You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2021/04/22 06:04:18 UTC
[GitHub] [iceberg] ayush-san opened a new issue #2504: Flink CDC | OOM during initial snapshot
ayush-san opened a new issue #2504:
URL: https://github.com/apache/iceberg/issues/2504
I am using flink CDC to stream CDC changes in an iceberg table. When I first run the flink job for a topic with all the data for a table, it gets out of heap memory as flink tries to load all the data during my 15mins checkpointing interval. Right now, the only solution I have is to pass `-ytm 8192 -yjm 2048m` for a table with 10M rows and then reduce it after the flink has consumed all the data.
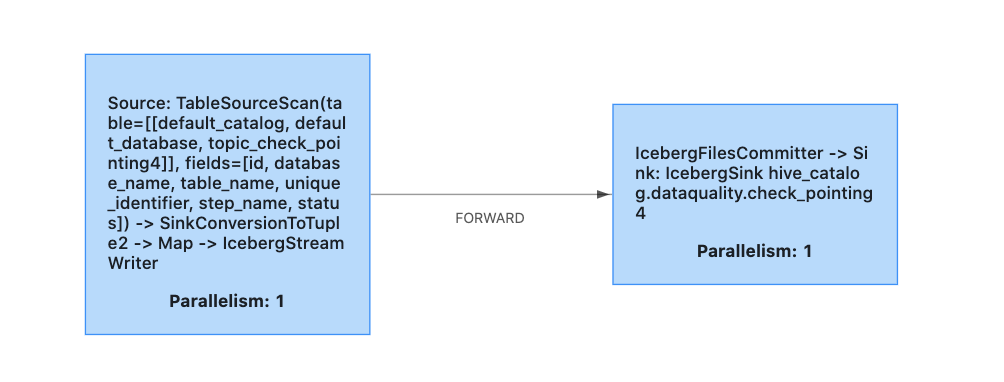
Shouldn't my iceberg sink have propagated the back-pressure up the source since it has not written that data yet and it will only do that after the checkpointing interval?
```
FlinkSink.forRowData(rowDataDataStream)
.table(icebergTable)
.tableSchema(FlinkSchemaUtil.toSchema(FlinkSchemaUtil.convert(icebergTable.schema())))
.tableLoader(tableLoader)
.equalityFieldColumns(tableConfig.getEqualityColumns())
.build();
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on issue #2504: Flink CDC | OOM during initial snapshot
Posted by GitBox <gi...@apache.org>.
openinx commented on issue #2504:
URL: https://github.com/apache/iceberg/issues/2504#issuecomment-867278938
@ayush-san I think you may want to try this PR so that we could get ride of OOM when ingest the whole snapshots from the upstream mysql databases: https://github.com/apache/iceberg/pull/2680
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san edited a comment on issue #2504: Flink CDC | OOM during initial snapshot
Posted by GitBox <gi...@apache.org>.
ayush-san edited a comment on issue #2504:
URL: https://github.com/apache/iceberg/issues/2504#issuecomment-824615294
@openinx What should be the immediate solution for now? I can think of two ways
* Increase the job and task manager memory and keep the checkpoint the same
* During the initial few hours, reduce the checkpoint to 1 min or 2 mins
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2504: Flink CDC | OOM during initial snapshot
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2504:
URL: https://github.com/apache/iceberg/issues/2504#issuecomment-824615294
@openinx What should be the immediate solution for now? I can think of two ways
* Increase the job and task manager memory and keep the checkpoint the same
* During the initial few hours, reduce the checkpoint to 1/2 mins
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on issue #2504: Flink CDC | OOM during initial snapshot
Posted by GitBox <gi...@apache.org>.
openinx commented on issue #2504:
URL: https://github.com/apache/iceberg/issues/2504#issuecomment-824582275
@ayush-san , I think that's because we've maintained all the keys that come from the same checkpoint in a __in-memory__ HashMap, it mainly used to locate the `<file_id, pos>` for the rows that was written in the current checkpoint before. In the long run, we need to change this HashMap to a Map that can spill to disk or replace it with an embedded KV lib, so that we can take on a larger number of rows in a single checkpoint. [This](https://docs.google.com/presentation/d/18xL5hhGfJKEVJyv-fbfoLYWgioRMqoEutpKFDjXhyKA/edit#slide=id.gb479a3dd40_0_948) would be a good document to describe the current design.
FYI @rdblue .
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org