You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@doris.apache.org by lu...@apache.org on 2023/06/29 06:09:16 UTC
[doris-website] branch master updated: add two blogs (#256)
This is an automated email from the ASF dual-hosted git repository.
luzhijing pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/doris-website.git
The following commit(s) were added to refs/heads/master by this push:
new 92065e70935 add two blogs (#256)
92065e70935 is described below
commit 92065e70935fadaafc6c07eeca2bb6abf20dab7b
Author: Hu Yanjun <10...@users.noreply.github.com>
AuthorDate: Thu Jun 29 14:09:09 2023 +0800
add two blogs (#256)
---
blog/HCDS.md | 362 +++++++++++++++++++++
blog/Memory_Management.md | 166 ++++++++++
i18n/zh-CN/docusaurus-plugin-content-blog/HCDS.md | 343 +++++++++++++++++++
.../Memory_Management.md | 184 +++++++++++
static/images/HCDS_1.png | Bin 0 -> 146716 bytes
static/images/HCDS_2.png | Bin 0 -> 33406 bytes
static/images/HCDS_3.png | Bin 0 -> 153038 bytes
static/images/HCDS_4.png | Bin 0 -> 77974 bytes
static/images/HCDS_5.png | Bin 0 -> 292292 bytes
static/images/OOM_1.png | Bin 0 -> 41725 bytes
static/images/OOM_10.png | Bin 0 -> 175010 bytes
static/images/OOM_2.png | Bin 0 -> 59839 bytes
static/images/OOM_3.png | Bin 0 -> 79211 bytes
static/images/OOM_4.png | Bin 0 -> 129804 bytes
static/images/OOM_5.png | Bin 0 -> 484537 bytes
static/images/OOM_6.png | Bin 0 -> 106042 bytes
static/images/OOM_7.png | Bin 0 -> 153390 bytes
static/images/OOM_8.png | Bin 0 -> 110385 bytes
static/images/OOM_9.png | Bin 0 -> 260355 bytes
19 files changed, 1055 insertions(+)
diff --git a/blog/HCDS.md b/blog/HCDS.md
new file mode 100644
index 00000000000..5975a505fac
--- /dev/null
+++ b/blog/HCDS.md
@@ -0,0 +1,362 @@
+---
+{
+ 'title': 'Hot-Cold Data Separation: What, Why, and How?',
+ 'summary': "Hot data is the frequently accessed data, while cold data is the one you seldom visit but still need. Separating them is for higher efficiency in computation and storage.",
+ 'date': '2023-06-23',
+ 'author': 'Apache Doris',
+ 'tags': ['Tech Sharing'],
+}
+
+---
+
+<!--
+Licensed to the Apache Software Foundation (ASF) under one
+or more contributor license agreements. See the NOTICE file
+distributed with this work for additional information
+regarding copyright ownership. The ASF licenses this file
+to you under the Apache License, Version 2.0 (the
+"License"); you may not use this file except in compliance
+with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing,
+software distributed under the License is distributed on an
+"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+KIND, either express or implied. See the License for the
+specific language governing permissions and limitations
+under the License.
+-->
+
+Apparently hot-cold data separation is hot now. But first of all:
+
+## What is Hot/Cold Data?
+
+In simple terms, hot data is the frequently accessed data, while cold data is the one you seldom visit but still need. Normally in data analytics, data is "hot" when it is new, and gets "colder" and "colder" as time goes by.
+
+For example, orders of the past six months are "hot" and logs from years ago are "cold". But no matter how cold the logs are, you still need them to be somewhere you can find.
+
+## Why Separate Hot and Cold Data?
+
+Hot-Cold Data Separation is an idea often seen in real life: You put your favorite book on your bedside table, your Christmas ornament in the attic, and your childhood art project in the garage or a cheap self-storage space on the other side of town. The purpose is a tidy and efficient life.
+
+Similarly, companies separate hot and cold data for more efficient computation and more cost-effective storage, because storage that allows quick read/write is always expensive, like SSD. On the other hand, HDD is cheaper but slower. So it is more sensible to put hot data on SSD and cold data on HDD. If you are looking for an even lower-cost option, you can go for object storage.
+
+In data analytics, hot-cold data separation is implemented by a tiered storage mechanism in the database. For example, Apache Doris supports three-tiered storage: SSD, HDD, and object storage. For newly ingested data, after a specified cooldown period, it will turn from hot data into cold data and be moved to object storage. In addition, object storage only preserves one copy of data, which further cuts down storage costs and the relevant computation/network overheads.
+
+
+
+How much can you save by hot-cold data separation? Here is some math.
+
+In public cloud services, cloud disks generally cost 5~10 times as much as object storage. If 80% of your data asset is cold data and you put it in object storage instead of cloud disks, you can expect a cost reduction of around 70%.
+
+Let the percentage of cold data be "rate", the price of object storage be "OS", and the price of cloud disk be "CloudDisk", this is how much you can save by hot-cold data separation instead of putting all your data on cloud disks:
+
+
+
+Now let's put real-world numbers in this formula:
+
+AWS pricing, US East (Ohio):
+
+- **S3 Standard Storage**: 23 USD per TB per month
+- **Throughput Optimized HDD (st 1)**: 102 USD per TB per month
+- **General Purpose SSD (gp2)**: 158 USD per TB per month
+
+
+
+## How Is Hot-Cold Separation Implemented?
+
+Till now, hot-cold separation sounds nice, but the biggest concern is: how can we implement it without compromising query performance? This can be broken down to three questions:
+
+- How to enable quick reading of cold data?
+- How to ensure high availability of data?
+- How to reduce I/O and CPU overheads?
+
+In what follows, I will show you how Apache Doris addresses them one by one.
+
+### Quick Reading of Cold Data
+
+Accessing cold data from object storage will indeed be slow. One solution is to cache cold data in local disks for use in queries. In Apache Doris 2.0, when a query requests cold data, only the first-time access will entail a full network I/O operation from object storage. Subsequent queries will be able to read data directly from local cache.
+
+The granularity of caching matters, too. A coarse granularity might lead to a waste of cache space, but a fine granularity could be the reason for low I/O efficiency. Apache Doris bases its caching on data blocks. It downloads cold data blocks from object storage onto local Block Cache. This is the "pre-heating" process. With cold data fully pre-heated, queries on tables with hot-cold data separation will be basically as fast as those on tablets without. We drew this conclusion from test [...]
+
+
+
+- ***Test Data****: SSB SF100 dataset*
+- ***Configuration****: 3 × 16C 64G, a cluster of 1 frontend and 3 backends*
+
+P.S. Block Cache adopts the LRU algorithm, so the more frequently accessed data will stay in Block Cache for longer.
+
+### High Availability of Data
+
+In object storage, only one copy of cold data is preserved. Within Apache Doris, hot data and metadata are put in the backend nodes, and there are multiple replicas of them across different backend nodes in order to ensure high data availability. These replicas are called "local replicas". The metadata of cold data is synchronized to all local replicas, so that Doris can ensure high availability of cold data without using too much storage space.
+
+Implementation-wise, the Doris frontend picks a local replica as the Leader. Updates to the Leader will be synchronized to all other local replicas via a regular report mechanism. Also, as the Leader uploads data to object storage, the relevant metadata will be updated to other local replicas, too.
+
+
+
+### Reduced I/O and CPU Overhead
+
+This is realized by cold data [compaction](https://medium.com/gitconnected/understanding-data-compaction-in-3-minutes-d2b5a1f7446f). Some scenarios require large-scale update of historical data. In this case, part of the cold data in object storage should be deleted. Apache Doris 2.0 supports cold data compaction, which ensures that the updated cold data will be reorganized and compacted, so that it will take up storage space.
+
+A thread in Doris backend will regularly pick N tablets from the cold data and start compaction. Every tablet has a CooldownReplica and only the CooldownReplica will execute cold data compaction for the tablet. Every time 5MB of data is compacted, it will be uploaded to object storage to clear up space locally. Once the compaction is done, the CooldownReplica will update the new metadata to object storage. Other replicas only need to synchronize the metadata from object storage. This is [...]
+
+## Tutorial
+
+Separating hot and cold data in storage is a huge cost saver and there have been ways to ensure the same fast query performance. Executing hot-cold data separation is a simple 6-step process, so you can find out how it works yourself:
+
+
+
+To begin with, you need **an object storage bucket** and the relevant **Access Key (AK)** and **Secret Access Key (SK)**.
+
+Then you can start cold/hot data separation by following these six steps.
+
+### 1. Create Resource
+
+You can create a resource using the object storage bucket with the AK and SK. Apache Doris supports object storage on various cloud service providers including AWS, Azure, and Alibaba Cloud.
+
+```
+CREATE RESOURCE IF NOT EXISTS "${resource_name}"
+ PROPERTIES(
+ "type"="s3",
+ "s3.endpoint" = "${S3Endpoint}",
+ "s3.region" = "${S3Region}",
+ "s3.root.path" = "path/to/root",
+ "s3.access_key" = "${S3AK}",
+ "s3.secret_key" = "${S3SK}",
+ "s3.connection.maximum" = "50",
+ "s3.connection.request.timeout" = "3000",
+ "s3.connection.timeout" = "1000",
+ "s3.bucket" = "${S3BucketName}"
+ );
+```
+
+### 2. Create Storage Policy
+
+With the Storage Policy, you can specify the cooling-down period of data (including absolute cooling-down period and relative cooling-down period).
+
+```
+CREATE STORAGE POLICY testPolicy
+PROPERTIES(
+ "storage_resource" = "remote_s3",
+ "cooldown_ttl" = "1d"
+);
+```
+
+In the above snippet, the Storage Policy is named `testPolicy`, and data will start to cool down one day after it is ingested. The cold data will be moved under the `root path` of the object storage `remote_s3`. Apart from setting the TTL, you can also specify the timepoint when the cooling down starts.
+
+```
+CREATE STORAGE POLICY testPolicyForTTlDatatime
+PROPERTIES(
+ "storage_resource" = "remote_s3",
+ "cooldown_datetime" = "2023-06-07 21:00:00"
+);
+```
+
+### 3. Specify Storage Policy for a Table/Partition
+
+With an established Resource and a Storage Policy, you can set a Storage Policy for a data table or a specific data partition.
+
+The following snippet uses the lineitem table in the TPC-H dataset as an example. To set a Storage Policy for the whole table, specify the PROPERTIES as follows:
+
+```
+CREATE TABLE IF NOT EXISTS lineitem1 (
+ L_ORDERKEY INTEGER NOT NULL,
+ L_PARTKEY INTEGER NOT NULL,
+ L_SUPPKEY INTEGER NOT NULL,
+ L_LINENUMBER INTEGER NOT NULL,
+ L_QUANTITY DECIMAL(15,2) NOT NULL,
+ L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
+ L_DISCOUNT DECIMAL(15,2) NOT NULL,
+ L_TAX DECIMAL(15,2) NOT NULL,
+ L_RETURNFLAG CHAR(1) NOT NULL,
+ L_LINESTATUS CHAR(1) NOT NULL,
+ L_SHIPDATE DATEV2 NOT NULL,
+ L_COMMITDATE DATEV2 NOT NULL,
+ L_RECEIPTDATE DATEV2 NOT NULL,
+ L_SHIPINSTRUCT CHAR(25) NOT NULL,
+ L_SHIPMODE CHAR(10) NOT NULL,
+ L_COMMENT VARCHAR(44) NOT NULL
+ )
+ DUPLICATE KEY(L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER)
+ PARTITION BY RANGE(`L_SHIPDATE`)
+ (
+ PARTITION `p202301` VALUES LESS THAN ("2017-02-01"),
+ PARTITION `p202302` VALUES LESS THAN ("2017-03-01")
+ )
+ DISTRIBUTED BY HASH(L_ORDERKEY) BUCKETS 3
+ PROPERTIES (
+ "replication_num" = "3",
+ "storage_policy" = "${policy_name}"
+ )
+```
+
+You can check the Storage Policy of a tablet via the `show tablets` command. If the `CooldownReplicaId` is anything rather than `-1` and the `CooldownMetaId` is not null, that means the current tablet has been specified with a Storage Policy.
+
+```
+ TabletId: 3674797
+ ReplicaId: 3674799
+ BackendId: 10162
+ SchemaHash: 513232100
+ Version: 1
+ LstSuccessVersion: 1
+ LstFailedVersion: -1
+ LstFailedTime: NULL
+ LocalDataSize: 0
+ RemoteDataSize: 0
+ RowCount: 0
+ State: NORMAL
+LstConsistencyCheckTime: NULL
+ CheckVersion: -1
+ VersionCount: 1
+ QueryHits: 0
+ PathHash: 8030511811695924097
+ MetaUrl: http://172.16.0.16:6781/api/meta/header/3674797
+ CompactionStatus: http://172.16.0.16:6781/api/compaction/show?tablet_id=3674797
+ CooldownReplicaId: 3674799
+ CooldownMetaId: TUniqueId(hi:-8987737979209762207, lo:-2847426088899160152)
+```
+
+To set a Storage Policy for a specific partition, add the policy name to the partition PROPERTIES as follows:
+
+```
+CREATE TABLE IF NOT EXISTS lineitem1 (
+ L_ORDERKEY INTEGER NOT NULL,
+ L_PARTKEY INTEGER NOT NULL,
+ L_SUPPKEY INTEGER NOT NULL,
+ L_LINENUMBER INTEGER NOT NULL,
+ L_QUANTITY DECIMAL(15,2) NOT NULL,
+ L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
+ L_DISCOUNT DECIMAL(15,2) NOT NULL,
+ L_TAX DECIMAL(15,2) NOT NULL,
+ L_RETURNFLAG CHAR(1) NOT NULL,
+ L_LINESTATUS CHAR(1) NOT NULL,
+ L_SHIPDATE DATEV2 NOT NULL,
+ L_COMMITDATE DATEV2 NOT NULL,
+ L_RECEIPTDATE DATEV2 NOT NULL,
+ L_SHIPINSTRUCT CHAR(25) NOT NULL,
+ L_SHIPMODE CHAR(10) NOT NULL,
+ L_COMMENT VARCHAR(44) NOT NULL
+ )
+ DUPLICATE KEY(L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER)
+ PARTITION BY RANGE(`L_SHIPDATE`)
+ (
+ PARTITION `p202301` VALUES LESS THAN ("2017-02-01") ("storage_policy" = "${policy_name}"),
+ PARTITION `p202302` VALUES LESS THAN ("2017-03-01")
+ )
+ DISTRIBUTED BY HASH(L_ORDERKEY) BUCKETS 3
+ PROPERTIES (
+ "replication_num" = "3"
+ )
+```
+
+**This is how you can confirm that only the target partition is set with a Storage Policy:**
+
+In the above example, Table Lineitem1 has 2 partitions, each partition has 3 buckets, and `replication_num` is set to "3". That means there are 2*3 = 6 tablets and 6*3 = 18 replicas in total.
+
+Now, if you check the replica information of all tablets via the `show tablets` command, you will see that only the replicas of tablets of the target partion have a CooldownReplicaId and a CooldownMetaId. (For a clear comparison, you can check replica information of a specific partition via the `ADMIN SHOW REPLICA STATUS FROM TABLE PARTITION(PARTITION)` command.)
+
+For instance, Tablet 3691990 belongs to Partition p202301, which is the target partition, so the 3 replicas of this tablet have a CooldownReplicaId and a CooldownMetaId:
+
+```
+*****************************************************************
+ TabletId: 3691990
+ ReplicaId: 3691991
+ CooldownReplicaId: 3691993
+ CooldownMetaId: TUniqueId(hi:-7401335798601697108, lo:3253711199097733258)
+*****************************************************************
+ TabletId: 3691990
+ ReplicaId: 3691992
+ CooldownReplicaId: 3691993
+ CooldownMetaId: TUniqueId(hi:-7401335798601697108, lo:3253711199097733258)
+*****************************************************************
+ TabletId: 3691990
+ ReplicaId: 3691993
+ CooldownReplicaId: 3691993
+ CooldownMetaId: TUniqueId(hi:-7401335798601697108, lo:3253711199097733258)
+```
+
+Also, the above snippet means that all these 3 replicas have been specified with the same CooldownReplica: 3691993, so only the data in Replica 3691993 will be stored in the Resource.
+
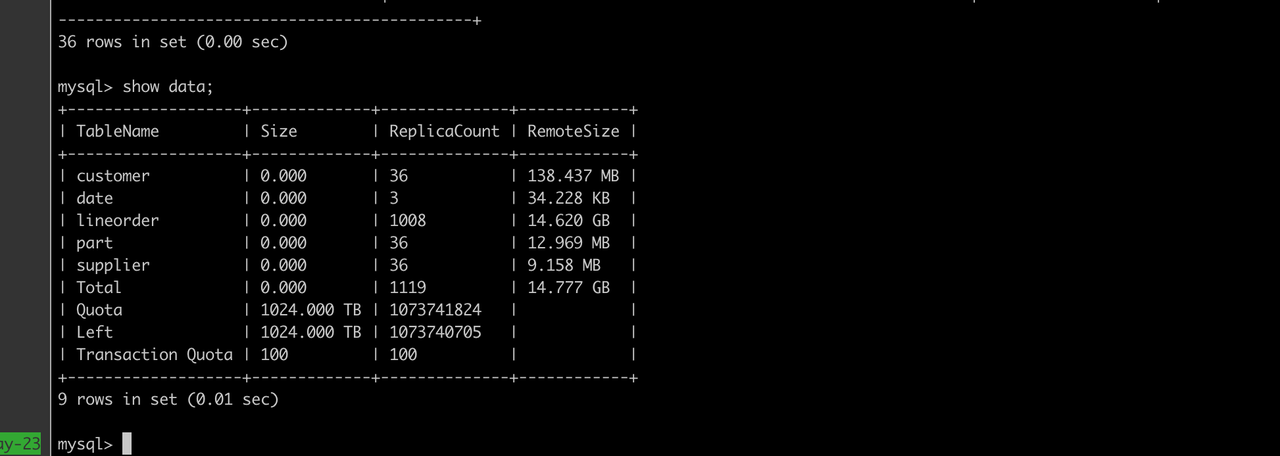
+### 4. View Tablet Details
+
+You can view the detailed information of Table Lineitem1 via a `show tablets from lineitem1` command. Among all the properties, `LocalDataSize` represents the size of locally stored data and `RemoteDataSize` represents the size of cold data in object storage.
+
+For example, when the data is newly ingested into the Doris backends, you can see that all data is stored locally.
+
+```
+*************************** 1. row ***************************
+ TabletId: 2749703
+ ReplicaId: 2749704
+ BackendId: 10090
+ SchemaHash: 1159194262
+ Version: 3
+ LstSuccessVersion: 3
+ LstFailedVersion: -1
+ LstFailedTime: NULL
+ LocalDataSize: 73001235
+ RemoteDataSize: 0
+ RowCount: 1996567
+ State: NORMAL
+LstConsistencyCheckTime: NULL
+ CheckVersion: -1
+ VersionCount: 3
+ QueryHits: 0
+ PathHash: -8567514893400420464
+ MetaUrl: http://172.16.0.8:6781/api/meta/header/2749703
+ CompactionStatus: http://172.16.0.8:6781/api/compaction/show?tablet_id=2749703
+ CooldownReplicaId: 2749704
+ CooldownMetaId:
+```
+
+When the data has cooled down, you will see that the data has been moved to remote object storage.
+
+```
+*************************** 1. row ***************************
+ TabletId: 2749703
+ ReplicaId: 2749704
+ BackendId: 10090
+ SchemaHash: 1159194262
+ Version: 3
+ LstSuccessVersion: 3
+ LstFailedVersion: -1
+ LstFailedTime: NULL
+ LocalDataSize: 0
+ RemoteDataSize: 73001235
+ RowCount: 1996567
+ State: NORMAL
+LstConsistencyCheckTime: NULL
+ CheckVersion: -1
+ VersionCount: 3
+ QueryHits: 0
+ PathHash: -8567514893400420464
+ MetaUrl: http://172.16.0.8:6781/api/meta/header/2749703
+ CompactionStatus: http://172.16.0.8:6781/api/compaction/show?tablet_id=2749703
+ CooldownReplicaId: 2749704
+ CooldownMetaId: TUniqueId(hi:-8697097432131255833, lo:9213158865768502666)
+```
+
+You can also check your cold data from the object storage side by finding the data files under the path specified in the Storage Policy.
+
+Data in object storage only has a single copy.
+
+
+
+### 5. Execute Queries
+
+When all data in Table Lineitem1 has been moved to object storage and a query requests data from Table Lineitem1, Apache Doris will follow the root path specified in the Storage Policy of the relevant data partition, and download the requested data for local computation.
+
+Apache Doris 2.0 has been optimized for cold data queries. Only the first-time access to the cold data will entail a full network I/O operation from object storage. After that, the downloaded data will be put in cache to be available for subsequent queries, so as to improve query speed.
+
+### 6. Update Cold Data
+
+In Apache Doris, each data ingestion leads to the generation of a new Rowset, so the update of historical data will be put in a Rowset that is separated from those of newly loaded data. That’s how it makes sure the updating of cold data does not interfere with the ingestion of hot data. Once the rowsets cool down, they will be moved to S3 and deleted locally, and the updated historical data will go to the partition where it belongs.
+
+If you any questions, come find Apache Doris developers on [Slack](https://t.co/ZxJuNJHXb2). We will be happy to provide targeted support.
+
+
+
+
+
+
+
diff --git a/blog/Memory_Management.md b/blog/Memory_Management.md
new file mode 100644
index 00000000000..b658ea278b6
--- /dev/null
+++ b/blog/Memory_Management.md
@@ -0,0 +1,166 @@
+---
+{
+ 'title': 'Say Goodbye to OOM Crashes',
+ 'summary': "A more robust and flexible memory management solution with optimizations in memory allocation, memory tracking, and memory limit.",
+ 'date': '2023-06-16',
+ 'author': 'Apache Doris',
+ 'tags': ['Tech Sharing'],
+}
+
+
+---
+
+<!--
+Licensed to the Apache Software Foundation (ASF) under one
+or more contributor license agreements. See the NOTICE file
+distributed with this work for additional information
+regarding copyright ownership. The ASF licenses this file
+to you under the Apache License, Version 2.0 (the
+"License"); you may not use this file except in compliance
+with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing,
+software distributed under the License is distributed on an
+"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+KIND, either express or implied. See the License for the
+specific language governing permissions and limitations
+under the License.
+-->
+
+What guarantees system stability in large data query tasks? It is an effective memory allocation and monitoring mechanism. It is how you speed up computation, avoid memory hotspots, promptly respond to insufficient memory, and minimize OOM errors.
+
+
+
+From a database user's perspective, how do they suffer from bad memory management? This is a list of things that used to bother our users:
+
+- OOM errors cause backend processes to crash. To quote one of our community members: Hi, Apache Doris, it's okay to slow things down or fail a few tasks when you are short of memory, but throwing a downtime is just not cool.
+- Backend processes consume too much memory space, but there is no way to find the exact task to blame or limit the memory usage for a single query.
+- It is hard to set a proper memory size for each query, so chances are that a query gets canceled even when there is plenty of memory space.
+- High-concurrency queries are disproportionately slow, and memory hotspots are hard to locate.
+- Intermediate data during HashTable creation cannot be flushed to disks, so join queries between two large tables often fail due to OOM.
+
+Luckily, those dark days are behind us, because we have improved our memory management mechanism from the bottom up. Now get ready, things are going to be intensive.
+
+## Memory Allocation
+
+In Apache Doris, we have a one-and-only interface for memory allocation: **Allocator**. It will make adjustments as it sees appropriate to keep memory usage efficient and under control. Also, MemTrackers are in place to track the allocated or released memory size, and three different data structures are responsible for large memory allocation in operator execution (we will get to them immediately).
+
+
+
+### Data Structures in Memory
+
+As different queries have different memory hotspot patterns in execution, Apache Doris provides three different in-memory data structures: **Arena**, **HashTable**, and **PODArray**. They are all under the reign of the Allocator.
+
+
+
+**1. Arena**
+
+The Arena is a memory pool that maintains a list of chunks, which are to be allocated upon request from the Allocator. The chunks support memory alignment. They exist throughout the lifespan of the Arena, and will be freed up upon destruction (usually when the query is completed). Chunks are mainly used to store the serialized or deserialized data during Shuffle, or the serialized Keys in HashTables.
+
+The initial size of a chunk is 4096 bytes. If the current chunk is smaller than the requested memory, a new chunk will be added to the list. If the current chunk is smaller than 128M, the new chunk will double its size; if it is larger than 128M, the new chunk will, at most, be 128M larger than what is required. The old small chunk will not be allocated for new requests. There is a cursor to mark the dividing line of chunks allocated and those unallocated.
+
+**2. HashTable**
+
+HashTables are applicable for Hash Joins, aggregations, set operations, and window functions. The PartitionedHashTable structure supports no more than 16 sub-HashTables. It also supports the parallel merging of HashTables and each sub-Hash Join can be scaled independently. These can reduce overall memory usage and the latency caused by scaling.
+
+If the current HashTable is smaller than 8M, it will be scaled by a factor of 4;
+
+If it is larger than 8M, it will be scaled by a factor of 2;
+
+If it is smaller than 2G, it will be scaled when it is 50% full;
+
+And if it is larger than 2G, it will be scaled when it is 75% full.
+
+The newly created HashTables will be pre-scaled based on how much data it is going to have. We also provide different types of HashTables for different scenarios. For example, for aggregations, you can apply PHmap.
+
+**3. PODArray**
+
+PODArray, as the name suggests, is a dynamic array of POD. The difference between it and `std::vector` is that PODArray does not initialize elements. It supports memory alignment and some interfaces of `std::vector`. It is scaled by a factor of 2. In destruction, instead of calling the destructor function for each element, it releases memory of the whole PODArray. PODArray is mainly used to save strings in columns and is applicable in many function computation and expression filtering.
+
+### Memory Interface
+
+As the only interface that coordinates Arena, PODArray, and HashTable, the Allocator executes memory mapping (MMAP) allocation for requests larger than 64M. Those smaller than 4K will be directly allocated from the system via malloc/free; and those in between will be accelerated by a general-purpose caching ChunkAllocator, which brings a 10% performance increase according to our benchmarking results. The ChunkAllocator will try and retrieve a chunk of the specified size from the FreeList [...]
+
+We chose Jemalloc over TCMalloc after experience with both of them. We tried TCMalloc in our high-concurrency tests and noticed that Spin Lock in CentralFreeList took up 40% of the total query time. Disabling "aggressive memory decommit" made things better, but that brought much more memory usage, so we had to use an individual thread to regularly recycle cache. Jemalloc, on the other hand, was more performant and stable in high-concurrency queries. After fine-tuning for other scenarios, [...]
+
+### Memory Reuse
+
+Memory reuse is widely executed on the execution layer of Apache Doris. For example, data blocks will be reused throughout the execution of a query. During Shuffle, there will be two blocks at the Sender end and they work alternately, one receiving data and the other in RPC transport. When reading a tablet, Doris will reuse the predicate column, implement cyclic reading, filter, copy filtered data to the upper block, and then clear. When ingesting data into an Aggregate Key table, once t [...]
+
+Memory reuse is executed in data scanning, too. Before the scanning starts, a number of free blocks (depending on the number of scanners and threads) will be allocated to the scanning task. During each scanner scheduling, one of the free blocks will be passed to the storage layer for data reading. After data reading, the block will be put into the producer queue for consumption of the upper operators in subsequent computation. Once an upper operator has copied the computation data from t [...]
+
+## Memory Tracking
+
+ Apache Doris uses MemTrackers to follow up on the allocation and releasing of memory while analyzing memory hotspots. The MemTrackers keep records of each data query, data ingestion, data compaction task, and the memory size of each global object, such as Cache and TabletMeta. It supports both manual counting and MemHook auto-tracking. Users can view the real-time memory usage in Doris backend on a Web page.
+
+### Structure of MemTrackers
+
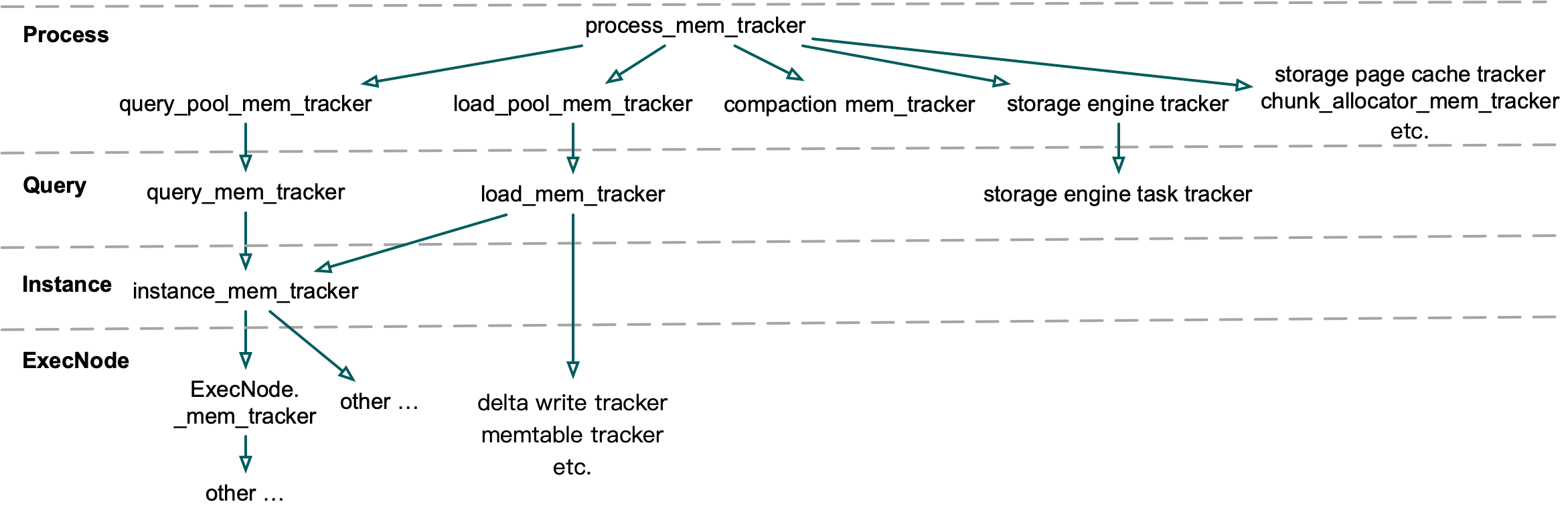
+The MemTracker system before Apache Doris 1.2.0 was in a hierarchical tree structure, consisting of process_mem_tracker, query_pool_mem_tracker, query_mem_tracker, instance_mem_tracker, ExecNode_mem_tracker and so on. MemTrackers of two neighbouring layers are of parent-child relationship. Hence, any calculation mistakes in a child MemTracker will be accumulated all the way up and result in a larger scale of incredibility.
+
+
+
+In Apache Doris 1.2.0 and newer, we made the structure of MemTrackers much simpler. MemTrackers are only divided into two types based on their roles: **MemTracker Limiter** and the others. MemTracker Limiter, monitoring memory usage, is unique in every query/ingestion/compaction task and global object; while the other MemTrackers traces the memory hotspots in query execution, such as HashTables in Join/Aggregation/Sort/Window functions and intermediate data in serialization, to give a pi [...]
+
+The parent-child relationship between MemTracker Limiter and other MemTrackers is only manifested in snapshot printing. You can think of such a relationship as a symbolic link. They are not consumed at the same time, and the lifecycle of one does not affect that of the other. This makes it much easier for developers to understand and use them.
+
+MemTrackers (including MemTracker Limiter and the others) are put into a group of Maps. They allow users to print overall MemTracker type snapshot, Query/Load/Compaction task snapshot, and find out the Query/Load with the most memory usage or the most memory overusage.
+
+
+
+### How MemTracker Works
+
+To calculate memory usage of a certain execution, a MemTracker is added to a stack in Thread Local of the current thread. By reloading the malloc/free/realloc in Jemalloc or TCMalloc, MemHook obtains the actual size of the memory allocated or released, and records it in Thread Local of the current thread. When an execution is done, the relevant MemTracker will be removed from the stack. At the bottom of the stack is the MemTracker that records memory usage during the whole query/load exe [...]
+
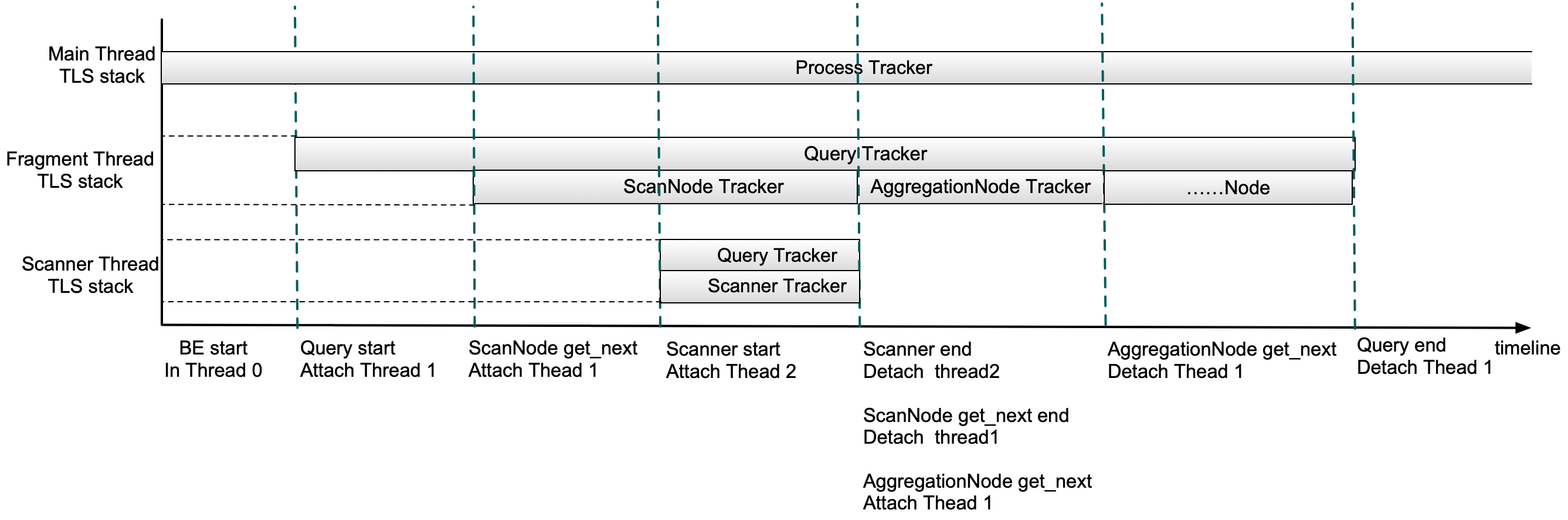
+Now let me explain with a simplified query execution process.
+
+- After a Doris backend node starts, the memory usage of all threads will be recorded in the Process MemTracker.
+- When a query is submitted, a **Query MemTracker** will be added to the Thread Local Storage(TLS) Stack in the fragment execution thread.
+- Once a ScanNode is scheduled, a **ScanNode MemTracker** will be added to Thread Local Storage(TLS) Stack in the fragment execution thread. Then, any memory allocated or released in this thread will be recorded into both the Query MemTracker and the ScanNode MemTracker.
+- After a Scanner is scheduled, a Query MemTracker and a **Scanner MemTracker** will be added to the TLS Stack of the Scanner thread.
+- When the scanning is done, all MemTrackers in the Scanner Thread TLS Stack will be removed. When the ScanNode scheduling is done, the ScanNode MemTracker will be removed from the fragment execution thread. Then, similarly, when an aggregation node is scheduled, an **AggregationNode MemTracker** will be added to the fragment execution thread TLS Stack, and get removed after the scheduling is done.
+- If the query is completed, the Query MemTracker will be removed from the fragment execution thread TLS Stack. At this point, this stack should be empty. Then, from the QueryProfile, you can view the peak memory usage during the whole query execution as well as each phase (scanning, aggregation, etc.).
+
+
+
+### How to Use MemTracker
+
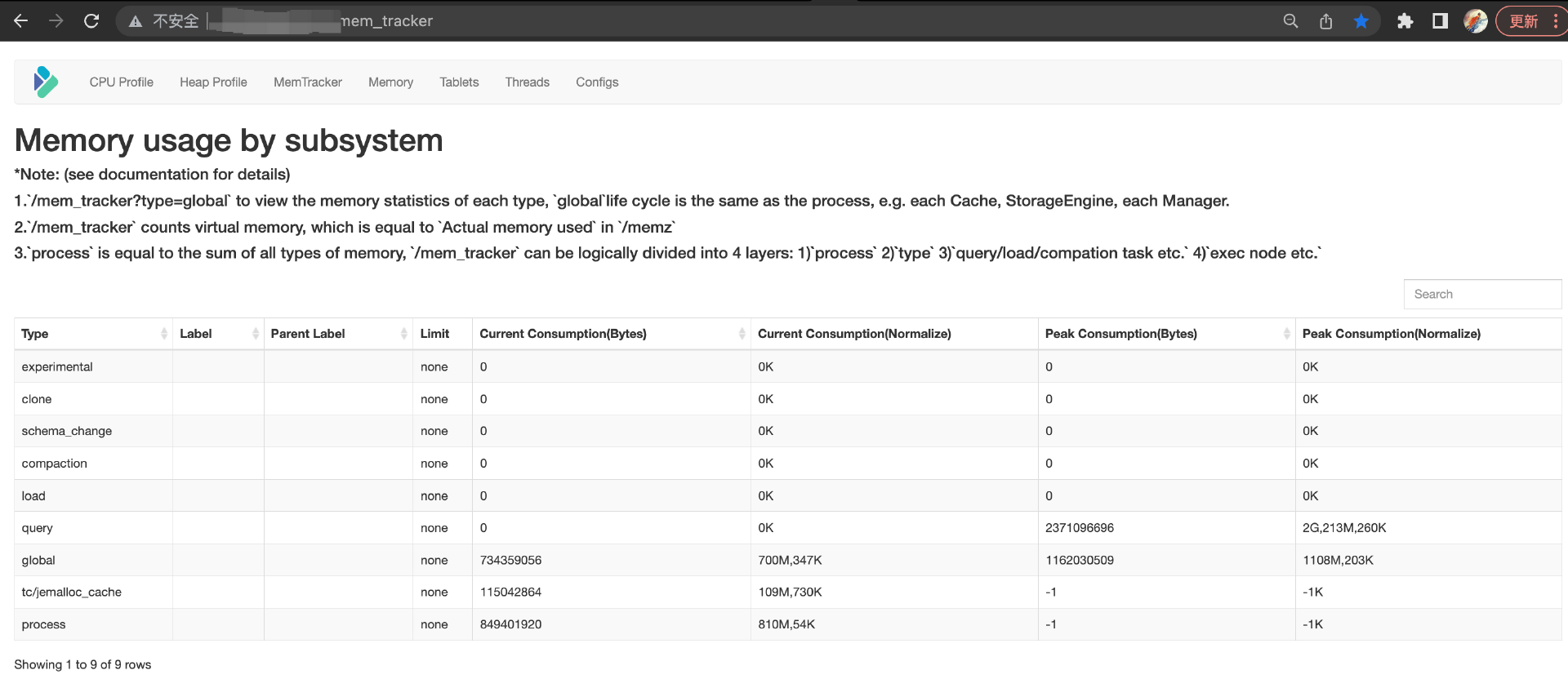
+The Doris backend Web page demonstrates real-time memory usage, which is divided into types: Query/Load/Compaction/Global. Current memory consumption and peak consumption are shown.
+
+
+
+The Global types include MemTrackers of Cache and TabletMeta.
+
+
+
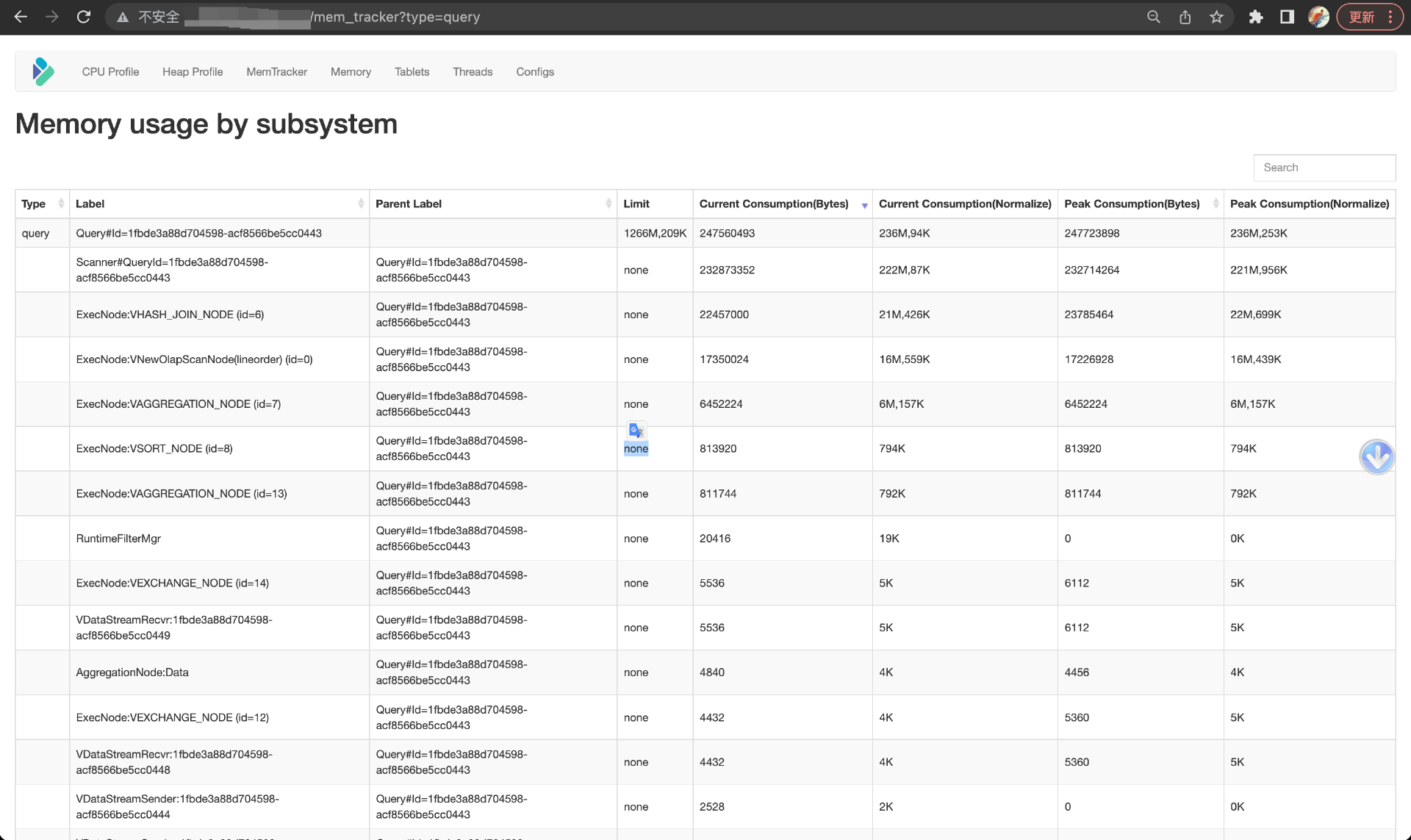
+From the Query types, you can see the current memory consumption and peak consumption of the current query and the operators it involves (you can tell how they are related from the labels). For memory statistics of historical queries, you can check the Doris FE audit logs or BE INFO logs.
+
+
+
+## Memory Limit
+
+With widely implemented memory tracking in Doris backends, we are one step closer to eliminating OOM, the cause of backend downtime and large-scale query failures. The next step is to optimize the memory limit on queries and processes to keep memory usage under control.
+
+### Memory Limit on Query
+
+Users can put a memory limit on every query. If that limit is exceeded during execution, the query will be canceled. But since version 1.2, we have allowed Memory Overcommit, which is a more flexible memory limit control. If there are sufficient memory resources, a query can consume more memory than the limit without being canceled, so users don't have to pay extra attention to memory usage; if there are not, the query will wait until new memory space is allocated; only when the newly fr [...]
+
+While in Apache Doris 2.0, we have realized exception safety for queries. That means any insufficient memory allocation will immediately cause the query to be canceled, which saves the trouble of checking "Cancel" status in subsequent steps.
+
+### Memory Limit on Process
+
+On a regular basis, Doris backend retrieves the physical memory of processes and the currently available memory size from the system. Meanwhile, it collects MemTracker snapshots of all Query/Load/Compaction tasks. If a backend process exceeds its memory limit or there is insufficient memory, Doris will free up some memory space by clearing Cache and cancelling a number of queries or data ingestion tasks. These will be executed by an individual GC thread regularly.
+
+
+
+If the process memory consumed is over the SoftMemLimit (81% of total system memory, by default), or the available system memory drops below the Warning Water Mark (less than 3.2GB), **Minor GC** will be triggered. At this moment, query execution will be paused at the memory allocation step, the cached data in data ingestion tasks will be force flushed, and part of the Data Page Cache and the outdated Segment Cache will be released. If the newly released memory does not cover 10% of the [...]
+
+If the process memory consumed is beyond the MemLimit (90% of total system memory, by default), or the available system memory drops below the Low Water Mark (less than 1.6GB), **Full GC** will be triggered. At this time, data ingestion tasks will be stopped, and all Data Page Cache and most other Cache will be released. If, after all these steps, the newly released memory does not cover 20% of the process memory, Doris will look into all MemTrackers and find the most memory-consuming qu [...]
+
+## Influences and Outcomes
+
+After optimizations in memory allocation, memory tracking, and memory limit, we have substantially increased the stability and high-concurrency performance of Apache Doris as a real-time analytic data warehouse platform. OOM crash in the backend is a rare scene now. Even if there is an OOM, users can locate the problem root based on the logs and then fix it. In addition, with more flexible memory limits on queries and data ingestion, users don't have to spend extra effort taking care of [...]
+
+In the next phase, we plan to ensure completion of queries in memory overcommitment, which means less queries will have to be canceled due to memory shortage. We have broken this objective into specific directions of work: exception safety, memory isolation between resource groups, and the flushing mechanism of intermediate data. If you want to meet our developers, [this is where you find us](https://t.co/XD4uUSROft).
+
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/HCDS.md b/i18n/zh-CN/docusaurus-plugin-content-blog/HCDS.md
new file mode 100644
index 00000000000..89e9297df9e
--- /dev/null
+++ b/i18n/zh-CN/docusaurus-plugin-content-blog/HCDS.md
@@ -0,0 +1,343 @@
+---
+{
+ 'title': 'Apache Doris 冷热分层技术如何实现存储成本降低 70%?',
+ 'summary': "冷热数据分层技术的诞生是为了更好地满足企业降本增效的趋势。顾名思义,冷热分层是将冷热数据分别存储在成本不同的存储介质上,例如热数据存储在成本更高的 SSD 盘上、以提高时效数据的查询速度和响应能力,而冷数据则存储在相对低成本的 HDD 盘甚至更为廉价的对象存储上,以降低存储成本。",
+ 'date': '2023-06-23',
+ 'author': 'Apache Doris',
+ 'tags': ['技术解析'],
+}
+---
+
+<!--
+Licensed to the Apache Software Foundation (ASF) under one
+or more contributor license agreements. See the NOTICE file
+distributed with this work for additional information
+regarding copyright ownership. The ASF licenses this file
+to you under the Apache License, Version 2.0 (the
+"License"); you may not use this file except in compliance
+with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing,
+software distributed under the License is distributed on an
+"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+KIND, either express or implied. See the License for the
+specific language governing permissions and limitations
+under the License.
+-->
+
+在数据分析的实际场景中,冷热数据往往面临着不同的查询频次及响应速度要求。例如在电商订单场景中,用户经常访问近 6 个月的订单,时间较久远的订单访问次数非常少;在行为分析场景中,需支持近期流量数据的高频查询且时效性要求高,但为了保证历史数据随时可查,往往要求数据保存周期更为久远;在日志分析场景中,历史数据的访问频次很低,但需长时间备份以保证后续的审计和回溯的工作...往往历史数据的应用价值会随着时间推移而降低,且需要应对的查询需求也会随之锐减。而随着历史数据的不断增多,如果我们将所有数据存储在本地,将造成大量的资源浪费。
+
+为了解决满足以上问题,冷热数据分层技术应运而生,以更好满足企业降本增效的趋势。顾名思义,**冷热分层是将冷热数据分别存储在成本不同的存储介质上**,例如热数据存储在成本更高的 SSD 盘上、以提高时效数据的查询速度和响应能力,而冷数据则存储在相对低成本的 HDD 盘甚至更为廉价的对象存储上,以降低存储成本。我们还可以根据实际业务需求进行灵活的配置和调整,以满足不同场景的要求。
+
+**冷热分层一般适用于以下需求场景:**
+
+* 数据存储周期长:面对历史数据的不断增加,存储成本也随之增加;
+
+* 冷热数据访问频率及性能要求不同:热数据访问频率高且需要快速响应,而冷数据访问频率低且响应速度要求不高;
+
+* 数据备份和恢复成本高:备份和恢复大量数据需要消耗大量的时间和资源。
+
+* ......
+
+# 更高存储效率的冷热分层技术
+
+自 Apache Doris 0.12 版本引入动态分区功能,开始支持对表分区进行生命周期管理,可以设置热数据转冷时间以及存储介质标识,通过后台任务将热数据从 SSD 自动冷却到 HDD,以帮助用户较大程度地降低存储成本。用户可以在建表属性中配置参数 `storage_cooldown_time` 或者 `dynamic_partition.hot_partition_num` 来控制数据从 SSD 冷却到 HDD,当分区满足冷却条件时,Doris 会自动执行任务。而 HDD 上的数据是以多副本的方式存储的,并没有做到最大程度的成本节约,因此对于冷数据存储成本仍然有较大的优化空间。
+
+为了帮助用户进一步降低存储成本,社区在已有功能上进行了优化,并在 Apache Doris 2.0 版本中推出了**冷热** **数据** **分层的功能**。冷热数据分层功能使 Apache Doris 可以将冷数据下沉到存储成本更加低廉的对象存储中,同时冷数据在对象存储上的保存方式也从多副本变为单副本,存储成本进一步降至原先的三分之一,同时也减少了因存储附加的计算资源成本和网络开销成本。
+
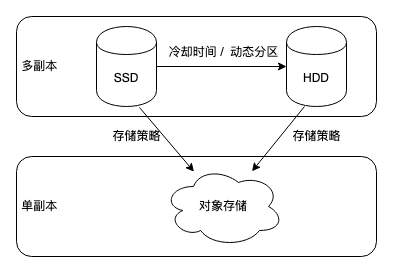
+如下图所示,在 Apache Doris 2.0 版本中支持三级存储,分别是 SSD、HDD 和对象存储。用户可以配置使数据从 SSD 下沉到 HDD,并使用冷热分层功能将数据从 SSD 或者 HDD 下沉到对象存储中。
+
+
+
+以公有云价格为例,云磁盘的价格通常是对象存储的 5-10 倍,如果可以将 80% 的冷数据保存到对象存储中,存储成本至少可降低 70%。
+
+我们使用以下公式计算节约的成本,设冷数据比率为 rate,对象存储价格为 OSS,云磁盘价格为 CloudDisk
+
+$1 - \frac{rate * 100 * OSS + (1 - rate) * 100 * CloudDisk}{100 * CloudDisk}$
+
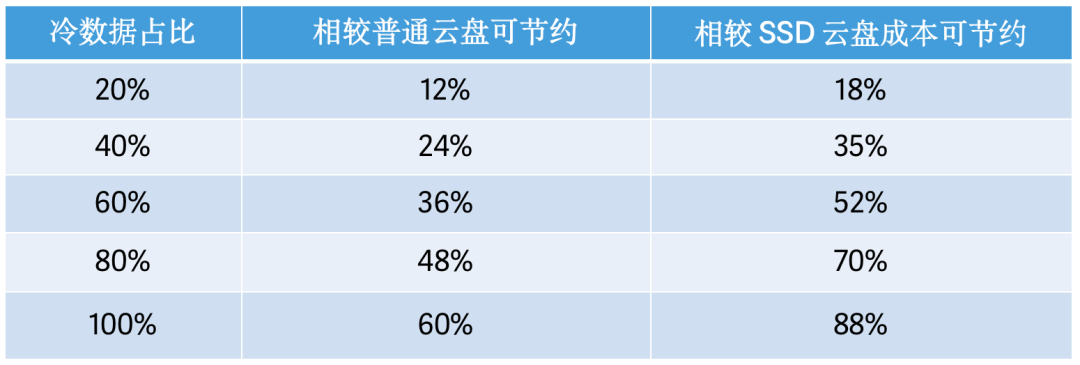
+这里我们假设用户有 100TB 的数据,我们按照不同比例将冷数据迁移到对象存储,来计算一下**如果使用冷热分层之后,相较于全量使用普通云盘、SSD 云盘** **可节约** **多少** **成本**。
+
+* 阿里云 OSS 标准存储成本是 120 元/ T /月
+* 阿里云普通云盘的价格是 300 元/ T /月
+* 阿里云 SSD 云盘的价格是 1000 元/ T /月
+
+
+
+例如在 80% 冷数据占比的情况下,剩余 20% 使用普通云盘每月仅花费 80T*120 + 20T \* 300 = 15600元,而全量使用普通云盘则需要花费 30000 元,通过冷热数据分层节省了 48% 的存储成本。如果用户使用的是 SSD 云盘,那么花费则会从全量使用需花费的 100000 元降低到 80T*120 + 20T \* 1000 = 29600元,存储成本最高降低超过 70%!
+
+# 使用指南
+
+若要使用 Doris 的冷热分层功能,首先需要准备一个对象存储的 Bucket 并获取对应的 AK/SK。当准备就绪之后,下面为具体的使用步骤:
+
+**1. 创建 Resource**
+
+可以使用对象存储的 Bucket 以及 AK/SK 创建 Resource,目前支持 AWS、Azure、阿里云、华为云、腾讯云、百度云等多个云的对象存储。
+
+ CREATE RESOURCE IF NOT EXISTS "${resource_name}"
+ PROPERTIES(
+ "type"="s3",
+ "s3.endpoint" = "${S3Endpoint}",
+ "s3.region" = "${S3Region}",
+ "s3.root.path" = "path/to/root",
+ "s3.access_key" = "${S3AK}",
+ "s3.secret_key" = "${S3SK}",
+ "s3.connection.maximum" = "50",
+ "s3.connection.request.timeout" = "3000",
+ "s3.connection.timeout" = "1000",
+ "s3.bucket" = "${S3BucketName}"
+ );
+
+**2. 创建 Storage Policy**
+
+可以通过 Storage Policy 控制数据冷却时间,目前支持相对和绝对两种冷却时间的设置。
+
+ CREATE STORAGE POLICY testPolicy
+ PROPERTIES(
+ "storage_resource" = "remote_s3",
+ "cooldown_ttl" = "1d"
+ );
+
+例如上方代码中名为 `testPolicy` 的 `storage policy `设置了新导入的数据将在一天后开始冷却,并且冷却后的冷数据会存放到 `remote_s3 `所表示的对象存储的 `root path` 下。除了设置 TTL 以外,在 Policy 中也支持设置冷却的时间点,可以直接设置为:
+
+```sql
+CREATE STORAGE POLICY testPolicyForTTlDatatime
+PROPERTIES(
+ "storage_resource" = "remote_s3",
+ "cooldown_datetime" = "2023-06-07 21:00:00"
+);
+```
+
+**3. 给表或者分区设置 Storage Policy**
+
+在创建出对应的 Resource 和 Storage Policy 之后,我们可以在建表的时候对整张表设置 Cooldown Policy,也可以针对某个 Partition 设置 Cooldown Policy。这里以 TPCH 测试数据集中的 lineitem 表举例。如果需要将整张表都设置冷却的策略,则可以直接在整张表的 properties 中设置:
+
+ CREATE TABLE IF NOT EXISTS lineitem1 (
+ L_ORDERKEY INTEGER NOT NULL,
+ L_PARTKEY INTEGER NOT NULL,
+ L_SUPPKEY INTEGER NOT NULL,
+ L_LINENUMBER INTEGER NOT NULL,
+ L_QUANTITY DECIMAL(15,2) NOT NULL,
+ L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
+ L_DISCOUNT DECIMAL(15,2) NOT NULL,
+ L_TAX DECIMAL(15,2) NOT NULL,
+ L_RETURNFLAG CHAR(1) NOT NULL,
+ L_LINESTATUS CHAR(1) NOT NULL,
+ L_SHIPDATE DATEV2 NOT NULL,
+ L_COMMITDATE DATEV2 NOT NULL,
+ L_RECEIPTDATE DATEV2 NOT NULL,
+ L_SHIPINSTRUCT CHAR(25) NOT NULL,
+ L_SHIPMODE CHAR(10) NOT NULL,
+ L_COMMENT VARCHAR(44) NOT NULL
+ )
+ DUPLICATE KEY(L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER)
+ PARTITION BY RANGE(`L_SHIPDATE`)
+ (
+ PARTITION `p202301` VALUES LESS THAN ("2017-02-01"),
+ PARTITION `p202302` VALUES LESS THAN ("2017-03-01")
+ )
+ DISTRIBUTED BY HASH(L_ORDERKEY) BUCKETS 3
+ PROPERTIES (
+ "replication_num" = "3",
+ "storage_policy" = "${policy_name}"
+ )
+
+用户可以通过 show tablets 获得每个 Tablet 的信息,其中 CooldownReplicaId 不为 -1 并且 CooldownMetaId 不为空的 Tablet 说明使用了 Storage Policy。如下方代码,通过 show tablets 可以看到上面的 Table 的所有 Tablet 都设置了 CooldownReplicaId 和 CooldownMetaId,这说明整张表都是使用了 Storage Policy。
+
+ TabletId: 3674797
+ ReplicaId: 3674799
+ BackendId: 10162
+ SchemaHash: 513232100
+ Version: 1
+ LstSuccessVersion: 1
+ LstFailedVersion: -1
+ LstFailedTime: NULL
+ LocalDataSize: 0
+ RemoteDataSize: 0
+ RowCount: 0
+ State: NORMAL
+ LstConsistencyCheckTime: NULL
+ CheckVersion: -1
+ VersionCount: 1
+ QueryHits: 0
+ PathHash: 8030511811695924097
+ MetaUrl: http://172.16.0.16:6781/api/meta/header/3674797
+ CompactionStatus: http://172.16.0.16:6781/api/compaction/show?tablet_id=3674797
+ CooldownReplicaId: 3674799
+ CooldownMetaId: TUniqueId(hi:-8987737979209762207, lo:-2847426088899160152)
+
+我们也可以对某个具体的 Partition 设置 Storage Policy,只需要在 Partition 的 Properties 中加上具体的 Policy Name 即可:
+
+ CREATE TABLE IF NOT EXISTS lineitem1 (
+ L_ORDERKEY INTEGER NOT NULL,
+ L_PARTKEY INTEGER NOT NULL,
+ L_SUPPKEY INTEGER NOT NULL,
+ L_LINENUMBER INTEGER NOT NULL,
+ L_QUANTITY DECIMAL(15,2) NOT NULL,
+ L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
+ L_DISCOUNT DECIMAL(15,2) NOT NULL,
+ L_TAX DECIMAL(15,2) NOT NULL,
+ L_RETURNFLAG CHAR(1) NOT NULL,
+ L_LINESTATUS CHAR(1) NOT NULL,
+ L_SHIPDATE DATEV2 NOT NULL,
+ L_COMMITDATE DATEV2 NOT NULL,
+ L_RECEIPTDATE DATEV2 NOT NULL,
+ L_SHIPINSTRUCT CHAR(25) NOT NULL,
+ L_SHIPMODE CHAR(10) NOT NULL,
+ L_COMMENT VARCHAR(44) NOT NULL
+ )
+ DUPLICATE KEY(L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER)
+ PARTITION BY RANGE(`L_SHIPDATE`)
+ (
+ PARTITION `p202301` VALUES LESS THAN ("2017-02-01") ("storage_policy" = "${policy_name}"),
+ PARTITION `p202302` VALUES LESS THAN ("2017-03-01")
+ )
+ DISTRIBUTED BY HASH(L_ORDERKEY) BUCKETS 3
+ PROPERTIES (
+ "replication_num" = "3"
+ )
+
+这张 Lineitem1 设置了两个分区,每个分区 3 个 Bucket,另外副本数设置为 3,可以计算出一共有 2*3 = 6 个 Tablet,那么副本数一共是 6*3 = 18 个 Replica,通过 `show tablets` 命令可以查看到所有的 Tablet 以及 Replica 的信息,可以看到只有部分 Tablet 的 Replica 是设置了CooldownReplicaId 和 CooldownMetaId 。用户可以通过 A`DMIN SHOW REPLICA STATUS FROM TABLE PARTITION(PARTITION)`` `查看 Partition 下的 Tablet 以及Replica,通过对比可以发现其中只有属于 p202301 这个 Partition 的 Tablet 的 Replica 设置了CooldownReplicaId 和 CooldownMetaId,而属于 p202302 这个 Partition 下的数据没有设置,所以依旧会全部存放到本地磁盘。 以上表的 Tablet 3691990 为例,该 Tab [...]
+
+ *****************************************************************
+ TabletId: 3691990
+ ReplicaId: 3691991
+ CooldownReplicaId: 3691993
+ CooldownMetaId: TUniqueId(hi:-7401335798601697108, lo:3253711199097733258)
+ *****************************************************************
+ TabletId: 3691990
+ ReplicaId: 3691992
+ CooldownReplicaId: 3691993
+ CooldownMetaId: TUniqueId(hi:-7401335798601697108, lo:3253711199097733258)
+ *****************************************************************
+ TabletId: 3691990
+ ReplicaId: 3691993
+ CooldownReplicaId: 3691993
+ CooldownMetaId: TUniqueId(hi:-7401335798601697108, lo:3253711199097733258)
+
+可以观察到 3691990 的 3 个副本都选择了 3691993 副本作为 CooldownReplica,在用户指定的 Resource 上也只会保存这个副本的数据。
+
+**4. 查看数据信息**
+
+我们可以按照上述 3 中的 Linetem1 来演示如何查看是使用冷热数据分层策略的 Table 的数据信息,一般可以通过 `show tablets from lineitem1 `直接查看这张表的 Tablet 信息。Tablet 信息中区分了 LocalDataSize 和 RemoteDataSize,前者表示存储在本地的数据,后者表示已经冷却并移动到对象存储上的数据。具体信息可见下方代码:
+
+下方为数据刚导入到 BE 时的数据信息,可以看到数据还全部存储在本地。
+
+ *************************** 1. row ***************************
+ TabletId: 2749703
+ ReplicaId: 2749704
+ BackendId: 10090
+ SchemaHash: 1159194262
+ Version: 3
+ LstSuccessVersion: 3
+ LstFailedVersion: -1
+ LstFailedTime: NULL
+ LocalDataSize: 73001235
+ RemoteDataSize: 0
+ RowCount: 1996567
+ State: NORMAL
+ LstConsistencyCheckTime: NULL
+ CheckVersion: -1
+ VersionCount: 3
+ QueryHits: 0
+ PathHash: -8567514893400420464
+ MetaUrl: http://172.16.0.8:6781/api/meta/header/2749703
+ CompactionStatus: http://172.16.0.8:6781/api/compaction/show?tablet_id=2749703
+ CooldownReplicaId: 2749704
+ CooldownMetaId:
+
+当数据到达冷却时间后,再次进行 `show tablets from table` 可以看到对应的数据变化。
+
+ *************************** 1. row ***************************
+ TabletId: 2749703
+ ReplicaId: 2749704
+ BackendId: 10090
+ SchemaHash: 1159194262
+ Version: 3
+ LstSuccessVersion: 3
+ LstFailedVersion: -1
+ LstFailedTime: NULL
+ LocalDataSize: 0
+ RemoteDataSize: 73001235
+ RowCount: 1996567
+ State: NORMAL
+ LstConsistencyCheckTime: NULL
+ CheckVersion: -1
+ VersionCount: 3
+ QueryHits: 0
+ PathHash: -8567514893400420464
+ MetaUrl: http://172.16.0.8:6781/api/meta/header/2749703
+ CompactionStatus: http://172.16.0.8:6781/api/compaction/show?tablet_id=2749703
+ CooldownReplicaId: 2749704
+ CooldownMetaId: TUniqueId(hi:-8697097432131255833, lo:9213158865768502666)
+
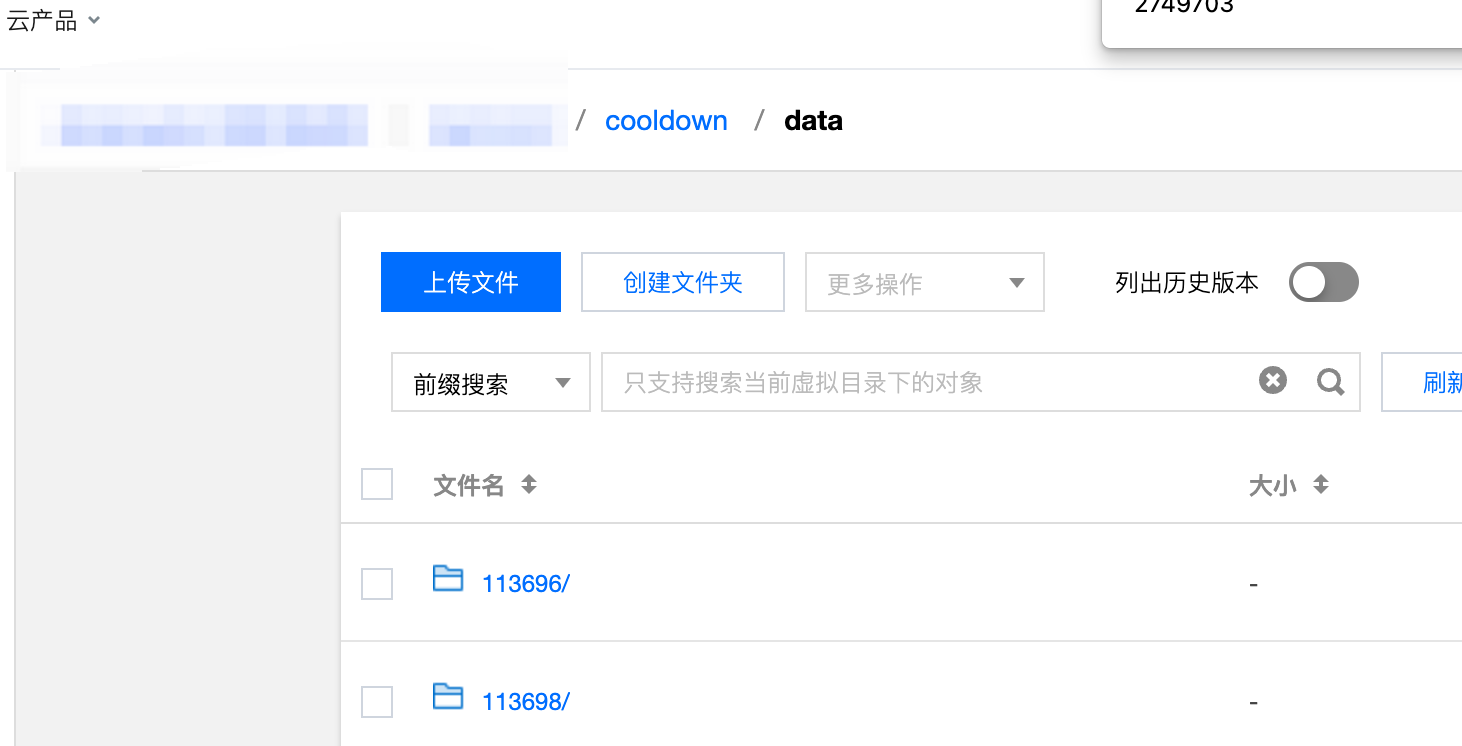
+除了通过上述命令查看数据信息之外,我们也可以在对象存储上查看冷数据的信息。以腾讯云为例,可以在 Policy 指定的 Bucket 的 Path 下可以查看冷却过后的数据的信息:
+
+
+
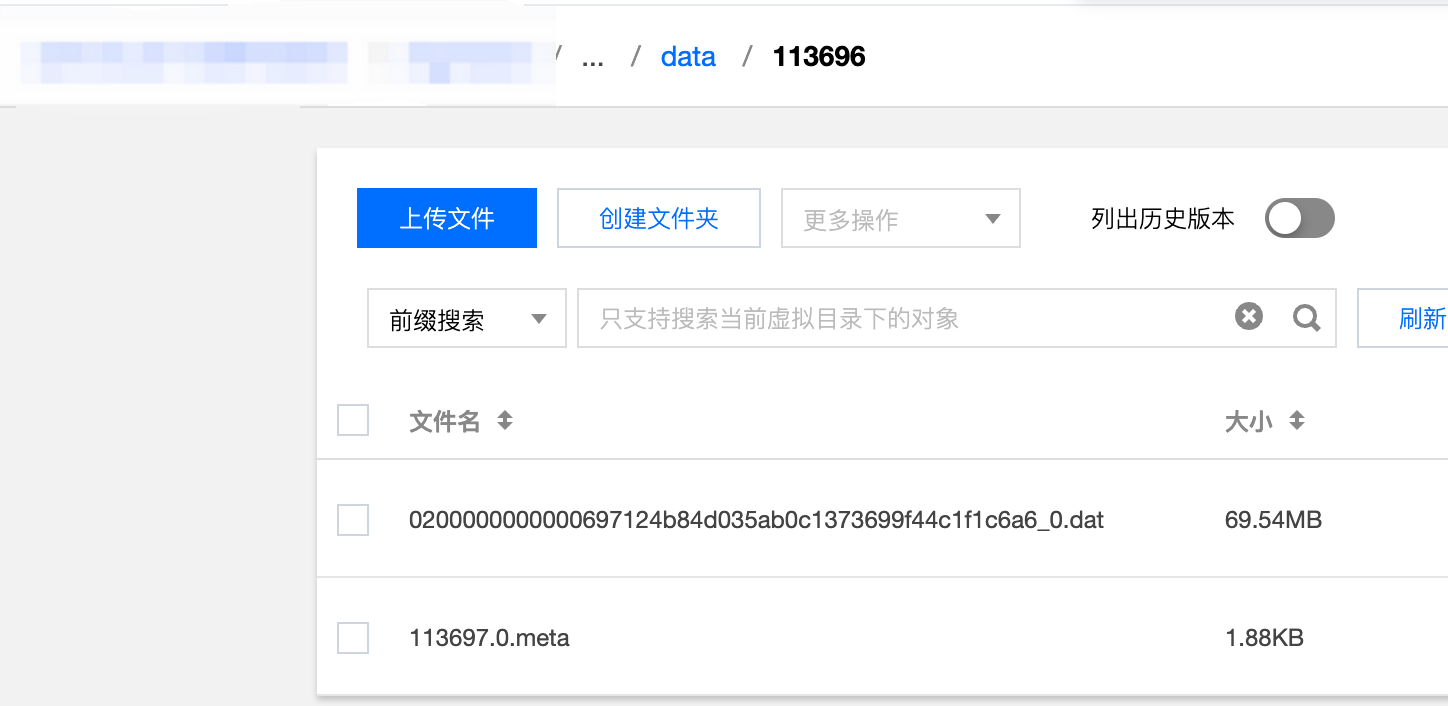
+进入对应文件后可以看到数据和元数据文件
+
+
+
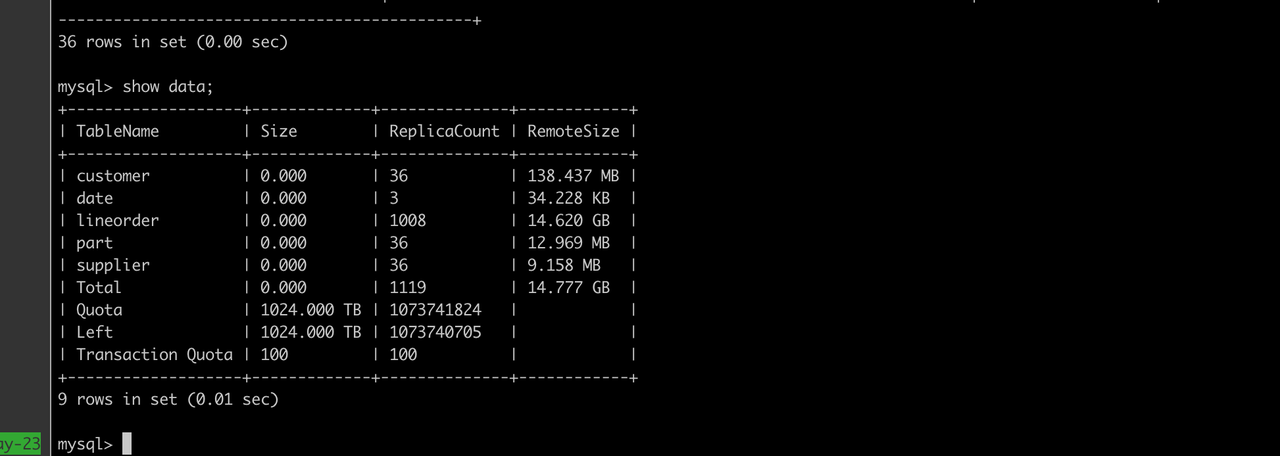
+我们可以看到在对象存储上数据是单副本。
+
+
+
+**5. 查询**
+
+假设 Table Lineitem1 中的所有数据都已经冷却并且上传到对象存储中,如果用户在 Lineitem1 上进行对应的查询,Doris 会根据对应 Partition 使用的 Policy 信息找到对应的 Bucket 的 Root Path,并根据不同 Tablet 下的 Rowset 信息下载查询所需的数据到本地进行运算。
+
+Doris 2.0 在查询上进行了优化,冷数据第一次查询会进行完整的 S3 网络 IO,并将 Remote Rowset 的数据下载到本地后,存放到对应的 Cache 之中,后续的查询将自动命中 Cache,以此来保证查询效率。(性能对比可见后文评测部分)。
+
+**6. 冷却后继续导入数据**
+
+在某些场景下,用户需要对历史数据进行数据的修正或补充数据,而新数据会按照分区列信息导入到对应的 Partition中。在 Doris 中,每次数据导入都会产生一个新的 Rowset,以保证冷数据的 Rowset 在不会影响新导入数据的 Rowset 的前提下,满足冷热数据同时存储的需求。Doris 2.0 的冷热分层粒度是基于 Rowset 的,当到达冷却时间时会将当前满足条件的 Rowset 全部上传到 S3 上并删除本地数据,之后新导入的数据生成的新 Rowset 会在到达冷却时间后也上传到 S3。
+
+# 查询性能测试
+
+为了测试使用冷热分层功能之后,查询对象存储中的数据是否占用会较大网络 I/O,从而影响查询性能,因此我们以 SSB SF100 标准集为例,对冷热分层表和非冷热分层表进行了查询耗时的对比测试。
+
+配置:均在 3 台 16C 64G 的机器上部署 1FE、3BE 的集群
+
+暂时无法在飞书文档外展示此内容
+
+如上图所示,在充分预热之后(数据已经缓存在 Cache 中),冷热分层表共耗时 5.799s,非冷热分层表共耗时 5.822s,由此可知,使用冷热分层查询表和非冷热分层表的查询性能几乎相同。这表明,使用 Doris 2.0 提供的冷热分层功能,不会对查询性能造成的影响。
+
+# 冷热分层技术的具体实现
+
+## **存储方式的优化**
+
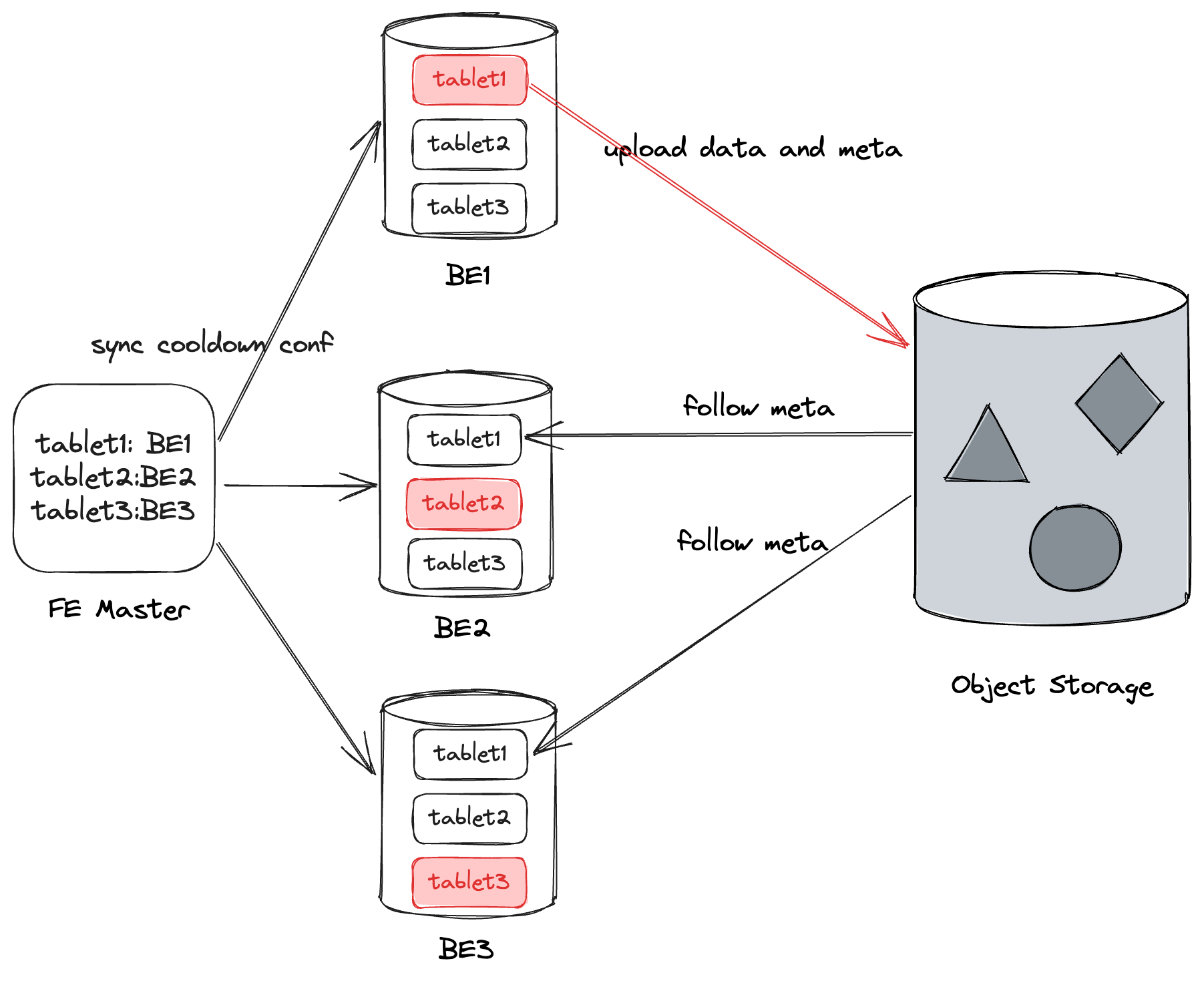
+在 Doris 之前的版本中,数据从 SSD 冷却到 HDD 后,为了保证数据的高可用和可靠性,通常会将一个 Tablet 存储多份副本在不同 BE 上,为了进一步降低成本,我们在 Apache Doris 2.0 版本引入了对象存储,推出了冷热分层功能。由于对象存储本身具有高可靠高可用性,冷数据在对象存储上只需要一份即可,元数据以及热数据仍然保存在 BE,我们称之为本地副本,本地副本同步冷数据的元数据,这样就可以实现多个本地副本共用一份冷却数据的目的,有效避免冷数据占用过多的存储空间,从而降低数据存储成本。
+
+具体而言,Doris 的 FE 会从 Tablet 的所有可用本地副本中选择一个本地副本作为上传数据的 Leader,并通过 Doris 的周期汇报机制同步 Leader 的信息给其它本地副本。在 Leader 上传冷却数据时,也会将冷却数据的元数据上传到对象存储,以便其他副本同步元数据。因此,任何本地副本都可以提供查询所需的数据,同时也保证了数据的高可用性和可靠性。
+
+
+
+## **冷数据 Compaction**
+
+在一些场景下会有大量修补数据的需求,在大量补数据的场景下往往需要删除历史数据,删除可以通过 `delete where`实现,Doris 在 Compaction 时会对符合删除条件的数据做物理删除。基于这些场景,冷热分层也必须实现对冷数据进行 Compaction,因此在 Doris 2.0 版本中我们支持了对冷却到对象存储的冷数据进行 Compaction(ColdDataCompaction)的能力,用户可以通过冷数据 Compaction,将分散的冷数据重新组织并压缩成更紧凑的格式,从而减少存储空间的占用,提高存储效率。
+
+Doris 对于本地副本是各自进行 Compaction,在后续版本中会优化为单副本进行 Compaction。由于冷数据只有一份,因此天然的单副本做 Compaction 是最优秀方案,同时也会简化处理数据冲突的操作。BE 后台线程会定期从冷却的 Tablet 按照一定规则选出 N 个 Tablet 发起 ColdDataCompaction。与数据冷却流程类似,只有 CooldownReplica 能执行该 Tablet 的 ColdDataCompaction。Compaction下刷数据时每积累一定大小(默认5MB)的数据,就会上传一个 Part 到对象,而不会占用大量本地存储空间。Compaction 完成后,CooldownReplica 将冷却数据的元数据更新到对象存储,其他 Replica 只需从对象存储同步元数据,从而大量减少对象存储的 IO 和节点自身的 CPU 开销。
+
+## **冷数据 Cache**
+
+冷数据 Cache 在数据查询中具有重要的作用。冷数据通常是数据量较大、使用频率较低的数据,如果每次查询都需要从对象中读取,会导致查询效率低下。通过冷数据 Cache 技术,可以将冷数据缓存在本地磁盘中,提高数据读取速度,从而提高查询效率。而 Cache 的粒度大小直接影响 Cache 的效率,比较大的粒度会导致 Cache 空间以及带宽的浪费,过小粒度的 Cache 会导致对象存储 IO 效率低下,Apache Doris 采用了以 Block 为粒度的 Cache 实现。
+
+如前文所述,Apache Doris 的冷热分层会将冷数据上传到对象存储上,上传成功后本地的数据将会被删除。因此,后续涉及到冷数据的查询均需要对对象存储发起 IO 。为了优化性能,Apache Doris 实现了基于了 Block 粒度的 Cache 功能,当远程数据被访问时会先将数据按照 Block 的粒度下载到本地的 Block Cache 中存储,且 Block Cache 中的数据访问性能和非冷热分层表的数据性能一致(可见后文查询性能测试)。
+
+具体来讲,前文提到 Doris 的冷热分层是在 Rowset 级别进行的,当某个 Rowset 在冷却后其所有的数据都会上传到对象存储上。而 Doris 在进行查询的时候会读取涉及到的 Tablet 的 Rowset 进行数据聚合和运算,当读取到冷却的 Rowset 时,会把查询需要的冷数据下载到本地 Block Cache 之中。基于性能考量,Doris 的 Cache 按照 Block 对数据进行划分。Block Cache 本身采用的是简单的 LRU 策略,可以保证越是使用程度较高数据越能在 Block Cache 中存放的久。
+
+# 结束语
+
+Apache Doris 2.0 版本实现了基于对象存储的冷热数据分层,该功能可以帮助我们有效降低存储成本、提高存储效率,并提高数据查询和处理效率。未来,Apache Doris 将会基于冷热数据分层以及弹性计算节点,为用户提供更好的资源弹性、更低的使用成本以及更灵活的负载隔离服务。
+
+在前段时间推出的 [Apache Doris 2.0 Alpha 版本](https://github.com/apache/doris/releases/tag/2.0.0-alpha1)中,已经实现了[单节点数万 QPS 的高并发点查询能力](http://mp.weixin.qq.com/s?__biz=Mzg3Njc2NDAwOA==\&mid=2247516978\&idx=1\&sn=eb3f1f74eedd2306ca0180b8076fe773\&chksm=cf2f8d35f85804238fd680c18b7ab2bc4c53d62adfa271cb31811bd6139404cc8d2222b9d561\&scene=21#wechat_redirect)、[高性能的倒排索引](http://mp.weixin.qq.com/s?__biz=Mzg3Njc2NDAwOA==\&mid=2247519079\&idx=1\&sn=a232a72695ff93eea0ffe79635936dcb\&chksm=cf2f8560f8580c768bbde [...]
+
+为了让用户可以体验社区开发的最新特性,同时保证最新功能可以收获到更广范围的使用反馈,我们建立了 2.0 版本的专项支持群,[请大家填写申请](https://wenjuan.feishu.cn/m?t=sF2FZOL1KXKi-m73g),欢迎广大社区用户在使用最新版本过程中多多反馈使用意见,帮助 Apache Doris 持续改进。
+
+# **作者介绍:**
+
+杨勇强,SelectDB 联合创始人、技术副总裁
+
+岳靖、程宇轩,SelectDB 存储层研发工程师
\ No newline at end of file
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/Memory_Management.md b/i18n/zh-CN/docusaurus-plugin-content-blog/Memory_Management.md
new file mode 100644
index 00000000000..fc250d7f0c4
--- /dev/null
+++ b/i18n/zh-CN/docusaurus-plugin-content-blog/Memory_Management.md
@@ -0,0 +1,184 @@
+---
+{
+ 'title': '一文揭秘高效稳定的 Apache Doris 内存管理机制',
+ 'summary': "在面临内存资源消耗巨大的复杂计算和大规模作业时,有效的内存分配、统计、管控对于系统的稳定性起着十分关键的作用——更快的内存分配速度将有效提升查询性能,通过对内存的分配、跟踪与限制可以保证不存在内存热点,及时准确地响应内存不足并尽可能规避 OOM 和查询失败,这一系列机制都将显著提高系统稳定性;更精确的内存统计,也是大查询落盘的基础。",
+ 'date': '2023-06-16',
+ 'author': 'Apache Doris',
+ 'tags': ['技术解析'],
+}
+---
+
+<!--
+Licensed to the Apache Software Foundation (ASF) under one
+or more contributor license agreements. See the NOTICE file
+distributed with this work for additional information
+regarding copyright ownership. The ASF licenses this file
+to you under the Apache License, Version 2.0 (the
+"License"); you may not use this file except in compliance
+with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing,
+software distributed under the License is distributed on an
+"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+KIND, either express or implied. See the License for the
+specific language governing permissions and limitations
+under the License.
+-->
+
+
+
+作者:SelectDB 高级研发工程师、Apache Doris Committer 邹新一
+
+# 背景
+
+[Apache Doris](https://github.com/apache/doris) 作为基于 MPP 架构的 OLAP 数据库,数据从磁盘加载到内存后,会在算子间流式传递并计算,在内存中存储计算的中间结果,这种方式减少了频繁的磁盘 I/O 操作,充分利用多机多核的并行计算能力,可在性能上呈现巨大优势。
+
+在面临内存资源消耗巨大的复杂计算和大规模作业时,**有效的内存分配** **、统计、** **管控对于系统的稳定性起着十分关键的作用**——更快的内存分配速度将有效提升查询性能,通过对内存的分配、跟踪与限制可以保证不存在内存热点,及时准确地响应内存不足并尽可能规避 OOM 和查询失败,这一系列机制都将显著提高系统稳定性;更精确的内存统计,也是大查询落盘的基础。
+
+
+
+# 问题和思考
+
+- 在内存充足时内存管理通常对用户是无感的,但真实场景中往往面临着各式各样的极端 Case ,这些都将为内存性能和稳定性带来挑战,在过去版本中,用户在使用 Apache Doris 时在内存管理方面遭遇了以下挑战:
+- - OOM 导致 BE 进程崩溃。内存不足时,用户可以接受执行性能稍慢一些,或是让后到的任务排队,或是让少量任务失败,总之希望有效限制进程的内存使用而不是宕机;
+ - BE 进程占用内存较高。用户反馈 BE 进程占用了较多内存,但很难找到对应内存消耗大的查询或导入任务,也无法有效限制单个查询的内存使用;
+ - 用户很难合理的设置每个query的内存大小,所以经常出现内存还很充足,但是query 被cancel了;
+ - 高并发性能下降严重,也无法快速定位到内存热点;
+ - 构建 HashTable 的中间数据不支持落盘,两个大表的 Join 由于内存超限无法完成。
+
+针对开发者而言又存在另外一些问题,比如内存数据结构功能重叠且使用混乱,MemTracker 的结构难以理解且手动统计易出错等。
+
+针对以上问题,我们经历了过去多个版本的迭代与优化。从 Apache Doris 1.1.0 版本开始,我们逐渐统一内存数据结构、重构 MemTracker、开始支持查询内存软限,并引入进程内存超限后的 GC 机制,同时优化了高并发的查询性能等。在 Apache Doris 1.2.4 版本中,Apache Doris 内存管理机制已趋于完善,在 Benchmark、压力测试和真实用户业务场景的反馈中,基本消除了内存热点以及 OOM 导致 BE 宕机的问题,同时可定位内存 Top 的查询、支持查询内存灵活限制。**而在最新的 Doris 2.0 alpha 版本中,我们实现了查询的异常安全,并将逐步配合 Pipeline 执行引擎和中间数据落盘** **,** **让用户不再受内存不足困扰。**
+
+在此我们将系统介绍 Apache Doris 在内存管理部分的实现与优化。
+
+# 内存管理优化与实现
+
+
+
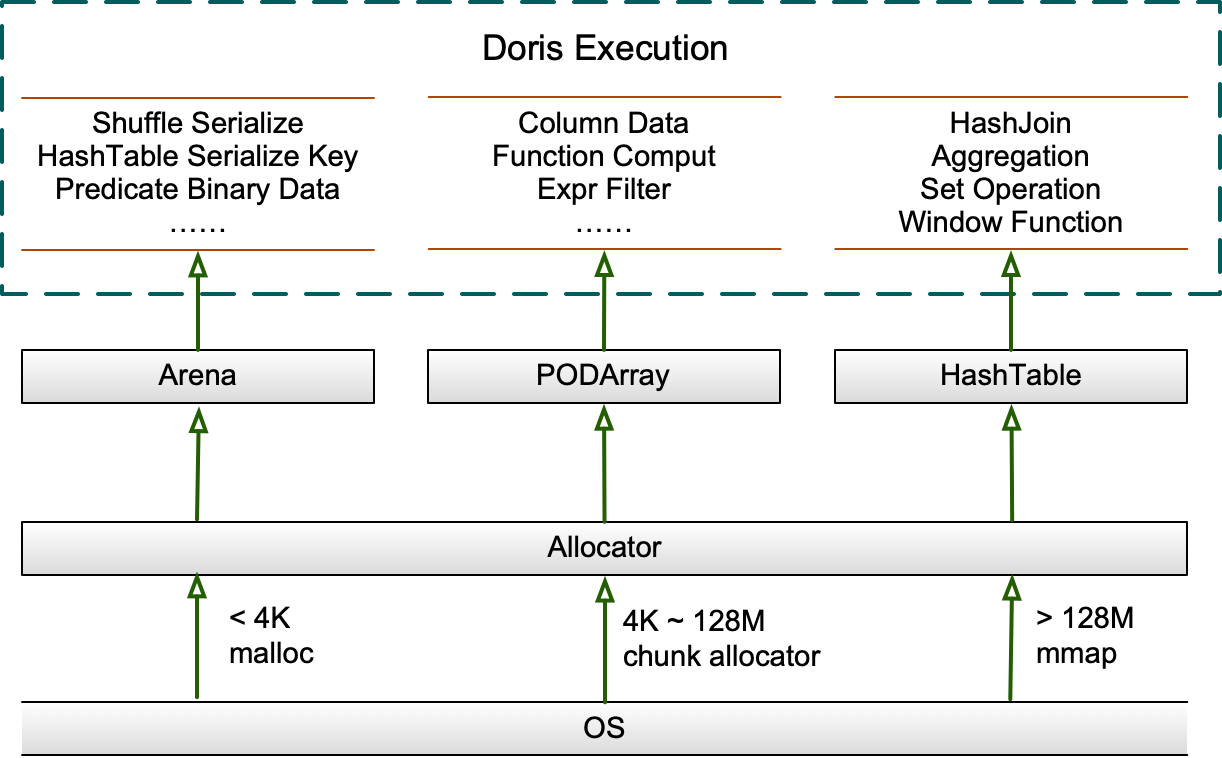
+Allocator 作为系统中大块内存申请的统一的入口从系统申请内存,并在申请过程中使用 MemTracker 跟踪内存申请和释放的大小,执行算子所需批量申请的大内存将交由不同的数据结构管理,并在合适的时机干预限制内存分配的过程,确保内存申请的高效可控。
+
+## 内存分配
+
+早期 Apache Doris 内存分配的核心理念是尽可能接管系统内存自己管理,使用通用的全局缓存满足大内存申请的性能要求,并在 LRU Cache 中缓存 Data Page、Index Page、RowSet Segment、Segment Index 等数据。
+
+随着 Doris 使用 Jemalloc 替换 TCMalloc,Jemalloc 的并发性能已足够优秀,所以不在 Doris 内部继续全面接管系统内存,转而针对内存热点位置的特点,使用多种内存数据结构并接入统一的系统内存接口,实现内存统一管理和局部的内存复用。
+
+
+
+### 内存数据结构
+
+查询执行过程中大块内存的分配主要使用 Arena、HashTable、PODArray 这三个数据结构管理。
+
+1. **Arena**
+
+Arena 是一个内存池,维护一个内存块列表,并从中分配内存以响应 alloc 请求,从而减少从系统申请内存的次数以提升性能,内存块被称为 Chunk,在内存池的整个生命周期内存在,在析构时统一释放,这通常和查询生命周期相同,并支持内存对齐,主要用于保存 Shuffle 过程中序列化/反序列化数据、HashTable 中序列化 Key 等。
+
+Chunk 初始 4096 字节,内部使用游标记录分配过的内存位置,如果当前 Chunk 剩余大小无法满足当前内存申请,则申请一个新的 Chunk 添加到列表中,为减少从系统申请内存的次数,在当前 Chunk 小于 128M 时,每次新申请的 Chunk 大小加倍,在当前 Chunk 大于 128M 时,新申请的 Chunk 大小在满足本次内存申请的前提下至多额外分配 128M ,避免浪费过多内存,默认之前的 Chunk 不会再参与后续 alloc。
+
+2. **HashTable**
+
+Doris 中的 HashTable 主要在 Hash Join、聚合、集合运算、窗口函数中应用,主要使用的 PartitionedHashTable 最多包含 16 个子 HashTable,支持两个 HashTable 的并行化合并,每个子 Hash Join 独立扩容,预期可减少总内存的使用,扩容期间的延迟也将被分摊。
+
+在 HashTable 小于 8M 时将以 4 的倍数扩容,在 HashTable 大于 8M 时将以 2 的倍数扩容,在 HashTable 小于 2G 时扩容因子为 50%,即在 HashTable 被填充到 50% 时触发扩容,在 HashTable 大于 2G 后扩容因子被调整为 75%,为了避免浪费过多内存,在构建 HashTable 前通常会依据数据量预扩容。此外 Doris 为不同场景设计了不同的 HashTable,比如聚合场景使用 PHmap 优化并发性能。
+
+3. **PODArray**
+
+PODArray 是一个 POD 类型的动态数组,与 std::vector 的区别在于不会初始化元素,支持部分 std::vector 的接口,同样支持内存对齐并以 2 的倍数扩容,PODArray 析构时不会调用每个元素的析构函数,而是直接释放掉整块内存,主要用于保存 String 等 Column 中的数据,此外在函数计算和表达式过滤中也被大量使用。
+
+### 统一的内存接口
+
+Allocator 作为 Arena、PODArray、HashTable 的统一内存接口,对大于 64M 的内存使用 MMAP 申请,并通过预取加速性能,对小于 4K 的内存直接 malloc/free 从系统申请,对大于 4K 小于 64M 的内存,使用一个通用的缓存 ChunkAllocator 加速,在 Benchmark 测试中这可带来 10% 的性能提升,ChunkAllocator 会优先从当前 Core 的 FreeList 中无锁的获取一个指定大小的 Chunk,若不存在则有锁的从其他 Core 的 FreeList 中获取,若仍不存在则从系统申请指定内存大小封装为 Chunk 后返回。
+
+Allocator 使用通用内存分配器申请内存,在 Jemalloc 和 TCMalloc 的选择上,Doris 之前在高并发测试时 TCMalloc 中 CentralFreeList 的 Spin Lock 能占到查询总耗时的 40%,虽然关闭aggressive memory decommit能有效提升性能,但这会浪费非常多的内存,为此不得不单独用一个线程定期回收 TCMalloc 的缓存。Jemalloc 在高并发下性能优于 TCMalloc 且成熟稳定,在 Doris 1.2.2 版本中我们切换为 Jemalloc,调优后在大多数场景下性能和 TCMalloc 持平,并使用更少的内存,高并发场景的性能也有明显提升。
+
+### 内存复用
+
+Doris 在执行层做了大量内存复用,可见的内存热点基本都被屏蔽。比如对数据块 Block 的复用贯穿 Query 执行的始终;比如 Shuffle 的 Sender 端始终保持一个 Block 接收数据,一个 Block 在 RPC 传输中,两个 Block 交替使用;还有存储层在读一个 Tablet 时复用谓词列循环读数、过滤、拷贝到上层 Block、Clear;导入 Aggregate Key 表时缓存数据的 MemTable 到达一定大小预聚合收缩后继续写入,等等。
+
+此外 Doris 会在数据 Scan 开始前依据 Scanner 个数和线程数预分配一批 Free Block,每次调度 Scanner 时会从中获取一个 Block 并传递到存储层读取数据,读取完成后会将 Block 放到生产者队列中,供上层算子消费并进行后续计算,上层算子将数据拷走后会将 Block 重新放回 Free Block 中,用于下次 Scanner 调度,从而实现内存复用,数据 Scan 完成后 Free Block 会在之前预分配的线程统一释放,避免内存申请和释放不在同一个线程而导致的额外开销,Free Block 的个数一定程度上还控制着数据 Scan 的并发。
+
+## 内存跟踪
+
+Doris 使用 MemTracker 跟踪内存的申请和释放来实时分析进程和查询的内存热点位置,MemTracker 记录着每一个查询、导入、Compaction 等任务以及Cache、TabletMeta等全局对象的内存大小,支持手动统计或 MemHook 自动跟踪,支持在 Web 页面查看实时的 Doris BE 内存统计。
+
+### MemTracker 结构
+
+过去 Doris MemTracker 是具有层次关系的树状结构,自上而下包含 process、query pool、query、fragment instance、exec node、exprs/hash table/etc.等多层,上一层 MemTracker是下一层的 Parent,开发者使用时需理清它们之间的父子关系,然后手动计算内存申请和释放的大小并消费 MemTracker,此时会同时消费这个 MemTracker 的所有 Parent。这依赖开发者时刻关注内存使用,后续迭代过程中若 MemTracker 统计错误将产生连锁反应,对 Child MemTracker 的统计误差会不断累积到他的 Parent MemTracker 中,导致整体结果不可信。
+
+
+
+在 Doris 1.2.0 中引入了新的 MemTracker 结构,去掉了 Fragment、Instance 等不必要的层级,根据使用方式分为两类,第一类 Memtracker Limiter,在每个查询、导入、Compaction 等任务和全局 Cache、TabletMeta 唯一,用于观测和控制内存使用;第二类 MemTracker,主要用于跟踪查询执行过程中的内存热点,如 Join/Aggregation/Sort/窗口函数中的 HashTable、序列化的中间数据等,来分析查询中不同算子的内存使用情况,以及用于导入数据下刷的内存控制。后文没单独指明的地方,统称二者为 MemTracker。
+
+二者之间的父子关系只用于快照的打印,使用Lable名称关联,相当于一层软链接,不再依赖父子关系同时消费,生命周期互不影响,减少开发者理解和使用的成本。所有 MemTracker 存放在一组 Map 中,并提供打印所有 MemTracker Type 的快照、打印 Query/Load/Compaction 等 Task 的快照、获取当前使用内存最多的一组 Query/Load、获取当前过量使用内存最多的一组 Query/Load 等方法。
+
+
+
+### MemTracker 统计方式
+
+为统计某一段执行过程的内存,将一个 MemTracker 添加到当前线程 Thread Local 的一个栈中,使用 MemHook 重载 Jemalloc 或 TCMalloc 的 malloc/free/realloc 等方法,获取本次申请或释放内存的实际大小并记录在当前线程的 Thread Local 中,在当前线程内存使用量累计到一定值时消费栈中的所有 MemTracker,这段执行过程结束时会将这个 MemTracker 从栈中弹出,栈底通常是整个查询或导入唯一的 Memtracker,记录整个查询执行过程的内存。
+
+下面以一个简化的查询执行过程为例:
+
+- Doris BE 启动后所有线程的内存将默认记录在 Process MemTracker 中。
+- Query 提交后,将 Query MemTracker 添加到 Fragment 执行线程的 Thread Local Storage(TLS) Stack 中。
+- ScanNode 被调度后,将 ScanNode MemTracker 继续添加到 Fragment 执行线程的 TLS Stack 中,此时线程申请和释放的内存会同时记录到 Query MemTracker 和 ScanNode MemTracker。
+- Scanner 被调度后,将 Query MemTracker 和 Scanner MemTracker 同时添加到 Scanner 线程的 TLS Stack 中。
+- Scanner 结束后,将 Scanner 线程 TLS Stack 中的 MemTracker 全部移除,随后 ScanNode 调度结束,将ScanNode MemTracker 从 Fragment 执行线程中移除。随后 AggregationNode 被调度时同样将 MemTracker 添加到 Fragment 执行线程中,并在调度结束后将自己的 MemTracker 从 Fragment 执行线程移除。
+- 后续 Query 结束后,将 Query MemTracker 从 Fragment 执行线程 TLS Stack 中移除,此时 Stack 应为空,在 QueryProfile 中即可看到 Query 整体、ScanNode、AggregationNode 等执行期间内存的峰值。
+
+
+
+可见为跟踪一个查询的内存使用,在查询所有线程启动时将 Query MemTracker 绑定到线程 Thread Local,在算子执行的代码区间内,将算子 MemTracker 同样绑定到线程 Thread Local,此后这些线程所有的内存申请和释放都将记录在这个查询中,在算子调度结束和查询结束时分别解除绑定,从而统计一个查询生命周期内各个算子和查询整体的内存使用。
+
+期待开发者能将 Doris 执行过程中长时间持有的内存尽可能多地统计到 MemTracker 中,这有助于内存问题的分析,不必担心统计误差,这不会影响查询整体统计的准确性,也不必担心影响性能,在 ThreadLocal 中按批消费 MemTracker 对性能的影响微乎其微。
+
+### MemTracker 使用
+
+通过 Doris BE 的 Web 页面可以看到实时的内存统计结果,将 Doris BE 内存分为了 Query/Load/Compaction/Global 等几部分,并分别展示它们当前使用的内存和历史的峰值内存,具体使用方法和字段含义可参考 Doris 管理手册:
+
+
+
+Global 类型的 MemTracker 中,包括全局的 Cache、TabletMeta 等。
+
+
+
+Query 类型的 MemTracker 中,可以看到 Query 和其算子当前使用的内存和峰值内存,通过 Label 将他们关联,历史查询的内存统计可以查看 FE 审计日志或 BE INFO 日志。
+
+
+
+## 内存限制
+
+内存不足导致 OOM 引起 BE 宕机或查询大量失败一直是用户的痛点,为此在 Doris BE 大多数内存被跟踪后,开始着手改进查询和进程的内存限制,在关键内存分配时检测内存限制来保证内存可控。
+
+### 查询内存限制
+
+每个查询都可以指定内存上限,查询运行过程中内存超过上限会触发 Cancel。从 Doris 1.2 开始查询支持内存超发(overcommit),旨在允许查询设置更灵活的内存限制,内存充足时即使查询内存超过上限也不会被 Cancel,所以通常用户无需关注查询内存使用。内存不足时,任何查询都会在尝试分配新内存时等待一段时间,如果等待过程中内存释放的大小满足需求,查询将继续执行, 否则将抛出异常并终止查询。
+
+Doris 2.0 初步实现了查询的异常安全,这使得任何位置在发现内存不足时随时可抛出异常并终止查询,而无需依赖后续执行过程中异步的检查 Cancel 状态,这将使查询终止的速度更快。
+
+### 进程内存限制
+
+Doris BE 会定时从系统获取进程的物理内存和系统当前剩余可用内存,并收集所有查询、导入、Compaction 任务 MemTracker 的快照,当 BE 进程内存超限或系统剩余可用内存不足时,Doris 将释放 Cache 和终止部分查询或导入来释放内存,这个过程由一个单独的 GC 线程定时执行。
+
+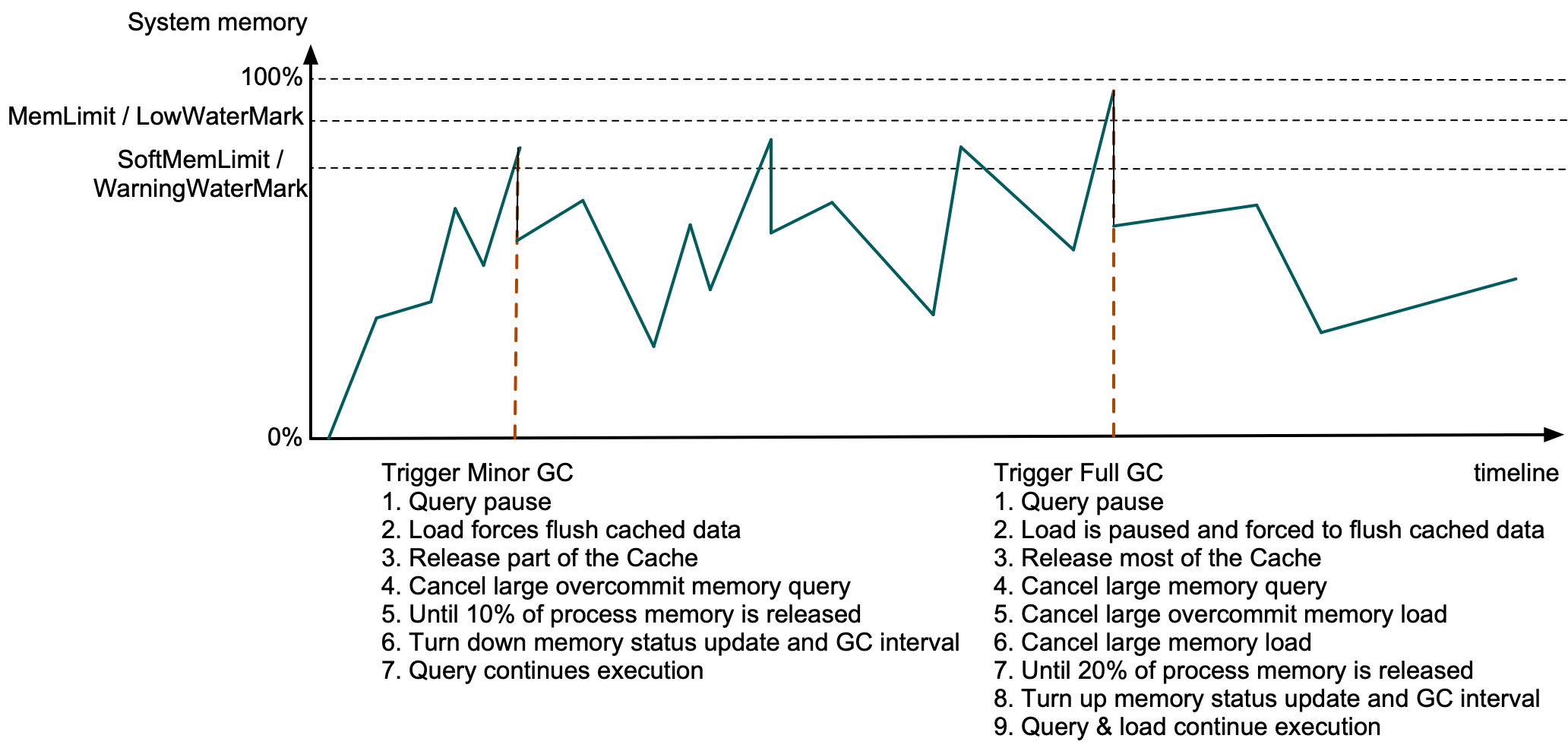
+
+若 Doris BE 进程内存超过 SoftMemLimit(默认系统总内存的 81%)或系统剩余可用内存低于 Warning 水位线(通常不大于 3.2GB)时触发 Minor GC,此时查询会在 Allocator 分配内存时暂停,同时导入强制下刷缓存中的数据,并释放部分 Data Page Cache 以及过期的 Segment Cache 等,若释放的内存不足进程内存的 10%,若启用了查询内存超发,则从内存超发比例大的查询开始 Cancel,直到释放 10% 的进程内存或没有查询可被 Cancel,然后调低系统内存状态获取间隔和 GC 间隔,其他查询在发现剩余内存后将继续执行。
+
+若 BE 进程内存超过 MemLimit(默认系统总内存的 90%)或系统剩余可用内存低于 Low 水位线(通常不大于1.6GB)时触发 Full GC,此时除上述操作外,导入在强制下刷缓存数据时也将暂停,并释放全部 Data Page Cache 和大部分其他 Cache,如果释放的内存不足 20%,将开始按一定策略在所有查询和导入的 MemTracker 列表中查找,依次 Cancel 内存占用大的查询、内存超发比例大的导入、内存占用大的导入,直到释放 20% 的进程内存后,调高系统内存状态获取间隔和 GC 间隔,其他查询和导入也将继续执行,GC 的耗时通常在几百 us 到几十 ms 之间。
+
+# 总结规划
+
+通过上述一系列的优化,高并发性能和稳定性有明显改善,OOM 导致 BE 宕机的次数也明显降低,即使发生 OOM 通常也可依据日志定位内存位置,并针对性调优,从而让集群恢复稳定,对查询和导入的内存限制也更加灵活,在内存充足时让用户无需感知内存使用。
+
+为了让用户可以体验社区开发的最新特性,同时保证最新功能可以收获到更广范围的使用反馈,我们建立了 [2.0 Alpha 版本的专项支持群](https://wenjuan.feishu.cn/m?t=sF2FZOL1KXKi-m73g),欢迎广大社区用户在使用最新版本过程中多多反馈使用意见,帮助 Apache Doris 持续改进。
+
+后续我们将让 Apache Doris 从“能有效限制内存”转为“内存超限时能完成计算”,尽可能减少查询因内存不足被 Cancel,主要工作将聚焦在异常安全、资源组内存隔离、中间数据落盘上:
+
+1. 查询和导入支持异常安全,从而可以随时随地的抛出内存分配失败的 Exception,外部捕获后触发异常处理或释放内存,而不是在内存超限后单纯依赖异步 Cancel。
+1. Pipeline 调度中将支持资源组内存隔离,用户可以划分资源组并指定优先级,从而更灵活的管理不同类型任务使用的内存,资源组内部和资源组之间同样支持内存的“硬限”和“软限”,并在内存不足时支持排队机制。
+1. Doris 将实现统一的落盘机制,支持 Sort,Hash Join,Agg 等算子的落盘,在内存紧张时将中间数据临时写入磁盘并释放内存,从而在有限的内存空间下,对数据分批处理,支持超大数据量的计算,在避免 Cancel 让查询能跑出来的前提下尽可能保证性能。
+
+以上方向的工作都已处于规划或开发中,如果有小伙伴对以上方向感兴趣,也欢迎参与到社区中的开发来。期待有更多人参与到 Apache Doris 社区的建设中 ,欢迎你的加入!
diff --git a/static/images/HCDS_1.png b/static/images/HCDS_1.png
new file mode 100644
index 00000000000..539384a38af
Binary files /dev/null and b/static/images/HCDS_1.png differ
diff --git a/static/images/HCDS_2.png b/static/images/HCDS_2.png
new file mode 100644
index 00000000000..5f974862bff
Binary files /dev/null and b/static/images/HCDS_2.png differ
diff --git a/static/images/HCDS_3.png b/static/images/HCDS_3.png
new file mode 100644
index 00000000000..2d710b22567
Binary files /dev/null and b/static/images/HCDS_3.png differ
diff --git a/static/images/HCDS_4.png b/static/images/HCDS_4.png
new file mode 100644
index 00000000000..f54649a91d3
Binary files /dev/null and b/static/images/HCDS_4.png differ
diff --git a/static/images/HCDS_5.png b/static/images/HCDS_5.png
new file mode 100644
index 00000000000..93f6f47e505
Binary files /dev/null and b/static/images/HCDS_5.png differ
diff --git a/static/images/OOM_1.png b/static/images/OOM_1.png
new file mode 100644
index 00000000000..4aa207bd191
Binary files /dev/null and b/static/images/OOM_1.png differ
diff --git a/static/images/OOM_10.png b/static/images/OOM_10.png
new file mode 100644
index 00000000000..533c4e940f9
Binary files /dev/null and b/static/images/OOM_10.png differ
diff --git a/static/images/OOM_2.png b/static/images/OOM_2.png
new file mode 100644
index 00000000000..f68ccc05ffb
Binary files /dev/null and b/static/images/OOM_2.png differ
diff --git a/static/images/OOM_3.png b/static/images/OOM_3.png
new file mode 100644
index 00000000000..64438b54bbe
Binary files /dev/null and b/static/images/OOM_3.png differ
diff --git a/static/images/OOM_4.png b/static/images/OOM_4.png
new file mode 100644
index 00000000000..84f5602e0da
Binary files /dev/null and b/static/images/OOM_4.png differ
diff --git a/static/images/OOM_5.png b/static/images/OOM_5.png
new file mode 100644
index 00000000000..0abf61e9801
Binary files /dev/null and b/static/images/OOM_5.png differ
diff --git a/static/images/OOM_6.png b/static/images/OOM_6.png
new file mode 100644
index 00000000000..45dfc493534
Binary files /dev/null and b/static/images/OOM_6.png differ
diff --git a/static/images/OOM_7.png b/static/images/OOM_7.png
new file mode 100644
index 00000000000..761de2f0e3f
Binary files /dev/null and b/static/images/OOM_7.png differ
diff --git a/static/images/OOM_8.png b/static/images/OOM_8.png
new file mode 100644
index 00000000000..a2a23df512c
Binary files /dev/null and b/static/images/OOM_8.png differ
diff --git a/static/images/OOM_9.png b/static/images/OOM_9.png
new file mode 100644
index 00000000000..50bd80f4c22
Binary files /dev/null and b/static/images/OOM_9.png differ
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org