 3A CC 93 AA 00 F4 1D D3 FF F8 14] |
| 4 | 1 | tiger | 1515466860000 | [01 03 03 00 00 3A CC 93 28 32 FA 04 88 6A BA 4B] |
```java
writeOptions.put("writer.dimensions","[ \"animal\" ]");
writeOptions.put("writer.metrics","[ { \"type\": \"count\", \"name\": \"count\" }, { \"type\": \"longSum\", \"name\": \"number\", \"fieldName\": \"number\" }, { \"name\": \"animalTheta\", \"type\": \"thetaSketch\", \"fieldName\": \"animal\", \"isInputThetaSketch\": true } ]");
```
Write operation fails with the error below:
`
org.apache.druid.java.util.common.ISE: Object is not of a type[class org.apache.spark.unsafe.types.UTF8String] that can be deserialized to sketch.
at org.apache.druid.query.aggregation.datasketches.theta.SketchHolder.deserialize(SketchHolder.java:223) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.query.aggregation.datasketches.theta.SketchMergeComplexMetricSerde$1.extractValue(SketchMergeComplexMetricSerde.java:62) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.query.aggregation.datasketches.theta.SketchMergeComplexMetricSerde$1.extractValue(SketchMergeComplexMetricSerde.java:50) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.serde.ComplexMetricExtractor.extractValue(ComplexMetricExtractor.java:41) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.incremental.IncrementalIndex$1IncrementalIndexInputRowColumnSelectorFactory$1.getObject(IncrementalIndex.java:184) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.query.aggregation.datasketches.theta.SketchAggregator.aggregate(SketchAggregator.java:54) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.incremental.OnheapIncrementalIndex.doAggregate(OnheapIncrementalIndex.java:254) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.incremental.OnheapIncrementalIndex.addToFacts(OnheapIncrementalIndex.java:167) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.incremental.IncrementalIndex.add(IncrementalIndex.java:481) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.incremental.IncrementalIndex.add(IncrementalIndex.java:462) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.spark.v2.writer.DruidDataWriter.write(DruidDataWriter.scala:171) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.spark.v2.writer.DruidDataWriter.write(DruidDataWriter.scala:68) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.$anonfun$run$2(WriteToDataSourceV2Exec.scala:118) ~[spark-sql_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1394) ~[spark-core_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.run(WriteToDataSourceV2Exec.scala:116) ~[spark-sql_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec.$anonfun$doExecute$2(WriteToDataSourceV2Exec.scala:67) ~[spark-sql_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90) ~[spark-core_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.scheduler.Task.run(Task.scala:123) ~[spark-core_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:414) ~[spark-core_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360) [spark-core_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:417) [spark-core_2.12-2.4.8.jar:2.4.8]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_271]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_271]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_271]
`
Tried to debug it but couldn't get anywhere. It seems like it tries to deserialize `UTF8String` but we provide thetaSketches as `byte array`.
<img width="875" alt="Screenshot 2022-01-27 at 23 54 02" src="https://user-images.githubusercontent.com/4068390/151456714-2e98c961-5988-4cab-8ffd-83ccba120af0.png">
Do you have any ideas how we can resolve this issue?
P.S. Azure Deep Storage implementation is working. We didn't encounter any problem there.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] Lakomoff commented on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
Lakomoff commented on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1041198560
> @Lakomoff you are correct, this pull request has not yet been merged into the main Druid branch. You can view the source code [here](https://github.com/JulianJaffePinterest/druid/tree/spark_druid_piecemeal_writer) - the connector code is in the spark module (for future reference, you can click the link at the top of a pr to access the source and target branches) 
Thank you, Julian!
I was managed to compile connector.
But now I am not able to connect to postgresql type metadata store. Is it supported? If yes how it should be configured?
I'v got
Exception in thread "main" org.apache.druid.java.util.common.IAE: Unrecognized metadata DB type postgresql
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1038724386
@JulianJaffePinterest hi, I import a month's data to druid by spark connector. The data is partitioned by day. The number of lines per segment is in the tens of millions.
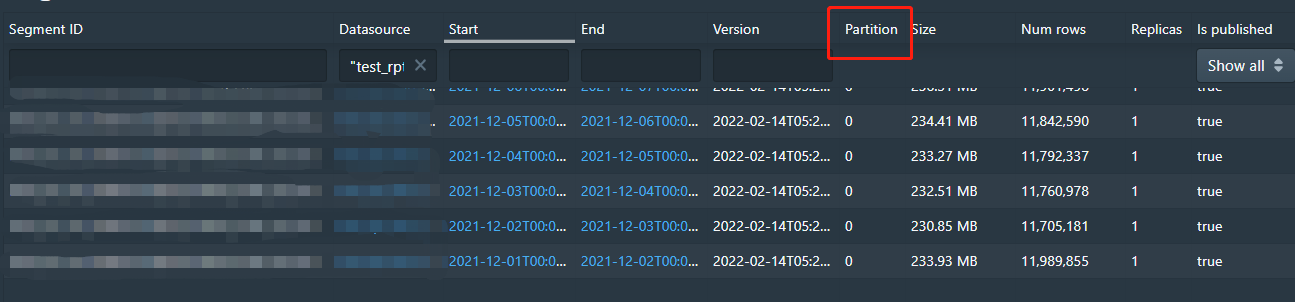
In my tests, I found that the import job took about an hour. How can I speed up the import? Whether the segment can be split into numShard format for import?
` Dataset<Row> dataset = sparkSession.sql(querySql);
SingleDimensionPartitioner partitioner = new SingleDimensionPartitioner(dataset);
Dataset<Row> partitionedDataSet = partitioner.partition(
"time_stamp", "millis", "DAY",
7500000, "dim1", false);`
I understand that when each segment exceeds 7.5 million rows, it should be split into multiple Shard fragments ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1050596278
@JulianJaffePinterest
I use the way:
` package$.MODULE$.DruidDataFrame(dataset).partitionAndWrite( "time_stamp", "millis", "DAY", 1000, false, Option.empty()).format("druid").mode(SaveMode.Overwrite).options(map).save();`
The segment is divided into multiple shards, but
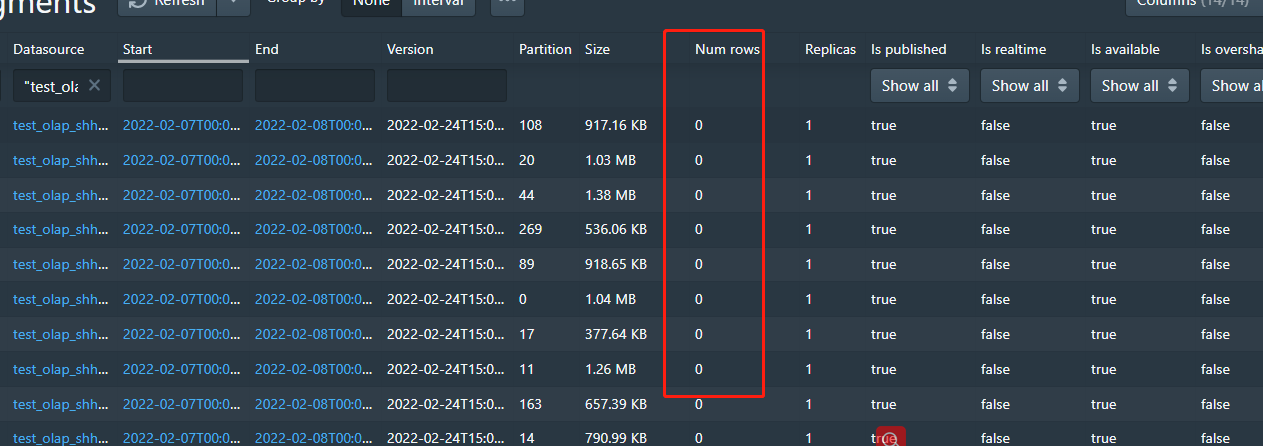
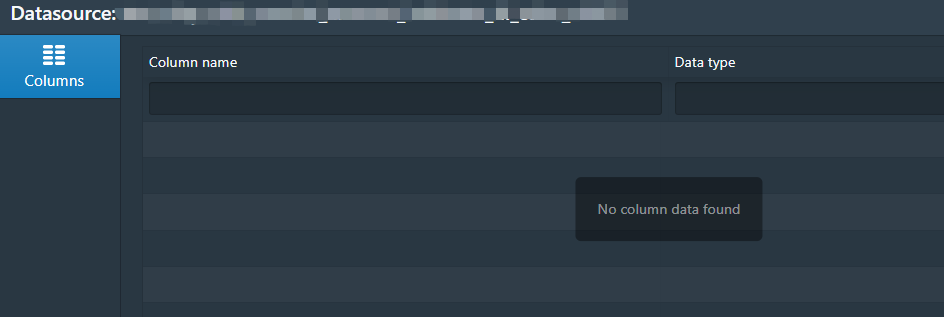
the datasource lost row number and schem info
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] JulianJaffePinterest commented on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
JulianJaffePinterest commented on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1013764057
@jihoonson @samarthjain this is the final spark connector pr 🙂
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] ilhanadiyaman edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
ilhanadiyaman edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1023724261
Hi @JulianJaffePinterest, thank you for your great work. We consider using this connector in the production, however, while testing this PR, we encountered an error while writing the segment that includes `thetaSketch`.
We first read a segment directly from the deep storage by providing the `reader.segments`.
| number | count | animal | __time | animalTheta |
|--------|-------|---------|---------------|---------------------------------------------------|
| 32 | 1 | bear | 1515459660000 | [01 03 03 00 00 3A CC 93 5E 90 53 47 FF 46 AD 47] |
| 3 | 1 | bird | 1515466860000 | [01 03 03 00 00 3A CC 93 AA 00 F4 1D D3 FF F8 14] |
| 4 | 1 | tiger | 1515466860000 | [01 03 03 00 00 3A CC 93 28 32 FA 04 88 6A BA 4B] |
Then we updated the `bear` to `giraffe` and try to write back the segment with `writer.metrics` and `writer.dimensions` provided.
| number | count | animal | __time | animalTheta |
|--------|-------|---------|---------------|---------------------------------------------------|
| 32 | 1 | giraffe | 1515459660000 | [01 03 03 00 00 3A CC 93 91 0C 5B F9 33 1B E6 17] |
| 3 | 1 | bird | 1515466860000 | [01 03 03 00 00 3A CC 93 AA 00 F4 1D D3 FF F8 14] |
| 4 | 1 | tiger | 1515466860000 | [01 03 03 00 00 3A CC 93 28 32 FA 04 88 6A BA 4B] |
```java
writeOptions.put("writer.dimensions","[ \"animal\" ]");
writeOptions.put("writer.metrics","[ { \"type\": \"count\", \"name\": \"count\" }, { \"type\": \"longSum\", \"name\": \"number\", \"fieldName\": \"number\" }, { \"name\": \"animalTheta\", \"type\": \"thetaSketch\", \"fieldName\": \"animal\", \"isInputThetaSketch\": true } ]");
```
Write operation fails with the error below:
`
org.apache.druid.java.util.common.ISE: Object is not of a type[class org.apache.spark.unsafe.types.UTF8String] that can be deserialized to sketch.
at org.apache.druid.query.aggregation.datasketches.theta.SketchHolder.deserialize(SketchHolder.java:223) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.query.aggregation.datasketches.theta.SketchMergeComplexMetricSerde$1.extractValue(SketchMergeComplexMetricSerde.java:62) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.query.aggregation.datasketches.theta.SketchMergeComplexMetricSerde$1.extractValue(SketchMergeComplexMetricSerde.java:50) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.serde.ComplexMetricExtractor.extractValue(ComplexMetricExtractor.java:41) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.incremental.IncrementalIndex$1IncrementalIndexInputRowColumnSelectorFactory$1.getObject(IncrementalIndex.java:184) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.query.aggregation.datasketches.theta.SketchAggregator.aggregate(SketchAggregator.java:54) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.incremental.OnheapIncrementalIndex.doAggregate(OnheapIncrementalIndex.java:254) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.incremental.OnheapIncrementalIndex.addToFacts(OnheapIncrementalIndex.java:167) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.incremental.IncrementalIndex.add(IncrementalIndex.java:481) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.incremental.IncrementalIndex.add(IncrementalIndex.java:462) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.spark.v2.writer.DruidDataWriter.write(DruidDataWriter.scala:171) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.spark.v2.writer.DruidDataWriter.write(DruidDataWriter.scala:68) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.$anonfun$run$2(WriteToDataSourceV2Exec.scala:118) ~[spark-sql_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1394) ~[spark-core_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.run(WriteToDataSourceV2Exec.scala:116) ~[spark-sql_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec.$anonfun$doExecute$2(WriteToDataSourceV2Exec.scala:67) ~[spark-sql_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90) ~[spark-core_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.scheduler.Task.run(Task.scala:123) ~[spark-core_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:414) ~[spark-core_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360) [spark-core_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:417) [spark-core_2.12-2.4.8.jar:2.4.8]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_271]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_271]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_271]
`
Tried to debug it but couldn't get anywhere. It seems like it tries to deserialize `UTF8String` but we provide thetaSketches as `byte array`.
<img width="875" alt="Screenshot 2022-01-27 at 23 54 02" src="https://user-images.githubusercontent.com/4068390/151456714-2e98c961-5988-4cab-8ffd-83ccba120af0.png">
Do you have any ideas how we can resolve this issue?
P.S. Azure Deep Storage implementation is working great. We didn't encounter any problem there.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1042657139
@JulianJaffePinterest I tested it this way
`Dataset<Row> dataset = sparkSession.createDataFrame(list, schema);`
` Dataset<Row> bucketedDataset = dataset.withColumn("quick_col",SparkUdfs.bucketRow().apply(functions.col("_timeBucketCol"),functions.lit("millis"),functions.lit("DAY")));`
` Dataset<Row> partitionedDataSet1 = bucketedDataset.repartition(functions.col("quick_col")).drop(functions.col("quick_col"));`
` Dataset<Row> partitionedDataSet2 = partitionedDataSet1.repartition(10);` // Increase parallelism
` partitionedDataSet2.write().format("druid").mode(SaveMode.Overwrite).options(map).save();`
but in log I find it :

I think it should be five segments, but only two segment
Corresponding code block:

Code url:
https://github.com/JulianJaffePinterest/druid/blob/2dd1cda37289b780328e26d08bedfb1f57bac0e3/spark/src/main/scala/org/apache/druid/spark/utils/SegmentRationalizer.scala
What configuration items do I need to modify ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1050596278
@JulianJaffePinterest
I use the way:
` package$.MODULE$.DruidDataFrame(dataset).partitionAndWrite( "time_stamp", "millis", "DAY", 1000, false, Option.empty()).format("druid").mode(SaveMode.Overwrite).options(map).save();`
The segment is divided into multiple shards, but
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1038724386
@JulianJaffePinterest hi, I import a month's data to druid by spark connector. The data is partitioned by day. The number of lines per segment is in the tens of millions.

In my tests, I found that the import job took about an hour. How can I speed up the import? Whether the segment can be split into numShard format for import?
` Dataset<Row> dataset = sparkSession.sql(querySql);
SingleDimensionPartitioner partitioner = new SingleDimensionPartitioner(dataset);
Dataset<Row> partitionedDataSet = partitioner.partition("time_stamp", "millis", "DAY",7500000, "dim1", false);`
I understand that when each segment exceeds 7.5 million rows, it should be split into multiple Shard fragments ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1042657139
@JulianJaffePinterest I tested it this way
`Dataset<Row> dataset = sparkSession.createDataFrame(list, schema);`
` Dataset<Row> bucketedDataset = dataset.withColumn("quick_col",`
` SparkUdfs.bucketRow().apply(functions.col("_timeBucketCol"),`
` functions.lit("millis"),`
` functions.lit("DAY")));`
` Dataset<Row> partitionedDataSet1 = bucketedDataset.repartition(functions.col("quick_col"))`
` .drop(functions.col("quick_col"));`
` Dataset<Row> partitionedDataSet2 = partitionedDataSet1.repartition(10);`
` partitionedDataSet2.write().format("druid").mode(SaveMode.Overwrite).options(map).save();`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1042657139
@JulianJaffePinterest I tested it this way
`Dataset<Row> dataset = sparkSession.createDataFrame(list, schema);`
` Dataset<Row> bucketedDataset = dataset.withColumn("quick_col",` SparkUdfs.bucketRow().apply(functions.col("_timeBucketCol"),functions.lit("millis"),functions.lit("DAY")));`
` Dataset<Row> partitionedDataSet1 = bucketedDataset.repartition(functions.col("quick_col"))`
` .drop(functions.col("quick_col"));`
` Dataset<Row> partitionedDataSet2 = partitionedDataSet1.repartition(10);`
` partitionedDataSet2.write().format("druid").mode(SaveMode.Overwrite).options(map).save();`
but in log I find it :


I think it should be five segments, but only two segment
Corresponding code block:

What configuration items do I need to modify ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 commented on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 commented on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1038724386
@JulianJaffePinterest hi, I import a month's data to druid by spark connector. The data is partitioned by day. The number of lines per segment is in the tens of millions.

In my tests, I found that the import job took about an hour. How can I speed up the import? Whether the segment can be split into numShard format for import?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] JulianJaffePinterest commented on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
JulianJaffePinterest commented on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1041211386
@Lakomoff PostgreSQL metadata stores should be supported using the metadata db type `postgres` (it looks like you're using `postgresql`). I'll update the documentation to list the options that ship with support - thank for catching!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] JulianJaffePinterest commented on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
JulianJaffePinterest commented on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1042729998
@wangxiaobaidu11 calling `.repartition` _after_ the first repartition blows away the first repartition. If you want to generate more segments for a given bucket, use the NumberedPartitioner.
That pointer aside, the error is saying that multiple versions are being detected for a particular interval. In particular, it suggests that the version assignment logic for the case where no version is specified at write time has migrated to a per-partition or per-executor location instead of only occurring once. I checked the `DataWriterFactory` and that was the case, so I've pulled the version assignment logic back out to a run-once location. I also improved the logging for the error message you were seeing so in the future it will list the conflicting versions instead of just warning about them.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1042657139
@JulianJaffePinterest I tested it this way
`Dataset<Row> dataset = sparkSession.createDataFrame(list, schema);`
` Dataset<Row> bucketedDataset = dataset.withColumn("quick_col",` SparkUdfs.bucketRow().apply(functions.col("_timeBucketCol"),functions.lit("millis"),functions.lit("DAY")));`
` Dataset<Row> partitionedDataSet1 = bucketedDataset.repartition(functions.col("quick_col"))`
` .drop(functions.col("quick_col"));`
` Dataset<Row> partitionedDataSet2 = partitionedDataSet1.repartition(10);`
` partitionedDataSet2.write().format("druid").mode(SaveMode.Overwrite).options(map).save();`
but in log I find it :


Corresponding code block:

What configuration items do I need to modify ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1046145314
@JulianJaffePinterest
I use these code:
` NumberedPartitioner partitioner = new NumberedPartitioner(dataset.select(colSeq));`
` Dataset<Row> partitionedDataSet = partitioner.partition(`
` "time_stamp", "millis", "DAY", 2000, false, Option.empty());`
` partitionedDataSet.write().format("druid").mode(SaveMode.Overwrite).options(map).save();`
Import the data of one day, the data is about 400,000 rows, I think it will be 200 partition num
But the process is overshadowed, only reserve 1 partition


--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 removed a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 removed a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1046145314
@JulianJaffePinterest
I use these code:
` NumberedPartitioner partitioner = new NumberedPartitioner(dataset.select(colSeq));`
` Dataset<Row> partitionedDataSet = partitioner.partition(`
` "time_stamp", "millis", "DAY", 2000, false, Option.empty());`
` partitionedDataSet.write().format("druid").mode(SaveMode.Overwrite).options(map).save();`
Import the data of one day, the data is about 400,000 rows, I think it will be 200 partition num
But the process is overshadowed, only reserve 1 partition


--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1050596278
@JulianJaffePinterest
I use the way:
` package$.MODULE$.DruidDataFrame(dataset).partitionAndWrite( "time_stamp", "millis", "DAY", 1000, false, Option.empty()).format("druid").mode(SaveMode.Overwrite).options(map).save();`
The segment is divided into multiple shards, but


the datasource miss row number and schem info
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] JulianJaffePinterest commented on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
JulianJaffePinterest commented on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1041400963
@wangxiaobaidu11 sorry Xiao Wang, I think I misinterpreted your question in my earlier comment. You're right to partition your dataframe by timestamp. I thought you were already doing that before the code snippet you shared and then applying the SingleDimensionPartitioner on top of the previous partition. If you were using the SingleDimensionPartitioner to partition your dataframe by timestamp, you will still need to do the partitioning but it will likely be faster to partition directly. You could start with
```java
Dataset<Row> dataset = sparkSession.sql(querySql);
Dataset<Row> bucketedDataset = dataset.withColumn(<column_name>, SparkUdfs.bucketRow(col(tsCol), lit(tsFormat), lit(segmentGranularity)));
Dataset<Row> partitionedDataSet = bucketedDataset.repartition(col(<column name>)).dropColumn(<column name>);
```
if you want a single partition per segment or using the NumberedPartitioner as described above if you want to set the rows per partition. If that's not fast enough or you want to guarantee each bucket will correspond to exactly one partition, you can use a custom partitioner.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] JulianJaffePinterest commented on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
JulianJaffePinterest commented on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1038773263
@wangxiaobaidu11 there are a number of factors that affect the runtime of this connector. I don't know the specifics of your data, but it looks like you're trying to use a single-dimension partitioner on a timestamp. If that timestamp is the druid time column, you don't need to do that partitioning yourself - all druid segments are partitioned on the time column regardless of any other partitioning. In your case, the segments you're generating are probably ok size-wise (~200 MB) but if you wanted them to have fewer rows (and thus have more, smaller segments) you could use the numbered partitioner with a target row count. This would increase the parallelism of your spark job and allow your writing to happen sooner, but could slow down your query speed. You'll have to use your judgement on what's more important to you. You might also want to look at the metrics for your import jobs and determine exactly where time is being spent - if the time it takes to read in data is small and t
he job spends most of its time writing to druid, you could check if you're memory-bound on your job (in which case giving your executors more memory will help) or cpu-bound (in which case you'll need to trade off more executors for more files). If you're reading from an external system you also may be able to shape your reads in such a way as to minimize or eliminate shuffling in Spark, which will greatly speed up your write. Keep in mind that the provided partitioners don't have any knowledge of your data and so will be slower than a partitioning approach that can take your data in to account.
More generally, the writing logic is some of the oldest in the connectors and there is likely substantial room for improvement in performance. Because the write performance has been mostly acceptable to users, I've been focused on getting these connectors merged into Druid rather than further latency or throughput improvements but hopefully Druid committers like @jihoonson will have some useful feedback in their reviews.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1038724386
@JulianJaffePinterest hi, I import a month's data to druid by spark connector. The data is partitioned by day. The number of lines per segment is in the tens of millions.

In my tests, I found that the import job took about an hour. How can I speed up the import? Whether the segment can be split into numShard format for import?
` Dataset<Row> dataset = sparkSession.sql(querySql);
SingleDimensionPartitioner partitioner = new SingleDimensionPartitioner(dataset);
Dataset<Row> partitionedDataSet = partitioner.partition(
"time_stamp", "millis", "DAY",
7500000, "dim1", false);`
I understand that when each segment exceeds 7.5 million rows, it should be split into multiple Shard fragments ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 commented on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 commented on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1042657139
@JulianJaffePinterest I tested it this way
`Dataset<Row> dataset = sparkSession.createDataFrame(list, schema);`
` Dataset<Row> bucketedDataset = dataset.withColumn("quick_col",
SparkUdfs.bucketRow().apply(functions.col("_timeBucketCol"),
functions.lit("millis"),
functions.lit("DAY")));
Dataset<Row> partitionedDataSet1 = bucketedDataset.repartition(functions.col("quick_col"))
.drop(functions.col("quick_col"));
Dataset<Row> partitionedDataSet2 = partitionedDataSet1.repartition(10);
partitionedDataSet2.write().format("druid").mode(SaveMode.Overwrite).options(map).save();`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1042657139
@JulianJaffePinterest I tested it this way
`Dataset<Row> dataset = sparkSession.createDataFrame(list, schema);`
` Dataset<Row> bucketedDataset = dataset.withColumn("quick_col",SparkUdfs.bucketRow().apply(functions.col("_timeBucketCol"),functions.lit("millis"),functions.lit("DAY")));`
` Dataset<Row> partitionedDataSet1 = bucketedDataset.repartition(functions.col("quick_col"))`
` .drop(functions.col("quick_col"));`
` Dataset<Row> partitionedDataSet2 = partitionedDataSet1.repartition(10);`
` partitionedDataSet2.write().format("druid").mode(SaveMode.Overwrite).options(map).save();`
but in log I find it :


I think it should be five segments, but only two segment
Corresponding code block:

What configuration items do I need to modify ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1038724386
@JulianJaffePinterest hi, I import a month's data to druid by spark connector. The data is partitioned by day. The number of lines per segment is in the tens of millions.

In my tests, I found that the import job took about an hour. How can I speed up the import? Whether the segment can be split into numShard format for import?
` Dataset<Row> dataset = sparkSession.sql(querySql);
SingleDimensionPartitioner partitioner = new SingleDimensionPartitioner(dataset);
Dataset<Row> partitionedDataSet = partitioner.partition("time_stamp", "millis", "DAY",7500000, "dim1", false);`
I understand that when each segment exceeds 7.5 million rows, it should be split into multiple Shard fragments ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 commented on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 commented on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1039963799
> @wangxiaobaidu11 there are a number of factors that affect the runtime of this connector. I don't know the specifics of your data, but it looks like you're trying to use a single-dimension partitioner on a timestamp. If that timestamp is the druid time column, you don't need to do that partitioning yourself - all druid segments are partitioned on the time column regardless of any other partitioning. In your case, the segments you're generating are probably ok size-wise (~200 MB) but if you wanted them to have fewer rows (and thus have more, smaller segments) you could use the numbered partitioner with a target row count. This would increase the parallelism of your spark job and allow your writing to happen sooner, but could slow down your query speed. You'll have to use your judgement on what's more important to you. You might also want to look at the metrics for your import jobs and determine exactly where time is being spent - if the time it takes to read in data is small and
the job spends most of its time writing to druid, you could check if you're memory-bound on your job (in which case giving your executors more memory will help) or cpu-bound (in which case you'll need to trade off more executors for more files). If you're reading from an external system you also may be able to shape your reads in such a way as to minimize or eliminate shuffling in Spark, which will greatly speed up your write. Keep in mind that the provided partitioners don't have any knowledge of your data and so will be slower than a partitioning approach that can take your data in to account.
>
> More generally, the writing logic is some of the oldest in the connectors and there is likely substantial room for improvement in performance. Because the write performance has been mostly acceptable to users, I've been focused on getting these connectors merged into Druid rather than further latency or throughput improvements but hopefully Druid committers like @jihoonson will have some useful feedback in their reviews.
Thank you for your answer!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1039963799
@JulianJaffePinterest
Thank you for your answer!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1050596278
@JulianJaffePinterest
I use the way:
` package$.MODULE$.DruidDataFrame(dataset).partitionAndWrite( "time_stamp", "millis", "DAY", 1000, false, Option.empty()).format("druid").mode(SaveMode.Overwrite).options(map).save();`
The segment is divided into multiple shards, but the datasource lost row number and schem info. Do you know why?


--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] Lakomoff commented on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
Lakomoff commented on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1029040137
Hi,
Is it true that this functionality is not present in official release of Druid?
From where Is possible to download compiled jar-file for latest version of connector? If there are only source files I'v got the same question....
I am not using github a lot and can not find a way to download only a branch that contains source code for this extension.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1038724386
@JulianJaffePinterest hi, I import a month's data to druid by spark connector. The data is partitioned by day. The number of lines per segment is in the tens of millions.

In my tests, I found that the import job took about an hour. How can I speed up the import? Whether the segment can be split into numShard format for import?
`Dataset<Row> dataset = sparkSession.sql(querySql);
SingleDimensionPartitioner partitioner = new SingleDimensionPartitioner(dataset);
Dataset<Row> partitionedDataSet = partitioner.partition("time_stamp", "millis", "DAY",7500000, "dim1", false);`
I understand that when each segment exceeds 7.5 million rows, it should be split into multiple Shard fragments ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1038724386
@JulianJaffePinterest hi, I import a month's data to druid by spark connector. The data is partitioned by day. The number of lines per segment is in the tens of millions.

In my tests, I found that the import job took about an hour. How can I speed up the import? Whether the segment can be split into numShard format for import?
`Dataset<Row> dataset = sparkSession.sql(querySql);SingleDimensionPartitioner partitioner = new SingleDimensionPartitioner(dataset);Dataset<Row> partitionedDataSet = partitioner.partition("time_stamp", "millis", "DAY",7500000, "dim1", false);`
I understand that when each segment exceeds 7.5 million rows, it should be split into multiple Shard fragments ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1038724386
@JulianJaffePinterest hi, I import a month's data to druid by spark connector. The data is partitioned by day. Num row per segment is in the tens of millions.

In my tests, I found that the import job took about an hour. How can I speed up the import? Whether the segment can be split into numShard format for import?
`Dataset<Row> dataset = sparkSession.sql(querySql);`
`SingleDimensionPartitioner partitioner = new SingleDimensionPartitioner(dataset);`
`Dataset<Row> partitionedDataSet = partitioner.partition("time_stamp", "millis", "DAY",7500000, "dim1", false);`
I understand that when each segment exceeds 7.5 million rows, it should be split into multiple Shard fragments ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1042657139
@JulianJaffePinterest I tested it this way
`Dataset<Row> dataset = sparkSession.createDataFrame(list, schema);`
` Dataset<Row> bucketedDataset = dataset.withColumn("quick_col",SparkUdfs.bucketRow().apply(functions.col("_timeBucketCol"),functions.lit("millis"),functions.lit("DAY")));`
` Dataset<Row> partitionedDataSet1 = bucketedDataset.repartition(functions.col("quick_col")).drop(functions.col("quick_col"));`
` Dataset<Row> partitionedDataSet2 = partitionedDataSet1.repartition(10);`
` partitionedDataSet2.write().format("druid").mode(SaveMode.Overwrite).options(map).save();`
but in log I find it :


I think it should be five segments, but only two segment
Corresponding code block:

What configuration items do I need to modify ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] JulianJaffePinterest commented on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
JulianJaffePinterest commented on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1060286099
@wangxiaobaidu11 are you able to query the segments correctly or are they corrupted as well? (Trying to ascertain if this is a problem with the data in the segments or an issue with the segment analysis that powers the Druid console)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1050596278
@JulianJaffePinterest
I use the way:
` package$.MODULE$.DruidDataFrame(dataset).partitionAndWrite( "time_stamp", "millis", "DAY", 1000, false, Option.empty()).format("druid").mode(SaveMode.Overwrite).options(map).save();`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 commented on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 commented on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1039963799
> @wangxiaobaidu11 there are a number of factors that affect the runtime of this connector. I don't know the specifics of your data, but it looks like you're trying to use a single-dimension partitioner on a timestamp. If that timestamp is the druid time column, you don't need to do that partitioning yourself - all druid segments are partitioned on the time column regardless of any other partitioning. In your case, the segments you're generating are probably ok size-wise (~200 MB) but if you wanted them to have fewer rows (and thus have more, smaller segments) you could use the numbered partitioner with a target row count. This would increase the parallelism of your spark job and allow your writing to happen sooner, but could slow down your query speed. You'll have to use your judgement on what's more important to you. You might also want to look at the metrics for your import jobs and determine exactly where time is being spent - if the time it takes to read in data is small and
the job spends most of its time writing to druid, you could check if you're memory-bound on your job (in which case giving your executors more memory will help) or cpu-bound (in which case you'll need to trade off more executors for more files). If you're reading from an external system you also may be able to shape your reads in such a way as to minimize or eliminate shuffling in Spark, which will greatly speed up your write. Keep in mind that the provided partitioners don't have any knowledge of your data and so will be slower than a partitioning approach that can take your data in to account.
>
> More generally, the writing logic is some of the oldest in the connectors and there is likely substantial room for improvement in performance. Because the write performance has been mostly acceptable to users, I've been focused on getting these connectors merged into Druid rather than further latency or throughput improvements but hopefully Druid committers like @jihoonson will have some useful feedback in their reviews.
Thank you for your answer!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] JulianJaffePinterest commented on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
JulianJaffePinterest commented on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1038757088
@Lakomoff you are correct, this pull request has not yet been merged into the main Druid branch. You can view the source code [here](https://github.com/JulianJaffePinterest/druid/tree/spark_druid_piecemeal_writer) - the connector code is in the spark module (for future reference, you can click the link at the top of a pr to access the source and target branches)

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1039963799
> @wangxiaobaidu11 there are a number of factors that affect the runtime of this connector. I don't know the specifics of your data, but it looks like you're trying to use a single-dimension partitioner on a timestamp. If that timestamp is the druid time column, you don't need to do that partitioning yourself - all druid segments are partitioned on the time column regardless of any other partitioning. In your case, the segments you're generating are probably ok size-wise (~200 MB) but if you wanted them to have fewer rows (and thus have more, smaller segments) you could use the numbered partitioner with a target row count. This would increase the parallelism of your spark job and allow your writing to happen sooner, but could slow down your query speed. You'll have to use your judgement on what's more important to you. You might also want to look at the metrics for your import jobs and determine exactly where time is being spent - if the time it takes to read in data is small and
the job spends most of its time writing to druid, you could check if you're memory-bound on your job (in which case giving your executors more memory will help) or cpu-bound (in which case you'll need to trade off more executors for more files). If you're reading from an external system you also may be able to shape your reads in such a way as to minimize or eliminate shuffling in Spark, which will greatly speed up your write. Keep in mind that the provided partitioners don't have any knowledge of your data and so will be slower than a partitioning approach that can take your data in to account.
>
> More generally, the writing logic is some of the oldest in the connectors and there is likely substantial room for improvement in performance. Because the write performance has been mostly acceptable to users, I've been focused on getting these connectors merged into Druid rather than further latency or throughput improvements but hopefully Druid committers like @jihoonson will have some useful feedback in their reviews.
@JulianJaffePinterest
Thank you for your answer!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 commented on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 commented on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1046145314
@JulianJaffePinterest I pulled up your latest code
Execute “mvn clean install -DskipTests"

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] ilhanadiyaman removed a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
ilhanadiyaman removed a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1023724261
Hi @JulianJaffePinterest, thank you for your great work. We consider using this connector in the production, however, while testing this PR, we encountered an error while writing the segment that includes `thetaSketch`.
We first read a segment directly from the deep storage by providing the `reader.segments`.
| number | count | animal | __time | animalTheta |
|--------|-------|---------|---------------|---------------------------------------------------|
| 32 | 1 | bear | 1515459660000 | [01 03 03 00 00 3A CC 93 5E 90 53 47 FF 46 AD 47] |
| 3 | 1 | bird | 1515466860000 | [01 03 03 00 00 3A CC 93 AA 00 F4 1D D3 FF F8 14] |
| 4 | 1 | tiger | 1515466860000 | [01 03 03 00 00 3A CC 93 28 32 FA 04 88 6A BA 4B] |
Then we updated the `bear` to `giraffe` and try to write back the segment with `writer.metrics` and `writer.dimensions` provided.
| number | count | animal | __time | animalTheta |
|--------|-------|---------|---------------|---------------------------------------------------|
| 32 | 1 | giraffe | 1515459660000 | [01 03 03 00 00 3A CC 93 91 0C 5B F9 33 1B E6 17] |
| 3 | 1 | bird | 1515466860000 | [01 03 03 00 00 3A CC 93 AA 00 F4 1D D3 FF F8 14] |
| 4 | 1 | tiger | 1515466860000 | [01 03 03 00 00 3A CC 93 28 32 FA 04 88 6A BA 4B] |
```java
writeOptions.put("writer.dimensions","[ \"animal\" ]");
writeOptions.put("writer.metrics","[ { \"type\": \"count\", \"name\": \"count\" }, { \"type\": \"longSum\", \"name\": \"number\", \"fieldName\": \"number\" }, { \"name\": \"animalTheta\", \"type\": \"thetaSketch\", \"fieldName\": \"animal\", \"isInputThetaSketch\": true } ]");
```
Write operation fails with the error below:
`
org.apache.druid.java.util.common.ISE: Object is not of a type[class org.apache.spark.unsafe.types.UTF8String] that can be deserialized to sketch.
at org.apache.druid.query.aggregation.datasketches.theta.SketchHolder.deserialize(SketchHolder.java:223) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.query.aggregation.datasketches.theta.SketchMergeComplexMetricSerde$1.extractValue(SketchMergeComplexMetricSerde.java:62) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.query.aggregation.datasketches.theta.SketchMergeComplexMetricSerde$1.extractValue(SketchMergeComplexMetricSerde.java:50) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.serde.ComplexMetricExtractor.extractValue(ComplexMetricExtractor.java:41) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.incremental.IncrementalIndex$1IncrementalIndexInputRowColumnSelectorFactory$1.getObject(IncrementalIndex.java:184) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.query.aggregation.datasketches.theta.SketchAggregator.aggregate(SketchAggregator.java:54) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.incremental.OnheapIncrementalIndex.doAggregate(OnheapIncrementalIndex.java:254) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.incremental.OnheapIncrementalIndex.addToFacts(OnheapIncrementalIndex.java:167) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.incremental.IncrementalIndex.add(IncrementalIndex.java:481) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.segment.incremental.IncrementalIndex.add(IncrementalIndex.java:462) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.spark.v2.writer.DruidDataWriter.write(DruidDataWriter.scala:171) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.druid.spark.v2.writer.DruidDataWriter.write(DruidDataWriter.scala:68) ~[druid-spark.jar:0.22.0-SNAPSHOT]
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.$anonfun$run$2(WriteToDataSourceV2Exec.scala:118) ~[spark-sql_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1394) ~[spark-core_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.run(WriteToDataSourceV2Exec.scala:116) ~[spark-sql_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec.$anonfun$doExecute$2(WriteToDataSourceV2Exec.scala:67) ~[spark-sql_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90) ~[spark-core_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.scheduler.Task.run(Task.scala:123) ~[spark-core_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:414) ~[spark-core_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360) [spark-core_2.12-2.4.8.jar:2.4.8]
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:417) [spark-core_2.12-2.4.8.jar:2.4.8]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_271]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_271]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_271]
`
Tried to debug it but couldn't get anywhere. It seems like it tries to deserialize `UTF8String` but we provide thetaSketches as `byte array`.
<img width="875" alt="Screenshot 2022-01-27 at 23 54 02" src="https://user-images.githubusercontent.com/4068390/151456714-2e98c961-5988-4cab-8ffd-83ccba120af0.png">
Do you have any ideas how we can resolve this issue?
P.S. Azure Deep Storage implementation is working great. We didn't encounter any problem there.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] ilhanadiyaman commented on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
ilhanadiyaman commented on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1023734645
Hi @JulianJaffePinterest, you can ignore my previous comment. The error was the definition of thetaSketch in the `writer.metrics`. Thank you again for great work!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1039963799
> @wangxiaobaidu11 there are a number of factors that affect the runtime of this connector. I don't know the specifics of your data, but it looks like you're trying to use a single-dimension partitioner on a timestamp. If that timestamp is the druid time column, you don't need to do that partitioning yourself - all druid segments are partitioned on the time column regardless of any other partitioning. In your case, the segments you're generating are probably ok size-wise (~200 MB) but if you wanted them to have fewer rows (and thus have more, smaller segments) you could use the numbered partitioner with a target row count. This would increase the parallelism of your spark job and allow your writing to happen sooner, but could slow down your query speed. You'll have to use your judgement on what's more important to you. You might also want to look at the metrics for your import jobs and determine exactly where time is being spent - if the time it takes to read in data is small and
the job spends most of its time writing to druid, you could check if you're memory-bound on your job (in which case giving your executors more memory will help) or cpu-bound (in which case you'll need to trade off more executors for more files). If you're reading from an external system you also may be able to shape your reads in such a way as to minimize or eliminate shuffling in Spark, which will greatly speed up your write. Keep in mind that the provided partitioners don't have any knowledge of your data and so will be slower than a partitioning approach that can take your data in to account.
>
> More generally, the writing logic is some of the oldest in the connectors and there is likely substantial room for improvement in performance. Because the write performance has been mostly acceptable to users, I've been focused on getting these connectors merged into Druid rather than further latency or throughput improvements but hopefully Druid committers like @jihoonson will have some useful feedback in their reviews.
@JulianJaffePinterest
Thank you for your answer!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1038724386
@JulianJaffePinterest hi, I import a month's data to druid by spark connector. The data is partitioned by day. Num row per segment is in the tens of millions.

In my tests, I found that the import job took about an hour. How can I speed up the import? Whether the segment can be split into numShard format for import?
`Dataset<Row> dataset = sparkSession.sql(querySql);`
`SingleDimensionPartitioner partitioner = new SingleDimensionPartitioner(dataset);`
`Dataset<Row> partitionedDataSet = partitioner.partition("time_stamp", "millis", "DAY",7500000, "dim1", false);`
I understand that when each segment exceeds 7.5 million rows, it should be split into multiple Shard fragments ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1042657139
@JulianJaffePinterest I tested it this way
`Dataset<Row> dataset = sparkSession.createDataFrame(list, schema);`
` Dataset<Row> bucketedDataset = dataset.withColumn("quick_col",` SparkUdfs.bucketRow().apply(functions.col("_timeBucketCol"),functions.lit("millis"),functions.lit("DAY")));`
` Dataset<Row> partitionedDataSet1 = bucketedDataset.repartition(functions.col("quick_col"))`
` .drop(functions.col("quick_col"));`
` Dataset<Row> partitionedDataSet2 = partitionedDataSet1.repartition(10);`
` partitionedDataSet2.write().format("druid").mode(SaveMode.Overwrite).options(map).save();`
but in log I find it :

Corresponding code block:

What configuration items do I need to modify ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1042657139
@JulianJaffePinterest I tested it this way
`Dataset<Row> dataset = sparkSession.createDataFrame(list, schema);`
` Dataset<Row> bucketedDataset = dataset.withColumn("quick_col",SparkUdfs.bucketRow().apply(functions.col("_timeBucketCol"),functions.lit("millis"),functions.lit("DAY")));`
` Dataset<Row> partitionedDataSet1 = bucketedDataset.repartition(functions.col("quick_col")).drop(functions.col("quick_col"));`
` Dataset<Row> partitionedDataSet2 = partitionedDataSet1.repartition(10);` // Increase parallelism
` partitionedDataSet2.write().format("druid").mode(SaveMode.Overwrite).options(map).save();`
but in log I find it :


I think it should be five segments, but only two segment
Corresponding code block:

Code url:
https://github.com/JulianJaffePinterest/druid/blob/2dd1cda37289b780328e26d08bedfb1f57bac0e3/spark/src/main/scala/org/apache/druid/spark/utils/SegmentRationalizer.scala
What configuration items do I need to modify ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1042657139
@JulianJaffePinterest I tested it this way
`Dataset<Row> dataset = sparkSession.createDataFrame(list, schema);`
` Dataset<Row> bucketedDataset = dataset.withColumn("quick_col",SparkUdfs.bucketRow().apply(functions.col("_timeBucketCol"),functions.lit("millis"),functions.lit("DAY")));`
` Dataset<Row> partitionedDataSet1 = bucketedDataset.repartition(functions.col("quick_col")).drop(functions.col("quick_col"));`
` Dataset<Row> partitionedDataSet2 = partitionedDataSet1.repartition(10);` // Increase parallelism
` partitionedDataSet2.write().format("druid").mode(SaveMode.Overwrite).options(map).save();`
but in log I find it :

I think it should be five segments, but only two segment
Corresponding code block:

Code url:
https://github.com/JulianJaffePinterest/druid/blob/2dd1cda37289b780328e26d08bedfb1f57bac0e3/spark/src/main/scala/org/apache/druid/spark/utils/SegmentRationalizer.scala
What configuration items do I need to modify ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1038724386
@JulianJaffePinterest hi, I import a month's data to druid by spark connector. The data is partitioned by day. The number of lines per segment is in the tens of millions.

In my tests, I found that the import job took about an hour. How can I speed up the import? Whether the segment can be split into numShard format for import?
`Dataset<Row> dataset = sparkSession.sql(querySql);`
`SingleDimensionPartitioner partitioner = new SingleDimensionPartitioner(dataset);`
`Dataset<Row> partitionedDataSet = partitioner.partition("time_stamp", "millis", "DAY",7500000, "dim1", false);`
I understand that when each segment exceeds 7.5 million rows, it should be split into multiple Shard fragments ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 edited a comment on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1046145314
@JulianJaffePinterest
I use these code:
` NumberedPartitioner partitioner = new NumberedPartitioner(dataset.select(colSeq));`
` Dataset<Row> partitionedDataSet = partitioner.partition(`
` "time_stamp", "millis", "DAY", 2000, false, Option.empty());`
` partitionedDataSet.write().format("druid").mode(SaveMode.Overwrite).options(map).save();`
Import the data of one day, the data is about 400,000 rows, I think it will be 200 partition num
But the process is overshadowed, only reserve 1 partition

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] wangxiaobaidu11 commented on pull request #12159: Add Spark Writer support.
Posted by GitBox <gi...@apache.org>.
wangxiaobaidu11 commented on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1050596278
@JulianJaffePinterest
I use the way:
` package$.MODULE$.DruidDataFrame(dataset).partitionAndWrite(`
` "time_stamp", "millis", "DAY",`
` 1000,`
` false, Option.empty()).format("druid").mode(SaveMode.Overwrite).options(map).save();`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org