You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by "MihawkZoro (via GitHub)" <gi...@apache.org> on 2023/02/03 08:31:37 UTC
[GitHub] [hudi] MihawkZoro opened a new issue, #7839: [BUG] the deleted data reappeared after clustering on the table
MihawkZoro opened a new issue, #7839:
URL: https://github.com/apache/hudi/issues/7839
**Environment Description**
* Hudi version :
0.12.2
* Spark version :
3.2.2
* Hadoop version :
2.7.3
* Storage :
hdfs
**Describe the problem you faced**
I have a hudi table and I deleted some records, then I clustered it, finally I found that the deleted data reappeared when I check the result.
**To Reproduce**
1. I have a hudi table called cluster_test and delete some records
```
deldelete from cluster_test where id in (2,8,11);
```
the result after delete is :
<img width="877" alt="企业微信截图_e767a9a0-741c-4d83-b25b-bd1c747bf68a" src="https://user-images.githubusercontent.com/32875366/216547022-cda0100d-0d17-4a79-83c5-c1558cfac593.png">
2. then I submit a cluster job
```
spark-submit --class org.apache.hudi.utilities.HoodieClusteringJob hudi-utilities-bundle_2.12-0.12.2.jar \
--props file:///Users/qishuiqing/develop/hudi/clusteringjob.properties \
--mode scheduleAndExecute --base-path 'hdfs://localhost:9000/user/hive/warehouse/hudi.db/cluster_test' \
--table-name cluster_test --parallelism 4 \
--spark-memory 4g
```
the result after cluster is :
<img width="1131" alt="企业微信截图_f9e34400-113c-43e9-9e26-1d3b095b7752" src="https://user-images.githubusercontent.com/32875366/216547899-c7b30c10-93a0-4810-b4f4-518a552feb8c.png">
3. table struct
```
col_name data_type comment
_hoodie_commit_time string
_hoodie_commit_seqno string
_hoodie_record_key string
_hoodie_partition_path string
_hoodie_file_name string
id int
name string
ts bigint
# Detailed Table Information
Database hudi
Table cluster_test
Created By Spark 3.2.2
Type EXTERNAL
Provider hudi
Table Properties [preCombineField=ts, primaryKey=id, type=mor]
Statistics 2173911 bytes
Location hdfs://localhost:9000/user/hive/warehouse/hudi.db/cluster_test
Serde Library org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
InputFormat org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
```
**conclusion**
this is a sericous bug needed to be fixed
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #7839: [BUG] the deleted data reappeared after clustering on the table
Posted by "nsivabalan (via GitHub)" <gi...@apache.org>.
nsivabalan commented on issue #7839:
URL: https://github.com/apache/hudi/issues/7839#issuecomment-1420029313
hey @MihawkZoro :
is the delete command issued from spark-sql?
can you post the contents of ".hoodie" directory.
can you post all write configs used.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] MihawkZoro commented on issue #7839: [BUG] the deleted data reappeared after clustering on the table
Posted by "MihawkZoro (via GitHub)" <gi...@apache.org>.
MihawkZoro commented on issue #7839:
URL: https://github.com/apache/hudi/issues/7839#issuecomment-1420123763
> hey @MihawkZoro : is the delete command issued from spark-sql? can you post the contents of ".hoodie" directory. can you post all write configs used.
@nsivabalan hi, configs used:
```
hoodie.table.precombine.field=ts
hoodie.datasource.write.drop.partition.columns=false
hoodie.table.partition.fields=
hoodie.table.type=MERGE_ON_READ
hoodie.archivelog.folder=archived
hoodie.compaction.payload.class=org.apache.hudi.common.model.OverwriteWithLatestAvroPayload
hoodie.timeline.layout.version=1
hoodie.table.version=5
hoodie.table.metadata.partitions=files
hoodie.table.recordkey.fields=id
hoodie.datasource.write.partitionpath.urlencode=false
hoodie.database.name=hudi
hoodie.table.keygenerator.class=org.apache.hudi.keygen.ComplexKeyGenerator
hoodie.table.name=cluster_test
hoodie.datasource.write.hive_style_partitioning=true
hoodie.table.checksum=1916678829
hoodie.table.create.schema={"type"\:"record","name"\:"topLevelRecord","fields"\:[{"name"\:"_hoodie_commit_time","type"\:["string","null"]},{"name"\:"_hoodie_commit_seqno","type"\:["string","null"]},{"name"\:"_hoodie_record_key","type"\:["string","null"]},{"name"\:"_hoodie_partition_path","type"\:["string","null"]},{"name"\:"_hoodie_file_name","type"\:["string","null"]},{"name"\:"id","type"\:["int","null"]},{"name"\:"name","type"\:["string","null"]},{"name"\:"ts","type"\:["long","null"]}]}
```
there are some timeline data before cluster:
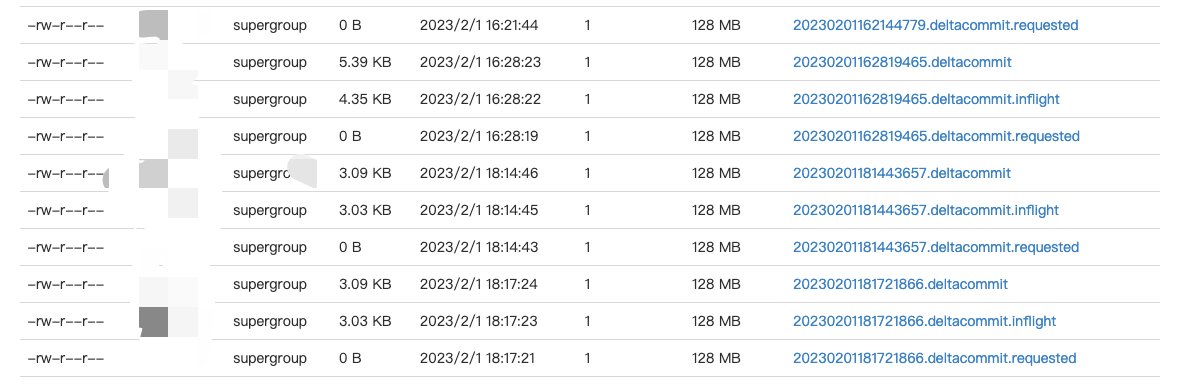
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] MihawkZoro commented on issue #7839: [BUG] the deleted data reappeared after clustering on the table
Posted by "MihawkZoro (via GitHub)" <gi...@apache.org>.
MihawkZoro commented on issue #7839:
URL: https://github.com/apache/hudi/issues/7839#issuecomment-1420111468
> Hey @MihawkZoro : I could not reproduce on my end. Here is the steps I followed.
>
> 1. Created a table via spark-sql
>
> ```
> create table parquet_tbl1 using parquet location 'file:///tmp/tbl1/*.parquet';
> drop table hudi_ctas_cow1;
> create table hudi_ctas_cow1 using hudi location 'file:/tmp/hudi/hudi_tbl/' options (
> type = 'cow',
> primaryKey = 'tpep_pickup_datetime',
> preCombineField = 'tpep_dropoff_datetime'
> )
> partitioned by (date_col) as select * from parquet_tbl1;
> ```
>
> 2. Read data from one of the partition w/ "VendorId = 1".
>
> ```
> select VendorId, count(*) from hudi_ctas_cow1 where date_col = '2019-08-10' group by 1;
> ```
>
> this returned 1, 1914 2, 3988
>
> 3. Issue deletes to records w/ VendorId = 1 for this specific partition.
>
> ```
> delete from hudi_ctas_cow1 where date_col = '2019-08-10' and VendorID = 1;
> ```
>
> Verified from ".hoodie", that a new commit has succeeded and it added one new parquet file to 2019-08-10 partition.
>
> ```
> ls -ltr /tmp/hudi/hudi_tbl/date_col=2019-08-10/
> total 2192
> -rw-r--r-- 1 nsb wheel 571011 Feb 6 17:19 f5fa2a6c-8128-4591-9f27-94b5b7880a86-0_10-27-119_20230206171846307.parquet
> -rw-r--r-- 1 nsb wheel 529348 Feb 6 17:24 f5fa2a6c-8128-4591-9f27-94b5b7880a86-0_0-83-1538_20230206172355871.parquet
> ```
>
> the 2nd parquet file was written due to the delete operation.
>
> 4. Triggered clustering job.
> Property file contents
>
> ```
> cat /tmp/cluster.props
>
> hoodie.datasource.write.recordkey.field=tpep_pickup_datetime
> hoodie.datasource.write.partitionpath.field=date_col
> hoodie.datasource.write.precombine.field=tpep_dropoff_datetime
>
> hoodie.upsert.shuffle.parallelism=8
> hoodie.insert.shuffle.parallelism=8
> hoodie.delete.shuffle.parallelism=8
> hoodie.bulkinsert.shuffle.parallelism=8
>
> hoodie.clustering.plan.strategy.sort.columns=date_col,tpep_pickup_datetime
> hoodie.clustering.execution.strategy.class=org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy
>
> hoodie.parquet.small.file.limit=0
> hoodie.clustering.inline=true
> hoodie.clustering.inline.max.commits=1
> hoodie.clustering.plan.strategy.target.file.max.bytes=1073741824
> hoodie.clustering.plan.strategy.small.file.limit=629145600
> hoodie.clustering.async.enabled=true
> hoodie.clustering.async.max.commits=1
> ```
>
> ```
> ./bin/spark-submit --class org.apache.hudi.utilities.HoodieClusteringJob ~/Downloads/hudi-utilities-bundle_2.11-0.12.2.jar --props /tmp/cluster.props --mode scheduleAndExecute --base-path /tmp/hudi/hudi_tbl/ --table-name hudi_ctas_cow1 --spark-memory 4g
> ```
>
> Verified from ".hoodie" that I could see replace commit and it has succeeded.
>
> 5. re-launched spark-sql and queried the table.
>
> ```
> refresh table hudi_ctas_cow1;
> select VendorId, count(*) from hudi_ctas_cow1 where date_col = '2019-08-10' group by 1;
> ```
>
> output
>
> ```
> 2 3988
> Time taken: 3.818 seconds, Fetched 1 row(s)
> ```
the table is mor
<img width="623" alt="image" src="https://user-images.githubusercontent.com/32875366/217133399-ba18e8be-4b75-4983-9a0d-58787906b222.png">
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #7839: [BUG] the deleted data reappeared after clustering on the table
Posted by "nsivabalan (via GitHub)" <gi...@apache.org>.
nsivabalan commented on issue #7839:
URL: https://github.com/apache/hudi/issues/7839#issuecomment-1473107897
hmmm, interesting. I could not reproduce. can you give me a reproducible script.
https://gist.github.com/nsivabalan/17125d03e56fc5e4d72381536a8ea5ae
I tried joining the snapshot read w/ dataframe that got delete and don't find any matches.
but my clustering configs are very simple. not sure if that plays a part.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] MihawkZoro commented on issue #7839: [BUG] the deleted data reappeared after clustering on the table
Posted by "MihawkZoro (via GitHub)" <gi...@apache.org>.
MihawkZoro commented on issue #7839:
URL: https://github.com/apache/hudi/issues/7839#issuecomment-1420489417
Clustering job property file contents
```
hoodie.clustering.async.enabled=true
hoodie.clustering.async.max.commits=0
hoodie.clustering.plan.strategy.target.file.max.bytes=805306368
hoodie.clustering.plan.strategy.small.file.limit=268435456
hoodie.clustering.execution.strategy.class=org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy
hoodie.clustering.plan.strategy.sort.columns=ts
hoodie.clustering.plan.strategy.max.num.groups=100
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] codope commented on issue #7839: [BUG] the deleted data reappeared after clustering on the table
Posted by "codope (via GitHub)" <gi...@apache.org>.
codope commented on issue #7839:
URL: https://github.com/apache/hudi/issues/7839#issuecomment-1522091991
Downgrading the priority as the issue is not reproducible. Please provide more info as requested above.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #7839: [BUG] the deleted data reappeared after clustering on the table
Posted by "nsivabalan (via GitHub)" <gi...@apache.org>.
nsivabalan commented on issue #7839:
URL: https://github.com/apache/hudi/issues/7839#issuecomment-1474193835
@MihawkZoro : did you try inline clustering. did that also result in deletes re-appearing again.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #7839: [BUG] the deleted data reappeared after clustering on the table
Posted by "nsivabalan (via GitHub)" <gi...@apache.org>.
nsivabalan commented on issue #7839:
URL: https://github.com/apache/hudi/issues/7839#issuecomment-1420045535
Hey @MihawkZoro : I could not reproduce on my end. Here is the steps I followed.
1. Created a table via spark-sql
```
create table parquet_tbl1 using parquet location 'file:///tmp/tbl1/*.parquet';
drop table hudi_ctas_cow1;
create table hudi_ctas_cow1 using hudi location 'file:/tmp/hudi/hudi_tbl/' options (
type = 'cow',
primaryKey = 'tpep_pickup_datetime',
preCombineField = 'tpep_dropoff_datetime'
)
partitioned by (date_col) as select * from parquet_tbl1;
```
2. Read data from one of the partition w/ "VendorId = 1".
```
select VendorId, count(*) from hudi_ctas_cow1 where date_col = '2019-08-10' group by 1;
```
this returned
1, 1914
2, 3988
3. Issue deletes to records w/ VendorId = 1 for this specific partition.
```
delete from hudi_ctas_cow1 where date_col = '2019-08-10' and VendorID = 1;
```
Verified from ".hoodie", that a new commit has succeeded and it added one new parquet file to 2019-08-10 partition.
```
ls -ltr /tmp/hudi/hudi_tbl/date_col=2019-08-10/
total 2192
-rw-r--r-- 1 nsb wheel 571011 Feb 6 17:19 f5fa2a6c-8128-4591-9f27-94b5b7880a86-0_10-27-119_20230206171846307.parquet
-rw-r--r-- 1 nsb wheel 529348 Feb 6 17:24 f5fa2a6c-8128-4591-9f27-94b5b7880a86-0_0-83-1538_20230206172355871.parquet
```
the 2nd parquet file was written due to the delete operation.
4. Triggered clustering job.
Property file contents
```
cat /tmp/cluster.props
hoodie.datasource.write.recordkey.field=tpep_pickup_datetime
hoodie.datasource.write.partitionpath.field=date_col
hoodie.datasource.write.precombine.field=tpep_dropoff_datetime
hoodie.upsert.shuffle.parallelism=8
hoodie.insert.shuffle.parallelism=8
hoodie.delete.shuffle.parallelism=8
hoodie.bulkinsert.shuffle.parallelism=8
hoodie.clustering.plan.strategy.sort.columns=date_col,tpep_pickup_datetime
hoodie.clustering.execution.strategy.class=org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy
hoodie.parquet.small.file.limit=0
hoodie.clustering.inline=true
hoodie.clustering.inline.max.commits=1
hoodie.clustering.plan.strategy.target.file.max.bytes=1073741824
hoodie.clustering.plan.strategy.small.file.limit=629145600
hoodie.clustering.async.enabled=true
hoodie.clustering.async.max.commits=1
```
```
./bin/spark-submit --class org.apache.hudi.utilities.HoodieClusteringJob ~/Downloads/hudi-utilities-bundle_2.11-0.12.2.jar --props /tmp/cluster.props --mode scheduleAndExecute --base-path /tmp/hudi/hudi_tbl/ --table-name hudi_ctas_cow1 --spark-memory 4g
```
Verified from ".hoodie" that I could see replace commit and it has succeeded.
5. re-launched spark-sql and queried the table.
```
refresh table hudi_ctas_cow1;
select VendorId, count(*) from hudi_ctas_cow1 where date_col = '2019-08-10' group by 1;
```
output
```
2 3988
Time taken: 3.818 seconds, Fetched 1 row(s)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] ad1happy2go commented on issue #7839: [BUG] the deleted data reappeared after clustering on the table
Posted by "ad1happy2go (via GitHub)" <gi...@apache.org>.
ad1happy2go commented on issue #7839:
URL: https://github.com/apache/hudi/issues/7839#issuecomment-1486674244
@MihawkZoro I also tried to reproduce with extract config and cluster config you provided but unable to reproduce the same. Are you still facing this issue?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org