You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2021/10/22 10:51:15 UTC
[GitHub] [spark] zhengruifeng opened a new pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
zhengruifeng opened a new pull request #34367:
URL: https://github.com/apache/spark/pull/34367
### What changes were proposed in this pull request?
add a new node `RankLimit` to filter out uncessary data in the map side.
### Why are the changes needed?
1, reduce the shuffle amount;
2, solve skewed-window problem, a practice case is optimized from 2.5h to 26min
### Does this PR introduce _any_ user-facing change?
a new config is added
### How was this patch tested?
added testsuits
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] wangyum commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
wangyum commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950039381
cc @opensky142857
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950481576
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/49041/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979054207
**[Test build #145625 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145625/testReport)** for PR 34367 at commit [`16242b0`](https://github.com/apache/spark/commit/16242b04a97414b0a936cdbfc5ed54cd93706f67).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-983328709
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50263/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977958055
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng edited a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng edited a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-978884601
@wangyum
this PR was updated to support `rank` and `dense_rank`
```
scala> spark.conf.set("spark.sql.rankLimit.enabled", "true")
scala> spark.sql("""SELECT a, b, rank() OVER (PARTITION BY a ORDER BY b) as rk FROM VALUES ('A1', 1), ('A1', 1), ('A2', 3), ('A1', 1) tab(a, b);""").where("rk = 1").queryExecution.optimizedPlan
res1: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Filter (rk#0 = 1)
+- Window [rank(b#4) windowspecdefinition(a#3, b#4 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#0], [a#3], [b#4 ASC NULLS FIRST]
+- RankLimit [a#3], [b#4 ASC NULLS FIRST], rank(b#4), 1
+- LocalRelation [a#3, b#4]
scala> spark.sql("""SELECT a, b, rank() OVER (PARTITION BY a ORDER BY b) as rk FROM VALUES ('A1', 1), ('A1', 1), ('A2', 3), ('A1', 1) tab(a, b);""").where("rk = 1").show
+---+---+---+
| a| b| rk|
+---+---+---+
| A1| 1| 1|
| A1| 1| 1|
| A1| 1| 1|
| A2| 3| 1|
+---+---+---+
```
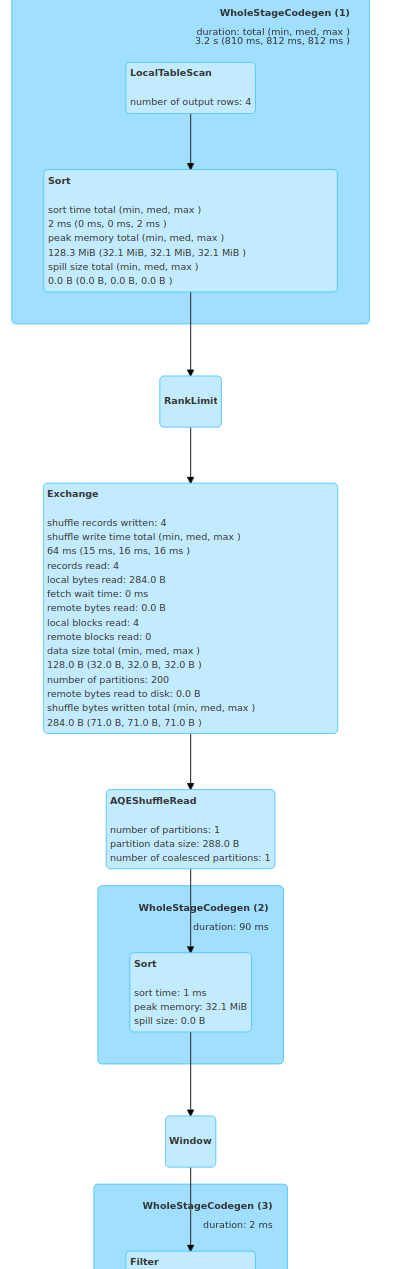
```
== Physical Plan ==
AdaptiveSparkPlan (17)
+- == Final Plan ==
* Project (10)
+- * Filter (9)
+- Window (8)
+- * Sort (7)
+- AQEShuffleRead (6)
+- ShuffleQueryStage (5)
+- Exchange (4)
+- RankLimit (3)
+- * Sort (2)
+- * LocalTableScan (1)
+- == Initial Plan ==
Project (16)
+- Filter (15)
+- Window (14)
+- Sort (13)
+- Exchange (12)
+- RankLimit (11)
+- Sort (2)
+- LocalTableScan (1)
(1) LocalTableScan [codegen id : 1]
Output [2]: [a#17, b#18]
Arguments: [a#17, b#18]
(2) Sort [codegen id : 1]
Input [2]: [a#17, b#18]
Arguments: [a#17 ASC NULLS FIRST, b#18 ASC NULLS FIRST], false, 0
(3) RankLimit
Input [2]: [a#17, b#18]
Arguments: [a#17], [b#18 ASC NULLS FIRST], rank(b#18), 1
(4) Exchange
Input [2]: [a#17, b#18]
Arguments: hashpartitioning(a#17, 200), ENSURE_REQUIREMENTS, [id=#37]
(5) ShuffleQueryStage
Output [2]: [a#17, b#18]
Arguments: 0
(6) AQEShuffleRead
Input [2]: [a#17, b#18]
Arguments: coalesced
(7) Sort [codegen id : 2]
Input [2]: [a#17, b#18]
Arguments: [a#17 ASC NULLS FIRST, b#18 ASC NULLS FIRST], false, 0
(8) Window
Input [2]: [a#17, b#18]
Arguments: [rank(b#18) windowspecdefinition(a#17, b#18 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#14], [a#17], [b#18 ASC NULLS FIRST]
(9) Filter [codegen id : 3]
Input [3]: [a#17, b#18, rk#14]
Condition : (rk#14 = 1)
(10) Project [codegen id : 3]
Output [3]: [a#17, cast(b#18 as string) AS b#32, cast(rk#14 as string) AS rk#33]
Input [3]: [a#17, b#18, rk#14]
(11) RankLimit
Input [2]: [a#17, b#18]
Arguments: [a#17], [b#18 ASC NULLS FIRST], rank(b#18), 1
(12) Exchange
Input [2]: [a#17, b#18]
Arguments: hashpartitioning(a#17, 200), ENSURE_REQUIREMENTS, [id=#23]
(13) Sort
Input [2]: [a#17, b#18]
Arguments: [a#17 ASC NULLS FIRST, b#18 ASC NULLS FIRST], false, 0
(14) Window
Input [2]: [a#17, b#18]
Arguments: [rank(b#18) windowspecdefinition(a#17, b#18 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#14], [a#17], [b#18 ASC NULLS FIRST]
(15) Filter
Input [3]: [a#17, b#18, rk#14]
Condition : (rk#14 = 1)
(16) Project
Output [3]: [a#17, cast(b#18 as string) AS b#32, cast(rk#14 as string) AS rk#33]
Input [3]: [a#17, b#18, rk#14]
(17) AdaptiveSparkPlan
Output [3]: [a#17, b#32, rk#33]
Arguments: isFinalPlan=true
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977809636
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50047/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979195663
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50100/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979427976
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145632/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-989823509
**[Test build #146030 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/146030/testReport)** for PR 34367 at commit [`6d2efab`](https://github.com/apache/spark/commit/6d2efab0549c8283f582bf8fe019b2c223f0681d).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-949514645
**[Test build #144536 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/144536/testReport)** for PR 34367 at commit [`134067f`](https://github.com/apache/spark/commit/134067f5e34ef4f6d177a93f38ed7a65592ad026).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950758625
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/144576/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950529376
**[Test build #144576 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/144576/testReport)** for PR 34367 at commit [`3c51865`](https://github.com/apache/spark/commit/3c518652d74e50bcb85024dd5e5e75dc63121ce7).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-949600168
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/49007/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950443311
**[Test build #144570 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/144570/testReport)** for PR 34367 at commit [`134067f`](https://github.com/apache/spark/commit/134067f5e34ef4f6d177a93f38ed7a65592ad026).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #34367:
URL: https://github.com/apache/spark/pull/34367#discussion_r767467761
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/window/RankLimitExec.scala
##########
@@ -0,0 +1,280 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions._
+import org.apache.spark.sql.catalyst.expressions.codegen._
+import org.apache.spark.sql.catalyst.plans.physical._
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.metric.SQLMetrics
+import org.apache.spark.util.collection.Utils
+
+
+sealed trait RankLimitMode
+
+case object Partial extends RankLimitMode
+
+case object Final extends RankLimitMode
+
+
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec,
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class RankLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankFunction: Expression,
+ limit: Int,
+ mode: RankLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+ assert(orderSpec.nonEmpty && limit > 0)
+
+ private val shouldPass = child match {
+ case r: RankLimitExec =>
+ partitionSpec.size == r.partitionSpec.size &&
+ partitionSpec.zip(r.partitionSpec).forall(p => p._1.semanticEquals(p._2)) &&
+ orderSpec.size == r.orderSpec.size &&
+ orderSpec.zip(r.orderSpec).forall(o => o._1.semanticEquals(o._2)) &&
+ rankFunction.semanticEquals(r.rankFunction) &&
+ mode == Final && r.mode == Partial && limit == r.limit
+ case _ => false
+ }
+
+ private val shouldApplyTakeOrdered: Boolean = {
+ rankFunction match {
+ case _: RowNumber => limit < conf.topKSortFallbackThreshold
+ case _: Rank => false
+ case _: DenseRank => false
+ case f => throw new IllegalArgumentException(s"Unsupported rank function: $f")
+ }
+ }
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] = {
+ if (shouldApplyTakeOrdered) {
+ Seq(partitionSpec.map(SortOrder(_, Ascending)))
+ } else {
+ // Should be the same as [[WindowExec#requiredChildOrdering]]
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+ }
+ }
+
+ override def outputOrdering: Seq[SortOrder] = {
+ partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec
+ }
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ // Should be the same as [[WindowExec#requiredChildDistribution]]
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else ClusteredDistribution(partitionSpec) :: Nil
+ }
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ override lazy val metrics = Map(
+ "numOutputRows" -> SQLMetrics.createMetric(sparkContext, "number of output rows"))
+
+ private lazy val ordering = GenerateOrdering.generate(orderSpec, output)
+
+ private lazy val limitFunction = rankFunction match {
+ case _: RowNumber if shouldApplyTakeOrdered =>
+ (stream: Iterator[InternalRow]) =>
+ Utils.takeOrdered(stream.map(_.copy()), limit)(ordering)
Review comment:
```
val TOP_K_SORT_FALLBACK_THRESHOLD =
buildConf("spark.sql.execution.topKSortFallbackThreshold")
.doc("In SQL queries with a SORT followed by a LIMIT like " +
"'SELECT x FROM t ORDER BY y LIMIT m', if m is under this threshold, do a top-K sort" +
" in memory, otherwise do a global sort which spills to disk if necessary.")
.version("2.4.0")
.intConf
.createWithDefault(ByteArrayMethods.MAX_ROUNDED_ARRAY_LENGTH)
```
I think we can still share the same threshold. The problem is that its default value is too high, which should be set to a relative smaller number in practice, such as 10000.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979933220
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50138/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981477450
retest this please
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-978884601
@wangyum
this PR was updated to support `rank` and `dense_rank`
```
scala> spark.conf.set("spark.sql.rankLimit.enabled", "true")
scala> spark.sql("""SELECT a, b, rank() OVER (PARTITION BY a ORDER BY b) as rk FROM VALUES ('A1', 1), ('A1', 1), ('A2', 3), ('A1', 1) tab(a, b);""").where("rk = 1").queryExecution.optimizedPlan
res1: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Filter (rk#0 = 1)
+- Window [rank(b#4) windowspecdefinition(a#3, b#4 ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#0], [a#3], [b#4 ASC NULLS FIRST]
+- RankLimit [a#3], [b#4 ASC NULLS FIRST], rank(b#4), 1
+- LocalRelation [a#3, b#4]
scala> spark.sql("""SELECT a, b, rank() OVER (PARTITION BY a ORDER BY b) as rk FROM VALUES ('A1', 1), ('A1', 1), ('A2', 3), ('A1', 1) tab(a, b);""").where("rk = 1").show
+---+---+---+
| a| b| rk|
+---+---+---+
| A1| 1| 1|
| A1| 1| 1|
| A1| 1| 1|
| A2| 3| 1|
+---+---+---+
```

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977721203
**[Test build #145574 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145574/testReport)** for PR 34367 at commit [`562fbb1`](https://github.com/apache/spark/commit/562fbb1d8dabf701472a1f76b8b6de42cbe1a706).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977958055
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979089982
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50097/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979328359
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145629/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979328359
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145629/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977667783
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145562/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977548067
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50034/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950636191
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/144573/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-949719335
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/144536/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-949719335
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/144536/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950459065
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/49041/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950481576
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/49041/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950587579
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/49047/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-989635974
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50506/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-989670320
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50506/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-989827534
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/146030/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-978101415
**[Test build #145584 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145584/testReport)** for PR 34367 at commit [`7c1e6c6`](https://github.com/apache/spark/commit/7c1e6c600c3999bb9e1fe1637c18c26046f651c8).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979285386
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145625/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979657376
**[Test build #145644 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145644/testReport)** for PR 34367 at commit [`b1006ee`](https://github.com/apache/spark/commit/b1006eecef9c2bc18422abaab27a932de6be5c47).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #34367:
URL: https://github.com/apache/spark/pull/34367#discussion_r756544659
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/window/RankLimitExec.scala
##########
@@ -0,0 +1,93 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions._
+import org.apache.spark.sql.catalyst.expressions.codegen.LazilyGeneratedOrdering
+import org.apache.spark.sql.catalyst.plans.physical._
+import org.apache.spark.sql.execution.{GroupedIterator, SparkPlan, UnaryExecNode}
+import org.apache.spark.util.collection.Utils
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec,
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ */
+case class RankLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ limit: Int,
+ child: SparkPlan) extends UnaryExecNode {
+ assert(orderSpec.nonEmpty && limit > 0)
+
+ // apply Utils.takeOrdered when partitionSpec is empty and row_number is used.
+ private def applyTakeOrdered: Boolean = partitionSpec.isEmpty
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] = {
+ if (applyTakeOrdered) {
+ super.requiredChildOrdering
+ } else {
+ // Should be the same as [[WindowExec#requiredChildOrdering]]
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+ }
+ }
+
+ override def outputOrdering: Seq[SortOrder] = {
+ if (applyTakeOrdered) {
+ orderSpec
+ } else {
+ child.outputOrdering
+ }
+ }
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ // TODO: support rank and dense_rank
Review comment:
within each maptask:
1, sort the partion by `(a,b)`;
2, group the iterator by `a`: `GroupedIterator.apply(stream, partitionSpec, output)`
3, within each group, group again by `b`, compute the `rk`, and skip if `rk` > 1.
the `limitFunc` for `rank` and `dense_rank` may be like:
```
case _: Rank =>
(partitionedStream: Iterator[InternalRow]) =>
new Iterator[InternalRow]() {
private val internalIter =
GroupedIterator.apply(partitionedStream, orderSpec.map(_.child), output)
private var cnt = 0
private var rank = 0
private var currentGroup: Iterator[InternalRow] = null
fetchNextGroup()
private def fetchNextGroup(): Unit = {
if (internalIter.hasNext && rank < limit) {
currentGroup = internalIter.next()._2
rank = cnt + 1
} else {
currentGroup = null
}
}
override def hasNext: Boolean = currentGroup != null && currentGroup.hasNext
override def next(): InternalRow = {
val row = currentGroup.next()
if (currentGroup.isEmpty) {
fetchNextGroup()
}
cnt += 1
row
}
}
case _: DenseRank =>
(partitionedStream: Iterator[InternalRow]) =>
GroupedIterator
.apply(partitionedStream, orderSpec.map(_.child), output)
.take(limit)
.flatMap(_._2)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979243636
**[Test build #145632 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145632/testReport)** for PR 34367 at commit [`2a47f39`](https://github.com/apache/spark/commit/2a47f39063454cc7274c0dfe8e5a34d086f6cb91).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979278292
**[Test build #145625 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145625/testReport)** for PR 34367 at commit [`16242b0`](https://github.com/apache/spark/commit/16242b04a97414b0a936cdbfc5ed54cd93706f67).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981573488
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50180/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981741230
**[Test build #145710 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145710/testReport)** for PR 34367 at commit [`354b445`](https://github.com/apache/spark/commit/354b445a7fe645c95bddca0030ad3b56135a0106).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950527904
retest this please
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng edited a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng edited a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-949516811
a simple example:
```
import org.apache.spark.sql.expressions.Window
val df1 = spark.range(0, 100000000, 1, 9).select(when('id < 90000000, 123).otherwise('id).as("key1"), 'id as "value1").withColumn("hash1", abs(hash(col("key1"))).mod(1000))
df1.withColumn("rank", row_number().over(Window.partitionBy("hash1").orderBy("value1"))).where(col("rank") <= 1).write.mode("overwrite").parquet("/tmp/tmp1")
spark.conf.set("spark.sql.rankLimit.enabled", "true")
df1.withColumn("rank", row_number().over(Window.partitionBy("hash1").orderBy("value1"))).where(col("rank") <= 1).write.mode("overwrite").parquet("/tmp/tmp2")
```

existing plan took 33 sec, while the new plan with `RankLimit` took only 8 sec.

and the shuffle write was reduced from 544.9 MiB to 26.7 KiB
```
== Physical Plan ==
Execute InsertIntoHadoopFsRelationCommand (18)
+- AdaptiveSparkPlan (17)
+- == Final Plan ==
* Filter (11)
+- Window (10)
+- * Sort (9)
+- AQEShuffleRead (8)
+- ShuffleQueryStage (7)
+- Exchange (6)
+- RankLimit (5)
+- * Sort (4)
+- * Project (3)
+- * Project (2)
+- * Range (1)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950580099
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/49047/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950758625
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/144576/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950500260
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/49044/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977667783
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145562/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
wangyum commented on a change in pull request #34367:
URL: https://github.com/apache/spark/pull/34367#discussion_r756486047
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/window/RankLimitExec.scala
##########
@@ -0,0 +1,93 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions._
+import org.apache.spark.sql.catalyst.expressions.codegen.LazilyGeneratedOrdering
+import org.apache.spark.sql.catalyst.plans.physical._
+import org.apache.spark.sql.execution.{GroupedIterator, SparkPlan, UnaryExecNode}
+import org.apache.spark.util.collection.Utils
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec,
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ */
+case class RankLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ limit: Int,
+ child: SparkPlan) extends UnaryExecNode {
+ assert(orderSpec.nonEmpty && limit > 0)
+
+ // apply Utils.takeOrdered when partitionSpec is empty and row_number is used.
+ private def applyTakeOrdered: Boolean = partitionSpec.isEmpty
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] = {
+ if (applyTakeOrdered) {
+ super.requiredChildOrdering
+ } else {
+ // Should be the same as [[WindowExec#requiredChildOrdering]]
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+ }
+ }
+
+ override def outputOrdering: Seq[SortOrder] = {
+ if (applyTakeOrdered) {
+ orderSpec
+ } else {
+ child.outputOrdering
+ }
+ }
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ // TODO: support rank and dense_rank
Review comment:
How can we support `rank` and `dense_rank`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977530622
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50034/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-978982024
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50093/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977940598
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50057/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-978893149
**[Test build #145621 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145621/testReport)** for PR 34367 at commit [`873083f`](https://github.com/apache/spark/commit/873083fe8e55c32ba7310e621430950c0a8328a3).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #34367:
URL: https://github.com/apache/spark/pull/34367#discussion_r756752125
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/window/RankLimitExec.scala
##########
@@ -0,0 +1,93 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions._
+import org.apache.spark.sql.catalyst.expressions.codegen.LazilyGeneratedOrdering
+import org.apache.spark.sql.catalyst.plans.physical._
+import org.apache.spark.sql.execution.{GroupedIterator, SparkPlan, UnaryExecNode}
+import org.apache.spark.util.collection.Utils
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec,
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ */
+case class RankLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ limit: Int,
+ child: SparkPlan) extends UnaryExecNode {
+ assert(orderSpec.nonEmpty && limit > 0)
+
+ // apply Utils.takeOrdered when partitionSpec is empty and row_number is used.
+ private def applyTakeOrdered: Boolean = partitionSpec.isEmpty
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] = {
+ if (applyTakeOrdered) {
+ super.requiredChildOrdering
+ } else {
+ // Should be the same as [[WindowExec#requiredChildOrdering]]
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+ }
+ }
+
+ override def outputOrdering: Seq[SortOrder] = {
+ if (applyTakeOrdered) {
+ orderSpec
+ } else {
+ child.outputOrdering
+ }
+ }
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ // TODO: support rank and dense_rank
Review comment:
The correctness exists in:
for all three rank functions (row_number, rank, dense_rank), `global rank` >= `partial rank`, so we can safely remove rows with `partial rank > limit`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979427252
**[Test build #145632 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145632/testReport)** for PR 34367 at commit [`2a47f39`](https://github.com/apache/spark/commit/2a47f39063454cc7274c0dfe8e5a34d086f6cb91).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979098755
**[Test build #145629 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145629/testReport)** for PR 34367 at commit [`d17fcf8`](https://github.com/apache/spark/commit/d17fcf88585f7b58f0709cbbf4952aa050fa9017).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979137002
**[Test build #145621 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145621/testReport)** for PR 34367 at commit [`873083f`](https://github.com/apache/spark/commit/873083fe8e55c32ba7310e621430950c0a8328a3).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981743370
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145710/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979143823
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50100/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979195663
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50100/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-982677202
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50242/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-983449556
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145790/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-982900233
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145770/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-982711759
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50242/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] bersprockets commented on a change in pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
bersprockets commented on a change in pull request #34367:
URL: https://github.com/apache/spark/pull/34367#discussion_r766913169
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/window/RankLimitExec.scala
##########
@@ -0,0 +1,280 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions._
+import org.apache.spark.sql.catalyst.expressions.codegen._
+import org.apache.spark.sql.catalyst.plans.physical._
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.metric.SQLMetrics
+import org.apache.spark.util.collection.Utils
+
+
+sealed trait RankLimitMode
+
+case object Partial extends RankLimitMode
+
+case object Final extends RankLimitMode
+
+
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec,
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class RankLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankFunction: Expression,
+ limit: Int,
+ mode: RankLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+ assert(orderSpec.nonEmpty && limit > 0)
+
+ private val shouldPass = child match {
+ case r: RankLimitExec =>
+ partitionSpec.size == r.partitionSpec.size &&
+ partitionSpec.zip(r.partitionSpec).forall(p => p._1.semanticEquals(p._2)) &&
+ orderSpec.size == r.orderSpec.size &&
+ orderSpec.zip(r.orderSpec).forall(o => o._1.semanticEquals(o._2)) &&
+ rankFunction.semanticEquals(r.rankFunction) &&
+ mode == Final && r.mode == Partial && limit == r.limit
+ case _ => false
+ }
+
+ private val shouldApplyTakeOrdered: Boolean = {
+ rankFunction match {
+ case _: RowNumber => limit < conf.topKSortFallbackThreshold
+ case _: Rank => false
+ case _: DenseRank => false
+ case f => throw new IllegalArgumentException(s"Unsupported rank function: $f")
+ }
+ }
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] = {
+ if (shouldApplyTakeOrdered) {
+ Seq(partitionSpec.map(SortOrder(_, Ascending)))
+ } else {
+ // Should be the same as [[WindowExec#requiredChildOrdering]]
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+ }
+ }
+
+ override def outputOrdering: Seq[SortOrder] = {
+ partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec
+ }
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ // Should be the same as [[WindowExec#requiredChildDistribution]]
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else ClusteredDistribution(partitionSpec) :: Nil
+ }
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ override lazy val metrics = Map(
+ "numOutputRows" -> SQLMetrics.createMetric(sparkContext, "number of output rows"))
+
+ private lazy val ordering = GenerateOrdering.generate(orderSpec, output)
+
+ private lazy val limitFunction = rankFunction match {
+ case _: RowNumber if shouldApplyTakeOrdered =>
+ (stream: Iterator[InternalRow]) =>
+ Utils.takeOrdered(stream.map(_.copy()), limit)(ordering)
Review comment:
By default, `spark.sql.execution.topKSortFallbackThreshold` is set to a pretty big number (Integer.MAX_VALUE - 15). Therefore, by default anyway, this line of code will attempt to do a sort with guava regardless of the size of the rank limit.
For example, using your example [here](https://github.com/apache/spark/pull/34367#issuecomment-949516811), but changing the where clause to `col("rank") <= 1000000`, I get:
```
java.lang.OutOfMemoryError: GC overhead limit exceeded
```
Whereas I don't get that with `spark.sql.rankLimit.enabled=false`.
If I set `spark.sql.execution.topKSortFallbackThreshold=10000`, it succeeds with `spark.sql.rankLimit.enabled=true`.
Maybe it needs its own threshold? Or something to make users more aware (since it is not always super clear from the stack traces what was causing the OOMs).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950482209
**[Test build #144573 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/144573/testReport)** for PR 34367 at commit [`3c51865`](https://github.com/apache/spark/commit/3c518652d74e50bcb85024dd5e5e75dc63121ce7).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950587579
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/49047/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950529376
**[Test build #144576 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/144576/testReport)** for PR 34367 at commit [`3c51865`](https://github.com/apache/spark/commit/3c518652d74e50bcb85024dd5e5e75dc63121ce7).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979146991
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979316433
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50103/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979933220
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50138/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979933187
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50138/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
wangyum commented on a change in pull request #34367:
URL: https://github.com/apache/spark/pull/34367#discussion_r756528430
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/window/RankLimitExec.scala
##########
@@ -0,0 +1,93 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions._
+import org.apache.spark.sql.catalyst.expressions.codegen.LazilyGeneratedOrdering
+import org.apache.spark.sql.catalyst.plans.physical._
+import org.apache.spark.sql.execution.{GroupedIterator, SparkPlan, UnaryExecNode}
+import org.apache.spark.util.collection.Utils
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec,
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ */
+case class RankLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ limit: Int,
+ child: SparkPlan) extends UnaryExecNode {
+ assert(orderSpec.nonEmpty && limit > 0)
+
+ // apply Utils.takeOrdered when partitionSpec is empty and row_number is used.
+ private def applyTakeOrdered: Boolean = partitionSpec.isEmpty
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] = {
+ if (applyTakeOrdered) {
+ super.requiredChildOrdering
+ } else {
+ // Should be the same as [[WindowExec#requiredChildOrdering]]
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+ }
+ }
+
+ override def outputOrdering: Seq[SortOrder] = {
+ if (applyTakeOrdered) {
+ orderSpec
+ } else {
+ child.outputOrdering
+ }
+ }
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ // TODO: support rank and dense_rank
Review comment:
For example:
```
0: jdbc:hive2://10.211.174.27:10000/access_vi> SELECT a, b, rank() OVER (PARTITION BY a ORDER BY b) as rk FROM VALUES ('A1', 1), ('A1', 1), ('A2', 3), ('A1', 1) tab(a, b);
+-----+----+-----+--+
| a | b | rk |
+-----+----+-----+--+
| A1 | 1 | 1 |
| A1 | 1 | 1 |
| A1 | 1 | 1 |
| A2 | 3 | 1 |
+-----+----+-----+--+
4 rows selected (8.259 seconds)
```
If we add a filter condition: `rk = 1`. How can we ensure the result is correct if we use `RankLimitExec`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979283960
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50103/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977856204
**[Test build #145584 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145584/testReport)** for PR 34367 at commit [`7c1e6c6`](https://github.com/apache/spark/commit/7c1e6c600c3999bb9e1fe1637c18c26046f651c8).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979657176
test benchmark results on my laptop:
```
[info] Java HotSpot(TM) 64-Bit Server VM 1.8.0_301-b09 on Linux 5.11.0-40-generic
[info] Intel(R) Core(TM) i7-8850H CPU @ 2.60GHz
[info] Benchmark Top-K: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] ROW_NUMBER WITHOUT PARTITION 2368 2584 163 8.9 112.9 1.0X
[info] ROW_NUMBER WITHOUT PARTITION (RANKLIMIT) 1019 1047 21 20.6 48.6 2.3X
[info] RANK WITHOUT PARTITION 2934 3087 142 7.1 139.9 0.8X
[info] RANK WITHOUT PARTITION (RANKLIMIT) 26 36 13 800.7 1.2 90.4X
[info] DENSE_RANK WITHOUT PARTITION 2762 2873 106 7.6 131.7 0.9X
[info] DENSE_RANK WITHOUT PARTITION (RANKLIMIT) 22 28 4 934.7 1.1 105.5X
[info] ROW_NUMBER WITH PARTITION 19493 19758 319 1.1 929.5 0.1X
[info] ROW_NUMBER WITH PARTITION (RANKLIMIT) 6373 6576 228 3.3 303.9 0.4X
[info] RANK WITH PARTITION 20696 21254 274 1.0 986.8 0.1X
[info] RANK WITH PARTITION (RANKLIMIT) 6172 6472 213 3.4 294.3 0.4X
[info] DENSE_RANK WITH PARTITION 19070 19346 284 1.1 909.3 0.1X
[info] DENSE_RANK WITH PARTITION (RANKLIMIT) 6249 6439 131 3.4 298.0 0.4X
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977664510
**[Test build #145562 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145562/testReport)** for PR 34367 at commit [`728d485`](https://github.com/apache/spark/commit/728d485058d0e0147e45e1588bd7b5cf0b838c95).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979146992
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979890157
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50138/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950476042
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/49041/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981299164
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50162/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-989689730
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50506/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-989603356
**[Test build #146030 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/146030/testReport)** for PR 34367 at commit [`6d2efab`](https://github.com/apache/spark/commit/6d2efab0549c8283f582bf8fe019b2c223f0681d).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] bersprockets commented on a change in pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
bersprockets commented on a change in pull request #34367:
URL: https://github.com/apache/spark/pull/34367#discussion_r766913169
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/window/RankLimitExec.scala
##########
@@ -0,0 +1,280 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions._
+import org.apache.spark.sql.catalyst.expressions.codegen._
+import org.apache.spark.sql.catalyst.plans.physical._
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.metric.SQLMetrics
+import org.apache.spark.util.collection.Utils
+
+
+sealed trait RankLimitMode
+
+case object Partial extends RankLimitMode
+
+case object Final extends RankLimitMode
+
+
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec,
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class RankLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankFunction: Expression,
+ limit: Int,
+ mode: RankLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+ assert(orderSpec.nonEmpty && limit > 0)
+
+ private val shouldPass = child match {
+ case r: RankLimitExec =>
+ partitionSpec.size == r.partitionSpec.size &&
+ partitionSpec.zip(r.partitionSpec).forall(p => p._1.semanticEquals(p._2)) &&
+ orderSpec.size == r.orderSpec.size &&
+ orderSpec.zip(r.orderSpec).forall(o => o._1.semanticEquals(o._2)) &&
+ rankFunction.semanticEquals(r.rankFunction) &&
+ mode == Final && r.mode == Partial && limit == r.limit
+ case _ => false
+ }
+
+ private val shouldApplyTakeOrdered: Boolean = {
+ rankFunction match {
+ case _: RowNumber => limit < conf.topKSortFallbackThreshold
+ case _: Rank => false
+ case _: DenseRank => false
+ case f => throw new IllegalArgumentException(s"Unsupported rank function: $f")
+ }
+ }
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] = {
+ if (shouldApplyTakeOrdered) {
+ Seq(partitionSpec.map(SortOrder(_, Ascending)))
+ } else {
+ // Should be the same as [[WindowExec#requiredChildOrdering]]
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+ }
+ }
+
+ override def outputOrdering: Seq[SortOrder] = {
+ partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec
+ }
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ // Should be the same as [[WindowExec#requiredChildDistribution]]
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else ClusteredDistribution(partitionSpec) :: Nil
+ }
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ override lazy val metrics = Map(
+ "numOutputRows" -> SQLMetrics.createMetric(sparkContext, "number of output rows"))
+
+ private lazy val ordering = GenerateOrdering.generate(orderSpec, output)
+
+ private lazy val limitFunction = rankFunction match {
+ case _: RowNumber if shouldApplyTakeOrdered =>
+ (stream: Iterator[InternalRow]) =>
+ Utils.takeOrdered(stream.map(_.copy()), limit)(ordering)
Review comment:
By default, `spark.sql.execution.topKSortFallbackThreshold` is set to a pretty big number (Integer.MAX_VALUE - 15). Therefore, by default anyway, this line of code will attempt to do a sort with guava regardless of the size of the rank limit.
For example, using your example [here](https://github.com/apache/spark/pull/34367#issuecomment-949516811), but changing the where clause to `col("rank") <= 1000000`, I get:
```
java.lang.OutOfMemoryError: GC overhead limit exceeded
```
Whereas I don't get that with `spark.sql.rankLimit.enabled=false`.
If I set `spark.sql.execution.topKSortFallbackThreshold=10000`, it succeeds with `spark.sql.rankLimit.enabled=true`.
Maybe it needs its own threshold? Or something to make users more aware (since it is not always super clear from the stack traces what was causing the OOMs).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981538947
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50180/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-982890565
**[Test build #145770 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145770/testReport)** for PR 34367 at commit [`101f6c5`](https://github.com/apache/spark/commit/101f6c5f74f5a5d875dc43095c8bc3c8f57c6f6b).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-983256901
**[Test build #145790 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145790/testReport)** for PR 34367 at commit [`877558e`](https://github.com/apache/spark/commit/877558e439663d1028028e9a332a5e4e6a18ad6c).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950441852
retest this please
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950527923
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/49044/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-949548326
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/49007/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-949717978
**[Test build #144536 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/144536/testReport)** for PR 34367 at commit [`134067f`](https://github.com/apache/spark/commit/134067f5e34ef4f6d177a93f38ed7a65592ad026).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds the following public classes _(experimental)_:
* `case class RankLimit(`
* `case class RankLimitExec(`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977497924
**[Test build #145562 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145562/testReport)** for PR 34367 at commit [`728d485`](https://github.com/apache/spark/commit/728d485058d0e0147e45e1588bd7b5cf0b838c95).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977809636
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50047/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977856204
**[Test build #145584 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145584/testReport)** for PR 34367 at commit [`7c1e6c6`](https://github.com/apache/spark/commit/7c1e6c600c3999bb9e1fe1637c18c26046f651c8).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-978982024
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50093/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979427976
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145632/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981299850
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50162/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981356532
**[Test build #145692 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145692/testReport)** for PR 34367 at commit [`354b445`](https://github.com/apache/spark/commit/354b445a7fe645c95bddca0030ad3b56135a0106).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981263291
**[Test build #145692 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145692/testReport)** for PR 34367 at commit [`354b445`](https://github.com/apache/spark/commit/354b445a7fe645c95bddca0030ad3b56135a0106).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950511716
**[Test build #144570 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/144570/testReport)** for PR 34367 at commit [`134067f`](https://github.com/apache/spark/commit/134067f5e34ef4f6d177a93f38ed7a65592ad026).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds the following public classes _(experimental)_:
* `case class RankLimit(`
* `case class RankLimitExec(`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-949514645
**[Test build #144536 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/144536/testReport)** for PR 34367 at commit [`134067f`](https://github.com/apache/spark/commit/134067f5e34ef4f6d177a93f38ed7a65592ad026).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977497924
**[Test build #145562 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145562/testReport)** for PR 34367 at commit [`728d485`](https://github.com/apache/spark/commit/728d485058d0e0147e45e1588bd7b5cf0b838c95).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-978918945
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50093/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979054207
**[Test build #145625 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145625/testReport)** for PR 34367 at commit [`16242b0`](https://github.com/apache/spark/commit/16242b04a97414b0a936cdbfc5ed54cd93706f67).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977721203
**[Test build #145574 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145574/testReport)** for PR 34367 at commit [`562fbb1`](https://github.com/apache/spark/commit/562fbb1d8dabf701472a1f76b8b6de42cbe1a706).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977809612
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50047/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-980046005
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145668/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-983328709
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50263/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-982633822
**[Test build #145770 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145770/testReport)** for PR 34367 at commit [`101f6c5`](https://github.com/apache/spark/commit/101f6c5f74f5a5d875dc43095c8bc3c8f57c6f6b).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-983313959
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50263/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-983449556
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145790/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979846280
**[Test build #145668 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145668/testReport)** for PR 34367 at commit [`d23c431`](https://github.com/apache/spark/commit/d23c4319bd46e30f3d7971039f9f5ceda1d76072).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981582558
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50180/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981496871
**[Test build #145710 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145710/testReport)** for PR 34367 at commit [`354b445`](https://github.com/apache/spark/commit/354b445a7fe645c95bddca0030ad3b56135a0106).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-982633822
**[Test build #145770 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145770/testReport)** for PR 34367 at commit [`101f6c5`](https://github.com/apache/spark/commit/101f6c5f74f5a5d875dc43095c8bc3c8f57c6f6b).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979769184
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145644/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981496871
**[Test build #145710 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145710/testReport)** for PR 34367 at commit [`354b445`](https://github.com/apache/spark/commit/354b445a7fe645c95bddca0030ad3b56135a0106).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-978952004
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50093/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979098755
**[Test build #145629 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145629/testReport)** for PR 34367 at commit [`d17fcf8`](https://github.com/apache/spark/commit/d17fcf88585f7b58f0709cbbf4952aa050fa9017).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979326802
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50103/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979657376
**[Test build #145644 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145644/testReport)** for PR 34367 at commit [`b1006ee`](https://github.com/apache/spark/commit/b1006eecef9c2bc18422abaab27a932de6be5c47).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #34367:
URL: https://github.com/apache/spark/pull/34367#discussion_r756518072
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/window/RankLimitExec.scala
##########
@@ -0,0 +1,93 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions._
+import org.apache.spark.sql.catalyst.expressions.codegen.LazilyGeneratedOrdering
+import org.apache.spark.sql.catalyst.plans.physical._
+import org.apache.spark.sql.execution.{GroupedIterator, SparkPlan, UnaryExecNode}
+import org.apache.spark.util.collection.Utils
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec,
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ */
+case class RankLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ limit: Int,
+ child: SparkPlan) extends UnaryExecNode {
+ assert(orderSpec.nonEmpty && limit > 0)
+
+ // apply Utils.takeOrdered when partitionSpec is empty and row_number is used.
+ private def applyTakeOrdered: Boolean = partitionSpec.isEmpty
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] = {
+ if (applyTakeOrdered) {
+ super.requiredChildOrdering
+ } else {
+ // Should be the same as [[WindowExec#requiredChildOrdering]]
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+ }
+ }
+
+ override def outputOrdering: Seq[SortOrder] = {
+ if (applyTakeOrdered) {
+ orderSpec
+ } else {
+ child.outputOrdering
+ }
+ }
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ // TODO: support rank and dense_rank
Review comment:
1, for `rank` and `dense_rank`, no matter whether partitionSpec is empty, `requiredChildOrdering = Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)`;
2, then in the map side, we can compute the `rank` and `dense_rank` for each row, and filter out unnecessary rows.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-980038095
**[Test build #145668 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145668/testReport)** for PR 34367 at commit [`d23c431`](https://github.com/apache/spark/commit/d23c4319bd46e30f3d7971039f9f5ceda1d76072).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977557630
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50034/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979682381
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50116/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979657176
test benchmark results on my laptop:
```
[info] Java HotSpot(TM) 64-Bit Server VM 1.8.0_301-b09 on Linux 5.11.0-40-generic
[info] Intel(R) Core(TM) i7-8850H CPU @ 2.60GHz
[info] Benchmark Top-K: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------
[info] ROW_NUMBER WITHOUT PARTITION 2368 2584 163 8.9 112.9 1.0X
[info] ROW_NUMBER WITHOUT PARTITION (RANKLIMIT) 1019 1047 21 20.6 48.6 2.3X
[info] RANK WITHOUT PARTITION 2934 3087 142 7.1 139.9 0.8X
[info] RANK WITHOUT PARTITION (RANKLIMIT) 26 36 13 800.7 1.2 90.4X
[info] DENSE_RANK WITHOUT PARTITION 2762 2873 106 7.6 131.7 0.9X
[info] DENSE_RANK WITHOUT PARTITION (RANKLIMIT) 22 28 4 934.7 1.1 105.5X
[info] ROW_NUMBER WITH PARTITION 19493 19758 319 1.1 929.5 0.1X
[info] ROW_NUMBER WITH PARTITION (RANKLIMIT) 6373 6576 228 3.3 303.9 0.4X
[info] RANK WITH PARTITION 20696 21254 274 1.0 986.8 0.1X
[info] RANK WITH PARTITION (RANKLIMIT) 6172 6472 213 3.4 294.3 0.4X
[info] DENSE_RANK WITH PARTITION 19070 19346 284 1.1 909.3 0.1X
[info] DENSE_RANK WITH PARTITION (RANKLIMIT) 6249 6439 131 3.4 298.0 0.4X
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-978893149
**[Test build #145621 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145621/testReport)** for PR 34367 at commit [`873083f`](https://github.com/apache/spark/commit/873083fe8e55c32ba7310e621430950c0a8328a3).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979142008
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50097/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979243636
**[Test build #145632 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145632/testReport)** for PR 34367 at commit [`2a47f39`](https://github.com/apache/spark/commit/2a47f39063454cc7274c0dfe8e5a34d086f6cb91).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-989603356
**[Test build #146030 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/146030/testReport)** for PR 34367 at commit [`6d2efab`](https://github.com/apache/spark/commit/6d2efab0549c8283f582bf8fe019b2c223f0681d).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950482209
**[Test build #144573 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/144573/testReport)** for PR 34367 at commit [`3c51865`](https://github.com/apache/spark/commit/3c518652d74e50bcb85024dd5e5e75dc63121ce7).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950443311
**[Test build #144570 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/144570/testReport)** for PR 34367 at commit [`134067f`](https://github.com/apache/spark/commit/134067f5e34ef4f6d177a93f38ed7a65592ad026).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950512011
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/144570/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950517863
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/49044/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-1002525886
@cloud-fan @wangyum @dongjoon-hyun Could you please help take a look when you have time? Thanks
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981282705
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50162/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981357027
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145692/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-982738859
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50242/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng edited a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng edited a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-949516811
a simple skewed window example:
```
import org.apache.spark.sql.expressions.Window
val df1 = spark.range(0, 100000000, 1, 9).select(when('id < 90000000, 123).otherwise('id).as("key1"), 'id as "value1").withColumn("hash1", abs(hash(col("key1"))).mod(1000))
df1.withColumn("rank", row_number().over(Window.partitionBy("hash1").orderBy("value1"))).where(col("rank") <= 1).write.mode("overwrite").parquet("/tmp/tmp1")
spark.conf.set("spark.sql.rankLimit.enabled", "true")
df1.withColumn("rank", row_number().over(Window.partitionBy("hash1").orderBy("value1"))).where(col("rank") <= 1).write.mode("overwrite").parquet("/tmp/tmp2")
```

existing plan took 60 sec, while the new plan with `RankLimit` took only 8 sec.

and the shuffle write was reduced from 544.9 MiB to 26.7 KiB
```
== Physical Plan ==
Execute InsertIntoHadoopFsRelationCommand (20)
+- AdaptiveSparkPlan (19)
+- == Final Plan ==
* Filter (12)
+- Window (11)
+- RankLimit (10)
+- * Sort (9)
+- AQEShuffleRead (8)
+- ShuffleQueryStage (7)
+- Exchange (6)
+- RankLimit (5)
+- * Sort (4)
+- * Project (3)
+- * Project (2)
+- * Range (1)
+- == Initial Plan ==
Filter (18)
+- Window (17)
+- RankLimit (16)
+- Sort (15)
+- Exchange (14)
+- RankLimit (13)
+- Sort (4)
+- Project (3)
+- Project (2)
+- Range (1)
(1) Range [codegen id : 1]
Output [1]: [id#0L]
Arguments: Range (0, 100000000, step=1, splits=Some(9))
(2) Project [codegen id : 1]
Output [2]: [CASE WHEN (id#0L < 90000000) THEN 123 ELSE id#0L END AS key1#2L, id#0L AS value1#3L]
Input [1]: [id#0L]
(3) Project [codegen id : 1]
Output [3]: [key1#2L, value1#3L, (abs(hash(key1#2L, 42), false) % 1000) AS hash1#6]
Input [2]: [key1#2L, value1#3L]
(4) Sort [codegen id : 1]
Input [3]: [key1#2L, value1#3L, hash1#6]
Arguments: [hash1#6 ASC NULLS FIRST], false, 0
(5) RankLimit
Input [3]: [key1#2L, value1#3L, hash1#6]
Arguments: [hash1#6], [value1#3L ASC NULLS FIRST], row_number(), 1, Partial
(6) Exchange
Input [3]: [key1#2L, value1#3L, hash1#6]
Arguments: hashpartitioning(hash1#6, 200), ENSURE_REQUIREMENTS, [id=#119]
(7) ShuffleQueryStage
Output [3]: [key1#2L, value1#3L, hash1#6]
Arguments: 0
(8) AQEShuffleRead
Input [3]: [key1#2L, value1#3L, hash1#6]
Arguments: coalesced
(9) Sort [codegen id : 2]
Input [3]: [key1#2L, value1#3L, hash1#6]
Arguments: [hash1#6 ASC NULLS FIRST], false, 0
(10) RankLimit
Input [3]: [key1#2L, value1#3L, hash1#6]
Arguments: [hash1#6], [value1#3L ASC NULLS FIRST], row_number(), 1, Final
(11) Window
Input [3]: [key1#2L, value1#3L, hash1#6]
Arguments: [row_number() windowspecdefinition(hash1#6, value1#3L ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rank#21], [hash1#6], [value1#3L ASC NULLS FIRST]
(12) Filter [codegen id : 3]
Input [4]: [key1#2L, value1#3L, hash1#6, rank#21]
Condition : (rank#21 <= 1)
(13) RankLimit
Input [3]: [key1#2L, value1#3L, hash1#6]
Arguments: [hash1#6], [value1#3L ASC NULLS FIRST], row_number(), 1, Partial
(14) Exchange
Input [3]: [key1#2L, value1#3L, hash1#6]
Arguments: hashpartitioning(hash1#6, 200), ENSURE_REQUIREMENTS, [id=#100]
(15) Sort
Input [3]: [key1#2L, value1#3L, hash1#6]
Arguments: [hash1#6 ASC NULLS FIRST], false, 0
(16) RankLimit
Input [3]: [key1#2L, value1#3L, hash1#6]
Arguments: [hash1#6], [value1#3L ASC NULLS FIRST], row_number(), 1, Final
(17) Window
Input [3]: [key1#2L, value1#3L, hash1#6]
Arguments: [row_number() windowspecdefinition(hash1#6, value1#3L ASC NULLS FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rank#21], [hash1#6], [value1#3L ASC NULLS FIRST]
(18) Filter
Input [4]: [key1#2L, value1#3L, hash1#6, rank#21]
Condition : (rank#21 <= 1)
(19) AdaptiveSparkPlan
Output [4]: [key1#2L, value1#3L, hash1#6, rank#21]
Arguments: isFinalPlan=true
(20) Execute InsertIntoHadoopFsRelationCommand
Input [4]: [key1#2L, value1#3L, hash1#6, rank#21]
Arguments: file:/tmp/tmp2, false, Parquet, [path=/tmp/tmp2], Overwrite, [key1, value1, hash1, rank]
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981299850
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50162/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979285386
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145625/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979326802
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50103/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #34367:
URL: https://github.com/apache/spark/pull/34367#discussion_r756544659
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/window/RankLimitExec.scala
##########
@@ -0,0 +1,93 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions._
+import org.apache.spark.sql.catalyst.expressions.codegen.LazilyGeneratedOrdering
+import org.apache.spark.sql.catalyst.plans.physical._
+import org.apache.spark.sql.execution.{GroupedIterator, SparkPlan, UnaryExecNode}
+import org.apache.spark.util.collection.Utils
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec,
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ */
+case class RankLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ limit: Int,
+ child: SparkPlan) extends UnaryExecNode {
+ assert(orderSpec.nonEmpty && limit > 0)
+
+ // apply Utils.takeOrdered when partitionSpec is empty and row_number is used.
+ private def applyTakeOrdered: Boolean = partitionSpec.isEmpty
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] = {
+ if (applyTakeOrdered) {
+ super.requiredChildOrdering
+ } else {
+ // Should be the same as [[WindowExec#requiredChildOrdering]]
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+ }
+ }
+
+ override def outputOrdering: Seq[SortOrder] = {
+ if (applyTakeOrdered) {
+ orderSpec
+ } else {
+ child.outputOrdering
+ }
+ }
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ // TODO: support rank and dense_rank
Review comment:
within each maptask:
1, sort the partion by `(a,b)`;
2, group the iterator by `a`: `GroupedIterator.apply(stream, partitionSpec, output)`
3, within each group, group again by `b`, compute the `rk`, and skip if `rk` > 1.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979699595
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50116/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979699595
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50116/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977901467
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50057/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977954219
**[Test build #145574 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145574/testReport)** for PR 34367 at commit [`562fbb1`](https://github.com/apache/spark/commit/562fbb1d8dabf701472a1f76b8b6de42cbe1a706).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977557630
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50034/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979767907
**[Test build #145644 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145644/testReport)** for PR 34367 at commit [`b1006ee`](https://github.com/apache/spark/commit/b1006eecef9c2bc18422abaab27a932de6be5c47).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979769184
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145644/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981357027
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145692/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981743370
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145710/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979846280
**[Test build #145668 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145668/testReport)** for PR 34367 at commit [`d23c431`](https://github.com/apache/spark/commit/d23c4319bd46e30f3d7971039f9f5ceda1d76072).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981263291
**[Test build #145692 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145692/testReport)** for PR 34367 at commit [`354b445`](https://github.com/apache/spark/commit/354b445a7fe645c95bddca0030ad3b56135a0106).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-983419906
**[Test build #145790 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145790/testReport)** for PR 34367 at commit [`877558e`](https://github.com/apache/spark/commit/877558e439663d1028028e9a332a5e4e6a18ad6c).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-989689730
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50506/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950527923
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/49044/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950756038
**[Test build #144576 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/144576/testReport)** for PR 34367 at commit [`3c51865`](https://github.com/apache/spark/commit/3c518652d74e50bcb85024dd5e5e75dc63121ce7).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-962989084
cc @cloud-fan
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-989827534
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/146030/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-981582558
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50180/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-980046005
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145668/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #34367:
URL: https://github.com/apache/spark/pull/34367#discussion_r756752125
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/window/RankLimitExec.scala
##########
@@ -0,0 +1,93 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions._
+import org.apache.spark.sql.catalyst.expressions.codegen.LazilyGeneratedOrdering
+import org.apache.spark.sql.catalyst.plans.physical._
+import org.apache.spark.sql.execution.{GroupedIterator, SparkPlan, UnaryExecNode}
+import org.apache.spark.util.collection.Utils
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec,
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ */
+case class RankLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ limit: Int,
+ child: SparkPlan) extends UnaryExecNode {
+ assert(orderSpec.nonEmpty && limit > 0)
+
+ // apply Utils.takeOrdered when partitionSpec is empty and row_number is used.
+ private def applyTakeOrdered: Boolean = partitionSpec.isEmpty
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] = {
+ if (applyTakeOrdered) {
+ super.requiredChildOrdering
+ } else {
+ // Should be the same as [[WindowExec#requiredChildOrdering]]
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+ }
+ }
+
+ override def outputOrdering: Seq[SortOrder] = {
+ if (applyTakeOrdered) {
+ orderSpec
+ } else {
+ child.outputOrdering
+ }
+ }
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ // TODO: support rank and dense_rank
Review comment:
The correctness exists in:
for all three rank functions (row_number, rank, dense_rank), `global rank` <= `partial rank`, so we can safely remove rows with `partial rank > limit`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979327079
**[Test build #145629 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145629/testReport)** for PR 34367 at commit [`d17fcf8`](https://github.com/apache/spark/commit/d17fcf88585f7b58f0709cbbf4952aa050fa9017).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-977763552
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50047/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-978106053
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145584/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-978106053
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145584/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979189685
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50100/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-979695211
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50116/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950633872
**[Test build #144573 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/144573/testReport)** for PR 34367 at commit [`3c51865`](https://github.com/apache/spark/commit/3c518652d74e50bcb85024dd5e5e75dc63121ce7).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950636191
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/144573/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-949516811
a simple example:
```
import org.apache.spark.sql.expressions.Window
val df1 = spark.range(0, 100000000, 1, 9).select(when('id < 90000000, 123).otherwise('id).as("key1"), 'id as "value1").withColumn("hash1", abs(hash(col("key1"))).mod(1000))
df1.withColumn("rank", row_number().over(Window.partitionBy("hash1").orderBy("value1"))).where(col("rank") <= 1).write.mode("overwrite").parquet("/tmp/tmp1")
spark.conf.set("spark.sql.replaceWindowTop.enabled", "true")
df1.withColumn("rank", row_number().over(Window.partitionBy("hash1").orderBy("value1"))).where(col("rank") <= 1).write.mode("overwrite").parquet("/tmp/tmp2")
```

existing plan took 33 sec, while the new plan with `RankLimit` took only 8 sec.

and the shuffle write was reduced from 544.9 MiB to 26.7 KiB
```
== Physical Plan ==
Execute InsertIntoHadoopFsRelationCommand (18)
+- AdaptiveSparkPlan (17)
+- == Final Plan ==
* Filter (11)
+- Window (10)
+- * Sort (9)
+- AQEShuffleRead (8)
+- ShuffleQueryStage (7)
+- Exchange (6)
+- RankLimit (5)
+- * Sort (4)
+- * Project (3)
+- * Project (2)
+- * Range (1)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-949578066
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/49007/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950549267
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/49047/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-949600168
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/49007/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-950512011
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/144570/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-983256901
**[Test build #145790 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/145790/testReport)** for PR 34367 at commit [`877558e`](https://github.com/apache/spark/commit/877558e439663d1028028e9a332a5e4e6a18ad6c).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-982900233
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/145770/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-982738859
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/50242/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #34367: [SPARK-37099][SQL] Impl a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-983295626
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/50263/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #34367: [SPARK-37099][SQL] Introduce a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on pull request #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-1082701022
retest this please
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org