You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2020/10/24 04:39:18 UTC
[GitHub] [spark] AngersZhuuuu opened a new pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
AngersZhuuuu opened a new pull request #30144:
URL: https://github.com/apache/spark/pull/30144
### What changes were proposed in this pull request?
### Why are the changes needed?
Support more SQL scenario.
### Does this PR introduce _any_ user-facing change?
User can use sql like
```
select a, b, c, agg_expr() from table group by a, cube(b, c)
```
### How was this patch tested?
Added UT
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-751644388
**[Test build #133440 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133440/testReport)** for PR 30144 at commit [`c1c551c`](https://github.com/apache/spark/commit/c1c551c6f9656ec71d6da03fb8fd4c4119d66c3a).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-720467422
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816615033
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41706/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811851340
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41394/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816917458
**[Test build #137139 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137139/testReport)** for PR 30144 at commit [`4359aef`](https://github.com/apache/spark/commit/4359aefc4653b018814001df49d5eec84a463e72).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816765547
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41717/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r609768175
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -88,6 +89,41 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. For example:
Review comment:
We can say that: `group_expression`s will be added to each group in the GROUPING SETS.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r605551784
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,27 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ val (groupingSetExprs, others) = exprs.partition(_.isInstanceOf[GroupingSet])
+ if (groupingSetExprs.isEmpty) {
+ None
+ } else {
+ val groupingSets = groupingSetExprs.map(_.asInstanceOf[GroupingSet])
+ val groups = groupingSets.flatMap(_.groupByExprs) ++ others
+ val selectedGroupByExprs = groupingSets.map(_.selectedGroupByExprs)
+ .foldRight(Seq.empty[Seq[Expression]]) { (x, y) =>
+ if (y.isEmpty) {
+ x
+ } else {
+ for (a <- x; b <- y) yield b ++ a
+ }
+ }.map(others ++ _).map(_.distinct)
Review comment:
> ```
> }.map { groupByExprs =>
> (others ++ groupByExprs).distinct
> }
> ```
>
> ?
Done
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,27 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ val (groupingSetExprs, others) = exprs.partition(_.isInstanceOf[GroupingSet])
+ if (groupingSetExprs.isEmpty) {
+ None
+ } else {
+ val groupingSets = groupingSetExprs.map(_.asInstanceOf[GroupingSet])
+ val groups = groupingSets.flatMap(_.groupByExprs) ++ others
+ val selectedGroupByExprs = groupingSets.map(_.selectedGroupByExprs)
+ .foldRight(Seq.empty[Seq[Expression]]) { (x, y) =>
+ if (y.isEmpty) {
+ x
+ } else {
+ for (a <- x; b <- y) yield b ++ a
+ }
+ }.map(others ++ _).map(_.distinct)
+ Some(selectedGroupByExprs,
+ groupingSetExprs.flatMap(_.asInstanceOf[GroupingSet].groupingSets), groups.distinct)
Review comment:
> `groupingSetExprs.flatMap(_.asInstanceOf[GroupingSet].groupingSets)` -> `groupingSets.flatMap(_.groupingSets)`?
DOne
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,27 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ val (groupingSetExprs, others) = exprs.partition(_.isInstanceOf[GroupingSet])
+ if (groupingSetExprs.isEmpty) {
+ None
+ } else {
+ val groupingSets = groupingSetExprs.map(_.asInstanceOf[GroupingSet])
+ val groups = groupingSets.flatMap(_.groupByExprs) ++ others
+ val selectedGroupByExprs = groupingSets.map(_.selectedGroupByExprs)
Review comment:
> ```
> val X = groupingSets.map(_.selectedGroupByExprs)
> val selectedGroupByExprs = X.tail.foldLeft(X.head) { (x, y) =>
> for (a <- x; b <- y) yield b ++ a
> }.map(others ++ _).map(_.distinct)
> ```
Nice suggestion!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-814671956
**[Test build #137017 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137017/testReport)** for PR 30144 at commit [`5463920`](https://github.com/apache/spark/commit/5463920e284eca5972df61bafb0d53f9f08e57ba).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-815398553
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41624/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810827595
Kubernetes integration test unable to build dist.
exiting with code: 1
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41332/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r605527431
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,27 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ val (groupingSetExprs, others) = exprs.partition(_.isInstanceOf[GroupingSet])
+ if (groupingSetExprs.isEmpty) {
+ None
+ } else {
+ val groupingSets = groupingSetExprs.map(_.asInstanceOf[GroupingSet])
+ val groups = groupingSets.flatMap(_.groupByExprs) ++ others
+ val selectedGroupByExprs = groupingSets.map(_.selectedGroupByExprs)
+ .foldRight(Seq.empty[Seq[Expression]]) { (x, y) =>
+ if (y.isEmpty) {
+ x
+ } else {
+ for (a <- x; b <- y) yield b ++ a
+ }
+ }.map(others ++ _).map(_.distinct)
Review comment:
```
}.map { g =>
(others ++ g).distinct
}
```
?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-817236113
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41750/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610510273
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +229,30 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
Review comment:
> the `unapply` here should return None if the given expressions are not resolved yet.
Will throw other exception like before this pr
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-814882669
**[Test build #137017 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137017/testReport)** for PR 30144 at commit [`5463920`](https://github.com/apache/spark/commit/5463920e284eca5972df61bafb0d53f9f08e57ba).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and mixed grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810930672
**[Test build #136758 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136758/testReport)** for PR 30144 at commit [`84de8b6`](https://github.com/apache/spark/commit/84de8b6e1bec0b83e1cc1a20ce757b184d48da84).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-815958713
**[Test build #137089 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137089/testReport)** for PR 30144 at commit [`be93d9e`](https://github.com/apache/spark/commit/be93d9ed873497b04cd0b3742b5beab501941453).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-715749524
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r511753662
##########
File path: sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
##########
@@ -3691,6 +3691,26 @@ class SQLQuerySuite extends QueryTest with SharedSparkSession with AdaptiveSpark
checkAnswer(sql("SELECT id FROM t WHERE (SELECT true)"), Row(0L))
}
}
+
+ test("SPARK-33229: Support GROUP BY use Separate columns and CUBE/ROLLUP") {
+ withTable("t") {
+ sql("CREATE TABLE t USING PARQUET AS SELECT id AS a, id AS b, id AS c FROM range(1)")
Review comment:
Could you move these tests into `SQLQueryTestSuite`?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816687857
**[Test build #137137 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137137/testReport)** for PR 30144 at commit [`c7de14c`](https://github.com/apache/spark/commit/c7de14cf8d4aff1814407f3e626785904190ab21).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716529288
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/34882/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810967003
**[Test build #136763 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136763/testReport)** for PR 30144 at commit [`31f9fbd`](https://github.com/apache/spark/commit/31f9fbd6efe90af781ff2ac78f93af8268f1a1b4).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816795746
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-815395423
**[Test build #137045 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137045/testReport)** for PR 30144 at commit [`3d6e2c4`](https://github.com/apache/spark/commit/3d6e2c475747c5c3eb981aee8faa504b5af7df59).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811037306
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41347/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-814831237
**[Test build #137016 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137016/testReport)** for PR 30144 at commit [`a0f8cf2`](https://github.com/apache/spark/commit/a0f8cf276edeaf294896718eedd78e514ab9b5d3).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds the following public classes _(experimental)_:
* `class KoalasFrameMethods(object):`
* `class KoalasSeriesMethods(object):`
* `class IndexOpsMixin(object, metaclass=ABCMeta):`
* `class CategoricalAccessor(object):`
* ` however, expected types are [(<class 'float'>, <class 'int'>)].`
* `class OptionError(AttributeError, KeyError):`
* `class DatetimeMethods(object):`
* `class DataError(Exception):`
* `class SparkPandasIndexingError(Exception):`
* `class SparkPandasNotImplementedError(NotImplementedError):`
* `class PandasNotImplementedError(NotImplementedError):`
* ` new_class = type(\"NameType\", (NameTypeHolder,), `
* ` new_class = type(\"NameType\", (NameTypeHolder,), `
* `class DataFrame(Frame, Generic[T]):`
* ` [defaultdict(<class 'list'>, `
* `defaultdict(<class 'list'>, `
* `class CachedDataFrame(DataFrame):`
* `class Frame(object, metaclass=ABCMeta):`
* `class GroupBy(object, metaclass=ABCMeta):`
* `class DataFrameGroupBy(GroupBy):`
* `class SeriesGroupBy(GroupBy):`
* `class Index(IndexOpsMixin):`
* `class CategoricalIndex(Index):`
* `class DatetimeIndex(Index):`
* `class MultiIndex(Index):`
* ` a single :class:`Index` (or subclass thereof).`
* `class NumericIndex(Index):`
* `class IntegerIndex(NumericIndex):`
* `class Int64Index(IntegerIndex):`
* `class Float64Index(NumericIndex):`
* `class IndexerLike(object):`
* `class AtIndexer(IndexerLike):`
* `class iAtIndexer(IndexerLike):`
* `class LocIndexerLike(IndexerLike, metaclass=ABCMeta):`
* `class LocIndexer(LocIndexerLike):`
* `class iLocIndexer(LocIndexerLike):`
* `class InternalFrame(object):`
* `class _MissingPandasLikeDataFrame(object):`
* `class MissingPandasLikeDataFrameGroupBy(object):`
* `class MissingPandasLikeSeriesGroupBy(object):`
* `class MissingPandasLikeIndex(object):`
* `class MissingPandasLikeDatetimeIndex(MissingPandasLikeIndex):`
* `class MissingPandasLikeCategoricalIndex(MissingPandasLikeIndex):`
* `class MissingPandasLikeMultiIndex(object):`
* `class MissingPandasLikeSeries(object):`
* `class MissingPandasLikeExpanding(object):`
* `class MissingPandasLikeRolling(object):`
* `class MissingPandasLikeExpandingGroupby(object):`
* `class MissingPandasLikeRollingGroupby(object):`
* `class PythonModelWrapper(object):`
* `class KoalasPlotAccessor(PandasObject):`
* `class KoalasBarPlot(PandasBarPlot, TopNPlotBase):`
* `class KoalasBoxPlot(PandasBoxPlot, BoxPlotBase):`
* `class KoalasHistPlot(PandasHistPlot, HistogramPlotBase):`
* `class KoalasPiePlot(PandasPiePlot, TopNPlotBase):`
* `class KoalasAreaPlot(PandasAreaPlot, SampledPlotBase):`
* `class KoalasLinePlot(PandasLinePlot, SampledPlotBase):`
* `class KoalasBarhPlot(PandasBarhPlot, TopNPlotBase):`
* `class KoalasScatterPlot(PandasScatterPlot, TopNPlotBase):`
* `class KoalasKdePlot(PandasKdePlot, KdePlotBase):`
* ` new_class = type(\"NameType\", (NameTypeHolder,), `
* ` new_class = param.type if isinstance(param, np.dtype) else param`
* `class Series(Frame, IndexOpsMixin, Generic[T]):`
* ` dictionary is a ``dict`` subclass that defines ``__missing__`` (i.e.`
* ` defaultdict(<class 'list'>, `
* `class SparkIndexOpsMethods(object, metaclass=ABCMeta):`
* `class SparkSeriesMethods(SparkIndexOpsMethods):`
* `class SparkIndexMethods(SparkIndexOpsMethods):`
* `class SparkFrameMethods(object):`
* `class CachedSparkFrameMethods(SparkFrameMethods):`
* `class SQLProcessor(object):`
* `class StringMethods(object):`
* `class SeriesType(Generic[T]):`
* `class DataFrameType(object):`
* `class ScalarType(object):`
* `class UnknownType(object):`
* `class NameTypeHolder(object):`
* ` The returned type class indicates both dtypes (a pandas only dtype object`
* `class KoalasUsageLogger(object):`
* `class RollingAndExpanding(object):`
* `class Rolling(RollingAndExpanding):`
* `class RollingGroupby(Rolling):`
* `class Expanding(RollingAndExpanding):`
* `class ExpandingGroupby(Expanding):`
* `case class TryCast(child: Expression, dataType: DataType, timeZoneId: Option[String] = None)`
* `case class SubtractTimestamps(`
* `public class OrcArrayColumnVector extends OrcColumnVector `
* `public class OrcAtomicColumnVector extends OrcColumnVector `
* `public abstract class OrcColumnVector extends org.apache.spark.sql.vectorized.ColumnVector `
* `class OrcColumnVectorUtils `
* `public class OrcMapColumnVector extends OrcColumnVector `
* `public class OrcStructColumnVector extends OrcColumnVector `
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-814829127
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41595/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610460647
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -32,8 +32,6 @@ trait BaseGroupingSets extends Expression with CodegenFallback {
def selectedGroupByExprs: Seq[Seq[Expression]]
def groupByExprs: Seq[Expression] = {
- assert(children.forall(_.resolved),
- "Cannot call BaseGroupingSets.groupByExprs before the children expressions are all resolved.")
Review comment:
Have you figured out it?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and mixed grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810967003
**[Test build #136763 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136763/testReport)** for PR 30144 at commit [`31f9fbd`](https://github.com/apache/spark/commit/31f9fbd6efe90af781ff2ac78f93af8268f1a1b4).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-812034816
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136812/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816614190
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41708/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-815596450
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137050/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610683750
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +235,32 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Expression])] = {
+ val resolved = exprs.map {
+ case gs: BaseGroupingSets => gs.childrenResolved
+ case other => other.resolved
+ }.forall(_ == true)
+ if (!resolved) {
+ None
+ } else if (!exprs.exists(e => e.find(_.isInstanceOf[BaseGroupingSets]).isDefined)) {
Review comment:
BTW this check can go first, as `isInstanceOf[BaseGroupingSets]` is cheaper to run
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816947716
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137141/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610623805
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -24,7 +24,9 @@ license: |
The `GROUP BY` clause is used to group the rows based on a set of specified grouping expressions and compute aggregations on
the group of rows based on one or more specified aggregate functions. Spark also supports advanced aggregations to do multiple
aggregations for the same input record set via `GROUPING SETS`, `CUBE`, `ROLLUP` clauses.
-When a FILTER clause is attached to an aggregate function, only the matching rows are passed to that function.
+These grouping analytics clauses can be specified with regular grouping expressions (partial grouping analytics) and
+the grouping analytics clauses can be specified together (concatenated groupings).
Review comment:
The grouping expressions and advanced aggregations can be mixed in the `GROUP BY` clause. See more details in the `Mixed Grouping Analytics` section.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r611112158
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +235,34 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Expression])] = {
+ if (!exprs.exists(_.isInstanceOf[BaseGroupingSets])) {
+ None
+ } else {
+ val resolved = exprs.forall {
+ case gs: BaseGroupingSets => gs.childrenResolved
+ case other => other.resolved
+ }
+ if (!resolved) {
+ None
+ } else {
+ val groups = exprs.flatMap {
+ case gs: BaseGroupingSets => gs.groupByExprs
+ case other: Expression => other :: Nil
+ }
+ val unmergedSelectedGroupByExprs = exprs.map {
+ case gs: BaseGroupingSets => gs.selectedGroupByExprs
+ case other: Expression => Seq(Seq(other))
+ }
+ val selectedGroupByExprs = unmergedSelectedGroupByExprs.init
+ .foldLeft(unmergedSelectedGroupByExprs.last) { (x, y) =>
Review comment:
Done
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -24,7 +24,9 @@ license: |
The `GROUP BY` clause is used to group the rows based on a set of specified grouping expressions and compute aggregations on
the group of rows based on one or more specified aggregate functions. Spark also supports advanced aggregations to do multiple
aggregations for the same input record set via `GROUPING SETS`, `CUBE`, `ROLLUP` clauses.
-When a FILTER clause is attached to an aggregate function, only the matching rows are passed to that function.
+The grouping expressions and advanced aggregations can be mixed in the `GROUP BY` clause.
+See more details in the `Mixed Grouping Analytics` section. When a FILTER clause is attached to
+an aggregate function, only the matching.
Review comment:
Done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810866475
Please update the SQL doc accordingly as well.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610452928
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -93,6 +95,38 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. `CUBE` and `ROLLUP` are just syntax sugar for GROUPING SETS, for how to use
Review comment:
``..., please refer to the section above for how to use `CUBE` and `ROLLUP` ``
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816763066
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816918895
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137139/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816220741
**[Test build #137089 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137089/testReport)** for PR 30144 at commit [`be93d9e`](https://github.com/apache/spark/commit/be93d9ed873497b04cd0b3742b5beab501941453).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-812680536
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716540471
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/34880/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r609764899
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -88,6 +89,41 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. For example:
Review comment:
Oracle has descriptions as well as examples: `In this case, the GROUP BY clause creates subtotals at (2+1=3) aggregation levels. That is, at level (expr1, expr2, expr3), (expr1, expr2), and (expr1).`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816034400
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41667/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-715830759
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-719117589
Any more suggestion?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811882395
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41395/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716540487
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-715830789
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/130227/
Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716131532
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716545894
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/34884/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716157686
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716487868
Merged build finished. Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610678666
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -24,7 +24,10 @@ license: |
The `GROUP BY` clause is used to group the rows based on a set of specified grouping expressions and compute aggregations on
the group of rows based on one or more specified aggregate functions. Spark also supports advanced aggregations to do multiple
aggregations for the same input record set via `GROUPING SETS`, `CUBE`, `ROLLUP` clauses.
-When a FILTER clause is attached to an aggregate function, only the matching rows are passed to that function.
+These grouping analytics clauses can be specified with regular grouping expressions (partial grouping analytics) and
+the grouping analytics clauses can be specified together (concatenated groupings). When a FILTER clause is attached to
+an aggregate function, only the matching. The grouping expressions and advanced aggregations can be mixed in the `GROUP BY` clause.
+See more details in the `Mixed Grouping Analytics` section.
Review comment:
It's a mess now...
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-751644388
**[Test build #133440 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133440/testReport)** for PR 30144 at commit [`c1c551c`](https://github.com/apache/spark/commit/c1c551c6f9656ec71d6da03fb8fd4c4119d66c3a).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-817257213
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137172/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r605527431
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,27 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ val (groupingSetExprs, others) = exprs.partition(_.isInstanceOf[GroupingSet])
+ if (groupingSetExprs.isEmpty) {
+ None
+ } else {
+ val groupingSets = groupingSetExprs.map(_.asInstanceOf[GroupingSet])
+ val groups = groupingSets.flatMap(_.groupByExprs) ++ others
+ val selectedGroupByExprs = groupingSets.map(_.selectedGroupByExprs)
+ .foldRight(Seq.empty[Seq[Expression]]) { (x, y) =>
+ if (y.isEmpty) {
+ x
+ } else {
+ for (a <- x; b <- y) yield b ++ a
+ }
+ }.map(others ++ _).map(_.distinct)
Review comment:
```
}.map { groupByExprs =>
(others ++ groupByExprs).distinct
}
```
?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610669416
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -23,8 +23,8 @@ license: |
The `GROUP BY` clause is used to group the rows based on a set of specified grouping expressions and compute aggregations on
the group of rows based on one or more specified aggregate functions. Spark also supports advanced aggregations to do multiple
-aggregations for the same input record set via `GROUPING SETS`, `CUBE`, `ROLLUP` clauses.
-When a FILTER clause is attached to an aggregate function, only the matching rows are passed to that function.
Review comment:
Done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811882395
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41395/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816745551
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41715/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811015911
Kubernetes integration test unable to build dist.
exiting with code: 1
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41347/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610463559
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +229,30 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ if (!exprs.exists(_.find(_.isInstanceOf[BaseGroupingSets]).isDefined)) {
+ None
+ } else {
+ val groups = exprs.flatMap {
+ case gs: BaseGroupingSets => gs.groupByExprs
+ case others: Expression => others :: Nil
+ }
+ val groupingSets = exprs.flatMap {
+ case gs: BaseGroupingSets => gs.groupingSets
+ case _ => Nil
+ }
+ val unmergedSelectedGroupByExprs = exprs.map {
+ case gs: BaseGroupingSets => gs.selectedGroupByExprs
+ case others: Expression => Seq(Seq(others))
+ }
+ val selectedGroupByExprs = unmergedSelectedGroupByExprs.init
+ .foldLeft(unmergedSelectedGroupByExprs.last) { (x, y) =>
+ for (a <- x; b <- y) yield a ++ b
+ }
+ Some(selectedGroupByExprs, groupingSets, groups.distinct)
Review comment:
let's follow `BaseGroupingSets.groupByExprs`, use semanticEquals to dedup instead of `distinct `
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-817231288
**[Test build #137172 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137172/testReport)** for PR 30144 at commit [`2ae3c16`](https://github.com/apache/spark/commit/2ae3c161de8048e089cd4385f77130cb29b1d2d8).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r609763113
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -24,7 +24,9 @@ license: |
The `GROUP BY` clause is used to group the rows based on a set of specified grouping expressions and compute aggregations on
the group of rows based on one or more specified aggregate functions. Spark also supports advanced aggregations to do multiple
aggregations for the same input record set via `GROUPING SETS`, `CUBE`, `ROLLUP` clauses.
-When a FILTER clause is attached to an aggregate function, only the matching rows are passed to that function.
+These grouping analytics clauses can be specified with regular grouping expressions (partial grouping analytics) and
+the different grouping analytics clauses can be specified together (concatenated groupings).
Review comment:
`different`, do you mean `GROUP BY cube(a, b), cube(a, b)` is not allowed?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811157553
**[Test build #136763 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136763/testReport)** for PR 30144 at commit [`31f9fbd`](https://github.com/apache/spark/commit/31f9fbd6efe90af781ff2ac78f93af8268f1a1b4).
* This patch **fails PySpark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-815432933
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816795746
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r609840794
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +229,24 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ val (groupingSetExprs, others) = exprs.partition(_.isInstanceOf[BaseGroupingSets])
Review comment:
> does the order matter? e.g. `GROUP BY a, GROUPING SETS((b))` and `GROUP BY GROUPING SETS((b)), a`, are they the same?
The result should be same, the only concern is the result order. I have checked before that
`group by a, b` is same result as `group by b, a`. So here also can't be a concern
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816615064
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41706/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811824813
**[Test build #136811 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136811/testReport)** for PR 30144 at commit [`ceec0df`](https://github.com/apache/spark/commit/ceec0df5a07442da7604e3955d8ecc1b479e39be).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810783018
**[Test build #136750 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136750/testReport)** for PR 30144 at commit [`f5763e8`](https://github.com/apache/spark/commit/f5763e8580ebb70a2c89679852e1e2301d58641d).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816811618
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810859079
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-817236113
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41750/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816726809
**[Test build #137141 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137141/testReport)** for PR 30144 at commit [`133e073`](https://github.com/apache/spark/commit/133e07360368e75b0d67855f53f47b39f81c4267).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816615064
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41706/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610732090
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##########
@@ -636,16 +633,17 @@ class Analyzer(override val catalogManager: CatalogManager)
// CUBE/ROLLUP/GROUPING SETS. This also replace grouping()/grouping_id() in resolved
// Filter/Sort.
def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperatorsDown {
- case h @ UnresolvedHaving(_, agg @ Aggregate(Seq(gs: BaseGroupingSets), aggExprs, _))
- if agg.childrenResolved && (gs.children ++ aggExprs).forall(_.resolved) =>
- tryResolveHavingCondition(h)
+ case h @ UnresolvedHaving(_, agg @ Aggregate(
+ GroupingAnalytics(selectedGroupByExprs, groupByExprs), aggExprs, _))
+ if agg.childrenResolved && aggExprs.forall(_.resolved) =>
+ tryResolveHavingCondition(h, agg, selectedGroupByExprs, groupByExprs)
case a if !a.childrenResolved => a // be sure all of the children are resolved.
// Ensure group by expressions and aggregate expressions have been resolved.
- case Aggregate(Seq(gs: BaseGroupingSets), aggregateExpressions, child)
- if (gs.children ++ aggregateExpressions).forall(_.resolved) =>
- constructAggregate(gs.selectedGroupByExprs, gs.groupByExprs, aggregateExpressions, child)
+ case Aggregate(GroupingAnalytics(selectedGroupByExprs, groupByExprs), aggExprs, child)
+ if aggExprs.forall(_.resolved) =>
Review comment:
`aggExprs.forall(_.resolved)` is missing
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610683447
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +235,32 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Expression])] = {
+ val resolved = exprs.map {
+ case gs: BaseGroupingSets => gs.childrenResolved
+ case other => other.resolved
+ }.forall(_ == true)
+ if (!resolved) {
+ None
+ } else if (!exprs.exists(e => e.find(_.isInstanceOf[BaseGroupingSets]).isDefined)) {
Review comment:
do we need to call `find`? I think `BaseGroupingSets` can only appear in the top level.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810851420
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41334/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r605473810
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -88,6 +89,41 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. For example:
+ `GROUP BY warehouse, CUBE(product, location)` is equivalent to
+ `GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse, location), (warehouse))`.
+ `GROUP BY warehouse, ROLLUP(product, location)` is equivalent to
+ `GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse))`.
+ `GROUP BY warehouse, GROUPING SETS((product, location), (producet), ())` is equivalent to
+ `GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, location), (warehouse))`.
+
+* **Concatenated Groupings**
+
+ Concatenated grouping analytics offer a concise way to generate useful combinations of groupings. Groupings specified
+ with concatenated groupings yield the cross-product of groupings from each grouping set. The cross-product
+ operation enables even a small number of concatenated groupings to generate a large number of final groups.
+ The concatenated groupings are specified simply by listing multiple `GROUPING SETS`, `CUBES`, and `ROLLUP`,
Review comment:
We can just say that CUBE/ROLLUP are just syntax sugar for GROUPING SETS, then the document can just focus on GROUPING SETS.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816977212
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137143/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811876744
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41395/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716493826
**[Test build #130284 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/130284/testReport)** for PR 30144 at commit [`dc4e148`](https://github.com/apache/spark/commit/dc4e148cd6f2b1e3d4c8e35cf3a5b9690b51416f).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716658454
**[Test build #130284 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/130284/testReport)** for PR 30144 at commit [`dc4e148`](https://github.com/apache/spark/commit/dc4e148cd6f2b1e3d4c8e35cf3a5b9690b51416f).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r609771416
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +229,24 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ val (groupingSetExprs, others) = exprs.partition(_.isInstanceOf[BaseGroupingSets])
Review comment:
does the order matter? e.g. `GROUP BY a, GROUPING SETS((b))` and `GROUP BY GROUPING SETS((b)), a`, are they the same?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r609766883
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -93,6 +95,39 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. For example:
+ `GROUP BY warehouse, CUBE(product, location)` is equivalent to
Review comment:
the example can focus on GROUPING SETS. We can just say that ROLLUP/CUBE is syntax sugar for GROUPING SETS and will be expanded to GROUPING SETS, then apply the Partial Grouping Analytics semantic.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-815397425
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137045/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r609849786
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -32,8 +32,6 @@ trait BaseGroupingSets extends Expression with CodegenFallback {
def selectedGroupByExprs: Seq[Seq[Expression]]
def groupByExprs: Seq[Expression] = {
- assert(children.forall(_.resolved),
- "Cannot call BaseGroupingSets.groupByExprs before the children expressions are all resolved.")
Review comment:
> why do we remove this assert? The following code calls `semanticEquals` and we may get wrong if children are not resolved.
With this check it will failed. Hmm I'm still checking the analysis sequence of the analyzer to see why this happens.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810849940
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-814899961
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137017/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810783018
**[Test build #136750 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136750/testReport)** for PR 30144 at commit [`f5763e8`](https://github.com/apache/spark/commit/f5763e8580ebb70a2c89679852e1e2301d58641d).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r605477279
##########
File path: sql/core/src/test/resources/sql-tests/inputs/group-analytics.sql
##########
@@ -59,4 +59,12 @@ SELECT course, year FROM courseSales GROUP BY CUBE(course, year) ORDER BY groupi
-- Aliases in SELECT could be used in ROLLUP/CUBE/GROUPING SETS
SELECT a + b AS k1, b AS k2, SUM(a - b) FROM testData GROUP BY CUBE(k1, k2);
SELECT a + b AS k, b, SUM(a - b) FROM testData GROUP BY ROLLUP(k, b);
-SELECT a + b, b AS k, SUM(a - b) FROM testData GROUP BY a + b, k GROUPING SETS(k)
+SELECT a + b, b AS k, SUM(a - b) FROM testData GROUP BY a + b, k GROUPING SETS(k);
+
+-- GROUP BY use mixed Separate columns and CUBE/ROLLUP
+SELECT a, b, count(1) FROM testData GROUP BY a, b, CUBE(a, b);
+SELECT a, b, count(1) FROM testData GROUP BY a, b, ROLLUP(a, b);
+SELECT a, b, count(1) FROM testData GROUP BY CUBE(a, b), ROLLUP(a, b);
+SELECT a, b, count(1) FROM testData GROUP BY a, CUBE(a, b), ROLLUP(b);
+SELECT a, b, count(1) FROM testData GROUP BY CUBE(a, b), ROLLUP(a, b) GROUPING SETS(a, b);
Review comment:
are you sure we can support `ROLLUP(a, b) GROUPING SETS(a, b)`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816765547
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41717/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816962274
**[Test build #137143 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137143/testReport)** for PR 30144 at commit [`9d1a115`](https://github.com/apache/spark/commit/9d1a115dcb7ffb75da2d955587144d7c1483a83e).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610681240
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##########
@@ -636,16 +637,17 @@ class Analyzer(override val catalogManager: CatalogManager)
// CUBE/ROLLUP/GROUPING SETS. This also replace grouping()/grouping_id() in resolved
// Filter/Sort.
def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperatorsDown {
- case h @ UnresolvedHaving(_, agg @ Aggregate(Seq(gs: BaseGroupingSets), aggExprs, _))
- if agg.childrenResolved && (gs.children ++ aggExprs).forall(_.resolved) =>
+ case h @ UnresolvedHaving(_, agg @ Aggregate(
+ GroupingAnalytics(_, groupByExprs), aggregateExpressions, _))
+ if agg.childrenResolved && aggregateExpressions.forall(_.resolved) =>
tryResolveHavingCondition(h)
Review comment:
We can pass `groupByExprs` to `tryResolveHavingCondition`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r606314039
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##########
@@ -632,9 +632,10 @@ class Analyzer(override val catalogManager: CatalogManager)
if (resolvedInfo.nonEmpty) {
val (extraAggExprs, resolvedHavingCond) = resolvedInfo.get
val newChild = h.child match {
- case Aggregate(Seq(gs: GroupingSet), aggregateExpressions, child) =>
+ case Aggregate(
+ GroupingAnalytics(selectedGroupByExprs, _, groupByExprs), aggregateExpressions, child) =>
Review comment:
nit:
```
case Aggregate(GroupingAnalytics(selectedGroupByExprs, _, groupByExprs),
aggregateExpressions, child) =>
constructAggregate(
```
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##########
@@ -658,16 +659,18 @@ class Analyzer(override val catalogManager: CatalogManager)
// CUBE/ROLLUP/GROUPING SETS. This also replace grouping()/grouping_id() in resolved
// Filter/Sort.
def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperatorsDown {
- case h @ UnresolvedHaving(_, agg @ Aggregate(Seq(gs: GroupingSet), aggregateExpressions, _))
- if agg.childrenResolved && (gs.groupByExprs ++ aggregateExpressions).forall(_.resolved) =>
+ case h @ UnresolvedHaving(_, agg @ Aggregate(
+ GroupingAnalytics(_, _, groupByExprs), aggregateExpressions, _))
+ if agg.childrenResolved && (groupByExprs ++ aggregateExpressions).forall(_.resolved) =>
tryResolveHavingCondition(h)
case a if !a.childrenResolved => a // be sure all of the children are resolved.
// Ensure group by expressions and aggregate expressions have been resolved.
- case Aggregate(Seq(gs: GroupingSet), aggregateExpressions, child)
- if (gs.groupByExprs ++ aggregateExpressions).forall(_.resolved) =>
- constructAggregate(gs.selectedGroupByExprs, gs.groupByExprs, aggregateExpressions, child)
+ case Aggregate(
+ GroupingAnalytics(selectedGroupByExprs, _, groupByExprs), aggregateExpressions, child)
Review comment:
nit: ` case Aggregate(GroupingAnalytics(selectedGroupByExprs, _, groupByExprs), aggExprs, child)`
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,25 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ val (groupingSetExprs, others) = exprs.partition(_.isInstanceOf[GroupingSet])
+ if (groupingSetExprs.isEmpty) {
+ None
+ } else {
+ val groupingSets = groupingSetExprs.map(_.asInstanceOf[GroupingSet])
+ val groups = groupingSets.flatMap(_.groupByExprs) ++ others
+ val unMergedSelectedGroupByExprs = groupingSets.map(_.selectedGroupByExprs)
Review comment:
nit: `unMerged` -> `unmerged`?
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -23,8 +23,9 @@ license: |
The `GROUP BY` clause is used to group the rows based on a set of specified grouping expressions and compute aggregations on
the group of rows based on one or more specified aggregate functions. Spark also supports advanced aggregations to do multiple
-aggregations for the same input record set via `GROUPING SETS`, `CUBE`, `ROLLUP` clauses.
-When a FILTER clause is attached to an aggregate function, only the matching rows are passed to that function.
+aggregations for the same input record set via `GROUPING SETS`, `CUBE`, `ROLLUP` clauses, also spark support partial grouping
Review comment:
```
the group of rows based on one or more specified aggregate functions. Spark also supports advanced aggregations to do multiple
aggregations for the same input record set via `GROUPING SETS`, `CUBE`, `ROLLUP` clauses.
These grouping analytics clauses can be specified with regular grouping expressions (partial grouping analytics) and
the different grouping analytics clauses can be specified together (concatenated groupings).
When a FILTER clause is attached to an aggregate function, only the matching
```
?
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,25 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
Review comment:
nit: remove this blank line.
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##########
@@ -658,16 +659,18 @@ class Analyzer(override val catalogManager: CatalogManager)
// CUBE/ROLLUP/GROUPING SETS. This also replace grouping()/grouping_id() in resolved
// Filter/Sort.
def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperatorsDown {
- case h @ UnresolvedHaving(_, agg @ Aggregate(Seq(gs: GroupingSet), aggregateExpressions, _))
- if agg.childrenResolved && (gs.groupByExprs ++ aggregateExpressions).forall(_.resolved) =>
+ case h @ UnresolvedHaving(_, agg @ Aggregate(
+ GroupingAnalytics(_, _, groupByExprs), aggregateExpressions, _))
+ if agg.childrenResolved && (groupByExprs ++ aggregateExpressions).forall(_.resolved) =>
Review comment:
nit:
```
GroupingAnalytics(_, _, groupByExprs), aggregateExpressions, _))
if agg.childrenResolved && (groupByExprs ++ aggregateExpressions).forall(_.resolved) =>
```
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,25 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ val (groupingSetExprs, others) = exprs.partition(_.isInstanceOf[GroupingSet])
+ if (groupingSetExprs.isEmpty) {
+ None
+ } else {
+ val groupingSets = groupingSetExprs.map(_.asInstanceOf[GroupingSet])
+ val groups = groupingSets.flatMap(_.groupByExprs) ++ others
+ val unMergedSelectedGroupByExprs = groupingSets.map(_.selectedGroupByExprs)
+ val selectedGroupByExprs = unMergedSelectedGroupByExprs.tail
+ .foldRight(unMergedSelectedGroupByExprs.head) { (x, y) =>
+ for (a <- x; b <- y) yield b ++ a
+ }.map { groupByExprs =>
+ (others ++ groupByExprs).distinct
+ }
Review comment:
nit: indents
```
}.map { groupByExprs =>
(others ++ groupByExprs).distinct
}
```
##########
File path: sql/core/src/test/resources/sql-tests/results/group-analytics.sql.out
##########
@@ -1,5 +1,5 @@
-- Automatically generated by SQLQueryTestSuite
--- Number of queries: 37
+-- Number of queries: 45
Review comment:
NOTE: I've checked the the output result are the same with the PostgreSQL ones.
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,25 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ val (groupingSetExprs, others) = exprs.partition(_.isInstanceOf[GroupingSet])
+ if (groupingSetExprs.isEmpty) {
+ None
+ } else {
+ val groupingSets = groupingSetExprs.map(_.asInstanceOf[GroupingSet])
+ val groups = groupingSets.flatMap(_.groupByExprs) ++ others
+ val unMergedSelectedGroupByExprs = groupingSets.map(_.selectedGroupByExprs)
+ val selectedGroupByExprs = unMergedSelectedGroupByExprs.tail
+ .foldRight(unMergedSelectedGroupByExprs.head) { (x, y) =>
Review comment:
nit: `foldRight` -> `foldLeft`? (I think most code use `foldLeft` if both `foldLeft`/`foldRight` can work)
##########
File path: sql/core/src/test/resources/sql-tests/inputs/group-analytics.sql
##########
@@ -59,4 +59,12 @@ SELECT course, year FROM courseSales GROUP BY CUBE(course, year) ORDER BY groupi
-- Aliases in SELECT could be used in ROLLUP/CUBE/GROUPING SETS
SELECT a + b AS k1, b AS k2, SUM(a - b) FROM testData GROUP BY CUBE(k1, k2);
SELECT a + b AS k, b, SUM(a - b) FROM testData GROUP BY ROLLUP(k, b);
-SELECT a + b, b AS k, SUM(a - b) FROM testData GROUP BY a + b, k GROUPING SETS(k)
+SELECT a + b, b AS k, SUM(a - b) FROM testData GROUP BY a + b, k GROUPING SETS(k);
+
+-- GROUP BY use mixed Separate columns and CUBE/ROLLUP
+SELECT a, b, count(1) FROM testData GROUP BY a, b, CUBE(a, b);
+SELECT a, b, count(1) FROM testData GROUP BY a, b, ROLLUP(a, b);
+SELECT a, b, count(1) FROM testData GROUP BY CUBE(a, b), ROLLUP(a, b);
+SELECT a, b, count(1) FROM testData GROUP BY a, CUBE(a, b), ROLLUP(b);
+SELECT a, b, count(1) FROM testData GROUP BY CUBE(a, b), ROLLUP(a, b) GROUPING SETS(a, b);
Review comment:
It looks an invalid query.
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,25 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ val (groupingSetExprs, others) = exprs.partition(_.isInstanceOf[GroupingSet])
+ if (groupingSetExprs.isEmpty) {
+ None
+ } else {
+ val groupingSets = groupingSetExprs.map(_.asInstanceOf[GroupingSet])
+ val groups = groupingSets.flatMap(_.groupByExprs) ++ others
+ val unMergedSelectedGroupByExprs = groupingSets.map(_.selectedGroupByExprs)
+ val selectedGroupByExprs = unMergedSelectedGroupByExprs.tail
+ .foldRight(unMergedSelectedGroupByExprs.head) { (x, y) =>
+ for (a <- x; b <- y) yield b ++ a
Review comment:
nit: `b ++ a` -> `a ++ b` for a natural order.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-815414821
**[Test build #137050 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137050/testReport)** for PR 30144 at commit [`f67242d`](https://github.com/apache/spark/commit/f67242dd67d07ea7fbbe998943fcfe9461c6ada5).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-814823455
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41594/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan closed pull request #30144:
URL: https://github.com/apache/spark/pull/30144
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and mixed grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810972990
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41342/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811824813
**[Test build #136811 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136811/testReport)** for PR 30144 at commit [`ceec0df`](https://github.com/apache/spark/commit/ceec0df5a07442da7604e3955d8ecc1b479e39be).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-815596450
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137050/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811979424
**[Test build #136811 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136811/testReport)** for PR 30144 at commit [`ceec0df`](https://github.com/apache/spark/commit/ceec0df5a07442da7604e3955d8ecc1b479e39be).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811998229
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136811/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r605573083
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -88,6 +89,41 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. For example:
+ `GROUP BY warehouse, CUBE(product, location)` is equivalent to
+ `GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse, location), (warehouse))`.
+ `GROUP BY warehouse, ROLLUP(product, location)` is equivalent to
+ `GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse))`.
+ `GROUP BY warehouse, GROUPING SETS((product, location), (producet), ())` is equivalent to
+ `GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, location), (warehouse))`.
+
+* **Concatenated Groupings**
+
+ Concatenated grouping analytics offer a concise way to generate useful combinations of groupings. Groupings specified
+ with concatenated groupings yield the cross-product of groupings from each grouping set. The cross-product
+ operation enables even a small number of concatenated groupings to generate a large number of final groups.
+ The concatenated groupings are specified simply by listing multiple `GROUPING SETS`, `CUBES`, and `ROLLUP`,
Review comment:
> We can just say that CUBE/ROLLUP are just syntax sugar for GROUPING SETS, then the document can just focus on GROUPING SETS.
Done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r606355838
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##########
@@ -632,9 +632,10 @@ class Analyzer(override val catalogManager: CatalogManager)
if (resolvedInfo.nonEmpty) {
val (extraAggExprs, resolvedHavingCond) = resolvedInfo.get
val newChild = h.child match {
- case Aggregate(Seq(gs: GroupingSet), aggregateExpressions, child) =>
+ case Aggregate(
+ GroupingAnalytics(selectedGroupByExprs, _, groupByExprs), aggregateExpressions, child) =>
Review comment:
> nit:
>
> ```
> case Aggregate(GroupingAnalytics(selectedGroupByExprs, _, groupByExprs),
> aggregateExpressions, child) =>
> constructAggregate(
> ```
Done
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##########
@@ -658,16 +659,18 @@ class Analyzer(override val catalogManager: CatalogManager)
// CUBE/ROLLUP/GROUPING SETS. This also replace grouping()/grouping_id() in resolved
// Filter/Sort.
def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperatorsDown {
- case h @ UnresolvedHaving(_, agg @ Aggregate(Seq(gs: GroupingSet), aggregateExpressions, _))
- if agg.childrenResolved && (gs.groupByExprs ++ aggregateExpressions).forall(_.resolved) =>
+ case h @ UnresolvedHaving(_, agg @ Aggregate(
+ GroupingAnalytics(_, _, groupByExprs), aggregateExpressions, _))
+ if agg.childrenResolved && (groupByExprs ++ aggregateExpressions).forall(_.resolved) =>
Review comment:
DOne
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,25 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
Review comment:
Done
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,25 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ val (groupingSetExprs, others) = exprs.partition(_.isInstanceOf[GroupingSet])
+ if (groupingSetExprs.isEmpty) {
+ None
+ } else {
+ val groupingSets = groupingSetExprs.map(_.asInstanceOf[GroupingSet])
+ val groups = groupingSets.flatMap(_.groupByExprs) ++ others
+ val unMergedSelectedGroupByExprs = groupingSets.map(_.selectedGroupByExprs)
Review comment:
DOne
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,25 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ val (groupingSetExprs, others) = exprs.partition(_.isInstanceOf[GroupingSet])
+ if (groupingSetExprs.isEmpty) {
+ None
+ } else {
+ val groupingSets = groupingSetExprs.map(_.asInstanceOf[GroupingSet])
+ val groups = groupingSets.flatMap(_.groupByExprs) ++ others
+ val unMergedSelectedGroupByExprs = groupingSets.map(_.selectedGroupByExprs)
+ val selectedGroupByExprs = unMergedSelectedGroupByExprs.tail
+ .foldRight(unMergedSelectedGroupByExprs.head) { (x, y) =>
+ for (a <- x; b <- y) yield b ++ a
Review comment:
DOne
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r611424495
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -93,6 +95,25 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Mixed Grouping Analytics**
+
+ A GROUP BY clause can include multiple `group_expression`s and multiple `CUBE|ROLLUP|GROUPING SETS`s.
+ `CUBE|ROLLUP` is just a syntax sugar for `GROUPING SETS`, please refer to the sections above for
+ how to translate `CUBE|ROLLUP` to `GROUPING SETS`. `group_expression` can be treated as a single-group
+ `GROUPING SETS` under this context. For multiple `GROUPING SETS` in the `GROUP BY` clause, we generate
+ a single `GROUPING SETS` by doing a cross-product of the original `GROUPING SETS`s. For example,
+ `GROUP BY warehouse, GROUPING SETS((product), ()), GROUPING SETS((location, size), (location), (size), ())`
+ and `GROUP BY warehouse, ROLLUP(warehouse), CUBE(location, size)` is equivalent to
Review comment:
> typo? `ROLLUP(warehouse)` -> `ROLLUP(product)`
yea, thanks
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816583502
**[Test build #137128 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137128/testReport)** for PR 30144 at commit [`0046d40`](https://github.com/apache/spark/commit/0046d40bd8f97b8a850f3e2d34b89fe2d8ff3662).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610459759
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -93,6 +95,38 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. `CUBE` and `ROLLUP` are just syntax sugar for GROUPING SETS, for how to use
+ `CUBE` and `ROLLUP` can refer to the section above about `CUBE` and `ROLLUP`. For example:
+ `GROUP BY warehouse, GROUPING SETS((product, location), (product), (location), ())` is equivalent to
+ `GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse, location), (warehouse))`.
+ `GROUP BY warehouse, GROUPING SETS((product, location), (producet), ())` is equivalent to
+ `GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, location), (warehouse))`.
+
+* **Concatenated Grouping Analytics**
Review comment:
I think we can combine these 2 new sections:
```
* **Mixed Grouping Analytics**
A GROUP BY clause can include multiple `group_expression`s and multiple `CUBE|ROLLUP|GROUPING SETS`s.
`CUBE|ROLLUP` is just a syntax sugar for `GROUPING SETS`, please refer to the sections above for
how to translate `CUBE|ROLLUP` to `GROUPING SETS`. `group_expression` can be treated as a single-group
`GROUPING SETS` under this context. For multiple `GROUPING SETS` in the `GROUP BY` clause, we generate
a single `GROUPING SETS` by doing a cross-product of the original `GROUPING SETS`s. For example, ...
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716487868
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610521762
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +229,30 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ if (!exprs.exists(_.find(_.isInstanceOf[BaseGroupingSets]).isDefined)) {
+ None
+ } else {
+ val groups = exprs.flatMap {
+ case gs: BaseGroupingSets => gs.groupByExprs
+ case others: Expression => others :: Nil
+ }
+ val groupingSets = exprs.flatMap {
+ case gs: BaseGroupingSets => gs.groupingSets
+ case _ => Nil
+ }
+ val unmergedSelectedGroupByExprs = exprs.map {
+ case gs: BaseGroupingSets => gs.selectedGroupByExprs
+ case others: Expression => Seq(Seq(others))
+ }
+ val selectedGroupByExprs = unmergedSelectedGroupByExprs.init
+ .foldLeft(unmergedSelectedGroupByExprs.last) { (x, y) =>
+ for (a <- x; b <- y) yield a ++ b
+ }
+ Some(selectedGroupByExprs, groupingSets, groups.distinct)
Review comment:
> let's follow `BaseGroupingSets.groupByExprs`, use semanticEquals to dedup instead of `distinct `
Done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716527908
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/34880/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716157364
**[Test build #130243 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/130243/testReport)** for PR 30144 at commit [`68c3e48`](https://github.com/apache/spark/commit/68c3e48b2e8d186b8d210c33467cacb4655c1da1).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610629414
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -23,8 +23,8 @@ license: |
The `GROUP BY` clause is used to group the rows based on a set of specified grouping expressions and compute aggregations on
the group of rows based on one or more specified aggregate functions. Spark also supports advanced aggregations to do multiple
-aggregations for the same input record set via `GROUPING SETS`, `CUBE`, `ROLLUP` clauses.
-When a FILTER clause is attached to an aggregate function, only the matching rows are passed to that function.
Review comment:
this sentence should be kept.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and mixed grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810928961
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41337/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816721847
**[Test build #137139 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137139/testReport)** for PR 30144 at commit [`4359aef`](https://github.com/apache/spark/commit/4359aefc4653b018814001df49d5eec84a463e72).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810859118
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41336/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-720433951
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610679976
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##########
@@ -599,8 +599,8 @@ class Analyzer(override val catalogManager: CatalogManager)
val aggForResolving = h.child match {
// For CUBE/ROLLUP expressions, to avoid resolving repeatedly, here we delete them from
// groupingExpressions for condition resolving.
- case a @ Aggregate(Seq(gs: BaseGroupingSets), _, _) =>
- a.copy(groupingExpressions = gs.groupByExprs)
+ case a @ Aggregate(GroupingAnalytics(_, groupByExprs), _, _) =>
Review comment:
can we pass `groupByExprs` as the parameter of `tryResolveHavingCondition`? It's already available in the caller side.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716660475
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811136576
**[Test build #136758 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136758/testReport)** for PR 30144 at commit [`84de8b6`](https://github.com/apache/spark/commit/84de8b6e1bec0b83e1cc1a20ce757b184d48da84).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r604881020
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -88,6 +89,41 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. For example:
+ `GROUP BY warehouse, CUBE(product, location)` is equivalent to
+ `GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse, location), (warehouse))`.
+ `GROUP BY warehouse, ROLLUP(product, location)` is equivalent to
+ `GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse))`.
+ `GROUP BY warehouse, GROUPING SETS((product, location), (producet), ())` is equivalent to
Review comment:
> ah, previously we support `group by a grouping sets(a)`, but not `group by a, grouping sets(a)`
Yea. They are not same.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716487848
**[Test build #130281 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/130281/testReport)** for PR 30144 at commit [`a3d1b60`](https://github.com/apache/spark/commit/a3d1b603959af357ef1e5890d08a093712a4d327).
* This patch **fails Scala style tests**.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and mixed grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810973015
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41342/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816034400
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41667/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610628844
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -24,7 +24,9 @@ license: |
The `GROUP BY` clause is used to group the rows based on a set of specified grouping expressions and compute aggregations on
the group of rows based on one or more specified aggregate functions. Spark also supports advanced aggregations to do multiple
aggregations for the same input record set via `GROUPING SETS`, `CUBE`, `ROLLUP` clauses.
-When a FILTER clause is attached to an aggregate function, only the matching rows are passed to that function.
+These grouping analytics clauses can be specified with regular grouping expressions (partial grouping analytics) and
+the grouping analytics clauses can be specified together (concatenated groupings).
Review comment:
> The grouping expressions and advanced aggregations can be mixed in the `GROUP BY` clause. See more details in the `Mixed Grouping Analytics` section.
Done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816010787
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816614171
Kubernetes integration test unable to build dist.
exiting with code: 1
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41708/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816614190
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41708/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816687857
**[Test build #137137 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137137/testReport)** for PR 30144 at commit [`c7de14c`](https://github.com/apache/spark/commit/c7de14cf8d4aff1814407f3e626785904190ab21).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-815398553
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41624/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610628356
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +229,30 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
Review comment:
What's wrong with my proposal that returning None if the given expressions are not resolved yet?
```
if (exprs.exists(!_.resolved)) {
None
} else ...
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-814823455
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610460429
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -93,6 +95,38 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. `CUBE` and `ROLLUP` are just syntax sugar for GROUPING SETS, for how to use
+ `CUBE` and `ROLLUP` can refer to the section above about `CUBE` and `ROLLUP`. For example:
+ `GROUP BY warehouse, GROUPING SETS((product, location), (product), (location), ())` is equivalent to
+ `GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse, location), (warehouse))`.
+ `GROUP BY warehouse, GROUPING SETS((product, location), (producet), ())` is equivalent to
+ `GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, location), (warehouse))`.
+
+* **Concatenated Grouping Analytics**
Review comment:
Both `CUBE|ROLLUP` and `group_expression` can be translated to GROUPING SETS under this context, then it's much easier to describe the semantic.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-817257213
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137172/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716131532
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r515765822
##########
File path: sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
##########
@@ -3691,6 +3691,32 @@ class SQLQuerySuite extends QueryTest with SharedSparkSession with AdaptiveSpark
checkAnswer(sql("SELECT id FROM t WHERE (SELECT true)"), Row(0L))
}
}
+
+ test("SPARK-33229: Support GROUP BY use Separate columns and CUBE/ROLLUP") {
+ withTable("t") {
+ sql("CREATE TABLE t USING PARQUET AS SELECT id AS a, id AS b, id AS c FROM range(1)")
+ checkAnswer(sql("SELECT a, b, c, count(*) FROM t GROUP BY CUBE(a, b, c)"),
+ Row(0, 0, 0, 1) :: Row(0, 0, null, 1) ::
+ Row(0, null, 0, 1) :: Row(0, null, null, 1) ::
+ Row(null, 0, 0, 1) :: Row(null, 0, null, 1) ::
+ Row(null, null, 0, 1) :: Row(null, null, null, 1) :: Nil)
+ checkAnswer(sql("SELECT a, b, c, count(*) FROM t GROUP BY a, CUBE(b, c)"),
Review comment:
what's the semantic of it?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816759206
**[Test build #137143 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137143/testReport)** for PR 30144 at commit [`9d1a115`](https://github.com/apache/spark/commit/9d1a115dcb7ffb75da2d955587144d7c1483a83e).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816831724
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41722/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610628356
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +229,30 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
Review comment:
What's wrong with my proposal that returning None if the given expressions are not resolved yet?
```
if (exprs.exists(!_.resolved)) {
None
} else if (!exprs.exists(e => e.find(_.isInstanceOf[BaseGroupingSets]).isDefined)) ...
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610461587
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +229,30 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ if (!exprs.exists(_.find(_.isInstanceOf[BaseGroupingSets]).isDefined)) {
+ None
+ } else {
+ val groups = exprs.flatMap {
+ case gs: BaseGroupingSets => gs.groupByExprs
+ case others: Expression => others :: Nil
Review comment:
nit: `others` -> `other`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r605575398
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -88,6 +89,41 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. For example:
Review comment:
> Can we describe the behavior with documents instead of examples? We can also take a look at how other databases document this feature.
Oracle document https://docs.oracle.com/cd/E11882_01/server.112/e25554/aggreg.htm#DWHSG8612
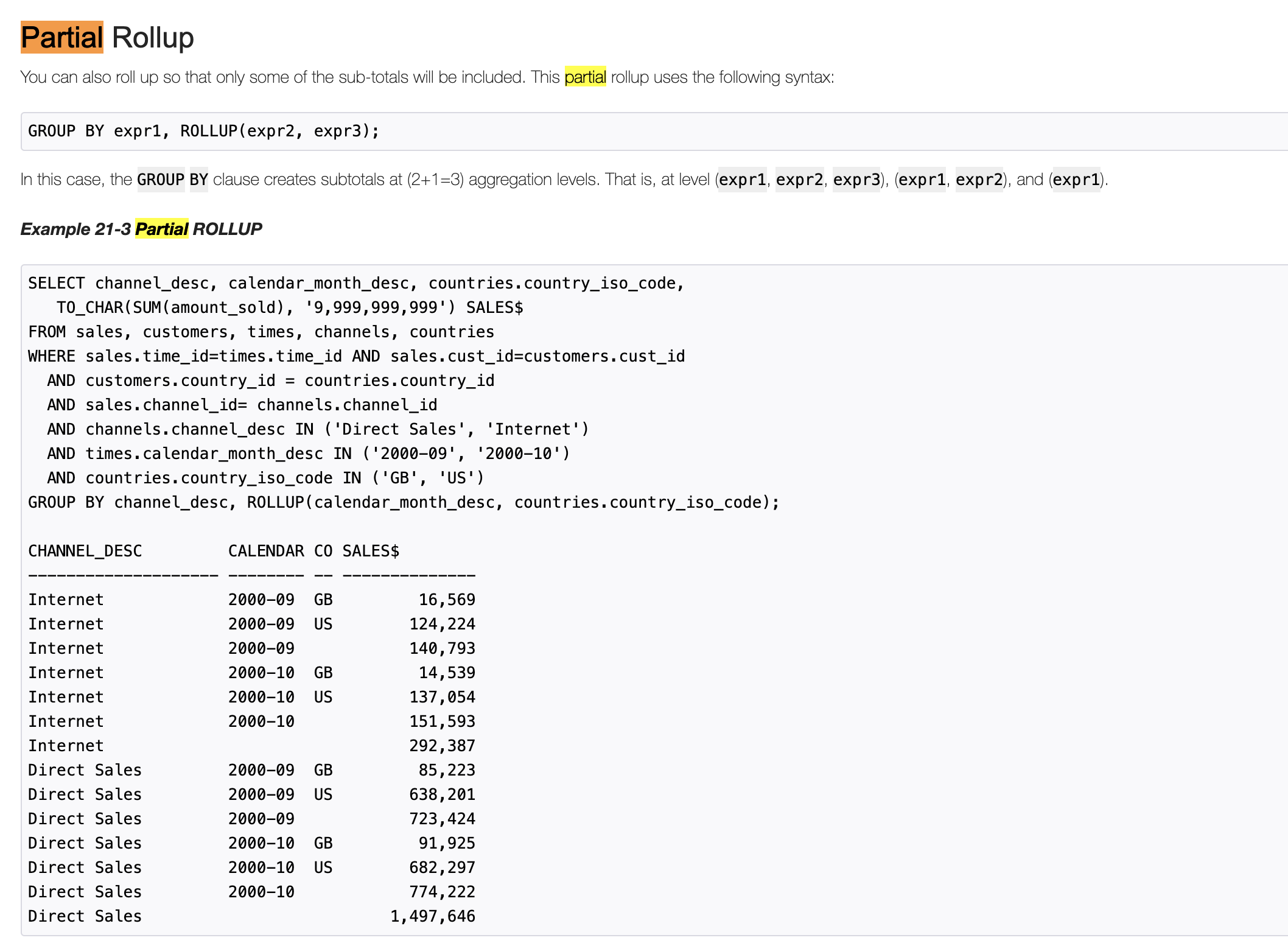
All have example, easier to understand.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-814667895
**[Test build #137016 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137016/testReport)** for PR 30144 at commit [`a0f8cf2`](https://github.com/apache/spark/commit/a0f8cf276edeaf294896718eedd78e514ab9b5d3).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610682905
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +235,32 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Expression])] = {
+ val resolved = exprs.map {
+ case gs: BaseGroupingSets => gs.childrenResolved
+ case other => other.resolved
+ }.forall(_ == true)
Review comment:
nit: `exprs.map` -> `exprs.forall`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610461155
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +229,30 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
Review comment:
the `unapply` here should return None if the give expressions are not resolved yet.
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +229,30 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
Review comment:
the `unapply` here should return None if the given expressions are not resolved yet.
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +229,30 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
Review comment:
then we can fix https://github.com/apache/spark/pull/30144/files#r609770387
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810815784
**[Test build #136753 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136753/testReport)** for PR 30144 at commit [`005b697`](https://github.com/apache/spark/commit/005b6974d11ed37351f54de8dd43717f7b13aa71).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716545909
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r604725030
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,29 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression]):
+ Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+
+ val (groupingSets, others) = exprs.partition(_.isInstanceOf[GroupingSet])
+ if (groupingSets.isEmpty) {
+ None
+ } else {
+ val groups =
+ groupingSets.flatMap(_.asInstanceOf[GroupingSet].groupByExprs) ++ others
+ val selectedGroupByExprs =
+ groupingSets.map(_.asInstanceOf[GroupingSet].selectedGroupByExprs)
+ .foldRight(Seq.empty[Seq[Expression]]) { (x, y) =>
+ if (y.isEmpty) {
Review comment:
> We need this check? We cannot write it like this?
>
> ```
> .foldRight(Seq.empty[Seq[Expression]]) { (x, y) =>
> for (a <- x; b <- y) yield b ++ a
> }.map(others ++ _).map(_.distinct)
> ```
Can't, since `foldRight(Seq.empty[Seq[Expresstion]])`, this empty Seq should be handled.
Is there any other Scala collection can avoid this problem?
##########
File path: sql/core/src/test/resources/sql-tests/inputs/group-analytics.sql
##########
@@ -69,4 +69,17 @@ SELECT course, year FROM courseSales GROUP BY CUBE(course, year) ORDER BY groupi
-- Aliases in SELECT could be used in ROLLUP/CUBE/GROUPING SETS
SELECT a + b AS k1, b AS k2, SUM(a - b) FROM testData GROUP BY CUBE(k1, k2);
SELECT a + b AS k, b, SUM(a - b) FROM testData GROUP BY ROLLUP(k, b);
-SELECT a + b, b AS k, SUM(a - b) FROM testData GROUP BY a + b, k GROUPING SETS(k)
+SELECT a + b, b AS k, SUM(a - b) FROM testData GROUP BY a + b, k GROUPING SETS(k);
+
+-- GROUP BY use mixed Separate columns and CUBE/ROLLUP/Gr
+SELECT a, b, count(1) FROM testData GROUP BY a, b, CUBE(a, b);
+SELECT a, b, count(1) FROM testData GROUP BY a, b, ROLLUP(a, b);
+SELECT a, b, count(1) FROM testData GROUP BY CUBE(a, b), ROLLUP(a, b);
+SELECT a, b, count(1) FROM testData GROUP BY a, CUBE(a, b), ROLLUP(b);
+SELECT a, b, count(1) FROM testData GROUP BY a, GROUPING SETS((a, b), (a), ());
+SELECT a, b, count(1) FROM testData GROUP BY a, CUBE(a, b), GROUPING SETS((a, b), (a), ());
+SELECT a, b, count(1) FROM testData GROUP BY a, CUBE(a, b), ROLLUP(a, b), GROUPING SETS((a, b), (a), ());
+
Review comment:
> nit: we don't need the two blank lines.
Done
##########
File path: sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
##########
@@ -3714,6 +3714,32 @@ class SQLQuerySuite extends QueryTest with SharedSparkSession with AdaptiveSpark
}
}
+ test("SPARK-33229: Support GROUP BY use Separate columns and CUBE/ROLLUP") {
Review comment:
> We still need this test?
Removed
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,29 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression]):
+ Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+
+ val (groupingSets, others) = exprs.partition(_.isInstanceOf[GroupingSet])
+ if (groupingSets.isEmpty) {
+ None
+ } else {
+ val groups =
+ groupingSets.flatMap(_.asInstanceOf[GroupingSet].groupByExprs) ++ others
Review comment:
> Since the cast `.asInstanceOf[GroupingSet]` appears three times, could you cast it only once at the beginning?
Done
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,29 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression]):
+ Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+
Review comment:
> nit: remove the unnecessary blank.
DOne
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,29 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression]):
+ Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
Review comment:
> ```
> def unapply(exprs: Seq[Expression])
> : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
> ```
Done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811879585
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41395/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810815784
**[Test build #136753 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136753/testReport)** for PR 30144 at commit [`005b697`](https://github.com/apache/spark/commit/005b6974d11ed37351f54de8dd43717f7b13aa71).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-748385991
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/37640/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-817234569
Kubernetes integration test unable to build dist.
exiting with code: 1
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41750/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816759206
**[Test build #137143 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137143/testReport)** for PR 30144 at commit [`9d1a115`](https://github.com/apache/spark/commit/9d1a115dcb7ffb75da2d955587144d7c1483a83e).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-715680465
**[Test build #130227 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/130227/testReport)** for PR 30144 at commit [`68c3e48`](https://github.com/apache/spark/commit/68c3e48b2e8d186b8d210c33467cacb4655c1da1).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816977212
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137143/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610669060
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -32,8 +32,6 @@ trait BaseGroupingSets extends Expression with CodegenFallback {
def selectedGroupByExprs: Seq[Seq[Expression]]
def groupByExprs: Seq[Expression] = {
- assert(children.forall(_.resolved),
- "Cannot call BaseGroupingSets.groupByExprs before the children expressions are all resolved.")
Review comment:
Fix this
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-814667895
**[Test build #137016 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137016/testReport)** for PR 30144 at commit [`a0f8cf2`](https://github.com/apache/spark/commit/a0f8cf276edeaf294896718eedd78e514ab9b5d3).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810817452
**[Test build #136754 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136754/testReport)** for PR 30144 at commit [`7224e01`](https://github.com/apache/spark/commit/7224e01acfe2eed282369cb4a96dadb0e401b627).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610693703
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##########
@@ -599,8 +599,8 @@ class Analyzer(override val catalogManager: CatalogManager)
val aggForResolving = h.child match {
// For CUBE/ROLLUP expressions, to avoid resolving repeatedly, here we delete them from
// groupingExpressions for condition resolving.
- case a @ Aggregate(Seq(gs: BaseGroupingSets), _, _) =>
- a.copy(groupingExpressions = gs.groupByExprs)
+ case a @ Aggregate(GroupingAnalytics(_, groupByExprs), _, _) =>
Review comment:
Pass more parameter like current code can reduce more repeated code
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##########
@@ -636,16 +637,17 @@ class Analyzer(override val catalogManager: CatalogManager)
// CUBE/ROLLUP/GROUPING SETS. This also replace grouping()/grouping_id() in resolved
// Filter/Sort.
def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperatorsDown {
- case h @ UnresolvedHaving(_, agg @ Aggregate(Seq(gs: BaseGroupingSets), aggExprs, _))
- if agg.childrenResolved && (gs.children ++ aggExprs).forall(_.resolved) =>
+ case h @ UnresolvedHaving(_, agg @ Aggregate(
+ GroupingAnalytics(_, groupByExprs), aggregateExpressions, _))
Review comment:
Done
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +235,32 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Expression])] = {
+ val resolved = exprs.map {
+ case gs: BaseGroupingSets => gs.childrenResolved
+ case other => other.resolved
+ }.forall(_ == true)
Review comment:
Done
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +235,32 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Expression])] = {
+ val resolved = exprs.map {
+ case gs: BaseGroupingSets => gs.childrenResolved
+ case other => other.resolved
+ }.forall(_ == true)
+ if (!resolved) {
+ None
+ } else if (!exprs.exists(e => e.find(_.isInstanceOf[BaseGroupingSets]).isDefined)) {
Review comment:
DOne
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816763111
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41718/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r511756403
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -151,3 +151,26 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object MixedExprsWithCube {
Review comment:
> If you define extractors for the mixed case, I think we need to make them more general for extracting more complicated cases, mix of cube/rollup, mix of rollup/grouping sets, ...
Since current code only support one cube/rollup expr, so I just support one cube/rollup expr.
Since other engine support mixed case, IMO, we should and we can support these feature and it's compatible with the previous behavior。
I will update this later.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610731090
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -24,7 +24,9 @@ license: |
The `GROUP BY` clause is used to group the rows based on a set of specified grouping expressions and compute aggregations on
the group of rows based on one or more specified aggregate functions. Spark also supports advanced aggregations to do multiple
aggregations for the same input record set via `GROUPING SETS`, `CUBE`, `ROLLUP` clauses.
-When a FILTER clause is attached to an aggregate function, only the matching rows are passed to that function.
+The grouping expressions and advanced aggregations can be mixed in the `GROUP BY` clause.
+See more details in the `Mixed Grouping Analytics` section. When a FILTER clause is attached to
+an aggregate function, only the matching.
Review comment:
only the matching rows are passed to that function.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-815397407
**[Test build #137045 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137045/testReport)** for PR 30144 at commit [`3d6e2c4`](https://github.com/apache/spark/commit/3d6e2c475747c5c3eb981aee8faa504b5af7df59).
* This patch **fails to build**.
* This patch merges cleanly.
* This patch adds the following public classes _(experimental)_:
* `class SQLProcessor(object):`
* `trait FunctionRegistryBase[T] `
* `trait SimpleFunctionRegistryBase[T] extends FunctionRegistryBase[T] with Logging `
* `trait EmptyFunctionRegistryBase[T] extends FunctionRegistryBase[T] `
* `trait FunctionRegistry extends FunctionRegistryBase[Expression] `
* `trait TableFunctionRegistry extends FunctionRegistryBase[LogicalPlan] `
* `class NoSuchFunctionException(`
* `case class ResolveTableValuedFunctions(catalog: SessionCatalog) extends Rule[LogicalPlan] `
* `abstract class QuaternaryExpression extends Expression with QuaternaryLike[Expression] `
* `abstract class Covariance(val left: Expression, val right: Expression, nullOnDivideByZero: Boolean)`
* `trait BaseGroupingSets extends Expression with CodegenFallback `
* `case class Cube(`
* `trait SimpleHigherOrderFunction extends HigherOrderFunction with BinaryLike[Expression] `
* `trait QuaternaryLike[T <: TreeNode[T]] `
* `trait DataWritingCommand extends UnaryCommand `
* `trait RunnableCommand extends Command `
* `trait BaseCacheTableExec extends LeafV2CommandExec `
* `sealed trait V1FallbackWriters extends LeafV2CommandExec with SupportsV1Write `
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-815397425
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137045/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810998370
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r511755095
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -151,3 +151,26 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object MixedExprsWithCube {
Review comment:
If you define extractors for the mixed case, I think we need to make them more general for extracting more complicated cases, mix of cube/rollup, mix of rollup/grouping sets, ...
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810844906
**[Test build #136750 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136750/testReport)** for PR 30144 at commit [`f5763e8`](https://github.com/apache/spark/commit/f5763e8580ebb70a2c89679852e1e2301d58641d).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-812011158
**[Test build #136812 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136812/testReport)** for PR 30144 at commit [`b1e04de`](https://github.com/apache/spark/commit/b1e04de75e2b97ef8095df4a7529179b5fc8043f).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816926425
**[Test build #137141 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137141/testReport)** for PR 30144 at commit [`133e073`](https://github.com/apache/spark/commit/133e07360368e75b0d67855f53f47b39f81c4267).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716538666
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-812665178
**[Test build #136868 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136868/testReport)** for PR 30144 at commit [`9b3a504`](https://github.com/apache/spark/commit/9b3a50473e6df95b084f90efb554169914228eba).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-817231288
**[Test build #137172 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137172/testReport)** for PR 30144 at commit [`2ae3c16`](https://github.com/apache/spark/commit/2ae3c161de8048e089cd4385f77130cb29b1d2d8).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811037306
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41347/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810817452
**[Test build #136754 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136754/testReport)** for PR 30144 at commit [`7224e01`](https://github.com/apache/spark/commit/7224e01acfe2eed282369cb4a96dadb0e401b627).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810859118
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41336/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810851420
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41334/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816765522
Kubernetes integration test unable to build dist.
exiting with code: 1
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41717/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r604847343
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -88,6 +89,41 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. For example:
+ `GROUP BY warehouse, CUBE(product, location)` is equivalent to
+ `GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse, location), (warehouse))`.
+ `GROUP BY warehouse, ROLLUP(product, location)` is equivalent to
+ `GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse))`.
+ `GROUP BY warehouse, GROUPING SETS((product, location), (producet), ())` is equivalent to
Review comment:
ah, previously we support `group by a grouping sets(a)`, but not `group by a, grouping sets(a)`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-812751318
**[Test build #136868 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136868/testReport)** for PR 30144 at commit [`9b3a504`](https://github.com/apache/spark/commit/9b3a50473e6df95b084f90efb554169914228eba).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816908719
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137137/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-815578746
**[Test build #137050 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137050/testReport)** for PR 30144 at commit [`f67242d`](https://github.com/apache/spark/commit/f67242dd67d07ea7fbbe998943fcfe9461c6ada5).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816223288
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137089/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816736829
**[Test build #137128 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137128/testReport)** for PR 30144 at commit [`0046d40`](https://github.com/apache/spark/commit/0046d40bd8f97b8a850f3e2d34b89fe2d8ff3662).
* This patch **fails PySpark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r609768175
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -88,6 +89,41 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. For example:
Review comment:
We can say that: `group_expression`s will be prepended to each group in the GROUPING SETS.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r609770387
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -32,8 +32,6 @@ trait BaseGroupingSets extends Expression with CodegenFallback {
def selectedGroupByExprs: Seq[Seq[Expression]]
def groupByExprs: Seq[Expression] = {
- assert(children.forall(_.resolved),
- "Cannot call BaseGroupingSets.groupByExprs before the children expressions are all resolved.")
Review comment:
why do we remove this assert? The following code calls `semanticEquals` and we may get wrong if children are not resolved.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-751691158
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/133440/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-748385991
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/37640/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716487876
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/130281/
Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811167191
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610733898
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +235,34 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Expression])] = {
+ if (!exprs.exists(_.isInstanceOf[BaseGroupingSets])) {
+ None
+ } else {
+ val resolved = exprs.forall {
+ case gs: BaseGroupingSets => gs.childrenResolved
+ case other => other.resolved
+ }
+ if (!resolved) {
+ None
+ } else {
+ val groups = exprs.flatMap {
+ case gs: BaseGroupingSets => gs.groupByExprs
+ case other: Expression => other :: Nil
+ }
+ val unmergedSelectedGroupByExprs = exprs.map {
+ case gs: BaseGroupingSets => gs.selectedGroupByExprs
+ case other: Expression => Seq(Seq(other))
+ }
+ val selectedGroupByExprs = unmergedSelectedGroupByExprs.init
+ .foldLeft(unmergedSelectedGroupByExprs.last) { (x, y) =>
Review comment:
why do we put `unmergedSelectedGroupByExprs.last` as the first one? how about
```
unmergedSelectedGroupByExprs.tail.foldLeft(unmergedSelectedGroupByExprs.head)...
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610512769
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +229,30 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ if (!exprs.exists(_.find(_.isInstanceOf[BaseGroupingSets]).isDefined)) {
+ None
+ } else {
+ val groups = exprs.flatMap {
+ case gs: BaseGroupingSets => gs.groupByExprs
+ case others: Expression => others :: Nil
Review comment:
Done
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -93,6 +95,38 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. `CUBE` and `ROLLUP` are just syntax sugar for GROUPING SETS, for how to use
+ `CUBE` and `ROLLUP` can refer to the section above about `CUBE` and `ROLLUP`. For example:
+ `GROUP BY warehouse, GROUPING SETS((product, location), (product), (location), ())` is equivalent to
+ `GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, product), (warehouse, location), (warehouse))`.
+ `GROUP BY warehouse, GROUPING SETS((product, location), (producet), ())` is equivalent to
+ `GROUP BY GROUPING SETS((warehouse, product, location), (warehouse, location), (warehouse))`.
+
+* **Concatenated Grouping Analytics**
Review comment:
Done
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -93,6 +95,38 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. `CUBE` and `ROLLUP` are just syntax sugar for GROUPING SETS, for how to use
Review comment:
Done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810888422
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41337/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816223288
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137089/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610627718
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -32,8 +32,6 @@ trait BaseGroupingSets extends Expression with CodegenFallback {
def selectedGroupByExprs: Seq[Seq[Expression]]
def groupByExprs: Seq[Expression] = {
- assert(children.forall(_.resolved),
- "Cannot call BaseGroupingSets.groupByExprs before the children expressions are all resolved.")
Review comment:
It's fragile to rely on rule order. `ResolveGroupingAnalytics` should only be triggered after expressions are all resolved.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811848992
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41394/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810849940
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and mixed grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810973015
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41342/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810938681
**[Test build #136759 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136759/testReport)** for PR 30144 at commit [`9f03c88`](https://github.com/apache/spark/commit/9f03c8832197b632821ced83d22e744bb552abbf).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and mixed grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810968637
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41341/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610629715
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -32,8 +32,6 @@ trait BaseGroupingSets extends Expression with CodegenFallback {
def selectedGroupByExprs: Seq[Seq[Expression]]
def groupByExprs: Seq[Expression] = {
- assert(children.forall(_.resolved),
- "Cannot call BaseGroupingSets.groupByExprs before the children expressions are all resolved.")
Review comment:
Let me make it clear: we must keep the assert here, it's wrong to call `semanticEquals` if the expression is not resolved yet.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716660475
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716122535
retest this please
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r604634949
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,29 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
+object GroupByOperator {
Review comment:
`GroupByOperator` -> `GroupingAnalytics`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r609848700
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -93,6 +95,39 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. For example:
+ `GROUP BY warehouse, CUBE(product, location)` is equivalent to
Review comment:
> the example can focus on GROUPING SETS. We can just say that ROLLUP/CUBE is syntax sugar for GROUPING SETS and will be expanded to GROUPING SETS, then apply the Partial Grouping Analytics semantic.
Done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and mixed grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810938681
**[Test build #136759 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136759/testReport)** for PR 30144 at commit [`9f03c88`](https://github.com/apache/spark/commit/9f03c8832197b632821ced83d22e744bb552abbf).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816726809
**[Test build #137141 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137141/testReport)** for PR 30144 at commit [`133e073`](https://github.com/apache/spark/commit/133e07360368e75b0d67855f53f47b39f81c4267).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816721847
**[Test build #137139 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137139/testReport)** for PR 30144 at commit [`4359aef`](https://github.com/apache/spark/commit/4359aefc4653b018814001df49d5eec84a463e72).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-817254435
**[Test build #137172 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137172/testReport)** for PR 30144 at commit [`2ae3c16`](https://github.com/apache/spark/commit/2ae3c161de8048e089cd4385f77130cb29b1d2d8).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and mixed grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810937600
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu edited a comment on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu edited a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716442277
> postgres=# select a, b, c, sum(v) from t group by rollup(a, b), cube(b, c), grouping sets(a, c);
FYI @maropu, for this sql, we should support
```
SELECT A, B, SUM(C) FROM TBL GROUP BY A, grouping sets(A, B)
```
first, I will rase a new jira for this.
How about support mixed CUBE/ROLLUP first then implement GROUPING SETS in that pr.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-814821528
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-715728829
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/34827/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716131521
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/34843/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r511757086
##########
File path: sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
##########
@@ -3691,6 +3691,26 @@ class SQLQuerySuite extends QueryTest with SharedSparkSession with AdaptiveSpark
checkAnswer(sql("SELECT id FROM t WHERE (SELECT true)"), Row(0L))
}
}
+
+ test("SPARK-33229: Support GROUP BY use Separate columns and CUBE/ROLLUP") {
+ withTable("t") {
+ sql("CREATE TABLE t USING PARQUET AS SELECT id AS a, id AS b, id AS c FROM range(1)")
Review comment:
> Could you move these tests into `SQLQueryTestSuite`?
Update this at the end, since we need to add more UT about support mixed case.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716493826
**[Test build #130284 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/130284/testReport)** for PR 30144 at commit [`dc4e148`](https://github.com/apache/spark/commit/dc4e148cd6f2b1e3d4c8e35cf3a5b9690b51416f).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-715680465
**[Test build #130227 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/130227/testReport)** for PR 30144 at commit [`68c3e48`](https://github.com/apache/spark/commit/68c3e48b2e8d186b8d210c33467cacb4655c1da1).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810851327
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41334/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610641688
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +229,30 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
Review comment:
> What's wrong with my proposal that returning None if the given expressions are not resolved yet?
>
> ```
> if (exprs.exists(!_.resolved)) {
> None
> } else if (!exprs.exists(e => e.find(_.isInstanceOf[BaseGroupingSets]).isDefined)) ...
> ```
If here we return none, then it can't be resolved in current `ResolveGroupingAnalytics` then will failed in `CheckAnalysis` when call datatype of CUBE/ROLLUP/GROUPING SETS and throw `UnsupportedOperationException`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r604635105
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -212,3 +212,29 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+
+object GroupByOperator {
Review comment:
> `GroupByOperator` -> `GroupingAnalytics`?
Just changed
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-815958713
**[Test build #137089 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137089/testReport)** for PR 30144 at commit [`be93d9e`](https://github.com/apache/spark/commit/be93d9ed873497b04cd0b3742b5beab501941453).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816918895
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137139/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-815395423
**[Test build #137045 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137045/testReport)** for PR 30144 at commit [`3d6e2c4`](https://github.com/apache/spark/commit/3d6e2c475747c5c3eb981aee8faa504b5af7df59).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-715749485
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/34827/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r606356143
##########
File path: sql/core/src/test/resources/sql-tests/results/group-analytics.sql.out
##########
@@ -1,5 +1,5 @@
-- Automatically generated by SQLQueryTestSuite
--- Number of queries: 37
+-- Number of queries: 45
Review comment:
> NOTE: I've checked the the output result are the same with the PostgreSQL ones.
Yea. Thanks
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -23,8 +23,9 @@ license: |
The `GROUP BY` clause is used to group the rows based on a set of specified grouping expressions and compute aggregations on
the group of rows based on one or more specified aggregate functions. Spark also supports advanced aggregations to do multiple
-aggregations for the same input record set via `GROUPING SETS`, `CUBE`, `ROLLUP` clauses.
-When a FILTER clause is attached to an aggregate function, only the matching rows are passed to that function.
+aggregations for the same input record set via `GROUPING SETS`, `CUBE`, `ROLLUP` clauses, also spark support partial grouping
Review comment:
DOne
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r605469239
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -88,6 +89,41 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. For example:
Review comment:
Can we describe the behavior with documents instead of examples? We can also take a look at how other databases document this feature.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r605575398
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -88,6 +89,41 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Partial Grouping Analytics**
+
+ Partial grouping analytics means there are both `group_expression` and `CUBE|ROLLUP|GROUPING SETS`
+ in GROUP BY clause. For example:
Review comment:
> Can we describe the behavior with documents instead of examples? We can also take a look at how other databases document this feature.
Oracle document https://docs.oracle.com/cd/E11882_01/server.112/e25554/aggreg.htm#DWHSG8612


All have an example data then demo sql and result.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-720467422
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-751690584
**[Test build #133440 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/133440/testReport)** for PR 30144 at commit [`c1c551c`](https://github.com/apache/spark/commit/c1c551c6f9656ec71d6da03fb8fd4c4119d66c3a).
* This patch passes all tests.
* This patch **does not merge cleanly**.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-715830759
Merged build finished. Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811998229
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136811/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-812034816
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136812/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-811852723
**[Test build #136812 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136812/testReport)** for PR 30144 at commit [`b1e04de`](https://github.com/apache/spark/commit/b1e04de75e2b97ef8095df4a7529179b5fc8043f).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r609845488
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -24,7 +24,9 @@ license: |
The `GROUP BY` clause is used to group the rows based on a set of specified grouping expressions and compute aggregations on
the group of rows based on one or more specified aggregate functions. Spark also supports advanced aggregations to do multiple
aggregations for the same input record set via `GROUPING SETS`, `CUBE`, `ROLLUP` clauses.
-When a FILTER clause is attached to an aggregate function, only the matching rows are passed to that function.
+These grouping analytics clauses can be specified with regular grouping expressions (partial grouping analytics) and
+the different grouping analytics clauses can be specified together (concatenated groupings).
Review comment:
> `different`, do you mean `GROUP BY cube(a, b), cube(a, b)` is not allowed?
no, remove `different`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r609841547
##########
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##########
@@ -231,3 +229,24 @@ object GroupingID {
if (SQLConf.get.integerGroupingIdEnabled) IntegerType else LongType
}
}
+
+object GroupingAnalytics {
+ def unapply(exprs: Seq[Expression])
+ : Option[(Seq[Seq[Expression]], Seq[Seq[Expression]], Seq[Expression])] = {
+ val (groupingSetExprs, others) = exprs.partition(_.isInstanceOf[BaseGroupingSets])
Review comment:
And how about current code here, It can keep order when expand grouping sets.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-817600315
The last commit just fixed a typo in the doc, no need to wait for jenkins again. Thanks, merging to master!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816590446
**[Test build #137130 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137130/testReport)** for PR 30144 at commit [`8cca908`](https://github.com/apache/spark/commit/8cca908beb7b6de3dd92419cf4dad12e3dfcc355).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL]Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-715749524
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810998371
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816590446
**[Test build #137130 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137130/testReport)** for PR 30144 at commit [`8cca908`](https://github.com/apache/spark/commit/8cca908beb7b6de3dd92419cf4dad12e3dfcc355).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r610697005
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -24,7 +24,10 @@ license: |
The `GROUP BY` clause is used to group the rows based on a set of specified grouping expressions and compute aggregations on
the group of rows based on one or more specified aggregate functions. Spark also supports advanced aggregations to do multiple
aggregations for the same input record set via `GROUPING SETS`, `CUBE`, `ROLLUP` clauses.
-When a FILTER clause is attached to an aggregate function, only the matching rows are passed to that function.
+These grouping analytics clauses can be specified with regular grouping expressions (partial grouping analytics) and
+the grouping analytics clauses can be specified together (concatenated groupings). When a FILTER clause is attached to
+an aggregate function, only the matching. The grouping expressions and advanced aggregations can be mixed in the `GROUP BY` clause.
+See more details in the `Mixed Grouping Analytics` section.
Review comment:
Hmmmmm
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #30144:
URL: https://github.com/apache/spark/pull/30144#discussion_r611420882
##########
File path: docs/sql-ref-syntax-qry-select-groupby.md
##########
@@ -93,6 +95,25 @@ aggregate_name ( [ DISTINCT ] expression [ , ... ] ) [ FILTER ( WHERE boolean_ex
(product, warehouse, location), (warehouse), (product), (warehouse, product), ())`.
The N elements of a `CUBE` specification results in 2^N `GROUPING SETS`.
+* **Mixed Grouping Analytics**
+
+ A GROUP BY clause can include multiple `group_expression`s and multiple `CUBE|ROLLUP|GROUPING SETS`s.
+ `CUBE|ROLLUP` is just a syntax sugar for `GROUPING SETS`, please refer to the sections above for
+ how to translate `CUBE|ROLLUP` to `GROUPING SETS`. `group_expression` can be treated as a single-group
+ `GROUPING SETS` under this context. For multiple `GROUPING SETS` in the `GROUP BY` clause, we generate
+ a single `GROUPING SETS` by doing a cross-product of the original `GROUPING SETS`s. For example,
+ `GROUP BY warehouse, GROUPING SETS((product), ()), GROUPING SETS((location, size), (location), (size), ())`
+ and `GROUP BY warehouse, ROLLUP(warehouse), CUBE(location, size)` is equivalent to
Review comment:
typo? `ROLLUP(warehouse)` -> `ROLLUP(product)`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-810992796
**[Test build #136753 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136753/testReport)** for PR 30144 at commit [`005b697`](https://github.com/apache/spark/commit/005b6974d11ed37351f54de8dd43717f7b13aa71).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-812665178
**[Test build #136868 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136868/testReport)** for PR 30144 at commit [`9b3a504`](https://github.com/apache/spark/commit/9b3a50473e6df95b084f90efb554169914228eba).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716538666
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716486982
**[Test build #130281 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/130281/testReport)** for PR 30144 at commit [`a3d1b60`](https://github.com/apache/spark/commit/a3d1b603959af357ef1e5890d08a093712a4d327).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-716442277
> postgres=# select a, b, c, sum(v) from t group by rollup(a, b), cube(b, c), grouping sets(a, c);
FYI @maropu, for this sql, we should support
```
SELECT A, B, SUM(C) FROM TBL GROUP BY A, grouping sets(A, B)
```
first, I will rase a new jira for this.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30144: [SPARK-33229][SQL] Support GROUP BY use Separate columns and CUBE/ROLLUP
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-720433951
**[Test build #130526 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/130526/testReport)** for PR 30144 at commit [`c1c551c`](https://github.com/apache/spark/commit/c1c551c6f9656ec71d6da03fb8fd4c4119d66c3a).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816583502
**[Test build #137128 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137128/testReport)** for PR 30144 at commit [`0046d40`](https://github.com/apache/spark/commit/0046d40bd8f97b8a850f3e2d34b89fe2d8ff3662).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30144: [SPARK-33229][SQL] Support partial grouping analytics and concatenated grouping analytics
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #30144:
URL: https://github.com/apache/spark/pull/30144#issuecomment-816763111
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41718/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org