You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@mxnet.apache.org by GitBox <gi...@apache.org> on 2018/03/29 21:24:10 UTC
[GitHub] astonzhang closed pull request #10130: Fix typo in autograd doc
astonzhang closed pull request #10130: Fix typo in autograd doc
URL: https://github.com/apache/incubator-mxnet/pull/10130
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/.github/PULL_REQUEST_TEMPLATE.md b/.github/PULL_REQUEST_TEMPLATE.md
index 193f5b02c4f..cd6fb45e7c2 100644
--- a/.github/PULL_REQUEST_TEMPLATE.md
+++ b/.github/PULL_REQUEST_TEMPLATE.md
@@ -3,7 +3,8 @@
## Checklist ##
### Essentials ###
-- [ ] Passed code style checking (`make lint`)
+Please feel free to remove inapplicable items for your PR.
+- [ ] The PR title starts with [MXNET-$JIRA_ID], where $JIRA_ID refers to the relevant [JIRA issue](https://issues.apache.org/jira/projects/MXNET/issues) created (except PRs with tiny changes)
- [ ] Changes are complete (i.e. I finished coding on this PR)
- [ ] All changes have test coverage:
- Unit tests are added for small changes to verify correctness (e.g. adding a new operator)
@@ -13,6 +14,7 @@
- For user-facing API changes, API doc string has been updated.
- For new C++ functions in header files, their functionalities and arguments are documented.
- For new examples, README.md is added to explain the what the example does, the source of the dataset, expected performance on test set and reference to the original paper if applicable
+- Check the API doc at http://mxnet-ci-doc.s3-accelerate.dualstack.amazonaws.com/PR-$PR_ID/$BUILD_ID/index.html
- [ ] To the my best knowledge, examples are either not affected by this change, or have been fixed to be compatible with this change
### Changes ###
diff --git a/.gitmodules b/.gitmodules
index cdb8a553679..e10eae20fe9 100644
--- a/.gitmodules
+++ b/.gitmodules
@@ -1,17 +1,17 @@
-[submodule "mshadow"]
- path = mshadow
+[submodule "3rdparty/mshadow"]
+ path = 3rdparty/mshadow
url = https://github.com/dmlc/mshadow.git
-[submodule "dmlc-core"]
- path = dmlc-core
+[submodule "3rdparty/dmlc-core"]
+ path = 3rdparty/dmlc-core
url = https://github.com/dmlc/dmlc-core.git
-[submodule "ps-lite"]
- path = ps-lite
+[submodule "3rdparty/ps-lite"]
+ path = 3rdparty/ps-lite
url = https://github.com/dmlc/ps-lite
-[submodule "nnvm"]
- path = nnvm
+[submodule "3rdparty/nnvm"]
+ path = 3rdparty/nnvm
url = https://github.com/dmlc/nnvm
-[submodule "dlpack"]
- path = dlpack
+[submodule "3rdparty/dlpack"]
+ path = 3rdparty/dlpack
url = https://github.com/dmlc/dlpack
[submodule "3rdparty/openmp"]
path = 3rdparty/openmp
diff --git a/dlpack b/3rdparty/dlpack
similarity index 100%
rename from dlpack
rename to 3rdparty/dlpack
diff --git a/dmlc-core b/3rdparty/dmlc-core
similarity index 100%
rename from dmlc-core
rename to 3rdparty/dmlc-core
diff --git a/mshadow b/3rdparty/mshadow
similarity index 100%
rename from mshadow
rename to 3rdparty/mshadow
diff --git a/nnvm b/3rdparty/nnvm
similarity index 100%
rename from nnvm
rename to 3rdparty/nnvm
diff --git a/ps-lite b/3rdparty/ps-lite
similarity index 100%
rename from ps-lite
rename to 3rdparty/ps-lite
diff --git a/CMakeLists.txt b/CMakeLists.txt
index b3a895583b4..116de37fb85 100644
--- a/CMakeLists.txt
+++ b/CMakeLists.txt
@@ -15,7 +15,7 @@ mxnet_option(USE_NCCL "Use NVidia NCCL with CUDA" OFF)
mxnet_option(USE_OPENCV "Build with OpenCV support" ON)
mxnet_option(USE_OPENMP "Build with Openmp support" ON)
mxnet_option(USE_CUDNN "Build with cudnn support" ON) # one could set CUDNN_ROOT for search path
-mxnet_option(USE_SSE "Build with x86 SSE instruction support" AUTO)
+mxnet_option(USE_SSE "Build with x86 SSE instruction support" ON)
mxnet_option(USE_LAPACK "Build with lapack support" ON IF NOT MSVC)
mxnet_option(USE_MKL_IF_AVAILABLE "Use MKL if found" ON)
mxnet_option(USE_MKLML_MKL "Use MKLDNN variant of MKL (if MKL found)" ON IF USE_MKL_IF_AVAILABLE AND UNIX AND (NOT APPLE))
@@ -97,7 +97,7 @@ else(MSVC)
check_cxx_compiler_flag("-std=c++0x" SUPPORT_CXX0X)
# For cross compilation, we can't rely on the compiler which accepts the flag, but mshadow will
# add platform specific includes not available in other arches
- if(USE_SSE STREQUAL "AUTO")
+ if(USE_SSE)
check_cxx_compiler_flag("-msse2" SUPPORT_MSSE2)
else()
set(SUPPORT_MSSE2 FALSE)
@@ -132,7 +132,9 @@ else(MSVC)
endif()
endif(MSVC)
-set(mxnet_LINKER_LIBS "")
+if(NOT mxnet_LINKER_LIBS)
+ set(mxnet_LINKER_LIBS "")
+endif(NOT mxnet_LINKER_LIBS)
if(USE_GPROF)
message(STATUS "Using GPROF")
@@ -221,14 +223,14 @@ endif()
if(USE_CUDA AND FIRST_CUDA)
include(cmake/ChooseBlas.cmake)
- include(mshadow/cmake/Utils.cmake)
+ include(3rdparty/mshadow/cmake/Utils.cmake)
include(cmake/FirstClassLangCuda.cmake)
include_directories(${CMAKE_CUDA_TOOLKIT_INCLUDE_DIRECTORIES})
else()
- if(EXISTS ${CMAKE_CURRENT_SOURCE_DIR}/mshadow/cmake)
- include(mshadow/cmake/mshadow.cmake)
- include(mshadow/cmake/Utils.cmake)
- include(mshadow/cmake/Cuda.cmake)
+ if(EXISTS ${CMAKE_CURRENT_SOURCE_DIR}/3rdparty/mshadow/cmake)
+ include(3rdparty/mshadow/cmake/mshadow.cmake)
+ include(3rdparty/mshadow/cmake/Utils.cmake)
+ include(3rdparty/mshadow/cmake/Cuda.cmake)
else()
include(mshadowUtils)
include(Cuda)
@@ -243,16 +245,16 @@ foreach(var ${C_CXX_INCLUDE_DIRECTORIES})
endforeach()
include_directories("include")
-include_directories("mshadow")
+include_directories("3rdparty/mshadow")
include_directories("3rdparty/cub")
-include_directories("nnvm/include")
-include_directories("nnvm/tvm/include")
-include_directories("dmlc-core/include")
-include_directories("dlpack/include")
+include_directories("3rdparty/nnvm/include")
+include_directories("3rdparty/nnvm/tvm/include")
+include_directories("3rdparty/dmlc-core/include")
+include_directories("3rdparty/dlpack/include")
# commented out until PR goes through
-#if(EXISTS ${CMAKE_CURRENT_SOURCE_DIR}/dlpack)
-# add_subdirectory(dlpack)
+#if(EXISTS ${CMAKE_CURRENT_SOURCE_DIR}/3rdparty/dlpack)
+# add_subdirectory(3rdparty/dlpack)
#endif()
# Prevent stripping out symbols (operator registrations, for example)
@@ -390,37 +392,37 @@ if(USE_CUDNN AND USE_CUDA)
endif()
endif()
-if(EXISTS ${CMAKE_CURRENT_SOURCE_DIR}/dmlc-core/cmake)
- add_subdirectory("dmlc-core")
+if(EXISTS ${CMAKE_CURRENT_SOURCE_DIR}/3rdparty/dmlc-core/cmake)
+ add_subdirectory("3rdparty/dmlc-core")
endif()
-if(EXISTS ${CMAKE_CURRENT_SOURCE_DIR}/mshadow/cmake)
- add_subdirectory("mshadow")
+if(EXISTS ${CMAKE_CURRENT_SOURCE_DIR}/3rdparty/mshadow/cmake)
+ add_subdirectory("3rdparty/mshadow")
endif()
FILE(GLOB_RECURSE SOURCE "src/*.cc" "src/*.h" "include/*.h")
FILE(GLOB_RECURSE CUDA "src/*.cu" "src/*.cuh")
# add nnvm to source
FILE(GLOB_RECURSE NNVMSOURCE
- nnvm/src/c_api/*.cc
- nnvm/src/core/*.cc
- nnvm/src/pass/*.cc
- nnvm/src/c_api/*.h
- nnvm/src/core/*.h
- nnvm/src/pass/*.h
- nnvm/include/*.h)
+ 3rdparty/nnvm/src/c_api/*.cc
+ 3rdparty/nnvm/src/core/*.cc
+ 3rdparty/nnvm/src/pass/*.cc
+ 3rdparty/nnvm/src/c_api/*.h
+ 3rdparty/nnvm/src/core/*.h
+ 3rdparty/nnvm/src/pass/*.h
+ 3rdparty/nnvm/include/*.h)
list(APPEND SOURCE ${NNVMSOURCE})
# add mshadow file
-FILE(GLOB_RECURSE MSHADOWSOURCE "mshadow/mshadow/*.h")
-FILE(GLOB_RECURSE MSHADOW_CUDASOURCE "mshadow/mshadow/*.cuh")
+FILE(GLOB_RECURSE MSHADOWSOURCE "3rdparty/mshadow/mshadow/*.h")
+FILE(GLOB_RECURSE MSHADOW_CUDASOURCE "3rdparty/mshadow/mshadow/*.cuh")
list(APPEND SOURCE ${MSHADOWSOURCE})
list(APPEND CUDA ${MSHADOW_CUDASOURCE})
# add source group
-FILE(GLOB_RECURSE GROUP_SOURCE "src/*.cc" "nnvm/*.cc" "plugin/*.cc")
-FILE(GLOB_RECURSE GROUP_Include "src/*.h" "nnvm/*.h" "mshadow/mshadow/*.h" "plugin/*.h")
-FILE(GLOB_RECURSE GROUP_CUDA "src/*.cu" "src/*.cuh" "mshadow/mshadow/*.cuh" "plugin/*.cu"
+FILE(GLOB_RECURSE GROUP_SOURCE "src/*.cc" "3rdparty/nnvm/*.cc" "plugin/*.cc")
+FILE(GLOB_RECURSE GROUP_Include "src/*.h" "3rdparty/nnvm/*.h" "3rdparty/mshadow/mshadow/*.h" "plugin/*.h")
+FILE(GLOB_RECURSE GROUP_CUDA "src/*.cu" "src/*.cuh" "3rdparty/mshadow/mshadow/*.cuh" "plugin/*.cu"
"plugin/*.cuh" "3rdparty/cub/cub/*.cuh")
assign_source_group("Source" ${GROUP_SOURCE})
assign_source_group("Include" ${GROUP_Include})
@@ -559,7 +561,7 @@ if(USE_PLUGIN_CAFFE)
endif()
endif()
-if(NOT EXISTS "${CMAKE_CURRENT_SOURCE_DIR}/nnvm/CMakeLists.txt")
+if(NOT EXISTS "${CMAKE_CURRENT_SOURCE_DIR}/3rdparty/nnvm/CMakeLists.txt")
set(nnvm_LINKER_LIBS nnvm)
list(APPEND mxnet_LINKER_LIBS ${nnvm_LINKER_LIBS})
endif()
@@ -571,7 +573,14 @@ if(NOT MSVC)
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS}")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++0x")
else()
- set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} /EHsc")
+ set(CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG} /EHsc")
+ set(CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE} /EHsc /Gy")
+ set(CMAKE_CXX_FLAGS_MINSIZEREL "${CMAKE_CXX_FLAGS_MINSIZEREL} /EHsc /Gy")
+ set(CMAKE_CXX_FLAGS_RELWITHDEBINFO "${CMAKE_CXX_FLAGS_RELWITHDEBINFO} /EHsc /Gy")
+ set(CMAKE_SHARED_LINKER_FLAGS_RELEASE "${CMAKE_SHARED_LINKER_FLAGS_RELEASE} /OPT:REF /OPT:ICF")
+ set(CMAKE_SHARED_LINKER_FLAGS_MINSIZEREL "${CMAKE_SHARED_LINKER_FLAGS_MINSIZEREL} /OPT:REF /OPT:ICF")
+ set(CMAKE_SHARED_LINKER_FLAGS_RELWITHDEBINFO "${CMAKE_SHARED_LINKER_FLAGS_RELWITHDEBINFO} /OPT:REF /OPT:ICF")
+
endif()
set(MXNET_INSTALL_TARGETS mxnet)
@@ -588,13 +597,13 @@ endif()
if(USE_CUDA)
if(FIRST_CUDA AND MSVC)
- target_compile_options(mxnet PUBLIC "$<$<CONFIG:DEBUG>:-Xcompiler=-MTd>")
- target_compile_options(mxnet PUBLIC "$<$<CONFIG:RELEASE>:-Xcompiler=-MT>")
+ target_compile_options(mxnet PUBLIC "$<$<CONFIG:DEBUG>:-Xcompiler=-MTd -Gy>")
+ target_compile_options(mxnet PUBLIC "$<$<CONFIG:RELEASE>:-Xcompiler=-MT -Gy>")
endif()
endif()
if(USE_DIST_KVSTORE)
- if(EXISTS ${CMAKE_CURRENT_SOURCE_DIR}/ps-lite/CMakeLists.txt)
- add_subdirectory("ps-lite")
+ if(EXISTS ${CMAKE_CURRENT_SOURCE_DIR}/3rdparty/ps-lite/CMakeLists.txt)
+ add_subdirectory("3rdparty/ps-lite")
list(APPEND pslite_LINKER_LIBS pslite protobuf)
target_link_libraries(mxnet PUBLIC debug ${pslite_LINKER_LIBS_DEBUG})
target_link_libraries(mxnet PUBLIC optimized ${pslite_LINKER_LIBS_RELEASE})
@@ -707,4 +716,4 @@ if(MSVC)
endif()
set(LINT_DIRS "include src plugin cpp-package tests")
set(EXCLUDE_PATH "src/operator/contrib/ctc_include")
-add_custom_target(mxnet_lint COMMAND ${CMAKE_COMMAND} -DMSVC=${MSVC} -DPYTHON_EXECUTABLE=${PYTHON_EXECUTABLE} -DLINT_DIRS=${LINT_DIRS} -DPROJECT_SOURCE_DIR=${CMAKE_CURRENT_SOURCE_DIR} -DPROJECT_NAME=mxnet -DEXCLUDE_PATH=${EXCLUDE_PATH} -P ${CMAKE_CURRENT_SOURCE_DIR}/dmlc-core/cmake/lint.cmake)
+add_custom_target(mxnet_lint COMMAND ${CMAKE_COMMAND} -DMSVC=${MSVC} -DPYTHON_EXECUTABLE=${PYTHON_EXECUTABLE} -DLINT_DIRS=${LINT_DIRS} -DPROJECT_SOURCE_DIR=${CMAKE_CURRENT_SOURCE_DIR} -DPROJECT_NAME=mxnet -DEXCLUDE_PATH=${EXCLUDE_PATH} -P ${CMAKE_CURRENT_SOURCE_DIR}/3rdparty/dmlc-core/cmake/lint.cmake)
diff --git a/CONTRIBUTORS.md b/CONTRIBUTORS.md
index 8079ce41911..4e5dfdb4255 100644
--- a/CONTRIBUTORS.md
+++ b/CONTRIBUTORS.md
@@ -160,3 +160,5 @@ List of Contributors
* [Sorokin Evgeniy](https://github.com/TheTweak)
* [dwSun](https://github.com/dwSun/)
* [David Braude](https://github.com/dabraude/)
+* [Nick Robinson](https://github.com/nickrobinson)
+* [Kan Wu](https://github.com/wkcn)
diff --git a/Jenkinsfile b/Jenkinsfile
index 73e73f27a71..b7be68c6f73 100644
--- a/Jenkinsfile
+++ b/Jenkinsfile
@@ -21,11 +21,11 @@
// See documents at https://jenkins.io/doc/book/pipeline/jenkinsfile/
// mxnet libraries
-mx_lib = 'lib/libmxnet.so, lib/libmxnet.a, dmlc-core/libdmlc.a, nnvm/lib/libnnvm.a'
+mx_lib = 'lib/libmxnet.so, lib/libmxnet.a, 3rdparty/dmlc-core/libdmlc.a, 3rdparty/nnvm/lib/libnnvm.a'
// mxnet cmake libraries, in cmake builds we do not produce a libnvvm static library by default.
-mx_cmake_lib = 'build/libmxnet.so, build/libmxnet.a, build/dmlc-core/libdmlc.a, build/tests/mxnet_unit_tests, build/3rdparty/openmp/runtime/src/libomp.so'
-mx_cmake_mkldnn_lib = 'build/libmxnet.so, build/libmxnet.a, build/dmlc-core/libdmlc.a, build/tests/mxnet_unit_tests, build/3rdparty/openmp/runtime/src/libomp.so, build/3rdparty/mkldnn/src/libmkldnn.so, build/3rdparty/mkldnn/src/libmkldnn.so.0'
-mx_mkldnn_lib = 'lib/libmxnet.so, lib/libmxnet.a, lib/libiomp5.so, lib/libmklml_gnu.so, lib/libmkldnn.so, lib/libmkldnn.so.0, lib/libmklml_intel.so, dmlc-core/libdmlc.a, nnvm/lib/libnnvm.a'
+mx_cmake_lib = 'build/libmxnet.so, build/libmxnet.a, build/3rdparty/dmlc-core/libdmlc.a, build/tests/mxnet_unit_tests, build/3rdparty/openmp/runtime/src/libomp.so'
+mx_cmake_mkldnn_lib = 'build/libmxnet.so, build/libmxnet.a, build/3rdparty/dmlc-core/libdmlc.a, build/tests/mxnet_unit_tests, build/3rdparty/openmp/runtime/src/libomp.so, build/3rdparty/mkldnn/src/libmkldnn.so, build/3rdparty/mkldnn/src/libmkldnn.so.0'
+mx_mkldnn_lib = 'lib/libmxnet.so, lib/libmxnet.a, lib/libiomp5.so, lib/libmkldnn.so.0, lib/libmklml_intel.so, 3rdparty/dmlc-core/libdmlc.a, 3rdparty/nnvm/lib/libnnvm.a'
// command to start a docker container
docker_run = 'tests/ci_build/ci_build.sh'
// timeout in minutes
@@ -141,6 +141,15 @@ try {
}
}
},
+ 'CPU: CentOS 7 MKLDNN': {
+ node('mxnetlinux-cpu') {
+ ws('workspace/build-centos7-mkldnn') {
+ init_git()
+ sh "ci/build.py --build --platform centos7_cpu /work/runtime_functions.sh build_centos7_mkldnn"
+ pack_lib('centos7_mkldnn')
+ }
+ }
+ },
'GPU: CentOS 7': {
node('mxnetlinux-cpu') {
ws('workspace/build-centos7-gpu') {
@@ -211,11 +220,11 @@ try {
}
}
},
- 'GPU: CUDA8.0+cuDNN5': {
+ 'GPU: CUDA9.1+cuDNN7': {
node('mxnetlinux-cpu') {
ws('workspace/build-gpu') {
init_git()
- sh "ci/build.py --build --platform ubuntu_build_cuda /work/runtime_functions.sh build_ubuntu_gpu_cuda8_cudnn5"
+ sh "ci/build.py --build --platform ubuntu_build_cuda /work/runtime_functions.sh build_ubuntu_gpu_cuda91_cudnn7"
pack_lib('gpu')
stash includes: 'build/cpp-package/example/test_score', name: 'cpp_test_score'
stash includes: 'build/cpp-package/example/test_optimizer', name: 'cpp_test_optimizer'
@@ -278,9 +287,9 @@ try {
copy build_vc14_cpu\\Release\\libmxnet.dll pkg_vc14_cpu\\build
xcopy python pkg_vc14_cpu\\python /E /I /Y
xcopy include pkg_vc14_cpu\\include /E /I /Y
- xcopy dmlc-core\\include pkg_vc14_cpu\\include /E /I /Y
- xcopy mshadow\\mshadow pkg_vc14_cpu\\include\\mshadow /E /I /Y
- xcopy nnvm\\include pkg_vc14_cpu\\nnvm\\include /E /I /Y
+ xcopy 3rdparty\\dmlc-core\\include pkg_vc14_cpu\\include /E /I /Y
+ xcopy 3rdparty\\mshadow\\mshadow pkg_vc14_cpu\\include\\mshadow /E /I /Y
+ xcopy 3rdparty\\nnvm\\include pkg_vc14_cpu\\nnvm\\include /E /I /Y
del /Q *.7z
7z.exe a vc14_cpu.7z pkg_vc14_cpu\\
'''
@@ -311,9 +320,9 @@ try {
copy build_vc14_gpu\\libmxnet.dll pkg_vc14_gpu\\build
xcopy python pkg_vc14_gpu\\python /E /I /Y
xcopy include pkg_vc14_gpu\\include /E /I /Y
- xcopy dmlc-core\\include pkg_vc14_gpu\\include /E /I /Y
- xcopy mshadow\\mshadow pkg_vc14_gpu\\include\\mshadow /E /I /Y
- xcopy nnvm\\include pkg_vc14_gpu\\nnvm\\include /E /I /Y
+ xcopy 3rdparty\\dmlc-core\\include pkg_vc14_gpu\\include /E /I /Y
+ xcopy 3rdparty\\mshadow\\mshadow pkg_vc14_gpu\\include\\mshadow /E /I /Y
+ xcopy 3rdparty\\nnvm\\include pkg_vc14_gpu\\nnvm\\include /E /I /Y
del /Q *.7z
7z.exe a vc14_gpu.7z pkg_vc14_gpu\\
'''
@@ -338,6 +347,14 @@ try {
sh "ci/build.py --build --platform armv7 /work/runtime_functions.sh build_armv7"
}
}
+ },
+ 'Raspberry / ARMv6l':{
+ node('mxnetlinux-cpu') {
+ ws('workspace/build-raspberry-armv6') {
+ init_git()
+ sh "ci/build.py --build --platform armv6 /work/runtime_functions.sh build_armv6"
+ }
+ }
}
} // End of stage('Build')
@@ -378,6 +395,24 @@ try {
}
}
},
+ 'Python2: Quantize GPU': {
+ node('mxnetlinux-gpu-p3') {
+ ws('workspace/ut-python2-quantize-gpu') {
+ init_git()
+ unpack_lib('gpu', mx_lib)
+ sh "ci/build.py --nvidiadocker --build --platform ubuntu_gpu /work/runtime_functions.sh unittest_ubuntu_python2_quantization_gpu"
+ }
+ }
+ },
+ 'Python3: Quantize GPU': {
+ node('mxnetlinux-gpu-p3') {
+ ws('workspace/ut-python3-quantize-gpu') {
+ init_git()
+ unpack_lib('gpu', mx_lib)
+ sh "ci/build.py --nvidiadocker --build --platform ubuntu_gpu /work/runtime_functions.sh unittest_ubuntu_python3_quantization_gpu"
+ }
+ }
+ },
'Python2: MKLDNN-CPU': {
node('mxnetlinux-cpu') {
ws('workspace/ut-python2-mkldnn-cpu') {
@@ -637,6 +672,7 @@ try {
}
}
}
+
// set build status to success at the end
currentBuild.result = "SUCCESS"
} catch (caughtError) {
diff --git a/LICENSE b/LICENSE
index e7d50c37723..b783e3ce3ca 100644
--- a/LICENSE
+++ b/LICENSE
@@ -219,14 +219,14 @@
2. MXNet rcnn - For details, see, example/rcnn/LICENSE
3. scala-package - For details, see, scala-package/LICENSE
4. Warp-CTC - For details, see, src/operator/contrib/ctc_include/LICENSE
- 5. dlpack - For details, see, dlpack/LICENSE
- 6. dmlc-core - For details, see, dmlc-core/LICENSE
- 7. mshadow - For details, see, mshadow/LICENSE
- 8. nnvm/dmlc-core - For details, see, nnvm/dmlc-core/LICENSE
- 9. nnvm - For details, see, nnvm/LICENSE
- 10. nnvm-fusion - For details, see, nnvm/plugin/nnvm-fusion/LICENSE
- 11. ps-lite - For details, see, ps-lite/LICENSE
- 12. nnvm/tvm - For details, see, nnvm/tvm/LICENSE
+ 5. 3rdparty/dlpack - For details, see, 3rdparty/dlpack/LICENSE
+ 6. 3rdparty/dmlc-core - For details, see, 3rdparty/dmlc-core/LICENSE
+ 7. 3rdparty/mshadow - For details, see, 3rdparty/mshadow/LICENSE
+ 8. 3rdparty/nnvm/dmlc-core - For details, see, 3rdparty/nnvm/dmlc-core/LICENSE
+ 9. 3rdparty/nnvm - For details, see, 3rdparty/nnvm/LICENSE
+ 10. nnvm-fusion - For details, see, 3rdparty/nnvm/plugin/nnvm-fusion/LICENSE
+ 11. 3rdparty/ps-lite - For details, see, 3rdparty/ps-lite/LICENSE
+ 12. 3rdparty/nnvm/tvm - For details, see, 3rdparty/nnvm/tvm/LICENSE
13. googlemock scripts/generator - For details, see, 3rdparty/googletest/googlemock/scripts/generator/LICENSE
diff --git a/Makefile b/Makefile
index 2bef8e85779..dba649f7311 100644
--- a/Makefile
+++ b/Makefile
@@ -16,6 +16,7 @@
# under the License.
ROOTDIR = $(CURDIR)
+TPARTYDIR = $(ROOTDIR)/3rdparty
SCALA_VERSION_PROFILE := scala-2.11
@@ -36,16 +37,16 @@ endif
endif
ifndef DMLC_CORE
- DMLC_CORE = $(ROOTDIR)/dmlc-core
+ DMLC_CORE = $(TPARTYDIR)/dmlc-core
endif
CORE_INC = $(wildcard $(DMLC_CORE)/include/*/*.h)
ifndef NNVM_PATH
- NNVM_PATH = $(ROOTDIR)/nnvm
+ NNVM_PATH = $(TPARTYDIR)/nnvm
endif
ifndef DLPACK_PATH
- DLPACK_PATH = $(ROOTDIR)/dlpack
+ DLPACK_PATH = $(ROOTDIR)/3rdparty/dlpack
endif
ifndef AMALGAMATION_PATH
@@ -73,7 +74,7 @@ ifeq ($(USE_MKLDNN), 1)
export USE_MKLML = 1
endif
-include mshadow/make/mshadow.mk
+include $(TPARTYDIR)/mshadow/make/mshadow.mk
include $(DMLC_CORE)/make/dmlc.mk
# all tge possible warning tread
@@ -91,7 +92,7 @@ ifeq ($(DEBUG), 1)
else
CFLAGS += -O3 -DNDEBUG=1
endif
-CFLAGS += -I$(ROOTDIR)/mshadow/ -I$(ROOTDIR)/dmlc-core/include -fPIC -I$(NNVM_PATH)/include -I$(DLPACK_PATH)/include -I$(NNVM_PATH)/tvm/include -Iinclude $(MSHADOW_CFLAGS)
+CFLAGS += -I$(TPARTYDIR)/mshadow/ -I$(TPARTYDIR)/dmlc-core/include -fPIC -I$(NNVM_PATH)/include -I$(DLPACK_PATH)/include -I$(NNVM_PATH)/tvm/include -Iinclude $(MSHADOW_CFLAGS)
LDFLAGS = -pthread $(MSHADOW_LDFLAGS) $(DMLC_LDFLAGS)
ifeq ($(DEBUG), 1)
NVCCFLAGS += -std=c++11 -Xcompiler -D_FORCE_INLINES -g -G -O0 -ccbin $(CXX) $(MSHADOW_NVCCFLAGS)
@@ -293,7 +294,7 @@ $(info Running CUDA_ARCH: $(CUDA_ARCH))
endif
# ps-lite
-PS_PATH=$(ROOTDIR)/ps-lite
+PS_PATH=$(ROOTDIR)/3rdparty/ps-lite
DEPS_PATH=$(shell pwd)/deps
include $(PS_PATH)/make/ps.mk
ifeq ($(USE_DIST_KVSTORE), 1)
@@ -431,9 +432,9 @@ lib/libmxnet.so: $(ALLX_DEP)
-Wl,${WHOLE_ARCH} $(filter %libnnvm.a, $^) -Wl,${NO_WHOLE_ARCH}
ifeq ($(USE_MKLDNN), 1)
ifeq ($(UNAME_S), Darwin)
- install_name_tool -change '@rpath/libmklml.dylib' '@loader_path/libmklml.dylib' lib/libmxnet.so
- install_name_tool -change '@rpath/libiomp5.dylib' '@loader_path/libiomp5.dylib' lib/libmxnet.so
- install_name_tool -change '@rpath/libmkldnn.0.dylib' '@loader_path/libmkldnn.0.dylib' lib/libmxnet.so
+ install_name_tool -change '@rpath/libmklml.dylib' '@loader_path/libmklml.dylib' $@
+ install_name_tool -change '@rpath/libiomp5.dylib' '@loader_path/libiomp5.dylib' $@
+ install_name_tool -change '@rpath/libmkldnn.0.dylib' '@loader_path/libmkldnn.0.dylib' $@
endif
endif
@@ -472,7 +473,7 @@ test: $(TEST)
lint: cpplint rcpplint jnilint pylint
cpplint:
- dmlc-core/scripts/lint.py mxnet cpp include src plugin cpp-package tests \
+ 3rdparty/dmlc-core/scripts/lint.py mxnet cpp include src plugin cpp-package tests \
--exclude_path src/operator/contrib/ctc_include
pylint:
@@ -504,7 +505,7 @@ cyclean:
# R related shortcuts
rcpplint:
- dmlc-core/scripts/lint.py mxnet-rcpp ${LINT_LANG} R-package/src
+ 3rdparty/dmlc-core/scripts/lint.py mxnet-rcpp ${LINT_LANG} R-package/src
rpkg:
mkdir -p R-package/inst
@@ -513,8 +514,8 @@ rpkg:
cp -rf lib/libmxnet.so R-package/inst/libs
mkdir -p R-package/inst/include
cp -rf include/* R-package/inst/include
- cp -rf dmlc-core/include/* R-package/inst/include/
- cp -rf nnvm/include/* R-package/inst/include
+ cp -rf 3rdparty/dmlc-core/include/* R-package/inst/include/
+ cp -rf 3rdparty/nnvm/include/* R-package/inst/include
Rscript -e "if(!require(devtools)){install.packages('devtools', repo = 'https://cloud.r-project.org/')}"
Rscript -e "library(devtools); library(methods); options(repos=c(CRAN='https://cloud.r-project.org/')); install_deps(pkg='R-package', dependencies = TRUE)"
echo "import(Rcpp)" > R-package/NAMESPACE
@@ -562,7 +563,7 @@ scaladeploy:
-Dlddeps="$(LIB_DEP) $(ROOTDIR)/lib/libmxnet.a")
jnilint:
- dmlc-core/scripts/lint.py mxnet-jnicpp cpp scala-package/native/src
+ 3rdparty/dmlc-core/scripts/lint.py mxnet-jnicpp cpp scala-package/native/src
ifneq ($(EXTRA_OPERATORS),)
clean: cyclean $(EXTRA_PACKAGES_CLEAN)
diff --git a/amalgamation/Makefile b/amalgamation/Makefile
index bd9403e620c..9c45885b7cf 100644
--- a/amalgamation/Makefile
+++ b/amalgamation/Makefile
@@ -16,6 +16,7 @@
# under the License.
export MXNET_ROOT=`pwd`/..
+export TPARTYDIR=`pwd`/../3rdparty
# Change this to path or specify in make command
ifndef OPENBLAS_ROOT
@@ -72,15 +73,15 @@ nnvm.d:
dmlc.d: dmlc-minimum0.cc
${CXX} ${CFLAGS} -M -MT dmlc-minimum0.o \
- -I ${MXNET_ROOT}/dmlc-core/include \
+ -I ${TPARTYDIR}/dmlc-core/include \
-D__MIN__=$(MIN) $+ > dmlc.d
mxnet_predict0.d: mxnet_predict0.cc nnvm.d dmlc.d
${CXX} ${CFLAGS} -M -MT mxnet_predict0.o \
- -I ${MXNET_ROOT}/ -I ${MXNET_ROOT}/mshadow/ -I ${MXNET_ROOT}/dmlc-core/include -I ${MXNET_ROOT}/dmlc-core/src \
- -I ${MXNET_ROOT}/nnvm/include \
- -I ${MXNET_ROOT}/dlpack/include \
+ -I ${MXNET_ROOT}/ -I ${TPARTYDIR}/mshadow/ -I ${TPARTYDIR}/dmlc-core/include -I ${TPARTYDIR}/dmlc-core/src \
+ -I ${TPARTYDIR}/nnvm/include \
+ -I ${MXNET_ROOT}/3rdparty/dlpack/include \
-I ${MXNET_ROOT}/include \
-D__MIN__=$(MIN) mxnet_predict0.cc > mxnet_predict0.d
cat dmlc.d >> mxnet_predict0.d
diff --git a/amalgamation/amalgamation.py b/amalgamation/amalgamation.py
index 45742249a69..e038fa44b98 100644
--- a/amalgamation/amalgamation.py
+++ b/amalgamation/amalgamation.py
@@ -85,7 +85,11 @@ def find_source(name, start, stage):
if not candidates: return ''
if len(candidates) == 1: return candidates[0]
for x in candidates:
- if x.split('/')[1] == start.split('/')[1]: return x
+ if '3rdparty' in x:
+ # make sure to compare the directory name after 3rdparty
+ if x.split('/')[2] == start.split('/')[2]: return x
+ else:
+ if x.split('/')[1] == start.split('/')[1]: return x
return ''
@@ -98,6 +102,18 @@ def find_source(name, start, stage):
def expand(x, pending, stage):
+ """
+ Expand the pending files in the current stage.
+
+ Parameters
+ ----------
+ x: str
+ The file to expand.
+ pending : str
+ The list of pending files to expand.
+ stage: str
+ The current stage for file expansion, used for matching the prefix of files.
+ """
if x in history and x not in ['mshadow/mshadow/expr_scalar-inl.h']: # MULTIPLE includes
return
@@ -126,7 +142,8 @@ def expand(x, pending, stage):
if not m:
print(uline + ' not found')
continue
- h = m.groups()[0].strip('./')
+ path = m.groups()[0]
+ h = path.strip('./') if "../3rdparty/" not in path else path
source = find_source(h, x, stage)
if not source:
if (h not in blacklist and
@@ -149,8 +166,8 @@ def expand(x, pending, stage):
expand.fileCount = 0
# Expand the stages
-expand(sys.argv[2], [], "dmlc")
-expand(sys.argv[3], [], "nnvm")
+expand(sys.argv[2], [], "3rdparty/dmlc-core")
+expand(sys.argv[3], [], "3rdparty/nnvm")
expand(sys.argv[4], [], "src")
# Write to amalgamation file
diff --git a/amalgamation/dmlc-minimum0.cc b/amalgamation/dmlc-minimum0.cc
index be1793a51d7..87e08d31c4d 100644
--- a/amalgamation/dmlc-minimum0.cc
+++ b/amalgamation/dmlc-minimum0.cc
@@ -22,13 +22,13 @@
* \brief Mininum DMLC library Amalgamation, used for easy plugin of dmlc lib.
* Normally this is not needed.
*/
-#include "../dmlc-core/src/io/line_split.cc"
-#include "../dmlc-core/src/io/recordio_split.cc"
-#include "../dmlc-core/src/io/indexed_recordio_split.cc"
-#include "../dmlc-core/src/io/input_split_base.cc"
-#include "../dmlc-core/src/io/local_filesys.cc"
-#include "../dmlc-core/src/data.cc"
-#include "../dmlc-core/src/io.cc"
-#include "../dmlc-core/src/recordio.cc"
+#include "../3rdparty/dmlc-core/src/io/line_split.cc"
+#include "../3rdparty/dmlc-core/src/io/recordio_split.cc"
+#include "../3rdparty/dmlc-core/src/io/indexed_recordio_split.cc"
+#include "../3rdparty/dmlc-core/src/io/input_split_base.cc"
+#include "../3rdparty/dmlc-core/src/io/local_filesys.cc"
+#include "../3rdparty/dmlc-core/src/data.cc"
+#include "../3rdparty/dmlc-core/src/io.cc"
+#include "../3rdparty/dmlc-core/src/recordio.cc"
diff --git a/amalgamation/prep_nnvm.sh b/amalgamation/prep_nnvm.sh
index 53498d71b54..b9222945a98 100755
--- a/amalgamation/prep_nnvm.sh
+++ b/amalgamation/prep_nnvm.sh
@@ -17,11 +17,11 @@
# specific language governing permissions and limitations
# under the License.
-DMLC_CORE=$(pwd)/../dmlc-core
-cd ../nnvm/amalgamation
+DMLC_CORE=$(pwd)/../3rdparty/dmlc-core
+cd ../3rdparty/nnvm/amalgamation
make clean
make DMLC_CORE_PATH=$DMLC_CORE nnvm.d
-cp nnvm.d ../../amalgamation/
+cp nnvm.d ../../../amalgamation/
echo '#define MSHADOW_FORCE_STREAM
#ifndef MSHADOW_USE_CBLAS
@@ -43,4 +43,4 @@ echo '#define MSHADOW_FORCE_STREAM
#include "nnvm/tuple.h"
#include "mxnet/tensor_blob.h"' > temp
cat nnvm.cc >> temp
-mv temp ../../amalgamation/nnvm.cc
+mv temp ../../../amalgamation/nnvm.cc
diff --git a/benchmark/python/quantization/benchmark_op.py b/benchmark/python/quantization/benchmark_op.py
new file mode 100644
index 00000000000..5ba7740cc91
--- /dev/null
+++ b/benchmark/python/quantization/benchmark_op.py
@@ -0,0 +1,90 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import time
+import mxnet as mx
+from mxnet.test_utils import check_speed
+
+
+def quantize_int8_helper(data):
+ min_data = mx.nd.min(data)
+ max_data = mx.nd.max(data)
+ return mx.nd.contrib.quantize(data, min_data, max_data, out_type='int8')
+
+
+def benchmark_convolution(data_shape, kernel, num_filter, pad, stride, no_bias=True, layout='NCHW', repeats=20):
+ ctx_gpu = mx.gpu(0)
+ data = mx.sym.Variable(name="data", shape=data_shape, dtype='float32')
+ # conv cudnn
+ conv_cudnn = mx.sym.Convolution(data=data, kernel=kernel, num_filter=num_filter, pad=pad, stride=stride,
+ no_bias=no_bias, layout=layout, cudnn_off=False, name="conv_cudnn")
+ arg_shapes, _, _ = conv_cudnn.infer_shape(data=data_shape)
+ input_data = mx.nd.random.normal(0, 0.2, shape=data_shape, ctx=ctx_gpu)
+ conv_weight_name = conv_cudnn.list_arguments()[1]
+ args = {data.name: input_data, conv_weight_name: mx.random.normal(0, 1, shape=arg_shapes[1], ctx=ctx_gpu)}
+ conv_cudnn_time = check_speed(sym=conv_cudnn, location=args, ctx=ctx_gpu, N=repeats,
+ grad_req='null', typ='forward') * 1000
+
+ # quantized_conv2d
+ qdata = mx.sym.Variable(name='qdata', shape=data_shape, dtype='int8')
+ weight = mx.sym.Variable(name='weight', shape=arg_shapes[1], dtype='int8')
+ min_data = mx.sym.Variable(name='min_data', shape=(1,), dtype='float32')
+ max_data = mx.sym.Variable(name='max_data', shape=(1,), dtype='float32')
+ min_weight = mx.sym.Variable(name='min_weight', shape=(1,), dtype='float32')
+ max_weight = mx.sym.Variable(name='max_weight', shape=(1,), dtype='float32')
+ quantized_conv2d = mx.sym.contrib.quantized_conv(data=qdata, weight=weight, min_data=min_data, max_data=max_data,
+ min_weight=min_weight, max_weight=max_weight,
+ kernel=kernel, num_filter=num_filter, pad=pad, stride=stride,
+ no_bias=no_bias, layout=layout, cudnn_off=False,
+ name='quantized_conv2d')
+ qargs = {qdata.name: quantize_int8_helper(input_data)[0],
+ min_data.name: quantize_int8_helper(input_data)[1],
+ max_data.name: quantize_int8_helper(input_data)[2],
+ weight.name: quantize_int8_helper(args[conv_weight_name])[0],
+ min_weight.name: quantize_int8_helper(args[conv_weight_name])[1],
+ max_weight.name: quantize_int8_helper(args[conv_weight_name])[2]}
+ qconv_time = check_speed(sym=quantized_conv2d, location=qargs, ctx=ctx_gpu, N=repeats,
+ grad_req='null', typ='forward') * 1000
+
+ print('==================================================================================================')
+ print('data=%s, kernel=%s, num_filter=%s, pad=%s, stride=%s, no_bias=%s, layout=%s, repeats=%s'
+ % (data_shape, kernel, num_filter, pad, stride, no_bias, layout, repeats))
+ print('%s , ctx=%s, time=%.2f ms' % (conv_cudnn.name + '-FP32', ctx_gpu, conv_cudnn_time))
+ print('%s, ctx=%s, time=%.2f ms' % (quantized_conv2d.name, ctx_gpu, qconv_time))
+ print('quantization speedup: %.1fX' % (conv_cudnn_time / qconv_time))
+ print('\n')
+
+
+if __name__ == '__main__':
+ for batch_size in [32, 64, 128]:
+ benchmark_convolution(data_shape=(batch_size, 64, 56, 56), kernel=(1, 1), num_filter=256,
+ pad=(0, 0), stride=(1, 1), layout='NCHW', repeats=20)
+
+ benchmark_convolution(data_shape=(batch_size, 256, 56, 56), kernel=(1, 1), num_filter=64,
+ pad=(0, 0), stride=(1, 1), layout='NCHW', repeats=20)
+
+ benchmark_convolution(data_shape=(batch_size, 256, 56, 56), kernel=(1, 1), num_filter=128,
+ pad=(0, 0), stride=(2, 2), layout='NCHW', repeats=20)
+
+ benchmark_convolution(data_shape=(batch_size, 128, 28, 28), kernel=(3, 3), num_filter=128,
+ pad=(1, 1), stride=(1, 1), layout='NCHW', repeats=20)
+
+ benchmark_convolution(data_shape=(batch_size, 1024, 14, 14), kernel=(1, 1), num_filter=256,
+ pad=(0, 0), stride=(1, 1), layout='NCHW', repeats=20)
+
+ benchmark_convolution(data_shape=(batch_size, 2048, 7, 7), kernel=(1, 1), num_filter=512,
+ pad=(0, 0), stride=(1, 1), layout='NCHW', repeats=20)
diff --git a/benchmark/python/sparse/sparse_end2end.py b/benchmark/python/sparse/sparse_end2end.py
index ecd9057dedf..d032f9d6c38 100644
--- a/benchmark/python/sparse/sparse_end2end.py
+++ b/benchmark/python/sparse/sparse_end2end.py
@@ -239,8 +239,8 @@ def row_sparse_pull(kv, key, data, slices, weight_array, priority):
device = 'gpu' + str(args.num_gpu)
name = 'profile_' + args.dataset + '_' + device + '_nworker' + str(num_worker)\
+ '_batchsize' + str(args.batch_size) + '_outdim' + str(args.output_dim) + '.json'
- mx.profiler.profiler_set_config(mode='all', filename=name)
- mx.profiler.profiler_set_state('run')
+ mx.profiler.set_config(profile_all=True, filename=name)
+ mx.profiler.set_state('run')
logging.debug('start training ...')
start = time.time()
@@ -301,7 +301,7 @@ def row_sparse_pull(kv, key, data, slices, weight_array, priority):
logging.info('|cpu/{} cores| {} | {} | {} |'.format(str(num_cores), str(num_worker), str(average_cost_epoch), rank))
data_iter.reset()
if profiler:
- mx.profiler.profiler_set_state('stop')
+ mx.profiler.set_state('stop')
end = time.time()
time_cost = end - start
logging.info('num_worker = {}, rank = {}, time cost = {}'.format(str(num_worker), str(rank), str(time_cost)))
diff --git a/benchmark/python/sparse/updater.py b/benchmark/python/sparse/updater.py
new file mode 100644
index 00000000000..72f2bfd04a2
--- /dev/null
+++ b/benchmark/python/sparse/updater.py
@@ -0,0 +1,78 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import time
+import mxnet as mx
+from mxnet.ndarray.sparse import adam_update
+import numpy as np
+import argparse
+
+mx.random.seed(0)
+np.random.seed(0)
+
+parser = argparse.ArgumentParser(description='Benchmark adam updater')
+parser.add_argument('--dim-in', type=int, default=240000, help='weight.shape[0]')
+parser.add_argument('--dim-out', type=int, default=512, help='weight.shape[1]')
+parser.add_argument('--nnr', type=int, default=5000, help='grad.indices.shape[0]')
+parser.add_argument('--repeat', type=int, default=1000, help='num repeat')
+parser.add_argument('--dense-grad', action='store_true',
+ help='if set to true, both gradient and weight are dense.')
+parser.add_argument('--dense-state', action='store_true',
+ help='if set to true, states are dense, indicating standard update')
+parser.add_argument('--cpu', action='store_true')
+
+
+args = parser.parse_args()
+dim_in = args.dim_in
+dim_out = args.dim_out
+nnr = args.nnr
+ctx = mx.cpu() if args.cpu else mx.gpu()
+
+ones = mx.nd.ones((dim_in, dim_out), ctx=ctx)
+
+if not args.dense_grad:
+ weight = ones.tostype('row_sparse')
+ indices = np.arange(dim_in)
+ np.random.shuffle(indices)
+ indices = np.unique(indices[:nnr])
+ indices = mx.nd.array(indices, ctx=ctx)
+ grad = mx.nd.sparse.retain(weight, indices)
+else:
+ weight = ones.copy()
+ grad = ones.copy()
+
+if args.dense_state:
+ mean = ones.copy()
+else:
+ mean = ones.tostype('row_sparse')
+
+var = mean.copy()
+
+# warmup
+for i in range(10):
+ adam_update(weight, grad, mean, var, out=weight, lr=1, wd=0, beta1=0.9,
+ beta2=0.99, rescale_grad=0.5, epsilon=1e-8)
+weight.wait_to_read()
+
+# measure speed
+a = time.time()
+for i in range(args.repeat):
+ adam_update(weight, grad, mean, var, out=weight, lr=1, wd=0, beta1=0.9,
+ beta2=0.99, rescale_grad=0.5, epsilon=1e-8)
+weight.wait_to_read()
+b = time.time()
+print(b - a)
diff --git a/ci/docker/Dockerfile.build.armv6 b/ci/docker/Dockerfile.build.armv6
new file mode 100755
index 00000000000..471846243fc
--- /dev/null
+++ b/ci/docker/Dockerfile.build.armv6
@@ -0,0 +1,40 @@
+# -*- mode: dockerfile -*-
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+#
+# Dockerfile to build MXNet for ARMv6
+
+FROM dockcross/linux-armv6
+
+ENV ARCH armv6l
+ENV CC /usr/bin/arm-linux-gnueabihf-gcc
+ENV CXX /usr/bin/arm-linux-gnueabihf-g++
+ENV FC /usr/bin/arm-linux-gnueabihf-gfortran
+ENV HOSTCC gcc
+ENV TARGET ARMV6
+
+WORKDIR /work/deps
+
+# Build OpenBLAS
+ADD https://api.github.com/repos/xianyi/OpenBLAS/git/refs/tags/v0.2.9 openblas_version.json
+RUN git clone --recursive -b v0.2.9 https://github.com/xianyi/OpenBLAS.git && \
+ cd OpenBLAS && \
+ make -j$(nproc) && \
+ make PREFIX=$CROSS_ROOT install
+
+COPY runtime_functions.sh /work/
+WORKDIR /work/mxnet
diff --git a/ci/docker/Dockerfile.build.centos7_cpu b/ci/docker/Dockerfile.build.centos7_cpu
index 665f7ddd99a..a44d6464ee3 100755
--- a/ci/docker/Dockerfile.build.centos7_cpu
+++ b/ci/docker/Dockerfile.build.centos7_cpu
@@ -28,6 +28,8 @@ COPY install/centos7_core.sh /work/
RUN /work/centos7_core.sh
COPY install/centos7_python.sh /work/
RUN /work/centos7_python.sh
+COPY install/ubuntu_mklml.sh /work/
+RUN /work/ubuntu_mklml.sh
COPY install/centos7_adduser.sh /work/
RUN /work/centos7_adduser.sh
diff --git a/ci/docker/Dockerfile.build.centos7_gpu b/ci/docker/Dockerfile.build.centos7_gpu
index 3d7482161c4..4dcf5bf08ca 100755
--- a/ci/docker/Dockerfile.build.centos7_gpu
+++ b/ci/docker/Dockerfile.build.centos7_gpu
@@ -18,7 +18,7 @@
#
# Dockerfile to build and run MXNet on CentOS 7 for GPU
-FROM nvidia/cuda:8.0-cudnn5-devel-centos7
+FROM nvidia/cuda:9.1-cudnn7-devel-centos7
ARG USER_ID=0
diff --git a/ci/docker/Dockerfile.build.ubuntu_build_cuda b/ci/docker/Dockerfile.build.ubuntu_build_cuda
index 18c8af7deb2..8bafed43b83 100755
--- a/ci/docker/Dockerfile.build.ubuntu_build_cuda
+++ b/ci/docker/Dockerfile.build.ubuntu_build_cuda
@@ -21,7 +21,7 @@
# package generation, requiring the actual CUDA library to be
# present
-FROM nvidia/cuda:8.0-cudnn5-devel
+FROM nvidia/cuda:9.1-cudnn7-devel
ARG USER_ID=0
@@ -37,8 +37,6 @@ COPY install/ubuntu_r.sh /work/
RUN /work/ubuntu_r.sh
COPY install/ubuntu_perl.sh /work/
RUN /work/ubuntu_perl.sh
-COPY install/ubuntu_lint.sh /work/
-RUN /work/ubuntu_lint.sh
COPY install/ubuntu_clang.sh /work/
RUN /work/ubuntu_clang.sh
COPY install/ubuntu_mklml.sh /work/
@@ -54,4 +52,4 @@ RUN /work/ubuntu_nvidia.sh
COPY runtime_functions.sh /work/
WORKDIR /work/mxnet
-ENV LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/lib
\ No newline at end of file
+ENV LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/lib
diff --git a/ci/docker/Dockerfile.build.ubuntu_cpu b/ci/docker/Dockerfile.build.ubuntu_cpu
index d652a0d89c5..f706f88461f 100755
--- a/ci/docker/Dockerfile.build.ubuntu_cpu
+++ b/ci/docker/Dockerfile.build.ubuntu_cpu
@@ -34,8 +34,6 @@ COPY install/ubuntu_r.sh /work/
RUN /work/ubuntu_r.sh
COPY install/ubuntu_perl.sh /work/
RUN /work/ubuntu_perl.sh
-COPY install/ubuntu_lint.sh /work/
-RUN /work/ubuntu_lint.sh
COPY install/ubuntu_clang.sh /work/
RUN /work/ubuntu_clang.sh
COPY install/ubuntu_mklml.sh /work/
diff --git a/ci/docker/Dockerfile.build.ubuntu_gpu b/ci/docker/Dockerfile.build.ubuntu_gpu
index 826836c78cf..625d57009c9 100755
--- a/ci/docker/Dockerfile.build.ubuntu_gpu
+++ b/ci/docker/Dockerfile.build.ubuntu_gpu
@@ -18,7 +18,7 @@
#
# Dockerfile to run MXNet on Ubuntu 16.04 for CPU
-FROM nvidia/cuda:8.0-cudnn5-devel
+FROM nvidia/cuda:9.1-cudnn7-devel
ARG USER_ID=0
@@ -34,8 +34,6 @@ COPY install/ubuntu_r.sh /work/
RUN /work/ubuntu_r.sh
COPY install/ubuntu_perl.sh /work/
RUN /work/ubuntu_perl.sh
-COPY install/ubuntu_lint.sh /work/
-RUN /work/ubuntu_lint.sh
COPY install/ubuntu_clang.sh /work/
RUN /work/ubuntu_clang.sh
COPY install/ubuntu_mklml.sh /work/
diff --git a/ci/docker/install/centos7_core.sh b/ci/docker/install/centos7_core.sh
index 1688b81ba89..1d7e120d6ae 100755
--- a/ci/docker/install/centos7_core.sh
+++ b/ci/docker/install/centos7_core.sh
@@ -31,9 +31,9 @@ yum -y install openblas-devel
yum -y install lapack-devel
yum -y install opencv-devel
yum -y install openssl-devel
-yum -y install gcc-c++
+yum -y install gcc-c++-4.8.*
yum -y install make
yum -y install cmake
yum -y install wget
yum -y install unzip
-yum -y install ninja-build
\ No newline at end of file
+yum -y install ninja-build
diff --git a/ci/docker/install/ubuntu_core.sh b/ci/docker/install/ubuntu_core.sh
index e78f29ae0a9..dc9b091f205 100755
--- a/ci/docker/install/ubuntu_core.sh
+++ b/ci/docker/install/ubuntu_core.sh
@@ -34,9 +34,7 @@ apt-get install -y \
unzip \
sudo \
software-properties-common \
- ninja-build \
- python-pip
+ ninja-build
# Link Openblas to Cblas as this link does not exist on ubuntu16.04
ln -s /usr/lib/libopenblas.so /usr/lib/libcblas.so
-pip install cpplint==1.3.0 pylint==1.8.2
\ No newline at end of file
diff --git a/ci/docker/install/ubuntu_nvidia.sh b/ci/docker/install/ubuntu_nvidia.sh
index bb1c73eec76..e6d7926dadb 100755
--- a/ci/docker/install/ubuntu_nvidia.sh
+++ b/ci/docker/install/ubuntu_nvidia.sh
@@ -17,13 +17,10 @@
# specific language governing permissions and limitations
# under the License.
-# build and install are separated so changes to build don't invalidate
-# the whole docker cache for the image
-
set -ex
apt install -y software-properties-common
add-apt-repository -y ppa:graphics-drivers
# Retrieve ppa:graphics-drivers and install nvidia-drivers.
# Note: DEBIAN_FRONTEND required to skip the interactive setup steps
apt update
-DEBIAN_FRONTEND=noninteractive apt install -y --no-install-recommends cuda-8-0
\ No newline at end of file
+DEBIAN_FRONTEND=noninteractive apt install -y --no-install-recommends cuda-9-1
diff --git a/ci/docker/install/ubuntu_onnx.sh b/ci/docker/install/ubuntu_onnx.sh
index 72613cd5788..07acba01908 100755
--- a/ci/docker/install/ubuntu_onnx.sh
+++ b/ci/docker/install/ubuntu_onnx.sh
@@ -30,5 +30,5 @@ echo "Installing libprotobuf-dev and protobuf-compiler ..."
apt-get install -y libprotobuf-dev protobuf-compiler
echo "Installing pytest, pytest-cov, protobuf, Pillow, ONNX and tabulate ..."
-pip2 install pytest==3.4.0 pytest-cov==2.5.1 protobuf==3.0.0 onnx==1.0.1 Pillow==5.0.0 tabulate==0.7.5
-pip3 install pytest==3.4.0 pytest-cov==2.5.1 protobuf==3.0.0 onnx==1.0.1 Pillow==5.0.0 tabulate==0.7.5
+pip2 install pytest==3.4.0 pytest-cov==2.5.1 protobuf==3.5.2 onnx==1.1.1 Pillow==5.0.0 tabulate==0.7.5
+pip3 install pytest==3.4.0 pytest-cov==2.5.1 protobuf==3.5.2 onnx==1.1.1 Pillow==5.0.0 tabulate==0.7.5
diff --git a/ci/docker/install/ubuntu_python.sh b/ci/docker/install/ubuntu_python.sh
index b19448eecab..b906b55f750 100755
--- a/ci/docker/install/ubuntu_python.sh
+++ b/ci/docker/install/ubuntu_python.sh
@@ -29,5 +29,5 @@ wget -nv https://bootstrap.pypa.io/get-pip.py
python3 get-pip.py
python2 get-pip.py
-pip2 install nose pylint numpy nose-timer requests h5py scipy
-pip3 install nose pylint numpy nose-timer requests h5py scipy
\ No newline at end of file
+pip2 install nose cpplint==1.3.0 pylint==1.8.3 numpy nose-timer requests h5py scipy
+pip3 install nose cpplint==1.3.0 pylint==1.8.3 numpy nose-timer requests h5py scipy
diff --git a/ci/docker/runtime_functions.sh b/ci/docker/runtime_functions.sh
index 39809f28127..f35de6bef0b 100755
--- a/ci/docker/runtime_functions.sh
+++ b/ci/docker/runtime_functions.sh
@@ -73,6 +73,34 @@ build_jetson() {
popd
}
+build_armv6() {
+ set -ex
+ pushd .
+ cd /work/build
+
+ # Lapack functionality will be included and statically linked to openblas.
+ # But USE_LAPACK needs to be set to OFF, otherwise the main CMakeLists.txt
+ # file tries to add -llapack. Lapack functionality though, requires -lgfortran
+ # to be linked additionally.
+
+ cmake \
+ -DCMAKE_TOOLCHAIN_FILE=$CROSS_ROOT/Toolchain.cmake \
+ -DUSE_CUDA=OFF \
+ -DUSE_OPENCV=OFF \
+ -DUSE_SIGNAL_HANDLER=ON \
+ -DCMAKE_BUILD_TYPE=RelWithDebInfo \
+ -DUSE_MKL_IF_AVAILABLE=OFF \
+ -DUSE_LAPACK=OFF \
+ -Dmxnet_LINKER_LIBS=-lgfortran \
+ -G Ninja /work/mxnet
+ ninja
+ export MXNET_LIBRARY_PATH=`pwd`/libmxnet.so
+ cd /work/mxnet/python
+ python setup.py bdist_wheel --universal
+ cp dist/*.whl /work/build
+ popd
+}
+
build_armv7() {
set -ex
pushd .
@@ -156,6 +184,19 @@ build_centos7_cpu() {
-j$(nproc)
}
+build_centos7_mkldnn() {
+ set -ex
+ cd /work/mxnet
+ make \
+ DEV=1 \
+ USE_LAPACK=1 \
+ USE_LAPACK_PATH=/usr/lib64/liblapack.so \
+ USE_PROFILER=1 \
+ USE_MKLDNN=1 \
+ USE_BLAS=openblas \
+ -j$(nproc)
+}
+
build_centos7_gpu() {
set -ex
cd /work/mxnet
@@ -256,7 +297,7 @@ build_ubuntu_gpu_mkldnn() {
-j$(nproc)
}
-build_ubuntu_gpu_cuda8_cudnn5() {
+build_ubuntu_gpu_cuda91_cudnn7() {
set -ex
make \
DEV=1 \
@@ -333,6 +374,7 @@ unittest_ubuntu_python2_cpu() {
export MXNET_STORAGE_FALLBACK_LOG_VERBOSE=0
nosetests-2.7 --verbose tests/python/unittest
nosetests-2.7 --verbose tests/python/train
+ nosetests-2.7 --verbose tests/python/quantization
}
unittest_ubuntu_python3_cpu() {
@@ -343,6 +385,7 @@ unittest_ubuntu_python3_cpu() {
#export MXNET_MKLDNN_DEBUG=1 # Ignored if not present
export MXNET_STORAGE_FALLBACK_LOG_VERBOSE=0
nosetests-3.4 --verbose tests/python/unittest
+ nosetests-3.4 --verbose tests/python/quantization
}
unittest_ubuntu_python2_gpu() {
@@ -365,6 +408,30 @@ unittest_ubuntu_python3_gpu() {
nosetests-3.4 --verbose tests/python/gpu
}
+# quantization gpu currently only runs on P3 instances
+# need to separte it from unittest_ubuntu_python2_gpu()
+unittest_ubuntu_python2_quantization_gpu() {
+ set -ex
+ export PYTHONPATH=./python/
+ # MXNET_MKLDNN_DEBUG is buggy and produces false positives
+ # https://github.com/apache/incubator-mxnet/issues/10026
+ #export MXNET_MKLDNN_DEBUG=1 # Ignored if not present
+ export MXNET_STORAGE_FALLBACK_LOG_VERBOSE=0
+ nosetests-2.7 --verbose tests/python/quantization_gpu
+}
+
+# quantization gpu currently only runs on P3 instances
+# need to separte it from unittest_ubuntu_python3_gpu()
+unittest_ubuntu_python3_quantization_gpu() {
+ set -ex
+ export PYTHONPATH=./python/
+ # MXNET_MKLDNN_DEBUG is buggy and produces false positives
+ # https://github.com/apache/incubator-mxnet/issues/10026
+ #export MXNET_MKLDNN_DEBUG=1 # Ignored if not present
+ export MXNET_STORAGE_FALLBACK_LOG_VERBOSE=0
+ nosetests-3.4 --verbose tests/python/quantization_gpu
+}
+
unittest_ubuntu_cpu_scala() {
set -ex
make scalapkg USE_BLAS=openblas
diff --git a/cpp-package/example/Makefile b/cpp-package/example/Makefile
index e1b341794c4..7c1216d1dbd 100644
--- a/cpp-package/example/Makefile
+++ b/cpp-package/example/Makefile
@@ -18,7 +18,7 @@
CPPEX_SRC = $(wildcard *.cpp)
CPPEX_EXE = $(patsubst %.cpp, %, $(CPPEX_SRC))
-CFLAGS += -I../../include -I../../nnvm/include -I../../dmlc-core/include
+CFLAGS += -I../../include -I../../3rdparty/nnvm/include -I../../3rdparty/dmlc-core/include
CPPEX_CFLAGS += -I../include
CPPEX_EXTRA_LDFLAGS := -L. -lmxnet
diff --git a/docs/api/python/autograd/autograd.md b/docs/api/python/autograd/autograd.md
index 410d6a94e26..2f9f5710b12 100644
--- a/docs/api/python/autograd/autograd.md
+++ b/docs/api/python/autograd/autograd.md
@@ -39,7 +39,7 @@ and do some computation. Finally, call `backward()` on the result:
## Train mode and Predict Mode
Some operators (Dropout, BatchNorm, etc) behave differently in
-when training and when making predictions.
+training and making predictions.
This can be controlled with `train_mode` and `predict_mode` scope.
By default, MXNet is in `predict_mode`.
@@ -50,9 +50,9 @@ call record with `train_mode=False` and then call `backward(train_mode=False)`
Although training usually coincides with recording,
this isn't always the case.
-To control *training* vs *predict_mode* without changing
+To control *training* vs. *predict_mode* without changing
*recording* vs *not recording*,
-Use a `with autograd.train_mode():`
+use a `with autograd.train_mode():`
or `with autograd.predict_mode():` block.
Detailed tutorials are available in Part 1 of
@@ -60,9 +60,6 @@ Detailed tutorials are available in Part 1 of
-
-
-
<script type="text/javascript" src='../../_static/js/auto_module_index.js'></script>
## Autograd
diff --git a/docs/api/python/gluon/data.md b/docs/api/python/gluon/data.md
index 28433c0ae36..3c6bb02e47c 100644
--- a/docs/api/python/gluon/data.md
+++ b/docs/api/python/gluon/data.md
@@ -69,6 +69,51 @@ In the rest of this document, we list routines provided by the `gluon.data` pack
ImageFolderDataset
```
+#### Vision Transforms
+
+```eval_rst
+.. currentmodule:: mxnet.gluon.data.vision.transforms
+```
+
+Transforms can be used to augment input data during training. You
+can compose multiple transforms sequentially, for example:
+
+```python
+from mxnet.gluon.data.vision import MNIST, transforms
+from mxnet import gluon
+transform = transforms.Compose([
+ transforms.Resize(300),
+ transforms.RandomResizedCrop(224),
+ transforms.RandomBrightness(0.1),
+ transforms.ToTensor(),
+ transforms.Normalize(0, 1)])
+data = MNIST(train=True).transform_first(transform)
+data_loader = gluon.data.DataLoader(data, batch_size=32, num_workers=1)
+for data, label in data_loader:
+ # do something with data and label
+```
+
+```eval_rst
+.. autosummary::
+ :nosignatures:
+
+ Compose
+ Cast
+ ToTensor
+ Normalize
+ RandomResizedCrop
+ CenterCrop
+ Resize
+ RandomFlipLeftRight
+ RandomFlipTopBottom
+ RandomBrightness
+ RandomContrast
+ RandomSaturation
+ RandomHue
+ RandomColorJitter
+ RandomLighting
+```
+
## API Reference
<script type="text/javascript" src='../../../_static/js/auto_module_index.js'></script>
@@ -84,6 +129,9 @@ In the rest of this document, we list routines provided by the `gluon.data` pack
.. automodule:: mxnet.gluon.data.vision.datasets
:members:
+
+.. automodule:: mxnet.gluon.data.vision.transforms
+ :members:
```
diff --git a/docs/api/python/image/image.md b/docs/api/python/image/image.md
index 1a1d0fd1110..a3e2a1697d3 100644
--- a/docs/api/python/image/image.md
+++ b/docs/api/python/image/image.md
@@ -43,7 +43,7 @@ Iterators support loading image from binary `Record IO` and raw image files.
... print(d.shape)
>>> # we can apply lots of augmentations as well
>>> data_iter = mx.image.ImageIter(4, (3, 224, 224), path_imglist='data/custom.lst',
- rand_crop=resize=True, rand_mirror=True, mean=True,
+ rand_crop=True, rand_resize=True, rand_mirror=True, mean=True,
brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1,
pca_noise=0.1, rand_gray=0.05)
>>> data = data_iter.next()
diff --git a/docs/api/python/ndarray/random.md b/docs/api/python/ndarray/random.md
index ae9e69f758f..4341a3ce2cd 100644
--- a/docs/api/python/ndarray/random.md
+++ b/docs/api/python/ndarray/random.md
@@ -35,6 +35,8 @@ In the rest of this document, we list routines provided by the `ndarray.random`
normal
poisson
uniform
+ multinomial
+ shuffle
mxnet.random.seed
```
diff --git a/docs/api/python/symbol/random.md b/docs/api/python/symbol/random.md
index a3492f6f840..22c686ff2fd 100644
--- a/docs/api/python/symbol/random.md
+++ b/docs/api/python/symbol/random.md
@@ -35,6 +35,8 @@ In the rest of this document, we list routines provided by the `symbol.random` p
normal
poisson
uniform
+ multinomial
+ shuffle
mxnet.random.seed
```
diff --git a/docs/build_version_doc/build_doc.sh b/docs/build_version_doc/build_doc.sh
index 427f40c592a..b8a6974c7c9 100755
--- a/docs/build_version_doc/build_doc.sh
+++ b/docs/build_version_doc/build_doc.sh
@@ -83,10 +83,6 @@ then
git checkout tags/$latest_tag
make docs || exit 1
- tests/ci_build/ci_build.sh doc python docs/build_version_doc/AddVersion.py --file_path "docs/_build/html/" --current_version "$latest_tag"
- tests/ci_build/ci_build.sh doc python docs/build_version_doc/AddPackageLink.py \
- --file_path "docs/_build/html/install/index.html" --current_version "$latest_tag"
-
# Update the tag_list (tag.txt).
###### content of tag.txt########
# <latest_tag_goes_here>
@@ -97,6 +93,10 @@ then
echo "++++ Adding $latest_tag to the top of the $tag_list_file ++++"
echo -e "$latest_tag\n$(cat $tag_list_file)" > "$tag_list_file"
cat $tag_list_file
+
+ tests/ci_build/ci_build.sh doc python docs/build_version_doc/AddVersion.py --file_path "docs/_build/html/" --current_version "$latest_tag"
+ tests/ci_build/ci_build.sh doc python docs/build_version_doc/AddPackageLink.py \
+ --file_path "docs/_build/html/install/index.html" --current_version "$latest_tag"
# The following block does the following:
# a. copies the static html that was built from new tag to a local sandbox folder.
diff --git a/docs/faq/env_var.md b/docs/faq/env_var.md
index af698ca639a..f29301dec7a 100644
--- a/docs/faq/env_var.md
+++ b/docs/faq/env_var.md
@@ -73,7 +73,11 @@ export MXNET_GPU_WORKER_NTHREADS=3
* MXNET_KVSTORE_REDUCTION_NTHREADS
- Values: Int ```(default=4)```
- - The number of CPU threads used for summing big arrays.
+ - The number of CPU threads used for summing up big arrays on a single machine
+ - This will also be used for `dist_sync` kvstore to sum up arrays from different contexts on a single machine.
+ - This does not affect summing up of arrays from different machines on servers.
+ - Summing up of arrays for `dist_sync_device` kvstore is also unaffected as that happens on GPUs.
+
* MXNET_KVSTORE_BIGARRAY_BOUND
- Values: Int ```(default=1000000)```
- The minimum size of a "big array".
@@ -110,9 +114,13 @@ When USE_PROFILER is enabled in Makefile or CMake, the following environments ca
## Other Environment Variables
* MXNET_CUDNN_AUTOTUNE_DEFAULT
- - Values: 0(false) or 1(true) ```(default=1)```
- - The default value of cudnn auto tunning for convolution layers.
- - Auto tuning is turned off by default. For benchmarking, set this to 1 to turn it on by default.
+ - Values: 0, 1, or 2 ```(default=1)```
+ - The default value of cudnn auto tuning for convolution layers.
+ - Value of 0 means there is no auto tuning to pick the convolution algo
+ - Performance tests are run to pick the convolution algo when value is 1 or 2
+ - Value of 1 chooses the best algo in a limited workspace
+ - Value of 2 chooses the fastest algo whose memory requirements may be larger than the default workspace threshold
+
* MXNET_GLUON_REPO
- Values: String ```(default='https://apache-mxnet.s3-accelerate.dualstack.amazonaws.com/'```
diff --git a/docs/faq/index.md b/docs/faq/index.md
index 099cd509b14..098d37f5fc0 100644
--- a/docs/faq/index.md
+++ b/docs/faq/index.md
@@ -56,6 +56,8 @@ and full working examples, visit the [tutorials section](../tutorials/index.md).
* [How do I create new operators in MXNet?](http://mxnet.io/faq/new_op.html)
+* [How do I implement sparse operators in MXNet backend?](https://cwiki.apache.org/confluence/display/MXNET/A+Guide+to+Implementing+Sparse+Operators+in+MXNet+Backend)
+
* [How do I contribute an example or tutorial?](https://github.com/apache/incubator-mxnet/tree/master/example#contributing)
* [How do I set MXNet's environmental variables?](http://mxnet.io/faq/env_var.html)
diff --git a/docs/faq/perf.md b/docs/faq/perf.md
index e021f1e9a21..b5d73f69a03 100644
--- a/docs/faq/perf.md
+++ b/docs/faq/perf.md
@@ -228,12 +228,12 @@ See [example/profiler](https://github.com/dmlc/mxnet/tree/master/example/profile
for complete examples of how to use the profiler in code, but briefly, the Python code looks like:
```
- mx.profiler.profiler_set_config(mode='all', filename='profile_output.json')
- mx.profiler.profiler_set_state('run')
+ mx.profiler.set_config(profile_all=True, filename='profile_output.json')
+ mx.profiler.set_state('run')
# Code to be profiled goes here...
- mx.profiler.profiler_set_state('stop')
+ mx.profiler.set_state('stop')
```
The `mode` parameter can be set to
diff --git a/docs/install/index.md b/docs/install/index.md
index e4767618e65..d9d78dd3693 100644
--- a/docs/install/index.md
+++ b/docs/install/index.md
@@ -994,11 +994,11 @@ Refer to [#8671](https://github.com/apache/incubator-mxnet/issues/8671) for stat
<br/>
To build and install MXNet yourself, you need the following dependencies. Install the required dependencies:
-1. If [Microsoft Visual Studio 2015](https://www.visualstudio.com/downloads/) is not already installed, download and install it. You can download and install the free community edition.
+1. If [Microsoft Visual Studio 2015](https://www.visualstudio.com/vs/older-downloads/) is not already installed, download and install it. You can download and install the free community edition.
2. Download and install [CMake](https://cmake.org/) if it is not already installed.
3. Download and install [OpenCV](http://sourceforge.net/projects/opencvlibrary/files/opencv-win/3.0.0/opencv-3.0.0.exe/download).
4. Unzip the OpenCV package.
-5. Set the environment variable ```OpenCV_DIR``` to point to the ```OpenCV build directory```.
+5. Set the environment variable ```OpenCV_DIR``` to point to the ```OpenCV build directory``` (```C:\opencv\build\x64\vc14``` for example). Also, you need to add the OpenCV bin directory (```C:\opencv\build\x64\vc14\bin``` for example) to the ``PATH`` variable.
6. If you don't have the Intel Math Kernel Library (MKL) installed, download and install [OpenBlas](http://sourceforge.net/projects/openblas/files/v0.2.14/).
7. Set the environment variable ```OpenBLAS_HOME``` to point to the ```OpenBLAS``` directory that contains the ```include``` and ```lib``` directories. Typically, you can find the directory in ```C:\Program files (x86)\OpenBLAS\```.
8. Download and install [CUDA](https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64) and [cuDNN](https://developer.nvidia.com/cudnn). To get access to the download link, register as an NVIDIA community user.
@@ -1213,7 +1213,7 @@ Edit the Makefile to install the MXNet with CUDA bindings to leverage the GPU on
echo "USE_CUDNN=1" >> config.mk
```
-Edit the Mshadow Makefile to ensure MXNet builds with Pascal's hardware level low precision acceleration by editing mshadow/make/mshadow.mk and adding the following after line 122:
+Edit the Mshadow Makefile to ensure MXNet builds with Pascal's hardware level low precision acceleration by editing 3rdparty/mshadow/make/mshadow.mk and adding the following after line 122:
```bash
MSHADOW_CFLAGS += -DMSHADOW_USE_PASCAL=1
```
diff --git a/docs/install/osx_setup.md b/docs/install/osx_setup.md
index c1fa0fcd7f1..4d979b3dccf 100644
--- a/docs/install/osx_setup.md
+++ b/docs/install/osx_setup.md
@@ -1,4 +1,4 @@
-# Installing MXNet froum source on OS X (Mac)
+# Installing MXNet from source on OS X (Mac)
**NOTE:** For prebuild MXNet with Python installation, please refer to the [new install guide](http://mxnet.io/install/index.html).
@@ -65,8 +65,8 @@ Install the dependencies, required for MXNet, with the following commands:
brew install openblas
brew tap homebrew/core
brew install opencv
- # For getting pip
- brew install python
+ # Get pip
+ easy_install pip
# For visualization of network graphs
pip install graphviz
# Jupyter notebook
@@ -167,6 +167,12 @@ You might want to add this command to your ```~/.bashrc``` file. If you do, you
For more details about installing and using MXNet with Julia, see the [MXNet Julia documentation](http://dmlc.ml/MXNet.jl/latest/user-guide/install/).
## Install the MXNet Package for Scala
+
+If you haven't installed maven yet, you need to install it now (required by the makefile):
+```bash
+ brew install maven
+```
+
Before you build MXNet for Scala from source code, you must complete [building the shared library](#build-the-shared-library). After you build the shared library, run the following command from the MXNet source root directory to build the MXNet Scala package:
```bash
diff --git a/docs/install/windows_setup.md b/docs/install/windows_setup.md
index 598a12fc4cc..09a39e2c469 100755
--- a/docs/install/windows_setup.md
+++ b/docs/install/windows_setup.md
@@ -21,11 +21,11 @@ This produces a library called ```libmxnet.dll```.
To build and install MXNet yourself, you need the following dependencies. Install the required dependencies:
-1. If [Microsoft Visual Studio 2015](https://www.visualstudio.com/downloads/) is not already installed, download and install it. You can download and install the free community edition.
+1. If [Microsoft Visual Studio 2015](https://www.visualstudio.com/vs/older-downloads/) is not already installed, download and install it. You can download and install the free community edition.
2. Download and Install [CMake](https://cmake.org/) if it is not already installed.
3. Download and install [OpenCV](http://sourceforge.net/projects/opencvlibrary/files/opencv-win/3.0.0/opencv-3.0.0.exe/download).
4. Unzip the OpenCV package.
-5. Set the environment variable ```OpenCV_DIR``` to point to the ```OpenCV build directory``` (```c:\utils\opencv\build``` for example).
+5. Set the environment variable ```OpenCV_DIR``` to point to the ```OpenCV build directory``` (```C:\opencv\build\x64\vc14``` for example). Also, you need to add the OpenCV bin directory (```C:\opencv\build\x64\vc14\bin``` for example) to the ``PATH`` variable.
6. If you have Intel Math Kernel Library (MKL) installed, set ```MKL_ROOT``` to point to ```MKL``` directory that contains the ```include``` and ```lib```. Typically, you can find the directory in
```C:\Program Files (x86)\IntelSWTools\compilers_and_libraries_2018\windows\mkl```.
7. If you don't have the Intel Math Kernel Library (MKL) installed, download and install [OpenBlas](http://sourceforge.net/projects/openblas/files/v0.2.14/).
diff --git a/docs/mxdoc.py b/docs/mxdoc.py
index caf135680dd..7f567f0b8d0 100644
--- a/docs/mxdoc.py
+++ b/docs/mxdoc.py
@@ -80,9 +80,9 @@ def build_r_docs(app):
def build_scala_docs(app):
"""build scala doc and then move the outdir"""
- scala_path = app.builder.srcdir + '/../scala-package/core/src/main/scala/ml/dmlc/mxnet'
+ scala_path = app.builder.srcdir + '/../scala-package'
# scaldoc fails on some apis, so exit 0 to pass the check
- _run_cmd('cd ' + scala_path + '; scaladoc `find . | grep .*scala`; exit 0')
+ _run_cmd('cd ' + scala_path + '; scaladoc `find . -type f -name "*.scala" | egrep \"\/core|\/infer\" | egrep -v \"Suite\"`; exit 0')
dest_path = app.builder.outdir + '/api/scala/docs'
_run_cmd('rm -rf ' + dest_path)
_run_cmd('mkdir -p ' + dest_path)
@@ -265,9 +265,11 @@ def _get_python_block_output(src, global_dict, local_dict):
ret_status = False
return (ret_status, s.getvalue()+err)
-def _get_jupyter_notebook(lang, lines):
+def _get_jupyter_notebook(lang, all_lines):
cells = []
- for in_code, blk_lang, lines in _get_blocks(lines):
+ # Exclude lines containing <!--notebook-skip-line-->
+ filtered_lines = [line for line in all_lines if "<!--notebook-skip-line-->" not in line]
+ for in_code, blk_lang, lines in _get_blocks(filtered_lines):
if blk_lang != lang:
in_code = False
src = '\n'.join(lines)
diff --git a/docs/tutorials/index.md b/docs/tutorials/index.md
index 3eff299d778..8a597e95bfb 100644
--- a/docs/tutorials/index.md
+++ b/docs/tutorials/index.md
@@ -119,6 +119,8 @@ The Gluon and Module tutorials are in Python, but you can also find a variety of
- [Simple autograd example](http://mxnet.incubator.apache.org/tutorials/gluon/autograd.html)
+- [Inference using an ONNX model](http://mxnet.incubator.apache.org/tutorials/onnx/inference_on_onnx_model.html)
+
</div> <!--end of applications-->
</div> <!--end of gluon-->
diff --git a/docs/tutorials/onnx/inference_on_onnx_model.md b/docs/tutorials/onnx/inference_on_onnx_model.md
new file mode 100644
index 00000000000..182a2ae74cd
--- /dev/null
+++ b/docs/tutorials/onnx/inference_on_onnx_model.md
@@ -0,0 +1,273 @@
+
+# Running inference on MXNet/Gluon from an ONNX model
+
+[Open Neural Network Exchange (ONNX)](https://github.com/onnx/onnx) provides an open source format for AI models. It defines an extensible computation graph model, as well as definitions of built-in operators and standard data types.
+
+In this tutorial we will:
+
+- learn how to load a pre-trained .onnx model file into MXNet/Gluon
+- learn how to test this model using the sample input/output
+- learn how to test the model on custom images
+
+## Pre-requisite
+
+To run the tutorial you will need to have installed the following python modules:
+- [MXNet](http://mxnet.incubator.apache.org/install/index.html)
+- [onnx](https://github.com/onnx/onnx) (follow the install guide)
+- [onnx-mxnet](https://github.com/onnx/onnx-mxnet)
+- matplotlib
+- wget
+
+
+```python
+import numpy as np
+import mxnet as mx
+from mxnet.contrib import onnx as onnx_mxnet
+from mxnet import gluon, nd
+%matplotlib inline
+import matplotlib.pyplot as plt
+import tarfile, os
+import wget
+import json
+```
+
+### Downloading supporting files
+These are images and a vizualisation script
+
+
+```python
+image_folder = "images"
+utils_file = "utils.py" # contain utils function to plot nice visualization
+image_net_labels_file = "image_net_labels.json"
+images = ['apron', 'hammerheadshark', 'dog', 'wrench', 'dolphin', 'lotus']
+base_url = "https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/doc/tutorials/onnx/{}?raw=true"
+
+if not os.path.isdir(image_folder):
+ os.makedirs(image_folder)
+ for image in images:
+ wget.download(base_url.format("{}/{}.jpg".format(image_folder, image)), image_folder)
+if not os.path.isfile(utils_file):
+ wget.download(base_url.format(utils_file))
+if not os.path.isfile(image_net_labels_file):
+ wget.download(base_url.format(image_net_labels_file))
+```
+
+
+```python
+from utils import *
+```
+
+## Downloading a model from the ONNX model zoo
+
+We download a pre-trained model, in our case the [vgg16](https://arxiv.org/abs/1409.1556) model, trained on [ImageNet](http://www.image-net.org/) from the [ONNX model zoo](https://github.com/onnx/models). The model comes packaged in an archive `tar.gz` file containing an `model.onnx` model file and some sample input/output data.
+
+
+```python
+base_url = "https://s3.amazonaws.com/download.onnx/models/"
+current_model = "vgg16"
+model_folder = "model"
+archive = "{}.tar.gz".format(current_model)
+archive_file = os.path.join(model_folder, archive)
+url = "{}{}".format(base_url, archive)
+```
+
+Create the model folder and download the zipped model
+
+
+```python
+if not os.path.isdir(model_folder):
+ os.makedirs(model_folder)
+if not os.path.isfile(archive_file):
+ wget.download(url, model_folder)
+```
+
+Extract the model
+
+
+```python
+if not os.path.isdir(os.path.join(model_folder, current_model)):
+ tar = tarfile.open(archive_file, "r:gz")
+ tar.extractall(model_folder)
+ tar.close()
+```
+
+The models have been pre-trained on ImageNet, let's load the label mapping of the 1000 classes.
+
+
+```python
+categories = json.load(open(image_net_labels_file, 'r'))
+```
+
+## Loading the model into MXNet Gluon
+
+
+```python
+onnx_path = os.path.join(model_folder, current_model, "model.onnx")
+```
+
+We get the symbol and parameter objects
+
+
+```python
+sym, arg_params, aux_params = onnx_mxnet.import_model(onnx_path)
+```
+
+We pick a context, CPU or GPU
+
+
+```python
+ctx = mx.cpu()
+```
+
+And load them into a MXNet Gluon symbol block. For ONNX models the default input name is `input_0`.
+
+
+```python
+net = gluon.nn.SymbolBlock(outputs=sym, inputs=mx.sym.var('input_0'))
+net_params = net.collect_params()
+for param in arg_params:
+ if param in net_params:
+ net_params[param]._load_init(arg_params[param], ctx=ctx)
+for param in aux_params:
+ if param in net_params:
+ net_params[param]._load_init(aux_params[param], ctx=ctx)
+```
+
+We can now cache the computational graph through [hybridization](https://mxnet.incubator.apache.org/tutorials/gluon/hybrid.html) to gain some performance
+
+
+
+```python
+net.hybridize()
+```
+
+## Test using sample inputs and outputs
+The model comes with sample input/output we can use to test that whether model is correctly loaded
+
+
+```python
+numpy_path = os.path.join(model_folder, current_model, 'test_data_0.npz')
+sample = np.load(numpy_path, encoding='bytes')
+inputs = sample['inputs']
+outputs = sample['outputs']
+```
+
+
+```python
+print("Input format: {}".format(inputs[0].shape))
+print("Output format: {}".format(outputs[0].shape))
+```
+
+`Input format: (1, 3, 224, 224)` <!--notebook-skip-line-->
+
+
+`Output format: (1, 1000)` <!--notebook-skip-line-->
+
+
+
+We can visualize the network (requires graphviz installed)
+
+
+```python
+mx.visualization.plot_network(sym, node_attrs={"shape":"oval","fixedsize":"false"})
+```
+
+
+
+
+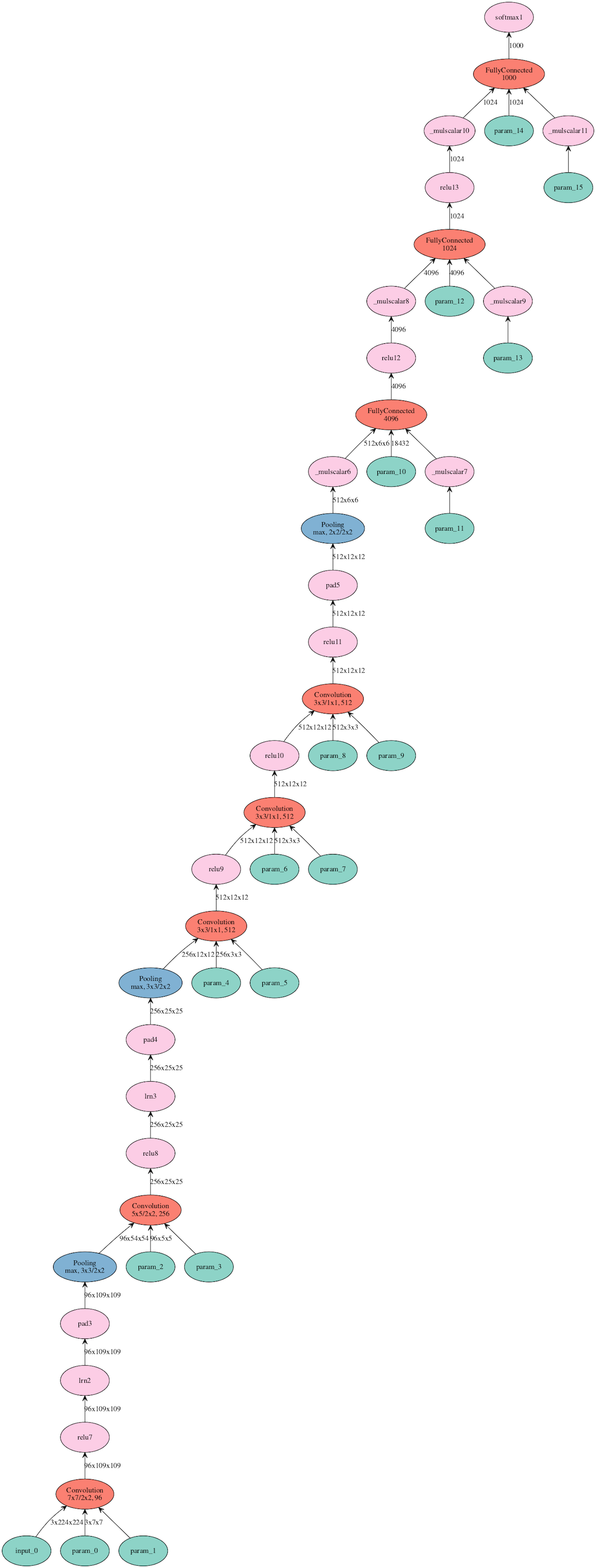<!--notebook-skip-line-->
+
+
+
+This is a helper function to run M batches of data of batch-size N through the net and collate the outputs into an array of shape (K, 1000) where K=MxN is the total number of examples (mumber of batches x batch-size) run through the network.
+
+
+```python
+def run_batch(net, data):
+ results = []
+ for batch in data:
+ outputs = net(batch)
+ results.extend([o for o in outputs.asnumpy()])
+ return np.array(results)
+```
+
+
+```python
+result = run_batch(net, nd.array([inputs[0]], ctx))
+```
+
+
+```python
+print("Loaded model and sample output predict the same class: {}".format(np.argmax(result) == np.argmax(outputs[0])))
+```
+
+Loaded model and sample output predict the same class: True <!--notebook-skip-line-->
+
+
+Good the sample output and our prediction match, now we can run against real data
+
+## Test using real images
+
+
+```python
+TOP_P = 3 # How many top guesses we show in the visualization
+```
+
+
+Transform function to set the data into the format the network expects, (N, 3, 224, 224) where N is the batch size.
+
+
+```python
+def transform(img):
+ return np.expand_dims(np.transpose(img, (2,0,1)),axis=0).astype(np.float32)
+```
+
+
+We load two sets of images in memory
+
+
+```python
+image_net_images = [plt.imread('images/{}.jpg'.format(path)) for path in ['apron', 'hammerheadshark','dog']]
+caltech101_images = [plt.imread('images/{}.jpg'.format(path)) for path in ['wrench', 'dolphin','lotus']]
+images = image_net_images + caltech101_images
+```
+
+And run them as a batch through the network to get the predictions
+
+```python
+batch = nd.array(np.concatenate([transform(img) for img in images], axis=0), ctx=ctx)
+result = run_batch(net, [batch])
+```
+
+
+```python
+plot_predictions(image_net_images, result[:3], categories, TOP_P)
+```
+
+
+<!--notebook-skip-line-->
+
+
+**Well done!** Looks like it is doing a pretty good job at classifying pictures when the category is a ImageNet label
+
+Let's now see the results on the 3 other images
+
+
+```python
+plot_predictions(caltech101_images, result[3:7], categories, TOP_P)
+```
+
+
+<!--notebook-skip-line-->
+
+
+**Hmm, not so good...** Even though predictions are close, they are not accurate, which is due to the fact that the ImageNet dataset does not contain `wrench`, `dolphin`, or `lotus` categories and our network has been trained on ImageNet.
+
+Lucky for us, the [Caltech101 dataset](http://www.vision.caltech.edu/Image_Datasets/Caltech101/) has them, let's see how we can fine-tune our network to classify these categories correctly.
+
+We show that in our next tutorials:
+
+- Fine-tuning a ONNX Model using the modern imperative MXNet/Gluon API(Coming soon)
+- Fine-tuning a ONNX Model using the symbolic MXNet/Module API(Coming soon)
+
+<!-- INSERT SOURCE DOWNLOAD BUTTONS -->
diff --git a/docs/tutorials/python/linear-regression.md b/docs/tutorials/python/linear-regression.md
index 9dfcf07981d..0a5e308f04f 100644
--- a/docs/tutorials/python/linear-regression.md
+++ b/docs/tutorials/python/linear-regression.md
@@ -49,8 +49,8 @@ tells the iterator to randomize the order in which examples are shown to the mod
```python
-train_iter = mx.io.NDArrayIter(train_data,train_label, batch_size, shuffle=True,label_name='lin_reg_label')
-eval_iter = mx.io.NDArrayIter(eval_data, eval_label, batch_size, shuffle=False)
+train_iter = mx.io.NDArrayIter(train_data, train_label, batch_size, shuffle=True, label_name='lin_reg_label')
+eval_iter = mx.io.NDArrayIter(eval_data, eval_label, batch_size, shuffle=False, label_name='lin_reg_label')
```
In the above example, we have made use of `NDArrayIter`, which is useful for iterating
@@ -184,7 +184,7 @@ Let us try and add some noise to the evaluation data and see how the MSE changes
```python
eval_data = np.array([[7,2],[6,10],[12,2]])
eval_label = np.array([11.1,26.1,16.1]) #Adding 0.1 to each of the values
-eval_iter = mx.io.NDArrayIter(eval_data, eval_label, batch_size, shuffle=False)
+eval_iter = mx.io.NDArrayIter(eval_data, eval_label, batch_size, shuffle=False, label_name='lin_reg_label')
model.score(eval_iter, metric)
```
diff --git a/docs/tutorials/sparse/row_sparse.md b/docs/tutorials/sparse/row_sparse.md
index d4f68844114..65b7d05ae3f 100644
--- a/docs/tutorials/sparse/row_sparse.md
+++ b/docs/tutorials/sparse/row_sparse.md
@@ -17,9 +17,6 @@ Y = mx.nd.dot(X, W)
{'X': X, 'W': W, 'Y': Y}
```
-
-
-
{'W':
[[ 3. 4. 5.]
[ 6. 7. 8.]]
@@ -30,7 +27,6 @@ Y = mx.nd.dot(X, W)
<NDArray 1x3 @cpu(0)>}
-
As you can see,
```
@@ -80,7 +76,7 @@ In this tutorial, we will describe what the row sparse format is and how to use
To complete this tutorial, we need:
-- MXNet. See the instructions for your operating system in [Setup and Installation](https://mxnet.io/install/index.html)
+- MXNet. See the instructions for your operating system in [Setup and Installation](https://mxnet.incubator.apache.org/install/index.html)
- [Jupyter](http://jupyter.org/)
```
pip install jupyter
@@ -391,7 +387,7 @@ rsp_retained = mx.nd.sparse.retain(rsp, mx.nd.array([0, 1]))
## Sparse Operators and Storage Type Inference
-Operators that have specialized implementation for sparse arrays can be accessed in ``mx.nd.sparse``. You can read the [mxnet.ndarray.sparse API documentation](http://mxnet.io/versions/master/api/python/ndarray/sparse.html) to find what sparse operators are available.
+Operators that have specialized implementation for sparse arrays can be accessed in ``mx.nd.sparse``. You can read the [mxnet.ndarray.sparse API documentation](http://mxnet.incubator.apache.org/api/python/ndarray/sparse.html) to find what sparse operators are available.
```python
@@ -537,8 +533,8 @@ sgd.update(0, weight, grad, momentum)
-Note that both [mxnet.optimizer.SGD](https://mxnet.incubator.apache.org/api/python/optimization.html#mxnet.optimizer.SGD)
-and [mxnet.optimizer.Adam](https://mxnet.incubator.apache.org/api/python/optimization.html#mxnet.optimizer.Adam) support sparse updates in MXNet.
+Note that both [mxnet.optimizer.SGD](https://mxnet.incubator.apache.org/api/python/optimization/optimization.html#mxnet.optimizer.SGD)
+and [mxnet.optimizer.Adam](https://mxnet.incubator.apache.org/api/python/optimization/optimization.html#mxnet.optimizer.Adam) support sparse updates in MXNet.
## Advanced Topics
diff --git a/example/README.md b/example/README.md
index 49484a09e97..1ad66e942de 100644
--- a/example/README.md
+++ b/example/README.md
@@ -38,6 +38,12 @@ The site expects the format to be markdown, so export your notebook as a .md via
<!-- INSERT SOURCE DOWNLOAD BUTTONS -->
```
+If you want some lines to show-up in the markdown but not in the generated notebooks, add this comment `<!--notebook-skip-line-->` after your ``. Like this:
+```
+<!--notebook-skip-line-->
+```
+Typically when you have a `plt.imshow()` you want the image tag `[png](img.png)` in the `.md` but not in the downloaded notebook as the user will re-generate the plot at run-time.
+
## <a name="list-of-examples"></a>List of examples
### <a name="language-binding-examples"></a>Languages Binding Examples
diff --git a/example/gluon/data.py b/example/gluon/data.py
index c996c9af9ed..56e89065afe 100644
--- a/example/gluon/data.py
+++ b/example/gluon/data.py
@@ -80,7 +80,7 @@ def get_imagenet_iterator(root, batch_size, num_workers, data_shape=224, dtype='
train_data = DataLoader(train_dataset, batch_size, shuffle=True,
last_batch='discard', num_workers=num_workers)
val_dir = os.path.join(root, 'val')
- if not os.path.isdir(os.path.join(os.path.expanduser(root, 'val', 'n01440764'))):
+ if not os.path.isdir(os.path.expanduser(os.path.join(root, 'val', 'n01440764'))):
user_warning = 'Make sure validation images are stored in one subdir per category, a helper script is available at https://git.io/vNQv1'
raise ValueError(user_warning)
logging.info("Loading image folder %s, this may take a bit long...", val_dir)
diff --git a/example/gluon/image_classification.py b/example/gluon/image_classification.py
index 9acfda51d17..a67a31790a0 100644
--- a/example/gluon/image_classification.py
+++ b/example/gluon/image_classification.py
@@ -22,6 +22,7 @@
import mxnet as mx
from mxnet import gluon
+from mxnet import profiler
from mxnet.gluon import nn
from mxnet.gluon.model_zoo import vision as models
from mxnet import autograd as ag
@@ -96,6 +97,7 @@
parser.add_argument('--profile', action='store_true',
help='Option to turn on memory profiling for front-end, '\
'and prints out the memory usage by python function at the end.')
+parser.add_argument('--builtin-profiler', type=int, default=0, help='Enable built-in profiler (0=off, 1=on)')
opt = parser.parse_args()
# global variables
@@ -194,6 +196,9 @@ def train(opt, ctx):
kvstore = kv)
loss = gluon.loss.SoftmaxCrossEntropyLoss()
+
+ total_time = 0
+ num_epochs = 0
best_acc = [0]
for epoch in range(opt.start_epoch, opt.epochs):
trainer = update_learning_rate(opt.lr, trainer, epoch, opt.lr_factor, lr_steps)
@@ -223,16 +228,29 @@ def train(opt, ctx):
epoch, i, batch_size/(time.time()-btic), name[0], acc[0], name[1], acc[1]))
btic = time.time()
+ epoch_time = time.time()-tic
+
+ # First epoch will usually be much slower than the subsequent epics,
+ # so don't factor into the average
+ if num_epochs > 0:
+ total_time = total_time + epoch_time
+ num_epochs = num_epochs + 1
+
name, acc = metric.get()
logger.info('[Epoch %d] training: %s=%f, %s=%f'%(epoch, name[0], acc[0], name[1], acc[1]))
- logger.info('[Epoch %d] time cost: %f'%(epoch, time.time()-tic))
+ logger.info('[Epoch %d] time cost: %f'%(epoch, epoch_time))
name, val_acc = test(ctx, val_data)
logger.info('[Epoch %d] validation: %s=%f, %s=%f'%(epoch, name[0], val_acc[0], name[1], val_acc[1]))
# save model if meet requirements
save_checkpoint(epoch, val_acc[0], best_acc)
+ if num_epochs > 1:
+ print('Average epoch time: {}'.format(float(total_time)/(num_epochs - 1)))
def main():
+ if opt.builtin_profiler > 0:
+ profiler.set_config(profile_all=True, aggregate_stats=True)
+ profiler.set_state('run')
if opt.mode == 'symbolic':
data = mx.sym.var('data')
out = net(data)
@@ -254,6 +272,9 @@ def main():
if opt.mode == 'hybrid':
net.hybridize()
train(opt, context)
+ if opt.builtin_profiler > 0:
+ profiler.set_state('stop')
+ print(profiler.dumps())
if __name__ == '__main__':
if opt.profile:
diff --git a/example/gluon/word_language_model/README.md b/example/gluon/word_language_model/README.md
index ff8ea56b206..f99a3a63a46 100644
--- a/example/gluon/word_language_model/README.md
+++ b/example/gluon/word_language_model/README.md
@@ -1,32 +1,18 @@
# Word-level language modeling RNN
-This example trains a multi-layer RNN (Elman, GRU, or LSTM) on Penn Treebank (PTB) language modeling benchmark.
+This example trains a multi-layer RNN (Elman, GRU, or LSTM) on WikiText-2 language modeling benchmark.
-The model obtains the state-of-the-art result on PTB using LSTM, getting a test perplexity of ~72.
-And ~97 ppl in WikiText-2, outperform than basic LSTM(99.3) and reach Variational LSTM(96.3).
+The model obtains ~107 ppl in WikiText-2 using LSTM.
-The following techniques have been adopted for SOTA results:
+The following techniques have been adopted for SOTA results:
- [LSTM for LM](https://arxiv.org/pdf/1409.2329.pdf)
- [Weight tying](https://arxiv.org/abs/1608.05859) between word vectors and softmax output embeddings
## Data
-### PTB
-
-The PTB data is the processed version from [(Mikolov et al, 2010)](http://www.fit.vutbr.cz/research/groups/speech/publi/2010/mikolov_interspeech2010_IS100722.pdf):
-
-```bash
-bash get_ptb_data.sh
-python data.py
-```
-
### Wiki Text
-The wikitext-2 data is downloaded from [(The wikitext long term dependency language modeling dataset)](https://www.salesforce.com/products/einstein/ai-research/the-wikitext-dependency-language-modeling-dataset/):
-
-```bash
-bash get_wikitext2_data.sh
-```
+The wikitext-2 data is from [(The wikitext long term dependency language modeling dataset)](https://www.salesforce.com/products/einstein/ai-research/the-wikitext-dependency-language-modeling-dataset/). The training script automatically loads the dataset into `$PWD/data`.
## Usage
@@ -34,12 +20,7 @@ bash get_wikitext2_data.sh
Example runs and the results:
```
-python train.py -data ./data/ptb. --cuda --tied --nhid 650 --emsize 650 --dropout 0.5 # Test ppl of 75.3 in ptb
-python train.py -data ./data/ptb. --cuda --tied --nhid 1500 --emsize 1500 --dropout 0.65 # Test ppl of 72.0 in ptb
-```
-
-```
-python train.py -data ./data/wikitext-2/wiki. --cuda --tied --nhid 256 --emsize 256 # Test ppl of 97.07 in wikitext-2
+python train.py --cuda --tied --nhid 256 --emsize 256 # Test ppl of 106.9 in wikitext-2
```
@@ -47,21 +28,32 @@ python train.py -data ./data/wikitext-2/wiki. --cuda --tied --nhid 256 --emsize
`python train.py --help` gives the following arguments:
```
-Optional arguments:
- -h, --help show this help message and exit
- --data DATA location of the data corpus
- --model MODEL type of recurrent net (rnn_tanh, rnn_relu, lstm, gru)
- --emsize EMSIZE size of word embeddings
- --nhid NHID number of hidden units per layer
- --nlayers NLAYERS number of layers
- --lr LR initial learning rate
- --clip CLIP gradient clipping
- --epochs EPOCHS upper epoch limit
- --batch_size N batch size
- --bptt BPTT sequence length
- --dropout DROPOUT dropout applied to layers (0 = no dropout)
- --tied tie the word embedding and softmax weights
- --cuda Whether to use gpu
- --log-interval N report interval
- --save SAVE path to save the final model
+usage: train.py [-h] [--model MODEL] [--emsize EMSIZE] [--nhid NHID]
+ [--nlayers NLAYERS] [--lr LR] [--clip CLIP] [--epochs EPOCHS]
+ [--batch_size N] [--bptt BPTT] [--dropout DROPOUT] [--tied]
+ [--cuda] [--log-interval N] [--save SAVE] [--gctype GCTYPE]
+ [--gcthreshold GCTHRESHOLD]
+
+MXNet Autograd RNN/LSTM Language Model on Wikitext-2.
+
+optional arguments:
+ -h, --help show this help message and exit
+ --model MODEL type of recurrent net (rnn_tanh, rnn_relu, lstm, gru)
+ --emsize EMSIZE size of word embeddings
+ --nhid NHID number of hidden units per layer
+ --nlayers NLAYERS number of layers
+ --lr LR initial learning rate
+ --clip CLIP gradient clipping
+ --epochs EPOCHS upper epoch limit
+ --batch_size N batch size
+ --bptt BPTT sequence length
+ --dropout DROPOUT dropout applied to layers (0 = no dropout)
+ --tied tie the word embedding and softmax weights
+ --cuda Whether to use gpu
+ --log-interval N report interval
+ --save SAVE path to save the final model
+ --gctype GCTYPE type of gradient compression to use, takes `2bit` or
+ `none` for now.
+ --gcthreshold GCTHRESHOLD
+ threshold for 2bit gradient compression
```
diff --git a/example/gluon/word_language_model/train.py b/example/gluon/word_language_model/train.py
index b69fd173200..e7bfc920aee 100644
--- a/example/gluon/word_language_model/train.py
+++ b/example/gluon/word_language_model/train.py
@@ -18,11 +18,11 @@
import argparse
import time
import math
+import os
import mxnet as mx
from mxnet import gluon, autograd
from mxnet.gluon import contrib
import model
-import data
parser = argparse.ArgumentParser(description='MXNet Autograd RNN/LSTM Language Model on Wikitext-2.')
parser.add_argument('--model', type=str, default='lstm',
@@ -71,9 +71,14 @@
else:
context = mx.cpu(0)
-train_dataset = contrib.data.text.WikiText2('./data', 'train', seq_len=args.bptt)
+dirname = './data'
+dirname = os.path.expanduser(dirname)
+if not os.path.exists(dirname):
+ os.makedirs(dirname)
+
+train_dataset = contrib.data.text.WikiText2(dirname, 'train', seq_len=args.bptt)
vocab = train_dataset.vocabulary
-val_dataset, test_dataset = [contrib.data.text.WikiText2('./data', segment,
+val_dataset, test_dataset = [contrib.data.text.WikiText2(dirname, segment,
vocab=vocab,
seq_len=args.bptt)
for segment in ['validation', 'test']]
diff --git a/example/image-classification/data/caltech256.sh b/example/image-classification/data/caltech256.sh
index 3fc329a9b83..187d026f801 100755
--- a/example/image-classification/data/caltech256.sh
+++ b/example/image-classification/data/caltech256.sh
@@ -46,8 +46,8 @@ done
# generate lst files
CUR_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
MX_DIR=${CUR_DIR}/../../../
-python ${MX_DIR}/tools/im2rec.py --list True --recursive True caltech256-train ${TRAIN_DIR}/
-python ${MX_DIR}/tools/im2rec.py --list True --recursive True caltech256-val 256_ObjectCategories/
+python ${MX_DIR}/tools/im2rec.py --list --recursive caltech256-train ${TRAIN_DIR}/
+python ${MX_DIR}/tools/im2rec.py --list --recursive caltech256-val 256_ObjectCategories/
mv caltech256-train_train.lst caltech256-train.lst
rm caltech256-train_*
mv caltech256-val_train.lst caltech256-val.lst
diff --git a/example/image-classification/predict-cpp/Makefile b/example/image-classification/predict-cpp/Makefile
index edf00400dcd..3f8968b3b9b 100644
--- a/example/image-classification/predict-cpp/Makefile
+++ b/example/image-classification/predict-cpp/Makefile
@@ -28,4 +28,4 @@ clean:
rm -f *.d *.o
lint:
- python ../../../dmlc-core/scripts/lint.py mxnet "cpp" ./
+ python ../../../3rdparty/dmlc-core/scripts/lint.py mxnet "cpp" ./
diff --git a/example/onnx/super_resolution.py b/example/onnx/super_resolution.py
index 1392b77715c..f7c7886d0df 100644
--- a/example/onnx/super_resolution.py
+++ b/example/onnx/super_resolution.py
@@ -37,9 +37,9 @@ def import_onnx():
download(model_url, 'super_resolution.onnx')
LOGGER.info("Converting onnx format to mxnet's symbol and params...")
- sym, params = onnx_mxnet.import_model('super_resolution.onnx')
+ sym, arg_params, aux_params = onnx_mxnet.import_model('super_resolution.onnx')
LOGGER.info("Successfully Converted onnx format to mxnet's symbol and params...")
- return sym, params
+ return sym, arg_params, aux_params
def get_test_image():
"""Download and process the test image"""
@@ -53,12 +53,12 @@ def get_test_image():
input_image = np.array(img_y)[np.newaxis, np.newaxis, :, :]
return input_image, img_cb, img_cr
-def perform_inference(sym, params, input_img, img_cb, img_cr):
+def perform_inference(sym, arg_params, aux_params, input_img, img_cb, img_cr):
"""Perform inference on image using mxnet"""
# create module
mod = mx.mod.Module(symbol=sym, data_names=['input_0'], label_names=None)
mod.bind(for_training=False, data_shapes=[('input_0', input_img.shape)])
- mod.set_params(arg_params=params, aux_params=None)
+ mod.set_params(arg_params=arg_params, aux_params=aux_params)
# run inference
batch = namedtuple('Batch', ['data'])
@@ -79,6 +79,6 @@ def perform_inference(sym, params, input_img, img_cb, img_cr):
return result_img
if __name__ == '__main__':
- MX_SYM, MX_PARAM = import_onnx()
+ MX_SYM, MX_ARG_PARAM, MX_AUX_PARAM = import_onnx()
INPUT_IMG, IMG_CB, IMG_CR = get_test_image()
- perform_inference(MX_SYM, MX_PARAM, INPUT_IMG, IMG_CB, IMG_CR)
+ perform_inference(MX_SYM, MX_ARG_PARAM, MX_AUX_PARAM, INPUT_IMG, IMG_CB, IMG_CR)
diff --git a/example/profiler/profiler_executor.py b/example/profiler/profiler_executor.py
index 117a8df4926..8ab417a9744 100644
--- a/example/profiler/profiler_executor.py
+++ b/example/profiler/profiler_executor.py
@@ -128,7 +128,7 @@ def benchmark(mod, dry_run=10, iterations=10):
t0 = time.clock()
- profiler.profiler_set_state('run')
+ profiler.set_state('run')
# real run
for i in range(iterations):
mod.forward(batch, is_train=True)
@@ -136,7 +136,7 @@ def benchmark(mod, dry_run=10, iterations=10):
mod.update()
for output in mod.get_outputs(merge_multi_context=False)[0]:
output.wait_to_read()
- profiler.profiler_set_state('stop')
+ profiler.set_state('stop')
t1 = time.clock()
return (t1 - t0)*1000.0 / iterations
@@ -152,7 +152,7 @@ def executor(num_iteration):
args = parse_args()
if __name__ == '__main__':
- mx.profiler.profiler_set_config(mode='symbolic', filename=args.profile_filename)
+ mx.profiler.set_config(profile_symbolic=True, filename=args.profile_filename)
print('profile file save to {0}'.format(args.profile_filename))
print('executor num_iteration: {0}'.format(args.iter_num))
executor_time = executor(args.iter_num)
diff --git a/example/profiler/profiler_imageiter.py b/example/profiler/profiler_imageiter.py
index 77ca412358b..c8e747835ba 100644
--- a/example/profiler/profiler_imageiter.py
+++ b/example/profiler/profiler_imageiter.py
@@ -40,7 +40,7 @@ def run_imageiter(path_rec, n, batch_size=32):
if __name__ == '__main__':
- mx.profiler.profiler_set_config(mode='all', filename='profile_imageiter.json')
- mx.profiler.profiler_set_state('run')
+ mx.profiler.set_config(profile_all=True, filename='profile_imageiter.json')
+ mx.profiler.set_state('run')
run_imageiter('test.rec', 20) # See http://mxnet.io/tutorials/python/image_io.html for how to create .rec files.
- mx.profiler.profiler_set_state('stop')
+ mx.profiler.set_state('stop')
diff --git a/example/profiler/profiler_matmul.py b/example/profiler/profiler_matmul.py
index a23545cb06e..6b92bcc21ec 100644
--- a/example/profiler/profiler_matmul.py
+++ b/example/profiler/profiler_matmul.py
@@ -33,7 +33,7 @@ def parse_args():
args = parse_args()
if __name__ == '__main__':
- mx.profiler.profiler_set_config(mode='symbolic', filename=args.profile_filename)
+ mx.profiler.set_config(profile_symbolic=True, filename=args.profile_filename)
print('profile file save to {0}'.format(args.profile_filename))
A = mx.sym.Variable('A')
@@ -53,10 +53,10 @@ def parse_args():
for i in range(args.iter_num):
if i == args.begin_profiling_iter:
t0 = time.clock()
- mx.profiler.profiler_set_state('run')
+ mx.profiler.set_state('run')
if i == args.end_profiling_iter:
t1 = time.clock()
- mx.profiler.profiler_set_state('stop')
+ mx.profiler.set_state('stop')
executor.forward()
c = executor.outputs[0]
c.wait_to_read()
diff --git a/example/profiler/profiler_ndarray.py b/example/profiler/profiler_ndarray.py
index 5c233c64ed6..e34b536d5d5 100644
--- a/example/profiler/profiler_ndarray.py
+++ b/example/profiler/profiler_ndarray.py
@@ -316,8 +316,8 @@ def test_broadcast_to():
if __name__ == '__main__':
- mx.profiler.profiler_set_config(mode='all', filename='profile_ndarray.json')
- mx.profiler.profiler_set_state('run')
+ mx.profiler.set_config(profile_all=True, filename='profile_ndarray.json')
+ mx.profiler.set_state('run')
test_ndarray_slice_along_axis()
test_broadcast()
test_ndarray_elementwise()
@@ -333,4 +333,4 @@ def test_broadcast_to():
test_ndarray_onehot()
test_ndarray_fill()
test_reduce()
- mx.profiler.profiler_set_state('stop')
+ mx.profiler.set_state('stop')
diff --git a/example/quantization/README.md b/example/quantization/README.md
new file mode 100644
index 00000000000..63b65574d3a
--- /dev/null
+++ b/example/quantization/README.md
@@ -0,0 +1,22 @@
+# Model Quantization with Calibration Examples
+This folder contains examples of quantizing a FP32 model with or without calibration and using the calibrated
+quantized for inference. Two pre-trained imagenet models are taken as examples for quantization. One is
+[Resnet-152](http://data.mxnet.io/models/imagenet/resnet/152-layers/), and the other one is
+[Inception with BatchNorm](http://data.mxnet.io/models/imagenet/inception-bn/). The calibration dataset
+is the [validation dataset](http://data.mxnet.io/data/val_256_q90.rec) for testing the pre-trained models.
+
+Here are the details of the four files in this folder.
+- `imagenet_gen_qsym.py` This script provides an example of taking FP32 models and calibration dataset to generate
+calibrated quantized models. When launched for the first time, the script would download the user-specified model,
+either Resnet-152 or Inception,
+and calibration dataset into `model` and `data` folders, respectively. The generated quantized models can be found in
+the `model` folder.
+- `imagenet_inference.py` This script is used for calculating the accuracy of FP32 models or quantized models on the
+validation dataset which was downloaded for calibration in `imagenet_gen_qsym.py`.
+- `launch_quantize.sh` This is a shell script that generates various quantized models for Resnet-152 and
+Inception with BatchNorm with different configurations. Users can copy and paste the command from the script to
+the console to run model quantization for a specific configuration.
+- `launch_inference.sh` This is a shell script that calculate the accuracies of all the quantized models generated
+by invoking `launch_quantize.sh`.
+
+**NOTE**: This example has only been tested on Linux systems.
\ No newline at end of file
diff --git a/example/quantization/common b/example/quantization/common
new file mode 120000
index 00000000000..cafb9140ab6
--- /dev/null
+++ b/example/quantization/common
@@ -0,0 +1 @@
+../image-classification/common
\ No newline at end of file
diff --git a/example/quantization/imagenet_gen_qsym.py b/example/quantization/imagenet_gen_qsym.py
new file mode 100644
index 00000000000..045ce62489a
--- /dev/null
+++ b/example/quantization/imagenet_gen_qsym.py
@@ -0,0 +1,194 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import argparse
+import os
+import logging
+from common import modelzoo
+import mxnet as mx
+from mxnet.contrib.quantization import *
+
+
+def download_calib_dataset(dataset_url, calib_dataset, logger=None):
+ if logger is not None:
+ logger.info('Downloading calibration dataset from %s to %s' % (dataset_url, calib_dataset))
+ mx.test_utils.download(dataset_url, calib_dataset)
+
+
+def download_model(model_name, logger=None):
+ dir_path = os.path.dirname(os.path.realpath(__file__))
+ model_path = os.path.join(dir_path, 'model')
+ if logger is not None:
+ logger.info('Downloading model %s... into path %s' % (model_name, model_path))
+ return modelzoo.download_model(args.model, os.path.join(dir_path, 'model'))
+
+
+def save_symbol(fname, sym, logger=None):
+ if logger is not None:
+ logger.info('Saving symbol into file at %s' % fname)
+ sym.save(fname)
+
+
+def save_params(fname, arg_params, aux_params, logger=None):
+ if logger is not None:
+ logger.info('Saving params into file at %s' % fname)
+ save_dict = {('arg:%s' % k): v.as_in_context(cpu()) for k, v in arg_params.items()}
+ save_dict.update({('aux:%s' % k): v.as_in_context(cpu()) for k, v in aux_params.items()})
+ mx.nd.save(fname, save_dict)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='Generate a calibrated quantized model from a FP32 model')
+ parser.add_argument('--model', type=str, choices=['imagenet1k-resnet-152', 'imagenet1k-inception-bn'],
+ help='currently only supports imagenet1k-resnet-152 or imagenet1k-inception-bn')
+ parser.add_argument('--batch-size', type=int, default=32)
+ parser.add_argument('--label-name', type=str, default='softmax_label')
+ parser.add_argument('--calib-dataset', type=str, default='data/val_256_q90.rec',
+ help='path of the calibration dataset')
+ parser.add_argument('--image-shape', type=str, default='3,224,224')
+ parser.add_argument('--data-nthreads', type=int, default=60,
+ help='number of threads for data decoding')
+ parser.add_argument('--num-calib-batches', type=int, default=10,
+ help='number of batches for calibration')
+ parser.add_argument('--exclude-first-conv', action='store_true', default=True,
+ help='excluding quantizing the first conv layer since the'
+ ' number of channels is usually not a multiple of 4 in that layer'
+ ' which does not satisfy the requirement of cuDNN')
+ parser.add_argument('--shuffle-dataset', action='store_true', default=True,
+ help='shuffle the calibration dataset')
+ parser.add_argument('--shuffle-chunk-seed', type=int, default=3982304,
+ help='shuffling chunk seed, see'
+ ' https://mxnet.incubator.apache.org/api/python/io/io.html?highlight=imager#mxnet.io.ImageRecordIter'
+ ' for more details')
+ parser.add_argument('--shuffle-seed', type=int, default=48564309,
+ help='shuffling seed, see'
+ ' https://mxnet.incubator.apache.org/api/python/io/io.html?highlight=imager#mxnet.io.ImageRecordIter'
+ ' for more details')
+ parser.add_argument('--calib-mode', type=str, default='entropy',
+ help='calibration mode used for generating calibration table for the quantized symbol; supports'
+ ' 1. none: no calibration will be used. The thresholds for quantization will be calculated'
+ ' on the fly. This will result in inference speed slowdown and loss of accuracy'
+ ' in general.'
+ ' 2. naive: simply take min and max values of layer outputs as thresholds for'
+ ' quantization. In general, the inference accuracy worsens with more examples used in'
+ ' calibration. It is recommended to use `entropy` mode as it produces more accurate'
+ ' inference results.'
+ ' 3. entropy: calculate KL divergence of the fp32 output and quantized output for optimal'
+ ' thresholds. This mode is expected to produce the best inference accuracy of all three'
+ ' kinds of quantized models if the calibration dataset is representative enough of the'
+ ' inference dataset.')
+ args = parser.parse_args()
+
+ logging.basicConfig()
+ logger = logging.getLogger('logger')
+ logger.setLevel(logging.INFO)
+
+ logger.info('shuffle_dataset=%s' % args.shuffle_dataset)
+
+ calib_mode = args.calib_mode
+ logger.info('calibration mode set to %s' % calib_mode)
+
+ # download calibration dataset
+ if calib_mode != 'none':
+ download_calib_dataset('http://data.mxnet.io/data/val_256_q90.rec', args.calib_dataset)
+
+ # download model
+ prefix, epoch = download_model(model_name=args.model, logger=logger)
+ sym, arg_params, aux_params = mx.model.load_checkpoint(prefix, epoch)
+
+ # get batch size
+ batch_size = args.batch_size
+ logger.info('batch size = %d for calibration' % batch_size)
+
+ # get number of batches for calibration
+ num_calib_batches = args.num_calib_batches
+ if calib_mode != 'none':
+ logger.info('number of batches = %d for calibration' % num_calib_batches)
+
+ # get number of threads for decoding the dataset
+ data_nthreads = args.data_nthreads
+
+ # get image shape
+ image_shape = args.image_shape
+
+ exclude_first_conv = args.exclude_first_conv
+ excluded_sym_names = []
+ if args.model == 'imagenet1k-resnet-152':
+ rgb_mean = '0,0,0'
+ calib_layer = lambda name: name.endswith('_output') and (name.find('conv') != -1
+ or name.find('sc') != -1
+ or name.find('fc') != -1)
+ if exclude_first_conv:
+ excluded_sym_names = ['conv0']
+ elif args.model == 'imagenet1k-inception-bn':
+ rgb_mean = '123.68,116.779,103.939'
+ calib_layer = lambda name: name.endswith('_output') and (name.find('conv') != -1
+ or name.find('fc') != -1)
+ if exclude_first_conv:
+ excluded_sym_names = ['conv_1']
+ else:
+ raise ValueError('model %s is not supported in this script' % args.model)
+
+ label_name = args.label_name
+ logger.info('label_name = %s' % label_name)
+
+ data_shape = tuple([int(i) for i in image_shape.split(',')])
+ logger.info('Input data shape = %s' % str(data_shape))
+
+ logger.info('rgb_mean = %s' % rgb_mean)
+ rgb_mean = [float(i) for i in rgb_mean.split(',')]
+ mean_args = {'mean_r': rgb_mean[0], 'mean_g': rgb_mean[1], 'mean_b': rgb_mean[2]}
+
+ if calib_mode == 'none':
+ logger.info('Quantizing FP32 model %s' % args.model)
+ qsym, qarg_params, aux_params = quantize_model(sym=sym, arg_params=arg_params, aux_params=aux_params,
+ excluded_sym_names=excluded_sym_names,
+ calib_mode=calib_mode, logger=logger)
+ sym_name = '%s-symbol.json' % (prefix + '-quantized')
+ save_symbol(sym_name, qsym, logger)
+ else:
+ logger.info('Creating ImageRecordIter for reading calibration dataset')
+ data = mx.io.ImageRecordIter(path_imgrec=args.calib_dataset,
+ label_width=1,
+ preprocess_threads=data_nthreads,
+ batch_size=batch_size,
+ data_shape=data_shape,
+ label_name=label_name,
+ rand_crop=False,
+ rand_mirror=False,
+ shuffle=args.shuffle_dataset,
+ shuffle_chunk_seed=args.shuffle_chunk_seed,
+ seed=args.shuffle_seed,
+ **mean_args)
+
+ cqsym, qarg_params, aux_params = quantize_model(sym=sym, arg_params=arg_params, aux_params=aux_params,
+ ctx=mx.gpu(0), excluded_sym_names=excluded_sym_names,
+ calib_mode=calib_mode, calib_data=data,
+ num_calib_examples=num_calib_batches * batch_size,
+ calib_layer=calib_layer, logger=logger)
+ if calib_mode == 'entropy':
+ suffix = '-quantized-%dbatches-entropy' % num_calib_batches
+ elif calib_mode == 'naive':
+ suffix = '-quantized-%dbatches-naive' % num_calib_batches
+ else:
+ raise ValueError('unknow calibration mode %s received, only supports `none`, `naive`, and `entropy`'
+ % calib_mode)
+ sym_name = '%s-symbol.json' % (prefix + suffix)
+ save_symbol(sym_name, cqsym, logger)
+
+ param_name = '%s-%04d.params' % (prefix + '-quantized', epoch)
+ save_params(param_name, qarg_params, aux_params, logger)
diff --git a/example/quantization/imagenet_inference.py b/example/quantization/imagenet_inference.py
new file mode 100644
index 00000000000..fe3f2661c65
--- /dev/null
+++ b/example/quantization/imagenet_inference.py
@@ -0,0 +1,176 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import argparse
+import logging
+import os
+import time
+import mxnet as mx
+from mxnet import nd
+from mxnet.contrib.quantization import *
+
+
+def download_dataset(dataset_url, dataset_dir, logger=None):
+ if logger is not None:
+ logger.info('Downloading dataset for inference from %s to %s' % (dataset_url, dataset_dir))
+ mx.test_utils.download(dataset_url, dataset_dir)
+
+
+def load_model(symbol_file, param_file, logger=None):
+ cur_path = os.path.dirname(os.path.realpath(__file__))
+ symbol_file_path = os.path.join(cur_path, symbol_file)
+ if logger is not None:
+ logger.info('Loading symbol from file %s' % symbol_file_path)
+ symbol = mx.sym.load(symbol_file_path)
+
+ param_file_path = os.path.join(cur_path, param_file)
+ if logger is not None:
+ logger.info('Loading params from file %s' % param_file_path)
+ save_dict = nd.load(param_file_path)
+ arg_params = {}
+ aux_params = {}
+ for k, v in save_dict.items():
+ tp, name = k.split(':', 1)
+ if tp == 'arg':
+ arg_params[name] = v
+ if tp == 'aux':
+ aux_params[name] = v
+ return symbol, arg_params, aux_params
+
+
+def advance_data_iter(data_iter, n):
+ assert n >= 0
+ if n == 0:
+ return data_iter
+ has_next_batch = True
+ while has_next_batch:
+ try:
+ data_iter.next()
+ n -= 1
+ if n == 0:
+ return data_iter
+ except StopIteration:
+ has_next_batch = False
+
+
+def score(sym, arg_params, aux_params, data, devs, label_name, max_num_examples, logger=None):
+ metrics = [mx.metric.create('acc'),
+ mx.metric.create('top_k_accuracy', top_k=5)]
+ if not isinstance(metrics, list):
+ metrics = [metrics, ]
+ mod = mx.mod.Module(symbol=sym, context=devs, label_names=[label_name, ])
+ mod.bind(for_training=False,
+ data_shapes=data.provide_data,
+ label_shapes=data.provide_label)
+ mod.set_params(arg_params, aux_params)
+
+ tic = time.time()
+ num = 0
+ for batch in data:
+ mod.forward(batch, is_train=False)
+ for m in metrics:
+ mod.update_metric(m, batch.label)
+ num += batch_size
+ if max_num_examples is not None and num >= max_num_examples:
+ break
+
+ speed = num / (time.time() - tic)
+
+ if logger is not None:
+ logger.info('Finished inference with %d images' % num)
+ logger.info('Finished with %f images per second', speed)
+ for m in metrics:
+ logger.info(m.get())
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='Score a model on a dataset')
+ parser.add_argument('--symbol-file', type=str, required=True, help='symbol file path')
+ parser.add_argument('--param-file', type=str, required=True, help='param file path')
+ parser.add_argument('--batch-size', type=int, default=32)
+ parser.add_argument('--label-name', type=str, default='softmax_label')
+ parser.add_argument('--dataset', type=str, required=True, help='dataset path')
+ parser.add_argument('--rgb-mean', type=str, default='0,0,0')
+ parser.add_argument('--image-shape', type=str, default='3,224,224')
+ parser.add_argument('--data-nthreads', type=int, default=60, help='number of threads for data decoding')
+ parser.add_argument('--num-skipped-batches', type=int, default=0, help='skip the number of batches for inference')
+ parser.add_argument('--num-inference-batches', type=int, required=True, help='number of images used for inference')
+ parser.add_argument('--shuffle-dataset', action='store_true', default=True,
+ help='shuffle the calibration dataset')
+ parser.add_argument('--shuffle-chunk-seed', type=int, default=3982304,
+ help='shuffling chunk seed, see'
+ ' https://mxnet.incubator.apache.org/api/python/io/io.html?highlight=imager#mxnet.io.ImageRecordIter'
+ ' for more details')
+ parser.add_argument('--shuffle-seed', type=int, default=48564309,
+ help='shuffling seed, see'
+ ' https://mxnet.incubator.apache.org/api/python/io/io.html?highlight=imager#mxnet.io.ImageRecordIter'
+ ' for more details')
+
+ args = parser.parse_args()
+
+ logging.basicConfig()
+ logger = logging.getLogger('logger')
+ logger.setLevel(logging.INFO)
+
+ symbol_file = args.symbol_file
+ param_file = args.param_file
+ data_nthreads = args.data_nthreads
+
+ batch_size = args.batch_size
+ logger.info('batch size = %d for inference' % batch_size)
+
+ rgb_mean = args.rgb_mean
+ logger.info('rgb_mean = %s' % rgb_mean)
+ rgb_mean = [float(i) for i in rgb_mean.split(',')]
+ mean_args = {'mean_r': rgb_mean[0], 'mean_g': rgb_mean[1], 'mean_b': rgb_mean[2]}
+
+ label_name = args.label_name
+ logger.info('label_name = %s' % label_name)
+
+ image_shape = args.image_shape
+ data_shape = tuple([int(i) for i in image_shape.split(',')])
+ logger.info('Input data shape = %s' % str(data_shape))
+
+ dataset = args.dataset
+ download_dataset('http://data.mxnet.io/data/val_256_q90.rec', dataset)
+ logger.info('Dataset for inference: %s' % dataset)
+
+ # creating data iterator
+ data = mx.io.ImageRecordIter(path_imgrec=dataset,
+ label_width=1,
+ preprocess_threads=data_nthreads,
+ batch_size=batch_size,
+ data_shape=data_shape,
+ label_name=label_name,
+ rand_crop=False,
+ rand_mirror=False,
+ shuffle=True,
+ shuffle_chunk_seed=3982304,
+ seed=48564309,
+ **mean_args)
+
+ # loading model
+ sym, arg_params, aux_params = load_model(symbol_file, param_file, logger)
+
+ # make sure that fp32 inference works on the same images as calibrated quantized model
+ logger.info('Skipping the first %d batches' % args.num_skipped_batches)
+ data = advance_data_iter(data, args.num_skipped_batches)
+
+ num_inference_images = args.num_inference_batches * batch_size
+ logger.info('Running model %s for inference' % symbol_file)
+ score(sym, arg_params, aux_params, data, [mx.gpu(0)], label_name,
+ max_num_examples=num_inference_images, logger=logger)
diff --git a/example/quantization/launch_inference.sh b/example/quantization/launch_inference.sh
new file mode 100755
index 00000000000..8c839ba0f61
--- /dev/null
+++ b/example/quantization/launch_inference.sh
@@ -0,0 +1,45 @@
+#!/bin/sh
+
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+set -ex
+
+python imagenet_inference.py --symbol-file=./model/imagenet1k-resnet-152-symbol.json --param-file=./model/imagenet1k-resnet-152-0000.params --rgb-mean=0,0,0 --num-skipped-batches=50 --num-inference-batches=500 --dataset=./data/val_256_q90.rec
+
+python imagenet_inference.py --symbol-file=./model/imagenet1k-resnet-152-quantized-symbol.json --param-file=./model/imagenet1k-resnet-152-quantized-0000.params --rgb-mean=0,0,0 --num-skipped-batches=50 --num-inference-batches=500 --dataset=./data/val_256_q90.rec
+
+python imagenet_inference.py --symbol-file=./model/imagenet1k-resnet-152-quantized-5batches-naive-symbol.json --param-file=./model/imagenet1k-resnet-152-quantized-0000.params --rgb-mean=0,0,0 --num-skipped-batches=50 --num-inference-batches=500 --dataset=./data/val_256_q90.rec
+python imagenet_inference.py --symbol-file=./model/imagenet1k-resnet-152-quantized-10batches-naive-symbol.json --param-file=./model/imagenet1k-resnet-152-quantized-0000.params --rgb-mean=0,0,0 --num-skipped-batches=50 --num-inference-batches=500 --dataset=./data/val_256_q90.rec
+python imagenet_inference.py --symbol-file=./model/imagenet1k-resnet-152-quantized-50batches-naive-symbol.json --param-file=./model/imagenet1k-resnet-152-quantized-0000.params --rgb-mean=0,0,0 --num-skipped-batches=50 --num-inference-batches=500 --dataset=./data/val_256_q90.rec
+
+python imagenet_inference.py --symbol-file=./model/imagenet1k-resnet-152-quantized-5batches-entropy-symbol.json --param-file=./model/imagenet1k-resnet-152-quantized-0000.params --rgb-mean=0,0,0 --num-skipped-batches=50 --num-inference-batches=500 --dataset=./data/val_256_q90.rec
+python imagenet_inference.py --symbol-file=./model/imagenet1k-resnet-152-quantized-10batches-entropy-symbol.json --param-file=./model/imagenet1k-resnet-152-quantized-0000.params --rgb-mean=0,0,0 --num-skipped-batches=50 --num-inference-batches=500 --dataset=./data/val_256_q90.rec
+python imagenet_inference.py --symbol-file=./model/imagenet1k-resnet-152-quantized-50batches-entropy-symbol.json --param-file=./model/imagenet1k-resnet-152-quantized-0000.params --rgb-mean=0,0,0 --num-skipped-batches=50 --num-inference-batches=500 --dataset=./data/val_256_q90.rec
+
+
+python imagenet_inference.py --symbol-file=./model/imagenet1k-inception-bn-symbol.json --param-file=./model/imagenet1k-inception-bn-0000.params --rgb-mean=123.68,116.779,103.939 --num-skipped-batches=50 --num-inference-batches=500 --dataset=./data/val_256_q90.rec
+
+python imagenet_inference.py --symbol-file=./model/imagenet1k-inception-bn-quantized-symbol.json --param-file=./model/imagenet1k-inception-bn-quantized-0000.params --rgb-mean=123.68,116.779,103.939 --num-skipped-batches=50 --num-inference-batches=500 --dataset=./data/val_256_q90.rec
+
+python imagenet_inference.py --symbol-file=./model/imagenet1k-inception-bn-quantized-5batches-naive-symbol.json --param-file=./model/imagenet1k-inception-bn-quantized-0000.params --rgb-mean=123.68,116.779,103.939 --num-skipped-batches=50 --num-inference-batches=500 --dataset=./data/val_256_q90.rec
+python imagenet_inference.py --symbol-file=./model/imagenet1k-inception-bn-quantized-10batches-naive-symbol.json --param-file=./model/imagenet1k-inception-bn-quantized-0000.params --rgb-mean=123.68,116.779,103.939 --num-skipped-batches=50 --num-inference-batches=500 --dataset=./data/val_256_q90.rec
+python imagenet_inference.py --symbol-file=./model/imagenet1k-inception-bn-quantized-50batches-naive-symbol.json --param-file=./model/imagenet1k-inception-bn-quantized-0000.params --rgb-mean=123.68,116.779,103.939 --num-skipped-batches=50 --num-inference-batches=500 --dataset=./data/val_256_q90.rec
+
+python imagenet_inference.py --symbol-file=./model/imagenet1k-inception-bn-quantized-5batches-entropy-symbol.json --param-file=./model/imagenet1k-inception-bn-quantized-0000.params --rgb-mean=123.68,116.779,103.939 --num-skipped-batches=50 --num-inference-batches=500 --dataset=./data/val_256_q90.rec
+python imagenet_inference.py --symbol-file=./model/imagenet1k-inception-bn-quantized-10batches-entropy-symbol.json --param-file=./model/imagenet1k-inception-bn-quantized-0000.params --rgb-mean=123.68,116.779,103.939 --num-skipped-batches=50 --num-inference-batches=500 --dataset=./data/val_256_q90.rec
+python imagenet_inference.py --symbol-file=./model/imagenet1k-inception-bn-quantized-50batches-entropy-symbol.json --param-file=./model/imagenet1k-inception-bn-quantized-0000.params --rgb-mean=123.68,116.779,103.939 --num-skipped-batches=50 --num-inference-batches=500 --dataset=./data/val_256_q90.rec
diff --git a/example/quantization/launch_quantize.sh b/example/quantization/launch_quantize.sh
new file mode 100755
index 00000000000..9aa4bee4bff
--- /dev/null
+++ b/example/quantization/launch_quantize.sh
@@ -0,0 +1,41 @@
+#!/bin/sh
+
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+set -ex
+
+python imagenet_gen_qsym.py --model=imagenet1k-resnet-152 --calib-mode=none
+
+python imagenet_gen_qsym.py --model=imagenet1k-resnet-152 --calib-dataset=./data/val_256_q90.rec --num-calib-batches=5 --calib-mode=naive
+python imagenet_gen_qsym.py --model=imagenet1k-resnet-152 --calib-dataset=./data/val_256_q90.rec --num-calib-batches=10 --calib-mode=naive
+python imagenet_gen_qsym.py --model=imagenet1k-resnet-152 --calib-dataset=./data/val_256_q90.rec --num-calib-batches=50 --calib-mode=naive
+
+python imagenet_gen_qsym.py --model=imagenet1k-resnet-152 --calib-dataset=./data/val_256_q90.rec --num-calib-batches=5 --calib-mode=entropy
+python imagenet_gen_qsym.py --model=imagenet1k-resnet-152 --calib-dataset=./data/val_256_q90.rec --num-calib-batches=10 --calib-mode=entropy
+python imagenet_gen_qsym.py --model=imagenet1k-resnet-152 --calib-dataset=./data/val_256_q90.rec --num-calib-batches=50 --calib-mode=entropy
+
+
+python imagenet_gen_qsym.py --model=imagenet1k-inception-bn --calib-mode=none
+
+python imagenet_gen_qsym.py --model=imagenet1k-inception-bn --calib-dataset=./data/val_256_q90.rec --num-calib-batches=5 --calib-mode=naive
+python imagenet_gen_qsym.py --model=imagenet1k-inception-bn --calib-dataset=./data/val_256_q90.rec --num-calib-batches=10 --calib-mode=naive
+python imagenet_gen_qsym.py --model=imagenet1k-inception-bn --calib-dataset=./data/val_256_q90.rec --num-calib-batches=50 --calib-mode=naive
+
+python imagenet_gen_qsym.py --model=imagenet1k-inception-bn --calib-dataset=./data/val_256_q90.rec --num-calib-batches=5 --calib-mode=entropy
+python imagenet_gen_qsym.py --model=imagenet1k-inception-bn --calib-dataset=./data/val_256_q90.rec --num-calib-batches=10 --calib-mode=entropy
+python imagenet_gen_qsym.py --model=imagenet1k-inception-bn --calib-dataset=./data/val_256_q90.rec --num-calib-batches=50 --calib-mode=entropy
diff --git a/example/recommenders/recotools.py b/example/recommenders/recotools.py
index 250baa5c07c..70e069cd1d9 100644
--- a/example/recommenders/recotools.py
+++ b/example/recommenders/recotools.py
@@ -28,6 +28,7 @@ def CosineLoss(a, b, label):
dot = mx.symbol.sum_axis(dot, axis=1)
dot = mx.symbol.Flatten(dot)
cosine = 1 - dot
+ cosine = cosine / 2
return mx.symbol.MAERegressionOutput(data=cosine, label=label)
def SparseRandomProjection(indexes, values, input_dim, output_dim, ngram=1):
diff --git a/example/reinforcement-learning/a3c/launcher.py b/example/reinforcement-learning/a3c/launcher.py
index e0bda21891f..1fe053fb8c2 100644
--- a/example/reinforcement-learning/a3c/launcher.py
+++ b/example/reinforcement-learning/a3c/launcher.py
@@ -27,8 +27,8 @@
import argparse
import signal
-sys.path.append(os.path.join(os.environ['HOME'], "mxnet/dmlc-core/tracker"))
-sys.path.append(os.path.join('/scratch', "mxnet/dmlc-core/tracker"))
+sys.path.append(os.path.join(os.environ['HOME'], "mxnet/3rdparty/dmlc-core/tracker"))
+sys.path.append(os.path.join('/scratch', "mxnet/3rdparty/dmlc-core/tracker"))
from dmlc_tracker import tracker
keepalive = """
diff --git a/example/rnn/large_word_lm/custom_module.py b/example/rnn/large_word_lm/custom_module.py
new file mode 100644
index 00000000000..05d0fb75af7
--- /dev/null
+++ b/example/rnn/large_word_lm/custom_module.py
@@ -0,0 +1,182 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import logging
+import warnings
+
+import mxnet as mx
+import numpy as np
+from mxnet.module import Module
+from mxnet.model import load_checkpoint
+
+class CustomModule(Module):
+
+ def __init__(self, symbol, data_names=('data',), label_names=('softmax_label',),
+ logger=logging, context=mx.cpu(), work_load_list=None,
+ fixed_param_names=None, state_names=None, group2ctxs=None,
+ compression_params=None):
+
+ super(CustomModule, self).__init__(symbol, data_names=data_names, label_names=label_names,
+ logger=logger, context=context, work_load_list=work_load_list,
+ fixed_param_names=fixed_param_names, state_names=state_names,
+ group2ctxs=group2ctxs, compression_params=compression_params)
+
+ def prepare_sparse_params(self, param_rowids):
+ '''Prepares the module for processing a data batch by pulling row_sparse
+ parameters from kvstore to all devices based on rowids.
+
+ Parameters
+ ----------
+ param_rowids : dict of str to NDArray of list of NDArrays
+ '''
+ if not self._kvstore:
+ return
+ assert(isinstance(param_rowids, dict))
+ for param_name, rowids in param_rowids.items():
+ if isinstance(rowids, (tuple, list)):
+ rowids_1d = []
+ for r in rowids:
+ rowids_1d.append(r.reshape((-1,)).astype(np.int64))
+ rowid = mx.nd.concat(*rowids_1d, dim=0)
+ else:
+ rowid = rowids
+ param_idx = self._exec_group.param_names.index(param_name)
+ param_val = self._exec_group.param_arrays[param_idx]
+ self._kvstore.row_sparse_pull(param_name, param_val, row_ids=rowid,
+ priority=-param_idx)
+
+ @staticmethod
+ def load(prefix, epoch, load_optimizer_states=False, **kwargs):
+ """Creates a model from previously saved checkpoint.
+
+ Parameters
+ ----------
+ prefix : str
+ path prefix of saved model files. You should have
+ "prefix-symbol.json", "prefix-xxxx.params", and
+ optionally "prefix-xxxx.states", where xxxx is the
+ epoch number.
+ epoch : int
+ epoch to load.
+ load_optimizer_states : bool
+ whether to load optimizer states. Checkpoint needs
+ to have been made with save_optimizer_states=True.
+ data_names : list of str
+ Default is `('data')` for a typical model used in image classification.
+ label_names : list of str
+ Default is `('softmax_label')` for a typical model used in image
+ classification.
+ logger : Logger
+ Default is `logging`.
+ context : Context or list of Context
+ Default is ``cpu()``.
+ work_load_list : list of number
+ Default ``None``, indicating uniform workload.
+ fixed_param_names: list of str
+ Default ``None``, indicating no network parameters are fixed.
+ """
+ sym, args, auxs = load_checkpoint(prefix, epoch)
+ mod = CustomModule(symbol=sym, **kwargs)
+ mod._arg_params = args
+ mod._aux_params = auxs
+ mod.params_initialized = True
+ if load_optimizer_states:
+ mod._preload_opt_states = '%s-%04d.states'%(prefix, epoch)
+ return mod
+
+ def save_params(self, fname):
+ """Saves model parameters to file.
+ Parameters
+ ----------
+ fname : str
+ Path to output param file.
+ Examples
+ --------
+ >>> # An example of saving module parameters.
+ >>> mod.save_params('myfile')
+ """
+ arg_params, aux_params = self.get_params_from_kv(self._arg_params, self._aux_params)
+ save_dict = {('arg:%s' % k) : v.as_in_context(mx.cpu()) for k, v in arg_params.items()}
+ save_dict.update({('aux:%s' % k) : v.as_in_context(mx.cpu()) for k, v in aux_params.items()})
+ mx.nd.save(fname, save_dict)
+
+ def get_params_from_kv(self, arg_params, aux_params):
+ """ Copy data from kvstore to `arg_params` and `aux_params`.
+ Parameters
+ ----------
+ arg_params : list of NDArray
+ Target parameter arrays.
+ aux_params : list of NDArray
+ Target aux arrays.
+ Notes
+ -----
+ - This function will inplace update the NDArrays in arg_params and aux_params.
+ """
+ assert(self._kvstore is not None)
+ for name, block in zip(self._exec_group.param_names, self._exec_group.param_arrays):
+ assert(isinstance(block, list))
+ if block[0].stype == 'row_sparse':
+ row_ids = mx.nd.arange(start=0, stop=block[0].shape[0], dtype='int64')
+ self._kvstore.row_sparse_pull(name, arg_params[name], row_ids=row_ids)
+ else:
+ assert(block[0].stype == 'default')
+ self._kvstore.pull(name, out=arg_params[name])
+ if len(aux_params) > 0:
+ raise NotImplementedError()
+ return arg_params, aux_params
+
+ def clip_by_global_norm_per_ctx(self, max_norm=1.0, param_names=None):
+ """Clips gradient norm.
+
+ The norm is computed over all gradients together, as if they were
+ concatenated into a single vector. Gradients are modified in-place.
+
+ The method is first used in
+ `[ICML2013] On the difficulty of training recurrent neural networks`
+
+ Note that the gradients are concatenated per context in this implementation.
+
+ Examples
+ --------
+ An example of using clip_grad_norm to clip the gradient before updating the parameters::
+ >>> #Get the gradient via back-propagation
+ >>> net.forward_backward(data_batch=data_batch)
+ >>> norm_val = net.clip_by_global_norm(max_norm=2.0, param_names='w0')
+ >>> net.update()
+ """
+ assert self.binded and self.params_initialized and self.optimizer_initialized
+ num_ctx = len(self._exec_group.grad_arrays[0])
+ grad_array_per_ctx = [[] for i in range(num_ctx)]
+ assert(param_names is not None)
+ for param_name in param_names:
+ param_idx = self._exec_group.param_names.index(param_name)
+ grad_val = self._exec_group.grad_arrays[param_idx]
+ assert(len(grad_val) == num_ctx)
+ for i in range(num_ctx):
+ grad_array_per_ctx[i].append(grad_val[i])
+ norm_vals = []
+ for i in range(num_ctx):
+ mx.gluon.utils.clip_global_norm(grad_array_per_ctx[i], max_norm)
+
+ def rescale_grad(self, scale=None, param_name=None):
+ """ Rescale the gradient of provided parameters by a certain scale """
+ if scale is None or param_name is None:
+ return
+ param_idx = self._exec_group.param_names.index(param_name)
+ grad_vals = self._exec_group.grad_arrays[param_idx]
+ for grad in grad_vals:
+ grad[:] *= scale
diff --git a/example/rnn/large_word_lm/data.py b/example/rnn/large_word_lm/data.py
new file mode 100644
index 00000000000..b9cc3e8a89e
--- /dev/null
+++ b/example/rnn/large_word_lm/data.py
@@ -0,0 +1,202 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import mxnet as mx
+import numpy as np
+import codecs, glob, random, logging, collections
+
+class Vocabulary(object):
+ """ A dictionary for words.
+ Adapeted from @rafaljozefowicz's implementation.
+ """
+ def __init__(self):
+ self._token_to_id = {}
+ self._token_to_count = collections.Counter()
+ self._id_to_token = []
+ self._num_tokens = 0
+ self._total_count = 0
+ self._s_id = None
+ self._unk_id = None
+
+ @property
+ def num_tokens(self):
+ return self._num_tokens
+
+ @property
+ def unk(self):
+ return "<UNK>"
+
+ @property
+ def unk_id(self):
+ return self._unk_id
+
+ @property
+ def s(self):
+ return "<S>"
+
+ @property
+ def s_id(self):
+ return self._s_id
+
+ def add(self, token, count):
+ self._token_to_id[token] = self._num_tokens
+ self._token_to_count[token] = count
+ self._id_to_token.append(token)
+ self._num_tokens += 1
+ self._total_count += count
+
+ def finalize(self):
+ self._s_id = self.get_id(self.s)
+ self._unk_id = self.get_id(self.unk)
+
+ def get_id(self, token):
+ # Unseen token are mapped to UNK
+ return self._token_to_id.get(token, self.unk_id)
+
+ def get_token(self, id_):
+ return self._id_to_token[id_]
+
+ @staticmethod
+ def from_file(filename):
+ vocab = Vocabulary()
+ with codecs.open(filename, "r", "utf-8") as f:
+ for line in f:
+ word, count = line.strip().split()
+ vocab.add(word, int(count))
+ vocab.finalize()
+ return vocab
+
+class Dataset(object):
+ """ A dataset for truncated bptt with multiple sentences.
+ Adapeted from @rafaljozefowicz's implementation.
+ """
+ def __init__(self, vocab, file_pattern, shuffle=False):
+ self._vocab = vocab
+ self._file_pattern = file_pattern
+ self._shuffle = shuffle
+
+ def _parse_sentence(self, line):
+ s_id = self._vocab.s_id
+ return [s_id] + [self._vocab.get_id(word) for word in line.strip().split()] + [s_id]
+
+ def _parse_file(self, file_name):
+ logging.debug("Processing file: %s" % file_name)
+ with codecs.open(file_name, "r", "utf-8") as f:
+ lines = [line.strip() for line in f]
+ if not self._shuffle:
+ random.shuffle(lines)
+ logging.debug("Finished processing!")
+ for line in lines:
+ yield self._parse_sentence(line)
+
+ def _sentence_stream(self, file_stream):
+ for file_name in file_stream:
+ for sentence in self._parse_file(file_name):
+ yield sentence
+
+ def _iterate(self, sentences, batch_size, num_steps):
+ streams = [None] * batch_size
+ x = np.zeros([batch_size, num_steps], np.int32)
+ y = np.zeros([batch_size, num_steps], np.int32)
+ w = np.zeros([batch_size, num_steps], np.uint8)
+ while True:
+ x[:] = 0
+ y[:] = 0
+ w[:] = 0
+ for i in range(batch_size):
+ tokens_filled = 0
+ try:
+ while tokens_filled < num_steps:
+ if streams[i] is None or len(streams[i]) <= 1:
+ streams[i] = next(sentences)
+ num_tokens = min(len(streams[i]) - 1, num_steps - tokens_filled)
+ x[i, tokens_filled:tokens_filled+num_tokens] = streams[i][:num_tokens]
+ y[i, tokens_filled:tokens_filled + num_tokens] = streams[i][1:num_tokens+1]
+ w[i, tokens_filled:tokens_filled + num_tokens] = 1
+ streams[i] = streams[i][num_tokens:]
+ tokens_filled += num_tokens
+ except StopIteration:
+ pass
+ if not np.any(w):
+ return
+
+ yield x, y, w
+
+ def iterate_once(self, batch_size, num_steps):
+ def file_stream():
+ file_patterns = glob.glob(self._file_pattern)
+ if not self._shuffle:
+ random.shuffle(file_patterns)
+ for file_name in file_patterns:
+ yield file_name
+ for value in self._iterate(self._sentence_stream(file_stream()), batch_size, num_steps):
+ yield value
+
+ def iterate_forever(self, batch_size, num_steps):
+ def file_stream():
+ while True:
+ file_patterns = glob.glob(self._file_pattern)
+ if not self._shuffle:
+ random.shuffle(file_patterns)
+ for file_name in file_patterns:
+ yield file_name
+ for value in self._iterate(self._sentence_stream(file_stream()), batch_size, num_steps):
+ yield value
+
+class MultiSentenceIter(mx.io.DataIter):
+ """ An MXNet iterator that returns the a batch of sequence data and label each time.
+ It also returns a mask which indicates padded/missing data at the end of the dataset.
+ The iterator re-shuffles the data when reset is called.
+ """
+ def __init__(self, data_file, vocab, batch_size, bptt):
+ super(MultiSentenceIter, self).__init__()
+ self.batch_size = batch_size
+ self.bptt = bptt
+ self.provide_data = [('data', (batch_size, bptt), np.int32), ('mask', (batch_size, bptt))]
+ self.provide_label = [('label', (batch_size, bptt))]
+ self.vocab = vocab
+ self.data_file = data_file
+ self._dataset = Dataset(self.vocab, data_file, shuffle=True)
+ self._iter = self._dataset.iterate_once(batch_size, bptt)
+
+ def iter_next(self):
+ data = self._iter.next()
+ if data is None:
+ return False
+ self._next_data = mx.nd.array(data[0], dtype=np.int32)
+ self._next_label = mx.nd.array(data[1])
+ self._next_mask = mx.nd.array(data[2])
+ return True
+
+ def next(self):
+ if self.iter_next():
+ return mx.io.DataBatch(data=self.getdata(), label=self.getlabel())
+ else:
+ raise StopIteration
+
+ def reset(self):
+ self._dataset = Dataset(self.vocab, self.data_file, shuffle=False)
+ self._iter = self._dataset.iterate_once(self.batch_size, self.bptt)
+ self._next_data = None
+ self._next_label = None
+ self._next_mask = None
+
+ def getdata(self):
+ return [self._next_data, self._next_mask]
+
+ def getlabel(self):
+ return [self._next_label]
diff --git a/example/gluon/word_language_model/get_ptb_data.sh b/example/rnn/large_word_lm/get_vocab_file.sh
similarity index 56%
rename from example/gluon/word_language_model/get_ptb_data.sh
rename to example/rnn/large_word_lm/get_vocab_file.sh
index 2dc4034a938..97fa29bf884 100755
--- a/example/gluon/word_language_model/get_ptb_data.sh
+++ b/example/rnn/large_word_lm/get_vocab_file.sh
@@ -17,17 +17,11 @@
# specific language governing permissions and limitations
# under the License.
-echo
-echo "NOTE: To continue, you need to review the licensing of the data sets used by this script"
-echo "See https://catalog.ldc.upenn.edu/ldc99t42 for the licensing"
-read -p "Please confirm you have reviewed the licensing [Y/n]:" -n 1 -r
-echo
-
-if [ $REPLY != "Y" ]
-then
- echo "License was not reviewed, aborting script."
- exit 1
-fi
+echo ""
+echo "NOTE: This script only downloads the pre-processed vocabulary file. "
+echo "For the full training and testing dataset, please download from "
+echo "http://www.statmt.org/lm-benchmark/1-billion-word-language-modeling-benchmark-r13output.tar.gz"
+echo ""
RNN_DIR=$(cd `dirname $0`; pwd)
DATA_DIR="${RNN_DIR}/data/"
@@ -37,7 +31,4 @@ if [[ ! -d "${DATA_DIR}" ]]; then
mkdir -p ${DATA_DIR}
fi
-wget -P ${DATA_DIR} https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/ptb/ptb.train.txt;
-wget -P ${DATA_DIR} https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/ptb/ptb.valid.txt;
-wget -P ${DATA_DIR} https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/ptb/ptb.test.txt;
-wget -P ${DATA_DIR} https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/tinyshakespeare/input.txt;
+wget -P ${DATA_DIR} wget https://s3-us-west-2.amazonaws.com/sparse-dataset/gbw/1b_word_vocab.txt;
diff --git a/example/rnn/large_word_lm/model.py b/example/rnn/large_word_lm/model.py
new file mode 100644
index 00000000000..7ee010efb71
--- /dev/null
+++ b/example/rnn/large_word_lm/model.py
@@ -0,0 +1,181 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+# Licensed to the Apache Software Soundation (ASS) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASS licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OS ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import mxnet as mx
+import mxnet.symbol as S
+import numpy as np
+
+def cross_entropy_loss(inputs, labels, rescale_loss=1):
+ """ cross entropy loss with a mask """
+ criterion = mx.gluon.loss.SoftmaxCrossEntropyLoss(weight=rescale_loss)
+ loss = criterion(inputs, labels)
+ mask = S.var('mask')
+ loss = loss * S.reshape(mask, shape=(-1,))
+ return S.make_loss(loss.mean())
+
+def rnn(bptt, vocab_size, num_embed, nhid, num_layers, dropout, num_proj, batch_size):
+ """ word embedding + LSTM Projected """
+ embed = mx.sym.contrib.SparseEmbedding
+ state_names = []
+ data = S.var('data')
+ weight = S.var("encoder_weight", stype='row_sparse')
+ embed = embed(data=data, weight=weight, input_dim=vocab_size,
+ output_dim=num_embed, name='embed', deterministic=True)
+ states = []
+ outputs = S.Dropout(embed, p=dropout)
+ for i in range(num_layers):
+ prefix = 'lstmp%d_' % i
+ init_h = S.var(prefix + 'init_h', shape=(batch_size, num_proj), init=mx.init.Zero())
+ init_c = S.var(prefix + 'init_c', shape=(batch_size, nhid), init=mx.init.Zero())
+ state_names += [prefix + 'init_h', prefix + 'init_c']
+ lstmp = mx.gluon.contrib.rnn.LSTMPCell(nhid, num_proj)
+ outputs, next_states = lstmp.unroll(bptt, outputs, begin_state=[init_h, init_c], \
+ layout='NTC', merge_outputs=True)
+ outputs = S.Dropout(outputs, p=dropout)
+ states += [S.stop_gradient(s) for s in next_states]
+ outputs = S.reshape(outputs, shape=(-1, num_proj))
+
+ trainable_lstm_args = []
+ for arg in outputs.list_arguments():
+ if 'lstmp' in arg and 'init' not in arg:
+ trainable_lstm_args.append(arg)
+ return outputs, states, trainable_lstm_args, state_names
+
+def sampled_softmax(num_classes, num_samples, in_dim, inputs, weight, bias,
+ sampled_values, remove_accidental_hits=True):
+ """ Sampled softmax via importance sampling.
+ This under-estimates the full softmax and is only used for training.
+ """
+ # inputs = (n, in_dim)
+ embed = mx.sym.contrib.SparseEmbedding
+ sample, prob_sample, prob_target = sampled_values
+
+ # (num_samples, )
+ sample = S.var('sample', shape=(num_samples,), dtype='float32')
+ # (n, )
+ label = S.var('label')
+ label = S.reshape(label, shape=(-1,), name="label_reshape")
+ # (num_samples+n, )
+ sample_label = S.concat(sample, label, dim=0)
+ # lookup weights and biases
+ # (num_samples+n, dim)
+ sample_target_w = embed(data=sample_label, weight=weight,
+ input_dim=num_classes, output_dim=in_dim,
+ deterministic=True)
+ # (num_samples+n, 1)
+ sample_target_b = embed(data=sample_label, weight=bias,
+ input_dim=num_classes, output_dim=1, deterministic=True)
+ # (num_samples, dim)
+ sample_w = S.slice(sample_target_w, begin=(0, 0), end=(num_samples, None))
+ target_w = S.slice(sample_target_w, begin=(num_samples, 0), end=(None, None))
+ sample_b = S.slice(sample_target_b, begin=(0, 0), end=(num_samples, None))
+ target_b = S.slice(sample_target_b, begin=(num_samples, 0), end=(None, None))
+
+ # target
+ # (n, 1)
+ true_pred = S.sum(target_w * inputs, axis=1, keepdims=True) + target_b
+ # samples
+ # (n, num_samples)
+ sample_b = S.reshape(sample_b, (-1,))
+ sample_pred = S.FullyConnected(inputs, weight=sample_w, bias=sample_b,
+ num_hidden=num_samples)
+
+ # remove accidental hits
+ if remove_accidental_hits:
+ label_v = S.reshape(label, (-1, 1))
+ sample_v = S.reshape(sample, (1, -1))
+ neg = S.broadcast_equal(label_v, sample_v) * -1e37
+ sample_pred = sample_pred + neg
+
+ prob_sample = S.reshape(prob_sample, shape=(1, num_samples))
+ p_target = true_pred - S.log(prob_target)
+ p_sample = S.broadcast_sub(sample_pred, S.log(prob_sample))
+
+ # return logits and new_labels
+ # (n, 1+num_samples)
+ logits = S.concat(p_target, p_sample, dim=1)
+ new_targets = S.zeros_like(label)
+ return logits, new_targets
+
+def generate_samples(label, num_splits, num_samples, num_classes):
+ """ Split labels into `num_splits` and
+ generate candidates based on log-uniform distribution.
+ """
+ def listify(x):
+ return x if isinstance(x, list) else [x]
+ label_splits = listify(label.split(num_splits, axis=0))
+ prob_samples = []
+ prob_targets = []
+ samples = []
+ for label_split in label_splits:
+ label_split_2d = label_split.reshape((-1,1))
+ sampled_value = mx.nd.contrib.rand_zipfian(label_split_2d, num_samples, num_classes)
+ sampled_classes, exp_cnt_true, exp_cnt_sampled = sampled_value
+ samples.append(sampled_classes.astype(np.float32))
+ prob_targets.append(exp_cnt_true.astype(np.float32))
+ prob_samples.append(exp_cnt_sampled.astype(np.float32))
+ return samples, prob_samples, prob_targets
+
+class Model():
+ """ LSTMP with Importance Sampling """
+ def __init__(self, args, ntokens, rescale_loss):
+ out = rnn(args.bptt, ntokens, args.emsize, args.nhid, args.nlayers,
+ args.dropout, args.num_proj, args.batch_size)
+ rnn_out, self.last_states, self.lstm_args, self.state_names = out
+ # decoder weight and bias
+ decoder_w = S.var("decoder_weight", stype='row_sparse')
+ decoder_b = S.var("decoder_bias", shape=(ntokens, 1), stype='row_sparse')
+
+ # sampled softmax for training
+ sample = S.var('sample', shape=(args.k,))
+ prob_sample = S.var("prob_sample", shape=(args.k,))
+ prob_target = S.var("prob_target")
+ self.sample_names = ['sample', 'prob_sample', 'prob_target']
+ logits, new_targets = sampled_softmax(ntokens, args.k, args.num_proj,
+ rnn_out, decoder_w, decoder_b,
+ [sample, prob_sample, prob_target])
+ self.train_loss = cross_entropy_loss(logits, new_targets, rescale_loss=rescale_loss)
+
+ # full softmax for testing
+ eval_logits = S.FullyConnected(data=rnn_out, weight=decoder_w,
+ num_hidden=ntokens, name='decode_fc', bias=decoder_b)
+ label = S.Variable('label')
+ label = S.reshape(label, shape=(-1,))
+ self.eval_loss = cross_entropy_loss(eval_logits, label)
+
+ def eval(self):
+ return S.Group(self.last_states + [self.eval_loss])
+
+ def train(self):
+ return S.Group(self.last_states + [self.train_loss])
diff --git a/example/rnn/large_word_lm/readme.md b/example/rnn/large_word_lm/readme.md
new file mode 100644
index 00000000000..d74ffbd1a21
--- /dev/null
+++ b/example/rnn/large_word_lm/readme.md
@@ -0,0 +1,66 @@
+# Large-Scale Language Model
+This example implements the baseline model in
+[Exploring the Limits of Language Modeling](https://arxiv.org/abs/1602.02410) on the
+[Google 1-Billion Word](https://github.com/ciprian-chelba/1-billion-word-language-modeling-benchmark) (GBW) dataset.
+
+This example reaches **41.97 perplexity** after 5 training epochs on a 1-layer, 2048-unit, 512-projection LSTM Language Model.
+The result is slightly better than the one reported in the paper(43.7 perplexity).
+The main differences with the original implementation include:
+* Synchronized gradient updates instead of asynchronized updates
+* Noise candidates are sampled with replacement
+
+Each epoch for training takes around 80 minutes on a p3.8xlarge instance, which comes with 4 Volta V100 GPUs.
+
+# Setup - Original Data Format
+1. Download 1-Billion Word Dataset - [Link](http://www.statmt.org/lm-benchmark/1-billion-word-language-modeling-benchmark-r13output.tar.gz)
+2. Download pre-processed vocabulary file which maps tokens into ids.
+
+# Run the Script
+```
+usage: train.py [-h] [--data DATA] [--test TEST] [--vocab VOCAB]
+ [--emsize EMSIZE] [--nhid NHID] [--num-proj NUM_PROJ]
+ [--nlayers NLAYERS] [--epochs EPOCHS]
+ [--batch-size BATCH_SIZE] [--dropout DROPOUT] [--eps EPS]
+ [--bptt BPTT] [--k K] [--gpus GPUS]
+ [--log-interval LOG_INTERVAL] [--seed SEED]
+ [--checkpoint-dir CHECKPOINT_DIR] [--lr LR] [--clip CLIP]
+ [--rescale-embed RESCALE_EMBED]
+
+Language Model on GBW
+
+optional arguments:
+ -h, --help show this help message and exit
+ --data DATA location of the training data
+ --test TEST location of the test data
+ --vocab VOCAB location of the corpus vocabulary file
+ --emsize EMSIZE size of word embeddings
+ --nhid NHID number of hidden units per layer
+ --num-proj NUM_PROJ number of projection units per layer
+ --nlayers NLAYERS number of LSTM layers
+ --epochs EPOCHS number of epoch for training
+ --batch-size BATCH_SIZE
+ batch size per gpu
+ --dropout DROPOUT dropout applied to layers (0 = no dropout)
+ --eps EPS epsilon for adagrad
+ --bptt BPTT sequence length
+ --k K number of noise samples for estimation
+ --gpus GPUS list of gpus to run, e.g. 0 or 0,2,5. empty means
+ using gpu(0).
+ --log-interval LOG_INTERVAL
+ report interval
+ --seed SEED random seed
+ --checkpoint-dir CHECKPOINT_DIR
+ dir for checkpoint
+ --lr LR initial learning rate
+ --clip CLIP gradient clipping by global norm.
+ --rescale-embed RESCALE_EMBED
+ scale factor for the gradients of the embedding layer
+```
+
+To reproduce the result, run
+```
+train.py --gpus=0,1,2,3 --clip=1 --lr=0.05 --dropout=0.01 --eps=0.0001 --rescale-embed=128
+--test=/path/to/heldout-monolingual.tokenized.shuffled/news.en.heldout-00000-of-00050
+--data=/path/to/training-monolingual.tokenized.shuffled/*
+# ~42 perplexity for 5 epochs of training
+```
diff --git a/example/rnn/large_word_lm/run_utils.py b/example/rnn/large_word_lm/run_utils.py
new file mode 100644
index 00000000000..7650530e80d
--- /dev/null
+++ b/example/rnn/large_word_lm/run_utils.py
@@ -0,0 +1,87 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import argparse, time, logging, math
+
+def get_parser():
+ parser = argparse.ArgumentParser(description='Language Model on GBW')
+ parser.add_argument('--data', type=str,
+ default='/path/to/training-monolingual.tokenized.shuffled/*',
+ help='location of the training data')
+ parser.add_argument('--test', type=str,
+ default='/path/to/heldout-monolingual.tokenized.shuffled/news.en.heldout-00000-of-00050',
+ help='location of the test data')
+ parser.add_argument('--vocab', type=str, default='./data/1b_word_vocab.txt',
+ help='location of the corpus vocabulary file')
+ parser.add_argument('--emsize', type=int, default=512,
+ help='size of word embeddings')
+ parser.add_argument('--nhid', type=int, default=2048,
+ help='number of hidden units per layer')
+ parser.add_argument('--num-proj', type=int, default=512,
+ help='number of projection units per layer')
+ parser.add_argument('--nlayers', type=int, default=1,
+ help='number of LSTM layers')
+ parser.add_argument('--epochs', type=int, default=8,
+ help='number of epoch for training')
+ parser.add_argument('--batch-size', type=int, default=128,
+ help='batch size per gpu')
+ parser.add_argument('--dropout', type=float, default=0.1,
+ help='dropout applied to layers (0 = no dropout)')
+ parser.add_argument('--eps', type=float, default=0.0001,
+ help='epsilon for adagrad')
+ parser.add_argument('--bptt', type=int, default=20,
+ help='sequence length')
+ parser.add_argument('--k', type=int, default=8192,
+ help='number of noise samples for estimation')
+ parser.add_argument('--gpus', type=str,
+ help='list of gpus to run, e.g. 0 or 0,2,5. empty means using gpu(0).')
+ parser.add_argument('--log-interval', type=int, default=200,
+ help='report interval')
+ parser.add_argument('--seed', type=int, default=1,
+ help='random seed')
+ parser.add_argument('--checkpoint-dir', type=str, default='./checkpoint/cp',
+ help='dir for checkpoint')
+ parser.add_argument('--lr', type=float, default=0.1,
+ help='initial learning rate')
+ parser.add_argument('--clip', type=float, default=1,
+ help='gradient clipping by global norm.')
+ parser.add_argument('--rescale-embed', type=float, default=None,
+ help='scale factor for the gradients of the embedding layer')
+ return parser
+
+def evaluate(mod, data_iter, epoch, log_interval):
+ """ Run evaluation on cpu. """
+ start = time.time()
+ total_L = 0.0
+ nbatch = 0
+ mod.set_states(value=0)
+ for batch in data_iter:
+ mod.forward(batch, is_train=False)
+ outputs = mod.get_outputs(merge_multi_context=False)
+ states = outputs[:-1]
+ total_L += outputs[-1][0].asscalar()
+ mod.set_states(states=states)
+ nbatch += 1
+ if (nbatch + 1) % log_interval == 0:
+ logging.info("Eval batch %d loss : %.7f" % (nbatch, total_L / nbatch))
+ data_iter.reset()
+ loss = total_L / nbatch
+ ppl = math.exp(loss) if loss < 100 else 1e37
+ end = time.time()
+ logging.info('Iter[%d]\t\t CE loss %.7f, ppl %.7f. Eval duration = %.2f seconds ' % \
+ (epoch, loss, ppl, end - start))
+ return loss
diff --git a/example/rnn/large_word_lm/train.py b/example/rnn/large_word_lm/train.py
new file mode 100644
index 00000000000..a1b4e3140df
--- /dev/null
+++ b/example/rnn/large_word_lm/train.py
@@ -0,0 +1,152 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import numpy as np
+import mxnet as mx
+import mxnet.symbol as S
+import run_utils
+from data import MultiSentenceIter, Vocabulary
+from model import *
+from custom_module import CustomModule
+import os, math, logging, sys
+
+if __name__ == '__main__':
+ # parser
+ parser = run_utils.get_parser()
+ args = parser.parse_args()
+ head = '%(asctime)-15s %(message)s'
+ ctx = [mx.gpu(int(i)) for i in args.gpus.split(',')] if args.gpus else [mx.gpu()]
+ ngpus = len(ctx)
+ rescale_loss = args.bptt
+
+ # logging
+ logging.basicConfig(level=logging.INFO, format=head)
+ logging.info(args)
+ logging.debug(sys.argv)
+
+ # seeding
+ mx.random.seed(args.seed)
+ np.random.seed(args.seed)
+
+ # data
+ vocab = Vocabulary.from_file(args.vocab)
+ ntokens = vocab.num_tokens
+ train_data = mx.io.PrefetchingIter(MultiSentenceIter(args.data, vocab,
+ args.batch_size * ngpus, args.bptt))
+ # model
+ model = Model(args, ntokens, rescale_loss)
+ train_loss_and_states = model.train()
+ eval_loss_and_states = model.eval()
+
+ # training module
+ data_names, label_names = ['data', 'mask'], ['label']
+ eval_state_names = model.state_names
+ num_sample_names = len(model.sample_names)
+ train_state_names = model.state_names + model.sample_names
+
+ module = CustomModule(symbol=train_loss_and_states, context=ctx,
+ state_names=train_state_names,
+ data_names=data_names, label_names=label_names)
+ module.bind(data_shapes=train_data.provide_data, label_shapes=train_data.provide_label)
+ module.init_params(initializer=mx.init.Xavier(factor_type='out'))
+
+ # create kvstore and sparse optimizer
+ kvstore = mx.kv.create('device')
+ optimizer = mx.optimizer.create('adagrad', learning_rate=args.lr, \
+ rescale_grad=1.0/ngpus, eps=args.eps)
+ module.init_optimizer(optimizer=optimizer, kvstore=kvstore)
+
+ # speedometer
+ num_words_per_batch = args.batch_size * ngpus * args.bptt
+ speedometer = mx.callback.Speedometer(num_words_per_batch, args.log_interval)
+
+ # training loop
+ logging.info("Training started ... ")
+ for epoch in range(args.epochs):
+ total_L = mx.nd.array([0.0])
+ nbatch = 0
+ # reset initial LSTMP states
+ module.set_states(value=0)
+ state_cache = module.get_states(merge_multi_context=False)[:-num_sample_names]
+ next_batch = train_data.next()
+ next_sampled_values = generate_samples(next_batch.label[0], ngpus, args.k, ntokens)
+ stop_iter = False
+ while not stop_iter:
+ batch = next_batch
+ state_cache += next_sampled_values
+ # propagate LSTMP states from the previous batch
+ module.set_states(states=state_cache)
+ # selectively pull row_sparse weight to multiple devices based on the data batch
+ target_ids = [batch.label[0]]
+ sampled_ids = next_sampled_values[0]
+ param_rowids = {'encoder_weight': batch.data[0],
+ 'decoder_weight': sampled_ids + target_ids,
+ 'decoder_bias': sampled_ids + target_ids}
+ module.prepare_sparse_params(param_rowids)
+ # forward
+ module.forward(batch)
+ try:
+ # prefetch the next batch of data and samples
+ next_batch = train_data.next()
+ next_sampled_values = generate_samples(next_batch.label[0], ngpus,
+ args.k, ntokens)
+ except StopIteration:
+ stop_iter = True
+ # cache LSTMP states of the current batch
+ outputs = module.get_outputs(merge_multi_context=False)
+ state_cache = outputs[:-1]
+ # backward
+ module.backward()
+ for g in range(ngpus):
+ total_L += outputs[-1][g].copyto(mx.cpu()) / ngpus
+
+ # rescaling the gradient for embedding layer emperically leads to faster convergence
+ module.rescale_grad(args.rescale_embed, 'encoder_weight')
+ # clip lstm params on each device based on norm
+ norm = module.clip_by_global_norm_per_ctx(max_norm=args.clip, param_names=model.lstm_args)
+ # update parameters
+ module.update()
+ speedometer_param = mx.model.BatchEndParam(epoch=epoch, nbatch=nbatch,
+ eval_metric=None, locals=locals())
+ speedometer(speedometer_param)
+ # update training metric
+ if nbatch % args.log_interval == 0 and nbatch > 0:
+ cur_L = total_L.asscalar() / args.log_interval / rescale_loss
+ ppl = math.exp(cur_L) if cur_L < 100 else 1e36
+ logging.info('Iter[%d] Batch [%d] \tloss %.7f, ppl %.7f'%(epoch, nbatch, cur_L, ppl))
+ total_L[:] = 0.0
+ nbatch += 1
+
+ # run evaluation with full softmax on cpu
+ module.save_checkpoint(args.checkpoint_dir, epoch, save_optimizer_states=False)
+ cpu_train_mod = CustomModule.load(args.checkpoint_dir, epoch, context=mx.cpu(),
+ state_names=train_state_names,
+ data_names=data_names, label_names=label_names)
+ # eval data iter
+ eval_data = mx.io.PrefetchingIter(MultiSentenceIter(args.test, vocab,
+ args.batch_size, args.bptt))
+ cpu_train_mod.bind(data_shapes=eval_data.provide_data, label_shapes=eval_data.provide_label)
+
+ # eval module
+ eval_module = CustomModule(symbol=eval_loss_and_states, context=mx.cpu(), data_names=data_names,
+ label_names=label_names, state_names=eval_state_names)
+ # use `shared_module` to share parameter with the training module
+ eval_module.bind(data_shapes=eval_data.provide_data, label_shapes=eval_data.provide_label,
+ shared_module=cpu_train_mod, for_training=False)
+ val_L = run_utils.evaluate(eval_module, eval_data, epoch, 20)
+ train_data.reset()
+ logging.info("Training completed. ")
diff --git a/include/mxnet/base.h b/include/mxnet/base.h
index 0e58765aaf4..c0eb97aa0b3 100644
--- a/include/mxnet/base.h
+++ b/include/mxnet/base.h
@@ -365,6 +365,10 @@ inline std::ostream& operator<<(std::ostream &out, const Context &ctx) {
#define MXNET_DESCRIBE(...) describe(__VA_ARGS__ "\n\nFrom:" __FILE__ ":" STRINGIZE(__LINE__))
#define ADD_FILELINE "\n\nDefined in " __FILE__ ":L" STRINGIZE(__LINE__)
+#if MXNET_USE_MKLDNN == 1
+constexpr size_t kMKLDNNAlign = 64;
+#endif
+
} // namespace mxnet
#include "./tensor_blob.h"
diff --git a/include/mxnet/c_api.h b/include/mxnet/c_api.h
index e85afe522f0..ede137e89b7 100644
--- a/include/mxnet/c_api.h
+++ b/include/mxnet/c_api.h
@@ -1386,8 +1386,37 @@ MXNET_DLL int MXSymbolInferType(SymbolHandle sym,
const int **aux_type_data,
int *complete);
-
-
+/*!
+ * \brief Convert a symbol into a quantized symbol where FP32 operators are replaced with INT8
+ * \param sym_handle symbol to be converted
+ * \param ret_sym_handle quantized symbol result
+ * \param num_excluded_symbols number of layers excluded from being quantized in the input symbol
+ * \param excluded_symbols array of symbols to be excluded from being quantized
+ * \param num_offline number of parameters that are quantized offline
+ * \param offline_params array of c strings representing the names of params quantized offline
+ */
+MXNET_DLL int MXQuantizeSymbol(SymbolHandle sym_handle,
+ SymbolHandle *ret_sym_handle,
+ const mx_uint num_excluded_symbols,
+ const SymbolHandle *excluded_symbols,
+ const mx_uint num_offline,
+ const char **offline_params);
+
+/*!
+ * \brief Set calibration table to node attributes in the sym
+ * \param sym_handle symbol whose node attributes are to be set by calibration table
+ * \param num_layers number of layers in the calibration table
+ * \param layer names stored as keys in the calibration table
+ * \param low_quantiles low quantiles of layers stored in the calibration table
+ * \param high_quantiles high quantiles of layers stored in the calibration table
+ * \param ret_sym_handle returned symbol
+ */
+MXNET_DLL int MXSetCalibTableToQuantizedSymbol(SymbolHandle qsym_handle,
+ const mx_uint num_layers,
+ const char** layer_names,
+ const float* low_quantiles,
+ const float* high_quantiles,
+ SymbolHandle* ret_sym_handle);
//--------------------------------------------
// Part 4: Executor interface
diff --git a/include/mxnet/ndarray.h b/include/mxnet/ndarray.h
index e6e7468a1f4..b8b7f20fcf3 100644
--- a/include/mxnet/ndarray.h
+++ b/include/mxnet/ndarray.h
@@ -279,12 +279,12 @@ class NDArray {
CHECK_EQ(aux_shape(rowsparse::kIdx)[0], storage_shape()[0])
<< "inconsistent storage shape " << storage_shape()
<< " vs. aux shape " << aux_shape(rowsparse::kIdx);
- return aux_shape(0).Size() != 0;
+ return aux_shape(rowsparse::kIdx).Size() != 0;
} else if (stype == kCSRStorage) {
CHECK_EQ(aux_shape(csr::kIdx)[0], storage_shape()[0])
<< "inconsistent storage shape " << storage_shape()
<< " vs. aux shape " << aux_shape(csr::kIdx);
- return aux_shape(0).Size() != 0;
+ return aux_shape(csr::kIdx).Size() != 0;
} else {
LOG(FATAL) << "Unknown storage type";
}
@@ -623,18 +623,6 @@ class NDArray {
mkldnn::memory *CreateMKLDNNData(
const mkldnn::memory::primitive_desc &desc);
- /*
- * Reorder the memory to the specified layout.
- */
- void MKLDNNDataReorder(const mkldnn::memory::primitive_desc &desc) {
- CHECK_EQ(storage_type(), kDefaultStorage);
- ptr_->MKLDNNDataReorder(desc);
- }
- void Reorder2Default() {
- CHECK_EQ(storage_type(), kDefaultStorage);
- ptr_->Reorder2Default();
- }
-
/*
* These are the async version of the methods above.
* It changes the layout of this NDArray, but it happens after all accesses to
diff --git a/include/mxnet/op_attr_types.h b/include/mxnet/op_attr_types.h
index fb41d396099..800872b6646 100644
--- a/include/mxnet/op_attr_types.h
+++ b/include/mxnet/op_attr_types.h
@@ -49,8 +49,8 @@ enum OpReqType {
kWriteTo,
/*!
* \brief perform an inplace write,
- * Target shares memory with one of input arguments.
* This option only happen when
+ * Target shares memory with one of input arguments.
*/
kWriteInplace,
/*! \brief add to the provided space */
@@ -239,7 +239,6 @@ using FCompute = std::function<void (const nnvm::NodeAttrs& attrs,
const std::vector<TBlob>& outputs)>;
/*!
* \brief Resiger an NDArray compute function for simple stateless forward only operator
- *
* \note Register under "FComputeEx<xpu>" and "FComputeEx<xpu>"
* Dispatched only when inferred dispatch_mode is FDispatchComputeEx
*/
@@ -261,6 +260,20 @@ using FInferStorageType = std::function<bool (const NodeAttrs& attrs,
std::vector<int>* in_attrs,
std::vector<int>* out_attrs)>;
+/*!
+ * \brief Register a quantized node creation function based on the attrs of the node
+ * \note Register under "FQuantizedOp" for non-quantized operators
+ */
+using FQuantizedOp = std::function<nnvm::NodePtr (const NodeAttrs& attrs)>;
+
+/*!
+ * \brief Register a function to determine if the output of a quantized operator
+ * needs to be requantized. This is usually used for the operators
+ * taking int8 data types while accumulating in int32, e.g. quantized_conv.
+ * \note Register under "FNeedRequantize" for non-quantized operators
+ */
+using FNeedRequantize = std::function<bool (const NodeAttrs& attrs)>;
+
} // namespace mxnet
#endif // MXNET_OP_ATTR_TYPES_H_
diff --git a/perl-package/AI-NNVMCAPI/Makefile.PL b/perl-package/AI-NNVMCAPI/Makefile.PL
index fe6365473d2..58824013583 100644
--- a/perl-package/AI-NNVMCAPI/Makefile.PL
+++ b/perl-package/AI-NNVMCAPI/Makefile.PL
@@ -47,7 +47,7 @@ WriteMakefile(
VERSION_FROM => 'lib/AI/NNVMCAPI.pm',
ABSTRACT_FROM => 'lib/AI/NNVMCAPI.pm',
LIBS => ['-L../../lib -lmxnet'],
- INC => '-I../../nnvm/include/nnvm',
+ INC => '-I../../3rdparty/nnvm/include/nnvm',
OBJECT => 'nnvm_wrap.o',
LDDLFLAGS => join(' ', @lddlflags),
PREREQ_PM => {
diff --git a/plugin/caffe/caffe_common.h b/plugin/caffe/caffe_common.h
index ba7b9ad7b8d..211d8c44d51 100644
--- a/plugin/caffe/caffe_common.h
+++ b/plugin/caffe/caffe_common.h
@@ -91,7 +91,7 @@ class LayerRegistry {
/*! \brief override type_name for caffe::LayerParameter */
namespace dmlc {
- DMLC_DECLARE_TYPE_NAME(::caffe::LayerParameter, "caffe-layer-parameter")
+ DMLC_DECLARE_TYPE_NAME(::caffe::LayerParameter, "caffe-layer-parameter");
}
#endif // PLUGIN_CAFFE_CAFFE_COMMON_H_
diff --git a/prepare_mkldnn.sh b/prepare_mkldnn.sh
index 50552eb22f6..df5e9b99656 100755
--- a/prepare_mkldnn.sh
+++ b/prepare_mkldnn.sh
@@ -73,9 +73,13 @@ if [ ! -z "$HOME_MKLDNN" ]; then
fi
if [ $OSTYPE == "darwin16" ]; then
- MKLDNN_LIBFILE="$MKLDNN_INSTALLDIR/lib/libmkldnn.dylib"
+ OMP_LIBFILE="$MKLDNN_INSTALLDIR/lib/libiomp5.dylib"
+ MKLML_LIBFILE="$MKLDNN_INSTALLDIR/lib/libmklml.dylib"
+ MKLDNN_LIBFILE="$MKLDNN_INSTALLDIR/lib/libmkldnn.0.dylib"
else
- MKLDNN_LIBFILE="$MKLDNN_INSTALLDIR/lib/libmkldnn.so"
+ OMP_LIBFILE="$MKLDNN_INSTALLDIR/lib/libiomp5.so"
+ MKLML_LIBFILE="$MKLDNN_INSTALLDIR/lib/libmklml_intel.so"
+ MKLDNN_LIBFILE="$MKLDNN_INSTALLDIR/lib/libmkldnn.so.0"
fi
if [ -z $MKLDNNROOT ]; then
@@ -103,7 +107,9 @@ if [ ! -f $MKLDNN_LIBFILE ]; then
make -C $MKLDNN_BUILDDIR install >&2
rm -rf $MKLDNN_BUILDDIR
mkdir -p $MKLDNN_LIBDIR
- cp $MKLDNN_INSTALLDIR/lib/* $MKLDNN_LIBDIR
+ cp $OMP_LIBFILE $MKLDNN_LIBDIR
+ cp $MKLML_LIBFILE $MKLDNN_LIBDIR
+ cp $MKLDNN_LIBFILE $MKLDNN_LIBDIR
fi
MKLDNNROOT=$MKLDNN_INSTALLDIR
fi
diff --git a/python/mxnet/contrib/__init__.py b/python/mxnet/contrib/__init__.py
index 63cd8ce2664..fbfd3469678 100644
--- a/python/mxnet/contrib/__init__.py
+++ b/python/mxnet/contrib/__init__.py
@@ -30,3 +30,5 @@
from . import text
from . import onnx
from . import io
+from . import quantization
+from . import quantization as quant
diff --git a/python/mxnet/contrib/onnx/_import/import_helper.py b/python/mxnet/contrib/onnx/_import/import_helper.py
index 80541ec3577..175c2fb6a00 100644
--- a/python/mxnet/contrib/onnx/_import/import_helper.py
+++ b/python/mxnet/contrib/onnx/_import/import_helper.py
@@ -27,7 +27,7 @@
from .op_translations import global_avgpooling, global_maxpooling, linalg_gemm
from .op_translations import sigmoid, pad, relu, matrix_multiplication, batch_norm
from .op_translations import dropout, local_response_norm, conv, deconv
-from .op_translations import reshape, cast, split, _slice, transpose, squeeze
+from .op_translations import reshape, cast, split, _slice, transpose, squeeze, flatten
from .op_translations import reciprocal, squareroot, power, exponent, _log
from .op_translations import reduce_max, reduce_mean, reduce_min, reduce_sum
from .op_translations import reduce_prod, avg_pooling, max_pooling
@@ -83,6 +83,7 @@
'Slice' : _slice,
'Transpose' : transpose,
'Squeeze' : squeeze,
+ 'Flatten' : flatten,
#Powers
'Reciprocal' : reciprocal,
'Sqrt' : squareroot,
diff --git a/python/mxnet/contrib/onnx/_import/import_model.py b/python/mxnet/contrib/onnx/_import/import_model.py
index 1df429b4690..d8d32a96a21 100644
--- a/python/mxnet/contrib/onnx/_import/import_model.py
+++ b/python/mxnet/contrib/onnx/_import/import_model.py
@@ -46,5 +46,5 @@ def import_model(model_file):
except ImportError:
raise ImportError("Onnx and protobuf need to be installed")
model_proto = onnx.load(model_file)
- sym, params = graph.from_onnx(model_proto.graph)
- return sym, params
+ sym, arg_params, aux_params = graph.from_onnx(model_proto.graph)
+ return sym, arg_params, aux_params
diff --git a/python/mxnet/contrib/onnx/_import/import_onnx.py b/python/mxnet/contrib/onnx/_import/import_onnx.py
index 56181c777be..037790c8080 100644
--- a/python/mxnet/contrib/onnx/_import/import_onnx.py
+++ b/python/mxnet/contrib/onnx/_import/import_onnx.py
@@ -61,12 +61,12 @@ def _convert_operator(self, node_name, op_name, attrs, inputs):
raise NotImplementedError("Operator {} not implemented.".format(op_name))
if isinstance(op_name, string_types):
new_op = getattr(symbol, op_name, None)
+ if not new_op:
+ raise RuntimeError("Unable to map op_name {} to sym".format(op_name))
if node_name is None:
mxnet_sym = new_op(*inputs, **new_attrs)
else:
mxnet_sym = new_op(name=node_name, *inputs, **new_attrs)
- if not mxnet_sym:
- raise RuntimeError("Unable to map op_name {} to sym".format(op_name))
return mxnet_sym
return op_name
@@ -110,6 +110,10 @@ def from_onnx(self, graph):
self._nodes[name_input] = symbol.Variable(name=name_input)
self._renames[i.name] = name_input
+ # For storing arg and aux params for the graph.
+ auxDict = {}
+ argDict = {}
+
# constructing nodes, nodes are stored as directed acyclic graph
# converting NodeProto message
for node in graph.node:
@@ -120,19 +124,24 @@ def from_onnx(self, graph):
inputs = [self._nodes[self._renames.get(i, i)] for i in node.input]
mxnet_sym = self._convert_operator(node_name, op_name, onnx_attr, inputs)
- assert len(node.output) == len(mxnet_sym.list_outputs()), (
- "Output dimension mismatch between the onnx operator and the mxnet symbol " +
- "{} vs {} for the operator - {}.".format(
- len(node.output), len(mxnet_sym.list_outputs()), op_name))
- for k, i in zip(list(node.output), range(len(node.output))):
+ for k, i in zip(list(node.output), range(len(mxnet_sym.list_outputs()))):
self._nodes[k] = mxnet_sym[i]
+
+ # splitting params into args and aux params
+ for args in mxnet_sym.list_arguments():
+ if args in self._params:
+ argDict.update({args: nd.array(self._params[args])})
+ for aux in mxnet_sym.list_auxiliary_states():
+ if aux in self._params:
+ auxDict.update({aux: nd.array(self._params[aux])})
+
# now return the outputs
out = [self._nodes[i.name] for i in graph.output]
if len(out) > 1:
out = symbol.Group(out)
else:
out = out[0]
- return out, self._params
+ return out, argDict, auxDict
def _parse_array(self, tensor_proto):
"""Grab data in TensorProto and convert to numpy array."""
diff --git a/python/mxnet/contrib/onnx/_import/op_translations.py b/python/mxnet/contrib/onnx/_import/op_translations.py
index a67c18199eb..de341321785 100644
--- a/python/mxnet/contrib/onnx/_import/op_translations.py
+++ b/python/mxnet/contrib/onnx/_import/op_translations.py
@@ -164,10 +164,14 @@ def matrix_multiplication(attrs, inputs, cls):
def batch_norm(attrs, inputs, cls):
"""Batch normalization."""
- new_attrs = translation_utils._fix_attribute_names(attrs, {'epsilon' : 'eps'})
+ new_attrs = translation_utils._fix_attribute_names(attrs, {'epsilon' : 'eps',
+ 'is_test':'fix_gamma'})
new_attrs = translation_utils._remove_attributes(new_attrs,
- ['spatial', 'is_test', 'consumed_inputs'])
+ ['spatial', 'consumed_inputs'])
new_attrs = translation_utils._add_extra_attributes(new_attrs, {'cudnn_off': 1})
+
+ # in test mode "fix_gamma" should be unset.
+ new_attrs['fix_gamma'] = 0 if new_attrs['fix_gamma'] == 1 else 1
return 'BatchNorm', new_attrs, inputs
@@ -245,7 +249,7 @@ def global_maxpooling(attrs, inputs, cls):
new_attrs = translation_utils._add_extra_attributes(attrs, {'global_pool': True,
'kernel': (1, 1),
'pool_type': 'max'})
- return 'pooling', new_attrs, inputs
+ return 'Pooling', new_attrs, inputs
def global_avgpooling(attrs, inputs, cls):
@@ -253,28 +257,49 @@ def global_avgpooling(attrs, inputs, cls):
new_attrs = translation_utils._add_extra_attributes(attrs, {'global_pool': True,
'kernel': (1, 1),
'pool_type': 'avg'})
- return 'pooling', new_attrs, inputs
+ return 'Pooling', new_attrs, inputs
def linalg_gemm(attrs, inputs, cls):
"""Performs general matrix multiplication and accumulation"""
+ trans_a = 0
+ trans_b = 0
+ alpha = 1
+ beta = 1
+ if 'transA' in attrs:
+ trans_a = attrs['transA']
+ if 'transB' in attrs:
+ trans_b = attrs['transB']
+ if 'alpha' in attrs:
+ alpha = attrs['alpha']
+ if 'beta' in attrs:
+ beta = attrs['beta']
+ flatten_a = symbol.flatten(inputs[0])
+ matmul_op = symbol.linalg_gemm2(A=flatten_a, B=inputs[1],
+ transpose_a=trans_a, transpose_b=trans_b,
+ alpha=alpha)
+ gemm_op = symbol.broadcast_add(matmul_op, beta*inputs[2])
new_attrs = translation_utils._fix_attribute_names(attrs, {'transA': 'transpose_a',
'transB': 'transpose_b'})
new_attrs = translation_utils._remove_attributes(new_attrs, ['broadcast'])
- return translation_utils._fix_gemm('FullyConnected', inputs, new_attrs, cls)
+ return gemm_op, new_attrs, inputs
-def local_response_norm(op_name, attrs, inputs):
+def local_response_norm(attrs, inputs, cls):
"""Local Response Normalization."""
new_attrs = translation_utils._fix_attribute_names(attrs,
{'bias': 'knorm',
'size' : 'nsize'})
return 'LRN', new_attrs, inputs
-def dropout(op_name, attrs, inputs):
+def dropout(attrs, inputs, cls):
"""Dropout Regularization."""
+ mode = 'training'
+ if attrs['is_test'] == 0:
+ mode = 'always'
new_attrs = translation_utils._fix_attribute_names(attrs,
{'ratio': 'p'})
new_attrs = translation_utils._remove_attributes(new_attrs, ['is_test'])
+ new_attrs = translation_utils._add_extra_attributes(new_attrs, {'mode': mode})
return 'Dropout', new_attrs, inputs
# Changing shape and type.
@@ -285,6 +310,7 @@ def reshape(attrs, inputs, cls):
def cast(attrs, inputs, cls):
""" Cast input to a given dtype"""
new_attrs = translation_utils._fix_attribute_names(attrs, {'to' : 'dtype'})
+ new_attrs['dtype'] = new_attrs['dtype'].lower()
return 'cast', new_attrs, inputs
def split(attrs, inputs, cls):
@@ -328,6 +354,15 @@ def squeeze(attrs, inputs, cls):
mxnet_op = symbol.split(mxnet_op, axis=i-1, num_outputs=1, squeeze_axis=1)
return mxnet_op, new_attrs, inputs
+
+def flatten(attrs, inputs, cls):
+ """Flattens the input array into a 2-D array by collapsing the higher dimensions."""
+ #Mxnet does not have axis support. By default uses axis=1
+ if 'axis' in attrs and attrs['axis'] != 1:
+ raise RuntimeError("Flatten operator only supports axis=1")
+ new_attrs = translation_utils._remove_attributes(attrs, ['axis'])
+ return 'Flatten', new_attrs, inputs
+
#Powers
def reciprocal(attrs, inputs, cls):
"""Returns the reciprocal of the argument, element-wise."""
@@ -387,8 +422,7 @@ def avg_pooling(attrs, inputs, cls):
'pads': 'pad',
})
new_attrs = translation_utils._add_extra_attributes(new_attrs,
- {'pool_type': 'avg',
- 'pooling_convention': 'valid'
+ {'pooling_convention': 'valid'
})
new_op = translation_utils._fix_pooling('avg', inputs, new_attrs)
@@ -402,9 +436,9 @@ def max_pooling(attrs, inputs, cls):
'strides': 'stride',
'pads': 'pad',
})
+
new_attrs = translation_utils._add_extra_attributes(new_attrs,
- {'pool_type': 'avg',
- 'pooling_convention': 'valid'
+ {'pooling_convention': 'valid'
})
new_op = translation_utils._fix_pooling('max', inputs, new_attrs)
diff --git a/python/mxnet/contrib/onnx/_import/translation_utils.py b/python/mxnet/contrib/onnx/_import/translation_utils.py
index 0fdef647b50..1d84bd70d7e 100644
--- a/python/mxnet/contrib/onnx/_import/translation_utils.py
+++ b/python/mxnet/contrib/onnx/_import/translation_utils.py
@@ -90,10 +90,51 @@ def _fix_pooling(pool_type, inputs, new_attr):
stride = new_attr.get('stride')
kernel = new_attr.get('kernel')
padding = new_attr.get('pad')
- pad_width = (0, 0, 0, 0) + _pad_sequence_fix(padding, len(kernel))
- new_pad_op = symbol.pad(inputs[0], mode='constant', pad_width=pad_width)
- new_pooling_op = symbol.Pooling(new_pad_op, pool_type=pool_type,
- stride=stride, kernel=kernel)
+
+ # Adding default stride.
+ if stride is None:
+ stride = (1,) * len(kernel)
+
+ # Add padding attr if not provided.
+ if padding is None:
+ padding = (0,) * len(kernel) * 2
+
+ # Mxnet Pad operator supports only 4D/5D tensors.
+ # For 1D case, these are the steps:
+ # Step 1. Add extra dummy dimension to make it 4D. Adding to axis = 2
+ # Step 2. Apply padding to this changed tensor
+ # Step 3. Remove the extra dimension added in step 1.
+ if len(kernel) == 1:
+ dummy_axis = 2
+ # setting 0 padding to the new dim to be added.
+ padding = (0, padding[0], 0, padding[1])
+ pad_width = (0, 0, 0, 0) + _pad_sequence_fix(padding, kernel_dim=2)
+
+ # Step 1.
+ curr_sym = symbol.expand_dims(inputs[0], axis=dummy_axis)
+
+ # Step 2. Common for all tensor sizes
+ new_pad_op = symbol.pad(curr_sym, mode='edge', pad_width=pad_width)
+
+ # Step 3: Removing extra dim added.
+ new_pad_op = symbol.split(new_pad_op, axis=dummy_axis, num_outputs=1, squeeze_axis=1)
+ else:
+ # For 2D/3D cases:
+ # Apply padding
+ pad_width = (0, 0, 0, 0) + _pad_sequence_fix(padding, kernel_dim=len(kernel))
+ curr_sym = inputs[0]
+
+ if pool_type == 'max':
+ # For max pool : mode = 'edge', we should replicate the
+ # edge values to pad, so that we only include input data values
+ # for calculating 'max'
+ new_pad_op = symbol.pad(curr_sym, mode='edge', pad_width=pad_width)
+ else:
+ # For avg pool, we should add 'zeros' for padding so mode='constant'
+ new_pad_op = symbol.pad(curr_sym, mode='constant', pad_width=pad_width)
+
+ # Apply pooling without pads.
+ new_pooling_op = symbol.Pooling(new_pad_op, pool_type=pool_type, stride=stride, kernel=kernel)
return new_pooling_op
def _fix_bias(op_name, attrs, num_inputs):
diff --git a/python/mxnet/contrib/quantization.py b/python/mxnet/contrib/quantization.py
new file mode 100644
index 00000000000..c9c58a9c9ba
--- /dev/null
+++ b/python/mxnet/contrib/quantization.py
@@ -0,0 +1,520 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+"""Quantization module for generating quantized (INT8) models from FP32 models."""
+
+from __future__ import absolute_import
+
+try:
+ from scipy import stats
+except ImportError:
+ stats = None
+
+import ctypes
+import logging
+import os
+import numpy as np
+from ..base import _LIB, check_call, py_str
+from ..base import c_array, c_str, mx_uint, c_str_array
+from ..base import NDArrayHandle, SymbolHandle
+from ..symbol import Symbol
+from ..symbol import load as sym_load
+from .. import ndarray
+from ..ndarray import load as nd_load
+from ..ndarray import NDArray
+from ..io import DataIter
+from ..context import cpu, Context
+from ..module import Module
+
+
+def _quantize_params(qsym, params):
+ """Given a quantized symbol and a dict of params that have not been quantized,
+ generate quantized params. Currently only supports quantizing the arg_params
+ with names of `weight` or `bias`, not aux_params. If `qsym` contains symbols
+ that are excluded from being quantized, their corresponding params will
+ not be quantized, but saved together with quantized params of the symbols that
+ have been quantized.
+
+ Parameters
+ ----------
+ qsym : Symbol
+ Quantized symbol from FP32 symbol.
+ params : dict of str->NDArray
+ """
+ inputs_name = qsym.list_arguments()
+ quantized_params = {}
+ for name in inputs_name:
+ if name.endswith(('weight_quantize', 'bias_quantize')):
+ original_name = name[:-len('_quantize')]
+ param = params[original_name]
+ val, vmin, vmax = ndarray.contrib.quantize(data=param,
+ min_range=ndarray.min(param),
+ max_range=ndarray.max(param),
+ out_type='int8')
+ quantized_params[name] = val
+ quantized_params[name+'_min'] = vmin
+ quantized_params[name+'_max'] = vmax
+ elif name in params:
+ quantized_params[name] = params[name]
+ return quantized_params
+
+
+def _quantize_symbol(sym, excluded_symbols=None, offline_params=None):
+ """Given a symbol object representing a neural network of data type FP32,
+ quantize it into a INT8 network.
+
+ Parameters
+ ----------
+ sym : Symbol
+ FP32 neural network symbol.
+ excluded_symbols : list of symbols
+ Nodes in the network that users do not want to replace with a symbol of INT8 data type.
+ offline_params : list of strs
+ Names of the parameters that users want to quantize offline. It's always recommended to
+ quantize parameters offline so that quantizing parameters during the inference can be
+ avoided.
+ """
+ num_excluded_symbols = 0
+ excluded_handles = []
+ if excluded_symbols is not None:
+ assert isinstance(excluded_symbols, list)
+ num_excluded_symbols = len(excluded_symbols)
+ for s in excluded_symbols:
+ excluded_handles.append(s.handle)
+
+ num_offline = 0
+ offline = []
+ if offline_params is not None:
+ num_offline = len(offline_params)
+ for k in offline_params:
+ offline.append(c_str(k))
+
+ out = SymbolHandle()
+ check_call(_LIB.MXQuantizeSymbol(sym.handle,
+ ctypes.byref(out),
+ mx_uint(num_excluded_symbols),
+ c_array(SymbolHandle, excluded_handles),
+ mx_uint(num_offline),
+ c_array(ctypes.c_char_p, offline)))
+ return Symbol(out)
+
+
+class _LayerOutputCollector(object):
+ """Saves layer output NDArray in a dict with layer names as keys and lists of NDArrays as
+ values. The collected NDArrays will be used for calculating the optimal thresholds for
+ quantization using KL divergence.
+ """
+ def __init__(self, include_layer=None, logger=None):
+ self.nd_dict = {}
+ self.include_layer = include_layer
+ self.logger = logger
+
+ def collect(self, name, arr):
+ """Callback function for collecting layer output NDArrays."""
+ name = py_str(name)
+ if self.include_layer is not None and not self.include_layer(name):
+ return
+ handle = ctypes.cast(arr, NDArrayHandle)
+ arr = NDArray(handle, writable=False).copyto(cpu())
+ if self.logger is not None:
+ self.logger.info("Collecting layer %s output of shape %s" % (name, arr.shape))
+ if name in self.nd_dict:
+ self.nd_dict[name].append(arr)
+ else:
+ self.nd_dict[name] = [arr]
+
+
+class _LayerOutputMinMaxCollector(object):
+ """Saves layer output min and max values in a dict with layer names as keys.
+ The collected min and max values will be directly used as thresholds for quantization.
+ """
+ def __init__(self, include_layer=None, logger=None):
+ self.min_max_dict = {}
+ self.include_layer = include_layer
+ self.logger = logger
+
+ def collect(self, name, arr):
+ """Callback function for collecting min and max values from an NDArray."""
+ name = py_str(name)
+ if self.include_layer is not None and not self.include_layer(name):
+ return
+ handle = ctypes.cast(arr, NDArrayHandle)
+ arr = NDArray(handle, writable=False)
+ min_range = ndarray.min(arr).asscalar()
+ max_range = ndarray.max(arr).asscalar()
+ if name in self.min_max_dict:
+ cur_min_max = self.min_max_dict[name]
+ self.min_max_dict[name] = (min(cur_min_max[0], min_range),
+ max(cur_min_max[1], max_range))
+ else:
+ self.min_max_dict[name] = (min_range, max_range)
+ if self.logger is not None:
+ self.logger.info("Collecting layer %s output min_range=%f, max_range=%f"
+ % (name, min_range, max_range))
+
+
+def _calibrate_quantized_sym(qsym, th_dict):
+ """Given a dictionary containing the thresholds for quantizing the layers,
+ set the thresholds into the quantized symbol as the params of requantize operators.
+ """
+ if th_dict is None or len(th_dict) == 0:
+ return qsym
+ num_layer_outputs = len(th_dict)
+ layer_output_names = []
+ min_vals = []
+ max_vals = []
+ for k, v in th_dict.items():
+ layer_output_names.append(k)
+ min_vals.append(v[0])
+ max_vals.append(v[1])
+
+ calibrated_sym = SymbolHandle()
+ check_call(_LIB.MXSetCalibTableToQuantizedSymbol(qsym.handle,
+ mx_uint(num_layer_outputs),
+ c_str_array(layer_output_names),
+ c_array(ctypes.c_float, min_vals),
+ c_array(ctypes.c_float, max_vals),
+ ctypes.byref(calibrated_sym)))
+ return Symbol(calibrated_sym)
+
+
+def _collect_layer_statistics(mod, data, collector, max_num_examples=None, logger=None):
+ if not isinstance(data, DataIter):
+ raise ValueError('Only supports data as a type of DataIter, while received type %s'
+ % str(type(data)))
+ mod._exec_group.execs[0].set_monitor_callback(collector.collect)
+ num_batches = 0
+ num_examples = 0
+ for batch in data:
+ mod.forward(data_batch=batch, is_train=False)
+ num_batches += 1
+ num_examples += data.batch_size
+ if max_num_examples is not None and num_examples >= max_num_examples:
+ break
+ if logger is not None:
+ logger.info("Collected statistics from %d batches with batch_size=%d"
+ % (num_batches, data.batch_size))
+ return num_examples
+
+
+def _collect_layer_output_min_max(mod, data, include_layer=None,
+ max_num_examples=None, logger=None):
+ """Collect min and max values from layer outputs and save them in
+ a dictionary mapped by layer names.
+ """
+ collector = _LayerOutputMinMaxCollector(include_layer=include_layer, logger=logger)
+ num_examples = _collect_layer_statistics(mod, data, collector, max_num_examples, logger)
+ return collector.min_max_dict, num_examples
+
+
+def _collect_layer_outputs(mod, data, include_layer=None, max_num_examples=None, logger=None):
+ """Collect layer outputs and save them in a dictionary mapped by layer names."""
+ collector = _LayerOutputCollector(include_layer=include_layer, logger=logger)
+ num_examples = _collect_layer_statistics(mod, data, collector, max_num_examples, logger)
+ return collector.nd_dict, num_examples
+
+
+def _smooth_distribution(p, eps=0.0001):
+ """Given a discrete distribution (may have not been normalized to 1),
+ smooth it by replacing zeros with eps multiplied by a scaling factor and taking the
+ corresponding amount off the non-zero values.
+ Ref: http://web.engr.illinois.edu/~hanj/cs412/bk3/KL-divergence.pdf
+ """
+ is_zeros = (p == 0).astype(np.float32)
+ is_nonzeros = (p != 0).astype(np.float32)
+ n_zeros = is_zeros.sum()
+ n_nonzeros = p.size - n_zeros
+ eps1 = eps * float(n_zeros) / float(n_nonzeros)
+ assert eps1 < 1.0, 'n_zeros=%d, n_nonzeros=%d, eps1=%f' % (n_zeros, n_nonzeros, eps1)
+ hist = p.astype(np.float32)
+ hist += eps * is_zeros + (-eps1) * is_nonzeros
+ assert (hist <= 0).sum() == 0
+ return hist
+
+
+# pylint: disable=line-too-long
+def _get_optimal_threshold(arr, num_bins=8001, num_quantized_bins=255):
+ """Given a dataset, find the optimal threshold for quantizing it.
+ Ref: http://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf
+ """
+ if isinstance(arr, NDArray):
+ arr = arr.asnumpy()
+ elif isinstance(arr, list):
+ assert len(arr) != 0
+ for i, nd in enumerate(arr):
+ if isinstance(nd, NDArray):
+ arr[i] = nd.asnumpy()
+ elif not isinstance(nd, np.ndarray):
+ raise TypeError('get_optimal_threshold only supports input type of NDArray,'
+ ' list of np.ndarrays or NDArrays, and np.ndarray,'
+ ' while received type=%s' % (str(type(nd))))
+ arr = np.concatenate(arr)
+ elif not isinstance(arr, np.ndarray):
+ raise TypeError('get_optimal_threshold only supports input type of NDArray,'
+ ' list of NDArrays and np.ndarray,'
+ ' while received type=%s' % (str(type(arr))))
+ min_val = np.min(arr)
+ max_val = np.max(arr)
+ th = max(abs(min_val), abs(max_val))
+
+ hist, hist_edeges = np.histogram(arr, bins=num_bins, range=(-th, th))
+ zero_bin_idx = num_bins // 2
+ num_half_quantized_bins = num_quantized_bins // 2
+ assert np.allclose(hist_edeges[zero_bin_idx] + hist_edeges[zero_bin_idx + 1],
+ 0, rtol=1e-5, atol=1e-7)
+
+ thresholds = np.zeros(num_bins // 2 + 1 - num_quantized_bins // 2)
+ divergence = np.zeros_like(thresholds)
+ quantized_bins = np.zeros(num_quantized_bins, dtype=np.int32)
+ # i means the number of bins on half axis excluding the zero bin
+ for i in range(num_quantized_bins // 2,
+ num_bins // 2 + 1):
+ p_bin_idx_start = zero_bin_idx - i
+ p_bin_idx_stop = zero_bin_idx + i + 1
+ thresholds[i - num_half_quantized_bins] = hist_edeges[p_bin_idx_stop]
+ # sliced_nd_hist is used to generate candidate distribution q
+ sliced_nd_hist = hist[p_bin_idx_start:p_bin_idx_stop]
+
+ # generate reference distribution p
+ p = sliced_nd_hist.copy()
+ assert p.size % 2 == 1
+ assert p.size >= num_quantized_bins
+ # put left outlier count in p[0]
+ left_outlier_count = np.sum(hist[0:p_bin_idx_start])
+ p[0] += left_outlier_count
+ # put right outlier count in p[-1]
+ right_outlier_count = np.sum(hist[p_bin_idx_stop:])
+ p[-1] += right_outlier_count
+ # is_nonzeros[k] indicates whether hist[k] is nonzero
+ is_nonzeros = (sliced_nd_hist != 0).astype(np.int32)
+
+ # calculate how many bins should be merged to generate quantized distribution q
+ num_merged_bins = p.size // num_quantized_bins
+ # merge hist into num_quantized_bins bins
+ for j in range(num_quantized_bins):
+ start = j * num_merged_bins
+ stop = start + num_merged_bins
+ quantized_bins[j] = sliced_nd_hist[start:stop].sum()
+ quantized_bins[-1] += sliced_nd_hist[num_quantized_bins * num_merged_bins:].sum()
+ # expand quantized_bins into p.size bins
+ q = np.zeros(p.size, dtype=np.float32)
+ for j in range(num_quantized_bins):
+ start = j * num_merged_bins
+ if j == num_quantized_bins - 1:
+ stop = -1
+ else:
+ stop = start + num_merged_bins
+ norm = is_nonzeros[start:stop].sum()
+ if norm != 0:
+ q[start:stop] = float(quantized_bins[j]) / float(norm)
+ q[sliced_nd_hist == 0] = 0
+ p = _smooth_distribution(p)
+ q = _smooth_distribution(q)
+ divergence[i - num_half_quantized_bins] = stats.entropy(p, q)
+ quantized_bins[:] = 0
+
+ min_divergence_idx = np.argmin(divergence)
+ min_divergence = divergence[min_divergence_idx]
+ opt_th = thresholds[min_divergence_idx]
+ return min_val, max_val, min_divergence, opt_th
+# pylint: enable=line-too-long
+
+
+def _get_optimal_thresholds(nd_dict, num_bins=8001, num_quantized_bins=255, logger=None):
+ """Given a ndarray dict, find the optimal threshold for quantizing each value of the key."""
+ if stats is None:
+ raise ImportError('scipy.stats is required for running entropy mode of calculating'
+ ' the optimal thresholds for quantizing FP32 ndarrays into int8.'
+ ' Please check if the scipy python bindings are installed.')
+ assert isinstance(nd_dict, dict)
+ if logger is not None:
+ logger.info('Calculating optimal thresholds for quantization using KL divergence'
+ ' with num_bins=%d and num_quantized_bins=%d' % (num_bins, num_quantized_bins))
+ th_dict = {}
+ # copy nd_dict keys since the keys() only returns a view in python3
+ layer_names = list(nd_dict.keys())
+ for name in layer_names:
+ assert name in nd_dict
+ min_val, max_val, min_divergence, opt_th =\
+ _get_optimal_threshold(nd_dict[name], num_bins=num_bins,
+ num_quantized_bins=num_quantized_bins)
+ del nd_dict[name] # release the memory of ndarray
+ th_dict[name] = (-opt_th, opt_th)
+ if logger is not None:
+ logger.info('layer=%s, min_val=%f, max_val=%f, min_divergence=%f, optimal_threshold=%f'
+ % (name, min_val, max_val, min_divergence, opt_th))
+ return th_dict
+
+
+def _load_sym(sym, logger=logging):
+ """Given a str as a path the symbol .json file or a symbol, returns a Symbol object."""
+ if isinstance(sym, str): # sym is a symbol file path
+ cur_path = os.path.dirname(os.path.realpath(__file__))
+ symbol_file_path = os.path.join(cur_path, sym)
+ logger.info('Loading symbol from file %s' % symbol_file_path)
+ return sym_load(symbol_file_path)
+ elif isinstance(sym, Symbol):
+ return sym
+ else:
+ raise ValueError('_load_sym only accepts Symbol or path to the symbol file,'
+ ' while received type %s' % str(type(sym)))
+
+
+def _load_params(params, logger=logging):
+ """Given a str as a path to the .params file or a pair of params,
+ returns two dictionaries representing arg_params and aux_params.
+ """
+ if isinstance(params, str):
+ cur_path = os.path.dirname(os.path.realpath(__file__))
+ param_file_path = os.path.join(cur_path, params)
+ logger.info('Loading params from file %s' % param_file_path)
+ save_dict = nd_load(param_file_path)
+ arg_params = {}
+ aux_params = {}
+ for k, v in save_dict.items():
+ tp, name = k.split(':', 1)
+ if tp == 'arg':
+ arg_params[name] = v
+ if tp == 'aux':
+ aux_params[name] = v
+ return arg_params, aux_params
+ elif isinstance(params, (tuple, list)) and len(params) == 2:
+ return params[0], params[1]
+ else:
+ raise ValueError('Unsupported params provided. Must be either a path to the param file or'
+ ' a pair of dictionaries representing arg_params and aux_params')
+
+
+def quantize_model(sym, arg_params, aux_params,
+ data_names=('data',), label_names=('softmax_label',),
+ ctx=cpu(), excluded_sym_names=None, calib_mode='entropy',
+ calib_data=None, num_calib_examples=None, calib_layer=None, logger=logging):
+ """User-level API for generating a quantized model from a FP32 model w/ or w/o calibration.
+ The backend quantized operators are only enabled for Linux systems. Please do not run
+ inference using the quantized models on Windows for now.
+ The quantization implementation adopts the TensorFlow's approach:
+ https://www.tensorflow.org/performance/quantization.
+ The calibration implementation borrows the idea of Nvidia's 8-bit Inference with TensorRT:
+ http://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf
+ and adapts the method to MXNet.
+
+ Parameters
+ ----------
+ sym : str or Symbol
+ Defines the structure of a neural network for FP32 data types.
+ arg_params : dict
+ Dictionary of name to `NDArray`.
+ aux_params : dict
+ Dictionary of name to `NDArray`.
+ data_names : a list of strs
+ Data names required for creating a Module object to run forward propagation on the
+ calibration dataset.
+ label_names : a list of strs
+ Label names required for creating a Module object to run forward propagation on the
+ calibration dataset.
+ ctx : Context
+ Defines the device that users want to run forward propagation on the calibration
+ dataset for collecting layer output statistics. Currently, only supports single context.
+ excluded_sym_names : list of strings
+ A list of strings representing the names of the symbols that users want to excluding
+ from being quantized.
+ calib_mode : str
+ If calib_mode='none', no calibration will be used and the thresholds for
+ requantization after the corresponding layers will be calculated at runtime by
+ calling min and max operators. The quantized models generated in this
+ mode are normally 10-20% slower than those with calibrations during inference.
+ If calib_mode='naive', the min and max values of the layer outputs from a calibration
+ dataset will be directly taken as the thresholds for quantization.
+ If calib_mode='entropy' (default mode), the thresholds for quantization will be
+ derived such that the KL divergence between the distributions of FP32 layer outputs and
+ quantized layer outputs is minimized based upon the calibration dataset.
+ calib_data : DataIter
+ A data iterator initialized by the calibration dataset.
+ num_calib_examples : int or None
+ The maximum number of examples that user would like to use for calibration. If not provided,
+ the whole calibration dataset will be used.
+ calib_layer : function
+ Given a layer's output name in string, return True or False for deciding whether to
+ calibrate this layer. If yes, the statistics of the layer's output will be collected;
+ otherwise, no information of the layer's output will be collected. If not provided,
+ all the layers' outputs that need requantization will be collected.
+ logger : Object
+ A logging object for printing information during the process of quantization.
+
+ Returns
+ -------
+ tuple
+ A tuple of quantized symbol, quantized arg_params, and aux_params.
+ -------
+ """
+ if excluded_sym_names is None:
+ excluded_sym_names = []
+ if not isinstance(excluded_sym_names, list):
+ raise ValueError('excluded_sym_names must be a list of strings representing'
+ ' the names of the symbols that will not be quantized,'
+ ' while received type %s' % str(type(excluded_sym_names)))
+ excluded_syms = []
+ if excluded_sym_names is not None:
+ for sym_name in excluded_sym_names:
+ nodes = sym.get_internals()
+ idx = nodes.list_outputs().index(sym_name + '_output')
+ excluded_syms.append(nodes[idx])
+ logger.info('Quantizing symbol')
+ qsym = _quantize_symbol(sym, excluded_symbols=excluded_syms,
+ offline_params=list(arg_params.keys()))
+
+ logger.info('Quantizing parameters')
+ qarg_params = _quantize_params(qsym, arg_params)
+
+ if calib_mode is not None and calib_mode != 'none':
+ if not isinstance(ctx, Context):
+ raise ValueError('currently only supports single ctx, while received %s' % str(ctx))
+ if calib_data is None:
+ raise ValueError('calib_data must be provided when calib_mode=%s' % calib_mode)
+ if not isinstance(calib_data, DataIter):
+ raise ValueError('calib_data must be of DataIter type when calib_mode=%s,'
+ ' while received type %s' % (calib_mode, str(type(calib_data))))
+ if calib_layer is None:
+ calib_layer = lambda name: name.endswith('_output')
+
+ mod = Module(symbol=sym, data_names=data_names, label_names=label_names, context=ctx)
+ if len(calib_data.provide_label) > 0:
+ mod.bind(for_training=False, data_shapes=calib_data.provide_data,
+ label_shapes=calib_data.provide_label)
+ else:
+ mod.bind(for_training=False, data_shapes=calib_data.provide_data)
+ mod.set_params(arg_params, aux_params)
+ if calib_mode == 'entropy':
+ nd_dict, num_examples = _collect_layer_outputs(mod, calib_data,
+ include_layer=calib_layer,
+ max_num_examples=num_calib_examples,
+ logger=logger)
+ logger.info('Collected layer outputs from FP32 model using %d examples' % num_examples)
+ logger.info('Calculating optimal thresholds for quantization')
+ th_dict = _get_optimal_thresholds(nd_dict, logger=logger)
+ elif calib_mode == 'naive':
+ th_dict, num_examples = _collect_layer_output_min_max(
+ mod, calib_data, include_layer=calib_layer, max_num_examples=num_calib_examples,
+ logger=logger)
+ logger.info('Collected layer output min/max values from FP32 model using %d examples'
+ % num_examples)
+ else:
+ raise ValueError('unknown calibration mode %s received,'
+ ' expected `none`, `naive`, or `entropy`' % calib_mode)
+ logger.info('Calibrating quantized symbol')
+ qsym = _calibrate_quantized_sym(qsym, th_dict)
+
+ return qsym, qarg_params, aux_params
diff --git a/python/mxnet/contrib/tensorboard.py b/python/mxnet/contrib/tensorboard.py
index 2bb766e7d69..f2149178221 100644
--- a/python/mxnet/contrib/tensorboard.py
+++ b/python/mxnet/contrib/tensorboard.py
@@ -70,4 +70,4 @@ def __call__(self, param):
for name, value in name_value:
if self.prefix is not None:
name = '%s-%s' % (self.prefix, name)
- self.summary_writer.add_scalar(name, value)
+ self.summary_writer.add_scalar(name, value, global_step=param.epoch)
diff --git a/python/mxnet/gluon/block.py b/python/mxnet/gluon/block.py
index 6ed3b792289..3571b15ee06 100644
--- a/python/mxnet/gluon/block.py
+++ b/python/mxnet/gluon/block.py
@@ -28,6 +28,7 @@
from ..symbol import Symbol
from ..ndarray import NDArray
from .. import name as _name
+from ..context import cpu
from .parameter import Parameter, ParameterDict, DeferredInitializationError
from .utils import _indent
@@ -299,13 +300,13 @@ def save_params(self, filename):
"""
self.collect_params().save(filename, strip_prefix=self.prefix)
- def load_params(self, filename, ctx, allow_missing=False,
+ def load_params(self, filename, ctx=cpu(), allow_missing=False,
ignore_extra=False):
"""Load parameters from file.
filename : str
Path to parameter file.
- ctx : Context or list of Context
+ ctx : Context or list of Context, default cpu()
Context(s) initialize loaded parameters on.
allow_missing : bool, default False
Whether to silently skip loading parameters not represents in the file.
diff --git a/python/mxnet/gluon/contrib/rnn/rnn_cell.py b/python/mxnet/gluon/contrib/rnn/rnn_cell.py
index b964c712ace..1b9afee14bf 100644
--- a/python/mxnet/gluon/contrib/rnn/rnn_cell.py
+++ b/python/mxnet/gluon/contrib/rnn/rnn_cell.py
@@ -17,13 +17,12 @@
# coding: utf-8
"""Definition of various recurrent neural network cells."""
-__all__ = ['VariationalDropoutCell']
+__all__ = ['VariationalDropoutCell', 'LSTMPCell']
-from ...rnn import BidirectionalCell, SequentialRNNCell, ModifierCell
+from ...rnn import BidirectionalCell, SequentialRNNCell, ModifierCell, HybridRecurrentCell
from ...rnn.rnn_cell import _format_sequence, _get_begin_state, _mask_sequence_variable_length
from ... import tensor_types
-
class VariationalDropoutCell(ModifierCell):
"""
Applies Variational Dropout on base cell.
@@ -193,3 +192,126 @@ def unroll(self, length, inputs, begin_state=None, layout='NTC', merge_outputs=N
outputs = _mask_sequence_variable_length(F, outputs, length, valid_length, axis,
merge_outputs)
return outputs, states
+
+
+class LSTMPCell(HybridRecurrentCell):
+ r"""Long-Short Term Memory Projected (LSTMP) network cell.
+ (https://arxiv.org/abs/1402.1128)
+ Each call computes the following function:
+ .. math::
+ \begin{array}{ll}
+ i_t = sigmoid(W_{ii} x_t + b_{ii} + W_{ri} r_{(t-1)} + b_{ri}) \\
+ f_t = sigmoid(W_{if} x_t + b_{if} + W_{rf} r_{(t-1)} + b_{rf}) \\
+ g_t = \tanh(W_{ig} x_t + b_{ig} + W_{rc} r_{(t-1)} + b_{rg}}) \\
+ o_t = sigmoid(W_{io} x_t + b_{io} + W_{ro} r_{(t-1)} + b_{ro}) \\
+ c_t = f_t * c_{(t-1)} + i_t * g_t \\
+ h_t = o_t * \tanh(c_t) \\
+ r_t = W_{hr} h_t
+ \end{array}
+ where :math:`r_t` is the projected recurrent activation at time `t`,
+ math:`h_t` is the hidden state at time `t`, :math:`c_t` is the
+ cell state at time `t`, :math:`x_t` is the input at time `t`, and :math:`i_t`,
+ :math:`f_t`, :math:`g_t`, :math:`o_t` are the input, forget, cell, and
+ out gates, respectively.
+ Parameters
+ ----------
+ hidden_size : int
+ Number of units in cell state symbol.
+ projection_size : int
+ Number of units in output symbol.
+ i2h_weight_initializer : str or Initializer
+ Initializer for the input weights matrix, used for the linear
+ transformation of the inputs.
+ h2h_weight_initializer : str or Initializer
+ Initializer for the recurrent weights matrix, used for the linear
+ transformation of the hidden state.
+ h2r_weight_initializer : str or Initializer
+ Initializer for the projection weights matrix, used for the linear
+ transformation of the recurrent state.
+ i2h_bias_initializer : str or Initializer, default 'lstmbias'
+ Initializer for the bias vector. By default, bias for the forget
+ gate is initialized to 1 while all other biases are initialized
+ to zero.
+ h2h_bias_initializer : str or Initializer
+ Initializer for the bias vector.
+ prefix : str, default 'lstmp_'
+ Prefix for name of `Block`s
+ (and name of weight if params is `None`).
+ params : Parameter or None
+ Container for weight sharing between cells.
+ Created if `None`.
+ Inputs:
+ - **data**: input tensor with shape `(batch_size, input_size)`.
+ - **states**: a list of two initial recurrent state tensors, with shape
+ `(batch_size, projection_size)` and `(batch_size, hidden_size)` respectively.
+ Outputs:
+ - **out**: output tensor with shape `(batch_size, num_hidden)`.
+ - **next_states**: a list of two output recurrent state tensors. Each has
+ the same shape as `states`.
+ """
+ def __init__(self, hidden_size, projection_size,
+ i2h_weight_initializer=None, h2h_weight_initializer=None,
+ h2r_weight_initializer=None,
+ i2h_bias_initializer='zeros', h2h_bias_initializer='zeros',
+ input_size=0, prefix=None, params=None):
+ super(LSTMPCell, self).__init__(prefix=prefix, params=params)
+
+ self._hidden_size = hidden_size
+ self._input_size = input_size
+ self._projection_size = projection_size
+ self.i2h_weight = self.params.get('i2h_weight', shape=(4*hidden_size, input_size),
+ init=i2h_weight_initializer,
+ allow_deferred_init=True)
+ self.h2h_weight = self.params.get('h2h_weight', shape=(4*hidden_size, projection_size),
+ init=h2h_weight_initializer,
+ allow_deferred_init=True)
+ self.h2r_weight = self.params.get('h2r_weight', shape=(projection_size, hidden_size),
+ init=h2r_weight_initializer,
+ allow_deferred_init=True)
+ self.i2h_bias = self.params.get('i2h_bias', shape=(4*hidden_size,),
+ init=i2h_bias_initializer,
+ allow_deferred_init=True)
+ self.h2h_bias = self.params.get('h2h_bias', shape=(4*hidden_size,),
+ init=h2h_bias_initializer,
+ allow_deferred_init=True)
+
+ def state_info(self, batch_size=0):
+ return [{'shape': (batch_size, self._projection_size), '__layout__': 'NC'},
+ {'shape': (batch_size, self._hidden_size), '__layout__': 'NC'}]
+
+ def _alias(self):
+ return 'lstmp'
+
+ def __repr__(self):
+ s = '{name}({mapping})'
+ shape = self.i2h_weight.shape
+ proj_shape = self.h2r_weight.shape
+ mapping = '{0} -> {1} -> {2}'.format(shape[1] if shape[1] else None,
+ shape[0], proj_shape[0])
+ return s.format(name=self.__class__.__name__,
+ mapping=mapping,
+ **self.__dict__)
+
+ # pylint: disable= arguments-differ
+ def hybrid_forward(self, F, inputs, states, i2h_weight,
+ h2h_weight, h2r_weight, i2h_bias, h2h_bias):
+ prefix = 't%d_'%self._counter
+ i2h = F.FullyConnected(data=inputs, weight=i2h_weight, bias=i2h_bias,
+ num_hidden=self._hidden_size*4, name=prefix+'i2h')
+ h2h = F.FullyConnected(data=states[0], weight=h2h_weight, bias=h2h_bias,
+ num_hidden=self._hidden_size*4, name=prefix+'h2h')
+ gates = i2h + h2h
+ slice_gates = F.SliceChannel(gates, num_outputs=4, name=prefix+'slice')
+ in_gate = F.Activation(slice_gates[0], act_type="sigmoid", name=prefix+'i')
+ forget_gate = F.Activation(slice_gates[1], act_type="sigmoid", name=prefix+'f')
+ in_transform = F.Activation(slice_gates[2], act_type="tanh", name=prefix+'c')
+ out_gate = F.Activation(slice_gates[3], act_type="sigmoid", name=prefix+'o')
+ next_c = F._internal._plus(forget_gate * states[1], in_gate * in_transform,
+ name=prefix+'state')
+ hidden = F._internal._mul(out_gate, F.Activation(next_c, act_type="tanh"),
+ name=prefix+'hidden')
+ next_r = F.FullyConnected(data=hidden, num_hidden=self._projection_size,
+ weight=h2r_weight, no_bias=True, name=prefix+'out')
+
+ return next_r, [next_r, next_c]
+ # pylint: enable= arguments-differ
diff --git a/python/mxnet/gluon/data/vision/transforms.py b/python/mxnet/gluon/data/vision/transforms.py
index 8a87f374e46..a0734676a8d 100644
--- a/python/mxnet/gluon/data/vision/transforms.py
+++ b/python/mxnet/gluon/data/vision/transforms.py
@@ -32,6 +32,22 @@ class Compose(Sequential):
----------
transforms : list of transform Blocks.
The list of transforms to be composed.
+
+
+ Inputs:
+ - **data**: input tensor with shape of the first transform Block requires.
+
+ Outputs:
+ - **out**: output tensor with shape of the last transform Block produces.
+
+ Examples
+ --------
+ >>> transformer = transforms.Compose([transforms.Resize(300),
+ ... transforms.CenterCrop(256),
+ ... transforms.ToTensor()])
+ >>> image = mx.nd.random.uniform(0, 255, (224, 224, 3)).astype(dtype=np.uint8)
+ >>> transformer(image)
+ <NDArray 3x256x256 @cpu(0)>
"""
def __init__(self, transforms):
super(Compose, self).__init__()
@@ -60,6 +76,13 @@ class Cast(HybridBlock):
----------
dtype : str, default 'float32'
The target data type, in string or `numpy.dtype`.
+
+
+ Inputs:
+ - **data**: input tensor with arbitrary shape.
+
+ Outputs:
+ - **out**: output tensor with the same shape as `data`.
"""
def __init__(self, dtype='float32'):
super(Cast, self).__init__()
@@ -75,6 +98,31 @@ class ToTensor(HybridBlock):
Converts an image NDArray of shape (H x W x C) in the range
[0, 255] to a float32 tensor NDArray of shape (C x H x W) in
the range [0, 1).
+
+ Inputs:
+ - **data**: input tensor with (H x W x C) shape and uint8 type.
+
+ Outputs:
+ - **out**: output tensor with (C x H x W) shape and float32 type.
+
+ Examples
+ --------
+ >>> transformer = vision.transforms.ToTensor()
+ >>> image = mx.nd.random.uniform(0, 255, (4, 2, 3)).astype(dtype=np.uint8)
+ >>> transformer(image)
+ [[[ 0.85490197 0.72156864]
+ [ 0.09019608 0.74117649]
+ [ 0.61960787 0.92941177]
+ [ 0.96470588 0.1882353 ]]
+ [[ 0.6156863 0.73725492]
+ [ 0.46666667 0.98039216]
+ [ 0.44705883 0.45490196]
+ [ 0.01960784 0.8509804 ]]
+ [[ 0.39607844 0.03137255]
+ [ 0.72156864 0.52941179]
+ [ 0.16470589 0.7647059 ]
+ [ 0.05490196 0.70588237]]]
+ <NDArray 3x4x2 @cpu(0)>
"""
def __init__(self):
super(ToTensor, self).__init__()
@@ -100,6 +148,13 @@ class Normalize(HybridBlock):
The mean values.
std : float or tuple of floats
The standard deviation values.
+
+
+ Inputs:
+ - **data**: input tensor with (C x H x W) shape.
+
+ Outputs:
+ - **out**: output tensor with the shape as `data`.
"""
def __init__(self, mean, std):
super(Normalize, self).__init__()
@@ -129,6 +184,13 @@ class RandomResizedCrop(Block):
interpolation : int
Interpolation method for resizing. By default uses bilinear
interpolation. See OpenCV's resize function for available choices.
+
+
+ Inputs:
+ - **data**: input tensor with (Hi x Wi x C) shape.
+
+ Outputs:
+ - **out**: output tensor with (H x W x C) shape.
"""
def __init__(self, size, scale=(0.08, 1.0), ratio=(3.0/4.0, 4.0/3.0),
interpolation=2):
@@ -153,6 +215,20 @@ class CenterCrop(Block):
interpolation : int
Interpolation method for resizing. By default uses bilinear
interpolation. See OpenCV's resize function for available choices.
+
+
+ Inputs:
+ - **data**: input tensor with (Hi x Wi x C) shape.
+
+ Outputs:
+ - **out**: output tensor with (H x W x C) shape.
+
+ Examples
+ --------
+ >>> transformer = vision.transforms.CenterCrop(size=(1000, 500))
+ >>> image = mx.nd.random.uniform(0, 255, (2321, 3482, 3)).astype(dtype=np.uint8)
+ >>> transformer(image)
+ <NDArray 500x1000x3 @cpu(0)>
"""
def __init__(self, size, interpolation=2):
super(CenterCrop, self).__init__()
@@ -174,6 +250,20 @@ class Resize(Block):
interpolation : int
Interpolation method for resizing. By default uses bilinear
interpolation. See OpenCV's resize function for available choices.
+
+
+ Inputs:
+ - **data**: input tensor with (Hi x Wi x C) shape.
+
+ Outputs:
+ - **out**: output tensor with (H x W x C) shape.
+
+ Examples
+ --------
+ >>> transformer = vision.transforms.Resize(size=(1000, 500))
+ >>> image = mx.nd.random.uniform(0, 255, (224, 224, 3)).astype(dtype=np.uint8)
+ >>> transformer(image)
+ <NDArray 500x1000x3 @cpu(0)>
"""
def __init__(self, size, interpolation=2):
super(Resize, self).__init__()
@@ -188,6 +278,12 @@ def forward(self, x):
class RandomFlipLeftRight(HybridBlock):
"""Randomly flip the input image left to right with a probability
of 0.5.
+
+ Inputs:
+ - **data**: input tensor with (H x W x C) shape.
+
+ Outputs:
+ - **out**: output tensor with same shape as `data`.
"""
def __init__(self):
super(RandomFlipLeftRight, self).__init__()
@@ -199,6 +295,12 @@ def hybrid_forward(self, F, x):
class RandomFlipTopBottom(HybridBlock):
"""Randomly flip the input image top to bottom with a probability
of 0.5.
+
+ Inputs:
+ - **data**: input tensor with (H x W x C) shape.
+
+ Outputs:
+ - **out**: output tensor with same shape as `data`.
"""
def __init__(self):
super(RandomFlipTopBottom, self).__init__()
@@ -210,6 +312,19 @@ def hybrid_forward(self, F, x):
class RandomBrightness(HybridBlock):
"""Randomly jitters image brightness with a factor
chosen from `[max(0, 1 - brightness), 1 + brightness]`.
+
+ Parameters
+ ----------
+ brightness: float
+ How much to jitter brightness. brightness factor is randomly
+ chosen from `[max(0, 1 - brightness), 1 + brightness]`.
+
+
+ Inputs:
+ - **data**: input tensor with (H x W x C) shape.
+
+ Outputs:
+ - **out**: output tensor with same shape as `data`.
"""
def __init__(self, brightness):
super(RandomBrightness, self).__init__()
@@ -222,6 +337,19 @@ def hybrid_forward(self, F, x):
class RandomContrast(HybridBlock):
"""Randomly jitters image contrast with a factor
chosen from `[max(0, 1 - contrast), 1 + contrast]`.
+
+ Parameters
+ ----------
+ contrast: float
+ How much to jitter contrast. contrast factor is randomly
+ chosen from `[max(0, 1 - contrast), 1 + contrast]`.
+
+
+ Inputs:
+ - **data**: input tensor with (H x W x C) shape.
+
+ Outputs:
+ - **out**: output tensor with same shape as `data`.
"""
def __init__(self, contrast):
super(RandomContrast, self).__init__()
@@ -234,6 +362,19 @@ def hybrid_forward(self, F, x):
class RandomSaturation(HybridBlock):
"""Randomly jitters image saturation with a factor
chosen from `[max(0, 1 - saturation), 1 + saturation]`.
+
+ Parameters
+ ----------
+ saturation: float
+ How much to jitter saturation. saturation factor is randomly
+ chosen from `[max(0, 1 - saturation), 1 + saturation]`.
+
+
+ Inputs:
+ - **data**: input tensor with (H x W x C) shape.
+
+ Outputs:
+ - **out**: output tensor with same shape as `data`.
"""
def __init__(self, saturation):
super(RandomSaturation, self).__init__()
@@ -246,6 +387,19 @@ def hybrid_forward(self, F, x):
class RandomHue(HybridBlock):
"""Randomly jitters image hue with a factor
chosen from `[max(0, 1 - hue), 1 + hue]`.
+
+ Parameters
+ ----------
+ hue: float
+ How much to jitter hue. hue factor is randomly
+ chosen from `[max(0, 1 - hue), 1 + hue]`.
+
+
+ Inputs:
+ - **data**: input tensor with (H x W x C) shape.
+
+ Outputs:
+ - **out**: output tensor with same shape as `data`.
"""
def __init__(self, hue):
super(RandomHue, self).__init__()
@@ -273,6 +427,13 @@ class RandomColorJitter(HybridBlock):
hue : float
How much to jitter hue. hue factor is randomly
chosen from `[max(0, 1 - hue), 1 + hue]`.
+
+
+ Inputs:
+ - **data**: input tensor with (H x W x C) shape.
+
+ Outputs:
+ - **out**: output tensor with same shape as `data`.
"""
def __init__(self, brightness=0, contrast=0, saturation=0, hue=0):
super(RandomColorJitter, self).__init__()
@@ -289,6 +450,13 @@ class RandomLighting(HybridBlock):
----------
alpha : float
Intensity of the image.
+
+
+ Inputs:
+ - **data**: input tensor with (H x W x C) shape.
+
+ Outputs:
+ - **out**: output tensor with same shape as `data`.
"""
def __init__(self, alpha):
super(RandomLighting, self).__init__()
diff --git a/python/mxnet/gluon/nn/basic_layers.py b/python/mxnet/gluon/nn/basic_layers.py
index eb33199671c..3801c84b56f 100644
--- a/python/mxnet/gluon/nn/basic_layers.py
+++ b/python/mxnet/gluon/nn/basic_layers.py
@@ -353,7 +353,7 @@ def __repr__(self):
class Embedding(HybridBlock):
r"""Turns non-negative integers (indexes/tokens) into dense vectors
- of fixed size. eg. [[4], [20]] -> [[0.25, 0.1], [0.6, -0.2]]
+ of fixed size. eg. [4, 20] -> [[0.25, 0.1], [0.6, -0.2]]
Parameters
@@ -369,10 +369,10 @@ class Embedding(HybridBlock):
Inputs:
- - **data**: 2D tensor with shape: `(x1, x2)`.
+ - **data**: (N-1)-D tensor with shape: `(x1, x2, ..., xN-1)`.
Output:
- - **out**: 3D tensor with shape: `(x1, x2, output_dim)`.
+ - **out**: N-D tensor with shape: `(x1, x2, ..., xN-1, output_dim)`.
"""
def __init__(self, input_dim, output_dim, dtype='float32',
weight_initializer=None, **kwargs):
diff --git a/python/mxnet/gluon/parameter.py b/python/mxnet/gluon/parameter.py
index 7dc72433926..5a9277b2d63 100644
--- a/python/mxnet/gluon/parameter.py
+++ b/python/mxnet/gluon/parameter.py
@@ -574,13 +574,32 @@ def get(self, name, **kwargs):
"""
name = self.prefix + name
param = self._get_impl(name)
- if param is None:
+ if param is None: # pylint: disable=too-many-nested-blocks
param = Parameter(name, **kwargs)
self._params[name] = param
else:
for k, v in kwargs.items():
if hasattr(param, k) and getattr(param, k) is not None:
- assert v is None or v == getattr(param, k), \
+ existing = getattr(param, k)
+ if k == 'shape' and len(v) == len(existing):
+ inferred_shape = []
+ matched = True
+ for dim1, dim2 in zip(v, existing):
+ if dim1 != dim2 and dim1 * dim2 != 0:
+ matched = False
+ break
+ elif dim1 == dim2:
+ inferred_shape.append(dim1)
+ elif dim1 == 0:
+ inferred_shape.append(dim2)
+ else:
+ inferred_shape.append(dim1)
+
+ if matched:
+ param._shape = tuple(inferred_shape)
+ continue
+
+ assert v is None or v == existing, \
"Cannot retrieve Parameter %s because desired attribute " \
"does not match with stored for attribute %s: " \
"desired %s vs stored %s."%(
diff --git a/python/mxnet/gluon/rnn/rnn_layer.py b/python/mxnet/gluon/rnn/rnn_layer.py
index 2fac39923c7..c82e95333e6 100644
--- a/python/mxnet/gluon/rnn/rnn_layer.py
+++ b/python/mxnet/gluon/rnn/rnn_layer.py
@@ -254,7 +254,7 @@ class RNN(_RNNLayer):
The number of features in the hidden state h.
num_layers: int, default 1
Number of recurrent layers.
- activation: {'relu' or 'tanh'}, default 'tanh'
+ activation: {'relu' or 'tanh'}, default 'relu'
The activation function to use.
layout : str, default 'TNC'
The format of input and output tensors. T, N and C stand for
diff --git a/python/mxnet/initializer.py b/python/mxnet/initializer.py
index 78afa2dbd29..1297c3da9a7 100755
--- a/python/mxnet/initializer.py
+++ b/python/mxnet/initializer.py
@@ -530,9 +530,9 @@ def _init_weight(self, _, arr):
nout = arr.shape[0]
nin = np.prod(arr.shape[1:])
if self.rand_type == "uniform":
- tmp = np.random.uniform(-1.0, 1.0, (nout, nin))
+ tmp = random.uniform(-1.0, 1.0, shape=(nout, nin)).asnumpy()
elif self.rand_type == "normal":
- tmp = np.random.normal(0.0, 1.0, (nout, nin))
+ tmp = random.normal(0.0, 1.0, shape=(nout, nin)).asnumpy()
u, _, v = np.linalg.svd(tmp, full_matrices=False) # pylint: disable=invalid-name
if u.shape == tmp.shape:
res = u
diff --git a/python/mxnet/io.py b/python/mxnet/io.py
index 201414e8f6e..2bace6f526f 100644
--- a/python/mxnet/io.py
+++ b/python/mxnet/io.py
@@ -39,6 +39,8 @@
from .ndarray import _ndarray_cls
from .ndarray import array
from .ndarray import concatenate
+from .ndarray import arange
+from .ndarray.random import shuffle as random_shuffle
class DataDesc(namedtuple('DataDesc', ['name', 'shape'])):
"""DataDesc is used to store name, shape, type and layout
@@ -651,12 +653,14 @@ def __init__(self, data, label=None, batch_size=1, shuffle=False,
raise NotImplementedError("`NDArrayIter` only supports ``CSRNDArray``" \
" with `last_batch_handle` set to `discard`.")
- self.idx = np.arange(self.data[0][1].shape[0])
# shuffle data
if shuffle:
- np.random.shuffle(self.idx)
+ tmp_idx = arange(self.data[0][1].shape[0], dtype=np.int32)
+ self.idx = random_shuffle(tmp_idx, out=tmp_idx).asnumpy()
self.data = _shuffle(self.data, self.idx)
self.label = _shuffle(self.label, self.idx)
+ else:
+ self.idx = np.arange(self.data[0][1].shape[0])
# batching
if last_batch_handle == 'discard':
diff --git a/python/mxnet/kvstore.py b/python/mxnet/kvstore.py
index 221b94fda0f..5520597530e 100644
--- a/python/mxnet/kvstore.py
+++ b/python/mxnet/kvstore.py
@@ -424,7 +424,7 @@ def set_gradient_compression(self, compression_params):
Other keys in this dictionary are optional and specific to the type
of gradient compression.
"""
- if ('device' in self.type) or ('dist' in self.type):
+ if ('device' in self.type) or ('dist' in self.type): # pylint: disable=unsupported-membership-test
ckeys, cvals = _ctype_dict(compression_params)
check_call(_LIB.MXKVStoreSetGradientCompression(self.handle,
mx_uint(len(compression_params)),
@@ -466,7 +466,7 @@ def set_optimizer(self, optimizer):
check_call(_LIB.MXKVStoreIsWorkerNode(ctypes.byref(is_worker)))
# pylint: disable=invalid-name
- if 'dist' in self.type and is_worker.value:
+ if 'dist' in self.type and is_worker.value: # pylint: disable=unsupported-membership-test
# send the optimizer to server
try:
# use ASCII protocol 0, might be slower, but not a big ideal
diff --git a/python/mxnet/model.py b/python/mxnet/model.py
index 33dae173259..26e885a1cd8 100644
--- a/python/mxnet/model.py
+++ b/python/mxnet/model.py
@@ -28,7 +28,7 @@
import numpy as np
from . import io
-from . import nd
+from . import ndarray as nd
from . import symbol as sym
from . import optimizer as opt
from . import metric
@@ -592,15 +592,17 @@ def __setstate__(self, state):
def _init_predictor(self, input_shapes, type_dict=None):
"""Initialize the predictor module for running prediction."""
+ shapes = {name: self.arg_params[name].shape for name in self.arg_params}
+ shapes.update(dict(input_shapes))
if self._pred_exec is not None:
- arg_shapes, _, _ = self.symbol.infer_shape(**dict(input_shapes))
+ arg_shapes, _, _ = self.symbol.infer_shape(**shapes)
assert arg_shapes is not None, "Incomplete input shapes"
pred_shapes = [x.shape for x in self._pred_exec.arg_arrays]
if arg_shapes == pred_shapes:
return
# for now only use the first device
pred_exec = self.symbol.simple_bind(
- self.ctx[0], grad_req='null', type_dict=type_dict, **dict(input_shapes))
+ self.ctx[0], grad_req='null', type_dict=type_dict, **shapes)
pred_exec.copy_params_from(self.arg_params, self.aux_params)
_check_arguments(self.symbol)
@@ -848,7 +850,7 @@ def fit(self, X, y=None, eval_data=None, eval_metric='acc',
# init optmizer
if isinstance(self.optimizer, str):
batch_size = data.batch_size
- if kvstore and 'dist' in kvstore.type and not '_async' in kvstore.type:
+ if kvstore and 'dist' in kvstore.type and '_async' not in kvstore.type:
batch_size *= kvstore.num_workers
optimizer = opt.create(self.optimizer,
rescale_grad=(1.0/batch_size),
diff --git a/python/mxnet/module/bucketing_module.py b/python/mxnet/module/bucketing_module.py
index d93ef3bed1b..2f5cc9e784b 100644
--- a/python/mxnet/module/bucketing_module.py
+++ b/python/mxnet/module/bucketing_module.py
@@ -31,6 +31,7 @@
from .base_module import BaseModule, _check_input_names
from .module import Module
+from ..name import NameManager
class BucketingModule(BaseModule):
"""This module helps to deal efficiently with varying-length inputs.
@@ -71,7 +72,7 @@ def __init__(self, sym_gen, default_bucket_key=None, logger=logging,
self._default_bucket_key = default_bucket_key
self._sym_gen = sym_gen
- symbol, data_names, label_names = sym_gen(default_bucket_key)
+ symbol, data_names, label_names = self._call_sym_gen(default_bucket_key)
data_names = list(data_names) if data_names is not None else []
label_names = list(label_names) if label_names is not None else []
state_names = list(state_names) if state_names is not None else []
@@ -102,13 +103,17 @@ def _reset_bind(self):
self._curr_module = None
self._curr_bucket_key = None
+ def _call_sym_gen(self, *args, **kwargs):
+ with NameManager():
+ return self._sym_gen(*args, **kwargs)
+
@property
def data_names(self):
"""A list of names for data required by this module."""
if self.binded:
return self._curr_module.data_names
else:
- _, data_names, _ = self._sym_gen(self._default_bucket_key)
+ _, data_names, _ = self._call_sym_gen(self._default_bucket_key)
return data_names
@property
@@ -117,7 +122,7 @@ def output_names(self):
if self.binded:
return self._curr_module.output_names
else:
- symbol, _, _ = self._sym_gen(self._default_bucket_key)
+ symbol, _, _ = self._call_sym_gen(self._default_bucket_key)
return symbol.list_outputs()
@property
@@ -327,7 +332,7 @@ def bind(self, data_shapes, label_shapes=None, for_training=True,
self.inputs_need_grad = inputs_need_grad
self.binded = True
- symbol, data_names, label_names = self._sym_gen(self._default_bucket_key)
+ symbol, data_names, label_names = self._call_sym_gen(self._default_bucket_key)
module = Module(symbol, data_names, label_names, logger=self.logger,
context=self._context, work_load_list=self._work_load_list,
fixed_param_names=self._fixed_param_names,
@@ -358,7 +363,7 @@ def switch_bucket(self, bucket_key, data_shapes, label_shapes=None):
"""
assert self.binded, 'call bind before switching bucket'
if not bucket_key in self._buckets:
- symbol, data_names, label_names = self._sym_gen(bucket_key)
+ symbol, data_names, label_names = self._call_sym_gen(bucket_key)
module = Module(symbol, data_names, label_names,
logger=self.logger, context=self._context,
work_load_list=self._work_load_list,
diff --git a/python/mxnet/ndarray/ndarray.py b/python/mxnet/ndarray/ndarray.py
index 536784586e3..7dc2acf07e5 100644
--- a/python/mxnet/ndarray/ndarray.py
+++ b/python/mxnet/ndarray/ndarray.py
@@ -1683,7 +1683,7 @@ def shape(self):
pdata = ctypes.POINTER(mx_uint)()
check_call(_LIB.MXNDArrayGetShape(
self.handle, ctypes.byref(ndim), ctypes.byref(pdata)))
- return tuple(pdata[:ndim.value])
+ return tuple(pdata[:ndim.value]) # pylint: disable=invalid-slice-index
@property
diff --git a/python/mxnet/ndarray/random.py b/python/mxnet/ndarray/random.py
index af125753e5e..93f97e80b47 100644
--- a/python/mxnet/ndarray/random.py
+++ b/python/mxnet/ndarray/random.py
@@ -24,7 +24,7 @@
__all__ = ['uniform', 'normal', 'poisson', 'exponential', 'gamma', 'multinomial',
- 'negative_binomial', 'generalized_negative_binomial']
+ 'negative_binomial', 'generalized_negative_binomial', 'shuffle']
def _random_helper(random, sampler, params, shape, dtype, ctx, out, kwargs):
@@ -431,3 +431,35 @@ def multinomial(data, shape=_Null, get_prob=False, out=None, **kwargs):
<NDArray 2 @cpu(0)>
"""
return _internal._sample_multinomial(data, shape, get_prob, out=out, **kwargs)
+
+
+def shuffle(data, **kwargs):
+ """Shuffle the elements randomly.
+
+ This shuffles the array along the first axis.
+ The order of the elements in each subarray does not change.
+ For example, if a 2D array is given, the order of the rows randomly changes,
+ but the order of the elements in each row does not change.
+
+ Parameters
+ ----------
+ data : NDArray
+ Input data array.
+ out : NDArray
+ Array to store the result.
+
+ Examples
+ --------
+ >>> data = mx.nd.array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
+ >>> mx.nd.random.shuffle(data)
+ [[ 0. 1. 2.]
+ [ 6. 7. 8.]
+ [ 3. 4. 5.]]
+ <NDArray 2x3 @cpu(0)>
+ >>> mx.nd.random.shuffle(data)
+ [[ 3. 4. 5.]
+ [ 0. 1. 2.]
+ [ 6. 7. 8.]]
+ <NDArray 2x3 @cpu(0)>
+ """
+ return _internal._shuffle(data, **kwargs)
diff --git a/python/mxnet/profiler.py b/python/mxnet/profiler.py
index 3ef262e38a1..0e7a31c687e 100644
--- a/python/mxnet/profiler.py
+++ b/python/mxnet/profiler.py
@@ -58,7 +58,7 @@ def set_config(**kwargs):
def profiler_set_config(mode='symbolic', filename='profile.json'):
- """Set up the configure of profiler.
+ """Set up the configure of profiler (Deprecated).
Parameters
----------
@@ -68,7 +68,7 @@ def profiler_set_config(mode='symbolic', filename='profile.json'):
filename : string, optional
The name of output trace file. Defaults to 'profile.json'.
"""
- warnings.warn('profiler.profiler_set_config() is deprecated. ' \
+ warnings.warn('profiler.profiler_set_config() is deprecated. '
'Please use profiler.set_config() instead')
keys = c_str_array([key for key in ["profile_" + mode, "filename"]])
values = c_str_array([str(val) for val in [True, filename]])
@@ -89,6 +89,19 @@ def set_state(state='stop'):
check_call(_LIB.MXSetProfilerState(ctypes.c_int(state2int[state])))
+def profiler_set_state(state='stop'):
+ """Set up the profiler state to 'run' or 'stop' (Deprecated).
+
+ Parameters
+ ----------
+ state : string, optional
+ Indicates whether to run the profiler, can
+ be 'stop' or 'run'. Default is `stop`.
+ """
+ warnings.warn('profiler.profiler_set_state() is deprecated. '
+ 'Please use profiler.set_state() instead')
+ set_state(state)
+
def dump(finished=True):
"""Dump profile and stop profiler. Use this to save profile
in advance in case your program cannot exit normally.
@@ -106,7 +119,7 @@ def dump(finished=True):
def dump_profile():
"""Dump profile and stop profiler. Use this to save profile
in advance in case your program cannot exit normally."""
- warnings.warn('profiler.dump_profile() is deprecated. ' \
+ warnings.warn('profiler.dump_profile() is deprecated. '
'Please use profiler.dump() instead')
dump(True)
diff --git a/python/mxnet/symbol/random.py b/python/mxnet/symbol/random.py
index f0d05ad0561..721a1daa95e 100644
--- a/python/mxnet/symbol/random.py
+++ b/python/mxnet/symbol/random.py
@@ -23,7 +23,7 @@
__all__ = ['uniform', 'normal', 'poisson', 'exponential', 'gamma', 'multinomial',
- 'negative_binomial', 'generalized_negative_binomial']
+ 'negative_binomial', 'generalized_negative_binomial', 'shuffle']
def _random_helper(random, sampler, params, shape, dtype, kwargs):
@@ -247,3 +247,34 @@ def multinomial(data, shape=_Null, get_prob=True, **kwargs):
reward as head gradient w.r.t. this array to estimate gradient.
"""
return _internal._sample_multinomial(data, shape, get_prob, **kwargs)
+
+
+def shuffle(data, **kwargs):
+ """Shuffle the elements randomly.
+
+ This shuffles the array along the first axis.
+ The order of the elements in each subarray does not change.
+ For example, if a 2D array is given, the order of the rows randomly changes,
+ but the order of the elements in each row does not change.
+
+ Parameters
+ ----------
+ data : NDArray
+ Input data array.
+ Examples
+ --------
+ >>> data = mx.nd.array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
+ >>> a = mx.sym.Variable('a')
+ >>> b = mx.sym.random.shuffle(a)
+ >>> b.eval(a=data)
+ [[ 0. 1. 2.]
+ [ 6. 7. 8.]
+ [ 3. 4. 5.]]
+ <NDArray 2x3 @cpu(0)>
+ >>> b.eval(a=data)
+ [[ 3. 4. 5.]
+ [ 0. 1. 2.]
+ [ 6. 7. 8.]]
+ <NDArray 2x3 @cpu(0)>
+ """
+ return _internal._shuffle(data, **kwargs)
diff --git a/python/mxnet/symbol/register.py b/python/mxnet/symbol/register.py
index 7b293f5fbea..6f9e868e232 100644
--- a/python/mxnet/symbol/register.py
+++ b/python/mxnet/symbol/register.py
@@ -126,7 +126,7 @@ def %s(*%s, **kwargs):"""%(func_name, arr_name))
else:
keys.append(k)
vals.append(v)"""%(func_name.lower()))
- if key_var_num_args:
+ if key_var_num_args: # pylint: disable=using-constant-test
code.append("""
if '%s' not in kwargs:
keys.append('%s')
diff --git a/python/mxnet/symbol/symbol.py b/python/mxnet/symbol/symbol.py
index 59402e66c60..6d5c8c3a146 100644
--- a/python/mxnet/symbol/symbol.py
+++ b/python/mxnet/symbol/symbol.py
@@ -750,6 +750,7 @@ def list_outputs(self):
self.handle, ctypes.byref(size), ctypes.byref(sarr)))
return [py_str(sarr[i]) for i in range(size.value)]
+ # pylint: disable=invalid-length-returned
def __len__(self):
"""Get number of outputs for the symbol.
diff --git a/python/mxnet/torch.py b/python/mxnet/torch.py
index fc815b14692..dde1eed0893 100644
--- a/python/mxnet/torch.py
+++ b/python/mxnet/torch.py
@@ -142,18 +142,20 @@ def generic_torch_function(*args, **kwargs):
for k in kwargs:
kwargs[k] = str(kwargs[k])
- check_call(_LIB.MXFuncInvokeEx( \
- handle, \
- c_handle_array(ndargs[n_mutate_vars:]), \
- c_array(mx_float, []), \
- c_handle_array(ndargs[:n_mutate_vars]),
- ctypes.c_int(len(kwargs)),
- c_str_array(kwargs.keys()),
- c_str_array(kwargs.values())))
+ check_call(_LIB.MXFuncInvokeEx(
+ handle,
+ c_handle_array(ndargs[n_mutate_vars:]), # pylint: disable=invalid-slice-index
+ c_array(mx_float, []),
+ c_handle_array(ndargs[:n_mutate_vars]), # pylint: disable=invalid-slice-index
+ ctypes.c_int(len(kwargs)),
+ c_str_array(kwargs.keys()),
+ c_str_array(kwargs.values())))
+
if n_mutate_vars == 1:
return ndargs[0]
else:
- return ndargs[:n_mutate_vars]
+ return ndargs[:n_mutate_vars] # pylint: disable=invalid-slice-index
+
# End of function declaration
ret_function = generic_torch_function
ret_function.__name__ = func_name[4:]
diff --git a/python/setup.py b/python/setup.py
index cf94adf982d..a34a0e047c2 100644
--- a/python/setup.py
+++ b/python/setup.py
@@ -89,7 +89,7 @@ def config_cython():
ret.append(Extension(
"mxnet/%s/.%s" % (subdir, fn[:-4]),
["mxnet/cython/%s" % fn],
- include_dirs=["../include/", "../nnvm/include"],
+ include_dirs=["../include/", "../3rdparty/nnvm/include"],
library_dirs=library_dirs,
libraries=libraries,
language="c++"))
diff --git a/scala-package/core/src/main/scala/ml/dmlc/mxnet/IO.scala b/scala-package/core/src/main/scala/ml/dmlc/mxnet/IO.scala
index 7bc936fc124..84263165ade 100644
--- a/scala-package/core/src/main/scala/ml/dmlc/mxnet/IO.scala
+++ b/scala-package/core/src/main/scala/ml/dmlc/mxnet/IO.scala
@@ -230,6 +230,10 @@ abstract class DataPack() extends Iterable[DataBatch] {
// Named data desc description contains name, shape, type and other extended attributes.
case class DataDesc(name: String, shape: Shape,
dtype: DType = Base.MX_REAL_TYPE, layout: String = "NCHW") {
+ require(shape.length == layout.length, ("number of dimensions in shape :%d with" +
+ " shape: %s should match the length of the layout: %d with layout: %s").
+ format(shape.length, shape.toString, layout.length, layout))
+
override def toString(): String = {
s"DataDesc[$name,$shape,$dtype,$layout]"
}
diff --git a/scala-package/core/src/test/scala/ml/dmlc/mxnet/ModuleSuite.scala b/scala-package/core/src/test/scala/ml/dmlc/mxnet/ModuleSuite.scala
index ab48ef7d192..d747c63e8fe 100644
--- a/scala-package/core/src/test/scala/ml/dmlc/mxnet/ModuleSuite.scala
+++ b/scala-package/core/src/test/scala/ml/dmlc/mxnet/ModuleSuite.scala
@@ -22,7 +22,6 @@ import ml.dmlc.mxnet.CheckUtils._
import ml.dmlc.mxnet.module._
import ml.dmlc.mxnet.optimizer._
import ml.dmlc.mxnet.io._
-
class ModuleSuite extends FunSuite with BeforeAndAfterAll {
test ("model dtype") {
val dType = DType.Float16
@@ -55,9 +54,9 @@ class ModuleSuite extends FunSuite with BeforeAndAfterAll {
val mod = new Module(c, IndexedSeq("b", "c", "a"), null,
contexts = Array(Context.cpu(0), Context.cpu(1)))
mod.bind(dataShapes = IndexedSeq(
- DataDesc("b", Shape(5, 5)),
- DataDesc("c", Shape(5, 5)),
- DataDesc("a", Shape(5, 5))),
+ DataDesc("b", Shape(5, 5), layout = "NT"),
+ DataDesc("c", Shape(5, 5), layout = "NT"),
+ DataDesc("a", Shape(5, 5), layout = "NT")),
inputsNeedGrad = true
)
mod.initParams()
@@ -108,14 +107,14 @@ class ModuleSuite extends FunSuite with BeforeAndAfterAll {
// single device
var mod = new Module(sym, IndexedSeq("data"), null)
- mod.bind(dataShapes = IndexedSeq(DataDesc("data", Shape(10, 10))))
+ mod.bind(dataShapes = IndexedSeq(DataDesc("data", Shape(10, 10), layout = "NT")))
mod.initParams()
mod.initOptimizer(optimizer = new SGD(learningRate = 0.1f, momentum = 0.9f))
mod.update()
mod.saveCheckpoint("test", 0, saveOptStates = true)
var mod2 = Module.loadCheckpoint("test", 0, loadOptimizerStates = true)
- mod2.bind(dataShapes = IndexedSeq(DataDesc("data", Shape(10, 10))))
+ mod2.bind(dataShapes = IndexedSeq(DataDesc("data", Shape(10, 10), layout = "NT")))
mod2.initOptimizer(optimizer = new SGD(learningRate = 0.1f, momentum = 0.9f))
assert(mod.getSymbol.toJson == mod2.getSymbol.toJson)
mapEqu(mod.getParams._1, mod2.getParams._1)
@@ -123,14 +122,14 @@ class ModuleSuite extends FunSuite with BeforeAndAfterAll {
// multi device
mod = new Module(sym, IndexedSeq("data"), null,
contexts = Array(Context.cpu(0), Context.cpu(1)))
- mod.bind(dataShapes = IndexedSeq(DataDesc("data", Shape(10, 10))))
+ mod.bind(dataShapes = IndexedSeq(DataDesc("data", Shape(10, 10), layout = "NT" )))
mod.initParams()
mod.initOptimizer(optimizer = new SGD(learningRate = 0.1f, momentum = 0.9f))
mod.update()
mod.saveCheckpoint("test", 0, saveOptStates = true)
mod2 = Module.loadCheckpoint("test", 0, loadOptimizerStates = true)
- mod2.bind(dataShapes = IndexedSeq(DataDesc("data", Shape(10, 10))))
+ mod2.bind(dataShapes = IndexedSeq(DataDesc("data", Shape(10, 10), layout = "NT")))
mod2.initOptimizer(optimizer = new SGD(learningRate = 0.1f, momentum = 0.9f))
assert(mod.getSymbol.toJson == mod2.getSymbol.toJson)
mapEqu(mod.getParams._1, mod2.getParams._1)
@@ -143,7 +142,7 @@ class ModuleSuite extends FunSuite with BeforeAndAfterAll {
var dShape = Shape(7, 20)
val mod = new Module(sym, IndexedSeq("data"), null,
contexts = Array(Context.cpu(0), Context.cpu(1)))
- mod.bind(dataShapes = IndexedSeq(DataDesc("data", dShape)))
+ mod.bind(dataShapes = IndexedSeq(DataDesc("data", dShape, layout = "NT")))
mod.initParams()
mod.initOptimizer(optimizer = new SGD(learningRate = 1f))
@@ -156,7 +155,7 @@ class ModuleSuite extends FunSuite with BeforeAndAfterAll {
assert(mod.getParams._1("fc_bias").toArray.forall(_ == -1f))
dShape = Shape(14, 20)
- mod.reshape(IndexedSeq(DataDesc("data", dShape)))
+ mod.reshape(IndexedSeq(DataDesc("data", dShape, layout = "NT")))
mod.forward(new DataBatch(
data = IndexedSeq(NDArray.ones(dShape)),
label = null, index = null, pad = 0))
@@ -167,8 +166,8 @@ class ModuleSuite extends FunSuite with BeforeAndAfterAll {
}
test ("module setParams") {
- val data = NDArray.array(Array(0.05f, 0.1f), Shape(1, 2))
- val label = NDArray.array(Array(0.01f, 0.99f), Shape(1, 2))
+ val data = NDArray.array(Array(0.05f, 0.1f), Shape(1, 1, 1, 2))
+ val label = NDArray.array(Array(0.01f, 0.99f), Shape(1, 1, 1, 2))
val trainData = new NDArrayIter(
IndexedSeq(data), IndexedSeq(label), labelName = "softmax_label")
@@ -217,8 +216,8 @@ class ModuleSuite extends FunSuite with BeforeAndAfterAll {
test ("monitor") {
// data iter
- val data = NDArray.array(Array(0.05f, 0.1f), Shape(1, 2))
- val label = NDArray.array(Array(0.01f, 0.99f), Shape(1, 2))
+ val data = NDArray.array(Array(0.05f, 0.1f), Shape(1, 1, 1, 2))
+ val label = NDArray.array(Array(0.01f, 0.99f), Shape(1, 1, 1, 2))
val trainData = new NDArrayIter(
IndexedSeq(data), IndexedSeq(label), labelName = "softmax_label")
@@ -295,8 +294,8 @@ class ModuleSuite extends FunSuite with BeforeAndAfterAll {
val mod = new Module(sym, IndexedSeq("data1", "data2"))
mod.bind(dataShapes = IndexedSeq(
- DataDesc("data1", dShape1), DataDesc("data2", dShape2)),
- labelShapes = Option(IndexedSeq(DataDesc("softmax_label", lShape)))
+ DataDesc("data1", dShape1), DataDesc("data2", dShape2, layout = "NCHW")),
+ labelShapes = Option(IndexedSeq(DataDesc("softmax_label", lShape, layout = "N")))
)
mod.initParams()
mod.initOptimizer(optimizer = new SGD(learningRate = 0.01f))
diff --git a/scala-package/examples/pom.xml b/scala-package/examples/pom.xml
index 351f71fa852..5919b3e7f7b 100644
--- a/scala-package/examples/pom.xml
+++ b/scala-package/examples/pom.xml
@@ -14,6 +14,24 @@
<name>MXNet Scala Package - Examples</name>
<profiles>
+ <profile>
+ <id>osx-x86_64-cpu</id>
+ <properties>
+ <platform>osx-x86_64-cpu</platform>
+ </properties>
+ </profile>
+ <profile>
+ <id>linux-x86_64-cpu</id>
+ <properties>
+ <platform>linux-x86_64-cpu</platform>
+ </properties>
+ </profile>
+ <profile>
+ <id>linux-x86_64-gpu</id>
+ <properties>
+ <platform>linux-x86_64-gpu</platform>
+ </properties>
+ </profile>
<profile>
<id>release</id>
<build>
@@ -107,13 +125,22 @@
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
</plugin>
+ <plugin>
+ <groupId>org.scalatest</groupId>
+ <artifactId>scalatest-maven-plugin</artifactId>
+ <configuration>
+ <argLine>
+ -Djava.library.path=${project.parent.basedir}/native/${platform}/target \
+ -Dlog4j.configuration=file://${project.basedir}/src/test/resources/log4j.properties
+ </argLine>
+ </configuration>
+ </plugin>
<plugin>
<groupId>org.scalastyle</groupId>
<artifactId>scalastyle-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
-
<dependencies>
<dependency>
<groupId>ml.dmlc.mxnet</groupId>
@@ -121,6 +148,12 @@
<version>1.2.0-SNAPSHOT</version>
<scope>provided</scope>
</dependency>
+ <dependency>
+ <groupId>ml.dmlc.mxnet</groupId>
+ <artifactId>mxnet-infer_${scala.binary.version}</artifactId>
+ <version>1.2.0-SNAPSHOT</version>
+ <scope>provided</scope>
+ </dependency>
<dependency>
<groupId>com.sksamuel.scrimage</groupId>
<artifactId>scrimage-core_2.11</artifactId>
@@ -141,5 +174,10 @@
<artifactId>opencv</artifactId>
<version>2.4.9-7</version>
</dependency>
+ <dependency>
+ <groupId>org.slf4j</groupId>
+ <artifactId>slf4j-simple</artifactId>
+ <version>1.7.5</version>
+ </dependency>
</dependencies>
</project>
diff --git a/scala-package/examples/scripts/inferexample/imageclassifier/get_resnet_data.sh b/scala-package/examples/scripts/inferexample/imageclassifier/get_resnet_data.sh
new file mode 100755
index 00000000000..0fbd3237f00
--- /dev/null
+++ b/scala-package/examples/scripts/inferexample/imageclassifier/get_resnet_data.sh
@@ -0,0 +1,41 @@
+#!/bin/bash
+
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+set -e
+
+MXNET_ROOT=$(cd "$(dirname $0)/../../.."; pwd)
+
+data_path=$MXNET_ROOT/scripts/inferexample/models/resnet-152/
+
+image_path=$MXNET_ROOT/scripts/inferexample/images/
+
+if [ ! -d "$data_path" ]; then
+ mkdir -p "$data_path"
+fi
+
+if [ ! -d "$image_path" ]; then
+ mkdir -p "$image_path"
+fi
+
+if [ ! -f "$data_path" ]; then
+ wget http://data.mxnet.io/models/imagenet-11k/resnet-152/resnet-152-0000.params -P $data_path
+ wget http://data.mxnet.io/models/imagenet-11k/resnet-152/resnet-152-symbol.json -P $data_path
+ wget http://data.mxnet.io/models/imagenet-11k/synset.txt -P $data_path
+ wget https://s3.amazonaws.com/model-server/inputs/kitten.jpg -P $image_path
+fi
diff --git a/scala-package/examples/scripts/inferexample/imageclassifier/run_classifier_example.sh b/scala-package/examples/scripts/inferexample/imageclassifier/run_classifier_example.sh
new file mode 100755
index 00000000000..d8c4c3ea54c
--- /dev/null
+++ b/scala-package/examples/scripts/inferexample/imageclassifier/run_classifier_example.sh
@@ -0,0 +1,36 @@
+#!/bin/bash
+
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+set -e
+
+MXNET_ROOT=$(cd "$(dirname $0)/../../../../.."; pwd)
+CLASS_PATH=$MXNET_ROOT/scala-package/assembly/osx-x86_64-cpu/target/*:$MXNET_ROOT/scala-package/examples/target/*:$MXNET_ROOT/scala-package/examples/target/classes/lib/*:$MXNET_ROOT/scala-package/infer/target/*
+
+# model dir
+MODEL_PATH_PREFIX=$1
+# input image
+INPUT_IMG=$2
+# which input image dir
+INPUT_DIR=$3
+
+java -Xmx8G -Dmxnet.traceLeakedObjects=true -cp $CLASS_PATH \
+ ml.dmlc.mxnetexamples.inferexample.imageclassifier.ImageClassifierExample \
+ --model-path-prefix $MODEL_PATH_PREFIX \
+ --input-image $INPUT_IMG \
+ --input-dir $INPUT_DIR
diff --git a/scala-package/examples/scripts/inferexample/objectdetector/get_ssd_data.sh b/scala-package/examples/scripts/inferexample/objectdetector/get_ssd_data.sh
new file mode 100755
index 00000000000..09f4c4b8f74
--- /dev/null
+++ b/scala-package/examples/scripts/inferexample/objectdetector/get_ssd_data.sh
@@ -0,0 +1,46 @@
+#!/bin/bash
+
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+
+set -e
+
+MXNET_ROOT=$(cd "$(dirname $0)/../../../.."; pwd)
+
+data_path=$MXNET_ROOT/examples/scripts/inferexample/models/resnet50_ssd
+
+image_path=$MXNET_ROOT/examples/scripts/inferexample/images
+
+if [ ! -d "$data_path" ]; then
+ mkdir -p "$data_path"
+fi
+
+if [ ! -d "$image_path" ]; then
+ mkdir -p "$image_path"
+fi
+
+if [ ! -f "$data_path" ]; then
+ wget https://s3.amazonaws.com/model-server/models/resnet50_ssd/resnet50_ssd_model-symbol.json -P $data_path
+ wget https://s3.amazonaws.com/model-server/models/resnet50_ssd/resnet50_ssd_model-0000.params -P $data_path
+ wget https://raw.githubusercontent.com/awslabs/mxnet-model-server/master/examples/ssd/synset.txt -P $data_path
+ cd $image_path
+ wget https://cloud.githubusercontent.com/assets/3307514/20012566/cbb53c76-a27d-11e6-9aaa-91939c9a1cd5.jpg -O 000001.jpg
+ wget https://cloud.githubusercontent.com/assets/3307514/20012567/cbb60336-a27d-11e6-93ff-cbc3f09f5c9e.jpg -O dog.jpg
+ wget https://cloud.githubusercontent.com/assets/3307514/20012563/cbb41382-a27d-11e6-92a9-18dab4fd1ad3.jpg -O person.jpg
+fi
+
diff --git a/scala-package/examples/scripts/inferexample/objectdetector/run_ssd_example.sh b/scala-package/examples/scripts/inferexample/objectdetector/run_ssd_example.sh
new file mode 100755
index 00000000000..3bdcf5166f8
--- /dev/null
+++ b/scala-package/examples/scripts/inferexample/objectdetector/run_ssd_example.sh
@@ -0,0 +1,35 @@
+#!/bin/bash
+
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+
+MXNET_ROOT=$(cd "$(dirname $0)/../../../../../"; pwd)
+CLASS_PATH=$MXNET_ROOT/scala-package/assembly/osx-x86_64-cpu/target/*:$MXNET_ROOT/scala-package/examples/target/*:$MXNET_ROOT/scala-package/examples/target/classes/lib/*:$MXNET_ROOT/scala-package/infer/target/*
+
+# model dir and prefix
+MODEL_DIR=$1
+# input image
+INPUT_IMG=$2
+# which input image dir
+INPUT_DIR=$3
+
+java -Xmx8G -cp $CLASS_PATH \
+ ml.dmlc.mxnetexamples.inferexample.objectdetector.SSDClassifierExample \
+ --model-path-prefix $MODEL_DIR \
+ --input-image $INPUT_IMG \
+ --input-dir $INPUT_DIR
diff --git a/scala-package/examples/src/main/scala/ml/dmlc/mxnetexamples/inferexample/imageclassifier/ImageClassifierExample.scala b/scala-package/examples/src/main/scala/ml/dmlc/mxnetexamples/inferexample/imageclassifier/ImageClassifierExample.scala
new file mode 100644
index 00000000000..22c49e928f1
--- /dev/null
+++ b/scala-package/examples/src/main/scala/ml/dmlc/mxnetexamples/inferexample/imageclassifier/ImageClassifierExample.scala
@@ -0,0 +1,126 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package ml.dmlc.mxnetexamples.inferexample.imageclassifier
+
+import ml.dmlc.mxnet.Shape
+import org.kohsuke.args4j.{CmdLineParser, Option}
+import org.slf4j.LoggerFactory
+
+import ml.dmlc.mxnet.{DType, DataDesc}
+import ml.dmlc.mxnet.infer.ImageClassifier
+
+import scala.collection.JavaConverters._
+import java.io.File
+
+/**
+ * Example showing usage of Infer package to do inference on resnet-152 model
+ * Follow instructions in README.md to run this example.
+ */
+object ImageClassifierExample {
+ private val logger = LoggerFactory.getLogger(classOf[ImageClassifierExample])
+
+ def runInferenceOnSingleImage(modelPathPrefix: String, inputImagePath: String):
+ IndexedSeq[IndexedSeq[(String, Float)]] = {
+ val dType = DType.Float32
+ val inputShape = Shape(1, 3, 224, 224)
+
+ val inputDescriptor = IndexedSeq(DataDesc("data", inputShape, dType, "NCHW"))
+
+ // Create object of ImageClassifier class
+ val imgClassifier: ImageClassifier = new
+ ImageClassifier(modelPathPrefix, inputDescriptor)
+
+ // Loading single image from file and getting BufferedImage
+ val img = ImageClassifier.loadImageFromFile(inputImagePath)
+
+ // Running inference on single image
+ val output = imgClassifier.classifyImage(img, Some(5))
+
+ output
+ }
+
+ def runInferenceOnBatchOfImage(modelPathPrefix: String, inputImageDir: String):
+ IndexedSeq[IndexedSeq[(String, Float)]] = {
+ val dType = DType.Float32
+ val inputShape = Shape(1, 3, 224, 224)
+
+ val inputDescriptor = IndexedSeq(DataDesc("data", inputShape, dType, "NCHW"))
+
+ // Create object of ImageClassifier class
+ val imgClassifier: ImageClassifier = new
+ ImageClassifier(modelPathPrefix, inputDescriptor)
+
+ // Loading batch of images from the directory path
+ val imgList = ImageClassifier.loadInputBatch(inputImageDir)
+
+ // Running inference on batch of images loaded in previous step
+ val outputList = imgClassifier.classifyImageBatch(imgList, Some(5))
+
+ outputList
+ }
+
+ def main(args: Array[String]): Unit = {
+ val inst = new ImageClassifierExample
+ val parser: CmdLineParser = new CmdLineParser(inst)
+ try {
+ parser.parseArgument(args.toList.asJava)
+
+ val modelPathPrefix = if (inst.modelPathPrefix == null) System.getenv("MXNET_DATA_DIR")
+ else inst.modelPathPrefix
+
+ val inputImagePath = if (inst.inputImagePath == null) System.getenv("MXNET_DATA_DIR")
+ else inst.inputImagePath
+
+ val inputImageDir = if (inst.inputImageDir == null) System.getenv("MXNET_DATA_DIR")
+ else inst.inputImageDir
+
+ val singleOutput = runInferenceOnSingleImage(modelPathPrefix, inputImagePath)
+
+ // Printing top 5 class probabilities
+ for (i <- singleOutput) {
+ printf("Classes with top 5 probability = %s \n", i)
+ }
+
+ val batchOutput = runInferenceOnBatchOfImage(modelPathPrefix, inputImageDir)
+
+ val d = new File(inputImageDir)
+ val filenames = d.listFiles.filter(_.isFile).toList
+
+ // Printing filename and inference class with top 5 probabilities
+ for ((f, inferOp) <- (filenames zip batchOutput)) {
+ printf("Input image %s ", f)
+ printf("Class with probability =%s \n", inferOp)
+ }
+ } catch {
+ case ex: Exception => {
+ logger.error(ex.getMessage, ex)
+ parser.printUsage(System.err)
+ sys.exit(1)
+ }
+ }
+ }
+}
+
+class ImageClassifierExample {
+ @Option(name = "--model-path-prefix", usage = "the input model directory")
+ private val modelPathPrefix: String = "/resnet-152/resnet-152"
+ @Option(name = "--input-image", usage = "the input image")
+ private val inputImagePath: String = "/images/kitten.jpg"
+ @Option(name = "--input-dir", usage = "the input batch of images directory")
+ private val inputImageDir: String = "/images/"
+}
diff --git a/scala-package/examples/src/main/scala/ml/dmlc/mxnetexamples/inferexample/imageclassifier/README.md b/scala-package/examples/src/main/scala/ml/dmlc/mxnetexamples/inferexample/imageclassifier/README.md
new file mode 100644
index 00000000000..99e8edb8814
--- /dev/null
+++ b/scala-package/examples/src/main/scala/ml/dmlc/mxnetexamples/inferexample/imageclassifier/README.md
@@ -0,0 +1,88 @@
+# Image Classification
+
+This folder contains an example for image classification with the [MXNet Scala Infer API](https://github.com/apache/incubator-mxnet/tree/master/scala-package/infer).
+The goal of image classification is to identify the objects contained in images.
+The following example shows recognized object classes with corresponding probabilities using a pre-trained model.
+
+
+## Contents
+
+1. [Prerequisites](#prerequisites)
+2. [Download artifacts](#download-artifacts)
+3. [Run the image inference example](#run-the-image-inference-example)
+4. [Pretrained models](#pretrained-models)
+5. [Infer APIs](#infer-api-details)
+6. [Next steps](#next-steps)
+
+
+## Prerequisites
+
+1. MXNet
+2. MXNet Scala Package
+3. [IntelliJ IDE (or alternative IDE) project setup](http://mxnet.incubator.apache.org/tutorials/scala/mxnet_scala_on_intellij.html) with the MXNet Scala Package
+4. wget
+
+
+## Download Artifacts
+
+For this tutorial, you can get the model and sample input image by running following bash file. This script will use `wget` to download these artifacts from AWS S3.
+
+From the `scala-package/examples/scripts/inferexample/imageclassifier/` folder run:
+
+```bash
+./get_resnet_data.sh
+```
+
+**Note**: You may need to run `chmod +x get_resnet_data.sh` before running this script.
+
+
+## Run the Image Inference Example
+
+Now that you have the model files and the test kitten image, you can run the following script to pass the necessary parameters to the JDK to run this inference example.
+
+```bash
+./run_classifier_example.sh \
+../resnet/resnet-152 ../images/kitten.jpg ../images/
+```
+
+**Notes**:
+* These are relative paths to this script.
+* You may need to run `chmod +x run_predictor_example.sh` before running this script.
+
+There are few options which you can provide to run the example. Use the `--help` argument to list them.
+
+```bash
+./run_predictor_example.sh --help
+```
+
+The available arguments are as follows:
+
+| Argument | Comments |
+| ----------------------------- | ---------------------------------------- |
+| `model-dir` | Folder path with prefix to the model (including json, params, and any synset file). |
+| `input-image` | The image to run inference on. |
+| `input-dir` | The directory of images to run inference on. |
+
+* You must use `model-dir`.
+* You must use `input-image` and `input-dir` as this example shows single image inference as well as batch inference together.
+
+
+## Pretrained Models
+
+The MXNet project repository provides several [pre-trained models on various datasets](https://github.com/apache/incubator-mxnet/tree/master/example/image-classification#pre-trained-models) and examples on how to train them. You may use the [modelzoo.py](https://github.com/apache/incubator-mxnet/blob/master/example/image-classification/common/modelzoo.py) helper script to download these models. Many ImageNet models may be also be downloaded directly from [http://data.mxnet.io/models/imagenet/](http://data.mxnet.io/models/imagenet/).
+
+
+## Infer API Details
+
+This example uses the [ImageClassifier](https://github.com/apache/incubator-mxnet/blob/master/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/ImageClassifier.scala)
+class provided by the [MXNet Scala Infer API](https://github.com/apache/incubator-mxnet/tree/master/scala-package/infer).
+It provides methods to load the images, create a NDArray out of a `BufferedImage`, and run prediction using the following Infer APIs:
+* [Classifier](https://github.com/apache/incubator-mxnet/blob/master/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/Classifier.scala)
+* [Predictor](https://github.com/apache/incubator-mxnet/blob/master/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/Predictor.scala)
+
+
+## Next Steps
+
+Check out the following related tutorials and examples for the Infer API:
+
+* [Single Shot Detector with the MXNet Scala Infer API](../objectdetector/README.md)
diff --git a/scala-package/examples/src/main/scala/ml/dmlc/mxnetexamples/inferexample/objectdetector/README.md b/scala-package/examples/src/main/scala/ml/dmlc/mxnetexamples/inferexample/objectdetector/README.md
new file mode 100644
index 00000000000..bc7f337f1b7
--- /dev/null
+++ b/scala-package/examples/src/main/scala/ml/dmlc/mxnetexamples/inferexample/objectdetector/README.md
@@ -0,0 +1,116 @@
+# Single Shot Multi Object Detection using Scala Inference API
+
+In this example, you will learn how to use Scala Inference API to run Inference on pre-trained Single Shot Multi Object Detection (SSD) MXNet model.
+
+The model is trained on the [Pascal VOC 2012 dataset](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html). The network is a SSD model built on Resnet50 as base network to extract image features. The model is trained to detect the following entities (classes): ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']. For more details about the model, you can refer to the [MXNet SSD example](https://github.com/apache/incubator-mxnet/tree/master/example/ssd).
+
+
+## Contents
+
+1. [Prerequisites](#prerequisites)
+2. [Download artifacts](#download-artifacts)
+3. [Setup datapath and parameters](#setup-datapath-and-parameters)
+4. [Run the image inference example](#run-the-image-inference-example)
+5. [Infer APIs](#infer-api-details)
+6. [Next steps](#next-steps)
+
+
+## Prerequisites
+
+1. MXNet
+2. MXNet Scala Package
+3. [IntelliJ IDE (or alternative IDE) project setup](http://mxnet.incubator.apache.org/tutorials/scala/mxnet_scala_on_intellij.html) with the MXNet Scala Package
+4. wget
+
+
+## Setup Guide
+
+### Download Artifacts
+#### Step 1
+You can download the files using the script `get_ssd_data.sh`. It will download and place the model files in a `model` folder and the test image files in a `image` folder in the current directory.
+From the `scala-package/examples/scripts/inferexample/imageclassifier/` folder run:
+
+```bash
+./get_resnet_data.sh
+```
+
+**Note**: You may need to run `chmod +x get_resnet_data.sh` before running this script.
+
+Alternatively use the following links to download the Symbol and Params files via your browser:
+- [resnet50_ssd_model-symbol.json](https://s3.amazonaws.com/model-server/models/resnet50_ssd/resnet50_ssd_model-symbol.json)
+- [resnet50_ssd_model-0000.params](https://s3.amazonaws.com/model-server/models/resnet50_ssd/resnet50_ssd_model-0000.params)
+- [synset.txt](https://github.com/awslabs/mxnet-model-server/blob/master/examples/ssd/synset.txt)
+
+In the pre-trained model, the `input_name` is `data` and shape is `(1, 3, 512, 512)`.
+This shape translates to: a batch of `1` image, the image has color and uses `3` channels (RGB), and the image has the dimensions of `512` pixels in height by `512` pixels in width.
+
+`image/jpeg` is the expected input type, since this example's image pre-processor only supports the handling of binary JPEG images.
+
+The output shape is `(1, 6132, 6)`. As with the input, the `1` is the number of images. `6132` is the number of prediction results, and `6` is for the size of each prediction. Each prediction contains the following components:
+- `Class`
+- `Accuracy`
+- `Xmin`
+- `Ymin`
+- `Xmax`
+- `Ymax`
+
+
+### Setup Datapath and Parameters
+#### Step 2
+The code `Line 31: val baseDir = System.getProperty("user.dir")` in the example will automatically searches the work directory you have defined. Please put the files in your [work directory](https://stackoverflow.com/questions/16239130/java-user-dir-property-what-exactly-does-it-mean). <!-- how do you define the work directory? -->
+
+Alternatively, if you would like to use your own path, please change line 31 into your own path
+```scala
+val baseDir = <Your Own Path>
+```
+
+The followings is the parameters defined for this example, you can find more information in the `class SSDClassifierExample`.
+
+| Argument | Comments |
+| ----------------------------- | ---------------------------------------- |
+| `model-path-prefix` | Folder path with prefix to the model (including json, params, and any synset file). |
+| `input-image` | The image to run inference on. |
+| `input-dir` | The directory of images to run inference on. |
+
+
+## How to Run Inference
+After the previous steps, you should be able to run the code using the following script that will pass all of the required parameters to the Infer API.
+
+From the `scala-package/examples/scripts/inferexample/objectdetector/` folder run:
+
+```bash
+./run_ssd_example.sh ../model/resnet50_ssd_model ../image/dog.jpg ../image
+```
+
+**Notes**:
+* These are relative paths to this script.
+* You may need to run `chmod +x run_ssd_example.sh` before running this script.
+
+The example should give expected output as shown below:
+```
+Class: car
+Probabilties: 0.99847263
+(Coord:,312.21335,72.0291,456.01443,150.66176)
+Class: bicycle
+Probabilties: 0.90473825
+(Coord:,155.95807,149.96362,383.8369,418.94513)
+Class: dog
+Probabilties: 0.8226818
+(Coord:,83.82353,179.13998,206.63783,476.7875)
+```
+the outputs come from the the input image, with top3 predictions picked.
+
+
+## Infer API Details
+This example uses ObjectDetector class provided by MXNet's scala package Infer APIs. It provides methods to load the images, create NDArray out of Java BufferedImage and run prediction using Classifier and Predictor APIs.
+
+
+## References
+This documentation used the model and inference setup guide from the [MXNet Model Server SSD example](https://github.com/awslabs/mxnet-model-server/blob/master/examples/ssd/README.md).
+
+
+## Next Steps
+
+Check out the following related tutorials and examples for the Infer API:
+
+* [Image Classification with the MXNet Scala Infer API](../imageclassifier/README.md)
\ No newline at end of file
diff --git a/scala-package/examples/src/main/scala/ml/dmlc/mxnetexamples/inferexample/objectdetector/SSDClassifierExample.scala b/scala-package/examples/src/main/scala/ml/dmlc/mxnetexamples/inferexample/objectdetector/SSDClassifierExample.scala
new file mode 100644
index 00000000000..9b8a26c988d
--- /dev/null
+++ b/scala-package/examples/src/main/scala/ml/dmlc/mxnetexamples/inferexample/objectdetector/SSDClassifierExample.scala
@@ -0,0 +1,147 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package ml.dmlc.mxnetexamples.inferexample.objectdetector
+
+import ml.dmlc.mxnet.{DType, Shape, DataDesc}
+import ml.dmlc.mxnet.infer._
+import org.kohsuke.args4j.{CmdLineParser, Option}
+import org.slf4j.LoggerFactory
+
+import scala.collection.JavaConverters._
+import java.nio.file.{Files, Paths}
+
+class SSDClassifierExample {
+ @Option(name = "--model-path-prefix", usage = "the input model directory and prefix of the model")
+ private val modelPathPrefix: String = "/model/ssd_resnet50_512"
+ @Option(name = "--input-image", usage = "the input image")
+ private val inputImagePath: String = "/images/dog.jpg"
+ @Option(name = "--input-dir", usage = "the input batch of images directory")
+ private val inputImageDir: String = "/images/"
+}
+
+object SSDClassifierExample {
+
+ private val logger = LoggerFactory.getLogger(classOf[SSDClassifierExample])
+ private type SSDOut = (String, Array[Float])
+
+ def runObjectDetectionSingle(modelPathPrefix: String, inputImagePath: String):
+ IndexedSeq[IndexedSeq[(String, Array[Float])]] = {
+ val dType = DType.Float32
+ val inputShape = Shape(1, 3, 512, 512)
+ // ssd detections, numpy.array([[id, score, x1, y1, x2, y2]...])
+ val outputShape = Shape(1, 6132, 6)
+ val inputDescriptors = IndexedSeq(DataDesc("data", inputShape, dType, "NCHW"))
+ val img = ImageClassifier.loadImageFromFile(inputImagePath)
+ val objDetector = new ObjectDetector(modelPathPrefix, inputDescriptors)
+ val output = objDetector.imageObjectDetect(img, Some(3))
+
+ output
+ }
+
+ def runObjectDetectionBatch(modelPathPrefix: String, inputImageDir: String):
+ IndexedSeq[IndexedSeq[(String, Array[Float])]] = {
+ val dType = DType.Float32
+ val inputShape = Shape(1, 3, 512, 512)
+ // ssd detections, numpy.array([[id, score, x1, y1, x2, y2]...])
+ val outputShape = Shape(1, 6132, 6)
+ val inputDescriptors = IndexedSeq(DataDesc("data", inputShape, dType, "NCHW"))
+ val imgList = ImageClassifier.loadInputBatch(inputImageDir)
+ val objDetector = new ObjectDetector(modelPathPrefix, inputDescriptors)
+ val outputList = objDetector.imageBatchObjectDetect(imgList, Some(1))
+ outputList
+ }
+
+ def main(args: Array[String]): Unit = {
+ val inst = new SSDClassifierExample
+ val parser : CmdLineParser = new CmdLineParser(inst)
+ parser.parseArgument(args.toList.asJava)
+ val baseDir = System.getProperty("user.dir")
+ val mdprefixDir = baseDir + inst.modelPathPrefix
+ val imgPath = baseDir + inst.inputImagePath
+ val imgDir = baseDir + inst.inputImageDir
+ if (!checkExist(Array(mdprefixDir + "-symbol.json", imgDir, imgPath))) {
+ logger.error("Model or input image path does not exist")
+ sys.exit(1)
+ }
+
+ try {
+ val inputShape = Shape(1, 3, 512, 512)
+ val outputShape = Shape(1, 6132, 6)
+
+ val width = inputShape(2)
+ val height = inputShape(3)
+ var outputStr : String = "\n"
+
+ val output = runObjectDetectionSingle(mdprefixDir, imgPath)
+
+
+ for (ele <- output) {
+ for (i <- ele) {
+ outputStr += "Class: " + i._1 + "\n"
+ val arr = i._2
+ outputStr += "Probabilties: " + arr(0) + "\n"
+ val coord = Array[Float](
+ arr(1) * width, arr(2) * height,
+ arr(3) * width, arr(4) * height
+ )
+ outputStr += "Coord:" + coord.mkString(",") + "\n"
+ }
+ }
+ logger.info(outputStr)
+
+ val outputList = runObjectDetectionBatch(mdprefixDir, imgDir)
+
+ outputStr = "\n"
+ for (idx <- outputList.indices) {
+ outputStr += "*** Image " + (idx + 1) + "***" + "\n"
+ for (i <- outputList(idx)) {
+ outputStr += "Class: " + i._1 + "\n"
+ val arr = i._2
+ outputStr += "Probabilties: " + arr(0) + "\n"
+ val coord = Array[Float](
+ arr(1) * width, arr(2) * height,
+ arr(3) * width, arr(4) * height
+ )
+ outputStr += "Coord:" + coord.mkString(",") + "\n"
+ }
+ }
+ logger.info(outputStr)
+
+ } catch {
+ case ex: Exception => {
+ logger.error(ex.getMessage, ex)
+ parser.printUsage(System.err)
+ sys.exit(1)
+ }
+ }
+ sys.exit(0)
+ }
+
+
+ def checkExist(arr : Array[String]) : Boolean = {
+ var exist : Boolean = true
+ for (item <- arr) {
+ exist = Files.exists(Paths.get(item)) && exist
+ if (!exist) {
+ logger.error("Cannot find: " + item)
+ }
+ }
+ exist
+ }
+
+}
diff --git a/ci/docker/install/ubuntu_lint.sh b/scala-package/examples/src/test/resources/log4j.properties
old mode 100755
new mode 100644
similarity index 70%
rename from ci/docker/install/ubuntu_lint.sh
rename to scala-package/examples/src/test/resources/log4j.properties
index f3a1d6ba244..ef523cb7bc4
--- a/ci/docker/install/ubuntu_lint.sh
+++ b/scala-package/examples/src/test/resources/log4j.properties
@@ -1,5 +1,3 @@
-#!/bin/bash
-
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
@@ -7,9 +5,9 @@
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
-#
+#
# http://www.apache.org/licenses/LICENSE-2.0
-#
+#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
@@ -17,9 +15,10 @@
# specific language governing permissions and limitations
# under the License.
-# build and install are separated so changes to build don't invalidate
-# the whole docker cache for the image
+# for development debugging
+log4j.rootLogger = info, stdout
-set -ex
-apt-get update
-apt-get install -y python-pip sudo
\ No newline at end of file
+log4j.appender.stdout = org.apache.log4j.ConsoleAppender
+log4j.appender.stdout.Target = System.out
+log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
+log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c] [%p] - %m%n
diff --git a/scala-package/examples/src/test/scala/ml/dmlc/mxnetexamples/inferexample/imageclassifier/ImageClassifierExampleSuite.scala b/scala-package/examples/src/test/scala/ml/dmlc/mxnetexamples/inferexample/imageclassifier/ImageClassifierExampleSuite.scala
new file mode 100644
index 00000000000..18608b05acd
--- /dev/null
+++ b/scala-package/examples/src/test/scala/ml/dmlc/mxnetexamples/inferexample/imageclassifier/ImageClassifierExampleSuite.scala
@@ -0,0 +1,70 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package ml.dmlc.mxnetexamples.inferexample.imageclassifier
+
+import org.scalatest.{BeforeAndAfterAll, FunSuite}
+import org.slf4j.LoggerFactory
+
+import java.io.File
+import sys.process.Process
+
+/**
+ * Integration test for imageClassifier example.
+ * This will run as a part of "make scalatest"
+ */
+class ImageClassifierExampleSuite extends FunSuite with BeforeAndAfterAll {
+ private val logger = LoggerFactory.getLogger(classOf[ImageClassifierExampleSuite])
+
+ test("testImageClassifierExample") {
+ logger.info("Downloading resnet-18 model")
+
+ val tempDirPath = System.getProperty("java.io.tmpdir")
+ logger.info("tempDirPath: %s".format(tempDirPath))
+
+ Process("wget http://data.mxnet.io/models/imagenet/resnet/18-layers/resnet-18-symbol.json " +
+ "-P " + tempDirPath + "/resnet18/ -q") !
+
+ Process("wget http://data.mxnet.io/models/imagenet/resnet/18-layers/resnet-18-0000.params " +
+ "-P " + tempDirPath + "/resnet18/ -q") !
+
+ Process("wget http://data.mxnet.io/models/imagenet/resnet/synset.txt -P " + tempDirPath +
+ "/resnet18/ -q") !
+
+ Process("wget " +
+ "https://s3.amazonaws.com/model-server/inputs/Pug-Cookie.jpg " +
+ "-P " + tempDirPath + "/inputImages/") !
+
+ val modelDirPath = tempDirPath + File.separator + "resnet18/"
+ val inputImagePath = tempDirPath + File.separator +
+ "inputImages/Pug-Cookie.jpg"
+ val inputImageDir = tempDirPath + File.separator + "inputImages/"
+
+ val output = ImageClassifierExample.runInferenceOnSingleImage(modelDirPath + "resnet-18",
+ inputImagePath)
+
+ assert(output(0).toList.head._1 === "n02110958 pug, pug-dog")
+
+ val outputList = ImageClassifierExample.runInferenceOnBatchOfImage(modelDirPath + "resnet-18",
+ inputImageDir)
+
+ assert(outputList(0).toList.head._1 === "n02110958 pug, pug-dog")
+
+ Process("rm -rf " + modelDirPath + " " + inputImageDir) !
+
+ }
+}
diff --git a/scala-package/examples/src/test/scala/ml/dmlc/mxnetexamples/inferexample/objectdetector/ObjectDetectorExampleSuite.scala b/scala-package/examples/src/test/scala/ml/dmlc/mxnetexamples/inferexample/objectdetector/ObjectDetectorExampleSuite.scala
new file mode 100644
index 00000000000..77f540e14b0
--- /dev/null
+++ b/scala-package/examples/src/test/scala/ml/dmlc/mxnetexamples/inferexample/objectdetector/ObjectDetectorExampleSuite.scala
@@ -0,0 +1,74 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package ml.dmlc.mxnetexamples.inferexample.objectdetector
+
+import java.io.File
+
+import org.scalatest.{BeforeAndAfterAll, FunSuite}
+import org.slf4j.LoggerFactory
+
+import scala.sys.process.Process
+
+class ObjectDetectorExampleSuite extends FunSuite with BeforeAndAfterAll {
+ private val logger = LoggerFactory.getLogger(classOf[ObjectDetectorExampleSuite])
+
+ test("testObjectDetectionExample") {
+ logger.info("Downloading resnetssd model")
+ val tempDirPath = System.getProperty("java.io.tmpdir")
+
+ logger.info("tempDirPath: %s".format(tempDirPath))
+
+ val modelBase = "https://s3.amazonaws.com/model-server/models/resnet50_ssd/"
+ val synsetBase = "https://raw.githubusercontent.com/awslabs/mxnet-model-server/master/examples/"
+ val imageBase = "https://s3.amazonaws.com/model-server/inputs/"
+
+ Process("wget " + modelBase + "resnet50_ssd_model-symbol.json " + "-P " +
+ tempDirPath + "/resnetssd/ -q") !
+
+
+ Process("wget " + modelBase + "resnet50_ssd_model-0000.params " +
+ "-P " + tempDirPath + "/resnetssd/ -q") !
+
+
+ Process("wget " + synsetBase + "ssd/synset.txt " + "-P" +
+ tempDirPath + "/resnetssd/ -q") !
+
+ Process("wget " +
+ imageBase + "dog-ssd.jpg " +
+ "-P " + tempDirPath + "/inputImages/") !
+
+
+ val modelDirPath = tempDirPath + File.separator + "resnetssd/"
+ val inputImagePath = tempDirPath + File.separator +
+ "inputImages/dog-ssd.jpg"
+ val inputImageDir = tempDirPath + File.separator + "inputImages/"
+
+ val output = SSDClassifierExample.runObjectDetectionSingle(modelDirPath + "resnet50_ssd_model",
+ inputImagePath)
+
+ assert(output(0)(0)._1 === "car")
+
+ val outputList = SSDClassifierExample.runObjectDetectionBatch(
+ modelDirPath + "resnet50_ssd_model",
+ inputImageDir)
+
+ assert(output(0)(0)._1 === "car")
+
+ Process("rm -rf " + modelDirPath + " " + inputImageDir) !
+ }
+}
diff --git a/scala-package/infer/pom.xml b/scala-package/infer/pom.xml
new file mode 100644
index 00000000000..d8c10971d4e
--- /dev/null
+++ b/scala-package/infer/pom.xml
@@ -0,0 +1,85 @@
+<?xml version="1.0" encoding="UTF-8"?>
+<project xmlns="http://maven.apache.org/POM/4.0.0"
+ xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
+ xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
+ <modelVersion>4.0.0</modelVersion>
+ <parent>
+ <artifactId>mxnet-parent_2.11</artifactId>
+ <groupId>ml.dmlc.mxnet</groupId>
+ <version>1.2.0-SNAPSHOT</version>
+ <relativePath>../pom.xml</relativePath>
+ </parent>
+
+ <artifactId>mxnet-infer_2.11</artifactId>
+ <name>MXNet Scala Package - Inference</name>
+
+ <profiles>
+ <profile>
+ <id>osx-x86_64-cpu</id>
+ <properties>
+ <platform>osx-x86_64-cpu</platform>
+ </properties>
+ </profile>
+ <profile>
+ <id>linux-x86_64-cpu</id>
+ <properties>
+ <platform>linux-x86_64-cpu</platform>
+ </properties>
+ </profile>
+ <profile>
+ <id>linux-x86_64-gpu</id>
+ <properties>
+ <platform>linux-x86_64-gpu</platform>
+ </properties>
+ </profile>
+ </profiles>
+
+ <build>
+ <plugins>
+ <plugin>
+ <groupId>org.apache.maven.plugins</groupId>
+ <artifactId>maven-jar-plugin</artifactId>
+ <configuration>
+ <excludes>
+ <exclude>META-INF/*.SF</exclude>
+ <exclude>META-INF/*.DSA</exclude>
+ <exclude>META-INF/*.RSA</exclude>
+ </excludes>
+ </configuration>
+ </plugin>
+ <plugin>
+ <groupId>org.apache.maven.plugins</groupId>
+ <artifactId>maven-compiler-plugin</artifactId>
+ </plugin>
+ <plugin>
+ <groupId>org.scalatest</groupId>
+ <artifactId>scalatest-maven-plugin</artifactId>
+ <configuration>
+ <argLine>
+ -Djava.library.path=${project.parent.basedir}/native/${platform}/target \
+ -Dlog4j.configuration=file://${project.basedir}/src/test/resources/log4j.properties
+ </argLine>
+ </configuration>
+ </plugin>
+ <plugin>
+ <groupId>org.scalastyle</groupId>
+ <artifactId>scalastyle-maven-plugin</artifactId>
+ </plugin>
+ </plugins>
+ </build>
+ <dependencies>
+ <dependency>
+ <groupId>ml.dmlc.mxnet</groupId>
+ <artifactId>mxnet-core_${scala.binary.version}</artifactId>
+ <version>1.2.0-SNAPSHOT</version>
+ <scope>provided</scope>
+ </dependency>
+ <!-- https://mvnrepository.com/artifact/org.mockito/mockito-all -->
+ <dependency>
+ <groupId>org.mockito</groupId>
+ <artifactId>mockito-all</artifactId>
+ <version>1.10.19</version>
+ <scope>test</scope>
+ </dependency>
+ </dependencies>
+</project>
diff --git a/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/Classifier.scala b/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/Classifier.scala
new file mode 100644
index 00000000000..6eec81c467b
--- /dev/null
+++ b/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/Classifier.scala
@@ -0,0 +1,170 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package ml.dmlc.mxnet.infer
+
+import ml.dmlc.mxnet.{Context, DataDesc, NDArray}
+import java.io.File
+
+import org.slf4j.LoggerFactory
+
+import scala.io
+import scala.collection.mutable.ListBuffer
+
+trait ClassifierBase {
+
+ /**
+ * Takes an Array of Floats and returns corresponding labels, score tuples.
+ * @param input: IndexedSequence one-dimensional array of Floats.
+ * @param topK: (Optional) How many top_k(sorting will be based on the last axis)
+ * elements to return, if not passed returns unsorted output.
+ * @return IndexedSequence of (Label, Score) tuples.
+ */
+ def classify(input: IndexedSeq[Array[Float]],
+ topK: Option[Int] = None): IndexedSeq[(String, Float)]
+
+ /**
+ * Takes a Sequence of NDArrays and returns Label, Score tuples.
+ * @param input: Indexed Sequence of NDArrays
+ * @param topK: (Optional) How many top_k(sorting will be based on the last axis)
+ * elements to return, if not passed returns unsorted output.
+ * @return Traversable Sequence of (Label, Score) tuple
+ */
+ def classifyWithNDArray(input: IndexedSeq[NDArray],
+ topK: Option[Int] = None): IndexedSeq[IndexedSeq[(String, Float)]]
+}
+
+/**
+ * A class for classifier tasks
+ * @param modelPathPrefix PathPrefix from where to load the symbol, parameters and synset.txt
+ * Example: file://model-dir/resnet-152(containing resnet-152-symbol.json
+ * file://model-dir/synset.txt
+ * @param inputDescriptors Descriptors defining the input node names, shape,
+ * layout and Type parameters
+ * @param contexts Device Contexts on which you want to run Inference, defaults to CPU.
+ * @param epoch Model epoch to load, defaults to 0.
+ */
+class Classifier(modelPathPrefix: String,
+ protected val inputDescriptors: IndexedSeq[DataDesc],
+ protected val contexts: Array[Context] = Context.cpu(),
+ protected val epoch: Option[Int] = Some(0))
+ extends ClassifierBase {
+
+ private val logger = LoggerFactory.getLogger(classOf[Classifier])
+
+ protected[infer] val predictor: PredictBase = getPredictor()
+
+ protected[infer] val synsetFilePath = getSynsetFilePath(modelPathPrefix)
+
+ protected[infer] val synset = readSynsetFile(synsetFilePath)
+
+ protected[infer] val handler = MXNetHandler()
+
+ /**
+ * Takes a flat arrays as input and returns a List of (Label, tuple)
+ * @param input: IndexedSequence one-dimensional array of Floats.
+ * @param topK: (Optional) How many top_k(sorting will be based on the last axis)
+ * elements to return, if not passed returns unsorted output.
+ * @return IndexedSequence of (Label, Score) tuples.
+ */
+ override def classify(input: IndexedSeq[Array[Float]],
+ topK: Option[Int] = None): IndexedSeq[(String, Float)] = {
+
+ // considering only the first output
+ val predictResult = predictor.predict(input)(0)
+ var result: IndexedSeq[(String, Float)] = IndexedSeq.empty
+
+ if (topK.isDefined) {
+ val sortedIndex = predictResult.zipWithIndex.sortBy(-_._1).map(_._2).take(topK.get)
+ result = sortedIndex.map(i => (synset(i), predictResult(i))).toIndexedSeq
+ } else {
+ result = synset.zip(predictResult).toIndexedSeq
+ }
+ result
+ }
+
+ /**
+ * Takes input as NDArrays, useful when you want to perform multiple operations on
+ * the input Array or when you want to pass a batch of input.
+ * @param input: Indexed Sequence of NDArrays
+ * @param topK: (Optional) How many top_k(sorting will be based on the last axis)
+ * elements to return, if not passed returns unsorted output.
+ * @return Traversable Sequence of (Label, Score) tuple
+ */
+ override def classifyWithNDArray(input: IndexedSeq[NDArray], topK: Option[Int] = None)
+ : IndexedSeq[IndexedSeq[(String, Float)]] = {
+
+ // considering only the first output
+ val predictResultND: NDArray = predictor.predictWithNDArray(input)(0)
+
+ val predictResult: ListBuffer[Array[Float]] = ListBuffer[Array[Float]]()
+
+ // iterating over the individual items(batch size is in axis 0)
+ for (i <- 0 until predictResultND.shape(0)) {
+ val r = predictResultND.at(i)
+ predictResult += r.toArray
+ r.dispose()
+ }
+
+ var result: ListBuffer[IndexedSeq[(String, Float)]] =
+ ListBuffer.empty[IndexedSeq[(String, Float)]]
+
+ if (topK.isDefined) {
+ val sortedIndices = predictResult.map(r =>
+ r.zipWithIndex.sortBy(-_._1).map(_._2).take(topK.get)
+ )
+ for (i <- sortedIndices.indices) {
+ result += sortedIndices(i).map(sIndx =>
+ (synset(sIndx), predictResult(i)(sIndx))).toIndexedSeq
+ }
+ } else {
+ for (i <- predictResult.indices) {
+ result += synset.zip(predictResult(i)).toIndexedSeq
+ }
+ }
+
+ handler.execute(predictResultND.dispose())
+
+ result.toIndexedSeq
+ }
+
+ private[infer] def getSynsetFilePath(modelPathPrefix: String): String = {
+ val dirPath = modelPathPrefix.substring(0, 1 + modelPathPrefix.lastIndexOf(File.separator))
+ val d = new File(dirPath)
+ require(d.exists && d.isDirectory, "directory: %s not found".format(dirPath))
+
+ val s = new File(dirPath + "synset.txt")
+ require(s.exists() && s.isFile, "File synset.txt should exist inside modelPath: %s".format
+ (dirPath + "synset.txt"))
+
+ s.getCanonicalPath
+ }
+
+ private[infer] def readSynsetFile(synsetFilePath: String): IndexedSeq[String] = {
+ val f = io.Source.fromFile(synsetFilePath)
+ try {
+ f.getLines().toIndexedSeq
+ } finally {
+ f.close
+ }
+ }
+
+ private[infer] def getPredictor(): PredictBase = {
+ new Predictor(modelPathPrefix, inputDescriptors, contexts, epoch)
+ }
+
+}
diff --git a/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/ImageClassifier.scala b/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/ImageClassifier.scala
new file mode 100644
index 00000000000..f05b2e2cd8f
--- /dev/null
+++ b/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/ImageClassifier.scala
@@ -0,0 +1,213 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package ml.dmlc.mxnet.infer
+
+import ml.dmlc.mxnet.{Context, DataDesc, NDArray, Shape}
+
+import scala.collection.mutable.ListBuffer
+
+// scalastyle:off
+import java.awt.image.BufferedImage
+// scalastyle:on
+import java.io.File
+import javax.imageio.ImageIO
+
+
+/**
+ * A class for Image classification tasks.
+ * Contains helper methods.
+ *
+ * @param modelPathPrefix PathPrefix from where to load the symbol, parameters and synset.txt
+ * Example: file://model-dir/resnet-152(containing resnet-152-symbol.json
+ * file://model-dir/synset.txt
+ * @param inputDescriptors Descriptors defining the input node names, shape,
+ * layout and Type parameters
+ * @param contexts Device Contexts on which you want to run Inference, defaults to CPU.
+ * @param epoch Model epoch to load, defaults to 0.
+ */
+class ImageClassifier(modelPathPrefix: String,
+ inputDescriptors: IndexedSeq[DataDesc],
+ contexts: Array[Context] = Context.cpu(),
+ epoch: Option[Int] = Some(0))
+ extends Classifier(modelPathPrefix,
+ inputDescriptors, contexts, epoch) {
+
+ protected[infer] val inputLayout = inputDescriptors.head.layout
+
+ require(inputDescriptors.nonEmpty, "Please provide input descriptor")
+ require(inputDescriptors.head.layout == "NCHW", "Provided layout doesn't match NCHW format")
+
+ protected[infer] val inputShape = inputDescriptors.head.shape
+
+ // Considering 'NCHW' as default layout when not provided
+ // Else get axis according to the layout
+ // [TODO] if layout is different than the bufferedImage layout,
+ // transpose to match the inputdescriptor shape
+ protected[infer] val batch = inputShape(inputLayout.indexOf('N'))
+ protected[infer] val channel = inputShape(inputLayout.indexOf('C'))
+ protected[infer] val height = inputShape(inputLayout.indexOf('H'))
+ protected[infer] val width = inputShape(inputLayout.indexOf('W'))
+
+ /**
+ * To classify the image according to the provided model
+ *
+ * @param inputImage PathPrefix of the input image
+ * @param topK Get top k elements with maximum probability
+ * @return List of list of tuples of (class, probability)
+ */
+ def classifyImage(inputImage: BufferedImage,
+ topK: Option[Int] = None): IndexedSeq[IndexedSeq[(String, Float)]] = {
+
+ val scaledImage = ImageClassifier.reshapeImage(inputImage, width, height)
+ val pixelsNDArray = ImageClassifier.bufferedImageToPixels(scaledImage, inputShape)
+ inputImage.flush()
+ scaledImage.flush()
+
+ val output = super.classifyWithNDArray(IndexedSeq(pixelsNDArray), topK)
+
+ handler.execute(pixelsNDArray.dispose())
+
+ IndexedSeq(output(0))
+ }
+
+ /**
+ * To classify batch of input images according to the provided model
+ *
+ * @param inputBatch Input batch of Buffered images
+ * @param topK Get top k elements with maximum probability
+ * @return List of list of tuples of (class, probability)
+ */
+ def classifyImageBatch(inputBatch: Traversable[BufferedImage], topK: Option[Int] = None):
+ IndexedSeq[IndexedSeq[(String, Float)]] = {
+
+ val imageBatch = ListBuffer[NDArray]()
+ for (image <- inputBatch) {
+ val scaledImage = ImageClassifier.reshapeImage(image, width, height)
+ val pixelsNDArray = ImageClassifier.bufferedImageToPixels(scaledImage, inputShape)
+ imageBatch += pixelsNDArray
+ }
+ val op = NDArray.concatenate(imageBatch)
+
+ val result = super.classifyWithNDArray(IndexedSeq(op), topK)
+ handler.execute(op.dispose())
+ handler.execute(imageBatch.foreach(_.dispose()))
+
+ result
+ }
+
+ private[infer] def getClassifier(modelPathPrefix: String,
+ inputDescriptors: IndexedSeq[DataDesc],
+ contexts: Array[Context] = Context.cpu(),
+ epoch: Option[Int] = Some(0)): Classifier = {
+ new Classifier(modelPathPrefix, inputDescriptors, contexts, epoch)
+ }
+}
+
+object ImageClassifier {
+
+ /**
+ * Reshape the input image to a new shape
+ *
+ * @param img input image
+ * @param newWidth rescale to new width
+ * @param newHeight rescale to new height
+ * @return Rescaled BufferedImage
+ */
+ def reshapeImage(img: BufferedImage, newWidth: Int, newHeight: Int): BufferedImage = {
+ val resizedImage = new BufferedImage(newWidth, newHeight, BufferedImage.TYPE_INT_RGB)
+ val g = resizedImage.createGraphics()
+ g.drawImage(img, 0, 0, newWidth, newHeight, null)
+ g.dispose()
+
+ resizedImage
+ }
+
+ /**
+ * Convert input BufferedImage to NDArray of input shape
+ *
+ * <p>
+ * Note: Caller is responsible to dispose the NDArray
+ * returned by this method after the use.
+ *
+ * @param resizedImage BufferedImage to get pixels from
+ * @param inputImageShape Should be same as inputDescriptor shape
+ * @return NDArray pixels array
+ */
+ def bufferedImageToPixels(resizedImage: BufferedImage, inputImageShape: Shape): NDArray = {
+ // Get height and width of the image
+ val w = resizedImage.getWidth()
+ val h = resizedImage.getHeight()
+
+ // get an array of integer pixels in the default RGB color mode
+ val pixels = resizedImage.getRGB(0, 0, w, h, null, 0, w)
+
+ // 3 times height and width for R,G,B channels
+ val result = new Array[Float](3 * h * w)
+
+ var row = 0
+ // copy pixels to array vertically
+ while (row < h) {
+ var col = 0
+ // copy pixels to array horizontally
+ while (col < w) {
+ val rgb = pixels(row * w + col)
+ // getting red color
+ result(0 * h * w + row * w + col) = (rgb >> 16) & 0xFF
+ // getting green color
+ result(1 * h * w + row * w + col) = (rgb >> 8) & 0xFF
+ // getting blue color
+ result(2 * h * w + row * w + col) = rgb & 0xFF
+ col += 1
+ }
+ row += 1
+ }
+ resizedImage.flush()
+
+ // creating NDArray according to the input shape
+ val pixelsArray = NDArray.array(result, shape = inputImageShape)
+ pixelsArray
+ }
+
+ /**
+ * Loading input batch of images
+ * @param inputImagePath Path of single input image
+ * @return BufferedImage Buffered image
+ */
+ def loadImageFromFile(inputImagePath: String): BufferedImage = {
+ val img = ImageIO.read(new File(inputImagePath))
+ img
+ }
+
+ /**
+ * Loading input batch of images
+ * @param inputImageDirPath
+ * @return List of buffered images
+ */
+ def loadInputBatch(inputImageDirPath: String): List[BufferedImage] = {
+ val dir = new File(inputImageDirPath)
+ require(dir.exists && dir.isDirectory,
+ "input image directory: %s not found".format(inputImageDirPath))
+
+ val inputBatch = ListBuffer[BufferedImage]()
+ for (imgFile: File <- dir.listFiles()){
+ val img = ImageIO.read(imgFile)
+ inputBatch += img
+ }
+ inputBatch.toList
+ }
+}
diff --git a/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/MXNetHandler.scala b/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/MXNetHandler.scala
new file mode 100644
index 00000000000..47ee15ce27c
--- /dev/null
+++ b/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/MXNetHandler.scala
@@ -0,0 +1,104 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package ml.dmlc.mxnet.infer
+
+import java.util.concurrent._
+
+import org.slf4j.LoggerFactory
+
+private[infer] trait MXNetHandler {
+
+ def execute[T](f: => T): T
+
+ val executor: ExecutorService
+
+}
+
+private[infer] object MXNetHandlerType extends Enumeration {
+
+ type MXNetHandlerType = Value
+ val SingleThreadHandler = Value("MXNetSingleThreadHandler")
+ val OneThreadPerModelHandler = Value("MXNetOneThreadPerModelHandler")
+}
+
+private[infer] class MXNetThreadPoolHandler(numThreads: Int = 1)
+ extends MXNetHandler {
+
+ require(numThreads > 0, "numThreads should be a positive number, you passed:%d".
+ format(numThreads))
+
+ private val logger = LoggerFactory.getLogger(classOf[MXNetThreadPoolHandler])
+ private var threadCount: Int = 0
+
+ private val threadFactory = new ThreadFactory {
+ override def newThread(r: Runnable): Thread = new Thread(r) {
+ setName(classOf[MXNetThreadPoolHandler].getCanonicalName
+ + "-%d".format(threadCount))
+ // setting to daemon threads to exit along with the main threads
+ setDaemon(true)
+ threadCount += 1
+ }
+ }
+
+ override val executor: ExecutorService =
+ Executors.newFixedThreadPool(numThreads, threadFactory)
+
+ private val creatorThread = executor.submit(new Callable[Thread] {
+ override def call(): Thread = Thread.currentThread()
+ }).get()
+
+ override def execute[T](f: => T): T = {
+
+ if (Thread.currentThread() eq creatorThread) {
+ f
+ } else {
+
+ val task = new Callable[T] {
+ override def call(): T = {
+ logger.info("threadId: %s".format(Thread.currentThread().getId()))
+ f
+ }
+ }
+
+ val result = executor.submit(task)
+ try {
+ result.get()
+ } catch {
+ case e : InterruptedException => throw e
+ // unwrap the exception thrown by the task
+ case e1: Exception => throw e1.getCause()
+ }
+ }
+ }
+
+}
+
+private[infer] object MXNetSingleThreadHandler extends MXNetThreadPoolHandler(1) {
+
+}
+
+private[infer] object MXNetHandler {
+
+ def apply(): MXNetHandler = {
+ if (handlerType == MXNetHandlerType.OneThreadPerModelHandler) {
+ new MXNetThreadPoolHandler(1)
+ } else {
+ MXNetSingleThreadHandler
+ }
+ }
+}
diff --git a/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/ObjectDetector.scala b/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/ObjectDetector.scala
new file mode 100644
index 00000000000..5af3fe99a8e
--- /dev/null
+++ b/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/ObjectDetector.scala
@@ -0,0 +1,168 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package ml.dmlc.mxnet.infer
+
+// scalastyle:off
+import java.awt.image.BufferedImage
+// scalastyle:on
+
+import ml.dmlc.mxnet.{Context, DataDesc, NDArray}
+import scala.collection.mutable.ListBuffer
+
+/**
+ * A class for object detection tasks
+ *
+ * @param modelPathPrefix PathPrefix from where to load the symbol, parameters and synset.txt
+ * Example: file://model-dir/ssd_resnet50_512
+ * (will resolve both ssd_resnet50_512-symbol.json
+ * and ssd_resnet50_512-0000.params)
+ * file://model-dir/synset.txt
+ * @param inputDescriptors Descriptors defining the input node names, shape,
+ * layout and Type parameters
+ * @param contexts Device Contexts on which you want to run Inference, defaults to CPU.
+ * @param epoch Model epoch to load, defaults to 0.
+ */
+class ObjectDetector(modelPathPrefix: String,
+ inputDescriptors: IndexedSeq[DataDesc],
+ contexts: Array[Context] = Context.cpu(),
+ epoch: Option[Int] = Some(0)) {
+
+ protected[infer] val imgClassifier: ImageClassifier =
+ getImageClassifier(modelPathPrefix, inputDescriptors, contexts, epoch)
+
+ protected[infer] val inputShape = imgClassifier.inputShape
+
+ protected[infer] val handler = imgClassifier.handler
+
+ protected[infer] val predictor = imgClassifier.predictor
+
+ protected[infer] val synset = imgClassifier.synset
+
+ protected[infer] val height = imgClassifier.height
+
+ protected[infer] val width = imgClassifier.width
+
+ /**
+ * To Detect bounding boxes and corresponding labels
+ *
+ * @param inputImage : PathPrefix of the input image
+ * @param topK : Get top k elements with maximum probability
+ * @return List of List of tuples of (class, [probability, xmin, ymin, xmax, ymax])
+ */
+ def imageObjectDetect(inputImage: BufferedImage,
+ topK: Option[Int] = None)
+ : IndexedSeq[IndexedSeq[(String, Array[Float])]] = {
+
+ val scaledImage = ImageClassifier.reshapeImage(inputImage, width, height)
+ val pixelsNDArray = ImageClassifier.bufferedImageToPixels(scaledImage, inputShape)
+ val output = objectDetectWithNDArray(IndexedSeq(pixelsNDArray), topK)
+ handler.execute(pixelsNDArray.dispose())
+ output
+ }
+
+ /**
+ * Takes input images as NDArrays. Useful when you want to perform multiple operations on
+ * the input Array, or when you want to pass a batch of input images.
+ *
+ * @param input : Indexed Sequence of NDArrays
+ * @param topK : (Optional) How many top_k(sorting will be based on the last axis)
+ * elements to return. If not passed, returns all unsorted output.
+ * @return List of List of tuples of (class, [probability, xmin, ymin, xmax, ymax])
+ */
+ def objectDetectWithNDArray(input: IndexedSeq[NDArray], topK: Option[Int])
+ : IndexedSeq[IndexedSeq[(String, Array[Float])]] = {
+
+ val predictResult = predictor.predictWithNDArray(input)(0)
+ var batchResult = ListBuffer[IndexedSeq[(String, Array[Float])]]()
+ for (i <- 0 until predictResult.shape(0)) {
+ val r = predictResult.at(i)
+ batchResult += sortAndReformat(r, topK)
+ handler.execute(r.dispose())
+ }
+ handler.execute(predictResult.dispose())
+ batchResult.toIndexedSeq
+ }
+
+ private[infer] def sortAndReformat(predictResultND: NDArray, topK: Option[Int])
+ : IndexedSeq[(String, Array[Float])] = {
+ val predictResult: ListBuffer[Array[Float]] = ListBuffer[Array[Float]]()
+ val accuracy: ListBuffer[Float] = ListBuffer[Float]()
+
+ // iterating over the all the predictions
+ val length = predictResultND.shape(0)
+
+ for (i <- 0 until length) {
+ val r = predictResultND.at(i)
+ val tempArr = r.toArray
+ if (tempArr(0) != -1.0) {
+ predictResult += tempArr
+ accuracy += tempArr(1)
+ } else {
+ // Ignore the minus 1 part
+ }
+ handler.execute(r.dispose())
+ }
+ var result = IndexedSeq[(String, Array[Float])]()
+ if (topK.isDefined) {
+ var sortedIndices = accuracy.zipWithIndex.sortBy(-_._1).map(_._2)
+ sortedIndices = sortedIndices.take(topK.get)
+ // takeRight(5) would provide the output as Array[Accuracy, Xmin, Ymin, Xmax, Ymax
+ result = sortedIndices.map(idx
+ => (synset(predictResult(idx)(0).toInt),
+ predictResult(idx).takeRight(5))).toIndexedSeq
+ } else {
+ result = predictResult.map(ele
+ => (synset(ele(0).toInt), ele.takeRight(5))).toIndexedSeq
+ }
+
+ result
+ }
+
+ /**
+ * To classify batch of input images according to the provided model
+ *
+ * @param inputBatch Input batch of Buffered images
+ * @param topK Get top k elements with maximum probability
+ * @return List of list of tuples of (class, probability)
+ */
+ def imageBatchObjectDetect(inputBatch: Traversable[BufferedImage], topK: Option[Int] = None):
+ IndexedSeq[IndexedSeq[(String, Array[Float])]] = {
+
+ val imageBatch = ListBuffer[NDArray]()
+ for (image <- inputBatch) {
+ val scaledImage = ImageClassifier.reshapeImage(image, width, height)
+ val pixelsNdarray = ImageClassifier.bufferedImageToPixels(scaledImage, inputShape)
+ imageBatch += pixelsNdarray
+ }
+ val op = NDArray.concatenate(imageBatch)
+
+ val result = objectDetectWithNDArray(IndexedSeq(op), topK)
+ handler.execute(op.dispose())
+ handler.execute(imageBatch.foreach(_.dispose()))
+ result
+ }
+
+ private[infer] def getImageClassifier(modelPathPrefix: String,
+ inputDescriptors: IndexedSeq[DataDesc],
+ contexts: Array[Context] = Context.cpu(),
+ epoch: Option[Int] = Some(0)):
+ ImageClassifier = {
+ new ImageClassifier(modelPathPrefix, inputDescriptors, contexts, epoch)
+ }
+
+}
diff --git a/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/Predictor.scala b/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/Predictor.scala
new file mode 100644
index 00000000000..6be3b98fd35
--- /dev/null
+++ b/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/Predictor.scala
@@ -0,0 +1,198 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package ml.dmlc.mxnet.infer
+
+import ml.dmlc.mxnet.io.NDArrayIter
+import ml.dmlc.mxnet.{Context, DataDesc, NDArray, Shape}
+import ml.dmlc.mxnet.module.Module
+
+import scala.collection.mutable.ListBuffer
+import org.slf4j.LoggerFactory
+
+/**
+ * Base Trait for MXNet Predictor classes.
+ */
+private[infer] trait PredictBase {
+
+ /**
+ * This method will take input as IndexedSeq one dimensional arrays and creates
+ * NDArray needed for inference. The array will be reshaped based on the input descriptors.
+ * @param input: A IndexedSequence of Scala one-dimensional array, An IndexedSequence is
+ * is needed when the model has more than one input
+ * @return IndexedSequence array of outputs.
+ */
+ def predict(input: IndexedSeq[Array[Float]]): IndexedSeq[Array[Float]]
+
+ /**
+ * Predict using NDArray as input. This method is useful when the input is a batch of data
+ * or when multiple operations on the input have to performed.
+ * Note: User is responsible for managing allocation/deallocation of NDArrays.
+ * @param input: IndexedSequence NDArrays.
+ * @return output of Predictions as NDArrays.
+ */
+ def predictWithNDArray(input: IndexedSeq[NDArray]): IndexedSeq[NDArray]
+
+}
+
+/**
+ * Implementation of predict routines.
+ *
+ * @param modelPathPrefix PathPrefix from where to load the model.
+ * Example: file://model-dir/resnet-152(containing resnet-152-symbol.json,
+ * @param inputDescriptors Descriptors defining the input node names, shape,
+ * layout and Type parameters.
+ * <p>Note: If the input Descriptors is missing batchSize('N' in layout),
+ * a batchSize of 1 is assumed for the model.
+ * </p>
+ * @param contexts Device Contexts on which you want to run Inference, defaults to CPU.
+ * @param epoch Model epoch to load, defaults to 0.
+ */
+class Predictor(modelPathPrefix: String,
+ protected val inputDescriptors: IndexedSeq[DataDesc],
+ protected val contexts: Array[Context] = Context.cpu(),
+ protected val epoch: Option[Int] = Some(0))
+ extends PredictBase {
+
+ private val logger = LoggerFactory.getLogger(classOf[Predictor])
+
+ require(inputDescriptors.head.layout.size != 0, "layout size should not be zero")
+
+ protected[infer] var batchIndex = inputDescriptors(0).layout.indexOf('N')
+ protected[infer] var batchSize = if (batchIndex != -1) inputDescriptors(0).shape(batchIndex)
+ else 1
+
+ protected[infer] var iDescriptors = inputDescriptors
+
+ inputDescriptors.foreach((f: DataDesc) => require(f.layout.indexOf('N') == batchIndex,
+ "batch size should be in the same index for all inputs"))
+
+ if (batchIndex != -1) {
+ inputDescriptors.foreach((f: DataDesc) => require(f.shape(batchIndex) == batchSize,
+ "batch size should be same for all inputs"))
+ } else {
+ // Note: this is assuming that the input needs a batch
+ logger.warn("InputDescriptor does not have batchSize, using 1 as the default batchSize")
+ iDescriptors = inputDescriptors.map((f: DataDesc) => new DataDesc(f.name,
+ Shape(1 +: f.shape.toVector), f.dtype, 'N' +: f.layout))
+ batchIndex = 1
+ }
+
+ protected[infer] val mxNetHandler = MXNetHandler()
+
+ protected[infer] val mod = loadModule()
+
+ /**
+ * This method will take input as IndexedSeq one dimensional arrays and creates
+ * NDArray needed for inference. The array will be reshaped based on the input descriptors.
+ *
+ * @param input : A IndexedSequence of Scala one-dimensional array, An IndexedSequence is
+ * is needed when the model has more than one input
+ * @return IndexedSequence array of outputs.
+ */
+ override def predict(input: IndexedSeq[Array[Float]])
+ : IndexedSeq[Array[Float]] = {
+
+ require(input.length == inputDescriptors.length, "number of inputs provided: %d" +
+ " does not match number of inputs in inputDescriptors: %d".format(input.length,
+ inputDescriptors.length))
+
+ for((i, d) <- input.zip(inputDescriptors)) {
+ require (i.length == d.shape.product/batchSize, "number of elements:" +
+ " %d in the input does not match the shape:%s".format( i.length, d.shape.toString()))
+ }
+ var inputND: ListBuffer[NDArray] = ListBuffer.empty[NDArray]
+
+ for((i, d) <- input.zip(inputDescriptors)) {
+ val shape = d.shape.toVector.patch(from = batchIndex, patch = Vector(1), replaced = 1)
+
+ inputND += mxNetHandler.execute(NDArray.array(i, Shape(shape)))
+ }
+
+ // rebind with batchsize 1
+ if (batchSize != 1) {
+ val desc = iDescriptors.map((f : DataDesc) => new DataDesc(f.name,
+ Shape(f.shape.toVector.patch(batchIndex, Vector(1), 1)), f.dtype, f.layout) )
+ mxNetHandler.execute(mod.bind(desc, forceRebind = true,
+ forTraining = false))
+ }
+
+ val resultND = mxNetHandler.execute(mod.predict(new NDArrayIter(
+ inputND.toIndexedSeq, dataBatchSize = 1)))
+
+ val result = resultND.map((f : NDArray) => f.toArray)
+
+ mxNetHandler.execute(inputND.foreach(_.dispose))
+ mxNetHandler.execute(resultND.foreach(_.dispose))
+
+ // rebind to batchSize
+ if (batchSize != 1) {
+ mxNetHandler.execute(mod.bind(inputDescriptors, forTraining = false, forceRebind = true))
+ }
+
+ result
+ }
+
+ /**
+ * Predict using NDArray as input. This method is useful when the input is a batch of data
+ * Note: User is responsible for managing allocation/deallocation of input/output NDArrays.
+ *
+ * @param inputBatch : IndexedSequence NDArrays.
+ * @return output of Predictions as NDArrays.
+ */
+ override def predictWithNDArray(inputBatch: IndexedSeq[NDArray]): IndexedSeq[NDArray] = {
+
+ require(inputBatch.length == inputDescriptors.length, "number of inputs provided: %d" +
+ " do not match number of inputs in inputDescriptors: %d".format(inputBatch.length,
+ inputDescriptors.length))
+
+ // Shape validation, remove this when backend throws better error messages.
+ for((i, d) <- inputBatch.zip(iDescriptors)) {
+ require(inputBatch(0).shape(batchIndex) == i.shape(batchIndex),
+ "All inputs should be of same batch size")
+ require(i.shape.drop(batchIndex + 1) == d.shape.drop(batchIndex + 1),
+ "Input Data Shape: %s should match the inputDescriptor shape: %s except batchSize".format(
+ i.shape.toString, d.shape.toString))
+ }
+
+ val inputBatchSize = inputBatch(0).shape(batchIndex)
+
+ // rebind with the new batchSize
+ if (batchSize != inputBatchSize) {
+ val desc = iDescriptors.map((f : DataDesc) => new DataDesc(f.name,
+ Shape(f.shape.toVector.patch(batchIndex, Vector(inputBatchSize), 1)), f.dtype, f.layout) )
+ mxNetHandler.execute(mod.bind(desc, forceRebind = true,
+ forTraining = false))
+ }
+
+ val resultND = mxNetHandler.execute(mod.predict(new NDArrayIter(
+ inputBatch, dataBatchSize = inputBatchSize)))
+
+ if (batchSize != inputBatchSize) {
+ mxNetHandler.execute(mod.bind(iDescriptors, forceRebind = true,
+ forTraining = false))
+ }
+ resultND
+ }
+
+ private[infer] def loadModule(): Module = {
+ val mod = mxNetHandler.execute(Module.loadCheckpoint(modelPathPrefix, epoch.get,
+ contexts = contexts))
+ mxNetHandler.execute(mod.bind(inputDescriptors, forTraining = false))
+ mod
+ }
+}
diff --git a/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/package.scala b/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/package.scala
new file mode 100644
index 00000000000..4e99d565619
--- /dev/null
+++ b/scala-package/infer/src/main/scala/ml/dmlc/mxnet/infer/package.scala
@@ -0,0 +1,22 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package ml.dmlc.mxnet
+
+package object infer {
+ private[mxnet] val handlerType = MXNetHandlerType.SingleThreadHandler
+}
diff --git a/scala-package/infer/src/test/resources/log4j.properties b/scala-package/infer/src/test/resources/log4j.properties
new file mode 100644
index 00000000000..d82fd7ea4f3
--- /dev/null
+++ b/scala-package/infer/src/test/resources/log4j.properties
@@ -0,0 +1,24 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+# for development debugging
+log4j.rootLogger = debug, stdout
+
+log4j.appender.stdout = org.apache.log4j.ConsoleAppender
+log4j.appender.stdout.Target = System.out
+log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
+log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c] [%p] - %m%n
diff --git a/scala-package/infer/src/test/scala/ml/dmlc/mxnet/infer/ClassifierSuite.scala b/scala-package/infer/src/test/scala/ml/dmlc/mxnet/infer/ClassifierSuite.scala
new file mode 100644
index 00000000000..1a2f423b8ee
--- /dev/null
+++ b/scala-package/infer/src/test/scala/ml/dmlc/mxnet/infer/ClassifierSuite.scala
@@ -0,0 +1,205 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package ml.dmlc.mxnet.infer
+
+import java.io.File
+import java.nio.file.{Files, Paths}
+import java.util
+
+import ml.dmlc.mxnet.module.Module
+import ml.dmlc.mxnet.{Context, DataDesc, NDArray, Shape}
+import org.mockito.Matchers._
+import org.mockito.Mockito
+import org.scalatest.{BeforeAndAfterAll, FunSuite}
+import org.slf4j.LoggerFactory
+
+import scala.io
+
+class ClassifierSuite extends FunSuite with BeforeAndAfterAll {
+
+ private val logger = LoggerFactory.getLogger(classOf[Predictor])
+
+ var modelPath = ""
+
+ var synFilePath = ""
+
+ def createTempModelFiles(): Unit = {
+ val tempDirPath = System.getProperty("java.io.tmpdir")
+ logger.info("tempDirPath: %s".format(tempDirPath))
+
+ val modelDirPath = tempDirPath + File.separator + "model"
+ val synPath = tempDirPath + File.separator + "synset.txt"
+ val synsetFile = new File(synPath)
+ synsetFile.createNewFile()
+ val lines: util.List[String] = util.Arrays.
+ asList("class1 label1", "class2 label2", "class3 label3", "class4 label4")
+ val path = Paths.get(synPath)
+ Files.write(path, lines)
+
+ this.modelPath = modelDirPath
+ this.synFilePath = synsetFile.getCanonicalPath
+ logger.info("modelPath: %s".format(this.modelPath))
+ logger.info("synFilePath: %s".format(this.synFilePath))
+ }
+
+ override def beforeAll() {
+ createTempModelFiles
+ }
+
+ override def afterAll() {
+ new File(synFilePath).delete()
+ }
+
+ class MyClassyPredictor(val modelPathPrefix: String,
+ override val inputDescriptors: IndexedSeq[DataDesc])
+ extends Predictor(modelPathPrefix, inputDescriptors, epoch = Some(0)) {
+
+ override def loadModule(): Module = mockModule
+
+ val getIDescriptor: IndexedSeq[DataDesc] = iDescriptors
+ val getBatchSize: Int = batchSize
+ val getBatchIndex: Int = batchIndex
+
+ lazy val mockModule: Module = Mockito.mock(classOf[Module])
+ }
+
+ class MyClassifier(modelPathPrefix: String,
+ protected override val inputDescriptors: IndexedSeq[DataDesc])
+ extends Classifier(modelPathPrefix, inputDescriptors, Context.cpu(), Some(0)) {
+
+ override def getPredictor(): MyClassyPredictor = {
+ Mockito.mock(classOf[MyClassyPredictor])
+ }
+ def getSynset(): IndexedSeq[String] = synset
+ }
+
+ test("ClassifierSuite-getSynsetFilePath") {
+ val inputDescriptor = IndexedSeq[DataDesc](new DataDesc("data", Shape(2, 3, 2, 2)))
+ val testClassifer = new MyClassifier(modelPath, inputDescriptor)
+
+ assertResult(this.synFilePath) {
+ testClassifer.synsetFilePath
+ }
+ }
+
+ test("ClassifierSuite-readSynsetFile") {
+ val inputDescriptor = IndexedSeq[DataDesc](new DataDesc("data", Shape(2, 3, 2, 2)))
+ val testClassifer = new MyClassifier(modelPath, inputDescriptor)
+
+ assertResult(io.Source.fromFile(this.synFilePath).getLines().toList) {
+ testClassifer.getSynset()
+ }
+ }
+
+ test("ClassifierSuite-flatArray-topK") {
+ val inputDescriptor = IndexedSeq[DataDesc](new DataDesc("data", Shape(2, 3, 2, 2)))
+ val inputData = Array.fill[Float](12)(1)
+
+ val predictResult : IndexedSeq[Array[Float]] =
+ IndexedSeq[Array[Float]](Array(.98f, 0.97f, 0.96f, 0.99f))
+
+ val testClassifier = new MyClassifier(modelPath, inputDescriptor)
+
+ Mockito.doReturn(predictResult).when(testClassifier.predictor)
+ .predict(any(classOf[IndexedSeq[Array[Float]]]))
+
+ val result: IndexedSeq[(String, Float)] = testClassifier.
+ classify(IndexedSeq(inputData), topK = Some(10))
+
+ assertResult(predictResult(0).sortBy(-_)) {
+ result.map(_._2).toArray
+ }
+
+ }
+
+ test("ClassifierSuite-flatArrayInput") {
+ val inputDescriptor = IndexedSeq[DataDesc](new DataDesc("data", Shape(2, 3, 2, 2)))
+ val inputData = Array.fill[Float](12)(1)
+
+ val predictResult : IndexedSeq[Array[Float]] =
+ IndexedSeq[Array[Float]](Array(.98f, 0.97f, 0.96f, 0.99f))
+
+ val testClassifier = new MyClassifier(modelPath, inputDescriptor)
+
+ Mockito.doReturn(predictResult).when(testClassifier.predictor)
+ .predict(any(classOf[IndexedSeq[Array[Float]]]))
+
+ val result: IndexedSeq[(String, Float)] = testClassifier.
+ classify(IndexedSeq(inputData))
+
+ assertResult(predictResult(0)) {
+ result.map(_._2).toArray
+ }
+ }
+
+ test("ClassifierSuite-NDArray1InputWithoutTopK") {
+ val inputDescriptor = IndexedSeq[DataDesc](new DataDesc("data", Shape(2, 3, 2, 2)))
+ val inputDataShape = Shape(1, 3, 2, 2)
+ val inputData = NDArray.ones(inputDataShape)
+ val predictResult: IndexedSeq[Array[Float]] =
+ IndexedSeq[Array[Float]](Array(.98f, 0.97f, 0.96f, 0.99f))
+
+ val predictResultND: NDArray = NDArray.array(predictResult.flatten.toArray, Shape(1, 4))
+
+ val testClassifier = new MyClassifier(modelPath, inputDescriptor)
+
+ Mockito.doReturn(IndexedSeq(predictResultND)).when(testClassifier.predictor)
+ .predictWithNDArray(any(classOf[IndexedSeq[NDArray]]))
+
+ val result: IndexedSeq[IndexedSeq[(String, Float)]] = testClassifier.
+ classifyWithNDArray(IndexedSeq(inputData))
+
+ assert(predictResult.size == result.size)
+
+ for(i <- predictResult.indices) {
+ assertResult(predictResult(i)) {
+ result(i).map(_._2).toArray
+ }
+ }
+ }
+
+ test("ClassifierSuite-NDArray3InputWithTopK") {
+
+ val inputDescriptor = IndexedSeq[DataDesc](new DataDesc("data", Shape(2, 3, 2, 2)))
+ val inputDataShape = Shape(3, 3, 2, 2)
+ val inputData = NDArray.ones(inputDataShape)
+
+ val predictResult: IndexedSeq[Array[Float]] =
+ IndexedSeq[Array[Float]](Array(.98f, 0.97f, 0.96f, 0.99f),
+ Array(.98f, 0.97f, 0.96f, 0.99f), Array(.98f, 0.97f, 0.96f, 0.99f))
+
+ val predictResultND: NDArray = NDArray.array(predictResult.flatten.toArray, Shape(3, 4))
+
+ val testClassifier = new MyClassifier(modelPath, inputDescriptor)
+
+ Mockito.doReturn(IndexedSeq(predictResultND)).when(testClassifier.predictor)
+ .predictWithNDArray(any(classOf[IndexedSeq[NDArray]]))
+
+ val result: IndexedSeq[IndexedSeq[(String, Float)]] = testClassifier.
+ classifyWithNDArray(IndexedSeq(inputData), topK = Some(10))
+
+ assert(predictResult.size == result.size)
+
+ for(i <- predictResult.indices) {
+ assertResult(predictResult(i).sortBy(-_)) {
+ result(i).map(_._2).toArray
+ }
+ }
+ }
+
+}
diff --git a/scala-package/infer/src/test/scala/ml/dmlc/mxnet/infer/ImageClassifierSuite.scala b/scala-package/infer/src/test/scala/ml/dmlc/mxnet/infer/ImageClassifierSuite.scala
new file mode 100644
index 00000000000..85059be43aa
--- /dev/null
+++ b/scala-package/infer/src/test/scala/ml/dmlc/mxnet/infer/ImageClassifierSuite.scala
@@ -0,0 +1,154 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package ml.dmlc.mxnet.infer
+
+import ml.dmlc.mxnet._
+import org.mockito.Matchers._
+import org.mockito.Mockito
+import org.scalatest.BeforeAndAfterAll
+
+// scalastyle:off
+import java.awt.image.BufferedImage
+// scalastyle:on
+
+/**
+ * Unit tests for ImageClassifier
+ */
+class ImageClassifierSuite extends ClassifierSuite with BeforeAndAfterAll {
+
+ class MyImageClassifier(modelPathPrefix: String,
+ inputDescriptors: IndexedSeq[DataDesc])
+ extends ImageClassifier(modelPathPrefix, inputDescriptors) {
+
+ override def getPredictor(): MyClassyPredictor = {
+ Mockito.mock(classOf[MyClassyPredictor])
+ }
+
+ override def getClassifier(modelPathPrefix: String, inputDescriptors:
+ IndexedSeq[DataDesc], contexts: Array[Context] = Context.cpu(),
+ epoch: Option[Int] = Some(0)): Classifier = {
+ Mockito.mock(classOf[Classifier])
+ }
+
+ def getSynset(): IndexedSeq[String] = synset
+ }
+
+ test("ImageClassifierSuite-testRescaleImage") {
+ val image1 = new BufferedImage(100, 200, BufferedImage.TYPE_BYTE_GRAY)
+ val image2 = ImageClassifier.reshapeImage(image1, 1000, 2000)
+
+ assert(image2.getWidth === 1000)
+ assert(image2.getHeight === 2000)
+ }
+
+ test("ImageClassifierSuite-testConvertBufferedImageToNDArray") {
+ val dType = DType.Float32
+ val inputDescriptor = IndexedSeq[DataDesc](new DataDesc(modelPath, Shape(1, 3, 2, 2),
+ dType, "NCHW"))
+
+ val image1 = new BufferedImage(100, 200, BufferedImage.TYPE_BYTE_GRAY)
+ val image2 = ImageClassifier.reshapeImage(image1, 2, 2)
+
+ val result = ImageClassifier.bufferedImageToPixels(image2, Shape(1, 3, 2, 2))
+
+ assert(result.shape == inputDescriptor(0).shape)
+ }
+
+ test("ImageClassifierSuite-testWithInputImage") {
+ val dType = DType.Float32
+ val inputDescriptor = IndexedSeq[DataDesc](new DataDesc(modelPath, Shape(1, 3, 512, 512),
+ dType, "NCHW"))
+
+ val inputImage = new BufferedImage(224, 224, BufferedImage.TYPE_INT_RGB)
+
+ val testImageClassifier: ImageClassifier =
+ new MyImageClassifier(modelPath, inputDescriptor)
+
+ val predictExpected: IndexedSeq[Array[Float]] =
+ IndexedSeq[Array[Float]](Array(.98f, 0.97f, 0.96f, 0.99f))
+
+ val synset = testImageClassifier.synset
+
+ val predictExpectedOp: List[(String, Float)] =
+ List[(String, Float)]((synset(1), .98f), (synset(2), .97f),
+ (synset(3), .96f), (synset(0), .99f))
+
+ val predictExpectedND: NDArray = NDArray.array(predictExpected.flatten.toArray, Shape(1, 4))
+
+ Mockito.doReturn(IndexedSeq(predictExpectedND)).when(testImageClassifier.predictor)
+ .predictWithNDArray(any(classOf[IndexedSeq[NDArray]]))
+
+ Mockito.doReturn(IndexedSeq(predictExpectedOp))
+ .when(testImageClassifier.getClassifier(modelPath, inputDescriptor))
+ .classifyWithNDArray(any(classOf[IndexedSeq[NDArray]]), Some(anyInt()))
+
+ val predictResult: IndexedSeq[IndexedSeq[(String, Float)]] =
+ testImageClassifier.classifyImage(inputImage, Some(4))
+
+ for (i <- predictExpected.indices) {
+ assertResult(predictExpected(i).sortBy(-_)) {
+ predictResult(i).map(_._2).toArray
+ }
+ }
+ }
+
+ test("ImageClassifierSuite-testWithInputBatchImage") {
+ val dType = DType.Float32
+ val inputDescriptor = IndexedSeq[DataDesc](new DataDesc(modelPath, Shape(1, 3, 512, 512),
+ dType, "NCHW"))
+
+ val inputImage = new BufferedImage(224, 224, BufferedImage.TYPE_INT_RGB)
+ val imageBatch = IndexedSeq[BufferedImage](inputImage, inputImage)
+
+ val testImageClassifier: ImageClassifier =
+ new MyImageClassifier(modelPath, inputDescriptor)
+
+ val predictExpected: IndexedSeq[Array[Array[Float]]] =
+ IndexedSeq[Array[Array[Float]]](Array(Array(.98f, 0.97f, 0.96f, 0.99f),
+ Array(.98f, 0.97f, 0.96f, 0.99f)))
+
+ val synset = testImageClassifier.synset
+
+ val predictExpectedOp: List[List[(String, Float)]] =
+ List[List[(String, Float)]](List((synset(1), .98f), (synset(2), .97f),
+ (synset(3), .96f), (synset(0), .99f)),
+ List((synset(1), .98f), (synset(2), .97f),
+ (synset(3), .96f), (synset(0), .99f)))
+
+ val predictExpectedND: NDArray = NDArray.array(predictExpected.flatten.flatten.toArray,
+ Shape(2, 4))
+
+ Mockito.doReturn(IndexedSeq(predictExpectedND)).when(testImageClassifier.predictor)
+ .predictWithNDArray(any(classOf[IndexedSeq[NDArray]]))
+
+ Mockito.doReturn(IndexedSeq(predictExpectedOp))
+ .when(testImageClassifier.getClassifier(modelPath, inputDescriptor))
+ .classifyWithNDArray(any(classOf[IndexedSeq[NDArray]]), Some(anyInt()))
+
+ val result: IndexedSeq[IndexedSeq[(String, Float)]] =
+ testImageClassifier.classifyImageBatch(imageBatch, Some(4))
+
+ for (i <- predictExpected.indices) {
+ for (idx <- predictExpected(i).indices) {
+ assertResult(predictExpected(i)(idx).sortBy(-_)) {
+ result(i).map(_._2).toArray
+ }
+ }
+ }
+ }
+}
diff --git a/scala-package/infer/src/test/scala/ml/dmlc/mxnet/infer/ObjectDetectorSuite.scala b/scala-package/infer/src/test/scala/ml/dmlc/mxnet/infer/ObjectDetectorSuite.scala
new file mode 100644
index 00000000000..5e6f32f1107
--- /dev/null
+++ b/scala-package/infer/src/test/scala/ml/dmlc/mxnet/infer/ObjectDetectorSuite.scala
@@ -0,0 +1,168 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package ml.dmlc.mxnet.infer
+
+
+// scalastyle:off
+import java.awt.image.BufferedImage
+// scalastyle:on
+import ml.dmlc.mxnet.Context
+import ml.dmlc.mxnet.DataDesc
+import ml.dmlc.mxnet.{Context, NDArray, Shape}
+import org.mockito.Matchers.any
+import org.mockito.Mockito
+import org.scalatest.BeforeAndAfterAll
+
+
+class ObjectDetectorSuite extends ClassifierSuite with BeforeAndAfterAll {
+
+ class MyObjectDetector(modelPathPrefix: String,
+ inputDescriptors: IndexedSeq[DataDesc])
+ extends ObjectDetector(modelPathPrefix, inputDescriptors) {
+
+ override def getImageClassifier(modelPathPrefix: String, inputDescriptors:
+ IndexedSeq[DataDesc], contexts: Array[Context] = Context.cpu(),
+ epoch: Option[Int] = Some(0)): ImageClassifier = {
+ new MyImageClassifier(modelPathPrefix, inputDescriptors)
+ }
+
+ }
+
+ class MyImageClassifier(modelPathPrefix: String,
+ protected override val inputDescriptors: IndexedSeq[DataDesc])
+ extends ImageClassifier(modelPathPrefix, inputDescriptors, Context.cpu(), Some(0)) {
+
+ override def getPredictor(): MyClassyPredictor = {
+ Mockito.mock(classOf[MyClassyPredictor])
+ }
+
+ override def getClassifier(modelPathPrefix: String, inputDescriptors: IndexedSeq[DataDesc],
+ contexts: Array[Context] = Context.cpu(),
+ epoch: Option[Int] = Some(0)):
+ Classifier = {
+ new MyClassifier(modelPathPrefix, inputDescriptors)
+ }
+ }
+
+ class MyClassifier(modelPathPrefix: String,
+ protected override val inputDescriptors: IndexedSeq[DataDesc])
+ extends Classifier(modelPathPrefix, inputDescriptors) {
+
+ override def getPredictor(): MyClassyPredictor = {
+ Mockito.mock(classOf[MyClassyPredictor])
+ }
+ def getSynset(): IndexedSeq[String] = synset
+ }
+
+ test("objectDetectWithInputImage") {
+ val inputDescriptor = IndexedSeq[DataDesc](new DataDesc(modelPath, Shape(1, 3, 512, 512)))
+ val inputImage = new BufferedImage(512, 512, BufferedImage.TYPE_INT_RGB)
+ val testObjectDetector: ObjectDetector =
+ new MyObjectDetector(modelPath, inputDescriptor)
+
+ val predictRaw: IndexedSeq[Array[Array[Float]]] =
+ IndexedSeq[Array[Array[Float]]](Array(
+ Array(1.0f, 0.42f, 0.45f, 0.66f, 0.72f, 0.88f),
+ Array(2.0f, 0.88f, 0.21f, 0.33f, 0.45f, 0.66f),
+ Array(3.0f, 0.62f, 0.50f, 0.42f, 0.68f, 0.99f)
+ ))
+ val predictResultND: NDArray =
+ NDArray.array(predictRaw.flatten.flatten.toArray, Shape(1, 3, 6))
+
+ val synset = testObjectDetector.synset
+
+ val predictResult: IndexedSeq[IndexedSeq[(String, Array[Float])]] =
+ IndexedSeq[IndexedSeq[(String, Array[Float])]](
+ IndexedSeq[(String, Array[Float])](
+ (synset(2), Array(0.88f, 0.21f, 0.33f, 0.45f, 0.66f)),
+ (synset(3), Array(0.62f, 0.50f, 0.42f, 0.68f, 0.99f)),
+ (synset(1), Array(0.42f, 0.45f, 0.66f, 0.72f, 0.88f))
+ )
+ )
+
+ Mockito.doReturn(IndexedSeq(predictResultND)).when(testObjectDetector.predictor)
+ .predictWithNDArray(any(classOf[IndexedSeq[NDArray]]))
+
+ val result: IndexedSeq[IndexedSeq[(String, Array[Float])]] =
+ testObjectDetector.imageObjectDetect(inputImage, Some(3))
+
+ for (idx <- predictResult(0).indices) {
+ assert(predictResult(0)(idx)._1 == result(0)(idx)._1)
+ for (arridx <- predictResult(0)(idx)._2.indices) {
+ assert(predictResult(0)(idx)._2(arridx) == result(0)(idx)._2(arridx))
+ }
+ }
+ }
+
+ test("objectDetectWithBatchImages") {
+ val inputDescriptor = IndexedSeq[DataDesc](new DataDesc(modelPath, Shape(1, 3, 512, 512)))
+ val inputImage = new BufferedImage(224, 224, BufferedImage.TYPE_INT_RGB)
+ val imageBatch = IndexedSeq[BufferedImage](inputImage, inputImage)
+
+ val testObjectDetector: ObjectDetector =
+ new MyObjectDetector(modelPath, inputDescriptor)
+
+ val predictRaw: IndexedSeq[Array[Array[Float]]] =
+ IndexedSeq[Array[Array[Float]]](
+ Array(
+ Array(1.0f, 0.42f, 0.45f, 0.66f, 0.72f, 0.88f),
+ Array(2.0f, 0.88f, 0.21f, 0.33f, 0.45f, 0.66f),
+ Array(3.0f, 0.62f, 0.50f, 0.42f, 0.68f, 0.99f)
+ ),
+ Array(
+ Array(0.0f, 0.42f, 0.45f, 0.66f, 0.72f, 0.88f),
+ Array(2.0f, 0.23f, 0.21f, 0.33f, 0.45f, 0.66f),
+ Array(2.0f, 0.94f, 0.50f, 0.42f, 0.68f, 0.99f)
+ )
+ )
+ val predictResultND: NDArray =
+ NDArray.array(predictRaw.flatten.flatten.toArray, Shape(2, 3, 6))
+
+ val synset = testObjectDetector.synset
+
+ val predictResult: IndexedSeq[IndexedSeq[(String, Array[Float])]] =
+ IndexedSeq[IndexedSeq[(String, Array[Float])]](
+ IndexedSeq[(String, Array[Float])](
+ (synset(2), Array(0.88f, 0.21f, 0.33f, 0.45f, 0.66f)),
+ (synset(3), Array(0.62f, 0.50f, 0.42f, 0.68f, 0.99f)),
+ (synset(1), Array(0.42f, 0.45f, 0.66f, 0.72f, 0.88f))
+ ),
+ IndexedSeq[(String, Array[Float])](
+ (synset(2), Array(0.94f, 0.50f, 0.42f, 0.68f, 0.99f)),
+ (synset(0), Array(0.42f, 0.45f, 0.66f, 0.72f, 0.88f)),
+ (synset(2), Array(0.23f, 0.21f, 0.33f, 0.45f, 0.66f))
+ )
+ )
+
+ Mockito.doReturn(IndexedSeq(predictResultND)).when(testObjectDetector.predictor)
+ .predictWithNDArray(any(classOf[IndexedSeq[NDArray]]))
+
+ val result: IndexedSeq[IndexedSeq[(String, Array[Float])]] =
+ testObjectDetector.imageBatchObjectDetect(imageBatch, Some(3))
+ for (preidx <- predictResult.indices) {
+ for (idx <- predictResult(preidx).indices) {
+ assert(predictResult(preidx)(idx)._1 == result(preidx)(idx)._1)
+ for (arridx <- predictResult(preidx)(idx)._2.indices) {
+ assert(predictResult(preidx)(idx)._2(arridx) == result(preidx)(idx)._2(arridx))
+ }
+ }
+ }
+
+ }
+
+}
diff --git a/scala-package/infer/src/test/scala/ml/dmlc/mxnet/infer/PredictorSuite.scala b/scala-package/infer/src/test/scala/ml/dmlc/mxnet/infer/PredictorSuite.scala
new file mode 100644
index 00000000000..da4d965010d
--- /dev/null
+++ b/scala-package/infer/src/test/scala/ml/dmlc/mxnet/infer/PredictorSuite.scala
@@ -0,0 +1,114 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package ml.dmlc.mxnet.infer
+
+
+import ml.dmlc.mxnet.io.NDArrayIter
+import ml.dmlc.mxnet.module.{BaseModule, Module}
+import ml.dmlc.mxnet.{DataDesc, NDArray, Shape}
+import org.mockito.Matchers._
+import org.mockito.Mockito
+import org.scalatest.{BeforeAndAfterAll, FunSuite}
+
+class PredictorSuite extends FunSuite with BeforeAndAfterAll {
+
+ class MyPredictor(val modelPathPrefix: String,
+ override val inputDescriptors: IndexedSeq[DataDesc])
+ extends Predictor(modelPathPrefix, inputDescriptors, epoch = Some(0)) {
+
+ override def loadModule(): Module = mockModule
+
+ val getIDescriptor: IndexedSeq[DataDesc] = iDescriptors
+ val getBatchSize: Int = batchSize
+ val getBatchIndex: Int = batchIndex
+
+ lazy val mockModule: Module = Mockito.mock(classOf[Module])
+ }
+
+ test("PredictorSuite-testPredictorConstruction") {
+ val inputDescriptor = IndexedSeq[DataDesc](new DataDesc("data", Shape(1, 3, 2, 2)))
+
+ val mockPredictor = new MyPredictor("xyz", inputDescriptor)
+
+ assert(mockPredictor.getBatchSize == 1)
+ assert(mockPredictor.getBatchIndex == inputDescriptor(0).layout.indexOf('N'))
+
+ val inputDescriptor2 = IndexedSeq[DataDesc](new DataDesc("data", Shape(1, 3, 2, 2)),
+ new DataDesc("data", Shape(2, 3, 2, 2)))
+
+ assertThrows[IllegalArgumentException] {
+ val mockPredictor = new MyPredictor("xyz", inputDescriptor2)
+ }
+
+ // batchsize is defaulted to 1
+ val iDesc2 = IndexedSeq[DataDesc](new DataDesc("data", Shape(3, 2, 2), layout = "CHW"))
+ val p2 = new MyPredictor("xyz", inputDescriptor)
+ assert(p2.getBatchSize == 1, "should use a default batch size of 1")
+
+ }
+
+ test("PredictorSuite-testWithFlatArrays") {
+
+ val inputDescriptor = IndexedSeq[DataDesc](new DataDesc("data", Shape(2, 3, 2, 2)))
+ val inputData = Array.fill[Float](12)(1)
+
+ // this will disposed at the end of the predict call on Predictor.
+ val predictResult = IndexedSeq(NDArray.ones(Shape(1, 3, 2, 2)))
+
+ val testPredictor = new MyPredictor("xyz", inputDescriptor)
+
+ Mockito.doReturn(predictResult).when(testPredictor.mockModule)
+ .predict(any(classOf[NDArrayIter]), any[Int], any[Boolean])
+
+ val testFun = testPredictor.predict(IndexedSeq(inputData))
+
+ assert(testFun.size == 1, "output size should be 1 ")
+
+ assert(Array.fill[Float](12)(1).mkString == testFun(0).mkString)
+
+ // Verify that the module was bound with batch size 1 and rebound back to the original
+ // input descriptor. the number of times is twice here because loadModule overrides the
+ // initial bind.
+ Mockito.verify(testPredictor.mockModule, Mockito.times(2)).bind(any[IndexedSeq[DataDesc]],
+ any[Option[IndexedSeq[DataDesc]]], any[Boolean], any[Boolean], any[Boolean]
+ , any[Option[BaseModule]], any[String])
+ }
+
+ test("PredictorSuite-testWithNDArray") {
+ val inputDescriptor = IndexedSeq[DataDesc](new DataDesc("data", Shape(2, 3, 2, 2)))
+ val inputData = NDArray.ones(Shape(1, 3, 2, 2))
+
+ // this will disposed at the end of the predict call on Predictor.
+ val predictResult = IndexedSeq(NDArray.ones(Shape(1, 3, 2, 2)))
+
+ val testPredictor = new MyPredictor("xyz", inputDescriptor)
+
+ Mockito.doReturn(predictResult).when(testPredictor.mockModule)
+ .predict(any(classOf[NDArrayIter]), any[Int], any[Boolean])
+
+ val testFun = testPredictor.predictWithNDArray(IndexedSeq(inputData))
+
+ assert(testFun.size == 1, "output size should be 1")
+
+ assert(Array.fill[Float](12)(1).mkString == testFun(0).toArray.mkString)
+
+ Mockito.verify(testPredictor.mockModule, Mockito.times(2)).bind(any[IndexedSeq[DataDesc]],
+ any[Option[IndexedSeq[DataDesc]]], any[Boolean], any[Boolean], any[Boolean]
+ , any[Option[BaseModule]], any[String])
+ }
+}
diff --git a/scala-package/native/osx-x86_64-cpu/pom.xml b/scala-package/native/osx-x86_64-cpu/pom.xml
index fa0f5b6c49d..529b1264b51 100644
--- a/scala-package/native/osx-x86_64-cpu/pom.xml
+++ b/scala-package/native/osx-x86_64-cpu/pom.xml
@@ -67,7 +67,7 @@
<linkerMiddleOption>-Wl,-x</linkerMiddleOption>
<linkerMiddleOption>${lddeps}</linkerMiddleOption>
<linkerMiddleOption>-force_load ../../../lib/libmxnet.a</linkerMiddleOption>
- <linkerMiddleOption>-force_load ../../../nnvm/lib/libnnvm.a</linkerMiddleOption>
+ <linkerMiddleOption>-force_load ../../../3rdparty/nnvm/lib/libnnvm.a</linkerMiddleOption>
</linkerMiddleOptions>
<linkerEndOptions>
<linkerEndOption>${ldflags}</linkerEndOption>
diff --git a/scala-package/pom.xml b/scala-package/pom.xml
index 02bcd86f695..27dfe2f2d93 100644
--- a/scala-package/pom.xml
+++ b/scala-package/pom.xml
@@ -37,6 +37,7 @@
<module>macros</module>
<module>core</module>
<module>native</module>
+ <module>infer</module>
<module>examples</module>
<module>spark</module>
<module>assembly</module>
diff --git a/setup-utils/install-mxnet-virtualenv.sh b/setup-utils/install-mxnet-virtualenv.sh
new file mode 100755
index 00000000000..5e00f79647e
--- /dev/null
+++ b/setup-utils/install-mxnet-virtualenv.sh
@@ -0,0 +1,123 @@
+#!/usr/bin/env bash
+
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+######################################################################
+# This script installs MXNet for Python in a virtualenv on OSX and ubuntu
+######################################################################
+set -e
+#set -x
+
+BUILDIR=build
+VENV=mxnet_py3
+
+setup_virtualenv() {
+ if [ ! -d $VENV ];then
+ virtualenv -p `which python3` $VENV
+ fi
+ source $VENV/bin/activate
+}
+
+gpu_count() {
+ nvidia-smi -L | wc -l
+}
+
+detect_platform() {
+ unameOut="$(uname -s)"
+ case "${unameOut}" in
+ Linux*)
+ distro=$(awk -F= '/^NAME/{gsub(/"/, "", $2); print $2}' /etc/os-release)
+ machine="Linux/$distro"
+ ;;
+ Darwin*) machine=Mac;;
+ CYGWIN*) machine=Cygwin;;
+ MINGW*) machine=MinGw;;
+ *) machine="UNKNOWN:${unameOut}"
+ esac
+ echo ${machine}
+}
+
+
+if [ $(gpu_count) -ge 1 ];then
+ USE_CUDA=ON
+else
+ USE_CUDA=OFF
+fi
+
+PLATFORM=$(detect_platform)
+echo "Detected platform '$PLATFORM'"
+
+if [ $PLATFORM = "Mac" ];then
+ USE_OPENMP=OFF
+else
+ USE_OPENMP=ON
+fi
+
+if [ $PLATFORM = "Linux/Ubuntu" ];then
+ install_dependencies_ubuntu() {
+ sudo apt-get update
+ sudo apt-get install -y build-essential libatlas-base-dev libopencv-dev graphviz virtualenv cmake\
+ ninja-build libopenblas-dev liblapack-dev python3 python3-dev
+ }
+ echo "Installing build dependencies in Ubuntu!"
+ install_dependencies_ubuntu
+fi
+
+echo "Preparing a Python virtualenv in ${VENV}"
+setup_virtualenv
+
+echo "Building MXNet core. This can take a few minutes..."
+build_mxnet() {
+ pushd .
+ set -x
+ mkdir -p $BUILDIR && cd $BUILDIR
+ cmake -DUSE_CUDA=$USE_CUDA -DUSE_OPENCV=ON -DUSE_OPENMP=$USE_OPENMP -DUSE_SIGNAL_HANDLER=ON -DCMAKE_BUILD_TYPE=Release -GNinja ..
+ ninja
+ set +x
+ popd
+}
+
+
+build_mxnet
+
+echo "Installing mxnet under virtualenv ${VENV}"
+install_mxnet() {
+ pushd .
+ cd python
+ pip3 install -e .
+ pip3 install opencv-python matplotlib graphviz jupyter ipython
+ popd
+}
+
+install_mxnet
+
+echo "
+
+========================================================================================
+Done! MXNet for Python installation is complete. Go ahead and explore MXNet with Python.
+========================================================================================
+
+Use the following command to enter the virtualenv:
+$ source ${VENV}/bin/activate
+$ iptyhon
+
+You can then start using mxnet
+
+import mxnet as mx
+x = mx.nd.ones((5,5))
+"
diff --git a/src/c_api/c_api_symbolic.cc b/src/c_api/c_api_symbolic.cc
index 3668af06006..4666b6adf0c 100644
--- a/src/c_api/c_api_symbolic.cc
+++ b/src/c_api/c_api_symbolic.cc
@@ -571,3 +571,54 @@ int MXSymbolGrad(SymbolHandle sym, mx_uint num_wrt, const char** wrt, SymbolHand
LOG(FATAL) << "not implemented";
API_END();
}
+
+int MXQuantizeSymbol(SymbolHandle sym_handle,
+ SymbolHandle *ret_sym_handle,
+ const mx_uint num_excluded_symbols,
+ const SymbolHandle *excluded_symbols,
+ const mx_uint num_offline,
+ const char **offline_params) {
+ nnvm::Symbol *s = new nnvm::Symbol();
+ API_BEGIN();
+ nnvm::Symbol *sym = static_cast<nnvm::Symbol*>(sym_handle);
+ nnvm::Graph g = Symbol2Graph(*sym);
+ std::unordered_set<nnvm::NodePtr> excluded_nodes;
+ for (size_t i = 0; i < num_excluded_symbols; ++i) {
+ nnvm::Symbol* sym = static_cast<nnvm::Symbol*>(excluded_symbols[i]);
+ for (const auto& e : sym->outputs) {
+ excluded_nodes.emplace(e.node);
+ }
+ }
+ g.attrs["excluded_nodes"] = std::make_shared<nnvm::any>(std::move(excluded_nodes));
+ std::unordered_set<std::string> offline;
+ for (size_t i = 0; i < num_offline; ++i) {
+ offline.emplace(offline_params[i]);
+ }
+ g.attrs["offline_params"] = std::make_shared<nnvm::any>(std::move(offline));
+ g = ApplyPass(std::move(g), "QuantizeGraph");
+ s->outputs = g.outputs;
+ *ret_sym_handle = s;
+ API_END_HANDLE_ERROR(delete s);
+}
+
+int MXSetCalibTableToQuantizedSymbol(SymbolHandle qsym_handle,
+ const mx_uint num_layers,
+ const char** layer_names,
+ const float* min_ranges,
+ const float* max_ranges,
+ SymbolHandle* ret_qsym_handle) {
+ nnvm::Symbol* s = new nnvm::Symbol();
+ API_BEGIN();
+ nnvm::Symbol* sym = static_cast<nnvm::Symbol*>(qsym_handle);
+ nnvm::Graph g = Symbol2Graph(*sym);
+ const std::string prefix = "quantized_";
+ std::unordered_map<std::string, std::pair<float, float>> calib_table;
+ for (size_t i = 0; i < num_layers; ++i) {
+ calib_table.emplace(prefix+layer_names[i], std::make_pair(min_ranges[i], max_ranges[i]));
+ }
+ g.attrs["calib_table"] = std::make_shared<nnvm::any>(std::move(calib_table));
+ g = ApplyPass(std::move(g), "SetCalibTableToQuantizedGraph");
+ s->outputs = g.outputs;
+ *ret_qsym_handle = s;
+ API_END_HANDLE_ERROR(delete s);
+}
diff --git a/src/engine/threaded_engine.cc b/src/engine/threaded_engine.cc
index 77b14b43a7b..ca5602bb482 100644
--- a/src/engine/threaded_engine.cc
+++ b/src/engine/threaded_engine.cc
@@ -326,8 +326,7 @@ void ThreadedEngine::PushSync(SyncFn exec_fn, Context exec_ctx,
FnProperty prop,
int priority,
const char* opr_name) {
- BulkStatus& bulk_status = *BulkStatusStore::Get();
- if (!bulk_status.bulk_size || prop != FnProperty::kNormal || priority) {
+ if (!bulk_size() || prop != FnProperty::kNormal || priority) {
this->PushAsync([exec_fn](RunContext ctx, CallbackOnComplete on_complete) {
exec_fn(ctx);
on_complete();
@@ -335,9 +334,9 @@ void ThreadedEngine::PushSync(SyncFn exec_fn, Context exec_ctx,
return;
}
+ const BulkStatus& bulk_status = *BulkStatusStore::Get();
if (bulk_status.count && exec_ctx != bulk_status.ctx) BulkFlush();
BulkAppend(exec_fn, exec_ctx, const_vars, mutable_vars);
- return;
}
void ThreadedEngine::DeleteVariable(SyncFn delete_fn,
diff --git a/src/engine/threaded_engine.h b/src/engine/threaded_engine.h
index 1b9453f903b..d72784d0498 100644
--- a/src/engine/threaded_engine.h
+++ b/src/engine/threaded_engine.h
@@ -398,7 +398,7 @@ class ThreadedEngine : public Engine {
}
int bulk_size() const override {
- return BulkStatusStore::Get()->bulk_size;
+ return profiler::Profiler::Get()->AggregateRunning() ? 0 : BulkStatusStore::Get()->bulk_size;
}
int set_bulk_size(int bulk_size) override {
diff --git a/src/executor/graph_executor.cc b/src/executor/graph_executor.cc
index 7d31a31b839..fa5931e5c84 100644
--- a/src/executor/graph_executor.cc
+++ b/src/executor/graph_executor.cc
@@ -802,17 +802,17 @@ void GraphExecutor::InitArguments(const nnvm::IndexedGraph& idx,
CHECK_EQ(inferred_stype, arg_nd_stype)
<< "Inferred stype does not match shared_exec.arg_array's stype"
" Therefore, the allocated memory for shared_exec.arg_array cannot"
- " be resued for creating NDArray of the argument"
+ " be resued for creating NDArray of the argument "
<< arg_name << " for the current executor";
CHECK_EQ(inferred_shape, in_arg_nd.shape())
<< "Inferred shape does not match shared_exec.arg_array's shape"
" Therefore, the allocated memory for shared_exec.arg_array cannot"
- " be resued for creating NDArray of the argument"
+ " be resued for creating NDArray of the argument "
<< arg_name << " for the current executor";
CHECK_EQ(inferred_dtype, in_arg_nd.dtype())
<< "Inferred dtype does not match shared_exec.arg_array's dtype"
" Therefore, the allocated memory for shared_exec.arg_array cannot"
- " be resued for creating NDArray of the argument"
+ " be resued for creating NDArray of the argument "
<< arg_name << " for the current executor";
in_arg_vec->emplace_back(in_arg_nd);
} else {
@@ -1348,7 +1348,8 @@ void GraphExecutor::InitOpSegs() {
// Generate segments based on the graph structure
bool prefer_bulk_exec_inference = dmlc::GetEnv("MXNET_EXEC_BULK_EXEC_INFERENCE", true);
// Whether to perform bulk exec for training
- bool prefer_bulk_exec = dmlc::GetEnv("MXNET_EXEC_BULK_EXEC_TRAIN", 1);
+ bool prefer_bulk_exec = dmlc::GetEnv("MXNET_EXEC_BULK_EXEC_TRAIN", 1)
+ && !profiler::Profiler::Get()->AggregateEnabled();
bool is_training = num_forward_nodes_ != total_num_nodes;
@@ -1359,8 +1360,6 @@ void GraphExecutor::InitOpSegs() {
if (prefer_bulk_exec_inference && !is_training) {
this->BulkInferenceOpSegs();
}
-
- return;
}
void GraphExecutor::BulkTrainingOpSegs(size_t total_num_nodes) {
diff --git a/src/io/image_iter_common.h b/src/io/image_iter_common.h
index c61e3d12a82..56822888a44 100644
--- a/src/io/image_iter_common.h
+++ b/src/io/image_iter_common.h
@@ -85,6 +85,14 @@ class ImageLabelMap {
CHECK(it != idx2label_.end()) << "fail to find imagelabel for id " << imid;
return mshadow::Tensor<cpu, 1>(it->second, mshadow::Shape1(label_width));
}
+ /*! \brief find a label for corresponding index, return vector as copy */
+ inline std::vector<float> FindCopy(size_t imid) const {
+ std::unordered_map<size_t, real_t*>::const_iterator it
+ = idx2label_.find(imid);
+ CHECK(it != idx2label_.end()) << "fail to find imagelabel for id " << imid;
+ const real_t *ptr = it->second;
+ return std::vector<float>(ptr, ptr + label_width);
+ }
private:
// label with_
diff --git a/src/io/inst_vector.h b/src/io/inst_vector.h
index 2682b94b4fa..f06a4e4aabe 100644
--- a/src/io/inst_vector.h
+++ b/src/io/inst_vector.h
@@ -29,6 +29,7 @@
#include <mxnet/io.h>
#include <mxnet/base.h>
+#include <mxnet/tensor_blob.h>
#include <dmlc/base.h>
#include <mshadow/tensor.h>
#include <vector>
diff --git a/src/io/iter_image_recordio_2.cc b/src/io/iter_image_recordio_2.cc
index fd8b6d7be83..b6ff6e99b03 100644
--- a/src/io/iter_image_recordio_2.cc
+++ b/src/io/iter_image_recordio_2.cc
@@ -538,8 +538,23 @@ inline unsigned ImageRecordIOParser2<DType>::ParseChunk(DType* data_dptr, real_t
LOG(FATAL) << "Invalid output shape " << param_.data_shape;
}
const int n_channels = res.channels();
+ // load label before augmentations
+ std::vector<float> label_buf;
+ if (label_map_ != nullptr) {
+ label_buf = label_map_->FindCopy(rec.image_index());
+ } else if (rec.label != NULL) {
+ CHECK_EQ(param_.label_width, rec.num_label)
+ << "rec file provide " << rec.num_label << "-dimensional label "
+ "but label_width is set to " << param_.label_width;
+ label_buf.assign(rec.label, rec.label + rec.num_label);
+ } else {
+ CHECK_EQ(param_.label_width, 1)
+ << "label_width must be 1 unless an imglist is provided "
+ "or the rec file is packed with multi dimensional label";
+ label_buf.assign(&rec.header.label, &rec.header.label + 1);
+ }
for (auto& aug : augmenters_[tid]) {
- res = aug->Process(res, nullptr, prnds_[tid].get());
+ res = aug->Process(res, &label_buf, prnds_[tid].get());
}
mshadow::Tensor<cpu, 3, DType> data;
if (idx < batch_param_.batch_size) {
@@ -584,20 +599,8 @@ inline unsigned ImageRecordIOParser2<DType>::ParseChunk(DType* data_dptr, real_t
label = out_tmp.label().Back();
}
- if (label_map_ != nullptr) {
- mshadow::Copy(label, label_map_->Find(rec.image_index()));
- } else if (rec.label != NULL) {
- CHECK_EQ(param_.label_width, rec.num_label)
- << "rec file provide " << rec.num_label << "-dimensional label "
- "but label_width is set to " << param_.label_width;
- mshadow::Copy(label, mshadow::Tensor<cpu, 1>(rec.label,
- mshadow::Shape1(rec.num_label)));
- } else {
- CHECK_EQ(param_.label_width, 1)
- << "label_width must be 1 unless an imglist is provided "
- "or the rec file is packed with multi dimensional label";
- label[0] = rec.header.label;
- }
+ mshadow::Copy(label, mshadow::Tensor<cpu, 1>(dmlc::BeginPtr(label_buf),
+ mshadow::Shape1(label_buf.size())));
res.release();
}
}
diff --git a/src/io/iter_sparse_batchloader.h b/src/io/iter_sparse_batchloader.h
index d5c9bd2f457..398d6e00fe7 100644
--- a/src/io/iter_sparse_batchloader.h
+++ b/src/io/iter_sparse_batchloader.h
@@ -68,53 +68,36 @@ class SparseBatchLoader : public BatchLoader, public SparseIIterator<TBlobBatch>
// if overflown from previous round, directly return false, until before first is called
if (num_overflow_ != 0) return false;
index_t top = 0;
- inst_cache_.clear();
+ offsets_.clear();
while (sparse_base_->Next()) {
- inst_cache_.emplace_back(sparse_base_->Value());
- if (inst_cache_.size() >= param_.batch_size) break;
- }
- // no more data instance
- if (inst_cache_.size() == 0) {
- return false;
+ const DataInst& inst = sparse_base_->Value();
+ // initialize the data buffer, only called once
+ if (data_.size() == 0) this->InitData(inst);
+ // initialize the number of elements in each buffer, called once per batch
+ if (offsets_.size() == 0) offsets_.resize(inst.data.size(), 0);
+ CopyData(inst, top);
+ if (++top >= param_.batch_size) {
+ SetOutputShape();
+ return true;
+ }
}
- if (inst_cache_.size() < param_.batch_size) {
- CHECK_GT(param_.round_batch, 0);
+ if (top != 0) {
+ CHECK_NE(param_.round_batch, 0)
+ << "round_batch = False is not supported for sparse data iterator";
num_overflow_ = 0;
sparse_base_->BeforeFirst();
- for (; inst_cache_.size() < param_.batch_size; ++num_overflow_) {
+ for (; top < param_.batch_size; ++top, ++num_overflow_) {
CHECK(sparse_base_->Next()) << "number of input must be bigger than batch size";
- inst_cache_.emplace_back(sparse_base_->Value());
- }
- }
- out_.num_batch_padd = num_overflow_;
- CHECK_EQ(inst_cache_.size(), param_.batch_size);
- this->InitDataFromBatch();
- for (size_t j = 0; j < inst_cache_.size(); j++) {
- const auto& d = inst_cache_[j];
- out_.inst_index[top] = d.index;
- // TODO(haibin) double check the type?
- int64_t unit_size = 0;
- for (size_t i = 0; i < d.data.size(); ++i) {
- // indptr tensor
- if (IsIndPtr(i)) {
- auto indptr = data_[i].get<cpu, 1, int64_t>();
- if (j == 0) indptr[0] = 0;
- indptr[j + 1] = indptr[j] + unit_size;
- offsets_[i] = j;
- } else {
- // indices and values tensor
- unit_size = d.data[i].shape_.Size();
- MSHADOW_TYPE_SWITCH(data_[i].type_flag_, DType, {
- const auto begin = offsets_[i];
- const auto end = offsets_[i] + unit_size;
- mshadow::Copy(data_[i].get<cpu, 1, DType>().Slice(begin, end),
- d.data[i].get_with_shape<cpu, 1, DType>(mshadow::Shape1(unit_size)));
- });
- offsets_[i] += unit_size;
- }
+ const DataInst& inst = sparse_base_->Value();
+ // copy data
+ CopyData(inst, top);
}
+ SetOutputShape();
+ out_.num_batch_padd = num_overflow_;
+ return true;
}
- return true;
+ // no more data instance
+ return false;
}
virtual const TBlobBatch &Value(void) const {
@@ -138,14 +121,16 @@ class SparseBatchLoader : public BatchLoader, public SparseIIterator<TBlobBatch>
private:
/*! \brief base sparse iterator */
SparseIIterator<DataInst> *sparse_base_;
- /*! \brief data instances */
- std::vector<DataInst> inst_cache_;
/*! \brief data storage type */
NDArrayStorageType data_stype_;
/*! \brief data label type */
NDArrayStorageType label_stype_;
- /*! \brief tensor offset for slicing */
+ /*! \brief tensor offsets for slicing */
std::vector<size_t> offsets_;
+ /*! \brief tensor dtypes */
+ std::vector<int> dtypes_;
+ /*! \brief whether the offset correspond to an indptr array */
+ std::vector<bool> indptr_;
// check whether ith position is the indptr tensor for a CSR tensor
inline bool IsIndPtr(size_t i) {
@@ -157,44 +142,109 @@ class SparseBatchLoader : public BatchLoader, public SparseIIterator<TBlobBatch>
return true;
}
// label indptr
- if (i == label_indptr_offset && label_stype_ == kCSRStorage && data_stype_ == kCSRStorage) {
+ if (i == label_indptr_offset && label_stype_ == kCSRStorage &&
+ data_stype_ == kCSRStorage) {
return true;
}
return false;
}
// initialize the data holder by using from the batch
- inline void InitDataFromBatch() {
+ inline void InitData(const DataInst& first_inst) {
CHECK(data_stype_ == kCSRStorage || label_stype_ == kCSRStorage);
- CHECK_GT(inst_cache_.size(), 0);
out_.data.clear();
data_.clear();
offsets_.clear();
-
- size_t total_size = inst_cache_[0].data.size();
- data_.resize(total_size);
- offsets_.resize(total_size, 0);
- std::vector<size_t> vec_sizes(total_size, 0);
- // accumulate the memory required for a batch
- for (size_t i = 0; i < total_size; ++i) {
- size_t size = 0;
- // vec_size for indptr
+ indptr_.clear();
+
+ // num_arrays is the number of arrays in inputs
+ // if both data and label are in the csr format,
+ // num_arrays will be 3 + 3 = 6.
+ size_t num_arrays = first_inst.data.size();
+ data_.resize(num_arrays);
+ offsets_.resize(num_arrays, 0);
+ indptr_.resize(num_arrays, false);
+ // tensor buffer sizes
+ std::vector<size_t> buff_sizes(num_arrays, 0);
+ dtypes_.resize(num_arrays);
+ out_.data.resize(num_arrays);
+ // estimate the memory required for a batch
+ for (size_t i = 0; i < num_arrays; ++i) {
+ // shape for indptr
if (IsIndPtr(i)) {
- size = param_.batch_size + 1;
+ buff_sizes[i] = param_.batch_size + 1;
+ indptr_[i] = true;
} else {
- for (const auto &d : inst_cache_) size += d.data[i].shape_.Size();
+ // estimated the size for the whole batch based on the first instance
+ buff_sizes[i] = first_inst.data[i].Size() * param_.batch_size;
+ indptr_[i] = false;
}
- vec_sizes[i] = size;
+ dtypes_[i] = first_inst.data[i].type_flag_;
}
- CHECK_EQ(vec_sizes[0], vec_sizes[1]);
- for (size_t i = 0; i < total_size; ++i) {
- int src_type_flag = inst_cache_[0].data[i].type_flag_;
+ CHECK_EQ(buff_sizes[0], buff_sizes[1]);
+ // allocate buffer
+ for (size_t i = 0; i < num_arrays; ++i) {
// init object attributes
- TShape dst_shape(mshadow::Shape1(vec_sizes[i]));
- data_[i].resize(mshadow::Shape1(vec_sizes[i]), src_type_flag);
+ TShape dst_shape(mshadow::Shape1(buff_sizes[i]));
+ data_[i].resize(mshadow::Shape1(buff_sizes[i]), dtypes_[i]);
CHECK(data_[i].dptr_ != nullptr);
- out_.data.push_back(TBlob(data_[i].dptr_, dst_shape, cpu::kDevMask, src_type_flag));
+ }
+ }
+
+ /* \brief set the shape of the outputs based on actual shapes */
+ inline void SetOutputShape() {
+ for (size_t i = 0; i < out_.data.size(); i++) {
+ out_.data[i] = TBlob(data_[i].dptr_, mshadow::Shape1(offsets_[i]),
+ Context::kCPU, dtypes_[i]);
+ }
+ }
+
+ /* \brief increase the size of i-th data buffer by a factor of 2, while retaining the content */
+ inline void ResizeBuffer(size_t src_size, size_t i) {
+ MSHADOW_TYPE_SWITCH(data_[i].type_flag_, DType, {
+ TBlobContainer temp;
+ temp.resize(mshadow::Shape1(src_size), dtypes_[i]);
+ mshadow::Copy(temp.get<cpu, 1, DType>(), data_[i].get<cpu, 1, DType>().Slice(0, src_size));
+ // increase the size of space exponentially
+ size_t capacity = data_[i].Size();
+ capacity = capacity * 2 + 1;
+ data_[i] = TBlobContainer();
+ data_[i].resize(mshadow::Shape1(capacity), dtypes_[i]);
+ // copy back
+ mshadow::Copy(data_[i].get<cpu, 1, DType>().Slice(0, src_size), temp.get<cpu, 1, DType>());
+ });
+ }
+
+ /* \brief copy the data instance to data buffer */
+ void CopyData(const DataInst& inst, const size_t top) {
+ int64_t unit_size = 0;
+ out_.inst_index[top] = inst.index;
+ for (size_t i = 0; i < inst.data.size(); ++i) {
+ if (!indptr_[i]) {
+ // indices and values tensor
+ unit_size = inst.data[i].shape_.Size();
+ MSHADOW_TYPE_SWITCH(data_[i].type_flag_, DType, {
+ const size_t begin = offsets_[i];
+ const size_t end = offsets_[i] + unit_size;
+ size_t capacity = data_[i].Size();
+ // resize the data buffer if estimated space is not sufficient
+ while (capacity < end) {
+ ResizeBuffer(begin, i);
+ capacity = data_[i].Size();
+ }
+ mshadow::Copy(data_[i].get<cpu, 1, DType>().Slice(begin, end),
+ inst.data[i].get_with_shape<cpu, 1, DType>(mshadow::Shape1(unit_size)));
+ });
+ offsets_[i] += unit_size;
+ } else {
+ // indptr placeholder
+ auto indptr = data_[i].get<cpu, 1, int64_t>();
+ // initialize the first indptr, which is always 0
+ if (top == 0) indptr[0] = 0;
+ indptr[top + 1] = indptr[top] + unit_size;
+ offsets_[i] = top + 2;
+ }
}
}
}; // class BatchLoader
diff --git a/src/kvstore/kvstore_dist_server.h b/src/kvstore/kvstore_dist_server.h
index f1637c4e57d..c2ddcd8708d 100644
--- a/src/kvstore/kvstore_dist_server.h
+++ b/src/kvstore/kvstore_dist_server.h
@@ -297,9 +297,6 @@ class KVStoreDistServer {
CopyFromTo(recved, &merged.array, 0);
} else {
NDArray out(kRowSparseStorage, stored.shape(), Context());
- std::vector<Engine::VarHandle> const_vars;
- const_vars.push_back(recved.var());
- const_vars.push_back(merged.array.var());
// accumulate row_sparse gradients
// TODO(haibin) override + operator for row_sparse NDArray
// instead of calling BinaryComputeRspRsp directly
@@ -309,7 +306,7 @@ class KVStoreDistServer {
op::ElemwiseBinaryOp::ComputeEx<cpu, op::mshadow_op::plus>(
{}, {}, {recved, merged.array}, {kWriteTo}, {out});
on_complete();
- }, recved.ctx(), const_vars, {out.var()},
+ }, recved.ctx(), {recved.var(), merged.array.var()}, {out.var()},
FnProperty::kNormal, 0, PROFILER_MESSAGE_FUNCNAME);
CopyFromTo(out, &merged.array, 0);
}
diff --git a/src/ndarray/ndarray.cc b/src/ndarray/ndarray.cc
index d4a6583254b..52b96fad692 100644
--- a/src/ndarray/ndarray.cc
+++ b/src/ndarray/ndarray.cc
@@ -742,10 +742,8 @@ void NDArray::SetTBlob() const {
auto stype = storage_type();
if (stype == kDefaultStorage) {
#if MXNET_USE_MKLDNN == 1
- if (IsMKLDNNData()) {
- ptr_->Reorder2Default();
- dptr = static_cast<char*>(ptr_->shandle.dptr);
- }
+ CHECK(!IsMKLDNNData()) << "We can't generate TBlob for MKLDNN data. "
+ << "Please use Reorder2Default() to generate a new NDArray first";
#endif
dptr += byte_offset_;
} else if (stype == kCSRStorage || stype == kRowSparseStorage) {
@@ -824,16 +822,18 @@ void TernaryOp(const NDArray &lhs,
}
/*!
- * \brief run a binary operation
- * \param lhs left operand
- * \param rhs right operand
- * \param out the output ndarray
- * \param binary_op the real
- */
+* \brief Performs some preparation required to apply binary operators.
+* Checks context and shape of ndarrays, allocates space for output
+* and prepares const variables for engine
+* \param lhs left operand
+* \param rhs right operand
+* \param out the output ndarray
+* \param binary_op the real operation
+*/
template<typename OP>
-void BinaryOp(const NDArray &lhs,
- const NDArray &rhs,
- NDArray *out) {
+std::vector<Engine::VarHandle> BinaryOpPrepare(const NDArray &lhs,
+ const NDArray &rhs,
+ NDArray *out) {
// no check if both of them are on cpu
if (lhs.ctx().dev_mask() != cpu::kDevMask || rhs.ctx().dev_mask() != cpu::kDevMask) {
CHECK(lhs.ctx() == rhs.ctx()) << "operands context mismatch";
@@ -848,15 +848,71 @@ void BinaryOp(const NDArray &lhs,
CHECK(out->ctx() == lhs.ctx()) << "target context mismatch";
}
CHECK(out->shape() == OP::GetShape(lhs.shape(), rhs.shape()))
- << "target shape mismatch";
+ << "target shape mismatch";
}
+ std::vector<Engine::VarHandle> const_vars;
+ // prepare const variables for engine
+ if (lhs.var() != out->var()) const_vars.push_back(lhs.var());
+ if (rhs.var() != out->var()) const_vars.push_back(rhs.var());
+ return const_vars;
+}
+
+/*!
+* \brief run a binary operation using the kernel launch method
+* \param lhs left operand
+* \param rhs right operand
+* \param out the output ndarray
+* \param binary_op the real operation
+*/
+template<typename OP>
+void BinaryOpKernel(const NDArray &lhs,
+ const NDArray &rhs,
+ NDArray *out) {
+ std::vector<Engine::VarHandle> const_vars = BinaryOpPrepare<OP>(lhs, rhs, out);
// important: callback must always capture by value
NDArray ret = *out;
- // get the const variables
- std::vector<Engine::VarHandle> const_vars;
- if (lhs.var() != ret.var()) const_vars.push_back(lhs.var());
- if (rhs.var() != ret.var()) const_vars.push_back(rhs.var());
+ switch (lhs.ctx().dev_mask()) {
+ case cpu::kDevMask: {
+ Engine::Get()->PushSync([lhs, rhs, ret](RunContext ctx) {
+ TBlob tmp = ret.data();
+ mshadow::Stream<cpu>* s = ctx.get_stream<cpu>();
+ ndarray::BinaryOpKernelImpl<OP>(s, lhs.data(), rhs.data(), &tmp);
+ },
+ lhs.ctx(), const_vars, {ret.var()},
+ FnProperty::kNormal, 0, PROFILER_MESSAGE_FUNCNAME);
+ break;
+ }
+#if MXNET_USE_CUDA
+ case gpu::kDevMask: {
+ Engine::Get()->PushSync([lhs, rhs, ret](RunContext ctx) {
+ TBlob tmp = ret.data();
+ mshadow::Stream<gpu>* s = ctx.get_stream<gpu>();
+ ndarray::BinaryOpKernelImpl<OP>(s, lhs.data(), rhs.data(), &tmp);
+ // Wait GPU kernel to complete
+ ctx.get_stream<gpu>()->Wait();
+ }, lhs.ctx(), const_vars, {ret.var()},
+ FnProperty::kNormal, 0, PROFILER_MESSAGE_FUNCNAME);
+ break;
+}
+#endif
+ default: LOG(FATAL) << MXNET_GPU_NOT_ENABLED_ERROR;
+ }
+}
+/*!
+ * \brief run a binary operation using mshadow operations
+ * \param lhs left operand
+ * \param rhs right operand
+ * \param out the output ndarray
+ * \param binary_op the real operation
+ */
+template<typename OP>
+void BinaryOp(const NDArray &lhs,
+ const NDArray &rhs,
+ NDArray *out) {
+ std::vector<Engine::VarHandle> const_vars = BinaryOpPrepare<OP>(lhs, rhs, out);
+ // important: callback must always capture by value
+ NDArray ret = *out;
// redirect everything to mshadow operations
switch (lhs.ctx().dev_mask()) {
case cpu::kDevMask: {
@@ -1421,7 +1477,7 @@ template<typename OP>
inline NDArray BinaryOpRet(const NDArray &lhs,
const NDArray &rhs) {
NDArray ret;
- BinaryOp<OP>(lhs, rhs, &ret);
+ BinaryOpKernel<OP>(lhs, rhs, &ret);
return ret;
}
@@ -1436,7 +1492,7 @@ inline NDArray ScalarOpRet(const NDArray &lhs,
template<typename OP>
inline NDArray &BinaryOpApply(NDArray *dst,
const NDArray &src) {
- BinaryOp<OP>(*dst, src, dst);
+ BinaryOpKernel<OP>(*dst, src, dst);
return *dst;
}
diff --git a/src/ndarray/ndarray_function-inl.h b/src/ndarray/ndarray_function-inl.h
index a80d9db3637..d494f0882bb 100644
--- a/src/ndarray/ndarray_function-inl.h
+++ b/src/ndarray/ndarray_function-inl.h
@@ -47,6 +47,15 @@
}
#endif
+#ifndef DECL_BINARY_LAUNCH
+#define DECL_BINARY_LAUNCH(XPU, OP) \
+ template <> \
+ void BinaryOpKernelImpl<OP, XPU>(mshadow::Stream<XPU> *s, \
+ const TBlob& lhs, const TBlob& rhs, TBlob *out) { \
+ BinaryOpKernelLaunch<OP>(s, lhs, rhs, out); \
+ }
+#endif
+
#ifndef DECL_SCALAR
#define DECL_SCALAR(XPU, OP, FUN, REVERSE) \
template<> \
@@ -433,18 +442,31 @@ void EvalBroadcast<DEVICE>(TBlob const& src, TBlob* ret, int size, RunContext ct
out = mshadow::expr::broadcast_with_axis(in, 0, size);
}
+template<typename OP, typename xpu>
+void BinaryOpKernelLaunch(mshadow::Stream<xpu>* s, const TBlob& lhs, const TBlob& rhs, TBlob *out) {
+ using namespace op::mxnet_op;
+ using namespace mshadow;
+ MSHADOW_TYPE_SWITCH(out->type_flag_, DType, {
+ Kernel<op_with_req<OP, kWriteInplace>, xpu >::
+ Launch(s,
+ lhs.Size(),
+ out->dptr<DType>(),
+ lhs.dptr<DType>(),
+ rhs.dptr<DType>());
+ });
+}
// declarations
DECL_BINARY(DEVICE, MatChooseRowElem, EvalMatChooseRowElem_)
DECL_TERNARY(DEVICE, MatFillRowElem, EvalMatFillRowElem_)
DECL_BINARY(DEVICE, OneHotEncode, EvalOneHot_)
-DECL_BINARY(DEVICE, Plus, EvalBinary_)
-DECL_BINARY(DEVICE, Minus, EvalBinary_)
-DECL_BINARY(DEVICE, Mul, EvalBinary_)
-DECL_BINARY(DEVICE, Div, EvalBinary_)
DECL_SCALAR(DEVICE, Plus, EvalScalar_, true)
DECL_SCALAR(DEVICE, Minus, EvalScalar_, true)
DECL_SCALAR(DEVICE, Mul, EvalScalar_, true)
DECL_SCALAR(DEVICE, Div, EvalScalar_, true)
+DECL_BINARY_LAUNCH(DEVICE, Plus)
+DECL_BINARY_LAUNCH(DEVICE, Minus)
+DECL_BINARY_LAUNCH(DEVICE, Mul)
+DECL_BINARY_LAUNCH(DEVICE, Div)
// for reverse seq
DECL_SCALAR(DEVICE, Plus, EvalScalar_, false)
diff --git a/src/ndarray/ndarray_function.h b/src/ndarray/ndarray_function.h
index 518bb773170..97c23b67592 100644
--- a/src/ndarray/ndarray_function.h
+++ b/src/ndarray/ndarray_function.h
@@ -46,20 +46,20 @@ struct BinaryBase {
};
// operators
-struct Plus : public BinaryBase {
- typedef op::mshadow_op::plus mshadow_op;
+struct Plus : public BinaryBase, public mshadow::op::plus {
+ typedef mshadow::op::plus mshadow_op;
};
-struct Minus : public BinaryBase {
- typedef op::mshadow_op::minus mshadow_op;
+struct Minus : public BinaryBase, public mshadow::op::minus {
+ typedef mshadow::op::minus mshadow_op;
};
-struct Mul : public BinaryBase {
- typedef op::mshadow_op::mul mshadow_op;
+struct Mul : public BinaryBase, public mshadow::op::mul {
+ typedef mshadow::op::mul mshadow_op;
};
-struct Div : public BinaryBase {
- typedef op::mshadow_op::div mshadow_op;
+struct Div : public BinaryBase, public mshadow::op::div {
+ typedef mshadow::op::div mshadow_op;
};
struct Mod : public BinaryBase {
@@ -208,6 +208,10 @@ void Eval(mshadow::Stream<xpu> *s,
template <typename Device>
void EvalBroadcast(TBlob const& src, TBlob* ret, int size, RunContext ctx);
+template <typename OP, typename xpu>
+void BinaryOpKernelImpl(mshadow::Stream<xpu> *s, const TBlob& lhs,
+ const TBlob& rhs, TBlob *out);
+
} // namespace ndarray
} // namespace mxnet
#endif // MXNET_NDARRAY_NDARRAY_FUNCTION_H_
diff --git a/src/nnvm/legacy_json_util.cc b/src/nnvm/legacy_json_util.cc
index bdd983cd3a6..935a64c7c22 100644
--- a/src/nnvm/legacy_json_util.cc
+++ b/src/nnvm/legacy_json_util.cc
@@ -1,3 +1,22 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
/*!
* Copyright (c) 2016 by Contributors
* \file legacy_json_util.cc
diff --git a/src/nnvm/legacy_op_util.cc b/src/nnvm/legacy_op_util.cc
index e5d1d1c8def..4260e685601 100644
--- a/src/nnvm/legacy_op_util.cc
+++ b/src/nnvm/legacy_op_util.cc
@@ -1,3 +1,22 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
/*!
* Copyright (c) 2015 by Contributors
* \file legacy_op_util.cc
diff --git a/src/operator/contrib/multi_proposal.cc b/src/operator/contrib/multi_proposal.cc
index cd00e877a11..0c52b9b7cfc 100644
--- a/src/operator/contrib/multi_proposal.cc
+++ b/src/operator/contrib/multi_proposal.cc
@@ -22,11 +22,262 @@
* Licensed under The Apache-2.0 License [see LICENSE for details]
* \file multi_proposal.cc
* \brief
- * \author Xizhou Zhu
+ * \author Xizhou Zhu, Kan Wu
*/
#include "./multi_proposal-inl.h"
+//============================
+// Bounding Box Transform Utils
+//============================
+namespace mxnet {
+namespace op {
+namespace utils {
+
+// bbox prediction and clip to the image borders
+inline void BBoxTransformInv(const mshadow::Tensor<cpu, 2>& boxes,
+ const mshadow::Tensor<cpu, 3>& deltas,
+ const float im_height,
+ const float im_width,
+ const int real_height,
+ const int real_width,
+ mshadow::Tensor<cpu, 2> *out_pred_boxes) {
+ CHECK_GE(boxes.size(1), 4);
+ CHECK_GE(out_pred_boxes->size(1), 4);
+ int anchors = deltas.size(0) / 4;
+ int heights = deltas.size(1);
+ int widths = deltas.size(2);
+
+ #pragma omp parallel for num_threads(engine::OpenMP::Get()->GetRecommendedOMPThreadCount())
+ for (int index = 0; index < anchors * heights * widths; ++index) {
+ // index_t index = h * (widths * anchors) + w * (anchors) + a;
+ int a = index % anchors;
+ int w = (index / anchors) % widths;
+ int h = index / (widths * anchors);
+
+ float width = boxes[index][2] - boxes[index][0] + 1.0;
+ float height = boxes[index][3] - boxes[index][1] + 1.0;
+ float ctr_x = boxes[index][0] + 0.5 * (width - 1.0);
+ float ctr_y = boxes[index][1] + 0.5 * (height - 1.0);
+
+ float dx = deltas[a*4 + 0][h][w];
+ float dy = deltas[a*4 + 1][h][w];
+ float dw = deltas[a*4 + 2][h][w];
+ float dh = deltas[a*4 + 3][h][w];
+
+ float pred_ctr_x = dx * width + ctr_x;
+ float pred_ctr_y = dy * height + ctr_y;
+ float pred_w = exp(dw) * width;
+ float pred_h = exp(dh) * height;
+
+ float pred_x1 = pred_ctr_x - 0.5 * (pred_w - 1.0);
+ float pred_y1 = pred_ctr_y - 0.5 * (pred_h - 1.0);
+ float pred_x2 = pred_ctr_x + 0.5 * (pred_w - 1.0);
+ float pred_y2 = pred_ctr_y + 0.5 * (pred_h - 1.0);
+
+ pred_x1 = std::max(std::min(pred_x1, im_width - 1.0f), 0.0f);
+ pred_y1 = std::max(std::min(pred_y1, im_height - 1.0f), 0.0f);
+ pred_x2 = std::max(std::min(pred_x2, im_width - 1.0f), 0.0f);
+ pred_y2 = std::max(std::min(pred_y2, im_height - 1.0f), 0.0f);
+
+ (*out_pred_boxes)[index][0] = pred_x1;
+ (*out_pred_boxes)[index][1] = pred_y1;
+ (*out_pred_boxes)[index][2] = pred_x2;
+ (*out_pred_boxes)[index][3] = pred_y2;
+
+ if (h >= real_height || w >= real_width) {
+ (*out_pred_boxes)[index][4] = -1.0;
+ }
+ }
+}
+
+// iou prediction and clip to the image border
+inline void IoUTransformInv(const mshadow::Tensor<cpu, 2>& boxes,
+ const mshadow::Tensor<cpu, 3>& deltas,
+ const float im_height,
+ const float im_width,
+ const int real_height,
+ const int real_width,
+ mshadow::Tensor<cpu, 2> *out_pred_boxes) {
+ CHECK_GE(boxes.size(1), 4);
+ CHECK_GE(out_pred_boxes->size(1), 4);
+ int anchors = deltas.size(0) / 4;
+ int heights = deltas.size(1);
+ int widths = deltas.size(2);
+
+ #pragma omp parallel for num_threads(engine::OpenMP::Get()->GetRecommendedOMPThreadCount())
+ for (int index = 0; index < anchors * heights * widths; ++index) {
+ // index_t index = h * (widths * anchors) + w * (anchors) + a;
+ int a = index % anchors;
+ int w = (index / anchors) % widths;
+ int h = index / (widths * anchors);
+
+ float x1 = boxes[index][0];
+ float y1 = boxes[index][1];
+ float x2 = boxes[index][2];
+ float y2 = boxes[index][3];
+
+ float dx1 = deltas[a * 4 + 0][h][w];
+ float dy1 = deltas[a * 4 + 1][h][w];
+ float dx2 = deltas[a * 4 + 2][h][w];
+ float dy2 = deltas[a * 4 + 3][h][w];
+
+ float pred_x1 = x1 + dx1;
+ float pred_y1 = y1 + dy1;
+ float pred_x2 = x2 + dx2;
+ float pred_y2 = y2 + dy2;
+
+ pred_x1 = std::max(std::min(pred_x1, im_width - 1.0f), 0.0f);
+ pred_y1 = std::max(std::min(pred_y1, im_height - 1.0f), 0.0f);
+ pred_x2 = std::max(std::min(pred_x2, im_width - 1.0f), 0.0f);
+ pred_y2 = std::max(std::min(pred_y2, im_height - 1.0f), 0.0f);
+
+ (*out_pred_boxes)[index][0] = pred_x1;
+ (*out_pred_boxes)[index][1] = pred_y1;
+ (*out_pred_boxes)[index][2] = pred_x2;
+ (*out_pred_boxes)[index][3] = pred_y2;
+
+ if (h >= real_height || w >= real_width) {
+ (*out_pred_boxes)[index][4] = -1.0f;
+ }
+ }
+}
+
+// filter box by set confidence to zero
+// * height or width < rpn_min_size
+inline void FilterBox(mshadow::Tensor<cpu, 2> *dets,
+ const float min_size) {
+ #pragma omp parallel for num_threads(engine::OpenMP::Get()->GetRecommendedOMPThreadCount())
+ for (int i = 0; i < static_cast<int>(dets->size(0)); ++i) {
+ float iw = (*dets)[i][2] - (*dets)[i][0] + 1.0f;
+ float ih = (*dets)[i][3] - (*dets)[i][1] + 1.0f;
+ if (iw < min_size || ih < min_size) {
+ (*dets)[i][0] -= min_size / 2;
+ (*dets)[i][1] -= min_size / 2;
+ (*dets)[i][2] += min_size / 2;
+ (*dets)[i][3] += min_size / 2;
+ (*dets)[i][4] = -1.0f;
+ }
+ }
+}
+
+} // namespace utils
+} // namespace op
+} // namespace mxnet
+
+//=====================
+// NMS Utils
+//=====================
+namespace mxnet {
+namespace op {
+namespace utils {
+
+struct ReverseArgsortCompl {
+ const float *val_;
+ explicit ReverseArgsortCompl(float *val)
+ : val_(val) {}
+ bool operator() (float i, float j) {
+ return (val_[static_cast<index_t>(i)] >
+ val_[static_cast<index_t>(j)]);
+ }
+};
+
+// copy score and init order
+inline void CopyScore(const mshadow::Tensor<cpu, 2>& dets,
+ mshadow::Tensor<cpu, 1> *score,
+ mshadow::Tensor<cpu, 1> *order) {
+ #pragma omp parallel for num_threads(engine::OpenMP::Get()->GetRecommendedOMPThreadCount())
+ for (int i = 0; i < static_cast<int>(dets.size(0)); ++i) {
+ (*score)[i] = dets[i][4];
+ (*order)[i] = i;
+ }
+}
+
+// sort order array according to score
+inline void ReverseArgsort(const mshadow::Tensor<cpu, 1>& score,
+ mshadow::Tensor<cpu, 1> *order) {
+ ReverseArgsortCompl cmpl(score.dptr_);
+ std::sort(order->dptr_, order->dptr_ + score.size(0), cmpl);
+}
+
+// reorder proposals according to order and keep the pre_nms_top_n proposals
+// dets.size(0) == pre_nms_top_n
+inline void ReorderProposals(const mshadow::Tensor<cpu, 2>& prev_dets,
+ const mshadow::Tensor<cpu, 1>& order,
+ const index_t pre_nms_top_n,
+ mshadow::Tensor<cpu, 2> *dets) {
+ CHECK_EQ(dets->size(0), pre_nms_top_n);
+ const int dets_size0 = static_cast<int>(dets->size(0));
+ const int dets_size1 = static_cast<int>(dets->size(1));
+ #pragma omp parallel for num_threads(engine::OpenMP::Get()->GetRecommendedOMPThreadCount())
+ for (int k = 0; k < dets_size0 * dets_size1; ++k) {
+ int i = k / dets_size1;
+ int j = k % dets_size1;
+ const index_t index = order[i];
+ (*dets)[i][j] = prev_dets[index][j];
+ }
+}
+
+// greedily keep the max detections (already sorted)
+inline void NonMaximumSuppression(const mshadow::Tensor<cpu, 2>& dets,
+ const float thresh,
+ const index_t post_nms_top_n,
+ mshadow::Tensor<cpu, 1> *area,
+ mshadow::Tensor<cpu, 1> *suppressed,
+ mshadow::Tensor<cpu, 1> *keep,
+ int *out_size) {
+ CHECK_EQ(dets.shape_[1], 5) << "dets: [x1, y1, x2, y2, score]";
+ CHECK_GT(dets.shape_[0], 0);
+ CHECK_EQ(dets.CheckContiguous(), true);
+ CHECK_EQ(area->CheckContiguous(), true);
+ CHECK_EQ(suppressed->CheckContiguous(), true);
+ CHECK_EQ(keep->CheckContiguous(), true);
+ // calculate area
+ #pragma omp parallel for num_threads(engine::OpenMP::Get()->GetRecommendedOMPThreadCount())
+ for (int i = 0; i < static_cast<int>(dets.size(0)); ++i) {
+ (*area)[i] = (dets[i][2] - dets[i][0] + 1) *
+ (dets[i][3] - dets[i][1] + 1);
+ }
+
+ // calculate nms
+ *out_size = 0;
+ for (index_t i = 0; i < dets.size(0) && (*out_size) < static_cast<int>(post_nms_top_n); ++i) {
+ float ix1 = dets[i][0];
+ float iy1 = dets[i][1];
+ float ix2 = dets[i][2];
+ float iy2 = dets[i][3];
+ float iarea = (*area)[i];
+
+ if ((*suppressed)[i] > 0.0f) {
+ continue;
+ }
+
+ (*keep)[(*out_size)++] = i;
+ #pragma omp parallel for num_threads(engine::OpenMP::Get()->GetRecommendedOMPThreadCount())
+ for (int j = i + 1; j < static_cast<int>(dets.size(0)); ++j) {
+ if ((*suppressed)[j] > 0.0f) {
+ continue;
+ }
+ float xx1 = std::max(ix1, dets[j][0]);
+ float yy1 = std::max(iy1, dets[j][1]);
+ float xx2 = std::min(ix2, dets[j][2]);
+ float yy2 = std::min(iy2, dets[j][3]);
+ float w = std::max(0.0f, xx2 - xx1 + 1.0f);
+ float h = std::max(0.0f, yy2 - yy1 + 1.0f);
+ float inter = w * h;
+ float ovr = inter / (iarea + (*area)[j] - inter);
+ if (ovr > thresh) {
+ (*suppressed)[j] = 1.0f;
+ }
+ }
+ }
+}
+
+} // namespace utils
+} // namespace op
+} // namespace mxnet
+
+
namespace mxnet {
namespace op {
@@ -43,7 +294,168 @@ class MultiProposalOp : public Operator{
const std::vector<OpReqType> &req,
const std::vector<TBlob> &out_data,
const std::vector<TBlob> &aux_states) {
- LOG(FATAL) << "not implemented";
+ using namespace mshadow;
+ using namespace mshadow::expr;
+ CHECK_EQ(in_data.size(), 3);
+ CHECK_EQ(out_data.size(), 2);
+ CHECK_GT(req.size(), 1);
+ CHECK_EQ(req[proposal::kOut], kWriteTo);
+
+ Stream<xpu> *s = ctx.get_stream<xpu>();
+
+ Tensor<cpu, 4> scores = in_data[proposal::kClsProb].get<cpu, 4, real_t>(s);
+ Tensor<cpu, 4> bbox_deltas = in_data[proposal::kBBoxPred].get<cpu, 4, real_t>(s);
+ Tensor<cpu, 2> im_info = in_data[proposal::kImInfo].get<cpu, 2, real_t>(s);
+
+ Tensor<cpu, 2> out = out_data[proposal::kOut].get<cpu, 2, real_t>(s);
+ Tensor<cpu, 2> out_score = out_data[proposal::kScore].get<cpu, 2, real_t>(s);
+
+ int num_images = scores.size(0);
+ int num_anchors = scores.size(1) / 2;
+ int height = scores.size(2);
+ int width = scores.size(3);
+ int count_anchors = num_anchors * height * width;
+ int rpn_pre_nms_top_n =
+ (param_.rpn_pre_nms_top_n > 0) ? param_.rpn_pre_nms_top_n : count_anchors;
+ rpn_pre_nms_top_n = std::min(rpn_pre_nms_top_n, count_anchors);
+ int rpn_post_nms_top_n = std::min(param_.rpn_post_nms_top_n, rpn_pre_nms_top_n);
+
+ int workspace_size =
+ num_images * (count_anchors * 5 + 2 * count_anchors +
+ rpn_pre_nms_top_n * 5 + 3 * rpn_pre_nms_top_n);
+
+ Tensor<cpu, 1> workspace = ctx.requested[proposal::kTempResource].get_space<cpu>(
+ Shape1(workspace_size), s);
+ int start = 0;
+ Tensor<cpu, 3> workspace_proposals(workspace.dptr_ +
+ start, Shape3(num_images, count_anchors, 5));
+ start += num_images * count_anchors * 5;
+ Tensor<cpu, 3> workspace_pre_nms(workspace.dptr_ + start, Shape3(num_images, 2, count_anchors));
+ start += num_images * 2 * count_anchors;
+ Tensor<cpu, 3> workspace_ordered_proposals(workspace.dptr_ + start,
+ Shape3(num_images, rpn_pre_nms_top_n, 5));
+ start += num_images * rpn_pre_nms_top_n * 5;
+ Tensor<cpu, 3> workspace_nms(workspace.dptr_ + start, Shape3(num_images, 3, rpn_pre_nms_top_n));
+ start += num_images * 3 * rpn_pre_nms_top_n;
+ CHECK_EQ(workspace_size, start) << workspace_size << " " << start << std::endl;
+
+ // Generate anchors
+ std::vector<float> base_anchor(4);
+ base_anchor[0] = 0.0;
+ base_anchor[1] = 0.0;
+ base_anchor[2] = param_.feature_stride - 1.0;
+ base_anchor[3] = param_.feature_stride - 1.0;
+ CHECK_EQ(num_anchors, param_.ratios.ndim() * param_.scales.ndim());
+ std::vector<float> anchors;
+ utils::GenerateAnchors(base_anchor,
+ param_.ratios,
+ param_.scales,
+ &anchors);
+ std::memcpy(workspace_proposals.dptr_, &anchors[0], sizeof(float) * anchors.size());
+
+ Tensor<cpu, 2> workspace_proposals0 = workspace_proposals[0];
+ // Enumerate all shifted anchors
+ #pragma omp parallel for num_threads(engine::OpenMP::Get()->GetRecommendedOMPThreadCount())
+ for (int index = 0; index < num_anchors * height * width; ++index) {
+ // index_t index = j * (width * num_anchors) + k * (num_anchors) + i;
+ int i = index % num_anchors;
+ int k = (index / num_anchors) % width;
+ int j = index / (width * num_anchors);
+ workspace_proposals0[index][0] =
+ workspace_proposals0[i][0] + k * param_.feature_stride;
+ workspace_proposals0[index][1] =
+ workspace_proposals0[i][1] + j * param_.feature_stride;
+ workspace_proposals0[index][2] =
+ workspace_proposals0[i][2] + k * param_.feature_stride;
+ workspace_proposals0[index][3] =
+ workspace_proposals0[i][3] + j * param_.feature_stride;
+ workspace_proposals0[index][4] = scores[0][i + num_anchors][j][k];
+ }
+
+ // Copy shifted anchors to other images
+ #pragma omp parallel for num_threads(engine::OpenMP::Get()->GetRecommendedOMPThreadCount())
+ for (int t = count_anchors; t < num_images * count_anchors; ++t) {
+ int b = t / count_anchors;
+ int index = t % count_anchors;
+ int i = index % num_anchors;
+ int k = (index / num_anchors) % width;
+ int j = index / (width * num_anchors);
+ for (int w = 0; w < 4; ++w) {
+ workspace_proposals[b][index][w] = workspace_proposals[0][index][w];
+ }
+ workspace_proposals[b][index][4] = scores[b][i + num_anchors][j][k];
+ }
+
+ // Assign Foreground Scores for each anchor
+ #pragma omp parallel for num_threads(engine::OpenMP::Get()->GetRecommendedOMPThreadCount())
+ for (int b = 0; b < num_images; ++b) {
+ // prevent padded predictions
+ int real_height = static_cast<int>(im_info[b][0] / param_.feature_stride);
+ int real_width = static_cast<int>(im_info[b][1] / param_.feature_stride);
+ CHECK_GE(height, real_height) << height << " " << real_height << std::endl;
+ CHECK_GE(width, real_width) << width << " " << real_width << std::endl;
+
+ Tensor<cpu, 2> workspace_proposals_i = workspace_proposals[b];
+ Tensor<cpu, 2> workspace_pre_nms_i = workspace_pre_nms[b];
+ Tensor<cpu, 2> workspace_ordered_proposals_i =
+ workspace_ordered_proposals[b];
+ Tensor<cpu, 2> workspace_nms_i = workspace_nms[b];
+
+ if (param_.iou_loss) {
+ utils::IoUTransformInv(workspace_proposals_i, bbox_deltas[b], im_info[b][0], im_info[b][1],
+ real_height, real_width, &(workspace_proposals_i));
+ } else {
+ utils::BBoxTransformInv(workspace_proposals_i, bbox_deltas[b], im_info[b][0], im_info[b][1],
+ real_height, real_width, &(workspace_proposals_i));
+ }
+ utils::FilterBox(&workspace_proposals_i, param_.rpn_min_size * im_info[b][2]);
+
+ Tensor<cpu, 1> score = workspace_pre_nms_i[0];
+ Tensor<cpu, 1> order = workspace_pre_nms_i[1];
+
+ utils::CopyScore(workspace_proposals_i,
+ &score,
+ &order);
+ utils::ReverseArgsort(score,
+ &order);
+ utils::ReorderProposals(workspace_proposals_i,
+ order,
+ rpn_pre_nms_top_n,
+ &workspace_ordered_proposals_i);
+ int out_size = 0;
+ Tensor<cpu, 1> area = workspace_nms_i[0];
+ Tensor<cpu, 1> suppressed = workspace_nms_i[1];
+ Tensor<cpu, 1> keep = workspace_nms_i[2];
+ suppressed = 0; // surprised!
+
+ utils::NonMaximumSuppression(workspace_ordered_proposals_i,
+ param_.threshold,
+ rpn_post_nms_top_n,
+ &area,
+ &suppressed,
+ &keep,
+ &out_size);
+
+ // fill in output rois and output scores
+ #pragma omp parallel for num_threads(engine::OpenMP::Get()->GetRecommendedOMPThreadCount())
+ for (int i = 0; i < param_.rpn_post_nms_top_n; ++i) {
+ int out_index = b * param_.rpn_post_nms_top_n + i;
+ out[out_index][0] = b;
+ if (i < out_size) {
+ index_t index = keep[i];
+ for (index_t j = 0; j < 4; ++j) {
+ out[out_index][j + 1] = workspace_ordered_proposals_i[index][j];
+ }
+ out_score[out_index][0] = workspace_ordered_proposals_i[index][4];
+ } else {
+ index_t index = keep[i % out_size];
+ for (index_t j = 0; j < 4; ++j) {
+ out[out_index][j + 1] = workspace_ordered_proposals_i[index][j];
+ }
+ out_score[out_index][0] = workspace_ordered_proposals_i[index][4];
+ }
+ }
+ }
}
virtual void Backward(const OpContext &ctx,
@@ -53,7 +465,19 @@ class MultiProposalOp : public Operator{
const std::vector<OpReqType> &req,
const std::vector<TBlob> &in_grad,
const std::vector<TBlob> &aux_states) {
- LOG(FATAL) << "not implemented";
+ using namespace mshadow;
+ using namespace mshadow::expr;
+ CHECK_EQ(in_grad.size(), 3);
+
+ Stream<xpu> *s = ctx.get_stream<xpu>();
+ Tensor<xpu, 4> gscores = in_grad[proposal::kClsProb].get<xpu, 4, real_t>(s);
+ Tensor<xpu, 4> gbbox = in_grad[proposal::kBBoxPred].get<xpu, 4, real_t>(s);
+ Tensor<xpu, 2> ginfo = in_grad[proposal::kImInfo].get<xpu, 2, real_t>(s);
+
+ // can not assume the grad would be zero
+ Assign(gscores, req[proposal::kClsProb], 0);
+ Assign(gbbox, req[proposal::kBBoxPred], 0);
+ Assign(ginfo, req[proposal::kImInfo], 0);
}
private:
diff --git a/src/operator/contrib/multi_proposal.cu b/src/operator/contrib/multi_proposal.cu
index a2a17d74908..4552ae49d70 100644
--- a/src/operator/contrib/multi_proposal.cu
+++ b/src/operator/contrib/multi_proposal.cu
@@ -326,6 +326,7 @@ __global__ void nms_kernel(const int n_boxes, const float nms_overlap_thresh,
void _nms(const mshadow::Tensor<gpu, 2>& boxes,
const float nms_overlap_thresh,
+ const int rpn_post_nms_top_n,
int *keep,
int *num_out) {
const int threadsPerBlock = sizeof(uint64_t) * 8;
@@ -363,6 +364,7 @@ void _nms(const mshadow::Tensor<gpu, 2>& boxes,
if (!(remv[nblock] & (1ULL << inblock))) {
keep[num_to_keep++] = i;
+ if (num_to_keep >= rpn_post_nms_top_n) break;
uint64_t *p = &mask_host[0] + i * col_blocks;
for (int j = nblock; j < col_blocks; j++) {
remv[j] |= p[j];
@@ -555,6 +557,7 @@ class MultiProposalGPUOp : public Operator{
int out_size = 0;
_nms(workspace_ordered_proposals,
param_.threshold,
+ rpn_post_nms_top_n,
&_keep[0],
&out_size);
@@ -563,11 +566,12 @@ class MultiProposalGPUOp : public Operator{
cudaMemcpyHostToDevice));
// copy results after nms
- dimGrid.x = (rpn_post_nms_top_n + kMaxThreadsPerBlock - 1) / kMaxThreadsPerBlock;
+ dimGrid.x = (param_.rpn_post_nms_top_n + kMaxThreadsPerBlock - 1) / kMaxThreadsPerBlock;
CheckLaunchParam(dimGrid, dimBlock, "PrepareOutput");
PrepareOutput << <dimGrid, dimBlock >> >(
- rpn_post_nms_top_n, workspace_ordered_proposals.dptr_, keep, out_size, b,
- out.dptr_ + b * rpn_post_nms_top_n * 5, out_score.dptr_ + b * rpn_post_nms_top_n);
+ param_.rpn_post_nms_top_n, workspace_ordered_proposals.dptr_, keep, out_size, b,
+ out.dptr_ + b * param_.rpn_post_nms_top_n * 5,
+ out_score.dptr_ + b * param_.rpn_post_nms_top_n);
FRCNN_CUDA_CHECK(cudaPeekAtLastError());
}
// free temporary memory
diff --git a/src/operator/contrib/proposal.cc b/src/operator/contrib/proposal.cc
index dd6ed5a93da..fa28c26ace6 100644
--- a/src/operator/contrib/proposal.cc
+++ b/src/operator/contrib/proposal.cc
@@ -400,8 +400,8 @@ class ProposalOp : public Operator{
&keep,
&out_size);
- // fill in output rois
- for (index_t i = 0; i < out.size(0); ++i) {
+ // fill in output rois and output score
+ for (index_t i = 0; i < static_cast<index_t>(param_.rpn_post_nms_top_n); ++i) {
// batch index 0
out[i][0] = 0;
if (i < out_size) {
@@ -409,21 +409,12 @@ class ProposalOp : public Operator{
for (index_t j = 0; j < 4; ++j) {
out[i][j + 1] = workspace_ordered_proposals[index][j];
}
+ out_score[i][0] = workspace_ordered_proposals[index][4];
} else {
index_t index = keep[i % out_size];
for (index_t j = 0; j < 4; ++j) {
out[i][j + 1] = workspace_ordered_proposals[index][j];
}
- }
- }
-
- // fill in output score
- for (index_t i = 0; i < out_score.size(0); i++) {
- if (i < out_size) {
- index_t index = keep[i];
- out_score[i][0] = workspace_ordered_proposals[index][4];
- } else {
- index_t index = keep[i % out_size];
out_score[i][0] = workspace_ordered_proposals[index][4];
}
}
diff --git a/src/operator/contrib/proposal.cu b/src/operator/contrib/proposal.cu
index 2d676aca93a..446c92b35ce 100644
--- a/src/operator/contrib/proposal.cu
+++ b/src/operator/contrib/proposal.cu
@@ -307,6 +307,7 @@ __global__ void nms_kernel(const int n_boxes, const float nms_overlap_thresh,
void _nms(const mshadow::Tensor<gpu, 2>& boxes,
const float nms_overlap_thresh,
+ const int rpn_post_nms_top_n,
int *keep,
int *num_out) {
const int threadsPerBlock = sizeof(uint64_t) * 8;
@@ -344,6 +345,7 @@ void _nms(const mshadow::Tensor<gpu, 2>& boxes,
if (!(remv[nblock] & (1ULL << inblock))) {
keep[num_to_keep++] = i;
+ if (num_to_keep >= rpn_post_nms_top_n) break;
uint64_t *p = &mask_host[0] + i * col_blocks;
for (int j = nblock; j < col_blocks; j++) {
remv[j] |= p[j];
@@ -543,6 +545,7 @@ class ProposalGPUOp : public Operator{
int out_size = 0;
_nms(workspace_ordered_proposals,
param_.threshold,
+ rpn_post_nms_top_n,
&_keep[0],
&out_size);
@@ -553,10 +556,10 @@ class ProposalGPUOp : public Operator{
cudaMemcpyHostToDevice));
// copy results after nms
- dimGrid.x = (rpn_post_nms_top_n + kMaxThreadsPerBlock - 1) / kMaxThreadsPerBlock;
+ dimGrid.x = (param_.rpn_post_nms_top_n + kMaxThreadsPerBlock - 1) / kMaxThreadsPerBlock;
CheckLaunchParam(dimGrid, dimBlock, "PrepareOutput");
PrepareOutput<<<dimGrid, dimBlock>>>(
- rpn_post_nms_top_n, workspace_ordered_proposals.dptr_, keep, out_size,
+ param_.rpn_post_nms_top_n, workspace_ordered_proposals.dptr_, keep, out_size,
out.dptr_, out_score.dptr_);
FRCNN_CUDA_CHECK(cudaPeekAtLastError());
diff --git a/src/operator/contrib/quadratic_op-inl.h b/src/operator/contrib/quadratic_op-inl.h
new file mode 100644
index 00000000000..71cb76a7b56
--- /dev/null
+++ b/src/operator/contrib/quadratic_op-inl.h
@@ -0,0 +1,227 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * \file quad_function-inl.h
+ * \brief Operator implementing quadratic function.
+ * For using as an exmaple in the tutorial of adding operators
+ * in MXNet backend.
+ */
+#ifndef MXNET_OPERATOR_CONTRIB_QUADRATIC_OP_INL_H_
+#define MXNET_OPERATOR_CONTRIB_QUADRATIC_OP_INL_H_
+
+#include <mxnet/operator_util.h>
+#include <vector>
+#include "../mshadow_op.h"
+#include "../mxnet_op.h"
+#include "../operator_common.h"
+#include "../elemwise_op_common.h"
+#include "../tensor/init_op.h"
+
+namespace mxnet {
+namespace op {
+
+struct QuadraticParam : public dmlc::Parameter<QuadraticParam> {
+ float a, b, c;
+ DMLC_DECLARE_PARAMETER(QuadraticParam) {
+ DMLC_DECLARE_FIELD(a)
+ .set_default(0.0)
+ .describe("Coefficient of the quadratic term in the quadratic function.");
+ DMLC_DECLARE_FIELD(b)
+ .set_default(0.0)
+ .describe("Coefficient of the linear term in the quadratic function.");
+ DMLC_DECLARE_FIELD(c)
+ .set_default(0.0)
+ .describe("Constant term in the quadratic function.");
+ }
+};
+
+inline bool QuadraticOpShape(const nnvm::NodeAttrs& attrs,
+ std::vector<TShape>* in_attrs,
+ std::vector<TShape>* out_attrs) {
+ CHECK_EQ(in_attrs->size(), 1U);
+ CHECK_EQ(out_attrs->size(), 1U);
+
+ SHAPE_ASSIGN_CHECK(*out_attrs, 0, in_attrs->at(0));
+ SHAPE_ASSIGN_CHECK(*in_attrs, 0, out_attrs->at(0));
+ return out_attrs->at(0).ndim() != 0U && out_attrs->at(0).Size() != 0U;
+}
+
+inline bool QuadraticOpType(const nnvm::NodeAttrs& attrs,
+ std::vector<int>* in_attrs,
+ std::vector<int>* out_attrs) {
+ CHECK_EQ(in_attrs->size(), 1U);
+ CHECK_EQ(out_attrs->size(), 1U);
+
+ TYPE_ASSIGN_CHECK(*out_attrs, 0, in_attrs->at(0));
+ TYPE_ASSIGN_CHECK(*in_attrs, 0, out_attrs->at(0));
+ return out_attrs->at(0) != -1;
+}
+
+inline bool QuadraticOpStorageType(const nnvm::NodeAttrs& attrs,
+ const int dev_mask,
+ DispatchMode* dispatch_mode,
+ std::vector<int>* in_attrs,
+ std::vector<int>* out_attrs) {
+ CHECK_EQ(in_attrs->size(), 1U);
+ CHECK_EQ(out_attrs->size(), 1U);
+ const QuadraticParam& param = nnvm::get<QuadraticParam>(attrs.parsed);
+ const int in_stype = in_attrs->at(0);
+ int& out_stype = out_attrs->at(0);
+ bool dispatched = false;
+ if (!dispatched && in_stype == kDefaultStorage) {
+ // dns -> dns
+ dispatched = storage_type_assign(&out_stype, kDefaultStorage,
+ dispatch_mode, DispatchMode::kFCompute);
+ }
+ if (!dispatched && in_stype == kCSRStorage && param.c == 0.0) {
+ // csr -> csr
+ dispatched = storage_type_assign(&out_stype, kCSRStorage,
+ dispatch_mode, DispatchMode::kFComputeEx);
+ }
+ if (!dispatched) {
+ dispatched = dispatch_fallback(out_attrs, dispatch_mode);
+ }
+ return dispatched;
+}
+
+template<int req>
+struct quadratic_forward {
+ template<typename DType>
+ MSHADOW_XINLINE static void Map(int i, DType* out_data, const DType* in_data,
+ const float a, const float b, const float c) {
+ KERNEL_ASSIGN(out_data[i], req, in_data[i] * (a * in_data[i] + b) + c);
+ }
+};
+
+template<int req>
+struct quadratic_backward {
+ template<typename DType>
+ MSHADOW_XINLINE static void Map(int i, DType* in_grad, const DType* out_grad,
+ const DType* in_data, const float a, const float b) {
+ KERNEL_ASSIGN(in_grad[i], req, out_grad[i] * (2 * a * in_data[i] + b));
+ }
+};
+
+template<typename xpu>
+void QuadraticOpForward(const nnvm::NodeAttrs& attrs,
+ const OpContext& ctx,
+ const std::vector<TBlob>& inputs,
+ const std::vector<OpReqType>& req,
+ const std::vector<TBlob>& outputs) {
+ CHECK_EQ(inputs.size(), 1U);
+ CHECK_EQ(outputs.size(), 1U);
+ CHECK_EQ(req.size(), 1U);
+ mshadow::Stream<xpu> *s = ctx.get_stream<xpu>();
+ const TBlob& in_data = inputs[0];
+ const TBlob& out_data = outputs[0];
+ const QuadraticParam& param = nnvm::get<QuadraticParam>(attrs.parsed);
+ using namespace mxnet_op;
+ MSHADOW_TYPE_SWITCH(out_data.type_flag_, DType, {
+ MXNET_ASSIGN_REQ_SWITCH(req[0], req_type, {
+ Kernel<quadratic_forward<req_type>, xpu>::Launch(
+ s, out_data.Size(), out_data.dptr<DType>(), in_data.dptr<DType>(),
+ param.a, param.b, param.c);
+ });
+ });
+}
+
+template<typename xpu>
+void QuadraticOpForwardCsrImpl(const QuadraticParam& param,
+ const OpContext& ctx,
+ const NDArray& input,
+ const OpReqType req,
+ const NDArray& output) {
+ using namespace mshadow;
+ using namespace mxnet_op;
+ using namespace csr;
+ if (req == kNullOp) return;
+ CHECK_EQ(req, kWriteTo) << "QuadraticOp with CSR only supports kWriteTo";
+ Stream<xpu> *s = ctx.get_stream<xpu>();
+ if (!input.storage_initialized()) {
+ FillZerosCsrImpl(s, output);
+ return;
+ }
+ const nnvm::dim_t nnz = input.storage_shape()[0];
+ const nnvm::dim_t num_rows = output.shape()[0];
+ output.CheckAndAlloc({Shape1(num_rows + 1), Shape1(nnz)});
+ CHECK_EQ(output.aux_type(kIdx), output.aux_type(kIndPtr))
+ << "The dtypes of indices and indptr don't match";
+ MSHADOW_TYPE_SWITCH(output.dtype(), DType, {
+ MSHADOW_IDX_TYPE_SWITCH(output.aux_type(kIdx), IType, {
+ MXNET_ASSIGN_REQ_SWITCH(req, req_type, {
+ Kernel<quadratic_forward<req_type>, xpu>::Launch(
+ s, nnz, output.data().dptr<DType>(), input.data().dptr<DType>(),
+ param.a, param.b, param.c);
+ Copy(output.aux_data(kIdx).FlatTo1D<xpu, IType>(s),
+ input.aux_data(kIdx).FlatTo1D<xpu, IType>(s), s);
+ Copy(output.aux_data(kIndPtr).FlatTo1D<xpu, IType>(s),
+ input.aux_data(kIndPtr).FlatTo1D<xpu, IType>(s), s);
+ });
+ });
+ });
+}
+
+template<typename xpu>
+void QuadraticOpForwardEx(const nnvm::NodeAttrs& attrs,
+ const OpContext& ctx,
+ const std::vector<NDArray>& inputs,
+ const std::vector<OpReqType>& req,
+ const std::vector<NDArray>& outputs) {
+ CHECK_EQ(inputs.size(), 1U);
+ CHECK_EQ(outputs.size(), 1U);
+ CHECK_EQ(req.size(), 1U);
+ const QuadraticParam& param = nnvm::get<QuadraticParam>(attrs.parsed);
+ const auto in_stype = inputs[0].storage_type();
+ const auto out_stype = outputs[0].storage_type();
+ if (in_stype == kCSRStorage && out_stype == kCSRStorage && param.c == 0.0) {
+ QuadraticOpForwardCsrImpl<xpu>(param, ctx, inputs[0], req[0], outputs[0]);
+ } else {
+ LogUnimplementedOp(attrs, ctx, inputs, req, outputs);
+ }
+}
+
+template<typename xpu>
+void QuadraticOpBackward(const nnvm::NodeAttrs& attrs,
+ const OpContext& ctx,
+ const std::vector<TBlob>& inputs,
+ const std::vector<OpReqType>& req,
+ const std::vector<TBlob>& outputs) {
+ CHECK_EQ(inputs.size(), 2U);
+ CHECK_EQ(outputs.size(), 1U);
+ CHECK_EQ(req.size(), 1U);
+ mshadow::Stream<xpu> *s = ctx.get_stream<xpu>();
+ const TBlob& out_grad = inputs[0];
+ const TBlob& in_data = inputs[1];
+ const TBlob& in_grad = outputs[0];
+ const QuadraticParam& param = nnvm::get<QuadraticParam>(attrs.parsed);
+ using namespace mxnet_op;
+ MSHADOW_TYPE_SWITCH(out_grad.type_flag_, DType, {
+ MXNET_ASSIGN_REQ_SWITCH(req[0], req_type, {
+ Kernel<quadratic_backward<req_type>, xpu>::Launch(
+ s, in_grad.Size(), in_grad.dptr<DType>(), out_grad.dptr<DType>(),
+ in_data.dptr<DType>(), param.a, param.b);
+ });
+ });
+}
+
+} // namespace op
+} // namespace mxnet
+
+#endif // MXNET_OPERATOR_CONTRIB_QUADRATIC_OP_INL_H_
diff --git a/src/operator/contrib/quadratic_op.cc b/src/operator/contrib/quadratic_op.cc
new file mode 100644
index 00000000000..d8b2d785c79
--- /dev/null
+++ b/src/operator/contrib/quadratic_op.cc
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * \file quadratic_op.cc
+ * \brief CPU Implementation of quadratic op
+ */
+#include "./quadratic_op-inl.h"
+
+namespace mxnet {
+namespace op {
+
+DMLC_REGISTER_PARAMETER(QuadraticParam);
+
+NNVM_REGISTER_OP(_contrib_quadratic)
+.describe(R"code(This operators implements the quadratic function:
+.. math::
+ f(x) = ax^2+bx+c
+where :math:`x` is an input tensor and all operations
+in the function are element-wise.
+Example::
+ x = [[1, 2], [3, 4]]
+ y = quadratic(data=x, a=1, b=2, c=3)
+ y = [[6, 11], [18, 27]]
+
+The storage type of ``quadratic`` output depends on storage types of inputs
+ - quadratic(csr, a, b, 0) = csr
+ - quadratic(default, a, b, c) = default
+
+)code" ADD_FILELINE)
+.set_attr_parser(ParamParser<QuadraticParam>)
+.set_num_inputs(1)
+.set_num_outputs(1)
+.set_attr<nnvm::FListInputNames>("FListInputNames",
+ [](const NodeAttrs& attrs) {
+ return std::vector<std::string>{"data"};
+ })
+.set_attr<nnvm::FInferShape>("FInferShape", QuadraticOpShape)
+.set_attr<nnvm::FInferType>("FInferType", QuadraticOpType)
+.set_attr<FInferStorageType>("FInferStorageType", QuadraticOpStorageType)
+.set_attr<FCompute>("FCompute<cpu>", QuadraticOpForward<cpu>)
+.set_attr<nnvm::FGradient>("FGradient", ElemwiseGradUseIn{"_contrib_backward_quadratic"})
+.set_attr<nnvm::FInplaceOption>("FInplaceOption",
+ [](const NodeAttrs& attrs) {
+ return std::vector<std::pair<int, int> >{{0, 0}};
+ })
+.add_argument("data", "NDArray-or-Symbol", "Input ndarray")
+.add_arguments(QuadraticParam::__FIELDS__());
+
+NNVM_REGISTER_OP(_contrib_backward_quadratic)
+.set_attr_parser(ParamParser<QuadraticParam>)
+.set_num_inputs(2)
+.set_num_outputs(1)
+.set_attr<nnvm::TIsBackward>("TIsBackward", true)
+.set_attr<FCompute>("FCompute<cpu>", QuadraticOpBackward<cpu>)
+.set_attr<FComputeEx>("FComputeEx<cpu>", QuadraticOpForwardEx<cpu>);
+
+} // namespace op
+} // namespace mxnet
diff --git a/src/operator/contrib/quadratic_op.cu b/src/operator/contrib/quadratic_op.cu
new file mode 100644
index 00000000000..72d15ab3749
--- /dev/null
+++ b/src/operator/contrib/quadratic_op.cu
@@ -0,0 +1,37 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * \file quadratic_op.cu
+ * \brief GPU Implementation of quadratic op
+ */
+#include "./quadratic_op-inl.h"
+
+namespace mxnet {
+namespace op {
+
+NNVM_REGISTER_OP(_contrib_quadratic)
+.set_attr<FComputeEx>("FComputeEx<gpu>", QuadraticOpForwardEx<gpu>)
+.set_attr<FCompute>("FCompute<gpu>", QuadraticOpForward<gpu>);
+
+NNVM_REGISTER_OP(_contrib_backward_quadratic)
+.set_attr<FCompute>("FCompute<gpu>", QuadraticOpBackward<gpu>);
+
+} // namespace op
+} // namespace mxnet
diff --git a/src/operator/correlation-inl.h b/src/operator/correlation-inl.h
index 957931db108..7266a0a9184 100644
--- a/src/operator/correlation-inl.h
+++ b/src/operator/correlation-inl.h
@@ -232,10 +232,10 @@ void Init(const std::vector<std::pair<std::string, std::string> >& kwargs) overr
std::vector<int> *out_type,
std::vector<int> *aux_type) const override {
int dtype = (*in_type)[0];
- type_assign(&(*in_type)[1], dtype);
- type_assign(&(*out_type)[0], dtype);
- type_assign(&(*out_type)[1], dtype);
- type_assign(&(*out_type)[2], dtype);
+ type_assign(&dtype, (*in_type)[1]);
+ type_assign(&dtype, (*out_type)[0]);
+ type_assign(&dtype, (*out_type)[1]);
+ type_assign(&dtype, (*out_type)[2]);
TYPE_ASSIGN_CHECK(*in_type, 0, dtype);
TYPE_ASSIGN_CHECK(*in_type, 1, dtype);
diff --git a/src/operator/l2_normalization-inl.h b/src/operator/l2_normalization-inl.h
index cb8e740d7ff..d53e0c5caf9 100644
--- a/src/operator/l2_normalization-inl.h
+++ b/src/operator/l2_normalization-inl.h
@@ -66,7 +66,7 @@ struct L2NormalizationParam : public dmlc::Parameter<L2NormalizationParam> {
* \brief This is the implementation of l2 normalization operator.
* \tparam xpu The device that the op will be executed on.
*/
-template<typename xpu>
+template<typename xpu, typename DType>
class L2NormalizationOp : public Operator {
public:
explicit L2NormalizationOp(L2NormalizationParam p) {
@@ -89,41 +89,53 @@ class L2NormalizationOp : public Operator {
if (param_.mode == l2_normalization::kInstance) {
Shape<2> dshape = Shape2(orig_shape[0],
orig_shape.ProdShape(1, orig_shape.ndim()));
- Tensor<xpu, 2> data = in_data[l2_normalization::kData]
- .get_with_shape<xpu, 2, real_t>(dshape, s);
- Tensor<xpu, 2> out = out_data[l2_normalization::kOut]
- .get_with_shape<xpu, 2, real_t>(dshape, s);
- Tensor<xpu, 1> norm = out_data[l2_normalization::kNorm].get<xpu, 1, real_t>(s);
+ Tensor<xpu, 2, DType> data = in_data[l2_normalization::kData]
+ .get_with_shape<xpu, 2, DType>(dshape, s);
+ Tensor<xpu, 2, DType> out = out_data[l2_normalization::kOut]
+ .get_with_shape<xpu, 2, DType>(dshape, s);
+ Tensor<xpu, 1, DType> norm = out_data[l2_normalization::kNorm].get<xpu, 1, DType>(s);
norm = sumall_except_dim<0>(F<mxnet::op::mshadow_op::square>(data));
- norm = F<mxnet::op::mshadow_op::square_root>(norm + param_.eps);
+ MXNET_ASSIGN_REQ_SWITCH(req[0], Req, {
+ mxnet_op::Kernel<mxnet_op::op_with_req<mxnet::op::mshadow_op::plus, Req>, xpu>::Launch(
+ s, norm.size(0), norm.dptr_, norm.dptr_, DType(param_.eps));
+ });
+ norm = F<mxnet::op::mshadow_op::square_root>(norm);
out = data / broadcast<0>(norm, out.shape_);
} else if (param_.mode == l2_normalization::kChannel) {
CHECK_GE(orig_shape.ndim(), 3U);
Shape<3> dshape = Shape3(orig_shape[0], orig_shape[1],
orig_shape.ProdShape(2, orig_shape.ndim()));
- Tensor<xpu, 3> data = in_data[l2_normalization::kData]
- .get_with_shape<xpu, 3, real_t>(dshape, s);
- Tensor<xpu, 3> out = out_data[l2_normalization::kOut]
- .get_with_shape<xpu, 3, real_t>(dshape, s);
+ Tensor<xpu, 3, DType> data = in_data[l2_normalization::kData]
+ .get_with_shape<xpu, 3, DType>(dshape, s);
+ Tensor<xpu, 3, DType> out = out_data[l2_normalization::kOut]
+ .get_with_shape<xpu, 3, DType>(dshape, s);
Shape<2> norm_shape = Shape2(dshape[0], dshape[2]);
- Tensor<xpu, 2> norm = out_data[l2_normalization::kNorm]
- .get_with_shape<xpu, 2, real_t>(norm_shape, s);
+ Tensor<xpu, 2, DType> norm = out_data[l2_normalization::kNorm]
+ .get_with_shape<xpu, 2, DType>(norm_shape, s);
norm = reduce_with_axis<red::sum, false>(F<mxnet::op::mshadow_op::square>(data), 1);
- norm = F<mxnet::op::mshadow_op::square_root>(norm + param_.eps);
+ MXNET_ASSIGN_REQ_SWITCH(req[0], Req, {
+ mxnet_op::Kernel<mxnet_op::op_with_req<mxnet::op::mshadow_op::plus, Req>, xpu>::Launch(
+ s, norm.size(0) * norm.size(1), norm.dptr_, norm.dptr_, DType(param_.eps));
+ });
+ norm = F<mxnet::op::mshadow_op::square_root>(norm);
out = data / broadcast_with_axis(norm, 0, orig_shape[1]);
} else if (param_.mode == l2_normalization::kSpatial) {
CHECK_GE(orig_shape.ndim(), 3U);
Shape<3> dshape = Shape3(orig_shape[0], orig_shape[1],
orig_shape.ProdShape(2, orig_shape.ndim()));
- Tensor<xpu, 3> data = in_data[l2_normalization::kData]
- .get_with_shape<xpu, 3, real_t>(dshape, s);
- Tensor<xpu, 3> out = out_data[l2_normalization::kOut]
- .get_with_shape<xpu, 3, real_t>(dshape, s);
+ Tensor<xpu, 3, DType> data = in_data[l2_normalization::kData]
+ .get_with_shape<xpu, 3, DType>(dshape, s);
+ Tensor<xpu, 3, DType> out = out_data[l2_normalization::kOut]
+ .get_with_shape<xpu, 3, DType>(dshape, s);
Shape<2> norm_shape = Shape2(dshape[0], dshape[1]);
- Tensor<xpu, 2> norm = out_data[l2_normalization::kNorm]
- .get_with_shape<xpu, 2, real_t>(norm_shape, s);
+ Tensor<xpu, 2, DType> norm = out_data[l2_normalization::kNorm]
+ .get_with_shape<xpu, 2, DType>(norm_shape, s);
norm = reduce_with_axis<red::sum, false>(F<mxnet::op::mshadow_op::square>(data), 2);
- norm = F<mxnet::op::mshadow_op::square_root>(norm + param_.eps);
+ MXNET_ASSIGN_REQ_SWITCH(req[0], Req, {
+ mxnet_op::Kernel<mxnet_op::op_with_req<mxnet::op::mshadow_op::plus, Req>, xpu>::Launch(
+ s, norm.size(0) * norm.size(1), norm.dptr_, norm.dptr_, DType(param_.eps));
+ });
+ norm = F<mxnet::op::mshadow_op::square_root>(norm);
out = data / broadcast_with_axis(norm, 1, dshape[2]);
} else {
LOG(FATAL) << "Unexpected mode in l2 normalization";
@@ -148,15 +160,15 @@ class L2NormalizationOp : public Operator {
if (param_.mode == l2_normalization::kInstance) {
Shape<2> dshape = Shape2(orig_shape[0],
orig_shape.ProdShape(1, orig_shape.ndim()));
- Tensor<xpu, 2> data = out_data[l2_normalization::kOut]
- .get_with_shape<xpu, 2, real_t>(dshape, s);
- Tensor<xpu, 2> grad_in = in_grad[l2_normalization::kData]
- .get_with_shape<xpu, 2, real_t>(dshape, s);
- Tensor<xpu, 2> grad_out = out_grad[l2_normalization::kOut]
- .get_with_shape<xpu, 2, real_t>(dshape, s);
- Tensor<xpu, 1> norm = out_data[l2_normalization::kNorm].get<xpu, 1, real_t>(s);
- Tensor<xpu, 1> temp = ctx.requested[l2_normalization::kTempSpace]
- .get_space<xpu>(mshadow::Shape1(data.shape_[0]), s);
+ Tensor<xpu, 2, DType> data = out_data[l2_normalization::kOut]
+ .get_with_shape<xpu, 2, DType>(dshape, s);
+ Tensor<xpu, 2, DType> grad_in = in_grad[l2_normalization::kData]
+ .get_with_shape<xpu, 2, DType>(dshape, s);
+ Tensor<xpu, 2, DType> grad_out = out_grad[l2_normalization::kOut]
+ .get_with_shape<xpu, 2, DType>(dshape, s);
+ Tensor<xpu, 1, DType> norm = out_data[l2_normalization::kNorm].get<xpu, 1, DType>(s);
+ Tensor<xpu, 1, DType> temp = ctx.requested[l2_normalization::kTempSpace]
+ .get_space_typed<xpu, 1, DType>(mshadow::Shape1(data.shape_[0]), s);
temp = sumall_except_dim<0>(grad_out * data);
Assign(grad_in, req[l2_normalization::kData],
(grad_out - data * broadcast<0>(temp, data.shape_)) /
@@ -165,17 +177,17 @@ class L2NormalizationOp : public Operator {
CHECK_GE(orig_shape.ndim(), 3U);
Shape<3> dshape = Shape3(orig_shape[0], orig_shape[1],
orig_shape.ProdShape(2, orig_shape.ndim()));
- Tensor<xpu, 3> data = out_data[l2_normalization::kOut]
- .get_with_shape<xpu, 3, real_t>(dshape, s);
- Tensor<xpu, 3> grad_in = in_grad[l2_normalization::kData]
- .get_with_shape<xpu, 3, real_t>(dshape, s);
- Tensor<xpu, 3> grad_out = out_grad[l2_normalization::kOut]
- .get_with_shape<xpu, 3, real_t>(dshape, s);
+ Tensor<xpu, 3, DType> data = out_data[l2_normalization::kOut]
+ .get_with_shape<xpu, 3, DType>(dshape, s);
+ Tensor<xpu, 3, DType> grad_in = in_grad[l2_normalization::kData]
+ .get_with_shape<xpu, 3, DType>(dshape, s);
+ Tensor<xpu, 3, DType> grad_out = out_grad[l2_normalization::kOut]
+ .get_with_shape<xpu, 3, DType>(dshape, s);
Shape<2> norm_shape = Shape2(dshape[0], dshape[2]);
- Tensor<xpu, 2> norm = out_data[l2_normalization::kNorm]
- .get_with_shape<xpu, 2, real_t>(norm_shape, s);
- Tensor<xpu, 2> temp = ctx.requested[l2_normalization::kTempSpace]
- .get_space<xpu>(mshadow::Shape2(data.shape_[0], data.shape_[2]), s);
+ Tensor<xpu, 2, DType> norm = out_data[l2_normalization::kNorm]
+ .get_with_shape<xpu, 2, DType>(norm_shape, s);
+ Tensor<xpu, 2, DType> temp = ctx.requested[l2_normalization::kTempSpace]
+ .get_space_typed<xpu, 2, DType>(mshadow::Shape2(data.shape_[0], data.shape_[2]), s);
temp = reduce_with_axis<red::sum, false>(grad_out * data, 1);
Assign(grad_in, req[l2_normalization::kData],
(grad_out - data * broadcast_with_axis(temp, 0, orig_shape[1])) /
@@ -184,17 +196,17 @@ class L2NormalizationOp : public Operator {
CHECK_GE(orig_shape.ndim(), 3U);
Shape<3> dshape = Shape3(orig_shape[0], orig_shape[1],
orig_shape.ProdShape(2, orig_shape.ndim()));
- Tensor<xpu, 3> data = out_data[l2_normalization::kOut]
- .get_with_shape<xpu, 3, real_t>(dshape, s);
- Tensor<xpu, 3> grad_in = in_grad[l2_normalization::kData]
- .get_with_shape<xpu, 3, real_t>(dshape, s);
- Tensor<xpu, 3> grad_out = out_grad[l2_normalization::kOut]
- .get_with_shape<xpu, 3, real_t>(dshape, s);
+ Tensor<xpu, 3, DType> data = out_data[l2_normalization::kOut]
+ .get_with_shape<xpu, 3, DType>(dshape, s);
+ Tensor<xpu, 3, DType> grad_in = in_grad[l2_normalization::kData]
+ .get_with_shape<xpu, 3, DType>(dshape, s);
+ Tensor<xpu, 3, DType> grad_out = out_grad[l2_normalization::kOut]
+ .get_with_shape<xpu, 3, DType>(dshape, s);
Shape<2> norm_shape = Shape2(dshape[0], dshape[1]);
- Tensor<xpu, 2> norm = out_data[l2_normalization::kNorm]
- .get_with_shape<xpu, 2, real_t>(norm_shape, s);
- Tensor<xpu, 2> temp = ctx.requested[l2_normalization::kTempSpace]
- .get_space<xpu>(mshadow::Shape2(data.shape_[0], data.shape_[1]), s);
+ Tensor<xpu, 2, DType> norm = out_data[l2_normalization::kNorm]
+ .get_with_shape<xpu, 2, DType>(norm_shape, s);
+ Tensor<xpu, 2, DType> temp = ctx.requested[l2_normalization::kTempSpace]
+ .get_space_typed<xpu, 2, DType>(mshadow::Shape2(data.shape_[0], data.shape_[1]), s);
temp = reduce_with_axis<red::sum, false>(grad_out * data, 2);
Assign(grad_in, req[l2_normalization::kData],
(grad_out - data * broadcast_with_axis(temp, 1, dshape[2])) /
@@ -210,7 +222,7 @@ class L2NormalizationOp : public Operator {
// Decalre Factory function, used for dispatch specialization
template<typename xpu>
-Operator* CreateOp(L2NormalizationParam param);
+Operator* CreateOp(L2NormalizationParam param, int dtype);
#if DMLC_USE_CXX11
class L2NormalizationProp : public OperatorProperty {
@@ -235,6 +247,19 @@ class L2NormalizationProp : public OperatorProperty {
return param_.__DICT__();
}
+ bool InferType(std::vector<int> *in_type,
+ std::vector<int> *out_type,
+ std::vector<int> *aux_type) const override {
+ int dtype = (*in_type)[0];
+ type_assign(&dtype, (*out_type)[0]);
+ type_assign(&dtype, (*out_type)[1]);
+
+ TYPE_ASSIGN_CHECK(*in_type, 0, dtype);
+ TYPE_ASSIGN_CHECK(*out_type, 0, dtype);
+ TYPE_ASSIGN_CHECK(*out_type, 1, dtype);
+ return dtype != -1;
+ }
+
bool InferShape(std::vector<TShape> *in_shape,
std::vector<TShape> *out_shape,
std::vector<TShape> *aux_shape) const override {
@@ -294,7 +319,13 @@ class L2NormalizationProp : public OperatorProperty {
return {ResourceRequest::kTempSpace};
}
- Operator* CreateOperator(Context ctx) const override;
+ Operator* CreateOperator(Context ctx) const override {
+ LOG(FATAL) << "Not Implemented.";
+ return NULL;
+ }
+
+ Operator* CreateOperatorEx(Context ctx, std::vector<TShape> *in_shape,
+ std::vector<int> *in_type) const override;
private:
L2NormalizationParam param_;
diff --git a/src/operator/l2_normalization.cc b/src/operator/l2_normalization.cc
index 76e64c8d350..c313b442442 100644
--- a/src/operator/l2_normalization.cc
+++ b/src/operator/l2_normalization.cc
@@ -26,13 +26,18 @@
namespace mxnet {
namespace op {
template<>
-Operator* CreateOp<cpu>(L2NormalizationParam param) {
- return new L2NormalizationOp<cpu>(param);
+Operator* CreateOp<cpu>(L2NormalizationParam param, int dtype) {
+ Operator* op = NULL;
+ MSHADOW_REAL_TYPE_SWITCH(dtype, DType, {
+ op = new L2NormalizationOp<cpu, DType>(param);
+ });
+ return op;
}
// DO_BIND_DISPATCH comes from static_operator_common.h
-Operator* L2NormalizationProp::CreateOperator(Context ctx) const {
- DO_BIND_DISPATCH(CreateOp, param_);
+Operator* L2NormalizationProp::CreateOperatorEx(Context ctx, std::vector<TShape> *in_shape,
+ std::vector<int> *in_type) const {
+ DO_BIND_DISPATCH(CreateOp, param_, in_type->at(0));
}
DMLC_REGISTER_PARAMETER(L2NormalizationParam);
diff --git a/src/operator/l2_normalization.cu b/src/operator/l2_normalization.cu
index 1c1c0e5ed09..2034f984174 100644
--- a/src/operator/l2_normalization.cu
+++ b/src/operator/l2_normalization.cu
@@ -26,8 +26,12 @@
namespace mxnet {
namespace op {
template<>
-Operator* CreateOp<gpu>(L2NormalizationParam param) {
- return new L2NormalizationOp<gpu>(param);
+Operator* CreateOp<gpu>(L2NormalizationParam param, int dtype) {
+ Operator* op = NULL;
+ MSHADOW_REAL_TYPE_SWITCH(dtype, DType, {
+ op = new L2NormalizationOp<gpu, DType>(param);
+ });
+ return op;
}
} // namespace op
} // namespace mxnet
diff --git a/src/operator/leaky_relu-inl.h b/src/operator/leaky_relu-inl.h
index 77eba43155c..c99280ac7ea 100644
--- a/src/operator/leaky_relu-inl.h
+++ b/src/operator/leaky_relu-inl.h
@@ -34,8 +34,11 @@
#include <string>
#include <vector>
#include <utility>
+#include "../common/random_generator.h"
#include "./operator_common.h"
#include "./mshadow_op.h"
+#include "./random/sampler.h"
+#include "./random/sample_op.h"
namespace mxnet {
namespace op {
@@ -75,7 +78,7 @@ struct prelu_grad {
}
};
-template<typename xpu>
+template<typename xpu, typename DType>
class LeakyReLUOp : public Operator {
public:
explicit LeakyReLUOp(LeakyReLUParam param) {
@@ -92,25 +95,25 @@ class LeakyReLUOp : public Operator {
size_t expected = param_.act_type == leakyrelu::kPReLU ? 2 : 1;
CHECK_EQ(in_data.size(), expected);
Stream<xpu> *s = ctx.get_stream<xpu>();
- Tensor<xpu, 3> data;
- Tensor<xpu, 3> out;
- Tensor<xpu, 3> mask;
- Tensor<xpu, 1> weight;
+ Tensor<xpu, 3, DType> data;
+ Tensor<xpu, 3, DType> out;
+ Tensor<xpu, 3, DType> mask;
+ Tensor<xpu, 1, DType> weight;
int n = in_data[leakyrelu::kData].shape_[0];
int k = in_data[leakyrelu::kData].shape_[1];
Shape<3> dshape = Shape3(n, k, in_data[leakyrelu::kData].Size()/n/k);
- data = in_data[leakyrelu::kData].get_with_shape<xpu, 3, real_t>(dshape, s);
- out = out_data[leakyrelu::kOut].get_with_shape<xpu, 3, real_t>(dshape, s);
- if (param_.act_type == leakyrelu::kRReLU) {
- mask = out_data[leakyrelu::kMask].get_with_shape<xpu, 3, real_t>(dshape, s);
- }
+ data = in_data[leakyrelu::kData].get_with_shape<xpu, 3, DType>(dshape, s);
+ out = out_data[leakyrelu::kOut].get_with_shape<xpu, 3, DType>(dshape, s);
switch (param_.act_type) {
case leakyrelu::kLeakyReLU: {
- Assign(out, req[leakyrelu::kOut], F<mshadow_op::xelu>(data, param_.slope));
+ MXNET_ASSIGN_REQ_SWITCH(req[leakyrelu::kOut], Req, {
+ mxnet_op::Kernel<mxnet_op::op_with_req<mxnet::op::mshadow_op::xelu, Req>, xpu>::Launch(
+ s, out.size(0) * out.size(1) * out.size(2), out.dptr_, data.dptr_, DType(param_.slope));
+ });
break;
}
case leakyrelu::kPReLU: {
- weight = in_data[leakyrelu::kGamma].get<xpu, 1, real_t>(s);
+ weight = in_data[leakyrelu::kGamma].get<xpu, 1, DType>(s);
if (weight.shape_.Size() == 1) {
Assign(out, req[leakyrelu::kOut],
F<mshadow_op::xelu>(data, mshadow::expr::broadcast_scalar(weight, out.shape_)));
@@ -122,18 +125,43 @@ class LeakyReLUOp : public Operator {
}
case leakyrelu::kRReLU: {
if (ctx.is_train) {
- Random<xpu>* prnd = ctx.requested[leakyrelu::kRandom].get_random<xpu, real_t>(s);
- mask = prnd->uniform(mask.shape_);
- mask = mask * (param_.upper_bound - param_.lower_bound) + param_.lower_bound;
- Assign(out, req[leakyrelu::kOut], F<mshadow_op::xelu>(data, mask));
+ mask = out_data[leakyrelu::kMask].get_with_shape<xpu, 3, DType>(dshape, s);
+ mxnet::op::UniformSampler<xpu> sampler;
+ Tensor<xpu, 1, DType> low, high;
+ mxnet::op::GetSamplingTempData<xpu, DType>(DType(0.0f), DType(1.0f), ctx, &low, &high);
+ mxnet::common::random::RandGenerator<xpu, DType> *pgen =
+ ctx.requested[0].get_parallel_random<xpu, DType>();
+ Tensor<xpu, 1, DType> out = mask.FlatTo1D();
+ sampler.Sample(low, high, out, pgen, s);
+ MXNET_ASSIGN_REQ_SWITCH(req[leakyrelu::kMask], Req, {
+ mxnet_op::Kernel<mxnet_op::op_with_req<mxnet::op::mshadow_op::mul, Req>, xpu>::Launch(
+ s, mask.size(0) * mask.size(1) * mask.size(2), mask.dptr_, mask.dptr_,
+ DType(param_.upper_bound - param_.lower_bound));
+ });
+ MXNET_ASSIGN_REQ_SWITCH(req[leakyrelu::kMask], Req, {
+ mxnet_op::Kernel<mxnet_op::op_with_req<mxnet::op::mshadow_op::plus, Req>, xpu>::Launch(
+ s, mask.size(0) * mask.size(1) * mask.size(2), mask.dptr_, mask.dptr_,
+ DType(param_.lower_bound));
+ });
+ MXNET_ASSIGN_REQ_SWITCH(req[leakyrelu::kOut], Req, {
+ mxnet_op::Kernel<mxnet_op::op_with_req<mxnet::op::mshadow_op::xelu, Req>, xpu>::Launch(
+ s, mask.size(0) * mask.size(1) * mask.size(2), out.dptr_, data.dptr_, mask.dptr_);
+ });
} else {
const float slope = (param_.lower_bound + param_.upper_bound) / 2.0f;
- Assign(out, req[leakyrelu::kOut], F<mshadow_op::xelu>(data, slope));
+ MXNET_ASSIGN_REQ_SWITCH(req[leakyrelu::kOut], Req, {
+ mxnet_op::Kernel<mxnet_op::op_with_req<mxnet::op::mshadow_op::xelu, Req>, xpu>::Launch(
+ s, out.size(0) * out.size(1) * out.size(2), out.dptr_, data.dptr_, DType(slope));
+ });
}
break;
}
case leakyrelu::kELU: {
- Assign(out, req[leakyrelu::kOut], F<mshadow_op::elu>(data, param_.slope));
+ MXNET_ASSIGN_REQ_SWITCH(req[leakyrelu::kOut], Req, {
+ mxnet_op::Kernel<mxnet_op::op_with_req<mxnet::op::mshadow_op::elu, Req>, xpu>::Launch(
+ s, out.size(0) * out.size(1) * out.size(2), out.dptr_, data.dptr_,
+ DType(param_.slope));
+ });
break;
}
default:
@@ -155,33 +183,38 @@ class LeakyReLUOp : public Operator {
CHECK_EQ(req.size(), expected);
CHECK_EQ(in_data.size(), expected);
Stream<xpu> *s = ctx.get_stream<xpu>();
- Tensor<xpu, 3> output;
- Tensor<xpu, 3> data;
- Tensor<xpu, 3> gdata;
- Tensor<xpu, 3> grad;
- Tensor<xpu, 3> mask;
- Tensor<xpu, 1> weight;
- Tensor<xpu, 1> grad_weight;
+ Tensor<xpu, 3, DType> output;
+ Tensor<xpu, 3, DType> data;
+ Tensor<xpu, 3, DType> gdata;
+ Tensor<xpu, 3, DType> grad;
+ Tensor<xpu, 3, DType> mask;
+ Tensor<xpu, 1, DType> weight;
+ Tensor<xpu, 1, DType> grad_weight;
int n = out_grad[leakyrelu::kOut].shape_[0];
int k = out_grad[leakyrelu::kOut].shape_[1];
Shape<3> dshape = Shape3(n, k, out_grad[leakyrelu::kOut].Size()/n/k);
- grad = out_grad[leakyrelu::kOut].get_with_shape<xpu, 3, real_t>(dshape, s);
- gdata = in_grad[leakyrelu::kData].get_with_shape<xpu, 3, real_t>(dshape, s);
- output = out_data[leakyrelu::kOut].get_with_shape<xpu, 3, real_t>(dshape, s);
+ grad = out_grad[leakyrelu::kOut].get_with_shape<xpu, 3, DType>(dshape, s);
+ gdata = in_grad[leakyrelu::kData].get_with_shape<xpu, 3, DType>(dshape, s);
+ output = out_data[leakyrelu::kOut].get_with_shape<xpu, 3, DType>(dshape, s);
if (param_.act_type == leakyrelu::kRReLU) {
- mask = out_data[leakyrelu::kMask].get_with_shape<xpu, 3, real_t>(dshape, s);
+ mask = out_data[leakyrelu::kMask].get_with_shape<xpu, 3, DType>(dshape, s);
}
if (param_.act_type == leakyrelu::kPReLU) {
- data = in_data[leakyrelu::kData].get_with_shape<xpu, 3, real_t>(dshape, s);
+ data = in_data[leakyrelu::kData].get_with_shape<xpu, 3, DType>(dshape, s);
}
switch (param_.act_type) {
case leakyrelu::kLeakyReLU: {
- Assign(gdata, req[leakyrelu::kData], F<mshadow_op::xelu_grad>(output, param_.slope) * grad);
+ MXNET_ASSIGN_REQ_SWITCH(req[leakyrelu::kData], Req, {
+ mxnet_op::Kernel<mxnet_op::op_with_req<
+ mxnet_op::backward_grad_tuned<mxnet::op::mshadow_op::xelu_grad>, Req>, xpu>::Launch(
+ s, gdata.size(0) * gdata.size(1) * gdata.size(2), gdata.dptr_, grad.dptr_,
+ output.dptr_, DType(param_.slope));
+ });
break;
}
case leakyrelu::kPReLU: {
- weight = in_data[leakyrelu::kGamma].get<xpu, 1, real_t>(s);
- grad_weight = in_grad[leakyrelu::kGamma].get<xpu, 1, real_t>(s);
+ weight = in_data[leakyrelu::kGamma].get<xpu, 1, DType>(s);
+ grad_weight = in_grad[leakyrelu::kGamma].get<xpu, 1, DType>(s);
if (weight.shape_.Size() == 1) {
Shape<4> gshape = Shape4(1, grad.shape_[0], grad.shape_[1], grad.shape_[2]);
Assign(grad_weight, req[leakyrelu::kGamma],
@@ -204,7 +237,12 @@ class LeakyReLUOp : public Operator {
break;
}
case leakyrelu::kELU: {
- Assign(gdata, req[leakyrelu::kData], F<mshadow_op::elu_grad>(output, param_.slope) * grad);
+ MXNET_ASSIGN_REQ_SWITCH(req[leakyrelu::kData], Req, {
+ mxnet_op::Kernel<mxnet_op::op_with_req<
+ mxnet_op::backward_grad_tuned<mxnet::op::mshadow_op::elu_grad>, Req>, xpu>::Launch(
+ s, gdata.size(0) * gdata.size(1) * gdata.size(2), gdata.dptr_, grad.dptr_,
+ output.dptr_, DType(param_.slope));
+ });
break;
}
default:
@@ -217,7 +255,7 @@ class LeakyReLUOp : public Operator {
}; // class LeakyReLUOp
template<typename xpu>
-Operator* CreateOp(LeakyReLUParam type);
+Operator* CreateOp(LeakyReLUParam type, int dtype);
#if DMLC_USE_CXX11
class LeakyReLUProp : public OperatorProperty {
@@ -256,6 +294,26 @@ class LeakyReLUProp : public OperatorProperty {
return true;
}
+ bool InferType(std::vector<int> *in_type,
+ std::vector<int> *out_type,
+ std::vector<int> *aux_type) const override {
+ int dtype = -1;
+ for (const int& type : *in_type) {
+ type_assign(&dtype, type);
+ }
+ for (const int& type : *out_type) {
+ type_assign(&dtype, type);
+ }
+
+ for (size_t i = 0; i < in_type->size(); ++i) {
+ TYPE_ASSIGN_CHECK(*in_type, i, dtype);
+ }
+ for (size_t i = 0; i < out_type->size(); ++i) {
+ TYPE_ASSIGN_CHECK(*out_type, i, dtype);
+ }
+ return dtype != -1;
+ }
+
OperatorProperty* Copy() const override {
auto ptr = new LeakyReLUProp();
ptr->param_ = param_;
@@ -338,7 +396,13 @@ class LeakyReLUProp : public OperatorProperty {
}
}
- Operator* CreateOperator(Context ctx) const override;
+ Operator* CreateOperator(Context ctx) const override {
+ LOG(FATAL) << "Not Implemented.";
+ return NULL;
+ }
+
+ Operator* CreateOperatorEx(Context ctx, std::vector<TShape> *in_shape,
+ std::vector<int> *in_type) const override;
private:
LeakyReLUParam param_;
diff --git a/src/operator/leaky_relu.cc b/src/operator/leaky_relu.cc
index 6e6fa53ce6e..99b6ba362f7 100644
--- a/src/operator/leaky_relu.cc
+++ b/src/operator/leaky_relu.cc
@@ -30,12 +30,17 @@
namespace mxnet {
namespace op {
template<>
-Operator *CreateOp<cpu>(LeakyReLUParam param) {
- return new LeakyReLUOp<cpu>(param);
+Operator *CreateOp<cpu>(LeakyReLUParam param, int dtype) {
+ Operator* op = NULL;
+ MSHADOW_REAL_TYPE_SWITCH(dtype, DType, {
+ op = new LeakyReLUOp<cpu, DType>(param);
+ });
+ return op;
}
-Operator *LeakyReLUProp::CreateOperator(Context ctx) const {
- DO_BIND_DISPATCH(CreateOp, param_);
+Operator *LeakyReLUProp::CreateOperatorEx(Context ctx, std::vector<TShape> *in_shape,
+ std::vector<int> *in_type) const {
+ DO_BIND_DISPATCH(CreateOp, param_, in_type->at(0));
}
DMLC_REGISTER_PARAMETER(LeakyReLUParam);
diff --git a/src/operator/leaky_relu.cu b/src/operator/leaky_relu.cu
index 9de237c5734..74b444d8759 100644
--- a/src/operator/leaky_relu.cu
+++ b/src/operator/leaky_relu.cu
@@ -29,8 +29,12 @@
namespace mxnet {
namespace op {
template<>
-Operator *CreateOp<gpu>(LeakyReLUParam param) {
- return new LeakyReLUOp<gpu>(param);
+Operator *CreateOp<gpu>(LeakyReLUParam param, int dtype) {
+ Operator* op = NULL;
+ MSHADOW_REAL_TYPE_SWITCH(dtype, DType, {
+ op = new LeakyReLUOp<gpu, DType>(param);
+ });
+ return op;
}
} // namespace op
diff --git a/src/operator/mshadow_op.h b/src/operator/mshadow_op.h
index 1d4284e1ac2..5606c64369a 100644
--- a/src/operator/mshadow_op.h
+++ b/src/operator/mshadow_op.h
@@ -89,6 +89,13 @@ MXNET_UNARY_MATH_OP_NC(identity, a);
MXNET_UNARY_MATH_OP(identity_grad, 1);
+struct identity_with_cast {
+ template<typename DTypeIn, typename DTypeOut>
+ MSHADOW_XINLINE static void Map(int i, DTypeOut *out, DTypeIn *in) {
+ out[i] = DTypeOut(in[i]);
+ }
+};
+
MXNET_BINARY_MATH_OP_NC(left, a);
MXNET_BINARY_MATH_OP_NC(right, b);
@@ -119,13 +126,13 @@ MXNET_UNARY_MATH_OP_NC(relu, a > DType(0) ? a : DType(0));
MXNET_UNARY_MATH_OP_NC(relu_grad, a > DType(0) ? DType(1) : DType(0));
-MXNET_BINARY_MATH_OP(xelu, a > DType(0) ? math::id(a) :
- math::id(a) * math::id(b));
+MXNET_BINARY_MATH_OP_NC(xelu, a > DType(0) ? a :
+ DType(static_cast<float>(a) * static_cast<float>(b)));
MXNET_BINARY_MATH_OP_NC(xelu_grad, a > DType(0) ? DType(1) : b);
-MXNET_BINARY_MATH_OP(elu, a > DType(0) ? math::id(a) :
- math::id(b) * math::expm1(a));
+MXNET_BINARY_MATH_OP_NC(elu, a > DType(0) ? a :
+ DType(math::id(b) * math::expm1(a)));
MXNET_BINARY_MATH_OP_NC(elu_grad, a > DType(0) ? DType(1) : DType(b + a));
diff --git a/src/operator/mxnet_op.h b/src/operator/mxnet_op.h
index 30b3c8577ce..c3f6dc6558e 100644
--- a/src/operator/mxnet_op.h
+++ b/src/operator/mxnet_op.h
@@ -322,7 +322,7 @@ MSHADOW_CINLINE void copy(mshadow::Stream<xpu> *s, const TBlob& to, const TBlob&
CHECK_EQ(from.dev_mask(), to.dev_mask());
MSHADOW_TYPE_SWITCH(to.type_flag_, DType, {
if (to.type_flag_ == from.type_flag_) {
- mshadow::Copy(to.FlatTo1D<xpu, DType>(), from.FlatTo1D<xpu, DType>(), s);
+ mshadow::Copy(to.FlatTo1D<xpu, DType>(s), from.FlatTo1D<xpu, DType>(s), s);
} else {
MSHADOW_TYPE_SWITCH(from.type_flag_, SrcDType, {
to.FlatTo1D<xpu, DType>(s) = mshadow::expr::tcast<DType>(from.FlatTo1D<xpu, SrcDType>(s));
diff --git a/src/operator/nn/batch_norm-inl.h b/src/operator/nn/batch_norm-inl.h
index 48638de20cc..3f47d58bb8c 100644
--- a/src/operator/nn/batch_norm-inl.h
+++ b/src/operator/nn/batch_norm-inl.h
@@ -224,16 +224,25 @@ void BatchNormForward(const OpContext &ctx, const BatchNormParam& param,
*/
template <typename xpu, typename DType, typename AccReal>
void BatchNormBackward(const OpContext &ctx, const BatchNormParam& param,
- const std::vector<TBlob> &out_grad,
- const std::vector<TBlob> &in_data,
- const std::vector<TBlob> &out_data,
+ const std::vector<TBlob> &inputs,
const std::vector<OpReqType> &req,
- const std::vector<TBlob> &in_grad,
- const std::vector<TBlob> &aux_states) {
- CHECK_EQ(out_grad.size(), param.output_mean_var ? 3U : 1U);
- CHECK_EQ(in_data.size(), 3U);
- CHECK_EQ(out_data.size(), 3U);
- CHECK_EQ(in_grad.size(), 3U);
+ const std::vector<TBlob> &outputs) {
+ CHECK_EQ(inputs.size(), 8U);
+ CHECK_EQ(outputs.size(), 3U);
+ std::vector<TBlob> out_grad(1);
+ std::vector<TBlob> out_data(3);
+ std::vector<TBlob> in_data(3);
+ std::vector<TBlob> aux_states(2);
+
+ out_grad[0] = inputs[0];
+ out_data[batchnorm::kMean] = inputs[1];
+ out_data[batchnorm::kVar] = inputs[2];
+ in_data[batchnorm::kData] = inputs[3];
+ in_data[batchnorm::kGamma] = inputs[4];
+ in_data[batchnorm::kBeta] = inputs[5];
+ aux_states[batchnorm::kMovingMean] = inputs[6];
+ aux_states[batchnorm::kMovingVar] = inputs[7];
+ const std::vector<TBlob> &in_grad = outputs;
mshadow::Stream<xpu> *s = ctx.get_stream<xpu>();
BatchNormBackwardImpl<xpu, DType, AccReal>(s, ctx, param, out_grad, in_data,
out_data, req, in_grad, aux_states);
@@ -261,23 +270,11 @@ void BatchNormGradCompute(const nnvm::NodeAttrs& attrs,
const OpContext& ctx, const std::vector<TBlob>& inputs,
const std::vector<OpReqType>& req,
const std::vector<TBlob>& outputs) {
- CHECK_EQ(inputs.size(), 11U);
+ CHECK_EQ(inputs.size(), 8U);
const BatchNormParam& param = nnvm::get<BatchNormParam>(attrs.parsed);
- int num_out_grads = param.output_mean_var ? 3U : 1U;
- int in_data_start = 3;
- int aux_states_start = in_data_start + batchnorm::kInMovingMean;
- int out_data_start = in_data_start + batchnorm::kInMovingVar + 1;
- std::vector<TBlob> out_grad(inputs.begin(), inputs.begin() + num_out_grads);
- std::vector<TBlob> in_data(inputs.begin() + in_data_start,
- inputs.begin() + aux_states_start);
- std::vector<TBlob> aux_states(inputs.begin() + aux_states_start,
- inputs.begin() + out_data_start);
- std::vector<TBlob> out_data(inputs.begin() + out_data_start, inputs.end());
- std::vector<TBlob> in_grad(outputs.begin(), outputs.begin() + 3);
-
- MSHADOW_REAL_TYPE_SWITCH_EX(out_grad[0].type_flag_, DType, AccReal, {
- BatchNormBackward<xpu, DType, AccReal>(ctx, param, out_grad, in_data, out_data, req,
- in_grad, aux_states);
+
+ MSHADOW_REAL_TYPE_SWITCH_EX(inputs[0].type_flag_, DType, AccReal, {
+ BatchNormBackward<xpu, DType, AccReal>(ctx, param, inputs, req, outputs);
});
}
diff --git a/src/operator/nn/batch_norm.cc b/src/operator/nn/batch_norm.cc
index c8b5d58156e..457f536d7fa 100644
--- a/src/operator/nn/batch_norm.cc
+++ b/src/operator/nn/batch_norm.cc
@@ -413,24 +413,26 @@ void BatchNormGradComputeExCPU(const nnvm::NodeAttrs &attrs,
const std::vector<NDArray> &inputs,
const std::vector<OpReqType> &req,
const std::vector<NDArray> &outputs) {
- CHECK_EQ(inputs.size(), 11U);
+ CHECK_EQ(inputs.size(), 8U);
const BatchNormParam ¶m = nnvm::get<BatchNormParam>(attrs.parsed);
- int num_out_grads = param.output_mean_var ? 3U : 1U;
- int in_data_start = 3;
- int aux_states_start = in_data_start + batchnorm::kInMovingMean;
- int out_data_start = in_data_start + batchnorm::kInMovingVar + 1;
TShape shape = inputs[0].shape();
// MKLDNN batchnorm only works well on the special MKLDNN layout.
if (SupportMKLDNNBN(inputs[0], param)
- && (inputs[in_data_start].IsMKLDNNData() || inputs[0].IsMKLDNNData())) {
- std::vector<NDArray> out_grad(inputs.begin(), inputs.begin() + num_out_grads);
- std::vector<NDArray> in_data(inputs.begin() + in_data_start,
- inputs.begin() + aux_states_start);
- std::vector<NDArray> aux_states(inputs.begin() + aux_states_start,
- inputs.begin() + out_data_start);
- std::vector<NDArray> out_data(inputs.begin() + out_data_start, inputs.end());
- std::vector<NDArray> in_grad(outputs.begin(), outputs.begin() + 3);
+ && (inputs[3].IsMKLDNNData() || inputs[0].IsMKLDNNData())) {
+ std::vector<NDArray> out_grad(1);
+ std::vector<NDArray> out_data(3);
+ std::vector<NDArray> in_data(3);
+ std::vector<NDArray> aux_states(2);
+ out_grad[0] = inputs[0];
+ out_data[batchnorm::kMean] = inputs[1];
+ out_data[batchnorm::kVar] = inputs[2];
+ in_data[batchnorm::kData] = inputs[3];
+ in_data[batchnorm::kGamma] = inputs[4];
+ in_data[batchnorm::kBeta] = inputs[5];
+ aux_states[batchnorm::kMovingMean] = inputs[6];
+ aux_states[batchnorm::kMovingVar] = inputs[7];
+ const std::vector<NDArray> &in_grad = outputs;
if (inputs[0].dtype() == mshadow::kFloat32) {
MKLDNN_OPCHECK_INIT(true, outputs.size(), inputs, outputs);
@@ -470,8 +472,6 @@ static inline bool backward_BatchNormStorageType(const nnvm::NodeAttrs &attrs,
DispatchMode *dispatch_mode,
std::vector<int> *in_attrs,
std::vector<int> *out_attrs) {
- CHECK_EQ(in_attrs->size(), 11);
- CHECK_EQ(out_attrs->size(), 5);
DispatchMode wanted_mode;
#if MXNET_USE_MKLDNN == 1
if (dev_mask == mshadow::cpu::kDevMask)
@@ -486,6 +486,46 @@ static inline bool backward_BatchNormStorageType(const nnvm::NodeAttrs &attrs,
dispatch_mode, wanted_mode);
}
+std::vector<nnvm::NodeEntry> BatchNormGrad(const nnvm::NodePtr& n,
+ const std::vector<nnvm::NodeEntry>& ograds) {
+ std::vector<nnvm::NodeEntry> out_data(n->num_outputs());
+ for (uint32_t i = 0; i < out_data.size(); ++i) {
+ out_data[i] = nnvm::NodeEntry{n, i, 0};
+ }
+ std::vector<nnvm::NodeEntry> heads;
+ heads.reserve(8);
+ heads.push_back(ograds[0]);
+ heads.push_back(out_data[batchnorm::kMean]);
+ heads.push_back(out_data[batchnorm::kVar]);
+ heads.push_back(n->inputs[batchnorm::kData]);
+ heads.push_back(n->inputs[batchnorm::kGamma]);
+ heads.push_back(n->inputs[batchnorm::kBeta]);
+ heads.push_back(n->inputs[batchnorm::kInMovingMean]);
+ heads.push_back(n->inputs[batchnorm::kInMovingVar]);
+
+ nnvm::NodePtr gnode = nnvm::Node::Create();
+ gnode->inputs = std::move(heads);
+ gnode->control_deps.emplace_back(n);
+ gnode->attrs = n->attrs;
+ gnode->attrs.op = nnvm::Op::Get("_backward_BatchNorm");
+ gnode->attrs.name = n->attrs.name + "_backward";
+ // The input of batchnorm
+ std::vector<nnvm::NodeEntry> in_grad(5);
+ for (uint32_t i = 0; i < 3; ++i) {
+ in_grad[i] = nnvm::NodeEntry{gnode, i, 0};
+ }
+
+ // attach no gradient node to forbid gradient on aux_state
+ nnvm::NodePtr ng = nnvm::Node::Create();
+ ng->attrs.op = Op::Get("_NoGradient");
+ ng->attrs.name = "NoGradient";
+ // the aux state of batchnorm
+ for (uint32_t i = 0; i < 2; ++i) {
+ in_grad[i + 3] = nnvm::NodeEntry{ng, 0, 0};
+ }
+ return in_grad;
+}
+
NNVM_REGISTER_OP(BatchNorm)
.describe(R"code(Batch normalization.
@@ -559,7 +599,7 @@ then set ``gamma`` to 1 and its gradient to 0.
#if MXNET_USE_MKLDNN == 1
.set_attr<FComputeEx>("FComputeEx<cpu>", BatchNormComputeExCPU)
#endif
-.set_attr<nnvm::FGradient>("FGradient", ElemwiseGradUseInOut{"_backward_BatchNorm"})
+.set_attr<nnvm::FGradient>("FGradient", BatchNormGrad)
#if MXNET_USE_MKLDNN == 1
.set_attr<FResourceRequest>("FResourceRequest", [](const NodeAttrs& n) {
return std::vector<ResourceRequest>{ResourceRequest::kTempSpace};
@@ -583,7 +623,7 @@ then set ``gamma`` to 1 and its gradient to 0.
});
NNVM_REGISTER_OP(_backward_BatchNorm)
-.set_num_outputs(5)
+.set_num_outputs(3)
.set_attr<nnvm::TIsBackward>("TIsBackward", true)
.set_attr<FInferStorageType>("FInferStorageType", backward_BatchNormStorageType)
#if MXNET_USE_MKLDNN == 1
diff --git a/src/operator/nn/batch_norm.cu b/src/operator/nn/batch_norm.cu
index b8657fc4d36..703ed398938 100644
--- a/src/operator/nn/batch_norm.cu
+++ b/src/operator/nn/batch_norm.cu
@@ -690,13 +690,8 @@ void BatchNormGradCompute<gpu>(const nnvm::NodeAttrs& attrs,
const OpContext& ctx, const std::vector<TBlob>& inputs,
const std::vector<OpReqType>& req,
const std::vector<TBlob>& outputs) {
- CHECK_EQ(inputs.size(), 11U);
+ CHECK_EQ(inputs.size(), 8U);
BatchNormParam param = nnvm::get<BatchNormParam>(attrs.parsed);
- std::vector<TBlob> out_grad(1, inputs[0]);
- std::vector<TBlob> in_data(inputs.begin() + 3, inputs.begin() + 6);
- std::vector<TBlob> aux_states(inputs.begin() + 6, inputs.begin() + 8);
- std::vector<TBlob> out_data(inputs.begin() + 8, inputs.end());
- std::vector<TBlob> in_grad(outputs.begin(), outputs.begin() + 3);
int dtype = inputs[0].type_flag_;
TShape shape = inputs[0].shape_;
@@ -705,19 +700,16 @@ void BatchNormGradCompute<gpu>(const nnvm::NodeAttrs& attrs,
if (!param.use_global_stats && !param.cudnn_off && shape.ndim() <= 4
&& param.axis == mxnet::op::batchnorm::DEFAULT_AXIS) {
MSHADOW_REAL_TYPE_SWITCH(dtype, DType, {
- GetCuDNNOp<DType>(param).Backward(ctx, out_grad, in_data, out_data,
- req, in_grad, aux_states);
+ GetCuDNNOp<DType>(param).Backward(ctx, inputs, req, outputs);
})
} else {
MSHADOW_REAL_TYPE_SWITCH_EX(dtype, DType, AccReal, {
- BatchNormBackward<gpu, DType, AccReal>(ctx, param, out_grad,
- in_data, out_data, req, in_grad, aux_states);
+ BatchNormBackward<gpu, DType, AccReal>(ctx, param, inputs, req, outputs);
})
}
#else
MSHADOW_REAL_TYPE_SWITCH_EX(out_grad[0].type_flag_, DType, AccReal, {
- BatchNormBackward<gpu, DType, AccReal>(ctx, param, out_grad,
- in_data, out_data, req, in_grad, aux_states);
+ BatchNormBackward<gpu, DType, AccReal>(ctx, param, inputs, req, outputs);
});
#endif
}
diff --git a/src/operator/nn/convolution-inl.h b/src/operator/nn/convolution-inl.h
index d0dd7dd27a6..5632d73c261 100644
--- a/src/operator/nn/convolution-inl.h
+++ b/src/operator/nn/convolution-inl.h
@@ -32,6 +32,7 @@
#include <mxnet/ndarray.h>
#include <mxnet/operator.h>
#include <mxnet/operator_util.h>
+#include <mxnet/op_attr_types.h>
#include <dmlc/logging.h>
#include <dmlc/optional.h>
#include <algorithm>
@@ -124,6 +125,8 @@ struct ConvolutionParam : public dmlc::Parameter<ConvolutionParam> {
}
};
+typedef ParamOpSign<ConvolutionParam> ConvSignature;
+
} // namespace op
} // namespace mxnet
diff --git a/src/operator/nn/convolution.cc b/src/operator/nn/convolution.cc
index 951063fb4b2..7aafe9d82f7 100644
--- a/src/operator/nn/convolution.cc
+++ b/src/operator/nn/convolution.cc
@@ -468,6 +468,10 @@ There are other options to tune the performance.
else
return std::vector<std::string>{"data", "weight", "bias"};
})
+.set_attr<nnvm::FListOutputNames>("FListOutputNames",
+ [](const NodeAttrs& attrs) {
+ return std::vector<std::string>{"output"};
+})
.set_attr<nnvm::FInferShape>("FInferShape", ConvolutionShape)
.set_attr<nnvm::FInferType>("FInferType", ConvolutionType)
.set_attr<FInferStorageType>("FInferStorageType", ConvStorageType)
diff --git a/src/operator/nn/convolution.cu b/src/operator/nn/convolution.cu
index d7f9e564a60..f6d14e3558b 100644
--- a/src/operator/nn/convolution.cu
+++ b/src/operator/nn/convolution.cu
@@ -41,13 +41,40 @@ static CuDNNConvolutionOp<DType> &GetCuDNNConvOp(const ConvolutionParam& param,
const std::vector<TShape>& in_shape, const std::vector<TShape>& out_shape,
const Context& ctx) {
#if DMLC_CXX11_THREAD_LOCAL
- static thread_local CuDNNConvolutionOp<DType> op;
+ static thread_local std::unordered_map<ConvSignature,
+ std::shared_ptr<CuDNNConvolutionOp<DType> >,
+ OpHash> ops;
#else
- static MX_THREAD_LOCAL CuDNNConvolutionOp<DType> op;
+ static MX_THREAD_LOCAL std::unordered_map<ConvSignature,
+ std::shared_ptr<CuDNNConvolutionOp<DType> >,
+ OpHash> ops;
#endif
- op.Init(param, forward_compute_type, backward_compute_type,
- in_shape, out_shape, ctx);
- return op;
+ ConvSignature key(param);
+ size_t ndim = 0;
+ for (auto &s : in_shape)
+ ndim += s.ndim();
+ for (auto &s : out_shape)
+ ndim += s.ndim();
+ key.Reserve(1 /* for forward_compute_type */ + 1 /* for backward_compute_type */
+ + ndim + 1 /* for dev_id */);
+
+ key.AddSign(forward_compute_type);
+ key.AddSign(backward_compute_type);
+ key.AddSign(in_shape);
+ key.AddSign(out_shape);
+ key.AddSign(ctx.dev_id);
+
+ auto it = ops.find(key);
+ if (it == ops.end()) {
+ std::shared_ptr<CuDNNConvolutionOp<DType>> op(new CuDNNConvolutionOp<DType>());
+ auto ins_ret = ops.insert(std::pair<ConvSignature, std::shared_ptr<CuDNNConvolutionOp<DType>>>(
+ key, op));
+ CHECK(ins_ret.second);
+ it = ins_ret.first;
+ it->second->Init(param, forward_compute_type, backward_compute_type, in_shape,
+ out_shape, ctx);
+ }
+ return *it->second;
}
#endif
diff --git a/src/operator/nn/cudnn/cudnn_batch_norm-inl.h b/src/operator/nn/cudnn/cudnn_batch_norm-inl.h
index e2337049060..e3d5dd9204b 100644
--- a/src/operator/nn/cudnn/cudnn_batch_norm-inl.h
+++ b/src/operator/nn/cudnn/cudnn_batch_norm-inl.h
@@ -67,10 +67,10 @@ class CuDNNBatchNormOp {
}
void Forward(const OpContext &ctx,
- const std::vector<TBlob> &in_data,
- const std::vector<OpReqType> &req,
- const std::vector<TBlob> &out_data,
- const std::vector<TBlob> &aux_states) {
+ const std::vector<TBlob> &in_data,
+ const std::vector<OpReqType> &req,
+ const std::vector<TBlob> &out_data,
+ const std::vector<TBlob> &aux_states) {
using namespace mshadow;
using namespace mshadow::expr;
CHECK_EQ(in_data.size(), 3U);
@@ -158,29 +158,30 @@ class CuDNNBatchNormOp {
}
void Backward(const OpContext &ctx,
- const std::vector<TBlob> &out_grad,
- const std::vector<TBlob> &in_data,
- const std::vector<TBlob> &out_data,
- const std::vector<OpReqType> &req,
- const std::vector<TBlob> &in_grad,
- const std::vector<TBlob> &aux_states) {
+ const std::vector<TBlob> &inputs,
+ const std::vector<OpReqType> &req,
+ const std::vector<TBlob> &outputs) {
using namespace mshadow;
using namespace mshadow::expr;
- CHECK_EQ(out_grad.size(), 1U);
- CHECK_EQ(in_data.size(), 3U);
- CHECK_EQ(out_data.size(), 3U);
- CHECK_EQ(in_grad.size(), 3U);
+ CHECK_EQ(inputs.size(), 8U);
+ CHECK_EQ(outputs.size(), 3U);
CHECK(ctx.is_train && !param_.use_global_stats)
<< "use global statistics is not yet supported in CuDNNBatchNorm";
- Init(in_data[cudnnbatchnorm::kData]);
+ // Rename the inputs and outputs.
+ const TBlob &out_grad = inputs[0];
+ const TBlob &out_mean = inputs[1];
+ const TBlob &out_var = inputs[2];
+ const TBlob &in_data = inputs[3];
+ const TBlob &in_gamma = inputs[4];
+ const std::vector<TBlob> &in_grad = outputs;
+
+ Init(in_data);
Stream<gpu> *s = ctx.get_stream<gpu>();
- Tensor<gpu, 4, DType> x =
- in_data[cudnnbatchnorm::kData].get_with_shape<gpu, 4, DType>(shape_, s);
+ Tensor<gpu, 4, DType> x = in_data.get_with_shape<gpu, 4, DType>(shape_, s);
Tensor<gpu, 4, DType> dx =
in_grad[cudnnbatchnorm::kData].get_with_shape<gpu, 4, DType>(shape_, s);
- Tensor<gpu, 4, DType> dy =
- out_grad[cudnnbatchnorm::kOut].get_with_shape<gpu, 4, DType>(shape_, s);
+ Tensor<gpu, 4, DType> dy = out_grad.get_with_shape<gpu, 4, DType>(shape_, s);
#if CUDNN_VERSION >= 4007
#if CUDNN_VERSION >= 7002
@@ -190,15 +191,15 @@ class CuDNNBatchNormOp {
#endif
MSHADOW_REAL_TYPE_SWITCH(dtype_param_, DTypeParam, {
Tensor<gpu, 1, DTypeParam> gamma =
- in_data[cudnnbatchnorm::kGamma].get_with_shape<gpu, 1, DTypeParam>(Shape1(shape_[1]), s);
+ in_gamma.get_with_shape<gpu, 1, DTypeParam>(Shape1(shape_[1]), s);
Tensor<gpu, 1, DTypeParam> dbeta =
in_grad[cudnnbatchnorm::kBeta].get_with_shape<gpu, 1, DTypeParam>(Shape1(shape_[1]), s);
Tensor<gpu, 1, DTypeParam> dgamma =
in_grad[cudnnbatchnorm::kGamma].get_with_shape<gpu, 1, DTypeParam>(Shape1(shape_[1]), s);
Tensor<gpu, 1, DTypeParam> save_mean =
- out_data[cudnnbatchnorm::kMean].get_with_shape<gpu, 1, DTypeParam>(Shape1(shape_[1]), s);
+ out_mean.get_with_shape<gpu, 1, DTypeParam>(Shape1(shape_[1]), s);
Tensor<gpu, 1, DTypeParam> save_inv_var =
- out_data[cudnnbatchnorm::kInvVar].get_with_shape<gpu, 1, DTypeParam>(Shape1(shape_[1]), s);
+ out_var.get_with_shape<gpu, 1, DTypeParam>(Shape1(shape_[1]), s);
typename DataType<DType>::ScaleType a = 1.0f;
typename DataType<DType>::ScaleType b = 0.0f;
@@ -232,15 +233,15 @@ class CuDNNBatchNormOp {
#else // CUDNN_VERSION < 4007
MSHADOW_REAL_TYPE_SWITCH(dtype_param_, DTypeParam, {
Tensor<gpu, 1, DTypeParam> gamma =
- in_data[cudnnbatchnorm::kGamma].get_with_shape<gpu, 1, DTypeParam>(Shape1(shape_[1]), s);
+ in_gamma.get_with_shape<gpu, 1, DTypeParam>(Shape1(shape_[1]), s);
Tensor<gpu, 1, DTypeParam> dbeta =
in_grad[cudnnbatchnorm::kBeta].get_with_shape<gpu, 1, DTypeParam>(Shape1(shape_[1]), s);
Tensor<gpu, 1, DTypeParam> dgamma =
in_grad[cudnnbatchnorm::kGamma].get_with_shape<gpu, 1, DTypeParam>(Shape1(shape_[1]), s);
Tensor<gpu, 1, DTypeParam> save_mean =
- out_data[cudnnbatchnorm::kMean].get_with_shape<gpu, 1, DTypeParam>(Shape1(shape_[1]), s);
+ out_mean.get_with_shape<gpu, 1, DTypeParam>(Shape1(shape_[1]), s);
Tensor<gpu, 1, DTypeParam> save_inv_var =
- out_data[cudnnbatchnorm::kInvVar].get_with_shape<gpu, 1, DTypeParam>(Shape1(shape_[1]), s);
+ out_var.get_with_shape<gpu, 1, DTypeParam>(Shape1(shape_[1]), s);
typename DataType<DType>::ScaleType a = 1.0f;
typename DataType<DType>::ScaleType b = 0.0f;
diff --git a/src/operator/nn/deconvolution-inl.h b/src/operator/nn/deconvolution-inl.h
index badbb8b9d67..b41ecf4aa41 100644
--- a/src/operator/nn/deconvolution-inl.h
+++ b/src/operator/nn/deconvolution-inl.h
@@ -169,6 +169,8 @@ struct DeconvolutionParam : public dmlc::Parameter<DeconvolutionParam> {
}
};
+typedef ParamOpSign<DeconvolutionParam> DeconvSignature;
+
} // namespace op
} // namespace mxnet
diff --git a/src/operator/nn/deconvolution.cu b/src/operator/nn/deconvolution.cu
index c7395428c2a..086b47000b2 100644
--- a/src/operator/nn/deconvolution.cu
+++ b/src/operator/nn/deconvolution.cu
@@ -40,9 +40,35 @@ static CuDNNDeconvolutionOp<DType> &GetCuDNNDeconvOp(const DeconvolutionParam& p
const std::vector<TShape>& in_shape,
const std::vector<TShape>& out_shape,
const Context& ctx) {
- static thread_local CuDNNDeconvolutionOp<DType> op;
- op.Init(param, forward_compute_type, backward_compute_type, in_shape, out_shape, ctx);
- return op;
+ static thread_local std::unordered_map<DeconvSignature,
+ std::shared_ptr<CuDNNDeconvolutionOp<DType> >,
+ OpHash> ops;
+ DeconvSignature key(param);
+ size_t ndim = 0;
+ for (auto &s : in_shape)
+ ndim += s.ndim();
+ for (auto &s : out_shape)
+ ndim += s.ndim();
+ key.Reserve(1 /* for forward_compute_type */ + 1 /* for backward_compute_type */
+ + ndim + 1 /* for dev_id */);
+
+ key.AddSign(forward_compute_type);
+ key.AddSign(backward_compute_type);
+ key.AddSign(in_shape);
+ key.AddSign(out_shape);
+ key.AddSign(ctx.dev_id);
+
+ auto it = ops.find(key);
+ if (it == ops.end()) {
+ std::shared_ptr<CuDNNDeconvolutionOp<DType>> op(new CuDNNDeconvolutionOp<DType>());
+ auto ins_ret = ops.insert(
+ std::pair<DeconvSignature, std::shared_ptr<CuDNNDeconvolutionOp<DType>>>(key, op));
+ CHECK(ins_ret.second);
+ it = ins_ret.first;
+ it->second->Init(param, forward_compute_type, backward_compute_type, in_shape,
+ out_shape, ctx);
+ }
+ return *it->second;
}
#endif
diff --git a/src/operator/nn/fully_connected-inl.h b/src/operator/nn/fully_connected-inl.h
index e8e95643e64..7eba2e20e57 100644
--- a/src/operator/nn/fully_connected-inl.h
+++ b/src/operator/nn/fully_connected-inl.h
@@ -95,11 +95,20 @@ void FCForward(const OpContext &ctx, const FullyConnectedParam ¶m,
Shape2(oshape[0], oshape.ProdShape(1, oshape.ndim())), s);
}
+ CHECK_EQ(data.shape_[1], wmat.shape_[1])
+ << "Incomplete weight tensor detected: weight.data().shape[1] != prod(data.data().shape[1:])."
+ " This is not supported by FCForward. If weight is in row_sparse format,"
+ " please make sure all row ids are present.";
// Legacy approach shown here for comparison:
// out = dot(data, wmat.T());
linalg_gemm(data, wmat, out, false, true, s);
if (!param.no_bias) {
- Tensor<xpu, 1, DType> bias = in_data[fullc::kBias].get<xpu, 1, DType>(s);
+ Tensor<xpu, 1, DType> bias = in_data[fullc::kBias].get_with_shape<xpu, 1, DType>(
+ Shape1(wmat.shape_[0]), s);
+ CHECK_EQ(bias.shape_[0], wmat.shape_[0])
+ << "Incomplete bias tensor detected: bias.data().shape[1] != weight.data().shape[0]."
+ " This is not supported by FCForward. If bias is in row_sparse format, please"
+ " make sure all row ids are present.";
out += repmat(bias, data.size(0));
}
}
diff --git a/src/operator/nn/fully_connected.cc b/src/operator/nn/fully_connected.cc
index 4362408a23a..278c130064f 100644
--- a/src/operator/nn/fully_connected.cc
+++ b/src/operator/nn/fully_connected.cc
@@ -56,7 +56,10 @@ static bool FullyConnectedShape(const nnvm::NodeAttrs& attrs,
}
SHAPE_ASSIGN_CHECK(*in_shape, fullc::kWeight, Shape2(param.num_hidden, num_input));
if (!param.no_bias) {
- SHAPE_ASSIGN_CHECK(*in_shape, fullc::kBias, Shape1(param.num_hidden));
+ if (!shape_assign(&(*in_shape)[fullc::kBias], Shape1(param.num_hidden)) &&
+ !shape_assign(&(*in_shape)[fullc::kBias], Shape2(param.num_hidden, 1))) {
+ LOG(FATAL) << "Unexpected shape for bias " << (*in_shape)[fullc::kBias];
+ }
}
if (!param.flatten) {
@@ -73,22 +76,67 @@ static bool FullyConnectedShape(const nnvm::NodeAttrs& attrs,
return true;
}
-#if MXNET_USE_MKLDNN == 1
void FullyConnectedComputeExCPU(const nnvm::NodeAttrs& attrs,
const OpContext &ctx,
const std::vector<NDArray> &inputs,
const std::vector<OpReqType> &req,
const std::vector<NDArray> &outputs) {
- if (SupportMKLDNN(inputs[0])) {
- MKLDNN_OPCHECK_INIT(false, outputs.size(), inputs, outputs);
- MKLDNNFCForward(attrs, ctx, inputs, req, outputs);
- MKLDNN_OPCHECK_RUN(FullyConnectedCompute<cpu>, attrs, ctx, inputs, req,
- outputs);
+ const FullyConnectedParam& param = nnvm::get<FullyConnectedParam>(attrs.parsed);
+ const bool valid_data = inputs[0].storage_type() == kDefaultStorage;
+ const bool valid_weight = inputs[1].storage_type() == kDefaultStorage ||
+ inputs[1].storage_type() == kRowSparseStorage;
+ const bool valid_out = outputs[0].storage_type() == kDefaultStorage;
+ bool valid_bias = true;
+ if (!param.no_bias) {
+ valid_bias = inputs[2].storage_type() == kDefaultStorage ||
+ inputs[2].storage_type() == kRowSparseStorage;
+ }
+#if MXNET_USE_MKLDNN == 1
+ if (common::ContainsOnlyStorage(inputs, kDefaultStorage) &&
+ common::ContainsOnlyStorage(outputs, kDefaultStorage)) {
+ if (SupportMKLDNN(inputs[0])) {
+ MKLDNN_OPCHECK_INIT(false, outputs.size(), inputs, outputs);
+ MKLDNNFCForward(attrs, ctx, inputs, req, outputs);
+ MKLDNN_OPCHECK_RUN(FullyConnectedCompute<cpu>, attrs, ctx, inputs, req,
+ outputs);
+ } else {
+ FallBackCompute(FullyConnectedCompute<cpu>, attrs, ctx, inputs, req, outputs);
+ }
return;
+ } else if (valid_data && valid_weight && valid_bias && valid_out) {
+ // inputs
+ std::vector<NDArray> temp_ndarrays;
+ std::vector<TBlob> in_blobs;
+ for (const NDArray& in : inputs) {
+ // if ndarray is in default storage and MKLDNN is available,
+ // need to make sure cpu layout data is used, instead of MKL layout
+ if (in.storage_type() == kDefaultStorage) {
+ temp_ndarrays.push_back(in.Reorder2Default());
+ in_blobs.emplace_back(temp_ndarrays.back().data());
+ } else {
+ in_blobs.emplace_back(in.data());
+ }
+ }
+ // output
+ if (req[0] == kWriteTo) const_cast<NDArray &>(outputs[0]).InvalidateMKLDNNData();
+ FullyConnectedCompute<cpu>(attrs, ctx, in_blobs, req, {outputs[0].data()});
+ } else {
+ LogUnimplementedOp(attrs, ctx, inputs, req, outputs);
}
- FallBackCompute(FullyConnectedCompute<cpu>, attrs, ctx, inputs, req, outputs);
+#else
+ if (valid_data && valid_weight && valid_bias && valid_out) {
+ std::vector<TBlob> in_blobs(inputs.size());
+ for (size_t i = 0; i < in_blobs.size(); i++) in_blobs[i] = inputs[i].data();
+ std::vector<TBlob> out_blobs(outputs.size());
+ for (size_t i = 0; i < out_blobs.size(); i++) out_blobs[i] = outputs[i].data();
+ FullyConnectedCompute<cpu>(attrs, ctx, in_blobs, req, out_blobs);
+ } else {
+ LogUnimplementedOp(attrs, ctx, inputs, req, outputs);
+ }
+#endif
}
+#if MXNET_USE_MKLDNN == 1
void FullyConnectedGradComputeExCPU(const nnvm::NodeAttrs& attrs,
const OpContext &ctx,
const std::vector<NDArray> &inputs,
@@ -129,19 +177,27 @@ inline static bool FCStorageType(const nnvm::NodeAttrs& attrs,
std::vector<int> *in_attrs,
std::vector<int> *out_attrs) {
const FullyConnectedParam& param = nnvm::get<FullyConnectedParam>(attrs.parsed);
- uint32_t in_expected = param.no_bias ? 2 : 3;
+ const bool valid_data = in_attrs->at(0) == kDefaultStorage;
+ const bool valid_weight = in_attrs->at(1) == kDefaultStorage ||
+ in_attrs->at(1) == kRowSparseStorage;
+ bool valid_bias = true;
+ uint32_t in_expected = 2;
+ if (!param.no_bias) {
+ in_expected = 3;
+ valid_bias = in_attrs->at(2) == kDefaultStorage || in_attrs->at(2) == kRowSparseStorage;
+ }
CHECK_EQ(in_attrs->size(), in_expected);
CHECK_EQ(out_attrs->size(), 1);
-
- DispatchMode wanted_mode;
-#if MXNET_USE_MKLDNN == 1
- if (dev_mask == mshadow::cpu::kDevMask)
- wanted_mode = DispatchMode::kFComputeEx;
- else
-#endif
- wanted_mode = DispatchMode::kFCompute;
- return storage_type_assign(out_attrs, mxnet::kDefaultStorage,
- dispatch_mode, wanted_mode);
+ // dispatch to kFComputeEx is fine even if all inputs are dense and no MKL is present
+ bool dispatched = false;
+ if (!dispatched && valid_data && valid_weight && valid_bias) {
+ dispatched = storage_type_assign(out_attrs, mxnet::kDefaultStorage,
+ dispatch_mode, DispatchMode::kFComputeEx);
+ }
+ if (!dispatched) {
+ dispatched = dispatch_fallback(out_attrs, dispatch_mode);
+ }
+ return dispatched;
}
inline static bool BackwardFCStorageType(const nnvm::NodeAttrs& attrs,
@@ -170,6 +226,7 @@ inline static bool BackwardFCStorageType(const nnvm::NodeAttrs& attrs,
DMLC_REGISTER_PARAMETER(FullyConnectedParam);
NNVM_REGISTER_OP(FullyConnected)
+MXNET_ADD_SPARSE_OP_ALIAS(FullyConnected)
.describe(R"code(Applies a linear transformation: :math:`Y = XW^T + b`.
If ``flatten`` is set to be true, then the shapes are:
@@ -190,6 +247,10 @@ The learnable parameters include both ``weight`` and ``bias``.
If ``no_bias`` is set to be true, then the ``bias`` term is ignored.
+Note that the operator also supports forward computation with `row_sparse` weight and bias,
+where the length of `weight.indices` and `bias.indices` must be equal to `num_hidden`.
+This could be used for model inference with `row_sparse` weights trained with `SparseEmbedding`.
+
)code" ADD_FILELINE)
.set_num_inputs([](const NodeAttrs& attrs) {
const FullyConnectedParam& params = nnvm::get<FullyConnectedParam>(attrs.parsed);
@@ -206,6 +267,10 @@ If ``no_bias`` is set to be true, then the ``bias`` term is ignored.
return std::vector<std::string>{"data", "weight"};
}
})
+.set_attr<nnvm::FListOutputNames>("FListOutputNames",
+ [](const NodeAttrs& attrs) {
+ return std::vector<std::string>{"output"};
+})
#if MXNET_USE_MKLDNN == 1
.set_attr<FResourceRequest>("FResourceRequest", [](const NodeAttrs& n) {
return std::vector<ResourceRequest>{ResourceRequest::kTempSpace};
@@ -214,9 +279,7 @@ If ``no_bias`` is set to be true, then the ``bias`` term is ignored.
.set_attr<nnvm::FInferShape>("FInferShape", FullyConnectedShape)
.set_attr<nnvm::FInferType>("FInferType", FullyConnectedType)
.set_attr<FCompute>("FCompute<cpu>", FullyConnectedCompute<cpu>)
-#if MXNET_USE_MKLDNN == 1
.set_attr<FComputeEx>("FComputeEx<cpu>", FullyConnectedComputeExCPU)
-#endif
.set_attr<nnvm::FGradient>("FGradient", FullyConnectedGrad{"_backward_FullyConnected"})
.add_argument("data", "NDArray-or-Symbol", "Input data.")
.add_argument("weight", "NDArray-or-Symbol", "Weight matrix.")
diff --git a/src/operator/nn/layer_norm-inl.h b/src/operator/nn/layer_norm-inl.h
index ff429df9d7b..18f088f758e 100644
--- a/src/operator/nn/layer_norm-inl.h
+++ b/src/operator/nn/layer_norm-inl.h
@@ -103,7 +103,8 @@ void LayerNormCompute(const nnvm::NodeAttrs& attrs,
size_t workspace_size = 0;
MSHADOW_REAL_TYPE_SWITCH(outputs[0].type_flag_, DType, {
BROADCAST_NDIM_SWITCH(red_dst_shape.ndim(), NDim, {
- workspace_size = broadcast::ReduceWorkspaceSize<NDim, DType>(s, mean_data, req[0], in_data);
+ workspace_size =
+ broadcast::ReduceWorkspaceSize<NDim, DType>(s, mean_data.shape_, req[0], in_data.shape_);
});
});
workspace = ctx.requested[0].get_space_typed<xpu, 1, char>(Shape1(workspace_size), s);
@@ -202,16 +203,14 @@ void LayerNormGradCompute(const nnvm::NodeAttrs& attrs,
BROADCAST_NDIM_SWITCH(red_dst_shape.ndim(), NDim, {
reduce_workspace_size =
std::max(reduce_workspace_size,
- broadcast::ReduceWorkspaceSize<NDim, DType>(
- s, ograd.reshape(red_src_shape), kAddTo,
- mean.reshape(red_dst_shape)));
+ broadcast::ReduceWorkspaceSize<NDim, DType>(s, red_src_shape,
+ kAddTo, red_dst_shape));
});
BROADCAST_NDIM_SWITCH(red_exclude_dst_shape.ndim(), NDim, {
reduce_workspace_size =
std::max(reduce_workspace_size,
- broadcast::ReduceWorkspaceSize<NDim, DType>(
- s, ograd.reshape(red_exclude_src_shape), kAddTo,
- gamma.reshape(red_exclude_dst_shape)));
+ broadcast::ReduceWorkspaceSize<NDim, DType>(s, red_exclude_src_shape, kAddTo,
+ red_exclude_dst_shape));
});
});
workspace = ctx.requested[0].get_space_typed<xpu, 1, char>(
diff --git a/src/operator/nn/lrn.cc b/src/operator/nn/lrn.cc
index 2359b49abab..68d32617e9d 100644
--- a/src/operator/nn/lrn.cc
+++ b/src/operator/nn/lrn.cc
@@ -181,6 +181,14 @@ number of kernels in the layer.
.set_attr<nnvm::FInferShape>("FInferShape", LRNShape)
.set_attr<nnvm::FInferType>("FInferType", LRNType)
.set_attr<FInferStorageType>("FInferStorageType", LRNForwardInferStorageType)
+.set_attr<nnvm::FListInputNames>("FListInputNames",
+ [](const NodeAttrs& attrs) {
+ return std::vector<std::string>{"data"};
+})
+.set_attr<nnvm::FListInputNames>("FListOutputNames",
+ [](const NodeAttrs& attrs) {
+ return std::vector<std::string>{"output", "tmp_norm"};
+})
.set_attr<FCompute>("FCompute<cpu>", LRNCompute<cpu>)
#if MXNET_USE_MKLDNN == 1
.set_attr<FComputeEx>("FComputeEx<cpu>", LRNComputeExCPU)
diff --git a/src/operator/nn/mkldnn/mkldnn_act.cc b/src/operator/nn/mkldnn/mkldnn_act.cc
index 71fdf4ca585..8c19850ced3 100644
--- a/src/operator/nn/mkldnn/mkldnn_act.cc
+++ b/src/operator/nn/mkldnn/mkldnn_act.cc
@@ -93,7 +93,7 @@ static mkldnn::eltwise_forward::primitive_desc GetActFwdDescImpl(
return mkldnn::eltwise_forward::primitive_desc(desc, cpu_engine);
}
-typedef MKLDNNParamOpSign<ActivationParam> MKLDNNActSignature;
+typedef ParamOpSign<ActivationParam> MKLDNNActSignature;
class MKLDNNActForward {
std::shared_ptr<mkldnn::eltwise_forward> fwd;
@@ -137,7 +137,7 @@ class MKLDNNActForward {
static MKLDNNActForward &GetActForward(const ActivationParam& param,
const OpContext &ctx, const NDArray &in_data,
const mkldnn::memory &in_mem) {
- static thread_local std::unordered_map<MKLDNNActSignature, MKLDNNActForward, MKLDNNOpHash> fwds;
+ static thread_local std::unordered_map<MKLDNNActSignature, MKLDNNActForward, OpHash> fwds;
MKLDNNActSignature key(param);
key.AddSign(ctx.is_train);
key.AddSign(param.act_type);
diff --git a/src/operator/nn/mkldnn/mkldnn_base-inl.h b/src/operator/nn/mkldnn/mkldnn_base-inl.h
index 1c583e1f671..61bef117a88 100644
--- a/src/operator/nn/mkldnn/mkldnn_base-inl.h
+++ b/src/operator/nn/mkldnn/mkldnn_base-inl.h
@@ -227,7 +227,7 @@ class TmpMemMgr {
size_t curr_size;
// This estimate the required temp memory size in an operator.
size_t est_size;
- const size_t alignment = 4096;
+ const size_t alignment = kMKLDNNAlign;
public:
static TmpMemMgr *Get() {
@@ -296,111 +296,6 @@ class MKLDNNStream {
}
};
-class MKLDNNOpSignature {
- std::vector<int> eles;
- uint64_t hash;
-
- public:
- MKLDNNOpSignature() {
- hash = 0;
- }
-
- explicit MKLDNNOpSignature(uint64_t hash) {
- this->hash = hash;
- }
-
- /*
- * We provide different methods to add signature to an op.
- * For operations, such as convolutin and fully connected, which determines
- * the optimal data layout for the op, we only need to use the shape and data
- * type to sign the op. For other operations, such as activation, which uses
- * whatever layout in the input array, we have to use the shape, the data type
- * and the layout to sign the op.
- */
-
- void AddSign(const mkldnn::memory &mem) {
- auto desc = mem.get_primitive_desc().desc();
- hash = hash * 2 + desc.data.format;
- eles.push_back(desc.data.format);
- hash = hash * 2 + desc.data.data_type;
- eles.push_back(desc.data.data_type);
- for (int i = 0; i < desc.data.ndims; i++) {
- hash = hash * 2 + desc.data.dims[i];
- eles.push_back(desc.data.dims[i]);
- }
- }
-
- void AddSign(const std::vector<NDArray> &arrs) {
- for (auto &arr : arrs) {
- AddSign(arr);
- }
- }
-
- void AddSign(const NDArray &arr) {
- if (arr.IsMKLDNNData()) {
- AddSign(*(arr.GetMKLDNNData()));
- } else {
- hash = hash * 2 + arr.dtype();
- eles.push_back(arr.dtype());
- AddSign(arr.shape());
- }
- }
-
- void AddSign(const TShape &shape) {
- for (size_t i = 0; i < shape.ndim(); i++) {
- hash = hash * 2 + shape[i];
- eles.push_back(shape[i]);
- }
- }
-
- void AddSign(int val) {
- hash = hash * 2 + val;
- eles.push_back(val);
- }
-
- bool operator==(const MKLDNNOpSignature &sign) const {
- if (hash != sign.hash)
- return false;
- if (eles.size() != sign.eles.size())
- return false;
- for (size_t i = 0; i < eles.size(); i++)
- if (eles[i] != sign.eles[i])
- return false;
- return true;
- }
-
- uint64_t GetHash() const {
- return hash;
- }
-};
-
-struct MKLDNNOpHash {
- size_t operator()(const MKLDNNOpSignature &sign) const {
- return sign.GetHash();
- }
-};
-
-template<typename ParamType>
-class MKLDNNParamOpSign: public MKLDNNOpSignature {
- const ParamType param;
-
- static size_t hash(const ParamType ¶m) {
- std::hash<ParamType> fn;
- return fn(param);
- }
-
- public:
- explicit MKLDNNParamOpSign(const ParamType &_param): MKLDNNOpSignature(
- hash(_param)), param(_param) {
- }
-
- bool operator==(const MKLDNNParamOpSign<ParamType> &sign) const {
- const MKLDNNOpSignature &this_upper = *this;
- const MKLDNNOpSignature &other_upper = sign;
- return this_upper == other_upper && param == sign.param;
- }
-};
-
enum OutDataOp {
Noop,
CopyBack,
diff --git a/src/operator/nn/mkldnn/mkldnn_batch_norm-inl.h b/src/operator/nn/mkldnn/mkldnn_batch_norm-inl.h
index a685ebfb4ab..16f9874bd5c 100644
--- a/src/operator/nn/mkldnn/mkldnn_batch_norm-inl.h
+++ b/src/operator/nn/mkldnn/mkldnn_batch_norm-inl.h
@@ -98,7 +98,7 @@ inline static t_bn_b_pdesc _GetBwd(const mkldnn::memory &data_mem,
return t_bn_b_pdesc(bnBwd_desc, engine, _GetFwd(data_mem, true, eps, flags));
}
-typedef MKLDNNParamOpSign<BatchNormParam> MKLDNNBNSignature;
+typedef ParamOpSign<BatchNormParam> MKLDNNBNSignature;
class MKLDNNBNForward {
std::shared_ptr<const mkldnn::memory> data_m;
@@ -184,7 +184,7 @@ template<typename DType>
static MKLDNNBNForward &GetBNForward(const BatchNormParam& param,
const OpContext &ctx, const NDArray &in_data,
unsigned flags) {
- static thread_local std::unordered_map<MKLDNNBNSignature, MKLDNNBNForward, MKLDNNOpHash> fwds;
+ static thread_local std::unordered_map<MKLDNNBNSignature, MKLDNNBNForward, OpHash> fwds;
MKLDNNBNSignature key(param);
key.AddSign(ctx.is_train);
key.AddSign(in_data);
@@ -302,7 +302,7 @@ void MKLDNNBatchNormBackward(const OpContext &ctx, const BatchNormParam ¶m,
const std::vector<NDArray> &in_grad,
const std::vector<NDArray> &aux_states) {
TmpMemMgr::Get()->Init(ctx.requested[batchnorm::kTempSpace]);
- CHECK_EQ(out_grad.size(), param.output_mean_var ? 3U : 1U);
+ CHECK_EQ(out_grad.size(), 1U);
CHECK_EQ(in_data.size(), 3U);
CHECK_EQ(out_data.size(), 3U);
CHECK_EQ(in_grad.size(), 3U);
diff --git a/src/operator/nn/mkldnn/mkldnn_convolution.cc b/src/operator/nn/mkldnn/mkldnn_convolution.cc
index 76efc244fc4..453221f9b37 100644
--- a/src/operator/nn/mkldnn/mkldnn_convolution.cc
+++ b/src/operator/nn/mkldnn/mkldnn_convolution.cc
@@ -226,13 +226,13 @@ class MKLDNNConvForward {
}
};
-typedef MKLDNNParamOpSign<ConvolutionParam> MKLDNNConvSignature;
+typedef ParamOpSign<ConvolutionParam> MKLDNNConvSignature;
static inline MKLDNNConvForward &GetConvFwd(
const nnvm::NodeAttrs& attrs, bool is_train,
const NDArray &data, const NDArray &weights,
const NDArray *bias, const NDArray &output) {
- static thread_local std::unordered_map<MKLDNNConvSignature, MKLDNNConvForward, MKLDNNOpHash> fwds;
+ static thread_local std::unordered_map<MKLDNNConvSignature, MKLDNNConvForward, OpHash> fwds;
const ConvolutionParam& param = nnvm::get<ConvolutionParam>(attrs.parsed);
MKLDNNConvSignature key(param);
key.AddSign(is_train);
diff --git a/src/operator/nn/mkldnn/mkldnn_deconvolution.cc b/src/operator/nn/mkldnn/mkldnn_deconvolution.cc
index a0d3df7bb47..af57b68cfd3 100644
--- a/src/operator/nn/mkldnn/mkldnn_deconvolution.cc
+++ b/src/operator/nn/mkldnn/mkldnn_deconvolution.cc
@@ -289,16 +289,14 @@ static void MKLDNNDeconvFwdBiasPostProcess(const DeconvolutionParam& param,
}
}
-typedef MKLDNNParamOpSign<DeconvolutionParam> MKLDNNDeconvSignature;
-
static inline MKLDNNDeconvForward &GetDeconvFwd(
const nnvm::NodeAttrs& attrs, const NDArray &data,
const NDArray &weights, const NDArray *bias,
const NDArray &output) {
static thread_local
- std::unordered_map<MKLDNNDeconvSignature, MKLDNNDeconvForward, MKLDNNOpHash> fwds;
+ std::unordered_map<DeconvSignature, MKLDNNDeconvForward, OpHash> fwds;
const DeconvolutionParam& param = nnvm::get<DeconvolutionParam>(attrs.parsed);
- MKLDNNDeconvSignature key(param);
+ DeconvSignature key(param);
// Here we can sign the conv op with NDArray because conv primitive will
// decide the right layout for the, so we only need to get the shape and the
// data type of the arrays.
@@ -313,7 +311,7 @@ static inline MKLDNNDeconvForward &GetDeconvFwd(
bool has_bias = (bias != nullptr);
MKLDNNDeconvForward fwd(param, data, weights, has_bias, output);
auto ins_ret = fwds.insert(
- std::pair<MKLDNNDeconvSignature, MKLDNNDeconvForward>(key, fwd));
+ std::pair<DeconvSignature, MKLDNNDeconvForward>(key, fwd));
CHECK(ins_ret.second);
it = ins_ret.first;
}
diff --git a/src/operator/nn/mkldnn/mkldnn_pooling-inl.h b/src/operator/nn/mkldnn/mkldnn_pooling-inl.h
index 61895b4d442..2097d57ba92 100644
--- a/src/operator/nn/mkldnn/mkldnn_pooling-inl.h
+++ b/src/operator/nn/mkldnn/mkldnn_pooling-inl.h
@@ -104,7 +104,7 @@ inline bool MKLDNNRequireWorkspace(const PoolingParam ¶m) {
return param.pool_type != pool_enum::kAvgPooling;
}
-typedef MKLDNNParamOpSign<PoolingParam> MKLDNNPoolingSignature;
+typedef ParamOpSign<PoolingParam> MKLDNNPoolingSignature;
void MKLDNNPoolingCompute(const OpContext &ctx, const PoolingParam ¶m,
const NDArray &in_data, const OpReqType req,
const NDArray &out_data, const NDArray *workspace);
diff --git a/src/operator/nn/mkldnn/mkldnn_pooling.cc b/src/operator/nn/mkldnn/mkldnn_pooling.cc
index 86f13145eaa..1aeb7d48dc3 100644
--- a/src/operator/nn/mkldnn/mkldnn_pooling.cc
+++ b/src/operator/nn/mkldnn/mkldnn_pooling.cc
@@ -188,7 +188,7 @@ MKLDNNPoolingFwd &GetPoolingFwd(const PoolingParam ¶m,
const NDArray &output) {
static thread_local std::unordered_map<MKLDNNPoolingSignature,
MKLDNNPoolingFwd,
- MKLDNNOpHash> pooling_fwds;
+ OpHash> pooling_fwds;
bool with_workspace = is_train && MKLDNNRequireWorkspace(param);
MKLDNNPoolingSignature key(param);
diff --git a/src/operator/operator_common.h b/src/operator/operator_common.h
index 10581d14ba7..a629ba5eed8 100644
--- a/src/operator/operator_common.h
+++ b/src/operator/operator_common.h
@@ -489,6 +489,130 @@ inline void LogUnimplementedOp(const nnvm::NodeAttrs& attrs,
LOG(FATAL) << "Not implemented: " << operator_string(attrs, ctx, inputs, req, outputs);
}
+class OpSignature {
+ std::vector<int> eles;
+ uint64_t hash;
+
+ public:
+ OpSignature() {
+ hash = 0;
+ }
+
+ explicit OpSignature(uint64_t hash) {
+ this->hash = hash;
+ }
+
+ /*
+ * This is to reserve space for the vector.
+ */
+ void Reserve(size_t num) {
+ eles.reserve(num);
+ }
+
+ /*
+ * We provide different methods to add signature to an op.
+ * For operations, such as convolutin and fully connected, which determines
+ * the optimal data layout for the op, we only need to use the shape and data
+ * type to sign the op. For other operations, such as activation, which uses
+ * whatever layout in the input array, we have to use the shape, the data type
+ * and the layout to sign the op.
+ */
+
+#if MXNET_USE_MKLDNN == 1
+ void AddSign(const mkldnn::memory &mem) {
+ auto desc = mem.get_primitive_desc().desc();
+ hash = hash * 2 + desc.data.format;
+ eles.push_back(desc.data.format);
+ hash = hash * 2 + desc.data.data_type;
+ eles.push_back(desc.data.data_type);
+ for (int i = 0; i < desc.data.ndims; i++) {
+ hash = hash * 2 + desc.data.dims[i];
+ eles.push_back(desc.data.dims[i]);
+ }
+ }
+#endif
+
+ void AddSign(const std::vector<NDArray> &arrs) {
+ for (auto &arr : arrs) {
+ AddSign(arr);
+ }
+ }
+
+ void AddSign(const NDArray &arr) {
+#if MXNET_USE_MKLDNN == 1
+ if (arr.IsMKLDNNData()) {
+ AddSign(*(arr.GetMKLDNNData()));
+ } else {
+#endif
+ hash = hash * 2 + arr.dtype();
+ eles.push_back(arr.dtype());
+ AddSign(arr.shape());
+#if MXNET_USE_MKLDNN == 1
+ }
+#endif
+ }
+
+ void AddSign(const std::vector<TShape> &shapes) {
+ for (auto &shape : shapes) {
+ AddSign(shape);
+ }
+ }
+
+ void AddSign(const TShape &shape) {
+ for (size_t i = 0; i < shape.ndim(); i++) {
+ hash = hash * 2 + shape[i];
+ eles.push_back(shape[i]);
+ }
+ }
+
+ void AddSign(int val) {
+ hash = hash * 2 + val;
+ eles.push_back(val);
+ }
+
+ bool operator==(const OpSignature &sign) const {
+ if (hash != sign.hash)
+ return false;
+ if (eles.size() != sign.eles.size())
+ return false;
+ for (size_t i = 0; i < eles.size(); i++)
+ if (eles[i] != sign.eles[i])
+ return false;
+ return true;
+ }
+
+ uint64_t GetHash() const {
+ return hash;
+ }
+};
+
+struct OpHash {
+ size_t operator()(const OpSignature &sign) const {
+ return sign.GetHash();
+ }
+};
+
+template<typename ParamType>
+class ParamOpSign: public OpSignature {
+ const ParamType param;
+
+ static size_t hash(const ParamType ¶m) {
+ std::hash<ParamType> fn;
+ return fn(param);
+ }
+
+ public:
+ explicit ParamOpSign(const ParamType &_param): OpSignature(
+ hash(_param)), param(_param) {
+ }
+
+ bool operator==(const ParamOpSign<ParamType> &sign) const {
+ const OpSignature &this_upper = *this;
+ const OpSignature &other_upper = sign;
+ return this_upper == other_upper && param == sign.param;
+ }
+};
+
} // namespace op
} // namespace mxnet
#endif // MXNET_OPERATOR_OPERATOR_COMMON_H_
diff --git a/src/operator/operator_tune.cc b/src/operator/operator_tune.cc
index c13f1ac2fae..c48d83a3be8 100644
--- a/src/operator/operator_tune.cc
+++ b/src/operator/operator_tune.cc
@@ -314,9 +314,13 @@ IMPLEMENT_BINARY_WORKLOAD_FWD(mxnet::op::mshadow_op::right); // NOLINT()
IMPLEMENT_BINARY_WORKLOAD_BWD(mxnet::op::mshadow_op::right); // NOLINT()
IMPLEMENT_BINARY_WORKLOAD_FWD(mxnet::op::mshadow_op::power); // NOLINT()
IMPLEMENT_BINARY_WORKLOAD_FWD(mxnet::op::mshadow_op::rpower); // NOLINT()
+IMPLEMENT_BINARY_WORKLOAD_FWD(mxnet::op::mshadow_op::xelu); // NOLINT()
+IMPLEMENT_BINARY_WORKLOAD_FWD(mxnet::op::mshadow_op::elu); // NOLINT()
IMPLEMENT_BINARY_WORKLOAD_BWD(mxnet::op::mshadow_op::power_grad); // NOLINT()
IMPLEMENT_BINARY_WORKLOAD_BWD(mxnet::op::mshadow_op::rpower_grad); // NOLINT()
IMPLEMENT_BINARY_WORKLOAD_BWD(mxnet::op::mshadow_op::power_rgrad); // NOLINT()
+IMPLEMENT_BINARY_WORKLOAD_BWD(mxnet::op::mshadow_op::xelu_grad); // NOLINT()
+IMPLEMENT_BINARY_WORKLOAD_BWD(mxnet::op::mshadow_op::elu_grad); // NOLINT()
IMPLEMENT_BINARY_WORKLOAD_FWD(mxnet::op::mshadow_op::maximum); // NOLINT()
IMPLEMENT_BINARY_WORKLOAD_FWD(mxnet::op::mshadow_op::minimum); // NOLINT()
IMPLEMENT_BINARY_WORKLOAD_FWD(mxnet::op::mshadow_op::hypot); // NOLINT()
diff --git a/src/operator/optimizer_op-inl.h b/src/operator/optimizer_op-inl.h
index 55d215602ee..104f20a61ee 100644
--- a/src/operator/optimizer_op-inl.h
+++ b/src/operator/optimizer_op-inl.h
@@ -749,6 +749,9 @@ inline void AdamUpdate(const nnvm::NodeAttrs& attrs,
});
}
+template<int req, typename xpu>
+struct AdamDnsRspDnsKernel;
+
/*!
* Note: this kernel performs sparse adam update. For each row-slice in row_sparse
* gradient, it finds the corresponding elements in weight, mean and var and performs
@@ -756,7 +759,7 @@ inline void AdamUpdate(const nnvm::NodeAttrs& attrs,
* The kernel assumes dense weight/mean/var, and row_sparse gradient
*/
template<int req>
-struct AdamDnsRspDnsKernel {
+struct AdamDnsRspDnsKernel<req, cpu> {
template<typename DType, typename IType>
MSHADOW_XINLINE static void Map(int i, const nnvm::dim_t row_length, DType* out_data,
DType* mean_data, DType* var_data, const DType* weight_data, const IType* grad_idx,
@@ -788,6 +791,33 @@ struct AdamDnsRspDnsKernel {
};
+template<int req>
+struct AdamDnsRspDnsKernel<req, gpu> {
+ template<typename DType, typename IType>
+ MSHADOW_XINLINE static void Map(int i, const nnvm::dim_t row_length, DType* out_data,
+ DType* mean_data, DType* var_data, const DType* weight_data, const IType* grad_idx,
+ const DType* grad_data, const DType clip_gradient, const DType beta1, const DType beta2,
+ const DType lr, const DType wd, const DType epsilon, const DType rescale_grad) {
+ using nnvm::dim_t;
+ using namespace mshadow_op;
+ const dim_t row_id = i / row_length;
+ const dim_t col_id = i % row_length;
+ const dim_t row_offset = grad_idx[row_id] * row_length;
+ // index in data/mean/var
+ const dim_t data_i = row_offset + col_id;
+ // index in grad
+ DType grad_rescaled = grad_data[i] * rescale_grad + weight_data[data_i] * wd;
+ if (clip_gradient >= 0.0f) {
+ grad_rescaled = clip::Map(grad_rescaled, clip_gradient);
+ }
+ mean_data[data_i] = beta1 * mean_data[data_i] + (1.f - beta1) * grad_rescaled;
+ var_data[data_i] = beta2 * var_data[data_i] +
+ (1.f - beta2) * grad_rescaled * grad_rescaled;
+ KERNEL_ASSIGN(out_data[data_i], req, weight_data[data_i] - lr * mean_data[data_i] /
+ (square_root::Map(var_data[data_i]) + epsilon));
+ }
+};
+
template<typename xpu>
inline void AdamUpdateDnsRspDnsImpl(const AdamParam& param,
const OpContext& ctx,
@@ -817,8 +847,12 @@ inline void AdamUpdateDnsRspDnsImpl(const AdamParam& param,
DType* out_data = out->dptr<DType>();
nnvm::dim_t num_rows = grad.aux_shape(kIdx)[0];
const auto row_length = weight.shape_.ProdShape(1, weight.ndim());
- Kernel<AdamDnsRspDnsKernel<req_type>, xpu>::Launch(s, num_rows, row_length,
- out_data, mean_data, var_data, weight_data, grad_idx, grad_val,
+ size_t num_threads = num_rows;
+ if (std::is_same<xpu, gpu>::value) {
+ num_threads = num_rows * row_length;
+ }
+ Kernel<AdamDnsRspDnsKernel<req_type, xpu>, xpu>::Launch(s, num_threads,
+ row_length, out_data, mean_data, var_data, weight_data, grad_idx, grad_val,
static_cast<DType>(param.clip_gradient), static_cast<DType>(param.beta1),
static_cast<DType>(param.beta2), static_cast<DType>(param.lr),
static_cast<DType>(param.wd), static_cast<DType>(param.epsilon),
@@ -858,42 +892,8 @@ inline void AdamUpdateRspRspRspImpl(const AdamParam& param,
var.data(), req, &out_blob);
}
-template<int req>
-struct AdamStdDnsRspDnsKernel {
- template<typename DType, typename IType, typename RType>
- MSHADOW_XINLINE static void Map(int i, const nnvm::dim_t row_length, DType* out_data,
- DType* mean_data, DType* var_data, const DType* weight_data, const IType* grad_idx,
- const DType* grad_data, const RType* prefix_sum, const DType clip_gradient,
- const DType beta1, const DType beta2, const DType lr, const DType wd,
- const DType epsilon, const DType rescale_grad) {
- using namespace mshadow_op;
- const bool non_zero = (i == 0) ? prefix_sum[0] > 0
- : prefix_sum[i] > prefix_sum[i-1];
-
- const index_t row_i = i * row_length;
- const RType grad_i = (prefix_sum[i]-1) * row_length;
- for (index_t j = 0; j < row_length; j++) {
- const index_t data_i = row_i + j;
- const DType grad_rescaled = non_zero ? static_cast<DType>(
- grad_data[grad_i + j] * rescale_grad +
- weight_data[data_i] * wd)
- : static_cast<DType>(weight_data[data_i] * wd);
- if (clip_gradient >= 0.0f) {
- mean_data[data_i] = beta1 * mean_data[data_i] + (1.f - beta1) *
- clip::Map(grad_rescaled, clip_gradient);
- var_data[data_i] = beta2 * var_data[data_i] + (1.f - beta2) * square::Map(
- clip::Map(grad_rescaled, clip_gradient));
- } else {
- mean_data[data_i] = beta1 * mean_data[data_i] + (1.f - beta1) * grad_rescaled;
- var_data[data_i] = beta2 * var_data[data_i] +
- (1.f - beta2) * square::Map(grad_rescaled);
- }
- KERNEL_ASSIGN(out_data[data_i], req, weight_data[data_i] - lr * mean_data[data_i] /
- (square_root::Map(var_data[data_i]) + epsilon));
- }
- }
-};
-
+template<int req, typename xpu>
+struct AdamStdDnsRspDnsKernel;
template<typename xpu>
void AdamStdUpdateDnsRspDnsImpl(const AdamParam& param,
diff --git a/src/operator/optimizer_op.cc b/src/operator/optimizer_op.cc
index 741092ad784..f7ccbbb739d 100644
--- a/src/operator/optimizer_op.cc
+++ b/src/operator/optimizer_op.cc
@@ -149,6 +149,43 @@ void SGDMomStdUpdateDnsRspDnsImpl<cpu>(const SGDMomParam& param,
});
}
+template<int req>
+struct AdamStdDnsRspDnsKernel<req, cpu> {
+ template<typename DType, typename IType, typename RType>
+ MSHADOW_XINLINE static void Map(int i, const nnvm::dim_t row_length, DType* out_data,
+ DType* mean_data, DType* var_data, const DType* weight_data, const IType* grad_idx,
+ const DType* grad_data, const RType* prefix_sum, const DType clip_gradient,
+ const DType beta1, const DType beta2, const DType lr, const DType wd,
+ const DType epsilon, const DType rescale_grad) {
+ using namespace mshadow_op;
+ const bool non_zero = (i == 0) ? prefix_sum[0] > 0
+ : prefix_sum[i] > prefix_sum[i-1];
+
+ const index_t row_i = i * row_length;
+ const RType grad_i = (prefix_sum[i]-1) * row_length;
+ for (index_t j = 0; j < row_length; j++) {
+ const index_t data_i = row_i + j;
+ const DType grad_rescaled = non_zero ? static_cast<DType>(
+ grad_data[grad_i + j] * rescale_grad +
+ weight_data[data_i] * wd)
+ : static_cast<DType>(weight_data[data_i] * wd);
+ if (clip_gradient >= 0.0f) {
+ mean_data[data_i] = beta1 * mean_data[data_i] + (1.f - beta1) *
+ clip::Map(grad_rescaled, clip_gradient);
+ var_data[data_i] = beta2 * var_data[data_i] + (1.f - beta2) * square::Map(
+ clip::Map(grad_rescaled, clip_gradient));
+ } else {
+ mean_data[data_i] = beta1 * mean_data[data_i] + (1.f - beta1) * grad_rescaled;
+ var_data[data_i] = beta2 * var_data[data_i] +
+ (1.f - beta2) * square::Map(grad_rescaled);
+ }
+ KERNEL_ASSIGN(out_data[data_i], req, weight_data[data_i] - lr * mean_data[data_i] /
+ (square_root::Map(var_data[data_i]) + epsilon));
+ }
+ }
+};
+
+
template<>
void AdamStdUpdateDnsRspDnsImpl<cpu>(const AdamParam& param,
const OpContext& ctx,
@@ -194,7 +231,7 @@ void AdamStdUpdateDnsRspDnsImpl<cpu>(const AdamParam& param,
}
}
- Kernel<AdamStdDnsRspDnsKernel<req_type>, cpu>::Launch(s, num_rows, row_length,
+ Kernel<AdamStdDnsRspDnsKernel<req_type, cpu>, cpu>::Launch(s, num_rows, row_length,
out_data, mean_data, var_data, weight_data, grad_idx, grad_val, prefix_sum,
static_cast<DType>(param.clip_gradient), static_cast<DType>(param.beta1),
static_cast<DType>(param.beta2), static_cast<DType>(param.lr),
diff --git a/src/operator/optimizer_op.cu b/src/operator/optimizer_op.cu
index c49af68a5f6..18ee66a729c 100644
--- a/src/operator/optimizer_op.cu
+++ b/src/operator/optimizer_op.cu
@@ -94,6 +94,35 @@ void SGDMomStdUpdateDnsRspDnsImpl<gpu>(const SGDMomParam& param,
});
}
+template<int req>
+struct AdamStdDnsRspDnsKernel<req, gpu> {
+ template<typename DType, typename IType, typename RType>
+ MSHADOW_XINLINE static void Map(int i, const nnvm::dim_t row_length, DType* out_data,
+ DType* mean_data, DType* var_data, const DType* weight_data, const IType* grad_idx,
+ const DType* grad_data, const RType* prefix_sum, const DType clip_gradient,
+ const DType beta1, const DType beta2, const DType lr, const DType wd,
+ const DType epsilon, const DType rescale_grad) {
+ using namespace mshadow_op;
+ using nnvm::dim_t;
+ const dim_t row_id = i / row_length;
+ const dim_t col_id = i % row_length;
+ const bool non_zero = (row_id == 0) ? prefix_sum[0] > 0
+ : prefix_sum[row_id] > prefix_sum[row_id - 1];
+ const RType grad_offset = (prefix_sum[row_id] - 1) * row_length + col_id;
+ DType grad_rescaled = non_zero ? static_cast<DType>(grad_data[grad_offset] * rescale_grad
+ + weight_data[i] * wd)
+ : static_cast<DType>(weight_data[i] * wd);
+ if (clip_gradient >= 0.0f) {
+ grad_rescaled = clip::Map(grad_rescaled, clip_gradient);
+ }
+ mean_data[i] = beta1 * mean_data[i] + (1.f - beta1) * grad_rescaled;
+ var_data[i] = beta2 * var_data[i] +
+ (1.f - beta2) * square::Map(grad_rescaled);
+ KERNEL_ASSIGN(out_data[i], req, weight_data[i] - lr * mean_data[i] /
+ (square_root::Map(var_data[i]) + epsilon));
+ }
+};
+
template<>
void AdamStdUpdateDnsRspDnsImpl<gpu>(const AdamParam& param,
const OpContext& ctx,
@@ -122,8 +151,8 @@ void AdamStdUpdateDnsRspDnsImpl<gpu>(const AdamParam& param,
DType* mean_data = mean.dptr<DType>();
DType* var_data = var.dptr<DType>();
DType* out_data = out->dptr<DType>();
- nnvm::dim_t num_rows = weight.shape_[0];
- nnvm::dim_t row_length = weight.shape_.ProdShape(1, weight.ndim());
+ const nnvm::dim_t num_rows = weight.shape_[0];
+ const nnvm::dim_t row_length = weight.shape_.ProdShape(1, weight.ndim());
nnvm::dim_t* prefix_sum = NULL;
void* d_temp_storage = NULL;
size_t temp_storage_bytes = 0;
@@ -152,8 +181,8 @@ void AdamStdUpdateDnsRspDnsImpl<gpu>(const AdamParam& param,
Stream<gpu>::GetStream(s));
}
- Kernel<AdamStdDnsRspDnsKernel<req_type>, gpu>::Launch(s, num_rows, row_length,
- out_data, mean_data, var_data, weight_data, grad_idx, grad_val, prefix_sum,
+ Kernel<AdamStdDnsRspDnsKernel<req_type, gpu>, gpu>::Launch(s, weight.shape_.Size(),
+ row_length, out_data, mean_data, var_data, weight_data, grad_idx, grad_val, prefix_sum,
static_cast<DType>(param.clip_gradient), static_cast<DType>(param.beta1),
static_cast<DType>(param.beta2), static_cast<DType>(param.lr),
static_cast<DType>(param.wd), static_cast<DType>(param.epsilon),
diff --git a/src/operator/contrib/dequantize-inl.h b/src/operator/quantization/dequantize-inl.h
similarity index 52%
rename from src/operator/contrib/dequantize-inl.h
rename to src/operator/quantization/dequantize-inl.h
index 8f24a8fd7b5..799e1366566 100644
--- a/src/operator/contrib/dequantize-inl.h
+++ b/src/operator/quantization/dequantize-inl.h
@@ -22,8 +22,8 @@
* \file dequantize-inl.h
* \brief Implementation of dequantize operation
*/
-#ifndef MXNET_OPERATOR_CONTRIB_DEQUANTIZE_INL_H_
-#define MXNET_OPERATOR_CONTRIB_DEQUANTIZE_INL_H_
+#ifndef MXNET_OPERATOR_QUANTIZATION_DEQUANTIZE_INL_H_
+#define MXNET_OPERATOR_QUANTIZATION_DEQUANTIZE_INL_H_
#include <mxnet/operator_util.h>
#include <vector>
@@ -31,6 +31,7 @@
#include "../elemwise_op_common.h"
#include "../mshadow_op.h"
#include "../mxnet_op.h"
+#include "./quantization_utils.h"
namespace mxnet {
namespace op {
@@ -40,18 +41,30 @@ struct DequantizeParam : public dmlc::Parameter<DequantizeParam> {
DMLC_DECLARE_PARAMETER(DequantizeParam) {
DMLC_DECLARE_FIELD(out_type)
.add_enum("float32", mshadow::kFloat32)
+ .set_default(mshadow::kFloat32)
.describe("Output data type.");
}
};
-struct dequantize {
+// dequantize unsigned int8 to float32
+struct dequantize_unsigned {
template<typename DstDType, typename SrcDType>
MSHADOW_XINLINE static void Map(int i, DstDType *out, const SrcDType *in,
- float *imin_range, float *imax_range,
- double imin_limit, double imax_limit,
- float half_range) {
- float scale = (*imax_range - *imin_range) / (imax_limit - imin_limit);
- out[i] = static_cast<DstDType>((in[i] + half_range) * scale + *imin_range);
+ const float *imin_range, const float *imax_range,
+ const float imin_limit, const float imax_limit) {
+ const float scale = (*imax_range - *imin_range) / (imax_limit - imin_limit);
+ out[i] = static_cast<DstDType>(in[i] * scale + *imin_range);
+ }
+};
+
+// keep zero-center
+struct dequantize_zero_centered {
+ template<typename DstDType, typename SrcDType>
+ MSHADOW_XINLINE static void Map(int i, DstDType *out, const SrcDType *in,
+ const float *imin_range, const float *imax_range,
+ const float quantized_range) {
+ const float real_range = MaxAbs(*imax_range, *imin_range);
+ out[i] = in[i] * (real_range / quantized_range);
}
};
@@ -63,20 +76,20 @@ void DequantizeCompute(const nnvm::NodeAttrs& attrs,
const std::vector<TBlob>& outputs) {
using namespace mshadow;
using namespace mxnet_op;
+ using mshadow::red::limits::MinValue;
+ using mshadow::red::limits::MaxValue;
Stream<xpu> *s = ctx.get_stream<xpu>();
-
- // for now, only supports dequantize from float to uint8
- typedef float DstDType;
- typedef uint8_t SrcDType;
- double min_limit = static_cast<double>(std::numeric_limits<SrcDType>::min());
- double max_limit = static_cast<double>(std::numeric_limits<SrcDType>::max());
- float half_range = !std::is_signed<SrcDType>::value
- ? 0.0f
- : (max_limit - min_limit + 1) / 2.0;
-
- Kernel<dequantize, xpu>::Launch(s, outputs[0].Size(), outputs[0].dptr<DstDType>(),
- inputs[0].dptr<SrcDType>(), inputs[1].dptr<float>(), inputs[2].dptr<float>(),
- min_limit, max_limit, half_range);
+ if (inputs[0].type_flag_ == mshadow::kUint8) {
+ Kernel<dequantize_unsigned, xpu>::Launch(s, outputs[0].Size(), outputs[0].dptr<float>(),
+ inputs[0].dptr<uint8_t>(), inputs[1].dptr<float>(), inputs[2].dptr<float>(),
+ MinValue<uint8_t>(), MaxValue<uint8_t>());
+ } else if (inputs[0].type_flag_ == mshadow::kInt8) {
+ Kernel<dequantize_zero_centered, xpu>::Launch(s, outputs[0].Size(), outputs[0].dptr<float>(),
+ inputs[0].dptr<int8_t>(), inputs[1].dptr<float>(), inputs[2].dptr<float>(),
+ MinAbs(MaxValue<int8_t>(), MinValue<int8_t>()));
+ } else {
+ LOG(FATAL) << "dequantize op only supports input type int8 or uint8";
+ }
}
inline bool DequantizeShape(const nnvm::NodeAttrs& attrs,
@@ -85,30 +98,27 @@ inline bool DequantizeShape(const nnvm::NodeAttrs& attrs,
CHECK_EQ(in_attrs->size(), 3U);
CHECK_EQ(out_attrs->size(), 1U);
- CHECK(!shape_is_none(in_attrs->at(0)));
for (size_t i = 1; i < 3; ++i) {
- CHECK(shape_is_scalar(in_attrs->at(i))) << in_attrs->at(i);
+ SHAPE_ASSIGN_CHECK(*in_attrs, i, TShape({1}));
}
SHAPE_ASSIGN_CHECK(*out_attrs, 0, in_attrs->at(0));
- return true;
+ return !shape_is_none(out_attrs->at(0));
}
inline bool DequantizeType(const nnvm::NodeAttrs& attrs,
- std::vector<int> *in_attrs,
- std::vector<int> *out_attrs) {
+ std::vector<int> *in_attrs,
+ std::vector<int> *out_attrs) {
CHECK_EQ(in_attrs->size(), 3U);
CHECK_EQ(out_attrs->size(), 1U);
- CHECK_EQ((*in_attrs)[0], mshadow::kUint8)
- << "`dequantize` only supports uint8 input for now";
- CHECK_EQ((*in_attrs)[1], mshadow::kFloat32)
- << "the second input of `dequantize` should be a tensor with type of float";
- CHECK_EQ((*in_attrs)[2], mshadow::kFloat32)
- << "the third input of `dequantize` should be a tensor with type of float";
+ CHECK(in_attrs->at(0) == mshadow::kUint8 || in_attrs->at(0) == mshadow::kInt8)
+ << "the input data type of dequantize op must be provided, either uint8 or int8";
+ TYPE_ASSIGN_CHECK(*in_attrs, 1, mshadow::kFloat32);
+ TYPE_ASSIGN_CHECK(*in_attrs, 2, mshadow::kFloat32);
TYPE_ASSIGN_CHECK(*out_attrs, 0, mshadow::kFloat32);
return (*in_attrs)[0] != -1;
}
} // namespace op
} // namespace mxnet
-#endif // MXNET_OPERATOR_CONTRIB_DEQUANTIZE_INL_H_
+#endif // MXNET_OPERATOR_QUANTIZATION_DEQUANTIZE_INL_H_
diff --git a/src/operator/contrib/dequantize.cc b/src/operator/quantization/dequantize.cc
similarity index 71%
rename from src/operator/contrib/dequantize.cc
rename to src/operator/quantization/dequantize.cc
index 7814a157719..92b808dd460 100644
--- a/src/operator/contrib/dequantize.cc
+++ b/src/operator/quantization/dequantize.cc
@@ -30,14 +30,20 @@ DMLC_REGISTER_PARAMETER(DequantizeParam);
NNVM_REGISTER_OP(_contrib_dequantize)
.describe(R"code(Dequantize the input tensor into a float tensor.
-[min_range, max_range] are scalar floats that spcify the range for
+min_range and max_range are scalar floats that specify the range for
the output data.
-Each value of the tensor will undergo the following:
+When input data type is `uint8`, the output is calculated using the following equation:
-`out[i] = min_range + (in[i] * (max_range - min_range) / range(INPUT_TYPE))`
+`out[i] = in[i] * (max_range - min_range) / 255.0`,
-here `range(T) = numeric_limits<T>::max() - numeric_limits<T>::min()`
+When input data type is `int8`, the output is calculate using the following equation
+by keep zero centered for the quantized value:
+
+`out[i] = in[i] * MaxAbs(min_range, max_range) / 127.0`,
+
+.. Note::
+ This operator only supports forward propogation. DO NOT use it in training.
)code" ADD_FILELINE)
.set_attr_parser(ParamParser<DequantizeParam>)
.set_num_inputs(3)
@@ -45,12 +51,11 @@ here `range(T) = numeric_limits<T>::max() - numeric_limits<T>::min()`
.set_attr<nnvm::FInferShape>("FInferShape", DequantizeShape)
.set_attr<nnvm::FInferType>("FInferType", DequantizeType)
.set_attr<FCompute>("FCompute<cpu>", DequantizeCompute<cpu>)
-.set_attr<nnvm::FGradient>("FGradient", ElemwiseGradUseNone{"_dequantize"})
-.add_argument("input", "NDArray-or-Symbol", "A ndarray/symbol of type `uint8`")
+.add_argument("data", "NDArray-or-Symbol", "A ndarray/symbol of type `uint8`")
.add_argument("min_range", "NDArray-or-Symbol", "The minimum scalar value "
- "possibly produced for the input")
+ "possibly produced for the input in float32")
.add_argument("max_range", "NDArray-or-Symbol", "The maximum scalar value "
- "possibly produced for the input")
+ "possibly produced for the input in float32")
.add_arguments(DequantizeParam::__FIELDS__());
} // namespace op
diff --git a/src/operator/contrib/dequantize.cu b/src/operator/quantization/dequantize.cu
similarity index 100%
rename from src/operator/contrib/dequantize.cu
rename to src/operator/quantization/dequantize.cu
diff --git a/src/operator/quantization/quantization_utils.h b/src/operator/quantization/quantization_utils.h
new file mode 100644
index 00000000000..5b096ac0057
--- /dev/null
+++ b/src/operator/quantization/quantization_utils.h
@@ -0,0 +1,174 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * Copyright (c) 2017 by Contributors
+ * \file quantization_utils-inl.h
+ */
+#ifndef MXNET_OPERATOR_QUANTIZATION_QUANTIZATION_UTILS_H_
+#define MXNET_OPERATOR_QUANTIZATION_QUANTIZATION_UTILS_H_
+
+#include <mxnet/base.h>
+#include <algorithm>
+#include "../mxnet_op.h"
+
+namespace mxnet {
+namespace op {
+
+
+template<typename T>
+MSHADOW_XINLINE int Sign(T val) {
+ return (val > T(0)) - (val < T(0));
+}
+
+template<typename T>
+MSHADOW_XINLINE T Abs(T a) {
+#ifdef __CUDACC__
+ return ::abs(a);
+#else
+ return std::abs(a);
+#endif
+}
+
+template<typename T>
+MSHADOW_XINLINE T Max(T a, T b) {
+#ifdef __CUDACC__
+ return ::max(a, b);
+#else
+ return std::max(a, b);
+#endif
+}
+
+template<typename T>
+MSHADOW_XINLINE T Min(T a, T b) {
+#ifdef __CUDACC__
+ return ::min(a, b);
+#else
+ return std::min(a, b);
+#endif
+}
+
+template<typename T>
+MSHADOW_XINLINE float MaxAbs(T a, T b) {
+ return Max(Abs(static_cast<float>(a)), Abs(static_cast<float>(b)));
+}
+
+template<typename T>
+MSHADOW_XINLINE float MinAbs(T a, T b) {
+ return Min(Abs(static_cast<float>(a)), Abs(static_cast<float>(b)));
+}
+
+template<typename T>
+MSHADOW_XINLINE T FloatToQuantized(float input, float min_range, float max_range) {
+ using mshadow::red::limits::MinValue;
+ using mshadow::red::limits::MaxValue;
+ float real_range = MaxAbs(min_range, max_range);
+ float quantized_range = MinAbs(MaxValue<T>(), MinValue<T>());
+ float scale = quantized_range / real_range;
+ return Sign(input) * Min(Abs(input) * scale + 0.5f, quantized_range);
+}
+
+template <typename T>
+MSHADOW_XINLINE float QuantizedToFloat(T input, float min_range, float max_range) {
+ using mshadow::red::limits::MinValue;
+ using mshadow::red::limits::MaxValue;
+ float quantized_range = MinAbs(MinValue<T>(), MaxValue<T>());
+ float real_range = MaxAbs(min_range, max_range);
+ float scale = real_range / quantized_range;
+ return input * scale;
+}
+
+struct QuantizedToFloatStruct {
+ template<typename T>
+ MSHADOW_XINLINE static void Map(int i, float *output, const T *input,
+ const float *range_min, const float *range_max) {
+ output[i] = QuantizedToFloat(input[i], *range_min, *range_max);
+ }
+};
+
+template <class T1, class T2>
+MSHADOW_XINLINE T2 RequantizeInNewRange(T1 input, float min_input, float max_input,
+ float min_new, float max_new) {
+ const float input_float = QuantizedToFloat<T1>(input, min_input, max_input);
+ return FloatToQuantized<T2>(input_float, min_new, max_new);
+}
+
+template <class T1, class T2>
+MSHADOW_XINLINE void RequantizeManyInNewRange(size_t count, T2* output, const T1 *input,
+ float input_min, float input_max,
+ float actual_min, float actual_max) {
+ for (size_t i = 0; i < count; ++i) {
+ const float input_float =
+ QuantizedToFloat<T1>(input[i], input_min, input_max);
+ output[i] = FloatToQuantized<T2>(input_float, actual_min, actual_max);
+ }
+}
+
+/*!
+ * \brief Get the scaling factor for converting type T to float.
+ */
+template<typename T>
+MSHADOW_XINLINE float FloatForOneQuantizedLevel(float range_min, float range_max) {
+ using mshadow::red::limits::MinValue;
+ using mshadow::red::limits::MaxValue;
+ const int64_t highest = static_cast<int64_t>(MaxValue<T>());
+ const int64_t lowest = static_cast<int64_t>(MinValue<T>());
+ const float float_for_one_quantized_level =
+ (range_max - range_min) / (highest - lowest);
+ return float_for_one_quantized_level;
+}
+
+template <typename TA, typename TB, typename TC>
+MSHADOW_XINLINE void QuantizationRangeForMultiplication(float min_a, float max_a,
+ float min_b, float max_b,
+ float* min_c, float* max_c) {
+ using mshadow::red::limits::MinValue;
+ using mshadow::red::limits::MaxValue;
+ const float a_float_for_one_quant_level =
+ FloatForOneQuantizedLevel<TA>(min_a, max_a);
+ const float b_float_for_one_quant_level =
+ FloatForOneQuantizedLevel<TB>(min_b, max_b);
+
+ const int64_t c_highest =
+ static_cast<int64_t>(MaxValue<TC>());
+ const int64_t c_lowest =
+ static_cast<int64_t>(MinValue<TC>());
+ const float c_float_for_one_quant_level =
+ a_float_for_one_quant_level * b_float_for_one_quant_level;
+
+ *min_c = c_float_for_one_quant_level * c_lowest;
+ *max_c = c_float_for_one_quant_level * c_highest;
+}
+
+struct QuantizationRangeForMultiplicationStruct {
+ MSHADOW_XINLINE static void Map(int i,
+ float *min_c,
+ float *max_c,
+ const float *min_a,
+ const float *max_a,
+ const float *min_b,
+ const float *max_b) {
+ QuantizationRangeForMultiplication<int8_t, int8_t, int32_t>(
+ min_a[i], max_a[i], min_b[i], max_b[i], min_c, max_c);
+ }
+};
+
+} // namespace op
+} // namespace mxnet
+#endif // MXNET_OPERATOR_QUANTIZATION_QUANTIZATION_UTILS_H_
diff --git a/src/operator/contrib/quantize-inl.h b/src/operator/quantization/quantize-inl.h
similarity index 52%
rename from src/operator/contrib/quantize-inl.h
rename to src/operator/quantization/quantize-inl.h
index 4d55b1b5c6d..8b7a11cc5a8 100644
--- a/src/operator/contrib/quantize-inl.h
+++ b/src/operator/quantization/quantize-inl.h
@@ -22,8 +22,8 @@
* \file quantize-inl.h
* \brief implementation of quantize operation
*/
-#ifndef MXNET_OPERATOR_CONTRIB_QUANTIZE_INL_H_
-#define MXNET_OPERATOR_CONTRIB_QUANTIZE_INL_H_
+#ifndef MXNET_OPERATOR_QUANTIZATION_QUANTIZE_INL_H_
+#define MXNET_OPERATOR_QUANTIZATION_QUANTIZE_INL_H_
#include <mxnet/operator_util.h>
#include <vector>
@@ -31,6 +31,7 @@
#include "../elemwise_op_common.h"
#include "../mshadow_op.h"
#include "../mxnet_op.h"
+#include "./quantization_utils.h"
namespace mxnet {
namespace op {
@@ -39,25 +40,47 @@ struct QuantizeParam : public dmlc::Parameter<QuantizeParam> {
int out_type;
DMLC_DECLARE_PARAMETER(QuantizeParam) {
DMLC_DECLARE_FIELD(out_type)
+ .add_enum("int8", mshadow::kInt8)
.add_enum("uint8", mshadow::kUint8)
.set_default(mshadow::kUint8)
.describe("Output data type.");
}
};
-struct quantize {
+// quantize float to uint8_t
+struct quantize_unsigned {
template<typename DstDType, typename SrcDType>
MSHADOW_XINLINE static void Map(int i, DstDType *out, float *omin_range,
float *omax_range, const SrcDType *in,
const float *imin_range, const float *imax_range,
- double min_limit, double max_limit) {
- float scale = (max_limit - min_limit) / (*imax_range - *imin_range);
+ const double min_limit, const double max_limit) {
+ using mshadow::red::limits::MinValue;
+ using mshadow::red::limits::MaxValue;
+ const float scale = (max_limit - min_limit) / (*imax_range - *imin_range);
out[i] = static_cast<DstDType>((in[i] - *imin_range) * scale + 0.5);
*omin_range = *imin_range;
*omax_range = *imax_range;
}
};
+
+// keep zero-center
+struct quantize_zero_centered {
+ template<typename DstDType, typename SrcDType>
+ MSHADOW_XINLINE static void Map(int i, DstDType *out, float *omin_range,
+ float *omax_range, const SrcDType *in,
+ const float *imin_range, const float *imax_range,
+ const float quantized_range) {
+ float real_range = MaxAbs(*imin_range, *imax_range);
+ float scale = quantized_range / real_range;
+ SrcDType x = in[i];
+ out[i] = static_cast<DstDType>(
+ Sign(x) * Min(Abs(x) * scale + 0.5f, quantized_range));
+ *omin_range = -real_range;
+ *omax_range = real_range;
+ }
+};
+
template<typename xpu>
void QuantizeCompute(const nnvm::NodeAttrs& attrs,
const OpContext& ctx,
@@ -66,16 +89,24 @@ void QuantizeCompute(const nnvm::NodeAttrs& attrs,
const std::vector<TBlob>& outputs) {
using namespace mshadow;
using namespace mxnet_op;
+ using mshadow::red::limits::MinValue;
+ using mshadow::red::limits::MaxValue;
Stream<xpu> *s = ctx.get_stream<xpu>();
- // for now, only supports quantize from uint8 to float
- // TODO(ziheng) consider add MSHADOW_INTEGER_TYPE_SWITCH
- typedef uint8_t DstDType;
- typedef float SrcDType;
- Kernel<quantize, xpu>::Launch(s, outputs[0].Size(),
- outputs[0].dptr<DstDType>(), outputs[1].dptr<float>(), outputs[2].dptr<float>(),
- inputs[0].dptr<SrcDType>(), inputs[1].dptr<float>(), inputs[2].dptr<float>(),
- std::numeric_limits<DstDType>::min(), std::numeric_limits<DstDType>::max());
+ const QuantizeParam& param = nnvm::get<QuantizeParam>(attrs.parsed);
+ if (param.out_type == mshadow::kUint8) {
+ Kernel<quantize_unsigned, xpu>::Launch(s, outputs[0].Size(),
+ outputs[0].dptr<uint8_t>(), outputs[1].dptr<float>(), outputs[2].dptr<float>(),
+ inputs[0].dptr<float>(), inputs[1].dptr<float>(), inputs[2].dptr<float>(),
+ MinValue<uint8_t>(), MaxValue<uint8_t>());
+ } else if (param.out_type == mshadow::kInt8) { // zero-centered quantization
+ Kernel<quantize_zero_centered, xpu>::Launch(s, outputs[0].Size(),
+ outputs[0].dptr<int8_t>(), outputs[1].dptr<float>(), outputs[2].dptr<float>(),
+ inputs[0].dptr<float>(), inputs[1].dptr<float>(), inputs[2].dptr<float>(),
+ MinAbs(MaxValue<int8_t>(), MinValue<int8_t>()));
+ } else {
+ LOG(FATAL) << "quantize op only supports int8 and uint8 as output type";
+ }
}
inline bool QuantizeShape(const nnvm::NodeAttrs& attrs,
@@ -84,15 +115,14 @@ inline bool QuantizeShape(const nnvm::NodeAttrs& attrs,
CHECK_EQ(in_attrs->size(), 3U);
CHECK_EQ(out_attrs->size(), 3U);
- CHECK(!shape_is_none(in_attrs->at(0)));
for (size_t i = 1; i < 3; ++i) {
- CHECK(shape_is_scalar(in_attrs->at(i)));
+ SHAPE_ASSIGN_CHECK(*in_attrs, i, TShape({1}));
}
SHAPE_ASSIGN_CHECK(*out_attrs, 0, in_attrs->at(0));
SHAPE_ASSIGN_CHECK(*out_attrs, 1, TShape{1});
SHAPE_ASSIGN_CHECK(*out_attrs, 2, TShape{1});
- return true;
+ return !shape_is_none(out_attrs->at(0));
}
inline bool QuantizeType(const nnvm::NodeAttrs& attrs,
@@ -100,13 +130,17 @@ inline bool QuantizeType(const nnvm::NodeAttrs& attrs,
std::vector<int> *out_attrs) {
CHECK_EQ(in_attrs->size(), 3U);
CHECK_EQ(out_attrs->size(), 3U);
- CHECK_EQ((*in_attrs)[0], mshadow::kFloat32)
- << "`quantize` only supports float32 input for now";
- CHECK_EQ((*in_attrs)[1], mshadow::kFloat32)
- << "the second input of `quantize` should be a tensor with type of float";
- CHECK_EQ((*in_attrs)[2], mshadow::kFloat32)
- << "the third input of `quantize` should be a tensor with type of float";
- TYPE_ASSIGN_CHECK(*out_attrs, 0, mshadow::kUint8);
+ const QuantizeParam& param = nnvm::get<QuantizeParam>(attrs.parsed);
+ TYPE_ASSIGN_CHECK(*in_attrs, 0, mshadow::kFloat32);
+ TYPE_ASSIGN_CHECK(*in_attrs, 1, mshadow::kFloat32);
+ TYPE_ASSIGN_CHECK(*in_attrs, 2, mshadow::kFloat32);
+ if (param.out_type == mshadow::kUint8) {
+ TYPE_ASSIGN_CHECK(*out_attrs, 0, mshadow::kUint8);
+ } else if (param.out_type == mshadow::kInt8) {
+ TYPE_ASSIGN_CHECK(*out_attrs, 0, mshadow::kInt8);
+ } else {
+ LOG(FATAL) << "quantize op only supports int8 and uint8 as output type";
+ }
TYPE_ASSIGN_CHECK(*out_attrs, 1, mshadow::kFloat32);
TYPE_ASSIGN_CHECK(*out_attrs, 2, mshadow::kFloat32);
return (*in_attrs)[0] != -1;
@@ -114,4 +148,4 @@ inline bool QuantizeType(const nnvm::NodeAttrs& attrs,
} // namespace op
} // namespace mxnet
-#endif // MXNET_OPERATOR_CONTRIB_QUANTIZE_INL_H_
+#endif // MXNET_OPERATOR_QUANTIZATION_QUANTIZE_INL_H_
diff --git a/src/operator/contrib/quantize.cc b/src/operator/quantization/quantize.cc
similarity index 65%
rename from src/operator/contrib/quantize.cc
rename to src/operator/quantization/quantize.cc
index 43d60d1dd83..32eb952fa5d 100644
--- a/src/operator/contrib/quantize.cc
+++ b/src/operator/quantization/quantize.cc
@@ -32,21 +32,37 @@ NNVM_REGISTER_OP(_contrib_quantize)
.describe(R"code(Quantize a input tensor from float to `out_type`,
with user-specified `min_range` and `max_range`.
-[min_range, max_range] are scalar floats that spcify the range for
-the input data. Each value of the tensor will undergo the following:
+min_range and max_range are scalar floats that specify the range for
+the input data.
-`out[i] = (in[i] - min_range) * range(OUTPUT_TYPE) / (max_range - min_range)`
+When out_type is `uint8`, the output is calculated using the following equation:
-here `range(T) = numeric_limits<T>::max() - numeric_limits<T>::min()`
-)code" ADD_FILELINE)
+`out[i] = (in[i] - min_range) * range(OUTPUT_TYPE) / (max_range - min_range) + 0.5`,
+
+where `range(T) = numeric_limits<T>::max() - numeric_limits<T>::min()`.
+
+When out_type is `int8`, the output is calculate using the following equation
+by keep zero centered for the quantized value:
+
+`out[i] = sign(in[i]) * min(abs(in[i] * scale + 0.5f, quantized_range)`,
+
+where
+`quantized_range = MinAbs(max(int8), min(int8))` and
+`scale = quantized_range / MaxAbs(min_range, max_range).`
+
+.. Note::
+ This operator only supports forward propogation. DO NOT use it in training.)code" ADD_FILELINE)
.set_attr_parser(ParamParser<QuantizeParam>)
.set_num_inputs(3)
.set_num_outputs(3)
+.set_attr<nnvm::FListInputNames>("FListInputNames",
+ [](const NodeAttrs& attrs) {
+ return std::vector<std::string>{"data", "min_range", "max_range"};
+ })
.set_attr<nnvm::FInferShape>("FInferShape", QuantizeShape)
.set_attr<nnvm::FInferType>("FInferType", QuantizeType)
.set_attr<FCompute>("FCompute<cpu>", QuantizeCompute<cpu>)
-.set_attr<nnvm::FGradient>("FGradient", ElemwiseGradUseNone{"_quantize"})
-.add_argument("input", "NDArray-or-Symbol", "A ndarray/symbol of type `float32`")
+.add_argument("data", "NDArray-or-Symbol", "A ndarray/symbol of type `float32`")
.add_argument("min_range", "NDArray-or-Symbol", "The minimum scalar value "
"possibly produced for the input")
.add_argument("max_range", "NDArray-or-Symbol", "The maximum scalar value "
diff --git a/src/operator/contrib/quantize.cu b/src/operator/quantization/quantize.cu
similarity index 100%
rename from src/operator/contrib/quantize.cu
rename to src/operator/quantization/quantize.cu
diff --git a/src/operator/quantization/quantize_graph_pass.cc b/src/operator/quantization/quantize_graph_pass.cc
new file mode 100644
index 00000000000..5ec745ccdf3
--- /dev/null
+++ b/src/operator/quantization/quantize_graph_pass.cc
@@ -0,0 +1,308 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * Copyright (c) 2016 by Contributors
+ * \file quantization.cc
+ * \brief
+ */
+#include <nnvm/graph.h>
+#include <nnvm/pass.h>
+#include <mxnet/op_attr_types.h>
+#include <unordered_set>
+
+namespace mxnet {
+namespace op {
+
+using nnvm::Symbol;
+using nnvm::Node;
+using nnvm::NodePtr;
+using nnvm::NodeEntry;
+using nnvm::Graph;
+
+NodePtr CreateNode(std::string op_name, std::string node_name) {
+ NodePtr node = Node::Create();
+ node->attrs.name = node_name;
+ if (op_name == "nullptr") {
+ node->attrs.op = nullptr;
+ // ugly workaround because VariableParam is not exposed
+ node->attrs.parsed =
+ nnvm::Symbol::CreateVariable(node->attrs.name).outputs[0].node->attrs.parsed;
+ } else {
+ node->attrs.op = Op::Get(op_name);
+ }
+ return node;
+}
+
+/*!
+ * \brief Insert a node named with node_name holding the op of op_name
+ * before the node current and after the node previous.
+ */
+NodePtr InsertNode(std::string op_name,
+ std::string node_name, NodePtr current, NodeEntry previous) {
+ NodePtr node = CreateNode(op_name, node_name);
+ node->inputs.emplace_back(previous);
+ current->inputs.emplace_back(NodeEntry{node, 0, 0});
+ return node;
+}
+
+std::vector<NodeEntry> OfflineParams(std::vector<NodeEntry>&& outputs,
+ std::unordered_set<std::string>&& offline_params) {
+ std::string node_suffixs[3] = {"", "_min", "_max"};
+ std::unordered_map<Node*, NodePtr> mirror_map;
+ nnvm::NodeEntryMap<NodePtr> entry_var;
+ auto need_offline = [&](NodePtr n) {
+ return n->op() &&
+ (n->op()->name == "_contrib_quantize") &&
+ n->inputs[0].node->is_variable() &&
+ offline_params.count(n->inputs[0].node->attrs.name);
+ };
+ DFSVisit(outputs, [&](const NodePtr& node) {
+ for (NodeEntry& e : node->inputs) {
+ if (need_offline(e.node)) {
+ std::string node_name = e.node->attrs.name;
+ if (!entry_var.count(e)) {
+ entry_var[e] = CreateNode("nullptr", node_name + node_suffixs[e.index]);
+ }
+ e.node = entry_var[e];
+ e.index = 0;
+ e.version = 0;
+ }
+ }
+ });
+ return outputs;
+}
+
+inline bool NeedQuantize(NodePtr node, const std::unordered_set<NodePtr> excluded_nodes) {
+ static auto& quantized_op_map = Op::GetAttr<mxnet::FQuantizedOp>("FQuantizedOp");
+ return quantized_op_map.count(node->op()) && !excluded_nodes.count(node);
+}
+
+Graph QuantizeGraph(Graph &&src) {
+ static auto& quantized_op_map = Op::GetAttr<mxnet::FQuantizedOp>("FQuantizedOp");
+ static auto& need_requantize_map = Op::GetAttr<mxnet::FNeedRequantize>("FNeedRequantize");
+ auto offline_params = src.GetAttr<std::unordered_set<std::string>>("offline_params");
+ auto excluded_nodes = src.GetAttr<std::unordered_set<NodePtr>>("excluded_nodes");
+
+ // mirror_map stores the mapping from the currently visited graph to the newly created quantized
+ // graph. Key is the currently visited graph's node pointer, and value is a copied node of the key
+ // node. The existing key's value may be updated with the newly created quantize/dequantize op.
+ std::unordered_map<Node*, NodePtr> mirror_map;
+ DFSVisit(src.outputs, [&](const NodePtr& node) {
+ NodePtr new_node = Node::Create();
+ // If the currently visited node needs quantization, insert a quantize op node before the
+ // current node and replace the current node with the quantized version in the new graph.
+ if (NeedQuantize(node, excluded_nodes)) {
+ auto fquantized_op = quantized_op_map[node->op()];
+ // If the currently visited node's op registered the FQuantizedOp property, new_node is a
+ // quantizated version of a that op, such as quantized_conv2d.
+ new_node = fquantized_op(node->attrs);
+
+ // add data into quantized op input
+ for (const auto& e : node->inputs) {
+ NodePtr mirror_node = mirror_map.at(e.node.get());
+ NodeEntry mirror_entry = NodeEntry{
+ mirror_node, e.index, e.version};
+ // If the NodeEntry e's node does not need quantization, and (the mirror_node is a variable,
+ // or the mirror_node's op is not a quantize op), create quantize op, min op, and max op
+ // taking mirror_entry as input to generate a quantized NDArray. Save the mapping between
+ // e's source node and the newly created quantize op so that the quantize op can be
+ // reused next time when the same entry is visited again.
+ if (!NeedQuantize(e.node, excluded_nodes) &&
+ (mirror_node->op() == nullptr ||
+ mirror_node->op()->name != "_contrib_quantize")) {
+ NodePtr quantize_node = InsertNode("_contrib_quantize",
+ e.node->attrs.name + "_quantize", new_node, mirror_entry);
+ quantize_node->attrs.dict["out_type"] = "int8";
+ quantize_node->op()->attr_parser(&(quantize_node->attrs));
+
+ NodePtr min_node = InsertNode("min",
+ e.node->attrs.name + "_min", quantize_node, mirror_entry);
+ min_node->op()->attr_parser(&(min_node->attrs));
+
+ NodePtr max_node = InsertNode("max",
+ e.node->attrs.name + "_max", quantize_node, mirror_entry);
+ max_node->op()->attr_parser(&(max_node->attrs));
+
+ mirror_map[e.node.get()] = std::move(quantize_node);
+ } else {
+ // If the entry e's node needs quantization, or mirror_entry is from a quantize op,
+ // simply add mirror_entry to the input of the new_node.
+ new_node->inputs.emplace_back(mirror_entry);
+ }
+ // the input should be `quantize` or quantized version op now
+ }
+
+ // add min and max into quantized op input assume order of quantized op inputs is:
+ // data1, data2, ..., min1, max1, min2, max2, ...
+ for (const auto& e : node->inputs) {
+ NodePtr mirror_node = mirror_map.at(e.node.get());
+ NodeEntry mirror_entry = NodeEntry{
+ mirror_node, e.index, e.version};
+ // for quantize node
+ uint32_t min_index = 1;
+ uint32_t max_index = 2;
+ if (quantized_op_map.count(e.node->op())) {
+ size_t num_outputs = e.node->num_outputs();
+ min_index = num_outputs + 2 * e.index;
+ max_index = num_outputs + 2 * e.index + 1;
+ } else {
+ CHECK(mirror_node->op()->name == "_contrib_quantize")
+ << "The input is not quantize or quantized_op";
+ }
+ new_node->inputs.emplace_back(NodeEntry{mirror_node, min_index, 0});
+ new_node->inputs.emplace_back(NodeEntry{mirror_node, max_index, 0});
+ }
+
+ // If the new_node op registered attr FNeedRequantize, insert requantize node after it.
+ // Here it's assumed that the quantized_op node only produces three outputs:
+ // out_data, min_range, and max_range.
+ if (need_requantize_map.count(new_node->op()) > 0
+ && need_requantize_map[new_node->op()](new_node->attrs)) {
+ NodePtr requantize_node = Node::Create();
+ requantize_node->attrs.op = Op::Get("_contrib_requantize");
+ requantize_node->attrs.name = "requantize_" + node->attrs.name;
+ if (requantize_node->op()->attr_parser != nullptr) {
+ requantize_node->op()->attr_parser(&(requantize_node->attrs));
+ }
+ for (size_t i = 0; i < 3; ++i) {
+ requantize_node->inputs.emplace_back(NodeEntry{new_node, static_cast<uint32_t>(i), 0});
+ }
+ new_node = requantize_node;
+ }
+ } else {
+ // If the currently visited node does not need quantization, copy the current node to become
+ // the new_node. Meanwhile, check whether any inputs of the current node need quantization
+ // (e.g., a quantized_conv2d node), and insert a dequantize op node in the new graph if there
+ // are any. Otherwise, simply add a copy of the current node's entry to the inputs of
+ // the new_node.
+ *new_node = *node;
+ new_node->inputs.clear();
+ for (const auto& e : node->inputs) {
+ NodePtr mirror_node = mirror_map.at(e.node.get());
+ NodeEntry mirror_entry = NodeEntry{
+ mirror_node, e.index, e.version};
+ size_t num_outputs = e.node->num_outputs();
+ uint32_t min_index = num_outputs + 2 * e.index;
+ uint32_t max_index = num_outputs + 2 * e.index + 1;
+
+ // if input node is quantized operator, add dequantize node
+ if (NeedQuantize(e.node, excluded_nodes)) {
+ NodePtr dequantize_node = CreateNode("_contrib_dequantize",
+ e.node->attrs.name + "_dequantize");
+ dequantize_node->inputs.emplace_back(mirror_entry);
+ dequantize_node->inputs.emplace_back(NodeEntry{mirror_node, min_index, 0});
+ dequantize_node->inputs.emplace_back(NodeEntry{mirror_node, max_index, 0});
+ dequantize_node->op()->attr_parser(&(dequantize_node->attrs));
+
+ new_node->inputs.emplace_back(NodeEntry{dequantize_node, 0, 0});
+ mirror_map[e.node.get()] = std::move(dequantize_node);
+ } else {
+ new_node->inputs.emplace_back(NodeEntry{mirror_node, e.index, e.version});
+ }
+ }
+ }
+ mirror_map[node.get()] = std::move(new_node);
+ });
+
+ std::vector<NodeEntry> outputs;
+ for (const auto& e : src.outputs) {
+ if (quantized_op_map.count(e.node->op())) {
+ NodePtr mirror_node = mirror_map.at(e.node.get());
+ NodeEntry mirror_entry = NodeEntry{mirror_node, e.index, e.version};
+ size_t num_inputs = e.node->num_inputs();
+ uint32_t min_index = num_inputs + 2 * e.index;
+ uint32_t max_index = num_inputs + 2 * e.index + 1;
+
+ NodePtr dequantize_node = CreateNode("_contrib_dequantize",
+ e.node->attrs.name + "_dequantize");
+ dequantize_node->inputs.emplace_back(mirror_entry);
+ dequantize_node->inputs.emplace_back(NodeEntry{mirror_node, min_index, 0});
+ dequantize_node->inputs.emplace_back(NodeEntry{mirror_node, max_index, 0});
+ dequantize_node->op()->attr_parser(&(dequantize_node->attrs));
+ outputs.emplace_back(NodeEntry{dequantize_node, 0, 0});
+ } else {
+ outputs.emplace_back(NodeEntry{mirror_map.at(e.node.get()), e.index, e.version});
+ }
+ }
+
+ if (!offline_params.empty()) outputs =
+ OfflineParams(std::move(outputs), std::move(offline_params));
+
+ Graph ret;
+ ret.outputs = std::move(outputs);
+ return ret;
+}
+
+Graph SetCalibTableToQuantizedGraph(Graph&& g) {
+ static const auto& flist_outputs =
+ nnvm::Op::GetAttr<nnvm::FListOutputNames>("FListOutputNames");
+ static const auto& need_requantize_map =
+ nnvm::Op::GetAttr<mxnet::FNeedRequantize>("FNeedRequantize");
+ const auto& calib_table =
+ g.GetAttr<std::unordered_map<std::string, std::pair<float, float>>>("calib_table");
+ DFSVisit(g.outputs, [&](const NodePtr& node) {
+ // If the current op is requantize
+ // find the thresholds from the calibration table with the key equal
+ // to the current op's input node name, e.g. a quantized_conv2d node.
+ if (node->op() != nullptr && node->op()->name == "_contrib_requantize") {
+ NodePtr quantized_op_node = node->inputs[0].node;
+ CHECK(quantized_op_node->op() != nullptr) << quantized_op_node->attrs.name
+ << " must be an quantized op node";
+ CHECK(need_requantize_map.count(quantized_op_node->op()) > 0
+ && need_requantize_map[quantized_op_node->op()](quantized_op_node->attrs))
+ << quantized_op_node->attrs.name << " op must register FNeedRequantize attr"
+ " and the attr func should return true";
+ std::string out_data_name = quantized_op_node->attrs.name + "_";
+ auto list_output_names_func = flist_outputs.get(quantized_op_node->op(), nullptr);
+ // Here it's assumed that the quantized_op node only produces three outputs:
+ // out_data, min_range, and max_range. So we want to get the pre-calculated min_calib_range
+ // and max_calib_range from the calibration table for out_data. Here we create the output
+ // data name same as its constructed in GraphExecutor::ExecuteMonCallback.
+ if (list_output_names_func != nullptr) {
+ std::vector<std::string> names = list_output_names_func(quantized_op_node->attrs);
+ CHECK_EQ(names.size(), 3U) << "ListOutputNames is expected to return three string for"
+ " quantized operators";
+ out_data_name += names[0];
+ } else {
+ out_data_name += "0";
+ }
+ const auto calib_table_iter = calib_table.find(out_data_name);
+ if (calib_table_iter != calib_table.end()) {
+ node->attrs.dict["min_calib_range"] = std::to_string(calib_table_iter->second.first);
+ node->attrs.dict["max_calib_range"] = std::to_string(calib_table_iter->second.second);
+ node->op()->attr_parser(&(node->attrs));
+ }
+ }
+ });
+ return g;
+}
+
+NNVM_REGISTER_PASS(QuantizeGraph)
+.describe("")
+.set_body(QuantizeGraph)
+.set_change_graph(true);
+
+NNVM_REGISTER_PASS(SetCalibTableToQuantizedGraph)
+.describe("")
+.set_body(SetCalibTableToQuantizedGraph)
+.set_change_graph(true);
+
+} // namespace op
+} // namespace mxnet
diff --git a/src/operator/quantization/quantized_conv.cc b/src/operator/quantization/quantized_conv.cc
new file mode 100644
index 00000000000..d7dc9fe4dbd
--- /dev/null
+++ b/src/operator/quantization/quantized_conv.cc
@@ -0,0 +1,169 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * Copyright (c) 2017 by Contributors
+ * \file quantized_conv.cc
+ * \brief
+ * \author Ziheng Jiang, Jun Wu
+*/
+#include "../nn/convolution-inl.h"
+
+namespace mxnet {
+namespace op {
+
+bool QuantizedConvShape(const nnvm::NodeAttrs& attrs,
+ std::vector<TShape>* in_shape,
+ std::vector<TShape>* out_shape) {
+ using namespace mshadow;
+ const ConvolutionParam& param = nnvm::get<ConvolutionParam>(attrs.parsed);
+ CHECK_EQ(param.num_group, 1U) << "quantized_conv only supports num_group=1 for now";
+ CHECK_EQ(in_shape->size(), param.no_bias? 6U : 9U);
+ CHECK_EQ(out_shape->size(), 3U);
+ if (param.layout.has_value()) {
+ CHECK_EQ(param.layout.value(), mshadow::kNCHW) << "quantized_conv only supports NCHW for now";
+ }
+ CHECK_EQ(param.kernel.ndim(), 2U) << "quantized_conv only supports 2D convolution for now";
+ CHECK(param.dilate.ndim() == 0U || param.dilate.Size() == 1U)
+ << "quantized_conv only supports dilation=1 for all dimensions";
+ const TShape& dshape = in_shape->at(0);
+ CHECK_EQ(dshape.ndim(), 4U);
+ if (dshape.ndim() == 0U) return false;
+
+ const int N = 0, H = 2, W = 3, C = 1;
+ CHECK_EQ(dshape[C] % 4, 0U)
+ << "for 8bit cudnn conv, the number of channel must be multiple of 4";
+ CHECK_EQ(param.num_filter % 4, 0U)
+ << "for 8bit cudnn conv, the number of channel must be multiple of 4";
+
+ TShape wshape{0, 0, 0, 0};
+ wshape[N] = param.num_filter;
+ wshape[H] = param.kernel[0];
+ wshape[W] = param.kernel[1];
+ wshape[C] = dshape[C];
+ SHAPE_ASSIGN_CHECK(*in_shape, 1, wshape);
+ const int start = param.no_bias? 2 : 3;
+ const int end = param.no_bias? 6 : 9;
+ for (int i = start; i < end; ++i) {
+ SHAPE_ASSIGN_CHECK(*in_shape, i, TShape{1});
+ }
+ if (!param.no_bias) {
+ SHAPE_ASSIGN_CHECK(*in_shape, 2, Shape1(param.num_filter));
+ }
+
+ auto AddPad = [](index_t dsize, index_t pad) { return dsize + 2 * pad; };
+ TShape oshape{1, 1, 1, 1};
+ oshape[N] = dshape[N];
+ oshape[C] = wshape[N];
+ oshape[H] = (AddPad(dshape[H], param.pad[0]) - wshape[H]) / param.stride[0] + 1;
+ oshape[W] = (AddPad(dshape[W], param.pad[1]) - wshape[W]) / param.stride[1] + 1;
+
+ SHAPE_ASSIGN_CHECK(*out_shape, 0, oshape);
+ SHAPE_ASSIGN_CHECK(*out_shape, 1, TShape({1}));
+ SHAPE_ASSIGN_CHECK(*out_shape, 2, TShape({1}));
+ return true;
+}
+
+bool QuantizedConvType(const nnvm::NodeAttrs& attrs,
+ std::vector<int> *in_type,
+ std::vector<int> *out_type) {
+ const ConvolutionParam& param = nnvm::get<ConvolutionParam>(attrs.parsed);
+ CHECK_EQ(in_type->size(), param.no_bias? 6U : 9U);
+ CHECK_EQ(out_type->size(), 3U);
+ TYPE_ASSIGN_CHECK(*in_type, 0, mshadow::kInt8);
+ TYPE_ASSIGN_CHECK(*in_type, 1, mshadow::kInt8);
+ if (!param.no_bias) {
+ TYPE_ASSIGN_CHECK(*in_type, 2, mshadow::kInt8);
+ }
+
+ const size_t start = param.no_bias? 2 : 3;
+ const size_t end = param.no_bias? 6 : 9;
+ for (size_t i = start; i < end; ++i) {
+ TYPE_ASSIGN_CHECK(*in_type, i, mshadow::kFloat32);
+ }
+
+ TYPE_ASSIGN_CHECK(*out_type, 0, mshadow::kInt32);
+ TYPE_ASSIGN_CHECK(*out_type, 1, mshadow::kFloat32);
+ TYPE_ASSIGN_CHECK(*out_type, 2, mshadow::kFloat32);
+ return true;
+}
+
+NNVM_REGISTER_OP(_contrib_quantized_conv)
+.describe(R"code(Convolution operator for input, weight and bias data type of int8,
+and accumulates in type int32 for the output. For each argument, two more arguments of type
+float32 must be provided representing the thresholds of quantizing argument from data
+type float32 to int8. The final outputs contain the convolution result in int32, and min
+and max thresholds representing the threholds for quantizing the float32 output into int32.
+
+.. Note::
+ This operator only supports forward propogation. DO NOT use it in training.)code" ADD_FILELINE)
+.set_num_inputs(
+ [](const NodeAttrs& attrs) {
+ const ConvolutionParam& param = nnvm::get<ConvolutionParam>(attrs.parsed);
+ return param.no_bias? 6 : 9;
+ })
+.set_num_outputs(3)
+.set_attr_parser(ParamParser<ConvolutionParam>)
+.set_attr<nnvm::FListInputNames>("FListInputNames",
+ [](const NodeAttrs& attrs) {
+ const ConvolutionParam& param = nnvm::get<ConvolutionParam>(attrs.parsed);
+ if (param.no_bias) {
+ return std::vector<std::string>{"data", "weight", "min_data", "max_data",
+ "min_weight", "max_weight"};
+ } else {
+ return std::vector<std::string>{"data", "weight", "bias", "min_data", "max_data",
+ "min_weight", "max_weight", "min_bias", "max_bias"};
+ }
+ })
+.set_attr<nnvm::FListOutputNames>("FListOutputNames",
+ [](const NodeAttrs& attrs) {
+ return std::vector<std::string>{"output", "min_output", "max_output"};
+ })
+.set_attr<nnvm::FInferShape>("FInferShape", QuantizedConvShape)
+.set_attr<nnvm::FInferType>("FInferType", QuantizedConvType)
+.set_attr<FResourceRequest>("FResourceRequest",
+ [](const NodeAttrs& attrs) {
+ return std::vector<ResourceRequest>(1, ResourceRequest::kTempSpace);
+ })
+.set_attr<FNeedRequantize>("FNeedRequantize", [](const NodeAttrs& attrs) { return true; })
+.add_argument("data", "NDArray-or-Symbol", "Input data.")
+.add_argument("weight", "NDArray-or-Symbol", "weight.")
+.add_argument("bias", "NDArray-or-Symbol", "bias.")
+.add_argument("min_data", "NDArray-or-Symbol", "Minimum value of data.")
+.add_argument("max_data", "NDArray-or-Symbol", "Maximum value of data.")
+.add_argument("min_weight", "NDArray-or-Symbol", "Minimum value of weight.")
+.add_argument("max_weight", "NDArray-or-Symbol", "Maximum value of weight.")
+.add_argument("min_bias", "NDArray-or-Symbol", "Minimum value of bias.")
+.add_argument("max_bias", "NDArray-or-Symbol", "Maximum value of bias.")
+.add_arguments(ConvolutionParam::__FIELDS__());
+
+NNVM_REGISTER_OP(Convolution)
+.set_attr<FQuantizedOp>("FQuantizedOp", [](const NodeAttrs& attrs) {
+ nnvm::NodePtr node = nnvm::Node::Create();
+ node->attrs.op = Op::Get("_contrib_quantized_conv");
+ node->attrs.name = "quantized_" + attrs.name;
+ node->attrs.dict = attrs.dict;
+ if (node->op()->attr_parser != nullptr) {
+ node->op()->attr_parser(&(node->attrs));
+ }
+ return node;
+ });
+
+} // namespace op
+} // namespace mxnet
diff --git a/src/operator/quantization/quantized_conv.cu b/src/operator/quantization/quantized_conv.cu
new file mode 100644
index 00000000000..2db5416309b
--- /dev/null
+++ b/src/operator/quantization/quantized_conv.cu
@@ -0,0 +1,291 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * Copyright (c) 2017 by Contributors
+ * \file quantized_conv.cu
+ * \brief
+ * \author Ziheng Jiang, Jun Wu
+*/
+#include "../nn/convolution-inl.h"
+#include "./quantization_utils.h"
+#include "../tensor/matrix_op-inl.h"
+
+namespace mxnet {
+namespace op {
+
+// value + bias_value * (range1 / limit_range1) * (limit_range2 / range2)
+struct QuantizedBiasAddKernel {
+ MSHADOW_XINLINE static void Map(int i, size_t bias_size, int32_t *out,
+ const int8_t *bias, const float *min_out,
+ const float *max_out, const float *min_bias,
+ const float *max_bias, const size_t spatial_size) {
+ using mshadow::red::limits::MinValue;
+ using mshadow::red::limits::MaxValue;
+ float float_for_one_out_quant =
+ MaxAbs(*min_out, *max_out) / static_cast<double>(MaxValue<int32_t>());
+ float float_for_one_bias_quant =
+ MaxAbs(*min_bias, *max_bias) / static_cast<double>(MaxValue<int8_t>());
+ const size_t channel_id = (i / spatial_size) % bias_size;
+ out[i] = (out[i] * float_for_one_out_quant +
+ bias[channel_id] * float_for_one_bias_quant) /
+ float_for_one_out_quant;
+ }
+};
+
+#if MXNET_USE_CUDNN == 1 && CUDNN_MAJOR >= 6
+template<typename SrcType, typename DstType, typename CmpType>
+class QuantizedCuDNNConvOp {
+ public:
+ QuantizedCuDNNConvOp() {
+ CUDNN_CALL(cudnnCreateConvolutionDescriptor(&conv_desc_));
+ CUDNN_CALL(cudnnCreateTensorDescriptor(&data_desc_));
+ CUDNN_CALL(cudnnCreateTensorDescriptor(&out_desc_));
+ CUDNN_CALL(cudnnCreateFilterDescriptor(&filter_desc_));
+ }
+
+ void Init(const ConvolutionParam& param,
+ const OpContext& ctx,
+ const std::vector<TShape>& in_shape,
+ const std::vector<TShape>& out_shape) {
+ param_ = param;
+ CHECK_EQ(param_.kernel.ndim(), 2U)
+ << "QuantizedCuDNNConvOp only supports 2D convolution for now";
+ if (param_.layout.has_value()) {
+ CHECK_EQ(param_.layout.value(), mshadow::kNCHW)
+ << "QuantizedConvOp only supports NCHW for now";
+ }
+ if (param_.stride.ndim() == 0U) param_.stride = mshadow::Shape2(1, 1);
+ if (param_.dilate.ndim() == 0U) param_.dilate = mshadow::Shape2(1, 1);
+ if (param_.pad.ndim() == 0U) param_.pad = mshadow::Shape2(0, 0);
+ N = 0, H = 2, W = 3, C = 1;
+ src_type_ = mshadow::DataType<SrcType>::kCudnnFlag;
+ dst_type_ = mshadow::DataType<DstType>::kCudnnFlag;
+ cmp_type_ = mshadow::DataType<CmpType>::kCudnnFlag;
+ algo_ = CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM;
+ format_ = CUDNN_TENSOR_NHWC;
+ InitDescriptors(in_shape, out_shape);
+ GetTempSize(ctx);
+ }
+
+ ~QuantizedCuDNNConvOp() {
+ CUDNN_CALL(cudnnDestroyFilterDescriptor(filter_desc_));
+ CUDNN_CALL(cudnnDestroyTensorDescriptor(data_desc_));
+ CUDNN_CALL(cudnnDestroyTensorDescriptor(out_desc_));
+ CUDNN_CALL(cudnnDestroyConvolutionDescriptor(conv_desc_));
+ }
+
+ void Forward(const OpContext &ctx,
+ const std::vector<TBlob> &in_data,
+ const std::vector<OpReqType> &req,
+ const std::vector<TBlob> &out_data) {
+ CHECK_EQ(param_.kernel.ndim(), 2U)
+ << "QuantizedCuDNNConvOp only supports 2D convolution for now";
+ using namespace mshadow;
+ CHECK_EQ(in_data.size(), param_.no_bias? 6U : 9U);
+ CHECK_EQ(out_data.size(), 3U);
+ Stream<gpu> *s = ctx.get_stream<gpu>();
+ CHECK_EQ(s->dnn_handle_ownership_, Stream<gpu>::OwnHandle);
+
+ const TBlob& data = in_data[0];
+ const TBlob& filter = in_data[1];
+ const TBlob& out = out_data[0];
+ const TShape& dshape = data.shape_;
+ const TShape& fshape = filter.shape_;
+ const TShape& oshape = out.shape_;
+
+ // allocate workspace
+ const int dev_id = ctx.run_ctx.ctx.dev_id;
+ const int dev_mask = gpu::kDevMask;
+ if (!param_.layout.has_value() || param_.layout.value() == mshadow::kNCHW) {
+ const size_t data_size = dshape.Size();
+ const size_t weight_size = fshape.Size();
+ const size_t output_size = oshape.Size();
+ size_t total_temp_bytes = (workspace_ + data_size + weight_size) * sizeof(SrcType)
+ + output_size * (sizeof(DstType) + sizeof(int32_t));
+ Tensor<gpu, 1, char> temp_space =
+ ctx.requested[0].get_space_typed<gpu, 1, char>(mshadow::Shape1(total_temp_bytes), s);
+ char* temp_dptr = temp_space.dptr_;
+ TBlob data_(reinterpret_cast<SrcType*>(temp_dptr),
+ TShape({dshape[N], dshape[H], dshape[W], dshape[C]}),
+ dev_mask, DataType<SrcType>::kFlag, dev_id);
+ temp_dptr += data_size * sizeof(SrcType);
+ TBlob filter_(reinterpret_cast<SrcType*>(temp_dptr),
+ TShape({fshape[N], fshape[H], fshape[W], fshape[C]}),
+ dev_mask, DataType<SrcType>::kFlag, dev_id);
+ temp_dptr += weight_size * sizeof(SrcType);
+
+ // input: [NCHW] => [NHWC](batch, in_height, in_width, in_channels)
+ // filter: [NCHW] => [NHWC](out_channels, filter_height, filter_width, in_channels)
+ TransposeImpl<gpu>(ctx.run_ctx, data, data_, TShape({N, H, W, C}));
+ TransposeImpl<gpu>(ctx.run_ctx, filter, filter_, TShape({N, H, W, C}));
+ TBlob out_(reinterpret_cast<DstType*>(temp_dptr),
+ TShape({oshape[N], oshape[H], oshape[W], oshape[C]}),
+ dev_mask, DataType<DstType>::kFlag, dev_id);
+ temp_dptr += output_size * sizeof(DstType);
+ TBlob out_tcast(reinterpret_cast<int32_t*>(temp_dptr),
+ TShape({oshape[N], oshape[H], oshape[W], oshape[C]}),
+ dev_mask, DataType<int32_t>::kFlag, dev_id);
+ temp_dptr += output_size * sizeof(int32_t);
+ // input: [NHWC](batch, in_height, in_width, in_channels)
+ // filter: [HWNC](out_channels, filter_height, filter_width, in_channels)
+ // output: [NHWC](batch, out_height, out_width, out_channels)
+
+ CUDNN_CALL(cudnnConvolutionForward(s->dnn_handle_,
+ &alpha_,
+ data_desc_,
+ data_.dptr_,
+ filter_desc_,
+ filter_.dptr_,
+ conv_desc_,
+ algo_,
+ temp_dptr,
+ workspace_byte_,
+ &beta_,
+ out_desc_,
+ out_.dptr_));
+
+ Tensor<gpu, 1, DstType> out_tensor = out_.FlatTo1D<gpu, DstType>(s);
+ Tensor<gpu, 1, int32_t> out_tcast_tensor = out_tcast.FlatTo1D<gpu, int32_t>(s);
+ Assign(out_tcast_tensor, kWriteTo, mshadow::expr::tcast<int32_t>(out_tensor));
+ // output: [NHWC](batch, out_height, out_width, out_channels) => [NCHW]
+ TransposeImpl<gpu>(ctx.run_ctx, out_tcast, out, TShape({0, 3, 1, 2}));
+ } else {
+ LOG(FATAL) << "quantized_conv only supports NCHW for now";
+ }
+
+ // calculate the min/max range for out_data as it's a multiplication
+ // of in_data[0] and in_data[1]. Need to rescale the min/max range of out_data
+ // based on the min/max ranges of in_data[0] and in_data[1].
+ const size_t num_inputs = param_.no_bias ? 2 : 3;
+ mxnet_op::Kernel<QuantizationRangeForMultiplicationStruct, gpu>::Launch(s, 1,
+ out_data[1].dptr<float>(), out_data[2].dptr<float>(),
+ in_data[num_inputs].dptr<float>(), in_data[num_inputs+1].dptr<float>(),
+ in_data[num_inputs+2].dptr<float>(), in_data[num_inputs+3].dptr<float>());
+
+ if (!param_.no_bias) {
+ if (param_.layout.has_value()) {
+ CHECK_EQ(param_.layout.value(), mshadow::kNCHW)
+ << "quantized_conv only supports NCHW when there is a bias";
+ }
+ const TBlob& bias = in_data[2];
+ mxnet_op::Kernel<QuantizedBiasAddKernel, gpu>::Launch(s, out.Size(),
+ bias.Size(), out.dptr<int32_t>(), bias.dptr<int8_t>(),
+ out_data[1].dptr<float>(), out_data[2].dptr<float>(),
+ in_data[7].dptr<float>(), in_data[8].dptr<float>(),
+ oshape[2] * oshape[3]);
+ }
+ }
+
+ void InitDescriptors(const std::vector<TShape>& in_shape,
+ const std::vector<TShape>& out_shape) {
+ const TShape& dshape = in_shape[0];
+ const TShape& kshape = in_shape[1];
+ const TShape& oshape = out_shape[0];
+ CUDNN_CALL(cudnnSetConvolution2dDescriptor(conv_desc_,
+ param_.pad[0],
+ param_.pad[1],
+ param_.stride[0],
+ param_.stride[1],
+ 1,
+ 1,
+ CUDNN_CROSS_CORRELATION,
+ cmp_type_));
+
+ CUDNN_CALL(cudnnSetTensor4dDescriptor(data_desc_,
+ format_,
+ src_type_,
+ dshape[N],
+ dshape[C],
+ dshape[H],
+ dshape[W]));
+ CUDNN_CALL(cudnnSetTensor4dDescriptor(out_desc_,
+ format_,
+ dst_type_,
+ oshape[N],
+ oshape[C],
+ oshape[H],
+ oshape[W]));
+ CUDNN_CALL(cudnnSetFilter4dDescriptor(filter_desc_,
+ src_type_,
+ format_,
+ kshape[N],
+ kshape[C],
+ kshape[H],
+ kshape[W]));
+ }
+
+ void GetTempSize(const OpContext& ctx) {
+ mshadow::Stream<gpu> *s = ctx.get_stream<gpu>();
+ CUDNN_CALL(cudnnGetConvolutionForwardWorkspaceSize(s->dnn_handle_,
+ data_desc_,
+ filter_desc_,
+ conv_desc_,
+ out_desc_,
+ algo_,
+ &workspace_byte_));
+ workspace_ = workspace_byte_ / sizeof(SrcType) + 1;
+ }
+
+ private:
+ ConvolutionParam param_;
+ size_t workspace_;
+ size_t workspace_byte_;
+ cudnnDataType_t src_type_;
+ cudnnDataType_t dst_type_;
+ cudnnDataType_t cmp_type_;
+ cudnnTensorFormat_t format_;
+ cudnnConvolutionDescriptor_t conv_desc_;
+ cudnnTensorDescriptor_t data_desc_;
+ cudnnFilterDescriptor_t filter_desc_;
+ cudnnTensorDescriptor_t out_desc_;
+ cudnnConvolutionFwdAlgo_t algo_;
+ uint32_t N, H, W, C;
+ float alpha_ = 1.0f;
+ float beta_ = 0.0f;
+}; // class QuantizedCuDNNConvOp
+#endif // MXNET_USE_CUDNN == 1 && CUDNN_MAJOR >= 6
+
+void QuantizedConvForwardGPU(const nnvm::NodeAttrs& attrs,
+ const OpContext& ctx,
+ const std::vector<TBlob>& inputs,
+ const std::vector<OpReqType>& req,
+ const std::vector<TBlob>& outputs) {
+ const ConvolutionParam& param = nnvm::get<ConvolutionParam>(attrs.parsed);
+ CHECK_EQ(param.kernel.ndim(), 2U)
+ << "QuantizedConvForward<gpu> only supports 2D convolution for now";
+#if MXNET_USE_CUDNN == 1 && CUDNN_MAJOR >= 6
+ typedef QuantizedCuDNNConvOp<int8_t, float, int32_t> QuantizedConvOpInt8;
+#if DMLC_CXX11_THREAD_LOCAL
+ static thread_local QuantizedConvOpInt8 op;
+#else
+ static MX_THREAD_LOCAL QuantizedConvOpInt8 op;
+#endif // DMLC_CXX11_THREAD_LOCAL
+ op.Init(param, ctx, {inputs[0].shape_, inputs[1].shape_}, {outputs[0].shape_});
+ op.Forward(ctx, inputs, req, outputs);
+#else
+ LOG(FATAL) << "QuantizedConvForward<gpu> only supports cudnnConvolutionForward for now";
+#endif // MXNET_USE_CUDNN == 1 && CUDNN_MAJOR >= 6
+}
+
+NNVM_REGISTER_OP(_contrib_quantized_conv)
+.set_attr<FCompute>("FCompute<gpu>", QuantizedConvForwardGPU);
+
+} // namespace op
+} // namespace mxnet
diff --git a/src/operator/quantization/quantized_flatten-inl.h b/src/operator/quantization/quantized_flatten-inl.h
new file mode 100644
index 00000000000..95f36615402
--- /dev/null
+++ b/src/operator/quantization/quantized_flatten-inl.h
@@ -0,0 +1,110 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * Copyright (c) 2017 by Contributors
+ * \file quantized_flatten-inl.h
+ * \brief implementation of quantized flatten operation
+ */
+#ifndef MXNET_OPERATOR_QUANTIZATION_QUANTIZED_FLATTEN_INL_H_
+#define MXNET_OPERATOR_QUANTIZATION_QUANTIZED_FLATTEN_INL_H_
+
+#include <mxnet/operator_util.h>
+#include <vector>
+#include <limits>
+#include "../elemwise_op_common.h"
+#include "../mshadow_op.h"
+#include "../mxnet_op.h"
+#include "./quantization_utils.h"
+
+namespace mxnet {
+namespace op {
+
+// keep zero-center
+struct quantized_flatten {
+ template<typename DstDType, typename SrcDType>
+ MSHADOW_XINLINE static void Map(int i, DstDType *out, float *omin_range,
+ float *omax_range, const SrcDType *in,
+ const float *imin_range, const float *imax_range) {
+ out[i] = in[i];
+ omin_range[0] = imin_range[0];
+ omax_range[0] = imax_range[0];
+ }
+};
+
+template<typename xpu>
+void QuantizedFlattenCompute(const nnvm::NodeAttrs& attrs,
+ const OpContext& ctx,
+ const std::vector<TBlob>& inputs,
+ const std::vector<OpReqType>& req,
+ const std::vector<TBlob>& outputs) {
+ CHECK_EQ(inputs.size(), 3U);
+ CHECK_EQ(outputs.size(), 3U);
+ CHECK_EQ(req.size(), 3U);
+ if (req[0] == kWriteInplace && req[1] == kWriteInplace && req[2] == kWriteInplace) return;
+ using namespace mshadow;
+ using namespace mxnet_op;
+ Stream<xpu> *s = ctx.get_stream<xpu>();
+
+ typedef int8_t DstDType;
+ typedef int8_t SrcDType;
+ Kernel<quantized_flatten, xpu>::Launch(s, outputs[0].Size(),
+ outputs[0].dptr<DstDType>(), outputs[1].dptr<float>(), outputs[2].dptr<float>(),
+ inputs[0].dptr<SrcDType>(), inputs[1].dptr<float>(), inputs[2].dptr<float>());
+}
+
+inline bool QuantizedFlattenShape(const nnvm::NodeAttrs& attrs,
+ std::vector<TShape> *in_attrs,
+ std::vector<TShape> *out_attrs) {
+ CHECK_EQ(in_attrs->size(), 3U);
+ CHECK_EQ(out_attrs->size(), 3U);
+
+ const TShape &dshape = (*in_attrs)[0];
+ if (shape_is_none(dshape)) return false;
+
+ uint32_t target_dim = 1;
+ for (uint32_t i = 1; i < dshape.ndim(); ++i) {
+ target_dim *= dshape[i];
+ }
+
+ SHAPE_ASSIGN_CHECK(*in_attrs, 1, TShape{1});
+ SHAPE_ASSIGN_CHECK(*in_attrs, 2, TShape{1});
+ SHAPE_ASSIGN_CHECK(*out_attrs, 0, mshadow::Shape2(dshape[0], target_dim));
+ SHAPE_ASSIGN_CHECK(*out_attrs, 1, TShape{1});
+ SHAPE_ASSIGN_CHECK(*out_attrs, 2, TShape{1});
+ return true;
+}
+
+inline bool QuantizedFlattenType(const nnvm::NodeAttrs& attrs,
+ std::vector<int> *in_attrs,
+ std::vector<int> *out_attrs) {
+ CHECK_EQ(in_attrs->size(), 3U);
+ CHECK_EQ(out_attrs->size(), 3U);
+ TYPE_ASSIGN_CHECK(*in_attrs, 0, mshadow::kInt8);
+ TYPE_ASSIGN_CHECK(*in_attrs, 1, mshadow::kFloat32);
+ TYPE_ASSIGN_CHECK(*in_attrs, 2, mshadow::kFloat32);
+ TYPE_ASSIGN_CHECK(*out_attrs, 0, mshadow::kInt8);
+ TYPE_ASSIGN_CHECK(*out_attrs, 1, mshadow::kFloat32);
+ TYPE_ASSIGN_CHECK(*out_attrs, 2, mshadow::kFloat32);
+ return (*in_attrs)[0] != -1;
+}
+
+} // namespace op
+} // namespace mxnet
+#endif // MXNET_OPERATOR_QUANTIZATION_QUANTIZED_FLATTEN_INL_H_
diff --git a/src/operator/quantization/quantized_flatten.cc b/src/operator/quantization/quantized_flatten.cc
new file mode 100644
index 00000000000..3f426a59bdd
--- /dev/null
+++ b/src/operator/quantization/quantized_flatten.cc
@@ -0,0 +1,68 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * Copyright (c) 2017 by Contributors
+ * \file quantized_flatten.cc
+ * \brief
+ */
+#include <mxnet/op_attr_types.h>
+#include "./quantized_flatten-inl.h"
+
+namespace mxnet {
+namespace op {
+
+NNVM_REGISTER_OP(_contrib_quantized_flatten)
+.set_num_inputs(3)
+.set_num_outputs(3)
+.set_attr<nnvm::FInferShape>("FInferShape", QuantizedFlattenShape)
+.set_attr<nnvm::FInferType>("FInferType", QuantizedFlattenType)
+.set_attr<FCompute>("FCompute<cpu>", QuantizedFlattenCompute<cpu>)
+.set_attr<nnvm::FListInputNames>("FListInputNames",
+ [](const NodeAttrs& attrs) {
+ return std::vector<std::string>{"data", "min_data", "max_data"};
+ })
+.set_attr<nnvm::FListOutputNames>("FListOutputNames",
+ [](const NodeAttrs& attrs) {
+ return std::vector<std::string>{"output", "min_output", "max_output"};
+ })
+.set_attr<nnvm::FInplaceOption>("FInplaceOption",
+ [](const NodeAttrs& attrs){
+ return std::vector<std::pair<int, int> >{{0, 0}, {1, 1}, {2, 2}};
+ })
+.add_argument("data", "NDArray-or-Symbol", "A ndarray/symbol of type `float32`")
+.add_argument("min_data", "NDArray-or-Symbol", "The minimum scalar value "
+ "possibly produced for the data")
+.add_argument("max_data", "NDArray-or-Symbol", "The maximum scalar value "
+ "possibly produced for the data");
+
+NNVM_REGISTER_OP(Flatten)
+.set_attr<FQuantizedOp>("FQuantizedOp", [](const NodeAttrs& attrs) {
+ nnvm::NodePtr node = nnvm::Node::Create();
+ node->attrs.op = Op::Get("_contrib_quantized_flatten");
+ node->attrs.name = "quantized_" + attrs.name;
+ node->attrs.dict = attrs.dict;
+ if (node->op()->attr_parser != nullptr) {
+ node->op()->attr_parser(&(node->attrs));
+ }
+ return node;
+ });
+
+} // namespace op
+} // namespace mxnet
diff --git a/src/operator/quantization/quantized_flatten.cu b/src/operator/quantization/quantized_flatten.cu
new file mode 100644
index 00000000000..4f0c8f93ab0
--- /dev/null
+++ b/src/operator/quantization/quantized_flatten.cu
@@ -0,0 +1,34 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * Copyright (c) 2017 by Contributors
+ * \file quantized_flatten.cu
+ * \brief
+ */
+#include "./quantized_flatten-inl.h"
+
+namespace mxnet {
+namespace op {
+
+NNVM_REGISTER_OP(_contrib_quantized_flatten)
+.set_attr<FCompute>("FCompute<gpu>", QuantizedFlattenCompute<gpu>);
+
+} // namespace op
+} // namespace mxnet
diff --git a/src/operator/quantization/quantized_fully_connected.cc b/src/operator/quantization/quantized_fully_connected.cc
new file mode 100644
index 00000000000..e334fe7ec9b
--- /dev/null
+++ b/src/operator/quantization/quantized_fully_connected.cc
@@ -0,0 +1,140 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * Copyright (c) 2017 by Contributors
+ * \file quantized_fully_connected.cc
+ * \brief
+ * \author Ziheng Jiang, Jun Wu
+*/
+#include "../nn/fully_connected-inl.h"
+
+namespace mxnet {
+namespace op {
+
+bool QuantizedFullyConnectedShape(const nnvm::NodeAttrs& attrs,
+ std::vector<TShape> *in_shape,
+ std::vector<TShape> *out_shape) {
+ const FullyConnectedParam& param = nnvm::get<FullyConnectedParam>(attrs.parsed);
+ CHECK(param.flatten) << "QuantizedFullyConnectedOp only supports flatten=true for now";
+ using namespace mshadow;
+ uint32_t num_inputs = param.no_bias ? 2 : 3;
+ CHECK_EQ(in_shape->size(), num_inputs * 3);
+ CHECK_EQ(out_shape->size(), 3U);
+
+ CHECK(!shape_is_none(in_shape->at(0)))
+ << "QuantizedFullyConnectedOp input data shape must be given";
+ const TShape& dshape = in_shape->at(0);
+ TShape wshape = Shape2(param.num_hidden, dshape.ProdShape(1, dshape.ndim()));
+ SHAPE_ASSIGN_CHECK(*in_shape, 1, wshape);
+ if (!param.no_bias) {
+ TShape bshape = Shape1(param.num_hidden);
+ SHAPE_ASSIGN_CHECK(*in_shape, 2, bshape);
+ }
+
+ for (size_t i = num_inputs; i < 3 * num_inputs; ++i) {
+ SHAPE_ASSIGN_CHECK(*in_shape, i, TShape{1});
+ }
+
+ SHAPE_ASSIGN_CHECK(*out_shape, 0, TShape({dshape[0], wshape[0]}));
+ SHAPE_ASSIGN_CHECK(*out_shape, 1, TShape({1}));
+ SHAPE_ASSIGN_CHECK(*out_shape, 2, TShape({1}));
+ return true;
+}
+
+bool QuantizedFullyConnectedType(const nnvm::NodeAttrs& attrs,
+ std::vector<int> *in_type,
+ std::vector<int> *out_type) {
+ const FullyConnectedParam& param = nnvm::get<FullyConnectedParam>(attrs.parsed);
+ uint32_t num_inputs = param.no_bias ? 2 : 3;
+ CHECK_EQ(in_type->size(), num_inputs * 3);
+ CHECK_EQ(out_type->size(), 3U);
+
+ for (size_t i = 0; i < num_inputs; ++i) {
+ TYPE_ASSIGN_CHECK(*in_type, i, mshadow::kInt8);
+ }
+ for (size_t i = num_inputs; i < 3 * num_inputs; ++i) {
+ TYPE_ASSIGN_CHECK(*in_type, i, mshadow::kFloat32);
+ }
+
+ TYPE_ASSIGN_CHECK(*out_type, 0, mshadow::kInt32);
+ TYPE_ASSIGN_CHECK(*out_type, 1, mshadow::kFloat32);
+ TYPE_ASSIGN_CHECK(*out_type, 2, mshadow::kFloat32);
+ return true;
+}
+
+NNVM_REGISTER_OP(_contrib_quantized_fully_connected)
+.describe(R"code(Fully Connected operator for input, weight and bias data type of int8,
+and accumulates in type int32 for the output. For each argument, two more arguments of type
+float32 must be provided representing the thresholds of quantizing argument from data
+type float32 to int8. The final outputs contain the convolution result in int32, and min
+and max thresholds representing the threholds for quantizing the float32 output into int32.
+
+.. Note::
+ This operator only supports forward propogation. DO NOT use it in training.)code" ADD_FILELINE)
+.set_num_inputs(
+ [](const NodeAttrs& attrs) {
+ const FullyConnectedParam& param = nnvm::get<FullyConnectedParam>(attrs.parsed);
+ return param.no_bias? 6 : 9;
+ })
+.set_num_outputs(3)
+.set_attr_parser(ParamParser<FullyConnectedParam>)
+.set_attr<nnvm::FListInputNames>("FListInputNames",
+ [](const NodeAttrs& attrs) {
+ const FullyConnectedParam& param = nnvm::get<FullyConnectedParam>(attrs.parsed);
+ if (param.no_bias) {
+ return std::vector<std::string>{"data", "weight", "min_data", "max_data",
+ "min_weight", "max_weight"};
+ } else {
+ return std::vector<std::string>{"data", "weight", "bias", "min_data", "max_data",
+ "min_weight", "max_weight", "min_bias", "max_bias"};
+ }
+ })
+.set_attr<nnvm::FListOutputNames>("FListOutputNames",
+ [](const NodeAttrs& attrs) {
+ return std::vector<std::string>{"output", "min_output", "max_output"};
+ })
+.set_attr<nnvm::FInferShape>("FInferShape", QuantizedFullyConnectedShape)
+.set_attr<nnvm::FInferType>("FInferType", QuantizedFullyConnectedType)
+.set_attr<FNeedRequantize>("FNeedRequantize", [](const NodeAttrs& attrs) { return true; })
+.add_argument("data", "NDArray-or-Symbol", "Input data.")
+.add_argument("weight", "NDArray-or-Symbol", "weight.")
+.add_argument("bias", "NDArray-or-Symbol", "bias.")
+.add_argument("min_data", "NDArray-or-Symbol", "Minimum value of data.")
+.add_argument("max_data", "NDArray-or-Symbol", "Maximum value of data.")
+.add_argument("min_weight", "NDArray-or-Symbol", "Minimum value of weight.")
+.add_argument("max_weight", "NDArray-or-Symbol", "Maximum value of weight.")
+.add_argument("min_bias", "NDArray-or-Symbol", "Minimum value of bias.")
+.add_argument("max_bias", "NDArray-or-Symbol", "Maximum value of bias.")
+.add_arguments(FullyConnectedParam::__FIELDS__());
+
+NNVM_REGISTER_OP(FullyConnected)
+.set_attr<FQuantizedOp>("FQuantizedOp", [](const NodeAttrs& attrs) {
+ nnvm::NodePtr node = nnvm::Node::Create();
+ node->attrs.op = Op::Get("_contrib_quantized_fully_connected");
+ node->attrs.name = "quantized_" + attrs.name;
+ node->attrs.dict = attrs.dict;
+ if (node->op()->attr_parser != nullptr) {
+ node->op()->attr_parser(&(node->attrs));
+ }
+ return node;
+ });
+
+} // namespace op
+} // namespace mxnet
diff --git a/src/operator/quantization/quantized_fully_connected.cu b/src/operator/quantization/quantized_fully_connected.cu
new file mode 100644
index 00000000000..ac7ba1e21df
--- /dev/null
+++ b/src/operator/quantization/quantized_fully_connected.cu
@@ -0,0 +1,122 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * Copyright (c) 2017 by Contributors
+ * \file quantized_fully_connected.cu
+ * \brief
+ * \author Ziheng Jiang, Jun Wu
+*/
+#include "./quantization_utils.h"
+#include "../mxnet_op.h"
+#include "../nn/fully_connected-inl.h"
+
+namespace mxnet {
+namespace op {
+
+// value + bias_value * (range1 / limit_range1) * (limit_range2 / range2)
+struct QuantizedBiasAddKernel {
+ MSHADOW_XINLINE static void Map(int i, size_t k, int32_t *out,
+ const int8_t *bias, const float *min_out,
+ const float *max_out, const float *min_bias,
+ const float *max_bias) {
+ typedef int32_t T1;
+ typedef int8_t T2;
+ using mshadow::red::limits::MinValue;
+ using mshadow::red::limits::MaxValue;
+ float float_for_one_out_quant =
+ MaxAbs(*min_out, *max_out) / static_cast<double>(MaxValue<T1>());
+ float float_for_one_bias_quant =
+ MaxAbs(*min_bias, *max_bias) / static_cast<double>(MaxValue<T2>());
+ out[i] = (out[i] * float_for_one_out_quant +
+ bias[i%k] * float_for_one_bias_quant) /
+ float_for_one_out_quant;
+ }
+};
+
+template<typename SrcType, typename DstType, typename CmpType>
+void QuantizedFullyConnectedForwardGPU(const nnvm::NodeAttrs& attrs,
+ const OpContext &ctx,
+ const std::vector<TBlob> &inputs,
+ const std::vector<OpReqType> &req,
+ const std::vector<TBlob> &outputs) {
+ const FullyConnectedParam& param = nnvm::get<FullyConnectedParam>(attrs.parsed);
+ using namespace mshadow;
+ using namespace mxnet_op;
+ size_t num_inputs = param.no_bias ? 2 : 3;
+ CHECK_EQ(inputs.size(), num_inputs * 3);
+ CHECK_EQ(outputs.size(), 3U);
+ Stream<gpu> *s = ctx.get_stream<gpu>();
+ CHECK_EQ(s->blas_handle_ownership_, Stream<gpu>::OwnHandle);
+ const TBlob& data = inputs[0];
+ const TBlob& weight = inputs[1];
+ const TBlob& out = outputs[0];
+ TShape dshape = data.shape_;
+ TShape wshape = weight.shape_;
+ TShape oshape = out.shape_;
+ // (m, n) * (k, n).T = (m, k)
+ // A * B.T = C
+
+ // row_C = col_C(T) = cublas(col_B * col_A(T)) = cublas(row_B(T), row_A)
+ // row_C = col_C(T) = cublas(col_B(T) * col_A(T)) = cublas(row_B, row_A)
+ const int m = dshape[0], n = dshape.ProdShape(1, dshape.ndim()), k = wshape[0];
+ CmpType alpha = 1.0f;
+ CmpType beta = 0.0f;
+ const cudaDataType src_type = mshadow::DataType<SrcType>::kCudaFlag;
+ const cudaDataType dst_type = mshadow::DataType<DstType>::kCudaFlag;
+ const cudaDataType cmp_type = mshadow::DataType<CmpType>::kCudaFlag;
+ CUBLAS_CALL(cublasGemmEx(s->blas_handle_,
+ CUBLAS_OP_T,
+ CUBLAS_OP_N,
+ k,
+ m,
+ n,
+ &alpha,
+ weight.dptr_,
+ src_type,
+ n,
+ data.dptr_,
+ src_type,
+ n,
+ &beta,
+ out.dptr_,
+ dst_type,
+ k,
+ cmp_type,
+ CUBLAS_GEMM_DFALT));
+
+ Kernel<QuantizationRangeForMultiplicationStruct, gpu>::Launch(s, 1,
+ outputs[1].dptr<float>(), outputs[2].dptr<float>(),
+ inputs[num_inputs].dptr<float>(), inputs[num_inputs+1].dptr<float>(),
+ inputs[num_inputs+2].dptr<float>(), inputs[num_inputs+3].dptr<float>());
+
+ if (!param.no_bias) {
+ const TBlob& bias = inputs[2];
+ Kernel<QuantizedBiasAddKernel, gpu>::Launch(s, out.Size(),
+ k, out.dptr<int32_t>(), bias.dptr<int8_t>(),
+ outputs[1].dptr<float>(), outputs[2].dptr<float>(),
+ inputs[7].dptr<float>(), inputs[8].dptr<float>());
+ }
+}
+
+NNVM_REGISTER_OP(_contrib_quantized_fully_connected)
+.set_attr<FCompute>("FCompute<gpu>", QuantizedFullyConnectedForwardGPU<int8_t, int32_t, int32_t>);
+
+} // namespace op
+} // namespace mxnet
diff --git a/src/operator/quantization/quantized_pooling.cc b/src/operator/quantization/quantized_pooling.cc
new file mode 100644
index 00000000000..71f4e738161
--- /dev/null
+++ b/src/operator/quantization/quantized_pooling.cc
@@ -0,0 +1,150 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * Copyright (c) 2017 by Contributors
+ * \file quantized_pooling.cc
+*/
+#include <mxnet/op_attr_types.h>
+#include "../nn/pooling-inl.h"
+
+namespace mxnet {
+namespace op {
+
+bool QuantizedPoolingShape(const nnvm::NodeAttrs& attrs,
+ std::vector<TShape> *in_shape,
+ std::vector<TShape> *out_shape) {
+ const PoolingParam& param = nnvm::get<PoolingParam>(attrs.parsed);
+ CHECK_EQ(in_shape->size(), 3U);
+ if (shape_is_none(in_shape->at(0))) return false;
+ const TShape &dshape = (*in_shape)[0];
+ CHECK_EQ(dshape.ndim(), 4U)
+ << "quantized_pooling: Input data should be 4D in "
+ << "(batch, channel, y, x)";
+ // NCHW layout
+ const int N = 0, H = 2, W = 3, C = 1;
+ TShape oshape(4);
+ CHECK_EQ(param.kernel.ndim(), 2) << "QuantizedPoolingOp only supports 2D pooling for now";
+ CHECK(param.kernel[0] <= dshape[H] + 2 * param.pad[0])
+ << "kernel size (" << param.kernel[0]
+ << ") exceeds input (" << dshape[H]
+ << " padded to " << (dshape[H] + 2*param.pad[0]) << ")";
+ CHECK(param.kernel[1] <= dshape[W] + 2 * param.pad[1])
+ << "kernel size (" << param.kernel[1]
+ << ") exceeds input (" << dshape[W]
+ << " padded to " << (dshape[W] + 2*param.pad[1]) << ")";
+ // only support valid convention
+ oshape[N] = dshape[N];
+ oshape[C] = dshape[C];
+ if (param.global_pool) {
+ oshape[H] = 1;
+ oshape[W] = 1;
+ } else {
+ oshape[H] = 1 + (dshape[H] + 2 * param.pad[0] - param.kernel[0]) /
+ param.stride[0];
+ oshape[W] = 1 + (dshape[W] + 2 * param.pad[1] - param.kernel[1]) /
+ param.stride[1];
+ }
+
+ SHAPE_ASSIGN_CHECK(*in_shape, 1, TShape{1});
+ SHAPE_ASSIGN_CHECK(*in_shape, 2, TShape{1});
+
+ out_shape->clear();
+ out_shape->push_back(oshape);
+ out_shape->push_back(TShape{1});
+ out_shape->push_back(TShape{1});
+ return true;
+}
+
+bool QuantizedPoolingType(const nnvm::NodeAttrs& attrs,
+ std::vector<int> *in_type,
+ std::vector<int> *out_type) {
+ const PoolingParam& param = nnvm::get<PoolingParam>(attrs.parsed);
+ CHECK_EQ(in_type->size(), 3U);
+ CHECK_EQ(out_type->size(), 3U);
+ if (param.pool_type == pool_enum::kMaxPooling || param.pool_type == pool_enum::kAvgPooling) {
+ TYPE_ASSIGN_CHECK(*in_type, 0, mshadow::kInt8);
+ TYPE_ASSIGN_CHECK(*out_type, 0, mshadow::kInt8);
+ } else {
+ LOG(FATAL) << "QuantizedPoolingOp only supports pool_type=max/avg for now";
+ }
+ TYPE_ASSIGN_CHECK(*in_type, 1, mshadow::kFloat32);
+ TYPE_ASSIGN_CHECK(*in_type, 2, mshadow::kFloat32);
+ TYPE_ASSIGN_CHECK(*out_type, 1, mshadow::kFloat32);
+ TYPE_ASSIGN_CHECK(*out_type, 2, mshadow::kFloat32);
+ return true;
+}
+
+NNVM_REGISTER_OP(_contrib_quantized_pooling)
+.set_num_inputs(3)
+.set_num_outputs(3)
+.set_attr_parser(ParamParser<PoolingParam>)
+.set_attr<nnvm::FListInputNames>("FListInputNames",
+ [](const NodeAttrs& attrs) {
+ return std::vector<std::string>{"data", "min_data", "max_data"};
+ })
+.set_attr<nnvm::FListOutputNames>("FListOutputNames",
+ [](const NodeAttrs& attrs) {
+ return std::vector<std::string>{"output", "min_output", "max_output"};
+ })
+.set_attr<nnvm::FInferShape>("FInferShape", QuantizedPoolingShape)
+.set_attr<nnvm::FInferType>("FInferType", QuantizedPoolingType)
+.set_attr<FNeedRequantize>("FNeedRequantize",
+ [](const NodeAttrs& attrs) {
+ const PoolingParam& param = nnvm::get<PoolingParam>(attrs.parsed);
+ CHECK(param.pool_type == pool_enum::kMaxPooling || param.pool_type == pool_enum::kAvgPooling)
+ << "QuantizedPoolingOp only supports pool_type=max/avg for now";
+ return false;
+ })
+.add_argument("data", "NDArray-or-Symbol", "Input data.")
+.add_argument("min_data", "NDArray-or-Symbol", "Minimum value of data.")
+.add_argument("max_data", "NDArray-or-Symbol", "Maximum value of data.")
+.add_arguments(PoolingParam::__FIELDS__());
+
+NNVM_REGISTER_OP(Pooling)
+.describe(R"code(Pooling operator for input and output data type of int8.
+The input and output data comes with min and max thresholds for quantizing
+the float32 data into int8.
+
+.. Note::
+ This operator only supports forward propogation. DO NOT use it in training.
+ This operator only supports `pool_type` of `avg` or `max`.)code" ADD_FILELINE)
+.set_attr<FQuantizedOp>("FQuantizedOp", [](const NodeAttrs& attrs) {
+ PoolingParam param;
+ param.Init(attrs.dict);
+ // TODO(junwu): Uncomment the following line and remove the above lines
+ // after pooling op is refactored
+ // const PoolingParam& param = nnvm::get<PoolingParam>(attrs.parsed);
+ nnvm::NodePtr node = nnvm::Node::Create();
+ if (param.pool_type == pool_enum::kMaxPooling || param.pool_type == pool_enum::kAvgPooling) {
+ node->attrs.op = Op::Get("_contrib_quantized_pooling");
+ node->attrs.name = "quantized_" + attrs.name;
+ } else {
+ node->attrs.op = Op::Get("Pooling");
+ node->attrs.name = attrs.name;
+ }
+ node->attrs.dict = attrs.dict;
+ if (node->op()->attr_parser != nullptr) {
+ node->op()->attr_parser(&(node->attrs));
+ }
+ return node;
+ });
+
+} // namespace op
+} // namespace mxnet
diff --git a/src/operator/quantization/quantized_pooling.cu b/src/operator/quantization/quantized_pooling.cu
new file mode 100644
index 00000000000..78011b885c5
--- /dev/null
+++ b/src/operator/quantization/quantized_pooling.cu
@@ -0,0 +1,145 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * Copyright (c) 2017 by Contributors
+ * \file quantized_pooling.cu
+*/
+#include <mxnet/operator_util.h>
+#include <vector>
+#include "../nn/pooling-inl.h"
+#include "../mshadow_op.h"
+
+namespace mxnet {
+namespace op {
+
+#if MXNET_USE_CUDNN == 1 && CUDNN_MAJOR >= 6
+template<typename DType>
+class QuantizedCuDNNPoolingOp {
+ public:
+ QuantizedCuDNNPoolingOp() {
+ CUDNN_CALL(cudnnCreatePoolingDescriptor(&pool_desc_));
+ CUDNN_CALL(cudnnCreateTensorDescriptor(&in_desc_));
+ CUDNN_CALL(cudnnCreateTensorDescriptor(&out_desc_));
+ }
+
+ void Init(const PoolingParam& param, const TShape& dshape, const TShape& oshape) {
+ const int N = 0, H = 2, W = 3, C = 1;
+ const cudnnDataType_t dtype = mshadow::DataType<DType>::kCudnnFlag;
+ CHECK(param.kernel.ndim() == 2) << "Only support 2D pooling";
+ if (param.pool_type == pool_enum::kMaxPooling) {
+ mode_ = CUDNN_POOLING_MAX;
+ } else if (param.pool_type == pool_enum::kAvgPooling) {
+ mode_ = CUDNN_POOLING_AVERAGE_COUNT_INCLUDE_PADDING;
+ } else {
+ LOG(FATAL) << "QuantizedCuDNNPoolingOp only supports pool_type=max/avg";
+ }
+ CUDNN_CALL(cudnnSetTensor4dDescriptor(in_desc_,
+ CUDNN_TENSOR_NCHW,
+ dtype,
+ dshape[N],
+ dshape[C],
+ dshape[H],
+ dshape[W]));
+ CUDNN_CALL(cudnnSetTensor4dDescriptor(out_desc_,
+ CUDNN_TENSOR_NCHW,
+ dtype,
+ oshape[N],
+ oshape[C],
+ oshape[H],
+ oshape[W]));
+ CUDNN_CALL(cudnnSetPooling2dDescriptor(pool_desc_,
+ mode_,
+ CUDNN_NOT_PROPAGATE_NAN,
+ param.global_pool ? dshape[2] : param.kernel[0],
+ param.global_pool ? dshape[3] : param.kernel[1],
+ param.pad[0],
+ param.pad[1],
+ param.global_pool ? 1 : param.stride[0],
+ param.global_pool ? 1 :param.stride[1]));
+ }
+
+ ~QuantizedCuDNNPoolingOp() {
+ CUDNN_CALL(cudnnDestroyTensorDescriptor(in_desc_));
+ CUDNN_CALL(cudnnDestroyTensorDescriptor(out_desc_));
+ CUDNN_CALL(cudnnDestroyPoolingDescriptor(pool_desc_));
+ }
+
+ void Forward(mshadow::Stream<gpu>* s,
+ const std::vector<TBlob> &inputs,
+ const std::vector<OpReqType> &req,
+ const std::vector<TBlob> &outputs) {
+ CHECK_EQ(inputs.size(), 3U);
+ CHECK_EQ(outputs.size(), 3U);
+ using namespace mshadow;
+ using namespace mshadow::expr;
+ CHECK_EQ(s->dnn_handle_ownership_, mshadow::Stream<gpu>::OwnHandle);
+ float alpha = 1.0f;
+ float beta = 0.0f;
+ CUDNN_CALL(cudnnPoolingForward(s->dnn_handle_,
+ pool_desc_,
+ &alpha,
+ in_desc_,
+ inputs[0].dptr_,
+ &beta,
+ out_desc_,
+ outputs[0].dptr_));
+
+ Tensor<gpu, 1, float> omin_range = outputs[1].FlatTo1D<gpu, float>(s);
+ Tensor<gpu, 1, float> omax_range = outputs[2].FlatTo1D<gpu, float>(s);
+ ASSIGN_DISPATCH(omin_range, req[1],
+ F<mshadow_op::identity>(inputs[1].FlatTo1D<gpu, float>(s)));
+ ASSIGN_DISPATCH(omax_range, req[2],
+ F<mshadow_op::identity>(inputs[2].FlatTo1D<gpu, float>(s)));
+ }
+
+ private:
+ cudnnPoolingMode_t mode_;
+ cudnnTensorDescriptor_t in_desc_;
+ cudnnTensorDescriptor_t out_desc_;
+ cudnnPoolingDescriptor_t pool_desc_;
+}; // class QuantizedCuDNNPoolingOp
+#endif // MXNET_USE_CUDNN == 1 && CUDNN_MAJOR >= 6
+
+void QuantizedPoolingForwardGPU(const nnvm::NodeAttrs& attrs,
+ const OpContext& ctx,
+ const std::vector<TBlob>& inputs,
+ const std::vector<OpReqType>& req,
+ const std::vector<TBlob>& outputs) {
+ const PoolingParam& param = nnvm::get<PoolingParam>(attrs.parsed);
+ CHECK_EQ(param.kernel.ndim(), 2U)
+ << "QuantizedPoolingForward<gpu> only supports 2D convolution for now";
+#if MXNET_USE_CUDNN == 1 && CUDNN_MAJOR >= 6
+#if DMLC_CXX11_THREAD_LOCAL
+ static thread_local QuantizedCuDNNPoolingOp<int8_t> op;
+#else
+ static MX_THREAD_LOCAL QuantizedCuDNNPoolingOp<int8_t> op;
+#endif // DMLC_CXX11_THREAD_LOCAL
+ op.Init(param, {inputs[0].shape_}, {outputs[0].shape_});
+ op.Forward(ctx.get_stream<gpu>(), inputs, req, outputs);
+#else
+ LOG(FATAL) << "QuantizedPoolingForward<gpu> only supports cudnnPoolingForward for now";
+#endif // MXNET_USE_CUDNN == 1 && CUDNN_MAJOR >= 6
+}
+
+NNVM_REGISTER_OP(_contrib_quantized_pooling)
+.set_attr<FCompute>("FCompute<gpu>", QuantizedPoolingForwardGPU);
+
+} // namespace op
+} // namespace mxnet
diff --git a/src/operator/quantization/requantize-inl.h b/src/operator/quantization/requantize-inl.h
new file mode 100644
index 00000000000..e07a149f8a6
--- /dev/null
+++ b/src/operator/quantization/requantize-inl.h
@@ -0,0 +1,167 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * Copyright (c) 2017 by Contributors
+ * \file requantize-inl.h
+ * \brief implementation of quantize operation
+ */
+#ifndef MXNET_OPERATOR_QUANTIZATION_REQUANTIZE_INL_H_
+#define MXNET_OPERATOR_QUANTIZATION_REQUANTIZE_INL_H_
+
+#include <mxnet/operator_util.h>
+#include <vector>
+#include <limits>
+#include "../elemwise_op_common.h"
+#include "../mshadow_op.h"
+#include "../mxnet_op.h"
+#include "./quantization_utils.h"
+#include "../tensor/broadcast_reduce_op.h"
+
+namespace mxnet {
+namespace op {
+
+struct RequantizeParam : public dmlc::Parameter<RequantizeParam> {
+ dmlc::optional<float> min_calib_range; // min float value calculated from calibration dataset
+ dmlc::optional<float> max_calib_range; // max float value calculated from calibration dataset
+ DMLC_DECLARE_PARAMETER(RequantizeParam) {
+ DMLC_DECLARE_FIELD(min_calib_range)
+ .set_default(dmlc::optional<float>())
+ .describe("The minimum scalar value in the form of float32 obtained "
+ "through calibration. If present, it will be used to requantize the "
+ "int32 data into int8.");
+ DMLC_DECLARE_FIELD(max_calib_range)
+ .set_default(dmlc::optional<float>())
+ .describe("The maximum scalar value in the form of float32 obtained "
+ "through calibration. If present, it will be used to requantize the "
+ "int32 data into int8.");
+ }
+};
+
+inline bool RequantizeType(const nnvm::NodeAttrs& attrs,
+ std::vector<int> *in_attrs,
+ std::vector<int> *out_attrs) {
+ CHECK_EQ(in_attrs->size(), 3U);
+ CHECK_EQ(out_attrs->size(), 3U);
+ TYPE_ASSIGN_CHECK(*in_attrs, 0, mshadow::kInt32);
+ TYPE_ASSIGN_CHECK(*in_attrs, 1, mshadow::kFloat32);
+ TYPE_ASSIGN_CHECK(*in_attrs, 2, mshadow::kFloat32);
+ TYPE_ASSIGN_CHECK(*out_attrs, 0, mshadow::kInt8);
+ TYPE_ASSIGN_CHECK(*out_attrs, 1, mshadow::kFloat32);
+ TYPE_ASSIGN_CHECK(*out_attrs, 2, mshadow::kFloat32);
+ return (*in_attrs)[0] != -1;
+}
+
+struct RequantizeKernel {
+ template<typename T1, typename T2>
+ MSHADOW_XINLINE static void Map(int i, T2 *output, float *omin_range, float *omax_range,
+ const T1 *input, const float *imin_range, const float *imax_range, const float real_range) {
+ const float input_float = QuantizedToFloat<T1>(input[i], *imin_range, *imax_range);
+ *omin_range = -real_range;
+ *omax_range = real_range;
+ output[i] = FloatToQuantized<T2>(input_float, -real_range, real_range);
+ }
+
+ template<typename T1, typename T2>
+ MSHADOW_XINLINE static void Map(int i, T2 *output, float *omin_range, float *omax_range,
+ const T1 *input, const float *imin_range, const float *imax_range,
+ const float *actual_min, const float *actual_max) {
+ Map(i, output, omin_range, omax_range, input, imin_range, imax_range,
+ MaxAbs(*actual_min, *actual_max));
+ }
+};
+
+template<typename xpu, typename DType>
+inline size_t ConfigReduce(mshadow::Stream<xpu>* s,
+ const TShape& data_shape,
+ const TShape& out_shape,
+ TShape* src_shape,
+ TShape* dst_shape) {
+ BroadcastReduceShapeCompact(data_shape, out_shape, src_shape, dst_shape);
+ constexpr int NDim = 2;
+ CHECK_EQ(src_shape->ndim(), NDim);
+ CHECK_EQ(dst_shape->ndim(), NDim);
+
+ return broadcast::ReduceWorkspaceSize<NDim, DType>(s, *dst_shape, kWriteTo, *src_shape);
+}
+
+template<typename xpu>
+void RequantizeForward(const nnvm::NodeAttrs& attrs,
+ const OpContext& ctx,
+ const std::vector<TBlob>& inputs,
+ const std::vector<OpReqType>& req,
+ const std::vector<TBlob>& outputs) {
+ using namespace mshadow;
+ using namespace mxnet_op;
+ typedef int32_t SrcDType;
+ typedef int8_t DstDType;
+ Stream<xpu> *s = ctx.get_stream<xpu>();
+ const RequantizeParam& param =
+ nnvm::get<RequantizeParam>(attrs.parsed);
+
+ if (param.min_calib_range.has_value() && param.max_calib_range.has_value()) {
+ Kernel<RequantizeKernel, xpu>::Launch(s, inputs[0].Size(),
+ outputs[0].dptr<DstDType>(), outputs[1].dptr<float>(), outputs[2].dptr<float>(),
+ inputs[0].dptr<SrcDType>(), inputs[1].dptr<float>(), inputs[2].dptr<float>(),
+ MaxAbs(param.min_calib_range.value(), param.max_calib_range.value()));
+ } else { // model is not calibrated
+ TShape src_shape, dst_shape;
+ const size_t actual_float_size = sizeof(float);
+ const size_t actual_quantized_size = sizeof(SrcDType);
+ const size_t temp_reduce_size = ConfigReduce<xpu, SrcDType>(
+ s, inputs[0].shape_, TShape({1}), &src_shape, &dst_shape);
+ Tensor<xpu, 1, char> temp_space =
+ ctx.requested[0].get_space_typed<xpu, 1, char>(
+ Shape1(2*actual_float_size+2*actual_quantized_size+temp_reduce_size), s);
+ Tensor<xpu, 1, float> actual_min_float(
+ reinterpret_cast<float*>(temp_space.dptr_), Shape1(1), s);
+ Tensor<xpu, 1, float> actual_max_float(
+ reinterpret_cast<float*>(temp_space.dptr_) + 1, Shape1(1), s);
+
+ const int dev_id = ctx.run_ctx.ctx.dev_id;
+ TBlob actual_min_quantized(reinterpret_cast<SrcDType*>(
+ temp_space.dptr_ + 8), Shape1(1), xpu::kDevMask, dev_id);
+ TBlob actual_max_quantized(reinterpret_cast<SrcDType*>(
+ temp_space.dptr_ + 8) + 1, Shape1(1), xpu::kDevMask, dev_id);
+ Tensor<xpu, 1, char> workspace(
+ temp_space.dptr_+2*actual_float_size+2*actual_quantized_size, Shape1(temp_reduce_size), s);
+ broadcast::Reduce<red::minimum, 2, SrcDType, mshadow::op::identity>(
+ s, actual_min_quantized.reshape(dst_shape),
+ kWriteTo, workspace, inputs[0].reshape(src_shape));
+ Kernel<QuantizedToFloatStruct, xpu>::Launch(s, 1,
+ actual_min_float.dptr_, actual_min_quantized.dptr<SrcDType>(),
+ inputs[1].dptr<float>(), inputs[2].dptr<float>());
+
+ broadcast::Reduce<red::maximum, 2, SrcDType, mshadow::op::identity>(
+ s, actual_max_quantized.reshape(dst_shape),
+ kWriteTo, workspace, inputs[0].reshape(src_shape));
+ Kernel<QuantizedToFloatStruct, xpu>::Launch(s, 1,
+ actual_max_float.dptr_, actual_max_quantized.dptr<SrcDType>(),
+ inputs[1].dptr<float>(), inputs[2].dptr<float>());
+
+ Kernel<RequantizeKernel, xpu>::Launch(s, inputs[0].Size(),
+ outputs[0].dptr<DstDType>(), outputs[1].dptr<float>(), outputs[2].dptr<float>(),
+ inputs[0].dptr<SrcDType>(), inputs[1].dptr<float>(), inputs[2].dptr<float>(),
+ actual_min_float.dptr_, actual_max_float.dptr_);
+ }
+}
+
+} // namespace op
+} // namespace mxnet
+#endif // MXNET_OPERATOR_QUANTIZATION_REQUANTIZE_INL_H_
diff --git a/src/operator/quantization/requantize.cc b/src/operator/quantization/requantize.cc
new file mode 100644
index 00000000000..83ea37b835c
--- /dev/null
+++ b/src/operator/quantization/requantize.cc
@@ -0,0 +1,64 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * Copyright (c) 2017 by Contributors
+ * \file requantize.cc
+ * \brief
+ */
+#include "./requantize-inl.h"
+#include "./quantize-inl.h"
+
+namespace mxnet {
+namespace op {
+DMLC_REGISTER_PARAMETER(RequantizeParam);
+
+NNVM_REGISTER_OP(_contrib_requantize)
+.describe(R"code(Given data that is quantized in int32 and the corresponding thresholds,
+requantize the data into int8 using min and max thresholds either calculated at runtime
+or from calibration. It's highly recommended to pre-calucate the min and max thresholds
+through calibration since it is able to save the runtime of the operator and improve the
+inference accuracy.
+
+.. Note::
+ This operator only supports forward propogation. DO NOT use it in training.)code" ADD_FILELINE)
+.set_attr_parser(ParamParser<RequantizeParam>)
+.set_num_inputs(3)
+.set_num_outputs(3)
+.set_attr<nnvm::FInferShape>("FInferShape", QuantizeShape)
+.set_attr<nnvm::FInferType>("FInferType", RequantizeType)
+.set_attr<FCompute>("FCompute<cpu>", RequantizeForward<cpu>)
+.set_attr<FResourceRequest>("FResourceRequest", [](const NodeAttrs& attrs) {
+ const RequantizeParam& param =
+ nnvm::get<RequantizeParam>(attrs.parsed);
+ if (param.min_calib_range.has_value() && param.max_calib_range.has_value()) {
+ return std::vector<ResourceRequest>();
+ } else {
+ return std::vector<ResourceRequest>(1, ResourceRequest::kTempSpace);
+ }
+ })
+.add_argument("data", "NDArray-or-Symbol", "A ndarray/symbol of type `int32`")
+.add_argument("min_range", "NDArray-or-Symbol", "The original minimum scalar value "
+ "in the form of float32 used for quantizing data into int32.")
+.add_argument("max_range", "NDArray-or-Symbol", "The original maximum scalar value "
+ "in the form of float32 used for quantizing data into int32.")
+.add_arguments(RequantizeParam::__FIELDS__());
+
+} // namespace op
+} // namespace mxnet
diff --git a/src/operator/quantization/requantize.cu b/src/operator/quantization/requantize.cu
new file mode 100644
index 00000000000..be8ae59124e
--- /dev/null
+++ b/src/operator/quantization/requantize.cu
@@ -0,0 +1,34 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * Copyright (c) 2017 by Contributors
+ * \file quantize.cu
+ * \brief
+ */
+#include "./requantize-inl.h"
+
+namespace mxnet {
+namespace op {
+
+NNVM_REGISTER_OP(_contrib_requantize)
+.set_attr<FCompute>("FCompute<gpu>", RequantizeForward<gpu>);
+
+} // namespace op
+} // namespace mxnet
diff --git a/src/operator/random/shuffle_op.cc b/src/operator/random/shuffle_op.cc
new file mode 100644
index 00000000000..d2a3e2d3df0
--- /dev/null
+++ b/src/operator/random/shuffle_op.cc
@@ -0,0 +1,134 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * Copyright (c) 2018 by Contributors
+ * \file shuffle_op.cc
+ * \brief Operator to shuffle elements of an NDArray
+ */
+#if (__GNUC__ > 4 && !defined(__clang__major__)) || (__clang_major__ > 4 && __linux__)
+ #define USE_GNU_PARALLEL_SHUFFLE
+#endif
+
+#include <mxnet/operator_util.h>
+#include <algorithm>
+#include <random>
+#include <vector>
+#ifdef USE_GNU_PARALLEL_SHUFFLE
+ #include <parallel/algorithm>
+#endif
+#include "../elemwise_op_common.h"
+
+namespace mxnet {
+namespace op {
+
+namespace {
+
+template<typename DType, typename Rand>
+void Shuffle1D(DType* const out, const index_t size, Rand* const prnd) {
+ #ifdef USE_GNU_PARALLEL_SHUFFLE
+ auto rand_n = [prnd](index_t n) {
+ std::uniform_int_distribution<index_t> dist(0, n - 1);
+ return dist(*prnd);
+ };
+ __gnu_parallel::random_shuffle(out, out + size, rand_n);
+ #else
+ std::shuffle(out, out + size, *prnd);
+ #endif
+}
+
+template<typename DType, typename Rand>
+void ShuffleND(DType* const out, const index_t size, const index_t first_axis_len,
+ Rand* const prnd) {
+ // Fisher-Yates shuffling
+ const index_t stride = size / first_axis_len;
+ auto rand_n = [prnd](index_t n) {
+ std::uniform_int_distribution<index_t> dist(0, n - 1);
+ return dist(*prnd);
+ };
+ CHECK_GT(first_axis_len, 0U);
+ for (index_t i = first_axis_len - 1; i > 0; --i) {
+ const index_t j = rand_n(i + 1);
+ if (i != j) {
+ std::swap_ranges(out + stride * i, out + stride * (i + 1), out + stride * j);
+ }
+ }
+}
+
+} // namespace
+
+void ShuffleForwardCPU(const nnvm::NodeAttrs& attrs,
+ const OpContext& ctx,
+ const std::vector<TBlob>& inputs,
+ const std::vector<OpReqType>& req,
+ const std::vector<TBlob>& outputs) {
+ using namespace mxnet_op;
+ if (req[0] == kNullOp) {
+ return;
+ }
+ CHECK_NE(req[0], kAddTo) << "Shuffle does not support AddTo";
+ const TShape& input_shape = inputs[0].shape_;
+ const index_t size = inputs[0].Size();
+ const index_t first_axis_len = input_shape[0];
+ Stream<cpu> *s = ctx.get_stream<cpu>();
+ MSHADOW_TYPE_SWITCH(inputs[0].type_flag_, DType, {
+ Tensor<cpu, 1, DType> in = inputs[0].get_with_shape<cpu, 1, DType>(Shape1(size), s);
+ Tensor<cpu, 1, DType> out = outputs[0].get_with_shape<cpu, 1, DType>(Shape1(size), s);
+ auto& prnd = ctx.requested[0].get_random<cpu, index_t>(ctx.get_stream<cpu>())->GetRndEngine();
+ if (req[0] != kWriteInplace) {
+ std::copy(in.dptr_, in.dptr_ + size, out.dptr_);
+ }
+ if (input_shape.ndim() == 1) {
+ Shuffle1D(out.dptr_, size, &prnd);
+ } else {
+ ShuffleND(out.dptr_, size, first_axis_len, &prnd);
+ }
+ });
+}
+
+
+// No parameter is declared.
+// No backward computation is registered. Shuffling is not differentiable.
+
+NNVM_REGISTER_OP(_shuffle)
+.add_alias("shuffle")
+.describe(R"code(Randomly shuffle the elements.
+
+This shuffles the array along the first axis.
+The order of the elements in each subarray does not change.
+For example, if a 2D array is given, the order of the rows randomly changes,
+but the order of the elements in each row does not change.
+)code")
+.set_num_inputs(1)
+.set_num_outputs(1)
+.set_attr<nnvm::FInferShape>("FInferShape", ElemwiseShape<1, 1>)
+.set_attr<nnvm::FInferType>("FInferType", ElemwiseType<1, 1>)
+.set_attr<FResourceRequest>("FResourceRequest",
+ [](const nnvm::NodeAttrs& attrs) {
+ return std::vector<ResourceRequest>{ResourceRequest::kRandom, ResourceRequest::kTempSpace};
+ })
+.set_attr<nnvm::FInplaceOption>("FInplaceOption",
+ [](const NodeAttrs& attrs) {
+ return std::vector<std::pair<int, int>>{{0, 0}};
+ })
+.set_attr<FCompute>("FCompute<cpu>", ShuffleForwardCPU)
+.add_argument("data", "NDArray-or-Symbol", "Data to be shuffled.");
+
+} // namespace op
+} // namespace mxnet
diff --git a/src/operator/random/shuffle_op.cu b/src/operator/random/shuffle_op.cu
new file mode 100644
index 00000000000..5bf8320c078
--- /dev/null
+++ b/src/operator/random/shuffle_op.cu
@@ -0,0 +1,106 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+/*!
+ * Copyright (c) 2018 by Contributors
+ * \file shuffle_op.cc
+ * \brief Operator to shuffle elements of an NDArray
+ */
+#include <mxnet/operator_util.h>
+#include <algorithm>
+#include <random>
+#include <vector>
+#include "../elemwise_op_common.h"
+#include "../tensor/init_op.h"
+
+namespace mxnet {
+namespace op {
+
+namespace {
+
+struct CopyForShuffle {
+ template<typename DType>
+ MSHADOW_XINLINE static void Map(int i, const DType* const in, DType* out,
+ const index_t* indices, const index_t stride) {
+ out[i] = in[indices[i / stride] * stride + i % stride];
+ }
+};
+
+} // namespace
+
+void ShuffleForwardGPU(const nnvm::NodeAttrs& attrs,
+ const OpContext& ctx,
+ const std::vector<TBlob>& inputs,
+ const std::vector<OpReqType>& req,
+ const std::vector<TBlob>& outputs) {
+ using namespace mxnet_op;
+ if (req[0] == kNullOp) {
+ return;
+ }
+ CHECK_NE(req[0], kAddTo) << "Shuffle does not support AddTo";
+ const TShape& input_shape = inputs[0].shape_;
+ const index_t size = inputs[0].Size();
+ const index_t first_axis_len = input_shape[0];
+ const index_t stride = size / first_axis_len;
+ Stream<gpu> *s = ctx.get_stream<gpu>();
+ MSHADOW_TYPE_SWITCH(inputs[0].type_flag_, DType, {
+ using KeyType = index_t;
+ Tensor<gpu, 1, DType> in = inputs[0].get_with_shape<gpu, 1, DType>(Shape1(size), s);
+ Tensor<gpu, 1, DType> out = outputs[0].get_with_shape<gpu, 1, DType>(Shape1(size), s);
+ Random<gpu, KeyType> *prnd = ctx.requested[0].get_random<gpu, KeyType>(s);
+ if (input_shape.ndim() == 1) {
+ if (req[0] != kWriteInplace) {
+ Copy(out, in, s);
+ }
+ Tensor<gpu, 1, KeyType> keys =
+ ctx.requested[1].get_space_typed<gpu, 1, KeyType>(Shape1(size), s);
+ prnd->GetRandInt(keys);
+ SortByKey(keys, out, true);
+ } else {
+ const size_t tmp_space_size = req[0] == kWriteInplace ?
+ 2 * first_axis_len * sizeof(index_t) + size * sizeof(DType) :
+ 2 * first_axis_len * sizeof(index_t);
+ Tensor<gpu, 1, char> tmp_space =
+ ctx.requested[1].get_space_typed<gpu, 1, char>(Shape1(tmp_space_size), s);
+ char* tmp_space_ptr = tmp_space.dptr_;
+ Tensor<gpu, 1, index_t> indices(reinterpret_cast<index_t*>(tmp_space_ptr),
+ Shape1(first_axis_len), s);
+ tmp_space_ptr += sizeof(index_t) * first_axis_len;
+ Kernel<range_fwd, gpu>::Launch(s, first_axis_len, 1, 0U, 1U, kWriteTo, indices.dptr_);
+ Tensor<gpu, 1, KeyType> keys(reinterpret_cast<KeyType*>(tmp_space_ptr),
+ Shape1(first_axis_len), s);
+ tmp_space_ptr += sizeof(KeyType) * first_axis_len;
+ prnd->GetRandInt(keys);
+ SortByKey(keys, indices, true);
+ if (req[0] == kWriteInplace) {
+ Tensor<gpu, 1, DType> buf(reinterpret_cast<DType*>(tmp_space_ptr), Shape1(size), s);
+ Copy(buf, in, s);
+ Kernel<CopyForShuffle, gpu>::Launch(s, size, buf.dptr_, out.dptr_, indices.dptr_, stride);
+ } else {
+ Kernel<CopyForShuffle, gpu>::Launch(s, size, in.dptr_, out.dptr_, indices.dptr_, stride);
+ }
+ }
+ });
+}
+
+NNVM_REGISTER_OP(_shuffle)
+.set_attr<FCompute>("FCompute<gpu>", ShuffleForwardGPU);
+
+} // namespace op
+} // namespace mxnet
diff --git a/src/operator/tensor/broadcast_reduce-inl.cuh b/src/operator/tensor/broadcast_reduce-inl.cuh
index 630fef65a52..b6bb39a1984 100644
--- a/src/operator/tensor/broadcast_reduce-inl.cuh
+++ b/src/operator/tensor/broadcast_reduce-inl.cuh
@@ -348,21 +348,21 @@ static inline uint64_t calc_num_load(const int X, const int Y, const int* stride
}
template<int ndim, typename DType>
-ReduceImplConfig<ndim> ConfigureReduceImpl(const TBlob& small, const TBlob& big, const TBlob* lhs,
- const TBlob* rhs) {
+ReduceImplConfig<ndim> ConfigureReduceImpl(const TShape& small, const TShape& big, const TShape* lhs,
+ const TShape* rhs) {
ReduceImplConfig<ndim> config;
- diff(small.shape_.get<ndim>(), big.shape_.get<ndim>(), &config.rshape, &config.rstride);
- config.N = small.shape_.Size();
+ diff(small.get<ndim>(), big.get<ndim>(), &config.rshape, &config.rstride);
+ config.N = small.Size();
config.M = config.rshape.Size();
bool multiOp = false;
if (lhs != NULL) {
CHECK_NOTNULL(rhs);
- diff(small.shape_.get<ndim>(), lhs->shape_.get<ndim>(), &config.lhs_shape,
+ diff(small.get<ndim>(), lhs->get<ndim>(), &config.lhs_shape,
&config.lhs_stride);
- diff(small.shape_.get<ndim>(), rhs->shape_.get<ndim>(), &config.rhs_shape,
+ diff(small.get<ndim>(), rhs->get<ndim>(), &config.rhs_shape,
&config.rhs_stride);
multiOp = true;
}
@@ -376,20 +376,20 @@ ReduceImplConfig<ndim> ConfigureReduceImpl(const TBlob& small, const TBlob& big,
} else {
int reduce_strides[3];
- reduce_strides[0] = fastest_stride(small.shape_.get<ndim>(), big.shape_.get<ndim>(),
- big.shape_.get<ndim>());
- reduce_strides[1] = (multiOp) ? fastest_stride(small.shape_.get<ndim>(),
- lhs->shape_.get<ndim>(), lhs->shape_.get<ndim>()) : 1;
- reduce_strides[2] = (multiOp) ? fastest_stride(small.shape_.get<ndim>(),
- rhs->shape_.get<ndim>(), rhs->shape_.get<ndim>()) : 1;
+ reduce_strides[0] = fastest_stride(small.get<ndim>(), big.get<ndim>(),
+ big.get<ndim>());
+ reduce_strides[1] = (multiOp) ? fastest_stride(small.get<ndim>(),
+ lhs->get<ndim>(), lhs->get<ndim>()) : 1;
+ reduce_strides[2] = (multiOp) ? fastest_stride(small.get<ndim>(),
+ rhs->get<ndim>(), rhs->get<ndim>()) : 1;
int reduce_strides_transp[3];
- reduce_strides_transp[0] = fastest_stride(small.shape_.get<ndim>(), config.rshape,
+ reduce_strides_transp[0] = fastest_stride(small.get<ndim>(), config.rshape,
config.rstride);
reduce_strides_transp[1] = (multiOp) ?
- fastest_stride(small.shape_.get<ndim>(), config.lhs_shape, config.lhs_stride) : 1;
+ fastest_stride(small.get<ndim>(), config.lhs_shape, config.lhs_stride) : 1;
reduce_strides_transp[2] = (multiOp) ?
- fastest_stride(small.shape_.get<ndim>(), config.rhs_shape, config.rhs_stride) : 1;
+ fastest_stride(small.get<ndim>(), config.rhs_shape, config.rhs_stride) : 1;
uint64_t num_load = calc_num_load(config.N, config.M, reduce_strides);
uint64_t num_load_transp = calc_num_load(config.M, config.N, reduce_strides_transp);
@@ -597,7 +597,8 @@ void Reduce(Stream<gpu> *s, const TBlob& small, const OpReqType req,
const Tensor<gpu, 1, char>& workspace, const TBlob& big) {
if (req == kNullOp) return;
cudaStream_t stream = Stream<gpu>::GetStream(s);
- ReduceImplConfig<ndim> config = ConfigureReduceImpl<ndim, DType>(small, big, NULL, NULL);
+ ReduceImplConfig<ndim> config =
+ ConfigureReduceImpl<ndim, DType>(small.shape_, big.shape_, NULL, NULL);
ReduceImpl<Reducer, ndim, DType, OP>(stream, small, req, big, workspace, config);
}
@@ -607,21 +608,22 @@ void Reduce(Stream<gpu> *s, const TBlob& small, const OpReqType req,
const TBlob& lhs, const TBlob& rhs) {
if (req == kNullOp) return;
cudaStream_t stream = Stream<gpu>::GetStream(s);
- ReduceImplConfig<ndim> config = ConfigureReduceImpl<ndim, DType>(small, big, &lhs, &rhs);
+ ReduceImplConfig<ndim> config =
+ ConfigureReduceImpl<ndim, DType>(small.shape_, big.shape_, &lhs.shape_, &rhs.shape_);
ReduceImpl<Reducer, ndim, DType, OP1, OP2>(stream, small, lhs, rhs, req, big, workspace, config);
}
template<int ndim, typename DType>
-size_t ReduceWorkspaceSize(Stream<gpu> *s, const TBlob& small, const OpReqType req,
- const TBlob& big) {
+size_t ReduceWorkspaceSize(Stream<gpu> *s, const TShape& small, const OpReqType req,
+ const TShape& big) {
if (req == kNullOp) return 0;
ReduceImplConfig<ndim> config = ConfigureReduceImpl<ndim, DType>(small, big, NULL, NULL);
return config.workspace_size;
}
template<int ndim, typename DType>
-size_t ReduceWorkspaceSize(Stream<gpu> *s, const TBlob& small, const OpReqType req,
- const TBlob& big, const TBlob& lhs, const TBlob& rhs) {
+size_t ReduceWorkspaceSize(Stream<gpu> *s, const TShape& small, const OpReqType req,
+ const TShape& big, const TShape& lhs, const TShape& rhs) {
if (req == kNullOp) return 0;
ReduceImplConfig<ndim> config = ConfigureReduceImpl<ndim, DType>(small, big, &lhs, &rhs);
return config.workspace_size;
diff --git a/src/operator/tensor/broadcast_reduce-inl.h b/src/operator/tensor/broadcast_reduce-inl.h
index 7f3e5685a08..76ec92a9e72 100644
--- a/src/operator/tensor/broadcast_reduce-inl.h
+++ b/src/operator/tensor/broadcast_reduce-inl.h
@@ -217,14 +217,14 @@ void Reduce(Stream<cpu> *s, const TBlob& small, const OpReqType req,
}
template<int ndim, typename DType>
-size_t ReduceWorkspaceSize(Stream<cpu> *s, const TBlob& small, const OpReqType req,
- const TBlob& big) {
+size_t ReduceWorkspaceSize(Stream<cpu> *s, const TShape& small, const OpReqType req,
+ const TShape& big) {
return 0;
}
template<int ndim, typename DType>
-size_t ReduceWorkspaceSize(Stream<cpu> *s, const TBlob& small, const OpReqType req,
- const TBlob& big, const TBlob& lhs, const TBlob& rhs) {
+size_t ReduceWorkspaceSize(Stream<cpu> *s, const TShape& small, const OpReqType req,
+ const TShape& big, const TShape& lhs, const TShape& rhs) {
return 0;
}
diff --git a/src/operator/tensor/broadcast_reduce_op.h b/src/operator/tensor/broadcast_reduce_op.h
index 02d48b46970..f124ba3021e 100644
--- a/src/operator/tensor/broadcast_reduce_op.h
+++ b/src/operator/tensor/broadcast_reduce_op.h
@@ -421,7 +421,7 @@ void ReduceAxesComputeImpl(const nnvm::NodeAttrs& attrs,
const TBlob out_data = outputs[0].reshape(dst_shape);
BROADCAST_NDIM_SWITCH(dst_shape.ndim(), NDim, {
size_t workspace_size = broadcast::ReduceWorkspaceSize<NDim, DType>(
- s, out_data, req[0], in_data);
+ s, out_data.shape_, req[0], in_data.shape_);
Tensor<xpu, 1, char> workspace =
ctx.requested[0].get_space_typed<xpu, 1, char>(Shape1(workspace_size), s);
broadcast::Reduce<reducer, NDim, DType, op::mshadow_op::identity>(
diff --git a/src/operator/tensor/elemwise_binary_broadcast_op.h b/src/operator/tensor/elemwise_binary_broadcast_op.h
index af5f5ce3af8..a2e63fefad5 100644
--- a/src/operator/tensor/elemwise_binary_broadcast_op.h
+++ b/src/operator/tensor/elemwise_binary_broadcast_op.h
@@ -205,8 +205,10 @@ void BinaryBroadcastBackwardUseNone(const nnvm::NodeAttrs& attrs,
const TBlob out = inputs[0].reshape(new_oshape);
BROADCAST_NDIM_SWITCH(ndim, NDim, {
// Request temporary storage
- size_t workspace_size_l = ReduceWorkspaceSize<NDim, DType>(s, lhs, req[0], out);
- size_t workspace_size_r = ReduceWorkspaceSize<NDim, DType>(s, rhs, req[1], out);
+ size_t workspace_size_l = ReduceWorkspaceSize<NDim, DType>(
+ s, lhs.shape_, req[0], out.shape_);
+ size_t workspace_size_r = ReduceWorkspaceSize<NDim, DType>(
+ s, rhs.shape_, req[1], out.shape_);
size_t workspace_size = std::max(workspace_size_l, workspace_size_r);
Tensor<xpu, 1, char> workspace =
ctx.requested[0].get_space_typed<xpu, 1, char>(Shape1(workspace_size), s);
@@ -234,8 +236,10 @@ inline void BinaryBroadcastBackwardUseInImpl(const OpContext& ctx,
const TBlob ograd = inputs[0].reshape(new_oshape);
const TBlob lhs = inputs[1].reshape(new_lshape);
const TBlob rhs = inputs[2].reshape(new_rshape);
- size_t workspace_size_l = ReduceWorkspaceSize<ndim, DType>(s, lgrad, req[0], ograd, lhs, rhs);
- size_t workspace_size_r = ReduceWorkspaceSize<ndim, DType>(s, rgrad, req[1], ograd, lhs, rhs);
+ size_t workspace_size_l = ReduceWorkspaceSize<ndim, DType>(
+ s, lgrad.shape_, req[0], ograd.shape_, lhs.shape_, rhs.shape_);
+ size_t workspace_size_r = ReduceWorkspaceSize<ndim, DType>(
+ s, rgrad.shape_, req[1], ograd.shape_, lhs.shape_, rhs.shape_);
size_t workspace_size = std::max(workspace_size_l, workspace_size_r);
Tensor<xpu, 1, char> workspace =
ctx.requested[0].get_space_typed<xpu, 1, char>(Shape1(workspace_size), s);
diff --git a/src/operator/tensor/init_op.h b/src/operator/tensor/init_op.h
index 475409e6a77..0c74cac2dca 100644
--- a/src/operator/tensor/init_op.h
+++ b/src/operator/tensor/init_op.h
@@ -88,6 +88,7 @@ struct EyeParam : public dmlc::Parameter<EyeParam> {
.add_enum("float64", mshadow::kFloat64)
.add_enum("float16", mshadow::kFloat16)
.add_enum("uint8", mshadow::kUint8)
+ .add_enum("int8", mshadow::kInt8)
.add_enum("int32", mshadow::kInt32)
.add_enum("int64", mshadow::kInt64)
.describe("Target data type.");
diff --git a/src/profiler/profiler.h b/src/profiler/profiler.h
index 768a0bc7d71..b8d0e8ef340 100644
--- a/src/profiler/profiler.h
+++ b/src/profiler/profiler.h
@@ -391,6 +391,14 @@ class Profiler {
return aggregate_stats_.get() != nullptr;
}
+ /*!
+ * \brief Whether aggregate stats are currently being recorded
+ * \return true if aggregate stats are currently being recorded
+ */
+ inline bool AggregateRunning() const {
+ return GetState() == kRunning && AggregateEnabled();
+ }
+
public:
/*!
* \brief Constructor
diff --git a/src/storage/cpu_device_storage.h b/src/storage/cpu_device_storage.h
index 6b85ba8dabe..43e98fe04a1 100644
--- a/src/storage/cpu_device_storage.h
+++ b/src/storage/cpu_device_storage.h
@@ -55,9 +55,9 @@ class CPUDeviceStorage {
* \brief Alignment of allocation.
*/
#if MXNET_USE_MKLDNN == 1
- // MKLDNN requires special alignment. 4096 is used by the MKLDNN library in
+ // MKLDNN requires special alignment. 64 is used by the MKLDNN library in
// memory allocation.
- static constexpr size_t alignment_ = 4096;
+ static constexpr size_t alignment_ = kMKLDNNAlign;
#else
static constexpr size_t alignment_ = 16;
#endif
diff --git a/tests/ci_build/deploy/ci_deploy_doc.sh b/tests/ci_build/deploy/ci_deploy_doc.sh
index 44c8192e7a5..a300794b55d 100755
--- a/tests/ci_build/deploy/ci_deploy_doc.sh
+++ b/tests/ci_build/deploy/ci_deploy_doc.sh
@@ -26,10 +26,7 @@
#
# BUILD_ID: the current build ID for the specified PR
#
+set -ex
-# TODO szha@: installation of awscli here should be removed once slave hosts have them during
-# bootstrap. The following line along with the "aws" script should both be removed then.
-pip install --user awscli
-
-tests/ci_build/deploy/aws s3 sync --delete docs/_build/html/ s3://mxnet-ci-doc/$1/$2 \
+aws s3 sync --delete docs/_build/html/ s3://mxnet-ci-doc/$1/$2 \
&& echo "Doc is hosted at http://mxnet-ci-doc.s3-accelerate.dualstack.amazonaws.com/$1/$2/index.html"
diff --git a/tests/cpp/include/test_core_op.h b/tests/cpp/include/test_core_op.h
index 63f5c91911e..7dc05fda2cc 100644
--- a/tests/cpp/include/test_core_op.h
+++ b/tests/cpp/include/test_core_op.h
@@ -141,8 +141,9 @@ class CoreOpExecutor : public test::op::OperatorDataInitializer<DType>
static auto gradient = nnvm::Op::GetAttr<nnvm::FGradient>("FGradient");
nnvm::FGradient grad_fun = gradient.get(op_, nullptr);
if (grad_fun) {
- std::vector<nnvm::NodeEntry> out_grads;
- std::vector<nnvm::NodeEntry> entries = grad_fun(MakeNode(), out_grads);
+ auto n = MakeNode();
+ std::vector<nnvm::NodeEntry> out_grads(n->num_outputs());
+ std::vector<nnvm::NodeEntry> entries = grad_fun(n, out_grads);
CHECK_GE(entries.size(), 1U);
res.reserve(entries.size());
for (const nnvm::NodeEntry& node_entry : entries) {
@@ -467,7 +468,7 @@ class CoreOpExecutor : public test::op::OperatorDataInitializer<DType>
input_shapes_ = input_shapes;
// BWD Output shapes
output_shapes = backward_for_op->input_shapes_;
- CHECK_EQ(output_shapes.size(), inferred_num_outputs);
+ output_shapes.resize(inferred_num_outputs);
} else {
output_shapes = input_shapes;
output_shapes.resize(inferred_num_outputs);
diff --git a/tests/cpp/operator/batchnorm_test.cc b/tests/cpp/operator/batchnorm_test.cc
index 4b08d985de3..2f9de742a35 100644
--- a/tests/cpp/operator/batchnorm_test.cc
+++ b/tests/cpp/operator/batchnorm_test.cc
@@ -77,10 +77,10 @@ enum ForwardOutputs {
* \brief Backward
*/
enum BackwardInputs {
- /* out_grad */ bwd_out_grad_Grad, bwd_out_grad_Mean, bwd_out_grad_Var,
+ /* out_grad */ bwd_out_grad_Grad,
+ /* out_data */ bwd_out_data_Mean, bwd_out_data_Var,
/* in_data */ bwd_in_data_Data, bwd_in_data_Gamma, bwd_in_data_Beta,
- /* aux_states */ bwd_aux_states_MovingMean, bwd_aux_states_MovingVar,
- /* in_grad */ bwd_out_data_Data, bwd_out_data_Mean, bwd_out_data_Var
+ /* aux_states */ bwd_aux_states_MovingMean, bwd_aux_states_MovingVar
};
enum BackwardOutputs {
/* in_grad */ bwd_in_grad_Data /* Original input data */,
@@ -250,17 +250,12 @@ class BNOperatorExecutor : public test::op::CoreOpExecutor<DType, AccReal> {
test::try_fill(ctx().run_ctx, &GetBlob(bwd_aux_states_MovingMean), 0);
test::try_fill(ctx().run_ctx, &GetBlob(bwd_aux_states_MovingVar), 1);
- val = -.101;
- test::patternFill(ctx().run_ctx, &GetBlob(bwd_out_data_Data), [&val]() -> double {
- return val += 1; });
test::try_fill(ctx().run_ctx, &GetBlob(bwd_out_data_Mean), 0.0);
test::try_fill(ctx().run_ctx, &GetBlob(bwd_out_data_Var), 1.0);
val = -.001;
test::patternFill(ctx().run_ctx, &GetBlob(bwd_out_grad_Grad), [&val]() -> double {
return val += 0.01; });
- test::try_fill(ctx().run_ctx, &GetBlob(bwd_out_grad_Mean), 0.0);
- test::try_fill(ctx().run_ctx, &GetBlob(bwd_out_grad_Var), 1.0);
}
const bool hasWeightAndBias_; // This will cause forward pass validation to fail
diff --git a/tests/cpp/operator/mkldnn.cc b/tests/cpp/operator/mkldnn.cc
index a8a3d26fac3..c3e03df195e 100644
--- a/tests/cpp/operator/mkldnn.cc
+++ b/tests/cpp/operator/mkldnn.cc
@@ -28,6 +28,7 @@
#include "gtest/gtest.h"
#include "../../src/operator/nn/mkldnn/mkldnn_base-inl.h"
+#if __GNUC__ >= 5
bool test_mem_align(void *mem, size_t size, size_t alignment, size_t space) {
void *ret1, *ret2;
size_t space1, space2;
@@ -39,12 +40,13 @@ bool test_mem_align(void *mem, size_t size, size_t alignment, size_t space) {
EXPECT_EQ(space1, space2);
return ret1 == ret2;
}
+#endif
TEST(MKLDNN_UTIL_FUNC, AlignMem) {
+#if __GNUC__ >= 5
size_t alignment = 4096;
void *mem;
size_t size, space;
-
// When mem has been aligned.
mem = reinterpret_cast<void *>(0x10000);
size = 1000;
@@ -69,5 +71,10 @@ TEST(MKLDNN_UTIL_FUNC, AlignMem) {
space = random() % 2000;
test_mem_align(mem, size, alignment, space);
}
+#else
+ // std::align is not supported in GCC < 5.0, this test case will be checked
+ // with newer version
+ LOG(INFO) << "Skipped for GCC " << __GNUC__ << "." << __GNUC_MINOR__;
+#endif
}
#endif
diff --git a/tests/python-pytest/onnx/backend.py b/tests/python-pytest/onnx/backend.py
index 3b99563bccf..0e0a6a680b7 100644
--- a/tests/python-pytest/onnx/backend.py
+++ b/tests/python-pytest/onnx/backend.py
@@ -94,12 +94,15 @@ def run_node(cls, node, inputs, device='CPU'):
result obtained after running the operator
"""
graph = GraphProto()
- sym, _ = graph.from_onnx(MXNetBackend.make_graph(node, inputs))
- data_names = [i for i in sym.get_internals().list_inputs()]
+ sym, arg_params, aux_params = graph.from_onnx(MXNetBackend.make_graph(node, inputs))
+ data_names = [graph_input for graph_input in sym.list_inputs()
+ if graph_input not in arg_params and graph_input not in aux_params]
data_shapes = []
dim_change_op_types = set(['ReduceMin', 'ReduceMax', 'ReduceMean',
'ReduceProd', 'ReduceSum', 'Slice', 'Pad',
- 'Squeeze', 'Upsample', 'Reshape', 'Conv'])
+ 'Squeeze', 'Upsample', 'Reshape', 'Conv',
+ 'Concat', 'Softmax', 'Flatten', 'Transpose',
+ 'GlobalAveragePool', 'GlobalMaxPool'])
# Adding extra dimension of batch_size 1 if the batch_size is different for multiple inputs.
for idx, input_name in enumerate(data_names):
@@ -123,7 +126,10 @@ def run_node(cls, node, inputs, device='CPU'):
mod.bind(for_training=False, data_shapes=data_shapes, label_shapes=None)
# initializing parameters for calculating result of each individual node
- mod.init_params()
+ if arg_params is None and aux_params is None:
+ mod.init_params()
+ else:
+ mod.set_params(arg_params=arg_params, aux_params=aux_params)
data_forward = []
for idx, input_name in enumerate(data_names):
@@ -162,8 +168,8 @@ def prepare(cls, model, device='CPU', **kwargs):
used to run inference on the input model and return the result for comparison.
"""
graph = GraphProto()
- sym, params = graph.from_onnx(model.graph)
- return MXNetBackendRep(sym, params, device)
+ sym, arg_params, aux_params = graph.from_onnx(model.graph)
+ return MXNetBackendRep(sym, arg_params, aux_params, device)
@classmethod
def supports_device(cls, device):
diff --git a/tests/python-pytest/onnx/backend_rep.py b/tests/python-pytest/onnx/backend_rep.py
index a125086bce2..47ea6c1585a 100644
--- a/tests/python-pytest/onnx/backend_rep.py
+++ b/tests/python-pytest/onnx/backend_rep.py
@@ -37,9 +37,10 @@
class MXNetBackendRep(BackendRep):
"""Running model inference on mxnet engine and return the result
to onnx test infrastructure for comparison."""
- def __init__(self, symbol, params, device):
+ def __init__(self, symbol, arg_params, aux_params, device):
self.symbol = symbol
- self.params = params
+ self.arg_params = arg_params
+ self.aux_params = aux_params
self.device = device
def run(self, inputs, **kwargs):
@@ -67,7 +68,7 @@ def run(self, inputs, **kwargs):
label_names=None)
mod.bind(for_training=False, data_shapes=[('input_0', input_data.shape)],
label_shapes=None)
- mod.set_params(arg_params=self.params, aux_params=None)
+ mod.set_params(arg_params=self.arg_params, aux_params=self.aux_params)
# run inference
batch = namedtuple('Batch', ['data'])
diff --git a/tests/python-pytest/onnx/onnx_backend_test.py b/tests/python-pytest/onnx/onnx_backend_test.py
index 28e2aaefcdd..4ea31e5aac9 100644
--- a/tests/python-pytest/onnx/onnx_backend_test.py
+++ b/tests/python-pytest/onnx/onnx_backend_test.py
@@ -34,7 +34,7 @@
BACKEND_TEST = onnx.backend.test.BackendTest(mxnet_backend, __name__)
-IMPLEMENTED_OPERATORS = [
+IMPLEMENTED_OPERATORS_TEST = [
#Generator Functions
#'test_constant*', # Identity Function
#'test_random_uniform',
@@ -57,37 +57,40 @@
'test_floor',
## Joining and spliting
- #'test_concat.*', #---Failing test
+ 'test_concat',
#Basic neural network functions
'test_sigmoid',
'test_relu',
- #'test_constant_pad',
- #'test_edge_pad',
- #'test_reflect_pad',
+ 'test_constant_pad',
+ 'test_edge_pad',
+ 'test_reflect_pad',
'test_matmul',
'test_leakyrelu',
'test_elu',
- #'test_softmax*',
+ 'test_softmax_example',
+ 'test_softmax_large_number',
+ 'test_softmax_axis_2',
'test_conv',
'test_basic_conv',
- #'test_globalmaxpool',
- #'test_globalaveragepool',
- #'test_batch_norm',
+ 'test_transpose',
+ 'test_globalmaxpool',
+ 'test_globalaveragepool',
+ #'test_batch_norm', - tests to be added
+ #'test_gather',
#Changing shape and type.
'test_reshape_',
- #'test_AvgPool2D*',
- #'test_MaxPool2D*',
- #'test_cast',
+ 'test_cast',
#'test_split',
'test_slice_cpu',
'test_default_axes', #make PR against onnx to fix the test name(grep-able)
'test_slice_neg',
#'test_slice_start_out_of_bounds',
#'test_slice_end_out_of_bounds',
- #'test_transpose*',
+ #'test_transpose',
'test_squeeze_',
+ 'test_flatten_default',
#Powers
'test_reciprocal',
@@ -103,12 +106,62 @@
'test_argmax',
'test_argmin',
'test_max',
- 'test_min'
+ 'test_min',
+
+ #pytorch operator tests
+ #'test_operator_chunk',
+ #'test_operator_clip',
+ 'test_operator_conv',
+ #'test_operator_equal',
+ 'test_operator_exp',
+ #'test_operator_flatten',
+ #'test_operator_max',
+ 'test_operator_maxpool',
+ 'test_operator_non_float_params',
+ 'test_operator_params',
+ 'test_operator_permute2',
+ #'test_operator_transpose',
+ #'test_operator_view'
]
-for op_test in IMPLEMENTED_OPERATORS:
+BASIC_MODEL_TESTS = [
+ 'test_AvgPool2D',
+ 'test_BatchNorm',
+ 'test_ConstantPad2d'
+ 'test_Conv2d',
+ 'test_ELU',
+ 'test_LeakyReLU',
+ 'test_MaxPool',
+ 'test_PReLU',
+ 'test_ReLU',
+ 'test_Sigmoid',
+ 'test_Softmax',
+ 'test_softmax_functional',
+ 'test_softmax_lastdim',
+ 'test_Tanh'
+ ]
+
+STANDARD_MODEL = [
+ 'test_bvlc_alexnet',
+ 'test_densenet121',
+ #'test_inception_v1',
+ #'test_inception_v2',
+ 'test_resnet50',
+ #'test_shufflenet',
+ 'test_squeezenet',
+ 'test_vgg16',
+ 'test_vgg19'
+ ]
+
+for op_test in IMPLEMENTED_OPERATORS_TEST:
BACKEND_TEST.include(op_test)
+for std_model_test in STANDARD_MODEL:
+ BACKEND_TEST.include(std_model_test)
+
+for basic_model_test in BASIC_MODEL_TESTS:
+ BACKEND_TEST.include(basic_model_test)
+
# import all test cases at global scope to make them visible to python.unittest
globals().update(BACKEND_TEST.enable_report().test_cases)
diff --git a/tests/python-pytest/onnx/onnx_test.py b/tests/python-pytest/onnx/onnx_test.py
index 016490a4c4b..ddc633e28f6 100644
--- a/tests/python-pytest/onnx/onnx_test.py
+++ b/tests/python-pytest/onnx/onnx_test.py
@@ -21,19 +21,37 @@
ONNX backend test framework. Once we have PRs on the ONNX repo and get
those PRs merged, this file will get EOL'ed.
"""
+# pylint: disable=too-many-locals,wrong-import-position,import-error
from __future__ import absolute_import
import sys
import os
import unittest
import logging
import hashlib
+import tarfile
+from collections import namedtuple
import numpy as np
import numpy.testing as npt
from onnx import helper
-import backend as mxnet_backend
+from onnx import numpy_helper
+from onnx import TensorProto
+from mxnet.test_utils import download
+from mxnet.contrib import onnx as onnx_mxnet
+import mxnet as mx
CURR_PATH = os.path.dirname(os.path.abspath(os.path.expanduser(__file__)))
sys.path.insert(0, os.path.join(CURR_PATH, '../../python/unittest'))
from common import with_seed
+import backend as mxnet_backend
+
+
+URLS = {
+ 'bvlc_googlenet' :
+ 'https://s3.amazonaws.com/onnx-mxnet/model-zoo/bvlc_googlenet.tar.gz',
+ 'bvlc_reference_caffenet' :
+ 'https://s3.amazonaws.com/onnx-mxnet/model-zoo/bvlc_reference_caffenet.tar.gz',
+ 'bvlc_reference_rcnn_ilsvrc13' :
+ 'https://s3.amazonaws.com/onnx-mxnet/model-zoo/bvlc_reference_rcnn_ilsvrc13.tar.gz',
+}
@with_seed()
def test_reduce_max():
@@ -93,9 +111,9 @@ def test_super_resolution_example():
sys.path.insert(0, os.path.join(CURR_PATH, '../../../example/onnx/'))
import super_resolution
- sym, params = super_resolution.import_onnx()
+ sym, arg_params, aux_params = super_resolution.import_onnx()
assert sym is not None
- assert params is not None
+ assert arg_params is not None
inputs = sym.list_inputs()
assert len(inputs) == 9
@@ -116,7 +134,7 @@ def test_super_resolution_example():
'transpose0']):
assert key_item in attrs_keys
- param_keys = params.keys()
+ param_keys = arg_params.keys()
assert len(param_keys) == 8
for i, param_item in enumerate(['param_5', 'param_4', 'param_7', 'param_6',
'param_1', 'param_0', 'param_3', 'param_2']):
@@ -126,11 +144,111 @@ def test_super_resolution_example():
output_img_dim = 672
input_image, img_cb, img_cr = super_resolution.get_test_image()
- result_img = super_resolution.perform_inference(sym, params, input_image,
- img_cb, img_cr)
+ result_img = super_resolution.perform_inference(sym, arg_params, aux_params,
+ input_image, img_cb, img_cr)
assert hashlib.md5(result_img.tobytes()).hexdigest() == '0d98393a49b1d9942106a2ed89d1e854'
assert result_img.size == (output_img_dim, output_img_dim)
+def get_test_files(name):
+ """Extract tar file and returns model path and input, output data"""
+ tar_name = download(URLS.get(name), dirname=CURR_PATH.__str__())
+ # extract tar file
+ tar_path = os.path.join(CURR_PATH, tar_name)
+ tar = tarfile.open(tar_path.__str__(), "r:*")
+ tar.extractall(path=CURR_PATH.__str__())
+ tar.close()
+ data_dir = os.path.join(CURR_PATH, name)
+ model_path = os.path.join(data_dir, 'model.onnx')
+
+ inputs = []
+ outputs = []
+ # get test files
+ for test_file in os.listdir(data_dir):
+ case_dir = os.path.join(data_dir, test_file)
+ # skip the non-dir files
+ if not os.path.isdir(case_dir):
+ continue
+ input_file = os.path.join(case_dir, 'input_0.pb')
+ input_tensor = TensorProto()
+ with open(input_file, 'rb') as proto_file:
+ input_tensor.ParseFromString(proto_file.read())
+ inputs.append(numpy_helper.to_array(input_tensor))
+
+ output_tensor = TensorProto()
+ output_file = os.path.join(case_dir, 'output_0.pb')
+ with open(output_file, 'rb') as proto_file:
+ output_tensor.ParseFromString(proto_file.read())
+ outputs.append(numpy_helper.to_array(output_tensor))
+
+ return model_path, inputs, outputs
+
+def test_bvlc_googlenet():
+ """ Tests Googlenet model"""
+ model_path, inputs, outputs = get_test_files('bvlc_googlenet')
+ logging.info("Translating Googlenet model from ONNX to Mxnet")
+ sym, arg_params, aux_params = onnx_mxnet.import_model(model_path)
+
+ # run test for each test file
+ for input_data, output_data in zip(inputs, outputs):
+ # create module
+ mod = mx.mod.Module(symbol=sym, data_names=['input_0'], context=mx.cpu(), label_names=None)
+ mod.bind(for_training=False, data_shapes=[('input_0', input_data.shape)], label_shapes=None)
+ mod.set_params(arg_params=arg_params, aux_params=aux_params,
+ allow_missing=True, allow_extra=True)
+ # run inference
+ batch = namedtuple('Batch', ['data'])
+ mod.forward(batch([mx.nd.array(input_data)]), is_train=False)
+
+ # verify the results
+ npt.assert_equal(mod.get_outputs()[0].shape, output_data.shape)
+ npt.assert_almost_equal(output_data, mod.get_outputs()[0].asnumpy(), decimal=3)
+ logging.info("Googlenet model conversion Successful")
+
+def test_bvlc_reference_caffenet():
+ """Tests the bvlc cafenet model"""
+ model_path, inputs, outputs = get_test_files('bvlc_reference_caffenet')
+ logging.info("Translating Caffenet model from ONNX to Mxnet")
+ sym, arg_params, aux_params = onnx_mxnet.import_model(model_path)
+
+ # run test for each test file
+ for input_data, output_data in zip(inputs, outputs):
+ # create module
+ mod = mx.mod.Module(symbol=sym, data_names=['input_0'], context=mx.cpu(), label_names=None)
+ mod.bind(for_training=False, data_shapes=[('input_0', input_data.shape)], label_shapes=None)
+ mod.set_params(arg_params=arg_params, aux_params=aux_params,
+ allow_missing=True, allow_extra=True)
+ # run inference
+ batch = namedtuple('Batch', ['data'])
+ mod.forward(batch([mx.nd.array(input_data)]), is_train=False)
+
+ # verify the results
+ npt.assert_equal(mod.get_outputs()[0].shape, output_data.shape)
+ npt.assert_almost_equal(output_data, mod.get_outputs()[0].asnumpy(), decimal=3)
+ logging.info("Caffenet model conversion Successful")
+
+def test_bvlc_rcnn_ilsvrc13():
+ """Tests the bvlc rcnn model"""
+ model_path, inputs, outputs = get_test_files('bvlc_reference_rcnn_ilsvrc13')
+ logging.info("Translating rcnn_ilsvrc13 model from ONNX to Mxnet")
+ sym, arg_params, aux_params = onnx_mxnet.import_model(model_path)
+
+ # run test for each test file
+ for input_data, output_data in zip(inputs, outputs):
+ # create module
+ mod = mx.mod.Module(symbol=sym, data_names=['input_0'], context=mx.cpu(), label_names=None)
+ mod.bind(for_training=False, data_shapes=[('input_0', input_data.shape)], label_shapes=None)
+ mod.set_params(arg_params=arg_params, aux_params=aux_params,
+ allow_missing=True, allow_extra=True)
+ # run inference
+ batch = namedtuple('Batch', ['data'])
+ mod.forward(batch([mx.nd.array(input_data)]), is_train=False)
+
+ # verify the results
+ npt.assert_equal(mod.get_outputs()[0].shape, output_data.shape)
+ npt.assert_almost_equal(output_data, mod.get_outputs()[0].asnumpy(), decimal=3)
+ logging.info("rcnn_ilsvrc13 model conversion Successful")
+
+
if __name__ == '__main__':
unittest.main()
diff --git a/tests/python/gpu/test_operator_gpu.py b/tests/python/gpu/test_operator_gpu.py
index 0d149685873..cb422e2263a 100644
--- a/tests/python/gpu/test_operator_gpu.py
+++ b/tests/python/gpu/test_operator_gpu.py
@@ -1657,6 +1657,94 @@ def test_cross_device_autograd():
assert_almost_equal(dx, x.grad.asnumpy())
+@unittest.skip("JIRA issue: https://issues.apache.org/jira/projects/MXNET/issues/MXNET-130")
+@with_seed()
+def test_multi_proposal_op():
+ # paramters
+ feature_stride = 16
+ scales = (8, 16, 32)
+ ratios = (0.5, 1, 2)
+ rpn_pre_nms_top_n = 12000
+ rpn_post_nms_top_n = 2000
+ threshold = 0.7
+ rpn_min_size = feature_stride
+
+ feat_len = (1000 + 15) // 16
+ H, W = feat_len, feat_len
+ num_anchors = len(scales) * len(ratios)
+ count_anchors = H * W * num_anchors
+
+ def get_new_data(batch_size, ctx):
+ '''
+ cls_prob: (batch_size, 2 * num_anchors, H, W)
+ bbox_pred: (batch_size, 4 * num_anchors, H, W)
+ im_info: (batch_size, 3)
+ '''
+
+ dtype = np.float32
+ cls_prob = mx.nd.empty((batch_size, 2 * num_anchors, H, W), dtype = dtype, ctx = ctx)
+ bbox_pred = mx.nd.empty((batch_size, 4 * num_anchors, H, W), dtype = dtype, ctx = ctx)
+ im_info = mx.nd.empty((batch_size, 3), dtype = dtype, ctx = ctx)
+
+ cls = [1.0 * (i + 1) / cls_prob.size for i in range(cls_prob.size)]
+ np.random.shuffle(cls)
+ cls_prob = mx.nd.reshape(mx.nd.array(cls, dtype = dtype, ctx = ctx), shape = cls_prob.shape)
+ bbox_pred = mx.nd.array(np.random.randint(-2, 3, size = bbox_pred.shape), dtype = dtype, ctx = ctx)
+
+ for i in range(batch_size):
+ im_size = np.random.randint(600, feat_len * feature_stride, size = (2,))
+ im_scale = np.random.randint(80, 100) / 100.0
+ im_info[i, :] = [im_size[0], im_size[1], im_scale]
+ return cls_prob, bbox_pred, im_info
+
+ def check_proposal_consistency(op, batch_size):
+ '''
+ op is mx.nd.contrib.Proposal or mx.nd.contrib.MultiProposal
+ '''
+ cls_prob, bbox_pred, im_info = get_new_data(batch_size, mx.cpu(0))
+ rois_cpu, score_cpu = op(
+ cls_score = cls_prob,
+ bbox_pred = bbox_pred,
+ im_info = im_info,
+ feature_stride = feature_stride,
+ scales = scales,
+ ratios = ratios,
+ rpn_pre_nms_top_n = rpn_pre_nms_top_n,
+ rpn_post_nms_top_n = rpn_post_nms_top_n,
+ threshold = threshold,
+ rpn_min_size = rpn_min_size, output_score = True)
+
+ gpu_ctx = mx.gpu(0)
+
+ # copy data to gpu from cpu
+ cls_prob_gpu = cls_prob.as_in_context(gpu_ctx)
+ bbox_pred_gpu = bbox_pred.as_in_context(gpu_ctx)
+ im_info_gpu = im_info.as_in_context(gpu_ctx)
+
+ rois_gpu, score_gpu = op(
+ cls_score = cls_prob_gpu,
+ bbox_pred = bbox_pred_gpu,
+ im_info = im_info_gpu,
+ feature_stride = feature_stride,
+ scales = scales,
+ ratios = ratios,
+ rpn_pre_nms_top_n = rpn_pre_nms_top_n,
+ rpn_post_nms_top_n = rpn_post_nms_top_n,
+ threshold = threshold,
+ rpn_min_size = rpn_min_size, output_score = True)
+
+ rois_cpu_np = rois_cpu.asnumpy()
+ rois_gpu_np = rois_gpu.asnumpy()
+
+ score_cpu_np = score_cpu.asnumpy()
+ score_gpu_np = score_gpu.asnumpy()
+
+ assert_almost_equal(score_cpu_np, score_gpu_np, atol = 1e-3, rtol = 1e-3)
+ assert_almost_equal(rois_cpu_np, rois_gpu_np, atol = 1e-3, rtol = 1e-3)
+
+ check_proposal_consistency(mx.nd.contrib.Proposal, 1)
+ check_proposal_consistency(mx.nd.contrib.MultiProposal, 20)
+
# The following 2 functions launch 0-thread kernels, an error that should be caught and signaled.
def kernel_error_check_imperative():
diff --git a/tests/python/quantization/common.py b/tests/python/quantization/common.py
new file mode 120000
index 00000000000..dccb90b1067
--- /dev/null
+++ b/tests/python/quantization/common.py
@@ -0,0 +1 @@
+../unittest/common.py
\ No newline at end of file
diff --git a/tests/python/quantization/test_quantization.py b/tests/python/quantization/test_quantization.py
new file mode 100644
index 00000000000..7b08f46e836
--- /dev/null
+++ b/tests/python/quantization/test_quantization.py
@@ -0,0 +1,447 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+"""Some of the tests using CUDNN require a special GPU instruction called dp4a.
+Ref: http://images.nvidia.com/content/pdf/tesla/184457-Tesla-P4-Datasheet-NV-Final-Letter-Web.pdf
+"""
+import mxnet as mx
+import numpy as np
+from mxnet.test_utils import assert_almost_equal, rand_ndarray, rand_shape_nd, same, DummyIter
+from common import with_seed
+from mxnet.module import Module
+from mxnet.io import NDArrayIter
+
+
+@with_seed()
+def test_quantize_float32_to_int8():
+ shape = rand_shape_nd(4)
+ data = rand_ndarray(shape, 'default', dtype='float32')
+ min_range = mx.nd.min(data)
+ max_range = mx.nd.max(data)
+ qdata, min_val, max_val = mx.nd.contrib.quantize(data, min_range, max_range, out_type='int8')
+ data_np = data.asnumpy()
+ min_range = min_range.asscalar()
+ max_range = max_range.asscalar()
+ real_range = np.maximum(np.abs(min_range), np.abs(max_range))
+ quantized_range = 127.0
+ scale = quantized_range / real_range
+ assert qdata.dtype == np.int8
+ assert min_val.dtype == np.float32
+ assert max_val.dtype == np.float32
+ assert same(min_val.asscalar(), -real_range)
+ assert same(max_val.asscalar(), real_range)
+ qdata_np = (np.sign(data_np) * np.minimum(np.abs(data_np) * scale + 0.5, quantized_range)).astype(np.int8)
+ assert same(qdata.asnumpy(), qdata_np)
+
+
+@with_seed()
+def test_dequantize_int8_to_float32():
+ shape = rand_shape_nd(4)
+ qdata_np = np.random.uniform(low=-127, high=127, size=shape).astype(dtype=np.int8)
+ qdata = mx.nd.array(qdata_np, dtype=np.int8)
+ real_range = 402.3347
+ min_range = mx.nd.array([-real_range], dtype=np.float32)
+ max_range = mx.nd.array([real_range], dtype=np.float32)
+ data = mx.nd.contrib.dequantize(qdata, min_range, max_range, out_type='float32')
+ quantized_range = 127.0
+ scale = real_range / quantized_range
+ assert data.dtype == np.float32
+ data_np = qdata_np * scale
+ assert_almost_equal(data.asnumpy(), data_np)
+
+
+@with_seed()
+def test_requantize_int32_to_int8():
+ def quantized_int32_to_float(qdata, min_range, max_range):
+ assert qdata.dtype == 'int32'
+ quantized_range = np.iinfo('int32').max
+ real_range = np.maximum(np.abs(min_range), np.abs(max_range))
+ scale = float(real_range) / float(quantized_range)
+ return qdata.astype('float32') * scale
+
+ def float_to_quantized_int8(data, min_range, max_range):
+ assert data.dtype == 'float32'
+ real_range = np.maximum(np.abs(min_range), np.abs(max_range))
+ quantized_range = np.iinfo('int8').max
+ scale = float(quantized_range) / float(real_range)
+ return (np.sign(data) * np.minimum(np.abs(data) * scale + 0.5, quantized_range)).astype('int8')
+
+ def requantize(qdata, min_data, max_data, real_range):
+ data = quantized_int32_to_float(qdata, min_data, max_data)
+ output = float_to_quantized_int8(data, -real_range, real_range)
+ return output, -real_range, real_range
+
+ def requantize_baseline(qdata, min_data, max_data, min_calib_range=None, max_calib_range=None):
+ if min_calib_range is not None and max_calib_range is not None:
+ real_range = np.maximum(np.abs(min_calib_range), np.abs(max_calib_range))
+ return requantize(qdata, min_data, max_data, real_range)
+ else:
+ min_range = quantized_int32_to_float(np.min(qdata), min_data, max_data)
+ max_range = quantized_int32_to_float(np.max(qdata), min_data, max_data)
+ return requantize(qdata, min_data, max_data, np.maximum(np.abs(min_range), np.abs(max_range)))
+
+ def check_requantize(shape, min_calib_range=None, max_calib_range=None):
+ qdata = mx.nd.random.uniform(low=-1000.0, high=1000.0, shape=shape).astype('int32')
+ min_range = mx.nd.array([-1010.0])
+ max_range = mx.nd.array([1020.0])
+ if min_calib_range is None or max_calib_range is None:
+ qdata_int8, min_output, max_output = mx.nd.contrib.requantize(qdata, min_range, max_range)
+ else:
+ qdata_int8, min_output, max_output = mx.nd.contrib.requantize(qdata, min_range, max_range,
+ min_calib_range, max_calib_range)
+
+ qdata_int8_np, min_output_np, max_output_np = requantize_baseline(qdata.asnumpy(), min_range.asscalar(),
+ max_range.asscalar(),
+ min_calib_range=min_calib_range,
+ max_calib_range=max_calib_range)
+ assert_almost_equal(qdata_int8.asnumpy(), qdata_int8_np)
+ assert_almost_equal(min_output.asnumpy(), np.array([min_output_np]))
+ assert_almost_equal(max_output.asnumpy(), np.array([max_output_np]))
+
+ check_requantize((3, 4, 10, 10))
+ check_requantize((32, 3, 23, 23))
+ check_requantize((3, 4, 10, 10), min_calib_range=-1050.0, max_calib_range=1040.0)
+ check_requantize((32, 3, 23, 23), min_calib_range=-134.349, max_calib_range=523.43)
+
+
+@with_seed()
+def test_quantized_conv():
+ if mx.current_context().device_type != 'gpu':
+ print('skipped testing quantized_conv on cpu since it is not implemented yet')
+ return
+
+ def check_quantized_conv(data_shape, kernel, num_filter, pad, stride, no_bias):
+ with mx.Context('gpu', 0):
+ # run fp32 conv
+ data = mx.sym.Variable(name='data', shape=data_shape, dtype='float32')
+ conv2d = mx.sym.Convolution(data=data, kernel=kernel, num_filter=num_filter, pad=pad, stride=stride,
+ no_bias=no_bias, cudnn_off=False, name='conv2d')
+ arg_shapes, _, _ = conv2d.infer_shape(data=data_shape)
+ arg_names = conv2d.list_arguments()
+ conv_exe_fp32 = conv2d.simple_bind(ctx=mx.current_context(), grad_req='null')
+ conv_exe_fp32.arg_dict[arg_names[0]][:] = mx.nd.random.uniform(low=-127.0, high=127.0,
+ shape=data_shape).astype('int32')
+ conv_exe_fp32.arg_dict[arg_names[1]][:] = mx.nd.random.uniform(low=-127.0, high=127.0,
+ shape=arg_shapes[1]).astype('int32')
+ if not no_bias:
+ conv_exe_fp32.arg_dict[arg_names[2]][:] = mx.nd.random.uniform(low=-127.0, high=127.0,
+ shape=arg_shapes[2]).astype('int32')
+ output = conv_exe_fp32.forward()[0]
+
+ # run quantized conv
+ qdata = mx.sym.Variable(name='qdata', shape=data_shape, dtype='int8')
+ qweight = mx.sym.Variable(name='qweight', dtype='int8')
+ min_data = mx.sym.Variable(name='min_data')
+ max_data = mx.sym.Variable(name='max_data')
+ min_weight = mx.sym.Variable(name='min_weight')
+ max_weight = mx.sym.Variable(name='max_weight')
+ quantized_conv2d = mx.sym.contrib.quantized_conv(data=qdata, weight=qweight, min_data=min_data,
+ max_data=max_data, min_weight=min_weight,
+ max_weight=max_weight, kernel=kernel,
+ num_filter=num_filter, pad=pad, stride=stride,
+ no_bias=no_bias)
+ qarg_names = quantized_conv2d.list_arguments()
+ type_dict = None
+ if not no_bias:
+ type_dict = {qarg_names[2]: 'int8'}
+ conv_exe_int8 = quantized_conv2d.simple_bind(ctx=mx.current_context(), type_dict=type_dict, grad_req='null')
+ conv_exe_int8.arg_dict[qarg_names[0]][:] = conv_exe_fp32.arg_dict[arg_names[0]].astype('int8')
+ conv_exe_int8.arg_dict[qarg_names[1]][:] = conv_exe_fp32.arg_dict[arg_names[1]].astype('int8')
+ quantized_range = 127.0
+ if no_bias:
+ conv_exe_int8.arg_dict[qarg_names[2]][:] = -quantized_range
+ conv_exe_int8.arg_dict[qarg_names[3]][:] = quantized_range
+ conv_exe_int8.arg_dict[qarg_names[4]][:] = -quantized_range
+ conv_exe_int8.arg_dict[qarg_names[5]][:] = quantized_range
+ else:
+ conv_exe_int8.arg_dict[qarg_names[2]][:] = conv_exe_fp32.arg_dict[arg_names[2]].astype('int8')
+ conv_exe_int8.arg_dict[qarg_names[3]][:] = -quantized_range
+ conv_exe_int8.arg_dict[qarg_names[4]][:] = quantized_range
+ conv_exe_int8.arg_dict[qarg_names[5]][:] = -quantized_range
+ conv_exe_int8.arg_dict[qarg_names[6]][:] = quantized_range
+ conv_exe_int8.arg_dict[qarg_names[7]][:] = -quantized_range
+ conv_exe_int8.arg_dict[qarg_names[8]][:] = quantized_range
+ qoutput, min_range, max_range = conv_exe_int8.forward()
+
+ if no_bias:
+ assert_almost_equal(output.asnumpy(), qoutput.asnumpy())
+ else:
+ # with adding bias, accuracy loss should not be greater than one
+ diff = mx.nd.abs(output - qoutput.astype(output.dtype))
+ cond = mx.nd.lesser(2, diff).sum().asscalar()
+ assert cond == 0
+
+ check_quantized_conv((3, 4, 28, 28), (3, 3), 128, (1, 1), (1, 1), True)
+ check_quantized_conv((3, 4, 28, 28), (3, 3), 128, (1, 1), (1, 1), False)
+
+
+@with_seed()
+def test_quantized_pooling():
+ if mx.current_context().device_type != 'gpu':
+ print('skipped testing quantized_pooling on cpu since it is not implemented yet')
+ return
+
+ def check_quantized_pooling(data_shape, kernel, pool_type, pad, stride, global_pool):
+ with mx.Context('gpu', 0):
+ data = mx.sym.Variable(name='data', shape=data_shape, dtype='float32')
+ pooling_fp32 = mx.sym.Pooling(data=data, kernel=kernel, pad=pad, stride=stride,
+ pool_type=pool_type, global_pool=global_pool, cudnn_off=False)
+ arg_shapes, _, _ = pooling_fp32.infer_shape(data=data_shape)
+ arg_names = pooling_fp32.list_arguments()
+ pooling_fp32_exe = pooling_fp32.simple_bind(ctx=mx.current_context(), grad_req='null')
+ pooling_fp32_exe.arg_dict[arg_names[0]][:] = mx.nd.random.uniform(low=-127.0, high=127.0,
+ shape=data_shape).astype('int32')
+ output = pooling_fp32_exe.forward()[0]
+
+ qdata = mx.sym.Variable(name='qdata', shape=data_shape, dtype='int8')
+ min_data = mx.sym.Variable(name='min_data')
+ max_data = mx.sym.Variable(name='max_data')
+ quantized_pooling = mx.sym.contrib.quantized_pooling(data=qdata, min_data=min_data,
+ max_data=max_data, kernel=kernel,
+ pad=pad, stride=stride, pool_type=pool_type,
+ global_pool=global_pool)
+ pooling_int8_exe = quantized_pooling.simple_bind(ctx=mx.current_context(), grad_req='null')
+ qarg_names = quantized_pooling.list_arguments()
+ pooling_int8_exe.arg_dict[qarg_names[0]][:] = pooling_fp32_exe.arg_dict[arg_names[0]].astype('int8')
+ quantized_range = 127.0
+ pooling_int8_exe.arg_dict[qarg_names[1]][:] = -quantized_range
+ pooling_int8_exe.arg_dict[qarg_names[2]][:] = quantized_range
+ qoutput, min_range, max_range = pooling_int8_exe.forward()
+
+ if pool_type == 'max':
+ assert_almost_equal(output.asnumpy(), qoutput.asnumpy())
+ elif pool_type == 'avg': # for avg pooling, fp32 and int8 may be different due to rounding errors
+ diff = mx.nd.abs(output - qoutput.astype(output.dtype))
+ cond = mx.nd.lesser(2, diff).sum().asscalar()
+ assert cond == 0
+
+ check_quantized_pooling((3, 4, 56, 56), (3, 3), 'max', (0, 0), (2, 2), False)
+ check_quantized_pooling((3, 4, 56, 56), (3, 3), 'max', (0, 0), (2, 2), True)
+ check_quantized_pooling((3, 512, 7, 7), (7, 7), 'avg', (0, 0), (1, 1), False)
+ check_quantized_pooling((3, 512, 7, 7), (7, 7), 'avg', (0, 0), (1, 1), True)
+
+
+@with_seed()
+def test_quantized_fc():
+ if mx.current_context().device_type != 'gpu':
+ print('skipped testing quantized_fc on cpu since it is not implemented yet')
+ return
+
+ def check_quantized_fc(data_shape, num_hidden, no_bias, flatten=True):
+ with mx.Context('gpu', 0):
+ data = mx.sym.Variable(name='data', shape=data_shape, dtype='float32')
+ fc_fp32 = mx.sym.FullyConnected(data=data, num_hidden=num_hidden, no_bias=no_bias, flatten=flatten)
+ arg_shapes, _, _ = fc_fp32.infer_shape(data=data_shape)
+ arg_names = fc_fp32.list_arguments()
+ fc_fp32_exe = fc_fp32.simple_bind(ctx=mx.current_context(), grad_req='null')
+ fc_fp32_exe.arg_dict[arg_names[0]][:] = mx.nd.random.uniform(low=-127.0, high=127.0,
+ shape=data_shape).astype('int32')
+ fc_fp32_exe.arg_dict[arg_names[1]][:] = mx.nd.random.uniform(low=-127.0, high=127.0,
+ shape=arg_shapes[1]).astype('int32')
+ if not no_bias:
+ fc_fp32_exe.arg_dict[arg_names[2]][:] = mx.nd.random.uniform(low=-127.0, high=127.0,
+ shape=arg_shapes[2]).astype('int32')
+ output = fc_fp32_exe.forward()[0]
+
+ qdata = mx.sym.Variable(name='qdata', shape=data_shape, dtype='int8')
+ fc_int8 = mx.sym.contrib.quantized_fully_connected(data=qdata, num_hidden=num_hidden,
+ no_bias=no_bias, flatten=flatten)
+ qarg_names = fc_int8.list_arguments()
+ type_dict = {qarg_names[1]: 'int8'}
+ if not no_bias:
+ type_dict.update({qarg_names[2]: 'int8'})
+ fc_int8_exe = fc_int8.simple_bind(ctx=mx.current_context(), type_dict=type_dict, grad_req='null')
+ fc_int8_exe.arg_dict[qarg_names[0]][:] = fc_fp32_exe.arg_dict[arg_names[0]].astype('int8')
+ fc_int8_exe.arg_dict[qarg_names[1]][:] = fc_fp32_exe.arg_dict[arg_names[1]].astype('int8')
+ quantized_range = 127.0
+ if no_bias:
+ fc_int8_exe.arg_dict[qarg_names[2]][:] = -quantized_range
+ fc_int8_exe.arg_dict[qarg_names[3]][:] = quantized_range
+ fc_int8_exe.arg_dict[qarg_names[4]][:] = -quantized_range
+ fc_int8_exe.arg_dict[qarg_names[5]][:] = quantized_range
+ else:
+ fc_int8_exe.arg_dict[qarg_names[2]][:] = fc_fp32_exe.arg_dict[arg_names[2]].astype('int8')
+ fc_int8_exe.arg_dict[qarg_names[3]][:] = -quantized_range
+ fc_int8_exe.arg_dict[qarg_names[4]][:] = quantized_range
+ fc_int8_exe.arg_dict[qarg_names[5]][:] = -quantized_range
+ fc_int8_exe.arg_dict[qarg_names[6]][:] = quantized_range
+ fc_int8_exe.arg_dict[qarg_names[7]][:] = -quantized_range
+ fc_int8_exe.arg_dict[qarg_names[8]][:] = quantized_range
+ qoutput, min_range, max_range = fc_int8_exe.forward()
+
+ if no_bias:
+ assert_almost_equal(output.asnumpy(), qoutput.asnumpy())
+ else:
+ # with adding bias, accuracy loss should not be greater than one
+ diff = mx.nd.abs(output - qoutput.astype(output.dtype))
+ cond = mx.nd.lesser(2, diff).sum().asscalar()
+ assert cond == 0
+
+ check_quantized_fc((32, 512, 2, 2), 100, True)
+ check_quantized_fc((32, 111, 2, 2), 100, True)
+ check_quantized_fc((32, 512, 2, 2), 100, False)
+ check_quantized_fc((32, 111, 2, 2), 100, False)
+
+
+@with_seed()
+def test_quantized_flatten():
+ def check_quantized_flatten(shape):
+ qdata = mx.nd.random.uniform(low=-127, high=127, shape=shape).astype('int8')
+ min_data = mx.nd.array([-1023.343], dtype='float32')
+ max_data = mx.nd.array([2343.324275], dtype='float32')
+ qoutput, min_output, max_output = mx.nd.contrib.quantized_flatten(qdata, min_data, max_data)
+ assert qoutput.ndim == 2
+ assert qoutput.shape[0] == qdata.shape[0]
+ assert qoutput.shape[1] == np.prod(qdata.shape[1:])
+ assert same(qdata.asnumpy().flatten(), qoutput.asnumpy().flatten())
+ assert same(min_data.asnumpy(), min_output.asnumpy())
+ assert same(max_data.asnumpy(), max_output.asnumpy())
+
+ check_quantized_flatten((10,))
+ check_quantized_flatten((10, 15))
+ check_quantized_flatten((10, 15, 18))
+ check_quantized_flatten((3, 4, 23, 23))
+
+
+@with_seed()
+def test_quantize_params():
+ data = mx.sym.Variable('data')
+ conv = mx.sym.Convolution(data, kernel=(1, 1), num_filter=2048, name='conv')
+ sym = mx.sym.BatchNorm(data=conv, eps=2e-05, fix_gamma=False, momentum=0.9, use_global_stats=False, name='bn')
+ offline_params = [name for name in sym.list_arguments()
+ if not name.startswith('data') and not name.endswith('label')]
+ params = {}
+ for name in offline_params:
+ params[name] = mx.nd.uniform(shape=(2, 2))
+ qsym = mx.contrib.quant._quantize_symbol(sym, offline_params=offline_params)
+ qparams = mx.contrib.quant._quantize_params(qsym, params)
+ param_names = params.keys()
+ qparam_names = qparams.keys()
+ for name in qparam_names:
+ if name.startswith('bn'):
+ assert name in param_names
+ elif name.startswith('conv'):
+ assert name not in param_names
+ assert name.find('quantize') != -1
+
+
+def get_fp32_sym():
+ data = mx.sym.Variable('data')
+ conv = mx.sym.Convolution(data, kernel=(1, 1), num_filter=16, name='conv')
+ bn = mx.sym.BatchNorm(data=conv, eps=2e-05, fix_gamma=False, momentum=0.9, use_global_stats=False, name='bn')
+ act = mx.sym.Activation(data=bn, act_type='relu', name='relu')
+ pool = mx.sym.Pooling(act, kernel=(4, 4), pool_type='avg', name='pool')
+ fc = mx.sym.FullyConnected(pool, num_hidden=10, flatten=True, name='fc')
+ sym = mx.sym.SoftmaxOutput(fc, grad_scale=1, ignore_label=-1, multi_output=False,
+ out_grad=False, preserve_shape=False, use_ignore=False, name='softmax')
+ return sym
+
+
+@with_seed()
+def test_quantize_model():
+ def check_params(params, qparams, qsym=None):
+ if qsym is None:
+ assert len(params) == len(qparams)
+ for k, v in params.items():
+ assert k in qparams
+ assert same(v.asnumpy(), qparams[k].asnumpy())
+ else:
+ qparams_ground_truth = mx.contrib.quant._quantize_params(qsym, params)
+ assert len(qparams) == len(qparams_ground_truth)
+ for k, v in qparams_ground_truth.items():
+ assert k in qparams
+ assert same(v.asnumpy(), qparams[k].asnumpy())
+
+ def check_qsym_calibrated(qsym):
+ attrs = qsym.attr_dict()
+ for k, v in attrs.items():
+ if k.find('requantize_') != -1:
+ assert 'min_calib_range' in v
+ assert 'max_calib_range' in v
+
+ sym = get_fp32_sym()
+ mod = Module(symbol=sym)
+ batch_size = 4
+ data_shape = (batch_size, 4, 10, 10)
+ label_shape = (batch_size, 10)
+ mod.bind(data_shapes=[('data', data_shape)], label_shapes=[('softmax_label', label_shape)])
+ mod.init_params()
+ arg_params, aux_params = mod.get_params()
+ qsym, qarg_params, qaux_params = mx.contrib.quant.quantize_model(sym=sym,
+ arg_params=arg_params,
+ aux_params=aux_params,
+ ctx=mx.current_context(),
+ calib_mode='none')
+ check_params(arg_params, qarg_params, qsym)
+ check_params(aux_params, qaux_params)
+
+ calib_data = mx.nd.random.uniform(shape=data_shape)
+ calib_data = NDArrayIter(data=calib_data)
+ calib_data = DummyIter(calib_data)
+ qsym, qarg_params, qaux_params = mx.contrib.quant.quantize_model(sym=sym,
+ arg_params=arg_params,
+ aux_params=aux_params,
+ ctx=mx.current_context(),
+ calib_mode='naive',
+ calib_data=calib_data,
+ num_calib_examples=20)
+ check_params(arg_params, qarg_params, qsym)
+ check_params(aux_params, qaux_params)
+ check_qsym_calibrated(qsym)
+
+
+@with_seed()
+def test_quantize_sym_with_calib():
+ sym = get_fp32_sym()
+ offline_params = [name for name in sym.list_arguments()
+ if not name.startswith('data') and not name.endswith('label')]
+ qsym = mx.contrib.quant._quantize_symbol(sym, offline_params=offline_params)
+ requantize_op_names = ['requantize_conv', 'requantize_fc']
+ th_dict = {'conv_output': (np.random.uniform(low=100.0, high=200.0), np.random.uniform(low=100.0, high=200.0)),
+ 'fc_output': (np.random.uniform(low=100.0, high=200.0), np.random.uniform(low=100.0, high=200.0))}
+ op_name_to_th_name = {'requantize_conv': 'conv_output', 'requantize_fc': 'fc_output'}
+ cqsym = mx.contrib.quant._calibrate_quantized_sym(qsym, th_dict)
+ attr_dict = cqsym.attr_dict()
+ for name in requantize_op_names:
+ assert name in attr_dict
+ lhs = float(attr_dict[name]['min_calib_range'])
+ rhs = th_dict[op_name_to_th_name[name]][0]
+ assert_almost_equal(np.array([lhs]), np.array([rhs]))
+ lhs = float(attr_dict[name]['max_calib_range'])
+ rhs = th_dict[op_name_to_th_name[name]][1]
+ assert_almost_equal(np.array([lhs]), np.array([rhs]), rtol=1e-3, atol=1e-4)
+
+
+@with_seed()
+def test_get_optimal_thresholds():
+ # Given an ndarray with elements following a uniform distribution, the optimal threshold
+ # for quantizing the ndarray should be either abs(min(nd)) or abs(max(nd)).
+ def get_threshold(nd):
+ min_nd = mx.nd.min(nd)
+ max_nd = mx.nd.max(nd)
+ return mx.nd.maximum(mx.nd.abs(min_nd), mx.nd.abs(max_nd)).asnumpy()
+
+ nd_dict = {'layer1': mx.nd.uniform(low=-10.532, high=11.3432, shape=(8, 3, 23, 23))}
+ expected_threshold = get_threshold(nd_dict['layer1'])
+ th_dict = mx.contrib.quant._get_optimal_thresholds(nd_dict)
+ assert 'layer1' in th_dict
+ assert_almost_equal(np.array([th_dict['layer1'][1]]), expected_threshold, rtol=0.001, atol=0.001)
+
+
+if __name__ == "__main__":
+ import nose
+ nose.runmodule()
diff --git a/tests/ci_build/deploy/aws b/tests/python/quantization_gpu/test_quantization_gpu.py
old mode 100755
new mode 100644
similarity index 73%
rename from tests/ci_build/deploy/aws
rename to tests/python/quantization_gpu/test_quantization_gpu.py
index 810a0b9bdda..4f2d70effd4
--- a/tests/ci_build/deploy/aws
+++ b/tests/python/quantization_gpu/test_quantization_gpu.py
@@ -1,5 +1,3 @@
-#!/usr/bin/env python
-
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
@@ -16,14 +14,19 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
-import sys
import os
+import sys
+import mxnet as mx
+
+
+curr_path = os.path.dirname(os.path.abspath(os.path.expanduser(__file__)))
+sys.path.insert(0, os.path.join(curr_path, '../quantization'))
+from mxnet.test_utils import set_default_context
+from test_quantization import *
-if os.environ.get('LC_CTYPE', '') == 'UTF-8':
- os.environ['LC_CTYPE'] = 'en_US.UTF-8'
-import awscli.clidriver
+set_default_context(mx.gpu(0))
-main = awscli.clidriver.main
if __name__ == '__main__':
- sys.exit(main())
+ import nose
+ nose.runmodule()
diff --git a/tests/python/unittest/test_gluon.py b/tests/python/unittest/test_gluon.py
index ba2e7aba9f6..952fdf7e366 100644
--- a/tests/python/unittest/test_gluon.py
+++ b/tests/python/unittest/test_gluon.py
@@ -82,16 +82,16 @@ def hybrid_forward(self, F, x, const):
@with_seed()
def test_parameter_sharing():
class Net(gluon.Block):
- def __init__(self, **kwargs):
+ def __init__(self, in_units=0, **kwargs):
super(Net, self).__init__(**kwargs)
with self.name_scope():
- self.dense0 = nn.Dense(5, in_units=5)
- self.dense1 = nn.Dense(5, in_units=5)
+ self.dense0 = nn.Dense(5, in_units=in_units)
+ self.dense1 = nn.Dense(5, in_units=in_units)
def forward(self, x):
return self.dense1(self.dense0(x))
- net1 = Net(prefix='net1_')
+ net1 = Net(prefix='net1_', in_units=5)
net2 = Net(prefix='net2_', params=net1.collect_params())
net1.collect_params().initialize()
net2(mx.nd.zeros((3, 5)))
@@ -101,6 +101,16 @@ def forward(self, x):
net3 = Net(prefix='net3_')
net3.load_params('net1.params', mx.cpu())
+ net4 = Net(prefix='net4_')
+ net5 = Net(prefix='net5_', in_units=5, params=net4.collect_params())
+ net4.collect_params().initialize()
+ net5(mx.nd.zeros((3, 5)))
+
+ net4.save_params('net4.params')
+
+ net6 = Net(prefix='net6_')
+ net6.load_params('net4.params', mx.cpu())
+
@with_seed()
def test_parameter_str():
diff --git a/tests/python/unittest/test_gluon_contrib.py b/tests/python/unittest/test_gluon_contrib.py
index 29850dce6ae..729ec8407f2 100644
--- a/tests/python/unittest/test_gluon_contrib.py
+++ b/tests/python/unittest/test_gluon_contrib.py
@@ -108,6 +108,22 @@ def test_conv_fill_shape():
check_rnn_forward(cell, mx.nd.ones((8, 3, 5, 7)))
assert cell.i2h_weight.shape[1] == 5, cell.i2h_weight.shape[1]
+@with_seed()
+def test_lstmp():
+ nhid = 100
+ nproj = 64
+ cell = contrib.rnn.LSTMPCell(nhid, nproj, prefix='rnn_')
+ inputs = [mx.sym.Variable('rnn_t%d_data'%i) for i in range(3)]
+ outputs, _ = cell.unroll(3, inputs)
+ outputs = mx.sym.Group(outputs)
+ expected_params = ['rnn_h2h_bias', 'rnn_h2h_weight', 'rnn_h2r_weight', 'rnn_i2h_bias', 'rnn_i2h_weight']
+ expected_outputs = ['rnn_t0_out_output', 'rnn_t1_out_output', 'rnn_t2_out_output']
+ assert sorted(cell.collect_params().keys()) == expected_params
+ assert outputs.list_outputs() == expected_outputs, outputs.list_outputs()
+
+ args, outs, auxs = outputs.infer_shape(rnn_t0_data=(10,50), rnn_t1_data=(10,50), rnn_t2_data=(10,50))
+ assert outs == [(10, nproj), (10, nproj), (10, nproj)]
+
@with_seed()
def test_vardrop():
diff --git a/tests/python/unittest/test_image.py b/tests/python/unittest/test_image.py
index 124c94c5eb3..78c3ce14eb4 100644
--- a/tests/python/unittest/test_image.py
+++ b/tests/python/unittest/test_image.py
@@ -110,9 +110,9 @@ def test_resize_short(self):
for _ in range(3):
new_size = np.random.randint(1, 1000)
if h > w:
- new_h, new_w = new_size * h / w, new_size
+ new_h, new_w = new_size * h // w, new_size
else:
- new_h, new_w = new_size, new_size * w / h
+ new_h, new_w = new_size, new_size * w // h
for interp in range(0, 2):
# area-based/lanczos don't match with cv2?
cv_resized = cv2.resize(cv_img, (new_w, new_h), interpolation=interp)
diff --git a/tests/python/unittest/test_io.py b/tests/python/unittest/test_io.py
index 4e23a22e09e..e986ae7bf71 100644
--- a/tests/python/unittest/test_io.py
+++ b/tests/python/unittest/test_io.py
@@ -219,7 +219,9 @@ def check_libSVMIter_synthetic():
i = 0
for batch in iter(data_train):
expected = first.asnumpy() if i == 0 else second.asnumpy()
- assert_almost_equal(data_train.getdata().asnumpy(), expected)
+ data = data_train.getdata()
+ data.check_format(True)
+ assert_almost_equal(data.asnumpy(), expected)
i += 1
def check_libSVMIter_news_data():
@@ -227,7 +229,7 @@ def check_libSVMIter_news_data():
'name': 'news20.t',
'origin_name': 'news20.t.bz2',
'url': "https://apache-mxnet.s3-accelerate.dualstack.amazonaws.com/gluon/dataset/news20.t.bz2",
- 'feature_dim': 62060,
+ 'feature_dim': 62060 + 1,
'num_classes': 20,
'num_examples': 3993,
}
@@ -243,8 +245,11 @@ def check_libSVMIter_news_data():
num_batches = 0
for batch in data_train:
# check the range of labels
- assert(np.sum(batch.label[0].asnumpy() > 20) == 0)
- assert(np.sum(batch.label[0].asnumpy() <= 0) == 0)
+ data = batch.data[0]
+ label = batch.label[0]
+ data.check_format(True)
+ assert(np.sum(label.asnumpy() > 20) == 0)
+ assert(np.sum(label.asnumpy() <= 0) == 0)
num_batches += 1
expected_num_batches = num_examples / batch_size
assert(num_batches == int(expected_num_batches)), num_batches
diff --git a/tests/python/unittest/test_module.py b/tests/python/unittest/test_module.py
index d6e15c2c0e0..ae950457444 100644
--- a/tests/python/unittest/test_module.py
+++ b/tests/python/unittest/test_module.py
@@ -274,7 +274,7 @@ def sym_gen(seq_len):
data = mx.sym.Variable('data')
label = mx.sym.Variable('softmax_label')
embed = mx.sym.Embedding(data=data, input_dim=vocab_dim,
- output_dim=num_embedding, name='embed')
+ output_dim=num_embedding)
stack = mx.rnn.SequentialRNNCell()
for i in range(num_layer):
stack.add(mx.rnn.LSTMCell(num_hidden=num_hidden, prefix='lstm_l%d_'%i))
@@ -299,6 +299,10 @@ def create_bucketing_module(key):
return model
#initialize the bucketing module with the default bucket key
bucketing_model = create_bucketing_module(default_key)
+ #check name
+ assert bucketing_model.symbol.list_arguments()[1] == "embedding0_weight",\
+ "Error in assigning names for args in BucketingModule"
+
#switch to test_key
bucketing_model.switch_bucket(test_key, [('data', (batch_size, test_key))],
[('softmax_label', (batch_size, test_key))])
diff --git a/tests/python/unittest/test_operator.py b/tests/python/unittest/test_operator.py
index d6280eaf2e3..561e6952557 100644
--- a/tests/python/unittest/test_operator.py
+++ b/tests/python/unittest/test_operator.py
@@ -24,6 +24,7 @@
import itertools
from numpy.testing import assert_allclose, assert_array_equal
from mxnet.test_utils import *
+from mxnet.base import py_str
from common import setup_module, with_seed
import unittest
@@ -489,6 +490,87 @@ def frelu_grad(x):
check_symbolic_backward(y, [xa], [np.ones(shape)], [ga])
+# NOTE(haojin2): Skipping the numeric check tests for float16 data type due to precision issues,
+# the analytical checks are still performed on each and every data type to verify the correctness.
+@with_seed()
+def test_leaky_relu():
+ def fleaky_relu(x, act_type, slope=0.25):
+ neg_indices = x < 0
+ out = x.copy()
+ if act_type == 'elu':
+ out[neg_indices] = slope * (np.exp(out[neg_indices]) - 1.)
+ elif act_type == 'leaky':
+ out[neg_indices] = slope * out[neg_indices]
+ return out
+ def fleaky_relu_grad(grad, x, y, act_type, slope=0.25):
+ neg_indices = x < 0
+ out = np.ones(x.shape)
+ if act_type == 'elu':
+ out[neg_indices] = y[neg_indices] + slope
+ elif act_type == 'leaky':
+ out[neg_indices] = slope
+ return out * grad
+ shape = (3, 4)
+ x = mx.symbol.Variable("x")
+ slp = 0.25
+ for dtype in [np.float16, np.float32, np.float64]:
+ xa = np.random.uniform(low=-1.0,high=1.0,size=shape).astype(dtype)
+ eps = 1e-4
+ rtol = 1e-4
+ atol = 1e-3
+ xa[abs(xa) < eps] = 1.0
+ for act_type in ['elu', 'leaky']:
+ y = mx.symbol.LeakyReLU(data=x, slope=slp, act_type=act_type)
+ ya = fleaky_relu(xa, slope=slp, act_type=act_type)
+ ga = fleaky_relu_grad(np.ones(shape), xa, ya, slope=slp, act_type=act_type)
+ # Skip numeric check for float16 type to get rid of flaky behavior
+ if dtype is not np.float16:
+ check_numeric_gradient(y, [xa], numeric_eps=eps, rtol=rtol, atol=atol, dtype=dtype)
+ check_symbolic_forward(y, [xa], [ya], rtol=rtol, atol=atol, dtype=dtype)
+ check_symbolic_backward(y, [xa], [np.ones(shape)], [ga], rtol=rtol, atol=atol, dtype=dtype)
+
+
+# NOTE(haojin2): Skipping the numeric check tests for float16 data type due to precision issues,
+# the analytical checks are still performed on each and every data type to verify the correctness.
+@with_seed()
+def test_prelu():
+ def fprelu(x, gamma):
+ pos_indices = x > 0
+ out = x.copy()
+ out = np.multiply(out, gamma)
+ out[pos_indices] = x[pos_indices]
+ return out
+ def fprelu_grad(x, y, gamma):
+ pos_indices = x > 0
+ grad_x = np.multiply(np.ones(x.shape), gamma)
+ grad_gam = np.zeros(gamma.shape)
+ copy_x = x.copy()
+ copy_x[pos_indices] = 0.0
+ grad_x[pos_indices] = 1.0
+ if gamma.shape[0] == 1:
+ grad_gam = np.sum(np.sum(copy_x))
+ elif gamma.shape[0] > 1:
+ grad_gam = np.sum(copy_x, axis=0)
+ return (grad_x, grad_gam)
+ shape = (3,4)
+ x = mx.symbol.Variable("x")
+ gamma = mx.symbol.Variable("gamma")
+ for dtype in [np.float16, np.float32, np.float64]:
+ for gam in [np.array([0.1, 0.2, 0.3, 0.4], dtype=dtype)]:
+ xa = np.random.uniform(low=-1.0,high=1.0,size=shape).astype(dtype)
+ rtol = 1e-3
+ atol = 1e-3
+ eps = 1e-4
+ xa[abs(xa) < eps] = 1.0
+ y = mx.symbol.LeakyReLU(data=x, gamma=gamma, act_type='prelu')
+ ya = fprelu(xa, gam)
+ g_xa, g_gam = fprelu_grad(xa, ya, gamma=gam)
+ # Skip numeric check for float16 type to get rid of flaky behavior
+ if dtype is not np.float16:
+ check_numeric_gradient(y, [xa, gam], numeric_eps=eps, rtol=rtol, atol=atol, dtype=dtype)
+ check_symbolic_forward(y, [xa, gam], [ya], rtol=rtol, atol=atol, dtype=dtype)
+ check_symbolic_backward(y, [xa, gam], [np.ones(shape), np.ones(gam.shape)], [g_xa, g_gam], rtol=rtol, atol=atol, dtype=dtype)
+
@with_seed()
def test_sigmoid():
def fsigmoid(a):
@@ -2198,7 +2280,29 @@ def unittest_correlation(data_shape,kernel_size,max_displacement,stride1,stride2
@with_seed()
def test_correlation():
+ def test_infer_type(dtype):
+ a = mx.sym.Variable('a')
+ b = mx.sym.Variable('b')
+ corr = mx.sym.Correlation(data1=a, data2=b)
+ arg_type1, out_type1, _ = corr.infer_type(a=dtype)
+ if arg_type1[0] != np.dtype(dtype) and arg_type1[1] != np.dtype(dtype) and out_type1[0] != np.dtype(dtype):
+ msg = npt.npt.build_err_msg([a, b],
+ err_msg="Inferred type from a is not as expected, "
+ "Expected :%s %s %s, Got: %s %s %s"
+ % (dtype, dtype, dtype, arg_type1[0], arg_type1[1], out_type1[0]),
+ names=['a', 'b'])
+ raise AssertionError(msg)
+ arg_type2, out_type2, _ = corr.infer_type(b=dtype)
+ if arg_type2[0] != np.dtype(dtype) and arg_type2[1] != np.dtype(dtype) and out_type2[0] != np.dtype(dtype):
+ msg = npt.npt.build_err_msg([a, b],
+ err_msg="Inferred type from b is not as expected, "
+ "Expected :%s %s %s, Got: %s %s %s"
+ % (dtype, dtype, dtype, arg_type1[0], arg_type1[1], out_type1[0]),
+ names=['a', 'b'])
+ raise AssertionError(msg)
+
for dtype in ['float16', 'float32', 'float64']:
+ test_infer_type(dtype)
unittest_correlation((1,3,10,10), kernel_size = 1,max_displacement = 4,stride1 = 1,stride2 = 1,pad_size = 4,is_multiply = False, dtype = dtype)
unittest_correlation((5,1,15,15), kernel_size = 1,max_displacement = 5,stride1 = 1,stride2 = 1,pad_size = 5,is_multiply = False, dtype = dtype)
unittest_correlation((5,1,15,15), kernel_size = 1,max_displacement = 5,stride1 = 1,stride2 = 1,pad_size = 5,is_multiply = True, dtype = dtype)
@@ -2369,11 +2473,11 @@ def test_instance_normalization():
check_instance_norm_with_shape((3,3,2,3,2,1,1), default_context())
-def check_l2_normalization(in_shape, mode, norm_eps=1e-10):
+def check_l2_normalization(in_shape, mode, dtype, norm_eps=1e-10):
ctx = default_context()
data = mx.symbol.Variable('data')
out = mx.symbol.L2Normalization(data=data, mode=mode, eps=norm_eps)
- in_data = np.random.uniform(-1, 1, in_shape)
+ in_data = np.random.uniform(-1, 1, in_shape).astype(dtype)
# calculate numpy results
if mode == 'channel':
assert in_data.ndim > 2
@@ -2397,7 +2501,7 @@ def check_l2_normalization(in_shape, mode, norm_eps=1e-10):
exe = out.simple_bind(ctx=ctx, data=in_data.shape)
output = exe.forward(is_train=True, data=in_data)
# compare numpy + mxnet
- assert_almost_equal(exe.outputs[0].asnumpy(), np_out, rtol=1e-5)
+ assert_almost_equal(exe.outputs[0].asnumpy(), np_out, rtol=1e-2 if dtype is 'float16' else 1e-5, atol=1e-5)
# check gradient
check_numeric_gradient(out, [in_data], numeric_eps=1e-3, rtol=1e-2, atol=1e-3)
@@ -2405,24 +2509,25 @@ def check_l2_normalization(in_shape, mode, norm_eps=1e-10):
# TODO(szha): Seeding this masks failures. We need to do a deep dive for failures without this seed.
@with_seed(1234)
def test_l2_normalization():
- for mode in ['channel', 'spatial', 'instance']:
- for nbatch in [1, 4]:
- for nchannel in [3, 5]:
- for height in [4, 6]:
- check_l2_normalization((nbatch, nchannel, height), mode)
- for width in [5, 7]:
- check_l2_normalization((nbatch, nchannel, height, width), mode)
+ for dtype in ['float16', 'float32', 'float64']:
+ for mode in ['channel', 'spatial', 'instance']:
+ for nbatch in [1, 4]:
+ for nchannel in [3, 5]:
+ for height in [4, 6]:
+ check_l2_normalization((nbatch, nchannel, height), mode, dtype)
+ for width in [5, 7]:
+ check_l2_normalization((nbatch, nchannel, height, width), mode, dtype)
-def check_layer_normalization(in_shape, axis, eps, dtype=np.float32):
+def check_layer_normalization(in_shape, axis, eps, dtype=np.float32, forward_check_eps=1E-3):
def npy_layer_norm(data, gamma, beta, axis=1, eps=1E-5):
if axis < 0:
axis += data.ndim
broadcast_shape = [1 for _ in range(data.ndim)]
broadcast_shape[axis] = data.shape[axis]
- mean = data.mean(axis=axis, keepdims=True)
- var = data.var(axis=axis, keepdims=True)
- std = np.sqrt(var + eps)
+ mean = data.mean(axis=axis, keepdims=True).astype(dtype)
+ var = data.var(axis=axis, keepdims=True).astype(dtype)
+ std = np.sqrt(var + dtype(eps)).astype(dtype)
out = np.reshape(gamma, broadcast_shape) * (data - mean) / std + \
np.reshape(beta, broadcast_shape)
return out
@@ -2441,18 +2546,20 @@ def npy_layer_norm(data, gamma, beta, axis=1, eps=1E-5):
exe.arg_dict['beta'][:] = beta
out_nd = exe.forward()[0]
out = npy_layer_norm(data, gamma, beta, axis, eps)
- assert_allclose(out, out_nd.asnumpy(), 1E-4, 1E-4)
+ assert_almost_equal(out, out_nd.asnumpy(), forward_check_eps, forward_check_eps)
for req in ['write', 'add']:
check_numeric_gradient(out_s, {'data': data, 'gamma': gamma, 'beta': beta},
grad_nodes={'data': req, 'gamma': req, 'beta': req},
- numeric_eps=1e-2, rtol=1e-2, atol=1e-3)
+ numeric_eps=1e-2, rtol=1e-2, atol=1e-2)
def test_layer_norm():
- for dtype in [np.float16, np.float32, np.float64]:
- for in_shape in [(10, 6, 5), (5, 5)]:
+ for dtype, forward_check_eps in zip([np.float16, np.float32, np.float64],
+ [1E-2, 1E-3, 1E-4]):
+ for in_shape in [(10, 6, 5), (10, 10)]:
for axis in range(-len(in_shape), len(in_shape)):
- for eps in [1E-3, 1E-4]:
- check_layer_normalization(in_shape, axis, eps)
+ for eps in [1E-2, 1E-3]:
+ check_layer_normalization(in_shape, axis, eps, dtype=dtype,
+ forward_check_eps=forward_check_eps)
# Numpy Implementation of Sequence Ops
@@ -5159,6 +5266,173 @@ def check_squeeze_op(shape, axis=None):
test = mx.sym.squeeze(data, axis=(2, 4))
check_numeric_gradient(test, [data_tmp])
+@with_seed()
+def test_multi_proposal_op():
+ # paramters
+ feature_stride = 16
+ scales = (8, 16, 32)
+ ratios = (0.5, 1, 2)
+ rpn_pre_nms_top_n = 12000
+ rpn_post_nms_top_n = 2000
+ threshold = 0.7
+ rpn_min_size = 16
+
+ batch_size = 20
+ feat_len = 14
+ H, W = feat_len, feat_len
+ num_anchors = len(scales) * len(ratios)
+ count_anchors = H * W * num_anchors
+
+ '''
+ cls_prob: (batch_size, 2 * num_anchors, H, W)
+ bbox_pred: (batch_size, 4 * num_anchors, H, W)
+ im_info: (batch_size, 3)
+ '''
+
+ cls_prob = mx.nd.empty((batch_size, 2 * num_anchors, H, W), dtype = np.float32)
+ bbox_pred = mx.nd.empty((batch_size, 4 * num_anchors, H, W), dtype = np.float32)
+ im_info = mx.nd.empty((batch_size, 3), dtype = np.float32)
+
+ cls_prob = mx.nd.array(np.random.random(cls_prob.shape))
+ bbox_pred = mx.nd.array(np.random.random(bbox_pred.shape))
+
+ for i in range(batch_size):
+ im_size = np.random.randint(100, feat_len * feature_stride, size = (2,))
+ im_scale = np.random.randint(70, 100) / 100.0
+ im_info[i, :] = [im_size[0], im_size[1], im_scale]
+
+ def get_sub(arr, i):
+ new_shape = list(arr.shape)
+ new_shape[0] = 1
+ res = arr[i].reshape(new_shape)
+ return res
+
+ def check_forward(rpn_pre_nms_top_n, rpn_post_nms_top_n):
+ single_proposal = []
+ single_score = []
+ for i in range(batch_size):
+ rois, score = mx.nd.contrib.Proposal(
+ cls_score = get_sub(cls_prob, i),
+ bbox_pred = get_sub(bbox_pred, i),
+ im_info = get_sub(im_info, i),
+ feature_stride = feature_stride,
+ scales = scales,
+ ratios = ratios,
+ rpn_pre_nms_top_n = rpn_pre_nms_top_n,
+ rpn_post_nms_top_n = rpn_post_nms_top_n,
+ threshold = threshold,
+ rpn_min_size = rpn_min_size, output_score = True)
+ single_proposal.append(rois)
+ single_score.append(score)
+
+ multi_proposal, multi_score = mx.nd.contrib.MultiProposal(
+ cls_score = cls_prob,
+ bbox_pred = bbox_pred,
+ im_info = im_info,
+ feature_stride = feature_stride,
+ scales = scales,
+ ratios = ratios,
+ rpn_pre_nms_top_n = rpn_pre_nms_top_n,
+ rpn_post_nms_top_n = rpn_post_nms_top_n,
+ threshold = threshold,
+ rpn_min_size = rpn_min_size, output_score = True)
+
+ single_proposal = mx.nd.stack(*single_proposal).reshape(multi_proposal.shape)
+ single_score = mx.nd.stack(*single_score).reshape(multi_score.shape)
+
+ single_proposal_np = single_proposal.asnumpy()
+ multi_proposal_np = multi_proposal.asnumpy()
+
+ single_score_np = single_score.asnumpy()
+ multi_score_np = multi_score.asnumpy()
+
+ # check rois x1,y1,x2,y2
+ assert np.allclose(single_proposal_np[:, 1:], multi_proposal_np[:, 1:])
+ # check rois batch_idx
+ for i in range(batch_size):
+ start = i * rpn_post_nms_top_n
+ end = start + rpn_post_nms_top_n
+ assert (multi_proposal_np[start:end, 0] == i).all()
+ # check score
+ assert np.allclose(single_score_np, multi_score_np)
+
+ def check_backward(rpn_pre_nms_top_n, rpn_post_nms_top_n):
+
+ im_info_sym = mx.sym.Variable('im_info')
+ cls_prob_sym = mx.sym.Variable('cls_prob')
+ bbox_pred_sym = mx.sym.Variable('bbox_pred')
+
+ sym = mx.sym.contrib.MultiProposal(
+ cls_prob = cls_prob_sym,
+ bbox_pred = bbox_pred_sym,
+ im_info = im_info_sym,
+ feature_stride = feature_stride,
+ scales = scales,
+ ratios = ratios,
+ rpn_pre_nms_top_n = rpn_pre_nms_top_n,
+ rpn_post_nms_top_n = rpn_post_nms_top_n,
+ threshold = threshold,
+ rpn_min_size = rpn_min_size, output_score = False)
+
+ location = [cls_prob.asnumpy(), bbox_pred.asnumpy(), im_info.asnumpy()]
+
+ expected = [np.zeros_like(e) for e in location]
+
+ out_grads = [np.ones((rpn_post_nms_top_n, 5))]
+
+ check_symbolic_backward(sym, location, out_grads, expected)
+
+ check_forward(rpn_pre_nms_top_n, rpn_post_nms_top_n)
+ check_forward(rpn_pre_nms_top_n, 1500)
+ check_forward(1000, 500)
+ check_backward(rpn_pre_nms_top_n, rpn_post_nms_top_n)
+
+@with_seed()
+def test_quadratic_function():
+ def f(x, a, b, c):
+ return a * x**2 + b * x + c
+
+ a = np.random.random_sample()
+ b = np.random.random_sample()
+ c = np.random.random_sample()
+ # check forward
+ for ndim in range(1, 6):
+ shape = rand_shape_nd(ndim, 5)
+ data = rand_ndarray(shape=shape, stype='default')
+ data_np = data.asnumpy()
+ expected = f(data_np, a, b, c)
+ output = mx.nd.contrib.quadratic(data, a=a, b=b, c=c)
+ assert_almost_equal(output.asnumpy(), expected, rtol=0.001, atol=0.0001)
+
+ # check backward using finite difference
+ data = mx.sym.Variable('data')
+ quad_sym = mx.sym.contrib.quadratic(data=data, a=a, b=b, c=c)
+ check_numeric_gradient(quad_sym, [data_np], atol=0.001)
+
+
+def test_op_output_names_monitor():
+ def check_name(op_sym, expected_names):
+ output_names = []
+
+ def get_output_names_callback(name, arr):
+ output_names.append(py_str(name))
+
+ op_exe = op_sym.simple_bind(ctx=mx.current_context(), grad_req='null')
+ op_exe.set_monitor_callback(get_output_names_callback)
+ op_exe.forward()
+ for output_name, expected_name in zip(output_names, expected_names):
+ assert output_name == expected_name
+
+ data = mx.sym.Variable('data', shape=(10, 3, 10, 10))
+ conv_sym = mx.sym.Convolution(data, kernel=(2, 2), num_filter=1, name='conv')
+ check_name(conv_sym, ['conv_output'])
+
+ fc_sym = mx.sym.FullyConnected(data, num_hidden=10, name='fc')
+ check_name(fc_sym, ['fc_output'])
+
+ lrn_sym = mx.sym.LRN(data, nsize=1, name='lrn')
+ check_name(lrn_sym, ['lrn_output', 'lrn_tmp_norm'])
+
if __name__ == '__main__':
import nose
diff --git a/tests/python/unittest/test_optimizer.py b/tests/python/unittest/test_optimizer.py
index f71e2c81e27..bbd7845f66f 100644
--- a/tests/python/unittest/test_optimizer.py
+++ b/tests/python/unittest/test_optimizer.py
@@ -543,13 +543,13 @@ def test_ftml():
class PyAdam(mx.optimizer.Optimizer):
"""python reference implemenation of adam"""
def __init__(self, learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8,
- decay_factor=(1 - 1e-8), sparse_update=False, **kwargs):
+ decay_factor=(1 - 1e-8), lazy_update=False, **kwargs):
super(PyAdam, self).__init__(learning_rate=learning_rate, **kwargs)
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
self.decay_factor = decay_factor
- self.sparse_update = sparse_update
+ self.lazy_update = lazy_update
def create_state(self, index, weight):
"""Create additional optimizer state: mean, variance
@@ -595,7 +595,7 @@ def update(self, index, weight, grad, state):
# check row slices of all zeros
all_zeros = mx.test_utils.almost_equal(grad[row].asnumpy(), np.zeros_like(grad[row].asnumpy()))
# skip zeros during sparse update
- if all_zeros and self.sparse_update:
+ if all_zeros and self.lazy_update:
continue
grad[row] = grad[row] * self.rescale_grad + wd * weight[row]
# clip gradients
@@ -638,7 +638,7 @@ def test_adam():
compare_optimizer(opt1(**kwarg), opt2(**kwarg), shape, dtype,
rtol=1e-4, atol=2e-5)
# atol 2e-5 needed to pass with seed 781809840
- compare_optimizer(opt1(sparse_update=True, **kwarg), opt2(**kwarg), shape,
+ compare_optimizer(opt1(lazy_update=True, **kwarg), opt2(**kwarg), shape,
dtype, w_stype='row_sparse', g_stype='row_sparse',
rtol=1e-4, atol=2e-5)
compare_optimizer(opt1(**kwarg), opt2(lazy_update=False, **kwarg), shape,
@@ -883,12 +883,12 @@ class PyFtrl(mx.optimizer.Optimizer):
\\eta_{t,i} = \\frac{learningrate}{\\beta+\\sqrt{\\sum_{s=1}^tg_{s,i}^t}}
"""
- def __init__(self, lamda1=0.01, learning_rate=0.1, beta=1, sparse_update=False, **kwargs):
+ def __init__(self, lamda1=0.01, learning_rate=0.1, beta=1, lazy_update=False, **kwargs):
super(PyFtrl, self).__init__(**kwargs)
self.lamda1 = lamda1
self.beta = beta
self.lr = learning_rate
- self.sparse_update = sparse_update
+ self.lazy_update = lazy_update
def create_state(self, index, weight):
return (mx.nd.zeros(weight.shape, weight.context, dtype=weight.dtype), # dn
@@ -903,7 +903,7 @@ def update(self, index, weight, grad, state):
dn, n = state
for row in range(num_rows):
all_zeros = mx.test_utils.almost_equal(grad[row].asnumpy(), np.zeros_like(grad[row].asnumpy()))
- if all_zeros and self.sparse_update:
+ if all_zeros and self.lazy_update:
continue
grad[row] = grad[row] * self.rescale_grad
if self.clip_gradient is not None:
@@ -933,7 +933,7 @@ def test_ftrl():
{'clip_gradient': 0.5, 'wd': 0.07, 'lamda1': 1.0}]
for kwarg in kwargs:
compare_optimizer(opt1(**kwarg), opt2(**kwarg), shape, np.float32)
- compare_optimizer(opt1(sparse_update=True, **kwarg), opt2(**kwarg), shape,
+ compare_optimizer(opt1(lazy_update=True, **kwarg), opt2(**kwarg), shape,
np.float32, w_stype='row_sparse', g_stype='row_sparse')
@with_seed(1234)
diff --git a/tests/python/unittest/test_profiler.py b/tests/python/unittest/test_profiler.py
index 7654cd26382..cdc1be4b829 100644
--- a/tests/python/unittest/test_profiler.py
+++ b/tests/python/unittest/test_profiler.py
@@ -83,7 +83,7 @@ def test_profile_create_domain():
def test_profile_create_domain_dept():
- profiler.profiler_set_config(mode='symbolic', filename='test_profile_create_domain_dept.json')
+ profiler.set_config(profile_symbolic=True, filename='test_profile_create_domain_dept.json')
profiler.set_state('run')
domain = profiler.Domain(name='PythonDomain')
print("Domain created: {}".format(str(domain)))
diff --git a/tests/python/unittest/test_random.py b/tests/python/unittest/test_random.py
index f042f57c4e9..c8dc3c97a81 100644
--- a/tests/python/unittest/test_random.py
+++ b/tests/python/unittest/test_random.py
@@ -16,6 +16,8 @@
# under the License.
import os
+import math
+import itertools
import mxnet as mx
from mxnet.test_utils import verify_generator, gen_buckets_probs_with_ppf
import numpy as np
@@ -552,6 +554,81 @@ def compute_expected_prob():
mx.test_utils.assert_almost_equal(exp_cnt_sampled.asnumpy(), exp_cnt[sampled_classes].asnumpy(), rtol=1e-1, atol=1e-2)
mx.test_utils.assert_almost_equal(exp_cnt_true.asnumpy(), exp_cnt[true_classes].asnumpy(), rtol=1e-1, atol=1e-2)
+@with_seed()
+def test_shuffle():
+ def check_first_axis_shuffle(arr):
+ stride = int(arr.size / arr.shape[0])
+ column0 = arr.reshape((arr.size,))[::stride].sort()
+ seq = mx.nd.arange(0, arr.size - stride + 1, stride, ctx=arr.context)
+ assert (column0 == seq).prod() == 1
+ for i in range(arr.shape[0]):
+ subarr = arr[i].reshape((arr[i].size,))
+ start = subarr[0].asscalar()
+ seq = mx.nd.arange(start, start + stride, ctx=arr.context)
+ assert (subarr == seq).prod() == 1
+
+ # This tests that the shuffling is along the first axis with `repeat1` number of shufflings
+ # and the outcomes are uniformly distributed with `repeat2` number of shufflings.
+ # Note that the enough number of samples (`repeat2`) to verify the uniformity of the distribution
+ # of the outcomes grows factorially with the length of the first axis of the array `data`.
+ # So we have to settle down with small arrays in practice.
+ # `data` must be a consecutive sequence of integers starting from 0 if it is flattened.
+ def testSmall(data, repeat1, repeat2):
+ # Check that the shuffling is along the first axis.
+ # The order of the elements in each subarray must not change.
+ # This takes long time so `repeat1` need to be small.
+ for i in range(repeat1):
+ ret = mx.nd.random.shuffle(data)
+ check_first_axis_shuffle(ret)
+ # Count the number of each different outcome.
+ # The sequence composed of the first elements of the subarrays is enough to discriminate
+ # the outcomes as long as the order of the elements in each subarray does not change.
+ count = {}
+ stride = int(data.size / data.shape[0])
+ for i in range(repeat2):
+ ret = mx.nd.random.shuffle(data)
+ h = str(ret.reshape((ret.size,))[::stride])
+ c = count.get(h, 0)
+ count[h] = c + 1
+ # Check the total number of possible outcomes.
+ # If `repeat2` is not large enough, this could fail with high probability.
+ assert len(count) == math.factorial(data.shape[0])
+ # The outcomes must be uniformly distributed.
+ # If `repeat2` is not large enough, this could fail with high probability.
+ for p in itertools.permutations(range(0, data.size - stride + 1, stride)):
+ assert abs(1. * count[str(mx.nd.array(p))] / repeat2 - 1. / math.factorial(data.shape[0])) < 0.01
+ # Check symbol interface
+ a = mx.sym.Variable('a')
+ b = mx.sym.random.shuffle(a)
+ c = mx.sym.random.shuffle(data=b, name='c')
+ d = mx.sym.sort(c, axis=0)
+ assert (d.eval(a=data, ctx=mx.current_context())[0] == data).prod() == 1
+
+ # This test is weaker than `testSmall` and to test larger arrays.
+ # `repeat` should be much smaller than the factorial of `len(x.shape[0])`.
+ # `data` must be a consecutive sequence of integers starting from 0 if it is flattened.
+ def testLarge(data, repeat):
+ # Check that the shuffling is along the first axis
+ # and count the number of different outcomes.
+ stride = int(data.size / data.shape[0])
+ count = {}
+ for i in range(repeat):
+ ret = mx.nd.random.shuffle(data)
+ check_first_axis_shuffle(ret)
+ h = str(ret.reshape((ret.size,))[::stride])
+ c = count.get(h, 0)
+ count[h] = c + 1
+ # The probability of duplicated outcomes is very low for large arrays.
+ assert len(count) == repeat
+
+ # Test small arrays with different shapes
+ testSmall(mx.nd.arange(0, 3), 100, 20000)
+ testSmall(mx.nd.arange(0, 9).reshape((3, 3)), 100, 20000)
+ testSmall(mx.nd.arange(0, 18).reshape((3, 2, 3)), 100, 20000)
+ # Test larger arrays
+ testLarge(mx.nd.arange(0, 100000).reshape((10, 10000)), 10)
+ testLarge(mx.nd.arange(0, 100000).reshape((10000, 10)), 10)
+
if __name__ == '__main__':
import nose
nose.runmodule()
diff --git a/tests/python/unittest/test_sparse_ndarray.py b/tests/python/unittest/test_sparse_ndarray.py
index 3d6f9d0711f..182e70c8d7b 100644
--- a/tests/python/unittest/test_sparse_ndarray.py
+++ b/tests/python/unittest/test_sparse_ndarray.py
@@ -872,6 +872,7 @@ def test_sparse_nd_check_format():
a = mx.nd.sparse.row_sparse_array((data_list, indices_list), shape=shape)
assertRaises(mx.base.MXNetError, a.check_format)
+@with_seed()
def test_sparse_nd_norm():
def check_sparse_nd_norm(stype, shape, density):
data, _ = rand_sparse_ndarray(shape, stype, density)
@@ -886,6 +887,23 @@ def check_sparse_nd_norm(stype, shape, density):
for density in densities:
check_sparse_nd_norm(stype, shape, density)
+@with_seed()
+def test_sparse_fc():
+ def check_sparse_fc(batch_size, dim_in, dim_out, stype):
+ data = rand_ndarray((batch_size, dim_in), stype, density=0.5)
+ weight = rand_ndarray((dim_out, dim_in), 'row_sparse', density=1)
+ bias = rand_ndarray((dim_out, 1), 'row_sparse', density=1)
+ out = mx.nd.sparse.FullyConnected(data, weight, num_hidden=dim_out, bias=bias)
+ data_dns = data.tostype('default')
+ weight_dns = weight.tostype('default')
+ out_dns = mx.nd.FullyConnected(data_dns, weight_dns, num_hidden=dim_out, bias=bias)
+ assert_almost_equal(out.asnumpy(), out_dns.asnumpy())
+
+ # test FC with row_sparse weight w/ density=1, dense data
+ check_sparse_fc(5, 10, 8, 'default')
+ # test FC with row_sparse weight w/ density=1, csr data (fallback)
+ check_sparse_fc(5, 10, 8, 'csr')
+
if __name__ == '__main__':
import nose
nose.runmodule()
diff --git a/tests/python/unittest/test_sparse_operator.py b/tests/python/unittest/test_sparse_operator.py
index a8bf5a5ed3c..9417df31748 100644
--- a/tests/python/unittest/test_sparse_operator.py
+++ b/tests/python/unittest/test_sparse_operator.py
@@ -1820,6 +1820,21 @@ def check_scatter_ops(name, shape, lhs_stype, rhs_stype, forward_mxnet_call, for
lambda l, r: l + r,
rhs_is_scalar=True, verbose=False, density=0.5)
+@with_seed()
+def test_mkldnn_sparse():
+ # This test is trying to create a race condition describedd in
+ # https://github.com/apache/incubator-mxnet/issues/10189
+ arr = mx.nd.random.uniform(shape=(10, 10, 32, 32))
+ weight1 = mx.nd.random.uniform(shape=(10, 10, 3, 3))
+ arr = mx.nd.Convolution(data=arr, weight=weight1, no_bias=True, kernel=(3, 3), num_filter=10)
+
+ rs_arr = mx.nd.sparse.row_sparse_array((mx.nd.zeros_like(arr), np.arange(arr.shape[0])))
+ weight2 = mx.nd.random.uniform(shape=(10, np.prod(arr.shape[1:4])))
+ fc_res = mx.nd.FullyConnected(data=arr, weight=weight2, no_bias=True, num_hidden=10)
+ sum_res = mx.nd.elemwise_sub(arr, rs_arr)
+ res1 = np.dot(mx.nd.flatten(sum_res).asnumpy(), weight2.asnumpy().T)
+ print(res1 - fc_res.asnumpy())
+ almost_equal(res1, fc_res.asnumpy())
@with_seed()
def test_sparse_nd_where():
@@ -1918,6 +1933,26 @@ def test_where_numeric_gradient(shape):
test_where_helper((5, 9))
test_where_numeric_gradient((5, 9))
+@with_seed()
+def test_sparse_quadratic_function():
+ def f(x, a, b, c):
+ return a * x**2 + b * x + c
+
+ def check_sparse_quadratic_function(a, b, c, expected_stype):
+ # check forward and compare the result with dense op
+ ndim = 2
+ shape = rand_shape_nd(ndim, 5)
+ data = rand_ndarray(shape=shape, stype='csr')
+ data_np = data.asnumpy()
+ expected = f(data_np, a, b, c)
+ output = mx.nd.contrib.quadratic(data, a=a, b=b, c=c)
+ assert(output.stype == expected_stype)
+ assert_almost_equal(output.asnumpy(), expected)
+
+ a = np.random.random_sample()
+ b = np.random.random_sample()
+ check_sparse_quadratic_function(a, b, 0.0, 'csr')
+ check_sparse_quadratic_function(a, b, 1.0, 'default')
if __name__ == '__main__':
import nose
diff --git a/tools/launch.py b/tools/launch.py
index 0908950636e..a4a392264f9 100755
--- a/tools/launch.py
+++ b/tools/launch.py
@@ -26,7 +26,7 @@
import logging
curr_path = os.path.abspath(os.path.dirname(__file__))
-sys.path.append(os.path.join(curr_path, "../dmlc-core/tracker"))
+sys.path.append(os.path.join(curr_path, "../3rdparty/dmlc-core/tracker"))
def dmlc_opts(opts):
"""convert from mxnet's opts to dmlc's opts
diff --git a/tools/license_header.py b/tools/license_header.py
index 14d3f587d93..0ee4049338b 100755
--- a/tools/license_header.py
+++ b/tools/license_header.py
@@ -61,14 +61,8 @@
# the folders or files that will be ignored
_WHITE_LIST = ['R-package/',
- 'cub/',
'docker/Dockerfiles',
- 'dlpack/',
- 'dmlc-core/',
- 'mshadow/',
- 'nnvm',
'3rdparty',
- 'ps-lite',
'src/operator/mkl/',
'src/operator/special_functions-inl.h',
'src/operator/nn/pool.h',
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services