You are viewing a plain text version of this content. The canonical link for it is here.
Posted to github@arrow.apache.org by GitBox <gi...@apache.org> on 2020/06/16 13:58:56 UTC
[GitHub] [arrow] maartenbreddels opened a new pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
maartenbreddels opened a new pull request #7449:
URL: https://github.com/apache/arrow/pull/7449
This is the initial working version, which is *very* slow though (>100x slower than the ascii versions). It also required libutf8proc to be present.
Please let me know if the general code style etc is ok. I'm using CRTP here, judging from the metaprogramming seen in the rest of the code base, I guess that's fine.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-647572424
Validating the utf8 string made the results slightly slower, but still much better then the initial results.
Invalid utf8 characters are now replaced by a '?', as commented in the code. The unicode \U+FFFD would be more appropriate, but can lead to string length growth (3x). I think we can discuss this separately from this PR.
Recap:
Because we cannot use unlib (license issue), and utf8proc gives worse performance (even when inlined), we now have our own utf8 encode/decode. Also, calling upper and lower case functions in utf8proc is quite slow, and is now implemented with a lookup table (also suggested in https://github.com/JuliaStrings/utf8proc/issues/12#issuecomment-645563386) for codepoints up to `0xFFFF`.
Initial performance:
```
Utf8Lower 193873803 ns 193823124 ns 3 bytes_per_second=102.387M/s items_per_second=5.40996M/s
Utf8Upper 197154929 ns 197093083 ns 4 bytes_per_second=100.688M/s items_per_second=5.32021M/s
```
Current performance:
```
Utf8Lower 19677038 ns 19672550 ns 35 bytes_per_second=1008.76M/s items_per_second=53.3015M/s
Utf8Upper 20362432 ns 20360109 ns 34 bytes_per_second=974.698M/s items_per_second=51.5015M/s
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-646605458
Note that the unitests should fail, the PR isn't done, but the tests seem to run 👍
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] nealrichardson commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
nealrichardson commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651369436
> > The version installed is compiled with gcc 8. RTools 35 uses gcc 4.9
>
> What difference does it make? This is plain C.
:shrug: then I'll leave it to you to sort out as this is beyond my knowledge. In the past, undefined symbols error + only compiled for rtools-packages (gcc8) = you need to get it built with rtools-backports too. Maybe something's off with the lib that was built, IDK if anyone has verified that it works.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] kou commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
kou commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-648518023
I've added a workaround we already used: https://github.com/apache/arrow/pull/7449/commits/782499f8641da4a23d86125bcc812546107f2ce5
But it doesn't solve this yet.
I'm trying reproducing this on my local environment.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r447161391
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -30,6 +31,124 @@ namespace internal {
namespace {
+// lookup tables
+std::vector<uint32_t> lut_upper_codepoint;
+std::vector<uint32_t> lut_lower_codepoint;
+std::once_flag flag_case_luts;
+
+constexpr uint32_t REPLACEMENT_CHAR =
+ '?'; // the proper replacement char would be the 0xFFFD codepoint, but that can
+ // increase string length by a factor of 3
+constexpr int MAX_CODEPOINT_LUT = 0xffff; // up to this codepoint is in a lookup table
+
+static inline void utf8_encode(uint8_t*& str, uint32_t codepoint) {
+ if (codepoint < 0x80) {
+ *str++ = codepoint;
+ } else if (codepoint < 0x800) {
+ *str++ = 0xC0 + (codepoint >> 6);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else if (codepoint < 0x10000) {
+ *str++ = 0xE0 + (codepoint >> 12);
+ *str++ = 0x80 + ((codepoint >> 6) & 0x3F);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else if (codepoint < 0x200000) {
+ *str++ = 0xF0 + (codepoint >> 18);
+ *str++ = 0x80 + ((codepoint >> 12) & 0x3F);
+ *str++ = 0x80 + ((codepoint >> 6) & 0x3F);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else {
+ *str++ = codepoint;
+ }
+}
+
+static inline bool utf8_is_continuation(const uint8_t codeunit) {
+ return (codeunit & 0xC0) == 0x80; // upper two bits should be 10
+}
+
+static inline uint32_t utf8_decode(const uint8_t*& str, int64_t& length) {
+ if (*str < 0x80) { //
+ length -= 1;
+ return *str++;
+ } else if (*str < 0xC0) { // invalid non-ascii char
+ length -= 1;
+ str++;
+ return REPLACEMENT_CHAR;
Review comment:
There's no reason a priori to be forgiving on invalid data. It there's a use case to be tolerant, we may add an option. But by default we should error out on invalid input, IMHO.
cc @wesm for opinions
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r445417901
##########
File path: cpp/src/arrow/compute/kernels/scalar_string_benchmark.cc
##########
@@ -52,8 +55,18 @@ static void AsciiUpper(benchmark::State& state) {
UnaryStringBenchmark(state, "ascii_upper");
}
+static void Utf8Upper(benchmark::State& state) {
+ UnaryStringBenchmark(state, "utf8_upper", true);
Review comment:
Note that `RandomArrayGenerator::String` generates an array of pure Ascii characters between `A` and `z`.
Perhaps we need two sets of benchmarks:
* one with pure Ascii values
* one with partly non-Ascii values
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -30,6 +31,124 @@ namespace internal {
namespace {
+// lookup tables
+std::vector<uint32_t> lut_upper_codepoint;
+std::vector<uint32_t> lut_lower_codepoint;
+std::once_flag flag_case_luts;
+
+constexpr uint32_t REPLACEMENT_CHAR =
+ '?'; // the proper replacement char would be the 0xFFFD codepoint, but that can
+ // increase string length by a factor of 3
+constexpr int MAX_CODEPOINT_LUT = 0xffff; // up to this codepoint is in a lookup table
+
+static inline void utf8_encode(uint8_t*& str, uint32_t codepoint) {
+ if (codepoint < 0x80) {
+ *str++ = codepoint;
+ } else if (codepoint < 0x800) {
+ *str++ = 0xC0 + (codepoint >> 6);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else if (codepoint < 0x10000) {
+ *str++ = 0xE0 + (codepoint >> 12);
+ *str++ = 0x80 + ((codepoint >> 6) & 0x3F);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else if (codepoint < 0x200000) {
+ *str++ = 0xF0 + (codepoint >> 18);
+ *str++ = 0x80 + ((codepoint >> 12) & 0x3F);
+ *str++ = 0x80 + ((codepoint >> 6) & 0x3F);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else {
+ *str++ = codepoint;
+ }
+}
+
+static inline bool utf8_is_continuation(const uint8_t codeunit) {
+ return (codeunit & 0xC0) == 0x80; // upper two bits should be 10
+}
+
+static inline uint32_t utf8_decode(const uint8_t*& str, int64_t& length) {
+ if (*str < 0x80) { //
+ length -= 1;
+ return *str++;
+ } else if (*str < 0xC0) { // invalid non-ascii char
+ length -= 1;
+ str++;
+ return REPLACEMENT_CHAR;
Review comment:
Hmm, I don't really agree with this... If there's some invalid input, we should bail out with `Status::Invalid`, IMO.
##########
File path: cpp/src/arrow/compute/kernels/scalar_string_benchmark.cc
##########
@@ -41,7 +42,9 @@ static void UnaryStringBenchmark(benchmark::State& state, const std::string& fun
ABORT_NOT_OK(CallFunction(func_name, {values}));
}
state.SetItemsProcessed(state.iterations() * array_length);
- state.SetBytesProcessed(state.iterations() * values->data()->buffers[2]->size());
+ state.SetBytesProcessed(state.iterations() *
+ ((touches_offsets ? values->data()->buffers[1]->size() : 0) +
Review comment:
Hmm, this looks a bit pedantic and counter-productive to me. We want Ascii and UTF8 numbers to be directly comparable, so let's keep the original calculation.
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -30,6 +31,124 @@ namespace internal {
namespace {
+// lookup tables
+std::vector<uint32_t> lut_upper_codepoint;
+std::vector<uint32_t> lut_lower_codepoint;
+std::once_flag flag_case_luts;
+
+constexpr uint32_t REPLACEMENT_CHAR =
+ '?'; // the proper replacement char would be the 0xFFFD codepoint, but that can
+ // increase string length by a factor of 3
+constexpr int MAX_CODEPOINT_LUT = 0xffff; // up to this codepoint is in a lookup table
+
+static inline void utf8_encode(uint8_t*& str, uint32_t codepoint) {
Review comment:
By the way, all those helper functions (encoding/decoding) may also go into `arrow/util/utf8.h`.
##########
File path: cpp/src/arrow/compute/kernels/scalar_string_test.cc
##########
@@ -68,6 +76,64 @@ TYPED_TEST(TestStringKernels, AsciiLower) {
this->string_type(), "[\"aaazzæÆ&\", null, \"\", \"bbb\"]");
}
+TEST(TestStringKernels, Utf8Upper32bitGrowth) {
Review comment:
I'm not convinced it's a good idea to consume more than 2GB RAM in a test. We have something called `LARGE_MEMORY_TEST` for such tests (you can grep for it), though I'm not sure they get exercised on a regular basis.
##########
File path: cpp/src/arrow/compute/kernels/scalar_string_test.cc
##########
@@ -81,5 +147,40 @@ TYPED_TEST(TestStringKernels, StrptimeDoesNotProvideDefaultOptions) {
ASSERT_RAISES(Invalid, CallFunction("strptime", {input}));
}
+TEST(TestStringKernels, UnicodeLibraryAssumptions) {
+ uint8_t output[4];
+ for (utf8proc_int32_t codepoint = 0x100; codepoint < 0x110000; codepoint++) {
+ utf8proc_ssize_t encoded_nbytes = utf8proc_encode_char(codepoint, output);
+ utf8proc_int32_t codepoint_upper = utf8proc_toupper(codepoint);
+ utf8proc_ssize_t encoded_nbytes_upper = utf8proc_encode_char(codepoint_upper, output);
+ if (encoded_nbytes == 2) {
+ EXPECT_LE(encoded_nbytes_upper, 3)
+ << "Expected the upper case codepoint for a 2 byte encoded codepoint to be "
+ "encoded in maximum 3 bytes, not "
+ << encoded_nbytes_upper;
+ }
+ if (encoded_nbytes == 3) {
Review comment:
And what about `encoded_nbytes == 4`?
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +158,121 @@ struct AsciiLength {
}
};
+template <typename Type, template <typename> class Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using DerivedClass = Derived<Type>;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* dest = output;
+ utf8_transform(input, input + input_string_ncodeunits, dest,
+ DerivedClass::TransformCodepoint);
+ return (offset_type)(dest - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ std::call_once(flag_case_luts, []() {
Review comment:
Could make this a separate helper function, for clarity.
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +158,121 @@ struct AsciiLength {
}
};
+template <typename Type, template <typename> class Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using DerivedClass = Derived<Type>;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* dest = output;
+ utf8_transform(input, input + input_string_ncodeunits, dest,
+ DerivedClass::TransformCodepoint);
+ return (offset_type)(dest - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ std::call_once(flag_case_luts, []() {
+ lut_upper_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ lut_lower_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ for (int i = 0; i <= MAX_CODEPOINT_LUT; i++) {
+ lut_upper_codepoint.push_back(utf8proc_toupper(i));
+ lut_lower_codepoint.push_back(utf8proc_tolower(i));
+ }
+ });
+ const ArrayData& input = *batch[0].array();
+ ArrayType input_boxed(batch[0].array());
+ ArrayData* output = out->mutable_array();
+
+ offset_type const* input_string_offsets = input.GetValues<offset_type>(1);
+ utf8proc_uint8_t const* input_str =
+ input.buffers[2]->data() + input_boxed.value_offset(0);
+ offset_type input_ncodeunits = input_boxed.total_values_length();
+ offset_type input_nstrings = (offset_type)input.length;
+
+ // Section 5.18 of the Unicode spec claim that the number of codepoints for case
+ // mapping can grow by a factor of 3. This means grow by a factor of 3 in bytes
+ // However, since we don't support all casings (SpecialCasing.txt) the growth
+ // is actually only at max 3/2 (as covered by the unittest).
+ // Note that rounding down the 3/2 is ok, since only codepoints encoded by
+ // two code units (even) can grow to 3 code units.
+
+ int64_t output_ncodeunits_max = ((int64_t)input_ncodeunits) * 3 / 2;
+ if (output_ncodeunits_max > std::numeric_limits<offset_type>::max()) {
+ ctx->SetStatus(Status::CapacityError(
+ "Result might not fit in a 32bit utf8 array, convert to large_utf8"));
+ return;
+ }
+
+ KERNEL_RETURN_IF_ERROR(
+ ctx, ctx->Allocate(output_ncodeunits_max).Value(&output->buffers[2]));
+ // We could reuse the buffer if it is all ascii, benchmarking showed this not to
+ // matter
+ // output->buffers[1] = input.buffers[1];
+ KERNEL_RETURN_IF_ERROR(ctx,
+ ctx->Allocate((input_nstrings + 1) * sizeof(offset_type))
+ .Value(&output->buffers[1]));
+ utf8proc_uint8_t* output_str = output->buffers[2]->mutable_data();
+ offset_type* output_string_offsets = output->GetMutableValues<offset_type>(1);
+ offset_type output_ncodeunits = 0;
+
+ offset_type output_string_offset = 0;
+ *output_string_offsets = output_string_offset;
+ offset_type input_string_first_offset = input_string_offsets[0];
+ for (int64_t i = 0; i < input_nstrings; i++) {
+ offset_type input_string_offset =
+ input_string_offsets[i] - input_string_first_offset;
+ offset_type input_string_end =
+ input_string_offsets[i + 1] - input_string_first_offset;
+ offset_type input_string_ncodeunits = input_string_end - input_string_offset;
+ offset_type encoded_nbytes = DerivedClass::Transform(
+ input_str + input_string_offset, input_string_ncodeunits,
+ output_str + output_ncodeunits);
+ output_ncodeunits += encoded_nbytes;
+ output_string_offsets[i + 1] = output_ncodeunits;
+ }
+
+ // trim the codepoint buffer, since we allocated too much
+ KERNEL_RETURN_IF_ERROR(
+ ctx,
+ output->buffers[2]->CopySlice(0, output_ncodeunits).Value(&output->buffers[2]));
Review comment:
Hmm, we should be able to resize the buffer instead... except that `KernelContext::Allocate` doesn't return a `ResizableBuffer`. @wesm Do you think we can change that?
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +158,121 @@ struct AsciiLength {
}
};
+template <typename Type, template <typename> class Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using DerivedClass = Derived<Type>;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* dest = output;
+ utf8_transform(input, input + input_string_ncodeunits, dest,
+ DerivedClass::TransformCodepoint);
+ return (offset_type)(dest - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ std::call_once(flag_case_luts, []() {
+ lut_upper_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ lut_lower_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ for (int i = 0; i <= MAX_CODEPOINT_LUT; i++) {
+ lut_upper_codepoint.push_back(utf8proc_toupper(i));
+ lut_lower_codepoint.push_back(utf8proc_tolower(i));
+ }
+ });
+ const ArrayData& input = *batch[0].array();
+ ArrayType input_boxed(batch[0].array());
+ ArrayData* output = out->mutable_array();
+
+ offset_type const* input_string_offsets = input.GetValues<offset_type>(1);
+ utf8proc_uint8_t const* input_str =
+ input.buffers[2]->data() + input_boxed.value_offset(0);
+ offset_type input_ncodeunits = input_boxed.total_values_length();
+ offset_type input_nstrings = (offset_type)input.length;
+
+ // Section 5.18 of the Unicode spec claim that the number of codepoints for case
+ // mapping can grow by a factor of 3. This means grow by a factor of 3 in bytes
+ // However, since we don't support all casings (SpecialCasing.txt) the growth
+ // is actually only at max 3/2 (as covered by the unittest).
+ // Note that rounding down the 3/2 is ok, since only codepoints encoded by
+ // two code units (even) can grow to 3 code units.
+
+ int64_t output_ncodeunits_max = ((int64_t)input_ncodeunits) * 3 / 2;
+ if (output_ncodeunits_max > std::numeric_limits<offset_type>::max()) {
+ ctx->SetStatus(Status::CapacityError(
+ "Result might not fit in a 32bit utf8 array, convert to large_utf8"));
+ return;
+ }
+
+ KERNEL_RETURN_IF_ERROR(
+ ctx, ctx->Allocate(output_ncodeunits_max).Value(&output->buffers[2]));
+ // We could reuse the buffer if it is all ascii, benchmarking showed this not to
+ // matter
+ // output->buffers[1] = input.buffers[1];
+ KERNEL_RETURN_IF_ERROR(ctx,
+ ctx->Allocate((input_nstrings + 1) * sizeof(offset_type))
+ .Value(&output->buffers[1]));
+ utf8proc_uint8_t* output_str = output->buffers[2]->mutable_data();
+ offset_type* output_string_offsets = output->GetMutableValues<offset_type>(1);
+ offset_type output_ncodeunits = 0;
+
+ offset_type output_string_offset = 0;
+ *output_string_offsets = output_string_offset;
+ offset_type input_string_first_offset = input_string_offsets[0];
+ for (int64_t i = 0; i < input_nstrings; i++) {
+ offset_type input_string_offset =
+ input_string_offsets[i] - input_string_first_offset;
+ offset_type input_string_end =
+ input_string_offsets[i + 1] - input_string_first_offset;
+ offset_type input_string_ncodeunits = input_string_end - input_string_offset;
+ offset_type encoded_nbytes = DerivedClass::Transform(
+ input_str + input_string_offset, input_string_ncodeunits,
+ output_str + output_ncodeunits);
+ output_ncodeunits += encoded_nbytes;
+ output_string_offsets[i + 1] = output_ncodeunits;
+ }
+
+ // trim the codepoint buffer, since we allocated too much
+ KERNEL_RETURN_IF_ERROR(
+ ctx,
+ output->buffers[2]->CopySlice(0, output_ncodeunits).Value(&output->buffers[2]));
+ } else {
+ const auto& input = checked_cast<const BaseBinaryScalar&>(*batch[0].scalar());
+ auto result = checked_pointer_cast<BaseBinaryScalar>(MakeNullScalar(out->type()));
+ if (input.is_valid) {
+ result->is_valid = true;
+ offset_type data_nbytes = (offset_type)input.value->size();
+ // See note above in the Array version explaining the 3 / 2
+ KERNEL_RETURN_IF_ERROR(ctx,
+ ctx->Allocate(data_nbytes * 3 / 2).Value(&result->value));
+ offset_type encoded_nbytes = DerivedClass::Transform(
+ input.value->data(), data_nbytes, result->value->mutable_data());
+ KERNEL_RETURN_IF_ERROR(
+ ctx, result->value->CopySlice(0, encoded_nbytes).Value(&result->value));
+ }
+ out->value = result;
+ }
+ }
+};
+
+template <typename Type>
+struct Utf8Upper : Utf8Transform<Type, Utf8Upper> {
+ inline static uint32_t TransformCodepoint(char32_t codepoint) {
Review comment:
Why `char32_t`? We're using `uint32_t` elsewhere.
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -30,6 +31,124 @@ namespace internal {
namespace {
+// lookup tables
+std::vector<uint32_t> lut_upper_codepoint;
+std::vector<uint32_t> lut_lower_codepoint;
+std::once_flag flag_case_luts;
+
+constexpr uint32_t REPLACEMENT_CHAR =
+ '?'; // the proper replacement char would be the 0xFFFD codepoint, but that can
+ // increase string length by a factor of 3
+constexpr int MAX_CODEPOINT_LUT = 0xffff; // up to this codepoint is in a lookup table
+
+static inline void utf8_encode(uint8_t*& str, uint32_t codepoint) {
+ if (codepoint < 0x80) {
+ *str++ = codepoint;
+ } else if (codepoint < 0x800) {
+ *str++ = 0xC0 + (codepoint >> 6);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else if (codepoint < 0x10000) {
+ *str++ = 0xE0 + (codepoint >> 12);
+ *str++ = 0x80 + ((codepoint >> 6) & 0x3F);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else if (codepoint < 0x200000) {
+ *str++ = 0xF0 + (codepoint >> 18);
+ *str++ = 0x80 + ((codepoint >> 12) & 0x3F);
+ *str++ = 0x80 + ((codepoint >> 6) & 0x3F);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else {
+ *str++ = codepoint;
Review comment:
Invalid characters should not be emitted silently.
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -30,6 +31,124 @@ namespace internal {
namespace {
+// lookup tables
+std::vector<uint32_t> lut_upper_codepoint;
+std::vector<uint32_t> lut_lower_codepoint;
+std::once_flag flag_case_luts;
+
+constexpr uint32_t REPLACEMENT_CHAR =
+ '?'; // the proper replacement char would be the 0xFFFD codepoint, but that can
+ // increase string length by a factor of 3
+constexpr int MAX_CODEPOINT_LUT = 0xffff; // up to this codepoint is in a lookup table
Review comment:
For constants, the recommended spelling would be e.g. `constexpr uint32_t kMaxCodepointLookup`.
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +158,121 @@ struct AsciiLength {
}
};
+template <typename Type, template <typename> class Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using DerivedClass = Derived<Type>;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* dest = output;
+ utf8_transform(input, input + input_string_ncodeunits, dest,
+ DerivedClass::TransformCodepoint);
+ return (offset_type)(dest - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ std::call_once(flag_case_luts, []() {
+ lut_upper_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ lut_lower_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ for (int i = 0; i <= MAX_CODEPOINT_LUT; i++) {
+ lut_upper_codepoint.push_back(utf8proc_toupper(i));
+ lut_lower_codepoint.push_back(utf8proc_tolower(i));
+ }
+ });
+ const ArrayData& input = *batch[0].array();
+ ArrayType input_boxed(batch[0].array());
+ ArrayData* output = out->mutable_array();
+
+ offset_type const* input_string_offsets = input.GetValues<offset_type>(1);
+ utf8proc_uint8_t const* input_str =
+ input.buffers[2]->data() + input_boxed.value_offset(0);
+ offset_type input_ncodeunits = input_boxed.total_values_length();
+ offset_type input_nstrings = (offset_type)input.length;
+
+ // Section 5.18 of the Unicode spec claim that the number of codepoints for case
+ // mapping can grow by a factor of 3. This means grow by a factor of 3 in bytes
+ // However, since we don't support all casings (SpecialCasing.txt) the growth
+ // is actually only at max 3/2 (as covered by the unittest).
+ // Note that rounding down the 3/2 is ok, since only codepoints encoded by
+ // two code units (even) can grow to 3 code units.
+
+ int64_t output_ncodeunits_max = ((int64_t)input_ncodeunits) * 3 / 2;
+ if (output_ncodeunits_max > std::numeric_limits<offset_type>::max()) {
+ ctx->SetStatus(Status::CapacityError(
+ "Result might not fit in a 32bit utf8 array, convert to large_utf8"));
+ return;
+ }
+
+ KERNEL_RETURN_IF_ERROR(
+ ctx, ctx->Allocate(output_ncodeunits_max).Value(&output->buffers[2]));
+ // We could reuse the buffer if it is all ascii, benchmarking showed this not to
+ // matter
+ // output->buffers[1] = input.buffers[1];
+ KERNEL_RETURN_IF_ERROR(ctx,
+ ctx->Allocate((input_nstrings + 1) * sizeof(offset_type))
+ .Value(&output->buffers[1]));
+ utf8proc_uint8_t* output_str = output->buffers[2]->mutable_data();
+ offset_type* output_string_offsets = output->GetMutableValues<offset_type>(1);
+ offset_type output_ncodeunits = 0;
+
+ offset_type output_string_offset = 0;
+ *output_string_offsets = output_string_offset;
+ offset_type input_string_first_offset = input_string_offsets[0];
+ for (int64_t i = 0; i < input_nstrings; i++) {
+ offset_type input_string_offset =
+ input_string_offsets[i] - input_string_first_offset;
+ offset_type input_string_end =
+ input_string_offsets[i + 1] - input_string_first_offset;
+ offset_type input_string_ncodeunits = input_string_end - input_string_offset;
+ offset_type encoded_nbytes = DerivedClass::Transform(
+ input_str + input_string_offset, input_string_ncodeunits,
+ output_str + output_ncodeunits);
+ output_ncodeunits += encoded_nbytes;
+ output_string_offsets[i + 1] = output_ncodeunits;
+ }
+
+ // trim the codepoint buffer, since we allocated too much
+ KERNEL_RETURN_IF_ERROR(
+ ctx,
+ output->buffers[2]->CopySlice(0, output_ncodeunits).Value(&output->buffers[2]));
+ } else {
+ const auto& input = checked_cast<const BaseBinaryScalar&>(*batch[0].scalar());
+ auto result = checked_pointer_cast<BaseBinaryScalar>(MakeNullScalar(out->type()));
+ if (input.is_valid) {
+ result->is_valid = true;
+ offset_type data_nbytes = (offset_type)input.value->size();
+ // See note above in the Array version explaining the 3 / 2
+ KERNEL_RETURN_IF_ERROR(ctx,
+ ctx->Allocate(data_nbytes * 3 / 2).Value(&result->value));
+ offset_type encoded_nbytes = DerivedClass::Transform(
+ input.value->data(), data_nbytes, result->value->mutable_data());
+ KERNEL_RETURN_IF_ERROR(
+ ctx, result->value->CopySlice(0, encoded_nbytes).Value(&result->value));
+ }
+ out->value = result;
+ }
+ }
+};
+
+template <typename Type>
+struct Utf8Upper : Utf8Transform<Type, Utf8Upper> {
Review comment:
Why is this templated on Type?
##########
File path: cpp/src/arrow/compute/kernels/scalar_string_test.cc
##########
@@ -68,6 +76,64 @@ TYPED_TEST(TestStringKernels, AsciiLower) {
this->string_type(), "[\"aaazzæÆ&\", null, \"\", \"bbb\"]");
}
+TEST(TestStringKernels, Utf8Upper32bitGrowth) {
+ std::string str(0xffff, 'a');
+ arrow::StringBuilder builder;
+ // 0x7fff * 0xffff is the max a 32 bit string array can hold
+ // since the utf8_upper kernel can grow it by 3/2, the max we should accept is is
+ // 0x7fff * 0xffff * 2/3 = 0x5555 * 0xffff, so this should give us a CapacityError
+ for (int64_t i = 0; i < 0x5556; i++) {
+ ASSERT_OK(builder.Append(str));
+ }
+ std::shared_ptr<arrow::Array> array;
+ arrow::Status st = builder.Finish(&array);
+ const FunctionOptions* options = nullptr;
+ EXPECT_RAISES_WITH_MESSAGE_THAT(CapacityError,
+ testing::HasSubstr("Result might not fit"),
+ CallFunction("utf8_upper", {array}, options));
+}
+
+TYPED_TEST(TestStringKernels, Utf8Upper) {
+ this->CheckUnary("utf8_upper", "[\"aAazZæÆ&\", null, \"\", \"b\"]", this->string_type(),
+ "[\"AAAZZÆÆ&\", null, \"\", \"B\"]");
+
+ // test varying encoding lenghts and thus changing indices/offsets
+ this->CheckUnary("utf8_upper", "[\"ɑɽⱤoW\", null, \"ıI\", \"b\"]", this->string_type(),
+ "[\"ⱭⱤⱤOW\", null, \"II\", \"B\"]");
+
+ // ῦ to Υ͂ not supported
+ // this->CheckUnary("utf8_upper", "[\"ῦɐɜʞȿ\"]", this->string_type(),
+ // "[\"Υ͂ⱯꞫꞰⱾ\"]");
+
+ // test maximum buffer growth
+ this->CheckUnary("utf8_upper", "[\"ɑɑɑɑ\"]", this->string_type(), "[\"ⱭⱭⱭⱭ\"]");
+
+ // Test replacing invalid data by ? (ὖ == \xe1\xbd\x96)
Review comment:
Why do you mention `ὖ` in this comment?
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -30,6 +31,124 @@ namespace internal {
namespace {
+// lookup tables
+std::vector<uint32_t> lut_upper_codepoint;
+std::vector<uint32_t> lut_lower_codepoint;
+std::once_flag flag_case_luts;
+
+constexpr uint32_t REPLACEMENT_CHAR =
+ '?'; // the proper replacement char would be the 0xFFFD codepoint, but that can
+ // increase string length by a factor of 3
+constexpr int MAX_CODEPOINT_LUT = 0xffff; // up to this codepoint is in a lookup table
+
+static inline void utf8_encode(uint8_t*& str, uint32_t codepoint) {
Review comment:
Also, it disallows non-const references. Instead, you may take a pointer argument.
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -30,6 +31,124 @@ namespace internal {
namespace {
+// lookup tables
+std::vector<uint32_t> lut_upper_codepoint;
+std::vector<uint32_t> lut_lower_codepoint;
+std::once_flag flag_case_luts;
+
+constexpr uint32_t REPLACEMENT_CHAR =
+ '?'; // the proper replacement char would be the 0xFFFD codepoint, but that can
+ // increase string length by a factor of 3
+constexpr int MAX_CODEPOINT_LUT = 0xffff; // up to this codepoint is in a lookup table
+
+static inline void utf8_encode(uint8_t*& str, uint32_t codepoint) {
Review comment:
Our coding style mandates CamelCase except for trivial accessors.
##########
File path: cpp/src/arrow/compute/kernels/scalar_string_test.cc
##########
@@ -68,6 +76,64 @@ TYPED_TEST(TestStringKernels, AsciiLower) {
this->string_type(), "[\"aaazzæÆ&\", null, \"\", \"bbb\"]");
}
+TEST(TestStringKernels, Utf8Upper32bitGrowth) {
+ std::string str(0xffff, 'a');
+ arrow::StringBuilder builder;
+ // 0x7fff * 0xffff is the max a 32 bit string array can hold
+ // since the utf8_upper kernel can grow it by 3/2, the max we should accept is is
+ // 0x7fff * 0xffff * 2/3 = 0x5555 * 0xffff, so this should give us a CapacityError
+ for (int64_t i = 0; i < 0x5556; i++) {
+ ASSERT_OK(builder.Append(str));
+ }
+ std::shared_ptr<arrow::Array> array;
+ arrow::Status st = builder.Finish(&array);
+ const FunctionOptions* options = nullptr;
+ EXPECT_RAISES_WITH_MESSAGE_THAT(CapacityError,
+ testing::HasSubstr("Result might not fit"),
+ CallFunction("utf8_upper", {array}, options));
+}
+
+TYPED_TEST(TestStringKernels, Utf8Upper) {
+ this->CheckUnary("utf8_upper", "[\"aAazZæÆ&\", null, \"\", \"b\"]", this->string_type(),
+ "[\"AAAZZÆÆ&\", null, \"\", \"B\"]");
+
+ // test varying encoding lenghts and thus changing indices/offsets
+ this->CheckUnary("utf8_upper", "[\"ɑɽⱤoW\", null, \"ıI\", \"b\"]", this->string_type(),
+ "[\"ⱭⱤⱤOW\", null, \"II\", \"B\"]");
+
+ // ῦ to Υ͂ not supported
+ // this->CheckUnary("utf8_upper", "[\"ῦɐɜʞȿ\"]", this->string_type(),
+ // "[\"Υ͂ⱯꞫꞰⱾ\"]");
+
+ // test maximum buffer growth
+ this->CheckUnary("utf8_upper", "[\"ɑɑɑɑ\"]", this->string_type(), "[\"ⱭⱭⱭⱭ\"]");
+
+ // Test replacing invalid data by ? (ὖ == \xe1\xbd\x96)
+ this->CheckUnary("utf8_upper", "[\"ɑa\xFFɑ\", \"ɽ\xe1\xbdɽaa\"]", this->string_type(),
+ "[\"ⱭA?Ɑ\", \"Ɽ?ⱤAA\"]");
+}
+
+TYPED_TEST(TestStringKernels, Utf8Lower) {
+ this->CheckUnary("utf8_lower", "[\"aAazZæÆ&\", null, \"\", \"b\"]", this->string_type(),
+ "[\"aaazzææ&\", null, \"\", \"b\"]");
+
+ // test varying encoding lenghts and thus changing indices/offsets
+ this->CheckUnary("utf8_lower", "[\"ⱭɽⱤoW\", null, \"ıI\", \"B\"]", this->string_type(),
+ "[\"ɑɽɽow\", null, \"ıi\", \"b\"]");
+
+ // ῦ to Υ͂ is not supported, but in principle the reverse is, but it would need
+ // normalization
+ // this->CheckUnary("utf8_lower", "[\"Υ͂ⱯꞫꞰⱾ\"]", this->string_type(),
+ // "[\"ῦɐɜʞȿ\"]");
+
+ // test maximum buffer growth
+ this->CheckUnary("utf8_lower", "[\"ȺȺȺȺ\"]", this->string_type(), "[\"ⱥⱥⱥⱥ\"]");
+
+ // Test replacing invalid data by ? (ὖ == \xe1\xbd\x96)
Review comment:
Why do you mention `ὖ` in this comment?
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +158,121 @@ struct AsciiLength {
}
};
+template <typename Type, template <typename> class Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using DerivedClass = Derived<Type>;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* dest = output;
+ utf8_transform(input, input + input_string_ncodeunits, dest,
+ DerivedClass::TransformCodepoint);
+ return (offset_type)(dest - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ std::call_once(flag_case_luts, []() {
+ lut_upper_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ lut_lower_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ for (int i = 0; i <= MAX_CODEPOINT_LUT; i++) {
+ lut_upper_codepoint.push_back(utf8proc_toupper(i));
+ lut_lower_codepoint.push_back(utf8proc_tolower(i));
+ }
+ });
+ const ArrayData& input = *batch[0].array();
+ ArrayType input_boxed(batch[0].array());
+ ArrayData* output = out->mutable_array();
+
+ offset_type const* input_string_offsets = input.GetValues<offset_type>(1);
+ utf8proc_uint8_t const* input_str =
+ input.buffers[2]->data() + input_boxed.value_offset(0);
+ offset_type input_ncodeunits = input_boxed.total_values_length();
+ offset_type input_nstrings = (offset_type)input.length;
Review comment:
`static_cast<offset_type>(input.length)`
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +158,121 @@ struct AsciiLength {
}
};
+template <typename Type, template <typename> class Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using DerivedClass = Derived<Type>;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* dest = output;
+ utf8_transform(input, input + input_string_ncodeunits, dest,
+ DerivedClass::TransformCodepoint);
+ return (offset_type)(dest - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ std::call_once(flag_case_luts, []() {
+ lut_upper_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ lut_lower_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ for (int i = 0; i <= MAX_CODEPOINT_LUT; i++) {
+ lut_upper_codepoint.push_back(utf8proc_toupper(i));
+ lut_lower_codepoint.push_back(utf8proc_tolower(i));
+ }
+ });
+ const ArrayData& input = *batch[0].array();
+ ArrayType input_boxed(batch[0].array());
+ ArrayData* output = out->mutable_array();
+
+ offset_type const* input_string_offsets = input.GetValues<offset_type>(1);
+ utf8proc_uint8_t const* input_str =
+ input.buffers[2]->data() + input_boxed.value_offset(0);
+ offset_type input_ncodeunits = input_boxed.total_values_length();
+ offset_type input_nstrings = (offset_type)input.length;
+
+ // Section 5.18 of the Unicode spec claim that the number of codepoints for case
+ // mapping can grow by a factor of 3. This means grow by a factor of 3 in bytes
+ // However, since we don't support all casings (SpecialCasing.txt) the growth
+ // is actually only at max 3/2 (as covered by the unittest).
+ // Note that rounding down the 3/2 is ok, since only codepoints encoded by
+ // two code units (even) can grow to 3 code units.
+
+ int64_t output_ncodeunits_max = ((int64_t)input_ncodeunits) * 3 / 2;
+ if (output_ncodeunits_max > std::numeric_limits<offset_type>::max()) {
+ ctx->SetStatus(Status::CapacityError(
+ "Result might not fit in a 32bit utf8 array, convert to large_utf8"));
+ return;
+ }
+
+ KERNEL_RETURN_IF_ERROR(
+ ctx, ctx->Allocate(output_ncodeunits_max).Value(&output->buffers[2]));
+ // We could reuse the buffer if it is all ascii, benchmarking showed this not to
+ // matter
+ // output->buffers[1] = input.buffers[1];
+ KERNEL_RETURN_IF_ERROR(ctx,
+ ctx->Allocate((input_nstrings + 1) * sizeof(offset_type))
+ .Value(&output->buffers[1]));
+ utf8proc_uint8_t* output_str = output->buffers[2]->mutable_data();
+ offset_type* output_string_offsets = output->GetMutableValues<offset_type>(1);
+ offset_type output_ncodeunits = 0;
+
+ offset_type output_string_offset = 0;
+ *output_string_offsets = output_string_offset;
+ offset_type input_string_first_offset = input_string_offsets[0];
+ for (int64_t i = 0; i < input_nstrings; i++) {
+ offset_type input_string_offset =
+ input_string_offsets[i] - input_string_first_offset;
+ offset_type input_string_end =
+ input_string_offsets[i + 1] - input_string_first_offset;
+ offset_type input_string_ncodeunits = input_string_end - input_string_offset;
+ offset_type encoded_nbytes = DerivedClass::Transform(
+ input_str + input_string_offset, input_string_ncodeunits,
+ output_str + output_ncodeunits);
+ output_ncodeunits += encoded_nbytes;
+ output_string_offsets[i + 1] = output_ncodeunits;
+ }
+
+ // trim the codepoint buffer, since we allocated too much
+ KERNEL_RETURN_IF_ERROR(
+ ctx,
+ output->buffers[2]->CopySlice(0, output_ncodeunits).Value(&output->buffers[2]));
+ } else {
+ const auto& input = checked_cast<const BaseBinaryScalar&>(*batch[0].scalar());
+ auto result = checked_pointer_cast<BaseBinaryScalar>(MakeNullScalar(out->type()));
+ if (input.is_valid) {
+ result->is_valid = true;
+ offset_type data_nbytes = (offset_type)input.value->size();
Review comment:
`static_cast<offset_type>(...)`
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +158,121 @@ struct AsciiLength {
}
};
+template <typename Type, template <typename> class Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using DerivedClass = Derived<Type>;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* dest = output;
+ utf8_transform(input, input + input_string_ncodeunits, dest,
+ DerivedClass::TransformCodepoint);
+ return (offset_type)(dest - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ std::call_once(flag_case_luts, []() {
+ lut_upper_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ lut_lower_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ for (int i = 0; i <= MAX_CODEPOINT_LUT; i++) {
+ lut_upper_codepoint.push_back(utf8proc_toupper(i));
+ lut_lower_codepoint.push_back(utf8proc_tolower(i));
+ }
+ });
+ const ArrayData& input = *batch[0].array();
+ ArrayType input_boxed(batch[0].array());
+ ArrayData* output = out->mutable_array();
+
+ offset_type const* input_string_offsets = input.GetValues<offset_type>(1);
+ utf8proc_uint8_t const* input_str =
+ input.buffers[2]->data() + input_boxed.value_offset(0);
+ offset_type input_ncodeunits = input_boxed.total_values_length();
+ offset_type input_nstrings = (offset_type)input.length;
+
+ // Section 5.18 of the Unicode spec claim that the number of codepoints for case
+ // mapping can grow by a factor of 3. This means grow by a factor of 3 in bytes
+ // However, since we don't support all casings (SpecialCasing.txt) the growth
+ // is actually only at max 3/2 (as covered by the unittest).
+ // Note that rounding down the 3/2 is ok, since only codepoints encoded by
+ // two code units (even) can grow to 3 code units.
+
+ int64_t output_ncodeunits_max = ((int64_t)input_ncodeunits) * 3 / 2;
+ if (output_ncodeunits_max > std::numeric_limits<offset_type>::max()) {
+ ctx->SetStatus(Status::CapacityError(
+ "Result might not fit in a 32bit utf8 array, convert to large_utf8"));
+ return;
+ }
+
+ KERNEL_RETURN_IF_ERROR(
+ ctx, ctx->Allocate(output_ncodeunits_max).Value(&output->buffers[2]));
+ // We could reuse the buffer if it is all ascii, benchmarking showed this not to
+ // matter
+ // output->buffers[1] = input.buffers[1];
+ KERNEL_RETURN_IF_ERROR(ctx,
+ ctx->Allocate((input_nstrings + 1) * sizeof(offset_type))
+ .Value(&output->buffers[1]));
+ utf8proc_uint8_t* output_str = output->buffers[2]->mutable_data();
+ offset_type* output_string_offsets = output->GetMutableValues<offset_type>(1);
+ offset_type output_ncodeunits = 0;
+
+ offset_type output_string_offset = 0;
+ *output_string_offsets = output_string_offset;
+ offset_type input_string_first_offset = input_string_offsets[0];
+ for (int64_t i = 0; i < input_nstrings; i++) {
+ offset_type input_string_offset =
+ input_string_offsets[i] - input_string_first_offset;
+ offset_type input_string_end =
+ input_string_offsets[i + 1] - input_string_first_offset;
+ offset_type input_string_ncodeunits = input_string_end - input_string_offset;
Review comment:
Why not simply call `GetView` instead?
```c++
const auto input = boxed_input.GetView(i);
```
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +158,121 @@ struct AsciiLength {
}
};
+template <typename Type, template <typename> class Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using DerivedClass = Derived<Type>;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* dest = output;
+ utf8_transform(input, input + input_string_ncodeunits, dest,
+ DerivedClass::TransformCodepoint);
+ return (offset_type)(dest - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ std::call_once(flag_case_luts, []() {
+ lut_upper_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ lut_lower_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ for (int i = 0; i <= MAX_CODEPOINT_LUT; i++) {
+ lut_upper_codepoint.push_back(utf8proc_toupper(i));
+ lut_lower_codepoint.push_back(utf8proc_tolower(i));
+ }
+ });
+ const ArrayData& input = *batch[0].array();
+ ArrayType input_boxed(batch[0].array());
+ ArrayData* output = out->mutable_array();
+
+ offset_type const* input_string_offsets = input.GetValues<offset_type>(1);
+ utf8proc_uint8_t const* input_str =
Review comment:
Just use `uint8_t`.
Also, you should be able to write:
```c++
const uint8_t* input_str = input_boxed->raw_value_offsets();
```
##########
File path: cpp/src/arrow/compute/kernels/scalar_string_test.cc
##########
@@ -81,5 +147,40 @@ TYPED_TEST(TestStringKernels, StrptimeDoesNotProvideDefaultOptions) {
ASSERT_RAISES(Invalid, CallFunction("strptime", {input}));
}
+TEST(TestStringKernels, UnicodeLibraryAssumptions) {
+ uint8_t output[4];
+ for (utf8proc_int32_t codepoint = 0x100; codepoint < 0x110000; codepoint++) {
+ utf8proc_ssize_t encoded_nbytes = utf8proc_encode_char(codepoint, output);
+ utf8proc_int32_t codepoint_upper = utf8proc_toupper(codepoint);
+ utf8proc_ssize_t encoded_nbytes_upper = utf8proc_encode_char(codepoint_upper, output);
+ if (encoded_nbytes == 2) {
+ EXPECT_LE(encoded_nbytes_upper, 3)
+ << "Expected the upper case codepoint for a 2 byte encoded codepoint to be "
+ "encoded in maximum 3 bytes, not "
+ << encoded_nbytes_upper;
+ }
+ if (encoded_nbytes == 3) {
Review comment:
(also, what's the point of two different conditionals if you're doing the same thing inside?)
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +158,121 @@ struct AsciiLength {
}
};
+template <typename Type, template <typename> class Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using DerivedClass = Derived<Type>;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* dest = output;
+ utf8_transform(input, input + input_string_ncodeunits, dest,
+ DerivedClass::TransformCodepoint);
+ return (offset_type)(dest - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ std::call_once(flag_case_luts, []() {
+ lut_upper_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ lut_lower_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ for (int i = 0; i <= MAX_CODEPOINT_LUT; i++) {
+ lut_upper_codepoint.push_back(utf8proc_toupper(i));
+ lut_lower_codepoint.push_back(utf8proc_tolower(i));
+ }
+ });
+ const ArrayData& input = *batch[0].array();
+ ArrayType input_boxed(batch[0].array());
+ ArrayData* output = out->mutable_array();
+
+ offset_type const* input_string_offsets = input.GetValues<offset_type>(1);
+ utf8proc_uint8_t const* input_str =
+ input.buffers[2]->data() + input_boxed.value_offset(0);
+ offset_type input_ncodeunits = input_boxed.total_values_length();
+ offset_type input_nstrings = (offset_type)input.length;
+
+ // Section 5.18 of the Unicode spec claim that the number of codepoints for case
+ // mapping can grow by a factor of 3. This means grow by a factor of 3 in bytes
+ // However, since we don't support all casings (SpecialCasing.txt) the growth
+ // is actually only at max 3/2 (as covered by the unittest).
+ // Note that rounding down the 3/2 is ok, since only codepoints encoded by
+ // two code units (even) can grow to 3 code units.
+
+ int64_t output_ncodeunits_max = ((int64_t)input_ncodeunits) * 3 / 2;
+ if (output_ncodeunits_max > std::numeric_limits<offset_type>::max()) {
+ ctx->SetStatus(Status::CapacityError(
+ "Result might not fit in a 32bit utf8 array, convert to large_utf8"));
+ return;
+ }
+
+ KERNEL_RETURN_IF_ERROR(
+ ctx, ctx->Allocate(output_ncodeunits_max).Value(&output->buffers[2]));
+ // We could reuse the buffer if it is all ascii, benchmarking showed this not to
+ // matter
+ // output->buffers[1] = input.buffers[1];
+ KERNEL_RETURN_IF_ERROR(ctx,
+ ctx->Allocate((input_nstrings + 1) * sizeof(offset_type))
+ .Value(&output->buffers[1]));
+ utf8proc_uint8_t* output_str = output->buffers[2]->mutable_data();
Review comment:
Please use `uint8_t`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
wesm commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-647860226
@kou utf8proc should only be used in a small number of compilation units, so what do you think about just using `set_target_properties(... PROPERTIES COMPILE_DEFINITIONS UTF8PROC_STATIC)` in those files?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] xhochy commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
xhochy commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-645401816
> Would a lookup table in the order of 256kb (generated at runtime, not in the binary) per case mapping be acceptable for Arrow?
I would find that acceptable if the mapping is only generated if needed (thus you will have a one-off payment when using a UTF8-kernel). I would though prefer if `utf8proc` could implement it just like this on their side. Can you open an issue there?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
wesm commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-645413587
I also agree with inlining the utf8proc functions until utf8proc can be patched to have better performance. I doubt that these optimizations will meaningfully impact the macroperformance of applications
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r447154836
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -15,13 +15,15 @@
// specific language governing permissions and limitations
// under the License.
+#include <utf8proc.h>
Review comment:
Np, I'd rather do it correct.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
wesm commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-647519089
> The downside is that users of the Arrow library are exposed to the implementation details of how each kernel can grow the resulting array.
I'm not saying that. I'm proposing instead a layered implementation approach. You will still write "utf8_lower(x)" in Python but the execution layer will decide when it's appropriate to split inputs or do type promotion. So Vaex shouldn't have to deal with these details.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] kou commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
kou commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-647834815
The change doesn't add `UTF8PROC_STATIC` definition...
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r446946562
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -30,6 +31,124 @@ namespace internal {
namespace {
+// lookup tables
+std::vector<uint32_t> lut_upper_codepoint;
+std::vector<uint32_t> lut_lower_codepoint;
+std::once_flag flag_case_luts;
+
+constexpr uint32_t REPLACEMENT_CHAR =
+ '?'; // the proper replacement char would be the 0xFFFD codepoint, but that can
+ // increase string length by a factor of 3
+constexpr int MAX_CODEPOINT_LUT = 0xffff; // up to this codepoint is in a lookup table
+
+static inline void utf8_encode(uint8_t*& str, uint32_t codepoint) {
+ if (codepoint < 0x80) {
+ *str++ = codepoint;
+ } else if (codepoint < 0x800) {
+ *str++ = 0xC0 + (codepoint >> 6);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else if (codepoint < 0x10000) {
+ *str++ = 0xE0 + (codepoint >> 12);
+ *str++ = 0x80 + ((codepoint >> 6) & 0x3F);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else if (codepoint < 0x200000) {
+ *str++ = 0xF0 + (codepoint >> 18);
+ *str++ = 0x80 + ((codepoint >> 12) & 0x3F);
+ *str++ = 0x80 + ((codepoint >> 6) & 0x3F);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else {
+ *str++ = codepoint;
+ }
+}
+
+static inline bool utf8_is_continuation(const uint8_t codeunit) {
+ return (codeunit & 0xC0) == 0x80; // upper two bits should be 10
+}
+
+static inline uint32_t utf8_decode(const uint8_t*& str, int64_t& length) {
+ if (*str < 0x80) { //
+ length -= 1;
+ return *str++;
+ } else if (*str < 0xC0) { // invalid non-ascii char
+ length -= 1;
+ str++;
+ return REPLACEMENT_CHAR;
Review comment:
Well, I'm not sure why it would make sense to ignore invalid input data here, unless not ignoring it has a significant cost (which sounds unlikely).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] kszucs commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
kszucs commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-645539612
Added `libutf8proc` dependency to the ursabot builders, same could be done for the docker-compose images. The tests are failing though.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou closed pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou closed pull request #7449:
URL: https://github.com/apache/arrow/pull/7449
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r446934815
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +158,121 @@ struct AsciiLength {
}
};
+template <typename Type, template <typename> class Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using DerivedClass = Derived<Type>;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* dest = output;
+ utf8_transform(input, input + input_string_ncodeunits, dest,
+ DerivedClass::TransformCodepoint);
+ return (offset_type)(dest - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ std::call_once(flag_case_luts, []() {
+ lut_upper_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ lut_lower_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ for (int i = 0; i <= MAX_CODEPOINT_LUT; i++) {
+ lut_upper_codepoint.push_back(utf8proc_toupper(i));
+ lut_lower_codepoint.push_back(utf8proc_tolower(i));
+ }
+ });
+ const ArrayData& input = *batch[0].array();
+ ArrayType input_boxed(batch[0].array());
+ ArrayData* output = out->mutable_array();
+
+ offset_type const* input_string_offsets = input.GetValues<offset_type>(1);
+ utf8proc_uint8_t const* input_str =
+ input.buffers[2]->data() + input_boxed.value_offset(0);
+ offset_type input_ncodeunits = input_boxed.total_values_length();
+ offset_type input_nstrings = (offset_type)input.length;
+
+ // Section 5.18 of the Unicode spec claim that the number of codepoints for case
+ // mapping can grow by a factor of 3. This means grow by a factor of 3 in bytes
+ // However, since we don't support all casings (SpecialCasing.txt) the growth
+ // is actually only at max 3/2 (as covered by the unittest).
+ // Note that rounding down the 3/2 is ok, since only codepoints encoded by
+ // two code units (even) can grow to 3 code units.
+
+ int64_t output_ncodeunits_max = ((int64_t)input_ncodeunits) * 3 / 2;
+ if (output_ncodeunits_max > std::numeric_limits<offset_type>::max()) {
+ ctx->SetStatus(Status::CapacityError(
+ "Result might not fit in a 32bit utf8 array, convert to large_utf8"));
+ return;
+ }
+
+ KERNEL_RETURN_IF_ERROR(
+ ctx, ctx->Allocate(output_ncodeunits_max).Value(&output->buffers[2]));
+ // We could reuse the buffer if it is all ascii, benchmarking showed this not to
+ // matter
+ // output->buffers[1] = input.buffers[1];
+ KERNEL_RETURN_IF_ERROR(ctx,
+ ctx->Allocate((input_nstrings + 1) * sizeof(offset_type))
+ .Value(&output->buffers[1]));
+ utf8proc_uint8_t* output_str = output->buffers[2]->mutable_data();
+ offset_type* output_string_offsets = output->GetMutableValues<offset_type>(1);
+ offset_type output_ncodeunits = 0;
+
+ offset_type output_string_offset = 0;
+ *output_string_offsets = output_string_offset;
+ offset_type input_string_first_offset = input_string_offsets[0];
+ for (int64_t i = 0; i < input_nstrings; i++) {
+ offset_type input_string_offset =
+ input_string_offsets[i] - input_string_first_offset;
+ offset_type input_string_end =
+ input_string_offsets[i + 1] - input_string_first_offset;
+ offset_type input_string_ncodeunits = input_string_end - input_string_offset;
+ offset_type encoded_nbytes = DerivedClass::Transform(
+ input_str + input_string_offset, input_string_ncodeunits,
+ output_str + output_ncodeunits);
+ output_ncodeunits += encoded_nbytes;
+ output_string_offsets[i + 1] = output_ncodeunits;
+ }
+
+ // trim the codepoint buffer, since we allocated too much
+ KERNEL_RETURN_IF_ERROR(
+ ctx,
+ output->buffers[2]->CopySlice(0, output_ncodeunits).Value(&output->buffers[2]));
+ } else {
+ const auto& input = checked_cast<const BaseBinaryScalar&>(*batch[0].scalar());
+ auto result = checked_pointer_cast<BaseBinaryScalar>(MakeNullScalar(out->type()));
+ if (input.is_valid) {
+ result->is_valid = true;
+ offset_type data_nbytes = (offset_type)input.value->size();
+ // See note above in the Array version explaining the 3 / 2
+ KERNEL_RETURN_IF_ERROR(ctx,
+ ctx->Allocate(data_nbytes * 3 / 2).Value(&result->value));
+ offset_type encoded_nbytes = DerivedClass::Transform(
+ input.value->data(), data_nbytes, result->value->mutable_data());
+ KERNEL_RETURN_IF_ERROR(
+ ctx, result->value->CopySlice(0, encoded_nbytes).Value(&result->value));
+ }
+ out->value = result;
+ }
+ }
+};
+
+template <typename Type>
+struct Utf8Upper : Utf8Transform<Type, Utf8Upper> {
Review comment:
Good catch, that was preparing for Upcasting, which would need this, since we agreed not to upcast, we can remove it.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r446988586
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +158,121 @@ struct AsciiLength {
}
};
+template <typename Type, template <typename> class Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using DerivedClass = Derived<Type>;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* dest = output;
+ utf8_transform(input, input + input_string_ncodeunits, dest,
+ DerivedClass::TransformCodepoint);
+ return (offset_type)(dest - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ std::call_once(flag_case_luts, []() {
+ lut_upper_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ lut_lower_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ for (int i = 0; i <= MAX_CODEPOINT_LUT; i++) {
+ lut_upper_codepoint.push_back(utf8proc_toupper(i));
+ lut_lower_codepoint.push_back(utf8proc_tolower(i));
+ }
+ });
+ const ArrayData& input = *batch[0].array();
+ ArrayType input_boxed(batch[0].array());
+ ArrayData* output = out->mutable_array();
+
+ offset_type const* input_string_offsets = input.GetValues<offset_type>(1);
+ utf8proc_uint8_t const* input_str =
+ input.buffers[2]->data() + input_boxed.value_offset(0);
+ offset_type input_ncodeunits = input_boxed.total_values_length();
+ offset_type input_nstrings = (offset_type)input.length;
+
+ // Section 5.18 of the Unicode spec claim that the number of codepoints for case
+ // mapping can grow by a factor of 3. This means grow by a factor of 3 in bytes
+ // However, since we don't support all casings (SpecialCasing.txt) the growth
+ // is actually only at max 3/2 (as covered by the unittest).
+ // Note that rounding down the 3/2 is ok, since only codepoints encoded by
+ // two code units (even) can grow to 3 code units.
+
+ int64_t output_ncodeunits_max = ((int64_t)input_ncodeunits) * 3 / 2;
+ if (output_ncodeunits_max > std::numeric_limits<offset_type>::max()) {
+ ctx->SetStatus(Status::CapacityError(
+ "Result might not fit in a 32bit utf8 array, convert to large_utf8"));
+ return;
+ }
+
+ KERNEL_RETURN_IF_ERROR(
+ ctx, ctx->Allocate(output_ncodeunits_max).Value(&output->buffers[2]));
+ // We could reuse the buffer if it is all ascii, benchmarking showed this not to
+ // matter
+ // output->buffers[1] = input.buffers[1];
+ KERNEL_RETURN_IF_ERROR(ctx,
+ ctx->Allocate((input_nstrings + 1) * sizeof(offset_type))
+ .Value(&output->buffers[1]));
+ utf8proc_uint8_t* output_str = output->buffers[2]->mutable_data();
+ offset_type* output_string_offsets = output->GetMutableValues<offset_type>(1);
+ offset_type output_ncodeunits = 0;
+
+ offset_type output_string_offset = 0;
+ *output_string_offsets = output_string_offset;
+ offset_type input_string_first_offset = input_string_offsets[0];
+ for (int64_t i = 0; i < input_nstrings; i++) {
+ offset_type input_string_offset =
+ input_string_offsets[i] - input_string_first_offset;
+ offset_type input_string_end =
+ input_string_offsets[i + 1] - input_string_first_offset;
+ offset_type input_string_ncodeunits = input_string_end - input_string_offset;
Review comment:
Using GetValue now, much cleaner 👍
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] xhochy commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
xhochy commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-645253060
The major difference between `unilib` and `utf8proc` in uppercasing a character seems to be that [unilib looks up the uppercase value directly](https://github.com/ufal/unilib/blob/d8276e70b7c11c677897f71030de7258cbb1f99e/unilib/unicode.h#L81) wheras [utf8proc first gets a struct with all properties](https://github.com/JuliaStrings/utf8proc/blob/08f9999a0698639f15d07b12c0065a4494f2d504/utf8proc.c#L377) from which it extracts the uppercase value. Pre-computing the uppercase dictionary first could bring `utf8proc` en par with the performance.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r446964243
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +158,121 @@ struct AsciiLength {
}
};
+template <typename Type, template <typename> class Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using DerivedClass = Derived<Type>;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* dest = output;
+ utf8_transform(input, input + input_string_ncodeunits, dest,
+ DerivedClass::TransformCodepoint);
+ return (offset_type)(dest - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ std::call_once(flag_case_luts, []() {
+ lut_upper_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ lut_lower_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ for (int i = 0; i <= MAX_CODEPOINT_LUT; i++) {
+ lut_upper_codepoint.push_back(utf8proc_toupper(i));
+ lut_lower_codepoint.push_back(utf8proc_tolower(i));
+ }
+ });
+ const ArrayData& input = *batch[0].array();
+ ArrayType input_boxed(batch[0].array());
+ ArrayData* output = out->mutable_array();
+
+ offset_type const* input_string_offsets = input.GetValues<offset_type>(1);
+ utf8proc_uint8_t const* input_str =
Review comment:
That's the offset, I don't see a similar method for the data, let me know if I'm wrong.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r446934057
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -30,6 +31,124 @@ namespace internal {
namespace {
+// lookup tables
+std::vector<uint32_t> lut_upper_codepoint;
+std::vector<uint32_t> lut_lower_codepoint;
+std::once_flag flag_case_luts;
+
+constexpr uint32_t REPLACEMENT_CHAR =
+ '?'; // the proper replacement char would be the 0xFFFD codepoint, but that can
+ // increase string length by a factor of 3
+constexpr int MAX_CODEPOINT_LUT = 0xffff; // up to this codepoint is in a lookup table
+
+static inline void utf8_encode(uint8_t*& str, uint32_t codepoint) {
+ if (codepoint < 0x80) {
+ *str++ = codepoint;
+ } else if (codepoint < 0x800) {
+ *str++ = 0xC0 + (codepoint >> 6);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else if (codepoint < 0x10000) {
+ *str++ = 0xE0 + (codepoint >> 12);
+ *str++ = 0x80 + ((codepoint >> 6) & 0x3F);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else if (codepoint < 0x200000) {
+ *str++ = 0xF0 + (codepoint >> 18);
+ *str++ = 0x80 + ((codepoint >> 12) & 0x3F);
+ *str++ = 0x80 + ((codepoint >> 6) & 0x3F);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else {
+ *str++ = codepoint;
+ }
+}
+
+static inline bool utf8_is_continuation(const uint8_t codeunit) {
+ return (codeunit & 0xC0) == 0x80; // upper two bits should be 10
+}
+
+static inline uint32_t utf8_decode(const uint8_t*& str, int64_t& length) {
+ if (*str < 0x80) { //
+ length -= 1;
+ return *str++;
+ } else if (*str < 0xC0) { // invalid non-ascii char
+ length -= 1;
+ str++;
+ return REPLACEMENT_CHAR;
Review comment:
Would you mind we keep it as is for now, and maybe discuss this separately? Happy to take this to the mailing list.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-644949978
It's not *that* slow, it was 40% of Vaex' performance (single threaded), so I think there is a bit more to be gained still. But I have added an optimization that tries ASCII conversion first. This gives it a 7x (compared to Vaex) to 10x speedup (in the benchmarks).
Before:
```
Utf8Lower 193873803 ns 193823124 ns 3 bytes_per_second=102.387M/s items_per_second=5.40996M/s
Utf8Upper 197154929 ns 197093083 ns 4 bytes_per_second=100.688M/s items_per_second=5.32021M/s
```
After:
```
Utf8Lower 19508443 ns 19493652 ns 36 bytes_per_second=1018.02M/s items_per_second=53.7906M/s
Utf8Upper 19846885 ns 19832066 ns 35 bytes_per_second=1000.65M/s items_per_second=52.8728M/s
```
There is one loose end, the growth of the string can cause a utf8 array to be promoted to a large_utf8.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] nealrichardson commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
nealrichardson commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651261388
The R Windows builds will fail until either utf8proc is not required by default (https://issues.apache.org/jira/browse/ARROW-9220) or until libutf8proc is added as a dependency to https://github.com/apache/arrow/blob/master/ci/scripts/PKGBUILD (@xhochy has done the necessary to get it built for Rtools in https://github.com/r-windows/rtools-packages/pull/124).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r447171303
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -133,23 +134,23 @@ struct Utf8Transform {
output_string_offsets[i + 1] = output_ncodeunits;
}
- // trim the codepoint buffer, since we allocated too much
+ // Trim the codepoint buffer, since we allocated too much
KERNEL_RETURN_IF_ERROR(
- ctx,
- output->buffers[2]->CopySlice(0, output_ncodeunits).Value(&output->buffers[2]));
+ ctx, values_buffer->Resize(output_ncodeunits, /*shrink_to_fit=*/true));
Review comment:
:-)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-647711867
@xhochy I see at least an `undefined reference to `_imp__utf8proc_toupper'` in the MinGW builds, hope that helps.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r447149548
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -30,6 +31,124 @@ namespace internal {
namespace {
+// lookup tables
+std::vector<uint32_t> lut_upper_codepoint;
+std::vector<uint32_t> lut_lower_codepoint;
+std::once_flag flag_case_luts;
+
+constexpr uint32_t REPLACEMENT_CHAR =
+ '?'; // the proper replacement char would be the 0xFFFD codepoint, but that can
+ // increase string length by a factor of 3
+constexpr int MAX_CODEPOINT_LUT = 0xffff; // up to this codepoint is in a lookup table
+
+static inline void utf8_encode(uint8_t*& str, uint32_t codepoint) {
+ if (codepoint < 0x80) {
+ *str++ = codepoint;
+ } else if (codepoint < 0x800) {
+ *str++ = 0xC0 + (codepoint >> 6);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else if (codepoint < 0x10000) {
+ *str++ = 0xE0 + (codepoint >> 12);
+ *str++ = 0x80 + ((codepoint >> 6) & 0x3F);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else if (codepoint < 0x200000) {
+ *str++ = 0xF0 + (codepoint >> 18);
+ *str++ = 0x80 + ((codepoint >> 12) & 0x3F);
+ *str++ = 0x80 + ((codepoint >> 6) & 0x3F);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else {
+ *str++ = codepoint;
+ }
+}
+
+static inline bool utf8_is_continuation(const uint8_t codeunit) {
+ return (codeunit & 0xC0) == 0x80; // upper two bits should be 10
+}
+
+static inline uint32_t utf8_decode(const uint8_t*& str, int64_t& length) {
+ if (*str < 0x80) { //
+ length -= 1;
+ return *str++;
+ } else if (*str < 0xC0) { // invalid non-ascii char
+ length -= 1;
+ str++;
+ return REPLACEMENT_CHAR;
Review comment:
there are different strategies that are 'common', replacement by a replacement character (similar to what I do here), or assuming Latin 1 encoding, and try to salvage it a bit.
But I wonder what a common strategy should be, should we be forgiving on invalid data, should we bail out and have separate 'corrections' kernels? I'm not sure what the best place is for addressing this.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] xhochy commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
xhochy commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-644795203
> We'll need to make utf8proc a proper toolchain library, @pitrou should be able to help you with that.
I can take care of that!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] nealrichardson commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
nealrichardson commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651355763
> > This means there also needs to be a PKGBUILD
>
> Why? `libutf8proc` is installed.
The version installed is compiled with gcc 8. RTools 35 uses gcc 4.9. Most of our deps have to be compiled for both, and this is apparently one of those. That's what https://github.com/r-windows/rtools-backports is for.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou edited a comment on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou edited a comment on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-650606456
@wesm I can also take this since you already have quite a bit on your plate for 1.0.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r446958717
##########
File path: cpp/src/arrow/compute/kernels/scalar_string_test.cc
##########
@@ -81,5 +147,40 @@ TYPED_TEST(TestStringKernels, StrptimeDoesNotProvideDefaultOptions) {
ASSERT_RAISES(Invalid, CallFunction("strptime", {input}));
}
+TEST(TestStringKernels, UnicodeLibraryAssumptions) {
+ uint8_t output[4];
+ for (utf8proc_int32_t codepoint = 0x100; codepoint < 0x110000; codepoint++) {
+ utf8proc_ssize_t encoded_nbytes = utf8proc_encode_char(codepoint, output);
+ utf8proc_int32_t codepoint_upper = utf8proc_toupper(codepoint);
+ utf8proc_ssize_t encoded_nbytes_upper = utf8proc_encode_char(codepoint_upper, output);
+ if (encoded_nbytes == 2) {
+ EXPECT_LE(encoded_nbytes_upper, 3)
+ << "Expected the upper case codepoint for a 2 byte encoded codepoint to be "
+ "encoded in maximum 3 bytes, not "
+ << encoded_nbytes_upper;
+ }
+ if (encoded_nbytes == 3) {
Review comment:
This code tests the assumption that the byte length growth for case mapping can only be at max 3/2, which is what we use for pre-allocation of the buffers. Unicode codepoints encoded in 4 bytes can only be 4 bytes or less when upper cased or lower cased, so we don't need to check them here. We can also skip the test that tests that case for `encoded_nbytes=3`, since it will not matter. I'll add a comment why we do the test.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r447155149
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +73,103 @@ struct AsciiLength {
}
};
+template <typename Type, typename Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* output_end = arrow::util::Utf8Transform(
+ input, input + input_string_ncodeunits, output, Derived::TransformCodepoint);
+ return static_cast<offset_type>(output_end - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ EnsureLookupTablesFilled();
+ const ArrayData& input = *batch[0].array();
+ ArrayType input_boxed(batch[0].array());
+ ArrayData* output = out->mutable_array();
+
+ offset_type input_ncodeunits = input_boxed.total_values_length();
+ offset_type input_nstrings = static_cast<offset_type>(input.length);
+
+ // Section 5.18 of the Unicode spec claim that the number of codepoints for case
+ // mapping can grow by a factor of 3. This means grow by a factor of 3 in bytes
+ // However, since we don't support all casings (SpecialCasing.txt) the growth
+ // is actually only at max 3/2 (as covered by the unittest).
+ // Note that rounding down the 3/2 is ok, since only codepoints encoded by
+ // two code units (even) can grow to 3 code units.
+
+ int64_t output_ncodeunits_max = ((int64_t)input_ncodeunits) * 3 / 2;
Review comment:
Old habit, doing my best :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r447161925
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +158,121 @@ struct AsciiLength {
}
};
+template <typename Type, template <typename> class Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using DerivedClass = Derived<Type>;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* dest = output;
+ utf8_transform(input, input + input_string_ncodeunits, dest,
+ DerivedClass::TransformCodepoint);
+ return (offset_type)(dest - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ std::call_once(flag_case_luts, []() {
+ lut_upper_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ lut_lower_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ for (int i = 0; i <= MAX_CODEPOINT_LUT; i++) {
+ lut_upper_codepoint.push_back(utf8proc_toupper(i));
+ lut_lower_codepoint.push_back(utf8proc_tolower(i));
+ }
+ });
+ const ArrayData& input = *batch[0].array();
+ ArrayType input_boxed(batch[0].array());
+ ArrayData* output = out->mutable_array();
+
+ offset_type const* input_string_offsets = input.GetValues<offset_type>(1);
+ utf8proc_uint8_t const* input_str =
+ input.buffers[2]->data() + input_boxed.value_offset(0);
+ offset_type input_ncodeunits = input_boxed.total_values_length();
+ offset_type input_nstrings = (offset_type)input.length;
+
+ // Section 5.18 of the Unicode spec claim that the number of codepoints for case
+ // mapping can grow by a factor of 3. This means grow by a factor of 3 in bytes
+ // However, since we don't support all casings (SpecialCasing.txt) the growth
+ // is actually only at max 3/2 (as covered by the unittest).
+ // Note that rounding down the 3/2 is ok, since only codepoints encoded by
+ // two code units (even) can grow to 3 code units.
+
+ int64_t output_ncodeunits_max = ((int64_t)input_ncodeunits) * 3 / 2;
+ if (output_ncodeunits_max > std::numeric_limits<offset_type>::max()) {
+ ctx->SetStatus(Status::CapacityError(
+ "Result might not fit in a 32bit utf8 array, convert to large_utf8"));
+ return;
+ }
+
+ KERNEL_RETURN_IF_ERROR(
+ ctx, ctx->Allocate(output_ncodeunits_max).Value(&output->buffers[2]));
+ // We could reuse the buffer if it is all ascii, benchmarking showed this not to
+ // matter
+ // output->buffers[1] = input.buffers[1];
+ KERNEL_RETURN_IF_ERROR(ctx,
+ ctx->Allocate((input_nstrings + 1) * sizeof(offset_type))
+ .Value(&output->buffers[1]));
+ utf8proc_uint8_t* output_str = output->buffers[2]->mutable_data();
+ offset_type* output_string_offsets = output->GetMutableValues<offset_type>(1);
+ offset_type output_ncodeunits = 0;
+
+ offset_type output_string_offset = 0;
+ *output_string_offsets = output_string_offset;
+ offset_type input_string_first_offset = input_string_offsets[0];
+ for (int64_t i = 0; i < input_nstrings; i++) {
+ offset_type input_string_offset =
+ input_string_offsets[i] - input_string_first_offset;
+ offset_type input_string_end =
+ input_string_offsets[i + 1] - input_string_first_offset;
+ offset_type input_string_ncodeunits = input_string_end - input_string_offset;
+ offset_type encoded_nbytes = DerivedClass::Transform(
+ input_str + input_string_offset, input_string_ncodeunits,
+ output_str + output_ncodeunits);
+ output_ncodeunits += encoded_nbytes;
+ output_string_offsets[i + 1] = output_ncodeunits;
+ }
+
+ // trim the codepoint buffer, since we allocated too much
+ KERNEL_RETURN_IF_ERROR(
+ ctx,
+ output->buffers[2]->CopySlice(0, output_ncodeunits).Value(&output->buffers[2]));
Review comment:
Ok, I just pushed a change which resizes the buffer (hopefully in-place). This makes the benchmarks a bit faster.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
wesm commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651793397
thanks @maartenbreddels!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
wesm commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-647226180
> There is one loose end, the growth of the string can cause a utf8 array to be promoted to a large_utf8.
I'd like to treat in-kernel type promotions as an anti-pattern in general. If there is the possibility of overflowing the capacity of a StringArray, then it would be better to do the type promotion (if that is really what is desired) prior to choosing and invoking a kernel (so you would promote to LARGE_STRING and then use the large_utf8 kernel variant).
A better and more efficient strategy would be to break the array into pieces with `Slice` (based on some size heuristic, e.g. 1MB-8MB of data per slice at most) and process the smaller chunks separately. This also means that you can execute the kernel in parallel. This is the decision that will be made by the expression execution layer once that is developed (I plan to work on it after the 1.0.0 release) because it permits both parallel execution and operator pipelining.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] github-actions[bot] commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
github-actions[bot] commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-644804943
https://issues.apache.org/jira/browse/ARROW-9133
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r447142388
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +73,103 @@ struct AsciiLength {
}
};
+template <typename Type, typename Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* output_end = arrow::util::Utf8Transform(
+ input, input + input_string_ncodeunits, output, Derived::TransformCodepoint);
+ return static_cast<offset_type>(output_end - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ EnsureLookupTablesFilled();
+ const ArrayData& input = *batch[0].array();
+ ArrayType input_boxed(batch[0].array());
+ ArrayData* output = out->mutable_array();
+
+ offset_type input_ncodeunits = input_boxed.total_values_length();
+ offset_type input_nstrings = static_cast<offset_type>(input.length);
+
+ // Section 5.18 of the Unicode spec claim that the number of codepoints for case
+ // mapping can grow by a factor of 3. This means grow by a factor of 3 in bytes
+ // However, since we don't support all casings (SpecialCasing.txt) the growth
+ // is actually only at max 3/2 (as covered by the unittest).
+ // Note that rounding down the 3/2 is ok, since only codepoints encoded by
+ // two code units (even) can grow to 3 code units.
+
+ int64_t output_ncodeunits_max = ((int64_t)input_ncodeunits) * 3 / 2;
Review comment:
Nit: `static_cast<int64_t>` as per our style guide :-)
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +158,121 @@ struct AsciiLength {
}
};
+template <typename Type, template <typename> class Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using DerivedClass = Derived<Type>;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* dest = output;
+ utf8_transform(input, input + input_string_ncodeunits, dest,
+ DerivedClass::TransformCodepoint);
+ return (offset_type)(dest - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ std::call_once(flag_case_luts, []() {
+ lut_upper_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ lut_lower_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ for (int i = 0; i <= MAX_CODEPOINT_LUT; i++) {
+ lut_upper_codepoint.push_back(utf8proc_toupper(i));
+ lut_lower_codepoint.push_back(utf8proc_tolower(i));
+ }
+ });
+ const ArrayData& input = *batch[0].array();
+ ArrayType input_boxed(batch[0].array());
+ ArrayData* output = out->mutable_array();
+
+ offset_type const* input_string_offsets = input.GetValues<offset_type>(1);
+ utf8proc_uint8_t const* input_str =
+ input.buffers[2]->data() + input_boxed.value_offset(0);
+ offset_type input_ncodeunits = input_boxed.total_values_length();
+ offset_type input_nstrings = (offset_type)input.length;
+
+ // Section 5.18 of the Unicode spec claim that the number of codepoints for case
+ // mapping can grow by a factor of 3. This means grow by a factor of 3 in bytes
+ // However, since we don't support all casings (SpecialCasing.txt) the growth
+ // is actually only at max 3/2 (as covered by the unittest).
+ // Note that rounding down the 3/2 is ok, since only codepoints encoded by
+ // two code units (even) can grow to 3 code units.
+
+ int64_t output_ncodeunits_max = ((int64_t)input_ncodeunits) * 3 / 2;
+ if (output_ncodeunits_max > std::numeric_limits<offset_type>::max()) {
+ ctx->SetStatus(Status::CapacityError(
+ "Result might not fit in a 32bit utf8 array, convert to large_utf8"));
+ return;
+ }
+
+ KERNEL_RETURN_IF_ERROR(
+ ctx, ctx->Allocate(output_ncodeunits_max).Value(&output->buffers[2]));
+ // We could reuse the buffer if it is all ascii, benchmarking showed this not to
+ // matter
+ // output->buffers[1] = input.buffers[1];
+ KERNEL_RETURN_IF_ERROR(ctx,
+ ctx->Allocate((input_nstrings + 1) * sizeof(offset_type))
+ .Value(&output->buffers[1]));
+ utf8proc_uint8_t* output_str = output->buffers[2]->mutable_data();
+ offset_type* output_string_offsets = output->GetMutableValues<offset_type>(1);
+ offset_type output_ncodeunits = 0;
+
+ offset_type output_string_offset = 0;
+ *output_string_offsets = output_string_offset;
+ offset_type input_string_first_offset = input_string_offsets[0];
+ for (int64_t i = 0; i < input_nstrings; i++) {
+ offset_type input_string_offset =
+ input_string_offsets[i] - input_string_first_offset;
+ offset_type input_string_end =
+ input_string_offsets[i + 1] - input_string_first_offset;
+ offset_type input_string_ncodeunits = input_string_end - input_string_offset;
+ offset_type encoded_nbytes = DerivedClass::Transform(
+ input_str + input_string_offset, input_string_ncodeunits,
+ output_str + output_ncodeunits);
+ output_ncodeunits += encoded_nbytes;
+ output_string_offsets[i + 1] = output_ncodeunits;
+ }
+
+ // trim the codepoint buffer, since we allocated too much
+ KERNEL_RETURN_IF_ERROR(
+ ctx,
+ output->buffers[2]->CopySlice(0, output_ncodeunits).Value(&output->buffers[2]));
+ } else {
+ const auto& input = checked_cast<const BaseBinaryScalar&>(*batch[0].scalar());
+ auto result = checked_pointer_cast<BaseBinaryScalar>(MakeNullScalar(out->type()));
+ if (input.is_valid) {
+ result->is_valid = true;
+ offset_type data_nbytes = (offset_type)input.value->size();
+ // See note above in the Array version explaining the 3 / 2
+ KERNEL_RETURN_IF_ERROR(ctx,
+ ctx->Allocate(data_nbytes * 3 / 2).Value(&result->value));
+ offset_type encoded_nbytes = DerivedClass::Transform(
+ input.value->data(), data_nbytes, result->value->mutable_data());
+ KERNEL_RETURN_IF_ERROR(
+ ctx, result->value->CopySlice(0, encoded_nbytes).Value(&result->value));
+ }
+ out->value = result;
+ }
+ }
+};
+
+template <typename Type>
+struct Utf8Upper : Utf8Transform<Type, Utf8Upper> {
Review comment:
Uh, right, you need the template for subclassing. Sorry.
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -15,13 +15,15 @@
// specific language governing permissions and limitations
// under the License.
+#include <utf8proc.h>
Review comment:
Nit, but please separate this include from the standard library includes (and put it below them).
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -30,6 +32,38 @@ namespace internal {
namespace {
+// lookup tables
+constexpr int kMaxCodepointLookup = 0xffff; // up to this codepoint is in a lookup table
Review comment:
Make this a `uint32_t` to avoid signed/unsigned comparison issues.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651353338
> This means there also needs to be a PKGBUILD
Why? `libutf8proc` is installed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651338264
@xhochy Could you help on the utf8proc issue on RTools 3.5?
See here: https://github.com/apache/arrow/pull/7449/checks?check_run_id=819772618#step:10:169
It seems that `UTF8PROC_STATIC` would need to be defined when building Arrow. But it's not set by `Findutf8proc.cmake`.
Also, `libutf8proc.pc.in` added in https://github.com/r-windows/rtools-packages/pull/124 doesn't set it either.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wesm edited a comment on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
wesm edited a comment on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-647860226
@kou utf8proc should only be used in a small number of compilation units, so what do you think about just using `set_source_files_properties(... PROPERTIES COMPILE_DEFINITIONS UTF8PROC_STATIC)` in those files?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r446934218
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -30,6 +31,124 @@ namespace internal {
namespace {
+// lookup tables
+std::vector<uint32_t> lut_upper_codepoint;
+std::vector<uint32_t> lut_lower_codepoint;
+std::once_flag flag_case_luts;
+
+constexpr uint32_t REPLACEMENT_CHAR =
+ '?'; // the proper replacement char would be the 0xFFFD codepoint, but that can
+ // increase string length by a factor of 3
+constexpr int MAX_CODEPOINT_LUT = 0xffff; // up to this codepoint is in a lookup table
+
+static inline void utf8_encode(uint8_t*& str, uint32_t codepoint) {
Review comment:
Great, didn't see that, will move it.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou edited a comment on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou edited a comment on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651282959
Main point remaining is whether we raise an error on invalid UTF8 input. I see no reason not to (an Arrow string array has to be valid UTF8 as per the spec, just like a Python unicode string cannot contain characters outside of the unicode code range).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-645382201
Let's step back a bit: why do we care about micro-optimizing this?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
wesm commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-645698551
I just merged my changes for the ASCII kernels making those work on sliced arrays
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651366993
> The version installed is compiled with gcc 8. RTools 35 uses gcc 4.9
What difference does it make? This is plain C.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] nealrichardson commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
nealrichardson commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651342350
> @xhochy Could you help on the utf8proc issue on RTools 3.5?
> See here: https://github.com/apache/arrow/pull/7449/checks?check_run_id=819772618#step:10:169
This means there also needs to be a PKGBUILD submitted to `r-windows/rtools-backports` for the old toolchain.
>
> It seems that `UTF8PROC_STATIC` would need to be defined when building Arrow. But it's not set by `Findutf8proc.cmake`.
> Also, `libutf8proc.pc.in` added in [r-windows/rtools-packages#124](https://github.com/r-windows/rtools-packages/pull/124) doesn't set it either.
Just a reminder that nothing in the R bindings touches these new functions, so turning off utf8proc in the C++ build is also an option for now.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651282415
> Having a benchmark run on non-ascii codepoints (I think we want to do this separate from this PR, but important point).
Yes, I think we can defer that to a separate PR.
> The existing decoder based on http://bjoern.hoehrmann.de/utf-8/decoder/dfa/ was new to me. Very interesting work, but unfortunately led to a performance regression (~50->30 M/s), which I'm surprised about actually. Maybe worth comparing again when we have a benchmark with non-ascii codepoints.
Yes, too. The main point of this state-machine-based decoder is that it's branchless, and so it will perform roughly as well on non-Ascii data with unpredictable branching. On pure Ascii data, a branch-based decoder may be faster since the branches will always be predicted right.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-647429536
> I'd like to treat in-kernel type promotions as an anti-pattern in general.
There are upsides and downsides to it. The downside is that users of the Arrow library are exposed to the implementation details of how each kernel can grow the resulting array. I see this being quite a burden in vaex, to keep track of which kernel does what, and when to promote.
Vaex does something similar, slicing the array's in smaller chunks, but still, it would need to check the sizes, no matter how small the slices are.
Maybe it's best to keep this PR simple first (so give an error?), and discuss the behavior of string growth on the mailing list?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
wesm commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-645341259
Since the Unilib developer isn't interested in changing the license I think our effort would be better invested in optimizing utf8proc
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-645276441
I used valgrind/callgrind to see how where time spent:
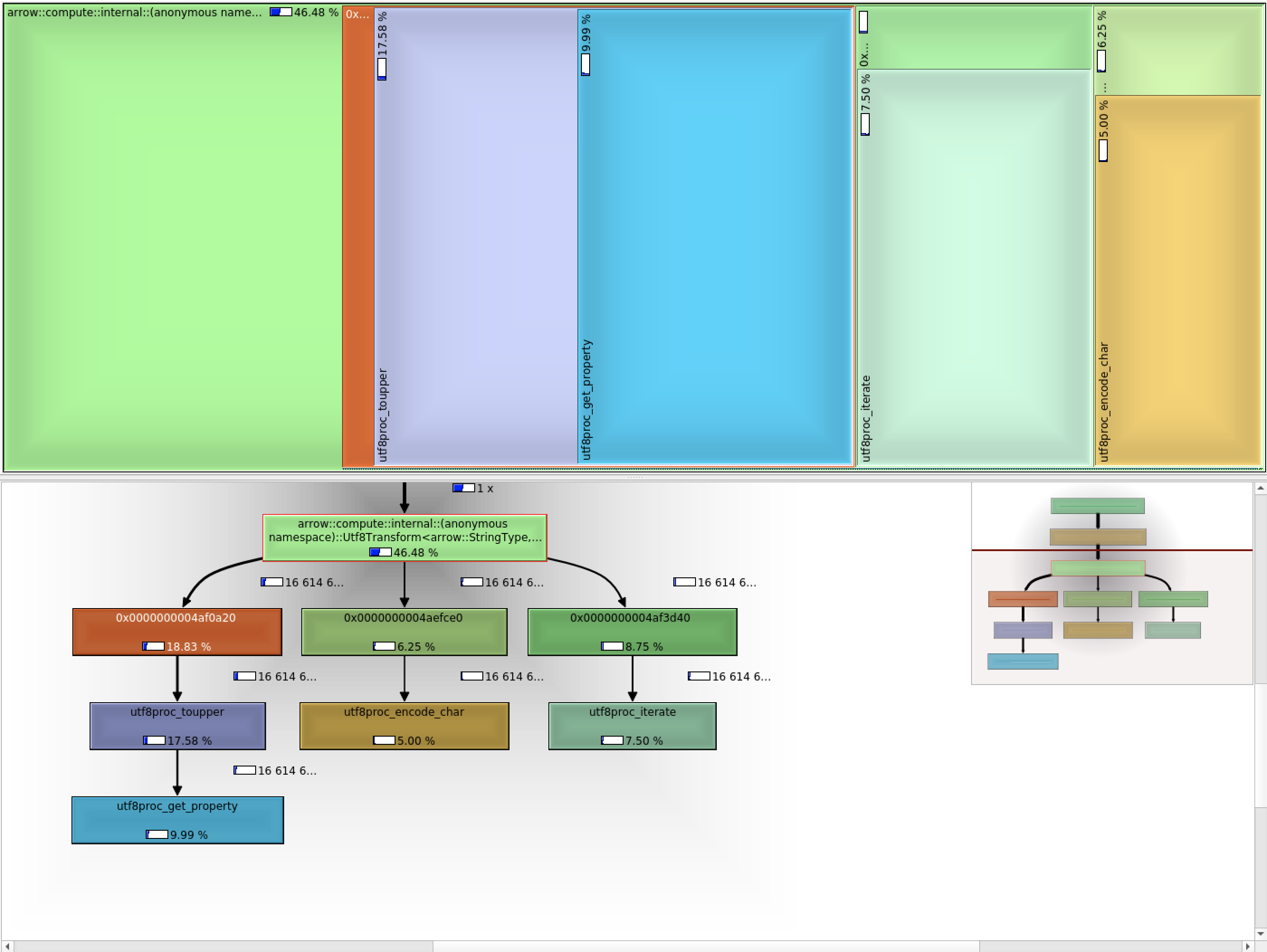
I wanted to compare that to unilib, but all calls get inlined directly (making that not visible).
Using unilib, it's almost 3x faster now compared to utf8proc (disabling the fast ascii path, so it should be compared to the items_per_second =5M/s above):
```
Utf8Lower 74023038 ns 74000707 ns 9 bytes_per_second=268.173M/s items_per_second=14.1698M/s
Utf8Upper 76741459 ns 76715981 ns 9 bytes_per_second=258.681M/s items_per_second=13.6683M/s
```
This is about 2x faster compared to Vaex (again, ignoring the fast ascii path).
The fact that utf8proc is not inline-able (4 calls per codepoint) will explain part of the overhead already. As an experiment, I make sure the calls to unicode's encode/append are not inlined, and that brings back the performance to:
```
Utf8Lower 131853749 ns 131822537 ns 5 bytes_per_second=150.543M/s items_per_second=7.95445M/s
Utf8Upper 134526167 ns 134487477 ns 5 bytes_per_second=147.56M/s items_per_second=7.79683M/s
```
Confirming call overhead plays a role.
Also, utf8proc contains information we don't care about (such as which direction text goes), explaining probably why utf8proc is bigger (300kb vs 120kb compiled).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wesm edited a comment on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
wesm edited a comment on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-645341259
Since the Unilib developer isn't interested in changing the license I think our effort would be better invested in optimizing utf8proc (if this can be Demonstrated to be worthwhile in realistic workloads, not just benchmarks)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r446952269
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +158,121 @@ struct AsciiLength {
}
};
+template <typename Type, template <typename> class Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using DerivedClass = Derived<Type>;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* dest = output;
+ utf8_transform(input, input + input_string_ncodeunits, dest,
+ DerivedClass::TransformCodepoint);
+ return (offset_type)(dest - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ std::call_once(flag_case_luts, []() {
+ lut_upper_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ lut_lower_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ for (int i = 0; i <= MAX_CODEPOINT_LUT; i++) {
+ lut_upper_codepoint.push_back(utf8proc_toupper(i));
+ lut_lower_codepoint.push_back(utf8proc_tolower(i));
+ }
+ });
+ const ArrayData& input = *batch[0].array();
+ ArrayType input_boxed(batch[0].array());
+ ArrayData* output = out->mutable_array();
+
+ offset_type const* input_string_offsets = input.GetValues<offset_type>(1);
+ utf8proc_uint8_t const* input_str =
+ input.buffers[2]->data() + input_boxed.value_offset(0);
+ offset_type input_ncodeunits = input_boxed.total_values_length();
+ offset_type input_nstrings = (offset_type)input.length;
+
+ // Section 5.18 of the Unicode spec claim that the number of codepoints for case
+ // mapping can grow by a factor of 3. This means grow by a factor of 3 in bytes
+ // However, since we don't support all casings (SpecialCasing.txt) the growth
+ // is actually only at max 3/2 (as covered by the unittest).
+ // Note that rounding down the 3/2 is ok, since only codepoints encoded by
+ // two code units (even) can grow to 3 code units.
+
+ int64_t output_ncodeunits_max = ((int64_t)input_ncodeunits) * 3 / 2;
+ if (output_ncodeunits_max > std::numeric_limits<offset_type>::max()) {
+ ctx->SetStatus(Status::CapacityError(
+ "Result might not fit in a 32bit utf8 array, convert to large_utf8"));
+ return;
+ }
+
+ KERNEL_RETURN_IF_ERROR(
+ ctx, ctx->Allocate(output_ncodeunits_max).Value(&output->buffers[2]));
+ // We could reuse the buffer if it is all ascii, benchmarking showed this not to
+ // matter
+ // output->buffers[1] = input.buffers[1];
+ KERNEL_RETURN_IF_ERROR(ctx,
+ ctx->Allocate((input_nstrings + 1) * sizeof(offset_type))
+ .Value(&output->buffers[1]));
+ utf8proc_uint8_t* output_str = output->buffers[2]->mutable_data();
+ offset_type* output_string_offsets = output->GetMutableValues<offset_type>(1);
+ offset_type output_ncodeunits = 0;
+
+ offset_type output_string_offset = 0;
+ *output_string_offsets = output_string_offset;
+ offset_type input_string_first_offset = input_string_offsets[0];
+ for (int64_t i = 0; i < input_nstrings; i++) {
+ offset_type input_string_offset =
+ input_string_offsets[i] - input_string_first_offset;
+ offset_type input_string_end =
+ input_string_offsets[i + 1] - input_string_first_offset;
+ offset_type input_string_ncodeunits = input_string_end - input_string_offset;
+ offset_type encoded_nbytes = DerivedClass::Transform(
+ input_str + input_string_offset, input_string_ncodeunits,
+ output_str + output_ncodeunits);
+ output_ncodeunits += encoded_nbytes;
+ output_string_offsets[i + 1] = output_ncodeunits;
+ }
+
+ // trim the codepoint buffer, since we allocated too much
+ KERNEL_RETURN_IF_ERROR(
+ ctx,
+ output->buffers[2]->CopySlice(0, output_ncodeunits).Value(&output->buffers[2]));
+ } else {
+ const auto& input = checked_cast<const BaseBinaryScalar&>(*batch[0].scalar());
+ auto result = checked_pointer_cast<BaseBinaryScalar>(MakeNullScalar(out->type()));
+ if (input.is_valid) {
+ result->is_valid = true;
+ offset_type data_nbytes = (offset_type)input.value->size();
+ // See note above in the Array version explaining the 3 / 2
+ KERNEL_RETURN_IF_ERROR(ctx,
+ ctx->Allocate(data_nbytes * 3 / 2).Value(&result->value));
+ offset_type encoded_nbytes = DerivedClass::Transform(
+ input.value->data(), data_nbytes, result->value->mutable_data());
+ KERNEL_RETURN_IF_ERROR(
+ ctx, result->value->CopySlice(0, encoded_nbytes).Value(&result->value));
+ }
+ out->value = result;
+ }
+ }
+};
+
+template <typename Type>
+struct Utf8Upper : Utf8Transform<Type, Utf8Upper> {
Review comment:
Hmm, I think you meant something else. Do you mean to ask why I am passing Type to Utf8Transform? I need both utf8 and large_utf8 strings right, or is there some other way to express this?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] nealrichardson commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
nealrichardson commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-648889866
@xhochy if you're trying to add R Windows dependencies, see the discussion on https://issues.apache.org/jira/browse/ARROW-6960 for pointers
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] xhochy commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
xhochy commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-648648745
@kou What is the problematic CI job that shows your problem? The MinGW ones seem fine.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651289874
@pitrou your size commit made the benchmark go from `52->60 M/s` 👍
> Yes, too. The main point of this state-machine-based decoder is that it's branchless, and so it will perform roughly as well on non-Ascii data with unpredictable branching. On pure Ascii data, a branch-based decoder may be faster since the branches will always be predicted right.
Yes, it would be interesting to see how the two methods deals with a 25/25/25/25% mix of 1-2-3 or 4 byte encoded codepoints, vs say a few % non-ascii.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] kou commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
kou commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-649090497
Rebased.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
wesm commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-644787086
Yes, CRTP is certainly fine. We'll need to make utf8proc a proper toolchain library, @pitrou should be able to help you with that.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
wesm commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651368104
Indeed, toolchain incompatibilities only affect C++ code
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] xhochy commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
xhochy commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-645279445
Also crossreferenced this in https://github.com/JuliaStrings/utf8proc/issues/12 to make the `utf8proc` maintainers aware of what we're doing in case they are interested.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
wesm commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-645023981
I went ahead and asked https://github.com/ufal/unilib/issues/2
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651257793
We still have 2 failures, one might need a restart (travis / no output), the other is still a linker error:
```
C:/rtools40/mingw32/bin/../lib/gcc/i686-w64-mingw32/8.3.0/../../../../i686-w64-mingw32/bin/ld.exe: ../windows/arrow-0.17.1.9000/lib/i386/libarrow.a(scalar_string.cc.obj):(.text+0x45df): undefined reference to `utf8proc_tolower'
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wesm commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
wesm commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r445574693
##########
File path: cpp/src/arrow/compute/kernels/scalar_string_test.cc
##########
@@ -68,6 +76,64 @@ TYPED_TEST(TestStringKernels, AsciiLower) {
this->string_type(), "[\"aaazzæÆ&\", null, \"\", \"bbb\"]");
}
+TEST(TestStringKernels, Utf8Upper32bitGrowth) {
Review comment:
I think it's fine to have this test but it definitely should be marked as LARGE_MEMORY_TEST
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
wesm commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-650616427
Ok thanks, that's much appreciated
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] xhochy commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
xhochy commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-648653322
> The R ones probably?
For these, we need to add `utf8proc` to rtools40 and rtools35 and add them to the linker line of the R build.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-645381472
Would a lookup table in the order of 256kb (generated at runtime, not in the binary) per case mapping be acceptable for Arrow?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wesm commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
wesm commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-650579924
@maartenbreddels let me know if I can help with anything to get this merge-ready -- I want to make the utf8proc-depending code optional so I will need to make a small refactor after this lands
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] kszucs commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
kszucs commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-645538795
@ursabot build
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wesm commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
wesm commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r446541086
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -39,6 +158,121 @@ struct AsciiLength {
}
};
+template <typename Type, template <typename> class Derived>
+struct Utf8Transform {
+ using offset_type = typename Type::offset_type;
+ using DerivedClass = Derived<Type>;
+ using ArrayType = typename TypeTraits<Type>::ArrayType;
+
+ static offset_type Transform(const uint8_t* input, offset_type input_string_ncodeunits,
+ uint8_t* output) {
+ uint8_t* dest = output;
+ utf8_transform(input, input + input_string_ncodeunits, dest,
+ DerivedClass::TransformCodepoint);
+ return (offset_type)(dest - output);
+ }
+
+ static void Exec(KernelContext* ctx, const ExecBatch& batch, Datum* out) {
+ if (batch[0].kind() == Datum::ARRAY) {
+ std::call_once(flag_case_luts, []() {
+ lut_upper_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ lut_lower_codepoint.reserve(MAX_CODEPOINT_LUT + 1);
+ for (int i = 0; i <= MAX_CODEPOINT_LUT; i++) {
+ lut_upper_codepoint.push_back(utf8proc_toupper(i));
+ lut_lower_codepoint.push_back(utf8proc_tolower(i));
+ }
+ });
+ const ArrayData& input = *batch[0].array();
+ ArrayType input_boxed(batch[0].array());
+ ArrayData* output = out->mutable_array();
+
+ offset_type const* input_string_offsets = input.GetValues<offset_type>(1);
+ utf8proc_uint8_t const* input_str =
+ input.buffers[2]->data() + input_boxed.value_offset(0);
+ offset_type input_ncodeunits = input_boxed.total_values_length();
+ offset_type input_nstrings = (offset_type)input.length;
+
+ // Section 5.18 of the Unicode spec claim that the number of codepoints for case
+ // mapping can grow by a factor of 3. This means grow by a factor of 3 in bytes
+ // However, since we don't support all casings (SpecialCasing.txt) the growth
+ // is actually only at max 3/2 (as covered by the unittest).
+ // Note that rounding down the 3/2 is ok, since only codepoints encoded by
+ // two code units (even) can grow to 3 code units.
+
+ int64_t output_ncodeunits_max = ((int64_t)input_ncodeunits) * 3 / 2;
+ if (output_ncodeunits_max > std::numeric_limits<offset_type>::max()) {
+ ctx->SetStatus(Status::CapacityError(
+ "Result might not fit in a 32bit utf8 array, convert to large_utf8"));
+ return;
+ }
+
+ KERNEL_RETURN_IF_ERROR(
+ ctx, ctx->Allocate(output_ncodeunits_max).Value(&output->buffers[2]));
+ // We could reuse the buffer if it is all ascii, benchmarking showed this not to
+ // matter
+ // output->buffers[1] = input.buffers[1];
+ KERNEL_RETURN_IF_ERROR(ctx,
+ ctx->Allocate((input_nstrings + 1) * sizeof(offset_type))
+ .Value(&output->buffers[1]));
+ utf8proc_uint8_t* output_str = output->buffers[2]->mutable_data();
+ offset_type* output_string_offsets = output->GetMutableValues<offset_type>(1);
+ offset_type output_ncodeunits = 0;
+
+ offset_type output_string_offset = 0;
+ *output_string_offsets = output_string_offset;
+ offset_type input_string_first_offset = input_string_offsets[0];
+ for (int64_t i = 0; i < input_nstrings; i++) {
+ offset_type input_string_offset =
+ input_string_offsets[i] - input_string_first_offset;
+ offset_type input_string_end =
+ input_string_offsets[i + 1] - input_string_first_offset;
+ offset_type input_string_ncodeunits = input_string_end - input_string_offset;
+ offset_type encoded_nbytes = DerivedClass::Transform(
+ input_str + input_string_offset, input_string_ncodeunits,
+ output_str + output_ncodeunits);
+ output_ncodeunits += encoded_nbytes;
+ output_string_offsets[i + 1] = output_ncodeunits;
+ }
+
+ // trim the codepoint buffer, since we allocated too much
+ KERNEL_RETURN_IF_ERROR(
+ ctx,
+ output->buffers[2]->CopySlice(0, output_ncodeunits).Value(&output->buffers[2]));
Review comment:
Yes we can change that
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r446990168
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -30,6 +31,124 @@ namespace internal {
namespace {
+// lookup tables
+std::vector<uint32_t> lut_upper_codepoint;
+std::vector<uint32_t> lut_lower_codepoint;
+std::once_flag flag_case_luts;
+
+constexpr uint32_t REPLACEMENT_CHAR =
+ '?'; // the proper replacement char would be the 0xFFFD codepoint, but that can
+ // increase string length by a factor of 3
+constexpr int MAX_CODEPOINT_LUT = 0xffff; // up to this codepoint is in a lookup table
+
+static inline void utf8_encode(uint8_t*& str, uint32_t codepoint) {
+ if (codepoint < 0x80) {
+ *str++ = codepoint;
+ } else if (codepoint < 0x800) {
+ *str++ = 0xC0 + (codepoint >> 6);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else if (codepoint < 0x10000) {
+ *str++ = 0xE0 + (codepoint >> 12);
+ *str++ = 0x80 + ((codepoint >> 6) & 0x3F);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else if (codepoint < 0x200000) {
+ *str++ = 0xF0 + (codepoint >> 18);
+ *str++ = 0x80 + ((codepoint >> 12) & 0x3F);
+ *str++ = 0x80 + ((codepoint >> 6) & 0x3F);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else {
+ *str++ = codepoint;
Review comment:
Agree, this is not useful. Now also replacing that by '?', in principle, it should not happen, it can only happen when there is an internal bug (e.g. uppercase gives the wrong codepoint), but now it's more informative.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r447170380
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -133,23 +134,23 @@ struct Utf8Transform {
output_string_offsets[i + 1] = output_ncodeunits;
}
- // trim the codepoint buffer, since we allocated too much
+ // Trim the codepoint buffer, since we allocated too much
KERNEL_RETURN_IF_ERROR(
- ctx,
- output->buffers[2]->CopySlice(0, output_ncodeunits).Value(&output->buffers[2]));
+ ctx, values_buffer->Resize(output_ncodeunits, /*shrink_to_fit=*/true));
Review comment:
Nice way to make code more readable.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-650606456
@wesm I can also take this since you already have quite a bit on your plate.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r447161391
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -30,6 +31,124 @@ namespace internal {
namespace {
+// lookup tables
+std::vector<uint32_t> lut_upper_codepoint;
+std::vector<uint32_t> lut_lower_codepoint;
+std::once_flag flag_case_luts;
+
+constexpr uint32_t REPLACEMENT_CHAR =
+ '?'; // the proper replacement char would be the 0xFFFD codepoint, but that can
+ // increase string length by a factor of 3
+constexpr int MAX_CODEPOINT_LUT = 0xffff; // up to this codepoint is in a lookup table
+
+static inline void utf8_encode(uint8_t*& str, uint32_t codepoint) {
+ if (codepoint < 0x80) {
+ *str++ = codepoint;
+ } else if (codepoint < 0x800) {
+ *str++ = 0xC0 + (codepoint >> 6);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else if (codepoint < 0x10000) {
+ *str++ = 0xE0 + (codepoint >> 12);
+ *str++ = 0x80 + ((codepoint >> 6) & 0x3F);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else if (codepoint < 0x200000) {
+ *str++ = 0xF0 + (codepoint >> 18);
+ *str++ = 0x80 + ((codepoint >> 12) & 0x3F);
+ *str++ = 0x80 + ((codepoint >> 6) & 0x3F);
+ *str++ = 0x80 + (codepoint & 0x3F);
+ } else {
+ *str++ = codepoint;
+ }
+}
+
+static inline bool utf8_is_continuation(const uint8_t codeunit) {
+ return (codeunit & 0xC0) == 0x80; // upper two bits should be 10
+}
+
+static inline uint32_t utf8_decode(const uint8_t*& str, int64_t& length) {
+ if (*str < 0x80) { //
+ length -= 1;
+ return *str++;
+ } else if (*str < 0xC0) { // invalid non-ascii char
+ length -= 1;
+ str++;
+ return REPLACEMENT_CHAR;
Review comment:
There's no reason a priori to be forgiving on invalid data. It there's use case to be tolerant, we may add an option. But by default we should error out on invalid input.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651316656
I pushed a commit that raises an error on invalid UTF8. It does not seem to make the benchmarks slower.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r446952433
##########
File path: cpp/src/arrow/compute/kernels/scalar_string_benchmark.cc
##########
@@ -41,7 +42,9 @@ static void UnaryStringBenchmark(benchmark::State& state, const std::string& fun
ABORT_NOT_OK(CallFunction(func_name, {values}));
}
state.SetItemsProcessed(state.iterations() * array_length);
- state.SetBytesProcessed(state.iterations() * values->data()->buffers[2]->size());
+ state.SetBytesProcessed(state.iterations() *
+ ((touches_offsets ? values->data()->buffers[1]->size() : 0) +
Review comment:
fair point, indeed makes them more comparable.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r446938183
##########
File path: cpp/src/arrow/compute/kernels/scalar_string_test.cc
##########
@@ -68,6 +76,64 @@ TYPED_TEST(TestStringKernels, AsciiLower) {
this->string_type(), "[\"aaazzæÆ&\", null, \"\", \"bbb\"]");
}
+TEST(TestStringKernels, Utf8Upper32bitGrowth) {
+ std::string str(0xffff, 'a');
+ arrow::StringBuilder builder;
+ // 0x7fff * 0xffff is the max a 32 bit string array can hold
+ // since the utf8_upper kernel can grow it by 3/2, the max we should accept is is
+ // 0x7fff * 0xffff * 2/3 = 0x5555 * 0xffff, so this should give us a CapacityError
+ for (int64_t i = 0; i < 0x5556; i++) {
+ ASSERT_OK(builder.Append(str));
+ }
+ std::shared_ptr<arrow::Array> array;
+ arrow::Status st = builder.Finish(&array);
+ const FunctionOptions* options = nullptr;
+ EXPECT_RAISES_WITH_MESSAGE_THAT(CapacityError,
+ testing::HasSubstr("Result might not fit"),
+ CallFunction("utf8_upper", {array}, options));
+}
+
+TYPED_TEST(TestStringKernels, Utf8Upper) {
+ this->CheckUnary("utf8_upper", "[\"aAazZæÆ&\", null, \"\", \"b\"]", this->string_type(),
+ "[\"AAAZZÆÆ&\", null, \"\", \"B\"]");
+
+ // test varying encoding lenghts and thus changing indices/offsets
+ this->CheckUnary("utf8_upper", "[\"ɑɽⱤoW\", null, \"ıI\", \"b\"]", this->string_type(),
+ "[\"ⱭⱤⱤOW\", null, \"II\", \"B\"]");
+
+ // ῦ to Υ͂ not supported
+ // this->CheckUnary("utf8_upper", "[\"ῦɐɜʞȿ\"]", this->string_type(),
+ // "[\"Υ͂ⱯꞫꞰⱾ\"]");
+
+ // test maximum buffer growth
+ this->CheckUnary("utf8_upper", "[\"ɑɑɑɑ\"]", this->string_type(), "[\"ⱭⱭⱭⱭ\"]");
+
+ // Test replacing invalid data by ? (ὖ == \xe1\xbd\x96)
+ this->CheckUnary("utf8_upper", "[\"ɑa\xFFɑ\", \"ɽ\xe1\xbdɽaa\"]", this->string_type(),
+ "[\"ⱭA?Ɑ\", \"Ɽ?ⱤAA\"]");
+}
+
+TYPED_TEST(TestStringKernels, Utf8Lower) {
+ this->CheckUnary("utf8_lower", "[\"aAazZæÆ&\", null, \"\", \"b\"]", this->string_type(),
+ "[\"aaazzææ&\", null, \"\", \"b\"]");
+
+ // test varying encoding lenghts and thus changing indices/offsets
+ this->CheckUnary("utf8_lower", "[\"ⱭɽⱤoW\", null, \"ıI\", \"B\"]", this->string_type(),
+ "[\"ɑɽɽow\", null, \"ıi\", \"b\"]");
+
+ // ῦ to Υ͂ is not supported, but in principle the reverse is, but it would need
+ // normalization
+ // this->CheckUnary("utf8_lower", "[\"Υ͂ⱯꞫꞰⱾ\"]", this->string_type(),
+ // "[\"ῦɐɜʞȿ\"]");
+
+ // test maximum buffer growth
+ this->CheckUnary("utf8_lower", "[\"ȺȺȺȺ\"]", this->string_type(), "[\"ⱥⱥⱥⱥ\"]");
+
+ // Test replacing invalid data by ? (ὖ == \xe1\xbd\x96)
Review comment:
I added a truncated encoded byte string of that, I'll clarity in the comment.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] wesm commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
wesm commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r441146931
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -30,6 +31,21 @@ namespace internal {
namespace {
+// Code units in the range [a-z] can only be an encoding of an ascii
+// character/codepoint, not the 2nd, 3rd or 4th code unit (byte) of an different
+// codepoint. This guaranteed by non-overlap design of the unicode standard. (see
+// section 2.5 of Unicode Standard Core Specification v13.0)
+
+uint8_t ascii_tolower(uint8_t utf8_code_unit) {
Review comment:
I think you will want this to be `static inline` (not sure all compilers will inline it otherwise)
##########
File path: cpp/src/arrow/compute/kernels/scalar_string.cc
##########
@@ -159,11 +282,23 @@ void MakeUnaryStringBatchKernel(std::string name, ArrayKernelExec exec,
DCHECK_OK(registry->AddFunction(std::move(func)));
}
+template <template <typename> typename Transformer>
Review comment:
I think some compilers demand that "class" be used for the last "typename"
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r447143530
##########
File path: cpp/src/arrow/compute/kernels/scalar_string_test.cc
##########
@@ -81,5 +147,40 @@ TYPED_TEST(TestStringKernels, StrptimeDoesNotProvideDefaultOptions) {
ASSERT_RAISES(Invalid, CallFunction("strptime", {input}));
}
+TEST(TestStringKernels, UnicodeLibraryAssumptions) {
+ uint8_t output[4];
+ for (utf8proc_int32_t codepoint = 0x100; codepoint < 0x110000; codepoint++) {
+ utf8proc_ssize_t encoded_nbytes = utf8proc_encode_char(codepoint, output);
+ utf8proc_int32_t codepoint_upper = utf8proc_toupper(codepoint);
+ utf8proc_ssize_t encoded_nbytes_upper = utf8proc_encode_char(codepoint_upper, output);
+ if (encoded_nbytes == 2) {
+ EXPECT_LE(encoded_nbytes_upper, 3)
+ << "Expected the upper case codepoint for a 2 byte encoded codepoint to be "
+ "encoded in maximum 3 bytes, not "
+ << encoded_nbytes_upper;
+ }
+ if (encoded_nbytes == 3) {
Review comment:
Ok, thank you.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on a change in pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on a change in pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#discussion_r446943865
##########
File path: cpp/src/arrow/compute/kernels/scalar_string_test.cc
##########
@@ -68,6 +76,64 @@ TYPED_TEST(TestStringKernels, AsciiLower) {
this->string_type(), "[\"aaazzæÆ&\", null, \"\", \"bbb\"]");
}
+TEST(TestStringKernels, Utf8Upper32bitGrowth) {
Review comment:
Great, I was hoping such a system existed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651282959
Main point remaining is whether we raise an error on invalid UTF8 input. I see no reason not too (an Arrow string array has to be valid UTF8 as per the spec, just like a Python unicode string cannot contain characters outside of the unicode code range).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-645278822
I don't know how important it is to get good performance on non-ASCII data. Note that the ASCII fast path could well be applied to subsets of the array.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] kou commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
kou commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-647791287
Ah, we need the `UTF8PROC_STATIC` definition.
Does this work?
```diff
diff --git a/cpp/cmake_modules/ThirdpartyToolchain.cmake b/cpp/cmake_modules/ThirdpartyToolchain.cmake
index 5ab29cf2c..aa2bbf0dd 100644
--- a/cpp/cmake_modules/ThirdpartyToolchain.cmake
+++ b/cpp/cmake_modules/ThirdpartyToolchain.cmake
@@ -2060,7 +2060,9 @@ macro(build_utf8proc)
set_target_properties(utf8proc::utf8proc
PROPERTIES IMPORTED_LOCATION "${UTF8PROC_STATIC_LIB}"
INTERFACE_INCLUDE_DIRECTORIES
- "${UTF8PROC_PREFIX}/include")
+ "${UTF8PROC_PREFIX}/include"
+ INTERFACE_COMPILER_DEFINITIONS
+ "UTF8PROC_STATIC")
add_dependencies(toolchain utf8proc_ep)
add_dependencies(utf8proc::utf8proc utf8proc_ep)
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651165626
@pitrou many thanks for the review. I've implemented all you suggestions except:
* Raising an error on invalid utf8 data (see comment)
* Having a benchmark run on non-ascii codepoints (I think we want to do this separate from this PR, but important point).
Btw, I wasn't aware of existing utf8 code already in Arrow. The existing decoder based on http://bjoern.hoehrmann.de/utf-8/decoder/dfa/ was new to me. Very interesting work, but unfortunately led to a performance regression (~50->30 M/s), which I'm surprised about actually. Maybe worth comparing again when we have a benchmark with non-ascii codepoints.
@wesm I hope this is ready to go 👍
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-645546979
I've added my own utf encode/decode for now. With lookup tables I now get:
```
Utf8Lower_median 18414820 ns 18408392 ns 3 bytes_per_second=1078.04M/s items_per_second=56.9618M/s
Utf8Upper_median 17004210 ns 17003407 ns 3 bytes_per_second=1.13976G/s items_per_second=61.6686M/s
```
which is faster than the 'ascii' version implemented previously (that got `items_per_second=53 M/s`).
Benchmark results vary a lot between `items_per_second=55-66M/s` .
Using utf8proc's encode/decode (inlined), this goes down to `18M/s`. I have to look a bit into why that is the case since they do a bit more sanity checking. Ideally, some of this goes upstream.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] xhochy commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
xhochy commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-648649038
The R ones probably?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651322087
I just concluded the same :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651717472
Phew. It worked. RTools 4.0 is still broken, but there doesn't seem to be anything we can do, except perhaps disable that job. I'm gonna merge and leave the R cleanup to someone else.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-651796902
You're welcome. Thanks all for your help. Impressed by the project, setup (CI/CMake), and people, and happy with the results:
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] pitrou commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
pitrou commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-645389395
I think it would be more acceptable to inline the relevant utf8proc functions.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] maartenbreddels commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
maartenbreddels commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-645388555
I want to move Vaex from using its own string functions to using Arrow. If I make all functions at least faster, I'm more than happy to scrap my own code. I don't like to see a regression by moving to using Arrow kernels.
I don't call a factor of 3x micro optimizing though :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] kou commented on pull request #7449: ARROW-9133: [C++] Add utf8_upper and utf8_lower
Posted by GitBox <gi...@apache.org>.
kou commented on pull request #7449:
URL: https://github.com/apache/arrow/pull/7449#issuecomment-649065240
Oh, sorry.
It seems that I saw wrong CI jobs.
The link problem has been fixed by the workaround.
I'll cherry pick the workaround to https://github.com/apache/arrow/pull/7452 and merge it.
Then I'll rebase this branch.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org