You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@dolphinscheduler.apache.org by GitBox <gi...@apache.org> on 2021/07/08 10:07:46 UTC
[GitHub] [dolphinscheduler] github-actions[bot] removed a comment on issue #5752: [Feature][Module Name] Add Blocking Task
github-actions[bot] removed a comment on issue #5752:
URL: https://github.com/apache/dolphinscheduler/issues/5752#issuecomment-874194637
[English](#en) | [中文](#zh-cn)
# <a id="en">About Adding Blocking Task</a>
## Scenarios & Goal
Normally, we execute the whole workflow from start to the end. But sometimes, we want to pause the workflow to check the intermediate result. If correct, execution process continue. If not, pause the workflow and inform someone to solve it. So, I propose blocking task. The aim of blocking task is to pause the execution process properly based on user settings.
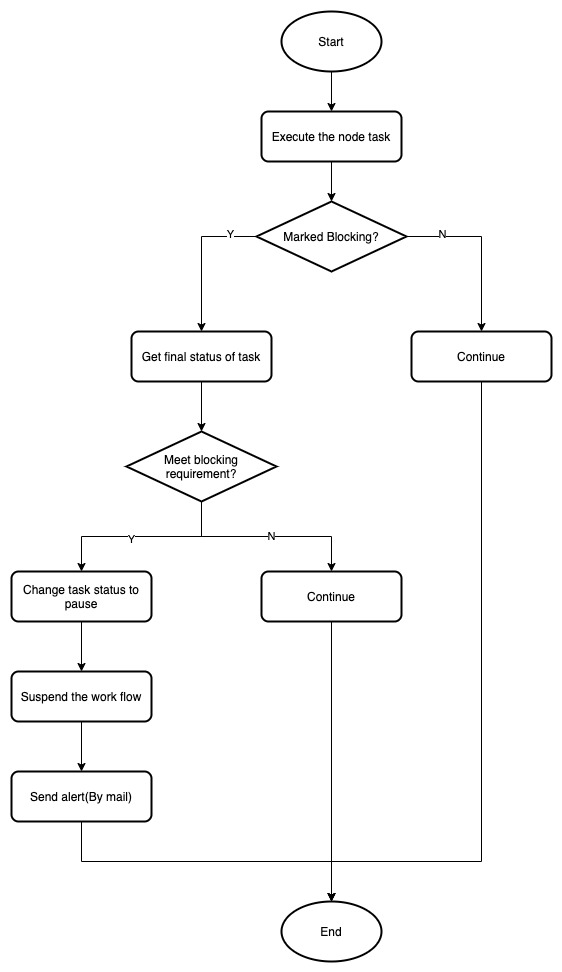
## Main Flow
- When execute to a node, **run the task directly**.
- After the task finished, check if the task has been marked for blocking by user.
- If **marked**, I need to **get the final status of the task**.
- If the task status **meets the blocking trigger setting by user**, change the status of the task to pause. Then, Suspend the whole workflow.
- If not, continue the workflow.
- If not, continue the workflow.
The flow chart has been shown blow:
## Implementation
The implementation can be taken into two parts: one for user web interface, another for Java.
***This is a DRAFT implementation, WELCOME to discuss it in the COMMENT!***
### User Interface
#### Node Setting
When a node supports blocking function, user will see the following screen.
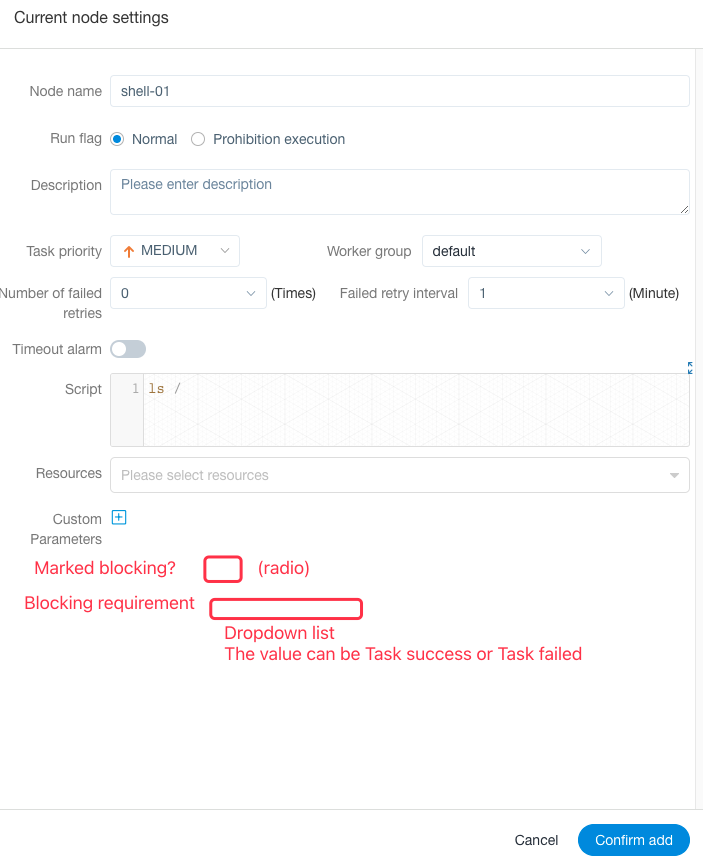
In the node setting view, there is a radio and a drop down list.
The radio is used to mark the node. If user ticks it, it means user wants to set this node as a blocking task.
The drop down list is activated **if and only if the radio has been ticked**. In the drop down list, user can choose when to pause the workflow (Task success or Task failed).
#### JSON Expression
In the JSON definition of a task, I need to add two items **at least**.
- Whether to mark the node as a blocking task
- When to pause the workflow (task success or failed)
### The Java Part
#### Modification of Task Instance Entity
Based on discussed above, you know that I add some new items in the original task JSON expression. These should also be reflected in the task instance entity. Namely, I should add two members in the entity. One is used to mark whether the node has a blocking feature. Another one is used to indicate when to pause the workflow (task success or task failed).
#### Implementation of Blocking function
Blocking function can be condisered as an additional feature of a node. Only task is finished and has a result, the blocking process will be run.
According to the latest DS release, When a task node is finished with success or failure status, the operations of workflow (like submit subsequence nodes, retry, etc.) will be activated. So, the blocking task can be devided into two sections: blocking on task success and blocking on task failed.
Now, I will introduce them respectively.
##### Blocking on task success
After the task execution, if the final status is **success**, run the following steps:
- I need a condition statement to consider if the task final status meets blocking trigger. It will check the blocking flag and confirm if user want to pause the workflow when task **success**. The two information will be taken from task instance entity.
- If true, pause the whole workflow and send alert (by email).
- if false, do nothing.
##### Blocking on task failed
After the task execution, if the final status is **failed**, run the following steps:
- If task can retry, retry first.
- After that, if the task final status still failed, do the following steps **first**:
- I need a condition statement to consider if the task final status meets blocking trigger. It will check the blocking flag and confirm if user want to pause the workflow when task **failed**. The two information will be taken from task instance entity.
- If true, pause the whole workflow and send alert (by email).
- if false, do nothing.
> ⚠️: When user start a workflow, he or she will set a "Failure Strategy". When a task failed, this strategy will allow workflow to continue exectution process or stop. As I mentioned above, if a task is marked with blocking, blocking feature has become a part of this task. As for the priority, blocking function is higher than failure strategy. So, when a task failed, I should run the blocking process first.
It is easy to notice that blocking process on task success and blocking process on task failed are similar. So I can write a function and call the function on properly time at properly place.
#### Node
Now, I will give some concrete scenarios to describe the problem more clearly.
- Blocking on task success: The upstream prepared some data, which needs to be approved by your boss. So, you have to pause the workflow.
- Blocking on task failed: The upstream produced some files that you will not expected. So you need to pause the workflow to check what cause this problem.
### Discussing The Solutions
As for solutions, two options come to mind.
- Modify current task node, adding blocking function to them
- Add a new type of node, called blocking node
Now, I begin to discuss this two options.
> The blocking methods are varied. User will block by one task status or by multi tasks status. The all options mentioned above can meet these requirements.
#### Modify Current Task Node
In this solution, based on the current node functionality, additional support blocking feature.
For blocking by one task status, user can mark the node supporting blocking feature directly.
For blocking by multi tasks status, user can use condition node.
##### Advantages
- After node setting (click the radio), the node has blocking function.
##### Disadvantages
- DS has two type of nodes. The one will sent to woker to execute, like SQL, Shell, MR etc. Another will control the workflow, like sub_process, condition etc. If I make all kinds of nodes supporting blocking, the nodes which will be sent to worker have the right to control workflow in a way. From this perspective, coupling appeared.
- In DAG, it is hard to recognize which node marked to be blocking node without double click to see the node detail information.
**Another case of this solution is modifying condition node only.** The reason is that the blocking process and condition process are **familiar**. Maybe they can merge into one node. The current version of condition node cannot be save with one branch declared. In order to support blocking, this rule will be break. Because the subsequence of blocking process can not only be multi branches but also one branch.
#### Add a New Type of Node
In this solution, add a new type of node. This node is familiar with condition node. According to the final results of one or more direct predecessor, condition node considers how to control workflow. But the condition node changes the flow direction, the blocking node pause the execution process of workflow.
##### Advantages
- As I menthond above, there are two kinds of nodes in DS. In this sicuation, no coupling occurred.
- User can easy recognize which node has been marked for blocking.
##### Disadvantages
- In order to complete a blocking task. It is necessary to place one or more task nodes in front of blocking node. Maybe this is not convenient compared with solution I.
#### Concrete Scenario Analysis
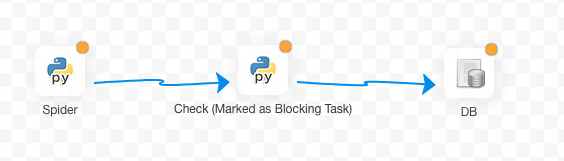
Suppose I have a task: First, use spider claws some infomation from the Internet. Then, check data Integrity. If data correct, put them into database, otherwise, pause the workflow and send alert.
In solution I, the DAG maybe like this.
In solution II, the DAG maybe like this.
<img width="743" alt="阻断实现2-en" src="https://user-images.githubusercontent.com/23556693/124493295-0a4e8000-dde8-11eb-80c1-739acee5252f.png">
# <a id="zh-cn">关于添加阻断类任务</a>
## 场景和目标
在工作流的执行中,有时我们并不希望从头一直执行到底,我们希望在工作流中间能够设立一些“检查站”,检查上游任务的执行情况,如果检查满足预期,则继续往下执行;如果检查不通过,就需要暂停当前工作流,告警相关人员进行干预,干预成功后再往下执行。
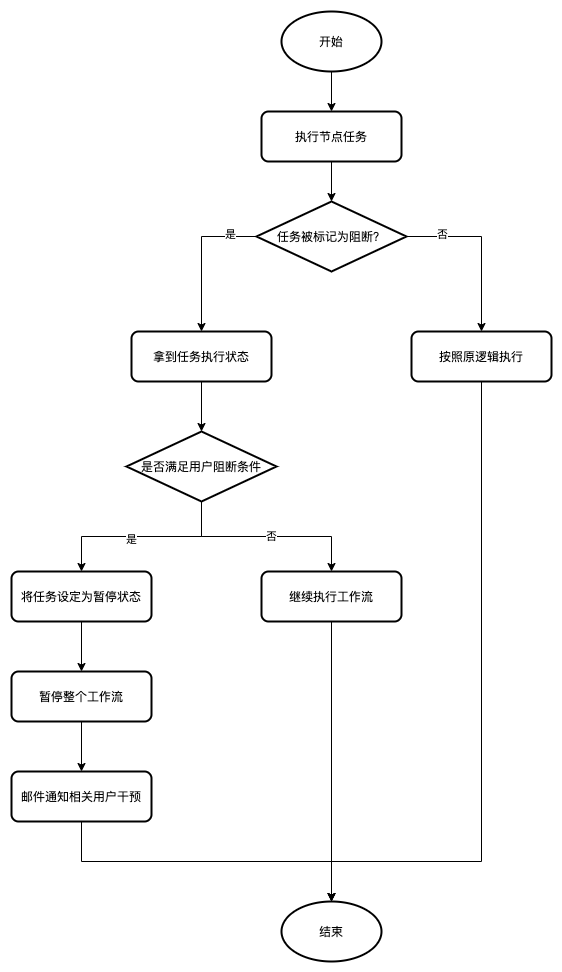
## 主流程
- 当执行到一个节点时,先按照**原有逻辑**执行任务
- 当任务执行完毕后,检查该节点是否被用户标记为阻断节点
- 如果**被标记**为阻断节点,则需要拿到任务的**最终执行状态**
- 如果**满足**用户设置的暂停逻辑,就将该任务的状态修改为暂停,进而可以将整个工作流暂停
- 如果**不满足**用户设定的暂停逻辑,就按照系统原有逻辑执行
- 如果**没有被标记**为阻断节点,则按照系统原有逻辑执行
整个过程的流程图如下所示:
## 大致实现逻辑
实现逻辑分为两个部分,一是用户操作逻辑,二是后台逻辑
### 用户操作逻辑
#### 设置界面
当节点被赋予阻断功能后,用户在设置节点时,会看到以下界面
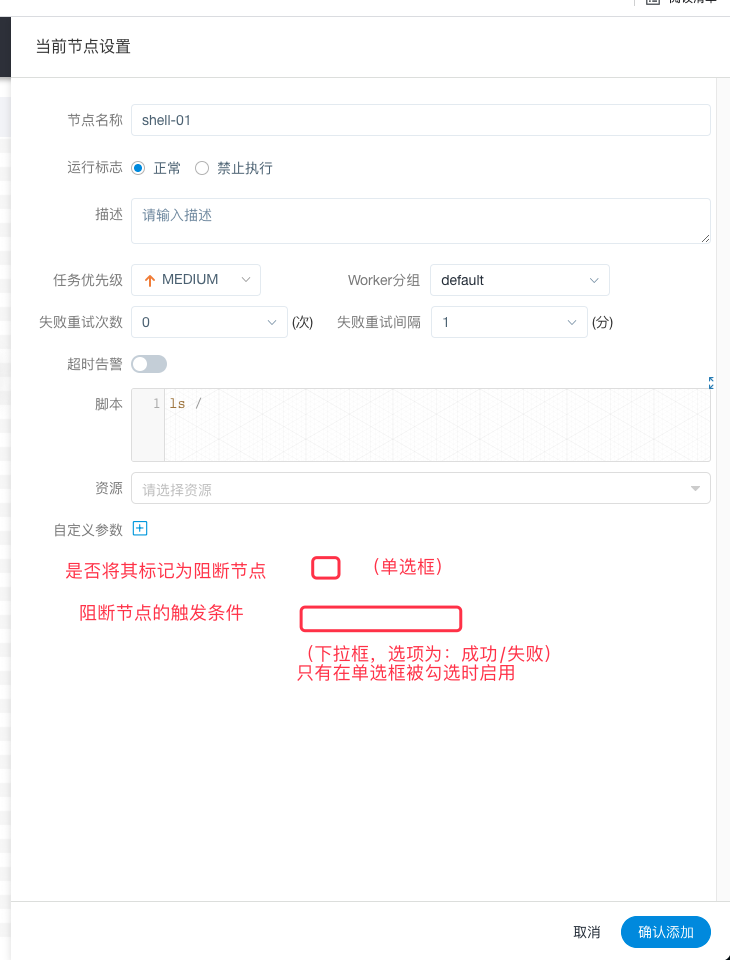
在界面中,有一个单选框,用于标记该节点是否被赋予阻断功能;在单选框下面,有一个下拉框,用户可以选择触发条件(任务成功触发 / 任务失败触发)。**当且仅当,单选框被勾选时,下拉框生效。**
#### 任务节点的JSON表示
在任务节点的JSON定义中,**至少**需要增加两个信息:
- 是否将其标记为阻断节点
- 是希望任务成功时阻断,还是失败时阻断
### 后台逻辑
#### 任务对象实体类的修改
从用户操作逻辑中可知,在原有的任务JSON定义中,新增了新的内容,这些新内容,**在任务对象的实体类中也要有所体现**,也就是至少需要增加两个字段,一个字段来标记节点是否被作为阻断节点;另一个字段用来表示是在任务成功时暂停工作流,还是失败时暂停工作流。
#### 阻断方法的实现逻辑
阻断功能可以认为是节点的**附加功能**,它是定义在节点本身执行结果之上的,**只有节点执行完成且有结果**,阻断功能才有机会执行。
结合DS的现有逻辑,对工作流的操作(提交后续节点、重试、执行失败策略等),是在判断任务执行成功 / 失败后执行,因此,阻断功能也可分为两个部分:任务执行成功时阻断、任务执行失败时阻断。同时,阻断方法的放置位置应遵守现有结构。下面对这两种情况分别进行说明。
##### 成功时阻断
任务执行完成后,如果任务状态为成功,执行以下操作:
- 需要设定一个判断语句,判断是否满足阻断触发条件。判断语句需要判断当前处理节点是否被标记为阻断节点、是否是任务成功时阻断,这两个信息都需要从任务对象实体类中获取
- 如果判定结果为真,执行暂停工作流的方法,工作流成功暂停后,使用告警策略(邮件)通知相关用户进行干预
- 如果判定结果为假,则什么也不做,按照原有逻辑执行
##### 失败时阻断
任务执行完成后,如果任务状态失败,执行以下操作:
- 如果任务允许重试,则重试任务
- 如果任务重试次数耗尽后依然失败,**首先**执行以下操作:
- 需要设定一个判断语句,判断是否满足阻断触发条件。判断语句需要判断当前节点是否被标记为阻断节点,是否是失败时阻断,这两个信息都需要从任务对象实体类中获取
- 如果判定结果为真,执行暂停工作流的方法,工作流成功暂停后,使用告警策略(邮件)通知相关用户进行干预
- 如果判定结果为假,则什么也不做,按照原有逻辑执行
> 这里需要注意,用户在开启工作流时,会设定一个“失败策略”,这个策略允许当任务失败后,继续执行工作流还是停止执行工作流。前面提到,阻断功能是节点的附加功能,**如果某个节点被标记成为阻断节点,那么阻断功能就成为了节点功能的一部分**。因此,在优先级上,**阻断功能大于失败策略**。所以,当重试失败后,最先执行的,应该是阻断功能。
从以上分析不难看出,成功时阻断和失败时阻断的逻辑是差不多的,因此可以将这个过程提炼出一个方法,在合适的时机调用即可。
### 备注
这里附上成功时阻断与失败时阻断的应用场景举例:
- 成功时阻断:上游工作流准备了一些数据,这些数据需要上级领导审批,审批通过后,再继续执行,这时,就需要暂停工作流。
- 失败时阻断:上游工作流出现问题,生成了不符合用户预期的文件,这时需要暂停工作流,人工介入干预。
## 实现方案讨论
对于阻断节点的实现方案,目前想到的有两种:
- 将原有节点(无论是否是有实际任务执行的节点)赋予阻断功能
- 在现有的节点中新增一种节点,专门用于阻断任务
下面分别对这两种方案进行分析。
> 用户阻断的方式是多样的,可能根据单任务的执行结果阻断,也可以根据多任务的执行结果混合阻断。上述这两种方案都可以实现。
### 基于现有节点修改
这种实现方案是说,对于现有的所有节点,都在其节点设置中赋予阻断功能。对于根据单任务进行阻断的情况,直接将对应任务标记为阻断节点即可,至于根据多任务进行阻断,可考虑使用条件节点实现。
#### 优势
- 只需要在现有节点设置完成后,就可以完成阻断功能
#### 缺点
- ds中的节点可以分为两类,一类是有实际任务执行的节点,比如Shell、MR等,它们会被发到worker去执行;另一类为没有实际任务的节点,例如Condition、sub_process等,它们主要负责工作流本身的控制,并不会被发到worker去执行。如果将所有节点都赋予阻断功能的话,那么对于一个有实际任务的节点来说,某种程度上,拥有了控制工作流的功能,**出现了耦合**。
- 在DAG表现中,如果不双击查看节点信息,难以从图标区分哪个是阻断节点。
一种比较有趣的做法是**只修改条件节点**,这么做的原因是条件节点的中有很多功能与即将添加的阻断功能**类似**,或许可以合并。在原有的条件节点设计中,一定要设定成功失败两个分支才可以保存,但是如果将其增加阻断功能后,这个设定会被打破。这是因为,在阻断节点后,可以是单分支的,也可以是多分支的。
### 新增节点种类
这种实现方式是说,在现有节点的基础上,另外新增一种节点,这种节点类似条件节点的实现方式,即根据其一个或多个直接前驱节点的执行结果,判断是否触发某种行为,只不过它的功能不是流转工作流,而是阻断工作流。
#### 优势
- 前面提到,ds中有两类节点,使用这种实现方式,就将有实际任务的节点和没有实际任务的节点进行解耦
- 可以从图标区分哪个是阻断节点
#### 缺点
- 这种节点是无法单独使用的,需要在其前驱有一个或多个有实际任务的节点,它们互相配合才能完成阻断逻辑,**并没有使用单一节点阻断来的干脆**
### 简单场景举例
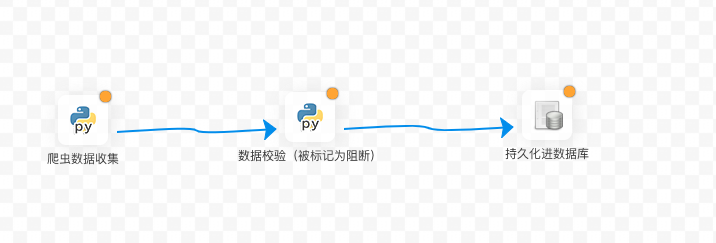
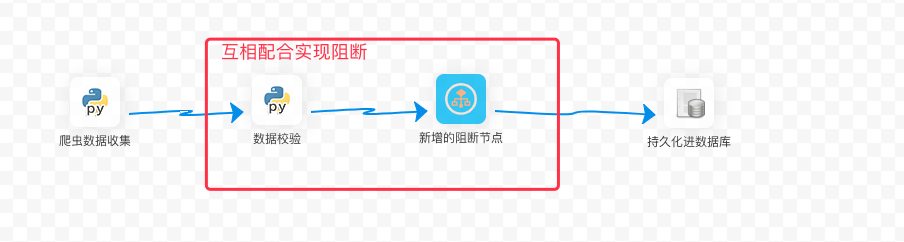
现在有一个任务:要先利用爬虫去互联网上爬取数据,然后检查数据完整性,检查通过,继续执行并存入数据库,检查不通过,通知相关人员进行干预。
使用第一种实现方式的DAG
使用第二种实现方式的DAG
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@dolphinscheduler.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org