You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by BryanCutler <gi...@git.apache.org> on 2017/10/25 18:12:48 UTC
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
GitHub user BryanCutler opened a pull request:
https://github.com/apache/spark/pull/19575
[WIP][SPARK-22221][DOCS] Adding User Documentation for Arrow
## What changes were proposed in this pull request?
Adding user facing documentation for working with Arrow in Spark
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/BryanCutler/spark arrow-user-docs-SPARK-2221
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/19575.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #19575
----
commit 0723e862bc4b644e1eca433fe2e22040e266a73d
Author: Bryan Cutler <cu...@gmail.com>
Date: 2017-10-25T18:10:34Z
adding high level headers for arrow docs
----
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86218/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86720 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86720/testReport)** for PR 19575 at commit [`8b629bc`](https://github.com/apache/spark/commit/8b629bc7a873b8f2d95f0ba0aea3b4ef5f21a0fb).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on the issue:
https://github.com/apache/spark/pull/19575
Yes, I think we do need something to at least highlight some differences if using Arrow. I've been meaning to work on this, just been too busy lately. @icexelloss if you're able to help out on this, that would be great!
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163851527
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
+module with the command "pip install pyspark[sql]". Otherwise, you must ensure that pyarrow is
--- End diff --
maybe `` `pip install pyspark[sql]` ``
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on the issue:
https://github.com/apache/spark/pull/19575
Seems fine otherwise.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163964479
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
# Declare the function and create the UDF
-def multiply_func(a, b):
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
return a * b
-multiply = pandas_udf(multiply_func, returnType=LongType())
-
-# The function for a pandas_udf should be able to execute with local Pandas data
-x = pd.Series([1, 2, 3])
-print(multiply_func(x, x))
-# 0 1
-# 1 4
-# 2 9
-# dtype: int64
-
-# Create a Spark DataFrame, 'spark' is an existing SparkSession
-df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
-
-# Execute function as a Spark vectorized UDF
-df.select(multiply(col("x"), col("x"))).show()
-# +-------------------+
-# |multiply_func(x, x)|
-# +-------------------+
-# | 1|
-# | 4|
-# | 9|
-# +-------------------+
--- End diff --
Oh, I wanted to keep the example simple. I can add them back if you think they are useful. Maybe as another section? It's cleaner to separate the code that is needed to use the API and code that explains what's going on.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86610/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163986579
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
# Declare the function and create the UDF
-def multiply_func(a, b):
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
return a * b
-multiply = pandas_udf(multiply_func, returnType=LongType())
-
-# The function for a pandas_udf should be able to execute with local Pandas data
-x = pd.Series([1, 2, 3])
-print(multiply_func(x, x))
-# 0 1
-# 1 4
-# 2 9
-# dtype: int64
-
-# Create a Spark DataFrame, 'spark' is an existing SparkSession
-df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
-
-# Execute function as a Spark vectorized UDF
-df.select(multiply(col("x"), col("x"))).show()
-# +-------------------+
-# |multiply_func(x, x)|
-# +-------------------+
-# | 1|
-# | 4|
-# | 9|
-# +-------------------+
--- End diff --
Example reverted.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164065094
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows users to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can be used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+function should take `pandas.Series` as inputs and return a `pandas.Series` of the same length. Internally,
+Spark will split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`,
+and concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use groupby apply, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+The following example shows how to use groupby apply to subtract the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example group_map_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+For detailed usage, please see `pyspark.sql.functions.pandas_udf` and
+`pyspark.sql.GroupedData.apply`.
--- End diff --
and this:
```
[`pyspark.sql.GroupedData.apply`](api/python/pyspark.sql.html#pyspark.sql.GroupedData.apply)
```
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164176830
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows users to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
--- End diff --
I think this should say that it doesn't need the configuration from the prev section to be enabled
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86755 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86755/testReport)** for PR 19575 at commit [`e46ff0f`](https://github.com/apache/spark/commit/e46ff0f8a199c8e2722564ac522595a3e13556cb).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86719/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86675/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/149/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/246/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/297/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on the issue:
https://github.com/apache/spark/pull/19575
cc @jaceklaskowski, mind if I ask to skim this doc if you are available? We should make it to 2.3.0. Contents look generally fine but I think it'd be nicer if we can do the grammar nits in batch.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163908787
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
--- End diff --
remove the section on installing or just the header and merge with the above section?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163861140
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
+module with the command "pip install pyspark[sql]". Otherwise, you must ensure that pyarrow is
+installed and available on all cluster node Python environments. The current supported version is
+0.8.0. You can install using pip or conda from the conda-forge channel. See pyarrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
--- End diff --
Can we have a example file separately?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86669 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86669/testReport)** for PR 19575 at commit [`3f31930`](https://github.com/apache/spark/commit/3f3193059d10c598c02cf36c13da4bc92905130a).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163994595
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,204 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select("*").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same length. Internally, Spark will
--- End diff --
`returns ` -> `return`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164175559
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
--- End diff --
I wouldn't hurt to remind the user that this collects all data to the driver, I'll try to work that in
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163863186
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
--- End diff --
Could we leave a word "PySpark" somewhere at the first?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164131001
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
--- End diff --
> I feel we should discourage the use of toPandas
I am not sure that's necessary. I think it's reasonable to down-sample/aggregate data in Spark and use `toPandas()` to bring small data to local and analyze further or visualize. Maybe instead we should discourage use of `toPandas` with large amounts of data?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163861482
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
+module with the command "pip install pyspark[sql]". Otherwise, you must ensure that pyarrow is
+installed and available on all cluster node Python environments. The current supported version is
+0.8.0. You can install using pip or conda from the conda-forge channel. See pyarrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## How to Enable for Conversion to/from Pandas
--- End diff --
maybe "Enabling for Conversion to/from Pandas" just to match the sentence form
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163988528
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,254 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
--- End diff --
> Create a Spark DataFrame from Pandas data using Arrow
->
> Create a Spark DataFrame from Pandas DataFrame using Arrow
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86218 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86218/testReport)** for PR 19575 at commit [`5699d1b`](https://github.com/apache/spark/commit/5699d1b740eb55c49ded6fd25a37b3c388b49ca6).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163972275
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,250 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select("*").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import pandas as pd
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
+
+# Declare the function and create the UDF
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
+ return a * b
+
+df.select(multiply_udf(df.v, df.v)).show()
+# +------------------+
+# |multiply_udf(v, v)|
+# +------------------+
+# | 1|
+# | 4|
+# | 9|
+# +------------------+
+
+{% endhighlight %}
+</div>
+</div>
+
+Note that there are two important requirement when using scalar pandas UDFs:
+* The input and output series must have the same size.
+* How a column is splitted into multiple `pandas.Series` is internal to Spark, and therefore the result
+ of user-defined function must be independent of the splitting.
+
+### Group Map
+Group map pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use groupby apply, user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+Here we show two examples of using group map pandas UDFs.
+
+The first example shows a simple use case: subtracting the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+from pyspark.sql.functions import pandas_udf, PandasUDFType
+
+df = spark.createDataFrame(
+ [(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
+ ("id", "v"))
+
+@pandas_udf("id long, v double", PandasUDFType.GROUP_MAP)
+def substract_mean(pdf):
+ # pdf is a pandas.DataFrame
+ v = pdf.v
+ return pdf.assign(v=v - v.mean())
+
+df.groupby("id").apply(substract_mean).show()
+# +---+----+
+# | id| v|
+# +---+----+
+# | 1|-0.5|
+# | 1| 0.5|
+# | 2|-3.0|
+# | 2|-1.0|
+# | 2| 4.0|
+# +---+----+
+
+{% endhighlight %}
+</div>
+</div>
+
+The second example is a more complicated example. It shows how to run a OLS linear regression
+for each group using statsmodels. For each group, we calculate beta b = (b1, b2) for X = (x1, x2)
+according to statistical model Y = bX + c.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+import pandas as pd
+import statsmodels.api as sm
+
+df = spark.createDataFrame(
+ [(1, 1.0, 1.0, -3.0),
+ (1, 2.0, 2.0, -6.0),
+ (2, 3.0, 6.0, -6.0),
+ (2, 5.0, 10.0, -10.0),
+ (2, 10.0, 20.0, -20.0)],
+ ("id", "y", 'x1', 'x2'))
+
+group_column = 'id'
+y_column = 'y'
+x_columns = ['x1', 'x2']
+schema = df.select(group_column, *x_columns).schema
+
+@pandas_udf(schema, PandasUDFType.GROUP_MAP)
+# Input/output are both a pandas.DataFrame
+def ols(pdf):
+ group_key = pdf[group_column].iloc[0]
+ Y = pdf[y_column]
--- End diff --
Can we avoid this uppercased variable?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163910122
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
+module with the command "pip install pyspark[sql]". Otherwise, you must ensure that pyarrow is
+installed and available on all cluster node Python environments. The current supported version is
+0.8.0. You can install using pip or conda from the conda-forge channel. See pyarrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select(" * ").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## How to Write Vectorized UDFs
+
+A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
+Pandas Series, which allow the function to be composed with vectorized operations. This function
+can then be run very efficiently in Spark where data is sent in batches to Python and then
+is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
+Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
+keyword, no additional configuration is required.
+
+The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import pandas as pd
+from pyspark.sql.functions import col, pandas_udf
+from pyspark.sql.types import LongType
+
+# Declare the function and create the UDF
+def multiply_func(a, b):
+ return a * b
+
+multiply = pandas_udf(multiply_func, returnType=LongType())
+
+# The function for a pandas_udf should be able to execute with local Pandas data
+x = pd.Series([1, 2, 3])
+print(multiply_func(x, x))
+# 0 1
+# 1 4
+# 2 9
+# dtype: int64
+
+# Create a Spark DataFrame, 'spark' is an existing SparkSession
+df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
+
+# Execute function as a Spark vectorized UDF
+df.select(multiply(col("x"), col("x"))).show()
+# +-------------------+
+# |multiply_func(x, x)|
+# +-------------------+
+# | 1|
+# | 4|
+# | 9|
+# +-------------------+
+
+{% endhighlight %}
+</div>
+</div>
+
+## GroupBy-Apply UDFs
+
+## Usage Notes
+
+### Supported types
+
+Currently, all Spark SQL data types are supported except `MapType`, `ArrayType` of `TimestampType`, and
+nested `StructType`.
+
+### Setting Arrow Batch Size
+
+Data partitions in Spark are converted into Arrow record batches, which can temporarily lead to
+high memory usage in the JVM. To avoid possible out of memory exceptions, the size of the Arrow
+record batches can be adjusted by setting the conf "spark.sql.execution.arrow.maxRecordsPerBatch"
+to an integer that will determine the maximum number of rows for each batch. The default value is
+10,000 records per batch and does not take into account the number of columns, so it should be
+adjusted accordingly. Using this limit, each data partition will be made into 1 or more record
+batches for processing.
+
+### Timestamp with Time Zone Semantics
+
+Spark internally stores timestamps as UTC values, and timestamp data that is brought in without
+a specified time zone is converted as local time to UTC with microsecond resolution. When timestamp
+data is exported or displayed in Spark, the session time zone is used to localize the timestamp
+values. The session time zone is set with the conf 'spark.sql.session.timeZone' and will default
+to the JVM system local time zone if not set. Pandas uses a `datetime64` type with nanosecond
+resolution, `datetime64[ns]`, and optional time zone that can be applied on a per-column basis.
+
+When timestamp data is transferred from Spark to Pandas it will be converted to nanoseconds
+and each column will be made time zone aware using the Spark session time zone. This will occur
+when calling `toPandas()` or `pandas_udf` with a timestamp column. For example if the session time
+zone is 'America/Los_Angeles' then the Pandas timestamp column will be of type
+`datetime64[ns, America/Los_Angeles]`.
--- End diff --
Sorry, I should have refreshed my memory better before writing.. fixing now
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163961036
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,250 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select("*").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a Vectorized UDFs)
--- End diff --
minor, but if you're going to say aka, it's missing the last period -> "a.k.a."
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163986511
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
# Declare the function and create the UDF
-def multiply_func(a, b):
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
return a * b
-multiply = pandas_udf(multiply_func, returnType=LongType())
-
-# The function for a pandas_udf should be able to execute with local Pandas data
-x = pd.Series([1, 2, 3])
-print(multiply_func(x, x))
-# 0 1
-# 1 4
-# 2 9
-# dtype: int64
-
-# Create a Spark DataFrame, 'spark' is an existing SparkSession
-df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
-
-# Execute function as a Spark vectorized UDF
-df.select(multiply(col("x"), col("x"))).show()
-# +-------------------+
-# |multiply_func(x, x)|
-# +-------------------+
-# | 1|
-# | 4|
-# | 9|
-# +-------------------+
+df.select(multiply_udf(df.v, df.v)).show()
+# +------------------+
+# |multiply_udf(v, v)|
+# +------------------+
+# | 1|
+# | 4|
+# | 9|
+# +------------------+
{% endhighlight %}
</div>
</div>
-## GroupBy-Apply
-GroupBy-Apply implements the "split-apply-combine" pattern. Split-apply-combine consists of three steps:
+Note that there are two important requirement when using scalar pandas UDFs:
+* The input and output series must have the same size.
+* How a column is splitted into multiple `pandas.Series` is internal to Spark, and therefore the result
--- End diff --
Fixed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163961045
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
--- End diff --
Oh sorry my bad. I will make sure they run.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163986071
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,250 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select("*").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
--- End diff --
I think pandas is lower case because the references I found are lower case:
https://pandas.pydata.org/
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163956861
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
# Declare the function and create the UDF
-def multiply_func(a, b):
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
return a * b
-multiply = pandas_udf(multiply_func, returnType=LongType())
-
-# The function for a pandas_udf should be able to execute with local Pandas data
-x = pd.Series([1, 2, 3])
-print(multiply_func(x, x))
-# 0 1
-# 1 4
-# 2 9
-# dtype: int64
-
-# Create a Spark DataFrame, 'spark' is an existing SparkSession
-df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
-
-# Execute function as a Spark vectorized UDF
-df.select(multiply(col("x"), col("x"))).show()
-# +-------------------+
-# |multiply_func(x, x)|
-# +-------------------+
-# | 1|
-# | 4|
-# | 9|
-# +-------------------+
--- End diff --
@icexelloss why did you remove so much here? I thought it was helpful to explicitly show pandas.Series as inputs to the function so the user knows exactly what is happening.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164055326
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
--- End diff --
Maybe we should also add "Apache" to the headline above?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #83053 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/83053/testReport)** for PR 19575 at commit [`0723e86`](https://github.com/apache/spark/commit/0723e862bc4b644e1eca433fe2e22040e266a73d).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86218 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86218/testReport)** for PR 19575 at commit [`5699d1b`](https://github.com/apache/spark/commit/5699d1b740eb55c49ded6fd25a37b3c388b49ca6).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by asfgit <gi...@git.apache.org>.
Github user asfgit closed the pull request at:
https://github.com/apache/spark/pull/19575
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164250138
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
--- End diff --
@rxin WDYT about this name?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163994525
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,204 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select("*").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same length. Internally, Spark will
--- End diff --
`should takes` -> `function should take`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on the issue:
https://github.com/apache/spark/pull/19575
Thanks @gatorsmile , I made https://issues.apache.org/jira/browse/SPARK-23258 to track changing the `maxRecordsPerBatch` conf and I will externalize it in this PR.
> group map -> grouped map We need to also update PythonEvalType.
It seems like we are changing around the groupBy-apply name a lot and I don't want to change things here unless this has been agreed upon, can you confirm @icexelloss ?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86658 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86658/testReport)** for PR 19575 at commit [`dd51af1`](https://github.com/apache/spark/commit/dd51af1de42d3846be839a7067370a559f252c54).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163836168
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
+module with the command "pip install pyspark[sql]". Otherwise, you must ensure that pyarrow is
+installed and available on all cluster node Python environments. The current supported version is
+0.8.0. You can install using pip or conda from the conda-forge channel. See pyarrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select(" * ").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## How to Write Vectorized UDFs
+
+A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
+Pandas Series, which allow the function to be composed with vectorized operations. This function
+can then be run very efficiently in Spark where data is sent in batches to Python and then
+is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
+Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
+keyword, no additional configuration is required.
+
+The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import pandas as pd
+from pyspark.sql.functions import col, pandas_udf
+from pyspark.sql.types import LongType
+
+# Declare the function and create the UDF
+def multiply_func(a, b):
+ return a * b
+
+multiply = pandas_udf(multiply_func, returnType=LongType())
+
+# The function for a pandas_udf should be able to execute with local Pandas data
+x = pd.Series([1, 2, 3])
+print(multiply_func(x, x))
+# 0 1
+# 1 4
+# 2 9
+# dtype: int64
+
+# Create a Spark DataFrame, 'spark' is an existing SparkSession
+df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
+
+# Execute function as a Spark vectorized UDF
+df.select(multiply(col("x"), col("x"))).show()
+# +-------------------+
+# |multiply_func(x, x)|
+# +-------------------+
+# | 1|
+# | 4|
+# | 9|
+# +-------------------+
+
+{% endhighlight %}
+</div>
+</div>
+
+## GroupBy-Apply UDFs
+
+## Usage Notes
+
+### Supported types
+
+Currently, all Spark SQL data types are supported except `MapType`, `ArrayType` of `TimestampType`, and
+nested `StructType`.
+
+### Setting Arrow Batch Size
+
+Data partitions in Spark are converted into Arrow record batches, which can temporarily lead to
+high memory usage in the JVM. To avoid possible out of memory exceptions, the size of the Arrow
+record batches can be adjusted by setting the conf "spark.sql.execution.arrow.maxRecordsPerBatch"
+to an integer that will determine the maximum number of rows for each batch. The default value is
+10,000 records per batch and does not take into account the number of columns, so it should be
+adjusted accordingly. Using this limit, each data partition will be made into 1 or more record
+batches for processing.
+
+### Timestamp with Time Zone Semantics
+
+Spark internally stores timestamps as UTC values, and timestamp data that is brought in without
+a specified time zone is converted as local time to UTC with microsecond resolution. When timestamp
+data is exported or displayed in Spark, the session time zone is used to localize the timestamp
+values. The session time zone is set with the conf 'spark.sql.session.timeZone' and will default
+to the JVM system local time zone if not set. Pandas uses a `datetime64` type with nanosecond
+resolution, `datetime64[ns]`, and optional time zone that can be applied on a per-column basis.
+
+When timestamp data is transferred from Spark to Pandas it will be converted to nanoseconds
+and each column will be made time zone aware using the Spark session time zone. This will occur
+when calling `toPandas()` or `pandas_udf` with a timestamp column. For example if the session time
+zone is 'America/Los_Angeles' then the Pandas timestamp column will be of type
+`datetime64[ns, America/Los_Angeles]`.
+
+When timestamp data is transferred from Pandas to Spark, it will be converted to UTC microseconds. This
+occurs when calling `createDataFrame` with a Pandas DataFrame or when returning a timestamp from a
+`pandas_udf`. These conversions are done automatically to ensure Spark will have data in the
+expected format, so it is not necessary to do any of these conversions yourself. Any nanosecond
+values will be truncated.
+
+Note that a standard UDF (non-Pandas) will load timestamp data as Python datetime objects, which is
+different than a Pandas timestamp. It is recommended to use Pandas time series functionality when
+working with timestamps in `pandas_udf`s to get the best performance, see
+[here](https://pandas.pydata.org/pandas-docs/stable/timeseries.html) for details.
--- End diff --
ditto for a trailing whitespace
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164345403
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
--- End diff --
I can change to whatever you guys like, but I think these two section names were made to reflect the different pandas_udf types - scalar and group map. Is that right @icexelloss ?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164337710
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
--- End diff --
`a Spark DataFrame to Pandas` -> `a Spark DataFrame to Pandas DataFrame`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164509836
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use `groupBy().apply()`, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+The following example shows how to use `groupby().apply()` to subtract the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example group_map_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf) and
+[`pyspark.sql.GroupedData.apply`](api/python/pyspark.sql.html#pyspark.sql.GroupedData.apply).
+
+## Usage Notes
+
+### Supported SQL-Arrow Types
+
+Currently, all Spark SQL data types are supported except `MapType`, `ArrayType` of `TimestampType`, and
+nested `StructType`.
+
+### Setting Arrow Batch Size
+
+Data partitions in Spark are converted into Arrow record batches, which can temporarily lead to
+high memory usage in the JVM. To avoid possible out of memory exceptions, the size of the Arrow
+record batches can be adjusted by setting the conf "spark.sql.execution.arrow.maxRecordsPerBatch"
--- End diff --
Yes, it's not an ideal approach. I'm happy to make a JIRA to followup and look into other ways to break up the batches, but that won't be in before 2.3. So does that mean our options here are (unless I'm not understanding internal/external conf correctly)
1. Keep `maxRecordsPerBatch` internal and remove this doc section.
2. Externalize this conf and deprecate once a better approach is found.
I think (2) is better because if the user hits memory issues, then they can at least find someway to adjust it
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164346090
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use `groupBy().apply()`, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+The following example shows how to use `groupby().apply()` to subtract the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example group_map_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf) and
+[`pyspark.sql.GroupedData.apply`](api/python/pyspark.sql.html#pyspark.sql.GroupedData.apply).
+
+## Usage Notes
+
+### Supported SQL-Arrow Types
+
+Currently, all Spark SQL data types are supported except `MapType`, `ArrayType` of `TimestampType`, and
+nested `StructType`.
+
+### Setting Arrow Batch Size
+
+Data partitions in Spark are converted into Arrow record batches, which can temporarily lead to
+high memory usage in the JVM. To avoid possible out of memory exceptions, the size of the Arrow
+record batches can be adjusted by setting the conf "spark.sql.execution.arrow.maxRecordsPerBatch"
--- End diff --
It's possible to estimate the size of the arrow buffer used, but it does make it more complicated to implement in Spark. I also wonder how useful this would be if the user hits memory problems. At least with a number of records, it's easy to understand and change.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164337734
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
--- End diff --
`a Spark DataFrame from Pandas` -> `a Spark DataFrame from Pandas DataFrame`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164175878
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows users to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can be used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+function should take `pandas.Series` as inputs and return a `pandas.Series` of the same length. Internally,
+Spark will split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`,
+and concat the results together to be a new column.
--- End diff --
yeah, I think this worded a little confusing too
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163956524
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
--- End diff --
@icexelloss I think there is a typo -> `PandasUDFTypr`
Please make sure the example run
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164470776
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
--- End diff --
That is correct. The names in this section matches the enums in `PandasUDFType`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86755 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86755/testReport)** for PR 19575 at commit [`e46ff0f`](https://github.com/apache/spark/commit/e46ff0f8a199c8e2722564ac522595a3e13556cb).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163857867
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
+module with the command "pip install pyspark[sql]". Otherwise, you must ensure that pyarrow is
+installed and available on all cluster node Python environments. The current supported version is
+0.8.0. You can install using pip or conda from the conda-forge channel. See pyarrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select(" * ").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## How to Write Vectorized UDFs
+
+A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
+Pandas Series, which allow the function to be composed with vectorized operations. This function
--- End diff --
`Pandas Series` -> `Pandas Series/DataFrame` maybe also saying please check the API doc. Maybe this one needs a help from @icexelloss to generally organise these and clean up. This description sounds only for scalar UDFs.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on the issue:
https://github.com/apache/spark/pull/19575
@BryanCutler can you add me as a collaborator to the branch?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163856122
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
+module with the command "pip install pyspark[sql]". Otherwise, you must ensure that pyarrow is
+installed and available on all cluster node Python environments. The current supported version is
+0.8.0. You can install using pip or conda from the conda-forge channel. See pyarrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select(" * ").toPandas()
--- End diff --
nit: `" * "` -> `"*"`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163483209
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,147 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. It's usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you have installed pyspark using pip, then pyarrow will automatically be brought in as a dependency.
+Otherwise, you must ensure that pyarrow is installed and available on all cluster node Python
+environments. The current supported version is 0.8.0. You can install using pip or conda from the
+conda-forge channel. See pyarrow [installation](https://arrow.apache.org/docs/python/install.html)
+for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select(" * ").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## How to Write Vectorized UDFs
+
+A vectorized UDF is similar to a standard UDF in Spark except the inputs and output of the will
--- End diff --
`output of the will` -> `output of the udf will`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163964598
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
# Declare the function and create the UDF
-def multiply_func(a, b):
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
return a * b
-multiply = pandas_udf(multiply_func, returnType=LongType())
-
-# The function for a pandas_udf should be able to execute with local Pandas data
-x = pd.Series([1, 2, 3])
-print(multiply_func(x, x))
-# 0 1
-# 1 4
-# 2 9
-# dtype: int64
-
-# Create a Spark DataFrame, 'spark' is an existing SparkSession
-df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
-
-# Execute function as a Spark vectorized UDF
-df.select(multiply(col("x"), col("x"))).show()
-# +-------------------+
-# |multiply_func(x, x)|
-# +-------------------+
-# | 1|
-# | 4|
-# | 9|
-# +-------------------+
+df.select(multiply_udf(df.v, df.v)).show()
+# +------------------+
+# |multiply_udf(v, v)|
+# +------------------+
+# | 1|
+# | 4|
+# | 9|
+# +------------------+
{% endhighlight %}
</div>
</div>
-## GroupBy-Apply
-GroupBy-Apply implements the "split-apply-combine" pattern. Split-apply-combine consists of three steps:
+Note that there are two important requirement when using scalar pandas UDFs:
+* The input and output series must have the same size.
+* How a column is splitted into multiple `pandas.Series` is internal to Spark, and therefore the result
+ of user-defined function must be independent of the splitting.
--- End diff --
Yeah I don't know a great way of saying this. Do you have any suggestions?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86669/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163984933
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
# Declare the function and create the UDF
-def multiply_func(a, b):
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
return a * b
-multiply = pandas_udf(multiply_func, returnType=LongType())
-
-# The function for a pandas_udf should be able to execute with local Pandas data
-x = pd.Series([1, 2, 3])
-print(multiply_func(x, x))
-# 0 1
-# 1 4
-# 2 9
-# dtype: int64
-
-# Create a Spark DataFrame, 'spark' is an existing SparkSession
-df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
-
-# Execute function as a Spark vectorized UDF
-df.select(multiply(col("x"), col("x"))).show()
-# +-------------------+
-# |multiply_func(x, x)|
-# +-------------------+
-# | 1|
-# | 4|
-# | 9|
-# +-------------------+
+df.select(multiply_udf(df.v, df.v)).show()
+# +------------------+
+# |multiply_udf(v, v)|
+# +------------------+
+# | 1|
+# | 4|
+# | 9|
+# +------------------+
{% endhighlight %}
</div>
</div>
-## GroupBy-Apply
-GroupBy-Apply implements the "split-apply-combine" pattern. Split-apply-combine consists of three steps:
+Note that there are two important requirement when using scalar pandas UDFs:
+* The input and output series must have the same size.
+* How a column is splitted into multiple `pandas.Series` is internal to Spark, and therefore the result
+ of user-defined function must be independent of the splitting.
--- End diff --
Ok let me remove these.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86664 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86664/testReport)** for PR 19575 at commit [`a32d67a`](https://github.com/apache/spark/commit/a32d67adee89506379c79fa03440aef80f311917).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164251821
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use `groupBy().apply()`, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+The following example shows how to use `groupby().apply()` to subtract the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example group_map_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf) and
+[`pyspark.sql.GroupedData.apply`](api/python/pyspark.sql.html#pyspark.sql.GroupedData.apply).
+
+## Usage Notes
+
+### Supported SQL-Arrow Types
+
+Currently, all Spark SQL data types are supported except `MapType`, `ArrayType` of `TimestampType`, and
--- End diff --
`are supported` -> `are supported by Arrow-based conversion`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164260764
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use `groupBy().apply()`, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+The following example shows how to use `groupby().apply()` to subtract the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example group_map_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf) and
+[`pyspark.sql.GroupedData.apply`](api/python/pyspark.sql.html#pyspark.sql.GroupedData.apply).
+
+## Usage Notes
+
+### Supported SQL-Arrow Types
+
+Currently, all Spark SQL data types are supported except `MapType`, `ArrayType` of `TimestampType`, and
+nested `StructType`.
+
+### Setting Arrow Batch Size
+
+Data partitions in Spark are converted into Arrow record batches, which can temporarily lead to
+high memory usage in the JVM. To avoid possible out of memory exceptions, the size of the Arrow
+record batches can be adjusted by setting the conf "spark.sql.execution.arrow.maxRecordsPerBatch"
--- End diff --
No, both can be used where applicable.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163862652
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
--- End diff --
Seems there are more sub topics than I thought. Probably, we could consider remove this one too.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on the issue:
https://github.com/apache/spark/pull/19575
How about a critical @felixcheung? I will focus on this one anyway to get this into 2.3.0. Seems RC3 will be going on if I didn't misunderstand.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86664/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163985361
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
# Declare the function and create the UDF
-def multiply_func(a, b):
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
return a * b
-multiply = pandas_udf(multiply_func, returnType=LongType())
-
-# The function for a pandas_udf should be able to execute with local Pandas data
-x = pd.Series([1, 2, 3])
-print(multiply_func(x, x))
-# 0 1
-# 1 4
-# 2 9
-# dtype: int64
-
-# Create a Spark DataFrame, 'spark' is an existing SparkSession
-df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
-
-# Execute function as a Spark vectorized UDF
-df.select(multiply(col("x"), col("x"))).show()
-# +-------------------+
-# |multiply_func(x, x)|
-# +-------------------+
-# | 1|
-# | 4|
-# | 9|
-# +-------------------+
+df.select(multiply_udf(df.v, df.v)).show()
+# +------------------+
+# |multiply_udf(v, v)|
+# +------------------+
+# | 1|
+# | 4|
+# | 9|
+# +------------------+
{% endhighlight %}
</div>
</div>
-## GroupBy-Apply
-GroupBy-Apply implements the "split-apply-combine" pattern. Split-apply-combine consists of three steps:
+Note that there are two important requirement when using scalar pandas UDFs:
+* The input and output series must have the same size.
+* How a column is splitted into multiple `pandas.Series` is internal to Spark, and therefore the result
+ of user-defined function must be independent of the splitting.
--- End diff --
BTW, just to be clear, I think we don't have to write this in every detail but rather only key ones. Users will see the pydoc if they want some advanced details.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163696684
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,147 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. It's usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you have installed pyspark using pip, then pyarrow will automatically be brought in as a dependency.
+Otherwise, you must ensure that pyarrow is installed and available on all cluster node Python
+environments. The current supported version is 0.8.0. You can install using pip or conda from the
+conda-forge channel. See pyarrow [installation](https://arrow.apache.org/docs/python/install.html)
+for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select(" * ").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## How to Write Vectorized UDFs
+
+A vectorized UDF is similar to a standard UDF in Spark except the inputs and output of the will
--- End diff --
ooops, I think I meant `the inputs and output will be Pandas Series`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163972751
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,250 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select("*").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
--- End diff --
Should we `pandas` -> `Pandas`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163986923
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,254 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
--- End diff --
`, this` -> `. This`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on the issue:
https://github.com/apache/spark/pull/19575
@HyukjinKwon @ueshin @gatorsmile does this seem like an appropriate place to put Arrow related user docs? I think we just need to add something for additional pandas_udfs and it's still a little rough so I will go over it all again.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164251759
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use `groupBy().apply()`, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+The following example shows how to use `groupby().apply()` to subtract the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example group_map_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf) and
+[`pyspark.sql.GroupedData.apply`](api/python/pyspark.sql.html#pyspark.sql.GroupedData.apply).
+
+## Usage Notes
+
+### Supported SQL-Arrow Types
--- End diff --
-> `SQL Types`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/83053/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163960394
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,250 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select("*").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import pandas as pd
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
+
+# Declare the function and create the UDF
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
+ return a * b
+
+df.select(multiply_udf(df.v, df.v)).show()
+# +------------------+
+# |multiply_udf(v, v)|
+# +------------------+
+# | 1|
+# | 4|
+# | 9|
+# +------------------+
+
+{% endhighlight %}
+</div>
+</div>
+
+Note that there are two important requirement when using scalar pandas UDFs:
+* The input and output series must have the same size.
+* How a column is splitted into multiple `pandas.Series` is internal to Spark, and therefore the result
+ of user-defined function must be independent of the splitting.
+
+### Group Map
+Group map pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use groupby apply, user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+Here we show two examples of using group map pandas UDFs.
+
+The first example shows a simple use case: subtracting the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+from pyspark.sql.functions import pandas_udf, PandasUDFType
+
+df = spark.createDataFrame(
+ [(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
+ ("id", "v"))
+
+@pandas_udf("id long, v double", PandasUDFType.GROUP_MAP)
+def substract_mean(pdf):
+ # pdf is a pandas.DataFrame
+ v = pdf.v
+ return pdf.assign(v=v - v.mean())
+
+df.groupby("id").apply(substract_mean).show()
+# +---+----+
+# | id| v|
+# +---+----+
+# | 1|-0.5|
+# | 1| 0.5|
+# | 2|-3.0|
+# | 2|-1.0|
+# | 2| 4.0|
+# +---+----+
+
+{% endhighlight %}
+</div>
+</div>
+
+The second example is a more complicated example. It shows how to run a OLS linear regression
--- End diff --
would this second example be better as a separate file in "examples" instead of including in the user guide?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163988418
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,254 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
--- End diff --
`Generate sample data`
->
`Generate a Pandas DataFrame`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164252270
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use `groupBy().apply()`, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+The following example shows how to use `groupby().apply()` to subtract the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example group_map_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf) and
+[`pyspark.sql.GroupedData.apply`](api/python/pyspark.sql.html#pyspark.sql.GroupedData.apply).
+
+## Usage Notes
+
+### Supported SQL-Arrow Types
+
+Currently, all Spark SQL data types are supported except `MapType`, `ArrayType` of `TimestampType`, and
+nested `StructType`.
+
+### Setting Arrow Batch Size
+
+Data partitions in Spark are converted into Arrow record batches, which can temporarily lead to
+high memory usage in the JVM. To avoid possible out of memory exceptions, the size of the Arrow
+record batches can be adjusted by setting the conf "spark.sql.execution.arrow.maxRecordsPerBatch"
+to an integer that will determine the maximum number of rows for each batch. The default value is
+10,000 records per batch and does not take into account the number of columns, so it should be
--- End diff --
> The default value is 10,000 records per batch. Since the number of columns could be huge, the value should be adjusted accordingly.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163957070
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
# Declare the function and create the UDF
-def multiply_func(a, b):
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
return a * b
-multiply = pandas_udf(multiply_func, returnType=LongType())
-
-# The function for a pandas_udf should be able to execute with local Pandas data
-x = pd.Series([1, 2, 3])
-print(multiply_func(x, x))
-# 0 1
-# 1 4
-# 2 9
-# dtype: int64
-
-# Create a Spark DataFrame, 'spark' is an existing SparkSession
-df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
-
-# Execute function as a Spark vectorized UDF
-df.select(multiply(col("x"), col("x"))).show()
-# +-------------------+
-# |multiply_func(x, x)|
-# +-------------------+
-# | 1|
-# | 4|
-# | 9|
-# +-------------------+
+df.select(multiply_udf(df.v, df.v)).show()
+# +------------------+
+# |multiply_udf(v, v)|
+# +------------------+
+# | 1|
+# | 4|
+# | 9|
+# +------------------+
{% endhighlight %}
</div>
</div>
-## GroupBy-Apply
-GroupBy-Apply implements the "split-apply-combine" pattern. Split-apply-combine consists of three steps:
+Note that there are two important requirement when using scalar pandas UDFs:
--- End diff --
requirement -> requirements
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164007221
--- Diff: examples/src/main/python/sql/arrow.py ---
@@ -0,0 +1,125 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+"""
+A simple example demonstrating Arrow in Spark.
+Run with:
+ ./bin/spark-submit examples/src/main/python/sql/arrow.py
+"""
+
+from __future__ import print_function
+
+from pyspark.sql import SparkSession
+from pyspark.sql.utils import require_minimum_pandas_version, require_minimum_pyarrow_version
+
+require_minimum_pandas_version()
+require_minimum_pyarrow_version()
+
+
+def dataframe_with_arrow_example(spark):
+ # $example on:dataframe_with_arrow$
+ import numpy as np
+ import pandas as pd
+
+ # Enable Arrow-based columnar data transfers
+ spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+ # Generate a Pandas DataFrame
+ pdf = pd.DataFrame(np.random.rand(100, 3))
+
+ # Create a Spark DataFrame from a Pandas DataFrame using Arrow
+ df = spark.createDataFrame(pdf)
+
+ # Convert the Spark DataFrame back to a Pandas DataFrame using Arrow
+ result_pdf = df.select("*").toPandas()
+ # $example off:dataframe_with_arrow$
+
--- End diff --
I mean I don't mind to be clear ..
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164345006
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
--- End diff --
I added a note for this
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164053213
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows users to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can be used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+function should take `pandas.Series` as inputs and return a `pandas.Series` of the same length. Internally,
+Spark will split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`,
+and concat the results together to be a new column.
--- End diff --
I don't completely get the "to be a new column" part - should we just leave it as "concat the results together"?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86675 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86675/testReport)** for PR 19575 at commit [`c446716`](https://github.com/apache/spark/commit/c4467162fbc0b671e63d145d0e71a4098ee46f8e).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164055523
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
--- End diff --
> is 'spark.sql.execution.arrow.enabled' to 'true' only for toPandas and does not affect pandas_udf?
Yup, it is. It's for both `toPandas` and `createDataFrame`.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163962882
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
# Declare the function and create the UDF
-def multiply_func(a, b):
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
return a * b
-multiply = pandas_udf(multiply_func, returnType=LongType())
-
-# The function for a pandas_udf should be able to execute with local Pandas data
-x = pd.Series([1, 2, 3])
-print(multiply_func(x, x))
-# 0 1
-# 1 4
-# 2 9
-# dtype: int64
-
-# Create a Spark DataFrame, 'spark' is an existing SparkSession
-df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
-
-# Execute function as a Spark vectorized UDF
-df.select(multiply(col("x"), col("x"))).show()
-# +-------------------+
-# |multiply_func(x, x)|
-# +-------------------+
-# | 1|
-# | 4|
-# | 9|
-# +-------------------+
+df.select(multiply_udf(df.v, df.v)).show()
+# +------------------+
+# |multiply_udf(v, v)|
+# +------------------+
+# | 1|
+# | 4|
+# | 9|
+# +------------------+
{% endhighlight %}
</div>
</div>
-## GroupBy-Apply
-GroupBy-Apply implements the "split-apply-combine" pattern. Split-apply-combine consists of three steps:
+Note that there are two important requirement when using scalar pandas UDFs:
--- End diff --
Done
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164261725
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use `groupBy().apply()`, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
--- End diff --
We need to warn users that, the Group Map Pandas UDF requires to load all the data of a group into memory, which is not controlled by `spark.sql.execution.arrow.maxRecordsPerBatch`, and may OOM if the data is skewed and some partitions have a lot of records.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on the issue:
https://github.com/apache/spark/pull/19575
Updated screens:



---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163835922
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
+module with the command "pip install pyspark[sql]". Otherwise, you must ensure that pyarrow is
+installed and available on all cluster node Python environments. The current supported version is
+0.8.0. You can install using pip or conda from the conda-forge channel. See pyarrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
--- End diff --
tiny nit: there's a trailing whitespace
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163962833
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
# Declare the function and create the UDF
-def multiply_func(a, b):
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
return a * b
-multiply = pandas_udf(multiply_func, returnType=LongType())
-
-# The function for a pandas_udf should be able to execute with local Pandas data
-x = pd.Series([1, 2, 3])
-print(multiply_func(x, x))
-# 0 1
-# 1 4
-# 2 9
-# dtype: int64
-
-# Create a Spark DataFrame, 'spark' is an existing SparkSession
-df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
-
-# Execute function as a Spark vectorized UDF
-df.select(multiply(col("x"), col("x"))).show()
-# +-------------------+
-# |multiply_func(x, x)|
-# +-------------------+
-# | 1|
-# | 4|
-# | 9|
-# +-------------------+
+df.select(multiply_udf(df.v, df.v)).show()
+# +------------------+
+# |multiply_udf(v, v)|
+# +------------------+
+# | 1|
+# | 4|
+# | 9|
+# +------------------+
{% endhighlight %}
</div>
</div>
-## GroupBy-Apply
-GroupBy-Apply implements the "split-apply-combine" pattern. Split-apply-combine consists of three steps:
+Note that there are two important requirement when using scalar pandas UDFs:
+* The input and output series must have the same size.
--- End diff --
Yeah I think length is better. Changed to length
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/256/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86670 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86670/testReport)** for PR 19575 at commit [`eb1b347`](https://github.com/apache/spark/commit/eb1b347aa6ffee462a039f2d512298ce37a9cc4b).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86610 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86610/testReport)** for PR 19575 at commit [`b33346c`](https://github.com/apache/spark/commit/b33346cda29662abada85ea8f5c112679ebae91e).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on the issue:
https://github.com/apache/spark/pull/19575
Ohaa, let me open a PR first to this branch. I should resolve the conflicts otherwise :( ..
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86658/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on the issue:
https://github.com/apache/spark/pull/19575
it looks like maybe we have a blocker for RC2?
let's try to get this in soon so it could get into 2.3.0?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86648 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86648/testReport)** for PR 19575 at commit [`85e895c`](https://github.com/apache/spark/commit/85e895cf7f98fc6257f4ac182b28e15dffdbd084).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163855755
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
+module with the command "pip install pyspark[sql]". Otherwise, you must ensure that pyarrow is
+installed and available on all cluster node Python environments. The current supported version is
+0.8.0. You can install using pip or conda from the conda-forge channel. See pyarrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
--- End diff --
conf -> configuration
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on the issue:
https://github.com/apache/spark/pull/19575
is it possible to decide on the names for groupBy()-apply() UDFs as a followup? it sounds like there are still things that need discussion
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163995416
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,254 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
--- End diff --
BTW, please be consistent. If we want to use lower-case `pandas`, we need to do it everywhere
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86719 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86719/testReport)** for PR 19575 at commit [`67ab5e9`](https://github.com/apache/spark/commit/67ab5e913efad37f5150a600715993d6e95a5947).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163696279
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,147 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. It's usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you have installed pyspark using pip, then pyarrow will automatically be brought in as a dependency.
+Otherwise, you must ensure that pyarrow is installed and available on all cluster node Python
+environments. The current supported version is 0.8.0. You can install using pip or conda from the
+conda-forge channel. See pyarrow [installation](https://arrow.apache.org/docs/python/install.html)
+for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select(" * ").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## How to Write Vectorized UDFs
+
+A vectorized UDF is similar to a standard UDF in Spark except the inputs and output of the will
+be Pandas Series, which allow the function to be composed with vectorized operations. This function
+can then be run very efficiently in Spark where data is sent in batches to Python and the function
+is executed using Pandas Series as input. The exected output of the function is also a Pandas
+Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
+keyword, no additional configuration is required.
+
+The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import pandas as pd
+from pyspark.sql.functions import col, pandas_udf
+from pyspark.sql.types import LongType
+
+# Declare the function and create the UDF
+def multiply_func(a, b):
+ return a * b
+
+multiply = pandas_udf(multiply_func, returnType=LongType())
+
+# The function for a pandas_udf should be able to execute with local Pandas data
+x = pd.Series([1, 2, 3])
+print(multiply_func(x, x))
+# 0 1
+# 1 4
+# 2 9
+# dtype: int64
+
+# Create a Spark DataFrame
+df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
+
+# Execute function as a Spark vectorized UDF
+df.select(multiply(col("x"), col("x"))).show()
+# +-------------------+
+# |multiply_func(x, x)|
+# +-------------------+
+# | 1|
+# | 4|
+# | 9|
+# +-------------------+
+
+{% endhighlight %}
+</div>
+</div>
+
+## GroupBy-Apply UDFs
+
+## Usage Notes
+
+### Supported types
+
+Currently, all Spark SQL data types are supported except `MapType`, `ArrayType` of `TimestampType`, and
+nested `StructType`.
+
+### Setting Arrow Batch Size
+
+Data partitions in Spark are converted into Arrow record batches, which can temporarily lead to
+high memory usage in the JVM. To avoid possible out of memory exceptions, the size of the Arrow
+record batches can be adjusted by setting the conf "spark.sql.execution.arrow.maxRecordsPerBatch"
+to an integer that will determine the maximum number of rows for each batch. Using this limit,
+each data partition will be made into 1 or more record batches for processing.
+
+### Date and Timestamp Semantics
+
+Spark internally stores timestamps as UTC values and timestamp data that is brought in without
+a specified time zone, it is converted as local time to UTC with microsecond resolution. Pandas uses
+a `datetime64` type with nanosecond resolution, `datetime64[ns]` with optional time zone.
+
+When timestamp data is transferred from Spark to Pandas it will be converted to nanoseconds
+and made time zone aware using the Spark session time zone, if set, or local Python system time
--- End diff --
I guess I was thinking of when `respectSessionTimeZone` is false, but since it is true by default and will is deprecated. But to keep things simple maybe best not to mention this conf and just say session tz or JVM default?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164286075
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
--- End diff --
`Scalar Vectorized UDFs`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/324/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164062967
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows users to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can be used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+function should take `pandas.Series` as inputs and return a `pandas.Series` of the same length. Internally,
+Spark will split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`,
+and concat the results together to be a new column.
--- End diff --
`concat` -> `concatenate` too.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86648 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86648/testReport)** for PR 19575 at commit [`85e895c`](https://github.com/apache/spark/commit/85e895cf7f98fc6257f4ac182b28e15dffdbd084).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164053364
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows users to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can be used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+function should take `pandas.Series` as inputs and return a `pandas.Series` of the same length. Internally,
+Spark will split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`,
+and concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use groupby apply, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+The following example shows how to use groupby apply to subtract the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example group_map_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+For detailed usage, please see `pyspark.sql.functions.pandas_udf` and
--- End diff --
can we link into the API page directly?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164062504
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
--- End diff --
` error will be raised` -> ` error can be raised` (because we fall back in createDataFrame).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/19575
Actually, aggregation can only be executed on grouped data, so `SQL_PANDAS_GROUPED_AGG_UDF` doesn't seem to be very concise. How about `SQL_PANDAS_UDAF`? My only concern is how to support partial aggregate in the future, will we add new APIs?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on the issue:
https://github.com/apache/spark/pull/19575
Thanks to everyone for contributing and reviewing!
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86670 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86670/testReport)** for PR 19575 at commit [`eb1b347`](https://github.com/apache/spark/commit/eb1b347aa6ffee462a039f2d512298ce37a9cc4b).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86675 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86675/testReport)** for PR 19575 at commit [`c446716`](https://github.com/apache/spark/commit/c4467162fbc0b671e63d145d0e71a4098ee46f8e).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164275737
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
--- End diff --
`Group Map`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163696299
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,147 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. It's usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you have installed pyspark using pip, then pyarrow will automatically be brought in as a dependency.
+Otherwise, you must ensure that pyarrow is installed and available on all cluster node Python
+environments. The current supported version is 0.8.0. You can install using pip or conda from the
+conda-forge channel. See pyarrow [installation](https://arrow.apache.org/docs/python/install.html)
+for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select(" * ").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## How to Write Vectorized UDFs
+
+A vectorized UDF is similar to a standard UDF in Spark except the inputs and output of the will
+be Pandas Series, which allow the function to be composed with vectorized operations. This function
+can then be run very efficiently in Spark where data is sent in batches to Python and the function
+is executed using Pandas Series as input. The exected output of the function is also a Pandas
+Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
+keyword, no additional configuration is required.
+
+The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import pandas as pd
+from pyspark.sql.functions import col, pandas_udf
+from pyspark.sql.types import LongType
+
+# Declare the function and create the UDF
+def multiply_func(a, b):
+ return a * b
+
+multiply = pandas_udf(multiply_func, returnType=LongType())
+
+# The function for a pandas_udf should be able to execute with local Pandas data
+x = pd.Series([1, 2, 3])
+print(multiply_func(x, x))
+# 0 1
+# 1 4
+# 2 9
+# dtype: int64
+
+# Create a Spark DataFrame
+df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
+
+# Execute function as a Spark vectorized UDF
+df.select(multiply(col("x"), col("x"))).show()
+# +-------------------+
+# |multiply_func(x, x)|
+# +-------------------+
+# | 1|
+# | 4|
+# | 9|
+# +-------------------+
+
+{% endhighlight %}
+</div>
+</div>
+
+## GroupBy-Apply UDFs
+
+## Usage Notes
+
+### Supported types
+
+Currently, all Spark SQL data types are supported except `MapType`, `ArrayType` of `TimestampType`, and
+nested `StructType`.
+
+### Setting Arrow Batch Size
+
+Data partitions in Spark are converted into Arrow record batches, which can temporarily lead to
+high memory usage in the JVM. To avoid possible out of memory exceptions, the size of the Arrow
+record batches can be adjusted by setting the conf "spark.sql.execution.arrow.maxRecordsPerBatch"
+to an integer that will determine the maximum number of rows for each batch. Using this limit,
+each data partition will be made into 1 or more record batches for processing.
--- End diff --
yes
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on the issue:
https://github.com/apache/spark/pull/19575
@BryanCutler I added a section for groupby apply here: https://github.com/BryanCutler/spark/pull/29/files
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86648/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86658 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86658/testReport)** for PR 19575 at commit [`dd51af1`](https://github.com/apache/spark/commit/dd51af1de42d3846be839a7067370a559f252c54).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163897711
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
+module with the command "pip install pyspark[sql]". Otherwise, you must ensure that pyarrow is
+installed and available on all cluster node Python environments. The current supported version is
+0.8.0. You can install using pip or conda from the conda-forge channel. See pyarrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select(" * ").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## How to Write Vectorized UDFs
+
+A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
+Pandas Series, which allow the function to be composed with vectorized operations. This function
--- End diff --
Yeah I can help with that. @BryanCutler do you mind if I make some change to this section?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86540 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86540/testReport)** for PR 19575 at commit [`47bfc21`](https://github.com/apache/spark/commit/47bfc2113e18fac41a2ca818f97931c5b406f8a2).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163486863
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,147 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. It's usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you have installed pyspark using pip, then pyarrow will automatically be brought in as a dependency.
+Otherwise, you must ensure that pyarrow is installed and available on all cluster node Python
+environments. The current supported version is 0.8.0. You can install using pip or conda from the
+conda-forge channel. See pyarrow [installation](https://arrow.apache.org/docs/python/install.html)
+for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select(" * ").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## How to Write Vectorized UDFs
+
+A vectorized UDF is similar to a standard UDF in Spark except the inputs and output of the will
+be Pandas Series, which allow the function to be composed with vectorized operations. This function
+can then be run very efficiently in Spark where data is sent in batches to Python and the function
+is executed using Pandas Series as input. The exected output of the function is also a Pandas
+Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
+keyword, no additional configuration is required.
+
+The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import pandas as pd
+from pyspark.sql.functions import col, pandas_udf
+from pyspark.sql.types import LongType
+
+# Declare the function and create the UDF
+def multiply_func(a, b):
+ return a * b
+
+multiply = pandas_udf(multiply_func, returnType=LongType())
+
+# The function for a pandas_udf should be able to execute with local Pandas data
+x = pd.Series([1, 2, 3])
+print(multiply_func(x, x))
+# 0 1
+# 1 4
+# 2 9
+# dtype: int64
+
+# Create a Spark DataFrame
+df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
+
+# Execute function as a Spark vectorized UDF
+df.select(multiply(col("x"), col("x"))).show()
+# +-------------------+
+# |multiply_func(x, x)|
+# +-------------------+
+# | 1|
+# | 4|
+# | 9|
+# +-------------------+
+
+{% endhighlight %}
+</div>
+</div>
+
+## GroupBy-Apply UDFs
+
+## Usage Notes
+
+### Supported types
+
+Currently, all Spark SQL data types are supported except `MapType`, `ArrayType` of `TimestampType`, and
+nested `StructType`.
+
+### Setting Arrow Batch Size
+
+Data partitions in Spark are converted into Arrow record batches, which can temporarily lead to
+high memory usage in the JVM. To avoid possible out of memory exceptions, the size of the Arrow
+record batches can be adjusted by setting the conf "spark.sql.execution.arrow.maxRecordsPerBatch"
+to an integer that will determine the maximum number of rows for each batch. Using this limit,
+each data partition will be made into 1 or more record batches for processing.
+
+### Date and Timestamp Semantics
+
+Spark internally stores timestamps as UTC values and timestamp data that is brought in without
+a specified time zone, it is converted as local time to UTC with microsecond resolution. Pandas uses
+a `datetime64` type with nanosecond resolution, `datetime64[ns]` with optional time zone.
+
+When timestamp data is transferred from Spark to Pandas it will be converted to nanoseconds
+and made time zone aware using the Spark session time zone, if set, or local Python system time
--- End diff --
We use session time zone anyway. If not set, the default is JVM system timezone (the value returned by `TimeZone.getDefault()`).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86663 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86663/testReport)** for PR 19575 at commit [`15a116f`](https://github.com/apache/spark/commit/15a116f6b4f2d8c0f8b2b0bb17d4264b3caacdf2).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164513778
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use `groupBy().apply()`, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+The following example shows how to use `groupby().apply()` to subtract the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example group_map_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf) and
+[`pyspark.sql.GroupedData.apply`](api/python/pyspark.sql.html#pyspark.sql.GroupedData.apply).
+
+## Usage Notes
+
+### Supported SQL-Arrow Types
+
+Currently, all Spark SQL data types are supported except `MapType`, `ArrayType` of `TimestampType`, and
+nested `StructType`.
+
+### Setting Arrow Batch Size
+
+Data partitions in Spark are converted into Arrow record batches, which can temporarily lead to
+high memory usage in the JVM. To avoid possible out of memory exceptions, the size of the Arrow
+record batches can be adjusted by setting the conf "spark.sql.execution.arrow.maxRecordsPerBatch"
--- End diff --
Since it is too late to add a new conf for 2.3 release, we can do it in 2.4 release. In the 2.4 release, we can respect both conf. We just need to change the default of `maxRecordsPerBatch ` to int.max. I am fine to externalize it in 2.3 release.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164054702
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
--- End diff --
Wow, I just learnt it .. 👍
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164063514
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows users to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can be used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+function should take `pandas.Series` as inputs and return a `pandas.Series` of the same length. Internally,
+Spark will split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`,
+and concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use groupby apply, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+The following example shows how to use groupby apply to subtract the mean from each value in the group.
--- End diff --
`groupby apply` -> `` `groupBy().apply()` ``
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86540 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86540/testReport)** for PR 19575 at commit [`47bfc21`](https://github.com/apache/spark/commit/47bfc2113e18fac41a2ca818f97931c5b406f8a2).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164347106
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use `groupBy().apply()`, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+The following example shows how to use `groupby().apply()` to subtract the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example group_map_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf) and
+[`pyspark.sql.GroupedData.apply`](api/python/pyspark.sql.html#pyspark.sql.GroupedData.apply).
+
+## Usage Notes
+
+### Supported SQL-Arrow Types
+
+Currently, all Spark SQL data types are supported except `MapType`, `ArrayType` of `TimestampType`, and
+nested `StructType`.
+
+### Setting Arrow Batch Size
+
+Data partitions in Spark are converted into Arrow record batches, which can temporarily lead to
+high memory usage in the JVM. To avoid possible out of memory exceptions, the size of the Arrow
+record batches can be adjusted by setting the conf "spark.sql.execution.arrow.maxRecordsPerBatch"
+to an integer that will determine the maximum number of rows for each batch. The default value is
+10,000 records per batch and does not take into account the number of columns, so it should be
--- End diff --
How about "The default value is 10,000 records per batch. If the number of columns is large, the value should be adjusted accordingly"
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163499909
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,147 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. It's usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you have installed pyspark using pip, then pyarrow will automatically be brought in as a dependency.
+Otherwise, you must ensure that pyarrow is installed and available on all cluster node Python
+environments. The current supported version is 0.8.0. You can install using pip or conda from the
+conda-forge channel. See pyarrow [installation](https://arrow.apache.org/docs/python/install.html)
+for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select(" * ").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## How to Write Vectorized UDFs
+
+A vectorized UDF is similar to a standard UDF in Spark except the inputs and output of the will
+be Pandas Series, which allow the function to be composed with vectorized operations. This function
+can then be run very efficiently in Spark where data is sent in batches to Python and the function
+is executed using Pandas Series as input. The exected output of the function is also a Pandas
+Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
+keyword, no additional configuration is required.
+
+The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import pandas as pd
+from pyspark.sql.functions import col, pandas_udf
+from pyspark.sql.types import LongType
+
+# Declare the function and create the UDF
+def multiply_func(a, b):
+ return a * b
+
+multiply = pandas_udf(multiply_func, returnType=LongType())
+
+# The function for a pandas_udf should be able to execute with local Pandas data
+x = pd.Series([1, 2, 3])
+print(multiply_func(x, x))
+# 0 1
+# 1 4
+# 2 9
+# dtype: int64
+
+# Create a Spark DataFrame
+df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
+
+# Execute function as a Spark vectorized UDF
+df.select(multiply(col("x"), col("x"))).show()
+# +-------------------+
+# |multiply_func(x, x)|
+# +-------------------+
+# | 1|
+# | 4|
+# | 9|
+# +-------------------+
+
+{% endhighlight %}
+</div>
+</div>
+
+## GroupBy-Apply UDFs
+
+## Usage Notes
+
+### Supported types
+
+Currently, all Spark SQL data types are supported except `MapType`, `ArrayType` of `TimestampType`, and
+nested `StructType`.
+
+### Setting Arrow Batch Size
+
+Data partitions in Spark are converted into Arrow record batches, which can temporarily lead to
+high memory usage in the JVM. To avoid possible out of memory exceptions, the size of the Arrow
+record batches can be adjusted by setting the conf "spark.sql.execution.arrow.maxRecordsPerBatch"
+to an integer that will determine the maximum number of rows for each batch. Using this limit,
+each data partition will be made into 1 or more record batches for processing.
--- End diff --
Should we mention about the default value of `spark.sql.execution.arrow.maxRecordsPerBatch`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on the issue:
https://github.com/apache/spark/pull/19575
Thanks for the review @ueshin! If the RC passes, will this still be able to get in before the docs are updated? @icexelloss will you be able to write a brief section on groupby/apply soon, in case this can be merged?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on the issue:
https://github.com/apache/spark/pull/19575
This is a WIP to start adding user documentation on how to use and describe any differences that the user might see working with Arrow enabled functionality. I'm not sure if the SQL programming guide is the right place to add it, but I'll start here and can move if needed.
Here is a high-level list of things to add
- [ ] brief description and how to install pyarrow
- [ ] how to use Arrow for `toPandas()`
- [ ] how to use `pandas_udf` for basic udfs
- [ ] how to use `pandas_udf` for groupby apply etc
- [ ] cover any differences user might see in data, i.e. timestamps
- [ ] unsupported types
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163957579
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
# Declare the function and create the UDF
-def multiply_func(a, b):
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
return a * b
-multiply = pandas_udf(multiply_func, returnType=LongType())
-
-# The function for a pandas_udf should be able to execute with local Pandas data
-x = pd.Series([1, 2, 3])
-print(multiply_func(x, x))
-# 0 1
-# 1 4
-# 2 9
-# dtype: int64
-
-# Create a Spark DataFrame, 'spark' is an existing SparkSession
-df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
-
-# Execute function as a Spark vectorized UDF
-df.select(multiply(col("x"), col("x"))).show()
-# +-------------------+
-# |multiply_func(x, x)|
-# +-------------------+
-# | 1|
-# | 4|
-# | 9|
-# +-------------------+
+df.select(multiply_udf(df.v, df.v)).show()
+# +------------------+
+# |multiply_udf(v, v)|
+# +------------------+
+# | 1|
+# | 4|
+# | 9|
+# +------------------+
{% endhighlight %}
</div>
</div>
-## GroupBy-Apply
-GroupBy-Apply implements the "split-apply-combine" pattern. Split-apply-combine consists of three steps:
+Note that there are two important requirement when using scalar pandas UDFs:
+* The input and output series must have the same size.
+* How a column is splitted into multiple `pandas.Series` is internal to Spark, and therefore the result
+ of user-defined function must be independent of the splitting.
--- End diff --
This sentence is a little confusing, I think I addressed this point earlier too
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86610 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86610/testReport)** for PR 19575 at commit [`b33346c`](https://github.com/apache/spark/commit/b33346cda29662abada85ea8f5c112679ebae91e).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86663 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86663/testReport)** for PR 19575 at commit [`15a116f`](https://github.com/apache/spark/commit/15a116f6b4f2d8c0f8b2b0bb17d4264b3caacdf2).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164052169
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
--- End diff --
let's say "Apache Arrow" here and in L1643? (ASF policy...)
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on the issue:
https://github.com/apache/spark/pull/19575
You can take a look at the sql programming guide - you could include content from an external file into the guide and the external file can also be a runnable stand-alone example.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on the issue:
https://github.com/apache/spark/pull/19575
BTW, Thanks for your great works! I will add all your names in the contributors of this PR
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/239/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163851282
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
--- End diff --
sql -> SQL
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/209/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163972469
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
# Declare the function and create the UDF
-def multiply_func(a, b):
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
return a * b
-multiply = pandas_udf(multiply_func, returnType=LongType())
-
-# The function for a pandas_udf should be able to execute with local Pandas data
-x = pd.Series([1, 2, 3])
-print(multiply_func(x, x))
-# 0 1
-# 1 4
-# 2 9
-# dtype: int64
-
-# Create a Spark DataFrame, 'spark' is an existing SparkSession
-df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
-
-# Execute function as a Spark vectorized UDF
-df.select(multiply(col("x"), col("x"))).show()
-# +-------------------+
-# |multiply_func(x, x)|
-# +-------------------+
-# | 1|
-# | 4|
-# | 9|
-# +-------------------+
--- End diff --
Yes, please put the example back to how it was. I don't think we need any additional sections, but we can discuss here if you think it should be changed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163957265
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
# Declare the function and create the UDF
-def multiply_func(a, b):
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
return a * b
-multiply = pandas_udf(multiply_func, returnType=LongType())
-
-# The function for a pandas_udf should be able to execute with local Pandas data
-x = pd.Series([1, 2, 3])
-print(multiply_func(x, x))
-# 0 1
-# 1 4
-# 2 9
-# dtype: int64
-
-# Create a Spark DataFrame, 'spark' is an existing SparkSession
-df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
-
-# Execute function as a Spark vectorized UDF
-df.select(multiply(col("x"), col("x"))).show()
-# +-------------------+
-# |multiply_func(x, x)|
-# +-------------------+
-# | 1|
-# | 4|
-# | 9|
-# +-------------------+
+df.select(multiply_udf(df.v, df.v)).show()
+# +------------------+
+# |multiply_udf(v, v)|
+# +------------------+
+# | 1|
+# | 4|
+# | 9|
+# +------------------+
{% endhighlight %}
</div>
</div>
-## GroupBy-Apply
-GroupBy-Apply implements the "split-apply-combine" pattern. Split-apply-combine consists of three steps:
+Note that there are two important requirement when using scalar pandas UDFs:
+* The input and output series must have the same size.
--- End diff --
is length more appropriate than size?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on the issue:
https://github.com/apache/spark/pull/19575
Thanks everyone for reviewing! I think I addressed all the comments, so please take one more look.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164056831
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
--- End diff --
then in doc and example I think it would be great to pull that outside of toPandas to avoid confusion?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164052606
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows users to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can be used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+function should take `pandas.Series` as inputs and return a `pandas.Series` of the same length. Internally,
+Spark will split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`,
+and concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use groupby apply, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+The following example shows how to use groupby apply to subtract the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example group_map_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+For detailed usage, please see `pyspark.sql.functions.pandas_udf` and
+`pyspark.sql.GroupedData.apply`.
+
+## Usage Notes
+
+### Supported types
--- End diff --
nit: this is a bit generic to list in the table of content? perhaps add SQL-Arrow type or something?
note: there is a link from L1677
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on the issue:
https://github.com/apache/spark/pull/19575
@gatorsmile I don't think any change of naming (group map, group agg, etc) has been agreed upon yet. We can certainly open an PR to discuss it.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163987716
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,254 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
--- End diff --
`Enable Arrow, 'spark' is an existing SparkSession`
->
`Enable Arrow-based columnar data transfers`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on the issue:
https://github.com/apache/spark/pull/19575
Hi Bryan, sorry I haven't got chance to take a look at this. Yes I can write the groupby apply section tomorrow.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163909315
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
+module with the command "pip install pyspark[sql]". Otherwise, you must ensure that pyarrow is
+installed and available on all cluster node Python environments. The current supported version is
+0.8.0. You can install using pip or conda from the conda-forge channel. See pyarrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
--- End diff --
I was thinking that too as they were a little bit longer than I thought. How about we leave them here for now and then follow up with separate files with proper runnable examples?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163784133
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
+module with the command "pip install pyspark[sql]". Otherwise, you must ensure that pyarrow is
+installed and available on all cluster node Python environments. The current supported version is
+0.8.0. You can install using pip or conda from the conda-forge channel. See pyarrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select(" * ").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## How to Write Vectorized UDFs
+
+A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
+Pandas Series, which allow the function to be composed with vectorized operations. This function
+can then be run very efficiently in Spark where data is sent in batches to Python and then
+is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
+Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
+keyword, no additional configuration is required.
+
+The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import pandas as pd
+from pyspark.sql.functions import col, pandas_udf
+from pyspark.sql.types import LongType
+
+# Declare the function and create the UDF
+def multiply_func(a, b):
+ return a * b
+
+multiply = pandas_udf(multiply_func, returnType=LongType())
+
+# The function for a pandas_udf should be able to execute with local Pandas data
+x = pd.Series([1, 2, 3])
+print(multiply_func(x, x))
+# 0 1
+# 1 4
+# 2 9
+# dtype: int64
+
+# Create a Spark DataFrame, 'spark' is an existing SparkSession
+df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
+
+# Execute function as a Spark vectorized UDF
+df.select(multiply(col("x"), col("x"))).show()
+# +-------------------+
+# |multiply_func(x, x)|
+# +-------------------+
+# | 1|
+# | 4|
+# | 9|
+# +-------------------+
+
+{% endhighlight %}
+</div>
+</div>
+
+## GroupBy-Apply UDFs
+
+## Usage Notes
+
+### Supported types
+
+Currently, all Spark SQL data types are supported except `MapType`, `ArrayType` of `TimestampType`, and
+nested `StructType`.
+
+### Setting Arrow Batch Size
+
+Data partitions in Spark are converted into Arrow record batches, which can temporarily lead to
+high memory usage in the JVM. To avoid possible out of memory exceptions, the size of the Arrow
+record batches can be adjusted by setting the conf "spark.sql.execution.arrow.maxRecordsPerBatch"
+to an integer that will determine the maximum number of rows for each batch. The default value is
+10,000 records per batch and does not take into account the number of columns, so it should be
+adjusted accordingly. Using this limit, each data partition will be made into 1 or more record
+batches for processing.
+
+### Timestamp with Time Zone Semantics
+
+Spark internally stores timestamps as UTC values, and timestamp data that is brought in without
+a specified time zone is converted as local time to UTC with microsecond resolution. When timestamp
+data is exported or displayed in Spark, the session time zone is used to localize the timestamp
+values. The session time zone is set with the conf 'spark.sql.session.timeZone' and will default
+to the JVM system local time zone if not set. Pandas uses a `datetime64` type with nanosecond
+resolution, `datetime64[ns]`, and optional time zone that can be applied on a per-column basis.
+
+When timestamp data is transferred from Spark to Pandas it will be converted to nanoseconds
+and each column will be made time zone aware using the Spark session time zone. This will occur
+when calling `toPandas()` or `pandas_udf` with a timestamp column. For example if the session time
+zone is 'America/Los_Angeles' then the Pandas timestamp column will be of type
+`datetime64[ns, America/Los_Angeles]`.
--- End diff --
I'm afraid this is not correct.
The timestamp value will be timezone naive anyway which represents the timestamp respecting the session timezone, but the timezone info will be dropped. As a result, the timestamp column will be of type `datetime64[ns]`.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86663/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164052969
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
--- End diff --
is `'spark.sql.execution.arrow.enabled' to 'true'` only for toPandas and does not affect `pandas_udf`?
As a side note, I feel we should discourage the use of toPandas since it will force everything to the Driver...
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163909693
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
+module with the command "pip install pyspark[sql]". Otherwise, you must ensure that pyarrow is
+installed and available on all cluster node Python environments. The current supported version is
+0.8.0. You can install using pip or conda from the conda-forge channel. See pyarrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select(" * ").toPandas()
--- End diff --
Doing that caused my editor to change all formatting for some reason.. I think it's just the editor so I'll change it back
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86720 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86720/testReport)** for PR 19575 at commit [`8b629bc`](https://github.com/apache/spark/commit/8b629bc7a873b8f2d95f0ba0aea3b4ef5f21a0fb).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/257/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on the issue:
https://github.com/apache/spark/pull/19575
`SKIP_API=1 jekyll build`
you can see instructions in docs/README.md
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163993883
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,204 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select("*").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
--- End diff --
Just a question, is `pandas.Series` well known by our PySpark users.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on the issue:
https://github.com/apache/spark/pull/19575
@icexelloss Thanks for your reply. Welcome your comment in my PR https://github.com/apache/spark/pull/20428
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164496233
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use `groupBy().apply()`, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+The following example shows how to use `groupby().apply()` to subtract the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example group_map_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf) and
+[`pyspark.sql.GroupedData.apply`](api/python/pyspark.sql.html#pyspark.sql.GroupedData.apply).
+
+## Usage Notes
+
+### Supported SQL-Arrow Types
+
+Currently, all Spark SQL data types are supported except `MapType`, `ArrayType` of `TimestampType`, and
+nested `StructType`.
+
+### Setting Arrow Batch Size
+
+Data partitions in Spark are converted into Arrow record batches, which can temporarily lead to
+high memory usage in the JVM. To avoid possible out of memory exceptions, the size of the Arrow
+record batches can be adjusted by setting the conf "spark.sql.execution.arrow.maxRecordsPerBatch"
--- End diff --
The current approach is just to make the external users hard to tune. Now, `maxRecordsPerBatch` also depends on the width your output schema. This is not user friendly to end users.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163993506
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,204 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select("*").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
--- End diff --
`user ` -> `users`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86755/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on the issue:
https://github.com/apache/spark/pull/19575
I have two major comments.
- `group map` -> `grouped map` We need to also update `PythonEvalType`.
> SQL_PANDAS_GROUP_MAP_UDF -> SQL_PANDAS_GROUPED_MAP_UDF
> SQL_PANDAS_GROUP_AGG_UDF -> SQL_PANDAS_GROUPED_AGG_UDF
- Open a JIRA to add another limit in the next release (2.4) based on memory consumption, instead of number of rows. My major reason is the row size might be different and thus it is possible that the session-based SQLConf `spark.sql.execution.arrow.maxRecordsPerBatch` needs to be adjusted for different queries. It is hard for users to tune such a conf.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86669 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86669/testReport)** for PR 19575 at commit [`3f31930`](https://github.com/apache/spark/commit/3f3193059d10c598c02cf36c13da4bc92905130a).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164007174
--- Diff: examples/src/main/python/sql/arrow.py ---
@@ -0,0 +1,125 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+"""
+A simple example demonstrating Arrow in Spark.
+Run with:
+ ./bin/spark-submit examples/src/main/python/sql/arrow.py
+"""
+
+from __future__ import print_function
+
+from pyspark.sql import SparkSession
+from pyspark.sql.utils import require_minimum_pandas_version, require_minimum_pyarrow_version
+
+require_minimum_pandas_version()
+require_minimum_pyarrow_version()
+
+
+def dataframe_with_arrow_example(spark):
+ # $example on:dataframe_with_arrow$
+ import numpy as np
+ import pandas as pd
+
+ # Enable Arrow-based columnar data transfers
+ spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+ # Generate a Pandas DataFrame
+ pdf = pd.DataFrame(np.random.rand(100, 3))
+
+ # Create a Spark DataFrame from a Pandas DataFrame using Arrow
+ df = spark.createDataFrame(pdf)
+
+ # Convert the Spark DataFrame back to a Pandas DataFrame using Arrow
+ result_pdf = df.select("*").toPandas()
+ # $example off:dataframe_with_arrow$
+
--- End diff --
Yup, I just copied your examples. Sure.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164063467
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows users to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can be used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+function should take `pandas.Series` as inputs and return a `pandas.Series` of the same length. Internally,
+Spark will split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`,
+and concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use groupby apply, the user needs to define the following:
--- End diff --
`groupby apply` -> `` `groupBy().apply()` ``
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164056622
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
--- End diff --
yes, what I mean by L1643.
We should at least use the full name in header(s) and the first mention before simplifying it to "Arrow" afterwards
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164002789
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,204 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select("*").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
--- End diff --
I think it's fine.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on the issue:
https://github.com/apache/spark/pull/19575
Yea, I would like to know it too.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by ueshin <gi...@git.apache.org>.
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163490326
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,147 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. It's usage is not automatic and might require some minor
--- End diff --
`It's usage is` -> `Its usage is`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163975188
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
+module with the command "pip install pyspark[sql]". Otherwise, you must ensure that pyarrow is
+installed and available on all cluster node Python environments. The current supported version is
+0.8.0. You can install using pip or conda from the conda-forge channel. See pyarrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
--- End diff --
Yuo, sounds fine.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86719 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86719/testReport)** for PR 19575 at commit [`67ab5e9`](https://github.com/apache/spark/commit/67ab5e913efad37f5150a600715993d6e95a5947).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on the issue:
https://github.com/apache/spark/pull/19575
Yup, I suggested this in https://github.com/apache/spark/pull/19575#discussion_r163861140. Will make a PR to this branch soon.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163957412
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
# Declare the function and create the UDF
-def multiply_func(a, b):
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
return a * b
-multiply = pandas_udf(multiply_func, returnType=LongType())
-
-# The function for a pandas_udf should be able to execute with local Pandas data
-x = pd.Series([1, 2, 3])
-print(multiply_func(x, x))
-# 0 1
-# 1 4
-# 2 9
-# dtype: int64
-
-# Create a Spark DataFrame, 'spark' is an existing SparkSession
-df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
-
-# Execute function as a Spark vectorized UDF
-df.select(multiply(col("x"), col("x"))).show()
-# +-------------------+
-# |multiply_func(x, x)|
-# +-------------------+
-# | 1|
-# | 4|
-# | 9|
-# +-------------------+
+df.select(multiply_udf(df.v, df.v)).show()
+# +------------------+
+# |multiply_udf(v, v)|
+# +------------------+
+# | 1|
+# | 4|
+# | 9|
+# +------------------+
{% endhighlight %}
</div>
</div>
-## GroupBy-Apply
-GroupBy-Apply implements the "split-apply-combine" pattern. Split-apply-combine consists of three steps:
+Note that there are two important requirement when using scalar pandas UDFs:
+* The input and output series must have the same size.
+* How a column is splitted into multiple `pandas.Series` is internal to Spark, and therefore the result
--- End diff --
splitted -> split
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163993991
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,204 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select("*").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
--- End diff --
`used` -> `be used`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86670/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on the issue:
https://github.com/apache/spark/pull/19575
Thanks all, I'll merge the groupby PR and do an update now
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163918993
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
--- End diff --
I changed to a sub-heading, let me know if you think that is better
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163850901
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
--- End diff --
Maybe, pyarrow -> PyArrow
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163985608
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
# Declare the function and create the UDF
-def multiply_func(a, b):
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
return a * b
-multiply = pandas_udf(multiply_func, returnType=LongType())
-
-# The function for a pandas_udf should be able to execute with local Pandas data
-x = pd.Series([1, 2, 3])
-print(multiply_func(x, x))
-# 0 1
-# 1 4
-# 2 9
-# dtype: int64
-
-# Create a Spark DataFrame, 'spark' is an existing SparkSession
-df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
-
-# Execute function as a Spark vectorized UDF
-df.select(multiply(col("x"), col("x"))).show()
-# +-------------------+
-# |multiply_func(x, x)|
-# +-------------------+
-# | 1|
-# | 4|
-# | 9|
-# +-------------------+
--- End diff --
Sure. Will do
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164007019
--- Diff: examples/src/main/python/sql/arrow.py ---
@@ -0,0 +1,125 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+"""
+A simple example demonstrating Arrow in Spark.
+Run with:
+ ./bin/spark-submit examples/src/main/python/sql/arrow.py
+"""
+
+from __future__ import print_function
+
+from pyspark.sql import SparkSession
+from pyspark.sql.utils import require_minimum_pandas_version, require_minimum_pyarrow_version
+
+require_minimum_pandas_version()
+require_minimum_pyarrow_version()
+
+
+def dataframe_with_arrow_example(spark):
+ # $example on:dataframe_with_arrow$
+ import numpy as np
+ import pandas as pd
+
+ # Enable Arrow-based columnar data transfers
+ spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+ # Generate a Pandas DataFrame
+ pdf = pd.DataFrame(np.random.rand(100, 3))
+
+ # Create a Spark DataFrame from a Pandas DataFrame using Arrow
+ df = spark.createDataFrame(pdf)
+
+ # Convert the Spark DataFrame back to a Pandas DataFrame using Arrow
+ result_pdf = df.select("*").toPandas()
+ # $example off:dataframe_with_arrow$
+
--- End diff --
@HyukjinKwon mind if I add a print at the end here? I think it can be confusing to have examples that run, but don't show anything
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/252/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #83053 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/83053/testReport)** for PR 19575 at commit [`0723e86`](https://github.com/apache/spark/commit/0723e862bc4b644e1eca433fe2e22040e266a73d).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on the issue:
https://github.com/apache/spark/pull/19575
Thanks! I will submit a follow-up PR to rename it.
Merged to 2.3 and master.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164175749
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
--- End diff --
Good point, maybe it should be mentioned that it will fall back
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86720/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164172824
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
--- End diff --
Yea, I am actually slightly with you more but let's leave that discussion out here.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on the issue:
https://github.com/apache/spark/pull/19575
@BryanCutler what's the comment you use to build the docs?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164473702
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
--- End diff --
On the side note, I think in the context here. `Pandas UDFs` and `Vectorized UDFs` are interchangeable from a user's point of view, I am not sure the need for introducing both to the users. Maybe we should just stick to one of them?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on the issue:
https://github.com/apache/spark/pull/19575
I just opened - https://github.com/BryanCutler/spark/pull/30
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164346796
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use `groupBy().apply()`, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
--- End diff --
yeah good point, I'll add that
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163909807
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
+module with the command "pip install pyspark[sql]". Otherwise, you must ensure that pyarrow is
+installed and available on all cluster node Python environments. The current supported version is
+0.8.0. You can install using pip or conda from the conda-forge channel. See pyarrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## How to Enable for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark conf
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select(" * ").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## How to Write Vectorized UDFs
+
+A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
+Pandas Series, which allow the function to be composed with vectorized operations. This function
--- End diff --
No, I don't mind please go ahead
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163696709
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,147 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. It's usage is not automatic and might require some minor
--- End diff --
yes, you're right
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164064918
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows users to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can be used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+function should take `pandas.Series` as inputs and return a `pandas.Series` of the same length. Internally,
+Spark will split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`,
+and concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use groupby apply, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+The following example shows how to use groupby apply to subtract the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example group_map_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+For detailed usage, please see `pyspark.sql.functions.pandas_udf` and
--- End diff --
This should work:
```
[`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
```
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163855425
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
+module with the command "pip install pyspark[sql]". Otherwise, you must ensure that pyarrow is
+installed and available on all cluster node Python environments. The current supported version is
--- End diff --
"on all cluster node Python environments" this one looks a bit awkward ..
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [WIP][SPARK-22221][DOCS] Adding User Documentatio...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163851208
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,154 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+## Ensure pyarrow Installed
+
+If you install pyspark using pip, then pyarrow can be brought in as an extra dependency of the sql
--- End diff --
maybe, pyspark -> PySpark
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163973280
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
# Declare the function and create the UDF
-def multiply_func(a, b):
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
return a * b
-multiply = pandas_udf(multiply_func, returnType=LongType())
-
-# The function for a pandas_udf should be able to execute with local Pandas data
-x = pd.Series([1, 2, 3])
-print(multiply_func(x, x))
-# 0 1
-# 1 4
-# 2 9
-# dtype: int64
-
-# Create a Spark DataFrame, 'spark' is an existing SparkSession
-df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
-
-# Execute function as a Spark vectorized UDF
-df.select(multiply(col("x"), col("x"))).show()
-# +-------------------+
-# |multiply_func(x, x)|
-# +-------------------+
-# | 1|
-# | 4|
-# | 9|
-# +-------------------+
+df.select(multiply_udf(df.v, df.v)).show()
+# +------------------+
+# |multiply_udf(v, v)|
+# +------------------+
+# | 1|
+# | 4|
+# | 9|
+# +------------------+
{% endhighlight %}
</div>
</div>
-## GroupBy-Apply
-GroupBy-Apply implements the "split-apply-combine" pattern. Split-apply-combine consists of three steps:
+Note that there are two important requirement when using scalar pandas UDFs:
+* The input and output series must have the same size.
+* How a column is splitted into multiple `pandas.Series` is internal to Spark, and therefore the result
+ of user-defined function must be independent of the splitting.
--- End diff --
I don't think it's a _requirement_ of using UDFs, just a helpful note. I talk about batches under "Setting Arrow Batch Size" and I mention the output length above, so I think maybe you can just remove these notes. What do you think?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on the issue:
https://github.com/apache/spark/pull/19575
I am happy to help out with some sections.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86540/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [WIP][SPARK-22221][DOCS] Adding User Documentation for A...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on the issue:
https://github.com/apache/spark/pull/19575
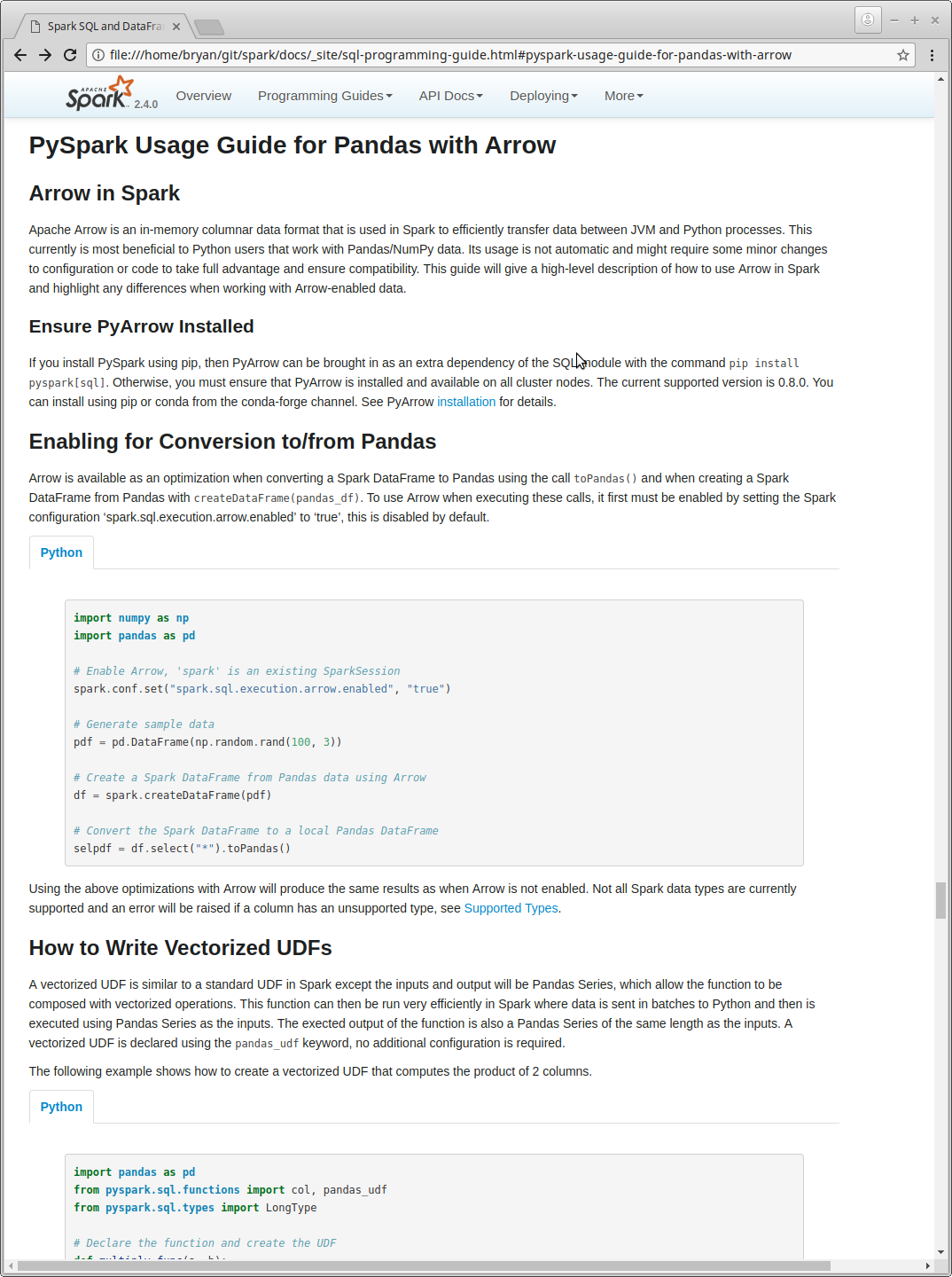
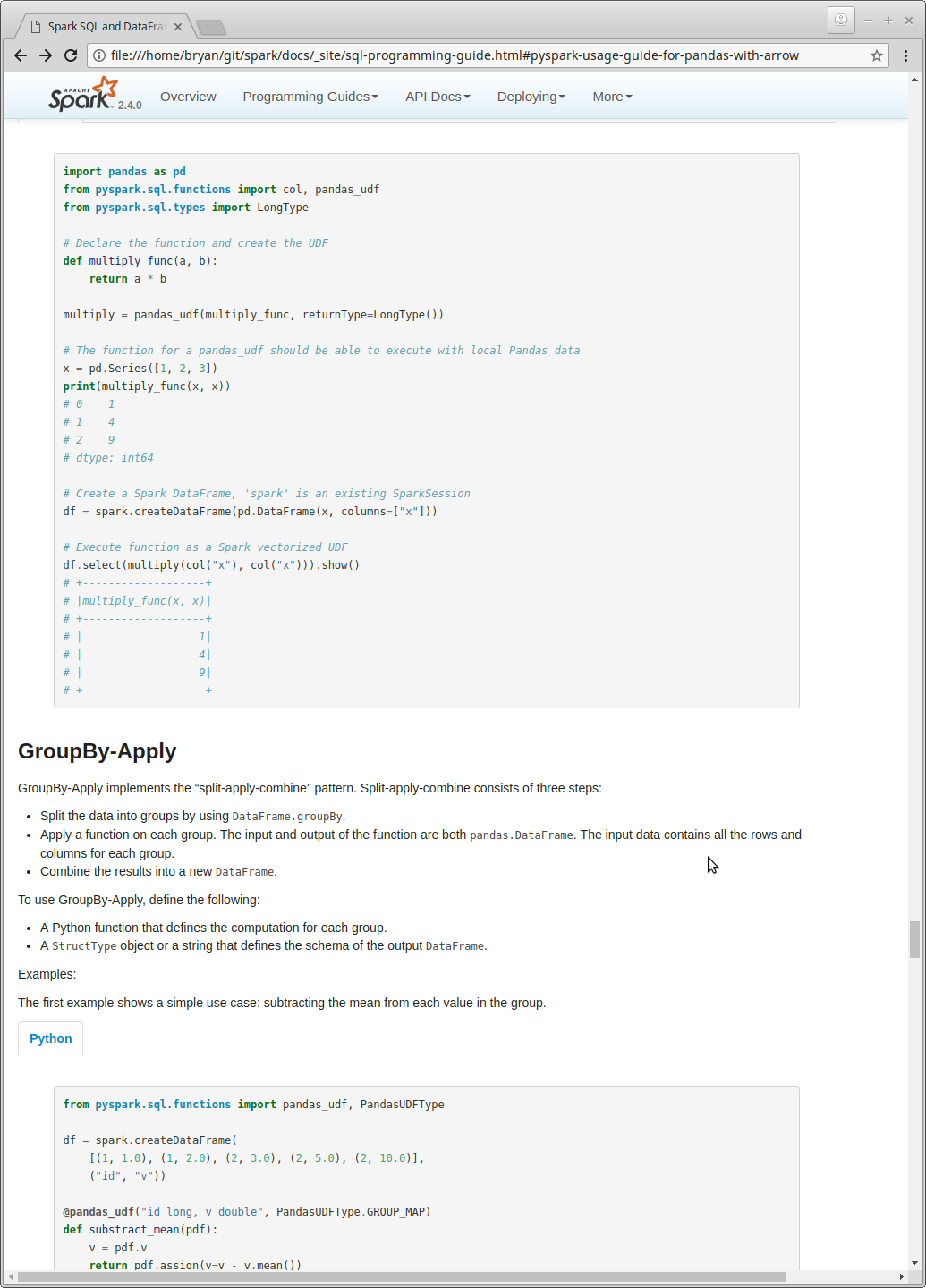
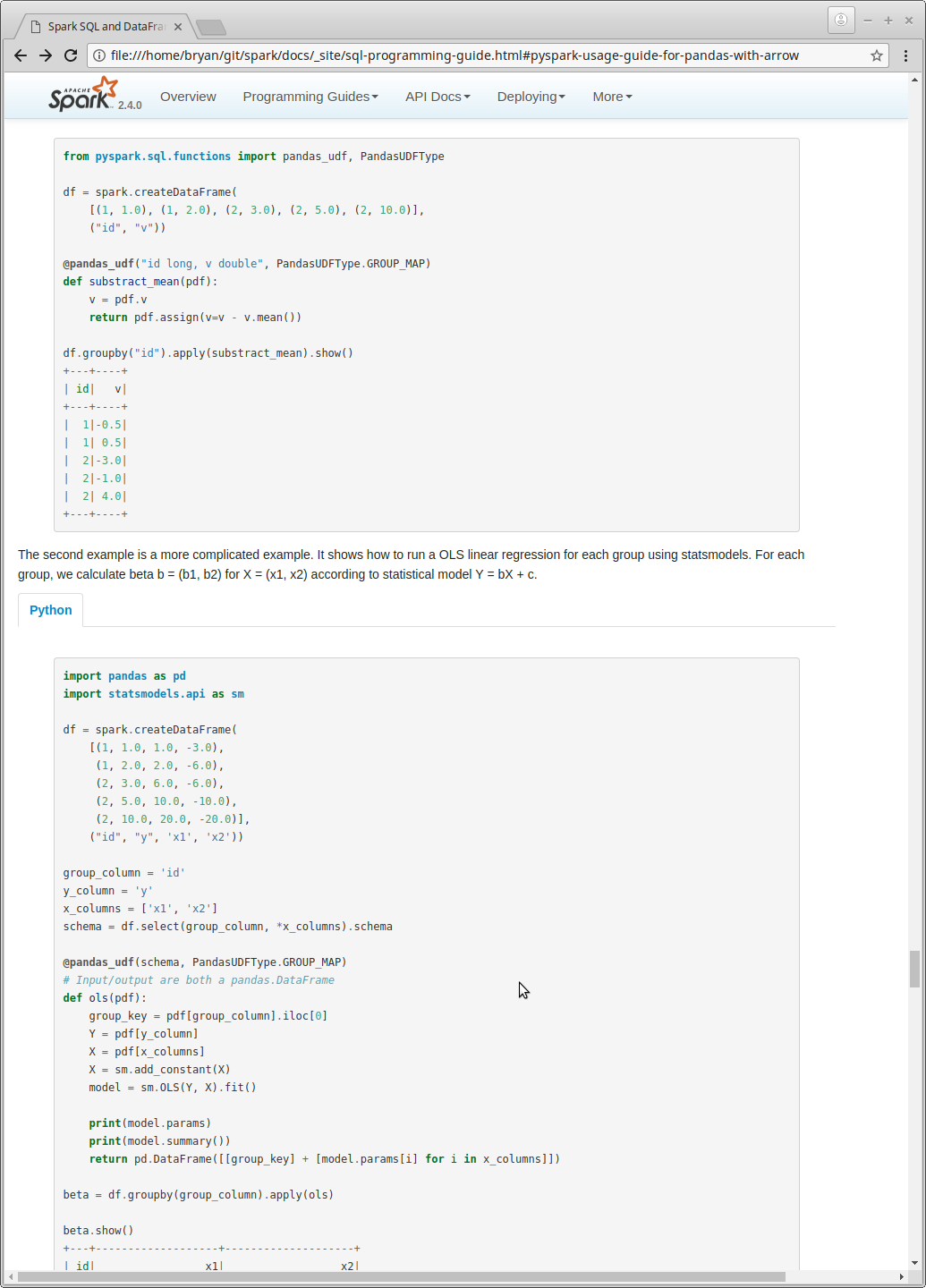
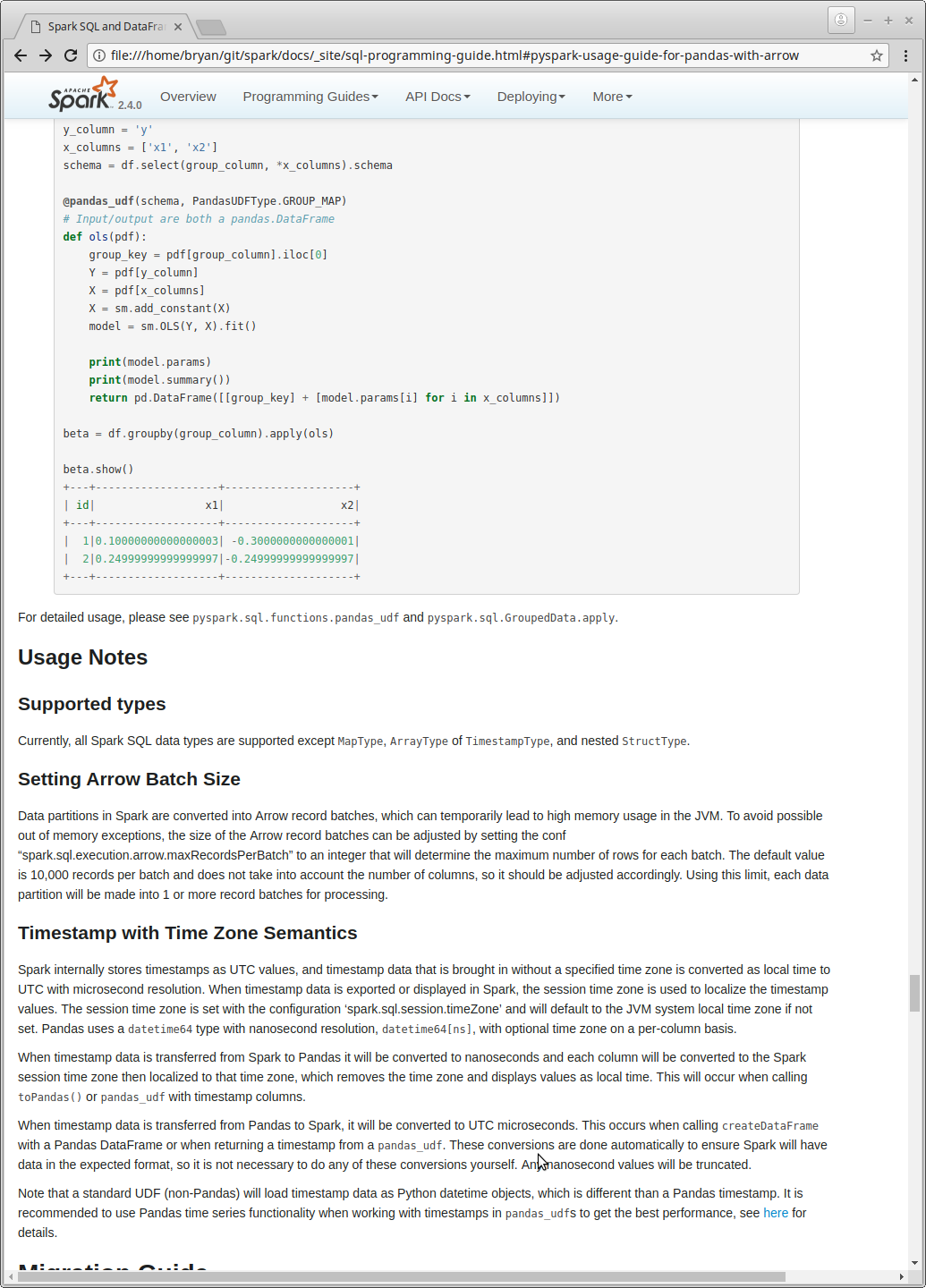
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/259/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/296/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164261639
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use `groupBy().apply()`, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+The following example shows how to use `groupby().apply()` to subtract the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example group_map_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf) and
+[`pyspark.sql.GroupedData.apply`](api/python/pyspark.sql.html#pyspark.sql.GroupedData.apply).
+
+## Usage Notes
+
+### Supported SQL-Arrow Types
+
+Currently, all Spark SQL data types are supported except `MapType`, `ArrayType` of `TimestampType`, and
+nested `StructType`.
+
+### Setting Arrow Batch Size
+
+Data partitions in Spark are converted into Arrow record batches, which can temporarily lead to
+high memory usage in the JVM. To avoid possible out of memory exceptions, the size of the Arrow
+record batches can be adjusted by setting the conf "spark.sql.execution.arrow.maxRecordsPerBatch"
--- End diff --
We went with `maxRecordsPerBatch` because it's easy to implement, otherwise we may need some way to estimate/calculate the memory consumption of arrow data. @BryanCutler is it easy to do?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/19575
**[Test build #86664 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86664/testReport)** for PR 19575 at commit [`a32d67a`](https://github.com/apache/spark/commit/a32d67adee89506379c79fa03440aef80f311917).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on the issue:
https://github.com/apache/spark/pull/19575
I just quickly scanned 50% docs. When writing the doc, we might be more cautious about the grammar errors.
BTW, thanks for your work! Will scan the remaining 50% docs later.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163987307
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,254 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
--- End diff --
`it first must be enabled by setting ` -> `users need to set`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164286074
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
--- End diff --
`Grouped Vectorized UDFs`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by BryanCutler <gi...@git.apache.org>.
Github user BryanCutler commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164195790
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
--- End diff --
I took another spin at this section and below to hopefully make it a bit clearer and indicate that `pandas_udf` doesn't need any configuration to be set.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164252424
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use `groupBy().apply()`, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+The following example shows how to use `groupby().apply()` to subtract the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example group_map_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+For detailed usage, please see [`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf) and
+[`pyspark.sql.GroupedData.apply`](api/python/pyspark.sql.html#pyspark.sql.GroupedData.apply).
+
+## Usage Notes
+
+### Supported SQL-Arrow Types
+
+Currently, all Spark SQL data types are supported except `MapType`, `ArrayType` of `TimestampType`, and
+nested `StructType`.
+
+### Setting Arrow Batch Size
+
+Data partitions in Spark are converted into Arrow record batches, which can temporarily lead to
+high memory usage in the JVM. To avoid possible out of memory exceptions, the size of the Arrow
+record batches can be adjusted by setting the conf "spark.sql.execution.arrow.maxRecordsPerBatch"
--- End diff --
Based on this description, it sounds like we should not use the number of records, right? cc @cloud-fan @taku-k too
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163986460
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,250 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select("*").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a Vectorized UDFs)
--- End diff --
Fixed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163983904
--- Diff: docs/sql-programming-guide.md ---
@@ -1693,70 +1693,70 @@ Using the above optimizations with Arrow will produce the same results as when A
enabled. Not all Spark data types are currently supported and an error will be raised if a column
has an unsupported type, see [Supported Types](#supported-types).
-## How to Write Vectorized UDFs
+## Pandas UDFs (a.k.a Vectorized UDFs)
-A vectorized UDF is similar to a standard UDF in Spark except the inputs and output will be
-Pandas Series, which allow the function to be composed with vectorized operations. This function
-can then be run very efficiently in Spark where data is sent in batches to Python and then
-is executed using Pandas Series as the inputs. The exected output of the function is also a Pandas
-Series of the same length as the inputs. A vectorized UDF is declared using the `pandas_udf`
-keyword, no additional configuration is required.
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
-The following example shows how to create a vectorized UDF that computes the product of 2 columns.
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
<div class="codetabs">
<div data-lang="python" markdown="1">
{% highlight python %}
import pandas as pd
-from pyspark.sql.functions import col, pandas_udf
-from pyspark.sql.types import LongType
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
# Declare the function and create the UDF
-def multiply_func(a, b):
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
return a * b
-multiply = pandas_udf(multiply_func, returnType=LongType())
-
-# The function for a pandas_udf should be able to execute with local Pandas data
-x = pd.Series([1, 2, 3])
-print(multiply_func(x, x))
-# 0 1
-# 1 4
-# 2 9
-# dtype: int64
-
-# Create a Spark DataFrame, 'spark' is an existing SparkSession
-df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
-
-# Execute function as a Spark vectorized UDF
-df.select(multiply(col("x"), col("x"))).show()
-# +-------------------+
-# |multiply_func(x, x)|
-# +-------------------+
-# | 1|
-# | 4|
-# | 9|
-# +-------------------+
+df.select(multiply_udf(df.v, df.v)).show()
+# +------------------+
+# |multiply_udf(v, v)|
+# +------------------+
+# | 1|
+# | 4|
+# | 9|
+# +------------------+
{% endhighlight %}
</div>
</div>
-## GroupBy-Apply
-GroupBy-Apply implements the "split-apply-combine" pattern. Split-apply-combine consists of three steps:
+Note that there are two important requirement when using scalar pandas UDFs:
+* The input and output series must have the same size.
+* How a column is splitted into multiple `pandas.Series` is internal to Spark, and therefore the result
+ of user-defined function must be independent of the splitting.
--- End diff --
I think removing seems okay.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163987675
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,250 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select("*").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+should takes `pandas.Series` and returns a `pandas.Series` of the same size. Internally, Spark will
+split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`, and
+concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import pandas as pd
+from pyspark.sql.functions import pandas_udf, PandasUDFTypr
+
+df = spark.createDataFrame(
+ [(1,), (2,), (3,)],
+ ['v'])
+
+# Declare the function and create the UDF
+@pandas_udf('long', PandasUDFType.SCALAR)
+def multiply_udf(a, b):
+ # a and b are both pandas.Series
+ return a * b
+
+df.select(multiply_udf(df.v, df.v)).show()
+# +------------------+
+# |multiply_udf(v, v)|
+# +------------------+
+# | 1|
+# | 4|
+# | 9|
+# +------------------+
+
+{% endhighlight %}
+</div>
+</div>
+
+Note that there are two important requirement when using scalar pandas UDFs:
+* The input and output series must have the same size.
+* How a column is splitted into multiple `pandas.Series` is internal to Spark, and therefore the result
+ of user-defined function must be independent of the splitting.
+
+### Group Map
+Group map pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use groupby apply, user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+Here we show two examples of using group map pandas UDFs.
+
+The first example shows a simple use case: subtracting the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+from pyspark.sql.functions import pandas_udf, PandasUDFType
+
+df = spark.createDataFrame(
+ [(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
+ ("id", "v"))
+
+@pandas_udf("id long, v double", PandasUDFType.GROUP_MAP)
+def substract_mean(pdf):
+ # pdf is a pandas.DataFrame
+ v = pdf.v
+ return pdf.assign(v=v - v.mean())
+
+df.groupby("id").apply(substract_mean).show()
+# +---+----+
+# | id| v|
+# +---+----+
+# | 1|-0.5|
+# | 1| 0.5|
+# | 2|-3.0|
+# | 2|-1.0|
+# | 2| 4.0|
+# +---+----+
+
+{% endhighlight %}
+</div>
+</div>
+
+The second example is a more complicated example. It shows how to run a OLS linear regression
--- End diff --
I don't have strong opinion. I think a separate file is hard to discover by user. I actually think we should include the example in python doc, I often find having multiple examples in python doc is useful.
I am fine with removing this example here.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164059019
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
--- End diff --
+1 for any way to explicitly express it.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164260619
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
--- End diff --
Which name? If you mean "split-apply-combine", I think it's fine - https://pandas.pydata.org/pandas-docs/stable/groupby.html
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164495519
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,133 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Apache Arrow
+
+## Apache Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Note that even with Arrow, `toPandas()` results in the collection of all records in the
+DataFrame to the driver program and should be done on a small subset of the data. Not all Spark
+data types are currently supported and an error can be raised if a column has an unsupported type,
+see [Supported Types](#supported-sql-arrow-types). If an error occurs during `createDataFrame()`,
+Spark will fall back to create the DataFrame without Arrow.
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and
+Pandas to work with the data. A Pandas UDF is defined using the keyword `pandas_udf` as a decorator
+or to wrap the function, no additional configuration is required. Currently, there are two types of
+Pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar Pandas UDFs are used for vectorizing scalar operations. They can be used with functions such
+as `select` and `withColumn`. The Python function should take `pandas.Series` as inputs and return
+a `pandas.Series` of the same length. Internally, Spark will execute a Pandas UDF by splitting
+columns into batches and calling the function for each batch as a subset of the data, then
+concatenating the results together.
+
+The following example shows how to create a scalar Pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map Pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
--- End diff --
@icexelloss we already agreed on the names when we wrote the blog, right?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #19575: [SPARK-22221][DOCS] Adding User Documentation for Arrow
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/19575
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/250/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by HyukjinKwon <gi...@git.apache.org>.
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r164066958
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,129 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, users need to first set the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true'. This is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example dataframe_with_arrow python/sql/arrow.py %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows users to use functions that operate on `pandas.Series`
+and `pandas.DataFrame` with Spark. Currently, there are two types of pandas UDF: Scalar and Group Map.
+
+### Scalar
+
+Scalar pandas UDFs are used for vectorizing scalar operations. They can be used with functions such as `select`
+and `withColumn`. To define a scalar pandas UDF, use `pandas_udf` to annotate a Python function. The Python
+function should take `pandas.Series` as inputs and return a `pandas.Series` of the same length. Internally,
+Spark will split a column into multiple `pandas.Series` and invoke the Python function with each `pandas.Series`,
+and concat the results together to be a new column.
+
+The following example shows how to create a scalar pandas UDF that computes the product of 2 columns.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example scalar_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+### Group Map
+Group map pandas UDFs are used with `groupBy().apply()` which implements the "split-apply-combine" pattern.
+Split-apply-combine consists of three steps:
+* Split the data into groups by using `DataFrame.groupBy`.
+* Apply a function on each group. The input and output of the function are both `pandas.DataFrame`. The
+ input data contains all the rows and columns for each group.
+* Combine the results into a new `DataFrame`.
+
+To use groupby apply, the user needs to define the following:
+* A Python function that defines the computation for each group.
+* A `StructType` object or a string that defines the schema of the output `DataFrame`.
+
+The following example shows how to use groupby apply to subtract the mean from each value in the group.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% include_example group_map_pandas_udf python/sql/arrow.py %}
+</div>
+</div>
+
+For detailed usage, please see `pyspark.sql.functions.pandas_udf` and
--- End diff --
This would work:
```
[`pyspark.sql.functions.pandas_udf`](api/python/pyspark.sql.html#pyspark.sql.functions.pandas_udf)
```
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #19575: [SPARK-22221][DOCS] Adding User Documentation for...
Posted by icexelloss <gi...@git.apache.org>.
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/19575#discussion_r163995961
--- Diff: docs/sql-programming-guide.md ---
@@ -1640,6 +1640,204 @@ Configuration of Hive is done by placing your `hive-site.xml`, `core-site.xml` a
You may run `./bin/spark-sql --help` for a complete list of all available
options.
+# PySpark Usage Guide for Pandas with Arrow
+
+## Arrow in Spark
+
+Apache Arrow is an in-memory columnar data format that is used in Spark to efficiently transfer
+data between JVM and Python processes. This currently is most beneficial to Python users that
+work with Pandas/NumPy data. Its usage is not automatic and might require some minor
+changes to configuration or code to take full advantage and ensure compatibility. This guide will
+give a high-level description of how to use Arrow in Spark and highlight any differences when
+working with Arrow-enabled data.
+
+### Ensure PyArrow Installed
+
+If you install PySpark using pip, then PyArrow can be brought in as an extra dependency of the
+SQL module with the command `pip install pyspark[sql]`. Otherwise, you must ensure that PyArrow
+is installed and available on all cluster nodes. The current supported version is 0.8.0.
+You can install using pip or conda from the conda-forge channel. See PyArrow
+[installation](https://arrow.apache.org/docs/python/install.html) for details.
+
+## Enabling for Conversion to/from Pandas
+
+Arrow is available as an optimization when converting a Spark DataFrame to Pandas using the call
+`toPandas()` and when creating a Spark DataFrame from Pandas with `createDataFrame(pandas_df)`.
+To use Arrow when executing these calls, it first must be enabled by setting the Spark configuration
+'spark.sql.execution.arrow.enabled' to 'true', this is disabled by default.
+
+<div class="codetabs">
+<div data-lang="python" markdown="1">
+{% highlight python %}
+
+import numpy as np
+import pandas as pd
+
+# Enable Arrow, 'spark' is an existing SparkSession
+spark.conf.set("spark.sql.execution.arrow.enabled", "true")
+
+# Generate sample data
+pdf = pd.DataFrame(np.random.rand(100, 3))
+
+# Create a Spark DataFrame from Pandas data using Arrow
+df = spark.createDataFrame(pdf)
+
+# Convert the Spark DataFrame to a local Pandas DataFrame
+selpdf = df.select("*").toPandas()
+
+{% endhighlight %}
+</div>
+</div>
+
+Using the above optimizations with Arrow will produce the same results as when Arrow is not
+enabled. Not all Spark data types are currently supported and an error will be raised if a column
+has an unsupported type, see [Supported Types](#supported-types).
+
+## Pandas UDFs (a.k.a. Vectorized UDFs)
+
+With Arrow, we introduce a new type of UDF - pandas UDF. Pandas UDF is defined with a new function
+`pyspark.sql.functions.pandas_udf` and allows user to use functions that operate on `pandas.Series`
--- End diff --
I think for this should be well-known to targeted users of this functionality. For PySpark users that are not familiar with pandas, this functionality is less relevant anyway I think.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org