You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2020/12/11 08:08:51 UTC
[GitHub] [iceberg] 172403678 opened a new issue #1911: iceberg data file name shouldnot starts with partitionId
172403678 opened a new issue #1911:
URL: https://github.com/apache/iceberg/issues/1911
output file starts with partitionId so file is starts with 00000 and so on but in iceberg on cos scene , cos file name shouldnot begin with the same prefix
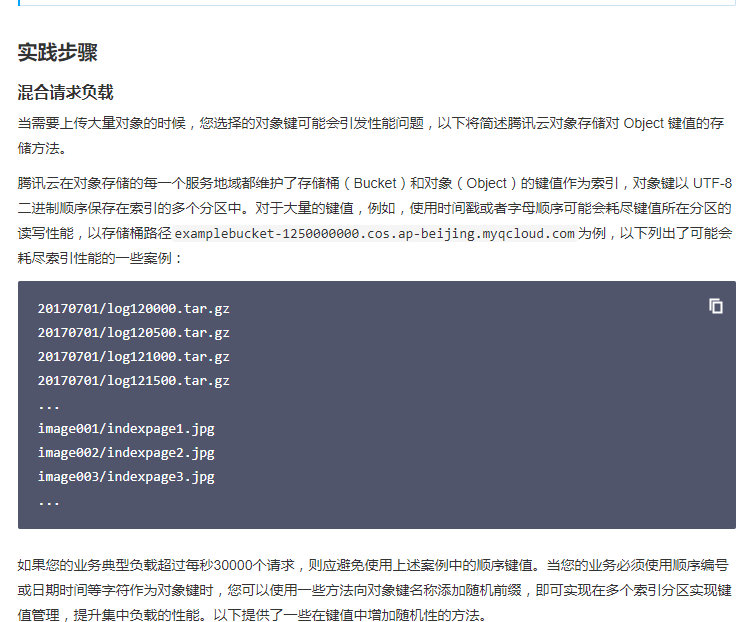
The cloud maintains the key values of buckets and objects as indexes in each service area of object storage. Object keys are stored in multiple partitions of the index in UTF-8 binary order. For a large number of key values, for example, using timestamp or alphabetical order may exhaust the read and write performance of the partition where the key value is located. Take the bucket path examplebucket-1250000000.cos.ap-beijing.myqcloud.com as an example, as shown below Some cases that may exhaust index performance:
such as
https://cloud.tencent.com/document/product/436/13653
in file OutputFileFactory
private String generateFilename() {
return this.format.addExtension(String.format("%05d-%d-%s-%05d", this.partitionId, this.taskId, this.uuid, this.fileCount.incrementAndGet()));
}
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] 172403678 commented on issue #1911: iceberg data file name shouldnot starts with partitionId
Posted by GitBox <gi...@apache.org>.
172403678 commented on issue #1911:
URL: https://github.com/apache/iceberg/issues/1911#issuecomment-743062804
https://github.com/apache/iceberg/pull/1913/commits
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue closed issue #1911: iceberg data file name shouldnot starts with partitionId
Posted by GitBox <gi...@apache.org>.
rdblue closed issue #1911:
URL: https://github.com/apache/iceberg/issues/1911
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] HeartSaVioR commented on issue #1911: iceberg data file name shouldnot starts with partitionId
Posted by GitBox <gi...@apache.org>.
HeartSaVioR commented on issue #1911:
URL: https://github.com/apache/iceberg/issues/1911#issuecomment-745005063
I wouldn't rather say any specific project should take all existing cloud providers into account. You can expect the smoother AWS support in Iceberg project due to the nature of where Iceberg project came from, and even more, AWS engineers are around here to contribute. The project has both contributors and heavy users for AWS, which is quite essential to lead the actual improvements.
It seems that you can provide the implementation of location provider via `write.location-provider.impl` in table properties. You can copy the code into your project (You can even fork Iceberg but there's public extension point so I'd rather use that instead), modify it, and specify the class name into the property. Just need to check the license before you do, but Apache License is relatively quite open so in many cases you won't be struggled.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] txdong-sz commented on issue #1911: iceberg data file name shouldnot starts with partitionId
Posted by GitBox <gi...@apache.org>.
txdong-sz commented on issue #1911:
URL: https://github.com/apache/iceberg/issues/1911#issuecomment-743764425
@HeartSaVioR i think that iceberg is Works with any cloud store and reduces NN congestion when in HDFS, by avoiding listing and renames
so iceberg should take storage compatibility into consideration. iceberg storge with cloud is advantage, but store with hdfs is also supoort the two storage facility is different
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] txdong-sz commented on issue #1911: iceberg data file name shouldnot starts with partitionId
Posted by GitBox <gi...@apache.org>.
txdong-sz commented on issue #1911:
URL: https://github.com/apache/iceberg/issues/1911#issuecomment-744115275
@rdblue get ObjectStoreLocationProvider may meet the need thanks.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] txdong-sz edited a comment on issue #1911: iceberg data file name shouldnot starts with partitionId
Posted by GitBox <gi...@apache.org>.
txdong-sz edited a comment on issue #1911:
URL: https://github.com/apache/iceberg/issues/1911#issuecomment-744115275
@rdblue ObjectStoreLocationProvider may meet the need thanks.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on issue #1911: iceberg data file name shouldnot starts with partitionId
Posted by GitBox <gi...@apache.org>.
openinx commented on issue #1911:
URL: https://github.com/apache/iceberg/issues/1911#issuecomment-743071114
@172403678 Sorry, I did not quite understand your concern actually. All data files are maintained in apache iceberg's manifests, so when planing a scan job, it will load the iceberg's manifests and get the correct data file paths for each task. For each task, it just GET the data from specific data file. Which step will hurt the performance you mean ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] txdong-sz commented on issue #1911: iceberg data file name shouldnot starts with partitionId
Posted by GitBox <gi...@apache.org>.
txdong-sz commented on issue #1911:
URL: https://github.com/apache/iceberg/issues/1911#issuecomment-743763097
@rdblue i donnot think that config write.object-storage.path will meet my need . write.object-storage.path can ensuer table with the different perfix but our case is one table with huge data.
our problem is that we write about we need to store all origin data to cos with iceberg format, one table is very huge and so we need to improve the write performance to cos . from the cos architecture . data file with salt approach can improve the cos write performance .
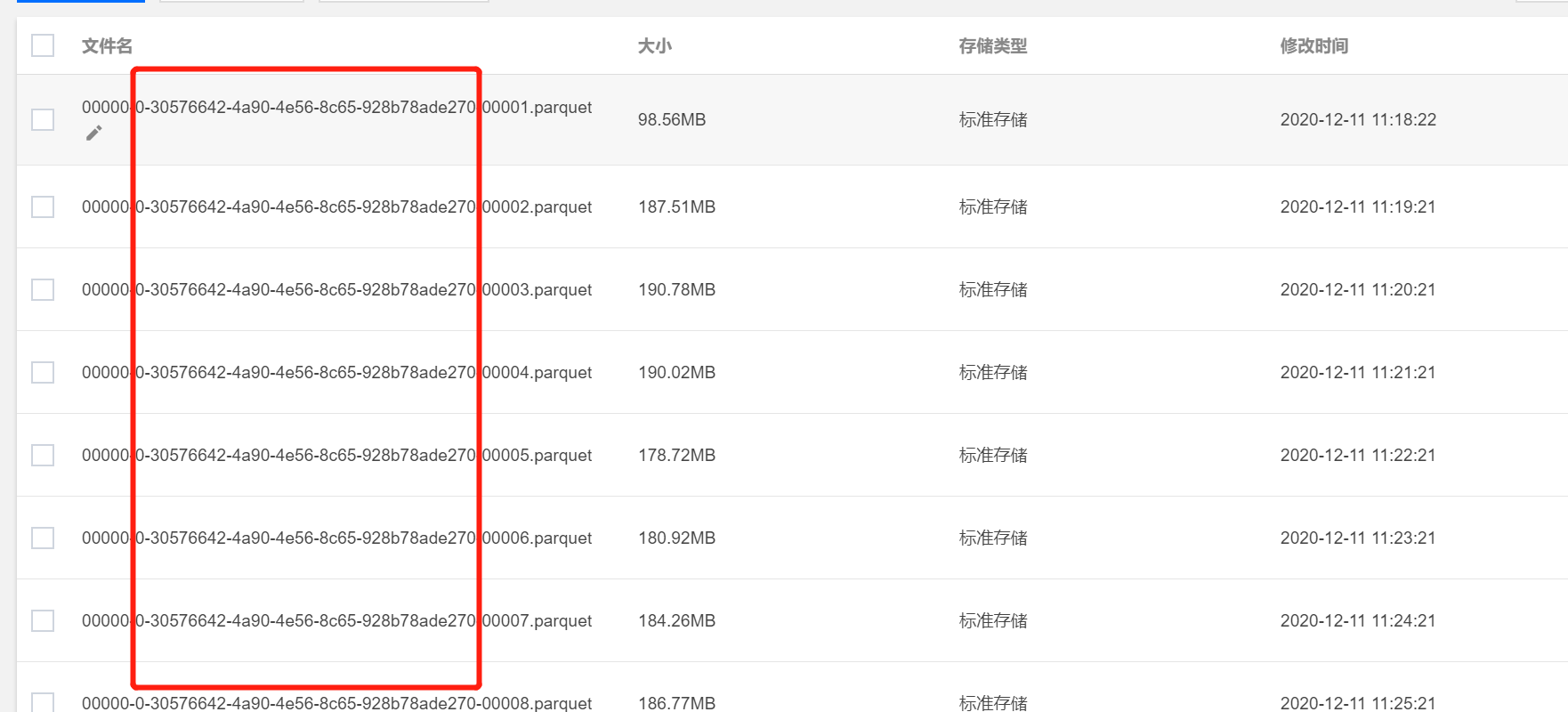
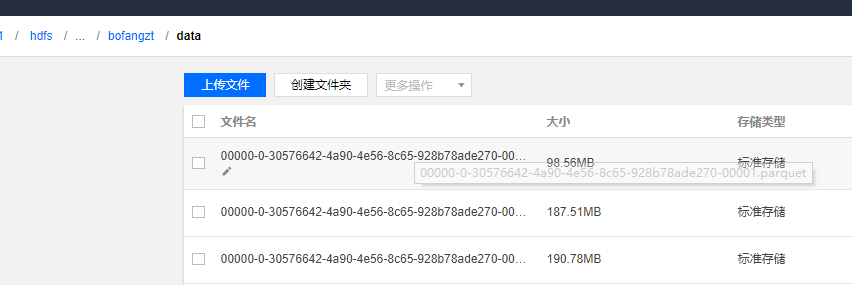
in our cos case file name 00000-0-30576642-4a90-4e56-8c65-928b78ade270-00001.parquet starts with 00000 is slow than
4a90-4e56-8c65-928b78ade270-00000-0-30576642-00001.parquet
more widely k/v storage need key is more hash . so i think default data file name starts with uuid will meet the need.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] jerryshao commented on issue #1911: iceberg data file name shouldnot starts with partitionId
Posted by GitBox <gi...@apache.org>.
jerryshao commented on issue #1911:
URL: https://github.com/apache/iceberg/issues/1911#issuecomment-743082122
The key problem is that Iceberg's data file sequential name policy will somehow hit the COS (Tencent Cloud Object Store) hotspot and introduce the performance issue. The suggestion is to add salt on the file name to distribute the load.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] 172403678 commented on issue #1911: iceberg data file name shouldnot starts with partitionId
Posted by GitBox <gi...@apache.org>.
172403678 commented on issue #1911:
URL: https://github.com/apache/iceberg/issues/1911#issuecomment-743072625
in write the data file to cos
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on issue #1911: iceberg data file name shouldnot starts with partitionId
Posted by GitBox <gi...@apache.org>.
openinx commented on issue #1911:
URL: https://github.com/apache/iceberg/issues/1911#issuecomment-743081464
OK, got your point. You mean now we are creating so many objects with the same prefix ( here is `partitionId`) in the same bucket when bulk loading data into a new iceberg table. In that case, the metadata service of tencent could storage will hit the hot-spot issue, that sounds reasonable.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] HeartSaVioR commented on issue #1911: iceberg data file name shouldnot starts with partitionId
Posted by GitBox <gi...@apache.org>.
HeartSaVioR commented on issue #1911:
URL: https://github.com/apache/iceberg/issues/1911#issuecomment-743200232
I agree that it should be ideal to customize the file name format so that it could be customized against the internal of filesystem or external storage. Though it's unfortunately against my expectation for the object store that the physical location is somehow related to the object key.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on issue #1911: iceberg data file name shouldnot starts with partitionId
Posted by GitBox <gi...@apache.org>.
rdblue commented on issue #1911:
URL: https://github.com/apache/iceberg/issues/1911#issuecomment-743899255
@txdong-sz, if you need to modify the file name, you can do that by building your own `LocationProvider`.
I think that the object storage feature would work because it adds a hash of the file name (or file name and partition) just after the object storage path. That should work for this case because the data would be sharded across many different paths. Again, if you want to customize then you should plug in your own provider.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue edited a comment on issue #1911: iceberg data file name shouldnot starts with partitionId
Posted by GitBox <gi...@apache.org>.
rdblue edited a comment on issue #1911:
URL: https://github.com/apache/iceberg/issues/1911#issuecomment-743334192
Iceberg supports a `LocationProvider` implementation so that tables can customize the file layout. We already have a [`LocationProvider` that hashes to distribute files](https://github.com/apache/iceberg/blob/master/core/src/main/java/org/apache/iceberg/LocationProviders.java#L91-L131) and avoid this problem that you can enable by setting [`write.object-storage.enabled=true`](https://github.com/apache/iceberg/blob/09c69a129cbcba83637d2c4c292850803d5a9b03/core/src/main/java/org/apache/iceberg/TableProperties.java#L87-L90) for a table and providing a base location with `write.object-storage.path`.
Hopefully that should already implement what you need to solve this problem. It doesn't currently alter the file names that are passed in, but you could write a `LocationProvider` that does basically the same thing and adds a prefix to the file path as well.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on issue #1911: iceberg data file name shouldnot starts with partitionId
Posted by GitBox <gi...@apache.org>.
openinx commented on issue #1911:
URL: https://github.com/apache/iceberg/issues/1911#issuecomment-743086202
@rdblue , Did you encounter the same issue when loading Netflix data into aws s3 bucket ? The salt approach (from @jerryshao ) will need to create a customized `OutputFileFactory` I think ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] txdong-sz commented on issue #1911: iceberg data file name shouldnot starts with partitionId
Posted by GitBox <gi...@apache.org>.
txdong-sz commented on issue #1911:
URL: https://github.com/apache/iceberg/issues/1911#issuecomment-744990726
@rdblue the reson why we use iceberg is that iceberg is cloud native.
Works with any cloud store and reduces NN congestion when in HDFS, by avoiding listing and renames
i think that we need to consider everything about cloud object storeing
we have one table with 30TB data stilll small data in our business
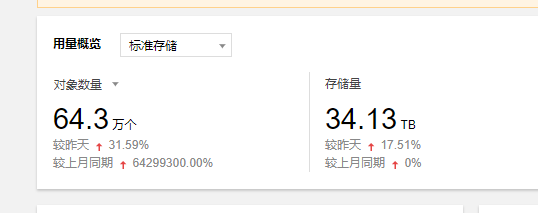
and we list table take about 10 seconds .
so i think that the defualt implement need to be native cloud base if the code is not effect other functions .
and we need to review every code about list files to avoid avoid performance loss
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on issue #1911: iceberg data file name shouldnot starts with partitionId
Posted by GitBox <gi...@apache.org>.
rdblue commented on issue #1911:
URL: https://github.com/apache/iceberg/issues/1911#issuecomment-743334192
Iceberg supports a `LocationProvider` implementation so that tables can customize the file layout. We already have a [`LocationProvider` that hashes to distribute files](https://github.com/apache/iceberg/blob/master/core/src/main/java/org/apache/iceberg/LocationProviders.java#L91-L131) and avoid this problem that you can enable by setting [`write.object-storage.enabled=true`](https://github.com/apache/iceberg/blob/09c69a129cbcba83637d2c4c292850803d5a9b03/core/src/main/java/org/apache/iceberg/TableProperties.java#L87-L90) for a table and providing a base location with `write.object-storage.path`.
Hopefully that should already implement what you need to solve this problem.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org