You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2022/10/25 12:19:44 UTC
[GitHub] [hudi] ssandona opened a new issue, #7059: [SUPPORT] Metadata table column_stats index not used for range pruning when using a CompositeKey of two columns
ssandona opened a new issue, #7059:
URL: https://github.com/apache/hudi/issues/7059
I'm using **Hudi 0.11.1** and noticed an interesting behavior related to meta table column statistics, range pruning and kind of recordkey.
I enabled the columns stats and bloom index filter on the metadata table while writing:
```
"hoodie.metadata.index.column.stats.enable":"true",
"hoodie.bloom.index.use.metadata":"true",
"hoodie.metadata.index.bloom.filter.enable":"true",
```
1. If I use as recordkey a CompositeKey of columns "a,b" (2 string columns) I see on the Spark WebUi both the jobs **loadColumnRangesFromMetaIndex** and **loadColumnRangesFromFiles** being executed. This behavior is observed for every upsert operation
2. If I use as recordkey a single column "c" obtained from the concatenation of columns "a,b" I see on the Spark WebUi both the jobs **loadColumnRangesFromMetaIndex** and **loadColumnRangesFromFiles** being executed only for the first upsert on a partition. Then for all the next upserts on the same partition I only see the **loadColumnRangesFromMetaIndex** job being executed
The second observed behavior is the expected one as key ranges should only be retrieved from the metatable column_stats index and not from the files.
Is there any issue related to using as recordKey a CompositeKey of 2 columns and multi-modal index for range pruning while upserting?
By checking the code this line seems the one causing the behavior
[https://github.com/apache/hudi/blob/release-0.11.1/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/index/bloom/HoodieBloomIndex.java#L150](https://github.com/apache/hudi/blob/release-0.11.1/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/index/bloom/HoodieBloomIndex.java#L150)
it seems to me the **fileInfoList** returned by **loadColumnRangesFromMetaIndex** is always empty for the first scenario.
Here a sample code to reproduce this:
## Scenario1
```
inputDF = spark.createDataFrame(
[
("W01D000", "53.3572085", "202001150800","2020","01"),
("W01D001", "53.3572085", "202001150800","2020","01"),
("W01D002", "53.3572085", "202001150800","2020","01"),
("W01D003", "53.3572085", "202001150800","2020","01")
],
["device_id", "value", "timestamp","year","month"]
)
RECORD_KEY="timestamp,device_id"
PARTITION_FIELD="year,month"
PRECOMBINE_FIELD="timestamp"
COW_TABLE_LOCATION_TEST_ISSUE_TABLE="s3://MYBUCKET/datasets/test_issue_table/"
COW_TABLE_NAME="test_issue_table"
DATABASE="mydb"
hudi_options = {
"hoodie.metadata.index.column.stats.enable":"true",
"hoodie.bloom.index.use.metadata":"true",
"hoodie.metadata.index.bloom.filter.enable":"true",
"hoodie.table.name": COW_TABLE_NAME,
"hoodie.table.type": "COPY_ON_WRITE",
"hoodie.datasource.write.recordkey.field": RECORD_KEY,
"hoodie.datasource.write.partitionpath.field": PARTITION_FIELD,
"hoodie.datasource.write.hive_style_partitioning": "true",
"hoodie.datasource.write.precombine.field": PRECOMBINE_FIELD,
"hoodie.datasource.hive_sync.enable": "true",
"hoodie.datasource.hive_sync.table": COW_TABLE_NAME,
"hoodie.datasource.hive_sync.database": DATABASE,
"hoodie.datasource.hive_sync.partition_fields": PARTITION_FIELD,
"hoodie.datasource.hive_sync.partition_extractor_class": "org.apache.hudi.hive.MultiPartKeysValueExtractor",
"hoodie.datasource.hive_sync.use_jdbc": "false",
"hoodie.datasource.hive_sync.mode":"hms"
}
inputDF.write.format("org.apache.hudi").option(
"hoodie.datasource.write.operation", "upsert"
).options(**hudi_options).mode("append").save(COW_TABLE_LOCATION_TEST_ISSUE_TABLE)
inputDF.write.format("org.apache.hudi").option(
"hoodie.datasource.write.operation", "upsert"
).options(**hudi_options).mode("append").save(COW_TABLE_LOCATION_TEST_ISSUE_TABLE)
```
The second upsert looks like this on the Spark History:
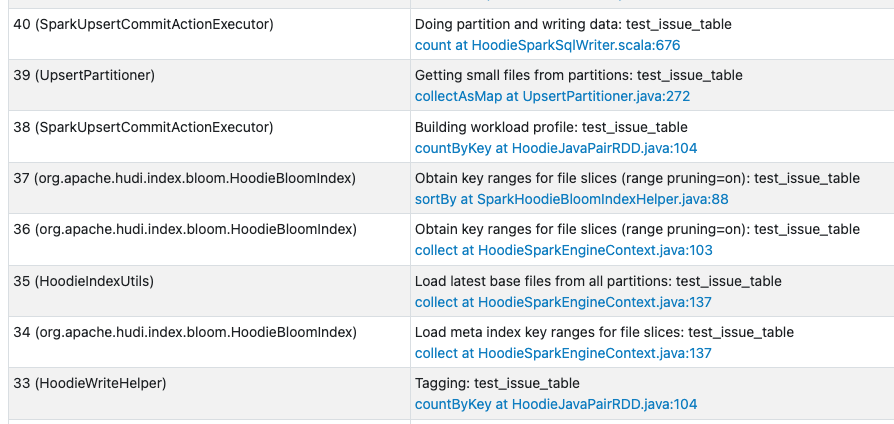
As we can see there are the both jobs highlighted with **Load meta index key ranges for file slices** and **Obtain key ranges for file slices (range pruning=on)** (**loadColumnRangesFromMetaIndex** and **loadColumnRangesFromFiles** functions)
## Scenario2
```
inputDF = spark.createDataFrame(
[
("W01D000", "53.3572085", "202001150800","2020","01"),
("W01D001", "53.3572085", "202001150800","2020","01"),
("W01D002", "53.3572085", "202001150800","2020","01"),
("W01D003", "53.3572085", "202001150800","2020","01")
],
["device_id", "value", "timestamp","year","month"]
)
inputDFNew=inputDF.withColumn("id",concat(inputDF.timestamp,inputDF.device_id))
RECORD_KEY="id"
PARTITION_FIELD="year,month"
PRECOMBINE_FIELD="timestamp"
COW_TABLE_LOCATION_TEST_ISSUE_TABLE="s3://MYBUCKET/datasets/test_issue_table_2/"
COW_TABLE_NAME="test_issue_table_2"
DATABASE="mydb"
hudi_options = {
"hoodie.metadata.index.column.stats.enable":"true",
"hoodie.bloom.index.use.metadata":"true",
"hoodie.metadata.index.bloom.filter.enable":"true",
"hoodie.bulkinsert.shuffle.parallelism":"100",
"hoodie.table.name": COW_TABLE_NAME,
"hoodie.table.type": "COPY_ON_WRITE",
"hoodie.datasource.write.recordkey.field": RECORD_KEY,
"hoodie.datasource.write.partitionpath.field": PARTITION_FIELD,
"hoodie.datasource.write.hive_style_partitioning": "true",
"hoodie.datasource.write.precombine.field": PRECOMBINE_FIELD,
"hoodie.datasource.hive_sync.enable": "true",
"hoodie.datasource.hive_sync.table": COW_TABLE_NAME,
"hoodie.datasource.hive_sync.database": DATABASE,
"hoodie.datasource.hive_sync.partition_fields": PARTITION_FIELD,
"hoodie.datasource.hive_sync.partition_extractor_class": "org.apache.hudi.hive.MultiPartKeysValueExtractor",
"hoodie.datasource.hive_sync.use_jdbc": "false",
"hoodie.datasource.hive_sync.mode":"hms"
}
inputDFNew.write.format("org.apache.hudi").option(
"hoodie.datasource.write.operation", "upsert"
).options(**hudi_options).mode("append").save(COW_TABLE_LOCATION_TEST_ISSUE_TABLE)
inputDFNew.write.format("org.apache.hudi").option(
"hoodie.datasource.write.operation", "upsert"
).options(**hudi_options).mode("append").save(COW_TABLE_LOCATION_TEST_ISSUE_TABLE)
```
The second upsert looks like this on the Spark History:
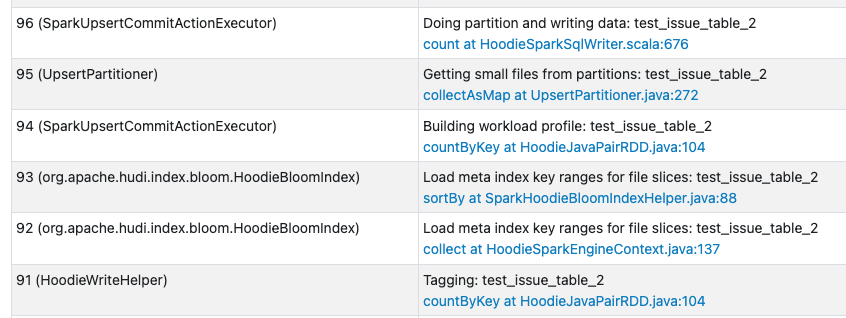
As we can see there are only jobs highlighted with **Load meta index key ranges for file slices** , no traces of jobs with **Obtain key ranges for file slices (range pruning=on)** (only **loadColumnRangesFromMetaIndex** function)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] xushiyan closed issue #7059: [SUPPORT] Metadata table column_stats index not used for range pruning when using a CompositeKey of two columns
Posted by "xushiyan (via GitHub)" <gi...@apache.org>.
xushiyan closed issue #7059: [SUPPORT] Metadata table column_stats index not used for range pruning when using a CompositeKey of two columns
URL: https://github.com/apache/hudi/issues/7059
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] ad1happy2go commented on issue #7059: [SUPPORT] Metadata table column_stats index not used for range pruning when using a CompositeKey of two columns
Posted by "ad1happy2go (via GitHub)" <gi...@apache.org>.
ad1happy2go commented on issue #7059:
URL: https://github.com/apache/hudi/issues/7059#issuecomment-1606687255
@ssandona This issue was fixed in later versions of hudi.
I am able to see this behaviour with composite key with hudi 0.11.1. But with 0.13.X version, we no longer see the file comparison and only metadata table is getting used.
<img width="1728" alt="image" src="https://github.com/apache/hudi/assets/63430370/ede77b87-e174-4a3f-89cf-a8b65e1cecc8">
<img width="1728" alt="image" src="https://github.com/apache/hudi/assets/63430370/7b674d04-b252-4d53-93e3-909bbca7eec7">
Closing this issue. Please reopen in case of any concerns.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org