You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2020/08/29 01:45:09 UTC
[GitHub] [hudi] wangxianghu opened a new pull request #1827: [HUDI-1089] [WIP]Refactor hudi-client to support multi-engine
wangxianghu opened a new pull request #1827:
URL: https://github.com/apache/hudi/pull/1827
## *Tips*
- *Thank you very much for contributing to Apache Hudi.*
- *Please review https://hudi.apache.org/contributing.html before opening a pull request.*
## What is the purpose of the pull request
*Refactor hudi-client to support multi-engine*
## Brief change log
- *Refactor hudi-client to support multi-engine*
## Verify this pull request
*This pull request is already covered by existing tests*.
## Committer checklist
- [ ] Has a corresponding JIRA in PR title & commit
- [ ] Commit message is descriptive of the change
- [ ] CI is green
- [ ] Necessary doc changes done or have another open PR
- [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Mathieu1124 commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
Mathieu1124 commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r457127004
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,48 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
Review comment:
>
>
> Just bump into this... Since this is a generic engine context, will it be better to use a generic name like `engineConfig`?
Hi, henry thanks for your review. This class holds more than config stuff(your can see its child class `HoodieSparkEngineContext`), maybe context is better, WDYT?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-702174407
@leesf do you see the following exception? could not understand how you ll get the other one even.
```
LOG.info("Starting Timeline service !!");
Option<String> hostAddr = context.getProperty(EngineProperty.EMBEDDED_SERVER_HOST);
if (!hostAddr.isPresent()) {
throw new HoodieException("Unable to find host address to bind timeline server to.");
}
timelineServer = Option.of(new EmbeddedTimelineService(context, hostAddr.get(),
config.getClientSpecifiedViewStorageConfig()));
```
Either way, good pointer. the behavior has changed around this a bit actually. So will try and tweak and push a fix
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-693113074
> @wangxianghu on the checkstyle change to bump up the line count to 500, I think we should revert to 200 as it is now.
> I checked out a few of the issues. they can be brought within limit, by folding like below.
> if not, we can turn off checkstyle selectively in that block?
>
> ```
>
> public class HoodieSparkMergeHandle<T extends HoodieRecordPayload> extends
> HoodieWriteHandle<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> {
> ```
Good idea. I'll give a try.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r485027583
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/io/HoodieSparkMergeHandle.java
##########
@@ -71,34 +77,25 @@
protected boolean useWriterSchema;
private HoodieBaseFile baseFileToMerge;
- public HoodieMergeHandle(HoodieWriteConfig config, String instantTime, HoodieTable<T> hoodieTable,
- Iterator<HoodieRecord<T>> recordItr, String partitionPath, String fileId, SparkTaskContextSupplier sparkTaskContextSupplier) {
- super(config, instantTime, partitionPath, fileId, hoodieTable, sparkTaskContextSupplier);
+ public HoodieSparkMergeHandle(HoodieWriteConfig config, String instantTime, HoodieTable hoodieTable,
+ Iterator<HoodieRecord<T>> recordItr, String partitionPath, String fileId, TaskContextSupplier taskContextSupplier) {
+ super(config, instantTime, partitionPath, fileId, hoodieTable, taskContextSupplier);
init(fileId, recordItr);
init(fileId, partitionPath, hoodieTable.getBaseFileOnlyView().getLatestBaseFile(partitionPath, fileId).get());
}
/**
* Called by compactor code path.
*/
- public HoodieMergeHandle(HoodieWriteConfig config, String instantTime, HoodieTable<T> hoodieTable,
- Map<String, HoodieRecord<T>> keyToNewRecords, String partitionPath, String fileId,
- HoodieBaseFile dataFileToBeMerged, SparkTaskContextSupplier sparkTaskContextSupplier) {
- super(config, instantTime, partitionPath, fileId, hoodieTable, sparkTaskContextSupplier);
+ public HoodieSparkMergeHandle(HoodieWriteConfig config, String instantTime, HoodieTable hoodieTable,
+ Map<String, HoodieRecord<T>> keyToNewRecords, String partitionPath, String fileId,
+ HoodieBaseFile dataFileToBeMerged, TaskContextSupplier taskContextSupplier) {
+ super(config, instantTime, partitionPath, fileId, hoodieTable, taskContextSupplier);
this.keyToNewRecords = keyToNewRecords;
this.useWriterSchema = true;
init(fileId, this.partitionPath, dataFileToBeMerged);
}
- @Override
Review comment:
> please refrain from moving methods around within the file. it makes life hard during review :(
sorry for the inconvenient, let me see what I can do to avoid this :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Mathieu1124 commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
Mathieu1124 commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-659898064
> @Mathieu1124 @leesf can you please share any tests you may have done in your own environment to ensure existing functionality is in tact.. This is a major signal we may not completely get with a PR review
My test is limited, just all the unit tests in source code, and all the demos in the Quick-Start Guide. I am planning to test it in docker env.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484832824
##########
File path: hudi-client/pom.xml
##########
@@ -68,6 +107,12 @@
</build>
<dependencies>
+ <!-- Scala -->
+ <dependency>
+ <groupId>org.scala-lang</groupId>
Review comment:
> should we limit scala to just the spark module?
Yes, it is better. can we do it in another PR?
because although some classes have nothing to do with spark, it used `scala.Tuple2`, so scala is still needed.
we can replace it with 'org.apache.hudi.common.util.collection.Pair'
WDYT?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-695785338
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r493999114
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/commit/BaseMergeHelper.java
##########
@@ -161,11 +108,11 @@ private static GenericRecord transformRecordBasedOnNewSchema(GenericDatumReader<
/**
* Consumer that dequeues records from queue and sends to Merge Handle.
*/
- private static class UpdateHandler extends BoundedInMemoryQueueConsumer<GenericRecord, Void> {
+ static class UpdateHandler extends BoundedInMemoryQueueConsumer<GenericRecord, Void> {
- private final HoodieMergeHandle upsertHandle;
+ private final HoodieWriteHandle upsertHandle;
Review comment:
> why is this no longer a mergeHandle?
With `parallelDo` method introduced in, this change is no longer needed. rollback already
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Mathieu1124 edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
Mathieu1124 edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-662474645
> @Mathieu1124 , @leesf : @n3nash said he is half way through reviewing. I took another pass and this seems low risk enough for us to merge for 0.6.0.
>
> We have some large PRs pending though #1702 #1678 #1834 . I would like to merge those and then rework this a bit on top of this. How painful do you think the rebase would be? (I can help as much as I can as well). Does this sound like a good plan to you
@vinothchandar, I have taken a quick pass about that three PRs above, can't say that'll be little work, but I am ok with this plan because these three PRs are based on the same base, so leaving this PR at the last could greatly reduce their workload on rebasing and gives more time for us to test this PR.
we'll do our best to push this PR, and merge this for 0.6.0
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484933755
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/io/SparkCreateHandleFactory.java
##########
@@ -0,0 +1,46 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.io;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.client.WriteStatus;
+import org.apache.hudi.common.model.HoodieKey;
+import org.apache.hudi.common.model.HoodieRecord;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.collection.Pair;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.table.HoodieTable;
+import org.apache.spark.api.java.JavaPairRDD;
+import org.apache.spark.api.java.JavaRDD;
+
+public class SparkCreateHandleFactory<T extends HoodieRecordPayload> extends WriteHandleFactory<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> {
+
+ @Override
+ public HoodieSparkCreateHandle create(final HoodieWriteConfig hoodieConfig,
Review comment:
> same. is there a way to not make these spark specific
I'll give a try
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-691505048
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484828652
##########
File path: style/checkstyle.xml
##########
@@ -62,7 +62,7 @@
<property name="allowNonPrintableEscapes" value="true"/>
</module>
<module name="LineLength">
- <property name="max" value="200"/>
+ <property name="max" value="500"/>
Review comment:
> let's discuss this in a separate PR? 500 is a really large threshold
very sorry to say this ...
According to the current abstraction,some declaration of the method is longer than 200.
such as `org.apache.hudi.table.action.compact.HoodieSparkMergeOnReadTableCompactor#generateCompactionPlan`
It is 357 characters long
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484928117
##########
File path: hudi-spark/src/main/java/org/apache/hudi/bootstrap/SparkParquetBootstrapDataProvider.java
##########
@@ -43,18 +43,18 @@
/**
* Spark Data frame based bootstrap input provider.
*/
-public class SparkParquetBootstrapDataProvider extends FullRecordBootstrapDataProvider {
+public class SparkParquetBootstrapDataProvider extends FullRecordBootstrapDataProvider<JavaRDD<HoodieRecord>> {
private final transient SparkSession sparkSession;
public SparkParquetBootstrapDataProvider(TypedProperties props,
- JavaSparkContext jsc) {
- super(props, jsc);
- this.sparkSession = SparkSession.builder().config(jsc.getConf()).getOrCreate();
+ HoodieSparkEngineContext context) {
+ super(props, context);
+ this.sparkSession = SparkSession.builder().config(context.getJavaSparkContext().getConf()).getOrCreate();
}
@Override
- public JavaRDD<HoodieRecord> generateInputRecordRDD(String tableName, String sourceBasePath,
+ public JavaRDD<HoodieRecord> generateInputRecord(String tableName, String sourceBasePath,
Review comment:
> rename: generateInputRecords
done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484921994
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/index/hbase/BaseHoodieHBaseIndex.java
##########
@@ -0,0 +1,295 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.index.hbase;
+
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.common.table.timeline.HoodieTimeline;
+import org.apache.hudi.common.util.ReflectionUtils;
+import org.apache.hudi.config.HoodieHBaseIndexConfig;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.exception.HoodieDependentSystemUnavailableException;
+import org.apache.hudi.index.HoodieIndex;
+import org.apache.hudi.table.HoodieTable;
+
+import org.apache.hadoop.conf.Configuration;
+import org.apache.hadoop.hbase.HBaseConfiguration;
+import org.apache.hadoop.hbase.HRegionLocation;
+import org.apache.hadoop.hbase.TableName;
+import org.apache.hadoop.hbase.client.BufferedMutator;
+import org.apache.hadoop.hbase.client.Connection;
+import org.apache.hadoop.hbase.client.ConnectionFactory;
+import org.apache.hadoop.hbase.client.Get;
+import org.apache.hadoop.hbase.client.HTable;
+import org.apache.hadoop.hbase.client.Mutation;
+import org.apache.hadoop.hbase.client.RegionLocator;
+import org.apache.hadoop.hbase.client.Result;
+import org.apache.hadoop.hbase.util.Bytes;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.List;
+
+/**
+ * Hoodie Index implementation backed by HBase.
+ */
+public abstract class BaseHoodieHBaseIndex<T extends HoodieRecordPayload, I, K, O, P> extends HoodieIndex<T, I, K, O, P> {
Review comment:
> are there any code changes here, i.e logic changes?
nothing changed
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-698619431
Alright, taking over the wheel :) thanks @wangxianghu . This is true champion effort!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-692257956
That sounds promising. We cannot easily fix `T,R,O` though right at the class level. it will be different in each setting, right?
We can use generic methods though I think and what I had in mind was something little different
if the method signature can be the following
```
public abstract <I,O> List<O> parallelDo(List<I> data, Function<I, O> func, int parallelism);
```
and for the Spark the implementation
```
public <I,O> List<O> parallelDo(List<I> data, Function<I, O> func, int parallelism) {
return jsc.parallelize(data, parallelism).map(func).collectAsList();
}
```
and the invocation
```
engineContext.parallelDo(Arrays.asList(1,2,3), (a) -> {
return 0;
}, 3);
```
Can you a small Flink implementation as well and confirm this approach will work for Flink as well. Thats another key thing to answer, before we finalize the approach.
Note that
a) some of the code that uses `rdd.mapToPair()` etc before collecting, have to be rewritten using Java Streams. i.e
`engineContext.parallelDo().map()` instead of `jsc.parallelize().map().mapToPair()` currently.
b) Also we should limit the use of parallelDo() to only cases where there are no grouping/aggregations involved. for e.g if we are doing `jsc.parallelize(files, ..).map(record).reduceByKey(..)`, collecting without reducing will lead to OOMs. We can preserve what you are doing currently, for such cases.
But the parallelDo should help up reduce the amount of code broken up (and thus reduce the effort for the flink engine).
@wangxianghu I am happy to shepherd this PR through from this point as well. lmk
cc @yanghua @leesf
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-702318528
@vinothchandar The warn log issue is fixed
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-702222008
@vinothchandar @yanghua @leesf The demo runs well in my local, except the warning `WARN embedded.EmbeddedTimelineService: Unable to find driver bind address from spark config`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r492449543
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
@wangxianghu functionality wise, you are correct. it can be implemented just using Java. but, we do parallelization of different pieces of code e.g deletion of files in parallel using spark for a reason. It significantly speeds these up, for large tables.
All I am saying is to implement the `HoodieSparkEngineContext#map` like below
```
public <I, O> List<O> map(List<I> data, Function<I, O> func, int parallelism) {
return javaSparkContext.parallelize(data, parallelism).map(func).collect();
}
```
similarly for the other two methods. I don't see any issues with this. do you?
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
Is it possible to take a `java.util.function.Function` and then within `HoodieSparkEngineContext#map` wrap that into a `org.apache.spark.api.java.function.Function` ?
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
In Spark, there is a functional interface defined like this
```
package org.apache.spark.api.java.function;
import java.io.Serializable;
/**
* Base interface for functions whose return types do not create special RDDs. PairFunction and
* DoubleFunction are handled separately, to allow PairRDDs and DoubleRDDs to be constructed
* when mapping RDDs of other types.
*/
@FunctionalInterface
public interface Function<T1, R> extends Serializable {
R call(T1 v1) throws Exception;
}
```
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
when the use passes in a regular lambda, into `rdd.map()`, this is what it gets converted into
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
@wangxianghu This is awesome. Hopefully this can reduce the amount of code you need to write for Flink significantly. `TestMarkerFiles` seems to pass, so guess the serialization etc is working as expected.
We can go ahead with doing more files in this approach and remerge the base/child classes back as much as possible. cc @leesf @yanghua as well in case they have more things to add.
cc @bvaradar as well as FYI
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r492493739
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> when the use passes in a regular lambda, into `rdd.map()`, this is what it gets converted into
The serializable issue can be solved by introducing a seriableFuncition to replace `java.util.function.Function`
```
public interface SerializableFunction<I, O> extends Serializable {
O call(I v1) throws Exception;
}
```
`HoodieEngineContext` can be
```
public abstract class HoodieEngineContext {
public abstract <I, O> List<O> map(List<I> data, SerializableFunction<I, O> func, int parallelism) ;
}
```
`HoodieSparkEngineContext` can be
```
public class HoodieSparkEngineContext extends HoodieEngineContext {
private static JavaSparkContext jsc;
// tmp
static {
SparkConf conf = new SparkConf()
.setMaster("local[4]")
.set("spark.driver.host","localhost")
.setAppName("HoodieSparkEngineContext");
jsc = new JavaSparkContext(conf);
}
@Override
public <I, O> List<O> map(List<I> data, SerializableFunction<I, O> func, int parallelism) {
return jsc.parallelize(data, parallelism).map(func::call).collect();
}
}
```
this works :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-702217863
> @leesf do you see the following exception? could not understand how you ll get the other one even.
>
> ```
> LOG.info("Starting Timeline service !!");
> Option<String> hostAddr = context.getProperty(EngineProperty.EMBEDDED_SERVER_HOST);
> if (!hostAddr.isPresent()) {
> throw new HoodieException("Unable to find host address to bind timeline server to.");
> }
> timelineServer = Option.of(new EmbeddedTimelineService(context, hostAddr.get(),
> config.getClientSpecifiedViewStorageConfig()));
> ```
>
> Either way, good pointer. the behavior has changed around this a bit actually. So will try and tweak and push a fix
I got this warning too. The code here seems not the same.
```
// Run Embedded Timeline Server
LOG.info("Starting Timeline service !!");
Option<String> hostAddr = context.getProperty(EngineProperty.EMBEDDED_SERVER_HOST);
timelineServer = Option.of(new EmbeddedTimelineService(context, hostAddr.orElse(null),
config.getClientSpecifiedViewStorageConfig()));
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yanghua commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
yanghua commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-690922454
@leesf Thanks for your awesome work. Can you squash these commits for the subsequent review?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-692604118
> That sounds promising. We cannot easily fix `T,R,O` though right at the class level. it will be different in each setting, right?
>
> We can use generic methods though I think and what I had in mind was something little different
> if the method signature can be the following
>
> ```
> public abstract <I,O> List<O> parallelDo(List<I> data, Function<I, O> func, int parallelism);
> ```
>
> and for the Spark the implementation
>
> ```
> public <I,O> List<O> parallelDo(List<I> data, Function<I, O> func, int parallelism) {
> return jsc.parallelize(data, parallelism).map(func).collectAsList();
> }
> ```
>
> and the invocation
>
> ```
> engineContext.parallelDo(Arrays.asList(1,2,3), (a) -> {
> return 0;
> }, 3);
> ```
>
> Can you a small Flink implementation as well and confirm this approach will work for Flink as well. Thats another key thing to answer, before we finalize the approach.
>
> Note that
>
> a) some of the code that uses `rdd.mapToPair()` etc before collecting, have to be rewritten using Java Streams. i.e
>
> `engineContext.parallelDo().map()` instead of `jsc.parallelize().map().mapToPair()` currently.
>
> b) Also we should limit the use of parallelDo() to only cases where there are no grouping/aggregations involved. for e.g if we are doing `jsc.parallelize(files, ..).map(record).reduceByKey(..)`, collecting without reducing will lead to OOMs. We can preserve what you are doing currently, for such cases.
>
> But the parallelDo should help up reduce the amount of code broken up (and thus reduce the effort for the flink engine).
>
> @wangxianghu I am happy to shepherd this PR through from this point as well. lmk
>
> cc @yanghua @leesf
Yes, I noticed that problem lately. we should use generic methods. I also agree with the a) and b) you mentioned.
In the `parallelDo` method flink engine can operate the list directly using Java Stream, I have verified that. but there is a problem:
The function used in spark map operator is `org.apache.spark.api.java.function.Function` while what flink can use is `java.util.function.Function` we should align it.
maybe we can use `java.util.function.Function` only, If this way, there is no need to distinguish spark and flink, there both use java stream to implement those kind operations. the generic method could be like this:
```public class HoodieEngineContext {
public <I, O> List<O> parallelDo(List<I> data, Function<I, O> func) {
return data.stream().map(func).collect(Collectors.toList());
}
}```
WDYT?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r492434405
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> I think we should leave this abstract and let the engines implement this? even for Java. Its better to have a `HoodieJavaEngineContext`. From what I can see, this is not overridden in `HoodieSparkEngineContext` and thus we lose the parallel execution that we currently have with Spark with this change.
as we discussed before, parallelDo model need a function as input parameter, Unfortunately, different engines need different type function, its hard to align them in an abstract parallelDo method. so we agree to use ` java.util.function.Function` as the unified input function. in this way, there is no need to distinguish spark and flink, and the parallelism is not needed too.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-698161234
> @wangxianghu Looks like we have much less class splitting now. I want to try and reduce this further if possible.
> If its alright with you, I can take over from here, make some changes and push another commit on top of yours, to try and get this across the finish line. Want to coordinate so that we are not making parallel changes,
@vinothchandar, Yeah, Of course, you can take over from here, this will greatly facilitate the process
thanks 👍
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-659789500
@Mathieu1124 @leesf can you please share any tests you may have done in your own environment to ensure existing functionality is in tact.. This is a major signal we may not completely get with a PR review
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-691745384
I can help address the remaining feedback. I will push a small diff today/tmrw.
Overall, looks like a reasonable start.
The major feedback I still have is the following
>would a parallelDo(func, parallelism) method in HoodieEngineContext help us avoid a lot of base/child class duplication of logic like this?
Lot of usages are like `jsc.parallelize(list, parallelism).map(func)` , which all require a base-child class now. I am wondering if its easier to take those usages alone and implement as `engineContext.parallelDo(list, func, parallelism)`. This can be the lowest common denominator across Spark/Flink etc. We can avoid splitting a good chunk of classes if we do this IMO. If this is interesting, and we agree, I can try to quantify.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r492262964
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/common/HoodieSparkEngineContext.java
##########
@@ -0,0 +1,56 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.SparkTaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+import org.apache.spark.api.java.JavaSparkContext;
+import org.apache.spark.sql.SQLContext;
+
+/**
+ * A Spark engine implementation of HoodieEngineContext.
+ */
+public class HoodieSparkEngineContext extends HoodieEngineContext {
Review comment:
can we implement versiosn of `map`, `flatMap`, `forEach` here which use `javaSparkContext.parallelize()` ? It would be good to keep this PR free of any changes in terms of whether we are executing the deletes/lists in parallel or in serial.
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/SparkMarkerFiles.java
##########
@@ -0,0 +1,124 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.table;
+
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.LocatedFileStatus;
+import org.apache.hadoop.fs.Path;
+import org.apache.hadoop.fs.RemoteIterator;
+import org.apache.hudi.bifunction.wrapper.ThrowingFunction;
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.config.SerializableConfiguration;
+import org.apache.hudi.common.model.IOType;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Set;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+import static org.apache.hudi.bifunction.wrapper.BiFunctionWrapper.throwingConsumerWrapper;
+import static org.apache.hudi.bifunction.wrapper.BiFunctionWrapper.throwingFlatMapWrapper;
+
+public class SparkMarkerFiles extends BaseMarkerFiles {
+
+ private static final Logger LOG = LogManager.getLogger(SparkMarkerFiles.class);
+
+ public SparkMarkerFiles(HoodieTable table, String instantTime) {
+ super(table, instantTime);
+ }
+
+ public SparkMarkerFiles(FileSystem fs, String basePath, String markerFolderPath, String instantTime) {
+ super(fs, basePath, markerFolderPath, instantTime);
+ }
+
+ @Override
+ public boolean deleteMarkerDir(HoodieEngineContext context, int parallelism) {
+ try {
+ if (fs.exists(markerDirPath)) {
+ FileStatus[] fileStatuses = fs.listStatus(markerDirPath);
+ List<String> markerDirSubPaths = Arrays.stream(fileStatuses)
+ .map(fileStatus -> fileStatus.getPath().toString())
+ .collect(Collectors.toList());
+
+ if (markerDirSubPaths.size() > 0) {
+ SerializableConfiguration conf = new SerializableConfiguration(fs.getConf());
+ context.foreach(markerDirSubPaths, throwingConsumerWrapper(subPathStr -> {
+ Path subPath = new Path(subPathStr);
+ FileSystem fileSystem = subPath.getFileSystem(conf.get());
+ fileSystem.delete(subPath, true);
+ }));
+ }
+
+ boolean result = fs.delete(markerDirPath, true);
+ LOG.info("Removing marker directory at " + markerDirPath);
+ return result;
+ }
+ } catch (IOException ioe) {
+ throw new HoodieIOException(ioe.getMessage(), ioe);
+ }
+ return false;
+ }
+
+ @Override
+ public Set<String> createdAndMergedDataPaths(HoodieEngineContext context, int parallelism) throws IOException {
Review comment:
we are not using parallelism here. This will lead to a perf regression w.r.t master.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
Also these APIs should take in a `parallelism` parameter, no?
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/SparkMarkerFiles.java
##########
@@ -0,0 +1,124 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.table;
+
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.LocatedFileStatus;
+import org.apache.hadoop.fs.Path;
+import org.apache.hadoop.fs.RemoteIterator;
+import org.apache.hudi.bifunction.wrapper.ThrowingFunction;
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.config.SerializableConfiguration;
+import org.apache.hudi.common.model.IOType;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Set;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+import static org.apache.hudi.bifunction.wrapper.BiFunctionWrapper.throwingConsumerWrapper;
+import static org.apache.hudi.bifunction.wrapper.BiFunctionWrapper.throwingFlatMapWrapper;
+
+public class SparkMarkerFiles extends BaseMarkerFiles {
Review comment:
Given this file is now free of Spark, we dont have the need of breaking these into base and child classes right.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
I think we should leave this abstract and let the engines implement this? even for Java. Its better to have a `HoodieJavaEngineContext`. From what I can see, this is not overridden in `HoodieSparkEngineContext` and thus we lose the parallel execution that we currently have with Spark with this change.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-701414946
rebasing against master now, its a pretty tricky one, given #2048 has introduced a new action and made changes on top of WriteClient
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r492872504
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
@wangxianghu This is awesome. Hopefully this can reduce the amount of code you need to write for Flink significantly. `TestMarkerFiles` seems to pass, so guess the serialization etc is working as expected.
We can go ahead with doing more files in this approach and remerge the base/child classes back as much as possible. cc @leesf @yanghua as well in case they have more things to add.
cc @bvaradar as well as FYI
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-692074997
> I can help address the remaining feedback. I will push a small diff today/tmrw.
> Overall, looks like a reasonable start.
>
> The major feedback I still have is the following
>
> > would a parallelDo(func, parallelism) method in HoodieEngineContext help us avoid a lot of base/child class duplication of logic like this?
>
> Lot of usages are like `jsc.parallelize(list, parallelism).map(func)` , which all require a base-child class now. I am wondering if its easier to take those usages alone and implement as `engineContext.parallelDo(list, func, parallelism)`. This can be the lowest common denominator across Spark/Flink etc. We can avoid splitting a good chunk of classes if we do this IMO. If this is interesting, and we agree, I can try to quantify.
Hi @vinothchandar, how about this demo?

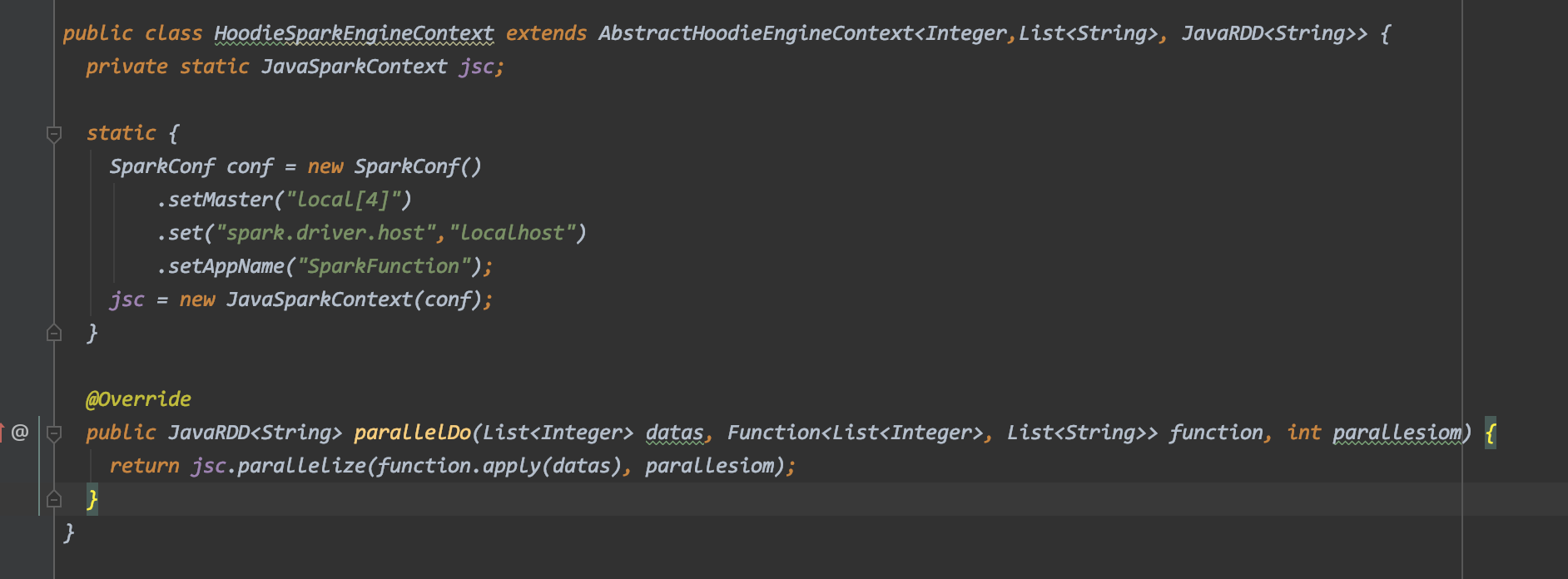
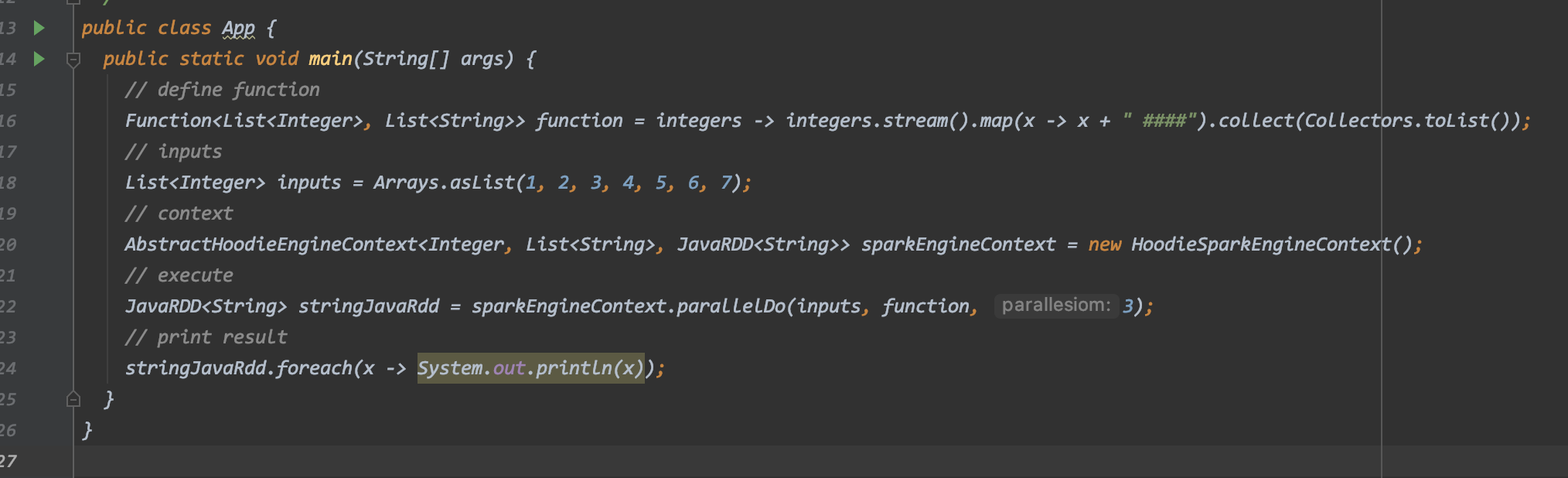
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar merged pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar merged pull request #1827:
URL: https://github.com/apache/hudi/pull/1827
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484933013
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/HoodieSparkWriteClient.java
##########
@@ -0,0 +1,360 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client;
+
+import com.codahale.metrics.Timer;
+import org.apache.hadoop.conf.Configuration;
+import org.apache.hudi.client.embebbed.BaseEmbeddedTimelineService;
+import org.apache.hudi.client.embedded.SparkEmbeddedTimelineService;
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.HoodieSparkEngineContext;
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.model.HoodieKey;
+import org.apache.hudi.common.model.HoodieRecord;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.common.model.HoodieWriteStat;
+import org.apache.hudi.common.model.WriteOperationType;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.common.table.HoodieTableVersion;
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.table.timeline.HoodieTimeline;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.collection.Pair;
+import org.apache.hudi.config.HoodieCompactionConfig;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.exception.HoodieCommitException;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.hudi.index.HoodieIndex;
+import org.apache.hudi.index.HoodieSparkIndexFactory;
+import org.apache.hudi.table.BaseHoodieTimelineArchiveLog;
+import org.apache.hudi.table.BulkInsertPartitioner;
+import org.apache.hudi.table.HoodieSparkTable;
+import org.apache.hudi.table.HoodieSparkTimelineArchiveLog;
+import org.apache.hudi.table.HoodieTable;
+import org.apache.hudi.table.SparkMarkerFiles;
+import org.apache.hudi.table.action.HoodieWriteMetadata;
+import org.apache.hudi.table.action.compact.SparkCompactHelpers;
+import org.apache.hudi.table.upgrade.SparkUpgradeDowngrade;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+import org.apache.spark.SparkConf;
+import org.apache.spark.api.java.JavaPairRDD;
+import org.apache.spark.api.java.JavaRDD;
+
+import java.io.IOException;
+import java.text.ParseException;
+import java.util.List;
+import java.util.Map;
+
+public class HoodieSparkWriteClient<T extends HoodieRecordPayload> extends AbstractHoodieWriteClient<T,
+ JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> {
+
+ private static final Logger LOG = LogManager.getLogger(HoodieSparkWriteClient.class);
+
+ public HoodieSparkWriteClient(HoodieEngineContext context, HoodieWriteConfig clientConfig) {
+ super(context, clientConfig);
+ }
+
+ public HoodieSparkWriteClient(HoodieEngineContext context, HoodieWriteConfig writeConfig, boolean rollbackPending) {
+ super(context, writeConfig, rollbackPending);
+ }
+
+ public HoodieSparkWriteClient(HoodieEngineContext context, HoodieWriteConfig writeConfig, boolean rollbackPending, Option<BaseEmbeddedTimelineService> timelineService) {
+ super(context, writeConfig, rollbackPending, timelineService);
+ }
+
+ /**
+ * Register hudi classes for Kryo serialization.
+ *
+ * @param conf instance of SparkConf
+ * @return SparkConf
+ */
+ public static SparkConf registerClasses(SparkConf conf) {
+ conf.registerKryoClasses(new Class[]{HoodieWriteConfig.class, HoodieRecord.class, HoodieKey.class});
+ return conf;
+ }
+
+ @Override
+ protected HoodieIndex<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> createIndex(HoodieWriteConfig writeConfig) {
+ return HoodieSparkIndexFactory.createIndex(config);
+ }
+
+ @Override
+ public boolean commit(String instantTime, JavaRDD<WriteStatus> writeStatuses, Option<Map<String, String>> extraMetadata) {
+ List<HoodieWriteStat> stats = writeStatuses.map(WriteStatus::getStat).collect();
+ return commitStats(instantTime, stats, extraMetadata);
+ }
+
+ @Override
+ protected HoodieTable<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> createTable(HoodieWriteConfig config, Configuration hadoopConf) {
+ return HoodieSparkTable.create(config, context);
+ }
+
+ @Override
+ public JavaRDD<HoodieRecord<T>> filterExists(JavaRDD<HoodieRecord<T>> hoodieRecords) {
+ // Create a Hoodie table which encapsulated the commits and files visible
+ HoodieTable table = HoodieSparkTable.create(config, context);
+ Timer.Context indexTimer = metrics.getIndexCtx();
+ JavaRDD<HoodieRecord<T>> recordsWithLocation = getIndex().tagLocation(hoodieRecords, context, table);
+ metrics.updateIndexMetrics(LOOKUP_STR, metrics.getDurationInMs(indexTimer == null ? 0L : indexTimer.stop()));
+ return recordsWithLocation.filter(v1 -> !v1.isCurrentLocationKnown());
+ }
+
+ /**
+ * Main API to run bootstrap to hudi.
+ */
+ @Override
+ public void bootstrap(Option<Map<String, String>> extraMetadata) {
+ if (rollbackPending) {
+ rollBackInflightBootstrap();
+ }
+ HoodieSparkTable table = (HoodieSparkTable) getTableAndInitCtx(WriteOperationType.UPSERT, HoodieTimeline.METADATA_BOOTSTRAP_INSTANT_TS);
+ table.bootstrap(context, extraMetadata);
+ }
+
+ @Override
+ public JavaRDD<WriteStatus> upsert(JavaRDD<HoodieRecord<T>> records, String instantTime) {
+ HoodieSparkTable table = (HoodieSparkTable) getTableAndInitCtx(WriteOperationType.UPSERT, instantTime);
+ table.validateUpsertSchema();
+ setOperationType(WriteOperationType.UPSERT);
+ startAsyncCleaningIfEnabled(this, instantTime);
Review comment:
> why are we not hanging onto the returned object?
my bad. done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r493120922
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> @wangxianghu This is awesome. Hopefully this can reduce the amount of code you need to write for Flink significantly. `TestMarkerFiles` seems to pass, so guess the serialization etc is working as expected.
>
> We can go ahead with doing more files in this approach and remerge the base/child classes back as much as possible. cc @leesf @yanghua as well in case they have more things to add.
>
> cc @bvaradar as well as FYI
Yes, it also reduce tons of code in the refactoring. I'm working on it ,hope to finish it today or tomorrow
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-693760147
> @wangxianghu are we set on the `parallelDo` approach. it would be nice if you or @leesf @yanghua confirm once that it works for Flink also and we can close that loop.
>
> Like I said, also please let me know if you need help on the PR. Would love to get this landed soon :)
@vinothchandar, I'm working on the 'parallelDo' approach, it works for flink too.
I have added three functions to `HoodieEngineContext` , to do the `map`, `flatMap`, `foreach` separately. more function can be added when needed.
```
public <I, O> List<O> map(List<I> data, Function<I, O> func) {
return data.stream().map(func).collect(Collectors.toList());
}
public <I, O> List<O> flatMap(List<I> data, Function<? super I, ? extends Stream<? extends O>> func) {
return data.stream().flatMap(func).collect(Collectors.toList());
}
public <I> void foreach(List<I> data, Consumer<I> func) {
data.forEach(func);
}
```
Of course, it would be great if you could provide some help, I‘d like to land this pr ASAP too
From now on , I can focus on refactoring this code with bi function, you can change anywhere you feel unsuitable, WDYT? :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r495650705
##########
File path: hudi-cli/src/test/java/org/apache/hudi/cli/commands/TestArchivedCommitsCommand.java
##########
@@ -92,8 +93,9 @@ public void init() throws IOException {
metaClient.getActiveTimeline().reload().getAllCommitsTimeline().filterCompletedInstants();
// archive
- HoodieTimelineArchiveLog archiveLog = new HoodieTimelineArchiveLog(cfg, hadoopConf);
- archiveLog.archiveIfRequired(jsc);
+ HoodieSparkTable table = HoodieSparkTable.create(cfg, context, metaClient);
Review comment:
> can we replace more of the code to direclty just use `HoodieTable` instead. Need to examine cases that need an explicit HoodieSparkTable
yes, make sense
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r485026581
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/io/HoodieSparkMergeHandle.java
##########
@@ -54,9 +60,9 @@
import java.util.Set;
@SuppressWarnings("Duplicates")
-public class HoodieMergeHandle<T extends HoodieRecordPayload> extends HoodieWriteHandle<T> {
+public class HoodieSparkMergeHandle<T extends HoodieRecordPayload> extends HoodieWriteHandle<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> {
Review comment:
> at the MergeHandle level, we need not introduce any notion of RDDs. the `io` package should be free of spark already. All we need to do is to pass in the taskContextSupplier correctly? This is a large outstanding issue we need to resolve
Actually not yet. https://github.com/apache/hudi/pull/1756 added support for rollbacks using marker files, and `MarkerFiles` is spark related.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-701903486
@wangxianghu @yanghua I have rebased this against master. Please take a look at my changes.
High level, we could re-use more code, but it needs an abstraction that can wrap `RDD` or `DataSet` or `DataStream` adequately and support basic operations like `.map()`, `reduceByKey()` etc. We can do this in a second pass once we have a working Flink impl. For now this will do.
I am trying to get the tests to pass. if they do, we could go ahead and merge
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-702248781
@wangxianghu can you please test the latest commit. To be clear, you are saying you don't get the warning on master, but get it on this branch. right?
if this round of tests pass, and you confirm, we can land from my perspective
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-698161234
> @wangxianghu Looks like we have much less class splitting now. I want to try and reduce this further if possible.
> If its alright with you, I can take over from here, make some changes and push another commit on top of yours, to try and get this across the finish line. Want to coordinate so that we are not making parallel changes,
@vinothchandar, Yeah, Of course, you can take over from here, this will greatly facilitate the process
thanks 👍
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-698069429
> @wangxianghu on the checkstyle change to bump up the line count to 500, I think we should revert to 200 as it is now.
> I checked out a few of the issues. they can be brought within limit, by folding like below.
> if not, we can turn off checkstyle selectively in that block?
>
> ```
>
> public class HoodieSparkMergeHandle<T extends HoodieRecordPayload> extends
> HoodieWriteHandle<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> {
> ```
done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-702302083
> @wangxianghu can you please test the latest commit. To be clear, you are saying you don't get the warning on master, but get it on this branch. right?
>
> if this round of tests pass, and you confirm, we can land from my perspective
Hi @vinothchandar.
> @wangxianghu can you please test the latest commit. To be clear, you are saying you don't get the warning on master, but get it on this branch. right?
>
> if this round of tests pass, and you confirm, we can land from my perspective
Hi @vinothchandar The warn log is still there in HUDI-1089 branch.(master is ok, no warn log)
I think we should check `embeddedTimelineServiceHostAddr` instead of `hostAddr`.
```
private void setHostAddr(String embeddedTimelineServiceHostAddr) {
// here we should check embeddedTimelineServiceHostAddr instead of hostAddr, hostAddr is always null
if (hostAddr != null) {
LOG.info("Overriding hostIp to (" + embeddedTimelineServiceHostAddr + ") found in spark-conf. It was " + this.hostAddr);
this.hostAddr = embeddedTimelineServiceHostAddr;
} else {
LOG.warn("Unable to find driver bind address from spark config");
this.hostAddr = NetworkUtils.getHostname();
}
}
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-687960061
Hi, @vinothchandar thanks for your review. I'll address your concerns ASAP.
The unit test should be ok. The CI failure seems caused by timeout(50min), can you help figure this out, I don't know how to adjust this threshold.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yanghua commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
yanghua commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-692580624
+1 to turn to function API fashion and standard / reduce some API's behavior. We are verifying and discussing with @wangxianghu offline.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r492262964
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/common/HoodieSparkEngineContext.java
##########
@@ -0,0 +1,56 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.SparkTaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+import org.apache.spark.api.java.JavaSparkContext;
+import org.apache.spark.sql.SQLContext;
+
+/**
+ * A Spark engine implementation of HoodieEngineContext.
+ */
+public class HoodieSparkEngineContext extends HoodieEngineContext {
Review comment:
can we implement versiosn of `map`, `flatMap`, `forEach` here which use `javaSparkContext.parallelize()` ? It would be good to keep this PR free of any changes in terms of whether we are executing the deletes/lists in parallel or in serial.
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/SparkMarkerFiles.java
##########
@@ -0,0 +1,124 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.table;
+
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.LocatedFileStatus;
+import org.apache.hadoop.fs.Path;
+import org.apache.hadoop.fs.RemoteIterator;
+import org.apache.hudi.bifunction.wrapper.ThrowingFunction;
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.config.SerializableConfiguration;
+import org.apache.hudi.common.model.IOType;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Set;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+import static org.apache.hudi.bifunction.wrapper.BiFunctionWrapper.throwingConsumerWrapper;
+import static org.apache.hudi.bifunction.wrapper.BiFunctionWrapper.throwingFlatMapWrapper;
+
+public class SparkMarkerFiles extends BaseMarkerFiles {
+
+ private static final Logger LOG = LogManager.getLogger(SparkMarkerFiles.class);
+
+ public SparkMarkerFiles(HoodieTable table, String instantTime) {
+ super(table, instantTime);
+ }
+
+ public SparkMarkerFiles(FileSystem fs, String basePath, String markerFolderPath, String instantTime) {
+ super(fs, basePath, markerFolderPath, instantTime);
+ }
+
+ @Override
+ public boolean deleteMarkerDir(HoodieEngineContext context, int parallelism) {
+ try {
+ if (fs.exists(markerDirPath)) {
+ FileStatus[] fileStatuses = fs.listStatus(markerDirPath);
+ List<String> markerDirSubPaths = Arrays.stream(fileStatuses)
+ .map(fileStatus -> fileStatus.getPath().toString())
+ .collect(Collectors.toList());
+
+ if (markerDirSubPaths.size() > 0) {
+ SerializableConfiguration conf = new SerializableConfiguration(fs.getConf());
+ context.foreach(markerDirSubPaths, throwingConsumerWrapper(subPathStr -> {
+ Path subPath = new Path(subPathStr);
+ FileSystem fileSystem = subPath.getFileSystem(conf.get());
+ fileSystem.delete(subPath, true);
+ }));
+ }
+
+ boolean result = fs.delete(markerDirPath, true);
+ LOG.info("Removing marker directory at " + markerDirPath);
+ return result;
+ }
+ } catch (IOException ioe) {
+ throw new HoodieIOException(ioe.getMessage(), ioe);
+ }
+ return false;
+ }
+
+ @Override
+ public Set<String> createdAndMergedDataPaths(HoodieEngineContext context, int parallelism) throws IOException {
Review comment:
we are not using parallelism here. This will lead to a perf regression w.r.t master.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
Also these APIs should take in a `parallelism` parameter, no?
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/SparkMarkerFiles.java
##########
@@ -0,0 +1,124 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.table;
+
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.LocatedFileStatus;
+import org.apache.hadoop.fs.Path;
+import org.apache.hadoop.fs.RemoteIterator;
+import org.apache.hudi.bifunction.wrapper.ThrowingFunction;
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.config.SerializableConfiguration;
+import org.apache.hudi.common.model.IOType;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Set;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+import static org.apache.hudi.bifunction.wrapper.BiFunctionWrapper.throwingConsumerWrapper;
+import static org.apache.hudi.bifunction.wrapper.BiFunctionWrapper.throwingFlatMapWrapper;
+
+public class SparkMarkerFiles extends BaseMarkerFiles {
Review comment:
Given this file is now free of Spark, we dont have the need of breaking these into base and child classes right.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
I think we should leave this abstract and let the engines implement this? even for Java. Its better to have a `HoodieJavaEngineContext`. From what I can see, this is not overridden in `HoodieSparkEngineContext` and thus we lose the parallel execution that we currently have with Spark with this change.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
@wangxianghu functionality wise, you are correct. it can be implemented just using Java. but, we do parallelization of different pieces of code e.g deletion of files in parallel using spark for a reason. It significantly speeds these up, for large tables.
All I am saying is to implement the `HoodieSparkEngineContext#map` like below
```
public <I, O> List<O> map(List<I> data, Function<I, O> func, int parallelism) {
return javaSparkContext.parallelize(data, parallelism).map(func).collect();
}
```
similarly for the other two methods. I don't see any issues with this. do you?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484931317
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/HoodieSparkWriteClient.java
##########
@@ -0,0 +1,360 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client;
+
+import com.codahale.metrics.Timer;
+import org.apache.hadoop.conf.Configuration;
+import org.apache.hudi.client.embebbed.BaseEmbeddedTimelineService;
+import org.apache.hudi.client.embedded.SparkEmbeddedTimelineService;
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.HoodieSparkEngineContext;
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.model.HoodieKey;
+import org.apache.hudi.common.model.HoodieRecord;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.common.model.HoodieWriteStat;
+import org.apache.hudi.common.model.WriteOperationType;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.common.table.HoodieTableVersion;
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.table.timeline.HoodieTimeline;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.collection.Pair;
+import org.apache.hudi.config.HoodieCompactionConfig;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.exception.HoodieCommitException;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.hudi.index.HoodieIndex;
+import org.apache.hudi.index.HoodieSparkIndexFactory;
+import org.apache.hudi.table.BaseHoodieTimelineArchiveLog;
+import org.apache.hudi.table.BulkInsertPartitioner;
+import org.apache.hudi.table.HoodieSparkTable;
+import org.apache.hudi.table.HoodieSparkTimelineArchiveLog;
+import org.apache.hudi.table.HoodieTable;
+import org.apache.hudi.table.SparkMarkerFiles;
+import org.apache.hudi.table.action.HoodieWriteMetadata;
+import org.apache.hudi.table.action.compact.SparkCompactHelpers;
+import org.apache.hudi.table.upgrade.SparkUpgradeDowngrade;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+import org.apache.spark.SparkConf;
+import org.apache.spark.api.java.JavaPairRDD;
+import org.apache.spark.api.java.JavaRDD;
+
+import java.io.IOException;
+import java.text.ParseException;
+import java.util.List;
+import java.util.Map;
+
+public class HoodieSparkWriteClient<T extends HoodieRecordPayload> extends AbstractHoodieWriteClient<T,
Review comment:
> Let's name this `SparkRDDWriteClient` ?
done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Mathieu1124 commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
Mathieu1124 commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r456247721
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/storage/HoodieParquetWriter.java
##########
@@ -40,7 +39,7 @@
* HoodieParquetWriter extends the ParquetWriter to help limit the size of underlying file. Provides a way to check if
* the current file can take more records with the <code>canWrite()</code>
*/
-public class HoodieParquetWriter<T extends HoodieRecordPayload, R extends IndexedRecord>
+public class HoodieParquetWriter<R extends IndexedRecord>
Review comment:
> Why do we need to change this class?
The Generic "T" is useless in this class, and it causes some generic problems in the abstraction, so I removed it.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-699730167
> testing
Ok, please ping me when it is ready.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r492468540
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> Is it possible to take a `java.util.function.Function` and then within `HoodieSparkEngineContext#map` wrap that into a `org.apache.spark.api.java.function.Function` ?
let me try
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r494000687
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/io/SparkAppendHandleFactory.java
##########
@@ -0,0 +1,45 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.io;
+
+import org.apache.hudi.client.SparkTaskContextSupplier;
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.client.WriteStatus;
+import org.apache.hudi.common.model.HoodieKey;
+import org.apache.hudi.common.model.HoodieRecord;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.collection.Pair;
+import org.apache.hudi.config.HoodieWriteConfig;
+
+import org.apache.hudi.table.HoodieTable;
+import org.apache.spark.api.java.JavaPairRDD;
+import org.apache.spark.api.java.JavaRDD;
+
+/**
+ * Factory to create {@link HoodieSparkAppendHandle}.
+ */
+public class SparkAppendHandleFactory<T extends HoodieRecordPayload> extends WriteHandleFactory<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> {
Review comment:
> same here. we need to make sure these factory methods don't have spark vs non-spark versions
done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r492435531
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/SparkMarkerFiles.java
##########
@@ -0,0 +1,124 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.table;
+
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.LocatedFileStatus;
+import org.apache.hadoop.fs.Path;
+import org.apache.hadoop.fs.RemoteIterator;
+import org.apache.hudi.bifunction.wrapper.ThrowingFunction;
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.config.SerializableConfiguration;
+import org.apache.hudi.common.model.IOType;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Set;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+import static org.apache.hudi.bifunction.wrapper.BiFunctionWrapper.throwingConsumerWrapper;
+import static org.apache.hudi.bifunction.wrapper.BiFunctionWrapper.throwingFlatMapWrapper;
+
+public class SparkMarkerFiles extends BaseMarkerFiles {
Review comment:
> Given this file is now free of Spark, we dont have the need of breaking these into base and child classes right.
Yes, this is an example to show you the bi function, if you agree with this implementation, I'll rollback them in one class
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484931707
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
##########
@@ -716,32 +674,97 @@ private void rollbackPendingCommits() {
* @param compactionInstantTime Compaction Instant Time
* @return RDD of Write Status
*/
- private JavaRDD<WriteStatus> compact(String compactionInstantTime, boolean shouldComplete) {
- HoodieTable<T> table = HoodieTable.create(config, hadoopConf);
- HoodieTimeline pendingCompactionTimeline = table.getActiveTimeline().filterPendingCompactionTimeline();
- HoodieInstant inflightInstant = HoodieTimeline.getCompactionInflightInstant(compactionInstantTime);
- if (pendingCompactionTimeline.containsInstant(inflightInstant)) {
- rollbackInflightCompaction(inflightInstant, table);
- table.getMetaClient().reloadActiveTimeline();
- }
- compactionTimer = metrics.getCompactionCtx();
- HoodieWriteMetadata compactionMetadata = table.compact(jsc, compactionInstantTime);
- JavaRDD<WriteStatus> statuses = compactionMetadata.getWriteStatuses();
- if (shouldComplete && compactionMetadata.getCommitMetadata().isPresent()) {
- completeCompaction(compactionMetadata.getCommitMetadata().get(), statuses, table, compactionInstantTime);
- }
- return statuses;
- }
+ protected abstract O compact(String compactionInstantTime, boolean shouldComplete);
/**
* Performs a compaction operation on a table, serially before or after an insert/upsert action.
*/
- private Option<String> inlineCompact(Option<Map<String, String>> extraMetadata) {
+ protected Option<String> inlineCompact(Option<Map<String, String>> extraMetadata) {
Option<String> compactionInstantTimeOpt = scheduleCompaction(extraMetadata);
compactionInstantTimeOpt.ifPresent(compactionInstantTime -> {
// inline compaction should auto commit as the user is never given control
compact(compactionInstantTime, true);
});
return compactionInstantTimeOpt;
}
+
+ /**
+ * Finalize Write operation.
+ *
+ * @param table HoodieTable
+ * @param instantTime Instant Time
+ * @param stats Hoodie Write Stat
+ */
+ protected void finalizeWrite(HoodieTable<T, I, K, O, P> table, String instantTime, List<HoodieWriteStat> stats) {
+ try {
+ final Timer.Context finalizeCtx = metrics.getFinalizeCtx();
+ table.finalizeWrite(context, instantTime, stats);
+ if (finalizeCtx != null) {
+ Option<Long> durationInMs = Option.of(metrics.getDurationInMs(finalizeCtx.stop()));
+ durationInMs.ifPresent(duration -> {
+ LOG.info("Finalize write elapsed time (milliseconds): " + duration);
+ metrics.updateFinalizeWriteMetrics(duration, stats.size());
+ });
+ }
+ } catch (HoodieIOException ioe) {
+ throw new HoodieCommitException("Failed to complete commit " + instantTime + " due to finalize errors.", ioe);
+ }
+ }
+
+ public HoodieMetrics getMetrics() {
+ return metrics;
+ }
+
+ public HoodieIndex<T, I, K, O, P> getIndex() {
+ return index;
+ }
+
+ /**
+ * Get HoodieTable and init {@link Timer.Context}.
+ *
+ * @param operationType write operation type
+ * @param instantTime current inflight instant time
+ * @return HoodieTable
+ */
+ protected abstract HoodieTable<T, I, K, O, P> getTableAndInitCtx(WriteOperationType operationType, String instantTime);
+
+ /**
+ * Sets write schema from last instant since deletes may not have schema set in the config.
+ */
+ protected void setWriteSchemaForDeletes(HoodieTableMetaClient metaClient) {
+ try {
+ HoodieActiveTimeline activeTimeline = metaClient.getActiveTimeline();
+ Option<HoodieInstant> lastInstant =
+ activeTimeline.filterCompletedInstants().filter(s -> s.getAction().equals(metaClient.getCommitActionType()))
+ .lastInstant();
+ if (lastInstant.isPresent()) {
+ HoodieCommitMetadata commitMetadata = HoodieCommitMetadata.fromBytes(
+ activeTimeline.getInstantDetails(lastInstant.get()).get(), HoodieCommitMetadata.class);
+ if (commitMetadata.getExtraMetadata().containsKey(HoodieCommitMetadata.SCHEMA_KEY)) {
+ config.setSchema(commitMetadata.getExtraMetadata().get(HoodieCommitMetadata.SCHEMA_KEY));
+ } else {
+ throw new HoodieIOException("Latest commit does not have any schema in commit metadata");
+ }
+ } else {
+ throw new HoodieIOException("Deletes issued without any prior commits");
+ }
+ } catch (IOException e) {
+ throw new HoodieIOException("IOException thrown while reading last commit metadata", e);
+ }
+ }
+
+ public abstract AsyncCleanerService startAsyncCleaningIfEnabled(AbstractHoodieWriteClient<T, I, K, O, P> client, String instantTime);
+
+ @Override
+ public void close() {
Review comment:
> need to ensure the ordering of closing resources is the same as before/
Yes, they are the same.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r494648857
##########
File path: hudi-cli/src/test/java/org/apache/hudi/cli/commands/TestRollbacksCommand.java
##########
@@ -88,7 +88,7 @@ public void init() throws IOException {
HoodieWriteConfig config = HoodieWriteConfig.newBuilder().withPath(tablePath)
.withIndexConfig(HoodieIndexConfig.newBuilder().withIndexType(HoodieIndex.IndexType.INMEMORY).build()).build();
- try (HoodieWriteClient client = getHoodieWriteClient(config)) {
+ try (AbstractHoodieWriteClient client = getHoodieWriteClient(config)) {
Review comment:
just like this, we should try to use the abstract class as much as we can
##########
File path: hudi-cli/src/test/java/org/apache/hudi/cli/commands/TestArchivedCommitsCommand.java
##########
@@ -92,8 +93,9 @@ public void init() throws IOException {
metaClient.getActiveTimeline().reload().getAllCommitsTimeline().filterCompletedInstants();
// archive
- HoodieTimelineArchiveLog archiveLog = new HoodieTimelineArchiveLog(cfg, hadoopConf);
- archiveLog.archiveIfRequired(jsc);
+ HoodieSparkTable table = HoodieSparkTable.create(cfg, context, metaClient);
Review comment:
can we replace more of the code to direclty just use `HoodieTable` instead. Need to examine cases that need an explicit HoodieSparkTable
##########
File path: hudi-client/hudi-client-common/pom.xml
##########
@@ -0,0 +1,264 @@
+<?xml version="1.0" encoding="UTF-8"?>
+<!--
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+-->
+<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
Review comment:
we are missing the dependency we had on hbase-client and hbase-server here. Will punt for now, as it will get picked up from hudi-common.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieWriteConfig.java
##########
@@ -100,6 +99,7 @@
public static final String EMBEDDED_TIMELINE_SERVER_ENABLED = "hoodie.embed.timeline.server";
public static final String DEFAULT_EMBEDDED_TIMELINE_SERVER_ENABLED = "true";
+ public static final String EMBEDDED_TIMELINE_SERVER_HOST = "hoodie.embed.timeline.server.host";
Review comment:
this cannot be configurable. yarn/k8s will decide the actual driver host. changing it to how it was before
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
##########
@@ -716,32 +669,95 @@ private void rollbackPendingCommits() {
* @param compactionInstantTime Compaction Instant Time
* @return RDD of Write Status
*/
- private JavaRDD<WriteStatus> compact(String compactionInstantTime, boolean shouldComplete) {
- HoodieTable<T> table = HoodieTable.create(config, hadoopConf);
- HoodieTimeline pendingCompactionTimeline = table.getActiveTimeline().filterPendingCompactionTimeline();
- HoodieInstant inflightInstant = HoodieTimeline.getCompactionInflightInstant(compactionInstantTime);
- if (pendingCompactionTimeline.containsInstant(inflightInstant)) {
- rollbackInflightCompaction(inflightInstant, table);
- table.getMetaClient().reloadActiveTimeline();
- }
- compactionTimer = metrics.getCompactionCtx();
- HoodieWriteMetadata compactionMetadata = table.compact(jsc, compactionInstantTime);
- JavaRDD<WriteStatus> statuses = compactionMetadata.getWriteStatuses();
- if (shouldComplete && compactionMetadata.getCommitMetadata().isPresent()) {
- completeCompaction(compactionMetadata.getCommitMetadata().get(), statuses, table, compactionInstantTime);
- }
- return statuses;
- }
+ protected abstract O compact(String compactionInstantTime, boolean shouldComplete);
/**
* Performs a compaction operation on a table, serially before or after an insert/upsert action.
*/
- private Option<String> inlineCompact(Option<Map<String, String>> extraMetadata) {
+ protected Option<String> inlineCompact(Option<Map<String, String>> extraMetadata) {
Option<String> compactionInstantTimeOpt = scheduleCompaction(extraMetadata);
compactionInstantTimeOpt.ifPresent(compactionInstantTime -> {
// inline compaction should auto commit as the user is never given control
compact(compactionInstantTime, true);
});
return compactionInstantTimeOpt;
}
+
+ /**
+ * Finalize Write operation.
+ *
+ * @param table HoodieTable
+ * @param instantTime Instant Time
+ * @param stats Hoodie Write Stat
+ */
+ protected void finalizeWrite(HoodieTable<T, I, K, O, P> table, String instantTime, List<HoodieWriteStat> stats) {
+ try {
+ final Timer.Context finalizeCtx = metrics.getFinalizeCtx();
+ table.finalizeWrite(context, instantTime, stats);
+ if (finalizeCtx != null) {
+ Option<Long> durationInMs = Option.of(metrics.getDurationInMs(finalizeCtx.stop()));
+ durationInMs.ifPresent(duration -> {
+ LOG.info("Finalize write elapsed time (milliseconds): " + duration);
+ metrics.updateFinalizeWriteMetrics(duration, stats.size());
+ });
+ }
+ } catch (HoodieIOException ioe) {
+ throw new HoodieCommitException("Failed to complete commit " + instantTime + " due to finalize errors.", ioe);
+ }
+ }
+
+ public HoodieMetrics getMetrics() {
+ return metrics;
+ }
+
+ public HoodieIndex<T, I, K, O, P> getIndex() {
Review comment:
this needs to be removed. but not the issue for this PR to be bothered about may be
##########
File path: hudi-client/pom.xml
##########
@@ -24,294 +24,14 @@
<modelVersion>4.0.0</modelVersion>
<artifactId>hudi-client</artifactId>
- <packaging>jar</packaging>
+ <packaging>pom</packaging>
<properties>
<main.basedir>${project.parent.basedir}</main.basedir>
</properties>
- <build>
Review comment:
Need to ensure there are no side effects in the pom due to this. i.e something that can affect bundles so forth.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
##########
@@ -18,120 +18,195 @@
package org.apache.hudi.client;
+import com.codahale.metrics.Timer;
+import org.apache.hadoop.conf.Configuration;
import org.apache.hudi.avro.model.HoodieCleanMetadata;
import org.apache.hudi.avro.model.HoodieCompactionPlan;
import org.apache.hudi.avro.model.HoodieRestoreMetadata;
import org.apache.hudi.avro.model.HoodieRollbackMetadata;
-import org.apache.hudi.client.embedded.EmbeddedTimelineService;
+import org.apache.hudi.callback.HoodieWriteCommitCallback;
+import org.apache.hudi.callback.common.HoodieWriteCommitCallbackMessage;
+import org.apache.hudi.callback.util.HoodieCommitCallbackFactory;
+import org.apache.hudi.client.embebbed.BaseEmbeddedTimelineService;
+import org.apache.hudi.common.HoodieEngineContext;
import org.apache.hudi.common.model.HoodieCommitMetadata;
import org.apache.hudi.common.model.HoodieKey;
-import org.apache.hudi.common.model.HoodieRecord;
import org.apache.hudi.common.model.HoodieRecordPayload;
import org.apache.hudi.common.model.HoodieWriteStat;
import org.apache.hudi.common.model.WriteOperationType;
import org.apache.hudi.common.table.HoodieTableMetaClient;
import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
import org.apache.hudi.common.table.timeline.HoodieInstant;
-import org.apache.hudi.common.table.timeline.HoodieInstant.State;
import org.apache.hudi.common.table.timeline.HoodieTimeline;
import org.apache.hudi.common.util.Option;
import org.apache.hudi.common.util.ValidationUtils;
-import org.apache.hudi.config.HoodieCompactionConfig;
import org.apache.hudi.config.HoodieWriteConfig;
+
import org.apache.hudi.exception.HoodieCommitException;
import org.apache.hudi.exception.HoodieIOException;
import org.apache.hudi.exception.HoodieRestoreException;
import org.apache.hudi.exception.HoodieRollbackException;
import org.apache.hudi.exception.HoodieSavepointException;
import org.apache.hudi.index.HoodieIndex;
import org.apache.hudi.metrics.HoodieMetrics;
-import org.apache.hudi.table.HoodieTable;
-import org.apache.hudi.table.HoodieTimelineArchiveLog;
-import org.apache.hudi.table.MarkerFiles;
import org.apache.hudi.table.BulkInsertPartitioner;
+import org.apache.hudi.table.HoodieTable;
import org.apache.hudi.table.action.HoodieWriteMetadata;
-import org.apache.hudi.table.action.compact.CompactHelpers;
import org.apache.hudi.table.action.savepoint.SavepointHelpers;
-
-import com.codahale.metrics.Timer;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
-import org.apache.spark.SparkConf;
-import org.apache.spark.api.java.JavaRDD;
-import org.apache.spark.api.java.JavaSparkContext;
import java.io.IOException;
+import java.nio.charset.StandardCharsets;
import java.text.ParseException;
import java.util.Collection;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
- * Hoodie Write Client helps you build tables on HDFS [insert()] and then perform efficient mutations on an HDFS
- * table [upsert()]
- * <p>
- * Note that, at any given time, there can only be one Spark job performing these operations on a Hoodie table.
+ * Abstract Write Client providing functionality for performing commit, index updates and rollback
+ * Reused for regular write operations like upsert/insert/bulk-insert.. as well as bootstrap
+ *
+ * @param <T> Sub type of HoodieRecordPayload
+ * @param <I> Type of inputs
+ * @param <K> Type of keys
+ * @param <O> Type of outputs
+ * @param <P> Type of record position [Key, Option[partitionPath, fileID]] in hoodie table
*/
-public class HoodieWriteClient<T extends HoodieRecordPayload> extends AbstractHoodieWriteClient<T> {
-
+public abstract class AbstractHoodieWriteClient<T extends HoodieRecordPayload, I, K, O, P> extends AbstractHoodieClient {
private static final long serialVersionUID = 1L;
- private static final Logger LOG = LogManager.getLogger(HoodieWriteClient.class);
- private static final String LOOKUP_STR = "lookup";
- private final boolean rollbackPending;
- private final transient HoodieMetrics metrics;
- private transient Timer.Context compactionTimer;
+ private static final Logger LOG = LogManager.getLogger(AbstractHoodieWriteClient.class);
+
+ protected final transient HoodieMetrics metrics;
+ private final transient HoodieIndex<T, I, K, O, P> index;
+
+ protected transient Timer.Context writeContext = null;
+ private transient WriteOperationType operationType;
+ private transient HoodieWriteCommitCallback commitCallback;
+
+ protected static final String LOOKUP_STR = "lookup";
+ protected final boolean rollbackPending;
+ protected transient Timer.Context compactionTimer;
private transient AsyncCleanerService asyncCleanerService;
+ public void setOperationType(WriteOperationType operationType) {
+ this.operationType = operationType;
+ }
+
+ public WriteOperationType getOperationType() {
+ return this.operationType;
+ }
+
/**
* Create a write client, without cleaning up failed/inflight commits.
*
- * @param jsc Java Spark Context
+ * @param context Java Spark Context
* @param clientConfig instance of HoodieWriteConfig
*/
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig clientConfig) {
- this(jsc, clientConfig, false);
+ public AbstractHoodieWriteClient(HoodieEngineContext context, HoodieWriteConfig clientConfig) {
+ this(context, clientConfig, false);
}
/**
* Create a write client, with new hudi index.
*
- * @param jsc Java Spark Context
- * @param writeConfig instance of HoodieWriteConfig
+ * @param context HoodieEngineContext
+ * @param writeConfig instance of HoodieWriteConfig
* @param rollbackPending whether need to cleanup pending commits
*/
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig writeConfig, boolean rollbackPending) {
- this(jsc, writeConfig, rollbackPending, HoodieIndex.createIndex(writeConfig));
- }
-
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig writeConfig, boolean rollbackPending, HoodieIndex index) {
- this(jsc, writeConfig, rollbackPending, index, Option.empty());
+ public AbstractHoodieWriteClient(HoodieEngineContext context, HoodieWriteConfig writeConfig, boolean rollbackPending) {
+ this(context, writeConfig, rollbackPending, Option.empty());
}
/**
- * Create a write client, allows to specify all parameters.
+ * Create a write client, allows to specify all parameters.
*
- * @param jsc Java Spark Context
- * @param writeConfig instance of HoodieWriteConfig
+ * @param context HoodieEngineContext
+ * @param writeConfig instance of HoodieWriteConfig
* @param rollbackPending whether need to cleanup pending commits
* @param timelineService Timeline Service that runs as part of write client.
*/
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig writeConfig, boolean rollbackPending,
- HoodieIndex index, Option<EmbeddedTimelineService> timelineService) {
- super(jsc, index, writeConfig, timelineService);
+ public AbstractHoodieWriteClient(HoodieEngineContext context, HoodieWriteConfig writeConfig, boolean rollbackPending,
+ Option<BaseEmbeddedTimelineService> timelineService) {
+ super(context, writeConfig, timelineService);
this.metrics = new HoodieMetrics(config, config.getTableName());
this.rollbackPending = rollbackPending;
+ this.index = createIndex(writeConfig);
Review comment:
Understood
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
##########
@@ -716,32 +669,95 @@ private void rollbackPendingCommits() {
* @param compactionInstantTime Compaction Instant Time
* @return RDD of Write Status
*/
- private JavaRDD<WriteStatus> compact(String compactionInstantTime, boolean shouldComplete) {
- HoodieTable<T> table = HoodieTable.create(config, hadoopConf);
- HoodieTimeline pendingCompactionTimeline = table.getActiveTimeline().filterPendingCompactionTimeline();
- HoodieInstant inflightInstant = HoodieTimeline.getCompactionInflightInstant(compactionInstantTime);
- if (pendingCompactionTimeline.containsInstant(inflightInstant)) {
- rollbackInflightCompaction(inflightInstant, table);
- table.getMetaClient().reloadActiveTimeline();
- }
- compactionTimer = metrics.getCompactionCtx();
- HoodieWriteMetadata compactionMetadata = table.compact(jsc, compactionInstantTime);
- JavaRDD<WriteStatus> statuses = compactionMetadata.getWriteStatuses();
- if (shouldComplete && compactionMetadata.getCommitMetadata().isPresent()) {
- completeCompaction(compactionMetadata.getCommitMetadata().get(), statuses, table, compactionInstantTime);
- }
- return statuses;
- }
+ protected abstract O compact(String compactionInstantTime, boolean shouldComplete);
/**
* Performs a compaction operation on a table, serially before or after an insert/upsert action.
*/
- private Option<String> inlineCompact(Option<Map<String, String>> extraMetadata) {
+ protected Option<String> inlineCompact(Option<Map<String, String>> extraMetadata) {
Option<String> compactionInstantTimeOpt = scheduleCompaction(extraMetadata);
compactionInstantTimeOpt.ifPresent(compactionInstantTime -> {
// inline compaction should auto commit as the user is never given control
compact(compactionInstantTime, true);
});
return compactionInstantTimeOpt;
}
+
+ /**
+ * Finalize Write operation.
+ *
+ * @param table HoodieTable
+ * @param instantTime Instant Time
+ * @param stats Hoodie Write Stat
+ */
+ protected void finalizeWrite(HoodieTable<T, I, K, O, P> table, String instantTime, List<HoodieWriteStat> stats) {
+ try {
+ final Timer.Context finalizeCtx = metrics.getFinalizeCtx();
+ table.finalizeWrite(context, instantTime, stats);
+ if (finalizeCtx != null) {
+ Option<Long> durationInMs = Option.of(metrics.getDurationInMs(finalizeCtx.stop()));
+ durationInMs.ifPresent(duration -> {
+ LOG.info("Finalize write elapsed time (milliseconds): " + duration);
+ metrics.updateFinalizeWriteMetrics(duration, stats.size());
+ });
+ }
+ } catch (HoodieIOException ioe) {
+ throw new HoodieCommitException("Failed to complete commit " + instantTime + " due to finalize errors.", ioe);
+ }
+ }
+
+ public HoodieMetrics getMetrics() {
+ return metrics;
+ }
+
+ public HoodieIndex<T, I, K, O, P> getIndex() {
+ return index;
+ }
+
+ /**
+ * Get HoodieTable and init {@link Timer.Context}.
+ *
+ * @param operationType write operation type
+ * @param instantTime current inflight instant time
+ * @return HoodieTable
+ */
+ protected abstract HoodieTable<T, I, K, O, P> getTableAndInitCtx(WriteOperationType operationType, String instantTime);
+
+ /**
+ * Sets write schema from last instant since deletes may not have schema set in the config.
+ */
+ protected void setWriteSchemaForDeletes(HoodieTableMetaClient metaClient) {
+ try {
+ HoodieActiveTimeline activeTimeline = metaClient.getActiveTimeline();
+ Option<HoodieInstant> lastInstant =
+ activeTimeline.filterCompletedInstants().filter(s -> s.getAction().equals(metaClient.getCommitActionType()))
+ .lastInstant();
+ if (lastInstant.isPresent()) {
+ HoodieCommitMetadata commitMetadata = HoodieCommitMetadata.fromBytes(
+ activeTimeline.getInstantDetails(lastInstant.get()).get(), HoodieCommitMetadata.class);
+ if (commitMetadata.getExtraMetadata().containsKey(HoodieCommitMetadata.SCHEMA_KEY)) {
+ config.setSchema(commitMetadata.getExtraMetadata().get(HoodieCommitMetadata.SCHEMA_KEY));
+ } else {
+ throw new HoodieIOException("Latest commit does not have any schema in commit metadata");
+ }
+ } else {
+ throw new HoodieIOException("Deletes issued without any prior commits");
+ }
+ } catch (IOException e) {
+ throw new HoodieIOException("IOException thrown while reading last commit metadata", e);
+ }
+ }
+
+ @Override
+ public void close() {
+ // Stop timeline-server if running
+ super.close();
+ // Calling this here releases any resources used by your index, so make sure to finish any related operations
+ // before this point
+ this.index.close();
+
+ // release AsyncCleanerService
+ AsyncCleanerService.forceShutdown(asyncCleanerService);
+ asyncCleanerService = null;
Review comment:
this was actually same. fixing it
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieMergeHandle.java
##########
@@ -149,7 +148,7 @@ private void init(String fileId, String partitionPath, HoodieBaseFile baseFileTo
private void init(String fileId, Iterator<HoodieRecord<T>> newRecordsItr) {
try {
// Load the new records in a map
- long memoryForMerge = SparkConfigUtils.getMaxMemoryPerPartitionMerge(config.getProps());
+ long memoryForMerge = config.getMaxMemoryPerPartitionMerge();
Review comment:
this is a problem. it changes behavior and needs to be reworked.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-696181800
@wangxianghu let me check that out and circle back by your morning time/EOD PST. we can go from there. Thanks!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-685031856
Hi, @vinothchandar @yanghua @leesf @n3nash Sorry for the delay, This PR is ready for review now :)
I have tested this PR by executing the insert, update, query, delete demo in my local, It works ok.
I know this test is far from enough, this refactor is so huge, It surely has some problems that I didn't find now.
So, in order to finish it ASAP, would you mind start to review it now, and I will focus on testing it with more scenes, and improving it.
Thanks
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] leesf commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
leesf commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-658490359
> Hi, @vinothchandar @yanghua @leesf as the refactor is finished, I have filed a Jira ticket to track this work,
> please review the refactor work on this pr :)
ack. @Mathieu1124 pls check travis failure.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r493998442
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/common/HoodieSparkEngineContext.java
##########
@@ -0,0 +1,56 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.SparkTaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+import org.apache.spark.api.java.JavaSparkContext;
+import org.apache.spark.sql.SQLContext;
+
+/**
+ * A Spark engine implementation of HoodieEngineContext.
+ */
+public class HoodieSparkEngineContext extends HoodieEngineContext {
Review comment:
> can we implement versiosn of `map`, `flatMap`, `forEach` here which use `javaSparkContext.parallelize()` ? It would be good to keep this PR free of any changes in terms of whether we are executing the deletes/lists in parallel or in serial.
done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-658505880
Good to get @n3nash 's review here as well to make sure we are not breaking anything for the RDD client users..
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-696181800
@wangxianghu let me check that out and circle back by your morning time/EOD PST. we can go from there. Thanks!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r492460719
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
Is it possible to take a `java.util.function.Function` and then within `HoodieSparkEngineContext#map` wrap that into a `org.apache.spark.api.java.function.Function` ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-695785338
> @wangxianghu may be we can first do a few classes with parallelDo and see how it looks? We can then even split up the remaining work
Yes, it makes sense
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r492434405
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> I think we should leave this abstract and let the engines implement this? even for Java. Its better to have a `HoodieJavaEngineContext`. From what I can see, this is not overridden in `HoodieSparkEngineContext` and thus we lose the parallel execution that we currently have with Spark with this change.
as we discussed before, parallelDo model need a function as input parameter, Unfortunately, different engines need different type function, its hard to align them in an abstract parallelDo method. so we agreed to use ` java.util.function.Function` as the unified input function. in this way, there is no need to distinguish spark and flink, and the parallelism is not needed too.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-685433291
> @wangxianghu sounds good. Thanks for this monumental effort!
>
> Will start in the earliest. can we get the CI to pass ?
Ack, will check it tonight
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Mathieu1124 commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
Mathieu1124 commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-658535590
> > Hi, @vinothchandar @yanghua @leesf as the refactor is finished, I have filed a Jira ticket to track this work,
> > please review the refactor work on this pr :)
>
> ack. @Mathieu1124 pls check travis failure.
copy, have resolved the ci failure and conflicts with master, will push it after work.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Mathieu1124 commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
Mathieu1124 commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-659094743
Hi, @vinothchandar @yanghua @leesf @n3nash, ci is green, this pr is ready for review now :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-698161234
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] codecov-commenter commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
codecov-commenter commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-701949671
# [Codecov](https://codecov.io/gh/apache/hudi/pull/1827?src=pr&el=h1) Report
> Merging [#1827](https://codecov.io/gh/apache/hudi/pull/1827?src=pr&el=desc) into [master](https://codecov.io/gh/apache/hudi/commit/a99e93bed542c8ae30a641d1df616cc2cd5798e1?el=desc) will **decrease** coverage by `3.75%`.
> The diff coverage is `30.00%`.
[](https://codecov.io/gh/apache/hudi/pull/1827?src=pr&el=tree)
```diff
@@ Coverage Diff @@
## master #1827 +/- ##
============================================
- Coverage 59.89% 56.14% -3.76%
+ Complexity 4454 2658 -1796
============================================
Files 558 324 -234
Lines 23378 14775 -8603
Branches 2348 1539 -809
============================================
- Hits 14003 8295 -5708
+ Misses 8355 5783 -2572
+ Partials 1020 697 -323
```
| Flag | Coverage Δ | Complexity Δ | |
|---|---|---|---|
| #hudicli | `38.37% <30.00%> (-27.83%)` | `193.00 <0.00> (-1615.00)` | |
| #hudiclient | `100.00% <ø> (+25.46%)` | `0.00 <ø> (-1615.00)` | :arrow_up: |
| #hudicommon | `54.74% <ø> (ø)` | `1793.00 <ø> (ø)` | |
| #hudihadoopmr | `?` | `?` | |
| #hudispark | `67.18% <ø> (-0.02%)` | `311.00 <ø> (ø)` | |
| #huditimelineservice | `64.43% <ø> (ø)` | `49.00 <ø> (ø)` | |
| #hudiutilities | `69.43% <ø> (+0.05%)` | `312.00 <ø> (ø)` | |
Flags with carried forward coverage won't be shown. [Click here](https://docs.codecov.io/docs/carryforward-flags#carryforward-flags-in-the-pull-request-comment) to find out more.
| [Impacted Files](https://codecov.io/gh/apache/hudi/pull/1827?src=pr&el=tree) | Coverage Δ | Complexity Δ | |
|---|---|---|---|
| [...rg/apache/hudi/cli/commands/SavepointsCommand.java](https://codecov.io/gh/apache/hudi/pull/1827/diff?src=pr&el=tree#diff-aHVkaS1jbGkvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY2xpL2NvbW1hbmRzL1NhdmVwb2ludHNDb21tYW5kLmphdmE=) | `14.28% <0.00%> (ø)` | `3.00 <0.00> (ø)` | |
| [...main/java/org/apache/hudi/cli/utils/SparkUtil.java](https://codecov.io/gh/apache/hudi/pull/1827/diff?src=pr&el=tree#diff-aHVkaS1jbGkvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY2xpL3V0aWxzL1NwYXJrVXRpbC5qYXZh) | `0.00% <0.00%> (ø)` | `0.00 <0.00> (ø)` | |
| [...n/java/org/apache/hudi/cli/commands/SparkMain.java](https://codecov.io/gh/apache/hudi/pull/1827/diff?src=pr&el=tree#diff-aHVkaS1jbGkvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvY2xpL2NvbW1hbmRzL1NwYXJrTWFpbi5qYXZh) | `6.43% <37.50%> (+0.40%)` | `4.00 <0.00> (ø)` | |
| [...src/main/java/org/apache/hudi/DataSourceUtils.java](https://codecov.io/gh/apache/hudi/pull/1827/diff?src=pr&el=tree#diff-aHVkaS1zcGFyay9zcmMvbWFpbi9qYXZhL29yZy9hcGFjaGUvaHVkaS9EYXRhU291cmNlVXRpbHMuamF2YQ==) | `45.36% <0.00%> (ø)` | `21.00% <0.00%> (ø%)` | |
| [...in/scala/org/apache/hudi/HoodieStreamingSink.scala](https://codecov.io/gh/apache/hudi/pull/1827/diff?src=pr&el=tree#diff-aHVkaS1zcGFyay9zcmMvbWFpbi9zY2FsYS9vcmcvYXBhY2hlL2h1ZGkvSG9vZGllU3RyZWFtaW5nU2luay5zY2FsYQ==) | `24.00% <0.00%> (ø)` | `10.00% <0.00%> (ø%)` | |
| [...n/scala/org/apache/hudi/HoodieSparkSqlWriter.scala](https://codecov.io/gh/apache/hudi/pull/1827/diff?src=pr&el=tree#diff-aHVkaS1zcGFyay9zcmMvbWFpbi9zY2FsYS9vcmcvYXBhY2hlL2h1ZGkvSG9vZGllU3BhcmtTcWxXcml0ZXIuc2NhbGE=) | `56.20% <0.00%> (ø)` | `0.00% <0.00%> (ø%)` | |
| [...in/java/org/apache/hudi/utilities/UtilHelpers.java](https://codecov.io/gh/apache/hudi/pull/1827/diff?src=pr&el=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL1V0aWxIZWxwZXJzLmphdmE=) | `64.59% <0.00%> (ø)` | `30.00% <0.00%> (ø%)` | |
| [...apache/hudi/utilities/deltastreamer/DeltaSync.java](https://codecov.io/gh/apache/hudi/pull/1827/diff?src=pr&el=tree#diff-aHVkaS11dGlsaXRpZXMvc3JjL21haW4vamF2YS9vcmcvYXBhY2hlL2h1ZGkvdXRpbGl0aWVzL2RlbHRhc3RyZWFtZXIvRGVsdGFTeW5jLmphdmE=) | `68.16% <0.00%> (ø)` | `39.00% <0.00%> (ø%)` | |
| [.../hudi/async/SparkStreamingAsyncCompactService.java](https://codecov.io/gh/apache/hudi/pull/1827/diff?src=pr&el=tree#diff-aHVkaS1zcGFyay9zcmMvbWFpbi9qYXZhL29yZy9hcGFjaGUvaHVkaS9hc3luYy9TcGFya1N0cmVhbWluZ0FzeW5jQ29tcGFjdFNlcnZpY2UuamF2YQ==) | `0.00% <0.00%> (ø)` | `0.00% <0.00%> (ø%)` | |
| [.../hudi/internal/HoodieDataSourceInternalWriter.java](https://codecov.io/gh/apache/hudi/pull/1827/diff?src=pr&el=tree#diff-aHVkaS1zcGFyay9zcmMvbWFpbi9qYXZhL29yZy9hcGFjaGUvaHVkaS9pbnRlcm5hbC9Ib29kaWVEYXRhU291cmNlSW50ZXJuYWxXcml0ZXIuamF2YQ==) | `87.50% <0.00%> (ø)` | `8.00% <0.00%> (ø%)` | |
| ... and [46 more](https://codecov.io/gh/apache/hudi/pull/1827/diff?src=pr&el=tree-more) | |
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-694979219
@wangxianghu may be we can first do a few classes with parallelDo and see how it looks? We can then even split up the remaining work
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r487575888
##########
File path: hudi-client/pom.xml
##########
@@ -68,6 +107,12 @@
</build>
<dependencies>
+ <!-- Scala -->
+ <dependency>
+ <groupId>org.scala-lang</groupId>
Review comment:
fair. let me take a closer look
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yanghua commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
yanghua commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r498188986
##########
File path: hudi-cli/pom.xml
##########
@@ -148,7 +148,14 @@
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
- <artifactId>hudi-client</artifactId>
+ <artifactId>hudi-client-common</artifactId>
+ <version>${project.version}</version>
+ <scope>test</scope>
+ <type>test-jar</type>
+ </dependency>
+ <dependency>
+ <groupId>org.apache.hudi</groupId>
+ <artifactId>hudi-spark-client</artifactId>
Review comment:
So, will we keep `hudi-spark-client`? We have had a `hudi-spark` module.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-698151969
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yanghua commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
yanghua commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-690922454
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yanghua commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
yanghua commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-690922454
@leesf Thanks for your awesome work. Can you squash these commits for the subsequent review?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-687960061
Hi, @vinothchandar thanks for your review. I'll address your concerns ASAP.
The CI failure seems caused by timeout(50min), can you help figure this out, I don't know how to adjust this threshold.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu removed a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu removed a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-702217863
> @leesf do you see the following exception? could not understand how you ll get the other one even.
>
> ```
> LOG.info("Starting Timeline service !!");
> Option<String> hostAddr = context.getProperty(EngineProperty.EMBEDDED_SERVER_HOST);
> if (!hostAddr.isPresent()) {
> throw new HoodieException("Unable to find host address to bind timeline server to.");
> }
> timelineServer = Option.of(new EmbeddedTimelineService(context, hostAddr.get(),
> config.getClientSpecifiedViewStorageConfig()));
> ```
>
> Either way, good pointer. the behavior has changed around this a bit actually. So will try and tweak and push a fix
I got this warning too. The code here seems not the same.
```
// Run Embedded Timeline Server
LOG.info("Starting Timeline service !!");
Option<String> hostAddr = context.getProperty(EngineProperty.EMBEDDED_SERVER_HOST);
timelineServer = Option.of(new EmbeddedTimelineService(context, hostAddr.orElse(null),
config.getClientSpecifiedViewStorageConfig()));
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r492434405
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> I think we should leave this abstract and let the engines implement this? even for Java. Its better to have a `HoodieJavaEngineContext`. From what I can see, this is not overridden in `HoodieSparkEngineContext` and thus we lose the parallel execution that we currently have with Spark with this change.
as we discussed before, parallelDo model need a function as input parameter, Unfortunately, different engines need different type function, its hard to align them in an abstract parallelDo method. so we agree to use ` java.util.function.Function` as the unified input function. in this way, there is no need to distinguish spark and flink, and the parallelism is not needed too.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> I think we should leave this abstract and let the engines implement this? even for Java. Its better to have a `HoodieJavaEngineContext`. From what I can see, this is not overridden in `HoodieSparkEngineContext` and thus we lose the parallel execution that we currently have with Spark with this change.
as we discussed before, parallelDo model need a function as input parameter, Unfortunately, different engines need different type function, its hard to align them in an abstract parallelDo method. so we agreed to use ` java.util.function.Function` as the unified input function. in this way, there is no need to distinguish spark and flink, and the parallelism is not needed too.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> I think we should leave this abstract and let the engines implement this? even for Java. Its better to have a `HoodieJavaEngineContext`. From what I can see, this is not overridden in `HoodieSparkEngineContext` and thus we lose the parallel execution that we currently have with Spark with this change.
as we discussed before, parallelDo model need a function as input parameter, Unfortunately, different engines need different type function, its hard to align them in an abstract parallelDo method. so we agreed to use ` java.util.function.Function` as the unified input function. in this way, there is no need to distinguish spark and flink, no need to make it abstract and the parallelism is not needed too. its just java, can be implemented directly.
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/SparkMarkerFiles.java
##########
@@ -0,0 +1,124 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.table;
+
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.LocatedFileStatus;
+import org.apache.hadoop.fs.Path;
+import org.apache.hadoop.fs.RemoteIterator;
+import org.apache.hudi.bifunction.wrapper.ThrowingFunction;
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.config.SerializableConfiguration;
+import org.apache.hudi.common.model.IOType;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Set;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+import static org.apache.hudi.bifunction.wrapper.BiFunctionWrapper.throwingConsumerWrapper;
+import static org.apache.hudi.bifunction.wrapper.BiFunctionWrapper.throwingFlatMapWrapper;
+
+public class SparkMarkerFiles extends BaseMarkerFiles {
Review comment:
> Given this file is now free of Spark, we dont have the need of breaking these into base and child classes right.
Yes, this is an example to show you the bi function, if you agree with this implementation, I'll rollback them in one class
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> @wangxianghu functionality wise, you are correct. it can be implemented just using Java. but, we do parallelization of different pieces of code e.g deletion of files in parallel using spark for a reason. It significantly speeds these up, for large tables.
>
> All I am saying is to implement the `HoodieSparkEngineContext#map` like below
>
> ```
> public <I, O> List<O> map(List<I> data, Function<I, O> func, int parallelism) {
> return javaSparkContext.parallelize(data, parallelism).map(func).collect();
> }
> ```
>
> similarly for the other two methods. I don't see any issues with this. do you?
I know what you mean.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> @wangxianghu functionality wise, you are correct. it can be implemented just using Java. but, we do parallelization of different pieces of code e.g deletion of files in parallel using spark for a reason. It significantly speeds these up, for large tables.
>
> All I am saying is to implement the `HoodieSparkEngineContext#map` like below
>
> ```
> public <I, O> List<O> map(List<I> data, Function<I, O> func, int parallelism) {
> return javaSparkContext.parallelize(data, parallelism).map(func).collect();
> }
> ```
>
> similarly for the other two methods. I don't see any issues with this. do you?
I know what you mean.
what I am saying is that the `func` in `HoodieSparkEngineContext#map` and `HoodieEngineContext#map` is not the same type.
for `HoodieEngineContext#map` it is `java.util.function.Function`,
for `HoodieSparkEngineContext#map` it is `org.apache.spark.api.java.function.Function`.
`HoodieSparkEngineContext#map` can not override from `HoodieEngineContext#map`
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> Is it possible to take a `java.util.function.Function` and then within `HoodieSparkEngineContext#map` wrap that into a `org.apache.spark.api.java.function.Function` ?
let me try
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> when the use passes in a regular lambda, into `rdd.map()`, this is what it gets converted into
The serializable issue can be solved by introducing a seriableFuncition to replace `java.util.function.Function`
```
public interface SerializableFunction<I, O> extends Serializable {
O call(I v1) throws Exception;
}
```
`HoodieEngineContext` can be
```
public abstract class HoodieEngineContext {
public abstract <I, O> List<O> map(List<I> data, SerializableFunction<I, O> func, int parallelism) ;
}
```
`HoodieSparkEngineContext` can be
```
public class HoodieSparkEngineContext extends HoodieEngineContext {
private static JavaSparkContext jsc;
// tmp
static {
SparkConf conf = new SparkConf()
.setMaster("local[4]")
.set("spark.driver.host","localhost")
.setAppName("HoodieSparkEngineContext");
jsc = new JavaSparkContext(conf);
}
@Override
public <I, O> List<O> map(List<I> data, SerializableFunction<I, O> func, int parallelism) {
return jsc.parallelize(data, parallelism).map(func::call).collect();
}
}
```
this works :)
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> @wangxianghu This is awesome. Hopefully this can reduce the amount of code you need to write for Flink significantly. `TestMarkerFiles` seems to pass, so guess the serialization etc is working as expected.
>
> We can go ahead with doing more files in this approach and remerge the base/child classes back as much as possible. cc @leesf @yanghua as well in case they have more things to add.
>
> cc @bvaradar as well as FYI
Yes, it also reduce tons of code in the refactoring. I'm working on it ,hope to finish it today or tomorrow
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484816690
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/KeyGeneratorInterface.java
##########
@@ -34,8 +33,4 @@
List<String> getRecordKeyFieldNames();
- String getRecordKey(Row row);
Review comment:
> we should make sure there are no backwards incompatible changes to the key generator interface
Yes, I moved it to `SparkKeyGeneratorInterface`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484940203
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/action/bootstrap/SparkBootstrapCommitActionExecutor.java
##########
@@ -77,34 +81,44 @@
import org.apache.parquet.hadoop.ParquetReader;
import org.apache.parquet.hadoop.metadata.ParquetMetadata;
import org.apache.parquet.schema.MessageType;
-import org.apache.spark.Partitioner;
+import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.time.Duration;
+import java.time.Instant;
import java.util.Collection;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
-public class BootstrapCommitActionExecutor<T extends HoodieRecordPayload<T>>
- extends BaseCommitActionExecutor<T, HoodieBootstrapWriteMetadata> {
+public class SparkBootstrapCommitActionExecutor<T extends HoodieRecordPayload>
+ extends BaseCommitActionExecutor<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>, HoodieBootstrapWriteMetadata> {
- private static final Logger LOG = LogManager.getLogger(BootstrapCommitActionExecutor.class);
+ private static final Logger LOG = LogManager.getLogger(SparkBootstrapCommitActionExecutor.class);
protected String bootstrapSchema = null;
private transient FileSystem bootstrapSourceFileSystem;
- public BootstrapCommitActionExecutor(JavaSparkContext jsc, HoodieWriteConfig config, HoodieTable<?> table,
- Option<Map<String, String>> extraMetadata) {
- super(jsc, new HoodieWriteConfig.Builder().withProps(config.getProps())
- .withAutoCommit(true).withWriteStatusClass(BootstrapWriteStatus.class)
- .withBulkInsertParallelism(config.getBootstrapParallelism())
- .build(), table, HoodieTimeline.METADATA_BOOTSTRAP_INSTANT_TS, WriteOperationType.BOOTSTRAP,
+ public SparkBootstrapCommitActionExecutor(HoodieSparkEngineContext context,
+ HoodieWriteConfig config,
+ HoodieTable<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> table,
+ Option<Map<String, String>> extraMetadata) {
+ super(context, new HoodieWriteConfig.Builder().withProps(config.getProps())
+ .withAutoCommit(true).withWriteStatusClass(BootstrapWriteStatus.class)
+ .withBulkInsertParallelism(config.getBootstrapParallelism())
+ .build(), table, HoodieTimeline.METADATA_BOOTSTRAP_INSTANT_TS, WriteOperationType.BOOTSTRAP,
extraMetadata);
bootstrapSourceFileSystem = FSUtils.getFs(config.getBootstrapSourceBasePath(), hadoopConf);
}
+ @Override
+ public HoodieWriteMetadata<JavaRDD<WriteStatus>> execute(JavaRDD<HoodieRecord<T>> inputRecordsRDD) {
Review comment:
> hmmm? why do we return null here
`BootstrapCommitActionExecutor` dose not need this method actually, inherited from its parent class.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yanghua commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
yanghua commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r498188986
##########
File path: hudi-cli/pom.xml
##########
@@ -148,7 +148,14 @@
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
- <artifactId>hudi-client</artifactId>
+ <artifactId>hudi-client-common</artifactId>
+ <version>${project.version}</version>
+ <scope>test</scope>
+ <type>test-jar</type>
+ </dependency>
+ <dependency>
+ <groupId>org.apache.hudi</groupId>
+ <artifactId>hudi-spark-client</artifactId>
Review comment:
So, will we keep `hudi-spark-client`? We have had a `hudi-spark` module. IMHO, this naming may not seem so clear.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r492474495
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
when the use passes in a regular lambda, into `rdd.map()`, this is what it gets converted into
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-702407275
@wangxianghu Just merged! Thanks again for the herculean effort.
May be some followups could pop up. Would you be interested in taking them up? if so, I ll mention you along the way
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-661504763
@satishkotha @nbalajee @prashantwason @modi95 please take a look as well.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-688571862
@wangxianghu the issue with the tests is that, now most of the tests are moved to hudi-spark-client. previously we had split tests into hudi-client and others. We need to edit `travis.yml` to adjust the splits again
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-698161234
> @wangxianghu Looks like we have much less class splitting now. I want to try and reduce this further if possible.
> If its alright with you, I can take over from here, make some changes and push another commit on top of yours, to try and get this across the finish line. Want to coordinate so that we are not making parallel changes,
@vinothchandar, Yeah, Of course, you can take over from here, this will greatly facilitate the process
thanks 👍
BTW, the CI is green now in my repository, you can start anytime you want :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r498806514
##########
File path: hudi-cli/pom.xml
##########
@@ -148,7 +148,14 @@
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
- <artifactId>hudi-client</artifactId>
+ <artifactId>hudi-client-common</artifactId>
+ <version>${project.version}</version>
+ <scope>test</scope>
+ <type>test-jar</type>
+ </dependency>
+ <dependency>
+ <groupId>org.apache.hudi</groupId>
+ <artifactId>hudi-spark-client</artifactId>
Review comment:
> So, will we keep `hudi-spark-client`? We have had a `hudi-spark` module. IMHO, this naming may not seem so clear.
@vinothchandar @yanghua I have filed a pr to rename `hudi-spark-client` to `hudi-client-spark` : https://github.com/apache/hudi/pull/2139
please take a look when free
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-696120725
@vinothchandar I have refactored `org.apache.hudi.table.SparkMarkerFiles` with `parallelDo ` function, it works ok in my local(`org.apache.hudi.table.TestMarkerFiles` passed), and the Ci has passed in my repository by now.
do you have other concerns about the `parallelDo`? can I start to refactor this pr with `parallelDo ` function now?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-699724973
@vinothchandar, Thanks for your patience and detailed review and fix. It's a really big help!
Do you mean I take over the rest of the work from here? :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-692604118
> That sounds promising. We cannot easily fix `T,R,O` though right at the class level. it will be different in each setting, right?
>
> We can use generic methods though I think and what I had in mind was something little different
> if the method signature can be the following
>
> ```
> public abstract <I,O> List<O> parallelDo(List<I> data, Function<I, O> func, int parallelism);
> ```
>
> and for the Spark the implementation
>
> ```
> public <I,O> List<O> parallelDo(List<I> data, Function<I, O> func, int parallelism) {
> return jsc.parallelize(data, parallelism).map(func).collectAsList();
> }
> ```
>
> and the invocation
>
> ```
> engineContext.parallelDo(Arrays.asList(1,2,3), (a) -> {
> return 0;
> }, 3);
> ```
>
> Can you a small Flink implementation as well and confirm this approach will work for Flink as well. Thats another key thing to answer, before we finalize the approach.
>
> Note that
>
> a) some of the code that uses `rdd.mapToPair()` etc before collecting, have to be rewritten using Java Streams. i.e
>
> `engineContext.parallelDo().map()` instead of `jsc.parallelize().map().mapToPair()` currently.
>
> b) Also we should limit the use of parallelDo() to only cases where there are no grouping/aggregations involved. for e.g if we are doing `jsc.parallelize(files, ..).map(record).reduceByKey(..)`, collecting without reducing will lead to OOMs. We can preserve what you are doing currently, for such cases.
>
> But the parallelDo should help up reduce the amount of code broken up (and thus reduce the effort for the flink engine).
>
> @wangxianghu I am happy to shepherd this PR through from this point as well. lmk
>
> cc @yanghua @leesf
Yes, I noticed that problem lately. we should use generic methods. I also agree with the a) and b) you mentioned.
In the `parallelDo` method flink engine can operate the list directly using Java Stream, I have verified that. but there is a problem:
The function used in spark map operator is `org.apache.spark.api.java.function.Function` while what flink can use is `java.util.function.Function` we should align it.
maybe we can use `java.util.function.Function` only, If this way, there is no need to distinguish spark and flink, there both use java stream to implement those kind operations. the generic method could be like this:
`public class HoodieEngineContext {
public <I, O> List<O> parallelDo(List<I> data, Function<I, O> func) {
return data.stream().map(func).collect(Collectors.toList());
}
}`
WDYT?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-685234513
@wangxianghu sounds good. Thanks for this monumental effort!
Will start in the earliest. can we get the CI to pass ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484815015
##########
File path: hudi-client/hudi-client-common/pom.xml
##########
@@ -0,0 +1,44 @@
+<?xml version="1.0" encoding="UTF-8"?>
+<!--
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+-->
+<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
+ xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
+ <parent>
+ <artifactId>hudi-client</artifactId>
+ <groupId>org.apache.hudi</groupId>
+ <version>0.6.1-SNAPSHOT</version>
+ </parent>
+ <modelVersion>4.0.0</modelVersion>
+
+ <artifactId>hudi-client-common</artifactId>
Review comment:
have moved dependencies from hudi-client to hudi-client-common
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/asyc/AbstractAsyncService.java
##########
@@ -16,7 +16,7 @@
* limitations under the License.
*/
-package org.apache.hudi.async;
+package org.apache.hudi.asyc;
Review comment:
done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-692074997
> I can help address the remaining feedback. I will push a small diff today/tmrw.
> Overall, looks like a reasonable start.
>
> The major feedback I still have is the following
>
> > would a parallelDo(func, parallelism) method in HoodieEngineContext help us avoid a lot of base/child class duplication of logic like this?
>
> Lot of usages are like `jsc.parallelize(list, parallelism).map(func)` , which all require a base-child class now. I am wondering if its easier to take those usages alone and implement as `engineContext.parallelDo(list, func, parallelism)`. This can be the lowest common denominator across Spark/Flink etc. We can avoid splitting a good chunk of classes if we do this IMO. If this is interesting, and we agree, I can try to quantify.
Hi @vinothchandar, how about this demo?
`public abstract class AbstractHoodieEngineContext<T, R, O> {
public abstract O parallelDo(List<T> datas, Function<List<T>, R> function, int parallesiom);
}`
`public class HoodieSparkEngineContext extends AbstractHoodieEngineContext<Integer,List<String>, JavaRDD<String>> {
private static JavaSparkContext jsc;
static {
SparkConf conf = new SparkConf()
.setMaster("local[4]")
.set("spark.driver.host","localhost")
.setAppName("SparkFunction");
jsc = new JavaSparkContext(conf);
}
@Override
public JavaRDD<String> parallelDo(List<Integer> datas, Function<List<Integer>, List<String>> function, int parallesiom) {
return jsc.parallelize(function.apply(datas), parallesiom);
}
}`
`public class App {
public static void main(String[] args) {
// define function
Function<List<Integer>, List<String>> function = integers -> integers.stream().map(x -> x + " ####").collect(Collectors.toList());
// inputs
List<Integer> inputs = Arrays.asList(1, 2, 3, 4, 5, 6, 7);
// context
AbstractHoodieEngineContext<Integer, List<String>, JavaRDD<String>> sparkEngineContext = new HoodieSparkEngineContext();
// execute
JavaRDD<String> stringJavaRdd = sparkEngineContext.parallelDo(inputs, function, 3);
// print result
stringJavaRdd.foreach(x -> System.out.println(x));
}
}`
The result are as follows:
`3 ####
4 ####
1 ####
2 ####
5 ####
6 ####
7 ####`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484828823
##########
File path: hudi-spark/src/main/scala/org/apache/hudi/IncrementalRelation.scala
##########
@@ -64,8 +64,7 @@ class IncrementalRelation(val sqlContext: SQLContext,
throw new HoodieException("Incremental view not implemented yet, for merge-on-read tables")
}
// TODO : Figure out a valid HoodieWriteConfig
- private val hoodieTable = HoodieTable.create(metaClient, HoodieWriteConfig.newBuilder().withPath(basePath).build(),
- sqlContext.sparkContext.hadoopConfiguration)
+ private val hoodieTable = HoodieSparkTable.create(HoodieWriteConfig.newBuilder().withPath(basePath).build(), new HoodieSparkEngineContext(new JavaSparkContext(sqlContext.sparkContext)) ,metaClient)
Review comment:
> nit: no space before `,` and space after `, metaClient`
done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-692604118
> That sounds promising. We cannot easily fix `T,R,O` though right at the class level. it will be different in each setting, right?
>
> We can use generic methods though I think and what I had in mind was something little different
> if the method signature can be the following
>
> ```
> public abstract <I,O> List<O> parallelDo(List<I> data, Function<I, O> func, int parallelism);
> ```
>
> and for the Spark the implementation
>
> ```
> public <I,O> List<O> parallelDo(List<I> data, Function<I, O> func, int parallelism) {
> return jsc.parallelize(data, parallelism).map(func).collectAsList();
> }
> ```
>
> and the invocation
>
> ```
> engineContext.parallelDo(Arrays.asList(1,2,3), (a) -> {
> return 0;
> }, 3);
> ```
>
> Can you a small Flink implementation as well and confirm this approach will work for Flink as well. Thats another key thing to answer, before we finalize the approach.
>
> Note that
>
> a) some of the code that uses `rdd.mapToPair()` etc before collecting, have to be rewritten using Java Streams. i.e
>
> `engineContext.parallelDo().map()` instead of `jsc.parallelize().map().mapToPair()` currently.
>
> b) Also we should limit the use of parallelDo() to only cases where there are no grouping/aggregations involved. for e.g if we are doing `jsc.parallelize(files, ..).map(record).reduceByKey(..)`, collecting without reducing will lead to OOMs. We can preserve what you are doing currently, for such cases.
>
> But the parallelDo should help up reduce the amount of code broken up (and thus reduce the effort for the flink engine).
>
> @wangxianghu I am happy to shepherd this PR through from this point as well. lmk
>
> cc @yanghua @leesf
Yes, I noticed that problem lately. we should use generic methods. I also agree with the a) and b) you mentioned.
In the `parallelDo` method flink engine can operate the list directly using Java Stream, I have verified that. but there is a problem:
The function used in spark map operator is `org.apache.spark.api.java.function.Function` while what flink can use is `java.util.function.Function` we should align it.
maybe we can use `java.util.function.Function` only, If this way, there is no need to distinguish spark and flink, there both use java stream to implement those kind operations. the generic method could be like this:
`public class HoodieEngineContext {
public <I, O> List<O> parallelDo(List<I> data, Function<I, O> func) {
return data.stream().map(func).collect(Collectors.toList());
}
}`
WDYT?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-692604118
> That sounds promising. We cannot easily fix `T,R,O` though right at the class level. it will be different in each setting, right?
>
> We can use generic methods though I think and what I had in mind was something little different
> if the method signature can be the following
>
> ```
> public abstract <I,O> List<O> parallelDo(List<I> data, Function<I, O> func, int parallelism);
> ```
>
> and for the Spark the implementation
>
> ```
> public <I,O> List<O> parallelDo(List<I> data, Function<I, O> func, int parallelism) {
> return jsc.parallelize(data, parallelism).map(func).collectAsList();
> }
> ```
>
> and the invocation
>
> ```
> engineContext.parallelDo(Arrays.asList(1,2,3), (a) -> {
> return 0;
> }, 3);
> ```
>
> Can you a small Flink implementation as well and confirm this approach will work for Flink as well. Thats another key thing to answer, before we finalize the approach.
>
> Note that
>
> a) some of the code that uses `rdd.mapToPair()` etc before collecting, have to be rewritten using Java Streams. i.e
>
> `engineContext.parallelDo().map()` instead of `jsc.parallelize().map().mapToPair()` currently.
>
> b) Also we should limit the use of parallelDo() to only cases where there are no grouping/aggregations involved. for e.g if we are doing `jsc.parallelize(files, ..).map(record).reduceByKey(..)`, collecting without reducing will lead to OOMs. We can preserve what you are doing currently, for such cases.
>
> But the parallelDo should help up reduce the amount of code broken up (and thus reduce the effort for the flink engine).
>
> @wangxianghu I am happy to shepherd this PR through from this point as well. lmk
>
> cc @yanghua @leesf
Yes, I noticed that problem lately. we should use generic methods. I also agree with the a) and b) you mentioned.
In the `parallelDo` method flink engine can operate the list directly using Java Stream, I have verified that. but there is a problem:
The function used in spark map operator is `org.apache.spark.api.java.function.Function` while what flink can use is `java.util.function.Function` we should align it.
maybe we can use `java.util.function.Function` only, If this way, there is no need to distinguish spark and flink, there both use java stream to implement those kind operations. the generic method could be like this:
```
public class HoodieEngineContext {
public <I, O> List<O> parallelDo(List<I> data, Function<I, O> func) {
return data.stream().map(func).collect(Collectors.toList());
}
}
```
WDYT?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Mathieu1124 commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
Mathieu1124 commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r456239385
##########
File path: hudi-cli/src/main/java/org/apache/hudi/cli/commands/CompactionCommand.java
##########
@@ -593,8 +592,8 @@ public String repairCompaction(
return output;
}
- private String getRenamesToBePrinted(List<RenameOpResult> res, Integer limit, String sortByField, boolean descending,
- boolean headerOnly, String operation) {
+ private String getRenamesToBePrinted(List<BaseCompactionAdminClient.RenameOpResult> res, Integer limit, String sortByField, boolean descending,
+ boolean headerOnly, String operation) {
Review comment:
Hi, @yanghua thanks for your review. I am not sure which one is right either, I will roll back these style issues just to keep as same as before.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r485016294
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/embedded/SparkEmbeddedTimelineService.java
##########
@@ -0,0 +1,51 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client.embedded;
+
+import org.apache.hudi.client.embebbed.BaseEmbeddedTimelineService;
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.HoodieSparkEngineContext;
+import org.apache.hudi.common.table.view.FileSystemViewStorageConfig;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+import org.apache.spark.SparkConf;
+
+/**
+ * Spark implementation of Timeline Service.
+ */
+public class SparkEmbeddedTimelineService extends BaseEmbeddedTimelineService {
+
+ private static final Logger LOG = LogManager.getLogger(SparkEmbeddedTimelineService.class);
+
+ public SparkEmbeddedTimelineService(HoodieEngineContext context, FileSystemViewStorageConfig config) {
+ super(context, config);
+ }
+
+ @Override
+ public void setHostAddrFromContext(HoodieEngineContext context) {
+ SparkConf sparkConf = HoodieSparkEngineContext.getSparkContext(context).getConf();
+ String hostAddr = sparkConf.get("spark.driver.host", null);
Review comment:
> I think we can eliminate the need for breaking this up into spark vs non-spark, by just passing in the host. This class does not make much sense being broken up.
done, add `hoodie.embed.timeline.server.host` to `HoodieWriteConfig`, it can be obtained via method `getEmbeddedServerHost()`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-692027032
> I can help address the remaining feedback. I will push a small diff today/tmrw.
> Overall, looks like a reasonable start.
>
> The major feedback I still have is the following
>
> > would a parallelDo(func, parallelism) method in HoodieEngineContext help us avoid a lot of base/child class duplication of logic like this?
>
> Lot of usages are like `jsc.parallelize(list, parallelism).map(func)` , which all require a base-child class now. I am wondering if its easier to take those usages alone and implement as `engineContext.parallelDo(list, func, parallelism)`. This can be the lowest common denominator across Spark/Flink etc. We can avoid splitting a good chunk of classes if we do this IMO. If this is interesting, and we agree, I can try to quantify.
@vinothchandar thanks for your help, I think introducing a method to replace `jsc.parallelize(list, parallelism).map(func)` is a good idea. I'll give a try about this.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-701951988
> @wangxianghu @yanghua I have rebased this against master. Please take a look at my changes.
>
> High level, we could re-use more code, but it needs an abstraction that can wrap `RDD` or `DataSet` or `D
> @wangxianghu @yanghua I have rebased this against master. Please take a look at my changes.
>
> High level, we could re-use more code, but it needs an abstraction that can wrap `RDD` or `DataSet` or `DataStream` adequately and support basic operations like `.map()`, `reduceByKey()` etc. We can do this in a second pass once we have a working Flink impl. For now this will do.
>
> I am trying to get the tests to pass. if they do, we could go ahead and merge
Thanks, @vinothchandar, this is really great work!
Yes, we can do more abstractions about basic `map`, `reduceByKey` methods in `HoodieEngineContext`, or some Util classes next.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r485591618
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
##########
@@ -18,120 +18,195 @@
package org.apache.hudi.client;
+import com.codahale.metrics.Timer;
+import org.apache.hadoop.conf.Configuration;
import org.apache.hudi.avro.model.HoodieCleanMetadata;
import org.apache.hudi.avro.model.HoodieCompactionPlan;
import org.apache.hudi.avro.model.HoodieRestoreMetadata;
import org.apache.hudi.avro.model.HoodieRollbackMetadata;
-import org.apache.hudi.client.embedded.EmbeddedTimelineService;
+import org.apache.hudi.callback.HoodieWriteCommitCallback;
+import org.apache.hudi.callback.common.HoodieWriteCommitCallbackMessage;
+import org.apache.hudi.callback.util.HoodieCommitCallbackFactory;
+import org.apache.hudi.client.embebbed.BaseEmbeddedTimelineService;
+import org.apache.hudi.common.HoodieEngineContext;
import org.apache.hudi.common.model.HoodieCommitMetadata;
import org.apache.hudi.common.model.HoodieKey;
-import org.apache.hudi.common.model.HoodieRecord;
import org.apache.hudi.common.model.HoodieRecordPayload;
import org.apache.hudi.common.model.HoodieWriteStat;
import org.apache.hudi.common.model.WriteOperationType;
import org.apache.hudi.common.table.HoodieTableMetaClient;
import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
import org.apache.hudi.common.table.timeline.HoodieInstant;
-import org.apache.hudi.common.table.timeline.HoodieInstant.State;
import org.apache.hudi.common.table.timeline.HoodieTimeline;
import org.apache.hudi.common.util.Option;
import org.apache.hudi.common.util.ValidationUtils;
-import org.apache.hudi.config.HoodieCompactionConfig;
import org.apache.hudi.config.HoodieWriteConfig;
+
import org.apache.hudi.exception.HoodieCommitException;
import org.apache.hudi.exception.HoodieIOException;
import org.apache.hudi.exception.HoodieRestoreException;
import org.apache.hudi.exception.HoodieRollbackException;
import org.apache.hudi.exception.HoodieSavepointException;
import org.apache.hudi.index.HoodieIndex;
import org.apache.hudi.metrics.HoodieMetrics;
-import org.apache.hudi.table.HoodieTable;
-import org.apache.hudi.table.HoodieTimelineArchiveLog;
-import org.apache.hudi.table.MarkerFiles;
import org.apache.hudi.table.BulkInsertPartitioner;
+import org.apache.hudi.table.HoodieTable;
import org.apache.hudi.table.action.HoodieWriteMetadata;
-import org.apache.hudi.table.action.compact.CompactHelpers;
import org.apache.hudi.table.action.savepoint.SavepointHelpers;
-
-import com.codahale.metrics.Timer;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
-import org.apache.spark.SparkConf;
-import org.apache.spark.api.java.JavaRDD;
-import org.apache.spark.api.java.JavaSparkContext;
import java.io.IOException;
+import java.nio.charset.StandardCharsets;
import java.text.ParseException;
import java.util.Collection;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
- * Hoodie Write Client helps you build tables on HDFS [insert()] and then perform efficient mutations on an HDFS
- * table [upsert()]
- * <p>
- * Note that, at any given time, there can only be one Spark job performing these operations on a Hoodie table.
+ * Abstract Write Client providing functionality for performing commit, index updates and rollback
+ * Reused for regular write operations like upsert/insert/bulk-insert.. as well as bootstrap
+ *
+ * @param <T> Sub type of HoodieRecordPayload
+ * @param <I> Type of inputs
+ * @param <K> Type of keys
+ * @param <O> Type of outputs
+ * @param <P> Type of record position [Key, Option[partitionPath, fileID]] in hoodie table
*/
-public class HoodieWriteClient<T extends HoodieRecordPayload> extends AbstractHoodieWriteClient<T> {
-
+public abstract class AbstractHoodieWriteClient<T extends HoodieRecordPayload, I, K, O, P> extends AbstractHoodieClient {
private static final long serialVersionUID = 1L;
- private static final Logger LOG = LogManager.getLogger(HoodieWriteClient.class);
- private static final String LOOKUP_STR = "lookup";
- private final boolean rollbackPending;
- private final transient HoodieMetrics metrics;
- private transient Timer.Context compactionTimer;
+ private static final Logger LOG = LogManager.getLogger(AbstractHoodieWriteClient.class);
+
+ protected final transient HoodieMetrics metrics;
+ private final transient HoodieIndex<T, I, K, O, P> index;
+
+ protected transient Timer.Context writeContext = null;
+ private transient WriteOperationType operationType;
+ private transient HoodieWriteCommitCallback commitCallback;
+
+ protected static final String LOOKUP_STR = "lookup";
+ protected final boolean rollbackPending;
+ protected transient Timer.Context compactionTimer;
private transient AsyncCleanerService asyncCleanerService;
+ public void setOperationType(WriteOperationType operationType) {
+ this.operationType = operationType;
+ }
+
+ public WriteOperationType getOperationType() {
+ return this.operationType;
+ }
+
/**
* Create a write client, without cleaning up failed/inflight commits.
*
- * @param jsc Java Spark Context
+ * @param context Java Spark Context
* @param clientConfig instance of HoodieWriteConfig
*/
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig clientConfig) {
- this(jsc, clientConfig, false);
+ public AbstractHoodieWriteClient(HoodieEngineContext context, HoodieWriteConfig clientConfig) {
+ this(context, clientConfig, false);
}
/**
* Create a write client, with new hudi index.
*
- * @param jsc Java Spark Context
- * @param writeConfig instance of HoodieWriteConfig
+ * @param context HoodieEngineContext
+ * @param writeConfig instance of HoodieWriteConfig
* @param rollbackPending whether need to cleanup pending commits
*/
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig writeConfig, boolean rollbackPending) {
- this(jsc, writeConfig, rollbackPending, HoodieIndex.createIndex(writeConfig));
- }
-
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig writeConfig, boolean rollbackPending, HoodieIndex index) {
- this(jsc, writeConfig, rollbackPending, index, Option.empty());
+ public AbstractHoodieWriteClient(HoodieEngineContext context, HoodieWriteConfig writeConfig, boolean rollbackPending) {
+ this(context, writeConfig, rollbackPending, Option.empty());
}
/**
- * Create a write client, allows to specify all parameters.
+ * Create a write client, allows to specify all parameters.
*
- * @param jsc Java Spark Context
- * @param writeConfig instance of HoodieWriteConfig
+ * @param context HoodieEngineContext
+ * @param writeConfig instance of HoodieWriteConfig
* @param rollbackPending whether need to cleanup pending commits
* @param timelineService Timeline Service that runs as part of write client.
*/
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig writeConfig, boolean rollbackPending,
- HoodieIndex index, Option<EmbeddedTimelineService> timelineService) {
- super(jsc, index, writeConfig, timelineService);
+ public AbstractHoodieWriteClient(HoodieEngineContext context, HoodieWriteConfig writeConfig, boolean rollbackPending,
+ Option<BaseEmbeddedTimelineService> timelineService) {
+ super(context, writeConfig, timelineService);
this.metrics = new HoodieMetrics(config, config.getTableName());
this.rollbackPending = rollbackPending;
+ this.index = createIndex(writeConfig);
}
+ protected abstract HoodieIndex<T, I, K, O, P> createIndex(HoodieWriteConfig writeConfig);
+
/**
- * Register hudi classes for Kryo serialization.
- *
- * @param conf instance of SparkConf
- * @return SparkConf
+ * Commit changes performed at the given instantTime marker.
*/
- public static SparkConf registerClasses(SparkConf conf) {
Review comment:
> guessing this is all moved to spark client now?
yes, In `SparkRDDWriteClient` now
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r483291007
##########
File path: hudi-cli/src/test/java/org/apache/hudi/cli/commands/TestArchivedCommitsCommand.java
##########
@@ -92,8 +92,9 @@ public void init() throws IOException {
metaClient.getActiveTimeline().reload().getAllCommitsTimeline().filterCompletedInstants();
// archive
- HoodieTimelineArchiveLog archiveLog = new HoodieTimelineArchiveLog(cfg, hadoopConf);
- archiveLog.archiveIfRequired(jsc);
+
Review comment:
nit: extra line.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/asyc/AbstractAsyncService.java
##########
@@ -16,7 +16,7 @@
* limitations under the License.
*/
-package org.apache.hudi.async;
+package org.apache.hudi.asyc;
Review comment:
typo: async
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
##########
@@ -18,120 +18,195 @@
package org.apache.hudi.client;
+import com.codahale.metrics.Timer;
+import org.apache.hadoop.conf.Configuration;
import org.apache.hudi.avro.model.HoodieCleanMetadata;
import org.apache.hudi.avro.model.HoodieCompactionPlan;
import org.apache.hudi.avro.model.HoodieRestoreMetadata;
import org.apache.hudi.avro.model.HoodieRollbackMetadata;
-import org.apache.hudi.client.embedded.EmbeddedTimelineService;
+import org.apache.hudi.callback.HoodieWriteCommitCallback;
+import org.apache.hudi.callback.common.HoodieWriteCommitCallbackMessage;
+import org.apache.hudi.callback.util.HoodieCommitCallbackFactory;
+import org.apache.hudi.client.embebbed.BaseEmbeddedTimelineService;
+import org.apache.hudi.common.HoodieEngineContext;
import org.apache.hudi.common.model.HoodieCommitMetadata;
import org.apache.hudi.common.model.HoodieKey;
-import org.apache.hudi.common.model.HoodieRecord;
import org.apache.hudi.common.model.HoodieRecordPayload;
import org.apache.hudi.common.model.HoodieWriteStat;
import org.apache.hudi.common.model.WriteOperationType;
import org.apache.hudi.common.table.HoodieTableMetaClient;
import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
import org.apache.hudi.common.table.timeline.HoodieInstant;
-import org.apache.hudi.common.table.timeline.HoodieInstant.State;
import org.apache.hudi.common.table.timeline.HoodieTimeline;
import org.apache.hudi.common.util.Option;
import org.apache.hudi.common.util.ValidationUtils;
-import org.apache.hudi.config.HoodieCompactionConfig;
import org.apache.hudi.config.HoodieWriteConfig;
+
import org.apache.hudi.exception.HoodieCommitException;
import org.apache.hudi.exception.HoodieIOException;
import org.apache.hudi.exception.HoodieRestoreException;
import org.apache.hudi.exception.HoodieRollbackException;
import org.apache.hudi.exception.HoodieSavepointException;
import org.apache.hudi.index.HoodieIndex;
import org.apache.hudi.metrics.HoodieMetrics;
-import org.apache.hudi.table.HoodieTable;
-import org.apache.hudi.table.HoodieTimelineArchiveLog;
-import org.apache.hudi.table.MarkerFiles;
import org.apache.hudi.table.BulkInsertPartitioner;
+import org.apache.hudi.table.HoodieTable;
import org.apache.hudi.table.action.HoodieWriteMetadata;
-import org.apache.hudi.table.action.compact.CompactHelpers;
import org.apache.hudi.table.action.savepoint.SavepointHelpers;
-
-import com.codahale.metrics.Timer;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
-import org.apache.spark.SparkConf;
-import org.apache.spark.api.java.JavaRDD;
-import org.apache.spark.api.java.JavaSparkContext;
import java.io.IOException;
+import java.nio.charset.StandardCharsets;
import java.text.ParseException;
import java.util.Collection;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
- * Hoodie Write Client helps you build tables on HDFS [insert()] and then perform efficient mutations on an HDFS
- * table [upsert()]
- * <p>
- * Note that, at any given time, there can only be one Spark job performing these operations on a Hoodie table.
+ * Abstract Write Client providing functionality for performing commit, index updates and rollback
+ * Reused for regular write operations like upsert/insert/bulk-insert.. as well as bootstrap
+ *
+ * @param <T> Sub type of HoodieRecordPayload
+ * @param <I> Type of inputs
+ * @param <K> Type of keys
+ * @param <O> Type of outputs
+ * @param <P> Type of record position [Key, Option[partitionPath, fileID]] in hoodie table
*/
-public class HoodieWriteClient<T extends HoodieRecordPayload> extends AbstractHoodieWriteClient<T> {
-
+public abstract class AbstractHoodieWriteClient<T extends HoodieRecordPayload, I, K, O, P> extends AbstractHoodieClient {
private static final long serialVersionUID = 1L;
- private static final Logger LOG = LogManager.getLogger(HoodieWriteClient.class);
- private static final String LOOKUP_STR = "lookup";
- private final boolean rollbackPending;
- private final transient HoodieMetrics metrics;
- private transient Timer.Context compactionTimer;
+ private static final Logger LOG = LogManager.getLogger(AbstractHoodieWriteClient.class);
+
+ protected final transient HoodieMetrics metrics;
+ private final transient HoodieIndex<T, I, K, O, P> index;
+
+ protected transient Timer.Context writeContext = null;
+ private transient WriteOperationType operationType;
+ private transient HoodieWriteCommitCallback commitCallback;
+
+ protected static final String LOOKUP_STR = "lookup";
+ protected final boolean rollbackPending;
+ protected transient Timer.Context compactionTimer;
private transient AsyncCleanerService asyncCleanerService;
+ public void setOperationType(WriteOperationType operationType) {
+ this.operationType = operationType;
+ }
+
+ public WriteOperationType getOperationType() {
+ return this.operationType;
+ }
+
/**
* Create a write client, without cleaning up failed/inflight commits.
*
- * @param jsc Java Spark Context
+ * @param context Java Spark Context
* @param clientConfig instance of HoodieWriteConfig
*/
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig clientConfig) {
- this(jsc, clientConfig, false);
+ public AbstractHoodieWriteClient(HoodieEngineContext context, HoodieWriteConfig clientConfig) {
+ this(context, clientConfig, false);
}
/**
* Create a write client, with new hudi index.
*
- * @param jsc Java Spark Context
- * @param writeConfig instance of HoodieWriteConfig
+ * @param context HoodieEngineContext
+ * @param writeConfig instance of HoodieWriteConfig
* @param rollbackPending whether need to cleanup pending commits
*/
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig writeConfig, boolean rollbackPending) {
- this(jsc, writeConfig, rollbackPending, HoodieIndex.createIndex(writeConfig));
- }
-
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig writeConfig, boolean rollbackPending, HoodieIndex index) {
- this(jsc, writeConfig, rollbackPending, index, Option.empty());
+ public AbstractHoodieWriteClient(HoodieEngineContext context, HoodieWriteConfig writeConfig, boolean rollbackPending) {
+ this(context, writeConfig, rollbackPending, Option.empty());
}
/**
- * Create a write client, allows to specify all parameters.
+ * Create a write client, allows to specify all parameters.
*
- * @param jsc Java Spark Context
- * @param writeConfig instance of HoodieWriteConfig
+ * @param context HoodieEngineContext
+ * @param writeConfig instance of HoodieWriteConfig
* @param rollbackPending whether need to cleanup pending commits
* @param timelineService Timeline Service that runs as part of write client.
*/
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig writeConfig, boolean rollbackPending,
- HoodieIndex index, Option<EmbeddedTimelineService> timelineService) {
- super(jsc, index, writeConfig, timelineService);
+ public AbstractHoodieWriteClient(HoodieEngineContext context, HoodieWriteConfig writeConfig, boolean rollbackPending,
+ Option<BaseEmbeddedTimelineService> timelineService) {
+ super(context, writeConfig, timelineService);
this.metrics = new HoodieMetrics(config, config.getTableName());
this.rollbackPending = rollbackPending;
+ this.index = createIndex(writeConfig);
}
+ protected abstract HoodieIndex<T, I, K, O, P> createIndex(HoodieWriteConfig writeConfig);
Review comment:
same point, not sure if this is correct.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
##########
@@ -242,150 +286,93 @@ protected void rollBackInflightBootstrap() {
* de-duped if needed.
*
* @param preppedRecords HoodieRecords to insert
- * @param instantTime Instant time of the commit
+ * @param instantTime Instant time of the commit
* @return JavaRDD[WriteStatus] - RDD of WriteStatus to inspect errors and counts
*/
- public JavaRDD<WriteStatus> insertPreppedRecords(JavaRDD<HoodieRecord<T>> preppedRecords, final String instantTime) {
- HoodieTable<T> table = getTableAndInitCtx(WriteOperationType.INSERT_PREPPED, instantTime);
- table.validateInsertSchema();
- setOperationType(WriteOperationType.INSERT_PREPPED);
- this.asyncCleanerService = AsyncCleanerService.startAsyncCleaningIfEnabled(this, instantTime);
- HoodieWriteMetadata result = table.insertPrepped(jsc,instantTime, preppedRecords);
- return postWrite(result, instantTime, table);
- }
+ public abstract O insertPreppedRecords(I preppedRecords, final String instantTime);
/**
* Loads the given HoodieRecords, as inserts into the table. This is suitable for doing big bulk loads into a Hoodie
* table for the very first time (e.g: converting an existing table to Hoodie).
* <p>
* This implementation uses sortBy (which does range partitioning based on reservoir sampling) and attempts to control
- * the numbers of files with less memory compared to the {@link HoodieWriteClient#insert(JavaRDD, String)}
+ * the numbers of files with less memory compared to the {@link AbstractHoodieWriteClient#insert(I, String)}
*
- * @param records HoodieRecords to insert
+ * @param records HoodieRecords to insert
* @param instantTime Instant time of the commit
* @return JavaRDD[WriteStatus] - RDD of WriteStatus to inspect errors and counts
*/
- public JavaRDD<WriteStatus> bulkInsert(JavaRDD<HoodieRecord<T>> records, final String instantTime) {
- return bulkInsert(records, instantTime, Option.empty());
- }
+ public abstract O bulkInsert(I records, final String instantTime);
/**
* Loads the given HoodieRecords, as inserts into the table. This is suitable for doing big bulk loads into a Hoodie
* table for the very first time (e.g: converting an existing table to Hoodie).
* <p>
* This implementation uses sortBy (which does range partitioning based on reservoir sampling) and attempts to control
- * the numbers of files with less memory compared to the {@link HoodieWriteClient#insert(JavaRDD, String)}. Optionally
+ * the numbers of files with less memory compared to the {@link AbstractHoodieWriteClient#insert(I, String)}. Optionally
* it allows users to specify their own partitioner. If specified then it will be used for repartitioning records. See
* {@link BulkInsertPartitioner}.
*
- * @param records HoodieRecords to insert
- * @param instantTime Instant time of the commit
+ * @param records HoodieRecords to insert
+ * @param instantTime Instant time of the commit
* @param userDefinedBulkInsertPartitioner If specified then it will be used to partition input records before they are inserted
- * into hoodie.
+ * into hoodie.
* @return JavaRDD[WriteStatus] - RDD of WriteStatus to inspect errors and counts
*/
- public JavaRDD<WriteStatus> bulkInsert(JavaRDD<HoodieRecord<T>> records, final String instantTime,
- Option<BulkInsertPartitioner> userDefinedBulkInsertPartitioner) {
- HoodieTable<T> table = getTableAndInitCtx(WriteOperationType.BULK_INSERT, instantTime);
- table.validateInsertSchema();
- setOperationType(WriteOperationType.BULK_INSERT);
- this.asyncCleanerService = AsyncCleanerService.startAsyncCleaningIfEnabled(this, instantTime);
- HoodieWriteMetadata result = table.bulkInsert(jsc,instantTime, records, userDefinedBulkInsertPartitioner);
- return postWrite(result, instantTime, table);
- }
+ public abstract O bulkInsert(I records, final String instantTime,
+ Option<BulkInsertPartitioner<I>> userDefinedBulkInsertPartitioner);
+
/**
* Loads the given HoodieRecords, as inserts into the table. This is suitable for doing big bulk loads into a Hoodie
* table for the very first time (e.g: converting an existing table to Hoodie). The input records should contain no
* duplicates if needed.
* <p>
* This implementation uses sortBy (which does range partitioning based on reservoir sampling) and attempts to control
- * the numbers of files with less memory compared to the {@link HoodieWriteClient#insert(JavaRDD, String)}. Optionally
+ * the numbers of files with less memory compared to the {@link AbstractHoodieWriteClient#insert(I, String)}. Optionally
* it allows users to specify their own partitioner. If specified then it will be used for repartitioning records. See
* {@link BulkInsertPartitioner}.
*
- * @param preppedRecords HoodieRecords to insert
- * @param instantTime Instant time of the commit
+ * @param preppedRecords HoodieRecords to insert
Review comment:
it would be great, if you can avoid the whitespace changes :) Have to fish for what the real changes are
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/index/HoodieIndex.java
##########
@@ -21,94 +21,52 @@
import org.apache.hudi.ApiMaturityLevel;
import org.apache.hudi.PublicAPIClass;
import org.apache.hudi.PublicAPIMethod;
-import org.apache.hudi.client.WriteStatus;
+import org.apache.hudi.common.HoodieEngineContext;
import org.apache.hudi.common.model.FileSlice;
import org.apache.hudi.common.model.HoodieKey;
-import org.apache.hudi.common.model.HoodieRecord;
import org.apache.hudi.common.model.HoodieRecordPayload;
-import org.apache.hudi.common.util.Option;
-import org.apache.hudi.common.util.ReflectionUtils;
-import org.apache.hudi.common.util.StringUtils;
-import org.apache.hudi.common.util.collection.Pair;
import org.apache.hudi.config.HoodieWriteConfig;
import org.apache.hudi.exception.HoodieIndexException;
-import org.apache.hudi.index.bloom.HoodieBloomIndex;
-import org.apache.hudi.index.bloom.HoodieGlobalBloomIndex;
-import org.apache.hudi.index.hbase.HBaseIndex;
-import org.apache.hudi.index.simple.HoodieGlobalSimpleIndex;
-import org.apache.hudi.index.simple.HoodieSimpleIndex;
import org.apache.hudi.table.HoodieTable;
-import org.apache.spark.api.java.JavaPairRDD;
-import org.apache.spark.api.java.JavaRDD;
-import org.apache.spark.api.java.JavaSparkContext;
-
import java.io.Serializable;
/**
* Base class for different types of indexes to determine the mapping from uuid.
*/
@PublicAPIClass(maturity = ApiMaturityLevel.EVOLVING)
-public abstract class HoodieIndex<T extends HoodieRecordPayload> implements Serializable {
+public abstract class HoodieIndex<T extends HoodieRecordPayload, I, K, O, P> implements Serializable {
protected final HoodieWriteConfig config;
protected HoodieIndex(HoodieWriteConfig config) {
this.config = config;
}
- public static <T extends HoodieRecordPayload> HoodieIndex<T> createIndex(
- HoodieWriteConfig config) throws HoodieIndexException {
- // first use index class config to create index.
- if (!StringUtils.isNullOrEmpty(config.getIndexClass())) {
- Object instance = ReflectionUtils.loadClass(config.getIndexClass(), config);
- if (!(instance instanceof HoodieIndex)) {
- throw new HoodieIndexException(config.getIndexClass() + " is not a subclass of HoodieIndex");
- }
- return (HoodieIndex) instance;
- }
- switch (config.getIndexType()) {
- case HBASE:
- return new HBaseIndex<>(config);
- case INMEMORY:
- return new InMemoryHashIndex<>(config);
- case BLOOM:
- return new HoodieBloomIndex<>(config);
- case GLOBAL_BLOOM:
- return new HoodieGlobalBloomIndex<>(config);
- case SIMPLE:
- return new HoodieSimpleIndex<>(config);
- case GLOBAL_SIMPLE:
- return new HoodieGlobalSimpleIndex<>(config);
- default:
- throw new HoodieIndexException("Index type unspecified, set " + config.getIndexType());
- }
- }
-
/**
* Checks if the given [Keys] exists in the hoodie table and returns [Key, Option[partitionPath, fileID]] If the
* optional is empty, then the key is not found.
*/
@PublicAPIMethod(maturity = ApiMaturityLevel.STABLE)
- public abstract JavaPairRDD<HoodieKey, Option<Pair<String, String>>> fetchRecordLocation(
- JavaRDD<HoodieKey> hoodieKeys, final JavaSparkContext jsc, HoodieTable<T> hoodieTable);
+ public abstract P fetchRecordLocation(
+ K hoodieKeys, final HoodieEngineContext context, HoodieTable<T, I, K, O, P> hoodieTable);
/**
* Looks up the index and tags each incoming record with a location of a file that contains the row (if it is actually
* present).
*/
@PublicAPIMethod(maturity = ApiMaturityLevel.STABLE)
Review comment:
these annotations needs to moved over to a `SparkHoodieIndex` class? it will be hard for end developers to program against `HoodieIndex` directly anymore. This is a general point actually. The current public APIs should all be annotated against the Spark child classes. wdyt?
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/keygen/KeyGeneratorInterface.java
##########
@@ -34,8 +33,4 @@
List<String> getRecordKeyFieldNames();
- String getRecordKey(Row row);
Review comment:
we should make sure there are no backwards incompatible changes to the key generator interface
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
##########
@@ -18,120 +18,195 @@
package org.apache.hudi.client;
+import com.codahale.metrics.Timer;
+import org.apache.hadoop.conf.Configuration;
import org.apache.hudi.avro.model.HoodieCleanMetadata;
import org.apache.hudi.avro.model.HoodieCompactionPlan;
import org.apache.hudi.avro.model.HoodieRestoreMetadata;
import org.apache.hudi.avro.model.HoodieRollbackMetadata;
-import org.apache.hudi.client.embedded.EmbeddedTimelineService;
+import org.apache.hudi.callback.HoodieWriteCommitCallback;
+import org.apache.hudi.callback.common.HoodieWriteCommitCallbackMessage;
+import org.apache.hudi.callback.util.HoodieCommitCallbackFactory;
+import org.apache.hudi.client.embebbed.BaseEmbeddedTimelineService;
+import org.apache.hudi.common.HoodieEngineContext;
import org.apache.hudi.common.model.HoodieCommitMetadata;
import org.apache.hudi.common.model.HoodieKey;
-import org.apache.hudi.common.model.HoodieRecord;
import org.apache.hudi.common.model.HoodieRecordPayload;
import org.apache.hudi.common.model.HoodieWriteStat;
import org.apache.hudi.common.model.WriteOperationType;
import org.apache.hudi.common.table.HoodieTableMetaClient;
import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
import org.apache.hudi.common.table.timeline.HoodieInstant;
-import org.apache.hudi.common.table.timeline.HoodieInstant.State;
import org.apache.hudi.common.table.timeline.HoodieTimeline;
import org.apache.hudi.common.util.Option;
import org.apache.hudi.common.util.ValidationUtils;
-import org.apache.hudi.config.HoodieCompactionConfig;
import org.apache.hudi.config.HoodieWriteConfig;
+
import org.apache.hudi.exception.HoodieCommitException;
import org.apache.hudi.exception.HoodieIOException;
import org.apache.hudi.exception.HoodieRestoreException;
import org.apache.hudi.exception.HoodieRollbackException;
import org.apache.hudi.exception.HoodieSavepointException;
import org.apache.hudi.index.HoodieIndex;
import org.apache.hudi.metrics.HoodieMetrics;
-import org.apache.hudi.table.HoodieTable;
-import org.apache.hudi.table.HoodieTimelineArchiveLog;
-import org.apache.hudi.table.MarkerFiles;
import org.apache.hudi.table.BulkInsertPartitioner;
+import org.apache.hudi.table.HoodieTable;
import org.apache.hudi.table.action.HoodieWriteMetadata;
-import org.apache.hudi.table.action.compact.CompactHelpers;
import org.apache.hudi.table.action.savepoint.SavepointHelpers;
-
-import com.codahale.metrics.Timer;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
-import org.apache.spark.SparkConf;
-import org.apache.spark.api.java.JavaRDD;
-import org.apache.spark.api.java.JavaSparkContext;
import java.io.IOException;
+import java.nio.charset.StandardCharsets;
import java.text.ParseException;
import java.util.Collection;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
- * Hoodie Write Client helps you build tables on HDFS [insert()] and then perform efficient mutations on an HDFS
- * table [upsert()]
- * <p>
- * Note that, at any given time, there can only be one Spark job performing these operations on a Hoodie table.
+ * Abstract Write Client providing functionality for performing commit, index updates and rollback
+ * Reused for regular write operations like upsert/insert/bulk-insert.. as well as bootstrap
+ *
+ * @param <T> Sub type of HoodieRecordPayload
+ * @param <I> Type of inputs
+ * @param <K> Type of keys
+ * @param <O> Type of outputs
+ * @param <P> Type of record position [Key, Option[partitionPath, fileID]] in hoodie table
*/
-public class HoodieWriteClient<T extends HoodieRecordPayload> extends AbstractHoodieWriteClient<T> {
-
+public abstract class AbstractHoodieWriteClient<T extends HoodieRecordPayload, I, K, O, P> extends AbstractHoodieClient {
private static final long serialVersionUID = 1L;
- private static final Logger LOG = LogManager.getLogger(HoodieWriteClient.class);
- private static final String LOOKUP_STR = "lookup";
- private final boolean rollbackPending;
- private final transient HoodieMetrics metrics;
- private transient Timer.Context compactionTimer;
+ private static final Logger LOG = LogManager.getLogger(AbstractHoodieWriteClient.class);
+
+ protected final transient HoodieMetrics metrics;
+ private final transient HoodieIndex<T, I, K, O, P> index;
+
+ protected transient Timer.Context writeContext = null;
+ private transient WriteOperationType operationType;
+ private transient HoodieWriteCommitCallback commitCallback;
+
+ protected static final String LOOKUP_STR = "lookup";
+ protected final boolean rollbackPending;
+ protected transient Timer.Context compactionTimer;
private transient AsyncCleanerService asyncCleanerService;
+ public void setOperationType(WriteOperationType operationType) {
+ this.operationType = operationType;
+ }
+
+ public WriteOperationType getOperationType() {
+ return this.operationType;
+ }
+
/**
* Create a write client, without cleaning up failed/inflight commits.
*
- * @param jsc Java Spark Context
+ * @param context Java Spark Context
* @param clientConfig instance of HoodieWriteConfig
*/
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig clientConfig) {
- this(jsc, clientConfig, false);
+ public AbstractHoodieWriteClient(HoodieEngineContext context, HoodieWriteConfig clientConfig) {
+ this(context, clientConfig, false);
}
/**
* Create a write client, with new hudi index.
*
- * @param jsc Java Spark Context
- * @param writeConfig instance of HoodieWriteConfig
+ * @param context HoodieEngineContext
+ * @param writeConfig instance of HoodieWriteConfig
* @param rollbackPending whether need to cleanup pending commits
*/
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig writeConfig, boolean rollbackPending) {
- this(jsc, writeConfig, rollbackPending, HoodieIndex.createIndex(writeConfig));
- }
-
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig writeConfig, boolean rollbackPending, HoodieIndex index) {
- this(jsc, writeConfig, rollbackPending, index, Option.empty());
+ public AbstractHoodieWriteClient(HoodieEngineContext context, HoodieWriteConfig writeConfig, boolean rollbackPending) {
+ this(context, writeConfig, rollbackPending, Option.empty());
}
/**
- * Create a write client, allows to specify all parameters.
+ * Create a write client, allows to specify all parameters.
*
- * @param jsc Java Spark Context
- * @param writeConfig instance of HoodieWriteConfig
+ * @param context HoodieEngineContext
+ * @param writeConfig instance of HoodieWriteConfig
* @param rollbackPending whether need to cleanup pending commits
* @param timelineService Timeline Service that runs as part of write client.
*/
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig writeConfig, boolean rollbackPending,
- HoodieIndex index, Option<EmbeddedTimelineService> timelineService) {
- super(jsc, index, writeConfig, timelineService);
+ public AbstractHoodieWriteClient(HoodieEngineContext context, HoodieWriteConfig writeConfig, boolean rollbackPending,
+ Option<BaseEmbeddedTimelineService> timelineService) {
+ super(context, writeConfig, timelineService);
this.metrics = new HoodieMetrics(config, config.getTableName());
this.rollbackPending = rollbackPending;
+ this.index = createIndex(writeConfig);
Review comment:
why did this constructor have to change
##########
File path: hudi-client/hudi-client-common/pom.xml
##########
@@ -0,0 +1,44 @@
+<?xml version="1.0" encoding="UTF-8"?>
+<!--
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+-->
+<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
+ xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
+ <parent>
+ <artifactId>hudi-client</artifactId>
+ <groupId>org.apache.hudi</groupId>
+ <version>0.6.1-SNAPSHOT</version>
+ </parent>
+ <modelVersion>4.0.0</modelVersion>
+
+ <artifactId>hudi-client-common</artifactId>
Review comment:
surprised that this has so few dependencies.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
##########
@@ -18,120 +18,195 @@
package org.apache.hudi.client;
+import com.codahale.metrics.Timer;
+import org.apache.hadoop.conf.Configuration;
import org.apache.hudi.avro.model.HoodieCleanMetadata;
import org.apache.hudi.avro.model.HoodieCompactionPlan;
import org.apache.hudi.avro.model.HoodieRestoreMetadata;
import org.apache.hudi.avro.model.HoodieRollbackMetadata;
-import org.apache.hudi.client.embedded.EmbeddedTimelineService;
+import org.apache.hudi.callback.HoodieWriteCommitCallback;
+import org.apache.hudi.callback.common.HoodieWriteCommitCallbackMessage;
+import org.apache.hudi.callback.util.HoodieCommitCallbackFactory;
+import org.apache.hudi.client.embebbed.BaseEmbeddedTimelineService;
+import org.apache.hudi.common.HoodieEngineContext;
import org.apache.hudi.common.model.HoodieCommitMetadata;
import org.apache.hudi.common.model.HoodieKey;
-import org.apache.hudi.common.model.HoodieRecord;
import org.apache.hudi.common.model.HoodieRecordPayload;
import org.apache.hudi.common.model.HoodieWriteStat;
import org.apache.hudi.common.model.WriteOperationType;
import org.apache.hudi.common.table.HoodieTableMetaClient;
import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
import org.apache.hudi.common.table.timeline.HoodieInstant;
-import org.apache.hudi.common.table.timeline.HoodieInstant.State;
import org.apache.hudi.common.table.timeline.HoodieTimeline;
import org.apache.hudi.common.util.Option;
import org.apache.hudi.common.util.ValidationUtils;
-import org.apache.hudi.config.HoodieCompactionConfig;
import org.apache.hudi.config.HoodieWriteConfig;
+
import org.apache.hudi.exception.HoodieCommitException;
import org.apache.hudi.exception.HoodieIOException;
import org.apache.hudi.exception.HoodieRestoreException;
import org.apache.hudi.exception.HoodieRollbackException;
import org.apache.hudi.exception.HoodieSavepointException;
import org.apache.hudi.index.HoodieIndex;
import org.apache.hudi.metrics.HoodieMetrics;
-import org.apache.hudi.table.HoodieTable;
-import org.apache.hudi.table.HoodieTimelineArchiveLog;
-import org.apache.hudi.table.MarkerFiles;
import org.apache.hudi.table.BulkInsertPartitioner;
+import org.apache.hudi.table.HoodieTable;
import org.apache.hudi.table.action.HoodieWriteMetadata;
-import org.apache.hudi.table.action.compact.CompactHelpers;
import org.apache.hudi.table.action.savepoint.SavepointHelpers;
-
-import com.codahale.metrics.Timer;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
-import org.apache.spark.SparkConf;
-import org.apache.spark.api.java.JavaRDD;
-import org.apache.spark.api.java.JavaSparkContext;
import java.io.IOException;
+import java.nio.charset.StandardCharsets;
import java.text.ParseException;
import java.util.Collection;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
- * Hoodie Write Client helps you build tables on HDFS [insert()] and then perform efficient mutations on an HDFS
- * table [upsert()]
- * <p>
- * Note that, at any given time, there can only be one Spark job performing these operations on a Hoodie table.
+ * Abstract Write Client providing functionality for performing commit, index updates and rollback
+ * Reused for regular write operations like upsert/insert/bulk-insert.. as well as bootstrap
+ *
+ * @param <T> Sub type of HoodieRecordPayload
+ * @param <I> Type of inputs
+ * @param <K> Type of keys
+ * @param <O> Type of outputs
+ * @param <P> Type of record position [Key, Option[partitionPath, fileID]] in hoodie table
*/
-public class HoodieWriteClient<T extends HoodieRecordPayload> extends AbstractHoodieWriteClient<T> {
-
+public abstract class AbstractHoodieWriteClient<T extends HoodieRecordPayload, I, K, O, P> extends AbstractHoodieClient {
private static final long serialVersionUID = 1L;
- private static final Logger LOG = LogManager.getLogger(HoodieWriteClient.class);
- private static final String LOOKUP_STR = "lookup";
- private final boolean rollbackPending;
- private final transient HoodieMetrics metrics;
- private transient Timer.Context compactionTimer;
+ private static final Logger LOG = LogManager.getLogger(AbstractHoodieWriteClient.class);
+
+ protected final transient HoodieMetrics metrics;
+ private final transient HoodieIndex<T, I, K, O, P> index;
Review comment:
not sure if this is right. index must be not be needed at the the write client level.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AsyncCleanerService.java
##########
@@ -52,19 +52,6 @@ protected AsyncCleanerService(HoodieWriteClient<?> writeClient, String cleanInst
}), executor);
}
- public static AsyncCleanerService startAsyncCleaningIfEnabled(HoodieWriteClient writeClient,
Review comment:
this method need not have moved?
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
##########
@@ -18,120 +18,195 @@
package org.apache.hudi.client;
+import com.codahale.metrics.Timer;
+import org.apache.hadoop.conf.Configuration;
import org.apache.hudi.avro.model.HoodieCleanMetadata;
import org.apache.hudi.avro.model.HoodieCompactionPlan;
import org.apache.hudi.avro.model.HoodieRestoreMetadata;
import org.apache.hudi.avro.model.HoodieRollbackMetadata;
-import org.apache.hudi.client.embedded.EmbeddedTimelineService;
+import org.apache.hudi.callback.HoodieWriteCommitCallback;
+import org.apache.hudi.callback.common.HoodieWriteCommitCallbackMessage;
+import org.apache.hudi.callback.util.HoodieCommitCallbackFactory;
+import org.apache.hudi.client.embebbed.BaseEmbeddedTimelineService;
+import org.apache.hudi.common.HoodieEngineContext;
import org.apache.hudi.common.model.HoodieCommitMetadata;
import org.apache.hudi.common.model.HoodieKey;
-import org.apache.hudi.common.model.HoodieRecord;
import org.apache.hudi.common.model.HoodieRecordPayload;
import org.apache.hudi.common.model.HoodieWriteStat;
import org.apache.hudi.common.model.WriteOperationType;
import org.apache.hudi.common.table.HoodieTableMetaClient;
import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
import org.apache.hudi.common.table.timeline.HoodieInstant;
-import org.apache.hudi.common.table.timeline.HoodieInstant.State;
import org.apache.hudi.common.table.timeline.HoodieTimeline;
import org.apache.hudi.common.util.Option;
import org.apache.hudi.common.util.ValidationUtils;
-import org.apache.hudi.config.HoodieCompactionConfig;
import org.apache.hudi.config.HoodieWriteConfig;
+
import org.apache.hudi.exception.HoodieCommitException;
import org.apache.hudi.exception.HoodieIOException;
import org.apache.hudi.exception.HoodieRestoreException;
import org.apache.hudi.exception.HoodieRollbackException;
import org.apache.hudi.exception.HoodieSavepointException;
import org.apache.hudi.index.HoodieIndex;
import org.apache.hudi.metrics.HoodieMetrics;
-import org.apache.hudi.table.HoodieTable;
-import org.apache.hudi.table.HoodieTimelineArchiveLog;
-import org.apache.hudi.table.MarkerFiles;
import org.apache.hudi.table.BulkInsertPartitioner;
+import org.apache.hudi.table.HoodieTable;
import org.apache.hudi.table.action.HoodieWriteMetadata;
-import org.apache.hudi.table.action.compact.CompactHelpers;
import org.apache.hudi.table.action.savepoint.SavepointHelpers;
-
-import com.codahale.metrics.Timer;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
-import org.apache.spark.SparkConf;
-import org.apache.spark.api.java.JavaRDD;
-import org.apache.spark.api.java.JavaSparkContext;
import java.io.IOException;
+import java.nio.charset.StandardCharsets;
import java.text.ParseException;
import java.util.Collection;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
- * Hoodie Write Client helps you build tables on HDFS [insert()] and then perform efficient mutations on an HDFS
- * table [upsert()]
- * <p>
- * Note that, at any given time, there can only be one Spark job performing these operations on a Hoodie table.
+ * Abstract Write Client providing functionality for performing commit, index updates and rollback
+ * Reused for regular write operations like upsert/insert/bulk-insert.. as well as bootstrap
+ *
+ * @param <T> Sub type of HoodieRecordPayload
+ * @param <I> Type of inputs
+ * @param <K> Type of keys
+ * @param <O> Type of outputs
+ * @param <P> Type of record position [Key, Option[partitionPath, fileID]] in hoodie table
*/
-public class HoodieWriteClient<T extends HoodieRecordPayload> extends AbstractHoodieWriteClient<T> {
-
+public abstract class AbstractHoodieWriteClient<T extends HoodieRecordPayload, I, K, O, P> extends AbstractHoodieClient {
private static final long serialVersionUID = 1L;
- private static final Logger LOG = LogManager.getLogger(HoodieWriteClient.class);
- private static final String LOOKUP_STR = "lookup";
- private final boolean rollbackPending;
- private final transient HoodieMetrics metrics;
- private transient Timer.Context compactionTimer;
+ private static final Logger LOG = LogManager.getLogger(AbstractHoodieWriteClient.class);
+
+ protected final transient HoodieMetrics metrics;
+ private final transient HoodieIndex<T, I, K, O, P> index;
+
+ protected transient Timer.Context writeContext = null;
+ private transient WriteOperationType operationType;
+ private transient HoodieWriteCommitCallback commitCallback;
+
+ protected static final String LOOKUP_STR = "lookup";
Review comment:
can we move all the static members to the top, like how it was before.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/bootstrap/selector/BootstrapRegexModeSelector.java
##########
@@ -18,17 +18,18 @@
package org.apache.hudi.client.bootstrap.selector;
-import java.util.List;
-import java.util.Map;
-import java.util.regex.Pattern;
-import java.util.stream.Collectors;
import org.apache.hudi.avro.model.HoodieFileStatus;
import org.apache.hudi.client.bootstrap.BootstrapMode;
import org.apache.hudi.common.util.collection.Pair;
import org.apache.hudi.config.HoodieWriteConfig;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
+import java.util.List;
Review comment:
are these from reformatting via IDE .
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
##########
@@ -18,120 +18,195 @@
package org.apache.hudi.client;
+import com.codahale.metrics.Timer;
+import org.apache.hadoop.conf.Configuration;
import org.apache.hudi.avro.model.HoodieCleanMetadata;
import org.apache.hudi.avro.model.HoodieCompactionPlan;
import org.apache.hudi.avro.model.HoodieRestoreMetadata;
import org.apache.hudi.avro.model.HoodieRollbackMetadata;
-import org.apache.hudi.client.embedded.EmbeddedTimelineService;
+import org.apache.hudi.callback.HoodieWriteCommitCallback;
+import org.apache.hudi.callback.common.HoodieWriteCommitCallbackMessage;
+import org.apache.hudi.callback.util.HoodieCommitCallbackFactory;
+import org.apache.hudi.client.embebbed.BaseEmbeddedTimelineService;
+import org.apache.hudi.common.HoodieEngineContext;
import org.apache.hudi.common.model.HoodieCommitMetadata;
import org.apache.hudi.common.model.HoodieKey;
-import org.apache.hudi.common.model.HoodieRecord;
import org.apache.hudi.common.model.HoodieRecordPayload;
import org.apache.hudi.common.model.HoodieWriteStat;
import org.apache.hudi.common.model.WriteOperationType;
import org.apache.hudi.common.table.HoodieTableMetaClient;
import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
import org.apache.hudi.common.table.timeline.HoodieInstant;
-import org.apache.hudi.common.table.timeline.HoodieInstant.State;
import org.apache.hudi.common.table.timeline.HoodieTimeline;
import org.apache.hudi.common.util.Option;
import org.apache.hudi.common.util.ValidationUtils;
-import org.apache.hudi.config.HoodieCompactionConfig;
import org.apache.hudi.config.HoodieWriteConfig;
+
import org.apache.hudi.exception.HoodieCommitException;
import org.apache.hudi.exception.HoodieIOException;
import org.apache.hudi.exception.HoodieRestoreException;
import org.apache.hudi.exception.HoodieRollbackException;
import org.apache.hudi.exception.HoodieSavepointException;
import org.apache.hudi.index.HoodieIndex;
import org.apache.hudi.metrics.HoodieMetrics;
-import org.apache.hudi.table.HoodieTable;
-import org.apache.hudi.table.HoodieTimelineArchiveLog;
-import org.apache.hudi.table.MarkerFiles;
import org.apache.hudi.table.BulkInsertPartitioner;
+import org.apache.hudi.table.HoodieTable;
import org.apache.hudi.table.action.HoodieWriteMetadata;
-import org.apache.hudi.table.action.compact.CompactHelpers;
import org.apache.hudi.table.action.savepoint.SavepointHelpers;
-
-import com.codahale.metrics.Timer;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
-import org.apache.spark.SparkConf;
-import org.apache.spark.api.java.JavaRDD;
-import org.apache.spark.api.java.JavaSparkContext;
import java.io.IOException;
+import java.nio.charset.StandardCharsets;
import java.text.ParseException;
import java.util.Collection;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
- * Hoodie Write Client helps you build tables on HDFS [insert()] and then perform efficient mutations on an HDFS
- * table [upsert()]
- * <p>
- * Note that, at any given time, there can only be one Spark job performing these operations on a Hoodie table.
+ * Abstract Write Client providing functionality for performing commit, index updates and rollback
+ * Reused for regular write operations like upsert/insert/bulk-insert.. as well as bootstrap
+ *
+ * @param <T> Sub type of HoodieRecordPayload
+ * @param <I> Type of inputs
+ * @param <K> Type of keys
+ * @param <O> Type of outputs
+ * @param <P> Type of record position [Key, Option[partitionPath, fileID]] in hoodie table
*/
-public class HoodieWriteClient<T extends HoodieRecordPayload> extends AbstractHoodieWriteClient<T> {
-
+public abstract class AbstractHoodieWriteClient<T extends HoodieRecordPayload, I, K, O, P> extends AbstractHoodieClient {
private static final long serialVersionUID = 1L;
- private static final Logger LOG = LogManager.getLogger(HoodieWriteClient.class);
- private static final String LOOKUP_STR = "lookup";
- private final boolean rollbackPending;
- private final transient HoodieMetrics metrics;
- private transient Timer.Context compactionTimer;
+ private static final Logger LOG = LogManager.getLogger(AbstractHoodieWriteClient.class);
+
+ protected final transient HoodieMetrics metrics;
+ private final transient HoodieIndex<T, I, K, O, P> index;
+
+ protected transient Timer.Context writeContext = null;
+ private transient WriteOperationType operationType;
+ private transient HoodieWriteCommitCallback commitCallback;
+
+ protected static final String LOOKUP_STR = "lookup";
+ protected final boolean rollbackPending;
+ protected transient Timer.Context compactionTimer;
private transient AsyncCleanerService asyncCleanerService;
+ public void setOperationType(WriteOperationType operationType) {
+ this.operationType = operationType;
+ }
+
+ public WriteOperationType getOperationType() {
+ return this.operationType;
+ }
+
/**
* Create a write client, without cleaning up failed/inflight commits.
*
- * @param jsc Java Spark Context
+ * @param context Java Spark Context
* @param clientConfig instance of HoodieWriteConfig
*/
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig clientConfig) {
- this(jsc, clientConfig, false);
+ public AbstractHoodieWriteClient(HoodieEngineContext context, HoodieWriteConfig clientConfig) {
+ this(context, clientConfig, false);
}
/**
* Create a write client, with new hudi index.
*
- * @param jsc Java Spark Context
- * @param writeConfig instance of HoodieWriteConfig
+ * @param context HoodieEngineContext
+ * @param writeConfig instance of HoodieWriteConfig
* @param rollbackPending whether need to cleanup pending commits
*/
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig writeConfig, boolean rollbackPending) {
- this(jsc, writeConfig, rollbackPending, HoodieIndex.createIndex(writeConfig));
- }
-
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig writeConfig, boolean rollbackPending, HoodieIndex index) {
- this(jsc, writeConfig, rollbackPending, index, Option.empty());
+ public AbstractHoodieWriteClient(HoodieEngineContext context, HoodieWriteConfig writeConfig, boolean rollbackPending) {
+ this(context, writeConfig, rollbackPending, Option.empty());
}
/**
- * Create a write client, allows to specify all parameters.
+ * Create a write client, allows to specify all parameters.
*
- * @param jsc Java Spark Context
- * @param writeConfig instance of HoodieWriteConfig
+ * @param context HoodieEngineContext
+ * @param writeConfig instance of HoodieWriteConfig
* @param rollbackPending whether need to cleanup pending commits
* @param timelineService Timeline Service that runs as part of write client.
*/
- public HoodieWriteClient(JavaSparkContext jsc, HoodieWriteConfig writeConfig, boolean rollbackPending,
- HoodieIndex index, Option<EmbeddedTimelineService> timelineService) {
- super(jsc, index, writeConfig, timelineService);
+ public AbstractHoodieWriteClient(HoodieEngineContext context, HoodieWriteConfig writeConfig, boolean rollbackPending,
+ Option<BaseEmbeddedTimelineService> timelineService) {
+ super(context, writeConfig, timelineService);
this.metrics = new HoodieMetrics(config, config.getTableName());
this.rollbackPending = rollbackPending;
+ this.index = createIndex(writeConfig);
}
+ protected abstract HoodieIndex<T, I, K, O, P> createIndex(HoodieWriteConfig writeConfig);
+
/**
- * Register hudi classes for Kryo serialization.
- *
- * @param conf instance of SparkConf
- * @return SparkConf
+ * Commit changes performed at the given instantTime marker.
*/
- public static SparkConf registerClasses(SparkConf conf) {
Review comment:
guessing this is all moved to spark client now?
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/execution/BaseLazyInsertIterable.java
##########
@@ -18,64 +18,47 @@
package org.apache.hudi.execution;
-import org.apache.hudi.client.SparkTaskContextSupplier;
+import org.apache.avro.Schema;
+import org.apache.avro.generic.IndexedRecord;
+import org.apache.hudi.client.TaskContextSupplier;
import org.apache.hudi.client.WriteStatus;
import org.apache.hudi.client.utils.LazyIterableIterator;
import org.apache.hudi.common.model.HoodieRecord;
import org.apache.hudi.common.model.HoodieRecordPayload;
import org.apache.hudi.common.util.Option;
-import org.apache.hudi.common.util.queue.BoundedInMemoryExecutor;
import org.apache.hudi.config.HoodieWriteConfig;
-import org.apache.hudi.exception.HoodieException;
-import org.apache.hudi.io.CreateHandleFactory;
import org.apache.hudi.io.WriteHandleFactory;
import org.apache.hudi.table.HoodieTable;
-import org.apache.avro.Schema;
-import org.apache.avro.generic.IndexedRecord;
-
import java.util.Iterator;
import java.util.List;
import java.util.function.Function;
/**
* Lazy Iterable, that writes a stream of HoodieRecords sorted by the partitionPath, into new files.
*/
-public class LazyInsertIterable<T extends HoodieRecordPayload>
+public abstract class BaseLazyInsertIterable<T extends HoodieRecordPayload>
Review comment:
In general, not sure if this class is applicable outside of Spark. but we do use it in all of the code paths. So understand that we needed to do this.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/index/HoodieIndex.java
##########
@@ -21,94 +21,52 @@
import org.apache.hudi.ApiMaturityLevel;
import org.apache.hudi.PublicAPIClass;
import org.apache.hudi.PublicAPIMethod;
-import org.apache.hudi.client.WriteStatus;
+import org.apache.hudi.common.HoodieEngineContext;
import org.apache.hudi.common.model.FileSlice;
import org.apache.hudi.common.model.HoodieKey;
-import org.apache.hudi.common.model.HoodieRecord;
import org.apache.hudi.common.model.HoodieRecordPayload;
-import org.apache.hudi.common.util.Option;
-import org.apache.hudi.common.util.ReflectionUtils;
-import org.apache.hudi.common.util.StringUtils;
-import org.apache.hudi.common.util.collection.Pair;
import org.apache.hudi.config.HoodieWriteConfig;
import org.apache.hudi.exception.HoodieIndexException;
-import org.apache.hudi.index.bloom.HoodieBloomIndex;
-import org.apache.hudi.index.bloom.HoodieGlobalBloomIndex;
-import org.apache.hudi.index.hbase.HBaseIndex;
-import org.apache.hudi.index.simple.HoodieGlobalSimpleIndex;
-import org.apache.hudi.index.simple.HoodieSimpleIndex;
import org.apache.hudi.table.HoodieTable;
-import org.apache.spark.api.java.JavaPairRDD;
-import org.apache.spark.api.java.JavaRDD;
-import org.apache.spark.api.java.JavaSparkContext;
-
import java.io.Serializable;
/**
* Base class for different types of indexes to determine the mapping from uuid.
*/
@PublicAPIClass(maturity = ApiMaturityLevel.EVOLVING)
-public abstract class HoodieIndex<T extends HoodieRecordPayload> implements Serializable {
+public abstract class HoodieIndex<T extends HoodieRecordPayload, I, K, O, P> implements Serializable {
protected final HoodieWriteConfig config;
protected HoodieIndex(HoodieWriteConfig config) {
this.config = config;
}
- public static <T extends HoodieRecordPayload> HoodieIndex<T> createIndex(
Review comment:
some of these index types don't make sense without Spark Index now. actually almost all of them except may be HBaseIndex.
So these should all be renamed with the `Spark` prefix
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/index/HoodieIndex.java
##########
@@ -21,94 +21,52 @@
import org.apache.hudi.ApiMaturityLevel;
import org.apache.hudi.PublicAPIClass;
import org.apache.hudi.PublicAPIMethod;
-import org.apache.hudi.client.WriteStatus;
+import org.apache.hudi.common.HoodieEngineContext;
import org.apache.hudi.common.model.FileSlice;
import org.apache.hudi.common.model.HoodieKey;
-import org.apache.hudi.common.model.HoodieRecord;
import org.apache.hudi.common.model.HoodieRecordPayload;
-import org.apache.hudi.common.util.Option;
-import org.apache.hudi.common.util.ReflectionUtils;
-import org.apache.hudi.common.util.StringUtils;
-import org.apache.hudi.common.util.collection.Pair;
import org.apache.hudi.config.HoodieWriteConfig;
import org.apache.hudi.exception.HoodieIndexException;
-import org.apache.hudi.index.bloom.HoodieBloomIndex;
-import org.apache.hudi.index.bloom.HoodieGlobalBloomIndex;
-import org.apache.hudi.index.hbase.HBaseIndex;
-import org.apache.hudi.index.simple.HoodieGlobalSimpleIndex;
-import org.apache.hudi.index.simple.HoodieSimpleIndex;
import org.apache.hudi.table.HoodieTable;
-import org.apache.spark.api.java.JavaPairRDD;
-import org.apache.spark.api.java.JavaRDD;
-import org.apache.spark.api.java.JavaSparkContext;
-
import java.io.Serializable;
/**
* Base class for different types of indexes to determine the mapping from uuid.
*/
@PublicAPIClass(maturity = ApiMaturityLevel.EVOLVING)
-public abstract class HoodieIndex<T extends HoodieRecordPayload> implements Serializable {
+public abstract class HoodieIndex<T extends HoodieRecordPayload, I, K, O, P> implements Serializable {
protected final HoodieWriteConfig config;
protected HoodieIndex(HoodieWriteConfig config) {
this.config = config;
}
- public static <T extends HoodieRecordPayload> HoodieIndex<T> createIndex(
- HoodieWriteConfig config) throws HoodieIndexException {
- // first use index class config to create index.
- if (!StringUtils.isNullOrEmpty(config.getIndexClass())) {
- Object instance = ReflectionUtils.loadClass(config.getIndexClass(), config);
- if (!(instance instanceof HoodieIndex)) {
- throw new HoodieIndexException(config.getIndexClass() + " is not a subclass of HoodieIndex");
- }
- return (HoodieIndex) instance;
- }
- switch (config.getIndexType()) {
- case HBASE:
- return new HBaseIndex<>(config);
- case INMEMORY:
- return new InMemoryHashIndex<>(config);
- case BLOOM:
- return new HoodieBloomIndex<>(config);
- case GLOBAL_BLOOM:
- return new HoodieGlobalBloomIndex<>(config);
- case SIMPLE:
- return new HoodieSimpleIndex<>(config);
- case GLOBAL_SIMPLE:
- return new HoodieGlobalSimpleIndex<>(config);
- default:
- throw new HoodieIndexException("Index type unspecified, set " + config.getIndexType());
- }
- }
-
/**
* Checks if the given [Keys] exists in the hoodie table and returns [Key, Option[partitionPath, fileID]] If the
* optional is empty, then the key is not found.
*/
@PublicAPIMethod(maturity = ApiMaturityLevel.STABLE)
- public abstract JavaPairRDD<HoodieKey, Option<Pair<String, String>>> fetchRecordLocation(
- JavaRDD<HoodieKey> hoodieKeys, final JavaSparkContext jsc, HoodieTable<T> hoodieTable);
+ public abstract P fetchRecordLocation(
Review comment:
now I understand `P` better.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/index/hbase/BaseHoodieHBaseIndex.java
##########
@@ -0,0 +1,295 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.index.hbase;
+
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.common.table.timeline.HoodieTimeline;
+import org.apache.hudi.common.util.ReflectionUtils;
+import org.apache.hudi.config.HoodieHBaseIndexConfig;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.exception.HoodieDependentSystemUnavailableException;
+import org.apache.hudi.index.HoodieIndex;
+import org.apache.hudi.table.HoodieTable;
+
+import org.apache.hadoop.conf.Configuration;
+import org.apache.hadoop.hbase.HBaseConfiguration;
+import org.apache.hadoop.hbase.HRegionLocation;
+import org.apache.hadoop.hbase.TableName;
+import org.apache.hadoop.hbase.client.BufferedMutator;
+import org.apache.hadoop.hbase.client.Connection;
+import org.apache.hadoop.hbase.client.ConnectionFactory;
+import org.apache.hadoop.hbase.client.Get;
+import org.apache.hadoop.hbase.client.HTable;
+import org.apache.hadoop.hbase.client.Mutation;
+import org.apache.hadoop.hbase.client.RegionLocator;
+import org.apache.hadoop.hbase.client.Result;
+import org.apache.hadoop.hbase.util.Bytes;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.List;
+
+/**
+ * Hoodie Index implementation backed by HBase.
+ */
+public abstract class BaseHoodieHBaseIndex<T extends HoodieRecordPayload, I, K, O, P> extends HoodieIndex<T, I, K, O, P> {
Review comment:
are there any code changes here, i.e logic changes?
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/index/bloom/BaseHoodieBloomIndex.java
##########
@@ -0,0 +1,71 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.index.bloom;
+
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.exception.HoodieIndexException;
+import org.apache.hudi.index.HoodieIndex;
+import org.apache.hudi.table.HoodieTable;
+
+/**
+ * Indexing mechanism based on bloom filter. Each parquet file includes its row_key bloom filter in its metadata.
+ */
+public abstract class BaseHoodieBloomIndex<T extends HoodieRecordPayload, I, K, O, P> extends HoodieIndex<T, I, K, O, P> {
Review comment:
I suggest introducing a `SparkHoodieIndex` base class
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,48 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
Review comment:
I am okay leaving it as `hadoopConf` given that's what we wrap. leave it you both :)
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/commit/BaseMergeHelper.java
##########
@@ -161,11 +108,11 @@ private static GenericRecord transformRecordBasedOnNewSchema(GenericDatumReader<
/**
* Consumer that dequeues records from queue and sends to Merge Handle.
*/
- private static class UpdateHandler extends BoundedInMemoryQueueConsumer<GenericRecord, Void> {
+ static class UpdateHandler extends BoundedInMemoryQueueConsumer<GenericRecord, Void> {
- private final HoodieMergeHandle upsertHandle;
+ private final HoodieWriteHandle upsertHandle;
Review comment:
why is this no longer a mergeHandle?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484598559
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
##########
@@ -716,32 +674,97 @@ private void rollbackPendingCommits() {
* @param compactionInstantTime Compaction Instant Time
* @return RDD of Write Status
*/
- private JavaRDD<WriteStatus> compact(String compactionInstantTime, boolean shouldComplete) {
- HoodieTable<T> table = HoodieTable.create(config, hadoopConf);
- HoodieTimeline pendingCompactionTimeline = table.getActiveTimeline().filterPendingCompactionTimeline();
- HoodieInstant inflightInstant = HoodieTimeline.getCompactionInflightInstant(compactionInstantTime);
- if (pendingCompactionTimeline.containsInstant(inflightInstant)) {
- rollbackInflightCompaction(inflightInstant, table);
- table.getMetaClient().reloadActiveTimeline();
- }
- compactionTimer = metrics.getCompactionCtx();
- HoodieWriteMetadata compactionMetadata = table.compact(jsc, compactionInstantTime);
- JavaRDD<WriteStatus> statuses = compactionMetadata.getWriteStatuses();
- if (shouldComplete && compactionMetadata.getCommitMetadata().isPresent()) {
- completeCompaction(compactionMetadata.getCommitMetadata().get(), statuses, table, compactionInstantTime);
- }
- return statuses;
- }
+ protected abstract O compact(String compactionInstantTime, boolean shouldComplete);
/**
* Performs a compaction operation on a table, serially before or after an insert/upsert action.
*/
- private Option<String> inlineCompact(Option<Map<String, String>> extraMetadata) {
+ protected Option<String> inlineCompact(Option<Map<String, String>> extraMetadata) {
Option<String> compactionInstantTimeOpt = scheduleCompaction(extraMetadata);
compactionInstantTimeOpt.ifPresent(compactionInstantTime -> {
// inline compaction should auto commit as the user is never given control
compact(compactionInstantTime, true);
});
return compactionInstantTimeOpt;
}
+
+ /**
+ * Finalize Write operation.
+ *
+ * @param table HoodieTable
+ * @param instantTime Instant Time
+ * @param stats Hoodie Write Stat
+ */
+ protected void finalizeWrite(HoodieTable<T, I, K, O, P> table, String instantTime, List<HoodieWriteStat> stats) {
+ try {
+ final Timer.Context finalizeCtx = metrics.getFinalizeCtx();
+ table.finalizeWrite(context, instantTime, stats);
+ if (finalizeCtx != null) {
+ Option<Long> durationInMs = Option.of(metrics.getDurationInMs(finalizeCtx.stop()));
+ durationInMs.ifPresent(duration -> {
+ LOG.info("Finalize write elapsed time (milliseconds): " + duration);
+ metrics.updateFinalizeWriteMetrics(duration, stats.size());
+ });
+ }
+ } catch (HoodieIOException ioe) {
+ throw new HoodieCommitException("Failed to complete commit " + instantTime + " due to finalize errors.", ioe);
+ }
+ }
+
+ public HoodieMetrics getMetrics() {
+ return metrics;
+ }
+
+ public HoodieIndex<T, I, K, O, P> getIndex() {
+ return index;
+ }
+
+ /**
+ * Get HoodieTable and init {@link Timer.Context}.
+ *
+ * @param operationType write operation type
+ * @param instantTime current inflight instant time
+ * @return HoodieTable
+ */
+ protected abstract HoodieTable<T, I, K, O, P> getTableAndInitCtx(WriteOperationType operationType, String instantTime);
+
+ /**
+ * Sets write schema from last instant since deletes may not have schema set in the config.
+ */
+ protected void setWriteSchemaForDeletes(HoodieTableMetaClient metaClient) {
+ try {
+ HoodieActiveTimeline activeTimeline = metaClient.getActiveTimeline();
+ Option<HoodieInstant> lastInstant =
+ activeTimeline.filterCompletedInstants().filter(s -> s.getAction().equals(metaClient.getCommitActionType()))
+ .lastInstant();
+ if (lastInstant.isPresent()) {
+ HoodieCommitMetadata commitMetadata = HoodieCommitMetadata.fromBytes(
+ activeTimeline.getInstantDetails(lastInstant.get()).get(), HoodieCommitMetadata.class);
+ if (commitMetadata.getExtraMetadata().containsKey(HoodieCommitMetadata.SCHEMA_KEY)) {
+ config.setSchema(commitMetadata.getExtraMetadata().get(HoodieCommitMetadata.SCHEMA_KEY));
+ } else {
+ throw new HoodieIOException("Latest commit does not have any schema in commit metadata");
+ }
+ } else {
+ throw new HoodieIOException("Deletes issued without any prior commits");
+ }
+ } catch (IOException e) {
+ throw new HoodieIOException("IOException thrown while reading last commit metadata", e);
+ }
+ }
+
+ public abstract AsyncCleanerService startAsyncCleaningIfEnabled(AbstractHoodieWriteClient<T, I, K, O, P> client, String instantTime);
+
+ @Override
+ public void close() {
Review comment:
need to ensure the ordering of closing resources is the same as before/
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/HoodieSparkWriteClient.java
##########
@@ -0,0 +1,360 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client;
+
+import com.codahale.metrics.Timer;
+import org.apache.hadoop.conf.Configuration;
+import org.apache.hudi.client.embebbed.BaseEmbeddedTimelineService;
+import org.apache.hudi.client.embedded.SparkEmbeddedTimelineService;
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.HoodieSparkEngineContext;
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.model.HoodieKey;
+import org.apache.hudi.common.model.HoodieRecord;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.common.model.HoodieWriteStat;
+import org.apache.hudi.common.model.WriteOperationType;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.common.table.HoodieTableVersion;
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.table.timeline.HoodieTimeline;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.collection.Pair;
+import org.apache.hudi.config.HoodieCompactionConfig;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.exception.HoodieCommitException;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.hudi.index.HoodieIndex;
+import org.apache.hudi.index.HoodieSparkIndexFactory;
+import org.apache.hudi.table.BaseHoodieTimelineArchiveLog;
+import org.apache.hudi.table.BulkInsertPartitioner;
+import org.apache.hudi.table.HoodieSparkTable;
+import org.apache.hudi.table.HoodieSparkTimelineArchiveLog;
+import org.apache.hudi.table.HoodieTable;
+import org.apache.hudi.table.SparkMarkerFiles;
+import org.apache.hudi.table.action.HoodieWriteMetadata;
+import org.apache.hudi.table.action.compact.SparkCompactHelpers;
+import org.apache.hudi.table.upgrade.SparkUpgradeDowngrade;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+import org.apache.spark.SparkConf;
+import org.apache.spark.api.java.JavaPairRDD;
+import org.apache.spark.api.java.JavaRDD;
+
+import java.io.IOException;
+import java.text.ParseException;
+import java.util.List;
+import java.util.Map;
+
+public class HoodieSparkWriteClient<T extends HoodieRecordPayload> extends AbstractHoodieWriteClient<T,
Review comment:
Let's name this `SparkRDDWriteClient` ?
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/HoodieSparkWriteClient.java
##########
@@ -0,0 +1,360 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client;
+
+import com.codahale.metrics.Timer;
+import org.apache.hadoop.conf.Configuration;
+import org.apache.hudi.client.embebbed.BaseEmbeddedTimelineService;
+import org.apache.hudi.client.embedded.SparkEmbeddedTimelineService;
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.HoodieSparkEngineContext;
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.model.HoodieKey;
+import org.apache.hudi.common.model.HoodieRecord;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.common.model.HoodieWriteStat;
+import org.apache.hudi.common.model.WriteOperationType;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.common.table.HoodieTableVersion;
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.table.timeline.HoodieTimeline;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.collection.Pair;
+import org.apache.hudi.config.HoodieCompactionConfig;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.exception.HoodieCommitException;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.hudi.index.HoodieIndex;
+import org.apache.hudi.index.HoodieSparkIndexFactory;
+import org.apache.hudi.table.BaseHoodieTimelineArchiveLog;
+import org.apache.hudi.table.BulkInsertPartitioner;
+import org.apache.hudi.table.HoodieSparkTable;
+import org.apache.hudi.table.HoodieSparkTimelineArchiveLog;
+import org.apache.hudi.table.HoodieTable;
+import org.apache.hudi.table.SparkMarkerFiles;
+import org.apache.hudi.table.action.HoodieWriteMetadata;
+import org.apache.hudi.table.action.compact.SparkCompactHelpers;
+import org.apache.hudi.table.upgrade.SparkUpgradeDowngrade;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+import org.apache.spark.SparkConf;
+import org.apache.spark.api.java.JavaPairRDD;
+import org.apache.spark.api.java.JavaRDD;
+
+import java.io.IOException;
+import java.text.ParseException;
+import java.util.List;
+import java.util.Map;
+
+public class HoodieSparkWriteClient<T extends HoodieRecordPayload> extends AbstractHoodieWriteClient<T,
+ JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> {
+
+ private static final Logger LOG = LogManager.getLogger(HoodieSparkWriteClient.class);
+
+ public HoodieSparkWriteClient(HoodieEngineContext context, HoodieWriteConfig clientConfig) {
+ super(context, clientConfig);
+ }
+
+ public HoodieSparkWriteClient(HoodieEngineContext context, HoodieWriteConfig writeConfig, boolean rollbackPending) {
+ super(context, writeConfig, rollbackPending);
+ }
+
+ public HoodieSparkWriteClient(HoodieEngineContext context, HoodieWriteConfig writeConfig, boolean rollbackPending, Option<BaseEmbeddedTimelineService> timelineService) {
+ super(context, writeConfig, rollbackPending, timelineService);
+ }
+
+ /**
+ * Register hudi classes for Kryo serialization.
+ *
+ * @param conf instance of SparkConf
+ * @return SparkConf
+ */
+ public static SparkConf registerClasses(SparkConf conf) {
+ conf.registerKryoClasses(new Class[]{HoodieWriteConfig.class, HoodieRecord.class, HoodieKey.class});
+ return conf;
+ }
+
+ @Override
+ protected HoodieIndex<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> createIndex(HoodieWriteConfig writeConfig) {
+ return HoodieSparkIndexFactory.createIndex(config);
+ }
+
+ @Override
+ public boolean commit(String instantTime, JavaRDD<WriteStatus> writeStatuses, Option<Map<String, String>> extraMetadata) {
+ List<HoodieWriteStat> stats = writeStatuses.map(WriteStatus::getStat).collect();
+ return commitStats(instantTime, stats, extraMetadata);
+ }
+
+ @Override
+ protected HoodieTable<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> createTable(HoodieWriteConfig config, Configuration hadoopConf) {
+ return HoodieSparkTable.create(config, context);
+ }
+
+ @Override
+ public JavaRDD<HoodieRecord<T>> filterExists(JavaRDD<HoodieRecord<T>> hoodieRecords) {
+ // Create a Hoodie table which encapsulated the commits and files visible
+ HoodieTable table = HoodieSparkTable.create(config, context);
+ Timer.Context indexTimer = metrics.getIndexCtx();
+ JavaRDD<HoodieRecord<T>> recordsWithLocation = getIndex().tagLocation(hoodieRecords, context, table);
+ metrics.updateIndexMetrics(LOOKUP_STR, metrics.getDurationInMs(indexTimer == null ? 0L : indexTimer.stop()));
+ return recordsWithLocation.filter(v1 -> !v1.isCurrentLocationKnown());
+ }
+
+ /**
+ * Main API to run bootstrap to hudi.
+ */
+ @Override
+ public void bootstrap(Option<Map<String, String>> extraMetadata) {
+ if (rollbackPending) {
+ rollBackInflightBootstrap();
+ }
+ HoodieSparkTable table = (HoodieSparkTable) getTableAndInitCtx(WriteOperationType.UPSERT, HoodieTimeline.METADATA_BOOTSTRAP_INSTANT_TS);
+ table.bootstrap(context, extraMetadata);
+ }
+
+ @Override
+ public JavaRDD<WriteStatus> upsert(JavaRDD<HoodieRecord<T>> records, String instantTime) {
+ HoodieSparkTable table = (HoodieSparkTable) getTableAndInitCtx(WriteOperationType.UPSERT, instantTime);
+ table.validateUpsertSchema();
+ setOperationType(WriteOperationType.UPSERT);
+ startAsyncCleaningIfEnabled(this, instantTime);
Review comment:
why are we not hanging onto the returned object?
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/action/bootstrap/SparkBootstrapCommitActionExecutor.java
##########
@@ -77,34 +81,44 @@
import org.apache.parquet.hadoop.ParquetReader;
import org.apache.parquet.hadoop.metadata.ParquetMetadata;
import org.apache.parquet.schema.MessageType;
-import org.apache.spark.Partitioner;
+import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.io.IOException;
+import java.nio.charset.StandardCharsets;
+import java.time.Duration;
+import java.time.Instant;
import java.util.Collection;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
-public class BootstrapCommitActionExecutor<T extends HoodieRecordPayload<T>>
- extends BaseCommitActionExecutor<T, HoodieBootstrapWriteMetadata> {
+public class SparkBootstrapCommitActionExecutor<T extends HoodieRecordPayload>
+ extends BaseCommitActionExecutor<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>, HoodieBootstrapWriteMetadata> {
- private static final Logger LOG = LogManager.getLogger(BootstrapCommitActionExecutor.class);
+ private static final Logger LOG = LogManager.getLogger(SparkBootstrapCommitActionExecutor.class);
protected String bootstrapSchema = null;
private transient FileSystem bootstrapSourceFileSystem;
- public BootstrapCommitActionExecutor(JavaSparkContext jsc, HoodieWriteConfig config, HoodieTable<?> table,
- Option<Map<String, String>> extraMetadata) {
- super(jsc, new HoodieWriteConfig.Builder().withProps(config.getProps())
- .withAutoCommit(true).withWriteStatusClass(BootstrapWriteStatus.class)
- .withBulkInsertParallelism(config.getBootstrapParallelism())
- .build(), table, HoodieTimeline.METADATA_BOOTSTRAP_INSTANT_TS, WriteOperationType.BOOTSTRAP,
+ public SparkBootstrapCommitActionExecutor(HoodieSparkEngineContext context,
+ HoodieWriteConfig config,
+ HoodieTable<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> table,
+ Option<Map<String, String>> extraMetadata) {
+ super(context, new HoodieWriteConfig.Builder().withProps(config.getProps())
+ .withAutoCommit(true).withWriteStatusClass(BootstrapWriteStatus.class)
+ .withBulkInsertParallelism(config.getBootstrapParallelism())
+ .build(), table, HoodieTimeline.METADATA_BOOTSTRAP_INSTANT_TS, WriteOperationType.BOOTSTRAP,
extraMetadata);
bootstrapSourceFileSystem = FSUtils.getFs(config.getBootstrapSourceBasePath(), hadoopConf);
}
+ @Override
+ public HoodieWriteMetadata<JavaRDD<WriteStatus>> execute(JavaRDD<HoodieRecord<T>> inputRecordsRDD) {
Review comment:
hmmm? why do we return null here
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/HoodieSparkWriteClient.java
##########
@@ -0,0 +1,360 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client;
+
+import com.codahale.metrics.Timer;
+import org.apache.hadoop.conf.Configuration;
+import org.apache.hudi.client.embebbed.BaseEmbeddedTimelineService;
+import org.apache.hudi.client.embedded.SparkEmbeddedTimelineService;
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.HoodieSparkEngineContext;
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.model.HoodieKey;
+import org.apache.hudi.common.model.HoodieRecord;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.common.model.HoodieWriteStat;
+import org.apache.hudi.common.model.WriteOperationType;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.common.table.HoodieTableVersion;
+import org.apache.hudi.common.table.timeline.HoodieActiveTimeline;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.table.timeline.HoodieTimeline;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.collection.Pair;
+import org.apache.hudi.config.HoodieCompactionConfig;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.exception.HoodieCommitException;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.hudi.index.HoodieIndex;
+import org.apache.hudi.index.HoodieSparkIndexFactory;
+import org.apache.hudi.table.BaseHoodieTimelineArchiveLog;
+import org.apache.hudi.table.BulkInsertPartitioner;
+import org.apache.hudi.table.HoodieSparkTable;
+import org.apache.hudi.table.HoodieSparkTimelineArchiveLog;
+import org.apache.hudi.table.HoodieTable;
+import org.apache.hudi.table.SparkMarkerFiles;
+import org.apache.hudi.table.action.HoodieWriteMetadata;
+import org.apache.hudi.table.action.compact.SparkCompactHelpers;
+import org.apache.hudi.table.upgrade.SparkUpgradeDowngrade;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+import org.apache.spark.SparkConf;
+import org.apache.spark.api.java.JavaPairRDD;
+import org.apache.spark.api.java.JavaRDD;
+
+import java.io.IOException;
+import java.text.ParseException;
+import java.util.List;
+import java.util.Map;
+
+public class HoodieSparkWriteClient<T extends HoodieRecordPayload> extends AbstractHoodieWriteClient<T,
+ JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> {
+
+ private static final Logger LOG = LogManager.getLogger(HoodieSparkWriteClient.class);
+
+ public HoodieSparkWriteClient(HoodieEngineContext context, HoodieWriteConfig clientConfig) {
+ super(context, clientConfig);
+ }
+
+ public HoodieSparkWriteClient(HoodieEngineContext context, HoodieWriteConfig writeConfig, boolean rollbackPending) {
+ super(context, writeConfig, rollbackPending);
+ }
+
+ public HoodieSparkWriteClient(HoodieEngineContext context, HoodieWriteConfig writeConfig, boolean rollbackPending, Option<BaseEmbeddedTimelineService> timelineService) {
+ super(context, writeConfig, rollbackPending, timelineService);
+ }
+
+ /**
+ * Register hudi classes for Kryo serialization.
+ *
+ * @param conf instance of SparkConf
+ * @return SparkConf
+ */
+ public static SparkConf registerClasses(SparkConf conf) {
+ conf.registerKryoClasses(new Class[]{HoodieWriteConfig.class, HoodieRecord.class, HoodieKey.class});
+ return conf;
+ }
+
+ @Override
+ protected HoodieIndex<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> createIndex(HoodieWriteConfig writeConfig) {
+ return HoodieSparkIndexFactory.createIndex(config);
+ }
+
+ @Override
+ public boolean commit(String instantTime, JavaRDD<WriteStatus> writeStatuses, Option<Map<String, String>> extraMetadata) {
+ List<HoodieWriteStat> stats = writeStatuses.map(WriteStatus::getStat).collect();
+ return commitStats(instantTime, stats, extraMetadata);
+ }
+
+ @Override
+ protected HoodieTable<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> createTable(HoodieWriteConfig config, Configuration hadoopConf) {
+ return HoodieSparkTable.create(config, context);
+ }
+
+ @Override
+ public JavaRDD<HoodieRecord<T>> filterExists(JavaRDD<HoodieRecord<T>> hoodieRecords) {
+ // Create a Hoodie table which encapsulated the commits and files visible
+ HoodieTable table = HoodieSparkTable.create(config, context);
+ Timer.Context indexTimer = metrics.getIndexCtx();
+ JavaRDD<HoodieRecord<T>> recordsWithLocation = getIndex().tagLocation(hoodieRecords, context, table);
+ metrics.updateIndexMetrics(LOOKUP_STR, metrics.getDurationInMs(indexTimer == null ? 0L : indexTimer.stop()));
+ return recordsWithLocation.filter(v1 -> !v1.isCurrentLocationKnown());
+ }
+
+ /**
+ * Main API to run bootstrap to hudi.
+ */
+ @Override
+ public void bootstrap(Option<Map<String, String>> extraMetadata) {
+ if (rollbackPending) {
+ rollBackInflightBootstrap();
+ }
+ HoodieSparkTable table = (HoodieSparkTable) getTableAndInitCtx(WriteOperationType.UPSERT, HoodieTimeline.METADATA_BOOTSTRAP_INSTANT_TS);
+ table.bootstrap(context, extraMetadata);
+ }
+
+ @Override
+ public JavaRDD<WriteStatus> upsert(JavaRDD<HoodieRecord<T>> records, String instantTime) {
+ HoodieSparkTable table = (HoodieSparkTable) getTableAndInitCtx(WriteOperationType.UPSERT, instantTime);
+ table.validateUpsertSchema();
+ setOperationType(WriteOperationType.UPSERT);
+ startAsyncCleaningIfEnabled(this, instantTime);
+ HoodieWriteMetadata<JavaRDD<WriteStatus>> result = table.upsert(context, instantTime, records);
+ if (result.getIndexLookupDuration().isPresent()) {
+ metrics.updateIndexMetrics(LOOKUP_STR, result.getIndexLookupDuration().get().toMillis());
+ }
+ return postWrite(result, instantTime, table);
+ }
+
+ @Override
+ public JavaRDD<WriteStatus> upsertPreppedRecords(JavaRDD<HoodieRecord<T>> preppedRecords, String instantTime) {
+ HoodieSparkTable table = (HoodieSparkTable) getTableAndInitCtx(WriteOperationType.UPSERT_PREPPED, instantTime);
+ table.validateUpsertSchema();
+ setOperationType(WriteOperationType.UPSERT_PREPPED);
+ startAsyncCleaningIfEnabled(this, instantTime);
Review comment:
same here and everywhere else.
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/embedded/SparkEmbeddedTimelineService.java
##########
@@ -0,0 +1,51 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client.embedded;
+
+import org.apache.hudi.client.embebbed.BaseEmbeddedTimelineService;
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.HoodieSparkEngineContext;
+import org.apache.hudi.common.table.view.FileSystemViewStorageConfig;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+import org.apache.spark.SparkConf;
+
+/**
+ * Spark implementation of Timeline Service.
+ */
+public class SparkEmbeddedTimelineService extends BaseEmbeddedTimelineService {
+
+ private static final Logger LOG = LogManager.getLogger(SparkEmbeddedTimelineService.class);
+
+ public SparkEmbeddedTimelineService(HoodieEngineContext context, FileSystemViewStorageConfig config) {
+ super(context, config);
+ }
+
+ @Override
+ public void setHostAddrFromContext(HoodieEngineContext context) {
+ SparkConf sparkConf = HoodieSparkEngineContext.getSparkContext(context).getConf();
+ String hostAddr = sparkConf.get("spark.driver.host", null);
Review comment:
I think we can eliminate the need for breaking this up into spark vs non-spark, by just passing in the host. This class does not make much sense being broken up.
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/io/HoodieSparkMergeHandle.java
##########
@@ -54,9 +60,9 @@
import java.util.Set;
@SuppressWarnings("Duplicates")
-public class HoodieMergeHandle<T extends HoodieRecordPayload> extends HoodieWriteHandle<T> {
+public class HoodieSparkMergeHandle<T extends HoodieRecordPayload> extends HoodieWriteHandle<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> {
Review comment:
at the MergeHandle level, we need not introduce any notion of RDDs. the `io` package should be free of spark already. All we need to do is to pass in the taskContextSupplier correctly? This is a large outstanding issue we need to resolve
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/index/simple/HoodieSparkGlobalSimpleIndex.java
##########
@@ -71,43 +75,14 @@ public HoodieGlobalSimpleIndex(HoodieWriteConfig config) {
* @return {@link JavaRDD} of records with record locations set
*/
protected JavaRDD<HoodieRecord<T>> tagLocationInternal(JavaRDD<HoodieRecord<T>> inputRecordRDD, JavaSparkContext jsc,
- HoodieTable<T> hoodieTable) {
+ HoodieTable hoodieTable) {
JavaPairRDD<String, HoodieRecord<T>> keyedInputRecordRDD = inputRecordRDD.mapToPair(entry -> new Tuple2<>(entry.getRecordKey(), entry));
JavaPairRDD<HoodieKey, HoodieRecordLocation> allRecordLocationsInTable = fetchAllRecordLocations(jsc, hoodieTable,
config.getGlobalSimpleIndexParallelism());
return getTaggedRecords(keyedInputRecordRDD, allRecordLocationsInTable);
}
- /**
- * Fetch record locations for passed in {@link HoodieKey}s.
- *
- * @param jsc instance of {@link JavaSparkContext} to use
- * @param hoodieTable instance of {@link HoodieTable} of interest
- * @param parallelism parallelism to use
- * @return {@link JavaPairRDD} of {@link HoodieKey} and {@link HoodieRecordLocation}
- */
- protected JavaPairRDD<HoodieKey, HoodieRecordLocation> fetchAllRecordLocations(JavaSparkContext jsc,
- HoodieTable hoodieTable,
- int parallelism) {
- List<Pair<String, HoodieBaseFile>> latestBaseFiles = getAllBaseFilesInTable(jsc, hoodieTable);
- return fetchRecordLocations(jsc, hoodieTable, parallelism, latestBaseFiles);
- }
-
- /**
- * Load all files for all partitions as <Partition, filename> pair RDD.
- */
- protected List<Pair<String, HoodieBaseFile>> getAllBaseFilesInTable(final JavaSparkContext jsc, final HoodieTable hoodieTable) {
Review comment:
note to self: make sure these methods are in the base class now
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/index/hbase/HoodieSparkHBaseIndex.java
##########
@@ -18,169 +18,60 @@
package org.apache.hudi.index.hbase;
+import org.apache.hadoop.hbase.TableName;
+import org.apache.hadoop.hbase.client.BufferedMutator;
+import org.apache.hadoop.hbase.client.Delete;
+import org.apache.hadoop.hbase.client.Get;
+import org.apache.hadoop.hbase.client.HTable;
+import org.apache.hadoop.hbase.client.Mutation;
+import org.apache.hadoop.hbase.client.Put;
+import org.apache.hadoop.hbase.client.Result;
+import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hudi.client.WriteStatus;
import org.apache.hudi.client.utils.SparkConfigUtils;
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.HoodieSparkEngineContext;
import org.apache.hudi.common.model.HoodieKey;
import org.apache.hudi.common.model.HoodieRecord;
import org.apache.hudi.common.model.HoodieRecordLocation;
import org.apache.hudi.common.model.HoodieRecordPayload;
import org.apache.hudi.common.table.HoodieTableMetaClient;
-import org.apache.hudi.common.table.timeline.HoodieTimeline;
import org.apache.hudi.common.util.Option;
-import org.apache.hudi.common.util.ReflectionUtils;
import org.apache.hudi.common.util.collection.Pair;
-import org.apache.hudi.config.HoodieHBaseIndexConfig;
import org.apache.hudi.config.HoodieWriteConfig;
-import org.apache.hudi.exception.HoodieDependentSystemUnavailableException;
import org.apache.hudi.exception.HoodieIndexException;
-import org.apache.hudi.index.HoodieIndex;
import org.apache.hudi.table.HoodieTable;
-
-import org.apache.hadoop.conf.Configuration;
-import org.apache.hadoop.hbase.HBaseConfiguration;
-import org.apache.hadoop.hbase.HRegionLocation;
-import org.apache.hadoop.hbase.TableName;
-import org.apache.hadoop.hbase.client.BufferedMutator;
-import org.apache.hadoop.hbase.client.Connection;
-import org.apache.hadoop.hbase.client.ConnectionFactory;
-import org.apache.hadoop.hbase.client.Delete;
-import org.apache.hadoop.hbase.client.Get;
-import org.apache.hadoop.hbase.client.HTable;
-import org.apache.hadoop.hbase.client.Mutation;
-import org.apache.hadoop.hbase.client.Put;
-import org.apache.hadoop.hbase.client.RegionLocator;
-import org.apache.hadoop.hbase.client.Result;
-import org.apache.hadoop.hbase.util.Bytes;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
+import scala.Tuple2;
import java.io.IOException;
-import java.io.Serializable;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
-import scala.Tuple2;
+public class HoodieSparkHBaseIndex<T extends HoodieRecordPayload> extends BaseHoodieHBaseIndex<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> {
-/**
- * Hoodie Index implementation backed by HBase.
- */
-public class HBaseIndex<T extends HoodieRecordPayload> extends HoodieIndex<T> {
+ private static final Logger LOG = LogManager.getLogger(HoodieSparkHBaseIndex.class);
public static final String DEFAULT_SPARK_EXECUTOR_INSTANCES_CONFIG_NAME = "spark.executor.instances";
public static final String DEFAULT_SPARK_DYNAMIC_ALLOCATION_ENABLED_CONFIG_NAME = "spark.dynamicAllocation.enabled";
public static final String DEFAULT_SPARK_DYNAMIC_ALLOCATION_MAX_EXECUTORS_CONFIG_NAME =
"spark.dynamicAllocation.maxExecutors";
- private static final byte[] SYSTEM_COLUMN_FAMILY = Bytes.toBytes("_s");
- private static final byte[] COMMIT_TS_COLUMN = Bytes.toBytes("commit_ts");
- private static final byte[] FILE_NAME_COLUMN = Bytes.toBytes("file_name");
- private static final byte[] PARTITION_PATH_COLUMN = Bytes.toBytes("partition_path");
- private static final int SLEEP_TIME_MILLISECONDS = 100;
-
- private static final Logger LOG = LogManager.getLogger(HBaseIndex.class);
- private static Connection hbaseConnection = null;
- private HBaseIndexQPSResourceAllocator hBaseIndexQPSResourceAllocator = null;
- private float qpsFraction;
- private int maxQpsPerRegionServer;
- /**
- * multiPutBatchSize will be computed and re-set in updateLocation if
- * {@link HoodieHBaseIndexConfig#HBASE_PUT_BATCH_SIZE_AUTO_COMPUTE_PROP} is set to true.
- */
- private Integer multiPutBatchSize;
- private Integer numRegionServersForTable;
- private final String tableName;
- private HBasePutBatchSizeCalculator putBatchSizeCalculator;
-
- public HBaseIndex(HoodieWriteConfig config) {
+ public HoodieSparkHBaseIndex(HoodieWriteConfig config) {
super(config);
- this.tableName = config.getHbaseTableName();
- addShutDownHook();
- init(config);
- }
-
- private void init(HoodieWriteConfig config) {
- this.multiPutBatchSize = config.getHbaseIndexGetBatchSize();
- this.qpsFraction = config.getHbaseIndexQPSFraction();
- this.maxQpsPerRegionServer = config.getHbaseIndexMaxQPSPerRegionServer();
- this.putBatchSizeCalculator = new HBasePutBatchSizeCalculator();
- this.hBaseIndexQPSResourceAllocator = createQPSResourceAllocator(this.config);
- }
-
- public HBaseIndexQPSResourceAllocator createQPSResourceAllocator(HoodieWriteConfig config) {
Review comment:
note to self: make sure these methods are now in the base class
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/io/SparkCreateHandleFactory.java
##########
@@ -0,0 +1,46 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.io;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.client.WriteStatus;
+import org.apache.hudi.common.model.HoodieKey;
+import org.apache.hudi.common.model.HoodieRecord;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.collection.Pair;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.table.HoodieTable;
+import org.apache.spark.api.java.JavaPairRDD;
+import org.apache.spark.api.java.JavaRDD;
+
+public class SparkCreateHandleFactory<T extends HoodieRecordPayload> extends WriteHandleFactory<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> {
+
+ @Override
+ public HoodieSparkCreateHandle create(final HoodieWriteConfig hoodieConfig,
Review comment:
same. is there a way to not make these spark specific
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/io/SparkAppendHandleFactory.java
##########
@@ -0,0 +1,45 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.io;
+
+import org.apache.hudi.client.SparkTaskContextSupplier;
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.client.WriteStatus;
+import org.apache.hudi.common.model.HoodieKey;
+import org.apache.hudi.common.model.HoodieRecord;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.collection.Pair;
+import org.apache.hudi.config.HoodieWriteConfig;
+
+import org.apache.hudi.table.HoodieTable;
+import org.apache.spark.api.java.JavaPairRDD;
+import org.apache.spark.api.java.JavaRDD;
+
+/**
+ * Factory to create {@link HoodieSparkAppendHandle}.
+ */
+public class SparkAppendHandleFactory<T extends HoodieRecordPayload> extends WriteHandleFactory<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> {
Review comment:
same here. we need to make sure these factory methods don't have spark vs non-spark versions
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/io/HoodieSparkMergeHandle.java
##########
@@ -71,34 +77,25 @@
protected boolean useWriterSchema;
private HoodieBaseFile baseFileToMerge;
- public HoodieMergeHandle(HoodieWriteConfig config, String instantTime, HoodieTable<T> hoodieTable,
- Iterator<HoodieRecord<T>> recordItr, String partitionPath, String fileId, SparkTaskContextSupplier sparkTaskContextSupplier) {
- super(config, instantTime, partitionPath, fileId, hoodieTable, sparkTaskContextSupplier);
+ public HoodieSparkMergeHandle(HoodieWriteConfig config, String instantTime, HoodieTable hoodieTable,
+ Iterator<HoodieRecord<T>> recordItr, String partitionPath, String fileId, TaskContextSupplier taskContextSupplier) {
+ super(config, instantTime, partitionPath, fileId, hoodieTable, taskContextSupplier);
init(fileId, recordItr);
init(fileId, partitionPath, hoodieTable.getBaseFileOnlyView().getLatestBaseFile(partitionPath, fileId).get());
}
/**
* Called by compactor code path.
*/
- public HoodieMergeHandle(HoodieWriteConfig config, String instantTime, HoodieTable<T> hoodieTable,
- Map<String, HoodieRecord<T>> keyToNewRecords, String partitionPath, String fileId,
- HoodieBaseFile dataFileToBeMerged, SparkTaskContextSupplier sparkTaskContextSupplier) {
- super(config, instantTime, partitionPath, fileId, hoodieTable, sparkTaskContextSupplier);
+ public HoodieSparkMergeHandle(HoodieWriteConfig config, String instantTime, HoodieTable hoodieTable,
+ Map<String, HoodieRecord<T>> keyToNewRecords, String partitionPath, String fileId,
+ HoodieBaseFile dataFileToBeMerged, TaskContextSupplier taskContextSupplier) {
+ super(config, instantTime, partitionPath, fileId, hoodieTable, taskContextSupplier);
this.keyToNewRecords = keyToNewRecords;
this.useWriterSchema = true;
init(fileId, this.partitionPath, dataFileToBeMerged);
}
- @Override
Review comment:
please refrain from moving methods around within the file. it makes life hard during review :(
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/SparkWorkloadProfile.java
##########
@@ -22,49 +22,22 @@
import org.apache.hudi.common.model.HoodieRecordLocation;
import org.apache.hudi.common.model.HoodieRecordPayload;
import org.apache.hudi.common.util.Option;
-
import org.apache.spark.api.java.JavaRDD;
+import scala.Tuple2;
-import java.io.Serializable;
-import java.util.HashMap;
import java.util.Map;
-import java.util.Set;
-
-import scala.Tuple2;
/**
- * Information about incoming records for upsert/insert obtained either via sampling or introspecting the data fully.
- * <p>
- * TODO(vc): Think about obtaining this directly from index.tagLocation
+ * Spark implementation of {@link BaseWorkloadProfile}.
+ * @param <T>
*/
-public class WorkloadProfile<T extends HoodieRecordPayload> implements Serializable {
-
- /**
- * Input workload.
- */
- private final JavaRDD<HoodieRecord<T>> taggedRecords;
-
- /**
- * Computed workload profile.
- */
- private final HashMap<String, WorkloadStat> partitionPathStatMap;
-
- /**
- * Global workloadStat.
- */
- private final WorkloadStat globalStat;
-
- public WorkloadProfile(JavaRDD<HoodieRecord<T>> taggedRecords) {
- this.taggedRecords = taggedRecords;
- this.partitionPathStatMap = new HashMap<>();
- this.globalStat = new WorkloadStat();
- buildProfile();
+public class SparkWorkloadProfile<T extends HoodieRecordPayload> extends BaseWorkloadProfile<JavaRDD<HoodieRecord<T>>> {
Review comment:
we can actually try and keep this generic and just pass in what we need from `taggedRecords` to constructor instead of the entire thing
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-692604118
> That sounds promising. We cannot easily fix `T,R,O` though right at the class level. it will be different in each setting, right?
>
> We can use generic methods though I think and what I had in mind was something little different
> if the method signature can be the following
>
> ```
> public abstract <I,O> List<O> parallelDo(List<I> data, Function<I, O> func, int parallelism);
> ```
>
> and for the Spark the implementation
>
> ```
> public <I,O> List<O> parallelDo(List<I> data, Function<I, O> func, int parallelism) {
> return jsc.parallelize(data, parallelism).map(func).collectAsList();
> }
> ```
>
> and the invocation
>
> ```
> engineContext.parallelDo(Arrays.asList(1,2,3), (a) -> {
> return 0;
> }, 3);
> ```
>
> Can you a small Flink implementation as well and confirm this approach will work for Flink as well. Thats another key thing to answer, before we finalize the approach.
>
> Note that
>
> a) some of the code that uses `rdd.mapToPair()` etc before collecting, have to be rewritten using Java Streams. i.e
>
> `engineContext.parallelDo().map()` instead of `jsc.parallelize().map().mapToPair()` currently.
>
> b) Also we should limit the use of parallelDo() to only cases where there are no grouping/aggregations involved. for e.g if we are doing `jsc.parallelize(files, ..).map(record).reduceByKey(..)`, collecting without reducing will lead to OOMs. We can preserve what you are doing currently, for such cases.
>
> But the parallelDo should help up reduce the amount of code broken up (and thus reduce the effort for the flink engine).
>
> @wangxianghu I am happy to shepherd this PR through from this point as well. lmk
>
> cc @yanghua @leesf
Yes, I noticed that problem lately. we should use generic methods. I also agree with the a) and b) you mentioned.
In the `parallelDo` method flink engine can operate the list directly using Java Stream, I have verified that. but there is a problem:
The function used in spark map operator is `org.apache.spark.api.java.function.Function` while what flink can use is `java.util.function.Function` we should align it.
maybe we can use `java.util.function.Function` only, If this way, there is no need to distinguish spark and flink, there both use java stream to implement those kind operations. the generic method could be like this:
`public class HoodieEngineContext {
public <I, O> List<O> parallelDo(List<I> data, Function<I, O> func) {
return data.stream().map(func).collect(Collectors.toList());
}
}`
WDYT?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484134852
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/rollback/BaseMarkerBasedRollbackStrategy.java
##########
@@ -18,63 +18,58 @@
package org.apache.hudi.table.action.rollback;
+import org.apache.hadoop.fs.Path;
+import org.apache.hudi.common.HoodieEngineContext;
import org.apache.hudi.common.HoodieRollbackStat;
import org.apache.hudi.common.fs.FSUtils;
import org.apache.hudi.common.model.HoodieLogFile;
-import org.apache.hudi.common.model.IOType;
+import org.apache.hudi.common.model.HoodieRecordPayload;
import org.apache.hudi.common.table.log.HoodieLogFormat;
import org.apache.hudi.common.table.log.block.HoodieCommandBlock;
import org.apache.hudi.common.table.log.block.HoodieLogBlock;
import org.apache.hudi.common.table.timeline.HoodieInstant;
import org.apache.hudi.config.HoodieWriteConfig;
import org.apache.hudi.exception.HoodieIOException;
-import org.apache.hudi.exception.HoodieRollbackException;
import org.apache.hudi.table.HoodieTable;
-import org.apache.hudi.table.MarkerFiles;
-import org.apache.hadoop.fs.Path;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
-import org.apache.spark.api.java.JavaSparkContext;
import java.io.IOException;
import java.util.Collections;
-import java.util.List;
import java.util.Map;
-import scala.Tuple2;
-
/**
* Performs rollback using marker files generated during the write..
*/
-public class MarkerBasedRollbackStrategy implements BaseRollbackActionExecutor.RollbackStrategy {
+public abstract class BaseMarkerBasedRollbackStrategy<T extends HoodieRecordPayload, I, K, O, P> implements BaseRollbackActionExecutor.RollbackStrategy {
Review comment:
These sort of classes, we should have a way to implement with just a reference to `engineContext` ideally. Even though we cannot implement every method in `sparkContext`. This is a topic for later
##########
File path: hudi-utilities/src/main/java/org/apache/hudi/utilities/HoodieCompactionAdminTool.java
##########
@@ -60,38 +60,38 @@ public static void main(String[] args) throws Exception {
*/
public void run(JavaSparkContext jsc) throws Exception {
HoodieTableMetaClient metaClient = new HoodieTableMetaClient(jsc.hadoopConfiguration(), cfg.basePath);
- try (CompactionAdminClient admin = new CompactionAdminClient(jsc, cfg.basePath)) {
+ try (HoodieSparkCompactionAdminClient admin = new HoodieSparkCompactionAdminClient(new HoodieSparkEngineContext(jsc), cfg.basePath)) {
final FileSystem fs = FSUtils.getFs(cfg.basePath, jsc.hadoopConfiguration());
if (cfg.outputPath != null && fs.exists(new Path(cfg.outputPath))) {
throw new IllegalStateException("Output File Path already exists");
}
switch (cfg.operation) {
case VALIDATE:
- List<ValidationOpResult> res =
+ List<BaseCompactionAdminClient.ValidationOpResult> res =
admin.validateCompactionPlan(metaClient, cfg.compactionInstantTime, cfg.parallelism);
if (cfg.printOutput) {
printOperationResult("Result of Validation Operation :", res);
}
serializeOperationResult(fs, res);
break;
case UNSCHEDULE_FILE:
- List<RenameOpResult> r = admin.unscheduleCompactionFileId(
+ List<BaseCompactionAdminClient.RenameOpResult> r = admin.unscheduleCompactionFileId(
new HoodieFileGroupId(cfg.partitionPath, cfg.fileId), cfg.skipValidation, cfg.dryRun);
if (cfg.printOutput) {
System.out.println(r);
}
serializeOperationResult(fs, r);
break;
case UNSCHEDULE_PLAN:
- List<RenameOpResult> r2 = admin.unscheduleCompactionPlan(cfg.compactionInstantTime, cfg.skipValidation,
+ List<BaseCompactionAdminClient.RenameOpResult> r2 = admin.unscheduleCompactionPlan(cfg.compactionInstantTime, cfg.skipValidation,
Review comment:
wondering if this renaming will have any impact on deserializing older plans. cc @bvaradar to confirm
##########
File path: style/checkstyle.xml
##########
@@ -62,7 +62,7 @@
<property name="allowNonPrintableEscapes" value="true"/>
</module>
<module name="LineLength">
- <property name="max" value="200"/>
+ <property name="max" value="500"/>
Review comment:
let's discuss this in a separate PR? 500 is a really large threshold
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/rollback/BaseMarkerBasedRollbackStrategy.java
##########
@@ -132,32 +127,4 @@ private HoodieRollbackStat undoAppend(String appendBaseFilePath, HoodieInstant i
.build();
}
- @Override
- public List<HoodieRollbackStat> execute(HoodieInstant instantToRollback) {
- try {
- MarkerFiles markerFiles = new MarkerFiles(table, instantToRollback.getTimestamp());
- List<String> markerFilePaths = markerFiles.allMarkerFilePaths();
- int parallelism = Math.max(Math.min(markerFilePaths.size(), config.getRollbackParallelism()), 1);
- return jsc.parallelize(markerFilePaths, parallelism)
- .map(markerFilePath -> {
Review comment:
would a `parallelDo(func, parallelism)` method in `HoodieEngineContext` help us avoid a lot of base/child class duplication of logic like this?
Most of clean, compact, rollback, restore etc can be implemented this way. Most of them just take a list, parallelize it, and execute some function, collect results and get the objects back
##########
File path: hudi-spark/src/main/scala/org/apache/hudi/IncrementalRelation.scala
##########
@@ -64,8 +64,7 @@ class IncrementalRelation(val sqlContext: SQLContext,
throw new HoodieException("Incremental view not implemented yet, for merge-on-read tables")
}
// TODO : Figure out a valid HoodieWriteConfig
- private val hoodieTable = HoodieTable.create(metaClient, HoodieWriteConfig.newBuilder().withPath(basePath).build(),
- sqlContext.sparkContext.hadoopConfiguration)
+ private val hoodieTable = HoodieSparkTable.create(HoodieWriteConfig.newBuilder().withPath(basePath).build(), new HoodieSparkEngineContext(new JavaSparkContext(sqlContext.sparkContext)) ,metaClient)
Review comment:
nit: no space before `,` and space after `, metaClient`
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/rollback/RollbackUtils.java
##########
@@ -0,0 +1,134 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.table.action.rollback;
+
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import org.apache.hudi.common.HoodieRollbackStat;
+import org.apache.hudi.common.fs.FSUtils;
+import org.apache.hudi.common.model.FileSlice;
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.model.HoodieWriteStat;
+import org.apache.hudi.common.table.log.block.HoodieCommandBlock;
+import org.apache.hudi.common.table.log.block.HoodieLogBlock;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.table.timeline.HoodieTimeline;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.ValidationUtils;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.hudi.table.HoodieTable;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.List;
+import java.util.Map;
+import java.util.stream.Collectors;
+
+public class RollbackUtils {
+
+ private static final Logger LOG = LogManager.getLogger(RollbackUtils.class);
+
+ static Map<HoodieLogBlock.HeaderMetadataType, String> generateHeader(String instantToRollback, String rollbackInstantTime) {
+ // generate metadata
+ Map<HoodieLogBlock.HeaderMetadataType, String> header = new HashMap<>(3);
+ header.put(HoodieLogBlock.HeaderMetadataType.INSTANT_TIME, rollbackInstantTime);
+ header.put(HoodieLogBlock.HeaderMetadataType.TARGET_INSTANT_TIME, instantToRollback);
+ header.put(HoodieLogBlock.HeaderMetadataType.COMMAND_BLOCK_TYPE,
+ String.valueOf(HoodieCommandBlock.HoodieCommandBlockTypeEnum.ROLLBACK_PREVIOUS_BLOCK.ordinal()));
+ return header;
+ }
+
+ /**
+ * Helper to merge 2 rollback-stats for a given partition.
+ *
+ * @param stat1 HoodieRollbackStat
+ * @param stat2 HoodieRollbackStat
+ * @return Merged HoodieRollbackStat
+ */
+ static HoodieRollbackStat mergeRollbackStat(HoodieRollbackStat stat1, HoodieRollbackStat stat2) {
+ ValidationUtils.checkArgument(stat1.getPartitionPath().equals(stat2.getPartitionPath()));
+ final List<String> successDeleteFiles = new ArrayList<>();
+ final List<String> failedDeleteFiles = new ArrayList<>();
+ final Map<FileStatus, Long> commandBlocksCount = new HashMap<>();
+ final List<FileStatus> filesToRollback = new ArrayList<>();
+ Option.ofNullable(stat1.getSuccessDeleteFiles()).ifPresent(successDeleteFiles::addAll);
+ Option.ofNullable(stat2.getSuccessDeleteFiles()).ifPresent(successDeleteFiles::addAll);
+ Option.ofNullable(stat1.getFailedDeleteFiles()).ifPresent(failedDeleteFiles::addAll);
+ Option.ofNullable(stat2.getFailedDeleteFiles()).ifPresent(failedDeleteFiles::addAll);
+ Option.ofNullable(stat1.getCommandBlocksCount()).ifPresent(commandBlocksCount::putAll);
+ Option.ofNullable(stat2.getCommandBlocksCount()).ifPresent(commandBlocksCount::putAll);
+ return new HoodieRollbackStat(stat1.getPartitionPath(), successDeleteFiles, failedDeleteFiles, commandBlocksCount);
+ }
+
+ /**
+ * Generate all rollback requests that needs rolling back this action without actually performing rollback for COW table type.
+ * @param fs instance of {@link FileSystem} to use.
+ * @param basePath base path of interest.
+ * @param shouldAssumeDatePartitioning {@code true} if date partitioning should be assumed. {@code false} otherwise.
+ * @return {@link List} of {@link ListingBasedRollbackRequest}s thus collected.
+ */
+ public static List<ListingBasedRollbackRequest> generateRollbackRequestsByListingCOW(FileSystem fs, String basePath, boolean shouldAssumeDatePartitioning) {
Review comment:
the MOR equivalent method got moved I guess
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/async/HoodieSparkAsyncCompactService.java
##########
@@ -0,0 +1,93 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.async;
+
+import org.apache.hudi.asyc.BaseAsyncCompactService;
+import org.apache.hudi.client.AbstractHoodieWriteClient;
+import org.apache.hudi.client.BaseCompactor;
+import org.apache.hudi.client.HoodieSparkCompactor;
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.HoodieSparkEngineContext;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.util.collection.Pair;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+import org.apache.spark.api.java.JavaSparkContext;
+
+import java.io.IOException;
+import java.util.concurrent.CompletableFuture;
+import java.util.concurrent.ExecutorService;
+import java.util.concurrent.Executors;
+import java.util.stream.IntStream;
+
+public class HoodieSparkAsyncCompactService extends BaseAsyncCompactService {
+
+ private static final Logger LOG = LogManager.getLogger(HoodieSparkAsyncCompactService.class);
+
+ private transient JavaSparkContext jssc;
+ public HoodieSparkAsyncCompactService(HoodieEngineContext context, AbstractHoodieWriteClient client) {
+ super(context, client);
+ this.jssc = HoodieSparkEngineContext.getSparkContext(context);
+ }
+
+ public HoodieSparkAsyncCompactService(HoodieEngineContext context, AbstractHoodieWriteClient client, boolean runInDaemonMode) {
+ super(context, client, runInDaemonMode);
+ this.jssc = HoodieSparkEngineContext.getSparkContext(context);
+ }
+
+ @Override
+ protected BaseCompactor createCompactor(AbstractHoodieWriteClient client) {
+ return new HoodieSparkCompactor(client);
+ }
+
+ @Override
+ protected Pair<CompletableFuture, ExecutorService> startService() {
+ ExecutorService executor = Executors.newFixedThreadPool(maxConcurrentCompaction,
+ r -> {
+ Thread t = new Thread(r, "async_compact_thread");
+ t.setDaemon(isRunInDaemonMode());
+ return t;
+ });
+ return Pair.of(CompletableFuture.allOf(IntStream.range(0, maxConcurrentCompaction).mapToObj(i -> CompletableFuture.supplyAsync(() -> {
+ try {
+ // Set Compactor Pool Name for allowing users to prioritize compaction
+ LOG.info("Setting Spark Pool name for compaction to " + COMPACT_POOL_NAME);
+ jssc.setLocalProperty("spark.scheduler.pool", COMPACT_POOL_NAME);
Review comment:
might make sense to move the COMPACT_POOL_NAME also to the child class
##########
File path: hudi-spark/src/main/java/org/apache/hudi/bootstrap/SparkParquetBootstrapDataProvider.java
##########
@@ -43,18 +43,18 @@
/**
* Spark Data frame based bootstrap input provider.
*/
-public class SparkParquetBootstrapDataProvider extends FullRecordBootstrapDataProvider {
+public class SparkParquetBootstrapDataProvider extends FullRecordBootstrapDataProvider<JavaRDD<HoodieRecord>> {
private final transient SparkSession sparkSession;
public SparkParquetBootstrapDataProvider(TypedProperties props,
- JavaSparkContext jsc) {
- super(props, jsc);
- this.sparkSession = SparkSession.builder().config(jsc.getConf()).getOrCreate();
+ HoodieSparkEngineContext context) {
+ super(props, context);
+ this.sparkSession = SparkSession.builder().config(context.getJavaSparkContext().getConf()).getOrCreate();
}
@Override
- public JavaRDD<HoodieRecord> generateInputRecordRDD(String tableName, String sourceBasePath,
+ public JavaRDD<HoodieRecord> generateInputRecord(String tableName, String sourceBasePath,
Review comment:
rename: generateInputRecords
##########
File path: hudi-client/hudi-spark-client/src/test/java/org/apache/hudi/testutils/HoodieClientTestUtils.java
##########
@@ -81,7 +82,9 @@
*/
public static SparkConf getSparkConfForTest(String appName) {
SparkConf sparkConf = new SparkConf().setAppName(appName)
- .set("spark.serializer", "org.apache.spark.serializer.KryoSerializer").setMaster("local[8]");
+ .set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
+ .set("spark.driver.host","localhost")
Review comment:
why was this change required?
##########
File path: style/checkstyle.xml
##########
@@ -62,7 +62,7 @@
<property name="allowNonPrintableEscapes" value="true"/>
</module>
<module name="LineLength">
- <property name="max" value="200"/>
+ <property name="max" value="500"/>
Review comment:
why is this necessary for this PR?
##########
File path: hudi-client/pom.xml
##########
@@ -68,6 +107,12 @@
</build>
<dependencies>
+ <!-- Scala -->
+ <dependency>
+ <groupId>org.scala-lang</groupId>
Review comment:
should we limit scala to just the spark module?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r493996642
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieAppendHandle.java
##########
@@ -134,7 +138,7 @@ private void init(HoodieRecord record) {
writeStatus.setPartitionPath(partitionPath);
writeStatus.getStat().setPartitionPath(partitionPath);
writeStatus.getStat().setFileId(fileId);
- averageRecordSize = SizeEstimator.estimate(record);
+ averageRecordSize = sizeEstimator.sizeEstimate(record);
try {
Review comment:
Here, I used `org.apache.hudi.common.util.SizeEstimator#sizeEstimate` to replace `org.apache.spark.util.SizeEstimator#estimate` is it ok? @vinothchandar
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-698151969
@wangxianghu Looks like we have much less class splitting now. I want to try and reduce this further if possible.
If its alright with you, I can take over from here, make some changes and push another commit on top of yours, to try and get this across the finish line. Want to coordinate so that we are not making parallel changes,
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-696467101
> My primary motive of suggesting parallelDo model, is to avoid splitting the classes and still reap benefits of parallel execution, provided by each engine. I don't think we are realizing them, as this stage yet. Please let me know your thoughts.
@vinothchandar The `org.apache.hudi.table.SparkMarkerFiles` is used in many places and the refactor work is huge if rollback them in one class, so I refactored the function using bi function first(without packaging them in one class) just to show you the functional changes, thinking if you agree with this refactor then I can rollback them without splitting classes.
It is just an example.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484925689
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/commit/BaseMergeHelper.java
##########
@@ -161,11 +108,11 @@ private static GenericRecord transformRecordBasedOnNewSchema(GenericDatumReader<
/**
* Consumer that dequeues records from queue and sends to Merge Handle.
*/
- private static class UpdateHandler extends BoundedInMemoryQueueConsumer<GenericRecord, Void> {
+ static class UpdateHandler extends BoundedInMemoryQueueConsumer<GenericRecord, Void> {
- private final HoodieMergeHandle upsertHandle;
+ private final HoodieWriteHandle upsertHandle;
Review comment:
> why is this no longer a mergeHandle?
`HoodieWriteHandle` is spark-free, while `HoodieMergeHandle` is not. To abstract `MergeHelper`, the variables it holds should be spark-free too
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-688918271
> One more pass.
>
> @wangxianghu do the tests pass locally? 50 min is the travis limit, if its consistently exceeding that limit, we need to understand why and fix it. I can help unblock once you help me with the details.
>
> @wangxianghu can you confirm that there are no logic changes in this PR? High level it seems ok to me. Hardest/time consuming part of the review is actually, comparing line by line for any changes in the base/child classes everywhere. If you can give me some guidance, I can finish the review quickly
Hi @vinothchandar, there are no logic changes in this PR, just as you said purely refactoring and templatizing.
The unit test in my local is ok.
I'll give a list of the methods moved between base/child classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] [WIP]Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-678623196
> @wangxianghu please mention me once you have done with the rebasing. I will review this carefully and can do my part to land this safely, with some testing
sure, I am working on it theses days
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] [WIP]Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-678602677
@wangxianghu please mention me once you have done with the rebasing. I will review this carefully and can do my part to land this safely, with some testing
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Mathieu1124 commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
Mathieu1124 commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r457128988
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,48 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
Review comment:
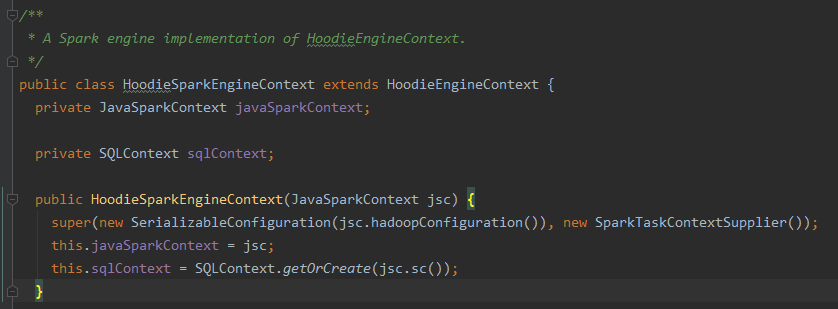
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] henrywu2019 commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
henrywu2019 commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r457798426
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,48 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
Review comment:
Oh...What I meant is at line 32 the name `hadoopConf`, not the class name, which implies `hadoop`. I bumped into this searching for Flink support from HUDI and this PR looks a big step moving in that direction. Thanks tons @Mathieu1124 and definitely @vinothchandar as well.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yanghua commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
yanghua commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r455702206
##########
File path: hudi-cli/src/main/java/org/apache/hudi/cli/commands/CompactionCommand.java
##########
@@ -593,8 +592,8 @@ public String repairCompaction(
return output;
}
- private String getRenamesToBePrinted(List<RenameOpResult> res, Integer limit, String sortByField, boolean descending,
- boolean headerOnly, String operation) {
+ private String getRenamesToBePrinted(List<BaseCompactionAdminClient.RenameOpResult> res, Integer limit, String sortByField, boolean descending,
+ boolean headerOnly, String operation) {
Review comment:
The new style or the old style, which one is right?
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/storage/HoodieParquetWriter.java
##########
@@ -40,7 +39,7 @@
* HoodieParquetWriter extends the ParquetWriter to help limit the size of underlying file. Provides a way to check if
* the current file can take more records with the <code>canWrite()</code>
*/
-public class HoodieParquetWriter<T extends HoodieRecordPayload, R extends IndexedRecord>
+public class HoodieParquetWriter<R extends IndexedRecord>
Review comment:
Why do we need to change this class?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-688918271
> One more pass.
>
> @wangxianghu do the tests pass locally? 50 min is the travis limit, if its consistently exceeding that limit, we need to understand why and fix it. I can help unblock once you help me with the details.
>
> @wangxianghu can you confirm that there are no logic changes in this PR? High level it seems ok to me. Hardest/time consuming part of the review is actually, comparing line by line for any changes in the base/child classes everywhere. If you can give me some guidance, I can finish the review quickly
Hi @vinothchandar, there are no logic changes in this PR, just as you said purely refactoring and templatizing.
The unit test in my local is ok.
I'll give a list of the methods moved between base/child classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484931161
##########
File path: hudi-client/hudi-spark-client/src/test/java/org/apache/hudi/testutils/HoodieClientTestUtils.java
##########
@@ -81,7 +82,9 @@
*/
public static SparkConf getSparkConfForTest(String appName) {
SparkConf sparkConf = new SparkConf().setAppName(appName)
- .set("spark.serializer", "org.apache.spark.serializer.KryoSerializer").setMaster("local[8]");
+ .set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
+ .set("spark.driver.host","localhost")
Review comment:
> why was this change required?
I have rolled back this.
The unit test is not runnable in my local yesterday, but ok now... weird
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] leesf commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
leesf commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-702125051
Run quickstart demo: found the warn log:
`20/10/01 21:11:18 WARN embedded.EmbeddedTimelineService: Unable to find driver bind address from spark config`, but not found the warn log in 0.6.0 @vinothchandar @wangxianghu
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r485058261
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/SparkWorkloadProfile.java
##########
@@ -22,49 +22,22 @@
import org.apache.hudi.common.model.HoodieRecordLocation;
import org.apache.hudi.common.model.HoodieRecordPayload;
import org.apache.hudi.common.util.Option;
-
import org.apache.spark.api.java.JavaRDD;
+import scala.Tuple2;
-import java.io.Serializable;
-import java.util.HashMap;
import java.util.Map;
-import java.util.Set;
-
-import scala.Tuple2;
/**
- * Information about incoming records for upsert/insert obtained either via sampling or introspecting the data fully.
- * <p>
- * TODO(vc): Think about obtaining this directly from index.tagLocation
+ * Spark implementation of {@link BaseWorkloadProfile}.
+ * @param <T>
*/
-public class WorkloadProfile<T extends HoodieRecordPayload> implements Serializable {
-
- /**
- * Input workload.
- */
- private final JavaRDD<HoodieRecord<T>> taggedRecords;
-
- /**
- * Computed workload profile.
- */
- private final HashMap<String, WorkloadStat> partitionPathStatMap;
-
- /**
- * Global workloadStat.
- */
- private final WorkloadStat globalStat;
-
- public WorkloadProfile(JavaRDD<HoodieRecord<T>> taggedRecords) {
- this.taggedRecords = taggedRecords;
- this.partitionPathStatMap = new HashMap<>();
- this.globalStat = new WorkloadStat();
- buildProfile();
+public class SparkWorkloadProfile<T extends HoodieRecordPayload> extends BaseWorkloadProfile<JavaRDD<HoodieRecord<T>>> {
Review comment:
> we can actually try and keep this generic and just pass in what we need from `taggedRecords` to constructor instead of the entire thing
done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu closed pull request #1827: [HUDI-1089] [WIP]Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu closed pull request #1827:
URL: https://github.com/apache/hudi/pull/1827
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484921612
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/index/bloom/BaseHoodieBloomIndex.java
##########
@@ -0,0 +1,71 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.index.bloom;
+
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.config.HoodieWriteConfig;
+import org.apache.hudi.exception.HoodieIndexException;
+import org.apache.hudi.index.HoodieIndex;
+import org.apache.hudi.table.HoodieTable;
+
+/**
+ * Indexing mechanism based on bloom filter. Each parquet file includes its row_key bloom filter in its metadata.
+ */
+public abstract class BaseHoodieBloomIndex<T extends HoodieRecordPayload, I, K, O, P> extends HoodieIndex<T, I, K, O, P> {
Review comment:
> I suggest introducing a `SparkHoodieIndex` base class
done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Mathieu1124 edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
Mathieu1124 edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-662474645
> @Mathieu1124 , @leesf : @n3nash said he is half way through reviewing. I took another pass and this seems low risk enough for us to merge for 0.6.0.
>
> We have some large PRs pending though #1702 #1678 #1834 . I would like to merge those and then rework this a bit on top of this. How painful do you think the rebase would be? (I can help as much as I can as well). Does this sound like a good plan to you
@vinothchandar, I have taken a quick pass about that three PRs above, can't say that'll be little work, but I am ok with this plan since these three PRs are based on the same base, so leaving this PR at the last could greatly reduce their workload on rebasing and gives more time for us to test this PR.
we'll do our best to push this PR, and merge this for 0.6.0
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r493999629
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/client/AsyncCleanerService.java
##########
@@ -52,19 +52,6 @@ protected AsyncCleanerService(HoodieWriteClient<?> writeClient, String cleanInst
}), executor);
}
- public static AsyncCleanerService startAsyncCleaningIfEnabled(HoodieWriteClient writeClient,
Review comment:
> this method need not have moved?
It is back now.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yanghua commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
yanghua commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r493978853
##########
File path: hudi-cli/pom.xml
##########
@@ -148,7 +148,14 @@
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
- <artifactId>hudi-client</artifactId>
+ <artifactId>hudi-client-common</artifactId>
+ <version>${project.version}</version>
+ <scope>test</scope>
+ <type>test-jar</type>
+ </dependency>
+ <dependency>
+ <groupId>org.apache.hudi</groupId>
+ <artifactId>hudi-spark-client</artifactId>
Review comment:
Actually, I am thinking `hudi-spark-client` and `hudi-client-spark`, which is better? Given there is a module named `hudi-client-common`. wdyt? @vinothchandar
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Mathieu1124 edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
Mathieu1124 edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-659898064
> @Mathieu1124 @leesf can you please share any tests you may have done in your own environment to ensure existing functionality is in tact.. This is a major signal we may not completely get with a PR review
@vinothchandar, My test is limited, just all the unit tests in source code, and all the demos in the Quick-Start Guide. I am planning to test it in docker env.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484815402
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/index/HoodieIndex.java
##########
@@ -21,94 +21,52 @@
import org.apache.hudi.ApiMaturityLevel;
import org.apache.hudi.PublicAPIClass;
import org.apache.hudi.PublicAPIMethod;
-import org.apache.hudi.client.WriteStatus;
+import org.apache.hudi.common.HoodieEngineContext;
import org.apache.hudi.common.model.FileSlice;
import org.apache.hudi.common.model.HoodieKey;
-import org.apache.hudi.common.model.HoodieRecord;
import org.apache.hudi.common.model.HoodieRecordPayload;
-import org.apache.hudi.common.util.Option;
-import org.apache.hudi.common.util.ReflectionUtils;
-import org.apache.hudi.common.util.StringUtils;
-import org.apache.hudi.common.util.collection.Pair;
import org.apache.hudi.config.HoodieWriteConfig;
import org.apache.hudi.exception.HoodieIndexException;
-import org.apache.hudi.index.bloom.HoodieBloomIndex;
-import org.apache.hudi.index.bloom.HoodieGlobalBloomIndex;
-import org.apache.hudi.index.hbase.HBaseIndex;
-import org.apache.hudi.index.simple.HoodieGlobalSimpleIndex;
-import org.apache.hudi.index.simple.HoodieSimpleIndex;
import org.apache.hudi.table.HoodieTable;
-import org.apache.spark.api.java.JavaPairRDD;
-import org.apache.spark.api.java.JavaRDD;
-import org.apache.spark.api.java.JavaSparkContext;
-
import java.io.Serializable;
/**
* Base class for different types of indexes to determine the mapping from uuid.
*/
@PublicAPIClass(maturity = ApiMaturityLevel.EVOLVING)
-public abstract class HoodieIndex<T extends HoodieRecordPayload> implements Serializable {
+public abstract class HoodieIndex<T extends HoodieRecordPayload, I, K, O, P> implements Serializable {
protected final HoodieWriteConfig config;
protected HoodieIndex(HoodieWriteConfig config) {
this.config = config;
}
- public static <T extends HoodieRecordPayload> HoodieIndex<T> createIndex(
- HoodieWriteConfig config) throws HoodieIndexException {
- // first use index class config to create index.
- if (!StringUtils.isNullOrEmpty(config.getIndexClass())) {
- Object instance = ReflectionUtils.loadClass(config.getIndexClass(), config);
- if (!(instance instanceof HoodieIndex)) {
- throw new HoodieIndexException(config.getIndexClass() + " is not a subclass of HoodieIndex");
- }
- return (HoodieIndex) instance;
- }
- switch (config.getIndexType()) {
- case HBASE:
- return new HBaseIndex<>(config);
- case INMEMORY:
- return new InMemoryHashIndex<>(config);
- case BLOOM:
- return new HoodieBloomIndex<>(config);
- case GLOBAL_BLOOM:
- return new HoodieGlobalBloomIndex<>(config);
- case SIMPLE:
- return new HoodieSimpleIndex<>(config);
- case GLOBAL_SIMPLE:
- return new HoodieGlobalSimpleIndex<>(config);
- default:
- throw new HoodieIndexException("Index type unspecified, set " + config.getIndexType());
- }
- }
-
/**
* Checks if the given [Keys] exists in the hoodie table and returns [Key, Option[partitionPath, fileID]] If the
* optional is empty, then the key is not found.
*/
@PublicAPIMethod(maturity = ApiMaturityLevel.STABLE)
- public abstract JavaPairRDD<HoodieKey, Option<Pair<String, String>>> fetchRecordLocation(
- JavaRDD<HoodieKey> hoodieKeys, final JavaSparkContext jsc, HoodieTable<T> hoodieTable);
+ public abstract P fetchRecordLocation(
+ K hoodieKeys, final HoodieEngineContext context, HoodieTable<T, I, K, O, P> hoodieTable);
/**
* Looks up the index and tags each incoming record with a location of a file that contains the row (if it is actually
* present).
*/
@PublicAPIMethod(maturity = ApiMaturityLevel.STABLE)
Review comment:
> these annotations needs to moved over to a `SparkHoodieIndex` class? it will be hard for end developers to program against `HoodieIndex` directly anymore. This is a general point actually. The current public APIs should all be annotated against the Spark child classes. wdyt?
good idea, done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484823465
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/rollback/RollbackUtils.java
##########
@@ -0,0 +1,134 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.table.action.rollback;
+
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import org.apache.hudi.common.HoodieRollbackStat;
+import org.apache.hudi.common.fs.FSUtils;
+import org.apache.hudi.common.model.FileSlice;
+import org.apache.hudi.common.model.HoodieCommitMetadata;
+import org.apache.hudi.common.model.HoodieWriteStat;
+import org.apache.hudi.common.table.log.block.HoodieCommandBlock;
+import org.apache.hudi.common.table.log.block.HoodieLogBlock;
+import org.apache.hudi.common.table.timeline.HoodieInstant;
+import org.apache.hudi.common.table.timeline.HoodieTimeline;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.ValidationUtils;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.hudi.table.HoodieTable;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.List;
+import java.util.Map;
+import java.util.stream.Collectors;
+
+public class RollbackUtils {
+
+ private static final Logger LOG = LogManager.getLogger(RollbackUtils.class);
+
+ static Map<HoodieLogBlock.HeaderMetadataType, String> generateHeader(String instantToRollback, String rollbackInstantTime) {
+ // generate metadata
+ Map<HoodieLogBlock.HeaderMetadataType, String> header = new HashMap<>(3);
+ header.put(HoodieLogBlock.HeaderMetadataType.INSTANT_TIME, rollbackInstantTime);
+ header.put(HoodieLogBlock.HeaderMetadataType.TARGET_INSTANT_TIME, instantToRollback);
+ header.put(HoodieLogBlock.HeaderMetadataType.COMMAND_BLOCK_TYPE,
+ String.valueOf(HoodieCommandBlock.HoodieCommandBlockTypeEnum.ROLLBACK_PREVIOUS_BLOCK.ordinal()));
+ return header;
+ }
+
+ /**
+ * Helper to merge 2 rollback-stats for a given partition.
+ *
+ * @param stat1 HoodieRollbackStat
+ * @param stat2 HoodieRollbackStat
+ * @return Merged HoodieRollbackStat
+ */
+ static HoodieRollbackStat mergeRollbackStat(HoodieRollbackStat stat1, HoodieRollbackStat stat2) {
+ ValidationUtils.checkArgument(stat1.getPartitionPath().equals(stat2.getPartitionPath()));
+ final List<String> successDeleteFiles = new ArrayList<>();
+ final List<String> failedDeleteFiles = new ArrayList<>();
+ final Map<FileStatus, Long> commandBlocksCount = new HashMap<>();
+ final List<FileStatus> filesToRollback = new ArrayList<>();
+ Option.ofNullable(stat1.getSuccessDeleteFiles()).ifPresent(successDeleteFiles::addAll);
+ Option.ofNullable(stat2.getSuccessDeleteFiles()).ifPresent(successDeleteFiles::addAll);
+ Option.ofNullable(stat1.getFailedDeleteFiles()).ifPresent(failedDeleteFiles::addAll);
+ Option.ofNullable(stat2.getFailedDeleteFiles()).ifPresent(failedDeleteFiles::addAll);
+ Option.ofNullable(stat1.getCommandBlocksCount()).ifPresent(commandBlocksCount::putAll);
+ Option.ofNullable(stat2.getCommandBlocksCount()).ifPresent(commandBlocksCount::putAll);
+ return new HoodieRollbackStat(stat1.getPartitionPath(), successDeleteFiles, failedDeleteFiles, commandBlocksCount);
+ }
+
+ /**
+ * Generate all rollback requests that needs rolling back this action without actually performing rollback for COW table type.
+ * @param fs instance of {@link FileSystem} to use.
+ * @param basePath base path of interest.
+ * @param shouldAssumeDatePartitioning {@code true} if date partitioning should be assumed. {@code false} otherwise.
+ * @return {@link List} of {@link ListingBasedRollbackRequest}s thus collected.
+ */
+ public static List<ListingBasedRollbackRequest> generateRollbackRequestsByListingCOW(FileSystem fs, String basePath, boolean shouldAssumeDatePartitioning) {
Review comment:
> the MOR equivalent method got moved I guess
Yes, MOR equivalent method moved to `SparkRollbackUtils`.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r492449543
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
@wangxianghu functionality wise, you are correct. it can be implemented just using Java. but, we do parallelization of different pieces of code e.g deletion of files in parallel using spark for a reason. It significantly speeds these up, for large tables.
All I am saying is to implement the `HoodieSparkEngineContext#map` like below
```
public <I, O> List<O> map(List<I> data, Function<I, O> func, int parallelism) {
return javaSparkContext.parallelize(data, parallelism).map(func).collect();
}
```
similarly for the other two methods. I don't see any issues with this. do you?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-662841424
@Mathieu1124 thanks for being awesome and understanding!. I will help out as much as I can as well. In fact, smoothly landing these large PRs is my sole focus now.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r494100797
##########
File path: hudi-cli/pom.xml
##########
@@ -148,7 +148,14 @@
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
- <artifactId>hudi-client</artifactId>
+ <artifactId>hudi-client-common</artifactId>
+ <version>${project.version}</version>
+ <scope>test</scope>
+ <type>test-jar</type>
+ </dependency>
+ <dependency>
+ <groupId>org.apache.hudi</groupId>
+ <artifactId>hudi-spark-client</artifactId>
Review comment:
> cc @wangxianghu probably `hudi-client-spark` is easier on the eyes?
I am ok with both of them :) let's rename it to `hudi-client-spark`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-690335395
@vinothchandar @yanghua @leesf The ci is green now
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-692604118
> That sounds promising. We cannot easily fix `T,R,O` though right at the class level. it will be different in each setting, right?
>
> We can use generic methods though I think and what I had in mind was something little different
> if the method signature can be the following
>
> ```
> public abstract <I,O> List<O> parallelDo(List<I> data, Function<I, O> func, int parallelism);
> ```
>
> and for the Spark the implementation
>
> ```
> public <I,O> List<O> parallelDo(List<I> data, Function<I, O> func, int parallelism) {
> return jsc.parallelize(data, parallelism).map(func).collectAsList();
> }
> ```
>
> and the invocation
>
> ```
> engineContext.parallelDo(Arrays.asList(1,2,3), (a) -> {
> return 0;
> }, 3);
> ```
>
> Can you a small Flink implementation as well and confirm this approach will work for Flink as well. Thats another key thing to answer, before we finalize the approach.
>
> Note that
>
> a) some of the code that uses `rdd.mapToPair()` etc before collecting, have to be rewritten using Java Streams. i.e
>
> `engineContext.parallelDo().map()` instead of `jsc.parallelize().map().mapToPair()` currently.
>
> b) Also we should limit the use of parallelDo() to only cases where there are no grouping/aggregations involved. for e.g if we are doing `jsc.parallelize(files, ..).map(record).reduceByKey(..)`, collecting without reducing will lead to OOMs. We can preserve what you are doing currently, for such cases.
>
> But the parallelDo should help up reduce the amount of code broken up (and thus reduce the effort for the flink engine).
>
> @wangxianghu I am happy to shepherd this PR through from this point as well. lmk
>
> cc @yanghua @leesf
Yes, I noticed that problem lately. we should use generic methods. I also agree with the a) and b) you mentioned.
In the `parallelDo` method flink engine can operate the list directly using Java Stream, I have verified that. but there is a problem:
The function used in spark map operator is `org.apache.spark.api.java.function.Function` while what flink can use is `java.util.function.Function` we should align it.
maybe we can use `java.util.function.Function` only, If this way, there is no need to distinguish spark and flink, there both use java stream to implement those kind operations. the generic method could be like this:
```
public class HoodieEngineContext {
public <I, O> List<O> parallelDo(List<I> data, Function<I, O> func) {
return data.stream().map(func).collect(Collectors.toList());
}
}
```
or implement the logic using java stream directly and don't introduce the `parallelDo` method.
WDYT?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-701963298
I actually figured out that we can remove `P` altogether. since `HoodieIndex#fetchRecordLocation` is not used much outside of internal APIs. So will push a final change for that . tests are passing now
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-702302083
> @wangxianghu can you please test the latest commit. To be clear, you are saying you don't get the warning on master, but get it on this branch. right?
>
> if this round of tests pass, and you confirm, we can land from my perspective
Hi @vinothchandar The warn log is still there in HUDI-1089 branch.(master is ok, no warn log)
I think we should check `embeddedTimelineServiceHostAddr` instead of `hostAddr`.
```
private void setHostAddr(String embeddedTimelineServiceHostAddr) {
// here we should check embeddedTimelineServiceHostAddr instead of hostAddr
if (hostAddr != null) {
LOG.info("Overriding hostIp to (" + embeddedTimelineServiceHostAddr + ") found in spark-conf. It was " + this.hostAddr);
this.hostAddr = embeddedTimelineServiceHostAddr;
} else {
LOG.warn("Unable to find driver bind address from spark config");
this.hostAddr = NetworkUtils.getHostname();
}
}
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-699728335
@wangxianghu I will continue to work on this. Planning to get this landed this week.
May need some help testing once I am there. Will ping you here!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-687960061
Hi, @vinothchandar thanks for your review. I'll address your concerns ASAP.
The unit test should be ok. The CI failure seems caused by timeout(50min), can you help figure this out, I don't know how to adjust this threshold.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-693112779
> > maybe we can use java.util.function.Function only, If this way, there is no need to distinguish spark and flink,
>
> I'd prefer this if possible. Makes life much simpler. We can add more overloads down the line with BiFunction etc.. as we go.
> wdyt?
It's good to me. I'll refactor the code with the BiFunction.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-693703726
@wangxianghu are we set on the `parallelDo` approach. it would be nice if you or @leesf @yanghua confirm once that it works for Flink also and we can close that loop.
Like I said, also please let me know if you need help on the PR. Would love to get this landed soon :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r494073875
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieAppendHandle.java
##########
@@ -134,7 +138,7 @@ private void init(HoodieRecord record) {
writeStatus.setPartitionPath(partitionPath);
writeStatus.getStat().setPartitionPath(partitionPath);
writeStatus.getStat().setFileId(fileId);
- averageRecordSize = SizeEstimator.estimate(record);
+ averageRecordSize = sizeEstimator.sizeEstimate(record);
try {
Review comment:
Should be okay.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-698161234
> @wangxianghu Looks like we have much less class splitting now. I want to try and reduce this further if possible.
> If its alright with you, I can take over from here, make some changes and push another commit on top of yours, to try and get this across the finish line. Want to coordinate so that we are not making parallel changes,
@vinothchandar, Yeah, Of course, you can take over from here, this will greatly facilitate the process
thanks 👍
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-692741066
>maybe we can use java.util.function.Function only, If this way, there is no need to distinguish spark and flink,
I'd prefer this if possible. Makes life much simpler. We can add more overloads down the line with BiFunction etc.. as we go.
wdyt?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-697358552
@vinothchandar @yanghua @leesf
I have refactored this pr with `parallelDo` function and fixed the checkstyle(lineLength > 200) issue
please take a look when free
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Mathieu1124 commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
Mathieu1124 commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-658151869
Hi, @vinothchandar @yanghua @leesf as the refactor is finished, I have filed a Jira ticket to track this work,
please review this on this pr :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-702302083
> @wangxianghu can you please test the latest commit. To be clear, you are saying you don't get the warning on master, but get it on this branch. right?
>
> if this round of tests pass, and you confirm, we can land from my perspective
Hi @vinothchandar The warn log is still there in HUDI-1089 branch.(master is ok, no warn log)
I think we should check `embeddedTimelineServiceHostAddr` instead of `hostAddr`.
```
private void setHostAddr(String embeddedTimelineServiceHostAddr) {
// here we should check embeddedTimelineServiceHostAddr instead of hostAddr, hostAddr is always null
if (hostAddr != null) {
LOG.info("Overriding hostIp to (" + embeddedTimelineServiceHostAddr + ") found in spark-conf. It was " + this.hostAddr);
this.hostAddr = embeddedTimelineServiceHostAddr;
} else {
LOG.warn("Unable to find driver bind address from spark config");
this.hostAddr = NetworkUtils.getHostname();
}
}
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r485016294
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/embedded/SparkEmbeddedTimelineService.java
##########
@@ -0,0 +1,51 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.client.embedded;
+
+import org.apache.hudi.client.embebbed.BaseEmbeddedTimelineService;
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.HoodieSparkEngineContext;
+import org.apache.hudi.common.table.view.FileSystemViewStorageConfig;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+import org.apache.spark.SparkConf;
+
+/**
+ * Spark implementation of Timeline Service.
+ */
+public class SparkEmbeddedTimelineService extends BaseEmbeddedTimelineService {
+
+ private static final Logger LOG = LogManager.getLogger(SparkEmbeddedTimelineService.class);
+
+ public SparkEmbeddedTimelineService(HoodieEngineContext context, FileSystemViewStorageConfig config) {
+ super(context, config);
+ }
+
+ @Override
+ public void setHostAddrFromContext(HoodieEngineContext context) {
+ SparkConf sparkConf = HoodieSparkEngineContext.getSparkContext(context).getConf();
+ String hostAddr = sparkConf.get("spark.driver.host", null);
Review comment:
> I think we can eliminate the need for breaking this up into spark vs non-spark, by just passing in the host. This class does not make much sense being broken up.
done, add `hoodie.embed.timeline.server.host` to `HoodieWriteConfig`, it can be obtained via method `getEmbeddedServerHost()`
This is not the same as before(acquired from sparkConf). users who enabled the embedded timeline service should config this `hostaddr` additionally.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-702308385
> > @wangxianghu can you please test the latest commit. To be clear, you are saying you don't get the warning on master, but get it on this branch. right?
> > if this round of tests pass, and you confirm, we can land from my perspective
>
> Hi @vinothchandar The warn log is still there in HUDI-1089 branch.(master is ok, no warn log)
> I think we should check `embeddedTimelineServiceHostAddr` instead of `hostAddr`.
>
> ```
> private void setHostAddr(String embeddedTimelineServiceHostAddr) {
> // here we should check embeddedTimelineServiceHostAddr instead of hostAddr
> if (hostAddr != null) {
> LOG.info("Overriding hostIp to (" + embeddedTimelineServiceHostAddr + ") found in spark-conf. It was " + this.hostAddr);
> this.hostAddr = embeddedTimelineServiceHostAddr;
> } else {
> LOG.warn("Unable to find driver bind address from spark config");
> this.hostAddr = NetworkUtils.getHostname();
> }
> }
> ```
I have tested the latest commit with the check condition changed to
```
if (embeddedTimelineServiceHostAddr != null) {
````
It runs well in my local, and the warn log disappeared.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-691505048
@wangxianghu That's awesome. Will resume the Review again this weekend
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-701989092
@wangxianghu Please help test this out if possible. Once the tests pass again, planning to merge this, morning PST
cc @yanghua
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Mathieu1124 commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
Mathieu1124 commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-662474645
> @Mathieu1124 , @leesf : @n3nash said he is half way through reviewing. I took another pass and this seems low risk enough for us to merge for 0.6.0.
>
> We have some large PRs pending though #1702 #1678 #1834 . I would like to merge those and then rework this a bit on top of this. How painful do you think the rebase would be? (I can help as much as I can as well). Does this sound like a good plan to you
@vinothchandar, I have taken a quick pass about these three PRs above, can't say that'll be little work, but I am ok with this plan because that three PRs are based on the same base, and leaving this PR at the last could greatly reduce their workload on rebasing and gives more time for us to test this PR.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-696467101
> My primary motive of suggesting parallelDo model, is to avoid splitting the classes and still reap benefits of parallel execution, provided by each engine. I don't think we are realizing them, as this stage yet. Please let me know your thoughts.
@vinothchandar The `org.apache.hudi.table.SparkMarkerFiles` is used in many places and the refactor work is huge if rollback them in one class, so I refactored the function using bi function first(without packaging them in one class) just to show you the functional changes, thinking if you agree with this refactor then I can rollback them without splitting classes.
It is just an example.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r494100797
##########
File path: hudi-cli/pom.xml
##########
@@ -148,7 +148,14 @@
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
- <artifactId>hudi-client</artifactId>
+ <artifactId>hudi-client-common</artifactId>
+ <version>${project.version}</version>
+ <scope>test</scope>
+ <type>test-jar</type>
+ </dependency>
+ <dependency>
+ <groupId>org.apache.hudi</groupId>
+ <artifactId>hudi-spark-client</artifactId>
Review comment:
> cc @wangxianghu probably `hudi-client-spark` is easier on the eyes?
I am ok with both of them :) let's rename it to `hudi-client-spark`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-662412357
@Mathieu1124 , @leesf : @n3nash said he is half way through reviewing. I took another pass and this seems low risk enough for us to merge for 0.6.0.
We have some large PRs pending though #1702 #1678 #1834 . I would like to merge those and then rework this a bit on top of this. How painful do you think the rebase would be? (I can help as much as I can as well). Does this sound like a good plan to you
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-692766014
@wangxianghu on the checkstyle change to bump up the line count to 500, I think we should revert to 200 as it is now.
I checked out a few of the issues. they can be brought within limit, by folding like below.
if not, we can turn off checkstyle selectively in that block?
```
public class HoodieSparkMergeHandle<T extends HoodieRecordPayload> extends
HoodieWriteHandle<T, JavaRDD<HoodieRecord<T>>, JavaRDD<HoodieKey>, JavaRDD<WriteStatus>, JavaPairRDD<HoodieKey, Option<Pair<String, String>>>> {
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-702335492
@wangxianghu duh ofc. I understand now. Thanks for jumping in @wangxianghu !
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-658505687
@leesf @Mathieu1124 @lw309637554 so this replaces #1727 right?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] leesf edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
leesf edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-702125051
1. Run quickstart demo: found the warn log:
`20/10/01 21:11:18 WARN embedded.EmbeddedTimelineService: Unable to find driver bind address from spark config`, but works fine, the warn log is not found in 0.6.0. @vinothchandar @wangxianghu
2. Ran my own unit tests, works fine.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Mathieu1124 commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
Mathieu1124 commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-658535113
> @leesf @Mathieu1124 @lw309637554 so this replaces #1727 right?
yes, https://github.com/apache/hudi/pull/1727 can be closed now
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-696120725
@vinothchandar I have refactored `org.apache.hudi.table.SparkMarkerFiles` with `parallelDo ` function, it works ok in my local(`org.apache.hudi.table.TestMarkerFiles` passed), and the Ci has passed in my repository by now.
do you have other concerns about the `parallelDo`? can I start to refactor this or with `parallelDo ` function now?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] Mathieu1124 edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
Mathieu1124 edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-658151869
Hi, @vinothchandar @yanghua @leesf as the refactor is finished, I have filed a Jira ticket to track this work,
please review the refactor work on this pr :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu edited a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu edited a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-696120725
@vinothchandar I have refactored `org.apache.hudi.table.SparkMarkerFiles` with `parallelDo ` function, it works ok in my local(`org.apache.hudi.table.TestMarkerFiles` passed), and the Ci has passed in my repository by now.
do you have other concerns about the `parallelDo`? can I start to refactor this pr with `parallelDo ` function now?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-690335395
@vinothchandar @yanghua @leesf The ci passed now
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r492434405
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> I think we should leave this abstract and let the engines implement this? even for Java. Its better to have a `HoodieJavaEngineContext`. From what I can see, this is not overridden in `HoodieSparkEngineContext` and thus we lose the parallel execution that we currently have with Spark with this change.
as we discussed before, parallelDo model need a function as input parameter, Unfortunately, different engines need different type function, its hard to align them in an abstract parallelDo method. so we agree to use ` java.util.function.Function` as the unified input function. in this way, there is no need to distinguish spark and flink, and the parallelism is not needed too.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> I think we should leave this abstract and let the engines implement this? even for Java. Its better to have a `HoodieJavaEngineContext`. From what I can see, this is not overridden in `HoodieSparkEngineContext` and thus we lose the parallel execution that we currently have with Spark with this change.
as we discussed before, parallelDo model need a function as input parameter, Unfortunately, different engines need different type function, its hard to align them in an abstract parallelDo method. so we agreed to use ` java.util.function.Function` as the unified input function. in this way, there is no need to distinguish spark and flink, and the parallelism is not needed too.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> I think we should leave this abstract and let the engines implement this? even for Java. Its better to have a `HoodieJavaEngineContext`. From what I can see, this is not overridden in `HoodieSparkEngineContext` and thus we lose the parallel execution that we currently have with Spark with this change.
as we discussed before, parallelDo model need a function as input parameter, Unfortunately, different engines need different type function, its hard to align them in an abstract parallelDo method. so we agreed to use ` java.util.function.Function` as the unified input function. in this way, there is no need to distinguish spark and flink, no need to make it abstract and the parallelism is not needed too. its just java, can be implemented directly.
##########
File path: hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/SparkMarkerFiles.java
##########
@@ -0,0 +1,124 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.table;
+
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.LocatedFileStatus;
+import org.apache.hadoop.fs.Path;
+import org.apache.hadoop.fs.RemoteIterator;
+import org.apache.hudi.bifunction.wrapper.ThrowingFunction;
+import org.apache.hudi.common.HoodieEngineContext;
+import org.apache.hudi.common.config.SerializableConfiguration;
+import org.apache.hudi.common.model.IOType;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.log4j.LogManager;
+import org.apache.log4j.Logger;
+
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Set;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+import static org.apache.hudi.bifunction.wrapper.BiFunctionWrapper.throwingConsumerWrapper;
+import static org.apache.hudi.bifunction.wrapper.BiFunctionWrapper.throwingFlatMapWrapper;
+
+public class SparkMarkerFiles extends BaseMarkerFiles {
Review comment:
> Given this file is now free of Spark, we dont have the need of breaking these into base and child classes right.
Yes, this is an example to show you the bi function, if you agree with this implementation, I'll rollback them in one class
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> @wangxianghu functionality wise, you are correct. it can be implemented just using Java. but, we do parallelization of different pieces of code e.g deletion of files in parallel using spark for a reason. It significantly speeds these up, for large tables.
>
> All I am saying is to implement the `HoodieSparkEngineContext#map` like below
>
> ```
> public <I, O> List<O> map(List<I> data, Function<I, O> func, int parallelism) {
> return javaSparkContext.parallelize(data, parallelism).map(func).collect();
> }
> ```
>
> similarly for the other two methods. I don't see any issues with this. do you?
I know what you mean.
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> @wangxianghu functionality wise, you are correct. it can be implemented just using Java. but, we do parallelization of different pieces of code e.g deletion of files in parallel using spark for a reason. It significantly speeds these up, for large tables.
>
> All I am saying is to implement the `HoodieSparkEngineContext#map` like below
>
> ```
> public <I, O> List<O> map(List<I> data, Function<I, O> func, int parallelism) {
> return javaSparkContext.parallelize(data, parallelism).map(func).collect();
> }
> ```
>
> similarly for the other two methods. I don't see any issues with this. do you?
I know what you mean.
what I am saying is that the `func` in `HoodieSparkEngineContext#map` and `HoodieEngineContext#map` is not the same type.
for `HoodieEngineContext#map` it is `java.util.function.Function`,
for `HoodieSparkEngineContext#map` it is `org.apache.spark.api.java.function.Function`.
`HoodieSparkEngineContext#map` can not override from `HoodieEngineContext#map`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-691505048
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-689916910
> @wangxianghu the issue with the tests is that, now most of the tests are moved to hudi-spark-client. previously we had split tests into hudi-client and others. We need to edit `travis.yml` to adjust the splits again
@vinothchandar could you please help me edit travis.yml to adjust the splits .. I am not familiar with that
thanks :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu removed a comment on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu removed a comment on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-689916910
> @wangxianghu the issue with the tests is that, now most of the tests are moved to hudi-spark-client. previously we had split tests into hudi-client and others. We need to edit `travis.yml` to adjust the splits again
@vinothchandar could you please help me edit travis.yml to adjust the splits .. I am not familiar with that
thanks :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#issuecomment-702420836
> @wangxianghu Just merged! Thanks again for the herculean effort.
>
> May be some followups could pop up. Would you be interested in taking them up? if so, I ll mention you along the way
sure, just ping me when needed
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r494073875
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieAppendHandle.java
##########
@@ -134,7 +138,7 @@ private void init(HoodieRecord record) {
writeStatus.setPartitionPath(partitionPath);
writeStatus.getStat().setPartitionPath(partitionPath);
writeStatus.getStat().setFileId(fileId);
- averageRecordSize = SizeEstimator.estimate(record);
+ averageRecordSize = sizeEstimator.sizeEstimate(record);
try {
Review comment:
Should be okay.
##########
File path: hudi-cli/pom.xml
##########
@@ -148,7 +148,14 @@
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
- <artifactId>hudi-client</artifactId>
+ <artifactId>hudi-client-common</artifactId>
+ <version>${project.version}</version>
+ <scope>test</scope>
+ <type>test-jar</type>
+ </dependency>
+ <dependency>
+ <groupId>org.apache.hudi</groupId>
+ <artifactId>hudi-spark-client</artifactId>
Review comment:
cc @wangxianghu probably `hudi-client-spark` is easier on the eyes?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r492434405
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
> I think we should leave this abstract and let the engines implement this? even for Java. Its better to have a `HoodieJavaEngineContext`. From what I can see, this is not overridden in `HoodieSparkEngineContext` and thus we lose the parallel execution that we currently have with Spark with this change.
as we discussed before, parallelDo model need a function as input parameter, Unfortunately, different engines need different type function, its hard to align them in an abstract parallelDo method. so we agreed to use ` java.util.function.Function` as the unified input function. in this way, there is no need to distinguish spark and flink, no need to make it abstract and the parallelism is not needed too. its just java, can be implemented directly.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] henrywu2019 commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
henrywu2019 commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r456980751
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,48 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
Review comment:
Just bump into this... Since this is a generic engine context, will it be better to use a generic name like `engineConfig`?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r494074365
##########
File path: hudi-cli/pom.xml
##########
@@ -148,7 +148,14 @@
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
- <artifactId>hudi-client</artifactId>
+ <artifactId>hudi-client-common</artifactId>
+ <version>${project.version}</version>
+ <scope>test</scope>
+ <type>test-jar</type>
+ </dependency>
+ <dependency>
+ <groupId>org.apache.hudi</groupId>
+ <artifactId>hudi-spark-client</artifactId>
Review comment:
cc @wangxianghu probably `hudi-client-spark` is easier on the eyes?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r492474108
##########
File path: hudi-client/hudi-client-common/src/main/java/org/apache/hudi/common/HoodieEngineContext.java
##########
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.common;
+
+import org.apache.hudi.client.TaskContextSupplier;
+import org.apache.hudi.common.config.SerializableConfiguration;
+
+import java.util.List;
+import java.util.function.Consumer;
+import java.util.function.Function;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Base class contains the context information needed by the engine at runtime. It will be extended by different
+ * engine implementation if needed.
+ */
+public class HoodieEngineContext {
+ /**
+ * A wrapped hadoop configuration which can be serialized.
+ */
+ private SerializableConfiguration hadoopConf;
+
+ private TaskContextSupplier taskContextSupplier;
+
+ public HoodieEngineContext(SerializableConfiguration hadoopConf, TaskContextSupplier taskContextSupplier) {
+ this.hadoopConf = hadoopConf;
+ this.taskContextSupplier = taskContextSupplier;
+ }
+
+ public SerializableConfiguration getHadoopConf() {
+ return hadoopConf;
+ }
+
+ public TaskContextSupplier getTaskContextSupplier() {
+ return taskContextSupplier;
+ }
+
+ public <I, O> List<O> map(List<I> data, Function<I, O> func) {
Review comment:
In Spark, there is a functional interface defined like this
```
package org.apache.spark.api.java.function;
import java.io.Serializable;
/**
* Base interface for functions whose return types do not create special RDDs. PairFunction and
* DoubleFunction are handled separately, to allow PairRDDs and DoubleRDDs to be constructed
* when mapping RDDs of other types.
*/
@FunctionalInterface
public interface Function<T1, R> extends Serializable {
R call(T1 v1) throws Exception;
}
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] wangxianghu commented on a change in pull request #1827: [HUDI-1089] Refactor hudi-client to support multi-engine
Posted by GitBox <gi...@apache.org>.
wangxianghu commented on a change in pull request #1827:
URL: https://github.com/apache/hudi/pull/1827#discussion_r484832824
##########
File path: hudi-client/pom.xml
##########
@@ -68,6 +107,12 @@
</build>
<dependencies>
+ <!-- Scala -->
+ <dependency>
+ <groupId>org.scala-lang</groupId>
Review comment:
> should we limit scala to just the spark module?
Yes, it is better. can we do it in another PR?
because although some classes have nothing to do with spark, it used `scala.Tuple2`, so scala is still needed.
we can replace it with 'org.apache.hudi.common.util.collection.Pair'
WDYT?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org