You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@dolphinscheduler.apache.org by GitBox <gi...@apache.org> on 2020/12/21 12:44:55 UTC
[GitHub] [incubator-dolphinscheduler] zixi0825 opened a new issue #4283: [Feature] Data Quality Design
zixi0825 opened a new issue #4283:
URL: https://github.com/apache/incubator-dolphinscheduler/issues/4283
# 1 Summary
Data quality inspection is an important part of the data processing process. After data synchronization and data processing, it is usually necessary to check the accuracy of the data, such as comparing the difference in the number of data between the source table and the target table, or checking according to a certain rule that calculate a certain column and compare the standard value and the calculated value to judge. At present, there is no such type of data quality check in the task type of DS, so it is necessary to add a new data quality task type so that the data quality check task can be directly added when defining the workflow, so that the entire data processing process is more complete.
# 2 Requirements Analysis
For data quality inspection tasks, the core functions are rule management, specific task execution, and execution result alarms. To achieve a lightweight data quality, the following functions must be met:
## 2.1 Rule Manager
### 2.1.1 RuleType
* SingleTableRule
* MultiTableRule
### 2.1.2 Rule Implementation
* InnerRule
* NullCheck
* RowCountCheck
* AverageCheck
* TimelinessCheck
* DuplicateCheck
* AccuracyCheck
* others
* CustomRule
### 2.1.3 Rule Definition and Parser
#### 2.1.3.1 Rule Definition
The complete rules should include connector information, executed SQL statements, the type of comparison value, the type of inspection, etc., that is, the parameters needed to define a data quality task can be obtained through the rules
#### 2.1.3.2 Rule Parser
The main responsibility of rule parser is to obtain an parameter that conforms to the execution of the data quality task by parsing the parameter value input by the user and the rule definition.
## 2.2 Task Execution Mode
Based on the existing task execution method of DolphinScheduler, a more appropriate way is to use Spark as the execution engine for data quality tasks, pass specific execution SQL to the Spark job to run through configuration, and write the execution results to the specified storage engine
### 2.1.2 Alert
Each rule configure alertrules, when the check result is abnormal, an alertoccurs. Use DS's alert module for alarm
# 3 Summary Design
## 3.1 Rule Manager Design
### 3.1.1 Rule Component Design
#### 3.1.1.1 Single Rule
* RuleDefinition
* RuleType
* rule_type
* RuleName
* rule_name
* RuleInputEntry
* DefaultInputEntry
* connector_type,eg. JDBC,HIVE
* datasource_id
* table
* filed
* filter
* StatisticsInputEntry
* statistics_name
* RuleMidExecuteSQLDefinition
* ExecuteSQLDefinition
* ExecuteSQL & TableAlias
* StatisticsExecuteSQLDefinition
* ExecuteSQLDefinition
* ExecuteSQL & TableAlias
* ComparsionExecuteSQLDefinition
* FixedValue
* InputEntry
* ComparsionRuleTilte:comparsion_title
* ComparsionName:comparsion_name
* ComparsionValue:comparsion_value
* CalculateValue
* InputEntry
* ComparsionRuleTitle:comparsion_title
* ComparsionName:comparsion_name
* ComparsionValue:comparsion_value
* ExecuteSQLDefinition
* ExecuteSQL & TableAlias
* CheckInputEntry
* CheckType:fixed/percentage, ${check_type}
* Threshold:1000/30%,${threshold}
* Operator:=,<,>,>=,<= ${operator}
* ResultOutputSQL
* according the comparsion type
* Fiexed
* get the ${comparsion_value} as result field value
* Calculate
* get the comparsion execute sql value as result field value
#### 3.1.1.2 MultiTableAccuracyRule
* RuleDefinition
* RuleType
* rule_type
* RuleName
* rule_name
* RuleInputEntry
* DefaultInputEntry
* src_connector_type
* src_datasource_id
* src_table
* src_filter
* target_connector_type
* target_datasource_id
* target_table
* target_filter
* mapping_columns
* on_clause
* StatisticsInputEntry
* statistics_name
* RuleMidExecuteSQLDefinition
* ExecuteSQLDefinition
* ExecuteSQL & TableAlias
* StatisticsExecuteSQLDefinition
* ExecuteSQLDefinition
* ExecuteSQL & TableAlias
* ComparsionExecuteSQLDefinition
* FixedValue
* InputEntry
* ComparsionRuleTilte:comparsion_title
* ComparsionName:comparsion_name
* ComparsionValue:comparsion_value
* CalculateValue
* InputEntry
* ComparsionRuleTitle:comparsion_title
* ComparsionName:comparsion_name
* ComparsionValue:comparsion_value
* ExecuteSQLDefinition
* ExecuteSQL & TableAlias
* CheckInputEntry
* CheckType:fixed/percentage, ${check_type}
* Threshold:1000/30%,${threshold}
* Operator:=,<,>,>=,<= ${operator}
* ResultOutputSQL
* according the comparsion type
* Fiexed
* get the ${comparsion_value} as result field value
* Calculate
* get the comparsion execute sql value as result field value
#### 3.1.1.3 ,MultiTableValueComparsionRule
* RuleDefinition
* RuleType
* rule_type
* RuleName
* rule_name
* RuleInputEntry
* DefaultInputEntry
* src_connector_type
* src_datasource_id
* statistics_name
* statistics_execute_sql
* target_connector_type
* target_datasource_id
* comparsion_name
* comparsion_execute_sql
* CheckInputEntry
* CheckType:fixed/percentage, ${check_type}
* Threshold:1000/30%,${threshold}
* Operator:=,<,>,>=,<= ${operator}
* ResultOutputSQL
* select ${statistics_name} as statistics_value,${comparsion_name} as coparsion_value from ${statistics_execute_sql} full join ${comparsion_execute_sql}
### 3.1.2 Custom Rule
* Support single table for custom rule calculation for single column
* Support cross-table value calculation comparison for single-column
## 3.2 Task Execute Process Design
### 3.2.1 Execution Engine
* Spark2.0+
### 3.2.2 Task Execution Process

## 3.3 Task Manager Design
Data quality tasks do not support separate definition and scheduled scheduling, which can be defined and scheduled in the workflow
## 3.4 Data Quality Task Definition UI Design
### 3.4.1 UI Generation Method
The data quality task definition UI interface will automatically generated by the front-end component according to a JSON string.
### 3.4.2 Task Define UI Prototype Diagram

### 3.4.3 Custom Rule UI Prototype Diagram

# 4 Detail Design
# 4.1 Database Design
### 4.1.1 RuleInfo
| column | type | comment |
| :---------- | :----- | :---------------------------------- |
| id | int | id |
| name | string | rule name |
| type | int | rule type:single-table/multi-table |
| rule_json | text | rule definition |
| create_time | date | create time |
| update_time | date | update time |
### 4.1.2 CheckResultInfo
| column | type | comment |
| :--------------- | :----- | :------------------------------------ |
| id | int | id |
| task_id | long | Task ID |
| task_instance_id | long | TaskInstance ID |
| rule_type | int | rule type |
| statistics_value | double | statistics value |
| comparsion_value | double | comparsion value |
| check_type | int | check type,fixed value or percentage |
| threshold | double | threshold |
| operator | int | operator:>,<,=,>=,<= |
| create_time | date | create time |
| update_time | date | update time |
### 4.1.3 CheckResultStatisticsInfo
# 4.2 Class Design
### 4.2.1 Rule Design
#### 4.2.1.1Rule Related Model
* RuleDefinition
```plain
public class RuleDefinition{
// ruleName
private String ruleName;
// ruleType
private String ruleType;
// input entry list
private List<RuleInputEntry> ruleInputEntryList;
// mid execute sql list
private List<ExecuteSqlDefinition> midExecuteSqlList;
// statistics execute sql list
private List<ExecuteSqlDefinition> statisticsExecuteSqlList;
// comparsion value type
private ComparsionValueType comparsionValueType;
// comparsion rule parameter
private String comparsionParameter;
}
```
* RuleInputEntry
```plain
public class RuleInputEntry{
// form field name
private String field;
// form type
private FormType type;
// form title
private String title;
// default value,can be null
private String value;
// default options,can be null
// [{label:"",value:""}]
private String options;
// ${field}
private String placeholder;
// the source type of options,use default options or other
private OptionSourceType optionSourceType;
// input entry type: string,array,number .etc
private ValueType valueType;
// whether to display on the front end
private Boolean isShow;
// input entry type: default,statistics,comparsion
private InputType inputType;
// whether to edit on the front end
private Boolean canEdit;
}
```
* ExecuteSqlDefinition
```plain
public class ExecuteSqlDefinition{
// index,ensure the execution order of sql
private int index;
// SQL Statement
private String sql;
// table alias name
private String tableAlias;
// is Middle sql
private boolean isMid;
}
```
* InputType
```plain
public enum InputType{
DEFAULT("default"),
STATISTICS("statistics"),
COMPARSION("comparsion");
private String inputType;
FormType(String inputType) {
this.inputType = inputType;
}
@JsonValue
public String getInputType() {
return this.inputType;
}
}
```
* FormType
```plain
public enum FormType{
INPUT("input"),
RADIO("radio"),
SELECT("select"),
CHECKBOX("checkbox"),
CASCADER("cascader");
private String formType;
FormType(String formType) {
this.formType = formType;
}
@JsonValue
public String getFormType() {
return this.formType;
}
}
```
* OptionSourceType
```plain
public enum OptionSourceType{
DEFAULT("default"),
DATASOURCE("datasource");
private String valueSourceType;
OptionSourceType(String optionSourceType) {
this.optionSourceType = optionSourceType;
}
@JsonValue
public String getOptionSourceType() {
return this.optionSourceType;
}
}
```
* ValueType
```plain
public enum ValueType{
STRING("string"),
LIST("list"),
NUMBER("number");
private String valueType;
ValueSourceType(String valueType) {
this.valueType = valueType;
}
@JsonValue
public String getValueType() {
return this.valueType;
}
}
```
* RuleType
```plain
public enum RuleType{
SINGLE_TABLE,
MULTI_TABLE_ACCURACY,
MULTI_TABLE_COMPARSION;
}
```
* ConnectorType
```plain
public enum ReaderType{
JDBC,HIVE;
}
```
* ComparsionValueType
```plain
public enum ComparsionValueType{
FIXED_VALUE,
CALCULATE_VALUE;
}
```
* CheckType
```plain
public enum CheckType{
FIXED_VALUE,
PERCENTAGE;
}
```
* FixedComparsionValueParameter
```plain
public class FixedComparsionValueParameter{
private List<RuleInputEntry> inputEntryList;
}
```
* CalculateComparsionValueParameter
```plain
public class CalculateComparsionValueParameter{
private List<RuleInputEntry> inputEntryList;
private List<ExecuteSqlDefinition> comparsionExecuteSqls;
}
```
* ConnectorDefinition
```plain
public class ConnectorDefintion{
private String url;
private String database;
private String username;
private String password;
}
```
#### 4.2.1.2 RuleParser
* Different types of rules have default input items, you can add exclusive input items on this basis
* After selecting the rule, it will read the rule input items in the content of the rule, construct a json string conforming to the form-create specification, and return it to the front end to generate the corresponding UI interface
* After filling in the rule parameters, after submission, the configured parameters will be constructed into a map and stored in the task parameters
* After the task is asssigned, the parameters are analyzed, and the parameters required for the task are constructed to execute the spark job
1)Connector Parameter Parser
To get the information of datasource including url, database, table, username, password according the datasource_id and constructed information of connector
2)Replace the placeholders in executeSQL to construct an executeSQL list
3)Construct writer configuration, including construct writer connector configuration and saveSQL
* The pseudo code for constructing save sql in Writer is as follows:
```plain
if(comparsionType == FIXED){
map.put("${comparsion_name}","fixed_value")
sql = "select ${comparsion_name} as comparsion_value from ${staticsTableName}
} else {
sql = "select ${comparsion_name} as comparsion_value from ${statics_table_Name} full join ${comparsion_table_Name}
}
resultSQL = sql.replacePlaceholder(map)
```
Finally, it will be constructed into the following json string and passed to the Spark application
```plain
{
\"name\": \"dqs-acc\",
\"readers\": [
{
\"type\": \"JDBC\",
\"config\": {
\"url\": \"jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8\",
\"database\": \"test\",
\"table\": \"test1\",
\"user\": \"test\",
\"password\": \"test\"
}
},
{
\"type\": \"JDBC\",
\"config\": {
\"url\": \"jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8\",
\"database\": \"test\",
\"table\": \"test1_1\",
\"user\": \"test\",
\"password\": \"test\"
}
}
],
\"writers\": [
{
\"type\": \"JDBC\",
\"config\": {
\"sql\": \"SELECT
1 as dqs_type,
2 as task_id,
3 as task_instance_id,
miss_count.miss AS statistics_value,
total_count.total AS comparsion_value,
1 as check_type,
1000 as threshold,
1 as operator
from miss_count FULL JOIN total_count\",
\"url\": \"jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8\",
\"database\": \"test\",
\"table\": \"dqs_result\",
\"user\": \"test\",
\"password\": \"test\"
}
}
],
\"execute.sql\": [
{
\"index\": \"0\",
\"sql\": \"SELECT * FROM test1
LEFT JOIN test1_1 ON
coalesce(test1.id, '') = coalesce(test1_1.id, '') and coalesce(test1.company, '') = coalesce(test1_1.company, '')
WHERE (NOT (test1.id IS NULL AND test1.company IS NULL)) AND (test1_1.id IS NULL AND test1_1.company IS NULL)\",
\"tableAlias\": \"miss_items\"
},
{
\"index\": \"1\",
\"sql\": \"SELECT COUNT(*) AS miss FROM miss_items\",
\"tableAlias\": \"miss_count\"
},
{
\"index\": \"2\",
\"sql\": \"SELECT COUNT(*) AS total FROM test1\",
\"tableAlias\": \"total_count\"
}
]
}
```
### 4.2.2 Task Design
#### 4.2.2.1 DolphinScheduler Task Design
* DataQualityParameter
```plain
public class DataQualityParameter{
private int ruleId;
private String ruleJson;
private Map<String,String> ruleInputParameter;
}
```
* DataQualityTask
* The main responsibility is to execute spark job
#### 4.2.2.2 Spark Data Quality Task Design
1)The data quality task is actually a Spark task. The main responsibilities of this task are as follows:
* Parse the parameters and obtain the parameters needed to construct Reader, Executor and Writer
* Construct corresponding types of Reader, Executor and Writer according to the parameters
* The main responsibility of Reader is to read the data of the specified data source and create a temporary table for subsequent use
* The main responsibility of Executor is to run the intermediate step SQL statement, the statistical step SQL statement and the comparison value calculation SQL statement
* The main responsibility of Writer is to write the calculation results of data quality tasks to the corresponding storage engine. Currently, it only supports writing back to the ds database
2)The execute mode has the follow options
* Package a DQApplicaiton.jar and upload it to hdfs, and load the default upload address when running
* This method is relatively more saving storage space and reducing jar upload time
* Put the packaged DQApplication.jar into the lib directory, and load the jar package when running
* This method is more insensitive to user deployment
3) Package Structure
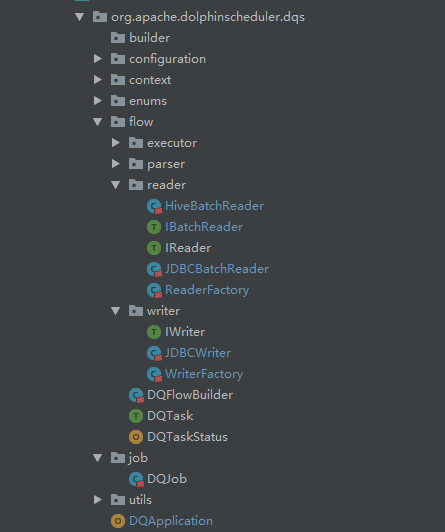
# 5 Todo List
* DataQualityTask UI Component
* DataQuailtyTask Component
* DataQualityParameter
* DataQualityTask
* Rule Component
* RuleModel
* RuleManager
* RuleConverter
* Spark DataQuality Component
# 6 related issue
---
# 1 摘要
数据质量检查是数据处理流程中比较重要的环节,在数据同步和数据处理后通常是需要检查数据的准确性,例如比较源表和目标表之间的数据条数差,或者根据某个规则对某一列进行计算,将标准值和计算值进行比较判断。目前在 DS 的任务类型没有数据质量检查这样的类型,所以需要新增数据质量任务类型,以便于在定义工作流的时候可以直接添加数据质量检查任务,让整个数据处理流程更加的完整。
# 2 需求分析
对于数据质量检查任务来说,核心的功能就是规则管理、具体的任务执行以及执行结果告警,实现一个轻量级的数据质量需要满足以下功能:
## 2.1 规则管理
### 2.1.1 规则类型
* 单表规则
* 跨表规则
### 2.1.2 规则实现方式
* 内置规则
* 空值检查
* 表行数检查
* 均值检查
* 及时性检查
* 重复性检查
* 准确性检查
* 等等
* 自定义规则
### 2.1.3 规则的定义和解析
#### 2.1.3.1 规则定义
完整的规则应该包括 connector 信息、执行的 sql 语句、比较值的类型,检查的类型等,即通过规则可以获取定义一个数据质量任务所需要的参数
#### 2.1.3.2 规则解析
规则解析主要职责是通过解析用户输入的参数值和规则定义得到一个符合数据质量任务运行的输入参数
## 2.2 任务的执行方式
基于 DolphinScheduler 现有的任务执行方式,比较合适的方式就是使用 Spark 作为数据质量任务的执行引擎,通过配置的方式将具体的执行 SQL 传入 Spark 作业来运行,并将执行的结果写到指定的存储引擎中
## 2.3 检查结果告警
每个规则都会配置告警规则,当检查结果为异常的话,则会进行告警。使用 DolphinScheduler 的告警模块进行告警
# 3 概要设计
## 3.1 规则管理设计
### 3.1.1 规则组成设计
#### 3.1.1.1 单表规则
* 规则的定义
* 规则的类型
* rule_type
* 规则的名称
* rule_name
* 规则输入项
* 常规输入项
* connector_type,例如 JDBC,HIVE
* datasource_id
* table
* filed
* filter
* 统计指标输入项
* statistics_name
* 规则中间运行语句
* ExecuteSQLDefinition
* ExecuteSQL & TableAlias
* 规则统计运行语句
* ExecuteSQLDefinition
* ExecuteSQL & TableAlias
* 比较值相关输入项
* 固定型
* 输入项
* 比较值规则标题:comparsion_title
* 比较值名:comparsion_name
* 比较值:comparsion_value
* 计算型
* 输入项
* 比较值规则标题:comparsion_title
* 比较值名:comparsion_name
* 比较值:comparsion_value
* 计算过程语句
* ExecuteSQL & TableAlias
* 校验规则输入项
* 检查方式:固定条数/百分比, ${check_type}
* 阈值:1000/30%,${threshold}
* 比较符:等于,小于,大于,大于等于,小于等于 ${operator}
* 结果输出运行语句(即将数据输出到某个存储引擎中,系统会自动生成)
* 根据比较值类型进行生成
* 固定型
* 直接读取参数值 comparsion_value 作为字段值
* 计算型
* 将统计运行语句的表和比较值计算语句进行 join 以后获取两个统计指标的值作为字段值进行插入
#### 3.1.1.2 跨表准确性规则
* 规则的定义
* 规则的类型
* rule_type
* 规则的名称
* rule_name
* 规则输入项
* 常规输入项
* src_connector_type
* src_datasource_id
* src_table
* src_filter
* target_connector_type
* target_datasource_id
* target_table
* target_filter
* mapping_columns
* on_clause
* 统计指标输入项
* statistics_name
* 规则中间运行语句
* ExecuteSQLDefinition
* ExecuteSQL & TableAlias
* 规则统计运行语句
* ExecuteSQLDefinition
* ExecuteSQL & TableAlias
* 比较值相关输入项
* 固定型
* 输入项
* 比较值规则标题:comparsion_title
* 比较值名:comparsion_name
* 比较值:comparsion_value
* 计算型
* 输入项
* 比较值规则标题:comparsion_title
* 比较值名:comparsion_name
* 比较值:comparsion_value
* 计算过程语句
* ExecuteSQL & TableAlias
* 校验规则输入项
* 检查方式:固定条数/百分比, ${check_type}
* 阈值:1000/30%,${threshold}
* 比较符:等于,小于,大于,大于等于,小于等于 ${operator}
* 结果输出运行语句(即将数据输出到某个存储引擎中,系统会自动生成)
* 根据比较值类型进行生成
* 固定型
* 直接读取参数值作为字段值
* 计算型
* 将统计运行语句的表和比较值计算语句进行 join 以后获取两个统计指标的值作为字段值进行插入
#### 3.1.1.3 跨表值比对规则
* 规则的定义
* 规则的类型
* rule_type
* 规则的名称
* rule_name
* 规则输入项
* 常规输入项
* src_connector_type
* src_datasource_id
* statistics_name
* statistics_execute_sql
* target_connector_type
* target_datasource_id
* comparsion_name
* comparsion_execute_sql
* 校验规则输入项
* 检查方式:固定条数/百分比, ${check_type}
* 阈值:1000/30%,${threshold}
* 比较符:等于,小于,大于,大于等于,小于等于 ${operator}
* 结果输出运行语句(即将数据输出到某个存储引擎中,系统会自动生成)
select ${statistics_name} as statistics_value,${comparsion_name} as coparsion_value from ${statistics_execute_sql} full join ${comparsion_execute_sql}
### 3.1.2 自定义规则
* 支持单表的对单列进行自定义规则计算
* 支持跨表对单列的值计算对比
## 3.2 任务执行流程设计
### 3.2.1 执行引擎
* Spark 计算引擎,2.0 以上
### 3.2.2 任务执行流程

## 3.3 任务管理设计
数据质量任务不支持单独定义和定时调度,可以通过在工作流中定义和定时调度
## 3.4 数据质量任务定义 UI 设计
### 3.4.1 UI 页面生成方式
数据质量任务定义 UI 界面会根据不同规则的参数生成 JSON 串由前端组件自动生成
### 3.4.2 任务定义 UI 示意图

### 3.4.3 自定义规则界面 UI 示意图

# 4 详细设计
# 4.1 数据库设计
### 4.1.1 规则表
| 字段 | 类型 | 解释 |
| :---------- | :----- | :-------------------------- |
| id | int | id |
| name | string | 规则名称 |
| type | int | 规则类型:单表规则/跨表规则 |
| rule_json | text | 规则定义 |
| create_time | date | 创建时间 |
| update_time | date | 更新时间 |
### 4.1.2 检查结果表
| 字段 | 类型 | 解释 |
| :--------------- | :----- | :--------------------------------------------------- |
| id | int | id |
| task_id | long | 任务 ID |
| task_instance_id | long | 任务实例 ID |
| rule_type | int | 规则类型 |
| statistics_value | double | 计算的指标值 |
| comparsion_value | double | 比对的指标值 |
| check_type | int | 检测类型,数值比较或者百分比 |
| threshold | double | 阈值 |
| operator | int | 操作符:大于,小于,等于,不等于,大于等于,小于等于 |
| create_time | date | 创建时间 |
| update_time | date | 更新时间 |
### 4.1.3 检查结果统计表
# 4.2 类设计
### 4.2.1 规则相关
#### 4.2.1.1 规则实体
* RuleDefinition 规则定义
```plain
public class RuleDefinition{
// 规则名称
private String ruleName;
// 规则类型
private String ruleType;
// 输入项列表
private List<RuleInputEntry> ruleInputEntryList;
// 中间执行 SQL 列表
private List<ExecuteSqlDefinition> midExecuteSqlList;
// 统计执行 SQL 列表
private List<ExecuteSqlDefinition> statisticsExecuteSqlList;
// 比较值的类型:固定/计算
private ComparsionValueType comparsionValueType;
// 比较值的参数
private String comparsionParameter;
}
```
* RuleInputEntry 输入项定义,每一个 RuleInputEntry 都有默认值,可以不修改
```plain
public class RuleInputEntry{
// 前端字段名
private String field;
//前端控件类型
private FormType type;
//前端展示标题
private String title;
//默认值,可为 null
private String value;
//默认选项,可为 null,也可根据 Vaule
// [{label:"",value:""}]
private String options;
// ${field 的值}
private String placeholder;
// options 的来源类型,使用默认还是通过其他方式获得
private OptionSourceType optionSourceType;
// 该输入项值的类型,字符串,数组,数字等等
private ValueType valueType;
// 是否在前端界面展示出来
private Boolean isShow;
// 该输入项的类型,default(常规),statistics(统计指标),comparsion(比较值)
private InputType inputType;
// 在前端页面上是否可以编辑
private Boolean canEdit;
}
```
* ExecuteSqlDefinition 执行 SQL 的定义
```plain
public class ExecuteSqlDefinition{
// 索引值,保证 sql 的执行顺序
private int index;
// SQL 语句
private String sql;
// 上述 SQL 语句执行结果生成一个临时表
private String tableAlias;
// 是否为中间执行 SQL 语句
private boolean isMid;
}
```
* InputType 输入项的类型
```plain
public enum InputType{
DEFAULT("default"),
STATISTICS("statistics"),
COMPARSION("comparsion");
private String inputType;
FormType(String inputType) {
this.inputType = inputType;
}
@JsonValue
public String getInputType() {
return this.inputType;
}
}
```
* FormType前端表单控间类型
```plain
public enum FormType{
INPUT("input"),
RADIO("radio"),
SELECT("select"),
CHECKBOX("checkbox"),
CASCADER("cascader");
private String formType;
FormType(String formType) {
this.formType = formType;
}
@JsonValue
public String getFormType() {
return this.formType;
}
}
```
* OptionSourceType 前端表单控间所需 Options 来源
```plain
public enum OptionSourceType{
DEFAULT("default"),
DATASOURCE("datasource");
private String valueSourceType;
OptionSourceType(String optionSourceType) {
this.optionSourceType = optionSourceType;
}
@JsonValue
public String getOptionSourceType() {
return this.optionSourceType;
}
}
```
* ValueType 输入项的值的类型
```plain
public enum ValueType{
STRING("string"),
LIST("list"),
NUMBER("number");
private String valueType;
ValueSourceType(String valueType) {
this.valueType = valueType;
}
@JsonValue
public String getValueType() {
return this.valueType;
}
}
```
* RuleType 规则类型
```plain
public enum RuleType{
//单表规则
SINGLE_TABLE,
//跨表准确性规则
MULTI_TABLE_ACCURACY,
//跨表值比对规则
MULTI_TABLE_COMPARSION;
}
```
* ConnectorType 数据源类型
```plain
public enum ReaderType{
JDBC,HIVE;
}
```
* ComparsionValueType 比较值类型
```plain
public enum ComparsionValueType{
//固定值
FIXED_VALUE,
//计算值
CALCULATE_VALUE;
}
```
* CheckType 检验类型
```plain
public enum CheckType{
// 固定数值
FIXED_VALUE,
// 百分比
PERCENTAGE;
}
```
* FixedComparsionValueParameter 固定数值比较值参数
```plain
public class FixedComparsionValueParameter{
// 输入项定义列表
private List<RuleInputEntry> inputEntryList;
}
```
* CalculateComparsionValueParameter 计算类型比较值参数
```plain
public class CalculateComparsionValueParameter{
// 输入项定义列表
private List<RuleInputEntry> inputEntryList;
// 执行计算值 SQL 语句数组
private List<ExecuteSqlDefinition> comparsionExecuteSqls;
}
```
* ConnectorDefinition
```plain
public class ConnectorDefintion{
private String url;
private String database;
private String username;
private String password;
}
```
#### 4.2.1.2 规则解析
1) 规则使用的流程分析
* 对于不同类型的规则都会有预先设计好的输入项,可以在此基础上添加专属输入项
* 选择规则以后,会读取规则的内容中的规则输入项,构造一个符合 form-create 规范的 json 字符串,返回给前端生成对应的 UI 界面
* 填写完成规则参数以后,提交以后会将配置好的的参数构造成一个 map 存储在任务参数中
* 下发任务后进行参数的解析,构造成任务运行所需要的参数执行 spark 作业
2)规则解析具体内容
* connector 数据解析
根据 datasource_id 拿到相关的数据源信息,包括 url,database,table,username,password,构造 connector 配置
* 对 executeSQL 中的占位符进行替换,构造 executeSQL 列表
* 构造 Writer 配置,包括构造 Writer 的 Connector 配置以及 saveSQL
* writer 中构造 saveSQL 的伪代码如下:
```plain
if(comparsionType == FIXED){
map.put("${comparsion_name}","fixed_value")
sql = "select ${comparsion_name} as comparsion_value from ${staticsTableName}
} else {
sql = "select ${comparsion_name} as comparsion_value from ${statics_table_Name} full join ${comparsion_table_Name}
}
resultSQL = sql.replacePlaceholder(map)
```
3)最终会构造成以下的 json 串传给 Spark 应用的 json 格式如下:
```plain
{
\"name\": \"dqs-acc\",
\"readers\": [
{
\"type\": \"JDBC\",
\"config\": {
\"url\": \"jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8\",
\"database\": \"test\",
\"table\": \"test1\",
\"user\": \"test\",
\"password\": \"test\"
}
},
{
\"type\": \"JDBC\",
\"config\": {
\"url\": \"jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8\",
\"database\": \"test\",
\"table\": \"test1_1\",
\"user\": \"test\",
\"password\": \"test\"
}
}
],
\"writers\": [
{
\"type\": \"JDBC\",
\"config\": {
\"sql\": \"SELECT
1 as rule_type,
2 as task_id,
3 as task_instance_id,
miss_count.miss AS statistics_value,
total_count.total AS comparsion_value,
1 as check_type,
1000 as threshold,
1 as operator
from miss_count FULL JOIN total_count\",
\"url\": \"jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8\",
\"database\": \"test\",
\"table\": \"dqs_result\",
\"user\": \"test\",
\"password\": \"test\"
}
}
],
\"execute.sql\": [
{
\"index\": \"0\",
\"sql\": \"SELECT * FROM test1
LEFT JOIN test1_1 ON
coalesce(test1.id, '') = coalesce(test1_1.id, '') and coalesce(test1.company, '') = coalesce(test1_1.company, '')
WHERE (NOT (test1.id IS NULL AND test1.company IS NULL)) AND (test1_1.id IS NULL AND test1_1.company IS NULL)\",
\"tableAlias\": \"miss_items\"
},
{
\"index\": \"1\",
\"sql\": \"SELECT COUNT(*) AS miss FROM miss_items\",
\"tableAlias\": \"miss_count\"
},
{
\"index\": \"2\",
\"sql\": \"SELECT COUNT(*) AS total FROM test1\",
\"tableAlias\": \"total_count\"
}
]
}
```
### 4.2.2 任务相关
#### 4.2.2.1 DolphinScheduler 任务设计
* DataQualityParameter
```plain
public class DataQualityParameter{
private int ruleId;
private String ruleJson;
private Map<String,String> ruleInputParameter;
}
```
* DataQualityTask
* 主要职责就是运行一个 Spark 作业
#### 4.2.2.2 Spark 数据质量任务设计
1)数据质量任务实际上是一个 Spark 任务,这个任务的主要责任是如下:
* 解析参数,获取构造 Reader,Executor 和 Writer 所需要的参数
* 根据参数构造对应类型的 Reader、Executor 和 Writer
* Reader 的主要职责是读取指定数据源的数据,并创建临时表供后续使用
* Executor 的主要职责是运行中间步骤 SQL 语句、统计步骤 SQL 语句和比较值计算 SQL 语句
* Writer 的主要职责是将数据质量任务的计算结果写到相应的存储引擎中,目前只支持写回 ds 的数据库中
2)运行方式可如下:
* 打包一个 DQApplicaiton.jar 上传至 hdfs 上,运行的时候加载默认的上传地址
* 这种方式相对来说更节省存储空间和减少 jar 上传的时间
* 将打包好的 DQApplication.jar 放至 lib 目录下,运行的时候加载该 jar 包
* 这种方式对于用户的部署更加无感
3)代码结构

# 5 Todo List
* DataQualityTask UI 相关开发
* DataQuailtyTask 相关开发
* DataQualityParameter设计
* DataQualityTask 设计
* Rule 相关开发
* RuleModel相关设计
* RuleManager设计开发
* RuleConverter
* Spark DataQuality 相关开发
# 6 相关 issue
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-dolphinscheduler] 597365581 commented on issue #4283: [Feature] Data Quality Design
Posted by GitBox <gi...@apache.org>.
597365581 commented on issue #4283:
URL: https://github.com/apache/incubator-dolphinscheduler/issues/4283#issuecomment-771331616
+1
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-dolphinscheduler] zixi0825 edited a comment on issue #4283: [Feature] Data Quality Design
Posted by GitBox <gi...@apache.org>.
zixi0825 edited a comment on issue #4283:
URL: https://github.com/apache/incubator-dolphinscheduler/issues/4283#issuecomment-770778660
### Development Planning:
Version 1.0
- Data quality type task development, including front end and back end (development completed)
- Automatic generation of rule input items by selecting rules in front-end interface (development completed)
- Provide a variety of detection methods (developed)
- Provide multiple failure strategies (development completed)
- The main responsibility of the executor with spark as the computing engine is to run data quality detection SQL (developed)
- Built in multiple detection rules, including single table null value detection, cross table accuracy detection, cross table value comparison and single table custom SQL detection, etc. (developed)
- Quality inspection results view, including front end and back end (development completed)
- You can view the workflow of the task (development completed)
- Rule management, only support view (development completed)
- Viewable rule definition (development completed)
- Data source only supports JDBC and hive (developed)
- Part of the front end experience Optimization (incomplete)
Version 2.0 (Time to be determined)
- Optimize the user experience of front-end input items, introduce metadata management of multiple data sources, select tables and columns, etc. (to be developed)
- Provide custom rule template, support single table rule customization (to be developed)
- New rules modification and deletion (to be developed)
- Support abnormal data export (to be developed)
- Support multiple data source detection, such as file, ES, etc. (to be developed)
- Support to run data quality inspection task independently (to be developed)
---------------------------------------------------------------------------------------------------------------------------------------
### 开发计划:
1.0 版本 (本地开发已完成95%以上,尚未提PR)
- 数据质量类型任务开发,包括前端和后端(已完成开发)
- 实现前端界面选择规则自动生成规则输入项(已完成开发)
- 提供多种检测方式(已完成开发)
- 提供多种失败策略(已完成开发)

- 以Spark为计算引擎的Executor,主要职责是运行数据质量检测SQL (已完成开发)
- 内置多种检测规则,包括单表空值检测、跨表准确性检测、跨表值比对和单表自定义SQL检测等等(已完成开发)
- 质量检测结果查看,包括前端和后端(已完成开发)
- 可查看任务所在工作流(已完成开发)

- 规则管理,仅支持查看(已完成开发)
- 可查看规则定义(已完成开发)

- 数据源仅支持JDBC和HIVE(已完成开发)
- 部分前端体验优化(未完成)
2.0 版本 (时间待定)
- 优化前端用户体验,包括输入项优化,引入多种数据源的元数据管理,选择表和列等(待开发)
- 提供自定义规则模板,支持单表规则的自定义(待开发)
- 新增规则修改和删除(待开发)
- 支持异常数据导出(待开发)
- 支持多种数据源检测,例如文件、ES等(待开发)
- 支持单独运行数据质量检测任务(待开发)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-dolphinscheduler] dailidong commented on issue #4283: [Feature] Data Quality Design
Posted by GitBox <gi...@apache.org>.
dailidong commented on issue #4283:
URL: https://github.com/apache/incubator-dolphinscheduler/issues/4283#issuecomment-771685324
+1
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-dolphinscheduler] zixi0825 edited a comment on issue #4283: [Feature] Data Quality Design
Posted by GitBox <gi...@apache.org>.
zixi0825 edited a comment on issue #4283:
URL: https://github.com/apache/incubator-dolphinscheduler/issues/4283#issuecomment-770778660
### Development Planning:
Version 1.0
- Data quality type task development, including front end and back end (development completed)
- Automatic generation of rule input items by selecting rules in front-end interface (development completed)
- Provide a variety of detection methods (developed)
- Provide multiple failure strategies (development completed)
- The main responsibility of the executor with spark as the computing engine is to run data quality detection SQL (developed)
- Built in multiple detection rules, including single table null value detection, cross table accuracy detection, cross table value comparison and single table custom SQL detection, etc. (developed)
- Quality inspection results view, including front end and back end (development completed)
- You can view the workflow of the task (development completed)
- Rule management, only support view (development completed)
- Viewable rule definition (development completed)
- Data source only supports JDBC and hive (developed)
- Part of the front end experience Optimization (incomplete)
Version 2.0 (Time to be determined)
- Optimize the user experience of front-end input items, introduce metadata management of multiple data sources, select tables and columns, etc. (to be developed)
- Provide custom rule template, support single table rule customization (to be developed)
- New rules modification and deletion (to be developed)
- Support abnormal data export (to be developed)
- Support multiple data source detection, such as file, ES, etc. (to be developed)
- Support to run data quality inspection task independently (to be developed)
---------------------------------------------------------------------------------------------------------------------------------------
### 开发计划:
1.0 版本 (本地开发已完成95%以上,尚未提PR)
- 数据质量类型任务开发,包括前端和后端(已完成开发)
- 实现前端界面选择规则自动生成规则输入项(已完成开发)
- 提供多种检测方式(已完成开发)
- 提供多种失败策略(已完成开发)

- 以Spark为计算引擎的Executor,主要职责是运行数据质量检测SQL (已完成开发)
- 内置多种检测规则,包括单表空值检测、跨表准确性检测、跨表值比对和单表自定义SQL检测等等(已完成开发)
- 质量检测结果查看,包括前端和后端(已完成开发)
- 可查看任务所在工作流(已完成开发)

- 规则管理,仅支持查看(已完成开发)
- 可查看规则定义(已完成开发)

- 数据源仅支持JDBC和HIVE(已完成开发)
- 部分前端体验优化(未完成)
2.0 版本 (时间待定)
- 优化前端用户体验,包括输入项优化,引入多种数据源的元数据管理,选择表和列等(待开发)
- 提供自定义规则模板,支持单表规则的自定义(待开发)
- 新增规则修改和删除(待开发)
- 支持异常数据导出(待开发)
- 支持多种数据源检测,例如文件、ES等(待开发)
- 支持单独运行数据质量检测任务(待开发)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-dolphinscheduler] zixi0825 commented on issue #4283: [Feature] Data Quality Design
Posted by GitBox <gi...@apache.org>.
zixi0825 commented on issue #4283:
URL: https://github.com/apache/incubator-dolphinscheduler/issues/4283#issuecomment-790400847
> @zixi0825 大佬,想请教一下怎么才能将您完成的功能跑起来?
It is not completed yet
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-dolphinscheduler] dailidong commented on issue #4283: [Feature] Data Quality Design
Posted by GitBox <gi...@apache.org>.
dailidong commented on issue #4283:
URL: https://github.com/apache/incubator-dolphinscheduler/issues/4283#issuecomment-771685324
+1
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-dolphinscheduler] ATLgo commented on issue #4283: [Feature] Data Quality Design
Posted by GitBox <gi...@apache.org>.
ATLgo commented on issue #4283:
URL: https://github.com/apache/incubator-dolphinscheduler/issues/4283#issuecomment-790395700
@zixi0825 大佬,想请教一下怎么才能将您完成的功能跑起来?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-dolphinscheduler] zixi0825 commented on issue #4283: [Feature] Data Quality Design
Posted by GitBox <gi...@apache.org>.
zixi0825 commented on issue #4283:
URL: https://github.com/apache/incubator-dolphinscheduler/issues/4283#issuecomment-770778660
### Development Planning:
Version 1.0
- Data quality type task development, including front end and back end (development completed)
- Automatic generation of rule input items by selecting rules in front-end interface (development completed)
- Provide a variety of detection methods (developed)
- Provide multiple failure strategies (development completed)
- The main responsibility of the executor with spark as the computing engine is to run data quality detection SQL (developed)
- Built in multiple detection rules, including single table null value detection, cross table accuracy detection, cross table value comparison and single table custom SQL detection, etc. (developed)
- Quality inspection results view, including front end and back end (development completed)
- You can view the workflow of the task (development completed)
- Rule management, only support view (development completed)
- Viewable rule definition (development completed)
- Data source only supports JDBC and hive (developed)
Version 2.0 (Time to be determined)
- Optimize the user experience of front-end input items, introduce metadata management of multiple data sources, select tables and columns, etc. (to be developed)
- Provide custom rule template, support single table rule customization (to be developed)
- New rules modification and deletion (to be developed)
- Support abnormal data export (to be developed)
- Support multiple data source detection, such as file, ES, etc. (to be developed)
- Support to run data quality inspection task independently (to be developed)
---------------------------------------------------------------------------------------------------------------------------------------
### 开发计划:
1.0 版本
- 数据质量类型任务开发,包括前端和后端(已完成开发)
- 实现前端界面选择规则自动生成规则输入项(已完成开发)
- 提供多种检测方式(已完成开发)
- 提供多种失败策略(已完成开发)

- 以Spark为计算引擎的Executor,主要职责是运行数据质量检测SQL (已完成开发)
- 内置多种检测规则,包括单表空值检测、跨表准确性检测、跨表值比对和单表自定义SQL检测等等(已完成开发)
- 质量检测结果查看,包括前端和后端(已完成开发)
- 可查看任务所在工作流(已完成开发)

- 规则管理,仅支持查看(已完成开发)
- 可查看规则定义(已完成开发)

- 数据源仅支持JDBC和HIVE(已完成开发)
2.0 版本 (时间待定)
- 优化前端用户体验,包括输入项优化,引入多种数据源的元数据管理,选择表和列等(待开发)
- 提供自定义规则模板,支持单表规则的自定义(待开发)
- 新增规则修改和删除(待开发)
- 支持异常数据导出(待开发)
- 支持多种数据源检测,例如文件、ES等(待开发)
- 支持单独运行数据质量检测任务(待开发)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-dolphinscheduler] dailidong commented on issue #4283: [Feature] Data Quality Design
Posted by GitBox <gi...@apache.org>.
dailidong commented on issue #4283:
URL: https://github.com/apache/incubator-dolphinscheduler/issues/4283#issuecomment-754678266
> Essential functions of big data ETL System~~Looking forward to going online soon
+1
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-dolphinscheduler] 597365581 commented on issue #4283: [Feature] Data Quality Design
Posted by GitBox <gi...@apache.org>.
597365581 commented on issue #4283:
URL: https://github.com/apache/incubator-dolphinscheduler/issues/4283#issuecomment-771331616
+1
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-dolphinscheduler] ATLgo commented on issue #4283: [Feature] Data Quality Design
Posted by GitBox <gi...@apache.org>.
ATLgo commented on issue #4283:
URL: https://github.com/apache/incubator-dolphinscheduler/issues/4283#issuecomment-788743140
+1
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-dolphinscheduler] lbjyuer commented on issue #4283: [Feature] Data Quality Design
Posted by GitBox <gi...@apache.org>.
lbjyuer commented on issue #4283:
URL: https://github.com/apache/incubator-dolphinscheduler/issues/4283#issuecomment-754546857
Essential functions of big data ETL System~~Looking forward to going online soon
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-dolphinscheduler] huzekang commented on issue #4283: [Feature] Data Quality Design
Posted by GitBox <gi...@apache.org>.
huzekang commented on issue #4283:
URL: https://github.com/apache/incubator-dolphinscheduler/issues/4283#issuecomment-752830905
LGTM
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-dolphinscheduler] zixi0825 edited a comment on issue #4283: [Feature] Data Quality Design
Posted by GitBox <gi...@apache.org>.
zixi0825 edited a comment on issue #4283:
URL: https://github.com/apache/incubator-dolphinscheduler/issues/4283#issuecomment-770778660
### Development Planning:
Version 1.0
- Data quality type task development, including front end and back end (development completed)
- Automatic generation of rule input items by selecting rules in front-end interface (development completed)
- Provide a variety of detection methods (developed)
- Provide multiple failure strategies (development completed)
- The main responsibility of the executor with spark as the computing engine is to run data quality detection SQL (developed)
- Built in multiple detection rules, including single table null value detection, cross table accuracy detection, cross table value comparison and single table custom SQL detection, etc. (developed)
- Quality inspection results view, including front end and back end (development completed)
- You can view the workflow of the task (development completed)
- Rule management, only support view (development completed)
- Viewable rule definition (development completed)
- Data source only supports JDBC and hive (developed)
Version 2.0 (Time to be determined)
- Optimize the user experience of front-end input items, introduce metadata management of multiple data sources, select tables and columns, etc. (to be developed)
- Provide custom rule template, support single table rule customization (to be developed)
- New rules modification and deletion (to be developed)
- Support abnormal data export (to be developed)
- Support multiple data source detection, such as file, ES, etc. (to be developed)
- Support to run data quality inspection task independently (to be developed)
---------------------------------------------------------------------------------------------------------------------------------------
### 开发计划:
1.0 版本 (已完成本地开发尚未提PR)
- 数据质量类型任务开发,包括前端和后端(已完成开发)
- 实现前端界面选择规则自动生成规则输入项(已完成开发)
- 提供多种检测方式(已完成开发)
- 提供多种失败策略(已完成开发)

- 以Spark为计算引擎的Executor,主要职责是运行数据质量检测SQL (已完成开发)
- 内置多种检测规则,包括单表空值检测、跨表准确性检测、跨表值比对和单表自定义SQL检测等等(已完成开发)
- 质量检测结果查看,包括前端和后端(已完成开发)
- 可查看任务所在工作流(已完成开发)

- 规则管理,仅支持查看(已完成开发)
- 可查看规则定义(已完成开发)

- 数据源仅支持JDBC和HIVE(已完成开发)
2.0 版本 (时间待定)
- 优化前端用户体验,包括输入项优化,引入多种数据源的元数据管理,选择表和列等(待开发)
- 提供自定义规则模板,支持单表规则的自定义(待开发)
- 新增规则修改和删除(待开发)
- 支持异常数据导出(待开发)
- 支持多种数据源检测,例如文件、ES等(待开发)
- 支持单独运行数据质量检测任务(待开发)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-dolphinscheduler] dailidong commented on issue #4283: [Feature] Data Quality Design
Posted by GitBox <gi...@apache.org>.
dailidong commented on issue #4283:
URL: https://github.com/apache/incubator-dolphinscheduler/issues/4283#issuecomment-751647515
good feature
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org