You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@airflow.apache.org by GitBox <gi...@apache.org> on 2022/08/01 15:08:45 UTC
[GitHub] [airflow] dene14 opened a new issue, #25448: Schduler polling is extremely heavy for big DAGs
dene14 opened a new issue, #25448:
URL: https://github.com/apache/airflow/issues/25448
### Apache Airflow version
2.3.3 (latest released)
### What happened
Scheduler polling for last occurrence of task execution is extremely heavy and slow.
### What you think should happen instead
Scheduler doing a lot of polling, all the queries should be highly optimized and lightweight.
### How to reproduce
Create a DAG that runs quite often (let's say hourly) that have many tasks in it e.g. 100.
Scheduler polling will create extremely heavy queries that consume a lot of CPU on database size (2-4 cores).
This, at least observed with mysql storage backend
### Operating System
official docker image
### Versions of Apache Airflow Providers
n/a
### Deployment
Official Apache Airflow Helm Chart
### Deployment details
_No response_
### Anything else
Original query constructed by ORM looks as follows for my DAG:
```
SELECT
task_instance.try_number AS task_instance_try_number,
task_instance.task_id AS task_instance_task_id,
task_instance.dag_id AS task_instance_dag_id,
task_instance.run_id AS task_instance_run_id,
task_instance.start_date AS task_instance_start_date,
task_instance.end_date AS task_instance_end_date,
task_instance.duration AS task_instance_duration,
task_instance.state AS task_instance_state,
task_instance.max_tries AS task_instance_max_tries,
task_instance.hostname AS task_instance_hostname,
task_instance.unixname AS task_instance_unixname,
task_instance.job_id AS task_instance_job_id,
task_instance.pool AS task_instance_pool,
task_instance.pool_slots AS task_instance_pool_slots,
task_instance.queue AS task_instance_queue,
task_instance.priority_weight AS task_instance_priority_weight,
task_instance.operator AS task_instance_operator,
task_instance.queued_dttm AS task_instance_queued_dttm,
task_instance.queued_by_job_id AS task_instance_queued_by_job_id,
task_instance.pid AS task_instance_pid,
task_instance.executor_config AS task_instance_executor_config,
task_instance.external_executor_id AS task_instance_external_executor_id,
task_instance.trigger_id AS task_instance_trigger_id,
task_instance.trigger_timeout AS task_instance_trigger_timeout,
task_instance.next_method AS task_instance_next_method,
task_instance.next_kwargs AS task_instance_next_kwargs,
dag_run_1.state AS dag_run_1_state,
dag_run_1.id AS dag_run_1_id,
dag_run_1.dag_id AS dag_run_1_dag_id,
dag_run_1.queued_at AS dag_run_1_queued_at,
dag_run_1.execution_date AS dag_run_1_execution_date,
dag_run_1.start_date AS dag_run_1_start_date,
dag_run_1.end_date AS dag_run_1_end_date,
dag_run_1.run_id AS dag_run_1_run_id,
dag_run_1.creating_job_id AS dag_run_1_creating_job_id,
dag_run_1.external_trigger AS dag_run_1_external_trigger,
dag_run_1.run_type AS dag_run_1_run_type,
dag_run_1.conf AS dag_run_1_conf,
dag_run_1.data_interval_start AS dag_run_1_data_interval_start,
dag_run_1.data_interval_end AS dag_run_1_data_interval_end,
dag_run_1.last_scheduling_decision AS dag_run_1_last_scheduling_decision,
dag_run_1.dag_hash AS dag_run_1_dag_hash
FROM
(
SELECT
task_instance.task_id AS task_id,
max(dag_run.execution_date) AS max_ti
FROM
task_instance USE INDEX (PRIMARY)
INNER JOIN dag_run ON
dag_run.dag_id = task_instance.dag_id
AND dag_run.run_id = task_instance.run_id
WHERE
task_instance.dag_id = 'aggregates'
AND (task_instance.state = 'success'
OR task_instance.state = 'skipped')
AND task_instance.task_id IN ('uslicer_exact_fact_new_looker', 'geo_device_fact', 'check_yesterday', 'yesterday.dsp_inexact.check_for_aggregate', 'yesterday.dsp_inexact.check_for_overlap', 'yesterday.dsp_inexact.proceed_with_union', 'yesterday.dsp_inexact.proceed_without_union', 'yesterday.dsp_inexact.union_versions', 'yesterday.dsp_inexact.load', 'yesterday.dsp_inexact.trigger_Druid', 'yesterday.dsp_inexact.trigger_RS', 'yesterday.dsp_inexact.slack_notify', 'yesterday.dsp_inexact.prom_stats_RS', 'yesterday.dsp_exact.check_for_aggregate', 'yesterday.dsp_exact.check_for_overlap', 'yesterday.dsp_exact.proceed_with_union', 'yesterday.dsp_exact.proceed_without_union', 'yesterday.dsp_exact.union_versions', 'yesterday.dsp_exact.load', 'yesterday.dsp_exact.trigger_Druid', 'yesterday.dsp_exact.trigger_RS', 'yesterday.dsp_exact.slack_notify', 'yesterday.dsp_exact.prom_stats_RS', 'yesterday.ssp_inexact.check_for_aggregate', 'yesterday.ssp_inexact.check_for_overlap', 'yesterday.ssp_inexact
.proceed_with_union', 'yesterday.ssp_inexact.proceed_without_union', 'yesterday.ssp_inexact.union_versions', 'yesterday.ssp_inexact.load', 'yesterday.ssp_inexact.trigger_Druid', 'yesterday.ssp_inexact.trigger_RS', 'yesterday.ssp_inexact.slack_notify', 'yesterday.ssp_inexact.prom_stats_RS', 'yesterday.ssp_exact.check_for_aggregate', 'yesterday.ssp_exact.check_for_overlap', 'yesterday.ssp_exact.proceed_with_union', 'yesterday.ssp_exact.proceed_without_union', 'yesterday.ssp_exact.union_versions', 'yesterday.ssp_exact.load', 'yesterday.ssp_exact.trigger_Druid', 'yesterday.ssp_exact.trigger_RS', 'yesterday.ssp_exact.slack_notify', 'yesterday.ssp_exact.prom_stats_RS', 'yesterday.ssp_exact.trigger_RS.trigger_agg_line_item', 'agg_line_item.slack_notify', 'yesterday.ssp_open.check_for_aggregate', 'yesterday.ssp_open.check_for_overlap', 'yesterday.ssp_open.proceed_with_union', 'yesterday.ssp_open.proceed_without_union', 'yesterday.ssp_open.union_versions', 'yesterday.ssp_open.load', 'yesterd
ay.ssp_open.trigger_RS', 'yesterday.ssp_open.slack_notify', 'yesterday.uuid_report.check_for_aggregate', 'yesterday.uuid_report.check_for_overlap', 'yesterday.uuid_report.proceed_with_union', 'yesterday.uuid_report.proceed_without_union', 'yesterday.uuid_report.union_versions', 'yesterday.uuid_report.load', 'yesterday.uuid_report.trigger_RS', 'yesterday.uuid_report.slack_notify', 'check_today', 'today.dsp_inexact.check_for_aggregate', 'today.dsp_inexact.check_for_overlap', 'today.dsp_inexact.proceed_with_union', 'today.dsp_inexact.proceed_without_union', 'today.dsp_inexact.union_versions', 'today.dsp_inexact.load', 'today.dsp_inexact.trigger_Druid', 'today.dsp_exact.check_for_aggregate', 'today.dsp_exact.check_for_overlap', 'today.dsp_exact.proceed_with_union', 'today.dsp_exact.proceed_without_union', 'today.dsp_exact.union_versions', 'today.dsp_exact.load', 'today.dsp_exact.trigger_Druid', 'today.ssp_inexact.check_for_aggregate', 'today.ssp_inexact.check_for_overlap', 'today.ssp_in
exact.proceed_with_union', 'today.ssp_inexact.proceed_without_union', 'today.ssp_inexact.union_versions', 'today.ssp_inexact.load', 'today.ssp_inexact.trigger_Druid', 'today.ssp_exact.check_for_aggregate', 'today.ssp_exact.check_for_overlap', 'today.ssp_exact.proceed_with_union', 'today.ssp_exact.proceed_without_union', 'today.ssp_exact.union_versions', 'today.ssp_exact.load', 'today.ssp_exact.trigger_Druid', 'today.uuid_report.check_for_aggregate', 'today.uuid_report.check_for_overlap', 'today.uuid_report.proceed_with_union', 'today.uuid_report.proceed_without_union', 'today.uuid_report.union_versions', 'today.uuid_report.load')
GROUP BY
task_instance.task_id) AS sq,
task_instance
INNER JOIN dag_run ON
dag_run.dag_id = task_instance.dag_id
AND dag_run.run_id = task_instance.run_id
INNER JOIN dag_run AS dag_run_1 ON
dag_run_1.dag_id = task_instance.dag_id
AND dag_run_1.run_id = task_instance.run_id
WHERE
task_instance.dag_id = 'aggregates'
AND task_instance.task_id = sq.task_id
AND dag_run.execution_date = sq.max_ti
```
As you can see, there're excessive joins generated by ORM (dag_run joined twice for some reason), base select could be also more lightweight for what we're trying to achieve... Corresponding explain plan for this query is as follows:
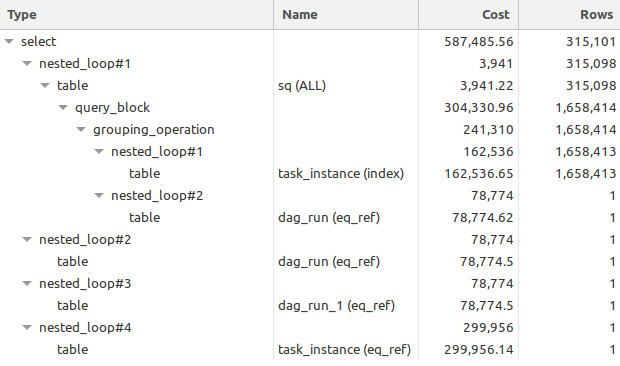
If I understood the logic correctly, what we need is as follows:
- get the latest instance of dag run
- attach task information associated with the dug run
- we're only interested in successful and skipped tasks
Then the simplified query might look like this:
```
SELECT
ti.try_number AS task_instance_try_number,
ti.task_id AS task_instance_task_id,
ti.dag_id AS task_instance_dag_id,
ti.run_id AS task_instance_run_id,
ti.start_date AS task_instance_start_date,
ti.end_date AS task_instance_end_date,
ti.duration AS task_instance_duration,
ti.state AS task_instance_state,
ti.max_tries AS task_instance_max_tries,
ti.hostname AS task_instance_hostname,
ti.unixname AS task_instance_unixname,
ti.job_id AS task_instance_job_id,
ti.pool AS task_instance_pool,
ti.pool_slots AS task_instance_pool_slots,
ti.queue AS task_instance_queue,
ti.priority_weight AS task_instance_priority_weight,
ti.operator AS task_instance_operator,
ti.queued_dttm AS task_instance_queued_dttm,
ti.queued_by_job_id AS task_instance_queued_by_job_id,
ti.pid AS task_instance_pid,
ti.executor_config AS task_instance_executor_config,
ti.external_executor_id AS task_instance_external_executor_id,
ti.trigger_id AS task_instance_trigger_id,
ti.trigger_timeout AS task_instance_trigger_timeout,
ti.next_method AS task_instance_next_method,
ti.next_kwargs AS task_instance_next_kwargs,
dr.state AS dag_run_1_state,
dr.id AS dag_run_1_id,
dr.dag_id AS dag_run_1_dag_id,
dr.queued_at AS dag_run_1_queued_at,
dr.execution_date AS dag_run_1_execution_date,
dr.start_date AS dag_run_1_start_date,
dr.end_date AS dag_run_1_end_date,
dr.run_id AS dag_run_1_run_id,
dr.creating_job_id AS dag_run_1_creating_job_id,
dr.external_trigger AS dag_run_1_external_trigger,
dr.run_type AS dag_run_1_run_type,
dr.conf AS dag_run_1_conf,
dr.data_interval_start AS dag_run_1_data_interval_start,
dr.data_interval_end AS dag_run_1_data_interval_end,
dr.last_scheduling_decision AS dag_run_1_last_scheduling_decision,
dr.dag_hash AS dag_run_1_dag_hash
FROM
(SELECT
dag_run.dag_id,
max(dag_run.execution_date) AS max_ti
FROM dag_run
WHERE
dag_run.dag_id = 'aggregates'
) s1
INNER JOIN dag_run dr ON
s1.dag_id = dr.dag_id
AND s1.max_ti = dr.execution_date
INNER JOIN task_instance ti ON
dr.dag_id = ti.dag_id
AND dr.run_id = ti.run_id
WHERE
(ti.state = 'success'
OR ti.state = 'skipped')
```
Corresponding explain plan:

I'm not sure, if my query is valid as per business logic, but I also noticed, that result of original query a bit off... It could be my misunderstanding of the logic, but it also could be a bug potentially...
Original query:

My query:

Both queries were executed at same time, they just return different results, original query returns previous task execution, not the latest, my query haven't such a problem.
This was done as a continuation of #25404 unfortunately I cannot prepare PR for this as I'm very bad at dealing with ORMs :)
### Are you willing to submit PR?
- [ ] Yes I am willing to submit a PR!
### Code of Conduct
- [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@airflow.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [airflow] potiuk commented on issue #25448: Schduler polling is extremely heavy for big DAGs
Posted by GitBox <gi...@apache.org>.
potiuk commented on issue #25448:
URL: https://github.com/apache/airflow/issues/25448#issuecomment-1203120078
I think this should start with optimising the ORM query itsellf @ashb here to chime-in. But you have to remember that we have multiple databases and SQLAlchemy mapping should work for all of them. Not all queries can be optimised, and - almost by definition - ORM is not there to run "most optimized" queries, but to run "portable queries" and to make it easier to manage and maintain the DB access. This means that not all cases and not all queries can (and should be) optimized.
However if you find a way to optimize certain ORM access using ORM features, that's what should be done.
Also theis is quite normal that some cases are better optimised than others and there are often trade-offs and compromises involved.
I do not want to comment on particular queries at this stage. But I would encourage you to take a look how the orm part can be improved - and working from that trying to follow the logic. If we cannot map super optimized query to ORM, it just might be not worthy doing it.
Some optimisations are not worth implementing.
But if we can both - show improvement and get an ORM way of getting there, then it's great.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@airflow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [airflow] boring-cyborg[bot] commented on issue #25448: Schduler polling is extremely heavy for big DAGs
Posted by GitBox <gi...@apache.org>.
boring-cyborg[bot] commented on issue #25448:
URL: https://github.com/apache/airflow/issues/25448#issuecomment-1201329760
Thanks for opening your first issue here! Be sure to follow the issue template!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@airflow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org