You are viewing a plain text version of this content. The canonical link for it is here.
Posted to mapreduce-issues@hadoop.apache.org by "ASF GitHub Bot (Jira)" <ji...@apache.org> on 2022/12/23 07:38:00 UTC
[jira] [Commented] (MAPREDUCE-7430) FileSystemCount enumeration changes will cause mapreduce application failure during upgrade
[ https://issues.apache.org/jira/browse/MAPREDUCE-7430?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17651512#comment-17651512 ]
ASF GitHub Bot commented on MAPREDUCE-7430:
-------------------------------------------
Daniel-009497 opened a new pull request, #5255:
URL: https://github.com/apache/hadoop/pull/5255
We found this issue when doing rollingUpgrade in our production setup.
A new mapreduce counter is introduced in the patch: [HADOOP-15507](https://issues.apache.org/jira/browse/HADOOP-15507). Add MapReduce counters about EC bytes read.
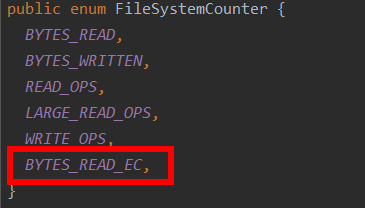
In upgrade scenario, if the user with old version mapreduce client try to run a job on yarn cluster with new version, the below exception will be thrown in container log:
2022-12-21 21:38:37,037 | INFO | IPC Server handler 28 on 27102 | Commit go/no-go request from attempt_1670928986900_1250_r_000000_0 | TaskAttemptListenerImpl.java:222
2022-12-21 21:38:37,037 | INFO | IPC Server handler 28 on 27102 | Result of canCommit for attempt_1670928986900_1250_r_000000_0:true | TaskImpl.java:592
2022-12-21 21:38:37,037 | WARN | Socket Reader #2 for port 27102 | Unable to read call parameters for client 192.168.4.96on connection protocol org.apache.hadoop.mapred.TaskUmbilicalProtocol for rpcKind RPC_WRITABLE | Server.java:2598
java.lang.ArrayIndexOutOfBoundsException: 5
at org.apache.hadoop.mapreduce.counters.FileSystemCounterGroup.readFields(FileSystemCounterGroup.java:304)
at org.apache.hadoop.mapred.Counters$Group.readFields(Counters.java:324)
at org.apache.hadoop.mapreduce.counters.AbstractCounters.readFields(AbstractCounters.java:307)
at org.apache.hadoop.mapred.TaskStatus.readFields(TaskStatus.java:489)
at org.apache.hadoop.mapred.ReduceTaskStatus.readFields(ReduceTaskStatus.java:140)
at org.apache.hadoop.io.ObjectWritable.readObject(ObjectWritable.java:285)
at org.apache.hadoop.ipc.WritableRpcEngine$Invocation.readFields(WritableRpcEngine.java:162)
at org.apache.hadoop.ipc.RpcWritable$WritableWrapper.readFrom(RpcWritable.java:85)
at org.apache.hadoop.ipc.RpcWritable$Buffer.getValue(RpcWritable.java:187)
at org.apache.hadoop.ipc.RpcWritable$Buffer.newInstance(RpcWritable.java:183)
at org.apache.hadoop.ipc.Server$Connection.processRpcRequest(Server.java:2594)
at org.apache.hadoop.ipc.Server$Connection.processOneRpc(Server.java:2515)
at org.apache.hadoop.ipc.Server$Connection.unwrapPacketAndProcessRpcs(Server.java:2469)
at org.apache.hadoop.ipc.Server$Connection.saslReadAndProcess(Server.java:1912)
at org.apache.hadoop.ipc.Server$Connection.processRpcOutOfBandRequest(Server.java:2723)
at org.apache.hadoop.ipc.Server$Connection.processOneRpc(Server.java:2509)
at org.apache.hadoop.ipc.Server$Connection.readAndProcess(Server.java:2258)
at org.apache.hadoop.ipc.Server$Listener.doRead(Server.java:1395)
at org.apache.hadoop.ipc.Server$Listener$Reader.doRunLoop(Server.java:1251)
at org.apache.hadoop.ipc.Server$Listener$Reader.run(Server.java:1222)
just ignore the line number which is not completely consistent with trunk, but it is easy to understand.
So a extra validate is needed in readFields() t5 avoid the array element to be read is in the array range.

> FileSystemCount enumeration changes will cause mapreduce application failure during upgrade
> -------------------------------------------------------------------------------------------
>
> Key: MAPREDUCE-7430
> URL: https://issues.apache.org/jira/browse/MAPREDUCE-7430
> Project: Hadoop Map/Reduce
> Issue Type: Improvement
> Reporter: Daniel Ma
> Assignee: Daniel Ma
> Priority: Major
> Attachments: screenshot-1.png, screenshot-2.png
>
>
> We found this issue when doing rollingUpgrade in our production setup.
> A new mapreduce counter is introduced in the patch: HADOOP-15507. Add MapReduce counters about EC bytes read.
> !screenshot-1.png!
> In upgrade scenario, if the user with old version mapreduce client try to run a job on yarn cluster with new version, the below exception will be thrown in container log:
> {code:java}
> 2022-12-21 21:38:37,037 | INFO | IPC Server handler 28 on 27102 | Commit go/no-go request from attempt_1670928986900_1250_r_000000_0 | TaskAttemptListenerImpl.java:222
> 2022-12-21 21:38:37,037 | INFO | IPC Server handler 28 on 27102 | Result of canCommit for attempt_1670928986900_1250_r_000000_0:true | TaskImpl.java:592
> 2022-12-21 21:38:37,037 | WARN | Socket Reader #2 for port 27102 | Unable to read call parameters for client 192.168.4.96on connection protocol org.apache.hadoop.mapred.TaskUmbilicalProtocol for rpcKind RPC_WRITABLE | Server.java:2598
> java.lang.ArrayIndexOutOfBoundsException: 5
> at org.apache.hadoop.mapreduce.counters.FileSystemCounterGroup.readFields(FileSystemCounterGroup.java:304)
> at org.apache.hadoop.mapred.Counters$Group.readFields(Counters.java:324)
> at org.apache.hadoop.mapreduce.counters.AbstractCounters.readFields(AbstractCounters.java:307)
> at org.apache.hadoop.mapred.TaskStatus.readFields(TaskStatus.java:489)
> at org.apache.hadoop.mapred.ReduceTaskStatus.readFields(ReduceTaskStatus.java:140)
> at org.apache.hadoop.io.ObjectWritable.readObject(ObjectWritable.java:285)
> at org.apache.hadoop.ipc.WritableRpcEngine$Invocation.readFields(WritableRpcEngine.java:162)
> at org.apache.hadoop.ipc.RpcWritable$WritableWrapper.readFrom(RpcWritable.java:85)
> at org.apache.hadoop.ipc.RpcWritable$Buffer.getValue(RpcWritable.java:187)
> at org.apache.hadoop.ipc.RpcWritable$Buffer.newInstance(RpcWritable.java:183)
> at org.apache.hadoop.ipc.Server$Connection.processRpcRequest(Server.java:2594)
> at org.apache.hadoop.ipc.Server$Connection.processOneRpc(Server.java:2515)
> at org.apache.hadoop.ipc.Server$Connection.unwrapPacketAndProcessRpcs(Server.java:2469)
> at org.apache.hadoop.ipc.Server$Connection.saslReadAndProcess(Server.java:1912)
> at org.apache.hadoop.ipc.Server$Connection.processRpcOutOfBandRequest(Server.java:2723)
> at org.apache.hadoop.ipc.Server$Connection.processOneRpc(Server.java:2509)
> at org.apache.hadoop.ipc.Server$Connection.readAndProcess(Server.java:2258)
> at org.apache.hadoop.ipc.Server$Listener.doRead(Server.java:1395)
> at org.apache.hadoop.ipc.Server$Listener$Reader.doRunLoop(Server.java:1251)
> at org.apache.hadoop.ipc.Server$Listener$Reader.run(Server.java:1222)
> {code}
> just ignore the line number which is not completely consistent with trunk, but it is easy to understand.
> So a extra validate is needed in readFields() t5 avoid the array element to be read is in the array range.
> !screenshot-2.png!
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
---------------------------------------------------------------------
To unsubscribe, e-mail: mapreduce-issues-unsubscribe@hadoop.apache.org
For additional commands, e-mail: mapreduce-issues-help@hadoop.apache.org