You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2020/08/31 13:01:53 UTC
[GitHub] [hudi] WTa-hash opened a new issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly
WTa-hash opened a new issue #2057:
URL: https://github.com/apache/hudi/issues/2057
I am having an issue where Hudi does not process deletes correctly when insert + delete for a particular record exist within the same batch. The original issue is reported here: https://issues.apache.org/jira/browse/HUDI-802, but marked as closed for 0.6.0 release.
Below are app versions:
AWS EMR: 5.30.1
Hudi version : 0.6.0
Spark version : 2.4.5
Hive version : 2.3.6
Hadoop version : 2.8.5
Storage (HDFS/S3/GCS..) : S3
Running on Docker? (yes/no) : no
Attached is the script to reproduce:
[Example.txt](https://github.com/apache/hudi/files/5150354/Example.txt)
Basically, I have a dataframe where ID=3 is marked as deleted:
+---+-------+-------------+-------+-------------------+----+
|id |name |desc |groupId|__timestamp |Op |
+---+-------+-------------+-------+-------------------+----+
|1 |Bob |Manager II |100 |1970-01-01 00:00:00|null|
|2 |John |Associate I |200 |1970-01-01 00:00:00|null|
|3 |Michael|null |200 |1970-01-01 00:00:00|null|
|3 |Michael|null |200 |2020-01-04 00:00:00|D |
|4 |William|Manager I |100 |1998-04-13 00:00:00|I |
|5 |Fred |Associate III|200 |2020-11-01 00:00:00|I |
+---+-------+-------------+-------+-------------------+----+
However, in the resulting Hudi table, ID=3 gets inserted instead of ignored:
+-------------------+--------------------+------------------+----------------------+------------------------------------------------------------------------+---+-------+-------------+-------+-------------------+----+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path|_hoodie_file_name |id |name |desc |groupId|__timestamp |Op|
+-------------------+--------------------+------------------+----------------------+------------------------------------------------------------------------+---+-------+-------------+-------+-------------------+----+
|20200831121552 |20200831121552_0_2 |id:1 |100 |b5f359af-37b5-4238-8138-1b8ce82179fe-0_0-22-12017_20200831121552.parquet|1 |Bob |Manager II |100 |1970-01-01 00:00:00|null|
|20200831121552 |20200831121552_1_1 |id:2 |200 |05c3d5c6-4696-41d3-a6d3-9b34d63eeb68-0_1-22-12018_20200831121552.parquet|2 |John |Associate I |200 |1970-01-01 00:00:00|null|
|20200831121552 |20200831121552_1_2 |id:3 |200 |05c3d5c6-4696-41d3-a6d3-9b34d63eeb68-0_1-22-12018_20200831121552.parquet|3 |Michael|null |200 |2020-01-04 00:00:00|D |
|20200831121552 |20200831121552_0_1 |id:4 |100 |b5f359af-37b5-4238-8138-1b8ce82179fe-0_0-22-12017_20200831121552.parquet|4 |William|Manager I |100 |1998-04-13 00:00:00|I |
|20200831121552 |20200831121552_1_3 |id:5 |200 |05c3d5c6-4696-41d3-a6d3-9b34d63eeb68-0_1-22-12018_20200831121552.parquet|5 |Fred |Associate III|200 |2020-11-01 00:00:00|I |
+-------------------+--------------------+------------------+----------------------+------------------------------------------------------------------------+---+-------+-------------+-------+-------------------+----+
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-691778577
@umehrot2 : Assigning this to you as this is specific to EMR.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-694437332
> @umehrot2 Could the IOException be due to #2089 ?
I'm not entirely sure if it's related to this issue as the steps to reproduce is different, but the thing I see in common is that both issues are referencing a MOR table. I don't get this issue when my table is COW.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash edited a comment on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash edited a comment on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-683835686
After implementing the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802. It seems processing insert + delete for a particular record within the same batch works correctly, but deletes do not work correctly in later batches and errors out.
Using Hudi 0.5.2, the error is:
20/08/31 13:17:40 WARN TaskSetManager: Lost task 0.0 in stage 184.0 (TID 64740, ip-xxx-xx-x-xxx.ec2.internal, executor 3): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
20/08/31 13:17:40 ERROR TaskSetManager: Task 0 in stage 184.0 failed 4 times; aborting job
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 184.0 failed 4 times, most recent failure: Lost task 0.3 in stage 184.0 (TID 64743, ip-xxx-xx-x-xxx.ec2.internal, executor 4): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:2043)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2031)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2030)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2030)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2264)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2213)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2202)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:778)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2061)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2082)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2101)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2126)
at org.apache.spark.rdd.RDD$$anonfun$collect$1.apply(RDD.scala:990)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.RDD.collect(RDD.scala:989)
at org.apache.spark.api.java.JavaRDDLike$class.collect(JavaRDDLike.scala:361)
at org.apache.spark.api.java.AbstractJavaRDDLike.collect(JavaRDDLike.scala:45)
at org.apache.hudi.client.HoodieWriteClient.doCompactionCommit(HoodieWriteClient.java:1123)
at org.apache.hudi.client.HoodieWriteClient.commitCompaction(HoodieWriteClient.java:1091)
at org.apache.hudi.client.HoodieWriteClient.runCompaction(HoodieWriteClient.java:1074)
at org.apache.hudi.client.HoodieWriteClient.compact(HoodieWriteClient.java:1045)
at org.apache.hudi.client.HoodieWriteClient.lambda$forceCompact$12(HoodieWriteClient.java:1160)
at org.apache.hudi.common.util.Option.ifPresent(Option.java:96)
at org.apache.hudi.client.HoodieWriteClient.forceCompact(HoodieWriteClient.java:1157)
at org.apache.hudi.client.HoodieWriteClient.postCommit(HoodieWriteClient.java:502)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:157)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:101)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:92)
at org.apache.hudi.HoodieSparkSqlWriter$.checkWriteStatus(HoodieSparkSqlWriter.scala:262)
at org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:184)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:108)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:173)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:169)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:197)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:194)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:169)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:114)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:112)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$executeQuery$1(SQLExecution.scala:83)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1$$anonfun$apply$1.apply(SQLExecution.scala:94)
at org.apache.spark.sql.execution.QueryExecutionMetrics$.withMetrics(QueryExecutionMetrics.scala:141)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$withMetrics(SQLExecution.scala:178)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:93)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:200)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:92)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:285)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:271)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:229)
... 51 elided
Caused by: org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Using Hudi 0.6.0, I get:
java.lang.NoSuchMethodError: org.apache.spark.sql.execution.datasources.PartitionedFile.<init>(Lorg/apache/spark/sql/catalyst/InternalRow;Ljava/lang/String;JJ[Ljava/lang/String;)V
at org.apache.hudi.MergeOnReadSnapshotRelation$$anonfun$3.apply(MergeOnReadSnapshotRelation.scala:145)
at org.apache.hudi.MergeOnReadSnapshotRelation$$anonfun$3.apply(MergeOnReadSnapshotRelation.scala:142)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at scala.collection.IterableLike$class.foreach(IterableLike.scala:72)
at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.AbstractTraversable.map(Traversable.scala:104)
at org.apache.hudi.MergeOnReadSnapshotRelation.buildFileIndex(MergeOnReadSnapshotRelation.scala:142)
at org.apache.hudi.MergeOnReadSnapshotRelation.<init>(MergeOnReadSnapshotRelation.scala:72)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:87)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:51)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:318)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:223)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:211)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:178)
... 51 elided
which is similar to what was reported here: [link](https://github.com/apache/hudi/pull/1848#issuecomment-665478130)
This can be reproduced by running the example script from the original post with DataSourceWriteOptions.PAYLOAD_CLASS_OPT_KEY set to the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802. I do not get the errors mentioned above on Copy-On-Write (COW) tables. COW tables seem to process later batches correctly after implementing the custom AWSDmsAvroPayload class.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-686604729
@WTa-hash : Thanks for the patience. I will look at this today and reply.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] garyli1019 commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
garyli1019 commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-687480558
Created a ticket to track NoSuchMethod error https://issues.apache.org/jira/browse/HUDI-1270. Looks like this error is pretty common for AWS EMR user since we have multiple reports on this?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash edited a comment on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly
Posted by GitBox <gi...@apache.org>.
WTa-hash edited a comment on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-683774247
After implementing the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802. It seems processing insert + delete for a particular record within the same batch works correctly, but deletes do not work correctly in later batches and errors out.
The error is:
20/08/31 13:17:40 WARN TaskSetManager: Lost task 0.0 in stage 184.0 (TID 64740, ip-xxx-xx-x-xxx.ec2.internal, executor 3): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
20/08/31 13:17:40 ERROR TaskSetManager: Task 0 in stage 184.0 failed 4 times; aborting job
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 184.0 failed 4 times, most recent failure: Lost task 0.3 in stage 184.0 (TID 64743, ip-172-29-7-151.ec2.internal, executor 4): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:2043)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2031)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2030)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2030)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2264)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2213)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2202)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:778)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2061)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2082)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2101)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2126)
at org.apache.spark.rdd.RDD$$anonfun$collect$1.apply(RDD.scala:990)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.RDD.collect(RDD.scala:989)
at org.apache.spark.api.java.JavaRDDLike$class.collect(JavaRDDLike.scala:361)
at org.apache.spark.api.java.AbstractJavaRDDLike.collect(JavaRDDLike.scala:45)
at org.apache.hudi.client.HoodieWriteClient.doCompactionCommit(HoodieWriteClient.java:1123)
at org.apache.hudi.client.HoodieWriteClient.commitCompaction(HoodieWriteClient.java:1091)
at org.apache.hudi.client.HoodieWriteClient.runCompaction(HoodieWriteClient.java:1074)
at org.apache.hudi.client.HoodieWriteClient.compact(HoodieWriteClient.java:1045)
at org.apache.hudi.client.HoodieWriteClient.lambda$forceCompact$12(HoodieWriteClient.java:1160)
at org.apache.hudi.common.util.Option.ifPresent(Option.java:96)
at org.apache.hudi.client.HoodieWriteClient.forceCompact(HoodieWriteClient.java:1157)
at org.apache.hudi.client.HoodieWriteClient.postCommit(HoodieWriteClient.java:502)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:157)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:101)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:92)
at org.apache.hudi.HoodieSparkSqlWriter$.checkWriteStatus(HoodieSparkSqlWriter.scala:262)
at org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:184)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:108)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:173)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:169)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:197)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:194)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:169)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:114)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:112)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$executeQuery$1(SQLExecution.scala:83)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1$$anonfun$apply$1.apply(SQLExecution.scala:94)
at org.apache.spark.sql.execution.QueryExecutionMetrics$.withMetrics(QueryExecutionMetrics.scala:141)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$withMetrics(SQLExecution.scala:178)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:93)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:200)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:92)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:285)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:271)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:229)
... 51 elided
Caused by: org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
This can be reproduced by running the example script from the original post with DataSourceWriteOptions.PAYLOAD_CLASS_OPT_KEY set to the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802. I do not get the error mentioned above on Copy-On-Write (COW) tables. COW tables seem to process later batches correctly after implementing the custom AWSDmsAvroPayload class.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] n3nash commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
n3nash commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-694691072
@umehrot2 It looks like for 0.6.0 where this issue is fixed, @WTa-hash is seeing the exception `java.lang.NoSuchMethodError: org.apache.spark.sql.execution.datasources.PartitionedFile.` originating from `at org.apache.hudi.MergeOnReadSnapshotRelation.buildFileIndex(MergeOnReadSnapshotRelation.scala:142)
`. Any ideas if this is wrong spark versions ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-684387783
Regarding 0.6.0 run
spark-shell --packages org.apache.hudi:hudi-spark-bundle_2.11:0.6.0,org.apache.hudi:hudi-utilities-bundle_2.11:0.6.0 --jars /usr/lib/spark/external/lib/spark-avro_2.11-2.4.5-amzn-0.jar
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
--conf 'spark.sql.hive.convertMetastoreParquet=false'
Can you run with apache spark-avro_2.11-2.4.4 and see if the problem goes away ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly
Posted by GitBox <gi...@apache.org>.
WTa-hash commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-683774247
After implementing the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802. It seems processing insert + delete for a particular record within the same batch works correctly, but it seems deletes do not work correctly in later batches and errors out.
The error is:
`20/08/31 13:17:40 WARN TaskSetManager: Lost task 0.0 in stage 184.0 (TID 64740, ip-xxx-xx-x-xxx.ec2.internal, executor 3): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
20/08/31 13:17:40 ERROR TaskSetManager: Task 0 in stage 184.0 failed 4 times; aborting job
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 184.0 failed 4 times, most recent failure: Lost task 0.3 in stage 184.0 (TID 64743, ip-172-29-7-151.ec2.internal, executor 4): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:2043)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2031)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2030)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2030)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2264)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2213)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2202)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:778)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2061)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2082)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2101)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2126)
at org.apache.spark.rdd.RDD$$anonfun$collect$1.apply(RDD.scala:990)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.RDD.collect(RDD.scala:989)
at org.apache.spark.api.java.JavaRDDLike$class.collect(JavaRDDLike.scala:361)
at org.apache.spark.api.java.AbstractJavaRDDLike.collect(JavaRDDLike.scala:45)
at org.apache.hudi.client.HoodieWriteClient.doCompactionCommit(HoodieWriteClient.java:1123)
at org.apache.hudi.client.HoodieWriteClient.commitCompaction(HoodieWriteClient.java:1091)
at org.apache.hudi.client.HoodieWriteClient.runCompaction(HoodieWriteClient.java:1074)
at org.apache.hudi.client.HoodieWriteClient.compact(HoodieWriteClient.java:1045)
at org.apache.hudi.client.HoodieWriteClient.lambda$forceCompact$12(HoodieWriteClient.java:1160)
at org.apache.hudi.common.util.Option.ifPresent(Option.java:96)
at org.apache.hudi.client.HoodieWriteClient.forceCompact(HoodieWriteClient.java:1157)
at org.apache.hudi.client.HoodieWriteClient.postCommit(HoodieWriteClient.java:502)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:157)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:101)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:92)
at org.apache.hudi.HoodieSparkSqlWriter$.checkWriteStatus(HoodieSparkSqlWriter.scala:262)
at org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:184)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:108)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:173)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:169)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:197)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:194)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:169)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:114)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:112)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$executeQuery$1(SQLExecution.scala:83)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1$$anonfun$apply$1.apply(SQLExecution.scala:94)
at org.apache.spark.sql.execution.QueryExecutionMetrics$.withMetrics(QueryExecutionMetrics.scala:141)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$withMetrics(SQLExecution.scala:178)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:93)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:200)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:92)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:285)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:271)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:229)
... 51 elided
Caused by: org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)`
This can be reproduced by running by the example script from the original post with DataSourceWriteOptions.PAYLOAD_CLASS_OPT_KEY set to the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash edited a comment on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash edited a comment on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-684836604
@bvaradar - This is all I have for 0.5.2 logs.
[0.5.2-logs.txt](https://github.com/apache/hudi/files/5156322/0.5.2-logs.txt)
The error is reproducible - you can try running the provided scala script from the original post. You just need to change the output path in the script.
For 0.6.0, I tried using:
spark-shell --packages org.apache.spark:spark-avro_2.11:2.4.4,org.apache.hudi:hudi-spark-bundle_2.11:0.6.0,org.apache.hudi:hudi-utilities-bundle_2.11:0.6.0 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.hive.convertMetastoreParquet=false'
and got the same error when trying to read the MOR hudi table:
java.lang.NoSuchMethodError: org.apache.spark.sql.execution.datasources.PartitionedFile.<init>(Lorg/apache/spark/sql/catalyst/InternalRow;Ljava/lang/String;JJ[Ljava/lang/String;)V
at org.apache.hudi.MergeOnReadSnapshotRelation$$anonfun$3.apply(MergeOnReadSnapshotRelation.scala:145)
at org.apache.hudi.MergeOnReadSnapshotRelation$$anonfun$3.apply(MergeOnReadSnapshotRelation.scala:142)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at scala.collection.IterableLike$class.foreach(IterableLike.scala:72)
at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.AbstractTraversable.map(Traversable.scala:104)
at org.apache.hudi.MergeOnReadSnapshotRelation.buildFileIndex(MergeOnReadSnapshotRelation.scala:142)
at org.apache.hudi.MergeOnReadSnapshotRelation.<init>(MergeOnReadSnapshotRelation.scala:72)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:87)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:51)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:318)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:223)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:211)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:178)
... 51 elided
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] umehrot2 commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
umehrot2 commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-693146719
@WTa-hash The first one is not really an issue. You are basically trying to run Hudi 0.6.0 on an EMR release which does not officially support it. That is why you face this interface compatibility issue since the hudi jar you built is not compiled with EMR's spark version. For now, like @zherenyu831 mentioned if you really want to use Hudi 0.6.0 on EMR you may have to get around it by shading spark-sql etc. Hudi 0.6.0 will be officially supported in upcoming EMR releases, after which you will not have to build your own 0.6.0 jars and will not run into this issue.
As for the second issue with deletes being missed seems like it has been fixed with https://github.com/apache/hudi/pull/2084 .
Is there any other question pending to be answered on this issue ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash edited a comment on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash edited a comment on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-683835686
After implementing the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802. It seems processing insert + delete for a particular record within the same batch works correctly, but deletes do not work correctly in later batches and errors out.
Using Hudi 0.5.2, the error is:
20/08/31 13:17:40 WARN TaskSetManager: Lost task 0.0 in stage 184.0 (TID 64740, ip-xxx-xx-x-xxx.ec2.internal, executor 3): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
20/08/31 13:17:40 ERROR TaskSetManager: Task 0 in stage 184.0 failed 4 times; aborting job
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 184.0 failed 4 times, most recent failure: Lost task 0.3 in stage 184.0 (TID 64743, ip-xxx-xx-x-xxx.ec2.internal, executor 4): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:2043)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2031)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2030)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2030)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2264)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2213)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2202)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:778)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2061)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2082)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2101)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2126)
at org.apache.spark.rdd.RDD$$anonfun$collect$1.apply(RDD.scala:990)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.RDD.collect(RDD.scala:989)
at org.apache.spark.api.java.JavaRDDLike$class.collect(JavaRDDLike.scala:361)
at org.apache.spark.api.java.AbstractJavaRDDLike.collect(JavaRDDLike.scala:45)
at org.apache.hudi.client.HoodieWriteClient.doCompactionCommit(HoodieWriteClient.java:1123)
at org.apache.hudi.client.HoodieWriteClient.commitCompaction(HoodieWriteClient.java:1091)
at org.apache.hudi.client.HoodieWriteClient.runCompaction(HoodieWriteClient.java:1074)
at org.apache.hudi.client.HoodieWriteClient.compact(HoodieWriteClient.java:1045)
at org.apache.hudi.client.HoodieWriteClient.lambda$forceCompact$12(HoodieWriteClient.java:1160)
at org.apache.hudi.common.util.Option.ifPresent(Option.java:96)
at org.apache.hudi.client.HoodieWriteClient.forceCompact(HoodieWriteClient.java:1157)
at org.apache.hudi.client.HoodieWriteClient.postCommit(HoodieWriteClient.java:502)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:157)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:101)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:92)
at org.apache.hudi.HoodieSparkSqlWriter$.checkWriteStatus(HoodieSparkSqlWriter.scala:262)
at org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:184)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:108)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:173)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:169)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:197)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:194)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:169)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:114)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:112)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$executeQuery$1(SQLExecution.scala:83)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1$$anonfun$apply$1.apply(SQLExecution.scala:94)
at org.apache.spark.sql.execution.QueryExecutionMetrics$.withMetrics(QueryExecutionMetrics.scala:141)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$withMetrics(SQLExecution.scala:178)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:93)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:200)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:92)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:285)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:271)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:229)
... 51 elided
Caused by: org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Using Hudi 0.6.0, I get:
java.lang.NoSuchMethodError: org.apache.spark.sql.execution.datasources.PartitionedFile.<init>(Lorg/apache/spark/sql/catalyst/InternalRow;Ljava/lang/String;JJ[Ljava/lang/String;)V
at org.apache.hudi.MergeOnReadSnapshotRelation$$anonfun$3.apply(MergeOnReadSnapshotRelation.scala:145)
at org.apache.hudi.MergeOnReadSnapshotRelation$$anonfun$3.apply(MergeOnReadSnapshotRelation.scala:142)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at scala.collection.IterableLike$class.foreach(IterableLike.scala:72)
at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.AbstractTraversable.map(Traversable.scala:104)
at org.apache.hudi.MergeOnReadSnapshotRelation.buildFileIndex(MergeOnReadSnapshotRelation.scala:142)
at org.apache.hudi.MergeOnReadSnapshotRelation.<init>(MergeOnReadSnapshotRelation.scala:72)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:87)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:51)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:318)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:223)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:211)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:178)
... 51 elided
which is similar to what was reported here: https://github.com/apache/hudi/pull/1848#issuecomment-665478130
This can be reproduced by running the example script from the original post with DataSourceWriteOptions.PAYLOAD_CLASS_OPT_KEY set to the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802. I do not get the error mentioned above on Copy-On-Write (COW) tables. COW tables seem to process later batches correctly after implementing the custom AWSDmsAvroPayload class.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-684385205
@WTa-hash : Regarding the 0.5.2 run, your logs should have the exception stack trace with "Got exception when reading log file". Can you find and paste them here ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] umehrot2 commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
umehrot2 commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-712453460
> > @umehrot2 Could the IOException be due to #2089 ?
>
> I'm not entirely sure if it's related to this issue as the steps to reproduce is different, but the thing I see in common is that both issues are referencing a MOR table. I don't get this issue when my table is COW.
@n3nash @WTa-hash Apologies for the late response here. I think we need the full stack trace here to be able to debug this. Looking at https://github.com/apache/hudi/blob/release-0.6.0/hudi-common/src/main/java/org/apache/hudi/common/table/log/AbstractHoodieLogRecordScanner.java#L244 it seems that the full exception is only logged at the executors. So, either the executor logs should be checked to see the full trace, or change the line here to throw the actual exception back to the driver. If this is still happening, you can also open a jira with some basic reproduction steps if possible. I do not personally think that it would be related to #2089 but we cannot be certain without seeing the full exception.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-683882871
Seems the first issue reported about AWSDmsAvroPayload not processing deletes correctly may be tracked here https://issues.apache.org/jira/browse/HUDI-979.
I'm keeping this issue open for the 2nd issue with error IOException when reading log file, which is might be similar to this: https://github.com/apache/hudi/issues/2042. I have the full stack trace above.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash edited a comment on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly
Posted by GitBox <gi...@apache.org>.
WTa-hash edited a comment on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-683774247
After implementing the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802. It seems processing insert + delete for a particular record within the same batch works correctly, but deletes do not work correctly in later batches and errors out.
The error is:
20/08/31 13:17:40 WARN TaskSetManager: Lost task 0.0 in stage 184.0 (TID 64740, ip-xxx-xx-x-xxx.ec2.internal, executor 3): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
20/08/31 13:17:40 ERROR TaskSetManager: Task 0 in stage 184.0 failed 4 times; aborting job
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 184.0 failed 4 times, most recent failure: Lost task 0.3 in stage 184.0 (TID 64743, ip-172-29-7-151.ec2.internal, executor 4): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:2043)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2031)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2030)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2030)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2264)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2213)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2202)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:778)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2061)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2082)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2101)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2126)
at org.apache.spark.rdd.RDD$$anonfun$collect$1.apply(RDD.scala:990)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.RDD.collect(RDD.scala:989)
at org.apache.spark.api.java.JavaRDDLike$class.collect(JavaRDDLike.scala:361)
at org.apache.spark.api.java.AbstractJavaRDDLike.collect(JavaRDDLike.scala:45)
at org.apache.hudi.client.HoodieWriteClient.doCompactionCommit(HoodieWriteClient.java:1123)
at org.apache.hudi.client.HoodieWriteClient.commitCompaction(HoodieWriteClient.java:1091)
at org.apache.hudi.client.HoodieWriteClient.runCompaction(HoodieWriteClient.java:1074)
at org.apache.hudi.client.HoodieWriteClient.compact(HoodieWriteClient.java:1045)
at org.apache.hudi.client.HoodieWriteClient.lambda$forceCompact$12(HoodieWriteClient.java:1160)
at org.apache.hudi.common.util.Option.ifPresent(Option.java:96)
at org.apache.hudi.client.HoodieWriteClient.forceCompact(HoodieWriteClient.java:1157)
at org.apache.hudi.client.HoodieWriteClient.postCommit(HoodieWriteClient.java:502)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:157)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:101)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:92)
at org.apache.hudi.HoodieSparkSqlWriter$.checkWriteStatus(HoodieSparkSqlWriter.scala:262)
at org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:184)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:108)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:173)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:169)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:197)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:194)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:169)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:114)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:112)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$executeQuery$1(SQLExecution.scala:83)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1$$anonfun$apply$1.apply(SQLExecution.scala:94)
at org.apache.spark.sql.execution.QueryExecutionMetrics$.withMetrics(QueryExecutionMetrics.scala:141)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$withMetrics(SQLExecution.scala:178)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:93)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:200)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:92)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:285)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:271)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:229)
... 51 elided
Caused by: org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
This can be reproduced by running by the example script from the original post with DataSourceWriteOptions.PAYLOAD_CLASS_OPT_KEY set to the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802. I do not get the error mentioned above on Copy-On-Write (COW) tables. COW tables seem to process later batches correctly after implementing the custom AWSDmsAvroPayload class.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash removed a comment on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash removed a comment on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-683774247
After implementing the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802. It seems processing insert + delete for a particular record within the same batch works correctly, but deletes do not work correctly in later batches and errors out.
The error is:
20/08/31 13:17:40 WARN TaskSetManager: Lost task 0.0 in stage 184.0 (TID 64740, ip-xxx-xx-x-xxx.ec2.internal, executor 3): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
20/08/31 13:17:40 ERROR TaskSetManager: Task 0 in stage 184.0 failed 4 times; aborting job
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 184.0 failed 4 times, most recent failure: Lost task 0.3 in stage 184.0 (TID 64743, ip-xxx-xx-x-xxx.ec2.internal, executor 4): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:2043)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2031)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2030)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2030)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2264)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2213)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2202)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:778)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2061)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2082)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2101)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2126)
at org.apache.spark.rdd.RDD$$anonfun$collect$1.apply(RDD.scala:990)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.RDD.collect(RDD.scala:989)
at org.apache.spark.api.java.JavaRDDLike$class.collect(JavaRDDLike.scala:361)
at org.apache.spark.api.java.AbstractJavaRDDLike.collect(JavaRDDLike.scala:45)
at org.apache.hudi.client.HoodieWriteClient.doCompactionCommit(HoodieWriteClient.java:1123)
at org.apache.hudi.client.HoodieWriteClient.commitCompaction(HoodieWriteClient.java:1091)
at org.apache.hudi.client.HoodieWriteClient.runCompaction(HoodieWriteClient.java:1074)
at org.apache.hudi.client.HoodieWriteClient.compact(HoodieWriteClient.java:1045)
at org.apache.hudi.client.HoodieWriteClient.lambda$forceCompact$12(HoodieWriteClient.java:1160)
at org.apache.hudi.common.util.Option.ifPresent(Option.java:96)
at org.apache.hudi.client.HoodieWriteClient.forceCompact(HoodieWriteClient.java:1157)
at org.apache.hudi.client.HoodieWriteClient.postCommit(HoodieWriteClient.java:502)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:157)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:101)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:92)
at org.apache.hudi.HoodieSparkSqlWriter$.checkWriteStatus(HoodieSparkSqlWriter.scala:262)
at org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:184)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:108)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:173)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:169)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:197)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:194)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:169)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:114)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:112)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$executeQuery$1(SQLExecution.scala:83)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1$$anonfun$apply$1.apply(SQLExecution.scala:94)
at org.apache.spark.sql.execution.QueryExecutionMetrics$.withMetrics(QueryExecutionMetrics.scala:141)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$withMetrics(SQLExecution.scala:178)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:93)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:200)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:92)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:285)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:271)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:229)
... 51 elided
Caused by: org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
This can be reproduced by running the example script from the original post with DataSourceWriteOptions.PAYLOAD_CLASS_OPT_KEY set to the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802. I do not get the error mentioned above on Copy-On-Write (COW) tables. COW tables seem to process later batches correctly after implementing the custom AWSDmsAvroPayload class.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash edited a comment on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash edited a comment on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-685015564
For the 0.6.0 issue with error: java.lang.NoSuchMethodError: org.apache.spark.sql.execution.datasources.PartitionedFile.(Lorg/apache/spark/sql/catalyst/InternalRow;Ljava/lang/String;JJ[Ljava/lang/String;)V
^ I can get pass this issue if I query the table using AWS Athena and remove Spark reads from the script.
This then brings up another issue. Keep in mind, I am using a custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802 with Hudi 0.6.0.
Using Hudi 0.6.0, I first create a Hudi table using this dataframe:
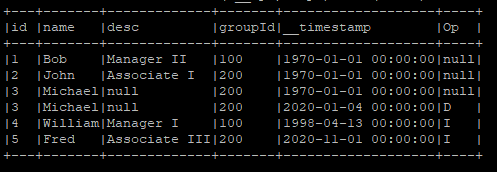
If I create a COW table, the dataframe gets processed correctly:

If I create a MOR table, the dataframe also gets processed correctly (read-optimized table, inline compaction=true):

Next, I process a new dataframe with some data changes on the existing Hudi table:
The updates are processed correctly in the COW table:

However, the updates did not process the deletion of ID=2 in MOR table (read-optimized table, inline compaction=true):

There were no errors when processing the MOR table.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] zherenyu831 commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
zherenyu831 commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-687981952
Regarding to hudi 0.6.0 on emr,
Please check this issue, and I also shared the workaround there
https://github.com/apache/hudi/issues/2041
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash edited a comment on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash edited a comment on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-683774247
After implementing the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802. It seems processing insert + delete for a particular record within the same batch works correctly, but deletes do not work correctly in later batches and errors out.
The error is:
20/08/31 13:17:40 WARN TaskSetManager: Lost task 0.0 in stage 184.0 (TID 64740, ip-xxx-xx-x-xxx.ec2.internal, executor 3): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
20/08/31 13:17:40 ERROR TaskSetManager: Task 0 in stage 184.0 failed 4 times; aborting job
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 184.0 failed 4 times, most recent failure: Lost task 0.3 in stage 184.0 (TID 64743, ip-xxx-xx-x-xxx.ec2.internal, executor 4): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:2043)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2031)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2030)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2030)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2264)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2213)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2202)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:778)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2061)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2082)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2101)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2126)
at org.apache.spark.rdd.RDD$$anonfun$collect$1.apply(RDD.scala:990)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.RDD.collect(RDD.scala:989)
at org.apache.spark.api.java.JavaRDDLike$class.collect(JavaRDDLike.scala:361)
at org.apache.spark.api.java.AbstractJavaRDDLike.collect(JavaRDDLike.scala:45)
at org.apache.hudi.client.HoodieWriteClient.doCompactionCommit(HoodieWriteClient.java:1123)
at org.apache.hudi.client.HoodieWriteClient.commitCompaction(HoodieWriteClient.java:1091)
at org.apache.hudi.client.HoodieWriteClient.runCompaction(HoodieWriteClient.java:1074)
at org.apache.hudi.client.HoodieWriteClient.compact(HoodieWriteClient.java:1045)
at org.apache.hudi.client.HoodieWriteClient.lambda$forceCompact$12(HoodieWriteClient.java:1160)
at org.apache.hudi.common.util.Option.ifPresent(Option.java:96)
at org.apache.hudi.client.HoodieWriteClient.forceCompact(HoodieWriteClient.java:1157)
at org.apache.hudi.client.HoodieWriteClient.postCommit(HoodieWriteClient.java:502)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:157)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:101)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:92)
at org.apache.hudi.HoodieSparkSqlWriter$.checkWriteStatus(HoodieSparkSqlWriter.scala:262)
at org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:184)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:108)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:173)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:169)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:197)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:194)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:169)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:114)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:112)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$executeQuery$1(SQLExecution.scala:83)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1$$anonfun$apply$1.apply(SQLExecution.scala:94)
at org.apache.spark.sql.execution.QueryExecutionMetrics$.withMetrics(QueryExecutionMetrics.scala:141)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$withMetrics(SQLExecution.scala:178)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:93)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:200)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:92)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:285)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:271)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:229)
... 51 elided
Caused by: org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
This can be reproduced by running the example script from the original post with DataSourceWriteOptions.PAYLOAD_CLASS_OPT_KEY set to the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802. I do not get the error mentioned above on Copy-On-Write (COW) tables. COW tables seem to process later batches correctly after implementing the custom AWSDmsAvroPayload class.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash edited a comment on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash edited a comment on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-684836604
@bvaradar - This is all I have for 0.5.2 logs. The error occurs right after "INFO HoodieMergeOnReadTableCompactor: Compactor compacting" for this MOR table.
[0.5.2-logs.txt](https://github.com/apache/hudi/files/5156322/0.5.2-logs.txt)
The error is reproducible - you can try running the provided scala script from the original post. You just need to change the output path in the script.
For 0.6.0, I tried using:
spark-shell --packages org.apache.spark:spark-avro_2.11:2.4.4,org.apache.hudi:hudi-spark-bundle_2.11:0.6.0,org.apache.hudi:hudi-utilities-bundle_2.11:0.6.0 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.hive.convertMetastoreParquet=false'
and got the same error when trying to read the MOR hudi table:
scala> var hudiDf: DataFrame = spark.read.format(hudiFormat).load(hudiReadPath).orderBy(primaryKey);
java.lang.NoSuchMethodError: org.apache.spark.sql.execution.datasources.PartitionedFile.<init>(Lorg/apache/spark/sql/catalyst/InternalRow;Ljava/lang/String;JJ[Ljava/lang/String;)V
at org.apache.hudi.MergeOnReadSnapshotRelation$$anonfun$3.apply(MergeOnReadSnapshotRelation.scala:145)
at org.apache.hudi.MergeOnReadSnapshotRelation$$anonfun$3.apply(MergeOnReadSnapshotRelation.scala:142)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at scala.collection.IterableLike$class.foreach(IterableLike.scala:72)
at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.AbstractTraversable.map(Traversable.scala:104)
at org.apache.hudi.MergeOnReadSnapshotRelation.buildFileIndex(MergeOnReadSnapshotRelation.scala:142)
at org.apache.hudi.MergeOnReadSnapshotRelation.<init>(MergeOnReadSnapshotRelation.scala:72)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:87)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:51)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:318)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:223)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:211)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:178)
... 51 elided
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] n3nash commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
n3nash commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-693547947
@umehrot2 Could the IOException be due to https://github.com/apache/hudi/issues/2089 ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash removed a comment on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash removed a comment on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-684936471
For java.lang.NoSuchMethodError: org.apache.spark.sql.execution.datasources.PartitionedFile.(Lorg/apache/spark/sql/catalyst/InternalRow;Ljava/lang/String;JJ[Ljava/lang/String;)V issue:
It seems baseFile.getFileLen from https://github.com/apache/hudi/blob/release-0.6.0/hudi-spark/src/main/scala/org/apache/hudi/MergeOnReadSnapshotRelation.scala#L145 is returning a STRING instead of a LONG.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-685015564
For the 0.6.0 issue with error: java.lang.NoSuchMethodError: org.apache.spark.sql.execution.datasources.PartitionedFile.(Lorg/apache/spark/sql/catalyst/InternalRow;Ljava/lang/String;JJ[Ljava/lang/String;)V
^ I can get pass this issue if I query the table using AWS Athena and remove Spark reads from the script.
This then brings up another issue. Keep in mind, I am using a custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802 with Hudi 0.6.0.
Using Hudi 0.6.0, I first create a Hudi table using this dataframe:

If I create a COW table, the dataframe gets processed correctly:

If I create a MOR table, the dataframe also gets processed correctly (read-optimized table):

Next, I process a new dataframe with some data changes on the existing Hudi table:

The updates are processed correctly in the COW table:

However, the updates did not process the deletion of ID=2 in MOR table:

There were no errors when processing the MOR table.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash edited a comment on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash edited a comment on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-684836604
@bvaradar - This is all I have for 0.5.2 logs.
[0.5.2-logs.txt](https://github.com/apache/hudi/files/5156322/0.5.2-logs.txt)
The error is reproducible - you can try running the provided scala script from the original post. You just need to change the output path in the script.
For 0.6.0, I tried using:
spark-shell --packages org.apache.spark:spark-avro_2.11:2.4.4,org.apache.hudi:hudi-spark-bundle_2.11:0.6.0,org.apache.hudi:hudi-utilities-bundle_2.11:0.6.0 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.hive.convertMetastoreParquet=false'
and got the same error when trying to read the MOR hudi table:
scala> var hudiDf: DataFrame = spark.read.format(hudiFormat).load(hudiReadPath).orderBy(primaryKey);
java.lang.NoSuchMethodError: org.apache.spark.sql.execution.datasources.PartitionedFile.<init>(Lorg/apache/spark/sql/catalyst/InternalRow;Ljava/lang/String;JJ[Ljava/lang/String;)V
at org.apache.hudi.MergeOnReadSnapshotRelation$$anonfun$3.apply(MergeOnReadSnapshotRelation.scala:145)
at org.apache.hudi.MergeOnReadSnapshotRelation$$anonfun$3.apply(MergeOnReadSnapshotRelation.scala:142)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at scala.collection.IterableLike$class.foreach(IterableLike.scala:72)
at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.AbstractTraversable.map(Traversable.scala:104)
at org.apache.hudi.MergeOnReadSnapshotRelation.buildFileIndex(MergeOnReadSnapshotRelation.scala:142)
at org.apache.hudi.MergeOnReadSnapshotRelation.<init>(MergeOnReadSnapshotRelation.scala:72)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:87)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:51)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:318)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:223)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:211)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:178)
... 51 elided
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] umehrot2 commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
umehrot2 commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-712454567
> @umehrot2 It looks like for 0.6.0 where this issue is fixed, @WTa-hash is seeing the exception `java.lang.NoSuchMethodError: org.apache.spark.sql.execution.datasources.PartitionedFile.` originating from `at org.apache.hudi.MergeOnReadSnapshotRelation.buildFileIndex(MergeOnReadSnapshotRelation.scala:142) `. Any ideas if this is wrong spark versions ?
@n3nash this issue is because of EMR environment. The jar @WTa-hash was building for 0.6.0 is not compiled against EMR's spark version. EMR has its own spark with various modifications. This issue should not be there in emr-5.31.0 where hudi 0.6.0 is officially supported. No need to replace that jar's there. The jar's we provide there are compiled against our own spark and it fixes this issue.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash closed issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash closed issue #2057:
URL: https://github.com/apache/hudi/issues/2057
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash edited a comment on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash edited a comment on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-683882871
Seems the first issue reported about AWSDmsAvroPayload not processing deletes correctly may be tracked here https://issues.apache.org/jira/browse/HUDI-979.
I'm keeping this issue open for the 2nd issue with error IOException when reading log file, which might be similar to this: https://github.com/apache/hudi/issues/2042. I have the full stack trace above.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-683835686
After implementing the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802. It seems processing insert + delete for a particular record within the same batch works correctly, but deletes do not work correctly in later batches and errors out.
The error is:
20/08/31 13:17:40 WARN TaskSetManager: Lost task 0.0 in stage 184.0 (TID 64740, ip-xxx-xx-x-xxx.ec2.internal, executor 3): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
20/08/31 13:17:40 ERROR TaskSetManager: Task 0 in stage 184.0 failed 4 times; aborting job
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 184.0 failed 4 times, most recent failure: Lost task 0.3 in stage 184.0 (TID 64743, ip-xxx-xx-x-xxx.ec2.internal, executor 4): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:2043)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2031)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2030)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2030)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2264)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2213)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2202)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:778)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2061)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2082)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2101)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2126)
at org.apache.spark.rdd.RDD$$anonfun$collect$1.apply(RDD.scala:990)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.RDD.collect(RDD.scala:989)
at org.apache.spark.api.java.JavaRDDLike$class.collect(JavaRDDLike.scala:361)
at org.apache.spark.api.java.AbstractJavaRDDLike.collect(JavaRDDLike.scala:45)
at org.apache.hudi.client.HoodieWriteClient.doCompactionCommit(HoodieWriteClient.java:1123)
at org.apache.hudi.client.HoodieWriteClient.commitCompaction(HoodieWriteClient.java:1091)
at org.apache.hudi.client.HoodieWriteClient.runCompaction(HoodieWriteClient.java:1074)
at org.apache.hudi.client.HoodieWriteClient.compact(HoodieWriteClient.java:1045)
at org.apache.hudi.client.HoodieWriteClient.lambda$forceCompact$12(HoodieWriteClient.java:1160)
at org.apache.hudi.common.util.Option.ifPresent(Option.java:96)
at org.apache.hudi.client.HoodieWriteClient.forceCompact(HoodieWriteClient.java:1157)
at org.apache.hudi.client.HoodieWriteClient.postCommit(HoodieWriteClient.java:502)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:157)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:101)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:92)
at org.apache.hudi.HoodieSparkSqlWriter$.checkWriteStatus(HoodieSparkSqlWriter.scala:262)
at org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:184)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:108)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:173)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:169)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:197)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:194)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:169)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:114)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:112)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$executeQuery$1(SQLExecution.scala:83)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1$$anonfun$apply$1.apply(SQLExecution.scala:94)
at org.apache.spark.sql.execution.QueryExecutionMetrics$.withMetrics(QueryExecutionMetrics.scala:141)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$withMetrics(SQLExecution.scala:178)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:93)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:200)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:92)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:285)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:271)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:229)
... 51 elided
Caused by: org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
This can be reproduced by running the example script from the original post with DataSourceWriteOptions.PAYLOAD_CLASS_OPT_KEY set to the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802. I do not get the error mentioned above on Copy-On-Write (COW) tables. COW tables seem to process later batches correctly after implementing the custom AWSDmsAvroPayload class.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash edited a comment on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly
Posted by GitBox <gi...@apache.org>.
WTa-hash edited a comment on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-683774247
After implementing the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802. It seems processing insert + delete for a particular record within the same batch works correctly, but deletes do not work correctly in later batches and errors out.
The error is:
20/08/31 13:17:40 WARN TaskSetManager: Lost task 0.0 in stage 184.0 (TID 64740, ip-xxx-xx-x-xxx.ec2.internal, executor 3): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
20/08/31 13:17:40 ERROR TaskSetManager: Task 0 in stage 184.0 failed 4 times; aborting job
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 184.0 failed 4 times, most recent failure: Lost task 0.3 in stage 184.0 (TID 64743, ip-172-29-7-151.ec2.internal, executor 4): org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:2043)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2031)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2030)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2030)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:967)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:967)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2264)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2213)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2202)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:778)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2061)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2082)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2101)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2126)
at org.apache.spark.rdd.RDD$$anonfun$collect$1.apply(RDD.scala:990)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.RDD.collect(RDD.scala:989)
at org.apache.spark.api.java.JavaRDDLike$class.collect(JavaRDDLike.scala:361)
at org.apache.spark.api.java.AbstractJavaRDDLike.collect(JavaRDDLike.scala:45)
at org.apache.hudi.client.HoodieWriteClient.doCompactionCommit(HoodieWriteClient.java:1123)
at org.apache.hudi.client.HoodieWriteClient.commitCompaction(HoodieWriteClient.java:1091)
at org.apache.hudi.client.HoodieWriteClient.runCompaction(HoodieWriteClient.java:1074)
at org.apache.hudi.client.HoodieWriteClient.compact(HoodieWriteClient.java:1045)
at org.apache.hudi.client.HoodieWriteClient.lambda$forceCompact$12(HoodieWriteClient.java:1160)
at org.apache.hudi.common.util.Option.ifPresent(Option.java:96)
at org.apache.hudi.client.HoodieWriteClient.forceCompact(HoodieWriteClient.java:1157)
at org.apache.hudi.client.HoodieWriteClient.postCommit(HoodieWriteClient.java:502)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:157)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:101)
at org.apache.hudi.client.AbstractHoodieWriteClient.commit(AbstractHoodieWriteClient.java:92)
at org.apache.hudi.HoodieSparkSqlWriter$.checkWriteStatus(HoodieSparkSqlWriter.scala:262)
at org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:184)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:108)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:173)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:169)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:197)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:194)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:169)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:114)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:112)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$executeQuery$1(SQLExecution.scala:83)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1$$anonfun$apply$1.apply(SQLExecution.scala:94)
at org.apache.spark.sql.execution.QueryExecutionMetrics$.withMetrics(QueryExecutionMetrics.scala:141)
at org.apache.spark.sql.execution.SQLExecution$.org$apache$spark$sql$execution$SQLExecution$$withMetrics(SQLExecution.scala:178)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:93)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:200)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:92)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:676)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:285)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:271)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:229)
... 51 elided
Caused by: org.apache.hudi.exception.HoodieIOException: IOException when reading log file
at org.apache.hudi.common.table.log.AbstractHoodieLogRecordScanner.scan(AbstractHoodieLogRecordScanner.java:244)
at org.apache.hudi.common.table.log.HoodieMergedLogRecordScanner.<init>(HoodieMergedLogRecordScanner.java:81)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.compact(HoodieMergeOnReadTableCompactor.java:126)
at org.apache.hudi.table.compact.HoodieMergeOnReadTableCompactor.lambda$compact$644ebad7$1(HoodieMergeOnReadTableCompactor.java:98)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:1040)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at org.apache.spark.storage.memory.MemoryStore.putIterator(MemoryStore.scala:221)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:349)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1181)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1090)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1155)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:881)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:357)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:308)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
This can be reproduced by running by the example script from the original post with DataSourceWriteOptions.PAYLOAD_CLASS_OPT_KEY set to the custom AWSDmsAvroPayload class referenced in https://issues.apache.org/jira/browse/HUDI-802.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-684836604
@bvaradar - This is all I have for 0.5.2 logs.
[0.5.2-logs.txt](https://github.com/apache/hudi/files/5156322/0.5.2-logs.txt)
The error is reproducible - you can try running the provided scala script from the original post. You just need to change the output path in the script.
For 0.6.0, I tried using:
spark-shell --packages org.apache.spark:spark-avro_2.11:2.4.4,org.apache.hudi:hudi-spark-bundle_2.11:0.6.0,org.apache.hudi:hudi-utilities-bundle_2.11:0.6.0 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.hive.convertMetastoreParquet=false'
and got the same error:
java.lang.NoSuchMethodError: org.apache.spark.sql.execution.datasources.PartitionedFile.<init>(Lorg/apache/spark/sql/catalyst/InternalRow;Ljava/lang/String;JJ[Ljava/lang/String;)V
at org.apache.hudi.MergeOnReadSnapshotRelation$$anonfun$3.apply(MergeOnReadSnapshotRelation.scala:145)
at org.apache.hudi.MergeOnReadSnapshotRelation$$anonfun$3.apply(MergeOnReadSnapshotRelation.scala:142)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at scala.collection.IterableLike$class.foreach(IterableLike.scala:72)
at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.AbstractTraversable.map(Traversable.scala:104)
at org.apache.hudi.MergeOnReadSnapshotRelation.buildFileIndex(MergeOnReadSnapshotRelation.scala:142)
at org.apache.hudi.MergeOnReadSnapshotRelation.<init>(MergeOnReadSnapshotRelation.scala:72)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:87)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:51)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:318)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:223)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:211)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:178)
... 51 elided
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-693403063
@umehrot2 - the only other issue is what I have here: https://github.com/apache/hudi/issues/2057#issuecomment-683835686 with error "org.apache.hudi.exception.HoodieIOException: IOException when reading log file" using Hudi 0.5.2 that came with EMR with MOR tables.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] WTa-hash commented on issue #2057: [SUPPORT] AWSDmsAvroPayload not processing Deletes correctly + IOException when reading log file
Posted by GitBox <gi...@apache.org>.
WTa-hash commented on issue #2057:
URL: https://github.com/apache/hudi/issues/2057#issuecomment-684936471
For java.lang.NoSuchMethodError: org.apache.spark.sql.execution.datasources.PartitionedFile.(Lorg/apache/spark/sql/catalyst/InternalRow;Ljava/lang/String;JJ[Ljava/lang/String;)V issue:
It seems baseFile.getFileLen from https://github.com/apache/hudi/blob/release-0.6.0/hudi-spark/src/main/scala/org/apache/hudi/MergeOnReadSnapshotRelation.scala#L145 is returning a STRING instead of a LONG.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org