You are viewing a plain text version of this content. The canonical link for it is here.
Posted to dev@tvm.apache.org by "Minmin Sun (孙敏敏)" <no...@github.com> on 2019/10/11 08:47:08 UTC
[dmlc/tvm] [RFC] Auto TensorCore CodeGen (#4105)
We propose a solution for TensorCore CodeGen with significant transparency, flexibility and usability. In this solution, the algorithm description and schedule of TensorCore CodeGen is no different than that of a normal CUDA CodeGen. All the information needed by wmma API, such as matrix_a/matrix_b/accumulator, row_major/col_major, warp tile size and so on, is automatically derived from the AST. Of course, not every algorithm and schedule is suitable for TensorCore computation. This solution will do the check and fall back to normal CUDA CodeGen for those that are not qualified for TensorCore CodeGen.
In this solution, 3 IRVisitors and 1 IRMutator are added.
* IRVisitors: BodyVisitor, MMAMatcher and BufferAnalyser.
* IRMutator: TensorCoreIRMutator.
BodyVisitor, which is called by ScheduleAnalyser, visits the body stmt of original ComputeOp to get the access indices of input matrices if it is recognized as matrix multiply. ScheduleAnalyser compares the access indices with the axis/reduce_axis of ComputeOp to figure out whether an input matrix is matrix_a or matrix_b, row_major or col_major.
MMAMatcher does the pattern matching on AST stmt. The pattern it tries to find out is as following:
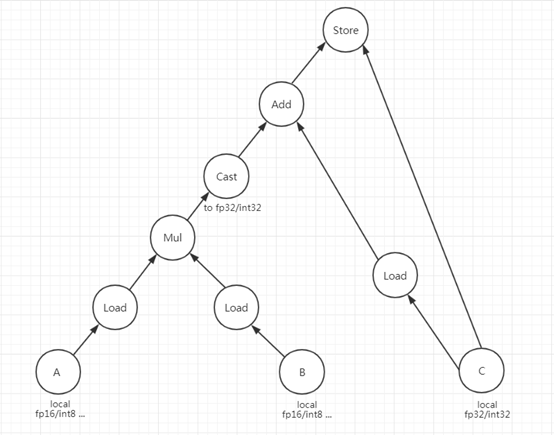
If matched, the a, b, c will be recorded as fragment registers, which are important inputs to the next visitor.
BufferAnalyser, the last visitor, will get all of the rest information needed for TensorCoreIRMutator, like strides of src/dst buffer for wmma load/store matrix operation, warp tile size for fragment allocation as well as checking whether the schedule is qualified for TensorCore, loops that need to be scaled after normal load/store and compute operation replaced by TensorCore operations, etc..
TensorCoreIRMutator mutates the AST stmt for TensorCore CodeGen. The subtree matched by MMAMatcher will be replaced with “mma_sync” extern call. Load/Store of fragments are replaced with “load/store_matrix_sync” extern call, with the thread index getting unified within a warp. Thread index unification, i.e. changing the index of every thread to the same as the first thread of the warp, is done by ThreadIdxMutator on the subtree.
The TensorCore IR Passes are applied before StorageFlatten because they need stride/shape and index of specific dimensions before they got flattened into one. Before StorageFlatten, “Allocation” is represented by Realize IR Node, which has no new_expr member as Allocate IR Node has. So we added it to Realize IR Node to carry the expr for fragment allocation and pass to Allocate IR Node. We noticed the comment of deprecating new_expr when merging with the latest TVM codebase. We would like to ask for a reconsideration of this decision, because it is really useful for some non-standard buffer allocations.
This solution is evaluated on a sample schedule of Matmul, which is based on AutoTVM. It supports fp16 and int8 data type, and three kinds of data layouts: NN, NT, TN.
On some model layers, we have already achieved better performance than CUBLAS/CUDNN:
### FP16 on V100, CUDA 9.0, Driver 396.44
* NMT Online Service (In-house Model)
| M, N, K | CUBLAS TensorCore | TVM TensorCore | Speed Up |
| -------- | -------- | -------- | -------- |
| 512, 64, 512 | 9.05us | 7.34us | 1.23X |
| 512, 32, 512 | 8.30us | 6.84us | 1.21X |
| 512, 16, 512 | 7.88us | 6.60us | 1.19X |
* MobileNet (Public Model)
| H W C_IN C_OUT KERNEL KERNEL PAD_H PAD_W STRIDE_H STRIDE_W |CUDNN TensorCore| TVM TensorCore | SpeedUp |
| -------- | -------- | -------- | -------- |
| 56 56 64 128 1 1 0 0 1 1 | 8.5220us | 6.9320us | 1.23X |
| 28 28 128 256 1 1 0 0 1 1 | 10.787us | 8.3490us | 1.29X |
| 28 28 256 256 1 1 0 0 1 1 | 15.188us |14.136us | 1.07X |
### Int8 on T4, CUDA10.1, Driver 418.39
* NMT Online Service (In-house Model)
| M, N, K | CUBLAS TensorCore | TVM TensorCore | Speed Up |
| -------- | -------- | -------- | -------- |
| 512, 64, 512 | 23.163us | 22.603us | 1.025X |
| 512, 32, 512 | 22.551us | 14.263us | 1.58X |
| 512, 16, 512 | 22.510us | 11.015us | 2.04X |
There are also many shapes on which CUBLAS/CUDNN is much better. The performance tuning is still on-going.
Thanks!
-- Minmin Sun, Lanbo Li, Chenfan Jia and Jun Yang of Alibaba PAI team
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/issues/4105
Re: [dmlc/tvm] [RFC] Auto TensorCore CodeGen (#4105)
Posted by "Minmin Sun (孙敏敏)" <no...@github.com>.
Opened PR #4234 for the re-implementation of our solution based on tensor intrinsic. Many thanks to @Hzfengsy for his valuable suggestions and close collaboration with us on this.
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/issues/4105#issuecomment-548317909
Re: [dmlc/tvm] [RFC] Auto TensorCore CodeGen (#4105)
Posted by Tianqi Chen <no...@github.com>.
Thanks for the RFC, also cross link to https://github.com/dmlc/tvm/issues/4052.
## Non standard buffer allocation
We are moving toward using special memory scopes to annotate the special memory(e.g. mma). The use of ```new_expr``` was convenient, but never the less a bit too close to low level and overlaps with what we can do with special memory scope. Adding ```new_expr``` to Realize seems to enforce that decision even earlier, which I would not recommend.
Here is an alternative solution: introduce a new scope for the special memory needed for lowering, then the special rule can be used to generate the corresponding memory needed. Of course there could be additional hints that are needed to lower the the allocation code, you can likely embed that additional information with a special AttrStmt outside the allocation scope.
## Place of Pattern Matching
Right now from the reading of RFC, seems the early pattern matching was done before flattening and was dependent on the compute structure.
I wonder if we could de-couple this, with some annotations, run some of the rewriting after storage flatten. Of course the low-level code does not enjoy the benefit of the multi-dimension indices, but the access pattern can still be detected by DetectLinearEquation.
One possible limitation I see the current approach is that whether we could support operations like conv2d, as we will need to explicitly express compute in this form(which is fine for now).
## Complement and Combine with Tensor Intrinsics based TensorCore support
It would be great to hear from more thoughts @Hzfengsy @minminsun about how can we combine the tensor intrinsics based approach with the more automatic pattern detector one. e.g
https://github.com/dmlc/tvm/issues/4052.
We always tries to have a philosophy to enable the manual scheduling options that can gives us a way to specify search space, then build automation on top. This allows us to takes a spectrum of approach, use more manual one if necessary, and build more diverse automated solution.
Our eventual goal would still be unify all tensorization support under tensor intrinsics, and build automation on top. One idea would be we still declare the lowering rules via tensor intrinsics, but reuses the pattern matching techniques in this RFC to rewrite to hints that applies the tensor intrinsics. This way we can organically combine the two ideas together.
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/issues/4105#issuecomment-541141436
Re: [dmlc/tvm] [RFC] Auto TensorCore CodeGen (#4105)
Posted by "Minmin Sun (孙敏敏)" <no...@github.com>.
#4052 @Hzfengsy
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/issues/4105#issuecomment-540978699
Re: [dmlc/tvm] [RFC] Auto TensorCore CodeGen (#4105)
Posted by "Minmin Sun (孙敏敏)" <no...@github.com>.
> Awesome solution! Just curios: for shapes which are worse than cudnn/cublas, what kind of tuning is using?
We haven’t spent much effort on performance tuning yet. For cases with bad performance we plan to do profiling to figure out the causes firstly. One possible way of optimization is to manually modify the generated code. If the manual optimization really works and it is general enough, we can try to implement it in the schedule.
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/issues/4105#issuecomment-541060356
Re: [dmlc/tvm] [RFC] Auto TensorCore CodeGen (#4105)
Posted by "Minmin Sun (孙敏敏)" <no...@github.com>.
> I have a proposal to minimize the invasion in TVM and also fundamentally support TensorCore in TVM. This is in the middle of both methodology of #4052 and this RFC.
> I suppose the current pain point of supporting TensorCore is the data structure provided by NVIDIA, which introduces non-standard buffer allocation.
> I wrote a microbenchmark before to see the generated ptx assembly code, which turned out that fragment no longer exists after codegen, and the tensorize intrinsic is just several assembly instructions with 16 operands.
> My proposal is that why do not we just extend the intrin and generate the code in embedded assembly?
> @tqchen
Sorry for the late reply. We were occupied by refactoring our implemention to combine with #4052.
Generating PTX or even SASS assembly is an intersting topic. We may have some investigations and disscussions on this later. As to the TensorCore CodeGen, I think the data structure is not the only pain point. The root is in the programming model of tensorcore, in which the threads inside a warp are no longer individual threads and some high level information sunch as matrix_a/b, row/col_major, strides of a buffer, is required in low level operations. So I guess generating PTX directly may not release these pains. @Hzfengsy what do you think about this?
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/issues/4105#issuecomment-548315125
Re: [dmlc/tvm] [RFC] Auto TensorCore CodeGen (#4105)
Posted by Andrew Tulloch <no...@github.com>.
This is really impressive work, congrats!
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/issues/4105#issuecomment-541259191
Re: [dmlc/tvm] [RFC] Auto TensorCore CodeGen (#4105)
Posted by Bing Xu <no...@github.com>.
Awesome solution! Just curios: for shapes which are worse than cudnn/cublas, what kind of tuning is using?
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/issues/4105#issuecomment-541014088
Re: [dmlc/tvm] [RFC] Auto TensorCore CodeGen (#4105)
Posted by Jian Weng <no...@github.com>.
I have a proposal to minimize the invasion in TVM and also fundamentally support TensorCore in TVM. This is in the middle of both methodology of #4052 and this RFC.
I suppose the current pain point of supporting TensorCore is the data structure provided by NVIDIA, which introduces non-standard buffer allocation.
I wrote a microbenchmark before to see the generated ptx assembly code, which turned out that fragment no longer exists after codegen, and the tensorize intrinsic is just several assembly instructions with 16 operands.
My proposal is that why do not we just extend the intrin and generate the code in embedded assembly?
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/issues/4105#issuecomment-544045155
Re: [dmlc/tvm] [RFC] Auto TensorCore CodeGen (#4105)
Posted by "Minmin Sun (孙敏敏)" <no...@github.com>.
Thanks @tqchen and @Hzfengsy for your valuable feedbacks. We are trying out some of your suggestions. Will have further discussions with you after we have made some evaluations and trials.
> As we know using TensorCores will decrease precision. So, NVIDIA set up a switch to turn on and off TensorCores in CUBLAS and CUDNN (default not use TensorCores). At least we should let users determine whether use them.
I doubt whether "using TensorCores will decrease precision", if the inputs are already in fp16 or int8. We did try to add an "enable_tensor_core" option in tvm.build_config, but it seems like build_config can't be passed to AutoTVM building. Any suggestion on where to add this option is welcome. But I think eventually we will not need this option, after the implementation is proven to be robust enough. For example, in Tensorflow, MatMul/Conv on fp16 data by default uses TensorCore Kernel of cublas/cudnn.
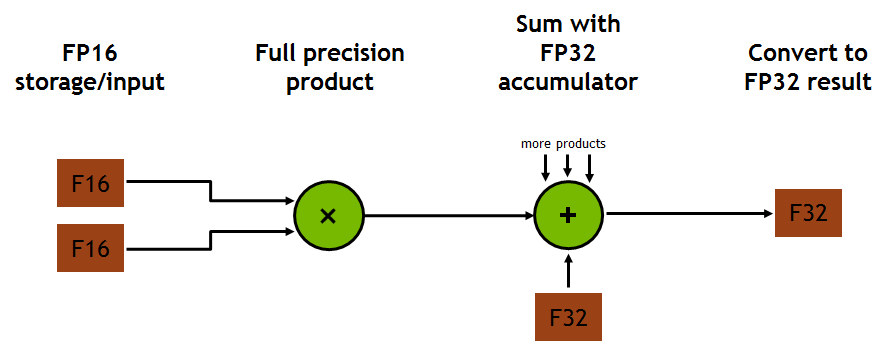
> In Volta Arichitecture Whitepaper, TensorCores do production in full precision, rather than half precision. I recommend changing the pattern into A/B -> Load -> Cast -> Mul -> Add if we still use pattern matching solution.
Thanks for correcting my understanding. So it seems like the tensorcore operation is more like *c = float(a)\*float(b) + c* than *c = float(a\*b) + c*
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/issues/4105#issuecomment-541282259
Re: [dmlc/tvm] [RFC] Auto TensorCore CodeGen (#4105)
Posted by Jun Yang <no...@github.com>.
> Awesome solution! Just curios: for shapes which are worse than cudnn/cublas, what kind of tuning is using?
Good point! We do have some internal discussions about whether we need to automatically search the schedule space based on performance between TensorCore and non-TensorCore kernel, since TensorCore implementation may not beat the non-TensorCore version for every shapes. This is one of the plan-to-do features and any further comments and inputs are also welcome. One possible solution is to expose TensorCore as another schedule configuration knob to let auto-tuner decide whether we need to turn it on or not. Another potential solution is that in the IR pass we decide on whether a certain shape may perform better with TensorCore with heuristics. There are pros and cons with both solution. For the former one, the tuner space will be enlarged, thus bringing a little bit larger tuning space. For the latter one, since we make decision in the IR pass internally, the tuner space is kept almost the same however introduce dependency upon the accuracy of the heuristics, although for TensorCore due it is hardware nature we think it might be clear to decide whether a shape is performance friendly for TensorCore or not, there is still possibility that we may choose a low-performance kernel.
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/issues/4105#issuecomment-541121603
Re: [dmlc/tvm] [RFC] Auto TensorCore CodeGen (#4105)
Posted by Siyuan Feng <no...@github.com>.
Thank you for the RFC. It is complete TensorCore support. It is nice that you can support different types and different data layouts, which is not supported in my solution currently.
## Lower Passes vs Intrinsic
Intrinsic is a tool for describing what instructions can be done in specific hardware. I believe TensorCore is one kind of specific hardware. It is perfect to use tensor intrinsic. It is standard and easy to maintain (if Nividia add another accelerator, we only need to add another intrinsic rather than a new pass)
Another thing is auto tensorization. Just as Tianqi says, our final goal is to generate schedules for all kinds of hardware using tensor intrinsics, which is my major work direction.
## Suggestions and Questions
- As we know using TensorCores will decrease precision. So, NVIDIA set up a switch to turn on and off TensorCores in CUBLAS and CUDNN (default not use TensorCores). At least we should let users determine whether use them.
- In Volta Arichitecture Whitepaper, TensorCores do production in full precision, rather than half precision. I recommend changing the pattern into `A/B -> Load -> Cast -> Mul -> Add` if we still use pattern matching solution.
- It shocks me that your solution is even faster than CUBLAS and CUDNN. I try to reproduce the result but fails. Did you use BatchMatMul and BatchConv? And which GPU did you test on? Could you show me the details about the performance?
## Combine with Tensor Intrinsics
I am glad to see a different solution for TensorCore. And it seems that it is more complete and faster than mine. However, tensor intrinsic is the solution that Tianqi and I recommend. It would benefit the project and the community if we can cooperate, combining my tensor intrinsic and your complete and well-performance backend.
After all, thank you again for this impressive RFC.
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/issues/4105#issuecomment-541222182
Re: [dmlc/tvm] [RFC] Auto TensorCore CodeGen (#4105)
Posted by Orion34C <no...@github.com>.
> * It shocks me that your solution is even faster than CUBLAS and CUDNN. I try to reproduce the result but fails. Did you use BatchMatMul and BatchConv? And which GPU did you test on? Could you show me the details about the performance?
>
Our fp16 TensorCore kernel are tuned on V100 with CUDA toolkit 9.0 with driver 396.44. The int8 TensorCore kernels are tuned on T4 with CUDA toolkit 10.1 with driver 418.39. On different GPUs, the performance of tuned kernels can be different.
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/issues/4105#issuecomment-541276574
Re: [dmlc/tvm] [RFC] Auto TensorCore CodeGen (#4105)
Posted by "Minmin Sun (孙敏敏)" <no...@github.com>.
We had a meeting with @Hzfengsy today. We discussed the difference and similarity of our solutions. They are different in the front-end: our solution tries to make it as transparent as possible to make it easy-using while #4095 provides more controllability to the user (schedule developer). They are actually targeting different users, so we think both solutions can co-exist. But we both agreed that the intrinsics in the back-end should combine. As to the fragment allocation, we are OK to change from new_expr to the way of introducing new scopes, but currently the new scope introduced in #4052 is not enough for the codegen of fragment allocation if it's extended to support different warp tile sizes and data layouts (col_major/row_major). One possible but not so elegant solution we proposed is to extend the scopes to also include tile size and data layout. @Hzfengsy is also trying to figure out a solution here. We will have more discussions on this.
cc @tqchen
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/issues/4105#issuecomment-542032766