You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2020/12/11 11:59:36 UTC
[GitHub] [iceberg] 172403678 opened a new issue #1914: Flink Table Without Timestamp Cannot Query By Spark
172403678 opened a new issue #1914:
URL: https://github.com/apache/iceberg/issues/1914
select count() from prod.iceberg_db.bofangzt;
20/12/11 19:56:02 ERROR thriftserver.SparkSQLDriver: Failed in [select count() from prod.iceberg_db.bofangzt]
java.lang.UnsupportedOperationException: Spark does not support timestamp without time zone fields
at org.apache.iceberg.spark.TypeToSparkType.primitive(TypeToSparkType.java:111)
at org.apache.iceberg.spark.TypeToSparkType.primitive(TypeToSparkType.java:45)
at org.apache.iceberg.types.TypeUtil.visit(TypeUtil.java:389)
at org.apache.iceberg.types.TypeUtil.visit(TypeUtil.java:343)
at org.apache.iceberg.types.TypeUtil.visit(TypeUtil.java:331)
at org.apache.iceberg.spark.SparkSchemaUtil.convert(SparkSchemaUtil.java:96)
at org.apache.iceberg.spark.source.SparkTable.schema(SparkTable.java:102)
at org.apache.spark.sql.execution.datasources.v2.DataSourceV2Relation$.create(DataSourceV2Relation.scala:150)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] HeartSaVioR commented on issue #1914: Flink Table Without Timestamp Cannot Query By Spark
Posted by GitBox <gi...@apache.org>.
HeartSaVioR commented on issue #1914:
URL: https://github.com/apache/iceberg/issues/1914#issuecomment-743177185
https://iceberg.apache.org/spark/#type-compatibility
Iceberg Spark doc explains the type compatibility between Iceberg and Spark - supported types are dependent on engine, hence if you're trying to use Iceberg with cross-engines, the table schema should be designed as taking "greatest common factor".
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] HeartSaVioR commented on issue #1914: Flink Table Without Timestamp Cannot Query By Spark
Posted by GitBox <gi...@apache.org>.
HeartSaVioR commented on issue #1914:
URL: https://github.com/apache/iceberg/issues/1914#issuecomment-743193351
Probably my comment would explain all your other issues - though I don't see type compatibility documentation for other engines yet.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] txdong-sz commented on issue #1914: Flink Table Without Timestamp Cannot Query By Spark
Posted by GitBox <gi...@apache.org>.
txdong-sz commented on issue #1914:
URL: https://github.com/apache/iceberg/issues/1914#issuecomment-744311338
@HeartSaVioR the reson why i need to use spark and flink is that
1. flink is not support by partition by hour
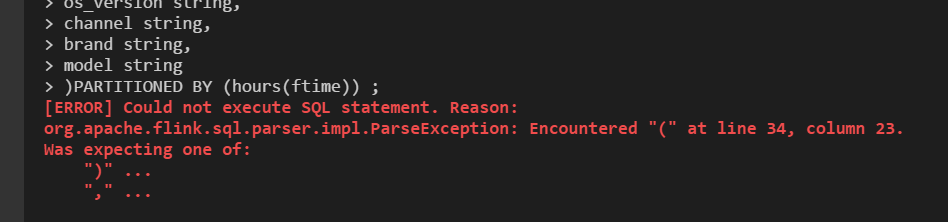
and my table is very huge . that is not a good parctice
2. flink sql is standalone . my table is huge ,so i need more resource to run sql and choose spark
we use flink to write stream data to cos . it is of efficiency
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] txdong-sz commented on issue #1914: Flink Table Without Timestamp Cannot Query By Spark
Posted by GitBox <gi...@apache.org>.
txdong-sz commented on issue #1914:
URL: https://github.com/apache/iceberg/issues/1914#issuecomment-744117524
@HeartSaVioR yes i think that compatibility is very importtant, we need to write table in flink but query by hive or spark is more convenient . because flink sql client is standalone so cannot run huge querys.
the schema is very basic information for a table . so "greatest common factor" should implement by other engines
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 edited a comment on issue #1914: Flink Table Without Timestamp Cannot Query By Spark
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 edited a comment on issue #1914:
URL: https://github.com/apache/iceberg/issues/1914#issuecomment-747146918
> @HeartSaVioR the reson why i need to use spark and flink is that
>
> 1. flink is not support by partition by hour
> 
> and my table is very huge . that is not a good parctice
> 2. flink sql is standalone . my table is huge ,so i need more resource to run sql and choose spark
>
> we use flink to write stream data to cos . it is of efficiency
1. you can create an iceberg table with flink sql
```
CREATE TABLE iceberg.iceberg_db.iceberg_table (
id BIGINT COMMENT 'unique id',
data STRING,
`day` int
`hour` int)
PARTITIONED BY (`day`,`hour`)
WITH ('connector'='iceberg','write.format.default'='orc')
```
and write into the iceberg table with flink streaming sql :
```
INSERT INTO iceberg.iceberg_db.iceberg_table
select id ,data,DAYOFMONTH(your_timestamp),hour(your_timestamp) from kafka_table
```
2. flink sql client can use standalone cluster and yarn session cluster , you can start a yarn session cluster first ,and then submit the flink sql job to the session cluster .
and set the parallelism for every flink sql job by the command:
```
set table.exec.resource.default-parallelism = 100
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] sshkvar commented on issue #1914: Flink Table Without Timestamp Cannot Query By Spark
Posted by GitBox <gi...@apache.org>.
sshkvar commented on issue #1914:
URL: https://github.com/apache/iceberg/issues/1914#issuecomment-747403484
We have the same issue, Spark can't read iceberg tables which were created by Presto.
Presto connector and Iceberg supports timestamp without timezone.
Is it possible to add support of timestamp without timezone to iceber-spark-runtime?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] HeartSaVioR commented on issue #1914: Flink Table Without Timestamp Cannot Query By Spark
Posted by GitBox <gi...@apache.org>.
HeartSaVioR commented on issue #1914:
URL: https://github.com/apache/iceberg/issues/1914#issuecomment-744212116
Engines' features are out of control from Iceberg. As you see the doc I linked, not every types of Iceberg are supported in Spark, and I expect the same for other engines. The greatest common factor is not something we can expect engines to implement. Unfortunately that's something end users may need to figure out according to the usages, and apply to the table schema.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] HeartSaVioR commented on issue #1914: Flink Table Without Timestamp Cannot Query By Spark
Posted by GitBox <gi...@apache.org>.
HeartSaVioR commented on issue #1914:
URL: https://github.com/apache/iceberg/issues/1914#issuecomment-744771533
I don't know much about Flink support on Iceberg. Probably @openinx can give more information here.
From Spark 3.0+ you can set up custom catalog for Iceberg and execute create table against the catalog, and partitioned by hours is supported in create table syntax. I don't know Flink will include this as a part of create table syntax though. The ability to write to the partitioned table is completely different story, so you may want to check whether you can write to the table partitioned by hours from Flink. (I guess you can, but just to double check.)
I don't know much about Flink itself, but it sounds odd if Flink SQL CLI (you meant CLI, not Flink SQL itself, right?) only works with standalone. I'd expect Flink SQL CLI to submit a job to the cluster and receive the output and print out, but well, I don't know.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] huadongliu commented on issue #1914: Flink Table Without Timestamp Cannot Query By Spark
Posted by GitBox <gi...@apache.org>.
huadongliu commented on issue #1914:
URL: https://github.com/apache/iceberg/issues/1914#issuecomment-837846615
I saw the same Spark error when loading a table with a timestamp column created by the Java API. It is expected by https://iceberg.apache.org/spark-writes/#iceberg-type-to-spark-type.
I was able to workaround it by `s/timestamp/timestamptz` in the schema section of the json snapshot file. Surprisingly, Spark still shows UTC timestamps while my local timezone is GMT-7. The parquet files have UTC timestamps.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on issue #1914: Flink Table Without Timestamp Cannot Query By Spark
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on issue #1914:
URL: https://github.com/apache/iceberg/issues/1914#issuecomment-747146918
> @HeartSaVioR the reson why i need to use spark and flink is that
>
> 1. flink is not support by partition by hour
> 
> and my table is very huge . that is not a good parctice
> 2. flink sql is standalone . my table is huge ,so i need more resource to run sql and choose spark
>
> we use flink to write stream data to cos . it is of efficiency
1. you can create an iceberg table with flink sql
```
CREATE TABLE iceberg.iceberg_db.iceberg_table (
id BIGINT COMMENT 'unique id',
data STRING,
`day` int
`hour` int)
PARTITIONED BY (`day`,`hour`)
WITH ('connector'='iceberg','write.format.default'='orc')
```
and write into the iceberg table with flink streaming sql :
```
INSERT INTO iceberg.iceberg_db.iceberg_table
select id ,data,DAYOFMONTH(your_timestamp),hour(your_timestamp) from kafka_table
```
2. flink sql client can use standalone cluster and yarn session cluster , you can start a yarn session cluster first ,and then submit the flink sql job to the session cluster .
3.
and set the parallelism for every flink sql job by the command:
```
set table.exec.resource.default-parallelism = 100
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] 172403678 commented on issue #1914: Flink Table Without Timestamp Cannot Query By Spark
Posted by GitBox <gi...@apache.org>.
172403678 commented on issue #1914:
URL: https://github.com/apache/iceberg/issues/1914#issuecomment-743156927
https://iceberg.apache.org/schemas/
iceberg schemas should support timestamp without zoneid
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on issue #1914: Flink Table Without Timestamp Cannot Query By Spark
Posted by GitBox <gi...@apache.org>.
openinx commented on issue #1914:
URL: https://github.com/apache/iceberg/issues/1914#issuecomment-750870864
@txdong-sz `PARTITIONED BY (HOURS(time))` is actually the feature that we named it `hidden partition`, apache iceberg support hidden partition, but flink SQL does not support it now. We are planning to file issue to apache flink for supporting it ( I'm not quite sure what's the priority for the apache flink community now, but will to discuss with them).
@zhangjun0x01 provides a temporary working solution for you case. About the time zone issue, did the comment from @XuQianJin-Stars answer your question ? https://github.com/apache/iceberg/issues/1915#issuecomment-744171957
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org