You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by Willymontaz <gi...@git.apache.org> on 2018/11/08 13:45:40 UTC
[GitHub] spark pull request #22981: SPARK-25975 - Spark History does not display nece...
GitHub user Willymontaz opened a pull request:
https://github.com/apache/spark/pull/22981
SPARK-25975 - Spark History does not display necessarily the incomplete applications when requested
Filtering of incomplete applications is made in javascript against the response returned by the API. The problem is that if the returned result is not big enough (because of spark.history.ui.maxApplications), it might not contain incomplete applications.
We can call the API with status RUNNING or COMPLETED depending on the view we want to fix this issue.
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/Willymontaz/spark SPARK-25975
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/22981.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #22981
----
commit 515e3c8f98f4c81dfe0a0359f185caaf6d6391cb
Author: William Montaz <w....@...>
Date: 2018-11-08T10:34:09Z
Show incomplete applications filters at endpoint site and not in javascript
----
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22981: SPARK-25975 - Spark History does not display necessarily...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22981
Can one of the admins verify this patch?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22981: SPARK-25975 - Spark History does not display necessarily...
Posted by wangyum <gi...@git.apache.org>.
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/22981
@Willymontaz Could you make a PR against `master` branch.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22981: SPARK-25975 - Spark History does not display necessarily...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22981
Can one of the admins verify this patch?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22981: SPARK-25975 - Spark History does not display nece...
Posted by Willymontaz <gi...@git.apache.org>.
Github user Willymontaz closed the pull request at:
https://github.com/apache/spark/pull/22981
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22981: SPARK-25975 - Spark History does not display necessarily...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22981
Can one of the admins verify this patch?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22981: SPARK-25975 - Spark History does not display nece...
Posted by Willymontaz <gi...@git.apache.org>.
Github user Willymontaz closed the pull request at:
https://github.com/apache/spark/pull/22981
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22981: SPARK-25975 - Spark History does not display necessarily...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22981
Can one of the admins verify this patch?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22981: SPARK-25975 - Spark History does not display nece...
Posted by Willymontaz <gi...@git.apache.org>.
GitHub user Willymontaz reopened a pull request:
https://github.com/apache/spark/pull/22981
SPARK-25975 - Spark History does not display necessarily the incomplete applications when requested
Filtering of incomplete applications is made in javascript against the response returned by the API. The problem is that if the returned result is not big enough (because of spark.history.ui.maxApplications), it might not contain incomplete applications.
We can call the API with status RUNNING or COMPLETED depending on the view we want to fix this issue.
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/Willymontaz/spark SPARK-25975
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/22981.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #22981
----
commit 507cff246cd9e15a418d67b66bf762be4ae71c67
Author: Tathagata Das <ta...@...>
Date: 2018-03-30T23:48:26Z
[SPARK-23827][SS] StreamingJoinExec should ensure that input data is partitioned into specific number of partitions
## What changes were proposed in this pull request?
Currently, the requiredChildDistribution does not specify the partitions. This can cause the weird corner cases where the child's distribution is `SinglePartition` which satisfies the required distribution of `ClusterDistribution(no-num-partition-requirement)`, thus eliminating the shuffle needed to repartition input data into the required number of partitions (i.e. same as state stores). That can lead to "file not found" errors on the state store delta files as the micro-batch-with-no-shuffle will not run certain tasks and therefore not generate the expected state store delta files.
This PR adds the required constraint on the number of partitions.
## How was this patch tested?
Modified test harness to always check that ANY stateful operator should have a constraint on the number of partitions. As part of that, the existing opt-in checks on child output partitioning were removed, as they are redundant.
Author: Tathagata Das <ta...@gmail.com>
Closes #20941 from tdas/SPARK-23827.
(cherry picked from commit 15298b99ac8944e781328423289586176cf824d7)
Signed-off-by: Tathagata Das <ta...@gmail.com>
commit f1f10da2b4a0913dd230b4a4de95bf05a4672dce
Author: Xianjin YE <ad...@...>
Date: 2018-04-01T14:58:52Z
[SPARK-23040][BACKPORT][CORE] Returns interruptible iterator for shuffle reader
Backport https://github.com/apache/spark/pull/20449 and https://github.com/apache/spark/pull/20920 to branch-2.3
---
## What changes were proposed in this pull request?
Before this commit, a non-interruptible iterator is returned if aggregator or ordering is specified.
This commit also ensures that sorter is closed even when task is cancelled(killed) in the middle of sorting.
## How was this patch tested?
Add a unit test in JobCancellationSuite
Author: Xianjin YE <ad...@gmail.com>
Author: Xingbo Jiang <xi...@databricks.com>
Closes #20954 from jiangxb1987/SPARK-23040-2.3.
commit 6ca6483c122baa40d69c1781bb34a3cd9e1361c0
Author: Marcelo Vanzin <va...@...>
Date: 2018-04-03T01:31:47Z
[SPARK-19964][CORE] Avoid reading from remote repos in SparkSubmitSuite.
These tests can fail with a timeout if the remote repos are not responding,
or slow. The tests don't need anything from those repos, so use an empty
ivy config file to avoid setting up the defaults.
The tests are passing reliably for me locally now, and failing more often
than not today without this change since http://dl.bintray.com/spark-packages/maven
doesn't seem to be loading from my machine.
Author: Marcelo Vanzin <va...@cloudera.com>
Closes #20916 from vanzin/SPARK-19964.
(cherry picked from commit 441d0d0766e9a6ac4c6ff79680394999ff7191fd)
Signed-off-by: hyukjinkwon <gu...@apache.org>
commit ce1565115481343af9043ecc4080d6d97eee698c
Author: lemonjing <93...@...>
Date: 2018-04-03T01:36:44Z
[MINOR][DOC] Fix a few markdown typos
## What changes were proposed in this pull request?
Easy fix in the markdown.
## How was this patch tested?
jekyII build test manually.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: lemonjing <93...@qq.com>
Closes #20897 from Lemonjing/master.
(cherry picked from commit 8020f66fc47140a1b5f843fb18c34ec80541d5ca)
Signed-off-by: hyukjinkwon <gu...@apache.org>
commit f36bdb40116b1600e1f788e460c31c20ca939353
Author: Xingbo Jiang <xi...@...>
Date: 2018-04-03T13:26:49Z
[MINOR][CORE] Show block manager id when remove RDD/Broadcast fails.
## What changes were proposed in this pull request?
Address https://github.com/apache/spark/pull/20924#discussion_r177987175, show block manager id when remove RDD/Broadcast fails.
## How was this patch tested?
N/A
Author: Xingbo Jiang <xi...@databricks.com>
Closes #20960 from jiangxb1987/bmid.
(cherry picked from commit 7cf9fab33457ccc9b2d548f15dd5700d5e8d08ef)
Signed-off-by: hyukjinkwon <gu...@apache.org>
commit 28c9adbd6537c1545cc2b448c8908444ca858c44
Author: Robert Kruszewski <ro...@...>
Date: 2018-04-04T00:25:54Z
[SPARK-23802][SQL] PropagateEmptyRelation can leave query plan in unresolved state
## What changes were proposed in this pull request?
Add cast to nulls introduced by PropagateEmptyRelation so in cases they're part of coalesce they will not break its type checking rules
## How was this patch tested?
Added unit test
Author: Robert Kruszewski <ro...@palantir.com>
Closes #20914 from robert3005/rk/propagate-empty-fix.
(cherry picked from commit 5cfd5fabcdbd77a806b98a6dd59b02772d2f6dee)
Signed-off-by: gatorsmile <ga...@gmail.com>
commit a81e20314ddd1c5078ae8b25b00e1efc3cb9652d
Author: Gengliang Wang <ge...@...>
Date: 2018-04-04T22:43:58Z
[SPARK-23838][WEBUI] Running SQL query is displayed as "completed" in SQL tab
## What changes were proposed in this pull request?
A running SQL query would appear as completed in the Spark UI:

We can see the query in "Completed queries", while in in the job page we see it's still running Job 132.
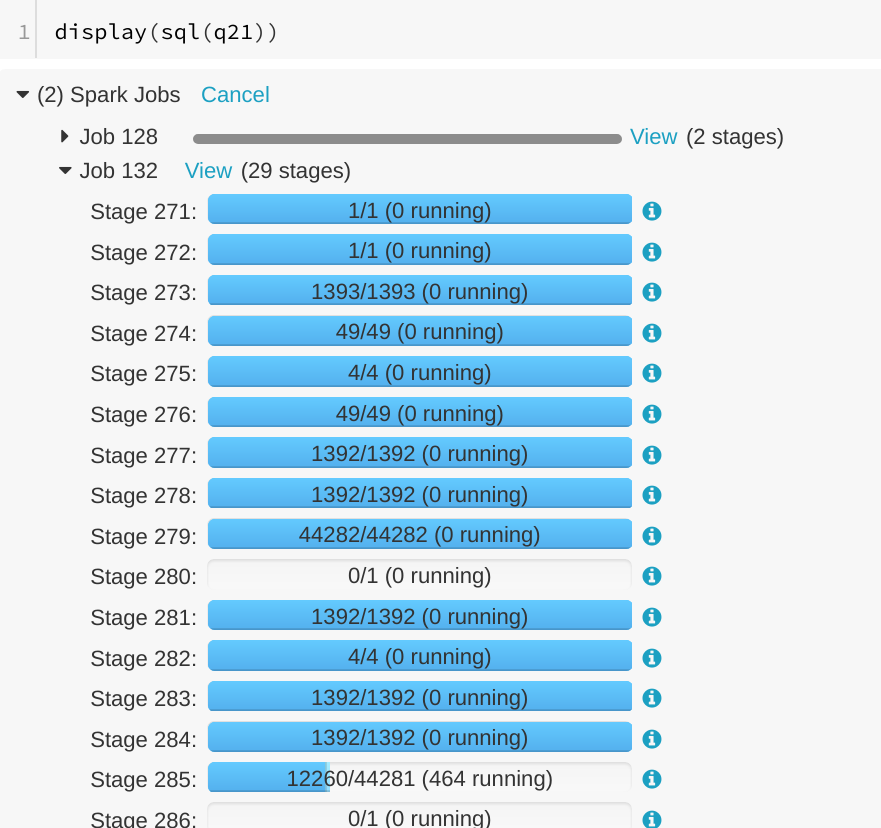
After some time in the query still appears in "Completed queries" (while it's still running), but the "Duration" gets increased.

To reproduce, we can run a query with multiple jobs. E.g. Run TPCDS q6.
The reason is that updates from executions are written into kvstore periodically, and the job start event may be missed.
## How was this patch tested?
Manually run the job again and check the SQL Tab. The fix is pretty simple.
Author: Gengliang Wang <ge...@databricks.com>
Closes #20955 from gengliangwang/jobCompleted.
(cherry picked from commit d8379e5bc3629f4e8233ad42831bdaf68c24cfeb)
Signed-off-by: Marcelo Vanzin <va...@cloudera.com>
commit 0b7b8cceda4ce7791d78259451b8c51b49fb2786
Author: jinxing <ji...@...>
Date: 2018-04-04T22:51:27Z
[SPARK-23637][YARN] Yarn might allocate more resource if a same executor is killed multiple times.
## What changes were proposed in this pull request?
`YarnAllocator` uses `numExecutorsRunning` to track the number of running executor. `numExecutorsRunning` is used to check if there're executors missing and need to allocate more.
In current code, `numExecutorsRunning` can be negative when driver asks to kill a same idle executor multiple times.
## How was this patch tested?
UT added
Author: jinxing <ji...@126.com>
Closes #20781 from jinxing64/SPARK-23637.
(cherry picked from commit d3bd0435ee4ff3d414f32cce3f58b6b9f67e68bc)
Signed-off-by: Marcelo Vanzin <va...@cloudera.com>
commit f93667f84b33537a69ee20a7d4dee664828803f6
Author: JiahuiJiang <jj...@...>
Date: 2018-04-06T03:06:08Z
[SPARK-23823][SQL] Keep origin in transformExpression
Fixes https://issues.apache.org/jira/browse/SPARK-23823
Keep origin for all the methods using transformExpression
## What changes were proposed in this pull request?
Keep origin in transformExpression
## How was this patch tested?
Manually tested that this fixes https://issues.apache.org/jira/browse/SPARK-23823 and columns have correct origins after Analyzer.analyze
Author: JiahuiJiang <jj...@palantir.com>
Author: Jiahui Jiang <jj...@palantir.com>
Closes #20961 from JiahuiJiang/jj/keep-origin.
(cherry picked from commit d65e531b44a388fed25d3cbf28fdce5a2d0598e6)
Signed-off-by: gatorsmile <ga...@gmail.com>
commit ccc4a20453bbbaf1f3e5e46fb7c0277f1e6c65b9
Author: Yuchen Huo <yu...@...>
Date: 2018-04-06T15:35:20Z
[SPARK-23822][SQL] Improve error message for Parquet schema mismatches
## What changes were proposed in this pull request?
This pull request tries to improve the error message for spark while reading parquet files with different schemas, e.g. One with a STRING column and the other with a INT column. A new ParquetSchemaColumnConvertNotSupportedException is added to replace the old UnsupportedOperationException. The Exception is again wrapped in FileScanRdd.scala to throw a more a general QueryExecutionException with the actual parquet file name which trigger the exception.
## How was this patch tested?
Unit tests added to check the new exception and verify the error messages.
Also manually tested with two parquet with different schema to check the error message.
<img width="1125" alt="screen shot 2018-03-30 at 4 03 04 pm" src="https://user-images.githubusercontent.com/37087310/38156580-dd58a140-3433-11e8-973a-b816d859fbe1.png">
Author: Yuchen Huo <yu...@databricks.com>
Closes #20953 from yuchenhuo/SPARK-23822.
(cherry picked from commit 94524019315ad463f9bc13c107131091d17c6af9)
Signed-off-by: gatorsmile <ga...@gmail.com>
commit 1a537a2ad5647782932337888f5db20a35ec422c
Author: Eric Liang <ek...@...>
Date: 2018-04-08T04:18:50Z
[SPARK-23809][SQL][BACKPORT] Active SparkSession should be set by getOrCreate
This backports https://github.com/apache/spark/pull/20927 to branch-2.3
## What changes were proposed in this pull request?
Currently, the active spark session is set inconsistently (e.g., in createDataFrame, prior to query execution). Many places in spark also incorrectly query active session when they should be calling activeSession.getOrElse(defaultSession) and so might get None even if a Spark session exists.
The semantics here can be cleaned up if we also set the active session when the default session is set.
Related: https://github.com/apache/spark/pull/20926/files
## How was this patch tested?
Unit test, existing test. Note that if https://github.com/apache/spark/pull/20926 merges first we should also update the tests there.
Author: Eric Liang <ek...@databricks.com>
Closes #20971 from ericl/backport-23809.
commit bf1dabede512ec89fec507f85bec0a8bae5753f0
Author: Xingbo Jiang <xi...@...>
Date: 2018-04-09T17:19:22Z
[SPARK-23881][CORE][TEST] Fix flaky test JobCancellationSuite."interruptible iterator of shuffle reader"
## What changes were proposed in this pull request?
The test case JobCancellationSuite."interruptible iterator of shuffle reader" has been flaky because `KillTask` event is handled asynchronously, so it can happen that the semaphore is released but the task is still running.
Actually we only have to check if the total number of processed elements is less than the input elements number, so we know the task get cancelled.
## How was this patch tested?
The new test case still fails without the purposed patch, and succeeded in current master.
Author: Xingbo Jiang <xi...@databricks.com>
Closes #20993 from jiangxb1987/JobCancellationSuite.
(cherry picked from commit d81f29ecafe8fc9816e36087e3b8acdc93d6cc1b)
Signed-off-by: gatorsmile <ga...@gmail.com>
commit 0f2aabc6bc64d2b5d46e59525111bd95fcd73610
Author: Imran Rashid <ir...@...>
Date: 2018-04-09T18:31:21Z
[SPARK-23816][CORE] Killed tasks should ignore FetchFailures.
SPARK-19276 ensured that FetchFailures do not get swallowed by other
layers of exception handling, but it also meant that a killed task could
look like a fetch failure. This is particularly a problem with
speculative execution, where we expect to kill tasks as they are reading
shuffle data. The fix is to ensure that we always check for killed
tasks first.
Added a new unit test which fails before the fix, ran it 1k times to
check for flakiness. Full suite of tests on jenkins.
Author: Imran Rashid <ir...@cloudera.com>
Closes #20987 from squito/SPARK-23816.
(cherry picked from commit 10f45bb8233e6ac838dd4f053052c8556f5b54bd)
Signed-off-by: Marcelo Vanzin <va...@cloudera.com>
commit 320269e49d11e0a9de4c8f01210d92227a37fe8d
Author: hyukjinkwon <gu...@...>
Date: 2018-04-11T11:44:01Z
[MINOR][DOCS] Fix R documentation generation instruction for roxygen2
## What changes were proposed in this pull request?
This PR proposes to fix `roxygen2` to `5.0.1` in `docs/README.md` for SparkR documentation generation.
If I use higher version and creates the doc, it shows the diff below. Not a big deal but it bothered me.
```diff
diff --git a/R/pkg/DESCRIPTION b/R/pkg/DESCRIPTION
index 855eb5bf77f..159fca61e06 100644
--- a/R/pkg/DESCRIPTION
+++ b/R/pkg/DESCRIPTION
-57,6 +57,6 Collate:
'types.R'
'utils.R'
'window.R'
-RoxygenNote: 5.0.1
+RoxygenNote: 6.0.1
VignetteBuilder: knitr
NeedsCompilation: no
```
## How was this patch tested?
Manually tested. I met this every time I set the new environment for Spark dev but I have kept forgetting to fix it.
Author: hyukjinkwon <gu...@apache.org>
Closes #21020 from HyukjinKwon/minor-r-doc.
(cherry picked from commit 87611bba222a95158fc5b638a566bdf47346da8e)
Signed-off-by: hyukjinkwon <gu...@apache.org>
Signed-off-by: hyukjinkwon <gu...@apache.org>
commit acfc156df551632007a47b7ec7a7c901a713082d
Author: Joseph K. Bradley <jo...@...>
Date: 2018-04-11T18:41:50Z
[SPARK-22883][ML] ML test for StructuredStreaming: spark.ml.feature, I-M
This backports https://github.com/apache/spark/pull/20964 to branch-2.3.
## What changes were proposed in this pull request?
Adds structured streaming tests using testTransformer for these suites:
* IDF
* Imputer
* Interaction
* MaxAbsScaler
* MinHashLSH
* MinMaxScaler
* NGram
## How was this patch tested?
It is a bunch of tests!
Author: Joseph K. Bradley <josephdatabricks.com>
Author: Joseph K. Bradley <jo...@databricks.com>
Closes #21042 from jkbradley/SPARK-22883-part2-2.3backport.
commit 03a4dfd6901595fb4622587e3387ec1ac8d77237
Author: JBauerKogentix <37...@...>
Date: 2018-04-11T22:52:13Z
typo rawPredicition changed to rawPrediction
MultilayerPerceptronClassifier had 4 occurrences
## What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
## How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: JBauerKogentix <37...@users.noreply.github.com>
Closes #21030 from JBauerKogentix/patch-1.
(cherry picked from commit 9d960de0814a1128318676cc2e91f447cdf0137f)
Signed-off-by: Joseph K. Bradley <jo...@databricks.com>
commit 571269519a49e0651575de18de81b788b6548afd
Author: Imran Rashid <ir...@...>
Date: 2018-04-12T07:58:04Z
[SPARK-23962][SQL][TEST] Fix race in currentExecutionIds().
SQLMetricsTestUtils.currentExecutionIds() was racing with the listener
bus, which lead to some flaky tests. We should wait till the listener bus is
empty.
I tested by adding some Thread.sleep()s in SQLAppStatusListener, which
reproduced the exceptions I saw on Jenkins. With this change, they went
away.
Author: Imran Rashid <ir...@cloudera.com>
Closes #21041 from squito/SPARK-23962.
(cherry picked from commit 6a2289ecf020a99cd9b3bcea7da5e78fb4e0303a)
Signed-off-by: Wenchen Fan <we...@databricks.com>
commit 908c681c6786ef0d772a43508285cb8891fc524a
Author: Patrick Pisciuneri <pa...@...>
Date: 2018-04-13T01:45:27Z
[SPARK-23867][SCHEDULER] use droppedCount in logWarning
## What changes were proposed in this pull request?
Get the count of dropped events for output in log message.
## How was this patch tested?
The fix is pretty trivial, but `./dev/run-tests` were run and were successful.
Please review http://spark.apache.org/contributing.html before opening a pull request.
vanzin cloud-fan
The contribution is my original work and I license the work to the project under the project’s open source license.
Author: Patrick Pisciuneri <Pa...@target.com>
Closes #20977 from phpisciuneri/fix-log-warning.
(cherry picked from commit 682002b6da844ed11324ee5ff4d00fc0294c0b31)
Signed-off-by: Wenchen Fan <we...@databricks.com>
commit 2995b79d6a78bf632aa4c1c99bebfc213fb31c54
Author: jerryshao <ss...@...>
Date: 2018-04-13T03:00:25Z
[SPARK-23748][SS] Fix SS continuous process doesn't support SubqueryAlias issue
## What changes were proposed in this pull request?
Current SS continuous doesn't support processing on temp table or `df.as("xxx")`, SS will throw an exception as LogicalPlan not supported, details described in [here](https://issues.apache.org/jira/browse/SPARK-23748).
So here propose to add this support.
## How was this patch tested?
new UT.
Author: jerryshao <ss...@hortonworks.com>
Closes #21017 from jerryshao/SPARK-23748.
(cherry picked from commit 14291b061b9b40eadbf4ed442f9a5021b8e09597)
Signed-off-by: Tathagata Das <ta...@gmail.com>
commit dfdf1bb9be19bd31e398f97310391b391fabfcfd
Author: Fangshi Li <fl...@...>
Date: 2018-04-13T05:46:34Z
[SPARK-23815][CORE] Spark writer dynamic partition overwrite mode may fail to write output on multi level partition
## What changes were proposed in this pull request?
Spark introduced new writer mode to overwrite only related partitions in SPARK-20236. While we are using this feature in our production cluster, we found a bug when writing multi-level partitions on HDFS.
A simple test case to reproduce this issue:
val df = Seq(("1","2","3")).toDF("col1", "col2","col3")
df.write.partitionBy("col1","col2").mode("overwrite").save("/my/hdfs/location")
If HDFS location "/my/hdfs/location" does not exist, there will be no output.
This seems to be caused by the job commit change in SPARK-20236 in HadoopMapReduceCommitProtocol.
In the commit job process, the output has been written into staging dir /my/hdfs/location/.spark-staging.xxx/col1=1/col2=2, and then the code calls fs.rename to rename /my/hdfs/location/.spark-staging.xxx/col1=1/col2=2 to /my/hdfs/location/col1=1/col2=2. However, in our case the operation will fail on HDFS because /my/hdfs/location/col1=1 does not exists. HDFS rename can not create directory for more than one level.
This does not happen in the new unit test added with SPARK-20236 which uses local file system.
We are proposing a fix. When cleaning current partition dir /my/hdfs/location/col1=1/col2=2 before the rename op, if the delete op fails (because /my/hdfs/location/col1=1/col2=2 may not exist), we call mkdirs op to create the parent dir /my/hdfs/location/col1=1 (if the parent dir does not exist) so the following rename op can succeed.
Reference: in official HDFS document(https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/filesystem/filesystem.html), the rename command has precondition "dest must be root, or have a parent that exists"
## How was this patch tested?
We have tested this patch on our production cluster and it fixed the problem
Author: Fangshi Li <fl...@linkedin.com>
Closes #20931 from fangshil/master.
(cherry picked from commit 4b07036799b01894826b47c73142fe282c607a57)
Signed-off-by: Wenchen Fan <we...@databricks.com>
commit d4f204c5321cdc3955a48e9717ba06aaebbc2ab4
Author: hyukjinkwon <gu...@...>
Date: 2018-04-14T13:44:06Z
[SPARK-23942][PYTHON][SQL][BRANCH-2.3] Makes collect in PySpark as action for a query executor listener
## What changes were proposed in this pull request?
This PR proposes to add `collect` to a query executor as an action.
Seems `collect` / `collect` with Arrow are not recognised via `QueryExecutionListener` as an action. For example, if we have a custom listener as below:
```scala
package org.apache.spark.sql
import org.apache.spark.internal.Logging
import org.apache.spark.sql.execution.QueryExecution
import org.apache.spark.sql.util.QueryExecutionListener
class TestQueryExecutionListener extends QueryExecutionListener with Logging {
override def onSuccess(funcName: String, qe: QueryExecution, durationNs: Long): Unit = {
logError("Look at me! I'm 'onSuccess'")
}
override def onFailure(funcName: String, qe: QueryExecution, exception: Exception): Unit = { }
}
```
and set `spark.sql.queryExecutionListeners` to `org.apache.spark.sql.TestQueryExecutionListener`
Other operations in PySpark or Scala side seems fine:
```python
>>> sql("SELECT * FROM range(1)").show()
```
```
18/04/09 17:02:04 ERROR TestQueryExecutionListener: Look at me! I'm 'onSuccess'
+---+
| id|
+---+
| 0|
+---+
```
```scala
scala> sql("SELECT * FROM range(1)").collect()
```
```
18/04/09 16:58:41 ERROR TestQueryExecutionListener: Look at me! I'm 'onSuccess'
res1: Array[org.apache.spark.sql.Row] = Array([0])
```
but ..
**Before**
```python
>>> sql("SELECT * FROM range(1)").collect()
```
```
[Row(id=0)]
```
```python
>>> spark.conf.set("spark.sql.execution.arrow.enabled", "true")
>>> sql("SELECT * FROM range(1)").toPandas()
```
```
id
0 0
```
**After**
```python
>>> sql("SELECT * FROM range(1)").collect()
```
```
18/04/09 16:57:58 ERROR TestQueryExecutionListener: Look at me! I'm 'onSuccess'
[Row(id=0)]
```
```python
>>> spark.conf.set("spark.sql.execution.arrow.enabled", "true")
>>> sql("SELECT * FROM range(1)").toPandas()
```
```
18/04/09 17:53:26 ERROR TestQueryExecutionListener: Look at me! I'm 'onSuccess'
id
0 0
```
## How was this patch tested?
I have manually tested as described above and unit test was added.
Author: hyukjinkwon <gu...@apache.org>
Closes #21060 from HyukjinKwon/PR_TOOL_PICK_PR_21007_BRANCH-2.3.
commit 9857e249c20f842868cb4681ea374b8e316c3ead
Author: Marco Gaido <ma...@...>
Date: 2018-04-17T13:45:20Z
[SPARK-23835][SQL] Add not-null check to Tuples' arguments deserialization
## What changes were proposed in this pull request?
There was no check on nullability for arguments of `Tuple`s. This could lead to have weird behavior when a null value had to be deserialized into a non-nullable Scala object: in those cases, the `null` got silently transformed in a valid value (like `-1` for `Int`), corresponding to the default value we are using in the SQL codebase. This situation was very likely to happen when deserializing to a Tuple of primitive Scala types (like Double, Int, ...).
The PR adds the `AssertNotNull` to arguments of tuples which have been asked to be converted to non-nullable types.
## How was this patch tested?
added UT
Author: Marco Gaido <ma...@gmail.com>
Closes #20976 from mgaido91/SPARK-23835.
(cherry picked from commit 0a9172a05e604a4a94adbb9208c8c02362afca00)
Signed-off-by: Wenchen Fan <we...@databricks.com>
commit 564019b926eddec39d0485217e693a1e6b4b8e14
Author: Marco Gaido <ma...@...>
Date: 2018-04-17T16:35:44Z
[SPARK-23986][SQL] freshName can generate non-unique names
## What changes were proposed in this pull request?
We are using `CodegenContext.freshName` to get a unique name for any new variable we are adding. Unfortunately, this method currently fails to create a unique name when we request more than one instance of variables with starting name `name1` and an instance with starting name `name11`.
The PR changes the way a new name is generated by `CodegenContext.freshName` so that we generate unique names in this scenario too.
## How was this patch tested?
added UT
Author: Marco Gaido <ma...@gmail.com>
Closes #21080 from mgaido91/SPARK-23986.
(cherry picked from commit f39e82ce150b6a7ea038e6858ba7adbaba3cad88)
Signed-off-by: Wenchen Fan <we...@databricks.com>
commit 6b99d5bc3f3898a0aff30468a623a3f64bb20b62
Author: jinxing <ji...@...>
Date: 2018-04-17T20:53:29Z
[SPARK-23948] Trigger mapstage's job listener in submitMissingTasks
## What changes were proposed in this pull request?
SparkContext submitted a map stage from `submitMapStage` to `DAGScheduler`,
`markMapStageJobAsFinished` is called only in (https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala#L933 and https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala#L1314);
But think about below scenario:
1. stage0 and stage1 are all `ShuffleMapStage` and stage1 depends on stage0;
2. We submit stage1 by `submitMapStage`;
3. When stage 1 running, `FetchFailed` happened, stage0 and stage1 got resubmitted as stage0_1 and stage1_1;
4. When stage0_1 running, speculated tasks in old stage1 come as succeeded, but stage1 is not inside `runningStages`. So even though all splits(including the speculated tasks) in stage1 succeeded, job listener in stage1 will not be called;
5. stage0_1 finished, stage1_1 starts running. When `submitMissingTasks`, there is no missing tasks. But in current code, job listener is not triggered.
We should call the job listener for map stage in `5`.
## How was this patch tested?
Not added yet.
Author: jinxing <jinxing6042126.com>
(cherry picked from commit 3990daaf3b6ca2c5a9f7790030096262efb12cb2)
Author: jinxing <ji...@126.com>
Closes #21085 from squito/cp.
commit a1c56b66970a683e458e3f44fd6788110e869093
Author: Takuya UESHIN <ue...@...>
Date: 2018-04-18T15:22:05Z
[SPARK-24007][SQL] EqualNullSafe for FloatType and DoubleType might generate a wrong result by codegen.
## What changes were proposed in this pull request?
`EqualNullSafe` for `FloatType` and `DoubleType` might generate a wrong result by codegen.
```scala
scala> val df = Seq((Some(-1.0d), None), (None, Some(-1.0d))).toDF()
df: org.apache.spark.sql.DataFrame = [_1: double, _2: double]
scala> df.show()
+----+----+
| _1| _2|
+----+----+
|-1.0|null|
|null|-1.0|
+----+----+
scala> df.filter("_1 <=> _2").show()
+----+----+
| _1| _2|
+----+----+
|-1.0|null|
|null|-1.0|
+----+----+
```
The result should be empty but the result remains two rows.
## How was this patch tested?
Added a test.
Author: Takuya UESHIN <ue...@databricks.com>
Closes #21094 from ueshin/issues/SPARK-24007/equalnullsafe.
(cherry picked from commit f09a9e9418c1697d198de18f340b1288f5eb025c)
Signed-off-by: gatorsmile <ga...@gmail.com>
commit 5bcb7bdccf967ff5ad3d8c76f4ad8c9c4031e7c2
Author: Bruce Robbins <be...@...>
Date: 2018-04-13T21:05:04Z
[SPARK-23963][SQL] Properly handle large number of columns in query on text-based Hive table
## What changes were proposed in this pull request?
TableReader would get disproportionately slower as the number of columns in the query increased.
I fixed the way TableReader was looking up metadata for each column in the row. Previously, it had been looking up this data in linked lists, accessing each linked list by an index (column number). Now it looks up this data in arrays, where indexing by column number works better.
## How was this patch tested?
Manual testing
All sbt unit tests
python sql tests
Author: Bruce Robbins <be...@gmail.com>
Closes #21043 from bersprockets/tabreadfix.
commit 130641102ceecf2a795d7f0dc6412c7e56eb03a8
Author: Gabor Somogyi <ga...@...>
Date: 2018-04-18T23:37:41Z
[SPARK-23775][TEST] Make DataFrameRangeSuite not flaky
## What changes were proposed in this pull request?
DataFrameRangeSuite.test("Cancelling stage in a query with Range.") stays sometimes in an infinite loop and times out the build.
There were multiple issues with the test:
1. The first valid stageId is zero when the test started alone and not in a suite and the following code waits until timeout:
```
eventually(timeout(10.seconds), interval(1.millis)) {
assert(DataFrameRangeSuite.stageToKill > 0)
}
```
2. The `DataFrameRangeSuite.stageToKill` was overwritten by the task's thread after the reset which ended up in canceling the same stage 2 times. This caused the infinite wait.
This PR solves this mentioned flakyness by removing the shared `DataFrameRangeSuite.stageToKill` and using `wait` and `CountDownLatch` for synhronization.
## How was this patch tested?
Existing unit test.
Author: Gabor Somogyi <ga...@gmail.com>
Closes #20888 from gaborgsomogyi/SPARK-23775.
(cherry picked from commit 0c94e48bc50717e1627c0d2acd5382d9adc73c97)
Signed-off-by: Marcelo Vanzin <va...@cloudera.com>
commit 32bec6ca3d9e47587c84f928d4166475fe29f596
Author: Liang-Chi Hsieh <vi...@...>
Date: 2018-04-19T02:00:57Z
[SPARK-24014][PYSPARK] Add onStreamingStarted method to StreamingListener
## What changes were proposed in this pull request?
The `StreamingListener` in PySpark side seems to be lack of `onStreamingStarted` method. This patch adds it and a test for it.
This patch also includes a trivial doc improvement for `createDirectStream`.
Original PR is #21057.
## How was this patch tested?
Added test.
Author: Liang-Chi Hsieh <vi...@gmail.com>
Closes #21098 from viirya/SPARK-24014.
(cherry picked from commit 8bb0df2c65355dfdcd28e362ff661c6c7ebc99c0)
Signed-off-by: jerryshao <ss...@hortonworks.com>
commit 7fb11176f285b4de47e61511c09acbbb79e5c44c
Author: wuyi <ng...@...>
Date: 2018-04-19T14:00:33Z
[SPARK-24021][CORE] fix bug in BlacklistTracker's updateBlacklistForFetchFailure
## What changes were proposed in this pull request?
There‘s a miswrite in BlacklistTracker's updateBlacklistForFetchFailure:
```
val blacklistedExecsOnNode =
nodeToBlacklistedExecs.getOrElseUpdate(exec, HashSet[String]())
blacklistedExecsOnNode += exec
```
where first **exec** should be **host**.
## How was this patch tested?
adjust existed test.
Author: wuyi <ng...@163.com>
Closes #21104 from Ngone51/SPARK-24021.
(cherry picked from commit 0deaa5251326a32a3d2d2b8851193ca926303972)
Signed-off-by: Imran Rashid <ir...@cloudera.com>
commit fb968215ca014c5cf40097a3c4588bbee11e2c02
Author: Wenchen Fan <we...@...>
Date: 2018-04-19T15:54:53Z
[SPARK-23989][SQL] exchange should copy data before non-serialized shuffle
## What changes were proposed in this pull request?
In Spark SQL, we usually reuse the `UnsafeRow` instance and need to copy the data when a place buffers non-serialized objects.
Shuffle may buffer objects if we don't make it to the bypass merge shuffle or unsafe shuffle.
`ShuffleExchangeExec.needToCopyObjectsBeforeShuffle` misses the case that, if `spark.sql.shuffle.partitions` is large enough, we could fail to run unsafe shuffle and go with the non-serialized shuffle.
This bug is very hard to hit since users wouldn't set such a large number of partitions(16 million) for Spark SQL exchange.
TODO: test
## How was this patch tested?
todo.
Author: Wenchen Fan <we...@databricks.com>
Closes #21101 from cloud-fan/shuffle.
(cherry picked from commit 6e19f7683fc73fabe7cdaac4eb1982d2e3e607b7)
Signed-off-by: Herman van Hovell <hv...@databricks.com>
----
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22981: SPARK-25975 - Spark History does not display necessarily...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22981
Can one of the admins verify this patch?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22981: SPARK-25975 - Spark History does not display necessarily...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22981
Can one of the admins verify this patch?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22981: SPARK-25975 - Spark History does not display necessarily...
Posted by Willymontaz <gi...@git.apache.org>.
Github user Willymontaz commented on the issue:
https://github.com/apache/spark/pull/22981
it is in https://issues.apache.org/jira/browse/SPARK-23088 and this is the associated PR https://github.com/apache/spark/pull/20335
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22981: SPARK-25975 - Spark History does not display necessarily...
Posted by Willymontaz <gi...@git.apache.org>.
Github user Willymontaz commented on the issue:
https://github.com/apache/spark/pull/22981
@wangyum It is fixed in master already with more elegant code, so it could be better to backport historypage.js from master to 2.3
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22981: SPARK-25975 - Spark History does not display necessarily...
Posted by wangyum <gi...@git.apache.org>.
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/22981
Do you know which PR fixed this issue?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org