You are viewing a plain text version of this content. The canonical link for it is here.
Posted to notifications@libcloud.apache.org by GitBox <gi...@apache.org> on 2023/01/17 15:02:16 UTC
[GitHub] [libcloud] Tobi995 opened a new pull request, #1847: optimize read_in_chunks
Tobi995 opened a new pull request, #1847:
URL: https://github.com/apache/libcloud/pull/1847
## Optimize read_in_chunks
### Description
We noticed that utils.files.read_in_chunks has significant memory & CPU cost when up or downloading large files with mismatching chunk sizes. This PR attempts to fix that by potentially yielding multiple chunks per read and by avoiding large slicing ops. This seems to remove some more than quadratic scaling, bringing massive speed ups.
```python
import tracemalloc
import numpy as np
import time
from libcloud.utils.files import read_in_chunks
import numpy as np
def run_scenario_1(data: bytes):
# similar to calling _upload_multipart_chunks with one large array of bytes
for a in read_in_chunks(iter([data]), chunk_size=5 * 1024 * 1024, fill_size=True):
...
def run_scenario_2(data: bytes):
# as in download_object_as_stream
response_chunk = 5 * 1024 * 1024
for a in read_in_chunks(iter([data[i:i+response_chunk] for i in range(0, len(data), response_chunk)]), chunk_size=8096, fill_size=True):
...
if __name__ == "__main__":
tracemalloc.start()
data = "c".encode("utf-8") * (40 * 1024 * 1024)
times = []
for i in range(10):
start_time = time.time()
run_scenario_1(data)
times.append(time.time() - start_time)
print("scenario 1", np.median(times))
times = []
for i in range(10):
start_time = time.time()
run_scenario_2(data)
times.append(time.time() - start_time)
print("scenario 2", np.median(times))
current_size, peak = tracemalloc.get_traced_memory()
print(f'Current consumption: {current_size / 1024 / 1024}mb, '
f'peak since last log: {peak / 1024 / 1024}mb.')
```
Gives the following stats:
Without this PR:
```
scenario 1 0.08405923843383789
scenario 2 30.04505753517151
Current consumption: 40.009538650512695mb, peak since last log: 159.9015874862671mb.
```
With this PR:
```
scenario 1 0.013306617736816406
scenario 2 0.060915589332580566
Current consumption: 40.01009464263916mb, peak since last log: 85.03302574157715mb.
```
Scenario 2 with different data sizes:
- 20Mb: Before 3.97s, After 0.028s
- 30Mb: Before 8.4s, After 0.04s
- 40Mb: Before 30.0s, After 0.05s
- 50Mb: Before 54s, After 0.07s
- 60Mb: Before 102s, After 0.096s
### Status
done, ready for review
### Checklist (tick everything that applies)
- [X] [Code linting](http://libcloud.readthedocs.org/en/latest/development.html#code-style-guide) (required, can be done after the PR checks)
- [ ] Documentation
- [X] [Tests](http://libcloud.readthedocs.org/en/latest/testing.html)
- [ ] [ICLA](http://libcloud.readthedocs.org/en/latest/development.html#contributing-bigger-changes) (required for bigger changes)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscribe@libcloud.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [libcloud] RunOrVeith commented on a diff in pull request #1847: optimize read_in_chunks
Posted by GitBox <gi...@apache.org>.
RunOrVeith commented on code in PR #1847:
URL: https://github.com/apache/libcloud/pull/1847#discussion_r1072344773
##########
libcloud/utils/files.py:
##########
@@ -75,7 +75,13 @@ def read_in_chunks(iterator, chunk_size=None, fill_size=False, yield_empty=False
return
if fill_size:
- if empty or len(data) >= chunk_size:
+ chunk_start = 0
Review Comment:
maybe add a quick explanation why it is smarter to do it this way than the old way
##########
libcloud/test/test_utils.py:
##########
@@ -202,15 +202,42 @@ def iterator():
for x in range(0, 1000):
yield "aa"
+ chunk_count = 0
for result in libcloud.utils.files.read_in_chunks(
iterator(), chunk_size=10, fill_size=False
):
+ chunk_count += 1
self.assertEqual(result, b("aa"))
+ self.assertEqual(chunk_count, 1000)
+ chunk_count = 0
for result in libcloud.utils.files.read_in_chunks(
iterator(), chunk_size=10, fill_size=True
):
+ chunk_count += 1
self.assertEqual(result, b("aaaaaaaaaa"))
+ self.assertEqual(chunk_count, 200)
+
+ def test_read_in_chunks_large_iterator_batches(self):
+ def iterator():
+ for x in range(0, 10):
+ yield "a" * 10_000
+
+ chunk_count = 0
+ for result in libcloud.utils.files.read_in_chunks(
+ iterator(), chunk_size=10, fill_size=False
+ ):
+ chunk_count += 1
+ self.assertEqual(result, b("a") * 10_000)
+ self.assertEqual(chunk_count, 10)
+
+ chunk_count = 0
+ for result in libcloud.utils.files.read_in_chunks(
+ iterator(), chunk_size=10, fill_size=True
+ ):
+ chunk_count += 1
+ self.assertEqual(result, b("aaaaaaaaaa"))
Review Comment:
If you make this b("a") * 10 it's clearer to see what is going on
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscribe@libcloud.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [libcloud] Germandrummer92 commented on a diff in pull request #1847: optimize read_in_chunks
Posted by GitBox <gi...@apache.org>.
Germandrummer92 commented on code in PR #1847:
URL: https://github.com/apache/libcloud/pull/1847#discussion_r1072754536
##########
libcloud/utils/files.py:
##########
@@ -75,7 +75,13 @@ def read_in_chunks(iterator, chunk_size=None, fill_size=False, yield_empty=False
return
if fill_size:
- if empty or len(data) >= chunk_size:
+ chunk_start = 0
Review Comment:
not sure if it makes it better just as an idea, but to encapsulate the comment also you could move it into a method now?
```python
def _optimized_chunked_generator(data: bytes, chunk_size: int) -> Generator[bytes, None, bytes]:
# We want to emit chunk_size large chunks, but chunk_size can be larger or smaller than the chunks returned
# by get_data. We need to yield in a loop to avoid large amounts of data piling up.
# The loop also avoids copying all data #chunks amount of times by keeping the original data as is.
chunk_start = 0
while chunk_start + chunk_size < len(data):
yield data[chunk_start : chunk_start + chunk_size]
chunk_start += chunk_size
data = data[chunk_start:]
return data
...
data = yield from _optimized_chunk_generator(data=data, chunk_size=chunk_size)
```
might make this method itself a tiny bit more readable?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscribe@libcloud.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [libcloud] Kami commented on pull request #1847: optimize read_in_chunks
Posted by "Kami (via GitHub)" <gi...@apache.org>.
Kami commented on PR #1847:
URL: https://github.com/apache/libcloud/pull/1847#issuecomment-1407374285
Awesome, thanks for this contribution.
I think it would also be good to add micro benchmarks for this function / code path to `libcloud/test/benchmarks/` so we can track performance over time, avoid regressions, etc.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscribe@libcloud.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [libcloud] Tobi995 commented on a diff in pull request #1847: optimize read_in_chunks
Posted by GitBox <gi...@apache.org>.
Tobi995 commented on code in PR #1847:
URL: https://github.com/apache/libcloud/pull/1847#discussion_r1073287455
##########
libcloud/utils/files.py:
##########
@@ -75,7 +75,13 @@ def read_in_chunks(iterator, chunk_size=None, fill_size=False, yield_empty=False
return
if fill_size:
- if empty or len(data) >= chunk_size:
+ chunk_start = 0
Review Comment:
Done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscribe@libcloud.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [libcloud] Kami commented on pull request #1847: optimize read_in_chunks
Posted by "Kami (via GitHub)" <gi...@apache.org>.
Kami commented on PR #1847:
URL: https://github.com/apache/libcloud/pull/1847#issuecomment-1407380788
I've added a basic baseline micro benchmark (to help us avoid regressions in the future) in 523838cd5e5a7f0c0dcab59651ebf4dee3fe6d1b.
I was indeed able to reproduce your results (large performance speed up). Right now this benchmark only measures CPU time and not memory usage. Measuring memory usage would be a nice addition, but that would be a bit more involved change since pytest-benchmark doesn't support doing something like that natively.
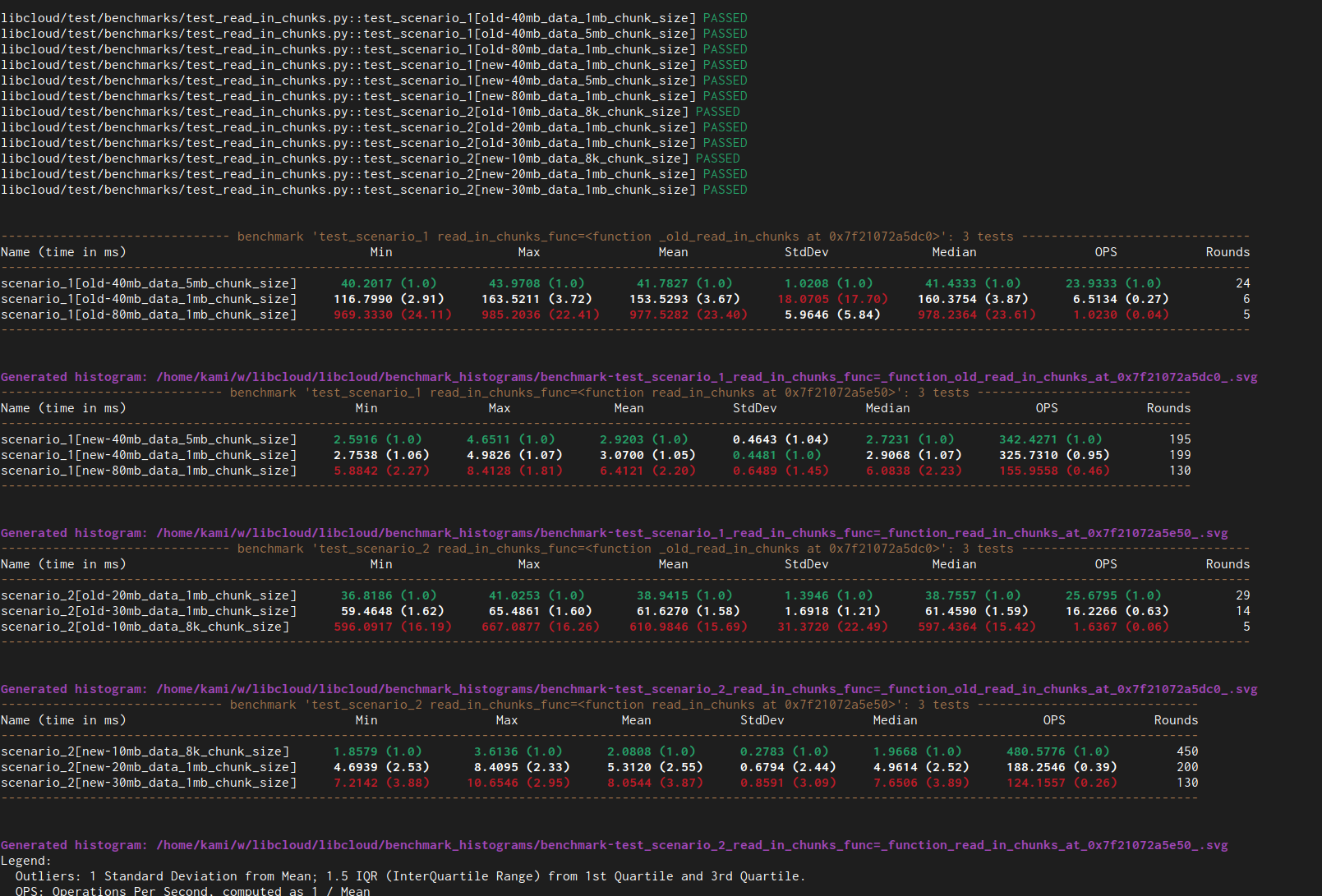
As you mentioned, the performance gets much worse with older implementation with larger object / input data size, but to prevent micro benchmarks for running too long, I used smaller data sizes.
Thanks again and great work :tada:
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscribe@libcloud.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [libcloud] codecov-commenter commented on pull request #1847: optimize read_in_chunks
Posted by "codecov-commenter (via GitHub)" <gi...@apache.org>.
codecov-commenter commented on PR #1847:
URL: https://github.com/apache/libcloud/pull/1847#issuecomment-1407375564
# [Codecov](https://codecov.io/gh/apache/libcloud/pull/1847?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) Report
> Merging [#1847](https://codecov.io/gh/apache/libcloud/pull/1847?src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) (fc05a9b) into [trunk](https://codecov.io/gh/apache/libcloud/commit/39877d8bc5bcda064d53c7a9f43ca1657c8ea9ee?el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) (39877d8) will **increase** coverage by `0.00%`.
> The diff coverage is `100.00%`.
[](https://codecov.io/gh/apache/libcloud/pull/1847?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation)
```diff
@@ Coverage Diff @@
## trunk #1847 +/- ##
=======================================
Coverage 83.40% 83.40%
=======================================
Files 402 402
Lines 88130 88158 +28
Branches 9330 9334 +4
=======================================
+ Hits 73502 73529 +27
Misses 11452 11452
- Partials 3176 3177 +1
```
| [Impacted Files](https://codecov.io/gh/apache/libcloud/pull/1847?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) | Coverage Δ | |
|---|---|---|
| [libcloud/test/test\_utils.py](https://codecov.io/gh/apache/libcloud/pull/1847?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#diff-bGliY2xvdWQvdGVzdC90ZXN0X3V0aWxzLnB5) | `98.02% <100.00%> (+0.21%)` | :arrow_up: |
| [libcloud/utils/files.py](https://codecov.io/gh/apache/libcloud/pull/1847?src=pr&el=tree&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation#diff-bGliY2xvdWQvdXRpbHMvZmlsZXMucHk=) | `98.18% <100.00%> (-1.82%)` | :arrow_down: |
------
[Continue to review full report at Codecov](https://codecov.io/gh/apache/libcloud/pull/1847?src=pr&el=continue&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation).
> **Legend** - [Click here to learn more](https://docs.codecov.io/docs/codecov-delta?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation)
> `Δ = absolute <relative> (impact)`, `ø = not affected`, `? = missing data`
> Powered by [Codecov](https://codecov.io/gh/apache/libcloud/pull/1847?src=pr&el=footer&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation). Last update [39877d8...fc05a9b](https://codecov.io/gh/apache/libcloud/pull/1847?src=pr&el=lastupdated&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation). Read the [comment docs](https://docs.codecov.io/docs/pull-request-comments?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscribe@libcloud.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [libcloud] Kami merged pull request #1847: optimize read_in_chunks
Posted by "Kami (via GitHub)" <gi...@apache.org>.
Kami merged PR #1847:
URL: https://github.com/apache/libcloud/pull/1847
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscribe@libcloud.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org