You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@mxnet.apache.org by GitBox <gi...@apache.org> on 2020/01/19 12:14:45 UTC
[GitHub] [incubator-mxnet] zhongyuchen opened a new issue #17381: High cpu
usage of gluon.data.Dataloader
zhongyuchen opened a new issue #17381: High cpu usage of gluon.data.Dataloader
URL: https://github.com/apache/incubator-mxnet/issues/17381
## Description
I found that if `num_workers=0`, there will be a high CPU usage (nearly ~50% of 48CPUs). This occurs whenever I enabling CUDA.
So when I have 4 threads run in parallel (e.g. data parallelism, each thread uses one GPU), **then there will be severe CPU resource preemption problem**. It will lead to extremely slow training speed. I have encountered this problem [here](https://github.com/bytedance/byteps/issues/194).
### Error Message
(Paste the complete error message. Please also include stack trace by setting environment variable `DMLC_LOG_STACK_TRACE_DEPTH=10` before running your script.)
## To Reproduce
(If you developed your own code, please provide a short script that reproduces the error. For existing examples, please provide link.)
### Steps to reproduce
(Paste the commands you ran that produced the error.)
1. `python example/gluon/mnist/mnist.py`
2. `htop` or `top`
2. see the high CPU usage

If you run `python example/gluon/mnist/mnist.py` for 4 times at one time, then you will observe all CPUs are running. And training process becomes extremely slow. **It is worth mentioning that in the figure below, `htop` reports blue CPU usage, which means low-priority threads are scheduled.**

This also occurs when enabling CUDA
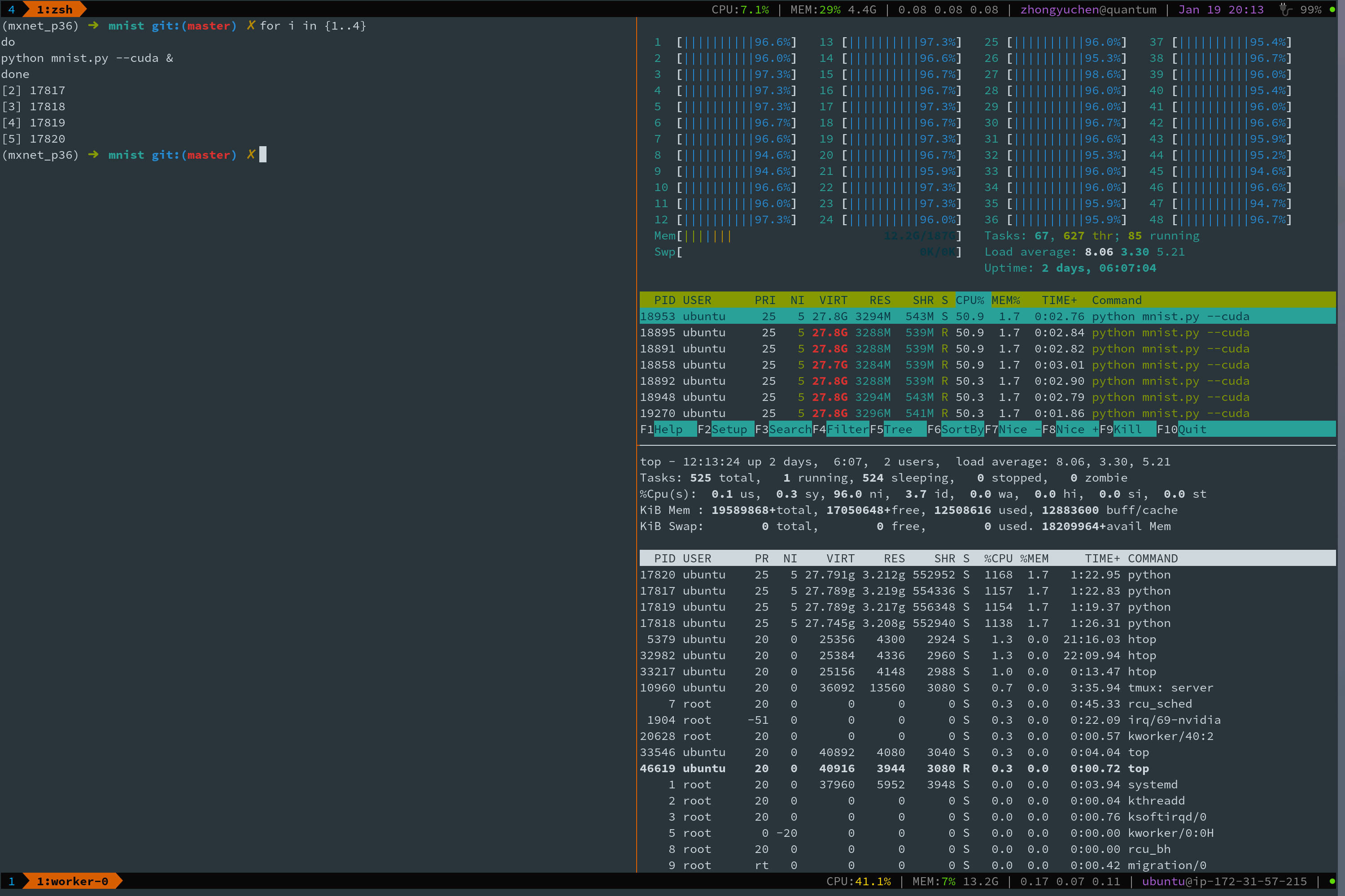
## What have you tried to solve it?
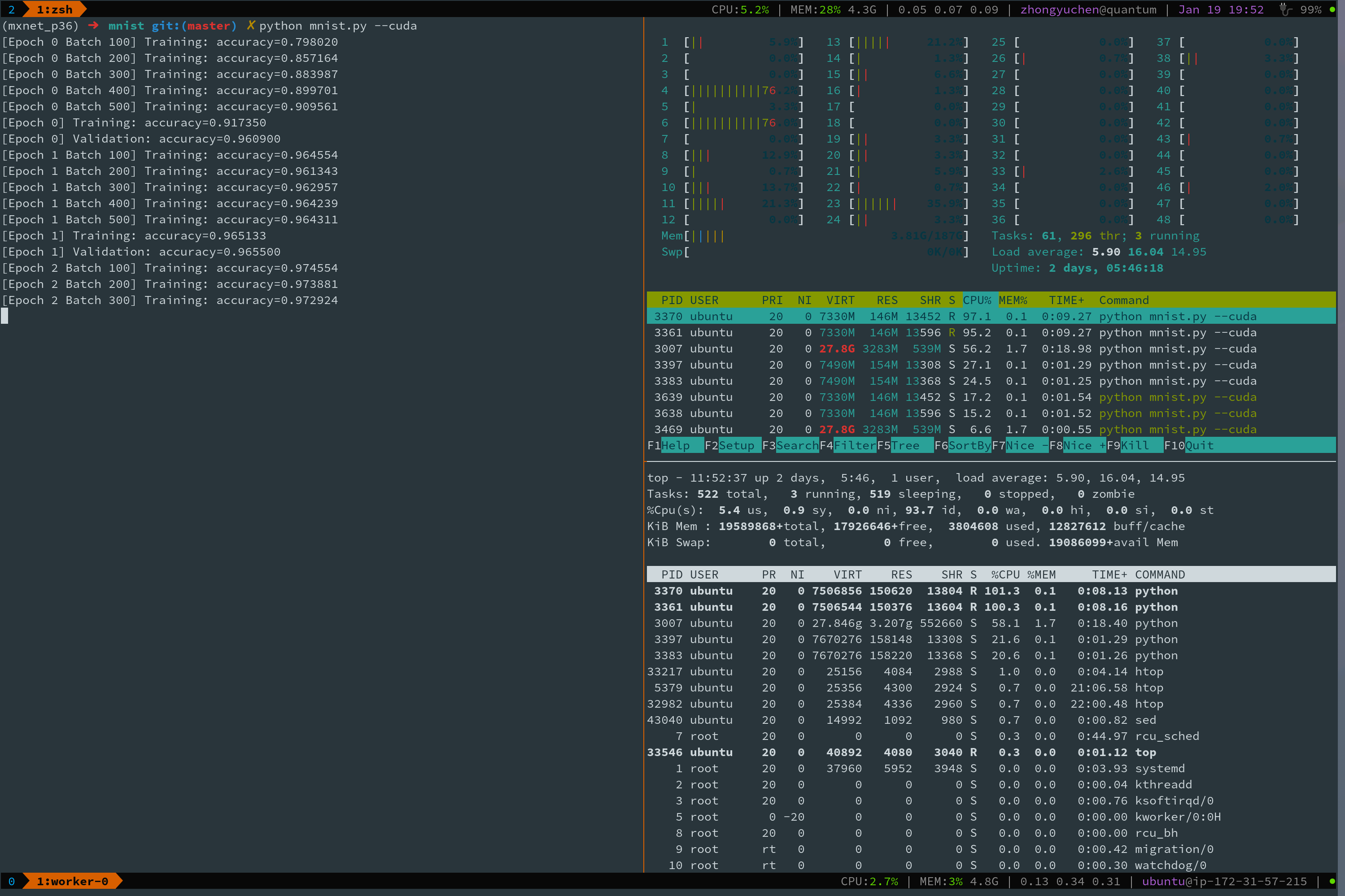
1. setting `num_workers > 0` solves the problem temporarily. see the following figure where I set both training dataloader and val dataloader `num_workers=2`.
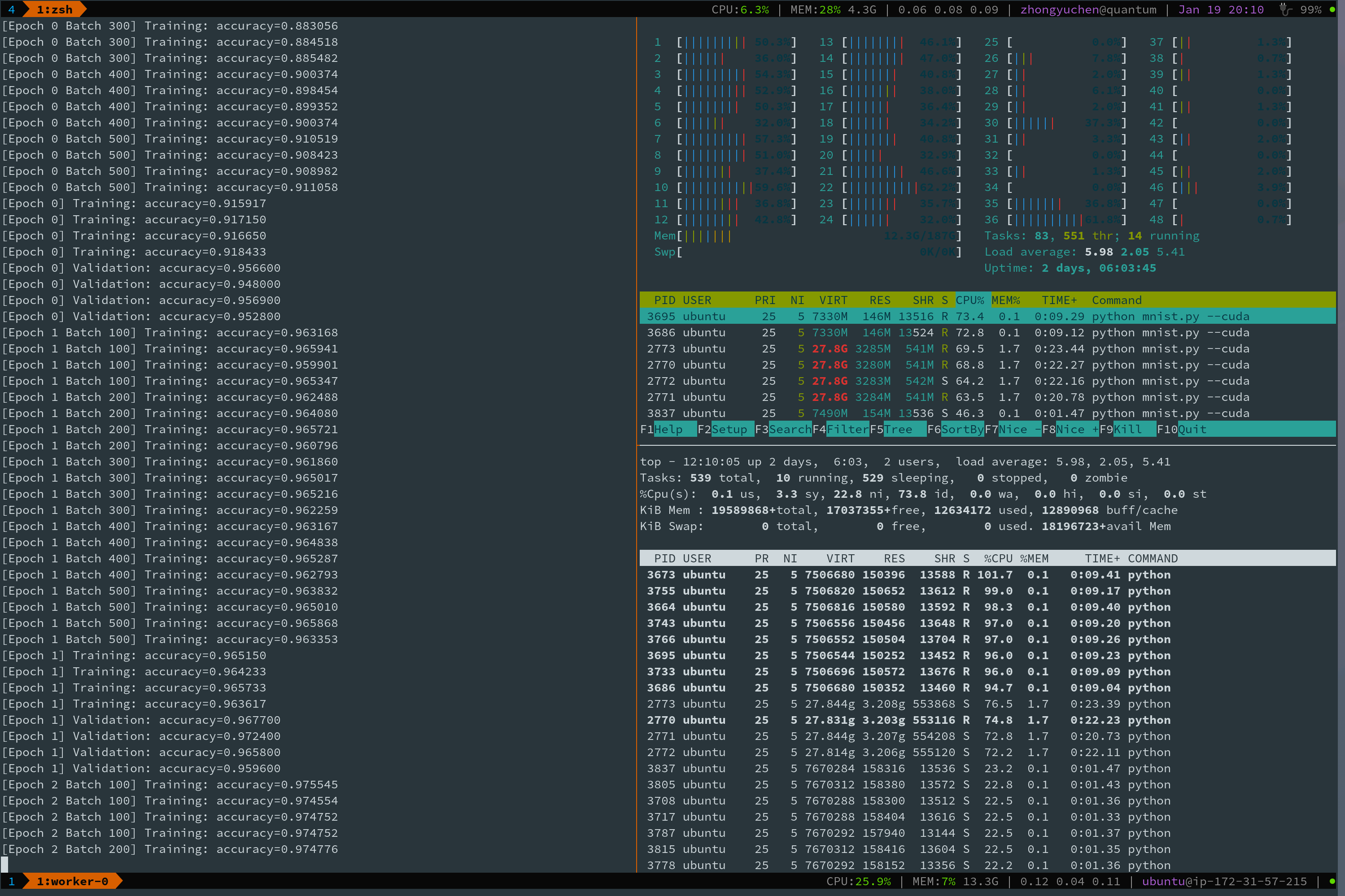
It also works when 4 threads run in parallel.
## Environment
g4.12xlarge
We recommend using our script for collecting the diagnositc information. Run the following command and paste the outputs below:
```
curl --retry 10 -s https://raw.githubusercontent.com/dmlc/gluon-nlp/master/tools/diagnose.py | python
# paste outputs here
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 24
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8259CL CPU @ 2.50GHz
Stepping: 7
CPU MHz: 2500.000
BogoMIPS: 5000.00
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 36608K
NUMA node0 CPU(s): 0-47
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl xtopology nonstop_tsc aperfmperf tsc_known_freq pni pclmulqdq monitor ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single kaiser fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx avx512f rdseed adx smap clflushopt clwb avx512cd xsaveopt xsavec xgetbv1 ida arat pku
----------Python Info----------
Version : 3.6.5
Compiler : GCC 7.2.0
Build : ('default', 'Apr 29 2018 16:14:56')
Arch : ('64bit', '')
------------Pip Info-----------
Version : 10.0.1
Directory : /home/ubuntu/anaconda3/envs/mxnet_p36/lib/python3.6/site-packages/pip
----------MXNet Info-----------
Version : 1.6.0.rc0
Directory : /home/ubuntu/anaconda3/envs/mxnet_p36/lib/python3.6/site-packages/mxnet
Num GPUs : 4
Hashtag not found. Not installed from pre-built package.
----------System Info----------
Platform : Linux-4.4.0-1098-aws-x86_64-with-debian-stretch-sid
system : Linux
node : ip-172-31-57-215
release : 4.4.0-1098-aws
version : #109-Ubuntu SMP Fri Nov 8 09:30:18 UTC 2019
----------Hardware Info----------
machine : x86_64
processor : x86_64
----------Network Test----------
Setting timeout: 10
Timing for MXNet: https://github.com/apache/incubator-mxnet, DNS: 0.0008 sec, LOAD: 0.3803 sec.
Timing for GluonNLP GitHub: https://github.com/dmlc/gluon-nlp, DNS: 0.0004 sec, LOAD: 0.3689 sec.
Timing for GluonNLP: http://gluon-nlp.mxnet.io, DNS: 0.0003 sec, LOAD: 0.0175 sec.
Timing for D2L: http://d2l.ai, DNS: 0.0004 sec, LOAD: 0.0027 sec.
Timing for D2L (zh-cn): http://zh.d2l.ai, DNS: 0.0002 sec, LOAD: 0.0026 sec.
Timing for FashionMNIST: https://repo.mxnet.io/gluon/dataset/fashion-mnist/train-labels-idx1-ubyte.gz, DNS: 0.0002 sec, LOAD: 0.0152 sec.
Timing for PYPI: https://pypi.python.org/pypi/pip, DNS: 0.0030 sec, LOAD: 0.0457 sec.
Timing for Conda: https://repo.continuum.io/pkgs/free/, DNS: 0.0002 sec, LOAD: 0.0286 sec.
```
___
This is a trap more than a bug, but I feel it is necessary to tell all about this.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services