You are viewing a plain text version of this content. The canonical link for it is here.
Posted to github@arrow.apache.org by GitBox <gi...@apache.org> on 2022/06/06 15:08:28 UTC
[GitHub] [arrow] ashsharma96 opened a new issue, #13320: Memory Consumption while calling a feather file in python dataframe(Urgent)
ashsharma96 opened a new issue, #13320:
URL: https://github.com/apache/arrow/issues/13320
Hey Apache Arrow Team,
I'm working on some project and I'm using feather file. I've made a dataframe in feather format in my aws jupyter instance by the name of code.production. Whenever I read this feather file in my aws jupyter instance then it uses too much RAM. It takes up of 28 GB of RAM. The size of feather file is 844MB. The dataframe which is converted in feather file contains 4.2 million rows and 50 columns. This feather takes 28GB RAM while calling. This is my code:
tFilename1 = 'code.production'
df_stored = feather.read_dataframe(tFilename1)
This is my dataframe looks like:

Columns shown in this dataframe are in list format except first two columns.
The library versions in my aws jupyter is:
arrow 1.2.1
feather 0.1.2
pyarrow 6.0.1
Can you guys help me in this like how should I use feather file with less RAM consumption. This RAM consumption sometimes leads to Kernel Die.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] ashsharma96 commented on issue #13320: Memory Consumption while calling a feather file in python dataframe(Urgent)
Posted by GitBox <gi...@apache.org>.
ashsharma96 commented on issue #13320:
URL: https://github.com/apache/arrow/issues/13320#issuecomment-1352607145
Hey @wjones127
Even after Updating the libraries the code is taking too much memory for calling feather file.
Any Update.
Regards
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] jorisvandenbossche commented on issue #13320: Memory Consumption while calling a feather file in python dataframe(Urgent)
Posted by GitBox <gi...@apache.org>.
jorisvandenbossche commented on issue #13320:
URL: https://github.com/apache/arrow/issues/13320#issuecomment-1352639266
I don't think this is using "too much" memory, but this is expected for this kind of data at the moment.
A quick rough calculation: you mention the data has 4.2 million rows and 50 columns. For the int64 and float64 columns, that is 8 bytes per element. But most of your columns seem to be list arrays. Those get converted to a column of numpy arrays in pandas, and even an empty numpy array already consumes 104 bytes per array (`sys.getsizeof(np.array([]))`), so this is unfortunately not very efficient.
Assuming this size of dataframe with just empty arrays in it:
```
>>> (4200000 * 50 * 104) / 1024**3
20.34008502960205
```
already gives 20GB. Assuming that there is some data in those columns, that will be more, and thus getting in the order of the 28GB you mention.
So while this is currently "expected", it's of course not efficient. That is due to pandas not having a built-in list data type (like arrow has). And thus the conversion from pyarrow -> pandas has to do something with those lists. Currently pyarrow converts it to an array of arrays, but if you have many tiny arrays, that's unfortunately not efficient.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wjones127 commented on issue #13320: Memory Consumption while calling a feather file in python dataframe(Urgent)
Posted by GitBox <gi...@apache.org>.
wjones127 commented on issue #13320:
URL: https://github.com/apache/arrow/issues/13320#issuecomment-1147602227
Two questions:
1. The version of the `feather` package you are using is over 6 years old! Is there a reason you aren't using a more recent version? Or just using the `pyarrow.feather.read_feather()`?
2. Is that loaded as a Pandas dataframe? How are the list columns being stored? (If in pandas, what is `df_stored.dtypes`?)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wjones127 commented on issue #13320: Memory Consumption while calling a feather file in python dataframe(Urgent)
Posted by GitBox <gi...@apache.org>.
wjones127 commented on issue #13320:
URL: https://github.com/apache/arrow/issues/13320#issuecomment-1147631834
> Please help me out in this. What is the latest versions of above mentioned libraries.
To find the version of Python libraries, you can search https://pypi.org for the package and look at the "Release History". For feather, that's: https://pypi.org/project/feather-format/#history
It looks like your Pandas DataFrame is storing those list columns as simple python objects (probably lists of integers), which have a lot of overhead at the row counts you have. You should find a more efficient representation for those. In PyArrow, we have a built-in List type for that (part of why the feather file is much smaller; it uses the Arrow format internally). But there might be a pandas / numpy solution to that, I'm not sure.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] ashsharma96 commented on issue #13320: Memory Consumption while calling a feather file in python dataframe(Urgent)
Posted by GitBox <gi...@apache.org>.
ashsharma96 commented on issue #13320:
URL: https://github.com/apache/arrow/issues/13320#issuecomment-1147623004
Hey @wjones127 First of all thank you for replying.
1. No there's no such reason. I think I never updated it. I'm just using these commands to read/write feather file:
For Reading:
import feather
tFilename1 = 'code.production'
df_stored = feather.read_dataframe(tFilename1)
For writing feather file:
feather.write_dataframe(df1,'code.production')
2. Yes this is loaded in pandas dataframe. dtypes for df_stored is like this:
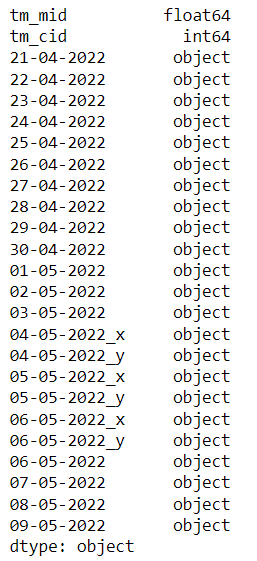
Please help me out in this. What is the latest versions of above mentioned libraries.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org