You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2019/12/11 07:20:24 UTC
[GitHub] [spark] zhengruifeng commented on issue #26803: [SPARK-30178][ML]
RobustScaler support large numFeatures
zhengruifeng commented on issue #26803: [SPARK-30178][ML] RobustScaler support large numFeatures
URL: https://github.com/apache/spark/pull/26803#issuecomment-564413213
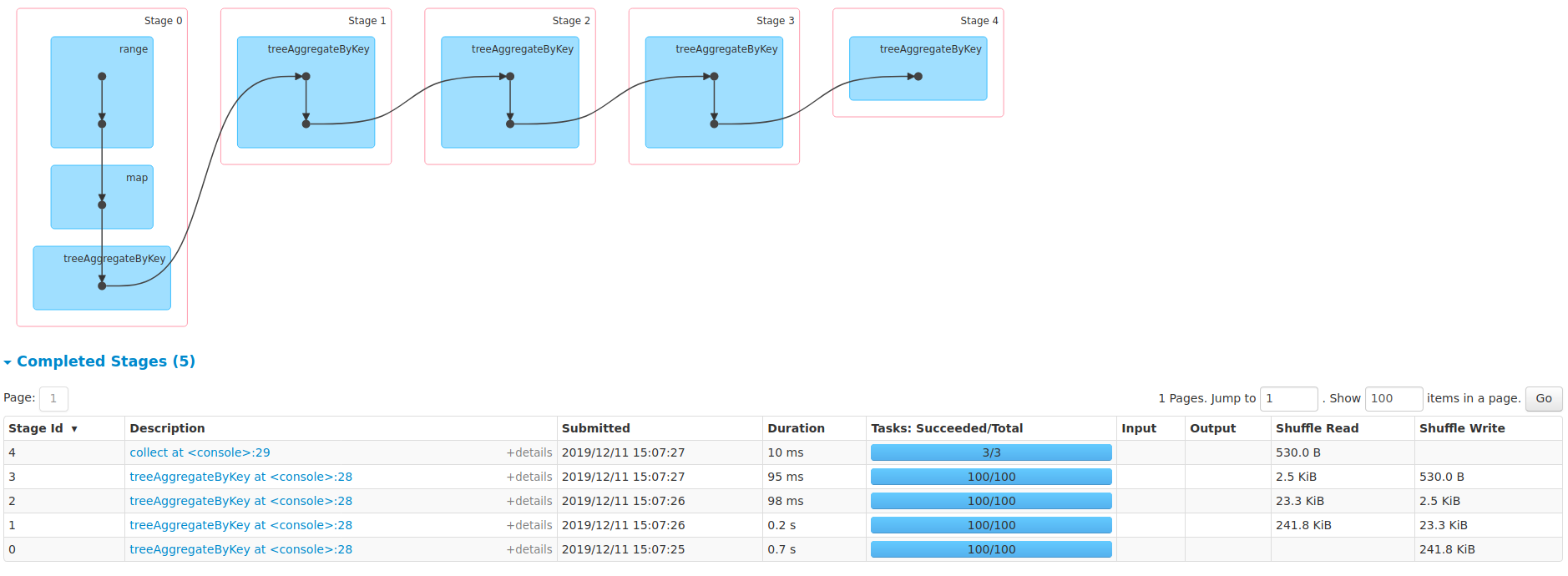
@srowen I impl a simple `treeAggregateByKey` [here](https://github.com/apache/spark/compare/master...zhengruifeng:treeAggByKey?expand=1), and made several local tests like:
```scala
val rdd = sc.range(0, 10000, 1, 100)
val rdd2 = rdd.map{i => (i % 10, i)}
val rdd3 = rdd2.treeAggregateByKey(0.0, new HashPartitioner(3))(_+_, _+_, 2)
rdd3.collect
```
and ran successfully.
BTW, it is reasonable to call `compress` before reduce tasks, so maybe a `aggregateByKeyWithinPartitions` is needed? Then we can call `compress` after locally aggregation within each partition. I guess they maybe common functions and we add this method in RDD/PairRDD?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org