You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@tvm.apache.org by tq...@apache.org on 2020/11/03 14:05:20 UTC
[incubator-tvm-site] branch main updated: Update stale link
This is an automated email from the ASF dual-hosted git repository.
tqchen pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/incubator-tvm-site.git
The following commit(s) were added to refs/heads/main by this push:
new ce2f2e9 Update stale link
ce2f2e9 is described below
commit ce2f2e98787d1c332a4c1e895dbd2150b3e2afcb
Author: tqchen <ti...@gmail.com>
AuthorDate: Tue Nov 3 09:01:49 2020 -0500
Update stale link
---
...g-GPU-Operators-with-TVM-A-Depthwise-Convolution-Example.md | 6 +++---
...ringing-AMDGPUs-to-TVM-Stack-and-NNVM-Compiler-with-ROCm.md | 2 +-
_posts/2018-07-12-vta-release-announcement.markdown | 10 +++++-----
_posts/2018-08-10-DLPack-Bridge.md | 2 +-
_posts/2018-12-18-lowprecision-conv.md | 4 ++--
_posts/2019-01-19-Golang.md | 6 +++---
_posts/2019-04-30-opt-cuda-quantized.md | 10 +++++-----
7 files changed, 20 insertions(+), 20 deletions(-)
diff --git a/_posts/2017-08-22-Optimize-Deep-Learning-GPU-Operators-with-TVM-A-Depthwise-Convolution-Example.md b/_posts/2017-08-22-Optimize-Deep-Learning-GPU-Operators-with-TVM-A-Depthwise-Convolution-Example.md
index 494d531..388b4bb 100644
--- a/_posts/2017-08-22-Optimize-Deep-Learning-GPU-Operators-with-TVM-A-Depthwise-Convolution-Example.md
+++ b/_posts/2017-08-22-Optimize-Deep-Learning-GPU-Operators-with-TVM-A-Depthwise-Convolution-Example.md
@@ -409,9 +409,9 @@ The advantage of operator fusion is obvious.
This is not the end, TVM can do operator fusion in a smarter way. You may refer to [this](https://github.com/dmlc/tvm/issues/215) and read the source code provided below.
## Show me the code
-- Declare: [https://github.com/dmlc/tvm/blob/master/topi/python/topi/nn/depthwise_conv2d.py](https://github.com/dmlc/tvm/blob/master/topi/python/topi/nn/depthwise_conv2d.py)
-- Schedule: [https://github.com/dmlc/tvm/blob/master/topi/python/topi/cuda/depthwise_conv2d.py](https://github.com/dmlc/tvm/blob/master/topi/python/topi/cuda/depthwise_conv2d.py)
-- Test: [https://github.com/dmlc/tvm/blob/master/topi/recipe/conv/depthwise_conv2d_test.py](https://github.com/dmlc/tvm/blob/master/topi/recipe/conv/depthwise_conv2d_test.py)
+- Declare: [https://github.com/apache/incubator-tvm/blob/main/topi/python/topi/nn/depthwise_conv2d.py](https://github.com/apache/incubator-tvm/blob/main/topi/python/topi/nn/depthwise_conv2d.py)
+- Schedule: [https://github.com/apache/incubator-tvm/blob/main/topi/python/topi/cuda/depthwise_conv2d.py](https://github.com/apache/incubator-tvm/blob/main/topi/python/topi/cuda/depthwise_conv2d.py)
+- Test: [https://github.com/apache/incubator-tvm/blob/main/topi/recipe/conv/depthwise_conv2d_test.py](https://github.com/apache/incubator-tvm/blob/main/topi/recipe/conv/depthwise_conv2d_test.py)
## Acknowledgements
The author has many thanks to Tianqi Chen for his helpful advice and inspiring discussion.
diff --git a/_posts/2017-10-30-Bringing-AMDGPUs-to-TVM-Stack-and-NNVM-Compiler-with-ROCm.md b/_posts/2017-10-30-Bringing-AMDGPUs-to-TVM-Stack-and-NNVM-Compiler-with-ROCm.md
index 3073e40..5500e39 100644
--- a/_posts/2017-10-30-Bringing-AMDGPUs-to-TVM-Stack-and-NNVM-Compiler-with-ROCm.md
+++ b/_posts/2017-10-30-Bringing-AMDGPUs-to-TVM-Stack-and-NNVM-Compiler-with-ROCm.md
@@ -82,7 +82,7 @@ The input images are taken from the original paper, and they are available [here
## A Note on performance
-The current support on ROCm focuses on the functionality coverage. We have already seen promising performance results by simply adopting existing TVM schedules for CUDA backend. For example, you can try running [the gemm test script](https://github.com/dmlc/tvm/blob/master/topi/recipe/gemm/cuda_gemm_square.py) in the TVM repository and see the result. For two types of cards we tested, the current gemm recipe for square matrix multiplication (not yet specifically optimized for AMD GPUs) a [...]
+The current support on ROCm focuses on the functionality coverage. We have already seen promising performance results by simply adopting existing TVM schedules for CUDA backend. For example, you can try running [the gemm test script](https://github.com/apache/incubator-tvm/blob/main/topi/recipe/gemm/cuda_gemm_square.py) in the TVM repository and see the result. For two types of cards we tested, the current gemm recipe for square matrix multiplication (not yet specifically optimized for A [...]
This is already a promising start, as it is very hard to optimize performance to get to peak and we
did not yet apply AMD GPU specific optimizations.
We are starting to look at performance optimization and we expect more improvement to come.
diff --git a/_posts/2018-07-12-vta-release-announcement.markdown b/_posts/2018-07-12-vta-release-announcement.markdown
index 440d484..eb4e929 100644
--- a/_posts/2018-07-12-vta-release-announcement.markdown
+++ b/_posts/2018-07-12-vta-release-announcement.markdown
@@ -21,7 +21,7 @@ We are excited to announce the launch of the Versatile Tensor Accelerator (VTA,
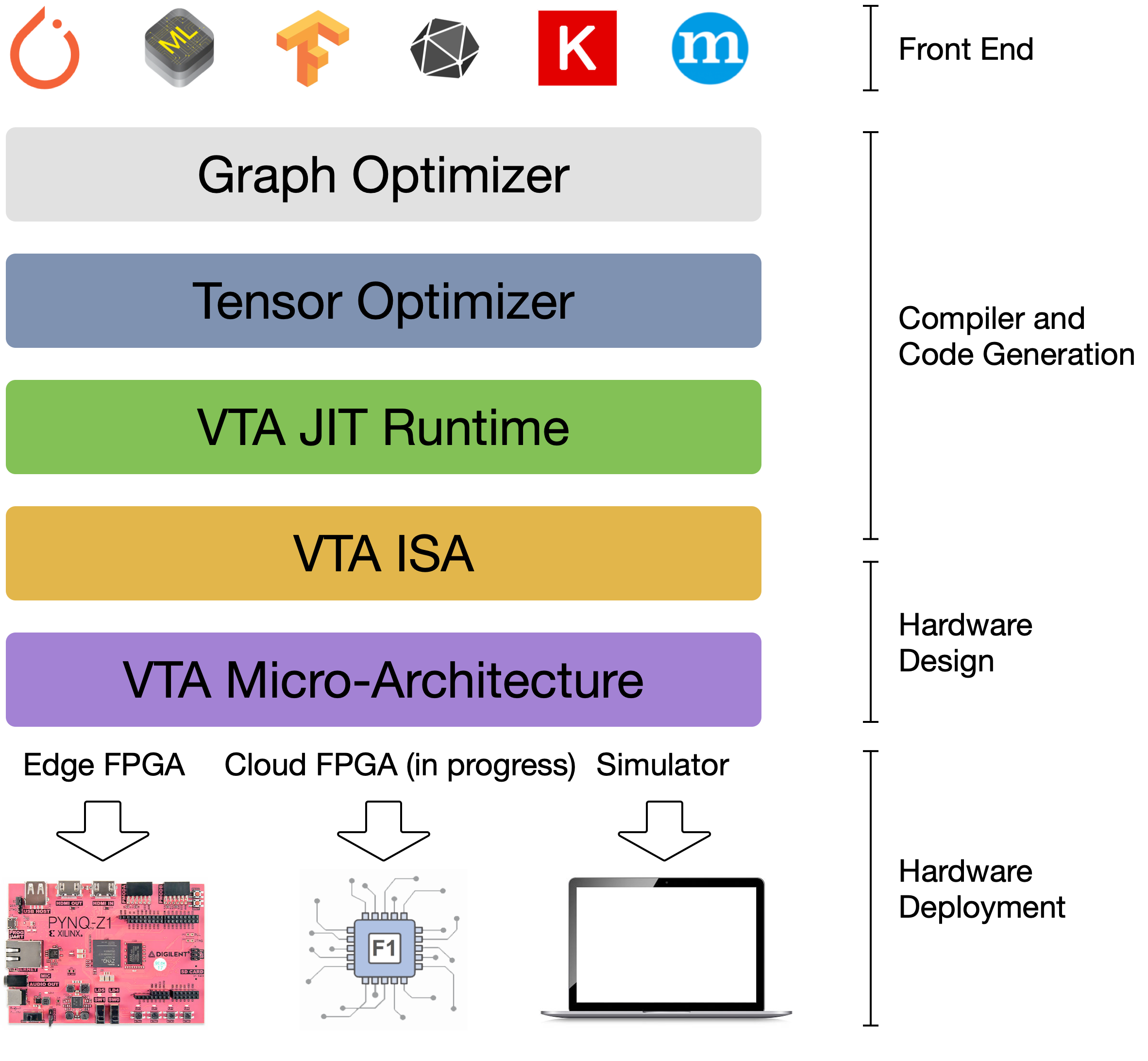
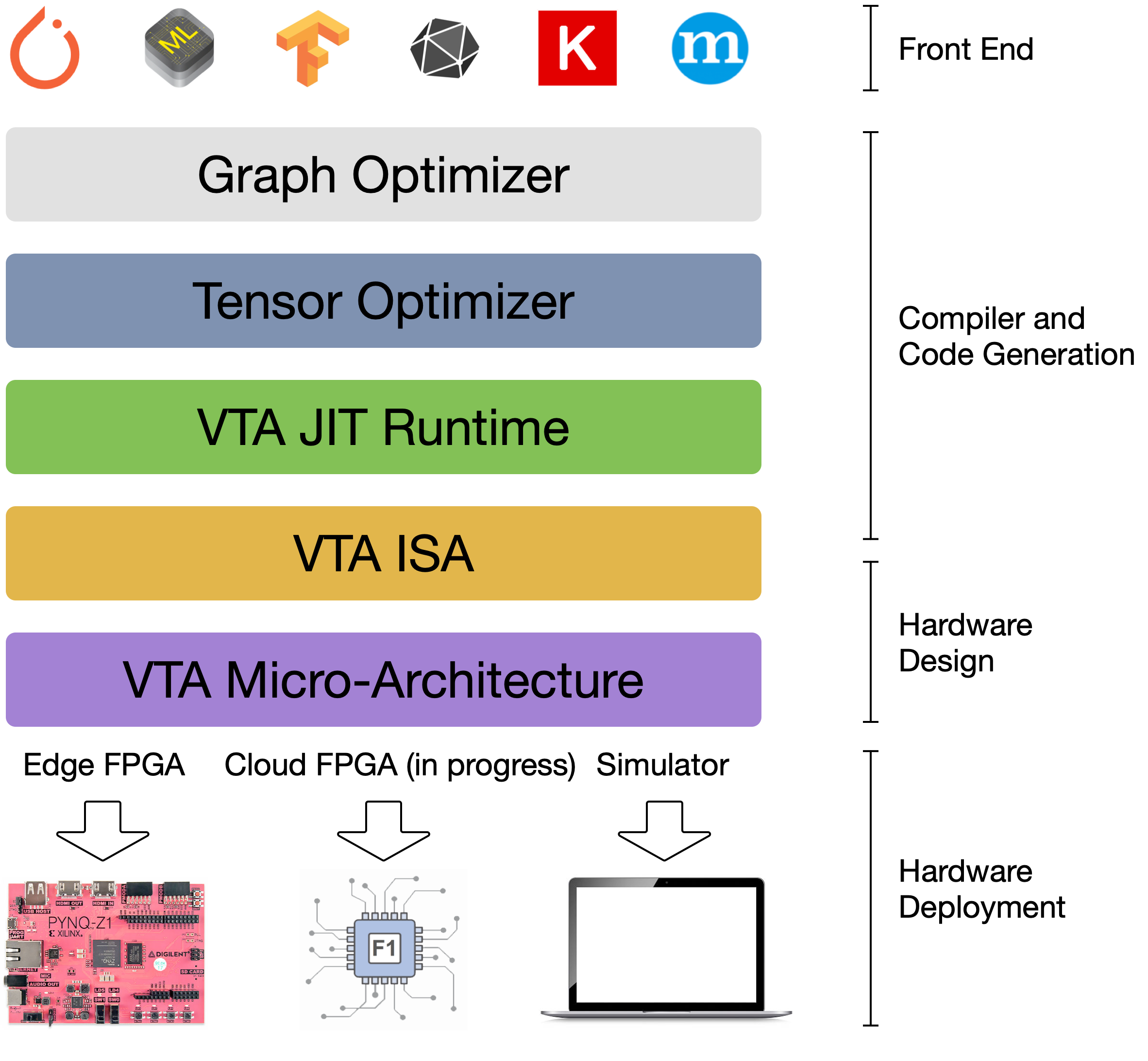
VTA is more than a standalone accelerator design: it’s an end-to-end solution that includes drivers, a JIT runtime, and an optimizing compiler stack based on TVM. The current release includes a behavioral hardware simulator, as well as the infrastructure to deploy VTA on low-cost FPGA hardware for fast prototyping. By extending the TVM stack with a customizable, and open source deep learning hardware accelerator design, we are exposing a transparent end-to-end deep learning stack from th [...]
{:center}
-{: width="50%"}
+{: width="50%"}
{:center}
The VTA and TVM stack together constitute a blueprint for end-to-end, accelerator-centric deep learning system that can:
@@ -76,7 +76,7 @@ The Vanilla Tensor Accelerator (VTA) is a generic deep learning accelerator buil
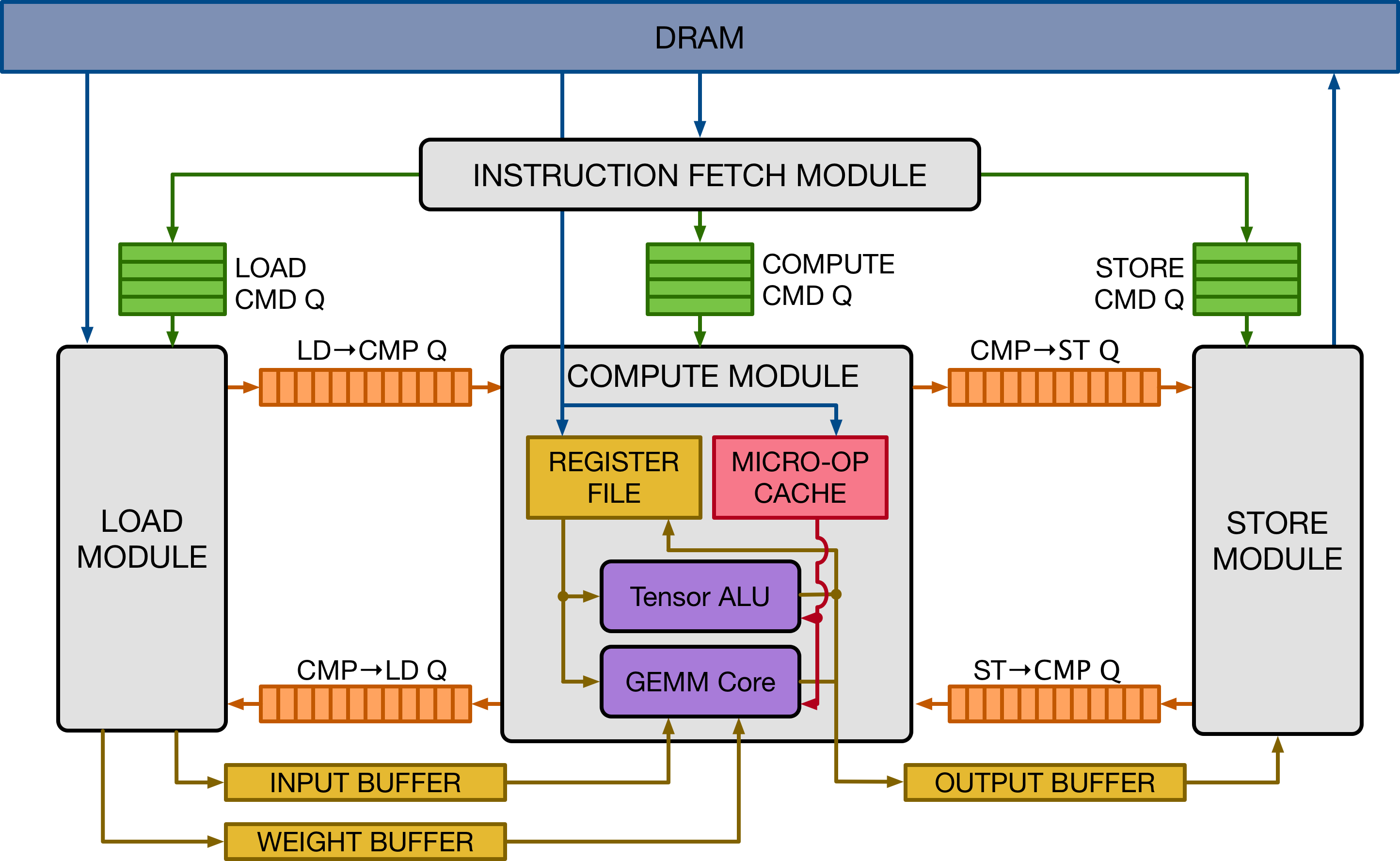
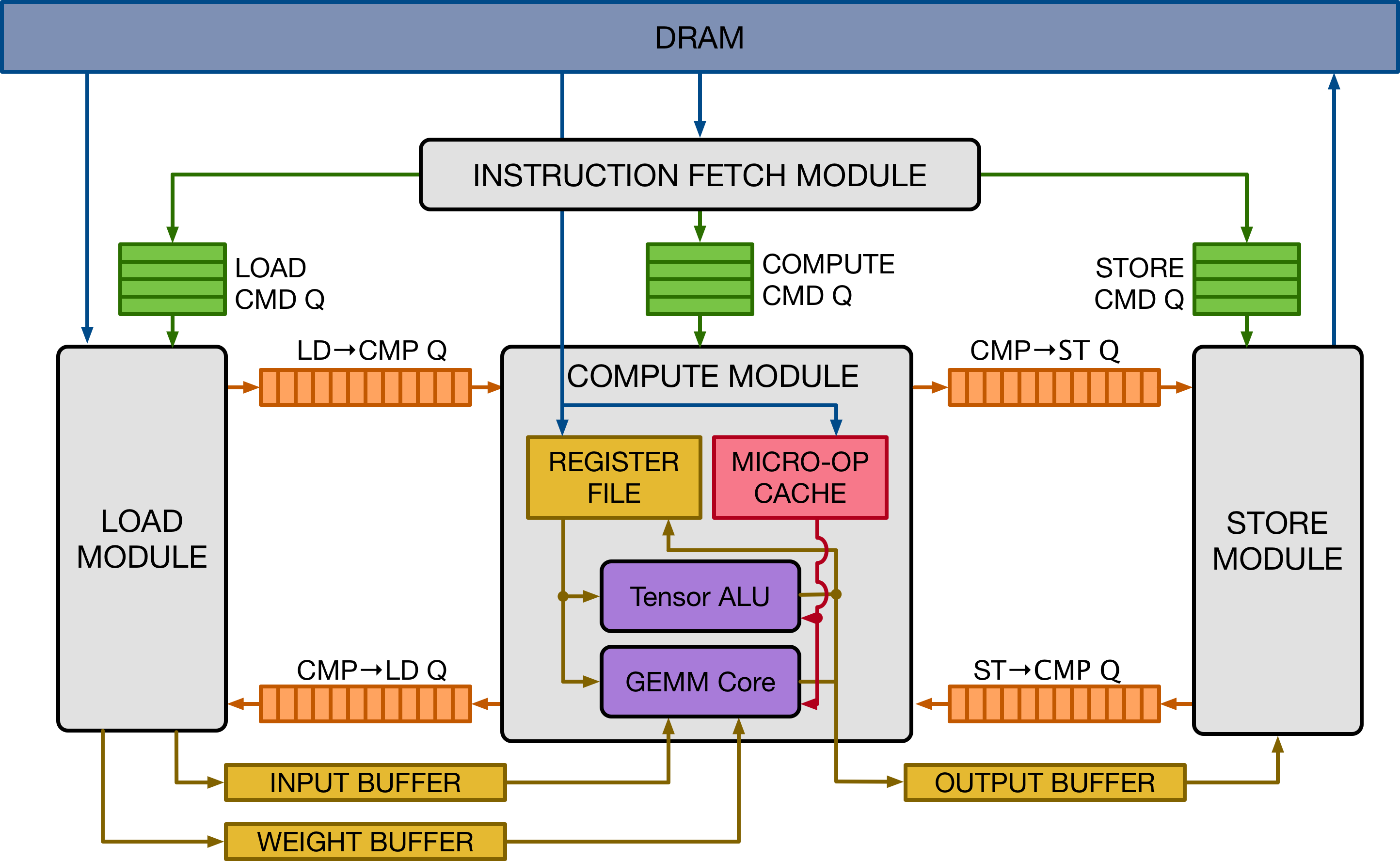
The design is inspired by mainstream deep learning accelerators, of the likes of Google's TPU accelerator. The design adopts decoupled access-execute to hide memory access latency and maximize utilization of compute resources. To a broader extent, VTA can serve as a template deep learning accelerator design, exposing a clean tensor computation abstraction to the compiler stack.
{:center}
-{: width="60%"}
+{: width="60%"}
{:center}
The figure above presents a high-level overview of the VTA hardware organization. VTA is composed of four modules that communicate between each other via FIFO queues and single-writer/single-reader SRAM memory blocks, to allow for task-level pipeline parallelism.
@@ -95,7 +95,7 @@ This simulator back-end is readily available for developers to experiment with.
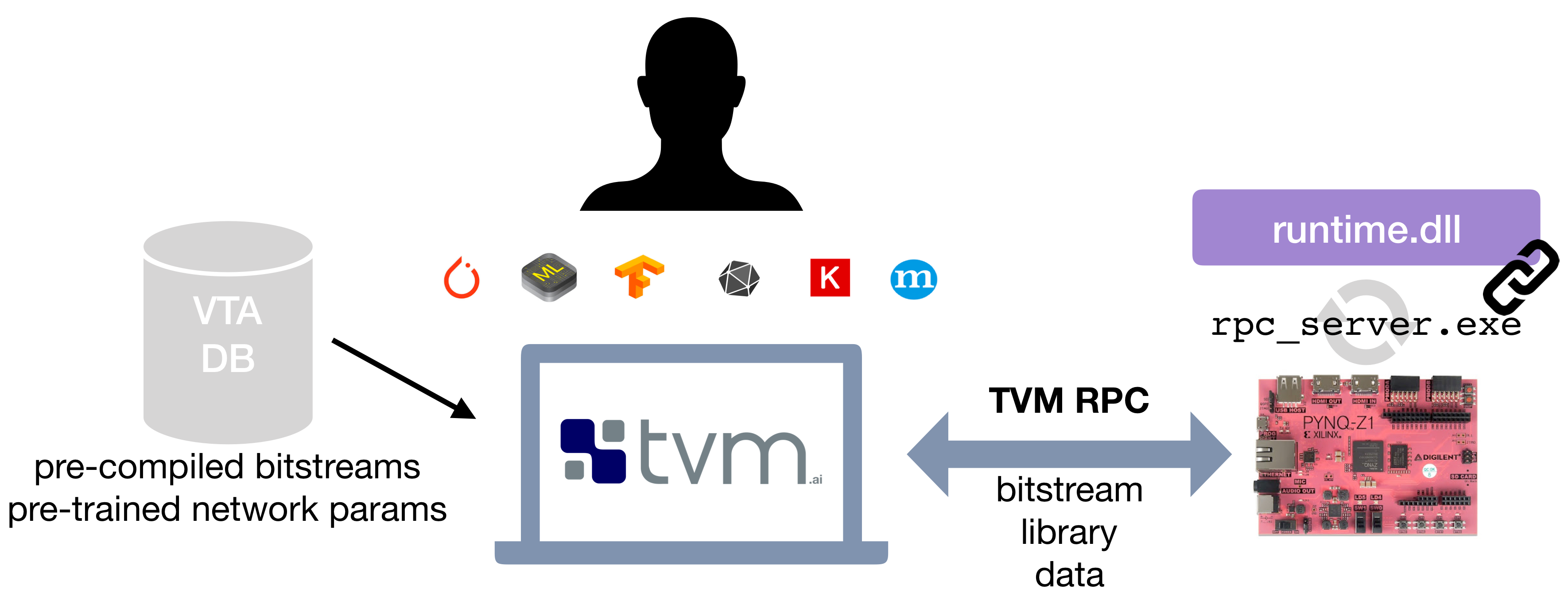
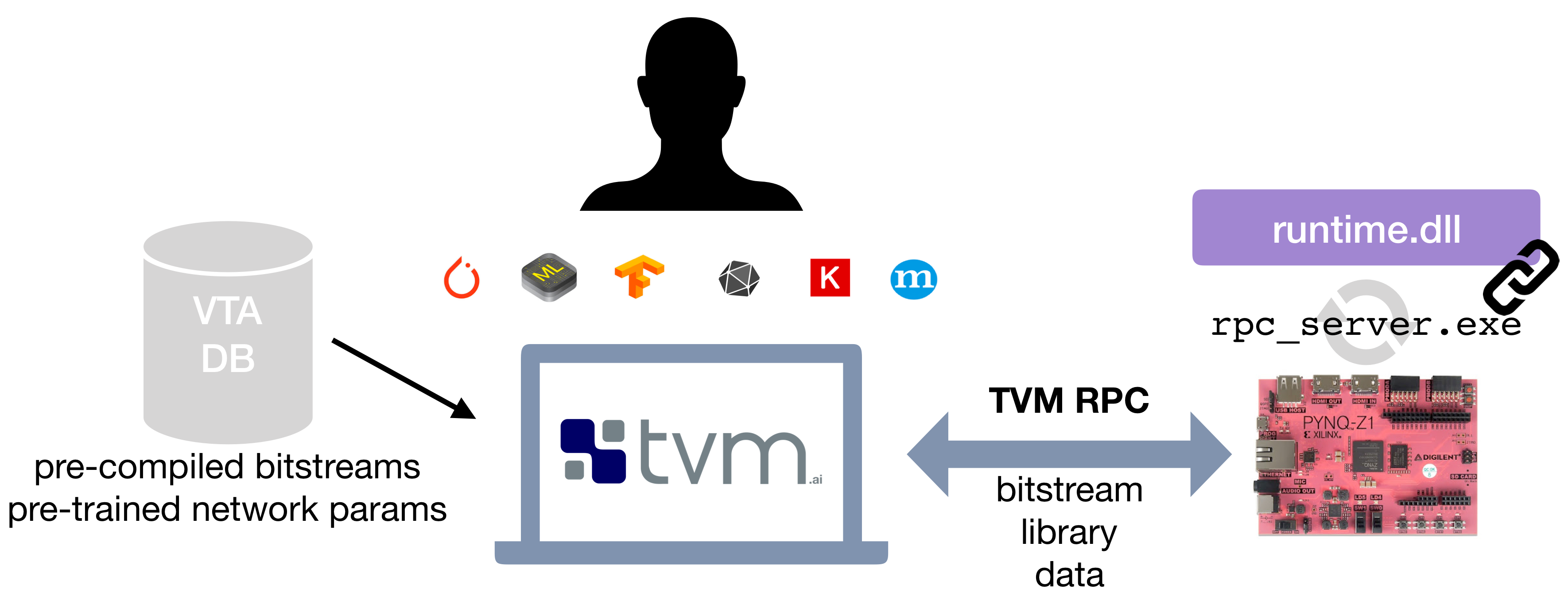
The second approach relies on an off-the-shelf and low-cost FPGA development board -- the [Pynq board](http://www.pynq.io/), which exposes a reconfigurable FPGA fabric and an ARM SoC.
{:center}
-{: width="70%"}
+{: width="70%"}
{:center}
The VTA release offers a simple compilation and deployment flow of the VTA hardware design and TVM workloads on the Pynq platform, with the help of an RPC server interface.
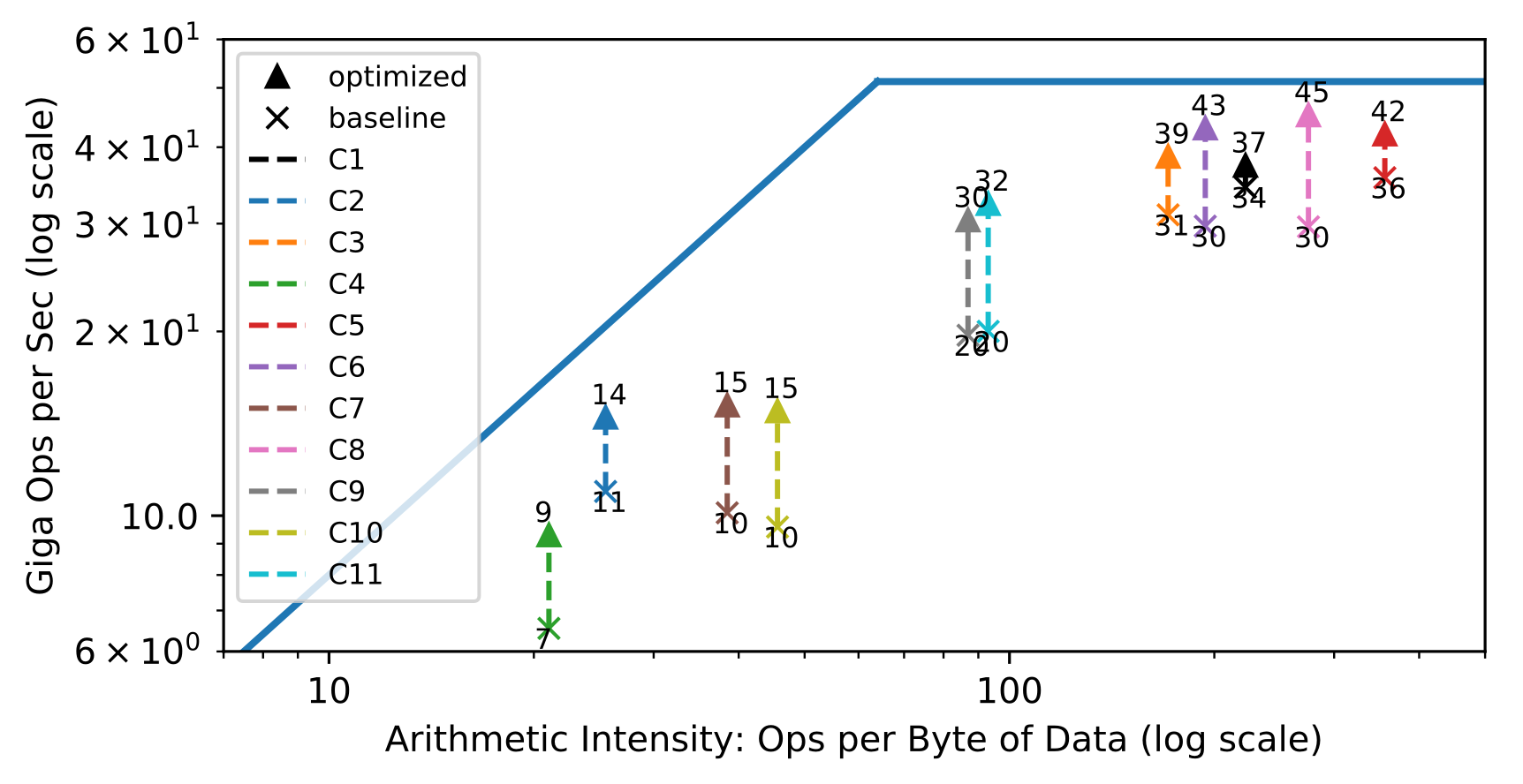
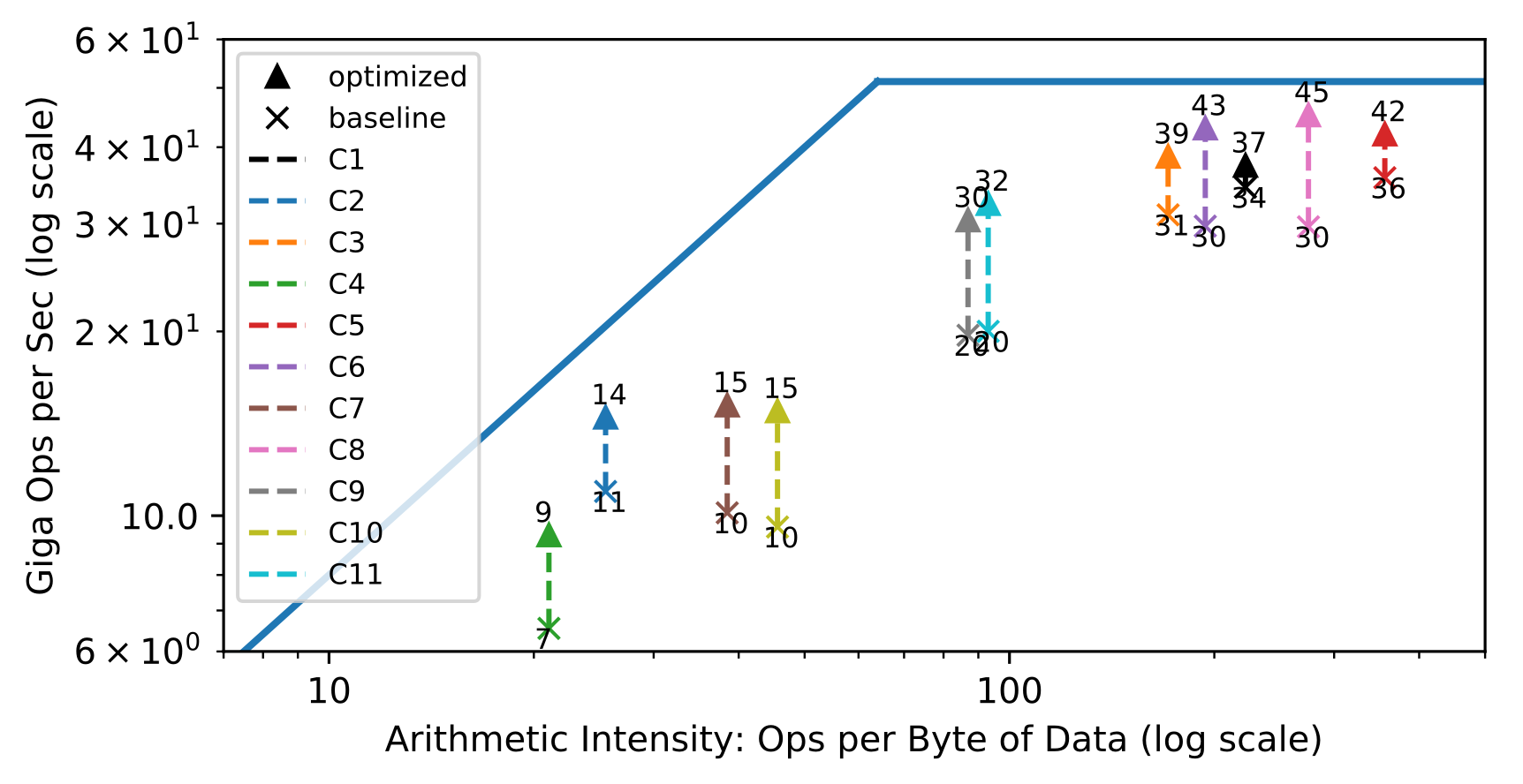
@@ -120,7 +120,7 @@ A popular method used to assess the efficient use of hardware are roofline diagr
In the left half, convolution layers are bandwidth limited, whereas on the right half, they are compute limited.
{:center}
-{: width="60%"}
+{: width="60%"}
{:center}
The goal behind designing a hardware architecture, and a compiler stack is to bring each workload as close as possible to the roofline of the target hardware.
@@ -131,7 +131,7 @@ The result is an overall higher utilization of the available compute and memory
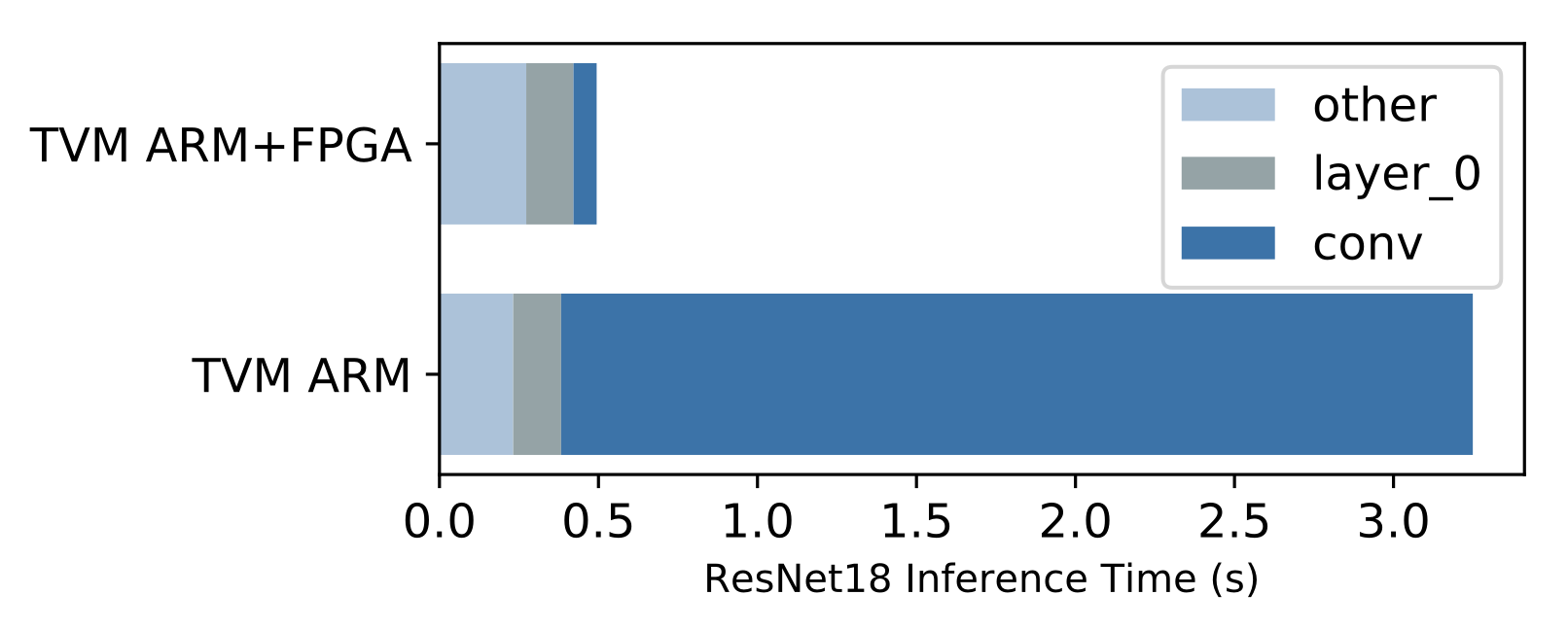
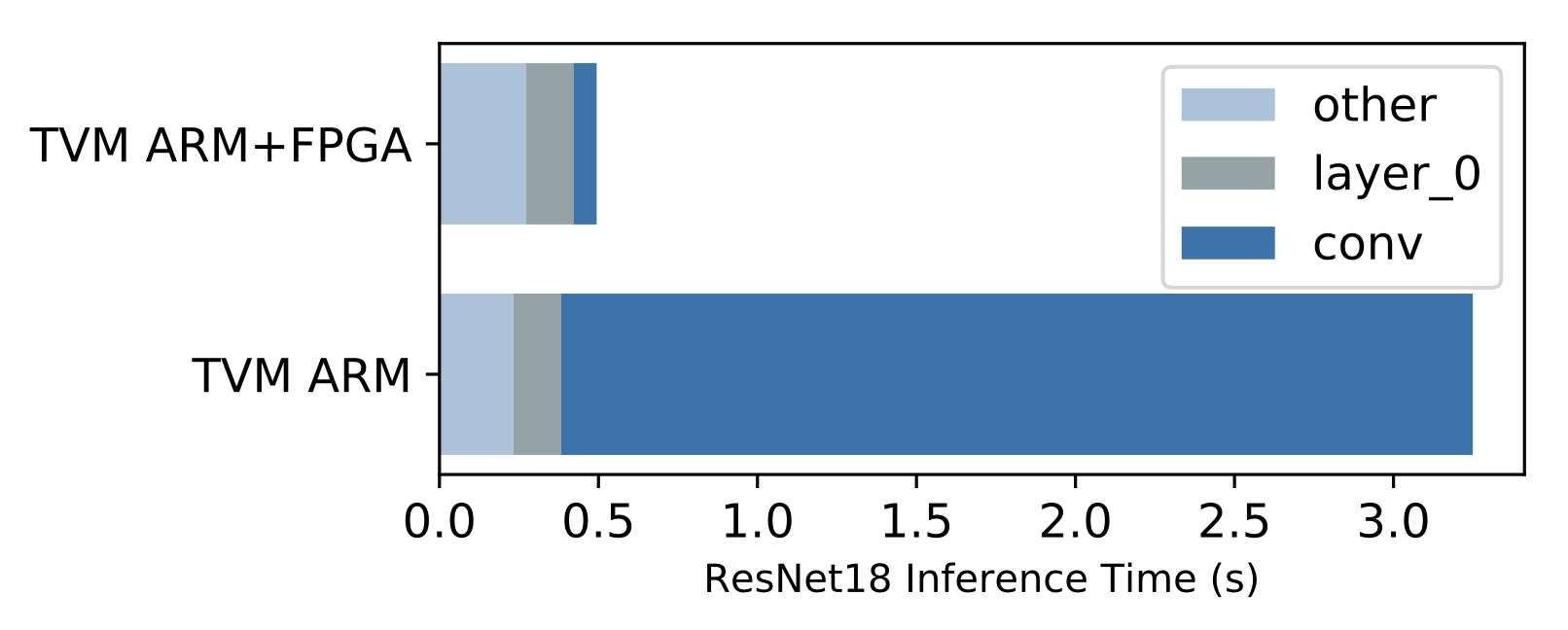
### End to end ResNet-18 evaluation
{:center}
-{: width="60%"}
+{: width="60%"}
{:center}
A benefit of having a complete compiler stack built for VTA is the ability to run end-to-end workloads. This is compelling in the context of hardware acceleration because we need to understand what performance bottlenecks, and Amdahl limitations stand in the way to obtaining faster performance.
diff --git a/_posts/2018-08-10-DLPack-Bridge.md b/_posts/2018-08-10-DLPack-Bridge.md
index fb4b2e2..8b9d875 100644
--- a/_posts/2018-08-10-DLPack-Bridge.md
+++ b/_posts/2018-08-10-DLPack-Bridge.md
@@ -126,7 +126,7 @@ We can repeat the same example, but using MxNet instead:
Under the hood of the PyTorch Example
-------------------------------------
-As TVM provides [functions](https://github.com/dmlc/tvm/blob/master/include/tvm/runtime/c_runtime_api.h#L455) to convert dlpack tensors to tvm `NDArray`s and
+As TVM provides [functions](https://github.com/apache/incubator-tvm/blob/main/include/tvm/runtime/c_runtime_api.h#L455) to convert dlpack tensors to tvm `NDArray`s and
vice-versa, so all that is needed is some syntactic sugar by wrapping functions.
`convert_func` is a generic converter for frameworks using tensors with dlpack
support, and can be used to implement convenient converters, such as
diff --git a/_posts/2018-12-18-lowprecision-conv.md b/_posts/2018-12-18-lowprecision-conv.md
index f8d2c62..58a4c1c 100644
--- a/_posts/2018-12-18-lowprecision-conv.md
+++ b/_posts/2018-12-18-lowprecision-conv.md
@@ -155,8 +155,8 @@ Note: x86 doesn’t support a vectorized popcount for this microarchitecture, so
## Show me the code
-- [TOPI bitserial convolution](https://github.com/dmlc/tvm/blob/master/topi/python/topi/nn/bitserial_conv2d.py)
-- [TOPI ARM cpu bitserial convolution](https://github.com/dmlc/tvm/blob/master/topi/python/topi/arm_cpu/bitserial_conv2d.py)
+- [TOPI bitserial convolution](https://github.com/apache/incubator-tvm/blob/main/topi/python/topi/nn/bitserial_conv2d.py)
+- [TOPI ARM cpu bitserial convolution](https://github.com/apache/incubator-tvm/blob/main/topi/python/topi/arm_cpu/bitserial_conv2d.py)
## References
diff --git a/_posts/2019-01-19-Golang.md b/_posts/2019-01-19-Golang.md
index 7825345..d559b14 100644
--- a/_posts/2019-01-19-Golang.md
+++ b/_posts/2019-01-19-Golang.md
@@ -147,13 +147,13 @@ func main() {
```
```gotvm``` extends the TVM packed function system to support golang function closures as packed functions.
-[Examples](https://github.com/dmlc/tvm/blob/master/golang/sample) available to register golang
+[Examples](https://github.com/apache/incubator-tvm/blob/main/golang/sample) available to register golang
closure as TVM packed function and invoke the same across programming language barriers.
## Show me the code
-- [Package Source](https://github.com/dmlc/tvm/blob/master/golang/src)
-- [Examples](https://github.com/dmlc/tvm/blob/master/golang/sample)
+- [Package Source](https://github.com/apache/incubator-tvm/blob/main/golang/src)
+- [Examples](https://github.com/apache/incubator-tvm/blob/main/golang/sample)
## References
diff --git a/_posts/2019-04-30-opt-cuda-quantized.md b/_posts/2019-04-30-opt-cuda-quantized.md
index ecacd6e..777d946 100644
--- a/_posts/2019-04-30-opt-cuda-quantized.md
+++ b/_posts/2019-04-30-opt-cuda-quantized.md
@@ -73,7 +73,7 @@ Figure 2. 2D convolution with data layout in NCHW4c and weight layout in OIHW4o4
<b>Right</b>: The output in NCHW4c layout. Inside the one element depicted, there are four packed elements in channel sub-dimension.
</div><p></p>
-After we have specified the layout of convolution layers, other operators such as `add` and activations can automatically adapt to the chosen layout during the [AlterOpLayout](https://github.com/dmlc/tvm/blob/master/src/relay/pass/alter_op_layout.cc) pass in Relay.
+After we have specified the layout of convolution layers, other operators such as `add` and activations can automatically adapt to the chosen layout during the [AlterOpLayout](https://github.com/apache/incubator-tvm/blob/main/src/relay/pass/alter_op_layout.cc) pass in Relay.
The layout transformation of the weight can be precomputed offline. Therefore, we can run the whole model in the same layout without extra overhead.
## Designing Search Space for Automatic Optimization
@@ -138,10 +138,10 @@ We show that automatic optimization in TVM makes it easy and flexible to support
# Show Me the Code
* [Benchmark](https://github.com/vinx13/tvm-cuda-int8-benchmark)
-* [CUDA int8 conv2d](https://github.com/dmlc/tvm/blob/master/topi/python/topi/cuda/conv2d_int8.py)
-* [CUDA int8 group conv2d](https://github.com/dmlc/tvm/blob/master/topi/python/topi/cuda/group_conv2d_nchw.py)
-* [CUDA int8 dense](https://github.com/dmlc/tvm/blob/master/topi/python/topi/cuda/dense.py)
-* [Tensor intrinsics declaration](https://github.com/dmlc/tvm/blob/master/topi/python/topi/cuda/tensor_intrin.py)
+* [CUDA int8 conv2d](https://github.com/apache/incubator-tvm/blob/main/topi/python/topi/cuda/conv2d_int8.py)
+* [CUDA int8 group conv2d](https://github.com/apache/incubator-tvm/blob/main/topi/python/topi/cuda/group_conv2d_nchw.py)
+* [CUDA int8 dense](https://github.com/apache/incubator-tvm/blob/main/topi/python/topi/cuda/dense.py)
+* [Tensor intrinsics declaration](https://github.com/apache/incubator-tvm/blob/main/topi/python/topi/cuda/tensor_intrin.py)
# Bio & Acknowledgement
[Wuwei Lin](https://wuwei.io/) is an undergraduate student at SJTU. He is currently an intern at TuSimple. The author has many thanks to [Tianqi Chen](https://homes.cs.washington.edu/~tqchen/) and [Eddie Yan](https://homes.cs.washington.edu/~eqy/) for their reviews.