You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2021/03/31 05:34:07 UTC
[GitHub] [iceberg] wuwangben opened a new issue #2397: When querying data by using the Flink DataStream API , the result is not correct.Is it a bug or is my usage wrong?
wuwangben opened a new issue #2397:
URL: https://github.com/apache/iceberg/issues/2397
### env:
flink version:1.12.2
iceberg commit:21e1922a8ddb93a82388ea86a5f500d9f23885b3
### code:
PartitionSpec spec = PartitionSpec.builderFor(schemaIceberg).identity("bucketCity").identity("partDay").identity("partHour").build();
public static void query(String baseHdfsPath,StreamExecutionEnvironment bsEnv) throws Exception {
Map<String, String> catalogProperties = Maps.newHashMap();
catalogProperties.put("type", "iceberg");
catalogProperties.put(FlinkCatalogFactory.ICEBERG_CATALOG_TYPE, "hive");
catalogProperties.put(CatalogProperties.WAREHOUSE_LOCATION, baseHdfsPath);
catalogProperties.put(CatalogProperties.FILE_IO_IMPL,"org.apache.iceberg.aws.s3.S3FileIO");
catalogProperties.put(AwsProperties.CLIENT_FACTORY,"com.cennavi.dataStore.s3.DidiS3ClinetFactory");
Configuration hadoopConf = new Configuration();
CatalogLoader catalogLoader = CatalogLoader.hive("hiveCataLogS3FIO",hadoopConf,catalogProperties);
TableIdentifier tableid = TableIdentifier.of(Namespace.of("icebergS3FIO"),"clinkJsonS3FIO");
TableLoader tableLoader = TableLoader.fromCatalog(catalogLoader,tableid);
TableSchema flinkSchema = TableSchema.builder()
.field("bucketCity",DataTypes.INT())
.field("partDay",DataTypes.STRING())
.field("partHour",DataTypes.STRING())
.field("cityCode",DataTypes.STRING())
.field("baseTime", DataTypes.INT())
.field("deviceId", DataTypes.STRING())
.field("linkID", DataTypes.BIGINT())
.field("stopCarInfo", DataTypes.STRING())
.build();
Expression filter =
Expressions.and(
Expressions.and(
Expressions.equal("bucketCity", 110000),
Expressions.equal("cityCode", "1100")
),
Expressions.equal("baseTime",1617081280)
);
DataStream<RowData> ds = FlinkSource.forRowData().env(bsEnv)
.filters(Collections.singletonList(filter)).project(flinkSchema)
.tableLoader(tableLoader).streaming(false).build();
ds.process(new ProcessFunction<RowData, Object>() {
@Override
public void processElement(RowData rowData, Context context, Collector<Object> collector) throws Exception {
log.info("datainfo==="+rowData.getInt(0)+","+rowData.getString(1)+","+rowData.getString(2)+","+rowData.getString(3)+","+rowData.getInt(4));
}
});
bsEnv.execute();
}
### result
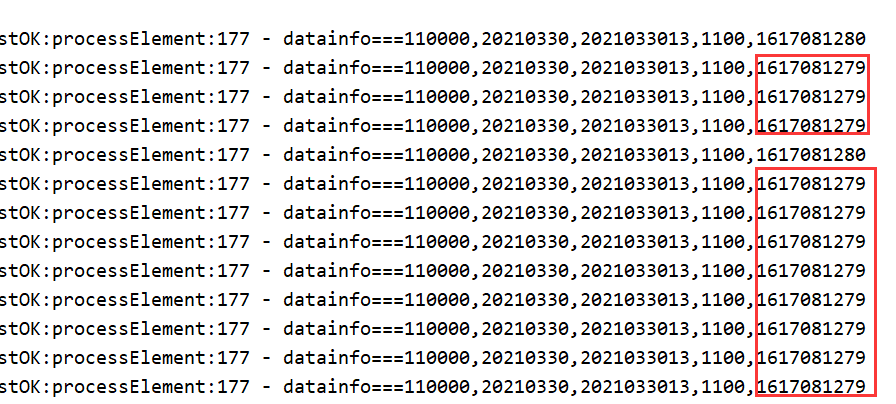
I want to get the result of basetime = 1617081280, but other values are actually returned, such as 1617081279**
Is it a bug or is my usage wrong?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx closed issue #2397: When querying data by using the Flink DataStream API , the result is not correct.Is it a bug or is my usage wrong?
Posted by GitBox <gi...@apache.org>.
openinx closed issue #2397:
URL: https://github.com/apache/iceberg/issues/2397
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on issue #2397: When querying data by using the Flink DataStream API , the result is not correct.Is it a bug or is my usage wrong?
Posted by GitBox <gi...@apache.org>.
openinx commented on issue #2397:
URL: https://github.com/apache/iceberg/issues/2397#issuecomment-810894095
@wuwangben In this lines:
```java
FlinkSource.forRowData().env(bsEnv).filters(Collections.singletonList(filter)).project(flinkSchema)
```
The `filters` are used to push down filters to data files, then we don't have read all the data files from iceberg table. But those filters won't be applied in row-level, that means we may still read more rows from the filtered data files. In you case, I think we will still need to filter the unexpected rows in `DataStream` by:
```java
dataStream.filter(FilterFunction func);
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] wuwangben commented on issue #2397: When querying data by using the Flink DataStream API , the result is not correct.Is it a bug or is my usage wrong?
Posted by GitBox <gi...@apache.org>.
wuwangben commented on issue #2397:
URL: https://github.com/apache/iceberg/issues/2397#issuecomment-810897399
tks
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org