You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2020/11/21 23:59:38 UTC
[GitHub] [hudi] asharma4-lucid opened a new issue #2269: [SUPPORT] - HUDI Table Bulk Insert for 5 gb parquet file progressively taking longer time to insert.
asharma4-lucid opened a new issue #2269:
URL: https://github.com/apache/hudi/issues/2269
I am trying to bulk insert 5 GB parquet s3 file in a partitioned HUDI table in s3. The input parquet s3 file is written by an upstream process where in the 5 GB data is divided across 200 part files. The hudi table load process takes a long time to load this data. There is no movement in the driver logs and in some cases the log appears to be stuck for ~4 hours at one place bringing the total execution time to 8 hrs. Out of these 8 hrs, the spark UI application stages show that the processing stages take around ~3 to 4 hours approximately, but there is a huge period of time when there is no processing that is visible on the spark UI and the driver log is also stuck for ~4 hours at one place. When I try to insert in a non-partitioned HUDI table, the write to the hudi table happens in 6 minutes without any issues. Also, another observation is when I try to write to the hudi table in HDFS instead of s3, then the process completes in ~1hr. Can you please advise on as to what is happen
ing here in terms of the driver log being stuck at one position and how can it be mitigated?
Attached the log file where in you can see that there is no movement in the driver log.
[log_2020_08_24.log](https://github.com/apache/hudi/files/5578693/log_2020_08_24.log)
Below is the log snippet where in the input 5 GB parquet file is being written. This file will be used in the second half of the process to write to the Hudi table.
```
20/11/20 07:27:12 INFO DAGScheduler: Job 3 finished: save at HistLoader.scala:75, took 29.940154 s
20/11/20 07:27:12 INFO MultipartUploadOutputStream: close closed:false s3://lucid-datalake-lt/temp_stage/_SUCCESS
20/11/20 07:27:12 INFO FileFormatWriter: Write Job fb9c88a3-d50a-4451-b623-5d23981df40e committed.
```
As advised, I am forcing a read of the above input file immediately after writing and it happens very quickly as can be seen from the logs.
```
20/11/20 07:27:13 INFO DAGScheduler: ResultStage 6 (show at HistLoader.scala:79) finished in 0.339 s
20/11/20 07:27:13 INFO DAGScheduler: Job 5 finished: show at HistLoader.scala:79, took 0.340348 s
+-----------+------------+-----------+------+--------------------+--------------------+
|survey_dbid|session_dbid|question_id|answer| respondent_id| timestamp|
+-----------+------------+-----------+------+--------------------+--------------------+
| 8292560| 6120232969| 44| IN|734e0eac-53fd-455...|2020-08-24 18:32:...|
| 8292560| 6120232969| 79400| 10|734e0eac-53fd-455...|2020-08-24 18:32:...|
```
Below is snippet from above attached log where it seems to be stuck for half an hour:
```
20/11/20 07:31:45 INFO ContextCleaner: Cleaned accumulator 13
20/11/20 07:31:45 INFO BlockManagerInfo: Removed broadcast_0_piece0 on ip-10-0-5-165.fulcrumex.com:39631 in memory (size: 33.9 KB, free: 57.8 GB)
20/11/20 08:04:17 INFO BlockManagerInfo: Added rdd_27_0 in memory on ip-10-0-5-170.fulcrumex.com:39049 (size: 719.7 KB, free: 51.4 GB)
20/11/20 08:04:17 INFO TaskSetManager: Starting task 10.0 in stage 8.0 (TID 13447, ip-10-0-5-170.fulcrumex.com, executor 11, partition 10, RACK_LOCAL, 9867 bytes)
```
Below is snippet from above attached log where it seems to be stuck for ~4 hrs 45 mins:
```
20/11/20 09:28:11 INFO ContextCleaner: Cleaned accumulator 206
20/11/20 09:28:11 INFO ContextCleaner: Cleaned accumulator 208
20/11/20 14:16:46 INFO SparkContext: Starting job: collect at CleanActionExecutor.java:90
20/11/20 14:16:46 INFO DAGScheduler: Got job 11 (collect at CleanActionExecutor.java:90) with 200 output partitions
```
Following in the configuration that I am using:
```
AWS EMR
- Master - r5.4x large
- 10 Core node - r5.4x large
- Release label:emr-5.31.0
- Spark - 2.4.6
- On acocunt of above the hudi version is 0.6.0 (hudi-spark-bundle_2.11-0.6.0-amzn-0.jar)
```
Spark Customizations: I changedthe below on account of containers getting killed by yarn during execution on account of less memory.
```
"spark.executor.memory":"98971M",
"spark.driver.memory":"98971M"
"spark.executor.cores":"1" - I reduced the number of cores from the default 4 to 1, assuming that each executor will have more memory at its disposal on account of the memory issues that I was seeing earlier.
```
Hudi table Load Options:
```
HoodieWriteConfig.TABLE_NAME -> "session_answers",
DataSourceWriteOptions.TABLE_TYPE_OPT_KEY -> DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL,
DataSourceWriteOptions.KEYGENERATOR_CLASS_OPT_KEY -> "org.apache.hudi.keygen.ComplexKeyGenerator",
DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY -> "session_dbid,question_id",
DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY -> "survey_dbid",
DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY -> "timestamp",
"hoodie.bulkinsert.shuffle.parallelism" -> "20", --- Initially I did not set it. But the process took even longer around 11 hrs with a lot of containers getting killed by yarn. So, I set to 20.
"hoodie.bulkinsert.sort.mode" -> "NONE",
DataSourceWriteOptions.OPERATION_OPT_KEY -> DataSourceWriteOptions.BULK_INSERT_OPERATION_OPT_VAL
```
Below is the code that I am running:
```
package com.lucidhq.etl.reports
import org.apache.spark.sql.{ DataFrame, SaveMode, SparkSession }
import org.apache.spark.sql.functions.{
col,
udf,
trim,
split,
size,
max,
lit,
when,
date_format,
concat_ws,
collect_list,
first
}
import scala.collection.mutable.ListBuffer
import org.apache.spark.sql.SaveMode
import org.apache.spark.sql.functions._
import org.apache.hudi.{ DataSourceWriteOptions, DataSourceReadOptions }
import org.apache.hudi.config.HoodieWriteConfig
//import org.apache.hudi.hive.MultiPartKeysValueExtractor
import scala.reflect.io.Directory
import java.io.File
import org.apache.log4j.Logger
object HistLoader {
val sourceFilePrefix = "s3://lucid-kafka-archive/respondent.profiles.v3"
val intermediateStagePath = "s3://lucid-datalake-lt/temp_stage/"
val logger = Logger.getLogger(getClass.getName)
var basePath = ""
var processDate = ""
def main(arg: Array[String]): Unit = {
val spark = SparkSession.builder.
appName("Sessions_hist_load").
config("spark.serializer", "org.apache.spark.serializer.KryoSerializer").
config("spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version", "2").
getOrCreate()
spark.sparkContext.hadoopConfiguration.set("mapreduce.fileoutputcommitter.algorithm.version", "2")
processDate = arg(0)
basePath = arg(1)
logger.info(s"""
processDate: ${processDate}
basePath: ${basePath}""")
val file_prefix = s"${sourceFilePrefix}/${processDate}/"
var df_intermediate = spark.read.json(file_prefix)
df_intermediate = df_intermediate.withColumn("answer", concat_ws("|", col("answer")))
df_intermediate = df_intermediate.select(
col("survey_dbid"),
col("session_dbid"),
col("question_id"),
col("answer"),
col("respondent_id"),
col("timestamp"))
// Repartition by hashing on surveyid instead of default record offset.
// And land intermediate file so that in case of task failure re-computation does lead to
// regeneration of the hashed surveyid partitioning again from source json files
df_intermediate.repartition(col("survey_dbid"))
.write
.format("parquet")
.mode("overwrite")
.save(intermediateStagePath)
df_intermediate.unpersist()
var df_load = spark.read.parquet(intermediateStagePath)
df_load.show()
val key = "session_dbid,question_id"
val combineKey = "timestamp"
val partitionKey = "survey_dbid"
val tablename = "session_answers"
loadHudiDataset(df_load, tablename, key, combineKey, partitionKey)
}
private def loadHudiDataset(df: DataFrame, tableName: String, key: String, combineKey: String,
partitionKey: String): Unit = {
val hudiOptions = Map[String, String](
HoodieWriteConfig.TABLE_NAME -> tableName,
DataSourceWriteOptions.TABLE_TYPE_OPT_KEY -> DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL,
DataSourceWriteOptions.KEYGENERATOR_CLASS_OPT_KEY -> "org.apache.hudi.keygen.ComplexKeyGenerator",
DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY -> key,
DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY -> partitionKey,
DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY -> combineKey,
"hoodie.bulkinsert.shuffle.parallelism" -> "20",
"hoodie.bulkinsert.sort.mode" -> "NONE")
// Write a DataFrame as a Hudi dataset
df.write
.format("org.apache.hudi")
.option(DataSourceWriteOptions.OPERATION_OPT_KEY, DataSourceWriteOptions.BULK_INSERT_OPERATION_OPT_VAL)
.options(hudiOptions)
.mode(SaveMode.Append)
.save(s"${basePath}/${tableName}/")
}
}
```
The spark UI screen shots are as follows:
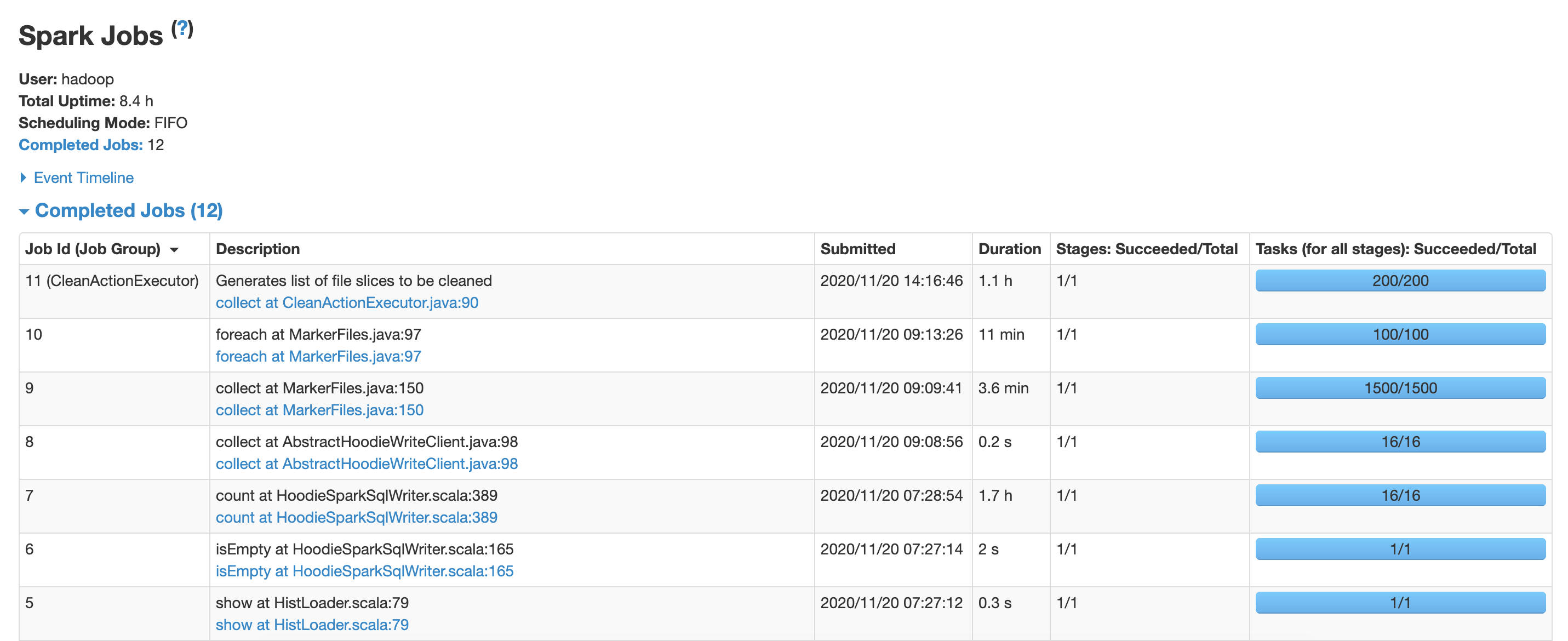
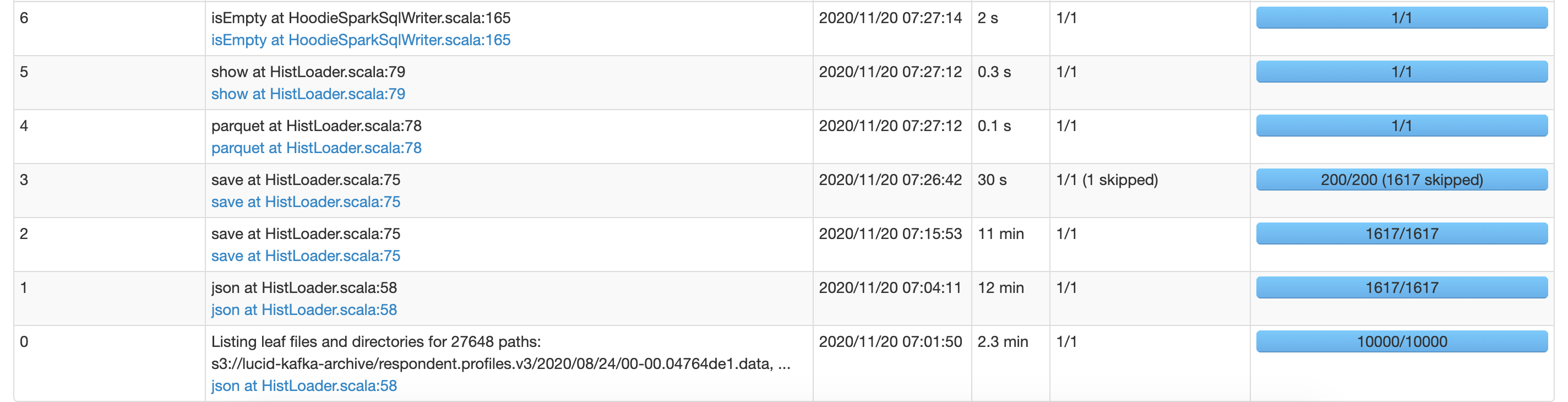
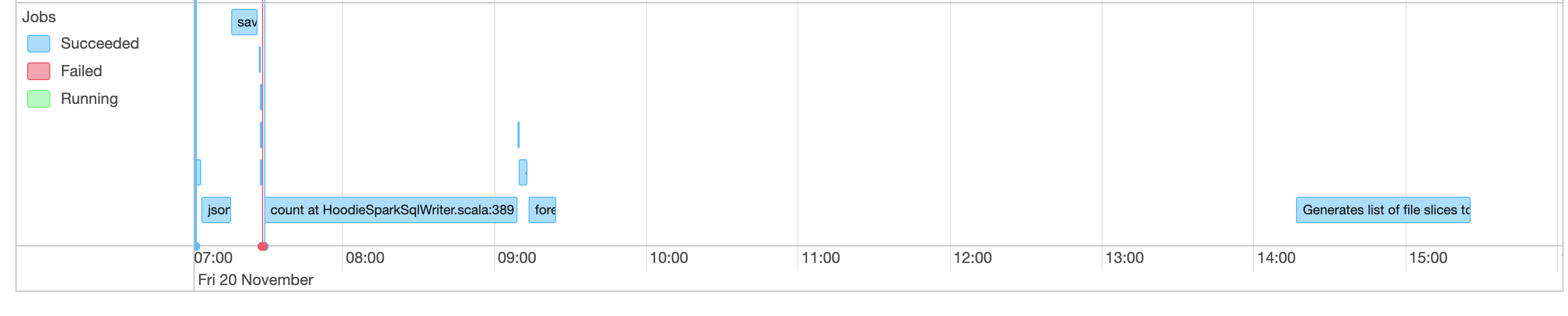
As you can see in the Jobs completed list, even though the job id 10 started at 09:13 and completed in 11 mins, the next job id 11 did not start until ~5 hrs later, i.e. at 14:16. The same is also visible in the event timeline gap screenshot.
Regarding your queries on slack following is my response:
1) Also, by loading the dataset, I mean writing to the HUDI table.
2) The number of output partitions for this execution whose log I have attached is 44938.
3) The number of partitions already present in the hudi table is 298880.
4) On an average everyday 12000 new partitions will be added and around 30000 will be updated.
5) The listing of .hoodie folder is as follows:
```
[hadoop@ip-10-0-5-174 ~]$ aws s3 ls s3://lucid-datalake/mkt_hudi_tables/public/session_answers/.hoodie/
PRE .aux/
2020-11-13 17:43:37 0 .aux_$folder$
2020-11-13 17:43:37 0 .temp_$folder$
2020-11-13 21:01:47 36023036 20201113174334.commit
2020-11-13 17:43:41 0 20201113174334.commit.requested
2020-11-13 17:43:41 0 20201113174334.inflight
2020-11-14 00:04:48 33727108 20201113213152.commit
2020-11-13 21:31:58 0 20201113213152.commit.requested
2020-11-13 21:32:00 0 20201113213152.inflight
2020-11-14 03:36:16 37912184 20201114004007.commit
2020-11-14 00:40:15 0 20201114004007.commit.requested
2020-11-14 00:40:18 0 20201114004007.inflight
2020-11-14 06:53:05 39230472 20201114040953.commit
2020-11-14 04:10:04 0 20201114040953.commit.requested
2020-11-14 04:10:07 0 20201114040953.inflight
2020-11-14 10:07:24 39733730 20201114072855.commit
2020-11-14 07:29:07 0 20201114072855.commit.requested
2020-11-14 07:29:11 0 20201114072855.inflight
2020-11-14 13:19:32 41089090 20201114104035.commit
2020-11-14 10:40:59 0 20201114104035.commit.requested
2020-11-14 10:41:09 0 20201114104035.inflight
2020-11-14 16:28:45 42134374 20201114135313.commit
2020-11-14 13:53:38 0 20201114135313.commit.requested
2020-11-14 13:53:49 0 20201114135313.inflight
2020-11-14 19:12:32 36778779 20201114170008.commit
2020-11-14 17:00:36 0 20201114170008.commit.requested
2020-11-14 17:00:47 0 20201114170008.inflight
2020-11-14 21:40:56 35306828 20201114194157.commit
2020-11-14 19:42:26 0 20201114194157.commit.requested
2020-11-14 19:42:37 0 20201114194157.inflight
2020-11-15 01:43:29 39314511 20201114221051.commit
2020-11-14 22:11:21 0 20201114221051.commit.requested
2020-11-14 22:11:33 0 20201114221051.inflight
2020-11-15 04:40:24 40687717 20201115022022.commit
2020-11-15 02:20:59 0 20201115022022.commit.requested
2020-11-15 02:21:13 0 20201115022022.inflight
2020-11-15 10:24:44 40196023 20201115081109.commit
2020-11-15 08:11:51 0 20201115081109.commit.requested
2020-11-15 08:12:07 0 20201115081109.inflight
2020-11-15 16:12:59 40939005 20201115135948.commit
2020-11-15 14:00:30 0 20201115135948.commit.requested
2020-11-15 14:00:47 0 20201115135948.inflight
2020-11-15 22:13:07 41510484 20201115200055.commit
2020-11-15 20:01:35 0 20201115200055.commit.requested
2020-11-15 20:01:52 0 20201115200055.inflight
2020-11-16 04:39:40 36662698 20201116021224.commit
2020-11-16 02:13:09 0 20201116021224.commit.requested
2020-11-16 02:13:27 0 20201116021224.inflight
2020-11-16 12:33:33 34875744 20201116101650.commit
2020-11-16 10:17:38 0 20201116101650.commit.requested
2020-11-16 10:17:58 0 20201116101650.inflight
2020-11-17 09:05:55 34875750 20201117065854.commit
2020-11-17 06:59:46 0 20201117065854.commit.requested
2020-11-17 07:00:10 0 20201117065854.inflight
2020-11-17 19:35:18 34875742 20201117171409.commit
2020-11-17 17:15:10 0 20201117171409.commit.requested
2020-11-17 17:15:34 0 20201117171409.inflight
2020-11-18 02:09:10 39673955 20201117234859.commit
2020-11-17 23:49:48 0 20201117234859.commit.requested
2020-11-17 23:50:09 0 20201117234859.inflight
2020-11-18 09:02:40 39423992 20201118064329.commit
2020-11-18 06:44:25 0 20201118064329.commit.requested
2020-11-18 06:44:49 0 20201118064329.inflight
2020-11-18 16:19:52 38855056 20201118135232.commit
2020-11-18 13:53:30 0 20201118135232.commit.requested
2020-11-18 13:53:55 0 20201118135232.inflight
2020-11-18 23:38:37 37912787 20201118212218.commit
2020-11-18 21:23:14 0 20201118212218.commit.requested
2020-11-18 21:23:37 0 20201118212218.inflight
2020-11-19 12:31:03 39340580 20201119063923.commit
2020-11-19 10:58:07 0 20201119063923.commit.requested
2020-11-19 10:58:41 0 20201119063923.inflight
2020-11-19 10:48:53 4685681 20201119063957.rollback
2020-11-19 10:48:53 0 20201119063957.rollback.inflight
2020-11-19 19:08:49 35691447 20201119173726.commit
2020-11-19 17:38:31 0 20201119173726.commit.requested
2020-11-19 17:39:00 0 20201119173726.inflight
2020-11-20 01:51:04 33863679 20201120000744.commit
2020-11-20 00:08:52 0 20201120000744.commit.requested
2020-11-20 00:09:21 0 20201120000744.inflight
2020-11-20 09:13:19 38344846 20201120072713.commit
2020-11-20 07:28:24 0 20201120072713.commit.requested
2020-11-20 07:28:55 0 20201120072713.inflight
2020-11-20 17:30:49 38464812 20201120155037.commit
2020-11-20 15:51:56 0 20201120155037.commit.requested
2020-11-20 15:52:28 0 20201120155037.inflight
2020-11-21 00:40:21 37365365 20201120230924.commit
2020-11-20 23:10:37 0 20201120230924.commit.requested
2020-11-20 23:11:08 0 20201120230924.inflight
2020-11-13 17:43:36 0 archived_$folder$
2020-11-13 17:43:38 236 hoodie.properties
[hadoop@ip-10-0-5-174 ~]$
```
6. The listing of a few partitions is as follows:
survey_dbid: 3324371 partition
```
[hadoop@ip-10-0-5-174 ~]$ aws s3 ls s3://lucid-datalake/mkt_hudi_tables/public/session_answers/3324371/
2020-11-20 16:31:46 93 .hoodie_partition_metadata
2020-11-20 17:01:30 436614 8ef7f3a5-4f2b-4a23-b5dd-cdfa151aba5f-636_10-8-13577_20201120155037.parquet
```
survey_dbid: 7885175 partition
```
[hadoop@ip-10-0-5-174 ~]$ aws s3 ls s3://lucid-datalake/mkt_hudi_tables/public/session_answers/7885175/
2020-11-14 08:31:46 93 .hoodie_partition_metadata
2020-11-14 09:34:16 436204 1c67edad-6b51-4609-bbac-f4936e30e760-4659_3-7-13437_20201114072855.parquet
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] asharma4-lucid commented on issue #2269: [SUPPORT] - HUDI Table Bulk Insert for 5 gb parquet file progressively taking longer time to insert.
Posted by GitBox <gi...@apache.org>.
asharma4-lucid commented on issue #2269:
URL: https://github.com/apache/hudi/issues/2269#issuecomment-734453893
Is there a downside to keeping hoodie.clean.automatic=false?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] asharma4-lucid commented on issue #2269: [SUPPORT] - HUDI Table Bulk Insert for 5 gb parquet file progressively taking longer time to insert.
Posted by GitBox <gi...@apache.org>.
asharma4-lucid commented on issue #2269:
URL: https://github.com/apache/hudi/issues/2269#issuecomment-736998571
Thanks @bvaradar. Would you know when 0.7.0 is slated for release as the S3 listing time will continue to grow for us as we add more partitions even with cleaning turned off? Also, since we are using a COW table and mostly inserts, would new versions of files still be created and hence would old versions be required to be cleaned up?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #2269: [SUPPORT] - HUDI Table Bulk Insert for 5 gb parquet file progressively taking longer time to insert.
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #2269:
URL: https://github.com/apache/hudi/issues/2269#issuecomment-733299492
@asharma4-lucid : ~5hrs is way too much. Can you disable cleaning using the config hoodie.clean.automatic=false and try. Is this a COW table ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] asharma4-lucid commented on issue #2269: [SUPPORT] - HUDI Table Bulk Insert for 5 gb parquet file progressively taking longer time to insert.
Posted by GitBox <gi...@apache.org>.
asharma4-lucid commented on issue #2269:
URL: https://github.com/apache/hudi/issues/2269#issuecomment-733323629
Yes this is a COW table.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #2269: [SUPPORT] - HUDI Table Bulk Insert for 5 gb parquet file progressively taking longer time to insert.
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #2269:
URL: https://github.com/apache/hudi/issues/2269#issuecomment-737415489
There is an email thread around 0.7.0 release in users@ mailing list. It is expected to be by end of this month.
Regarding inserts, Hudi takes care of automatically growing small files which indeed creates multiple versions of the files : https://cwiki.apache.org/confluence/display/HUDI/FAQ#FAQ-HowdoItoavoidcreatingtonsofsmallfiles
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar closed issue #2269: [SUPPORT] - HUDI Table Bulk Insert for 5 gb parquet file progressively taking longer time to insert.
Posted by GitBox <gi...@apache.org>.
bvaradar closed issue #2269:
URL: https://github.com/apache/hudi/issues/2269
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #2269: [SUPPORT] - HUDI Table Bulk Insert for 5 gb parquet file progressively taking longer time to insert.
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #2269:
URL: https://github.com/apache/hudi/issues/2269#issuecomment-735921130
@asharma4-lucid : Sorry for the delay in responding due to Thanksgiving weekend. It looks like cleaning is the one taking long time. Cleaner (in 0.6) runs in incremental mode by default but it could be that you are touching a lot of partitions. You need to enable this config once in a while (like every n commits) to delete old versions of the files.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] asharma4-lucid commented on issue #2269: [SUPPORT] - HUDI Table Bulk Insert for 5 gb parquet file progressively taking longer time to insert.
Posted by GitBox <gi...@apache.org>.
asharma4-lucid commented on issue #2269:
URL: https://github.com/apache/hudi/issues/2269#issuecomment-733174238
Thanks @bvaradar. I tried to insert just 5 records to the existing table with ~300K partitions and it took close to ~5 hrs. If I insert ~5 records in a new table it takes less than 2 mins. Is this extra time of ~5 hrs all because of cleaner and compaction processes? For our use case, we mostly get inserts. With that in mind, would it be beneficial for us if we switch to MOR from COW and do async compaction (I am most likely making an incorrect assumption that this huge extra processing time is only because of compaction) ? And also, since our data does not have frequent record level updates, would switching to MOR make any difference?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #2269: [SUPPORT] - HUDI Table Bulk Insert for 5 gb parquet file progressively taking longer time to insert.
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #2269:
URL: https://github.com/apache/hudi/issues/2269#issuecomment-731656591
@AakashPradeep : I can quickly tell that the number of partitions is really high relative to the file size in each partition. It looks like each partition has only very little records (Parquet size ~ 400K). S3 listing becomes a huge bottleneck in this case. I have seen S3 listing taking really long time to perform listing for ~100K partitions. With 0.7.0 (next release), we are going to have 0-listing writes supported which will avoid this bottleneck.
But generally, you have too many partitions relative to your dataset size. If possible, keeping lower cardinality column as partition would help.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #2269: [SUPPORT] - HUDI Table Bulk Insert for 5 gb parquet file progressively taking longer time to insert.
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #2269:
URL: https://github.com/apache/hudi/issues/2269#issuecomment-732367698
1. Only the files having records to be updated or added will be "touched" by Hudi.
2.Hudi write operations would only load the partitions that are needed for writing (only partitions that are getting affected). There are background processes like cleaner and compaction scheduling which would need to look at the entire dataset.
3.Apart of listing issue, if you are using HMS for your query, you would need to look at how it is performing during query planning phases when your queries are hitting it to prune directories to be queried.
4. Spark bucketing is not supported currently. You can add an explicit partition column which would bound the search space but would require users to include them in the query.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] asharma4-lucid commented on issue #2269: [SUPPORT] - HUDI Table Bulk Insert for 5 gb parquet file progressively taking longer time to insert.
Posted by GitBox <gi...@apache.org>.
asharma4-lucid commented on issue #2269:
URL: https://github.com/apache/hudi/issues/2269#issuecomment-731908622
Thanks @bvaradar for your response. I have a few more questions:
1) The reason we have kept the partition key that we are using is, because we wanted to gain O(1) read performance for the same. It is my understanding that this many number of partitions puts memory pressure on the executors as each executor creates as many writers as the partitions. (I am assuming in HDFS namenode would also be impacted, but since we are using S3, I am discounting that, but do let me know if I am mistaken). It is here that I wanted to confirm my understanding. Every day our process will update around ~12K partitions + insert ~33 K new partitions. So, my question is will the executors doing the hudi table write create ~44K writers contributing to the memory pressure. Or will the already existing partitions, i.e. ~300K also be touched in some way by the hudi table write executors leading to performance degradation as we continue to add more table to the hudi table?
2) Just to confirm my understanding, when you mentioned s3 listing as the bottleneck, you meant that the s3 listing of all the partitions and files for the hudi table and not just the partitions updated and/or inserted for that specific process. So, in my case, that would imply that the Hudi table write process is doing an s3 listing of already existing ~300 K partitions and associated files and not just the ~44K partitions for the specific execution. And this is probably in line with what we have observed as well. Because for the intial 15 day processes, each hudi table write completed in around 4 hrs and then from the 16th day onwards, it gradually started increasing from 4 to 5 to 6 and now to almost 9 hrs per day as we move ahead. Can you please confirm?
3) If s3 listing requirement is made optional in hudi 0.7.0, then can we continue to use the partition key that we are using assuming that every day our process will add/update ~44K partitions in the hudi table? I understand that is not the best partition key as it has very high cardinality, but our read requirement is what is driving us towards this. I guess this might be related to question 1 above, but my question is, is there any other downside as well that you could glean from our use of this partition key apart from the s3 listing dependency?
4) We are trying to see if spark bucketing on the key would be a good middle ground between partition on the key and not using partitioning. Does hudi table write support bucketed writes and consequently, are the hudi table reads able to use the buckets for optimal read performance? Something like, O(1) hash + O(log m) binary search where m is the number of records in each bucketed file.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] asharma4-lucid commented on issue #2269: [SUPPORT] - HUDI Table Bulk Insert for 5 gb parquet file progressively taking longer time to insert.
Posted by GitBox <gi...@apache.org>.
asharma4-lucid commented on issue #2269:
URL: https://github.com/apache/hudi/issues/2269#issuecomment-734450744
Thanks @bvaradar . Setting the value hoodie.clean.automatic=false has helped in reducing the processing time significantly. Now the 5 records got inserted in less than a minute.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org