You are viewing a plain text version of this content. The canonical link for it is here.
Posted to github@arrow.apache.org by GitBox <gi...@apache.org> on 2021/12/15 20:31:11 UTC
[GitHub] [arrow] mishbahr opened a new issue #11967: Parquet schema / data type for entire null object DataFrame columns
mishbahr opened a new issue #11967:
URL: https://github.com/apache/arrow/issues/11967
I'm writing some DataFrame to binary parquet format with one or more entire null object columns.
If I then load the parquet dataset with `use_legacy_dataset=False`
```python
parquet_dataset = pq.ParquetDataset(root_path, use_legacy_dataset=False, **kwargs)
type(parquet)
pyarrow.parquet._ParquetDatasetV2
```
It returns an `_ParquetDatasetV2` instance and when I check the schema.
```python
type(parquet_dataset.schema)
pyarrow.lib.Schema
```
If I load the same file but with `use_legacy_dataset=True`
```python
parquet_dataset2 = pq.ParquetDataset(root_path, use_legacy_dataset=True, **kwargs)
```
The schema for the file is an instance of `ParquetSchema`
```python
type(parquet_dataset2.schema)
pyarrow._parquet.ParquetSchema
```
This is as I would expect and I'm aware that I can get the "arrow schema" like this.
```python
arrow_schema = parquet_dataset2.schema.to_arrow_schema()
type(arrow_schema)
pyarrow.lib.Schema
```
i.e same format as when I use `use_legacy_dataset=False`
For an instance of `ParquetSchema`, I can get details of any column. e.g
```python
parquet_dataset2.schema[13]
<ParquetColumnSchema>
name: col13
path: col13
max_definition_level: 1
max_repetition_level: 0
physical_type: INT96
logical_type: None
converted_type (legacy): NONE
```
Here the "physical_type" for this column is INT96.
```python
parquet.schema[13].physical_type
'INT32'
```
For an instance of `pyarrow.lib.Schema`, if I get the "data type" for the same column.
```python
parquet_dataset.schema.field("col13").type
DataType(null)
```
i.e with no information about what the "data type" is supposed to be.
This information is available in the Parquet file. But how do I access it?
Is there way to convert instance of `pyarrow.lib.Schema` -> `pyarrow._parquet.ParquetSchema`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] westonpace commented on issue #11967: Parquet schema / data type for entire null object DataFrame columns
Posted by GitBox <gi...@apache.org>.
westonpace commented on issue #11967:
URL: https://github.com/apache/arrow/issues/11967#issuecomment-995263886
Copying my question from the gist:
What is parquet_file.schema[0].logical_type? For me, if I do not specify a schema, it is Null (which is different than None). In your first snippet the logical type is None so I assume you are specifying the schema when writing.
Perhaps you have some files with Null logical type and some with None logical type? This could explain the behavior as the new datasets API infers the schema from a single file (picked more or less at random). So if it picked one of the null ones then you may end up with the behavior you are describing.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] mishbahr commented on issue #11967: Parquet schema / data type for entire null object DataFrame columns
Posted by GitBox <gi...@apache.org>.
mishbahr commented on issue #11967:
URL: https://github.com/apache/arrow/issues/11967#issuecomment-995287905
```python
parquet_file.schema[0]
```
```python
<ParquetColumnSchema>
name: x
path: x
max_definition_level: 1
max_repetition_level: 0
physical_type: INT32
logical_type: Null
converted_type (legacy): NONE
```
Just incase there is some issue with my data source .
Now I'm using `df = pd.DataFrame(data={"x": [None, ]})` as input.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] mishbahr closed issue #11967: Parquet schema / data type for entire null object DataFrame columns
Posted by GitBox <gi...@apache.org>.
mishbahr closed issue #11967:
URL: https://github.com/apache/arrow/issues/11967
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] jorisvandenbossche commented on issue #11967: Parquet schema / data type for entire null object DataFrame columns
Posted by GitBox <gi...@apache.org>.
jorisvandenbossche commented on issue #11967:
URL: https://github.com/apache/arrow/issues/11967#issuecomment-995708589
> Where does pyarrow get `INT32` as "physical_type" when the column completely empty (only null values)
For Parquet, you need to distinguish the "physical_type" and "logical_type" (as shown in the output of the `ParquetColumnSchema`, this is "INT32" vs "Null" for this column of all nulls).
Parquet only has a limited set of physical types, see https://github.com/apache/parquet-format#types. And "Null" is not a physical type, but only a logical type. And a logical type always "annotates" some actual physical type.
So when Arrow saves a "null" column (in Arrow this is an actual, proper type) to Parquet, it can use a "Null" logical type, but it still needs to choose some physical type for the column in the Parquet file. And by default, Arrow uses INT32 for the physical type.
That explains where the "INT32" physical type is coming from. But in general, I think you don't need to care about this / you can ignore this. When reading the Parquet file to an Arrow table, we will correctly notice the "Null" logical type, and create a "null" column in the resulting Arrow table (basically ignoring the INT32 physical type of the Parquet field)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] mishbahr commented on issue #11967: Parquet schema / data type for entire null object DataFrame columns
Posted by GitBox <gi...@apache.org>.
mishbahr commented on issue #11967:
URL: https://github.com/apache/arrow/issues/11967#issuecomment-995718849
Ok. Thanks for the explanation.
I think I am going to change my code the use the v2 dataset API (`use_legacy_dataset=False`)
And then throw an error when `field.type == pa.null()` and ask the user to cast dataframe column with specific type.
e.g `df['x'] = df['x'].astype('string')`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] mishbahr commented on issue #11967: Parquet schema / data type for entire null object DataFrame columns
Posted by GitBox <gi...@apache.org>.
mishbahr commented on issue #11967:
URL: https://github.com/apache/arrow/issues/11967#issuecomment-995697816
Ignoring my initial code sample where I was using real parquet file as source.
This is fresh example using `df = pd.DataFrame(data={"col1": [None, ], "col2": ["foo1", ]})` as starting point.
Where does pyarrow get `INT32` as "physical_type" when the column completely empty (only null values)
```python
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
```
```python
df = pd.DataFrame(data={"col1": [None, ], "col2": ["foo1", ]})
```
```python
table = pa.Table.from_pandas(df)
```
```python
pq.write_table(table, '/tmp/data.parquet')
```
```python
legacy_dataset = pq.ParquetDataset('/tmp/data.parquet', use_legacy_dataset=True)
```
```python
dataset = pq.ParquetDataset('/tmp/data.parquet', use_legacy_dataset=False)
```
```python
legacy_dataset.schema
```
<pyarrow._parquet.ParquetSchema object at 0x7efc1dc51a40>
required group field_id=-1 schema {
optional int32 field_id=-1 col1 (Null);
optional binary field_id=-1 col2 (String);
}
```python
legacy_dataset.schema[0]
```
<ParquetColumnSchema>
name: col1
path: col1
max_definition_level: 1
max_repetition_level: 0
physical_type: INT32
logical_type: Null
converted_type (legacy): NONE
```python
dataset.schema[0].type
```
DataType(null)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] mishbahr commented on issue #11967: Parquet schema / data type for entire null object DataFrame columns
Posted by GitBox <gi...@apache.org>.
mishbahr commented on issue #11967:
URL: https://github.com/apache/arrow/issues/11967#issuecomment-995242509
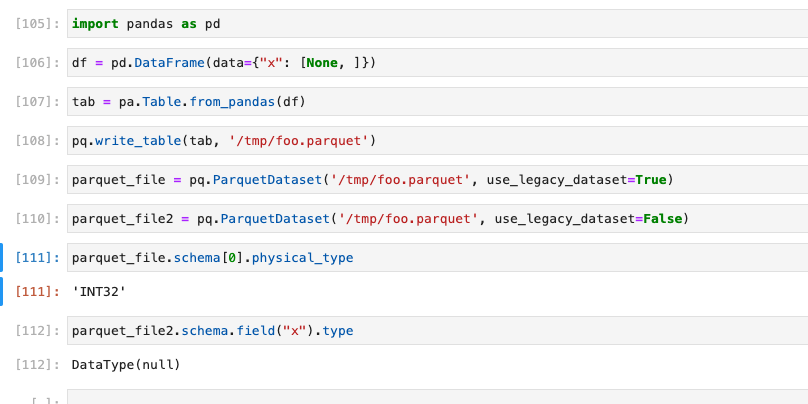
I recreated the error with a simple test dataframe.
I think there is a bug on the legacy datasets API.
Where is is getting the `INT32` physical type from?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] westonpace commented on issue #11967: Parquet schema / data type for entire null object DataFrame columns
Posted by GitBox <gi...@apache.org>.
westonpace commented on issue #11967:
URL: https://github.com/apache/arrow/issues/11967#issuecomment-995297427
This is a null array represented in parquet:
```
<ParquetColumnSchema>
name: x
path: x
max_definition_level: 1
max_repetition_level: 0
physical_type: INT32
logical_type: Null
converted_type (legacy): NONE
```
The original post was not a null array:
```
<ParquetColumnSchema>
name: col13
path: col13
max_definition_level: 1
max_repetition_level: 0
physical_type: INT96
logical_type: None
converted_type (legacy): NONE
```
In particular the `logical_type` is different between the two. I'm not actually sure what data type it is (maybe timestamp)? What is different between how the data is generated? Do all of your files look like the latter (`logical_type: None`) or is it possible that some of your files look like the former?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org