You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2021/05/19 04:29:00 UTC
[GitHub] [iceberg] ayush-san opened a new issue #2610: Flink CDC iceberg table have duplicate rows
ayush-san opened a new issue #2610:
URL: https://github.com/apache/iceberg/issues/2610
I am using flink CDC to stream CDC changes in an iceberg table. For some rows, I am getting duplicate rows in the table even though while writing I have passed equalityFieldColumns
```
FlinkSink.forRowData(rowDataDataStream)
.table(icebergTable)
.tableSchema(FlinkSchemaUtil.toSchema(FlinkSchemaUtil.convert(icebergTable.schema())))
.tableLoader(tableLoader)
.equalityFieldColumns(tableConfig.getEqualityColumns())
.build();
```
I have verified at both debezium and flink end that they are not producing duplicate rows. PFA the flink datastream output
```
+I(1616881,1293386,invoice,XXXXXXXX.....)
-U(1616881,1293386,invoice,XXXXXXXX.....)
+U(1616881,1293386,invoice,XXXXXXXX.....)
-U(1616881,1293386,invoice,XXXXXXXX.....)
+U(1616881,1293386,invoice,XXXXXXXX.....)
-U(1616881,1293386,invoice,XXXXXXXX.....)
+U(1616881,1293386,invoice,XXXXXXXX.....)
-U(1616881,1293386,invoice,XXXXXXXX.....)
+U(1616881,1293386,invoice,XXXXXXXX.....)
-U(1616881,1293386,invoice,XXXXXXXX.....)
+U(1616881,1293386,invoice,XXXXXXXX.....)
```
Here's the query result for same ID in spark-sql

I am facing this issue in most of my tables and only for some rows. What can be the reason behind this? Will it be solved by https://github.com/apache/iceberg/pull/2410?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on issue #2610: Flink CDC iceberg table have duplicate rows
Posted by GitBox <gi...@apache.org>.
openinx commented on issue #2610:
URL: https://github.com/apache/iceberg/issues/2610#issuecomment-851952014
> @openinx Can this be the reason behind duplicate data #2308?
You mean you have did any compaction when the flink job were upsert rows into apache iceberg table ? We have also other Asia users encountered this issue, If they don't do any compaction then we will never encounter any duplicated rows but once we enable the compaction service then duplicated rows happen. Yes, that's indeed a bug ( #2308) that we will need to fixed.
If you don't do any compaction, then we will need to consider other reasons, such as people may replay the duplicated change log events from mysql binlog to apache iceberg. For example, at timestamp t1, people scanned all the existing rows from mysql table and migrate them into apache iceberg by flink streaming job, then they start to migrate the incremental binlog events since the timestamp t1. If we don't record the binlog offset at timestamp t1 in a MySQL transaction, then we may choose to replay a bit more binlog events (which means exporting the binglog events before timestamp t1), in this case we may also encounter the duplicated rows in apache iceberg table. Because currently the apache iceberg table are maintaining the CDC events just as it happened, I mean if INSERT the same row twice, then the iceberg table will produce two duplicated rows rather than one row. This will be resolved if we provide an option at the flink streaming sink job side to indicate that w
e will transfer all the insert rows as UPSERT(s). Pls see this [PR](https://github.com/apache/iceberg/pull/1996).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2610: Flink CDC iceberg table have duplicate rows
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2610:
URL: https://github.com/apache/iceberg/issues/2610#issuecomment-854406583
Yes, I have done compaction when the flink CDC job was still running.
Before running the compaction job

After running compaction and manifest rewrite action
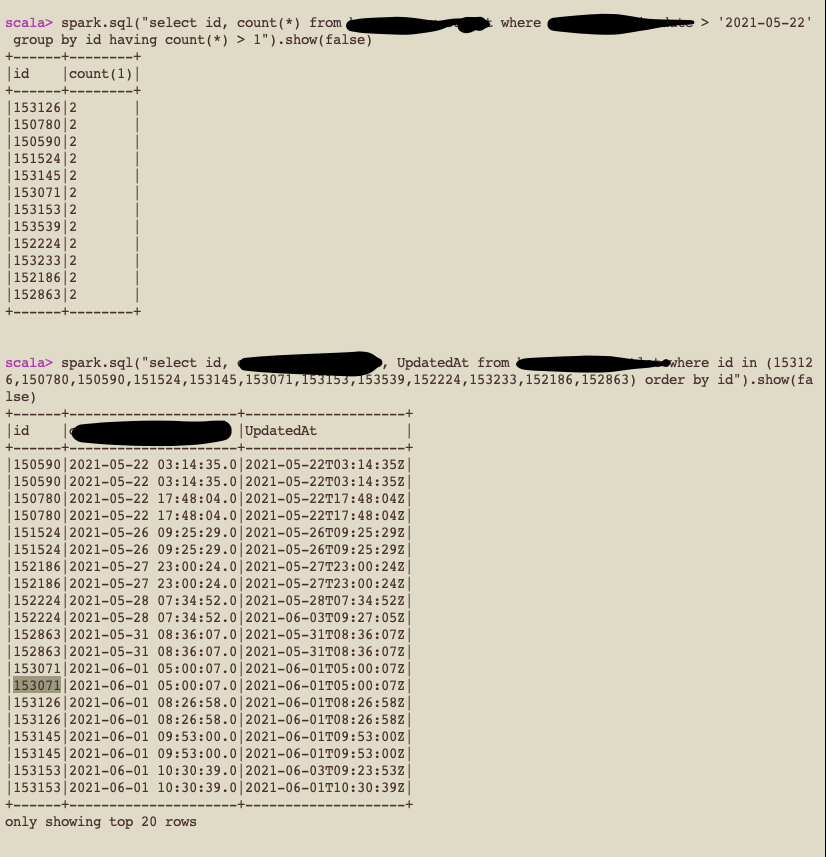
@openinx Here as you can see, we are getting duplicates for various rows which were updated over different times. I mean this issue does not happen for only those rows which got updated during the compaction job duration
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2610: Flink CDC iceberg table have duplicate rows
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2610:
URL: https://github.com/apache/iceberg/issues/2610#issuecomment-854406583
Yes, I have done compaction when the flink CDC job was still running.
Before running the compaction job

After running compaction and manifest rewrite action

@openinx Here as you can see, we are getting duplicates for various rows which were updated over different times. I mean this issue does not happen for only those rows which got updated during the compaction job duration
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2610: Flink CDC iceberg table have duplicate rows
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2610:
URL: https://github.com/apache/iceberg/issues/2610#issuecomment-844075792
@openinx All my tables are unpartitioned and not bucketed.
The changelog I have shared is the output of the flink aggregated data stream, but rowkind is set by debezium deserializer class. Only some updates are coming as duplicates, most of the updates are handled correctly as I am using v2 spec for the tables
```
// need to upgrade version to 2,otherwise 'java.lang.IllegalArgumentException: Cannot write
// delete files in a v1 table'
TableOperations tableOperations = ((BaseTable) icebergTable).operations();
TableMetadata metadata = tableOperations.current();
tableOperations.commit(metadata, metadata.upgradeToFormatVersion(2));
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on issue #2610: Flink CDC iceberg table have duplicate rows
Posted by GitBox <gi...@apache.org>.
openinx commented on issue #2610:
URL: https://github.com/apache/iceberg/issues/2610#issuecomment-843743215
What's your iceberg table schema? Is it possible that the rows with the same primary key located in two different partitions/buckets ? If sure, then we may encounter the duplicated rows that from two different partitions/buckets because we won't dedup the same rows from different partitions , it is high cost to accomplish that.
Another thing, all those change log events come from MYSQLbinlog or flink aggregate results ? If they are came from binlog, then each UPDATE will emit a `UPDATE_BEFORE` and a `UPDATE_AFTER`, currently we iceberg only support update (rather than UPSERT, that means we won't delete the existing rows explicitily but we have pending PR to do this) rows, in theory we won't encounter duplicate rows.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2610: Flink CDC iceberg table have duplicate rows
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2610:
URL: https://github.com/apache/iceberg/issues/2610#issuecomment-846872023
@openinx Can this be the reason behind duplicate data https://github.com/apache/iceberg/issues/2308?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on issue #2610: Flink CDC iceberg table have duplicate rows
Posted by GitBox <gi...@apache.org>.
openinx commented on issue #2610:
URL: https://github.com/apache/iceberg/issues/2610#issuecomment-844595929
Did you have multiple parallelism in flink job to write the same keys to unpartitioned table ? Assume there's two operations:
```
1. INSERT key1 value1;
2. DELETE key1 value1 ;
3. INSERT key1 value2 ;
```
As we have 2 parallelism to write those rows ( without shuffling by primary key), then it's possible that: The first parallelism accept the event2 ( DELETE key1 value1) and write to the iceberg table, the second parallelism accept the event1 and event3 and write to the iceberg table. Then finally the `DELETE key1 value1` won't mask the event1 & event3 because it happens before them and it would only delete all those events with the same key that happens before the delete. In this case, we will encounter two duplicate `INSERT key1` with different values `value1` and `value2`. The suggest solution to fix this issue is: shuffling by the primary key before writing those rows into apache iceberg table because we could ensure that the rows with the same keys are wrote to iceberg table with the same order as they produced.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2610: Flink CDC iceberg table have duplicate rows
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2610:
URL: https://github.com/apache/iceberg/issues/2610#issuecomment-845906296
@openinx Earlier I had task parallelism of 2 in the Source Kafka table, now I have reduced it to 1. Will monitor the job if it is working fine or not
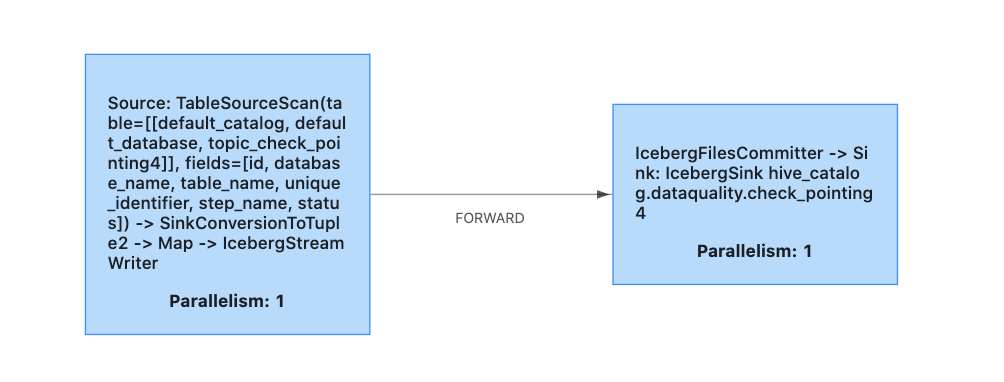
I have one question though, Will it be solved by your primary key PR? For some big tables, I need we will need parallelism of more than 1, so what should be done in that case?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx edited a comment on issue #2610: Flink CDC iceberg table have duplicate rows
Posted by GitBox <gi...@apache.org>.
openinx edited a comment on issue #2610:
URL: https://github.com/apache/iceberg/issues/2610#issuecomment-844595929
Did you have multiple parallelism in flink job to write the same keys to unpartitioned table ? Assume there's three operations:
```
1. INSERT key1 value1;
2. DELETE key1 value1 ;
3. INSERT key1 value2 ;
```
As we have 2 parallelism to write those rows ( without shuffling by primary key), then it's possible that: The first parallelism accept the event2 ( DELETE key1 value1) and write to the iceberg table, the second parallelism accept the event1 and event3 and write to the iceberg table. Then finally the `DELETE key1 value1` won't mask the event1 & event3 because it happens before them and it would only delete all those events with the same key that happens before the delete. In this case, we will encounter two duplicate `INSERT key1` with different values `value1` and `value2`. The suggest solution to fix this issue is: shuffling by the primary key before writing those rows into apache iceberg table because we could ensure that the rows with the same keys are wrote to iceberg table with the same order as they produced.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2610: Flink CDC iceberg table have duplicate rows
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2610:
URL: https://github.com/apache/iceberg/issues/2610#issuecomment-851850736
@stevenzwu @rdblue Can you help here?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2610: Flink CDC iceberg table have duplicate rows
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2610:
URL: https://github.com/apache/iceberg/issues/2610#issuecomment-846818484
Even after setting parallelism 1, I am getting duplicate rows.

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org