You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2021/03/11 16:50:48 UTC
[GitHub] [iceberg] ayush-san opened a new issue #2327: Error while evolving partition column of a table
ayush-san opened a new issue #2327:
URL: https://github.com/apache/iceberg/issues/2327
env:
spar version: 3.0.1
hive version: 3.1.2
hadoop version: 3.2.1-amzn-2
I was trying to do a small POC of the iceberg table partition evolution. Here the following set of commands I ran in spark-sql
```
spark-sql --packages org.apache.iceberg:iceberg-spark3-runtime:0.11.0 \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog \
--conf spark.sql.catalog.spark_catalog.type=hive \
--conf spark.sql.catalog.hive=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.hive.type=hive \
--conf spark.sql.catalog.hive.uri="thrift://localhost:9083"
```
```
CREATE TABLE hive.db.tb (
id bigint COMMENT 'id doc',
ts timestamp COMMENT 'ts doc')
USING iceberg
PARTITIONED BY (years(ts))
TBLPROPERTIES ('engine.hive.enabled'='true', 'write.format.default'='orc');
INSERT INTO db.tb SELECT 1, to_timestamp("2020-07-06 13:40:00");
INSERT INTO db.tb SELECT 2, to_timestamp("2020-07-06 14:30:00");
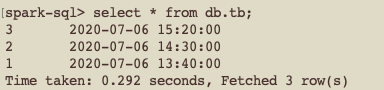
INSERT INTO db.tb SELECT 3, to_timestamp("2020-07-06 15:20:00");
select * from db.tb;
```
```
desc hive.db.tb;
```

Till now everything is working fine, here I decided to drop a partition and create a new partition on days(ts) instead of years(ts). After doing this I ran the `desc` statement again and got the following error.
```
ALTER TABLE hive.db.tb DROP PARTITION FIELD years(ts);
ALTER TABLE hive.db.tb ADD PARTITION FIELD days(ts);
desc hive.db.tb;
21/03/11 16:28:23 ERROR SparkSQLDriver: Failed in [desc hive.db.tb]
java.lang.UnsupportedOperationException: Void transform is not supported
at org.apache.iceberg.transforms.PartitionSpecVisitor.alwaysNull(PartitionSpecVisitor.java:86)
at org.apache.iceberg.transforms.PartitionSpecVisitor.visit(PartitionSpecVisitor.java:148)
at org.apache.iceberg.transforms.PartitionSpecVisitor.visit(PartitionSpecVisitor.java:120)
at org.apache.iceberg.transforms.PartitionSpecVisitor.visit(PartitionSpecVisitor.java:102)
at org.apache.iceberg.spark.Spark3Util.toTransforms(Spark3Util.java:236)
at org.apache.iceberg.spark.source.SparkTable.partitioning(SparkTable.java:127)
at org.apache.spark.sql.execution.datasources.v2.DescribeTableExec.addPartitioning(DescribeTableExec.scala:78)
at org.apache.spark.sql.execution.datasources.v2.DescribeTableExec.run(DescribeTableExec.scala:41)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result$lzycompute(V2CommandExec.scala:39)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result(V2CommandExec.scala:39)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.executeCollect(V2CommandExec.scala:45)
at org.apache.spark.sql.Dataset.$anonfun$logicalPlan$1(Dataset.scala:230)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3667)
at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:104)
at org.apache.spark.sql.execution.SQLExecution$.withTracker(SQLExecution.scala:227)
at org.apache.spark.sql.execution.SQLExecution$.executeQuery$1(SQLExecution.scala:107)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:132)
at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:104)
at org.apache.spark.sql.execution.SQLExecution$.withTracker(SQLExecution.scala:227)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:132)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:248)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:131)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:764)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:68)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3665)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:230)
at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:101)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:764)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:98)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:607)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:764)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:602)
at org.apache.spark.sql.SQLContext.sql(SQLContext.scala:650)
at org.apache.spark.sql.hive.thriftserver.SparkSQLDriver.run(SparkSQLDriver.scala:63)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.processCmd(SparkSQLCLIDriver.scala:377)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.$anonfun$processLine$1(SparkSQLCLIDriver.scala:496)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.processLine(SparkSQLCLIDriver.scala:490)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:282)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:936)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1015)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1024)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
java.lang.UnsupportedOperationException: Void transform is not supported
at org.apache.iceberg.transforms.PartitionSpecVisitor.alwaysNull(PartitionSpecVisitor.java:86)
at org.apache.iceberg.transforms.PartitionSpecVisitor.visit(PartitionSpecVisitor.java:148)
at org.apache.iceberg.transforms.PartitionSpecVisitor.visit(PartitionSpecVisitor.java:120)
at org.apache.iceberg.transforms.PartitionSpecVisitor.visit(PartitionSpecVisitor.java:102)
at org.apache.iceberg.spark.Spark3Util.toTransforms(Spark3Util.java:236)
at org.apache.iceberg.spark.source.SparkTable.partitioning(SparkTable.java:127)
at org.apache.spark.sql.execution.datasources.v2.DescribeTableExec.addPartitioning(DescribeTableExec.scala:78)
at org.apache.spark.sql.execution.datasources.v2.DescribeTableExec.run(DescribeTableExec.scala:41)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result$lzycompute(V2CommandExec.scala:39)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result(V2CommandExec.scala:39)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.executeCollect(V2CommandExec.scala:45)
at org.apache.spark.sql.Dataset.$anonfun$logicalPlan$1(Dataset.scala:230)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3667)
at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:104)
at org.apache.spark.sql.execution.SQLExecution$.withTracker(SQLExecution.scala:227)
at org.apache.spark.sql.execution.SQLExecution$.executeQuery$1(SQLExecution.scala:107)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:132)
at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:104)
at org.apache.spark.sql.execution.SQLExecution$.withTracker(SQLExecution.scala:227)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:132)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:248)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:131)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:764)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:68)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3665)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:230)
at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:101)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:764)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:98)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:607)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:764)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:602)
at org.apache.spark.sql.SQLContext.sql(SQLContext.scala:650)
at org.apache.spark.sql.hive.thriftserver.SparkSQLDriver.run(SparkSQLDriver.scala:63)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.processCmd(SparkSQLCLIDriver.scala:377)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.$anonfun$processLine$1(SparkSQLCLIDriver.scala:496)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.processLine(SparkSQLCLIDriver.scala:490)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:282)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:936)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1015)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1024)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
```
I also tried running insert SQL statement on the table but got the same above error
`INSERT INTO db.tb SELECT 4, to_timestamp("2020-07-06 16:10:00");`
Also, I have got the exception `java.lang.IllegalStateException: Unknown type for long field. Type name: java.lang.Integer` on the following SQL statements
```
select * from hive.db.tb.files;
select * from hive.db.tb.manifests;
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chinaboyll commented on issue #2327: Error while evolving partition column of a table
Posted by GitBox <gi...@apache.org>.
chinaboyll commented on issue #2327:
URL: https://github.com/apache/iceberg/issues/2327#issuecomment-799207665
I have the same problem。
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] nvitucci commented on issue #2327: Error while evolving partition column of a table
Posted by GitBox <gi...@apache.org>.
nvitucci commented on issue #2327:
URL: https://github.com/apache/iceberg/issues/2327#issuecomment-827965017
Same for me, although I applied an `ADD` first and a `DROP` on the same field afterwards.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org