You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@spark.apache.org by gu...@apache.org on 2021/10/07 09:36:32 UTC
[spark] branch master updated: [SPARK-36713][PYTHON][DOCS] Document
new syntax of type hints with index (pandas-on-Spark)
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 2e9b698 [SPARK-36713][PYTHON][DOCS] Document new syntax of type hints with index (pandas-on-Spark)
2e9b698 is described below
commit 2e9b698d3100f18595dadbf35abb06502c3d6123
Author: Hyukjin Kwon <gu...@apache.org>
AuthorDate: Thu Oct 7 18:35:20 2021 +0900
[SPARK-36713][PYTHON][DOCS] Document new syntax of type hints with index (pandas-on-Spark)
### What changes were proposed in this pull request?
This PR proposes to document the new syntax of type hints with index. Self-contained.
### Why are the changes needed?
To guide users about the new ways of typing to avoid creating default index.
### Does this PR introduce _any_ user-facing change?
Yes, it adds new sections in the pandas-on-Spark documentation.
### How was this patch tested?
Manually built the docs and verified the output HTMLs. Also manually ran the example codes.
Closes #34210 from HyukjinKwon/SPARK-36713.
Authored-by: Hyukjin Kwon <gu...@apache.org>
Signed-off-by: Hyukjin Kwon <gu...@apache.org>
---
.../user_guide/pandas_on_spark/typehints.rst | 123 ++++++++++++++++++++-
1 file changed, 117 insertions(+), 6 deletions(-)
diff --git a/python/docs/source/user_guide/pandas_on_spark/typehints.rst b/python/docs/source/user_guide/pandas_on_spark/typehints.rst
index 2b8628e..72519fc 100644
--- a/python/docs/source/user_guide/pandas_on_spark/typehints.rst
+++ b/python/docs/source/user_guide/pandas_on_spark/typehints.rst
@@ -60,10 +60,10 @@ it as a Spark schema. As an example, you can specify the return type hint as bel
>>> df = ps.DataFrame({'A': ['a', 'a', 'b'], 'B': [1, 2, 3], 'C': [4, 6, 5]})
>>> df.groupby('A').apply(pandas_div)
-The function ``pandas_div`` actually takes and outputs a pandas DataFrame instead of pandas-on-Spark :class:`DataFrame`.
-However, pandas API on Spark has to force to set the mismatched type hints.
+Notice that the function ``pandas_div`` actually takes and outputs a pandas DataFrame instead of
+pandas-on-Spark :class:`DataFrame`. So, technically the correct types should be of pandas.
-From pandas-on-Spark 1.0 with Python 3.7+, now you can specify the type hints by using pandas instances.
+With Python 3.7+, you can specify the type hints by using pandas instances as follows:
.. code-block:: python
@@ -91,7 +91,7 @@ plans to move gradually towards using pandas instances only as the stability bec
Type Hinting with Names
-----------------------
-In pandas-on-Spark 1.0, the new style of type hinting was introduced to overcome the limitations in the existing type
+This apporach is to overcome the limitations in the existing type
hinting especially for DataFrame. When you use a DataFrame as the return type hint, for example,
``DataFrame[int, int]``, there is no way to specify the names of each Series. In the old way, pandas API on Spark just generates
the column names as ``c#`` and this easily leads users to lose or forgot the Series mappings. See the example below:
@@ -139,7 +139,8 @@ programmatically generate the return type and schema.
.. code-block:: python
- >>> def transform(pdf) -> pd.DataFrame[zip(pdf.columns, pdf.dtypes)]:
+ >>> def transform(pdf) -> pd.DataFrame[
+ .. zip(sample.columns, sample.dtypes)]:
... return pdf + 1
...
>>> psdf.pandas_on_spark.apply_batch(transform)
@@ -148,7 +149,117 @@ Likewise, ``dtype`` instances from pandas DataFrame can be used alone and let pa
.. code-block:: python
- >>> def transform(pdf) -> pd.DataFrame[pdf.dtypes]:
+ >>> def transform(pdf) -> pd.DataFrame[sample.dtypes]:
... return pdf + 1
...
>>> psdf.pandas_on_spark.apply_batch(transform)
+
+
+Type Hinting with Index
+-----------------------
+
+When you omit index types in the type hints, pandas API on Spark attaches the default index (`compute.default_index_type`),
+and it loses the index column and information from the original data. The default index sometimes requires to have an
+expensive computation such as shuffle so it is best to specify the index type together.
+
+
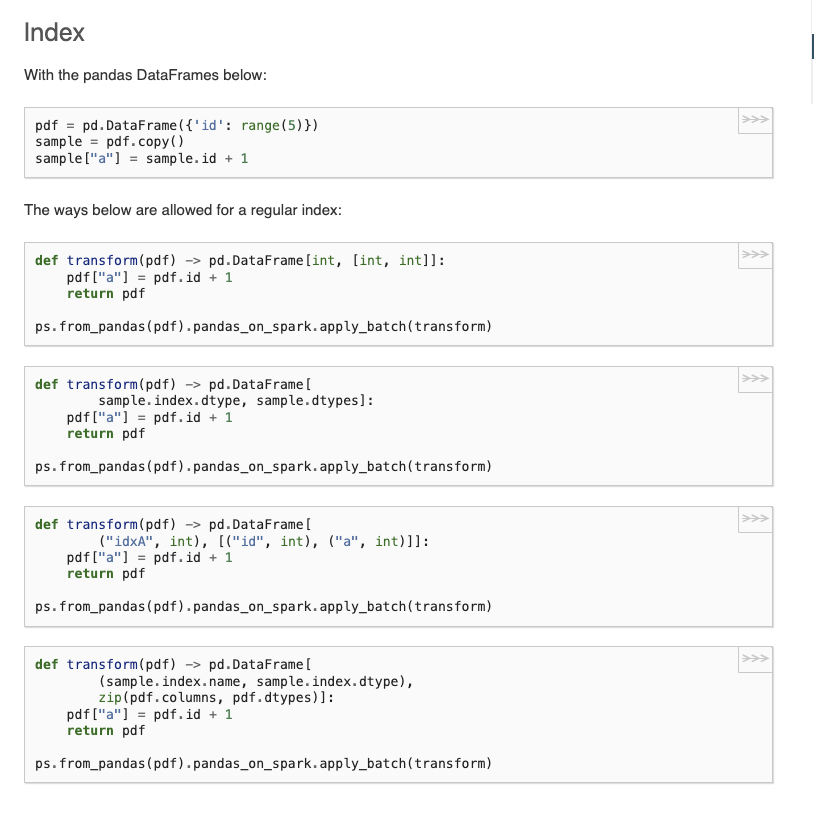
+Index
+~~~~~
+
+With the pandas DataFrames below:
+
+.. code-block:: python
+
+ >>> pdf = pd.DataFrame({'id': range(5)})
+ >>> sample = pdf.copy()
+ >>> sample["a"] = sample.id + 1
+
+The ways below are allowed for a regular index:
+
+.. code-block:: python
+
+ >>> def transform(pdf) -> pd.DataFrame[int, [int, int]]:
+ ... pdf["a"] = pdf.id + 1
+ ... return pdf
+ ...
+ >>> ps.from_pandas(pdf).pandas_on_spark.apply_batch(transform)
+
+.. code-block:: python
+
+ >>> def transform(pdf) -> pd.DataFrame[
+ ... sample.index.dtype, sample.dtypes]:
+ ... pdf["a"] = pdf.id + 1
+ ... return pdf
+ ...
+ >>> ps.from_pandas(pdf).pandas_on_spark.apply_batch(transform)
+
+.. code-block:: python
+
+ >>> def transform(pdf) -> pd.DataFrame[
+ ... ("idxA", int), [("id", int), ("a", int)]]:
+ ... pdf["a"] = pdf.id + 1
+ ... return pdf
+ ...
+ >>> ps.from_pandas(pdf).pandas_on_spark.apply_batch(transform)
+
+.. code-block:: python
+
+ >>> def transform(pdf) -> pd.DataFrame[
+ ... (sample.index.name, sample.index.dtype),
+ ... zip(sample.columns, sample.dtypes)]:
+ ... pdf["a"] = pdf.id + 1
+ ... return pdf
+ ...
+ >>> ps.from_pandas(pdf).pandas_on_spark.apply_batch(transform)
+
+
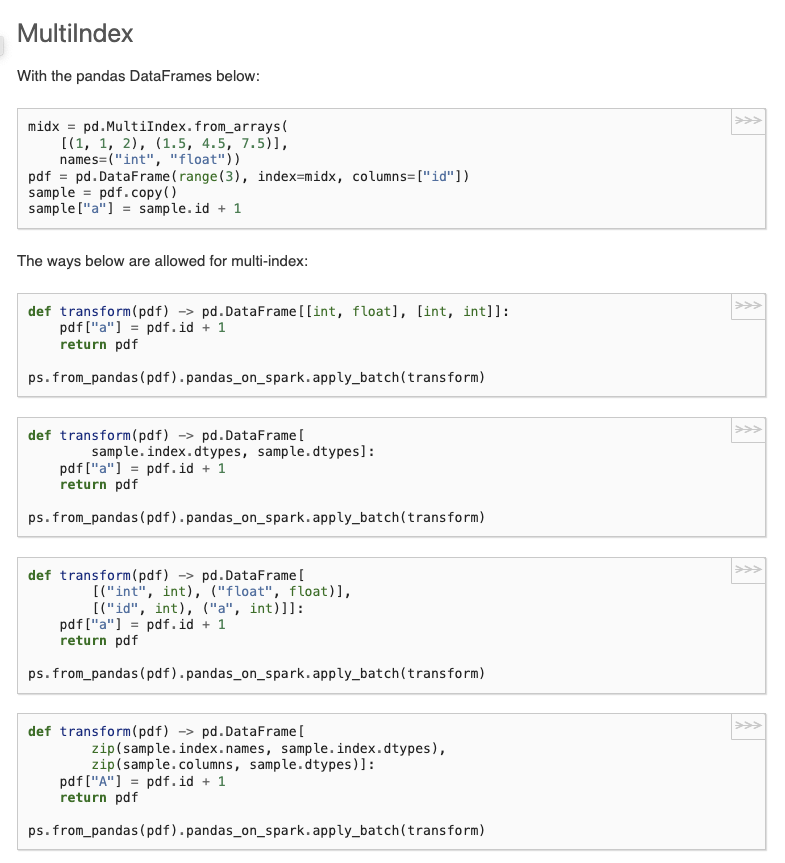
+MultiIndex
+~~~~~~~~~~
+
+With the pandas DataFrames below:
+
+ >>> midx = pd.MultiIndex.from_arrays(
+ ... [(1, 1, 2), (1.5, 4.5, 7.5)],
+ ... names=("int", "float"))
+ >>> pdf = pd.DataFrame(range(3), index=midx, columns=["id"])
+ >>> sample = pdf.copy()
+ >>> sample["a"] = sample.id + 1
+
+The ways below are allowed for multi-index:
+
+.. code-block:: python
+
+ >>> def transform(pdf) -> pd.DataFrame[[int, float], [int, int]]:
+ ... pdf["a"] = pdf.id + 1
+ ... return pdf
+ ...
+ >>> ps.from_pandas(pdf).pandas_on_spark.apply_batch(transform)
+
+.. code-block:: python
+
+ >>> def transform(pdf) -> pd.DataFrame[
+ ... sample.index.dtypes, sample.dtypes]:
+ ... pdf["a"] = pdf.id + 1
+ ... return pdf
+ ...
+ >>> ps.from_pandas(pdf).pandas_on_spark.apply_batch(transform)
+
+.. code-block:: python
+
+ >>> def transform(pdf) -> pd.DataFrame[
+ ... [("int", int), ("float", float)],
+ ... [("id", int), ("a", int)]]:
+ ... pdf["a"] = pdf.id + 1
+ ... return pdf
+ ...
+ >>> ps.from_pandas(pdf).pandas_on_spark.apply_batch(transform)
+
+.. code-block:: python
+
+ >>> def transform(pdf) -> pd.DataFrame[
+ ... zip(sample.index.names, sample.index.dtypes),
+ ... zip(sample.columns, sample.dtypes)]:
+ ... pdf["A"] = pdf.id + 1
+ ... return pdf
+ ...
+ >>> ps.from_pandas(pdf).pandas_on_spark.apply_batch(transform)
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@spark.apache.org
For additional commands, e-mail: commits-help@spark.apache.org