You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2020/08/19 08:33:29 UTC
[GitHub] [iceberg] Heltman opened a new issue #1359: java.lang.IllegalArgumentException: no location provided for warehouse
Heltman opened a new issue #1359:
URL: https://github.com/apache/iceberg/issues/1359
I use spark-3.0.0 and iceberg-0.9.0 make some test. I follow this doc:
https://iceberg.apache.org/getting-started/#creating-a-table
But I get a exception like the title:
java.lang.IllegalArgumentException: no location provided for warehouse
My code like below:
> bin/spark-shell \
--master yarn \
--jars iceberg-spark3-runtime-0.9.0.jar \
--executor-memory 2G \
--num-executors 20 \
--conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog \
--conf spark.sql.catalog.spark_catalog.type=hive \
--conf spark.sql.catalog.local=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.local.type=hadoop \
--conf spark.sql.catalog.local.uri=hdfs://nameservice1:8020/user/spark2/iceberg
> scala> spark.sql("CREATE TABLE local.db.table (id bigint, data string) USING iceberg")
Then I get below exception:
> java.lang.IllegalArgumentException: no location provided for warehouse
at org.apache.iceberg.relocated.com.google.common.base.Preconditions.checkArgument(Preconditions.java:142)
at org.apache.iceberg.hadoop.HadoopCatalog.<init>(HadoopCatalog.java:87)
at org.apache.iceberg.spark.SparkCatalog.buildIcebergCatalog(SparkCatalog.java:104)
at org.apache.iceberg.spark.SparkCatalog.initialize(SparkCatalog.java:372)
at org.apache.spark.sql.connector.catalog.Catalogs$.load(Catalogs.scala:61)
at org.apache.spark.sql.connector.catalog.CatalogManager.$anonfun$catalog$1(CatalogManager.scala:52)
at scala.collection.mutable.HashMap.getOrElseUpdate(HashMap.scala:86)
at org.apache.spark.sql.connector.catalog.CatalogManager.catalog(CatalogManager.scala:52)
at org.apache.spark.sql.connector.catalog.LookupCatalog$CatalogAndIdentifier$.unapply(LookupCatalog.scala:128)
at org.apache.spark.sql.connector.catalog.LookupCatalog$NonSessionCatalogAndIdentifier$.unapply(LookupCatalog.scala:78)
at org.apache.spark.sql.catalyst.analysis.ResolveCatalogs$NonSessionCatalogAndTable$.unapply(ResolveCatalogs.scala:202)
at org.apache.spark.sql.catalyst.analysis.ResolveCatalogs$$anonfun$apply$1.applyOrElse(ResolveCatalogs.scala:125)
at org.apache.spark.sql.catalyst.analysis.ResolveCatalogs$$anonfun$apply$1.applyOrElse(ResolveCatalogs.scala:34)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.$anonfun$resolveOperatorsDown$2(AnalysisHelper.scala:108)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:72)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.$anonfun$resolveOperatorsDown$1(AnalysisHelper.scala:108)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:194)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsDown(AnalysisHelper.scala:106)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsDown$(AnalysisHelper.scala:104)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsDown(LogicalPlan.scala:29)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperators(AnalysisHelper.scala:73)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperators$(AnalysisHelper.scala:72)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperators(LogicalPlan.scala:29)
at org.apache.spark.sql.catalyst.analysis.ResolveCatalogs.apply(ResolveCatalogs.scala:34)
at org.apache.spark.sql.catalyst.analysis.ResolveCatalogs.apply(ResolveCatalogs.scala:29)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$2(RuleExecutor.scala:149)
at scala.collection.LinearSeqOptimized.foldLeft(LinearSeqOptimized.scala:126)
at scala.collection.LinearSeqOptimized.foldLeft$(LinearSeqOptimized.scala:122)
at scala.collection.immutable.List.foldLeft(List.scala:89)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1(RuleExecutor.scala:146)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1$adapted(RuleExecutor.scala:138)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:138)
at org.apache.spark.sql.catalyst.analysis.Analyzer.org$apache$spark$sql$catalyst$analysis$Analyzer$$executeSameContext(Analyzer.scala:176)
at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:170)
at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:130)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$executeAndTrack$1(RuleExecutor.scala:116)
at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:88)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.executeAndTrack(RuleExecutor.scala:116)
at org.apache.spark.sql.catalyst.analysis.Analyzer.$anonfun$executeAndCheck$1(Analyzer.scala:154)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.markInAnalyzer(AnalysisHelper.scala:201)
at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:153)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$analyzed$1(QueryExecution.scala:68)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$executePhase$1(QueryExecution.scala:133)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.execution.QueryExecution.executePhase(QueryExecution.scala:133)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:68)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:66)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:58)
at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:99)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:97)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:606)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:601)
... 47 elided
What is it wrong? What do I need to do?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] Heltman commented on issue #1359: java.lang.IllegalArgumentException: no location provided for warehouse
Posted by GitBox <gi...@apache.org>.
Heltman commented on issue #1359:
URL: https://github.com/apache/iceberg/issues/1359#issuecomment-676060270
But a new problem:
> scala> df.writeTo("local.iceberg_test1").create()
20/08/19 17:50:28 WARN BaseMetastoreTableOperations: Could not find the table during refresh, setting current metadata to null
org.apache.iceberg.exceptions.NoSuchIcebergTableException: Not an iceberg table: spark_catalog.default.big_table (type=null)
...
> scala> spark.sql("select * from local.iceberg_test1").show()
java.lang.NoClassDefFoundError: org/apache/commons/compress/utils/Lists
at org.apache.iceberg.hadoop.HadoopInputFile.getBlockLocations(HadoopInputFile.java:182)
at org.apache.iceberg.hadoop.Util.blockLocations(Util.java:75)
at org.apache.iceberg.spark.source.SparkBatchScan$ReadTask.<init>(SparkBatchScan.java:322)
at org.apache.iceberg.spark.source.SparkBatchScan.planInputPartitions(SparkBatchScan.java:142)
at org.apache.spark.sql.execution.datasources.v2.BatchScanExec.partitions$lzycompute(BatchScanExec.scala:43)
at org.apache.spark.sql.execution.datasources.v2.BatchScanExec.partitions(BatchScanExec.scala:43)
at org.apache.spark.sql.execution.datasources.v2.DataSourceV2ScanExecBase.supportsColumnar(DataSourceV2ScanExecBase.scala:61)
at org.apache.spark.sql.execution.datasources.v2.DataSourceV2ScanExecBase.supportsColumnar$(DataSourceV2ScanExecBase.scala:60)
at org.apache.spark.sql.execution.datasources.v2.BatchScanExec.supportsColumnar(BatchScanExec.scala:29)
at org.apache.spark.sql.execution.datasources.v2.DataSourceV2Strategy.apply(DataSourceV2Strategy.scala:84)
at org.apache.spark.sql.catalyst.planning.QueryPlanner.$anonfun$plan$1(QueryPlanner.scala:63)
at scala.collection.Iterator$$anon$11.nextCur(Iterator.scala:484)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:490)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:489)
at org.apache.spark.sql.catalyst.planning.QueryPlanner.plan(QueryPlanner.scala:93)
at org.apache.spark.sql.execution.SparkStrategies.plan(SparkStrategies.scala:68)
at org.apache.spark.sql.catalyst.planning.QueryPlanner.$anonfun$plan$3(QueryPlanner.scala:78)
at scala.collection.TraversableOnce.$anonfun$foldLeft$1(TraversableOnce.scala:162)
at scala.collection.TraversableOnce.$anonfun$foldLeft$1$adapted(TraversableOnce.scala:162)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at scala.collection.TraversableOnce.foldLeft(TraversableOnce.scala:162)
at scala.collection.TraversableOnce.foldLeft$(TraversableOnce.scala:160)
at scala.collection.AbstractIterator.foldLeft(Iterator.scala:1429)
at org.apache.spark.sql.catalyst.planning.QueryPlanner.$anonfun$plan$2(QueryPlanner.scala:75)
at scala.collection.Iterator$$anon$11.nextCur(Iterator.scala:484)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:490)
at org.apache.spark.sql.catalyst.planning.QueryPlanner.plan(QueryPlanner.scala:93)
at org.apache.spark.sql.execution.SparkStrategies.plan(SparkStrategies.scala:68)
at org.apache.spark.sql.execution.QueryExecution$.createSparkPlan(QueryExecution.scala:330)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$sparkPlan$1(QueryExecution.scala:94)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$executePhase$1(QueryExecution.scala:133)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.execution.QueryExecution.executePhase(QueryExecution.scala:133)
at org.apache.spark.sql.execution.QueryExecution.sparkPlan$lzycompute(QueryExecution.scala:94)
at org.apache.spark.sql.execution.QueryExecution.sparkPlan(QueryExecution.scala:87)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$executedPlan$1(QueryExecution.scala:107)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$executePhase$1(QueryExecution.scala:133)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.execution.QueryExecution.executePhase(QueryExecution.scala:133)
at org.apache.spark.sql.execution.QueryExecution.executedPlan$lzycompute(QueryExecution.scala:107)
at org.apache.spark.sql.execution.QueryExecution.executedPlan(QueryExecution.scala:100)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$writePlans$5(QueryExecution.scala:199)
at org.apache.spark.sql.catalyst.plans.QueryPlan$.append(QueryPlan.scala:381)
at org.apache.spark.sql.execution.QueryExecution.org$apache$spark$sql$execution$QueryExecution$$writePlans(QueryExecution.scala:199)
at org.apache.spark.sql.execution.QueryExecution.toString(QueryExecution.scala:207)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:95)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:160)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:87)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3614)
at org.apache.spark.sql.Dataset.head(Dataset.scala:2695)
at org.apache.spark.sql.Dataset.take(Dataset.scala:2902)
at org.apache.spark.sql.Dataset.getRows(Dataset.scala:300)
at org.apache.spark.sql.Dataset.showString(Dataset.scala:337)
at org.apache.spark.sql.Dataset.show(Dataset.scala:824)
at org.apache.spark.sql.Dataset.show(Dataset.scala:783)
at org.apache.spark.sql.Dataset.show(Dataset.scala:792)
... 47 elided
Caused by: java.lang.ClassNotFoundException: org.apache.commons.compress.utils.Lists
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
Maybe I need more test!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] Heltman commented on issue #1359: java.lang.IllegalArgumentException: no location provided for warehouse
Posted by GitBox <gi...@apache.org>.
Heltman commented on issue #1359:
URL: https://github.com/apache/iceberg/issues/1359#issuecomment-676049225
> ```
> --conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog
> --conf spark.sql.catalog.spark_catalog.type=hive
> --conf spark.sql.catalog.local=org.apache.iceberg.spark.SparkCatalog
> --conf spark.sql.catalog.local.type=hadoop
> --conf spark.sql.catalog.local.uri=hdfs://nameservice1:8020/user/spark2/iceberg
> ```
>
> Once we group configs by catalog then configs for `local` catalog are following:
>
> ```
> --conf spark.sql.catalog.local=org.apache.iceberg.spark.SparkCatalog
> --conf spark.sql.catalog.local.type=hadoop
> --conf spark.sql.catalog.local.uri=hdfs://nameservice1:8020/user/spark2/iceberg
> ```
>
> `uri` is for hive-type catalog. hadoop-type catalog requires `warehouse`.
>
> Please refer https://iceberg.apache.org/spark/#configuring-catalogs to check required configurations.
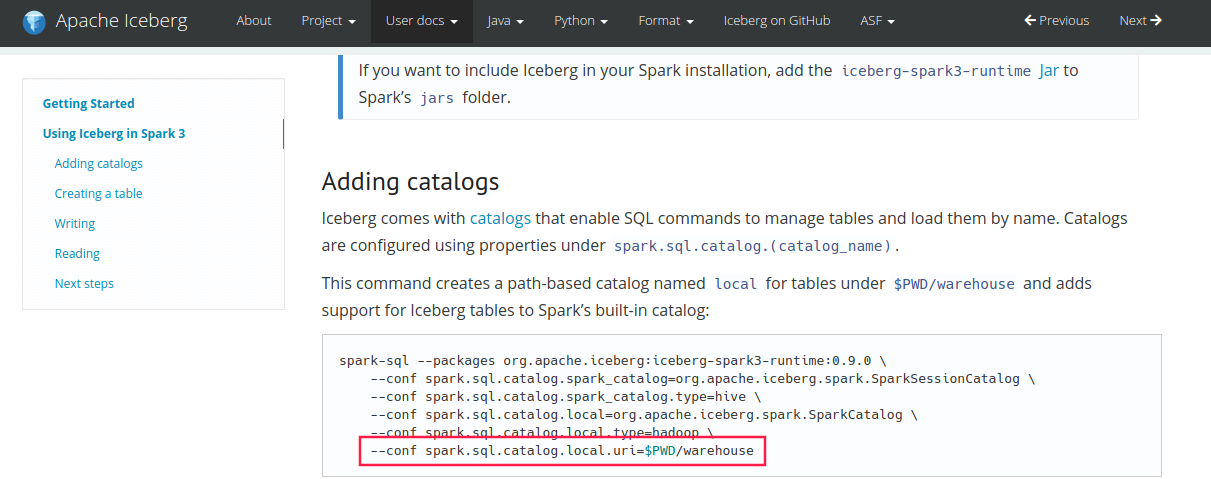
this mistake me...
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] HeartSaVioR commented on issue #1359: java.lang.IllegalArgumentException: no location provided for warehouse
Posted by GitBox <gi...@apache.org>.
HeartSaVioR commented on issue #1359:
URL: https://github.com/apache/iceberg/issues/1359#issuecomment-676027734
```
--conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog
--conf spark.sql.catalog.spark_catalog.type=hive
--conf spark.sql.catalog.local=org.apache.iceberg.spark.SparkCatalog
--conf spark.sql.catalog.local.type=hadoop
--conf spark.sql.catalog.local.uri=hdfs://nameservice1:8020/user/spark2/iceberg
```
Once we group configs by catalog then configs for `local` catalog are following:
```
--conf spark.sql.catalog.local=org.apache.iceberg.spark.SparkCatalog
--conf spark.sql.catalog.local.type=hadoop
--conf spark.sql.catalog.local.uri=hdfs://nameservice1:8020/user/spark2/iceberg
```
`uri` is for hive-type catalog. hadoop-type catalog requires `warehouse`.
Please refer https://iceberg.apache.org/spark/#configuring-catalogs to check required configurations.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] Heltman commented on issue #1359: java.lang.IllegalArgumentException: no location provided for warehouse
Posted by GitBox <gi...@apache.org>.
Heltman commented on issue #1359:
URL: https://github.com/apache/iceberg/issues/1359#issuecomment-676068946
Thanks! for all.The doc may need you to fix, I will close this issue!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] HeartSaVioR commented on issue #1359: java.lang.IllegalArgumentException: no location provided for warehouse
Posted by GitBox <gi...@apache.org>.
HeartSaVioR commented on issue #1359:
URL: https://github.com/apache/iceberg/issues/1359#issuecomment-676136550
Looks like it's already fixed via #1259 but the site hasn't been updated yet.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] HeartSaVioR commented on issue #1359: java.lang.IllegalArgumentException: no location provided for warehouse
Posted by GitBox <gi...@apache.org>.
HeartSaVioR commented on issue #1359:
URL: https://github.com/apache/iceberg/issues/1359#issuecomment-676123167
OK I'll provide the fix.
Btw, when you use "custom" catalog, you'll need to provide full table identifier like `catalog_name.db_name.table_name` - in your case, `local.default.iceberg_test1`.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] Heltman commented on issue #1359: java.lang.IllegalArgumentException: no location provided for warehouse
Posted by GitBox <gi...@apache.org>.
Heltman commented on issue #1359:
URL: https://github.com/apache/iceberg/issues/1359#issuecomment-676057020
It' s work! Thanks!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] Heltman closed issue #1359: java.lang.IllegalArgumentException: no location provided for warehouse
Posted by GitBox <gi...@apache.org>.
Heltman closed issue #1359:
URL: https://github.com/apache/iceberg/issues/1359
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] HeartSaVioR commented on issue #1359: java.lang.IllegalArgumentException: no location provided for warehouse
Posted by GitBox <gi...@apache.org>.
HeartSaVioR commented on issue #1359:
URL: https://github.com/apache/iceberg/issues/1359#issuecomment-676055345
Ah OK that looks a bug on doc, but could you please confirm changing `uri` to `warehouse` fixes your issue? Once you've confirmed, you are welcome to submit a PR to fix it (or if you mind I can do it). Thanks in advance!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org