You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@zeppelin.apache.org by zj...@apache.org on 2020/05/10 11:28:57 UTC
[zeppelin] branch branch-0.9 updated: [ZEPPELIN-4806]. Throw proper
exception when hadoop jar is missing in yarn mode for flink interpreter
This is an automated email from the ASF dual-hosted git repository.
zjffdu pushed a commit to branch branch-0.9
in repository https://gitbox.apache.org/repos/asf/zeppelin.git
The following commit(s) were added to refs/heads/branch-0.9 by this push:
new 357103f [ZEPPELIN-4806]. Throw proper exception when hadoop jar is missing in yarn mode for flink interpreter
357103f is described below
commit 357103f776bdf507d086eeefc6d0271ab6877747
Author: Jeff Zhang <zj...@apache.org>
AuthorDate: Sat May 9 11:49:26 2020 +0800
[ZEPPELIN-4806]. Throw proper exception when hadoop jar is missing in yarn mode for flink interpreter
### What is this PR for?
This PR actually solve 2 things in flink yarn mode.
1. You don't need flink-hadoop-shaded jar when flink is not in yarn mode (before this PR, it is still needed even when it is not in yarn mode)
2. Throw proper error message when hadoop jar is missing in yarn mode.
### What type of PR is it?
[ Improvement ]
### Todos
* [ ] - Task
### What is the Jira issue?
* https://issues.apache.org/jira/browse/ZEPPELIN-4806
### How should this be tested?
* CI pass
### Screenshots (if appropriate)
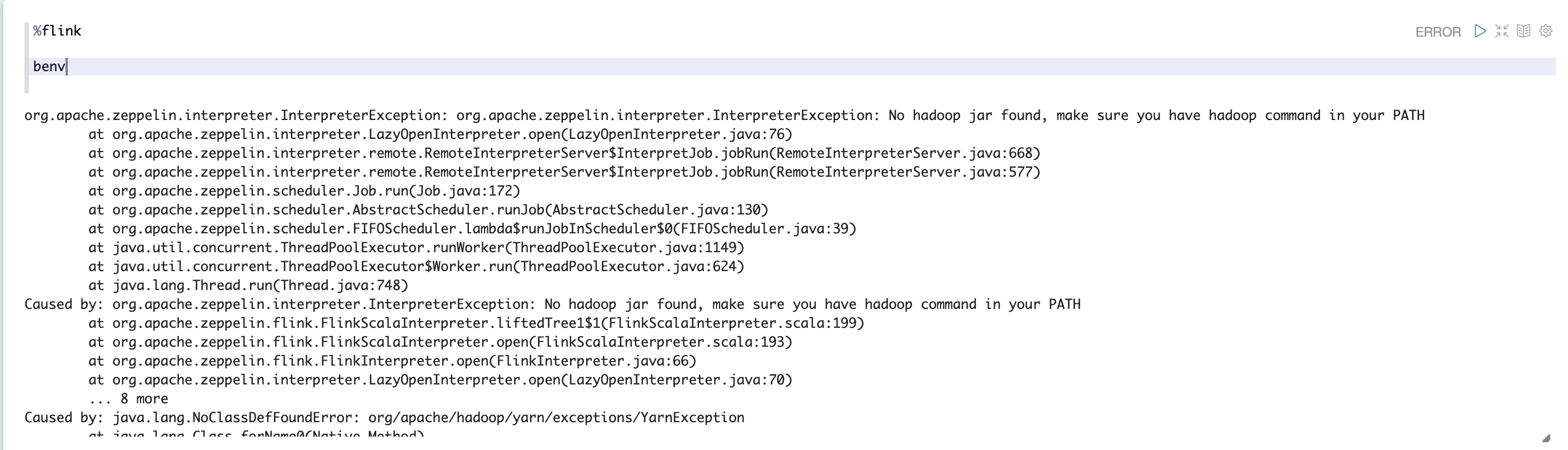
### Questions:
* Does the licenses files need update? No
* Is there breaking changes for older versions? No
* Does this needs documentation? NO
Author: Jeff Zhang <zj...@apache.org>
Closes #3767 from zjffdu/ZEPPELIN-4806 and squashes the following commits:
5b75838e6 [Jeff Zhang] [ZEPPELIN-4806]. Throw proper exception when hadoop jar is missing in yarn mode for flink interpreter
(cherry picked from commit f63fdf6f80825fd2105af0dbc059ac5c0afca923)
Signed-off-by: Jeff Zhang <zj...@apache.org>
---
bin/interpreter.sh | 4 ++
.../org/apache/zeppelin/flink/HadoopUtils.java | 68 ++++++++++++++++++++++
.../zeppelin/flink/FlinkScalaInterpreter.scala | 55 ++++++-----------
3 files changed, 90 insertions(+), 37 deletions(-)
diff --git a/bin/interpreter.sh b/bin/interpreter.sh
index e165fa4..7a34425 100755
--- a/bin/interpreter.sh
+++ b/bin/interpreter.sh
@@ -236,6 +236,10 @@ elif [[ "${INTERPRETER_ID}" == "flink" ]]; then
if [[ -n "${HADOOP_CONF_DIR}" ]] && [[ -d "${HADOOP_CONF_DIR}" ]]; then
ZEPPELIN_INTP_CLASSPATH+=":${HADOOP_CONF_DIR}"
+ if ! [ -x "$(command -v hadoop)" ]; then
+ echo 'Error: hadoop is not in PATH when HADOOP_CONF_DIR is specified.'
+ exit 1
+ fi
ZEPPELIN_INTP_CLASSPATH+=":`hadoop classpath`"
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR}
else
diff --git a/flink/src/main/java/org/apache/zeppelin/flink/HadoopUtils.java b/flink/src/main/java/org/apache/zeppelin/flink/HadoopUtils.java
new file mode 100644
index 0000000..6e7a489
--- /dev/null
+++ b/flink/src/main/java/org/apache/zeppelin/flink/HadoopUtils.java
@@ -0,0 +1,68 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.zeppelin.flink;
+
+import org.apache.flink.client.program.ClusterClient;
+import org.apache.hadoop.conf.Configuration;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+import org.apache.hadoop.yarn.api.records.ApplicationId;
+import org.apache.hadoop.yarn.client.api.YarnClient;
+import org.apache.hadoop.yarn.conf.YarnConfiguration;
+import org.apache.hadoop.yarn.exceptions.YarnException;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.IOException;
+
+/**
+ * Move the hadoop related operation (depends on hadoop api) out of FlinkScalaInterpreter to this
+ * class is because in this way we don't need to load hadoop class for non-yarn mode. Otherwise
+ * even in non-yarn mode, user still need hadoop shaded jar which doesnt' make sense.
+ */
+public class HadoopUtils {
+
+ private static final Logger LOGGER = LoggerFactory.getLogger(HadoopUtils.class);
+
+ public static String getYarnAppTrackingUrl(ClusterClient clusterClient) throws IOException, YarnException {
+ ApplicationId yarnAppId = (ApplicationId) clusterClient.getClusterId();
+ YarnClient yarnClient = YarnClient.createYarnClient();
+ YarnConfiguration yarnConf = new YarnConfiguration();
+ // disable timeline service as we only query yarn app here.
+ // Otherwise we may hit this kind of ERROR:
+ // java.lang.ClassNotFoundException: com.sun.jersey.api.client.config.ClientConfig
+ yarnConf.set("yarn.timeline-service.enabled", "false");
+ yarnClient.init(yarnConf);
+ yarnClient.start();
+ return yarnClient.getApplicationReport(yarnAppId).getTrackingUrl();
+ }
+
+ public static void cleanupStagingDirInternal(ClusterClient clusterClient) {
+ try {
+ ApplicationId appId = (ApplicationId) clusterClient.getClusterId();
+ FileSystem fs = FileSystem.get(new Configuration());
+ Path stagingDirPath = new Path(fs.getHomeDirectory(), ".flink/" + appId.toString());
+ if (fs.delete(stagingDirPath, true)) {
+ LOGGER.info("Deleted staging directory " + stagingDirPath);
+ }
+ } catch (IOException e){
+ LOGGER.warn("Failed to cleanup staging dir", e);
+ }
+ }
+}
diff --git a/flink/src/main/scala/org/apache/zeppelin/flink/FlinkScalaInterpreter.scala b/flink/src/main/scala/org/apache/zeppelin/flink/FlinkScalaInterpreter.scala
index 6e69629..625a8ed 100644
--- a/flink/src/main/scala/org/apache/zeppelin/flink/FlinkScalaInterpreter.scala
+++ b/flink/src/main/scala/org/apache/zeppelin/flink/FlinkScalaInterpreter.scala
@@ -18,10 +18,10 @@
package org.apache.zeppelin.flink
-import java.io.{BufferedReader, File, IOException}
+import java.io.{BufferedReader, File}
import java.net.{URL, URLClassLoader}
import java.nio.file.Files
-import java.util.{Map, Properties}
+import java.util.Properties
import java.util.concurrent.TimeUnit
import java.util.jar.JarFile
@@ -46,11 +46,7 @@ import org.apache.flink.table.catalog.hive.HiveCatalog
import org.apache.flink.table.functions.{AggregateFunction, ScalarFunction, TableAggregateFunction, TableFunction}
import org.apache.flink.table.module.ModuleManager
import org.apache.flink.table.module.hive.HiveModule
-import org.apache.hadoop.fs.{FileSystem, Path}
-import org.apache.hadoop.yarn.api.records.ApplicationId
-import org.apache.hadoop.yarn.client.api.YarnClient
-import org.apache.hadoop.yarn.conf
-import org.apache.hadoop.yarn.conf.YarnConfiguration
+import org.apache.flink.yarn.cli.FlinkYarnSessionCli
import org.apache.zeppelin.flink.util.DependencyUtils
import org.apache.zeppelin.interpreter.thrift.InterpreterCompletion
import org.apache.zeppelin.interpreter.util.InterpreterOutputStream
@@ -191,7 +187,19 @@ class FlinkScalaInterpreter(val properties: Properties) {
new JPrintWriter(Console.out, true)
}
- val (iLoop, cluster) = try {
+ val (iLoop, cluster) = {
+ // workaround of checking hadoop jars in yarn mode
+ if (mode == ExecutionMode.YARN) {
+ try {
+ Class.forName(classOf[FlinkYarnSessionCli].getName)
+ } catch {
+ case e: ClassNotFoundException =>
+ throw new InterpreterException("Unable to load FlinkYarnSessionCli for yarn mode", e)
+ case e: NoClassDefFoundError =>
+ throw new InterpreterException("No hadoop jar found, make sure you have hadoop command in your PATH", e)
+ }
+ }
+
val (effectiveConfig, cluster) = fetchConnectionInfo(config, configuration)
this.configuration = effectiveConfig
cluster match {
@@ -203,17 +211,7 @@ class FlinkScalaInterpreter(val properties: Properties) {
} else if (mode == ExecutionMode.YARN) {
LOGGER.info("Starting FlinkCluster in yarn mode")
if (properties.getProperty("flink.webui.yarn.useProxy", "false").toBoolean) {
- val yarnAppId = clusterClient.getClusterId.asInstanceOf[ApplicationId]
- val yarnClient = YarnClient.createYarnClient
- val yarnConf = new YarnConfiguration()
- // disable timeline service as we only query yarn app here.
- // Otherwise we may hit this kind of ERROR:
- // java.lang.ClassNotFoundException: com.sun.jersey.api.client.config.ClientConfig
- yarnConf.set("yarn.timeline-service.enabled", "false")
- yarnClient.init(yarnConf)
- yarnClient.start()
- val appReport = yarnClient.getApplicationReport(yarnAppId)
- this.jmWebUrl = appReport.getTrackingUrl
+ this.jmWebUrl = HadoopUtils.getYarnAppTrackingUrl(clusterClient)
} else {
this.jmWebUrl = clusterClient.getWebInterfaceURL
}
@@ -239,10 +237,6 @@ class FlinkScalaInterpreter(val properties: Properties) {
} finally {
Thread.currentThread().setContextClassLoader(classLoader)
}
- } catch {
- case e: IllegalArgumentException =>
- println(s"Error: ${e.getMessage}")
- sys.exit()
}
this.flinkILoop = iLoop
@@ -668,7 +662,7 @@ class FlinkScalaInterpreter(val properties: Properties) {
clusterClient.close()
// delete staging dir
if (mode == ExecutionMode.YARN) {
- cleanupStagingDirInternal(clusterClient.getClusterId.asInstanceOf[ApplicationId])
+ HadoopUtils.cleanupStagingDirInternal(clusterClient)
}
case None =>
LOGGER.info("Don't close the Remote FlinkCluster")
@@ -687,19 +681,6 @@ class FlinkScalaInterpreter(val properties: Properties) {
}
}
- private def cleanupStagingDirInternal(appId: ApplicationId): Unit = {
- try {
- val fs = FileSystem.get(new org.apache.hadoop.conf.Configuration())
- val stagingDirPath = new Path(fs.getHomeDirectory, ".flink/" + appId.toString)
- if (fs.delete(stagingDirPath, true)) {
- LOGGER.info(s"Deleted staging directory $stagingDirPath")
- }
- } catch {
- case ioe: IOException =>
- LOGGER.warn("Failed to cleanup staging dir", ioe)
- }
- }
-
def getExecutionEnvironment(): ExecutionEnvironment = this.benv
def getStreamExecutionEnvironment(): StreamExecutionEnvironment = this.senv