You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@phoenix.apache.org by mu...@apache.org on 2014/02/13 01:22:24 UTC
[2/4] Verify license compliance using Apache Rat. Remove unused
phoenix website generation code.
https://issues.apache.org/jira/browse/PHOENIX-45
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/Phoenix-in-15-minutes-or-less.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/Phoenix-in-15-minutes-or-less.md b/src/site/markdown/Phoenix-in-15-minutes-or-less.md
deleted file mode 100644
index bc01b18..0000000
--- a/src/site/markdown/Phoenix-in-15-minutes-or-less.md
+++ /dev/null
@@ -1,80 +0,0 @@
-# Phoenix in 15 minutes or less
-
-*<strong>What is this new [Phoenix](index.html) thing I've been hearing about?</strong>*<br/>
-Phoenix is an open source SQL skin for HBase. You use the standard JDBC APIs instead of the regular HBase client APIs to create tables, insert data, and query your HBase data.
-
-*<strong>Doesn't putting an extra layer between my application and HBase just slow things down?</strong>*<br/>
-Actually, no. Phoenix achieves as good or likely better [performance](performance.html) than if you hand-coded it yourself (not to mention with a heck of a lot less code) by:
-* compiling your SQL queries to native HBase scans
-* determining the optimal start and stop for your scan key
-* orchestrating the parallel execution of your scans
-* bringing the computation to the data by
- * pushing the predicates in your where clause to a server-side filter
- * executing aggregate queries through server-side hooks (called co-processors)
-
-In addition to these items, we've got some interesting enhancements in the works to further optimize performance:
-* secondary indexes to improve performance for queries on non row key columns
-* stats gathering to improve parallelization and guide choices between optimizations
-* skip scan filter to optimize IN, LIKE, and OR queries
-* optional salting of row keys to evenly distribute write load
-
-*<strong>Ok, so it's fast. But why SQL? It's so 1970s</strong>*<br/>
-Well, that's kind of the point: give folks something with which they're already familiar. What better way to spur the adoption of HBase? On top of that, using JDBC and SQL:
-* Reduces the amount of code users need to write
-* Allows for performance optimizations transparent to the user
-* Opens the door for leveraging and integrating lots of existing tooling
-
-*<strong>But how can SQL support my favorite HBase technique of x,y,z</strong>*<br/>
-Didn't make it to the last HBase Meetup did you? SQL is just a way of expressing *<strong>what you want to get</strong>* not *<strong>how you want to get it</strong>*. Check out my [presentation](http://files.meetup.com/1350427/IntelPhoenixHBaseMeetup.ppt) for various existing and to-be-done Phoenix features to support your favorite HBase trick. Have ideas of your own? We'd love to hear about them: file an [issue](issues.html) for us and/or join our [mailing list](mailing_list.html).
-
-*<strong>Blah, blah, blah - I just want to get started!</strong>*<br/>
-Ok, great! Just follow our [install instructions](download.html#Installation):
-* [download](download.html) and expand our installation tar
-* copy the phoenix jar into the HBase lib directory of every region server
-* restart the region servers
-* add the phoenix client jar to the classpath of your HBase client
-* download and [setup SQuirrel](download.html#SQL-Client) as your SQL client so you can issue adhoc SQL against your HBase cluster
-
-*<strong>I don't want to download and setup anything else!</strong>*<br/>
-Ok, fair enough - you can create your own SQL scripts and execute them using our command line tool instead. Let's walk through an example now. In the bin directory of your install location:
-* Create us_population.sql file
-<pre><code>CREATE TABLE IF NOT EXISTS us_population (
- state CHAR(2) NOT NULL,
- city VARCHAR NOT NULL,
- population BIGINT
- CONSTRAINT my_pk PRIMARY KEY (state, city));</code></pre>
-* Create us_population.csv file
-<pre><code>NY,New York,8143197
-CA,Los Angeles,3844829
-IL,Chicago,2842518
-TX,Houston,2016582
-PA,Philadelphia,1463281
-AZ,Phoenix,1461575
-TX,San Antonio,1256509
-CA,San Diego,1255540
-TX,Dallas,1213825
-CA,San Jose,912332
-</code></pre>
-* Create us_population_queries.sql file
-<pre><code>SELECT state as "State",count(city) as "City Count",sum(population) as "Population Sum"
-FROM us_population
-GROUP BY state
-ORDER BY sum(population) DESC;
-</code></pre>
-* Execute the following command from a command terminal
-<pre><code>./psql.sh <your_zookeeper_quorum> us_population.sql us_population.csv us_population_queries.sql
-</code></pre>
-
-Congratulations! You've just created your first Phoenix table, inserted data into it, and executed an aggregate query with just a few lines of code in 15 minutes or less!
-
-*<strong>Big deal - 10 rows! What else you got?</strong>*<br/>
-Ok, ok - tough crowd. Check out our <code>bin/performance.sh</code> script to create as many rows as you want, for any schema you come up with, and run timed queries against it.
-
-*<strong>Why is it called Phoenix anyway? Did some other project crash and burn and this is the next generation?</strong>*<br/>
-I'm sorry, but we're out of time and space, so we'll have to answer that next time!
-
-Thanks for your time,<br/>
-James Taylor<br/>
-http://phoenix-hbase.blogspot.com/
-<br/>
-@JamesPlusPlus<br/>
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/building.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/building.md b/src/site/markdown/building.md
deleted file mode 100644
index 92f9a6f..0000000
--- a/src/site/markdown/building.md
+++ /dev/null
@@ -1,20 +0,0 @@
-# Building Phoenix Project
-
-Phoenix is a fully mavenized project. That means you can build simply by doing:
-```
- $ mvn package
-```
-
-builds, test and package Phoenix and put the resulting jars (phoenix-[version].jar and phoenix-[version]-client.jar) in the generated target/ directory.
-
-To build, but skip running the tests, you can do:
-```
- $ mvn package -DskipTests
-```
-To only build the generated parser (i.e. <code>PhoenixSQLLexer</code> and <code>PhoenixSQLParser</code>), you can do:
-```
- $ mvn process-sources
-```
-
-To build an Eclipse project, install the m2e plugin and do an File->Import...->Import Existing Maven Projects selecting the root directory of Phoenix.
-
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/download.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/download.md b/src/site/markdown/download.md
deleted file mode 100644
index 147bc78..0000000
--- a/src/site/markdown/download.md
+++ /dev/null
@@ -1,84 +0,0 @@
-## Available Phoenix Downloads
-
-### Download link will be available soon.
-
-<br/>
-
-### Installation ###
-To install a pre-built phoenix, use these directions:
-
-* Download and expand the latest phoenix-[version]-install.tar
-* Add the phoenix-[version].jar to the classpath of every HBase region server. An easy way to do this is to copy it into the HBase lib directory.
-* Restart all region servers.
-* Add the phoenix-[version]-client.jar to the classpath of any Phoenix client.
-
-### Getting Started ###
-Wanted to get started quickly? Take a look at our [FAQs](faq.html) and take our quick start guide [here](Phoenix-in-15-minutes-or-less.html).
-
-<h4>Command Line</h4>
-
-A terminal interface to execute SQL from the command line is now bundled with Phoenix. To start it, execute the following from the bin directory:
-
- $ sqlline.sh localhost
-
-To execute SQL scripts from the command line, you can include a SQL file argument like this:
-
- $ sqlline.sh localhost ../examples/stock_symbol.sql
-
-
-
-For more information, see the [manual](http://www.hydromatic.net/sqlline/manual.html).
-
-<h5>Loading Data</h5>
-
-In addition, you can use the bin/psql.sh to load CSV data or execute SQL scripts. For example:
-
- $ psql.sh localhost ../examples/web_stat.sql ../examples/web_stat.csv ../examples/web_stat_queries.sql
-
-Other alternatives include:
-* Using our [map-reduce based CSV loader](mr_dataload.html) for bigger data sets
-* [Mapping an existing HBase table to a Phoenix table](index.html#Mapping-to-an-Existing-HBase-Table) and using the [UPSERT SELECT](language/index.html#upsert_select) command to populate a new table.
-* Populating the table through our [UPSERT VALUES](language/index.html#upsert_values) command.
-
-<h4>SQL Client</h4>
-
-If you'd rather use a client GUI to interact with Phoenix, download and install [SQuirrel](http://squirrel-sql.sourceforge.net/). Since Phoenix is a JDBC driver, integration with tools such as this are seamless. Here are the setup steps necessary:
-
-1. Remove prior phoenix-[version]-client.jar from the lib directory of SQuirrel
-2. Copy the phoenix-[version]-client.jar into the lib directory of SQuirrel (Note that on a Mac, this is the *internal* lib directory).
-3. Start SQuirrel and add new driver to SQuirrel (Drivers -> New Driver)
-4. In Add Driver dialog box, set Name to Phoenix
-5. Press List Drivers button and org.apache.phoenix.jdbc.PhoenixDriver should be automatically populated in the Class Name textbox. Press OK to close this dialog.
-6. Switch to Alias tab and create the new Alias (Aliases -> New Aliases)
-7. In the dialog box, Name: _any name_, Driver: Phoenix, User Name: _anything_, Password: _anything_
-8. Construct URL as follows: jdbc:phoenix: _zookeeper quorum server_. For example, to connect to a local HBase use: jdbc:phoenix:localhost
-9. Press Test (which should succeed if everything is setup correctly) and press OK to close.
-10. Now double click on your newly created Phoenix alias and click Connect. Now you are ready to run SQL queries against Phoenix.
-
-Through SQuirrel, you can issue SQL statements in the SQL tab (create tables, insert data, run queries), and inspect table metadata in the Object tab (i.e. list tables, their columns, primary keys, and types).
-
-
-
-### Samples ###
-The best place to see samples are in our unit tests under src/test/java. The ones in the endToEnd package are tests demonstrating how to use all aspects of the Phoenix JDBC driver. We also have some examples in the examples directory.
-
-### Phoenix Client - Server Compatibility
-
-Major and minor version should match between client and server (patch version can mismatch). Following is the list of compatible client and server version(s). It is recommended that same client and server version are used.
-
-Phoenix Client Version | Compatible Server Versions
------------------------|---
-1.0.0 | 1.0.0
-1.1.0 | 1.1.0
-1.2.0 | 1.2.0, 1.2.1
-1.2.1 | 1.2.0, 1.2.1
-2.0.0 | 2.0.0, 2.0.1, 2.0.2
-2.0.1 | 2.0.0, 2.0.1, 2.0.2
-2.0.2 | 2.0.0, 2.0.1, 2.0.2
-2.1.0 | 2.1.0, 2.1.1, 2.1.2
-2.1.1 | 2.1.0, 2.1.1, 2.1.2
-2.1.2 | 2.1.0, 2.1.1, 2.1.2
-2.2.0 | 2.2.0, 2.2.1
-2.2.1 | 2.2.0, 2.2.1
-
-[](http://githalytics.com/forcedotcom/phoenix.git)
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/dynamic_columns.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/dynamic_columns.md b/src/site/markdown/dynamic_columns.md
deleted file mode 100644
index 0c7d9ce..0000000
--- a/src/site/markdown/dynamic_columns.md
+++ /dev/null
@@ -1,17 +0,0 @@
-# Dynamic Columns
-
-Sometimes defining a static schema up front is not feasible. Instead, a subset of columns may be specified at table [create](language/index.html#create) time while the rest would be specified at [query](language/index.html#select) time. As of Phoenix 1.2, specifying columns dynamically is now supported by allowing column definitions to included in parenthesis after the table in the <code>FROM</code> clause on a <code>SELECT</code> statement. Although this is not standard SQL, it is useful to surface this type of functionality to leverage the late binding ability of HBase.
-
-For example:
-
- SELECT eventTime, lastGCTime, usedMemory, maxMemory
- FROM EventLog(lastGCTime TIME, usedMemory BIGINT, maxMemory BIGINT)
- WHERE eventType = 'OOM' AND lastGCTime < eventTime - 1
-
-Where you may have defined only a subset of your event columns at create time, since each event type may have different properties:
-
- CREATE TABLE EventLog (
- eventId BIGINT NOT NULL,
- eventTime TIME NOT NULL,
- eventType CHAR(3) NOT NULL
- CONSTRAINT pk PRIMARY KEY (eventId, eventTime))
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/faq.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/faq.md b/src/site/markdown/faq.md
deleted file mode 100644
index cbcfc0a..0000000
--- a/src/site/markdown/faq.md
+++ /dev/null
@@ -1,279 +0,0 @@
-# F.A.Q.
-
-* [I want to get started. Is there a Phoenix Hello World?](#I_want_to_get_started_Is_there_a_Phoenix_Hello_World)
-* [Is there a way to bulk load in Phoenix?](#Is_there_a_way_to_bulk_load_in_Phoenix)
-* [How do I create a VIEW in Phoenix? What's the difference between a VIEW and a TABLE?](#How_I_create_Views_in_Phoenix_Whatnulls_the_difference_between_ViewsTables)
-* [Are there any tips for optimizing Phoenix?](#Are_there_any_tips_for_optimizing_Phoenix)
-* [How do I create Secondary Index on a table?](#How_do_I_create_Secondary_Index_on_a_table)
-* [Why isn't my secondary index being used?](#Why_isnnullt_my_secondary_index_being_used)
-* [How fast is Phoenix? Why is it so fast?](#How_fast_is_Phoenix_Why_is_it_so_fast)
-* [How do I connect to secure HBase cluster?](#How_do_I_connect_to_secure_HBase_cluster)
-* [How do I connect with HBase running on Hadoop-2?](#How_do_I_connect_with_HBase_running_on_Hadoop-2)
-* [Can phoenix work on tables with arbitrary timestamp as flexible as HBase API?](#Can_phoenix_work_on_tables_with_arbitrary_timestamp_as_flexible_as_HBase_API)
-* [Why isn't my query doing a RANGE SCAN?](#Why_isnnullt_my_query_doing_a_RANGE_SCAN)
-
-
-### I want to get started. Is there a Phoenix _Hello World_?
-
-*Pre-requisite:* Download latest Phoenix from [here](download.html)
-and copy phoenix-*.jar to HBase lib folder and restart HBase.
-
-**1. Using console**
-
-1. Start Sqlline: `$ sqlline.sh [zookeeper]`
-2. Execute the following statements when Sqlline connects:
-
-```
-create table test (mykey integer not null primary key, mycolumn varchar);
-upsert into test values (1,'Hello');
-upsert into test values (2,'World!');
-select * from test;
-```
-
-3. You should get the following output
-
-```
-+-------+------------+
-| MYKEY | MYCOLUMN |
-+-------+------------+
-| 1 | Hello |
-| 2 | World! |
-+-------+------------+
-```
-
-
-**2. Using java**
-
-Create test.java file with the following content:
-
-```
-import java.sql.Connection;
-import java.sql.DriverManager;
-import java.sql.ResultSet;
-import java.sql.SQLException;
-import java.sql.PreparedStatement;
-import java.sql.Statement;
-
-public class test {
-
- public static void main(String[] args) throws SQLException {
- Statement stmt = null;
- ResultSet rset = null;
-
- Connection con = DriverManager.getConnection("jdbc:phoenix:[zookeeper]");
- stmt = con.createStatement();
-
- stmt.executeUpdate("create table test (mykey integer not null primary key, mycolumn varchar)");
- stmt.executeUpdate("upsert into test values (1,'Hello')");
- stmt.executeUpdate("upsert into test values (2,'World!')");
- con.commit();
-
- PreparedStatement statement = con.prepareStatement("select * from test");
- rset = statement.executeQuery();
- while (rset.next()) {
- System.out.println(rset.getString("mycolumn"));
- }
- statement.close();
- con.close();
- }
-}
-```
-Compile and execute on command line
-
-`$ javac test.java`
-
-`$ java -cp "../phoenix-[version]-client.jar:." test`
-
-
-You should get the following output
-
-`Hello`
-`World!`
-
-
-
-### Is there a way to bulk load in Phoenix?
-
-**Map Reduce**
-
-See the example [here](mr_dataload.html) Credit: Arun Singh
-
-**CSV**
-
-CSV data can be bulk loaded with built in utility named psql. Typical upsert rates are 20K - 50K rows per second (depends on how wide are the rows).
-
-Usage example:
-Create table using psql
-`$ psql.sh [zookeeper] ../examples/web_stat.sql`
-
-Upsert CSV bulk data
-`$ psql.sh [zookeeper] ../examples/web_stat.csv`
-
-
-
-### How I create Views in Phoenix? What's the difference between Views/Tables?
-
-You can create both a Phoenix table or view through the CREATE TABLE/CREATE VIEW DDL statement on a pre-existing HBase table. In both cases, we'll leave the HBase metadata as-is, except for with a TABLE we turn KEEP_DELETED_CELLS on. For CREATE TABLE, we'll create any metadata (table, column families) that doesn't already exist. We'll also add an empty key value for each row so that queries behave as expected (without requiring all columns to be projected during scans).
-
-The other caveat is that the way the bytes were serialized must match the way the bytes are serialized by Phoenix. For VARCHAR,CHAR, and UNSIGNED_* types, we use the HBase Bytes methods. The CHAR type expects only single-byte characters and the UNSIGNED types expect values greater than or equal to zero.
-
-Our composite row keys are formed by simply concatenating the values together, with a zero byte character used as a separator after a variable length type.
-
-If you create an HBase table like this:
-
-`create 't1', {NAME => 'f1', VERSIONS => 5}`
-
-then you have an HBase table with a name of 't1' and a column family with a name of 'f1'. Remember, in HBase, you don't model the possible KeyValues or the structure of the row key. This is the information you specify in Phoenix above and beyond the table and column family.
-
-So in Phoenix, you'd create a view like this:
-
-`CREATE VIEW "t1" ( pk VARCHAR PRIMARY KEY, "f1".val VARCHAR )`
-
-The "pk" column declares that your row key is a VARCHAR (i.e. a string) while the "f1".val column declares that your HBase table will contain KeyValues with a column family and column qualifier of "f1":VAL and that their value will be a VARCHAR.
-
-Note that you don't need the double quotes if you create your HBase table with all caps names (since this is how Phoenix normalizes strings, by upper casing them). For example, with:
-
-`create 'T1', {NAME => 'F1', VERSIONS => 5}`
-
-you could create this Phoenix view:
-
-`CREATE VIEW t1 ( pk VARCHAR PRIMARY KEY, f1.val VARCHAR )`
-
-Or if you're creating new HBase tables, just let Phoenix do everything for you like this (No need to use the HBase shell at all.):
-
-`CREATE TABLE t1 ( pk VARCHAR PRIMARY KEY, val VARCHAR )`
-
-
-
-### Are there any tips for optimizing Phoenix?
-
-* Use **Salting** to increase read/write performance
-Salting can significantly increase read/write performance by pre-splitting the data into multiple regions. Although Salting will yield better performance in most scenarios.
-
-Example:
-
-` CREATE TABLE TEST (HOST VARCHAR NOT NULL PRIMARY KEY, DESCRIPTION VARCHAR) SALT_BUCKETS=16`
-
-Note: Ideally for a 16 region server cluster with quad-core CPUs, choose salt buckets between 32-64 for optimal performance.
-
-* **Per-split** table
-Salting does automatic table splitting but in case you want to exactly control where table split occurs with out adding extra byte or change row key order then you can pre-split a table.
-
-Example:
-
-` CREATE TABLE TEST (HOST VARCHAR NOT NULL PRIMARY KEY, DESCRIPTION VARCHAR) SPLIT ON ('CS','EU','NA')`
-
-* Use **multiple column families**
-
-Column family contains related data in separate files. If you query use selected columns then it make sense to group those columns together in a column family to improve read performance.
-
-Example:
-
-Following create table DDL will create two column familes A and B.
-
-` CREATE TABLE TEST (MYKEY VARCHAR NOT NULL PRIMARY KEY, A.COL1 VARCHAR, A.COL2 VARCHAR, B.COL3 VARCHAR)`
-
-* Use **compression**
-On disk compression improves performance on large tables
-
-Example:
-
-` CREATE TABLE TEST (HOST VARCHAR NOT NULL PRIMARY KEY, DESCRIPTION VARCHAR) COMPRESSION='GZ'`
-
-* Create **indexes**
-See [faq.html#/How_do_I_create_Secondary_Index_on_a_table](faq.html#/How_do_I_create_Secondary_Index_on_a_table)
-
-* **Optimize cluster** parameters
-See http://hbase.apache.org/book/performance.html
-
-* **Optimize Phoenix** parameters
-See [tuning.html](tuning.html)
-
-
-
-### How do I create Secondary Index on a table?
-
-Starting with Phoenix version 2.1, Phoenix supports index over mutable and immutable data. Note that Phoenix 2.0.x only supports Index over immutable data. Index write performance index with immutable table is slightly faster than mutable table however data in immutable table cannot be updated.
-
-Example
-
-* Create table
-
-Immutable table: `create table test (mykey varchar primary key, col1 varchar, col2 varchar) IMMUTABLE_ROWS=true;`
-
-Mutable table: `create table test (mykey varchar primary key, col1 varchar, col2 varchar);`
-
-* Creating index on col2
-
-`create index idx on test (col2)`
-
-* Creating index on col1 and a covered index on col2
-
-`create index idx on test (col1) include (col2)`
-
-Upsert rows in this test table and Phoenix query optimizer will choose correct index to use. You can see in [explain plan](language/index.html#explain) if Phoenix is using the index table. You can also give a [hint](language/index.html#hint) in Phoenix query to use a specific index.
-
-
-
-### Why isn't my secondary index being used?
-
-The secondary index won't be used unless all columns used in the query are in it ( as indexed or covered columns). All columns making up the primary key of the data table will automatically be included in the index.
-
-Example: DDL `create table usertable (id varchar primary key, firstname varchar, lastname varchar); create index idx_name on usertable (firstname);`
-
-Query: DDL `select id, firstname, lastname from usertable where firstname = 'foo';`
-
-Index would not be used in this case as lastname is not part of indexed or covered column. This can be verified by looking at the explain plan. To fix this create index that has either lastname part of index or covered column. Example: `create idx_name on usertable (firstname) include (lastname);`
-
-
-### How fast is Phoenix? Why is it so fast?
-
-Phoenix is fast. Full table scan of 100M rows usually completes in 20 seconds (narrow table on a medium sized cluster). This time come down to few milliseconds if query contains filter on key columns. For filters on non-key columns or non-leading key columns, you can add index on these columns which leads to performance equivalent to filtering on key column by making copy of table with indexed column(s) part of key.
-
-Why is Phoenix fast even when doing full scan:
-
-1. Phoenix chunks up your query using the region boundaries and runs them in parallel on the client using a configurable number of threads
-2. The aggregation will be done in a coprocessor on the server-side, collapsing the amount of data that gets returned back to the client rather than returning it all.
-
-
-
-### How do I connect to secure HBase cluster?
-Check out excellent post by Anil Gupta
-http://bigdatanoob.blogspot.com/2013/09/connect-phoenix-to-secure-hbase-cluster.html
-
-
-
-### How do I connect with HBase running on Hadoop-2?
-Hadoop-2 profile exists in Phoenix pom.xml.
-
-
-### Can phoenix work on tables with arbitrary timestamp as flexible as HBase API?
-By default, Phoenix let's HBase manage the timestamps and just shows you the latest values for everything. However, Phoenix also allows arbitrary timestamps to be supplied by the user. To do that you'd specify a "CurrentSCN" (or PhoenixRuntime.CURRENT_SCN_ATTRIB if you want to use our constant) at connection time, like this:
-
- Properties props = new Properties();
- props.setProperty(PhoenixRuntime.CURRENT_SCN_ATTRIB, Long.toString(ts));
- Connection conn = DriverManager.connect(myUrl, props);
-
- conn.createStatement().execute("UPSERT INTO myTable VALUES ('a')");
- conn.commit();
-The above is equivalent to doing this with the HBase API:
-
- myTable.put(Bytes.toBytes('a'),ts);
-By specifying a CurrentSCN, you're telling Phoenix that you want everything for that connection to be done at that timestamp. Note that this applies to queries done on the connection as well - for example, a query over myTable above would not see the data it just upserted, since it only sees data that was created before its CurrentSCN property. This provides a way of doing snapshot, flashback, or point-in-time queries.
-
-Keep in mind that creating a new connection is *not* an expensive operation. The same underlying HConnection is used for all connections to the same cluster, so it's more or less like instantiating a few objects.
-
-
-### Why isn't my query doing a RANGE SCAN?
-
-`DDL: CREATE TABLE TEST (pk1 char(1) not null, pk2 char(1) not null, pk3 char(1) not null, non-pk varchar CONSTRAINT PK PRIMARY KEY(pk1, pk2, pk3));`
-
-RANGE SCAN means that only a subset of the rows in your table will be scanned over. This occurs if you use one or more leading columns from your primary key constraint. Query that is not filtering on leading PK columns ex. `select * from test where pk2='x' and pk3='y';` will result in full scan whereas the following query will result in range scan `select * from test where pk1='x' and pk2='y';`. Note that you can add a secondary index on your "pk2" and "pk3" columns and that would cause a range scan to be done for the first query (over the index table).
-
-DEGENERATE SCAN means that a query can't possibly return any rows. If we can determine that at compile time, then we don't bother to even run the scan.
-
-FULL SCAN means that all rows of the table will be scanned over (potentially with a filter applied if you have a WHERE clause)
-
-SKIP SCAN means that either a subset or all rows in your table will be scanned over, however it will skip large groups of rows depending on the conditions in your filter. See this blog for more detail. We don't do a SKIP SCAN if you have no filter on the leading primary key columns, but you can force a SKIP SCAN by using the /*+ SKIP_SCAN */ hint. Under some conditions, namely when the cardinality of your leading primary key columns is low, it will be more efficient than a FULL SCAN.
-
-
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/flume.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/flume.md b/src/site/markdown/flume.md
deleted file mode 100644
index 6cc9251..0000000
--- a/src/site/markdown/flume.md
+++ /dev/null
@@ -1,42 +0,0 @@
-# Apache Flume Plugin
-
-The plugin enables us to reliably and efficiently stream large amounts of data/logs onto HBase using the Phoenix API. The necessary configuration of the custom Phoenix sink and the Event Serializer has to be configured in the Flume configuration file for the Agent. Currently, the only supported Event serializer is a RegexEventSerializer which primarily breaks the Flume Event body based on the regex specified in the configuration file.
-
-#### Prerequisites:
-
-* Phoenix v 3.0.0 SNAPSHOT +
-* Flume 1.4.0 +
-
-#### Installation & Setup:
-
-1. Download and build Phoenix v 0.3.0 SNAPSHOT
-2. Follow the instructions as specified [here](building.html) to build the project as the Flume plugin is still under beta
-3. Create a directory plugins.d within $FLUME_HOME directory. Within that, create a sub-directories phoenix-sink/lib
-4. Copy the generated phoenix-3.0.0-SNAPSHOT-client.jar onto $FLUME_HOME/plugins.d/phoenix-sink/lib
-
-#### Configuration:
-
-Property Name |Default| Description
---------------------------|-------|---
-type | |org.apache.phoenix.flume.sink.PhoenixSink
-batchSize |100 |Default number of events per transaction
-zookeeperQuorum | |Zookeeper quorum of the HBase cluster
-table | |The name of the table in HBase to write to.
-ddl | |The CREATE TABLE query for the HBase table where the events will be upserted to. If specified, the query will be executed. Recommended to include the IF NOT EXISTS clause in the ddl.
-serializer |regex |Event serializers for processing the Flume Event . Currently , only regex is supported.
-serializer.regex |(.*) |The regular expression for parsing the event.
-serializer.columns | |The columns that will be extracted from the Flume event for inserting into HBase.
-serializer.headers | |Headers of the Flume Events that go as part of the UPSERT query. The data type for these columns are VARCHAR by default.
-serializer.rowkeyType | |A custom row key generator . Can be one of timestamp,date,uuid,random and nanotimestamp. This should be configured in cases where we need a custom row key value to be auto generated and set for the primary key column.
-
-
-For an example configuration for ingesting Apache access logs onto Phoenix, see [this](https://github.com/forcedotcom/phoenix/blob/master/src/main/config/apache-access-logs.properties) property file. Here we are using UUID as a row key generator for the primary key.
-
-#### Starting the agent:
- $ bin/flume-ng agent -f conf/flume-conf.properties -c ./conf -n agent
-
-#### Monitoring:
- For monitoring the agent and the sink process , enable JMX via flume-env.sh($FLUME_HOME/conf/flume-env.sh) script. Ensure you have the following line uncommented.
-
- JAVA_OPTS="-Xms1g -Xmx1g -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=3141 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false"
-
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/index.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/index.md b/src/site/markdown/index.md
deleted file mode 100644
index 8b9f0b0..0000000
--- a/src/site/markdown/index.md
+++ /dev/null
@@ -1,69 +0,0 @@
-# Overview
-
-Apache Phoenix is a SQL skin over HBase delivered as a client-embedded JDBC driver targeting low latency queries over HBase data. Apache Phoenix takes your SQL query, compiles it into a series of HBase scans, and orchestrates the running of those scans to produce regular JDBC result sets. The table metadata is stored in an HBase table and versioned, such that snapshot queries over prior versions will automatically use the correct schema. Direct use of the HBase API, along with coprocessors and custom filters, results in [performance](performance.html) on the order of milliseconds for small queries, or seconds for tens of millions of rows.
-
-## Mission
-Become the standard means of accessing HBase data through a well-defined, industry standard API.
-
-## Quick Start
-Tired of reading already and just want to get started? Take a look at our [FAQs](faq.html), listen to the Apache Phoenix talks from [Hadoop Summit 2013](http://www.youtube.com/watch?v=YHsHdQ08trg) and [HBaseConn 2013](http://www.cloudera.com/content/cloudera/en/resources/library/hbasecon/hbasecon-2013--how-and-why-phoenix-puts-the-sql-back-into-nosql-video.html), and jump over to our quick start guide [here](Phoenix-in-15-minutes-or-less.html).
-
-##SQL Support##
-To see what's supported, go to our [language reference](language/index.html). It includes all typical SQL query statement clauses, including `SELECT`, `FROM`, `WHERE`, `GROUP BY`, `HAVING`, `ORDER BY`, etc. It also supports a full set of DML commands as well as table creation and versioned incremental alterations through our DDL commands. We try to follow the SQL standards wherever possible.
-
-<a id="connStr"></a>Use JDBC to get a connection to an HBase cluster like this:
-
- Connection conn = DriverManager.getConnection("jdbc:phoenix:server1,server2:3333");
-where the connection string is composed of:
-<code><small>jdbc:phoenix</small></code> [ <code><small>:<zookeeper quorum></small></code> [ <code><small>:<port number></small></code> ] [ <code><small>:<root node></small></code> ] ]
-
-For any omitted part, the relevant property value, hbase.zookeeper.quorum, hbase.zookeeper.property.clientPort, and zookeeper.znode.parent will be used from hbase-site.xml configuration file.
-
-Here's a list of what is currently **not** supported:
-
-* **Full Transaction Support**. Although we allow client-side batching and rollback as described [here](#transactions), we do not provide transaction semantics above and beyond what HBase gives you out-of-the-box.
-* **Derived tables**. Nested queries are coming soon.
-* **Relational operators**. Union, Intersect, Minus.
-* **Miscellaneous built-in functions**. These are easy to add - read this [blog](http://phoenix-hbase.blogspot.com/2013/04/how-to-add-your-own-built-in-function.html) for step by step instructions.
-
-##<a id="schema"></a>Schema##
-
-Apache Phoenix supports table creation and versioned incremental alterations through DDL commands. The table metadata is stored in an HBase table.
-
-A Phoenix table is created through the [CREATE TABLE](language/index.html#create) DDL command and can either be:
-
-1. **built from scratch**, in which case the HBase table and column families will be created automatically.
-2. **mapped to an existing HBase table**, by creating either a read-write TABLE or a read-only VIEW, with the caveat that the binary representation of the row key and key values must match that of the Phoenix data types (see [Data Types reference](datatypes.html) for the detail on the binary representation).
- * For a read-write TABLE, column families will be created automatically if they don't already exist. An empty key value will be added to the first column family of each existing row to minimize the size of the projection for queries.
- * For a read-only VIEW, all column families must already exist. The only change made to the HBase table will be the addition of the Phoenix coprocessors used for query processing. The primary use case for a VIEW is to transfer existing data into a Phoenix table, since data modification are not allowed on a VIEW and query performance will likely be less than as with a TABLE.
-
-All schema is versioned, and prior versions are stored forever. Thus, snapshot queries over older data will pick up and use the correct schema for each row.
-
-####Salting
-A table could also be declared as salted to prevent HBase region hot spotting. You just need to declare how many salt buckets your table has, and Phoenix will transparently manage the salting for you. You'll find more detail on this feature [here](salted.html), along with a nice comparison on write throughput between salted and unsalted tables [here](performance.htm#salting).
-
-####Schema at Read-time
-Another schema-related feature allows columns to be defined dynamically at query time. This is useful in situations where you don't know in advance all of the columns at create time. You'll find more details on this feature [here](dynamic_columns.html).
-
-####<a id="mapping"></a>Mapping to an Existing HBase Table
-Apache Phoenix supports mapping to an existing HBase table through the [CREATE TABLE](language/index.html#create) and [CREATE VIEW](language/index.html#create) DDL statements. In both cases, the HBase metadata is left as-is, except for with CREATE TABLE the [KEEP_DELETED_CELLS](http://hbase.apache.org/book/cf.keep.deleted.html) option is enabled to allow for flashback queries to work correctly. For CREATE TABLE, any HBase metadata (table, column families) that doesn't already exist will be created. Note that the table and column family names are case sensitive, with Phoenix upper-casing all names. To make a name case sensitive in the DDL statement, surround it with double quotes as shown below:
- <pre><code>CREATE VIEW "MyTable" ("a".ID VARCHAR PRIMARY KEY)</code></pre>
-
-For CREATE TABLE, an empty key value will also be added for each row so that queries behave as expected (without requiring all columns to be projected during scans). For CREATE VIEW, this will not be done, nor will any HBase metadata be created. Instead the existing HBase metadata must match the metadata specified in the DDL statement or a <code>ERROR 505 (42000): Table is read only</code> will be thrown.
-
-The other caveat is that the way the bytes were serialized in HBase must match the way the bytes are expected to be serialized by Phoenix. For VARCHAR,CHAR, and UNSIGNED_* types, Phoenix uses the HBase Bytes utility methods to perform serialization. The CHAR type expects only single-byte characters and the UNSIGNED types expect values greater than or equal to zero.
-
-Our composite row keys are formed by simply concatenating the values together, with a zero byte character used as a separator after a variable length type. For more information on our type system, see the [Data Type](datatypes.html).
-
-##<a id="transactions"></a>Transactions##
-The DML commands of Apache Phoenix, [UPSERT VALUES](language/index.html#upsert_values), [UPSERT SELECT](language/index.html#upsert_select) and [DELETE](language/index.html#delete), batch pending changes to HBase tables on the client side. The changes are sent to the server when the transaction is committed and discarded when the transaction is rolled back. The only transaction isolation level we support is TRANSACTION_READ_COMMITTED. This includes not being able to see your own uncommitted data as well. Phoenix does not providing any additional transactional semantics beyond what HBase supports when a batch of mutations is submitted to the server. If auto commit is turned on for a connection, then Phoenix will, whenever possible, execute the entire DML command through a coprocessor on the server-side, so performance will improve.
-
-Most commonly, an application will let HBase manage timestamps. However, under some circumstances, an application needs to control the timestamps itself. In this case, a long-valued "CurrentSCN" property may be specified at connection time to control timestamps for any DDL, DML, or query. This capability may be used to run snapshot queries against prior row values, since Phoenix uses the value of this connection property as the max timestamp of scans.
-
-## Metadata ##
-The catalog of tables, their columns, primary keys, and types may be retrieved via the java.sql metadata interfaces: `DatabaseMetaData`, `ParameterMetaData`, and `ResultSetMetaData`. For retrieving schemas, tables, and columns through the DatabaseMetaData interface, the schema pattern, table pattern, and column pattern are specified as in a LIKE expression (i.e. % and _ are wildcards escaped through the \ character). The table catalog argument to the metadata APIs deviates from a more standard relational database model, and instead is used to specify a column family name (in particular to see all columns in a given column family).
-
-<hr/>
-## Disclaimer ##
-Apache Phoenix is an effort undergoing incubation at The Apache Software Foundation (ASF), sponsored by the [Apache Incubator PMC](http://incubator.apache.org/). Incubation is required of all newly accepted projects until a further review indicates that the infrastructure, communications, and decision making process have stabilized in a manner consistent with other successful ASF projects. While incubation status is not necessarily a reflection of the completeness or stability of the code, it does indicate that the project has yet to be fully endorsed by the ASF.
-<br/><br/><img src="http://incubator.apache.org/images/apache-incubator-logo.png"/>
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/issues.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/issues.md b/src/site/markdown/issues.md
deleted file mode 100644
index 64ea3ca..0000000
--- a/src/site/markdown/issues.md
+++ /dev/null
@@ -1,9 +0,0 @@
-# Issue Tracking
-
-This project uses JIRA issue tracking and project management application. Issues, bugs, and feature requests should be submitted to the following:
-
-<hr/>
-
-https://issues.apache.org/jira/browse/PHOENIX
-
-<hr/>
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/mailing_list.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/mailing_list.md b/src/site/markdown/mailing_list.md
deleted file mode 100644
index fbe9e43..0000000
--- a/src/site/markdown/mailing_list.md
+++ /dev/null
@@ -1,14 +0,0 @@
-# Mailing Lists
-
-These are the mailing lists that have been established for this project. For each list, there is a subscribe, unsubscribe and post link.
-
-<hr/>
-
-Name| Subscribe| Unsubscribe| Post
---------------------------|----|----|----
-User List | [Subscribe](mailto:user-subscribe@phoenix.incubator.apache.org) | [Unsubscribe](mailto:user-unsubscribe@phoenix.incubator.apache.org) | [Post](mailto:user@phoenix.incubator.apache.org)
-Developer List | [Subscribe](mailto:dev-subscribe@phoenix.incubator.apache.org) | [Unsubscribe](mailto:dev-unsubscribe@phoenix.incubator.apache.org) | [Post](mailto:dev@phoenix.incubator.apache.org)
-Private List | [Subscribe](mailto:private-subscribe@phoenix.incubator.apache.org) | [Unsubscribe](mailto:private-unsubscribe@phoenix.incubator.apache.org) | [Post](mailto:private@phoenix.incubator.apache.org)
-Commits List | [Subscribe](mailto:commits-subscribe@phoenix.incubator.apache.org) | [Unsubscribe](mailto:commits-unsubscribe@phoenix.incubator.apache.org) | [Post](mailto:commits@phoenix.incubator.apache.org)
-
-<hr/>
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/mr_dataload.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/mr_dataload.md b/src/site/markdown/mr_dataload.md
deleted file mode 100644
index b0053ac..0000000
--- a/src/site/markdown/mr_dataload.md
+++ /dev/null
@@ -1,63 +0,0 @@
-# Bulk CSV Data Load using Map-Reduce
-
-Phoenix v 2.1 provides support for loading CSV data into a new/existing Phoenix table using Hadoop Map-Reduce. This provides a means of bulk loading CSV data in parallel through map-reduce, yielding better performance in comparison with the existing [psql csv loader](download.html#Loading-Data).
-
-####Sample input CSV data:
-
-```
-12345, John, Doe
-67890, Mary, Poppins
-```
-
-####Compatible Phoenix schema to hold the above CSV data:
-
- CREATE TABLE ns.example (
- my_pk bigint not null,
- m.first_name varchar(50),
- m.last_name varchar(50)
- CONSTRAINT pk PRIMARY KEY (my_pk))
-
-<table>
-<tr><td>Row Key</td><td colspan="2" bgcolor="#00FF00"><center>Column Family (m)</center></td></tr>
-<tr><td><strong>my_pk</strong> BIGINT</td><td><strong>first_name</strong> VARCHAR(50)</td><td><strong>last_name</strong> VARCHAR(50)</td></tr>
-<tr><td>12345</td><td>John</td><td>Doe</td></tr>
-<tr><td>67890</td><td>Mary</td><td>Poppins</td></tr>
-</table>
-
-
-####How to run?
-
-1- Please make sure that Hadoop cluster is working correctly and you are able to run any job like [this](http://wiki.apache.org/hadoop/WordCount).
-
-2- Copy latest phoenix-[version].jar to hadoop/lib folder on each node or add it to Hadoop classpath.
-
-3- Run the bulk loader job using the script /bin/csv-bulk-loader.sh as below:
-
-```
-./csv-bulk-loader.sh <option value>
-
-<option> <value>
--i CSV data file path in hdfs (mandatory)
--s Phoenix schema name (mandatory if not default)
--t Phoenix table name (mandatory)
--sql Phoenix create table sql file path (mandatory)
--zk Zookeeper IP:<port> (mandatory)
--mr MapReduce Job Tracker IP:<port> (mandatory)
--hd HDFS NameNode IP:<port> (mandatory)
--o Output directory path in hdfs (optional)
--idx Phoenix index table name (optional, not yet supported)
--error Ignore error while reading rows from CSV ? (1-YES | 0-NO, default-1) (optional)
--help Print all options (optional)
-```
-Example
-
-```
-./csv-bulk-loader.sh -i hdfs://server:9000/mydir/data.csv -s ns -t example -sql ~/Documents/createTable.sql -zk server:2181 -hd hdfs://server:9000 -mr server:9001
-```
-
-This would create the phoenix table "ns.example" as specified in createTable.sql and will then load the CSV data from the file "data.csv" located in HDFS into the table.
-
-##### Notes
-1. You must provide an explicit column family name in your CREATE TABLE statement for your non primary key columns, as the default column family used by Phoenix is treated specially by HBase because it starts with an underscore.
-2. The current bulk loader does not support the migration of index related data yet. So, if you have created your phoenix table with index, please use the [psql CSV loader](download.html#Loading-Data).
-3. In case you want to further optimize the map-reduce performance, please refer to the current map-reduce optimization params in the file "src/main/config/csv-bulk-load-config.properties". In case you modify this list, please re-build the phoenix jar and re-run the job as described above.
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/paged.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/paged.md b/src/site/markdown/paged.md
deleted file mode 100644
index f01aedb..0000000
--- a/src/site/markdown/paged.md
+++ /dev/null
@@ -1,31 +0,0 @@
-# Paged Queries
-
-Phoenix v 2.1 supports the use in queries of row value constructors, a standard SQL construct to enable paged queries. A row value constructor is an ordered sequence of values delimited by parentheses. For example:
-
- (4, 'foo', 3.5)
- ('Doe', 'Jane')
- (my_col1, my_col2, 'bar')
-
-Just like with regular values, row value constructors may be used in comparison expression like this:
-
- WHERE (x,y,z) >= ('foo','bar')
- WHERE (last_name,first_name) = ('Jane','Doe')
-
-Row value constructors are compared by conceptually concatenating the values together and comparing them against each other, with the leftmost part being most significant. Section 8.2 (comparison predicates) of the SQL-92 standard explains this in detail, but here are a few examples of predicates that would evaluate to true:
-
- (9, 5, 3) > (8, 8)
- ('foo', 'bar') < 'g'
- (1,2) = (1,2)
-Row value constructors may also be used in an IN list expression to efficiently query for a set of rows given the composite primary key columns. For example, the following would be optimized to be a point get of three rows:
-
- WHERE (x,y) IN ((1,2),(3,4),(5,6))
-Another primary use case for row value constructors is to support query-more type functionality by enabling an ordered set of rows to be incrementally stepped through. For example, the following query would step through a set of rows, 20 rows at a time:
-
- SELECT title, author, isbn, description
- FROM library
- WHERE published_date > 2010
- AND (title, author, isbn) > (?, ?, ?)
- ORDER BY title, author, isbn
- LIMIT 20
-
-Assuming that the client binds the three bind variables to the values of the last row processed, the next invocation would find the next 20 rows that match the query. If the columns you supply in your row value constructor match in order the columns from your primary key (or from a secondary index), then Phoenix will be able to turn the row value constructor expression into the start row of your scan. This enables a very efficient mechanism to locate _at or after_ a row.
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/performance.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/performance.md b/src/site/markdown/performance.md
deleted file mode 100644
index 2f6c054..0000000
--- a/src/site/markdown/performance.md
+++ /dev/null
@@ -1,86 +0,0 @@
-# Performance
-
-Phoenix follows the philosophy of **bringing the computation to the data** by using:
-* **coprocessors** to perform operations on the server-side thus minimizing client/server data transfer
-* **custom filters** to prune data as close to the source as possible
-In addition, to minimize any startup costs, Phoenix uses native HBase APIs rather than going through the map/reduce framework.
-## Phoenix vs related products
-Below are charts showing relative performance between Phoenix and some other related products.
-
-### Phoenix vs Hive (running over HDFS and HBase)
-
-
-Query: select count(1) from table over 10M and 100M rows. Data is 5 narrow columns. Number of Region
-Servers: 4 (HBase heap: 10GB, Processor: 6 cores @ 3.3GHz Xeon)
-
-### Phoenix vs Impala (running over HBase)
-
-
-Query: select count(1) from table over 1M and 5M rows. Data is 3 narrow columns. Number of Region Server: 1 (Virtual Machine, HBase heap: 2GB, Processor: 2 cores @ 3.3GHz Xeon)
-
-***
-## Latest Automated Performance Run
-
-[Latest Automated Performance Run](http://phoenix-bin.github.io/client/performance/latest.htm) |
-[Automated Performance Runs History](http://phoenix-bin.github.io/client/performance/)
-
-***
-
-## Performance improvements in Phoenix 1.2
-
-### Essential Column Family
-Phoenix 1.2 query filter leverages [HBase Filter Essential Column Family](http://hbase.apache.org/apidocs/org/apache/hadoop/hbase/filter/SingleColumnValueFilter.html#isFamilyEssential(byte[]) feature which leads to improved performance when Phoenix query filters on data that is split in multiple column families (cf) by only loading essential cf. In second pass, all cf are are loaded as needed.
-
-Consider the following schema in which data is split in two cf
-`create table t (k varchar not null primary key, a.c1 integer, b.c2 varchar, b.c3 varchar, b.c4 varchar)`.
-
-Running a query similar to the following shows significant performance when a subset of rows match filter
-`select count(c2) from t where c1 = ?`
-
-Following chart shows query in-memory performance of running the above query with 10M rows on 4 region servers when 10% of the rows matches the filter. Note: cf-a is approx 8 bytes and cf-b is approx 400 bytes wide.
-
-
-
-
-### Skip Scan
-
-Skip Scan Filter leverages [SEEK_NEXT_USING_HINT](http://hbase.apache.org/apidocs/org/apache/hadoop/hbase/filter/Filter.ReturnCode.html#SEEK_NEXT_USING_HINT) of HBase Filter. It significantly improves point queries over key columns.
-
-Consider the following schema in which data is split in two cf
-`create table t (k varchar not null primary key, a.c1 integer, b.c2 varchar, b.c3 varchar)`.
-
-Running a query similar to the following shows significant performance when a subset of rows match filter
-`select count(c1) from t where k in (1% random k's)`
-
-Following chart shows query in-memory performance of running the above query with 10M rows on 4 region servers when 1% random keys over the entire range passed in query `IN` clause. Note: all varchar columns are approx 15 bytes.
-
-
-
-
-### Salting
-Salting in Phoenix 1.2 leads to both improved read and write performance by adding an extra hash byte at start of key and pre-splitting data in number of regions. This eliminates hot-spotting of single or few regions servers. Read more about this feature [here](salted.html).
-
-Consider the following schema
-
-`CREATE TABLE T (HOST CHAR(2) NOT NULL,DOMAIN VARCHAR NOT NULL,`
-`FEATURE VARCHAR NOT NULL,DATE DATE NOT NULL,USAGE.CORE BIGINT,USAGE.DB BIGINT,STATS.ACTIVE_VISITOR`
-`INTEGER CONSTRAINT PK PRIMARY KEY (HOST, DOMAIN, FEATURE, DATE)) SALT_BUCKETS = 4`.
-
-Following chart shows write performance with and without the use of Salting which splits table in 4 regions running on 4 region server cluster (Note: For optimal performance, number of salt buckets should match number of region servers).
-
-
-
-Following chart shows in-memory query performance for 10M row table where `host='NA'` filter matches 3.3M rows
-
-`select count(1) from t where host='NA'`
-
-
-
-
-### Top-N
-
-Following chart shows in-memory query time of running the Top-N query over 10M rows using Phoenix 1.2 and Hive over HBase
-
-`select core from t order by core desc limit 10`
-
-
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/phoenix_on_emr.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/phoenix_on_emr.md b/src/site/markdown/phoenix_on_emr.md
deleted file mode 100644
index 27ca2bc..0000000
--- a/src/site/markdown/phoenix_on_emr.md
+++ /dev/null
@@ -1,43 +0,0 @@
-# Phoenix on Amazon EMR
-
-Follow these steps to deploy HBase with Phoenix on Amazon's Elastic MapReduce (EMR).
-
-### 1. Amazon EMR Configuration
-
-1. Create a free/paid [EMR account](https://portal.aws.amazon.com/gp/aws/developer/registration/index.html)
-2. [Download](http://aws.amazon.com/developertools/2264) the latest CLI from and follow the setup instructions [here](http://docs.aws.amazon.com/ElasticMapReduce/latest/DeveloperGuide/emr-cli-install.html).
-
-_Note: Step 2 is a multi-step process in which you would install ruby, gem, create credentials file and create a S3 bucket._
-
-### 2. Deploy HBase with Phoenix on EMR using Web Console
-
-##### Using Web Console
-
-Go to _Elastic MapReduce > Create Cluster_ and follow the steps listed below:
-
-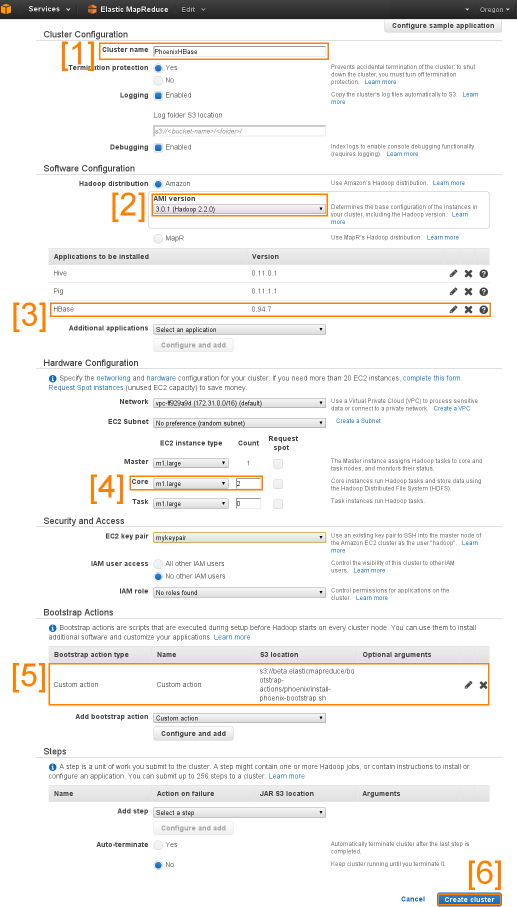
-
-1. Type your cluster name
-2. Set _AMI version_ to _3.0.1_
-3. From _Additional Application_ drop down, select HBase and add.
-4. In _Core_ text box, enter the number of HBase region server(s) you want configured for your cluster
-5. Add a _custom action bootstrap_ from dropdown and specify S3 location: ``s3://beta.elasticmapreduce/bootstrap-actions/phoenix/install-phoenix-bootstrap.sh`` and click add.
-6. Click _Create Cluster_
-
-##### Using CLI
-
-Instead of using _Web Console_, you may use following _CLI_ command to deploy _HBase_ with _Phoenix_:
-
- ```
-./elastic-mapreduce --create --instance-type c1.xlarge --name
-PHOENIX_2.2_install --ami-version 3.0.1 --hbase --alive --bootstrap-action
-"s3://beta.elasticmapreduce/bootstrap-actions/phoenix/install-phoenix-bootstrap.sh"
-```
-
-### 3. Usage
-
-_SSH_ to the _EMR Master_ and CD to _/home/hadoop/hbase/lib/phoenix/bin_
-
-Create test data: ``./performance localhost 1000000 ``
-
-SQL CLI: ``./sqlline localhost``
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/recent.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/recent.md b/src/site/markdown/recent.md
deleted file mode 100644
index 02bd39b..0000000
--- a/src/site/markdown/recent.md
+++ /dev/null
@@ -1,18 +0,0 @@
-# New Features
-
-As items are implemented from our road map, they are moved here to track the progress we've made:
-
-1. **Joins**. Join support through hash joins (where one side of the query is small enough to fit into memory) is now available in our master branch.
-2. **[Sequences](http://phoenix.incubator.apache.org/sequences.html)**. Support for CREATE/DROP SEQUENCE, NEXT VALUE FOR, and CURRENT VALUE FOR has been implemented and is now available in our master branch.
-2. **Multi-tenancy**. Support for creating multi-tenant tables is now available in our master branch.
-1. **[Secondary Indexes](secondary_indexing.html)**. Allows users to create indexes over mutable or immutable data through a new `CREATE INDEX` DDL command. Behind the scenes, Phoenix creates a separate HBase table with a different row key for the index. At query time, Phoenix takes care of choosing the best table to use based on how much of the row key can be formed. We support getting at the uncommitted <code>List<KeyValue></code> for both the data and the index tables to allow an HFile to be built without needing an HBase connection using the "connectionless" of our JDBC driver.
-2. **Row Value Constructors**. A standard SQL construct to efficiently locate the row at or after a composite key value. Enables a query-more capability to efficiently step through your data and optimizes IN list of composite key values to be point gets.
-3. **[Map-reduce-based CSV Bulk Loader](mr_dataload.html)** Builds Phoenix-compliant HFiles and load them into HBase.
-2. **Aggregation Enhancements**. <code>COUNT DISTINCT</code>, <code>PERCENTILE</code>, and <code>STDDEV</code> are now supported.
-4. **Type Additions**. The <code>FLOAT</code>, <code>DOUBLE</code>, <code>TINYINT</code>, and <code>SMALLINT</code> are now supported.
-2. **IN/OR/LIKE Optimizations**. When an IN (or the equivalent OR) and a LIKE appears in a query using the leading row key columns, compile it into a skip scanning filter to more efficiently retrieve the query results.
-3. **Support ASC/DESC declaration of primary key columns**. Allow a primary key column to be declared as ascending (the default) or descending such that the row key order can match the desired sort order (thus preventing an extra sort).
-3. **Salting Row Key**. To prevent hot spotting on writes, the row key may be *"salted"* by inserting a leading byte into the row key which is a mod over N buckets of the hash of the entire row key. This ensures even distribution of writes when the row key is a monotonically increasing value (often a timestamp representing the current time).
-4. **TopN Queries**. Support a query that returns the top N rows, through support for ORDER BY when used in conjunction with TopN.
-6. **Dynamic Columns**. For some use cases, it's difficult to model a schema up front. You may have columns that you'd like to specify only at query time. This is possible in HBase, in that every row (and column family) contains a map of values with keys that can be specified at run time. So, we'd like to support that.
-7. **Phoenix package for the Apache Bigtop distribution**. See [BIGTOP-993](http://issues.apache.org/jira/browse/BIGTOP-993) for more information.
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/roadmap.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/roadmap.md b/src/site/markdown/roadmap.md
deleted file mode 100644
index 201c3dc..0000000
--- a/src/site/markdown/roadmap.md
+++ /dev/null
@@ -1,35 +0,0 @@
-# Roadmap
-
-#### Note: Issues on Github would be converted to JIRAs soon.
-
-Our roadmap is driven by our user community. Below, in prioritized order, is the current plan for Phoenix:
-
-1. **Hash Joins**. Provide the ability to join together multiple tables, through a phased approach:
- <br/>**[Equi-join](https://github.com/forcedotcom/phoenix/issues/20)**. Support left, right, inner, outer equi-joins where one side of the join is small enough to fit into memory. **Available in master branch**
- <br/>**[Semi/anti-join](https://github.com/forcedotcom/phoenix/issues/36)**. Support correlated sub queries for exists and in where one side of the join is small enough to fit into memory.
-2. **[Multi-tenant Tables](https://github.com/forcedotcom/phoenix/issues/296)**. Allows the creation of multiple tables from a base tables on the same physical HBase table. **Available in master branch**
-3. **[Sequences](http://phoenix.incubator.apache.org/sequences.html)**. Support the atomic increment of sequence values through the CREATE SEQUENCE and the NEXT VALUE FOR statements.
-4. **Type Enhancements**. Additional work includes support for [DEFAULT declaration](https://github.com/forcedotcom/phoenix/issues/345) when creating a table, for [ARRAY](https://github.com/forcedotcom/phoenix/issues/178) (**available in master branch**), [STRUCT](https://github.com/forcedotcom/phoenix/issues/346), and [JSON](https://github.com/forcedotcom/phoenix/issues/497) data types.
-5. **Third Party Integration**. There are a number of open source projects with which interop with Phoenix could be added or improved:
- <br/> **[Flume sink](https://github.com/forcedotcom/phoenix/issues/225)**. Support a Flume sink that writes Phoenix-compliant HBase data. **Available in master branch**
- <br/> **[Hue integration](https://github.com/forcedotcom/phoenix/issues/224)**. Add Phoenix as an HBase service layer in Hue.
- <br/> **[Pentaho Mondrian support](https://github.com/forcedotcom/phoenix/issues/512)**. Allow Phoenix to be used as the JDBC driver for Pentaho Mondrian. **This effort is pretty far along already, with the Pentaho FoodMart demo running through Phoenix now**
- <br/> **[Cleanup Pig support](https://github.com/forcedotcom/phoenix/issues/499)** . Commonize the functions we use across Map-reduce and Pig processing. We should also upgrade our pom to reference the 0.12 version of Pig and map our DECIMAL type to their new decimal type.
- <br/> **[Improve Map-reduce integration](https://github.com/forcedotcom/phoenix/issues/556)**. It's possible that we could provide a processing model where the map and reduce functions can invoke Phoenix queries (though this needs some more thought).
-5. **[Derived Tables](https://github.com/forcedotcom/phoenix/issues/5)**. Allow a <code>SELECT</code> clause to be used in the FROM clause to define a derived table. This would include support for pipelining queries when necessary.
-3. **[Functional Indexes](https://github.com/forcedotcom/phoenix/issues/383)**. Enables an index to contain the evaluation of an expression as opposed to just a column value.
-2. **[Monitoring and Management](https://github.com/forcedotcom/phoenix/issues/46)**. Provide visibility into cpu, physical io, logical io, wait time, blocking time, and transmission time spent for each thread of execution across the HBase cluster, within coprocessors, and within the client-side thread pools for each query. On top of this, we should exposing things like active sessions and currently running queries. The [EXPLAIN PLAN](http://forcedotcom.github.io/phoenix/#explain) gives an idea of how a query will be executed, but we need more information to help users debug and tune their queries.
-9. **[Parent/child Join](https://github.com/forcedotcom/phoenix/issues/19)**. Unlike with standard relational databases, HBase allows you the flexibility of dynamically creating as many key values in a row as you'd like. Phoenix could leverage this by providing a way to model child rows inside of a parent row. The child row would be comprised of the set of key values whose column qualifier is prefixed with a known name and appended with the primary key of the child row. Phoenix could hide all this complexity, and allow querying over the nested children through joining to the parent row. Essentially, this would be an optimization of the general join case, but could support cases where both sides of the join are bigger than would fit into memory.
- <br/> **[Intra-row secondary indexes](https://github.com/forcedotcom/phoenix/issues/585)**. Once we support putting multiple "virtual" rows inside of a HBase row as prefixed KeyValues, we can support intra-row secondary indexes without much more effort.
-6. **[Port to HBase 0.96](https://github.com/forcedotcom/phoenix/issues/349)**. Currently Phoenix only works on the 0.94 branch of HBase. The latest branch of HBase is now 0.96, which has many breaking, non backward compatible changes (for example requiring that EndPoint coprocessors use protobufs). Ideally, we should create a shim that'll allow Phoenix to work with both 0.94 and 0.96, but barring that, we should have a branch of Phoenix that works under 0.96. Additional work includes replacing our type system with the new HBase type system in 0.96, but that would be significantly more work.
-5. **Security Features**. A number of existing HBase security features in 0.94 could be leverage and new security features being added to 0.98 could be leveraged in the future.
- <br/> **[Support GRANT and REVOKE](https://github.com/forcedotcom/phoenix/issues/541)**. Support the standard GRANT and REVOKE SQL commands through an HBase AccessController.
- <br/> **[Surface support for encryption] (https://github.com/forcedotcom/phoenix/issues/542)**. In HBase 0.98, transparent encryption will be possible. We should surface this in Phoenix.
- <br/> **[Support Cell-level security](https://github.com/forcedotcom/phoenix/issues/553)**. In HBase 0.98, it will be possible to apply labels at a per-cell granularity. We should surface this in Phoenix.
-7. **Cost-based Optimizer**. Once secondary indexing and joins are implemented, we'll need to [collect and maintains stats](https://github.com/forcedotcom/phoenix/issues/64) and [drive query optimization decisions based on them](https://github.com/forcedotcom/phoenix/issues/49) to produce the most efficient query plan.
-8. **[Query over Multiple Row Versions](https://github.com/forcedotcom/phoenix/issues/459)**. Expose the time dimension of rows through a built-in function to allow aggregation and trending over multiple row versions.
-8. **[OLAP Extensions](https://github.com/forcedotcom/phoenix/issues/23)**. Support the `WINDOW`, `PARTITION OVER`, `RANK`, etc. functionality.
-10. **[Table Sampling](https://github.com/forcedotcom/phoenix/issues/22)**. Support the <code>TABLESAMPLE</code> clause by implementing a filter that uses the guideposts established by stats gathering to only return n rows per region.
-13. **Nested-loop Join**. Support joins where both sides are big enough that they wouldn't fit into memory. As projects like [Apache Drill](http://incubator.apache.org/drill/) progress, the need for this may lessen, since these systems will be able to decompose the query and perform the join efficiently without Phoenix needing to as described [here](http://www.hbasecon.com/sessions/apache-drill-a-community-driven-initiative-to-deliver-ansi-sql-capabilities-for-apache-hbase-1210pm-1230pm/).
-11. **Schema Evolution**. Phoenix supports adding and removing columns through the [ALTER TABLE] (language/index.html#alter_table) DDL command, but changing the data type of, or renaming, an existing column is not yet supported.
-12. **[Transactions](https://github.com/forcedotcom/phoenix/issues/269?source=cc)**. Support transactions by integrating a system that controls time stamps like [OMID](https://github.com/yahoo/omid). For some ideas on how this might be done, see [here](https://github.com/forcedotcom/phoenix/issues/269).
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/salted.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/salted.md b/src/site/markdown/salted.md
deleted file mode 100644
index 6eddec8..0000000
--- a/src/site/markdown/salted.md
+++ /dev/null
@@ -1,25 +0,0 @@
-# Salted Tables
-
-HBase sequential write may suffer from region server hotspotting if your row key is monotonically increasing. Salting the row key provides a way to mitigate the problem. Details of the method would be found on [this link](http://blog.sematext.com/2012/04/09/hbasewd-avoid-regionserver-hotspotting-despite-writing-records-with-sequential-keys/).
-
-Phoenix provides a way to transparently salt the row key with a salting byte for a particular table. You need to specify this in table creation time by specifying a table property "SALT_BUCKETS" with a value from 1 to 256. Like this:
-
-CREATE TABLE table (a_key VARCHAR PRIMARY KEY, a_col VARCHAR) SALT_BUCKETS = 20;
-
-There are some cautions and difference in behavior you should be aware about when using a salted table.
-
-### Sequential Scan
-Since salting table would not store the data sequentially, a strict sequential scan would not return all the data in the natural sorted fashion. Clauses that currently would force a sequential scan, for example, clauses with LIMIT, would likely to return items that are different from a normal table.
-
-### Splitting
-If no split points are specified for the table, the salted table would be pre-split on salt bytes boundaries to ensure load distribution among region servers even during the initial phase of the table. If users are to provide split points manually, users need to include a salt byte in the split points they provide.
-
-### Row Key Ordering
-Pre-spliting also ensures that all entries in the region server all starts with the same salt byte, and therefore are stored in a sorted manner. When doing a parallel scan across all region servers, we can take advantage of this properties to perform a merge sort of the client side. The resulting scan would still be return sequentially as if it is from a normal table.
-
-This Rowkey order scan can be turned on by setting the <code>phoenix.query.rowKeyOrderSaltedTable</code> config property to <code>true</code> in your hbase-sites.xml. When set, we disallow user specified split points on salted table to ensure that each bucket will only contains entries with the same salt byte. When this property is turned on, the salted table would behave just like a normal table and would return items in rowkey order for scans.
-
-### Performance
-Using salted table with pre-split would help uniformly distribute write workload across all the region servers, thus improves the write performance. Our own [performance evaluation](performance.html#Salting) shows that a salted table achieves 80% write throughput increases over non-salted table.
-
-Reading from salted table can also reap benefits from the more uniform distribution of data. Our [performance evaluation](performance.html#Salting) shows much improved read performances on read queries with salted table over non-salted table when we focus our query on a subset of the data.
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/secondary_indexing.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/secondary_indexing.md b/src/site/markdown/secondary_indexing.md
deleted file mode 100644
index e36608c..0000000
--- a/src/site/markdown/secondary_indexing.md
+++ /dev/null
@@ -1,152 +0,0 @@
-# Secondary Indexing
-
-Secondary indexes are an orthogonal way to access data from its primary access path. In HBase, you have a single index that is lexicographically sorted on
-the primary row key. Access to records in any way other than through the primary row requires scanning over potentially all the rows in the table to test them against your filter. With secondary indexing, the columns you index form an alternate row key to allow point lookups and range scans along this new axis. Phoenix is particularly powerful in that we provide _covered_ indexes - we do not need to go back to the primary table once we have found the index entry. Instead, we bundle the data we care about right in the index rows, saving read-time overhead.
-
-Phoenix supports two main forms of indexing: mutable and immutable indexing. They are useful in different scenarios and have their own failure profiles and performance characteristics. Both indexes are 'global' indexes - they live on their own tables and are copies of primary table data, which Phoenix ensures remain in-sync.
-
-# Mutable Indexing
-
-Often, the rows you are inserting are changing - pretty much any time you are not doing time-series data. In this case, use mutable indexing to ensure that your index is properly maintained as your data changes.
-
-All the performance penalties for indexes occur at write time. We intercept the primary table updates on write ([DELETE](language/index.html#delete), [UPSERT VALUES](language/index.html#upsert_values) and [UPSERT SELECT](language/index.html#upsert_select)), build the index update and then sent any necessary updates to all interested index tables. At read time, Phoenix will select the index table to use that will produce the fastest query time and directly scan it just like any other HBase table.
-
-## Example
-
-Given the schema shown here:
-
- CREATE TABLE my_table (k VARCHAR PRIMARY KEY, v1 VARCHAR, v2 BIGINT);
-you'd create an index on the v1 column like this:
-
- CREATE INDEX my_index ON my_table (v1);
-A table may contain any number of indexes, but note that your write speed will drop as you add additional indexes.
-
-We can also include columns from the data table in the index apart from the indexed columns. This allows an index to be used more frequently, as it will only be used if all columns referenced in the query are contained by it.
-
- CREATE INDEX my_index ON my_table (v1) INCLUDE (v2);
-In addition, multiple columns may be indexed and their values may be stored in ascending or descending order.
-
- CREATE INDEX my_index ON my_table (v2 DESC, v1) INCLUDE (v3);
-Finally, just like with the <code>CREATE TABLE</code> statement, the <code>CREATE INDEX</code> statement may pass through properties to apply to the underlying HBase table, including the ability to salt it:
-
- CREATE INDEX my_index ON my_table (v2 DESC, v1) INCLUDE (v3)
- SALT_BUCKETS=10, DATA_BLOCK_ENCODING='NONE';
-Note that if the primary table is salted, then the index is automatically salted in the same way. In addition, the MAX_FILESIZE for the index is adjusted down, relative to the size of the primary versus index table. For more on salting see [here](salted.html).
-
-# Immutable Indexing
-
-Immutable indexing targets use cases that are _write once_, _append only_; this is common in time-series data, where you log once, but read multiple times. In this case, the indexing is managed entirely on the client - either we successfully write all the primary and index data or we return a failure to the client. Since once written, rows are never updated, no incremental index maintenance is required. This reduces the overhead of secondary indexing at write time. However, keep in mind that immutable indexing are only applicable in a limited set of use cases.
-
-## Example
-
-To use immutable indexing, supply an <code>IMMUTABLE_ROWS=true</code> property when you create your table like this:
-
- CREATE TABLE my_table (k VARCHAR PRIMARY KEY, v VARCHAR) IMMUTABLE_ROWS=true;
-
-Other than that, all of the previous examples are identical for immutable indexing.
-
-If you have an existing table that you'd like to switch from immutable indexing to mutable indexing, use the <code>ALTER TABLE</code> command as show below:
-
- ALTER TABLE my_table SET IMMUTABLE_ROWS=false;
-For the complete syntax, see our [Language Reference Guide](language/index.html#create_index).
-
-## Data Guarantees and Failure Management
-
-On successful return to the client, all data is guaranteed to be written to all interested indexes and the primary table. For each individual data row, updates are an all-or-nothing, with a small gap of being behind. From the perspective of a single client, it either thinks all-or-none of the update worked.
-
-We maintain index update durability by adding the index updates to the Write-Ahead-Log (WAL) entry of the primary table row. Only after the WAL entry is successfully synced to disk do we attempt to make the index/primary table updates. We write the index updates in parallel by default, leading to very high throughput. If the server crashes while we are writing the index updates, we replay the all the index updates to the index tables in the WAL recovery process and rely on the idempotence of the updates to ensure correctness. Therefore, index tables are only every a single edit ahead of the primary table.
-
-Its important to note several points:
- * We _do not provide full transactions_ so you could see the index table out of sync with the primary table.
- * As noted above, this is ok as we are only a very small bit ahead and out of sync for very short periods
- * Each data row and its index row(s) are guaranteed to to be written or lost - we never see partial updates
- * All data is first written to index tables before the primary table
-
-### Singular Write Path
-
-There is a single write path that guarantees the failure properties. All writes to the HRegion get intercepted by our coprocessor. We then build the index updates based on the pending update (or updates, in the case of the batch). These update are then appended to the WAL entry for the original update.
-
-If we get any failure up to this point, we return the failure to the client and no data is persisted or made visible to the client.
-
-Once the WAL is written, we ensure that the index and primary table data will become visible, even in the case of a failure.
- * If the server does _not_ crash, we just insert the index updates to their respective tables.
- * If the server _does_ crash, we then replay the index updates with the usual WAL replay mechanism
- ** If any of the index updates fails, we then fail the server, ensuring we get the WAL replay of the updates later.
-
-### Failure Policy
-
-In the event that the region server handling the data updates cannot write to the region server handling the index updates, the index is automatically disabled and will no longer be considered for use in queries (as it will no longer be in sync with the data table). To use it again, it must be manually rebuilt with the following command:
-
-```
-ALTER INDEX my_index ON my_table REBUILD;
-```
-
-If we cannot disable the index, then the server will be immediately aborted. If the abort fails, we call System.exit on the JVM, forcing the server to die. By killing the server, we ensure that the WAL will be replayed on recovery, replaying the index updates to their appropriate tables.
-
-**WARNING: indexing has the potential to bring down your entire cluster very quickly.**
-
-If the index tables are not setup correctly (Phoenix ensures that they are), this failure policy can cause a cascading failure as each region server attempts and fails to write the index update, subsequently killing itself to ensure the visibility concerns outlined above.
-
-## Setup
-
-Only mutable indexing requires special configuration options in the region server to run - phoenix ensures that they are setup correctly when you enable mutable indexing on the table; if the correct properties are not set, you will not be able to turn it on.
-
-You will need to add the following parameters to `hbase-site.xml`:
-```
-<property>
- <name>hbase.regionserver.wal.codec</name>
- <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
-</property>
-```
-
-This enables custom WAL edits to be written, ensuring proper writing/replay of the index updates. This codec supports the usual host of WALEdit options, most notably WALEdit compression.
-
-## Tuning
-Out the box, indexing is pretty fast. However, to optimize for your particular environment and workload, there are several properties you can tune.
-
-All the following parameters must be set in `hbase-site.xml` - they are true for the entire cluster and all index tables, as well as across all regions on the same server (so, for instance, a single server would not write to too many different index tables at once).
-
-1. index.builder.threads.max
- * Number of threads to used to build the index update from the primary table update
- * Increasing this value overcomes the bottleneck of reading the current row state from the underlying HRegion. Tuning this value too high will just bottleneck at the HRegion as it will not be able to handle too many concurrent scan requests as well as general thread-swapping concerns.
- * **Default: 10**
-
-2. index.builder.threads.keepalivetime
- * Amount of time in seconds after we expire threads in the builder thread pool.
- * Unused threads are immediately released after this amount of time and not core threads are retained (though this last is a small concern as tables are expected to sustain a fairly constant write load), but simultaneously allows us to drop threads if we are not seeing the expected load.
- * **Default: 60**
-
-3. index.writer.threads.max
- * Number of threads to use when writing to the target index tables.
- * The first level of parallelization, on a per-table basis - it should roughly correspond to the number of index tables
- * **Default: 10**
-
-4. index.writer.threads.keepalivetime
- * Amount of time in seconds after we expire threads in the writer thread pool.
- * Unused threads are immediately released after this amount of time and not core threads are retained (though this last is a small concern as tables are expected to sustain a fairly constant write load), but simultaneously allows us to drop threads if we are not seeing the expected load.
- * **Default: 60**
-
-5. hbase.htable.threads.max
- * Number of threads each index HTable can use for writes.
- * Increasing this allows more concurrent index updates (for instance across batches), leading to high overall throughput.
- * **Default: 2,147,483,647**
-
-6. hbase.htable.threads.keepalivetime
- * Amount of time in seconds after we expire threads in the HTable's thread pool.
- * Using the "direct handoff" approach, new threads will only be created if it is necessary and will grow unbounded. This could be bad but HTables only create as many Runnables as there are region servers; therefore, it also scales when new region servers are added.
- * **Default: 60**
-
-7. index.tablefactory.cache.size
- * Number of index HTables we should keep in cache.
- * Increasing this number ensures that we do not need to recreate an HTable for each attempt to write to an index table. Conversely, you could see memory pressure if this value is set too high.
- * **Default: 10**
-
-# Performance
-We track secondary index performance via our [performance framework](http://phoenix-bin.github.io/client/performance/latest.htm). This is a generic test of performance based on defaults - your results will vary based on hardware specs as well as you individual configuration.
-
-That said, we have seen secondary indexing (both immutable and mutable) go as quickly as < 2x the regular write path on a small, (3 node) desktop-based cluster. This is actually a phenomenal as we have to write to multiple tables as well as build the index update.
-
-# Presentations
-There have been several presentations given on how secondary indexing works in Phoenix that have a more indepth look at how indexing works (with pretty pictures!):
- * [San Francisco HBase Meetup](http://files.meetup.com/1350427/PhoenixIndexing-SF-HUG_09-26-13.pptx) - Sept. 26, 2013
- * [Los Anglees HBase Meetup](http://www.slideshare.net/jesse_yates/phoenix-secondary-indexing-la-hug-sept-9th-2013) - Sept, 4th, 2013
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/sequences.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/sequences.md b/src/site/markdown/sequences.md
deleted file mode 100644
index a613077..0000000
--- a/src/site/markdown/sequences.md
+++ /dev/null
@@ -1,47 +0,0 @@
-# Sequences
-
-Sequences are a standard SQL feature that allow for generating monotonically increasing numbers typically used to form an ID. To create a sequence, use the following command:
-
- CREATE SEQUENCE my_schema.my_sequence;
-
-This will start the sequence from 1, increment by 1 each time, and cache on your session the default number of sequence values based on the phoenix.sequence.cacheSize config parameter. The specification of a sequence schema is optional. Caching sequence values on your session improves performance, as we don't need to ask the server for more sequence values until we run out of cached values. The tradeoff is that you may end up with gaps in your sequence values when other sessions also use the same sequence.
-
-All of these parameters can be overridden when the sequence is created like this:
-
- CREATE SEQUENCE my_schema.my_sequence START WITH 100 INCREMENT BY 2 CACHE 50;
-
-Sequences are incremented using the NEXT VALUE FOR <sequence_name> expression in an UPSERT VALUES, UPSERT SELECT, or SELECT statement as shown below:
-
- UPSERT VALUES INTO my_table(id, col1, col2)
- VALUES( NEXT VALUE FOR my_schema.my_sequence, 'foo', 'bar');
-
-This will allocate a BIGINT based on the next value from the sequence (beginning with the START WITH value and incrementing from there based on the INCREMENT BY amount).
-
-When used in an UPSERT SELECT or SELECT statement, each row returned by the statement would have a unique value associated with it. For example:
-
- UPSERT INTO my_table(id, col1, col2)
- SELECT NEXT VALUE FOR my_schema.my_sequence, 'foo', 'bar' FROM my_other_table;
-
-would allocate a new sequence value for each row returned from the SELECT expression. A sequence is only increment once for a given statement, so multiple references to the same sequence by NEXT VALUE FOR produce the same value. For example, in the following statement, my_table.col1 and my_table.col2 would end up with the same value:
-
- UPSERT VALUES INTO my_table(col1, col2)
- VALUES( NEXT VALUE FOR my_schema.my_sequence, NEXT VALUE FOR my_schema.my_sequence);
-
-You may also access the last sequence value allocated using a CURRENT VALUE FOR expression as shown below:
-
- SELECT CURRENT VALUE FOR my_schema.my_sequence, col1, col2 FROM my_table;
-
-This would evaluate to the last sequence value allocated from the previous NEXT VALUE FOR expression for your session (i.e. all connections on the same JVM for the same client machine). If no NEXT VALUE FOR expression had been previously called, this would produce an exception. If in a given statement a CURRENT VALUE FOR expression is used together with a NEXT VALUE FOR expression for the same sequence, then both would evaluate to the value produced by the NEXT VALUE FOR expression.
-
-The NEXT VALUE FOR and CURRENT VALUE FOR expressions may only be used as SELECT expressions or in the UPSERT VALUES statement. Use in WHERE, GROUP BY, HAVING, or ORDER BY will produce an exception. In addition, they cannot be used as the argument to an aggregate function.
-
-To drop a sequence, issue the following command:
-
- DROP SEQUENCE my_schema.my_sequence;
-
-To discover all sequences that have been created, you may query the SYSTEM.SEQUENCE table as shown here:
-
- SELECT sequence_schema, sequence_name, start_with, increment_by, cache_size FROM SYSTEM."SEQUENCE";
-
-Note that only read-only access to the SYSTEM.SEQUENCE table is supported.
-
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/skip_scan.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/skip_scan.md b/src/site/markdown/skip_scan.md
deleted file mode 100644
index 3bc07b8..0000000
--- a/src/site/markdown/skip_scan.md
+++ /dev/null
@@ -1,22 +0,0 @@
-# Skip Scan
-
-Phoenix uses Skip Scan for intra-row scanning which allows for [significant performance improvement](performance.html#Skip-Scan) over Range Scan when rows are retrieved based on a given set of keys.
-
-The Skip Scan leverages <code>SEEK_NEXT_USING_HINT</code> of HBase Filter. It stores information about what set of keys/ranges of keys are being searched for in each column. It then takes a key (passed to it during filter evaluation), and figures out if it's in one of the combinations or range or not. If not, it figures out to which next highest key to jump.
-
-Input to the <code>SkipScanFilter</code> is a <code>List<List<KeyRange>></code> where the top level list represents each column in the row key (i.e. each primary key part), and the inner list represents ORed together byte array boundaries.
-
-
-Consider the following query:
-
- SELECT * from T
- WHERE ((KEY1 >='a' AND KEY1 <= 'b') OR (KEY1 > 'c' AND KEY1 <= 'e'))
- AND KEY2 IN (1, 2)
-
-The <code>List<List<KeyRange>></code> for <code>SkipScanFilter</code> for the above query would be [ [ [ a - b ], [ d - e ] ], [ 1, 2 ] ] where [ [ a - b ], [ d - e ] ] is the range for <code>KEY1</code> and [ 1, 2 ] keys for <code>KEY2</code>.
-
-The following diagram illustrates graphically how the skip scan is able to jump around the key space:
-
-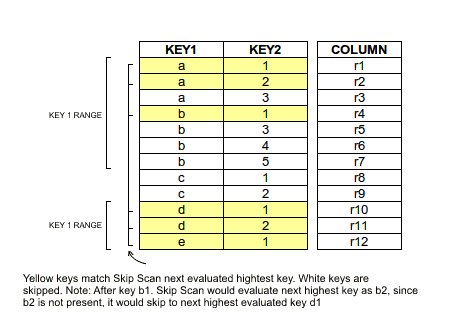
-
-
http://git-wip-us.apache.org/repos/asf/incubator-phoenix/blob/19f15b92/src/site/markdown/source.md
----------------------------------------------------------------------
diff --git a/src/site/markdown/source.md b/src/site/markdown/source.md
deleted file mode 100644
index a2d5467..0000000
--- a/src/site/markdown/source.md
+++ /dev/null
@@ -1,9 +0,0 @@
-# Source Repository
-
-Source will be moved over to Apache SVN soon! In meanwhile it is available at:
-
-<hr/>
-
-https://github.com/forcedotcom/phoenix
-
-<hr/>