You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@iotdb.apache.org by qi...@apache.org on 2021/07/27 13:16:19 UTC
[iotdb] branch master updated: [IOTDB-1530] Make documents style
better by adding a space between full-corner and half-corner characters
(#3632)
This is an automated email from the ASF dual-hosted git repository.
qiaojialin pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/iotdb.git
The following commit(s) were added to refs/heads/master by this push:
new d1729ea [IOTDB-1530] Make documents style better by adding a space between full-corner and half-corner characters (#3632)
d1729ea is described below
commit d1729eafc6d9ba7833f728439c401d9af3409414
Author: Potato <TX...@gmail.com>
AuthorDate: Tue Jul 27 21:15:42 2021 +0800
[IOTDB-1530] Make documents style better by adding a space between full-corner and half-corner characters (#3632)
---
docs/zh/Community/Community-Powered By.md | 41 ++-
docs/zh/Community/Feedback.md | 18 +-
docs/zh/Development/Committer.md | 38 +--
docs/zh/Development/ContributeGuide.md | 59 ++--
docs/zh/Development/HowToCommit.md | 40 ++-
docs/zh/Development/VoteRelease.md | 7 +-
docs/zh/Download/README.md | 73 ++---
docs/zh/SystemDesign/Architecture/Architecture.md | 1 -
docs/zh/SystemDesign/Client/RPC.md | 3 -
docs/zh/SystemDesign/Connector/Hive-TsFile.md | 11 +-
docs/zh/SystemDesign/Connector/Spark-IOTDB.md | 39 ++-
docs/zh/SystemDesign/Connector/Spark-TsFile.md | 25 +-
docs/zh/SystemDesign/DataQuery/AggregationQuery.md | 31 +-
.../SystemDesign/DataQuery/AlignByDeviceQuery.md | 12 +-
docs/zh/SystemDesign/DataQuery/FillFunction.md | 30 +-
docs/zh/SystemDesign/DataQuery/GroupByFillQuery.md | 37 +--
docs/zh/SystemDesign/DataQuery/GroupByQuery.md | 48 ++-
docs/zh/SystemDesign/DataQuery/LastQuery.md | 22 +-
docs/zh/SystemDesign/DataQuery/OrderByTimeQuery.md | 75 +++--
.../zh/SystemDesign/DataQuery/QueryFundamentals.md | 58 ++--
docs/zh/SystemDesign/DataQuery/RawDataQuery.md | 62 ++--
docs/zh/SystemDesign/DataQuery/SeriesReader.md | 24 +-
docs/zh/SystemDesign/QueryEngine/Planner.md | 1 -
.../QueryEngine/ResultSetConstruction.md | 2 +-
.../zh/SystemDesign/SchemaManager/SchemaManager.md | 151 +++++----
docs/zh/SystemDesign/StorageEngine/Compaction.md | 40 +--
.../SystemDesign/StorageEngine/DataManipulation.md | 41 ++-
.../zh/SystemDesign/StorageEngine/DataPartition.md | 24 +-
docs/zh/SystemDesign/StorageEngine/FileLists.md | 39 +--
docs/zh/SystemDesign/StorageEngine/FlushManager.md | 4 +-
docs/zh/SystemDesign/StorageEngine/MergeManager.md | 22 +-
docs/zh/SystemDesign/StorageEngine/Recover.md | 29 +-
.../zh/SystemDesign/StorageEngine/StorageEngine.md | 2 +-
docs/zh/SystemDesign/StorageEngine/WAL.md | 4 +-
docs/zh/SystemDesign/Tools/Sync.md | 105 +++---
docs/zh/SystemDesign/TsFile/Format.md | 140 ++++----
docs/zh/SystemDesign/TsFile/Read.md | 110 +++----
docs/zh/SystemDesign/TsFile/TsFile.md | 1 -
docs/zh/SystemDesign/TsFile/Write.md | 3 +-
.../zh/UserGuide/API/Programming-Cpp-Native-API.md | 87 ++---
docs/zh/UserGuide/API/Programming-Go-Native-API.md | 18 +-
docs/zh/UserGuide/API/Programming-JDBC.md | 14 +-
.../UserGuide/API/Programming-Java-Native-API.md | 59 ++--
.../UserGuide/API/Programming-Python-Native-API.md | 70 ++--
docs/zh/UserGuide/API/Programming-TsFile-API.md | 137 ++++----
docs/zh/UserGuide/API/Time-zone.md | 1 -
.../Administration-Management/Administration.md | 35 +-
docs/zh/UserGuide/Advanced-Features/Alerting.md | 15 +-
.../Advanced-Features/Continuous-Query.md | 17 +-
docs/zh/UserGuide/Advanced-Features/Triggers.md | 170 +++-------
.../Advanced-Features/UDF-User-Defined-Function.md | 225 +++++--------
docs/zh/UserGuide/Appendix/Config-Manual.md | 139 ++++----
docs/zh/UserGuide/Appendix/SQL-Reference.md | 160 +++++----
docs/zh/UserGuide/Appendix/Status-Codes.md | 19 +-
docs/zh/UserGuide/CLI/Command-Line-Interface.md | 123 ++++---
docs/zh/UserGuide/Cluster/Cluster-Setup-Example.md | 12 +-
docs/zh/UserGuide/Cluster/Cluster-Setup.md | 67 ++--
.../Collaboration-of-Edge-and-Cloud/Sync-Tool.md | 40 ++-
.../Programming-MQTT.md | 40 +--
.../Programming-Thrift.md | 30 +-
docs/zh/UserGuide/Comparison/TSDB-Comparison.md | 201 +++++-------
docs/zh/UserGuide/Data-Concept/Compression.md | 12 +-
.../Data-Concept/Data-Model-and-Terminology.md | 59 ++--
docs/zh/UserGuide/Data-Concept/Data-Type.md | 4 +-
docs/zh/UserGuide/Data-Concept/Encoding.md | 22 +-
docs/zh/UserGuide/Data-Concept/SDT.md | 30 +-
docs/zh/UserGuide/Ecosystem Integration/DBeaver.md | 20 +-
.../UserGuide/Ecosystem Integration/Flink IoTDB.md | 5 +-
.../Ecosystem Integration/Flink TsFile.md | 17 +-
docs/zh/UserGuide/Ecosystem Integration/Grafana.md | 72 ++--
.../UserGuide/Ecosystem Integration/Hive TsFile.md | 55 ++--
.../Ecosystem Integration/MapReduce TsFile.md | 39 +--
.../UserGuide/Ecosystem Integration/Spark IoTDB.md | 17 +-
.../Ecosystem Integration/Spark TsFile.md | 88 +++--
.../Ecosystem Integration/Writing Data on HDFS.md | 46 +--
.../Ecosystem Integration/Zeppelin-IoTDB.md | 51 +--
.../zh/UserGuide/FAQ/Frequently-asked-questions.md | 33 +-
.../UserGuide/IoTDB-Introduction/Architecture.md | 14 +-
docs/zh/UserGuide/IoTDB-Introduction/Features.md | 8 +-
.../zh/UserGuide/IoTDB-Introduction/Publication.md | 2 +-
docs/zh/UserGuide/IoTDB-Introduction/Scenario.md | 20 +-
.../UserGuide/IoTDB-Introduction/What-is-IoTDB.md | 4 +-
.../DDL-Data-Definition-Language.md | 68 ++--
.../DML-Data-Manipulation-Language.md | 364 ++++++++++-----------
.../IoTDB-SQL-Language/Maintenance-Command.md | 10 +-
docs/zh/UserGuide/QuickStart/Files.md | 17 +-
docs/zh/UserGuide/QuickStart/QuickStart.md | 78 ++---
docs/zh/UserGuide/QuickStart/ServerFileList.md | 64 ++--
docs/zh/UserGuide/QuickStart/WayToGetIoTDB.md | 43 ++-
docs/zh/UserGuide/System-Tools/CSV-Tool.md | 24 +-
docs/zh/UserGuide/System-Tools/JMX-Tool.md | 24 +-
.../UserGuide/System-Tools/Load-External-Tsfile.md | 4 +-
docs/zh/UserGuide/System-Tools/MLogParser-Tool.md | 7 +-
.../System-Tools/Monitor-and-Log-Tools.md | 96 +++---
docs/zh/UserGuide/System-Tools/NodeTool.md | 117 ++++---
.../Query-History-Visualization-Tool.md | 6 +-
docs/zh/UserGuide/System-Tools/Watermark-Tool.md | 34 +-
docs/zh/UserGuide/UserGuideReadme.md | 9 +-
98 files changed, 2108 insertions(+), 2626 deletions(-)
diff --git a/docs/zh/Community/Community-Powered By.md b/docs/zh/Community/Community-Powered By.md
index 9db805c..e649f7c 100644
--- a/docs/zh/Community/Community-Powered By.md
+++ b/docs/zh/Community/Community-Powered By.md
@@ -23,39 +23,36 @@
### 使用“IoTDB”的项目和产品名称
-
-其他组织或企业在使用Apache IoTDB建立项目或者产品时,应该应该注意尊重“Apache IoTDB”的商标。
+其他组织或企业在使用 Apache IoTDB 建立项目或者产品时,应该应该注意尊重“Apache IoTDB”的商标。
具体事项请参阅 [ASF Trademarks Guidance](https://www.apache.org/foundation/marks/)
-和[FAQ](https://www.apache.org/foundation/marks/faq/)。
+和 [FAQ](https://www.apache.org/foundation/marks/faq/)。
一般来说,我们建议不要仅使用"IoTDB"在任何名字中,以避免出现商标风险。
-例如,不应该给自己的产品命名为"IoTDB 大数据产品",因为这个名字中包含IoTDB。然而,如果说是命名为"Apache IoTDB赋能的大数据产品",
-或者"基于Apache IoTDB的大数据产品", 这种名字就是被允许的。
-简单来说,当你想在名字中出现IoTDB时,应为"Apache IoTDB",而不是仅"IoTDB"。
+例如,不应该给自己的产品命名为"IoTDB 大数据产品",因为这个名字中包含 IoTDB。然而,如果说是命名为"Apache IoTDB 赋能的大数据产品",
+或者"基于 Apache IoTDB 的大数据产品", 这种名字就是被允许的。
+简单来说,当你想在名字中出现 IoTDB 时,应为"Apache IoTDB",而不是仅"IoTDB"。
-在你(在Maven 或者其他模块名中)创建软件标识时,可以命名为例如"iotdb-tool"。
+在你(在 Maven 或者其他模块名中)创建软件标识时,可以命名为例如"iotdb-tool"。
-在产品描述中明确指出Apache IoTDB也是可以的,例如"该大数据产品是Apache IoTDB的一个子产品"。
+在产品描述中明确指出 Apache IoTDB 也是可以的,例如"该大数据产品是 Apache IoTDB 的一个子产品"。
### 相关贡献或应用的公司和组织
-要将自己添加到列表中,请给dev@iotdb.apache.org发送电子邮件,其中包含您的组织名称,URL,正在使用的IoTDB组件列表以及用例的简短描述。
-你也可以在[Github](https://github.com/apache/iotdb/issues/748) 留言。
-
+要将自己添加到列表中,请给 dev@iotdb.apache.org 发送电子邮件,其中包含您的组织名称,URL,正在使用的 IoTDB 组件列表以及用例的简短描述。
+你也可以在 [Github](https://github.com/apache/iotdb/issues/748) 留言。
-- 清华大学软件学院和大数据系统软件国家工程实验室最初开发了IoTDB,并捐献给Apache。
- - 我们有很多研究生和专业软件工程师在持续开发IoTDB
- - 我们在上海地铁和其他两个城市的地铁管理中使用IoTDB。
- - 我们在中国气象局使用IoTDB管理超过10年的站点实况数据。
+- 清华大学软件学院和大数据系统软件国家工程实验室最初开发了 IoTDB,并捐献给 Apache。
+ - 我们有很多研究生和专业软件工程师在持续开发 IoTDB
+ - 我们在上海地铁和其他两个城市的地铁管理中使用 IoTDB。
+ - 我们在中国气象局使用 IoTDB 管理超过 10 年的站点实况数据。
-- 联想开发了TsFile的Go语言版本,并用于长飞光纤项目。该项目收集了超过9万个测点,并基于TsFile同步到云端。
+- 联想开发了 TsFile 的 Go 语言版本,并用于长飞光纤项目。该项目收集了超过 9 万个测点,并基于 TsFile 同步到云端。
-- 金风科技使用IoTDB管理风机数据。他们首先从Kafka消费SCADA数据,然后写入IoTDB并从IoTDB进行查询。
+- 金风科技使用 IoTDB 管理风机数据。他们首先从 Kafka 消费 SCADA 数据,然后写入 IoTDB 并从 IoTDB 进行查询。
-- 大唐先一将IoTDB部署在了中国的许多电厂。
+- 大唐先一将 IoTDB 部署在了中国的许多电厂。
-- 北京智创新科使用IoTDB存储中国铁塔的2百万铁塔的蓄电池数据。
-
-- 北京清智物联使用IoTDB收集调相机(发电机)的监控数据。
+- 北京智创新科使用 IoTDB 存储中国铁塔的 2 百万铁塔的蓄电池数据。
-- 建龙钢铁在测试IoTDB。
+- 北京清智物联使用 IoTDB 收集调相机(发电机)的监控数据。
+- 建龙钢铁在测试 IoTDB。
diff --git a/docs/zh/Community/Feedback.md b/docs/zh/Community/Feedback.md
index 5d295d0..f84d4ef 100644
--- a/docs/zh/Community/Feedback.md
+++ b/docs/zh/Community/Feedback.md
@@ -21,13 +21,13 @@
## 联系我们
-作为Apache项目,我们使用邮件列表、JIRA和Github的issue模块来获取用户反馈。
+作为 Apache 项目,我们使用邮件列表、JIRA 和 Github 的 issue 模块来获取用户反馈。
-* 邮件列表: dev@iotdb.apache.org.
+* 邮件列表:dev@iotdb.apache.org.
- * 该列表同时用于用户反馈和开发者交流.
+ * 该列表同时用于用户反馈和开发者交流。
* 订阅方法:用想接收邮件的邮箱向 dev-subscribe@iotdb.apache.org 发一封邮件,主题内容不限,收到回复后,
- 再次向确认地址发一封确认邮件(确认地址比较长,推荐qq邮箱)。
+ 再次向确认地址发一封确认邮件(确认地址比较长,推荐 qq 邮箱)。
* JIRA issue: https://issues.apache.org/jira/projects/IOTDB/issues
@@ -35,12 +35,12 @@
* Twitter: https://twitter.com/apacheiotdb
-* 对中文用户,欢迎加入QQ群: 659990460.
+* 对中文用户,欢迎加入 QQ 群:659990460.
-* 我们非常期待您分享您使用IoTDB的经验: [调研问卷](https://github.com/apache/iotdb/issues/748)
+* 我们非常期待您分享您使用 IoTDB 的经验:[调研问卷](https://github.com/apache/iotdb/issues/748)
-* 对中文用户,欢迎关注微信公众号,IoTDB漫游指南
+* 对中文用户,欢迎关注微信公众号,IoTDB 漫游指南
-* 对中文用户,我们提供了钉钉群,可以搜索群名称加入:Apache IoTDB交流1群
+* 对中文用户,我们提供了钉钉群,可以搜索群名称加入:Apache IoTDB 交流 1 群
-IoTDB社区会不定期举办Meetup,相关信息会在邮件列表和[研讨会议和报告列表](https://iotdb.apache.org/Community/Materials.html) 页面找到。
+IoTDB 社区会不定期举办 Meetup,相关信息会在邮件列表和 [研讨会议和报告列表](https://iotdb.apache.org/Community/Materials.html) 页面找到。
diff --git a/docs/zh/Development/Committer.md b/docs/zh/Development/Committer.md
index 2391b53..4063c56 100644
--- a/docs/zh/Development/Committer.md
+++ b/docs/zh/Development/Committer.md
@@ -19,27 +19,27 @@
-->
-# 成为Committer
+# 成为 Committer
-Apache IoTDB [Committer](https://www.apache.org/foundation/how-it-works.html#committers) 拥有代码库的写权限,可以合并PR,但是您不必成为代码贡献者才能成为Committer。成为一个Committer意味着你获得了项目的信任。阅读[ASF文档](https://www.apache.org/dev/committers.html#committer-responsibilities) 以获取有关成为Apache Software Foundation中的提交者的更多信息。
+Apache IoTDB [Committer](https://www.apache.org/foundation/how-it-works.html#committers) 拥有代码库的写权限,可以合并 PR,但是您不必成为代码贡献者才能成为 Committer。成为一个 Committer 意味着你获得了项目的信任。阅读 [ASF 文档](https://www.apache.org/dev/committers.html#committer-responsibilities) 以获取有关成为 Apache Software Foundation 中的提交者的更多信息。
-项目管理委员会 [PMC](https://www.apache.org/foundation/how-it-works.html#pmc-members) 通过提名、讨论、并投票(且多数人投赞成票)来将某人增选为Committer。我们会使用尽可能多的数据来源来解释为什么增选某人。例如:
+项目管理委员会 [PMC](https://www.apache.org/foundation/how-it-works.html#pmc-members) 通过提名、讨论、并投票(且多数人投赞成票)来将某人增选为 Committer。我们会使用尽可能多的数据来源来解释为什么增选某人。例如:
-- IoTDB技术专家且是布道者(贡献文档、博客等)
+- IoTDB 技术专家且是布道者(贡献文档、博客等)
- 公开活动
-- PMC推荐
+- PMC 推荐
-对于想成为Committer的贡献者,PMC制定了以下的指导准则
+对于想成为 Committer 的贡献者,PMC 制定了以下的指导准则
## Apache IoTDB Committer
### 采取多种形式
-除了贡献代码之外,还有许多其他形式可以提高我们对贡献者的信任,例如代码审查,设计讨论,为其他用户提供支持,发展社区,改善IoTDB基础设施,文档,项目管理等。
+除了贡献代码之外,还有许多其他形式可以提高我们对贡献者的信任,例如代码审查,设计讨论,为其他用户提供支持,发展社区,改善 IoTDB 基础设施,文档,项目管理等。
-### 知道、支持并不断强化Apache Software Foundation的行为准则
+### 知道、支持并不断强化 Apache Software Foundation 的行为准则
-请参阅[ASF文档](https://www.apache.org/foundation/policies/conduct.html)。特别是,他们显然致力于:
+请参阅 [ASF 文档](https://www.apache.org/foundation/policies/conduct.html)。特别是,他们显然致力于:
- 开放
- 善解人意
@@ -50,29 +50,27 @@ Apache IoTDB [Committer](https://www.apache.org/foundation/how-it-works.html#com
- 好奇心强
- 注意言行
-### 知道、支持并不断强化作为Apache Software Foundation提交者的职责
+### 知道、支持并不断强化作为 Apache Software Foundation 提交者的职责
-请参阅[ASF文档](https://www.apache.org/dev/committers.html#committer-responsibilities)。
+请参阅 [ASF 文档](https://www.apache.org/dev/committers.html#committer-responsibilities)。
- 他们帮助创造的是一个产品,而不仅仅是某个贡献者的兴趣
-- 他们维护Apache社区的健康,并帮助社区成长
+- 他们维护 Apache 社区的健康,并帮助社区成长
- 他们帮忙做一些周边工作,例如维护网站、维护文档。
- 他们帮助用户
- 可以信任他们来决定何时准备发布代码,或何时需要别人一起做出判断。
- 可以信任他们来决定何时合并代码(如果是代码贡献者),或何时需要别人一起做出判断。
-### 知道、支持并不断强化IoTDB社区的实践
+### 知道、支持并不断强化 IoTDB 社区的实践
- 他们对项目有坚定的承诺
- 他们与社区分享他们的想法
- 他们接受社区反馈并将其整合到他们的计划,设计,代码等中。
-- 他们认真地尝试通过贡献使IoTDB更好
+- 他们认真地尝试通过贡献使 IoTDB 更好
- 特别是,如果代码贡献者:
- - 他们认真尝试用自己的代码使IoTDB更好
- - 他们认真地尝试通过代码审查使IoTDB更好
+ - 他们认真尝试用自己的代码使 IoTDB 更好
+ - 他们认真地尝试通过代码审查使 IoTDB 更好
- 他们接受并整合有关其代码的反馈
- - 他们在查看/合并代码(样式,文档,测试,向后兼容性等)时了解、遵守并不断优化IoTDB的最佳实践。
+ - 他们在查看/合并代码(样式,文档,测试,向后兼容性等)时了解、遵守并不断优化 IoTDB 的最佳实践。
-
-
-这个指导文档修改于[Apache Beam](https://beam.apache.org/contribute/become-a-committer/)
\ No newline at end of file
+这个指导文档修改于 [Apache Beam](https://beam.apache.org/contribute/become-a-committer/)
\ No newline at end of file
diff --git a/docs/zh/Development/ContributeGuide.md b/docs/zh/Development/ContributeGuide.md
index 98e93a0..5f00eee 100644
--- a/docs/zh/Development/ContributeGuide.md
+++ b/docs/zh/Development/ContributeGuide.md
@@ -39,19 +39,19 @@ Wiki 文档管理:https://cwiki.apache.org/confluence/display/IOTDB/Home
邮件列表地址:dev@iotdb.apache.org
-订阅方法:用想接收邮件的邮箱向 dev-subscribe@iotdb.apache.org 发一封邮件,主题内容不限,收到回复后,再次向确认地址发一封确认邮件(确认地址比较长,推荐qq邮箱)。
+订阅方法:用想接收邮件的邮箱向 dev-subscribe@iotdb.apache.org 发一封邮件,主题内容不限,收到回复后,再次向确认地址发一封确认邮件(确认地址比较长,推荐 qq 邮箱)。
-其他邮件列表:
-* notifications@iotdb.apache.org (用于接收JIRA通知.)
- * 如果你只想接收个别感兴趣的JIRA通知,你不需要订阅这个列表。你只需要在JIRA issue页面上点击"开始关注这个issue" 或者在这个issue上做评论就行了。
-* commits@iotdb.apache.org (任何代码改动都会通知到此处。该邮件列表邮件数量十分多,请注意。)
-* reviews@iotdb.apache.org (任何代码审阅意见都会通知到此处。该邮件列表邮件数量十分多,请注意。)
+其他邮件列表:
+* notifications@iotdb.apache.org (用于接收 JIRA 通知。)
+ * 如果你只想接收个别感兴趣的 JIRA 通知,你不需要订阅这个列表。你只需要在 JIRA issue 页面上点击"开始关注这个 issue" 或者在这个 issue 上做评论就行了。
+* commits@iotdb.apache.org (任何代码改动都会通知到此处。该邮件列表邮件数量十分多,请注意。)
+* reviews@iotdb.apache.org (任何代码审阅意见都会通知到此处。该邮件列表邮件数量十分多,请注意。)
-## 新功能、Bug反馈、改进等
+## 新功能、Bug 反馈、改进等
所有希望 IoTDB 做的功能或修的 bug,都可以在 Jira 上提 issue
-可以选择 issue 类型:bug、improvement、new feature等。新建的 issue 会自动向邮件列表中同步邮件,之后的讨论可在 jira 上留言,也可以在邮件列表进行。当问题解决后请关闭 issue。
+可以选择 issue 类型:bug、improvement、new feature 等。新建的 issue 会自动向邮件列表中同步邮件,之后的讨论可在 jira 上留言,也可以在邮件列表进行。当问题解决后请关闭 issue。
## 邮件讨论内容(英文)
@@ -84,31 +84,31 @@ IoTDB 所有官网上的内容都在项目根目录的 docs 中:
## 代码格式化
我们使用 [Spotless
-plugin](https://github.com/diffplug/spotless/tree/main/plugin-maven) 和 [google-java-format](https://github.com/google/google-java-format) 格式化Java代码. 你可以通过以下步骤将IDE配置为在保存时自动应用格式以IDEA为例):
+plugin](https://github.com/diffplug/spotless/tree/main/plugin-maven) 和 [google-java-format](https://github.com/google/google-java-format) 格式化 Java 代码。你可以通过以下步骤将 IDE 配置为在保存时自动应用格式以 IDEA 为例):
-1. 下载 [google-java-format-plugin v1.7.0.5](https://plugins.jetbrains.com/plugin/8527-google-java-format/versions/stable/83169), 安装到IDEA(Preferences -> plugins -> search google-java-format),[更详细的操作手册](https://github.com/google/google-java-format#intellij-android-studio-and-other-jetbrains-ides)
+1. 下载 [google-java-format-plugin v1.7.0.5](https://plugins.jetbrains.com/plugin/8527-google-java-format/versions/stable/83169), 安装到 IDEA(Preferences -> plugins -> search google-java-format),[更详细的操作手册](https://github.com/google/google-java-format#intellij-android-studio-and-other-jetbrains-ides)
2. 从磁盘安装 (Plugins -> little gear icon -> "Install plugin from disk" -> Navigate to downloaded zip file)
-3. 开启插件,并保持默认的GOOGLE格式 (2-space indents)
-4. 在Spotless没有升级到18+之前,不要升级google-java-format插件
-5. 安装 [Save Actions 插件](https://plugins.jetbrains.com/plugin/7642-save-actions) , 并开启插件, 打开 "Optimize imports" and "Reformat file" 选项.
-6. 在“Save Actions”设置页面中,将 "File Path Inclusion" 设置为.*\.java”, 避免在编辑的其他文件时候发生意外的重新格式化
+3. 开启插件,并保持默认的 GOOGLE 格式 (2-space indents)
+4. 在 Spotless 没有升级到 18+之前,不要升级 google-java-format 插件
+5. 安装 [Save Actions 插件](https://plugins.jetbrains.com/plugin/7642-save-actions) , 并开启插件,打开 "Optimize imports" and "Reformat file" 选项。
+6. 在“Save Actions”设置页面中,将 "File Path Inclusion" 设置为 .*\.java”, 避免在编辑的其他文件时候发生意外的重新格式化
## 贡献代码
可以到 jira 上领取现有 issue 或者自己创建 issue 再领取,评论说我要做这个 issue 就可以。
-* 克隆仓库到自己的本地的仓库,clone到本地,关联apache仓库为上游 upstream 仓库。
-* 从 master 切出新的分支,分支名根据这个分支的功能决定,一般叫 f_new_feature(如f_storage_engine) 或者 fix_bug(如fix_query_cache_bug)
-* 在 idea 中添加code style为 根目录的 java-google-style.xml
+* 克隆仓库到自己的本地的仓库,clone 到本地,关联 apache 仓库为上游 upstream 仓库。
+* 从 master 切出新的分支,分支名根据这个分支的功能决定,一般叫 f_new_feature(如 f_storage_engine) 或者 fix_bug(如 fix_query_cache_bug)
+* 在 idea 中添加 code style 为 根目录的 java-google-style.xml
* 修改代码,增加测试用例(单元测试、集成测试)
- * 集成测试参考: server/src/test/java/org/apache/iotdb/db/integration/IoTDBTimeZoneIT
+ * 集成测试参考:server/src/test/java/org/apache/iotdb/db/integration/IoTDBTimeZoneIT
* 用 `mvn spotless:check` 检查代码样式,并用`mvn spotless:apply`修复样式
-* 提交 PR, 以 [IOTDB-jira号] 开头
+* 提交 PR, 以 [IOTDB-jira 号] 开头
* 发邮件到 dev 邮件列表:(I've submitted a PR for issue IOTDB-xxx [link])
* 根据其他人的审阅意见进行修改,继续更新,直到合并
* 关闭 jira issue
-# IoTDB调试方式
+# IoTDB 调试方式
## 导入代码
@@ -130,28 +130,25 @@ import -> Maven -> Existing Maven Projects
## 调试代码
-* 服务器主函数:```server/src/main/java/org/apache/iotdb/db/service/IoTDB```,可以debug模式启动
+* 服务器主函数:```server/src/main/java/org/apache/iotdb/db/service/IoTDB```,可以 debug 模式启动
* 命令行界面:```cli/src/main/java/org/apache/iotdb/cli/```,linux 用 Cli,windows 用 WinCli,可以直接启动。启动时需要参数"-h 127.0.0.1 -p 6667 -u root -pw root"
* 服务器的 rpc 实现(主要用来客户端和服务器通信,一般在这里开始打断点):```server/src/main/java/org/apache/iotdb/db/service/TSServiceImpl```
- * jdbc所有语句:executeStatement(TSExecuteStatementReq req)
- * jdbc查询语句:executeQueryStatement(TSExecuteStatementReq req)
- * native写入接口:insertRecord(TSInsertRecordReq req)
+ * jdbc 所有语句:executeStatement(TSExecuteStatementReq req)
+ * jdbc 查询语句:executeQueryStatement(TSExecuteStatementReq req)
+ * native 写入接口:insertRecord(TSInsertRecordReq req)
* 存储引擎 org.apache.iotdb.db.engine.StorageEngine
* 查询引擎 org.apache.iotdb.db.qp.Planner
-
-
# 常见编译错误
-无法下载 thrift-* 等文件, 例如 `Could not get content
+无法下载 thrift-* 等文件,例如 `Could not get content
org.apache.maven.wagon.TransferFailedException: Transfer failed for https://github.com/apache/iotdb-bin-resources/blob/main/compile-tools/thrift-0.14-ubuntu`
这一般是网络问题,这时候需要手动下载上述文件:
- * 根据以下网址手动下载上述文件;
+ * 根据以下网址手动下载上述文件;
* https://github.com/apache/iotdb-bin-resources/blob/main/compile-tools/thrift-0.14-MacOS
* https://github.com/apache/iotdb-bin-resources/blob/main/compile-tools/thrift-0.14-ubuntu
- * 将该文件拷贝到thrift/target/tools/目录下
- * 重新执行maven的编译命令
-
+ * 将该文件拷贝到 thrift/target/tools/目录下
+ * 重新执行 maven 的编译命令
diff --git a/docs/zh/Development/HowToCommit.md b/docs/zh/Development/HowToCommit.md
index 059d053..f47a8e7 100644
--- a/docs/zh/Development/HowToCommit.md
+++ b/docs/zh/Development/HowToCommit.md
@@ -23,23 +23,23 @@
## 贡献途径
-IoTDB诚邀广大开发者参与开源项目构建
+IoTDB 诚邀广大开发者参与开源项目构建
-您可以查看[issues](https://issues.apache.org/jira/projects/IOTDB/issues)并参与解决,或者做其他改善。
+您可以查看 [issues](https://issues.apache.org/jira/projects/IOTDB/issues) 并参与解决,或者做其他改善。
-提交pr,通过Travis-CI测试和Sonar代码质量检测后,至少有一位以上Committer同意且代码无冲突,就可以合并了
+提交 pr,通过 Travis-CI 测试和 Sonar 代码质量检测后,至少有一位以上 Committer 同意且代码无冲突,就可以合并了
-## PR指南
+## PR 指南
-在Github上面可以很方便地提交 [Pull Request (PR)](https://help.github.com/articles/about-pull-requests/),下面将以本网站项目[apache/iotdb](https://github.com/apache/iotdb) 为例(如果是其他项目,请替换项目名iotdb)
+在 Github 上面可以很方便地提交 [Pull Request (PR)](https://help.github.com/articles/about-pull-requests/),下面将以本网站项目 [apache/iotdb](https://github.com/apache/iotdb) 为例(如果是其他项目,请替换项目名 iotdb)
-### Fork仓库
+### Fork 仓库
进入 apache/iotdb 的 [github 页面](https://github.com/apache/iotdb) ,点击右上角按钮 `Fork` 进行 Fork

-### 配置git和提交修改
+### 配置 git 和提交修改
- 将代码克隆到本地:
@@ -47,9 +47,9 @@ IoTDB诚邀广大开发者参与开源项目构建
git clone https://github.com/<your_github_name>/iotdb.git
```
-**请将 <your_github_name> 替换为您的github名字**
+**请将 <your_github_name> 替换为您的 github 名字**
-clone完成后,origin会默认指向github上的远程fork地址。
+clone 完成后,origin 会默认指向 github 上的远程 fork 地址。
- 将 apache/iotdb 添加为本地仓库的远程分支 upstream:
@@ -68,7 +68,7 @@ upstream https://github.com/apache/iotdb.git (fetch)
upstream https://github.com/apache/iotdb.git (push)
```
-- 新建分支以便在分支上做修改:(假设新建的分支名为fix)
+- 新建分支以便在分支上做修改:(假设新建的分支名为 fix)
```
git checkout -b fix
@@ -76,7 +76,7 @@ git checkout -b fix
创建完成后可进行代码更改。
-- 提交代码到远程分支:(此处以fix分支为例)
+- 提交代码到远程分支:(此处以 fix 分支为例)
```
git commit -a -m "<you_commit_message>"
@@ -85,17 +85,17 @@ git push origin fix
更多 git 使用方法请访问:[git 使用](https://www.atlassian.com/git/tutorials/setting-up-a-repository),这里不赘述。
-### 创建PR
+### 创建 PR
-在浏览器切换到自己的 github 仓库页面,切换分支到提交的分支 <your_branch_name> ,依次点击 `New pull request` 和 `Create pull request` 按钮进行创建,如果您解决的是[issues](https://issues.apache.org/jira/projects/IOTDB/issues),需要在开头加上[IOTDB-xxx],如下图所示:
+在浏览器切换到自己的 github 仓库页面,切换分支到提交的分支 <your_branch_name> ,依次点击 `New pull request` 和 `Create pull request` 按钮进行创建,如果您解决的是 [issues](https://issues.apache.org/jira/projects/IOTDB/issues),需要在开头加上 [IOTDB-xxx],如下图所示:

-至此,您的PR创建完成,更多关于 PR 请阅读 [collaborating-with-issues-and-pull-requests](https://help.github.com/categories/collaborating-with-issues-and-pull-requests/)
+至此,您的 PR 创建完成,更多关于 PR 请阅读 [collaborating-with-issues-and-pull-requests](https://help.github.com/categories/collaborating-with-issues-and-pull-requests/)
### 冲突解决
-提交PR时的代码冲突一般是由于多人编辑同一个文件引起的,解决冲突主要通过以下步骤即可:
+提交 PR 时的代码冲突一般是由于多人编辑同一个文件引起的,解决冲突主要通过以下步骤即可:
1:切换至主分支
@@ -109,13 +109,13 @@ git checkout master
git pull upstream master
```
-3:切换回刚才的分支(假设分支名为fix)
+3:切换回刚才的分支(假设分支名为 fix)
```
git checkout fix
```
-4:进行rebase
+4:进行 rebase
```
git rebase -i master
@@ -128,12 +128,10 @@ git add .
git rebase --continue
```
-依此往复,直至屏幕出现类似 *rebase successful* 字样即可,此时您可以进行往提交PR的分支进行更新:
+依此往复,直至屏幕出现类似 *rebase successful* 字样即可,此时您可以进行往提交 PR 的分支进行更新:
```
git push -f origin fix
```
-
-
-这个指导文档修改于[Apache ServiceComb](http://servicecomb.apache.org/developers/submit-codes/)
\ No newline at end of file
+这个指导文档修改于 [Apache ServiceComb](http://servicecomb.apache.org/developers/submit-codes/)
\ No newline at end of file
diff --git a/docs/zh/Development/VoteRelease.md b/docs/zh/Development/VoteRelease.md
index bdf3255..37f6603 100644
--- a/docs/zh/Development/VoteRelease.md
+++ b/docs/zh/Development/VoteRelease.md
@@ -50,10 +50,10 @@ pub rsa4096/28662AC6 2019-12-23 [SC]
下载公钥
```
-gpg2 --receive-keys 10F3B3F8A1201B79AA43F2E00FC7F131CAA00430 (或 28662AC6)
+gpg2 --receive-keys 10F3B3F8A1201B79AA43F2E00FC7F131CAA00430 (或 28662AC6)
-或 (指定 keyserver)
-gpg2 --keyserver p80.pool.sks-keyservers.net --recv-keys 10F3B3F8A1201B79AA43F2E00FC7F131CAA00430 (或 28662AC6)
+或 (指定 keyserver)
+gpg2 --keyserver p80.pool.sks-keyservers.net --recv-keys 10F3B3F8A1201B79AA43F2E00FC7F131CAA00430 (或 28662AC6)
```
### 第二种方法
@@ -179,7 +179,6 @@ Thanks,
xxx
```
-
## 小工具
* 打印出包含某些字符的行(只看最上边的输出就可以,下边的文件不需要看)
diff --git a/docs/zh/Download/README.md b/docs/zh/Download/README.md
index 8d61ccd..3e86873 100644
--- a/docs/zh/Download/README.md
+++ b/docs/zh/Download/README.md
@@ -48,7 +48,7 @@
<td><a href="https://downloads.apache.org/iotdb/0.12.1/apache-iotdb-0.12.1-cluster-bin.zip.asc">ASC</a></td>
</tr>
<tr>
- <td><a href="https://www.apache.org/dyn/closer.cgi/iotdb/0.12.1/apache-iotdb-0.12.1-grafana-bin.zip">Grafana连接器</a></td>
+ <td><a href="https://www.apache.org/dyn/closer.cgi/iotdb/0.12.1/apache-iotdb-0.12.1-grafana-bin.zip">Grafana 连接器</a></td>
<td><a href="https://downloads.apache.org/iotdb/0.12.1/apache-iotdb-0.12.1-grafana-bin.zip.sha512">SHA512</a></td>
<td><a href="https://downloads.apache.org/iotdb/0.12.1/apache-iotdb-0.12.1-grafana-bin.zip.asc">ASC</a></td>
</tr>
@@ -65,58 +65,53 @@
</tr>
</table>
-历史版本下载: [https://archive.apache.org/dist/iotdb/](https://archive.apache.org/dist/iotdb/)
-
+历史版本下载:[https://archive.apache.org/dist/iotdb/](https://archive.apache.org/dist/iotdb/)
**<font color=red>升级注意事项</font>**:
-- 如何升级小版本 (例如,从 v0.11.0 to v0.11.2)?
+- 如何升级小版本 (例如,从 v0.11.0 to v0.11.2)?
* 同一个大版本下的多个小版本是互相兼容的。
* 只需要下载新的小版本, 然后修改其配置文件,使其与原有版本的设置一致。
* 停掉旧版本进程,启动新版本即可。
-- 如何从v0.11.x或v0.10.x 升级到 v0.12.x?
- * 从0.11或0.10升级到0.12的过程与v0.9升级到v0.10类似,升级工具会自动进行数据文件的升级。
+- 如何从 v0.11.x 或 v0.10.x 升级到 v0.12.x?
+ * 从 0.11 或 0.10 升级到 0.12 的过程与 v0.9 升级到 v0.10 类似,升级工具会自动进行数据文件的升级。
* 停掉旧版本新数据写入。
- * 用CLI调用`flush`,确保关闭所有的TsFile文件.
- * 我们推荐提前备份数据文件(以及写前日志和mlog文件),以备回滚。
- * 下载最新版,解压并修改配置文件。将各数据目录都指向备份的或者v0.11或0.10原来使用的数据目录。 把0.11中的其他修改都放到0.12中。
- * 停止旧版本IoTDB的实例,启动v0.12的实例。IoTDB将后台自动升级数据文件格式。在升级过程中数据可以进行查询和写入。
+ * 用 CLI 调用`flush`,确保关闭所有的 TsFile 文件。
+ * 我们推荐提前备份数据文件(以及写前日志和 mlog 文件),以备回滚。
+ * 下载最新版,解压并修改配置文件。将各数据目录都指向备份的或者 v0.11 或 0.10 原来使用的数据目录。 把 0.11 中的其他修改都放到 0.12 中。
+ * 停止旧版本 IoTDB 的实例,启动 v0.12 的实例。IoTDB 将后台自动升级数据文件格式。在升级过程中数据可以进行查询和写入。
* 当日志中显示`All files upgraded successfully! ` 后代表升级成功。
- * __注意1:0.12的配置文件进行了较大改动,因此不要直接将原本的配置文件用于0.12__
- * __注意2: 由于0.12不支持从0.9或者更低版本升级,如果需要升级,请先升级到0.10版本__
- * __注意3: 在文件升级完成前,最好不要进行delete操作。如果删除某个存储组内的数据且该存储组内存在待升级文件,删除会失败。__
+ * __注意 1:0.12 的配置文件进行了较大改动,因此不要直接将原本的配置文件用于 0.12__
+ * __注意 2: 由于 0.12 不支持从 0.9 或者更低版本升级,如果需要升级,请先升级到 0.10 版本__
+ * __注意 3: 在文件升级完成前,最好不要进行 delete 操作。如果删除某个存储组内的数据且该存储组内存在待升级文件,删除会失败。__
-- 如何从v0.10.x 升级到 v0.11.x?
- * 0.10 与0.11的数据文件格式兼容,但写前日志等格式不兼容,因此需要进行升级(但速度很快):
- * 停掉0.10的新数据写入。
- * 用CLI调用`flush`,确保关闭所有的TsFile文件.
- * 我们推荐提前备份写前日志和mlog文件,以备回滚。
- * 下载最新版,解压并修改配置文件。将各数据目录都指向备份的或者v0.10原来使用的数据目录。
- * 停止v0.10的实例,启动v0.11的实例。IoTDB将自动升级不兼容的文件格式。
- * __注意:0.11的配置文件进行了较大改动,因此不要直接将0.10的配置文件用于0.11__
-
-
-- 如何从v0.9.x 升级到 v0.10.x?
- * 停掉0.9的新数据写入。
- * 用CLI调用`flush`,确保关闭所有的TsFile文件.
- * 我们推荐提前备份数据文件(以及写前日志和mlog文件),以备回滚。
- * 下载最新版,解压并修改配置文件。将各数据目录都指向备份的或者v0.9原来使用的数据目录。
- * 停止v0.9的实例,启动v0.10的实例。IoTDB将自动升级数据文件格式。
-
-- 如何从0.8.x 升级到 v0.9.x?
- * 我们推荐提前备份数据文件(以及写前日志和mlog文件),以备回滚。
- * 下载最新版,解压并修改配置文件。将各数据目录都指向备份的或者v0.8原来使用的数据目录。
- * 停止v0.8的实例,启动v0.9.x的实例。IoTDB将自动升级数据文件格式。
+- 如何从 v0.10.x 升级到 v0.11.x?
+ * 0.10 与 0.11 的数据文件格式兼容,但写前日志等格式不兼容,因此需要进行升级(但速度很快):
+ * 停掉 0.10 的新数据写入。
+ * 用 CLI 调用`flush`,确保关闭所有的 TsFile 文件。
+ * 我们推荐提前备份写前日志和 mlog 文件,以备回滚。
+ * 下载最新版,解压并修改配置文件。将各数据目录都指向备份的或者 v0.10 原来使用的数据目录。
+ * 停止 v0.10 的实例,启动 v0.11 的实例。IoTDB 将自动升级不兼容的文件格式。
+ * __注意:0.11 的配置文件进行了较大改动,因此不要直接将 0.10 的配置文件用于 0.11__
+
+- 如何从 v0.9.x 升级到 v0.10.x?
+ * 停掉 0.9 的新数据写入。
+ * 用 CLI 调用`flush`,确保关闭所有的 TsFile 文件。
+ * 我们推荐提前备份数据文件(以及写前日志和 mlog 文件),以备回滚。
+ * 下载最新版,解压并修改配置文件。将各数据目录都指向备份的或者 v0.9 原来使用的数据目录。
+ * 停止 v0.9 的实例,启动 v0.10 的实例。IoTDB 将自动升级数据文件格式。
+
+- 如何从 0.8.x 升级到 v0.9.x?
+ * 我们推荐提前备份数据文件(以及写前日志和 mlog 文件),以备回滚。
+ * 下载最新版,解压并修改配置文件。将各数据目录都指向备份的或者 v0.8 原来使用的数据目录。
+ * 停止 v0.8 的实例,启动 v0.9.x 的实例。IoTDB 将自动升级数据文件格式。
-
# 所有版本
-在 [Archive repository](https://archive.apache.org/dist/iotdb/)查看所有版本
-
-
+在 [Archive repository](https://archive.apache.org/dist/iotdb/) 查看所有版本
# 验证哈希和签名
-除了我们的发行版,我们还在* .sha512文件中提供了sha512散列,并在* .asc文件中提供了加密签名。 Apache Software Foundation提供了广泛的教程来 [验证哈希和签名](http://www.apache.org/info/verification.html),您可以使用任何这些发布签名的[KEYS](https://downloads.apache.org/iotdb/KEYS)来遵循这些哈希和签名。
+除了我们的发行版,我们还在 *.sha512 文件中提供了 sha512 散列,并在 *.asc 文件中提供了加密签名。 Apache Software Foundation 提供了广泛的教程来 [验证哈希和签名](http://www.apache.org/info/verification.html),您可以使用任何这些发布签名的 [KEYS](https://downloads.apache.org/iotdb/KEYS) 来遵循这些哈希和签名。
diff --git a/docs/zh/SystemDesign/Architecture/Architecture.md b/docs/zh/SystemDesign/Architecture/Architecture.md
index 19a15c8..8cf4a1b 100644
--- a/docs/zh/SystemDesign/Architecture/Architecture.md
+++ b/docs/zh/SystemDesign/Architecture/Architecture.md
@@ -52,4 +52,3 @@ IoTDB 与大数据系统进行了对接。
* [Spark-TsFile](../Connector/Spark-TsFile.md)
* [Spark-IoTDB](../Connector/Spark-IOTDB.md)
* [Grafana](../../UserGuide/Ecosystem%20Integration/Grafana.md)
-
diff --git a/docs/zh/SystemDesign/Client/RPC.md b/docs/zh/SystemDesign/Client/RPC.md
index da6a52d..e93c920 100644
--- a/docs/zh/SystemDesign/Client/RPC.md
+++ b/docs/zh/SystemDesign/Client/RPC.md
@@ -35,7 +35,6 @@ mvn clean compile -pl service-rpc -am -DskipTests
或者
-
```
mvn clean compile -pl thrift
```
@@ -53,5 +52,3 @@ session/src/main/java/org/apache/iotdb/session/Session.java
服务器端代码在
server/src/main/java/org/apache/iotdb/db/service/TSServiceImpl.java
-
-
diff --git a/docs/zh/SystemDesign/Connector/Hive-TsFile.md b/docs/zh/SystemDesign/Connector/Hive-TsFile.md
index 0384de5..00283b0 100644
--- a/docs/zh/SystemDesign/Connector/Hive-TsFile.md
+++ b/docs/zh/SystemDesign/Connector/Hive-TsFile.md
@@ -28,7 +28,7 @@ TsFile 的 Hive 连接器实现了通过 Hive 读取外部 TsFile 类型的文
* 将单个 TsFile 文件加载进 Hive,不论文件是存储在本地文件系统或者是 HDFS 中
* 将某个特定目录下的所有文件加载进 Hive,不论文件是存储在本地文件系统或者是 HDFS 中
* 使用 HQL 查询 TsFile
-* 到现在为止, 写操作在 hive-connector 中还不支持. 所以, HQL 中的 insert 操作是不被允许的
+* 到现在为止,写操作在 hive-connector 中还不支持。所以,HQL 中的 insert 操作是不被允许的
### 设计原理
@@ -79,33 +79,30 @@ public interface IReaderSet {
private List<String> deviceIdList = new ArrayList<>();
```
- 设备名列表,这个顺序与 dataSetList 的顺序一致,即 deviceIdList[i] 是 dataSetList[i] 的设备名.
+ 设备名列表,这个顺序与 dataSetList 的顺序一致,即 deviceIdList[i] 是 dataSetList[i] 的设备名。
* private int currentIndex = 0;
当前正在被处理的 QueryDataSet 的下标
-
这个类在构造函数里,调用了`TSFRecordReader`的`initialize(TSFInputSplit, Configuration, IReaderSet, List<QueryDataSet>, List<String>)`方法去初始化上面提到的一些类字段。它覆写了`RecordReader`的`next()`方法,用以返回从 TsFile 里读出的数据。
##### next(NullWritable, MapWritable)
我们注意到它从 TsFile 读取出来数据之后,是以`MapWritable`的形式返回的,这里的`MapWritable`其实就是一个`Map`,只不过它的 key 与 value 都做了序列化与反序列化的特殊适配,它的读取流程如下
-1. 首先判断`dataSetList`当前位置的`QueryDataSet`还有没有值,如果没有值,则将`currentIndex`递增1,直到找到第一个有值的`QueryDataSet`
+1. 首先判断`dataSetList`当前位置的`QueryDataSet`还有没有值,如果没有值,则将`currentIndex`递增 1,直到找到第一个有值的`QueryDataSet`
2. 然后调用`QueryDataSet`的`next()`方法获得`RowRecord`
3. 最后调用`TSFRecordReader`的`getCurrentValue()`方法,将`RowRecord`中的值放入`MapWritable`里
-
#### org.apache.iotdb.hive.TsFileSerDe
-这个类继承了`AbstractSerDe`,也是我们实现Hive从自定义输入格式中读取数据所必须的。
+这个类继承了`AbstractSerDe`,也是我们实现 Hive 从自定义输入格式中读取数据所必须的。
它覆写了`AbstractSerDe`的`initialize()`方法,在这个方法里,从用户的建表 sql 里,解析出相应的设备名,传感器名以及传感器对应的类型。还要构建出`ObjectInspector`对象,这个对象主要负责数据类型的转化,由于 TsFile 只支持原始数据类型,所以当出现其他数据类型时,需要抛出异常,具体的构建过程在`createObjectInspectorWorker()`方法中可以看到。
这个类的最主要职责就是序列化和反序列化不同文件格式的数据,由于我们的 Hive 连接器暂时只支持读取操作,并不支持 insert 操作,所以只有反序列化的过程,所以仅覆写了`deserialize(Writable)`方法,该方法里调用了`TsFileDeserializer`的`deserialize()`方法。
-
#### org.apache.iotdb.hive.TsFileDeserializer
这个类就是将数据反序列化为 Hive 的输出格式,仅有一个`deserialize()`方法。
diff --git a/docs/zh/SystemDesign/Connector/Spark-IOTDB.md b/docs/zh/SystemDesign/Connector/Spark-IOTDB.md
index 2224d0a..d1e6ff2 100644
--- a/docs/zh/SystemDesign/Connector/Spark-IOTDB.md
+++ b/docs/zh/SystemDesign/Connector/Spark-IOTDB.md
@@ -23,34 +23,33 @@
## 设计目的
-* 使用Spark SQL读取IOTDB的数据,以Spark DataFrame的形式返回给客户端
+* 使用 Spark SQL 读取 IOTDB 的数据,以 Spark DataFrame 的形式返回给客户端
## 核心思想
-由于IOTDB具有解析和执行SQL的能力,故该部分可以直接将SQL转发给IOTDB进程执行,将数据拿到后转换为RDD即可
+由于 IOTDB 具有解析和执行 SQL 的能力,故该部分可以直接将 SQL 转发给 IOTDB 进程执行,将数据拿到后转换为 RDD 即可
## 执行流程
#### 1. 入口
* src/main/scala/org/apache/iotdb/spark/db/DefaultSource.scala
-#### 2. 构建Relation
-Relation主要保存了RDD的元信息,比如列名字,分区策略等,调用Relation的buildScan方法可以创建RDD
+#### 2. 构建 Relation
+Relation 主要保存了 RDD 的元信息,比如列名字,分区策略等,调用 Relation 的 buildScan 方法可以创建 RDD
* src/main/scala/org/apache/iotdb/spark/db/IoTDBRelation.scala
-#### 3. 构建RDD
-RDD中执行对IOTDB的SQL请求,保存游标
+#### 3. 构建 RDD
+RDD 中执行对 IOTDB 的 SQL 请求,保存游标
-* src/main/scala/org/apache/iotdb/spark/db/IoTDBRDD.scala中的compute方法
+* src/main/scala/org/apache/iotdb/spark/db/IoTDBRDD.scala 中的 compute 方法
-#### 4. 迭代RDD
-由于Spark懒加载机制,用户遍历RDD时才具体调用RDD的迭代,也就是IOTDB的fetch Result
-
-* src/main/scala/org/apache/iotdb/spark/db/IoTDBRDD.scala中的getNext方法
+#### 4. 迭代 RDD
+由于 Spark 懒加载机制,用户遍历 RDD 时才具体调用 RDD 的迭代,也就是 IOTDB 的 fetch Result
+* src/main/scala/org/apache/iotdb/spark/db/IoTDBRDD.scala 中的 getNext 方法
## 宽窄表结构转换
-宽表结构:IOTDB原生路径格式
+宽表结构:IOTDB 原生路径格式
| time | root.ln.wf02.wt02.temperature | root.ln.wf02.wt02.status | root.ln.wf02.wt02.hardware | root.ln.wf01.wt01.temperature | root.ln.wf01.wt01.status | root.ln.wf01.wt01.hardware |
|------|-------------------------------|--------------------------|----------------------------|-------------------------------|--------------------------|----------------------------|
@@ -61,7 +60,7 @@ RDD中执行对IOTDB的SQL请求,保存游标
| 5 | null | null | null | null | false | null |
| 6 | null | null | ccc | null | null | null |
-窄表结构: 关系型数据库模式,IOTDB align by device格式
+窄表结构:关系型数据库模式,IOTDB align by device 格式
| time | device_name | status | hardware | temperature |
|------|-------------------------------|--------------------------|----------------------------|-------------------------------|
@@ -74,16 +73,16 @@ RDD中执行对IOTDB的SQL请求,保存游标
| 5 | root.ln.wf02.wt01 | false | null | null |
| 6 | root.ln.wf02.wt02 | null | ccc | null |
-由于IOTDB查询到的数据默认为宽表结构,所以需要宽窄表转换,有如下两个实现方法
+由于 IOTDB 查询到的数据默认为宽表结构,所以需要宽窄表转换,有如下两个实现方法
-#### 1. 使用IOTDB的group by device语句
-这种方式可以直接拿到窄表结构,计算由IOTDB完成
+#### 1. 使用 IOTDB 的 group by device 语句
+这种方式可以直接拿到窄表结构,计算由 IOTDB 完成
-#### 2. 使用Transformer
-可以使用Transformer进行宽窄表之间的转换,计算由Spark完成
+#### 2. 使用 Transformer
+可以使用 Transformer 进行宽窄表之间的转换,计算由 Spark 完成
* src/main/scala/org/apache/iotdb/spark/db/Transformer.scala
-宽表转窄表使用了遍历device列表,生成对应的窄表,在union起来的策略,并行性较好(无shuffle)
+宽表转窄表使用了遍历 device 列表,生成对应的窄表,在 union 起来的策略,并行性较好(无 shuffle)
-窄表转宽表使用了基于timestamp的join操作,有shuffle,可能存在潜在的性能问题
\ No newline at end of file
+窄表转宽表使用了基于 timestamp 的 join 操作,有 shuffle,可能存在潜在的性能问题
\ No newline at end of file
diff --git a/docs/zh/SystemDesign/Connector/Spark-TsFile.md b/docs/zh/SystemDesign/Connector/Spark-TsFile.md
index ccf947a..70bc881 100644
--- a/docs/zh/SystemDesign/Connector/Spark-TsFile.md
+++ b/docs/zh/SystemDesign/Connector/Spark-TsFile.md
@@ -39,7 +39,7 @@
| 5 | null | null | null | null | false | null |
| 6 | null | null | ccc | null | null | null |
-窄表结构: 关系型数据库模式,IoTDB align by device格式
+窄表结构:关系型数据库模式,IoTDB align by device 格式
| time | device_name | status | hardware | temperature |
|------|-------------------------------|--------------------------|----------------------------|-------------------------------|
@@ -56,29 +56,29 @@
#### 1. 表结构推断和生成
-该步骤是为了使DataFrame的表结构与需要查询的 TsFile 的表结构匹配
+该步骤是为了使 DataFrame 的表结构与需要查询的 TsFile 的表结构匹配
主要逻辑在 src/main/scala/org/apache/iotdb/spark/tsfile/DefaultSource.scala 中的 inferSchema 函数
-#### 2. SQL解析
+#### 2. SQL 解析
该步骤目的是为了将用户 SQL 语句转化为 TsFile 原生的查询表达式
主要逻辑在 src/main/scala/org/apache/iotdb/spark/tsfile/DefaultSource.scala 中的 buildReader 函数
-SQL解析分宽表结构与窄表结构
+SQL 解析分宽表结构与窄表结构
#### 3. 宽表结构
-宽表结构的SQL解析主要逻辑在 src/main/scala/org/apache/iotdb/spark/tsfile/WideConverter.scala 中
+宽表结构的 SQL 解析主要逻辑在 src/main/scala/org/apache/iotdb/spark/tsfile/WideConverter.scala 中
-该结构与 TsFile 原生查询结构基本相同,不需要特殊处理,直接将SQL语句转化为相应查询表达式即可
+该结构与 TsFile 原生查询结构基本相同,不需要特殊处理,直接将 SQL 语句转化为相应查询表达式即可
#### 4. 窄表结构
-宽表结构的SQL解析主要逻辑在 src/main/scala/org/apache/iotdb/spark/tsfile/NarrowConverter.scala中
+宽表结构的 SQL 解析主要逻辑在 src/main/scala/org/apache/iotdb/spark/tsfile/NarrowConverter.scala 中
-首先我们根据查询的schema确定要查询的时间序列,仅在tsfile中查询那些sql中存在的时间序列
+首先我们根据查询的 schema 确定要查询的时间序列,仅在 tsfile 中查询那些 sql 中存在的时间序列
```
requiredSchema.foreach((field: StructField) => {
if (field.name != QueryConstant.RESERVED_TIME
@@ -88,20 +88,20 @@ requiredSchema.foreach((field: StructField) => {
})
```
-SQL转化为表达式后,由于窄表结构与 TsFile 原生查询结构不同,需要先将表达式转化为与 device 有关的析取表达式
-,才可以转化为对 TsFile 的查询,转化代码在src/main/java/org/apache/iotdb/spark/tsfile/qp中
+SQL 转化为表达式后,由于窄表结构与 TsFile 原生查询结构不同,需要先将表达式转化为与 device 有关的析取表达式
+,才可以转化为对 TsFile 的查询,转化代码在 src/main/java/org/apache/iotdb/spark/tsfile/qp 中
例子:
```
select time, device_name, s1 from tsfile_table where time > 1588953600000 and time < 1589040000000 and device_name = 'root.group1.d1'
```
-此时仅查询时间序列root.group1.d1.s1,条件表达式为[time > 1588953600000] and [time < 1589040000000]
+此时仅查询时间序列 root.group1.d1.s1,条件表达式为 [time > 1588953600000] and [time < 1589040000000]
#### 5. 查询实际执行
实际数据查询执行由 TsFile 原生组件完成,参见:
-* [Tsfile原生查询流程](../TsFile/Read.md)
+* [Tsfile 原生查询流程](../TsFile/Read.md)
## 写入步骤流程
@@ -122,4 +122,3 @@ select time, device_name, s1 from tsfile_table where time > 1588953600000 and ti
* src/main/scala/org/apache/iotdb/spark/tsfile/NarrowConverter.scala 负责结构转化
* src/main/scala/org/apache/iotdb/spark/tsfile/NarrowTsFileOutputWriter.scala 负责匹配 spark 接口与执行写入,会调用上一个文件中的结构转化功能
-
diff --git a/docs/zh/SystemDesign/DataQuery/AggregationQuery.md b/docs/zh/SystemDesign/DataQuery/AggregationQuery.md
index bec99ab..b69fe91 100644
--- a/docs/zh/SystemDesign/DataQuery/AggregationQuery.md
+++ b/docs/zh/SystemDesign/DataQuery/AggregationQuery.md
@@ -27,7 +27,7 @@
## 不带值过滤条件的聚合查询
-对于不带值过滤条件的聚合查询,通过 `executeWithoutValueFilter()` 方法获得结果并构建 dataSet。首先使用 `mergeSameSeries()` 方法将对于相同时间序列的聚合查询合并,例如:如果需要计算count(s1), sum(s2), count(s3), sum(s1),即需要计算s1的两个聚合值,那么将会得到pathToAggrIndexesMap结果为:s1 -> 0, 3; s2 -> 1; s3 -> 2。
+对于不带值过滤条件的聚合查询,通过 `executeWithoutValueFilter()` 方法获得结果并构建 dataSet。首先使用 `mergeSameSeries()` 方法将对于相同时间序列的聚合查询合并,例如:如果需要计算 count(s1), sum(s2), count(s3), sum(s1),即需要计算 s1 的两个聚合值,那么将会得到 pathToAggrIndexesMap 结果为:s1 -> 0, 3; s2 -> 1; s3 -> 2。
那么将会得到 `pathToAggrIndexesMap`,其中每一个 entry 都是一个 series 的聚合查询,因此可以通过调用 `groupAggregationsBySeries()` 方法计算出其聚合值 `aggregateResults`。在最后创建结果集之前,需要将其顺序还原为用户查询的顺序。最后使用 `constructDataSet()` 方法创建结果集并返回。
@@ -38,9 +38,9 @@ IAggregateReader seriesReader = new SeriesAggregateReader(
.getQueryDataSource(seriesPath, context, timeFilter), timeFilter, null);
```
-对于每一个 entry(即series),首先为其每一种聚合查询创建一个聚合结果 `AggregateResult`,同时维护一个布尔值列表 `isCalculatedList`,对应每一个 `AggregateResult`是否已经计算完成,并记录需要剩余计算的聚合函数数目 `remainingToCalculate`。布尔值列表和这个计数值将会使得某些聚合函数(如 `FIRST_VALUE`)在获得结果后,不需要再继续进行整个循环过程。
+对于每一个 entry(即 series),首先为其每一种聚合查询创建一个聚合结果 `AggregateResult`,同时维护一个布尔值列表 `isCalculatedList`,对应每一个 `AggregateResult`是否已经计算完成,并记录需要剩余计算的聚合函数数目 `remainingToCalculate`。布尔值列表和这个计数值将会使得某些聚合函数(如 `FIRST_VALUE`)在获得结果后,不需要再继续进行整个循环过程。
-接下来,按照5.2节所介绍的 `aggregateReader` 使用方法,更新 `AggregateResult`:
+接下来,按照 5.2 节所介绍的 `aggregateReader` 使用方法,更新 `AggregateResult`:
```
while (aggregateReader.hasNextChunk()) {
@@ -72,7 +72,7 @@ while (aggregateReader.hasNextChunk()) {
}
```
-需要注意的是,在对于每一个result进行更新之前,需要首先判断其是否已经被计算完(利用 `isCalculatedList` 列表);每一次更新后,调用 `isCalculatedAggregationResult()` 方法同时更新列表中的布尔值。如果列表中所有值均为true,即 `remainingToCalculate` 值为0,证明所有聚合函数结果均已计算完,可以返回。
+需要注意的是,在对于每一个 result 进行更新之前,需要首先判断其是否已经被计算完(利用 `isCalculatedList` 列表);每一次更新后,调用 `isCalculatedAggregationResult()` 方法同时更新列表中的布尔值。如果列表中所有值均为 true,即 `remainingToCalculate` 值为 0,证明所有聚合函数结果均已计算完,可以返回。
```
if (Boolean.FALSE.equals(isCalculatedList.get(i))) {
AggregateResult aggregateResult = aggregateResultList.get(i);
@@ -95,7 +95,7 @@ if (Boolean.FALSE.equals(isCalculatedList.get(i))) {
初始化完成后,调用 `aggregateWithValueFilter()` 方法更新结果:
```
while (timestampGenerator.hasNext()) {
- // 生成timestamps
+ // 生成 timestamps
long[] timeArray = new long[aggregateFetchSize];
int timeArrayLength = 0;
for (int cnt = 0; cnt < aggregateFetchSize; cnt++) {
@@ -105,7 +105,7 @@ while (timestampGenerator.hasNext()) {
timeArray[timeArrayLength++] = timestampGenerator.next();
}
- // 利用timestamps计算聚合结果
+ // 利用 timestamps 计算聚合结果
for (int i = 0; i < readersOfSelectedSeries.size(); i++) {
aggregateResults.get(i).updateResultUsingTimestamps(timeArray, timeArrayLength,
readersOfSelectedSeries.get(i));
@@ -113,22 +113,21 @@ while (timestampGenerator.hasNext()) {
}
```
-## 使用Level来统计点数
+## 使用 Level 来统计点数
-对于count聚合查询,我们也可以使用level关键字来进一步汇总点数。
+对于 count 聚合查询,我们也可以使用 level 关键字来进一步汇总点数。
这个逻辑在 `AggregationExecutor`类里。
-1. 首先,把所有涉及到的时序按level来进行汇集,最后的路径。
- > 例如把root.sg1.d1.s0,root.sg1.d2.s1按level=1汇集成root.sg1。
+1. 首先,把所有涉及到的时序按 level 来进行汇集,最后的路径。
+ > 例如把 root.sg1.d1.s0,root.sg1.d2.s1 按 level=1 汇集成 root.sg1。
-2. 然后调用上述的聚合逻辑求出所有时序的总点数信息,这个会返回RowRecord数据结构。
+2. 然后调用上述的聚合逻辑求出所有时序的总点数信息,这个会返回 RowRecord 数据结构。
-3. 最后,把聚合查询返回的RowRecord按上述的final paths,进行累加,组合成新的RowRecord。
+3. 最后,把聚合查询返回的 RowRecord 按上述的 final paths,进行累加,组合成新的 RowRecord。
> 例如,把《root.sg1.d1.s0,3》,《root.sg1.d2.s1,4》聚合成《root.sg1,7》
-
-> 注意:
-> 1. 这里只支持count操作
-> 2. root的层级level=0
\ No newline at end of file
+> 注意:
+> 1. 这里只支持 count 操作
+> 2. root 的层级 level=0
\ No newline at end of file
diff --git a/docs/zh/SystemDesign/DataQuery/AlignByDeviceQuery.md b/docs/zh/SystemDesign/DataQuery/AlignByDeviceQuery.md
index 2305eec..8eae929 100644
--- a/docs/zh/SystemDesign/DataQuery/AlignByDeviceQuery.md
+++ b/docs/zh/SystemDesign/DataQuery/AlignByDeviceQuery.md
@@ -106,7 +106,7 @@ SELECT s1, '1', *, s2, s5 FROM root.sg.d1, root.sg.* WHERE time = 1 AND s1 < 25
}
// 分别取得带聚合函数和不带聚合函数(实际时间序列)的数据类型
- // 带聚合函数的数据类型 `columnDataTypes` 用于 1.数据类型一致性检查 2.表头计算,输出结果集
+ // 带聚合函数的数据类型 `columnDataTypes` 用于 1. 数据类型一致性检查 2. 表头计算,输出结果集
// 时间序列的实际数据类型 `measurementDataTypes` 则用于 AlignByDeviceDataSet 中的实际查询
String aggregation =
originAggregations != null && !originAggregations.isEmpty()
@@ -135,7 +135,7 @@ SELECT s1, '1', *, s2, s5 FROM root.sg.d1, root.sg.* WHERE time = 1 AND s1 < 25
// 进行到这一步说明该 Measurement 在该设备下存在且正确,
// 首先更新 measurementSetOfGivenSuffix,重复则不可再加入
- // 其次如果该 measurement 之前其被识别为 NonExist类型,则将其更新为 Exist
+ // 其次如果该 measurement 之前其被识别为 NonExist 类型,则将其更新为 Exist
if (measurementSetOfGivenSuffix.add(measurementChecked)
|| measurementTypeMap.get(measurementChecked) != MeasurementType.Exist) {
measurementTypeMap.put(measurementChecked, MeasurementType.Exist);
@@ -168,7 +168,7 @@ Map<String, IExpression> concatFilterByDevice(List<String> devices,
`concatFilterPath()` 方法遍历未拼接的 FilterOperator 二叉树,判断节点是否为叶子节点,如果是,则取该叶子结点的路径,如果路径以 time 或 root 开头则不做处理,否则将设备名与节点路径进行拼接后返回;如果不是,则对该节点的所有子节点进行迭代处理。
-示例中,设备1过滤条件拼接后的结果为 `time = 1 AND root.sg.d1.s1 < 25`,设备2为 `time = 1 AND root.sg.d2.s1 < 25`。
+示例中,设备 1 过滤条件拼接后的结果为 `time = 1 AND root.sg.d1.s1 < 25`,设备 2 为 `time = 1 AND root.sg.d2.s1 < 25`。
下面用示例总结一下通过该阶段计算得到的变量信息:
@@ -227,7 +227,7 @@ private void getAlignByDeviceQueryHeaders(
- org.apache.iotdb.db.utils.QueryDataSetUtils
-接下来需要填充结果,AlignByDeviceQuery 将调用 `TSServiceImpl.fillRpcReturnData()` 方法,然后根据查询类型进入 `QueryDataSetUtils.convertQueryDataSetByFetchSize()` 方法.
+接下来需要填充结果,AlignByDeviceQuery 将调用 `TSServiceImpl.fillRpcReturnData()` 方法,然后根据查询类型进入 `QueryDataSetUtils.convertQueryDataSetByFetchSize()` 方法。
`convertQueryDataSetByFetchSize()` 方法中获取结果的重要方法为 QueryDataSet 的 `hasNext()` 方法。
@@ -250,10 +250,10 @@ private void getAlignByDeviceQueryHeaders(
其具体实现逻辑如下:
-1. 首先判断当前结果集是否被初始化且有下一个结果,如果是则直接返回 true,即当前可以调用 `next()` 方法获取下一个 `RowRecord`;否则设置结果集未被初始化进入步骤2.
+1. 首先判断当前结果集是否被初始化且有下一个结果,如果是则直接返回 true,即当前可以调用 `next()` 方法获取下一个 `RowRecord`;否则设置结果集未被初始化进入步骤 2.
2. 迭代 `deviceIterator` 获取本次执行需要的设备,之后通过设备路径在 MManager 中查询到该设备节点,并取得该设备节点下的所有传感器节点,保存为 `measurementOfGivenDevice`.
3. 遍历当前查询中的所有 measurement,将其与执行设备的所有传感器节点进行比较,得到该设备需要查询的列 `executeColumns`. 之后拼接当前设备名与 measurements,计算当前设备的查询路径、数据类型及过滤条件,得到对应的字段分别为 `executePaths`, `tsDataTypes`, `expression`,如果是聚合查询,则还需要计算 `executeAggregations`。
-4. 判断当前子查询类型为 GroupByQuery, AggregationQuery, FillQuery 或 RawDataQuery 进行对应的查询并返回结果集,实现逻辑可参考[原始数据查询](../DataQuery/RawDataQuery.md),[聚合查询](../DataQuery/AggregationQuery.md),[降采样查询](../DataQuery/GroupByQuery.md)。
+4. 判断当前子查询类型为 GroupByQuery, AggregationQuery, FillQuery 或 RawDataQuery 进行对应的查询并返回结果集,实现逻辑可参考 [原始数据查询](../DataQuery/RawDataQuery.md),[聚合查询](../DataQuery/AggregationQuery.md),[降采样查询](../DataQuery/GroupByQuery.md)。
通过 `hasNextWithoutConstraint()` 方法初始化结果集并确保有下一结果后,则可调用 `QueryDataSet.next()` 方法获取下一个 `RowRecord`.
diff --git a/docs/zh/SystemDesign/DataQuery/FillFunction.md b/docs/zh/SystemDesign/DataQuery/FillFunction.md
index 0430276..3466018 100644
--- a/docs/zh/SystemDesign/DataQuery/FillFunction.md
+++ b/docs/zh/SystemDesign/DataQuery/FillFunction.md
@@ -25,11 +25,11 @@
* org.apache.iotdb.db.query.executor.FillQueryExecutor
-IoTDB 中支持两种填充方式,Previous填充和Linear填充。
+IoTDB 中支持两种填充方式,Previous 填充和 Linear 填充。
-## Previous填充
+## Previous 填充
-Previous填充是使用离查询时间戳最近且小于等于查询时间戳的值来进行填充的一种方式,下图展示了一种可能的填充情况。
+Previous 填充是使用离查询时间戳最近且小于等于查询时间戳的值来进行填充的一种方式,下图展示了一种可能的填充情况。
```
|
+-------------------------+ |
@@ -40,21 +40,20 @@ Previous填充是使用离查询时间戳最近且小于等于查询时间戳的
| unseq files | |
+---------------------------+
|
- |
queryTime
```
## 设计原理
-在实际生产场景中,可能需要在大量的顺序和乱序TsFile中查找可用的填充值,因此解开大量TsFile文件会成为性能瓶颈。我们设计的思路在于尽可能的减少需要解开tsFile文件的个数,从而加速找到填充值这一过程。
+在实际生产场景中,可能需要在大量的顺序和乱序 TsFile 中查找可用的填充值,因此解开大量 TsFile 文件会成为性能瓶颈。我们设计的思路在于尽可能的减少需要解开 tsFile 文件的个数,从而加速找到填充值这一过程。
## 顺序文件查找"最近点"
-首先在顺序文件中查询满足条件的"最近点"。由于所有顺序文件及其所有包含的chunk数据都已经按照顺序排列,因此这个"最近点"可以通过`retrieveValidLastPointFromSeqFiles()`方法很容易找到。
+首先在顺序文件中查询满足条件的"最近点"。由于所有顺序文件及其所有包含的 chunk 数据都已经按照顺序排列,因此这个"最近点"可以通过`retrieveValidLastPointFromSeqFiles()`方法很容易找到。
-这个找到的"最近点"是可以成为Previous填充的最终值的,因此它在接下来的搜索中能够被用来作为下界来寻找其他更好的的填充值。接下来只有那些时间戳大于这个下界的点才是Previous填充的结果值。
+这个找到的"最近点"是可以成为 Previous 填充的最终值的,因此它在接下来的搜索中能够被用来作为下界来寻找其他更好的的填充值。接下来只有那些时间戳大于这个下界的点才是 Previous 填充的结果值。
-下例中的unseq 文件由于其最大值没有超过"最近点",因此不需要再进一步搜索。
+下例中的 unseq 文件由于其最大值没有超过"最近点",因此不需要再进一步搜索。
```
last point
| |
@@ -71,11 +70,11 @@ Previous填充是使用离查询时间戳最近且小于等于查询时间戳的
## 筛选乱序文件
-筛选并解开乱序文件的逻辑在成员函数`UnpackOverlappedUnseqFiles(long lBoundTime)`中,该方法接受一个下界参数,将满足要求的乱序文件解开且把它们的TimeseriesMetadata结构存入`unseqTimeseriesMetadataList`中。
+筛选并解开乱序文件的逻辑在成员函数`UnpackOverlappedUnseqFiles(long lBoundTime)`中,该方法接受一个下界参数,将满足要求的乱序文件解开且把它们的 TimeseriesMetadata 结构存入`unseqTimeseriesMetadataList`中。
-`UnpackOverlappedUnseqFiles(long lBoundTime)`方法首先用 `lBoundTime`排除掉不满足要求的乱序文件,剩下被筛选后的乱序文件都一定会包含`queryTime`时间戳,即startTime <= queryTime and queryTime <= endTime。如果乱序文件的start time大于`lBoundTime`,更新`lBoundTime`。
+`UnpackOverlappedUnseqFiles(long lBoundTime)`方法首先用 `lBoundTime`排除掉不满足要求的乱序文件,剩下被筛选后的乱序文件都一定会包含`queryTime`时间戳,即 startTime <= queryTime and queryTime <= endTime。如果乱序文件的 start time 大于`lBoundTime`,更新`lBoundTime`。
-下图中,case 1中的`lBoundTime`将会被更新,而case 2中的则不会被更新。
+下图中,case 1 中的`lBoundTime`将会被更新,而 case 2 中的则不会被更新。
```
case1 case2
| | |
@@ -83,7 +82,6 @@ case1 case2
| | | unseq file | |
| +---------------------------+
| | |
- | | |
lBoundTime lBoundTime queryTime
```
@@ -106,7 +104,7 @@ while (!unseqFileResource.isEmpty()) {
}
```
-接下来我们可以使用得到的Timeseries Metadata来查找所有其他重叠的乱序文件。需要注意的依旧是当一个重叠的乱序文件被找到后,需要按情况更新`lBoundTime`。
+接下来我们可以使用得到的 Timeseries Metadata 来查找所有其他重叠的乱序文件。需要注意的依旧是当一个重叠的乱序文件被找到后,需要按情况更新`lBoundTime`。
```
while (!unseqFileResource.isEmpty()
@@ -149,11 +147,11 @@ public TimeValuePair getFillResult() throws IOException {
# Linear 填充
-对于T时间的 Linear Fill 线性填充值是由该时间序列的两个相关值做线性拟合得到的:T之前的最近时间戳对应的值,T之后的最早时间戳对应的值。
+对于 T 时间的 Linear Fill 线性填充值是由该时间序列的两个相关值做线性拟合得到的:T 之前的最近时间戳对应的值,T 之后的最早时间戳对应的值。
基于这种特点,线性填充只能被应用于数字类型如:int, double, float。
## 计算前时间值
-前时间值使用与 Previous Fill 中相同方式计算.
+前时间值使用与 Previous Fill 中相同方式计算。
## 计算后时间值
-后时间值使用聚合运算中的"MIN_TIME"和"FIRST_VALUE",分别计算出T时间之后最近的时间戳和对应的值,并组成time-value对返回。
\ No newline at end of file
+后时间值使用聚合运算中的"MIN_TIME"和"FIRST_VALUE",分别计算出 T 时间之后最近的时间戳和对应的值,并组成 time-value 对返回。
\ No newline at end of file
diff --git a/docs/zh/SystemDesign/DataQuery/GroupByFillQuery.md b/docs/zh/SystemDesign/DataQuery/GroupByFillQuery.md
index c34df6b..73a2b07 100644
--- a/docs/zh/SystemDesign/DataQuery/GroupByFillQuery.md
+++ b/docs/zh/SystemDesign/DataQuery/GroupByFillQuery.md
@@ -25,22 +25,20 @@ GroupByFill 查询的主要逻辑在 `GroupByFillDataSet`
* `org.apache.iotdb.db.query.dataset.groupby.GroupByFillDataSet`
-GroupByFill是对原降采样结果进行填充,目前仅支持使用前值填充的方式。
+GroupByFill 是对原降采样结果进行填充,目前仅支持使用前值填充的方式。
-* 在Group By Fill中,Group by子句不支持滑动步长,否则抛异常
-* Fill子句中仅能使用Previous和PREVIOUSUNTILLAST这两种插值方式,Linear不支持
-* Previous和PREVIOUSUNTILLAST对fill的时间不做限制
-* 填充只针对last_value这一聚合函数,其他的函数不支持,如果其他函数的聚合值查询结果为null,依旧为null,不进行填充
+* 在 Group By Fill 中,Group by 子句不支持滑动步长,否则抛异常
+* Fill 子句中仅能使用 Previous 和 PREVIOUSUNTILLAST 这两种插值方式,Linear 不支持
+* Previous 和 PREVIOUSUNTILLAST 对 fill 的时间不做限制
+* 填充只针对 last_value 这一聚合函数,其他的函数不支持,如果其他函数的聚合值查询结果为 null,依旧为 null,不进行填充
-## PREVIOUSUNTILLAST与PREVIOUS填充的区别
+## PREVIOUSUNTILLAST 与 PREVIOUS 填充的区别
-Previous填充方式的语意没有变,只要前面有值,就可以拿过来填充;
-PREVIOUSUNTILLAST考虑到在某些业务场景下,所填充的值的时间不能大于该时间序列last的时间戳(从业务角度考虑,取历史数据不能取未来历史数据)
+Previous 填充方式的语意没有变,只要前面有值,就可以拿过来填充;
+PREVIOUSUNTILLAST 考虑到在某些业务场景下,所填充的值的时间不能大于该时间序列 last 的时间戳(从业务角度考虑,取历史数据不能取未来历史数据)
看下面的例子,或许更容易理解
-A点时间戳为1,B为5,C为20,D为30,N为8,M为38
-
-
+A 点时间戳为 1,B 为 5,C 为 20,D 为 30,N 为 8,M 为 38
原始数据为<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/16079446/78784824-9f41ae00-79d8-11ea-9920-0825e081cae0.png">
@@ -56,8 +54,7 @@ A点时间戳为1,B为5,C为20,D为30,N为8,M为38
| 28 | 30 |
| 30 | 40 |
-
-当我们使用Previous插值方式时,即使D到M这一段是未来的数据,我们也会用D点的数据进行填充
+当我们使用 Previous 插值方式时,即使 D 到 M 这一段是未来的数据,我们也会用 D 点的数据进行填充
`SELECT last_value(temperature) as last_temperature FROM root.ln.wf01.wt01 GROUP BY([8, 39), 5m) FILL (int32[previous])`
@@ -71,7 +68,7 @@ A点时间戳为1,B为5,C为20,D为30,N为8,M为38
| 33 | 40 |
| 38 | 40 |
-当我们使用NONLASTPREVIOUS插值方式时,因为D到M这一段是未来的数据,我们不会进行插值,还是返回null
+当我们使用 NONLASTPREVIOUS 插值方式时,因为 D 到 M 这一段是未来的数据,我们不会进行插值,还是返回 null
`SELECT last_value(temperature) as last_temperature FROM root.ln.wf01.wt01 GROUP BY([8, 39), 5m) FILL (int32[PREVIOUSUNTILLAST])`
@@ -148,29 +145,25 @@ private long[] lastTimeArray;
```
protected RowRecord nextWithoutConstraint() throws IOException {
- // 首先通过groupByEngineDataSet,获得原始的降采样查询结果行
+ // 首先通过 groupByEngineDataSet,获得原始的降采样查询结果行
RowRecord rowRecord = groupByEngineDataSet.nextWithoutConstraint();
// 接下来对每个时间序列判断需不需要填充
for (int i = 0; i < paths.size(); i++) {
Field field = rowRecord.getFields().get(i);
- // 当前值为null,需要进行填充
+ // 当前值为 null,需要进行填充
if (field.getDataType() == null) {
- // 当前一个值不为null 并且 (填充方式不是PREVIOUSUNTILLAST 或者 当前时间小于改时间序列的最近时间戳)
+ // 当前一个值不为 null 并且 (填充方式不是 PREVIOUSUNTILLAST 或者 当前时间小于改时间序列的最近时间戳)
if (previousValue[i] != null
&& (!((PreviousFill) fillTypes.get(dataTypes.get(i))).isUntilLast()
|| rowRecord.getTimestamp() <= lastTimeArray[i])) {
rowRecord.getFields().set(i, Field.getField(previousValue[i], dataTypes.get(i)));
}
} else {
- // 当前值不为null,不需要填充,用当前值更新previousValue数组
+ // 当前值不为 null,不需要填充,用当前值更新 previousValue 数组
previousValue[i] = field.getObjectValue(field.getDataType());
}
}
return rowRecord;
}
```
-
-
-
-
diff --git a/docs/zh/SystemDesign/DataQuery/GroupByQuery.md b/docs/zh/SystemDesign/DataQuery/GroupByQuery.md
index 2b32473..3ee2814 100644
--- a/docs/zh/SystemDesign/DataQuery/GroupByQuery.md
+++ b/docs/zh/SystemDesign/DataQuery/GroupByQuery.md
@@ -38,8 +38,7 @@
* private int usedIndex;
* protected boolean hasCachedTimeInterval;
-
-`GroupByEngineDataSet` 的核心方法很容易,首先根据是否有缓存的时间段判断是否有下一分段,有则返回 `true`;如果没有就计算分段开始时间,将 `usedIndex` 增加1。如果分段开始时间已经超过了查询结束时间,返回 `false`,否则计算查询结束时间,将 `hasCachedTimeInterval` 置为`true`,并返回 `true`:
+`GroupByEngineDataSet` 的核心方法很容易,首先根据是否有缓存的时间段判断是否有下一分段,有则返回 `true`;如果没有就计算分段开始时间,将 `usedIndex` 增加 1。如果分段开始时间已经超过了查询结束时间,返回 `false`,否则计算查询结束时间,将 `hasCachedTimeInterval` 置为`true`,并返回 `true`:
```
protected boolean hasNextWithoutConstraint() {
if (hasCachedTimeInterval) {
@@ -62,7 +61,6 @@ protected boolean hasNextWithoutConstraint() {
不带值过滤条件的降采样查询逻辑主要在 `GroupByWithoutValueFilterDataSet` 类中,该类继承了 `GroupByEngineDataSet`。
-
该类有如下关键字段:
* private Map<Path, GroupByExecutor> pathExecutors 针对于相同 `Path` 的聚合函数进行归类,并封装成 `GroupByExecutor` ,
`GroupByExecutor` 封装了每个 `Path` 的数据计算逻辑和方法,在后面介绍
@@ -85,14 +83,13 @@ for (AggregateResult res : fields) {
}
```
-
### GroupByExecutor
封装了相同 path 下的所有聚合函数的计算方法,该类有如下关键字段:
* private IAggregateReader reader 读取当前 `Path` 数据用到的 `SeriesAggregateReader`
* private BatchData preCachedData 每次从 `Reader` 读取的数据是一批,很有可能会超过当前的时间段,那么这个 `BatchData` 就会被缓存留给下一次使用
* private List<Pair<AggregateResult, Integer>> results 存储了当前 `Path` 里所有的聚合方法,
例如:`select count(a),sum(a),avg(b)` ,`count` 和 `sum` 方法就被存到一起。
-右侧的 `Integer` 用于结果集转化为RowRecord之前,需要将其顺序还原为用户查询的顺序。
+右侧的 `Integer` 用于结果集转化为 RowRecord 之前,需要将其顺序还原为用户查询的顺序。
#### 主要方法
@@ -123,10 +120,10 @@ private boolean readAndCalcFromPage() throws IOException, QueryProcessException;
```
-`GroupByExecutor` 中因为相同 `path` 的不同聚合函数使用的数据是相同的,所以在入口方法 `calcResult` 中负责读取该 `Path` 的所有数据,
+`GroupByExecutor` 中因为相同 `path` 的不同聚合函数使用的数据是相同的,所以在入口方法 `calcResult` 中负责读取该 `Path` 的所有数据,
取出来的数据再调用 `calcFromBatch` 方法完成遍历所有聚合函数对 `BatchData` 的计算。
-`calcResult` 方法返回当前 Path 下的所有AggregateResult,以及当前聚合值在用户查询顺序里的位置,其主要逻辑:
+`calcResult` 方法返回当前 Path 下的所有 AggregateResult,以及当前聚合值在用户查询顺序里的位置,其主要逻辑:
```
//把上次遗留的数据先做计算,如果能直接获得结果就结束计算
@@ -134,17 +131,17 @@ if (calcFromCacheData()) {
return results;
}
-//因为一个chunk是包含多个page的,那么必须先使用完当前chunk的page,再打开下一个chunk
+//因为一个 chunk 是包含多个 page 的,那么必须先使用完当前 chunk 的 page,再打开下一个 chunk
if (readAndCalcFromPage()) {
return results;
}
-//遗留的数据如果计算完了就要打开新的chunk继续计算
+//遗留的数据如果计算完了就要打开新的 chunk 继续计算
while (reader.hasNextChunk()) {
Statistics chunkStatistics = reader.currentChunkStatistics();
// 判断能否使用 Statistics,并执行计算
....
- // 跳过当前chunk
+ // 跳过当前 chunk
reader.skipCurrentChunk();
// 如果已经获取到了所有结果就结束计算
if (isEndCalc()) {
@@ -152,23 +149,23 @@ while (reader.hasNextChunk()) {
}
continue;
}
- //如果不能使用 chunkStatistics 就需要使用page数据计算
+ //如果不能使用 chunkStatistics 就需要使用 page 数据计算
if (readAndCalcFromPage()) {
return results;
}
}
```
-`readAndCalcFromPage` 方法是从当前打开的chunk中获取page的数据,并计算聚合结果。当完成所有计算时返回 true,否则返回 false。主要逻辑:
+`readAndCalcFromPage` 方法是从当前打开的 chunk 中获取 page 的数据,并计算聚合结果。当完成所有计算时返回 true,否则返回 false。主要逻辑:
```
while (reader.hasNextPage()) {
Statistics pageStatistics = reader.currentPageStatistics();
- //只有page与其它page不相交时,才能使用 pageStatistics
+ //只有 page 与其它 page 不相交时,才能使用 pageStatistics
if (pageStatistics != null) {
// 判断能否使用 Statistics,并执行计算
....
- // 跳过当前page
+ // 跳过当前 page
reader.skipCurrentPage();
// 如果已经获取到了所有结果就结束计算
if (isEndCalc()) {
@@ -182,7 +179,7 @@ while (reader.hasNextPage()) {
if (batchData == null || !batchData.hasCurrent()) {
continue;
}
- // 如果刚打开的page就超过时间范围,缓存取出来的数据并直接结束计算
+ // 如果刚打开的 page 就超过时间范围,缓存取出来的数据并直接结束计算
if (batchData.currentTime() >= curEndTime) {
preCachedData = batchData;
return true;
@@ -194,7 +191,7 @@ while (reader.hasNextPage()) {
```
-`calcFromBatch` 方法是对于取出的BatchData数据,遍历所有聚合函数进行计算,主要逻辑为:
+`calcFromBatch` 方法是对于取出的 BatchData 数据,遍历所有聚合函数进行计算,主要逻辑为:
```
for (Pair<AggregateResult, Integer> result : results) {
@@ -267,22 +264,21 @@ for (int cnt = 1; cnt < timeStampFetchSize && timestampGenerator.hasNext(); cnt+
}
```
-## 使用Level来汇总降采样的总点数
+## 使用 Level 来汇总降采样的总点数
-降采样后,我们也可以使用level关键字来进一步汇总点数。
+降采样后,我们也可以使用 level 关键字来进一步汇总点数。
这个逻辑在 `GroupByTimeDataSet`类里。
-1. 首先,把所有涉及到的时序按level来进行汇集,最后的路径。
- > 例如把root.sg1.d1.s0,root.sg1.d2.s1按level=1汇集成root.sg1。
+1. 首先,把所有涉及到的时序按 level 来进行汇集,最后的路径。
+ > 例如把 root.sg1.d1.s0,root.sg1.d2.s1 按 level=1 汇集成 root.sg1。
-2. 然后调用上述的降采样逻辑求出所有时序的总点数信息,这个会返回RowRecord数据结构。
+2. 然后调用上述的降采样逻辑求出所有时序的总点数信息,这个会返回 RowRecord 数据结构。
-3. 最后,把降采样返回的RowRecord按上述的final paths,进行累加,组合成新的RowRecord。
+3. 最后,把降采样返回的 RowRecord 按上述的 final paths,进行累加,组合成新的 RowRecord。
> 例如,把《root.sg1.d1.s0,3》,《root.sg1.d2.s1,4》聚合成《root.sg1,7》
-
-> 注意:
-> 1. 这里只支持count操作
-> 2. root的层级level=0
\ No newline at end of file
+> 注意:
+> 1. 这里只支持 count 操作
+> 2. root 的层级 level=0
\ No newline at end of file
diff --git a/docs/zh/SystemDesign/DataQuery/LastQuery.md b/docs/zh/SystemDesign/DataQuery/LastQuery.md
index 7ac1027..8063982 100644
--- a/docs/zh/SystemDesign/DataQuery/LastQuery.md
+++ b/docs/zh/SystemDesign/DataQuery/LastQuery.md
@@ -25,11 +25,11 @@ Last 查询的主要逻辑在 LastQueryExecutor
* org.apache.iotdb.db.query.executor.LastQueryExecutor
-Last查询对每个指定的时间序列执行`calculateLastPairForOneSeries`方法。
+Last 查询对每个指定的时间序列执行`calculateLastPairForOneSeries`方法。
-## 读取MNode缓存数据
+## 读取 MNode 缓存数据
-我们在需要查询的时间序列所对应的MNode结构中添加Last数据缓存。`calculateLastPairForOneSeries`方法对于某个时间序列的Last查询,首先尝试读取MNode中的缓存数据。
+我们在需要查询的时间序列所对应的 MNode 结构中添加 Last 数据缓存。`calculateLastPairForOneSeries`方法对于某个时间序列的 Last 查询,首先尝试读取 MNode 中的缓存数据。
```
try {
node = IoTDB.metaManager.getDeviceNodeWithAutoCreateStorageGroup(seriesPath.toString());
@@ -40,12 +40,12 @@ if (((LeafMNode) node).getCachedLast() != null) {
return ((LeafMNode) node).getCachedLast();
}
```
-如果发现缓存没有被写入过,则执行下面的标准查询流程读取TsFile数据。
+如果发现缓存没有被写入过,则执行下面的标准查询流程读取 TsFile 数据。
-## Last标准查询流程
+## Last 标准查询流程
-Last标准查询流程需要以倒序方式扫描顺序文件和乱序文件,一旦得到满足要求的Last查询结果就将其写回到MNode缓存中并返回。算法中对顺序文件和乱序文件分别进行处理。
-- 顺序文件由于是按照写入时间已经排好序,因此直接使用`loadTimeSeriesMetadata()`方法取出最后一个不为空的`TimeseriesMetadata`。若`TimeseriesMetadata`的统计数据可用即可直接得到Last时间戳和对应的值;如不可用则需要使用`loadChunkMetadataList()`方法得到下一层的最后一个`ChunkMetadata`,通过统计数据得到Last结果。
+Last 标准查询流程需要以倒序方式扫描顺序文件和乱序文件,一旦得到满足要求的 Last 查询结果就将其写回到 MNode 缓存中并返回。算法中对顺序文件和乱序文件分别进行处理。
+- 顺序文件由于是按照写入时间已经排好序,因此直接使用`loadTimeSeriesMetadata()`方法取出最后一个不为空的`TimeseriesMetadata`。若`TimeseriesMetadata`的统计数据可用即可直接得到 Last 时间戳和对应的值;如不可用则需要使用`loadChunkMetadataList()`方法得到下一层的最后一个`ChunkMetadata`,通过统计数据得到 Last 结果。
```
for (int i = seqFileResources.size() - 1; i >= 0; i--) {
TimeseriesMetadata timeseriesMetadata = FileLoaderUtils.loadTimeSeriesMetadata(
@@ -72,7 +72,7 @@ Last标准查询流程需要以倒序方式扫描顺序文件和乱序文件,
}
}
```
-- 对于乱序文件,需要遍历所有不为空的`TimeseriesMetadata`结构并更新当前最大时间戳的Last数据,直到扫描完所有乱序文件为止。需要注意的是当多个`ChunkMetadata`拥有相同的最大时间戳时,我们取`version`值最大的`ChunkMatadata`中的数据作为Last的结果。
+- 对于乱序文件,需要遍历所有不为空的`TimeseriesMetadata`结构并更新当前最大时间戳的 Last 数据,直到扫描完所有乱序文件为止。需要注意的是当多个`ChunkMetadata`拥有相同的最大时间戳时,我们取`version`值最大的`ChunkMatadata`中的数据作为 Last 的结果。
```
long version = 0;
@@ -96,18 +96,18 @@ Last标准查询流程需要以倒序方式扫描顺序文件和乱序文件,
}
}
```
- - 最后将查询结果写入到MNode的Last缓存
+ - 最后将查询结果写入到 MNode 的 Last 缓存
```
((LeafMNode) node).updateCachedLast(resultPair, false, Long.MIN_VALUE);
```
## Last 缓存更新策略
-Last缓存更新的逻辑位于`LeafMNode`的`updateCachedLast`方法内,这里引入两个额外的参数`highPriorityUpdate`和`latestFlushTime`。`highPriorityUpdate`用来表示本次更新是否是高优先级的,新数据写入而导致的缓存更新都被认为是高优先级更新,而查询时更新缓存默认为低优先级更新。`latestFlushTime`用来记录当前已被写回到磁盘的数据的最大时间戳。
+Last 缓存更新的逻辑位于`LeafMNode`的`updateCachedLast`方法内,这里引入两个额外的参数`highPriorityUpdate`和`latestFlushTime`。`highPriorityUpdate`用来表示本次更新是否是高优先级的,新数据写入而导致的缓存更新都被认为是高优先级更新,而查询时更新缓存默认为低优先级更新。`latestFlushTime`用来记录当前已被写回到磁盘的数据的最大时间戳。
缓存更新的策略如下:
-1. 当缓存中没有记录时,对于查询到的Last数据,将查询的结果直接写入到缓存中。
+1. 当缓存中没有记录时,对于查询到的 Last 数据,将查询的结果直接写入到缓存中。
2. 当缓存中没有记录时,对于写入的最新数据如果时间戳大于或等于`latestFlushTime`,则将写入的数据写入到缓存中。
3. 当缓存中已有记录时,根据查询或写入的数据时间戳与当前缓存中时间戳作对比。写入的数据具有高优先级,时间戳不小于缓存记录则更新缓存;查询出的数据低优先级,必须大于缓存记录的时间戳才更新缓存。
diff --git a/docs/zh/SystemDesign/DataQuery/OrderByTimeQuery.md b/docs/zh/SystemDesign/DataQuery/OrderByTimeQuery.md
index be198dd..9d5bd42 100644
--- a/docs/zh/SystemDesign/DataQuery/OrderByTimeQuery.md
+++ b/docs/zh/SystemDesign/DataQuery/OrderByTimeQuery.md
@@ -23,19 +23,19 @@
## 实现原理
-倒序分为 3 个维度来实现,由内核层到用户层分别为: `TsFile`、`BatchData`、`数据集`.
+倒序分为 3 个维度来实现,由内核层到用户层分别为:`TsFile`、`BatchData`、`数据集`.
1. `TsFile` 是用来存储所有原始数据的文件格式,在存储时分为 `顺序文件` 和 `乱序文件`.
`ChunkData` 是 `TsFile` 中的基本数据块,保存了具体某一个测点的数据,且**数据是按照时间升序存储的**.
-2. `BatchData` 是基础数据交换结构,无论是从文件系统还是缓存读出的数据都会被转换成 `BatchData` 结构.
+2. `BatchData` 是基础数据交换结构,无论是从文件系统还是缓存读出的数据都会被转换成 `BatchData` 结构。
3. `数据集` 是封装根据用户输入的 `SQL` 语句的结果集格式,转换和封装 `BatchData` 中的数据。
实际系统需要考虑的方面会更多,但主要为以上 3 点。
-下面分别介绍各个层面如何实现基于时间的倒序查询:
+下面分别介绍各个层面如何实现基于时间的倒序查询:
## TsFile
-1.`TsFile` 在文件末尾存储了各个测点在文件中的最小时间(开始时间)和最大时间(结束时间),
-所以当我们按照开始时间升序排列文件并读取数据时,是升序读取;当使用结束时间倒序排列文件
-(**顺序文件也可以使用开始时间倒序排列**)并读取数据时,是**伪倒序读取**(因为文件内依然是升序存储的),数据示例:
+1.`TsFile` 在文件末尾存储了各个测点在文件中的最小时间(开始时间)和最大时间(结束时间),
+所以当我们按照开始时间升序排列文件并读取数据时,是升序读取;当使用结束时间倒序排列文件
+(**顺序文件也可以使用开始时间倒序排列**) 并读取数据时,是**伪倒序读取**(因为文件内依然是升序存储的), 数据示例:
```
按照开始时间升序排列 (1,6)
@@ -49,7 +49,7 @@
+-------------+ +-------------+
```
-2.上面的示例只描述了顺序文件,乱序文件的特点是: 文件中存储的数据与其他文件的数据存在相交,
+2. 上面的示例只描述了顺序文件,乱序文件的特点是:文件中存储的数据与其他文件的数据存在相交,
不仅仅和顺序文件相交,乱序和乱序文件之间也可能相交。
```
@@ -65,21 +65,21 @@
```
-3.对于**相交**的部分,需要使用`多路归并`查询出最终结果。具体处理细节可以参见[SeriesReader](../DataQuery/SeriesReader.md).
+3. 对于**相交**的部分,需要使用`多路归并`查询出最终结果。具体处理细节可以参见 [SeriesReader](../DataQuery/SeriesReader.md).
-4.对于文件层而言,我们抽象出了`TimeOrderUtils`,用来完成对升序、降序不同实现的方法提取。
+4. 对于文件层而言,我们抽象出了`TimeOrderUtils`,用来完成对升序、降序不同实现的方法提取。
```java
public interface TimeOrderUtils {
//排序使用的字段,升序使用开始时间,降序使用结束时间。
- //TsFileResource面对文件相关,Statistics面向Chunk和Page相关
+ //TsFileResource 面对文件相关,Statistics 面向 Chunk 和 Page 相关
long getOrderTime(Statistics statistics);
long getOrderTime(TsFileResource fileResource);
//判断是否相交使用的时间依据,升序使用结束时间,降序使用开始时间
long getOverlapCheckTime(Statistics range);
- //根据提供的时间判断是否相交,left为依据时间,right为要判断的文件
+ //根据提供的时间判断是否相交,left 为依据时间,right 为要判断的文件
boolean isOverlapped(Statistics left, Statistics right);
boolean isOverlapped(long time, Statistics right);
boolean isOverlapped(long time, TsFileResource right);
@@ -98,79 +98,78 @@
}
```
-5.完成了上述步骤,倒序取出来的数据如下:
+5. 完成了上述步骤,倒序取出来的数据如下:
```
6,7,8,9,10,1,2,3,4,5
```
-这是因为数据在Chunk、Page、缓存中都是升序存储,所以转移到 `BatchData` 中查看就是示例中的样子。
+这是因为数据在 Chunk、Page、缓存中都是升序存储,所以转移到 `BatchData` 中查看就是示例中的样子。
## BatchData
-1.为了兼容原有的文件读取数据方式,所以在数据放到 `BatchData` 之后倒序读取集合里的数据就可以得到最终结果。
+1. 为了兼容原有的文件读取数据方式,所以在数据放到 `BatchData` 之后倒序读取集合里的数据就可以得到最终结果。
-BatchData类似一个二维数组的格式,封装了写入和读取的方法,对于倒序,抽象了下面的子类:
+BatchData 类似一个二维数组的格式,封装了写入和读取的方法,对于倒序,抽象了下面的子类:
```java
public class DescBatchData extends BatchData {
- //判断是否还有值,正序时候判断是否读到写入的size位置,倒序就是判断是否读到了0的位置
+ //判断是否还有值,正序时候判断是否读到写入的 size 位置,倒序就是判断是否读到了 0 的位置
public boolean hasCurrent();
//指针移动到下一个数据,正序为 index+1 操作, 倒序为 index-1 操作
public void next();
- //重制指针位置,正序为重制到0,倒序重制到数据写入位置
+ //重制指针位置,正序为重制到 0,倒序重制到数据写入位置
public void resetBatchData();
- //就像是Nio中的Buffer类的flip操作,在数据写入完成时做的操作,为读取做好准备
+ //就像是 Nio 中的 Buffer 类的 flip 操作,在数据写入完成时做的操作,为读取做好准备
public BatchData flip();
- //使用具体时间获取值,正序时index从0到size遍历,倒序时从size到0遍历
+ //使用具体时间获取值,正序时 index 从 0 到 size 遍历,倒序时从 size 到 0 遍历
public Object getValueInTimestamp(long time);
}
```
-2.在需要倒序处理数据的位置构建`DescBatchData`类,为此,特意设计了一个`BatchDataFactory`类,
-根据ascending参数判断生产哪个类型的BatchData。
+2. 在需要倒序处理数据的位置构建`DescBatchData`类,为此,特意设计了一个`BatchDataFactory`类,
+根据 ascending 参数判断生产哪个类型的 BatchData。
-3.因为`MergeReader`使用了`PageReader`,所以在降序模式的时候数据会被倒序读出来(如下):
+3. 因为`MergeReader`使用了`PageReader`,所以在降序模式的时候数据会被倒序读出来(如下):
```
5 4 3 2 1
```
-这种情况会使得`BatchData`使用`getValueInTimestamp`方法变得困难(因为在正序模式的时候默认为越往后的数据时间越大,
-倒序模式的时候越后时间越小),但是按照如上数据示例无论在哪种模式下,都是违反了期望的数据时间比较,所以,新增了一个
+这种情况会使得`BatchData`使用`getValueInTimestamp`方法变得困难(因为在正序模式的时候默认为越往后的数据时间越大,
+倒序模式的时候越后时间越小),但是按照如上数据示例无论在哪种模式下,都是违反了期望的数据时间比较,所以,新增了一个
`getValueInTimestamp(long time, BiFunction<Long, Long, Boolean> compare)`方法,
让不同的使用场景抉择基于时间的数据查找方式。
-4.至此数据从磁盘和缓存中取出的数据都是严格按照时间排序的了。
+4. 至此数据从磁盘和缓存中取出的数据都是严格按照时间排序的了。
## 数据集
-1.原始数据查询
+1. 原始数据查询
```sql
select * from root order by time desc
select * from root where root.ln.d1.s1>100 order by time desc
select * from root where time >100 order by time desc
```
-原始数据查询中,只要向`SeriesReader`传递了正确的ascending参数就能得到正确的结果。
+原始数据查询中,只要向`SeriesReader`传递了正确的 ascending 参数就能得到正确的结果。
2.GroupBy
```sql
select max_time(*) from root group by ((0,10],2ms) order by time desc
```
-如上所示的Sql中,groupBy查询的区间分别为:
+如上所示的 Sql 中,groupBy 查询的区间分别为:
```
[0-2),[2-4),[4-6),[6-8),[8-10)
```
-倒序查询只需要将时间计算的过程修改为:
+倒序查询只需要将时间计算的过程修改为:
```
[8-10),[6-8),[4-6),[2-4),[0-2)
```
->计算方法为:
+>计算方法为:
>
-> ((结束时间-开始时间)/步长值) 结果向上取整,得到的值为GroupBy中会发生的遍历次数(记为i)。
+> ((结束时间-开始时间)/步长值) 结果向上取整,得到的值为 GroupBy 中会发生的遍历次数(记为 i)。
>
-> (步长 * (i-1) + 开始时间) 结果为第i次遍历的开始时间值。
+> (步长 * (i-1) + 开始时间) 结果为第 i 次遍历的开始时间值。
-
-对于BatchData中的数据大于每次遍历的结束时间时,进行skip,然后对 `AggregateResult` 新增
-minBound计算限制,限制为第i次遍历的开始时间值,
+对于 BatchData 中的数据大于每次遍历的结束时间时,进行 skip,然后对 `AggregateResult` 新增
+minBound 计算限制,限制为第 i 次遍历的开始时间值,
**数据无论是正序还是倒序遍历对于`AggregateResult`的结果是等价的**.
3.GroupByFill
@@ -178,7 +177,7 @@ minBound计算限制,限制为第i次遍历的开始时间值,
select last_value(s0) from root.ln.d1 group by ((0,5],1ms) fill (int32[Previous]) order by time desc
```
-对于升序的插值计算, 在 `GroupByFillDataSet` 中做了前值缓存,当本次查询的值不为空时,更新缓存;
+对于升序的插值计算,在 `GroupByFillDataSet` 中做了前值缓存,当本次查询的值不为空时,更新缓存;
为空时使用缓存中的数据。
对于降序查询,因为数据在倒序遍历,并不知道它的前值是多少,所以为 `GroupByEngineDataSet`
@@ -186,5 +185,5 @@ select last_value(s0) from root.ln.d1 group by ((0,5],1ms) fill (int32[Previous]
`GroupByFillDataSet` 中并遵从升序的补值方法,到当前的循环开始时间小于缓存的时间时缓存失效。
4.Last
-在`LastQueryExecutor`中,一次性将所有的结果集封装在了一个List中,
-当倒序时将List中的数据根据时间进行一次排序,就得到了结果,详情见`ListDataSet`.
+在`LastQueryExecutor`中,一次性将所有的结果集封装在了一个 List 中,
+当倒序时将 List 中的数据根据时间进行一次排序,就得到了结果,详情见`ListDataSet`.
diff --git a/docs/zh/SystemDesign/DataQuery/QueryFundamentals.md b/docs/zh/SystemDesign/DataQuery/QueryFundamentals.md
index 5dc59d7..2a42fc8 100644
--- a/docs/zh/SystemDesign/DataQuery/QueryFundamentals.md
+++ b/docs/zh/SystemDesign/DataQuery/QueryFundamentals.md
@@ -21,73 +21,68 @@
# 查询基础介绍
-## 顺序和乱序tsFile文件
+## 顺序和乱序 tsFile 文件
-在对某一个设备插入数据的过程中,由于插入数据的时间戳的特点会产生顺序和乱序的tsFile文件。如果我们按照时间戳递增的顺序插入数据,那么只会产生顺序文件。顺序数据被写入到磁盘后,一旦新写入的数据时间戳在顺序文件的最大时间戳之前则会产生乱序文件。
+在对某一个设备插入数据的过程中,由于插入数据的时间戳的特点会产生顺序和乱序的 tsFile 文件。如果我们按照时间戳递增的顺序插入数据,那么只会产生顺序文件。顺序数据被写入到磁盘后,一旦新写入的数据时间戳在顺序文件的最大时间戳之前则会产生乱序文件。
-IoTDB会将顺序和乱序文件分开存储在data/sequence和data/unsequence文件目录下。在查询过程中也会对顺序和乱序文件中的数据分别进行处理,我们总会使用`QueryResourceManager.java`中的`getQueryDataSource()`方法通过时间序列的全路径得到存储该时间序列的顺序和乱序文件。
+IoTDB 会将顺序和乱序文件分开存储在 data/sequence 和 data/unsequence 文件目录下。在查询过程中也会对顺序和乱序文件中的数据分别进行处理,我们总会使用`QueryResourceManager.java`中的`getQueryDataSource()`方法通过时间序列的全路径得到存储该时间序列的顺序和乱序文件。
+## 读取 TsFile 的一般流程
-## 读取TsFile的一般流程
-
-TsFile 各级结构在前面的[TsFile](../TsFile/TsFile.md)文档中已有介绍,读取一个时间序列的过程需要按照层级各级展开TsFileResource -> TimeseriesMetadata -> ChunkMetadata -> IPageReader -> BatchData。
+TsFile 各级结构在前面的 [TsFile](../TsFile/TsFile.md) 文档中已有介绍,读取一个时间序列的过程需要按照层级各级展开 TsFileResource -> TimeseriesMetadata -> ChunkMetadata -> IPageReader -> BatchData。
文件读取的功能方法在
`org.apache.iotdb.db.utils.FileLoaderUtils`
-* `loadTimeSeriesMetadata()`用来读取一个TsFileResource对应于某一个时间序列的 TimeseriesMetadata,该方法同时接受一个时间戳的Filter条件来保证该方法返回满足条件的 TimeseriesMetadata,若没有满足条件的 TimeseriesMetadata则返回null。
-* `loadChunkMetadataList()`得到这个timeseries所包含的所有ChunkMetadata列表。
-* `loadPageReaderList()`可以用来读取一个 ChunkMetadata 对应的 Chunk 所包含的所有page列表,用PageReader来进行访问。
+* `loadTimeSeriesMetadata()`用来读取一个 TsFileResource 对应于某一个时间序列的 TimeseriesMetadata,该方法同时接受一个时间戳的 Filter 条件来保证该方法返回满足条件的 TimeseriesMetadata,若没有满足条件的 TimeseriesMetadata 则返回 null。
+* `loadChunkMetadataList()`得到这个 timeseries 所包含的所有 ChunkMetadata 列表。
+* `loadPageReaderList()`可以用来读取一个 ChunkMetadata 对应的 Chunk 所包含的所有 page 列表,用 PageReader 来进行访问。
以上在对于时间序列数据的各种读取方法中总会涉及到读取内存和磁盘数据两种情况。
-读取内存数据是指读取存在于 Memtable 中但尚未被写入磁盘的数据,例如`loadTimeSeriesMetadata()`中使用`TsFileResource.getTimeSeriesMetadata()`得到一个未被封口的 TimeseriesMetadata。一旦这个 TimeseriesMetadata被刷新到磁盘中之后,我们将只能通过访问磁盘读取到其中的数据。磁盘和内存读取metadata的相关类为 DiskChunkMetadataLoader 和 MemChunkMetadataLoader。
-
-`loadPageReaderList()`读取page数据也是一样,分别通过两个辅助类 MemChunkLoader 和 DiskChunkLoader 进行处理。
-
+读取内存数据是指读取存在于 Memtable 中但尚未被写入磁盘的数据,例如`loadTimeSeriesMetadata()`中使用`TsFileResource.getTimeSeriesMetadata()`得到一个未被封口的 TimeseriesMetadata。一旦这个 TimeseriesMetadata 被刷新到磁盘中之后,我们将只能通过访问磁盘读取到其中的数据。磁盘和内存读取 metadata 的相关类为 DiskChunkMetadataLoader 和 MemChunkMetadataLoader。
+`loadPageReaderList()`读取 page 数据也是一样,分别通过两个辅助类 MemChunkLoader 和 DiskChunkLoader 进行处理。
## 顺序和乱序文件的数据特点
对于顺序和乱序文件的数据,其数据在文件中的分部特征有所不同。
-顺序文件的 TimeseriesMetadata 中所包含的 ChunkMetadata 也是有序的,也就是说如果按照chunkMetadata1, chunkMetadata2的顺序存储,那么将会保证chunkMetadata1.endtime <= chunkMetadata2.startTime。
+顺序文件的 TimeseriesMetadata 中所包含的 ChunkMetadata 也是有序的,也就是说如果按照 chunkMetadata1, chunkMetadata2 的顺序存储,那么将会保证 chunkMetadata1.endtime <= chunkMetadata2.startTime。
乱序文件的 TimeseriesMetadata 中所包含的 ChunkMetadata 是无序的,乱序文件中多个 Chunk 所覆盖的数据可能存在重叠,同时也可能与顺序文件中的 Chunk 数据存在重叠。
每个 Chunk 结构内部所包含的 Page 数据总是有序的,不管是从属于顺序文件还是乱序文件。也就是说前一个 Page 的最大时间戳不小于后一个的最小时间戳。因此在查询过程中可以充分利用这种有序性,通过统计信息对 Page 数据进行提前筛选。
-
-
## 查询中的数据修改处理
-IoTDB的数据删除操作对磁盘数据只记录了 mods 文件,并未真正执行删除逻辑,因此查询时需要考虑数据删除的逻辑。
+IoTDB 的数据删除操作对磁盘数据只记录了 mods 文件,并未真正执行删除逻辑,因此查询时需要考虑数据删除的逻辑。
如果一个文件中有数据被删除了,将删除操作记录到 mods 文件中。记录三列:删除的时间序列,删除范围的最大时间点,删除操作对应的版本。
### 相关类
-Modification文件: org.apache.iotdb.db.engine.modification.ModificationFile
+Modification 文件:org.apache.iotdb.db.engine.modification.ModificationFile
-删除操作: org.apache.iotdb.db.engine.modification.Modification
+删除操作:org.apache.iotdb.db.engine.modification.Modification
删除区间的内部表示:org.apache.iotdb.tsfile.read.common.TimeRange
### Modification 文件
-IoTDB 通过为包含数据的TsFile写入一个Modification文件来完成删除操作。
+IoTDB 通过为包含数据的 TsFile 写入一个 Modification 文件来完成删除操作。
-在0.11.0版本的IoTDB中对Modification文件中的删除记录格式进行了修改,每一行的删除记录包含删除的开始时间和结束时间。
-对之前版本产生的Modification文件依旧可以照常处理,旧的Modification文件中只记录一个"deleteAt"时间戳,现在会被视为删除了一个时间戳从Long.MIN_VALUE开始到"deleteAt"结束的范围数据。
+在 0.11.0 版本的 IoTDB 中对 Modification 文件中的删除记录格式进行了修改,每一行的删除记录包含删除的开始时间和结束时间。
+对之前版本产生的 Modification 文件依旧可以照常处理,旧的 Modification 文件中只记录一个"deleteAt"时间戳,现在会被视为删除了一个时间戳从 Long.MIN_VALUE 开始到"deleteAt"结束的范围数据。
### TimeRange
-相应的,TimeRange结构是删除区间在内存中的表示媒介。
+相应的,TimeRange 结构是删除区间在内存中的表示媒介。
-删除操作中所有的TimeRange都是闭区间,我们使用Long.MIN_VALUE和Long.MAX_VALUE表示正负无穷范围。
+删除操作中所有的 TimeRange 都是闭区间,我们使用 Long.MIN_VALUE 和 Long.MAX_VALUE 表示正负无穷范围。
### 包含删除区间的查询处理
-当对一个TVList进行查询的时候,该TVList的所有记录的删除区间会预先被排序和合并。例如初始的删除区间为[1,10], [5,12], [15,20], [16,21],会被预先处理为[1,12] and [15,21]两个区间。
+当对一个 TVList 进行查询的时候,该 TVList 的所有记录的删除区间会预先被排序和合并。例如初始的删除区间为 [1,10], [5,12], [15,20], [16,21],会被预先处理为 [1,12] and [15,21] 两个区间。
这样做的好处在于当删除区间很多的情况下,可以加快排除被删除数据的过程。
-具体的说,由于TVList中存储的是有序的时序数据,因此使用排序过后的TimeRange会有助于筛选出已经被删除的时间戳数据。
-使用一个标记位来标记TimeRange 列表中当前遍历到的TimeRange,由于时间戳是有序的,因此后面的数据不会落在当前TimeRange之前的范围之中。下面是一个具体遍历的实例:
+具体的说,由于 TVList 中存储的是有序的时序数据,因此使用排序过后的 TimeRange 会有助于筛选出已经被删除的时间戳数据。
+使用一个标记位来标记 TimeRange 列表中当前遍历到的 TimeRange,由于时间戳是有序的,因此后面的数据不会落在当前 TimeRange 之前的范围之中。下面是一个具体遍历的实例:
```
private boolean isPointDeleted(long timestamp) {
while (deletionList != null && deleteCursor < deletionList.size()) {
@@ -103,14 +98,13 @@ private boolean isPointDeleted(long timestamp) {
}
```
-### 查询流程处理Modification
-
-对于任意的 TimeseriesMetadata,ChunkMetadata和PageHeader都有相应的modified标记,表示当前的数据块是否存在更改。由于数据删除都是从一个时间节点删除该时间前面的数据,因此如果存在数据删除会导致数据块统计信息中的startTime失效。因此在使用统计信息中的startTime之前必须检查数据块是否包含modification。对于 TimeseriesMetadata,如果删除时间点等于endTime也会导致统计信息中的endTime失效。
+### 查询流程处理 Modification
+对于任意的 TimeseriesMetadata,ChunkMetadata 和 PageHeader 都有相应的 modified 标记,表示当前的数据块是否存在更改。由于数据删除都是从一个时间节点删除该时间前面的数据,因此如果存在数据删除会导致数据块统计信息中的 startTime 失效。因此在使用统计信息中的 startTime 之前必须检查数据块是否包含 modification。对于 TimeseriesMetadata,如果删除时间点等于 endTime 也会导致统计信息中的 endTime 失效。

-如上图所示,数据修改会对前面提到的TsFile层级数据读取产生影响
+如上图所示,数据修改会对前面提到的 TsFile 层级数据读取产生影响
* TsFileResource -> TimeseriesMetadata
```
@@ -121,7 +115,7 @@ FileLoaderUtils.loadTimeseriesMetadata()
* TimeseriesMetadata -> List\<ChunkMetadata\>
```
-// 对于每个 ChunkMetadata,找到比其 version 大的所有删除操作中最大时间戳, 设置到 ChunkMetadata 的 deleteAt 中,并标记 统计信息不可用
+// 对于每个 ChunkMetadata,找到比其 version 大的所有删除操作中最大时间戳,设置到 ChunkMetadata 的 deleteAt 中,并标记 统计信息不可用
FileLoaderUtils.loadChunkMetadataList()
```
diff --git a/docs/zh/SystemDesign/DataQuery/RawDataQuery.md b/docs/zh/SystemDesign/DataQuery/RawDataQuery.md
index 68521ba..7e5d21c 100644
--- a/docs/zh/SystemDesign/DataQuery/RawDataQuery.md
+++ b/docs/zh/SystemDesign/DataQuery/RawDataQuery.md
@@ -39,7 +39,7 @@
`RawQueryDataSetWithoutValueFilter`实现了没有值过滤条件,且需要按照时间戳对齐的查询逻辑。虽然最后的查询结果需要每个时间序列按照时间戳对齐,但是每个时间序列的查询是可以做并行化的。这里借助消费者-生产者队列的思想,将每个时间序列获取数据的操作与最后对所有时间序列进行对齐的操作解耦。每个时间序列对应一个生产者线程,且有其对应的`BlockingQueue`,生产者任务负责读取相应的时间序列的数据放进`BlockingQueue`中;消费者线程只有一个,负责从每个时间序列的`BlockingQueue`中取出数据,进行时间戳对齐之后,将结果组装成`TSQueryDataSet`形式返回。
-在具体实现的时候,考虑到机器的资源限制,并非为每个查询的每一个时间序列创建一个线程,而是采用线程池技术,将每一个时间序列的生产者任务当作一个`Runnable`的task提交到线程池中执行。
+在具体实现的时候,考虑到机器的资源限制,并非为每个查询的每一个时间序列创建一个线程,而是采用线程池技术,将每一个时间序列的生产者任务当作一个`Runnable`的 task 提交到线程池中执行。
下面就先介绍生产者的代码,它被封装在是`RawQueryDataSetWithoutValueFilter`的一个内部类`ReadTask`中,实现了`Runnable`接口。
@@ -52,8 +52,6 @@
private BlockingQueue<BatchData> blockingQueue;
```
-
-
`ManagedSeriesReader`接口继承了`IBatchReader`接口,主要用来读取单个时间序列的数据,并且新增了以下四个方法
```
@@ -66,7 +64,7 @@ boolean hasRemaining();
void setHasRemaining(boolean hasRemaining);
```
-前两个方法用以表征该时间序列对应的生产者任务有没有被查询管理器所管理,即生产者任务有没有因为阻塞队列满了,而自行退出(后文会解释为什么不阻塞等待,而是直接退出);后两个方法用以表征该时间序列对应的reader里还有没有数据。
+前两个方法用以表征该时间序列对应的生产者任务有没有被查询管理器所管理,即生产者任务有没有因为阻塞队列满了,而自行退出(后文会解释为什么不阻塞等待,而是直接退出);后两个方法用以表征该时间序列对应的 reader 里还有没有数据。
`blockingQueue`就是该生产者任务的阻塞队列,实际上该阻塞队列只会在消费者取数据时单边阻塞,生产者放数据时,如果发现队列满了,便会直接退出,不会阻塞。
@@ -77,36 +75,36 @@ void setHasRemaining(boolean hasRemaining);
```
public void run() {
try {
- // 这里加锁的原因是为了保证对于blockingQueue满不满的判断是正确同步的
+ // 这里加锁的原因是为了保证对于 blockingQueue 满不满的判断是正确同步的
synchronized (reader) {
- // 由于每次提交生产者任务时(不论是生产者自己递归的提交自己,还是消费者发现生产者任务自行退出而提交的),都会检查队列是不是满的,如果队列满了,是不会提交生产者任务的
- // 所以生产者任务一旦被提交,blockingQueue里一定是有空余位置的,我们不需要检查队列是否满
- // 如果时间序列对应的reader还有数据,进入循环体
+ // 由于每次提交生产者任务时(不论是生产者自己递归的提交自己,还是消费者发现生产者任务自行退出而提交的),都会检查队列是不是满的,如果队列满了,是不会提交生产者任务的
+ // 所以生产者任务一旦被提交,blockingQueue 里一定是有空余位置的,我们不需要检查队列是否满
+ // 如果时间序列对应的 reader 还有数据,进入循环体
while (reader.hasNextBatch()) {
BatchData batchData = reader.nextBatch();
- // 由于拿到的BatchData有可能为空,所以需要一直迭代到第一个不为空的BatchData
+ // 由于拿到的 BatchData 有可能为空,所以需要一直迭代到第一个不为空的 BatchData
if (batchData.isEmpty()) {
continue;
}
- // 将不为空的batchData放进阻塞队列中,此时的阻塞队列一定是不满的,所以不会阻塞
+ // 将不为空的 batchData 放进阻塞队列中,此时的阻塞队列一定是不满的,所以不会阻塞
blockingQueue.put(batchData);
- // 如果阻塞队列仍然没有满,生产者任务再次向线程池里递归地提交自己,进行下一个batchData的获取
+ // 如果阻塞队列仍然没有满,生产者任务再次向线程池里递归地提交自己,进行下一个 batchData 的获取
if (blockingQueue.remainingCapacity() > 0) {
pool.submit(this);
}
- // 如果阻塞队列满了,生产者任务退出,并将对应reader的managedByQueryManager置为false
+ // 如果阻塞队列满了,生产者任务退出,并将对应 reader 的 managedByQueryManager 置为 false
else {
reader.setManagedByQueryManager(false);
}
return;
}
- // 代码执行到这边,代表之前的while循环条件不满足,即该时间序列对应的reader里没有数据了
- // 我们往阻塞队列里放入一个SignalBatchData,用以告知消费者,这个时间序列已经没有数据了,不需要再从该时间序列对应的队列里取数据了
+ // 代码执行到这边,代表之前的 while 循环条件不满足,即该时间序列对应的 reader 里没有数据了
+ // 我们往阻塞队列里放入一个 SignalBatchData,用以告知消费者,这个时间序列已经没有数据了,不需要再从该时间序列对应的队列里取数据了
blockingQueue.put(SignalBatchData.getInstance());
- // 将reader的hasRemaining字段置为false
+ // 将 reader 的 hasRemaining 字段置为 false
// 通知消费者不需要再为这个时间序列提交生产者任务
reader.setHasRemaining(false);
- // 将reader的managedByQueryManager字段置为false
+ // 将 reader 的 managedByQueryManager 字段置为 false
reader.setManagedByQueryManager(false);
}
} catch (InterruptedException e) {
@@ -140,14 +138,13 @@ public void run() {
boolean[] noMoreDataInQueueArray
```
- 用以表征某个时间序列的阻塞队列里还有没有值,如果为false,则消费者不会再去调用`take()`方法,以防消费者线程被阻塞。
+ 用以表征某个时间序列的阻塞队列里还有没有值,如果为 false,则消费者不会再去调用`take()`方法,以防消费者线程被阻塞。
* ```
BatchData[] cachedBatchDataArray
```
- 缓存从阻塞队列里取出的一个BatchData,因为阻塞队列里`take()`出的`BatchData`并不能一次性消费完,所以需要做缓存
-
+ 缓存从阻塞队列里取出的一个 BatchData,因为阻塞队列里`take()`出的`BatchData`并不能一次性消费完,所以需要做缓存
在消费者`RawQueryDataSetWithoutValueFilter`的构造函数里首先调用了`init()`方法
@@ -165,7 +162,7 @@ private void init() throws InterruptedException {
}
// 初始化最小堆,填充每个时间序列对应的缓存
for (int i = 0; i < seriesReaderList.size(); i++) {
- // 调用fillCache(int)方法填充缓存
+ // 调用 fillCache(int) 方法填充缓存
fillCache(i);
// 尝试将每个时间序列的当前最小时间戳放进堆中
if (cachedBatchDataArray[i] != null && cachedBatchDataArray[i].hasCurrent()) {
@@ -184,20 +181,20 @@ private void init() throws InterruptedException {
private void fillCache(int seriesIndex) throws InterruptedException {
// 从阻塞队列中拿数据,如果没有数据,则会阻塞等待队列中有数据
BatchData batchData = blockingQueueArray[seriesIndex].take();
- // 如果是一个信号BatchData,则将相应时间序列的oMoreDataInQueue置为false
+ // 如果是一个信号 BatchData,则将相应时间序列的 oMoreDataInQueue 置为 false
if (batchData instanceof SignalBatchData) {
noMoreDataInQueueArray[seriesIndex] = true;
}
else {
- // 将取出的BatchData放进cachedBatchDataArray缓存起来
+ // 将取出的 BatchData 放进 cachedBatchDataArray 缓存起来
cachedBatchDataArray[seriesIndex] = batchData;
- // 这里加锁的原因与生产者任务那边一样,是为了保证对于blockingQueue满不满的判断是正确同步的
+ // 这里加锁的原因与生产者任务那边一样,是为了保证对于 blockingQueue 满不满的判断是正确同步的
synchronized (seriesReaderList.get(seriesIndex)) {
// 只有当阻塞队列不满的时候,我们才需要判断是不是需要提交生产者任务,这里也保证了生产者任务会被提交,当且仅当阻塞队列不满
if (blockingQueueArray[seriesIndex].remainingCapacity() > 0) {
ManagedSeriesReader reader = seriesReaderList.get(seriesIndex);、
- // 如果该时间序列的reader并没有被查询管理器管理(即生产者任务由于队列满了,自行退出),并且该reader里还有数据,我们需要再次提交该时间序列的生产者任务
+ // 如果该时间序列的 reader 并没有被查询管理器管理(即生产者任务由于队列满了,自行退出),并且该 reader 里还有数据,我们需要再次提交该时间序列的生产者任务
if (!reader.isManagedByQueryManager() && reader.hasRemaining()) {
reader.setManagedByQueryManager(true);
pool.submit(new ReadTask(reader, blockingQueueArray[seriesIndex]));
@@ -217,7 +214,7 @@ for (int seriesIndex = 0; seriesIndex < seriesNum; seriesIndex++) {
if (cachedBatchDataArray[seriesIndex] == null
|| !cachedBatchDataArray[seriesIndex].hasCurrent()
|| cachedBatchDataArray[seriesIndex].currentTime() != minTime) {
- // 该时间序列在当前时间戳没有数据,置为null
+ // 该时间序列在当前时间戳没有数据,置为 null
...
} else {
@@ -227,10 +224,10 @@ for (int seriesIndex = 0; seriesIndex < seriesNum; seriesIndex++) {
}
- // 将该时间序列缓存的batchdata游标向后移
+ // 将该时间序列缓存的 batchdata 游标向后移
cachedBatchDataArray[seriesIndex].next();
- // 如果当前缓存的batchdata为空,并且阻塞队列依然有数据,则再次调用fillCache()方法填充缓存
+ // 如果当前缓存的 batchdata 为空,并且阻塞队列依然有数据,则再次调用 fillCache() 方法填充缓存
if (!cachedBatchDataArray[seriesIndex].hasCurrent()
&& !noMoreDataInQueueArray[seriesIndex]) {
fillCache(seriesIndex);
@@ -248,7 +245,7 @@ for (int seriesIndex = 0; seriesIndex < seriesNum; seriesIndex++) {
### org.apache.iotdb.db.query.dataset.NonAlignEngineDataSet
-`NonAlignEngineDataSet`实现了没有值过滤条件,且不需要按照时间戳对齐的查询逻辑。这里的查询逻辑跟`RawQueryDataSetWithoutValueFilter`很类似,但是它的消费者逻辑更为简单,因为不需要做时间戳对齐的操作。并且每个生产者任务中也可以做更多的工作,不仅可以从Reader中取出BatchData,还可以进一步讲取出的BatchData格式化为结果集需要的输出,从而提高了程序的并行度。如此,消费者只需要从每个阻塞队列里取出数据,set进`TSQueryNonAlignDataSet`相应的位置即可。
+`NonAlignEngineDataSet`实现了没有值过滤条件,且不需要按照时间戳对齐的查询逻辑。这里的查询逻辑跟`RawQueryDataSetWithoutValueFilter`很类似,但是它的消费者逻辑更为简单,因为不需要做时间戳对齐的操作。并且每个生产者任务中也可以做更多的工作,不仅可以从 Reader 中取出 BatchData,还可以进一步讲取出的 BatchData 格式化为结果集需要的输出,从而提高了程序的并行度。如此,消费者只需要从每个阻塞队列里取出数据,set 进`TSQueryNonAlignDataSet`相应的位置即可。
具体的查询逻辑,在此就不再赘述了,可以参照`RawQueryDataSetWithoutValueFilter`的查询逻辑分析。
@@ -270,7 +267,7 @@ for (int seriesIndex = 0; seriesIndex < seriesNum; seriesIndex++) {
private List<IReaderByTimestamp> seriesReaderByTimestampList;
```
- 每个时间序列对应的reader,用来根据时间戳获取数据
+ 每个时间序列对应的 reader,用来根据时间戳获取数据
* ```
private boolean hasCachedRowRecord;
@@ -284,7 +281,6 @@ for (int seriesIndex = 0; seriesIndex < seriesNum; seriesIndex++) {
当前缓存的数据行
-
它的主要查询逻辑封装在`cacheRowRecord()`方法中,具体分析见代码中的注释
#### cacheRowRecord()
@@ -298,14 +294,14 @@ private boolean cacheRowRecord() throws IOException {
long timestamp = timeGenerator.next();
RowRecord rowRecord = new RowRecord(timestamp);
for (int i = 0; i < seriesReaderByTimestampList.size(); i++) {
- // 根获得每个时间序列当前时间戳下的value
+ // 根获得每个时间序列当前时间戳下的 value
IReaderByTimestamp reader = seriesReaderByTimestampList.get(i);
Object value = reader.getValueInTimestamp(timestamp);
- // 如果该时间序列在当前时间戳下没有值,则置null
+ // 如果该时间序列在当前时间戳下没有值,则置 null
if (value == null) {
rowRecord.addField(null);
}
- // 否则将hasField置为true
+ // 否则将 hasField 置为 true
else {
hasField = true;
rowRecord.addField(value, dataTypes.get(i));
diff --git a/docs/zh/SystemDesign/DataQuery/SeriesReader.md b/docs/zh/SystemDesign/DataQuery/SeriesReader.md
index 0c86cb8..244f42c 100644
--- a/docs/zh/SystemDesign/DataQuery/SeriesReader.md
+++ b/docs/zh/SystemDesign/DataQuery/SeriesReader.md
@@ -73,7 +73,7 @@ Statistics currentChunkStatistics();
// 跳过当前 Chunk
void skipCurrentChunk();
-// 判断当前Chunk是否还有下一个 Page
+// 判断当前 Chunk 是否还有下一个 Page
boolean hasNextPage() throws IOException;
// 判断能否使用当前 Page 的统计信息
@@ -139,7 +139,7 @@ Object[] getValuesInTimestamps(long[] timestamps) throws IOException;
#### 一般使用流程
-该接口在带值过滤的查询中被使用,TimeGenerator生成时间戳后,使用该接口获得该时间戳对应的value
+该接口在带值过滤的查询中被使用,TimeGenerator 生成时间戳后,使用该接口获得该时间戳对应的 value
```
Object value = readerByTimestamp.getValueInTimestamp(timestamp);
@@ -165,7 +165,7 @@ Object[] values = readerByTimestamp.getValueInTimestamp(timestamps);
设计原则是能用粒度大的就不用粒度小的。
-首先介绍一下SeriesReader里的几个重要字段
+首先介绍一下 SeriesReader 里的几个重要字段
```
@@ -173,7 +173,7 @@ Object[] values = readerByTimestamp.getValueInTimestamp(timestamps);
* 文件层
*/
private final List<TsFileResource> seqFileResource;
- 顺序文件列表,因为顺序文件本身就保证有序,且时间戳互不重叠,只需使用List进行存储
+ 顺序文件列表,因为顺序文件本身就保证有序,且时间戳互不重叠,只需使用 List 进行存储
private final PriorityQueue<TsFileResource> unseqFileResource;
乱序文件列表,因为乱序文件互相之间不保证顺序性,且可能有重叠,为了保证顺序,使用优先队列进行存储
@@ -213,17 +213,17 @@ private PriorityMergeReader mergeReader;
* 相交数据点产出结果的缓存
*/
private boolean hasCachedNextOverlappedPage;
- 是否缓存了下一个batch
+ 是否缓存了下一个 batch
private BatchData cachedBatchData;
- 缓存的下一个batch的引用
+ 缓存的下一个 batch 的引用
```
-下面介绍一下SeriesReader里的重要方法
+下面介绍一下 SeriesReader 里的重要方法
#### hasNextChunk()
-* 主要功能:判断该时间序列还有没有下一个chunk。
+* 主要功能:判断该时间序列还有没有下一个 chunk。
* 约束:在调用这个方法前,需要保证 `SeriesReader` 内已经没有 page 和 数据点 层级的数据了,也就是之前解开的 chunk 都消耗完了。
@@ -271,7 +271,7 @@ private BatchData cachedBatchData;
#### skipCurrentPage()
-跳过当前Page。只需要将 `firstPageReader` 置为 null。
+跳过当前 Page。只需要将 `firstPageReader` 置为 null。
#### nextPage()
@@ -290,7 +290,7 @@ private BatchData cachedBatchData;
否则,先调用 `tryToPutAllDirectlyOverlappedPageReadersIntoMergeReader()` 方法,将 `cachedPageReaders` 中所有与 `firstPageReader` 有重叠的放进 `mergeReader` 里。`mergeReader` 里维护了一个 `currentLargestEndTime` 变量,每次添加进新的 Reader 时被更新,用以记录当前添加进 `mergeReader` 的 page 的最大结束时间。
然后先从`mergeReader`里取出当前最大的结束时间,作为第一批数据的结束时间,记为`currentPageEndTime`。接着去遍历`mergeReader`,直到当前的时间戳大于`currentPageEndTime`。
- 每从 mergeReader 移出一个点前,我们先要判断是否有与当前时间戳重叠的file或者chunk或者page(这里之所以还要再做一次判断,是因为,比如当前page是1-30,和他直接相交的page是20-50,还有一个page是40-60,每取一个点判断一次是想把40-60解开),如果有,解开相应的file或者chunk或者page,并将其放入`mergeReader`。完成重叠的判断后,从`mergeReader`中取出相应数据。
+ 每从 mergeReader 移出一个点前,我们先要判断是否有与当前时间戳重叠的 file 或者 chunk 或者 page(这里之所以还要再做一次判断,是因为,比如当前 page 是 1-30,和他直接相交的 page 是 20-50,还有一个 page 是 40-60,每取一个点判断一次是想把 40-60 解开),如果有,解开相应的 file 或者 chunk 或者 page,并将其放入`mergeReader`。完成重叠的判断后,从`mergeReader`中取出相应数据。
完成迭代后将获得数据缓存在 `cachedBatchData` 中,并将 `hasCachedNextOverlappedPage` 置为 `true`。
@@ -375,10 +375,10 @@ return false;
设计思想:可以用统计信息的条件是当前 chunk 不重叠,并且满足过滤条件。
-先调用`SeriesReader`的`currentChunkStatistics()`方法,获得当前chunk的统计信息,再调用`SeriesReader`的`isChunkOverlapped()`方法判断当前chunk是否重叠,如果当前chunk不重叠,且其统计信息满足过滤条件,则返回`true`,否则返回`false`。
+先调用`SeriesReader`的`currentChunkStatistics()`方法,获得当前 chunk 的统计信息,再调用`SeriesReader`的`isChunkOverlapped()`方法判断当前 chunk 是否重叠,如果当前 chunk 不重叠,且其统计信息满足过滤条件,则返回`true`,否则返回`false`。
#### canUseCurrentPageStatistics()
设计思想:可以用统计信息的条件是当前 page 不重叠,并且满足过滤条件。
-先调用`SeriesReader`的 `currentPageStatistics()` 方法,获得当前page的统计信息,再调用`SeriesReader` 的 `isPageOverlapped()` 方法判断当前 page 是否重叠,如果当前page不重叠,且其统计信息满足过滤条件,则返回`true`,否则返回`false`。
\ No newline at end of file
+先调用`SeriesReader`的 `currentPageStatistics()` 方法,获得当前 page 的统计信息,再调用`SeriesReader` 的 `isPageOverlapped()` 方法判断当前 page 是否重叠,如果当前 page 不重叠,且其统计信息满足过滤条件,则返回`true`,否则返回`false`。
\ No newline at end of file
diff --git a/docs/zh/SystemDesign/QueryEngine/Planner.md b/docs/zh/SystemDesign/QueryEngine/Planner.md
index 2eb8e1c..f1cc02a 100644
--- a/docs/zh/SystemDesign/QueryEngine/Planner.md
+++ b/docs/zh/SystemDesign/QueryEngine/Planner.md
@@ -60,4 +60,3 @@ SQL 解析采用 Antlr4
## 物理计划生成器
* org.apache.iotdb.db.qp.strategy.PhysicalGenerator
-
diff --git a/docs/zh/SystemDesign/QueryEngine/ResultSetConstruction.md b/docs/zh/SystemDesign/QueryEngine/ResultSetConstruction.md
index 70b3dc9..bf5feae 100644
--- a/docs/zh/SystemDesign/QueryEngine/ResultSetConstruction.md
+++ b/docs/zh/SystemDesign/QueryEngine/ResultSetConstruction.md
@@ -148,7 +148,7 @@ SQL: `SELECT s2, s1, s2 FROM root.sg.d1;`
| ---- | ------------- | ------------- |
| | | |
-为了还原最终结果集,需要构造一个列名到其在查询结果集中位置的映射集 `columnOrdinalMap`,方便从查询结果集中取出某一列对应的结果,该部分逻辑在新建最终结果集 `IoTDBQueryResultSet` 的构造函数内完成.
+为了还原最终结果集,需要构造一个列名到其在查询结果集中位置的映射集 `columnOrdinalMap`,方便从查询结果集中取出某一列对应的结果,该部分逻辑在新建最终结果集 `IoTDBQueryResultSet` 的构造函数内完成。
- org.apache.iotdb.jdbc.AbstractIoTDBResultSet.AbstractIoTDBResultSet()
diff --git a/docs/zh/SystemDesign/SchemaManager/SchemaManager.md b/docs/zh/SystemDesign/SchemaManager/SchemaManager.md
index 97eb4a0..0493767 100644
--- a/docs/zh/SystemDesign/SchemaManager/SchemaManager.md
+++ b/docs/zh/SystemDesign/SchemaManager/SchemaManager.md
@@ -27,14 +27,13 @@ IoTDB 的元数据统一由 MManger 管理,包括以下几个部分:
* 元数据日志管理
* 标签/属性管理
-
## MManager
* 维护 tag 倒排索引:`Map<String, Map<String, Set<LeafMNode>>> tagIndex`
> tag key -> tag value -> timeseries LeafMNode
-该类初始化时,会replay mlog中的内容,将元数据信息还原出来,元数据操作日志主要有六种类型,每个操作前都会先获得整个元数据的写锁(存储在MManager中),操作完后释放:
+该类初始化时,会 replay mlog 中的内容,将元数据信息还原出来,元数据操作日志主要有六种类型,每个操作前都会先获得整个元数据的写锁(存储在 MManager 中),操作完后释放:
* 创建时间序列
* 检查存储组是否存在,如果不存在且开启自动创建,则创建存储组
@@ -43,17 +42,17 @@ IoTDB 的元数据统一由 MManger 管理,包括以下几个部分:
* 如果非重启(需要记录日志)
* 拿到标签文件当前 offset
* 将时间序列信息记录到 mlog 中
- * 将 tags/attributes 持久化到tlog中
+ * 将 tags/attributes 持久化到 tlog 中
* 如果是重启(需要恢复内存结构)
* 根据 mlog 中的 offset 读取标签文件,重建 tagIndex 索引
* 删除时间序列
- * 获得所有满足前缀的时间序列的fullPath
+ * 获得所有满足前缀的时间序列的 fullPath
* 遍历上一步获得的所有时间序列,并逐个在 MTree 中删除
- * 删除的时候,需要首先获得该时间序列所在device的InternalMNode的写锁
+ * 删除的时候,需要首先获得该时间序列所在 device 的 InternalMNode 的写锁
* 若获取成功
- * 删除MTree中对应的LeafMNode
- * 根据LeafMNode中的offset,读取标签文件,更新 tagIndex 索引
+ * 删除 MTree 中对应的 LeafMNode
+ * 根据 LeafMNode 中的 offset,读取标签文件,更新 tagIndex 索引
* 若发现某一个存储组为空,则记录下该空的存储组名
* 若获取失败
* 返回此未删除成功的时间序列
@@ -66,89 +65,86 @@ IoTDB 的元数据统一由 MManger 管理,包括以下几个部分:
* 设置存储组
* 在 MTree 中创建存储组
* 如果开启动态参数,检查内存是否满足
- * 如果非重启,将log持久化至mlog中
+ * 如果非重启,将 log 持久化至 mlog 中
* 删除存储组
- * 在 MTree 中删除对应的存储组,并返回该存储组下的所有时间序列的LeafMNode
- * 删除的时候,需要首先获得该存储组的InternalMNode的写锁
+ * 在 MTree 中删除对应的存储组,并返回该存储组下的所有时间序列的 LeafMNode
+ * 删除的时候,需要首先获得该存储组的 InternalMNode 的写锁
* 若获取成功
- * 删除MTree中对应的InternalMNode
+ * 删除 MTree 中对应的 InternalMNode
* 若获取失败
* 返回此未删除成功的存储组名
- * 遍历上一步返回的LeafMNode,根据LeafMNode中的offset,读取标签文件,更新tagIndex 索引
- * 如果非重启,将log持久化至mlog中
+ * 遍历上一步返回的 LeafMNode,根据 LeafMNode 中的 offset,读取标签文件,更新 tagIndex 索引
+ * 如果非重启,将 log 持久化至 mlog 中
-* 设置TTL
- * 获得对应存储组的StorageGroupMNode,修改其TTL属性
- * 如果非重启,将log持久化至mlog中
+* 设置 TTL
+ * 获得对应存储组的 StorageGroupMNode,修改其 TTL 属性
+ * 如果非重启,将 log 持久化至 mlog 中
-* 改变时间序列标签信息offset
- * 修改时间序列对应的LeafMNode中的offset
+* 改变时间序列标签信息 offset
+ * 修改时间序列对应的 LeafMNode 中的 offset
* 改变时间序列的别名
- * 更新LeafMNode中的alias属性,并更新其父节点中的aliasMap属性
-
+ * 更新 LeafMNode 中的 alias 属性,并更新其父节点中的 aliasMap 属性
-除了这七种需要记录日志的操作外,还有六种对时间序列标签/属性信息进行更新的操作,同样的,每个操作前都会先获得整个元数据的写锁(存储在MManager中),操作完后释放:
+除了这七种需要记录日志的操作外,还有六种对时间序列标签/属性信息进行更新的操作,同样的,每个操作前都会先获得整个元数据的写锁(存储在 MManager 中),操作完后释放:
* 重命名标签或属性
- * 获得该时间序列的LeafMNode
+ * 获得该时间序列的 LeafMNode
* 通过 LeafMNode 中的 offset 读取标签和属性信息
* 若新键已经存在,则抛异常
* 若新键不存在
* 若旧键不存在,则抛异常
- * 若旧键存在,用新键替换旧键,并持久化至tlog中
+ * 若旧键存在,用新键替换旧键,并持久化至 tlog 中
* 如果旧键是标签,则还需更新 tagIndex
* 重新设置标签或属性的值
- * 获得该时间序列的LeafMNode
+ * 获得该时间序列的 LeafMNode
* 通过 LeafMNode 中的 offset 读取标签和属性信息
* 若需要重新设置的标签或属性的键值不存在,则抛异常
* 若需要重新设置的是标签,则还需更新 tagIndex
- * 将更新后的标签和属性信息持久化至tlog中
+ * 将更新后的标签和属性信息持久化至 tlog 中
* 删除已经存在的标签或属性
- * 获得该时间序列的LeafMNode
+ * 获得该时间序列的 LeafMNode
* 通过 LeafMNode 中的 offset 读取标签和属性信息
* 遍历需要删除的标签或属性,若不存在,则跳过
* 若需要删除的是标签,则还需更新 tagIndex
- * 将更新后的标签和属性信息持久化至tlog中
+ * 将更新后的标签和属性信息持久化至 tlog 中
* 添加新的标签
- * 获得该时间序列的LeafMNode
+ * 获得该时间序列的 LeafMNode
* 通过 LeafMNode 中的 offset 读取标签信息
* 遍历需要添加的标签,若已存在,则抛异常
- * 将更新后的标签信息持久化至tlog中
+ * 将更新后的标签信息持久化至 tlog 中
* 根据添加的标签信息,更新 tagIndex
* 添加新的属性
- * 获得该时间序列的LeafMNode
+ * 获得该时间序列的 LeafMNode
* 通过 LeafMNode 中的 offset 读取属性信息
* 遍历需要添加的属性,若已存在,则抛异常
- * 将更新后的属性信息持久化至tlog中
+ * 将更新后的属性信息持久化至 tlog 中
* 更新插入标签和属性
- * 获得该时间序列的LeafMNode
- * 更新LeafMNode中的alias属性,并更新其父节点中的aliasMap属性
- * 讲更新后的别名持久化至mlog中
+ * 获得该时间序列的 LeafMNode
+ * 更新 LeafMNode 中的 alias 属性,并更新其父节点中的 aliasMap 属性
+ * 讲更新后的别名持久化至 mlog 中
* 通过 LeafMNode 中的 offset 读取标签和属性信息
* 遍历需要更新插入的标签和属性,若已存在,则用新值更新;若不存在,则添加
- * 将更新后的属性信息持久化至tlog中
+ * 将更新后的属性信息持久化至 tlog 中
* 如果包含更新插入中包含标签信息,还需更新 tagIndex
-
-
## 元数据树
* org.apache.iotdb.db.metadata.MTree
-树中包括三种节点:StorageGroupMNode、InternalMNode(非叶子节点)、LeafMNode(叶子节点),他们都是MNode的子类。
+树中包括三种节点:StorageGroupMNode、InternalMNode(非叶子节点)、LeafMNode(叶子节点),他们都是 MNode 的子类。
-每个InternalMNode中都有一个读写锁,查询元数据信息时,需要获得路径上每一个InternalMNode的读锁,修改元数据信息时,如果修改的是LeafMNode,需要获得其父节点的写锁,若修改的是InternalMNode,则只需获得本身的写锁。若该InternalMNode位于Device层,则还包含了一个`Map<String, MNode> aliasChildren`,用于存储别名信息。
+每个 InternalMNode 中都有一个读写锁,查询元数据信息时,需要获得路径上每一个 InternalMNode 的读锁,修改元数据信息时,如果修改的是 LeafMNode,需要获得其父节点的写锁,若修改的是 InternalMNode,则只需获得本身的写锁。若该 InternalMNode 位于 Device 层,则还包含了一个`Map<String, MNode> aliasChildren`,用于存储别名信息。
StorageGroupMNode 继承 InternalMNode,包含存储组的元数据信息,如 TTL。
-LeafMNode 中包含了对应时间序列的Schema信息,其别名(若没有别名,则为null)以及该时间序列的标签/属性信息在tlog文件中的offset(若没有标签/属性,则为-1)
+LeafMNode 中包含了对应时间序列的 Schema 信息,其别名(若没有别名,则为 null) 以及该时间序列的标签/属性信息在 tlog 文件中的 offset(若没有标签/属性,则为-1)
示例:
@@ -177,9 +173,9 @@ IoTDB 的元数据管理采用目录树的形式,倒数第二层为设备层
### 创建条件
为了加快 IoTDB 重启速度,我们为 MTree 设置了检查点,这样避免了在重启时按行读取并复现 `mlog.bin` 中的信息。创建 MTree 的快照有两种方式:
-1. 后台线程检查自动创建:每隔10分钟,后台线程检查 MTree 的最后修改时间,需要同时满足
- * 用户超过1小时(可配置)没修改 MTree,即`mlog.bin` 文件超过1小时没有修改
- * `mlog.bin` 中积累了100000行日志(可配置)
+1. 后台线程检查自动创建:每隔 10 分钟,后台线程检查 MTree 的最后修改时间,需要同时满足
+ * 用户超过 1 小时(可配置)没修改 MTree,即`mlog.bin` 文件超过 1 小时没有修改
+ * `mlog.bin` 中积累了 100000 行日志(可配置)
2. 手动创建:使用`create snapshot for schema`命令手动触发创建 MTree 快照
@@ -188,16 +184,16 @@ IoTDB 的元数据管理采用目录树的形式,倒数第二层为设备层
方法见`MManager.createMTreeSnapshot()`:
1. 首先给 MTree 加读锁,防止创建快照过程中对其进行修改
-2. 将 MTree 序列化进临时 snapshot 文件(`mtree.snapshot.tmp`)。MTree 的序列化采用“先子节点、后父节点”的深度优先序列化方式,将节点的信息按照类型转化成对应格式的字符串,便于反序列化时读取和组装MTree。
- * 普通节点:0,名字,子节点个数
- * 存储组节点:1,名字,TTL,子节点个数
- * 传感器节点:2,名字,别名,数据类型,编码,压缩方式,属性,偏移量,子节点个数
+2. 将 MTree 序列化进临时 snapshot 文件(`mtree.snapshot.tmp`)。MTree 的序列化采用“先子节点、后父节点”的深度优先序列化方式,将节点的信息按照类型转化成对应格式的字符串,便于反序列化时读取和组装 MTree。
+ * 普通节点:0, 名字,子节点个数
+ * 存储组节点:1, 名字,TTL, 子节点个数
+ * 传感器节点:2, 名字,别名,数据类型,编码,压缩方式,属性,偏移量,子节点个数
3. 序列化结束后,将临时文件重命名为正式文件(`mtree.snapshot`),防止在序列化过程中出现服务器人为或意外关闭,导致序列化失败的情况。
4. 调用`MLogWriter.clear()`方法,清空 `mlog.bin`:
* 关闭 BufferedWriter,删除`mlog.bin`文件;
* 新建一个 BufferedWriter;
- * 将 `logNumber` 置为0,`logNumber` 记录`mlog.bin`的日志行数,用于在后台检查时判断其是否超过用户配置的阈值而触发自动创建快照。
+ * 将 `logNumber` 置为 0,`logNumber` 记录`mlog.bin`的日志行数,用于在后台检查时判断其是否超过用户配置的阈值而触发自动创建快照。
5. 释放 MTree 读锁
@@ -215,52 +211,52 @@ IoTDB 的元数据管理采用目录树的形式,倒数第二层为设备层
系统重启时会重做 mlog.bin 中的日志,重做之前需要标记不需要记录日志。当重启结束后,标记需要记录日志。
-mlog.bin 存储二进制编码。我们可以使用[MlogParser Tool](https://iotdb.apache.org/UserGuide/Master/System-Tools/MLogParser-Tool.html) 将mlog解析为可读的mlog.txt版本。
+mlog.bin 存储二进制编码。我们可以使用 [MlogParser Tool](https://iotdb.apache.org/UserGuide/Master/System-Tools/MLogParser-Tool.html) 将 mlog 解析为可读的 mlog.txt 版本。
示例元数据操作及对应的 mlog 解析后记录:
-* 创建一个名为root.turbine的存储组
+* 创建一个名为 root.turbine 的存储组
> mlog: 2,root.turbine
- > 格式: 2,path
+ > 格式:2,path
-* 删除一个名为root.turbine的存储组
+* 删除一个名为 root.turbine 的存储组
> mlog: 11,root.turbine
- > 格式: 11,path
+ > 格式:11,path
-* 创建时间序列 create timeseries root.turbine.d1.s1(temprature) with datatype=FLOAT, encoding=RLE, compression=SNAPPY tags(tag1=v1, tag2=v2) attributes(attr1=v1, attr2=v2)
+* 创建时间序列 create timeseries root.turbine.d1.s1(temperature) with datatype=FLOAT, encoding=RLE, compression=SNAPPY tags(tag1=v1, tag2=v2) attributes(attr1=v1, attr2=v2)
- > mlog: 0,root.turbine.d1.s1,3,2,1,,温度,offset
+ > mlog: 0,root.turbine.d1.s1,3,2,1,temperature,offset
- > 格式: 0,path,TSDataType,TSEncoding,CompressionType,[properties],[alias],[tag-attribute offset]
+ > 格式:0,path,TSDataType,TSEncoding,CompressionType,[properties],[alias],[tag-attribute offset]
* 删除时间序列 root.turbine.d1.s1
> mlog: 1,root.turbine.d1.s1
- > 格式: 1,path
+ > 格式:1,path
* 给 root.turbine 设置时间为 10 秒的 ttl
> mlog: 10,root.turbine,10
- > 格式: 10,path,ttl
+ > 格式:10,path,ttl
* alter timeseries root.turbine.d1.s1 add tags(tag1=v1)
- > 只有当root.turbine.d1.s1原来不存在任何标签/属性信息时,该sql才会产生日志
+ > 只有当 root.turbine.d1.s1 原来不存在任何标签/属性信息时,该 sql 才会产生日志
> mlog: 12,root.turbine.d1.s1,10
- > 格式: 10,path,[change offset]
+ > 格式:10,path,[change offset]
* alter timeseries root.turbine.d1.s1 UPSERT ALIAS=newAlias
> mlog: 13,root.turbine.d1.s1,newAlias
- > 格式: 13,path,[new alias]
+ > 格式:13,path,[new alias]
* 创建元数据模版 create schema template temp1(
s1 INT32 with encoding=Gorilla and compression SNAPPY,
@@ -277,24 +273,23 @@ mlog.bin 存储二进制编码。我们可以使用[MlogParser Tool](https://iot
> mlog: 6,temp1,root.turbine
- > 格式: 6,template name,path
+ > 格式:6,template name,path
* 自动创建设备 (应用场景为在某个前缀路径上设置模版之后,写入时会自动创建设备)
> mlog: 4,root.turbine.d1
- > 格式: 4,path
+ > 格式:4,path
* 设置某设备正在使用模版 (应用场景为在某个设备路径上设置模版之后,表示该设备正在应用模版)
> mlog: 61,root.turbine.d1
- > 格式: 61,path
+ > 格式:61,path
## 标签文件
* org.apache.iotdb.db.metadata.TagLogFile
-
所有时间序列的标签/属性信息都会保存在标签文件中,此文件默认为 data/system/schema/mlog.bin。
* 每条时间序列的 tags 和 attributes 持久化总字节数为 L,在 iotdb-engine.properties 中配置。
@@ -303,7 +298,7 @@ mlog.bin 存储二进制编码。我们可以使用[MlogParser Tool](https://iot
> create timeseries root.turbine.d1.s1(temprature) with datatype=FLOAT, encoding=RLE, compression=SNAPPY tags(tag1=v1, tag2=v2) attributes (attr1=v1, attr2=v2)
-> 在tlog.txt中的内容:
+> 在 tlog.txt 中的内容:
> tagsSize (tag1=v1, tag2=v2) attributesSize (attr1=v1, attr2=v2)
@@ -321,30 +316,30 @@ mlog.bin 存储二进制编码。我们可以使用[MlogParser Tool](https://iot
#### getAllMeasurementSchema
-这里需要在findPath的时候就将limit(如果没有limit,则将请求的fetchSize当成limit)和offset参数传递下去,减少内存占用。
+这里需要在 findPath 的时候就将 limit(如果没有 limit,则将请求的 fetchSize 当成 limit)和 offset 参数传递下去,减少内存占用。
#### findPath
-这个方法封装了在MTree中遍历得到满足条件的时间序列的逻辑,是个递归方法,由根节点往下递归寻找,直到当前时间序列数量达到limit或者已经遍历完整个MTree。
+这个方法封装了在 MTree 中遍历得到满足条件的时间序列的逻辑,是个递归方法,由根节点往下递归寻找,直到当前时间序列数量达到 limit 或者已经遍历完整个 MTree。
### 带过滤条件的元数据查询
-这里的过滤条件只能是tag属性,否则抛异常。
+这里的过滤条件只能是 tag 属性,否则抛异常。
-通过在MManager中维护的tag的倒排索引,获得所有满足索引条件的`MeasurementMNode`。
+通过在 MManager 中维护的 tag 的倒排索引,获得所有满足索引条件的`MeasurementMNode`。
若需要根据热度排序,则根据`lastTimeStamp`进行排序,否则根据序列名的字母序排序,然后再做`offset`和`limit`的截断。
-### ShowTimeseries结果集
+### ShowTimeseries 结果集
-如果元数据量过多,一次show timeseries的结果可能导致OOM,所以增加fetch size参数,客户端跟服务器端交互时,服务器端一次最多只会取fetch size个时间序列。
+如果元数据量过多,一次 show timeseries 的结果可能导致 OOM,所以增加 fetch size 参数,客户端跟服务器端交互时,服务器端一次最多只会取 fetch size 个时间序列。
多次交互的状态信息就存在`ShowTimeseriesDataSet`中。`ShowTimeseriesDataSet`中保存了此次的`ShowTimeSeriesPlan`,当前的游标`index`以及缓存的结果行列表`List<RowRecord> result`。
-* 判断游标`index`是否等于缓存的结果行`List<RowRecord> result`的size
- * 若相等,则调用MManager中的`showTimeseries`方法取结果,放入缓存
- * 需要相应的修改plan中的offset,将offset向前推fetch size大小
- * 若`hasLimit`为`false`,则将index重新置为0
+* 判断游标`index`是否等于缓存的结果行`List<RowRecord> result`的 size
+ * 若相等,则调用 MManager 中的`showTimeseries`方法取结果,放入缓存
+ * 需要相应的修改 plan 中的 offset,将 offset 向前推 fetch size 大小
+ * 若`hasLimit`为`false`,则将 index 重新置为 0
* 若不相等
- * `index < result.size()`,返回true
- * `index > result.size()`,返回false
+ * `index < result.size()`,返回 true
+ * `index > result.size()`,返回 false
diff --git a/docs/zh/SystemDesign/StorageEngine/Compaction.md b/docs/zh/SystemDesign/StorageEngine/Compaction.md
index a1bf234..2d7cfc0 100644
--- a/docs/zh/SystemDesign/StorageEngine/Compaction.md
+++ b/docs/zh/SystemDesign/StorageEngine/Compaction.md
@@ -29,7 +29,7 @@
* iotdb-engine.properties 加一个参数 compaction_strategy:表示文件合并策略
* compaction_strategy 内置两个策略:LEVEL_COMPACTION 和 NO_COMPACTION
* LEVEL_COMPACTION 即开启合并并使用层级合并方法,NO_COMPACTION 即关闭合并
- * iotdb-engine.properties 中加 merge_chunk_point_number:最大的chunk大小限制,LEVEL_COMPACTION 时,当达到该参数就合并到最后一层
+ * iotdb-engine.properties 中加 merge_chunk_point_number:最大的 chunk 大小限制,LEVEL_COMPACTION 时,当达到该参数就合并到最后一层
* iotdb-engine.properties 加一个参数 max_level_num:LEVEL_COMPACTION 时最大层数
* 代码结构修改
* 新建一个 TsFileManagement 类,专门管理 StorageGroupProcessor 中的 seqFileList 和 unSeqFileList ,在这里写合并的主体逻辑,对外抽象对 seqFileList 和 unSeqFileList 的一系列所需接口
@@ -70,7 +70,7 @@
* 生成合并日志 .compaction.log
* 记录是层级合并
* 记录目标文件
- * 进行合并(每写完一个 device,记录日志 device - offset)
+ * 进行合并(每写完一个 device, 记录日志 device - offset)
* 生成 .resource 文件
* writer endFile
* 记录完成合并
@@ -97,15 +97,15 @@
## LEVEL_COMPACTION 例子
-设置 max_file_num_in_each_level = 3,tsfile_manage_strategy = LevelStrategy, max_level_num = 3,此时文件结构为,第0层、第1层、第2层,其中第2层是不再做合并的稳定的文件列表
+设置 max_file_num_in_each_level = 3,tsfile_manage_strategy = LevelStrategy, max_level_num = 3,此时文件结构为,第 0 层、第 1 层、第 2 层,其中第 2 层是不再做合并的稳定的文件列表
### 完全根据 level 合并的情况
-假设此时整个系统中有5个文件,最后一个文件没有关闭,则其结构及顺序分布如下
+假设此时整个系统中有 5 个文件,最后一个文件没有关闭,则其结构及顺序分布如下
```
level-0: t2-0 t3-0 t4-0
level-1: t0-1 t1-1
```
-当最后一个文件关闭,按如下方式合并(第0层的t2-0、t3-0、t4-0文件合并到了第1层的t2-1文件)
+当最后一个文件关闭,按如下方式合并(第 0 层的 t2-0、t3-0、t4-0 文件合并到了第 1 层的 t2-1 文件)
```
level-0: t2-0 t3-0 t4-0
\ \ |
@@ -114,7 +114,7 @@ level-0: t2-0 t3-0 t4-0
\ \ |
level-1: t0-1 t1-1 t2-1
```
-合并后发现第1层合并后也满了,则继续合并到第2层,最后整个系统只剩下了第2层的t0-2文件
+合并后发现第 1 层合并后也满了,则继续合并到第 2 层,最后整个系统只剩下了第 2 层的 t0-2 文件
```
level-0: t2-0 t3-0 t4-0
\ \ |
@@ -129,12 +129,12 @@ level-1: t0-1 t1-1 t2-1
level-2: t0-2
```
### 中途满足 merge_chunk_point_number 的情况
-假设此时整个系统中有4个文件,最后一个文件没有关闭,则其结构及顺序分布如下
+假设此时整个系统中有 4 个文件,最后一个文件没有关闭,则其结构及顺序分布如下
```
level-0: t2-0 t3-0
level-1: t0-1 t1-1
```
-当最后一个文件关闭,但是t0-1、t1-1、t2-0、t3-0文件的 chunk point 数量加起来已经满足 merge_chunk_point_number,则做如下合并,即直接将所有文件合并到第2层(稳定层)
+当最后一个文件关闭,但是 t0-1、t1-1、t2-0、t3-0 文件的 chunk point 数量加起来已经满足 merge_chunk_point_number,则做如下合并,即直接将所有文件合并到第 2 层(稳定层)
```
level-0: t2-0 t3-0
| |
@@ -147,17 +147,17 @@ level-2: t0-2
### 动态参数调整的例子
- 系统会严格按照上文中提到的 merge 流程对多层文件进行选择和合并,这里只介绍到参数调整时,系统初始化过程中文件会被放在哪一层
-- 假设max_file_num_in_each_level = 3
-* 从0.10.0升级
+- 假设 max_file_num_in_each_level = 3
+* 从 0.10.0 升级
* 将所有文件的 mergeVersion 置为 {max_level_num - 1}
* 即老版本的文件不会被重复合并
-假设整个系统中有5个文件,此时恢复后的文件结构为:
+假设整个系统中有 5 个文件,此时恢复后的文件结构为:
level-2: t0-2 t1-2 t2-2 t3-2 t4-2
* 提高 max_level_num
* 此时因为不会改变任何文件的原 level,所以 recover 时文件还会被放到原来的层上,或超出 {max_level_num - 1} 的文件被放在最后一层(考虑到多次调整的情况)
* 即原文件将基于原来的 level 继续合并,超出 {max_level_num - 1} 部分也不会有乱序问题,因为在最后一层的必然是老文件
-假设整个系统中有5个文件,原 max_file_num_in_each_level = 2,提高后的 max_file_num_in_each_level = 3,此时恢复后的文件结构为:
+假设整个系统中有 5 个文件,原 max_file_num_in_each_level = 2,提高后的 max_file_num_in_each_level = 3,此时恢复后的文件结构为:
```
level-0: t2-0 t3-0 t4-0
level-1: t0-1 t1-1
@@ -171,7 +171,7 @@ level-0: t2-0 t3-0 t4-0
\ \ |
level-1: t0-1 t1-1 t2-1
```
-合并后发现第1层合并后也满了,则继续合并到第2层,最后整个系统只剩下了第2层的t0-2文件
+合并后发现第 1 层合并后也满了,则继续合并到第 2 层,最后整个系统只剩下了第 2 层的 t0-2 文件
```
level-0: t2-0 t3-0 t4-0
\ \ |
@@ -188,7 +188,7 @@ level-2: t0-2
* 降低 max_level_num
* 此时因为不会改变任何文件的原 level,所以 recover 时小于此时 {max_level_num - 1} 的文件还会被放到原来的层上,而超出的文件将被放在最后一层
* 即部分文件将被继续合并,而超出 {max_level_num - 2} 的文件将不会再被合并
-假设整个系统中有7个文件,原max_file_num_in_each_level = 3,降低后的max_file_num_in_each_level = 2,此时恢复后的文件结构为:
+假设整个系统中有 7 个文件,原 max_file_num_in_each_level = 3,降低后的 max_file_num_in_each_level = 2,此时恢复后的文件结构为:
```
level-0: t4-0 t5-0 t6-0
level-1: t0-2 t1-1 t2-1 t3-1
@@ -202,7 +202,7 @@ level-0: t2-0 t3-0 t4-0
\ \ |
level-1: t0-2 t1-1 t2-1 t3-1 t4-1
```
-合并后发现第1层合并后也满了,则继续合并到第2层
+合并后发现第 1 层合并后也满了,则继续合并到第 2 层
```
level-0: t2-0 t3-0 t4-0
\ \ |
@@ -223,15 +223,15 @@ level-1: t3-1 t4-1
level-2: t0-2
```
* NO_COMPACTION -> LEVEL_COMPACTION
- * 此时因为删去了原始合并的 {mergeVersion + 1} 策略,所以所有文件将全部被放到0层
+ * 此时因为删去了原始合并的 {mergeVersion + 1} 策略,所以所有文件将全部被放到 0 层
* 每一次合并会最多取出满足 {merge_chunk_point_number} 的文件进行合并,直到将所有多余的文件合并完,进入正常的合并流程
-假设整个系统中有5个文件,此时恢复后的文件结构为:
+假设整个系统中有 5 个文件,此时恢复后的文件结构为:
```
level-2: t0-0 t1-0 t2-0 t3-0 t4-0
```
假设 {size(t0-0)+size(t1-0)>=merge_chunk_point_number},则进行第一次合并的过程如下
```
-level-0: t0-0 t1-0 t2-0 t3-0 t4-0 t5-0(新增了文件才会触发合并检查)
+level-0: t0-0 t1-0 t2-0 t3-0 t4-0 t5-0(新增了文件才会触发合并检查)
| /
| /
| /
@@ -239,7 +239,7 @@ level-2: t0-2
```
假设 {size(t2-0)+size(t3-0)>=merge_chunk_point_number},则进行第二次合并的过程如下
```
-level-0: t2-0 t3-0 t4-0 t5-0 t6-0(新增了文件才会触发合并检查)
+level-0: t2-0 t3-0 t4-0 t5-0 t6-0(新增了文件才会触发合并检查)
\ |
\ |
\ |
@@ -247,7 +247,7 @@ level-2: t0-2 t2-2
```
假设 {size(t4-0)+size(t5-0)+size(t6-0)+size(t7-0)< merge_chunk_point_number},则进行第三次合并的过程如下
```
-level-0: t4-0 t5-0 t6-0 t7-0(新增了文件才会触发合并检查)
+level-0: t4-0 t5-0 t6-0 t7-0(新增了文件才会触发合并检查)
| / /
| / /
| / /
diff --git a/docs/zh/SystemDesign/StorageEngine/DataManipulation.md b/docs/zh/SystemDesign/StorageEngine/DataManipulation.md
index be4aa25..5a84036 100644
--- a/docs/zh/SystemDesign/StorageEngine/DataManipulation.md
+++ b/docs/zh/SystemDesign/StorageEngine/DataManipulation.md
@@ -21,7 +21,7 @@
# 数据增删改
-下面介绍四种常用数据操控操作,分别是插入,更新,删除和TTL设置
+下面介绍四种常用数据操控操作,分别是插入,更新,删除和 TTL 设置
## 数据插入
@@ -31,15 +31,15 @@
* JDBC 的 execute 和 executeBatch 接口
* Session 的 insertRecord 和 insertRecords
-* 总入口: public void insert(InsertRowPlan insertRowPlan) StorageEngine.java
+* 总入口:public void insert(InsertRowPlan insertRowPlan) StorageEngine.java
* 找到对应的 StorageGroupProcessor
* 根据写入数据的时间以及当前设备落盘的最后时间戳,找到对应的 TsFileProcessor
* 写入 TsFileProcessor 对应的 memtable 中
- * 如果是乱序文件,则更新tsfileResource中的endTimeMap
- * 如果tsfile中没有该设备的信息,或新插入数据的时间小于已存startTime,则更新tsfileResource中的startTimeMap
+ * 如果是乱序文件,则更新 tsfileResource 中的 endTimeMap
+ * 如果 tsfile 中没有该设备的信息,或新插入数据的时间小于已存 startTime,则更新 tsfileResource 中的 startTimeMap
* 记录写前日志
* 根据 memtable 大小,来判断是否触发异步持久化 memtable 操作
- * 如果是顺序文件且执行了刷盘动作,则更新tsfileResource中的endTimeMap
+ * 如果是顺序文件且执行了刷盘动作,则更新 tsfileResource 中的 endTimeMap
* 根据当前磁盘 TsFile 的大小,判断是否触发文件关闭操作
### 批量数据(一个设备多个时间戳多个值)写入
@@ -47,21 +47,20 @@
* 对应的接口
* Session 的 insertTablet
-* 总入口: public void insertTablet(InsertTabletPlan insertTabletPlan) StorageEngine.java
+* 总入口:public void insertTablet(InsertTabletPlan insertTabletPlan) StorageEngine.java
* 找到对应的 StorageGroupProcessor
* 根据这批数据的时间以及当前设备落盘的最后时间戳,将这批数据分成小批,分别对应到一个 TsFileProcessor 中
* 分别将每小批写入 TsFileProcessor 对应的 memtable 中
- * 如果是乱序文件,则更新tsfileResource中的endTimeMap
- * 如果tsfile中没有该设备的信息,或新插入数据的时间小于已存startTime,则更新tsfileResource中的startTimeMap
+ * 如果是乱序文件,则更新 tsfileResource 中的 endTimeMap
+ * 如果 tsfile 中没有该设备的信息,或新插入数据的时间小于已存 startTime,则更新 tsfileResource 中的 startTimeMap
* 记录写前日志
* 根据 memtable 大小,来判断是否触发异步持久化 memtable 操作
- * 如果是顺序文件且执行了刷盘动作,则更新tsfileResource中的endTimeMap
+ * 如果是顺序文件且执行了刷盘动作,则更新 tsfileResource 中的 endTimeMap
* 根据当前磁盘 TsFile 的大小,判断是否触发文件关闭操作
-
## 数据更新
-目前不支持数据的原地更新操作,即update语句,但用户可以直接插入新的数据,在同一个时间点上的同一个时间序列以最新插入的数据为准
+目前不支持数据的原地更新操作,即 update 语句,但用户可以直接插入新的数据,在同一个时间点上的同一个时间序列以最新插入的数据为准
旧数据会通过合并来自动删除,参见:
* [文件合并机制](../StorageEngine/MergeManager.md)
@@ -69,14 +68,14 @@
## 数据删除
* 对应的接口
- * JDBC 的 execute 接口,使用delete SQL语句
+ * JDBC 的 execute 接口,使用 delete SQL 语句
每个 StorageGroupProsessor 中针对每个分区会维护一个自增的版本号,由 SimpleFileVersionController 管理。
每个内存缓冲区 memtable 在持久化的时候会申请一个版本号。持久化到 TsFile 后,会在 TsFileMetadata 中记录此 memtable 对应的 多个 ChunkGroup 的终止位置和版本号。
查询时会根据此信息对 ChunkMetadata 赋 version。
-StorageEngine.java中的delete入口:
+StorageEngine.java 中的 delete 入口:
```public void delete(String deviceId, String measurementId, long timestamp)```
* 找到对应的 StorageGroupProcessor
@@ -85,21 +84,21 @@ StorageEngine.java中的delete入口:
* 如果存在 working memtable:则删除内存中的数据
* 如果存在 正在 flush 的 memtable,记录一条记录,查询时跳过删掉的数据(注意此时文件中已经为这些 memtable 记录了 mods)
-Mods文件用来存储所有的删除记录。下图的mods文件中,d1.s1落在 [100, 200], [180, 300]范围的数据,以及d1.s2落在[500, 1000]范围中的数据将会被删除。
+Mods 文件用来存储所有的删除记录。下图的 mods 文件中,d1.s1 落在 [100, 200], [180, 300] 范围的数据,以及 d1.s2 落在 [500, 1000] 范围中的数据将会被删除。

-## 数据TTL设置
+## 数据 TTL 设置
* 对应的接口
- * JDBC 的 execute 接口,使用SET TTL语句
+ * JDBC 的 execute 接口,使用 SET TTL 语句
-* 总入口: public void setTTL(String storageGroup, long dataTTL) StorageEngine.java
+* 总入口:public void setTTL(String storageGroup, long dataTTL) StorageEngine.java
* 找到对应的 StorageGroupProcessor
- * 在 StorageGroupProcessor 中设置新的data ttl
- * 对所有TsfileResource进行TTL检查
- * 如果某个文件在当前TTL下失效,则删除文件
+ * 在 StorageGroupProcessor 中设置新的 data ttl
+ * 对所有 TsfileResource 进行 TTL 检查
+ * 如果某个文件在当前 TTL 下失效,则删除文件
-同时,我们在 StorageEngine 中启动了一个定时检查文件TTL的线程,详见
+同时,我们在 StorageEngine 中启动了一个定时检查文件 TTL 的线程,详见
* src/main/java/org/apache/iotdb/db/engine/StorageEngine.java 中的 start 方法
diff --git a/docs/zh/SystemDesign/StorageEngine/DataPartition.md b/docs/zh/SystemDesign/StorageEngine/DataPartition.md
index ae8ede4..de7d2c9 100644
--- a/docs/zh/SystemDesign/StorageEngine/DataPartition.md
+++ b/docs/zh/SystemDesign/StorageEngine/DataPartition.md
@@ -29,31 +29,29 @@
其拥有的主要字段为:
-* 一个读写锁: insertLock
+* 一个读写锁:insertLock
-* 每个时间分区所对应的未关闭的顺序文件处理器: workSequenceTsFileProcessors
+* 每个时间分区所对应的未关闭的顺序文件处理器:workSequenceTsFileProcessors
-* 每个时间分区所对应的未关闭的乱序文件处理器: workUnsequenceTsFileProcessors
+* 每个时间分区所对应的未关闭的乱序文件处理器:workUnsequenceTsFileProcessors
* 该存储组的全部顺序文件列表(按照时间排序): sequenceFileTreeSet
* 该存储组的全部乱序文件列表(无顺序): unSequenceFileList
-* 记录每一个设备最后写入时间的map,顺序数据刷盘时会使用该map记录的时间: latestTimeForEachDevice
+* 记录每一个设备最后写入时间的 map,顺序数据刷盘时会使用该 map 记录的时间:latestTimeForEachDevice
-* 记录每一个设备最后刷盘时间的map,用来区分顺序和乱序数据: latestFlushedTimeForEachDevice
-
-* 每个时间分区所对应的版本生成器map,便于查询时确定不同chunk的优先级: timePartitionIdVersionControllerMap
+* 记录每一个设备最后刷盘时间的 map,用来区分顺序和乱序数据:latestFlushedTimeForEachDevice
+* 每个时间分区所对应的版本生成器 map,便于查询时确定不同 chunk 的优先级:timePartitionIdVersionControllerMap
### 相关代码
* src/main/java/org/apache/iotdb/db/engine/StorageEngine.java
-
## 时间范围
-同一个存储组中的数据按照用户指定的时间范围进行分区,相关参数为partition_interval,默认为周,也就是不同周的数据会放在不同的分区中
+同一个存储组中的数据按照用户指定的时间范围进行分区,相关参数为 partition_interval,默认为周,也就是不同周的数据会放在不同的分区中
### 实现逻辑
@@ -67,17 +65,17 @@ data
-- sequence
----- [存储组名1]
+---- [存储组名 1]
------- [时间分区ID1]
+------ [时间分区 ID1]
-------- xxxx.tsfile
-------- xxxx.resource
------- [时间分区ID2]
+------ [时间分区 ID2]
----- [存储组名2]
+---- [存储组名 2]
-- unsequence
diff --git a/docs/zh/SystemDesign/StorageEngine/FileLists.md b/docs/zh/SystemDesign/StorageEngine/FileLists.md
index 2b24a61..90e684c 100644
--- a/docs/zh/SystemDesign/StorageEngine/FileLists.md
+++ b/docs/zh/SystemDesign/StorageEngine/FileLists.md
@@ -23,11 +23,11 @@
## 系统文件目录 data/system
-* data/system/schema/mlog.txt (元数据日志)
+* data/system/schema/mlog.txt (元数据日志)
http://iotdb.apache.org/SystemDesign/SchemaManager/SchemaManager.html#log-management-of-metadata
-* data/system/schema/system.properties (系统不可变参数)
+* data/system/schema/system.properties (系统不可变参数)
```
partition_interval=9223372036854775807
@@ -39,16 +39,15 @@
iotdb_version=UNKNOWN
```
-* data/system/schema/tlog.txt (标签、属性文件)
+* data/system/schema/tlog.txt (标签、属性文件)
http://iotdb.apache.org/SystemDesign/SchemaManager/SchemaManager.html#tlog
-
* data/system/storage_groups/{sg_name}/{partition}/Version-xxx (每个分区的版本控制文件,无内容)
-* data/system/storage_groups/upgrade/Version-xxx (升级过程的版本控制文件)
+* data/system/storage_groups/upgrade/Version-xxx (升级过程的版本控制文件)
-* data/system/upgrade/upgrade.txt (升级日志文件)
+* data/system/upgrade/upgrade.txt (升级日志文件)
格式:
@@ -70,7 +69,7 @@ xxx/root.group_11/upgrade/1587634378188-101-0.tsfile,3
...
```
-* data/system/users/{user_name}.profile (用户信息)
+* data/system/users/{user_name}.profile (用户信息)
```
1. username (UTF-8)
@@ -82,7 +81,7 @@ xxx/root.group_11/upgrade/1587634378188-101-0.tsfile,3
7. UseWaterMarkFlag (Boolean)
```
-* data/system/roles/ (权限信息)
+* data/system/roles/ (权限信息)
```
1. roleName (UTF-8)
@@ -100,42 +99,40 @@ Privilege 格式
## 数据文件目录 data/data
-* data/data/sequence/{storage_group}/{partition}/{timestamp}-{version}-{merge_times}.tsfile (数据文件)
+* data/data/sequence/{storage_group}/{partition}/{timestamp}-{version}-{merge_times}.tsfile (数据文件)
http://iotdb.apache.org/SystemDesign/TsFile/Format.html#_1-2-tsfile-overview
-* data/data/sequence/{storage_group}/{partition}/{tsfile}.resource (对应TsFile的设备时间索引)
+* data/data/sequence/{storage_group}/{partition}/{tsfile}.resource (对应 TsFile 的设备时间索引)
```
deviceId(String),start_time(long)
-deviceId(String),start_time(long)
-deviceId(String),end_time(long)
deviceId(String),end_time(long)
```
-* data/data/sequence/{storage_group}/{partition}/{tsfile}.mods (数据修改操作标记)
+* data/data/sequence/{storage_group}/{partition}/{tsfile}.mods (数据修改操作标记)
http://iotdb.apache.org/SystemDesign/DataQuery/QueryFundamentals.html#query-with-modifications
-* data/data/sequence/{storage_group}/{partition}/{tsfile}-{level}-{timestamp}.vm (未封口的 TsFile 文件)
+* data/data/sequence/{storage_group}/{partition}/{tsfile}-{level}-{timestamp}.vm (未封口的 TsFile 文件)
-* data/data/sequence/{storage_group}/{partition}/{tsfile}.flush (TsFile持久化memtable时的日志文件,无内容)
+* data/data/sequence/{storage_group}/{partition}/{tsfile}.flush (TsFile 持久化 memtable 时的日志文件,无内容)
-* data/data/sequence/{storage_group}/{partition}/{tsfile}.vm.log (合并 vm 的日志文件)
+* data/data/sequence/{storage_group}/{partition}/{tsfile}.vm.log (合并 vm 的日志文件)
```
源文件
-文件path
+文件 path
目标文件
-文件path
-device,offset (已经合并的设备和目标文件完整的ChunkGroup的offset)
+文件 path
+device,offset (已经合并的设备和目标文件完整的 ChunkGroup 的 offset)
```
## 写前日志目录 data/wal
-* data/wal/{storage_group}-{tsfile_name}/wal{x} (对应某个 TsFile 的写前日志文件)
+* data/wal/{storage_group}-{tsfile_name}/wal{x} (对应某个 TsFile 的写前日志文件)
-文件格式为写入执行计划的序列化内容: InsertRowPlan、InsertTabletPlan、DeletePlan
+文件格式为写入执行计划的序列化内容:InsertRowPlan、InsertTabletPlan、DeletePlan
## 性能追踪目录 data/tracing
diff --git a/docs/zh/SystemDesign/StorageEngine/FlushManager.md b/docs/zh/SystemDesign/StorageEngine/FlushManager.md
index 1850742..d652068 100644
--- a/docs/zh/SystemDesign/StorageEngine/FlushManager.md
+++ b/docs/zh/SystemDesign/StorageEngine/FlushManager.md
@@ -61,7 +61,7 @@ FlushManager 可以接受 memtable 的持久化任务,提交者有两个,第
* ioTask 线程
- IO线程,负责将编码好的 Chunk 持久化到磁盘的 TsFile 文件上。
+ IO 线程,负责将编码好的 Chunk 持久化到磁盘的 TsFile 文件上。
### 两个任务队列
@@ -75,7 +75,7 @@ FlushManager 可以接受 memtable 的持久化任务,提交者有两个,第
* EndChunkGroupIoTask:结束一个 device (ChunkGroup) 的持久化,encoding 不处理这个命令,直接发给 IO 线程。
-* ioTaskQueue: 编码线程->IO线程,包括三种任务
+* ioTaskQueue: 编码线程->IO 线程,包括三种任务
* StartFlushGroupIOTask:开始持久化一个 device (ChunkGroup)。
diff --git a/docs/zh/SystemDesign/StorageEngine/MergeManager.md b/docs/zh/SystemDesign/StorageEngine/MergeManager.md
index 6f7cbd7..2e4b341 100644
--- a/docs/zh/SystemDesign/StorageEngine/MergeManager.md
+++ b/docs/zh/SystemDesign/StorageEngine/MergeManager.md
@@ -30,12 +30,12 @@
## 调用过程
- 每一次 merge 会在用户 client 调用"merge"命令或根据配置中的 mergeIntervalSec 定时进行
-- merge 分为三个过程,包括选择文件(selector),进行 merge ,以及 merge 过程中断后的恢复(recover)
+- merge 分为三个过程,包括选择文件 (selector),进行 merge ,以及 merge 过程中断后的恢复 (recover)
<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/24886743/75313978-6c64b000-5899-11ea-8565-40b012f9c8a2.png">
## 合并的例子
-在 squeeze 合并策略下,当一系列的 seq 以及 unseq 文件进行合并,且并未超过时间及内存限制时,所有文件都将合并为一个命名为{时间戳}-{版本}-{merge次数+1}.tsfile.merge.squeeze的文件
+在 squeeze 合并策略下,当一系列的 seq 以及 unseq 文件进行合并,且并未超过时间及内存限制时,所有文件都将合并为一个命名为{时间戳}-{版本}-{merge 次数+1}.tsfile.merge.squeeze 的文件
当超出了时间或内存限制,文件选择过程将被中断,当前已被选中的 seq 以及 unseq 文件则会进行如上合并形成一个文件
@@ -53,9 +53,9 @@
* org.apache.iotdb.db.engine.merge.IRecoverMergeTask
- recover 过程的接口类,规定了 recoverMerge 接口,所有自定义的merge恢复策略均需继承此类
+ recover 过程的接口类,规定了 recoverMerge 接口,所有自定义的 merge 恢复策略均需继承此类
-此外,每一个自定义的MergeTask均需继承Callable\<void\>接口,以保证可以被回调
+此外,每一个自定义的 MergeTask 均需继承 Callable\<void\>接口,以保证可以被回调
* org.apache.iotdb.db.engine.merge.manage.MergeContext
@@ -69,7 +69,7 @@
Merge 过程中的资源类,负责管理 merge 过程中的 files,readers,writers,measurementSchemas,modifications 等资源
-## inplace策略
+## inplace 策略
### selector
@@ -77,19 +77,19 @@
### merge
-首先根据 storageGroupName 选出所有需要 merge 的 series ,然后针对 selector 中选出的每一个 seq 文件建立 chunkMetaHeap ,并根据配置中的 mergeChunkSubThreadNum 分多个子线程进行合并
+首先根据 storageGroupName 选出所有需要 merge 的 series ,然后针对 selector 中选出的每一个 seq 文件建立 chunkMetaHeap , 并根据配置中的 mergeChunkSubThreadNum 分多个子线程进行合并
-## squeeze策略
+## squeeze 策略
### selector
-在受限的内存和时间下,先依次选择 unseq 文件,每次根据 unseq 文件的时间范围选择与之重叠的seq文件,然后按次序重试每一个 seq 文件,尽可能在内存和时间受限的情况下多取一些 seq 文件
+在受限的内存和时间下,先依次选择 unseq 文件,每次根据 unseq 文件的时间范围选择与之重叠的 seq 文件,然后按次序重试每一个 seq 文件,尽可能在内存和时间受限的情况下多取一些 seq 文件
### merge
-基本与 inplace 策略类似,首先根据 storageGroupName 选出所有需要 merge 的 series ,然后针对 selector 中选出的每一个 seq 文件建立 chunkMetaHeap ,并根据配置中的 mergeChunkSubThreadNum 分多个子线程进行合并
+基本与 inplace 策略类似,首先根据 storageGroupName 选出所有需要 merge 的 series ,然后针对 selector 中选出的每一个 seq 文件建立 chunkMetaHeap , 并根据配置中的 mergeChunkSubThreadNum 分多个子线程进行合并
-## merge中断后的恢复
+## merge 中断后的恢复
merge 在系统突然关闭或者出现故障时,可能会被强行中断,此时系统会记录下被中断的 merge 并在下一次 StorageGroupProcessor 被创建时扫描 merge.log 文件,根据配置进行重新 merge,也就是 recover 过程
@@ -108,5 +108,5 @@ merge 会有以下几个状态,其中恢复过程均为优先放弃合并策
恢复时直接进行 cleanUp ,并执行 merge 完成的回调操作
### MERGE_END
-表面所有的文件已经被合并,此次merge已经完成
+表面所有的文件已经被合并,此次 merge 已经完成
原则上不会在 merge log 中出现此状态
\ No newline at end of file
diff --git a/docs/zh/SystemDesign/StorageEngine/Recover.md b/docs/zh/SystemDesign/StorageEngine/Recover.md
index cd4735b..1793dec 100644
--- a/docs/zh/SystemDesign/StorageEngine/Recover.md
+++ b/docs/zh/SystemDesign/StorageEngine/Recover.md
@@ -27,7 +27,7 @@
* org.apache.iotdb.db.engine.storagegroup.StorageGroupProcessor.recover()
-* 首先获得该存储组下所有以.tsfile结尾的数据文件,返回 TsFileResource,共有如下几个文件列表
+* 首先获得该存储组下所有以 .tsfile 结尾的数据文件,返回 TsFileResource,共有如下几个文件列表
* 顺序文件
* 0.10 版本的文件(封口/未封口)
@@ -36,24 +36,23 @@
* 0.10 版本的文件(封口/未封口)
* 0.9 版本的文件(封口)
-
* 若该存储组下有 0.9 版本的 TsFile 文件,则将旧版本的顺序和乱序文件分别加入`upgradeSeqFileList`和`upgradeSeqFileList`中,供升级和查询使用。
* 将顺序、乱序文件按照分区分组 Map<Long, List<TsFileResource>>
-* 恢复每个分区的顺序文件,将上一步获得的每个分区的顺序 TsFile 文件作为参数,调用`recoverTsFiles`进行恢复,该方法会将恢复后的顺序 TsFile 以TsFileResource 的形式放入`sequenceFileTreeSet`中,若该 TsFile 是此分区的最后一个,且未封口,则还要为其构造`TsFileProcessor`对象,并加入`workSequenceTsFileProcessors`中,该方法的具体细节会在下一小节阐述。
+* 恢复每个分区的顺序文件,将上一步获得的每个分区的顺序 TsFile 文件作为参数,调用`recoverTsFiles`进行恢复,该方法会将恢复后的顺序 TsFile 以 TsFileResource 的形式放入`sequenceFileTreeSet`中,若该 TsFile 是此分区的最后一个,且未封口,则还要为其构造`TsFileProcessor`对象,并加入`workSequenceTsFileProcessors`中,该方法的具体细节会在下一小节阐述。
* 恢复每个分区的乱序文件,将上一步获得的每个分区的乱序 TsFile 文件作为参数,调用`recoverTsFiles`进行恢复,该方法会将恢复后的乱序 TsFile 以 TsFileResource 的形式放入`unSequenceFileList`中,若该 TsFile 是此分区的最后一个,且未封口,则还要为其构造`TsFileProcessor`对象,并加入`workUnsequenceTsFileProcessors`中,该方法的具体细节会在下一小节阐述。
* 分别遍历上两步得到的`sequenceFileTreeSet`和`unSequenceFileList`,更新分区对应的版本号
-* 检查有没有merge时候的Modification文件,并调用`RecoverMergeTask.recoverMerge`方法对merge进行恢复
+* 检查有没有 merge 时候的 Modification 文件,并调用`RecoverMergeTask.recoverMerge`方法对 merge 进行恢复
-* 调用`updateLastestFlushedTime()`方法,用 0.9 版本的顺序tsfile文件,更新`latestTimeForEachDevice`, `partitionLatestFlushedTimeForEachDevice`以及`globalLatestFlushedTimeForEachDevice`
+* 调用`updateLastestFlushedTime()`方法,用 0.9 版本的顺序 tsfile 文件,更新`latestTimeForEachDevice`, `partitionLatestFlushedTimeForEachDevice`以及`globalLatestFlushedTimeForEachDevice`
- * `latestTimeForEachDevice` 记录了所有device已经插入的各个分区下的最新的时间戳(包括未flush的和已flush的)
- * `partitionLatestFlushedTimeForEachDevice` 记录了所有device已经flush的各个分区下的最新的时间戳,它用来判断一个新插入的点是不是乱序点
- * `globalLatestFlushedTimeForEachDevice` 记录了所有device已经flush的最新时间戳(是各个分区的最新时间戳的汇总)
+ * `latestTimeForEachDevice` 记录了所有 device 已经插入的各个分区下的最新的时间戳(包括未 flush 的和已 flush 的)
+ * `partitionLatestFlushedTimeForEachDevice` 记录了所有 device 已经 flush 的各个分区下的最新的时间戳,它用来判断一个新插入的点是不是乱序点
+ * `globalLatestFlushedTimeForEachDevice` 记录了所有 device 已经 flush 的最新时间戳(是各个分区的最新时间戳的汇总)
* 最后遍历`sequenceFileTreeSet`,用恢复出来的顺序文件,再次更新`latestTimeForEachDevice`, `partitionLatestFlushedTimeForEachDevice`以及`globalLatestFlushedTimeForEachDevice`
@@ -64,7 +63,7 @@
该方法主要负责遍历传进来的所有 TsFile,挨个进行恢复。
* 构造出`TsFileRecoverPerformer`对象,对 TsFile 文件进行恢复,恢复的逻辑封装在`TsFileRecoverPerformer`的`recover()`方法中(具体细节在下一小节展开阐述),该方法会返回一个恢复后的`RestorableTsFileIOWriter`对象。
- * 若恢复过程失败,则记录log,并跳过该tsfile
+ * 若恢复过程失败,则记录 log,并跳过该 tsfile
* 若该 TsFile 文件不是最后一个文件,或者该 TsFile 文件是最后一个文件,但已经被关闭或标记被关闭,只需将该 TsFile 文件在内存中对应的`TsFileResource`对象的`closed`属性置成`true`即可。
@@ -78,13 +77,13 @@
该方法主要负责每个具体的 TsFile 文件的恢复。
-* 首先用tsfile文件构造出一个`RestorableTsFileIOWriter`对象,在`RestorableTsFileIOWriter`的构造方法中,会对该tsfile的文件内容进行检查,必要时进行截断
+* 首先用 tsfile 文件构造出一个`RestorableTsFileIOWriter`对象,在`RestorableTsFileIOWriter`的构造方法中,会对该 tsfile 的文件内容进行检查,必要时进行截断
* 如果这个文件中没有任何内容,则为其写入`MAGIC_STRING`和`VERSION_NUMBER`后,直接返回,此时的`crashed`为`false`,`canWrite`为`true`;
* 如果文件中有内容,构造`TsFileSequenceReader`对象对内容进行解析,调用`selfCheck`方法进行自检,并将不完整的内容截断,初始化`truncatedSize`为`HeaderLength`
* 若文件内容完整(有完整的头部的`MAGIC_STRING`和`VERSION_NUMBER`,以及尾部的`MAGIC_STRING`),则返回`TsFileCheckStatus.COMPLETE_FILE`
* 若文件长度小于`HeaderLength(len(MAGIC_STRING) + len(VERSION_NUMBER))`,或者文件头部内容不是`MAGIC_STRING`,则返回`INCOMPATIBLE_FILE`
* 若文件长度刚好等于`HeaderLength`,且文件内容就是`MAGIC_STRING + VERSION_NUMBER`,则返回`HeaderLength`
- * 若文件长度大于`HeaderLength`,且文件头合法,但文件尾部没有`MAGIC_STRING`,表示该文件不完整,需要进行截断。从`VERSION_NUMBER`往后读,读出chunk中的数据,并根据chunk中的数据恢复出ChunkMetadata,若遇到`CHUNK_GROUP_FOOTER`,则表示整个ChunkGroup是完整的,更新`truncatedSize`至当前位置
+ * 若文件长度大于`HeaderLength`,且文件头合法,但文件尾部没有`MAGIC_STRING`,表示该文件不完整,需要进行截断。从`VERSION_NUMBER`往后读,读出 chunk 中的数据,并根据 chunk 中的数据恢复出 ChunkMetadata,若遇到`CHUNK_GROUP_FOOTER`,则表示整个 ChunkGroup 是完整的,更新`truncatedSize`至当前位置
* 返回`truncatedSize`
* 根据返回的`truncatedSize`,对文件进行截断
* 若`truncatedSize`等于`TsFileCheckStatus.COMPLETE_FILE`,则将`crashed`和`canWrite`置为`false`,并关闭文件的输出流
@@ -95,13 +94,13 @@
* 通过返回的 RestorableTsFileIOWriter 判断文件是否完整
* 若该 TsFile 文件是完整的
- * 若 TsFile 文件对应的 resource 文件存在,则将 resource 文件反序列化(包括每个设备在该tsfile文件中的最小和最大时间戳),并恢复文件版本号
- * 若 TsFile 文件对应的 resource 文件不存在,则重新生成resource 文件
+ * 若 TsFile 文件对应的 resource 文件存在,则将 resource 文件反序列化(包括每个设备在该 tsfile 文件中的最小和最大时间戳),并恢复文件版本号
+ * 若 TsFile 文件对应的 resource 文件不存在,则重新生成 resource 文件
* 返回生成的 `RestorableTsFileIOWriter`
* 若 TsFile 不完整
- * 调用`recoverResourceFromWriter`,通过`RestorableTsFileIOWriter`中的ChunkMetadata信息,恢复出resource信息
+ * 调用`recoverResourceFromWriter`,通过`RestorableTsFileIOWriter`中的 ChunkMetadata 信息,恢复出 resource 信息
* 调用`redoLogs`方法将这个文件对应的一个或多个写前日志文件中的数据都写到一个临时 Memtable 中,并持久化到这个不完整的 TsFile 中
* 对于顺序文件,跳过时间戳小于等于当前 resource 的 WAL
* 对于乱序文件,将 WAL 全部重做,有可能重复写入多个 device 的 ChunkGroup
- * 如果该 TsFile 不是当前分区的最后一个 TsFile,或者该 TsFile 有`.closing`文件存在,则调用`RestorableTsFileIOWriter`的`endFile()`方法,将文件封口,并删除`.closing`文件,并为其生成resource文件
\ No newline at end of file
+ * 如果该 TsFile 不是当前分区的最后一个 TsFile,或者该 TsFile 有`.closing`文件存在,则调用`RestorableTsFileIOWriter`的`endFile()`方法,将文件封口,并删除`.closing`文件,并为其生成 resource 文件
\ No newline at end of file
diff --git a/docs/zh/SystemDesign/StorageEngine/StorageEngine.md b/docs/zh/SystemDesign/StorageEngine/StorageEngine.md
index af44273..4497608 100644
--- a/docs/zh/SystemDesign/StorageEngine/StorageEngine.md
+++ b/docs/zh/SystemDesign/StorageEngine/StorageEngine.md
@@ -41,7 +41,7 @@
* org.apache.iotdb.db.engine.storagegroup.StorageGroupProcessor
- 负责一个存储组一个时间分区内的数据写入和访问。管理所有分区的TsFileProcessor。
+ 负责一个存储组一个时间分区内的数据写入和访问。管理所有分区的 TsFileProcessor。
* org.apache.iotdb.db.engine.storagegroup.TsFileProcessor
diff --git a/docs/zh/SystemDesign/StorageEngine/WAL.md b/docs/zh/SystemDesign/StorageEngine/WAL.md
index a91ebac..140ebb7 100644
--- a/docs/zh/SystemDesign/StorageEngine/WAL.md
+++ b/docs/zh/SystemDesign/StorageEngine/WAL.md
@@ -28,7 +28,7 @@
* WAL 记录细节
* 在 org.apache.iotdb.db.writelog.manager 中,会不断在 nodeMap 中积累 WAL
* WAL 刷磁盘有三种方式(同时启用)
- * 在 org.apache.iotdb.db.writelog.node.ExclusiveWriteLogNode 中会根据配置中的 wal_buffer_size 二分之一分配作为 WAL 的logBufferWorking 可写缓存,另外二分之一作为刷盘缓存区,如在新增 WAL 过程中超过了logBufferWorking 大小则刷到磁盘中
+ * 在 org.apache.iotdb.db.writelog.node.ExclusiveWriteLogNode 中会根据配置中的 wal_buffer_size 二分之一分配作为 WAL 的 logBufferWorking 可写缓存,另外二分之一作为刷盘缓存区,如在新增 WAL 过程中超过了 logBufferWorking 大小则刷到磁盘中
* 在 org.apache.iotdb.db.writelog.node.ExclusiveWriteLogNode 中每次写入记录会判断当前 node 积累的 WAL 大小是否超过配置中的 flush_wal_threshold,如超过则刷到磁盘中
* 在 org.apache.iotdb.db.writelog.manager.MultiFileLogNodeManager 启动时会生成一个定时线程,每隔 force_wal_period_in_ms 时间间隔定时调用线程将内存中的 nodeMap 刷到磁盘中
@@ -36,7 +36,7 @@
* 整个 forceTask 主要耗时都集中在 org.apache.iotdb.db.writelog.io.LogWriter.force(),且因磁盘属性不同差别巨大
* 分别对 SSD 和 HDD 进行 forceTask 的测试
- * 测试负载为1sg,1device,100sensor,每个sensor写100W个点,force_wal_period_in_ms=10
+ * 测试负载为 1sg,1device,100sensor, 每个 sensor 写 100W 个点,force_wal_period_in_ms=10
* 在 SSD 中,每秒可以刷大约 75MB 的数据到磁盘中
* 在 HDD 中,每秒可以刷大约 5MB 的数据到磁盘中
* 所以在 HDD 环境中,用户必须注意调节 force_wal_period_in_ms 不会太小,否则会严重影响写入性能
diff --git a/docs/zh/SystemDesign/Tools/Sync.md b/docs/zh/SystemDesign/Tools/Sync.md
index e230f9c..bb39dc0 100644
--- a/docs/zh/SystemDesign/Tools/Sync.md
+++ b/docs/zh/SystemDesign/Tools/Sync.md
@@ -40,7 +40,7 @@
- [文件清理](#文件清理)
- [文件传输模块](#文件传输模块)
- [包](#包-1)
- - [同步schema](#同步schema)
+ - [同步 schema](#同步-schema)
- [同步数据文件](#同步数据文件)
- [恢复模块](#恢复模块)
- [包](#包-2)
@@ -63,7 +63,7 @@
# 同步工具
-同步工具是定期将本地磁盘中和新增的已持久化的tsfile文件上传至云端并加载到Apache IoTDB的套件工具。
+同步工具是定期将本地磁盘中和新增的已持久化的 tsfile 文件上传至云端并加载到 Apache IoTDB 的套件工具。
## 概述
@@ -73,17 +73,17 @@
同步工具的需求主要有以下几个方面:
-* 在生产环境中,Apache IoTDB会收集数据源(工业设备、移动端等)产生的数据存储到本地。由于数据源可能分布在不同的地方,可能会有多个Apache IoTDB同时负责收集数据。针对每一个IoTDB,它需要将自己本地的数据同步到数据中心中。数据中心负责收集并管理来自多个Apache IoTDB的数据。
+* 在生产环境中,Apache IoTDB 会收集数据源(工业设备、移动端等)产生的数据存储到本地。由于数据源可能分布在不同的地方,可能会有多个 Apache IoTDB 同时负责收集数据。针对每一个 IoTDB,它需要将自己本地的数据同步到数据中心中。数据中心负责收集并管理来自多个 Apache IoTDB 的数据。
-* 随着Apache IoTDB系统的广泛应用,用户根据目标业务需求需要将一些Apache IoTDB实例生成的tsfile文件放在另一个Apache IoTDB实例的数据目录下加载并应用,实现数据同步。
+* 随着 Apache IoTDB 系统的广泛应用,用户根据目标业务需求需要将一些 Apache IoTDB 实例生成的 tsfile 文件放在另一个 Apache IoTDB 实例的数据目录下加载并应用,实现数据同步。
-* 同步模块在发送端以独立进程的形式存在,在接收端和Apache IoTDB位于同一进程内。
+* 同步模块在发送端以独立进程的形式存在,在接收端和 Apache IoTDB 位于同一进程内。
-* 支持一个发送端向多个接收端同步数据且一个接收端可同时接收多个发送端的数据,但需要保证多个发送端同步的数据不冲突(即一个设备的数据来源只能有一个),否则需要提示冲突。
+* 支持一个发送端向多个接收端同步数据且一个接收端可同时接收多个发送端的数据,但需要保证多个发送端同步的数据不冲突(即一个设备的数据来源只能有一个),否则需要提示冲突。
### 目标
-利用同步工具可以将数据文件在两个Apache IoTDB实例间传输并加载。在网络不稳定或宕机等情况发生时,保证文件能够被完整、正确地传送到数据中心。
+利用同步工具可以将数据文件在两个 Apache IoTDB 实例间传输并加载。在网络不稳定或宕机等情况发生时,保证文件能够被完整、正确地传送到数据中心。
## 目录结构
@@ -95,34 +95,34 @@
### 目录结构说明
-sync-sender文件夹中包含该节点作为发送端时同步数据期间的临时文件、状态日志等。
+sync-sender 文件夹中包含该节点作为发送端时同步数据期间的临时文件、状态日志等。
-sync-receiver文件夹中包含该节点作为接收端时接收数据并加载期间的临时文件、状态日志等。
+sync-receiver 文件夹中包含该节点作为接收端时接收数据并加载期间的临时文件、状态日志等。
-schema/sync文件夹下保存的是需要持久化的同步信息。
+schema/sync 文件夹下保存的是需要持久化的同步信息。
#### 发送端
-`data/sync-sender`为发送端文件夹,该目录下的文件夹名表示接收端的IP和端口,在该实例中有一个接收端`192.168.130.16:5555`, 每个文件夹下包含以下几个文件:
+`data/sync-sender`为发送端文件夹,该目录下的文件夹名表示接收端的 IP 和端口,在该实例中有一个接收端`192.168.130.16:5555`, 每个文件夹下包含以下几个文件:
* last_local_files.txt
-记录同步任务结束后所有已被同步的本地tsfile文件列表,每次同步任务结束后更新。
+记录同步任务结束后所有已被同步的本地 tsfile 文件列表,每次同步任务结束后更新。
* snapshot
-在同步数据期间,该文件夹下含有所有的待同步的tsfile文件的硬链接。
+在同步数据期间,该文件夹下含有所有的待同步的 tsfile 文件的硬链接。
* sync.log
记录同步模块的任务进度日志,用以系统宕机恢复时使用,后文会对该文件的结构进行详细阐述。
#### 接收端
-`sync-receiver`为接收端文件夹,该目录下的文件夹名表示发送端的IP和UUID,表示从该发送端接收到的数据文件和文件加载日志情况等,在该实例中有一个发送端`192.168.130.14`,它的UUID为`a45b6e63eb434aad891264b5c08d448e`。 每个文件夹下包含以下几个文件:
+`sync-receiver`为接收端文件夹,该目录下的文件夹名表示发送端的 IP 和 UUID,表示从该发送端接收到的数据文件和文件加载日志情况等,在该实例中有一个发送端`192.168.130.14`,它的 UUID 为`a45b6e63eb434aad891264b5c08d448e`。 每个文件夹下包含以下几个文件:
* load.log
-该文件是记录tsfile文件加载的任务进度日志,用以系统宕机恢复时使用。
+该文件是记录 tsfile 文件加载的任务进度日志,用以系统宕机恢复时使用。
* data
-该文件夹中含有已从发送端接收到的tsfile文件。
+该文件夹中含有已从发送端接收到的 tsfile 文件。
#### 其他
@@ -132,17 +132,17 @@ schema/sync文件夹下保存的是需要持久化的同步信息。
该文件锁的目的是保证同一个发送端对同一个接收端仅能启动一个发送端实例,即只有一个向该接收端同步数据的进程。图示中目录`192.168.130.16_5555/sync_lock`表示对接收端`192.168.130.16_5555`同步的
实例锁。每次启动时首先会检查该文件是否上锁,如果上锁说明已经有向该接收端同步数据的发送端,则停止本实例。
-* 作为发送端时,发送端的唯一标识UUID`uuid.txt`
+* 作为发送端时,发送端的唯一标识 UUID`uuid.txt`
每个发送端有一个唯一的标识,以供接收端区分不同的发送端
-* 作为发送端时,每个接收端的schema同步进度`sync_schema_pos`
+* 作为发送端时,每个接收端的 schema 同步进度`sync_schema_pos`
- 由于schema日志`mlog.txt`数据是追加的,其中记录了所有元信息的变化过程,因此每次同步完schema后记录下当前位置在下次同步时直接增量同步即可减少重复schema传输。
+ 由于 schema 日志`mlog.txt`数据是追加的,其中记录了所有元信息的变化过程,因此每次同步完 schema 后记录下当前位置在下次同步时直接增量同步即可减少重复 schema 传输。
* 作为接收端,接收端中每个设备的所有信息`device_owner.log`
同步工具的应用中,一个接收端可以同时接收多个发送端的数据,但是不能产生冲突,否则接收端将不能保证数据的正确性。因此需要记录下每个设备是由哪个发送端进行同步的,遵循先到先得原则。
-单独将这些信息放在schmea文件夹下的原因是一个Apache IoTDB实例可以拥有多个数据文件目录,也就是data目录可以有多个,但是schema文件夹只有一个,而这些信息是一个发送端实例共享的信息,而data文件夹下的信息表示的是该文件目录下的同步情况,属于子任务信息(每个数据文件目录即为一个子任务)。
+单独将这些信息放在 schmea 文件夹下的原因是一个 Apache IoTDB 实例可以拥有多个数据文件目录,也就是 data 目录可以有多个,但是 schema 文件夹只有一个,而这些信息是一个发送端实例共享的信息,而 data 文件夹下的信息表示的是该文件目录下的同步情况,属于子任务信息(每个数据文件目录即为一个子任务)。
## 同步工具发送端
@@ -162,21 +162,21 @@ org.apache.iotdb.db.sync.sender.manage
##### 文件选择
-文件选择的功能是选出当前Apache IoTDB实例中已封口的tsfile文件(有对应的`.resource`文件, 且不含`.modification`文件和`.merge`文件)列表和上次同步任务结束后记录的tsfile文件列表的差异,共有两部分:删除的tsfile文件列表和新增的tsfile文件列表。并对所有的新增的文件进行硬链接,防止同步期间由于系统运行导致的文件删除等操作。
+文件选择的功能是选出当前 Apache IoTDB 实例中已封口的 tsfile 文件(有对应的`.resource`文件,且不含`.modification`文件和`.merge`文件)列表和上次同步任务结束后记录的 tsfile 文件列表的差异,共有两部分:删除的 tsfile 文件列表和新增的 tsfile 文件列表。并对所有的新增的文件进行硬链接,防止同步期间由于系统运行导致的文件删除等操作。
##### 文件清理
当接收到文件传输模块的任务结束的通知时,执行以下命令:
-* 将`last_local_files.txt`文件中的文件名列表加载到内存形成set,并逐行解析`log.sync`对set进行删除和添加
+* 将`last_local_files.txt`文件中的文件名列表加载到内存形成 set,并逐行解析`log.sync`对 set 进行删除和添加
-* 将内存中的文件名列表set写入`current_local_files.txt`文件中
+* 将内存中的文件名列表 set 写入`current_local_files.txt`文件中
* 删除`last_local_files.txt`文件
* 将`current_local_files.txt`重命名为`last_local_files.txt`
-* 删除sequence文件夹和`sync.log`文件
+* 删除 sequence 文件夹和`sync.log`文件
#### 文件传输模块
@@ -184,9 +184,9 @@ org.apache.iotdb.db.sync.sender.manage
org.apache.iotdb.db.sync.sender.transfer
-##### 同步schema
+##### 同步 schema
-在同步数据文件前,首先同步新增的schmea信息,并更新`sync_schema_pos`。
+在同步数据文件前,首先同步新增的 schmea 信息,并更新`sync_schema_pos`。
##### 同步数据文件
@@ -194,15 +194,15 @@ org.apache.iotdb.db.sync.sender.transfer
1. 开始同步任务,在`sync.log`记录`sync start`
2. 开始同步删除的文件列表,在`sync.log`记录`sync deleted file names start`
-3. 通知接收端开始同步删除的文件名列表,
+3. 通知接收端开始同步删除的文件名列表,
4. 对删除列表中的每一个文件名
- 4.1. 向接收端传输文件名(示例`1581324718762-101-1.tsfile`)
+ 4.1. 向接收端传输文件名(示例`1581324718762-101-1.tsfile`)
4.2. 传输成功,在`sync.log`中记录`1581324718762-101-1.tsfile`
-5. 开始同步新增的tsfile文件列表,在`sync.log`记录`sync deleted file names end和 sync tsfile start`
+5. 开始同步新增的 tsfile 文件列表,在`sync.log`记录`sync deleted file names end 和 sync tsfile start`
6. 通知接收端开始同步文件
-7. 对新增列表中的每一个tsfile:
- 7.1. 将文件按块传输给接收端(示例`1581324718762-101-1.tsfile`)
- 7.2. 若文件传输失败,则多次尝试,若尝试超过一定次数(可由用户配置,默认为5),放弃该文件的传输;若传输成功,在`sync.log`中记录`1581324718762-101-1.tsfile`
+7. 对新增列表中的每一个 tsfile:
+ 7.1. 将文件按块传输给接收端(示例`1581324718762-101-1.tsfile`)
+ 7.2. 若文件传输失败,则多次尝试,若尝试超过一定次数(可由用户配置,默认为 5),放弃该文件的传输;若传输成功,在`sync.log`中记录`1581324718762-101-1.tsfile`
8. 通知接收端同步任务结束,在`sync.log`记录`sync tsfile end`和`sync end`
9. 调用文件管理模块清理文件
10. 结束同步任务
@@ -217,26 +217,25 @@ org.apache.iotdb.db.sync.sender.recover
同步工具发送端每次启动同步任务时,首先检查发送端文件夹下有没有对应的接收端文件夹,若没有,表示没有和该接收端进行过同步任务,跳过恢复模块;否则,根据该文件夹下的文件执行恢复算法:
-1. 若存在`current_local_files.txt`,跳转到步骤2;若不存在,跳转到步骤3
+1. 若存在`current_local_files.txt`,跳转到步骤 2;若不存在,跳转到步骤 3
2. 若存在`last_local_files.txt`,则删除`current_local_files.txt`文件并跳转到步骤
-3;若不存在,跳转到步骤7
-3. 若存在`sync.log`,跳转到步骤4;若不存在,跳转到步骤8
-4. 将`last_local_files.txt`文件中的文件名列表加载到内存形成set,并逐行解析
-`sync.log`对set进行删除和添加
-5. 将内存中的文件名列表set写入`current_local_files.txt`文件中
+3;若不存在,跳转到步骤 7
+3. 若存在`sync.log`,跳转到步骤 4;若不存在,跳转到步骤 8
+4. 将`last_local_files.txt`文件中的文件名列表加载到内存形成 set,并逐行解析
+`sync.log`对 set 进行删除和添加
+5. 将内存中的文件名列表 set 写入`current_local_files.txt`文件中
6. 删除`last_local_files.txt`文件
7. 将`current_local_files.txt`重命名为`last_local_files.txt`
-8. 删除sequence文件夹和`sync.log`文件
+8. 删除 sequence 文件夹和`sync.log`文件
9. 算法结束
-
## 同步工具接收端
### 需求说明
* 由于接收端需要同时接收来自多个发送端的文件,需要将不同发送端的文件区分开来,统一管理这些文件。
-* 接收端从发送端接收文件并检验文件名、文件数据和该文件的MD5值。文件接收完成后,存储文件到接收端本地,并对接收到的tsfile文件进行MD5值校验和文件尾部检查,若检查通过若未正确接收,则对文件进行重传。
+* 接收端从发送端接收文件并检验文件名、文件数据和该文件的 MD5 值。文件接收完成后,存储文件到接收端本地,并对接收到的 tsfile 文件进行 MD5 值校验和文件尾部检查,若检查通过若未正确接收,则对文件进行重传。
* 针对发送端传来的数据文件(可能包含了对旧数据的更新,新数据的插入等操作),需要将这部分数据合并到接收端本地的文件中。
@@ -252,17 +251,17 @@ org.apache.iotdb.db.sync.receiver.transfer
文件传输模块负责接收从发送端传输的文件名和文件,其流程如下:
-1. 接收到发送端的同步开始指令,检查是否存在sync.log文件,若存在则表示上次同步的数据还未加载完毕,拒绝本次同步任务;否则在sync.log中记录sync.start
-2. 接收到发送端的开始同步删除的文件名列表的指令,在sync.log中记录sync deleted file names start
+1. 接收到发送端的同步开始指令,检查是否存在 sync.log 文件,若存在则表示上次同步的数据还未加载完毕,拒绝本次同步任务;否则在 sync.log 中记录 sync.start
+2. 接收到发送端的开始同步删除的文件名列表的指令,在 sync.log 中记录 sync deleted file names start
3. 依次接收发送端传输的删除文件名
- 3.1. 接收到发送端传输的文件名(示例`1581324718762-101-1.tsfile`)
+ 3.1. 接收到发送端传输的文件名(示例`1581324718762-101-1.tsfile`)
3.2. 接收成功,在`sync.log`中记录`1581324718762-101-1.tsfile`,并提交给数据加载模块处理
4. 接收到发送单的开始同步传输的文件的指令,在`sync.log`中记录`sync deleted file names end`和`sync tsfile start`
-5. 依次接收发送端传输的tsfile文件
- 5.1. 按块接收发送端传输的文件(示例`1581324718762-101-2.tsfile`)
+5. 依次接收发送端传输的 tsfile 文件
+ 5.1. 按块接收发送端传输的文件(示例`1581324718762-101-2.tsfile`)
5.2. 对文件进行校验,若检验失败,删除该文件并通知发送端失败;否则,在`sync.log`中记录`1581324718762-101-2.tsfile`,并提交给数据加载模块处理
6. 接收到发送端的同步任务结束命令,在`sync.log`中记录`sync tsfile end`和`sync end`
-7. 创建sync.end空文件
+7. 创建 sync.end 空文件
#### 文件加载模块
@@ -272,13 +271,13 @@ org.apache.iotdb.db.sync.receiver.load
##### 文件删除
-对于需要删除的文件(示例`1581324718762-101-1.tsfile`),在内存中的`sequence tsfile list`中搜索是否有该文件,如有则将该文件从内存中维护的列表中删除并将磁盘中的文件删除。执行成功后在`load.log`中记录`delete 1581324718762-101-1.tsfile`。
+对于需要删除的文件(示例`1581324718762-101-1.tsfile`),在内存中的`sequence tsfile list`中搜索是否有该文件,如有则将该文件从内存中维护的列表中删除并将磁盘中的文件删除。执行成功后在`load.log`中记录`delete 1581324718762-101-1.tsfile`。
##### 加载新文件
-对于需要加载的文件(示例`1581324718762-101-1.tsfile`),首先用`device_owner.log`检查该文件是否符合应用场景,即是否和其他发送端传输了相同设备的数据导致了冲突),如果发生了冲突,则拒绝此次加载并向发送端发送错误信息;否则,更新`device_owner.log`信息。
+对于需要加载的文件(示例`1581324718762-101-1.tsfile`),首先用`device_owner.log`检查该文件是否符合应用场景,即是否和其他发送端传输了相同设备的数据导致了冲突),如果发生了冲突,则拒绝此次加载并向发送端发送错误信息;否则,更新`device_owner.log`信息。
-符合应用场景要求后,将该文件插入`sequence tsfile list`中合适的位置并将文件移动到`data/sequence`目录下。执行成功后在`load.log`中记录`load 1581324718762-101-1.tsfile`。每次文件加载完毕后,检查同步的目录下是否含有sync.end文件,如含有该文件且sequence文件夹下为空,则先删除sync.log文件,再删除load.log和sync.end文件。
+符合应用场景要求后,将该文件插入`sequence tsfile list`中合适的位置并将文件移动到`data/sequence`目录下。执行成功后在`load.log`中记录`load 1581324718762-101-1.tsfile`。每次文件加载完毕后,检查同步的目录下是否含有 sync.end 文件,如含有该文件且 sequence 文件夹下为空,则先删除 sync.log 文件,再删除 load.log 和 sync.end 文件。
#### 恢复模块
@@ -287,10 +286,10 @@ org.apache.iotdb.db.sync.receiver.recover
##### 流程
-ApacheIoTDB系统启动时,依次检查sync文件夹下的各个子文件夹,每个子文件表示由文件夹名所代表的发送端的同步任务。根据每个子文件夹下的文件执行恢复算法:
+ApacheIoTDB 系统启动时,依次检查 sync 文件夹下的各个子文件夹,每个子文件表示由文件夹名所代表的发送端的同步任务。根据每个子文件夹下的文件执行恢复算法:
-1. 若不存在`sync.log`文件,跳转到步骤4;若存在,跳转到步骤2
-2. 逐行扫描sync.log的日志,执行对应的删除文件的操作和加载文件的操作,若该操作已在`load.log`文件中记录,则表明已经执行完毕,跳过该操作。跳转到步骤3
+1. 若不存在`sync.log`文件,跳转到步骤 4;若存在,跳转到步骤 2
+2. 逐行扫描 sync.log 的日志,执行对应的删除文件的操作和加载文件的操作,若该操作已在`load.log`文件中记录,则表明已经执行完毕,跳过该操作。跳转到步骤 3
3. 删除`sync.log`文件
4. 删除`load.log`文件
5. 删除`sync.end`文件
diff --git a/docs/zh/SystemDesign/TsFile/Format.md b/docs/zh/SystemDesign/TsFile/Format.md
index 287d703..561d4fc 100644
--- a/docs/zh/SystemDesign/TsFile/Format.md
+++ b/docs/zh/SystemDesign/TsFile/Format.md
@@ -21,7 +21,6 @@
# TsFile 文件格式
-
## 1. TsFile 设计
本章是关于 TsFile 的设计细节。
@@ -33,7 +32,7 @@
- **可变长的字符串类型**
- 存储的方式是以一个 `int` 类型的 `Size` + 字符串组成。`Size` 的值可以为 0。
- `Size` 指的是字符串所占的字节数,它并不一定等于字符串的长度。
- - 举例来说,"sensor_1" 这个字符串将被存储为 `00 00 00 08` + "sensor_1" (ASCII编码)。
+ - 举例来说,"sensor_1" 这个字符串将被存储为 `00 00 00 08` + "sensor_1" (ASCII 编码)。
- 另外需要注意的一点是文件签名 "TsFile000001" (`Magic String` + `Version`), 因为他的 `Size(12)` 和 ASCII 编码值是固定的,所以没有必要在这个字符串前的写入 `Size` 值。
- **数据类型**
- 0: BOOLEAN
@@ -66,7 +65,7 @@
<!-- TODO
-下图是关于TsFile的结构图。
+下图是关于 TsFile 的结构图。
<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/33376433/123052025-f47aab80-d434-11eb-94c2-9b75429e5c54.png">
@@ -78,21 +77,21 @@ TsFile 整体分为两大部分:**数据区**和**索引区**。
**数据区**所包含的概念由小到大有如下三个:
-* **Page数据页**:一段时间序列,是数据块被反序列化的最小单元;
+* **Page 数据页**:一段时间序列,是数据块被反序列化的最小单元;
-* **Chunk数据块**:包含一条时间序列的多个 Page ,是数据块被IO读取的最小单元;
+* **Chunk 数据块**:包含一条时间序列的多个 Page ,是数据块被 IO 读取的最小单元;
-* **ChunkGroup数据块组**:包含一个实体的多个 Chunk。
+* **ChunkGroup 数据块组**:包含一个实体的多个 Chunk。
**索引区**分为三部分:
-* 按时间序列组织的 **TimeseriesIndex**,包含1个头信息和数据块索引(ChunkIndex)列表。头信息记录文件内某条时间序列的数据类型、统计信息(最大最小时间戳等);数据块索引列表记录该序列各Chunk在文件中的 offset,并记录相关统计信息(最大最小时间戳等);
+* 按时间序列组织的 **TimeseriesIndex**,包含 1 个头信息和数据块索引(ChunkIndex)列表。头信息记录文件内某条时间序列的数据类型、统计信息(最大最小时间戳等);数据块索引列表记录该序列各 Chunk 在文件中的 offset,并记录相关统计信息(最大最小时间戳等);
-* **IndexOfTimeseriesIndex**,用于索引各TimeseriesIndex在文件中的 offset;
+* **IndexOfTimeseriesIndex**,用于索引各 TimeseriesIndex 在文件中的 offset;
* **BloomFilter**,针对实体(Entity)的布隆过滤器。
-> 注:ChunkIndex 旧称 ChunkMetadata;TimeseriesIndex 旧称 TimeseriesMetadata;IndexOfTimeseriesIndex 旧称 TsFileMetadata。v0.13版本起,根据其索引区的特性和实际所索引的内容重新命名。
+> 注:ChunkIndex 旧称 ChunkMetadata;TimeseriesIndex 旧称 TimeseriesMetadata;IndexOfTimeseriesIndex 旧称 TsFileMetadata。v0.13 版本起,根据其索引区的特性和实际所索引的内容重新命名。
下图是关于 TsFile 的结构图。
@@ -109,17 +108,17 @@ TsFile 的查询流程,以查 d1.s1 为例:
#### 1.2.1 文件签名和版本号
-TsFile文件头由 6 个字节的 "Magic String" (`TsFile`) 和 6 个字节的版本号 (`000002`)组成。
+TsFile 文件头由 6 个字节的 "Magic String" (`TsFile`) 和 6 个字节的版本号 (`000002`) 组成。
#### 1.2.2 数据区
##### ChunkGroup 数据块组
-`ChunkGroup` 存储了一个实体(Entity) 一段时间的数据。由若干个 `Chunk`, 一个字节的分隔符 `0x00` 和 一个`ChunkFooter`组成。
+`ChunkGroup` 存储了一个实体 (Entity) 一段时间的数据。由若干个 `Chunk`, 一个字节的分隔符 `0x00` 和 一个`ChunkFooter`组成。
##### Chunk 数据块
-一个 `Chunk` 存储了一个物理量(Measurement) 一段时间的数据,Chunk 内数据是按时间递增序存储的。`Chunk` 是由一个字节的分隔符 `0x01`, 一个 `ChunkHeader` 和若干个 `Page` 构成。
+一个 `Chunk` 存储了一个物理量 (Measurement) 一段时间的数据,Chunk 内数据是按时间递增序存储的。`Chunk` 是由一个字节的分隔符 `0x01`, 一个 `ChunkHeader` 和若干个 `Page` 构成。
##### ChunkHeader 数据块头
@@ -127,21 +126,21 @@ TsFile文件头由 6 个字节的 "Magic String" (`TsFile`) 和 6 个字节的
| :--------------------------: | :----: | :----: |
| measurementID | String | 传感器名称 |
| dataSize | int | chunk 大小 |
-| dataType | TSDataType | chunk的数据类型 |
+| dataType | TSDataType | chunk 的数据类型 |
| compressionType | CompressionType | 压缩类型 |
| encodingType | TSEncoding | 编码类型 |
-| numOfPages | int | 包含的page数量 |
+| numOfPages | int | 包含的 page 数量 |
##### Page 数据页
-一个 `Page` 页存储了一段时间序列,是数据块被反序列化的最小单元。 它包含一个 `PageHeader` 和实际的数据(time-value 编码的键值对)。
+一个 `Page` 页存储了一段时间序列,是数据块被反序列化的最小单元。 它包含一个 `PageHeader` 和实际的数据 (time-value 编码的键值对)。
PageHeader 结构:
| 成员 | 类型 | 解释 |
| :----------------------------------: | :--------------: | :----: |
| uncompressedSize | int | 压缩前数据大小 |
-| compressedSize | int | SNAPPY压缩后数据大小 |
+| compressedSize | int | SNAPPY 压缩后数据大小 |
| statistics | Statistics | 统计量 |
这里是`statistics`的详细信息:
@@ -216,45 +215,43 @@ PageHeader 结构:
| name | String | 对应实体或物理量的名字 |
| offset | long | 偏移量 |
-所有的索引节点构成一棵类B+树结构的**索引树(二级索引)**,这棵树由两部分组成:实体索引部分和物理量索引部分。索引节点类型有四种,分别是`INTERNAL_ENTITY`、`LEAF_ENTITY`、`INTERNAL_MEASUREMENT`、`LEAF_MEASUREMENT`,分别对应实体索引部分的中间节点和叶子节点,和物理量索引部分的中间节点和叶子节点。 只有物理量索引部分的叶子节点(`LEAF_MEASUREMENT`) 指向 `TimeseriesIndex`。
+所有的索引节点构成一棵类 B+树结构的**索引树(二级索引)**,这棵树由两部分组成:实体索引部分和物理量索引部分。索引节点类型有四种,分别是`INTERNAL_ENTITY`、`LEAF_ENTITY`、`INTERNAL_MEASUREMENT`、`LEAF_MEASUREMENT`,分别对应实体索引部分的中间节点和叶子节点,和物理量索引部分的中间节点和叶子节点。 只有物理量索引部分的叶子节点 (`LEAF_MEASUREMENT`) 指向 `TimeseriesIndex`。
下面,我们使用四个例子来加以详细说明。
-索引树节点的度(即每个节点的最大子节点个数)可以由用户进行配置,配置项为`max_degree_of_index_node`,其默认值为256。在以下例子中,我们假定 `max_degree_of_index_node = 10`。
+索引树节点的度(即每个节点的最大子节点个数)可以由用户进行配置,配置项为`max_degree_of_index_node`,其默认值为 256。在以下例子中,我们假定 `max_degree_of_index_node = 10`。
-* 例1:5个实体,每个实体有5个物理量
+* 例 1:5 个实体,每个实体有 5 个物理量
<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/125254013-9d2d7400-e32c-11eb-9f95-1663e14cffbb.png">
-在5个实体,每个实体有5个物理量的情况下,由于实体数和物理量数均不超过 `max_degree_of_index_node`,因此索引树只有默认的物理量部分。在这部分中,每个 IndexNode 最多由10个 IndexEntry 组成。根节点是 `LEAF_ENTITY` 类型,其中的5个 IndexEntry 指向对应的实体的 IndexNode,这些节点直接指向 `TimeseriesIndex`,是 `LEAF_MEASUREMENT`。
+在 5 个实体,每个实体有 5 个物理量的情况下,由于实体数和物理量数均不超过 `max_degree_of_index_node`,因此索引树只有默认的物理量部分。在这部分中,每个 IndexNode 最多由 10 个 IndexEntry 组成。根节点是 `LEAF_ENTITY` 类型,其中的 5 个 IndexEntry 指向对应的实体的 IndexNode,这些节点直接指向 `TimeseriesIndex`,是 `LEAF_MEASUREMENT`。
-* 例2:1个实体,150个物理量
+* 例 2:1 个实体,150 个物理量
<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/125254022-a0c0fb00-e32c-11eb-8fd1-462936358288.png">
-在1个实体,实体中有150个物理量的情况下,物理量个数超过了 `max_degree_of_index_node`,索引树有默认的物理量层级。在这个层级里,每个 IndexNode 最多由10个 IndexEntry 组成。直接指向 `TimeseriesIndex`的节点类型均为 `LEAF_MEASUREMENT`;而后续产生的中间节点不是物理量索引层级的叶子节点,这些节点是 `INTERNAL_MEASUREMENT`;根节点是 `LEAF_ENTITY` 类型。
+在 1 个实体,实体中有 150 个物理量的情况下,物理量个数超过了 `max_degree_of_index_node`,索引树有默认的物理量层级。在这个层级里,每个 IndexNode 最多由 10 个 IndexEntry 组成。直接指向 `TimeseriesIndex`的节点类型均为 `LEAF_MEASUREMENT`;而后续产生的中间节点不是物理量索引层级的叶子节点,这些节点是 `INTERNAL_MEASUREMENT`;根节点是 `LEAF_ENTITY` 类型。
-* 例3:150个实体,每个实体有1个物理量
+* 例 3:150 个实体,每个实体有 1 个物理量
<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/122771008-9a64d380-d2d8-11eb-9044-5ac794dd38f7.png">
-在150个实体,每个实体中有1个物理量的情况下,实体个数超过了 `max_degree_of_index_node`,形成索引树的物理量层级和实体索引层级。在这两个层级里,每个 IndexNode 最多由10个 IndexEntry 组成。直接指向 `TimeseriesIndex` 的节点类型为 `LEAF_MEASUREMENT`,物理量索引层级的根节点同时作为实体索引层级的叶子节点,其节点类型为 `LEAF_ENTITY`;而后续产生的中间节点和根节点不是实体索引层级的叶子节点,因此节点类型为 `INTERNAL_ENTITY`。
+在 150 个实体,每个实体中有 1 个物理量的情况下,实体个数超过了 `max_degree_of_index_node`,形成索引树的物理量层级和实体索引层级。在这两个层级里,每个 IndexNode 最多由 10 个 IndexEntry 组成。直接指向 `TimeseriesIndex` 的节点类型为 `LEAF_MEASUREMENT`,物理量索引层级的根节点同时作为实体索引层级的叶子节点,其节点类型为 `LEAF_ENTITY`;而后续产生的中间节点和根节点不是实体索引层级的叶子节点,因此节点类型为 `INTERNAL_ENTITY`。
-* 例4:150个实体,每个实体有150个物理量
+* 例 4:150 个实体,每个实体有 150 个物理量
<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/122677241-1a753580-d214-11eb-817f-17bcf797251f.png">
-在150个实体,每个实体中有150个物理量的情况下,物理量和实体个数均超过了 `max_degree_of_index_node`,形成索引树的物理量层级和实体索引层级。在这两个层级里,每个 IndexNode 均最多由10个 IndexEntry 组成。如前所述,从根节点到实体索引层级的叶子节点,类型分别为`INTERNAL_ENTITY` 和 `LEAF_ENTITY`,而每个实体索引层级的叶子节点都是物理量索引层级的根节点,从这里到物理量索引层级的叶子节点,类型分别为`INTERNAL_MEASUREMENT` 和 `LEAF_MEASUREMENT`。
+在 150 个实体,每个实体中有 150 个物理量的情况下,物理量和实体个数均超过了 `max_degree_of_index_node`,形成索引树的物理量层级和实体索引层级。在这两个层级里,每个 IndexNode 均最多由 10 个 IndexEntry 组成。如前所述,从根节点到实体索引层级的叶子节点,类型分别为`INTERNAL_ENTITY` 和 `LEAF_ENTITY`,而每个实体索引层级的叶子节点都是物理量索引层级的根节点,从这里到物理量索引层级的叶子节点,类型分别为`INTERNAL_MEASUREMENT` 和 `LEAF_MEASUREMENT`。
索引采用树形结构进行设计的目的是在实体数或者物理量数量过大时,可以不用一次读取所有的 `TimeseriesIndex`,只需要根据所读取的物理量定位对应的节点,从而减少 I/O,加快查询速度。有关 TsFile 的读流程将在本章最后一节加以详细说明。
-
#### 1.2.4 Magic String
-TsFile 是以6个字节的magic string (`TsFile`) 作为结束。
-
+TsFile 是以 6 个字节的 magic string (`TsFile`) 作为结束。
-恭喜您, 至此您已经完成了 TsFile 的探秘之旅,祝您玩儿的开心!
+恭喜您,至此您已经完成了 TsFile 的探秘之旅,祝您玩儿的开心!
## 2 TsFile 的总览图
@@ -273,28 +270,27 @@ TsFile 是以6个字节的magic string (`TsFile`) 作为结束。
### v0.12 / 000003
<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/33376433/123052025-f47aab80-d434-11eb-94c2-9b75429e5c54.png">
-
-## 3 TsFile工具集
+## 3 TsFile 工具集
### 3.1 IoTDB Data Directory 快速概览工具
该工具的启动脚本会在编译 server 之后生成至 `server\target\iotdb-server-{version}\tools\tsfileToolSet` 目录中。
-使用方式:
+使用方式:
For Windows:
```
-.\print-iotdb-data-dir.bat <IoTDB数据文件夹路径,如果是多个文件夹用逗号分隔> (<输出结果的存储路径>)
+.\print-iotdb-data-dir.bat <IoTDB 数据文件夹路径,如果是多个文件夹用逗号分隔> (<输出结果的存储路径>)
```
For Linux or MacOs:
```
-./print-iotdb-data-dir.sh <IoTDB数据文件夹路径,如果是多个文件夹用逗号分隔> (<输出结果的存储路径>)
+./print-iotdb-data-dir.sh <IoTDB 数据文件夹路径,如果是多个文件夹用逗号分隔> (<输出结果的存储路径>)
```
-在Windows系统中的示例:
+在 Windows 系统中的示例:
```
D:\iotdb\server\target\iotdb-server-{version}\tools\tsfileToolSet>.\print-iotdb-data-dir.bat D:\\data\data
@@ -329,21 +325,21 @@ TsFile data dir num:1
该工具的启动脚本会在编译 server 之后生成至 `server\target\iotdb-server-{version}\tools\tsfileToolSet` 目录中。
-使用方式:
+使用方式:
Windows:
```
-.\print-tsfile-resource-files.bat <TsFileResource文件夹路径>
+.\print-tsfile-resource-files.bat <TsFileResource 文件夹路径>
```
Linux or MacOs:
```
-./print-tsfile-resource-files.sh <TsFileResource文件夹路径>
+./print-tsfile-resource-files.sh <TsFileResource 文件夹路径>
```
-在Windows系统中的示例:
+在 Windows 系统中的示例:
```
D:\iotdb\server\target\iotdb-server-{version}\tools\tsfileToolSet>.\print-tsfile-resource-files.bat D:\data\data\sequence\root.vehicle
@@ -360,25 +356,25 @@ analyzing the resource file finished.
该工具的启动脚本会在编译 server 之后生成至 `server\target\iotdb-server-{version}\tools\tsfileToolSet` 目录中。
-使用方式:
+使用方式:
Windows:
```
-.\print-tsfile-sketch.bat <TsFile文件路径> (<输出结果的存储路径>)
+.\print-tsfile-sketch.bat <TsFile 文件路径> (<输出结果的存储路径>)
```
-- 注意: 如果没有设置输出文件的存储路径, 将使用 "TsFile_sketch_view.txt" 做为默认值。
+- 注意:如果没有设置输出文件的存储路径,将使用 "TsFile_sketch_view.txt" 做为默认值。
Linux or MacOs:
```
-./print-tsfile-sketch.sh <TsFile文件路径> (<输出结果的存储路径>)
+./print-tsfile-sketch.sh <TsFile 文件路径> (<输出结果的存储路径>)
```
-- 注意: 如果没有设置输出文件的存储路径, 将使用 "TsFile_sketch_view.txt" 做为默认值。
+- 注意:如果没有设置输出文件的存储路径,将使用 "TsFile_sketch_view.txt" 做为默认值。
-在mac系统中的示例:
+在 mac 系统中的示例:
```
/iotdb/server/target/iotdb-server-{version}/tools/tsfileToolSet$ ./print-tsfile-sketch.sh test.tsfile
@@ -599,40 +595,40 @@ file length: 33436
### 3.4 TsFileSequenceRead
-您可以使用示例中的类 `example/tsfile/org/apache/iotdb/tsfile/TsFileSequenceRead` 顺序打印 TsFile 中的内容.
+您可以使用示例中的类 `example/tsfile/org/apache/iotdb/tsfile/TsFileSequenceRead` 顺序打印 TsFile 中的内容。
### 3.5 Vis Tool
-Vis是一个把TsFiles中的chunk数据的时间分布以及点数可视化的工具。你可以使用这个工具来帮助你debug,还可以用来观察数据分布等等。
+Vis 是一个把 TsFiles 中的 chunk 数据的时间分布以及点数可视化的工具。你可以使用这个工具来帮助你 debug,还可以用来观察数据分布等等。
欢迎使用这个工具,在社区里交流你的想法。

-- 图中的一个窄长矩形代表的是一个TsFile里的一个chunk,其可视化信息为\[tsName, fileName, chunkId, startTime, endTime, pointCountNum\]。
-- 矩形在x轴上的位置是由该chunk的startTime和endTime决定的。
-- 矩形在y轴上的位置是由以下三项共同决定的:
+- 图中的一个窄长矩形代表的是一个 TsFile 里的一个 chunk,其可视化信息为、[tsName, fileName, chunkId, startTime, endTime, pointCountNum\]。
+- 矩形在 x 轴上的位置是由该 chunk 的 startTime 和 endTime 决定的。
+- 矩形在 y 轴上的位置是由以下三项共同决定的:
- (a)`showSpecific`: 用户指定要显示的特定时间序列集合。
- - (b) seqKey/unseqKey显示规则: 从满足特定时间序列集合的keys提取seqKey或unseqKey时采取不同的显示规则:
- - b-1) unseqKey识别tsName和fileName,因此有相同tsName和fileName但是不同chunkIds的chunk数据将绘制在同一行;
- - b-2) seqKey识别tsName,因此有相同tsName但是不同fileNames和chunkIds的chunk数据将绘制在同一行,
- - (c)`isFileOrder`:根据`isFileOrder`对seqKey&unseqKey进行排序,true则以fileName优先的顺序排序,
- false则以tsName优先的顺序排序。当在一张图上同时显示多条时间序列时,该参数将给用户提供这两种可选的观察视角。
+ - (b) seqKey/unseqKey 显示规则:从满足特定时间序列集合的 keys 提取 seqKey 或 unseqKey 时采取不同的显示规则:
+ - b-1) unseqKey 识别 tsName 和 fileName,因此有相同 tsName 和 fileName 但是不同 chunkIds 的 chunk 数据将绘制在同一行;
+ - b-2) seqKey 识别 tsName,因此有相同 tsName 但是不同 fileNames 和 chunkIds 的 chunk 数据将绘制在同一行,
+ - (c)`isFileOrder`:根据`isFileOrder`对 seqKey&unseqKey 进行排序,true 则以 fileName 优先的顺序排序,
+ false 则以 tsName 优先的顺序排序。当在一张图上同时显示多条时间序列时,该参数将给用户提供这两种可选的观察视角。
-#### 3.5.1 如何运行Vis
+#### 3.5.1 如何运行 Vis
源数据包含两个文件:`TsFileExtractVisdata.java`和`vis.m`。
-`TsFileExtractVisdata.java`从输入的tsfile文件中提取必要的可视化信息,`vis.m`用这些信息来完成作图。
+`TsFileExtractVisdata.java`从输入的 tsfile 文件中提取必要的可视化信息,`vis.m`用这些信息来完成作图。
简单说就是:先运行`TsFileExtractVisdata.java`然后再运行`vis.m`。
-##### 第一步:运行TsFileExtractVisdata.java
+##### 第一步:运行 TsFileExtractVisdata.java
-`TsFileExtractVisdata.java`对输入的tsfiles的每一个chunk提取可视化信息[tsName, fileName, chunkId, startTime, endTime, pointCountNum],
+`TsFileExtractVisdata.java`对输入的 tsfiles 的每一个 chunk 提取可视化信息 [tsName, fileName, chunkId, startTime, endTime, pointCountNum],
并把这些信息保存到指定的输出文件里。
该工具的启动脚本会在编译 server 之后生成至 `server\target\iotdb-server-{version}\tools\tsfileToolSet` 目录中。
-使用方式:
+使用方式:
Windows:
@@ -646,18 +642,18 @@ Linux or MacOs:
./print-tsfile-visdata.sh path1 seqIndicator1 path2 seqIndicator2 ... pathN seqIndicatorN outputPath
```
-参数: [`path1` `seqIndicator1` `path2` `seqIndicator2` ... `pathN` `seqIndicatorN` `outputPath`]
+参数:[`path1` `seqIndicator1` `path2` `seqIndicator2` ... `pathN` `seqIndicatorN` `outputPath`]
-细节:
+细节:
-- 一共2N+1个参数。
-- `seqIndicator`:'true'或者'false' (大小写不敏感). 'true'表示是顺序文件, 'false'表示是乱序文件。
-- `Path`:可以是一个tsfile的全路径,也可以是一个文件夹路径。如果是文件夹路径,你需要确保这个文件夹下的所有tsfile文件的`seqIndicator`都是一样的。
-- 输入的所有TsFile文件必须是封好口的。处理未封口的文件留待未来有需要的情况再实现。
+- 一共 2N+1 个参数。
+- `seqIndicator`:'true'或者'false' (大小写不敏感). 'true'表示是顺序文件,'false'表示是乱序文件。
+- `Path`:可以是一个 tsfile 的全路径,也可以是一个文件夹路径。如果是文件夹路径,你需要确保这个文件夹下的所有 tsfile 文件的`seqIndicator`都是一样的。
+- 输入的所有 TsFile 文件必须是封好口的。处理未封口的文件留待未来有需要的情况再实现。
-##### 第二步:运行vis.m
+##### 第二步:运行 vis.m
-`vis.m`把`TsFileExtractVisdata`生成的visdata加载进来,然后基于visdata以及两个用户绘图参数`showSpecific`和`isFileOrder`来完成作图。
+`vis.m`把`TsFileExtractVisdata`生成的 visdata 加载进来,然后基于 visdata 以及两个用户绘图参数`showSpecific`和`isFileOrder`来完成作图。
```matlab
function [timeMap,countMap] = loadVisData(filePath,timestampUnit)
@@ -718,13 +714,11 @@ function draw(timeMap,countMap,showSpecific,isFileOrder)
% to sort seqKeys&unseqKeys by tsName priority.
```
-
-
#### 3.5.2 例子
-##### 例1
+##### 例 1
-使用由`IoTDBLargeDataIT.insertData`写出的tsfiles。
+使用由`IoTDBLargeDataIT.insertData`写出的 tsfiles。
小修改:`IoTDBLargeDataIT.insertData`最后添加一条`statement.execute("flush");`指令。
第一步:运行`TsFileExtractVisdata.java`
diff --git a/docs/zh/SystemDesign/TsFile/Read.md b/docs/zh/SystemDesign/TsFile/Read.md
index bcf89f6..2de26a9 100644
--- a/docs/zh/SystemDesign/TsFile/Read.md
+++ b/docs/zh/SystemDesign/TsFile/Read.md
@@ -25,7 +25,7 @@
* 1 过滤条件和查询表达式
* 1.1 Filter
- * 1.2 Expression表达式
+ * 1.2 Expression 表达式
* 1.2.1 SingleSeriesExpression 表达式
* 1.2.2 GlobalTimeExpression 表达式
* 1.2.3 IExpression 表达式
@@ -48,7 +48,7 @@
### 1.1 Filter
-Filter 表示基本的过滤条件。用户可以在时间戳上、或某一列的值上给出具体的过滤条件。将时间戳和列值的过滤条件加以区分后,设 t 表示某一时间戳常量,Filter 有以下12种基本类型,在实现上是继承关系。
+Filter 表示基本的过滤条件。用户可以在时间戳上、或某一列的值上给出具体的过滤条件。将时间戳和列值的过滤条件加以区分后,设 t 表示某一时间戳常量,Filter 有以下 12 种基本类型,在实现上是继承关系。
Filter|类型|含义|示例
----|----|---|------
@@ -58,12 +58,12 @@ TimeGtEq|时间过滤条件|时间戳大于等于某个值|TimeGtEq(t),表示
TimeLt|时间过滤条件|时间戳小于某个值|TimeLt(t),表示时间戳小于 t
TimeLtEq|时间过滤条件|时间戳小于等于某个值|TimeLtEq(t),表示时间戳小于等于 t
TimeNotEq|时间过滤条件|时间戳不等于某个值|TimeNotEq(t),表示时间戳不等于 t
-ValueEq|值过滤条件|该列数值等于某个值|ValueEq(2147483649),表示该列数值等于2147483649
-ValueGt|值过滤条件|该列数值大于某个值|ValueGt(100.5),表示该列数值大于100.5
-ValueGtEq|值过滤条件|该列数值大于等于某个值|ValueGtEq(2),表示该列数值大于等于2
+ValueEq|值过滤条件|该列数值等于某个值|ValueEq(2147483649),表示该列数值等于 2147483649
+ValueGt|值过滤条件|该列数值大于某个值|ValueGt(100.5),表示该列数值大于 100.5
+ValueGtEq|值过滤条件|该列数值大于等于某个值|ValueGtEq(2),表示该列数值大于等于 2
ValueLt|值过滤条件|该列数值小于某个值|ValueLt("string"),表示该列数值字典序小于"string"
ValueLtEq|值过滤条件|该列数值小于等于某个值|ValueLtEq(-100),表示该列数值小于等于-100
-ValueNotEq|值过滤条件|该列数值不等于某个值|ValueNotEq(true),表示该列数值的值不能为true
+ValueNotEq|值过滤条件|该列数值不等于某个值|ValueNotEq(true),表示该列数值的值不能为 true
Filter 可以由一个或两个子 Filter 组成。如果 Filter 由单一 Filter 构成,则称之为一元过滤条件,及 UnaryFilter 。若包含两个子 Filter,则称之为二元过滤条件,及 BinaryFilter。在二元过滤条件中,两个子 Filter 之间通过逻辑关系“与”、“或”进行连接,前者称为 AndFilter,后者称为 OrFilter。AndFilter 和 OrFilter 都是二元过滤条件。UnaryFilter 和 BinaryFilter 都是 Filter。
@@ -81,7 +81,7 @@ Filter 可以由一个或两个子 Filter 组成。如果 Filter 由单一 Filte
AndFilter := Filter && Filter
OrFilter := Filter || Filter
-为了便于表示,下面给出 Basic Filter、AndFilter 和 OrFilter 的符号化表示方法,其中 t 表示数据类型为 INT64 的变量;v表示数据类型为 BOOLEAN、INT32、INT64、FLOAT、DOUBLE 或 BINARY 的变量。
+为了便于表示,下面给出 Basic Filter、AndFilter 和 OrFilter 的符号化表示方法,其中 t 表示数据类型为 INT64 的变量;v 表示数据类型为 BOOLEAN、INT32、INT64、FLOAT、DOUBLE 或 BINARY 的变量。
<style> table th:nth-of-type(2) { width: 150px; } </style>
名称|符号化表示方法|示例
@@ -95,19 +95,19 @@ TimeNotEq| time != t| time != 14152176545,表示 timestamp �等于 14152176545
ValueEq| value == v| value == 10,表示 value 等于 10
ValueGt| value > v| value > 100.5,表示 value 大于 100.5
ValueGtEq| value >= v| value >= 2,表示 value 大于等于 2
-ValueLt| value < v| value < “string”,表示 value [1e小于“string”
+ValueLt| value < v| value < “string”,表示 value [1e 小于“string”
ValueLtEq| value <= v| value <= -100,表示 value 小于等于-100
-ValueNotEq| value != v| value != true,表示 value 的值不能为true
-AndFilter| \<Filter> && \<Filter>| 1. value > 100 && value < 200,表示 value大于100且小于200; <br>2. (value >= 100 && value <= 200) && time > 14152176545,表示“value 大于等于100 且 value 小于等于200” 且 “时间戳大于 14152176545”
-OrFilter| \<Filter> || \<Filter>| 1. value > 100 || time > 14152176545,表示value大于100或时间戳大于14152176545;<br>2. (value > 100 && value < 200)|| time > 14152176545,表示“value大于100且value小于200”或“时间戳大于14152176545”
+ValueNotEq| value != v| value != true,表示 value 的值不能为 true
+AndFilter| \<Filter> && \<Filter>| 1. value > 100 && value < 200, 表示 value 大于 100 且小于 200; <br>2. (value >= 100 && value <= 200) && time > 14152176545, 表示“value 大于等于 100 且 value 小于等于 200” 且 “时间戳大于 14152176545”
+OrFilter| \<Filter> || \<Filter>| 1. value > 100 || time > 14152176545,表示 value 大于 100 或时间戳大于 14152176545;<br>2. (value > 100 && value < 200)|| time > 14152176545,表示“value 大于 100 且 value 小于 200”或“时间戳大于 14152176545”
-### 1.2 Expression表达式
+### 1.2 Expression 表达式
-当一个过滤条件作用到一个时间序列上,就成为一个表达式。例如,“数值大于10” 是一个过滤条件;而 “序列 d1.s1 的数值大于10” 就是一条表达式。特殊地,对时间的过滤条件也是一个表达式,称为 GlobalTimeExpression。以下章节将对表达式进行展开介绍。
+当一个过滤条件作用到一个时间序列上,就成为一个表达式。例如,“数值大于 10” 是一个过滤条件;而 “序列 d1.s1 的数值大于 10” 就是一条表达式。特殊地,对时间的过滤条件也是一个表达式,称为 GlobalTimeExpression。以下章节将对表达式进行展开介绍。
-#### 1.2.1 SingleSeriesExpression表达式
+#### 1.2.1 SingleSeriesExpression 表达式
-SingleSeriesExpression 表示针对某一指定时间序列的过滤条件,一个 SingleSeriesExpression 包含一个 Path 和一个 Filter。Path 表示该时间序列的路径;Filter 即为2.1章节中介绍的 Filter,表示相应的过滤条件。
+SingleSeriesExpression 表示针对某一指定时间序列的过滤条件,一个 SingleSeriesExpression 包含一个 Path 和一个 Filter。Path 表示该时间序列的路径;Filter 即为 2.1 章节中介绍的 Filter,表示相应的过滤条件。
SingleSeriesExpression 的结构如下:
@@ -115,43 +115,42 @@ SingleSeriesExpression 的结构如下:
Path: 该 SingleSeriesExpression 指定的时间序列的路径
Filter:过滤条件
-在一次查询中,一个 SingleSeriesExpression 表示该时间序列的数据点必须满足 Filter所表示的过滤条件。下面给出 SingleSeriesExpression 的示例及对应的表示方法。
+在一次查询中,一个 SingleSeriesExpression 表示该时间序列的数据点必须满足 Filter 所表示的过滤条件。下面给出 SingleSeriesExpression 的示例及对应的表示方法。
-例1.
+例 1.
SingleSeriesExpression
Path: "d1.s1"
Filter: AndFilter(ValueGt(100), ValueLt(200))
-该 SingleSeriesExpression 表示"d1.s1"这一时间序列必须满足条件“值大于100且值小于200”。
+该 SingleSeriesExpression 表示"d1.s1"这一时间序列必须满足条件“值大于 100 且值小于 200”。
其符号化的表达方式为:SingleSeriesExpression(“d1.s1”, value > 100 && value < 200)
---------------------------
-例2.
+例 2.
SingleSeriesExpression
Path:“d1.s1”
Filter:AndFilter(AndFilter(ValueGt(100), ValueLt(200)), TimeGt(14152176545))
-该 SingleSeriesExpression 表示"d1.s1"这一时间序列必须满足条件“值大于100且小于200且时间戳大于14152176545”。
+该 SingleSeriesExpression 表示"d1.s1"这一时间序列必须满足条件“值大于 100 且小于 200 且时间戳大于 14152176545”。
其符号化表达方式为:SingleSeriesExpression(“d1.s1”, (value > 100 && value < 200) && time > 14152176545)
#### 1.2.2 GlobalTimeExpression 表达式
GlobalTimeExpression 表示全局的时间过滤条件,一个 GlobalTimeExpression 包含一个 Filter,且该 Filter 中包含的子 Filter 必须全为时间过滤条件。在一次查询中,一个 GlobalTimeExpression 表示查询返回数据点必须满足该表达式中 Filter 所表示的过滤条件。GlobalTimeExpression 的结构如下:
-
GlobalTimeExpression
Filter: 由一个或多个时间过滤条件组成的 Filter。
- 此处的Filter形式化定义如下:
+ 此处的 Filter 形式化定义如下:
Filter := TimeFilter | AndExpression | OrExpression
AndExpression := Filter && Filter
OrExpression := Filter || Filter
下面给出 GlobalTimeExpression 的一些例子,均采用符号化表示方法。
-1. GlobalTimeExpression(time > 14152176545 && time < 14152176645)表示所有被选择的列的时间戳必须满足“大于14152176545且小于14152176645”
-2. GlobalTimeExpression((time > 100 && time < 200) || (time > 400 && time < 500))表示所有被选择列的时间戳必须满足“大于100且小于200”或“大于400且小于500”
+1. GlobalTimeExpression(time > 14152176545 && time < 14152176645) 表示所有被选择的列的时间戳必须满足“大于 14152176545 且小于 14152176645”
+2. GlobalTimeExpression((time > 100 && time < 200) || (time > 400 && time < 500)) 表示所有被选择列的时间戳必须满足“大于 100 且小于 200”或“大于 400 且小于 500”
#### 1.2.3 IExpression 表达式
IExpression 为查询过滤条件。一个 IExpression 可以是一个 SingleSeriesExpression 或者一个 GlobalTimeExpression,这种情况下,IExpression 也称为一元表达式,即 UnaryExpression。一个 IExpression 也可以由两个 IExpression 通过逻辑关系“与”、“或”进行连接得到 “AndExpression” 或 “OrExpression” 二元表达式,即 BinaryExpression。
@@ -193,7 +192,6 @@ IExpression 为查询过滤条件。一个 IExpression 可以是一个 SingleSer
**解释**:该 IExpression 为一个 AndExpression,其要求"d1.s1"和"d1.s2"必须同时满足其对应的 Filter,且时间列必须满足 GlobalTimeExpression 定义的 Filter 条件。
-
#### 1.2.4 可执行表达式
便于理解执行过程,定义可执行表达式的概念。可执行表达式是带有一定限制条件的 IExpression。用户输入的查询条件或构造的 IExpression 将经过特定的优化算法(该算法将在后面章节中介绍)转化为可执行表达式。满足下面任意条件的 IExpression 即为可执行表达式。
@@ -212,25 +210,25 @@ IExpression 为查询过滤条件。一个 IExpression 可以是一个 SingleSer
下面给出 一些可执行表达式和非可执行表达式的示例:
-例1:
+例 1:
IExpression(SingleSeriesExpression(“d1.s1”, value > 100 && value < 200))
是否为可执行表达式:是
-**解释**:该 IExpression 为一个 SingleSeriesExpression,满足条件2
+**解释**:该 IExpression 为一个 SingleSeriesExpression,满足条件 2
----------------------------------
-例2:
+例 2:
IExpression(GlobalTimeExpression (time > 14152176545 && time < 14152176645))
是否为可执行表达式:是
-**解释**:该 IExpression 为一个 GlobalTimeExpression,满足条件1
+**解释**:该 IExpression 为一个 GlobalTimeExpression,满足条件 1
-----------------------
-例3:
+例 3:
IExpression(
AndExpression
@@ -240,11 +238,11 @@ IExpression 为查询过滤条件。一个 IExpression 可以是一个 SingleSer
是否为可执行表达式:否
-**解释**:该 IExpression 为一个 AndExpression,但其中包含了 GlobalTimeExpression,不满足条件3
+**解释**:该 IExpression 为一个 AndExpression,但其中包含了 GlobalTimeExpression,不满足条件 3
--------------------------
-例4:
+例 4:
IExpression(
OrExpression
@@ -256,11 +254,11 @@ IExpression 为查询过滤条件。一个 IExpression 可以是一个 SingleSer
是否为可执行表达式:是
-**解释**:该 IExpression 作为一个 OrExpression,其中叶子结点都是 SingleSeriesExpression,满足条件4.
+**解释**:该 IExpression 作为一个 OrExpression,其中叶子结点都是 SingleSeriesExpression,满足条件 4.
----------------------------
-例5:
+例 5:
IExpression(
AndExpression
@@ -272,9 +270,9 @@ IExpression 为查询过滤条件。一个 IExpression 可以是一个 SingleSer
是否为可执行表达式:否
-**解释**:该 IExpression 为一个 AndExpression,但其叶子结点中包含了 GlobalTimeExpression,不满足条件3
+**解释**:该 IExpression 为一个 AndExpression,但其叶子结点中包含了 GlobalTimeExpression,不满足条件 3
-#### 1.2.5 IExpression转化为可执行表达式的优化算法
+#### 1.2.5 IExpression 转化为可执行表达式的优化算法
本章节介绍将 IExpression 转化为一个可执行表达式的算法。
@@ -310,7 +308,7 @@ IExpression 为查询过滤条件。一个 IExpression 可以是一个 SingleSer
else if relation == OR:
return OrFilter(Filter1, Filter2)
- 算法实现是,使用 FilterFactory 类中的 AndFilter and(Filter left, Filter right) 和 OrFilter or(Filter left, Filter right)方法进行实现。
+ 算法实现是,使用 FilterFactory 类中的 AndFilter and(Filter left, Filter right) 和 OrFilter or(Filter left, Filter right) 方法进行实现。
* combineTwoGlobalTimeExpression: 将两个 GlobalTimeExpression 合并为一个 GlobalTimeExpression。
@@ -321,19 +319,18 @@ IExpression 为查询过滤条件。一个 IExpression 可以是一个 SingleSer
GlobalTimeExpression rightGlobalTimeExpression,
ExpressionType type)
- 输入参数1:leftGlobalTimeExpression,左侧表达式
- 输入参数2:rightGlobalTimeExpression,右侧表达式
- 输入参数3:type,表达式二元运算类型,为“AND”或“OR”
+ 输入参数 1:leftGlobalTimeExpression,左侧表达式
+ 输入参数 2:rightGlobalTimeExpression,右侧表达式
+ 输入参数 3:type,表达式二元运算类型,为“AND”或“OR”
输出:GlobalTimeExpression,最终合并后的表达式
该方法分为两个步骤:
- 1. 设 leftGlobalTimeExpression 的 Filter 为 filter1;rightGlobalTimeExpression 的 Filter 为 filter2,通过 MergeFilter 方法将其合并为一个新的Filter,设为 filter3。
+ 1. 设 leftGlobalTimeExpression 的 Filter 为 filter1;rightGlobalTimeExpression 的 Filter 为 filter2,通过 MergeFilter 方法将其合并为一个新的 Filter,设为 filter3。
2. 创建一个新的 GlobalTimeExpression,并将 filter3 作为其 Filter,返回该 GlobalTimeExpression。
下面给出一个合并两个 GlobalTimeExpression 的例子。
-
三个参数分别为:
leftGlobalTimeExpression:GlobalTimeExpression(Filter: time > 100 && time < 200)
@@ -352,16 +349,16 @@ IExpression 为查询过滤条件。一个 IExpression 可以是一个 SingleSer
List<Path> selectedSeries,
ExpressionType relation)
- 输入参数1:GlobalTimeExpression
- 输入参数2:IExpression
- 输入参数3:被投影的时间序列
- 输入参数4:两个待合并的表达式之间的关系,relation 的取值为 AND 或 OR
+ 输入参数 1:GlobalTimeExpression
+ 输入参数 2:IExpression
+ 输入参数 3:被投影的时间序列
+ 输入参数 4:两个待合并的表达式之间的关系,relation 的取值为 AND 或 OR
输出:合并后的 IExpression,即为可执行表达式。
该方法首先调用 optimize() 方法,将输入的第二个参数 IExpression 转化为可执行表达式(从 optimize() 方法上看为递归调用),然后再分为两种情况进行合并。
- *情况一*:GlobalTimeExpression 和优化后的 IExpression 的关系为 AND。这种情况下,记 GlobalTimeExpression 的 Filter 为 tFilter,则只需要 tFilter 合并到 IExpression 的每个 SingleSeriesExpression 的 Filter 中即可。void addTimeFilterToQueryFilter(Filter timeFilter, IExpression expression)为具体实现方法。例如:
+ *情况一*:GlobalTimeExpression 和优化后的 IExpression 的关系为 AND。这种情况下,记 GlobalTimeExpression 的 Filter 为 tFilter,则只需要 tFilter 合并到 IExpression 的每个 SingleSeriesExpression 的 Filter 中即可。void addTimeFilterToQueryFilter(Filter timeFilter, IExpression expression) 为具体实现方法。例如:
设要将如下 GlobaLTimeFilter 和 IExpression 合并,
@@ -387,7 +384,6 @@ IExpression 为查询过滤条件。一个 IExpression 可以是一个 SingleSer
2. 记 GlobalTimeExpression 的 Filter 为 tFilter,调用 pushGlobalTimeFilterToAllSeries() 方法为每个 Path 创建一个对应的 SingleSeriesExpression,且每个 SingleSeriesExpression 的 Filter 值均为 tFilter;将所有新创建的 SingleSeriesExpression 用 OR 运算符进行连接,得到一个 OrExpression,记其为 orExpression。
3. 调用 mergeSecondTreeToFirstTree 方法将 IExpression 中的节点与步骤二得到的 orExpression 中的节点进行合并,返回合并后的表达式。
-
例如,将如下 GlobaLTimeFilter 和 IExpression 按照关系 OR 进行合并,设该查询的被投影列为 PathList{path1, path2, path3}
1. GlobaLTimeFilter(tFilter)
@@ -426,11 +422,11 @@ IExpression 为查询过滤条件。一个 IExpression 可以是一个 SingleSer
1. 如果 IExpression 为一元表达式,即单一的 SingleSeriesExpression 或单一的 GlobalTimeExpression,则直接将其返回;否则,执行步骤二
2. 算法达到该步骤,说明 IExpression 为 AndExpression 或 OrExpression。
- a. 如果LeftIExpression和RightIExpression均为GlobalTimeExpression,则执行combineTwoGlobalTimeExpression方法,并返回对应的结果。
+ a. 如果 LeftIExpression 和 RightIExpression 均为 GlobalTimeExpression,则执行 combineTwoGlobalTimeExpression 方法,并返回对应的结果。
- b. 如果 LeftIExpression 为 GlobalTimeExpression,而 RightIExpression 不是GlobalTimeExpression,则调用 handleOneGlobalTimeExpressionr() 方法进行合并。
+ b. 如果 LeftIExpression 为 GlobalTimeExpression,而 RightIExpression 不是 GlobalTimeExpression,则调用 handleOneGlobalTimeExpressionr() 方法进行合并。
- c. 如果 LeftIExpression 不是 GlobalTimeExpression,而 RightIExpression 是 GlobalTimeExpression,则调用 handleOneGlobalTimeExpressionr()方法进行合并。
+ c. 如果 LeftIExpression 不是 GlobalTimeExpression,而 RightIExpression 是 GlobalTimeExpression,则调用 handleOneGlobalTimeExpressionr() 方法进行合并。
d. 如果 LeftIExpression 和 RightIExpression 均不是 GlobalTimeExpression,则对 LeftIExpression 递归调用 optimize() 方法得到左可执行表达式;对 RightIExpression 递归调用 optimize() 方法得到右可执行表达式。使用 MergeIExpression 方法,根据 type 的值将左可执行表达式和右可执行表达式合并为一个 IExpression。
@@ -479,7 +475,6 @@ org.apache.iotdb.tsfile.read.query.timegenerator.TsFileTimeGenerator
2. 返回下一个满足“选择条件”的时间戳
-
### 2.3 归并查询
org.apache.iotdb.tsfile.read.query.dataset.DataSetWithoutTimeGenerator
@@ -491,9 +486,9 @@ org.apache.iotdb.tsfile.read.query.dataset.DataSetWithoutTimeGenerator
(1) 创建一个最小堆,堆里面存储“时间戳”,该堆将按照每个时间戳的大小进行组织。
-(2) 初始化堆,依次访问每一个 FileSeriesReader,如果该 FileSeriesReader 中还有数据点,则获取数据点的时间戳并放入堆中。此时每个时间序列最多有1个时间戳被放入到堆中,即该序列最小的时间戳。
+(2) 初始化堆,依次访问每一个 FileSeriesReader,如果该 FileSeriesReader 中还有数据点,则获取数据点的时间戳并放入堆中。此时每个时间序列最多有 1 个时间戳被放入到堆中,即该序列最小的时间戳。
-(3) 如果堆的 size > 0,获取堆顶的时间戳,记为t,并将其在堆中删除,进入步骤(4);如果堆的 size 等于0,则跳到步骤(5),结束数据合并过程。
+(3) 如果堆的 size > 0,获取堆顶的时间戳,记为 t,并将其在堆中删除,进入步骤(4);如果堆的 size 等于 0,则跳到步骤(5),结束数据合并过程。
(4) 创建新的 RowRecord。依次遍历每一条时间序列。在处理其中一条时间序列时,如果该序列没有更多的数据点,则将该列标记为 null 并添加在 RowRecord 中;否则,判断最小的时间戳是否与 t 相同,若不相同,则将该列标记为 null 并添加在 RowRecord 中。若相同,将该数据点添加在 RowRecord 中,同时判断该时间序列是否有新的数据点,若存在,则将下一个时间戳 t' 添加在堆中,并将 t' 设为当前时间序列的最小时间戳。最后,返回步骤(3)。
@@ -515,7 +510,6 @@ org.apache.iotdb.tsfile.read.query.executor.ExecutorWithTimeGenerator
(5) 将步骤(4)中得到的所有数据点合并成一个 RowRecord,此时得到一条查询结果,返回步骤(3)计算下一个查询结果。
-
### 2.5 查询入口
org.apache.iotdb.tsfile.read.query.executor.TsFileExecutor
@@ -528,8 +522,6 @@ TsFileExecutor 接收一个 QueryExpression ,执行该查询并返回相应的
(3) 生成对应的 QueryDataSet,迭代地生成 RowRecord,将查询结果返回。
-
-
### 2.6 相关代码介绍
* Chunk:一段时间序列的内存结构,可供 IChunkReader 进行读取。
@@ -560,7 +552,3 @@ TsFileExecutor 接收一个 QueryExpression ,执行该查询并返回相应的
* 判断是否还有下一个 RowRecord
* 返回下一个 RowRecord
-
-
-
-
diff --git a/docs/zh/SystemDesign/TsFile/TsFile.md b/docs/zh/SystemDesign/TsFile/TsFile.md
index 7801fba..72ead39 100644
--- a/docs/zh/SystemDesign/TsFile/TsFile.md
+++ b/docs/zh/SystemDesign/TsFile/TsFile.md
@@ -23,7 +23,6 @@
TsFile 是 IoTDB 的底层数据文件,专门为时间序列数据设计的列式文件格式。
-
## 相关文档
* [文件格式](Format.md)
diff --git a/docs/zh/SystemDesign/TsFile/Write.md b/docs/zh/SystemDesign/TsFile/Write.md
index e771ede..cd0056b 100644
--- a/docs/zh/SystemDesign/TsFile/Write.md
+++ b/docs/zh/SystemDesign/TsFile/Write.md
@@ -49,7 +49,6 @@ TsFile 文件层的写入接口有两种
当调用 write 接口时,这个设备的数据会交给对应的 ChunkGroupWriter,其中的每个测点会交给对应的 ChunkWriter 进行写入。ChunkWriter 完成编码和打包(生成 Page)。
-
## 2、持久化 ChunkGroup
* TsFileWriter.flushAllChunkGroups()
@@ -62,7 +61,7 @@ TsFile 文件层的写入接口有两种
* TsFileWriter.close()
-根据内存中缓存的元数据,生成 TsFileMetadata 追加到文件尾部(`TsFileWriter.flushMetadataIndex()`),最后关闭文件。
+根据内存中缓存的元数据,生成 TsFileMetadata 追加到文件尾部 (`TsFileWriter.flushMetadataIndex()`),最后关闭文件。
生成 TsFileMetadata 的过程中比较重要的一步是建立元数据索引 (MetadataIndex) 树。正如我们提到过的,元数据索引采用树形结构进行设计的目的是在设备数或者传感器数量过大时,可以不用一次读取所有的 `TimeseriesMetadata`,只需要根据所读取的传感器定位对应的节点,从而减少 I/O,加快查询速度。以下是建立元数据索引树的详细算法和过程:
diff --git a/docs/zh/UserGuide/API/Programming-Cpp-Native-API.md b/docs/zh/UserGuide/API/Programming-Cpp-Native-API.md
index f46ba5a..9005c8c 100644
--- a/docs/zh/UserGuide/API/Programming-Cpp-Native-API.md
+++ b/docs/zh/UserGuide/API/Programming-Cpp-Native-API.md
@@ -30,23 +30,19 @@
- Boost
- OpenSSL 1.0+
-
-
### 安装方法
-编译C++客户端之前首先需要本地编译Thrift库,compile-tools模块负责编译Thrift,之后再编译client-cpp。
-
-
+编译 C++客户端之前首先需要本地编译 Thrift 库,compile-tools 模块负责编译 Thrift,之后再编译 client-cpp。
-#### 在Mac上编译Thrift
+#### 在 Mac 上编译 Thrift
- Bison
-Mac 环境下预安装了Bison 2.3版本,但该版本过低不能够用来编译Thrift。使用Bison 2.3版本是会报以下错误:
+Mac 环境下预安装了 Bison 2.3 版本,但该版本过低不能够用来编译 Thrift。使用 Bison 2.3 版本是会报以下错误:
```invalid directive: '%code'```
-使用下面brew 命令更新bison版本
+使用下面 brew 命令更新 bison 版本
``` shell
brew install bison
@@ -61,26 +57,23 @@ echo 'export PATH="/usr/local/opt/bison/bin:$PATH"' >> ~/.bash_profile
- Boost
-确保安装较新的Boost版本:
+确保安装较新的 Boost 版本:
```shell
brew install boost
brew link boost
```
-
- OpenSSL
-确保openssl库已安装,默认的openssl头文件路径为"/usr/local/opt/openssl/include"
-如果在编译Thrift过程中出现找不到openssl的错误,尝试添加
+确保 openssl 库已安装,默认的 openssl 头文件路径为"/usr/local/opt/openssl/include"
+如果在编译 Thrift 过程中出现找不到 openssl 的错误,尝试添加
`-Dopenssl.include.dir=""`
+#### 在 Linux 上编译 Thrift
-
-#### 在Linux上编译Thrift
-
-Linux下需要确保g++已被安装。
+Linux 下需要确保 g++已被安装。
一条命令安装所有依赖库:
@@ -96,41 +89,36 @@ CentOS:
yum install gcc g++ bison flex boost-devel
```
+#### 在 Windows 上编译 Thrift
+保证你的 Windows 系统已经搭建好了完整的 C/C++的编译构建环境。可以是 MSVC,MinGW 等。
-#### 在Windows上编译Thrift
-
-保证你的Windows系统已经搭建好了完整的C/C++的编译构建环境。可以是MSVC,MinGW等。
-
-如使用MS Visual Studio,在安装时需要勾选 Visual Studio C/C++ IDE and compiler(supporting CMake, Clang, MinGW)。
+如使用 MS Visual Studio,在安装时需要勾选 Visual Studio C/C++ IDE and compiler(supporting CMake, Clang, MinGW)。
- Flex 和 Bison
-Windows版的 Flex 和 Bison 可以从 SourceForge下载: https://sourceforge.net/projects/winflexbison/
+Windows 版的 Flex 和 Bison 可以从 SourceForge 下载:https://sourceforge.net/projects/winflexbison/
-下载后需要将可执行文件重命名为flex.exe和bison.exe以保证编译时能够被找到,添加可执行文件的目录到PATH环境变量中。
+下载后需要将可执行文件重命名为 flex.exe 和 bison.exe 以保证编译时能够被找到,添加可执行文件的目录到 PATH 环境变量中。
- Boost
-Boost官网下载新版本Boost: https://www.boost.org/users/download/
+Boost 官网下载新版本 Boost: https://www.boost.org/users/download/
-依次执行bootstrap.bat 和 b2.exe,本地编译boost
+依次执行 bootstrap.bat 和 b2.exe,本地编译 boost
```shell
bootstrap.bat
.\b2.exe
```
-为了帮助CMake本地安装好的Boost,在编译client-cpp的mvn命令中需添加:
+为了帮助 CMake 本地安装好的 Boost,在编译 client-cpp 的 mvn 命令中需添加:
`-Dboost.include.dir=${your boost header folder} -Dboost.library.dir=${your boost lib (stage) folder}`
-
-
#### CMake 生成器
-CMake需要根据不同编译平台使用不同的生成器。CMake支持的生成器列表如下(`cmake --help`的结果):
-
+CMake 需要根据不同编译平台使用不同的生成器。CMake 支持的生成器列表如下 (`cmake --help`的结果):
```
Visual Studio 16 2019 = Generates Visual Studio 2019 project files.
@@ -163,25 +151,20 @@ CMake需要根据不同编译平台使用不同的生成器。CMake支持的生
CodeBlocks - NMake Makefiles = Generates CodeBlocks project files.
```
-编译client-cpp 时的mvn命令中添加 -Dcmake.generator="" 选项来指定使用的生成器名称。
+编译 client-cpp 时的 mvn 命令中添加 -Dcmake.generator="" 选项来指定使用的生成器名称。
`mvn package -Dcmake.generator="Visual Studio 15 2017 [arch]"`
+#### 编译 C++ 客户端
-
-#### 编译C++ 客户端
-
-Maven 命令中添加"-P client-cpp" 选项编译client-cpp模块。client-cpp需要依赖编译好的thrift,即compile-tools模块。
-
-
-
+Maven 命令中添加"-P client-cpp" 选项编译 client-cpp 模块。client-cpp 需要依赖编译好的 thrift,即 compile-tools 模块。
#### 编译及测试
-完整的C++客户端命令如下:
+完整的 C++客户端命令如下:
`mvn package -P compile-cpp -pl example/client-cpp-example -am -DskipTest`
-注意在Windows下需提前安装好Boost,并添加以下Maven 编译选项:
+注意在 Windows 下需提前安装好 Boost,并添加以下 Maven 编译选项:
```shell
-Dboost.include.dir=${your boost header folder} -Dboost.library.dir=${your boost lib (stage) folder}`
@@ -194,11 +177,9 @@ mvn package -P compile-cpp -pl client-cpp,server,example/client-cpp-example -am
-D"boost.include.dir"="D:\boost_1_75_0" -D"boost.library.dir"="D:\boost_1_75_0\stage\lib" -DskipTests
```
+编译成功后,打包好的。zip 文件将位于:"client-cpp/target/client-cpp-${project.version}-cpp-${os}.zip"
-
-编译成功后,打包好的.zip文件将位于:"client-cpp/target/client-cpp-${project.version}-cpp-${os}.zip"
-
-解压后的目录结构如下图所示(Mac):
+解压后的目录结构如下图所示 (Mac):
```shell
.
@@ -214,29 +195,23 @@ mvn package -P compile-cpp -pl client-cpp,server,example/client-cpp-example -am
| +-- libiotdb_session.dylib
```
-
-
### Q&A
-#### Mac相关问题
+#### Mac 相关问题
-本地Maven编译Thrift时如出现以下链接的问题,可以尝试将xcode-commandline版本从12降低到11.5
+本地 Maven 编译 Thrift 时如出现以下链接的问题,可以尝试将 xcode-commandline 版本从 12 降低到 11.5
https://stackoverflow.com/questions/63592445/ld-unsupported-tapi-file-type-tapi-tbd-in-yaml-file/65518087#65518087
+#### Windows 相关问题
-
-#### Windows相关问题
-
-Maven编译Thrift时需要使用wget下载远端文件,可能出现以下报错:
+Maven 编译 Thrift 时需要使用 wget 下载远端文件,可能出现以下报错:
```
Failed to delete cached file C:\Users\Administrator\.m2\repository\.cache\download-maven-plugin\index.ser
```
-解决方法:
+解决方法:
- 尝试删除 ".m2\repository\\.cache\" 目录并重试。
-- 在添加 pom文件对应的 download-maven-plugin 中添加 "\<skipCache>true\</skipCache>"
-
-
+- 在添加 pom 文件对应的 download-maven-plugin 中添加 "\<skipCache>true\</skipCache>"
diff --git a/docs/zh/UserGuide/API/Programming-Go-Native-API.md b/docs/zh/UserGuide/API/Programming-Go-Native-API.md
index b4f55d0..1fa5423 100644
--- a/docs/zh/UserGuide/API/Programming-Go-Native-API.md
+++ b/docs/zh/UserGuide/API/Programming-Go-Native-API.md
@@ -27,21 +27,18 @@
* make >= 3.0
* curl >= 7.1.1
* thrift 0.13.x
- * Linux、Macos或其他类unix系统
+ * Linux、Macos 或其他类 unix 系统
* Windows+bash(WSL、cygwin、Git Bash)
-
-
-
### 安装方法
- * 通过go mod
+ * 通过 go mod
```sh
-# 切换到GOPATH的HOME路径,启用Go Modules功能
+# 切换到 GOPATH 的 HOME 路径,启用 Go Modules 功能
export GO111MODULE=on
-# 配置GOPROXY环境变量
+# 配置 GOPROXY 环境变量
export GOPROXY=https://goproxy.io
# 创建命名的文件夹或目录,并切换当前目录
@@ -50,7 +47,7 @@ mkdir session_example && cd session_example
# 保存文件,自动跳转到新的地址
curl -o session_example.go -L https://github.com/apache/iotdb-client-go/raw/main/example/session_example.go
-# 初始化go module环境
+# 初始化 go module 环境
go mod init session_example
# 下载依赖包
@@ -60,7 +57,7 @@ go mod tidy
go run session_example.go
```
-* 通过GOPATH
+* 通过 GOPATH
```sh
# get thrift 0.13.0
@@ -75,7 +72,7 @@ cd $GOPATH/src/iotdb-client-go-example/session_example
# 保存文件,自动跳转到新的地址
curl -o session_example.go -L https://github.com/apache/iotdb-client-go/raw/main/example/session_example.go
-# 初始化go module 环境
+# 初始化 go module 环境
go mod init
# 下载依赖包
@@ -84,4 +81,3 @@ go mod tidy
# 编译并运行程序
go run session_example.go
```
-
diff --git a/docs/zh/UserGuide/API/Programming-JDBC.md b/docs/zh/UserGuide/API/Programming-JDBC.md
index ed25d90..98d6e53 100644
--- a/docs/zh/UserGuide/API/Programming-JDBC.md
+++ b/docs/zh/UserGuide/API/Programming-JDBC.md
@@ -26,18 +26,14 @@
* JDK >= 1.8
* Maven >= 3.6
-
-
### 安装方法
-在根目录下执行下面的命令:
+在根目录下执行下面的命令:
```shell
mvn clean install -pl jdbc -am -Dmaven.test.skip=true
```
-
-
-#### 在MAVEN中使用 IoTDB JDBC
+#### 在 MAVEN 中使用 IoTDB JDBC
```xml
<dependencies>
@@ -49,15 +45,13 @@ mvn clean install -pl jdbc -am -Dmaven.test.skip=true
</dependencies>
```
-
-
#### 示例代码
本章提供了如何建立数据库连接、执行 SQL 和显示查询结果的示例。
要求您已经在工程中包含了数据库编程所需引入的包和 JDBC class.
-**注意:为了更快地插入,建议使用 executeBatch()**
+**注意:为了更快地插入,建议使用 executeBatch()**
```Java
import java.sql.*;
@@ -84,7 +78,6 @@ public class JDBCExample {
System.out.println(e.getMessage());
}
-
//Show storage group
statement.execute("SHOW STORAGE GROUP");
outputResult(statement.getResultSet());
@@ -115,7 +108,6 @@ public class JDBCExample {
//Execute insert statements in batch
statement.addBatch("insert into root.demo(timestamp,s0) values(1,1);");
- statement.addBatch("insert into root.demo(timestamp,s0) values(1,1);");
statement.addBatch("insert into root.demo(timestamp,s0) values(2,15);");
statement.addBatch("insert into root.demo(timestamp,s0) values(2,17);");
statement.addBatch("insert into root.demo(timestamp,s0) values(4,12);");
diff --git a/docs/zh/UserGuide/API/Programming-Java-Native-API.md b/docs/zh/UserGuide/API/Programming-Java-Native-API.md
index 645305a..973b29d 100644
--- a/docs/zh/UserGuide/API/Programming-Java-Native-API.md
+++ b/docs/zh/UserGuide/API/Programming-Java-Native-API.md
@@ -26,19 +26,15 @@
* JDK >= 1.8
* Maven >= 3.6
-
-
### 安装方法
-在根目录下运行:
+在根目录下运行:
```shell
mvn clean install -pl session -am -Dmaven.test.skip=true
```
-
-
-### 在MAVEN中使用原生接口
+### 在 MAVEN 中使用原生接口
```xml
<dependencies>
@@ -50,13 +46,11 @@ mvn clean install -pl session -am -Dmaven.test.skip=true
</dependencies>
```
-
-
### 原生接口说明
-下面将给出Session对应的接口的简要介绍和对应参数:
+下面将给出 Session 对应的接口的简要介绍和对应参数:
-* 初始化Session
+* 初始化 Session
```java
// 全部使用默认配置
@@ -87,13 +81,13 @@ mvn clean install -pl session -am -Dmaven.test.skip=true
.build();
```
-* 开启Session
+* 开启 Session
```java
Session.open()
```
-* 关闭Session
+* 关闭 Session
```java
Session.close()
@@ -189,7 +183,7 @@ void insertRecords(List<String> deviceIds, List<Long> times,
List<List<Object>> valuesList)
```
-* 插入同属于一个device的多个 Record。
+* 插入同属于一个 device 的多个 Record。
```java
void insertRecordsOfOneDevice(String deviceId, List<Long> times,
@@ -219,12 +213,12 @@ void executeNonQueryStatement(String sql)
```
* name: 设备模板名称
-* measurements: 工况名称列表,如果该工况是非对齐的,直接将其名称放入一个list中再放入measurements中,
-* 如果该工况是对齐的,将所有对齐工况名称放入一个list再放入measurements中
-* dataTypes: 数据类型名称列表,如果该工况是非对齐的,直接将其数据类型放入一个list中再放入dataTypes中,
- 如果该工况是对齐的,将所有对齐工况的数据类型放入一个list再放入dataTypes中
-* encodings: 编码类型名称列表,如果该工况是非对齐的,直接将其数据类型放入一个list中再放入encodings中,
- 如果该工况是对齐的,将所有对齐工况的编码类型放入一个list再放入encodings中
+* measurements: 工况名称列表,如果该工况是非对齐的,直接将其名称放入一个 list 中再放入 measurements 中,
+* 如果该工况是对齐的,将所有对齐工况名称放入一个 list 再放入 measurements 中
+* dataTypes: 数据类型名称列表,如果该工况是非对齐的,直接将其数据类型放入一个 list 中再放入 dataTypes 中,
+ 如果该工况是对齐的,将所有对齐工况的数据类型放入一个 list 再放入 dataTypes 中
+* encodings: 编码类型名称列表,如果该工况是非对齐的,直接将其数据类型放入一个 list 中再放入 encodings 中,
+ 如果该工况是对齐的,将所有对齐工况的编码类型放入一个 list 再放入 encodings 中
* compressors: 压缩方式列表
void createSchemaTemplate(
String templateName,
@@ -268,26 +262,23 @@ void testInsertRecord(String deviceId, long time, List<String> measurements,
List<TSDataType> types, List<Object> values)
```
-
* 测试 insertTablet,不实际写入数据,只将数据传输到 server 即返回。
```java
void testInsertTablet(Tablet tablet)
```
-
-
### 针对原生接口的连接池
-我们提供了一个针对原生接口的连接池(`SessionPool`),使用该接口时,你只需要指定连接池的大小,就可以在使用时从池中获取连接。
-如果超过60s都没得到一个连接的话,那么会打印一条警告日志,但是程序仍将继续等待。
+我们提供了一个针对原生接口的连接池 (`SessionPool`),使用该接口时,你只需要指定连接池的大小,就可以在使用时从池中获取连接。
+如果超过 60s 都没得到一个连接的话,那么会打印一条警告日志,但是程序仍将继续等待。
当一个连接被用完后,他会自动返回池中等待下次被使用;
当一个连接损坏后,他会从池中被删除,并重建一个连接重新执行用户的操作。
对于查询操作:
-1. 使用SessionPool进行查询时,得到的结果集是`SessionDataSet`的封装类`SessionDataSetWrapper`;
+1. 使用 SessionPool 进行查询时,得到的结果集是`SessionDataSet`的封装类`SessionDataSetWrapper`;
2. 若对于一个查询的结果集,用户并没有遍历完且不再想继续遍历时,需要手动调用释放连接的操作`closeResultSet`;
3. 若对一个查询的结果集遍历时出现异常,也需要手动调用释放连接的操作`closeResultSet`.
4. 可以调用 `SessionDataSetWrapper` 的 `getColumnNames()` 方法得到结果集列名
@@ -304,12 +295,10 @@ void testInsertTablet(Tablet tablet)
使用上述接口的示例代码在 ```example/session/src/main/java/org/apache/iotdb/SessionExample.java```
-
-
-### 集群信息相关的接口 (仅在集群模式下可用)
+### 集群信息相关的接口 (仅在集群模式下可用)
集群信息相关的接口允许用户获取如数据分区情况、节点是否当机等信息。
-要使用该API,需要增加依赖:
+要使用该 API,需要增加依赖:
```xml
<dependencies>
@@ -321,7 +310,7 @@ void testInsertTablet(Tablet tablet)
</dependencies>
```
-建立连接与关闭连接的示例:
+建立连接与关闭连接的示例:
```java
import org.apache.thrift.protocol.TBinaryProtocol;
@@ -355,7 +344,7 @@ import org.apache.iotdb.rpc.RpcTransportFactory;
}
```
-API列表:
+API 列表:
* 获取集群中的各个节点的信息(构成哈希环)
@@ -363,7 +352,7 @@ API列表:
list<Node> getRing();
```
-* 给定一个路径(应包括一个SG作为前缀)和起止时间,获取其覆盖的数据分区情况:
+* 给定一个路径(应包括一个 SG 作为前缀)和起止时间,获取其覆盖的数据分区情况:
```java
/**
@@ -374,7 +363,7 @@ list<Node> getRing();
list<DataPartitionEntry> getDataPartition(1:string path, 2:long startTime, 3:long endTime);
```
-* 给定一个路径(应包括一个SG作为前缀),获取其被分到了哪个节点上:
+* 给定一个路径(应包括一个 SG 作为前缀),获取其被分到了哪个节点上:
```java
/**
* @param path input path (should contains a Storage group name as its prefix)
@@ -383,7 +372,7 @@ list<Node> getRing();
list<Node> getMetaPartition(1:string path);
```
-* 获取所有节点的死活状态:
+* 获取所有节点的死活状态:
```java
/**
* @return key: node, value: live or not
@@ -391,7 +380,7 @@ list<Node> getRing();
map<Node, bool> getAllNodeStatus();
```
-* 获取当前连接节点的Raft组信息(投票编号等)(一般用户无需使用该接口):
+* 获取当前连接节点的 Raft 组信息(投票编号等)(一般用户无需使用该接口):
```java
/**
* @return A multi-line string with each line representing the total time consumption, invocation
diff --git a/docs/zh/UserGuide/API/Programming-Python-Native-API.md b/docs/zh/UserGuide/API/Programming-Python-Native-API.md
index 1bcf436..a3a9ed2 100644
--- a/docs/zh/UserGuide/API/Programming-Python-Native-API.md
+++ b/docs/zh/UserGuide/API/Programming-Python-Native-API.md
@@ -23,11 +23,9 @@
### 依赖
-在使用Python原生接口包前,您需要安装 thrift (>=0.13) 依赖。
+在使用 Python 原生接口包前,您需要安装 thrift (>=0.13) 依赖。
-
-
-### 如何使用 (示例)
+### 如何使用 (示例)
首先下载包:`pip3 install apache-iotdb`
@@ -50,13 +48,11 @@ zone = session.get_time_zone()
session.close()
```
-
-
### IoTDB Testcontainer
-Python客户端对测试的支持是基于`testcontainers`库 (https://testcontainers-python.readthedocs.io/en/latest/index.html)的,如果您想使用该特性,就需要将其安装到您的项目中。
+Python 客户端对测试的支持是基于`testcontainers`库 (https://testcontainers-python.readthedocs.io/en/latest/index.html) 的,如果您想使用该特性,就需要将其安装到您的项目中。
-要在Docker容器中启动(和停止)一个IoTDB数据库,只需这样做:
+要在 Docker 容器中启动(和停止)一个 IoTDB 数据库,只需这样做:
```python
class MyTestCase(unittest.TestCase):
@@ -70,15 +66,13 @@ class MyTestCase(unittest.TestCase):
session.close()
```
-默认情况下,它会拉取最新的IoTDB镜像 `apache/iotdb:latest`进行测试,如果您想指定待测IoTDB的版本,您只需要将版本信息像这样声明:`IoTDBContainer("apache/iotdb:0.12.0")`,此时,您就会得到一个`0.12.0`版本的IoTDB实例。
-
-
+默认情况下,它会拉取最新的 IoTDB 镜像 `apache/iotdb:latest`进行测试,如果您想指定待测 IoTDB 的版本,您只需要将版本信息像这样声明:`IoTDBContainer("apache/iotdb:0.12.0")`,此时,您就会得到一个`0.12.0`版本的 IoTDB 实例。
### 对 Pandas 的支持
-我们支持将查询结果轻松地转换为[Pandas Dataframe](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html)。
+我们支持将查询结果轻松地转换为 [Pandas Dataframe](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html)。
-SessionDataSet有一个方法`.todf()`,它的作用是消费SessionDataSet中的数据,并将数据转换为pandas dataframe。
+SessionDataSet 有一个方法`.todf()`,它的作用是消费 SessionDataSet 中的数据,并将数据转换为 pandas dataframe。
例子:
@@ -102,49 +96,40 @@ session.close()
df = ...
```
-
-
### 给开发人员
#### 介绍
-这是一个使用thrift rpc接口连接到IoTDB的示例。在Windows和Linux上操作几乎是一样的,但要注意路径分隔符等不同之处。
-
-
+这是一个使用 thrift rpc 接口连接到 IoTDB 的示例。在 Windows 和 Linux 上操作几乎是一样的,但要注意路径分隔符等不同之处。
#### 依赖
-首选Python3.7或更高版本。
+首选 Python3.7 或更高版本。
-必须安装thrift(0.11.0或更高版本)才能将thrift文件编译为Python代码。下面是官方的安装教程,最终,您应该得到一个thrift可执行文件。
+必须安装 thrift(0.11.0 或更高版本)才能将 thrift 文件编译为 Python 代码。下面是官方的安装教程,最终,您应该得到一个 thrift 可执行文件。
```
http://thrift.apache.org/docs/install/
```
-在开始之前,您还需要在Python环境中安装`requirements_dev.txt`中的其他依赖:
+在开始之前,您还需要在 Python 环境中安装`requirements_dev.txt`中的其他依赖:
```shell
pip install -r requirements_dev.txt
```
+#### 编译 thrift 库并调试
+在 IoTDB 源代码文件夹的根目录下,运行`mvn clean generate-sources -pl client-py -am`,
-#### 编译thrift库并调试
-
-在IoTDB源代码文件夹的根目录下,运行`mvn clean generate-sources -pl client-py -am`,
-
-这个指令将自动删除`iotdb/thrift`中的文件,并使用新生成的thrift文件重新填充该文件夹。
-
-这个文件夹在git中会被忽略,并且**永远不应该被推到git中!**
-
-**注意**不要将`iotdb/thrift`上传到git仓库中 !
-
+这个指令将自动删除`iotdb/thrift`中的文件,并使用新生成的 thrift 文件重新填充该文件夹。
+这个文件夹在 git 中会被忽略,并且**永远不应该被推到 git 中!**
+**注意**不要将`iotdb/thrift`上传到 git 仓库中 !
#### Session 客户端 & 使用示例
-我们将thrift接口打包到`client-py/src/iotdb/session.py `中(与Java版本类似),还提供了一个示例文件`client-py/src/SessionExample.py`来说明如何使用Session模块。请仔细阅读。
+我们将 thrift 接口打包到`client-py/src/iotdb/session.py `中(与 Java 版本类似),还提供了一个示例文件`client-py/src/SessionExample.py`来说明如何使用 Session 模块。请仔细阅读。
另一个简单的例子:
@@ -161,45 +146,35 @@ zone = session.get_time_zone()
session.close()
```
-
-
#### 测试
请在`tests`文件夹中添加自定义测试。
要运行所有的测试,只需在根目录中运行`pytest . `即可。
-**注意**一些测试需要在您的系统上使用docker,因为测试的IoTDB实例是使用[testcontainers](https://testcontainers-python.readthedocs.io/en/latest/index.html)在docker容器中启动的。
-
-
+**注意**一些测试需要在您的系统上使用 docker,因为测试的 IoTDB 实例是使用 [testcontainers](https://testcontainers-python.readthedocs.io/en/latest/index.html) 在 docker 容器中启动的。
#### 其他工具
[black](https://pypi.org/project/black/) 和 [flake8](https://pypi.org/project/flake8/) 分别用于自动格式化和 linting。
它们可以通过 `black .` 或 `flake8 .` 分别运行。
-
-
### 发版
要进行发版,
-只需确保您生成了正确的thrift代码,
+只需确保您生成了正确的 thrift 代码,
-运行了linting并进行了自动格式化,
+运行了 linting 并进行了自动格式化,
然后,确保所有测试都正常通过(通过`pytest . `),
-最后,您就可以将包发布到pypi了。
-
-
+最后,您就可以将包发布到 pypi 了。
#### 准备您的环境
首先,通过`pip install -r requirements_dev.txt`安装所有必要的开发依赖。
-
-
#### 发版
有一个脚本`release.sh`可以用来执行发版的所有步骤。
@@ -208,7 +183,7 @@ session.close()
* 删除所有临时目录(如果存在)
-* (重新)通过mvn生成所有必须的源代码
+* (重新)通过 mvn 生成所有必须的源代码
* 运行 linting (flke8)
@@ -217,4 +192,3 @@ session.close()
* Build
* 发布到 pypi
-
diff --git a/docs/zh/UserGuide/API/Programming-TsFile-API.md b/docs/zh/UserGuide/API/Programming-TsFile-API.md
index a546059..d748620 100644
--- a/docs/zh/UserGuide/API/Programming-TsFile-API.md
+++ b/docs/zh/UserGuide/API/Programming-TsFile-API.md
@@ -23,14 +23,11 @@
TsFile 是在 IoTDB 中使用的时间序列的文件格式。在这个章节中,我们将介绍这种文件格式的用法。
-
-
### 安装 TsFile library
-
在您自己的项目中有两种方法使用 TsFile .
-* 使用 jar 包: 编译源码生成 jar 包
+* 使用 jar 包:编译源码生成 jar 包
```shell
git clone https://github.com/apache/iotdb.git
@@ -40,9 +37,9 @@ mvn clean package -Dmaven.test.skip=true
命令执行完成之后,所有的 jar 包都可以从 `target/` 目录下找到。之后您可以在自己的工程中导入 `target/tsfile-0.13.0-SNAPSHOT.jar`.
-* 使用 Maven 依赖:
+* 使用 Maven 依赖:
-编译源码并且部署到您的本地仓库中需要 3 步:
+编译源码并且部署到您的本地仓库中需要 3 步:
1. 下载源码
@@ -55,7 +52,7 @@ git clone https://github.com/apache/iotdb.git
cd tsfile/
mvn clean install -Dmaven.test.skip=true
```
- 3. 在您自己的工程中增加依赖:
+ 3. 在您自己的工程中增加依赖:
```xml
<dependency>
@@ -65,10 +62,10 @@ mvn clean install -Dmaven.test.skip=true
</dependency>
```
-或者,您可以直接使用官方的 Maven 仓库:
+或者,您可以直接使用官方的 Maven 仓库:
1. 首先,在`${username}\.m2\settings.xml`目录下的`settings.xml`文件中`<profiles>`
- 节中增加`<profile>`,内容如下:
+ 节中增加`<profile>`,内容如下:
```xml
<profile>
@@ -89,7 +86,7 @@ mvn clean install -Dmaven.test.skip=true
</repositories>
</profile>
```
- 2. 之后您可以在您的工程中增加如下依赖:
+ 2. 之后您可以在您的工程中增加如下依赖:
```xml
<dependency>
@@ -99,48 +96,43 @@ mvn clean install -Dmaven.test.skip=true
</dependency>
```
-
-
### TsFile 的使用
-本章节演示TsFile的详细用法。
+本章节演示 TsFile 的详细用法。
-时序数据(Time-series Data)
-一个时序是由4个序列组成,分别是 device, measurement, time, value。
+时序数据 (Time-series Data)
+一个时序是由 4 个序列组成,分别是 device, measurement, time, value。
-* **measurement**: 时间序列描述的是一个物理或者形式的测量(measurement),比如:城市的温度,一些商品的销售数量或者是火车在不同时间的速度。
-传统的传感器(如温度计)也采用单次测量(measurement)并产生时间序列,我们将在下面交替使用测量(measurement)和传感器。
+* **measurement**: 时间序列描述的是一个物理或者形式的测量 (measurement),比如:城市的温度,一些商品的销售数量或者是火车在不同时间的速度。
+传统的传感器(如温度计)也采用单次测量 (measurement) 并产生时间序列,我们将在下面交替使用测量 (measurement) 和传感器。
-* **device**: 一个设备指的是一个正在进行多次测量(产生多个时间序列)的实体,例如,
+* **device**: 一个设备指的是一个正在进行多次测量(产生多个时间序列)的实体,例如,
一列正在运行的火车监控它的速度、油表、它已经运行的英里数,当前的乘客每个都被传送到一个时间序列。
-
**单行数据**: 在许多工业应用程序中,一个设备通常包含多个传感器,这些传感器可能同时具有多个值,这称为一行数据。
-在形式上,一行数据包含一个`device_id`,它是一个时间戳,表示从 1970年1月1日 00:00:00 开始的毫秒数,
+在形式上,一行数据包含一个`device_id`,它是一个时间戳,表示从 1970 年 1 月 1 日 00:00:00 开始的毫秒数,
以及由`measurement_id`和相应的`value`组成的几个数据对。一行中的所有数据对都属于这个`device_id`,并且具有相同的时间戳。
-如果其中一个度量值`measurements`在某个时间戳`timestamp`没有值`value`,将使用一个空格表示(实际上 TsFile 并不存储 null 值)。
+如果其中一个度量值`measurements`在某个时间戳`timestamp`没有值`value`,将使用一个空格表示(实际上 TsFile 并不存储 null 值)。
其格式如下:
```
device_id, timestamp, <measurement_id, value>...
```
-示例数据如下所示。在本例中,两个度量值(measurement)的数据类型分别是`INT32`和`FLOAT`。
+示例数据如下所示。在本例中,两个度量值 (measurement) 的数据类型分别是`INT32`和`FLOAT`。
```
device_1, 1490860659000, m1, 10, m2, 12.12
```
-
-
#### 写入 TsFile
-TsFile可以通过以下三个步骤生成,完整的代码参见"写入 TsFile 示例"章节。
+TsFile 可以通过以下三个步骤生成,完整的代码参见"写入 TsFile 示例"章节。
1. 构造一个`TsFileWriter`实例。
- 以下是可用的构造函数:
+ 以下是可用的构造函数:
* 没有预定义 schema
@@ -158,7 +150,7 @@ TsFile可以通过以下三个步骤生成,完整的代码参见"写入 TsFile
public TsFileWriter(TsFileOutput output, Schema schema) throws IOException
```
- 如果你想自己设置一些 TSFile 的配置,你可以使用`config`参数。比如:
+ 如果你想自己设置一些 TSFile 的配置,你可以使用`config`参数。比如:
```java
TSFileConfig conf = new TSFileConfig();
@@ -168,21 +160,21 @@ TsFile可以通过以下三个步骤生成,完整的代码参见"写入 TsFile
在上面的例子中,数据文件将存储在 HDFS 中,而不是本地文件系统中。如果你想在本地文件系统中存储数据文件,你可以使用`conf.setTSFileStorageFs("LOCAL")`,这也是默认的配置。
- 您还可以通过`config.setHdfsIp(...)`和`config.setHdfsPort(...)`来配置 HDFS 的 IP 和端口。默认的 IP是`localhost`,默认的`RPC`端口是`9000`.
+ 您还可以通过`config.setHdfsIp(...)`和`config.setHdfsPort(...)`来配置 HDFS 的 IP 和端口。默认的 IP 是`localhost`,默认的`RPC`端口是`9000`.
- **参数:**
+ **参数:**
* file : 写入 TsFile 数据的文件
* schema : 文件的 schemas,将在下章进行介绍
* config : TsFile 的一些配置项
-2. 添加测量值(measurement)
+2. 添加测量值 (measurement)
你也可以先创建一个`Schema`类的实例然后把它传递给`TsFileWriter`类的构造函数
`Schema`类保存的是一个映射关系,key 是一个 measurement 的名字,value 是 measurement schema.
- 下面是一系列接口:
+ 下面是一系列接口:
```java
// Create an empty Schema or from an existing map
@@ -198,13 +190,13 @@ TsFile可以通过以下三个步骤生成,完整的代码参见"写入 TsFile
public boolean hasMeasurement(String measurementId)
```
- 你可以在`TsFileWriter`类中使用以下接口来添加额外的测量(measurement):
+ 你可以在`TsFileWriter`类中使用以下接口来添加额外的测量 (measurement):
```java
public void addMeasurement(MeasurementSchema measurementSchema) throws WriteProcessException
```
- `MeasurementSchema`类保存了一个测量(measurement)的信息,有几个构造函数:
+ `MeasurementSchema`类保存了一个测量 (measurement) 的信息,有几个构造函数:
```java
public MeasurementSchema(String measurementId, TSDataType type, TSEncoding encoding)
@@ -213,22 +205,22 @@ TsFile可以通过以下三个步骤生成,完整的代码参见"写入 TsFile
Map<String, String> props)
```
- **参数:**
+ **参数:**
* measurementID: 测量的名称,通常是传感器的名称。
- * type: 数据类型,现在支持六种类型: `BOOLEAN`, `INT32`, `INT64`, `FLOAT`, `DOUBLE`, `TEXT`;
+ * type: 数据类型,现在支持六种类型:`BOOLEAN`, `INT32`, `INT64`, `FLOAT`, `DOUBLE`, `TEXT`;
- * encoding: 编码类型.
+ * encoding: 编码类型。
- * compression: 压缩方式. 现在支持 `UNCOMPRESSED` 和 `SNAPPY`.
+ * compression: 压缩方式。现在支持 `UNCOMPRESSED` 和 `SNAPPY`.
* props: 特殊数据类型的属性。比如说`FLOAT`和`DOUBLE`可以设置`max_point_number`,`TEXT`可以设置`max_string_length`。
- 可以使用Map来保存键值对,比如("max_point_number", "3")。
+ 可以使用 Map 来保存键值对,比如 ("max_point_number", "3")。
- > **注意:** 虽然一个测量(measurement)的名字可以被用在多个deltaObjects中, 但是它的参数是不允许被修改的。比如:
- 不允许多次为同一个测量(measurement)名添加不同类型的编码。下面是一个错误示例:
+ > **注意:** 虽然一个测量 (measurement) 的名字可以被用在多个 deltaObjects 中,但是它的参数是不允许被修改的。比如:
+ 不允许多次为同一个测量 (measurement) 名添加不同类型的编码。下面是一个错误示例:
```java
// The measurement "sensor_1" is float type
@@ -238,13 +230,13 @@ TsFile可以通过以下三个步骤生成,完整的代码参见"写入 TsFile
```
3. 插入和写入数据。
- 使用这个接口创建一个新的`TSRecord`(时间戳和设备对)。
+ 使用这个接口创建一个新的`TSRecord`(时间戳和设备对)。
```java
public TSRecord(long timestamp, String deviceId)
```
- 然后创建一个`DataPoint`(度量(measurement)和值的对应),并使用 addTuple 方法将数据 DataPoint 添加正确的值到 TsRecord。
+ 然后创建一个`DataPoint`(度量 (measurement) 和值的对应),并使用 addTuple 方法将数据 DataPoint 添加正确的值到 TsRecord。
用下面这种方法写
@@ -258,7 +250,6 @@ TsFile可以通过以下三个步骤生成,完整的代码参见"写入 TsFile
public void close() throws IOException
```
-
我们也支持将数据写入已关闭的 TsFile 文件中。
1. 使用`ForceAppendTsFileWriter`打开已经关闭的文件。
@@ -266,16 +257,14 @@ TsFile可以通过以下三个步骤生成,完整的代码参见"写入 TsFile
```java
public ForceAppendTsFileWriter(File file) throws IOException
```
-2. 调用 `doTruncate` 去掉文件的Metadata部分
+2. 调用 `doTruncate` 去掉文件的 Metadata 部分
3. 使用 `ForceAppendTsFileWriter` 构造另一个`TsFileWriter`
```java
public TsFileWriter(TsFileIOWriter fileWriter) throws IOException
```
-请注意 此时需要重新添加测量值(measurement) 再进行上述写入操作。
-
-
+请注意 此时需要重新添加测量值 (measurement) 再进行上述写入操作。
#### 写入 TsFile 示例
@@ -285,7 +274,7 @@ TsFile可以通过以下三个步骤生成,完整的代码参见"写入 TsFile
mvn clean install -pl tsfile -am -DskipTests
```
-如果存在**非对齐**的时序数据(比如:不是所有的传感器都有值),您可以通过构造**TSRecord**来写入。
+如果存在**非对齐**的时序数据(比如:不是所有的传感器都有值),您可以通过构造** TSRecord **来写入。
更详细的例子可以在
@@ -295,8 +284,7 @@ mvn clean install -pl tsfile -am -DskipTests
中查看
-
-如果所有时序数据都是**对齐**的,您可以通过构造**Tablet**来写入数据。
+如果所有时序数据都是**对齐**的,您可以通过构造** Tablet **来写入数据。
更详细的例子可以在
@@ -305,26 +293,23 @@ mvn clean install -pl tsfile -am -DskipTests
```
中查看
-在已关闭的TsFile 文件中写入新数据的详细例子可以在
+在已关闭的 TsFile 文件中写入新数据的详细例子可以在
```
/example/tsfile/src/main/java/org/apache/iotdb/tsfile/TsFileForceAppendWrite.java
```
中查看
-
-
#### 读取 TsFile 接口
-
* 路径的定义
-路径是一个点(.)分隔的字符串,它唯一地标识 TsFile 中的时间序列,例如:"root.area_1.device_1.sensor_1"。
-最后一部分"sensor_1"称为"measurementId",其余部分"root.area_1.device_1"称为deviceId。
-正如之前提到的,不同设备中的相同测量(measurement)具有相同的数据类型和编码,设备也是唯一的。
+路径是一个点 (.) 分隔的字符串,它唯一地标识 TsFile 中的时间序列,例如:"root.area_1.device_1.sensor_1"。
+最后一部分"sensor_1"称为"measurementId",其余部分"root.area_1.device_1"称为 deviceId。
+正如之前提到的,不同设备中的相同测量 (measurement) 具有相同的数据类型和编码,设备也是唯一的。
-在read接口中,参数`paths`表示要选择的测量值(measurement)。
-Path实例可以很容易地通过类`Path`来构造。例如:
+在 read 接口中,参数`paths`表示要选择的测量值 (measurement)。
+Path 实例可以很容易地通过类`Path`来构造。例如:
```java
Path p = new Path("device_1.sensor_1");
@@ -338,8 +323,7 @@ paths.add(new Path("device_1.sensor_1"));
paths.add(new Path("device_1.sensor_3"));
```
-> **注意:** 在构造路径时,参数的格式应该是一个点(.)分隔的字符串,最后一部分是measurement,其余部分确认为deviceId。
-
+> **注意:** 在构造路径时,参数的格式应该是一个点 (.) 分隔的字符串,最后一部分是 measurement,其余部分确认为 deviceId。
* 定义 Filter
@@ -350,7 +334,7 @@ paths.add(new Path("device_1.sensor_3"));
`IExpression`是一个过滤器表达式接口,它将被传递给系统查询时调用。
我们创建一个或多个筛选器表达式,并且可以使用`Binary Filter Operators`将它们连接形成最终表达式。
-* **创建一个Filter表达式**
+* **创建一个 Filter 表达式**
有两种类型的过滤器。
@@ -360,7 +344,7 @@ paths.add(new Path("device_1.sensor_3"));
IExpression timeFilterExpr = new GlobalTimeExpression(TimeFilter);
```
- 使用以下关系获得一个`TimeFilter`对象(值是一个 long 型变量)。
+ 使用以下关系获得一个`TimeFilter`对象(值是一个 long 型变量)。
|Relationship|Description|
|----|----|
@@ -372,7 +356,6 @@ paths.add(new Path("device_1.sensor_3"));
|TimeFilter.notEq(value)|选择时间不等于值的数据|
|TimeFilter.not(TimeFilter)|选择时间不满足另一个时间过滤器的数据|
-
* ValueFilter: 使用时序数据中的`value`过滤。
@@ -380,7 +363,7 @@ paths.add(new Path("device_1.sensor_3"));
IExpression valueFilterExpr = new SingleSeriesExpression(Path, ValueFilter);
```
- `ValueFilter`的用法与`TimeFilter`相同,只是需要确保值的类型等于measurement(在路径中定义)的类型。
+ `ValueFilter`的用法与`TimeFilter`相同,只是需要确保值的类型等于 measurement(在路径中定义)的类型。
* **Binary Filter Operators**
@@ -428,28 +411,28 @@ IExpression timeFilterExpr = BinaryExpression.or(
TsFileSequenceReader reader = new TsFileSequenceReader(path);
ReadOnlyTsFile readTsFile = new ReadOnlyTsFile(reader);
```
-接下来,我们准备路径数组和查询表达式,然后通过这个接口得到最终的`QueryExpression`对象:
+接下来,我们准备路径数组和查询表达式,然后通过这个接口得到最终的`QueryExpression`对象:
```java
QueryExpression queryExpression = QueryExpression.create(paths, statement);
```
-ReadOnlyTsFile类有两个`query`方法来执行查询。
+ReadOnlyTsFile 类有两个`query`方法来执行查询。
```java
public QueryDataSet query(QueryExpression queryExpression) throws IOException
public QueryDataSet query(QueryExpression queryExpression, long partitionStartOffset, long partitionEndOffset) throws IOException
```
-此方法是为高级应用(如 TsFile-Spark 连接器)设计的。
+此方法是为高级应用(如 TsFile-Spark 连接器)设计的。
-* **参数** : 对于第二个方法,添加了两个额外的参数来支持部分查询(Partial Query):
+* **参数** : 对于第二个方法,添加了两个额外的参数来支持部分查询 (Partial Query):
* `partitionStartOffset`: TsFile 的开始偏移量
* `partitionEndOffset`: TsFile 的结束偏移量
->什么是部分查询?
+>什么是部分查询?
-> 在一些分布式文件系统中(比如:HDFS), 文件被分成几个部分,这些部分被称为"Blocks"并存储在不同的节点中。在涉及的每个节点上并行执行查询可以提高效率。因此需要部分查询(Partial Query)。部分查询(Partial Query)仅支持查询 TsFile 中被`QueryConstant.PARTITION_START_OFFSET`和`QueryConstant.PARTITION_END_OFFSET`分割的部分。
+> 在一些分布式文件系统中(比如:HDFS), 文件被分成几个部分,这些部分被称为"Blocks"并存储在不同的节点中。在涉及的每个节点上并行执行查询可以提高效率。因此需要部分查询 (Partial Query)。部分查询 (Partial Query) 仅支持查询 TsFile 中被`QueryConstant.PARTITION_START_OFFSET`和`QueryConstant.PARTITION_END_OFFSET`分割的部分。
* QueryDataset 接口
@@ -459,7 +442,7 @@ public QueryDataSet query(QueryExpression queryExpression, long partitionStartOf
* `bool hasNext();`
- 如果该数据集仍然有数据,则返回true。
+ 如果该数据集仍然有数据,则返回 true。
* `List<Path> getPaths()`
获取这个数据集中的路径。
@@ -471,25 +454,22 @@ public QueryDataSet query(QueryExpression queryExpression, long partitionStartOf
获取下一条记录。
- `RowRecord`类包含一个`long`类型的时间戳和一个`List<Field>`,用于不同传感器中的数据,我们可以使用两个getter方法来获取它们。
+ `RowRecord`类包含一个`long`类型的时间戳和一个`List<Field>`,用于不同传感器中的数据,我们可以使用两个 getter 方法来获取它们。
```java
long getTimestamp();
List<Field> getFields();
```
- 要从一个字段获取数据,请使用以下方法:
+ 要从一个字段获取数据,请使用以下方法:
```java
TSDataType getDataType();
Object getObjectValue();
```
-
-
#### 读取现有 TsFile 示例
-
您需要安装 TsFile 到本地的 Maven 仓库中。
有关查询语句的更详细示例,请参见
@@ -573,12 +553,9 @@ public class TsFileRead {
}
```
-
-
### 修改 TsFile 配置项
```java
TSFileConfig config = TSFileDescriptor.getInstance().getConfig();
config.setXXX();
```
-
diff --git a/docs/zh/UserGuide/API/Time-zone.md b/docs/zh/UserGuide/API/Time-zone.md
index faf9889..3c4a098 100644
--- a/docs/zh/UserGuide/API/Time-zone.md
+++ b/docs/zh/UserGuide/API/Time-zone.md
@@ -82,4 +82,3 @@ IoTDB 服务器只针对时间戳进行存储和处理,时区只用来与客
```
注意,此时返回的时间戳是相同的,只是不同时区的日期不同。
-
diff --git a/docs/zh/UserGuide/Administration-Management/Administration.md b/docs/zh/UserGuide/Administration-Management/Administration.md
index e04fd71..7505463 100644
--- a/docs/zh/UserGuide/Administration-Management/Administration.md
+++ b/docs/zh/UserGuide/Administration-Management/Administration.md
@@ -21,9 +21,9 @@
# 权限管理
-IoTDB为用户提供了权限管理操作,从而为用户提供对于数据的权限管理功能,保障数据的安全。
+IoTDB 为用户提供了权限管理操作,从而为用户提供对于数据的权限管理功能,保障数据的安全。
-我们将通过以下几个具体的例子为您示范基本的用户权限操作,详细的SQL语句及使用方式详情请参见本文[数据模式与概念章节](../Data-Concept/Data-Model-and-Terminology.md)。同时,在JAVA编程环境中,您可以使用[JDBC API](../API/Programming-JDBC.md)单条或批量执行权限管理类语句。
+我们将通过以下几个具体的例子为您示范基本的用户权限操作,详细的 SQL 语句及使用方式详情请参见本文 [数据模式与概念章节](../Data-Concept/Data-Model-and-Terminology.md)。同时,在 JAVA 编程环境中,您可以使用 [JDBC API](../API/Programming-JDBC.md) 单条或批量执行权限管理类语句。
## 基本概念
@@ -33,7 +33,7 @@ IoTDB为用户提供了权限管理操作,从而为用户提供对于数据的
### 权限
-数据库提供多种操作,并不是所有的用户都能执行所有操作。如果一个用户可以执行某项操作,则称该用户有执行该操作的权限。权限可分为数据管理权限(如对数据进行增删改查)以及权限管理权限(用户、角色的创建与删除,权限的赋予与撤销等)。数据管理权限往往需要一个路径来限定其生效范围,它的生效范围是以该路径对应的节点为根的一棵子树(具体请参考IoTDB的数据组织)。
+数据库提供多种操作,并不是所有的用户都能执行所有操作。如果一个用户可以执行某项操作,则称该用户有执行该操作的权限。权限可分为数据管理权限(如对数据进行增删改查)以及权限管理权限(用户、角色的创建与删除,权限的赋予与撤销等)。数据管理权限往往需要一个路径来限定其生效范围,它的生效范围是以该路径对应的节点为根的一棵子树(具体请参考 IoTDB 的数据组织)。
### 角色
@@ -41,21 +41,21 @@ IoTDB为用户提供了权限管理操作,从而为用户提供对于数据的
### 默认用户及其具有的角色
-初始安装后的IoTDB中有一个默认用户:root,默认密码为root。该用户为管理员用户,固定拥有所有权限,无法被赋予、撤销权限,也无法被删除。
+初始安装后的 IoTDB 中有一个默认用户:root,默认密码为 root。该用户为管理员用户,固定拥有所有权限,无法被赋予、撤销权限,也无法被删除。
## 权限操作示例
-根据本文中描述的[样例数据](https://github.com/thulab/iotdb/files/4438687/OtherMaterial-Sample.Data.txt)内容,IoTDB的样例数据可能同时属于ln, sgcc等不同发电集团,不同的发电集团不希望其他发电集团获取自己的数据库数据,因此我们需要将不同的数据在集团层进行权限隔离。
+根据本文中描述的 [样例数据](https://github.com/thulab/iotdb/files/4438687/OtherMaterial-Sample.Data.txt) 内容,IoTDB 的样例数据可能同时属于 ln, sgcc 等不同发电集团,不同的发电集团不希望其他发电集团获取自己的数据库数据,因此我们需要将不同的数据在集团层进行权限隔离。
### 创建用户
-我们可以为ln和sgcc集团创建两个用户角色,名为ln_write_user, sgcc_write_user,密码均为write_pwd。SQL语句为:
+我们可以为 ln 和 sgcc 集团创建两个用户角色,名为 ln_write_user, sgcc_write_user,密码均为 write_pwd。SQL 语句为:
```
CREATE USER ln_write_user 'write_pwd'
CREATE USER sgcc_write_user 'write_pwd'
```
-此时使用展示用户的SQL语句:
+此时使用展示用户的 SQL 语句:
```
LIST USER
@@ -81,7 +81,7 @@ It costs 0.157s
### 赋予用户权限
-此时,虽然两个用户已经创建,但是他们不具有任何权限,因此他们并不能对数据库进行操作,例如我们使用ln_write_user用户对数据库中的数据进行写入,SQL语句为:
+此时,虽然两个用户已经创建,但是他们不具有任何权限,因此他们并不能对数据库进行操作,例如我们使用 ln_write_user 用户对数据库中的数据进行写入,SQL 语句为:
```
INSERT INTO root.ln.wf01.wt01(timestamp,status) values(1509465600000,true)
@@ -94,8 +94,7 @@ INSERT INTO root.ln.wf01.wt01(timestamp,status) values(1509465600000,true)
Msg: 602: No permissions for this operation INSERT
```
-
-现在,我们分别赋予他们向对应存储组数据的写入权限,并再次尝试向对应的存储组进行数据写入。SQL语句为:
+现在,我们分别赋予他们向对应存储组数据的写入权限,并再次尝试向对应的存储组进行数据写入。SQL 语句为:
```
GRANT USER ln_write_user PRIVILEGES 'INSERT_TIMESERIES' on root.ln
GRANT USER sgcc_write_user PRIVILEGES 'INSERT_TIMESERIES' on root.sgcc
@@ -118,9 +117,9 @@ Msg: The statement is executed successfully.
角色是权限的集合,而权限和角色都是用户的一种属性。即一个角色可以拥有若干权限。一个用户可以拥有若干角色与权限(称为用户自身权限)。
-目前在IoTDB中并不存在相互冲突的权限,因此一个用户真正具有的权限是用户自身权限与其所有的角色的权限的并集。即要判定用户是否能执行某一项操作,就要看用户自身权限或用户的角色的所有权限中是否有一条允许了该操作。用户自身权限与其角色权限,他的多个角色的权限之间可能存在相同的权限,但这并不会产生影响。
+目前在 IoTDB 中并不存在相互冲突的权限,因此一个用户真正具有的权限是用户自身权限与其所有的角色的权限的并集。即要判定用户是否能执行某一项操作,就要看用户自身权限或用户的角色的所有权限中是否有一条允许了该操作。用户自身权限与其角色权限,他的多个角色的权限之间可能存在相同的权限,但这并不会产生影响。
-需要注意的是:如果一个用户自身有某种权限(对应操作A),而他的某个角色有相同的权限。那么如果仅从该用户撤销该权限无法达到禁止该用户执行操作A的目的,还需要从这个角色中也撤销对应的权限,或者从这个用户将该角色撤销。同样,如果仅从上述角色将权限撤销,也不能禁止该用户执行操作A。
+需要注意的是:如果一个用户自身有某种权限(对应操作 A),而他的某个角色有相同的权限。那么如果仅从该用户撤销该权限无法达到禁止该用户执行操作 A 的目的,还需要从这个角色中也撤销对应的权限,或者从这个用户将该角色撤销。同样,如果仅从上述角色将权限撤销,也不能禁止该用户执行操作 A。
同时,对角色的修改会立即反映到所有拥有该角色的用户上,例如对角色增加某种权限将立即使所有拥有该角色的用户都拥有对应权限,删除某种权限也将使对应用户失去该权限(除非用户本身有该权限)。
@@ -137,7 +136,7 @@ Msg: The statement is executed successfully.
|DELETE\_TIMESERIES|删除数据或时间序列。路径相关|
|CREATE\_USER|创建用户。路径无关|
|DELETE\_USER|删除用户。路径无关|
-|MODIFY\_PASSWORD|修改所有用户的密码。路径无关。(没有该权限者仍然能够修改自己的密码。)|
+|MODIFY\_PASSWORD|修改所有用户的密码。路径无关。(没有该权限者仍然能够修改自己的密码。)|
|LIST\_USER|列出所有用户,列出某用户权限,列出某用户具有的角色三种操作的权限。路径无关|
|GRANT\_USER\_PRIVILEGE|赋予用户权限。路径无关|
|REVOKE\_USER\_PRIVILEGE|撤销用户权限。路径无关|
@@ -148,8 +147,8 @@ Msg: The statement is executed successfully.
|LIST\_ROLE|列出所有角色,列出某角色拥有的权限,列出拥有某角色的所有用户三种操作的权限。路径无关|
|GRANT\_ROLE\_PRIVILEGE|赋予角色权限。路径无关|
|REVOKE\_ROLE\_PRIVILEGE|撤销角色权限。路径无关|
-|CREATE_FUNCTION|注册UDF。路径无关|
-|DROP_FUNCTION|卸载UDF。路径无关|
+|CREATE_FUNCTION|注册 UDF。路径无关|
+|DROP_FUNCTION|卸载 UDF。路径无关|
|CREATE_TRIGGER|创建触发器。路径无关|
|DROP_TRIGGER|卸载触发器。路径无关|
|START_TRIGGER|启动触发器。路径无关|
@@ -159,12 +158,12 @@ Msg: The statement is executed successfully.
### 用户名限制
-IoTDB规定用户名的字符长度不小于4,其中用户名不能包含空格。
+IoTDB 规定用户名的字符长度不小于 4,其中用户名不能包含空格。
### 密码限制
-IoTDB规定密码的字符长度不小于4,其中密码不能包含空格,密码采用MD5进行加密。
+IoTDB 规定密码的字符长度不小于 4,其中密码不能包含空格,密码采用 MD5 进行加密。
### 角色名限制
-IoTDB规定角色名的字符长度不小于4,其中角色名不能包含空格。
+IoTDB 规定角色名的字符长度不小于 4,其中角色名不能包含空格。
diff --git a/docs/zh/UserGuide/Advanced-Features/Alerting.md b/docs/zh/UserGuide/Advanced-Features/Alerting.md
index 2df25bc..acc07fb 100644
--- a/docs/zh/UserGuide/Advanced-Features/Alerting.md
+++ b/docs/zh/UserGuide/Advanced-Features/Alerting.md
@@ -155,7 +155,6 @@ route:
owner: team-Y
receiver: team-Y-pager
-
# Inhibition rules allow to mute a set of alerts given that another alert is
# firing.
# We use this to mute any warning-level notifications if the same alert is
@@ -172,7 +171,6 @@ inhibit_rules:
# the inhibition rule will apply!
equal: ['alertname']
-
receivers:
- name: 'team-X-mails'
email_configs:
@@ -228,10 +226,9 @@ inhibit_rules:
equal: ['alertname']
````
-
### API
`AlertManager` API 分为 `v1` 和 `v2` 两个版本,当前 `AlertManager` API 版本为 `v2`
-(配置参见
+(配置参见
[api/v2/openapi.yaml](https://github.com/prometheus/alertmanager/blob/master/api/v2/openapi.yaml))。
默认配置的前缀为 `/api/v1` 或 `/api/v2`,
@@ -242,7 +239,6 @@ inhibit_rules:
发送告警的 endpoint 变为 `/alertmanager/api/v1/alerts`
或 `/alertmanager/api/v2/alerts`。
-
## 创建 trigger
### 编写 trigger 类
@@ -250,7 +246,7 @@ inhibit_rules:
用户通过自行创建 Java 类、编写钩子中的逻辑来定义一个触发器。
具体配置流程以及 Sink 模块提供的 `AlertManagerSink` 相关工具类的使用方法参见 [Triggers](Triggers.md)。
-下面的示例创建了 `org.apache.iotdb.trigger.AlertingExample` 类,
+下面的示例创建了 `org.apache.iotdb.trigger.AlertingExample` 类,
其 `alertManagerHandler`
成员变量可发送告警至地址为 `http://127.0.0.1:9093/` 的 AlertManager 实例。
@@ -376,10 +372,3 @@ INSERT INTO root.ln.wf01.wt01(timestamp, temperature) VALUES (5, 120);
`(5, 120)` 后触发的告警。
<img alt="alerting" src="https://user-images.githubusercontent.com/34649843/115957896-a9791080-a537-11eb-9962-541412bdcee6.png">
-
-
-
-
-
-
-
diff --git a/docs/zh/UserGuide/Advanced-Features/Continuous-Query.md b/docs/zh/UserGuide/Advanced-Features/Continuous-Query.md
index 194c112..671f212 100644
--- a/docs/zh/UserGuide/Advanced-Features/Continuous-Query.md
+++ b/docs/zh/UserGuide/Advanced-Features/Continuous-Query.md
@@ -52,7 +52,6 @@ END
、d、w、mo、y 等单位。
* `<level>`指按照序列第 `<level>` 层分组,将第 `<level>` 层以下的所有序列聚合。Group By Level 语句的具体语义及 `<level>` 的定义见 [路径层级分组聚合](../IoTDB-SQL-Language/DML-Data-Manipulation-Language.md)。
-
注:
* `<for_interval>`,`<every_interval>` 可选择指定。如果用户没有指定其中的某一项,则未指定项的值按照`<group_by_interval>` 处理。
@@ -69,8 +68,6 @@ END
* 若用户未指定 `<level>`,令原始时间序列最大层数为 `L`,
则系统生成的结果时间序列路径为 `root.${1}. ... .${L - 1}.<node_name>`。
-
-
#### 示例
##### 原始时间序列
@@ -85,7 +82,6 @@ END
+-----------------------------+-----+-------------+--------+--------+-----------+----+----------+
````
-
````
+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+
| Time|root.ln.wf02.wt02.temperature|root.ln.wf02.wt01.temperature|root.ln.wf01.wt02.temperature|root.ln.wf01.wt01.temperature|
@@ -111,15 +107,14 @@ END
需要注意的是,`${x}` 中的 `x` 应当大于等于 `1` 且小于等于 `<level>` 值
(若未指定 `<level>`,则应小于等于 `<path_prefix>` 层级)。在上例中,`x` 应当小于等于 `2`。
-
##### 创建 `cq1`
````
CREATE CONTINUOUS QUERY cq1 BEGIN SELECT max_value(temperature) INTO temperature_max FROM root.ln.*.* GROUP BY time(10s) END
````
-每隔 10s 查询 `root.ln.*.*.temperature` 在前 10s 内的最大值(结果以10s为一组),
+每隔 10s 查询 `root.ln.*.*.temperature` 在前 10s 内的最大值(结果以 10s 为一组),
将结果写入到 `root.${1}.${2}.${3}.temperature_max` 中,
-结果将产生4条新序列:
+结果将产生 4 条新序列:
````
+---------------------------------+-----+-------------+--------+--------+-----------+----+----------+
| timeseries|alias|storage group|dataType|encoding|compression|tags|attributes|
@@ -130,7 +125,6 @@ CREATE CONTINUOUS QUERY cq1 BEGIN SELECT max_value(temperature) INTO temperature
|root.ln.wf01.wt01.temperature_max| null| root.ln| FLOAT| GORILLA| SNAPPY|null| null|
+---------------------------------+-----+-------------+--------+--------+-----------+----+----------+
````
-````
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
| Time|root.ln.wf02.wt02.temperature_max|root.ln.wf02.wt01.temperature_max|root.ln.wf01.wt02.temperature_max|root.ln.wf01.wt01.temperature_max|
+-----------------------------+---------------------------------+---------------------------------+---------------------------------+---------------------------------+
@@ -145,7 +139,7 @@ CREATE CONTINUOUS QUERY cq1 BEGIN SELECT max_value(temperature) INTO temperature
CREATE CONTINUOUS QUERY cq2 RESAMPLE EVERY 20s FOR 20s BEGIN SELECT avg(temperature) INTO temperature_avg FROM root.ln.*.* GROUP BY time(10s), level=2 END
````
-每隔 20s 查询 `root.ln.*.*.temperature` 在前 20s 内的平均值(结果以10s为一组,按照第2层节点分组),
+每隔 20s 查询 `root.ln.*.*.temperature` 在前 20s 内的平均值(结果以 10s 为一组,按照第 2 层节点分组),
将结果写入到 `root.${1}.${2}.temperature_avg` 中。
结果将产生如下两条新序列,
其中 `root.ln.wf02.temperature_avg` 由 `root.ln.wf02.wt02.temperature` 和 `root.ln.wf02.wt01.temperature` 聚合计算生成,
@@ -159,7 +153,6 @@ CREATE CONTINUOUS QUERY cq2 RESAMPLE EVERY 20s FOR 20s BEGIN SELECT avg(temperat
|root.ln.wf01.temperature_avg| null| root.ln| DOUBLE| GORILLA| SNAPPY|null| null|
+----------------------------+-----+-------------+--------+--------+-----------+----+----------+
````
-````
+-----------------------------+----------------------------+----------------------------+
| Time|root.ln.wf02.temperature_avg|root.ln.wf01.temperature_avg|
+-----------------------------+----------------------------+----------------------------+
@@ -185,7 +178,6 @@ CREATE CONTINUOUS QUERY cq3 RESAMPLE EVERY 20s FOR 20s BEGIN SELECT avg(temperat
|root.ln_cq.wf01.temperature_avg| null| root.ln_cq| DOUBLE| GORILLA| SNAPPY|null| null|
+-------------------------------+-----+-------------+--------+--------+-----------+----+----------+
````
-````
+-----------------------------+-------------------------------+-------------------------------+
| Time|root.ln_cq.wf02.temperature_avg|root.ln_cq.wf01.temperature_avg|
+-----------------------------+-------------------------------+-------------------------------+
@@ -227,6 +219,3 @@ DROP CONTINUOUS QUERY cq3
| `continuous_query_execution_thread` | 执行连续查询任务的线程池的线程数 | int | max(1, CPU 核数 / 2)|
| `max_pending_continuous_query_tasks` | 队列中连续查询最大任务堆积数 | int | 64|
| `continuous_query_min_every_interval` | 连续查询执行时间间隔的最小值 | duration | 1s|
-
-
-
diff --git a/docs/zh/UserGuide/Advanced-Features/Triggers.md b/docs/zh/UserGuide/Advanced-Features/Triggers.md
index b3bd1e9..673dbbc 100644
--- a/docs/zh/UserGuide/Advanced-Features/Triggers.md
+++ b/docs/zh/UserGuide/Advanced-Features/Triggers.md
@@ -19,25 +19,21 @@
-->
-
-
# 触发器
触发器提供了一种侦听序列数据变动的机制。配合用户自定义逻辑,可完成告警、数据清洗、数据转发等功能。
-触发器基于Java反射机制实现。用户通过简单实现Java接口,即可实现数据侦听。IoTDB允许用户动态装载、卸载触发器,在装载、卸载期间,无需启停服务器。
+触发器基于 Java 反射机制实现。用户通过简单实现 Java 接口,即可实现数据侦听。IoTDB 允许用户动态装载、卸载触发器,在装载、卸载期间,无需启停服务器。
根据此文档,您将会很快学会触发器的编写与管理。
-
-
## 编写触发器
### 触发器依赖
-触发器的逻辑需要您编写Java类进行实现。
+触发器的逻辑需要您编写 Java 类进行实现。
-在编写触发器逻辑时,需要使用到下面展示的依赖。如果您使用[Maven](http://search.maven.org/),则可以直接从[Maven库](http://search.maven.org/)中搜索到它们。
+在编写触发器逻辑时,需要使用到下面展示的依赖。如果您使用 [Maven](http://search.maven.org/),则可以直接从 [Maven 库](http://search.maven.org/) 中搜索到它们。
``` xml
<dependency>
@@ -50,8 +46,6 @@
请注意选择和目标服务器版本相同的依赖版本。
-
-
### 用户编程接口
编写一个触发器需要实现`org.apache.iotdb.db.engine.trigger.api.Trigger`类。
@@ -60,27 +54,21 @@
下面是所有可供用户进行实现的接口的说明。
-
-
#### 生命周期钩子
| 接口定义 | 描述 |
| :----------------------------------------------------------- | ------------------------------------------------------------ |
-| `void onCreate(TriggerAttributes attributes) throws Exception` | 当您使用`CREATE TRIGGER`语句注册触发器后,该钩子会被调用一次。在每一个实例的生命周期内,该钩子会且仅仅会被调用一次。该钩子主要有如下作用:1. 帮助用户解析SQL语句中的自定义属性(使用`TriggerAttributes`)。 2. 创建或申请资源,如建立外部链接、打开文件等。 |
+| `void onCreate(TriggerAttributes attributes) throws Exception` | 当您使用`CREATE TRIGGER`语句注册触发器后,该钩子会被调用一次。在每一个实例的生命周期内,该钩子会且仅仅会被调用一次。该钩子主要有如下作用:1. 帮助用户解析 SQL 语句中的自定义属性(使用`TriggerAttributes`)。 2. 创建或申请资源,如建立外部链接、打开文件等。 |
| `void onDrop() throws Exception` | 当您使用`DROP TRIGGER`语句删除触发器后,该钩子会被调用。在每一个实例的生命周期内,该钩子会且仅仅会被调用一次。该钩子的主要作用是进行一些资源释放等的操作。 |
| `void onStart() throws Exception` | 当您使用`START TRIGGER`语句手动启动(被`STOP TRIGGER`语句停止的)触发器后,该钩子会被调用。 |
| `void onStop() throws Exception` | 当您使用`STOP TRIGGER`语句手动停止触发器后,该钩子会被调用。 |
-
-
#### 数据变动侦听钩子
目前触发器仅能侦听数据插入的操作。
数据变动侦听钩子的调用时机由`CREATE TRIGGER`语句显式指定,在编程接口层面不作区分。
-
-
##### 单点数据插入侦听钩子
``` java
@@ -96,8 +84,6 @@ Binary fire(long timestamp, Binary value) throws Exception;
注意,目前钩子的返回值是没有任何意义的。
-
-
##### 批量数据插入侦听钩子
```java
@@ -109,7 +95,7 @@ boolean[] fire(long[] timestamps, boolean[] values) throws Exception;
Binary[] fire(long[] timestamps, Binary[] values) throws Exception;
```
-如果您需要在业务场景中使用到Session API的`insertTablet`接口或`insertTablets`接口,那么您可以通过实现上述数据插入的侦听钩子来降低触发器的调用开销。
+如果您需要在业务场景中使用到 Session API 的`insertTablet`接口或`insertTablets`接口,那么您可以通过实现上述数据插入的侦听钩子来降低触发器的调用开销。
推荐您在实现上述批量数据插入的侦听钩子时, 保证批量数据插入侦听钩子与单点数据插入侦听钩子的行为具有一致性。当您不实现批量数据插入的侦听钩子时,它将遵循下面的默认逻辑。
@@ -125,21 +111,15 @@ default int[] fire(long[] timestamps, int[] values) throws Exception {
注意,目前钩子的返回值是没有任何意义的。
-
-
#### 重要注意事项
* 每条序列上注册的触发器都是一个完整的触发器类的实例,因此您可以在触发器中维护一些状态数据。
* 触发器维护的状态会在系统停止后被清空(除非您在钩子中主动将状态持久化)。换言之,系统启动后触发器的状态将会默认为初始值。
* 一个触发器所有钩子的调用都是串行化的。
-
-
## 管理触发器
-您可以通过SQL语句注册、卸载、启动或停止一个触发器实例,您也可以通过SQL语句查询到所有已经注册的触发器。
-
-
+您可以通过 SQL 语句注册、卸载、启动或停止一个触发器实例,您也可以通过 SQL 语句查询到所有已经注册的触发器。
### 触发器的状态
@@ -149,27 +129,23 @@ default int[] fire(long[] timestamps, int[] values) throws Exception {
注意,通过`CREATE TRIGGER`语句注册的触发器默认是`STARTED`的。
-
-
### 注册触发器
触发器只能注册在一个已经存在的时间序列上。任何时间序列只允许注册一个触发器。
被注册有触发器的序列将会被触发器侦听,当序列上有数据变动时,触发器中对应的钩子将会被调用。
-
-
注册一个触发器可以按如下流程进行:
-1. 实现一个完整的Trigger类,假定这个类的全类名为`org.apache.iotdb.db.engine.trigger.example.AlertListener`
+1. 实现一个完整的 Trigger 类,假定这个类的全类名为`org.apache.iotdb.db.engine.trigger.example.AlertListener`
-2. 将项目打成JAR包,如果您使用Maven管理项目,可以参考上述Maven项目示例的写法
+2. 将项目打成 JAR 包,如果您使用 Maven 管理项目,可以参考上述 Maven 项目示例的写法
-3. 将JAR包放置到目录 `iotdb-server-0.13.0-SNAPSHOT/ext/trigger` (也可以是`iotdb-server-0.13.0-SNAPSHOT/ext/trigger`的子目录)下。
+3. 将 JAR 包放置到目录 `iotdb-server-0.13.0-SNAPSHOT/ext/trigger` (也可以是`iotdb-server-0.13.0-SNAPSHOT/ext/trigger`的子目录)下。
- > 您可以通过修改配置文件中的`trigger_root_dir`来指定加载触发器JAR包的根路径。
+ > 您可以通过修改配置文件中的`trigger_root_dir`来指定加载触发器 JAR 包的根路径。
-4. 使用SQL语句注册该触发器,假定赋予该触发器的名字为`alert-listener-sg1d1s1`
+4. 使用 SQL 语句注册该触发器,假定赋予该触发器的名字为`alert-listener-sg1d1s1`
5. 使用`CREATE TRIGGER`语句注册该触发器
@@ -186,7 +162,7 @@ default int[] fire(long[] timestamps, int[] values) throws Exception {
-注册触发器的详细SQL语法如下:
+注册触发器的详细 SQL 语法如下:
```sql
CREATE TRIGGER <TRIGGER-NAME>
@@ -209,7 +185,7 @@ WITH (
)
```
-`TRIGGER-NAME`是用于标定触发器的全局唯一ID,它是大小写敏感的。
+`TRIGGER-NAME`是用于标定触发器的全局唯一 ID,它是大小写敏感的。
目前触发器可以侦听序列上的所有的数据插入操作,触发器可以选择在数据插入前(`BEFORE INSERT`)或者数据插入后(`AFTER INSERT`)触发钩子调用。
@@ -219,8 +195,6 @@ WITH (
请注意,`CLASSNAME`以及属性值中的`KEY`和`VALUE`都需要被单引号或者双引号引用起来。
-
-
### 卸载触发器
触发器会在下面几种情景下被卸载:
@@ -229,17 +203,13 @@ WITH (
2. 用户执行`DELETE STORAGE GROUP`时,对应存储组下注册的触发器会全部被卸载
3. 用户使用`DROP TRIGGER`语句主动卸载
-
-
-卸载触发器的SQL语法如下:
+卸载触发器的 SQL 语法如下:
```sql
DROP TRIGGER <TRIGGER-NAME>
```
-`TRIGGER-NAME`是用于标定触发器的全局唯一ID。
-
-
+`TRIGGER-NAME`是用于标定触发器的全局唯一 ID。
下面是一个`DROP TRIGGER`语句的例子:
@@ -247,23 +217,17 @@ DROP TRIGGER <TRIGGER-NAME>
DROP TRIGGER alert-listener-sg1d1s1
```
-
-
### 启动触发器
该操作是“停止触发器”的逆操作。它将运行状态为`STOPPED`的触发器的运行状态变更为`STARTED`,这会使得触发器重新侦听被注册序列上的操作,并对数据变动产生响应。
-
-
-启动触发器的SQL语法如下:
+启动触发器的 SQL 语法如下:
```sql
START TRIGGER <TRIGGER-NAME>
```
-`TRIGGER-NAME`是用于标定触发器的全局唯一ID。
-
-
+`TRIGGER-NAME`是用于标定触发器的全局唯一 ID。
下面是一个`START TRIGGER`语句的例子:
@@ -271,27 +235,19 @@ START TRIGGER <TRIGGER-NAME>
START TRIGGER alert-listener-sg1d1s1
```
-
-
注意,通过`CREATE TRIGGER`语句注册的触发器默认是`STARTED`的。
-
-
### 停止触发器
该操作将触发器的状态由`STARTED`变为`STOPPED`。当一个触发器的状态为`STOPPED`时,它将不会响应被注册序列上的操作(如插入数据点的操作),对外表现就会像是这个序列没有被注册过触发器一样。您可以使用`START TRIGGER`语句重新启动一个触发器。
-
-
-停止触发器的SQL语法如下:
+停止触发器的 SQL 语法如下:
```sql
STOP TRIGGER <TRIGGER-NAME>
```
-`TRIGGER-NAME`是用于标定触发器的全局唯一ID。
-
-
+`TRIGGER-NAME`是用于标定触发器的全局唯一 ID。
下面是一个`STOP TRIGGER`语句的例子:
@@ -299,40 +255,31 @@ STOP TRIGGER <TRIGGER-NAME>
STOP TRIGGER alert-listener-sg1d1s1
```
-
-
### 查询所有注册的触发器
-查询触发器的SQL语句如下:
+查询触发器的 SQL 语句如下:
``` sql
SHOW TRIGGERS
```
-该语句展示已注册触发器的ID、运行状态、触发时机、被注册的序列、触发器实例的全类名和注册触发器时用到的自定义属性。
-
-
+该语句展示已注册触发器的 ID、运行状态、触发时机、被注册的序列、触发器实例的全类名和注册触发器时用到的自定义属性。
### 用户权限管理
-用户在使用触发器时会涉及到4种权限:
+用户在使用触发器时会涉及到 4 种权限:
* `CREATE_TRIGGER`:具备该权限的用户才被允许注册触发器操作。
* `DROP_TRIGGER`:具备该权限的用户才被允许卸载触发器操作。
* `START_TRIGGER`:具备该权限的用户才被允许启动已被停止的触发器。
* `STOP_TRIGGER`:具备该权限的用户才被允许停止正在运行的触发器。
-更多用户权限相关的内容,请参考[权限管理语句](../Operation%20Manual/Administration.md)。
-
-
-
+更多用户权限相关的内容,请参考 [权限管理语句](../Operation%20Manual/Administration.md)。
## 实用工具类
实用工具类为常见的需求提供了编程范式和执行框架,它能够简化您编写触发器的一部分工作。
-
-
### 窗口工具类
窗口工具类能够辅助您定义滑动窗口以及窗口上的数据处理逻辑。它能够构造两类滑动窗口:一种滑动窗口是固定窗口内时间长度的(`SlidingTimeWindowEvaluationHandler`),另一种滑动窗口是固定窗口内数据点数的(`SlidingSizeWindowEvaluationHandler`)。
@@ -343,8 +290,6 @@ SHOW TRIGGERS
`Window`与`Evaluator`接口的定义见`org.apache.iotdb.db.utils.windowing.api`包。
-
-
#### 固定窗口内数据点数的滑动窗口
##### 窗口构造
@@ -382,8 +327,6 @@ SlidingSizeWindowEvaluationHandler handler =
窗口大小、滑动步长必须为正数。
-
-
##### 数据接收
``` java
@@ -398,8 +341,6 @@ hander.collect(timestamp, value);
还需要注意的是,`collect`方法不是线程安全的。
-
-
#### 固定窗口内时间长度的滑动窗口
##### 窗口构造
@@ -437,8 +378,6 @@ SlidingTimeWindowEvaluationHandler handler =
窗口内时间长度、滑动步长必须为正数。
-
-
##### 数据接收
``` java
@@ -453,13 +392,11 @@ hander.collect(timestamp, value);
还需要注意的是,`collect`方法不是线程安全的。
-
-
#### 拒绝策略
窗口计算的任务执行是异步的。
-当异步任务无法被执行线程池及时消费时,会产生任务堆积。在极端情况下,异步任务的堆积会导致系统OOM。因此,窗口计算线程池允许堆积的任务数量被设定为有限值。
+当异步任务无法被执行线程池及时消费时,会产生任务堆积。在极端情况下,异步任务的堆积会导致系统 OOM。因此,窗口计算线程池允许堆积的任务数量被设定为有限值。
当堆积的任务数量超出限值时,新提交的任务将无法进入线程池执行,此时,系统会调用您在侦听钩子(`Evaluator`)中制定的拒绝策略钩子`onRejection`进行处理。
@@ -490,29 +427,21 @@ SlidingTimeWindowEvaluationHandler handler =
});
```
-
-
#### 配置参数
##### concurrent_window_evaluation_thread
-窗口计算线程池的默认线程数。默认为CPU核数。
-
-
+窗口计算线程池的默认线程数。默认为 CPU 核数。
##### max_pending_window_evaluation_tasks
-最多允许堆积的窗口计算任务。默认为64个。
-
-
-
-### Sink工具类
-
-Sink工具类为触发器提供了连接外部系统的能力。
+最多允许堆积的窗口计算任务。默认为 64 个。
-它提供了一套编程范式。每一个Sink工具都包含一个用于处理数据发送的`Handler`、一个用于配置`Handler`的`Configuration`,还有一个用于描述发送数据的`Event`。
+### Sink 工具类
+Sink 工具类为触发器提供了连接外部系统的能力。
+它提供了一套编程范式。每一个 Sink 工具都包含一个用于处理数据发送的`Handler`、一个用于配置`Handler`的`Configuration`,还有一个用于描述发送数据的`Event`。
#### LocalIoTDBSink
@@ -551,8 +480,6 @@ for (int i = 0; i < 100; ++i) {
}
```
-
-
#### MQTTSink
触发器可以使用`MQTTSink`向其他的 IoTDB 实例发送数据点。
@@ -583,8 +510,6 @@ for (int i = 0; i < 100; ++i) {
}
```
-
-
#### AlertManagerSink
触发器可以使用`AlertManagerSink` 向 AlertManager 发送消息。
@@ -625,8 +550,6 @@ AlertManagerEvent(String alertname, Map<String, String> extraLabels, Map<String,
调用 `AlertManagerHandler` 的 `onEvent(AlertManagerEvent event)` 方法发送一个告警。
-
-
**使用示例 1:**
只传 `alertname`。
@@ -666,8 +589,6 @@ AlertManagerEvent alertManagerEvent = new AlertManagerEvent(alertName, extraLabe
alertManagerHandler.onEvent(alertManagerEvent);
```
-
-
**使用示例 3:**
传入 `alertname`, `extraLabels` 和 `annotations` 。
@@ -693,20 +614,18 @@ annotations.put("description", "{{.alertname}}: {{.series}} is {{.value}}");
alertManagerHandler.onEvent(new AlertManagerEvent(alertName, extraLabels, annotations));
```
+## 完整的 Maven 示例项目
+如果您使用 [Maven](http://search.maven.org/),可以参考我们编写的示例项目** trigger-example**。
-## 完整的Maven示例项目
-
-如果您使用[Maven](http://search.maven.org/),可以参考我们编写的示例项目**trigger-example**。
-
-您可以在[这里](https://github.com/apache/iotdb/tree/master/example/trigger)找到它。
+您可以在 [这里](https://github.com/apache/iotdb/tree/master/example/trigger) 找到它。
它展示了:
-* 如何使用Maven管理您的trigger项目
+* 如何使用 Maven 管理您的 trigger 项目
* 如何基于触发器的用户编程接口实现数据侦听
* 如何使用窗口工具类
-* 如何使用Sink工具类
+* 如何使用 Sink 工具类
```java
package org.apache.iotdb.trigger;
@@ -807,7 +726,6 @@ public class TriggerExample implements Trigger {
"127.0.0.1",
1883,
"root",
- "root",
new PartialPath(TARGET_DEVICE),
new String[]{"remote"}));
}
@@ -821,7 +739,7 @@ public class TriggerExample implements Trigger {
您可以按照下面的步骤试用这个触发器:
-* 在`iotdb-engine.properties`中启用MQTT服务
+* 在`iotdb-engine.properties`中启用 MQTT 服务
``` properties
# whether to enable the mqtt service.
@@ -836,11 +754,11 @@ public class TriggerExample implements Trigger {
CREATE TIMESERIES root.sg1.d1.s1 WITH DATATYPE=DOUBLE, ENCODING=PLAIN;
```
-* 将 **trigger-example** 中打包好的JAR(`trigger-example-0.13.0-SNAPSHOT.jar`)放置到目录 `iotdb-server-0.13.0-SNAPSHOT/ext/trigger` (也可以是`iotdb-server-0.13.0-SNAPSHOT/ext/trigger`的子目录)下
+* 将 **trigger-example** 中打包好的 JAR(`trigger-example-0.13.0-SNAPSHOT.jar`)放置到目录 `iotdb-server-0.13.0-SNAPSHOT/ext/trigger` (也可以是`iotdb-server-0.13.0-SNAPSHOT/ext/trigger`的子目录)下
- > 您可以通过修改配置文件中的`trigger_root_dir`来指定加载触发器JAR包的根路径。
+ > 您可以通过修改配置文件中的`trigger_root_dir`来指定加载触发器 JAR 包的根路径。
-* 使用SQL语句注册该触发器,假定赋予该触发器的名字为`window-avg-alerter`
+* 使用 SQL 语句注册该触发器,假定赋予该触发器的名字为`window-avg-alerter`
* 使用`CREATE TRIGGER`语句注册该触发器
@@ -892,18 +810,14 @@ public class TriggerExample implements Trigger {
以上就是基本的使用方法,希望您能喜欢 :D
-
-
## 重要注意事项
* 触发器是通过反射技术动态装载的,因此您在装载过程中无需启停服务器。
-* 不同的JAR包中最好不要有全类名相同但功能实现不一样的类。例如:触发器`trigger1`、`trigger2`分别对应资源`trigger1.jar`、`trigger2.jar`。如果两个JAR包里都包含一个`org.apache.iotdb.db.engine.trigger.example.AlertListener`类,当`CREATE TRIGGER`使用到这个类时,系统会随机加载其中一个JAR包中的类,最终导致触发器执行行为不一致以及其他的问题。
-
-* 拥有同一个全类名的触发器类的版本管理问题。IoTDB不允许系统中存在拥有同一全类名但是版本(逻辑)不一样的触发器。
-
- 相关问题:IoTDB预先注册了10个`org.apache.iotdb.db.engine.trigger.example.AlertListener`触发器实例,DBA更新了`org.apache.iotdb.db.engine.trigger.example.AlertListener`的实现和对应的JAR包,是否可以只卸载其中5个,将这5个替换为新的实现?
+* 不同的 JAR 包中最好不要有全类名相同但功能实现不一样的类。例如:触发器`trigger1`、`trigger2`分别对应资源`trigger1.jar`、`trigger2.jar`。如果两个 JAR 包里都包含一个`org.apache.iotdb.db.engine.trigger.example.AlertListener`类,当`CREATE TRIGGER`使用到这个类时,系统会随机加载其中一个 JAR 包中的类,最终导致触发器执行行为不一致以及其他的问题。
- 回答:无法做到。只有将预先注册的10个触发器全部卸载,才能装载到新的触发器实例。在原有触发器没有全部被卸载的情况下,新注册的拥有相同全类名的触发器行为只会与现有触发器的行为一致。
+* 拥有同一个全类名的触发器类的版本管理问题。IoTDB 不允许系统中存在拥有同一全类名但是版本(逻辑)不一样的触发器。
+ 相关问题:IoTDB 预先注册了 10 个`org.apache.iotdb.db.engine.trigger.example.AlertListener`触发器实例,DBA 更新了`org.apache.iotdb.db.engine.trigger.example.AlertListener`的实现和对应的 JAR 包,是否可以只卸载其中 5 个,将这 5 个替换为新的实现?
+ 回答:无法做到。只有将预先注册的 10 个触发器全部卸载,才能装载到新的触发器实例。在原有触发器没有全部被卸载的情况下,新注册的拥有相同全类名的触发器行为只会与现有触发器的行为一致。
diff --git a/docs/zh/UserGuide/Advanced-Features/UDF-User-Defined-Function.md b/docs/zh/UserGuide/Advanced-Features/UDF-User-Defined-Function.md
index 3dfcef1..a10f6eb 100644
--- a/docs/zh/UserGuide/Advanced-Features/UDF-User-Defined-Function.md
+++ b/docs/zh/UserGuide/Advanced-Features/UDF-User-Defined-Function.md
@@ -19,17 +19,13 @@
-->
+# 用户定义函数 (UDF)
+UDF(User Defined Function)即用户自定义函数。IoTDB 提供多种内建函数来满足您的计算需求,同时您还可以通过创建自定义函数来满足更多的计算需求。
-# 用户定义函数(UDF)
+根据此文档,您将会很快学会 UDF 的编写、注册、使用等操作。
-UDF(User Defined Function)即用户自定义函数。IoTDB提供多种内建函数来满足您的计算需求,同时您还可以通过创建自定义函数来满足更多的计算需求。
-
-根据此文档,您将会很快学会UDF的编写、注册、使用等操作。
-
-
-
-## UDF类型
+## UDF 类型
IoTDB 支持两种类型的 UDF 函数,如下表所示。
@@ -38,11 +34,9 @@ IoTDB 支持两种类型的 UDF 函数,如下表所示。
| UDTF(User Defined Timeseries Generating Function) | 自定义时间序列生成函数。该类函数允许接收多条时间序列,最终会输出一条时间序列,生成的时间序列可以有任意多数量的数据点。 |
| UDAF(User Defined Aggregation Function) | 正在开发,敬请期待。 |
+## UDF 依赖
-
-## UDF依赖
-
-如果您使用[Maven](http://search.maven.org/),可以从[Maven库](http://search.maven.org/)中搜索下面示例中的依赖。请注意选择和目标IoTDB服务器版本相同的依赖版本。
+如果您使用 [Maven](http://search.maven.org/),可以从 [Maven 库](http://search.maven.org/) 中搜索下面示例中的依赖。请注意选择和目标 IoTDB 服务器版本相同的依赖版本。
``` xml
<dependency>
@@ -53,25 +47,22 @@ IoTDB 支持两种类型的 UDF 函数,如下表所示。
</dependency>
```
-
-
## UDTF(User Defined Timeseries Generating Function)
-编写一个UDTF需要继承`org.apache.iotdb.db.query.udf.api.UDTF`类,并至少实现`beforeStart`方法和一种`transform`方法。
+编写一个 UDTF 需要继承`org.apache.iotdb.db.query.udf.api.UDTF`类,并至少实现`beforeStart`方法和一种`transform`方法。
下表是所有可供用户实现的接口说明。
-
| 接口定义 | 描述 | 是否必须 |
| :----------------------------------------------------------- | :----------------------------------------------------------- | ------------------ |
| `void validate(UDFParameterValidator validator) throws Exception` | 在初始化方法`beforeStart`调用前执行,用于检测`UDFParameters`中用户输入的参数是否合法。 | 否 |
-| `void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception` | 初始化方法,在UDTF处理输入数据前,调用用户自定义的初始化行为。用户每执行一次UDTF查询,框架就会构造一个新的UDF类实例,该方法在每个UDF类实例被初始化时调用一次。在每一个UDF类实例的生命周期内,该方法只会被调用一次。 | 是 |
+| `void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception` | 初始化方法,在 UDTF 处理输入数据前,调用用户自定义的初始化行为。用户每执行一次 UDTF 查询,框架就会构造一个新的 UDF 类实例,该方法在每个 UDF 类实例被初始化时调用一次。在每一个 UDF 类实例的生命周期内,该方法只会被调用一次。 | 是 |
| `void transform(Row row, PointCollector collector) throws Exception` | 这个方法由框架调用。当您在`beforeStart`中选择以`RowByRowAccessStrategy`的策略消费原始数据时,这个数据处理方法就会被调用。输入参数以`Row`的形式传入,输出结果通过`PointCollector`输出。您需要在该方法内自行调用`collector`提供的数据收集方法,以决定最终的输出数据。 | 与下面的方法二选一 |
| `void transform(RowWindow rowWindow, PointCollector collector) throws Exception` | 这个方法由框架调用。当您在`beforeStart`中选择以`SlidingSizeWindowAccessStrategy`或者`SlidingTimeWindowAccessStrategy`的策略消费原始数据时,这个数据处理方法就会被调用。输入参数以`RowWindow`的形式传入,输出结果通过`PointCollector`输出。您需要在该方法内自行调用`collector`提供的数据收集方法,以决定最终的输出数据。 | 与上面的方法二选一 |
-| `void terminate(PointCollector collector) throws Exception` | 这个方法由框架调用。该方法会在所有的`transform`调用执行完成后,在`beforeDestory`方法执行前被调用。在一个UDF查询过程中,该方法会且只会调用一次。您需要在该方法内自行调用`collector`提供的数据收集方法,以决定最终的输出数据。 | 否 |
-| `void beforeDestroy() ` | UDTF的结束方法。此方法由框架调用,并且只会被调用一次,即在处理完最后一条记录之后被调用。 | 否 |
+| `void terminate(PointCollector collector) throws Exception` | 这个方法由框架调用。该方法会在所有的`transform`调用执行完成后,在`beforeDestory`方法执行前被调用。在一个 UDF 查询过程中,该方法会且只会调用一次。您需要在该方法内自行调用`collector`提供的数据收集方法,以决定最终的输出数据。 | 否 |
+| `void beforeDestroy() ` | UDTF 的结束方法。此方法由框架调用,并且只会被调用一次,即在处理完最后一条记录之后被调用。 | 否 |
-在一个完整的UDTF实例生命周期中,各个方法的调用顺序如下:
+在一个完整的 UDTF 实例生命周期中,各个方法的调用顺序如下:
1. `void validate(UDFParameterValidator validator) throws Exception`
2. `void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception`
@@ -79,35 +70,29 @@ IoTDB 支持两种类型的 UDF 函数,如下表所示。
4. `void terminate(PointCollector collector) throws Exception`
5. `void beforeDestroy() `
-注意,框架每执行一次UDTF查询,都会构造一个全新的UDF类实例,查询结束时,对应的UDF类实例即被销毁,因此不同UDTF查询(即使是在同一个SQL语句中)UDF类实例内部的数据都是隔离的。您可以放心地在UDTF中维护一些状态数据,无需考虑并发对UDF类实例内部状态数据的影响。
+注意,框架每执行一次 UDTF 查询,都会构造一个全新的 UDF 类实例,查询结束时,对应的 UDF 类实例即被销毁,因此不同 UDTF 查询(即使是在同一个 SQL 语句中)UDF 类实例内部的数据都是隔离的。您可以放心地在 UDTF 中维护一些状态数据,无需考虑并发对 UDF 类实例内部状态数据的影响。
下面将详细介绍各个接口的使用方法。
-
-
* void validate(UDFParameterValidator validator) throws Exception
`validate`方法能够对用户输入的参数进行验证。
您可以在该方法中限制输入序列的数量和类型,检查用户输入的属性或者进行自定义逻辑的验证。
- `UDFParameterValidator`的使用方法请见Javadoc。
-
-
+ `UDFParameterValidator`的使用方法请见 Javadoc。
* void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception
`beforeStart`方法有两个作用:
- 1. 帮助用户解析SQL语句中的UDF参数
- 2. 配置UDF运行时必要的信息,即指定UDF访问原始数据时采取的策略和输出结果序列的类型
+ 1. 帮助用户解析 SQL 语句中的 UDF 参数
+ 2. 配置 UDF 运行时必要的信息,即指定 UDF 访问原始数据时采取的策略和输出结果序列的类型
3. 创建资源,比如建立外部链接,打开文件等。
-
-
#### UDFParameters
-`UDFParameters`的作用是解析SQL语句中的UDF参数(SQL中UDF函数名称后括号中的部分)。参数包括路径(及其序列类型)参数和字符串key-value对形式输入的属性参数。
+`UDFParameters`的作用是解析 SQL 语句中的 UDF 参数(SQL 中 UDF 函数名称后括号中的部分)。参数包括路径(及其序列类型)参数和字符串 key-value 对形式输入的属性参数。
例子:
@@ -135,11 +120,9 @@ void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) th
}
```
-
-
#### UDTFConfigurations
-您必须使用 `UDTFConfigurations` 指定UDF访问原始数据时采取的策略和输出结果序列的类型。
+您必须使用 `UDTFConfigurations` 指定 UDF 访问原始数据时采取的策略和输出结果序列的类型。
用法:
@@ -155,9 +138,7 @@ void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) th
}
```
-其中`setAccessStrategy`方法用于设定UDF访问原始数据时采取的策略,`setOutputDataType`用于设定输出结果序列的类型。
-
-
+其中`setAccessStrategy`方法用于设定 UDF 访问原始数据时采取的策略,`setOutputDataType`用于设定输出结果序列的类型。
* setAccessStrategy
@@ -167,17 +148,13 @@ void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) th
| 接口定义 | 描述 | 调用的`transform`方法 |
| :-------------------------------- | :----------------------------------------------------------- | ------------------------------------------------------------ |
-| `RowByRowAccessStrategy` | 逐行地处理原始数据。框架会为每一行原始数据输入调用一次`transform`方法。当UDF只有一个输入序列时,一行输入就是该输入序列中的一个数据点。当UDF有多个输入序列时,一行输入序列对应的是这些输入序列按时间对齐后的结果(一行数据中,可能存在某一列为`null`值,但不会全部都是`null`)。 | `void transform(Row row, PointCollector collector) throws Exception` |
+| `RowByRowAccessStrategy` | 逐行地处理原始数据。框架会为每一行原始数据输入调用一次`transform`方法。当 UDF 只有一个输入序列时,一行输入就是该输入序列中的一个数据点。当 UDF 有多个输入序列时,一行输入序列对应的是这些输入序列按时间对齐后的结果(一行数据中,可能存在某一列为`null`值,但不会全部都是`null`)。 | `void transform(Row row, PointCollector collector) throws Exception` |
| `SlidingTimeWindowAccessStrategy` | 以滑动时间窗口的方式处理原始数据。框架会为每一个原始数据输入窗口调用一次`transform`方法。一个窗口可能存在多行数据,每一行数据对应的是输入序列按时间对齐后的结果(一行数据中,可能存在某一列为`null`值,但不会全部都是`null`)。 | `void transform(RowWindow rowWindow, PointCollector collector) throws Exception` |
| `SlidingSizeWindowAccessStrategy` | 以固定行数的方式处理原始数据,即每个数据处理窗口都会包含固定行数的数据(最后一个窗口除外)。框架会为每一个原始数据输入窗口调用一次`transform`方法。一个窗口可能存在多行数据,每一行数据对应的是输入序列按时间对齐后的结果(一行数据中,可能存在某一列为`null`值,但不会全部都是`null`)。 | `void transform(RowWindow rowWindow, PointCollector collector) throws Exception` |
-
-
`RowByRowAccessStrategy`的构造不需要任何参数。
-
-
-`SlidingTimeWindowAccessStrategy`有多种构造方法,您可以向构造方法提供3类参数:
+`SlidingTimeWindowAccessStrategy`有多种构造方法,您可以向构造方法提供 3 类参数:
1. 时间轴显示时间窗开始和结束时间
2. 划分时间轴的时间间隔参数(必须为正数)
@@ -187,24 +164,20 @@ void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) th
滑动步长参数也不是必须的。当您不提供滑动步长参数时,滑动步长会被设定为划分时间轴的时间间隔。
-3类参数的关系可见下图。策略的构造方法详见Javadoc。
+3 类参数的关系可见下图。策略的构造方法详见 Javadoc。
<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/30497621/99787878-47b51480-2b5b-11eb-8ed3-84088c5c30f7.png">
-注意,最后的一些时间窗口的实际时间间隔可能小于规定的时间间隔参数。另外,可能存在某些时间窗口内数据行数量为0的情况,这种情况框架也会为该窗口调用一次`transform`方法。
-
-
+注意,最后的一些时间窗口的实际时间间隔可能小于规定的时间间隔参数。另外,可能存在某些时间窗口内数据行数量为 0 的情况,这种情况框架也会为该窗口调用一次`transform`方法。
-`SlidingSizeWindowAccessStrategy`有多种构造方法,您可以向构造方法提供2个参数:
+`SlidingSizeWindowAccessStrategy`有多种构造方法,您可以向构造方法提供 2 个参数:
1. 窗口大小,即一个数据处理窗口包含的数据行数。注意,最后一些窗口的数据行数可能少于规定的数据行数。
2. 滑动步长,即下一窗口第一个数据行与当前窗口第一个数据行间的数据行数(不要求大于等于窗口大小,但是必须为正数)
滑动步长参数不是必须的。当您不提供滑动步长参数时,滑动步长会被设定为窗口大小。
-策略的构造方法详见Javadoc。
-
-
+策略的构造方法详见 Javadoc。
* setOutputDataType
@@ -219,7 +192,7 @@ void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) th
| `BOOLEAN` | `boolean` |
| `TEXT` | `java.lang.String` 和 `org.apache.iotdb.tsfile.utils.Binary` |
-UDTF输出序列的类型是运行时决定的。您可以根据输入序列类型动态决定输出序列类型。
+UDTF 输出序列的类型是运行时决定的。您可以根据输入序列类型动态决定输出序列类型。
下面是一个简单的例子:
@@ -234,15 +207,13 @@ void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) th
}
```
-
-
* void transform(Row row, PointCollector collector) throws Exception
-当您在`beforeStart`方法中指定UDF读取原始数据的策略为 `RowByRowAccessStrategy`,您就需要实现该方法,在该方法中增加对原始数据处理的逻辑。
+当您在`beforeStart`方法中指定 UDF 读取原始数据的策略为 `RowByRowAccessStrategy`,您就需要实现该方法,在该方法中增加对原始数据处理的逻辑。
该方法每次处理原始数据的一行。原始数据由`Row`读入,由`PointCollector`输出。您可以选择在一次`transform`方法调用中输出任意数量的数据点。需要注意的是,输出数据点的类型必须与您在`beforeStart`方法中设置的一致,而输出数据点的时间戳必须是严格单调递增的。
-下面是一个实现了`void transform(Row row, PointCollector collector) throws Exception`方法的完整UDF示例。它是一个加法器,接收两列时间序列输入,当这两个数据点都不为`null`时,输出这两个数据点的代数和。
+下面是一个实现了`void transform(Row row, PointCollector collector) throws Exception`方法的完整 UDF 示例。它是一个加法器,接收两列时间序列输入,当这两个数据点都不为`null`时,输出这两个数据点的代数和。
``` java
import org.apache.iotdb.db.query.udf.api.UDTF;
@@ -272,15 +243,13 @@ public class Adder implements UDTF {
}
```
-
-
* void transform(RowWindow rowWindow, PointCollector collector) throws Exception
-当您在`beforeStart`方法中指定UDF读取原始数据的策略为 `SlidingTimeWindowAccessStrategy`或者`SlidingSizeWindowAccessStrategy`时,您就需要实现该方法,在该方法中增加对原始数据处理的逻辑。
+当您在`beforeStart`方法中指定 UDF 读取原始数据的策略为 `SlidingTimeWindowAccessStrategy`或者`SlidingSizeWindowAccessStrategy`时,您就需要实现该方法,在该方法中增加对原始数据处理的逻辑。
该方法每次处理固定行数或者固定时间间隔内的一批数据,我们称包含这一批数据的容器为窗口。原始数据由`RowWindow`读入,由`PointCollector`输出。`RowWindow`能够帮助您访问某一批次的`Row`,它提供了对这一批次的`Row`进行随机访问和迭代访问的接口。您可以选择在一次`transform`方法调用中输出任意数量的数据点,需要注意的是,输出数据点的类型必须与您在`beforeStart`方法中设置的一致,而输出数据点的时间戳必须是严格单调递增的。
-下面是一个实现了`void transform(RowWindow rowWindow, PointCollector collector) throws Exception`方法的完整UDF示例。它是一个计数器,接收任意列数的时间序列输入,作用是统计并输出指定时间范围内每一个时间窗口中的数据行数。
+下面是一个实现了`void transform(RowWindow rowWindow, PointCollector collector) throws Exception`方法的完整 UDF 示例。它是一个计数器,接收任意列数的时间序列输入,作用是统计并输出指定时间范围内每一个时间窗口中的数据行数。
```java
import java.io.IOException;
@@ -314,17 +283,15 @@ public class Counter implements UDTF {
}
```
-
-
* void terminate(PointCollector collector) throws Exception
-在一些场景下,UDF需要遍历完所有的原始数据后才能得到最后的输出结果。`terminate`接口为这类UDF提供了支持。
+在一些场景下,UDF 需要遍历完所有的原始数据后才能得到最后的输出结果。`terminate`接口为这类 UDF 提供了支持。
该方法会在所有的`transform`调用执行完成后,在`beforeDestory`方法执行前被调用。您可以选择使用`transform`方法进行单纯的数据处理,最后使用`terminate`将处理结果输出。
结果需要由`PointCollector`输出。您可以选择在一次`terminate`方法调用中输出任意数量的数据点。需要注意的是,输出数据点的类型必须与您在`beforeStart`方法中设置的一致,而输出数据点的时间戳必须是严格单调递增的。
-下面是一个实现了`void terminate(PointCollector collector) throws Exception`方法的完整UDF示例。它接收一个`INT32`类型的时间序列输入,作用是输出该序列的最大值点。
+下面是一个实现了`void terminate(PointCollector collector) throws Exception`方法的完整 UDF 示例。它接收一个`INT32`类型的时间序列输入,作用是输出该序列的最大值点。
```java
import java.io.IOException;
@@ -366,78 +333,66 @@ public class Max implements UDTF {
}
```
-
-
* void beforeDestroy()
-UDTF的结束方法,您可以在此方法中进行一些资源释放等的操作。
-
-此方法由框架调用。对于一个UDF类实例而言,生命周期中会且只会被调用一次,即在处理完最后一条记录之后被调用。
-
-
-
-## 完整Maven项目示例
+UDTF 的结束方法,您可以在此方法中进行一些资源释放等的操作。
-如果您使用[Maven](http://search.maven.org/),可以参考我们编写的示例项目**udf-example**。您可以在[这里](https://github.com/apache/iotdb/tree/master/example/udf)找到它。
+此方法由框架调用。对于一个 UDF 类实例而言,生命周期中会且只会被调用一次,即在处理完最后一条记录之后被调用。
+## 完整 Maven 项目示例
+如果您使用 [Maven](http://search.maven.org/),可以参考我们编写的示例项目** udf-example**。您可以在 [这里](https://github.com/apache/iotdb/tree/master/example/udf) 找到它。
-## UDF注册
+## UDF 注册
-注册一个UDF可以按如下流程进行:
+注册一个 UDF 可以按如下流程进行:
-1. 实现一个完整的UDF类,假定这个类的全类名为`org.apache.iotdb.udf.UDTFExample`
-2. 将项目打成JAR包,如果您使用Maven管理项目,可以参考上述Maven项目示例的写法
-3. 将JAR包放置到目录 `iotdb-server-0.13.0-SNAPSHOT/ext/udf` (也可以是`iotdb-server-0.13.0-SNAPSHOT/ext/udf`的子目录)下。
+1. 实现一个完整的 UDF 类,假定这个类的全类名为`org.apache.iotdb.udf.UDTFExample`
+2. 将项目打成 JAR 包,如果您使用 Maven 管理项目,可以参考上述 Maven 项目示例的写法
+3. 将 JAR 包放置到目录 `iotdb-server-0.13.0-SNAPSHOT/ext/udf` (也可以是`iotdb-server-0.13.0-SNAPSHOT/ext/udf`的子目录)下。
- > 您可以通过修改配置文件中的`udf_root_dir`来指定UDF加载Jar的根路径。
-4. 使用SQL语句注册该UDF,假定赋予该UDF的名字为`example`
+ > 您可以通过修改配置文件中的`udf_root_dir`来指定 UDF 加载 Jar 的根路径。
+4. 使用 SQL 语句注册该 UDF,假定赋予该 UDF 的名字为`example`
-注册UDF的SQL语法如下:
+注册 UDF 的 SQL 语法如下:
```sql
CREATE FUNCTION <UDF-NAME> AS <UDF-CLASS-FULL-PATHNAME>
```
-例子中注册UDF的SQL语句如下:
+例子中注册 UDF 的 SQL 语句如下:
```sql
CREATE FUNCTION example AS "org.apache.iotdb.udf.UDTFExample"
```
-由于IoTDB的UDF是通过反射技术动态装载的,因此您在装载过程中无需启停服务器。
+由于 IoTDB 的 UDF 是通过反射技术动态装载的,因此您在装载过程中无需启停服务器。
-注意:UDF函数名称是大小写不敏感的。
+注意:UDF 函数名称是大小写不敏感的。
-注意:请不要给UDF函数注册一个内置函数的名字。使用内置函数的名字给UDF注册会失败。
+注意:请不要给 UDF 函数注册一个内置函数的名字。使用内置函数的名字给 UDF 注册会失败。
-注意:不同的JAR包中最好不要有全类名相同但实现功能逻辑不一样的类。例如 UDF(UDAF/UDTF):`udf1`、`udf2`分别对应资源`udf1.jar`、`udf2.jar`。如果两个JAR包里都包含一个`org.apache.iotdb.udf.UDTFExample`类,当同一个SQL中同时使用到这两个UDF时,系统会随机加载其中一个类,导致UDF执行行为不一致。
+注意:不同的 JAR 包中最好不要有全类名相同但实现功能逻辑不一样的类。例如 UDF(UDAF/UDTF):`udf1`、`udf2`分别对应资源`udf1.jar`、`udf2.jar`。如果两个 JAR 包里都包含一个`org.apache.iotdb.udf.UDTFExample`类,当同一个 SQL 中同时使用到这两个 UDF 时,系统会随机加载其中一个类,导致 UDF 执行行为不一致。
+## UDF 卸载
-
-## UDF卸载
-
-卸载UDF的SQL语法如下:
+卸载 UDF 的 SQL 语法如下:
```sql
DROP FUNCTION <UDF-NAME>
```
-可以通过如下SQL语句卸载上面例子中的UDF:
+可以通过如下 SQL 语句卸载上面例子中的 UDF:
```sql
DROP FUNCTION example
```
+## UDF 查询
+UDF 的使用方法与普通内建函数的类似。
-## UDF查询
-
-UDF的使用方法与普通内建函数的类似。
-
-
-
-### 支持的基础SQL语法
+### 支持的基础 SQL 语法
* `SLIMIT` / `SOFFSET`
* `LIMIT` / `OFFSET`
@@ -445,8 +400,6 @@ UDF的使用方法与普通内建函数的类似。
* 支持值过滤
* 支持时间过滤
-
-
### 带 * 查询
假定现在有时间序列 `root.sg.d1.s1`和 `root.sg.d1.s2`。
@@ -463,66 +416,52 @@ UDF的使用方法与普通内建函数的类似。
那么结果集中将包括`example(root.sg.d1.s1, root.sg.d1.s1)`,`example(root.sg.d1.s2, root.sg.d1.s1)`,`example(root.sg.d1.s1, root.sg.d1.s2)` 和 `example(root.sg.d1.s2, root.sg.d1.s2)`的结果。
-
-
### 带自定义输入参数的查询
-您可以在进行UDF查询的时候,向UDF传入任意数量的键值对参数。键值对中的键和值都需要被单引号或者双引号引起来。注意,键值对参数只能在所有时间序列后传入。下面是一组例子:
+您可以在进行 UDF 查询的时候,向 UDF 传入任意数量的键值对参数。键值对中的键和值都需要被单引号或者双引号引起来。注意,键值对参数只能在所有时间序列后传入。下面是一组例子:
``` sql
SELECT example(s1, "key1"="value1", "key2"="value2"), example(*, "key3"="value3") FROM root.sg.d1;
SELECT example(s1, s2, "key1"="value1", "key2"="value2") FROM root.sg.d1;
```
-
-
### 与其他查询的混合查询
-目前IoTDB支持UDF查询与原始查询的混合查询,例如:
+目前 IoTDB 支持 UDF 查询与原始查询的混合查询,例如:
``` sql
SELECT s1, s2, example(s1, s2) FROM root.sg.d1;
SELECT *, example(*) FROM root.sg.d1 DISABLE ALIGN;
```
-暂不支持UDF查询与其他查询混合使用。
-
+暂不支持 UDF 查询与其他查询混合使用。
-
-## 查看所有注册的UDF
+## 查看所有注册的 UDF
``` sql
SHOW FUNCTIONS
```
-
-
## 用户权限管理
-用户在使用UDF时会涉及到3种权限:
-
-* `CREATE_FUNCTION`:具备该权限的用户才被允许执行UDF注册操作
-* `DROP_FUNCTION`:具备该权限的用户才被允许执行UDF卸载操作
-* `READ_TIMESERIES`:具备该权限的用户才被允许使用UDF进行查询
-
-更多用户权限相关的内容,请参考[权限管理语句](../Administration-Management/Administration.md)。
+用户在使用 UDF 时会涉及到 3 种权限:
+* `CREATE_FUNCTION`:具备该权限的用户才被允许执行 UDF 注册操作
+* `DROP_FUNCTION`:具备该权限的用户才被允许执行 UDF 卸载操作
+* `READ_TIMESERIES`:具备该权限的用户才被允许使用 UDF 进行查询
+更多用户权限相关的内容,请参考 [权限管理语句](../Administration-Management/Administration.md)。
## 配置项
-在SQL语句中使用自定义函数时,可能提示内存不足。这种情况下,您可以通过更改配置文件`iotdb-engine.properties`中的`udf_initial_byte_array_length_for_memory_control`,`udf_memory_budget_in_mb`和`udf_reader_transformer_collector_memory_proportion`并重启服务来解决此问题。
-
+在 SQL 语句中使用自定义函数时,可能提示内存不足。这种情况下,您可以通过更改配置文件`iotdb-engine.properties`中的`udf_initial_byte_array_length_for_memory_control`,`udf_memory_budget_in_mb`和`udf_reader_transformer_collector_memory_proportion`并重启服务来解决此问题。
-
-## 贡献UDF
+## 贡献 UDF
<!-- The template is copied and modified from the Apache Doris community-->
该部分主要讲述了外部用户如何将自己编写的 UDF 贡献给 IoTDB 社区。
-
-
### 前提条件
1. UDF 具有通用性。
@@ -533,63 +472,47 @@ SHOW FUNCTIONS
2. UDF 已经完成测试,且能够正常运行在用户的生产环境中。
-
-
### 贡献清单
1. UDF 的源代码
2. UDF 的测试用例
3. UDF 的使用说明
-
-
#### 源代码
1. 在`src/main/java/org/apache/iotdb/db/query/udf/builtin`或者它的子文件夹中创建 UDF 主类和相关的辅助类。
2. 在`src/main/java/org/apache/iotdb/db/query/udf/builtin/BuiltinFunction.java`中注册您编写的 UDF。
-
-
#### 测试用例
您至少需要为您贡献的 UDF 编写集成测试。
您可以在`server/src/test/java/org/apache/iotdb/db/integration`中为您贡献的 UDF 新增一个测试类进行测试。
-
-
#### 使用说明
-使用说明需要包含:UDF 的名称、UDF的作用、执行函数必须的属性参数、函数的适用的场景以及使用示例等。
+使用说明需要包含:UDF 的名称、UDF 的作用、执行函数必须的属性参数、函数的适用的场景以及使用示例等。
使用说明需包含中英文两个版本。应分别在 `docs/zh/UserGuide/Operation Manual/DML Data Manipulation Language.md` 和 `docs/UserGuide/Operation Manual/DML Data Manipulation Language.md` 中新增使用说明。
-
-
-### 提交PR
+### 提交 PR
当您准备好源代码、测试用例和使用说明后,就可以将 UDF 贡献到 IoTDB 社区了。在 [Github](https://github.com/apache/iotdb) 上面提交 Pull Request (PR) 即可。具体提交方式见:[Pull Request Guide](https://iotdb.apache.org/Development/HowToCommit.html)。
当 PR 评审通过并被合并后,您的 UDF 就已经贡献给 IoTDB 社区了!
+## 已知的 UDF 库实现
-
-
-## 已知的UDF库实现
-
-+ [IoTDB-Quality](https://thulab.github.io/iotdb-quality),一个关于数据质量的UDF库实现,包括数据画像、数据质量评估与修复等一系列函数。
-
-
-
++ [IoTDB-Quality](https://thulab.github.io/iotdb-quality),一个关于数据质量的 UDF 库实现,包括数据画像、数据质量评估与修复等一系列函数。
## Q&A
-**Q1: 如何修改已经注册的UDF?**
+**Q1: 如何修改已经注册的 UDF?**
-A1: 假设UDF的名称为`example`,全类名为`org.apache.iotdb.udf.UDTFExample`,由`example.jar`引入
+A1: 假设 UDF 的名称为`example`,全类名为`org.apache.iotdb.udf.UDTFExample`,由`example.jar`引入
1. 首先卸载已经注册的`example`函数,执行`DROP FUNCTION example`
2. 删除 `iotdb-server-0.13.0-SNAPSHOT/ext/udf` 目录下的`example.jar`
-3. 修改`org.apache.iotdb.udf.UDTFExample`中的逻辑,重新打包,JAR包的名字可以仍然为`example.jar`
-4. 将新的JAR包上传至 `iotdb-server-0.13.0-SNAPSHOT/ext/udf` 目录下
-5. 装载新的UDF,执行`CREATE FUNCTION example AS "org.apache.iotdb.udf.UDTFExample"`
+3. 修改`org.apache.iotdb.udf.UDTFExample`中的逻辑,重新打包,JAR 包的名字可以仍然为`example.jar`
+4. 将新的 JAR 包上传至 `iotdb-server-0.13.0-SNAPSHOT/ext/udf` 目录下
+5. 装载新的 UDF,执行`CREATE FUNCTION example AS "org.apache.iotdb.udf.UDTFExample"`
diff --git a/docs/zh/UserGuide/Appendix/Config-Manual.md b/docs/zh/UserGuide/Appendix/Config-Manual.md
index 4025d57..ba43084 100644
--- a/docs/zh/UserGuide/Appendix/Config-Manual.md
+++ b/docs/zh/UserGuide/Appendix/Config-Manual.md
@@ -19,44 +19,43 @@
-->
-# 附录1:配置参数
+# 附录 1:配置参数
-为方便IoTDB Server的配置与管理,IoTDB Server为用户提供三种配置项,使得用户可以在启动服务或服务运行时对其进行配置。
+为方便 IoTDB Server 的配置与管理,IoTDB Server 为用户提供三种配置项,使得用户可以在启动服务或服务运行时对其进行配置。
-三种配置项的配置文件均位于IoTDB安装目录:`$IOTDB_HOME/conf`文件夹下,其中涉及server配置的共有2个文件,分别为:`iotdb-env.sh`, `iotdb-engine.properties`。用户可以通过更改其中的配置项对系统运行的相关配置项进行配置。
+三种配置项的配置文件均位于 IoTDB 安装目录:`$IOTDB_HOME/conf`文件夹下,其中涉及 server 配置的共有 2 个文件,分别为:`iotdb-env.sh`, `iotdb-engine.properties`。用户可以通过更改其中的配置项对系统运行的相关配置项进行配置。
配置文件的说明如下:
-* `iotdb-env.sh`:环境配置项的默认配置文件。用户可以在文件中配置JAVA-JVM的相关系统配置项。
+* `iotdb-env.sh`:环境配置项的默认配置文件。用户可以在文件中配置 JAVA-JVM 的相关系统配置项。
-* `iotdb-engine.properties`:IoTDB引擎层系统配置项的默认配置文件。用户可以在文件中配置IoTDB引擎运行时的相关参数,如JDBC服务监听端口(`rpc_port`)、overflow数据文件存储目录(`overflow_data_dir`)等。此外,用户可以在文件中配置IoTDB存储时TsFile文件的相关信息,如每次将内存中的数据写入到磁盘时的数据大小(`group_size_in_byte`),内存中每个列打一次包的大小(`page_size_in_byte`)等。
+* `iotdb-engine.properties`:IoTDB 引擎层系统配置项的默认配置文件。用户可以在文件中配置 IoTDB 引擎运行时的相关参数,如 JDBC 服务监听端口 (`rpc_port`)、overflow 数据文件存储目录 (`overflow_data_dir`) 等。此外,用户可以在文件中配置 IoTDB 存储时 TsFile 文件的相关信息,如每次将内存中的数据写入到磁盘时的数据大小 (`group_size_in_byte`),内存中每个列打一次包的大小 (`page_size_in_byte`) 等。
## 热修改配置项
-为方便用户使用,IoTDB Server为用户提供了热修改功能,即在系统运行过程中修改`iotdb-engine.properties`中部分配置参数并即时应用到系统中。下面介绍的参数中,改后
+为方便用户使用,IoTDB Server 为用户提供了热修改功能,即在系统运行过程中修改`iotdb-engine.properties`中部分配置参数并即时应用到系统中。下面介绍的参数中,改后
生效方式为`触发生效`的均为支持热修改的配置参数。
-触发方式:客户端发送```load configuration```命令至IoTDB Server,客户端的使用方式详见[SQL命令行终端(CLI)](https://iotdb.apache.org/zh/UserGuide/Master/CLI/Command-Line-Interface.html)
+触发方式:客户端发送```load configuration```命令至 IoTDB Server,客户端的使用方式详见 [SQL 命令行终端(CLI)](https://iotdb.apache.org/zh/UserGuide/Master/CLI/Command-Line-Interface.html)
## 环境配置项
-环境配置项主要用于对IoTDB Server运行的Java环境相关参数进行配置,如JVM相关配置。IoTDB Server启动时,此部分配置会被传给JVM。用户可以通过查看 `iotdb-env.sh`(或`iotdb-env.bat`)文件查看环境配置项内容。详细配置项说明如下:
+环境配置项主要用于对 IoTDB Server 运行的 Java 环境相关参数进行配置,如 JVM 相关配置。IoTDB Server 启动时,此部分配置会被传给 JVM。用户可以通过查看 `iotdb-env.sh`(或`iotdb-env.bat`) 文件查看环境配置项内容。详细配置项说明如下:
* JMX\_LOCAL
|名字|JMX\_LOCAL|
|:---:|:---|
-|描述|JMX监控模式,配置为true表示仅允许本地监控,设置为false的时候表示允许远程监控|
-|类型|枚举String : “true”, “false”|
+|描述|JMX 监控模式,配置为 true 表示仅允许本地监控,设置为 false 的时候表示允许远程监控|
+|类型|枚举 String : “true”, “false”|
|默认值|true|
|改后生效方式|重启服务生效|
-
* JMX\_PORT
|名字|JMX\_PORT|
|:---:|:---|
-|描述|JMX监听端口。请确认该端口不是系统保留端口并且未被占用。|
+|描述|JMX 监听端口。请确认该端口不是系统保留端口并且未被占用。|
|类型|Short Int: [0,65535]|
|默认值|31999|
|改后生效方式|重启服务生效|
@@ -65,23 +64,23 @@
|名字|MAX\_HEAP\_SIZE|
|:---:|:---|
-|描述|IoTDB启动时能使用的最大堆内存大小。|
+|描述|IoTDB 启动时能使用的最大堆内存大小。|
|类型|String|
-|默认值|取决于操作系统和机器配置。在Linux或MacOS系统下默认为机器内存的四分之一。在Windows系统下,32位系统的默认值是512M,64位系统默认值是2G。|
+|默认值|取决于操作系统和机器配置。在 Linux 或 MacOS 系统下默认为机器内存的四分之一。在 Windows 系统下,32 位系统的默认值是 512M,64 位系统默认值是 2G。|
|改后生效方式|重启服务生效|
* HEAP\_NEWSIZE
|名字|HEAP\_NEWSIZE|
|:---:|:---|
-|描述|IoTDB启动时能使用的最小堆内存大小。|
+|描述|IoTDB 启动时能使用的最小堆内存大小。|
|类型|String|
-|默认值|取决于操作系统和机器配置。在Linux或MacOS系统下默认值为机器CPU核数乘以100M的值与MAX\_HEAP\_SIZE四分之一这二者的最小值。在Windows系统下,32位系统的默认值是512M,64位系统默认值是2G。。|
+|默认值|取决于操作系统和机器配置。在 Linux 或 MacOS 系统下默认值为机器 CPU 核数乘以 100M 的值与 MAX\_HEAP\_SIZE 四分之一这二者的最小值。在 Windows 系统下,32 位系统的默认值是 512M,64 位系统默认值是 2G。|
|改后生效方式|重启服务生效|
## 系统配置项
-系统配置项是IoTDB Server运行的核心配置,它主要用于设置IoTDB Server文件层和引擎层的参数,便于用户根据自身需求调整Server的相关配置,以达到较好的性能表现。系统配置项可分为两大模块:文件层配置项和引擎层配置项。用户可以通过`iotdb-engine.properties`,文件查看和修改两种配置项的内容。在0.7.0版本中字符串类型的配置项大小写敏感。
+系统配置项是 IoTDB Server 运行的核心配置,它主要用于设置 IoTDB Server 文件层和引擎层的参数,便于用户根据自身需求调整 Server 的相关配置,以达到较好的性能表现。系统配置项可分为两大模块:文件层配置项和引擎层配置项。用户可以通过`iotdb-engine.properties`, 文件查看和修改两种配置项的内容。在 0.7.0 版本中字符串类型的配置项大小写敏感。
### 文件层配置
@@ -90,7 +89,7 @@
|名字|compressor|
|:---:|:---|
|描述|数据压缩方法|
-|类型|枚举String : “UNCOMPRESSED”, “SNAPPY”, “LZ4”|
+|类型|枚举 String : “UNCOMPRESSED”, “SNAPPY”, “LZ4”|
|默认值| SNAPPY |
|改后生效方式|触发生效|
@@ -121,7 +120,6 @@
|默认值| 256 |
|改后生效方式|仅允许在第一次启动服务前修改|
-
* max\_string\_length
|名字| max\_string\_length |
@@ -145,7 +143,7 @@
|名字| time\_series\_data\_type |
|:---:|:---|
|描述|时间戳数据类型|
-|类型|枚举String: "INT32", "INT64"|
+|类型|枚举 String: "INT32", "INT64"|
|默认值| Int64 |
|改后生效方式|触发生效|
@@ -154,7 +152,7 @@
|名字| time\_encoder |
|:---:|:---|
|描述| 时间列编码方式|
-|类型|枚举String: “TS_2DIFF”,“PLAIN”,“RLE”|
+|类型|枚举 String: “TS_2DIFF”,“PLAIN”,“RLE”|
|默认值| TS_2DIFF |
|改后生效方式|触发生效|
@@ -162,8 +160,8 @@
|名字| value\_encoder |
|:---:|:---|
-|描述| value列编码方式|
-|类型|枚举String: “TS_2DIFF”,“PLAIN”,“RLE”|
+|描述| value 列编码方式|
+|类型|枚举 String: “TS_2DIFF”,“PLAIN”,“RLE”|
|默认值| PLAIN |
|改后生效方式|触发生效|
@@ -173,7 +171,7 @@
|:---:|:---|
|描述| 浮点数精度,为小数点后数字的位数 |
|类型|Int32|
-|默认值| 默认为2位。注意:32位浮点数的十进制精度为7位,64位浮点数的十进制精度为15位。如果设置超过机器精度将没有实际意义。|
+|默认值| 默认为 2 位。注意:32 位浮点数的十进制精度为 7 位,64 位浮点数的十进制精度为 15 位。如果设置超过机器精度将没有实际意义。|
|改后生效方式|触发生效|
### 引擎层配置
@@ -182,7 +180,7 @@
|名字| data\_dirs |
|:---:|:---|
-|描述| IoTDB数据存储路径,默认存放在和sbin目录同级的data目录下。相对路径的起始目录与操作系统相关,建议使用绝对路径。|
+|描述| IoTDB 数据存储路径,默认存放在和 sbin 目录同级的 data 目录下。相对路径的起始目录与操作系统相关,建议使用绝对路径。|
|类型|String|
|默认值| data/data |
|改后生效方式|触发生效|
@@ -191,7 +189,7 @@
|名字| system\_dirs |
|:---:|:---|
-|描述| IoTDB元数据存储路径,默认存放在和sbin目录同级的data目录下。相对路径的起始目录与操作系统相关,建议使用绝对路径。|
+|描述| IoTDB 元数据存储路径,默认存放在和 sbin 目录同级的 data 目录下。相对路径的起始目录与操作系统相关,建议使用绝对路径。|
|类型|String|
|默认值| data/system |
|改后生效方式|触发生效|
@@ -200,7 +198,7 @@
|名字| wal\_dirs |
|:---:|:---|
-|描述| IoTDB写前日志存储路径,默认存放在和sbin目录同级的data目录下。相对路径的起始目录与操作系统相关,建议使用绝对路径。|
+|描述| IoTDB 写前日志存储路径,默认存放在和 sbin 目录同级的 data 目录下。相对路径的起始目录与操作系统相关,建议使用绝对路径。|
|类型|String|
|默认值| data/wal |
|改后生效方式|触发生效|
@@ -209,7 +207,7 @@
|名字| enable\_wal |
|:---:|:---|
-|描述| 是否开启写前日志,默认值为true表示开启,配置成false表示关闭 |
+|描述| 是否开启写前日志,默认值为 true 表示开启,配置成 false 表示关闭 |
|类型|Bool|
|默认值| true |
|改后生效方式|触发生效|
@@ -218,7 +216,7 @@
|名字| enable\_discard\_out\_of\_order\_data |
|:---:|:---|
-|描述| 是否删除无序数据,默认值为false表示关闭 |
+|描述| 是否删除无序数据,默认值为 false 表示关闭 |
|类型|Bool|
|默认值| false |
|改后生效方式|触发生效|
@@ -236,7 +234,7 @@
|名字| enable\_partial\_insert |
|:---:|:---|
-|描述| 在一次insert请求中,如果部分测点写入失败,是否继续写入其他测点|
+|描述| 在一次 insert 请求中,如果部分测点写入失败,是否继续写入其他测点|
|类型| Bool |
|默认值| true |
|改后生效方式|重启服务生效|
@@ -254,7 +252,7 @@
|名字| mlog\_buffer\_size |
|:---:|:---|
-|描述| mlog的buffer大小 |
+|描述| mlog 的 buffer 大小 |
|类型|Int32|
|默认值| 1048576 |
|改后生效方式|触发生效|
@@ -263,7 +261,7 @@
|名字| force\_wal\_period\_in\_ms |
|:---:|:---|
-|描述| 写前日志定期刷新到磁盘的周期,单位毫秒,有可能丢失至多force\_wal\_period\_in\_ms毫秒的操作。 |
+|描述| 写前日志定期刷新到磁盘的周期,单位毫秒,有可能丢失至多 force\_wal\_period\_in\_ms 毫秒的操作。 |
|类型|Int32|
|默认值| 100 |
|改后生效方式|触发生效|
@@ -272,7 +270,7 @@
|名字| flush\_wal\_threshold |
|:---:|:---|
-|描述| 写前日志的条数达到该值之后,刷新到磁盘,有可能丢失至多flush\_wal\_threshold个操作 |
+|描述| 写前日志的条数达到该值之后,刷新到磁盘,有可能丢失至多 flush\_wal\_threshold 个操作 |
|类型|Int32|
|默认值| 10000 |
|改后生效方式|触发生效|
@@ -281,7 +279,7 @@
|名字| wal\_buffer\_size |
|:---:|:---|
-|描述| 写前日志的buffer大小 |
+|描述| 写前日志的 buffer 大小 |
|类型|Int32|
|默认值| 16777216 |
|改后生效方式|触发生效|
@@ -302,13 +300,13 @@
|描述| 内存缓冲区 memtable 阈值|
|类型|Long|
|默认值| 1073741824 |
-|改后生效方式|enable\_mem\_control为false时生效、重启服务生效|
+|改后生效方式|enable\_mem\_control 为 false 时生效、重启服务生效|
* avg\_series\_point\_number\_threshold
|名字| avg\_series\_point\_number\_threshold |
|:---:|:---|
-|描述| 内存中平均每个时间序列点数最大值,达到触发flush|
+|描述| 内存中平均每个时间序列点数最大值,达到触发 flush|
|类型|Int32|
|默认值| 10000 |
|改后生效方式|重启服务生效|
@@ -344,7 +342,7 @@
|名字| multi\_dir\_strategy |
|:---:|:---|
-|描述| IoTDB在tsfile\_dir中为TsFile选择目录时采用的策略。可使用简单类名或类名全称。系统提供以下三种策略:<br>1. SequenceStrategy:IoTDB按顺序从tsfile\_dir中选择目录,依次遍历tsfile\_dir中的所有目录,并不断轮循;<br>2. MaxDiskUsableSpaceFirstStrategy:IoTDB优先选择tsfile\_dir中对应磁盘空余空间最大的目录;<br>3. MinFolderOccupiedSpaceFirstStrategy:IoTDB优先选择tsfile\_dir中已使用空间最小的目录;<br>4. UserDfineStrategyPackage(用户自定义策略)<br>您可以通过以下方法完成用户自定义策略:<br>1. 继承cn.edu.tsinghua.iotdb.conf.directories.strategy.DirectoryStrategy类并实现自身的Strategy方法;<br>2. 将实现的类的完整类名(包名加类名,UserDfineStrategyPack [...]
+|描述| IoTDB 在 tsfile\_dir 中为 TsFile 选择目录时采用的策略。可使用简单类名或类名全称。系统提供以下三种策略:<br>1. SequenceStrategy:IoTDB 按顺序从 tsfile\_dir 中选择目录,依次遍历 tsfile\_dir 中的所有目录,并不断轮循;<br>2. MaxDiskUsableSpaceFirstStrategy:IoTDB 优先选择 tsfile\_dir 中对应磁盘空余空间最大的目录;<br>3. MinFolderOccupiedSpaceFirstStrategy:IoTDB 优先选择 tsfile\_dir 中已使用空间最小的目录;<br>4. UserDfineStrategyPackage(用户自定义策略)<br>您可以通过以下方法完成用户自定义策略:<br>1. 继承 cn.edu.tsinghua.iotdb.conf.directories.strategy.DirectoryStrategy 类并实现自身的 Strategy 方法;<br>2. 将实现的类的完整类名(包名加类名,U [...]
|类型|String|
|默认值| MaxDiskUsableSpaceFirstStrategy |
|改后生效方式|触发生效|
@@ -362,7 +360,7 @@
|名字| rpc\_port |
|:---:|:---|
-|描述|jdbc服务监听端口。请确认该端口不是系统保留端口并且未被占用。|
+|描述|jdbc 服务监听端口。请确认该端口不是系统保留端口并且未被占用。|
|类型|Short Int : [0,65535]|
|默认值| 6667 |
|改后生效方式|重启服务生效|
@@ -380,7 +378,7 @@
|名字| rpc\_thrift\_compression\_enable |
|:---:|:---|
-|描述|是否启用thrift的压缩机制。|
+|描述|是否启用 thrift 的压缩机制。|
|类型|true 或者 false|
|默认值| false |
|改后生效方式|重启服务生效|
@@ -389,7 +387,7 @@
|名字| rpc\_advanced\_compression\_enable |
|:---:|:---|
-|描述|是否启用thrift的自定制压缩机制。|
+|描述|是否启用 thrift 的自定制压缩机制。|
|类型|true 或者 false|
|默认值| false |
|改后生效方式|重启服务生效|
@@ -407,7 +405,7 @@
|名字| concurrent\_flush\_thread |
|:---:|:---|
-|描述| 当IoTDB将内存中的数据写入磁盘时,最多启动多少个线程来执行该操作。如果该值小于等于0,那么采用机器所安装的CPU核的数量。默认值为0。|
+|描述| 当 IoTDB 将内存中的数据写入磁盘时,最多启动多少个线程来执行该操作。如果该值小于等于 0,那么采用机器所安装的 CPU 核的数量。默认值为 0。|
|类型| Int32 |
|默认值| 0 |
|改后生效方式|重启服务生效|
@@ -416,7 +414,7 @@
|名字| tsfile\_storage\_fs |
|:---:|:---|
-|描述| Tsfile和相关数据文件的存储文件系统。目前支持LOCAL(本地文件系统)和HDFS两种|
+|描述| Tsfile 和相关数据文件的存储文件系统。目前支持 LOCAL(本地文件系统)和 HDFS 两种|
|类型| String |
|默认值|LOCAL |
|改后生效方式|仅允许在第一次启动服务前修改|
@@ -425,7 +423,7 @@
|名字| core\_site\_path |
|:---:|:---|
-|描述| 在Tsfile和相关数据文件存储到HDFS的情况下用于配置core-site.xml的绝对路径|
+|描述| 在 Tsfile 和相关数据文件存储到 HDFS 的情况下用于配置 core-site.xml 的绝对路径|
|类型| String |
|默认值|/etc/hadoop/conf/core-site.xml |
|改后生效方式|重启服务生效|
@@ -434,7 +432,7 @@
|名字| hdfs\_site\_path |
|:---:|:---|
-|描述| 在Tsfile和相关数据文件存储到HDFS的情况下用于配置hdfs-site.xml的绝对路径|
+|描述| 在 Tsfile 和相关数据文件存储到 HDFS 的情况下用于配置 hdfs-site.xml 的绝对路径|
|类型| String |
|默认值|/etc/hadoop/conf/hdfs-site.xml |
|改后生效方式|重启服务生效|
@@ -443,7 +441,7 @@
|名字| hdfs\_ip |
|:---:|:---|
-|描述| 在Tsfile和相关数据文件存储到HDFS的情况下用于配置HDFS的IP。**如果配置了多于1个hdfs\_ip,则表明启用了Hadoop HA**|
+|描述| 在 Tsfile 和相关数据文件存储到 HDFS 的情况下用于配置 HDFS 的 IP。**如果配置了多于 1 个 hdfs\_ip,则表明启用了 Hadoop HA**|
|类型| String |
|默认值|localhost |
|改后生效方式|重启服务生效|
@@ -452,7 +450,7 @@
|名字| hdfs\_port |
|:---:|:---|
-|描述| 在Tsfile和相关数据文件存储到HDFS的情况下用于配置HDFS的端口|
+|描述| 在 Tsfile 和相关数据文件存储到 HDFS 的情况下用于配置 HDFS 的端口|
|类型| String |
|默认值|9000 |
|改后生效方式|重启服务生效|
@@ -461,7 +459,7 @@
|名字| hdfs\_nameservices |
|:---:|:---|
-|描述| 在使用Hadoop HA的情况下用于配置HDFS的nameservices|
+|描述| 在使用 Hadoop HA 的情况下用于配置 HDFS 的 nameservices|
|类型| String |
|默认值|hdfsnamespace |
|改后生效方式|重启服务生效|
@@ -470,7 +468,7 @@
|名字| hdfs\_ha\_namenodes |
|:---:|:---|
-|描述| 在使用Hadoop HA的情况下用于配置HDFS的nameservices下的namenodes|
+|描述| 在使用 Hadoop HA 的情况下用于配置 HDFS 的 nameservices 下的 namenodes|
|类型| String |
|默认值|nn1,nn2 |
|改后生效方式|重启服务生效|
@@ -479,7 +477,7 @@
|名字| dfs\_ha\_automatic\_failover\_enabled |
|:---:|:---|
-|描述| 在使用Hadoop HA的情况下用于配置是否使用失败自动切换|
+|描述| 在使用 Hadoop HA 的情况下用于配置是否使用失败自动切换|
|类型| Boolean |
|默认值|true |
|改后生效方式|重启服务生效|
@@ -488,7 +486,7 @@
|名字| dfs\_client\_failover\_proxy\_provider |
|:---:|:---|
-|描述| 在使用Hadoop HA且使用失败自动切换的情况下配置失败自动切换的实现方式|
+|描述| 在使用 Hadoop HA 且使用失败自动切换的情况下配置失败自动切换的实现方式|
|类型| String |
|默认值|org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider |
|改后生效方式|重启服务生效|
@@ -497,7 +495,7 @@
|名字| hdfs\_use\_kerberos |
|:---:|:---|
-|描述| 是否使用kerberos验证访问hdfs|
+|描述| 是否使用 kerberos 验证访问 hdfs|
|类型| String |
|默认值|false |
|改后生效方式|重启服务生效|
@@ -520,7 +518,6 @@
|默认值|your principal |
|改后生效方式|重启服务生效|
-
* authorizer\_provider\_class
|名字| authorizer\_provider\_class |
@@ -535,19 +532,18 @@
|名字| openID\_url |
|:---:|:---|
-|描述| openID 服务器地址 (当OpenIdAuthorizer被启用时必须设定)|
-|类型| String (一个http地址) |
+|描述| openID 服务器地址 (当 OpenIdAuthorizer 被启用时必须设定)|
+|类型| String (一个 http 地址) |
|默认值| 无 |
|改后生效方式|重启服务生效|
-
* thrift\_max\_frame\_size
|名字| thrift\_max\_frame\_size |
|:---:|:---|
|描述| RPC 请求/响应的最大字节数|
|类型| long |
-|默认值| 67108864 (应大于等于 8 * 1024 * 1024) |
+|默认值| 67108864 (应大于等于 8 * 1024 * 1024) |
|改后生效方式|重启服务生效|
* thrift\_init\_buffer\_size
@@ -563,7 +559,7 @@
|名字| timestamp\_precision |
|:---:|:---|
-|描述| 时间戳精度,支持ms、us、ns |
+|描述| 时间戳精度,支持 ms、us、ns |
|类型|String |
|默认值| ms |
|改后生效方式|触发生效|
@@ -572,19 +568,18 @@
|名字| default\_ttl |
|:---:|:---|
-|描述| ttl时间,单位ms|
+|描述| ttl 时间,单位 ms|
|类型| long |
|默认值| 36000000 |
|改后生效方式|重启服务生效|
## 数据类型自动推断
-
* enable\_auto\_create\_schema
|名字| enable\_auto\_create\_schema |
|:---:|:---|
-|描述| 当写入的序列不存在时,是否自动创建序列到Schema|
+|描述| 当写入的序列不存在时,是否自动创建序列到 Schema|
|取值| true or false |
|默认值|true |
|改后生效方式|重启服务生效|
@@ -593,7 +588,7 @@
|名字| default\_storage\_group\_level |
|:---:|:---|
-|描述| 当写入的数据不存在且自动创建序列时,若需要创建相应的存储组,将序列路径的哪一层当做存储组. 例如, 如果我们接到一个新序列 root.sg0.d1.s2, 并且level=1, 那么root.sg0被视为存储组(因为root是level 0 层)|
+|描述| 当写入的数据不存在且自动创建序列时,若需要创建相应的存储组,将序列路径的哪一层当做存储组。例如,如果我们接到一个新序列 root.sg0.d1.s2, 并且 level=1, 那么 root.sg0 被视为存储组(因为 root 是 level 0 层)|
|取值| 整数 |
|默认值|1 |
|改后生效方式|重启服务生效|
@@ -647,7 +642,7 @@
|名字| default\_boolean\_encoding |
|:---:|:---|
-|描述| BOOLEAN类型编码格式|
+|描述| BOOLEAN 类型编码格式|
|取值| PLAIN, RLE |
|默认值|RLE |
|改后生效方式|重启服务生效|
@@ -656,7 +651,7 @@
|名字| default\_int32\_encoding |
|:---:|:---|
-|描述| int32类型编码格式|
+|描述| int32 类型编码格式|
|取值| PLAIN, RLE, TS_2DIFF, REGULAR, GORILLA |
|默认值|RLE |
|改后生效方式|重启服务生效|
@@ -665,7 +660,7 @@
|名字| default\_int64\_encoding |
|:---:|:---|
-|描述| int64类型编码格式|
+|描述| int64 类型编码格式|
|取值| PLAIN, RLE, TS_2DIFF, REGULAR, GORILLA |
|默认值|RLE |
|改后生效方式|重启服务生效|
@@ -674,7 +669,7 @@
|名字| default\_float\_encoding |
|:---:|:---|
-|描述| float类型编码格式|
+|描述| float 类型编码格式|
|取值| PLAIN, RLE, TS_2DIFF, GORILLA |
|默认值|GORILLA |
|改后生效方式|重启服务生效|
@@ -683,7 +678,7 @@
|名字| default\_double\_encoding |
|:---:|:---|
-|描述| double类型编码格式|
+|描述| double 类型编码格式|
|取值| PLAIN, RLE, TS_2DIFF, GORILLA |
|默认值|GORILLA |
|改后生效方式|重启服务生效|
@@ -692,15 +687,14 @@
|名字| default\_text\_encoding |
|:---:|:---|
-|描述| text类型编码格式|
+|描述| text 类型编码格式|
|取值| PLAIN |
|默认值|PLAIN |
|改后生效方式|重启服务生效|
-
-## 开启GC日志
-GC日志默认是关闭的。为了性能调优,用户可能会需要收集GC信息。
-若要打开GC日志,则需要在启动IoTDB Server的时候加上"printgc"参数:
+## 开启 GC 日志
+GC 日志默认是关闭的。为了性能调优,用户可能会需要收集 GC 信息。
+若要打开 GC 日志,则需要在启动 IoTDB Server 的时候加上"printgc"参数:
```bash
nohup sbin/start-server.sh printgc >/dev/null 2>&1 &
@@ -711,5 +705,4 @@ nohup sbin/start-server.sh printgc >/dev/null 2>&1 &
sbin\start-server.bat printgc
```
-GC日志会被存储在`IOTDB_HOME/logs/gc.log`. 至多会存储10个gc.log文件,每个文件最多10MB。
-
+GC 日志会被存储在`IOTDB_HOME/logs/gc.log`. 至多会存储 10 个 gc.log 文件,每个文件最多 10MB。
diff --git a/docs/zh/UserGuide/Appendix/SQL-Reference.md b/docs/zh/UserGuide/Appendix/SQL-Reference.md
index d8942c4..8abcf5a 100644
--- a/docs/zh/UserGuide/Appendix/SQL-Reference.md
+++ b/docs/zh/UserGuide/Appendix/SQL-Reference.md
@@ -19,7 +19,7 @@
-->
-# 附录2: SQL 参考文档
+# 附录 2: SQL 参考文档
## 显示版本号
@@ -37,7 +37,7 @@ Total line number = 1
It costs 0.417s
```
-## Schema语句
+## Schema 语句
* 设置存储组
@@ -222,7 +222,7 @@ Note: The path can be prefix path or star path.
Note: This statement can be used in IoTDB Client and JDBC.
```
-* 显示Merge状态语句
+* 显示 Merge 状态语句
```
SHOW MERGE
@@ -285,7 +285,7 @@ Note: The path can be prefix path or star path.
Note: This statement can be used in IoTDB Client and JDBC.
```
-* 显示ROOT节点的子节点名称语句
+* 显示 ROOT 节点的子节点名称语句
```
SHOW CHILD PATHS
@@ -435,10 +435,10 @@ Note: the statement needs to satisfy this constraint: <PrefixPath>(FromClause) +
Note: Integer in <TimeUnit> needs to be greater than 0
```
-* Group By Fill语句
+* Group By Fill 语句
```
-# time区间规则为:只能为左开右闭或左闭右开,例如:[20, 100)
+# time 区间规则为:只能为左开右闭或左闭右开,例如:[20, 100)
SELECT <SelectClause> FROM <FromClause> WHERE <WhereClause> GROUP BY <GroupByClause> (FILL <GROUPBYFillClause>)?
GroupByClause : LPAREN <TimeInterval> COMMA <TimeUnit> RPAREN
@@ -506,48 +506,48 @@ Note: The order of <LIMITClause> and <SLIMITClause> does not affect the grammati
Note: <FillClause> can not use <LIMITClause> but not <SLIMITClause>.
```
-* Align by device语句
+* Align by device 语句
```
AlignbyDeviceClause : ALIGN BY DEVICE
-规则:
-1. 大小写不敏感.
-正例: select * from root.sg1 align by device
-正例: select * from root.sg1 ALIGN BY DEVICE
-
-2. AlignbyDeviceClause 只能放在末尾.
-正例: select * from root.sg1 where time > 10 align by device
-错例: select * from root.sg1 align by device where time > 10
-
-3. Select子句中的path只能是单层,或者通配符,不允许有path分隔符"."。
-正例: select s0,s1 from root.sg1.* align by device
-正例: select s0,s1 from root.sg1.d0, root.sg1.d1 align by device
-正例: select * from root.sg1.* align by device
-正例: select * from root align by device
-正例: select s0,s1,* from root.*.* align by device
-错例: select d0.s1, d0.s2, d1.s0 from root.sg1 align by device
-错例: select *.s0, *.s1 from root.* align by device
-错例: select *.*.* from root align by device
-
-4.相同measurement的各设备的数据类型必须都相同,
-
-正例: select s0 from root.sg1.d0,root.sg1.d1 align by device
+规则:
+1. 大小写不敏感。
+正例:select * from root.sg1 align by device
+正例:select * from root.sg1 ALIGN BY DEVICE
+
+2. AlignbyDeviceClause 只能放在末尾。
+正例:select * from root.sg1 where time > 10 align by device
+错例:select * from root.sg1 align by device where time > 10
+
+3. Select 子句中的 path 只能是单层,或者通配符,不允许有 path 分隔符"."。
+正例:select s0,s1 from root.sg1.* align by device
+正例:select s0,s1 from root.sg1.d0, root.sg1.d1 align by device
+正例:select * from root.sg1.* align by device
+正例:select * from root align by device
+正例:select s0,s1,* from root.*.* align by device
+错例:select d0.s1, d0.s2, d1.s0 from root.sg1 align by device
+错例:select *.s0, *.s1 from root.* align by device
+错例:select *.*.* from root align by device
+
+4. 相同 measurement 的各设备的数据类型必须都相同,
+
+正例:select s0 from root.sg1.d0,root.sg1.d1 align by device
root.sg1.d0.s0 and root.sg1.d1.s0 are both INT32.
-正例: select count(s0) from root.sg1.d0,root.sg1.d1 align by device
+正例:select count(s0) from root.sg1.d0,root.sg1.d1 align by device
count(root.sg1.d0.s0) and count(root.sg1.d1.s0) are both INT64.
-错例: select s0 from root.sg1.d0, root.sg2.d3 align by device
+错例:select s0 from root.sg1.d0, root.sg2.d3 align by device
root.sg1.d0.s0 is INT32 while root.sg2.d3.s0 is FLOAT.
-5. 结果集的展示规则:对于select中给出的列,不论是否有数据(是否被注册),均会被显示。此外,select子句中还支持常数列(例如,'a', '123'等等)。
-例如, "select s0,s1,s2,'abc',s1,s2 from root.sg.d0, root.sg.d1, root.sg.d2 align by device". 假设只有下述三列有数据:
+5. 结果集的展示规则:对于 select 中给出的列,不论是否有数据(是否被注册),均会被显示。此外,select 子句中还支持常数列(例如,'a', '123'等等)。
+例如,"select s0,s1,s2,'abc',s1,s2 from root.sg.d0, root.sg.d1, root.sg.d2 align by device". 假设只有下述三列有数据:
- root.sg.d0.s0
- root.sg.d0.s1
- root.sg.d1.s0
-结果集形如:
+结果集形如:
| Time | Device | s0 | s1 | s2 | 'abc' | s1 | s2 |
| --- | --- | ---| ---| null | 'abc' | ---| null |
@@ -558,21 +558,21 @@ root.sg1.d0.s0 is INT32 while root.sg2.d3.s0 is FLOAT.
| 2 |root.sg.d1| 19 |null| null | 'abc' |null| null |
| ... | ... | ...| ...| null | 'abc' | ...| null |
-注意注意 设备'root.sg.d1'的's0'的值全为null
+注意注意 设备'root.sg.d1'的's0'的值全为 null
-6. 在From中重复写设备名字或者设备前缀是没有任何作用的。
-例如, "select s0,s1 from root.sg.d0,root.sg.d0,root.sg.d1 align by device" 等于 "select s0,s1 from root.sg.d0,root.sg.d1 align by device".
-例如. "select s0,s1 from root.sg.*,root.sg.d0 align by device" 等于 "select s0,s1 from root.sg.* align by device".
+6. 在 From 中重复写设备名字或者设备前缀是没有任何作用的。
+例如,"select s0,s1 from root.sg.d0,root.sg.d0,root.sg.d1 align by device" 等于 "select s0,s1 from root.sg.d0,root.sg.d1 align by device".
+例如。"select s0,s1 from root.sg.*,root.sg.d0 align by device" 等于 "select s0,s1 from root.sg.* align by device".
-7. 在Select子句中重复写列名是生效的。例如, "select s0,s0,s1 from root.sg.* align by device" 不等于 "select s0,s1 from root.sg.* align by device".
+7. 在 Select 子句中重复写列名是生效的。例如,"select s0,s0,s1 from root.sg.* align by device" 不等于 "select s0,s1 from root.sg.* align by device".
-8. 在Where子句中时间过滤条件和值过滤条件均可以使用,值过滤条件可以使用叶子节点 path,或以 root 开头的整个 path,不允许存在通配符。例如,
+8. 在 Where 子句中时间过滤条件和值过滤条件均可以使用,值过滤条件可以使用叶子节点 path,或以 root 开头的整个 path,不允许存在通配符。例如,
- select * from root.sg.* where time = 1 align by device
- select * from root.sg.* where s0 < 100 align by device
- select * from root.sg.* where time < 20 AND s0 > 50 align by device
- select * from root.sg.d0 where root.sg.d0.s0 = 15 align by device
-9. 更多正例:
+9. 更多正例:
- select * from root.vehicle align by device
- select s0,s0,s1 from root.vehicle.* align by device
- select s0,s1 from root.vehicle.* limit 10 offset 1 align by device
@@ -588,25 +588,25 @@ root.sg1.d0.s0 is INT32 while root.sg2.d3.s0 is FLOAT.
* Disable align 语句
```
-规则:
-1. 大小写均可.
-正例: select * from root.sg1 disable align
-正例: select * from root.sg1 DISABLE ALIGN
+规则:
+1. 大小写均可。
+正例:select * from root.sg1 disable align
+正例:select * from root.sg1 DISABLE ALIGN
-2. Disable Align只能用于查询语句句尾.
-正例: select * from root.sg1 where time > 10 disable align
-错例: select * from root.sg1 disable align where time > 10
+2. Disable Align 只能用于查询语句句尾。
+正例:select * from root.sg1 where time > 10 disable align
+错例:select * from root.sg1 disable align where time > 10
-3. Disable Align 不能用于聚合查询、Fill语句、Group by或Group by device语句,但可用于Limit语句。
-正例: select * from root.sg1 limit 3 offset 2 disable align
-正例: select * from root.sg1 slimit 3 soffset 2 disable align
-错例: select count(s0),count(s1) from root.sg1.d1 disable align
-错例: select * from root.vehicle where root.vehicle.d0.s0>0 disable align
-错例: select * from root.vehicle align by device disable align
+3. Disable Align 不能用于聚合查询、Fill 语句、Group by 或 Group by device 语句,但可用于 Limit 语句。
+正例:select * from root.sg1 limit 3 offset 2 disable align
+正例:select * from root.sg1 slimit 3 soffset 2 disable align
+错例:select count(s0),count(s1) from root.sg1.d1 disable align
+错例:select * from root.vehicle where root.vehicle.d0.s0>0 disable align
+错例:select * from root.vehicle align by device disable align
-4. 结果显示若无数据显示为空白.
+4. 结果显示若无数据显示为空白。
-查询结果样式如下表:
+查询结果样式如下表:
| Time | root.sg.d0.s1 | Time | root.sg.d0.s2 | Time | root.sg.d1.s1 |
| --- | --- | --- | --- | --- | --- |
| 1 | 100 | 20 | 300 | 400 | 600 |
@@ -614,7 +614,7 @@ root.sg1.d0.s0 is INT32 while root.sg2.d3.s0 is FLOAT.
| 4 | 500 | | | 800 | 1000 |
| | | | | 900 | 8000 |
-5. 一些正确使用样例:
+5. 一些正确使用样例:
- select * from root.vehicle disable align
- select s0,s0,s1 from root.vehicle.* disable align
- select s0,s1 from root.vehicle.* limit 10 offset 1 disable align
@@ -623,7 +623,7 @@ root.sg1.d0.s0 is INT32 while root.sg2.d3.s0 is FLOAT.
```
-* Last语句
+* Last 语句
Last 语句返回所要查询时间序列的最近时间戳的一条数据
@@ -640,10 +640,10 @@ Eg. SELECT LAST s1 FROM root.sg.d1, root.sg.d2
Eg. SELECT LAST s1 FROM root.sg.d1 where time > 100
Eg. SELECT LAST s1, s2 FROM root.sg.d1 where time >= 500
-规则:
-1. 需要满足PrefixPath.Path 为一条完整的时间序列,即 <PrefixPath> + <Path> = <Timeseries>
+规则:
+1. 需要满足 PrefixPath.Path 为一条完整的时间序列,即 <PrefixPath> + <Path> = <Timeseries>
-2. 当前SELECT LAST 语句只支持包含'>'或'>='的时间过滤条件
+2. 当前 SELECT LAST 语句只支持包含'>'或'>='的时间过滤条件
3. 结果集以三列的表格的固定形式返回。
例如 "select last s1, s2 from root.sg.d1, root.sg.d2", 结果集返回如下:
@@ -655,7 +655,7 @@ Eg. SELECT LAST s1, s2 FROM root.sg.d1 where time >= 500
| 4 | root.sg.d2.s1| 250 |
| 9 | root.sg.d2.s2| 600 |
-4. 注意LAST语句不支持与"disable align"关键词一起使用。
+4. 注意 LAST 语句不支持与"disable align"关键词一起使用。
```
@@ -968,18 +968,18 @@ Note: the statement needs to satisfy this constraint: <PrefixPath> + <Path> = <T
## TTL
-IoTDB支持对存储组级别设置数据存活时间(TTL),这使得IoTDB可以定期、自动地删除一定时间之前的数据。合理使用TTL
-可以帮助您控制IoTDB占用的总磁盘空间以避免出现磁盘写满等异常。并且,随着文件数量的增多,查询性能往往随之下降,
+IoTDB 支持对存储组级别设置数据存活时间(TTL),这使得 IoTDB 可以定期、自动地删除一定时间之前的数据。合理使用 TTL
+可以帮助您控制 IoTDB 占用的总磁盘空间以避免出现磁盘写满等异常。并且,随着文件数量的增多,查询性能往往随之下降,
内存占用也会有所提高。及时地删除一些较老的文件有助于使查询性能维持在一个较高的水平和减少内存资源的占用。
-IoTDB中的TTL操作可以由以下的语句进行实现:
+IoTDB 中的 TTL 操作可以由以下的语句进行实现:
* 设置 TTL
```
SET TTL TO StorageGroupName TTLTime
Eg. SET TTL TO root.group1 3600000
-这个例子展示了如何使得root.group1这个存储组只保留近一个小时的数据,一个小时前的数据会被删除或者进入不可见状态。
-注意: TTLTime 应是毫秒时间戳。一旦TTL被设置,超过TTL时间范围的写入将被拒绝。
+这个例子展示了如何使得 root.group1 这个存储组只保留近一个小时的数据,一个小时前的数据会被删除或者进入不可见状态。
+注意:TTLTime 应是毫秒时间戳。一旦 TTL 被设置,超过 TTL 时间范围的写入将被拒绝。
```
* 取消 TTL
@@ -987,7 +987,7 @@ Eg. SET TTL TO root.group1 3600000
```
UNSET TTL TO StorageGroupName
Eg. UNSET TTL TO root.group1
-这个例子展示了如何取消存储组root.group1的TTL,这将使得该存储组接受任意时刻的数据。
+这个例子展示了如何取消存储组 root.group1 的 TTL,这将使得该存储组接受任意时刻的数据。
```
* 显示 TTL
@@ -996,23 +996,23 @@ Eg. UNSET TTL TO root.group1
SHOW ALL TTL
SHOW TTL ON StorageGroupNames
Eg.1 SHOW ALL TTL
-这个例子会给出所有存储组的TTL。
+这个例子会给出所有存储组的 TTL。
Eg.2 SHOW TTL ON root.group1,root.group2,root.group3
-这个例子会显示指定的三个存储组的TTL。
-注意: 没有设置TTL的存储组的TTL将显示为null。
+这个例子会显示指定的三个存储组的 TTL。
+注意:没有设置 TTL 的存储组的 TTL 将显示为 null。
```
-注意:当您对某个存储组设置TTL的时候,超过TTL范围的数据将会立即不可见。但由于数据文件可能混合包含处在TTL范围内
-与范围外的数据,同时数据文件可能正在接受查询,数据文件的物理删除不会立即进行。如果你在此时取消或者调大TTL,
-一部分之前不可见的数据可能重新可见,而那些已经被物理删除的数据则将永久丢失。也就是说,TTL操作不会原子性地删除
-对应的数据。因此我们不推荐您频繁修改TTL,除非您能接受该操作带来的一定程度的不可预知性。
+注意:当您对某个存储组设置 TTL 的时候,超过 TTL 范围的数据将会立即不可见。但由于数据文件可能混合包含处在 TTL 范围内
+与范围外的数据,同时数据文件可能正在接受查询,数据文件的物理删除不会立即进行。如果你在此时取消或者调大 TTL,
+一部分之前不可见的数据可能重新可见,而那些已经被物理删除的数据则将永久丢失。也就是说,TTL 操作不会原子性地删除
+对应的数据。因此我们不推荐您频繁修改 TTL,除非您能接受该操作带来的一定程度的不可预知性。
-* 删除时间分区 (实验性功能)
+* 删除时间分区 (实验性功能)
```
DELETE PARTITION StorageGroupName INT(COMMA INT)*
Eg DELETE PARTITION root.sg1 0,1,2
-该例子将删除存储组root.sg1的前三个时间分区
+该例子将删除存储组 root.sg1 的前三个时间分区
```
partitionId 可以通过查看数据文件夹获取,或者是计算 `timestamp / partitionInterval`得到。
@@ -1041,7 +1041,6 @@ E.g. KILL QUERY
E.g. KILL QUERY 2
```
-
## 标识符列表
```
@@ -1099,11 +1098,9 @@ eg. _abc123
## 常量列表
-
```
PointValue : Integer | Float | StringLiteral | Boolean
```
-```
TimeValue : Integer | DateTime | ISO8601 | NOW()
Note: Integer means timestamp type.
@@ -1114,10 +1111,8 @@ eg. 2016-11-16T16:22:33.000+08:00
eg. 2016-11-16 16:22:33.000+08:00
Note: DateTime Type can support several types, see Chapter 3 Datetime section for details.
```
-```
PrecedenceEqualOperator : EQUAL | NOTEQUAL | LESSTHANOREQUALTO | LESSTHAN | GREATERTHANOREQUALTO | GREATERTHAN
```
-```
Timeseries : ROOT [DOT <LayerName>]* DOT <SensorName>
LayerName : Identifier
SensorName : Identifier
@@ -1132,7 +1127,6 @@ LayerName : Identifier | STAR
eg. root.sgcc
eg. root.*
```
-```
Path: (ROOT | <LayerName>) (DOT <LayerName>)*
LayerName: Identifier | STAR
eg. root.ln.wf01.wt01.status
diff --git a/docs/zh/UserGuide/Appendix/Status-Codes.md b/docs/zh/UserGuide/Appendix/Status-Codes.md
index d3ce65c..d272e1e 100644
--- a/docs/zh/UserGuide/Appendix/Status-Codes.md
+++ b/docs/zh/UserGuide/Appendix/Status-Codes.md
@@ -19,9 +19,9 @@
-->
-# 附录3:状态码
+# 附录 3:状态码
-从0.10版本开始IoTDB引入了**状态码**这一概念。例如,因为IoTDB需要在写入数据之前首先注册时间序列,一种可能的解决方案是:
+从 0.10 版本开始 IoTDB 引入了**状态码**这一概念。例如,因为 IoTDB 需要在写入数据之前首先注册时间序列,一种可能的解决方案是:
```
try {
@@ -54,8 +54,8 @@ try {
|301|PATH_NOT_EXIST_ERROR|路径不存在|
|302|UNSUPPORTED_FETCH_METADATA_OPERATION_ERROR|不支持的获取元数据操作|
|303|METADATA_ERROR|处理元数据错误|
-|305|OUT_OF_TTL_ERROR|插入时间少于TTL时间边界|
-|306|CONFIG_ADJUSTER|IoTDB系统负载过大|
+|305|OUT_OF_TTL_ERROR|插入时间少于 TTL 时间边界|
+|306|CONFIG_ADJUSTER|IoTDB 系统负载过大|
|307|MERGE_ERROR|合并错误|
|308|SYSTEM_CHECK_ERROR|系统检查错误|
|309|SYNC_DEVICE_OWNER_CONFLICT_ERROR|回传设备冲突错误|
@@ -63,17 +63,17 @@ try {
|311|STORAGE_GROUP_PROCESSOR_ERROR|存储组处理器相关错误|
|312|STORAGE_GROUP_ERROR|存储组相关错误|
|313|STORAGE_ENGINE_ERROR|存储引擎相关错误|
-|314|TSFILE_PROCESSOR_ERROR|TsFile处理器相关错误|
+|314|TSFILE_PROCESSOR_ERROR|TsFile 处理器相关错误|
|315|PATH_ILLEGAL|路径不合法|
|316|LOAD_FILE_ERROR|加载文件错误|
|317|STORAGE_GROUP_NOT_READY| 存储组还在恢复中,还不能接受读写操作 |
|400|EXECUTE_STATEMENT_ERROR|执行语句错误|
-|401|SQL_PARSE_ERROR|SQL语句分析错误|
+|401|SQL_PARSE_ERROR|SQL 语句分析错误|
|402|GENERATE_TIME_ZONE_ERROR|生成时区错误|
|403|SET_TIME_ZONE_ERROR|设置时区错误|
|404|NOT_STORAGE_GROUP_ERROR|操作对象不是存储组|
|405|QUERY_NOT_ALLOWED|查询语句不允许|
-|406|AST_FORMAT_ERROR|AST格式相关错误|
+|406|AST_FORMAT_ERROR|AST 格式相关错误|
|407|LOGICAL_OPERATOR_ERROR|逻辑符相关错误|
|408|LOGICAL_OPTIMIZE_ERROR|逻辑优化相关错误|
|409|UNSUPPORTED_FILL_TYPE_ERROR|不支持的填充类型|
@@ -95,12 +95,11 @@ try {
|603|UNINITIALIZED_AUTH_ERROR|授权人未初始化|
|700|PARTITION_NOT_READY|分区表未准备好|
|701|TIME_OUT|操作超时|
-|702|NO_LEADER|Leader找不到|
+|702|NO_LEADER|Leader 找不到|
|703|UNSUPPORTED_OPERATION|不支持的操作|
|704|NODE_READ_ONLY|节点只读|
|705|CONSISTENCY_FAILURE|一致性检查失败|
|706|NO_CONNECTION|连接获取失败|
|707|NEED_REDIRECTION|需要重定向|
-> 在最新版本中,我们重构了IoTDB的异常类。通过将错误信息统一提取到异常类中,并为所有异常添加不同的错误代码,从而当捕获到异常并引发更高级别的异常时,错误代码将保留并传递,以便用户了解详细的错误原因。
+> 在最新版本中,我们重构了 IoTDB 的异常类。通过将错误信息统一提取到异常类中,并为所有异常添加不同的错误代码,从而当捕获到异常并引发更高级别的异常时,错误代码将保留并传递,以便用户了解详细的错误原因。
除此之外,我们添加了一个基础异常类“ProcessException”,由所有异常扩展。
-
diff --git a/docs/zh/UserGuide/CLI/Command-Line-Interface.md b/docs/zh/UserGuide/CLI/Command-Line-Interface.md
index 93d4904..36c96a5 100644
--- a/docs/zh/UserGuide/CLI/Command-Line-Interface.md
+++ b/docs/zh/UserGuide/CLI/Command-Line-Interface.md
@@ -19,35 +19,32 @@
-->
+# SQL 命令行终端 (CLI)
-# SQL命令行终端(CLI)
-
-IOTDB为用户提供cli/Shell工具用于启动客户端和服务端程序。下面介绍每个cli/Shell工具的运行方式和相关参数。
-> \$IOTDB\_HOME表示IoTDB的安装目录所在路径。
+IOTDB 为用户提供 cli/Shell 工具用于启动客户端和服务端程序。下面介绍每个 cli/Shell 工具的运行方式和相关参数。
+> \$IOTDB\_HOME 表示 IoTDB 的安装目录所在路径。
## 安装
-在iotdb的根目录下执行
+在 iotdb 的根目录下执行
```shell
> mvn clean package -pl cli -am -DskipTests
```
-在生成完毕之后,IoTDB的cli工具位于文件夹"cli/target/iotdb-cli-{project.version}"中。
+在生成完毕之后,IoTDB 的 cli 工具位于文件夹"cli/target/iotdb-cli-{project.version}"中。
## 运行
-### Cli运行方式
-安装后的IoTDB中有一个默认用户:`root`,默认密码为`root`。用户可以使用该用户尝试运行IoTDB客户端以测试服务器是否正常启动。客户端启动脚本为$IOTDB_HOME/sbin文件夹下的`start-cli`脚本。启动脚本时需要指定运行IP和RPC PORT。以下为服务器在本机启动,且用户未更改运行端口号的示例,默认端口为6667。若用户尝试连接远程服务器或更改了服务器运行的端口号,请在-h和-p项处使用服务器的IP和RPC PORT。</br>
-用户也可以在启动脚本的最前方设置自己的环境变量,如JAVA_HOME等 (对于linux用户,脚本路径为:"/sbin/start-cli.sh"; 对于windows用户,脚本路径为:"/sbin/start-cli.bat")
-
-
+### Cli 运行方式
+安装后的 IoTDB 中有一个默认用户:`root`,默认密码为`root`。用户可以使用该用户尝试运行 IoTDB 客户端以测试服务器是否正常启动。客户端启动脚本为$IOTDB_HOME/sbin 文件夹下的`start-cli`脚本。启动脚本时需要指定运行 IP 和 RPC PORT。以下为服务器在本机启动,且用户未更改运行端口号的示例,默认端口为 6667。若用户尝试连接远程服务器或更改了服务器运行的端口号,请在-h 和-p 项处使用服务器的 IP 和 RPC PORT。</br>
+用户也可以在启动脚本的最前方设置自己的环境变量,如 JAVA_HOME 等 (对于 linux 用户,脚本路径为:"/sbin/start-cli.sh"; 对于 windows 用户,脚本路径为:"/sbin/start-cli.bat")
-Linux系统与MacOS系统启动命令如下:
+Linux 系统与 MacOS 系统启动命令如下:
```shell
Shell > sbin/start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root
```
-Windows系统启动命令如下:
+Windows 系统启动命令如下:
```shell
Shell > sbin\start-cli.bat -h 127.0.0.1 -p 6667 -u root -pw root
@@ -62,102 +59,101 @@ Shell > sbin\start-cli.bat -h 127.0.0.1 -p 6667 -u root -pw root
_| |_| \__. | _| |_ _| |_.' /_| |__) |
|_____|'.__.' |_____| |______.'|_______/ version <version>
-
IoTDB> login successfully
```
-输入`quit`或`exit`可退出cli结束本次会话,cli输出`quit normally`表示退出成功。
+输入`quit`或`exit`可退出 cli 结束本次会话,cli 输出`quit normally`表示退出成功。
-### Cli运行参数
+### Cli 运行参数
|参数名|参数类型|是否为必需参数| 说明| 例子 |
|:---|:---|:---|:---|:---|
-|-disableISO8601 |没有参数 | 否 |如果设置了这个参数,IoTDB将以数字的形式打印时间戳(timestamp)。|-disableISO8601|
-|-h <`host`> |string类型,不需要引号|是|IoTDB客户端连接IoTDB服务器的IP地址。|-h 10.129.187.21|
-|-help|没有参数|否|打印IoTDB的帮助信息|-help|
-|-p <`rpcPort`>|int类型|是|IoTDB连接服务器的端口号,IoTDB默认运行在6667端口。|-p 6667|
-|-pw <`password`>|string类型,不需要引号|否|IoTDB连接服务器所使用的密码。如果没有输入密码IoTDB会在Cli端提示输入密码。|-pw root|
-|-u <`username`>|string类型,不需要引号|是|IoTDB连接服务器锁使用的用户名。|-u root|
-|-maxPRC <`maxPrintRowCount`>|int类型|否|设置IoTDB返回客户端命令行中所显示的最大行数。|-maxPRC 10|
-|-e <`execute`> |string类型|否|在不进入客户端输入模式的情况下,批量操作IoTDB|-e "show storage group"|
-|-c | 空 | 否 | 如果服务器设置了 `rpc_thrift_compression_enable=true`, 则CLI必须使用 `-c` | -c |
+|-disableISO8601 |没有参数 | 否 |如果设置了这个参数,IoTDB 将以数字的形式打印时间戳 (timestamp)。|-disableISO8601|
+|-h <`host`> |string 类型,不需要引号|是|IoTDB 客户端连接 IoTDB 服务器的 IP 地址。|-h 10.129.187.21|
+|-help|没有参数|否|打印 IoTDB 的帮助信息|-help|
+|-p <`rpcPort`>|int 类型|是|IoTDB 连接服务器的端口号,IoTDB 默认运行在 6667 端口。|-p 6667|
+|-pw <`password`>|string 类型,不需要引号|否|IoTDB 连接服务器所使用的密码。如果没有输入密码 IoTDB 会在 Cli 端提示输入密码。|-pw root|
+|-u <`username`>|string 类型,不需要引号|是|IoTDB 连接服务器锁使用的用户名。|-u root|
+|-maxPRC <`maxPrintRowCount`>|int 类型|否|设置 IoTDB 返回客户端命令行中所显示的最大行数。|-maxPRC 10|
+|-e <`execute`> |string 类型|否|在不进入客户端输入模式的情况下,批量操作 IoTDB|-e "show storage group"|
+|-c | 空 | 否 | 如果服务器设置了 `rpc_thrift_compression_enable=true`, 则 CLI 必须使用 `-c` | -c |
-下面展示一条客户端命令,功能是连接IP为10.129.187.21的主机,端口为6667 ,用户名为root,密码为root,以数字的形式打印时间戳,IoTDB命令行显示的最大行数为10。
+下面展示一条客户端命令,功能是连接 IP 为 10.129.187.21 的主机,端口为 6667 ,用户名为 root,密码为 root,以数字的形式打印时间戳,IoTDB 命令行显示的最大行数为 10。
-Linux系统与MacOS系统启动命令如下:
+Linux 系统与 MacOS 系统启动命令如下:
```shell
Shell > sbin/start-cli.sh -h 10.129.187.21 -p 6667 -u root -pw root -disableISO8601 -maxPRC 10
```
-Windows系统启动命令如下:
+Windows 系统启动命令如下:
```shell
Shell > sbin\start-cli.bat -h 10.129.187.21 -p 6667 -u root -pw root -disableISO8601 -maxPRC 10
```
-### 使用OpenID作为用户名认证登录
+### 使用 OpenID 作为用户名认证登录
-OpenID Connect (OIDC)使用keycloack作为OIDC服务权限认证服务。
+OpenID Connect (OIDC) 使用 keycloack 作为 OIDC 服务权限认证服务。
#### 配置
-配置位于iotdb-engines.properties,设定authorizer_provider_class为org.apache.iotdb.db.auth.authorizer.OpenIdAuthorizer则开启了openID服务,默认情况下值为org.apache.iotdb.db.auth.authorizer.LocalFileAuthorizer表示没有开启openID服务。
+配置位于 iotdb-engines.properties,设定 authorizer_provider_class 为 org.apache.iotdb.db.auth.authorizer.OpenIdAuthorizer 则开启了 openID 服务,默认情况下值为 org.apache.iotdb.db.auth.authorizer.LocalFileAuthorizer 表示没有开启 openID 服务。
```
authorizer_provider_class=org.apache.iotdb.db.auth.authorizer.OpenIdAuthorizer
```
-如果开启了openID服务则openID_url为必填项,openID_url 值为http://ip:port/auth/realms/{realmsName}
+如果开启了 openID 服务则 openID_url 为必填项,openID_url 值为 http://ip:port/auth/realms/{realmsName}
```
openID_url=http://127.0.0.1:8080/auth/realms/iotdb/
```
-####keycloack配置
+####keycloack 配置
-1、下载keycloack程序,在keycloack/bin中启动keycloack
+1、下载 keycloack 程序,在 keycloack/bin 中启动 keycloack
```shell
Shell >cd bin
Shell >./standalone.sh
```
-2、使用https://ip:port/auth登陆keycloack,首次登陆需要创建用户
+2、使用 https://ip:port/auth 登陆 keycloack, 首次登陆需要创建用户
-3、点击Administration Console进入管理端
+3、点击 Administration Console 进入管理端
-4、在左侧的Master 菜单点击add Realm,输入Name创建一个新的Realm
+4、在左侧的 Master 菜单点击 add Realm, 输入 Name 创建一个新的 Realm
-5、点击左侧菜单Clients,创建client
+5、点击左侧菜单 Clients,创建 client
-6、点击左侧菜单User,创建user
+6、点击左侧菜单 User,创建 user
-7、点击新创建的用户id,点击Credentials导航输入密码和关闭Temporary选项,至此keyclork 配置完成
+7、点击新创建的用户 id,点击 Credentials 导航输入密码和关闭 Temporary 选项,至此 keyclork 配置完成
-以上步骤提供了一种keycloak登陆iotdb方式,更多方式请参考keycloak配置
+以上步骤提供了一种 keycloak 登陆 iotdb 方式,更多方式请参考 keycloak 配置
-若对应的IoTDB服务器开启了使用OpenID Connect (OIDC)作为权限认证服务,那么就不再需要使用用户名密码进行登录。
-替而代之的是使用Token,以及空密码。
+若对应的 IoTDB 服务器开启了使用 OpenID Connect (OIDC) 作为权限认证服务,那么就不再需要使用用户名密码进行登录。
+替而代之的是使用 Token,以及空密码。
此时,登录命令如下:
```shell
Shell > sbin/start-cli.sh -h 10.129.187.21 -p 6667 -u {my-access-token} -pw ""
```
-其中,需要将{my-access-token} (注意,包括{})替换成你的token。
+其中,需要将{my-access-token} (注意,包括{})替换成你的 token。
-如何获取token取决于你的OIDC设置。 最简单的一种情况是使用`password-grant`。例如,假设你在用keycloack作为你的OIDC服务,
-并且你在keycloack中有一个被定义成publich的`iotdb`客户的realm,那么你可以使用如下`curl`命令获得token。
-(注意例子中的{}和里面的内容需要替换成具体的服务器地址和realm名字):
+如何获取 token 取决于你的 OIDC 设置。 最简单的一种情况是使用`password-grant`。例如,假设你在用 keycloack 作为你的 OIDC 服务,
+并且你在 keycloack 中有一个被定义成 publich 的`iotdb`客户的 realm,那么你可以使用如下`curl`命令获得 token。
+(注意例子中的{}和里面的内容需要替换成具体的服务器地址和 realm 名字):
```shell
curl -X POST "http://{your-keycloack-server}/auth/realms/{your-realm}/protocol/openid-connect/token" \ -H "Content-Type: application/x-www-form-urlencoded" \
-d "username={username}" \
@@ -172,39 +168,39 @@ curl -X POST "http://{your-keycloack-server}/auth/realms/{your-realm}/protocol/o
{"access_token":"eyJhbGciOiJSUzI1NiIsInR5cCIgOiAiSldUIiwia2lkIiA6ICJxMS1XbTBvelE1TzBtUUg4LVNKYXAyWmNONE1tdWNXd25RV0tZeFpKNG93In0.eyJleHAiOjE1OTAzOTgwNzEsImlhdCI6MTU5MDM5Nzc3MSwianRpIjoiNjA0ZmYxMDctN2NiNy00NTRmLWIwYmQtY2M2ZDQwMjFiNGU4IiwiaXNzIjoiaHR0cDovL2F1dGguZGVtby5wcmFnbWF0aWNpbmR1c3RyaWVzLmRlL2F1dGgvcmVhbG1zL0lvVERCIiwiYXVkIjoiYWNjb3VudCIsInN1YiI6ImJhMzJlNDcxLWM3NzItNGIzMy04ZGE2LTZmZThhY2RhMDA3MyIsInR5cCI6IkJlYXJlciIsImF6cCI6ImlvdGRiIiwic2Vzc2lvbl9zdGF0ZSI6IjA2MGQyODYyLTE0ZWQtNDJmZS1 [...]
```
-### Cli的批量操作
-当您想要通过脚本的方式通过Cli / Shell对IoTDB进行批量操作时,可以使用-e参数。通过使用该参数,您可以在不进入客户端输入模式的情况下操作IoTDB。
+### Cli 的批量操作
+当您想要通过脚本的方式通过 Cli / Shell 对 IoTDB 进行批量操作时,可以使用-e 参数。通过使用该参数,您可以在不进入客户端输入模式的情况下操作 IoTDB。
-为了避免SQL语句和其他参数混淆,现在只支持-e参数作为最后的参数使用。
+为了避免 SQL 语句和其他参数混淆,现在只支持-e 参数作为最后的参数使用。
-针对cli/Shell工具的-e参数用法如下:
+针对 cli/Shell 工具的-e 参数用法如下:
-Linux系统与MacOS指令:
+Linux 系统与 MacOS 指令:
```shell
Shell > sbin/start-cli.sh -h {host} -p {rpcPort} -u {user} -pw {password} -e {sql for iotdb}
```
-Windows系统指令
+Windows 系统指令
```shell
Shell > sbin\start-cli.bat -h {host} -p {rpcPort} -u {user} -pw {password} -e {sql for iotdb}
```
-在Windows环境下,-e参数的SQL语句需要使用` `` `对于`" "`进行替换
+在 Windows 环境下,-e 参数的 SQL 语句需要使用` `` `对于`" "`进行替换
-为了更好的解释-e参数的使用,可以参考下面在Linux上执行的例子。
+为了更好的解释-e 参数的使用,可以参考下面在 Linux 上执行的例子。
-假设用户希望对一个新启动的IoTDB进行如下操作:
+假设用户希望对一个新启动的 IoTDB 进行如下操作:
-1.创建名为root.demo的存储组
+1. 创建名为 root.demo 的存储组
-2.创建名为root.demo.s1的时间序列
+2. 创建名为 root.demo.s1 的时间序列
-3.向创建的时间序列中插入三个数据点
+3. 向创建的时间序列中插入三个数据点
-4.查询验证数据是否插入成功
+4. 查询验证数据是否插入成功
-那么通过使用cli/Shell工具的-e参数,可以采用如下的脚本:
+那么通过使用 cli/Shell 工具的 -e 参数,可以采用如下的脚本:
```shell
# !/bin/bash
@@ -222,7 +218,7 @@ pass=root
./sbin/start-cli.sh -h ${host} -p ${rpcPort} -u ${user} -pw ${pass} -e "select s1 from root.demo"
```
-打印出来的结果显示如下,通过这种方式进行的操作与客户端的输入模式以及通过JDBC进行操作结果是一致的。
+打印出来的结果显示如下,通过这种方式进行的操作与客户端的输入模式以及通过 JDBC 进行操作结果是一致的。
```shell
Shell > ./shell.sh
@@ -237,5 +233,4 @@ Total line number = 3
It costs 0.267s
```
-
-需要特别注意的是,在脚本中使用-e参数时要对特殊字符进行转义。
+需要特别注意的是,在脚本中使用 -e 参数时要对特殊字符进行转义。
diff --git a/docs/zh/UserGuide/Cluster/Cluster-Setup-Example.md b/docs/zh/UserGuide/Cluster/Cluster-Setup-Example.md
index 60696b6..d94778b 100644
--- a/docs/zh/UserGuide/Cluster/Cluster-Setup-Example.md
+++ b/docs/zh/UserGuide/Cluster/Cluster-Setup-Example.md
@@ -20,12 +20,12 @@
-->
## 前提条件
-如果您在使用Windows系统,请安装MinGW,WSL或者git bash。
+如果您在使用 Windows 系统,请安装 MinGW,WSL 或者 git bash。
-## 3节点3副本分布式搭建示例
+## 3 节点 3 副本分布式搭建示例
假设我们需要在三个物理节点上部署分布式 IoTDB,这三个节点分别为 A, B 和 C,其公网 ip 分别为 A_public_ip,B_public_ip 和 C_public_ip,私网 ip 分别为 A_private_ip,B_private_ip 和 C_private_ip。
-注:如果没有公网 ip 或者私网 ip 则两者设置成一致即可, 只需要保证客户端能够访问到服务端即可。
+注:如果没有公网 ip 或者私网 ip 则两者设置成一致即可,只需要保证客户端能够访问到服务端即可。
以下为操作步骤:
1. 使用 `mvn clean package -pl cluster -am -DskipTests` 编译分布式模块或直接到 [官网](https://iotdb.apache.org/Download/) 下载最新版本。
@@ -35,9 +35,9 @@
5. 配置所有节点 conf/iotdb-cluster.properties 配置文件中的 internal_ip 为各自节点的 private_ip。
6. 配置所有节点 conf/iotdb-cluster.properties 配置文件中的 default_replica_num 为 3。
7. 配置所有节点 conf/iotdb-engine.properties 配置文件中的 rpc_address 为各自节点的 public_ip。
-8. 在 3 个节点上分别运行 sh sbin/start-node.sh 即可(后台运行也可)。
+8. 在 3 个节点上分别运行 sh sbin/start-node.sh 即可(后台运行也可)。
-## 1节点1副本分布式搭建示例
+## 1 节点 1 副本分布式搭建示例
### 源码编译:
```
mvn clean package -DskipTests
@@ -54,7 +54,7 @@ sed -i -e 's/^default_replica_num=3$/default_replica_num=1/g' conf/iotdb-cluster
nohup ./sbin/start-node.sh >/dev/null 2>&1 &
```
-## 单机部署3节点1副本示例
+## 单机部署 3 节点 1 副本示例
### 源码编译:
```
mvn clean package -DskipTests
diff --git a/docs/zh/UserGuide/Cluster/Cluster-Setup.md b/docs/zh/UserGuide/Cluster/Cluster-Setup.md
index f2f7c85..cb64161 100644
--- a/docs/zh/UserGuide/Cluster/Cluster-Setup.md
+++ b/docs/zh/UserGuide/Cluster/Cluster-Setup.md
@@ -20,9 +20,9 @@
-->
# 集群设置
-安装环境请参考[快速上手/安装环境章节](../QuickStart/QuickStart.md)
+安装环境请参考 [快速上手/安装环境章节](../QuickStart/QuickStart.md)
## 集群环境搭建
-您可以多节点部署或单机部署分布式集群,两者的主要区别是后者需要处理端口和文件目录的冲突,配置项含义请参考[配置项](#配置项)。
+您可以多节点部署或单机部署分布式集群,两者的主要区别是后者需要处理端口和文件目录的冲突,配置项含义请参考 [配置项](#配置项)。
启动其中一个节点的服务,需要执行如下命令:
```bash
@@ -32,17 +32,16 @@
# Windows
> sbin\start-node.bat [printgc] [<conf_path>]
```
-`printgc`表示在启动的时候,会开启GC日志。
+`printgc`表示在启动的时候,会开启 GC 日志。
`<conf_path>`使用`conf_path`文件夹里面的配置文件覆盖默认配置文件。
## 被覆盖的单机版选项
-iotdb-engines.properties配置文件中的部分内容会不再生效:
+iotdb-engines.properties 配置文件中的部分内容会不再生效:
* `enable_auto_create_schema` 不再生效,并被视为`false`. 应使用 iotdb-cluster.properties 中的
`enable_auto_create_schema` 来控制是否自动创建序列。
-
* `is_sync_enable` 不再生效,并被视为 `false`.
## 集群扩展
@@ -57,7 +56,7 @@ iotdb-engines.properties配置文件中的部分内容会不再生效:
# Windows
> sbin\add-node.bat [printgc] [<conf_path>]
```
-`printgc`表示在启动的时候,会开启GC日志。
+`printgc`表示在启动的时候,会开启 GC 日志。
`<conf_path>`使用`conf_path`文件夹里面的配置文件覆盖默认配置文件。
### 删除节点
@@ -69,32 +68,32 @@ iotdb-engines.properties配置文件中的部分内容会不再生效:
# Windows
> sbin\remove-node.bat <internal_ip> <internal_meta_port>
```
-`internal_ip`表示待删除节点的IP地址
-`internal_meta_port`表示待删除节点的meta服务端口
+`internal_ip`表示待删除节点的 IP 地址
+`internal_meta_port`表示待删除节点的 meta 服务端口
## 配置项
-为方便IoTDB Server的配置与管理,IoTDB Server为用户提供三种配置项,使得您可以在启动服务或服务运行时对其进行配置。
+为方便 IoTDB Server 的配置与管理,IoTDB Server 为用户提供三种配置项,使得您可以在启动服务或服务运行时对其进行配置。
-三种配置项的配置文件均位于IoTDB安装目录:`$IOTDB_HOME/conf`文件夹下,其中涉及server配置的共有4个文件,分别为:`iotdb-cluster.properties`、`iotdb-engine.properties`、`logback.xml` 和 `iotdb-env.sh`(Unix系统)/`iotdb-env.bat`(Windows系统), 您可以通过更改其中的配置项对系统运行的相关配置项进行配置。
+三种配置项的配置文件均位于 IoTDB 安装目录:`$IOTDB_HOME/conf`文件夹下,其中涉及 server 配置的共有 4 个文件,分别为:`iotdb-cluster.properties`、`iotdb-engine.properties`、`logback.xml` 和 `iotdb-env.sh`(Unix 系统)/`iotdb-env.bat`(Windows 系统), 您可以通过更改其中的配置项对系统运行的相关配置项进行配置。
配置文件的说明如下:
-* `iotdb-env.sh`/`iotdb-env.bat`:环境配置项的默认配置文件。您可以在文件中配置JAVA-JVM的相关系统配置项。
+* `iotdb-env.sh`/`iotdb-env.bat`:环境配置项的默认配置文件。您可以在文件中配置 JAVA-JVM 的相关系统配置项。
-* `iotdb-engine.properties`:IoTDB引擎层系统配置项的默认配置文件。您可以在文件中配置IoTDB引擎运行时的相关参数。此外,用户可以在文件中配置IoTDB存储时TsFile文件的相关信息,如每次将内存中的数据写入到磁盘前的缓存大小(`group_size_in_byte`),内存中每个列打一次包的大小(`page_size_in_byte`)等。
+* `iotdb-engine.properties`:IoTDB 引擎层系统配置项的默认配置文件。您可以在文件中配置 IoTDB 引擎运行时的相关参数。此外,用户可以在文件中配置 IoTDB 存储时 TsFile 文件的相关信息,如每次将内存中的数据写入到磁盘前的缓存大小 (`group_size_in_byte`),内存中每个列打一次包的大小 (`page_size_in_byte`) 等。
* `logback.xml`: 日志配置文件,比如日志级别等。
-* `iotdb-cluster.properties`: IoTDB集群所需要的一些配置。
+* `iotdb-cluster.properties`: IoTDB 集群所需要的一些配置。
-`iotdb-engine.properties`、`iotdb-env.sh`/`iotdb-env.bat` 两个配置文件详细说明请参考[附录/配置手册](../Appendix/Config-Manual.md),下面描述的配置项是在`iotdb-cluster.properties`文件中的,也可以直接查看[配置文件](https://github.com/apache/iotdb/blob/master/cluster/src/assembly/resources/conf/iotdb-cluster.properties) 中的注释。
+`iotdb-engine.properties`、`iotdb-env.sh`/`iotdb-env.bat` 两个配置文件详细说明请参考 [附录/配置手册](../Appendix/Config-Manual.md),下面描述的配置项是在`iotdb-cluster.properties`文件中的,也可以直接查看 [配置文件](https://github.com/apache/iotdb/blob/master/cluster/src/assembly/resources/conf/iotdb-cluster.properties) 中的注释。
* internal\_ip
|名字|internal\_ip|
|:---:|:---|
-|描述|IOTDB 集群各个节点之间内部通信的IP地址,比如心跳、snapshot快照、raft log等|
+|描述|IOTDB 集群各个节点之间内部通信的 IP 地址,比如心跳、snapshot 快照、raft log 等|
|类型|String|
|默认值|127.0.0.1|
|改后生效方式|重启服务生效,集群建立后不可再修改|
@@ -103,7 +102,7 @@ iotdb-engines.properties配置文件中的部分内容会不再生效:
|名字|internal\_meta\_port|
|:---:|:---|
-|描述|IoTDB meta服务端口,用于元数据组(又称集群管理组)通信,元数据组管理集群配置和存储组信息**IoTDB将为每个meta服务自动创建心跳端口。默认meta服务心跳端口为`internal_meta_port+1`,请确认这两个端口不是系统保留端口并且未被占用**|
+|描述|IoTDB meta 服务端口,用于元数据组(又称集群管理组)通信,元数据组管理集群配置和存储组信息** IoTDB 将为每个 meta 服务自动创建心跳端口。默认 meta 服务心跳端口为`internal_meta_port+1`,请确认这两个端口不是系统保留端口并且未被占用**|
|类型|Int32|
|默认值|9003|
|改后生效方式|重启服务生效,集群建立后不可再修改|
@@ -112,7 +111,7 @@ iotdb-engines.properties配置文件中的部分内容会不再生效:
|名字|internal\_data\_port|
|:---:|:---|
-|描述|IoTDB data服务端口,用于数据组通信,数据组管理数据模式和数据的存储**IoTDB将为每个data服务自动创建心跳端口。默认的data服务心跳端口为`internal_data_port+1`。请确认这两个端口不是系统保留端口并且未被占用**|
+|描述|IoTDB data 服务端口,用于数据组通信,数据组管理数据模式和数据的存储** IoTDB 将为每个 data 服务自动创建心跳端口。默认的 data 服务心跳端口为`internal_data_port+1`。请确认这两个端口不是系统保留端口并且未被占用**|
|类型|Int32|
|默认值|40010|
|改后生效方式|重启服务生效,集群建立后不可再修改|
@@ -121,7 +120,7 @@ iotdb-engines.properties配置文件中的部分内容会不再生效:
|名字|cluster\_info\_public\_port|
|:---:|:---|
-|描述|用于查看集群信息(如数据分区)的RPC服务的接口|
+|描述|用于查看集群信息(如数据分区)的 RPC 服务的接口|
|类型|Int32|
|默认值|6567|
|改后生效方式| 重启服务生效|
@@ -130,7 +129,7 @@ iotdb-engines.properties配置文件中的部分内容会不再生效:
|名字|open\_server\_rpc\_port|
|:---:|:---|
-|描述|是否打开单机模块的rpc port,用于调试模式,如果设置为true,则单机模块的rpc port设置为`rpc_port (in iotdb-engines.properties) + 1`|
+|描述|是否打开单机模块的 rpc port,用于调试模式,如果设置为 true,则单机模块的 rpc port 设置为`rpc_port (in iotdb-engines.properties) + 1`|
|类型|Boolean|
|默认值|false|
|改后生效方式|重启服务生效,集群建立后不可再修改|
@@ -139,7 +138,7 @@ iotdb-engines.properties配置文件中的部分内容会不再生效:
|名字|seed\_nodes|
|:---:|:---|
-|描述|集群中节点的地址,`{IP/DOMAIN}:internal_meta_port`格式,用逗号分割;对于伪分布式模式,可以都填写`localhost`,或是`127.0.0.1` 或是混合填写,但是不能够出现真实的ip地址;对于分布式模式,支持填写real ip 或是hostname,但是不能够出现`localhost`或是`127.0.0.1`。当使用`start-node.sh(.bat)`启动节点时,此配置意味着形成初始群集的节点,每个节点的`seed_nodes`应该一致,否则群集将初始化失败;当使用`add-node.sh(.bat)`添加节点到集群中时,此配置项可以是集群中已经存在的任何节点,不需要是用`start-node.sh(bat)`构建初始集群的节点。|
+|描述|集群中节点的地址,`{IP/DOMAIN}:internal_meta_port`格式,用逗号分割;对于伪分布式模式,可以都填写`localhost`,或是`127.0.0.1` 或是混合填写,但是不能够出现真实的 ip 地址;对于分布式模式,支持填写 real ip 或是 hostname,但是不能够出现`localhost`或是`127.0.0.1`。当使用`start-node.sh(.bat)`启动节点时,此配置意味着形成初始群集的节点,每个节点的`seed_nodes`应该一致,否则群集将初始化失败;当使用`add-node.sh(.bat)`添加节点到集群中时,此配置项可以是集群中已经存在的任何节点,不需要是用`start-node.sh(bat)`构建初始集群的节点。|
|类型|String|
|默认值|127.0.0.1:9003,127.0.0.1:9005,127.0.0.1:9007|
|改后生效方式|重启服务生效|
@@ -148,7 +147,7 @@ iotdb-engines.properties配置文件中的部分内容会不再生效:
|名字|rpc\_thrift\_compression\_enable|
|:---:|:---|
-|描述|是否开启thrift压缩通信,**注意这个参数要各个节点保持一致,也要与客户端保持一致,同时也要与`iotdb-engine.properties`中`rpc_thrift_compression_enable`参数保持一致**|
+|描述|是否开启 thrift 压缩通信,**注意这个参数要各个节点保持一致,也要与客户端保持一致,同时也要与`iotdb-engine.properties`中`rpc_thrift_compression_enable`参数保持一致**|
|类型| Boolean|
|默认值|false|
|改后生效方式|重启服务生效,需要整个集群同时更改|
@@ -166,7 +165,7 @@ iotdb-engines.properties配置文件中的部分内容会不再生效:
|名字|multi\_raft\_factor|
|:---:|:---|
-|描述|每个数据组启动的raft组实例数量,默认每个数据组启动一个raft组|
+|描述|每个数据组启动的 raft 组实例数量,默认每个数据组启动一个 raft 组|
|类型|Int32|
|默认值|1|
|改后生效方式|重启服务生效,集群建立后不可更改|
@@ -175,7 +174,7 @@ iotdb-engines.properties配置文件中的部分内容会不再生效:
|名字|cluster\_name|
|:---:|:---|
-|描述|集群名称,集群名称用以标识不同的集群,**一个集群中所有节点的cluster_name都应相同**|
+|描述|集群名称,集群名称用以标识不同的集群,**一个集群中所有节点的 cluster_name 都应相同**|
|类型|String|
|默认值|default|
|改后生效方式|重启服务生效|
@@ -184,7 +183,7 @@ iotdb-engines.properties配置文件中的部分内容会不再生效:
|名字|connection\_timeout\_ms|
|:---:|:---|
-|描述|同一个raft组各个节点之间的心跳超时时间,单位毫秒|
+|描述|同一个 raft 组各个节点之间的心跳超时时间,单位毫秒|
|类型|Int32|
|默认值|20000|
|改后生效方式|重启服务生效|
@@ -211,7 +210,7 @@ iotdb-engines.properties配置文件中的部分内容会不再生效:
|名字|min\_num\_of\_logs\_in\_mem|
|:---:|:---|
-|描述|删除日志操作执行后,内存中保留的最多的提交的日志的数量。增大这个值将减少在CatchUp使用快照的机会,但也会增加内存占用量|
+|描述|删除日志操作执行后,内存中保留的最多的提交的日志的数量。增大这个值将减少在 CatchUp 使用快照的机会,但也会增加内存占用量|
|类型|Int32|
|默认值|100|
|改后生效方式|重启服务生效|
@@ -220,7 +219,7 @@ iotdb-engines.properties配置文件中的部分内容会不再生效:
|名字|max\_num\_of\_logs\_in\_mem|
|:---:|:---|
-|描述|当内存中已提交的日志条数达到这个值之后,就会触发删除日志的操作,增大这个值将减少在CatchUp使用快照的机会,但也会增加内存占用量|
+|描述|当内存中已提交的日志条数达到这个值之后,就会触发删除日志的操作,增大这个值将减少在 CatchUp 使用快照的机会,但也会增加内存占用量|
|类型|Int32|
|默认值|1000|
|改后生效方式|重启服务生效|
@@ -229,7 +228,7 @@ iotdb-engines.properties配置文件中的部分内容会不再生效:
|名字|log\_deletion\_check\_interval\_second|
|:---:|:---|
-|描述|检查删除日志任务的时间间隔,每次删除日志任务将会把已提交日志超过min\_num\_of\_logs\_in\_mem条的最老部分删除,单位秒|
+|描述|检查删除日志任务的时间间隔,每次删除日志任务将会把已提交日志超过 min\_num\_of\_logs\_in\_mem 条的最老部分删除,单位秒|
|类型|Int32|
|默认值|60|
|改后生效方式|重启服务生效|
@@ -238,7 +237,7 @@ iotdb-engines.properties配置文件中的部分内容会不再生效:
|名字|enable\_auto\_create\_schema|
|:---:|:---|
-|描述|是否支持自动创建schema,**这个值会覆盖`iotdb-engine.properties`中`enable_auto_create_schema`的配置**|
+|描述|是否支持自动创建 schema,**这个值会覆盖`iotdb-engine.properties`中`enable_auto_create_schema`的配置**|
|类型|BOOLEAN|
|默认值|true|
|改后生效方式|重启服务生效|
@@ -247,7 +246,7 @@ iotdb-engines.properties配置文件中的部分内容会不再生效:
|名字|consistency\_level|
|:---:|:---|
-|描述|读一致性,目前支持3种一致性:strong、mid、weak。strong consistency每次操作都会尝试与Leader同步以获取最新的数据,如果失败(超时),则直接向用户返回错误; mid consistency每次操作将首先尝试与Leader进行同步,但是如果失败(超时),它将使用本地当前数据向用户提供服务; weak consistency不会与Leader进行同步,而只是使用本地数据向用户提供服务|
+|描述|读一致性,目前支持 3 种一致性:strong、mid、weak。strong consistency 每次操作都会尝试与 Leader 同步以获取最新的数据,如果失败(超时),则直接向用户返回错误; mid consistency 每次操作将首先尝试与 Leader 进行同步,但是如果失败(超时),它将使用本地当前数据向用户提供服务; weak consistency 不会与 Leader 进行同步,而只是使用本地数据向用户提供服务|
|类型|strong、mid、weak|
|默认值|mid|
|改后生效方式|重启服务生效|
@@ -256,14 +255,14 @@ iotdb-engines.properties配置文件中的部分内容会不再生效:
|名字|is\_enable\_raft\_log\_persistence|
|:---:|:---|
-|描述|是否开启raft log持久化|
+|描述|是否开启 raft log 持久化|
|类型|BOOLEAN|
|默认值|true|
|改后生效方式|重启服务生效|
-## 开启GC日志
-GC日志默认是关闭的。为了性能调优,用户可能会需要收集GC信息。
-若要打开GC日志,则需要在启动IoTDB Server的时候加上`printgc`参数:
+## 开启 GC 日志
+GC 日志默认是关闭的。为了性能调优,用户可能会需要收集 GC 信息。
+若要打开 GC 日志,则需要在启动 IoTDB Server 的时候加上`printgc`参数:
```bash
nohup sbin/start-node.sh printgc >/dev/null 2>&1 &
@@ -274,4 +273,4 @@ nohup sbin/start-node.sh printgc >/dev/null 2>&1 &
sbin\start-node.bat printgc
```
-GC日志会被存储在`IOTDB_HOME/logs/`下面。
+GC 日志会被存储在`IOTDB_HOME/logs/`下面。
diff --git a/docs/zh/UserGuide/Collaboration-of-Edge-and-Cloud/Sync-Tool.md b/docs/zh/UserGuide/Collaboration-of-Edge-and-Cloud/Sync-Tool.md
index 0549f05..c658695 100644
--- a/docs/zh/UserGuide/Collaboration-of-Edge-and-Cloud/Sync-Tool.md
+++ b/docs/zh/UserGuide/Collaboration-of-Edge-and-Cloud/Sync-Tool.md
@@ -25,11 +25,11 @@
### 介绍
-同步工具是定期将本地磁盘中新增的已持久化的tsfile文件上传至云端并加载到IoTDB的套件工具。
+同步工具是定期将本地磁盘中新增的已持久化的 tsfile 文件上传至云端并加载到 IoTDB 的套件工具。
-在同步工具的发送端,同步模块是一个独立的进程,独立于本地的IoTDB。通过独立的脚本进行启动和关闭(详见本章节`使用方式`),同步的频率周期可由用户设置。
+在同步工具的发送端,同步模块是一个独立的进程,独立于本地的 IoTDB。通过独立的脚本进行启动和关闭(详见本章节`使用方式`),同步的频率周期可由用户设置。
-在同步工具的接收端,同步模块内嵌于IoTDB的引擎,和IoTDB处于同一个进程中。同步模块监听一个独立的端口,该端口可由用户设置(详见本章节`配置参数`)。用户使用前,需要在同步接收端设置同步白名单,以网段形式表示,接收端的同步模块只接受位于白名单网段中的发送端同步的数据。
+在同步工具的接收端,同步模块内嵌于 IoTDB 的引擎,和 IoTDB 处于同一个进程中。同步模块监听一个独立的端口,该端口可由用户设置(详见本章节`配置参数`)。用户使用前,需要在同步接收端设置同步白名单,以网段形式表示,接收端的同步模块只接受位于白名单网段中的发送端同步的数据。
同步工具具有多对一的发送-接受模式,即一个同步接收端可以同时接受多个同步发送端传输的数据,一个同步发送端只能向一个同步接收端发送数据。
@@ -37,36 +37,35 @@
### 应用场景
-以一个工厂应用为例,通常有多个分厂和多个总厂,每个分厂中使用一个IoTDB实例收集数据,然后将数据定时汇总到总厂中进行备份或者分析等,一个总厂可以接收来自多个分厂的数据,在这种场景下每个IoTDB实例所管理的设备各不相同。
+以一个工厂应用为例,通常有多个分厂和多个总厂,每个分厂中使用一个 IoTDB 实例收集数据,然后将数据定时汇总到总厂中进行备份或者分析等,一个总厂可以接收来自多个分厂的数据,在这种场景下每个 IoTDB 实例所管理的设备各不相同。
-在sync模块中,每个分厂是发送端,总厂是接收端,发送端定时将数据同步给接收端,在上述应用场景下一个设备的数据只能由一个发送端来收集,因此多个发送端同步的数据之间必须是没有设备重叠的,否则不符合sync功能的应用场景。
+在 sync 模块中,每个分厂是发送端,总厂是接收端,发送端定时将数据同步给接收端,在上述应用场景下一个设备的数据只能由一个发送端来收集,因此多个发送端同步的数据之间必须是没有设备重叠的,否则不符合 sync 功能的应用场景。
-当出现异常场景时,即两个或两个以上的发送端向同一个接收端同步相同设备(其存储组设为root.sg)的数据时,后被接收端收到的含有该设备数据的发送端的root.sg数据将会被拒绝接收。示例:发送端1向接收端同步存储组root.sg1和root.sg2, 发送端2向接收端同步存储组root.sg2和root.sg3,
-均包括时间序列root.sg2.d0.s0, 若接收端先接收到发送端1的root.sg2.d0.s0的数据,那么接收端将拒绝发送端2的root.sg2同步的数据。
+当出现异常场景时,即两个或两个以上的发送端向同一个接收端同步相同设备(其存储组设为 root.sg) 的数据时,后被接收端收到的含有该设备数据的发送端的 root.sg 数据将会被拒绝接收。示例:发送端 1 向接收端同步存储组 root.sg1 和 root.sg2, 发送端 2 向接收端同步存储组 root.sg2 和 root.sg3,
+均包括时间序列 root.sg2.d0.s0, 若接收端先接收到发送端 1 的 root.sg2.d0.s0 的数据,那么接收端将拒绝发送端 2 的 root.sg2 同步的数据。
### 配置参数
#### 同步工具接收端
-同步工具接收端的参数配置位于IoTDB的配置文件iotdb-engine.properties中,其安装目录为$IOTDB_HOME/conf/iotdb-engine.properties。在该配置文件中,有四个参数和同步接收端有关,配置说明如下:
-
+同步工具接收端的参数配置位于 IoTDB 的配置文件 iotdb-engine.properties 中,其安装目录为$IOTDB_HOME/conf/iotdb-engine.properties。在该配置文件中,有四个参数和同步接收端有关,配置说明如下:
|参数名|is_sync_enable|
|--- |--- |
-|描述|同步功能开关,配置为true表示接收端允许接收同步的数据并加载,设置为false的时候表示接收端不允许接收同步的数据|
+|描述|同步功能开关,配置为 true 表示接收端允许接收同步的数据并加载,设置为 false 的时候表示接收端不允许接收同步的数据|
|类型|Boolean|
|默认值|false|
|改后生效方式|重启服务生效|
|参数名|ip_white_list|
|--- |--- |
-|描述|设置同步功能发送端IP地址的白名单,以网段的形式表示,多个网段之间用逗号分隔。发送端向接收端同步数据时,只有当该发送端IP地址处于该白名单设置的网段范围内,接收端才允许同步操作。如果白名单为空,则接收端不允许任何发送端同步数据。默认接收端接受全部IP的同步请求。|
+|描述|设置同步功能发送端 IP 地址的白名单,以网段的形式表示,多个网段之间用逗号分隔。发送端向接收端同步数据时,只有当该发送端 IP 地址处于该白名单设置的网段范围内,接收端才允许同步操作。如果白名单为空,则接收端不允许任何发送端同步数据。默认接收端接受全部 IP 的同步请求。|
|类型|String|
|默认值|0.0.0.0/0|
|改后生效方式|重启服务生效|
|参数名|sync_server_port|
|--- |--- |
-|描述|同步接收端服务器监听接口,请确认该端口不是系统保留端口并且未被占用。参数is_sync_enable设置为true时有效,参数is_sync_enable设置为false时无效|
+|描述|同步接收端服务器监听接口,请确认该端口不是系统保留端口并且未被占用。参数 is_sync_enable 设置为 true 时有效,参数 is_sync_enable 设置为 false 时无效|
|类型|Short Int : [0,65535]|
|默认值|5555|
|改后生效方式|重启服务生效|
@@ -76,7 +75,7 @@
|参数名|server_ip|
|--- |--- |
-|描述|同步接收端的IP地址|
+|描述|同步接收端的 IP 地址|
|类型|String|
|默认值|127.0.0.1|
|改后生效方式|重启同步功能发送端生效|
@@ -90,7 +89,7 @@
|参数名|sync_period_in_second|
|--- |--- |
-|描述|同步周期,两次同步任务开始时间的间隔,单位为秒(s)|
+|描述|同步周期,两次同步任务开始时间的间隔,单位为秒 (s)|
|类型|Int : [0,2147483647]|
|默认值|600|
|改后生效方式|重启同步功能发送端生效|
@@ -133,11 +132,11 @@
ip_white_list=0.0.0.0/0
```
-2. 启动IoTDB引擎,同步功能接收端会同时启动,启动时LOG日志会出现`IoTDB: start SYNC ServerService successfully`字样,表示同步接收端启动成功.
+2. 启动 IoTDB 引擎,同步功能接收端会同时启动,启动时 LOG 日志会出现`IoTDB: start SYNC ServerService successfully`字样,表示同步接收端启动成功。
#### 关闭同步功能接收端
-关闭IoTDB,同步功能接收端会同时关闭。
+关闭 IoTDB,同步功能接收端会同时关闭。
#### 启动同步功能发送端
1. 配置发送端的参数
@@ -164,11 +163,11 @@
2. 启动同步功能发送端
用户可以使用```$IOTDB_HOME/tools```文件夹下的脚本启动同步功能的发送端
-Linux系统与MacOS系统启动命令如下:
+Linux 系统与 MacOS 系统启动命令如下:
```
Shell >$IOTDB_HOME/tools/start-sync-client.sh
```
-Windows系统启动命令如下:
+Windows 系统启动命令如下:
```
Shell >$IOTDB_HOME\tools\start-sync-client.bat
```
@@ -176,12 +175,11 @@ Windows系统启动命令如下:
#### 关闭同步功能发送端
用户可以使用```$IOTDB_HOME/tools```文件夹下的脚本关闭同步功能的发送端。
-Linux系统与MacOS系统停止命令如下:
+Linux 系统与 MacOS 系统停止命令如下:
```
Shell >$IOTDB_HOME/tools/stop-sync-client.sh
```
-Windows系统停止命令如下:
+Windows 系统停止命令如下:
```
Shell >$IOTDB_HOME\tools\stop-sync-client.bat
```
-
diff --git a/docs/zh/UserGuide/Communication-Service-Protocol/Programming-MQTT.md b/docs/zh/UserGuide/Communication-Service-Protocol/Programming-MQTT.md
index 5fc4ef9..8172eef 100644
--- a/docs/zh/UserGuide/Communication-Service-Protocol/Programming-MQTT.md
+++ b/docs/zh/UserGuide/Communication-Service-Protocol/Programming-MQTT.md
@@ -19,25 +19,24 @@
-->
-## MQTT协议
+## MQTT 协议
-[MQTT](http://mqtt.org/)是机器对机器(M2M)/“物联网”连接协议。
+[MQTT](http://mqtt.org/) 是机器对机器(M2M)/“物联网”连接协议。
它被设计为一种非常轻量级的发布/订阅消息传递。
对于与需要较小代码占用和/或网络带宽非常宝贵的远程位置的连接很有用。
-IoTDB支持MQTT v3.1(OASIS标准)协议。
-IoTDB服务器包括内置的MQTT服务,该服务允许远程设备将消息直接发送到IoTDB服务器。
+IoTDB 支持 MQTT v3.1(OASIS 标准)协议。
+IoTDB 服务器包括内置的 MQTT 服务,该服务允许远程设备将消息直接发送到 IoTDB 服务器。
<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/6711230/78357432-0c71cf80-75e4-11ea-98aa-c43a54d469ce.png">
-
-### 内置MQTT服务
-内置的MQTT服务提供了通过MQTT直接连接到IoTDB的能力。 它侦听来自MQTT客户端的发布消息,然后立即将数据写入存储。
-MQTT主题与IoTDB时间序列相对应。
-消息有效载荷可以由Java SPI加载的`PayloadFormatter`格式化为事件,默认实现为`JSONPayloadFormatter`
- 默认的`json`格式化程序支持两种json格式,以下是MQTT消息有效负载示例:
+### 内置 MQTT 服务
+内置的 MQTT 服务提供了通过 MQTT 直接连接到 IoTDB 的能力。 它侦听来自 MQTT 客户端的发布消息,然后立即将数据写入存储。
+MQTT 主题与 IoTDB 时间序列相对应。
+消息有效载荷可以由 Java SPI 加载的`PayloadFormatter`格式化为事件,默认实现为`JSONPayloadFormatter`
+ 默认的`json`格式化程序支持两种 json 格式,以下是 MQTT 消息有效负载示例:
```json
{
@@ -59,22 +58,22 @@ MQTT主题与IoTDB时间序列相对应。
<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/6711230/78357469-1bf11880-75e4-11ea-978f-a53996667a0d.png">
-### MQTT配置
-默认情况下,IoTDB MQTT服务从`${IOTDB_HOME}/${IOTDB_CONF}/iotdbengine.properties`加载配置。
+### MQTT 配置
+默认情况下,IoTDB MQTT 服务从`${IOTDB_HOME}/${IOTDB_CONF}/iotdbengine.properties`加载配置。
配置如下:
| 名称 | 描述 | 默认 |
| ------------- |:-------------:|:------:|
-| enable_mqtt_service | 是否启用mqtt服务 | false |
-| mqtt_host | mqtt服务绑定主机 | 0.0.0.0 |
-| mqtt_port | mqtt服务绑定端口 | 1883 |
-| mqtt_handler_pool_size | 处理mqtt消息的处理程序池大小 | 1 |
-| mqtt_payload_formatter | mqtt消息有效负载格式化程序 | json |
-| mqtt_max_message_size | mqtt消息最大长度(字节)| 1048576 |
+| enable_mqtt_service | 是否启用 mqtt 服务 | false |
+| mqtt_host | mqtt 服务绑定主机 | 0.0.0.0 |
+| mqtt_port | mqtt 服务绑定端口 | 1883 |
+| mqtt_handler_pool_size | 处理 mqtt 消息的处理程序池大小 | 1 |
+| mqtt_payload_formatter | mqtt 消息有效负载格式化程序 | json |
+| mqtt_max_message_size | mqtt 消息最大长度(字节)| 1048576 |
### 示例代码
-以下是mqtt客户端将消息发送到IoTDB服务器的示例。
+以下是 mqtt 客户端将消息发送到 IoTDB 服务器的示例。
```java
MQTT mqtt = new MQTT();
@@ -101,6 +100,3 @@ connection.disconnect();
```
## Rest
-
-
-
diff --git a/docs/zh/UserGuide/Communication-Service-Protocol/Programming-Thrift.md b/docs/zh/UserGuide/Communication-Service-Protocol/Programming-Thrift.md
index 091d645..20c38ac 100644
--- a/docs/zh/UserGuide/Communication-Service-Protocol/Programming-Thrift.md
+++ b/docs/zh/UserGuide/Communication-Service-Protocol/Programming-Thrift.md
@@ -25,21 +25,20 @@
### 简介
-Thrift是一个远程方法调用软件框架,用来进行可扩展且跨语言的服务的开发。
+Thrift 是一个远程方法调用软件框架,用来进行可扩展且跨语言的服务的开发。
它结合了功能强大的软件堆栈和代码生成引擎,
以构建在 C++, Java, Go,Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, and OCaml 这些编程语言间无缝结合的、高效的服务。
-IoTDB服务端和客户端之间使用thrift进行通信,实际使用中建议使用IoTDB提供的原生客户端封装:
-Session或Session Pool。如有特殊需要,您也可以直接针对RPC接口进行编程
+IoTDB 服务端和客户端之间使用 thrift 进行通信,实际使用中建议使用 IoTDB 提供的原生客户端封装:
+Session 或 Session Pool。如有特殊需要,您也可以直接针对 RPC 接口进行编程
-默认IoTDB服务端使用6667端口作为RPC通信端口,可修改配置项中的
+默认 IoTDB 服务端使用 6667 端口作为 RPC 通信端口,可修改配置项中的
```
rpc_port=6667
```
更改默认接口
-
-### rpc接口
+### rpc 接口
```
// 打开一个 session
@@ -99,7 +98,7 @@ TSStatus deleteStorageGroups(1:i64 sessionId, 2:list<string> storageGroup);
// 按行插入数据
TSStatus insertRecord(1:TSInsertRecordReq req);
-// 按String格式插入一条数据
+// 按 String 格式插入一条数据
TSStatus insertStringRecord(1:TSInsertStringRecordReq req);
// 按列插入数据
@@ -114,7 +113,7 @@ TSStatus insertRecords(1:TSInsertRecordsReq req);
// 按行批量插入同属于某个设备的数据
TSStatus insertRecordsOfOneDevice(1:TSInsertRecordsOfOneDeviceReq req);
-// 按String格式批量按行插入数据
+// 按 String 格式批量按行插入数据
TSStatus insertStringRecords(1:TSInsertStringRecordsReq req);
// 测试按列插入数据的延迟,注意:该接口不真实插入数据,只用来测试网络延迟
@@ -126,7 +125,7 @@ TSStatus testInsertTablets(1:TSInsertTabletsReq req);
// 测试按行插入数据的延迟,注意:该接口不真实插入数据,只用来测试网络延迟
TSStatus testInsertRecord(1:TSInsertRecordReq req);
-// 测试按String格式按行插入数据的延迟,注意:该接口不真实插入数据,只用来测试网络延迟
+// 测试按 String 格式按行插入数据的延迟,注意:该接口不真实插入数据,只用来测试网络延迟
TSStatus testInsertStringRecord(1:TSInsertStringRecordReq req);
// 测试按行插入数据的延迟,注意:该接口不真实插入数据,只用来测试网络延迟
@@ -135,7 +134,7 @@ TSStatus testInsertRecords(1:TSInsertRecordsReq req);
// 测试按行批量插入同属于某个设备的数据的延迟,注意:该接口不真实插入数据,只用来测试网络延迟
TSStatus testInsertRecordsOfOneDevice(1:TSInsertRecordsOfOneDeviceReq req);
-// 测试按String格式批量按行插入数据的延迟,注意:该接口不真实插入数据,只用来测试网络延迟
+// 测试按 String 格式批量按行插入数据的延迟,注意:该接口不真实插入数据,只用来测试网络延迟
TSStatus testInsertStringRecords(1:TSInsertStringRecordsReq req);
// 删除数据
@@ -144,14 +143,13 @@ TSStatus deleteData(1:TSDeleteDataReq req);
// 执行原始数据查询
TSExecuteStatementResp executeRawDataQuery(1:TSRawDataQueryReq req);
-// 向服务器申请一个查询语句ID
+// 向服务器申请一个查询语句 ID
i64 requestStatementId(1:i64 sessionId);
```
-### IDL定义文件位置
-IDL定义文件的路径是thrift/src/main/thrift/rpc.thrift,其中包括了结构体定义与函数定义
+### IDL 定义文件位置
+IDL 定义文件的路径是 thrift/src/main/thrift/rpc.thrift,其中包括了结构体定义与函数定义
### 生成文件位置
-在mvn编译过程中,会调用thrift编译IDL文件,生成最终的.class文件
-生成的文件夹路径为thrift/target/classes/org/apache/iotdb/service/rpc/thrift
-
+在 mvn 编译过程中,会调用 thrift 编译 IDL 文件,生成最终的。class 文件
+生成的文件夹路径为 thrift/target/classes/org/apache/iotdb/service/rpc/thrift
diff --git a/docs/zh/UserGuide/Comparison/TSDB-Comparison.md b/docs/zh/UserGuide/Comparison/TSDB-Comparison.md
index 0c8681c..57bbb92 100644
--- a/docs/zh/UserGuide/Comparison/TSDB-Comparison.md
+++ b/docs/zh/UserGuide/Comparison/TSDB-Comparison.md
@@ -25,31 +25,27 @@

-
-
-**表格外观启发自[Andriy Zabavskyy: How to Select Time Series DB](https://towardsdatascience.com/how-to-select-time-series-db-123b0eb4ab82)*
-
-
+**表格外观启发自 [Andriy Zabavskyy: How to Select Time Series DB](https://towardsdatascience.com/how-to-select-time-series-db-123b0eb4ab82)*
## 1. 已知的时间序列数据库
随着时间序列数据变得越来越重要,一些开源的时间序列数据库(Time Series Databases,or TSDB)诞生了。
-但是,它们中很少有专门为物联网(IoT)或者工业物联网(Industrial IoT,缩写IIoT)场景开发的。
+但是,它们中很少有专门为物联网(IoT)或者工业物联网(Industrial IoT,缩写 IIoT)场景开发的。
-本文把IoTDB和下述三种类型的时间序列数据库进行了比较:
+本文把 IoTDB 和下述三种类型的时间序列数据库进行了比较:
- InfluxDB - 原生时间序列数据库
- InfluxDB是最流行的时间序列数据库之一。
+ InfluxDB 是最流行的时间序列数据库之一。
接口:InfluxQL and HTTP API
-- OpenTSDB和KairosDB - 基于NoSQL的时间序列数据库
+- OpenTSDB 和 KairosDB - 基于 NoSQL 的时间序列数据库
- 这两种数据库是相似的,但是OpenTSDB基于HBase而KairosDB基于Cassandra。
+ 这两种数据库是相似的,但是 OpenTSDB 基于 HBase 而 KairosDB 基于 Cassandra。
- 它们两个都提供RESTful风格的API。
+ 它们两个都提供 RESTful 风格的 API。
接口:Restful API
@@ -57,7 +53,7 @@
接口:SQL
-Prometheus和Druid也因为时间序列数据管理而闻名,但是Prometheus聚焦在数据采集、可视化和报警,Druid聚焦在OLAP负载的数据分析,因为本文省略了Prometheus和Druid。
+Prometheus 和 Druid 也因为时间序列数据管理而闻名,但是 Prometheus 聚焦在数据采集、可视化和报警,Druid 聚焦在 OLAP 负载的数据分析,因为本文省略了 Prometheus 和 Druid。
## 2. 比较
@@ -98,34 +94,34 @@ Prometheus和Druid也因为时间序列数据管理而闻名,但是Prometheus
- *OpenSource*:
- - IoTDB使用Apache License 2.0。
- - InfluxDB使用MIT license。但是,**它的集群版本没有开源**。
- - OpenTSDB使用LGPL2.1,**和Apache License不兼容**。
- - KairosDB使用Apache License 2.0。
- - TimescaleDB使用Timescale License,对企业来说不是免费的。
+ - IoTDB 使用 Apache License 2.0。
+ - InfluxDB 使用 MIT license。但是,**它的集群版本没有开源**。
+ - OpenTSDB 使用 LGPL2.1,**和 Apache License 不兼容**。
+ - KairosDB 使用 Apache License 2.0。
+ - TimescaleDB 使用 Timescale License,对企业来说不是免费的。
- *SQL-like*:
- - IoTDB和InfluxDB支持SQL-like语言。另外,IoTDB和Calcite的集成几乎完成(PR已经提交),这意味着IoTDB很快就能支持标准SQL。
- - OpenTSDB和KairosDB只支持Rest API。IoTDB也支持Rest API(PR已经提交)。
- - TimescaleDB使用的是和PostgreSQL一样的SQL。
+ - IoTDB 和 InfluxDB 支持 SQL-like 语言。另外,IoTDB 和 Calcite 的集成几乎完成(PR 已经提交),这意味着 IoTDB 很快就能支持标准 SQL。
+ - OpenTSDB 和 KairosDB 只支持 Rest API。IoTDB 也支持 Rest API(PR 已经提交)。
+ - TimescaleDB 使用的是和 PostgreSQL 一样的 SQL。
- *Schema*:
- - IoTDB:IoTDB提出了一种[基于树的schema](http://iotdb.apache.org/zh/UserGuide/Master/Data-Concept/Data-Model-and-Terminology.html)。这和其它时间序列数据库很不一样。这种schema有以下优点:
- - 在许多工业场景里,设备管理是有层次的,而不是扁平的。因此我们认为基于树的schema比基于tag-value的schema更好。
- - 在许多现实应用中,tag的名字是不变的。例如:风力发电机制造商总是用风机所在的国家、所属的风场以及在风场中的ID来标识一个风机,因此,一个4层高的树(“root.the-country-name.the-farm-name.the-id”)来表示就足矣。你不需要重复告诉IoTDB”树的第二层是国家名”、“树的第三层是风场名“等等这种信息。
- - 这样的基于路径的时间序列ID定义还能够支持灵活的查询,例如:”root.\*.a.b.\*“,其中\*是一个通配符。
- - InfluxDB, KairosDB, OpenTSDB:使用基于tag-value的schema。现在比较流行这种schema。
- - TimescaleDB使用关系表。
+ - IoTDB:IoTDB 提出了一种 [基于树的 schema](http://iotdb.apache.org/zh/UserGuide/Master/Data-Concept/Data-Model-and-Terminology.html)。这和其它时间序列数据库很不一样。这种 schema 有以下优点:
+ - 在许多工业场景里,设备管理是有层次的,而不是扁平的。因此我们认为基于树的 schema 比基于 tag-value 的 schema 更好。
+ - 在许多现实应用中,tag 的名字是不变的。例如:风力发电机制造商总是用风机所在的国家、所属的风场以及在风场中的 ID 来标识一个风机,因此,一个 4 层高的树(“root.the-country-name.the-farm-name.the-id”)来表示就足矣。你不需要重复告诉 IoTDB”树的第二层是国家名”、“树的第三层是风场名“等等这种信息。
+ - 这样的基于路径的时间序列 ID 定义还能够支持灵活的查询,例如:”root.\*.a.b.\*“,其中、*是一个通配符。
+ - InfluxDB, KairosDB, OpenTSDB:使用基于 tag-value 的 schema。现在比较流行这种 schema。
+ - TimescaleDB 使用关系表。
- *Order by time*:
- 对于时间序列数据库来说,Order by time好像是一个琐碎的功能。但是当我们考虑另一个叫做”align by time“的功能时,事情就变得有趣起来。这就是为什么我们把OpenTSDB和KairosDB标记为”不支持“。事实上,所有时间序列数据库都支持单条时间序列的按时间戳排序。但是,OpenTSDB和KairosDB不支持多条时间序列的按时间戳排序。
+ 对于时间序列数据库来说,Order by time 好像是一个琐碎的功能。但是当我们考虑另一个叫做”align by time“的功能时,事情就变得有趣起来。这就是为什么我们把 OpenTSDB 和 KairosDB 标记为”不支持“。事实上,所有时间序列数据库都支持单条时间序列的按时间戳排序。但是,OpenTSDB 和 KairosDB 不支持多条时间序列的按时间戳排序。
- 下面考虑一个新的例子:这里有两条时间序列,一条是风场1中的风速,一条是风场1中的风机1产生的电能。如果我们想要研究风速和产生电能之间的关系,我们首先需要知道二者在相同时间戳下的值。也就是说,我们需要按照时间戳对齐这两条时间序列。因此,结果应该是:
+ 下面考虑一个新的例子:这里有两条时间序列,一条是风场 1 中的风速,一条是风场 1 中的风机 1 产生的电能。如果我们想要研究风速和产生电能之间的关系,我们首先需要知道二者在相同时间戳下的值。也就是说,我们需要按照时间戳对齐这两条时间序列。因此,结果应该是:
- | 时间戳 | 风场1中的风速 | 风场1中的风机1产生的电能 |
+ | 时间戳 | 风场 1 中的风速 | 风场 1 中的风机 1 产生的电能 |
| ------ | ------------- | ------------------------ |
| 1 | 5.0 | 13.1 |
| 2 | 6.0 | 13.3 |
@@ -135,61 +131,57 @@ Prometheus和Druid也因为时间序列数据管理而闻名,但是Prometheus
| 时间戳 | 时间序列名 | 值 |
| ------ | ------------------------ | ---- |
- | 1 | 风场1中的风速 | 5.0 |
- | 1 | 风场1中的风机1产生的电能 | 13.1 |
- | 2 | 风场1中的风速 | 6.0 |
- | 2 | 风场1中的风机1产生的电能 | 13.3 |
- | 3 | 风场1中的风机1产生的电能 | 13.1 |
+ | 1 | 风场 1 中的风速 | 5.0 |
+ | 1 | 风场 1 中的风机 1 产生的电能 | 13.1 |
+ | 2 | 风场 1 中的风速 | 6.0 |
+ | 2 | 风场 1 中的风机 1 产生的电能 | 13.3 |
+ | 3 | 风场 1 中的风机 1 产生的电能 | 13.1 |
虽然第二个表格没有按照时间戳对齐两条时间序列,但是只需要逐行扫描数据就可以很容易地在客户端实现这个功能。
- IoTDB支持第一种表格格式(叫做align by time),InfluxDB支持第二种表格格式。
+ IoTDB 支持第一种表格格式(叫做 align by time),InfluxDB 支持第二种表格格式。
- *Downsampling*:
- Downsampling(降采样)用于改变时间序列的粒度,例如:从10Hz到1Hz,或者每天1个点。
+ Downsampling(降采样)用于改变时间序列的粒度,例如:从 10Hz 到 1Hz,或者每天 1 个点。
- 和其他数据库不同的是,IoTDB能够实时降采样数据,而其它时间序列数据库在磁盘上序列化降采样数据。
+ 和其他数据库不同的是,IoTDB 能够实时降采样数据,而其它时间序列数据库在磁盘上序列化降采样数据。
也就是说:
- - IoTDB支持在任意时间对数据进行即席(ad-hoc)降采样。例如:一条SQL返回从2020-04-27 08:00:00开始的每5分钟采样1个点的降采样数据,另一条SQL返回从2020-04-27 08:00:01开始的每5分10秒采样1个点的降采样数据。
+ - IoTDB 支持在任意时间对数据进行即席(ad-hoc)降采样。例如:一条 SQL 返回从 2020-04-27 08:00:00 开始的每 5 分钟采样 1 个点的降采样数据,另一条 SQL 返回从 2020-04-27 08:00:01 开始的每 5 分 10 秒采样 1 个点的降采样数据。
- (InfluxDB也支持即席降采样,但是性能似乎并不好。)
+ (InfluxDB 也支持即席降采样,但是性能似乎并不好。)
- - IoTDB的降采样不占用磁盘。
+ - IoTDB 的降采样不占用磁盘。
- *Fill*:
- 有时候我们认为数据是按照某种固定的频率采集的,比如1Hz(即每秒1个点)。但是通常我们会丢失一些数据点,可能由于网络不稳定、机器繁忙、机器宕机等等。在这些场景下,填充这些数据空洞是重要的。数据科学家可以因此避免很多所谓的”dirty work“比如数据清洗。
+ 有时候我们认为数据是按照某种固定的频率采集的,比如 1Hz(即每秒 1 个点)。但是通常我们会丢失一些数据点,可能由于网络不稳定、机器繁忙、机器宕机等等。在这些场景下,填充这些数据空洞是重要的。数据科学家可以因此避免很多所谓的”dirty work“比如数据清洗。
- InfluxDB和OpenTSDB只支持在group by语句里使用fill,而IoTDB能支持给定一个特定的时间戳的fill。此外,IoTDB还支持多种填充策略。
+ InfluxDB 和 OpenTSDB 只支持在 group by 语句里使用 fill,而 IoTDB 能支持给定一个特定的时间戳的 fill。此外,IoTDB 还支持多种填充策略。
- *Slimit*:
- Slimit是指返回指定数量的measurements(或者,InfluxDB中的fields)。
+ Slimit 是指返回指定数量的 measurements(或者,InfluxDB 中的 fields)。
- 例如:一个风机有1000个测点(风速、电压等等),使用slimit和soffset可以只返回其中的一部分测点。
+ 例如:一个风机有 1000 个测点(风速、电压等等),使用 slimit 和 soffset 可以只返回其中的一部分测点。
- *Latest value*:
最基础的时间序列应用之一是监视最新数据。因此,返回一条时间序列的最新点是非常重要的查询功能。
- IoTDB和OpenTSDB使用一个特殊的SQL或API来支持这个功能,而InfluxDB使用聚合函数来支持。
-
- IoTDB提供一个特殊的SQL的原因是IoTDB专门优化了查询。
-
+ IoTDB 和 OpenTSDB 使用一个特殊的 SQL 或 API 来支持这个功能,而 InfluxDB 使用聚合函数来支持。
+ IoTDB 提供一个特殊的 SQL 的原因是 IoTDB 专门优化了查询。
**结论:**
通过对基础功能的比较,我们可以发现:
-- OpenTSDB和KairosDB缺少一些重要的查询功能。
-- TimescaleDB不能被企业免费使用。
-- IoTDB和InfluxDB可以满足时间序列数据管理的大部分需求,同时它俩之间有一些不同之处。
-
-
+- OpenTSDB 和 KairosDB 缺少一些重要的查询功能。
+- TimescaleDB 不能被企业免费使用。
+- IoTDB 和 InfluxDB 可以满足时间序列数据管理的大部分需求,同时它俩之间有一些不同之处。
#### 2.1.2 高级功能
@@ -213,13 +205,13 @@ Prometheus和Druid也因为时间序列数据管理而闻名,但是Prometheus
- *Compression*:
- - IoTDB支持许多时间序列编码和压缩方法,比如RLE, 2DIFF, Gorilla等等,以及Snappy压缩。在IoTDB里,你可以根据数据分布选择你想要的编码方法。更多信息参考[这里](http://iotdb.apache.org/UserGuide/Master/Data-Concept/Encoding.html)。
- - InfluxDB也支持编码和压缩,但是你不能定义你想要的编码方法,编码只取决于数据类型。更多信息参考[这里](https://docs.influxdata.com/influxdb/v1.7/concepts/storage_engine/)。
- - OpenTSDB和KairosDB在后端使用HBase和Cassandra,并且没有针对时间序列的特殊编码。
+ - IoTDB 支持许多时间序列编码和压缩方法,比如 RLE, 2DIFF, Gorilla 等等,以及 Snappy 压缩。在 IoTDB 里,你可以根据数据分布选择你想要的编码方法。更多信息参考 [这里](http://iotdb.apache.org/UserGuide/Master/Data-Concept/Encoding.html)。
+ - InfluxDB 也支持编码和压缩,但是你不能定义你想要的编码方法,编码只取决于数据类型。更多信息参考 [这里](https://docs.influxdata.com/influxdb/v1.7/concepts/storage_engine/)。
+ - OpenTSDB 和 KairosDB 在后端使用 HBase 和 Cassandra,并且没有针对时间序列的特殊编码。
- *MQTT protocol support*:
- MQTT protocol是一个被工业用户广泛知晓的国际标准。只有IoTDB和InfluxDB支持用户使用MQTT客户端来写数据。
+ MQTT protocol 是一个被工业用户广泛知晓的国际标准。只有 IoTDB 和 InfluxDB 支持用户使用 MQTT 客户端来写数据。
- *Running on Edge-side Device*:
@@ -227,7 +219,7 @@ Prometheus和Druid也因为时间序列数据管理而闻名,但是Prometheus
在边缘侧部署时间序列数据库,对于管理边缘侧数据、服务于边缘计算来说,是有用的。
- 由于OpenTSDB和KairosDB依赖另外的数据库,它们的体系结构是臃肿的。特别是很难在边缘侧运行Hadoop。
+ 由于 OpenTSDB 和 KairosDB 依赖另外的数据库,它们的体系结构是臃肿的。特别是很难在边缘侧运行 Hadoop。
- *Multi-instance Sync*:
@@ -235,43 +227,39 @@ Prometheus和Druid也因为时间序列数据管理而闻名,但是Prometheus
一个解决方法是从这些实例读取数据,然后逐点写入到数据中心。
- IoTDB提供了另一个选项:把数据文件增量上传到数据中心,然后数据中心可以支持在数据上的服务。
+ IoTDB 提供了另一个选项:把数据文件增量上传到数据中心,然后数据中心可以支持在数据上的服务。
- *JDBC driver*:
- 现在只有IoTDB支持了JDBC driver(虽然不是所有接口都实现),这使得IoTDB可以整合许多其它的基于JDBC driver的软件。
+ 现在只有 IoTDB 支持了 JDBC driver(虽然不是所有接口都实现),这使得 IoTDB 可以整合许多其它的基于 JDBC driver 的软件。
- *Standard SQL*:
- 正如之前提到的,IoTDB和Calcite的集成几乎完成(PR已经提交),这意味着IoTDB很快就能支持标准SQL。
+ 正如之前提到的,IoTDB 和 Calcite 的集成几乎完成(PR 已经提交),这意味着 IoTDB 很快就能支持标准 SQL。
- *Spark and Hive integration*:
让大数据分析软件访问数据库中的数据来完成复杂数据分析是非常重要的。
- IoTDB支持Hive-connector和Spark-connector来完成更好的整合。
+ IoTDB 支持 Hive-connector 和 Spark-connector 来完成更好的整合。
- *Writing data to NFS (HDFS)*:
- Sharing nothing的体系结构是好的,但是有时候你不得不增加新的服务器,即便你的CPU和内存都是空闲的而磁盘已经满了。
-
- 此外,如果我们能直接把数据文件存储到HDFS中,用Spark和其它软件来分析数据将会更加简单,不需要ETL。
-
- - IoTDB支持往本地或者HDFS写数据。IoTDB还允许用户扩展实现在其它NFS上存储数据。
- - InfluxDB和KairosDB只能往本地写数据。
- - OpenTSDB只能往HDFS写数据。
+ Sharing nothing 的体系结构是好的,但是有时候你不得不增加新的服务器,即便你的 CPU 和内存都是空闲的而磁盘已经满了。
+ 此外,如果我们能直接把数据文件存储到 HDFS 中,用 Spark 和其它软件来分析数据将会更加简单,不需要 ETL。
+ - IoTDB 支持往本地或者 HDFS 写数据。IoTDB 还允许用户扩展实现在其它 NFS 上存储数据。
+ - InfluxDB 和 KairosDB 只能往本地写数据。
+ - OpenTSDB 只能往 HDFS 写数据。
**结论:**
-IoTDB拥有许多其它时间序列数据库不支持的强大功能。
-
-
+IoTDB 拥有许多其它时间序列数据库不支持的强大功能。
### 2.2 性能比较
-如果你觉得:”如果我只需要基础功能的话,IoTDB好像和其它的时间序列数据库没有什么不同。“
+如果你觉得:”如果我只需要基础功能的话,IoTDB 好像和其它的时间序列数据库没有什么不同。“
这好像是有道理的。但是如果考虑性能的话,你也许会改变你的想法。
@@ -287,13 +275,13 @@ IoTDB拥有许多其它时间序列数据库不支持的强大功能。
##### 写入性能
-我们从两个方面来测试写性能:batch size和client num。存储组的数量是10。有1000个设备,每个设备有100个传感器,也就是说一共有100K条时间序列。
+我们从两个方面来测试写性能:batch size 和 client num。存储组的数量是 10。有 1000 个设备,每个设备有 100 个传感器,也就是说一共有 100K 条时间序列。
-测试使用的IoTDB版本是`v0.11.1`。
+测试使用的 IoTDB 版本是`v0.11.1`。
-###### 改变batch size
+###### 改变 batch size
-10个客户端并发地写数据。IoTDB使用batch insertion API,batch size从1ms到1min变化(每次调用write API写N个数据点)。
+10 个客户端并发地写数据。IoTDB 使用 batch insertion API,batch size 从 1ms 到 1min 变化(每次调用 write API 写 N 个数据点)。
写入吞吐率(points/second)如下图所示:
@@ -301,19 +289,15 @@ IoTDB拥有许多其它时间序列数据库不支持的强大功能。
<center>Figure 1. Batch Size with Write throughput (points/second) IoTDB v0.11.1</center>
-
-
写入延迟(ms)如下图所示:

<center>Figure 2. Batch Size with Write Delay (ms) IoTDB v0.11.1</center>
+###### 改变 client num
-
-###### 改变client num
-
-client num从1到50变化。IoTDB使用batch insertion API,batch size是100(每次调用write API写100个数据点)。
+client num 从 1 到 50 变化。IoTDB 使用 batch insertion API,batch size 是 100(每次调用 write API 写 100 个数据点)。
写入吞吐率(points/second)如下图所示:
@@ -321,19 +305,13 @@ client num从1到50变化。IoTDB使用batch insertion API,batch size是100(
<center>Figure 3. Client Num with Write Throughput (points/second) IoTDB v0.11.1</center>
-
-
-
-
-
-
##### 查询性能
-10个客户端并发地读数据。存储组的数量是10。有10个设备,每个设备有10个传感器,也就是说一共有100条时间序列。
+10 个客户端并发地读数据。存储组的数量是 10。有 10 个设备,每个设备有 10 个传感器,也就是说一共有 100 条时间序列。
-数据类型是*double*,编码类型是*GORILLA*。
+数据类型是* double*,编码类型是* GORILLA*。
-测试使用的IoTDB版本是`v0.11.1`。
+测试使用的 IoTDB 版本是`v0.11.1`。
测试结果如下图所示:
@@ -341,63 +319,50 @@ client num从1到50变化。IoTDB使用batch insertion API,batch size是100(
<center>Figure 4. Raw data query 1 col time cost(ms) IoTDB v0.11.1</center>
-
-

<center>Figure 5. Aggregation query time cost(ms) IoTDB v0.11.1</center>
-
-

<center>Figure 6. Downsampling query time cost(ms) IoTDB v0.11.1</center>
-
-

<center>Figure 7. Latest query time cost(ms) IoTDB v0.11.1</center>
-
-
-可以看到,IoTDB的raw data query、aggregation query、downsampling query、latest query查询性能表现都超越了其它数据库。
-
-
+可以看到,IoTDB 的 raw data query、aggregation query、downsampling query、latest query 查询性能表现都超越了其它数据库。
#### 2.2.2 更多细节
-我们提供了一个benchmark工具,叫做[IoTDB-benchamrk](https://github.com/thulab/iotdb-benchmark)(你可以用dev branch来编译它)。它支持IoTDB, InfluxDB, KairosDB, TimescaleDB, OpenTSDB。
+我们提供了一个 benchmark 工具,叫做 [IoTDB-benchamrk](https://github.com/thulab/iotdb-benchmark)(你可以用 dev branch 来编译它)。它支持 IoTDB, InfluxDB, KairosDB, TimescaleDB, OpenTSDB。
-我们有一篇文章关于用这个benchmark工具比较这些时间序列数据库:[Benchmarking Time Series Databases with IoTDB-Benchmark for IoT Scenarios](https://arxiv.org/abs/1901.08304)。我们发表这个文章的时候,IoTDB才刚刚加入Apache incubator,所以我们在那篇文章里删去了IoTDB的性能测试。但是在比较之后,一些结果展示在这里:
+我们有一篇文章关于用这个 benchmark 工具比较这些时间序列数据库:[Benchmarking Time Series Databases with IoTDB-Benchmark for IoT Scenarios](https://arxiv.org/abs/1901.08304)。我们发表这个文章的时候,IoTDB 才刚刚加入 Apache incubator,所以我们在那篇文章里删去了 IoTDB 的性能测试。但是在比较之后,一些结果展示在这里:
-- 对于InfluxDB,我们把cache-max-memory-size和max-series-perbase设置成unlimited(否则它很快就会超时)。
-- 对于KairosDB,我们把Cassandra的read_repair_chance设置为0.1(但是这没有什么影响,因为我们只有一个结点)。
-- 对于TimescaleDB,我们用PGTune工具来优化PostgreSQL。
+- 对于 InfluxDB,我们把 cache-max-memory-size 和 max-series-perbase 设置成 unlimited(否则它很快就会超时)。
+- 对于 KairosDB,我们把 Cassandra 的 read_repair_chance 设置为 0.1(但是这没有什么影响,因为我们只有一个结点)。
+- 对于 TimescaleDB,我们用 PGTune 工具来优化 PostgreSQL。
所有的时间序列数据库运行的机器配置是:Intel(R) Core(TM) i7-10700 CPU @ 2.90GHz, (8 cores 16 threads), 32GB memory, 256G SSD and 10T HDD, OS: Ubuntu 16.04.7 LTS, 64bits.
所有的客户端运行的机器配置是:Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz,(6 cores 12 threads), 16GB memory, 256G SSD, OS: Ubuntu 16.04.7 LTS, 64bits.
-
-
## 3. 结论
-从以上所有实验中,我们可以看到IoTDB的性能大大优于其他数据库。
+从以上所有实验中,我们可以看到 IoTDB 的性能大大优于其他数据库。
-IoTDB具有最小的写入延迟。批处理大小越大,IoTDB的写入吞吐量就越高。这表明IoTDB最适合批处理数据写入方案。
+IoTDB 具有最小的写入延迟。批处理大小越大,IoTDB 的写入吞吐量就越高。这表明 IoTDB 最适合批处理数据写入方案。
-在高并发方案中,IoTDB也可以保持吞吐量的稳定增长。 (每秒1200万个点可能已达到千兆网卡的限制)
+在高并发方案中,IoTDB 也可以保持吞吐量的稳定增长。 (每秒 1200 万个点可能已达到千兆网卡的限制)
-在原始数据查询中,随着查询范围的扩大,IoTDB的优势开始显现。因为数据块的粒度更大,列式存储的优势体现出来,所以基于列的压缩和列迭代器都将加速查询。
+在原始数据查询中,随着查询范围的扩大,IoTDB 的优势开始显现。因为数据块的粒度更大,列式存储的优势体现出来,所以基于列的压缩和列迭代器都将加速查询。
在聚合查询中,我们使用文件层的统计信息并缓存统计信息。因此,多个查询仅需要执行内存计算(不需要遍历原始数据点,也不需要访问磁盘),因此聚合性能优势显而易见。
-降采样查询场景更加有趣,因为时间分区越来越大,IoTDB的查询性能逐渐提高。它可能上升了两倍,这对应于2个粒度(3小时和4.5天)的预先计算的信息。因此,分别加快了1天和1周范围内的查询。其他数据库仅上升一次,表明它们只有一个粒度统计。
+降采样查询场景更加有趣,因为时间分区越来越大,IoTDB 的查询性能逐渐提高。它可能上升了两倍,这对应于 2 个粒度(3 小时和 4.5 天)的预先计算的信息。因此,分别加快了 1 天和 1 周范围内的查询。其他数据库仅上升一次,表明它们只有一个粒度统计。
-如果您正在为您的IIoT应用程序考虑使用TSDB,那么新的时间序列数据库Apache IoTDB是您的最佳选择。
+如果您正在为您的 IIoT 应用程序考虑使用 TSDB,那么新的时间序列数据库 Apache IoTDB 是您的最佳选择。
发布新版本并完成实验后,我们将更新此页面。
-我们也欢迎更多的贡献者更正本文,为IoTDB做出贡献或复现实验。
-
+我们也欢迎更多的贡献者更正本文,为 IoTDB 做出贡献或复现实验。
diff --git a/docs/zh/UserGuide/Data-Concept/Compression.md b/docs/zh/UserGuide/Data-Concept/Compression.md
index 3af3afc..a53cfe8 100644
--- a/docs/zh/UserGuide/Data-Concept/Compression.md
+++ b/docs/zh/UserGuide/Data-Concept/Compression.md
@@ -21,13 +21,13 @@
## 压缩方式
-当时间序列写入并按照指定的类型编码为二进制数据后,IoTDB会使用压缩技术对该数据进行压缩,进一步提升空间存储效率。虽然编码和压缩都旨在提升存储效率,但编码技术通常只适合特定的数据类型(如二阶差分编码只适合与INT32或者INT64编码,存储浮点数需要先将他们乘以10m以转换为整数),然后将它们转换为二进制流。压缩方式(SNAPPY)针对二进制流进行压缩,因此压缩方式的使用不再受数据类型的限制。
+当时间序列写入并按照指定的类型编码为二进制数据后,IoTDB 会使用压缩技术对该数据进行压缩,进一步提升空间存储效率。虽然编码和压缩都旨在提升存储效率,但编码技术通常只适合特定的数据类型(如二阶差分编码只适合与 INT32 或者 INT64 编码,存储浮点数需要先将他们乘以 10m 以转换为整数),然后将它们转换为二进制流。压缩方式(SNAPPY)针对二进制流进行压缩,因此压缩方式的使用不再受数据类型的限制。
-IoTDB允许在创建一个时间序列的时候指定该列的压缩方式。现阶段IoTDB支持以下几种压缩方式:
+IoTDB 允许在创建一个时间序列的时候指定该列的压缩方式。现阶段 IoTDB 支持以下几种压缩方式:
* UNCOMPRESSED(不压缩)
-* SNAPPY压缩
-* LZ4压缩
-* GZIP压缩
+* SNAPPY 压缩
+* LZ4 压缩
+* GZIP 压缩
-压缩方式的指定语法详见本文[SQL 参考文档](../Appendix/SQL-Reference.md)。
+压缩方式的指定语法详见本文 [SQL 参考文档](../Appendix/SQL-Reference.md)。
diff --git a/docs/zh/UserGuide/Data-Concept/Data-Model-and-Terminology.md b/docs/zh/UserGuide/Data-Concept/Data-Model-and-Terminology.md
index 5690847..ea07bf0 100644
--- a/docs/zh/UserGuide/Data-Concept/Data-Model-and-Terminology.md
+++ b/docs/zh/UserGuide/Data-Concept/Data-Model-and-Terminology.md
@@ -25,11 +25,11 @@
我们以风电场物联网场景为例,说明如何在 IoTDB 中创建一个正确的数据模型。
-根据企业组织结构和设备实体层次结构,我们将其物联网数据模型表示为如下图所示的属性层级组织结构,即电力集团层-风电场层-实体层-物理量层。其中 ROOT 为根节点,物理量层的每一个节点为叶子节点。IoTDB 采用树形结构定义数据模式,以从ROOT 节点到叶子节点的路径来命名一个时间序列,层次间以“.”连接。例如,下图最左侧路径对应的时间序列名称为`ROOT.ln.wf01.wt01.status`。
+根据企业组织结构和设备实体层次结构,我们将其物联网数据模型表示为如下图所示的属性层级组织结构,即电力集团层-风电场层-实体层-物理量层。其中 ROOT 为根节点,物理量层的每一个节点为叶子节点。IoTDB 采用树形结构定义数据模式,以从 ROOT 节点到叶子节点的路径来命名一个时间序列,层次间以“.”连接。例如,下图最左侧路径对应的时间序列名称为`ROOT.ln.wf01.wt01.status`。
<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/123542457-5f511d00-d77c-11eb-8006-562d83069baa.png">
-IoTDB模型结构涉及如下基本概念:
+IoTDB 模型结构涉及如下基本概念:
* 物理量(Measurement,也称工况、字段 field)
@@ -37,41 +37,41 @@ IoTDB模型结构涉及如下基本概念:
* 物理分量(SubMeasurement、分量)
-在多元物理量中,包括多个分量。如 GPS 是一个多元物理量,包含3个分量:经度、维度、海拔。多元物理量通常被同时采集,共享时间列。
+在多元物理量中,包括多个分量。如 GPS 是一个多元物理量,包含 3 个分量:经度、维度、海拔。多元物理量通常被同时采集,共享时间列。
一元物理量则将分量名和物理量名字重合。如温度是一个一元物理量。
* 实体(Entity,也称设备,device)
-**一个物理实体**,是在实际场景中拥有物理量的设备或装置。在IoTDB当中,所有的物理量都有其对应的归属实体。
+**一个物理实体**,是在实际场景中拥有物理量的设备或装置。在 IoTDB 当中,所有的物理量都有其对应的归属实体。
* 存储组(Storage group)
-**一组物理实体**,用户可以将任意前缀路径设置成存储组。如有4条时间序列`root.ln.wf01.wt01.status`, `root.ln.wf01.wt01.temperature`, `root.ln.wf02.wt02.hardware`, `root.ln.wf02.wt02.status`,路径`root.ln`下的两个实体 `wt01`, `wt02`可能属于同一个业主,或者同一个制造商,这时候就可以将前缀路径`root.ln`指定为一个存储组。未来`root.ln`下增加了新的实体,也将属于该存储组。
+**一组物理实体**,用户可以将任意前缀路径设置成存储组。如有 4 条时间序列`root.ln.wf01.wt01.status`, `root.ln.wf01.wt01.temperature`, `root.ln.wf02.wt02.hardware`, `root.ln.wf02.wt02.status`,路径`root.ln`下的两个实体 `wt01`, `wt02`可能属于同一个业主,或者同一个制造商,这时候就可以将前缀路径`root.ln`指定为一个存储组。未来`root.ln`下增加了新的实体,也将属于该存储组。
一个存储组中的所有实体的数据会存储在同一个文件夹下,不同存储组的实体数据会存储在磁盘的不同文件夹下,从而实现物理隔离。
-> 注意1:不允许将一个完整路径(如上例的`root.ln.wf01.wt01.status`)设置成存储组。
+> 注意 1:不允许将一个完整路径(如上例的`root.ln.wf01.wt01.status`) 设置成存储组。
>
-> 注意2:一个时间序列其前缀必须属于某个存储组。在创建时间序列之前,用户必须设定该序列属于哪个存储组(Storage Group)。只有设置了存储组的时间序列才可以被持久化在磁盘上。
+> 注意 2:一个时间序列其前缀必须属于某个存储组。在创建时间序列之前,用户必须设定该序列属于哪个存储组(Storage Group)。只有设置了存储组的时间序列才可以被持久化在磁盘上。
一个前缀路径一旦被设定成存储组后就不可以再更改这个存储组的设定。
一个存储组设定后,其对应的前缀路径的祖先层级与孩子及后裔层级也不允许再设置存储组(如,`root.ln`设置存储组后,root 层级与`root.ln.wf01`不允许被设置为存储组)。
-存储组节点名只支持中英文字符、数字、下划线和中划线的组合。例如`root.存储组_1-组1` 。
+存储组节点名只支持中英文字符、数字、下划线和中划线的组合。例如`root. 存储组_1-组1` 。
* 数据点(Data point)
**一个“时间-值”对**。
-* 时间序列(一个实体的某个物理量对应一个时间序列,Timeseries,也称测点meter、时间线timeline,实时数据库中常被称作标签tag、参数parameter)
+* 时间序列(一个实体的某个物理量对应一个时间序列,Timeseries,也称测点 meter、时间线 timeline,实时数据库中常被称作标签 tag、参数 parameter)
**一个物理实体的某个物理量在时间轴上的记录**,是数据点的序列。
-例如,ln电力集团、wf01风电场的实体 wt01有名为 status的物理量,则它的时间序列可以表示为:`root.ln.wf01.wt01.status`。
+例如,ln 电力集团、wf01 风电场的实体 wt01 有名为 status 的物理量,则它的时间序列可以表示为:`root.ln.wf01.wt01.status`。
-* 一元时间序列(single-variable timeseries 或timeseries,v0.1 起支持)
+* 一元时间序列(single-variable timeseries 或 timeseries,v0.1 起支持)
一个实体的一个一元物理量对应一个一元时间序列。实体+物理量=时间序列
@@ -93,25 +93,24 @@ IoTDB模型结构涉及如下基本概念:
目前每一个路径节点仅允许挂载一个物理量模板,实体将使用其自身或最近祖先的物理量模板作为有效模板。
-
* 路径
-在IoTDB中,路径是指符合以下约束的表达式:
+在 IoTDB 中,路径是指符合以下约束的表达式:
```
path: LayerName (DOT LayerName)+
LayerName: Identifier | STAR
```
-其中STAR为“*”,DOT为“.”。
+其中 STAR 为“*”,DOT 为“.”。
-我们称一个路径中在两个“.”中间的部分叫做一个层级,则`root.a.b.c`为一个层级为4的路径。
+我们称一个路径中在两个“.”中间的部分叫做一个层级,则`root.a.b.c`为一个层级为 4 的路径。
-值得说明的是,在路径中,root为一个保留字符,它只允许出现在下文提到的时间序列的开头,若其他层级出现root,则无法解析,提示报错。
+值得说明的是,在路径中,root 为一个保留字符,它只允许出现在下文提到的时间序列的开头,若其他层级出现 root,则无法解析,提示报错。
-在路径中,不允许使用单引号。如果你想在LayerName中使用`.`等特殊字符,请使用双引号。例如,`root.sg."d.1"."s.1"`。双引号内支持使用转义符进行双引号的嵌套,如 `root.sg.d1."s.\"t\"1"`。
+在路径中,不允许使用单引号。如果你想在 LayerName 中使用`.`等特殊字符,请使用双引号。例如,`root.sg."d.1"."s.1"`。双引号内支持使用转义符进行双引号的嵌套,如 `root.sg.d1."s.\"t\"1"`。
-除了storage group 存储组,其他的LayerName中不用加双引号就支持的字符如下:
+除了 storage group 存储组,其他的 LayerName 中不用加双引号就支持的字符如下:
* 中文字符"\u2E80"到"\u9FFF"
* "+","&","%","$","#","@","/","_","-",":"
@@ -119,28 +118,28 @@ LayerName: Identifier | STAR
其中'-' 和 ':' 不能放置在第一位,不能使用单个 '+'。
-> 注意: storage group中的LayerName只支持数字,字母,汉字,下划线和中划线。另外,如果在Windows系统上部署,存储组层级名称是大小写不敏感的。例如同时创建`root.ln` 和 `root.LN` 是不被允许的。
+> 注意:storage group 中的 LayerName 只支持数字,字母,汉字,下划线和中划线。另外,如果在 Windows 系统上部署,存储组层级名称是大小写不敏感的。例如同时创建`root.ln` 和 `root.LN` 是不被允许的。
* 前缀路径
前缀路径是指一个时间序列的前缀所在的路径,一个前缀路径包含以该路径为前缀的所有时间序列。例如当前我们有`root.vehicle.device1.sensor1`, `root.vehicle.device1.sensor2`, `root.vehicle.device2.sensor1`三个传感器,则`root.vehicle.device1`前缀路径包含`root.vehicle.device1.sensor1`、`root.vehicle.device1.sensor2`两个时间序列,而不包含`root.vehicle.device2.sensor1`。
* 带`*`路径
-为了使得在表达多个时间序列或表达前缀路径的时候更加方便快捷,IoTDB为用户提供带`*`路径。`*`可以出现在路径中的任何层。按照`*`出现的位置,带`*`路径可以分为两种:
+为了使得在表达多个时间序列或表达前缀路径的时候更加方便快捷,IoTDB 为用户提供带`*`路径。`*`可以出现在路径中的任何层。按照`*`出现的位置,带`*`路径可以分为两种:
`*`出现在路径的结尾;
`*`出现在路径的中间;
-当`*`出现在路径的结尾时,其代表的是(`*`)+,即为一层或多层`*`。例如`root.vehicle.device1.*`代表的是`root.vehicle.device1.*`, `root.vehicle.device1.*.*`, `root.vehicle.device1.*.*.*`等所有以`root.vehicle.device1`为前缀路径的大于等于4层的路径。
+当`*`出现在路径的结尾时,其代表的是(`*`)+,即为一层或多层`*`。例如`root.vehicle.device1.*`代表的是`root.vehicle.device1.*`, `root.vehicle.device1.*.*`, `root.vehicle.device1.*.*.*`等所有以`root.vehicle.device1`为前缀路径的大于等于 4 层的路径。
-当`*`出现在路径的中间,其代表的是`*`本身,即为一层。例如`root.vehicle.*.sensor1`代表的是以`root.vehicle`为前缀,以`sensor1`为后缀,层次等于4层的路径。
+当`*`出现在路径的中间,其代表的是`*`本身,即为一层。例如`root.vehicle.*.sensor1`代表的是以`root.vehicle`为前缀,以`sensor1`为后缀,层次等于 4 层的路径。
> 注意:`*`不能放在路径开头。
> 注意:`*`放在末尾时与前缀路径表意相同,例如`root.vehicle.*`与`root.vehicle`为相同含义。
-> 注意:`*`create创建时,后面的路径同时不能含有`*`。
+> 注意:`*`create 创建时,后面的路径同时不能含有`*`。
* 时间戳
@@ -148,11 +147,11 @@ LayerName: Identifier | STAR
* 绝对时间戳
-IOTDB中绝对时间戳分为二种,一种为LONG类型,一种为DATETIME类型(包含DATETIME-INPUT, DATETIME-DISPLAY两个小类)。
+IOTDB 中绝对时间戳分为二种,一种为 LONG 类型,一种为 DATETIME 类型(包含 DATETIME-INPUT, DATETIME-DISPLAY 两个小类)。
-在用户在输入时间戳时,可以使用LONG类型的时间戳或DATETIME-INPUT类型的时间戳,其中DATETIME-INPUT类型的时间戳支持格式如表所示:
+在用户在输入时间戳时,可以使用 LONG 类型的时间戳或 DATETIME-INPUT 类型的时间戳,其中 DATETIME-INPUT 类型的时间戳支持格式如表所示:
-<center>**DATETIME-INPUT类型支持格式**
+<center>**DATETIME-INPUT 类型支持格式**
|format|
|:---|
@@ -184,9 +183,9 @@ IOTDB中绝对时间戳分为二种,一种为LONG类型,一种为DATETIME类
</center>
-IoTDB在显示时间戳时可以支持LONG类型以及DATETIME-DISPLAY类型,其中DATETIME-DISPLAY类型可以支持用户自定义时间格式。自定义时间格式的语法如表所示:
+IoTDB 在显示时间戳时可以支持 LONG 类型以及 DATETIME-DISPLAY 类型,其中 DATETIME-DISPLAY 类型可以支持用户自定义时间格式。自定义时间格式的语法如表所示:
-<center>**DATETIME-DISPLAY自定义时间格式的语法**
+<center>**DATETIME-DISPLAY 自定义时间格式的语法**
|Symbol|Meaning|Presentation|Examples|
|:---:|:---:|:---:|:---:|
@@ -253,7 +252,7 @@ IoTDB在显示时间戳时可以支持LONG类型以及DATETIME-DISPLAY类型,
例子:
```
- now() - 1d2h //比服务器时间早1天2小时的时间
- now() - 1w //比服务器时间早1周的时间
+ now() - 1d2h //比服务器时间早 1 天 2 小时的时间
+ now() - 1w //比服务器时间早 1 周的时间
```
> 注意:'+'和'-'的左右两边必须有空格
diff --git a/docs/zh/UserGuide/Data-Concept/Data-Type.md b/docs/zh/UserGuide/Data-Concept/Data-Type.md
index 2f7087a..a03f173 100644
--- a/docs/zh/UserGuide/Data-Concept/Data-Type.md
+++ b/docs/zh/UserGuide/Data-Concept/Data-Type.md
@@ -21,7 +21,7 @@
## 数据类型
-IoTDB支持:
+IoTDB 支持:
* BOOLEAN(布尔值)
* INT32(整型)
@@ -32,7 +32,7 @@ IoTDB支持:
一共六种数据类型。
-其中**FLOAT**与**DOUBLE**类型的序列,如果编码方式采用[RLE](Encoding.md)或[TS_2DIFF](Encoding.md)可以指定MAX_POINT_NUMBER,该项为浮点数的小数点后位数,若不指定则系统会根据配置文件`iotdb-engine.properties`文件中的[float_precision项](../Appendix/Config-Manual.md)配置。
+其中** FLOAT **与** DOUBLE **类型的序列,如果编码方式采用 [RLE](Encoding.md) 或 [TS_2DIFF](Encoding.md) 可以指定 MAX_POINT_NUMBER,该项为浮点数的小数点后位数,若不指定则系统会根据配置文件`iotdb-engine.properties`文件中的 [float_precision 项](../Appendix/Config-Manual.md) 配置。
当系统中用户输入的数据类型与该时间序列的数据类型不对应时,系统会提醒类型错误,如下所示,二阶差分编码不支持布尔类型:
diff --git a/docs/zh/UserGuide/Data-Concept/Encoding.md b/docs/zh/UserGuide/Data-Concept/Encoding.md
index 8750f95..8cb97b9 100644
--- a/docs/zh/UserGuide/Data-Concept/Encoding.md
+++ b/docs/zh/UserGuide/Data-Concept/Encoding.md
@@ -21,11 +21,11 @@
## 编码方式
-为了提高数据的存储效率,需要在数据写入的过程中对数据进行编码,从而减少磁盘空间的使用量。在写数据以及读数据的过程中都能够减少I/O操作的数据量从而提高性能。IoTDB支持多种针对不同类型的数据的编码方法:
+为了提高数据的存储效率,需要在数据写入的过程中对数据进行编码,从而减少磁盘空间的使用量。在写数据以及读数据的过程中都能够减少 I/O 操作的数据量从而提高性能。IoTDB 支持多种针对不同类型的数据的编码方法:
-* PLAIN编码(PLAIN)
+* PLAIN 编码(PLAIN)
-PLAIN编码,默认的编码方式,即不编码,支持多种数据类型,压缩和解压缩的时间效率较高,但空间存储效率较低。
+PLAIN 编码,默认的编码方式,即不编码,支持多种数据类型,压缩和解压缩的时间效率较高,但空间存储效率较低。
* 二阶差分编码(TS_2DIFF)
@@ -35,17 +35,17 @@ PLAIN编码,默认的编码方式,即不编码,支持多种数据类型,
游程编码,比较适合存储某些整数值连续出现的序列,不适合编码大部分情况下前后值不一样的序列数据。
-游程编码也可用于对浮点数进行编码,但在创建时间序列的时候需指定保留小数位数(MAX_POINT_NUMBER,具体指定方式参见本文[SQL 参考文档](../Operation%20Manual/SQL%20Reference.md))。比较适合存储某些浮点数值连续出现的序列数据,不适合存储对小数点后精度要求较高以及前后波动较大的序列数据。
+游程编码也可用于对浮点数进行编码,但在创建时间序列的时候需指定保留小数位数(MAX_POINT_NUMBER,具体指定方式参见本文 [SQL 参考文档](../Operation%20Manual/SQL%20Reference.md))。比较适合存储某些浮点数值连续出现的序列数据,不适合存储对小数点后精度要求较高以及前后波动较大的序列数据。
-> 游程编码(RLE)和二阶差分编码(TS_2DIFF)对 float 和 double 的编码是有精度限制的,默认保留2位小数。推荐使用 GORILLA。
+> 游程编码(RLE)和二阶差分编码(TS_2DIFF)对 float 和 double 的编码是有精度限制的,默认保留 2 位小数。推荐使用 GORILLA。
-* GORILLA编码(GORILLA)
+* GORILLA 编码(GORILLA)
-GORILLA编码是一种无损编码,它比较适合编码前后值比较接近的数值序列,不适合编码前后波动较大的数据。
+GORILLA 编码是一种无损编码,它比较适合编码前后值比较接近的数值序列,不适合编码前后波动较大的数据。
-当前系统中存在两个版本的GORILLA编码实现,推荐使用`GORILLA`,不推荐使用`GORILLA_V1`(已过时)。
+当前系统中存在两个版本的 GORILLA 编码实现,推荐使用`GORILLA`,不推荐使用`GORILLA_V1`(已过时)。
-使用限制:使用Gorilla编码INT32数据时,需要保证序列中不存在值为`Integer.MIN_VALUE`的数据点;使用Gorilla编码INT64数据时,需要保证序列中不存在值为`Long.MIN_VALUE`的数据点。
+使用限制:使用 Gorilla 编码 INT32 数据时,需要保证序列中不存在值为`Integer.MIN_VALUE`的数据点;使用 Gorilla 编码 INT64 数据时,需要保证序列中不存在值为`Long.MIN_VALUE`的数据点。
* 字典编码 (DICTIONARY)
@@ -53,9 +53,9 @@ GORILLA编码是一种无损编码,它比较适合编码前后值比较接近
* 数据类型与编码的对应关系
-前文介绍的五种编码适用于不同的数据类型,若对应关系错误,则无法正确创建时间序列。数据类型与支持其编码的编码方式对应关系总结如表格2-3。
+前文介绍的五种编码适用于不同的数据类型,若对应关系错误,则无法正确创建时间序列。数据类型与支持其编码的编码方式对应关系总结如表格 2-3。
-<div style="text-align: center;"> **表格2-3 数据类型与支持其编码的对应关系**
+<div style="text-align: center;"> **表格 2-3 数据类型与支持其编码的对应关系**
|数据类型 |支持的编码|
|:---:|:---:|
diff --git a/docs/zh/UserGuide/Data-Concept/SDT.md b/docs/zh/UserGuide/Data-Concept/SDT.md
index 4adf435..9766746 100644
--- a/docs/zh/UserGuide/Data-Concept/SDT.md
+++ b/docs/zh/UserGuide/Data-Concept/SDT.md
@@ -21,45 +21,45 @@
## 旋转门压缩
-旋转门压缩(SDT)算法是一种有损压缩算法。SDT的计算复杂度较低,并使用线性趋势来表示大量数据。
+旋转门压缩(SDT)算法是一种有损压缩算法。SDT 的计算复杂度较低,并使用线性趋势来表示大量数据。
-在IoTDB中,SDT在刷新到磁盘时会压缩并丢弃数据。
+在 IoTDB 中,SDT 在刷新到磁盘时会压缩并丢弃数据。
-IoTDB允许您在创建时间序列时指定SDT的属性,并支持以下三个属性:
+IoTDB 允许您在创建时间序列时指定 SDT 的属性,并支持以下三个属性:
* CompDev (Compression Deviation,压缩偏差)
-CompDev是SDT中最重要的参数,它表示当前样本与当前线性趋势之间的最大差值。CompDev设置的值需要大于0。
+CompDev 是 SDT 中最重要的参数,它表示当前样本与当前线性趋势之间的最大差值。CompDev 设置的值需要大于 0。
* CompMinTime (Compression Minimum Time Interval,最小压缩时间间隔)
-CompMinTime是测量两个存储的数据点之间的时间距离的参数,用于减少噪声。
+CompMinTime 是测量两个存储的数据点之间的时间距离的参数,用于减少噪声。
如果当前点和最后存储的点之间的时间间隔小于或等于其值,则无论压缩偏差如何,都不会存储当前点。
-默认值为0,单位为毫秒。
+默认值为 0,单位为毫秒。
* CompMaxTime (Compression Maximum Time Interval,最大压缩时间间隔)
-CompMaxTime是测量两个存储的数据点之间的时间距离的参数。
+CompMaxTime 是测量两个存储的数据点之间的时间距离的参数。
如果当前点和最后一个存储点之间的时间间隔大于或等于其值,
无论压缩偏差如何,都将存储当前点。
-默认值为9,223,372,036,854,775,807,单位为毫秒。
+默认值为 9,223,372,036,854,775,807,单位为毫秒。
-支持的数据类型:
+支持的数据类型:
* INT32(整型)
* INT64(长整型)
* FLOAT(单精度浮点数)
* DOUBLE(双精度浮点数)
-SDT的指定语法详见本文[SQL 参考文档](../Appendix/SQL-Reference.md)。
+SDT 的指定语法详见本文 [SQL 参考文档](../Appendix/SQL-Reference.md)。
-以下是使用SDT压缩的示例。
+以下是使用 SDT 压缩的示例。
```
IoTDB> CREATE TIMESERIES root.sg1.d0.s0 WITH DATATYPE=INT32,ENCODING=PLAIN,LOSS=SDT,COMPDEV=2
```
-刷入磁盘和SDT压缩之前,结果如下所示:
+刷入磁盘和 SDT 压缩之前,结果如下所示:
```
IoTDB> SELECT s0 FROM root.sg1.d0
@@ -82,7 +82,7 @@ Total line number = 11
It costs 0.008s
```
-刷入磁盘和SDT压缩之后,结果如下所示:
+刷入磁盘和 SDT 压缩之后,结果如下所示:
```
IoTDB> FLUSH
IoTDB> SELECT s0 FROM root.sg1.d0
@@ -99,8 +99,8 @@ Total line number = 5
It costs 0.044s
```
-SDT在刷新到磁盘时进行压缩。 SDT算法始终存储第一个点,并且不存储最后一个点。
+SDT 在刷新到磁盘时进行压缩。 SDT 算法始终存储第一个点,并且不存储最后一个点。
时间范围在 [2017-11-01T00:06:00.001, 2017-11-01T00:06:00.007] 的数据在压缩偏差内,因此被压缩和丢弃。
之所以存储时间为 2017-11-01T00:06:00.007 的数据点,是因为下一个数据点 2017-11-01T00:06:00.015 的值超过压缩偏差。
-当一个数据点超过压缩偏差时,SDT将存储上一个读取的数据点,并重新计算上下压缩边界。作为最后一个数据点,不存储时间 2017-11-01T00:06:00.018。
+当一个数据点超过压缩偏差时,SDT 将存储上一个读取的数据点,并重新计算上下压缩边界。作为最后一个数据点,不存储时间 2017-11-01T00:06:00.018。
diff --git a/docs/zh/UserGuide/Ecosystem Integration/DBeaver.md b/docs/zh/UserGuide/Ecosystem Integration/DBeaver.md
index 3a10f2f..d35d56f 100644
--- a/docs/zh/UserGuide/Ecosystem Integration/DBeaver.md
+++ b/docs/zh/UserGuide/Ecosystem Integration/DBeaver.md
@@ -21,21 +21,21 @@
## DBeaver-IoTDB
-DBeaver是一个SQL客户端和数据库管理工具。DBeaver可以使用IoTDB的JDBC驱动与IoTDB进行交互。
+DBeaver 是一个 SQL 客户端和数据库管理工具。DBeaver 可以使用 IoTDB 的 JDBC 驱动与 IoTDB 进行交互。
-### DBeaver安装
+### DBeaver 安装
-* DBeaver 下载地址: https://dbeaver.io/download/
+* DBeaver 下载地址:https://dbeaver.io/download/
### IoTDB 安装
-* 下载IoTDB二进制版本
- * IoTDB 下载地址: https://iotdb.apache.org/Download/
+* 下载 IoTDB 二进制版本
+ * IoTDB 下载地址:https://iotdb.apache.org/Download/
* 版本 >= 0.13.0
* 或者从源代码中编译
* 参考 https://github.com/apache/iotdb
-### 连接IoTDB与DBeaver
+### 连接 IoTDB 与 DBeaver
1. 启动 IoTDB 服务
@@ -47,7 +47,7 @@ DBeaver是一个SQL客户端和数据库管理工具。DBeaver可以使用IoTDB
3. 打开 Driver Manager
-4. 为IoTDB新建一个驱动类型
+4. 为 IoTDB 新建一个驱动类型
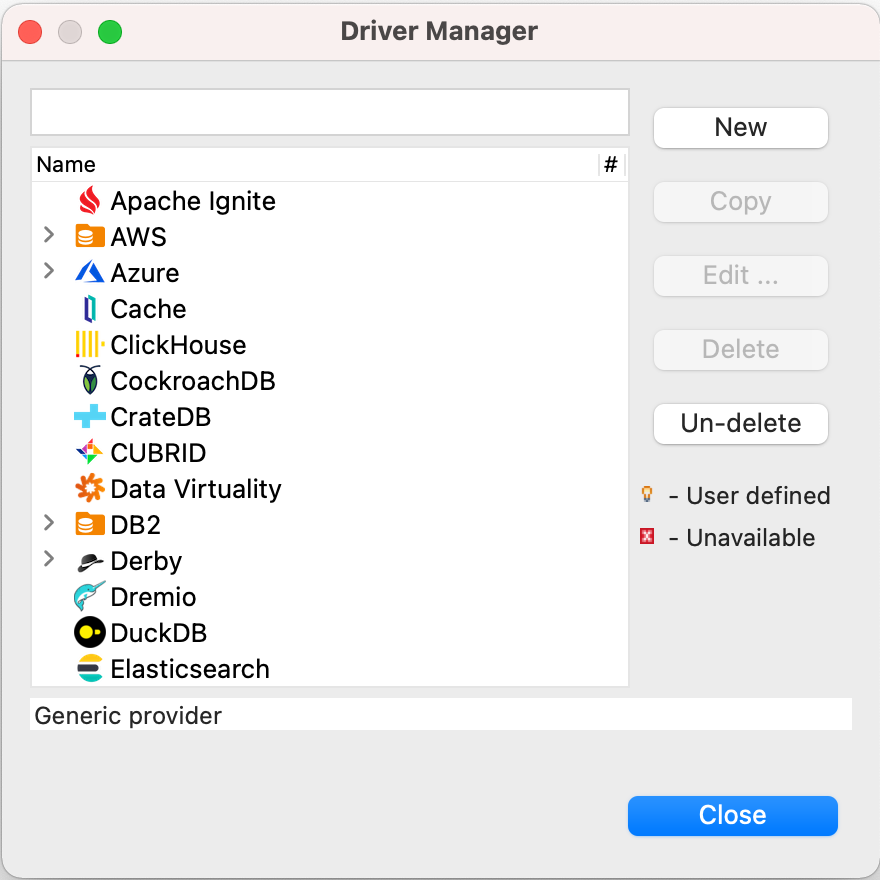
@@ -66,7 +66,7 @@ DBeaver是一个SQL客户端和数据库管理工具。DBeaver可以使用IoTDB
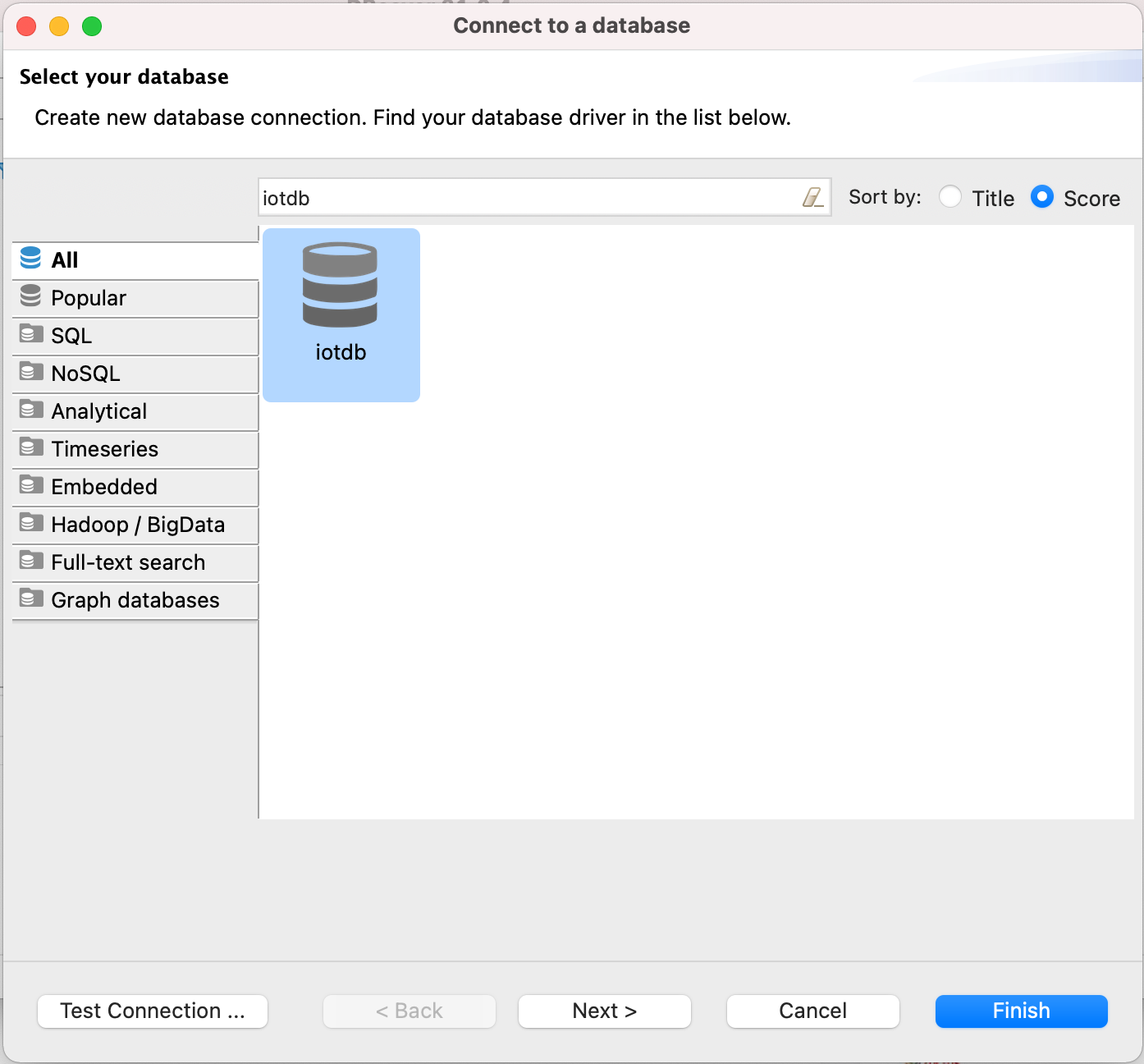
-8. 编辑JDBC连接设置
+8. 编辑 JDBC 连接设置
```
JDBC URL: jdbc:iotdb://127.0.0.1:6667/
@@ -79,8 +79,6 @@ DBeaver是一个SQL客户端和数据库管理工具。DBeaver可以使用IoTDB

-10. 可以开始通过DBeaver使用IoTDB
+10. 可以开始通过 DBeaver 使用 IoTDB
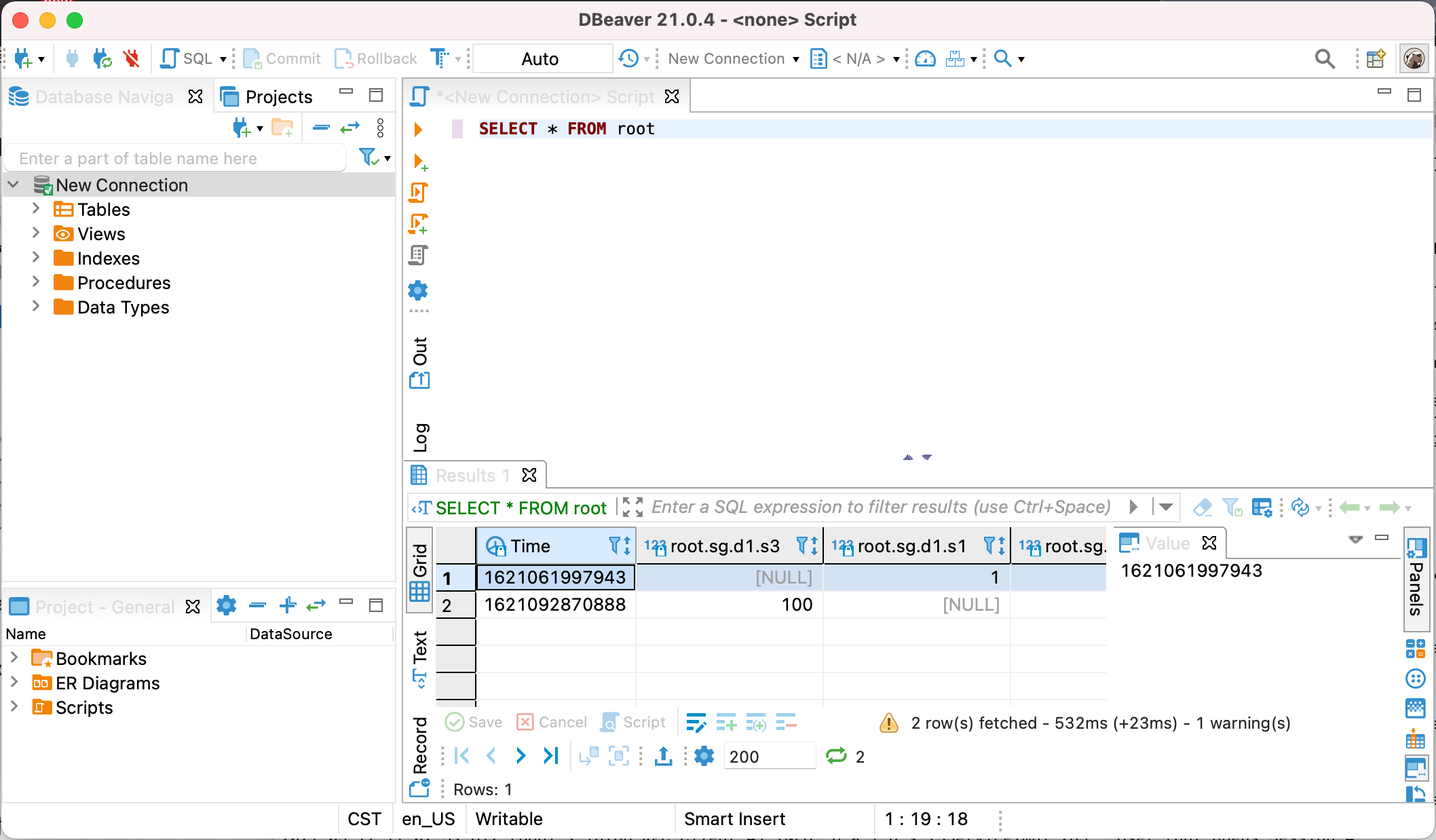
-
-
diff --git a/docs/zh/UserGuide/Ecosystem Integration/Flink IoTDB.md b/docs/zh/UserGuide/Ecosystem Integration/Flink IoTDB.md
index b739325..28f97af 100644
--- a/docs/zh/UserGuide/Ecosystem Integration/Flink IoTDB.md
+++ b/docs/zh/UserGuide/Ecosystem Integration/Flink IoTDB.md
@@ -21,7 +21,7 @@
## Flink IoTDB 连接器
-IoTDB 与 [Apache Flink](https://flink.apache.org/) 的集成. 此模块包含了 iotdb sink,允许 flink job 将时序数据写入IoTDB。
+IoTDB 与 [Apache Flink](https://flink.apache.org/) 的集成。此模块包含了 iotdb sink,允许 flink job 将时序数据写入 IoTDB。
### IoTDBSink
@@ -33,7 +33,7 @@ IoTDB 与 [Apache Flink](https://flink.apache.org/) 的集成. 此模块包含
- 一个模拟的 Source `SensorSource` 每秒钟产生一个数据点。
-- Flink使用 `IoTDBSink` 消费产生的数据并写入 IoTDB 。
+- Flink 使用 `IoTDBSink` 消费产生的数据并写入 IoTDB 。
```java
import org.apache.iotdb.tsfile.file.metadata.enums.CompressionType;
@@ -115,7 +115,6 @@ IoTDB 与 [Apache Flink](https://flink.apache.org/) 的集成. 此模块包含
-
### 运行方法
* 启动 IoTDB server
diff --git a/docs/zh/UserGuide/Ecosystem Integration/Flink TsFile.md b/docs/zh/UserGuide/Ecosystem Integration/Flink TsFile.md
index 477a7ad..519cb2f 100644
--- a/docs/zh/UserGuide/Ecosystem Integration/Flink TsFile.md
+++ b/docs/zh/UserGuide/Ecosystem Integration/Flink TsFile.md
@@ -23,11 +23,11 @@
### 关于 TsFile-Flink 连接器
-TsFile-Flink-Connector 对Tsfile类型的外部数据源实现 Flink 的支持。 这使用户可以通过 Flink DataStream/DataSet 进行读取,写入和查询。
+TsFile-Flink-Connector 对 Tsfile 类型的外部数据源实现 Flink 的支持。 这使用户可以通过 Flink DataStream/DataSet 进行读取,写入和查询。
使用此连接器,您可以
-* 从本地文件系统或 hdfs 加载单个或多个 TsFile (只支持以DataSet的形式)到 Flink 。
+* 从本地文件系统或 hdfs 加载单个或多个 TsFile (只支持以 DataSet 的形式)到 Flink 。
* 将本地文件系统或 hdfs 中特定目录中的所有文件加载到 Flink 中。
### 快速开始
@@ -50,7 +50,7 @@ TypeInformation[] typeInformations = new TypeInformation[] {
Types.LONG,
Types.FLOAT,
Types.INT,
- Types.INT,
+ Types.INT,
Types.FLOAT,
Types.INT,
Types.INT
@@ -107,11 +107,11 @@ String[] filedNames = {
"device_2.sensor_3"
};
TypeInformation[] typeInformations = new TypeInformation[] {
- Types.LONG,
- Types.LONG,
- Types.LONG,
- Types.LONG,
- Types.LONG,
+ Types.LONG,
+ Types.LONG,
+ Types.LONG,
+ Types.LONG,
+ Types.LONG,
Types.LONG,
Types.LONG
};
@@ -176,4 +176,3 @@ source.map(t -> {
}).returns(rowTypeInfo).write(outputFormat, path);
env.execute();
```
-
diff --git a/docs/zh/UserGuide/Ecosystem Integration/Grafana.md b/docs/zh/UserGuide/Ecosystem Integration/Grafana.md
index 9a539ce..e8d7a44 100644
--- a/docs/zh/UserGuide/Ecosystem Integration/Grafana.md
+++ b/docs/zh/UserGuide/Ecosystem Integration/Grafana.md
@@ -23,62 +23,61 @@
## Grafana-IoTDB
+Grafana 是开源的指标量监测和可视化工具,可用于展示时序数据和应用程序运行分析。Grafana 支持 Graphite,InfluxDB 等国际主流时序数据库作为数据源。在 IoTDB 项目中,我们开发了 Grafana 展现 IoTDB 中时序数据的连接器 IoTDB-Grafana,为您提供使用 Grafana 展示 IoTDB 数据库中的时序数据的可视化方法。
-Grafana是开源的指标量监测和可视化工具,可用于展示时序数据和应用程序运行分析。Grafana支持Graphite,InfluxDB等国际主流时序数据库作为数据源。在IoTDB项目中,我们开发了Grafana展现IoTDB中时序数据的连接器IoTDB-Grafana,为您提供使用Grafana展示IoTDB数据库中的时序数据的可视化方法。
-
-### Grafana的安装与部署
+### Grafana 的安装与部署
#### 安装
-* Grafana组件下载地址:https://grafana.com/grafana/download
+* Grafana 组件下载地址:https://grafana.com/grafana/download
* 版本 >= 4.4.1
-#### simple-json-datasource数据源插件安装
+#### simple-json-datasource 数据源插件安装
-* 插件名称: simple-json-datasource
-* 下载地址: https://github.com/grafana/simple-json-datasource
+* 插件名称:simple-json-datasource
+* 下载地址:https://github.com/grafana/simple-json-datasource
-具体下载方法是:到Grafana的插件目录中:`{Grafana文件目录}\data\plugins\`(Windows系统,启动Grafana后会自动创建`data\plugins`目录)或`/var/lib/grafana/plugins` (Linux系统,plugins目录需要手动创建)或`/usr/local/var/lib/grafana/plugins`(MacOS系统,具体位置参看使用`brew install`安装Grafana后命令行给出的位置提示。
+具体下载方法是:到 Grafana 的插件目录中:`{Grafana 文件目录}\data\plugins\`(Windows 系统,启动 Grafana 后会自动创建`data\plugins`目录)或`/var/lib/grafana/plugins` (Linux 系统,plugins 目录需要手动创建)或`/usr/local/var/lib/grafana/plugins`(MacOS 系统,具体位置参看使用`brew install`安装 Grafana 后命令行给出的位置提示。
执行下面的命令:
```
Shell > git clone https://github.com/grafana/simple-json-datasource.git
```
-然后重启Grafana服务器,在浏览器中登录Grafana,在“Add data source”页面中“Type”选项出现“SimpleJson”即为安装成功。
+然后重启 Grafana 服务器,在浏览器中登录 Grafana,在“Add data source”页面中“Type”选项出现“SimpleJson”即为安装成功。
-#### 启动Grafana
+#### 启动 Grafana
-进入Grafana的安装目录,使用以下命令启动Grafana:
-* Windows系统:
+进入 Grafana 的安装目录,使用以下命令启动 Grafana:
+* Windows 系统:
```
Shell > bin\grafana-server.exe
```
-* Linux系统:
+* Linux 系统:
```
Shell > sudo service grafana-server start
```
-* MacOS系统:
+* MacOS 系统:
```
Shell > grafana-server --config=/usr/local/etc/grafana/grafana.ini --homepath /usr/local/share/grafana cfg:default.paths.logs=/usr/local/var/log/grafana cfg:default.paths.data=/usr/local/var/lib/grafana cfg:default.paths.plugins=/usr/local/var/lib/grafana/plugins
```
-更多安装详情,请点[这里](https://grafana.com/docs/grafana/latest/installation/)
+更多安装详情,请点 [这里](https://grafana.com/docs/grafana/latest/installation/)
-### IoTDB安装
+### IoTDB 安装
-参见[https://github.com/apache/iotdb](https://github.com/apache/iotdb)
+参见 [https://github.com/apache/iotdb](https://github.com/apache/iotdb)
-### Grafana-IoTDB连接器安装
+### Grafana-IoTDB 连接器安装
```shell
git clone https://github.com/apache/iotdb.git
```
-### 启动Grafana-IoTDB
+### 启动 Grafana-IoTDB
* 方案一(适合开发者)
-导入整个项目,maven依赖安装完后,直接运行`iotdb/grafana/rc/main/java/org/apache/iotdb/web/grafana`目录下`TsfileWebDemoApplication.java`,这个grafana连接器采用springboot开发
+导入整个项目,maven 依赖安装完后,直接运行`iotdb/grafana/rc/main/java/org/apache/iotdb/web/grafana`目录下`TsfileWebDemoApplication.java`,这个 grafana 连接器采用 springboot 开发
* 方案二(适合使用者)
@@ -97,34 +96,34 @@ java -jar iotdb-grafana-{version}.war
...
```
-如果您需要配置属性,将`grafana/src/main/resources/application.properties`移动到war包同级目录下(`grafana/target`)
+如果您需要配置属性,将`grafana/src/main/resources/application.properties`移动到 war 包同级目录下(`grafana/target`)
-### 使用Grafana
+### 使用 Grafana
-Grafana以网页的dashboard形式为您展示数据,在使用时请您打开浏览器,访问http://\<ip\>:\<port\>
+Grafana 以网页的 dashboard 形式为您展示数据,在使用时请您打开浏览器,访问 http://\<ip\>:\<port\>
-默认地址为http://localhost:3000/
+默认地址为 http://localhost:3000/
-注:IP为您的Grafana所在的服务器IP,Port为Grafana的运行端口(默认3000)。默认登录的用户名和密码都是“admin”。
+注:IP 为您的 Grafana 所在的服务器 IP,Port 为 Grafana 的运行端口(默认 3000)。默认登录的用户名和密码都是“admin”。
-#### 添加IoTDB数据源
+#### 添加 IoTDB 数据源
点击左上角的“Grafana”图标,选择`Data Source`选项,然后再点击`Add data source`。
<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51664777-2766ae00-1ff5-11e9-9d2f-7489f8ccbfc2.png">
-在编辑数据源的时候,`Type`一栏选择`Simplejson`,`URL`一栏填写http://\<ip\>:\<port\>,IP为您的IoTDB-Grafana连接器所在的服务器IP,Port为运行端口(默认8888)。之后确保IoTDB已经启动,点击“Save & Test”,出现“Data Source is working”提示表示配置成功。
+在编辑数据源的时候,`Type`一栏选择`Simplejson`,`URL`一栏填写 http://\<ip\>:\<port\>,IP 为您的 IoTDB-Grafana 连接器所在的服务器 IP,Port 为运行端口(默认 8888)。之后确保 IoTDB 已经启动,点击“Save & Test”,出现“Data Source is working”提示表示配置成功。
<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51664842-554bf280-1ff5-11e9-97d2-54eebe0b2ca1.png">
-#### 操作Grafana
+#### 操作 Grafana
-进入Grafana可视化页面后,可以选择添加时间序列,如下图。您也可以按照Grafana官方文档进行相应的操作,详情可参看Grafana官方文档:http://docs.grafana.org/guides/getting_started/。
+进入 Grafana 可视化页面后,可以选择添加时间序列,如下图。您也可以按照 Grafana 官方文档进行相应的操作,详情可参看 Grafana 官方文档:http://docs.grafana.org/guides/getting_started/。
<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51664878-6e54a380-1ff5-11e9-9718-4d0e24627fa8.png">
-### 配置grafana
+### 配置 grafana
```
-# IoTDB的IP和端口
+# IoTDB 的 IP 和端口
spring.datasource.url=jdbc:iotdb://127.0.0.1:6667/
spring.datasource.username=root
spring.datasource.password=root
@@ -136,17 +135,17 @@ timestamp_precision=ms
# 是否开启降采样
isDownSampling=true
-# 默认采样interval
+# 默认采样 interval
interval=1m
-# 用于对连续数据(int, long, float, double)进行降采样的聚合函数
+# 用于对连续数据 (int, long, float, double) 进行降采样的聚合函数
# COUNT, FIRST_VALUE, LAST_VALUE, MAX_TIME, MAX_VALUE, AVG, MIN_TIME, MIN_VALUE, NOW, SUM
continuous_data_function=AVG
-# 用于对离散数据(boolean, string)进行降采样的聚合函数
+# 用于对离散数据 (boolean, string) 进行降采样的聚合函数
# COUNT, FIRST_VALUE, LAST_VALUE, MAX_TIME, MIN_TIME, NOW
discrete_data_function=LAST_VALUE
```
-其中interval具体配置信息如下
+其中 interval 具体配置信息如下
<1h: no sampling
@@ -156,9 +155,8 @@ discrete_data_function=LAST_VALUE
\>30d:intervals = 1d
-配置完后,请重新运行war包
+配置完后,请重新运行 war 包
```
java -jar iotdb-grafana-{version}.war
```
-
diff --git a/docs/zh/UserGuide/Ecosystem Integration/Hive TsFile.md b/docs/zh/UserGuide/Ecosystem Integration/Hive TsFile.md
index 6031b61..d1ce514 100644
--- a/docs/zh/UserGuide/Ecosystem Integration/Hive TsFile.md
+++ b/docs/zh/UserGuide/Ecosystem Integration/Hive TsFile.md
@@ -21,17 +21,16 @@
## Hive-TsFile
+### 什么是 TsFile 的 Hive 连接器
-### 什么是TsFile的Hive连接器
-
-TsFile的Hive连接器实现了对Hive读取外部Tsfile类型的文件格式的支持,
-使用户能够通过Hive操作Tsfile。
+TsFile 的 Hive 连接器实现了对 Hive 读取外部 Tsfile 类型的文件格式的支持,
+使用户能够通过 Hive 操作 Tsfile。
有了这个连接器,用户可以
-* 将单个Tsfile文件加载进Hive,不论文件是存储在本地文件系统或者是HDFS中
-* 将某个特定目录下的所有文件加载进Hive,不论文件是存储在本地文件系统或者是HDFS中
-* 使用HQL查询tsfile
-* 到现在为止, 写操作在hive-connector中还没有被支持. 所以, HQL中的insert操作是不被允许的
+* 将单个 Tsfile 文件加载进 Hive,不论文件是存储在本地文件系统或者是 HDFS 中
+* 将某个特定目录下的所有文件加载进 Hive,不论文件是存储在本地文件系统或者是 HDFS 中
+* 使用 HQL 查询 tsfile
+* 到现在为止,写操作在 hive-connector 中还没有被支持。所以,HQL 中的 insert 操作是不被允许的
### 系统环境要求
@@ -39,7 +38,6 @@ TsFile的Hive连接器实现了对Hive读取外部Tsfile类型的文件格式的
|------------- |------------ | ------------ |------------ |
| `2.7.3` or `3.2.1` | `2.3.6` or `3.1.2` | `1.8` | `0.13.0-SNAPSHOT+`|
-
### 数据类型对应关系
| TsFile 数据类型 | Hive 数据类型 |
@@ -51,14 +49,13 @@ TsFile的Hive连接器实现了对Hive读取外部Tsfile类型的文件格式的
| DOUBLE | Double |
| TEXT | STRING |
+### 为 Hive 添加依赖 jar 包
-### 为Hive添加依赖jar包
+为了在 Hive 中使用 Tsfile 的 hive 连接器,我们需要把 hive 连接器的 jar 导入进 hive。
-为了在Hive中使用Tsfile的hive连接器,我们需要把hive连接器的jar导入进hive。
+从 <https://github.com/apache/iotdb>下载完 iotdb 后,你可以使用 `mvn clean package -pl hive-connector -am -Dmaven.test.skip=true -P get-jar-with-dependencies`命令得到一个 `hive-connector-X.X.X-SNAPSHOT-jar-with-dependencies.jar`。
-从 <https://github.com/apache/iotdb>下载完iotdb后, 你可以使用 `mvn clean package -pl hive-connector -am -Dmaven.test.skip=true -P get-jar-with-dependencies`命令得到一个 `hive-connector-X.X.X-SNAPSHOT-jar-with-dependencies.jar`。
-
-然后在hive的命令行中,使用`add jar XXX`命令添加依赖。例如:
+然后在 hive 的命令行中,使用`add jar XXX`命令添加依赖。例如:
```shell
hive> add jar /Users/hive/iotdb/hive-connector/target/hive-connector-0.13.0-SNAPSHOT-jar-with-dependencies.jar;
@@ -67,20 +64,19 @@ Added [/Users/hive/iotdb/hive-connector/target/hive-connector-0.13.0-SNAPSHOT-ja
Added resources: [/Users/hive/iotdb/hive-connector/target/hive-connector-0.13.0-SNAPSHOT-jar-with-dependencies.jar]
```
+### 创建 Tsfile-backed 的 Hive 表
-### 创建Tsfile-backed的Hive表
-
-为了创建一个Tsfile-backed的表,需要将`serde`指定为`org.apache.iotdb.hive.TsFileSerDe`,
+为了创建一个 Tsfile-backed 的表,需要将`serde`指定为`org.apache.iotdb.hive.TsFileSerDe`,
将`inputformat`指定为`org.apache.iotdb.hive.TSFHiveInputFormat`,
将`outputformat`指定为`org.apache.iotdb.hive.TSFHiveOutputFormat`。
-同时要提供一个只包含两个字段的Schema,这两个字段分别是`time_stamp`和`sensor_id`。
-`time_stamp`代表的是时间序列的时间值,`sensor_id`是你想要从tsfile文件中提取出来分析的传感器名称,比如说`sensor_1`。
-表的名字可以是hive所支持的任何表名。
+同时要提供一个只包含两个字段的 Schema,这两个字段分别是`time_stamp`和`sensor_id`。
+`time_stamp`代表的是时间序列的时间值,`sensor_id`是你想要从 tsfile 文件中提取出来分析的传感器名称,比如说`sensor_1`。
+表的名字可以是 hive 所支持的任何表名。
-需要提供一个路径供hive-connector从其中拉取最新的数据。
+需要提供一个路径供 hive-connector 从其中拉取最新的数据。
-这个路径必须是一个指定的文件夹,这个文件夹可以在你的本地文件系统上,也可以在HDFS上,如果你启动了Hadoop的话。
+这个路径必须是一个指定的文件夹,这个文件夹可以在你的本地文件系统上,也可以在 HDFS 上,如果你启动了 Hadoop 的话。
如果是本地文件系统,要以这样的形式`file:///data/data/sequence/root.baic2.WWS.leftfrontdoor/`
最后需要在`TBLPROPERTIES`里指明`device_id`
@@ -110,21 +106,20 @@ sensor_1 bigint from deserializer
Time taken: 0.053 seconds, Fetched: 2 row(s)
```
-到目前为止, Tsfile-backed的表已经可以像hive中其他表一样被操作了。
+到目前为止,Tsfile-backed 的表已经可以像 hive 中其他表一样被操作了。
+### 从 Tsfile-backed 的 Hive 表中查询
-### 从Tsfile-backed的Hive表中查询
-
-在做任何查询之前,我们需要通过如下命令,在hive中设置`hive.input.format`:
+在做任何查询之前,我们需要通过如下命令,在 hive 中设置`hive.input.format`:
```
hive> set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
```
-现在,我们已经在hive中有了一个名为`only_sensor_1`的外部表。
-我们可以使用HQL做任何查询来分析其中的数据。
+现在,我们已经在 hive 中有了一个名为`only_sensor_1`的外部表。
+我们可以使用 HQL 做任何查询来分析其中的数据。
-例如:
+例如:
#### 选择查询语句示例
@@ -170,5 +165,3 @@ OK
1000000
Time taken: 11.334 seconds, Fetched: 1 row(s)
```
-
-
diff --git a/docs/zh/UserGuide/Ecosystem Integration/MapReduce TsFile.md b/docs/zh/UserGuide/Ecosystem Integration/MapReduce TsFile.md
index 945ff40..4976398 100644
--- a/docs/zh/UserGuide/Ecosystem Integration/MapReduce TsFile.md
+++ b/docs/zh/UserGuide/Ecosystem Integration/MapReduce TsFile.md
@@ -21,13 +21,12 @@
## Hadoop-TsFile
-
-TsFile的Hadoop连接器实现了对Hadoop读取外部Tsfile类型的文件格式的支持。让用户可以使用Hadoop的map、reduce等操作对Tsfile文件进行读取、写入和查询。
+TsFile 的 Hadoop 连接器实现了对 Hadoop 读取外部 Tsfile 类型的文件格式的支持。让用户可以使用 Hadoop 的 map、reduce 等操作对 Tsfile 文件进行读取、写入和查询。
有了这个连接器,用户可以
-* 将单个Tsfile文件加载进Hadoop,不论文件是存储在本地文件系统或者是HDFS中
-* 将某个特定目录下的所有文件加载进Hadoop,不论文件是存储在本地文件系统或者是HDFS中
-* 将Hadoop处理完后的结果以Tsfile的格式保存
+* 将单个 Tsfile 文件加载进 Hadoop,不论文件是存储在本地文件系统或者是 HDFS 中
+* 将某个特定目录下的所有文件加载进 Hadoop,不论文件是存储在本地文件系统或者是 HDFS 中
+* 将 Hadoop 处理完后的结果以 Tsfile 的格式保存
### 系统环境要求
@@ -35,7 +34,7 @@ TsFile的Hadoop连接器实现了对Hadoop读取外部Tsfile类型的文件格
|------------- | ------------ |------------ |
| `2.7.3` | `1.8` | `0.13.0-SNAPSHOT+`|
->注意:关于如何下载和使用Tsfile, 请参考以下链接: https://github.com/apache/iotdb/tree/master/tsfile.
+>注意:关于如何下载和使用 Tsfile, 请参考以下链接:https://github.com/apache/iotdb/tree/master/tsfile.
### 数据类型对应关系
@@ -48,15 +47,15 @@ TsFile的Hadoop连接器实现了对Hadoop读取外部Tsfile类型的文件格
| DOUBLE | DoubleWritable |
| TEXT | Text |
-### 关于TSFInputFormat的说明
+### 关于 TSFInputFormat 的说明
-TSFInputFormat继承了Hadoop中FileInputFormat类,重写了其中切片的方法。
+TSFInputFormat 继承了 Hadoop 中 FileInputFormat 类,重写了其中切片的方法。
-目前的切片方法是根据每个ChunkGroup的中点的offset是否属于Hadoop所切片的startOffset和endOffset之间,来判断是否将该ChunkGroup放入此切片。
+目前的切片方法是根据每个 ChunkGroup 的中点的 offset 是否属于 Hadoop 所切片的 startOffset 和 endOffset 之间,来判断是否将该 ChunkGroup 放入此切片。
-TSFInputFormat将tsfile中的数据以多个`MapWritable`记录的形式返回给用户。
+TSFInputFormat 将 tsfile 中的数据以多个`MapWritable`记录的形式返回给用户。
-假设我们想要从Tsfile中获得名为`d1`的设备的数据,该设备有三个传感器,名称分别为`s1`, `s2`, `s3`。
+假设我们想要从 Tsfile 中获得名为`d1`的设备的数据,该设备有三个传感器,名称分别为`s1`, `s2`, `s3`。
`s1`的类型是`BOOLEAN`, `s2`的类型是 `DOUBLE`, `s3`的类型是`TEXT`.
@@ -71,16 +70,16 @@ TSFInputFormat将tsfile中的数据以多个`MapWritable`记录的形式返回
}
```
-在Hadoop的Map job中,你可以采用如下方法获得你想要的任何值
+在 Hadoop 的 Map job 中,你可以采用如下方法获得你想要的任何值
`mapwritable.get(new Text("s1"))`
-> 注意: `MapWritable`中所有的键值类型都是`Text`。
+> 注意:`MapWritable`中所有的键值类型都是`Text`。
### 使用示例
-#### 读示例: 求和
+#### 读示例:求和
-首先,我们需要在TSFInputFormat中配置我们需要哪些数据
+首先,我们需要在 TSFInputFormat 中配置我们需要哪些数据
```
// configure reading time enable
@@ -95,7 +94,7 @@ String[] measurementIds = {"sensor_1", "sensor_2", "sensor_3"};
TSFInputFormat.setReadMeasurementIds(job, measurementIds);
```
-然后,必须指定mapper和reducer输出的键和值类型
+然后,必须指定 mapper 和 reducer 输出的键和值类型
```
// set inputformat and outputformat
@@ -138,10 +137,9 @@ public static class TSReducer extends Reducer<Text, DoubleWritable, Text, Double
}
```
-> 注意: 完整的代码示例可以在如下链接中找到:https://github.com/apache/iotdb/blob/master/example/hadoop/src/main/java/org/apache/iotdb/hadoop/tsfile/TSFMRReadExample.java
-
+> 注意:完整的代码示例可以在如下链接中找到:https://github.com/apache/iotdb/blob/master/example/hadoop/src/main/java/org/apache/iotdb/hadoop/tsfile/TSFMRReadExample.java
-### 写示例: 计算平均数并写入Tsfile中
+### 写示例:计算平均数并写入 Tsfile 中
除了`OutputFormatClass`,剩下的配置代码跟上面的读示例是一样的
@@ -199,5 +197,4 @@ public static class TSReducer extends Reducer<Text, MapWritable, NullWritable, H
}
}
```
-> 注意: 完整的代码示例可以在如下链接中找到:https://github.com/apache/iotdb/blob/master/example/hadoop/src/main/java/org/apache/iotdb/hadoop/tsfile/TSMRWriteExample.java
-
+> 注意:完整的代码示例可以在如下链接中找到:https://github.com/apache/iotdb/blob/master/example/hadoop/src/main/java/org/apache/iotdb/hadoop/tsfile/TSMRWriteExample.java
diff --git a/docs/zh/UserGuide/Ecosystem Integration/Spark IoTDB.md b/docs/zh/UserGuide/Ecosystem Integration/Spark IoTDB.md
index 4d7b0a9..aa2200e 100644
--- a/docs/zh/UserGuide/Ecosystem Integration/Spark IoTDB.md
+++ b/docs/zh/UserGuide/Ecosystem Integration/Spark IoTDB.md
@@ -23,7 +23,7 @@
### 版本
-Spark和Java所需的版本如下:
+Spark 和 Java 所需的版本如下:
| Spark Version | Scala Version | Java Version | TsFile |
| ------------- | ------------- | ------------ | -------- |
@@ -33,7 +33,7 @@ Spark和Java所需的版本如下:
mvn clean scala:compile compile install
-#### Maven依赖
+#### Maven 依赖
```
<dependency>
@@ -43,7 +43,7 @@ mvn clean scala:compile compile install
</dependency>
```
-#### Spark-shell用户指南
+#### Spark-shell 用户指南
```
spark-shell --jars spark-iotdb-connector-0.13.0-SNAPSHOT.jar,iotdb-jdbc-0.13.0-SNAPSHOT-jar-with-dependencies.jar
@@ -57,7 +57,7 @@ df.printSchema()
df.show()
```
-如果要对rdd进行分区,可以执行以下操作
+如果要对 rdd 进行分区,可以执行以下操作
```
spark-shell --jars spark-iotdb-connector-0.13.0-SNAPSHOT.jar,iotdb-jdbc-0.13.0-SNAPSHOT-jar-with-dependencies.jar
@@ -75,7 +75,7 @@ df.show()
#### 模式推断
-以下TsFile结构为例:TsFile模式中有三个度量:状态,温度和硬件。 这三种测量的基本信息如下:
+以下 TsFile 结构为例:TsFile 模式中有三个度量:状态,温度和硬件。 这三种测量的基本信息如下:
|名称|类型|编码|
|--- |--- |--- |
@@ -83,7 +83,7 @@ df.show()
|温度|Float|RLE|
|硬件|Text|PLAIN|
-TsFile中的现有数据如下:
+TsFile 中的现有数据如下:
* d1:root.ln.wf01.wt01
* d2:root.ln.wf02.wt02
@@ -94,7 +94,6 @@ time|d1.status|time|d1.temperature |time | d2.hardware |time|d2.status
3|True |2|2.2|4|"bbb"|2|False
5|False|3 |2.1|6 |"ccc"|4|True
-
宽(默认)表形式如下:
| time | root.ln.wf02.wt02.temperature | root.ln.wf02.wt02.status | root.ln.wf02.wt02.hardware | root.ln.wf01.wt01.temperature | root.ln.wf01.wt01.status | root.ln.wf01.wt01.hardware |
@@ -106,7 +105,7 @@ time|d1.status|time|d1.temperature |time | d2.hardware |time|d2.status
| 5 | null | null | null | null | false | null |
| 6 | null | null | ccc | null | null | null |
-你还可以使用窄表形式,如下所示:(您可以参阅第4部分,了解如何使用窄表形式)
+你还可以使用窄表形式,如下所示:(您可以参阅第 4 部分,了解如何使用窄表形式)
| 时间 | 设备名 | 状态 | 硬件 | 温度 |
| ---- | ----------------- | ----- | ---- | ---- |
@@ -138,7 +137,7 @@ import org.apache.iotdb.spark.db._
val wide_df = Transformer.toWideForm(spark, narrow_df)
```
-#### Java用户指南
+#### Java 用户指南
```
import org.apache.spark.sql.Dataset;
diff --git a/docs/zh/UserGuide/Ecosystem Integration/Spark TsFile.md b/docs/zh/UserGuide/Ecosystem Integration/Spark TsFile.md
index 4cf680e..20cdadb 100644
--- a/docs/zh/UserGuide/Ecosystem Integration/Spark TsFile.md
+++ b/docs/zh/UserGuide/Ecosystem Integration/Spark TsFile.md
@@ -23,13 +23,13 @@
### About TsFile-Spark-Connector
-TsFile-Spark-Connector对Tsfile类型的外部数据源实现Spark的支持。 这使用户可以通过Spark读取,写入和查询Tsfile。
+TsFile-Spark-Connector 对 Tsfile 类型的外部数据源实现 Spark 的支持。 这使用户可以通过 Spark 读取,写入和查询 Tsfile。
使用此连接器,您可以
-- 从本地文件系统或hdfs加载单个TsFile到Spark
-- 将本地文件系统或hdfs中特定目录中的所有文件加载到Spark中
-- 将数据从Spark写入TsFile
+- 从本地文件系统或 hdfs 加载单个 TsFile 到 Spark
+- 将本地文件系统或 hdfs 中特定目录中的所有文件加载到 Spark 中
+- 将数据从 Spark 写入 TsFile
### System Requirements
@@ -37,27 +37,27 @@ TsFile-Spark-Connector对Tsfile类型的外部数据源实现Spark的支持。
| ------------- | ------------- | ------------ | -------- |
| `2.4.3` | `2.11.8` | `1.8` | `0.13.0-SNAPSHOT` |
-> 注意:有关如何下载和使用TsFile的更多信息,请参见以下链接:https://github.com/apache/iotdb/tree/master/tsfile
-> 注意:spark版本目前仅支持2.4.3, 其他版本可能存在不适配的问题, 目前已知2.4.7的版本存在不适配的问题
+> 注意:有关如何下载和使用 TsFile 的更多信息,请参见以下链接:https://github.com/apache/iotdb/tree/master/tsfile
+> 注意:spark 版本目前仅支持 2.4.3, 其他版本可能存在不适配的问题,目前已知 2.4.7 的版本存在不适配的问题
### 快速开始
#### 本地模式
-在本地模式下使用TsFile-Spark-Connector启动Spark:
+在本地模式下使用 TsFile-Spark-Connector 启动 Spark:
```
./<spark-shell-path> --jars tsfile-spark-connector.jar,tsfile-{version}-jar-with-dependencies.jar,hadoop-tsfile-{version}-jar-with-dependencies.jar
```
-- \<spark-shell-path\>是您的spark-shell的真实路径。
-- 多个jar包用逗号分隔,没有任何空格。
-- 有关如何获取TsFile的信息,请参见https://github.com/apache/iotdb/tree/master/tsfile。
-- 获取到dependency 包:```mvn clean package -DskipTests -P get-jar-with-dependencies```
+- \<spark-shell-path\>是您的 spark-shell 的真实路径。
+- 多个 jar 包用逗号分隔,没有任何空格。
+- 有关如何获取 TsFile 的信息,请参见 https://github.com/apache/iotdb/tree/master/tsfile。
+- 获取到 dependency 包:```mvn clean package -DskipTests -P get-jar-with-dependencies```
#### 分布式模式
-在分布式模式下使用TsFile-Spark-Connector启动Spark(即,Spark集群通过spark-shell连接):
+在分布式模式下使用 TsFile-Spark-Connector 启动 Spark(即,Spark 集群通过 spark-shell 连接):
```
. /<spark-shell-path> --jars tsfile-spark-connector.jar,tsfile-{version}-jar-with-dependencies.jar,hadoop-tsfile-{version}-jar-with-dependencies.jar --master spark://ip:7077
@@ -65,13 +65,13 @@ TsFile-Spark-Connector对Tsfile类型的外部数据源实现Spark的支持。
注意:
-- \<spark-shell-path\>是您的spark-shell的真实路径。
-- 多个jar包用逗号分隔,没有任何空格。
-- 有关如何获取TsFile的信息,请参见https://github.com/apache/iotdb/tree/master/tsfile。
+- \<spark-shell-path\>是您的 spark-shell 的真实路径。
+- 多个 jar 包用逗号分隔,没有任何空格。
+- 有关如何获取 TsFile 的信息,请参见 https://github.com/apache/iotdb/tree/master/tsfile。
### 数据类型对应
-| TsFile数据类型 | SparkSQL数据类型 |
+| TsFile 数据类型 | SparkSQL 数据类型 |
| -------------- | ---------------- |
| BOOLEAN | BooleanType |
| INT32 | IntegerType |
@@ -82,7 +82,7 @@ TsFile-Spark-Connector对Tsfile类型的外部数据源实现Spark的支持。
### 模式推断
-显示TsFile的方式取决于架构。 以以下TsFile结构为例:TsFile模式中有三个度量:状态,温度和硬件。 这三种测量的基本信息如下:
+显示 TsFile 的方式取决于架构。 以以下 TsFile 结构为例:TsFile 模式中有三个度量:状态,温度和硬件。 这三种测量的基本信息如下:
|名称 | 类型 | 编码 |
| ---- | ---- | ---- |
@@ -90,8 +90,7 @@ TsFile-Spark-Connector对Tsfile类型的外部数据源实现Spark的支持。
|温度 | Float|RLE|
|硬件|Text|PLAIN|
-
-TsFile中的现有数据如下:
+TsFile 中的现有数据如下:
* d1:root.ln.wf01.wt01
* d2:root.ln.wf02.wt02
@@ -102,7 +101,7 @@ time|d1.status|time|d1.temperature |time | d2.hardware |time|d2.status
3|True |2|2.2|4|"bbb"|2|False
5|False|3 |2.1|6 |"ccc"|4|True
-相应的SparkSQL表如下:
+相应的 SparkSQL 表如下:
| time | root.ln.wf02.wt02.temperature | root.ln.wf02.wt02.status | root.ln.wf02.wt02.hardware | root.ln.wf01.wt01.temperature | root.ln.wf01.wt01.status | root.ln.wf01.wt01.hardware |
| ---- | ----------------------------- | ------------------------ | -------------------------- | ----------------------------- | ------------------------ | -------------------------- |
@@ -113,7 +112,7 @@ time|d1.status|time|d1.temperature |time | d2.hardware |time|d2.status
| 5 | null | null | null | null | false | null |
| 6 | null | null | ccc | null | null | null |
-您还可以使用如下所示的窄表形式:(您可以参阅第6部分,了解如何使用窄表形式)
+您还可以使用如下所示的窄表形式:(您可以参阅第 6 部分,了解如何使用窄表形式)
| time | device_name | status | hardware | temperature |
| ---- | ----------------- | ------ | -------- | ----------- |
@@ -126,12 +125,11 @@ time|d1.status|time|d1.temperature |time | d2.hardware |time|d2.status
| 5 | root.ln.wf02.wt01 | false | null | null |
| 6 | root.ln.wf02.wt02 | null | ccc | null |
-
### Scala API
注意:请记住预先分配必要的读写权限。
- * 示例1:从本地文件系统读取
+ * 示例 1:从本地文件系统读取
```scala
import org.apache.iotdb.spark.tsfile._
@@ -142,7 +140,7 @@ val narrow_df = spark.read.tsfile("test.tsfile", true)
narrow_df.show
```
- * 示例2:从hadoop文件系统读取
+ * 示例 2:从 hadoop 文件系统读取
```scala
import org.apache.iotdb.spark.tsfile._
@@ -153,7 +151,7 @@ val narrow_df = spark.read.tsfile("hdfs://localhost:9000/test.tsfile", true)
narrow_df.show
```
- * 示例3:从特定目录读取
+ * 示例 3:从特定目录读取
```scala
import org.apache.iotdb.spark.tsfile._
@@ -161,11 +159,11 @@ val df = spark.read.tsfile("hdfs://localhost:9000/usr/hadoop")
df.show
```
-注1:现在不支持目录中所有TsFile的全局时间排序。
+注 1:现在不支持目录中所有 TsFile 的全局时间排序。
-注2:具有相同名称的度量应具有相同的架构。
+注 2:具有相同名称的度量应具有相同的架构。
- * 示例4:广泛形式的查询
+ * 示例 4:广泛形式的查询
```scala
import org.apache.iotdb.spark.tsfile._
@@ -183,7 +181,7 @@ val newDf = spark.sql("select count(*) from tsfile_table")
newDf.show
```
- * 示例5:缩小形式的查询
+ * 示例 5:缩小形式的查询
```scala
import org.apache.iotdb.spark.tsfile._
@@ -201,7 +199,7 @@ val newDf = spark.sql("select count(*) from tsfile_table")
newDf.show
```
- * 例6:写宽格式
+ * 例 6:写宽格式
```scala
// we only support wide_form table to write
@@ -215,7 +213,7 @@ val newDf = spark.read.tsfile("hdfs://localhost:9000/output")
newDf.show
```
- * 例7:写窄格式
+ * 例 7:写窄格式
```scala
// we only support wide_form table to write
@@ -229,9 +227,9 @@ val newDf = spark.read.tsfile("hdfs://localhost:9000/output", true)
newDf.show
```
-附录A:模式推断的旧设计
+附录 A:模式推断的旧设计
-显示TsFile的方式与TsFile Schema有关。 以以下TsFile结构为例:TsFile架构中有三个度量:状态,温度和硬件。 这三个度量的基本信息如下:
+显示 TsFile 的方式与 TsFile Schema 有关。 以以下 TsFile 结构为例:TsFile 架构中有三个度量:状态,温度和硬件。 这三个度量的基本信息如下:
|名称 | 类型 | 编码 |
| ---- | ---- | ---- |
@@ -256,12 +254,12 @@ time|delta_object1.status|time|delta_object1.temperature |time | delta_object2.h
* 默认方式
-将创建两列来存储设备的完整路径:time(LongType)和delta_object(StringType)。
+将创建两列来存储设备的完整路径:time(LongType)和 delta_object(StringType)。
- `time`:时间戳记,LongType
- `delta_object`:Delta_object ID,StringType
-接下来,为每个度量创建一列以存储特定数据。 SparkSQL表结构如下:
+接下来,为每个度量创建一列以存储特定数据。 SparkSQL 表结构如下:
|time(LongType)|delta\_object(StringType)|status(BooleanType)|temperature(FloatType)|hardware(StringType)|
|--- |--- |--- |--- |--- |
@@ -285,15 +283,11 @@ time|delta_object1.status|time|delta_object1.temperature |time | delta_object2.h
|8|root.sgcc.wf03.wt01|null|8.8|null|
|9|root.sgcc.wf03.wt01|null|9.9|null|
+ * 展开 delta_object 列
+通过“。”将设备列展开为多个列,忽略根目录“root”。方便进行更丰富的聚合操作。如果用户想使用这种显示方式,需要在表创建语句中设置参数“delta\_object\_name”(参考本手册 5.1 节中的示例 5),在本例中,将参数“delta\_object\_name”设置为“root.device.turbine”。路径层的数量必须是一对一的。此时,除了“根”层之外,为设备路径的每一层创建一列。列名是参数中的名称,值是设备相应层的名称。接下来,将为每个度量创建一个列来存储特定的数据。
- * 展开delta_object列
-
-通过“。”将设备列展开为多个列,忽略根目录“root”。方便进行更丰富的聚合操作。如果用户想使用这种显示方式,需要在表创建语句中设置参数“delta\_object\_name”(参考本手册5.1节中的示例5),在本例中,将参数“delta\_object\_name”设置为“root.device.turbine”。路径层的数量必须是一对一的。此时,除了“根”层之外,为设备路径的每一层创建一列。列名是参数中的名称,值是设备相应层的名称。接下来,将为每个度量创建一个列来存储特定的数据。
-
-
-
-那么SparkSQL表结构如下:
+那么 SparkSQL 表结构如下:
|time(LongType)|group(StringType)|field(StringType)|device(StringType)|status(BooleanType)|temperature(FloatType)|hardware(StringType)|
|--- |--- |--- |--- |--- |--- |--- |
@@ -317,12 +311,10 @@ time|delta_object1.status|time|delta_object1.temperature |time | delta_object2.h
|8|sgcc|wf03|wt01|null|8.8|null|
|9|sgcc|wf03|wt01|null|9.9|null|
-TsFile-Spark-Connector可以通过SparkSQL在SparkSQL中以表的形式显示一个或多个tsfile。它还允许用户指定一个目录或使用通配符来匹配多个目录。如果有多个tsfile,那么所有tsfile中的度量值的并集将保留在表中,并且具有相同名称的度量值在默认情况下具有相同的数据类型。注意,如果存在名称相同但数据类型不同的情况,TsFile-Spark-Connector将不能保证结果的正确性。
-
-
+TsFile-Spark-Connector 可以通过 SparkSQL 在 SparkSQL 中以表的形式显示一个或多个 tsfile。它还允许用户指定一个目录或使用通配符来匹配多个目录。如果有多个 tsfile,那么所有 tsfile 中的度量值的并集将保留在表中,并且具有相同名称的度量值在默认情况下具有相同的数据类型。注意,如果存在名称相同但数据类型不同的情况,TsFile-Spark-Connector 将不能保证结果的正确性。
-写入过程是将数据aframe写入一个或多个tsfile。默认情况下,需要包含两个列:time和delta_object。其余的列用作测量。如果用户希望将第二个表结构写回TsFile,可以设置“delta\_object\_name”参数(请参阅本手册5.1节的5.1节)。
+写入过程是将数据 aframe 写入一个或多个 tsfile。默认情况下,需要包含两个列:time 和 delta_object。其余的列用作测量。如果用户希望将第二个表结构写回 TsFile,可以设置“delta\_object\_name”参数(请参阅本手册 5.1 节的 5.1 节)。
-附录B:旧注
+附录 B:旧注
-注意:检查Spark根目录中的jar软件包,并将libthrift-0.9.2.jar和libfb303-0.9.2.jar分别替换为libthrift-0.9.1.jar和libfb303-0.9.1.jar。
+注意:检查 Spark 根目录中的 jar 软件包,并将 libthrift-0.9.2.jar 和 libfb303-0.9.2.jar 分别替换为 libthrift-0.9.1.jar 和 libfb303-0.9.1.jar。
diff --git a/docs/zh/UserGuide/Ecosystem Integration/Writing Data on HDFS.md b/docs/zh/UserGuide/Ecosystem Integration/Writing Data on HDFS.md
index 0d62915..8ffd0ec 100644
--- a/docs/zh/UserGuide/Ecosystem Integration/Writing Data on HDFS.md
+++ b/docs/zh/UserGuide/Ecosystem Integration/Writing Data on HDFS.md
@@ -19,27 +19,27 @@
-->
-## HDFS集成
+## HDFS 集成
### 存储共享架构
-当前,TSFile(包括TSFile文件和相关的数据文件)支持存储在本地文件系统和Hadoop分布式文件系统(HDFS)。配置使用HDFS存储TSFile十分容易。
+当前,TSFile(包括 TSFile 文件和相关的数据文件)支持存储在本地文件系统和 Hadoop 分布式文件系统(HDFS)。配置使用 HDFS 存储 TSFile 十分容易。
#### 系统架构
-当你配置使用HDFS存储TSFile之后,你的数据文件将会被分布式存储。系统架构如下:
+当你配置使用 HDFS 存储 TSFile 之后,你的数据文件将会被分布式存储。系统架构如下:
<img style="width:100%; max-width:700px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/66922722-35180400-f05a-11e9-8ff0-7dd51716e4a8.png">
#### Config and usage
-如果你希望将TSFile存储在HDFS上,可以遵循以下步骤:
+如果你希望将 TSFile 存储在 HDFS 上,可以遵循以下步骤:
首先下载对应版本的源码发布版或者下载 github 仓库
-使用maven打包server和Hadoop模块:`mvn clean package -pl server,hadoop -am -Dmaven.test.skip=true -P get-jar-with-dependencies`
+使用 maven 打包 server 和 Hadoop 模块:`mvn clean package -pl server,hadoop -am -Dmaven.test.skip=true -P get-jar-with-dependencies`
-然后,将Hadoop模块的target jar包`hadoop-tsfile-X.X.X-jar-with-dependencies.jar`复制到server模块的target lib文件夹 `.../server/target/iotdb-server-X.X.X/lib`下。
+然后,将 Hadoop 模块的 target jar 包`hadoop-tsfile-X.X.X-jar-with-dependencies.jar`复制到 server 模块的 target lib 文件夹 `.../server/target/iotdb-server-X.X.X/lib`下。
编辑`iotdb-engine.properties`中的用户配置。相关配置项包括:
@@ -47,7 +47,7 @@
|名字| tsfile\_storage\_fs |
|:---:|:---|
-|描述| Tsfile和相关数据文件的存储文件系统。目前支持LOCAL(本地文件系统)和HDFS两种|
+|描述| Tsfile 和相关数据文件的存储文件系统。目前支持 LOCAL(本地文件系统)和 HDFS 两种|
|类型| String |
|默认值|LOCAL |
|改后生效方式|仅允许在第一次启动服务器前修改|
@@ -56,7 +56,7 @@
|Name| core\_site\_path |
|:---:|:---|
-|描述| 在Tsfile和相关数据文件存储到HDFS的情况下用于配置core-site.xml的绝对路径|
+|描述| 在 Tsfile 和相关数据文件存储到 HDFS 的情况下用于配置 core-site.xml 的绝对路径|
|类型| String |
|默认值|/etc/hadoop/conf/core-site.xml |
|改后生效方式|重启服务器生效|
@@ -65,7 +65,7 @@
|Name| hdfs\_site\_path |
|:---:|:---|
-|描述| 在Tsfile和相关数据文件存储到HDFS的情况下用于配置hdfs-site.xml的绝对路径|
+|描述| 在 Tsfile 和相关数据文件存储到 HDFS 的情况下用于配置 hdfs-site.xml 的绝对路径|
|类型| String |
|默认值|/etc/hadoop/conf/hdfs-site.xml |
|改后生效方式|重启服务器生效|
@@ -74,7 +74,7 @@
|名字| hdfs\_ip |
|:---:|:---|
-|描述| 在Tsfile和相关数据文件存储到HDFS的情况下用于配置HDFS的IP。**如果配置了多于1个hdfs\_ip,则表明启用了Hadoop HA**|
+|描述| 在 Tsfile 和相关数据文件存储到 HDFS 的情况下用于配置 HDFS 的 IP。**如果配置了多于 1 个 hdfs\_ip,则表明启用了 Hadoop HA**|
|类型| String |
|默认值|localhost |
|改后生效方式|重启服务器生效|
@@ -83,7 +83,7 @@
|名字| hdfs\_port |
|:---:|:---|
-|描述| 在Tsfile和相关数据文件存储到HDFS的情况下用于配置HDFS的端口|
+|描述| 在 Tsfile 和相关数据文件存储到 HDFS 的情况下用于配置 HDFS 的端口|
|类型| String |
|默认值|9000 |
|改后生效方式|重启服务器生效|
@@ -92,7 +92,7 @@
|名字| hdfs\_nameservices |
|:---:|:---|
-|描述| 在使用Hadoop HA的情况下用于配置HDFS的nameservices|
+|描述| 在使用 Hadoop HA 的情况下用于配置 HDFS 的 nameservices|
|类型| String |
|默认值|hdfsnamespace |
|改后生效方式|重启服务器生效|
@@ -101,7 +101,7 @@
|名字| hdfs\_ha\_namenodes |
|:---:|:---|
-|描述| 在使用Hadoop HA的情况下用于配置HDFS的nameservices下的namenodes|
+|描述| 在使用 Hadoop HA 的情况下用于配置 HDFS 的 nameservices 下的 namenodes|
|类型| String |
|默认值|nn1,nn2 |
|改后生效方式|重启服务器生效|
@@ -110,7 +110,7 @@
|名字| dfs\_ha\_automatic\_failover\_enabled |
|:---:|:---|
-|描述| 在使用Hadoop HA的情况下用于配置是否使用失败自动切换|
+|描述| 在使用 Hadoop HA 的情况下用于配置是否使用失败自动切换|
|类型| Boolean |
|默认值|true |
|改后生效方式|重启服务器生效|
@@ -119,7 +119,7 @@
|名字| dfs\_client\_failover\_proxy\_provider |
|:---:|:---|
-|描述| 在使用Hadoop HA且使用失败自动切换的情况下配置失败自动切换的实现方式|
+|描述| 在使用 Hadoop HA 且使用失败自动切换的情况下配置失败自动切换的实现方式|
|类型| String |
|默认值|org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider |
|改后生效方式|重启服务器生效
@@ -128,7 +128,7 @@
|名字| hdfs\_use\_kerberos |
|:---:|:---|
-|描述| 是否使用kerberos验证访问hdfs|
+|描述| 是否使用 kerberos 验证访问 hdfs|
|类型| String |
|默认值|false |
|改后生效方式|重启服务器生效|
@@ -151,21 +151,21 @@
|默认值|your principal |
|改后生效方式|重启服务器生效|
-启动server, Tsfile将会被存储到HDFS上。
+启动 server, Tsfile 将会被存储到 HDFS 上。
-如果你想要恢复将TSFile存储到本地文件系统,只需编辑配置项`tsfile_storage_fs`为`LOCAL`。在这种情况下,如果你已经在HDFS上存储了一些数据文件,你需要将它们下载到本地,并移动到你所配置的数据文件文件夹(默认为`../server/target/iotdb-server-X.X.X/data/data`), 或者重新开始你的整个导入数据过程。
+如果你想要恢复将 TSFile 存储到本地文件系统,只需编辑配置项`tsfile_storage_fs`为`LOCAL`。在这种情况下,如果你已经在 HDFS 上存储了一些数据文件,你需要将它们下载到本地,并移动到你所配置的数据文件文件夹(默认为`../server/target/iotdb-server-X.X.X/data/data`), 或者重新开始你的整个导入数据过程。
#### 常见问题
-1. 这个功能支持哪些Hadoop版本?
+1. 这个功能支持哪些 Hadoop 版本?
-A: Hadoop 2.x and Hadoop 3.x均可以支持。
+A: Hadoop 2.x and Hadoop 3.x 均可以支持。
2. 当启动服务器或创建时间序列时,我遇到了如下错误:
```
ERROR org.apache.iotdb.tsfile.fileSystem.fsFactory.HDFSFactory:62 - Failed to get Hadoop file system. Please check your dependency of Hadoop module.
```
-A: 这表明你没有将Hadoop模块的以来放到IoTDB server中。你可以这样解决:
-* 使用Maven打包Hadoop模块: `mvn clean package -pl hadoop -am -Dmaven.test.skip=true -P get-jar-with-dependencies`
-* 将Hadoop模块的target jar包`hadoop-tsfile-X.X.X-jar-with-dependencies.jar`复制到server模块的target lib文件夹 `.../server/target/iotdb-server-X.X.X/lib`下。
+A: 这表明你没有将 Hadoop 模块的以来放到 IoTDB server 中。你可以这样解决:
+* 使用 Maven 打包 Hadoop 模块:`mvn clean package -pl hadoop -am -Dmaven.test.skip=true -P get-jar-with-dependencies`
+* 将 Hadoop 模块的 target jar 包`hadoop-tsfile-X.X.X-jar-with-dependencies.jar`复制到 server 模块的 target lib 文件夹 `.../server/target/iotdb-server-X.X.X/lib`下。
diff --git a/docs/zh/UserGuide/Ecosystem Integration/Zeppelin-IoTDB.md b/docs/zh/UserGuide/Ecosystem Integration/Zeppelin-IoTDB.md
index 9c9911b..c870a9b 100644
--- a/docs/zh/UserGuide/Ecosystem Integration/Zeppelin-IoTDB.md
+++ b/docs/zh/UserGuide/Ecosystem Integration/Zeppelin-IoTDB.md
@@ -21,16 +21,13 @@
## Zeppelin-IoTDB
+### Zeppelin 简介
-### Zeppelin简介
-
-Apache Zeppelin 是一个基于网页的交互式数据分析系统。用户可以通过Zeppelin连接数据源并使用SQL、Scala等进行交互式操作。操作可以保存为文档(类似于Jupyter)。Zeppelin支持多种数据源,包括Spark、ElasticSearch、Cassandra和InfluxDB等等。现在,IoTDB已经支持使用Zeppelin进行操作。样例如下:
+Apache Zeppelin 是一个基于网页的交互式数据分析系统。用户可以通过 Zeppelin 连接数据源并使用 SQL、Scala 等进行交互式操作。操作可以保存为文档(类似于 Jupyter)。Zeppelin 支持多种数据源,包括 Spark、ElasticSearch、Cassandra 和 InfluxDB 等等。现在,IoTDB 已经支持使用 Zeppelin 进行操作。样例如下:

-
-
-### Zeppelin-IoTDB解释器
+### Zeppelin-IoTDB 解释器
#### 系统环境需求
@@ -41,15 +38,15 @@ Apache Zeppelin 是一个基于网页的交互式数据分析系统。用户可
安装 IoTDB:参考 [快速上手](https://iotdb.apache.org/zh/UserGuide/Master/QuickStart/QuickStart.html). 假设 IoTDB 安装在 `$IoTDB_HOME`.
安装 Zeppelin:
-> 方法1 直接下载:下载 [Zeppelin](https://zeppelin.apache.org/download.html#) 并解压二进制文件。推荐下载 [netinst](http://www.apache.org/dyn/closer.cgi/zeppelin/zeppelin-0.9.0/zeppelin-0.9.0-bin-netinst.tgz) 二进制包,此包由于未编译不相关的interpreter,因此大小相对较小。
... 3198 lines suppressed ...