You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@streampark.apache.org by be...@apache.org on 2022/09/19 04:50:03 UTC
[incubator-streampark-website] branch dev updated: project name streamx change to stremapark (#137)
This is an automated email from the ASF dual-hosted git repository.
benjobs pushed a commit to branch dev
in repository https://gitbox.apache.org/repos/asf/incubator-streampark-website.git
The following commit(s) were added to refs/heads/dev by this push:
new 8e989b6 project name streamx change to stremapark (#137)
8e989b6 is described below
commit 8e989b66ab404b3303354289c808be6077d4334b
Author: benjobs <be...@apache.org>
AuthorDate: Mon Sep 19 12:49:58 2022 +0800
project name streamx change to stremapark (#137)
* project name streamx change to stremapark
---
README_ZH.md | 2 +-
...\345\217\221\345\210\251\345\231\250StreamX.md" | 32 +++----
community/submit_guide/document.md | 2 +-
docs/connector/1-kafka.md | 96 ++++++++++-----------
docs/connector/2-jdbc.md | 34 ++++----
docs/connector/3-clickhouse.md | 8 +-
docs/connector/4-doris.md | 12 +--
docs/connector/5-es.md | 10 +--
docs/connector/6-hbase.md | 16 ++--
docs/connector/7-http.md | 4 +-
docs/connector/8-redis.md | 4 +-
docs/development/conf.md | 2 +-
docs/development/model.md | 18 ++--
docs/flink-k8s/1-deployment.md | 2 +-
docs/user-guide/{deployment.md => 1-deployment.md} | 14 +--
docs/user-guide/{quickstart.md => 2-quickstart.md} | 4 +-
.../{development.md => 3-development.md} | 14 +--
.../{dockerDeployment.md => 4-dockerDeployment.md} | 0
docs/user-guide/{LDAP.md => 5-LDAP.md} | 0
docs/user-guide/rainbondDeployment.md | 86 ------------------
.../current/connector/1-kafka.md | 94 ++++++++++----------
.../current/connector/2-jdbc.md | 34 ++++----
.../current/connector/3-clickhouse.md | 8 +-
.../current/connector/4-doris.md | 12 +--
.../current/connector/5-es.md | 12 +--
.../current/connector/6-hbase.md | 16 ++--
.../current/connector/7-http.md | 4 +-
.../current/connector/8-redis.md | 4 +-
.../current/development/conf.md | 4 +-
.../current/development/model.md | 20 ++---
.../current/intro.md | 2 +-
.../current/user-guide/deployment.md | 12 +--
.../current/user-guide/development.md | 8 +-
.../current/user-guide/dockerDeployment.md | 12 +--
.../current/user-guide/rainbondDeployment.md | 2 +-
package.json | 2 +-
static/home/streamx-archite.png | Bin 313125 -> 466387 bytes
static/image/{logo1.svg => logo_name.svg} | 0
static/image/users.png | Bin 0 -> 182179 bytes
39 files changed, 260 insertions(+), 346 deletions(-)
diff --git a/README_ZH.md b/README_ZH.md
index 8849b78..36a03c3 100644
--- a/README_ZH.md
+++ b/README_ZH.md
@@ -19,7 +19,7 @@ dev 默认分支
本网站是使用node编译的,使用的是Docusaurus框架组件
1. 下载并安装 nodejs(version>12.5.0)
-2. 克隆代码到本地 `git clone git@github.com:apache/incubator-streampark-website.git`
+2. 克隆代码到本地 `git clone git@github.com:apache/incubator-streampark-website.git`
2. 运行 `npm install` 来安装所需的依赖库。
3. 在根目录运行`npm run start`,可以访问http://localhost:3000查看站点英文模式预览
4. 在根目录运行`npm run start-zh`,可以访问http://localhost:3000查看站点的中文模式预览
diff --git "a/blog/Flink\345\274\200\345\217\221\345\210\251\345\231\250StreamX.md" "b/blog/Flink\345\274\200\345\217\221\345\210\251\345\231\250StreamX.md"
index 8dd9833..ae02932 100644
--- "a/blog/Flink\345\274\200\345\217\221\345\210\251\345\231\250StreamX.md"
+++ "b/blog/Flink\345\274\200\345\217\221\345\210\251\345\231\250StreamX.md"
@@ -1,5 +1,5 @@
---
-slug: flink-development-framework-streamx
+slug: flink-development-framework-streampark
title: Flink开发利器StreamPark
tags: [StreamPark, DataStream, FlinkSQL]
---
@@ -47,7 +47,7 @@ Flink从1.13版本开始,就支持Pod Template,我们可以在Pod Template
<br/>
-## 引入StreamX
+## 引入StreamPark
之前我们写Flink Sql 基本上都是使用Java包装Sql,打jar包,提交到s3平台上,通过命令行方式提交代码,但这种方式始终不友好,流程繁琐,开发和运维成本太大。我们希望能够进一步简化流程,将Flink TableEnvironment 抽象出来,有平台负责初始化、打包运行Flink任务,实现Flink应用程序的构建、测试和部署自动化。
@@ -114,7 +114,7 @@ Flink从1.13版本开始,就支持Pod Template,我们可以在Pod Template
<br/>
-调研过程中,我们与两者的主开发人员都进行了多次沟通。经过我们反复研究之后,还是决定将StreamX作为我们目前的Flink开发工具来使用。
+调研过程中,我们与两者的主开发人员都进行了多次沟通。经过我们反复研究之后,还是决定将 StreamPark 作为我们目前的Flink开发工具来使用。
<video src="http://assets.streamxhub.com/streamx-video.mp4" controls="controls" width="100%" height="100%"></video>
@@ -122,7 +122,7 @@ Flink从1.13版本开始,就支持Pod Template,我们可以在Pod Template
<br/>
-经过开发同学长时间开发测试,StreamX目前已经具备:
+经过开发同学长时间开发测试,StreamPark 目前已经具备:
* 完善的<span style={{"color": "red"}}>Sql校验功能</span>
* 实现了<span style={{"color": "red"}}>自动build/push镜像</span>
* 使用自定义类加载器,通过Child-first 加载方式 <span style={{"color": "red"}}>解决了YARN和K8s两种运行模式</span>、<span style={{"color": "red"}}>支持了自由切换Flink多版本</span>
@@ -133,10 +133,10 @@ Flink从1.13版本开始,就支持Pod Template,我们可以在Pod Template
<video src="http://assets.streamxhub.com/streamx-1.2.0.mp4" controls="controls" width="100%" height="100%"></video>
-<center style={{"color": "gray"}}>(StreamX对Flink多版本的支持演示视频)</center>
+<center style={{"color": "gray"}}>(StreamPark对Flink多版本的支持演示视频)</center>
<br/>
-在目前最新发布的1.2.0版本中,StreamX较为完善的支持了K8s-Native-Application和K8s-session-Application模式。
+在目前最新发布的1.2.0版本中,StreamPark较为完善的支持了K8s-Native-Application和K8s-session-Application模式。
<video src="http://assets.streamxhub.com/streamx-k8s.mp4" controls="controls" width="100%" height="100%"></video>
@@ -146,7 +146,7 @@ Flink从1.13版本开始,就支持Pod Template,我们可以在Pod Template
### K8s Native Application 模式
-在StreamX中,我们只需要配置相应的参数,并在Maven pom中填写相应的依赖,或者上传依赖jar包,点击Apply,相应的依赖就会生成。这就意味着我们也可以将所有使用的Udf打成jar包 and 各种 connector.jar,直接在sql中使用。如下图:
+在StreamPark中,我们只需要配置相应的参数,并在Maven pom中填写相应的依赖,或者上传依赖jar包,点击Apply,相应的依赖就会生成。这就意味着我们也可以将所有使用的Udf打成jar包 and 各种 connector.jar,直接在sql中使用。如下图:

@@ -159,7 +159,7 @@ Sql校验能力和 Zeppelin基本一致:

-程序保存后,点击运行时,也可以指定savepoint。任务提交成功后,StreamX会根据FlinkPod网络Exposed Type(loadBalancer/Nodeport/ClusterIp),返回相应的WebURL,从而自然的实现WebUI跳转,但是目前因为线上私有K8s集群出于安全性考虑,尚未打通Pod与客户端节点网络(目前也没有这个规划),所以我们只使用Nodeport。如果后续任务数过多,有使用ClusterIP的需求的话,我们可能会将StreamX 部署在K8s,或者同ingress做进一步整合。
+程序保存后,点击运行时,也可以指定savepoint。任务提交成功后,StreamPark会根据FlinkPod网络Exposed Type(loadBalancer/Nodeport/ClusterIp),返回相应的WebURL,从而自然的实现WebUI跳转,但是目前因为线上私有K8s集群出于安全性考虑,尚未打通Pod与客户端节点网络(目前也没有这个规划),所以我们只使用Nodeport。如果后续任务数过多,有使用ClusterIP的需求的话,我们可能会将StreamPark 部署在K8s,或者同ingress做进一步整合。

@@ -175,7 +175,7 @@ Sql校验能力和 Zeppelin基本一致:
### K8s Native Session 模式
-StreamX还较好的支持了 <span style={{"color": "red"}}> K8s Native-Sesson模式 </span>,这为我们后续做离线FlinkSql开发或部分资源隔离做了较好的技术支持。
+StreamPark还较好的支持了 <span style={{"color": "red"}}> K8s Native-Sesson模式 </span>,这为我们后续做离线FlinkSql开发或部分资源隔离做了较好的技术支持。
Native-session模式需要事先使用Flink命令创建一个运行在K8s中的Flink集群,如下:
@@ -193,7 +193,7 @@ Native-session模式需要事先使用Flink命令创建一个运行在K8s中的F

-如上图,使用该ClusterId作为StreamX的任务参数Kubernetes ClusterId。保存提交任务后,任务会很快处于Running状态
+如上图,使用该ClusterId作为StreamPark的任务参数Kubernetes ClusterId。保存提交任务后,任务会很快处于Running状态

@@ -203,14 +203,14 @@ Native-session模式需要事先使用Flink命令创建一个运行在K8s中的F

-可以看到,其实StreamX是将jar包通过Rest Api上传到Flink集群上,并调度执行任务的。
+可以看到,其实StreamPark是将jar包通过Rest Api上传到Flink集群上,并调度执行任务的。
<br/>
### Custom Code模式
-另我们惊喜的是,StreamPark 还支持代码编写DataStream/FlinkSql任务。对于特殊需求,我们可以自己写Java/Scala实现。可以根据StreamX推荐的脚手架方式编写任务,也可以编写一个标准普通的Flink任务,通过这种方式我们可以将代码管理交由Git实现,平台可以用来自动化编译打包与部署。当然,如果能用Sql实现的功能,我们会尽量避免自定义DataStream,减少不必要的运维麻烦。
+另我们惊喜的是,StreamPark 还支持代码编写DataStream/FlinkSql任务。对于特殊需求,我们可以自己写Java/Scala实现。可以根据StreamPark推荐的脚手架方式编写任务,也可以编写一个标准普通的Flink任务,通过这种方式我们可以将代码管理交由Git实现,平台可以用来自动化编译打包与部署。当然,如果能用Sql实现的功能,我们会尽量避免自定义DataStream,减少不必要的运维麻烦。
<br/><br/>
@@ -219,7 +219,7 @@ Native-session模式需要事先使用Flink命令创建一个运行在K8s中的F
## 改进意见
-当然StreamX还有很多需要改进的地方,就目前测试来看:
+当然StreamPark还有很多需要改进的地方,就目前测试来看:
* 资源管理还有待加强
多文件系统jar包等资源管理功能尚未添加,任务版本功能有待加强。
* 前端buttern 功能还不够丰富
@@ -227,7 +227,7 @@ Native-session模式需要事先使用Flink命令创建一个运行在K8s中的F
* 任务提交日志也需要可视化展示
任务提交伴随着加载class文件,打jar包,build镜像,提交镜像,提交任务等过程,每一个环节出错,都会导致任务的失败,但是失败日志往往不明确,或者因为某种原因导致异常未正常抛出,没有转换任务状态,用户会无从下手改进。
-众所周知,一个新事物的出现一开始总会不是那么完美。尽管有些许问题和需要改进的point,但是瑕不掩瑜,我们仍然选择StreamX作为我们的Flink DevOps,我们也将会和主开发人员一道共同完善StreamX,也欢迎更多的人来使用,为StreamX带来更多进步。
+众所周知,一个新事物的出现一开始总会不是那么完美。尽管有些许问题和需要改进的point,但是瑕不掩瑜,我们仍然选择StreamPark作为我们的Flink DevOps,我们也将会和主开发人员一道共同完善StreamPark,也欢迎更多的人来使用,为StreamPark带来更多进步。
<br/>
@@ -235,11 +235,11 @@ Native-session模式需要事先使用Flink命令创建一个运行在K8s中的F
* 我们会继续跟进doris,并将业务数据 + 日志数据统一入doris,通过Flink实现湖仓一体;
-* 我们也会逐步将探索StreamX同dolphinscheduler 2.x进行整合,完善dolphinscheduler离线任务,逐步用Flink 替换掉Spark,实现真正的流批一体;
+* 我们也会逐步将探索StreamPark同dolphinscheduler 2.x进行整合,完善dolphinscheduler离线任务,逐步用Flink 替换掉Spark,实现真正的流批一体;
* 基于我们自身在s3上的探索积累,fat-jar包 build 完成之后不再构建镜像,直接利用Pod Tempelet挂载pvc到Flink pod中的目录,进一步优化代码提交流程;
-* 将StreamX持续应用到我们生产中,并汇同社区开发人员,共同努力,增强StreamX在Flink流上的开发部署能力与运行监控能力,努力把StreamX打造成一个功能完善的流数据 DevOps。
+* 将StreamPark持续应用到我们生产中,并汇同社区开发人员,共同努力,增强StreamPark在Flink流上的开发部署能力与运行监控能力,努力把StreamPark打造成一个功能完善的流数据 DevOps。
附:
diff --git a/community/submit_guide/document.md b/community/submit_guide/document.md
index 01ad69a..4e10cee 100644
--- a/community/submit_guide/document.md
+++ b/community/submit_guide/document.md
@@ -30,7 +30,7 @@ Documentation for the StreamPark project is maintained in a separate [git reposi
First you need to fork the document project into your own github repository, and then clone the document to your local computer.
```shell
-git clone https://github.com/<your-github-user-name>/incubator-streampark-website
+git clone git@github.com:<your-github-user-name>/incubator-streampark-website
```
## Preview and generate static files
diff --git a/docs/connector/1-kafka.md b/docs/connector/1-kafka.md
index 735049c..516b8ba 100644
--- a/docs/connector/1-kafka.md
+++ b/docs/connector/1-kafka.md
@@ -17,8 +17,8 @@ import TabItem from '@theme/TabItem';
```xml
<dependency>
- <groupId>com.streamxhub.streamx</groupId>
- <artifactId>Streamx-flink-core</artifactId>
+ <groupId>org.apache.streampark/groupId>
+ <artifactId>streampark-flink-core</artifactId>
<version>${project.version}</version>
</dependency>
@@ -87,11 +87,11 @@ The prefix `kafka.source` is fixed, and the parameters related to kafka properti
<TabItem value="scala" label="Scala" default>
```scala
-package com.streamxhub.streamx.flink.quickstart
+package org.apache.streampark.flink.quickstart
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.JdbcSink
-import com.streamxhub.streamx.flink.core.scala.source.KafkaSource
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.JdbcSink
+import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.scala._
object kafkaSourceApp extends FlinkStreaming {
@@ -110,11 +110,11 @@ object kafkaSourceApp extends FlinkStreaming {
<TabItem value="Java" label="Java">
```java
-import com.streamxhub.streamx.flink.core.java.function.StreamEnvConfigFunction;
-import com.streamxhub.streamx.flink.core.java.source.KafkaSource;
-import com.streamxhub.streamx.flink.core.scala.StreamingContext;
-import com.streamxhub.streamx.flink.core.scala.source.KafkaRecord;
-import com.streamxhub.streamx.flink.core.scala.util.StreamEnvConfig;
+import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
+import org.apache.streampark.flink.core.java.source.KafkaSource;
+import org.apache.streampark.flink.core.scala.StreamingContext;
+import org.apache.streampark.flink.core.scala.source.KafkaRecord;
+import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
@@ -423,10 +423,10 @@ If you do not specify `deserializer`, the data in the topic will be deserialized
<TabItem value="Scala" label="Scala">
```scala
-import com.streamxhub.streamx.common.util.JsonUtils
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.JdbcSink
-import com.streamxhub.streamx.flink.core.scala.source.KafkaSource
+import org.apache.streampark.common.util.JsonUtils
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.JdbcSink
+import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.typeutils.TypeExtractor.getForClass
import org.apache.flink.api.scala._
@@ -461,11 +461,11 @@ case class User(name:String,age:Int,gender:Int,address:String)
```java
import com.fasterxml.jackson.databind.ObjectMapper;
-import com.streamxhub.streamx.flink.core.java.function.StreamEnvConfigFunction;
-import com.streamxhub.streamx.flink.core.java.source.KafkaSource;
-import com.streamxhub.streamx.flink.core.scala.StreamingContext;
-import com.streamxhub.streamx.flink.core.scala.source.KafkaRecord;
-import com.streamxhub.streamx.flink.core.scala.util.StreamEnvConfig;
+import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
+import org.apache.streampark.flink.core.java.source.KafkaSource;
+import org.apache.streampark.flink.core.scala.StreamingContext;
+import org.apache.streampark.flink.core.scala.source.KafkaRecord;
+import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
@@ -531,9 +531,9 @@ In the `StreamPark` run pass a `WatermarkStrategy` as a parameter to assign a `W
<TabItem value="Scala" label="Scala">
```scala
-import com.streamxhub.streamx.common.util.JsonUtils
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.source.{KafkaRecord, KafkaSource}
+import org.apache.streampark.common.util.JsonUtils
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.source.{KafkaRecord, KafkaSource}
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.typeutils.TypeExtractor.getForClass
@@ -581,11 +581,11 @@ case class User(name: String, age: Int, gender: Int, address: String, orderTime:
```java
import com.fasterxml.jackson.databind.ObjectMapper;
-import com.streamxhub.streamx.flink.core.java.function.StreamEnvConfigFunction;
-import com.streamxhub.streamx.flink.core.java.source.KafkaSource;
-import com.streamxhub.streamx.flink.core.scala.StreamingContext;
-import com.streamxhub.streamx.flink.core.scala.source.KafkaRecord;
-import com.streamxhub.streamx.flink.core.scala.util.StreamEnvConfig;
+import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
+import org.apache.streampark.flink.core.java.source.KafkaSource;
+import org.apache.streampark.flink.core.scala.StreamingContext;
+import org.apache.streampark.flink.core.scala.source.KafkaRecord;
+import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
@@ -807,11 +807,11 @@ In `KafkaSink`, the default serialization is not specified, and the `SimpleStrin
<TabItem value="scala" label="Scala" default>
```scala
-import com.streamxhub.streamx.common.util.JsonUtils
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
+import org.apache.streampark.common.util.JsonUtils
+import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.flink.api.common.serialization.SerializationSchema
-import com.streamxhub.streamx.flink.core.scala.sink.JdbcSink
-import com.streamxhub.streamx.flink.core.scala.source.KafkaSource
+import org.apache.streampark.flink.core.scala.sink.JdbcSink
+import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.scala._
object KafkaSinkApp extends FlinkStreaming {
@@ -840,12 +840,12 @@ case class User(name: String, age: Int, gender: Int, address: String)
```java
import com.fasterxml.jackson.databind.ObjectMapper;
-import com.streamxhub.streamx.flink.core.java.function.StreamEnvConfigFunction;
-import com.streamxhub.streamx.flink.core.java.sink.KafkaSink;
-import com.streamxhub.streamx.flink.core.java.source.KafkaSource;
-import com.streamxhub.streamx.flink.core.scala.StreamingContext;
-import com.streamxhub.streamx.flink.core.scala.source.KafkaRecord;
-import com.streamxhub.streamx.flink.core.scala.util.StreamEnvConfig;
+import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
+import org.apache.streampark.flink.core.java.sink.KafkaSink;
+import org.apache.streampark.flink.core.java.source.KafkaSource;
+import org.apache.streampark.flink.core.scala.StreamingContext;
+import org.apache.streampark.flink.core.scala.source.KafkaRecord;
+import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SerializationSchema;
@@ -898,11 +898,11 @@ In `KafkaSink`, the default serialization is not specified, and the `SimpleStrin
<TabItem value="scala" label="Scala" default>
```scala
-import com.streamxhub.streamx.common.util.JsonUtils
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
+import org.apache.streampark.common.util.JsonUtils
+import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.flink.api.common.serialization.SerializationSchema
-import com.streamxhub.streamx.flink.core.scala.sink.JdbcSink
-import com.streamxhub.streamx.flink.core.scala.source.KafkaSource
+import org.apache.streampark.flink.core.scala.sink.JdbcSink
+import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.scala._
object KafkaSinkApp extends FlinkStreaming {
@@ -930,12 +930,12 @@ case class User(name: String, age: Int, gender: Int, address: String)
```java
import com.fasterxml.jackson.databind.ObjectMapper;
-import com.streamxhub.streamx.flink.core.java.function.StreamEnvConfigFunction;
-import com.streamxhub.streamx.flink.core.java.sink.KafkaSink;
-import com.streamxhub.streamx.flink.core.java.source.KafkaSource;
-import com.streamxhub.streamx.flink.core.scala.StreamingContext;
-import com.streamxhub.streamx.flink.core.scala.source.KafkaRecord;
-import com.streamxhub.streamx.flink.core.scala.util.StreamEnvConfig;
+import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
+import org.apache.streampark.flink.core.java.sink.KafkaSink;
+import org.apache.streampark.flink.core.java.source.KafkaSource;
+import org.apache.streampark.flink.core.scala.StreamingContext;
+import org.apache.streampark.flink.core.scala.source.KafkaRecord;
+import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SerializationSchema;
diff --git a/docs/connector/2-jdbc.md b/docs/connector/2-jdbc.md
index baca62a..02992a0 100755
--- a/docs/connector/2-jdbc.md
+++ b/docs/connector/2-jdbc.md
@@ -86,8 +86,8 @@ jdbc:
<TabItem value="Scala" label="Scala">
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.source.JdbcSource
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.source.JdbcSource
import org.apache.flink.api.scala._
object MySQLSourceApp extends FlinkStreaming {
@@ -113,12 +113,12 @@ class Order(val marketId: String, val timestamp: String) extends Serializable
<TabItem value="Java" label="Java">
```java
-import com.streamxhub.streamx.flink.core.java.function.SQLQueryFunction;
-import com.streamxhub.streamx.flink.core.java.function.SQLResultFunction;
-import com.streamxhub.streamx.flink.core.java.function.StreamEnvConfigFunction;
-import com.streamxhub.streamx.flink.core.java.source.JdbcSource;
-import com.streamxhub.streamx.flink.core.scala.StreamingContext;
-import com.streamxhub.streamx.flink.core.scala.util.StreamEnvConfig;
+import org.apache.streampark.flink.core.java.function.SQLQueryFunction;
+import org.apache.streampark.flink.core.java.function.SQLResultFunction;
+import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
+import org.apache.streampark.flink.core.java.source.JdbcSource;
+import org.apache.streampark.flink.core.scala.StreamingContext;
+import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import java.io.Serializable;
@@ -237,10 +237,10 @@ This requires that the database being manipulated supports transactions(`mysql`,
<TabItem value="Scala" label="Scala">
```scala
-import com.streamxhub.streamx.common.util.JsonUtils
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.JdbcSink
-import com.streamxhub.streamx.flink.core.scala.source.KafkaSource
+import org.apache.streampark.common.util.JsonUtils
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.JdbcSink
+import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.typeutils.TypeExtractor.getForClass
import org.apache.flink.api.scala._
@@ -272,11 +272,11 @@ case class User(name:String,age:Int,gender:Int,address:String)
```java
import com.fasterxml.jackson.databind.ObjectMapper;
-import com.streamxhub.streamx.flink.core.java.function.StreamEnvConfigFunction;
-import com.streamxhub.streamx.flink.core.java.source.KafkaSource;
-import com.streamxhub.streamx.flink.core.scala.StreamingContext;
-import com.streamxhub.streamx.flink.core.scala.source.KafkaRecord;
-import com.streamxhub.streamx.flink.core.scala.util.StreamEnvConfig;
+import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
+import org.apache.streampark.flink.core.java.source.KafkaSource;
+import org.apache.streampark.flink.core.scala.StreamingContext;
+import org.apache.streampark.flink.core.scala.source.KafkaRecord;
+import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
diff --git a/docs/connector/3-clickhouse.md b/docs/connector/3-clickhouse.md
index 43157f5..dfaf171 100755
--- a/docs/connector/3-clickhouse.md
+++ b/docs/connector/3-clickhouse.md
@@ -92,8 +92,8 @@ clickhouse:
<TabItem value="Scala" label="Scala">
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.ClickHouseSink
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.ClickHouseSink
import org.apache.flink.api.scala._
object ClickHouseSinkApp extends FlinkStreaming {
@@ -221,8 +221,8 @@ clickhouse:
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.ClickHouseSink
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.ClickHouseSink
import org.apache.flink.api.scala._
object ClickHouseSinkApp extends FlinkStreaming {
diff --git a/docs/connector/4-doris.md b/docs/connector/4-doris.md
index 0c42407..ec8f1bc 100644
--- a/docs/connector/4-doris.md
+++ b/docs/connector/4-doris.md
@@ -43,13 +43,13 @@ doris.sink:
<TabItem value="Java" label="Java">
```java
-package com.streamxhub.streamx.test.flink.java.datastream;
+package org.apache.streampark.test.flink.java.datastream;
-import com.streamxhub.streamx.flink.core.StreamEnvConfig;
-import com.streamxhub.streamx.flink.core.java.sink.doris.DorisSink;
-import com.streamxhub.streamx.flink.core.java.source.KafkaSource;
-import com.streamxhub.streamx.flink.core.scala.StreamingContext;
-import com.streamxhub.streamx.flink.core.scala.source.KafkaRecord;
+import org.apache.streampark.flink.core.StreamEnvConfig;
+import org.apache.streampark.flink.core.java.sink.doris.DorisSink;
+import org.apache.streampark.flink.core.java.source.KafkaSource;
+import org.apache.streampark.flink.core.scala.StreamingContext;
+import org.apache.streampark.flink.core.scala.source.KafkaRecord;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
diff --git a/docs/connector/5-es.md b/docs/connector/5-es.md
index 2dda1cb..f343512 100755
--- a/docs/connector/5-es.md
+++ b/docs/connector/5-es.md
@@ -241,9 +241,9 @@ Using StreamPark writes to Elasticsearch
<TabItem value="scala">
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.ESSink
-import com.streamxhub.streamx.flink.core.scala.util.ElasticSearchUtils
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.ESSink
+import org.apache.streampark.flink.core.scala.util.ElasticSearchUtils
import org.apache.flink.api.scala._
import org.elasticsearch.action.index.IndexRequest
import org.json4s.DefaultFormats
@@ -289,10 +289,10 @@ object ConnectorApp extends FlinkStreaming {
</TabItem>
</Tabs>
-Flink ElasticsearchSinkFunction可以执行多种类型请求,如(DeleteRequest、 UpdateRequest、IndexRequest),StreamX也对以上功能进行了支持,对应方法如下:
+Flink ElasticsearchSinkFunction可以执行多种类型请求,如(DeleteRequest、 UpdateRequest、IndexRequest),StreamPark也对以上功能进行了支持,对应方法如下:
```scala
-import com.streamxhub.streamx.flink.core.scala.StreamingContext
+import org.apache.streampark.flink.core.scala.StreamingContext
import org.apache.flink.streaming.api.datastream.DataStreamSink
import org.apache.flink.streaming.api.scala.DataStream
import org.apache.flink.streaming.connectors.elasticsearch.ActionRequestFailureHandler
diff --git a/docs/connector/6-hbase.md b/docs/connector/6-hbase.md
index 8953a50..df91540 100755
--- a/docs/connector/6-hbase.md
+++ b/docs/connector/6-hbase.md
@@ -267,11 +267,11 @@ Writing to Hbase with StreamPark is very simple, the code is as follows:
```scala
-import com.streamxhub.streamx.common.util.ConfigUtils
-import com.streamxhub.streamx.flink.core.java.wrapper.HBaseQuery
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.request.HBaseRequest
-import com.streamxhub.streamx.flink.core.scala.source.HBaseSource
+import org.apache.streampark.common.util.ConfigUtils
+import org.apache.streampark.flink.core.java.wrapper.HBaseQuery
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.request.HBaseRequest
+import org.apache.streampark.flink.core.scala.source.HBaseSource
import org.apache.flink.api.scala.createTypeInformation
import org.apache.hadoop.hbase.CellUtil
import org.apache.hadoop.hbase.client.{Get, Scan}
@@ -323,10 +323,10 @@ object HBaseSourceApp extends FlinkStreaming {
<TabItem value="write HBase">
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.{HBaseOutputFormat, HBaseSink}
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.{HBaseOutputFormat, HBaseSink}
import org.apache.flink.api.scala._
-import com.streamxhub.streamx.common.util.ConfigUtils
+import org.apache.streampark.common.util.ConfigUtils
import org.apache.hadoop.hbase.client.{Mutation, Put}
import org.apache.hadoop.hbase.util.Bytes
diff --git a/docs/connector/7-http.md b/docs/connector/7-http.md
index df28c54..e6fd6ed 100755
--- a/docs/connector/7-http.md
+++ b/docs/connector/7-http.md
@@ -110,8 +110,8 @@ The program sample is scala
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.HttpSink
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.HttpSink
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.DataStream
diff --git a/docs/connector/8-redis.md b/docs/connector/8-redis.md
index dff66bd..94b2bad 100644
--- a/docs/connector/8-redis.md
+++ b/docs/connector/8-redis.md
@@ -224,8 +224,8 @@ Writing to redis with StreamPark is very simple, the code is as follows:
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.{RedisMapper, RedisSink}
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.{RedisMapper, RedisSink}
import org.apache.flink.api.scala._
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand
import org.json4s.DefaultFormats
diff --git a/docs/development/conf.md b/docs/development/conf.md
index fabb85b..72a3f12 100755
--- a/docs/development/conf.md
+++ b/docs/development/conf.md
@@ -126,7 +126,7 @@ flink:
shutdownOnAttachedExit:
jobmanager:
property: #@see: https://ci.apache.org/projects/flink/flink-docs-release-1.12/deployment/config.html
- $internal.application.main: com.streamxhub.streamx.flink.quickstart.QuickStartApp
+ $internal.application.main: org.apache.streampark.flink.quickstart.QuickStartApp
yarn.application.name: Streamx QuickStart App
yarn.application.queue:
taskmanager.numberOfTaskSlots: 1
diff --git a/docs/development/model.md b/docs/development/model.md
index 8fd5a15..b6ffc68 100644
--- a/docs/development/model.md
+++ b/docs/development/model.md
@@ -36,7 +36,7 @@ StreamPark provides both `scala` and `Java` APIs to develop `DataStream` program
<TabItem value="scala" label="Scala" default>
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.flink.api.scala._
object MyFlinkApp extends FlinkStreaming {
@@ -96,7 +96,7 @@ To develop Table & SQL jobs, TableEnvironment will be the recommended entry clas
<TabItem value="scala" label="Scala" default>
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkTable
+import org.apache.streampark.flink.core.scala.FlinkTable
object TableApp extends FlinkTable {
@@ -110,8 +110,8 @@ object TableApp extends FlinkTable {
<TabItem value="Java" label="Java">
```java
-import com.streamxhub.streamx.flink.core.scala.TableContext;
-import com.streamxhub.streamx.flink.core.scala.util.TableEnvConfig;
+import org.apache.streampark.flink.core.scala.TableContext;
+import org.apache.streampark.flink.core.scala.util.TableEnvConfig;
public class JavaTableApp {
@@ -142,9 +142,9 @@ The following code demonstrates how to develop a `StreamTableEnvironment` type j
<TabItem value="scala" label="Scala" default>
```scala
-package com.streamxhub.streamx.test.tablesql
+package org.apache.streampark.test.tablesql
-import com.streamxhub.streamx.flink.core.scala.FlinkStreamTable
+import org.apache.streampark.flink.core.scala.FlinkStreamTable
object StreamTableApp extends FlinkStreamTable {
@@ -160,8 +160,8 @@ object StreamTableApp extends FlinkStreamTable {
```java
-import com.streamxhub.streamx.flink.core.scala.StreamTableContext;
-import com.streamxhub.streamx.flink.core.scala.util.StreamTableEnvConfig;
+import org.apache.streampark.flink.core.scala.StreamTableContext;
+import org.apache.streampark.flink.core.scala.util.StreamTableEnvConfig;
public class JavaStreamTableApp {
@@ -526,7 +526,7 @@ The **destroy** stage is an optional stage that requires developer participation
## Catalog Structure
-The recommended project directory structure is as follows, please refer to the directory structure and configuration in [Streamx-flink-quickstart](https://github.com/streamxhub/streamx-quickstart)
+The recommended project directory structure is as follows, please refer to the directory structure and configuration in [Streamx-flink-quickstart](https://github.com/apache/incubator-streampark-quickstart)
``` tree
.
diff --git a/docs/flink-k8s/1-deployment.md b/docs/flink-k8s/1-deployment.md
index 567c454..58f7bc5 100644
--- a/docs/flink-k8s/1-deployment.md
+++ b/docs/flink-k8s/1-deployment.md
@@ -9,7 +9,7 @@ StreamPark Flink Kubernetes is based on [Flink Native Kubernetes](https://ci.apa
* Native-Kubernetes Application
* Native-Kubernetes Session
-At now, one StreamPark only supports one Kubernetes cluster.You can submit [Fearure Request Issue](https://github.com/streamxhub/streamx/issues) , when multiple Kubernetes clusters are needed.
+At now, one StreamPark only supports one Kubernetes cluster.You can submit [Fearure Request Issue](https://github.com/apache/incubator-streampark/issues) , when multiple Kubernetes clusters are needed.
<br></br>
## Environments requirement
diff --git a/docs/user-guide/deployment.md b/docs/user-guide/1-deployment.md
similarity index 96%
rename from docs/user-guide/deployment.md
rename to docs/user-guide/1-deployment.md
index 03cf168..a4e3e98 100755
--- a/docs/user-guide/deployment.md
+++ b/docs/user-guide/1-deployment.md
@@ -44,7 +44,7 @@ Using `Flink on Kubernetes` requires additional deployment/or use of an existing
## Build & Deploy
-You can directly download the compiled [**release package**](https://github.com/streamxhub/streamx/releases) (recommended), or you can choose to manually compile and install. The manual compilation and installation steps are as follows:
+You can directly download the compiled [**release package**](https://github.com/apache/streampark/releases) (recommended), or you can choose to manually compile and install. The manual compilation and installation steps are as follows:
### Environmental requirements
@@ -74,8 +74,8 @@ From 1.2.1 and later versions, StreamPark supports **mixed packaging** and **ind
##### mixed packaging
```bash
-git clone https://github.com/streamxhub/streamx.git
-cd streamx
+git clone git@github.com:apache/incubator-streampark.git streampark
+cd streampark
mvn clean install -DskipTests -Dscala.version=2.11.12 -Dscala.binary.version=2.11 -Pwebapp
```
@@ -88,9 +88,9 @@ mvn clean install -DskipTests -Dscala.version=2.11.12 -Dscala.binary.version=2.1
###### 1. Backend compilation
```bash
-git clone https://github.com/streamxhub/streamx.git
-cd streamx
-mvn clean install -Dscala.version=2.11.12 -Dscala.binary.version=2.11 -DskipTests
+git clone git@github.com:apache/incubator-streampark.git streampark
+cd streampark
+mvn clean install -Dscala.version=2.12.8 -Dscala.binary.version=2.12
```
###### 2. Front-end packaging
@@ -106,7 +106,7 @@ vi streampark/streampark-console/streampark-console-webapp/.env.production
- 2.2 Compile
```bash
-git clone https://github.com/apache/incubator-streampark.git streampark
+git clone git@github.com:apache/incubator-streampark.git streampark
cd streampark/streampark-console/streampark-console-webapp
npm install
npm run build
diff --git a/docs/user-guide/quickstart.md b/docs/user-guide/2-quickstart.md
similarity index 93%
rename from docs/user-guide/quickstart.md
rename to docs/user-guide/2-quickstart.md
index 63e69fb..33a2567 100755
--- a/docs/user-guide/quickstart.md
+++ b/docs/user-guide/2-quickstart.md
@@ -10,8 +10,8 @@ The installation of the one-stop platform `streampark-console` has been introduc
`streamx-quickstart` is a sample program for developing Flink by StreamPark. For details, please refer to:
-- Github: [https://github.com/streamxhub/streamx-quickstart.git](https://github.com/streamxhub/streamx-quickstart.git)
-- Gitee: [https://gitee.com/streamxhub/streamx-quickstart.git](https://gitee.com/streamxhub/streamx-quickstart.git)
+- Github: [https://github.com/apache/incubator-streampark-quickstart.git](https://github.com/apache/streampark-quickstart.git)
+- Gitee: [https://gitee.com/mirrors_apache/incubator-streampark-quickstart.git](https://gitee.com/mirrors_apache/incubator-streampark-quickstart.git)
### Deploy DataStream tasks
diff --git a/docs/user-guide/development.md b/docs/user-guide/3-development.md
similarity index 87%
rename from docs/user-guide/development.md
rename to docs/user-guide/3-development.md
index cd9542e..0f1cf33 100755
--- a/docs/user-guide/development.md
+++ b/docs/user-guide/3-development.md
@@ -4,7 +4,7 @@ title: 'Develop Environment'
sidebar_position: 3
---
-> [StreamPark](https://github.com/streamxhub/streamx) follows the Apache license 2.0, it will be a long-term active project. Welcome to submit [PR](https://github.com/streamxhub/streamx/pulls) Or [ISSUE](https://github.com/streamxhub/streamx/issues/new/choose). If you like, please give a [star](https://github.com/streamxhub/streamx/stargazers), your support is our greatest motivation. This project has been concerned and recognized by many friends since it was open source. Some friends ar [...]
+> [StreamPark](https://github.com/apache/incubator-streampark. follows the Apache license 2.0, it will be a long-term active project. Welcome to submit [PR](https://github.org.apache.streampark.pulls) Or [ISSUE](https://github.org.apache.streampark.issues/new/choose). If you like, please give a [star](https://github.org.apache.streampark.stargazers), your support is our greatest motivation. This project has been concerned and recognized by many friends since it was open source. Some frie [...]
StreamPark community is a very open, mutual assistance and respect for talents. We also welcome more developers to join us and contribute together, not only for the code, but also for the use of documents, experience reports, questions and answers.
More and more developers are not satisfied with the simple installation and use, and need to be further researched or expanded based on its source code, which requires further in-depth understanding of StreamPark. This chapter specifically describes how to build a development environment for the `streampark-console` streaming batch integration platform locally. For convenience of explanation, the `streampark-console` mentioned in this article refers to the `streampark-console platform`.
@@ -80,12 +80,12 @@ The backend of `streampark-console` is developed by springboot and mybatis, and
#### Backend compilation
-Firstly, download the `streamx` project and compile it.
+Firstly, download the `streampark` project and compile it.
```shell
-git clone https://github.com/streamxhub/streamx.git
-cd streamx
-mvn clean install -DskipTests -Denv=prod
+git clone git@github.com:apache/incubator-streampark.git streampark
+cd streampark
+mvn clean install -Dscala.version=2.12.8 -Dscala.binary.version=2.12 -DskipTests -Pwebapp
```
#### Backend decompression
@@ -141,7 +141,7 @@ java:
#### Backend startup
-`Streamx console` is a web application developed based on springboot, `com.streamxhub.streamx.console Streamxconsole` is the main class. Before startup, you need to set `VM options` and `environment variables`
+`Streamx console` is a web application developed based on springboot, `org.apache.streampark.console Streamxconsole` is the main class. Before startup, you need to set `VM options` and `environment variables`
##### VM options
@@ -163,7 +163,7 @@ If you use a non locally installed Hadoop cluster (test Hadoop), you need to con
<img src="/doc/image/streamx_ideaopt.jpg" />
-If everything is ready, you can start the `StreamXConsole` main class. If it is started successfully, you will see the printing information of successful startup.
+If everything is ready, you can start the `StreamParkConsole` main class. If it is started successfully, you will see the printing information of successful startup.
### Frontend deployment and configuration
diff --git a/docs/user-guide/dockerDeployment.md b/docs/user-guide/4-dockerDeployment.md
similarity index 100%
rename from docs/user-guide/dockerDeployment.md
rename to docs/user-guide/4-dockerDeployment.md
diff --git a/docs/user-guide/LDAP.md b/docs/user-guide/5-LDAP.md
similarity index 100%
rename from docs/user-guide/LDAP.md
rename to docs/user-guide/5-LDAP.md
diff --git a/docs/user-guide/rainbondDeployment.md b/docs/user-guide/rainbondDeployment.md
deleted file mode 100644
index 8fcc3f9..0000000
--- a/docs/user-guide/rainbondDeployment.md
+++ /dev/null
@@ -1,86 +0,0 @@
----
-id: 'rainbond-deployment'
-title: 'Rainbond Quick Deployment'
-sidebar_position: 5
----
-
-Current document description How do I install StreamPark using [Rainbond](https://www.rainbond.com/docs/) cloud native application management platform, This approach is suitable for users who are not familiar with complex technologies such as Kubernetes and containerization, Lowered the threshold to deploy StreamPark in Kubernetes.
-
-## Prepare
-
-* Deployment Rainbond cloud native application management platform, Ref: [Rainbond Quick Install](https://www.rainbond.com/docs/quick-start/quick-install)
-
-## 1. StreamPark Deployment
-
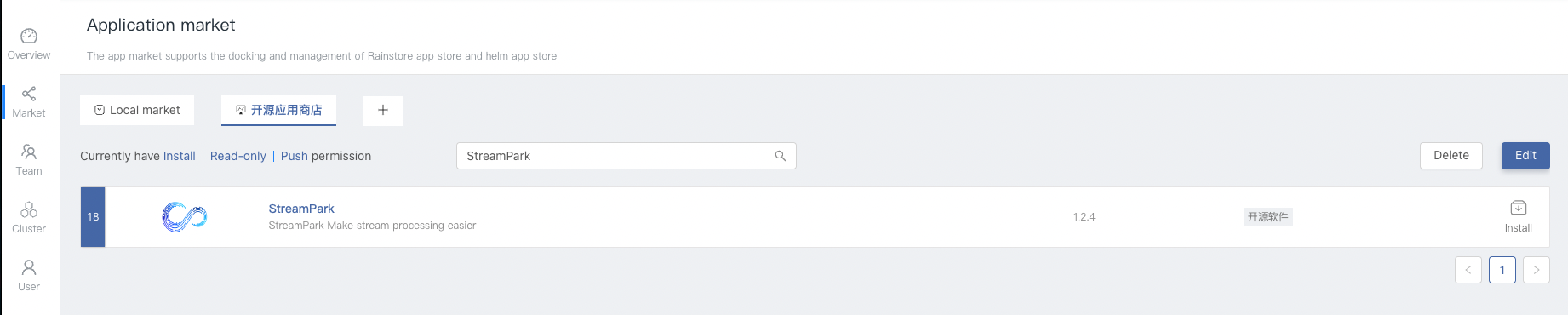
-1. Select the **Application Market** tab on the left, Switch to the **Open Source App Store** TAB on the page, Search for the keyword **StreamPark** to find StreamPark apps.
-
-
-
-
-
-2. Click **Install** on the right of StreamPark to go to the installation page, After filling in the basic information, Click **OK** to start the installation, The page automatically jumps to the topology view.
-
-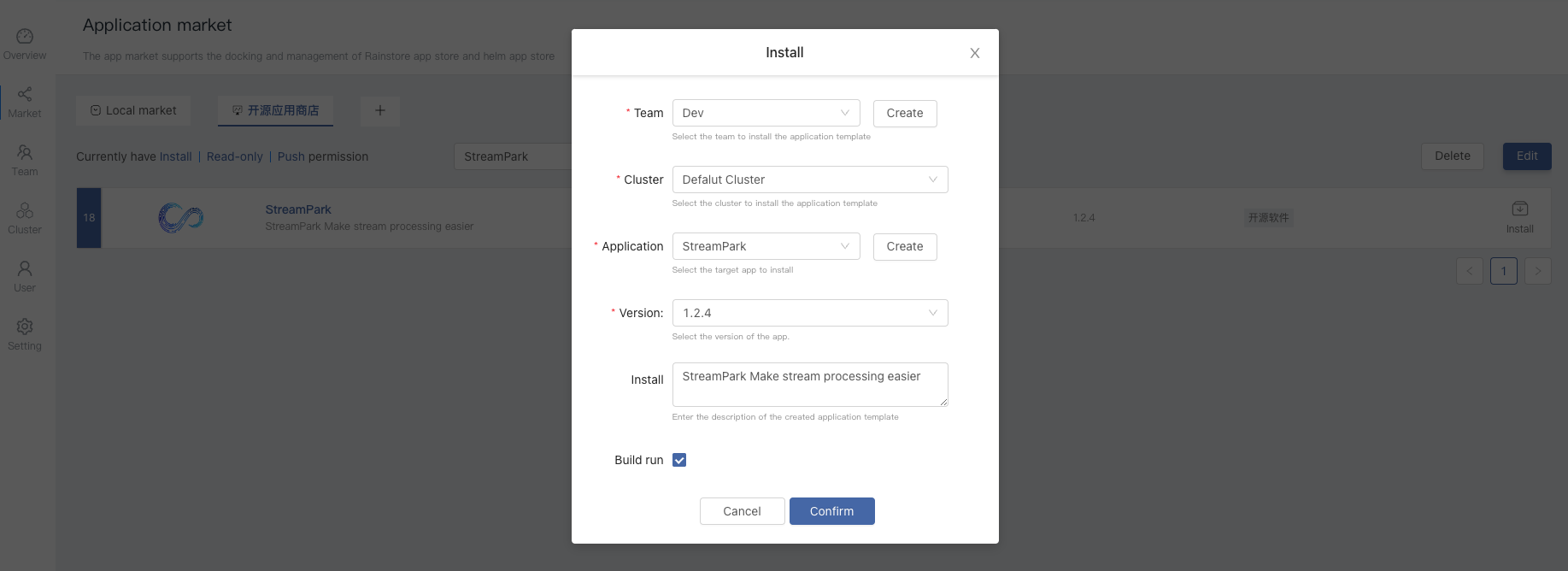
-
-Parameter Description:
-
-| Options | Description |
-| -------- | ------------------------------------------------------------ |
-| Team Name | User workspace, Isolate by namespace |
-| Cluster Name | Choose which Kubernetes cluster StreamPark is deployed to |
-| Select Application | Choose which application StreamPark is deployed to |
-| Application Version | Select the version of StreamPark, Currently available version is 1.2.4 |
-
-
-
-## 2. Apache Flink Deployment
-
-1. Select the **Application Market** tab on the left, Switch to the **Open Source App Store** TAB on the page, Search for the keyword **Flink** to find Flink apps.
-2. Click **Install** on the right of Flink to go to the installation page, After filling in the basic information, Click **OK** to start the installation, The page automatically jumps to the topology view.
-
-
-
-
-
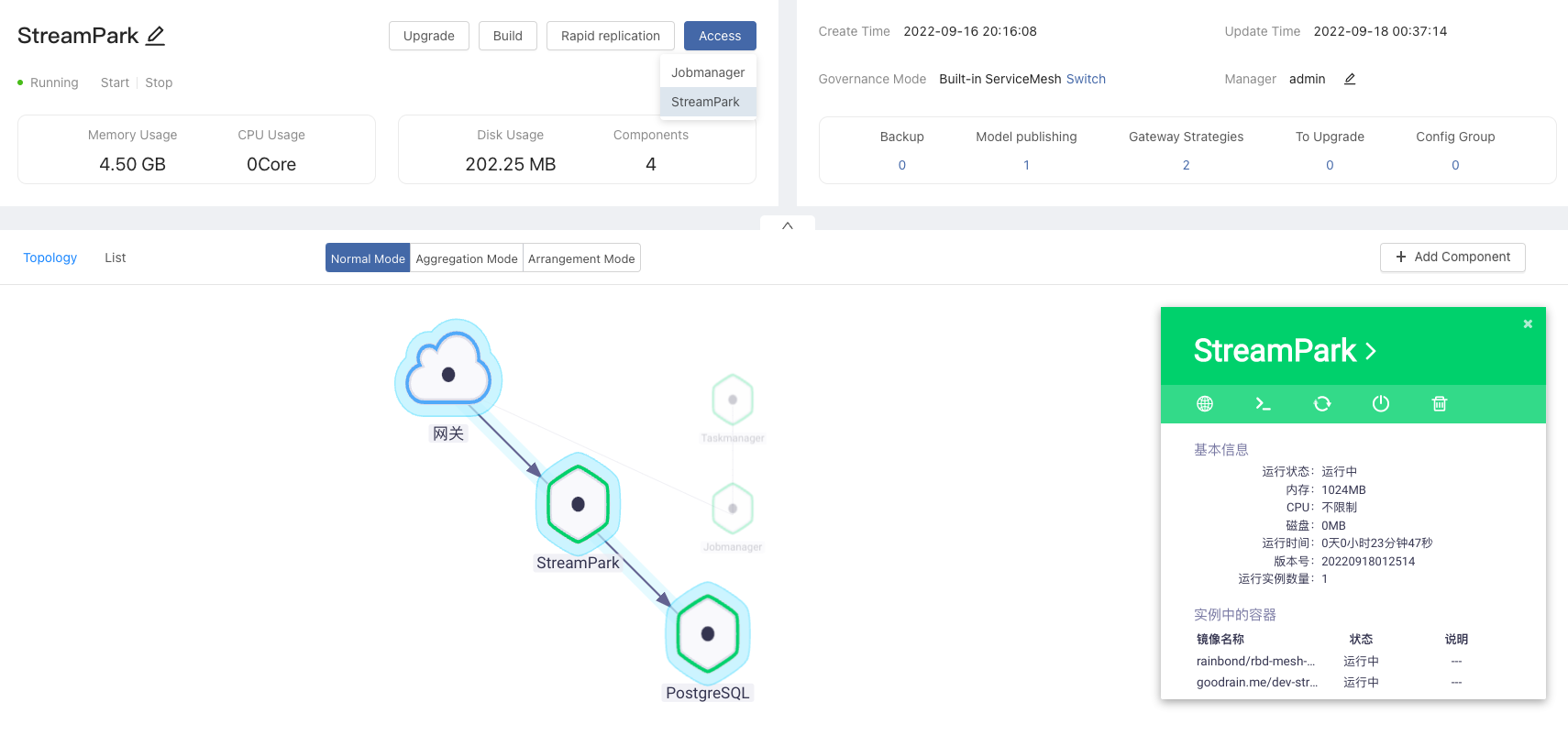
-## 3. Access StreamPark and Flink
-
-After the service starts, StreamPark can be accessed by clicking the Access button, Also have access to Flink. The default user and password for StreamPark are `admin` and `streamx`
-
-
-
-## 4. Set Flink Home On StreamPark Web Ui
-
-Setting -> Link Home -> Add New
-
-```
-/streamx/flink/
-```
-
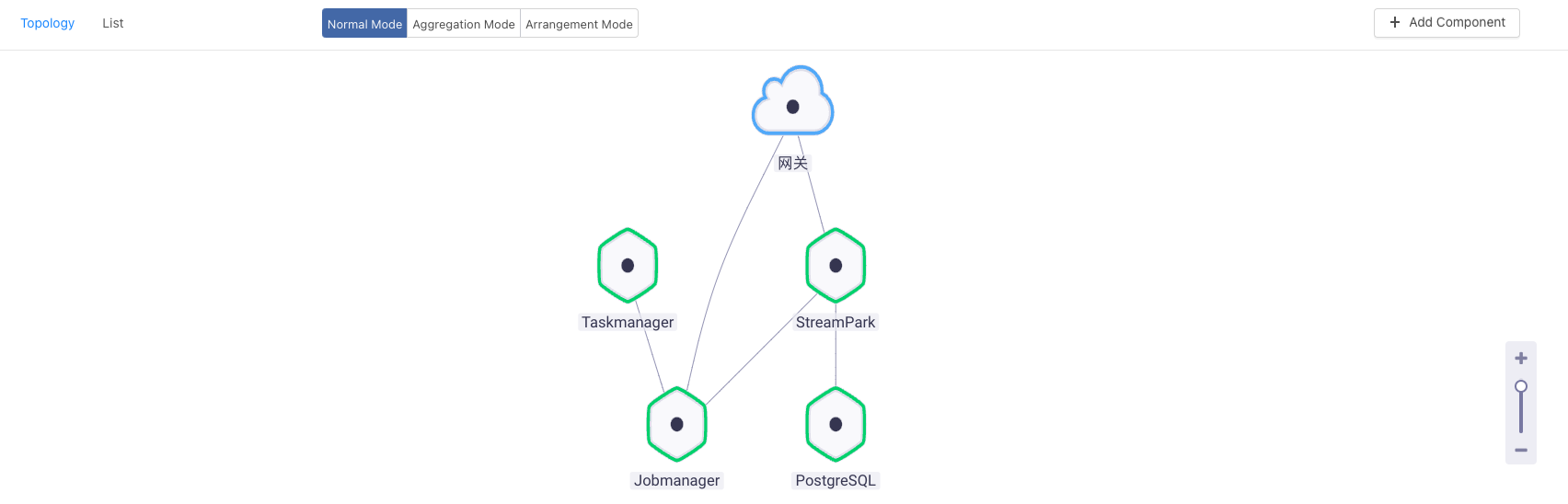
-## 5. Start Remote Session Cluster
-
-Start by connecting StreamPark to JobManager on the Rainbond topology page, Enter choreography mode -> Drag and drop to add dependencies.
-
-
-
-StreamPark web ui click Setting -> Flink Cluster -> Add New Create a `remote (standalone)` mode cluster.
-
-Address fill in:
-
-```
-http://127.0.0.1:8081
-```
-
-## More Features
-
-### 1. Continuous Development StreamPark
-
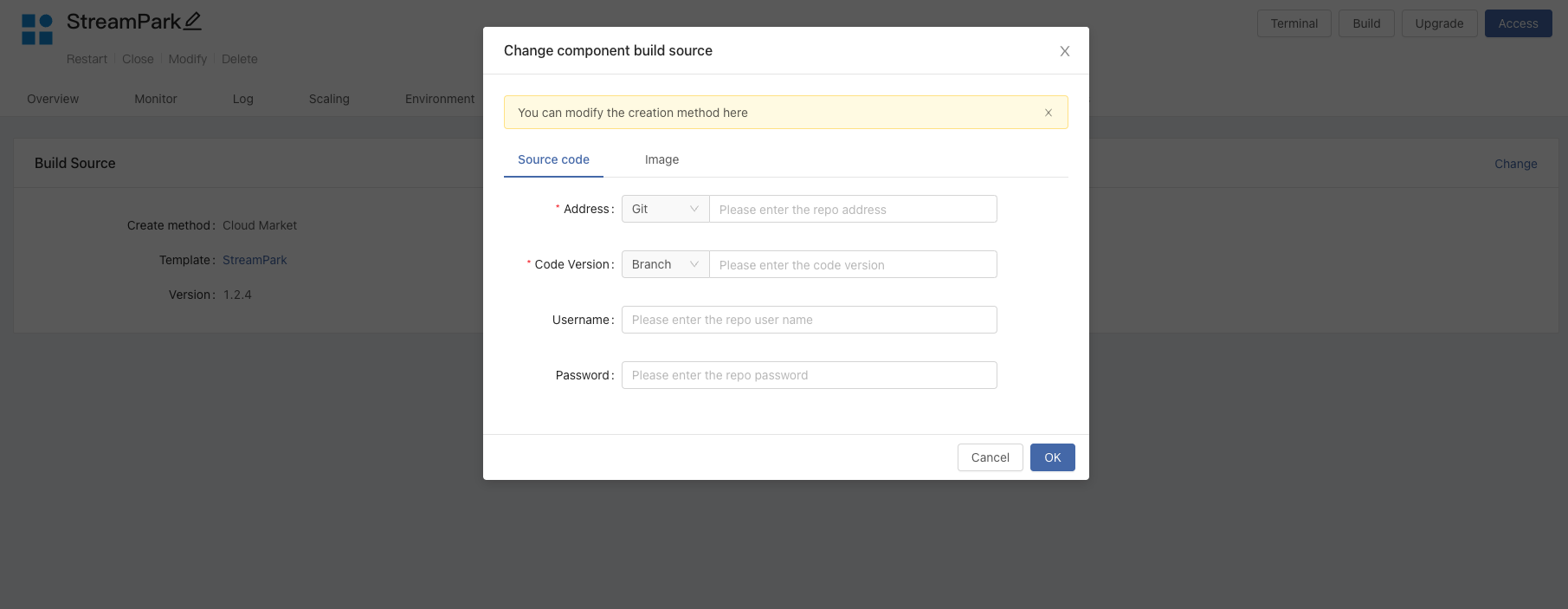
-If you modify the source code, you need to update StreamPark, StreamPark Components -> build source, change the build source to `source code` 或 `image`
-
-
-
-
-
-### TaskManager Scaling Instance
-
-TaskManager Component -> scaling, Set TaskManager instance number to 3 or more.
-
diff --git a/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/1-kafka.md b/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/1-kafka.md
index 755d8d9..f9d2092 100644
--- a/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/1-kafka.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/1-kafka.md
@@ -18,7 +18,7 @@ import TabItem from '@theme/TabItem';
<!--必须要导入的依赖-->
<dependency>
<groupId>com.streamxhub.streamx</groupId>
- <artifactId>Streamx-flink-core</artifactId>
+ <artifactId>streampark-flink-core</artifactId>
<version>${project.version}</version>
</dependency>
@@ -89,11 +89,11 @@ kafka.source:
<TabItem value="scala" label="Scala" default>
```scala
-package com.streamxhub.streamx.flink.quickstart
+package org.apache.streampark.flink.quickstart
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.JdbcSink
-import com.streamxhub.streamx.flink.core.scala.source.KafkaSource
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.JdbcSink
+import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.scala._
object kafkaSourceApp extends FlinkStreaming {
@@ -112,11 +112,11 @@ object kafkaSourceApp extends FlinkStreaming {
<TabItem value="Java" label="Java">
```java
-import com.streamxhub.streamx.flink.core.java.function.StreamEnvConfigFunction;
-import com.streamxhub.streamx.flink.core.java.source.KafkaSource;
-import com.streamxhub.streamx.flink.core.scala.StreamingContext;
-import com.streamxhub.streamx.flink.core.scala.source.KafkaRecord;
-import com.streamxhub.streamx.flink.core.scala.util.StreamEnvConfig;
+import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
+import org.apache.streampark.flink.core.java.source.KafkaSource;
+import org.apache.streampark.flink.core.scala.StreamingContext;
+import org.apache.streampark.flink.core.scala.source.KafkaRecord;
+import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
@@ -435,10 +435,10 @@ kafka.source:
<TabItem value="Scala" label="Scala">
```scala
-import com.streamxhub.streamx.common.util.JsonUtils
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.JdbcSink
-import com.streamxhub.streamx.flink.core.scala.source.KafkaSource
+import org.apache.streampark.common.util.JsonUtils
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.JdbcSink
+import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.typeutils.TypeExtractor.getForClass
import org.apache.flink.api.scala._
@@ -473,11 +473,11 @@ case class User(name:String,age:Int,gender:Int,address:String)
```java
import com.fasterxml.jackson.databind.ObjectMapper;
-import com.streamxhub.streamx.flink.core.java.function.StreamEnvConfigFunction;
-import com.streamxhub.streamx.flink.core.java.source.KafkaSource;
-import com.streamxhub.streamx.flink.core.scala.StreamingContext;
-import com.streamxhub.streamx.flink.core.scala.source.KafkaRecord;
-import com.streamxhub.streamx.flink.core.scala.util.StreamEnvConfig;
+import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
+import org.apache.streampark.flink.core.java.source.KafkaSource;
+import org.apache.streampark.flink.core.scala.StreamingContext;
+import org.apache.streampark.flink.core.scala.source.KafkaRecord;
+import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
@@ -542,9 +542,9 @@ class JavaUser implements Serializable {
<TabItem value="Scala" label="Scala">
```scala
-import com.streamxhub.streamx.common.util.JsonUtils
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.source.{KafkaRecord, KafkaSource}
+import org.apache.streampark.common.util.JsonUtils
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.source.{KafkaRecord, KafkaSource}
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.typeutils.TypeExtractor.getForClass
@@ -592,11 +592,11 @@ case class User(name: String, age: Int, gender: Int, address: String, orderTime:
```java
import com.fasterxml.jackson.databind.ObjectMapper;
-import com.streamxhub.streamx.flink.core.java.function.StreamEnvConfigFunction;
-import com.streamxhub.streamx.flink.core.java.source.KafkaSource;
-import com.streamxhub.streamx.flink.core.scala.StreamingContext;
-import com.streamxhub.streamx.flink.core.scala.source.KafkaRecord;
-import com.streamxhub.streamx.flink.core.scala.util.StreamEnvConfig;
+import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
+import org.apache.streampark.flink.core.java.source.KafkaSource;
+import org.apache.streampark.flink.core.scala.StreamingContext;
+import org.apache.streampark.flink.core.scala.source.KafkaRecord;
+import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
@@ -817,11 +817,11 @@ kafka.sink:
<TabItem value="scala" label="Scala" default>
```scala
-import com.streamxhub.streamx.common.util.JsonUtils
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
+import org.apache.streampark.common.util.JsonUtils
+import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.flink.api.common.serialization.SerializationSchema
-import com.streamxhub.streamx.flink.core.scala.sink.JdbcSink
-import com.streamxhub.streamx.flink.core.scala.source.KafkaSource
+import org.apache.streampark.flink.core.scala.sink.JdbcSink
+import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.scala._
object KafkaSinkApp extends FlinkStreaming {
@@ -850,12 +850,12 @@ case class User(name: String, age: Int, gender: Int, address: String)
```java
import com.fasterxml.jackson.databind.ObjectMapper;
-import com.streamxhub.streamx.flink.core.java.function.StreamEnvConfigFunction;
-import com.streamxhub.streamx.flink.core.java.sink.KafkaSink;
-import com.streamxhub.streamx.flink.core.java.source.KafkaSource;
-import com.streamxhub.streamx.flink.core.scala.StreamingContext;
-import com.streamxhub.streamx.flink.core.scala.source.KafkaRecord;
-import com.streamxhub.streamx.flink.core.scala.util.StreamEnvConfig;
+import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
+import org.apache.streampark.flink.core.java.sink.KafkaSink;
+import org.apache.streampark.flink.core.java.source.KafkaSource;
+import org.apache.streampark.flink.core.scala.StreamingContext;
+import org.apache.streampark.flink.core.scala.source.KafkaRecord;
+import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SerializationSchema;
@@ -907,11 +907,11 @@ class JavaUser implements Serializable {
<TabItem value="scala" label="Scala" default>
```scala
-import com.streamxhub.streamx.common.util.JsonUtils
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
+import org.apache.streampark.common.util.JsonUtils
+import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.flink.api.common.serialization.SerializationSchema
-import com.streamxhub.streamx.flink.core.scala.sink.JdbcSink
-import com.streamxhub.streamx.flink.core.scala.source.KafkaSource
+import org.apache.streampark.flink.core.scala.sink.JdbcSink
+import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.scala._
object KafkaSinkApp extends FlinkStreaming {
@@ -939,12 +939,12 @@ case class User(name: String, age: Int, gender: Int, address: String)
```java
import com.fasterxml.jackson.databind.ObjectMapper;
-import com.streamxhub.streamx.flink.core.java.function.StreamEnvConfigFunction;
-import com.streamxhub.streamx.flink.core.java.sink.KafkaSink;
-import com.streamxhub.streamx.flink.core.java.source.KafkaSource;
-import com.streamxhub.streamx.flink.core.scala.StreamingContext;
-import com.streamxhub.streamx.flink.core.scala.source.KafkaRecord;
-import com.streamxhub.streamx.flink.core.scala.util.StreamEnvConfig;
+import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
+import org.apache.streampark.flink.core.java.sink.KafkaSink;
+import org.apache.streampark.flink.core.java.source.KafkaSource;
+import org.apache.streampark.flink.core.scala.StreamingContext;
+import org.apache.streampark.flink.core.scala.source.KafkaRecord;
+import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SerializationSchema;
diff --git a/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/2-jdbc.md b/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/2-jdbc.md
index 30e526e..3ae5cf9 100755
--- a/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/2-jdbc.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/2-jdbc.md
@@ -85,8 +85,8 @@ jdbc:
<TabItem value="Scala" label="Scala">
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.source.JdbcSource
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.source.JdbcSource
import org.apache.flink.api.scala._
object MySQLSourceApp extends FlinkStreaming {
@@ -113,12 +113,12 @@ class Order(val marketId: String, val timestamp: String) extends Serializable
<TabItem value="Java" label="Java">
```java
-import com.streamxhub.streamx.flink.core.java.function.SQLQueryFunction;
-import com.streamxhub.streamx.flink.core.java.function.SQLResultFunction;
-import com.streamxhub.streamx.flink.core.java.function.StreamEnvConfigFunction;
-import com.streamxhub.streamx.flink.core.java.source.JdbcSource;
-import com.streamxhub.streamx.flink.core.scala.StreamingContext;
-import com.streamxhub.streamx.flink.core.scala.util.StreamEnvConfig;
+import org.apache.streampark.flink.core.java.function.SQLQueryFunction;
+import org.apache.streampark.flink.core.java.function.SQLResultFunction;
+import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
+import org.apache.streampark.flink.core.java.source.JdbcSource;
+import org.apache.streampark.flink.core.scala.StreamingContext;
+import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import java.io.Serializable;
@@ -254,10 +254,10 @@ jdbc:
<TabItem value="Scala" label="Scala">
```scala
-import com.streamxhub.streamx.common.util.JsonUtils
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.JdbcSink
-import com.streamxhub.streamx.flink.core.scala.source.KafkaSource
+import org.apache.streampark.common.util.JsonUtils
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.JdbcSink
+import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.typeutils.TypeExtractor.getForClass
import org.apache.flink.api.scala._
@@ -289,11 +289,11 @@ case class User(name:String,age:Int,gender:Int,address:String)
```java
import com.fasterxml.jackson.databind.ObjectMapper;
-import com.streamxhub.streamx.flink.core.java.function.StreamEnvConfigFunction;
-import com.streamxhub.streamx.flink.core.java.source.KafkaSource;
-import com.streamxhub.streamx.flink.core.scala.StreamingContext;
-import com.streamxhub.streamx.flink.core.scala.source.KafkaRecord;
-import com.streamxhub.streamx.flink.core.scala.util.StreamEnvConfig;
+import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
+import org.apache.streampark.flink.core.java.source.KafkaSource;
+import org.apache.streampark.flink.core.scala.StreamingContext;
+import org.apache.streampark.flink.core.scala.source.KafkaRecord;
+import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
diff --git a/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/3-clickhouse.md b/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/3-clickhouse.md
index 8d5e806..3f4e47b 100755
--- a/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/3-clickhouse.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/3-clickhouse.md
@@ -91,8 +91,8 @@ clickhouse:
<TabItem value="Scala" label="Scala">
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.ClickHouseSink
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.ClickHouseSink
import org.apache.flink.api.scala._
object ClickHouseSinkApp extends FlinkStreaming {
@@ -222,8 +222,8 @@ clickhouse:
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.ClickHouseSink
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.ClickHouseSink
import org.apache.flink.api.scala._
object ClickHouseSinkApp extends FlinkStreaming {
diff --git a/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/4-doris.md b/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/4-doris.md
index 31c62f6..a600cb0 100644
--- a/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/4-doris.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/4-doris.md
@@ -40,13 +40,13 @@ doris.sink:
<TabItem value="Java" label="Java">
```java
-package com.streamxhub.streamx.test.flink.java.datastream;
+package org.apache.streampark.test.flink.java.datastream;
-import com.streamxhub.streamx.flink.core.StreamEnvConfig;
-import com.streamxhub.streamx.flink.core.java.sink.doris.DorisSink;
-import com.streamxhub.streamx.flink.core.java.source.KafkaSource;
-import com.streamxhub.streamx.flink.core.scala.StreamingContext;
-import com.streamxhub.streamx.flink.core.scala.source.KafkaRecord;
+import org.apache.streampark.flink.core.StreamEnvConfig;
+import org.apache.streampark.flink.core.java.sink.doris.DorisSink;
+import org.apache.streampark.flink.core.java.source.KafkaSource;
+import org.apache.streampark.flink.core.scala.StreamingContext;
+import org.apache.streampark.flink.core.scala.source.KafkaRecord;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
diff --git a/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/5-es.md b/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/5-es.md
index aade4ad..b5c0a35 100755
--- a/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/5-es.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/5-es.md
@@ -219,9 +219,9 @@ host: localhost:9200
<TabItem value="scala">
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.ESSink
-import com.streamxhub.streamx.flink.core.scala.util.ElasticSearchUtils
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.ESSink
+import org.apache.streampark.flink.core.scala.util.ElasticSearchUtils
import org.apache.flink.api.scala._
import org.elasticsearch.action.index.IndexRequest
import org.json4s.DefaultFormats
@@ -266,9 +266,9 @@ object ConnectorApp extends FlinkStreaming {
</TabItem>
</Tabs>
-Flink ElasticsearchSinkFunction可以执行多种类型请求,如(DeleteRequest、 UpdateRequest、IndexRequest),StreamX也对以上功能进行了支持,对应方法如下:
+Flink ElasticsearchSinkFunction可以执行多种类型请求,如(DeleteRequest、 UpdateRequest、IndexRequest),StreamPark也对以上功能进行了支持,对应方法如下:
```scala
-import com.streamxhub.streamx.flink.core.scala.StreamingContext
+import org.apache.streampark.flink.core.scala.StreamingContext
import org.apache.flink.streaming.api.datastream.DataStreamSink
import org.apache.flink.streaming.api.scala.DataStream
import org.apache.flink.streaming.connectors.elasticsearch.ActionRequestFailureHandler
@@ -344,5 +344,5 @@ Elasticsearch 操作请求可能由于多种原因而失败,可以通过实现
[官方文档](https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/connectors/datastream/elasticsearch/#elasticsearch-sink)**处理失败的 Elasticsearch 请求** 单元
### 配置内部批量处理器
es内部`BulkProcessor`可以进一步配置其如何刷新缓存操作请求的行为详细查看[官方文档](https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/connectors/datastream/elasticsearch/#elasticsearch-sink)**配置内部批量处理器** 单元
-### StreamX配置
+### StreamPark配置
其他的所有的配置都必须遵守 **StreamPark** 配置,具体可配置项和各个参数的作用请参考[项目配置](/docs/development/conf)
diff --git a/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/6-hbase.md b/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/6-hbase.md
index f08f112..99472ac 100755
--- a/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/6-hbase.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/6-hbase.md
@@ -259,11 +259,11 @@ hbase:
```scala
-import com.streamxhub.streamx.common.util.ConfigUtils
-import com.streamxhub.streamx.flink.core.java.wrapper.HBaseQuery
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.request.HBaseRequest
-import com.streamxhub.streamx.flink.core.scala.source.HBaseSource
+import org.apache.streampark.common.util.ConfigUtils
+import org.apache.streampark.flink.core.java.wrapper.HBaseQuery
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.request.HBaseRequest
+import org.apache.streampark.flink.core.scala.source.HBaseSource
import org.apache.flink.api.scala.createTypeInformation
import org.apache.hadoop.hbase.CellUtil
import org.apache.hadoop.hbase.client.{Get, Scan}
@@ -315,10 +315,10 @@ object HBaseSourceApp extends FlinkStreaming {
<TabItem value="写入HBase">
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.{HBaseOutputFormat, HBaseSink}
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.{HBaseOutputFormat, HBaseSink}
import org.apache.flink.api.scala._
-import com.streamxhub.streamx.common.util.ConfigUtils
+import org.apache.streampark.common.util.ConfigUtils
import org.apache.hadoop.hbase.client.{Mutation, Put}
import org.apache.hadoop.hbase.util.Bytes
diff --git a/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/7-http.md b/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/7-http.md
index 6455c10..06973a4 100755
--- a/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/7-http.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/7-http.md
@@ -104,8 +104,8 @@ http.sink:
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.HttpSink
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.HttpSink
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.DataStream
diff --git a/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/8-redis.md b/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/8-redis.md
index 7ce8363..3c2f8c2 100755
--- a/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/8-redis.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-docs/current/connector/8-redis.md
@@ -227,8 +227,8 @@ redis.sink:
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
-import com.streamxhub.streamx.flink.core.scala.sink.{RedisMapper, RedisSink}
+import org.apache.streampark.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.sink.{RedisMapper, RedisSink}
import org.apache.flink.api.scala._
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand
import org.json4s.DefaultFormats
diff --git a/i18n/zh-CN/docusaurus-plugin-content-docs/current/development/conf.md b/i18n/zh-CN/docusaurus-plugin-content-docs/current/development/conf.md
index 35c1374..18dae56 100755
--- a/i18n/zh-CN/docusaurus-plugin-content-docs/current/development/conf.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-docs/current/development/conf.md
@@ -115,7 +115,7 @@ Flink Sql任务中将提取出来的sql放到`sql.yaml`中,这个有特定作用
## 配置文件
-在StreamX中,`DataStream`作业和`Flink Sql`作业配置文件是通用的,换言之,这个配置文件既能定义`DataStream`的各项配置,也能定义`Flink Sql`的各项配置(Flink Sql作业中配置文件是可选的), 配置文件的格式必须是`yaml`格式, 必须得符合yaml的格式规范
+在StreamPark中,`DataStream`作业和`Flink Sql`作业配置文件是通用的,换言之,这个配置文件既能定义`DataStream`的各项配置,也能定义`Flink Sql`的各项配置(Flink Sql作业中配置文件是可选的), 配置文件的格式必须是`yaml`格式, 必须得符合yaml的格式规范
下面我们来详细看看这个配置文件的各项配置都是如何进行配置的,有哪些注意事项
@@ -409,7 +409,7 @@ sql: |
:::danger 特别注意
-上面内容中 **sql:** 后面的 **|** 是必带的, 加上 **|** 会保留整段内容的格式,重点是保留了换行符, StreamX封装了Flink Sql的提交,可以直接将多个Sql一次性定义出来,每个Sql必须用 **;** 分割,每段 Sql也必须遵循Flink Sql规定的格式和规范
+上面内容中 **sql:** 后面的 **|** 是必带的, 加上 **|** 会保留整段内容的格式,重点是保留了换行符, StreamPark封装了Flink Sql的提交,可以直接将多个Sql一次性定义出来,每个Sql必须用 **;** 分割,每段 Sql也必须遵循Flink Sql规定的格式和规范
:::
## 总结
diff --git a/i18n/zh-CN/docusaurus-plugin-content-docs/current/development/model.md b/i18n/zh-CN/docusaurus-plugin-content-docs/current/development/model.md
index 4d52831..5dd5e18 100755
--- a/i18n/zh-CN/docusaurus-plugin-content-docs/current/development/model.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-docs/current/development/model.md
@@ -35,7 +35,7 @@ import TabItem from '@theme/TabItem';
<TabItem value="scala" label="Scala" default>
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkStreaming
+import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.flink.api.scala._
object MyFlinkApp extends FlinkStreaming {
@@ -98,7 +98,7 @@ Flink 社区一直在推进 DataStream 的批处理能力,统一流批一体,在
<TabItem value="scala" label="Scala" default>
```scala
-import com.streamxhub.streamx.flink.core.scala.FlinkTable
+import org.apache.streampark.flink.core.scala.FlinkTable
object TableApp extends FlinkTable {
@@ -112,8 +112,8 @@ object TableApp extends FlinkTable {
<TabItem value="Java" label="Java">
```java
-import com.streamxhub.streamx.flink.core.scala.TableContext;
-import com.streamxhub.streamx.flink.core.scala.util.TableEnvConfig;
+import org.apache.streampark.flink.core.scala.TableContext;
+import org.apache.streampark.flink.core.scala.util.TableEnvConfig;
public class JavaTableApp {
@@ -144,9 +144,9 @@ Scala API 必须继承 FlinkTable, Java API 开发需要手动构造 TableContex
<TabItem value="scala" label="Scala" default>
```scala
-package com.streamxhub.streamx.test.tablesql
+package org.apache.streampark.test.tablesql
-import com.streamxhub.streamx.flink.core.scala.FlinkStreamTable
+import org.apache.streampark.flink.core.scala.FlinkStreamTable
object StreamTableApp extends FlinkStreamTable {
@@ -162,8 +162,8 @@ object StreamTableApp extends FlinkStreamTable {
```java
-import com.streamxhub.streamx.flink.core.scala.StreamTableContext;
-import com.streamxhub.streamx.flink.core.scala.util.StreamTableEnvConfig;
+import org.apache.streampark.flink.core.scala.StreamTableContext;
+import org.apache.streampark.flink.core.scala.util.StreamTableEnvConfig;
public class JavaStreamTableApp {
@@ -393,7 +393,7 @@ class StreamTableContext(val parameter: ParameterTool,
```
-在StreamX中,`StreamTableContext` 是 Java API 编写 `StreamTableEnvironment` 类型的 `Table Sql` 作业的入口类,`StreamTableContext` 的构造方法中有一个是专门为 Java API 打造的,该构造函数定义如下:
+在StreamPark中,`StreamTableContext` 是 Java API 编写 `StreamTableEnvironment` 类型的 `Table Sql` 作业的入口类,`StreamTableContext` 的构造方法中有一个是专门为 Java API 打造的,该构造函数定义如下:
```scala
@@ -604,7 +604,7 @@ assembly.xml 是assembly打包插件需要用到的配置文件,定义如下:
## 打包部署
-推荐 [streamx-flink-quickstart](https://github.com/streamxhub/streampark/streampark-flink/streamx-flink-quickstart) 里的打包模式,直接运行`maven package`即可生成一个标准的StreamX推荐的项目包,解包后目录结构如下
+推荐 [streamx-flink-quickstart](https://github.com/streamxhub/streampark/streampark-flink/streamx-flink-quickstart) 里的打包模式,直接运行`maven package`即可生成一个标准的StreamPark推荐的项目包,解包后目录结构如下
``` text
.
diff --git a/i18n/zh-CN/docusaurus-plugin-content-docs/current/intro.md b/i18n/zh-CN/docusaurus-plugin-content-docs/current/intro.md
index b06a477..97fe141 100644
--- a/i18n/zh-CN/docusaurus-plugin-content-docs/current/intro.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-docs/current/intro.md
@@ -9,7 +9,7 @@ make stream processing easier!!!
> 一个神奇的框架,让流处理更简单
-## 🚀 什么是StreamX
+## 🚀 什么是StreamPark
实时即未来,在实时处理流域 `Apache Spark` 和 `Apache Flink` 是一个伟大的进步,尤其是`Apache Flink`被普遍认为是下一代大数据流计算引擎, 我们在使用 `Flink` & `Spark` 时发现从编程模型, 启动配置到运维管理都有很多可以抽象共用的地方, 我们将一些好的经验固化下来并结合业内的最佳实践, 通过不断努力终于诞生了今天的框架 —— `StreamPark`, 项目的初衷是 —— 让流处理更简单,
使用`StreamPark`开发,可以极大降低学习成本和开发门槛, 让开发者只用关心最核心的业务,`StreamPark` 规范了项目的配置,鼓励函数式编程,定义了最佳的编程方式,提供了一系列开箱即用的`Connectors`,标准化了配置、开发、测试、部署、监控、运维的整个过程, 提供了`scala`和`java`两套api,
diff --git a/i18n/zh-CN/docusaurus-plugin-content-docs/current/user-guide/deployment.md b/i18n/zh-CN/docusaurus-plugin-content-docs/current/user-guide/deployment.md
index 54e6679..b327aee 100755
--- a/i18n/zh-CN/docusaurus-plugin-content-docs/current/user-guide/deployment.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-docs/current/user-guide/deployment.md
@@ -75,8 +75,8 @@ export HADOOP_YARN_HOME=$HADOOP_HOME/../hadoop-yarn
##### 混合打包
```bash
-git clone https://github.com/streamxhub/streamx.git
-cd streamx
+git clone git@github.com:apache/incubator-streampark.git streampark
+cd streampark
mvn clean install -DskipTests -Dscala.version=2.11.12 -Dscala.binary.version=2.11 -Pwebapp
```
@@ -89,8 +89,8 @@ mvn clean install -DskipTests -Dscala.version=2.11.12 -Dscala.binary.version=2.1
###### 1. 后端编译
```bash
-git clone https://github.com/streamxhub/streamx.git
-cd streamx
+git clone git@github.com:apache/incubator-streampark.git streampark
+cd streampark
mvn clean install -Dscala.version=2.11.12 -Dscala.binary.version=2.11 -DskipTests
```
@@ -107,8 +107,8 @@ vi streamx/streampark-console/streampark-console-webapp/.env.production
- 2.2 编译
```bash
-git clone https://github.com/streamxhub/streamx.git
-cd streamx/streampark-console/streampark-console-webapp
+git clone https://github.com/apache/incubator-streampark.git streampark
+cd streampark/streampark-console/streampark-console-webapp
npm install
npm run build
```
diff --git a/i18n/zh-CN/docusaurus-plugin-content-docs/current/user-guide/development.md b/i18n/zh-CN/docusaurus-plugin-content-docs/current/user-guide/development.md
index 53dee77..57a9be5 100755
--- a/i18n/zh-CN/docusaurus-plugin-content-docs/current/user-guide/development.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-docs/current/user-guide/development.md
@@ -83,8 +83,8 @@ ln -s /root/apache-maven-3.8.1/bin/mvn /usr/bin/mvn
首先将 `StreamPark` 工程下载到本地并且编译
```shell
-git clone https://github.com/streamxhub/streamx.git
-cd streamx
+git clone git@github.com:apache/incubator-streampark.git streampark
+cd streampark
mvn clean install -DskipTests -Denv=prod
```
@@ -141,7 +141,7 @@ java:
#### 启动
-`streampark-console` 是基于 springBoot 开发的 web 应用,`com.streamxhub.streamx.console.StreamXConsole` 为主类, 在启动主类之前,需要设置下 `VM options` 和 `Environment variables`
+`streampark-console` 是基于 springBoot 开发的 web 应用,`com.streamxhub.streamx.console.StreamParkConsole` 为主类, 在启动主类之前,需要设置下 `VM options` 和 `Environment variables`
##### VM options
@@ -163,7 +163,7 @@ java:
<img src="/doc/image/streamx_ideaopt.jpg" />
-如果一切准假就绪,就可以直接启动 `StreamXConsole` 主类启动项目,后端就启动成功了。会看到有相关的启动信息打印输出
+如果一切准假就绪,就可以直接启动 `StreamParkConsole` 主类启动项目,后端就启动成功了。会看到有相关的启动信息打印输出
### 前端
diff --git a/i18n/zh-CN/docusaurus-plugin-content-docs/current/user-guide/dockerDeployment.md b/i18n/zh-CN/docusaurus-plugin-content-docs/current/user-guide/dockerDeployment.md
index db40166..34e7dec 100644
--- a/i18n/zh-CN/docusaurus-plugin-content-docs/current/user-guide/dockerDeployment.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-docs/current/user-guide/dockerDeployment.md
@@ -4,7 +4,7 @@ title: 'Docker 快速使用教程'
sidebar_position: 4
---
-本教程使用docker-compose方式通过 Docker 完成StreamX的部署。
+本教程使用docker-compose方式通过 Docker 完成StreamPark的部署。
## 前置条件
Docker 1.13.1+
Docker Compose 1.28.0+
@@ -19,14 +19,14 @@ sidebar_position: 4
Hyper-V 模式:点击 Docker Desktop -> Settings -> Resources -> Memory 调整内存大小
WSL 2 模式 模式:参考 WSL 2 utility VM 调整内存大小
-完成配置后,我们可以从下载页面获取StreamX文件的源包,并确保您获得正确的版本。下载软件包后,您可以运行以下命令。
+完成配置后,我们可以从下载页面获取StreamPark文件的源包,并确保您获得正确的版本。下载软件包后,您可以运行以下命令。
### 1.通过 mvn 构建
```
./build.sh
```

-注意:Flink的Scala版本和StreamX的Scala版本需要保持一致,本次构建请选择Scala 2.12。
+注意:Flink的Scala版本和StreamPark的Scala版本需要保持一致,本次构建请选择Scala 2.12。
### 2.执行 Docker Compose 构建命令
```
@@ -35,7 +35,7 @@ docker-compose up -d

### 3.登陆系统
-服务启动后,可以通过 http://localhost:10000 访问 StreamPark,同时也可以通过 http://localhost:8081访问Flink。访问StreamX链接后会跳转到登陆页面,StreamPark 默认的用户和密码分别为 admin 和 streamx。想要了解更多操作请参考用户手册快速上手。
+服务启动后,可以通过 http://localhost:10000 访问 StreamPark,同时也可以通过 http://localhost:8081访问Flink。访问StreamPark链接后会跳转到登陆页面,StreamPark 默认的用户和密码分别为 admin 和 streamx。想要了解更多操作请参考用户手册快速上手。
### 4.在 StreamPark Web Ui 上设置 Flink Home
```
@@ -44,11 +44,11 @@ docker-compose up -d

### 5.启动远程会话集群
-进入StreamX web ui点击Setting->Flink Cluster 创建一个remote (standalone)模式的集群。
+进入StreamPark web ui点击Setting->Flink Cluster 创建一个remote (standalone)模式的集群。

tips:mac电脑获取flink的真实ip地址,可以通过ifconfig。
### 6.完成以上步骤,进行Flink任务提交
-在StreamX web ui点击Application->Add New 创建一个remote (standalone)模式提交。
+在StreamPark web ui点击Application->Add New 创建一个remote (standalone)模式提交。

diff --git a/i18n/zh-CN/docusaurus-plugin-content-docs/current/user-guide/rainbondDeployment.md b/i18n/zh-CN/docusaurus-plugin-content-docs/current/user-guide/rainbondDeployment.md
index 73e9db5..acc0ec2 100644
--- a/i18n/zh-CN/docusaurus-plugin-content-docs/current/user-guide/rainbondDeployment.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-docs/current/user-guide/rainbondDeployment.md
@@ -62,7 +62,7 @@ Setting -> Link Home -> Add New

-进入StreamX web ui 点击 Setting -> Flink Cluster -> Add New 创建一个 `remote (standalone)` 模式的集群。
+进入StreamPark web ui 点击 Setting -> Flink Cluster -> Add New 创建一个 `remote (standalone)` 模式的集群。
Address 填写:
diff --git a/package.json b/package.json
index 5ee00a8..8d8bc0a 100644
--- a/package.json
+++ b/package.json
@@ -1,5 +1,5 @@
{
- "name": "streamx-website",
+ "name": "apache-streampark-website",
"version": "0.0.0",
"private": true,
"scripts": {
diff --git a/static/home/streamx-archite.png b/static/home/streamx-archite.png
index 53bfe4f..c774bd8 100644
Binary files a/static/home/streamx-archite.png and b/static/home/streamx-archite.png differ
diff --git a/static/image/logo1.svg b/static/image/logo_name.svg
similarity index 100%
rename from static/image/logo1.svg
rename to static/image/logo_name.svg
diff --git a/static/image/users.png b/static/image/users.png
new file mode 100644
index 0000000..09ed960
Binary files /dev/null and b/static/image/users.png differ