You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@doris.apache.org by lu...@apache.org on 2023/06/12 15:24:34 UTC
[doris-website] branch master updated: Add two blogs (#240)
This is an automated email from the ASF dual-hosted git repository.
luzhijing pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/doris-website.git
The following commit(s) were added to refs/heads/master by this push:
new be247f771de Add two blogs (#240)
be247f771de is described below
commit be247f771de8bd5e061f02b6871e5338623ede4e
Author: Hu Yanjun <10...@users.noreply.github.com>
AuthorDate: Mon Jun 12 23:24:27 2023 +0800
Add two blogs (#240)
---
blog/360.md | 116 +++++++++++
blog/Compaction.md | 130 ++++++++++++
i18n/zh-CN/docusaurus-plugin-content-blog/360.md | 175 ++++++++++++++++
.../docusaurus-plugin-content-blog/Compaction.md | 219 +++++++++++++++++++++
static/images/360_1.png | Bin 0 -> 919740 bytes
static/images/360_2.png | Bin 0 -> 955714 bytes
static/images/360_3.png | Bin 0 -> 927203 bytes
static/images/360_4.png | Bin 0 -> 309840 bytes
static/images/360_5.png | Bin 0 -> 541839 bytes
static/images/360_6.png | Bin 0 -> 629485 bytes
static/images/360_7.png | Bin 0 -> 224994 bytes
static/images/360_8.png | Bin 0 -> 157061 bytes
static/images/Compaction_1.png | Bin 0 -> 39847 bytes
static/images/Compaction_2.png | Bin 0 -> 362403 bytes
static/images/Compaction_3.png | Bin 0 -> 219932 bytes
static/images/Compaction_4.png | Bin 0 -> 31455 bytes
16 files changed, 640 insertions(+)
diff --git a/blog/360.md b/blog/360.md
new file mode 100644
index 00000000000..2a33dbdafd0
--- /dev/null
+++ b/blog/360.md
@@ -0,0 +1,116 @@
+---
+{
+ 'title': 'A/B Testing was a Handful, Until we Found the Replacement for Druid',
+ 'summary': "The recipe for successful A/B testing is quick computation, no duplication, and no data loss. For that, we used Apache Flink and Apache Doris to build our data platform.",
+ 'date': '2023-06-01',
+ 'author': 'Heyu Dou, Xinxin Wang',
+ 'tags': ['Best Practice'],
+}
+---
+
+<!--
+Licensed to the Apache Software Foundation (ASF) under one
+or more contributor license agreements. See the NOTICE file
+distributed with this work for additional information
+regarding copyright ownership. The ASF licenses this file
+to you under the Apache License, Version 2.0 (the
+"License"); you may not use this file except in compliance
+with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing,
+software distributed under the License is distributed on an
+"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+KIND, either express or implied. See the License for the
+specific language governing permissions and limitations
+under the License.
+-->
+
+Unlike normal reporting, A/B testing collects data of a different combination of dimensions every time. It is also a complicated kind of analysis of immense data. In our case, we have a real-time data volume of millions of OPS (Operations Per Second), with each operation involving around 20 data tags and over a dozen dimensions.
+
+For effective A/B testing, as data engineers, we must ensure quick computation as well as high data integrity (which means no duplication and no data loss). I'm sure I'm not the only one to say this: it is hard!
+
+Let me show you our long-term struggle with our previous Druid-based data platform.
+
+## Platform Architecture 1.0
+
+**Components**: Apache Storm + Apache Druid + MySQL
+
+This was our real-time datawarehouse, where Apache Storm was the real-time data processing engine and Apache Druid pre-aggregated the data. However, Druid did not support certain paging and join queries, so we wrote data from Druid to MySQL regularly, making MySQL the "materialized view" of Druid. But that was only a duct tape solution as it couldn't support our ever enlarging real-time data size. So data timeliness was unattainable.
+
+
+
+## Platform Architecture 2.0
+
+**Components**: Apache Flink + Apache Druid + TiDB
+
+This time, we replaced Storm with Flink, and MySQL with TiDB. Flink was more powerful in terms of semantics and features, while TiDB, with its distributed capability, was more maintainable than MySQL. But architecture 2.0 was nowhere near our goal of end-to-end data consistency, either, because when processing huge data, enabling TiDB transactions largely slowed down data writing. Plus, Druid itself did not support standard SQL, so there were some learning costs and frictions in usage.
+
+
+
+## Platform Architecture 3.0
+
+**Components**: Apache Flink + [Apache Doris](https://github.com/apache/doris)
+
+We replaced Apache Druid with Apache Doris as the OLAP engine, which could also serve as a unified data serving gateway. So in Architecture 3.0, we only need to maintain one set of query logic. And we layered our real-time datawarehouse to increase reusability of real-time data.
+
+
+
+Turns out the combination of Flink and Doris was the answer. We can exploit their features to realize quick computation and data consistency. Keep reading and see how we make it happen.
+
+## Quick Computation
+
+As one piece of operation data can be attached to 20 tags, in A/B testing, we compare two groups of data centering only one tag each time. At first, we thought about splitting one piece of operation data (with 20 tags) into 20 pieces of data of only one tag upon data ingestion, and then importing them into Doris for analysis, but that could cause a data explosion and thus huge pressure on our clusters.
+
+Then we tried moving part of such workload to the computation engine. So we tried and "exploded" the data in Flink, but soon regretted it, because when we aggregated the data using the global hash windows in Flink jobs, the network and CPU usage also "exploded".
+
+Our third shot was to aggregate data locally in Flink right after we split it. As is shown below, we create a window in the memory of one operator for local aggregation; then we further aggregate it using the global hash windows. Since two operators chained together are in one thread, transferring data between operators consumes much less network resources. **The two-step aggregation method, combined with the** **[Aggregate model](https://doris.apache.org/docs/dev/data-table/data-model)* [...]
+
+
+
+For convenience in A/B testing, we make the test tag ID the first sorted field in Apache Doris, so we can quickly locate the target data using sorted indexes. To further minimize data processing in queries, we create materialized views with the frequently used dimensions. With constant modification and updates, the materialized views are applicable in 80% of our queries.
+
+To sum up, with the application of sorted index and materialized views, we reduce our query response time to merely seconds in A/B testing.
+
+## Data Integrity Guarantee
+
+Imagine that your algorithm designers worked sweat and tears trying to improve the business, only to find their solution unable to be validated by A/B testing due to data loss. This is an unbearable situation, and we make every effort to avoid it.
+
+### Develop a Sink-to-Doris Component
+
+To ensure end-to-end data integrity, we developed a Sink-to-Doris component. It is built on our own Flink Stream API scaffolding and realized by the idempotent writing of Apache Doris and the two-stage commit mechanism of Apache Flink. On top of it, we have a data protection mechanism against anomalies.
+
+It is the result of our long-term evolution. We used to ensure data consistency by implementing "one writing for one tag ID". Then we realized we could make good use of the transactions in Apache Doris and the two-stage commit of Apache Flink.
+
+
+
+As is shown above, this is how two-stage commit works to guarantee data consistency:
+
+1. Write data into local files;
+2. Stage One: pre-commit data to Apache Doris. Save the Doris transaction ID into status;
+3. If checkpoint fails, manually abandon the transaction; if checkpoint succeeds, commit the transaction in Stage Two;
+4. If the commit fails after multiple retries, the transaction ID and the relevant data will be saved in HDFS, and we can restore the data via Broker Load.
+
+We make it possible to split a single checkpoint into multiple transactions, so that we can prevent one Stream Load from taking more time than a Flink checkpoint in the event of large data volumes.
+
+### Application Display
+
+This is how we implement Sink-to-Doris. The component has blocked API calls and topology assembly. With simple configuration, we can write data into Apache Doris via Stream Load.
+
+
+
+### Cluster Monitoring
+
+For cluster and host monitoring, we adopted the metrics templates provided by the Apache Doris community. For data monitoring, in addition to the template metrics, we added Stream Load request numbers and loading rates.
+
+
+
+Other metrics of our concerns include data writing speed and task processing time. In the case of anomalies, we will receive notifications in the form of phone calls, messages, and emails.
+
+
+
+## Key Takeaways
+
+The recipe for successful A/B testing is quick computation and high data integrity. For this purpose, we implement a two-step aggregation method in Apache Flink, utilize the Aggregate model, materialized view, and short indexes of Apache Doris. Then we develop a Sink-to-Doris component, which is realized by the idempotent writing of Apache Doris and the two-stage commit mechanism of Apache Flink.
+
diff --git a/blog/Compaction.md b/blog/Compaction.md
new file mode 100644
index 00000000000..ac6055970b6
--- /dev/null
+++ b/blog/Compaction.md
@@ -0,0 +1,130 @@
+---
+{
+ 'title': 'Understanding Data Compaction in 3 Minutes',
+ 'summary': "Think of your disks as a warehouse: The compaction mechanism is like a team of storekeepers who help put away the incoming data.",
+ 'date': '2023-06-09',
+ 'author': 'Apache Doris',
+ 'tags': ['Tech Sharing'],
+}
+
+---
+
+<!--
+Licensed to the Apache Software Foundation (ASF) under one
+or more contributor license agreements. See the NOTICE file
+distributed with this work for additional information
+regarding copyright ownership. The ASF licenses this file
+to you under the Apache License, Version 2.0 (the
+"License"); you may not use this file except in compliance
+with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing,
+software distributed under the License is distributed on an
+"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+KIND, either express or implied. See the License for the
+specific language governing permissions and limitations
+under the License.
+-->
+
+What is compaction in database? Think of your disks as a warehouse: The compaction mechanism is like a team of storekeepers (with genius organizing skills like Marie Kondo) who help put away the incoming data.
+
+In particular, the data (which is the inflowing cargo in this metaphor) comes in on a "conveyor belt", which does not allow cutting in line. This is how the **LSM-Tree** (Log Structured-Merge Tree) works: In data storage, data is written into **MemTables** in an append-only manner, and then the MemTables are flushed to disks to form files. (These files go by different names in different databases. In my community, we call them **Rowsets**). Just like putting small boxes of cargo into a l [...]
+
+- Although the items (data) in each box (rowset) are orderly arranged, the boxes themselves are not. Hence, one thing that the "storekeepers" do is to sort the boxes (rowsets) in a certain order so they can be quickly found once needed (quickening data reading).
+- If an item needs to be discarded or replaced, since no line-jump is allowed on the conveyor belt (append-only), you can only put a "note" (together with the substitution item) at the end of the queue on the belt to remind the "storekeepers", who will later perform replacing or discarding for you.
+- If needed, the "storekeepers" are even kind enough to pre-process the cargo for you (pre-aggregating data to reduce computation burden during data reading).
+
+
+
+As helpful as the "storekeepers" are, they can be troublemakers at times — that's why "team management" matters. For the compaction mechanism to work efficiently, you need wise planning and scheduling, or else you might need to deal with high memory and CPU usage, if not OOM in the backend or write error.
+
+Specifically, efficient compaction is added up by quick triggering of compaction tasks, controllable memory and CPU overheads, and easy parameter adjustment from the engineer's side. That begs the question: **How**? In this post, I will show you our way, including how we trigger, execute, and fine-tune compaction for faster and less resource-hungry execution.
+
+## Trigger Strategies
+
+The overall objective here is to trigger compaction tasks timely with the least resource consumption possible.
+
+### Active Trigger
+
+The most intuitive way to ensure timely compaction is to scan for potential compaction tasks upon data ingestion. Every time a new data tablet version is generated, a compaction task is triggered immediately, so you will never have to worry about version buildup. But this only works for newly ingested data. This is called **Cumulative Compaction**, as opposed to **Base Compaction**, which is the compaction of existing data.
+
+### Passive Scan
+
+Base compaction is triggered by passive scan. Passive scan is a much heavier job than active trigger, because it scans all metadata in all data tablets in the node. After identifying all potential compaction tasks, the system starts compaction for the most urgent data tablet.
+
+### Tablet Dormancy
+
+Frequent metadata scanning is a waste of CPU resources, so it is better to introduce domancy: For tablets that have been producing no compaction tasks for long, the system just stops looking at them for a while. If there is a sudden data-write on a dormant tablet, that will trigger cumulative compaction as mentioned above, so no worries, you won't miss anything.
+
+The combination of these three strategies is an example of cost-effective planning.
+
+## Execution
+
+### Vertical Compaction for Columnar Storage
+
+As columnar storage is the future for analytic databases, the execution of compaction should adapt to that. We call it vertical compaction. I illustrate this mechanism with the figure below:
+
+
+
+Hope all these tiny blocks and numbers don't make you dizzy. Actually, vertical compaction can be broken down into four simple steps:
+
+1. **Separate key columns and value columns**. Split out all key columns from the input rowsets and put them into one group, and all value columns into N groups.
+2. **Merge the key columns**. Heap sort is used in this step. The product here is a merged and ordered key column as well as a global sequence marker (**RowSources**).
+3. **Merge the value columns**. The value columns are merged and organized based on the sequence in **RowSources**.
+4. **Write the data**. All columns are assembled together and form one big rowset.
+
+As a supporting technique for columnar storage, vertical compaction avoids the need to load all columns in every merging operation. That means it can vastly reduce memory usage compared to traditional row-oriented compaction.
+
+### Segment Compaction to Avoid "Jams"
+
+As described in the beginning, in data ingestion, data will first be piled in the memory until it reaches a certain size, and then flushed to disks and stored in the form of files. Therefore, if you have ingested one huge batch of data at a time, you will have a large number of newly generated files on the disks. That adds to the scanning burden during data reading, and thus slows down data queries. (Imagine that suddenly you have to look into 50 boxes instead of 5, to find the item you [...]
+
+Segment compaction is the way to avoid that. It allows you to compact data at the same time you ingest it, so that the system can ingest a larger data size quickly without generating too many files.
+
+This is a flow chart that explains how segment compaction works:
+
+
+
+Segment compaction will be triggered once the number of newly generated files exceeds a certain limit (let's say, 10). It is executed asynchronously by a specialized merging thread. Every 10 files will be merged into one, and the original 10 files will be deleted. Segment compaction does not prolong the data ingestion process by much, but it can largely accelerate data queries.
+
+### Ordered Data Compaction
+
+Time series data analysis is an increasingly common analytic scenario.
+
+Time series data is "born orderly". It is already arranged chronologically, it is written at a regular pace, and every batch of it is of similar size. It is like the least-worried-about child in the family. Correspondingly, we have a tailored compaction method for it: ordered data compaction.
+
+
+
+Ordered data compaction is even simpler:
+
+1. **Upload**: Jot down the Min/Max Keys of the input rowset files.
+2. **Check**: Check if the rowset files are organized correctly based on the Min/Max Keys and the file size.
+3. **Merge**: Hard link the input rowsets to the new rowset, and create metadata for the new rowset (including number of rows, file size, Min/Max Key, etc.)
+
+See? It is a super neat and lightweight workload, involving only file linking and metadata creation. Statistically, **it just takes milliseconds to compact huge amounts of time series data but consumes nearly zero memory**.
+
+So far, these are strategic and algorithmic optimizations for compaction, implemented by [Apache Doris 2.0.0](https://github.com/apache/doris/issues/19231), a unified analytic database. Apart from these, we, as developers for the open source project, have fine-tuned it from an engineering perspective.
+
+## Engineering Optimizations
+
+### Zero-Copy
+
+In the backend nodes of Apache Doris, data goes through a few layers: Tablet -> Rowset -> Segment -> Column -> Page. The compaction process involves data transferring that consumes a lot of CPU resources. So we designed zero-copy compaction logic, which is realized by a data structure named BlockView. This brings another 5% increase in compaction efficiency.
+
+### Load-on-Demand
+
+In most cases, the rowsets are not 100% orderless, so we can take advantage of such partial orderliness. For a group of ordered rowsets, Apache Doris only loads the first one and then starts merging. As the merging goes on, it gradually loads the rowset files it needs. This is how it decreases memory usage.
+
+### **Idle Schedule**
+
+According to our experience, base compaction tasks are often resource-intensive and time-consuming, so they can easily stand in the way of data queries. Doris 2.0.0 enables Idle Schedule, deprioritizing those base compaction tasks with huge data, long execution, and low compaction rate.
+
+## Parameter Optimizations
+
+Every data engineer has somehow been harassed by complicated parameters and configurations. To protect our users from this nightmare, we have provided a streamlined set of parameters with the best-performing default configurations in the general environment.
+
+## Conclusion
+
+This is how we keep our "storekeepers" working efficiently and cost-effectively. If you wonder how these strategies and optimization work in real practice, we tested Apache Doris with ClickBench. It reaches a **compaction speed of 300,000 row/s**; in high-concurrency scenarios, it maintains **a stable compaction score of around 50**. Also, we are planning to implement auto-tuning and increase observability for the compaction mechanism. If you are interested in the [Apache Doris](https:// [...]
\ No newline at end of file
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/360.md b/i18n/zh-CN/docusaurus-plugin-content-blog/360.md
new file mode 100644
index 00000000000..b38178a5c4e
--- /dev/null
+++ b/i18n/zh-CN/docusaurus-plugin-content-blog/360.md
@@ -0,0 +1,175 @@
+---
+{
+ 'title': '日增百亿数据,查询结果秒出, Apache Doris 在 360商业化的统一 OLAP 应用实践',
+ 'summary': "360商业化为助力业务团队更好推进商业化增长,实时数仓共经历了三种模式的演进,分别是 Storm + Druid + MySQL 模式、Flink + Druid + TiDB 的模式 以及 Flink + Doris 的模式,基于 Apache Doris 的新一代架构的成功落地使得 360商业化团队完成了实时数仓在 OLAP 引擎上的统一,成功实现广泛实时场景下的秒级查询响应。本文将为大家进行详细介绍演进过程以及新一代实时数仓在广告业务场景中的具体落地实践。",
+ 'date': '2023-06-01',
+ 'author': '360商业化数据团队',
+ 'tags': ['最佳实践'],
+}
+
+
+---
+
+<!--
+Licensed to the Apache Software Foundation (ASF) under one
+or more contributor license agreements. See the NOTICE file
+distributed with this work for additional information
+regarding copyright ownership. The ASF licenses this file
+to you under the Apache License, Version 2.0 (the
+"License"); you may not use this file except in compliance
+with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing,
+software distributed under the License is distributed on an
+"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+KIND, either express or implied. See the License for the
+specific language governing permissions and limitations
+under the License.
+-->
+
+**导读**:360商业化为助力业务团队更好推进商业化增长,实时数仓共经历了三种模式的演进,分别是 Storm + Druid + MySQL 模式、Flink + Druid + TIDB 的模式 以及 Flink + Doris 的模式,基于 [Apache Doris](https://doris.apache.org/) 的新一代架构的成功落地使得 360商业化团队完成了实时数仓在 OLAP 引擎上的统一,成功实现广泛实时场景下的秒级查询响应。本文将为大家进行详细介绍演进过程以及新一代实时数仓在广告业务场景中的具体落地实践。
+
+作者|360商业化数据团队 窦和雨、王新新
+
+360 公司致力于成为互联网和安全服务提供商,是互联网免费安全的倡导者,先后推出 360安全卫士、360手机卫士、360安全浏览器等安全产品以及 360导航、360搜索等用户产品。
+
+360商业化依托 360产品庞大的用户覆盖能力和超强的用户粘性,通过专业数据处理和算法实现广告精准投放,助力数十万中小企业和 KA 企业实现价值增长。360商业化数据团队主要是对整个广告投放链路中所产生的数据进行计算处理,为产品运营团队提供策略调整的分析数据,为算法团队提供模型训练的优化数据,为广告主提供广告投放的效果数据。
+
+## 业务场景
+
+在正式介绍 Apache Doris 在 360 商业化的应用之前,我们先对广告业务中的典型使用场景进行简要介绍:
+
+- **实时大盘:** 实时大盘场景是我们对外呈现数据的关键载体,需要从多个维度监控商业化大盘的指标情况,包括流量指标、消费指标、转化指标和变现指标,因此其对数据的准确性要求非常高(保证数据不丢不重),同时对数据的时效性和稳定性要求也很高,要求实现秒级延迟、分钟级数据恢复。
+- **广告账户的实时消费数据场景:** 通过监控账户粒度下的多维度指标数据,及时发现账户的消费变化,便于产品团队根据实时消费情况推动运营团队对账户预算进行调整。在该场景下数据一旦出现问题,就可能导致账户预算的错误调整,从而影响广告的投放,这对公司和广告主将造成不可估量的损失,因此在该场景中,同样对数据准确性有很高的要求。目前在该场景下遇到的困难是如何在数据量比较大、查询交叉的粒度比较细的前提下,实现秒级别查询响应。
+- **AB 实验平台:** 在广告业务中,算法和策略同学会针对不同的场景进行实验,在该场景下,具有报表维度不固定、多种维度灵活组合、数据分析比较复杂、数据量较大等特点,这就需要可以在百万级 QPS 下保证数据写入存储引擎的性能,因此我们需要针对业务场景进行特定的模型设计和处理上的优化,提高实时数据处理的性能以及数据查询分析的效率,只有这样才能满足算法和策略同学对实验报表的查询分析需求。
+
+
+## 实时数仓演进
+
+为提升各场景下数据服务的效率,助力相关业务团队更好推进商业化增长,截至目前实时数仓共经历了三种模式的演进,分别是 Storm + Druid + MySQL 模式、Flink + Druid + TIDB 的模式 以及 Flink + Doris 的模式,本文将为大家进行详细介绍实时数仓演进过程以及新一代实时数仓在广告业务场景中的具体落地。
+
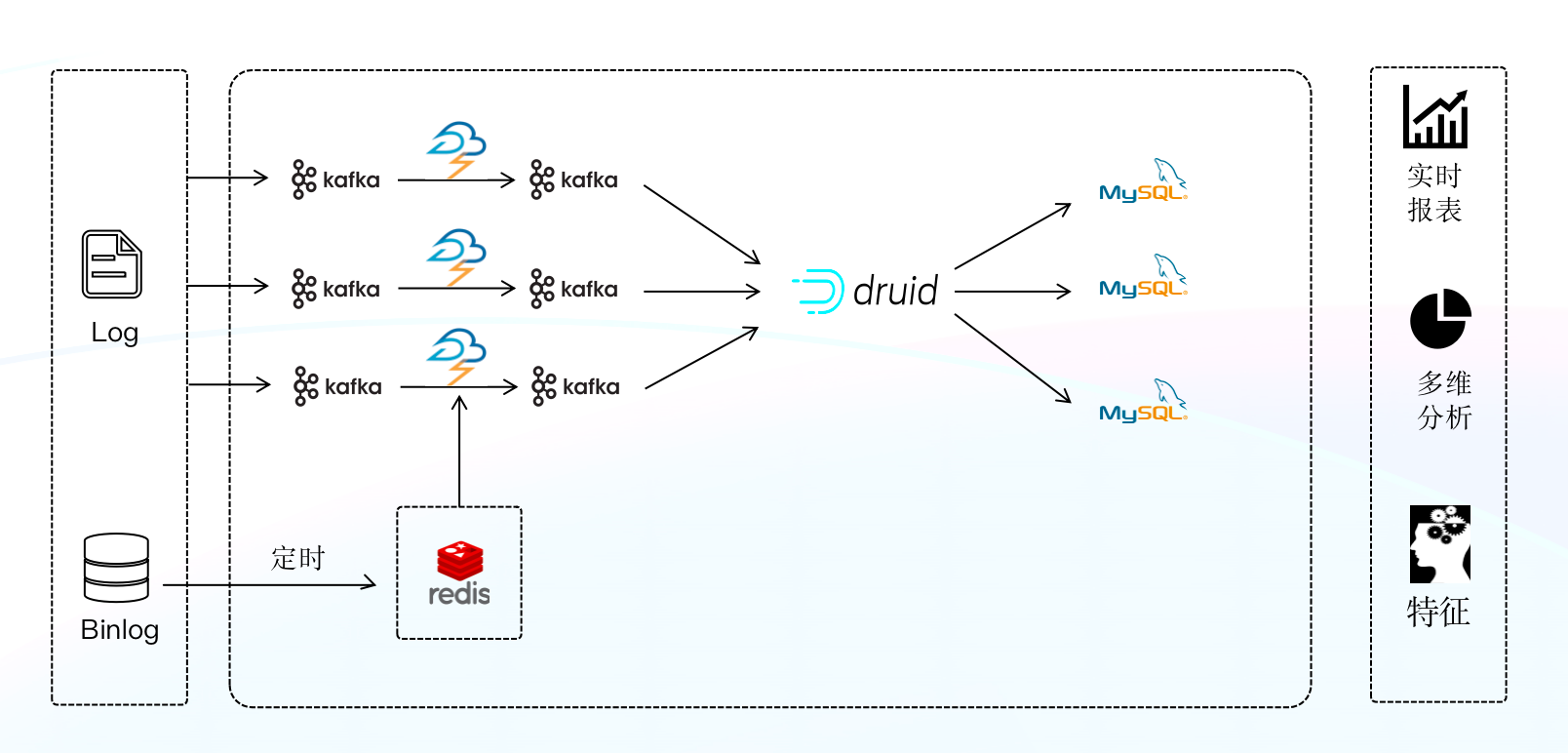
+### 第一代架构
+
+该阶段的实时数仓是基于 Storm + Druid + MySQL 来构建的,Storm 为实时处理引擎,数据经 Storm 处理后,将数据写入 Druid ,利用 Druid 的预聚合能力对写入数据进行聚合。
+
+
+
+**架构痛点:**
+
+最初我们试图依靠该架构解决业务上所有的实时问题,经由 Druid 统一对外提供数据查询服务,但是在实际的落地过程中我们发现 Druid 是无法满足某些分页查询和 Join 场景的,为解决该问题,我们只能利用 MySQL 定时任务的方式将数据定时从 Druid 写入 MySQL 中(类似于将 MySQL 作为 Druid 的物化视图),再通过 Druid + MySQL 的模式对外提供服务。通过这种方式暂时可以满足某些场景需求,但随着业务规模的逐步扩大,当面对更大规模数据下的查询分析需求时,该架构已难以为继,架构的缺陷也越发明显:
+
+- 面对数据量的持续增长,数据仓库压力空前剧增,已无法满足实时数据的时效性要求。
+- MySQL 的分库分表维护难度高、投入成本大,且 MySQL 表之间的数据一致性无法保障。
+
+
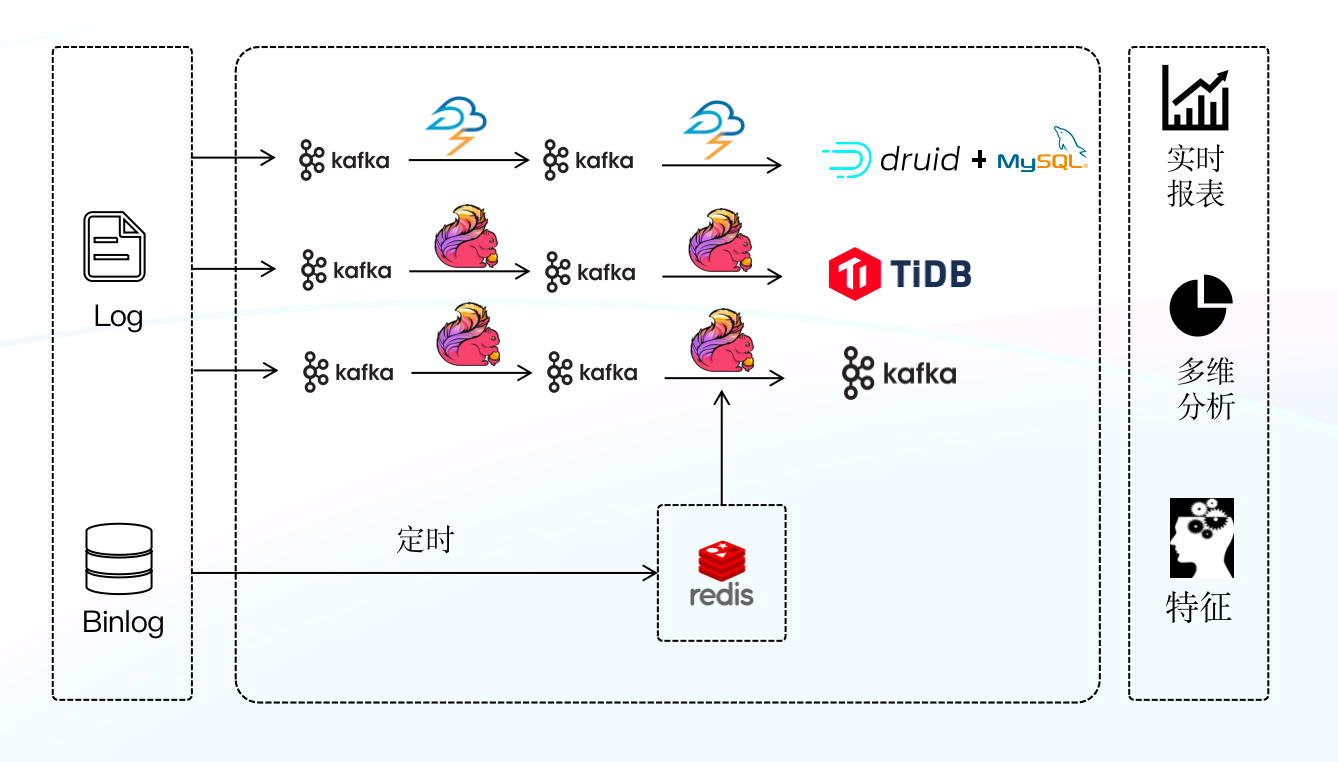
+### 第二代架构
+
+
+
+基于第一套架构存在的问题,我们进行了首次升级,这次升级的主要变化是将 Storm 替换成新的实时数据处理引擎 Flink ,Flink 相较于 Storm 不仅在许多语义和功能上进行了扩展,还对数据的一致性做了保证,这些特性使得报表的时效性大幅提升;其次我们使用 TiDB 替换了 MySQL ,利用 TIDB 分布式的特性,一定程度上解决了 MySQL 分库分表难以维护的问题(TiDB 在一定程度上比 MySQL 能够承载更大数据量,可以拆分更少表)。在升级完成后,我们按照不同业务场景的需求,将 Flink 处理完的数据分别写入 Druid 和 TiDB ,由 Druid 和 TIDB 对外提供数据查询服务。
+
+
+**架构痛点:**
+
+虽然该阶段的实时数仓架构有效提升了数据的时效性、降低了 MySQL 分库分表维护的难度,但在一段时间的使用之后又暴露出了新的问题,也迫使我们进行了第二次升级:
+
+- Flink + TIDB 无法实现端到端的一致性,原因是当其面对大规模的数据时,开启事务将对 TiDB 写入性能造成很大的影响,该场景下 TiDB 的事务形同虚设,心有余而力不足。
+- Druid 不支持标准 SQL ,使用有一定的门槛,相关团队使用数据时十分不便,这也直接导致了工作效率的下降。
+- 维护成本较高,需要维护两套引擎和两套查询逻辑,极大增加了维护和开发成本的投入。
+
+
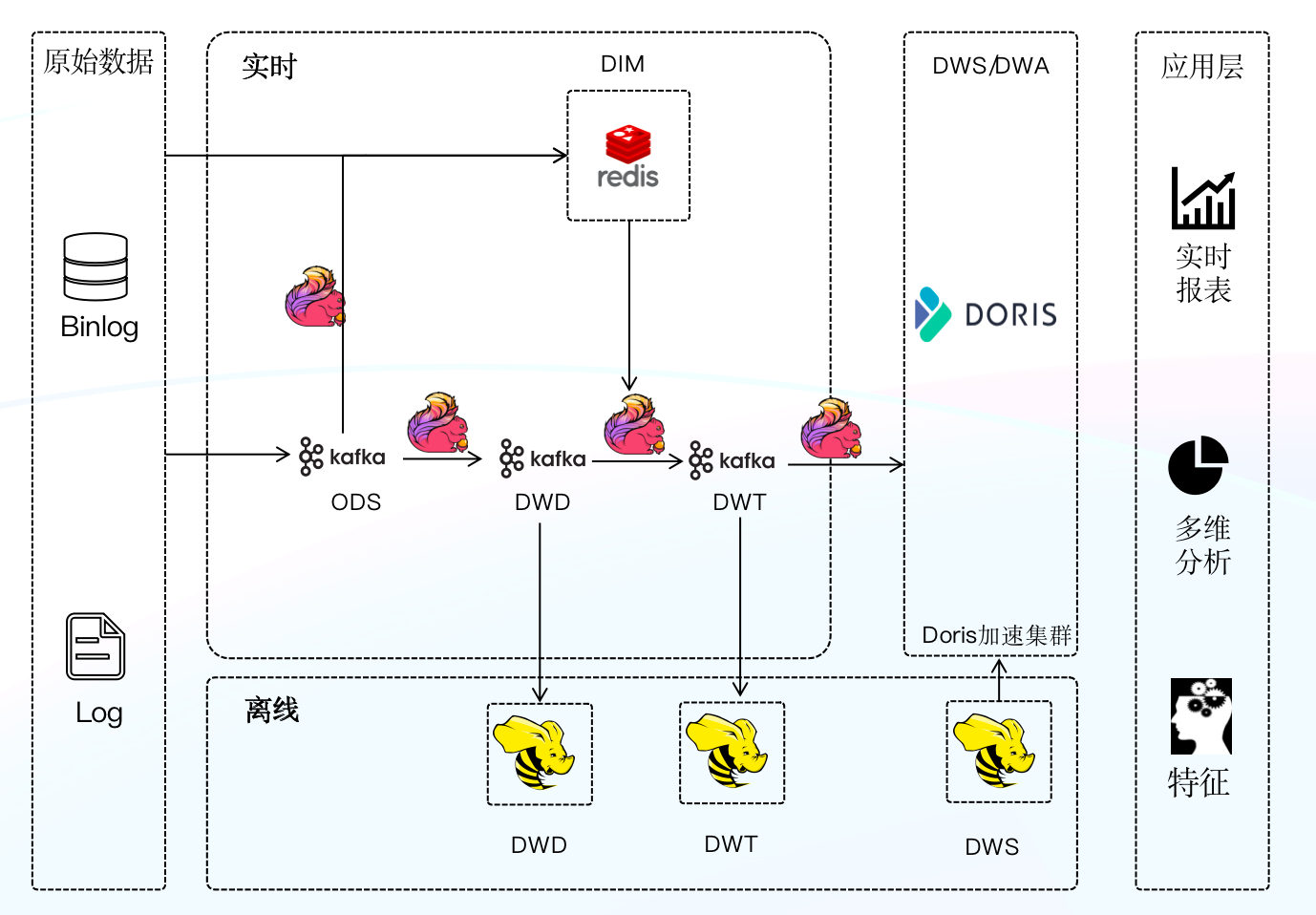
+### 新一代实时数仓架构
+
+第二次升级我们引入 Apache Doris 结合 Flink 构建了新一代实时数仓架构,借鉴离线数仓分层理念对实时数仓进行分层构建,并统一 Apache Doris 作为数仓 OLAP 引擎,由 Doris 统一对外提供服务。
+
+
+
+我们的数据主要源自于维表物料数据和业务打点日志。维表物料数据会定时全量同步到 Redis 或者 Aerospike (类似于 Redis 的 KV 存储)中,通过 Binlog 变更进行增量同步。业务数据由各个团队将日志收集到 Kafka,内部称为 ODS 原始数据(ODS 原始数据不做任何处理),我们对 ODS 层的数据进行归一化处理,包括字段命名、字段类型等,并对一些无效字段进行删减,并根据业务场景拆分生成 DWD 层数据,DWD 层的数据通过业务逻辑加工以及关联 Redis 中维表数据或者多流 Join,最后生成面向具体业务的大宽表(即 DWT 层数据),我们将 DWT 层数据经过聚合、经由 Stream Load 写入 Doris 中,由 Doris 对外提供数据查询服务。在离线数仓部分,同样也有一些场景需要每日将加工完的 DWS 数据经由 Broker Load 写入到 Doris 集群中,并利用 Doris 进行查询加速,以提升我们对外�
��供服务的效率。
+
+
+## 选择 Doris 的原因
+
+基于 Apache Doris 高性能、极简易用、实时统一等诸多特性,助力 360商业化成功构建了新一代实时数仓架构,本次升级不仅提升了实时数据的复用性、实现了 OLAP 引擎的统一,而且满足了各大业务场景严苛的数据查询分析需求,使得整体实时数据流程架构变得简单,大大降低了其维护和使用的成本。我们选择 Doris 作为统一 OLAP 引擎的重要原因大致可归结为以下几点:
+
+- **物化视图:** Doris 的物化视图与广告业务场景的特点契合度非常高,比如广告业务中大部分报表的查询维度相对比较固定,利用物化视图的特性可以提升查询的效率,同时 Doris 可以保证物化视图和底层数据的一致性,该特性可帮助我们降低维护成本的投入。
+- **数据一致性:** Doris 提供了 Stream Load Label 机制,我们可通过事务的方式与 Flink 二阶段提交进行结合,以保证幂等写入数据,另外我们通过自研 Flink Sink Doris 组件,实现了数据的端到端的一致性,保证了数据的准确性。
+- **SQL 协议兼容**:Doris 兼容 MySQL 协议,支持标准 SQL,这无论是对于开发同学,还是数据分析、产品同学,都可以实现无成本衔接,相关同学直接使用 SQL 就可以进行查询,使用门槛很低,为公司节省了大量培训和使用成本,同时也提升了工作效率。
+- **优秀的查询性能:** Apache Doris 已全面实现向量化查询引擎,使 Doris 的 OLAP 性能表现更加强悍,在多种查询场景下都有非常明显的性能提升,可极大优化了报表的询速度。同时依托列式存储引擎、现代的 MPP 架构、预聚合物化视图、数据索引的实现,在低延迟和高吞吐查询上,都达到了极速性能
+- **运维难度低:** Doris 对于集群和和数据副本管理上做了很多自动化工作,这些投入使得集群运维起来非常的简单,近乎于实现零门槛运维。
+
+## 在 AB 实验平台的具体落地
+
+Apache Doris 目前广泛应用于 360商业化内部的多个业务场景。比如在实时大盘场景中,我们利用 Doris 的 Aggregate 模型对请求、曝光、点击、转化等多个实时流进行事实表的 Join ;依靠 Doris 事务特性保证数据的一致性;通过多个物化视图,提前根据报表维度聚合数据、提升查询速度,由于物化视图和 Base 表的一致关系由 Doris 来维护保证,这也极大的降低了使用复杂度。比如在账户实时消费场景中,我们主要借助 Doris 优秀的查询优化器,通过 Join 来计算同环比......
+
+**接下来仅以 AB 实验平台这一典型业务场景为例,详尽的为大家介绍 Doris 在该场景下的落地实践,在上述所举场景中的应用将不再赘述。**
+
+
+AB 实验在广告场景中的应用非常广泛,是衡量设计、算法、模型、策略对产品指标提升的重要工具,也是精细化运营的重要手段,我们可以通过 AB实验平台对迭代方案进行测试,并结合数据进行分析和验证,从而优化产品方案、提升广告效果。
+
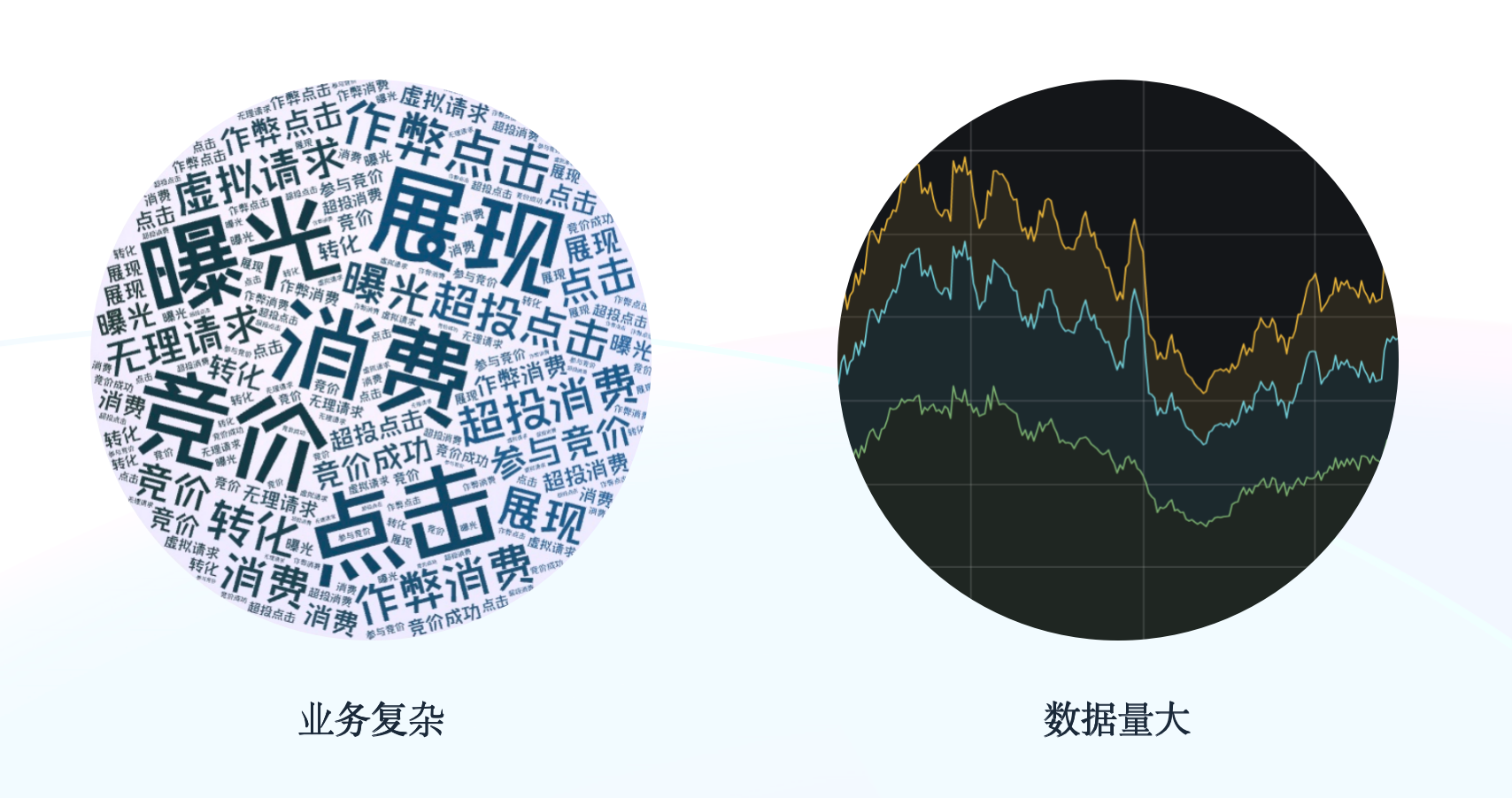
+在文章开头也有简单介绍,AB 实验场景所承载的业务相对比较复杂,这里再详细说明一下:
+
+- 各维度之间组合灵活度很高,例如需要对从 DSP 到流量类型再到广告位置等十几个维度进行分析,完成从请求、竞价、曝光、点击、转化等几十个指标的完整流量漏斗。
+- 数据量巨大,日均流量可以达到**百亿级别**,峰值可达**百万OPS**(Operations Per Second),一条流量可能包含**几十个实验标签 ID**。
+
+基于以上特点,我们在 AB实验场景中一方面需要保证数据算的快、数据延迟低、用户查询数据快,另一方面也要保证数据的准确性,保障数据不丢不重。
+
+
+
+
+### 数据落地
+
+当面对一条流量可能包含几十个实验标签 ID 的情况时,从分析角度出发,只需要选中一个实验标签和一个对照实验标签进行分析;而如果通过`like`的方式在几十个实验标签中去匹配选中的实验标签,实现效率就会非常低。
+
+最初我们期望从数据入口处将实验标签打散,将一条包含 20 个实验标签的流量拆分为 20 条只包含一个实验标签的流量,再导入 Doris 的聚合模型中进行数据分析。而在这个过程中我们遇到一个明显的问题,当数据被打散之后会膨胀数十倍,百亿级数据将膨胀为千亿级数据,即便 Doris 聚合模型会对数据再次压缩,但这个过程会对集群造成极大的压力。因此我们放弃该实现方式,开始尝试将压力分摊一部分到计算引擎,这里需要注意的是,如果将数据直接在 Flink 中打散,当 Job 全局 Hash 的窗口来 Merge 数据时,膨胀数十倍的数据也会带来几十倍的网络和 CPU 消耗。
+
+
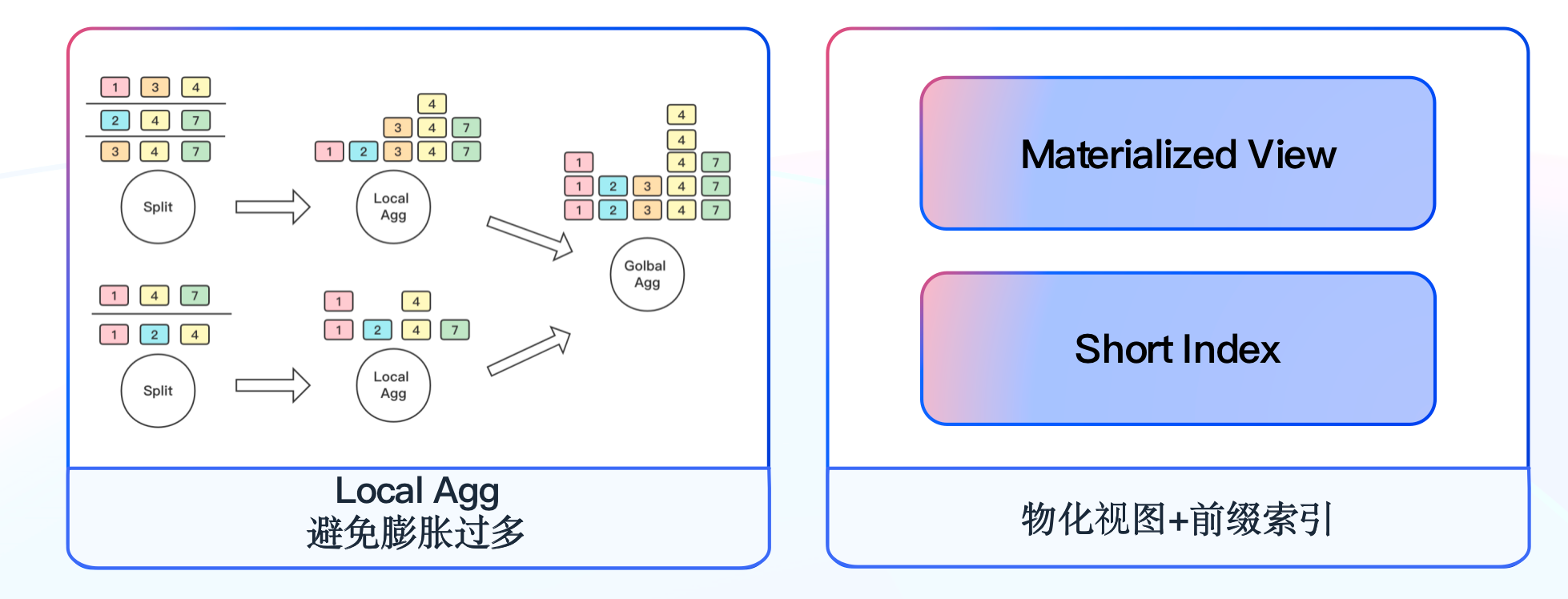
+接着我们开始第三次尝试,这次尝试我们考虑在 Flink 端将数据拆分后立刻进行 Local Merge,在同一个算子的内存中开一个窗口,先将拆分的数据进行一层聚合,再通过 Job 全局 Hash 窗口进行第二层聚合,因为 Chain 在一起的两个算子在同一个线程内,因此可以大幅降低膨胀后数据在不同算子之间传输的网络消耗。该方式**通过两层窗口的聚合,再结合 Doris 的聚合模型,有效降低了数据的膨胀程度**,其次我们也同步推动实业务方定期清理已下线的实验,减少计算资源的浪费。
+
+
+
+考虑到 AB实验分析场景的特点,我们将实验 ID 作为 Doris 的第一个排序字段,利用前缀索引可以很快定位到目标查询的数据。另外根据常用的维度组合建立物化视图,进一步缩小查询的数据量,**Doris 物化视图基本能够覆盖 80% 的查询场景**,我们会定期分析查询 SQL 来调整物化视图。**最终我们通过模型的设计、前缀索引的应用,结合物化视图能力,使大部分实验查询结果能够实现秒级返回。**
+
+
+### 数据一致性保障
+
+数据的准确性是 AB实验平台的基础,当算法团队呕心沥血优化的模型使广告效果提升了几个百分点,却因数据丢失看不出实验效果,这样的结果确实无法令人接受,同时这也是我们内部不允许出现的问题。那么我们该如何避免数据丢失、保障数据的一致性呢?
+
+#### **自研 Flink Sink Doris 组件**
+
+我们内部已有一套 Flink Stream API 脚手架,因此借助 Doris 的幂等写特性和 Flink 的二阶段提交特性,自研了 Sink To Doris 组件,保证了数据端到端的一致性,并在此基础上新增了异常情况的数据保障机制。
+
+
+
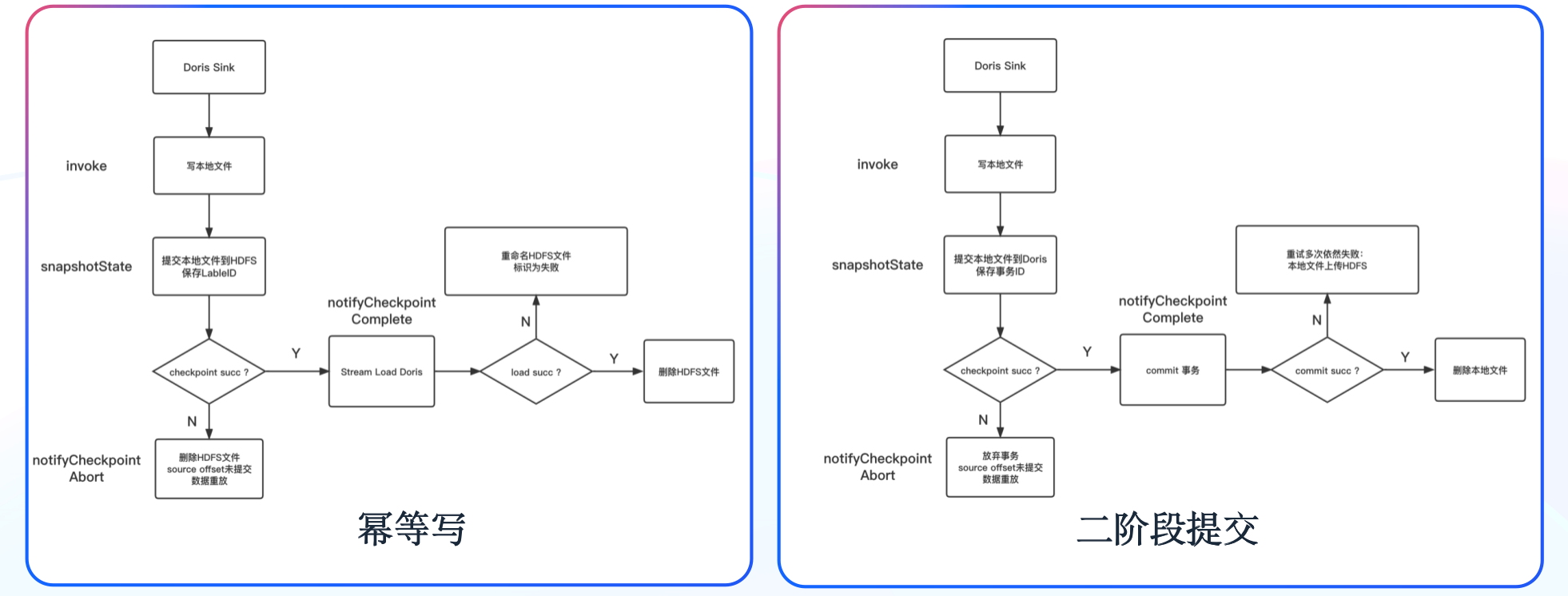
+在 Doris 0.14 版本中(初期使用的版本),我们一般通过“同一个 Label ID 只会被写入一次”的机制来保证数据的一致性;在 Doris 1.0 版本之后,通过 “Doris 的事务结合 Flink 二阶段提交”的机制来保证数据的一致性。这里详细分享使用 Doris 1.0 版本之后,通过 “Doris 的事务结合 Flink 二阶段提交”机制保证数据的一致性的原理与实现。
+
+> 在 Flink 中做到数据端到端的一致性有两种方式,一种为通过至少一次结合幂等写,一种为通过恰好一次的二阶段事务。
+
+如右图所示,我们首先在数据写入阶段先将数据写入本地文件,一阶段过程中将数据预提交到 Doris,并保存事务 ID 到状态,如果 Checkpoint 失败,则手动放弃 Doris 事务;如果 Checkpoint 成功,则在二阶段进行事务提交。对于二阶段提交重试多次仍然失败的数据,将提供数据以及事务 ID 保存到 HDFS 的选项,通过 Broker Load 进行手动恢复。为了避免单次提交数据量过大,而导致 Stream Load 时长超过 Flink Checkpoint 时间的情况,我们提供了将单次 Checkpoint 拆分为多个事务的选项。**最终成功通过二阶段提交的机制实现了对数据一致性的保障。**
+
+
+**应用展示**
+
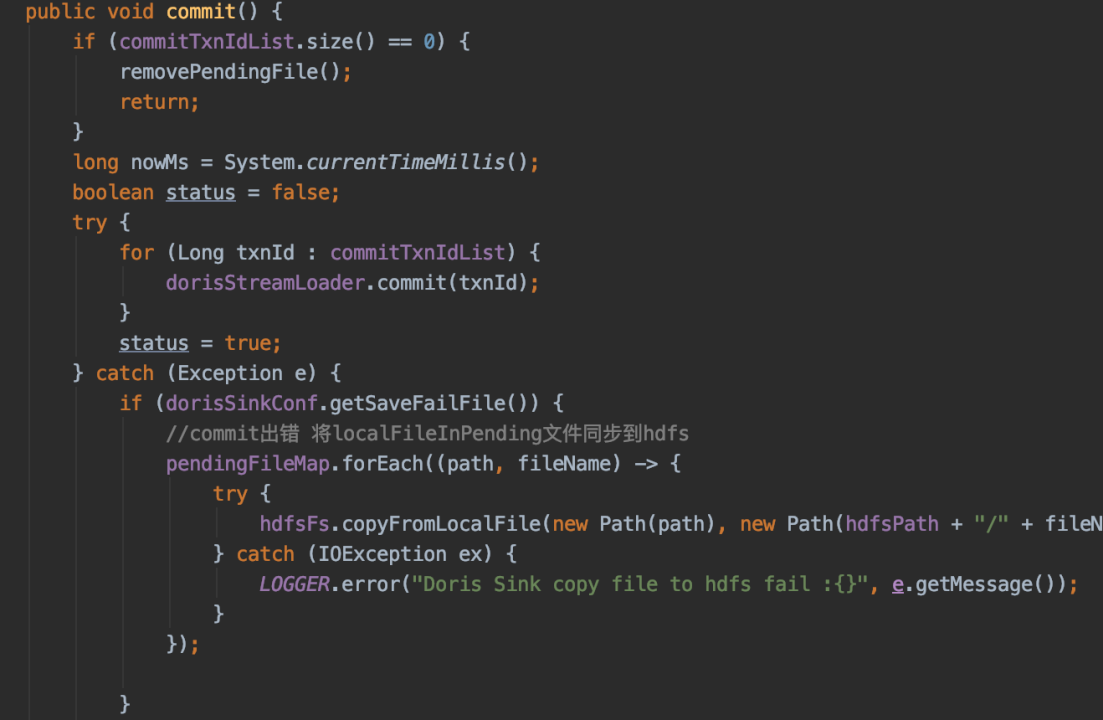
+下图为 Sink To Doris 的具体应用,整体工具屏蔽了 API 调用以及拓扑流的组装,只需要通过简单的配置即可完成 Stream Load 到 Doris 的数据写入 。
+
+
+
+
+### 集群监控
+
+在集群监控层面,我们采用了社区提供的监控模板,从集群指标监控、主机指标监控、数据处理监控三个方面出发来搭建 Doris 监控体系。其中集群指标监控和主机指标监控主要根据社区监控说明文档进行监控,以便我们查看集群整体运行的情况。除社区提供的模板之外,我们还新增了有关 Stream Load 的监控指标,比如对当前 Stream Load 数量以及写入数据量的监控,如下图所示:
+
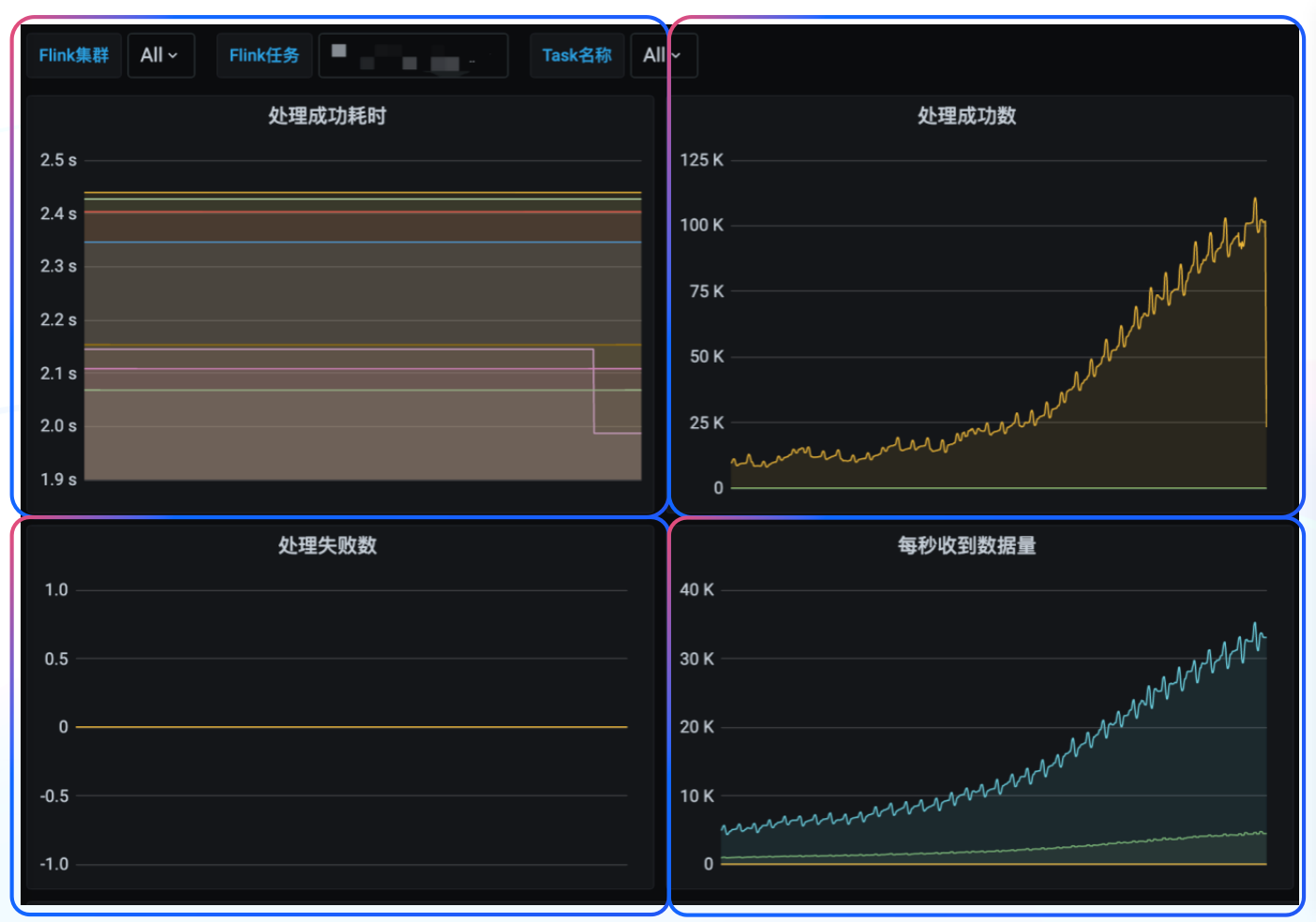
+
+
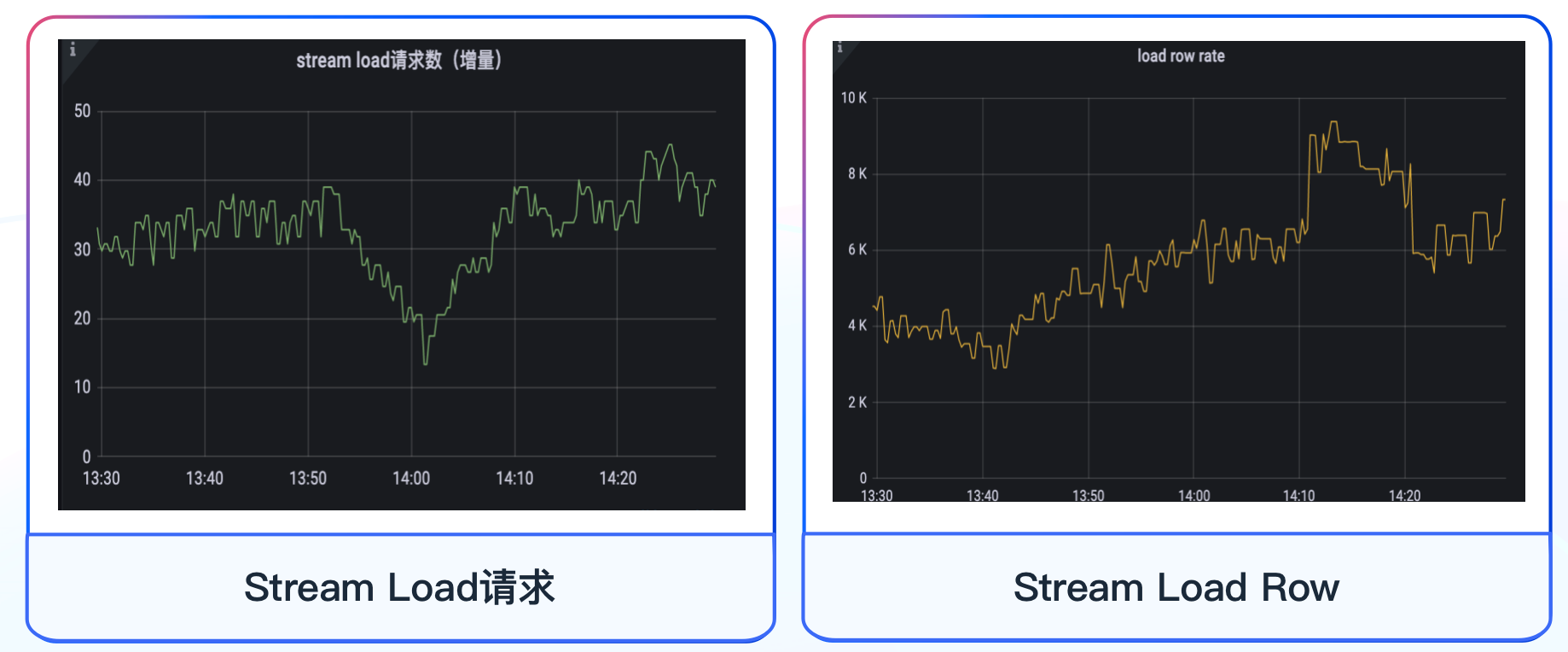
+除此之外,我们对数据写入 Doris 的时长以及写入的速度也比较关注,根据自身业务的需求,我们对任务写入数据速度、处理数据耗时等数据处理相关指标进行监控,帮助我们及时发现数据写入和读取的异常情况,借助公司内部的报警平台进行监控告警,报警方式支持电话、短信、推推、邮件等
+
+
+
+
+
+## 总结与规划
+
+目前 Apache Doris 主要应用于广告业务场景,**已有数十台集群机器,覆盖近 70% 的实时数据分析场景,实现了全量离线实验平台以及部分离线 DWS 层数据查询加速。当前日均新增数据规模可以达到百亿级别,在大部分实时场景中,其查询延迟在 1s 内**。同时,Apache Doris 的成功落地使得我们完成了实时数仓在 OLAP 引擎上的统一。Doris 优异的分析性能及简单易用的特点,也使得数仓架构更加简洁。
+
+未来我们将对 Doris 集群进行扩展,根据业务优先级进行资源隔离,完善资源管理机制,并计划将 Doris 应用到 360商业化内部更广泛的业务场景中,充分发挥 Doris 在 OLAP 场景的优势。最后我们将更加深入的参与到 Doris 社区中来,积极回馈社区,与 Doris 并肩同行,共同进步!
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/Compaction.md b/i18n/zh-CN/docusaurus-plugin-content-blog/Compaction.md
new file mode 100644
index 00000000000..277aeb9a3d7
--- /dev/null
+++ b/i18n/zh-CN/docusaurus-plugin-content-blog/Compaction.md
@@ -0,0 +1,219 @@
+---
+{
+ 'title': '资源消耗降低 90%,速度提升 50%,解读 Apache Doris Compaction 最新优化与实现',
+ 'summary': "在 Apache Doris 最新的 1.2.2 版本和即将发布的 2.0.0 版本中,我们对系统 Compaction 能力进行了全方位增强,在触发策略、执行方式、工程实现以及参数配置上都进行了大幅优化,在实时性、易用性与稳定性得到提升的同时更是彻底解决了查询效率问题。",
+ 'date': '2023-06-09',
+ 'author': 'Apache Doris',
+ 'tags': ['技术解析'],
+}
+
+
+---
+
+<!--
+Licensed to the Apache Software Foundation (ASF) under one
+or more contributor license agreements. See the NOTICE file
+distributed with this work for additional information
+regarding copyright ownership. The ASF licenses this file
+to you under the Apache License, Version 2.0 (the
+"License"); you may not use this file except in compliance
+with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing,
+software distributed under the License is distributed on an
+"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+KIND, either express or implied. See the License for the
+specific language governing permissions and limitations
+under the License.
+-->
+
+# 背景
+
+LSM-Tree( Log Structured-Merge Tree)是数据库中最为常见的存储结构之一,其核心思想在于充分发挥磁盘连续读写的性能优势、以短时间的内存与 IO 的开销换取最大的写入性能,数据以 Append-only 的方式写入 Memtable、达到阈值后冻结 Memtable 并 Flush 为磁盘文件、再结合 Compaction 机制将多个小文件进行多路归并排序形成新的文件,最终实现数据的高效写入。
+
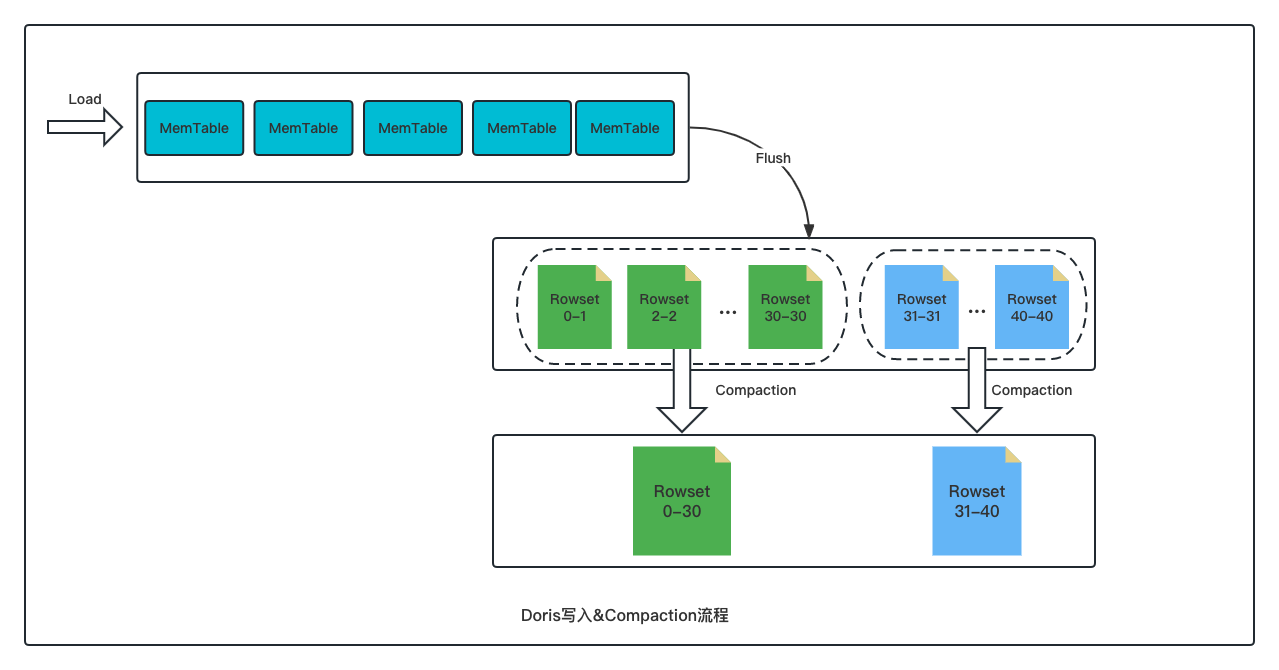
+[Apache Doris](https://github.com/apache/doris) 的存储模型也是采用类似的 LSM-Tree 数据模型。用户不同批次导入的数据会先写入内存结构,随后在磁盘上形成一个个的 Rowset 文件,每个 Rowset 文件对应一次数据导入版本。而 Doris 的 Compaction 则是负责将这些 Rowset 文件进行合并,将多个 Rowset 小文件合并成一个 Rowset 大文件。
+
+
+
+在此过程中 Compaction 发挥着以下作用:
+
+- 每个 Rowset 内的数据是按主键有序的,但 Rowset 与 Rowset 之间数据是无序的,Compaction 会将多个 Rowset 的数据从无序变为有序,提升数据在读取时的效率;
+- 数据以 Append-only 的方式进行写入,因此 Delete、Update 等操作都是标记写入,Compaction 会将标记的数据进行真正删除或更新,避免数据在读取时进行额外的扫描及过滤;
+- 在 Aggregate 模型上,Compaction 还可以将不同 Rowset 中相同 Key 的数据进行预聚合,减少数据读取时的聚合计算,进一步提升读取效率。
+
+# 问题与思考
+
+尽管 Compaction 在写入和查询性能方面发挥着十分关键的作用,但 Compaction 任务执行期间的写放大问题以及随之而来的磁盘 I/O 和 CPU 资源开销,也为系统稳定性和性能的充分发挥带来了新的挑战。
+
+在用户真实场景中,往往面临着各式各样的数据写入需求,并行写入任务的多少、单次提交数据量的大小、提交频次的高低等,各种场景可能需要搭配不同的 Compaction 策略。而不合理的 Compaction 策略则会带来一系列问题:
+
+- Compaction 任务调度不及时导致大量版本堆积、Compaction Score 过高,最终导致写入失败(-235/-238);
+- Compaction 任务执行速度慢,CPU 消耗高;
+- Compaction 任务内存占用高,影响查询性能甚至导致 BE OOM;
+
+与此同时,尽管 Apache Doris 提供了多个参数供用户进行调整,但相关参数众多且语义复杂,用户理解成本过高,也为人工调优增加了难度。
+
+
+
+
+基于以上问题,从 Apache Doris 1.1.0 版本开始,我们增加了主动触发式 QuickCompaction、引入了 Cumulative Compaction 任务的隔离调度并增加了小文件合并的梯度合并策略,对高并发写入和数据实时可见等场景都进行了针对性优化。
+
+而在 Apache Doris 最新的 1.2.2 版本和即将发布的 2.0.0 版本中,我们对系统 Compaction 能力进行了全方位增强,**在触发策略、执行方式 、 工程实现以及参数配置上都进行了大幅优化,** **在实时性、易用性与稳定性得到提升的同时更是彻底解决了查询效率问题**。
+
+# Compaction 优化与实现
+
+在设计和评估 Compaction 策略之时,我们需要综合权衡 Compaction 的任务模型和用户真实使用场景,核心优化思路包含以下几点:
+
+- **实时性和高效性**。Compaction 任务触发策略的实时性和任务执行方式的高效性直接影响到了查询执行的速度,版本堆积将导致 Compaction Score 过高且触发自我保护机制,导致后续数据写入失败。
+- **稳定性**。Compaction 任务对系统资源的消耗可控,不会因 Compaction 任务带来过多的内存与 CPU 开销造成系统不稳定。
+- **易用性**。由于 Compaction 任务涉及调度、策略、执行多个逻辑单元,部分特殊场景需要对 Compaction 进行调优,因此需要 Compaction 涉及的参数能够精简明了,指导用户快速进行场景化的调优。
+
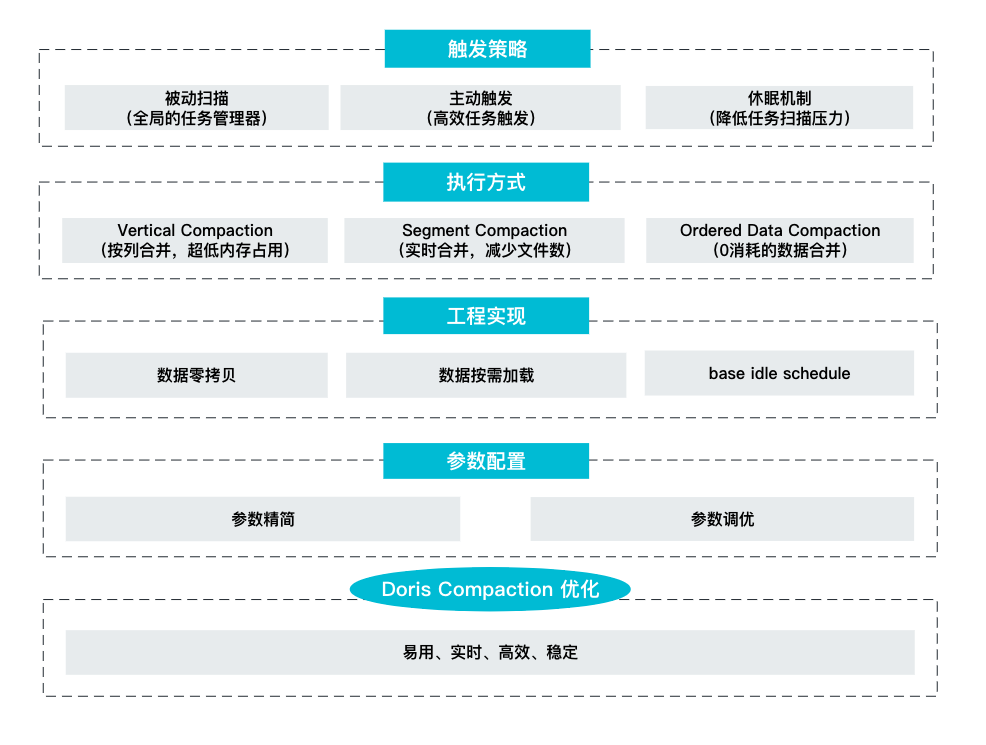
+具体在实现过程中,包含了触发策略、执行方式、工程实现以及参数配置这四个方面的优化。
+
+
+
+### Compaction 触发策略
+
+调度策略决定着 Compaction 任务的实时性。在 Apache Doris 2.0.0 版本中,我们在主动触发和被动扫描这两种方式的基础之上引入了 Tablet 休眠机制,力求在各类场景均能以最低的消耗保障最高的实时性。
+
+#### 主动触发
+
+主动触发是一种最为实时的方式,在数据导入的阶段就检查 Tablet 是否有待触发的 Compaction 任务,这样的方式保证了 Compaction 任务与数据导入任务同步进行,在新版本产生的同时就能够立即触发数据合并,能够让 Tablet 版本数维持在一个非常稳定的状态。主动触发主要针对增量数据的 Compaction (Cumulative Compaction),存量数据则依赖被动扫描完成。
+
+#### 被动扫描
+
+与主动触发不同,被动扫描主要负责触发大数据量的 Base Compaction 任务。Doris 通过启动一个后台线程,对该节点上所有的 Tablet 元数据进行扫描,根据 Tablet Compaction 任务的紧迫程度进行打分,选择得分最高的 Tablet 触发 Compaction 任务。这样的全局扫描模式能够选出最紧急的 Tablet 进行 Compaction,但一般其执行周期较长,所以需要配合主动触发策略实施。
+
+#### 休眠机制
+
+频繁的元信息扫描会导致大量的 CPU 资源浪费。因此在 Doris 2.0.0 版本中我们引入了 Tablet 休眠机制,来降低元数据扫描带来的 CPU 开销。通过对长时间没有 Compaction 任务的 Tablet 设置休眠时间,一段时间内不再对该 Tablet 进行扫描,能够大幅降低任务扫描的压力。同时如果休眠的 Tablet 有突发的导入,通过主动触发的方式也能顾唤醒 Compaction 任务,不会对任务的实时性有任何影响。
+
+通过上述的主动扫描+被动触发+休眠机制,使用最小的资源消耗,保证了 Compaction 任务触发的实时性。
+
+### Compaction 执行方式
+
+在 Doris 1.2.2 版本中中,我们引入了两种全新的 Compaction 执行方式:
+
+- Vertical Compaction,用以彻底解决 Compaction 的内存问题以及大宽表场景下的数据合并;
+- Segment Compaction,用以彻底解决上传过程中的 Segment 文件过多问题;
+
+而在即将发布的 Doris 2.0.0 版本,我们引入了 Ordered Data Compaction 以提升时序数据场景的数据合并能力。
+
+#### Vertical Compaction
+
+在之前的版本中,Compaction 通常采用行的方式进行,每次合并的基本单元为整行数据。由于存储引擎采用列式存储,行 Compaction 的方式对数据读取极其不友好,每次 Compaction 都需要加载所有列的数据,内存消耗极大,而这样的方式在宽表场景下也将带来内存的极大消耗。
+
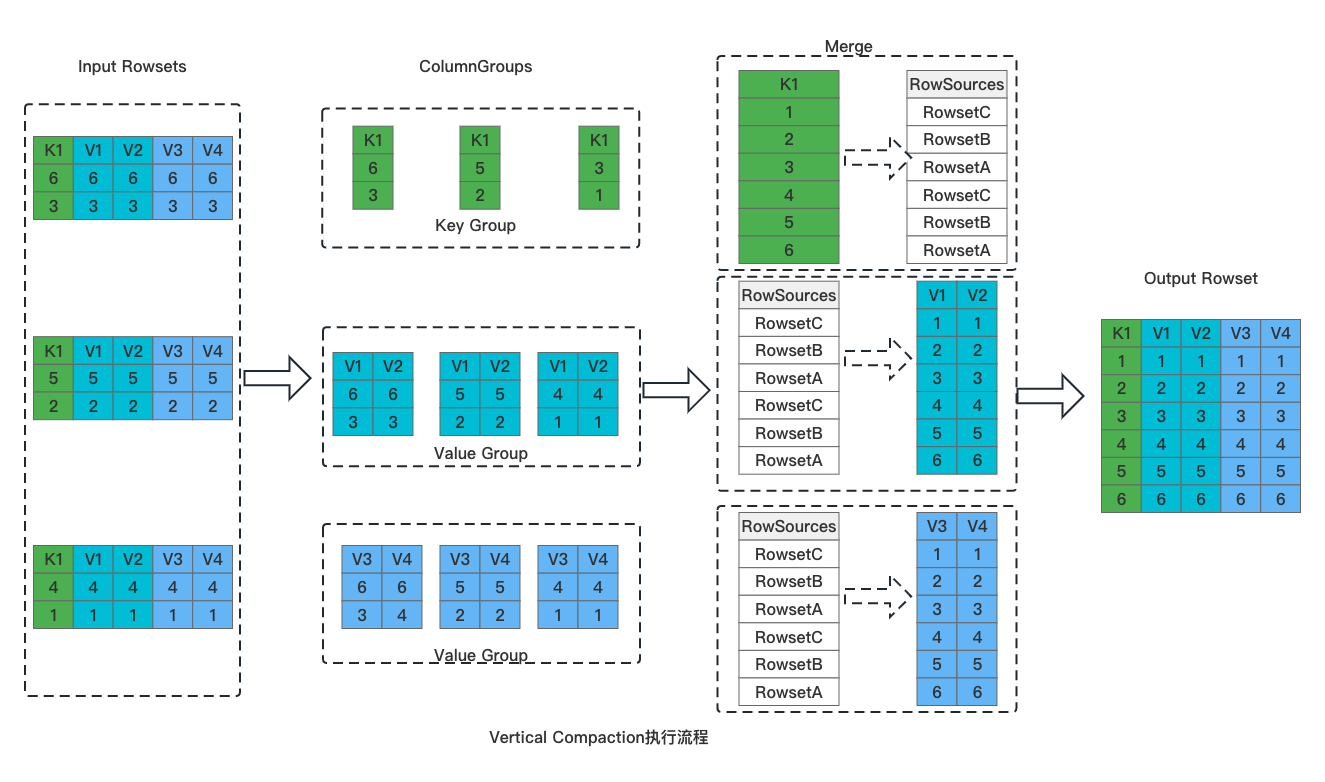
+针对上述问题,我们在 Doris 1.2.2 版本中实现了对列式存储更加友好的 Vertical Compaction,具体执行流程如下图:
+
+
+
+整体分为如下几个步骤:
+
+1. 切分列组。将输入 Rowset 按照列进行切分,所有的 Key 列一组、Value 列按 N 个一组,切分成多个 Column Group;
+1. Key 列合并。Key 列的顺序就是最终数据的顺序,多个 Rowset 的 Key 列采用堆排序进行合并,产生最终有序的 Key 列数据。在产生 Key 列数据的同时,会同时产生用于标记全局序 RowSources。
+1. Value 列的合并。逐一合并 Column Group 中的 Value 列,以 Key 列合并时产生的 RowSources 为依据对数据进行排序。
+1. 数据写入。数据按列写入,形成最终的 Rowset 文件。
+
+由于采用了按列组的方式进行数据合并,Vertical Compaction 天然与列式存储更加贴合,使用列组的方式进行数据合并,单次合并只需要加载部分列的数据,因此能够极大减少合并过程中的内存占用。在实际测试中,**Vertical** **C** **ompaction 使用内存仅为原有 Compaction 算法的 1/10,同时 Compaction 速率提升 15%。**
+
+Vertical Compaction 在 1.2.2 版本中默认关闭状态,需要在 BE 配置项中设置 `enable_vertical_compaction=true` 开启该功能。
+
+相关PR:https://github.com/apache/doris/pull/14524
+
+
+
+
+
+
+
+#### Segment Compaction
+
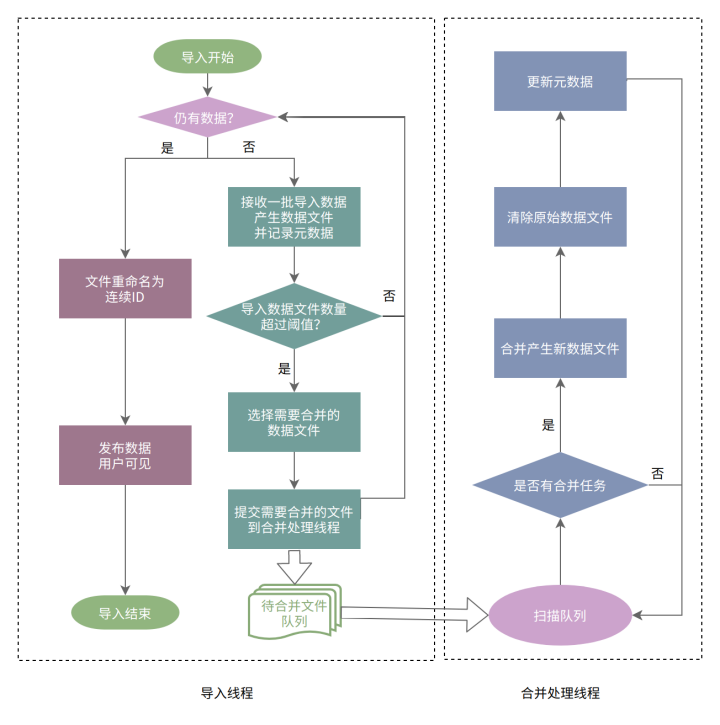
+在数据导入阶段,Doris 会在内存中积攒数据,到达一定大小时 Flush 到磁盘形成一个个的 Segment 文件。大批量数据导入时会形成大量的 Segment 文件进而影响后续查询性能,基于此 Doris 对一次导入的 Segment 文件数量做了限制。当用户导入大量数据时,可能会触发这个限制,此时系统将反馈 -238 (TOO_MANY_SEGMENTS) 同时终止对应的导入任务。Segment compaction 允许我们在导入数据的同时进行数据的实时合并,以有效控制 Segment 文件的数量,增加系统所能承载的导入数据量,同时优化后续查询效率。具体流程如下所示:
+
+
+
+在新增的 Segment 数量超过一定阈值(例如 10)时即触发该任务执行,由专门的合并线程异步执行。通过将每组 10个 Segment 合并成一个新的 Segment 并删除旧 Segment,导入完成后的实际 Segment 文件数量将下降 10 倍。Segment Compaction 会伴随导入的过程并行执行,在大数据量导入的场景下,能够在不显著增加导入时间的前提下大幅降低文件个数,提升查询效率。
+
+Segment Compaction 在 1.2.2 版本中默认关闭状态,需要在 BE 配置项中设置 ` enable_segcompaction = true `开启该功能。
+
+相关 PR : https://github.com/apache/doris/pull/12866
+
+
+#### Ordered Data Compaction
+
+随着越来越多用户在时序数据分析场景应用 Apache Doris,我们在 Apache Doris 2.0.0 版本实现了全新的 Ordered Data Compaction。
+
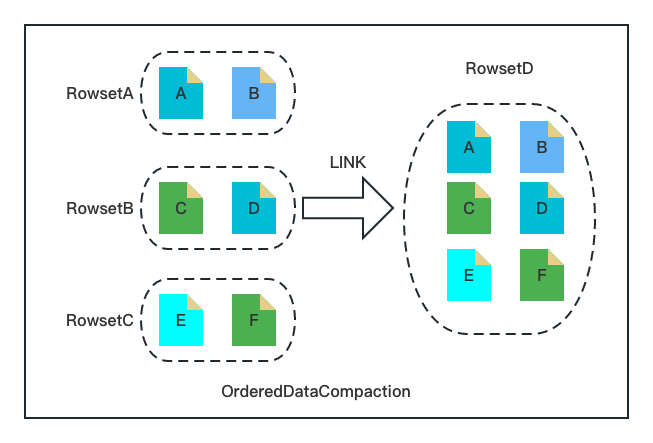
+时序数据分析场景一般具备如下特点:数据整体有序、写入速率恒定、单次导入文件大小相对平均。针对如上特点,Ordered Data Compaction 无需遍历数据,跳过了传统 Compaction 复杂的读数据、排序、聚合、输出的流程,通过文件 Link 的方式直接操作底层文件生成 Compaction 的目标文件。
+
+
+
+
+Ordered Data Compaction 执行流程包含如下几个关键阶段:
+
+1. 数据上传阶段。记录 Rowset 文件的 Min/Max Key,用于后续合并 Rowset 数据交叉性的判断;
+1. 数据检查阶段。检查参与 Compaction 的 Rowset 文件的有序性与整齐度,主要通过数据上传阶段的 Min /Max Key 以及文件大小进行判断。
+1. 数据合并阶段。将输入 Rowset 的文件硬链接到新 Rowset,然后构建新 Rowset 的元数据(包括行数,Size,Min/Max Key 等)。
+
+可以看到上述阶段与传统的 Compaction 流程完全不一样,只需要文件的 Link 以及内存元信息的构建,极其简洁、轻量。**针对时序场景设计的 Ordered Data Compaction 能够在毫秒级别完成大规模的 Compaction 任务,其内存消耗几乎为** ******0,对用户极其友好。**
+
+Ordered Data Compaction 在 2.0.0 版本中默认开启状态,如需调整在 BE 配置项中修改 ` enable_segcompaction `即可。
+
+使用方式:BE 配置 `enable_ordered_data_compaction=true`
+
+### Compaction 工程实现
+
+除了上述在触发策略和 Compaction 算法上的优化之外,Apache Doris 2.0.0 版本还对 Compaction 的工程实现进行了大量细节上的优化,包括数据零拷贝、按需加载、Idle Schedule 等。
+
+#### **数据零拷贝**
+
+Doris 采用分层的数据存储模型,数据在 BE 上可以分为如下几层:Tablet -> Rowset -> Segment -> Column -> Page,数据需要经过逐层处理。由于 Compaction 每次参与的数据量大,数据在各层之间的流转会带来大量的 CPU 消耗,在新版本中我们设计并实现了全流程无拷贝的 Compaction 逻辑,Block 从文件加载到内存中后,后续无序再进行拷贝,各个组件的使用都通过一个 BlockView 的数据结构完成,这样彻底的解决了数据逐层拷贝的问题,将 Compaction 的效率再次提升了 5%。
+
+#### **按需加载**
+
+Compaction 的逻辑本质上是要将多个无序的 Rowset 合并成一个有序的 Rowset,在大部分场景中,Rowset 内或者 Rowset 间的数据并不是完全无序的,可以充分利用局部有序性进行数据合并,在同一时间仅需加载有序文件中的第一个,这样随着合并的进行再逐渐加载。利用数据的局部有序性按需加载,能够极大减少数据合并过程中的内存消耗。
+
+#### **Idle schedule**
+
+在实际运行过程中,由于部分 Compaction 任务占用资源多、耗时长,经常出现因为 Compaction 任务影响查询性能的 Case。这类 Compaction 任务一般存在于 Base compaction 中,具备数据量大、执行时间长、版本合并少的特点,对任务执行的实时性要求不高。在新版本中,针对此类任务开启了线程 Idle Schedule 特性,降低此类任务的执行优先级,避免 Compaction 任务造成线上查询的性能波动。
+
+### 易用性
+
+在 Compaction 的易用性方面,Doris 2.0.0 版本进行了系统性优化。结合长期以来 Compaction 调优的一些经验数据,默认配置了一套通用环境下表现最优的参数,同时大幅精简了 Compaction 相关参数及语义,方便用户在特殊场景下的 Compaction 调优。
+
+
+
+# 总结规划
+
+通过上述一系列的优化方式, 全新版本在 Compaction 过程中取得了极为显著的改进效果。在 ClickBench 性能测试中,**新版本 Compaction 执行速度** **达到 30w row/s,相较于旧版本** **提升** **了** **50** **%** **;资源消耗降幅巨大,** **内存占用仅为原先的 10%** 。高并发数据导入场景下,Compaction Score 始终保持在 50 左右,且系统表现极为平稳。同时在时序数据场景中,Compaction 写放大系数降低 90%,极大提升了可承载的写入吞吐量。
+
+后续我们仍将进一步探索迭代优化的空间,主要的工作方向将聚焦在自动化、可观测性以及执行效率等方向上:
+
+1. 自动化调优。针对不同的用户场景,无需人工干预,系统支持进行自动化的 Compaction 调优;
+1. 可观测性增强。收集统计 Compaction 任务的各项指标,用于指导自动化以及手动调优;
+1. 并行 Vertical Compaction。通过 Value 列并发执行,进一步提升 Vertical Compaction 效率。
+
+以上方向的工作都已处于规划或开发中,如果有小伙伴对以上方向感兴趣,也欢迎参与到社区中的开发来。期待有更多人参与到 Apache Doris 社区的建设中 ,欢迎你的加入!
+
+# 作者介绍:
+
+一休,Apache Doris contributor,SelectDB 资深研发工程师
+
+张正宇,Apache Doris contributor,SelectDB 资深研发工程师
+
+
+
+**# 相关链接:**
+
+**SelectDB 官网**:
+
+https://selectdb.com
+
+**Apache Doris 官网**:
+
+http://doris.apache.org
+
+**Apache Doris Github**:
+
+https://github.com/apache/doris
diff --git a/static/images/360_1.png b/static/images/360_1.png
new file mode 100644
index 00000000000..7e066ebce1f
Binary files /dev/null and b/static/images/360_1.png differ
diff --git a/static/images/360_2.png b/static/images/360_2.png
new file mode 100644
index 00000000000..c255a327f34
Binary files /dev/null and b/static/images/360_2.png differ
diff --git a/static/images/360_3.png b/static/images/360_3.png
new file mode 100644
index 00000000000..3cd874b3937
Binary files /dev/null and b/static/images/360_3.png differ
diff --git a/static/images/360_4.png b/static/images/360_4.png
new file mode 100644
index 00000000000..436aee4d0d8
Binary files /dev/null and b/static/images/360_4.png differ
diff --git a/static/images/360_5.png b/static/images/360_5.png
new file mode 100644
index 00000000000..a406a2e6602
Binary files /dev/null and b/static/images/360_5.png differ
diff --git a/static/images/360_6.png b/static/images/360_6.png
new file mode 100644
index 00000000000..9d2584e48e1
Binary files /dev/null and b/static/images/360_6.png differ
diff --git a/static/images/360_7.png b/static/images/360_7.png
new file mode 100644
index 00000000000..509f341fb34
Binary files /dev/null and b/static/images/360_7.png differ
diff --git a/static/images/360_8.png b/static/images/360_8.png
new file mode 100644
index 00000000000..7e82fbd770f
Binary files /dev/null and b/static/images/360_8.png differ
diff --git a/static/images/Compaction_1.png b/static/images/Compaction_1.png
new file mode 100644
index 00000000000..5194d450cf2
Binary files /dev/null and b/static/images/Compaction_1.png differ
diff --git a/static/images/Compaction_2.png b/static/images/Compaction_2.png
new file mode 100644
index 00000000000..792b456d8e5
Binary files /dev/null and b/static/images/Compaction_2.png differ
diff --git a/static/images/Compaction_3.png b/static/images/Compaction_3.png
new file mode 100644
index 00000000000..4d0f2486be8
Binary files /dev/null and b/static/images/Compaction_3.png differ
diff --git a/static/images/Compaction_4.png b/static/images/Compaction_4.png
new file mode 100644
index 00000000000..63c5d432451
Binary files /dev/null and b/static/images/Compaction_4.png differ
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org