You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@lucenenet.apache.org by rc...@apache.org on 2022/03/23 20:43:49 UTC
[lucenenet] 07/08: website: New Quick Start area. Contains Index, Introduction, Tutorial & Learning Resources pages.
This is an automated email from the ASF dual-hosted git repository.
rclabo pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/lucenenet.git
commit fe4da0020c9f8cb8843d316abcd42fb7e45019c7
Author: Ron Clabo <ro...@GiftOasis.com>
AuthorDate: Mon Mar 21 17:39:33 2022 -0400
website: New Quick Start area. Contains Index, Introduction, Tutorial & Learning Resources pages.
---
websites/site/docfx.json | 15 +-
websites/site/docs.md | 1 +
websites/site/lucenetemplate/styles/main.css | 15 +-
websites/site/quick-start/index.md | 29 ++
websites/site/quick-start/introduction.md | 80 ++++
websites/site/quick-start/learning-resources.md | 78 ++++
websites/site/quick-start/toc.yml | 6 +
websites/site/quick-start/tutorial.md | 518 ++++++++++++++++++++++++
websites/site/toc.yml | 5 +-
9 files changed, 738 insertions(+), 9 deletions(-)
diff --git a/websites/site/docfx.json b/websites/site/docfx.json
index 281a618..2fe7086 100644
--- a/websites/site/docfx.json
+++ b/websites/site/docfx.json
@@ -3,13 +3,16 @@
"content": [
{
"files": [
- "contributing/**.md",
- "contributing/**/toc.yml",
- "download/**.md",
+ "quick-start/**.md",
+ "quick-start/**/toc.yml",
+ "contributing/**.md",
+ "contributing/**/toc.yml",
+ "download/**.md",
"download/**/toc.yml",
- "release-notes/**.md",
- "toc.yml",
- "*.md"]
+ "release-notes/**.md",
+ "toc.yml",
+ "*.md"
+ ]
}
],
"resource": [
diff --git a/websites/site/docs.md b/websites/site/docs.md
index aba2aff..95ad6a5 100644
--- a/websites/site/docs.md
+++ b/websites/site/docs.md
@@ -1,4 +1,5 @@
---
+uid: docs
_disableBreadcrumb: true
---
diff --git a/websites/site/lucenetemplate/styles/main.css b/websites/site/lucenetemplate/styles/main.css
index 9c2505a..ec35673 100644
--- a/websites/site/lucenetemplate/styles/main.css
+++ b/websites/site/lucenetemplate/styles/main.css
@@ -98,10 +98,19 @@ article img {
margin:15px 0 30px 0;
}
-article[data-uid="contributing/setup-java-debugging"] img {
+article[data-uid="contributing/setup-java-debugging"] img,
+article[data-uid="quick-start/tutorial"] img {
border: solid 1px #dedcd3
}
+article[data-uid="quick-start/introduction"] .diagram{
+ text-align:center;
+}
+
+article[data-uid="quick-start/introduction"] .diagram img{
+ max-width:400px
+}
+
.sidefilter {
top: 120px;
}
@@ -119,6 +128,10 @@ body .toc {
background-color: rgb(247, 247, 247);
}
+.sideaffix > div.contribution > ul > li > a.contribution-link {
+ opacity:80%;
+}
+
/* FORK ME ON GITHUB */
#forkongithub a {
background: #1764aa;
diff --git a/websites/site/quick-start/index.md b/websites/site/quick-start/index.md
new file mode 100644
index 0000000..2970edb
--- /dev/null
+++ b/websites/site/quick-start/index.md
@@ -0,0 +1,29 @@
+---
+uid: quick-start
+---
+
+# Quick Start
+
+---
+
+## Greetings
+
+Welcome. We are glad you're here. We hope this Quick Start section makes it easy to start learning about Lucene.NET. We assume you don't know anything about this awesome search library and are encountering it for the first time.
+
+Our goal here is to get you enough information and experience with Lucene.NET so that you have a sense for what it is and how it might be useful to you. We also hope you will come away from this section with enough knowledge to be able to be able to continue your leaning journey with the various other resources that are available.
+
+Lucene.NET is a sophisticated search library that has a lot of advanced features. But for now we are not concerned about that. We want to get you up and running quickly with the basic info you need to take Lucene.NET for a spin.
+
+
+## Introduction
+The Introduction page provides a bit of context about Lucene.NET. You'll learn where it came from and what it can do for you. See the [Introduction](xref:quick-start/introduction) page.
+
+
+## Tutorial
+As developers, one of the fastest ways to learn a new technology is to build a toy application with it. So that's the approach we are going to take to get you up and running with Lucene.NET.
+
+To get started building your first application go to the [Tutorial](xref:quick-start/tutorial) page.
+
+
+## Learning Resources
+In addition to the Introduction and Tutorial, we have compiled a list of learning resources to help you on your Lucene.NET journey. Some of these are part of the official Apache Lucene.NET project and others are from the community. You will likely find both types of resources helpful. So be sure to also checkout the [Learning Resources](xref:quick-start/learning-resources) page.
\ No newline at end of file
diff --git a/websites/site/quick-start/introduction.md b/websites/site/quick-start/introduction.md
new file mode 100644
index 0000000..09e2fb4
--- /dev/null
+++ b/websites/site/quick-start/introduction.md
@@ -0,0 +1,80 @@
+---
+uid: quick-start/introduction
+---
+
+# Introduction
+
+---
+
+## Background
+
+Apache Lucene.NET is a C# port of Java based Apache Lucene. Apache Lucene has a huge following and is used directly or indirectly to power search by many companies you probably know including Amazon, Twitter, LinkedIn, Netflix, Salesforce, SAS, and Microsoft Power BI.
+
+Apache Lucene is the core search library used by popular open source search servers like Apache Solr, ElasticSearch and OpenSearch. The reason Apache Lucene is so widely used is because it’s extremely powerful and can index large amounts of data quickly -- think 100s of GB/Hours. And it can perform full text search on that data in sub-second time. And unlike traditional sql databases, it’s data engine is optimized for full text search.
+
+The codebase for Apache Lucene is very mature. In March 2020, the open source project celebrated it's 20th birthday. You can scroll through the years and see the major [Apache Lucene milestones](https://www.elastic.co/celebrating-lucene).
+
+Apache Lucene.NET 4.8 is an open source project who’s aim is to be a line by line c# port of java based Apache Lucene 4.8. This port makes the power of Lucene available to all .NET developers. And makes it easy for them to contribute to the project or customize it since it's pure C#.
+
+Currently Lucene.NET 4.8 is in Beta but it is extremely stable and many developers already use it in production. It has far more features then Lucene.NET 3.03 and has much better unit test coverage then the older version. Lucene.NET has more than 7800+ passing unit tests. This test coverage is what makes Lucene.NET so stable.
+
+
+
+## Evolution of Lucene
+
+Porting Lucene from java to C# is a huge undertaking. There are over [644K lines of code](https://lucenenet.apache.org/images/contributing/source/lucenenet-repo-lines-of-code--jan-2022.png) not counting outside dependencies. This is why only a few specific versions have been ported. The prior Lucene.NET release was version 3.0.3 and the current release (which receives all the focus) is Lucene.NET 4.8. Version 4.8 is now in late Beta and, as I already mentioned, is used in production b [...]
+
+You might be aware that Java Lucene is at version 9.x. But don’t be misled by the number. The step up in features between 3.x and 4.x was the biggest in Lucene’s history and after that it was followed my many smaller releases. **So the reality is that Lucene.NET 4.8 contains the vast majority of features found in Java Lucene 9.x and in fact Lucene 4.x is more similar to Lucene 9.x than to Lucene 3.x.** If you'd like to dive deeper into this topic, [Lucene.NET 4.8 vs Java Lucene 9.x]( [...]
+
+
+ ## Lucene.NET is Multi-Platform
+Lucene.NET 4.8 runs everywhere .NET runs: Windows, Unix or Mac. And as a library it can be used to power search in desktop applications, websites, mobile apps (iOS or Android) or even on IoT devices like the Raspberry Pi. And because it’s licensed under the permissive Apache 2.0 license it’s typically considered suitable for both commercial and non-commercial use.
+
+ ## Lucene's LSM Inspired Architecture
+At this early stage of your journey it's probably good to cover a few things about how Lucene stores data. We are just going to hit the highlights here because it's a deep topic.
+
+Lucene and hence Lucene.NET stores data in immutable “segments.” Segments are made of multiple files. Segments automatically get merged together to form new bigger segments and then the old segments are typically deleted by the merge process. This approach is based on what is called a Log Structured Merge (LSM) design.
+
+LSM has become the defacto standard for NoSql databases and is used not only by Lucene but also by Google BigTable, Apache Hbase, Apache Cassandra and many others. The details of each implementation vary as does the number and types of files used. So let's take a look at what those files might look like for a Lucene.NET index.
+
+
+Here is an example of Lucene.NET’s files for a brand new index with one segment:
+
+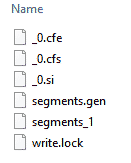
+
+
+Here is a two segment example that has gone through merges many times:
+
+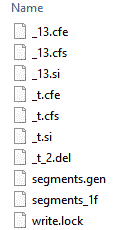
+
+
+ ## Important Lucene Concepts
+
+ ### Documents and Fields
+ Lucene stores document and documents are comprised of fields. The fields can be a variety of types like Text, string or Int32.
+
+ Documents may have as many fields as you like. There is no concept of schema and documents don't need to all have the same fields. When searching you can search any field and it will only return documents which have that field and where the data in that field matches the specified search criteria.
+
+ ### Writing and Reading Documents
+ Documents are written via an `IndexWriter` and read via an `IndexReader`. Although in practice we often use an `IndexSearcher` (which wraps an `IndexReader`) for searching and reading documents.
+
+
+ ### Lucene Directories
+ We already mentioned that the data is stored in segments. Those segments can be stored via different classes that inherit from `LuceneDirectory`. Some of those classes, like `FSDirectory` store to your local file system, other can store elsewhere. For example a `RAMDirectory` can be useful for unit tests as it stores the segments in RAM. So one of the things that we must provide an `IndexWriter` is a instance of a `LuceneDirectory` that is the type of directory we want to work with.
+
+
+ ### How the Pieces Fit Together
+
+ The diagram below provides a birds eye view of how the various parts of the system work together. It makes it easier to conceptualize the parts of Lucene that we have been talking about. It might be good idea to keep this diagram in mind when you work through the [tutorial examples](xref:quick-start/tutorial) and review the code provided there.
+
+
+ <div class="diagram">
+
+ 
+ </div>
+
+ \* In the diagram above "Files" is in quotes because if you are using a `RAMDirectory`, say for testing, then there will be no physical file, but rather their representation will be in memory only.
+
+
+### Wrapping Up
+I hope this introduction has helped you to understand a bit about Lucene.NET. The information we have covered so far should give you a bit of a foundation to work from as you work through the [tutorial examples](xref:quick-start/tutorial) and then dig deaper into the [Lucene.NET Documentation](xref:docs) and [Learning Resources](xref:quick-start/learning-resources).
\ No newline at end of file
diff --git a/websites/site/quick-start/learning-resources.md b/websites/site/quick-start/learning-resources.md
new file mode 100644
index 0000000..ee387d3
--- /dev/null
+++ b/websites/site/quick-start/learning-resources.md
@@ -0,0 +1,78 @@
+---
+uid: quick-start/learning-resources
+---
+
+# Learning Resources
+
+--
+
+
+## Lucene.NET Documentation
+
+Lucene.NET has fairly extensive documentation that can be found in the [Lucene.NET Documentation](xref:docs) section of the website. On that page you will find links to the documentation for various release versions. Click on the documentation link for the version of interest and you will see that it leads to a wealth of documentation. The project is organized as a collection of sub-projects, each one corresponding ultimately to a [nuget package](https://www.nuget.org/packages/Lucene. [...]
+
+Much of this documentation is compiled from the inline documentation comments from the source code and it originated from the Java Lucene code base. In addition to porting the Lucene code from Java to C# we are also working to convert the docs from Java to C# examples as well. Some of this work is completed and some of it remains.
+
+
+## Java Lucene Documentation
+
+Apache [Lucene.NET 4.8](https://github.com/apache/lucenenet) is a port of Java Apache [Lucene 4.8](https://github.com/apache/lucene/tree/releases/lucene-solr%2F4.8.0). In general we try to do a line by line port when possible. So if you did a comparison of the code for a file in the one [GitHub repo](https://github.com/apache/lucenenet) against the corresponding file in the [other repo](https://github.com/apache/lucene/tree/releases/lucene-solr%2F4.8.0) the two should in most cases loo [...]
+
+So for example, in Java it's common for method names start with a lower case letter, but of course in .NET we expect method names to start with an upper case letter. So we change the method names to confirm to .NET conventions when porting the code. Likewise, C# has support for properties with getters and setters but Java does not. So sometimes when converting the Java to C# a get method that is behaving like a property accessor will be turned into a C# property.
+
+But other then that, you will find that the documentation for Java Lucene 4.X can be very useful to your learning of Lucene.NET 4.8. Just keep in mind the ".NETifing" that we do to the code and it's pretty simple to translate in your head Java examples into the C# equivalent.
+
+
+## From the Community
+
+
+### Searching Lucene.NET Issues
+
+Another source of information about Lucene.NET is current and past GitHub issues for our repo. By default when you go to the GitHub issues page it defaults the search box criteria to open issues only but you can easily remove the `is:open` from the search box to search all issues for the repo. Or you can use this link to [search all issues](https://github.com/apache/lucenenet/issues?q=is%3Aissue+is%3Aopen+) in our repo.
+
+
+
+
+### Searching Java Lucene Issues
+In general, the Java Lucene Issues database can be a good place to learn about about how features were developed, the historical issues related to features, and how issues were resolved. One thing that can be helpful to know is that each major Lucene feature is assigned a Lucene issue number and it's often referenced using this format: LUCENE-<issue number> for example LUCENE-6001.
+
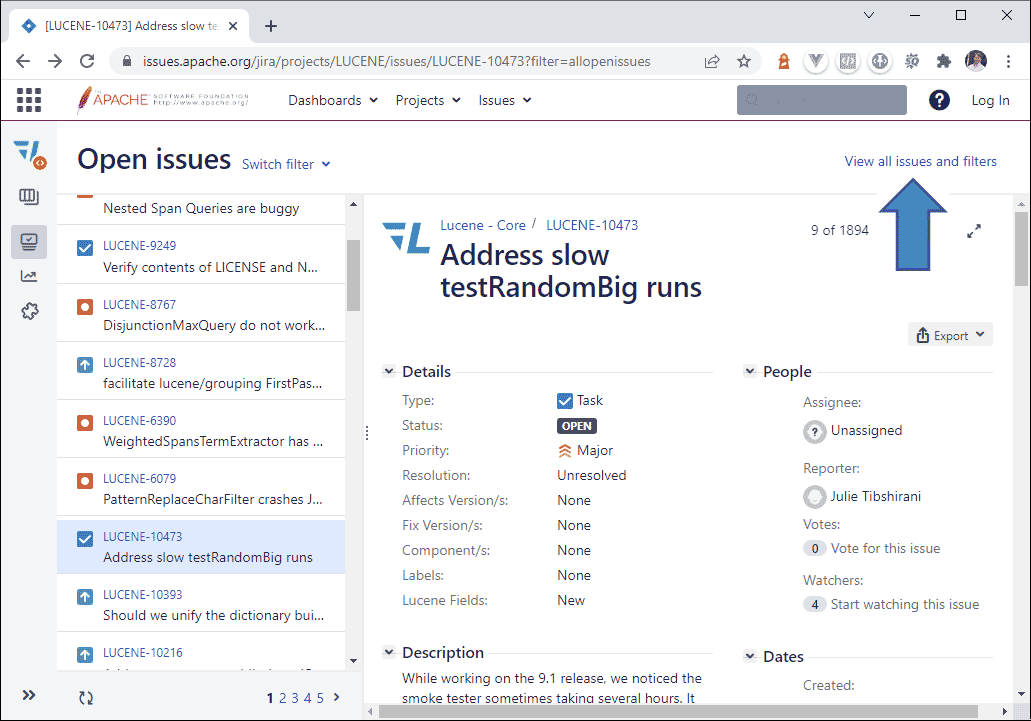
+Java Lucene has a GitHub mirror of their repo, but they don't track issues there. If you want to search issues for the Java Lucene project you need to search on the [apache.org issues website](https://issues.apache.org/jira/projects/LUCENE/issues/).
+
+By default that page shows only open issues but you can click the "View all issues and filters" link in the upper right corner of the screen (see arrow below) to see and search all issues.
+
+
+
+
+### Apache Lucene.NET Email Archives
+You can search the Lucene.NET dev email archives for past emails that may contain information of a topic you'd like to dig into. This can be especially useful, for example, to research why we may have chosen a specific porting approach for some code that wasn't so easy to port. https://lists.apache.org/list.html?dev@lucenenet.apache.org
+
+### Java Apache Lucene Email Archives
+You can search the Java Lucene dev email archives for past emails as well. If you the feature or patch you are trying to learn about has an issue number, searching the email archives for it formatted like LUCENE-<issue number> for example LUCENE-6001 can return some really great discussion about the rational that went into defining how that feature works. https://lists.apache.org/list.html?dev@lucene.apache.org
+
+### StackOverflow
+
+StackOverflow is a popular programmer question and answer website. Both Lucene and Lucene.NET both have tags on StackOverflow.
+
+One great way to learn about Lucene.NET is to read the [most upvoted Lucene.NET questions](https://stackoverflow.com/questions/tagged/lucene.net?sort=MostVotes) StackOverflow is also a great place to ask questions about Lucene.NET>
+
+Additionally you can read the [most upvoted Lucene questions](https://stackoverflow.com/questions/tagged/lucene.net?sort=MostVotes) on StackOverflow. Most of these questions and answers will apply to Lucene 4.8 but be aware that some may not if they are for related to features that came after version 4.8.
+
+> [!TIP]
+> StackOverflow is a great place to post questions about Lucene.NET. When you post questions there it's important to tag the question with both a `lucene.net` tag and a `lucene` tag if the question doesn't specifically pertain to the .NET platform. Having both tags will often result in a faster response.
+
+### Community Articles
+
+In the contributing section of this website we have a list of several community articles about Lucene.NET. You can fine them on the [Community Links](xref:contributing/community-links) page.
+
+### Books
+
+**[Instant Lucene.NET](https://www.amazon.com/Instant-Lucene-NET-Michael-Heydt/dp/1782165940)** - Currently this is the only book specifically about Lucene.NET. Based on the reviews it's primarily targeted towards those just getting started with Lucene.NET.
+
+**[Lucene 4 Cookbook](https://www.amazon.com/Lucene-4-Cookbook-Edwood-Ng/dp/1782162283/)** - The nice thing about this book is that it is specifically written for Lucene 4, so the examples are all from the era of Lucene.NET 4.X and will work great on Lucene.NET 4.8 While the code examples are in Java it's easy to convert them to C#. ie. change method names from starting with a lower case letter to an upper case letter. Change some getter methods to properties instead.
+
+**[Lucene In Action 2nd Edition](https://www.amazon.com/Lucene-Action-Second-Covers-Apache/dp/1933988177)** - This is a great book written by a core Lucene committer that dives deep into the inner workings of Lucene. It's packed full of great information about Lucene. It is written for Java Lucene rather then Lucene.NET but as I have already mentioned, it's generally not a big deal to translate Lucene code samples from Java to c#. That said, the one downside to this book is that it was [...]
+
+**[Introduction to Information Retrieval](https://nlp.stanford.edu/IR-book/information-retrieval-book.html)** - This book isn't written about Lucene per se but is a great resource on the subject of information retrieval which is the knowledgebase that underpins search software like Lucene. This book was written by two professors at Stanford University and one from the University of Stuttgart. The introduction in the book states "Introduction to Information Retrieval is the first textbo [...]
+
+
+
diff --git a/websites/site/quick-start/toc.yml b/websites/site/quick-start/toc.yml
new file mode 100644
index 0000000..2d46d2e
--- /dev/null
+++ b/websites/site/quick-start/toc.yml
@@ -0,0 +1,6 @@
+- name: Introduction
+ href: introduction.md
+- name: Tutorial
+ href: tutorial.md
+- name: Learning Resources
+ href: learning-resources.md
\ No newline at end of file
diff --git a/websites/site/quick-start/tutorial.md b/websites/site/quick-start/tutorial.md
new file mode 100644
index 0000000..aa06ce9
--- /dev/null
+++ b/websites/site/quick-start/tutorial.md
@@ -0,0 +1,518 @@
+---
+uid: quick-start/tutorial
+---
+
+# Tutorial
+
+---
+
+## Let's Build a Search App!
+Sometimes the best way to learn is just to see some working code. So that's what we are going to do. If you haven't read the [Introduction](xref:quick-start/introduction) page yet, do that first so that you have some context for understanding the code we are going to write.
+
+Now let's build a simple console application that can index a few documents, search those documents, and return some results. Actually, let's build two apps that do that. The first example will show how to do exact match searches and the 2nd example will show how to do a full text search. These example console applications will give you some working code that can serve as a great starting point for trying out various Lucene.NET features.
+
+## Multi-Platform
+It's worth mentioning that Lucene.NET runs everywhere that .NET runs. That means that Lucene.NET can be used in Windows and Unix applications, Asp.NET websites (Windows, Mac or Unix), iOS Apps, Android Apps and even on the Raspberry Pi.
+
+## Why the .NET CLI?
+In these examples we will use the .NET CLI (Command Line Interface) because it's a cross platform way to generate the project file we need and to add references to Nuget packages. We will be using PowerShell to invoke the .NET CLI because PowerShell provides a command line environment that is also cross platform.
+
+However you are totally free to use [Visual Studio](https://visualstudio.microsoft.com/) (Windows/Mac) or [Visual Studio Code](https://code.visualstudio.com/) (Windows/Unix/Max) to create the console application project and to add references to the Nuget packages. Whichever tool you use, you should end up with the same files and you can compare their contents to the contents that we show in the examples.
+
+## Download and Install the .NET SDK
+First you must install the .NET Core SDK, if it's not already installed on your machine. The .NET Core SDK contains the .NET runtime, .NET Libraries and the .NET CLI. If you haven't installed it yet, download it from https://dotnet.microsoft.com/en-us/download and run the installer. It's a pretty straightforward process. I’ll be using the **.NET 6.0 SDK** in this tutorial.
+
+> [!NOTE]
+> The C# code we present **requires the .NET 6.0 SDK or later**. However, with a few simple modifications it can run on older SDKs including 4.x. To do that, the Program.cs file will need to have a namespace, Program class and a static void main method. See Microsoft docs [here](https://docs.microsoft.com/en-us/dotnet/core/tutorials/with-visual-studio?pivots=dotnet-5-0#code-try-3) for details. You will also need to add [braces to the using statements](https://docs.microsoft.com/en-us/ [...]
+
+## Download and Install PowerShell
+PowerShell is cross platform and runs everywhere .NET runs, so we will be using PowerShell for all of our command line work. If you don't already have PowerShell installed you can download and find instructions for installing it on Window, Unix or Mac on this [Installing PowerShell](https://docs.microsoft.com/en-us/powershell/scripting/install/installing-powershell) page. In my examples I’m using PowerShell 7.2 but the specific version probably doesn’t make a difference.
+
+## Verify dotnet CLI Installed
+Let’s use PowerShell now to verify that you have the .NET SDK with the .NET CLI installed. Launch PowerShell however you do that on your OS, for Windows I’ll search for it in the start menu and select it from there. Once you have the PowerShell window open, execute the following command in PowerShell:
+
+`dotnet –info`
+
+This command will show the latest version of the .NET SDK installed and also show a list of all versions installed. If the .NET SDK is not installed this the command will return an error indicating the command was not found.
+
+Below I show the top of the results for the `dotnet -–info` command ran on my machine. You can see I'm using .NET SDK 6.0.200 on windows for this demo. In my case I had to scroll the screen up to see this info since I have many versions of the .NET SDK installed and it shows info on each version which scrolled the info about the latest version off the screen. Your latest version will likely be different than mine and perhaps you may be running on Unix or Mac. That's fine. But remember ** [...]
+
+<img src='https://lucenenet.apache.org/images/quick-start/tutorial/power-shell01.png'>
+
+Now that our prerequisites are installed, we are ready to get started with our first example of using Lucene.NET.
+
+## Example 1 - Step by Step
+We are going to create a console application that uses Lucene.NET to index three documents that each have two fields and then the app will search those docs on a certain field doing an exact match search and output some info about the results.
+
+This is actually pretty simple to do in Lucene.NET but since this in our very first Lucene.NET application we are going to walk through it step by step and provide a lot of explanation along the way.
+
+### Create a Directory for the Project
+Create a directory where you would like this project to live on your hard drive and call that directory `lucene-example1`. In my case that will be ` C:\Users\Ron\source\repos\lucene-example1` but you can chose any location you like. Then make that directory the current directory in PowerShell.
+
+In my case, since I’m on Windows, I’ll create the directory using the GUI and use the `cd` command in PowerShell to change directory to the one I created. So the exact PowerShell command I used was `cd C:\Users\Ron\source\repos\lucene-example1` but you will need to modify that command to specify the directory you created.
+
+<img src='https://lucenenet.apache.org/images/quick-start/tutorial/power-shell02.png'>
+
+### Create the Project Files
+To create a C# console application project in the current directory, type this command in PowerShell:
+
+`dotnet new console`
+
+<img src='https://lucenenet.apache.org/images/quick-start/tutorial/power-shell03.png'>
+
+### Add NuGet References
+We need to add references from our project to the Lucene.NET Nuget packages we need -- two separate packages in this case. Execute the first command in PowerShell: (Please note there are two dashes before prerelease not one.)
+
+`dotnet add package Lucene.Net --prerelease`
+
+
+<img src='https://lucenenet.apache.org/images/quick-start/tutorial/power-shell04.png'>
+
+And now add the 2nd Nuget package by executing this command in PowerShell:
+
+`dotnet add package Lucene.Net.Analysis.Common --prerelease`
+
+<img src='https://lucenenet.apache.org/images/quick-start/tutorial/power-shell05.png'>
+
+At this point, our directory has two files in it plus an obj directory with some additional files. We are mostly concerned with the lucene-example1.csproj project file and the Program.cs C# code file.
+
+Our directory looks like this:
+
+<img src='https://lucenenet.apache.org/images/quick-start/tutorial/directory-files-example1.png'>
+
+### Viewing the Two Main files
+From here on out, you can use your favorite editor to view and edit files as we walk through the rest of the example. I’ll be using Visual Studio 2022 on Windows, but you could just as easily use VIM, Visual Studio Code or any other editor and even be doing that on Ubuntu on a Raspberry Pi if you like. Remember, Lucene.NET and the .NET framework both support a wide variety of platforms.
+
+Below is what the project file looks like which we created using the dotnet CLI. Notice that it contains package references to the two Lucene.NET Nuget packages we specified.
+
+<img src='https://lucenenet.apache.org/images/quick-start/tutorial/example1.csproj.png'>
+
+Here is that file's contents:
+
+```
+<Project Sdk="Microsoft.NET.Sdk">
+
+ <PropertyGroup>
+ <OutputType>Exe</OutputType>
+ <TargetFramework>net6.0</TargetFramework>
+ <RootNamespace>lucene_example1</RootNamespace>
+ <ImplicitUsings>enable</ImplicitUsings>
+ <Nullable>enable</Nullable>
+ </PropertyGroup>
+
+ <ItemGroup>
+ <PackageReference Include="Lucene.Net" Version="4.8.0-beta00016" />
+ <PackageReference Include="Lucene.Net.Analysis.Common" Version="4.8.0-beta00016" />
+ </ItemGroup>
+
+</Project>
+```
+
+
+Now let's look at the `Program.cs` file that got generated. It looks like:
+
+<img src='https://lucenenet.apache.org/images/quick-start/tutorial/program01.png'>
+
+
+### Running the Application
+Before going further lets just run this console application and see that it generates the “Hello World!” output we expect.
+
+If you are using Visual Studio or Visual Studio Code you can just hit F5 to run it. But what if are using a plain text editor to do your work? No problem, we can run console application from PowerShell. Just type this command in PowerShell:
+
+`dotnet run`
+
+This will run the project from the PowerShell current directory after it does a restore of the Nuget packages for the project.
+
+<img src='https://lucenenet.apache.org/images/quick-start/tutorial/hello-world-example1.png'>
+
+And there you go. You can see in the window above that we get the output we expected.
+
+### Writing Some Lucene.NET Code
+Now use your editor to replace the existing code in the Program.cs with the following code that uses Lucene.NET:
+
+```c#
+using Lucene.Net.Analysis;
+using Lucene.Net.Analysis.Standard;
+using Lucene.Net.Documents;
+using Lucene.Net.Index;
+using Lucene.Net.Search;
+using Lucene.Net.Store;
+using Lucene.Net.Util;
+using System.Diagnostics;
+using LuceneDirectory = Lucene.Net.Store.Directory;
+
+// Specify the compatibility version we want
+const LuceneVersion luceneVersion = LuceneVersion.LUCENE_48;
+
+//Open the Directory using a Lucene Directory class
+string indexName = "example_index";
+string indexPath = Path.Combine(Environment.CurrentDirectory, indexName);
+
+using LuceneDirectory indexDir = FSDirectory.Open(indexPath);
+
+//Create an analyzer to process the text
+Analyzer standardAnalyzer = new StandardAnalyzer(luceneVersion);
+
+//Create an index writer
+IndexWriterConfig indexConfig = new IndexWriterConfig(luceneVersion, standardAnalyzer);
+indexConfig.OpenMode = OpenMode.CREATE; // create/overwrite index
+IndexWriter writer = new IndexWriter(indexDir, indexConfig);
+
+//Add three documents to the index
+Document doc = new Document();
+doc.Add(new TextField("titleTag", "The Apache Software Foundation - The world's largest open source foundation.", Field.Store.YES));
+doc.Add(new StringField("domain", "www.apache.org/", Field.Store.YES));
+writer.AddDocument(doc);
+
+doc = new Document();
+doc.Add(new TextField("title", "Powerful open source search library for .NET", Field.Store.YES));
+doc.Add(new StringField("domain", "lucenenet.apache.org", Field.Store.YES));
+writer.AddDocument(doc);
+
+doc = new Document();
+doc.Add(new TextField("title", "Unique gifts made by small businesses in North Carolina.", Field.Store.YES));
+doc.Add(new StringField("domain", "www.giftoasis.com", Field.Store.YES));
+writer.AddDocument(doc);
+
+//Flush and commit the index data to the directory
+writer.Commit();
+
+using DirectoryReader reader = writer.GetReader(applyAllDeletes: true);
+IndexSearcher searcher = new IndexSearcher(reader);
+
+Query query = new TermQuery(new Term("domain", "lucenenet.apache.org"));
+TopDocs topDocs = searcher.Search(query, n: 2); //indicate we want the first 2 results
+
+
+int numMatchingDocs = topDocs.TotalHits;
+Document resultDoc = searcher.Doc(topDocs.ScoreDocs[0].Doc); //read back first doc from results (ie 0 offset)
+string title = resultDoc.Get("title");
+
+Console.WriteLine($"Matching results: {topDocs.TotalHits}");
+Console.WriteLine($"Title of first result: {title}");
+```
+
+> [!WARNING]
+> As mentioned earlier, if you are not running .NET 6.0 SDK or later you will need to modify the above code in the following two ways: 1) Program.cs file will need to have a namespace, Program class and a static void main method. See Microsoft docs [here](https://docs.microsoft.com/en-us/dotnet/core/tutorials/with-visual-studio?pivots=dotnet-5-0#code-try-3) for details; and 2) you will need to add [braces to the using statements](https://docs.microsoft.com/en-us/dotnet/csharp/language-r [...]
+
+### Code Walkthrough
+Before running the code let’s talk about what it does.
+
+The using declarations at the top of the file specify the various namespaces we are going to use. Then we have this block of code that basically specifies that our Lucene.NET index will be in a subdirectory called “example_index”.
+
+ ```c#
+// Specify the compatibility version we want
+const LuceneVersion luceneVersion = LuceneVersion.LUCENE_48;
+
+//Open the Directory using a Lucene Directory class
+string indexName = "example_index";
+string indexPath = Path.Combine(Environment.CurrentDirectory, indexName);
+
+using LuceneDirectory indexDir = FSDirectory.Open(indexPath);
+```
+
+Then in the next block we create an `IndexWriter` that will use our `LuceneDirectory`. The `IndexWriter` is a important class in Lucene.NET and is used to write documents to the Index (among other things).
+
+The `IndexWriter` will create our subdirectory for us since it doesn’t yet exist and it will create the index since it also doesn’t yet exist. By using `OpenMode.CREATE` we are telling Lucene.NET that we want to recreate the index if it already exists. This works great for a demo like this since every time the console app is ran we will be recreating our LuceneIndex which means we will get the same output each time.
+
+```c#
+//Create an index writer
+IndexWriterConfig indexConfig = new IndexWriterConfig(luceneVersion, standardAnalyzer);
+indexConfig.OpenMode = OpenMode.CREATE; //create/overwrite index
+IndexWriter writer = new IndexWriter(indexDir, indexConfig);
+```
+
+Then in the next block we add three documents to the index. In this example we happen to specify that each document has two fields: title and domain. A document however could have as many fields as we like.
+
+We also specify here that title is a `TextField` which means that want the field to support full text searches, and we specify domain as a `StringField` which means we what to do exact match searches against that field.
+
+It’s worth noting that the documents are buffered in RAM initially and are not written to the index in the `Directory` until we call `writer.Commit();`
+
+```c#
+//Add three documents to the index
+Document doc = new Document();
+doc.Add(new TextField("title", "The Apache Software Foundation - The world's largest open source foundation.", Field.Store.YES));
+doc.Add(new StringField("domain", "www.apache.org/", Field.Store.YES));
+writer.AddDocument(doc);
+
+doc = new Document();
+doc.Add(new TextField("title", "Powerful open source search library for .NET", Field.Store.YES));
+doc.Add(new StringField("domain", "lucenenet.apache.org", Field.Store.YES));
+writer.AddDocument(doc);
+
+doc = new Document();
+doc.Add(new TextField("title", "Unique gifts made by small businesses in North Carolina.", Field.Store.YES));
+doc.Add(new StringField("domain", "www.giftoasis.com", Field.Store.YES));
+writer.AddDocument(doc);
+
+//Flush and commit the index data to the directory
+writer.Commit();
+```
+
+So now our documents are in the index and we want to see how to read a document from that index. That is exactly what the following block of code does.
+
+In the block of code below we search the index for all the documents that have a domain field value of "lucenenet.apache.org".
+
+> [!NOTE]
+> Note that in the block of code below we specify `applyAllDeletes: true` when getting a Reader. This means that uncommitted deleted documents will be applied to the reader we obtain. If this value were false then only committed deletes would be applied to the reader. In our example we don't delete any documents but when getting a Reader we must still specify some value for this parameter.
+
+We happen to specify that we want just the top 2 matching results from the search but based on the data in our example only one result matches and so only that one result will be returned. The code then writes out to the console the number of matching documents and the title of the first (and in this case only) matching result.
+
+
+```c#
+using DirectoryReader reader = writer.GetReader(applyAllDeletes: true);
+IndexSearcher searcher = new IndexSearcher(reader);
+
+Query query = new TermQuery(new Term("domain", "lucenenet.apache.org"));
+TopDocs topDocs = searcher.Search(query, n: 2); //indicate we want the first 2 results
+
+
+int numMatchingDocs = topDocs.TotalHits;
+Document resultDoc = searcher.Doc(topDocs.ScoreDocs[0].Doc); //read back first doc from results (ie 0 offset)
+string title = resultDoc.Get("title");
+
+Console.WriteLine($"Matching results: {topDocs.TotalHits}");
+Console.WriteLine($"Title of first result: {title}");
+```
+
+
+
+### View of the Project.cs file with Our Code
+The `Program.cs` file should now look something like this in your editor:
+
+<img src='https://lucenenet.apache.org/images/quick-start/tutorial/example1-new-program.cs.png'>
+
+### Run the Lucene.NET Code
+So now you can hit F5 in Visual Studio or VS Code or you can execute `dotnet run` in PowerShell to see the code run and to see if it outputs what we expect.
+
+<img src='https://lucenenet.apache.org/images/quick-start/tutorial/run-example1.png'>
+
+And in the above screenshot we can see that the 2nd time we executed `dotnet run` (ie. after we modified the Program.cs file, out output says:
+
+>Matching results: 1<br>
+Title of first result: Powerful open source search library for .NET
+
+This is exactly what we would expect.
+
+
+### Conclusion - Example 1
+While this example is not particularly complicated, it will get you started. It provides fully working code that uses Lucne.NET that you now understand.
+
+When looking at this code it’s pretty easy to imagine how one might use a while loop instead of inline code for adding documents and how one could perhaps add 10,000 documents (or a million documents) instead of just three. And it's pretty easy to imagine how one would add several fields per document rather then just two.
+
+I would encourage you to play with this code, modify it (maybe by adding more fields, or changing the field name or field values) and then run it to see the results. This iterative process is a great way to grow your knowledge of Lucene.NET.
+
+Then move onto the next example that demonstrates full text search.
+
+## Example 2 – Full Text Search
+We are going to create a console application that uses Lucene.NET to index three documents that each have two fields and then the app will search those docs on a certain field doing an full text search and output some info about the results.
+
+This example assumes you did Example 1 so:
+1. You already have the .NET SDK installed,
+2. You already have PowerShell installed,
+3. You know how to create a C# console application project,
+4. You are familiar with the Example 1 code.
+
+### Create the Project
+Create a directory where you would like this project to live, call it `lucene-example2`. Then create a .NET console application project in that folder of the same name and add Nuget references to the following packages:
+
+* Lucene.Net
+* Lucene.Net.Analysis.Common
+* Lucene.Net.QueryParser
+
+You can use whatever tool you choose for Example 1 to accomplish these steps. In my case I will created the directory in the GUI then make it the current directory in PowerShell and then execute these commands in PowerShell one at at time (similar to how I did it in Example 1):
+
+` dotnet new console`
+
+`dotnet add package Lucene.Net --prerelease`
+
+`dotnet add package Lucene.Net.Analysis.Common --prerelease`
+
+`dotnet add package Lucene.Net.QueryParser --prerelease`
+
+
+Technically the line above to `dotnet add package Lucene.Net --prerelease` is not needed because the `Lucene.Net.Analysis.Common` Nuget package has a dependency on the `Lucene.Net` Nuget package which means that when you execute this line `dotnet add package Lucene.Net.Analysis.Common --prerelease` it will automatically pull that dependency into the project too. But since this is another introductory example I chose to add each Nuget package explicitly so that I'm not counting on one pa [...]
+
+### View the Project Files
+Just like in the prior example the project folder will have two files and an obj directory with some files. Now use your favorite editor to view the project’s .proj file. It should look like this:
+
+<img src='https://lucenenet.apache.org/images/quick-start/tutorial/example2.csproj.png'>
+
+Here is that file's contents:
+
+```
+<Project Sdk="Microsoft.NET.Sdk">
+
+ <PropertyGroup>
+ <OutputType>Exe</OutputType>
+ <TargetFramework>net6.0</TargetFramework>
+ <RootNamespace>lucene_example2</RootNamespace>
+ <ImplicitUsings>enable</ImplicitUsings>
+ <Nullable>enable</Nullable>
+ </PropertyGroup>
+
+ <ItemGroup>
+ <PackageReference Include="Lucene.Net" Version="4.8.0-beta00016" />
+ <PackageReference Include="Lucene.Net.Analysis.Common" Version="4.8.0-beta00016" />
+ <PackageReference Include="Lucene.Net.QueryParser" Version="4.8.0-beta00016" />
+ </ItemGroup>
+
+</Project>
+
+```
+
+And the `Program.cs` file that got generated will look like this again:
+
+<img src='https://lucenenet.apache.org/images/quick-start/tutorial/program02.png'>
+
+### Run the App
+If you are using Visual Studio or VS Code you can hit F5 to run the app. I will execute `dotnet run` in PowerShell to run it:
+
+<img src='https://lucenenet.apache.org/images/quick-start/tutorial/hello-world-example2.png'>
+
+And we can see it output Hello World! Just as it did in Example 1.
+
+### Writing Some Lucene.NET Code
+Now use your editor to replace the existing code in the Program.cs with the following:
+
+```c#
+using Lucene.Net.Analysis;
+using Lucene.Net.Analysis.Standard;
+using Lucene.Net.Documents;
+using Lucene.Net.Index;
+using Lucene.Net.QueryParsers.Classic;
+using Lucene.Net.Search;
+using Lucene.Net.Store;
+using Lucene.Net.Util;
+using System.Diagnostics;
+using LuceneDirectory = Lucene.Net.Store.Directory;
+
+// Specify the compatibility version we want
+const LuceneVersion luceneVersion = LuceneVersion.LUCENE_48;
+
+//Open the Directory using a Lucene Directory class
+string indexName = "example_index";
+string indexPath = Path.Combine(Environment.CurrentDirectory, indexName);
+
+using LuceneDirectory indexDir = FSDirectory.Open(indexPath);
+
+// Create an analyzer to process the text
+Analyzer standardAnalyzer = new StandardAnalyzer(luceneVersion);
+
+//Create an index writer
+IndexWriterConfig indexConfig = new IndexWriterConfig(luceneVersion, standardAnalyzer);
+indexConfig.OpenMode = OpenMode.CREATE; // create/overwrite index
+IndexWriter writer = new IndexWriter(indexDir, indexConfig);
+
+//Add three documents to the index
+Document doc = new Document();
+doc.Add(new TextField("title", "The Apache Software Foundation - The world's largest open source foundation.", Field.Store.YES));
+doc.Add(new StringField("domain", "www.apache.org", Field.Store.YES));
+writer.AddDocument(doc);
+
+doc = new Document();
+doc.Add(new TextField("title", "Powerful open source search library for .NET", Field.Store.YES));
+doc.Add(new StringField("domain", "lucenenet.apache.org", Field.Store.YES));
+writer.AddDocument(doc);
+
+doc = new Document();
+doc.Add(new TextField("title", "Unique gifts made by small businesses in North Carolina.", Field.Store.YES));
+doc.Add(new StringField("domain", "www.giftoasis.com", Field.Store.YES));
+writer.AddDocument(doc);
+
+//Flush and commit the index data to the directory
+writer.Commit();
+
+using DirectoryReader reader = writer.GetReader(applyAllDeletes: true);
+IndexSearcher searcher = new IndexSearcher(reader);
+
+QueryParser parser = new QueryParser(luceneVersion, "title", standardAnalyzer);
+Query query = parser.Parse("open source");
+TopDocs topDocs = searcher.Search(query, n: 3); //indicate we want the first 3 results
+
+
+Console.WriteLine($"Matching results: {topDocs.TotalHits}");
+
+for (int i = 0; i < topDocs.TotalHits; i++)
+{
+ //read back a doc from results
+ Document resultDoc = searcher.Doc(topDocs.ScoreDocs[i].Doc);
+
+ string domain = resultDoc.Get("domain");
+ Console.WriteLine($"Domain of result {i + 1}: {domain}");
+}
+```
+
+> [!WARNING]
+> As mentioned earlier, if you are not running .NET 6.0 SDK or later you will need to modify the above code in the following two ways: 1) Program.cs file will need to have a namespace, Program class and a static void main method. See Microsoft docs [here](https://docs.microsoft.com/en-us/dotnet/core/tutorials/with-visual-studio?pivots=dotnet-5-0#code-try-3) for details; and 2) you will need to add [braces to the using statements](https://docs.microsoft.com/en-us/dotnet/csharp/language-r [...]
+
+### Code Walkthrough
+Before we run the code let’s talk about what’s different then the code in Example 1.
+
+As you might guess we have an additional using declaration `using Lucene.Net.QueryParsers.Classic` related to the additional Nuget package we added. But other than that the rest of the code at beginning and even middle of the code is just like what we already covered in Example1.
+
+We are creating a `LuceneDirectory` and `IndexWriter` the same way and we are adding the same documents and then committing them. All stuff we saw in Example1. Also in this example we get our index reader and searcher the same way we did in the last example.
+
+**But** the way we query back documents in this example is different.
+
+This time around, instead of using a `TermQuery` to do an exact match search, have these two lines of code:
+
+```c#
+QueryParser parser = new QueryParser(luceneVersion, "title", standardAnalyzer);
+Query query = parser.Parse("open source");
+```
+
+These lines allow us to create a query that will perform a full text search. This type of search is similar to what you are use to when doing a google or bing search.
+
+What we are saying in these two lines is that we want to create a query that will search the `title` field of our documents and we want back document that contain “open source” or just “open” or just “source” and we want them sorted by how well they match our “open source” query.
+
+So when the line of code below runs, Lucene.NET will score each of our docs that match the query and return the top 3 matching documents sorted by score.
+
+```c#
+TopDocs topDocs = searcher.Search(query, n: 3); //indicate we want the first 3 results
+```
+
+In our case only two documents match and they will be returned in `topDocs`. Then our final block of code just prints out the results.
+
+```c#
+Console.WriteLine($"Matching results: {topDocs.TotalHits}");
+
+for (int i = 0; i < topDocs.TotalHits; i++)
+{
+ //read back a doc from results
+ Document resultDoc = searcher.Doc(topDocs.ScoreDocs[i].Doc);
+
+ string domain = resultDoc.Get("domain");
+ Console.WriteLine($"Domain of result {i + 1}: {domain}");
+}
+```
+
+### View of the Project.cs file with Our Code
+The `Program.cs` file should now look something like this in your editor:
+
+<img src='https://lucenenet.apache.org/images/quick-start/tutorial/example2-new-program.cs.png'>
+
+### Run the Lucene.NET Code
+So now you can hit F5 in Visual Studio or VS Code or you can execute `dotnet run` in PowerShell to see the code run and to see if it outputs what we expect.
+
+<img src='https://lucenenet.apache.org/images/quick-start/tutorial/run-example2.png'>
+
+If you go back and review the contents of the `title` field for each document you will see the output from running the code does indeed return the only two documents that that contain “open source” in the title field.
+
+### Conclusion - Example 2
+In this Example we saw Lucene.NET’s full text search feature. But we only scratched the surface.
+
+It’s the responsibility of the analyzer to tokenize the text and it’s the tokens that are stored in the index as terms. In our case we used the `StandardAnalyzer` which removes punctuation, lower cases the text so it’s not case sensitive and removes stop words (common words like “a” “an” and “the”).
+
+But there are other analyzers we could choose. For example the `EnglishAnalyzer` does everything the `StandardAnalyzer` does but also “stems” the terms via the Porter Stemming algorithm. Without going into the details of what the stemmer does, it provides the ability for us to perform a search and match documents that contain other forms of the word we are searching on.
+
+So for example if we used the `EnglishAnalyzer` both for indexing our documents and searching our documents then if we searched on “run” we could match documents that contained “run”, “runs”, and “running”. And not only that, Lucene.NET contains Analyzers for 100s of other languages besides English.
+
+Based on what you just learned, I suspect you could find some fun ways to change the code in Example2 to further your experimenting and learning. For example you could add other documents with different field values, or use a different Analyzer and see how the results change.
+
+## Final Thoughts
+Now that you have working code and have seen at least the basics of how to use Lucene.NET I would encourage you to play with the code and see what you can accomplish. Depending on your skill level you might be able to read a tab delimited text file (which could for example be created via Excel) and build a Lucene.NET index from that data. Then search it.
+
+I would also encourage you to review the [Learning Resources](xref:quick-start/learning-resources) page to get up to speed on all the places you can go to learn more about Lucene.NET.
+
+Apache Lucene.NET is a powerful open source search library. Have fun with it!
diff --git a/websites/site/toc.yml b/websites/site/toc.yml
index b8b211a..474ed08 100644
--- a/websites/site/toc.yml
+++ b/websites/site/toc.yml
@@ -1,7 +1,8 @@
- name: About
href: /#about
-- name: Quick start
- href: /#quick-start
+- name: Quick Start
+ href: quick-start/
+ topicHref: quick-start/index.md
- name: Download
href: download/
topicHref: download/download.md