You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2021/09/21 19:23:23 UTC
[GitHub] [hudi] Rap70r opened a new issue #3697: [SUPPORT] Performance Tuning: How to speed up stages?
Rap70r opened a new issue #3697:
URL: https://github.com/apache/hudi/issues/3697
Hello,
We are using Spark and Hudi to upsert records into parquet in S3, extracted from Kafka, using EMR. The events could be either inserts or updates.
Currently, it takes 41 minutes for the process to extract and upsert 1,430,000 records (1714 Megabytes).
We are trying to increase the speed of this process. Below are the details of our environment
**Environment Description**
* Hudi version : 0.9.0
* EMR version : 6.4.0
> Master Instance: 1 r5.xlarge
> Core Instance: 1 c5.xlarge
> Task Instance: 25 c5.xlarge
* Spark version : 3.1.2
* Hive version : n/a
* Hadoop version : 3.2.1
* Source : Kafka
* Storage : S3 (as parquet)
* Partitions: 1100
* Partition Size: ~1MB to 30MB each
* Parallelism: 3000
* Operation: Upsert
* Partition : Concatenation of year, month and week of a date field
* Storage Type: COPY_ON_WRITE
* Running on Docker? : no
**Spark-Submit Configs**
`spark-submit --deploy-mode cluster --conf spark.dynamicAllocation.enabled=true --conf spark.dynamicAllocation.cachedExecutorIdleTimeout=300s --conf spark.dynamicAllocation.executorIdleTimeout=300s --conf spark.scheduler.mode=FAIR --conf spark.memory.fraction=0.4 --conf spark.memory.storageFraction=0.1 --conf spark.shuffle.service.enabled=true --conf spark.sql.hive.convertMetastoreParquet=false --conf spark.sql.parquet.mergeSchema=true --conf spark.driver.maxResultSize=4g --conf spark.driver.memory=4g --conf spark.executor.cores=4 --conf spark.driver.memoryOverhead=1g --conf spark.executor.instances=100 --conf spark.executor.memoryOverhead=1g --conf spark.driver.cores=4 --conf spark.executor.memory=4g --conf spark.rdd.compress=true --conf spark.kryoserializer.buffer.max=512m --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.yarn.nodemanager.vmem-check-enabled=false --conf yarn.nodemanager.pmem-check-enabled=false --conf spark.sql.shuffle.partitions=10
0 --conf spark.default.parallelism=100 --conf spark.task.cpus=2`
**Spark Job**
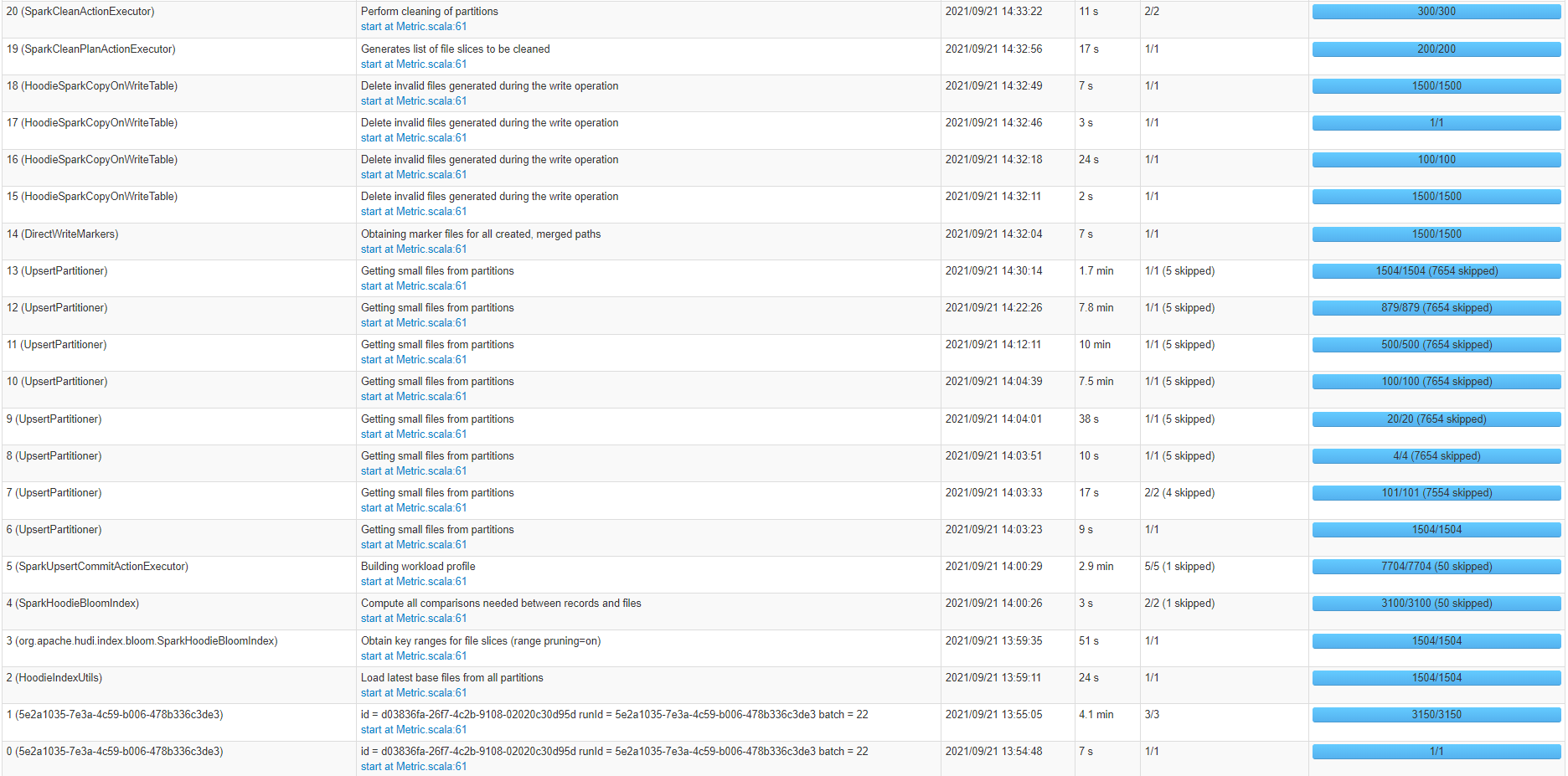
From the job above, it seems that most of the time is consumed by UpsertPartitioner and SparkUpsertCommitActionExecutor events.
Do you have any suggestions on how to reduce the time above job takes to complete?
Thank you
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] xushiyan commented on issue #3697: [SUPPORT] Performance Tuning: How to speed up stages?
Posted by GitBox <gi...@apache.org>.
xushiyan commented on issue #3697:
URL: https://github.com/apache/hudi/issues/3697#issuecomment-924644754
looks like there are too many partitions (1100) for a dataset < 2GB. This resulted in many small files. Some suggestions 1) reduce number of partitions to <100 2) double check number executors were created. c5.xlarge is a very small machine also with low memory to core ratio. You set 100 executors but each requires 5g memory 3) also tune parallelism settings in Hudi for the insert and upsert
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] xushiyan commented on issue #3697: [SUPPORT] Performance Tuning: How to speed up stages?
Posted by GitBox <gi...@apache.org>.
xushiyan commented on issue #3697:
URL: https://github.com/apache/hudi/issues/3697#issuecomment-927248813
From the parameters you show, i see the problem is mostly caused by not utilizing the machines' resources efficiently. Let's do some math:
Say you use 4 m5.4xlarge machines each has 16 cores and 64g memory.
set the below confs should allow you to run 19 executors with 1 driver for the spark job. double check spark UI to confirm the executors you're getting
```
spark.driver.cores=3
spark.driver.memory=6g
spark.driver.memoryOverhead=2g
spark.executor.cores=3
spark.executor.memory=6g
spark.executor.memoryOverhead=2g
spark.executor.instances=19
spark.sql.shuffle.partitions=200
spark.default.parallelism=200
spark.task.cpus=1
```
also set these hudi props in your spark writer options
```
"hoodie.upsert.shuffle.parallelism" = 200,
"hoodie.insert.shuffle.parallelism" = 200,
"hoodie.finalize.write.parallelism" = 200,
"hoodie.bulkinsert.shuffle.parallelism" = 200,
```
also you don't need to construct hoodie_key and hoodie_partition yourself, please set the hoodie key generator class options properly in Spark options. Refer to [this blog](https://hudi.incubator.apache.org/blog/2021/02/13/hudi-key-generators/).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Rap70r edited a comment on issue #3697: [SUPPORT] Performance Tuning: How to speed up stages?
Posted by GitBox <gi...@apache.org>.
Rap70r edited a comment on issue #3697:
URL: https://github.com/apache/hudi/issues/3697#issuecomment-926186766
Hi @xushiyan,
We did some tests using a different instance type (20 machines of type m5.2xlarge) and less partitions.
Here's the job flow for an upsert of 130K records (330 MB) against a Hudi collection with 230 partitions and 60 million records (6.2 GB) sitting on S3:
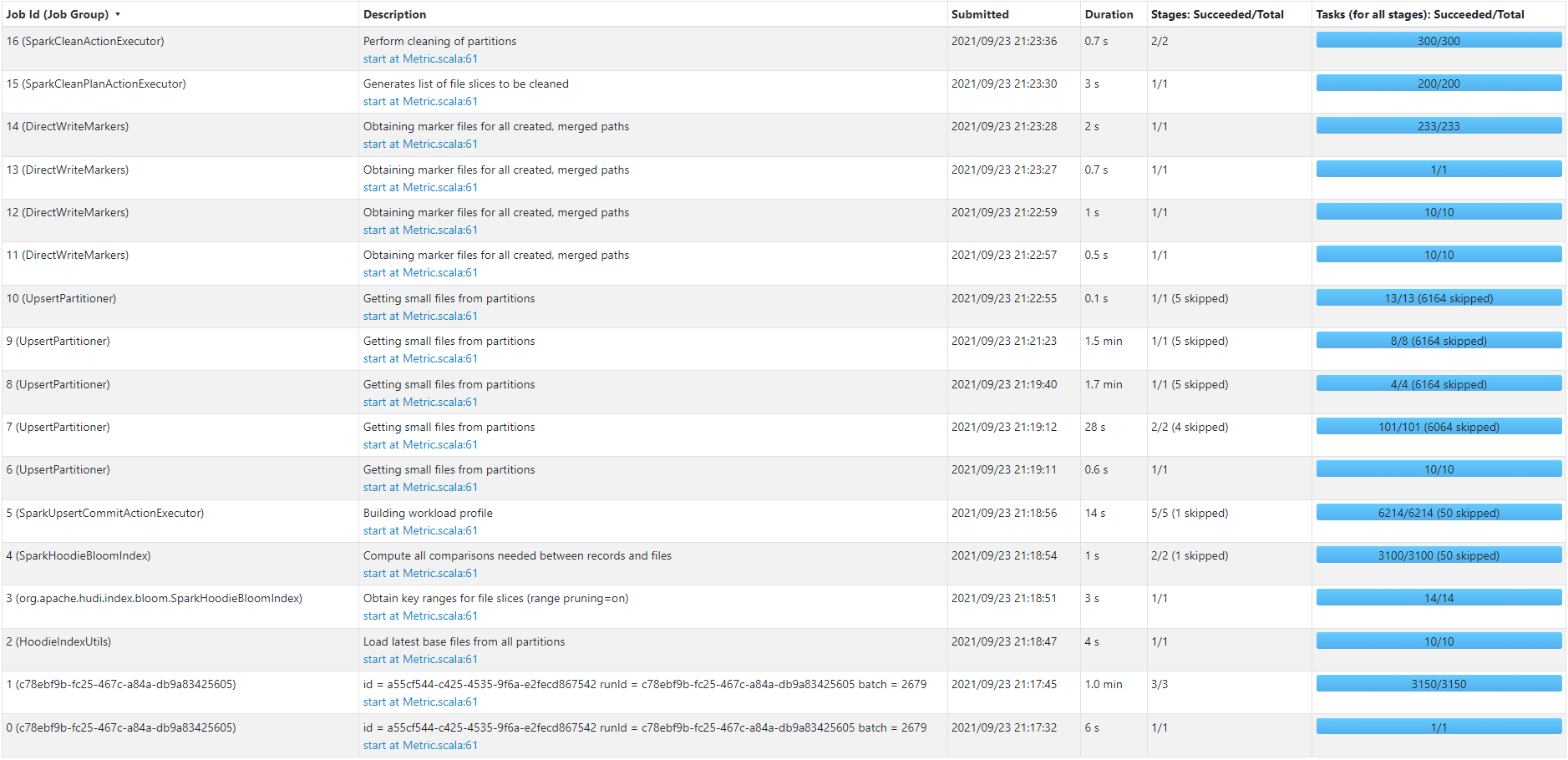
The job took ~6.3 min to finish. We would like to improve that time further. Seems like 6.3 minutes is too much for 130K records using 20 instances of type m5.2xlarge. And it seems like most of the time was taken by UpsertPartitioner step.
Do you recommend any further modifications or configurations we could test with to reduce the time?
**Spark-Submit Configs**
`spark-submit --deploy-mode cluster --conf spark.dynamicAllocation.enabled=true --conf spark.dynamicAllocation.cachedExecutorIdleTimeout=300s --conf spark.dynamicAllocation.executorIdleTimeout=300s --conf spark.scheduler.mode=FAIR --conf spark.memory.fraction=0.4 --conf spark.memory.storageFraction=0.1 --conf spark.shuffle.service.enabled=true --conf spark.sql.hive.convertMetastoreParquet=false --conf spark.sql.parquet.mergeSchema=true --conf spark.driver.maxResultSize=6g --conf spark.driver.memory=12g --conf spark.executor.cores=4 --conf spark.driver.memoryOverhead=4g --conf spark.executor.instances=100 --conf spark.executor.memoryOverhead=4g --conf spark.driver.cores=6 --conf spark.executor.memory=12g --conf spark.rdd.compress=true --conf spark.kryoserializer.buffer.max=512m --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.yarn.nodemanager.vmem-check-enabled=false --conf yarn.nodemanager.pmem-check-enabled=false --conf spark.sql.shuffle.partitions=
100 --conf spark.default.parallelism=100 --conf spark.task.cpus=2`
Also, not sure if it helps but we are using below Spark SQL to construct our hoodie_key and hoodie_partition:
`CONCAT(trim(string_field), unix_time_field, trim(string_field)) AS hoodie_key`
`from_unixtime(substr(unix_time_field, 0, length(unix_time_field) - 3), 'yyyyMM') AS hoodie_partition`
Thank you
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Rap70r commented on issue #3697: [SUPPORT] Performance Tuning: How to speed up stages?
Posted by GitBox <gi...@apache.org>.
Rap70r commented on issue #3697:
URL: https://github.com/apache/hudi/issues/3697#issuecomment-926186766
Hi @xushiyan,
We did some tests using a different instance type (20 machines of type m5.2xlarge) and less partitions.
Here's the job flow for an upsert of 130K records (330 MB) against a Hudi collection with 230 partitions and 60 million records (6.2 GB) sitting on S3:

The job took ~6.3 min to finish. We would like to improve that time further. Seems like 6.3 minutes is too much for 130K records using 20 instances of type m5.2xlarge. And it seems like most of the time was taken by UpsertPartitioner step.
Do you recommend any further modifications or configurations we could test with to reduce the time?
Thank you
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Rap70r commented on issue #3697: [SUPPORT] Performance Tuning: How to speed up stages?
Posted by GitBox <gi...@apache.org>.
Rap70r commented on issue #3697:
URL: https://github.com/apache/hudi/issues/3697#issuecomment-984910975
Hi @xushiyan,
I was wondering if is there a way to control the size of parquet files created under a partition. For example, if a partition has 1 million records, it will probably create a parquet file of size 100MB. Is there a way to split that parquet file to 10 smaller files of 10MB each within the same partition?
Thank you
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Rap70r edited a comment on issue #3697: [SUPPORT] Performance Tuning: How to speed up stages?
Posted by GitBox <gi...@apache.org>.
Rap70r edited a comment on issue #3697:
URL: https://github.com/apache/hudi/issues/3697#issuecomment-933893616
Hi @xushiyan,
Here is an update for our latest tests. I have switched to d3.xlarge instance type and used the following configs:
`spark-submit --deploy-mode cluster --conf spark.scheduler.mode=FAIR --conf spark.shuffle.service.enabled=true --conf spark.sql.hive.convertMetastoreParquet=false --conf spark.driver.maxResultSize=6g --conf spark.driver.memory=17g --conf spark.executor.cores=2 --conf spark.hadoop.parquet.enable.summary-metadata=false --conf spark.driver.memoryOverhead=6g --conf spark.network.timeout=600s --conf spark.executor.instances=50 --conf spark.executor.memoryOverhead=4g --conf spark.driver.cores=2 --conf spark.executor.memory=8g --conf spark.memory.storageFraction=0.1 --conf spark.executor.heartbeatInterval=120s --conf spark.memory.fraction=0.4 --conf spark.rdd.compress=true --conf spark.kryoserializer.buffer.max=200m --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.sql.shuffle.partitions=200 --conf spark.default.parallelism=200 --conf spark.task.cpus=2`
I also removed "spark.sql.parquet.mergeSchema".
I have noticed a significant increase of speed for all the steps except the one that extracts events from Kafka. That step I can't seem to improve. We are using st1 high throughput ebs that is attached to the emr's master node. The topic is compacted and it contains ~50 million records across 50 partitions. Even with the above powerful instance it takes 40 minutes to extract all records.
Basically, the part that is slow is the partition seeking part. It takes couple of minutes to seek from offset 50000 to 100000.
Do you have any suggestions on how to improve data ingestion from kafka using spark structured streaming?
Thank you
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] xushiyan edited a comment on issue #3697: [SUPPORT] Performance Tuning: How to speed up stages?
Posted by GitBox <gi...@apache.org>.
xushiyan edited a comment on issue #3697:
URL: https://github.com/apache/hudi/issues/3697#issuecomment-927248813
@Rap70r From the parameters you show, i see the problem is mostly caused by not utilizing the machines' resources efficiently. Let's do some math:
Say you use 4 m5.4xlarge machines each has 16 cores and 64g memory.
set the below confs should allow you to run 19 executors with 1 driver for the spark job. double check spark UI to confirm the executors you're getting
```
spark.driver.cores=3
spark.driver.memory=6g
spark.driver.memoryOverhead=2g
spark.executor.cores=3
spark.executor.memory=6g
spark.executor.memoryOverhead=2g
spark.executor.instances=19
spark.sql.shuffle.partitions=200
spark.default.parallelism=200
spark.task.cpus=1
```
also set these hudi props in your spark writer options
```
"hoodie.upsert.shuffle.parallelism" = 200,
"hoodie.insert.shuffle.parallelism" = 200,
"hoodie.finalize.write.parallelism" = 200,
"hoodie.bulkinsert.shuffle.parallelism" = 200,
```
also you don't need to construct hoodie_key and hoodie_partition yourself, please set the hoodie key generator class options properly in Spark options. Refer to [this blog](https://hudi.incubator.apache.org/blog/2021/02/13/hudi-key-generators/).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Rap70r commented on issue #3697: [SUPPORT] Performance Tuning: How to speed up stages?
Posted by GitBox <gi...@apache.org>.
Rap70r commented on issue #3697:
URL: https://github.com/apache/hudi/issues/3697#issuecomment-933893616
Hi @xushiyan,
Here is an update for our latest tests. I have switched to d3.xlarge instance type and used the following configs:
`spark-submit --deploy-mode cluster --conf spark.scheduler.mode=FAIR --conf spark.shuffle.service.enabled=true --conf spark.sql.hive.convertMetastoreParquet=false --conf spark.driver.maxResultSize=6g --conf spark.driver.memory=17g --conf spark.executor.cores=2 --conf spark.hadoop.parquet.enable.summary-metadata=false --conf spark.driver.memoryOverhead=6g --conf spark.network.timeout=600s --conf spark.executor.instances=50 --conf spark.executor.memoryOverhead=4g --conf spark.driver.cores=2 --conf spark.executor.memory=8g --conf spark.memory.storageFraction=0.1 --conf spark.executor.heartbeatInterval=120s --conf spark.memory.fraction=0.4 --conf spark.rdd.compress=true --conf spark.kryoserializer.buffer.max=200m --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.sql.shuffle.partitions=200 --conf spark.default.parallelism=200 --conf spark.task.cpus=2`
I also removed "spark.sql.parquet.mergeSchema".
I have noticed a significant increase of speed for all the steps except the one that extracts events from Kafka. That step I can't seem to improve. We are using st1 high throughput ebs that is attached to the emr's master node. The topic is compacted and it contains ~50 million records across 50 partitions. Even with the above powerful instance it takes 40 minutes to extract all records.
Do you have any suggestions on how to improve data ingestion from kafka using spark structured streaming?
Thank you
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Rap70r commented on issue #3697: [SUPPORT] Performance Tuning: How to speed up stages?
Posted by GitBox <gi...@apache.org>.
Rap70r commented on issue #3697:
URL: https://github.com/apache/hudi/issues/3697#issuecomment-924937292
Hello @xushiyan, Thank you for getting back to me.
Just a clarification that above data size (1714 Megabytes, 1.4 million records) is the usual incremental data size we expect on each upsert cycle. The total size of the entire data set sitting on S3 for this particular Hudi collection is 6.2 GB, with approximately 60 million records.
We used to have around 230 partitions but the time that takes for "UpsertPartitioner" increases significantly, as each partition goes up to over 100 MB. Considering this data size, what do you recommend as an ideal partition number?
Also, do you recommend maybe increase the number of partitions to something like 5K and keep using the same instance type? Wouldn't that allow smaller instance types to handle small partitions faster? Or should we reduce the number of partitions and use larger instance type?
For your second point, we use 25 Task instances of type c5.xlarge (4 vCore, 8 GiB memory). Using above configs, we get around 20 executors. What would be the recommended instance type/size for this type of data size? I was under the impression C5 type are generally recommended for this type of work.
And for your third point, we are using 3000 for parallelism (hoodie.upsert.shuffle.parallelism). Should we increase that?
And finally, is there a way we can increase the number of files under each partitions? Would that help?
Thank you
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Rap70r edited a comment on issue #3697: [SUPPORT] Performance Tuning: How to speed up stages?
Posted by GitBox <gi...@apache.org>.
Rap70r edited a comment on issue #3697:
URL: https://github.com/apache/hudi/issues/3697#issuecomment-933893616
Hi @xushiyan,
Here is an update for our latest tests. I have switched to d3.xlarge instance type and used the following configs:
`spark-submit --deploy-mode cluster --conf spark.scheduler.mode=FAIR --conf spark.shuffle.service.enabled=true --conf spark.sql.hive.convertMetastoreParquet=false --conf spark.driver.maxResultSize=6g --conf spark.driver.memory=17g --conf spark.executor.cores=2 --conf spark.hadoop.parquet.enable.summary-metadata=false --conf spark.driver.memoryOverhead=6g --conf spark.network.timeout=600s --conf spark.executor.instances=50 --conf spark.executor.memoryOverhead=4g --conf spark.driver.cores=2 --conf spark.executor.memory=8g --conf spark.memory.storageFraction=0.1 --conf spark.executor.heartbeatInterval=120s --conf spark.memory.fraction=0.4 --conf spark.rdd.compress=true --conf spark.kryoserializer.buffer.max=200m --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.sql.shuffle.partitions=200 --conf spark.default.parallelism=200 --conf spark.task.cpus=2`
I also removed "spark.sql.parquet.mergeSchema".
I have noticed a significant increase of speed for all the steps except the one that extracts events from Kafka. That step I can't seem to improve. We are using st1 high throughput ebs that is attached to the emr's master node. The topic is compacted and it contains ~50 million records across 50 partitions. Even with the above powerful instance it takes 40 minutes to extract all records.
Basically, the part that is slow is the seeking part. It takes couple of minutes to seek from offset 50000 to 100000.
Do you have any suggestions on how to improve data ingestion from kafka using spark structured streaming?
Thank you
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Rap70r commented on issue #3697: [SUPPORT] Performance Tuning: How to speed up stages?
Posted by GitBox <gi...@apache.org>.
Rap70r commented on issue #3697:
URL: https://github.com/apache/hudi/issues/3697#issuecomment-939628475
Hi @xushiyan,
We increased topic partitions from 50 to 400 and configured Spark properly to maximize executors. The speed has improved to a good level. If there are no additional suggestions we can try, I think we can close this ticket.
Thank you
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Rap70r edited a comment on issue #3697: [SUPPORT] Performance Tuning: How to speed up stages?
Posted by GitBox <gi...@apache.org>.
Rap70r edited a comment on issue #3697:
URL: https://github.com/apache/hudi/issues/3697#issuecomment-926186766
Hi @xushiyan,
We did some tests using a different instance type (20 machines of type m5.2xlarge) and less partitions.
Here's the job flow for an upsert of 130K records (330 MB) against a Hudi collection with 230 partitions and 60 million records (6.2 GB) sitting on S3:

The job took ~6.3 min to finish. We would like to improve that time further. Seems like 6.3 minutes is too much for 130K records using 20 instances of type m5.2xlarge. And it seems like most of the time was taken by UpsertPartitioner step.
Do you recommend any further modifications or configurations we could test with to reduce the time?
**Spark-Submit Configs**
`spark-submit --deploy-mode cluster --conf spark.dynamicAllocation.enabled=true --conf spark.dynamicAllocation.cachedExecutorIdleTimeout=300s --conf spark.dynamicAllocation.executorIdleTimeout=300s --conf spark.scheduler.mode=FAIR --conf spark.memory.fraction=0.4 --conf spark.memory.storageFraction=0.1 --conf spark.shuffle.service.enabled=true --conf spark.sql.hive.convertMetastoreParquet=false --conf spark.sql.parquet.mergeSchema=true --conf spark.driver.maxResultSize=6g --conf spark.driver.memory=12g --conf spark.executor.cores=4 --conf spark.driver.memoryOverhead=4g --conf spark.executor.instances=100 --conf spark.executor.memoryOverhead=4g --conf spark.driver.cores=6 --conf spark.executor.memory=12g --conf spark.rdd.compress=true --conf spark.kryoserializer.buffer.max=512m --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.yarn.nodemanager.vmem-check-enabled=false --conf yarn.nodemanager.pmem-check-enabled=false --conf spark.sql.shuffle.partitions=
100 --conf spark.default.parallelism=100 --conf spark.task.cpus=2`
Thank you
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Rap70r closed issue #3697: [SUPPORT] Performance Tuning: How to speed up stages?
Posted by GitBox <gi...@apache.org>.
Rap70r closed issue #3697:
URL: https://github.com/apache/hudi/issues/3697
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] xushiyan commented on issue #3697: [SUPPORT] Performance Tuning: How to speed up stages?
Posted by GitBox <gi...@apache.org>.
xushiyan commented on issue #3697:
URL: https://github.com/apache/hudi/issues/3697#issuecomment-947317362
@Rap70r glad you got it improved! sorry not able to get to it earlier.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Rap70r closed issue #3697: [SUPPORT] Performance Tuning: How to speed up stages?
Posted by GitBox <gi...@apache.org>.
Rap70r closed issue #3697:
URL: https://github.com/apache/hudi/issues/3697
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org