You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@kvrocks.apache.org by ti...@apache.org on 2022/06/21 15:59:34 UTC
[incubator-kvrocks-website] branch main updated: Migrate docs from the kvrocks GitHub wiki (#7)
This is an automated email from the ASF dual-hosted git repository.
tison pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/incubator-kvrocks-website.git
The following commit(s) were added to refs/heads/main by this push:
new 15663e7 Migrate docs from the kvrocks GitHub wiki (#7)
15663e7 is described below
commit 15663e774eaba32606bb7520bb99702a4eeb1623
Author: hulk <hu...@gmail.com>
AuthorDate: Tue Jun 21 23:59:29 2022 +0800
Migrate docs from the kvrocks GitHub wiki (#7)
---
docs/01-supported-commands.md | 245 +++++++++++++++++++
docs/02-server-installation.md | 43 ++++
docs/03-UserGuide/00-info-section-explain.md | 261 +++++++++++++++++++++
docs/03-UserGuide/01-namespace.md | 79 +++++++
docs/04-Design/00-design-structure-on-rocksdb.md | 187 +++++++++++++++
docs/04-Design/01-replication.md | 50 ++++
docs/05-Tools/00-kvrocks-exporter.md | 12 +
docs/06-Operations/00-how-to-backup.md | 9 +
docs/07-Cluster/00-kvrocks-cluster-introduction.md | 101 ++++++++
docs/08-Performance/how-we-use-rocksdb.md | 97 ++++++++
docs/supported-commands.md | 9 -
11 files changed, 1084 insertions(+), 9 deletions(-)
diff --git a/docs/01-supported-commands.md b/docs/01-supported-commands.md
new file mode 100644
index 0000000..d829fe1
--- /dev/null
+++ b/docs/01-supported-commands.md
@@ -0,0 +1,245 @@
+---
+sidebar_position: 1
+---
+
+# Supported Commands
+
+## String Commands
+
+| Command | Supported OR Not | Desc |
+| ----------- | ---------------- | -------------------- |
+| append | √ | |
+| decr | √ | |
+| decrby | √ | |
+| get | √ | |
+| getrange | √ | |
+| getset | √ | |
+| incr | √ | |
+| incrby | √ | |
+| incrbyfloat | √ | |
+| mget | √ | |
+| mset | √ | |
+| msetnx | √ | |
+| psetex | √ | only supports second |
+| set | √ | |
+| setex | √ | |
+| setnx | √ | |
+| setrange | √ | |
+| strlen | √ | |
+| unlink | √ | |
+| cas | √ | see https://github.com/KvrocksLabs/kvrocks/pull/415 |
+| cad | √ | see https://github.com/KvrocksLabs/kvrocks/pull/415 |
+
+## Hash Commands
+
+| Command | Supported OR Not | Desc |
+| ------------ | ---------------- | ---- |
+| hdel | √ | |
+| hexists | √ | |
+| hget | √ | |
+| hgetall | √ | |
+| hincrby | √ | |
+| hincrbyfloat | √ | |
+| hkeys | √ | |
+| hlen | √ | |
+| hmget | √ | |
+| hmset | √ | |
+| hset | √ | |
+| hsetnx | √ | |
+| hstrlen | √ | |
+| hvals | √ | |
+| hscan | √ | |
+
+## List Commands
+
+| Command | Supported OR Not | Desc |
+| ---------- | ---------------- | ------------------------------------------------------------ |
+| blpop | √ | |
+| brpop | √ | |
+| brpoplpush | X | |
+| lindex | √ | Caution: linsert is O(N) operation, don't use it when list was extreme long |
+| linsert | √ | |
+| llen | √ | |
+| lpop | √ | |
+| lpush | √ | |
+| lpushx | √ | |
+| lrange | √ | |
+| lrem | √ | Caution: lrem is O(N) operation, don't use it when list was extreme long |
+| lset | √ | |
+| ltrim | √ | Caution: ltrim is O(N) operation, don't use it when list was extreme long |
+| rpop | √ | |
+| rpoplpush | √ | |
+| rpush | √ | |
+| rpushx | √ | |
+| lmove | √ | |
+
+## Set Commands
+
+| Command | Supported OR Not | Desc |
+| ----------- | ---------------- | ------------------------------------- |
+| sadd | √ | |
+| scard | √ | |
+| sdiff | √ | |
+| sdiffstore | √ | |
+| sinter | √ | |
+| sinterstore | √ | |
+| sismember | √ | |
+| smembers | √ | |
+| smove | √ | |
+| spop | √ | pop the member with key oreder |
+| srandmember | √ | always first N members if not changed |
+| srem | √ | |
+| sunion | √ | |
+| sunionstore | √ | |
+| sscan | √ | |
+
+## ZSet Commands
+
+| Command | Supported OR Not | Desc |
+| ---------------- | ---------------- | ----------- |
+| bzpopmin | X | |
+| bzpopmax | X | |
+| zadd | √ | |
+| zcard | √ | |
+| zcount | √ | |
+| zincrby | √ | |
+| zinterstore | √ | |
+| zlexcount | √ | |
+| zpopmin | √ | |
+| zpopmax | √ | |
+| zrange | √ | |
+| zrangebylex | √ | |
+| zrangebyscore | √ | |
+| zrank | √ | |
+| zrem | √ | |
+| zremrangebylex | √ | |
+| zremrangebyrank | √ | |
+| zremrangebyscore | √ | |
+| zrevrank | √ | |
+| zrevrange | √ | |
+| zrevrangebylex | √ | |
+| zrevrangebyscore | √ | |
+| zscan | √ | |
+| zscore | √ | |
+| zmscore | √ |multi zscore |
+| zunionstore | √ | |
+
+## Key Commands
+
+| Command | Supported OR Not | Desc |
+| --------- | ---------------- | -------------------- |
+| del | √ | |
+| dump | X | |
+| exists | √ | |
+| expire | √ | |
+| expireat | √ | |
+| keys | √ | |
+| persist | √ | |
+| pexpire | √ | precision is seconds |
+| pexpireat | √ | precision is seconds |
+| pttl | √ | |
+| ttl | √ | |
+| type | √ | |
+| scan | √ | |
+| rename | X | |
+| randomkey | √ | |
+
+## Bit Commands
+
+| Command | Supported OR Not | Desc |
+| -------- | ---------------- | ---- |
+| getbit | √ | |
+| setbit | √ | |
+| bitcount | √ | |
+| bitpos | √ | |
+| bitfield | X | |
+| bitop | X | |
+
+**NOTE : String and Bitmap is different type in kvrocks, so you can't do bit with string, vice versa.**
+
+
+## Script Commands
+
+| Command | Supported OR Not | Desc |
+| --------- | ---------------- | ---- |
+| eval | √ | |
+| evalsha | √ | |
+| script | √ | script kill and debug subcommand are not supported |
+
+## Pub/Sub Commands
+
+| Command | Supported OR Not | Desc |
+| ------------ | ---------------- | ---- |
+| psubscribe | √ | |
+| publish | √ | |
+| pubsub | √ | |
+| punsubscribe | √ | |
+| subscribe | √ | |
+| unsubscribe | √ | |
+
+## Transaction Commands
+
+| Command | Supported OR Not | Desc |
+| --------- | ---------------- | ---- |
+| multi | √ | |
+| exec | √ | |
+| discard | √ | |
+| watch | X | |
+| unwatch | X | |
+
+## Sortedint Commands
+
+| Command | Supported OR Not | Desc |
+| ----------------- | ---------------- | ------------------------------------------------- |
+| sicard | √ | like scard |
+| siadd | √ | like sadd, but member is int |
+| sirem | √ | like srem, but member is int |
+| sirange | √ | sirange key offset count cursor since_id |
+| sirevrange | √ | sirevrange key offset count cursor max_id |
+| siexists | √ | siexists key member1 (member2 ...) |
+| sirangebyvalue | √ | sirangebyvalue key min max (LIMIT offset count) |
+| sirevrangebyvalue | √ | sirevrangebyvalue key max min (LIMIT offset count) |
+
+## Cluster Subcommands
+
+| Subcommand | Supported OR Not | Desc |
+| ------------ | ---------------- | ---- |
+| info | √ | |
+| nodes | √ | |
+| slots | √ | |
+| keyslot | √ | |
+
+## Server Commands
+
+| Command | Supported OR Not | Desc |
+| ------------ | ---------------- | ---- |
+| monitor | √ | |
+| info | √ | |
+| role | √ | |
+| config | √ | |
+| dbsize | √ | |
+| namespace | √ | |
+| flushdb | √ | |
+| flushall | √ | |
+| command | √ | |
+| clinet | √ | |
+| quit | √ | |
+| slowlog | √ | |
+| perflog | √ | |
+
+**NOTE : The db size was updated async after execute `dbsize scan` command**
+
+## GEO Commands
+
+| Command | Supported OR Not | Desc |
+| ------------ | ---------------- | ---- |
+| geoadd | √ | |
+| geodist | √ | |
+| geohash | √ | |
+| geopos | √ | |
+| georadius | √ | |
+| georadiusbymember | √ | |
+
+## Hyperloglog Commands
+
+**Not Supported**
diff --git a/docs/02-server-installation.md b/docs/02-server-installation.md
new file mode 100644
index 0000000..7b90521
--- /dev/null
+++ b/docs/02-server-installation.md
@@ -0,0 +1,43 @@
+# Server Installation
+## Run Kvrocks Using Docker
+
+For installing docker, follow the Docker installation instructions found here: https://docs.docker.com/engine/installation/.
+
+Start the kvrocks service:
+
+```shell
+$ docker run -it -p 6666:6666 kvrocks/kvrocks
+```
+then you can use the redis-cli to play the kvrocks server as Redis.
+
+## Run Kvrocks Using Binary
+
+We will automated build the release binary for the CentOS7 and Ubuntu(>= 18.04) when releasing a new version, please step forward to [kvrocks releases](https://github.com/KvrocksLabs/kvrocks/releases) page to download the binary zip file.
+
+## Run Kvrocks Using Source Code
+
+### 1. Install Dependencies
+
+```shell
+# Centos/Redhat
+sudo yum install -y epel-release && sudo yum install -y git gcc gcc-c++ make cmake autoconf automake libtool which
+
+# Ubuntu/Debian
+sudo apt update
+sudo apt-get install gcc g++ make cmake autoconf automake libtool
+
+# macOS
+brew install autoconf automake libtool cmake
+```
+
+### 2. Compile Kvrocks Source
+
+```
+$ git clone https://github.com/apache/incubator-kvrocks.git
+$ cd incubator-kvrocks
+$ ./build.sh build # `./build.sh -h` to check more options
+```
+
+The binary file `kvrocks` would be generated at `src` dir if everything was going well, or you can help to file an issue with your context.
+
+
diff --git a/docs/03-UserGuide/00-info-section-explain.md b/docs/03-UserGuide/00-info-section-explain.md
new file mode 100644
index 0000000..932bfe7
--- /dev/null
+++ b/docs/03-UserGuide/00-info-section-explain.md
@@ -0,0 +1,261 @@
+# Info Section Explanation
+
+The INFO command returns information and statistics about the server in a format that is simple to parse by computers and easy to read by humans.
+
+The optional parameter can be used to select a specific section of information:
+
+* server: General information about the Kvrocks server
+* clients: Client connections section
+* memory: Memory consumption related information
+* stats: General statistics
+* replication: Master/replica replication information
+* cpu: CPU consumption statistics
+* commandstats: Kvrocks command statistics
+* keyspace: Database related statistics
+* RocksDB: RocksDB related statistics
+
+### Return value
+Bulk string reply: as a collection of text lines.
+
+Lines can contain a section name (starting with a # character) or a property. All the properties are in the form of field:value terminated by \r\n.
+
+```shell
+# Server
+version:999.999.999
+git_sha1:d2c0afb
+os:Darwin 19.4.0 x86_64
+gcc_version:4.2.1
+arch_bits:64
+process_id:1467
+tcp_port:6666
+uptime_in_seconds:8
+uptime_in_days:0
+
+# Clients
+connected_clients:1
+monitor_clients:0
+# Memory
+used_memory_rss:19558400
+used_memory_human:18.65M
+used_memory_lua:35840
+used_memory_lua_human:35.00K
+
+# Persistence
+loading:0
+
+# Stats
+total_connections_received:1
+total_commands_processed:2
+instantaneous_ops_per_sec:0
+total_net_input_bytes:23
+total_net_output_bytes:8231
+instantaneous_input_kbps:0
+instantaneous_output_kbps:0
+sync_full:0
+sync_partial_ok:0
+sync_partial_err:0
+pubsub_channels:0
+pubsub_patterns:0
+
+# Replication
+role:master
+connected_slaves:0
+master_repl_offset:0
+
+# CPU
+used_cpu_sys:0
+used_cpu_user:0
+
+# Commandstats
+cmdstat_command:calls=1,usec=904,usec_per_call=904
+cmdstat_info:calls=1,usec=0,usec_per_call=0
+
+# Keyspace
+# Last scan db time: Thu Jan 1 08:00:00 1970
+db0:keys=0,expires=0,avg_ttl=0,expired=0
+sequence:0
+used_db_size:0
+max_db_size:0
+used_percent: 0%
+disk_capacity:499963174912
+used_disk_size:266419978240
+used_disk_percent: 53%
+
+# RocksDB
+estimate_keys[default]:0
+block_cache_usage[default]:0
+block_cache_pinned_usage[default]:0
+index_and_filter_cache_usage:[default]:0
+estimate_keys[metadata]:0
+block_cache_usage[metadata]:0
+block_cache_pinned_usage[metadata]:0
+index_and_filter_cache_usage:[metadata]:0
+estimate_keys[zset_score]:0
+block_cache_usage[zset_score]:0
+block_cache_pinned_usage[zset_score]:0
+index_and_filter_cache_usage:[zset_score]:0
+estimate_keys[pubsub]:0
+block_cache_usage[pubsub]:0
+block_cache_pinned_usage[pubsub]:0
+index_and_filter_cache_usage:[pubsub]:0
+estimate_keys[propagate]:0
+block_cache_usage[propagate]:0
+block_cache_pinned_usage[propagate]:0
+index_and_filter_cache_usage:[propagate]:0
+all_mem_tables:3520
+cur_mem_tables:3520
+snapshots:0
+num_immutable_tables:0
+num_running_flushes:0
+memtable_flush_pending:0
+compaction_pending:0
+num_running_compactions:0
+num_live_versions:5
+num_superversion:5
+num_background_errors:0
+flush_count:0
+compaction_count:0
+is_bgsaving:no
+is_compacting:no
+```
+## Server Section
+
+Here is the meaning of all fields in the server section:
+
+* version: Version of the Kvrocks server
+* git_sha1: Git SHA1
+* os: Operating system hosting the Kvrocks server
+* arch_bits: Architecture (32 or 64 bits)
+* gcc_version: Version of the GCC compiler used to compile the Kvrocks server
+* process_id: PID of the server process
+* tcp_port: TCP/IP listen port
+* uptime_in_seconds: Number of seconds since Kvrocks server start
+* uptime_in_days: Same value expressed in days
+
+## Clients Section
+
+Here is the meaning of all fields in the clients section:
+
+* connected_clients: Number of client connections (excluding connections from replicas)
+* monitor_clients: Number of monitor client connections
+
+## Memory Section
+
+Here is the meaning of all fields in the memory section:
+
+* used_memory_rss: Number of bytes that Kvrocks allocated as seen by the operating system (a.k.a resident set size). This is the number reported by tools such as top(1) and ps(1)
+* used_memory_rss_human: Human-readable representation of previous value
+* used_memory_lua: Number of bytes used by the Lua engine
+* used_memory_lua_human: Human-readable representation of previous value
+
+## Stats Section
+
+Here is the meaning of all fields in the stats section:
+
+* total_connections_received: Total number of connections accepted by the server
+* total_commands_processed: Total number of commands processed by the server
+* instantaneous_ops_per_sec: Number of commands processed per second
+* total_net_input_bytes: The total number of bytes read from the network
+* total_net_output_bytes: The total number of bytes written to the network
+* instantaneous_input_kbps: The network's read rate per second in KB/sec
+* instantaneous_output_kbps: The network's write rate per second in KB/sec
+* sync_full: The number of full resyncs with replicas
+* sync_partial_ok: The number of accepted partial resync requests
+* sync_partial_err: The number of denied partial resync requests
+* pubsub_channels: Global number of pub/sub channels with client subscriptions
+* pubsub_patterns: Global number of pub/sub pattern with client subscriptions
+
+## CommandStats Section
+
+The commandstats section provides statistics based on the command type, including the number of calls that reached command execution, the total CPU time consumed by these commands, the average CPU consumed per command execution.
+
+For each command type, the following line is added:
+
+***cmdstat_XXX: calls=XXX,usec=XXX,usec_per_call=XXX***
+
+## Persistence Section
+
+Here is the meaning of all fields in the replicatoin section:
+
+* loading: Flag indicating if the restore of the backup is on-going
+
+## Replication Section
+
+Here is the meaning of all fields in the replicatoin section:
+
+* role: Value is "master" if the instance is replica of no one, or "slave" if the instance is a replica of some master instance. Note that a replica can be master of another replica (chained replication).
+* master_repl_offset: The server's current replication offset
+
+If the instance is a replica, these additional fields are provided:
+
+* master_host: Host or IP address of the master
+* master_port: Master listening TCP port
+* master_link_status: Status of the link (up/down)
+* master_last_io_seconds_ago: Number of seconds since the last interaction with master
+* master_sync_in_progress: Indicate the master is syncing to the replica
+* slave_repl_offset: The replication offset of the replica instance
+* slave_priority: The priority of the instance as a candidate for failover
+
+## CPU Section
+
+Here is the meaning of all fields in the cpu section:
+
+* used_cpu_sys: System CPU consumed by the Kvrocks server, which is the sum of system CPU consumed by all threads of the server process (main thread and background threads)
+* used_cpu_user: User CPU consumed by the Kvrocks server, which is the sum of user CPU consumed by all threads of the server process (main thread and background threads)
+
+## Keyspace Section
+
+The keyspace section provides statistics on the main dictionary of each database. The statistics are the number of keys, and the number of keys with an expiration. Note that Kvrocks only have `db0` and keys statistics wasn't manipulated in memor, so we need to use the `dbsize scan` to async scan and calculate the keys number like below:
+
+```shell
+# Last scan db time: Sun Oct 31 17:13:14 2021
+db0:keys=0,expires=0,avg_ttl=0,expired=0
+```
+The line starts with `#` means the last scan was executed on `Oct 31 17:13:14 2021`.
+
+* sequence: The sequence number of the RocksDB
+* used_db_size: The total disk size used by Kvrocks(NOT included the WAL)
+* max_db_size: Max disk size can be used by Kvrocks, 0 means unlimited.
+* used_percent: Percent representation of used_db_size/max_db_size.
+* disk_capacity: The capacity of the disk.
+* used_disk_size: Total used size of the disk(NOT Kvrocks used disk size).
+* used_disk_percent: Percent representation of used_disk_size/disk_capacity.
+
+## RocksDB Section
+
+Here is the meaning of all fields in the rocksdb section:
+
+The rocksdb section provides statistics on the each rocksdb column family and all fields were exported by rocksdb, if the field was not explained clearly enough, you can also see more information on the rocksdb wiki.
+
+There are five column families on kvrocks:
+1. `default`: Used to store the subkeys of the complex data structure like hash/set/list/zset/geo.
+2. `metadata`: Used to store the metadata of the complex data structure and string.
+3. `zset score`: Used to store the mapping of zset's score to member, which would make the range by score operation faster.
+4. `pubsub`: Used to propagate the pubsub message to replicas.
+5. `propagate`: Used to propagate other commands to replicas except pubsub message.
+
+and below statistics were column family related:
+
+* estimate_keys[xxx]: Estimate keys in the column family, may contains the tombstone and expired keys, it's a fast way to know
+how many keys on the column family but not precise.
+* block_cache_usage[xxx]: Total block cache bytes used by this column family.
+* block_cache_pinned_usage[xxx]: Total pinned bytes in this column family.
+* index_and_filter_cache_usage: Total bytes was used to cache the index and filter block.
+
+those statistics were the entire rocksdb side:
+
+* all_mem_tables: Approximate size of active, unflushed immutable, and pinned immutable memtables in bytes.
+* cur_mem_tables: Approximate size of active and unflushed immutable memtable in bytes.
+* snapshots: Number of snapshots in rocksdb.
+* num_immutable_tables: Number of the immutable.
+* num_running_flushes: Number of currently running flushes.
+* memtable_flush_pending: This metric returns 1 if a memtable flush is pending; otherwhise it returns 0.
+* compaction_pending: This metric returns 1 if at least one compaction is pending; otherwise, the metric reports 0.
+* num_running_compactions: Number of currently running compactions.
+* num_live_versions: Number of live versions. More live versions often mean more SST files are held from being deleted, by iterators or unfinished compactions.
+* num_background_errors: Accumulated number of background errors.
+* flush_count: Number of flushes.
+* compaction_count: Number of compactions.
+* is_bgsaving: This metric returns 1 if the bgsave was running; otherwhise it reutrns 0.
+* is_compacting: This metric returns 1 if the compaction was running; otherwhise it reutrns 0.
+
diff --git a/docs/03-UserGuide/01-namespace.md b/docs/03-UserGuide/01-namespace.md
new file mode 100644
index 0000000..4a9bf12
--- /dev/null
+++ b/docs/03-UserGuide/01-namespace.md
@@ -0,0 +1,79 @@
+# Namespace
+
+Like the Redis database, Kvrocks uses the namespace to isolate the data between users,
+but unlike Redis, each namespace has its own password. The data would be stored in the
+default namespace when using `requirepass`. The namespace would have
+no effect when the cluster mode was enabled like the Redis DB.
+
+## Manage Namespace
+
+`requirepass` MUST be set if you want to add namespaces since we treat the `requirepass`
+user as administrator.
+
+```shell
+# Auth with the requirepass
+> redis-cli -p 6666 -a ${REQUIREPASS}
+
+# Add a new namespace with the token, the namespace name must be unique.
+127.0.0.1:6666> namespace add ${NEW NAMESPACE} ${NEW TOKEN}
+
+# Update the namespace's token
+127.0.0.1:6666> namespace set ${NAMESPACE} ${NEW TOKEN}
+
+# Delete the namespace, the namespace's data WOULD NOT be deleted,
+# unless you use the `flushdb` command to flush the DB data.
+127.0.0.1:6666> namespace del ${NAMESPACE}
+
+# Get the namespace's token
+127.0.0.1:6666> namespace get ${NAMESPACE}
+
+# List namespaces
+127.0.0.1:6666> namespace get *
+```
+
+Be careful that you MUST use the `config rewrite` command to persist
+the new namespaces into the config file.
+
+## Switch Namespace
+
+Firstly, we use the namespace command to create namespace `ns1` and `ns2` with the corresponding tokens `token1` and `token2`.
+
+```shell
+127.0.0.1:6666> namespace add ns1 token1
+127.0.0.1:6666> namespace add ns2 token2
+```
+
+Then we can use `token1` and `token2`, operate data between namespaces would NOT affect each other like below:
+
+```shell
+
+# Use token1 to switch to ns1
+127.0.0.1:6666> auth token1
+OK
+127.0.0.1:6666> set key 100
+OK
+127.0.0.1:6666> get key
+"100"
+
+# Use token2 to switch to ns2
+127.0.0.1:6666> auth token2
+OK
+127.0.0.1:6666> set key 200
+OK
+127.0.0.1:6666> get key
+"200"
+
+# Use token1 to switch to ns1 again, the value is still 100
+127.0.0.1:6666> auth token1
+OK
+127.0.0.1:6666> get key
+"100"
+
+```
+
+## How Kvrocks implement the namespace
+
+Kvrocks simply prepend the namespace prefix to the user key and remove it before retrieving.
+For example, we create a new namespace `foo` with token `bar`, then the `foo` would prepend
+to the user key. Another way was to split the namespace into different rocksdb column families,
+but we didn't do that for the sake of simplicity.
diff --git a/docs/04-Design/00-design-structure-on-rocksdb.md b/docs/04-Design/00-design-structure-on-rocksdb.md
new file mode 100644
index 0000000..8222d41
--- /dev/null
+++ b/docs/04-Design/00-design-structure-on-rocksdb.md
@@ -0,0 +1,187 @@
+# Design Complex Structure On Rocksdb
+
+kvrocks uses the rocksdb as storage, it's developed by Facebook which is built on LevelDB with many extra features, like column family, transaction and backup, see the rocksdb wiki: [Features Not In LevelDB](https://github.com/facebook/rocksdb/wiki/Features-Not-in-LevelDB). The basic operations in rocksdb are `Put(key, value)`, `Get(key)`, `Delete(key)`, other complex structures aren't supported. The main goal of this doc is to explain how we built the Redis hash/list/set/zset/bitmap on [...]
+
+## String
+
+Redis string is key-value with expire time, so it's very easy to translate the Redis string into rocksdb key-value.
+
+```shell
+ +----------+------------+--------------------+
+key => | flags | expire | payload |
+ | (1byte) | (4byte) | (Nbyte) |
+ +----------+------------+--------------------+
+```
+
+we prepend 1-byte `flags` and 4-bytes expire before the user's value:
+
+- `flags` is used to tell the kvrocks which type of this key-value, maybe `string`/`hash`/`list`/`zset`/`bitmap`
+- `expire` stores the absolute time of key should be expired, zero means the key-value would never expire
+- `payload` is the user's raw value
+
+## Hash
+
+Redis hashmap(dict) is like the hashmap in many programming languages, it is used to implement an associative array abstract data type, a structure that can map keys to values. The direct way to implement the hash in rocksdb is serialized the keys/values into one value and store it like the string, but the drawback is performance impact when the keys/values grew bigger. so we split the hash sub keys/values into a single key-value in rocksdb, track it with metadata.
+
+#### hash metadata
+
+```shell
+ +----------+------------+-----------+-----------+
+key => | flags | expire | version | size |
+ | (1byte) | (4byte) | (8byte) | (4byte) |
+ +----------+------------+-----------+-----------+
+```
+
+the value of key we call it metadata here, it stored the metadata of hash key includes:
+
+- `flags` like the string, the field shows what type this key is
+- `expire ` is the same as the string type, record the expiration time
+- `version` is used to accomplish fast delete when the number of sub keys/values grew bigger
+- `size` records the number sub keys/values in this hash key
+
+#### hash sub keys-values
+
+we use extra keys-values to store the hash keys-values, the format is like below:
+
+```shell
+ +---------------+
+key|version|field => | value |
+ +---------------+
+```
+
+we prepend the hash `key` and `version` before the hash field, the value of `version` is from the metadata. For example, when the request `hget h1 f1` is received, kvrocks fetches the metadata by hash key(here is `h1`), then concatenate the hash key, version, field as new key, then fetches the value with the new key.
+
+
+
+***Question1: why store version in the metadata***
+
+> we store the hash keys/values into a single key-value, if the store millions of sub keys-values in one hash key. If user delete this key, the kvrocks must iterator millions of sub keys-values and delete them, which would cause performance problem. With version we can quickly delete the metadata and then recycle the others keys-values in compaction background threads. The cost is those tombstone keys would take some disk storage. You can regard the version as an atomic increment number, [...]
+
+
+
+***Question2: what can we do if the user key is conflicted with the composed key?***
+
+> we store the metadata key and composed key in different column families, so it wouldn't happen.
+
+## Set
+
+Redis set can be regarded as a hash, with the value of sub-key always being null, the metadata is the same with the one in hash:
+
+```shell
+ +----------+------------+-----------+-----------+
+key => | flags | expire | version | size |
+ | (1byte) | (4byte) | (8byte) | (4byte) |
+ +----------+------------+-----------+-----------+
+```
+
+and the sub keys-values in rocksdb would be:
+
+```shell
+ +---------------+
+key|version|member => | NULL |
+ +---------------+
+```
+
+## List
+
+#### list metadata
+
+Redis list is also organized by metadata and sub keys-values, and sub key is index instead of the user key. Metadata is like below:
+
+```shell
+ +----------+------------+-----------+-----------+-----------+-----------+
+key => | flags | expire | version | size | head | tail |
+ | (1byte) | (4byte) | (8byte) | (4byte) | (8byte) | (8byte) |
+ +----------+------------+-----------+-----------+-----------+-----------+
+```
+
+- `head` is the starting position of the list head
+- `tail` is the stopping position of the list tail
+
+the meaning of other fields are the same as other types, just add extra head/tail to record the boundary of the list.
+
+#### list sub keys-values
+
+the subkey in list is composed by list key, version and index, index is calculated from metadata's head or tail. for example, when the user requests the `rpush list elem`, kvrocks would fetch the metadata with list key, then generate the subkey with list key, version and tail, simply increase the tail, then write the metadata and subkey's value back to rocksdb.
+
+```shell
+ +---------------+
+key|version|index => | value |
+ +---------------+
+```
+
+## ZSet
+
+Redis zset is set with sorted property, so it's a little different from other types. it must be able to search with the member, as well as to retrieve members with score range.
+
+#### zset metadata
+
+the metadata of zset is still same with set, like below:
+
+```shell
+ +----------+------------+-----------+-----------+
+key => | flags | expire | version | size |
+ | (1byte) | (4byte) | (8byte) | (4byte) |
+ +----------+------------+-----------+-----------+
+```
+
+#### zset sub keys-values
+
+The value of sub key isn't null, we need a way to range the members with the score. So the zset has two types of sub keys-values, one for mapping the members-scores, and one for score range.
+
+```shell
+ +---------------+
+key|version|member => | score | (1)
+ +---------------+
+
+ +---------------+
+key|version|score|member => | NULL | (2)
+ +---------------+
+```
+
+if the user wants to get the score of the member or check the member exists or not, it would try the first one.
+
+## Bitmap
+
+Redis bitmap is the most interesting part in kvrocks design, unlike other types, it's not subkey and the value would be very large if the user treats it as a sparse array. It's apparent that the things would break down if we store the bitmap into a single value, so we should break the bitmap value into multiple fragments. Another behavior of bitmap is writing to arbitrary index, it's very similar to the access model of the Linux virtual memory, so the idea of the bitmap design came from that.
+
+#### bitmap metadata
+
+```shell
+ +----------+------------+-----------+-----------+
+key => | flags | expire | version | size |
+ | (1byte) | (4byte) | (8byte) | (4byte) |
+ +----------+------------+-----------+-----------+
+```
+
+#### bitmap sub keys-values
+
+we break the bitmap values into fragments(1KiB, 8192 bits/fragment), and subkey is the index of the fragment. for example, when the request to set the bit of 1024 would locate in the first fragment with index 0, to set bit of 80970 would locate in 10th fragment with index 9.
+
+```shell
+ +---------------+
+key|version|index => | fragment |
+ +---------------+
+```
+
+when the user requests to get it of position P, kvrocks would first fetch the metadata with bitmap's key and calculate the index of the fragment with bit position, then fetch the bitmap fragment with composed key and find the bit in fragment offset. For example, `getbit bitmap 8193`, the fragment index is `1` (8193/8192) and subkey is `bitmap|1|1` (when the version is 1), then fetch the subkey from rocksdb and check if the bit of offset `1`(8193%8192) is set or not.
+
+## Sortedint
+
+Sortedint is a set with members being type int and sorted in ascending order:
+
+```shell
+ +----------+------------+-----------+-----------+
+key => | flags | expire | version | size |
+ | (1byte) | (4byte) | (8byte) | (4byte) |
+ +----------+------------+-----------+-----------+
+```
+
+and the sub keys-values in rocksdb would be:
+
+```shell
+ +---------------+
+key|version|id => | NULL |
+ +---------------+
+```
+
diff --git a/docs/04-Design/01-replication.md b/docs/04-Design/01-replication.md
new file mode 100644
index 0000000..3e5009f
--- /dev/null
+++ b/docs/04-Design/01-replication.md
@@ -0,0 +1,50 @@
+# Replication of rocksdb data
+
+A instance is turned into a slave role when `SLAVEOF` cmd is received. Slave will
+try to do a partial synchronization (AKA. incremental replication) if it is viable,
+Otherwise, slave will do a full-sync by copying all the rocksdb's latest backup files.
+After the full-sync is finished, the slave's DB will be erased and restored using
+the backup files downloaded from master, then partial-sync is triggered again.
+
+If everything go OK, the partial-sync is a ongoing procedure that keep receiving
+every batch the master gets.
+
+## Replication State Machine
+
+A state machine is used in the slave's replication thread to accommodate the complexity.
+
+On the slave side, replication is composed of the following steps:
+
+ 1. Send Auth
+ 2. Send db\_name to check if the master has the right DB
+ 3. Try PSYNC, if succeeds, slave is in the loop of receiving batches; if not, go to `4`
+ 4. Do FULLSYNC
+ 4.1. send _fetch_meta to get the latest backup meta data
+ 4.2. send _fetch_file to get all the backup files listed in the meta
+ 4.3. restore slave's DB using the backup
+ 5. goto `1`
+
+## Partial Synchronization (PSYNC)
+
+PSYNC takes advantage of the rocksdb's WAL iterator. If the PSYNC's requesting sequence
+number is in the range of the WAL files, PSYNC is considered viable.
+
+PSYNC is a command implemented on master role instance. Unlike other commands (eg. GET),
+PSYNC cmd is not a REQ-RESP command, but a REQ-RESP-RESP style. That's the response never
+ends once the req is accepted.
+
+so PSYNC has two main parts in the code:
+- A: libevent callback for sending the batches when the WAL iterator has new data.
+- B: timer callback, when A quited because of the exhaustion of the WAL data, timer cb
+ will check if WAL has new data available from time to time, so to awake the A again.
+
+## Full Synchronization
+
+On the master side, to support full synchronization, master must create a rocksdb backup
+every time the `_fetch_meta` request is received.
+
+On the slave side, after retrieving the meta data, the slave can fetch every file listed in
+the meta data (skip if already existed), and restore the backup. to accelerate a bit, file
+fetching is executed in parallel.
+
+
diff --git a/docs/05-Tools/00-kvrocks-exporter.md b/docs/05-Tools/00-kvrocks-exporter.md
new file mode 100644
index 0000000..f40aab1
--- /dev/null
+++ b/docs/05-Tools/00-kvrocks-exporter.md
@@ -0,0 +1,12 @@
+# Kvrocks Exporter
+
+Like the Redis metrics monitor, Kvrocks also exports the internal metrics to info commands.
+Users can collect and store those metrics, we also offer the Kvrocks exporter for the
+Prometheus metrics since it's widely used now.
+
+GitHub: [KvrocksLabs/kvrocks_exporter](https://github.com/KvrocksLabs/kvrocks_exporter)
+
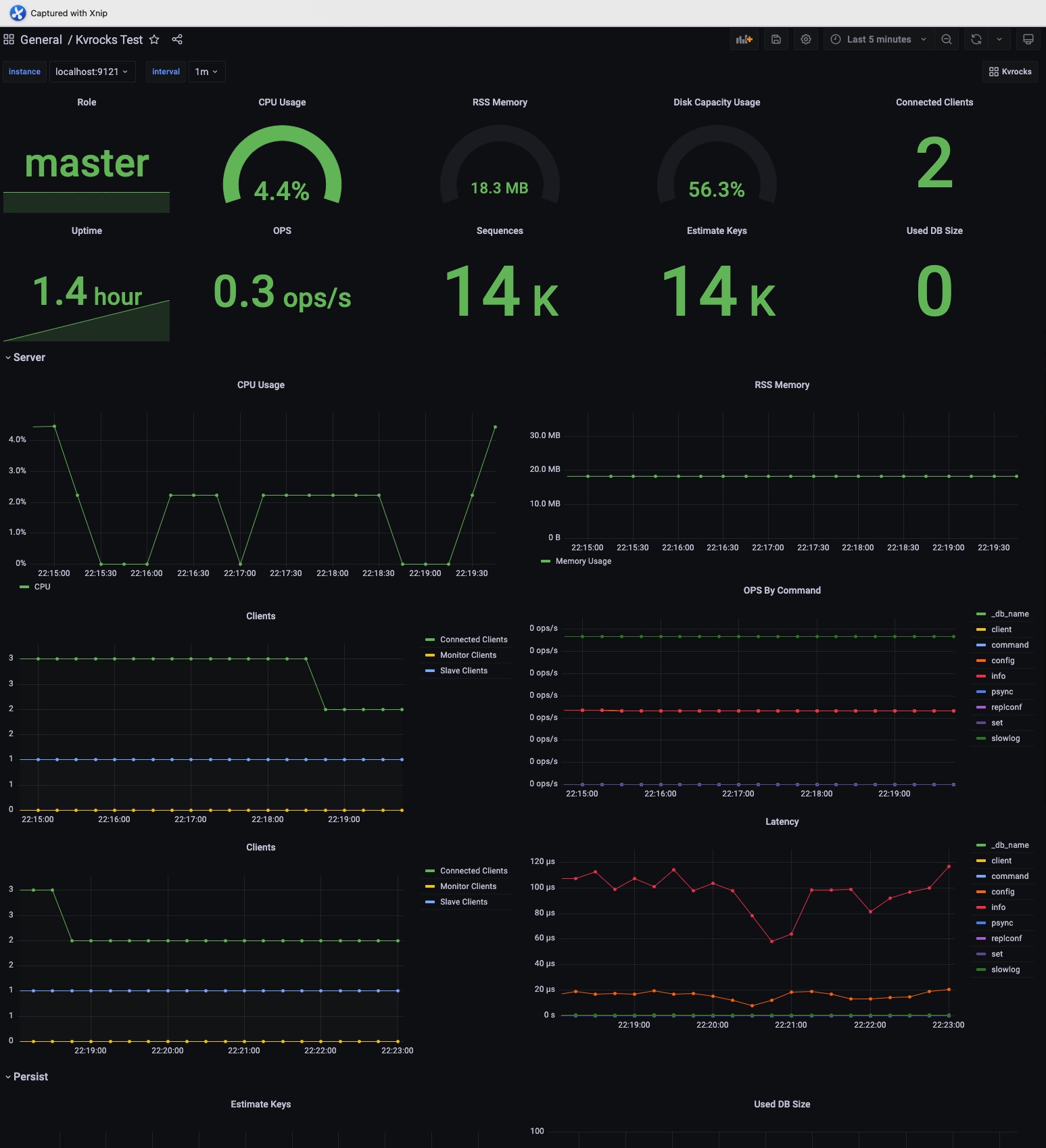
+Kvrocks Grafana dashboard template is available on Grafana.com and imports the Dashboard with ID 15286 or downloads the JSON file.
+
+Example Grafana screenshots:
+
diff --git a/docs/06-Operations/00-how-to-backup.md b/docs/06-Operations/00-how-to-backup.md
new file mode 100644
index 0000000..5ed2efb
--- /dev/null
+++ b/docs/06-Operations/00-how-to-backup.md
@@ -0,0 +1,9 @@
+# How to backup
+## Full backup
+Use `bgsave` command to trigger Kvrocks to generate a backup, and use `rsync` tool to copy all files of backup to remote server.
+
+## Incremental backup
+You can try use incremental backup if your kvrocks database doesn't be changed quickly, this way could use less network bandwidth.
+
+This solution is similar with kvrocks resuming broken transfer based files on full synchronization.
+Firstly, you should get old remote backup files list, and current new backup files list (by `bgsave` command and read `backup` directory); Secondly, by comparing them, you will know invalid files of old remote backup and delete them, please notice that `CURRENT` file may be invalid, you should always fetch it; Finally, you only copy files that old remote backup doesn't have but new backup has, and store into remote server.
diff --git a/docs/07-Cluster/00-kvrocks-cluster-introduction.md b/docs/07-Cluster/00-kvrocks-cluster-introduction.md
new file mode 100644
index 0000000..33bd93b
--- /dev/null
+++ b/docs/07-Cluster/00-kvrocks-cluster-introduction.md
@@ -0,0 +1,101 @@
+# Kvrocks Cluster Introduction
+
+Before releasing the cluster mode of Kvrocks, we usually used the pre-sharding way to scale out the capacity like sharding with Twemproxy, and used Redis Sentinel to guarantee the availability. Although it works well in most scenes since the capacity of Kvrocks was far larger than Redis, it’s still trivial to scale-out in-flight, so we decided to implement the cluster mode to make it easier.
+
+There’re two main types of Redis cluster solutions in the industry:
+
+* Redis cluster decentralized solution
+* Codis centralized solution
+
+For Redis cluster, the biggest advantage was NOT needing to depend on other components, but the shortcoming was also obvious that it’s hard to write the right implementation and not easy to maintain the cluster topology. Another big issue was Gossip protocol would limit the cluster size. For Codis solution, we need to import the proxy and centralized storage to keep the metadata, the proxy also added extra network communication cost and delay.
+
+In Kvrocks cluster design, we want to integrate advantages between those solutions, can access Kvrocks without the proxy, and scale-out easily.
+
+## Internal Design
+
+Each Kvrocks node can act as Redis node which can offer the cluster topology directly, and the Redis cluster client can also work on the Kvrocks cluster without any modifications. The topology was managed by the other control panel component which can avoid the complexity of the Gossip protocol(Redis community takes many years to complete the Gossip on cluster solution).
+
+
+
+
+### Topology Management
+
+Kvrocks uses the [Clusterx SetNodes](https://github.com/KvrocksLabs/kvrocks/pull/302) command to set up the cluster topology, be careful that we should apply the entire topology information to all nodes since nodes didn't communicate with each other. The command is like below:
+
+CLUSTERX SETNODES `$ALL_NODES_INFO` `$VERSION` `FORCE`
+
+- `$ALL_NODES_INFO`: was the cluster topology information, format: : `$node_id` `$ip` `$port` `$role` `$master_node_id` `$slot_range`
+ - `$node_id`: 40 chars string, it represents as the unique id in the cluster
+ - `$ip` and `$port`: the node IP address and the listening port
+ - `$role`: node's role, should be one of master or slave
+ - `$master_node_id`: set it to the master node id when the current node's role was a slave and set `-` if it's master
+ - `slot_range`: slots were served by current node, the format can be the range or single value, like 0-100 200 205 which means slots 0 to 100, 200 and 205 were served by this node
+- `$VERSION`: the topology information version is used to control update the order, the topology information can be updated iff the version is newer than the current version
+- `FORCE`: force update the topology information without verifying the version, we can use this flag when the topology information was totally broken
+
+**Example:**
+
+```shell
+CLUSTERX SETNODES
+ "67ed2db8d677e59ec4a4cefb06858cf2a1a89fa1 127.0.0.1 30002 master - 5461-10922 16380 16383
+ 07c37dfeb235213a872192d90877d0cd55635b91 127.0.0.1 30004 slave 67ed2db8d677e59ec4a4cefb06858cf2a1a89fa1"
+ 1
+```
+
+Although Kvrocks can recognize the node id by comparing the `ip`:`port` pair then finding out the serving slots, but users may set the IP address to `0.0.0.0` so that we can't match the right topology information. So Kvrocks gives the extra command [CLUSTERX SETNODEID](https://github.com/KvrocksLabs/kvrocks/pull/302 "CLUSTERX SETNODEID command") to set the id. The format is like this:
+
+```shell
+CLUSTERX SETNODEID $NODE_ID
+```
+
+`$NODE_ID`: should be 40 chars unique id in cluster
+
+### Node Management
+
+Kvrocks cluster can be set up as simple as using those cluster commands, we even can write a script to watch and apply cluster changes. Those commands can be integrated into those companies which have their own cluster solution. Kvrocks also offers the `CLUSTERX VERSION` command to inspect current cluster topology information, the controller can force to update topology information when the version was out of date or wrong.
+
+For a complete cluster solution, we need to depend on another controller to manage the topology information, failure detection, and failover. Kvrocks team was also developing the official controller to make the cluster manage and operate easier. But the manual resource was the bottleneck, welcome anyone who was interested in this project to build together.
+
+### Client Access
+
+Users can use Redis Cluster SDK to access the Kvrocks cluster since it's compatible with the Redis cluster solution(Kvrocks supported `CLUSTER NODES` and `CLUSTER SLOTS` command to respond to the cluster topology). Kvrocks also responds to the `MOVED $slot_id $ip:$port` to redirect the target node when the slot was NOT served by the current node. You can also use the Redis Cluster Proxy like `redis-cluster-proxy` to hide the cluster topology.
+
+### Deploy And Operate
+
+Users need to self-manage the cluster topology information since the Kvrocks controller was still under development. The deployment steps were below:
+
+1. Deploy Kvrocks nodes
+2. Design the kvrocks topology which was mentioned at #Topology Management
+3. Set node unique id for each node by using `CLUSTER SETNODEID` command
+4. Apply the topology information to all nodes by using `CLUSTER NODES` command
+
+Kvrocks would auto-setup the master-slave replication after receiving the setup topology command, and repeats steps 2-4 when we want to switch the node role or number.
+
+ Currently, Kvrocks topology modification was based on full state, that's we need to sync the full topology information to each node, which may cause high network and cpu cost but it can guarantee the correctness of the cluster. Also, the version-based modification can help us to achieve the increment modification if we want to do that, we would offer a way to add, update and delete nodes to make operation easier.
+
+**Cluster Command And Safty**
+
+To guarantee the correctness of client SDK, we rename the CLUSTER command to CLUSTERX to prevent the topology can being modified casually, but we can still use the CLUSTER command to fetch the cluster topology information.
+
+
+
+### Cluster Scaling
+
+Kvrocks data migration was based on the slot instead of the key-based like Reids, we can migrate one slot to another node at once. Kvrocks storage was based on disk instead of memory, so the key migration may be time cost. Now, the controller o DBA can use the CLUSTER MIGRATE command to migrate the slot. For more information can see the PR [#430](https://github.com/KvrocksLabs/kvrocks/pull/430).
+
+**Migrate Command**
+
+CLUSTERX SETSLOT `$slot` NODE `$node_id` `$new_version`
+
+* `$slot`: assign which slot to be migrated
+* `NODE`:same as the Redis cluster setslot
+* `$dest_nodeid`: which node of the slot is to be migrated
+* `$new_version`: the version of the topology information, noted that the version MUST be newer than the old version, or the node would refuse to apply the modification.
+
+We need to use the CLUSTERX MIGRATE command to migrate the slot then use CLUSTER SETSLOT to modify the topology information.
+
+## Summary
+
+Kvrocks cluster implementation was compatible with the Redis cluster, in which users can use the Redis cluster client to access the Kvrocks cluster, also didn't have the extra proxy latency like the Codis solution. By the way, Kvrocks cluster topology management and scaling have already finished from the latest version 2.0.6. We will continue improving the visibility, operation, and cluster management, to make the cluster better and easier.
+
+For the Kvrocks controller, the community was building the official [controller](https://github.com/KvrocksLabs/kvrocks_controller/tree/develop) to make the cluster management easier. Welcome anyone who was interested.
diff --git a/docs/08-Performance/how-we-use-rocksdb.md b/docs/08-Performance/how-we-use-rocksdb.md
new file mode 100644
index 0000000..88d8811
--- /dev/null
+++ b/docs/08-Performance/how-we-use-rocksdb.md
@@ -0,0 +1,97 @@
+# How we use RocksDB in Kvrocks
+
+Kvrocks is an open-source key-value database that is based on rocksdb and compatible with Redis protocol. Intention to decrease the cost of memory and increase the capability while compared to Redis. We would focus on how we use RocksDB features to improve the performance of the Redis on disk. Hopes this helps people who want to improve performance on RocksDB.
+
+## Background
+Let’s have a look at how Kvrocks uses the RocksDB before introducing performance optimization. From the implementation side, Kvrocks would encode the Redis data structure into the key-values and write them into the different RocksDB’s column families. There’s five column family type in Kvrocks:
+
+* Metadata Column Family: used to store the metadata(expired, size..) for complex data structures like Hash/Set/ZSet/List, also string key-value was stored in this column family
+* Subkey Column Family: used to store key-values for complex data structures were mentioned before
+* ZSetScore Column Family: only store the score of the sorted set
+* PubSub Column Family: used to store and propagate pubsub messages between the master and replicas
+* Propagated Column Family: used to propagate commands between the master and replicas
+
+Also, Kvrocks uses the RocksDB WAL to implement the replication, for more detail can see:
+* [Kvrocks: An Open-Source Distributed Disk Key-Value Storage With Redis Protocol](https://kvrocks.medium.com/distributed-disk-key-value-storage-kvrocks-7bc5101c8585)
+* [How to implement the Redis data structures on RocksDB](https://github.com/KvrocksLabs/kvrocks/blob/unstable/docs/metadata-design.md)
+
+We can have a glance at the Kvrocks architecture from 10,000 feet view:
+
+
+
+## How To Profiling RocksDB
+### Memtable Optimization
+Currently, Kvrocks was using the SkipList Memtable. Compared with the HashSkipList Memtable, it has better performance when searching across multiple prefixes and uses less memory. Kvrocks also enabled the whole_key_filtering the option which would create a bloom filter for the key in the memtble, it can reduce the number of comparisons, thereby reducing the CPU usage during point query.
+Related configuration:
+```C++
+metadata_opts.memtable_whole_key_filtering = true
+metadata_opts.memtable_prefix_bloom_size_ratio = 0.1
+```
+
+### Data Block Optimization
+Previously, Kvrocks used binary search when searching the data block, which may cause CPU cache miss and increase the CPU usage. As the point query was the most used scenario in the key-value service, so Kvrocks switched to the hash index to reduce the binary search comparisons. **Official test data shows that this feature can reduce CPU utilization by 21.8% and increase throughput by 10%, but it will increase space usage by 4.6%.** Compared with disk resources, CPU resources are more ex [...]
+
+Related configuration:
+
+```c++
+BlockBasedTableOptions::data_block_index_type = DataBlockIndexType::kDataBlockBinaryAndHash
+BlockBasedTableOptions::data_block_hash_table_util_ratio = 0.75
+```
+
+### Filter/Index Block
+The old version of RocksDB used Bloom Filter of BlockBasedFilter type by default. The basic mechanism is to generate a Filter for every 2KB of Key-Value data, and finally form a Filter array. When searching, first check the Index Block, and for the Data Block that may have the Key, then use the corresponding Filter Block to determine whether the key exists or not.
+
+The new version of RocksDB optimizes the original Filter mechanism by introducing Full Filter. Each SST has a Filter, which can check whether the Key exists or not in the SST and avoid reading the Index Block. However, in the scenario with a large key number in the SST, the Filter Block and Index Block will still be larger. For 256MB SST, the size of Index and Filter Block is about 0.5MB and 5MB, which is much larger than Data Block (usually 4–32KB). In the most ideal case, when the Inde [...]
+
+Kvrocks’ previous approach was to dynamically adjust the SST-related configuration so that the SST file will not be too large, thereby avoiding the Index/Filter Block from being too large. However, the problem with this mechanism is that when the amount of data is very large, too many SST files will take up more system resources and cause performance degradation. The new version of Kvrocks optimizes this and opens the related configuration of the Partitioned Block. The principle of the P [...]
+
+The advantages of Partitioned Block are as follows:
+* Increase the cache hit rate: Large Index/Filter Block will pollute the cache space. The large Block will be partitioned, allowing the Index/Filter Block to be loaded at a finer granularity, thereby effectively using the cache space
+* Improve cache efficiency: The partition Index/Filter Block will become smaller, the lock competition in the Cache will be further reduced, and the efficiency under high concurrency will be improved
+* Reduce IO utilization: When the cache Miss of the index/filter partition, only a small partition needs to be loaded from the disk. Compared with the Index/Filter Block that reads the entire SST file, this will make the load on the disk smaller
+
+Related configuration:
+```c++
+format_version = 5
+index_type = IndexType::kTwoLevelIndexSearch
+BlockBasedTableOptions::partition_filters = true
+cache_index_and_filter_blocks = true
+pin_top_level_index_and_filter = true
+cache_index_and_filter_blocks_with_high_priority = true
+pin_l0_filter_and_index_blocks_in_cache = true
+optimize_filters_for_memory = true
+```
+
+### Data compression optimization
+RocksDB compresses the data when it’s placed on the disk. We compared and tested different compression algorithms on Kvrocks and found that different compression algorithms have a great impact on performance, especially when CPU resources are tight, which will significantly increase latency.
+
+The following figure shows the test data of compression speed and compression ratio of different compression algorithms:
+
+
+
+In Kvrocks, compression is not set for the SST of the L0 and L1 layers, because these two layers have a small amount of data. Compressing the data at these levels cannot reduce a lot of disk space, but not compressing the data at these levels can save CPU. Each Compaction from L0 to L1 needs to access all files in L1. In addition, the range scan cannot use Bloom Filter, and it needs to find all files in L0. If you do not need to decompress when reading data in L0 and L1, and writing data [...]
+
+**Considering the trade-off between compression speed and compression ratio, Kvrocks mainly chooses two algorithms, LZ4 and ZSTD.** For other levels, LZ4 is used because the compression algorithm is faster and the compression ratio is higher. RocksDB officially recommends using LZ4. For scenes with large data volume and low QPS, the last layer will be set to ZSTD to further reduce storage space and reduce costs. The advantage of ZSTD is that the compression ratio is higher and the compre [...]
+
+### Cache optimization
+For the simple data type (String type), the data is directly stored in Metadata CF, while for complex data types, only the metadata is stored in Metadata CF, and the actual data is stored in Subkey CF. Kvrocks previously allocated the same size of Block Cache to these two CFs by default. However, the online scene is complicated and the user’s data type cannot be predicted, so it is not possible to allocate an appropriate Block Cache size to each CF in advance. If users use simple types a [...]
+In addition, Row Cache is also introduced to deal with the problem of hotkeys. RocksDB checks Row Cache first, then Block Cache. For scenes with hot spots, data will be stored in Row Cache first to further improve Cache utilization.
+
+### Key-Value Separation
+The LSM storage engine will store the Key and Value together. During the compaction process, both Key and Value will be rewritten. When the Value is large, it will cause serious write amplification problems. In response to this problem, the [WiscKey](https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf) paper proposed a Key-Value separation scheme. Based on this paper, the industry also realized the KV separation of LSM-type storage engines, such as RocksDB’s BlobD [...]
+
+RocksDB 6.18 version re-implemented BlobDB (RocksDB’s Key-Value separation scheme), integrated it into the main logic of RocksDB, and has been improving and optimizing BlobDB related features. **Kvrocks introduced this feature in 2.0.5 to deal with scenarios with large values. Tests show that when Kvrocks turns on the KV separation switch, for the scenario where Value is 10KB, the write performance is increased by 2.5 times, and the read performance is not attenuated; the larger the valu [...]
+
+Related configuration:
+```c++
+ColumnFamilyOptions.enable_blob_files = config_->RocksDB.enable_blob_files;
+min_blob_size = 4096
+blob_file_size = 128M
+blob_compression_type = lz4
+enable_blob_garbage_collection = true
+blob_garbage_collection_age_cutoff = 0.25
+blob_garbage_collection_force_threshold = 0.8
+```
+
+## Kvrocks Roadmap
+2021 is coming to an end, the related work of [Kvrocks 2.0](https://github.com/KvrocksLabs/kvrocks/projects/1) has been basically completed, and the plan of [Kvrocks 3.0](https://github.com/KvrocksLabs/kvrocks/projects/2) has also been listed on Github. This article lists the following two important features.
diff --git a/docs/supported-commands.md b/docs/supported-commands.md
deleted file mode 100644
index 84ea356..0000000
--- a/docs/supported-commands.md
+++ /dev/null
@@ -1,9 +0,0 @@
----
-sidebar_position: 1
----
-
-# Supported Commands
-
-Work in progress...
-
-You can read a legacy version of supported commands at [this page](https://github.com/apache/incubator-kvrocks/wiki/Support-Commands).