You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2021/05/25 04:04:44 UTC
[GitHub] [hudi] nmahmood630 opened a new issue #2987: [SUPPORT] Only able to retrieve last _hoodie_commit_time
nmahmood630 opened a new issue #2987:
URL: https://github.com/apache/hudi/issues/2987
**Describe the problem you faced**
I am trying to make an incremental query to get changes to my Hudi table since the last commit, but when I run:
```
commits = list(map(lambda row: row[0], spark.sql(
"select distinct(_hoodie_commit_time) as commitTime from aggregated_device_geo_ips_snapshot order by commitTime").limit(
50).collect()))
begin_time = commits[len(commits) - 2]
```
this only returns the latest commit (commits : ['20210525033453']), though I have upserted to the table 8 times. The .hoodie folder in S3 shows 8 commits:
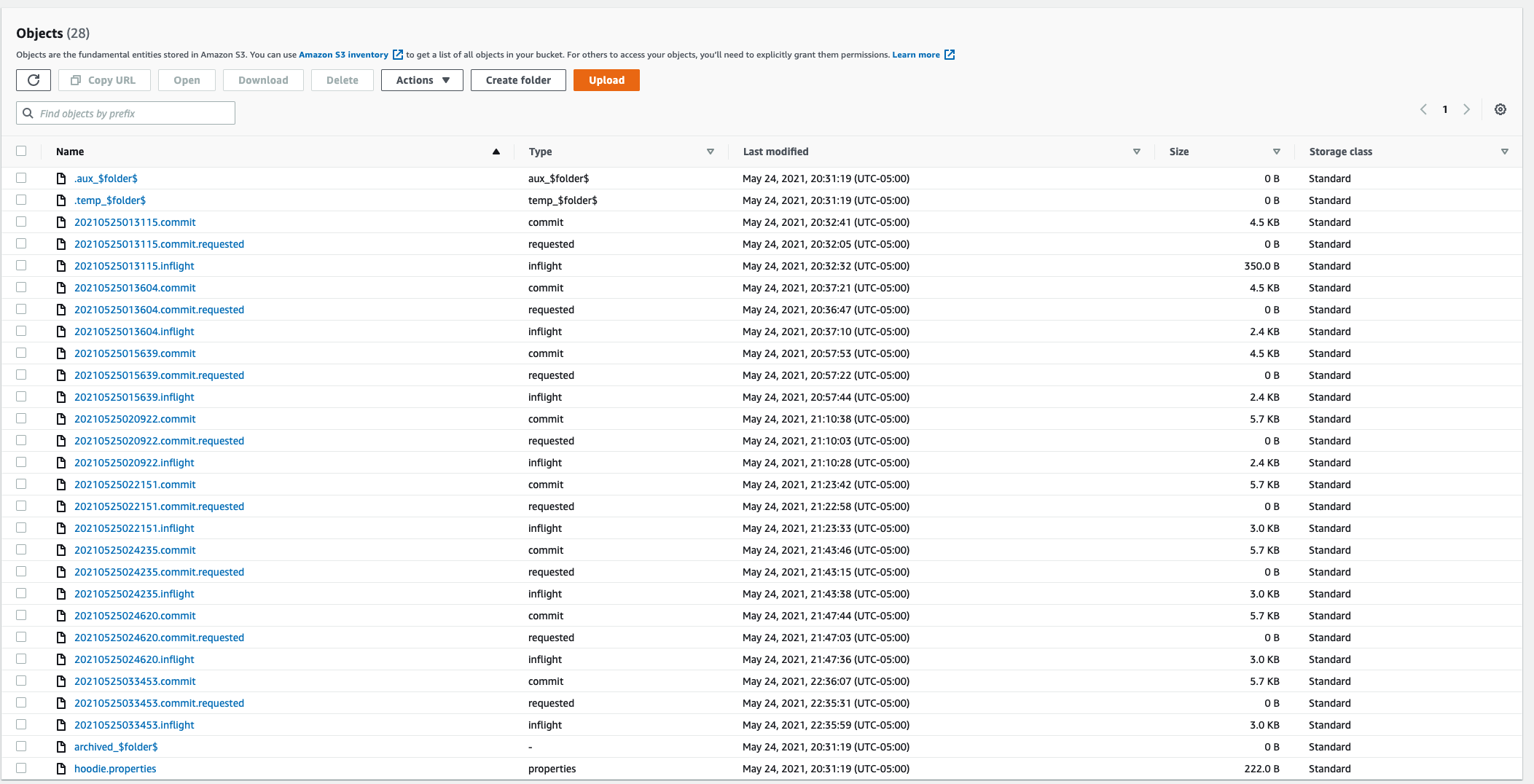
This is my code to read/write from the Hudi tables:
`def write_aggregated_data_to_hudi_table(data_frame, args):
hudi_table_name = 'aggregated_device_geo_ip'
hudi_table_path = 's3://' + args[HUDI_TABLE_S3_BUCKET_NAME] + '/' + hudi_table_name
hudi_options = {
'hoodie.table.name': hudi_table_name,
'hoodie.datasource.write.recordkey.field': 'customer_id, device_serial_number, device_type',
'hoodie.datasource.write.partitionpath.field': 'last_event_date',
'hoodie.datasource.write.keygenerator.class': 'org.apache.hudi.keygen.ComplexKeyGenerator',
'hoodie.datasource.write.table.name': hudi_table_path,
'hoodie.datasource.write.operation': 'upsert',
'hoodie.datasource.write.precombine.field': 'last_event_timestamp',
'hoodie.upsert.shuffle.parallelism': 20,
'hoodie.insert.shuffle.parallelism': 20
}
(
data_frame
.write
.format("hudi")
.options(**hudi_options)
.mode("Append")
.save(hudi_table_path)
)
def get_updated_device_geoips(spark, args):
hudi_table_name = 'aggregated_device_geo_ip'
hudi_table_path = 's3://' + args[HUDI_TABLE_S3_BUCKET_NAME] + '/' + hudi_table_name
spark. \
read. \
format("hudi"). \
load(hudi_table_path + "/*"). \
createOrReplaceTempView("aggregated_device_geo_ips_snapshot")
commits = list(map(lambda row: row[0], spark.sql(
"select distinct(_hoodie_commit_time) as commitTime from aggregated_device_geo_ips_snapshot order by commitTime").limit(
50).collect()))
print(commits)
begin_time = commits[len(commits) - 2]
print(begin_time)
# incrementally query data
incremental_read_options = {
'hoodie.datasource.query.type': 'incremental',
'hoodie.datasource.read.begin.instanttime': begin_time,
}
aggregated_device_geo_ip_incremental_df = spark.read.format("hudi"). \
options(**incremental_read_options). \
load(hudi_table_path)
# print("UPDATED_DEVICE_GEOIPS" + aggregated_device_geo_ip_incremental_df.to_string())
return aggregated_device_geo_ip_incremental_df`
**Expected behavior**
I expect all the commits listed in the .hoodie folder to be returned so that I can select the previous commit to do an incremental query.
**Environment Description**
* Hudi version :
* Spark version :
* Hive version :
* Hadoop version :
* Storage (HDFS/S3/GCS..) : S3
* Running on Docker? (yes/no) : no
**Additional context**
Add any other context about the problem here.
**Stacktrace**
```Add the stacktrace of the error.```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nmahmood630 commented on issue #2987: [SUPPORT] Only able to retrieve last _hoodie_commit_time
Posted by GitBox <gi...@apache.org>.
nmahmood630 commented on issue #2987:
URL: https://github.com/apache/hudi/issues/2987#issuecomment-848397902
I think the issue I am seeing is similar to: https://github.com/apache/hudi/issues/2002 where all the records commit time are getting updated since this table holds aggregation data that will be upserting duplicate rows. Is there any other way to get the commit history using spark that doesn't relay on the individual records commit time?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] n3nash commented on issue #2987: [SUPPORT] Only able to retrieve last _hoodie_commit_time
Posted by GitBox <gi...@apache.org>.
n3nash commented on issue #2987:
URL: https://github.com/apache/hudi/issues/2987#issuecomment-851717671
@nmahmood630 Currently, there is no way to get the list of commits that a particular record underwent multiple times due to an update operation. Like what @nsivabalan mentioned, spark read on hudi will only returned the latest commit. If you're looking to get the commit history, there is no way to do that in spark. There are Timeline API's in java and using the `HoodieActiveTimeline` class you can figure out all the commits that have happened on a dataset since the last commit.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #2987: [SUPPORT] Only able to retrieve last _hoodie_commit_time
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #2987:
URL: https://github.com/apache/hudi/issues/2987#issuecomment-850068596
I assume every commit updates all records. and by default if you read a table in hudi format in spark, it will return the latest snaphot and hence you are seeing just the last commit.
I can think of some hack that you can do. But not sure if there are some other elegant ways.
You can read the table in parquet format and retrieve all distinct commit times and then go from there. // don't think this is advisable though.
Also, if you have access to hudi-cli, you should be able to retrieve all commit info.
@n3nash @leesf @yanghua : any other ideas?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] n3nash commented on issue #2987: [SUPPORT] Only able to retrieve last _hoodie_commit_time
Posted by GitBox <gi...@apache.org>.
n3nash commented on issue #2987:
URL: https://github.com/apache/hudi/issues/2987#issuecomment-859316946
@nmahmood630 I've opened a feature request here -> https://issues.apache.org/jira/browse/HUDI-1998. If you are interested in contributing it, please comment on the JIRA and tag me - happy to guide you through it
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] n3nash closed issue #2987: [SUPPORT] Only able to retrieve last _hoodie_commit_time
Posted by GitBox <gi...@apache.org>.
n3nash closed issue #2987:
URL: https://github.com/apache/hudi/issues/2987
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nmahmood630 commented on issue #2987: [SUPPORT] Only able to retrieve last _hoodie_commit_time
Posted by GitBox <gi...@apache.org>.
nmahmood630 commented on issue #2987:
URL: https://github.com/apache/hudi/issues/2987#issuecomment-848311113
Any update on this?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org