You are viewing a plain text version of this content. The canonical link for it is here.
Posted to github@arrow.apache.org by GitBox <gi...@apache.org> on 2022/01/14 01:55:06 UTC
[GitHub] [arrow-datafusion] houqp opened a new pull request #1556: Arrow2 merge
houqp opened a new pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556
# Which issue does this PR close?
Close arrow2 milestone https://github.com/apache/arrow-datafusion/milestone/3
# Rationale for this change
Provide a complete arrow2 based datafusion implementation for full evaluation of the migration. This should give us a good feeling of the arrow2 API UX as well as a starting point for performance benchmarks within datafusion and downstream projects.
The goal is to merge the code into an official arrow2 branch in the short run, until we are comfortable doing the switch in master.
# What changes are included in this PR?
* Switched to arrow2
* Enabled miri test
Here is a TPCH benchmark I ran on my Linux laptop:

On avg, we are getting around 5% speed up across the board, with q5 at 11% gain and q12 at only 1%. If this performance gain can also be replicated in downstream projects, then I think it would be a strong case for us to do the arrow2 swtich.
# Are there any user-facing changes?
Yes, downstream consumer of datafusion will need to switch to arrow2 as well.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on a change in pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp commented on a change in pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#discussion_r785402462
##########
File path: datafusion/Cargo.toml
##########
@@ -39,25 +39,27 @@ path = "src/lib.rs"
[features]
default = ["crypto_expressions", "regex_expressions", "unicode_expressions"]
-simd = ["arrow/simd"]
+# FIXME: https://github.com/jorgecarleitao/arrow2/issues/580
+#simd = ["arrow/simd"]
+simd = []
crypto_expressions = ["md-5", "sha2", "blake2", "blake3"]
regex_expressions = ["regex"]
unicode_expressions = ["unicode-segmentation"]
-pyarrow = ["pyo3", "arrow/pyarrow"]
+# FIXME: add pyarrow support to arrow2 pyarrow = ["pyo3", "arrow/pyarrow"]
+pyarrow = ["pyo3"]
# Used for testing ONLY: causes all values to hash to the same value (test for collisions)
force_hash_collisions = []
# Used to enable the avro format
-avro = ["avro-rs", "num-traits"]
+avro = ["arrow/io_avro", "arrow/io_avro_async", "arrow/io_avro_compression", "num-traits", "avro-schema"]
[dependencies]
ahash = { version = "0.7", default-features = false }
hashbrown = { version = "0.11", features = ["raw"] }
-arrow = { version = "6.4.0", features = ["prettyprint"] }
-parquet = { version = "6.4.0", features = ["arrow"] }
+parquet = { package = "parquet2", version = "0.8", default_features = false, features = ["stream"] }
sqlparser = "0.13"
paste = "^1.0"
num_cpus = "1.13.0"
-chrono = { version = "0.4", default-features = false }
+chrono = { version = "0.4", default-features = false, features = ["clock"] }
Review comment:
It looks like datafusion is only depending on this to get the current system time in various places. I will file https://github.com/apache/arrow-datafusion/issues/1584 as a follow up
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp edited a comment on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp edited a comment on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1017175870
All integration and unit tests are passing now, the MIRI check is failing due to an upstream tokio issue I believe. I will file some follow up issues tomorrow to track the remaining work needed for us to make the final call on master merge.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1017175870
All tests are passing now, the MIRI check is failing due to an upstream tokio issue I believe. I will file some follow up issues tomorrow to track the remaining work needed for us to make the final call on master merge.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp merged pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp merged pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] xudong963 commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
xudong963 commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1017537586
Thanks @houqp , epic work !
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] ic4y commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
ic4y commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1012809108
I found that the peak memory usage of this branch increases by 80% compared to the master branch。
sql : select avg(user_id) from parquet_event_1 group by user_name limit 10
test dataset : total 450 million, 50 million users
| branch | peak memory |
| ---- | ---- |
| master(d7e465 and 35d65fc) | 10G |
| arrow2_merge | 6G |
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] andygrove edited a comment on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
andygrove edited a comment on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1013730047
Metrics and CPU activity charts for query 1 from master & arrow2.
## Master
```
=== Physical plan with metrics ===
SortExec: [l_returnflag@0 ASC NULLS LAST,l_linestatus@1 ASC NULLS LAST], metrics=[output_rows=4, elapsed_compute=148.532µs]
CoalescePartitionsExec, metrics=[output_rows=4, elapsed_compute=26.889µs]
ProjectionExec: expr=[l_returnflag@0 as l_returnflag, l_linestatus@1 as l_linestatus, SUM(lineitem.l_quantity)@2 as sum_qty, SUM(lineitem.l_extendedprice)@3 as sum_base_price, SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount)@4 as sum_disc_price, SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount * Int64(1) + lineitem.l_tax)@5 as sum_charge, AVG(lineitem.l_quantity)@6 as avg_qty, AVG(lineitem.l_extendedprice)@7 as avg_price, AVG(lineitem.l_discount)@8 as avg_disc, COUNT(UInt8(1))@9 as count_order], metrics=[output_rows=4, elapsed_compute=162.216µs]
HashAggregateExec: mode=FinalPartitioned, gby=[l_returnflag@0 as l_returnflag, l_linestatus@1 as l_linestatus], aggr=[SUM(lineitem.l_quantity), SUM(lineitem.l_extendedprice), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount Multiply Int64(1) Plus lineitem.l_tax), AVG(lineitem.l_quantity), AVG(lineitem.l_extendedprice), AVG(lineitem.l_discount), COUNT(UInt8(1))], metrics=[output_rows=4, elapsed_compute=836.092µs]
CoalesceBatchesExec: target_batch_size=2048, metrics=[output_rows=96, elapsed_compute=2.467991ms]
RepartitionExec: partitioning=Hash([Column { name: "l_returnflag", index: 0 }, Column { name: "l_linestatus", index: 1 }], 24), metrics=[fetch_time{inputPartition=0}=121.646159259s, repart_time{inputPartition=0}=1.068665ms, send_time{inputPartition=0}=181.052µs]
HashAggregateExec: mode=Partial, gby=[l_returnflag@5 as l_returnflag, l_linestatus@6 as l_linestatus], aggr=[SUM(lineitem.l_quantity), SUM(lineitem.l_extendedprice), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount Multiply Int64(1) Plus lineitem.l_tax), AVG(lineitem.l_quantity), AVG(lineitem.l_extendedprice), AVG(lineitem.l_discount), COUNT(UInt8(1))], metrics=[output_rows=96, elapsed_compute=62.022452324s]
ProjectionExec: expr=[l_extendedprice@1 * CAST(1 AS Float64) - l_discount@2 as BinaryExpr-*BinaryExpr--Column-lineitem.l_discountLiteral1Column-lineitem.l_extendedprice, l_quantity@0 as l_quantity, l_extendedprice@1 as l_extendedprice, l_discount@2 as l_discount, l_tax@3 as l_tax, l_returnflag@4 as l_returnflag, l_linestatus@5 as l_linestatus], metrics=[output_rows=591599326, elapsed_compute=2.333647686s]
CoalesceBatchesExec: target_batch_size=2048, metrics=[output_rows=591599326, elapsed_compute=18.07630248s]
FilterExec: l_shipdate@6 <= 10471, metrics=[output_rows=591599326, elapsed_compute=14.438278954s]
ParquetExec: batch_size=4096, limit=None, partitions=[/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-11.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-0.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet, /mnt/bigdata/tp
ch/sf100-24part-parquet/lineitem/part-4.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-9.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-18.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-15.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet], metrics=[predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-9.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24p
art-parquet/lineitem/part-18.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-11.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-11.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/
lineitem/part-9.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-18.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/l
ineitem/part-15.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-4.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/pa
rt-0.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet}=0, num_predicate_creation_errors=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-15.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-0.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet}=0, predicate_evaluation_errors{filename=
/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-4.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet}=0]
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+----------------------+-------------+
| l_returnflag | l_linestatus | sum_qty | sum_base_price | sum_disc_price | sum_charge | avg_qty | avg_price | avg_disc | count_order |
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+----------------------+-------------+
| A | F | 3775127569 | 5660775782243.051 | 5377736101986.644 | 5592847119226.674 | 25.49937018008533 | 38236.11640655464 | 0.05000224292310849 | 148047875 |
| N | F | 98553062 | 147771098385.98004 | 140384965965.03497 | 145999793032.7758 | 25.501556956882876 | 38237.19938880452 | 0.04998528433805398 | 3864590 |
| N | O | 7436302680 | 11150725250531.352 | 10593194904399.148 | 11016931834528.229 | 25.500009351223113 | 38237.22761127162 | 0.049997917972634566 | 291619606 |
| R | F | 3775724821 | 5661602800938.198 | 5378513347920.04 | 5593662028982.476 | 25.500066311082758 | 38236.6972423322 | 0.05000130406955949 | 148067255 |
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+----------------------+-------------+
Query 1 iteration 0 took 8165.9 ms
Query 1 avg time: 8165.94 ms
```
## Arrow2 PR
```
=== Physical plan with metrics ===
SortExec: [l_returnflag@0 ASC NULLS LAST,l_linestatus@1 ASC NULLS LAST], metrics=[output_rows=4, elapsed_compute=90.895µs]
CoalescePartitionsExec, metrics=[output_rows=4, elapsed_compute=16.752µs]
ProjectionExec: expr=[l_returnflag@0 as l_returnflag, l_linestatus@1 as l_linestatus, SUM(lineitem.l_quantity)@2 as sum_qty, SUM(lineitem.l_extendedprice)@3 as sum_base_price, SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount)@4 as sum_disc_price, SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount * Int64(1) + lineitem.l_tax)@5 as sum_charge, AVG(lineitem.l_quantity)@6 as avg_qty, AVG(lineitem.l_extendedprice)@7 as avg_price, AVG(lineitem.l_discount)@8 as avg_disc, COUNT(UInt8(1))@9 as count_order], metrics=[output_rows=4, elapsed_compute=269.589µs]
HashAggregateExec: mode=FinalPartitioned, gby=[l_returnflag@0 as l_returnflag, l_linestatus@1 as l_linestatus], aggr=[SUM(lineitem.l_quantity), SUM(lineitem.l_extendedprice), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount Multiply Int64(1) Plus lineitem.l_tax), AVG(lineitem.l_quantity), AVG(lineitem.l_extendedprice), AVG(lineitem.l_discount), COUNT(UInt8(1))], metrics=[output_rows=4, elapsed_compute=966.04µs]
CoalesceBatchesExec: target_batch_size=2048, metrics=[output_rows=96, elapsed_compute=3.118624ms]
RepartitionExec: partitioning=Hash([Column { name: "l_returnflag", index: 0 }, Column { name: "l_linestatus", index: 1 }], 24), metrics=[send_time{inputPartition=0}=202.529µs, fetch_time{inputPartition=0}=167.702662304s, repart_time{inputPartition=0}=881.476µs]
HashAggregateExec: mode=Partial, gby=[l_returnflag@5 as l_returnflag, l_linestatus@6 as l_linestatus], aggr=[SUM(lineitem.l_quantity), SUM(lineitem.l_extendedprice), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount Multiply Int64(1) Plus lineitem.l_tax), AVG(lineitem.l_quantity), AVG(lineitem.l_extendedprice), AVG(lineitem.l_discount), COUNT(UInt8(1))], metrics=[output_rows=96, elapsed_compute=69.277706429s]
ProjectionExec: expr=[l_extendedprice@1 * CAST(1 AS Float64) - l_discount@2 as BinaryExpr-*BinaryExpr--Column-lineitem.l_discountLiteral1Column-lineitem.l_extendedprice, l_quantity@0 as l_quantity, l_extendedprice@1 as l_extendedprice, l_discount@2 as l_discount, l_tax@3 as l_tax, l_returnflag@4 as l_returnflag, l_linestatus@5 as l_linestatus], metrics=[output_rows=591599326, elapsed_compute=1.948225184s]
CoalesceBatchesExec: target_batch_size=2048, metrics=[output_rows=591599326, elapsed_compute=19.900026641s]
FilterExec: l_shipdate@6 <= 10471, metrics=[output_rows=591599326, elapsed_compute=17.25811968s]
ParquetExec: batch_size=4096, limit=None, partitions=[/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-11.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-0.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet, /mnt/bigdata/tp
ch/sf100-24part-parquet/lineitem/part-4.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-9.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-18.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-15.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet], metrics=[row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24p
art-parquet/lineitem/part-11.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-0.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-0.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet}=0, num_predicate_creation_errors=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-4.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet}=0, predicate_evaluation_errors{filenam
e=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-9.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-18.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-4.parquet}=0, predicate_evaluation_errors{filename=/m
nt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-9.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-18.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet}=0, predicate_
evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-15.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-11.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-15.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet}=0, predicate_evaluation_errors{
filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet}=0]
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+---------------------+-------------+
| l_returnflag | l_linestatus | sum_qty | sum_base_price | sum_disc_price | sum_charge | avg_qty | avg_price | avg_disc | count_order |
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+---------------------+-------------+
| A | F | 3775127569 | 5660775782243.05 | 5377736101986.642 | 5592847119226.676 | 25.49937018008533 | 38236.11640655463 | 0.05000224292310846 | 148047875 |
| N | F | 98553062 | 147771098385.98004 | 140384965965.0348 | 145999793032.77588 | 25.501556956882876 | 38237.19938880452 | 0.04998528433805397 | 3864590 |
| N | O | 7436302680 | 11150725250531.35 | 10593194904399.143 | 11016931834528.23 | 25.500009351223113 | 38237.22761127161 | 0.04999791797263452 | 291619606 |
| R | F | 3775724821 | 5661602800938.199 | 5378513347920.042 | 5593662028982.476 | 25.500066311082758 | 38236.6972423322 | 0.05000130406955945 | 148067255 |
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+---------------------+-------------+
Query 1 iteration 0 took 27109.6 ms
Query 1 avg time: 27109.65 ms
```

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on a change in pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp commented on a change in pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#discussion_r785407092
##########
File path: .github/workflows/rust.yml
##########
@@ -116,6 +116,7 @@ jobs:
cargo test --no-default-features
cargo run --example csv_sql
cargo run --example parquet_sql
+ #nopass
Review comment:
not entirely sure, @Igosuki do you remember why you added these #nopass lines?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp edited a comment on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp edited a comment on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1015128595
update: all datafusion unit and integration tests are passing now, down to a single test failure in datafusion-cli related to json display format.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1015128595
all datafusion unit and integration tests are passing now, down to a single test failure in datafusion-cli related to json display format.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] andygrove commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
andygrove commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1013730047
Metrics for query 1 from master & arrow2.
## Master
```
=== Physical plan with metrics ===
SortExec: [l_returnflag@0 ASC NULLS LAST,l_linestatus@1 ASC NULLS LAST], metrics=[output_rows=4, elapsed_compute=148.532µs]
CoalescePartitionsExec, metrics=[output_rows=4, elapsed_compute=26.889µs]
ProjectionExec: expr=[l_returnflag@0 as l_returnflag, l_linestatus@1 as l_linestatus, SUM(lineitem.l_quantity)@2 as sum_qty, SUM(lineitem.l_extendedprice)@3 as sum_base_price, SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount)@4 as sum_disc_price, SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount * Int64(1) + lineitem.l_tax)@5 as sum_charge, AVG(lineitem.l_quantity)@6 as avg_qty, AVG(lineitem.l_extendedprice)@7 as avg_price, AVG(lineitem.l_discount)@8 as avg_disc, COUNT(UInt8(1))@9 as count_order], metrics=[output_rows=4, elapsed_compute=162.216µs]
HashAggregateExec: mode=FinalPartitioned, gby=[l_returnflag@0 as l_returnflag, l_linestatus@1 as l_linestatus], aggr=[SUM(lineitem.l_quantity), SUM(lineitem.l_extendedprice), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount Multiply Int64(1) Plus lineitem.l_tax), AVG(lineitem.l_quantity), AVG(lineitem.l_extendedprice), AVG(lineitem.l_discount), COUNT(UInt8(1))], metrics=[output_rows=4, elapsed_compute=836.092µs]
CoalesceBatchesExec: target_batch_size=2048, metrics=[output_rows=96, elapsed_compute=2.467991ms]
RepartitionExec: partitioning=Hash([Column { name: "l_returnflag", index: 0 }, Column { name: "l_linestatus", index: 1 }], 24), metrics=[fetch_time{inputPartition=0}=121.646159259s, repart_time{inputPartition=0}=1.068665ms, send_time{inputPartition=0}=181.052µs]
HashAggregateExec: mode=Partial, gby=[l_returnflag@5 as l_returnflag, l_linestatus@6 as l_linestatus], aggr=[SUM(lineitem.l_quantity), SUM(lineitem.l_extendedprice), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount Multiply Int64(1) Plus lineitem.l_tax), AVG(lineitem.l_quantity), AVG(lineitem.l_extendedprice), AVG(lineitem.l_discount), COUNT(UInt8(1))], metrics=[output_rows=96, elapsed_compute=62.022452324s]
ProjectionExec: expr=[l_extendedprice@1 * CAST(1 AS Float64) - l_discount@2 as BinaryExpr-*BinaryExpr--Column-lineitem.l_discountLiteral1Column-lineitem.l_extendedprice, l_quantity@0 as l_quantity, l_extendedprice@1 as l_extendedprice, l_discount@2 as l_discount, l_tax@3 as l_tax, l_returnflag@4 as l_returnflag, l_linestatus@5 as l_linestatus], metrics=[output_rows=591599326, elapsed_compute=2.333647686s]
CoalesceBatchesExec: target_batch_size=2048, metrics=[output_rows=591599326, elapsed_compute=18.07630248s]
FilterExec: l_shipdate@6 <= 10471, metrics=[output_rows=591599326, elapsed_compute=14.438278954s]
ParquetExec: batch_size=4096, limit=None, partitions=[/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-11.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-0.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet, /mnt/bigdata/tp
ch/sf100-24part-parquet/lineitem/part-4.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-9.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-18.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-15.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet], metrics=[predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-9.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24p
art-parquet/lineitem/part-18.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-11.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-11.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/
lineitem/part-9.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-18.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/l
ineitem/part-15.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-4.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/pa
rt-0.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet}=0, num_predicate_creation_errors=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-15.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-0.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet}=0, predicate_evaluation_errors{filename=
/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-4.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet}=0]
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+----------------------+-------------+
| l_returnflag | l_linestatus | sum_qty | sum_base_price | sum_disc_price | sum_charge | avg_qty | avg_price | avg_disc | count_order |
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+----------------------+-------------+
| A | F | 3775127569 | 5660775782243.051 | 5377736101986.644 | 5592847119226.674 | 25.49937018008533 | 38236.11640655464 | 0.05000224292310849 | 148047875 |
| N | F | 98553062 | 147771098385.98004 | 140384965965.03497 | 145999793032.7758 | 25.501556956882876 | 38237.19938880452 | 0.04998528433805398 | 3864590 |
| N | O | 7436302680 | 11150725250531.352 | 10593194904399.148 | 11016931834528.229 | 25.500009351223113 | 38237.22761127162 | 0.049997917972634566 | 291619606 |
| R | F | 3775724821 | 5661602800938.198 | 5378513347920.04 | 5593662028982.476 | 25.500066311082758 | 38236.6972423322 | 0.05000130406955949 | 148067255 |
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+----------------------+-------------+
Query 1 iteration 0 took 8165.9 ms
Query 1 avg time: 8165.94 ms
```
## Arrow2 PR
```
=== Physical plan with metrics ===
SortExec: [l_returnflag@0 ASC NULLS LAST,l_linestatus@1 ASC NULLS LAST], metrics=[output_rows=4, elapsed_compute=90.895µs]
CoalescePartitionsExec, metrics=[output_rows=4, elapsed_compute=16.752µs]
ProjectionExec: expr=[l_returnflag@0 as l_returnflag, l_linestatus@1 as l_linestatus, SUM(lineitem.l_quantity)@2 as sum_qty, SUM(lineitem.l_extendedprice)@3 as sum_base_price, SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount)@4 as sum_disc_price, SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount * Int64(1) + lineitem.l_tax)@5 as sum_charge, AVG(lineitem.l_quantity)@6 as avg_qty, AVG(lineitem.l_extendedprice)@7 as avg_price, AVG(lineitem.l_discount)@8 as avg_disc, COUNT(UInt8(1))@9 as count_order], metrics=[output_rows=4, elapsed_compute=269.589µs]
HashAggregateExec: mode=FinalPartitioned, gby=[l_returnflag@0 as l_returnflag, l_linestatus@1 as l_linestatus], aggr=[SUM(lineitem.l_quantity), SUM(lineitem.l_extendedprice), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount Multiply Int64(1) Plus lineitem.l_tax), AVG(lineitem.l_quantity), AVG(lineitem.l_extendedprice), AVG(lineitem.l_discount), COUNT(UInt8(1))], metrics=[output_rows=4, elapsed_compute=966.04µs]
CoalesceBatchesExec: target_batch_size=2048, metrics=[output_rows=96, elapsed_compute=3.118624ms]
RepartitionExec: partitioning=Hash([Column { name: "l_returnflag", index: 0 }, Column { name: "l_linestatus", index: 1 }], 24), metrics=[send_time{inputPartition=0}=202.529µs, fetch_time{inputPartition=0}=167.702662304s, repart_time{inputPartition=0}=881.476µs]
HashAggregateExec: mode=Partial, gby=[l_returnflag@5 as l_returnflag, l_linestatus@6 as l_linestatus], aggr=[SUM(lineitem.l_quantity), SUM(lineitem.l_extendedprice), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount Multiply Int64(1) Plus lineitem.l_tax), AVG(lineitem.l_quantity), AVG(lineitem.l_extendedprice), AVG(lineitem.l_discount), COUNT(UInt8(1))], metrics=[output_rows=96, elapsed_compute=69.277706429s]
ProjectionExec: expr=[l_extendedprice@1 * CAST(1 AS Float64) - l_discount@2 as BinaryExpr-*BinaryExpr--Column-lineitem.l_discountLiteral1Column-lineitem.l_extendedprice, l_quantity@0 as l_quantity, l_extendedprice@1 as l_extendedprice, l_discount@2 as l_discount, l_tax@3 as l_tax, l_returnflag@4 as l_returnflag, l_linestatus@5 as l_linestatus], metrics=[output_rows=591599326, elapsed_compute=1.948225184s]
CoalesceBatchesExec: target_batch_size=2048, metrics=[output_rows=591599326, elapsed_compute=19.900026641s]
FilterExec: l_shipdate@6 <= 10471, metrics=[output_rows=591599326, elapsed_compute=17.25811968s]
ParquetExec: batch_size=4096, limit=None, partitions=[/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-11.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-0.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet, /mnt/bigdata/tp
ch/sf100-24part-parquet/lineitem/part-4.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-9.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-18.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-15.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet], metrics=[row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24p
art-parquet/lineitem/part-11.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-0.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-0.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet}=0, num_predicate_creation_errors=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-4.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet}=0, predicate_evaluation_errors{filenam
e=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-9.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-18.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-4.parquet}=0, predicate_evaluation_errors{filename=/m
nt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-9.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-18.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet}=0, predicate_
evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-15.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-11.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-15.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet}=0, predicate_evaluation_errors{
filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet}=0]
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+---------------------+-------------+
| l_returnflag | l_linestatus | sum_qty | sum_base_price | sum_disc_price | sum_charge | avg_qty | avg_price | avg_disc | count_order |
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+---------------------+-------------+
| A | F | 3775127569 | 5660775782243.05 | 5377736101986.642 | 5592847119226.676 | 25.49937018008533 | 38236.11640655463 | 0.05000224292310846 | 148047875 |
| N | F | 98553062 | 147771098385.98004 | 140384965965.0348 | 145999793032.77588 | 25.501556956882876 | 38237.19938880452 | 0.04998528433805397 | 3864590 |
| N | O | 7436302680 | 11150725250531.35 | 10593194904399.143 | 11016931834528.23 | 25.500009351223113 | 38237.22761127161 | 0.04999791797263452 | 291619606 |
| R | F | 3775724821 | 5661602800938.199 | 5378513347920.042 | 5593662028982.476 | 25.500066311082758 | 38236.6972423322 | 0.05000130406955945 | 148067255 |
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+---------------------+-------------+
Query 1 iteration 0 took 27109.6 ms
Query 1 avg time: 27109.65 ms
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] alamb commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
alamb commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1013079492
Thank you @houqp and @Igosuki -- I'll try and take a look at this later today or tomorrow. I will also start the discussion of "what does this mean for arrow-rs", which I expect may take some time to come to consensus on today
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] ic4y edited a comment on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
ic4y edited a comment on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1012809108
I found that the peak memory usage of this branch increases by 80% compared to the master branch。
sql : select avg(user_id) from parquet_event_1 group by user_name limit 10
test dataset : total 450 million, 50 million users
| branch | peak memory |
| ---- | ---- |
| master(d7e465 and 35d65fc) | 6G |
| arrow2_merge | 10G |
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp edited a comment on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp edited a comment on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1013835311
Thank you everyone for all the reviews and comments so far. @Igosuki and I have addressed most of them. Here are the two remaining todo items:
- [x] Get the parquet row group filter test to pass
- [x] Restore sql integration test migration. All those sql tests were migrated and passing previously, but those changes got lost when we merged the sql test refactoring from master.
I will keep working on this tomorrow. In the mean time, feel free to send PRs to my fork if you are interested in helping. After these two items are fixed, I will run another round of benchmark to double check the performance fix. It's quite interesting that I got the opposite performance test result initial even without that file buf fix :P I will dig into what's causing that as well.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] yjshen commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
yjshen commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1017190215
Wow! Milestone reached! Thanks for driving on this and making it happen @houqp 👍
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1012678951
Thanks to @Igosuki and @yjshen , we are now down to a single parquet row group pruning related test failure. All other 855 tests are passing without error.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] alamb commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
alamb commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1013246630
@ic4y @tustvold mentioned to me in passing that one of the differences in memory usage might be related to parquet2 decoding entire pages at a time rather than reading them out in smaller batches. I am not sure if that matches your observations
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1017176758
Thank you @jorgecarleitao @yjshen and @Igosuki for your hard work on the migration thus far :)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] alamb commented on a change in pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
alamb commented on a change in pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#discussion_r785303506
##########
File path: .github/workflows/rust.yml
##########
@@ -116,6 +116,7 @@ jobs:
cargo test --no-default-features
cargo run --example csv_sql
cargo run --example parquet_sql
+ #nopass
Review comment:
What does `#nopass` mean?
##########
File path: datafusion/tests/mod.rs
##########
@@ -1,18 +0,0 @@
-// Licensed to the Apache Software Foundation (ASF) under one
Review comment:
By deleting this file (non obviously) prevents the sql integration tests from running
When I restored it
And then tried to run the sql integration tests:
```
cd /Users/alamb/Software/arrow-datafusion && CARGO_TARGET_DIR=/Users/alamb/Software/df-target cargo test -p datafusion --test mod
```
It doesn't compile.
```
cd /Users/alamb/Software/arrow-datafusion && CARGO_TARGET_DIR=/Users/alamb/Software/df-target cargo test -p datafusion --test mod
Compiling datafusion v6.0.0 (/Users/alamb/Software/arrow-datafusion/datafusion)
error[E0432]: unresolved import `arrow::util::display`
--> datafusion/tests/sql/mod.rs:23:11
|
23 | util::display::array_value_to_string,
| ^^^^^^^ could not find `display` in `util`
error[E0433]: failed to resolve: could not find `pretty` in `util`
--> datafusion/tests/sql/explain_analyze.rs:45:34
|
45 | let formatted = arrow::util::pretty::pretty_format_batches(&results).unwrap();
| ^^^^^^ could not find `pretty` in `util`
error[E0433]: failed to resolve: could not find `pretty` in `util`
--> datafusion/tests/sql/explain_analyze.rs:551:31
|
551 | let actual = arrow::util::pretty::pretty_format_batches(&actual).unwrap();
| ^^^^^^ could not find `pretty` in `util`
error[E0433]: failed to resolve: could not find `pretty` in `util`
--> datafusion/tests/sql/explain_analyze.rs:557:31
|
557 | let actual = arrow::util::pretty::pretty_format_batches(&actual).unwrap();
| ^^^^^^ could not find `pretty` in `util`
error[E0433]: failed to resolve: could not find `pretty` in `util`
--> datafusion/tests/sql/explain_analyze.rs:763:34
|
763 | let formatted = arrow::util::pretty::pretty_format_batches(&actual).unwrap();
| ^^^^^^ could not find `pretty` in `util`
error[E0433]: failed to resolve: could not find `pretty` in `util`
--> datafusion/tests/sql/explain_analyze.rs:783:34
|
783 | let formatted = arrow::util::pretty::pretty_format_batches(&actual).unwrap();
| ^^^^^^ could not find `pretty` in `util`
error[E0433]: failed to resolve: use of undeclared type `StringArray`
--> datafusion/tests/sql/functions.rs:89:22
|
89 | Arc::new(StringArray::from(vec!["", "a", "aa", "aaa"])),
| ^^^^^^^^^^^ use of undeclared type `StringArray`
....
```
This naming is very confusing -- I'll open a PR / issue to fix it shortly
##########
File path: .github/workflows/rust.yml
##########
@@ -318,8 +320,7 @@ jobs:
run: |
cargo miri setup
cargo clean
- # Ignore MIRI errors until we can get a clean run
- cargo miri test || true
+ cargo miri test
Review comment:
👍
##########
File path: ballista/rust/core/Cargo.toml
##########
@@ -35,23 +35,21 @@ async-trait = "0.1.36"
futures = "0.3"
hashbrown = "0.11"
log = "0.4"
-prost = "0.8"
+prost = "0.9"
serde = {version = "1", features = ["derive"]}
sqlparser = "0.13"
tokio = "1.0"
-tonic = "0.5"
+tonic = "0.6"
uuid = { version = "0.8", features = ["v4"] }
chrono = { version = "0.4", default-features = false }
-# workaround for https://github.com/apache/arrow-datafusion/issues/1498
-# should be able to remove when we update arrow-flight
-quote = "=1.0.10"
-arrow-flight = { version = "6.4.0" }
+arrow-format = { version = "0.3", features = ["flight-data", "flight-service"] }
Review comment:
https://crates.io/crates/arrow-format for anyone else following along
Perhaps that is something else we could consider putting into the official apache repo over time (to reduce maintenance costs / allow others to help do so)
##########
File path: datafusion/src/physical_plan/expressions/binary.rs
##########
@@ -981,249 +859,125 @@ mod tests {
// 4. verify that the resulting expression is of type C
// 5. verify that the results of evaluation are $VEC
macro_rules! test_coercion {
- ($A_ARRAY:ident, $A_TYPE:expr, $A_VEC:expr, $B_ARRAY:ident, $B_TYPE:expr, $B_VEC:expr, $OP:expr, $C_ARRAY:ident, $C_TYPE:expr, $VEC:expr) => {{
+ ($A_ARRAY:ident, $B_ARRAY:ident, $OP:expr, $C_ARRAY:ident) => {{
let schema = Schema::new(vec![
- Field::new("a", $A_TYPE, false),
- Field::new("b", $B_TYPE, false),
+ Field::new("a", $A_ARRAY.data_type().clone(), false),
+ Field::new("b", $B_ARRAY.data_type().clone(), false),
]);
- let a = $A_ARRAY::from($A_VEC);
- let b = $B_ARRAY::from($B_VEC);
-
// verify that we can construct the expression
let expression =
binary(col("a", &schema)?, $OP, col("b", &schema)?, &schema)?;
let batch = RecordBatch::try_new(
Arc::new(schema.clone()),
- vec![Arc::new(a), Arc::new(b)],
+ vec![Arc::new($A_ARRAY), Arc::new($B_ARRAY)],
)?;
// verify that the expression's type is correct
- assert_eq!(expression.data_type(&schema)?, $C_TYPE);
+ assert_eq!(&expression.data_type(&schema)?, $C_ARRAY.data_type());
// compute
let result = expression.evaluate(&batch)?.into_array(batch.num_rows());
// verify that the array's data_type is correct
Review comment:
```suggestion
// verify that the array is equal
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on a change in pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp commented on a change in pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#discussion_r785398875
##########
File path: datafusion/Cargo.toml
##########
@@ -74,14 +76,24 @@ regex = { version = "^1.4.3", optional = true }
lazy_static = { version = "^1.4.0" }
smallvec = { version = "1.6", features = ["union"] }
rand = "0.8"
-avro-rs = { version = "0.13", features = ["snappy"], optional = true }
num-traits = { version = "0.2", optional = true }
pyo3 = { version = "0.14", optional = true }
+avro-schema = { version = "0.2", optional = true }
Review comment:
yes, looks like this is required in order to create an arrow2 avro reader.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] jorgecarleitao commented on a change in pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
jorgecarleitao commented on a change in pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#discussion_r785394934
##########
File path: ballista/rust/core/Cargo.toml
##########
@@ -35,23 +35,21 @@ async-trait = "0.1.36"
futures = "0.3"
hashbrown = "0.11"
log = "0.4"
-prost = "0.8"
+prost = "0.9"
serde = {version = "1", features = ["derive"]}
sqlparser = "0.13"
tokio = "1.0"
-tonic = "0.5"
+tonic = "0.6"
uuid = { version = "0.8", features = ["v4"] }
chrono = { version = "0.4", default-features = false }
-# workaround for https://github.com/apache/arrow-datafusion/issues/1498
-# should be able to remove when we update arrow-flight
-quote = "=1.0.10"
-arrow-flight = { version = "6.4.0" }
+arrow-format = { version = "0.3", features = ["flight-data", "flight-service"] }
Review comment:
I agree.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] Igosuki commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
Igosuki commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1013898492
Yes sorry about that, these were simply comments to Indicate that these
particular feature tests were not passing.
Le dim. 16 janv. 2022 à 09:52, QP Hou ***@***.***> a écrit :
> Thank you everyone for all the reviews and comments so far. @Igosuki
> <https://github.com/Igosuki> and I have addressed most of them. Here are
> the two remaining todo items:
>
> - Get the parquet row group filter test to pass
> - Restore sql integration test migration. All those sql tests were
> migrated and passing previously, but those changes got lost when we merged
> the sql test refactoring from master.
>
> I will keep working on this tomorrow. In the mean time, feel free to send
> PRs to my fork if you are interested in helping. After these two items are
> fixed, I will run another round of benchmark to double check the
> performance fix. It's quite interesting that I got the opposite performance
> test result initial even without that file buf fix :P I will dig into
> what's causing that as well.
>
> —
> Reply to this email directly, view it on GitHub
> <https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1013835311>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AADDFBSPYHZOIG4O2XOGWZDUWKBLXANCNFSM5L5P5AVQ>
> .
> Triage notifications on the go with GitHub Mobile for iOS
> <https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>
> or Android
> <https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub>.
>
> You are receiving this because you were mentioned.Message ID:
> ***@***.***>
>
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1019727038
Quick update on this, I have cleaned up the issues in the arrow2 milestone: https://github.com/apache/arrow-datafusion/milestone/3. The main remaining items are:
* https://github.com/apache/arrow-datafusion/issues/1652
* https://github.com/apache/arrow-datafusion/issues/1656
* https://github.com/apache/arrow-datafusion/issues/1657
I will keep work on issues in the arrow2 milestone whenever I have capacity. If anyone of you are interested in helping, please feel free to comment on those issues or send PRs to the official arrow2 branch.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] alamb commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
alamb commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1013674164
Discussion of arrow-rs / arrow2 is here in case anyone missed it: https://github.com/apache/arrow-rs/issues/1176
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] Igosuki commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
Igosuki commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1013010833
Just use massif or heaptrack
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] Igosuki commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
Igosuki commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1013080406
Ok adding BufReader gave 50% perf on parquet. https://github.com/houqp/arrow-datafusion/pull/19/commits/d8a184969bd2a88292158cbc704e0cb959b28ea6
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1014163126
The parquet row group test failure turned out to be a red herring. The asserted expected result is actually not correct. I have filed a follow up issue at https://github.com/apache/arrow-datafusion/issues/1591. I changed the expected result in this branch to fix the test failure for now. What the predicate pruning logic returns in this branch is more correct than what we have in master, but still wrong. The proper fix is out of scope of arrow2 migration and tracked in #1591.
We are now passing all 856 unit tests. 2 more integration tests to fix, which are caused by difference in how arrow2 formats binary array.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] yjshen commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
yjshen commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1014180045
> The parquet row group test failure turned out to be a red herring. The asserted expected result is actually not correct. I have filed a follow up issue at #1591.
I shared the same observation in https://github.com/houqp/arrow-datafusion/pull/16, but ignored the test at the time.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] yjshen commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
yjshen commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1012813388
@ic4y I'm confused with the numbers and "increases by 80% compared to the master branch"
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on a change in pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp commented on a change in pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#discussion_r785403949
##########
File path: datafusion/src/datasource/object_store/mod.rs
##########
@@ -33,6 +33,12 @@ use local::LocalFileSystem;
use crate::error::{DataFusionError, Result};
+/// Both Read and Seek
+pub trait ReadSeek: Read + Seek {}
+
+impl<R: Read + Seek> ReadSeek for std::io::BufReader<R> {}
+impl<R: AsRef<[u8]>> ReadSeek for std::io::Cursor<R> {}
Review comment:
Nice tip on the generic approach. @Igosuki is right that this is not needed for BufRead and Cursor, It's only needed for `std::fs::File`, so I will keep the generic form. Here is the build error I got without it:
```
error[E0277]: the trait bound `std::fs::File: datasource::object_store::ReadSeek` is not satisfied
--> datafusion/src/datasource/object_store/local.rs:82:12
|
82 | Ok(Box::new(File::open(&self.file.path)?))
| -- ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `datasource::object_store::ReadSeek` is not implemented for `std::fs::File`
| |
| required by a bound introduced by this call
|
= note: required for the cast to the object type `dyn datasource::object_store::ReadSeek + std::marker::Send + std::marker::Sync`
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] jorgecarleitao commented on a change in pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
jorgecarleitao commented on a change in pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#discussion_r785396533
##########
File path: datafusion/src/datasource/file_format/parquet.rs
##########
@@ -238,29 +246,30 @@ fn summarize_min_max(
}
}
}
- _ => {}
+ PhysicalType::FixedLenByteArray(_) => {
+ // type not supported yet
+ }
}
+
+ Ok(())
}
/// Read and parse the schema of the Parquet file at location `path`
fn fetch_schema(object_reader: Arc<dyn ObjectReader>) -> Result<Schema> {
- let obj_reader = ChunkObjectReader(object_reader);
- let file_reader = Arc::new(SerializedFileReader::new(obj_reader)?);
- let mut arrow_reader = ParquetFileArrowReader::new(file_reader);
- let schema = arrow_reader.get_schema()?;
-
+ let mut reader = object_reader.sync_reader()?;
+ let meta_data = read_metadata(&mut reader)?;
+ let schema = get_schema(&meta_data)?;
Ok(schema)
}
/// Read and parse the statistics of the Parquet file at location `path`
fn fetch_statistics(object_reader: Arc<dyn ObjectReader>) -> Result<Statistics> {
- let obj_reader = ChunkObjectReader(object_reader);
- let file_reader = Arc::new(SerializedFileReader::new(obj_reader)?);
- let mut arrow_reader = ParquetFileArrowReader::new(file_reader);
- let schema = arrow_reader.get_schema()?;
+ let mut reader = object_reader.sync_reader()?;
Review comment:
IMO this is the culprit of the perf regressions since this does not buffer anything. Filled under #1583
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] Igosuki commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
Igosuki commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1017460977
Great work @houqp
Le jeu. 20 janv. 2022 à 08:27, Yijie Shen ***@***.***> a
écrit :
> Wow! Milestone reached! Thanks for driving on this and making it happen
> @houqp <https://github.com/houqp> 👍
>
> —
> Reply to this email directly, view it on GitHub
> <https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1017190215>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AADDFBWXQK6FFRP4FXB26JDUW62PLANCNFSM5L5P5AVQ>
> .
> Triage notifications on the go with GitHub Mobile for iOS
> <https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>
> or Android
> <https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub>.
>
> You are receiving this because you were mentioned.Message ID:
> ***@***.***>
>
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] alamb commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
alamb commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1015536714
I think we should merge it into the arrow2 branch and keep iterating from there. I suspect the next big chunk of work is the `RecordBatch` removal / adaptation in https://github.com/jorgecarleitao/arrow2/pull/717
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on a change in pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp commented on a change in pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#discussion_r785407309
##########
File path: datafusion/tests/mod.rs
##########
@@ -1,18 +0,0 @@
-// Licensed to the Apache Software Foundation (ASF) under one
Review comment:
oh wow, good catch!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] andygrove commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
andygrove commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1013718590
Here are some quick benchmark results comparing the master branch and this PR, running on a threadripper desktop with 24 cores and an NVMe drive. I ran each query once only.
These are the commands that I ran:
```
cargo build --release
cd benchmarks
cargo run --release --bin tpch -- benchmark datafusion --iterations 1 --path /mnt/bigdata/tpch/sf100-24part-parquet --format parquet --query 13 --batch-size 4096 --partitions 24
```
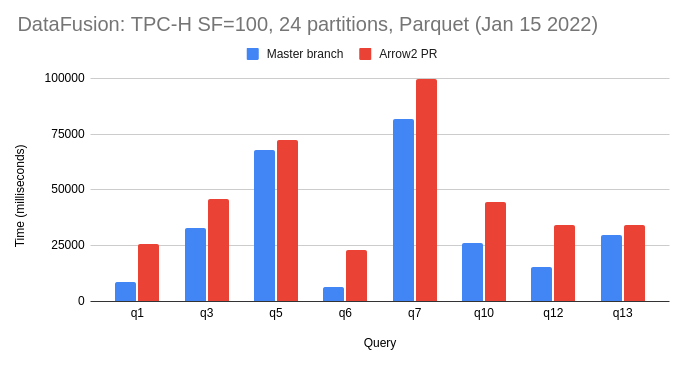
Queries 1 and 6 were both at least 3x slower and query 12 was more than 2x slower.
I used the following commits:
Master: 1c39f5ce865e3e1225b4895196073be560a93e82
Arrow2: e53d165f018a54d47f80ff2a132f83cee363c79c
I will poke around a bit myself this weekend and see if I can debug this based on metrics to try and determine where the performance issues are.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] jorgecarleitao commented on a change in pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
jorgecarleitao commented on a change in pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#discussion_r784507391
##########
File path: datafusion/Cargo.toml
##########
@@ -74,14 +76,24 @@ regex = { version = "^1.4.3", optional = true }
lazy_static = { version = "^1.4.0" }
smallvec = { version = "1.6", features = ["union"] }
rand = "0.8"
-avro-rs = { version = "0.13", features = ["snappy"], optional = true }
num-traits = { version = "0.2", optional = true }
pyo3 = { version = "0.14", optional = true }
+avro-schema = { version = "0.2", optional = true }
Review comment:
Is this needed?
##########
File path: datafusion/src/logical_plan/dfschema.rs
##########
@@ -536,9 +536,10 @@ mod tests {
fn from_qualified_schema_into_arrow_schema() -> Result<()> {
let schema = DFSchema::try_from_qualified_schema("t1", &test_schema_1())?;
let arrow_schema: Schema = schema.into();
- let expected = "Field { name: \"c0\", data_type: Boolean, nullable: true, dict_id: 0, dict_is_ordered: false, metadata: None }, \
Review comment:
note how `dict_id` and `dict_is_ordered`, two confusing attributes of `Field`, were removed. `dict_is_ordered` is now on the `DataType::Dictionary` itself, which allows implementations to leverage this flag in compute directly, `dict_id` is now only required when writing to IPC (via a different mechanism)
##########
File path: ballista/rust/core/src/execution_plans/shuffle_writer.rs
##########
@@ -532,6 +541,7 @@ mod tests {
.unwrap();
let num_rows = stats
+ // see https://github.com/jorgecarleitao/arrow2/pull/416 for fix
Review comment:
```suggestion
```
##########
File path: ballista/rust/core/Cargo.toml
##########
@@ -35,23 +35,21 @@ async-trait = "0.1.36"
futures = "0.3"
hashbrown = "0.11"
log = "0.4"
-prost = "0.8"
+prost = "0.9"
serde = {version = "1", features = ["derive"]}
sqlparser = "0.13"
tokio = "1.0"
-tonic = "0.5"
+tonic = "0.6"
uuid = { version = "0.8", features = ["v4"] }
chrono = { version = "0.4", default-features = false }
-# workaround for https://github.com/apache/arrow-datafusion/issues/1498
-# should be able to remove when we update arrow-flight
-quote = "=1.0.10"
-arrow-flight = { version = "6.4.0" }
+arrow-format = { version = "0.3", features = ["flight-data", "flight-service"] }
Review comment:
`arrow-format` is an auxiliary crate that only contains the IPC and flight. This is so that we can more easily follow changes to the Arrow spec there (and/or particular libs we use to derive proto/flat buffers).
##########
File path: datafusion/src/physical_plan/file_format/json.rs
##########
@@ -50,6 +54,43 @@ impl NdJsonExec {
}
}
+// TODO: implement iterator in upstream json::Reader type
+struct JsonBatchReader<R: Read> {
+ reader: R,
+ schema: SchemaRef,
+ batch_size: usize,
+ proj: Option<Vec<String>>,
+}
+
+impl<R: BufRead> Iterator for JsonBatchReader<R> {
+ type Item = ArrowResult<RecordBatch>;
+
+ fn next(&mut self) -> Option<Self::Item> {
+ // json::read::read_rows iterates on the empty vec and reads at most n rows
+ let mut rows = vec![String::default(); self.batch_size];
Review comment:
This can be moved to `JsonBatchReader` and re-used across batches (that is the idea, at least)
##########
File path: datafusion-examples/examples/simple_udaf.rs
##########
@@ -37,11 +37,11 @@ fn create_context() -> Result<ExecutionContext> {
// define data in two partitions
let batch1 = RecordBatch::try_new(
schema.clone(),
- vec![Arc::new(Float32Array::from(vec![2.0, 4.0, 8.0]))],
+ vec![Arc::new(Float32Array::from_values(vec![2.0, 4.0, 8.0]))],
Review comment:
```suggestion
vec![Arc::new(Float32Array::from_slice([2.0, 4.0, 8.0]))],
```
##########
File path: datafusion/Cargo.toml
##########
@@ -39,25 +39,27 @@ path = "src/lib.rs"
[features]
default = ["crypto_expressions", "regex_expressions", "unicode_expressions"]
-simd = ["arrow/simd"]
+# FIXME: https://github.com/jorgecarleitao/arrow2/issues/580
+#simd = ["arrow/simd"]
+simd = []
crypto_expressions = ["md-5", "sha2", "blake2", "blake3"]
regex_expressions = ["regex"]
unicode_expressions = ["unicode-segmentation"]
-pyarrow = ["pyo3", "arrow/pyarrow"]
+# FIXME: add pyarrow support to arrow2 pyarrow = ["pyo3", "arrow/pyarrow"]
+pyarrow = ["pyo3"]
# Used for testing ONLY: causes all values to hash to the same value (test for collisions)
force_hash_collisions = []
# Used to enable the avro format
-avro = ["avro-rs", "num-traits"]
+avro = ["arrow/io_avro", "arrow/io_avro_async", "arrow/io_avro_compression", "num-traits", "avro-schema"]
[dependencies]
ahash = { version = "0.7", default-features = false }
hashbrown = { version = "0.11", features = ["raw"] }
-arrow = { version = "6.4.0", features = ["prettyprint"] }
-parquet = { version = "6.4.0", features = ["arrow"] }
+parquet = { package = "parquet2", version = "0.8", default_features = false, features = ["stream"] }
sqlparser = "0.13"
paste = "^1.0"
num_cpus = "1.13.0"
-chrono = { version = "0.4", default-features = false }
+chrono = { version = "0.4", default-features = false, features = ["clock"] }
Review comment:
Note that this feature has a known vulnerability. `arrow-rs` depends on it, `arrow2` does not (casting from utf8 to datetime is consistent with the arrow spec's definitions of timezone-aware timezones). It seems that datafusion depends on this (due to how postgres casts string to datetimes?)
##########
File path: datafusion-examples/examples/simple_udaf.rs
##########
@@ -37,11 +37,11 @@ fn create_context() -> Result<ExecutionContext> {
// define data in two partitions
let batch1 = RecordBatch::try_new(
schema.clone(),
- vec![Arc::new(Float32Array::from(vec![2.0, 4.0, 8.0]))],
+ vec![Arc::new(Float32Array::from_values(vec![2.0, 4.0, 8.0]))],
)?;
let batch2 = RecordBatch::try_new(
schema.clone(),
- vec![Arc::new(Float32Array::from(vec![64.0]))],
+ vec![Arc::new(Float32Array::from_values(vec![64.0]))],
Review comment:
```suggestion
vec![Arc::new(Float32Array::from_slice([64.0]))],
```
##########
File path: datafusion/src/physical_plan/hash_join.rs
##########
@@ -681,8 +666,8 @@ fn build_join_indexes(
match join_type {
JoinType::Inner | JoinType::Semi | JoinType::Anti => {
// Using a buffer builder to avoid slower normal builder
- let mut left_indices = UInt64BufferBuilder::new(0);
- let mut right_indices = UInt32BufferBuilder::new(0);
+ let mut left_indices = Vec::<u64>::new();
Review comment:
this is another major difference: arrow2 is interoperable with `Vec`: `Buffer<T>` implements `From<Vec<T>>`
##########
File path: datafusion/Cargo.toml
##########
@@ -39,25 +39,27 @@ path = "src/lib.rs"
[features]
default = ["crypto_expressions", "regex_expressions", "unicode_expressions"]
-simd = ["arrow/simd"]
+# FIXME: https://github.com/jorgecarleitao/arrow2/issues/580
+#simd = ["arrow/simd"]
+simd = []
Review comment:
```suggestion
simd = ["arrow/simd"]
```
##########
File path: datafusion/src/datasource/file_format/parquet.rs
##########
@@ -342,12 +332,12 @@ mod tests {
use super::*;
use arrow::array::{
- BinaryArray, BooleanArray, Float32Array, Float64Array, Int32Array,
- TimestampNanosecondArray,
+ BinaryArray, BooleanArray, Float32Array, Float64Array, Int32Array, Int64Array,
};
use futures::StreamExt;
#[tokio::test]
+ /// Parquet2 lacks the ability to set batch size for parquet reader
Review comment:
it is by design: parquet's unit of parallel work is the column chunk. Setting a batch size breaks that unit of work since it requires shared state and synchronization across column chunks (longer version here: https://medium.com/@henry.yijieshen/for-csv-or-the-like-we-could-split-file-by-offsets-and-take-special-care-for-those-records-spread-3ff43195f90)
The upsell is that arrow2 supports parallel deserialization out of the box, e.g. [this example](https://github.com/jorgecarleitao/arrow2/blob/main/examples/parquet_read_parallel/src/main.rs), which allows to break from the usual one thread one file constraint found in other systems. In Polars we saw a 1.5-2x speedup when doing this (they use rayon, but the principle applies).
##########
File path: ballista-examples/src/bin/ballista-sql.rs
##########
@@ -27,7 +27,7 @@ async fn main() -> Result<()> {
.build()?;
let ctx = BallistaContext::remote("localhost", 50050, &config);
- let testdata = datafusion::arrow::util::test_util::arrow_test_data();
Review comment:
this was made private in `arrow2` because all tests in arrow2 are outside `src/`, so that adding tests does not require re-compiling the crate (and makes it easier to follow which changes are to the source and which changes are to the tests)
##########
File path: datafusion/Cargo.toml
##########
@@ -74,14 +76,24 @@ regex = { version = "^1.4.3", optional = true }
lazy_static = { version = "^1.4.0" }
smallvec = { version = "1.6", features = ["union"] }
rand = "0.8"
-avro-rs = { version = "0.13", features = ["snappy"], optional = true }
num-traits = { version = "0.2", optional = true }
pyo3 = { version = "0.14", optional = true }
+avro-schema = { version = "0.2", optional = true }
+
+[dependencies.arrow]
+package = "arrow2"
+version="0.8"
+features = ["io_csv", "io_json", "io_parquet", "io_parquet_compression", "io_ipc", "io_print", "ahash",
+ "compute_merge_sort", "compute_concatenate", "compute_regex_match", "compute_arithmetics",
+ "compute_cast", "compute_partition", "compute_temporal", "compute_take", "compute_aggregate",
+ "compute_comparison", "compute_if_then_else", "compute_nullif", "compute_boolean", "compute_length",
+ "compute_limit", "compute_boolean_kleene", "compute_like", "compute_filter", "compute_window",]
Review comment:
`"compute"` feature is an alias for all `compute_*` features.
##########
File path: datafusion/tests/parquet_pruning.rs
##########
@@ -697,13 +730,17 @@ fn make_timestamp_batch(offset: Duration) -> RecordBatch {
.map(|(i, _)| format!("Row {} + {}", i, offset))
.collect::<Vec<_>>();
- let arr_nanos = TimestampNanosecondArray::from_opt_vec(ts_nanos, None);
- let arr_micros = TimestampMicrosecondArray::from_opt_vec(ts_micros, None);
- let arr_millis = TimestampMillisecondArray::from_opt_vec(ts_millis, None);
- let arr_seconds = TimestampSecondArray::from_opt_vec(ts_seconds, None);
+ let arr_nanos = PrimitiveArray::<i64>::from(ts_nanos)
+ .to(DataType::Timestamp(TimeUnit::Nanosecond, None));
Review comment:
this is an example of why it is so easy to add timezone support in arrow2 - the physical type (`i64`) is separated from the logical type `DataType::Timestamp(TimeUnit::Nanosecond, None)` so that we "attach" logical types to the (physical) array.
##########
File path: ballista/rust/core/src/execution_plans/shuffle_writer.rs
##########
@@ -567,6 +577,7 @@ mod tests {
.downcast_ref::<StructArray>()
.unwrap();
let num_rows = stats
+ // see https://github.com/jorgecarleitao/arrow2/pull/416 for fix
Review comment:
```suggestion
```
##########
File path: datafusion-examples/examples/flight_client.rs
##########
@@ -57,23 +55,26 @@ async fn main() -> Result<(), Box<dyn std::error::Error>> {
// the schema should be the first message returned, else client should error
let flight_data = stream.message().await?.unwrap();
// convert FlightData to a stream
- let schema = Arc::new(Schema::try_from(&flight_data)?);
+ let (schema, ipc_schema) =
+ deserialize_schemas(flight_data.data_body.as_slice()).unwrap();
+ let schema = Arc::new(schema);
println!("Schema: {:?}", schema);
// all the remaining stream messages should be dictionary and record batches
let mut results = vec![];
- let dictionaries_by_field = vec![None; schema.fields().len()];
+ let dictionaries_by_field = HashMap::new();
Review comment:
this is a subtle change for interoperability with the arrow spec - arrow2 implements the complete arrow specification (all official integration tests pass against C++, [diff on the tests](https://github.com/jorgecarleitao/arrow2/blob/main/integration-testing/unskip.patch)).
##########
File path: ballista/rust/core/src/utils.rs
##########
@@ -30,16 +30,17 @@ use crate::memory_stream::MemoryStream;
use crate::serde::scheduler::PartitionStats;
use crate::config::BallistaConfig;
+use arrow::io::ipc::write::WriteOptions;
Review comment:
```suggestion
use datafusion::arrow::io::ipc::write::WriteOptions;
```
for consistency ^_^
##########
File path: datafusion/src/avro_to_arrow/reader.rs
##########
@@ -101,30 +100,49 @@ impl ReaderBuilder {
}
/// Create a new `Reader` from the `ReaderBuilder`
- pub fn build<'a, R>(self, source: R) -> Result<Reader<'a, R>>
+ pub fn build<R>(self, source: R) -> Result<Reader<R>>
where
R: Read + Seek,
{
let mut source = source;
// check if schema should be inferred
- let schema = match self.schema {
- Some(schema) => schema,
- None => Arc::new(super::read_avro_schema_from_reader(&mut source)?),
- };
source.seek(SeekFrom::Start(0))?;
- Reader::try_new(source, schema, self.batch_size, self.projection)
+ let (mut avro_schemas, mut schema, codec, file_marker) =
+ read::read_metadata(&mut source)?;
+ if let Some(proj) = self.projection {
Review comment:
projections on avro files are not tested in arrow2. Note that a projection in a row-based format is not so appealing because we still need to read the whole row to extract the correct columns and thus the bulk of the cost is still there.
A more defensive approach here is to perform the projection after read (i.e. remove columns from the RecordBatch). Filled upstream: https://github.com/jorgecarleitao/arrow2/issues/764
##########
File path: datafusion/src/datasource/object_store/mod.rs
##########
@@ -33,6 +33,12 @@ use local::LocalFileSystem;
use crate::error::{DataFusionError, Result};
+/// Both Read and Seek
+pub trait ReadSeek: Read + Seek {}
+
+impl<R: Read + Seek> ReadSeek for std::io::BufReader<R> {}
+impl<R: AsRef<[u8]>> ReadSeek for std::io::Cursor<R> {}
Review comment:
Not sure the trait is needed, but
```suggestion
impl<T: Read + Seek> ReadSeek for T {}
```
should generalize for everything.
##########
File path: datafusion/src/datasource/file_format/csv.rs
##########
@@ -96,18 +97,30 @@ impl FileFormat for CsvFormat {
let mut records_to_read = self.schema_infer_max_rec.unwrap_or(std::usize::MAX);
while let Some(obj_reader) = readers.next().await {
- let mut reader = obj_reader?.sync_reader()?;
- let (schema, records_read) = arrow::csv::reader::infer_reader_schema(
+ let mut reader = csv::read::ReaderBuilder::new()
+ .delimiter(self.delimiter)
+ .has_headers(self.has_header)
+ .from_reader(obj_reader?.sync_reader()?);
+
+ let schema = csv::read::infer_schema(
&mut reader,
- self.delimiter,
Some(records_to_read),
self.has_header,
+ &csv::read::infer,
)?;
- if records_read == 0 {
- continue;
- }
+
+ // if records_read == 0 {
+ // continue;
+ // }
+ // schemas.push(schema.clone());
+ // records_to_read -= records_read;
+ // if records_to_read == 0 {
+ // break;
+ // }
+ //
+ // FIXME: return recods_read from infer_schema
Review comment:
Addressed here: https://github.com/jorgecarleitao/arrow2/pull/765
##########
File path: datafusion/src/physical_plan/projection.rs
##########
@@ -70,16 +70,15 @@ impl ProjectionExec {
e.data_type(&input_schema)?,
e.nullable(&input_schema)?,
);
- field.set_metadata(get_field_metadata(e, &input_schema));
+ if let Some(metadata) = get_field_metadata(e, &input_schema) {
+ field = field.with_metadata(metadata);
Review comment:
```field.metadata = metadata;```
would also work when field is `mut` (since everything is public in `Field`)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] Igosuki edited a comment on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
Igosuki edited a comment on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1019463521
> 
@andygrove What tool did you use to get such a smooth CPU chart ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1014164828
I also noticed my benchmarks were ran with data generated from `tpch-gen.sh`, which only produces single partition CSV files. @andygrove could you share with me how you generated your sf100 dataset?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] ic4y commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
ic4y commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1012829112
@yjshen
Sorry, I made a typo, it has been corrected.
I want to express is the same query, using 6G memory on arrow but 10G memory on arrow2
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] andygrove edited a comment on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
andygrove edited a comment on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1013730047
Metrics for query 1 from master & arrow2.
## Master
```
=== Physical plan with metrics ===
SortExec: [l_returnflag@0 ASC NULLS LAST,l_linestatus@1 ASC NULLS LAST], metrics=[output_rows=4, elapsed_compute=148.532µs]
CoalescePartitionsExec, metrics=[output_rows=4, elapsed_compute=26.889µs]
ProjectionExec: expr=[l_returnflag@0 as l_returnflag, l_linestatus@1 as l_linestatus, SUM(lineitem.l_quantity)@2 as sum_qty, SUM(lineitem.l_extendedprice)@3 as sum_base_price, SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount)@4 as sum_disc_price, SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount * Int64(1) + lineitem.l_tax)@5 as sum_charge, AVG(lineitem.l_quantity)@6 as avg_qty, AVG(lineitem.l_extendedprice)@7 as avg_price, AVG(lineitem.l_discount)@8 as avg_disc, COUNT(UInt8(1))@9 as count_order], metrics=[output_rows=4, elapsed_compute=162.216µs]
HashAggregateExec: mode=FinalPartitioned, gby=[l_returnflag@0 as l_returnflag, l_linestatus@1 as l_linestatus], aggr=[SUM(lineitem.l_quantity), SUM(lineitem.l_extendedprice), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount Multiply Int64(1) Plus lineitem.l_tax), AVG(lineitem.l_quantity), AVG(lineitem.l_extendedprice), AVG(lineitem.l_discount), COUNT(UInt8(1))], metrics=[output_rows=4, elapsed_compute=836.092µs]
CoalesceBatchesExec: target_batch_size=2048, metrics=[output_rows=96, elapsed_compute=2.467991ms]
RepartitionExec: partitioning=Hash([Column { name: "l_returnflag", index: 0 }, Column { name: "l_linestatus", index: 1 }], 24), metrics=[fetch_time{inputPartition=0}=121.646159259s, repart_time{inputPartition=0}=1.068665ms, send_time{inputPartition=0}=181.052µs]
HashAggregateExec: mode=Partial, gby=[l_returnflag@5 as l_returnflag, l_linestatus@6 as l_linestatus], aggr=[SUM(lineitem.l_quantity), SUM(lineitem.l_extendedprice), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount Multiply Int64(1) Plus lineitem.l_tax), AVG(lineitem.l_quantity), AVG(lineitem.l_extendedprice), AVG(lineitem.l_discount), COUNT(UInt8(1))], metrics=[output_rows=96, elapsed_compute=62.022452324s]
ProjectionExec: expr=[l_extendedprice@1 * CAST(1 AS Float64) - l_discount@2 as BinaryExpr-*BinaryExpr--Column-lineitem.l_discountLiteral1Column-lineitem.l_extendedprice, l_quantity@0 as l_quantity, l_extendedprice@1 as l_extendedprice, l_discount@2 as l_discount, l_tax@3 as l_tax, l_returnflag@4 as l_returnflag, l_linestatus@5 as l_linestatus], metrics=[output_rows=591599326, elapsed_compute=2.333647686s]
CoalesceBatchesExec: target_batch_size=2048, metrics=[output_rows=591599326, elapsed_compute=18.07630248s]
FilterExec: l_shipdate@6 <= 10471, metrics=[output_rows=591599326, elapsed_compute=14.438278954s]
ParquetExec: batch_size=4096, limit=None, partitions=[/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-11.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-0.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet, /mnt/bigdata/tp
ch/sf100-24part-parquet/lineitem/part-4.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-9.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-18.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-15.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet], metrics=[predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-9.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24p
art-parquet/lineitem/part-18.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-11.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-11.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/
lineitem/part-9.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-18.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/l
ineitem/part-15.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-4.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/pa
rt-0.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet}=0, num_predicate_creation_errors=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-15.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-0.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet}=0, predicate_evaluation_errors{filename=
/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-4.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet}=0]
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+----------------------+-------------+
| l_returnflag | l_linestatus | sum_qty | sum_base_price | sum_disc_price | sum_charge | avg_qty | avg_price | avg_disc | count_order |
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+----------------------+-------------+
| A | F | 3775127569 | 5660775782243.051 | 5377736101986.644 | 5592847119226.674 | 25.49937018008533 | 38236.11640655464 | 0.05000224292310849 | 148047875 |
| N | F | 98553062 | 147771098385.98004 | 140384965965.03497 | 145999793032.7758 | 25.501556956882876 | 38237.19938880452 | 0.04998528433805398 | 3864590 |
| N | O | 7436302680 | 11150725250531.352 | 10593194904399.148 | 11016931834528.229 | 25.500009351223113 | 38237.22761127162 | 0.049997917972634566 | 291619606 |
| R | F | 3775724821 | 5661602800938.198 | 5378513347920.04 | 5593662028982.476 | 25.500066311082758 | 38236.6972423322 | 0.05000130406955949 | 148067255 |
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+----------------------+-------------+
Query 1 iteration 0 took 8165.9 ms
Query 1 avg time: 8165.94 ms
```

## Arrow2 PR
```
=== Physical plan with metrics ===
SortExec: [l_returnflag@0 ASC NULLS LAST,l_linestatus@1 ASC NULLS LAST], metrics=[output_rows=4, elapsed_compute=90.895µs]
CoalescePartitionsExec, metrics=[output_rows=4, elapsed_compute=16.752µs]
ProjectionExec: expr=[l_returnflag@0 as l_returnflag, l_linestatus@1 as l_linestatus, SUM(lineitem.l_quantity)@2 as sum_qty, SUM(lineitem.l_extendedprice)@3 as sum_base_price, SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount)@4 as sum_disc_price, SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount * Int64(1) + lineitem.l_tax)@5 as sum_charge, AVG(lineitem.l_quantity)@6 as avg_qty, AVG(lineitem.l_extendedprice)@7 as avg_price, AVG(lineitem.l_discount)@8 as avg_disc, COUNT(UInt8(1))@9 as count_order], metrics=[output_rows=4, elapsed_compute=269.589µs]
HashAggregateExec: mode=FinalPartitioned, gby=[l_returnflag@0 as l_returnflag, l_linestatus@1 as l_linestatus], aggr=[SUM(lineitem.l_quantity), SUM(lineitem.l_extendedprice), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount Multiply Int64(1) Plus lineitem.l_tax), AVG(lineitem.l_quantity), AVG(lineitem.l_extendedprice), AVG(lineitem.l_discount), COUNT(UInt8(1))], metrics=[output_rows=4, elapsed_compute=966.04µs]
CoalesceBatchesExec: target_batch_size=2048, metrics=[output_rows=96, elapsed_compute=3.118624ms]
RepartitionExec: partitioning=Hash([Column { name: "l_returnflag", index: 0 }, Column { name: "l_linestatus", index: 1 }], 24), metrics=[send_time{inputPartition=0}=202.529µs, fetch_time{inputPartition=0}=167.702662304s, repart_time{inputPartition=0}=881.476µs]
HashAggregateExec: mode=Partial, gby=[l_returnflag@5 as l_returnflag, l_linestatus@6 as l_linestatus], aggr=[SUM(lineitem.l_quantity), SUM(lineitem.l_extendedprice), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount), SUM(lineitem.l_extendedprice * Int64(1) - lineitem.l_discount Multiply Int64(1) Plus lineitem.l_tax), AVG(lineitem.l_quantity), AVG(lineitem.l_extendedprice), AVG(lineitem.l_discount), COUNT(UInt8(1))], metrics=[output_rows=96, elapsed_compute=69.277706429s]
ProjectionExec: expr=[l_extendedprice@1 * CAST(1 AS Float64) - l_discount@2 as BinaryExpr-*BinaryExpr--Column-lineitem.l_discountLiteral1Column-lineitem.l_extendedprice, l_quantity@0 as l_quantity, l_extendedprice@1 as l_extendedprice, l_discount@2 as l_discount, l_tax@3 as l_tax, l_returnflag@4 as l_returnflag, l_linestatus@5 as l_linestatus], metrics=[output_rows=591599326, elapsed_compute=1.948225184s]
CoalesceBatchesExec: target_batch_size=2048, metrics=[output_rows=591599326, elapsed_compute=19.900026641s]
FilterExec: l_shipdate@6 <= 10471, metrics=[output_rows=591599326, elapsed_compute=17.25811968s]
ParquetExec: batch_size=4096, limit=None, partitions=[/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-11.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-0.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet, /mnt/bigdata/tp
ch/sf100-24part-parquet/lineitem/part-4.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-9.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-18.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-15.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet, /mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet], metrics=[row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24p
art-parquet/lineitem/part-11.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-0.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-0.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-3.parquet}=0, num_predicate_creation_errors=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-4.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-2.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-23.parquet}=0, predicate_evaluation_errors{filenam
e=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-9.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-18.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-1.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-4.parquet}=0, predicate_evaluation_errors{filename=/m
nt/bigdata/tpch/sf100-24part-parquet/lineitem/part-5.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-9.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-21.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-7.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-12.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-8.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-18.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet}=0, predicate_
evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-15.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-10.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-16.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-17.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-11.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-15.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-6.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-13.parquet}=0, predicate_evaluation_errors{
filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-20.parquet}=0, predicate_evaluation_errors{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-14.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-19.parquet}=0, row_groups_pruned{filename=/mnt/bigdata/tpch/sf100-24part-parquet/lineitem/part-22.parquet}=0]
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+---------------------+-------------+
| l_returnflag | l_linestatus | sum_qty | sum_base_price | sum_disc_price | sum_charge | avg_qty | avg_price | avg_disc | count_order |
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+---------------------+-------------+
| A | F | 3775127569 | 5660775782243.05 | 5377736101986.642 | 5592847119226.676 | 25.49937018008533 | 38236.11640655463 | 0.05000224292310846 | 148047875 |
| N | F | 98553062 | 147771098385.98004 | 140384965965.0348 | 145999793032.77588 | 25.501556956882876 | 38237.19938880452 | 0.04998528433805397 | 3864590 |
| N | O | 7436302680 | 11150725250531.35 | 10593194904399.143 | 11016931834528.23 | 25.500009351223113 | 38237.22761127161 | 0.04999791797263452 | 291619606 |
| R | F | 3775724821 | 5661602800938.199 | 5378513347920.042 | 5593662028982.476 | 25.500066311082758 | 38236.6972423322 | 0.05000130406955945 | 148067255 |
+--------------+--------------+------------+--------------------+--------------------+--------------------+--------------------+-------------------+---------------------+-------------+
Query 1 iteration 0 took 27109.6 ms
Query 1 avg time: 27109.65 ms
```

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] Igosuki commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
Igosuki commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1019463521
> Query 1 iteration 0 took 27109.6 ms
> Query 1 avg time: 27109.65 ms
> ```
@andygrove What tool did you use to get such a smooth CPU chart ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] Igosuki commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
Igosuki commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1013038787
@houqp What hardware/setup did you use to run the benchmark ? I'm actually getting way worse performance if running tpch using parquet
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1013835311
Thank you everyone for all the reviews and comments so far. @Igosuki and I have addressed most of them. Here are the two remaining todo items:
* Get the parquet row group filter test to pass
* Restore sql integration test migration. All those sql tests were migrated and passing previously, but those changes got lost when we merged the sql test refactoring from master.
I will keep working on this tomorrow. In the mean time, feel free to send PRs to my fork if you are interested in helping. After these two items are fixed, I will run another round of benchmark to double check the performance fix. It's quite interesting that I got the opposite performance test result initial even without that file buf fix :P I will dig into what's causing that as well.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] jorgecarleitao commented on a change in pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
jorgecarleitao commented on a change in pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#discussion_r785396533
##########
File path: datafusion/src/datasource/file_format/parquet.rs
##########
@@ -238,29 +246,30 @@ fn summarize_min_max(
}
}
}
- _ => {}
+ PhysicalType::FixedLenByteArray(_) => {
+ // type not supported yet
+ }
}
+
+ Ok(())
}
/// Read and parse the schema of the Parquet file at location `path`
fn fetch_schema(object_reader: Arc<dyn ObjectReader>) -> Result<Schema> {
- let obj_reader = ChunkObjectReader(object_reader);
- let file_reader = Arc::new(SerializedFileReader::new(obj_reader)?);
- let mut arrow_reader = ParquetFileArrowReader::new(file_reader);
- let schema = arrow_reader.get_schema()?;
-
+ let mut reader = object_reader.sync_reader()?;
+ let meta_data = read_metadata(&mut reader)?;
+ let schema = get_schema(&meta_data)?;
Ok(schema)
}
/// Read and parse the statistics of the Parquet file at location `path`
fn fetch_statistics(object_reader: Arc<dyn ObjectReader>) -> Result<Statistics> {
- let obj_reader = ChunkObjectReader(object_reader);
- let file_reader = Arc::new(SerializedFileReader::new(obj_reader)?);
- let mut arrow_reader = ParquetFileArrowReader::new(file_reader);
- let schema = arrow_reader.get_schema()?;
+ let mut reader = object_reader.sync_reader()?;
Review comment:
```suggestion
let mut reader = object_reader.sync_reader()?;
```
IMO this is the culprit of the perf regressions since this does not buffer anything. Filled under #1583
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp edited a comment on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp edited a comment on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1013835311
Thank you everyone for all the reviews and comments so far. @Igosuki and I have addressed most of them. Here are the two remaining todo items:
- [ ] Get the parquet row group filter test to pass
- [x] Restore sql integration test migration. All those sql tests were migrated and passing previously, but those changes got lost when we merged the sql test refactoring from master.
I will keep working on this tomorrow. In the mean time, feel free to send PRs to my fork if you are interested in helping. After these two items are fixed, I will run another round of benchmark to double check the performance fix. It's quite interesting that I got the opposite performance test result initial even without that file buf fix :P I will dig into what's causing that as well.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp commented on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1016085515
oops, looks like the arrow2 branch got updated with latest commits from master, anyone mind if I revert it back to https://github.com/apache/arrow-datafusion/commit/2008b1dc06d5030f572634c7f8f2ba48562fa636 and handle master catch up in a follow up PR?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on a change in pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp commented on a change in pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#discussion_r785403551
##########
File path: datafusion/src/avro_to_arrow/reader.rs
##########
@@ -101,30 +100,49 @@ impl ReaderBuilder {
}
/// Create a new `Reader` from the `ReaderBuilder`
- pub fn build<'a, R>(self, source: R) -> Result<Reader<'a, R>>
+ pub fn build<R>(self, source: R) -> Result<Reader<R>>
where
R: Read + Seek,
{
let mut source = source;
// check if schema should be inferred
- let schema = match self.schema {
- Some(schema) => schema,
- None => Arc::new(super::read_avro_schema_from_reader(&mut source)?),
- };
source.seek(SeekFrom::Start(0))?;
- Reader::try_new(source, schema, self.batch_size, self.projection)
+ let (mut avro_schemas, mut schema, codec, file_marker) =
+ read::read_metadata(&mut source)?;
+ if let Some(proj) = self.projection {
Review comment:
I might be missing something here, if this is properly supported by arrow2, we don't need to play defense and do the post read projection right? I agree with @Igosuki that there is still benefit in saving compute and memory by doing this at parsing time.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on a change in pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
houqp commented on a change in pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#discussion_r785403949
##########
File path: datafusion/src/datasource/object_store/mod.rs
##########
@@ -33,6 +33,12 @@ use local::LocalFileSystem;
use crate::error::{DataFusionError, Result};
+/// Both Read and Seek
+pub trait ReadSeek: Read + Seek {}
+
+impl<R: Read + Seek> ReadSeek for std::io::BufReader<R> {}
+impl<R: AsRef<[u8]>> ReadSeek for std::io::Cursor<R> {}
Review comment:
Nice tip on the generic approach. @Igosuki is right that this is not needed for BufRead and Cursor, It's only needed for `std::fs::File`, so I will keep the generic form.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] Igosuki commented on a change in pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
Igosuki commented on a change in pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#discussion_r784746803
##########
File path: datafusion/src/avro_to_arrow/reader.rs
##########
@@ -101,30 +100,49 @@ impl ReaderBuilder {
}
/// Create a new `Reader` from the `ReaderBuilder`
- pub fn build<'a, R>(self, source: R) -> Result<Reader<'a, R>>
+ pub fn build<R>(self, source: R) -> Result<Reader<R>>
where
R: Read + Seek,
{
let mut source = source;
// check if schema should be inferred
- let schema = match self.schema {
- Some(schema) => schema,
- None => Arc::new(super::read_avro_schema_from_reader(&mut source)?),
- };
source.seek(SeekFrom::Start(0))?;
- Reader::try_new(source, schema, self.batch_size, self.projection)
+ let (mut avro_schemas, mut schema, codec, file_marker) =
+ read::read_metadata(&mut source)?;
+ if let Some(proj) = self.projection {
Review comment:
It can save a bit of computation and memory but not i/o obviously. Should we change this ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] Igosuki commented on a change in pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
Igosuki commented on a change in pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#discussion_r784748048
##########
File path: datafusion/src/datasource/object_store/mod.rs
##########
@@ -33,6 +33,12 @@ use local::LocalFileSystem;
use crate::error::{DataFusionError, Result};
+/// Both Read and Seek
+pub trait ReadSeek: Read + Seek {}
+
+impl<R: Read + Seek> ReadSeek for std::io::BufReader<R> {}
+impl<R: AsRef<[u8]>> ReadSeek for std::io::Cursor<R> {}
Review comment:
Yes they are not needed, I originally had just Read + Seek in my branch because BufReader is Seek if R is Seek and Cursor is Seek on &[u8] in std. Should be removed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] Igosuki edited a comment on pull request #1556: Officially maintained Arrow2 branch
Posted by GitBox <gi...@apache.org>.
Igosuki edited a comment on pull request #1556:
URL: https://github.com/apache/arrow-datafusion/pull/1556#issuecomment-1013038787
@houqp What hardware/setup did you use to run the benchmark ? I'm actually getting way worse performance if running tpch using parquet
Edit : ok flamegraphs showed me that the parquet reader in the arrow2 branch is not being passed a BufReader but a File instead
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org