You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by "ldwnt (via GitHub)" <gi...@apache.org> on 2023/02/28 07:07:16 UTC
[GitHub] [iceberg] ldwnt opened a new issue, #6956: data file rewriting spark job fails with oom
ldwnt opened a new issue, #6956:
URL: https://github.com/apache/iceberg/issues/6956
### Apache Iceberg version
0.13.0
### Query engine
Spark
### Please describe the bug 🐞
The iceberg table being rewritten has ~ 9 million rows and 2GB. The rewriting spark job runs with parameters: target-file-size-bytes=128M, spark.driver.memory=20g, spark.executor.memory=3g, num-executors 10, deploy-mode cluster, master=yarn.
Some executors report failed tasks with the logs as below:
```
23/02/28 05:02:33 WARN [executor-heartbeater] Executor: Issue communicating with driver in heartbeater
org.apache.spark.rpc.RpcTimeoutException: Futures timed out after [10000 milliseconds]. This timeout is controlled by spark.executor.heartbeatInterval
at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:47)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:62)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:58)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:38)
at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:76)
at org.apache.spark.rpc.RpcEndpointRef.askSync(RpcEndpointRef.scala:103)
at org.apache.spark.executor.Executor.reportHeartBeat(Executor.scala:1005)
at org.apache.spark.executor.Executor.$anonfun$heartbeater$1(Executor.scala:212)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:2019)
at org.apache.spark.Heartbeater$$anon$1.run(Heartbeater.scala:46)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.util.concurrent.TimeoutException: Futures timed out after [10000 milliseconds]
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:259)
at scala.concurrent.impl.Promise$DefaultPromise.result(Promise.scala:263)
at org.apache.spark.util.ThreadUtils$.awaitResult(ThreadUtils.scala:293)
at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:75)
... 13 more
```
Finally some executors end with oom and the spark job failed. The heap dump suggests that a huge StructLikeSet is being created from DeleteFilter
```
StructLikeSet deleteSet = Deletes.toEqualitySet(
CloseableIterable.transform(
records, record -> new InternalRecordWrapper(deleteSchema.asStruct()).wrap(record)),
deleteSchema.asStruct());
```
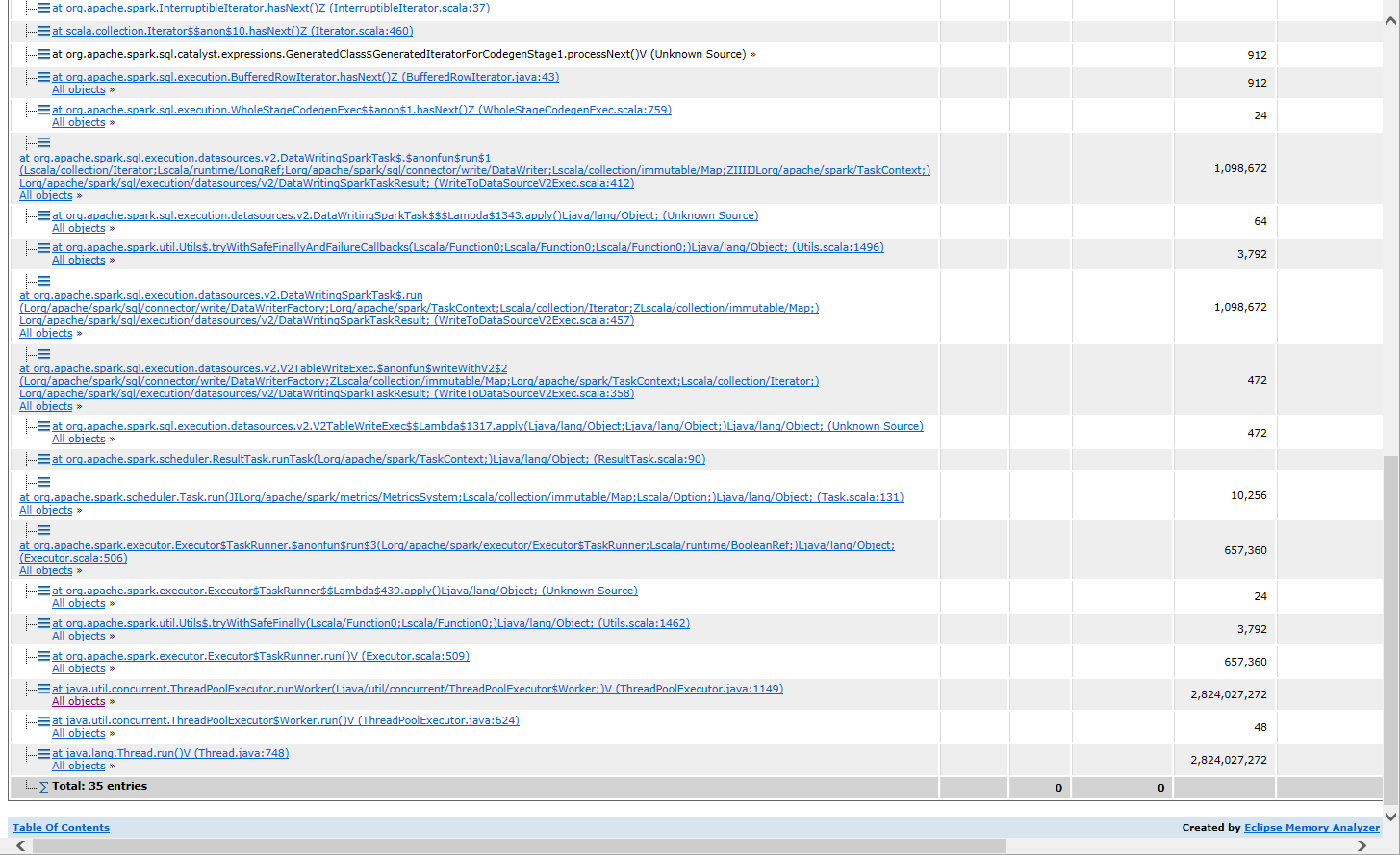
This table is updated every few days and each time the whole table is deleted and inserted again.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] github-actions[bot] commented on issue #6956: Spark: Data file rewriting spark job fails with oom
Posted by "github-actions[bot] (via GitHub)" <gi...@apache.org>.
github-actions[bot] commented on issue #6956:
URL: https://github.com/apache/iceberg/issues/6956#issuecomment-1696588385
This issue has been automatically marked as stale because it has been open for 180 days with no activity. It will be closed in next 14 days if no further activity occurs. To permanently prevent this issue from being considered stale, add the label 'not-stale', but commenting on the issue is preferred when possible.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on issue #6956: Spark: Data file rewriting spark job fails with oom
Posted by "rdblue (via GitHub)" <gi...@apache.org>.
rdblue commented on issue #6956:
URL: https://github.com/apache/iceberg/issues/6956#issuecomment-1448500702
@ldwnt, if the upstream table is completely refreshed every day, then why use a stream to move the data over to analytic storage? Seems like using a one-time copy after the refresh makes more sense.
I also think that, in general, directly updating an analytic table from Flink is a bad idea. It's usually much more efficient to write the changes directly into a table and periodically compact to materialize the latest table state.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] Fokko commented on issue #6956: data file rewriting spark job fails with oom
Posted by "Fokko (via GitHub)" <gi...@apache.org>.
Fokko commented on issue #6956:
URL: https://github.com/apache/iceberg/issues/6956#issuecomment-1447690156
@ldwnt It looks like you're using merge on read. Did you consider using copy-on-write? Even if the table is relatively small, the deletes might stack up.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ldwnt commented on issue #6956: Spark: Data file rewriting spark job fails with oom
Posted by "ldwnt (via GitHub)" <gi...@apache.org>.
ldwnt commented on issue #6956:
URL: https://github.com/apache/iceberg/issues/6956#issuecomment-1447700356
> @ldwnt It looks like you're using merge on read. Did you consider using copy-on-write? Even if the table is relatively small, the deletes might stack up.
This iceberg table is created by a flink connector v0.13.0. The write.delete.mode parameter seem not to be exposed in this version?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
Re: [I] Spark: Data file rewriting spark job fails with oom [iceberg]
Posted by "github-actions[bot] (via GitHub)" <gi...@apache.org>.
github-actions[bot] closed issue #6956: Spark: Data file rewriting spark job fails with oom
URL: https://github.com/apache/iceberg/issues/6956
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ldwnt commented on issue #6956: Spark: Data file rewriting spark job fails with oom
Posted by "ldwnt (via GitHub)" <gi...@apache.org>.
ldwnt commented on issue #6956:
URL: https://github.com/apache/iceberg/issues/6956#issuecomment-1449386215
> @ldwnt, if the upstream table is completely refreshed every day, then why use a stream to move the data over to analytic storage? Seems like using a one-time copy after the refresh makes more sense.
>
> I also think that, in general, directly updating an analytic table from Flink is a bad idea. It's usually much more efficient to write the changes directly into a table and periodically compact to materialize the latest table state.
It's possible to handle the completely refreshed tables in the way you metioned. The reason it's not is that I'm ingesting tables from 20 mysql dbs to iceberg and want to archieve the goal using the same set of flink applications.
I change the spark executor memory from 3g to 4g and the rewriting finishes without oom. It seems the cause of the oom is the many delete records collected in memory. Also, the 1.4g used memory of executor displayed in spark UI is not accurate.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
Re: [I] Spark: Data file rewriting spark job fails with oom [iceberg]
Posted by "github-actions[bot] (via GitHub)" <gi...@apache.org>.
github-actions[bot] commented on issue #6956:
URL: https://github.com/apache/iceberg/issues/6956#issuecomment-1872400046
This issue has been closed because it has not received any activity in the last 14 days since being marked as 'stale'
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] Fokko commented on issue #6956: Spark: Data file rewriting spark job fails with oom
Posted by "Fokko (via GitHub)" <gi...@apache.org>.
Fokko commented on issue #6956:
URL: https://github.com/apache/iceberg/issues/6956#issuecomment-1447709562
Ah, I see, using merge on read using Flink makes sense.
> And I have a question: with merge on read mode, in the worst case, does an executor have to read all delete records (in my case maybe all the rows before the whole table delete)?
There is some logic involved to optimize this, but equality deletes aren't the best choice when it comes to performance. Because at some point Flink will write a delete (`id=5`), and you have to apply this to the subsequent data files, which is quite costly as you might imagine. Of course, this is limited to the partitions that you're reading and will prune the deletes of the partitions that are outside of the scope of the query.
What also would work is to compact the table using a Spark job periodically (ideally the partitions that aren't being written to anymore). So you'll get rid of the deletes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ldwnt commented on issue #6956: Spark: Data file rewriting spark job fails with oom
Posted by "ldwnt (via GitHub)" <gi...@apache.org>.
ldwnt commented on issue #6956:
URL: https://github.com/apache/iceberg/issues/6956#issuecomment-1447723347
> Ah, I see, using merge on read using Flink makes sense.
>
> > And I have a question: with merge on read mode, in the worst case, does an executor have to read all delete records (in my case maybe all the rows before the whole table delete)?
>
> There is some logic involved to optimize this, but equality deletes aren't the best choice when it comes to performance. Because at some point Flink will write a delete (`id=5`), and you have to apply this to the subsequent data files, which is quite costly as you might imagine. Of course, this is limited to the partitions that you're reading and will prune the deletes of the partitions that are outside of the scope of the query.
>
> What also would work is to compact the table using a Spark job periodically (ideally the partitions that aren't being written to anymore). So you'll get rid of the deletes.
The iceberg table is written by a flink job with an iceberg sink, whose source is a mysql table. I can not control the way the source table is updated, which is deleting all rows and inserting the new ones. In this scenario, can I make the connector use position delete or by any means make the following rewriting more efficient?
Yes, the spark job is run everyday. Unfortunately due to the way the source table is updated, I'm still facing 9 millions row deletes in a single run.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org