You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2021/10/24 18:24:24 UTC
[GitHub] [hudi] Limess opened a new issue #3854: [SUPPORT] Lower performance using 0.9.0 vs 0.8.0
Limess opened a new issue #3854:
URL: https://github.com/apache/hudi/issues/3854
**Describe the problem you faced**
When benchmarking Hudi on a sample dataset we're seeing 30% lower performance using Hudi 0.9.0 vs Hudi 0.8.0 (on EMR, so technically Amazon's build of Hudi here).
0.8.0
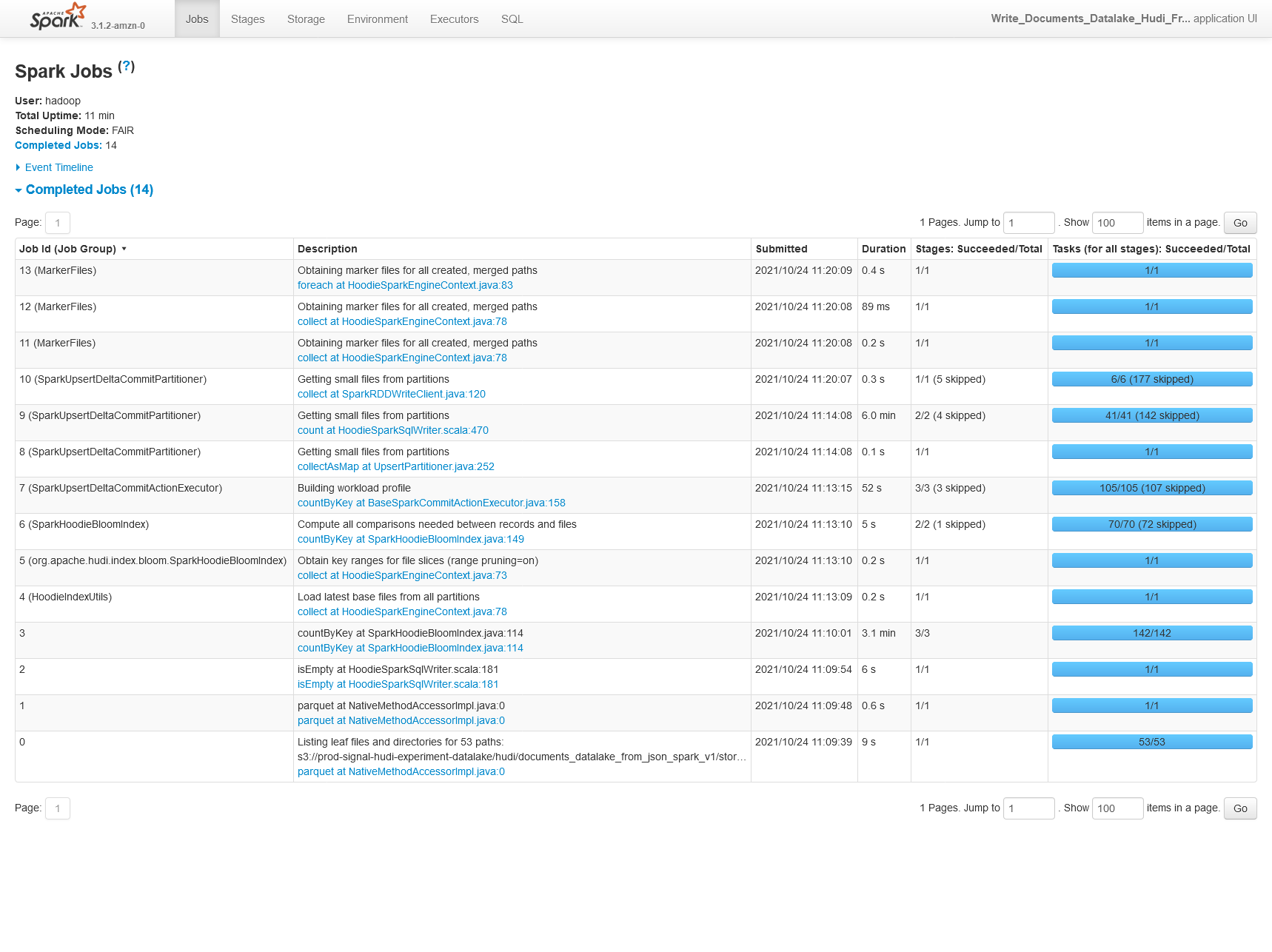
0.9.0
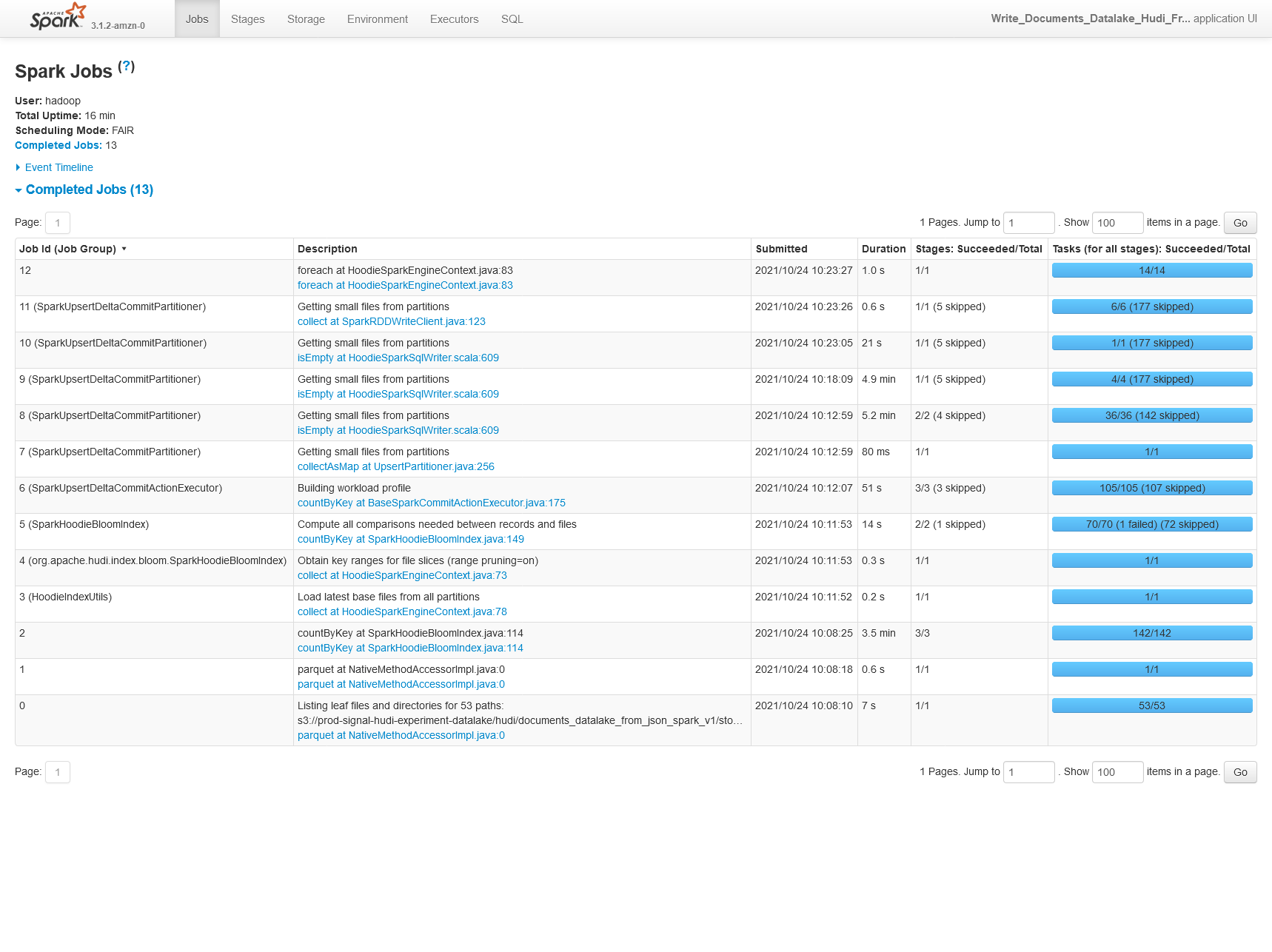
We're also seeing 30% worse performance on CoW upserts of 25% of the original partition storage (50% updates, 50% inserts).
0.8.0
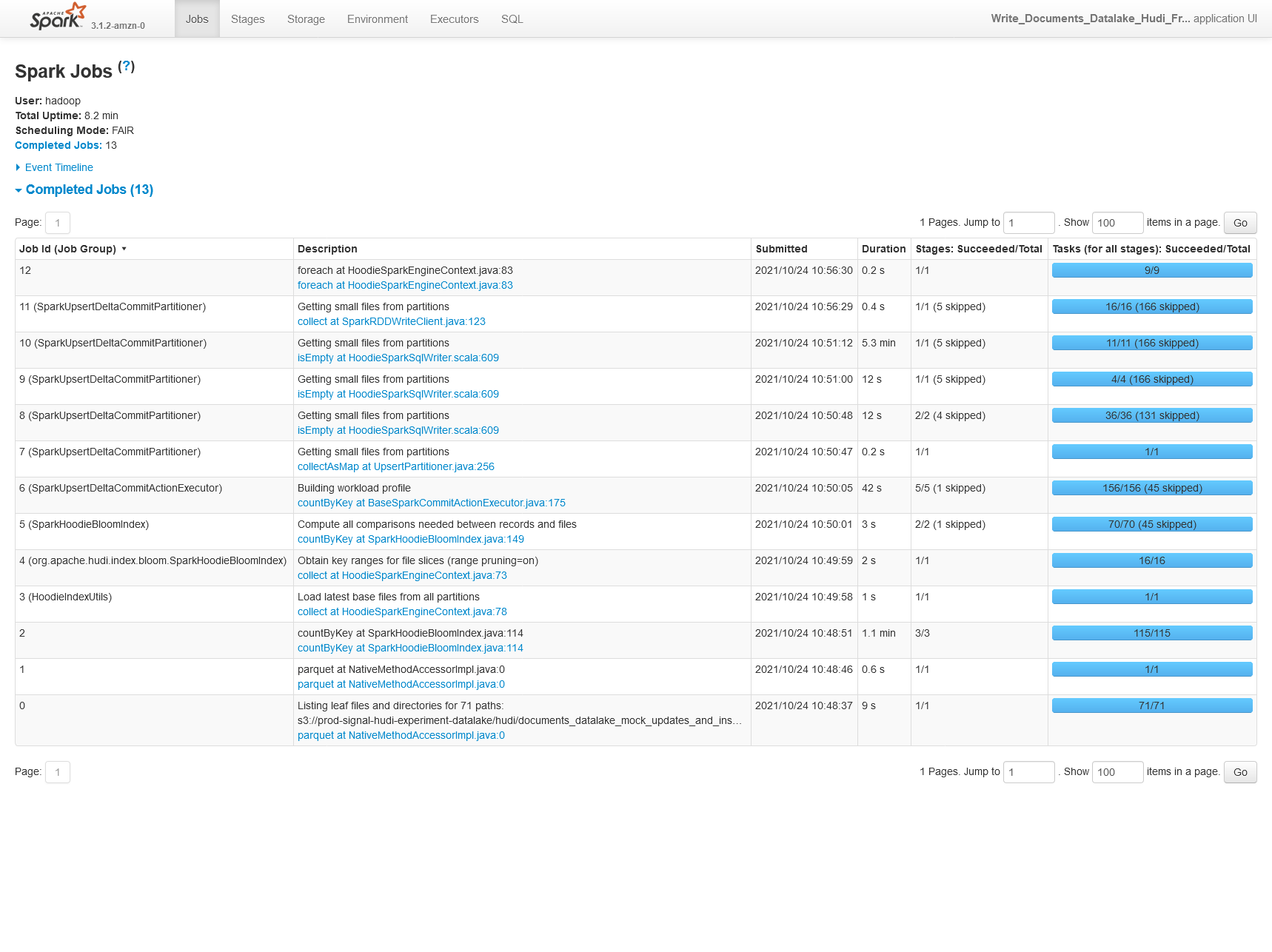
0.9.0
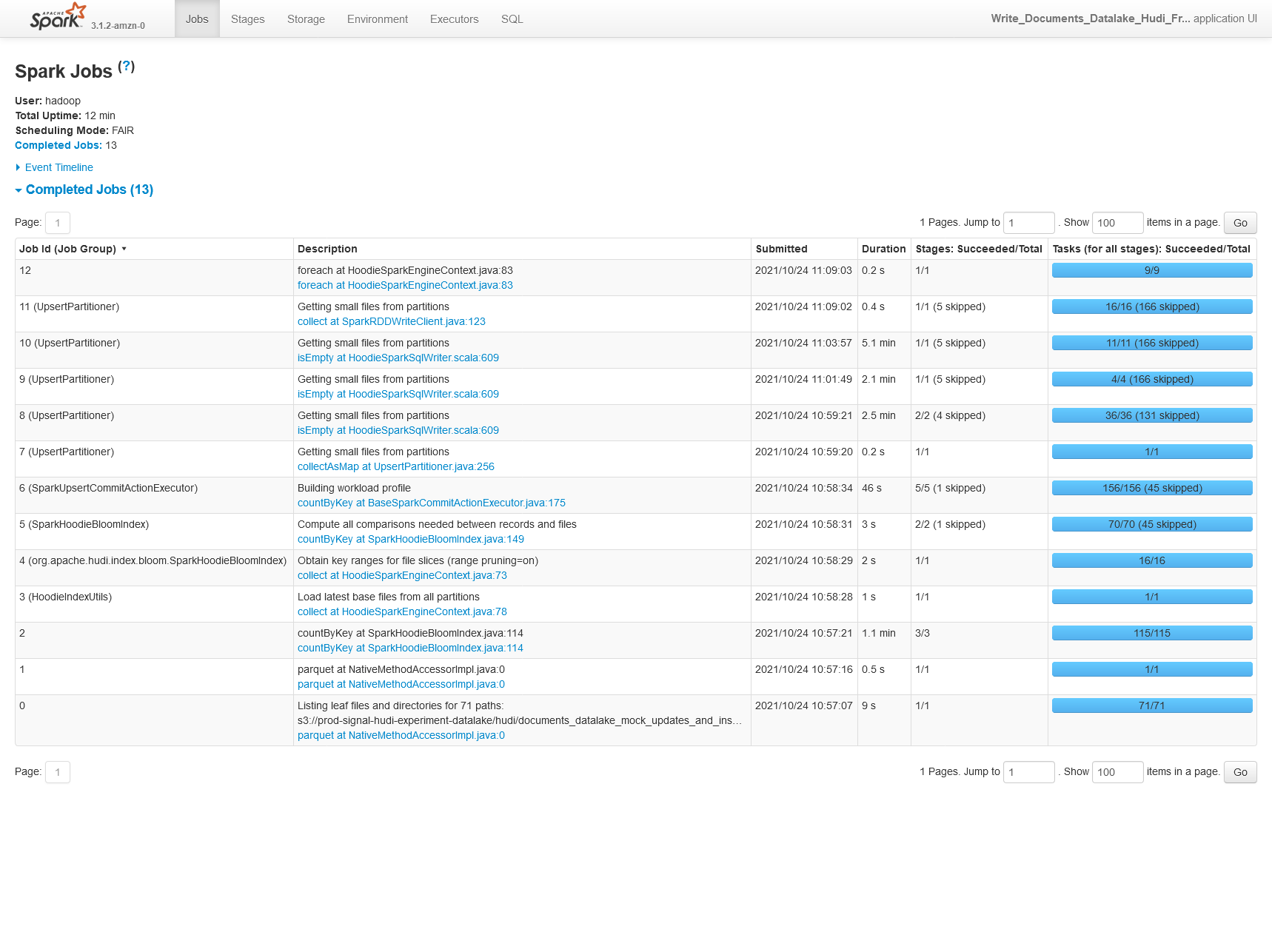
**Config**
```
"hoodie.table.name": hudi_table_name,
"hoodie.datasource.write.table.type": hudi_table_type,
"hoodie.parquet.max.file.size": str(int(0.5 * 1024.0 * 1024.0 * 1024.0)),
"hoodie.parquet.block.size": str(int(0.5 * 1024.0 * 1024.0 * 1024.0)),
"hoodie.parquet.small.file.limit": str(int(0.4 * 1024.0 * 1024.0 * 1024.0)),
# one of upsert (default), insert or bulk_insert
"hoodie.datasource.write.operation": hudi_write_operation,
# "hoodie.datasource.write.row.writer.enable": True,
"hoodie.datasource.write.recordkey.field": "_id",
"hoodie.datasource.write.precombine.field": "processed_date",
"hoodie.datasource.write.partitionpath.field": "story_published_date",
"hoodie.datasource.write.keygenerator.class": "org.apache.hudi.keygen.TimestampBasedKeyGenerator",
"hoodie.deltastreamer.keygen.timebased.timestamp.type": "DATE_STRING",
"hoodie.deltastreamer.keygen.timebased.input.dateformat": "yyyy-MM-dd'T'HH:mm:ssZ,yyyy-MM-dd'T'HH:mm:ss.SSSZ",
"hoodie.deltastreamer.keygen.timebased.input.dateformat.list.delimiter.regex": ",",
"hoodie.deltastreamer.keygen.timebased.input.timezone": "",
"hoodie.deltastreamer.keygen.timebased.output.dateformat": "yyyy-MM-dd",
"hoodie.deltastreamer.keygen.timebased.output.timezone": "UTC",
"hoodie.datasource.hive_sync.partition_extractor_class": "org.apache.hudi.hive.MultiPartKeysValueExtractor",
"hoodie.datasource.write.hive_style_partitioning": "true",
"hoodie.datasource.hive_sync.enable": "true",
"hoodie.datasource.hive_sync.database": "pipeline_reprocessing_hudi_experiment",
"hoodie.datasource.hive_sync.table": hudi_table_name,
"hoodie.datasource.hive_sync.partition_fields": "story_published_date",
"hoodie.datasource.hive_sync.jdbcurl": f"jdbc:hive2://{master_hostname}:10000",
"hoodie.write.markers.type": "TIMELINE_SERVER_BASED",
"hoodie.datasource.hive_sync.support_timestamp": "true",
**Environment Description**
EMR 6.4.0
Athena workgroup V2 (experienced on 2021/10/20)
Hudi version :
Tested on
0.9.0
0.8.0-amzn1
Spark version :
3.1.2
Hive version :
Hive 3.1.2
Hadoop version :
Amazon 3.2.1
Storage (HDFS/S3/GCS..) :
S3
Running on Docker? (yes/no) :
no
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] xushiyan commented on issue #3854: [SUPPORT] Lower performance using 0.9.0 vs 0.8.0
Posted by GitBox <gi...@apache.org>.
xushiyan commented on issue #3854:
URL: https://github.com/apache/hudi/issues/3854#issuecomment-950455798
@Limess thanks for providing benchmarks!
> bulk inserts are slightly faster with Hudi 0.9.0
This is most likely due to row writer enabled by default in 0.9.0 https://hudi.apache.org/docs/configurations#hoodiedatasourcewriterowwriterenable that boots bulkinsert in 0.9
@nsivabalan do you have any hints on what changes in 0.9 might cause the slower writes?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on issue #3854: [SUPPORT] Lower performance using 0.9.0 vs 0.8.0
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on issue #3854:
URL: https://github.com/apache/hudi/issues/3854#issuecomment-980438775
Can't think of anything that has changed between 0.8.0 and 0.9.0 on core upsert path. 0.10.0 is coming out shortly. But lets get to the bottom of this in dec.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #3854: [SUPPORT] Lower performance using 0.9.0 vs 0.8.0
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #3854:
URL: https://github.com/apache/hudi/issues/3854#issuecomment-974870498
Hey hi. Can you give it a try with open source across two versions.
@umehrot2 : Can you chime in wrt EMR spark versions. Is there any performance patches expected for hudi 0.9.0 anytime?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #3854: [SUPPORT] Lower performance using 0.9.0 vs 0.8.0
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #3854:
URL: https://github.com/apache/hudi/issues/3854#issuecomment-974870498
Hey hi. Can you give it a try with open source across two versions.
@umehrot2 : Can you chime in wrt EMR spark versions. Is there any performance patches expected for hudi 0.9.0 anytime?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #3854: [SUPPORT] Lower performance using 0.9.0 vs 0.8.0
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #3854:
URL: https://github.com/apache/hudi/issues/3854#issuecomment-965678397
yes, bulk insert boost is due to row writer, but not very sure on upsert operations.
Are you clarify for hudi and spark versions, is it EMR's version or open source one.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Limess commented on issue #3854: [SUPPORT] Lower performance using 0.9.0 vs 0.8.0
Posted by GitBox <gi...@apache.org>.
Limess commented on issue #3854:
URL: https://github.com/apache/hudi/issues/3854#issuecomment-975601661
Hey, I tried with open source Hudi 0.8 and the results were the same as the Amazon version (OS version was actually marginally faster but within a margin of error)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Limess commented on issue #3854: [SUPPORT] Lower performance using 0.9.0 vs 0.8.0
Posted by GitBox <gi...@apache.org>.
Limess commented on issue #3854:
URL: https://github.com/apache/hudi/issues/3854#issuecomment-965691677
EMR versions for Spark and Hudi 0.8.0, open source Hudi 0.9.0
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nikita-sheremet-clearscale commented on issue #3854: [SUPPORT] Lower performance using 0.9.0 vs 0.8.0
Posted by GitBox <gi...@apache.org>.
nikita-sheremet-clearscale commented on issue #3854:
URL: https://github.com/apache/hudi/issues/3854#issuecomment-993648234
I have moved from hudi 0.7.0-amz to hudi 0.9.0 and yes there is a performance problem. I can not provide exact comparison for 2 versions but 0.9.0 become about 1.5 times slower (maybe more).
See my post - https://github.com/apache/hudi/issues/4044
Btw @vinothchandar , @Limess , @xushiyan
Does hudi team have instructions or articles for hudi profiling? I understand that profiling java on local machine and on cluster with multiple nodes is not the same (a bit ;-) ) but anyway do you have a manual for that? I can not guarantee but probably I could try to do this. Maybe with different hudi versions. (Again I am not 100% sure)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org